The Energy Ceiling
Sustainable AI
Purpose
Why does energy consumption determine what machine learning systems can exist, not just what they cost to operate?
Power is not merely an operational expense but a hard physical constraint that limits what can be built. A data center has a fixed power budget determined by its electrical infrastructure and cooling capacity; exceeding that budget is not expensive but impossible. Training runs that require more power than available cannot happen regardless of budget. Deployment locations are constrained by grid capacity and cooling feasibility, not just real estate prices. At the largest scales, the question shifts from affordability to physical feasibility, and the answer depends on energy efficiency as much as algorithmic capability. Organizations that treat energy as a first-class engineering constraint alongside accuracy and latency can build systems that fit within the physical infrastructure available to them. Sustainability is where the thermodynamic limit closes over C³ co-design: no amount of compute, communication, or coordination can exceed the megawatt capacity of the facility.
Learning Objectives
- Explain why facility power and cooling limits constrain which ML systems can physically exist
- Analyze compute growth, hardware efficiency, and demand rebound to forecast fleet resource demand
- Calculate operational, embodied, and lifecycle carbon from energy use, power usage effectiveness, manufacturing, and grid intensity
- Analyze energy bottlenecks from operations, memory movement, cooling, water, and power delivery constraints
- Compare training, inference, edge, and federated workloads by energy, carbon, and battery budgets
- Design mitigation strategies across algorithms, infrastructure, scheduling, hardware lifetime, and carbon-aware operations
- Evaluate policy, offsets, and environmental justice claims against measurable reductions in fleet emissions
A model can be secure against adversaries and robust under distribution shift, yet still fail if the available grid cannot power its accelerators or the facility cannot cool them. Sustainability begins at that boundary: the point where accuracy, latency, and reliability are no longer enough because the system must also fit within power, cooling, water, carbon, and hardware lifetime budgets. Energy is the ultimate currency of machine learning, and power density is the ceiling on data-center computational capacity.1
1 Joule: The SI unit of energy (1 J = 1 Watt-second). To ground the scale of the fleet: a single A100 GPU at peak load consumes ~400 Joules every second. Large-model training runs are measured in billions to trillions of joules, so small per-operation inefficiencies scale into facility-level energy demand.
When an engineer optimizes a database query to save 100 ms, that is ordinary performance tuning. At fleet scale, the same saving repeated billions of times per day becomes megawatts of electrical power, cooling load, and avoided carbon emissions (Lacoste et al. 2019). A system that exceeds its operating envelope has failed operationally in the same sense as one that crashes, because it cannot be deployed at the intended scale.
That ceiling makes sustainability a design constraint, not a reporting category. The same engineering discipline that budgets memory, bandwidth, and fault tolerance must also budget joules, cooling load, embodied carbon, and hardware replacement cycles.
Contemporary machine learning applications operate at industrial scales, with environmental impact comparable to established heavy industries. Training a single large AI model can consume as much electricity as roughly 120 US homes do in an entire year. When compute demand grows faster than hardware efficiency, the result is the sustainability paradox in artificial intelligence (Sevilla et al. 2022). Sustainable AI treats that gap as a first-class systems problem rather than an externality to be managed after deployment.
Sevilla, Jaime, Lennart Heim, Anson Ho, Tamay Besiroglu, Marius Hobbhahn, and Pablo Villalobos. 2022. “Compute Trends Across Three Eras of Machine Learning.” 2022 International Joint Conference on Neural Networks (IJCNN), 1–8. https://doi.org/10.1109/ijcnn55064.2022.9891914.
Definition 1.1: Sustainable AI
Sustainable AI is the systems engineering practice of measuring and optimizing the full environmental cost of ML systems (energy, water, and embodied carbon across training, inference, and hardware manufacturing) and incorporating those costs as explicit constraints in architecture decisions alongside performance and accuracy objectives (Wynsberghe 2021; Lannelongue et al. 2021; Henderson et al. 2020).
- Significance: Training GPT-3 consumed approximately 1,287 MWh of energy (Li 2020), equivalent to roughly 120 US household-years of electricity. The same lifecycle logic applies after training: pretrained models can often be adapted with far less work than training from scratch, and high-volume inference can eventually dominate total energy. Sustainable AI therefore tracks both one-time training runs and recurring serving workloads rather than treating model training as the whole footprint.
- Distinction: Unlike corporate sustainability reporting (which aggregates energy usage into annual CO2 disclosures), sustainable AI engineering operates at the individual workload level—selecting hardware based on FLOP/s per watt efficiency, scheduling training during periods of high renewable availability, and choosing model architectures that minimize inference FLOPs rather than simply maximizing accuracy.
- Common pitfall: A frequent misconception is that switching to renewable energy solves the sustainability problem. For hardware-intensive ML, embodied carbon (the carbon emitted manufacturing the chips, servers, and cooling equipment before they ever run a training job) often equals or exceeds operational carbon; over 50 percent of an edge device’s lifecycle carbon can come from manufacturing, making hardware longevity and utilization rate as important as energy source.
Li, Chengwei. 2020. Estimating the Training Cost of GPT-3.
Lannelongue, Loı̈c, Jason Grealey, and Michael Inouye. 2021. “Green Algorithms: Quantifying the Carbon Footprint of Computation.” Advanced Science 8 (12): 2100707. https://doi.org/10.1002/advs.202100707.
Wynsberghe, Aimee van. 2021. “Sustainable AI: AI for Sustainability and the Sustainability of AI.” AI and Ethics 1: 213–18. https://doi.org/10.1007/s43681-021-00043-6.
The environmental impact of AI systems spans the complete lifecycle: from semiconductor manufacturing and data center construction to model training, inference deployment, and electronic waste (Wynsberghe 2021; Gupta et al. 2022; Luccioni et al. 2023). Treating this full lifecycle as an engineering problem rather than a corporate responsibility exercise transforms sustainability from a vague objective into a measurable engineering requirement. Before we can optimize this massive footprint, however, we must ground our intuition by calculating the raw physical energy required by a large training run.
Checkpoint 1.1: The energy of intelligence
A 175B parameter model requires approximately \(3.14 \times 10^{23}\) FLOPs to train. Assuming a data center PUE of 1.1 and an end-to-end realized training efficiency of 50 GFLOP/J:
That household-year figure is the stake; it is also only the electricity entering the building. The next question is where that energy physically goes: how much reaches the accelerators, how much the cooling and power-delivery overhead consumes, and how the grid behind the meter converts those kilowatts into carbon.
The scale of environmental impact
A training run measured in megawatt-hours is hard to reason about: few engineers carry an intuition for what a megawatt-hour of grid electricity costs the atmosphere. Converting that energy into emissions and then into a known carbon anchor, the CO2 of a trans-Atlantic flight, turns an abstract number into one with physical stakes.
Napkin Math 1.1: The carbon cost of training
Problem: A team trains a large model (GPT-3 size) consuming 1,287 MWh. How much CO2 is emitted, and how does that compare to a trans-Atlantic flight?
Math:
- Energy: Training energy consumption is 1,287 MWh = 1,287,000 kWh.
- Carbon intensity (US average): \(\approx\) 0.429 kg/kWh.
- Total Emissions: Training emissions are 1,287,000 kWh \(\times\) 0.429 kg/kWh \(\approx\) 552,123 kg.
- Comparison:
- One passenger, NY to London (round trip): \(\approx\) 1000 kg.
- Ratio: 552,123 kg / 1000 kg = 552.1.
Systems insight: A single training run emits as much carbon as hundreds of trans-Atlantic passenger round trips. Optimization matters. Moving this job to a hydro-powered region (0.020 kg/kWh) would reduce emissions by 21.4× to about 25.7 passenger round trips.
That arithmetic shows the carbon cost of one run; at large-cluster scale, the next constraint is whether enough power can be delivered to the cluster at all.
Lighthouse 1.1: Archetype A (GPT-4/Llama-3): The energy wall
Archetype A (GPT-4-class training) exposes the power problem most sharply. A single 25,000-GPU cluster drawing 700 W per chip requires 17.5 MW of accelerator power before server, network, and cooling overhead. The constraint is physical, not financial: it is a grid capacity problem. Organizations operating Archetype A workloads may need dedicated power infrastructure or regions with excess renewable energy, making carbon-aware scheduling (shifting nonurgent work toward cleaner grid hours) and geographic optimization (placing workloads where power, cooling, and carbon constraints fit the job) critical fleet decisions on the same tier as learning rate tuning.
That accelerator draw alone, before server, network, and cooling overhead, already competes with heavy industry for grid capacity, which makes where and when a job runs the dominant lever, the subject of the calculations that follow.
A two-region comparison is tractable by hand, but a real fleet weighs many regions against time-varying carbon intensity and regional electricity rates at once, a design space too large to eyeball. At that point the placement decision becomes an optimization problem, and a solver does the search.
Example 1.1: Automated carbon-aware placement
Scenario: A team is planning a large training run requiring 10,000 MWh of energy, choosing between three regions with different electricity prices and carbon intensities.
Problem: With an internal carbon tax of $100/tonne, which region minimizes the true Total Cost of Ownership (TCO)?
Approach: The PlacementOptimizer synthesizes grid carbon intensity, regional electricity rates, and the carbon tax into a single optimization objective, then evaluates the design space to select the global minimum.
- Optimal region: Carbon-aware scheduling selects Quebec.
- Total projected cost: $0.66M (including carbon penalty).
Systems insight: In a pure energy-cost-only model, engineers might choose the region with the lowest raw electricity rate. Once a carbon tax is introduced, the optimization objective internalizes a cost that would otherwise sit outside the engineering budget. The optimizer shows that the hydro-powered grid in Quebec is the most cost-effective choice, because the carbon savings more than offset any marginal difference in electricity pricing.
The scheduling optimizer treats carbon intensity as a time-varying input, shifting workloads to low-carbon hours within a single region. Geographic placement extends the same logic across space: because national grids differ by an order of magnitude in carbon intensity, choosing where to run a job can dwarf any gain from choosing when to run it. The following calculation isolates this geographic factor by holding energy demand constant and varying only the grid.
Napkin Math 1.2: The geography of carbon
Problem: A team is choosing a data center for a 10,000 MWh training run.
- Site A (Quebec): Hydropower, 20 g/kWh \(\text{CO}_2\).
- Site B (Poland): Coal-heavy, 820 g/kWh \(\text{CO}_2\). How does the location affect a model’s carbon footprint?
Math: Carbon = Energy \(\times\) Grid Intensity.
- Site A emissions: 10,000,000 kWh \(\times\) 20 g/kWh = 200,000,000 g = 200 t \(\text{CO}_2\).
- Site B emissions: 10,000,000 kWh \(\times\) 820 g/kWh = 8,200,000,000 g = 8200 t \(\text{CO}_2\).
- Ratio: 8200 t / 200 t = 41× difference.
Systems insight: Site selection dominates the modeled levers. The Quebec-versus-Poland pair gives a 41× difference, which exceeds many common algorithmic efficiency gains. Efficiency extends beyond FLOPs to the carbon-intensity of those FLOPs, making carbon-aware scheduling a first-class operational competency in the machine learning fleet.

The same job’s carbon emissions depend on where it runs.
This Quebec-versus-Poland pair is the canonical anchor for the geographic lever used throughout the chapter. Grid carbon intensity spans roughly ten to eighty times across the world’s grids, and representative region pairs land in the eight to forty times range, with the precise figure set by which two grids are compared and whether temporal variation is included. Later sections quote different numbers within this span; each names the assumption that moves it.
Training a single large language model consumes thousands of megawatt-hours of electricity, equivalent to powering hundreds of households for months.2 IEA projects global data-center electricity consumption to reach about 945 TWh by 2030, just under 3 percent of global electricity demand, with AI-accelerated servers driving much of the growth.3 Computational demands increased 350,000\(\times\) from 2012 to 2019 (Schwartz et al. 2020), while hardware efficiency improved at a far slower rate, creating an unsustainable growth trajectory.
2 Household Energy Baseline: The average U.S. household consumes 10.7 MWh annually. GPT-3’s verified 1,287 MWh training run equals roughly 120 households’ annual electricity, and larger later runs can require substantially more compute. This comparison anchors an otherwise abstract energy figure to physical infrastructure: a single training run can draw more grid capacity than a residential neighborhood.
3 Data Center Industrial Scale: IEA’s 2025 Energy and AI analysis projects data centers to consume about 945 TWh of electricity by 2030, just under 3 percent of global electricity demand. This is an electricity-demand metric, not directly comparable to aviation or cement shares of global emissions, but it still means AI infrastructure competes for grid capacity with heavy industry: regions that cannot expand power generation cannot expand AI deployment, regardless of demand.
4 GPU Manufacturing Embodied Carbon: NVIDIA’s HGX H100 product carbon footprint reports 1,312 kg CO2e for an eight-H100 baseboard, or roughly 164 kg CO2e per H100 if allocated evenly across the eight GPUs (NVIDIA Corporation 2025). Advanced-node manufacturing also requires substantial ultrapure water, specialty gases, chemicals, and high-temperature process steps. This embodied cost means that in clean-grid regions (hydro, nuclear), manufacturing emissions can rival or exceed operational carbon, making hardware longevity and circular economy reuse critical sustainability levers.
5 AI Hardware E-Waste: Global e-waste reached 53.6 million metric tons in 2019, with computing equipment contributing 15 percent. AI accelerators compound this: 3-5 year obsolescence cycles driven by rapidly advancing architectures mean that a fleet of 10,000 GPUs generates 10–20 metric tons of toxic e-waste per refresh cycle, containing lead, mercury, and cadmium requiring specialized disposal.
Beyond direct energy consumption, AI systems drive environmental impact through hardware manufacturing and resource consumption. Training and inference workloads depend on specialized processors that require rare earth metals whose extraction and processing generate pollution.4 The growing demand for AI applications accelerates electronic waste production, with global e-waste reaching 54 million metric tons annually (Forti et al. 2020). AI hardware rapidly becomes obsolete due to accelerating performance requirements.5
These environmental challenges are part of the energy ceiling, not an add-on to it: the communities that host land, water, grid capacity, and waste streams also carry part of the system cost. The scale calculations above turn sustainability into an allocation problem. AI progress creates benefits in one part of the system while assigning electricity, water, land, and disposal costs to another, so environmental responsibility must be treated as part of systems design rather than as postdeployment reporting.
Environmental justice and responsible development
Site selection therefore becomes an environmental-justice decision, not only a facilities decision. Environmental sustainability extends ML systems responsibility from model behavior to ecological stewardship (Vinuesa et al. 2020). The computational resources required for AI development concentrate environmental costs on specific communities while distributing benefits unequally across global populations. Data centers consume on the order of a few percent of global electricity and substantial water for cooling (Andrae and Edler 2015; Jones 2018), often in regions where energy grids rely on fossil fuels and water resources face stress from climate change.
Vinuesa, Ricardo, Hossein Azizpour, Iolanda Leite, Madeline Balaam, Virginia Dignum, Sami Domisch, Anna Felländer, Simone Daniela Langhans, Max Tegmark, and Francesco Fuso Nerini. 2020. “The Role of Artificial Intelligence in Achieving the Sustainable Development Goals.” Nature Communications 11 (1): 233. https://doi.org/10.1038/s41467-019-14108-y.
Andrae, Anders, and Tomas Edler. 2015. “On Global Electricity Usage of Communication Technology: Trends to 2030.” Challenges 6 (1): 117–57. https://doi.org/10.3390/challe6010117.
Jones, Nicola. 2018. “How to Stop Data Centres from Gobbling up the World’s Electricity.” Nature 561 (7722): 163–66. https://doi.org/10.1038/d41586-018-06610-y.
6 Environmental Justice in Data Center Siting: Data centers gravitate toward low-cost land and electricity, which often means economically disadvantaged areas. The result is an asymmetric externality: communities hosting AI infrastructure bear water depletion, heat island effects, and grid strain, while economic benefits concentrate in distant tech hubs. For ML systems engineers, this creates a design constraint: site selection must factor in social license alongside grid carbon intensity, because community opposition can block or delay facility expansion.
That geographic concentration creates environmental-justice risks that align with broader responsible AI frameworks.6 The fairness claim here is narrow and systems-specific: an ML fleet allocates benefits, electricity demand, water use, land pressure, and e-waste across different communities. Communities hosting AI infrastructure can bear disproportionate environmental burdens while having limited access to AI’s economic benefits, so site selection becomes part of the engineering design space rather than a facilities afterthought.
Exponential growth vs. physical constraints
Rapid growth in computational demands challenges the long-term sustainability of AI training and deployment. In the 2012–2019 window studied here, reported AI training compute increased 350,000×7 (Schwartz et al. 2020). Many large-model training regimes since then have continued to favor larger models, larger training datasets, or higher computational budgets. Sustaining that trajectory poses sustainability challenges when hardware efficiency gains fail to keep pace with workload demand.
7 AI Compute Growth Rate: The 350,000× increase from 2012 to 2019 implies a doubling time of approximately 4.6 months, roughly 5.3× faster than Moore’s Law’s 2-year doubling. This divergence is one major driver of the energy wall: no physically realizable improvement in silicon efficiency can match a doubling cadence measured in months by process scaling alone, making algorithmic efficiency and carbon-aware scheduling central sustainability levers at scale.
8 Moore’s Law: Gordon Moore’s 1965 observation that transistor density doubles every two years drove decades of “free” efficiency gains for the semiconductor industry. At single-digit-nanometer process nodes, physical limits make further gains harder: individual atoms become part of the constraint. For AI sustainability, the slowdown of process scaling means that additional efficiency gains must come from architectural specialization and algorithmic optimization rather than process shrinks alone.
9 Dennard Scaling: Robert Dennard observed in 1974 that smaller transistors could operate at constant power density by reducing voltage proportionally. This scaling pattern ended around 2005 when leakage current made further voltage reduction impractical. The consequence for AI sustainability is direct: without Dennard scaling, each process node no longer delivers proportional power savings, which pushes efficiency work toward specialized accelerators—GPUs and Tensor Processing Units (TPUs)—that exploit architectural parallelism rather than transistor physics alone.
Historically, computational efficiency improved with advances in semiconductor technology. Moore’s Law predicted that the number of transistors on a chip would double approximately every two years, leading to continuous improvements in processing power and energy efficiency.8 However, advanced process nodes face core physical limits, making further transistor scaling difficult and costly. Dennard scaling, which once ensured that smaller transistors would operate at lower power levels, has also ended, leading to stagnation in energy efficiency improvements per transistor.9
When AI models scale faster than the hardware running them improves, the energy budget opens a gap that algorithmic efficiency has to close. As figure 1 illustrates for the 2012–2019 compute-growth window, the divergence between computational demand and hardware efficiency creates an unsustainable trajectory in the sensitivity scenario. This technical reality underscores why sustainable AI development requires coordinated action across the entire systems stack, from individual algorithmic choices to infrastructure design and policy frameworks.
To make the uncertainty visible, figure 2 shows high-growth sensitivity scenarios for data center electricity usage rather than the IEA baseline forecast above. The spread between best, expected, and worst cases illustrates how strongly the outcome depends on efficiency improvements and demand growth assumptions.

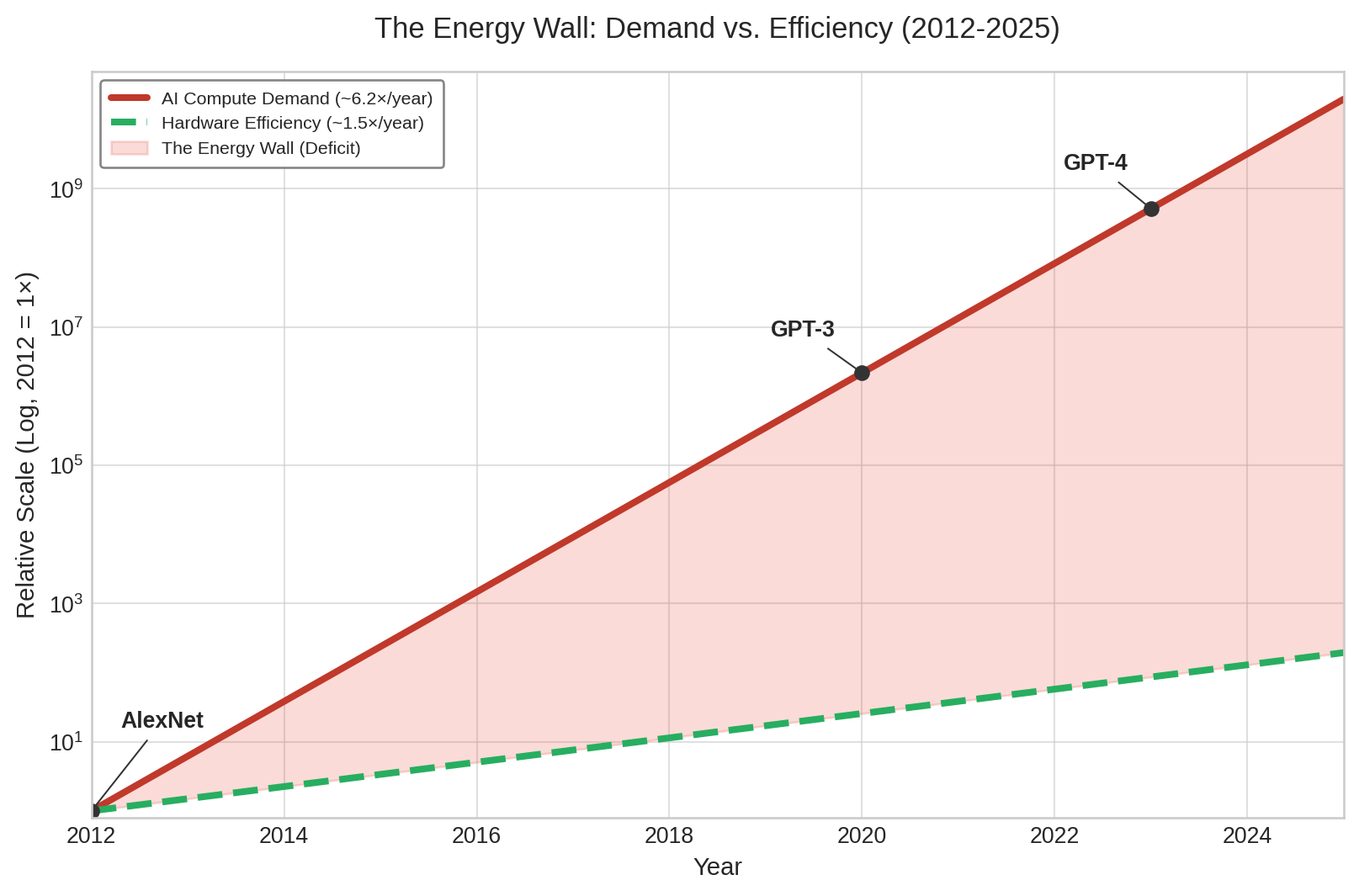
The energy wall: Divergent scaling
Figure 1 frames the energy wall as a divergence between compute demand and silicon efficiency, but silicon efficiency is only one ceiling. Even if every accelerator hit its theoretical limit, a second ceiling remains: the physical energy infrastructure of battery density and grid efficiency, which scales far more slowly than compute demand. AI sustainability presents a unique engineering challenge because it is a race between two fundamentally different physics: the exponential scaling of logic and the linear scaling of energy infrastructure.
As figure 3 shows, AI compute grew ~350,000\(\times\) over the 2012–2019 period cited above while battery density and grid efficiency improve at only ~2–5 percent annually.

While AI logic follows the “iron law” of software optimization, energy follows the laws of chemistry and thermodynamics. Over the same seven-year interval, battery energy density would improve by only ~40.7 percent at a 5 percent annual rate, and grid efficiency by ~14.9 percent at a 2 percent annual rate. The 248,738.5× gap between these curves is the energy wall—the point where we can no longer “buy our way out” of the efficiency problem with more power.
Data center grid dynamics
Sustainable AI requires looking beyond the server rack to the electrical grid interface. Traditional data centers are “Steady-State” loads; they pull constant power 24/7. ML training clusters, however, are transient loads.
War Story 1.1: When the grid became the bottleneck
Context: In July 2022, the Government of Ireland published its Government Statement on the Role of Data Centres in Ireland’s Enterprise Strategy, formalizing the country’s posture toward a sector that by then consumed roughly 18 percent of Ireland’s total metered electricity—concentrated almost entirely in the greater Dublin area (Government of Ireland 2022; International Energy Agency 2024).
Failure mode: Grid expansion did not keep pace with connection demand. EirGrid and the national regulator reported multiple gigawatts of prospective data-center load queued near Dublin, with the local transmission system pushed to its limit and reinforcement timelines stretching into the next decade.
Consequence: EirGrid effectively imposed a moratorium on new data-center grid connections in the Dublin region through 2028. New connections became a grid-planning and policy decision rather than a normal procurement step, with location, on-site generation, and reinforcement requirements shaping what could be built—and where AI capacity could land at all.
Systems lesson: Sustainable AI is constrained by interconnection, geography, and power-system adequacy. Efficient accelerators help, but the fleet cannot scale faster than the grid that feeds it, and the binding constraint moves from the chip to the substation.
International Energy Agency. 2024. Data Centre Electricity Demand Estimates as a Share of Total Electricity Demand in Ireland and Virginia, 2023. IEA chart.
Government of Ireland. 2022. Government Statement on the Role of Data Centres in Ireland’s Enterprise Strategy. Government policy statement.
The same grid-interface constraint appears at millisecond scale, with power-delivery hardware providing the mechanism behind it. A 10,000-GPU cluster can swing its load by 5–10 megawatts during an AllReduce synchronization step. For an electrical utility, this is a noise event: when thousands of GPUs suddenly stop computing to wait for the network, they cause a voltage spike on the grid; when they resume, they cause a voltage sag. Managing these transients requires Energy Buffering: using on-site battery arrays or massive capacitors to smooth the training iterations, ensuring the ML Fleet does not destabilize the local municipal power grid.
Heat is the paired facility constraint because a data center physically converts high-quality energy (electricity) into low-quality energy (waste heat). A sustainable fleet treats that heat as a recoverable byproduct rather than a pollutant. Modern facilities in Nordic regions, for example, use district heating to pipe waste heat into municipal heating systems, while industrial coupling can route low-grade waste heat at roughly 45°C into greenhouse climate control or water desalination. These data-center waste-heat recovery patterns offset nearby thermal demand instead of exhausting all heat into the atmosphere10 (Ebrahimi et al. 2014).
10 PUE (Power Usage Effectiveness): In the early 2000s, PUE values of 2.0-2.5 were common, meaning more power went to cooling than to computing (The Green Grid 2007). Google’s 2009 disclosure of PUE 1.21 proved that free-air cooling could halve data center overhead. The shift from PUE to CUE (Carbon Usage Effectiveness) and WUE (Water Usage Effectiveness) reflects a systems-level insight: optimizing watts alone is insufficient when water and carbon constraints bind independently.
The Green Grid. 2007. Green Grid Data Center Power Efficiency Metrics: PUE and DCIE. The Green Grid.
Training-scale energy concentration
The grid, siting, and heat-reuse constraints become severe because large training campaigns concentrate energy demand into long, synchronized runs. OpenAI’s GPT-311 exemplifies this scale: its 1,287 MWh training run, the chapter’s roughly 120-household-year anchor, reflects the computation required to train large language models on large datasets, with additional energy overhead from distributed-training communication12 (Maslej et al. 2023).
11 GPT-3 Energy Scale: GPT-3’s 1,287 MWh training cost translates to roughly $130,000 in US electricity and 552 metric tons of CO2 at average grid intensity. The energy-per-parameter ratio of approximately 7.35 MWh per billion parameters reveals the co-design opportunity: optimized architectures using mixed precision and sparsity achieve sub-1 MWh per billion parameters, a several-fold efficiency gain that compounds across large training runs.
12 Training Communication Overhead: Distributed training adds 15–30 percent energy overhead beyond raw computation due to gradient synchronization and checkpointing across nodes. For large models requiring thousands of GPUs, this communication tax alone can consume more energy than the entire training run of a mid-scale model, making parallelism strategy selection a first-order sustainability decision.
Maslej, Nestor, Loredana Fattorini, Erik Brynjolfsson, John Etchemendy, Katrina Ligett, Terah Lyons, James Manyika, et al. 2023. “Artificial Intelligence Index Report 2023.” ArXiv Preprint abs/2310.03715.
That concentration makes efficiency improvements an engineering imperative. Large generative models intensify the problem when successive generations increase parameter counts, token budgets, or both.
Within the ranges studied by Kaplan et al. (2020), model scaling laws showed that increasing model size, dataset size, and compute used for training improved performance smoothly. Figure 4 demonstrates that test loss decreases predictably across those studied ranges as each of these three factors increases. Beyond training, high-volume deployed systems such as large-scale recommender systems and generative services require continuous inference at scale, consuming energy even after training completes. The cumulative energy burden therefore depends on both the one-time training run and the sustained query volume that follows deployment.
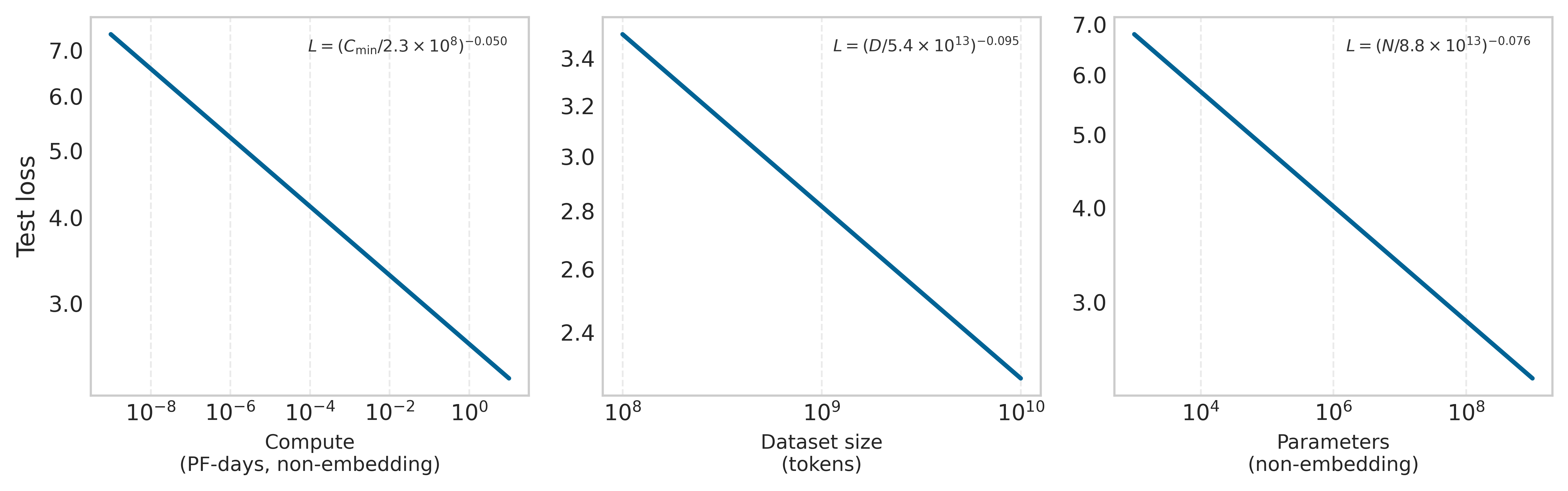
Kaplan, J., S. McCandlish, T. Henighan, T. B. Brown, B. Chess, R. Child, S. Gray, A. Radford, J. Wu, and D. Amodei. 2020. “Scaling Laws for Neural Language Models.” ArXiv Preprint abs/2001.08361.
The hardware choice is the first place where energy physics becomes an architecture decision. Different processor types affect environmental impact through their energy characteristics. Using pJ/FLOP as a common comparison point, central processing units consume approximately 100 pJ/FLOP, graphics processing units achieve roughly 10 pJ/FLOP for dense tensor operations, specialized tensor processors reach about 1–2 pJ/FLOP, and fixed-function low-precision accelerators approach 0.1 pJ/operation.13 These hardware platforms require rare earth metals and complex manufacturing processes with embodied carbon.
13 pJ/FLOP and pJ/MAC: Energy-efficiency specifications often mix floating-point operations and multiply-accumulate operations. One MAC performs a multiply and an add, so direct comparisons require converting the unit convention and precision. The simplified hierarchy used here aligns with the energy-efficiency comparison later in the chapter: CPUs at roughly 100 pJ/FLOP, GPUs around 10 pJ/FLOP for dense tensor operations, TPUs around 1–2 pJ/FLOP, and custom low-precision ASICs approaching 0.1 pJ/operation. This hierarchy defines the sustainability opportunity: choosing the right hardware tier for a given workload can reduce energy consumption by 100–1,000\(\times\) without any algorithmic changes.
The production of AI chips is energy-intensive, involving multiple fabrication steps that the Greenhouse Gas Protocol classifies as Scope 3 value-chain emissions rather than direct electricity use by the operator. As model sizes continue to grow, the demand for AI hardware increases, exacerbating the environmental impact of semiconductor production and disposal.
Theoretical efficiency limits as a sustainability model
To understand the scale of AI’s energy challenge, it helps to compare large digital systems with the theoretical limits of computational efficiency. Large language models (LLMs) can operate with an energy efficiency gap of roughly \(10^6\times\) compared with highly efficient physical and biological pattern-recognition systems. The comparison is approximate rather than a FLOP-for-synapse equivalence: it says that dense digital models spend enormous energy on always-on arithmetic and global data movement, while sparse physical systems often compute only when signals change. This gap is the headroom the energy wall leaves on the table.
Training a single model like GPT-3 creates a stark reminder of this gap: silicon-based systems consume megawatts to process trillions of tokens, while sparse, event-driven computation points toward far lower energy per useful operation for some pattern-recognition workloads. This motivates the search for alternative computing paradigms that prioritize energy-aware architecture over raw throughput.
Principles of high-efficiency computing
The sustainability lesson from high-efficiency computing is where dense ML wastes energy: continuous activation, data-hungry learning, and global movement. Three principles make those loss channels explicit:
- Selective, Event-Driven Activation: Rather than processing all information continuously, high-efficiency systems are asynchronous. They activate only small portions of the network at any time and consume energy only when actively processing changing signals.14
- Local Learning and Sample Efficiency: Dense language-model scaling often requires training on trillions of tokens to achieve broad competence. High-efficiency models use strong inductive biases and self-supervised local learning to acquire capabilities from 10,000\(\times\) less data in the motivating biological comparison, reducing the cumulative energy cost of the training phase.
- Sparsity and Sparse Interconnects: In accelerator workloads with high data movement and global synchronization, energy is often spent moving operands rather than performing arithmetic. High-efficiency systems use sparse representations where only 1-2 percent of parameters are active for any given task, reducing bandwidth and switching energy by 50–100\(\times\) when the sparsity maps to hardware-visible work removal.
14 Event-Driven Computing: A paradigm where computation triggers only on input changes rather than continuous clock cycles. Neuromorphic chips like Intel’s Loihi exploit this to achieve 100–1,000\(\times\) energy reductions for temporal tasks (audio, video, sensor data) by drawing near-zero power when inputs are static. The trade-off: event-driven architectures sacrifice throughput on batch workloads where all data changes simultaneously.
15 Spiking Neural Networks (SNNs): Third-generation neural networks that communicate through discrete spikes rather than continuous activations. SNNs process information only when spikes occur, achieving 10–100\(\times\) energy savings on temporal data (audio, video, sensor streams). The sustainability trade-off: SNN training algorithms remain less mature than backpropagation for many benchmarked workloads, but hardware implementations like Intel Loihi 2 demonstrate the efficiency ceiling these architectures can approach.
The biological model points toward promising research directions for sustainable AI. Architectures that implement Spiking Neural Networks (SNNs), event-driven models that communicate through discrete spikes, or sparse activation patterns can achieve significant energy reductions by mimicking sparse communication models15 (Prakash et al. 2023). Local learning algorithms and self-supervised approaches offer additional pathways toward more sample-efficient and energy-conscious systems.
Achieving sustainable AI requires a systematic shift in system design, moving from continuously active, dense architectures toward event-driven, sparse computation models. As compute demands outpace incremental efficiency improvements in silicon manufacturing, addressing AI’s environmental impact demands rethinking the fundamental “Physics” of the algorithm based on these efficiency principles.
Figure 5 shows how a six-step energy-gap intervention cascade can reduce the energy gap by approximately 10,000\(\times\), transforming an intractable divergence into an engineering challenge. The six per-step factors multiply to a larger figure on paper, but the headline 10,000\(\times\) is a deliberately conservative composite: overlapping levers do not stack cleanly, since each intervention erodes the savings available to the next. No single lever is sufficient; closing the gap requires simultaneous progress across algorithmic, hardware, and systemic fronts.

