From Single-Model to Platform Operations
ML Operations at Scale
Purpose
Why do practices that work for managing one model collapse when organizations deploy hundreds?
One model is a project. A hundred models is a system of systems, where interactions, dependencies, and failures cascade in ways that per-model practices cannot anticipate or contain. A data pipeline change affects twelve models built by four teams, but no single team owns the impact assessment. A deployment failure requires coordinating rollbacks across interconnected services. Monitoring dashboards multiply until alert fatigue makes them useless. The practices that let a single team manage a single model (manual deployment, ad-hoc monitoring, spreadsheet tracking) become organizational liabilities at scale. Machine learning operations (MLOps) at scale is the recognition that model management must become infrastructure: shared platforms with consistent APIs, automated pipelines that enforce quality gates, monitoring systems that aggregate signals across the fleet, and governance frameworks that track dependencies between artifacts nobody remembers creating. Without this infrastructure, organizations drown in operational complexity while their ML investments depreciate. In C³ terms, operations at scale transforms human coordination into automated compute, standardizing how the fleet is maintained and governed.
Learning Objectives
- Calculate return on investment, utilization, and total cost for shared ML platforms across model portfolios
- Design registries and release gates that preserve lineage, dependency safety, and rollback confidence
- Quantify technical debt using deployment velocity, incident rates, toil, and response-time metrics
- Evaluate monitoring and alerting hierarchies using signal quality, aggregation, and incident-response needs
- Design feature-store operations that manage freshness, ownership, compatibility, and training-serving skew
- Compare centralized, embedded, and hybrid platform teams for operating large model portfolios
- Diagnose incidents by tracing failures across data, platform, serving, model-control, and governance layers
Consider a team of five engineers maintaining a single recommendation model. When the model drifts, they manually retrain it. When the API latency spikes, they manually scale the instances. Now, scale that same team to support five hundred models across dozens of product surfaces. Manual intervention is no longer merely inefficient; it is mathematically impossible. The transition from single-model to platform operations replaces human-in-the-loop maintenance with automated, systemic governance.
The management layer is the fleet stack’s control plane: the dashboard, steering, and maintenance system that keeps physical infrastructure, training systems, serving paths, edge deployments, and governance rules from drifting apart. Once models span data centers, serving platforms, and heterogeneous edge fleets, reliability depends less on any single model and more on the operational machinery that keeps the whole fleet observable, coordinated, and recoverable.
Distributed serving architectures handle massive request volumes, while edge deployment pushes intelligence to smartphones, microcontrollers, and federated fleets spanning billions of heterogeneous devices. The question now is what happens when organizations must sustain not one but hundreds of such systems across this entire spectrum. Managing individual models and operating enterprise-scale ML platforms are fundamentally different problems, separated by a phase transition in operational complexity. Platform operations absorbs that complexity through fleet economics and total-cost models, multi-model management, CI/CD, monitoring systems, and feature-store foundations that let hundreds of models share one coherent operational substrate.
Single-model MLOps focuses on continuous integration, deployment pipelines, and monitoring for individual models, and every organization that scales discovers its limits through experience. The first few models can be managed with spreadsheets, manual deployments, and ad hoc monitoring, with each model team developing its own practices optimized for its specific requirements. The approach works initially because the models operate independently: what happens to the recommendation system does not affect the fraud detection model.
Independence vanishes as model count grows. Models begin sharing data sources, and changes to upstream data pipelines cascade through multiple consumers. Infrastructure becomes contested: deployment of one model delays deployment of another. Monitoring dashboards multiply until no single team can observe the complete system state. On-call rotations expand from single-model responsibility to cross-model coordination that requires understanding interactions between systems developed by different teams with different assumptions.
Infrastructure efficiency compounds these coordination challenges. Production ML workloads rarely achieve high accelerator utilization because training jobs run intermittently and inference loads fluctuate with user traffic. A single model team might accept 20 percent accelerator utilization because optimizing further is not worth the engineering investment. Multiply by one hundred models, and that underutilization represents millions of dollars in wasted infrastructure. Similarly, a single model’s occasional production incident is manageable, but one hundred models with independent failure modes produce a constant stream of alerts that exhaust on-call engineers and mask genuine emergencies.
The organizational response is platform thinking. Rather than treating each model as an independent system with its own infrastructure, platforms provide shared services that amortize operational costs across the entire model portfolio. Feature stores1 eliminate redundant feature computation. Unified deployment pipelines ensure consistent rollout practices. Centralized monitoring aggregates signals across models to detect system-wide issues and enable capacity planning. The challenge is designing, implementing, and operating these platforms so they scale with the portfolio rather than against it.
1 Feature Store: A centralized repository that manages the computation, storage, and serving of ML features. The core systems problem it solves is training-serving skew; this chapter develops that failure mode and the platform invariant that contains it in section 1.7.
The N-Models Problem
A typical technology organization’s journey with machine learning follows a predictable pattern. The first model might be a recommendation system for the homepage, followed by a search ranking model, then a fraud detection system, then content moderation. Each model team initially operates independently, developing bespoke pipelines for data processing, training, validation, and deployment. The absence of coordination overhead lets each team optimize for its specific requirements.
As the number of models grows, the problems that emerge are not multiplicative but combinatorial. One hundred models do not require 100 times the operational effort of one model; they introduce dependencies and interactions that create superlinear growth in operational complexity. Table 1 quantifies this growth across six operational dimensions, from deployment coordination that becomes critical path at scale to debugging complexity that demands distributed tracing across model boundaries.
| Operational Aspect | Single Model | 10 Models | 100 Models |
|---|---|---|---|
| Deployment coordination | None | Ad hoc | Critical path |
| Shared data dependencies | None | Some overlap | Dense graph |
| Monitoring dashboards | 1 | 10 | Unmanageable |
| On-call rotation scope | Single team | Multiple teams | Organization-wide |
| Infrastructure utilization | Often idle | Moderate sharing | Efficiency critical |
| Debugging complexity | Local | Cross-team | Distributed tracing required |
Napkin Math 1.1: The sharing dividend
Problem: A platform team manages a fleet of 100 GPUs. Under dedicated per-team quotas, average idle time is 70 percent. Moving to a multi-tenant ML platform that shares resources across teams and uses idle training GPUs for inference reduces aggregate idle time to 30 percent. What hardware cost does the platform save?
Math: For a fixed active workload, required hardware is inverse to utilization, while useful work per GPU is proportional to utilization.
- Efficiency Gain: 0.70 (Shared) / 0.30 (Dedicated) = 2.33\(\times\) more work per GPU.
- Hardware Reduction: 1 - (0.30/0.70) = 57.1 percent.
- Annual Savings: 57 percent of $1.75M budget \(\approx\) $1,000,000/year.
Systems insight: Multi-tenancy acts as an infrastructure multiplier. Breaking down resource silos reduces required hardware by 57 percent for the same workload; with the same hardware budget, it raises useful work from 30 to 70 active GPU-equivalents. In the machine learning fleet, statistical multiplexing (the principle that different teams’ peak demands rarely coincide) is the mechanism that makes shared platforms economically sustainable. The platform team’s primary role is to harvest this sharing dividend and reinvest it into future capacity growth.

One upstream embedding update can degrade every dependent model.
The fundamental insight is that per-model operational practices do not compose. When Model A depends on features computed by Pipeline B, which uses embeddings from Model C, changes to any component cascade unpredictably. A seemingly innocuous update to Model C’s embedding layer might shift the feature distributions that Model A depends upon, degrading its performance even though Model A itself has not changed. This cascading interdependence turns scale into a qualitatively different management problem.
Systems Perspective 1.1: The complexity explosion
Past a certain fleet size, the binding problem stops being individual model optimization and becomes system-level coordination: the interactions between models matter more than any single model does. Dependency graphs, shared features, and contention for the same infrastructure mean that the marginal cost of the hundredth model is dominated by how it couples to the other ninety-nine, not by the model itself.
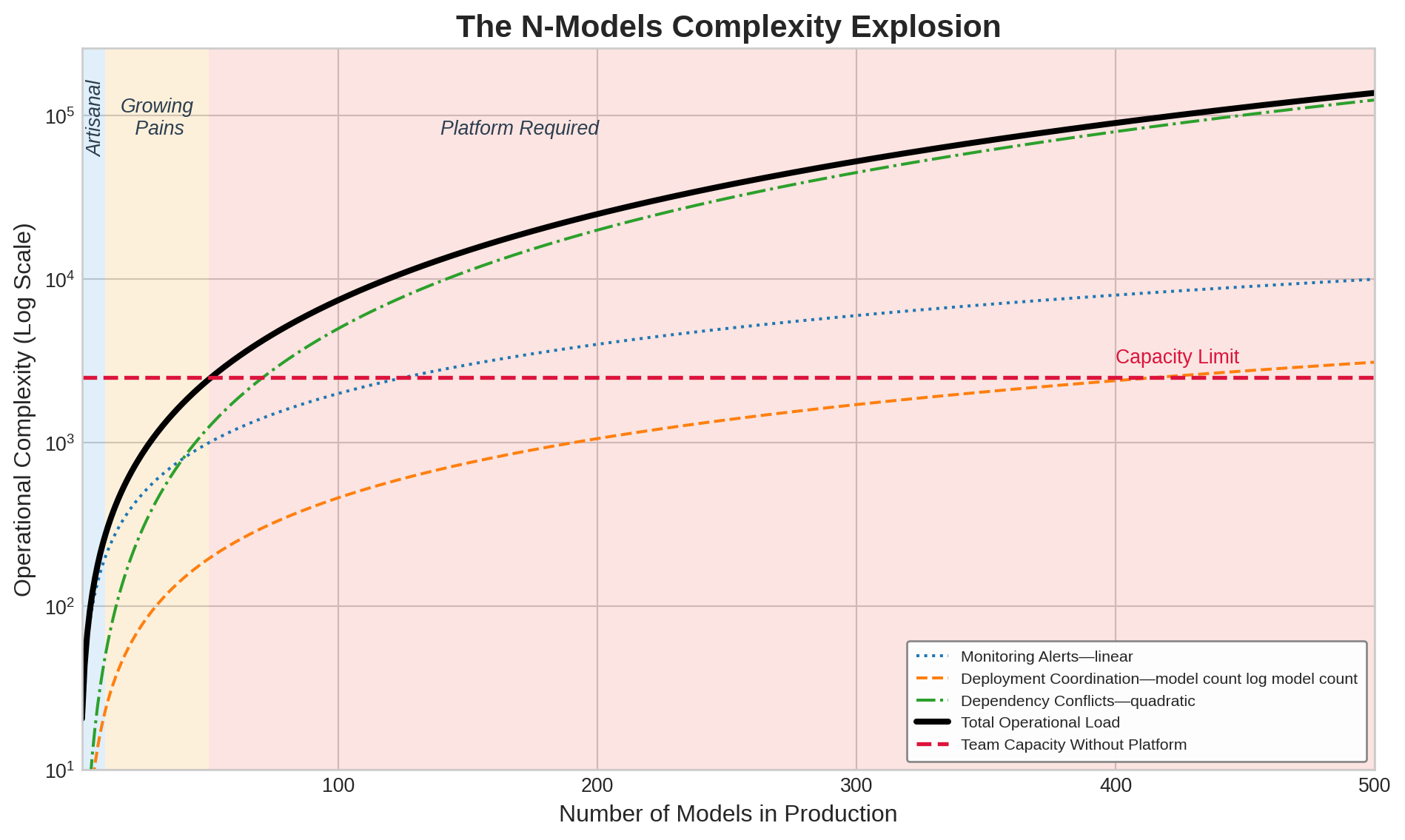
Figure 1 visualizes this superlinear growth across three complexity dimensions. Monitoring alerts grow linearly with model count, but dependency conflicts grow quadratically as models share features, data sources, and infrastructure. The total operational load crosses team capacity around 50 models, the empirical threshold where organizations discover they need platform engineering.