The convergence of exponential computational demands with hard physical efficiency limits creates an unsustainable trajectory that threatens the long-term viability of AI scaling. To alter this trajectory, we must move beyond back-of-the-envelope calculations and establish rigorous, systemic frameworks for measuring and assessing energy consumption across the entire ML infrastructure.
Energy Measurement and Modeling
Engineers cannot optimize what they cannot measure. A cluster consuming five megawatts during a large language model training run directs only a fraction of that power into matrix multiplications; the remainder is consumed by cooling fans removing the resulting heat. Effective energy modeling requires decomposing the monolithic data center power bill into granular, component-level metrics that engineers can target for optimization.
The data center infrastructure foundations from Compute Infrastructure established power and cooling as dominant engineering constraints. Systematic measurement transforms these constraints into actionable sustainability metrics across three critical areas: energy consumption tracking during training and inference, carbon footprint analysis across system lifecycles, and resource usage assessment for hardware and infrastructure. Just as performance engineering requires profiling before optimization, sustainable AI engineering requires measurement before mitigation.
The decision procedure is the same throughout the chapter: measure the dominant lifecycle term, identify the physical bottleneck behind it, choose the intervention that changes that term, and check whether rebound effects erase the gain. Operational electricity, embodied carbon, cooling overhead, water use, and e-waste each call for different levers. A scheduler cannot fix manufacturing emissions, and hardware longevity cannot fix carbon-intensive runtime placement, so sustainable design begins by locating the term that actually dominates the workload.
Carbon footprint analysis
Carbon footprint analysis turns sustainability from a general obligation into a design constraint. It links energy consumption, grid carbon intensity, and lifecycle resource demands to the same decisions that already govern performance and efficiency. Teams that build and deploy AI systems therefore need a workload-level accounting model before they can choose among larger models, lower-power hardware, cleaner regions, or deferred training.
The accounting model matters because it makes ethical trade-offs auditable. The pursuit of larger models can prioritize accuracy and capability over energy efficiency, increasing carbon emissions when compute growth outpaces efficiency gains. Optimizing for sustainability may introduce engineering trade-offs such as extra tuning effort, hardware constraints, or task-dependent accuracy changes, so the engineering task is to make those costs explicit against environmental benefits. Integrating environmental considerations into AI system design is therefore an engineering obligation, expressed through energy-aware training techniques, low-power hardware designs, and carbon-conscious deployment strategies (Schwartz et al. 2020; Patterson et al. 2021).
Schwartz, Roy, Jesse Dodge, Noah A. Smith, and Oren Etzioni. 2020. “Green AI.” Communications of the ACM 63 (12): 54–63. https://doi.org/10.1145/3381831.
Traceability is the technical bridge between sustainability measurement and accountability. Transparency, fairness, and accountability act as sustainability constraints (figure 6): transparency gaps obscure energy and carbon costs, fairness failures distribute harms unevenly, and weak accountability makes resource consumption difficult to trace. In this chapter, accountability means auditability of resource claims. A team should be able to connect a model version, training run, serving workload, region, energy source, and lifecycle estimate well enough that carbon and water claims can be checked.

For measurement to constrain design, reported metrics must expose workload-level cost rather than aggregate cloud-scale claims, which stay opaque when reporting holds at the company-total level. The practical standard is therefore accountability for resource usage across the full AI lifecycle, and it requires the same evidence chain used for latency, accuracy, and reliability: a claim should connect to logs, meters, model versions, and deployment decisions rather than to aggregate sustainability pledges alone. The carbon-footprint calculation makes that evidence chain explicit by combining workload energy, facility PUE, grid carbon intensity, and embodied carbon.
Napkin Math 1.3: Lifecycle carbon estimation
Problem: Calculate the total carbon footprint for training a 70B parameter model.
Variables: 2,048 H100 GPUs, 30 days, 700 W TDP, rack-profile support power, PUE 1.12, grid intensity 429 g \(\text{CO}_2\)/kWh.
Math: Accelerator power = 2,048 \(\times\) 0.7 kW \(\approx\) 1433.6 kW. Applying the DGX H100 rack profile for host, memory, networking, and conversion support raises the IT load to 1971.2 kW; facility power = 1971.2 kW \(\times\) 1.12 \(\approx\) 2,207.7 kW. Energy = 2,207.7 kW \(\times\) 24 h/day \(\times\) 30 days \(\approx\) 1,589,575.7 kWh. Emissions \(\approx\) 681.9 t \(\text{CO}_2\).
Embodied: Assume manufacturing footprint is \(\approx\) 164 kg \(\text{CO}_2\) per H100 GPU, allocating NVIDIA’s HGX H100 baseboard product carbon footprint evenly across its eight GPUs (NVIDIA Corporation 2025). Amortized for a 1-month window of a 3-year cycle: (2,048 \(\times\) 164 kg) / 36 \(\approx\) 9.3 t \(\text{CO}_2\).
Result: 681.9 t + 9.3 t \(\approx\) 691.3 t \(\text{CO}_2\).
Systems insight: The operational term dominates this training window, but embodied carbon is not zero. Lifecycle accounting prevents teams from hiding manufacturing emissions outside the training budget.
Translating power consumption into carbon emissions is only the first measurement challenge. A systematic lifecycle assessment across the full hardware lifecycle reveals where carbon emissions concentrate and where engineering interventions yield the greatest returns.
Three-phase lifecycle assessment framework
The practical question is which lifecycle phase dominates a given workload, because the answer determines the optimization lever. Effective carbon footprint measurement therefore separates three phases that collectively determine environmental impact.
For training-centric research workloads, the training phase often dominates operational emissions because mathematical optimization requires sustained parallel computation16. As demonstrated by the GPT-3 case study, large language model training runs exemplify this energy intensity. Geographic placement affects emissions: moving an identical workload between hydro-heavy and coal-heavy grids can create tens-fold differences in carbon intensity.17
16 Optimizer Memory as Energy Cost: Adaptive Moment Estimation (Adam) requires 3\(\times\) the memory of plain SGD because it stores per-parameter first and second moment estimates alongside the weights themselves. For a 70B model in FP32, this means 840 GB of optimizer state. The sustainability implication is direct: larger optimizer state means more HBM accesses per training step, and at 160 pJ/byte for DRAM, memory overhead can dominate the energy budget of parameter updates.
17 Carbon Intensity Variance: Grid carbon intensity spans two orders of magnitude: coal at 820 g CO2/kWh vs. hydro at 10–30 g CO2/kWh. Critically, intensity also varies temporally: Texas fluctuates 10\(\times\) within a single day based on wind generation. This dual geographic and temporal variance is what makes carbon-aware scheduling viable: combining the geographic lever (the 8 to 40 times range from section 1.0.1) with temporal shifting pushes the achievable spread toward the high end of the 10 to 80 times span, so identical training runs can differ several-fold in emissions based solely on when and where they execute.
For high-volume production services, the inference phase can dominate lifetime emissions because model serving repeats continuously after the training run is complete. While individual inferences require less computation than training, the cumulative impact scales with deployment breadth and usage frequency. Models serving millions of users generate ongoing emissions that can exceed training costs over extended deployment periods.
The manufacturing phase contributes embodied carbon from hardware production, including semiconductor fabrication, rare earth mining, and supply chain logistics.18 Its share is smaller for long-running workloads on carbon-intensive grids, but it can reach 30–50 percent of lifetime emissions on clean grids or low-utilization hardware. Often overlooked, this phase represents irreducible baseline emissions independent of operational efficiency.
18 Embodied Carbon: The CO2 emitted during manufacturing, transport, and disposal before a device computes its first FLOP. Allocating NVIDIA’s HGX H100 baseboard product carbon footprint evenly across its eight GPUs gives roughly 164 kg CO2e per H100 (NVIDIA Corporation 2025); at 700 W on the average U.S. grid, continuous operation matches embodied carbon in roughly three to four weeks. As data centers shift to renewables, embodied carbon’s share of total lifetime emissions grows, potentially exceeding 30 percent, making hardware refresh cycles a first-order sustainability decision.
NVIDIA Corporation. 2025. Product Carbon Footprint Summary for NVIDIA HGX H100. NVIDIA Datasheet.
Geographic and temporal optimization
Carbon intensity varies across geographic locations and time periods, creating optimization opportunities. Temporal scheduling can reduce emissions when deadline-tolerant workloads are shifted toward lower-carbon hours or regions, with the realized gain depending on workload flexibility, grid mix, and whether the scheduler uses average or marginal emissions (Patterson, Gonzalez, Le, et al. 2022; Radovanovic et al. 2021). Carbon-aware scheduling systems can automatically shift nonurgent training jobs to regions and times with lower carbon intensity.
Patterson, David, Joseph Gonzalez, Quoc Le, Maud Texier, and Jeff Dean. 2022. “Carbon-Aware Computing for Sustainable AI.” Communications of the ACM 65 (11): 50–58.
Development-time carbon tracking matters when it feeds placement and complexity decisions rather than becoming a report after the fact. Tools such as CarbonTracker (Anthony et al. 2020) and CodeCarbon (Schmidt et al. 2021) wrap the workload boundary, estimate energy from hardware counters or utilization models, attach the local grid intensity, and record the resulting emissions alongside the experiment metadata. The important systems pattern is not the API call but the timing of the measurement: the estimate must appear while model size, training duration, region, and schedule are still adjustable, before the run has already consumed its energy.
Power modeling fundamentals
Understanding where energy goes in AI systems requires grounding in the physics of digital computation. The CMOS power equation provides the foundation for reasoning about energy consumption in digital processors, but the useful model must climb three levels: chip power explains why voltage, precision, and activity matter; optimization techniques show how algorithms change those variables; and facility-level metrics reveal whether chip-level savings survive cooling and power-delivery overhead.
The CMOS power equation
Every digital circuit consumes power through two fundamental mechanisms. Dynamic power arises from switching transistors between states, while static power results from leakage current that flows even when transistors are nominally off. Equation 1 formalizes the total power consumption:
\[P_{\text{total}} = P_{\text{dynamic}} + P_{\text{static}} = \alpha_{\text{sw}} C V^2 f + V I_{\text{leak}} \tag{1}\]
The dynamic power component \(P_{\text{dynamic}} = \alpha_{\text{sw}} C V^2 f\) depends on four parameters. The switching activity factor \(\alpha_{\text{sw}}\) represents the fraction of transistors changing state per clock cycle, ranging from 0 to 1. General-purpose CPUs typically exhibit \(\alpha_{\text{sw}} \approx 0.1\) to \(0.3\) due to diverse instruction mixes, while specialized AI accelerators can achieve \(\alpha_{\text{sw}} \approx 0.6\) to \(0.8\) through optimized dataflow that keeps more circuits active during computation. The load capacitance \(C\) scales with transistor count and interconnect length. Supply voltage \(V\) enters quadratically, making voltage reduction the highest-impact lever for energy efficiency. Clock frequency \(f\) determines operations per second.
The static power component \(P_{\text{static}} = V \cdot I_{\text{leak}}\) represents leakage current that increases exponentially with temperature, approximately doubling for every 10 degrees Celsius rise. This thermal dependence creates a feedback loop: higher power generates heat, which increases leakage, which generates more heat. Managing this thermal runaway constrains achievable power density and explains why cooling infrastructure represents such a significant fraction of data center energy consumption (Dayarathna et al. 2016).
Dayarathna, Miyuru, Yonggang Wen, and Rui Fan. 2016. “Data Center Energy Consumption Modeling: A Survey.” IEEE Communications Surveys &Amp; Tutorials 18 (1): 732–94. https://doi.org/10.1109/comst.2015.2481183.
The practical implications for AI systems follow directly from these physics. The quadratic voltage dependence means that reducing voltage from 1V to 0.8V decreases dynamic power by 36 percent, even before considering that lower voltages often enable frequency reduction with additional linear savings. This relationship explains why specialized AI accelerators operating at lower voltages but higher utilization can achieve order-of-magnitude efficiency improvements over general-purpose processors.
Why optimization techniques save energy
The power equation illuminates why specific optimization techniques achieve their efficiency gains. Quantization reduces numerical precision from 32-bit floating point to 8-bit integers, which directly reduces datapath capacitance \(C\) by approximately 4 times since narrower datapaths require fewer transistors and shorter interconnects. Additionally, lower precision arithmetic enables reduced supply voltage \(V\) because the circuits have larger noise margins. The combined effect yields 6 to 10 times energy reduction per operation, closely matching published measurements of INT8 vs. FP32 inference efficiency.
Pruning removes weights from neural networks, reducing the effective capacitance \(C\) by eliminating computation paths that would otherwise consume switching energy. Structured pruning, which removes entire channels or attention heads, achieves larger efficiency gains than unstructured pruning because it eliminates complete circuit paths rather than individual operations that the hardware must still orchestrate.
Specialized accelerators improve the activity factor \(\alpha_{\text{sw}}\) by designing circuits specifically for matrix multiplication and convolution operations. Where a CPU might activate 10 percent of its transistors during typical ML workloads, a systolic array architecture can keep 70 percent or more of its compute units active, effectively performing more useful work per watt of power consumed.
Facility-level power metrics
Beyond chip-level power, data center infrastructure imposes additional energy overhead. Equation 2 captures this relationship through the Power Usage Effectiveness (PUE) metric:
\[\text{PUE} = \frac{P_{\text{total facility}}}{P_{\text{IT equipment}}} \tag{2}\]
Definition 1.2: Power usage effectiveness (PUE)
Power Usage Effectiveness (PUE) is the data-center efficiency ratio ML system operators use to compare total facility power consumption against the power consumed specifically by IT equipment \((P_{\text{facility}} / P_{\text{IT}})\).
- Significance: It measures the Infrastructure Overhead of the data center. A PUE of 1.0 is the theoretical ideal; a PUE of 1.10 means that for every 100 watts of computation, an additional 10 watts are required for cooling and power distribution.
- Distinction: Unlike Computing Efficiency (which focuses on FLOPs per Watt), PUE focuses on Facility Efficiency: it captures how much energy is “wasted” before it even reaches the processor.
- Common pitfall: A frequent misconception is that a low PUE means a “green” data center. In reality, PUE only measures Efficiency, not the Carbon Intensity of the energy source; a coal-powered data center can have a better PUE than a solar-powered one while having a much higher environmental impact.
Napkin Math 1.4: PUE: The cost of cooling
Problem: A team operates a 2 MW cluster. If the facility can be optimized from the industry average PUE (1.58) to state-of-the-art (1.10), how much energy and money does that save annually?
Math: Energy saved is the difference in infrastructure overhead \((\text{PUE}-1)\) across the IT load.
- Overhead Reduction: 1.58 - 1.10 = 0.48.
- Annual energy savings: 2 MW \(\times\) 0.48 \(\times\) 8760 h/year \(\approx\) 8,409.6 MWh.
- Financial Savings: 8,409.6 MWh \(\times\) $70/MWh \(\approx\) $588,672.
Systems insight: Infrastructure optimization is as valuable as algorithmic optimization. Dropping PUE by 0.48 is equivalent to discovering an algorithmic “free lunch” that makes the entire model 30 percent more efficient without changing a single line of training code. For large operators, cooling efficiency is the primary economic lever for sustainability.
A PUE of 1.0 would indicate perfect efficiency where all energy powers computation, though this is physically impossible since cooling, power distribution, and lighting require nonzero energy. Industry-average data centers operate at PUE of 1.5 to 2.0, meaning that 50 percent to 100 percent additional energy beyond computation goes to infrastructure (Uptime Institute 2022). Leading hyperscale facilities achieve PUE between 1.1 and 1.2 through advanced cooling techniques including free-air cooling in cold climates, liquid cooling for high-density GPU clusters, and optimized power distribution.
Uptime Institute. 2022. Uptime Institute Global Data Center Survey 2022. Uptime Institute.

PUE is the infrastructure energy tax on top of compute.
Equation 3 formalizes Water Usage Effectiveness (WUE), capturing the water consumption that evaporative cooling and other processes require:
\[\text{WUE} = \frac{W_{\text{annual\_water\_usage}}}{E_{\text{IT\_equipment}}} \tag{3}\]
The units are liters per kilowatt-hour, with typical values ranging from 0.5 to 2.0 L/kWh depending on climate and cooling technology. A data center with WUE of 1.8 L/kWh training a model requiring 10,000 MWh would consume 18 million liters of water, equivalent to roughly 40–50 US household-years of water use under a 380,000–450,000 L/year household baseline.
Facility-level metrics identify where engineering intervention yields the greatest returns. The following case study demonstrates how ML-driven optimization of PUE translates directly into measurable energy savings.
Case study: DeepMind energy efficiency
Google’s data centers form the backbone of services such as Search, Gmail, and YouTube, handling billions of queries daily (2023). These facilities require substantial electricity consumption, particularly for cooling infrastructure that ensures optimal server performance. Improving data center energy efficiency has long been a priority, but conventional engineering approaches faced diminishing returns due to cooling system complexity and highly dynamic environmental conditions (Buyya et al. 2010). To address these challenges, Google collaborated with DeepMind to develop a machine learning optimization system that automates and enhances energy management at scale.
Centers, Google Data. 2023. Efficiency: How We Do It.
Buyya, Rajkumar, Anton Beloglazov, and Jemal Abawajy. 2010. “Energy-Efficient Management of Data Center Resources for Cloud Computing: A Vision, Architectural Elements, and Open Challenges.” arXiv Preprint arXiv:1006.0308, 6–17. https://doi.org/10.48550/arXiv.1006.0308.
After more than a decade of efforts to optimize data center design, energy-efficient hardware, and renewable energy integration, DeepMind’s AI approach targeted cooling systems, among the most energy-intensive aspects of data centers. Traditional cooling relies on manually set heuristics that account for server heat output, external weather conditions, and architectural constraints. These systems exhibit nonlinear interactions, so simple rule-based optimizations often fail to capture the full complexity of their operations. The result was suboptimal cooling efficiency, leading to unnecessary energy waste.
DeepMind’s team trained a neural network model using Google’s historical sensor data, which included real-time temperature readings, power consumption levels, cooling pump activity, and other operational parameters. Building on Jim Gao’s earlier work demonstrating that machine learning could predict data center PUE with 99.6 percent accuracy (Gao 2014), the model learned the intricate relationships between these factors and could dynamically predict the most efficient cooling configurations. Unlike traditional approaches that relied on human engineers periodically adjusting system settings, the AI model continuously adapted in real time to changing environmental and workload conditions.
Gao, J. 2014. Machine Learning Applications for Data Center Optimization. Google; Google White Paper.
19 PUE Optimization via ML: Google’s best facilities achieve PUE 1.08, meaning only 8 percent energy overhead for cooling and power distribution. DeepMind’s reinforcement-learning controller reduced cooling energy by 40 percent by exploiting nonlinear interactions between chillers, pumps, and ambient conditions that rule-based systems miss. This is a rare positive feedback loop where AI improves the efficiency of the infrastructure that powers AI.
Barroso, Luiz André, Urs Hölzle, and Parthasarathy Ranganathan. 2019. The Datacenter as a Computer: Designing Warehouse-Scale Machines. Synthesis Lectures on Computer Architecture. Springer International Publishing. https://doi.org/10.1007/978-3-031-01761-2.
Evans, Richard, and Jim Gao. 2016. DeepMind AI Reduces Google Data Centre Cooling Bill by 40%. DeepMind Blog.
The results demonstrated significant efficiency gains. When deployed in live data center environments, DeepMind’s AI-driven cooling system reduced cooling energy consumption by 40 percent, leading to an overall 15 percent improvement in PUE19 (Barroso et al. 2019; Evans and Gao 2016). For a facility operating at the industry-average PUE of 1.5 from equation 2, a 15 percent improvement reclaims a substantial fraction of the energy lost to cooling overhead. These improvements were achieved without additional hardware modifications, demonstrating the potential of software-driven optimizations to reduce AI’s carbon footprint.
The DeepMind case study illustrates a rare positive feedback loop: machine learning optimizing the infrastructure that powers machine learning. The framework generalizes across facility designs and climate conditions, offering a scalable approach for global data center networks.
Carbon intensity and regional variation
The carbon impact of electricity consumption depends critically on the energy generation mix, quantified by carbon intensity measured in grams of CO2 equivalent per kilowatt-hour (g CO2eq/kWh). Table 1 quantifies carbon intensity by energy source, showing how dramatically these intensities vary:
| Energy Source | Carbon Intensity (g CO2eq/kWh) | Regional Examples |
|---|---|---|
| Coal | 820 to 1,200 | Poland, West Virginia |
| Natural Gas | 350 to 500 | Texas combined cycle plants |
| Solar PV | 20 to 50 | California, Arizona |
| Wind | 7 to 15 | Denmark, Scotland |
| Hydroelectric | 10 to 30 | Quebec, Norway |
| Nuclear | 5 to 20 | France, Ontario |
Geographic optimization can reduce carbon emissions by 10–50\(\times\) through strategic training location selection, as figure 7 illustrates across representative regions.

Systematic energy metrics
Quantifying energy efficiency requires systematic metrics that enable comparison across hardware architectures and algorithmic approaches. The metric ladder moves from energy per operation to energy per byte and then to the roofline relationship between arithmetic intensity and data movement. That progression matters because an optimization that reduces FLOPs may do little for a workload whose energy is spent moving bytes.
Energy per operation
The fundamental metric for computational energy efficiency is energy consumed per operation, typically measured in picojoules. For AI workloads, the most relevant metrics are energy per floating-point operation and energy per multiply-accumulate, where one MAC operation performs both a multiplication and addition, equivalent to two FLOPs.
Hardware architecture determines energy efficiency across orders of magnitude, spanning nearly four orders of magnitude from general-purpose CPUs to specialized analog accelerators. Table 2 quantifies energy efficiency by architecture:
| Architecture | Energy Efficiency (pJ/FLOP or pJ/MAC) | Characteristics |
|---|---|---|
| CPU (general) | 100 pJ/FLOP | Low utilization, high flexibility |
| GPU (tensor cores) | 10 pJ/FLOP | High throughput, parallel execution |
| TPU (systolic array) | 1-2 pJ/FLOP | Specialized matrix operations, optimized dataflow |
| Google Edge TPU | 2-4 pJ/FLOP | On-device inference, INT8 optimized |
| ARM Ethos-U55 | 0.5-2 pJ/MAC | Microcontroller NPU, sub-watt TinyML |
| Maxim MAX78000 | 0.3-1 pJ/MAC | CNN accelerator with local weight storage |
| ASIC (INT8) | 0.1 pJ/operation | Fixed-function, low precision |
| Analog/In-Memory Compute | 0.01-0.1 pJ/MAC | Emerging technology, compute in memory array |
The four-order-of-magnitude spread reflects both circuit-level efficiency and architectural choices affecting utilization. CPUs execute diverse instruction mixes with low average utilization of arithmetic units. GPUs achieve higher utilization through massive parallelism. TPUs and ASICs maximize utilization through specialized datapaths optimized for specific operation types.
Precision directly affects energy per operation. INT8 integer arithmetic consumes approximately one-sixteenth the energy of FP32 floating-point at the same frequency and voltage. This combines reduced datapath capacitance of 4\(\times\) from bit width with lower voltage requirements of 2\(\times\) from larger noise margins and simpler control logic of 2\(\times\) from reduced complexity.
Energy per byte
Data movement often dominates energy consumption in AI workloads with low arithmetic intensity. The energy cost of memory access spans five orders of magnitude across the storage hierarchy:

Per-byte move energy spans five orders, register to network.
Table 3 reveals a critical insight about memory hierarchy energy costs: moving data from DRAM consumes 10 to 100 times more energy than performing arithmetic operations. The rows trace the path from registers through L1 cache and L2 cache to DRAM, NVMe, and network transfers. For a GPU operating at 10 pJ/FLOP, accessing one FP32 operand from DRAM (4 bytes times 160 pJ/byte = 640 pJ) costs 64 times more than the computation itself. This table makes the energy hierarchy explicit.
| Memory Level | Energy Cost (pJ/byte) | Access Latency |
|---|---|---|
| Register | 0.1 pJ/byte | 1 cycle |
| L1 Cache | 1 pJ/byte | 3-5 cycles |
| L2 Cache | 5 pJ/byte | 10-20 cycles |
| DRAM | 160 pJ/byte | 200-300 cycles |
| NVMe SSD | 1000 pJ/byte | 50,000-100,000 cycles |
| Network | > 10000 pJ/byte | Millions of cycles |
The resulting design levers target movement rather than arithmetic:
- On-chip memory for data reuse (NVIDIA tensor cores with shared memory)
- Optimized data layouts minimizing DRAM access (Google TPU systolic arrays)
- Compression reducing data movement (sparse tensor representations)
Together, these levers make sustainability a locality-and-reuse problem, not only a faster-arithmetic problem.
Arithmetic intensity and energy roofline
The balance between computation and data movement determines whether energy consumption is compute-bound or memory-bound. Equation 4 defines arithmetic intensity (AI), the ratio that determines which resource dominates energy consumption. In these equations, \(O\) is the operation count in FLOPs, \(D_{\text{vol}}\) is data volume in bytes, \(E_{\text{compute}}\) is energy per FLOP, and \(E_{\text{move}}\) is energy per byte moved:
\[\text{AI} = \frac{O}{D_{\text{vol}}} \tag{4}\]
Arithmetic intensity measured in FLOP/byte determines the dominant energy consumer. Equation 5 expresses total energy as the sum of compute and memory contributions, while equation 6 isolates the roofline-style dominant term:
\[E_{\text{total}} = O \times E_{\text{compute}} + D_{\text{vol}} \times E_{\text{move}} \tag{5}\]
\[E_{\text{dominant}} = \max\left(O \times E_{\text{compute}}, D_{\text{vol}} \times E_{\text{move}}\right) \tag{6}\]
The maximum term identifies the dominant bottleneck for roofline reasoning; it is not the full energy in balanced cases. Equation 7 defines the crossover arithmetic intensity where compute and memory energy balance:
\[\text{AI}_{\text{crossover}} = \frac{E_{\text{move}}}{E_{\text{compute}}} \tag{7}\]
For a GPU with \(E_{\text{compute}}\) of 10 pJ/FLOP and \(E_{\text{move}}\) of 160 pJ/byte (DRAM access):
\[\text{AI}_{\text{crossover}} = \frac{160 \text{ pJ/byte}}{10 \text{ pJ/FLOP}} = 16 \text{ FLOP/byte}\]
The energy roofline model (figure 8) visualizes this relationship between arithmetic intensity and energy efficiency, revealing how different workload types are constrained by different bottlenecks. This energy roofline transposes the performance roofline onto the energy axis: The single-accelerator roofline derives the original ceiling and works the ridge-point analysis that separates memory-bound from compute-bound regimes, the same crossover that here divides memory-dominated from compute-dominated energy consumption.

To make this framework concrete, we can apply it to the most common operation in deep learning: matrix multiplication.
Example 1.2: MatMul energy analysis
Consider matrix multiplication \(C = A \times B\) for \(N_{\text{mat}}{\times}N_{\text{mat}}\) matrices in FP32 precision on a GPU with the energy characteristics above.
Table 4: Energy bottleneck comparison: The same energy model classifies small dense work, large dense work, and element-wise work by their dominant energy term.
Step 1: Calculate FLOPs and bytes.
- FLOPs: \(2N_{\text{mat}}^3\) (one multiply-add for each of \(N_{\text{mat}}^2\) output elements, accumulating over \(N_{\text{mat}}\) elements)
- Bytes: \(3N_{\text{mat}}^2 \times 4\) bytes (read matrices \(A\) and \(B\), write matrix \(C\), each FP32 = 4 bytes)
- Arithmetic intensity: \(\text{AI} = \frac{2N_{\text{mat}}^3}{12N_{\text{mat}}^2} = \frac{N_{\text{mat}}}{6}\) FLOP/byte
Step 2: Determine the energy-limiting factor. Table 4 compares the three regimes directly.
| Workload | Arithmetic intensity | Compute energy | Memory energy | Optimization priority |
|---|---|---|---|---|
| Small matrix (\(N_{\text{mat}}=\) 96) | \(\text{AI} = 96/6 = 16\) FLOP/byte | \(2 \times 96^3 \times 10 \text{ pJ} = 17.69\,\mu\text{J} = 0.0177\) mJ | \(3 \times 96^2 \times 4 \times 160 \text{ pJ} = 17.69\,\mu\text{J} = 0.0177\) mJ | Balanced at the crossover |
| Large matrix (\(N_{\text{mat}} = 1000\)) | \(\text{AI} = 1000/6 = 167\) FLOP/byte | \(2 \times 10^9 \times 10 \text{ pJ} = 20\) mJ | \(3 \times 10^6 \times 4 \times 160 \text{ pJ} = 1.92\) mJ | Improve compute efficiency |
| Vector addition (\(N_{\text{vec}} = 1000\)) | \(\text{AI} = 1000/12000 = 0.083\) FLOP/byte | \(1000 \times 10 \text{ pJ} = 0.00001\) mJ | \(12000 \times 160 \text{ pJ} = 0.00192\) mJ | Reduce data movement through fusion |
Systems insight: Energy optimization follows the same bottleneck logic as latency optimization. Dense matrix multiply rewards efficient arithmetic; element-wise work rewards reducing memory movement.
The energy roofline model reveals why different optimization strategies suit different workloads. Large dense matrix operations benefit from faster arithmetic units. Memory-bound operations like element-wise kernels benefit from data layout optimization, kernel fusion to reduce memory round-trips, and on-chip memory utilization. This framework guides architectural and algorithmic choices for sustainable AI system design.
Energy measurement techniques
Quantifying AI system energy consumption requires measurement at multiple levels of the hardware stack, from chip-level instrumentation to facility-wide monitoring. The method choice is itself an engineering trade-off: hardware counters provide fine attribution, mobile profilers expose platform-specific subsystems, edge instruments capture duty-cycle behavior, and system-level tools connect component measurements to the facility overhead that component counters miss.
Hardware power counters
Modern processors include dedicated circuitry for power measurement that software can query through manufacturer-provided interfaces. These hardware counters measure actual power draw rather than estimating from activity, providing ground-truth energy consumption data at microsecond resolution.
Intel’s Running Average Power Limit (RAPL) interface exposes energy measurements for CPU packages, DRAM, and integrated graphics through model-specific registers (MSRs). RAPL reports cumulative energy, so the measurement pattern is boundary based: sample the counter before a controlled workload region, run the workload, sample it again, and divide the energy delta by elapsed time to recover average power. This makes RAPL useful for CPU preprocessing, data loading, and host-side training work, but it also defines its boundary. RAPL does not cover discrete GPU energy, can require elevated permissions, and must be interpreted with awareness of package scope and counter rollover.
NVIDIA GPUs expose power measurements through the NVIDIA Management Library (NVML), accessible via the nvidia-smi command-line tool or programmatic bindings. GPU power monitoring usually starts with instantaneous power draw, which can vary significantly during computation because dynamic voltage and frequency scaling changes the device state from one kernel to the next. A reliable measurement therefore treats the inference or training interval as a trace: synchronize the workload boundary, sample power at a fixed cadence, integrate those samples over time, and report both average and peak power. When data-center GPUs expose accumulated energy counters, those counters are preferable because they avoid aliasing short kernels between samples.
Edge devices and microcontrollers present a different measurement problem. They often lack built-in power counters, operate at milliwatt rather than kilowatt scales, and require external instrumentation for accurate energy profiling. The relevant decision is how much temporal resolution, rail attribution, and cost the workload justifies. INA219 and INA226 I2C-based current sensors provide affordable measurement for development and validation, sampling at rates sufficient to capture inference-level energy consumption. For research requiring nanosecond-resolution measurements of individual operations, instruments like the Joulescope JS220 measure current from sub-microamp sleep states through ampere-level active peaks, enabling characterization of the full dynamic range of edge AI workloads. For large TinyML fleets, edge energy measurement becomes essential for comprehensive sustainability assessment because small per-device errors compound across deployment scale.
Mobile platform energy profiling
On mobile platforms, measurement depends on how much attribution the platform exposes. The available profilers trade direct wattage for per-component diagnostic value:
- Android PowerStats HAL: Provides per-component power attribution for CPU, GPU, NPU, and radio subsystems, enabling developers to identify which model operations dominate energy consumption.
- Qualcomm Trepn Profiler: Offers millisecond-resolution power measurement on Snapdragon platforms, correlating power traces with code execution for NPU workload optimization.
- ARM Streamline: Provides energy-annotated profiling for Cortex-A and Mali GPU platforms, enabling identification of inefficient kernel implementations.
- Apple Instruments Energy Log: Reports thermal state and energy impact scores for iOS applications, though without direct wattage measurements.
Mobile profiling tools integrate with development workflows, enabling iterative optimization of on-device inference energy consumption during model deployment. Table 5 summarizes edge power measurement instruments across platforms, including resolution, accuracy, and integration requirements.
| Instrument | Resolution | Accuracy | Use Case |
|---|---|---|---|
| INA219/INA226 | 100 microsecond sampling | plus or minus 1% | Low-cost embedded profiling |
| PAC1934 | 1 millisecond, 4 channels | plus or minus 2% | Multi-rail MCU measurement |
| Joulescope JS220 | Sub-microsecond, nanoamp range | plus or minus 0.1% | Professional TinyML benchmarking |
| Otii Arc Pro | 10 microsecond, automation | plus or minus 0.5% | Automated battery life testing |
Edge measurement methodology
Edge energy measurements are useful only when they reflect the deployed duty cycle, not a best-case active inference run. Reproducible results require four controls:
- Baseline characterization: Measure idle power consumption across all sleep states, as baseline power can vary from 1 microamp in deep sleep to 1 milliamp in idle active states on typical microcontrollers.
- Warm-up period: Execute 100 or more inference iterations before measurement to reach thermal equilibrium, as initial iterations may exhibit different power characteristics due to cache warming and voltage regulator settling.
- Duty cycle accounting: Report both peak inference power and average power at realistic duty cycles, because edge devices typically operate with significant idle periods between inferences.
- Peripheral isolation: Disable or account for peripheral power consumption, such as sensors, radios, and displays, when measuring model inference energy, because these can dominate total system power.
For duty cycle accounting, equation 8 expresses the relationship between active and idle power:
\[P_{\text{average}} = P_{\text{active}} \times \delta_{\text{duty}} + P_{\text{idle}} \times (1 - \delta_{\text{duty}}) \tag{8}\]
where \(\delta_{\text{duty}}\) is the duty cycle (fraction of time performing inference).
System-level energy profiling
Comprehensive energy accounting requires combining chip-level measurements with infrastructure overhead. Equation 9 formalizes total energy as the sum of component contributions scaled by facility overhead:
\[E_{\text{total}} = (E_{\text{CPU}} + E_{\text{GPU}} + E_{\text{memory}} + E_{\text{network}}) \times \text{PUE} \tag{9}\]
No single counter spans the full energy path, so system-level profilers like Intel VTune, NVIDIA Nsight Systems, and open-source tools such as PowerJoular aggregate measurements across components. For production deployments, smart power distribution units (PDUs) at the rack level provide facility-verified measurements that include cooling overhead.
Equation 10 expresses the relationship between measured component power and total facility energy:
\[P_{\text{facility}} = P_{\text{IT}} \times \text{PUE} = (P_{\text{servers}} + P_{\text{network}} + P_{\text{storage}}) \times \text{PUE} \tag{10}\]
For a cluster consuming 1 MW of IT power in a facility with PUE of 1.4, total facility power consumption reaches 1.4 MW, with the additional 400 kW powering cooling, power conversion, and infrastructure systems. That automatic 40 percent overhead on all computational power highlights the critical role of facility efficiency. However, operational power consumption is only one piece of the equation; to capture the true environmental cost of our systems, we must formalize how we convert raw kilowatts into tons of carbon emissions.
Self-Check: Question
A profiling run on an accelerator with approximately 10 pJ per FLOP of compute energy and approximately 100 pJ per byte of DRAM energy reports an arithmetic intensity of 3 FLOP/byte for an attention kernel. Which optimization family is most likely to move this workload closer to the energy roofline?
- Replacing the accelerator with one that advertises 2\(\times\) the peak FLOP/s per watt while keeping the memory subsystem unchanged, because raising the compute ceiling always lowers energy.
- Fusing operators and tiling to keep intermediate activations in on-chip SRAM, because the kernel sits far to the left of the energy crossover at about 10 FLOP/byte and pays most of its joules in DRAM traffic.
- Prioritizing a PUE reduction on the facility because chip-level bottlenecks do not affect per-query energy.
- Raising numerical precision from FP16 to FP32, because higher precision does more useful work per byte read.
A 2 MW cluster drops its PUE from 1.58 to 1.10 without changing any model code or hardware SKU. Explain why the chapter counts this as a first-order sustainability intervention, and quantify roughly what the facility saves per year.
An engineer must profile energy for a battery-powered microcontroller running a wake-word detector that sleeps most of the second. The device has no internal power counters and draws microwatts during deep sleep. Which measurement approach best matches the section’s edge methodology?
- Sample a tool such as nvidia-smi at 10 Hz and integrate the series, because server-grade sampling tools work across platforms.
- Use an external current-sense monitor such as an INA219 or Joulescope, sample at a rate that resolves the active burst and deep-sleep transitions, and explicitly account for duty cycle, warm-up, and peripherals.
- Estimate total energy by multiplying parameter count by a fixed J-per-parameter constant, because compute energy is the dominant term in TinyML.
- Rely on CPU-package RAPL counters, because they generalize from server CPUs to microcontroller-class devices.
A facility reports 4.2 MW of compute IT load and 6.3 MW of total site draw over the same hour. The sustainability team wants a single scalar that captures how much the non-IT infrastructure contributes to the total, so they can compare the site to peers year over year. Which metric gives them exactly that ratio, and what does a drop in it imply?
- Grid carbon intensity; a drop means the grid has decarbonized.
- Arithmetic intensity; a drop means the workload has become more memory-bound.
- PUE, computed as 6.3 / 4.2 = 1.5; a drop means every joule of useful IT work now carries less cooling and power-distribution overhead.
- Model FLOPs utilization; a drop means the accelerators are underused.
A profiling sweep across a training workload shows element-wise normalization and activation kernels spending roughly 8\(\times\) more joules on HBM reads than on arithmetic. The service owner proposes four follow-ups. Which best matches the energy model this section develops?
- Upgrading to a newer accelerator with 2\(\times\) peak tensor-core FLOP/s, because more FLOP/s always lowers total energy per step.
- Fusing the normalization and activation into adjacent matrix-multiply kernels so intermediate tensors stay in on-chip SRAM and round-trips to HBM collapse.
- Ignoring the kernel and investing only in carbon-aware scheduling, because chip-level energy is negligible once the grid is considered.
- Raising numerical precision to FP32 to make each byte of DRAM carry more useful arithmetic.
A team proposes to report total AI system energy as the simple sum of CPU, GPU, memory, and network component measurements. Explain why the section rejects this accounting and what form the corrected total must take.
Carbon Footprint Calculation
Consider a data center running on 100 percent renewable hydroelectric power. Its operational carbon emissions are effectively zero, but AI trained there is not carbon-free. Mining the silicon, manufacturing the GPUs, and pouring the concrete for the data center released thousands of tons of CO2 before the servers were ever turned on. A true carbon footprint calculation must account for both the energy consumed during operation and the “embodied carbon” emitted during construction.
The lifecycle notebook in section 1.1.1 already computed operational, embodied, and total carbon for one 70B run. This section turns that worked example into the formal accounting model: equations for each term that generalize across workloads, grids, and amortization assumptions rather than a single numeric answer.
Operational carbon calculation
Operational carbon emissions result from electricity consumption during training and inference, scaled by grid carbon intensity. Equation 11 quantifies this as the product of energy, grid carbon intensity, and facility overhead:
\[C_{\text{operational}} = E_{\text{total}} \times \text{CI}_{\text{grid}} \tag{11}\]
where \(E_{\text{total}}\) is the facility-level energy from equation 9 (component energy already scaled by \(\text{PUE}\)) and \(\text{CI}_{\text{grid}}\) is the carbon intensity of the electricity grid. The facility overhead enters once, through \(E_{\text{total}}\), so it does not appear again in the carbon equation. A concrete training emissions calculation illustrates this framework.
Example 1.3: Training emissions calculation
Consider training a 7 billion parameter model on 64 A100 GPUs for 14 days:
Step 1: Compute energy.
- GPU power: 400 W per A100 at typical training utilization
- Training time: 14 days \(\times\) 24 h/day = 336 hours
- GPU energy: 64 \(\times\) 400 W \(\times\) 336 hours = 8,601,600 Wh = 8,601.6 kWh
Step 2: Add IT support power and apply PUE.
- IT energy after rack-profile support load: 11,827.2 kWh
- Facility PUE: 1.12 (efficient hyperscale data center)
- Total facility energy: 11,827.2 kWh \(\times\) 1.12 = 13,246.5 kWh
Step 3: Calculate emissions.
- Grid carbon intensity: 429 g/kWh CO2 (US average)
- Operational emissions: 13,246.5 kWh \(\times\) 429 g/kWh = 5682.7 kg = 5.7 t
Analysis: Same training in low-carbon region.
- Quebec grid intensity: 20 g/kWh (low-carbon grid)
- Emissions: 13,246.5 kWh \(\times\) 20 g/kWh = 264.9 kg
Systems insight: The geographic choice alone produces a 21.5× difference in training emissions. Carbon-aware placement changes the environmental cost without changing the model architecture.
Embodied carbon assessment
As figure 9 illustrates, operational energy dominates total cost of ownership for typical deployments, but embodied carbon from semiconductor fabrication becomes the binding constraint as the grid shifts to renewables.