Quantifying platform economics
The economic case for platform operations rests on understanding both the costs of fragmented approaches and the returns from shared infrastructure. Equation 1 formalizes platform return on investment as the ratio of engineering time savings across all models to total platform cost:
\[\text{ROI}_{\text{platform}} = \frac{N_{\text{models}} \times T_{\text{saved}} \times C_{\text{engineer}}}{C_{\text{platform}}} \tag{1}\]
where \(N_{\text{models}}\) represents the number of models benefiting from the platform, \(T_{\text{saved}}\) is the engineering time saved per model per period, \(C_{\text{engineer}}\) is the fully-loaded cost per engineer hour, and \(C_{\text{platform}}\) is the total platform cost including development, infrastructure, and maintenance.
The equation reveals why platform investments make sense only at sufficient scale. For a small organization with five models, the denominator might exceed the numerator even with significant per-model savings. As model count grows, the numerator scales linearly with \(N_{\text{models}}\) while platform costs grow much more slowly, typically sublinearly due to infrastructure amortization.
Napkin Math 1.2: The platform dividend
Problem: An organization manages 50 models. A centralized ML Platform team costs $120,000/month. If the platform saves each model team 20 hours of manual toil per month, is the platform investment profitable?
Math:
- Gross Monthly Savings: 50 models \(\times\) 20 hours/model \(\times\) $150/hr = $150,000.
- Net Monthly Benefit: $150,000 (Savings) - $120,000/month (Cost) = $30,000.
- ROI Ratio: $150,000 / $120,000/month = 1.25.
Systems insight: Platforms exhibit a scaling threshold. At 50 models, this platform earns a 25 percent return on its cost. However, if the organization only had 20 models, the savings would be only $60,000—a 50 percent loss on the platform team’s salary. In MLOps, platform engineering is a fixed cost that pays off through variable savings. The right time to build a platform is when the “manual toil tax” across the model fleet exceeds the “platform maintenance tax.”
From artisanal to industrial operations
The platform-dividend calculation gives the general rule; this worked example turns it into an operating decision. The question is not whether shared tooling is aesthetically cleaner, but whether the fixed platform cost is smaller than the manual toil it removes across the model fleet.
Consider an organization evaluating whether to build a centralized ML platform. Five parameters define the current state:
- 50 production models across 8 teams
- Each model requires 40 engineer-hours monthly for operational tasks
- Engineers cost $150 per hour fully loaded
- Platform development cost: $2 million amortized over 3 years
- Expected time savings: 30 hours per model per month postplatform
Before platform (annual operational cost):
\(C_{\text{current}} = 50 \times 40 \times 12 \times 150 = \$3,600,000\)
After platform (annual operational cost plus amortized platform cost):
\(C_{\text{after}} = 50 \times 10 \times 12 \times 150 + \frac{2,000,000}{3} = \$900,000 + \$666,667 = \$1,566,666.7\)
Annual savings reach $2,033,333.3, a 56.5 percent reduction in operational costs. The platform pays for itself within the first year.
The economic gap explains why large technology companies have invested heavily in ML platforms while smaller organizations often struggle to justify similar investments. The economic threshold typically falls between 20 and 50 models, depending on model complexity and organizational structure.
Figure 2 visualizes this threshold effect by plotting platform ROI as a function of model count for two platform cost levels. A $2M/year platform breaks even at approximately 20 models, while a more expensive $5M/year enterprise platform requires roughly 50 models to justify the investment. Beyond break-even, ROI grows linearly because each additional model contributes the same per-model savings to the numerator of equation 1 while platform costs remain essentially fixed. At 100 models, the $2M platform delivers 5\(\times\) return on investment. This linearity is both the economic argument for platform investment and the explanation for why organizations that defer platform building until they are “at scale” often find themselves paralyzed by accumulated operational debt: the break-even point arrives earlier than intuition suggests.
The break-even count is not a universal constant; it moves with the two inputs the reader controls. The platform-dividend notebook above (a $120K/month platform team saving 20 hours per model) and the worked example (a $2M build amortized over three years, saving 30 hours per model) reach break-even at different model counts than this figure precisely because they assume different platform cost bases and different per-model savings. The figure’s curves fix the platform cost at a round annual figure and assume $100K of savings per model per year to isolate the threshold’s shape; the notebook and worked example trade that roundness for explicit operating assumptions. All three obey the same equation 1: change the numerator (savings per model) or the denominator (platform cost) and the break-even point slides, but the linear post-break-even slope does not.
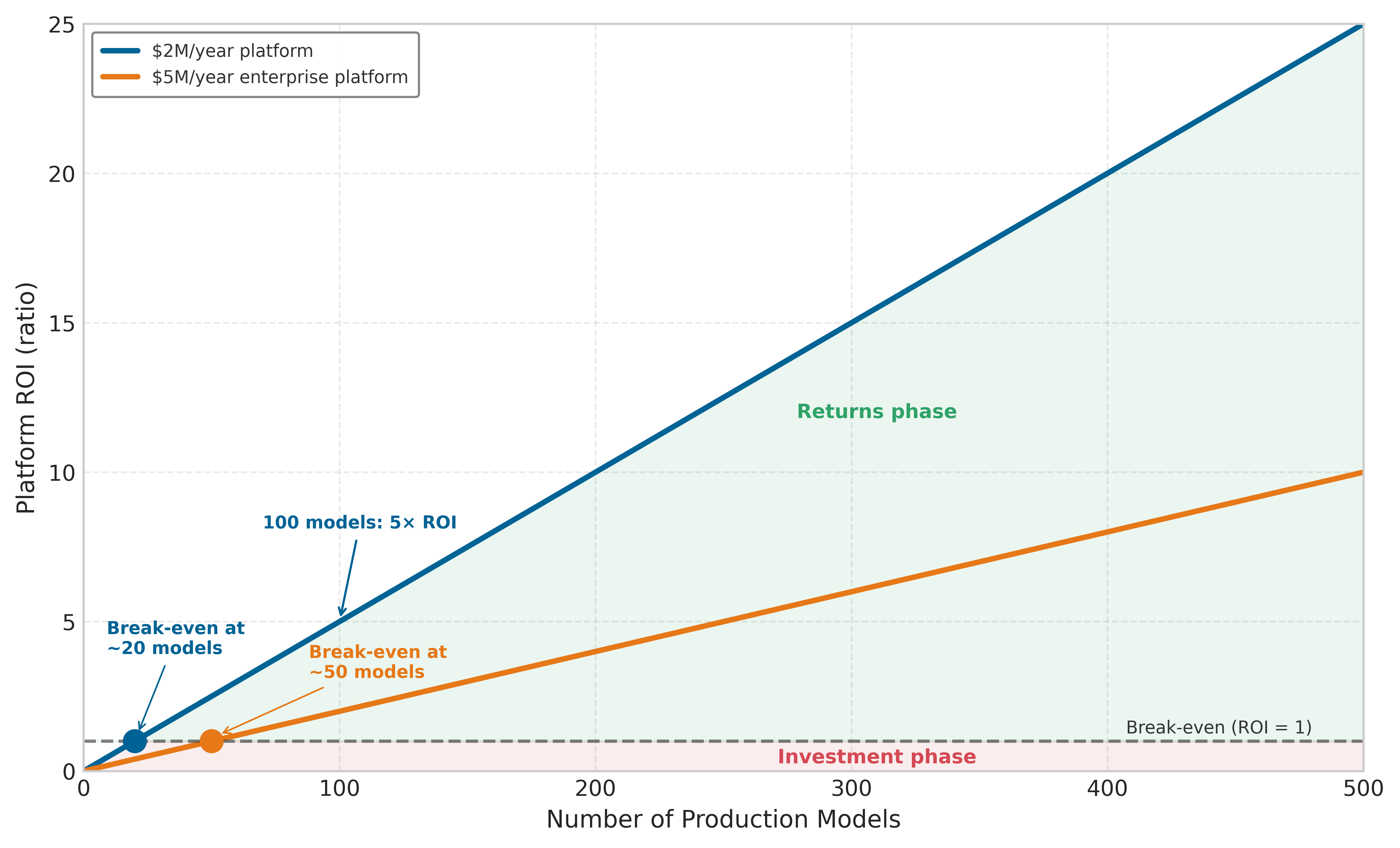
Checkpoint 1.1: Platform ROI break-even
Equation 1 expresses platform return on investment as \(N_{\text{models}} \times T_{\text{saved}} \times C_{\text{engineer}} / C_{\text{platform}}\). Figure 2 shows two cost curves and the linear ROI growth past break-even. Apply the formula to two concrete decisions.