The key insight from figure 9 is the shifting bottleneck: as grids decarbonize, embodied carbon from chip fabrication and data center construction can become the dominant term, making hardware utilization and longevity first-order sustainability levers.
Embodied carbon encompasses emissions from raw material extraction, semiconductor fabrication, assembly, transportation, and end-of-life disposal. For AI hardware, manufacturing emissions are dominated by the energy-intensive nature of advanced semiconductor processes.
Advanced-node AI accelerators carry substantial manufacturing footprints: an NVIDIA A100 GPU embodies approximately 150 kg CO2eq per unit (Luccioni et al. 2023), and NVIDIA’s HGX H100 product carbon footprint implies roughly 164 kg CO2e per H100 when the baseboard footprint is allocated evenly across its eight GPUs (NVIDIA Corporation 2025), including wafer fabrication at advanced process nodes, high-bandwidth memory production, and packaging. Equation 12 amortizes this embodied carbon over the hardware lifetime to compute per-use emissions:
\[C_{\text{embodied,daily}} = \frac{C_{\text{manufacturing}}}{T_{\text{lifetime}} \times 365} \tag{12}\]
Understanding how embodied carbon accumulates over time reveals why hardware utilization and lifetime dominate total lifecycle emissions.
Systems Perspective 1.1: Embodied carbon amortization
A hidden cost emerges when renting a GPU for an hour: the fee does not cover electricity alone but also amortizes the carbon debt of manufacturing.
The embodied-carbon amortization formula makes that allocation explicit: \[C_{\text{total}} = C_{\text{operational}} + \left( \frac{C_{\text{manufacturing}}}{T_{\text{lifetime,years}} \times 365 \times 24} \times T_{\text{job,hours}} \right)\]
Scenario: Training a model for 10 hours on 8 NVIDIA H100s.
- Operational: 8 \(\times\) 0.7 kW \(\times\) 10 hours = 56 kWh. At 0.429 kg/kWh (US-average grid) = 24 kg.
- Embodied: 8 \(\times\) 164 kg = 1312 kg.
- Amortization: Lifetime = 3 years (26280 hours).
- Hourly “Rent” = 1312 kg / 26280 hours \(\approx\) 0.050 kg/h.
- Job Cost = 0.050 kg/h \(\times\) 10 hours = 0.5 kg.
Systems insight: For long-lived hardware in dirty grids, electricity dominates (24 kg vs. 0.5 kg). However, in clean grids (hydro, 0.020 kg/kWh), operational drops to 1.1 kg, making embodied carbon a significant fraction (~30.8 percent) of the total footprint.
This worked example assumes a 4-year service life, slightly longer than the 3-year amortization window used in the lifecycle estimate above; the assumption matters because a longer life spreads the same manufacturing carbon over more service, lowering the per-job share. For an accelerator with 150 kg embodied carbon (per NVIDIA’s product carbon footprint) and that 4-year data center lifetime, the first step is daily amortization: 150 kg / (4 years \(\times\) 365 d/year) \(\approx\) 0.103 kg/day.
The second step assigns that daily share to the job. A training run lasting 14 days on 64 accelerators carries 64 \(\times\) 14 days \(\times\) 0.103 kg \(\approx\) 92.1 kg CO2 of amortized embodied carbon.
The embodied contribution of 92.1 kg represents approximately 1.6 percent of the operational emissions (5682.7 kg) calculated above for the US average grid. If training occurred in Quebec’s low-carbon grid, where the same run produced 264.9 kg of operational emissions, the embodied contribution would be about 25.8 percent of total emissions.
Lifecycle carbon accounting
Complete lifecycle assessment combines operational and embodied emissions across all phases. Equation 13 aggregates these contributions:
\[C_{\text{lifecycle}} = C_{\text{training}} + C_{\text{inference}} + C_{\text{embodied}} \tag{13}\]
As figure 10 shows, training dominates this single-deployment lifecycle snapshot, while manufacturing and inference remain significant factors.

That single-deployment snapshot in figure 10 tells only part of the story. The cumulative picture is the opposite: a model serving millions of queries per day can exceed its entire training carbon footprint within months, or within days for higher-traffic services, making inference optimization the highest-impact sustainability intervention for production systems over a model’s service life.

Cumulative inference emissions overtake the one-time training cost.
For models deployed at scale, inference emissions often dominate the lifecycle. Consider a model serving 10 million queries per day at 0.001 kWh per query. The annual inference energy and emissions break down as follows:
- Daily energy: 10 million queries \(\times\) 0.001 kWh = 10,000 kWh
- Annual energy: 10,000 kWh \(\times\) 365 d/year = 3,650,000 kWh
- Annual emissions (US grid): 3,650,000 kWh \(\times\) 0.429 kg/kWh = 1,565,850 kg = 1565.9 t
Compared with the 7B/64-A100 training example above (5.7 t), cumulative inference emissions exceed training emissions after approximately 1.3 days of deployment at this scale. For larger training runs, the crossover can shift to weeks or months depending on query volume, per-query energy, and grid intensity. The lifecycle perspective therefore sets the priority: optimize inference efficiency for widely-deployed models, and focus training efficiency efforts on models that undergo frequent retraining or experimental iteration.
Regional grid intensity data sources
Accurate carbon accounting requires grid intensity data matched to the decision being made. Real-time carbon intensity varies with generation mix, which changes hourly based on demand, renewable availability, and plant dispatch decisions. The data source choice depends on whether the team is estimating a future job, scheduling a live workload, or auditing a completed run.
The US Energy Information Administration (EIA) publishes historical grid emissions factors by region, updated annually. For prospective analysis, these annual averages provide reasonable estimates. ElectricityMap and WattTime provide real-time carbon intensity APIs covering major grids worldwide, enabling carbon-aware scheduling systems. For retrospective analysis of completed training runs, hourly marginal emissions data from these sources enables accurate attribution. Listing 1 implements a lifecycle carbon calculator that integrates energy measurements with grid intensity data:
def calculate_carbon_footprint(
gpu_power_watts: float,
num_gpus: int,
training_hours: float,
pue: float,
grid_intensity_gco2_kwh: float,
gpu_embodied_kg: float,
gpu_lifetime_years: float,
) -> dict:
"""Calculate lifecycle carbon footprint for a training run."""
# Operational emissions
energy_wh = gpu_power_watts * num_gpus * training_hours
energy_kwh = (energy_wh * watt * hour).to(kWh).magnitude
facility_energy_kwh = energy_kwh * pue
# g CO2 → kg (mlsysim does not export mass pint units yet).
operational_kg = (
facility_energy_kwh * grid_intensity_gco2_kwh / THOUSAND
)
# Embodied emissions (amortized)
daily_embodied = gpu_embodied_kg / (gpu_lifetime_years * 365)
training_days = training_hours / 24
embodied_kg = num_gpus * training_days * daily_embodied
return {
"energy_kwh": facility_energy_kwh,
"operational_carbon_kg": operational_kg,
"embodied_carbon_kg": embodied_kg,
"total_carbon_kg": operational_kg + embodied_kg,
"embodied_fraction": embodied_kg
/ (operational_kg + embodied_kg),
}
# Example: 7B model training
_us_grid = Infrastructure.Grids.US_Avg
result = calculate_carbon_footprint(
gpu_power_watts=400,
num_gpus=64,
training_hours=336, # 14 days
pue=_us_grid.pue,
grid_intensity_gco2_kwh=_us_grid.carbon_intensity_g_kwh,
gpu_embodied_kg=164,
gpu_lifetime_years=4,
)
print(
f"Total carbon footprint: {result['total_carbon_kg']:.0f} kg CO2"
)
print(f"Embodied fraction: {result['embodied_fraction']:.1%}")Teams can integrate total lifecycle carbon accounting directly into their orchestration dashboards using this programmatic approach. Calculating operational and embodied emissions for individual training runs, however, captures only one dimension of the problem. The macro-level patterns of how dense AI data centers consume resources at scale reveal additional constraints and optimization opportunities.
Self-Check: Question
Two engineers disagree about how to report the carbon footprint of a training run that used leased GPUs in a hydro-powered region. Which framing correctly separates operational and embodied carbon per this section’s equations?
- Operational carbon is the manufacturing and shipping footprint of the GPUs, while embodied carbon is the grid electricity used while training.
- Operational carbon is the electricity used during training and inference multiplied by grid intensity and facility PUE, while embodied carbon is the pre-use footprint of hardware and construction amortized over useful lifetime.
- Operational carbon applies only to cloud training, while embodied carbon applies only to on-premises hardware.
- Operational carbon is a concern only on fossil-heavy grids, while embodied carbon is a concern only for edge devices.
A team moves a training run from a fossil-heavy grid at roughly 800 gCO2/kWh to a hydro-powered grid at roughly 20 gCO2/kWh. They are surprised when their sustainability dashboard shows embodied carbon becoming the dominant term rather than operational. Explain the mechanism that causes this inversion and what it implies for hardware decisions.
True or False: A model trained in a datacenter powered 100 percent by hydroelectricity can honestly be reported as having a zero carbon footprint for its training run.
A deployed model serves 10 million queries per day at 0.001 kWh per query. Its single training run consumed 1,287 MWh. Using the section’s lifecycle reasoning, what is the most important accounting consequence?
- Training still dominates because a training run uses specialized accelerators at higher per-chip peak power than serving.
- Embodied carbon can be ignored because inference energy is metered daily.
- Cumulative serving energy can exceed the one-time training energy within months — 10 million queries at 0.001 kWh is 10 MWh per day, so the 1,287 MWh training is matched in roughly 130 days — making inference efficiency the highest-impact production lever.
- The main optimization target should be compressing training time even if it raises per-query inference energy.
Order the following steps of a lifecycle carbon estimate for a training run: (1) amortize hardware manufacturing and construction emissions over device lifetime to compute the run’s embodied share, (2) compute total facility energy from IT energy and PUE, (3) aggregate operational and embodied components into the lifecycle total, (4) convert operational energy to operational carbon by multiplying by grid carbon intensity.
Data Center Energy and Resource Consumption
When a traditional web server handles an HTTP request, the CPU briefly spikes to 20 percent utilization and immediately returns to idle. When a GPU cluster trains a foundation model, thousands of processors run at 100 percent utilization, drawing maximum power continuously for three straight months. This unprecedented, unyielding thermal density fundamentally breaks traditional data center design, forcing engineers to adopt liquid cooling and redesign entire power distribution networks.
Facility sustainability therefore has to be read as a chain of constraints rather than as a single PUE number. Persistent megawatt demand sets the grid and emissions exposure, power delivery determines how much electricity becomes useful IT load, cooling determines whether dense racks can operate without throttling, and water use determines whether a technically efficient site is locally sustainable.
Data center energy and AI workloads
At facility scale, the optimization target is no longer a single model but the overhead and grid context surrounding every watt of IT power. Data center energy efficiency varies significantly across facilities, so the same IT workload can impose different facility and carbon costs. Power Usage Effectiveness ranges from 1.1 in Google’s most efficient facilities to 2.5 in typical enterprise data centers, effectively doubling energy consumption through infrastructure overhead. Geographic location also impacts carbon intensity: the same model trained on a hydro-heavy grid can have tens-fold lower operational emissions than one trained on a coal-heavy grid under the representative intensities used earlier. Without access to renewable energy, these facilities rely heavily on nonrenewable sources such as coal and natural gas, contributing to global carbon emissions. In its 2025 Energy and AI analysis, IEA estimated data-center electricity-use emissions at about 180 Mt and projected roughly 300 Mt by 2035 in its Base Case while remaining below 1.5 percent of total energy-sector emissions.20 The energy burden of AI can grow with data center capacity, training workloads, and inference demand (Patterson et al. 2021). Without intervention, these trends risk making AI’s environmental footprint unsustainably large (Thompson et al. 2023; Dodge et al. 2022).
20 Data Center Emissions Scale: In IEA’s 2025 Energy and AI analysis, data centers consumed roughly 1–2 percent of global electricity, with AI contributing to demand growth. IEA estimated emissions from data-center electricity use at about 180 Mt and projected around 300 Mt by 2035 in its Base Case while remaining below 1.5 percent of total energy-sector emissions. The largest hyperscale facilities can draw over 100 MW continuously, equivalent to powering tens of thousands of homes.
Thompson, Neil, Tobias Spanuth, and Hyrum Anderson Matthews. 2023. “The Computational Limits of Deep Learning and the Future of AI.” Communications of the ACM 66 (3): 48–57.
Dodge, Jesse, Taylor Prewitt, Remi Tachet des Combes, Erika Odmark, Roy Schwartz, Emma Strubell, Alexandra Sasha Luccioni, Noah A. Smith, Nicole DeCario, and Will Buchanan. 2022. “Measuring the Carbon Intensity of AI in Cloud Instances.” 2022 ACM Conference on Fairness Accountability and Transparency, 1877–94. https://doi.org/10.1145/3531146.3533234.
Energy demands in data centers
The relevant facility quantity is persistent megawatt-class load, not the model name alone. Companies such as Meta operate hyperscale data centers spanning multiple football fields in size, housing large fleets of AI-optimized servers.21 Unofficial estimates have suggested GPT-4 may have used on the order of tens of thousands of A100-class GPUs for months (SemiAnalysis 2023), but OpenAI has not disclosed GPT-4’s hardware, training compute, model size, or training duration. These facilities rely on high-performance AI accelerators such as NVIDIA H100 GPUs, whose architecture targets high-throughput tensor workloads and improved performance per watt over prior generations (Choquette 2023). Lower-precision methods can improve compute and memory efficiency by replacing full-precision arithmetic when model accuracy permits (Gholami et al. 2021).
21 Hyperscale Data Center Footprint: Meta’s Prineville facility spans 230,000 m² and houses over 150,000 servers; major cloud fleets consume country-scale electricity annually. These physical scales matter for sustainability because each facility’s power demand (100–300 MW) locks in decades of grid-dependency decisions that no algorithmic optimization can undo.
SemiAnalysis. 2023. GPT-4 Architecture, Infrastructure, Training Dataset, Costs, Vision, MoE. SemiAnalysis Blog.
Choquette, Jack. 2023. “NVIDIA Hopper H100 GPU: Scaling Performance.” IEEE Micro 43 (3): 9–17. https://doi.org/10.1109/mm.2023.3256796.
Gholami, Amir, Sehoon Kim, Zhen Dong, Zhewei Yao, Michael W. Mahoney, and Kurt Keutzer. 2021. “A Survey of Quantization Methods for Efficient Neural Network Inference.” arXiv Preprint arXiv:2103.13630 abs/2103.13630: 291–326. https://doi.org/10.1201/9781003162810-13.
AI’s rapid adoption across industries drives this dramatic energy consumption. Figure 11 illustrates a high-growth scenario in which AI workloads add materially to total data center energy demand after 2024. Masanet et al. (2020) show why this scenario should be read against the historical context: efficiency gains have previously moderated data center energy growth, but sustained demand growth can erode that offset.
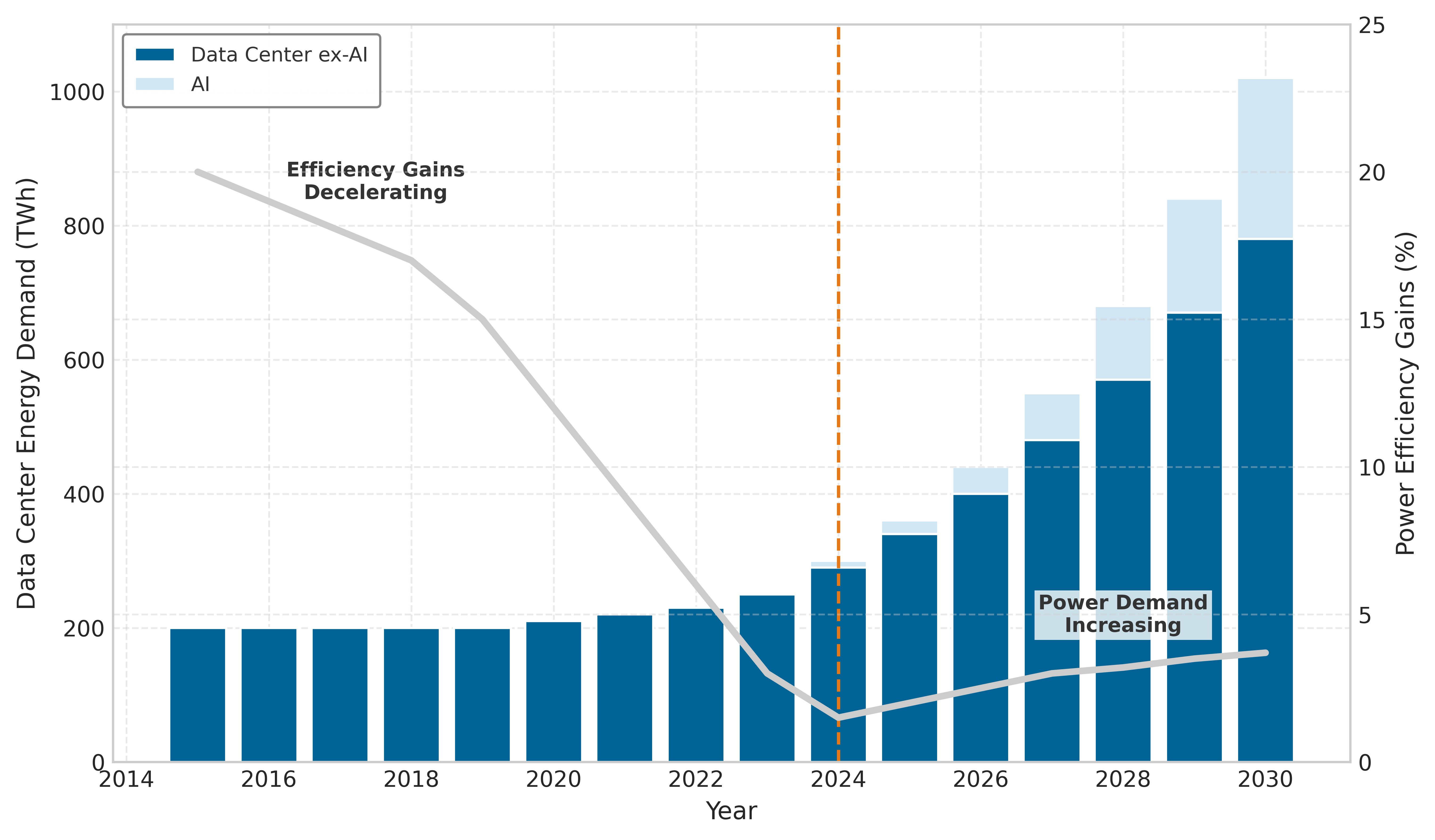
Masanet, Eric, Arman Shehabi, Nuoa Lei, Sarah Smith, and Jonathan Koomey. 2020. “Recalibrating Global Data Center Energy-Use Estimates.” Science 367 (6481): 984–86. https://doi.org/10.1126/science.aba3758.
Beyond computational demands, cooling accounts for 30–40 percent of data center energy consumption (Ebrahimi et al. 2014), as discussed in section 1.3.6.
Ebrahimi, K., G. F. Jones, and A. S. Fleischer. 2014. “A Review of Data Center Cooling Technology, Operating Conditions and the Corresponding Low-Grade Waste Heat Recovery Opportunities.” Renewable and Sustainable Energy Reviews 31: 622–38. https://doi.org/10.1016/j.rser.2013.12.007.
While figure 11 projects global trends, the United States alone illustrates how cloud and AI infrastructure can reshape national energy planning. Figure 12 presents US data center electricity consumption data from the Lawrence Berkeley National Laboratory (LBNL), showing that consumption tripled from 58 TWh in 2014 to 176 TWh in 2023. LBNL’s projection treats AI workloads as an important driver of further growth and projects a doubling or tripling by 2028, with the high-end scenario implying that data centers would consume approximately 12 percent of US electricity. This trajectory represents a physical constraint on AI scaling that software optimization alone cannot remove.
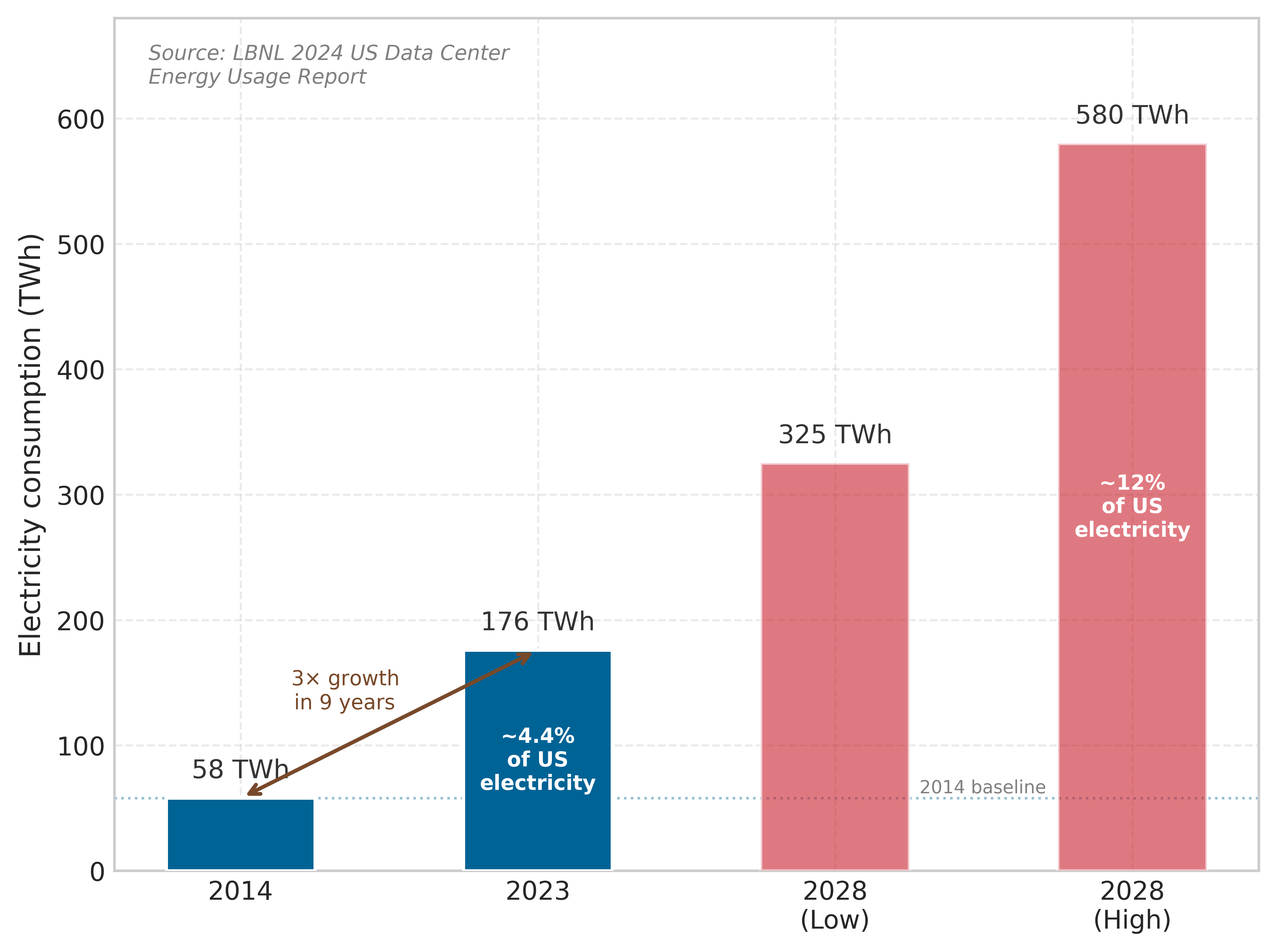
Distributed systems energy optimization
Large-scale AI training inherently requires distributed systems coordination, creating additional energy overhead that compounds computational demands. The parallelism strategies examined in Distributed Training introduce network communication costs that can account for 20–40 percent of total energy consumption in large clusters.22 This coordination across thousands of GPUs requires constant synchronization of computational updates and model parameters23, generating data movement between nodes. This communication overhead scales poorly: increasing cluster size can increase networking energy superlinearly for all-to-all communication patterns in gradient aggregation.
22 Parallelism Energy Overhead: Data, model, and pipeline parallelism each impose distinct communication patterns with different energy costs. Data parallelism broadcasts gradients (bandwidth-bound); model parallelism exchanges activations every layer (latency-bound); pipeline parallelism introduces bubble overhead (utilization-bound). GPT-3 combined all three, and the choice of parallelism strategy can swing total training energy by 20–40 percent for the same model.
23 Gradient Synchronization Energy Cost: Ring-allreduce scales communication linearly with message size but requires every node to participate, meaning one slow node wastes energy across the entire ring. At scale, gradient compression (1-2 bit quantization) can reduce network energy by 10–50\(\times\) per synchronization step, but introduces statistical noise that may require additional training iterations, partially offsetting the savings.
Addressing these communication overheads, cluster-wide energy optimization requires coordinated resource management that extends beyond individual server efficiency. Four operational levers move the energy budget at cluster scale:
- Dynamic workload placement: Consolidate training jobs onto fewer nodes during low-demand periods, allowing unused hardware to enter low-power states and achieving 15–25 percent energy savings.
- Intelligent scheduling: Coordinate training across multiple data centers so time-zone differences and regional renewable availability reduce carbon intensity by 30–50 percent through temporal load balancing.
- Multi-tenant sharing: Share clusters across model training jobs to improve GPU utilization from typical 40–60 percent to 80–90 percent, effectively halving energy consumption per model trained.
- Batch processing: Combine multiple smaller training jobs to use available compute capacity more effectively, reducing the energy overhead of maintaining idle infrastructure.
The common pattern is utilization discipline: the system saves energy by avoiding powered-on capacity that performs no useful model work.
Carbon benchmarks across AI workloads
The environmental impact of AI workloads has emerged as a concern, with carbon emissions approaching levels comparable to established carbon-intensive sectors. Strubell et al. made this concern concrete by estimating that development-scale training and architecture search for a large NLP model could emit as much carbon as several passenger vehicles over their lifetimes (Strubell et al. 2019). Patterson et al. later showed that the most widely quoted architecture-search estimate depended strongly on proxy-task, hardware, data-center efficiency, and grid carbon-intensity assumptions (Patterson et al. 2021). To contextualize AI’s environmental footprint, larger and more accurate BERT-family models carry meaningfully higher per-query carbon (figure 13). The scatter shows that the highest-accuracy variants sit near the top-right of the plot and that the carbon cost rises faster than the accuracy gain. The same trade-off underscores the need for more sustainable AI practices.24
24 Neural Architecture Search (NAS) Carbon Cost: The roughly 284,000 kg CO2e figure from Strubell et al. (2019) is the original Evolved Transformer NAS estimate, not the cost of training one final model. Patterson et al. (2021) later showed that the estimate drops sharply when the search’s proxy-task setup, Google’s TPU hardware, data-center efficiency, and grid mix are accounted for. The systems lesson is boundary discipline: search, tuning, and failed trials belong inside the accounting boundary, but reusable architecture search should be amortized across the models and domains that reuse the discovered design. This concern helped motivate efficient NAS work: weight sharing, continuous relaxations, and hardware-aware search reduce the search budget, so the meta-optimization of how we search for architectures is itself a sustainability lever (Elsken et al. 2019).
Strubell, Emma, Ananya Ganesh, and Andrew McCallum. 2019. “Energy and Policy Considerations for Deep Learning in NLP.” Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 3645–50. https://doi.org/10.18653/v1/p19-1355.
Patterson, David, Joseph Gonzalez, Quoc Le, Chen Liang, Lluis-Miquel Munguia, Daniel Rothchild, David So, Maud Texier, and Jeff Dean. 2021. “Carbon Emissions and Large Neural Network Training.” arXiv Preprint arXiv:2104.10350.
Elsken, Thomas, Jan Hendrik Metzen, and Frank Hutter. 2019. “Neural Architecture Search.” In The Springer Series on Challenges in Machine Learning, vol. 20. Springer International Publishing. https://doi.org/10.1007/978-3-030-05318-5_3.

The training phase of large natural language processing models can produce carbon dioxide emissions comparable to hundreds of transcontinental flights. At the broader industry scale, AI and data-center emissions are growing rapidly, but the IEA-scale estimates in this chapter do not yet support a direct parity claim with commercial aviation. As AI applications scale to serve billions of users globally, the cumulative emissions from continuous inference operations may ultimately exceed those generated during training.
The operational lesson is that carbon estimates must separate training-only results from deployed inference. Figure 14 provides a detailed analysis of carbon emissions across various large-scale machine learning tasks at Meta, illustrating the environmental impact of different AI applications and architectures. This quantitative assessment of AI’s carbon footprint grounds mitigation strategies in measured environmental costs rather than estimates.

Comprehensive carbon accounting methodologies
AI’s impact extends beyond operational energy consumption. Comprehensive carbon footprint assessment integrates the Three-Phase Lifecycle Analysis (training, inference, manufacturing) with the three standard emission scopes defined by the GHG Protocol. With AI projected to grow rapidly through 2030, understanding total lifecycle costs across all phases and scopes is essential for identifying the most impactful sustainability interventions.
Within an owned data-center facility boundary, Scope 1 emissions originate from on-site power generation including backup diesel generators, facility cooling systems, and owned power plants. While many AI data centers primarily use grid electricity, those with fossil-fuel backup systems or owned generation contribute directly to emissions.
Scope 2 emissions represent indirect emissions from electricity purchased to power AI infrastructure. This is often the dominant category for owned facility operations, and it varies dramatically by geographic location and grid energy mix. As established in section 1.0.1, this geographic lever sits in the 8 to 40 times range for representative region pairs; comparing the dirtiest coal grid against the cleanest hydro grid stretches it toward the high end of the 10 to 80 times span.
Scope 3 emissions constitute the most complex category, encompassing hardware manufacturing, cloud supply chains, transportation, disposal, and downstream use. Semiconductor manufacturing is carbon-intensive.25 For low-utilization hardware or clean-grid deployments, embodied accelerator emissions can rival months or years of operation; for sustained high-power training on carbon-intensive grids, the break-even can be much shorter. Under company-wide or value-chain AI accounting, Scope 3 can dominate even when Scope 2 dominates a single owned facility’s operational footprint.
25 EUV Lithography Energy Cost: Each ASML EUV machine draws 1 MW continuously and consumes 30,000 liters of ultrapure water daily, a 10\(\times\) energy increase over older deep-UV systems. Since EUV is required for sub-7 nm nodes used in many advanced AI accelerators, the embodied energy of each chip generation compounds: more transistors per die means more EUV exposure steps, making advanced-node fabrication an important component of AI’s Scope 3 emissions.
26 Edge AI Energy Paradox: Edge inference reduces per-query latency from 100–200 ms (cloud) to 1–10 ms, but distributes power draw across many always-on devices. Tesla’s FSD computer draws 72 W continuously while driving; scaling comparable onboard compute across a global vehicle fleet would imply roughly 100 GW of collective power, comparable to dozens of large power plants. The sustainability trade-off is that edge eliminates network energy but creates an unmetered, distributed energy footprint invisible to carbon accounting frameworks.
Beyond manufacturing, Scope 3 emissions include the downstream impact of AI once deployed. AI services such as search engines, social media platforms, and cloud-based recommendation systems operate at enormous scale, requiring continuous inference across millions or even billions of user interactions. The cumulative electricity demand of inference workloads can ultimately surpass the energy used for training, further amplifying AI’s carbon impact. End-user devices, including smartphones, IoT devices, and edge computing26 platforms, also contribute to Scope 3 emissions, as their AI-enabled functionality depends on sustained computation. In large technology-company sustainability reports, Scope 3 often dominates companywide emissions; attributing that share specifically to AI-powered services requires workload-level accounting rather than companywide totals alone.
Operational emissions capture only the production phase of AI. Software development itself adds another layer of environmental impact that is rarely accounted for.
The GHG Protocol27 framework (Institute and Sustainable Development 2023) provides the standard categorization for these emissions, summarized in figure 15. Three scopes provide an engineering classification checklist:
27 GHG Protocol: Developed jointly by the World Resources Institute and WBCSD, this framework is used by over 90 percent of Fortune 500 companies reporting to CDP. Its three-scope taxonomy matters for ML systems because most AI carbon hides in Scope 3 (hardware manufacturing, cloud compute supply chains), which companies historically underreport by 50–70 percent compared to Scopes 1 and 2.
Institute, World Resources, and World Business Council for Sustainable Development. 2023. Greenhouse Gas Protocol: Corporate Standard.
- Scope 1 (Direct Emissions): Arise from direct company operations—backup generators, company-owned power generation.
- Scope 2 (Indirect Energy Emissions): Electricity purchased from the grid, the primary emission source for cloud computing workloads.
- Scope 3 (Value Chain Emissions): Extend beyond direct control—semiconductor manufacturing, hardware transportation, end-of-life disposal of AI accelerators.