Platform ROI is one lever; the cost of individual training runs and the capacity decisions that follow are another. A single 2,048-GPU H100 run makes that capacity question concrete and connects it to fleet economics, where utilization, checkpointing, and carbon accounting become platform-level decisions rather than isolated experiment costs.
Capacity planning and cost of training
Capacity planning for large-scale ML is an exercise in optimizing the economics of the GPU-hour. Consider a concrete case: a 30-day training run on a 256-node H100 cluster (2,048 GPUs) at an illustrative market rate of $2/GPU-hour represents a direct investment of roughly $2.95M. At this scale, the cost per training run \((C_{\text{run}})\) becomes a primary design lever that dictates the sizing of the entire fleet. Faster time-to-market pushes the planner toward more GPUs, but larger jobs also suffer diminishing parallel efficiency and a higher probability of hardware interruption. Total cost is therefore not merely a function of compute time; it must account for data staging, checkpointing, and the cost of recovery from interruptions (Fault Tolerance).
The drive for efficiency forces capacity to behave like a dynamic resource rather than a static allocation. Organizations must decide when to buy additional permanent capacity and when to recover the same effective throughput through better orchestration or model optimization. The decision also has an energy dimension: powering thousands of GPUs for months consumes enough electricity that financial cost and carbon cost move together. Capacity planning therefore becomes a strategic lever that balances performance, budget, energy use, and responsible engineering in the same decision. Cost visibility also sharpens the case for paying down technical debt: the same metrics that reveal runaway training costs expose the hidden cost of unversioned data, brittle pipelines, and manual toil.
Quantifying and managing ML technical debt
Technical debt at fleet scale is a prioritization problem: the platform must find which hidden dependency is slowing deployments, raising incident rates, or consuming the most engineering toil, and pay that down first. The four categories below (data, configuration, model, and infrastructure debt) locate where the drag originates, and quantifying each makes them comparable across the fleet so the worst offender can be addressed first.
Napkin Math 1.3: The maintenance dividend
Problem: A team spends 40 hours/month manually fixing “broken plumbing” (stale data, failed scripts, manual monitoring). A one-month intensive cleanup (160 hours) is projected to reduce this to 8 hours/month. Is the cleanup worth it over 3 years of model lifecycle?
Math:
- Status quo (3 years): 36 months \(\times\) 40 hours/month \(\times\) $150/hr = $216000.
- Proactive Path: (160 hours investment + 36 months \(\times\) 8 hours/month) \(\times\) $150/hr = $67200.
- Net Savings: $216000 - $67200 = $148800.
- Dividend ratio: 3.2×.
Systems insight: Proactive maintenance reduces total cost by a factor of 3.2× over the model lifecycle. In the ML Fleet, “Plumbing” is more important than “Pipes”: an organization that ignores technical debt eventually spends its entire budget just keeping old models alive, leaving zero capacity for new development. The most successful teams treat refactoring as a high-yield investment, not a distraction.
The maintenance dividend becomes actionable only when the platform can compare unlike debts on a common operational scale. ML technical debt manifests in measurable symptoms that directly affect platform velocity and reliability (Sculley et al. 2015; Amershi et al. 2019).
Amershi, Saleema, Andrew Begel, Christian Bird, Robert DeLine, Harald Gall, Ece Kamar, Nachiappan Nagappan, Besmira Nushi, and Thomas Zimmermann. 2019. “Software Engineering for Machine Learning: A Case Study.” 2019 IEEE/ACM 41st International Conference on Software Engineering: Software Engineering in Practice (ICSE-SEIP), 291–300. https://doi.org/10.1109/icse-seip.2019.00042.
Debt categories and measurement
The debt category matters because each failure mode leaves a different operational trace. Table 2 turns the taxonomy into a measurement map: data debt appears as incidents and manual pipeline intervention, configuration debt as unvalidated release surface, model debt as glue-code drag, and infrastructure debt as toil that consumes platform capacity.
| Debt type | Operational symptom | Measurement signal | Warning threshold |
|---|---|---|---|
| Data debt | Unstable dependencies, missing versioning, weak validation | Data incidents per month and manual pipeline intervention | More than 10 data incidents/month or 30% manual runs. |
| Configuration debt | Ad-hoc files, duplicated parameters, absent validation | Deployment failures, lines of config, unvalidated parameters | More than 500 lines of unvalidated configuration per model. |
| Model debt | Glue code, undeclared consumers, tangled serving paths | Coupling score, undocumented consumers, trace time | More than 20% engineering time maintaining glue code. |
| Infrastructure debt | Brittle pipelines, manual deployment, environment drift | Toil hours, automation coverage, drift incidents | More than 50% platform capacity spent on toil. |
Quantification metrics
Table 3 turns four debt metrics into a baseline-and-threshold map, pairing each symptom with the point at which it becomes an escalation signal.
| Metric | Signal | Healthy baseline | Warning threshold |
|---|---|---|---|
| Deployment velocity | Time from code commit to production deployment; exposes release friction. | Less than one day for inference code changes and less than one week for training changes. | More than two weeks indicates configuration complexity, brittle dependencies, or inadequate automation. |
| Incident rate | Reliability harm visible as incidents per 1000 deployments. | Fewer than 5 incidents per 1000 deployments. | More than 20 incidents indicates debt in testing, validation, or deployment procedures. |
| Toil percentage | Team capacity consumed by manual operational work. | Less than 20% of capacity spent on toil. | More than 50% indicates automation debt that prevents the team from improving the platform. |
| Dependency staleness | Share of dependencies behind supported or current versions. | Less than 10% stale dependencies. | More than 30% indicates upgrade debt that increases security risk and limits performance improvements. |
The worked example applies that threshold logic to rank debt by the capacity each fix returns to the platform team.
Worked example: ML debt audit and prioritization
An ML platform team supporting 40 production models with 15 engineers faces deployment velocity problems. New models require 6 weeks to reach production, frustrating both platform and model teams. The audit must rank the debts by how much platform capacity each one unlocks, not by which symptom is most visible.
The audit records the three debt categories in table 4 before scoring them. Each row pairs an operational symptom with the impact measure that makes the debt comparable across teams.
| Debt category | Symptom | Impact metric | Technical measure | Estimated annual cost |
|---|---|---|---|---|
| Configuration debt | Each model has custom YAML (YAML Ain’t Markup Language) configuration files averaging 847 lines with no validation schema | 35% of deployment delays result from late config errors | Manual config review required for every deployment | 12 engineer-hours per deployment \(\times\) 80 deployments/year = 960 hours |
| Pipeline glue code | Data preprocessing uses 23 different scripts with 62% code duplication | 12 engineer-hours per week debugging pipeline breaks | No shared preprocessing library; each team implements custom logic | 12 hours/week \(\times\) 52 weeks = 624 hours |
| Monitoring debt | Each model uses ad-hoc monitoring, with no unified observability platform | Mean time to detect (MTTD) incidents is 4.2 hours | 23 monitoring approaches across 40 models | Extended incident duration costs $50K per incident \(\times\) 15 incidents/year = $750K |
The scoring approach uses three criteria: impact severity, frequency, and resolution cost, each scored 1 to 3. Table 5 ranks the three debt categories observed earlier. Higher impact and frequency raise priority; higher resolution cost lowers it.
| Debt Category | Impact | Frequency | Resolution Cost | Total Score | Priority |
|---|---|---|---|---|---|
| Configuration | 3 (High) | 3 (Daily) | 2 (Medium: 6 weeks) | 4.5 | 1st |
| Monitoring | 3 (High) | 2 (Weekly) | 2 (Medium: 8 weeks) | 3 | 2nd |
| Pipeline Glue | 2 (Medium) | 2 (Weekly) | 3 (High: 16 weeks) | 1.3 | 3rd |
The score makes configuration debt the first paydown target: build configuration schema validation and a templating system before addressing lower-scoring pipeline glue. The investment requires 6 weeks of engineering effort to build the configuration system. It removes 35 percent of the recurring configuration-review toil: 12 engineer-hours per deployment \(\times\) 80 deployments per year \(\times\) 35 percent = 336 engineer-hours saved per year. At $150/hour, that is $50K in annual savings, so the investment pays back in about 8.6 months.
Decision framework
The general debt paydown decision extends the worked score with an explicit benefit estimate, where Impact captures severity, Frequency captures how often the debt appears, Benefit captures avoided operational cost, and Resolution Cost captures the engineering effort required:
\[\text{Paydown Priority} = \frac{\text{Impact} \times \text{Frequency} \times \text{Benefit}}{\text{Resolution Cost}} \tag{2}\]
The paydown-priority formula in equation 2 keeps automation work tied to operational value: high-impact, frequent, high-benefit fixes outrank expensive work whose payoff is speculative.
Napkin Math 1.4: ROI of automation
Problem: A team spends 10 hours of manual toil per model deployment. Investing 120 hours in a CI/CD pipeline is projected to reduce deployment toil to 0.5 hours. At 3 deploys/week, how long until the automation pays for itself?
Math:
- Automation Cost: 120 hours \(\times\) $150/hr = $18000.
- Weekly Savings: 9.5 hours/deploy \(\times\) 3 deploys/week \(\times\) $150/hr = $4275/week.
- Payback Period: $18000 / $4275/week \(\approx\) 4.2 weeks.
Systems insight: Automation is a high-yield capital investment. A payback period of 4.2 weeks is an exceptional return on engineering time. In MLOps, “Toil” is the highest-interest technical debt an organization can carry: paying it down early yields massive dividends for the rest of the model’s lifecycle.
The decision rule is asymmetric. Pay debt when this ratio exceeds the expected value from feature development; the configuration debt above qualifies because it has high impact (blocks deployments), high frequency (every deployment), high benefit (eliminates 35 percent of delays), and moderate cost (6 weeks). Defer debt when it is localized to a single team, frequency is low (monthly or less), system sunset is planned within 12 months, or resolution cost exceeds 6 months of engineering effort.
The same prioritization logic must become organizational habit, or the measured debt will reaccumulate between audits. Quantified debt first becomes a backlog item with affected systems, estimated impact, resolution cost, and priority score. Quarterly review then updates that backlog as platform needs change, keeping the ranking tied to current deployment velocity, incident rates, and toil rather than stale complaints.
A debt budget turns that ranking into capacity. Allocating 20 to 30 percent of sprint capacity to paydown makes remediation compete explicitly with feature work, while teams spending less than 10 percent on debt usually see debt grow faster than they can address it. Prevention moves the same reasoning upstream into code and design review: every proposed change should ask whether it introduces configuration complexity, hard-to-maintain data dependencies, or manual operational procedures, because preventing debt creation costs less than paying it down later.
How operations differ at scale
The operational requirements for multi-model platforms differ qualitatively from single-model operations. Table 6 contrasts these approaches across six dimensions, revealing that platform-scale deployment demands dependency-aware scheduling, monitoring must shift from model-centric to system-centric aggregation, and governance evolves from team-specific policies to organization-wide standards:
| Aspect | Single-Model Operations | Multi-Model Platform (100+) |
|---|---|---|
| Deployment | Simple rollout, team-controlled | Dependency-aware scheduling, platform-coordinated |
| Monitoring | Model-centric metrics | System-centric with model aggregation |
| Debugging | Local to model and data | Distributed tracing across model boundaries |
| Resource Management | Dedicated allocation | Shared pools with multi-tenant isolation |
| Governance | Team-specific policies | Organization-wide standards and automation |
| Organization | Single team ownership | Platform team plus consumer teams |
The qualitative gap is most visible in deployment operations. Single-model deployment is straightforward: validate the new version, deploy to a canary, monitor for regressions, and proceed to full rollout. Platform-scale deployment must consider dependency ordering, where models that consume features from other models cannot be updated independently. Rollback coordination becomes essential, as reverting one model may require reverting dependent models. Resource contention arises when multiple deployments compete for GPU memory or network bandwidth. Blast radius management limits the impact of any single deployment failure.
For recommendation systems, this complexity is particularly acute. A typical recommendation request might involve 10–50 models executing in sequence or parallel: candidate retrieval models, ranking models, diversity filters, and business rule layers. Updating any component requires understanding its interactions with all others.
Monitoring requirements evolve similarly. At single-model scale, monitoring focuses on model-specific metrics: prediction accuracy, inference latency, and data drift indicators. At platform scale, this approach becomes untenable. With 100 models, 100 independent dashboards create information overload that prevents effective incident response.
Platform monitoring must therefore aggregate across models while maintaining the ability to drill down into specifics. This requires hierarchical metrics. Business metrics capture overall system health through revenue, engagement, and user satisfaction. Portfolio metrics aggregate model performance by domain or business unit. Model metrics track individual model accuracy, latency, and drift. Infrastructure metrics monitor GPU utilization, memory pressure, and network throughput.
Telemetry collection at scale
The transition to platform-scale observability requires a fundamental shift in telemetry paradigms at scale. When 10,000 edge nodes or hundreds of microservices generate logs simultaneously, the monitoring infrastructure itself can become a bottleneck, creating a “thundering herd” that overwhelms the network. Telemetry must be rigorously categorized and sampled to prevent the observability system from perturbing the production system. Table 7 separates the telemetry types by volume growth and operational use so the platform can choose what to collect continuously and what to sample.
| Telemetry Type | Definition | Volume | Primary Use Case |
|---|---|---|---|
| Metrics | Aggregated numerical data (counters, gauges, histograms). | Low (constant size) | Alerting, SLA tracking, and high-level dashboarding. |
| Logs | Discrete, timestamped text records of specific events. | High (scales with requests) | Post-incident root cause analysis and auditing. |
| Traces | End-to-end request paths across distributed microservices. | Very High | Diagnosing latency bottlenecks and distributed failures. |
Notice in table 7 that volume grows from constant (metrics) through linear (logs) to super-linear (traces) with request rate, which is why effective platforms present high-level metric dashboards by default and enable investigation into lower levels only when anomalies are detected.
Model-type operations diversity
Beyond scale considerations, different model types require fundamentally different operational patterns. The practices appropriate for deploying a large language model are entirely inappropriate for a fraud detection system, and vice versa. The archetype taxonomy in Three systems archetypes helps interpret the model-type operational requirements in table 8: LLMs demand staged rollouts over days to weeks with hours-long rollback windows, while fraud detection requires hourly updates with seconds-fast rollback to address adversarial dynamics.
| Model Type | Update Frequency | Deployment Pattern | Primary Risk | Rollback Speed |
|---|---|---|---|---|
| Archetype A (GPT-4/Llama-3) | Monthly to quarterly | Staged, careful | Quality regression, safety | Hours to days |
| Archetype B (DLRM at Scale) | Daily to weekly | Shadow, interleaving | Engagement drop | Minutes |
| Fraud Detection | Hourly to daily | Rapid with instant rollback | False negatives | Seconds |
| Vision (Classification) | Weekly to monthly | Canary | Accuracy regression | Minutes |
| Search Ranking | Daily | A/B with holdout | Relevance degradation | Minutes |
The table is a risk-to-cadence map, not a model catalog. Large language models sit at the slow end because size, cost, and subtle quality regressions make every release a high-stakes event. A minor degradation in response quality might not appear in automated metrics but could erode user satisfaction measurably, so LLM updates typically involve extended shadow deployment, human evaluation alongside automated metrics, staged rollouts over days or weeks, and safety evaluation before any production exposure.
The cost of regression becomes concrete when one model must preserve every capability at once:
Lighthouse 1.1: Archetype A (GPT-4/Llama-3): cost of regression
Archetype A (GPT-4/Llama-3), the general-purpose LLM introduced in Three systems archetypes, faces the “Generalist’s Dilemma.” Because the model serves millions of distinct use cases, a fine-tuning update to improve Python coding might silently degrade haiku writing. The release gate therefore combines broad capability benchmarks such as Massive Multitask Language Understanding (MMLU) and HumanEval with policy-based safety checks before any production rollout.
The operational cadence for LLMs is measured in weeks to months, with each update treated as a significant event requiring cross-functional coordination. Recommendation systems operate at the opposite end of the operational spectrum because freshness, not deployment fear, often dominates the risk profile (Steck et al. 2021; Gomez-Uribe and Hunt 2015). User preferences shift continuously, new content arrives constantly, and stale recommendation features risk degrading relevance before the next batch update catches up.
Steck, Harald, Linas Baltrunas, Ehtsham Elahi, Dawen Liang, Yves Raimond, and Justin Basilico. 2021. “Deep Learning for Recommender Systems: A Netflix Case Study.” AI Magazine 42 (3): 7–18. https://doi.org/10.1609/aimag.v42i3.18140.
Recommendation operations therefore emphasize four patterns:
- Continuous training: Pipelines produce daily or weekly model updates.
- Interleaving experiments: Multiple model variants are compared on the same requests.
- Rapid iteration: Changes can reach production within hours.
- Rigorous A/B testing: Statistical infrastructure separates real engagement changes from noise.
A key metric that captures this operational urgency is feature freshness latency, which measures how quickly user actions propagate into the model’s predictions.

Streaming closes the freshness lag that batch leaves open.
Example 1.1: Feature freshness latency
Scenario: A user clicks a “Basketball” video. The time required for their feed to show more basketball content is the feature freshness latency.
Math: \[T_{\text{freshness}} = T_{\text{available}} - T_{\text{event}}\]
Setup:
- Batch Pipeline (Daily): Events are aggregated at midnight.
- \(T_{\text{freshness}} \approx 12\text{--}24 \text{ hours}\).
- Impact: User leaves session before recommendations update.
- Streaming Pipeline (Real-time): Events flow through Kafka/Flink to Feature Store.
- \(T_{\text{freshness}} \approx 1\text{--}5 \text{ seconds}\).
- Impact: Next page load reflects the interest.
Systems insight: For session-based recommendations, moving from Batch \((T_{\text{freshness}} \approx 24\text{ h})\) to Streaming \((T_{\text{freshness}} \approx 5\text{ s})\) often yields a 10–20 percent lift in engagement, justifying the increased infrastructure cost.
The key insight is that recommendation operations are fundamentally about ensemble management. A single recommendation request might invoke ten to fifty distinct models, each requiring its own update cadence while maintaining coherent behavior as a system.
Fraud detection systems face a distinct set of operational challenges because their inputs are shaped by adaptive adversaries. Fraudsters actively probe systems to find exploits, then rapidly shift tactics once detected. A fraud model that cannot adapt within hours provides a window of vulnerability. These adversarial dynamics impose four operational requirements:
- Frequent updates: Models update hourly or more often in response to emerging patterns.
- Instant rollback: Serving can revert within seconds when false positive rates spike.
- Shadow scoring: All transactions are scored by candidate models for rapid comparison.
- Feature velocity monitoring: Sudden distribution shifts are detected before adversaries exploit them.
The risk profile is asymmetric. False negatives (missed fraud) cause direct financial losses, while false positives (legitimate transactions blocked) cause customer friction. Operations must balance these competing concerns in real time.
These diverse operational patterns reflect a single underlying principle: risk profile determines operational cadence. LLMs carry large deployment-risk surfaces, including bias, misuse, and environmental harms that motivate careful risk-benefit analysis before release (Bender et al. 2021). Recommendation systems operate rapidly because stale models lose relevance faster than bad updates can cause damage. Fraud detection operates continuously because adversaries do not wait for scheduled deployments. Understanding this principle enables teams to design appropriate operational practices for new model types by analyzing their risk characteristics rather than copying patterns from superficially similar systems.