Categorizing these emissions into Scope 1, 2, and 3 frameworks provides a standardized vocabulary for corporate environmental reporting. Correctly applying this framework in practice requires classifying the various hidden emission sources across a typical ML platform’s operational lifecycle.
Checkpoint 1.2: Accounting for invisible carbon
You are auditing the carbon footprint of a machine learning platform. Classify the following emission sources into Scope 1 (Direct), Scope 2 (Indirect Energy), or Scope 3 (Value Chain):
Accurately classifying these hidden emissions forces engineering teams to take responsibility for the entire value chain of their deployments. The abstract energy metrics of a facility, and the resulting carbon footprint, are ultimately governed by the physical thermodynamics of the rack. Delivering 120 kW to a single cabinet and extracting the resulting heat requires moving beyond traditional air conditioning.
Power delivery
Capacity planning fails when engineers budget only the accelerator TDP. Electricity loses energy and reliability margin at each transformation before it reaches a GPU’s voltage regulators, so the delivery path identifies both the facility bottleneck and the heat that cooling must remove. The path starts outside the building: utility power arrives as high-voltage AC, typically 13.8–69 kV depending on the country and facility size, and a dedicated substation or transformer yard steps it down to medium voltage. The largest ML facilities require their own substation, which takes 18–24 months to build and requires coordination with the local utility. The grid connection is the ultimate bottleneck: no amount of engineering inside the building can deliver more power than the grid provides.

Substation lead time can run 4\(\times\) longer than GPU procurement.
Systems Perspective 1.3: The interconnection queue
Deploying 10,000 GPUs and deploying the electrical substation required to power their IT load (9.6 MW, after the 7 MW GPU subtotal is expanded for rack support power) run on very different clocks. On the silicon path, GPU supply chains are volatile, but typical enterprise lead times are 6 months. On the infrastructure path, permitting, EPC (Engineering, Procurement, Construction), and grid connection for a new 10+ MW substation averages 24 months. Infrastructure therefore takes 4× longer to deploy than the accelerators themselves.
Systems insight: In the era of the ML Fleet, the primary bottleneck is not the supply chain of silicon, but the interconnection queue of the grid. As of 2024, there are over 2000 GW of capacity waiting for grid connection in the US alone. An engineer who optimizes for GPU utilization without a 2-year power roadmap will find their fleet “electrically stranded”: expensive silicon sitting in a dark building waiting for a transformer.
Inside the facility, an Uninterruptible Power Supply (UPS) conditions incoming power and provides battery backup during brief outages. Modern online double-conversion UPS systems convert AC to DC, charge a battery bank, and then convert back to AC, which ensures clean power but loses 3–5 percent efficiency. High-efficiency eco-mode designs bypass that double conversion during normal operation, achieving 98–99 percent efficiency with slightly less protection against input anomalies. The Power Distribution Unit (PDU) then distributes conditioned power from the UPS to racks, often providing the final AC step-down from 480 V to 208/240 V for servers.
Some ML facilities use 48 V DC distribution, which eliminates one conversion stage and improves efficiency by 2–3 percent. This improvement is not merely an incremental gain in a generic data center setting; for dense ML accelerator baseboards, it addresses a hard physical constraint imposed by the current demands of the hardware itself. A training node with eight H100 GPUs drawing 700 W each requires over 5,600 W just for the accelerators. At traditional 12 V delivery, meeting that demand requires pushing nearly 470 A across the baseboard busbars. At that current level, \(I^2R\) losses in the copper conductors themselves generate substantial heat and produce voltage drop that undermines the tight voltage tolerances of VRMs. Moving to 48 V reduces the delivered current by a factor of four, which reduces \(I^2R\) distribution losses by a factor of sixteen. For tightly integrated ML baseboards—such as NVIDIA’s HGX—48 V DC is less a design preference than a requirement for operating at rated power density without melting power connectors. Google pioneered 48 V DC distribution in their data centers, and the Open Compute Project (OCP) has standardized rack-level 48 V DC power buses for high-density compute.
At ML rack power densities, the difference between 95 percent and 98 percent distribution efficiency is meaningful. For a 33 kW rack, a 3 percent efficiency improvement saves approximately 0.99 kW of power per rack. Across a facility with 300 racks, this saves 297 kW, enough to power roughly 36 additional GPU nodes, or about 9 four-node racks under this rack-power mix. Over a 3-year lifecycle at $0.07/kWh, the efficiency improvement saves ~$546,361 in electricity costs.
The final conversions happen at the server and baseboard. Each server contains power supply units (PSUs) that convert rack-level voltage to 12 V DC or directly to the multiple voltages needed by baseboard components. A DGX H100, for example, uses multiple high-efficiency PSUs rated for 10 kW total, with N+1 redundancy so one failed PSU does not take the node offline. Voltage regulator modules (VRMs) then convert 12 V DC to the 0.7–1.0 V required by the GPU core and the 1.1–1.2 V required by HBM. These regulators must respond to load changes within microseconds as the GPU moves between idle and full-load computation, and they operate at 90–95 percent efficiency.
Checkpoint 1.3: Power delivery physics
Verify your understanding of the data center power path:
At 700 W per GPU, the VRM dissipates 35–70 W of heat, which must be cooled along with the GPU itself. This VRM heat is sometimes overlooked in thermal design: in a liquid-cooled system where cold plates cover the GPUs, the VRMs are typically still air-cooled by small fans, creating a thermal management challenge for the remaining components that do not have direct liquid cooling contact.
The cumulative efficiency across all five stages is typically 85–90 percent, meaning that for every 100 W of useful computation, 10–15 W is lost as heat in the power delivery chain itself. This overhead is part of the PUE calculation and represents an irreducible cost of converting utility power to useful computation.
To make this concrete, consider the power budget for a single rack containing four DGX H100 nodes:
Table 6 itemizes the full rack budget so facility sizing includes host, network, conversion, and cooling overhead rather than only GPU TDP.
| Component | Power (kW) | % of Rack Total |
|---|---|---|
| GPU compute | 22.4 kW | 67% |
| Host CPUs and DRAM | 3.2 kW | 10% |
| NVSwitch fabric | 1.6 kW | 5% |
| InfiniBand HCAs | 0.8 kW | 2% |
| Power conversion losses | 2.8 kW | 8% |
| Cooling overhead (PUE ~1.09) | 2.7 kW | 8% |
| Total | 33.5 kW | 100% |
As table 6 shows, 32 GPUs at 700 W each deliver 22.4 kW, but that GPU subtotal alone understates the true rack power requirement by roughly 50 percent. Infrastructure planners who size their facility based on GPU TDP alone will underestimate the electrical load and may discover during commissioning that their power capacity is insufficient.
ML training workloads impose a unique challenge on this power chain: synchronous transients. In traditional web-serving data centers, thousands of servers handle independent requests with uncorrelated power draws. The aggregate load is smooth and predictable, varying by perhaps 10–20 percent over the course of a day.
In a training cluster, the picture is radically different. All accelerators execute the same computation in lockstep. When a large matrix multiplication begins, thousands of Tensor Cores across the cluster activate simultaneously, and power demand surges by 40–60 percent within microseconds. When the computation pauses for gradient synchronization, demand drops just as sharply. These power ramps stress every component in the delivery chain, from the VRMs on the baseboard to the transformers in the substation.
Example 1.4: Power-ramp sizing
Scenario: A 512-GPU training cluster experiences intermittent node resets during synchronized training steps. The failures appear unrelated to the model code.
Failure mode: Hardware diagnostics show no component defects. The likely root cause is the power delivery chain: synchronous training steps can create a few-hundred-kilowatt load step – roughly 300 kW for a 600 W idle-to-peak swing across 512 GPUs before facility overhead – that exceeds the response time of upstream power-conditioning equipment.
Consequence: Voltage sags can trigger accelerator undervoltage protection circuits and force hard resets. The mitigation is local ride-through capacity, such as supercapacitor banks, that smooths the transient until slower UPS and facility systems respond.
Systems insight: ML clusters do not behave like traditional data center workloads: the temporal correlation of power demand across thousands of chips creates a qualitatively different electrical engineering challenge.
Modern ML data centers address power transients through a layered defense strategy, with each layer covering a different timescale. Supercapacitor banks provide the first line of defense, delivering hundreds of kilowatts within microseconds to smooth the initial surge. Unlike batteries, which have response times measured in milliseconds, supercapacitors store energy electrostatically and can discharge instantaneously. A typical installation places 50–100 kJ of supercapacitor storage per rack, enough to sustain a 100 kW transient for 0.5–1.0 seconds.
Battery-backed UPS systems with fast inverter response (under 10 ms switching time) handle longer transients and provide ride-through capability during brief grid disturbances lasting up to several minutes.
Dedicated electrical substations with custom transformer designs serve the largest installations. These transformers are rated for the high di/dt (rate of current change) characteristic of ML workloads, with custom winding configurations that can handle rapid load swings without voltage distortion. Standard utility transformers are designed for slowly varying loads and can experience magnetic saturation when subjected to the rapid load changes that ML training creates.
To appreciate the magnitude of these transients, consider a 1024-GPU cluster transitioning from communication phase (400 W per GPU average) to matrix multiplication phase (700 W per GPU). The power delta is 300 W \(\times\) 1024 = 307 kW, and this transition occurs in approximately 100 μs. The rate of power change is therefore 307 kW/100 μs = 3.07 GW/s. No passive electrical component can respond at this rate; only energy storage devices (supercapacitors) positioned physically close to the load can absorb the transient before it propagates into the building’s electrical distribution.

Training phase transitions create microsecond power shocks.
The power delivery chain itself introduces inefficiencies at each stage. Utility-to-medium-voltage transformation loses 1–2 percent. The UPS loses 3–5 percent (modern double-conversion designs) or 1–2 percent (eco-mode designs that bypass the inverter during normal operation). The PDU loses 2–3 percent. Voltage regulation on the baseboard loses another 5–8 percent. Cumulatively, 10–15 percent of the power drawn from the grid is dissipated as heat in the delivery chain before it ever reaches a transistor. This overhead is part of the PUE calculation: a PUE of 1.10 implies that the delivery chain and cooling together consume 10 percent above the IT load.
At the largest scales, the data center’s power draw represents a significant fraction of the local electrical grid’s capacity. A 100,000-GPU cluster at 700 W per GPU has a 70 MW accelerator subtotal, but rack-profile support power raises the IT load to 96.2 MW before PUE. With PUE, the total facility draw approaches 107.8 MW. This is equivalent to powering a small city. Such installations require dedicated feeds from the electrical grid, often with purpose-built substations and transmission lines. The lead time for grid interconnection can exceed two years, making power availability one of the longest-lead-time constraints in building ML infrastructure.
At large-cluster scale, the same delivery limit becomes a grid-procurement problem rather than an electricity bill. GPT-3’s 1,287 MWh training run is the chapter’s roughly 120-household-year anchor. Later large systems have not disclosed comparable training-energy accounts, which is precisely why the engineering discipline must track energy at the workload level instead of relying on public model cards alone.
This grid-procurement problem worsens when model and data growth multiply each other. The scaling of energy consumption with model size is approximately linear: doubling the model parameters roughly doubles the training energy (assuming the same number of training tokens per parameter). When both model size and dataset size increase simultaneously, total training energy grows super-linearly. A model with 10\(\times\) the parameters, trained on 10\(\times\) the data, requires approximately 100\(\times\) the energy.
The electricity consumed by a single large-model training campaign can become nonnegligible relative to the output of a power plant. A 100 MW training facility operating at full capacity for one year consumes 876 GWh, which is comparable to the annual output of a 100 MW wind farm (at 30 percent capacity factor, a wind farm produces about 262.8 GWh per year, so the training facility would require the equivalent of approximately 3.3 large wind farms).
Power availability and power source therefore become the same infrastructure decision. Organizations training large models may seek to match their electricity consumption with renewable energy generation, either by locating data centers near renewable sources (hydro, wind, solar) or by purchasing renewable energy certificates (RECs) to offset their grid consumption.
Direct investment in clean generation is the strongest form of this decision because it adds capacity rather than only reallocating credits. Microsoft, for example, has signed agreements to purchase nuclear energy from restarted reactors, recognizing that the scale and consistency of ML training loads require baseload power sources that renewable intermittent sources alone cannot provide. Google has similarly invested in geothermal energy projects, which provide consistent power output independent of weather conditions.
The carbon intensity of the energy grid dictates the true environmental cost of a training run. A facility powered by hydroelectric dams in the Pacific Northwest emits approximately 50 g CO2/kWh, while a coal-heavy grid can produce 400 g CO2/kWh or more. A single training run for our 175B model, consuming approximately 1,287 MWh, implies a carbon impact ranging from 64 tonnes to 515 tonnes depending solely on location – an 8\(\times\) variance that makes site selection a first-order decarbonization lever. This pairing of Pacific Northwest hydro against a moderate coal grid sits at the conservative end of the geographic span established in section 1.0.1; a cleaner hydro grid widens it further. This environmental calculus can drive infrastructure decisions: organizations that can locate training clusters in low-carbon regions may achieve both lower electricity costs (hydroelectric power is often cheaper than fossil-fuel generation) and lower carbon footprints, a rare alignment of economic and environmental incentives.
Cooling
Every watt of electrical power delivered to a GPU is ultimately converted to heat. The first law of thermodynamics guarantees this: the electrical energy is converted to computational work (switching transistors), but the “work” product is just bit flips in memory, which themselves have negligible energy. All of the input energy exits the system as thermal energy that must be physically removed from the chip, transported out of the rack, and rejected to the environment. The fundamental physics of heat transfer establishes an unavoidable constraint: the rack-level electrical load represented by 33.5 kW must be absorbed by a cooling medium and carried away at the same rate, continuously. If cooling falls behind even briefly, chip temperatures rise, triggering thermal throttling that reduces clock speeds and throughput. At extreme temperatures, the silicon can sustain permanent damage.

Below the thermal limit the chip runs safely; cross it and throttling climbs steeply.
Air cooling, the dominant technology for decades, works by blowing room-temperature air across heat sinks attached to the chips. The air absorbs heat at a rate determined by its specific heat capacity, roughly 1.0 kJ/kg/K. The heated air is exhausted from the rear of the rack, typically 15–20 degrees Celsius warmer than the inlet, and directed to a computer room air conditioning (CRAC) unit that cools it before recirculating.
The fundamental problem is that air is a poor thermal conductor. Its thermal conductivity is only 0.026 W/m/K, compared to 0.6 W/m/K for water and 400 W/m/K for copper. To remove 100 kW from a rack using air alone, the fans must move enormous volumes of air at high velocity, consuming 30–40 percent of the rack’s total power budget just for cooling.
The physics can be made precise with a simple calculation. The heat removal capacity of a fluid flow is:
\[Q = \dot{m} \times c_p \times \Delta T\]
where \(Q\) is the heat removed (watts), \(\dot{m}\) is the mass flow rate (kg/s), \(c_p\) is the specific heat capacity (J/kg/K), and \(\Delta T\) is the temperature difference between outlet and inlet. For air with \(c_p\) of 1,005 J/kg/K and a typical \(\Delta T\) of 15 K (inlet at 20 degrees C, outlet at 35 degrees C), removing 100 kW requires a mass flow rate of 100,000 \(\div\) (1,005 \(\times\) 15) \(\approx\) 6.6 kg/s. At sea-level air density of 1.2 kg/m³, this corresponds to a volumetric flow rate of 5.5 m³/s, or approximately 11,713 CFM (cubic feet per minute). Moving this much air through the confined space of a server rack requires powerful fans that themselves consume substantial power.
At higher power densities (above 30 kW per rack), the fan power begins to approach or exceed the compute power, at which point the cooling system is consuming more energy than the computation it supports. The Power Usage Effectiveness (PUE)28 metric captures this overhead: a PUE of 1.5 means that for every watt consumed by compute, an additional 0.5 watts is consumed by cooling and power distribution overhead.
28 PUE (Power Usage Effectiveness): Defined by The Green Grid consortium in 2007 as \(P_{\text{total}} / P_{\text{IT}}\). Google’s fleet-wide PUE averages 1.10; the industry average is ~1.58. For a 10,000-GPU cluster consuming 9.62 MW of IT power after rack support load, reducing PUE from 1.58 to 1.10 saves 4.62 MW of cooling overhead – roughly $2.8M per year in electricity and the equivalent of removing 3,800 residential homes from the grid. ML-specific facilities with direct-to-chip liquid cooling have demonstrated PUE values of 1.03–1.08.
Reducing PUE is a primary engineering objective for ML data centers because the cooling overhead is wasted energy that produces no useful computation. At the scale of a 10,000-GPU cluster consuming 9.62 MW of IT power after rack support load, the difference between PUE 1.5 and PUE 1.1 is 3.85 MW of wasted power, costing approximately $2.4M per year in electricity and requiring proportionally more cooling infrastructure to dissipate.
Water has a specific heat capacity of 4.18 kJ/kg/K, over four times that of air, and a thermal conductivity roughly 25\(\times\) higher. These physical properties make water an inherently superior heat transfer medium. To appreciate the magnitude of the difference, consider how much fluid must flow to remove 700 W from a single GPU. Air at a 15-degree temperature rise requires tens of liters per second of airflow (a small wind tunnel). Water at the same temperature rise requires only about 0.01 liters per second (a thin stream). This thousands-fold difference in volumetric flow rate is why air cooling requires massive fans and carefully designed airflow paths, while liquid cooling requires only thin pipes and small pumps.
Direct-to-chip liquid cooling routes chilled water (or a specialized dielectric coolant) through machined copper cold plates mounted directly on each GPU package. The cold plate makes physical contact with the GPU’s heat spreader through a thin layer of thermal interface material, creating a thermal path with a resistance of less than 0.1 K/W. The coolant absorbs heat within millimeters of the die surface and carries it via manifolds and pipes to a Coolant Distribution Unit (CDU) at the rack or row level.
The CDU transfers heat from the chip-level coolant loop (a closed loop using deionized water or dielectric fluid) to the building’s chilled water loop, which rejects the heat to the outside environment via cooling towers or dry coolers. This two-loop design isolates the chip-level coolant (which must be ultra-pure to avoid mineral deposits on the cold plates) from the building-level water (which is less rigorously filtered).
Because liquid coolant is far more effective at absorbing heat per unit volume, the server-level fans are eliminated entirely (or reduced to small units for auxiliary components like DIMMs and VRMs). The cooling power overhead drops to 3–8 percent of IT power, yielding PUE values of 1.03–1.08. An additional benefit is noise reduction: liquid-cooled data centers are dramatically quieter than their air-cooled counterparts, which matters for facilities co-located with offices or in noise-regulated areas.
A more aggressive approach, immersion cooling, submerges entire server boards in a tank of nonconductive dielectric fluid. The fluid absorbs heat through direct contact with every component surface, eliminating the need for cold plates, fans, and even heat sinks. The principle is simple: if every surface of the board is in contact with coolant, the heat has nowhere to accumulate and is removed uniformly across the entire assembly.
Single-phase immersion cooling uses a fluid that remains liquid throughout the process, with heat carried away by convection currents in the tank. The heated fluid rises to the surface, is pumped through a heat exchanger to reject the heat to the building’s chilled water loop, and returns to the bottom of the tank.
Two-phase immersion cooling takes this further: the fluid boils at the chip surface, absorbing the latent heat of vaporization (roughly 100\(\times\) more energy per gram than a simple temperature change), condenses on a cold surface at the top of the tank, and drips back down. This cycle is self-sustaining and remarkably efficient, removing over 200 kW per rack with PUE values approaching 1.02.
The trade-off is serviceability: accessing a failed component requires draining or partially submerging in fluid, and the dielectric fluids themselves are expensive ($20–50 per liter). A single immersion tank holding four server boards may contain 500-1,000 liters of fluid, representing $10,000-50,000 in coolant cost alone. The operational procedures for immersion-cooled facilities differ sharply from air-cooled ones, requiring specialized training for technicians and different approaches to cable management, since all connectors must be compatible with prolonged fluid exposure. Standard copper cables and connectors can corrode or swell when exposed to some dielectric fluids, necessitating the use of specialized fluid-resistant materials that add cost and reduce the available supply chain options. Table 7 compares the air and liquid regimes that determine when these operational costs become unavoidable.
| Metric | Air Cooling (Legacy) | Liquid Cooling (Modern) |
|---|---|---|
| Max Power Density | ~20–30 kW/Rack | >120 kW/Rack |
| Cooling Efficiency | PUE ~1.5–2.0 | PUE ~1.05–1.10 |
| Mechanism | Forced-Air Fans | Direct-to-Chip Coolant |
| Heat Carrier | Air (1.0 kJ/kg/K) | Water (4.18 kJ/kg/K) |
| Fan Power | 30–40% of IT load | <5% of IT load |
The architecture comparison in figure 16 shows the physical reason for that threshold: air moves heat through bulk airflow, while liquid moves heat through a direct thermal path from chip to coolant.

Figure 16 and table 7 together illustrate the stark contrast between these approaches. The capital cost of these cooling technologies spans an order of magnitude. Standard air cooling infrastructure costs $2,000–5,000 per rack (fans, CRAC units, raised floor tiles). Direct-to-chip liquid cooling costs $15,000–25,000 per rack (cold plates, manifolds, CDUs, piping). Full immersion cooling costs $30,000–50,000 per tank (dielectric fluid, sealed tanks, specialized heat exchangers). The break-even analysis between air and liquid cooling depends on rack power density: at 20 kW per rack, air cooling’s lower CapEx wins over a 3-year lifecycle. At 40 kW per rack, the electricity savings from liquid cooling’s lower PUE (1.08 vs. 1.5) offset the higher CapEx within 18–24 months. At 60+ kW per rack, a common regime for dense ML infrastructure, air cooling is physically impossible, making the comparison moot. For our 175B model’s 32-rack training cluster at 33.5 kW per rack, direct-to-chip liquid cooling is the reference choice, balancing density, serviceability, and cost. Immersion cooling offers marginal PUE improvement (1.03 vs. 1.08) but introduces operational complexity that many organizations may find unjustified at these rack densities.
Napkin Math 1.5: The cooling tax
Consider a 1,024-GPU cluster of H100s at 700 W each.
- IT Power: 1,024 \(\times\) 700 W = 716.8 kW
- Air cooling (PUE 1.5): Total facility power = 716.8 kW \(\times\) 1.5 = 1068.0 kW. Cooling overhead = 351.2 kW.
- Liquid cooling (PUE 1.08): Total facility power = 716.8 kW \(\times\) 1.08 = 774.1 kW. Cooling overhead = 57.3 kW.
Savings: Liquid cooling saves 293.9 kW of continuous power. At $0.07/kWh, the annual savings are approximately $180,212. Over a 3-year hardware lifecycle, the cooling savings alone total $540,636, which often exceeds the capital cost of installing the liquid cooling infrastructure.
The final link in the cooling chain is heat rejection: getting the heat from the building’s chilled water loop to the outside environment. The dominant technology is the cooling tower, which sprays warm water over a fill medium and uses evaporation to carry heat into the atmosphere. Evaporative cooling is remarkably efficient (the latent heat of vaporization of water is 2,260 kJ/kg, compared to 4.18 kJ/kg/K for sensible heating), but it consumes water.
A 10 MW data center with evaporative cooling towers can consume well over 100 million liters of water per year, depending on climate and cooling design, which has become a significant concern in water-stressed regions. To put this in perspective, 140 million liters is roughly the annual water consumption of about 1,000 households. As ML data centers grow to 100 MW and beyond, their water footprint becomes a meaningful factor in local resource planning.
Dry coolers, which use fans to blow air over a radiator without evaporation, eliminate water consumption but work efficiently only when the ambient air temperature is well below the coolant temperature, limiting their effectiveness in hot climates. Many facilities use hybrid approaches: dry coolers during cool weather and evaporative towers during heat waves.
Waste heat reuse treats the data center’s thermal output as a resource rather than a waste product. The thermal density of ML accelerator clusters creates an advantage over traditional CPU infrastructure that is easy to overlook: the grade of heat they produce. Traditional air-cooled CPU racks exhaust warm air at roughly 35 degrees Celsius, a temperature range too low for most practical reuse without energy-intensive heat pumps. A liquid-cooled ML cluster, by contrast, returns coolant from its Coolant Distribution Units at 50–65 degrees Celsius—high-grade heat well suited for district heating networks, greenhouse climate control, and industrial process applications. The same accelerator thermal density that demands direct-to-chip cooling thus makes ML racks thermodynamically superior candidates for municipal waste heat programs compared to traditional IT infrastructure. Several Nordic data centers supply their waste heat to municipal heating networks, offsetting the natural gas or electricity that would otherwise be required to heat buildings during winter. A 10 MW ML data center can supply approximately 8–9 MW of useful heat (accounting for heat pump efficiency), enough to heat several thousand apartments. When the economic value of the waste heat is credited against the data center’s operating costs, the effective PUE can drop below 1.0, meaning the facility produces more useful energy (computation plus heat) than it consumes from the grid.
The viability of waste heat reuse depends on the proximity of heat consumers. Urban data centers, despite their higher land and electricity costs, are often better positioned for waste heat reuse than remote facilities because they are close to residential and commercial heating loads. The result is a counterintuitive economic optimization: a data center in a Nordic city may have higher electricity costs but lower net operating costs after waste heat revenues, compared to a remote facility with cheaper electricity but no heat consumers nearby.
For our 175B model training cluster, the choice between cooling technologies is not optional. A cluster of 1,000 H100s dissipates 700 kW of heat from the GPUs alone, before accounting for CPUs, memory, networking, and power conversion losses. Only liquid cooling can remove this heat at the required density. The rack is the level at which the problem shifts from computation to physics, and the design of the cooling infrastructure often determines whether a training cluster can operate at full utilization or must be throttled to prevent thermal runaway.
Cooling system reliability
Cooling system failures have more severe consequences in ML clusters than in traditional data centers because of the higher power density. In a traditional air-cooled data center at 10 kW per rack, losing a CRAC unit causes temperatures to rise gradually over tens of minutes, providing ample time for operators to respond. In a liquid-cooled ML rack at 100+ kW, losing coolant flow causes temperatures to reach the GPU’s thermal shutdown threshold within 30–60 seconds, because the heat capacity of the cold plate and the small volume of coolant in the pipes provides minimal thermal buffer.
Rapid thermal runaway drives several design decisions. Coolant loops are designed with N+1 redundancy: each CDU has a backup pump, and the piping manifold includes bypass valves that can reroute coolant around a failed CDU. Temperature sensors at each cold plate trigger immediate alerts when the coolant outlet temperature exceeds a threshold (typically 65 degrees Celsius), and the GPU firmware will throttle power within milliseconds if the junction temperature approaches the 83-degree limit.
Some facilities also maintain an emergency air cooling capability as a last-resort backup. Even though air cooling cannot sustain full-power operation at ML rack densities, it can keep the hardware below damage thresholds (at reduced clock speeds) long enough for operators to repair the liquid cooling system. The defense-in-depth approach to cooling reliability reflects that a cooling failure in a 10,000-GPU cluster can simultaneously affect hundreds of GPUs, making the potential financial impact of a cooling outage far greater than the cost of the redundancy.
The failure modes of liquid cooling systems are qualitatively different from those of air cooling. Air cooling fails gracefully: a fan failure reduces airflow, causing temperatures to rise slowly over minutes, providing ample time for automated load shedding. Liquid cooling can fail catastrophically: a coolant leak can simultaneously damage hardware (if the coolant is conductive) and remove cooling capacity (if the leak drains the loop). Quick-disconnect fittings, which allow hot-swapping of server nodes without draining the entire coolant loop, are a critical design feature that reduces maintenance downtime from hours to minutes. However, these fittings are also the most common point of failure in the coolant loop, as the O-ring seals degrade over thousands of connect/disconnect cycles. Facilities that perform frequent hardware swaps (common in research environments where nodes are regularly reconfigured) must budget for quarterly O-ring replacement and maintain a stock of spare fittings.
The economics of cooling reliability shift dramatically when moving from independent inference servers to tightly coupled training clusters. In a distributed training run using synchronous parallelism, a cooling-loop failure that idles a pod-scale slice can halt the entire job. Consider a cooling failure that triggers a thermal shutdown of a 256-GPU pod within a 10,000-GPU cluster. The direct hardware cost is negligible, but the opportunity cost is immense. If the repair time for a CDU pump is 4 hours, the immediate loss of 256 GPUs at $4 per GPU-hour is only $4,096. However, because the training algorithm requires all workers to proceed in lockstep, the remaining 9,744 GPUs also sit idle, burning electricity without making progress. This straggler effect inflates the cost to $160,000 in lost compute time. When adding the overhead of checkpoint retrieval and the rollback to the last saved state – often losing 30 to 60 minutes of computation – the total financial impact of a single cooling component failure easily exceeds $200,000. The nonlinear scaling of failure costs makes N+1 redundancy in cooling loops a mathematical necessity for training economics.

One cooling failure can idle the whole training job.
Maintaining the physical integrity of the liquid loop requires managing complex hydro-chemical dynamics. The fluid circulating through direct-to-chip systems is typically deionized water mixed with specific corrosion inhibitors, not simple tap water. The conductivity must be rigorously maintained below 1 microsiemens per centimeter (\(\mu\)S/cm) to prevent galvanic corrosion, where the electrical potential difference between dissimilar metals in the loop (copper cold plates and stainless steel manifolds) eats away at the cooling surfaces. This chemical balance is unstable: inhibitors are consumed over time and dissolved gases accumulate, necessitating monthly quality testing and annual full-volume replacement. Biological contamination poses an equally severe threat. Biofilm growth on the internal micro-fins of a cold plate acts as a thermal insulator; a mere 50-micron layer of organic growth can degrade heat transfer coefficients by 30 percent, forcing pumps to run at maximum power to compensate. Regular biocide treatments and periodic system flushing are therefore as critical to cluster performance as driver updates or firmware patches.
Self-Check: Question
A facility engineer is redesigning a datacenter aisle to host training racks after hosting web-serving racks for a decade. Which property of AI workloads most forces the redesign, relative to a typical web stack?
- AI workloads demand sub-millisecond tail latency that web stacks do not, so racks must be packed less densely to keep idle spares available.
- AI training holds large numbers of accelerators near peak utilization for weeks, creating sustained thermal density and power draw rather than the bursty CPU spikes web stacks produce.
- AI workloads use less energy per request than web traffic, so the real change is accounting rules rather than physical design.
- AI workloads avoid cooling needs because regular matrix arithmetic produces less heat than irregular web request patterns.
A team consolidates training jobs from a fleet at 45 percent average utilization onto a smaller active cluster at 85 percent utilization, powering down the drained nodes. Explain why this yields a sustainability win even if no model becomes more accurate, and state what part of the section’s total-energy model it targets.
A team doubles the number of GPUs in a distributed training job, expecting roughly linear energy scaling. Instead, they observe networking energy growing much faster than 2\(\times\). Which mechanism does the section identify as the primary cause, and what sustainability risk does it create?
- Total arithmetic decreases, so the model has to train longer to recover lost FLOPs, raising total energy.
- AllReduce and all-to-all gradient synchronization scale worse than linearly with cluster size and can add 20 to 40 percent to total energy, making naive cluster-size scaling carbon-inefficient.
- Facility PUE automatically worsens in direct proportion to node count regardless of cooling design.
- Embodied carbon per chip vanishes once a model is split across enough nodes, masking the true energy cost.
You are auditing carbon accounting for a team running training on a leased GPU cluster. The team reports five emissions sources as shown. Which classification across the GHG Protocol scopes is correct?
S1: Diesel burned by backup generators the team owns on-site. S2: Electricity purchased from the grid to power the leased GPUs. S3: Cooling electricity drawn inside the same datacenter. S4: The embodied carbon from manufacturing the accelerators themselves. S5: Energy used by end-user phones that run the deployed model.
- S1 Scope 1; S2 Scope 2; S3 Scope 2; S4 Scope 3; S5 Scope 3.
- S1 Scope 2; S2 Scope 1; S3 Scope 3; S4 Scope 3; S5 Scope 2.
- S1 Scope 3; S2 Scope 3; S3 Scope 2; S4 Scope 1; S5 Scope 1.
- S1 Scope 1; S2 Scope 1; S3 Scope 1; S4 Scope 2; S5 Scope 2.
Which example is most clearly Scope 3 in the chapter’s accounting framework rather than Scope 1 or Scope 2?
- Diesel burned by backup generators owned by the datacenter operator.
- Grid electricity purchased to power a leased GPU cluster.
- Cooling electricity consumed inside the datacenter and billed on the same meter as compute.
- Embodied carbon from manufacturing accelerators plus downstream energy used by end-user devices running the deployed service.
Training vs. Inference Energy Analysis
Cooling infrastructure manages the intense thermal load of the cluster, but the total magnitude of that load depends on whether the fleet is executing a concentrated training run or a globally distributed inference workload. Training a massive language model is a spectacular, highly visible energy event, akin to launching a rocket. Deploying that same model to serve a billion daily queries is like operating an international airline fleet. Training burns thousands of megawatt-hours in a single, concentrated burst over several months; inference burns energy continuously, query by query, year after year. Understanding where the majority of the energy budget goes dictates where optimization efforts must concentrate.
Optimization opportunities differ across lifecycle phases. Training optimizations focus on computational efficiency and hardware utilization, while inference optimizations emphasize latency, throughput, and edge deployment strategies. Matching the sustainability intervention to the dominant energy consumer for each application yields the greatest returns.
Training energy demands
Training very large AI models can require computational infrastructure with hundreds of thousands of cores and specialized AI accelerators operating continuously for months. Microsoft’s 2020 disclosure of the OpenAI dedicated supercomputer, built specifically for large-scale AI training at the time, reported 285,000 CPU cores, 10,000 GPUs, and network bandwidth exceeding 400 gigabits per second per server (Langston 2020). This 2020 figure remains useful as a calibrated reference point rather than a claim about the largest infrastructure available in later generations.
Langston, Jennifer. 2020. Microsoft Announces New Supercomputer, Lays Out Vision for Future AI Work. Microsoft Source.
The intensive computational loads generate heat that cooling infrastructure must continuously remove, the overhead quantified for the cooling treatment in section 1.3.6. Reducing it requires co-optimization of hardware architecture, parallelism strategy, and algorithmic efficiency.
Training energy costs occur once per model, but that one-time cost still determines facility sizing, checkpoint storage, and carbon accounting for the run. The primary sustainability challenge often emerges during deployment, where inference workloads continuously serve millions or billions of users and can overtake training energy when request volume is large enough.
Inference energy costs
Inference workloads execute every time an AI model responds to queries, classifies images, or makes predictions. Unlike training, inference scales dynamically and continuously across applications such as search engines, recommendation systems, and generative AI models. Although each individual inference request consumes far less energy compared to training, the cumulative energy usage from high-volume deployed services can rival or exceed training-related consumption (Wu et al. 2022).
For example, AI-driven search engines handle billions of queries per day, recommendation systems provide personalized content continuously, and generative AI services such as ChatGPT or DALL-E have substantial per-query computational costs. The inference energy footprint is high in transformer-based models due to high memory and computational bandwidth requirements.
Early market forecasts anticipated this shift: a 2017 McKinsey projection (figure 17) expected the data-center inference market to roughly double from 4-5 to 9-10 billion dollars and edge inference to climb from near zero to 4-4.5 billion dollars by 2025, both outpacing the slower-growing training market. The stronger evidence is physical rather than economic. The Meta lifecycle measurements in figure 14 show inference serving at scale rivaling or exceeding training emissions for deployed recommendation models, and the chapter’s own accounting shows continuous serving overtaking a one-time training run once request volume is large enough.