Bender, E. M., T. Gebru, A. McMillan-Major, and S. Shmitchell. 2021. “On the Dangers of Stochastic Parrots: Can Language Models Be Too Big?” Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency, 610–23. https://doi.org/10.1145/3442188.3445922.
The rest of the chapter stays at the enterprise-fleet level: shared infrastructure for many interacting models, not the foundational move from ad-hoc notebooks to automated single-model pipelines. The question is when that shared layer becomes cheaper and safer than allowing each team to build its own operational stack.
Platform team justification
A dedicated ML platform team is justified when fragmentation costs more than the shared infrastructure needed to replace it. The decision therefore combines quantitative factors (cost savings, velocity improvements) with qualitative factors (consistency, governance, talent retention).
The ROI calculation presented earlier provides the primary quantitative argument, and the supporting metrics show where shared ownership converts into fleet-wide savings: infrastructure efficiency, time to production, and incident reduction. Infrastructure efficiency improves through shared GPU clusters, which achieve 70 to 80 percent utilization vs. 30 to 40 percent for dedicated per-team resources. For an organization with 100 GPUs at $2 per GPU-hour, moving from 35 percent to 75 percent effective utilization saves approximately $930,000 annually when the same 35 active GPU-equivalents can be served by fewer provisioned GPUs. Time to production decreases through platform abstractions that reduce the time from trained model to production deployment; if this acceleration enables one additional high-value model to reach production per quarter, the business value typically exceeds platform costs. Incident reduction follows from standardized deployments and monitoring, with mature platforms often reducing ML-related incidents by 60 to 80 percent and translating that reduction into both direct cost savings and improved user experience.
The qualitative case follows from the same fragmentation cost. Platform failures are coordination failures as much as infrastructure failures, and shared ownership improves four coordination surfaces:
- Consistency: Standardized practices ensure all models meet baseline quality standards for monitoring, rollback capability, and documentation.
- Knowledge sharing: Centralized teams make operational expertise available to all model teams rather than leaving it siloed.
- Career development: Platform roles provide career paths for ML engineers interested in infrastructure.
- Governance readiness: Platform-level controls provide the foundation for compliance as regulatory requirements for AI grow.
The decision to establish a platform team typically occurs when organizations recognize that the alternative, allowing fragmentation to continue, imposes costs exceeding the platform investment. This recognition often follows a significant production incident that revealed cross-model dependencies or operational gaps. The resulting economics show why platform operations become more valuable as the model fleet grows.
Systems Perspective 1.2: Platform returns improve with every model added
Because equation 1 scales the numerator linearly with \(N_{\text{models}}\) while platform cost stays roughly fixed, the ROI ratio rises with every model the platform serves: the per-model savings are recovered against a denominator that barely moves. The benefit is not a faster-than-linear payoff but a ratio that keeps climbing past break-even, which is why organizations that delay platform investment accumulate operational debt that becomes progressively more expensive to address as the fleet grows.
Fleet Economics and Utilization
While operational tooling saves engineering hours, the financial ledger of a deployed model fleet is dominated by utilization. A GPU that is idle between bursts, reserved for failed rollouts, or stranded behind a scheduling bottleneck costs the same as a GPU serving useful predictions. Deployment practices therefore cannot scale economically until the platform can see where capacity is used, where it is reserved, and where it is wasted.
Engineering constraints are ultimately economic constraints: every design decision trades cost against performance, and the “right” infrastructure is the one that maximizes useful computation per dollar over the system’s lifetime. Using the $350,000 per 8-GPU DGX H100 node assumption, a 10,000-GPU cluster represents about $437.5M in node hardware CapEx before networking, facility, staffing, and maintenance costs. The purchase price, however, is only the beginning. Over a typical three-year hardware lifecycle, power, cooling, facility, networking, staffing, and maintenance determine whether the fleet is an asset or an idle liability. Total cost of ownership (TCO)2 matters here because it turns utilization into the central operating invariant behind the broader ML-lifecycle accounting developed in section 1.6.11.
2 TCO (Total Cost of Ownership): A financial framework, formalized by Gartner in the 1980s for IT procurement, that sums CapEx (one-time acquisition) and OpEx (recurring operation) over a system’s lifecycle. For ML clusters, TCO analysis is uniquely consequential because power, cooling, staffing, facility, and network costs materially change the three-year economics, and a 60-percentage-point swing in utilization (20 percent to 80 percent) can flip the build-vs.-buy decision entirely without changing any hardware specification.
The economics of ML infrastructure differ from traditional IT in three fundamental ways. Accelerators depreciate quickly, power is a first-order operating cost, and utilization sensitivity is extreme: the same fleet can be a brilliant investment at 80 percent utilization or a financial disaster at 20 percent utilization, with no change in hardware or facility costs. For operations at scale, this is the central lesson. The platform must keep expensive capacity doing useful work while still preserving enough headroom for failures, rollbacks, and traffic spikes.
Cost centers as operating constraints
The total cost of an ML cluster decomposes into two broad categories. Capital expenditure (CapEx) covers the one-time costs of building the infrastructure: accelerators, servers, networking equipment, facility construction, and installation. Operational expenditure (OpEx) covers the recurring costs of running it: electricity, cooling, network bandwidth, staffing, maintenance, and software licenses. For a large on-premises cluster, the approximate breakdown is as follows.
Table 9 separates the cost stack into capital and operating centers, each with different utilization implications.
| Cost center | Cost class | Typical share | Included components and implications |
|---|---|---|---|
| Accelerators and servers | CapEx | 50–60% of CapEx | GPUs or TPUs, host servers, baseboard management controllers, and local storage; this category dominates upfront purchase and depreciation. |
| Networking | CapEx | 10–15% of CapEx | InfiniBand switches, HCAs, cables, and optical transceivers; a fat-tree fabric for 1,024 GPUs can cost $10–20 million. |
| Facilities and cooling | CapEx | 15–25% of CapEx | Building construction or retrofit, transformers, UPS systems, PDUs, and cooling plant; liquid cooling adds 10–15% to facility costs but reduces long-term OpEx. |
| Electricity | OpEx | 60–70% of OpEx | At $0.07/kWh, a 1,024-GPU H100 cluster consuming 1 MW including cooling at PUE 1.1 costs about $615,000 per year. |
| Staffing and maintenance | OpEx | 20–30% of OpEx | System administrators, hardware technicians, replacement parts, and software license fees. |
Consider a 175B-parameter frontier model as the running cost example for this analysis. For this model, a minimum viable training cluster requires approximately 1,024 H100 GPUs spread across 128 nodes to complete a training run in 2–4 weeks. Evaluating the TCO over a three-year lifecycle reveals a stark utilization dependency. The hardware CapEx dominates at $44.80M ($350,000 per node), supported by a $5 million investment in a two-tier InfiniBand fat-tree network and a proportional $10 million facility allocation. Operational costs add approximately $1.5 million annually for electricity (at $0.07/kWh with a PUE of 1.1) and specialized staffing, bringing the three-year total to roughly $64 million. If this dedicated cluster only trains six large models per year, the effective cost per run is $3.5 million. Renting the same 1,024-GPU allocation in the public cloud at $4.00 per GPU-hour costs about $1.3–2.7 million per run (1,024 times 336–672 hours \(\times\) $4), or $24–48 million over three years for six runs per year. The cloud is cheaper for this bursty cadence because the organization is not paying for idle weeks. The economic advantage of owning hardware only materializes at continuous utilization: if the cluster runs 24/7 (supporting training, inference, fine-tuning, and experimentation), the effective on-premises cost drops to approximately $2.40 per GPU-hour, significantly undercutting the cloud rate. This utilization dependency is the central tension in every build-vs.-buy analysis.
Utilization as the economic invariant
The most consequential economic question is whether the fleet can sustain enough useful load to amortize fixed capacity. Build-vs.-buy is one expression of that question, but the same invariant appears inside a deployed platform: reserved capacity, fallback pools, regional replicas, and canary headroom all become economical only when their reliability value justifies their idle cost. Figure 3 makes the utilization dependency visible by plotting cumulative cost over time for owned and rented capacity.

The plotted reference uses 1,024 H100 GPUs across 128 nodes at 80 percent sustained utilization. The on-premises curve starts at $59.80M in upfront CapEx and adds about $1.5M per year, while cloud rental at $4/GPU-hour grows by about $2.39M per month. Over 30 months, the cloud line reaches $71.8M, and the on-premises line crosses it around 26.4 months.
Cloud providers charge by the GPU-hour. At approximately $4.00 per H100-hour, a single 8-GPU node running at 80 percent utilization costs $224,256 per year. An on-premises DGX H100 node costs approximately $350,000 to purchase. Amortized over three years and combined with electricity costs of $4,519 per node per year, the total annual on-premises cost is approximately $121,186 per node. Solving the break-even equation with electricity scaling at the same utilization, on-premises infrastructure becomes favorable when sustained utilization exceeds roughly 42.5 percent.
The same calculation also explains why cloud pricing cannot be read as a simple price list. Reserved capacity lowers the per-hour rate by 40–60 percent, but it converts optionality into commitment. Spot or preemptible capacity can be 60–80 percent cheaper, but the discount arrives as interruption risk. Cheap capacity is therefore useful only when the training or serving system already has checkpointing, elasticity, and admission control that keep interruptions from becoming lost work or user-visible failures.
Owned capacity moves a different set of risks into the platform. Facility construction can add $500–1,000 per kW of IT capacity, and networking, staffing, maintenance, and hardware obsolescence continue to accrue even when the GPUs are idle. A three-year-old GPU may be economically stranded if the next generation delivers 3\(\times\) more performance per watt. The engineering question is therefore not whether one purchasing channel is universally cheaper; it is whether the workload mix can keep fixed capacity useful enough to compensate for its lifecycle and operating risks.
Hybrid designs follow from the same invariant. Owned infrastructure can carry predictable baseline work, while cloud allocations absorb peak demand, early hardware access, or bursty training campaigns. The hybrid split is not a compromise between two vendor categories; it is a scheduling policy over capital risk, utilization, and deadline risk.
For the 175B model, cadence is the variable that determines the answer. A team that trains one large model per year and serves it for the remaining eleven months may use owned training hardware only 15–20 percent of the time. A team running back-to-back experiments, hyperparameter sweeps, fine-tuning jobs, and model variants can sustain 70–80 percent utilization on the same fleet. The hardware has not changed; the workload mix has changed the economics. In the middle regime, the platform owns enough capacity for the continuous baseline and bursts to the cloud for the large training runs that temporarily require 5–10\(\times\) the baseline allocation.
Operational complexity
TCO also understates the operational complexity of owning the fleet. Hardware maintenance means diagnosing failed GPUs, NVLink cables, InfiniBand HCAs, and cooling components before a local fault becomes a cluster-wide slowdown. A 10,000-GPU cluster experiencing one GPU failure every five hours, as predicted by MTBF analysis at the canonical 50,000-hour per-GPU MTBF, needs replacement paths measured in hours rather than days. Component failure rates supplies the per-component MTTF baselines and converts them into the fleet-level failure rate behind this five-hour figure, so the staffing argument traces back to a measured reliability budget rather than an assumed one.
The software side creates the same coupling. CUDA, GPU drivers, InfiniBand drivers, container runtimes, schedulers, monitoring systems, and training frameworks all participate in the achieved utilization number. A driver/toolkit incompatibility can silently degrade performance, while a scheduler or monitoring gap can strand accelerators behind failed jobs. Large training clusters commonly need 5–15 infrastructure engineers per 10,000 GPUs because performance optimization is continuous: as models, frameworks, and hardware configurations change, communication patterns, memory pressure, and parallelism strategies change with them. Case 1: The underutilized fleet (Compute) works the underutilized fleet through the computation, communication, and coordination axes, giving the performance engineer a framework to locate where the lost utilization actually goes rather than tuning blindly.
Cloud providers charge a margin above raw hardware and electricity partly because they absorb this operating burden. The point is not that cloud is simpler in every technical sense; it exposes a different interface. The platform either pays for internal expertise in GPU kernel behavior, InfiniBand operations, distributed-systems debugging, liquid cooling, and power infrastructure, or it pays a provider to hide some of that machinery behind a service contract. In both cases, the economics are still governed by useful work per dollar.
From TCO to total value of ownership
A more complete framework than TCO is Total Value of Ownership (TVO), which includes the value generated by infrastructure rather than only its cost. Two clusters with identical TCO may create different outcomes if one reaches a result two weeks earlier, sustains higher scaling efficiency, starts jobs faster, checkpoints more cheaply, or serves the resulting model at lower cost per token. The value terms are hard to price exactly, but they are not optional in systems reasoning: time-to-result affects product deadlines, scaling efficiency affects final model quality under a fixed training window, experimentation velocity affects the number of hypotheses the team can test, and inference efficiency can dominate training cost over a multi-year deployment.
This value-oriented perspective changes the infrastructure decision from cost minimization to constraint management. A cheaper cluster that slows the research cycle or produces a model with higher serving cost may be more expensive over the model lifecycle. Conversely, a more expensive training platform can pay for itself if it enables a smaller or more efficient deployed model.
The inference dimension of TVO deserves particular emphasis because it often dominates the total economic picture. Training the 175B model is a one-time cost – even at $5 million per training run, it is a bounded expenditure. Serving the trained model, however, is an ongoing operational cost that accumulates indefinitely. A popular LLM serving 10 million queries per day, with each query generating an average of 500 tokens, processes 5 billion tokens daily. At an inference cost of $2.00 per million tokens on H100 hardware, the daily serving cost is $10,000, or approximately $3.6 million per year. The cumulative inference cost exceeds a $5 million training run after roughly 17 months, and exceeds it several times over during a multi-year deployment. This inversion means that infrastructure decisions optimized for training (maximizing TFLOP/s per dollar) may be suboptimal for the model’s total lifecycle cost. An organization that spends an additional $2 million on training infrastructure to produce a model that is 20 percent more efficient at inference (through better architecture search enabled by faster experimentation) can recover that investment over a three-year serving lifetime at this traffic level.
Napkin Math 1.5: The 10,000-GPU cluster
Consider a cluster of 1,250 DGX H100 nodes (10,000 GPUs) for training the 175B model.
On-premises (3-year lifecycle):
- Hardware CapEx: 1,250 \(\times\) $350,000 = $437.5M
- Network CapEx: ~$25M (InfiniBand fat-tree fabric)
- Facility CapEx: ~$75M (liquid-cooled data center hall)
- Annual Electricity: simplified GPU-only estimate: 10,000 GPUs \(\times\) 700 W \(\times\) PUE 1.1 \(\times\) 8,760 h/year \(\times\) $0.07/kWh = $4.7M/year
- Annual Staffing: ~$5M/year
- 3-year total: $537.5M + 3 years \(\times\) $9.7M = ~$566.7M
Cloud rental (3-year rental at 80 percent utilization):
- Annual Cost: 10,000 GPUs \(\times\) $4/GPU-hour \(\times\) 8,760 h/year \(\times\) 0.80 = $280.3M/year
- 3-year total: ~$841.0M
Systems insight: Utilization is the binding variable in fleet TCO. On-premises saves approximately $274.3M over three years at 80 percent utilization, but the savings disappear if utilization drops below roughly 53.9 percent because the on-premises hardware still incurs facility and staffing costs regardless of load.
That utilization threshold explains why infrastructure scale can become a competitive advantage.
Systems Perspective 1.3: The infrastructure moat
Building a 10,000-GPU cluster saves hundreds of millions over cloud rental, but only if the organization has enough workloads to keep it busy. Large technology companies with continuous training pipelines, frequent model refreshes, and massive inference workloads achieve 70–90 percent utilization, making on-premises infrastructure highly cost-effective. Smaller organizations with sporadic training needs may achieve only 20–30 percent utilization, making cloud rental cheaper despite the higher per-hour cost. This dynamic creates an infrastructure moat: organizations with scale can afford to build, and building makes scale cheaper, which enables more ambitious models, which require more infrastructure. The gap compounds over time, giving high-utilization organizations a structural advantage when training the largest models.
Depreciation and lifecycle
ML accelerators depreciate faster than any other category of IT equipment. Traditional servers have useful lifetimes of 5–7 years; network switches last even longer. ML accelerators become economically obsolete in 3–4 years because each new generation delivers more performance per watt. Under the low-precision efficiency basis in table 10, a V100-era fleet draws similar per-GPU power to an H100-class fleet but receives only about 1/6.8 the throughput per watt. The electricity cost per unit of useful computation is therefore about 6.8\(\times\) higher than a team using the H100-class reference hardware.
The economic impact of this depreciation is significant. A V100 GPU that cost $10,000–12,000 in 2018 could be purchased on the secondary market for $2,000–3,000 in 2023, a depreciation of 70–80 percent in five years. An A100 GPU that cost $15,000–20,000 in 2021 traded for $8,000–12,000 in 2024, after just three years. These depreciation rates are far steeper than traditional IT equipment, reflecting the rapid pace of accelerator innovation.
Rapid depreciation turns refresh policy into a scheduling problem. Most organizations depreciate ML accelerators over three years for accounting purposes, even if the hardware physically functions longer. Replacing the entire fleet at once creates a large CapEx spike, while staggered refresh lowers peak expenditure but leaves the scheduler with mixed-generation hardware. Training frameworks must then handle different compute capabilities, memory capacities, and communication bandwidths inside one fleet, so the accounting choice becomes a software and placement constraint.
The same lifecycle logic determines where older accelerators remain useful. A GPU that is inefficient for the largest training runs may still serve smaller models, fine-tuning jobs, or memory-bound inference economically because memory bandwidth improves more slowly than peak arithmetic throughput. Resale, repurposing, and capacity-sharing arrangements are all attempts to preserve utilization while the hardware’s market value falls. They work only when the platform can route work to the right generation without hiding performance cliffs from users.
Depreciation is most punitive for bursty workloads. If a team trains one large model per year, the GPUs lose value during the idle months even though they perform no useful computation. Cloud capacity amortizes the same depreciation across many customers, while owned capacity must amortize it across the owner’s own workload mix. That is why the utilization invariant appears again: the hardware must either stay busy or be cheap enough to strand.
For the 175B model, the depreciation calculus is stark. Under the $350,000-per-8-GPU-node assumption, a 1,000-GPU H100 cluster costs $43.75 million before network and facility costs. If that cluster has a resale value of approximately $7–10 million after a three-year refresh window because newer accelerators deliver 3–4\(\times\) the performance per watt, its net hardware depreciation is $33.75–36.75 million. If the cluster trained only two large models during its lifetime, each model effectively cost $16.9–18.4 million in depreciated hardware alone – before accounting for electricity, staffing, or facility costs. If the same cluster ran continuously at 80 percent utilization for three years (training, fine-tuning, inference, and experimentation), the depreciated hardware cost per GPU-hour drops to approximately $1.61–1.75 after resale, still well below the cloud rate. The depreciation math reinforces the central lesson of TCO analysis: utilization is the single most important variable in determining whether owned infrastructure is economically viable.
Power efficiency trajectory
The trajectory of power efficiency across accelerator generations provides a quantitative framework for making cluster refresh decisions. Replacing an older cluster with a newer generation can pay for itself through electricity savings alone, particularly at scale.
| Generation | Peak TFLOP/s (best precision) | TDP (W) | TFLOP/s per watt | Relative Efficiency |
|---|---|---|---|---|
| V100 (2017) | 125 TFLOP/s (FP16) | 300 W | 0.42 TFLOPs/s/W | 1× |
| A100 (2020) | 312 TFLOP/s (FP16) | 400 W | 0.78 TFLOPs/s/W | 1.9× |
| H100 (2022) | 1,979 TFLOP/s (FP8) | 700 W | 2.83 TFLOPs/s/W | 6.8× |
| B200 (2024) | 4500 TFLOP/s (FP8) | 1000 W | 4.50 TFLOPs/s/W | 10.8× |
As table 10 shows, the implication is that hardware refresh cycles are about getting more work per dollar of electricity, not just more FLOP/s. At scale, the electricity savings from upgrading to a more efficient generation can amortize a significant fraction of the new hardware’s purchase cost within the first year. This economic dynamic drives the rapid depreciation of ML accelerators: a three-year-old GPU is not just slower than a newer generation; it is more expensive to operate per unit of useful computation.