Unlike traditional software applications with fixed energy footprints, inference workloads dynamically scale with user demand. AI services like Alexa, Siri, and Google Assistant rely on continuous cloud-based inference, processing millions of voice queries per minute, necessitating uninterrupted operation of energy-intensive data center infrastructure.
The energy inefficiency of the decode phase
Inference at Scale introduced prefill and decode as latency phases; sustainability reuses the same split as an energy model. Prefill tends to saturate compute, while decode repeatedly streams model and KV-cache state through memory for each generated token. The serving footprint grows because decode wastes energy differently from prefill, and the gap between the two inference phases is striking (figure 18).

The prefill/decode distinction summarized in Prefill vs. Decode Characteristics extends beyond latency into energy efficiency. Recent analysis (Ma and Patterson 2026) reveals that autoregressive generation is inherently energy-wasteful compared to batch processing because the two phases stress different hardware limits. During prefill, high arithmetic intensity allows the GPU to perform thousands of operations for every byte read from memory, achieving near-peak energy efficiency in pJ/FLOP. During decode, the model must read the entire weight set from HBM to generate a single token; arithmetic intensity is low, so the compute units sit idle for much of the cycle.
Ma, Xiaoyu, and David Patterson. 2026. Challenges and Research Directions for Large Language Model Inference Hardware. No. 5. Vol. 59. https://doi.org/10.1109/mc.2026.3652916.
The result is Static Power Waste: the GPU draws significant leakage and clock power while waiting for memory transfers. Generating 1,000 tokens through 1,000 sequential decode steps can therefore consume 10–50\(\times\) more energy than processing the same 1,000 tokens in a single prefill batch. The inefficiency drives demand for specialized, memory-optimized NPUs and TPUs examined in Compute Infrastructure, which prioritize bandwidth-per-watt over raw TFLOP/s.
Edge AI impact
The edge intelligence architectures from Edge Intelligence enable inference beyond centralized data centers. This distributed approach offers unique sustainability advantages by reducing data transmission energy costs and lowering dependency on high-power cloud infrastructure. Instead of routing every AI request to centralized cloud servers, models can be deployed directly on user devices or at edge computing nodes.
However, running inference at the edge does not eliminate energy concerns, especially when AI is deployed at scale. Autonomous vehicles, for instance, require millisecond-latency AI inference, meaning cloud processing is impractical. Instead, vehicles use onboard AI accelerators that function as “data centers on wheels” (Sudhakar et al. 2023). These embedded computing systems process real-time sensor data equivalent to small data centers, consuming significant power even without relying on cloud inference.
Sudhakar, Soumya, Vivienne Sze, and Sertac Karaman. 2023. “Data Centers on Wheels: Emissions from Computing Onboard Autonomous Vehicles.” IEEE Micro 43 (1): 29–39. https://doi.org/10.1109/mm.2022.3219803.
Similarly, consumer devices such as smartphones, wearables, and IoT sensors individually consume milliwatts to watts of power but collectively add terawatt-hours to global energy use due to their sheer numbers. Therefore, the efficiency benefits of edge computing must be balanced against the extensive scale of device deployment.
Edge deployment can be more sustainable than cloud deployment when designed correctly. The combination of eliminated data transmission, local processing efficiency, and duty-cycled operation can reduce total system energy consumption by orders of magnitude compared to always-connected cloud inference.
Edge and mobile power budgets
ARM-based edge devices operate under fundamentally different power constraints than data center accelerators. The engineering choice is to match each inference workload to the smallest power tier that still satisfies latency and accuracy.
Power budgets reflect the physical constraints of battery capacity, thermal dissipation, and deployment environment. Table 8 groups edge AI power budget categories and shows how these constraints propagate: TinyML devices operating from coin cells or energy harvesting cannot exceed milliwatt average power, mobile devices must balance user experience with battery life, and automotive systems face thermal constraints within enclosed vehicle compartments despite having access to vehicle power.
| Platform Category | Idle Power | Active Power | Peak Power | Example Devices |
|---|---|---|---|---|
| TinyML (MCU) | 1–100 W | 1–50 mW | 100 mW | Arduino Nano 33, STM32H7, Nordic nRF5340 |
| Mobile NPU | 10-100 mW | 0.5–5 W | 10 W | Pixel Tensor, Apple Neural Engine, Snapdragon NPU |
| Edge GPU/TPU | 1-5 W | 5–30 W | 75 W | NVIDIA Jetson Orin NX (10–25 W) and AGX Orin (15–60 W), Google Edge TPU, RPi AI Kit |
| Autonomous Vehicle | 10–50 W | 50–200 W | 500 W | Tesla FSD Computer, Mobileye EyeQ, NVIDIA Drive |
TinyML power state dynamics
While Edge Intelligence examines TinyML from a systems architecture perspective, the energy efficiency of on-device inference is equally a sustainability consideration: each of the billions of edge inference calls aggregates into measurable carbon footprint at fleet scale. TinyML efficiency depends heavily on duty cycling, where devices alternate between deep sleep and active inference. Equation 14 expresses average power as a weighted sum of active and sleep power:
\[P_{\text{average}} = P_{\text{active}} \times \frac{t_{\text{inference}}}{T_{\text{period}}} + P_{\text{sleep}} \times \frac{T_{\text{period}} - t_{\text{inference}}}{T_{\text{period}}} \tag{14}\]
For a keyword-spotting model running on a Cortex-M4 microcontroller (Archetype C (Federated MobileNet) regime, Three systems archetypes):
- Active inference power: 15 mW for 20 ms per detection cycle
- Deep sleep power: 10 microamps at 3.3V (33 microwatts)
- Detection period: 1 second (continuous listening)
\[P_{\text{average}} = 15 \text{ mW} \times \frac{20 \text{ ms}}{1000 \text{ ms}} + 0.033 \text{ mW} \times \frac{980 \text{ ms}}{1000 \text{ ms}}\]
\[P_{\text{average}} = 0.30 \text{ mW} + 0.032 \text{ mW} = 0.33 \text{ mW}\]
At this average power, a 250 mAh coin cell battery (at 3.0V nominal) provides approximately 2,270 hours of operation, nearly 95 days of continuous always-on AI inference. This calculation demonstrates how TinyML enables sustainable AI deployment scenarios impossible with higher-power platforms. These power-aware design principles carry directly into practical industrial deployment scenarios.
Example 1.5: Battery life for TinyML
Consider deploying an anomaly detection model on a factory sensor node:
System parameters:
- Model: Autoencoder for vibration anomaly detection
- MCU: ARM Cortex-M4 at 80 MHz
- Inference latency: 5 ms per sample
- Sampling rate: 10 Hz (100 ms period)
- Active power: 12 mW during inference
- Sleep power: 5 microamps at 3.3V (16.5 microwatts)
- Battery: two AA cells (3000 mAh at 3.0V)
Step 1: Calculate duty cycle and average power. \[\delta_{\text{duty}} = \frac{5 \text{ ms}}{100 \text{ ms}} = 0.05 \text{ (5\% duty cycle)}\]
\[P_{\text{avg}} = 12 \text{ mW} \times 0.05 + 0.0165 \text{ mW} \times 0.95 = 0.60 + 0.016 = 0.616 \text{ mW}\]
Step 2: Calculate battery life. \[E_{\text{battery}} = 3000 \text{ mAh} \times 3.0 \text{ V} = 9000 \text{ mWh}\]
\[t_{\text{life}} = \frac{9000 \text{ mWh}}{0.616 \text{ mW}} = 14,610 \text{ hours} \approx 1.7 \text{ years}\]
Systems insight: The deployment achieves continuous AI-powered monitoring for nearly two years on standard batteries, demonstrating the sustainability potential of TinyML systems designed with power-aware principles.
On-device learning and the battery wall
While inference on TinyML devices is highly efficient, on-device learning introduces a much steeper energy challenge. Personalizing a model to a user’s specific voice or gait requires backpropagation, which demands 2–3\(\times\) more compute and memory than forward inference.
The thermal design power (TDP) of mobile processors creates hard constraints that shape every aspect of on-device learning strategies. Modern smartphones typically maintain sustained processing at 2–3 W for ML workloads to prevent thermal discomfort, but can burst to 5–10 W for brief periods before thermal throttling occurs. This thermal design power determines the entire feasible space of adaptive algorithms.
Napkin Math 1.6: The energy of learning
Problem: Consider fine-tuning a small language model (1B parameters) on a user’s smartphone overnight. Is this feasible within a 5 percent battery budget?
Math:
- Phone Battery: Typical capacity is approximately 15 Wh, or about 54000 J.
- Budget: 5 percent of 54000 J = 2700 J.
- Training Cost:
- Forward pass: \(\approx\) 2 nJ/param.
- Backward pass: \(\approx\) 4 nJ/param.
- Total per token: 6 nJ/param \(\times 10^9\) params = 6 J/token.
- Capacity: 2700 J / 6 J/token = 450 tokens.
Systems insight: Full fine-tuning is impossible within a reasonable daily battery budget. Sustainable on-device learning requires parameter-efficient fine-tuning (PEFT) or sparse updates to reduce the energy cost per token by 100\(\times\) or more.
The fundamental physics of energy consumption reveals why local processing is almost always preferable to cloud offloading for on-device learning, provided the model is sufficiently compact.
Systems Perspective 1.4: The energy hierarchy
Trade-off: The architectural choice between processing data locally and sending it to the cloud is governed by an energy budget. The physics of energy consumption provides a clear answer based on the energy-to-communication ratio.
Energy cost per operation (approximate):
- 32-bit integer add: 0.1 pJ
- 32-bit float mult: 4 pJ
- Wireless transmit (1 bit): 100,000–500,000 pJ (Bluetooth/Wi-Fi)
Systems insight: Transmitting a single bit of data costs roughly the same energy as performing 25,000 to 125,000 FP32 multiplies, or 1 million to 5 million 32-bit integer adds, under these operation-cost assumptions. When insight can be extracted from data using fewer than roughly 100,000 floating-point operations per bit, local processing is usually more energy efficient than cloud offloading. This ratio drives the architecture of federated learning: compute is cheap; radio transmission is expensive.

Radio transmission dwarfs local arithmetic in energy.
Energy harvesting for autonomous edge AI
With sufficient optimization, TinyML enables energy-autonomous operation where devices harvest ambient energy rather than relying on batteries:
Consider the energy harvesting power budgets in table 9: a keyword spotting model optimized to 0.5 mW average power can operate indefinitely on approximately 5 cm² of indoor solar harvesting only under bright indoor conditions near the top of the listed range. Typical indoor deployments need additional area, energy storage, duty cycling, or a lower average-power model to leave margin for conversion losses and dim lighting. This perpetual operation model represents the ultimate sustainable edge AI deployment, where operational energy comes entirely from ambient sources.
| Harvesting Source | Typical Power | Viable TinyML Applications |
|---|---|---|
| Indoor solar (1 cm²) | 10-100 microwatts | Periodic sensor classification |
| Outdoor solar (1 cm²) | 1-10 milliwatts | Continuous keyword spotting |
| Thermoelectric (body heat) | 10-100 microwatts | Wearable gesture recognition |
| RF harvesting (Wi-Fi) | 1-10 microwatts | Ultra-low-duty sensor nodes |
| Vibration piezoelectric | 100 microwatts-1 mW | Industrial monitoring |
Cascade inference architecture
Beyond individual device efficiency, architectural patterns determine total system energy consumption across edge-cloud boundaries. A cascade architecture deploys a small edge model (under 100 KB) to filter inputs before cloud inference. Equation 15 expresses total energy as the sum of local processing plus probabilistically-triggered cloud costs:
\[E_{\text{cascade}} = E_{\text{edge}} + p_{\text{escalate}} \times (E_{\text{transmit}} + E_{\text{cloud}}) \tag{15}\]
where \(p_{\text{escalate}}\) is the probability of requiring cloud inference (typically 5–20 percent for well-designed cascades).
For a visual inspection system:
- Edge model (MobileNet-v3 tiny): 0.5 mJ per image classification
- Cloud model (ResNet-152): 50 mJ per classification
- Transmission energy: 10 mJ per image (cellular)
- Escalation rate: 10 percent (only ambiguous cases sent to cloud)
\[E_{\text{cascade}} = 0.5 + 0.10 \times (10 + 50) = 0.5 + 6.0 = 6.5 \text{ mJ/image}\]
Compared to always-cloud inference at 60 mJ per image, the cascade architecture achieves 89 percent energy reduction while maintaining accuracy through selective cloud escalation.
Wake-word triggered systems
Always-on systems use hierarchical wake detection to minimize average power:
- Ultra-low-power analog front end: 10 microwatts continuous voice activity detection
- Tiny neural network wake detector: 100 microwatts when speech detected
- Full model inference: 10 mW for 50 ms when wake word confirmed
With typical speech activity rates of 5 percent and wake word occurrence of 0.1 percent:
\[P_{\text{average}} = 0.01 + 0.05 \times 0.1 + 0.001 \times 10 \times 0.05 = 0.0155 mW\]
The hierarchical approach achieves 15.5 µW average power compared to 10 mW for always-active full inference, a 645.2× reduction enabling battery-powered voice assistants with multi-year operation.
Federated learning energy analysis
Training at the edge eliminates data transmission but increases local compute. Equation 16 contrasts the energy trade-offs between federated and centralized approaches:
\[E_{\text{federated}} = N_{\text{clients}} \times E_{\text{local\_train}} + E_{\text{aggregation}}\] \[E_{\text{centralized}} = N_{\text{clients}} \times E_{\text{transmit}} + E_{\text{cloud\_train}} \tag{16}\]
Federated learning becomes more energy-efficient when data sizes exceed model update sizes. For privacy-sensitive applications with rich sensor data, federated approaches often achieve both privacy and energy benefits, as transmitting model weight updates (megabytes) requires less energy than transmitting raw data (gigabytes) for applications like on-device personalization. The edge analysis leaves one more lifecycle term: the physical supply chain that produces the devices and accelerators.
Water, chemicals, and critical materials
AI’s environmental footprint extends beyond electricity consumption to include physical resources—water, hazardous chemicals, and critical materials—that require different assessment approaches. Comprehensive assessment requires measuring additional ecological impacts including water consumption, hazardous chemical usage, rare material extraction, and biodiversity disruption that often receive less attention despite their ecological significance. Modern semiconductor fabrication plants producing AI chips require millions of liters of water daily and use over 250 hazardous substances in their processes. In regions already facing water stress, such as Taiwan, Arizona, and Singapore, this intensive usage threatens local ecosystems and communities. AI hardware also relies heavily on scarce materials like gallium, indium, arsenic, and helium, which face both geopolitical supply risks and depletion concerns (Jha 2014; Chen 2006).
Jha, A. R. 2014. Rare Earth Materials: Properties and Applications. CRC Press. https://doi.org/10.1201/b17045.
Chen, H.-W. 2006. “Gallium, Indium, and Arsenic Pollution of Groundwater from a Semiconductor Manufacturing Area of Taiwan.” Bulletin of Environmental Contamination and Toxicology 77 (2): 289–96. https://doi.org/10.1007/s00128-006-1062-3.
Cooper, Tom, Suzanne Fallender, Joyann Pafumi, Jon Dettling, Sebastien Humbert, and Lindsay Lessard. 2011. “A Semiconductor Company’s Examination of Its Water Footprint Approach.” Proceedings of the 2011 IEEE International Symposium on Sustainable Systems and Technology, 1–6. https://doi.org/10.1109/issst.2011.5936865.
29 Semiconductor Water Scale: TSMC’s Arizona fab will consume 12 billion liters annually (about 4,800 Olympic pools), and advanced-node AI chips require 5–10\(\times\) more water per die than older process nodes due to additional EUV and cleaning steps. This water dependency creates a direct sustainability constraint: fabs compete with municipal water supplies in drought-prone regions like Arizona and Taiwan, where semiconductor water demand can reach 3 percent of a city’s total allocation.
Reuters. 2024. Water-Guzzling Chipmaker TSMC and Drought-Plagued Arizona Are an Unlikely Pair, but Phoenix Says It Has Enough Water. Fortune magazine, 8 April 2024.
Semiconductor fabrication is an exceptionally water-intensive process (Cooper et al. 2011). TSMC’s fab in Arizona is projected to consume 34 million liters of water per day29 (Reuters 2024), accounting for nearly 3 percent of the city’s total water production. A single 300mm silicon wafer requires over 8,300 liters of water throughout the complete fabrication process. Figure 19 illustrates the typical fab water cycle, where advanced recycling can reclaim 60–80 percent of water but still leaves a substantial consumption footprint.

The critical takeaway from figure 19 is that even with 60–80 percent reclamation rates, the absolute volume of ultra-pure water consumed by advanced-node fabs remains enormous, creating a hard physical constraint on where AI chip manufacturing can sustainably operate.
Fabrication is also heavily reliant on hazardous chemicals for etching, doping, and cleaning. Strong acids (hydrofluoric, sulfuric), volatile organic compounds like xylene, and highly toxic gases (arsine, phosphine) are used in massive quantities—a large fab may consume over 2,000 metric tons of acids annually (Kim et al. 2018). These substances create hazardous waste streams requiring extensive treatment to prevent ecological harm.
Kim, Sunju, Chungsik Yoon, Seunghon Ham, Jihoon Park, Ohun Kwon, Donguk Park, Sangjun Choi, Seungwon Kim, Kwonchul Ha, and Won Kim. 2018. “Chemical Use in the Semiconductor Manufacturing Industry.” International Journal of Occupational and Environmental Health 24 (3-4): 109–18. https://doi.org/10.1080/10773525.2018.1519957.
Rhodes, Christopher J. 2019. “Endangered Elements, Critical Raw Materials and Conflict Minerals.” Science Progress 102 (4): 304–50. https://doi.org/10.1177/0036850419884873.
AI hardware depends on a suite of scarce and geopolitically sensitive critical materials. While silicon is abundant, high-performance chips require rare elements like gallium, indium, tantalum, and helium. Materials such as indium appear in critical-materials and endangered-elements analyses because supply can depend on byproduct extraction, substitution options, and recycling constraints (Rhodes 2019). The geographic concentration of rare earth refining creates significant supply chain vulnerabilities. Table 10 quantifies the scope of this material dependency challenge.
| Material | Application in AI Semiconductor Manufacturing | Supply Concerns |
|---|---|---|
| Silicon (Si) | Primary substrate for chips, wafers, transistors | • Processing constraints • Geopolitical risks |
| Gallium (Ga) | GaN-based power amplifiers, high-frequency components | • Limited availability • Byproduct of aluminum and zinc production |
| Germanium (Ge) | High-speed transistors, photodetectors, optical interconnects | • Scarcity • Geographically concentrated |
| Indium (In) | Indium Tin Oxide (ITO), optoelectronics | • Limited reserves • Recycling dependency |
| Tantalum (Ta) | Capacitors, stable integrated components | • Conflict mineral • Vulnerable supply chains |
| Rare Earth Elements (REEs) | Magnets, sensors, high-performance electronics | • High geopolitical risks • Environmental extraction concerns |
| Cobalt (Co) | Batteries for edge computing devices | • Human rights issues • Geographical concentration (Congo) |
| Tungsten (W) | Interconnects, barriers, heat sinks | • Limited production sites • Geopolitical concerns |
| Copper (Cu) | Interconnects, barriers, heat sinks | • Limited high-purity sources • Geopolitical concerns |
| Helium (He) | Semiconductor cooling, plasma etching, EUV lithography | • Nonrenewable • Irretrievable atmospheric loss • Limited extraction capacity |
The construction and operation of fabs and data centers also directly impacts natural ecosystems through habitat disruption, water stress, and pollution from chemical discharge. Semiconductor-industry effluents can contaminate nearby fluvial sediments with heavy metals and trace elements (Hsu et al. 2016). Waste generation from fabrication—including gaseous emissions, VOC-laden air, and metal-contaminated wastewater—requires advanced treatment systems, and the end-of-life disposal of AI hardware contributes to a growing e-waste crisis, with only 17.4 percent of global e-waste properly recycled (Singh and Ogunseitan 2022).
Hsu, Liang-Ching, Ching-Yi Huang, Yen-Hsun Chuang, Ho-Wen Chen, Ya-Ting Chan, Heng Yi Teah, Tsan-Yao Chen, Chiung-Fen Chang, Yu-Ting Liu, and Yu-Min Tzou. 2016. “Accumulation of Heavy Metals and Trace Elements in Fluvial Sediments Received Effluents from Traditional and Semiconductor Industries.” Scientific Reports 6 (1): 34250. https://doi.org/10.1038/srep34250.
The environmental toll of computational demand extends far beyond atmospheric carbon, manifesting as severe water stress and ecological disruption around manufacturing hubs. These supply-chain costs converge on the next design lever: how long massive, resource-intensive hardware clusters remain useful before they become waste.
Self-Check: Question
A model costs 1,287 MWh to train once and then serves 10 million queries per day at 0.001 kWh per query for a five-year product life. Which explanation best captures why inference often dominates lifecycle energy for widely deployed models?
- Inference always uses more power per operation than training because of serving-specific hardware.
- The model must be retrained on every query once in production, so inference and retraining overlap.
- Inference runs continuously across enormous cumulative query volume — here, about 10 MWh per day — so after roughly 130 days the cumulative serving energy matches the one-time training run, and after five years it dwarfs it.
- Inference cannot use specialized accelerators, unlike training, so it draws more grid power per step.
A profiler shows that the decode phase of an LLM serving stack sustains only 6 percent of peak FP16 TFLOP/s while HBM bandwidth sits near 90 percent utilization and static power keeps flowing. Which mechanism does the section identify as the dominant source of decode energy inefficiency, and what does it imply for optimization?
- Decode disables on-chip caches, so all work shifts to the CPU and server-class RAM.
- Decode is memory-bandwidth-bound — each token requires reading the model’s weights while the compute units idle — so the accelerator burns static power without producing proportional useful work; the fix is to reduce bytes read through quantization, smaller KV caches, or weight fusion.
- Prefill uses lower numerical precision while decode must always use FP32, so decode pays a precision tax.
- Decode inefficiency comes from a transient rise in facility PUE during serving hours.
A product manager claims that moving inference from the cloud to 50 million edge devices automatically solves the deployment’s sustainability problem. Explain why the chapter considers this claim incomplete and identify the lifecycle terms the edge decision can actually shift.
A keyword-spotting sensor runs 10 ms of active inference once per second and sleeps the remaining 990 ms at microwatt draw. Active power is 120 mW; sleep power is 50 uW. Which quantity most strongly determines the device’s average power, per the section’s duty-cycle reasoning?
- The duty cycle, because \((0.010 / 1.000) \times 120\text{ mW} + (0.990 / 1.000) \times 0.050\text{ mW}\) is roughly 1.25 mW - the active burst dominates this average, but the low duty cycle keeps power far below continuous 120 mW operation.
- The datacenter’s hourly carbon intensity, because the sensor uploads to a cloud pipeline.
- The model’s total parameter count, because larger models always consume more per-second energy.
- Whether the model was distilled from a larger teacher, because distillation changes average power directly.
A startup wants to support nightly on-device full fine-tuning of a 1B-parameter model on consumer smartphones. Explain why the chapter argues this is infeasible within a realistic overnight battery budget and which class of methods it recommends instead.
Order the following stages in a hierarchical wake-word cascade designed to minimize average power on a battery-powered smart speaker: (1) full large-model inference on the captured utterance, (2) ultra-low-power voice-activity detection running continuously at microwatts, (3) small neural wake-word detector running only when voice is present.
Hardware Lifecycle and E-Waste
The environmental cost of an AI accelerator begins long before its first FLOP is calculated (Gupta et al. 2022; Luccioni et al. 2023; NVIDIA Corporation 2025). The per-H100 manufacturing footprint quantified in section 1.2.1.1 is incurred entirely at fabrication.30 The fleet of thousands of such processors required to train our 175B parameter model—consuming 1,287 MWh of electricity—represents a significant upfront carbon investment before any computation occurs. A comprehensive Life Cycle Assessment (LCA) quantifies the cumulative environmental impact across four key phases: design, manufacture, use, and disposal. LCA can reveal manufacturing as a major share of lifecycle impact, making it a critical sustainability lever that operational efficiency improvements alone cannot address.
Gupta, Udit, Young Geun Kim, Sylvia Lee, Jordan Tse, Hsien-Hsin S Lee, Gu-Yeon Wei, David Brooks, and Carole-Jean Wu. 2022. “Chasing Carbon: The Elusive Environmental Footprint of Computing.” IEEE Micro 42 (4): 37–47. https://doi.org/10.1109/MM.2022.3163226.
30 Life Cycle Assessment (LCA): Standardized by ISO 14040/14044, LCA traces environmental impact from raw material extraction through disposal (International Organization for Standardization 2006a, 2006b). For AI hardware, LCA separates embodied manufacturing emissions from operational energy use, making hardware refresh cycles and accelerator lifespan extension first-order sustainability levers that operational efficiency alone cannot substitute.
International Organization for Standardization. 2006a. ISO 14040:2006 Environmental Management – Life Cycle Assessment – Principles and Framework. ISO standard.
International Organization for Standardization. 2006b. ISO 14044:2006 Environmental Management – Life Cycle Assessment – Requirements and Guidelines. ISO standard.
Checkpoint 1.4: The training-inference flip
Consider a vision model where training requires 2,000 GPU-hours at an average power draw of 300 W. Once deployed, the model serves 1 million requests per day, with each request taking 50 ms at an average draw of 100 W.
Life Cycle Assessments can show that discarding functional hardware purely for modest efficiency gains causes more environmental harm through embodied carbon than it saves in operational power. To evaluate the tipping point where new hardware becomes environmentally justified, we must estimate the intersection of training costs, inference scale, and hardware lifespans.
Each of the four primary lifecycle stages contributes to an AI system’s total environmental footprint. Figure 20 visualizes this progression from design through disposal, highlighting the interdependencies between phases and the environmental impact categories associated with each stage.

The lifecycle sequence is not a static taxonomy. The binding sustainability problem shifts as the system matures: design creates experimental waste, manufacturing locks in embodied carbon, use couples the workload to grid and cooling constraints, disposal externalizes e-waste, and lifespan extension becomes the lever that amortizes all earlier emissions over more useful work.
Design and experimentation phase
The design phase encompasses the research, development, and optimization of ML models before deployment—iterating on architectures, tuning hyperparameters, and running training experiments. The environmental cost of this phase is often underestimated because reported training energy (such as GPT-3’s 1,287 MWh) reflects only the final run, not the extensive trial-and-error that preceded it. Automated architecture search techniques evaluate hundreds or thousands of configurations, but their carbon footprint depends on what is counted: proxy search, full training runs, data-center efficiency, grid mix, and reuse across downstream models (Strubell et al. 2019; Patterson et al. 2021). Later efficient NAS methods use weight sharing, continuous relaxations, and hardware-aware search to reduce the search budget (Elsken et al. 2019). Table 11 reveals stark differences in model carbon footprint across model scales.
| AI Model | Training FLOPs | Estimated CO2 Emissions (kg) | Equivalent Car Distance |
|---|---|---|---|
| GPT-3 | \(3.1 \times 10^{23}\) | 502,000 kg | 1.9 million km |
| T5-11B | \(2.3 \times 10^{22}\) | 85,000 kg | 338,000 km |
| BERT (Base) | \(3.3 \times 10^{18}\) | 650 kg | 2,400 km |
| ResNet-50 | \(2.0 \times 10^{17}\) | 35 kg | 129 km |
Addressing the design phase’s sustainability challenges requires innovations in training efficiency: sparse training, low-precision arithmetic, weight-sharing, and energy-aware NAS approaches. Transfer learning and fine-tuning pretrained models reuse pretrained representations instead of requiring every task to be trained from scratch (Raffel et al. 2020).
Manufacturing phase
The manufacturing of AI hardware is enormously resource-intensive, carrying the per-H100 embodied carbon established in section 1.2.1.1 before any computation occurs. Semiconductor fabrication requires extreme precision through processes such as EUV lithography—each tool consuming approximately 1 MW of continuous power—chemical vapor deposition, and ion implantation. The resource demands detailed in section 1.4.3 reveal the scale: TSMC’s Arizona fab consumes 34 million liters of water daily, fabrication relies on over 250 hazardous substances, and the supply chain depends on geopolitically concentrated critical materials.
Two structural properties of AI accelerators amplify this manufacturing footprint relative to conventional chips. First, high-performance AI chips are typically fabricated at or near the reticle limit—the maximum die area a single lithography exposure can print. Larger dies yield fewer chips per wafer and are disproportionately vulnerable to random defects: a defect density that kills 5 percent of small dies may kill 20 percent or more of a reticle-limit die, effectively wasting the water, chemicals, and EUV energy consumed in fabricating every defective unit. Second, the memory bandwidth requirements of large-scale inference and training demand advanced 2.5D and 3D packaging—such as TSMC’s Chip-on-Wafer-on-Substrate (CoWoS) process—that bonds High Bandwidth Memory stacks directly to the accelerator die. This integration introduces additional fabrication stages, chemical cleaning cycles, and precision baking steps that a conventional monolithic CPU does not require. The result is that each viable AI accelerator embodies substantially more water consumption, hazardous chemical use, and process energy than its wafer area alone would suggest, making hardware longevity and high utilization first-order sustainability levers rather than secondary concerns.
The energy required to manufacture AI hardware is substantial, and in clean-grid regions embodied manufacturing impacts can rival operational impacts over useful life. Research on eco-friendly electronics points to lower-toxicity materials, improved recycling, and greener device and manufacturing approaches as sustainability directions for electronics production (Cenci et al. 2021; Irimia-Vladu 2014).
Cenci, Marcelo Pilotto, Tatiana Scarazzato, Daniel Dotto Munchen, Paula Cristina Dartora, Hugo Marcelo Veit, Andrea Moura Bernardes, and Pablo R. Dias. 2021. “Eco-Friendly Electronics—a Comprehensive Review.” Advanced Materials Technologies 7 (2): 2001263. https://doi.org/10.1002/admt.202001263.
Irimia-Vladu, M. 2014. “‘Green’ Electronics: Biodegradable and Biocompatible Materials and Devices for Sustainable Future.” Chemical Society Reviews 43 (2): 588–610. https://doi.org/10.1039/c3cs60235d.
Use phase
The operational energy consumed during training and inference is detailed in section 1.4. What merits attention here is the pattern of this consumption and its interaction with grid infrastructure. The 1,287 MWh required to train our 175B model represents a high, continuous power draw—but the character of that draw is not uniform across workload types, and that distinction shapes what scheduling interventions are practical.
A large distributed training run draws constant, correlated power across thousands of accelerators and is often described as inflexible. This characterization understates the scheduling flexibility that distributed training already builds in for fault tolerance. Because a single hardware failure in a thousand-node cluster can corrupt a run, production training systems checkpoint state to persistent storage every few minutes to hours. That checkpointing infrastructure is exactly the mechanism that enables carbon-aware scheduling: a training job can be paused during the late-afternoon grid peak (when solar generation drops and fossil peaker plants come online), with cluster state saved to checkpoint, and resumed when overnight wind generation raises renewable availability. The same engineering that protects against hardware failures thus doubles as a scheduling lever for grid decarbonization—a coupling of fault tolerance and sustainability that has no parallel in synchronous inference serving, which cannot be paused mid-request.
This flexibility stands in contrast to the duck curve problem that training clusters do exacerbate when they run continuously. The duck curve describes the steep ramp that grid operators must cover as solar power drops in the late afternoon: a data center pulling constant megawatts through the transition period deepens that ramp and increases reliance on fossil peaker plants. Cooling systems compound the problem, adding the overhead quantified in section 1.3.6 on top of the computational draw. Carbon-aware schedulers that exploit checkpointing to pause training through the high-carbon window—typically the two to four hours straddling the solar-to-peaker transition—can shift a meaningful fraction of training energy consumption to periods when the marginal grid carbon intensity is lower. Geographic optimization, as discussed in section 1.2, addresses the baseline, but temporal scheduling addresses the variation within a given grid region.
Disposal, e-waste, and embedded AI
The rapid pace of innovation in AI hardware creates a relentless upgrade cycle (Slade 2007), contributing to a growing global crisis of electronic waste (e-waste). Globally, humanity generates over 50 million metric tons of e-waste annually, of which only 17.4 percent is formally documented as collected and properly recycled (Singh and Ogunseitan 2022). The high-performance servers used for training large models have a typical service life of just three to five years before they are considered obsolete. Discarded AI hardware contains toxic materials—lead, mercury, cadmium, and beryllium—that can leach into soil and groundwater when disposed of in landfills or informal recycling facilities (Grossman 2007).
Slade, G. 2007. Made to Break: Technology and Obsolescence in America. Harvard University Press. https://doi.org/10.4159/9780674043756.
Singh, Narendra, and Oladele A. Ogunseitan. 2022. “Disentangling the Worldwide Web of e-Waste and Climate Change Co-Benefits.” Circular Economy 1 (2): 100011. https://doi.org/10.1016/j.cec.2022.100011.
Grossman, E. 2007. High Tech Trash: Digital Devices, Hidden Toxics, and Human Health. Island press.
Two mechanisms specific to ML infrastructure make this obsolescence faster and more wasteful than in traditional server environments. AI accelerators rarely reach the end of their physical silicon lifespan; instead, they become obsolete due to memory bandwidth and interconnect bottlenecks that new model architectures expose. A cluster of GPUs connected by PCIe Gen 4 may have perfectly functional compute silicon but fall below the minimum interconnect bandwidth required to sustain the collective communication patterns of a newer, larger model. Because the interconnect is embedded in the baseboard rather than the chip, the entire node—not just the accelerator—must be replaced. Unlike conventional CPUs that socket into standardized ATX or OCP motherboards, modern AI nodes mount accelerators on proprietary baseboards engineered around a specific generation of NVLink, NVSwitch, and HBM. When a fleet upgrade targets a new model architecture, the baseboard, networking host channel adapters, and often the host server are replaced together, rather than simply swapping a PCIe card. This architectural tight-coupling multiplies the mass of e-waste generated per upgrade cycle far beyond what the per-chip silicon accounts suggest.
The problem is compounded by the rise of embedded AI, where machine learning capabilities are integrated into billions of consumer devices. Figure 21 traces the connected-device population from 8.6 billion in 2019 to a projected 29.42 billion by 2030, a more than threefold rise over the decade with the historical-to-projected boundary falling around 2024 (Statista 2022). That trajectory creates a distributed, low-value, and exceptionally difficult-to-recycle form of e-waste. Many AI-powered IoT sensors, wearables, and smart appliances are built with short lifespans and limited upgradability, making them difficult or impossible to repair or recycle (Baldé et al. 2017). Nonreplaceable lithium-ion batteries, sealed enclosures, and proprietary components ensure that even minor failures lead to complete device replacement.
Statista. 2022. Number of Internet of Things (IoT) Connected Devices Worldwide from 2019 to 2030.
Baldé, Cornelis P, Vanessa Forti, Vanessa Gray, Ruediger Kuehr, and Paul Stegmann. 2017. “The Global e-Waste Monitor 2017: Quantities, Flows and Resources.” United Nations University, International Telecommunication Union, International Solid Waste Association.