Consider a concrete refresh scenario. An organization operating 1,000 V100 GPUs (300 W each, 0.42 TFLOPs/s/W) consumes 300 kW of IT power for 125,000 TFLOP/s of aggregate throughput. Replacing them with 1,000 H100 GPUs (700 W each, 2.83 TFLOPs/s/W) increases power consumption to 700 kW but delivers 1,979,000 TFLOP/s, a 15.8\(\times\) throughput increase for a 2.3\(\times\) power increase.
Alternatively, the organization could match the V100 fleet’s throughput with roughly 63 H100 GPUs, consuming only 44 kW and freeing 256 kW of power capacity for other workloads. The better strategy depends on whether the organization is throughput-constrained (wants to train larger models) or power-constrained (has a fixed electrical budget).
Both scenarios demonstrate that generational efficiency improvements reshape the economics of the fleet. The power-constrained case is particularly instructive: a data center with a fixed 300 kW power budget can deliver about 6.8\(\times\) more computation by replacing V100s with H100s, even though it can only install 43 percent as many GPUs. The 15.8\(\times\) throughput gain applies to a same-GPU-count refresh that raises power from 300 kW to 700 kW. Power, not procurement budget, is increasingly the binding constraint for fleet expansion.
The interplay between CapEx and OpEx also shapes procurement strategy. Cloud providers amortize their hardware over shorter periods (often 18–24 months) because they can sell older-generation instances at lower prices to price-sensitive customers, extracting residual value. On-premises operators typically amortize over 3–5 years, accepting that the hardware’s relative performance declines over time.
Some organizations adopt a hybrid approach: running baseline workloads on owned infrastructure for cost efficiency and bursting to the cloud for peak demand or for access to newer hardware before committing to a large purchase. This hybrid model fits mid-sized AI companies that have a steady-state training workload, which justifies owned hardware, but periodically need 2–3\(\times\) their base capacity for new model training campaigns.
The power efficiency trajectory has a direct implication for the 175B model’s training economics, and a V100-versus-H100 comparison makes that implication concrete. Training on 1,000 V100 GPUs would require approximately 300 W each (300 kW IT power for 1,000 GPUs) and take roughly 8 months (given the V100’s lower throughput). Training on 1,000 H100 GPUs requires 700 W each (700 kW IT power for 1,000 GPUs) but completes in approximately 2–4 weeks. The H100 cluster consumes 2.3\(\times\) more power per unit time but finishes 8–16\(\times\) faster, resulting in a net energy reduction of 3.5–7\(\times\) for the same training run. When electricity costs $0.07/kWh, the V100 training run costs approximately $120,000 in electricity while the H100 run costs approximately $25,000. The newer hardware is simultaneously faster, cheaper to operate, and more energy-efficient – a rare alignment that makes hardware refresh decisions straightforward for organizations with the capital to invest.
Capacity lead time as operational risk
The economics of ML infrastructure are not purely about hardware specifications and electricity rates. Capacity lead time is itself an operational risk: a platform that cannot acquire, reserve, or free capacity quickly enough may miss model launches, delay rollback-safe migrations, or run without the headroom needed for incident response.
The GPU supply chain is unusually concentrated. NVIDIA holds approximately 80–90 percent of the data center GPU market for ML workloads. TSMC manufactures essentially all high-end GPU dies. A small number of companies (SK Hynix, Samsung, and Micron) produce the HBM stacks. This concentration means that a disruption at any single point in the supply chain, whether a natural disaster at a fab, an equipment failure at an HBM manufacturer, or a geopolitical event affecting chip exports, can delay GPU deliveries across the entire industry.
The practical consequence of this concentration is that capacity changes slowly at large scale. Procurement timelines for large deployments (1,000+ GPUs) typically span 6–12 months from purchase decision to first usable capacity, and demand spikes can stretch that horizon further. For deployed fleets, that delay changes operations: the platform must forecast model growth, reserve refresh capacity, and maintain fallbacks before demand arrives rather than after dashboards turn red.
For the 175B model, the planning lesson is that hardware access becomes part of the deployment schedule. A minimum viable 1,000-H100 allocation represents approximately $44 million in node hardware under the $350,000-per-8-GPU-node assumption used above, but the operational risk is not only the purchase price. If the allocation arrives a quarter late, the platform may lack capacity for fine-tuning, shadow traffic, canary expansion, or rollback-safe serving during the model launch window. Capacity planning is therefore a reliability control, not just a procurement function.
Cloud capacity as an operations constraint
For organizations that choose the cloud path, the provider absorbs hardware ownership but exposes capacity, topology, and interruption risk as operating constraints. The specific instance types and pricing change frequently, so the durable distinction is not vendor branding; it is how the cloud allocation affects communication, scheduling, and fault tolerance.
First, the interconnect fabric determines whether distributed jobs and multi-node inference paths retain the scaling assumptions used in design. InfiniBand-like fabrics and Ethernet-based fabrics have different fixed-latency and per-byte costs; The α-β Communication Model separates those terms so the platform can decide whether the topology penalty matters for a given workload.
Second, provisioning granularity determines how much topology the platform controls. Individual instances maximize flexibility but force the team to assemble placement, networking, and scheduling policy. Pod-level allocations provide a preconnected unit but reduce composition freedom.
Third, custom accelerator options apply the same generality-efficiency trade-off introduced at the silicon level: lower cost per operation for supported workloads, but reduced flexibility for nonstandard architectures. The choice mirrors the on-premises accelerator decision, except that the exit path is a cloud migration rather than a hardware refresh.
The pricing models across providers share a common risk structure. On-demand instances buy flexibility at the highest per-hour cost. Reserved instances buy lower unit cost through commitment. Spot or preemptible instances buy the lowest unit cost by accepting interruption risk. The platform choice is therefore a fault-tolerance decision: cheap capacity is useful only when checkpointing, elasticity, and admission control keep interruptions from becoming user-visible failures.
The economics of spot instances deserve particular attention because they can dramatically reduce training costs for organizations with the engineering sophistication to exploit them. At a 70 percent discount, spot H100 instances cost approximately $1.20 per GPU-hour instead of $4.00. For the 175B model, the 1,000-GPU, 2–4 week workload consumes approximately 336,000–672,000 allocated GPU-hours. The on-demand cost is therefore about $1.3–2.7 million, while spot pricing would reduce the bill to roughly $0.4–0.8 million before accounting for interruptions. However, the stochastic nature of preemption transforms training from a deterministic process into a fault-tolerance engineering problem. If the cloud provider reclaims 5 percent of the nodes mid-training, a standard training job crashes instantly. Capturing spot economics requires an elastic training framework (such as TorchElastic) that can dynamically rebalance the computation graph when nodes are added or removed. The economic viability hinges on the checkpoint tax: if the system must checkpoint every 10 minutes to limit data loss from preemption, and each checkpoint takes 30 seconds, approximately 5 percent of the “cheap” compute is consumed by I/O overhead. There exists a break-even point where the frequency of preemption events combined with checkpoint overhead makes spot instances more expensive in wall-clock time than reserved instances, despite the lower hourly rate.
A critical consideration for cloud-based ML infrastructure is networking between instances. Unlike on-premises clusters where the network topology is custom-designed, cloud instances share the provider’s network fabric with other tenants. Cloud providers may offer placement groups or dedicated networking fabrics that reserve InfiniBand-like or equivalent bandwidth between instances within the same group.
However, cross-group or cross-zone communication may traverse shared infrastructure with lower bandwidth and higher latency. Training frameworks that span multiple placement groups or availability zones must account for this heterogeneous bandwidth topology, a challenge that does not arise in dedicated on-premises clusters. The practical consequence is that cloud-based training jobs must be sized to fit within a single placement group whenever possible, as crossing group boundaries can reduce scaling efficiency by 20–40 percent.
For the 175B model, the cloud path presents a specific challenge: securing 1,000+ GPUs in a single placement group for a multi-week training run. Cloud providers typically limit placement group sizes to 256–512 GPUs, meaning that a large training run must either negotiate a custom allocation, often requiring a substantial commitment, or accept the performance penalty of spanning multiple groups. The availability of large contiguous GPU allocations varies by region and time of day, and organizations can wait weeks for a sufficiently large allocation during periods of peak demand. This availability uncertainty is a hidden cost of the cloud path that does not appear in the per-GPU-hour pricing but can delay training timelines significantly.
Checkpoint 1.2: TCO decision framework
Your organization needs to train 10 models/year, each requiring 1,000 GPU-hours on H100s. You are evaluating whether to purchase an on-premises cluster with 8 GPUs or use cloud instances at $4/GPU-hour.
- Calculate the annual cloud cost.
- Calculate the annualized on-premises cost, assuming $350,000 per 8-GPU node, $0.07/kWh electricity at PUE 1.1, and 700 W per GPU.
- Solve for the number of annual training runs at which on-premises becomes cheaper.
Infrastructure planning methodology
Infrastructure planning begins when a workload requirement becomes a facility requirement. A large training run does not merely ask for more GPUs: the model size fixes the memory pressure, the token budget fixes the compute budget, the desired calendar time fixes aggregate throughput, and the communication pattern fixes the fabric that can make the cluster useful. Once an accelerator is chosen, its TDP constrains cooling, rack density, pod layout, facility power, and ultimately total cost of ownership. Planning is therefore a causal chain, not a purchasing checklist.