Short product lifecycles accelerate the cycle: limited software support windows, proprietary components that prevent repair, and sealed designs that make disassembly difficult all push devices toward replacement instead of reuse. A disproportionate share of this e-waste burden falls on developing nations, which often receive shipments of discarded electronics from wealthier countries, leading to significant environmental and social costs for populations least equipped to manage them.
Extending hardware lifespan
Countering the linear “take-make-dispose” model requires a shift toward a circular economy (Stahel 2016) that prioritizes reuse, refurbishment, and recycling. When embodied carbon dominates the lifecycle account, extending the functional lifespan of AI hardware is one of the largest reduction levers because it amortizes high manufacturing emissions over a longer period. Extending server life from three to five years reduces embodied carbon per year of service by 40 percent, a gain that can exceed many local software optimizations.
Stahel, Walter R. 2016. “The Circular Economy.” Nature 531 (7595): 435–38. https://doi.org/10.1038/531435a.
Four lifecycle interventions extend hardware service life by making systems repairable, upgradeable, supported, and reusable:
- Right-to-repair: Legislative and regulatory movements push back against repair restrictions by emphasizing access to parts, tools, diagnostics, and service information (Federal Trade Commission 2021).
- Modular design: AI hardware designs that allow independent upgrade of accelerators, memory, or networking interfaces prevent entire systems from being discarded when only one component is obsolete, following the principle demonstrated by companies like Framework in consumer laptops (Incorporated 2022).
- Extended support cycles: Longer software and firmware support keeps usable hardware secure and operational for longer, delaying its entry into the e-waste stream (Forti et al. 2020).
- Secondary-use programs: Moving older accelerators into research, batch, or lower-priority workloads further amortizes embodied carbon instead of sending hardware directly to disposal.
Federal Trade Commission. 2021. Nixing the Fix: An FTC Report to Congress on Repair Restrictions. Federal Trade Commission.
Incorporated, Framework Computer. 2022. Modular Laptops: A New Approach to Sustainable Computing.
Forti, V., C. P. Baldé, R. Kuehr, and G. Bel. 2020. The Global e-Waste Monitor 2020: Quantities, Flows and the Circular Economy Potential. United Nations University/United Nations Institute for Training; Research, International Telecommunication Union,; International Solid Waste Association.
These interventions move sustainability from disposal management to lifecycle engineering. Once the scale of the hardware, energy, and carbon footprint generated by AI systems is quantified, the question becomes what specific engineering techniques can reduce this impact.
Self-Check: Question
A procurement team is deciding whether to extend accelerator lifetime from three to five years. Which argument from this section best justifies treating the extension as one of the highest-leverage sustainability interventions?
- Older accelerators always become more energy-efficient after firmware updates, so per-query energy falls.
- Manufacturing emissions are large enough that amortizing them over five years instead of three cuts embodied carbon per year by roughly 40 percent, often yielding larger reductions than many per-query algorithmic optimizations.
- Datacenter PUE automatically improves as hardware ages because older chips accept higher inlet temperatures.
- Extending lifetime eliminates the need for recycling infrastructure because nothing ever leaves service.
A paper reports that training a model consumed 480 MWh for its final run. Explain why this number systematically understates the development phase’s environmental impact and name the mitigation categories the chapter recommends.
True or False: A hyperscaler migrates all training workloads to a 100 percent hydro-powered region. Because operational carbon per training run is now near zero, the use phase is no longer a meaningful engineering concern — only manufacturing emissions remain.
A consumer-electronics company plans to ship 200 million embedded-AI sensors over five years, each with a 2-year expected lifetime and a sealed non-serviceable enclosure. Which disposal-phase concern does the section emphasize most for this product class?
- Their per-device carbon footprint is negligible because each draws only microwatts, so aggregate e-waste can be ignored.
- They will be easy to recycle because standardized components and modular batteries enable automated recovery.
- Their combination of short lifetimes, sealed enclosures, non-replaceable batteries, and enormous scale creates a distributed e-waste stream that is hard to recover, refurbish, or safely dispose of.
- They matter primarily because their on-device models drift faster than cloud models.
A company is considering replacing its entire accelerator fleet because the new generation offers an 8 percent improvement in performance per watt. Which response best matches the section’s circular-economy logic?
- Refresh immediately, because any efficiency gain automatically outweighs manufacturing emissions.
- Retire the old fleet the moment peak benchmark performance falls below the new generation, even if the old hardware still serves lower-priority workloads well.
- Keep the older systems in secondary roles such as batch inference, development, or non-SLA internal workloads, and upgrade only components where modular upgrades are possible, because avoiding premature disposal often beats single-digit-percent runtime gains.
- Seal the existing hardware stack more tightly so maintenance costs fall even if repair becomes impossible.
Mitigation Strategies
When a data center hits its absolute power ceiling, the operator cannot simply buy more GPUs. The only path forward is extracting more intelligence from every watt through algorithmic intervention: quantizing FP32 weights down to INT4, pruning inactive neural pathways, and scheduling training runs to execute precisely when the local power grid is flooded with excess solar energy. Mitigation is the process of treating energy efficiency as a core algorithmic constraint.
The measurement frameworks developed in preceding sections revealed where environmental costs concentrate: training dominates for research workloads, inference dominates for deployed services, and manufacturing contributes a baseline that operational efficiency cannot eliminate. The findings guide implementation strategy along three axes: algorithmic optimization reduces per-operation costs, infrastructure choices determine whether those savings translate to actual emissions reduction, and policy frameworks ensure industry-wide adoption.
Implementation must account for Jevons Paradox31 (principle 19): making models 10\(\times\) more efficient can increase total usage enough to erase or even exceed the expected energy savings, because cheaper computation enables entirely new applications that were previously economically infeasible. This rebound effect is why sustainability strategies must focus on absolute limits (carbon budgets, renewable sourcing) rather than just rate efficiency (FLOP/s per watt), combining technical optimization with usage governance that prevents efficiency gains from being offset by exponential growth in deployment scale.
31 Jevons Paradox: Named after Jevons (1865), who observed that James Watt’s more efficient steam engine increased total coal consumption by making steam power economically viable for new applications. The pattern recurs in AI: making inference 10\(\times\) cheaper enables 100\(\times\) more applications (chatbots, code assistants, real-time translation), producing a net increase in total energy. This is why per-query efficiency alone cannot guarantee sustainability without usage governance.
Jevons, William Stanley. 1865. The Coal Question: An Inquiry Concerning the Progress of the Nation, and the Probable Exhaustion of Our Coal Mines. Macmillan; Co.
Multi-layer mitigation strategy framework
The most counterintuitive obstacle to sustainable AI is not inefficiency but success, which is why mitigation must choose both which layer owns each reduction and which absolute budget prevents rebound. Energy-efficient model design, optimized hardware deployment, sustainable infrastructure operations, and carbon-aware scheduling each attack a different term in the lifecycle footprint. Framework selection matters only insofar as it changes computation, memory movement, utilization, or reporting. Lifecycle-aware design keeps the optimization from ending at deployment by checking whether savings survive training, inference, manufacturing, and use.
Figure 22 captures this effect: as the cost per unit of computation drops, usage rises faster than efficiency brings the per-unit cost down, so total consumption, and environmental impact, rises rather than falls.

The paradox has profound implications for sustainable AI strategy because total energy depends on both per-query cost and demand elasticity.
Checkpoint 1.5: The efficiency trap (Jevons Paradox)
Your team optimizes a translation service, reducing the computational cost per query by 50 percent (2\(\times\) efficiency gain).
Jevons Paradox does not invalidate efficiency as a strategy; it simply means that efficiency must be paired with governance and capacity planning. At the level of individual systems, efficiency remains a central lever because it directly reduces cost, latency, and energy per useful operation.
Systems Perspective 1.5: Efficiency as sustainability
Every model optimization technique is simultaneously a sustainability tool. Pruning reduces computational complexity and energy consumption by eliminating unnecessary parameters. Quantization decreases memory requirements and accelerates inference while cutting power consumption. Knowledge distillation enables smaller models to achieve competitive performance with lower resource demands.
Performance engineering and environmental responsibility converge on the same objective. Optimizing a model to run faster or use less memory simultaneously reduces its carbon footprint. Designing efficient architectures or implementing hardware-software co-design produces systems that are both high-performing and environmentally sustainable.
The fundamental insight is that sustainable AI engineering overlaps strongly with efficient AI engineering, but extends beyond it. The engineering principles that enable systems to scale, perform better, and cost less to operate also make them more environmentally responsible, but sustainability adds lifecycle accounting, carbon-aware placement, absolute resource budgets, water and materials constraints, and governance against rebound effects. Sustainability is an integral part of good systems engineering, not a synonym for efficiency alone.
Lifecycle-aware development methodologies
Lifecycle-aware development starts from the largest environmental term in the workload and then selects the intervention that changes that term. Algorithmic design, infrastructure optimization, operational practice, and governance reduce impact only when they are sequenced around the measured bottleneck rather than applied as a generic checklist (Uddin and Rahman 2012).
Uddin, Mueen, and Azizah Abdul Rahman. 2012. “Energy Efficiency and Low Carbon Enabler Green IT Framework for Data Centers Considering Green Metrics.” Renewable and Sustainable Energy Reviews 16 (6): 4078–94. https://doi.org/10.1016/j.rser.2012.03.014.
Energy-efficient algorithmic design
Many deep learning models rely on billions of parameters, requiring trillions of FLOPs during training and inference.32 While these large models achieve top benchmark scores, research indicates that much of their computational complexity is unnecessary. Many parameters contribute little to final predictions, leading to wasteful resource consumption. Sustainable AI development treats energy efficiency as a design constraint rather than an optimization afterthought, requiring hardware-software co-design approaches that simultaneously optimize algorithmic choices and their hardware implementation for maximum efficiency per unit of computational capability.
32 FLOP/s vs. FLOPs: FLOP/s denotes a rate (operations per second); FLOPs denotes an operation count. The distinction matters for sustainability because energy scales with FLOPs (count), not FLOP/s (rate). GPT-3 required \(3.1 \times 10^{23}\) FLOPs total, and the energy cost per operation spans a 1000× range: CPUs at ~100 pJ/FLOP, GPUs at ~10 pJ/FLOP, TPUs at ~1 pJ/FLOP, and custom ASICs approaching 0.1 pJ/FLOP.
When the measured bottleneck is unused structure, bit width, or serving scale, the sustainable design lever changes. Table 12 maps the bottleneck to the intervention that changes the energy term.
| Technique | Measured bottleneck | Energy mechanism | Representative evidence |
|---|---|---|---|
| Pruning | Unused model structure | Removes redundant weights, reducing model size, compute, and memory movement during inference | Structured pruning can remove up to 90% of weights in models such as ResNet-50 while maintaining comparable accuracy |
| Quantization | Bit width | Lowers numerical precision so arithmetic units and memory transfers move fewer bits | INT8 operations consume about 16\(\times\) less energy than FP32, 4-bit operations can reach 64\(\times\) reductions, and Q8BERT reduces BERT size by 4\(\times\) with minimal degradation (Zafrir et al. 2019) |
| Knowledge distillation (Hinton et al. 2015) | Serving scale | Moves repeated inference cost into a one-time teacher-student training process | DistilBERT retains 97% of BERT accuracy with 40% fewer parameters and 60% faster inference (Sanh et al. 2019) |
Zafrir, Ofir, Guy Boudoukh, Peter Izsak, and Moshe Wasserblat. 2019. “Q8BERT: Quantized 8Bit BERT.” 2019 Fifth Workshop on Energy Efficient Machine Learning and Cognitive Computing - NeurIPS Edition (EMC2-NIPS), 36–39. https://doi.org/10.1109/emc2-nips53020.2019.00016.
Sanh, Victor, Lysandre Debut, Julien Chaumond, and Thomas Wolf. 2019. “DistilBERT, a Distilled Version of BERT: Smaller, Faster, Cheaper and Lighter.” arXiv Preprint arXiv:1910.01108, ahead of print. https://doi.org/10.48550/arXiv.1910.01108.
The table’s three levers have different deployment caveats: pruning33 depends on sparsity structure and hardware support, quantization34 compounds savings across arithmetic and memory movement, and knowledge distillation35 amortizes its extra training cost across repeated serving.
33 Pruning Energy Impact: Structured pruning at 90 percent sparsity reduces inference energy by 2–10\(\times\) because eliminated weights require neither storage nor computation, directly reducing both memory bandwidth and arithmetic. SparseGPT achieves 60 percent unstructured sparsity on LLMs with less than 1 percent accuracy loss, though realizing energy savings from unstructured sparsity requires hardware with native sparse execution support (for example, NVIDIA’s Sparse Tensor Cores).
34 Quantization Energy Savings: INT8 multiply-accumulate consumes roughly 16\(\times\) less energy than FP32 because both the arithmetic unit area and memory bandwidth shrink proportionally with bit-width. GPTQ enables 4-bit LLM quantization (64\(\times\) energy reduction per operation) with only 2 percent perplexity increase, reducing LLaMA-65B from 130 GB to 32 GB and enabling consumer-GPU deployment. The sustainability implication is multiplicative: lower precision reduces energy in both compute and memory movement simultaneously.
35 Knowledge Distillation: Introduced by Hinton et al. (2015), distillation trains a compact “student” model on soft probability targets from a larger “teacher,” capturing inter-class relationships that hard labels discard. DistilBERT retains 97 percent of BERT’s accuracy with 40 percent fewer parameters and 60 percent faster inference. The sustainability arithmetic is decisive: the one-time cost of training teacher plus student is amortized across millions of inference queries, making distillation one of the highest-ROI sustainability interventions for deployed services.
Hinton, Geoffrey, Oriol Vinyals, and Jeff Dean. 2015. “Distilling the Knowledge in a Neural Network.” arXiv Preprint.
Pruning, quantization, and distillation form the core toolkit for sustainable AI development, but their sustainability value depends on the measured bottleneck. In this chapter, the design question is not how to implement each compression method from first principles; it is how to rank these levers against memory movement, serving volume, carbon intensity, and lifecycle cost.
While model compression, efficient architectures, and carbon-aware scheduling provide the technical mechanisms for efficiency, deploying them haphazardly yields diminishing returns. To achieve maximum impact, engineering teams must synthesize these isolated techniques into a coherent, prioritized strategy that attacks the largest sources of emissions first.
Checkpoint 1.6: Prioritizing decarbonization strategy
You are deploying a 70B LLM for a latency-sensitive application.
TinyML optimization stack
TinyML makes the lifecycle argument concrete because the environmental budget appears as a hard physical envelope rather than a reporting category. A microcontroller deployment must fit the model and its peak activations into kilobytes of SRAM, finish inference before the sensor or user-facing deadline expires, and remain within a milliwatt or microwatt power budget. Standard INT8 quantization provides a 4\(\times\) memory reduction and often lowers energy substantially; structured pruning can add further savings when sparsity maps to hardware-visible work removal. Those techniques often get a model into the right range, but energy-harvesting devices require a stricter sequence: first make the memory plan feasible, then reduce switching activity, and only then search for an architecture that uses the harvested-energy budgets in table 9 well. Table 13 summarizes extreme TinyML optimization techniques at the end of that sequence.
Prakash, Shvetank, Matthew Stewart, Colby Banbury, Mark Mazumder, Pete Warden, Brian Plancher, and Vijay Janapa Reddi. 2023. “Is TinyML Sustainable? Assessing the Environmental Impacts of Machine Learning on Microcontrollers.” ArXiv Preprint abs/2301.11899.
| Technique | Typical Accuracy Impact | Memory Reduction | Energy Reduction |
|---|---|---|---|
| Binary Neural Networks | task-dependent | up to 32\(\times\) | order-of-magnitude when bit operations dominate |
| Neural Architecture Search for MCUs | varies | task-dependent | 2–5\(\times\) vs. baseline |
That sequence has three passes:
- Memory fit: Microcontrollers operate with 64 KB to 2 MB SRAM, so the memory pass starts with peak activation analysis, not just parameter count. A model that has small weights can still fail if one intermediate tensor exceeds the tensor arena, so TinyML runtimes rely on in-place operations, tensor-arena planning, and operator fusion to reuse buffers and avoid fragmentation.
- Switching energy: Once the memory plan fits, the energy pass asks whether ordinary INT8 arithmetic is still too expensive for the deployment. On devices powered by solar, vibration, or RF harvesting, Binary Neural Networks (BNNs) may be justified because XNOR-style operations replace multiply-accumulate work with bit operations (Courbariaux et al. 2016). That trade is not free: the accuracy loss is task-dependent, so BNNs belong in applications where always-on sensing within the harvested-energy budgets in table 9 matters more than full-precision classification margins.
- Architecture search: Automated design becomes useful only after the SRAM, latency, and harvested-energy constraints are explicit. MCUNet jointly searches the network and inference schedule for memory-limited microcontrollers and demonstrated ImageNet-scale accuracy on 256 KB SRAM devices (Lin et al. 2020); Once-for-All Networks amortize search by training a supernet from which device-specific subnetworks can be extracted (Cai et al. 2020); and ProxylessNAS optimizes directly against hardware latency and energy (Cai et al. 2019).
Courbariaux, Matthieu, Itay Hubara, Daniel Soudry, Ran El-Yaniv, and Yoshua Bengio. 2016. “Binarized Neural Networks: Training Deep Neural Networks with Weights and Activations Constrained to +1 or -1.” arXiv Preprint arXiv:1602.02830.
Lin, Ji, Wei-Ming Chen, Yujun Lin, John Cohn, Chuang Gan, and Song Han. 2020. “MCUNet: Tiny Deep Learning on IoT Devices.” In Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, Virtual, edited by Hugo Larochelle, Marc’Aurelio Ranzato, Raia Hadsell, Maria-Florina Balcan, and Hsuan-Tien Lin. Curran Associates.
Cai, Han, Chuang Gan, Tianzhe Wang, Zhekai Zhang, and Song Han. 2020. “Once-for-All: Train One Network and Specialize It for Efficient Deployment.” International Conference on Learning Representations.
Cai, Han, Ligeng Zhu, and Song Han. 2019. “ProxylessNAS: Direct Neural Architecture Search on Target Task and Hardware.” 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, May 6-9, 2019.
These methods should not be read as a menu of sustainable techniques. They are responses to a specific failure: the hand-designed model cannot simultaneously satisfy SRAM, latency, and harvested-energy constraints. The lifecycle budget must record the resulting trade-offs because accuracy loss, extra search or distillation training, and rebound-driven deployment growth can erase nominal per-inference savings.
Lifecycle-aware systems
Many AI deployments operate with a short-term mindset: train a model, deploy it, replace it a few months later, and treat the discarded training run or device generation as yesterday’s cost. Lifecycle-aware systems treat that churn as part of the footprint. If the model will be updated repeatedly, the first sustainability question is whether the next update requires full retraining. Incremental learning and transfer learning reduce this waste because fine-tuning pretrained models on new datasets can cut computational cost by orders of magnitude compared with training from scratch (Raffel et al. 2020).
Raffel, C., N. Shazeer, A. Roberts, K. Lee, S. Narang, M. Matena, Y. Zhou, W. Li, and P. J. Liu. 2020. “Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer.” Journal of Machine Learning Research 21 (140): 1–67.
Xu, Dianlei, Tong Li, Yong Li, Xiang Su, Sasu Tarkoma, Tao Jiang, Jon Crowcroft, and Pan Hui. 2020. “Edge Intelligence: Architectures, Challenges, and Applications.” arXiv Preprint arXiv:2003.12172.
The deployment boundary matters just as much as the training boundary. Edge deployment can reduce communication energy by running inference on specialized low-power hardware at the point of use (Xu et al. 2020), but the lifecycle account must include the embodied carbon of manufacturing and replacing those devices. Embedding LCA methodologies into AI workflows allows teams to see this trade-off early: a cloud model, an edge model, and a hybrid cascade may have different winners depending on query volume, device lifetime, grid carbon intensity, and retraining frequency (International Organization for Standardization 2006a, 2006b). Henderson et al. (2020) argue for systematic reporting of ML energy and carbon footprints precisely so these comparisons can be made consistently. As Jevons Paradox warns, the accounting must also include usage growth, because optimizing one stage may increase total impact if lower costs enable wider deployment.
Benchmarks and operating metrics
Benchmarks matter when they make efficiency visible at procurement and design time. The ML.ENERGY Leaderboard (ML.ENERGY Initiative et al. 2023) ranks models by energy efficiency and carbon footprint, encouraging researchers to optimize for sustainability alongside accuracy. MLCommons extends the same idea into standardized measurement: the MLPerf benchmark suite defines power-measurement protocols for data center and edge deployments, making sustainability claims comparable across hardware, software stacks, and workload classes.
ML.ENERGY Initiative, Jae-Won Chung, Jiachen Gu, Zhewei Yan, Tony Lo, Yejin Park, and Mosharaf Chowdhury. 2023. The ML.ENERGY Leaderboard. SymbioticLab, University of Michigan.
The right efficiency metric depends on the serving regime. Batch inference is naturally expressed as samples per joule, latency-sensitive serving as queries per joule, and generative workloads as joules per token because output length varies across requests. Standardization does not make one platform universally green; it makes the workload, measurement window, and energy denominator visible enough for procurement and architecture decisions to be argued quantitatively.
For sub-watt TinyML deployments, the MLPerf Tiny benchmark suite provides the same discipline at microcontroller scale. Table 14 summarizes benchmark tasks and typical energy requirements spanning from sub-millijoule to multi-millijoule ranges. The measurement methodology requires external power monitors such as INA219, INA226, or Joulescope-class instruments and specifies warm-up periods, measurement windows, and statistical reporting requirements so that tiny efficiency claims can be reproduced across submissions.
| Benchmark | Task | Reference Model | Typical Energy (mJ/inference) |
|---|---|---|---|
| Visual Wake Words | Image Classification (person detection) | MobileNetV1 0.25 (250 KB) | 0.1-1.0 mJ |
| Keyword Spotting | Audio Classification (12 keywords) | DS-CNN (19 KB) | 0.05-0.5 mJ |
| Anomaly Detection | Time Series (machine health) | Deep Autoencoder (5 KB) | 0.01-0.1 mJ |
| Image Classification | Visual Recognition (CIFAR-10) | ResNet-8 (70 KB) | 0.5-5.0 mJ |
Energy and latency still have to be read together. As equation 17 shows, the Energy Delay Product (EDP) balances energy consumption against response time by penalizing solutions that save power only by taking too long:
\[\text{EDP} = E \times T = P_{\text{average}} \times T^2 \tag{17}\]
where \(E\) is energy consumed, \(T\) is execution time, and \(P_{\text{average}}\) is average power. The quadratic delay term penalizes solutions that achieve low energy through excessive delays. Lower EDP indicates better efficiency, enabling comparison of systems with different energy-latency trade-offs.
For TinyML deployments, EDP helps identify optimal operating points. A microcontroller running at reduced clock frequency consumes less power but takes longer to complete inference. The EDP-minimizing configuration often operates at moderate frequencies where voltage can be reduced (exploiting the quadratic voltage term in CMOS power) without excessive latency penalties.
Sustainability metrics complement traditional performance benchmarks by creating evaluation frameworks that account for both capability and environmental impact. The EU AI Act’s 2024 requirements for providers of general-purpose AI models to document known or estimated model energy consumption illustrate how these metrics can move from voluntary reporting practice toward compliance requirements.
Infrastructure optimization
Algorithmic optimizations reduce per-operation energy, but the operational environment determines whether those savings translate to actual emissions reduction. Infrastructure-level innovations address the physical context where computational efficiency gains are realized: renewable energy integration, carbon-aware workload scheduling, and AI-driven cooling optimization each target a different layer of the data center stack.
Green data centers
A single hyperscale data center can consume over 100 MW of power—comparable to a small city36. Reducing this footprint requires three complementary strategies: renewable energy integration, advanced cooling, and AI-driven optimization.
36 PUE Gap: The industry-average PUE of 1.67 means 40 percent of electricity powers cooling and infrastructure rather than computation, while highly optimized Google facilities have reported PUE near 1.08 (only 7.4 percent overhead). For a 100 MW AI data center, this gap represents 59 MW of wasted power, enough to run 47,000 homes. Each 0.1 PUE improvement at hyperscale saves millions in annual electricity costs and tens of thousands of tonnes of CO2 per year on an average U.S. grid.
37 24/7 Carbon-Free Energy (CFE): Google’s published 2030 target requires matching every hour of consumption with real-time carbon-free generation, far harder than annual-average offsets. Closing the remaining gap requires substantial storage, transmission, and clean-generation investment. The distinction matters: annual-average carbon neutrality allows fossil-fuel hours offset by renewable credits, while hourly CFE forces genuine elimination of carbon-emitting generation from the supply chain.
Major cloud providers have announced renewable-energy commitments, but intermittency remains a challenge. AI infrastructure must incorporate energy storage solutions and intelligent scheduling that shifts workloads to times of peak renewable availability. Google’s published 2030 target for 24/7 carbon-free energy37 illustrates the harder version of this goal: matching every unit of electricity consumed with renewable generation in real time rather than relying on annual carbon offsets.
Cooling claims a large share of data center electricity (the cooling-overhead figure established for the PUE treatment in section 1.3.6)38. Liquid cooling, which transfers heat directly from accelerators using specially designed coolants, is significantly more effective than traditional air cooling and is used in high-density AI clusters. Software control of that cooling is the other lever: the DeepMind optimization in section 1.1.2.4 reclaimed a substantial fraction of cooling energy without any hardware change, demonstrating AI improving the sustainability of its own infrastructure.
38 Cooling Energy Density: AI accelerator racks can exceed 100 kW per cabinet, roughly 10\(\times\) the density of traditional servers, making air cooling physically inadequate. Direct liquid cooling reduces cooling energy from 38 percent to under 10 percent of total facility power by transferring heat at 3,000\(\times\) the volumetric efficiency of air. For AI data centers, the cooling system is no longer infrastructure overhead but an active constraint on how many accelerators can be physically co-located.
Carbon-aware scheduling
Grid carbon intensity fluctuates dramatically based on the mix of power sources available at any given time—from 50 g CO2/kWh in nuclear-heavy France to 820 g/kWh in coal-dependent Poland. Carbon-aware scheduling dynamically shifts AI computations to times and locations where low-carbon energy is available. For deadline-tolerant workloads with geographic or temporal flexibility, it can be one of the highest-leverage emissions levers.
Carbon-aware scheduling is fundamentally a load shifting software problem. The scheduler queries real-time grid carbon intensity APIs (for example, ElectricityMap, WattTime) to pause nonurgent training jobs during carbon-intensive periods, such as the evening peak, and migrate workloads to geographic regions with excess renewable energy, such as solar peaks in California or wind peaks in Iowa.
Google’s carbon-intelligent computing platform39 demonstrated this approach at scale, achieving a 40 percent reduction in carbon footprint under its global workload-shifting assumptions (Radovanovic et al. 2021). Within the broader energy-gap cascade of figure 23, carbon-aware scheduling is one of the systemic-stage steps, contributing a more conservative 1.3\(\times\) average reduction for mixed production fleets, where only some jobs are deadline-tolerant enough to move across time or geography.
39 Carbon-Aware Scheduling at Scale: Google’s carbon-aware data center study reports 15 percent carbon reduction through intra-region temporal shifting alone, and 40 percent globally by routing nonurgent batch compute across time zones to chase renewable peaks (Radovanovic et al. 2021). The key insight is that delay-tolerant workloads gain access to dramatically different grid carbon intensities without any model or infrastructure changes.
Radovanovic, Ana, Ross Koningstein, Ian Schneider, Bokan Chen, Alexandre Duarte, Binz Roy, Diyue Xiao, et al. 2021. “Carbon-Aware Computing for Datacenters.” arXiv Preprint arXiv:2106.11750, ahead of print. https://doi.org/10.48550/arXiv.2106.11750.
The effectiveness of carbon-aware scheduling depends on accurate real-time grid emissions data. Average grid intensity is useful for retrospective reporting because it estimates the emissions associated with energy already consumed. Marginal emissions are more useful for scheduling because they estimate which generator responds when the workload adds or removes demand. The Electricity Maps API provides real-time CO2 emissions data for power grids worldwide40, while WattTime provides marginal emissions data showing which power plants turn on or off next. Figure 24 demonstrates the scheduling opportunity: shifting training jobs to low-carbon hours in lower-carbon regions reduces emissions by up to 8\(\times\) without changing a single line of model code.
40 Marginal vs. Average Emissions: WattTime’s marginal emissions data identifies which power plant turns on next when load increases, enabling 2–5\(\times\) better carbon optimization than grid-average intensity. The distinction is critical: average intensity smooths out peaks, but marginal data reveals that adding 1 MW of load at the wrong hour can activate a coal peaker plant at 900 g/kWh even on a nominally “clean” grid.
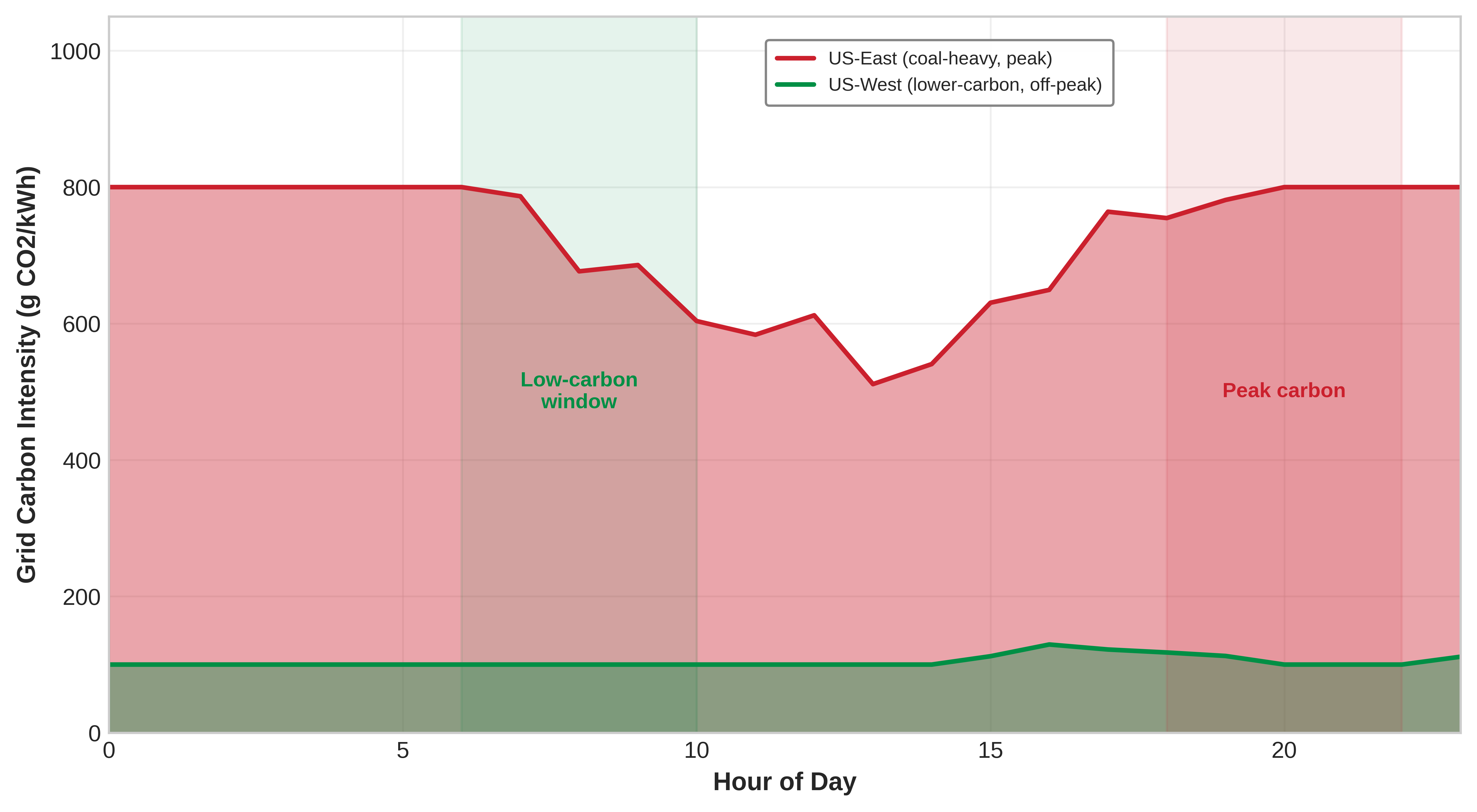
Renewable energy variability presents a key challenge for carbon-aware scheduling. Figure 25 captures European grid dynamics: solar energy peaks at midday, wind shows distinct peaks in mornings and evenings, and fossil generation fills the gaps. This temporal pattern determines when AI workloads can run on clean energy.
Energy-aware AI frameworks complement scheduling when they optimize the workload rather than only shifting its location. Zeus (You et al. 2023) achieves 75 percent energy savings on BERT training by automatically finding optimal energy-performance trade-offs, while Perseus (Chung et al. 2023) reduces large-model training energy consumption by up to 30 percent by mitigating energy bloat. These tools, alongside CodeCarbon for emissions tracking (Schmidt et al. 2021), democratize energy optimization beyond hyperscale companies.
You, Jie, Jae-Won Chung, and Mosharaf Chowdhury. 2023. “Zeus: Understanding and Optimizing GPU Energy Consumption of DNN Training.” 20th USENIX Symposium on Networked Systems Design and Implementation (NSDI 23), 119–39.
Chung, Jae-Won, Yile Gu, Insu Jang, Luoxi Meng, Nikhil Bansal, and Mosharaf Chowdhury. 2023. “Reducing Energy Bloat in Large Model Training.” Proceedings of the ACM SIGOPS 30th Symposium on Operating Systems Principles abs/2312.06902: 144–59. https://doi.org/10.1145/3694715.3695970.
AI-driven cooling optimization is a software-deployable lever for reducing data center energy consumption when the facility has sufficient sensing and controllable cooling equipment. Traditional cooling systems rely on fixed control policies with predefined temperature thresholds, often consuming more energy than necessary; a learned controller that adapts to real-time conditions reclaims much of that waste, as the DeepMind deployment analyzed in section 1.1.2.4 showed without any hardware change.
Complementing software optimization, liquid cooling and immersion cooling change the thermal design space for dense accelerator clusters. Liquid cooling transfers heat directly from accelerator chips using specially designed coolants, achieving 3,000\(\times\) better heat transfer than air. Immersion cooling submerges entire server racks in nonconductive liquid coolants, eliminating traditional air-based systems entirely. These approaches enable higher compute densities with lower power consumption—critical for accelerators whose thermal design power reaches hundreds of watts per chip.
Case study: Google’s framework
The value of Google’s case study is that it decomposes mitigation across the same layers this chapter has tracked: model, machine, mechanization, and map. Table 15 summarizes the “4 Ms” that Google engineers identified for reducing the carbon footprint of rapidly expanding AI workloads (Patterson, Gonzalez, Holzle, et al. 2022).
| Lever | Intervention | Reported efficiency effect | Example mechanism |
|---|---|---|---|
| Model | Select efficient AI architectures such as sparse models or neural-architecture-search-derived designs | 5–10\(\times\) lower computation requirements without compromising model quality | Evolved Transformer and Primer |
| Machine | Use AI-specific hardware rather than general-purpose systems | 2–5\(\times\) performance-per-watt improvement; TPUs show 5–13\(\times\) greater carbon efficiency relative to nonoptimized GPUs | Tensor Processing Units |
| Mechanization | Run optimized cloud infrastructure at high utilization | 1.4–2\(\times\) energy reduction compared to conventional on-premise data centers | Lower facility PUE than the industry-average baseline used in the 2021 study |
| Map | Place data centers in regions with low-carbon electricity supplies | 5–10\(\times\) lower gross emissions | Real-time monitoring of renewable energy usage across infrastructure |
The combined effect of these practices produces multiplicative efficiency gains. For instance, implementing the optimized Transformer model on TPUs in strategically located data centers reduced energy consumption by a factor of 83 and CO2 emissions by a factor of 747.
In the period studied by Patterson, Gonzalez, Holzle, et al. (2022), systematic efficiency improvements constrained energy consumption growth even as AI deployment expanded across Google’s product ecosystem. A significant indicator of this progress is the observation that AI workloads maintained a less-than-15-percent proportion of Google’s total energy consumption over the reported period. As AI functionality expanded across Google’s services, corresponding increases in compute cycles were offset by advancements in algorithms, specialized hardware, infrastructure design, and geographical optimization.
Patterson, David, Joseph Gonzalez, Urs Holzle, Quoc Le, Chen Liang, Lluis-Miquel Munguia, Daniel Rothchild, David R. So, Maud Texier, and Jeff Dean. 2022. “The Carbon Footprint of Machine Learning Training Will Plateau, Then Shrink.” Computer 55 (7): 18–28. https://doi.org/10.1109/mc.2022.3148714.
Du, Nan, Yanping Huang, Andrew M. Dai, Simon Tong, Dmitry Lepikhin, Yuanzhong Xu, Maxim Krikun, et al. 2022. “GLaM: Efficient Scaling of Language Models with Mixture-of-Experts.” In Proceedings of the 39th International Conference on Machine Learning, edited by Kamalika Chaudhuri, Stefanie Jegelka, Le Song, Csaba Szepesvari, Gang Niu, and Sivan Sabato, vol. 162. Proceedings of Machine Learning Research. PMLR.
Empirical case studies demonstrate how sustainable-AI engineering can improve both capability and environmental impact. For example, Patterson, Gonzalez, Holzle, et al. (2022) compare GPT-3 with Google’s GLaM and report improved quality metrics alongside reduced training computation and lower-carbon energy sources, while the GLaM model paper explains the mixture-of-experts architecture behind that efficient scaling (Du et al. 2022).
The strategy in the case study—combining systematic measurement, carbon-aware development, transparency in reporting, and renewable energy transition—is useful as a framework for sustainable AI scaling. The analysis also argues that earlier extrapolations overstated ML energy requirements by large factors because they did not account for efficiency improvements and workload measurement boundaries, underscoring the importance of empirical measurement over theoretical projections.
Engineering guidelines for sustainable AI development
Measurement, optimization, and scheduling frameworks provide the analytical foundation, but implementation requires prioritization. The following checklist should be read as a decision aid: first measure the dominant lifecycle term, then choose the lever that changes it.
- Measure first: Tools like CarbonTracker and CodeCarbon track the emissions of training runs. Teams cannot improve what they do not measure, and establishing baseline metrics is essential for validating the effectiveness of optimization efforts (Anthony et al. 2020; Schmidt et al. 2021).
- Choose the region: Train models in data centers powered by renewable energy. As established in section 1.0.1, grid carbon intensity spans the 8 to 40 times range for representative region pairs; scheduling workloads where clean energy is most abundant yields immediate reductions.
- Optimize the model: Avoid training the largest model possible by default. Pruning, quantization, and knowledge distillation find the smallest model that meets accuracy targets. A 90 percent accurate model requiring 10 percent of the resources often provides better real-world value than a 95 percent accurate model requiring full resources.
- Avoid retraining from scratch: Transfer learning and fine-tuning reduce computational requirements by orders of magnitude compared to full retraining.
- Select efficient hardware: Energy-efficient accelerators, such as TPUs or specialized inference chips, reduce deployment costs. The full hardware lifecycle and workload-specific platform selection matter as much as raw throughput.
- Account for the full lifecycle: Longer hardware refresh cycles and responsible e-waste policies reduce total environmental impact. Manufacturing often exceeds operational energy consumption, making hardware longevity a critical sustainability factor.
Anthony, L. F. W., B. Kanding, and R. Selvan. 2020. Carbontracker: Tracking and Predicting the Carbon Footprint of Training Deep Learning Models. ICML Workshop on Challenges in Deploying and monitoring Machine Learning Systems.
The cumulative impact of individual technical choices depends on systemic, industry-wide adoption. Without external pressure, market forces prioritize speed and scale over efficiency. Policy and regulatory frameworks translate engineering possibilities into industry-wide practice by making sustainable choices a financial and legal imperative.
Self-Check: Question
A translation service halves its per-query compute after deploying distillation. Within six months, total monthly energy has risen by 40 percent because cheaper translation unlocked new product integrations — chatbots, email assistants, accessibility tools. Which concept from this section best explains the net increase, and what does it imply about efficiency-only strategies?
- Distillation reduces accuracy too much for production, so total energy rose from re-running queries — accuracy-driven rebound.
- Jevons paradox: per-unit efficiency gains lowered the effective cost of translation and triggered enough new demand that total resource consumption grew; efficiency alone cannot guarantee sustainability without usage governance.
- Carbon accounting frameworks ignore improvements below the datacenter level, so the reported rise is an artifact of incomplete measurement.
- Efficient models can only run on specialized hardware that requires manufacturing new chips, so embodied emissions explain the rise.
A team must reduce the serving footprint of a latency-sensitive 70B-parameter model on current GPU hardware. They are weighing post-training quantization, knowledge distillation, and unstructured pruning. Justify why the chapter would likely prioritize the first two before unstructured pruning.
A platform team asks which single infrastructure-layer mitigation strategy, requiring no model or code changes, offers the highest leverage for reducing emissions of an existing production workload. Which lever does the section identify?
- Carbon-aware scheduling across regions and time windows with lower grid carbon intensity, because identical workloads can differ by 20–50\(\times\) in emissions purely by placement.
- Increasing batch size on every request until every workload becomes compute-bound, because higher arithmetic intensity always lowers energy.
- Replacing every deployed model with a binary neural network to cut arithmetic precision to the minimum.
- Retraining every deployed model from scratch weekly to keep it minimally sized.
When a vendor advertises a keyword-spotting accelerator’s energy-per-inference and accuracy on a microcontroller, the MLCommons benchmark suite that standardizes the tasks, measurement rules, and comparability requirements for sub-watt systems is ____.
In Google’s 4Ms sustainability framework, which element refers specifically to choosing low-carbon locations and matching workloads to cleaner electricity supply?
- Model — selecting efficient architectures.
- Machine — selecting efficient accelerators.
- Mechanization — operating cloud infrastructure efficiently.
- Map — siting and geographic workload placement to exploit regional electricity differences.
Explain why the chapter pairs technical efficiency with carbon budgets, governance, or usage limits rather than treating optimization as sufficient on its own.
Policy, Regulation, and the Path Forward
If a company can slash its cloud computing bill by relocating its training cluster to a region powered entirely by cheap, high-emission coal, the market alone will not prevent them from doing so. Engineering ingenuity can provide the tools for efficient computation, but it requires policy, regulation, and carbon pricing to ensure that using those tools becomes a financial and legal imperative rather than just a corporate public relations talking point.
For a systems reader, policy is the control plane that changes the objective function. Reporting rules make hidden energy and embodied-carbon costs measurable, carbon pricing turns location into a scheduling variable, and procurement standards make lifecycle accounting part of infrastructure design. The mechanisms below matter because they determine which optimizations become economically rational at fleet scale.
Regulatory mechanisms
Effective AI sustainability governance operates through a combination of mandatory reporting, emission restrictions, and financial incentives, though global policy fragmentation presents a significant implementation challenge. The European Union has taken a leading role with mandatory approaches, notably the EU AI Act41 and the Corporate Sustainability Reporting Directive (CSRD).42 The AI Act creates separate obligations for general-purpose AI models and for general-purpose AI models with systemic risk, including documentation of computational resources and known or estimated model energy consumption. The CSRD mandates that large companies disclose their environmental impacts, including Scope 1, 2, and 3 emissions from AI operations, according to standardized, audited reporting frameworks. This regulatory shift transforms energy monitoring from an optional optimization into a legal necessity.
41 EU AI Act (2024): The EU AI Act, adopted in 2024, is an early broad AI regulatory framework that creates obligations for general-purpose AI models and additional obligations for models with systemic risk, including models presumed to have high-impact capabilities above \(10^{25}\) FLOPs of training compute. Technical documentation must include computational resources and known or estimated model energy consumption. For violations by providers of general-purpose AI models, Article 101 permits fines up to 3 percent of annual worldwide turnover or EUR 15 million; the separate 7 percent maximum applies to prohibited-practice violations.
42 CSRD (Corporate Sustainability Reporting Directive): Effective 2024, this EU regulation requires 50,000+ companies to disclose audited Scope 1, 2, and 3 emissions using standardized ESRS frameworks. For AI infrastructure, CSRD forces disclosure of previously hidden costs: the embodied carbon of GPU procurement, energy from outsourced cloud training, and end-of-life hardware disposal that collectively constitute the majority of an AI system’s Scope 3 footprint.
43 Emissions Trading for Compute: The EU ETS (2005) pioneered cap-and-trade for industrial emissions; applying this model to AI compute would set aggregate energy budgets for training clusters and let organizations trade surplus capacity. The mechanism converts sustainability from a voluntary optimization into a priced constraint: organizations that invest in efficiency can sell unused allocation to less efficient competitors, creating a financial incentive aligned with the iron law’s utilization term (\(\eta_{\text{hw}}\)).
Beyond measurement mandates, governments are exploring direct restriction mechanisms. These include setting limits on computational power available for training large AI models, mirroring Emissions Trading Systems (ETS)43 used in environmental policy. Such “cap-and-trade” systems for compute would force organizations to operate within predefined energy budgets or procure additional capacity, creating a market for computational carbon credits. The expansion of carbon pricing and Carbon Border Adjustment Mechanisms (CBAM) is converting the geographic location of compute into a direct financial variable—the carbon intensity of regional electricity grids varies across the span established in section 1.0.1, making carbon-aware scheduling a key compliance strategy.
To balance these restrictions, government incentives play a proactive role. Financial support, tax benefits, and grants for Green AI research can make sustainability a competitive advantage. Governments can also use their public procurement power, mandating that vendors meet sustainability benchmarks such as operating on carbon-neutral data centers or using energy-efficient models. Broader corporate reporting frameworks—the Greenhouse Gas Protocol, TCFD, and ISSB—scrutinize Scope 3 emissions, encompassing the substantial embodied carbon of GPU procurement and data center construction alongside operational emissions of outsourced cloud compute.
Industry self-regulation and standards
Alongside government mandates, the AI industry is driving significant environmental improvements through self-regulation and common standards. The most visible commitments from major cloud providers—Google, Microsoft, and Amazon—focus on matching data center electricity consumption with renewable energy procurement and increasing direct clean-energy supply. Going further, the push for 24/7 Carbon-Free Energy (CFE) aims to match every hour of energy consumption with real-time clean energy procurement, moving beyond annual averages and carbon offsets that can obscure actual emissions from fossil-fuel-reliant grids (Monyei and Jenkins 2018).
Monyei, C. G., and Kirsten E. H. Jenkins. 2018. “Electrons Have No Identity: Setting Right Misrepresentations in Google and Apple’s Clean Energy Purchasing.” Energy Research &Amp; Social Science 46: 48–51. https://doi.org/10.1016/j.erss.2018.06.015.
Schmidt, Victor, Kamal Goyal, Aditya Joshi, Boris Feld, Liam Conell, Nikolas Laskaris, Doug Blank, Jonathan Wilson, Sorelle Friedler, and Sasha Luccioni. 2021. CodeCarbon: Estimate and Track Carbon Emissions from Machine Learning Computing. Zenodo software citation. https://doi.org/10.5281/zenodo.4658424.
Lacoste, Alexandre, Alexandra Luccioni, Victor Schmidt, and Thomas Dandres. 2019. “Quantifying the Carbon Emissions of Machine Learning.” arXiv Preprint arXiv:1910.09700.
Internal carbon pricing is another effective self-regulatory tool. By assigning a “shadow price” to carbon emissions, companies integrate environmental costs directly into financial decision-making for AI projects, naturally prioritizing investments in energy-efficient hardware and low-emission models. Voluntary checklists and open-source tools promote accountability when they feed those same project decisions: projects like CodeCarbon and ML CO2 Impact provide frameworks that allow developers to estimate and track model carbon footprints directly within their workflows (Schmidt et al. 2021; Lacoste et al. 2019).
Standardized benchmarks provide the objective data needed to validate these efforts. MLCommons, through its MLPerf benchmark suite, has incorporated power measurement protocols for both data center and edge deployments. By establishing metrics like “samples per Joule” and “Joules per token,” MLCommons enables fair, transparent comparison of AI system efficiency across different hardware and software platforms. These benchmarks, combined with independent sustainability audits from organizations like the Green Software Foundation, create a measurable mechanism for holding the industry accountable and driving competition toward genuinely greener AI.
Public engagement and environmental justice
Effective AI sustainability governance requires public support, which depends on transparency, clear communication, and equitable access. Currently, public understanding of AI’s environmental impact is limited and often polarized between narratives of technological salvation and ecological disaster. Fostering informed discourse requires moving beyond greenwashing44—the practice of making misleading claims about environmental responsibility—toward genuine, verifiable transparency.
44 Greenwashing in AI: Manifests as claiming “carbon neutrality” through offsets while expanding data center capacity, or highlighting per-query efficiency gains while total compute grows 10\(\times\). Green-claims rules can require verifiable evidence for environmental claims. For ML engineers, the technical litmus test is whether sustainability reporting covers all three GHG Protocol scopes, or conveniently omits Scope 3 (hardware manufacturing, cloud supply chain) where much of AI’s carbon can reside.
Pledge-style disclosure is useful only when it creates auditable data rather than reputational cover. The Montréal Carbon Pledge, originally a commitment by institutional investors to measure and disclose carbon footprints annually, is a useful model precisely because its value lies in the disclosed data, not the pledge itself; the same standard applies to an AI organization, whose sustainability claims are only as credible as the workload-level measurements behind them.
Transparency establishes the evidence base; environmental justice asks how the burdens and benefits revealed by that evidence are distributed. As section 1.0.2 established, an ML fleet allocates electricity demand, water use, land pressure, and e-waste across communities that often do not share in its economic benefits, which is why site selection is part of the engineering design space. At the policy layer, this distributional question becomes a reporting requirement: social impact assessments and equitable-access provisions for large-scale AI projects turn the fairness concern into auditable obligations rather than aspirations.
Future research directions
The research agenda follows the same engineering logic as the mitigation framework: remove data movement, close the measurement gap, and avoid redundant computation. One major direction is the development of non-von Neumann computing architectures45, such as neuromorphic computing and in-memory computing. By processing data where it is stored, these paradigms aim to eliminate the “von Neumann bottleneck”—the energy-intensive shuttling of data between memory and processing units that can account for 60–80 percent of a system’s power consumption. Successful implementation could yield energy efficiency improvements of 100–1000\(\times\) for certain AI workloads.
45 Von Neumann Bottleneck: John von Neumann’s 1945 stored-program architecture separates processing from memory, requiring constant data shuttling that consumes 60–80 percent of system power. For AI workloads dominated by matrix multiplications with low arithmetic intensity, this bottleneck means most energy moves data rather than computes results. In-memory and neuromorphic architectures attack this directly, with potential 100–1,000\(\times\) energy reductions for inference by eliminating the memory-processor round trip.
Henderson, Peter, Jieru Hu, Joshua Romoff, Emma Brunskill, Dan Jurafsky, and Joelle Pineau. 2020. “Towards the Systematic Reporting of the Energy and Carbon Footprints of Machine Learning.” CoRR abs/2002.05651 (248): 1–43. https://doi.org/10.48550/arxiv.2002.05651.
A critical implementation barrier is the “measurement gap”: AI teams need standardized, workload-level reporting of energy use and carbon emissions rather than relying only on coarse proxy metrics (Henderson et al. 2020). Coarse methods often rely on proxies such as GPU-hours multiplied by average grid intensity, which fail to capture the real-world dynamics required by reporting regimes that care about time, location, and workload boundary. Developing and standardizing granular, real-time energy and carbon accounting tools is essential for both compliance and effective optimization.
A second research direction reduces redundant computation before it reaches the accelerator. Research shows that the predictive value of training data often decays, meaning models are frequently trained on vast datasets with diminishing returns (Wu et al. 2022). Smarter data sampling, active learning, and data valuation techniques can optimize training processes to use only the most informative data, reducing computational waste without sacrificing accuracy. Ultimately, an integrated approach combining algorithmic efficiency, hardware innovation, renewable energy adoption, and transparent governance is necessary to ensure AI’s trajectory aligns with global sustainability goals.
Wu, Carole-Jean, Ramya Raghavendra, Udit Gupta, Bilge Acun, Newsha Ardalani, Kiwan Maeng, Gloria Chang, et al. 2022. “Sustainable AI: Environmental Implications, Challenges and Opportunities.” Proceedings of Machine Learning and Systems 4: 795–813.
Minimizing redundant computation through smarter data curation directly aligns regulatory compliance with operational efficiency. The most dangerous obstacles to sustainable AI are not technical limitations but incorrect assumptions—miscalculations that cause well-intentioned teams to inadvertently increase their environmental footprint.
Self-Check: Question
A sustainability team argues that carbon pricing is unnecessary because ‘rational firms will naturally choose greener options once they see the accounting.’ Which rebuttal from the section best explains why market incentives alone are insufficient?
- Datacenter operators are legally prohibited from choosing lower-cost electricity sources, so carbon choices are pre-decided by regulation.
- Without carbon pricing, the cheapest operational choice is often the dirtiest one, so firms optimizing cost will rationally pick fossil-heavy regions or hours and increase emissions even while reporting accurately.
- Renewable-powered regions always have the highest electricity prices, making green choices impossible.
- Cloud providers already disclose Scope 3 emissions with perfect accuracy, so no further mechanism is needed.
A compliance team is translating the EU AI Act and the Corporate Sustainability Reporting Directive (CSRD) into engineering requirements. Which framing best matches how the section describes their practical effect?
- Energy reporting and emissions accounting become mandatory design constraints: systems must be instrumented to produce audited Scope 1/2/3 disclosures, shifting sustainability from optional metric to compliance requirement.
- They ban foundation-model training above a fixed FLOPs threshold worldwide, so the engineering question is simply whether training fits under the cap.
- They replace direct power measurement with legal estimates based only on parameter count, so no new instrumentation is needed.
- They apply only to hardware manufacturers, not to organizations operating AI services.
Explain how an emissions-trading scheme or carbon price transforms carbon-aware scheduling from a purely voluntary practice into an economically rational default.
True or False: A company purchases enough annual Renewable Energy Certificates to match 100 percent of its yearly AI electricity use, but its evening serving load runs on a grid that is 60 percent coal-fired between 6 PM and midnight. By the section’s standard, this is equivalent to meeting 24/7 clean-energy matching.
Which future research direction does the section frame as directly attacking the von Neumann bottleneck’s energy cost rather than its measurement?
- Broader adoption of annual sustainability reports so more organizations see their numbers.
- Non-von-Neumann approaches such as neuromorphic and in-memory computing that reduce or eliminate data shuttling between memory and compute.
- Increasing model size so arithmetic intensity always sits right of the memory crossover.
- Replacing lifecycle accounting with benchmark-only reporting to simplify comparison.
Fallacies and Pitfalls
Sustainability involves counterintuitive physics where efficiency improvements can increase total consumption and geographic choices dominate all other optimizations. These fallacies and pitfalls capture errors that waste compute budgets and planetary resources through misallocated optimization effort.
Fallacy: Cloud computing automatically makes AI systems more environmentally sustainable.
Engineers assume cloud providers operate efficiently and sustainably. In production, geographic region dominates all other factors through grid carbon intensity differences. Training a 7B model on 64 A100s for 14 days produces 5.7 t CO2 on the US average grid (429 g/kWh) but only 264.9 kg CO2 on Quebec’s hydroelectric grid (20 g/kWh operational)—a roughly 21.5× difference for this US-average-versus-Quebec pairing, which sits inside the 8 to 40 times geographic range established in section 1.0.1. Coal-powered grids emit 800–1000 g CO2/kWh while well-managed hydroelectric sources emit 10–50 g CO2/kWh. As demonstrated in section 1.2, teams that deploy to default cloud regions without checking grid carbon intensity waste a large multiple of the carbon budget necessary, turning “cloud sustainability” into a geographic lottery rather than an inherent advantage.
Pitfall: Focusing only on operational energy consumption while ignoring embodied carbon and lifecycle impacts.
Teams optimize training efficiency while ignoring manufacturing emissions. In low-carbon grids, embodied carbon can dominate fleet-level footprint accounting. As quantified in section 1.2.1.1, an A100 accelerator embodies roughly 150 kg CO2 from manufacturing (Luccioni et al. 2023); for the 14-day, 64-A100 training run above, the unamortized upfront burden is roughly 9.6 metric tons CO2. Amortized over a 4-year service life, the share attributable to this specific 14-day job is about 90 kg, but the unamortized fleet-level number is what dominates total footprint accounting: it exceeds the job’s operational emissions on Quebec’s clean grid where operational emissions are minimal. Extending hardware lifetime from three to five years reduces amortized embodied carbon by 40 percent. Organizations focusing exclusively on operational efficiency miss this procurement and depreciation lever while optimizing marginal gains in PUE or compute efficiency.
Luccioni, Alexandra Sasha, Sylvain Viguier, and Anne-Laure Ligozat. 2023. “Estimating the Carbon Footprint of BLOOM, a 176B Parameter Language Model.” Journal of Machine Learning Research 24 (253): 1–15.
Fallacy: TDP is actual power consumption.
Thermal Design Power (TDP) is the maximum sustained draw the cooling system must handle, not the wattage the accelerator actually consumes under a given workload. Real power varies with utilization, memory access pattern, and clock frequency: an H100 idles around 50–80 W, runs inference workloads at 250–400 W, and approaches its 700 W TDP only during sustained training with high tensor-core occupancy. Using TDP for energy calculations overestimates carbon for inference fleets (which rarely sustain peak power) and underestimates it for sustained training on newer hardware with dynamic boost above the published envelope. Carbon and electricity-cost estimates that drive geographic-placement decisions (section 1.2) should use measured average power per workload class, not datasheet TDP.
Pitfall: Using PUE as a complete environmental metric.
Data-center operators report PUE in sustainability disclosures and engineers treat the figure as a single number that summarizes efficiency. PUE measures only the ratio of total facility power to IT power; it says nothing about water consumption, embodied carbon in manufacturing, or the carbon intensity of the electricity the facility consumes. A data center with PUE 1.06 running on a coal-heavy grid (820 g CO2/kWh) has a far larger operational carbon footprint than a data center with PUE 1.40 running on hydroelectric power (10 g CO2/kWh)—roughly a 60\(\times\) difference that PUE alone hides. Reporting total environmental impact requires PUE, WUE (water-usage effectiveness), grid carbon intensity, and embodied-carbon amortization together. No single metric is sufficient.
Fallacy: Efficiency improvements automatically reduce total environmental impact.
Engineers assume that halving inference cost cuts environmental impact in half. Jevons Paradox warns that efficiency improvements can increase total consumption by enabling expanded usage. In a rebound scenario, reducing token cost from $0.06 to $0.002 per 1,000 tokens (a 30\(\times\) improvement) while inducing a 100\(\times\) increase in query volume grows total emissions despite per-query efficiency gains. A quantization change that reduces inference energy by 4\(\times\) can still increase total energy if relaxed cost constraints expand deployment by more than 4\(\times\). Teams that optimize efficiency without usage governance can therefore transform sustainability wins into consumption growth, requiring carbon budgets and usage caps of the kind motivated by the Jevons analysis in figure 22.
Pitfall: Treating carbon offsets as a substitute for reducing actual emissions.
Organizations purchase offsets to neutralize emissions without validating offset quality. In reality, analysis of voluntary carbon markets reveals that 60–90 percent of credits fail to deliver claimed reductions due to inflated baselines, nonpermanent sequestration, or projects that would have occurred regardless. A company training models on coal grids (1000 g CO2/kWh) and buying offsets spends 2–3\(\times\) more than directly migrating to renewable regions (20–50 g CO2/kWh) while achieving inferior environmental outcomes. Offset projects take 5-20 years to sequester carbon while compute emissions are immediate. Teams that prioritize offsets over actual reduction miss the geographic leverage established in section 1.0.1 and delay renewable energy transitions that deliver permanent improvements.
Fallacy: Component-level optimization guarantees lifecycle improvement.
Teams reduce training cost to improve sustainability without analyzing deployment scale. In production, training-inference trade-offs often invert total emissions. A model pruned by 40 percent to save training energy but requiring 2\(\times\) inference compute increases total lifecycle emissions if it serves more than 100 million queries—a crossover point reached in three to six months for production systems. Edge deployment that reduces data center energy by 60 percent but requires manufacturing 10,000 specialized devices adds 1,500-2,000 kg embodied carbon (10\(\times\) the cloud training emissions). Extending GPU lifetime from three to five years reduces amortized embodied carbon by 40 percent but may sacrifice 15–25 percent operational efficiency; the lifecycle break-even depends on grid carbon intensity, with lifetime extension dominating on clean grids and efficiency winning on dirty grids. Effective sustainability requires holistic analysis across section 1.2.1.2 rather than local optimization.
Pitfall: Evaluating sustainability at the component boundary instead of the lifecycle boundary.
A model aggressively pruned to save training energy, only to require massive computational overhead during inference to compensate for lost accuracy, illustrates the danger of localized optimization. The same mistake appears when hardware teams report accelerator efficiency without procurement carbon, platform teams report PUE without grid intensity, or model teams report training emissions without expected serving volume. Avoiding these systemic pitfalls requires the lifecycle boundary developed in section 1.2.1.2: training, serving, embodied carbon, regional grid mix, hardware lifetime, and demand growth must be evaluated together before a change can be called sustainable.
Self-Check: Question
True or False: A team migrates a batch-training workload from an on-premises cluster in Virginia (roughly 400 gCO2/kWh) to a cloud region in West Virginia (roughly 700 gCO2/kWh) because the cloud provider markets its AI infrastructure as ‘green.’ The migration necessarily improves the run’s carbon footprint.
A team prunes a model aggressively to cut training energy, but the resulting deployment requires custom sparse-execution hardware and more total serving compute to hit accuracy targets. Which pitfall does this scenario illustrate, and what mitigation does the section recommend?
- Higher GPU utilization always increases embodied carbon per query, so any pruning gain is automatically lost to hardware.
- Local optimization of one lifecycle component (training energy) without accounting for inference scale, manufacturing burden, and hardware support can worsen total lifecycle emissions; the mitigation is full-lifecycle accounting before committing to the optimization.
- Measuring carbon intensity too often instead of using annual averages creates an appearance of higher emissions that disappears with averaging.
- Transfer learning makes lifecycle accounting impossible because the original training is hidden upstream.
Explain why the section treats buying carbon offsets as a weaker sustainability strategy than directly reducing emissions through location or system-design decisions.
Summary
The lifecycle boundary is the through-line for the final synthesis: a sustainable architecture must account for training, serving, embodied carbon, grid mix, hardware lifetime, and demand growth together. Sustainable AI represents the “physical limit” of the Machine Learning Fleet. High-performing ML systems can optimize logic, exploit specialized hardware, launch global services, and harden their defensive perimeter while still failing the environmental test. The final gating constraint is whether these systems can exist within the energy, water, and material boundaries of the planet.
Sustainability is a core engineering requirement, not a discretionary “nice-to-have.” The lifecycle carbon footprint spans from the per-H100 embodied carbon quantified in section 1.2.1.1 to the thousands of megawatt-hours consumed during training. Decode-phase bandwidth-bound inefficiency, where autoregressive generation leaves accelerators idling on memory rather than computing, explains why the shift to specialized, memory-optimized accelerators is a survival strategy for both the cloud and the edge. The Jevons rebound completes the picture: efficiency alone cannot solve the crisis if it leads to exponential increases in usage.
Sustainability is an engineering discipline, not a public relations exercise. Carbon budgets, power delivery constraints, and cooling capacity impose hard limits on fleet expansion that no amount of marketing language can circumvent. The Jevons Paradox makes this especially clear: efficiency gains that reduce per-query cost routinely trigger demand explosions that overwhelm the original savings, meaning that technical optimization without governance is self-defeating. Organizations that treat sustainability as a solved problem after adopting a few efficiency techniques are repeating the same mistake that drove industrial energy consumption upward for two centuries.
The practitioner who can quantify lifecycle carbon across training, inference, and embodied manufacturing emissions, and who can design carbon-aware scheduling policies that respect grid carbon intensity, brings sustainability into the same engineering discipline as latency budgets or memory capacity. These skills transform sustainability from an abstract corporate goal into a measurable engineering constraint. When regulation, procurement, or carbon pricing makes environmental impact part of the operating envelope, this accounting becomes as fundamental to ML systems engineering as fault tolerance or security.
Key Takeaways: Efficiency alone is not enough
- Power is a hard ceiling: A fleet cannot compute past the megawatts, cooling, water, and grid capacity its site can supply. Sustainability is therefore an existence constraint on model scale, not a public-relations layer around an otherwise finished architecture.
- Demand can outrun efficiency: In the 2012–2019 scaling window, AI compute demand grew about 6.2\(\times\) per year against a 1.5\(\times\) annual hardware-efficiency curve. Without algorithmic and governance limits, the power wall arrives even as each operation gets cheaper.
- Decode wastes energy structurally: Autoregressive serving spends long periods bandwidth-bound, leaving accelerators drawing static power while waiting on memory. Sustainable serving needs quantization, sparsity, batching discipline, and memory-optimized hardware because FLOP efficiency alone misses the dominant loss.
- Carbon starts before boot: Up to 30 percent of lifecycle emissions can be embodied in hardware manufacturing before the first query runs. Procurement, hardware lifetime, reuse, and e-waste policy are MLOps decisions when lifecycle accounting is the boundary.
- Location changes the footprint: Carbon-aware scheduling can cut emissions by the chapter’s 8 to 40 times representative regional factors when flexible jobs move across grids. Efficiency must be paired with workload placement and demand governance or Jevons rebound spends the savings.
For most of this book, efficiency has been the lever that made everything else possible, each chapter spending fewer bytes, fewer FLOPs, fewer joules for the same result. Sustainability is where that lever meets a wall it cannot move. A data center has a fixed power envelope, and no quantity of compute, communication, or coordination can draw more than the facility can deliver; the thermodynamic limit is the one constraint that closes over all three. Efficiency does not escape that ceiling, and the Jevons paradox shows it can hasten the approach, because cheaper computation is bought in greater quantity until the savings are spent. Staying beneath the limit therefore takes more than efficiency: it takes a deliberate decision about how much of the newly cheap capacity to actually use.
What’s Next: From sustainability to responsibility
The environmental footprint of the ML fleet is quantifiable and constrained, which makes physical viability part of the system design problem. Security, robustness, and sustainability together form the engineering foundation of production AI. A system that is technically sound, however, can still cause social harm. In Responsible AI, we turn to the governance frameworks, fairness requirements, and ethical guardrails that ensure our fleet serves the values of the society that built it, completing the transition from how to build the machine to whom it serves.
Self-Check: Question
Which statement best captures the chapter’s overall sustainability thesis?
- Sustainability is primarily an infrastructure sourcing problem: once per-query model efficiency is good enough, only the procurement team’s choice of renewable providers matters.
- Sustainability is a physical systems constraint on energy, cooling, carbon, water, and materials that can determine whether an ML system is deployable at all, and it must be reasoned about at every layer from architecture to governance.
- Sustainability is equivalent to running workloads on renewable power and can be separated from hardware design and inference engineering.
- Sustainability matters mainly for training because inference and hardware manufacturing are comparatively small contributors to total impact.
Explain why the chapter’s final message ties decode inefficiency, embodied carbon, and Jevons paradox into a single argument rather than treating them as separate issues.
A production team needs the highest immediate emissions reduction without changing model code. Which intervention does the chapter’s synthesis identify as the single highest-leverage near-term lever?
- Increasing parameter count to improve output quality so fewer retries are needed per user session.
- Moving the workload from a coal-heavy grid to a low-carbon region through carbon-aware scheduling, since identical workloads can differ by 20 to 50\(\times\) in emissions purely by placement.
- Dropping facility PUE through a cooling-upgrade program, accepting a 12-to-18-month capital project to realize a roughly 5-10 percent reduction in total facility energy.
- Applying post-training quantization to the deployed model to cut serving energy by a single-digit percentage per query.
Self-Check Answers
Self-Check: Answer
A profiling run on an accelerator with approximately 10 pJ per FLOP of compute energy and approximately 100 pJ per byte of DRAM energy reports an arithmetic intensity of 3 FLOP/byte for an attention kernel. Which optimization family is most likely to move this workload closer to the energy roofline?
- Replacing the accelerator with one that advertises 2\(\times\) the peak FLOP/s per watt while keeping the memory subsystem unchanged, because raising the compute ceiling always lowers energy.
- Fusing operators and tiling to keep intermediate activations in on-chip SRAM, because the kernel sits far to the left of the energy crossover at about 10 FLOP/byte and pays most of its joules in DRAM traffic.
- Prioritizing a PUE reduction on the facility because chip-level bottlenecks do not affect per-query energy.
- Raising numerical precision from FP16 to FP32, because higher precision does more useful work per byte read.
Answer: The correct answer is B. Dividing \(E_{\text{move}}\) by \(E_{\text{compute}}\) gives a crossover near 10 FLOP/byte; a kernel at 3 FLOP/byte is memory-energy bound, so joules come from data movement and fusion or tiling directly reduces them. A compute-ceiling swap attacks the wrong term — the kernel is not compute-bound. PUE multiplies total energy but does not change which on-chip term dominates. Raising precision increases both FLOPs and bytes, worsening the problem.
Learning Objective: Apply the energy-roofline crossover to classify a workload’s dominant energy term and select the matching optimization family
A 2 MW cluster drops its PUE from 1.58 to 1.10 without changing any model code or hardware SKU. Explain why the chapter counts this as a first-order sustainability intervention, and quantify roughly what the facility saves per year.
Answer: Total facility power is IT load multiplied by PUE, so the 2 MW IT load shifts from 3.16 MW to 2.20 MW of total draw — a saving of about 0.96 MW, or roughly 8,400 MWh per year at 24/7 operation. The saving is realized without touching model architecture, dataset, or accelerator choice: every joule the model spends now carries less cooling and power-distribution baggage. The practical consequence is that facility engineering is on the same leverage tier as a large algorithmic optimization; infrastructure-layer work can deliver model-optimization-sized wins.
Learning Objective: Analyze how facility-level efficiency changes total AI energy consumption independent of model and hardware changes
An engineer must profile energy for a battery-powered microcontroller running a wake-word detector that sleeps most of the second. The device has no internal power counters and draws microwatts during deep sleep. Which measurement approach best matches the section’s edge methodology?
- Sample a tool such as nvidia-smi at 10 Hz and integrate the series, because server-grade sampling tools work across platforms.
- Use an external current-sense monitor such as an INA219 or Joulescope, sample at a rate that resolves the active burst and deep-sleep transitions, and explicitly account for duty cycle, warm-up, and peripherals.
- Estimate total energy by multiplying parameter count by a fixed J-per-parameter constant, because compute energy is the dominant term in TinyML.
- Rely on CPU-package RAPL counters, because they generalize from server CPUs to microcontroller-class devices.
Answer: The correct answer is B. Sub-watt edge devices lack on-chip energy counters, so external instrumentation is the only way to capture the sleep-versus-burst behavior that actually dominates average power. A parameter-count estimate ignores sleep state, peripherals, and radio activity, which typically outweigh arithmetic on duty-cycled devices. nvidia-smi and RAPL are instruments tied to data-center-class silicon; they do not exist on this platform.
Learning Objective: Select an appropriate energy-measurement method for microcontroller-class edge systems with no internal counters
A facility reports 4.2 MW of compute IT load and 6.3 MW of total site draw over the same hour. The sustainability team wants a single scalar that captures how much the non-IT infrastructure contributes to the total, so they can compare the site to peers year over year. Which metric gives them exactly that ratio, and what does a drop in it imply?
- Grid carbon intensity; a drop means the grid has decarbonized.
- Arithmetic intensity; a drop means the workload has become more memory-bound.
- PUE, computed as 6.3 / 4.2 = 1.5; a drop means every joule of useful IT work now carries less cooling and power-distribution overhead.
- Model FLOPs utilization; a drop means the accelerators are underused.
Answer: The correct answer is C. PUE is total facility power divided by IT power — here, 1.5 — and it captures exactly the non-IT overhead the team wants to track. A lower PUE means the same compute work carries less cooling and distribution energy. Grid carbon intensity describes the electricity source, not the facility’s efficiency; arithmetic intensity and MFU are workload metrics, not facility metrics.
Learning Objective: Apply the facility-efficiency metric that translates IT power into total facility power and interpret its direction of change
A profiling sweep across a training workload shows element-wise normalization and activation kernels spending roughly 8\(\times\) more joules on HBM reads than on arithmetic. The service owner proposes four follow-ups. Which best matches the energy model this section develops?
- Upgrading to a newer accelerator with 2\(\times\) peak tensor-core FLOP/s, because more FLOP/s always lowers total energy per step.
- Fusing the normalization and activation into adjacent matrix-multiply kernels so intermediate tensors stay in on-chip SRAM and round-trips to HBM collapse.
- Ignoring the kernel and investing only in carbon-aware scheduling, because chip-level energy is negligible once the grid is considered.
- Raising numerical precision to FP32 to make each byte of DRAM carry more useful arithmetic.
Answer: The correct answer is B. The section emphasizes that for low-intensity kernels, DRAM energy dominates arithmetic energy; fusion removes entire HBM round-trips by keeping intermediates in SRAM. A tensor-core upgrade raises the compute ceiling, which is the wrong lever when memory traffic is the bottleneck. Carbon-aware scheduling complements but does not replace chip-level work. Raising precision increases both FLOPs and bytes, making the kernel more memory-bound, not less.
Learning Objective: Compare the energy significance of computation and data movement and select the optimization that targets the dominant term
A team proposes to report total AI system energy as the simple sum of CPU, GPU, memory, and network component measurements. Explain why the section rejects this accounting and what form the corrected total must take.
Answer: Component measurements capture IT energy but exclude cooling, power conversion, lighting, and distribution losses that are real energy draws on the grid. The section requires multiplying IT energy by PUE so that a 1 MW IT load in a 1.4 PUE facility is accounted as 1.4 MW of total draw. The practical implication is that workload-level profiling is necessary but not sufficient; engineering and accounting decisions must tie component numbers to facility overhead to match actual grid impact and carbon reporting.
Learning Objective: Justify why facility overhead must be incorporated into total energy accounting for AI systems
Self-Check: Answer
Two engineers disagree about how to report the carbon footprint of a training run that used leased GPUs in a hydro-powered region. Which framing correctly separates operational and embodied carbon per this section’s equations?
- Operational carbon is the manufacturing and shipping footprint of the GPUs, while embodied carbon is the grid electricity used while training.
- Operational carbon is the electricity used during training and inference multiplied by grid intensity and facility PUE, while embodied carbon is the pre-use footprint of hardware and construction amortized over useful lifetime.
- Operational carbon applies only to cloud training, while embodied carbon applies only to on-premises hardware.
- Operational carbon is a concern only on fossil-heavy grids, while embodied carbon is a concern only for edge devices.
Answer: The correct answer is B. The section defines operational carbon through the \(E \times CI \times PUE\) product and embodied carbon as the pre-use and end-of-life footprint amortized over lifetime. A version that assigns manufacturing to ‘operational’ inverts the definitions. Tying operational to deployment model or embodied to form factor confuses where the terms apply with what the terms mean.
Learning Objective: Differentiate operational and embodied carbon and connect each to its defining equation
A team moves a training run from a fossil-heavy grid at roughly 800 gCO2/kWh to a hydro-powered grid at roughly 20 gCO2/kWh. They are surprised when their sustainability dashboard shows embodied carbon becoming the dominant term rather than operational. Explain the mechanism that causes this inversion and what it implies for hardware decisions.
Answer: Operational carbon scales linearly with grid intensity, so a 40\(\times\) cleaner grid shrinks the operational term by roughly 40\(\times\) while manufacturing and infrastructure emissions remain fixed per device. The embodied term, previously hidden under a large operational bar, now represents a large fraction of total footprint — the section shows it can even exceed operational on the cleanest grids. The practical consequence is that on clean grids, extending hardware refresh cycles and maximizing accelerator utilization become first-order sustainability decisions, because those are the levers that amortize the now-dominant embodied term.
Learning Objective: Analyze why grid decarbonization shifts the dominant sustainability term from operational to embodied carbon
True or False: A model trained in a datacenter powered 100 percent by hydroelectricity can honestly be reported as having a zero carbon footprint for its training run.
Answer: False. Even with zero operational emissions from hydro, the GPUs, interconnect, and facility concrete carry embodied carbon from fabrication, transport, and construction. The section shows these pre-use emissions remain and must be amortized over the run’s share of device lifetime, so total carbon is not zero.
Learning Objective: Evaluate the common fallacy that renewable electricity sourcing eliminates lifecycle carbon
A deployed model serves 10 million queries per day at 0.001 kWh per query. Its single training run consumed 1,287 MWh. Using the section’s lifecycle reasoning, what is the most important accounting consequence?
- Training still dominates because a training run uses specialized accelerators at higher per-chip peak power than serving.
- Embodied carbon can be ignored because inference energy is metered daily.
- Cumulative serving energy can exceed the one-time training energy within months — 10 million queries at 0.001 kWh is 10 MWh per day, so the 1,287 MWh training is matched in roughly 130 days — making inference efficiency the highest-impact production lever.
- The main optimization target should be compressing training time even if it raises per-query inference energy.
Answer: The correct answer is C. The arithmetic sets the cumulative inference energy on a path to cross the one-time training footprint in about four months at this query volume, so for widely deployed models, serving-side efficiency dominates. A per-step-power argument misses that cumulative volume overwhelms instantaneous power. Ignoring embodied carbon understates total footprint; accelerating training at the expense of per-query energy is precisely the wrong trade at this scale.
Learning Objective: Infer when cumulative inference energy overtakes training energy in production systems and identify the implied optimization target
Order the following steps of a lifecycle carbon estimate for a training run: (1) amortize hardware manufacturing and construction emissions over device lifetime to compute the run’s embodied share, (2) compute total facility energy from IT energy and PUE, (3) aggregate operational and embodied components into the lifecycle total, (4) convert operational energy to operational carbon by multiplying by grid carbon intensity.
Answer: The correct order is: (2) compute total facility energy from IT energy and PUE, (4) convert operational energy to operational carbon by multiplying by grid carbon intensity, (1) amortize hardware manufacturing and construction emissions over device lifetime to compute the run’s embodied share, (3) aggregate operational and embodied components into the lifecycle total. Facility energy is the input operational carbon needs; the operational-carbon conversion cannot happen before energy is known; and the embodied share is independent but must exist before the final aggregation. Aggregating earlier would sum incomplete quantities and hide which term actually dominates.
Learning Objective: Sequence the operational and embodied steps of a lifecycle carbon accounting workflow
Self-Check: Answer
A facility engineer is redesigning a datacenter aisle to host training racks after hosting web-serving racks for a decade. Which property of AI workloads most forces the redesign, relative to a typical web stack?
- AI workloads demand sub-millisecond tail latency that web stacks do not, so racks must be packed less densely to keep idle spares available.
- AI training holds large numbers of accelerators near peak utilization for weeks, creating sustained thermal density and power draw rather than the bursty CPU spikes web stacks produce.
- AI workloads use less energy per request than web traffic, so the real change is accounting rules rather than physical design.
- AI workloads avoid cooling needs because regular matrix arithmetic produces less heat than irregular web request patterns.
Answer: The correct answer is B. The section contrasts short-lived web bursts with training clusters that run hot for months, and the sustained thermal density — not any burstiness — is what forces power-delivery and cooling redesign. A tail-latency framing describes serving, not the training pattern under discussion; a regular-arithmetic-means-less-heat claim inverts the physics — regular high-FLOP/s arithmetic produces more heat, not less.
Learning Objective: Compare the sustained power and thermal profile of AI training workloads to traditional web workloads
A team consolidates training jobs from a fleet at 45 percent average utilization onto a smaller active cluster at 85 percent utilization, powering down the drained nodes. Explain why this yields a sustainability win even if no model becomes more accurate, and state what part of the section’s total-energy model it targets.
Answer: At 45 percent utilization, the fleet’s fixed overhead — idle power, cooling for the whole building, embodied carbon per device — is amortized across little useful work, so energy and carbon per model trained are high. Consolidating to 85 percent lets the same useful work complete on fewer active devices while idle nodes enter low-power states, cutting both operational and embodied energy per training job. The practical implication is that scheduling and tenancy design reduce the energy bill without touching model architecture at all, attacking the denominator of energy-per-useful-work directly.
Learning Objective: Analyze how consolidation-driven utilization gains reduce energy consumed per unit of useful training work
A team doubles the number of GPUs in a distributed training job, expecting roughly linear energy scaling. Instead, they observe networking energy growing much faster than 2\(\times\). Which mechanism does the section identify as the primary cause, and what sustainability risk does it create?
- Total arithmetic decreases, so the model has to train longer to recover lost FLOPs, raising total energy.
- AllReduce and all-to-all gradient synchronization scale worse than linearly with cluster size and can add 20 to 40 percent to total energy, making naive cluster-size scaling carbon-inefficient.
- Facility PUE automatically worsens in direct proportion to node count regardless of cooling design.
- Embodied carbon per chip vanishes once a model is split across enough nodes, masking the true energy cost.
Answer: The correct answer is B. The section identifies gradient-synchronization traffic as a first-order energy term that can add 20 to 40 percent of total energy and scales super-linearly with parallelism, so doubling nodes can more than double networking energy. A PUE-scales-with-nodes claim confuses a facility metric with a parallelism tax. An embodied-carbon-disappears claim inverts the accounting — splitting the work across more chips increases total embodied exposure, not decreases it.
Learning Objective: Analyze how distributed-training communication patterns contribute to total cluster energy as parallelism scales
**You are auditing carbon accounting for a team running training on a leased GPU cluster. The team reports five emissions sources as shown. Which classification across the GHG Protocol scopes is correct?
S1: Diesel burned by backup generators the team owns on-site. S2: Electricity purchased from the grid to power the leased GPUs. S3: Cooling electricity drawn inside the same datacenter. S4: The embodied carbon from manufacturing the accelerators themselves. S5: Energy used by end-user phones that run the deployed model.**
- S1 Scope 1; S2 Scope 2; S3 Scope 2; S4 Scope 3; S5 Scope 3.
- S1 Scope 2; S2 Scope 1; S3 Scope 3; S4 Scope 3; S5 Scope 2.
- S1 Scope 3; S2 Scope 3; S3 Scope 2; S4 Scope 1; S5 Scope 1.
- S1 Scope 1; S2 Scope 1; S3 Scope 1; S4 Scope 2; S5 Scope 2.
Answer: The correct answer is the first option (S1 Scope 1, S2 Scope 2, S3 Scope 2, S4 Scope 3, S5 Scope 3). Direct on-site combustion the reporter owns — the diesel generators — is Scope 1. Purchased electricity for both GPUs and the cooling that supports them is Scope 2; the ‘cooling is Scope 3’ confusion shows up in practice but cooling drawn from the facility’s purchased-electricity meter is indirect energy use, not a value-chain flow. Embodied manufacturing and downstream device energy are classic Scope 3 value-chain items. An answer that places purchased electricity in Scope 1 misreads direct combustion vs. indirect energy; an answer placing embodied manufacturing in Scope 2 confuses purchased energy with purchased goods.
Learning Objective: Classify a mixed portfolio of emissions sources across the GHG Protocol scopes
Which example is most clearly Scope 3 in the chapter’s accounting framework rather than Scope 1 or Scope 2?
- Diesel burned by backup generators owned by the datacenter operator.
- Grid electricity purchased to power a leased GPU cluster.
- Cooling electricity consumed inside the datacenter and billed on the same meter as compute.
- Embodied carbon from manufacturing accelerators plus downstream energy used by end-user devices running the deployed service.
Answer: The correct answer is D. Scope 3 captures value-chain effects upstream and downstream of the operator — hardware manufacturing and end-user device energy fall there and are often large but undercounted. Generator diesel is direct on-site combustion (Scope 1); grid electricity for GPUs and cooling is purchased indirect energy (Scope 2). The Scope 3 breadth is why the chapter treats supply-chain and downstream use as a first-order engineering concern.
Learning Objective: Distinguish value-chain Scope 3 emissions from direct and purchased-energy scopes in AI systems
Self-Check: Answer
A model costs 1,287 MWh to train once and then serves 10 million queries per day at 0.001 kWh per query for a five-year product life. Which explanation best captures why inference often dominates lifecycle energy for widely deployed models?
- Inference always uses more power per operation than training because of serving-specific hardware.
- The model must be retrained on every query once in production, so inference and retraining overlap.
- Inference runs continuously across enormous cumulative query volume — here, about 10 MWh per day — so after roughly 130 days the cumulative serving energy matches the one-time training run, and after five years it dwarfs it.
- Inference cannot use specialized accelerators, unlike training, so it draws more grid power per step.
Answer: The correct answer is C. The chapter frames training as a concentrated burst and inference as an airline-like continuous operation; the cumulative volume, not per-step power, is what makes inference dominate. A ‘more power per operation’ framing is simplistic — per-step serving power is typically lower, not higher, than training. A ‘retrained every query’ claim describes no real production system; a ‘no accelerators for inference’ claim inverts current practice.
Learning Objective: Analyze why cumulative inference energy dominates one-time training energy for widely deployed production models
A profiler shows that the decode phase of an LLM serving stack sustains only 6 percent of peak FP16 TFLOP/s while HBM bandwidth sits near 90 percent utilization and static power keeps flowing. Which mechanism does the section identify as the dominant source of decode energy inefficiency, and what does it imply for optimization?
- Decode disables on-chip caches, so all work shifts to the CPU and server-class RAM.
- Decode is memory-bandwidth-bound — each token requires reading the model’s weights while the compute units idle — so the accelerator burns static power without producing proportional useful work; the fix is to reduce bytes read through quantization, smaller KV caches, or weight fusion.
- Prefill uses lower numerical precision while decode must always use FP32, so decode pays a precision tax.
- Decode inefficiency comes from a transient rise in facility PUE during serving hours.
Answer: The correct answer is B. Autoregressive decode fetches all weights for each token and cannot batch temporal dependencies, saturating HBM while leaving compute idle — static power still flows regardless. Optimizations that shrink bytes per token (quantization, KV-cache compression, paged attention) move the workload back toward the roofline. The cache-disabling and precision claims invent mechanisms not in modern decoders; PUE is a facility metric and cannot explain a per-kernel bandwidth signature.
Learning Objective: Explain the systems mechanism behind the decode phase’s energy inefficiency and identify the optimization family that addresses it
A product manager claims that moving inference from the cloud to 50 million edge devices automatically solves the deployment’s sustainability problem. Explain why the chapter considers this claim incomplete and identify the lifecycle terms the edge decision can actually shift.
Answer: Edge deployment reduces transmission and cloud-compute energy per query, but 50 million devices aggregate non-trivially and introduce a large new embodied-carbon footprint from manufacturing and eventual disposal. The section shows fleet-scale edge can beat cloud only when device power budgets, duty cycles, and lifetime extension are all designed for — otherwise embodied emissions and e-waste can outweigh the operational savings. The practical implication is that edge is a conditional win: it shifts the dominant term from operational-cloud to embodied-device, so the design must amortize hardware over long service lives and drive per-device energy toward idle-dominated profiles.
Learning Objective: Evaluate the sustainability trade-offs of shifting inference from cloud to edge and identify which lifecycle terms the move actually shifts
A keyword-spotting sensor runs 10 ms of active inference once per second and sleeps the remaining 990 ms at microwatt draw. Active power is 120 mW; sleep power is 50 uW. Which quantity most strongly determines the device’s average power, per the section’s duty-cycle reasoning?
- The duty cycle, because \((0.010 / 1.000) \times 120\text{ mW} + (0.990 / 1.000) \times 0.050\text{ mW}\) is roughly 1.25 mW - the active burst dominates this average, but the low duty cycle keeps power far below continuous 120 mW operation.
- The datacenter’s hourly carbon intensity, because the sensor uploads to a cloud pipeline.
- The model’s total parameter count, because larger models always consume more per-second energy.
- Whether the model was distilled from a larger teacher, because distillation changes average power directly.
Answer: The correct answer is A. The arithmetic gives 1.2 mW from the active window plus 0.05 mW from the sleep window, or roughly 1.25 mW total. For these values the active burst dominates the average, but the 1 percent duty cycle keeps average draw orders of magnitude below continuous 120 mW operation. Grid intensity is irrelevant to a battery-powered sensor’s own draw. Parameter count and distillation shape active power but do not change the duty-cycle arithmetic.
Learning Objective: Apply duty-cycle arithmetic to estimate average power in TinyML deployments and identify which term dominates
A startup wants to support nightly on-device full fine-tuning of a 1B-parameter model on consumer smartphones. Explain why the chapter argues this is infeasible within a realistic overnight battery budget and which class of methods it recommends instead.
Answer: Backpropagation through a 1B-parameter model requires storing activations for the full backward pass and performing roughly three times the compute of a forward pass, which on a phone with a 15 Wh battery exhausts a 5 percent overnight budget within minutes — far short of the weight updates the team wants. The section argues this is the battery wall: the energy budget is fixed by battery chemistry, not by model engineering. The recommended direction is PEFT — low-rank adapters or sparse updates — which modify only a small fraction of parameters and avoid storing full-model activations, fitting within a realistic overnight share of the battery.
Learning Objective: Justify why full backpropagation is energy-infeasible for large on-device models and identify the PEFT-family solution
Order the following stages in a hierarchical wake-word cascade designed to minimize average power on a battery-powered smart speaker: (1) full large-model inference on the captured utterance, (2) ultra-low-power voice-activity detection running continuously at microwatts, (3) small neural wake-word detector running only when voice is present.
Answer: The correct order is: (2) ultra-low-power voice-activity detection running continuously at microwatts, (3) small neural wake-word detector running only when voice is present, (1) full large-model inference on the captured utterance. The cascade must filter cheaply before escalating: the microwatt voice detector runs always, the small wake detector fires only when voice is present, and the full model fires only on a confirmed wake — each stage gating the next. Swapping the full model to the front defeats the cascade, since it would burn hundreds of milliwatts on every ambient noise event.
Learning Objective: Sequence the stages of a hierarchical wake-word cascade and justify why the ordering is necessary for sub-milliwatt average power
Self-Check: Answer
A procurement team is deciding whether to extend accelerator lifetime from three to five years. Which argument from this section best justifies treating the extension as one of the highest-leverage sustainability interventions?
- Older accelerators always become more energy-efficient after firmware updates, so per-query energy falls.
- Manufacturing emissions are large enough that amortizing them over five years instead of three cuts embodied carbon per year by roughly 40 percent, often yielding larger reductions than many per-query algorithmic optimizations.
- Datacenter PUE automatically improves as hardware ages because older chips accept higher inlet temperatures.
- Extending lifetime eliminates the need for recycling infrastructure because nothing ever leaves service.
Answer: The correct answer is B. Embodied carbon is amortized over useful life, so stretching that life from three to five years reduces the per-year share by roughly 40 percent without any runtime change. A firmware-makes-hardware-more-efficient framing confuses amortization with performance-per-watt. A PUE-improves-with-age claim inverts facility physics. An elimination-of-recycling claim ignores that all hardware eventually reaches end of life.
Learning Objective: Justify hardware lifespan extension as a high-leverage sustainability intervention
A paper reports that training a model consumed 480 MWh for its final run. Explain why this number systematically understates the development phase’s environmental impact and name the mitigation categories the chapter recommends.
Answer: The reported number covers only the final successful run, not the hyperparameter sweeps, architecture searches, debug restarts, and abandoned experiments that preceded it — and those can add an order of magnitude on top, as early neural architecture search work showed with 43,000-plus GPU-hour budgets. The mitigation categories are transfer learning to avoid training from scratch, more efficient search methods such as evolutionary or gradient-based NAS, and experimental discipline such as early stopping and shared ablation baselines. The practical implication is that sustainability accounting must capture the full research loop, not the triumphal final number.
Learning Objective: Analyze why experimentation overhead must be included in sustainability assessment of model development
True or False: A hyperscaler migrates all training workloads to a 100 percent hydro-powered region. Because operational carbon per training run is now near zero, the use phase is no longer a meaningful engineering concern — only manufacturing emissions remain.
Answer: False. A clean grid zeroes the operational carbon term but does not eliminate use-phase constraints: 24/7 inflexible load, cooling overhead, renewable timing mismatches, and grid dynamics such as the duck curve still shape what the facility can actually run when. Clean electricity changes the carbon mix; it does not remove the operational systems problem.
Learning Objective: Evaluate how a cleaner grid changes, but does not eliminate, use-phase operational constraints
A consumer-electronics company plans to ship 200 million embedded-AI sensors over five years, each with a 2-year expected lifetime and a sealed non-serviceable enclosure. Which disposal-phase concern does the section emphasize most for this product class?
- Their per-device carbon footprint is negligible because each draws only microwatts, so aggregate e-waste can be ignored.
- They will be easy to recycle because standardized components and modular batteries enable automated recovery.
- Their combination of short lifetimes, sealed enclosures, non-replaceable batteries, and enormous scale creates a distributed e-waste stream that is hard to recover, refurbish, or safely dispose of.
- They matter primarily because their on-device models drift faster than cloud models.
Answer: The correct answer is C. The section highlights short lifetimes, sealed enclosures, non-replaceable batteries, and massive scale as the defining embedded-AI e-waste problem. A low-per-device-power argument conflates operational energy with disposal impact — lifecycle accounting does not stop at the watt-hour. A standardized-components claim inverts the current reality, where embedded devices are typically less, not more, modular than servers. Model drift is a software concern, not a lifecycle-disposal concern.
Learning Objective: Identify the primary lifecycle risk introduced by large-scale embedded AI deployment
A company is considering replacing its entire accelerator fleet because the new generation offers an 8 percent improvement in performance per watt. Which response best matches the section’s circular-economy logic?
- Refresh immediately, because any efficiency gain automatically outweighs manufacturing emissions.
- Retire the old fleet the moment peak benchmark performance falls below the new generation, even if the old hardware still serves lower-priority workloads well.
- Keep the older systems in secondary roles such as batch inference, development, or non-SLA internal workloads, and upgrade only components where modular upgrades are possible, because avoiding premature disposal often beats single-digit-percent runtime gains.
- Seal the existing hardware stack more tightly so maintenance costs fall even if repair becomes impossible.
Answer: The correct answer is C. The circular-economy argument is that embodied carbon dominates small per-watt gains at single-digit percentages; keeping hardware in service via secondary deployment and modular upgrades amortizes the existing embodied cost while avoiding new manufacturing. The ‘any gain automatically justifies replacement’ framing ignores the manufacturing carbon a new fleet incurs. The ‘peak benchmark falls below’ trigger defines premature retirement. The ‘seal tighter’ framing trades reparability for short-term maintenance cost and worsens the lifecycle.
Learning Objective: Apply circular-economy principles to hardware refresh and retirement decisions
Self-Check: Answer
A translation service halves its per-query compute after deploying distillation. Within six months, total monthly energy has risen by 40 percent because cheaper translation unlocked new product integrations — chatbots, email assistants, accessibility tools. Which concept from this section best explains the net increase, and what does it imply about efficiency-only strategies?
- Distillation reduces accuracy too much for production, so total energy rose from re-running queries — accuracy-driven rebound.
- Jevons paradox: per-unit efficiency gains lowered the effective cost of translation and triggered enough new demand that total resource consumption grew; efficiency alone cannot guarantee sustainability without usage governance.
- Carbon accounting frameworks ignore improvements below the datacenter level, so the reported rise is an artifact of incomplete measurement.
- Efficient models can only run on specialized hardware that requires manufacturing new chips, so embodied emissions explain the rise.
Answer: The correct answer is B. Jevons paradox is exactly this pattern: a cheaper per-unit cost enables new use cases whose aggregate demand overwhelms the per-query gain. The chapter’s warning is that per-query efficiency is a necessary but insufficient sustainability lever — usage governance or absolute caps must accompany it. An accuracy-rebound framing invents a mechanism; an accounting-artifact framing confuses measurement with reality; an embodied-from-new-chips framing misattributes the operational energy growth.
Learning Objective: Explain Jevons paradox in AI deployment and justify why efficiency must be paired with governance
A team must reduce the serving footprint of a latency-sensitive 70B-parameter model on current GPU hardware. They are weighing post-training quantization, knowledge distillation, and unstructured pruning. Justify why the chapter would likely prioritize the first two before unstructured pruning.
Answer: Quantization lowers bytes per weight and distillation lowers total parameter count, and current GPUs exploit both directly — INT8 tensor cores execute quantized matmuls at higher energy efficiency, and a smaller student fits in less HBM and fewer bytes per token. Unstructured pruning, by contrast, zeros individual weights but leaves the tensor dense: without hardware or library support for arbitrary sparse GEMM, the zeroed positions still traverse the memory pipeline and cost nearly the same energy. The practical implication is that theoretically sparse models are not practically efficient without matching hardware; on today’s stack, quantization and distillation deliver realized energy savings while unstructured pruning often does not.
Learning Objective: Justify mitigation priorities by distinguishing theoretical from hardware-realizable energy savings
A platform team asks which single infrastructure-layer mitigation strategy, requiring no model or code changes, offers the highest leverage for reducing emissions of an existing production workload. Which lever does the section identify?
- Carbon-aware scheduling across regions and time windows with lower grid carbon intensity, because identical workloads can differ by 20–50\(\times\) in emissions purely by placement.
- Increasing batch size on every request until every workload becomes compute-bound, because higher arithmetic intensity always lowers energy.
- Replacing every deployed model with a binary neural network to cut arithmetic precision to the minimum.
- Retraining every deployed model from scratch weekly to keep it minimally sized.
Answer: The correct answer is A. The section argues that geographic and temporal placement is an infrastructure-layer lever that requires no code changes and can dominate per-query optimizations by an order of magnitude or more. A ‘force every workload compute-bound’ framing conflates one regime with a universal rule. Binary neural networks are useful in specific TinyML contexts but are not a general no-code mitigation. Weekly from-scratch retraining is a net energy increase, not a decrease.
Learning Objective: Identify the highest-leverage no-code mitigation lever available at the infrastructure scheduling layer
When a vendor advertises a keyword-spotting accelerator’s energy-per-inference and accuracy on a microcontroller, the MLCommons benchmark suite that standardizes the tasks, measurement rules, and comparability requirements for sub-watt systems is ____.
Answer: MLPerf Tiny. It defines a fixed set of TinyML tasks, measurement methodology for sub-watt devices, and power-integration rules so that vendor claims about energy-per-inference and accuracy can be compared across devices and implementations.
Learning Objective: Infer the standardized MLCommons benchmark suite used for TinyML energy and accuracy comparison
In Google’s 4Ms sustainability framework, which element refers specifically to choosing low-carbon locations and matching workloads to cleaner electricity supply?
- Model — selecting efficient architectures.
- Machine — selecting efficient accelerators.
- Mechanization — operating cloud infrastructure efficiently.
- Map — siting and geographic workload placement to exploit regional electricity differences.
Answer: The correct answer is D. Map is the geographic element that captures low-carbon siting and regional grid differences. Mechanization covers cloud-operational efficiency and utilization, so conflating the two mixes location with operational management. Model and Machine target architecture and hardware choice, each a different term in the framework.
Learning Objective: Classify components of Google’s 4Ms sustainability framework by their distinct roles
Explain why the chapter pairs technical efficiency with carbon budgets, governance, or usage limits rather than treating optimization as sufficient on its own.
Answer: Technical optimization lowers the cost per unit of AI, but — as Jevons paradox shows — cheaper AI can expand total usage enough to erase the per-unit savings. A serving stack that drops per-query cost by 50 percent can still increase total emissions if adoption grows more than 2\(\times\) as a consequence. The practical implication is that sustainable AI needs absolute constraints — carbon-aware scheduling with capacity caps, organizational carbon budgets, or policy limits — layered on top of better performance-per-watt, because only absolute constraints guarantee a ceiling on total impact.
Learning Objective: Evaluate why sustainability strategies must combine engineering optimization with governance mechanisms
Self-Check: Answer
A sustainability team argues that carbon pricing is unnecessary because ‘rational firms will naturally choose greener options once they see the accounting.’ Which rebuttal from the section best explains why market incentives alone are insufficient?
- Datacenter operators are legally prohibited from choosing lower-cost electricity sources, so carbon choices are pre-decided by regulation.
- Without carbon pricing, the cheapest operational choice is often the dirtiest one, so firms optimizing cost will rationally pick fossil-heavy regions or hours and increase emissions even while reporting accurately.
- Renewable-powered regions always have the highest electricity prices, making green choices impossible.
- Cloud providers already disclose Scope 3 emissions with perfect accuracy, so no further mechanism is needed.
Answer: The correct answer is B. The section shows that under current pricing, coal-heavy regions are often cheapest and firms optimizing cost will rationally land there unless carbon has a financial or legal price. A legal-prohibition framing gets the facts backward — operators have broad siting choice in most markets. A renewables-always-cost-more claim is increasingly false in practice. A perfect-Scope-3-disclosure claim contradicts the section’s explicit concern that value-chain emissions are undercounted.
Learning Objective: Explain why market incentives alone underprovide carbon reduction and justify the need for policy mechanisms
A compliance team is translating the EU AI Act and the Corporate Sustainability Reporting Directive (CSRD) into engineering requirements. Which framing best matches how the section describes their practical effect?
- Energy reporting and emissions accounting become mandatory design constraints: systems must be instrumented to produce audited Scope 1/2/3 disclosures, shifting sustainability from optional metric to compliance requirement.
- They ban foundation-model training above a fixed FLOPs threshold worldwide, so the engineering question is simply whether training fits under the cap.
- They replace direct power measurement with legal estimates based only on parameter count, so no new instrumentation is needed.
- They apply only to hardware manufacturers, not to organizations operating AI services.
Answer: The correct answer is the first option. The section presents these regulations as converting sustainability measurement into a compliance requirement — organizations must instrument, audit, and disclose — so engineering teams are forced to treat measurement as a first-class system requirement. A worldwide-FLOP-ban framing overstates the instruments; a parameter-count-replaces-measurement claim contradicts the audit-grade disclosure requirement; a hardware-only-scope framing misreads who bears the obligation.
Learning Objective: Identify how sustainability regulation translates into mandatory engineering instrumentation and practice
Explain how an emissions-trading scheme or carbon price transforms carbon-aware scheduling from a purely voluntary practice into an economically rational default.
Answer: A carbon price turns grid intensity into a per-kWh cost term, so two identical workloads on a 20 gCO2/kWh grid and an 800 gCO2/kWh grid now have different total costs even when raw electricity prices are similar. A scheduler optimizing total cost of ownership will then naturally route flexible workloads to cleaner regions or hours and defer non-urgent jobs, because the financial objective now includes the carbon term. The practical implication is that policy aligns financial optimization with the technical carbon-aware scheduling the engineering community already knows how to implement, so the two layers stop pulling in opposite directions.
Learning Objective: Analyze how carbon pricing changes workload placement incentives and aligns financial with sustainability objectives
True or False: A company purchases enough annual Renewable Energy Certificates to match 100 percent of its yearly AI electricity use, but its evening serving load runs on a grid that is 60 percent coal-fired between 6 PM and midnight. By the section’s standard, this is equivalent to meeting 24/7 clean-energy matching.
Answer: False. The section distinguishes annual-average REC-based matching from hourly 24/7 clean-energy matching; annual certificates can balance total volume while the actual operation still runs on fossil power in specific hours. The company’s evening load is physically coal-powered during those six hours regardless of annual purchases, so the hourly-matching standard is not met and the carbon claim is misleading.
Learning Objective: Evaluate the difference between annual renewable matching claims and hourly clean-energy matching in a realistic operational scenario
Which future research direction does the section frame as directly attacking the von Neumann bottleneck’s energy cost rather than its measurement?
- Broader adoption of annual sustainability reports so more organizations see their numbers.
- Non-von-Neumann approaches such as neuromorphic and in-memory computing that reduce or eliminate data shuttling between memory and compute.
- Increasing model size so arithmetic intensity always sits right of the memory crossover.
- Replacing lifecycle accounting with benchmark-only reporting to simplify comparison.
Answer: The correct answer is B. The von Neumann bottleneck is a physical-architecture constraint, and the section points to neuromorphic and in-memory computing as paradigms that attack the data-movement cost directly — not through better metrics or reports. Reporting frameworks matter for governance but do not remove the architectural source of the bottleneck. ‘Scale up until compute-bound’ ignores that larger models shift, not eliminate, memory traffic. Replacing lifecycle accounting with benchmarks would reduce visibility, not architecture.
Learning Objective: Explain how non-von-Neumann architectures could reduce AI energy consumption by targeting data-movement costs
Self-Check: Answer
True or False: A team migrates a batch-training workload from an on-premises cluster in Virginia (roughly 400 gCO2/kWh) to a cloud region in West Virginia (roughly 700 gCO2/kWh) because the cloud provider markets its AI infrastructure as ‘green.’ The migration necessarily improves the run’s carbon footprint.
Answer: False. Cloud is not inherently greener than on-premises; the section argues that regional grid intensity can create 20 to 50\(\times\) differences in emissions for identical workloads, and moving to a region with a dirtier grid — even within the same cloud provider — can increase total carbon. Cloud status alone is not the relevant variable; grid carbon intensity is.
Learning Objective: Critique the assumption that cloud deployment is inherently more sustainable than on-premises options
A team prunes a model aggressively to cut training energy, but the resulting deployment requires custom sparse-execution hardware and more total serving compute to hit accuracy targets. Which pitfall does this scenario illustrate, and what mitigation does the section recommend?
- Higher GPU utilization always increases embodied carbon per query, so any pruning gain is automatically lost to hardware.
- Local optimization of one lifecycle component (training energy) without accounting for inference scale, manufacturing burden, and hardware support can worsen total lifecycle emissions; the mitigation is full-lifecycle accounting before committing to the optimization.
- Measuring carbon intensity too often instead of using annual averages creates an appearance of higher emissions that disappears with averaging.
- Transfer learning makes lifecycle accounting impossible because the original training is hidden upstream.
Answer: The correct answer is B. The section warns that optimizing one lifecycle component in isolation often shifts emissions elsewhere — here, shrinking training at the price of larger serving compute and new hardware embodied emissions. Full-lifecycle accounting before committing is the recommended discipline. A frequency-of-measurement framing conflates visibility with the underlying problem. A transfer-learning framing misreads lifecycle as a measurement-impossibility rather than a scope problem.
Learning Objective: Identify how local optimization can increase total lifecycle impact and apply full-lifecycle accounting as the mitigation
Explain why the section treats buying carbon offsets as a weaker sustainability strategy than directly reducing emissions through location or system-design decisions.
Answer: Offsets are financial instruments with delayed, uncertain, and sometimes unverifiable realization, while the workload’s emissions occur immediately on a specific grid. A direct choice — moving compute from an 800 gCO2/kWh region to a 20 gCO2/kWh region — reduces actual emissions at the source on the same day the workload runs, and the reduction is directly measurable. The practical implication is that engineers should pursue real reductions first — placement, efficiency, hardware lifetime — and treat offsets as a residual measure for the emissions that genuinely cannot be avoided, not as a substitute for system design.
Learning Objective: Evaluate offsets against direct emissions-reduction strategies and justify prioritizing the latter in AI system design
Self-Check: Answer
Which statement best captures the chapter’s overall sustainability thesis?
- Sustainability is primarily an infrastructure sourcing problem: once per-query model efficiency is good enough, only the procurement team’s choice of renewable providers matters.
- Sustainability is a physical systems constraint on energy, cooling, carbon, water, and materials that can determine whether an ML system is deployable at all, and it must be reasoned about at every layer from architecture to governance.
- Sustainability is equivalent to running workloads on renewable power and can be separated from hardware design and inference engineering.
- Sustainability matters mainly for training because inference and hardware manufacturing are comparatively small contributors to total impact.
Answer: The correct answer is B. The summary presents sustainability as the final physical limit on the fleet — energy, cooling, carbon, water, and materials — rather than as a soft reporting concern, and argues it must be reasoned about holistically. An infrastructure-sourcing-only framing is a tempting but incomplete framing that ignores model and hardware layers the chapter explicitly raises. A renewables-only framing leaves out embodied carbon and rebound effects; a training-dominates framing contradicts the lifecycle arithmetic where cumulative inference and hardware often dominate.
Learning Objective: Synthesize the chapter’s definition of sustainability as a first-class ML systems constraint
Explain why the chapter’s final message ties decode inefficiency, embodied carbon, and Jevons paradox into a single argument rather than treating them as separate issues.
Answer: The three concepts describe different failure modes of the same system: decode inefficiency wastes energy during serving because the autoregressive loop is memory-bandwidth-bound, embodied carbon accumulates before operation begins and persists after it ends, and Jevons paradox shows that per-unit efficiency gains can be swamped by demand growth. A team that fixes only one — say, optimizing decode — can still increase total emissions if usage explodes or hardware is replaced too aggressively. The practical implication is that sustainable AI requires lifecycle accounting paired with governance, not a single isolated optimization win.
Learning Objective: Integrate multiple chapter themes into a coherent explanation of why sustainability requires lifecycle and governance thinking
A production team needs the highest immediate emissions reduction without changing model code. Which intervention does the chapter’s synthesis identify as the single highest-leverage near-term lever?
- Increasing parameter count to improve output quality so fewer retries are needed per user session.
- Moving the workload from a coal-heavy grid to a low-carbon region through carbon-aware scheduling, since identical workloads can differ by 20 to 50\(\times\) in emissions purely by placement.
- Dropping facility PUE through a cooling-upgrade program, accepting a 12-to-18-month capital project to realize a roughly 5-10 percent reduction in total facility energy.
- Applying post-training quantization to the deployed model to cut serving energy by a single-digit percentage per query.
Answer: The correct answer is B. The summary highlights geographic placement as the immediate, no-code lever whose 20 to 50\(\times\) multiplier dominates the other levers at short timescales. A PUE upgrade is real and valuable but capital-intensive and delivers a smaller multiplier; post-training quantization is a genuine model-side optimization but changes the deployment and yields a smaller per-unit win than geographic placement. Increasing parameter count raises per-query cost and is not a no-code emissions reduction.
Learning Objective: Identify the chapter’s highest-leverage near-term no-code intervention for reducing AI emissions