The first step is workload characterization. Target model size determines the minimum accelerator count and memory strategy. Dataset size, target throughput, and acceptable training time turn the training objective into a FLOP-hour requirement. Communication pattern then changes the network answer: dense models stress AllReduce, mixture-of-experts models stress AllToAll, and pipeline-parallel models introduce more point-to-point traffic. Inference requirements add another constraint because the hardware that trains a model efficiently may not be the hardware that serves it economically.
With those constraints explicit, bottom-up sizing works from the accelerator outward. Roofline analysis distinguishes compute-bound training from memory-bound serving. Compute-bound training optimizes for sustained TFLOP/s per dollar, while memory-bound inference often optimizes for bandwidth per dollar and latency per watt.
At that point, planning becomes a sequence of coupled design constraints rather than a shopping list. Node sizing decides how many accelerators share a host and which memory tier carries optimizer state, activations, and data staging. For the 175B model, that points toward eight GPUs per node with tensor parallelism and roughly 2 TB of host DRAM for optimizer-state offload. Cluster sizing then divides the total compute budget by sustained per-node throughput after MFU losses and adds 5–10 percent for a maintenance pool and spares.
Network design follows the primary collective and validates expected scaling with equation. The fabric is also a cost line, not just a performance one: Level 3: Switch and Topology derives the leaf and spine switch counts a fat-tree requires, but each InfiniBand NDR switch costs $15,000–30,000 and active optical cables add $500–1,000 per link, so the network for a 1,024-GPU cluster runs $5–15 million depending on oversubscription and optical mix. A RoCE (RDMA over Converged Ethernet) fabric lowers per-port cost but is lossy under the bursty, synchronized traffic of distributed training: even a 1 percent packet-retransmission rate can cut effective AllReduce throughput by 10–20 percent because every GPU waits for the slowest participant. When the GPU fleet is a $35+ million investment, the InfiniBand premium can pay for itself by keeping the network from becoming the bottleneck.
Power and cooling translate IT load through PUE, then sanity-check rack density locally: a four-node DGX H100 rack is roughly a 30–40 kW design point once GPUs, host systems, networking, power conversion, and cooling overhead are included. Higher density changes the cooling architecture, not just the electric bill. TCO and schedule remain design variables because the cluster must arrive in time to matter, and GPU supply or electrical work often dominates lead time.
The same chain becomes concrete for the 175B training plan. Large-batch training is compute bound, so the design optimizes for sustained TFLOP/s per dollar and selects H100s rather than a bandwidth-optimized inference accelerator. The 2.2 TB training state cannot live on one device, which forces tensor parallelism inside each node plus optimizer sharding, activation checkpointing, and offload across the wider data-parallel group. That memory constraint produces the DGX H100 node shape before the facility planner ever reaches the power spreadsheet.
Cluster size then follows from the compute budget. At 6 FLOPs per parameter-token over 175 billion parameters and 300 billion tokens, the run requires 3.15 × 10²³ FLOPs. Using a conservative BF16/FP16 planning basis rather than the FP8 headline peak, each H100 delivers 989 TFLOP/s peak and 445.1 TFLOP/s sustained at 45 percent MFU. With 1,024 GPUs, the cluster reaches roughly 455.7 PFLOP/s sustained and completes the run in about 8 days of idealized compute time, or 2–4 weeks with operational overhead. The TP-8, PP-4, DP-32 configuration generates structured AllReduce traffic suited to a rail-optimized InfiniBand fabric.
The 128 nodes draw 33.5 kW per 4-node rack across 32 racks at approximately 1.1 MW of facility-relevant load, necessitating liquid cooling. The 3-year TCO comes to approximately $63M on-premises; renting the six-runs-per-year workload in the cloud is roughly $24–48M depending on whether each run lasts 2 or 4 weeks, while continuous cloud use is more expensive. The break-even depends on sustained utilization beyond the initial training run. GPU procurement (6–12 months) and facility preparation must begin immediately, with phased deployment targeting initial capacity within 3 months.
Site selection and physical constraints
The planning chain has so far assumed a facility exists, but for a fleet at this scale the site itself is a planning variable that fixes several constraints before any accelerator is purchased. Power availability is the first and usually most binding. A 10,000-GPU pod requires 10–15 MW of continuous power, equivalent to a medium-sized factory, and at megawatt scale the gap between a favorable and an unfavorable electricity rate can amount to tens of millions of dollars over a hardware lifecycle. Locations near hydroelectric dams (the Pacific Northwest, Scandinavia, Quebec) offer abundant low-carbon power but are often remote from talent pools and existing fiber, so the trade-off between cheap power and proximity to engineers becomes one of the most consequential siting decisions.
Cooling environment is the second constraint. Sites in temperate or cold climates achieve lower PUE through free cooling (using outside air directly, without mechanical refrigeration) for much of the year; Meta’s Lulea, Sweden facility, where the average annual temperature is 1 degree Celsius, approaches a PUE of 1.03 on year-round free cooling. Hot, arid regions face both higher cooling costs and water scarcity for evaporative towers. A 10 MW facility using standard evaporative cooling can consume well over 100 million liters of water annually, which in water-stressed regions places a data center in direct competition with municipal and agricultural demand and can trigger permitting limits; closed-loop liquid or dry-cooler systems cut water use to near zero but raise capital cost and, in hot climates, PUE. Network connectivity is the third constraint: training clusters that ingest geographically distributed data need WAN bandwidth, while serving clusters need proximity to internet exchange points for end-user latency, which is why some organizations separate training pods in power-rich remote sites from serving pods near population centers.
These constraints are frequently in tension, and regulatory boundaries can override all of them. Export controls act as a hard filter on which accelerator classes a given geography may host, and data-sovereignty mandates such as the European Union’s General Data Protection Regulation (GDPR) can compel facilities into expensive, power-constrained regions to satisfy compliance rather than efficiency. The result is a power alley phenomenon that concentrates capacity in a few zones: Northern Virginia for connectivity, the Pacific Northwest for cheap hydroelectric power, the Nordics for free cooling. As those zones saturate, local grids face multi-year waits for new substation capacity, pushing operators toward unconventional “brownfield” sites (retired aluminum smelters, defunct coal plants) where high-voltage transmission exists but fiber and cooling must be built from scratch.
Construction and deployment timelines
Site choice feeds directly into schedule, and the timeline from decision to first computation is the planning constraint most organizations underestimate. Building a facility from scratch takes 18–30 months, with the electrical substation (18–24 months) and building shell (12–18 months) the longest-lead items; GPU lead times during high demand reach 6–12 months and run concurrently. The practical consequence is that infrastructure decisions must be made 18–30 months before the infrastructure is needed, often selecting a facility design for hardware that does not yet exist. To absorb that mismatch, experienced teams design for headroom: oversizing electrical infrastructure by 30–50 percent, designing the cooling plant for higher heat densities than the initial deployment requires, and specifying flexible rack layouts, at a typical premium of 10–20 percent of facility CapEx that buys the ability to upgrade compute without reconstructing the building.
The construction timeline is governed by a critical path that must align two disparate workstreams: the facility track (site, power, shell, cooling) and the hardware track (silicon allocation, server assembly, network integration). GPU procurement captures headlines, but the true bottleneck is frequently the electrical substation, whose permitting and transformer delivery cannot be compressed by spending more. This creates a high-stakes synchronization problem: a 20,000-GPU allocation ($500M+) secured before the facility is ready depreciates in a warehouse, while a $200M shell completed before silicon arrives leaves capital assets idle. To hedge it, teams use phased deployment, commissioning the facility in waves rather than targeting a single go-live date, often bringing up an initial 10–20 percent of capacity (2,000 of 10,000 GPUs) while construction continues. The early phase lets the software team validate the distributed-training stack and tune collective-communication kernels on the real topology while simultaneously stress-testing power distribution and cooling, surfacing hotspots and cabling defects at small scale.
What justifies these contortions is the time value of compute. For large-model development, the cost of delay can exceed the interest on capital, because delayed compute postpones experiments, product launches, and downstream capabilities. A model projected to generate $10 million per month in value loses $30 million to a three-month construction delay, often exceeding the cost of the facility’s electrical infrastructure entirely. That calculus can justify paying premiums for prefabricated modular data centers or leasing temporary colocation space to bridge the gap between silicon delivery and facility readiness, and it is why capacity planning is a reliability and product-velocity control, not only a procurement function.
Checkpoint 1.3: Infrastructure planning exercise
Your team needs to train a 70B-parameter model on 1T tokens within 4 weeks. Using the following specifications:
- H100 GPU: 1979 TFLOP/s FP8 peak, assume 45 percent MFU
- Compute budget: \(6 \times 70 \times 10^9 \times 10^{12} = 4.2 \times 10^{23}\) FLOPs
- Available power: 2 MW
- Determine the minimum number of GPUs needed.
- Evaluate sufficiency of the 2 MW power budget, assuming PUE 1.1, 700 W per GPU, and 50 percent overhead for non-GPU components.
- Estimate the training-run cost at $4/GPU-hour in the cloud and $350,000 per 8-GPU node on premises.
While the economic justification for platform operations becomes clear at scale, the technical implementation begins with a deceptively difficult problem: preventing independent models from colliding. Multi-model management requires untangling the hidden dependencies that emerge when hundreds of models share the same data, infrastructure, and user experiences.
Self-Check: Question
An organization trains one 175B-parameter model per year, requiring 1,000 H100 GPUs for four weeks, and leaves the GPUs idle for the remaining 48 weeks. Under the utilization invariant, which deployment strategy minimizes total cost of ownership (TCO) and why?
- On-premises ownership, because avoiding the cloud provider’s hourly margin over 48 weeks yields the lowest total lifecycle cost.
- Cloud rental, because the organization only pays for the active four weeks and avoids amortizing massive CapEx and continuous facility OpEx over the idle months.
- A hybrid architecture, because the platform can run the steady-state baseline on owned hardware while bursting to the cloud for the four-week training run.
- On-premises ownership with a delayed refresh cycle, because retaining the hardware for five to seven years fully amortizes the facility costs regardless of utilization.
A team spends 5 million dollars to train a model that will serve 10 million queries per day. Explain how the total value of ownership (TVO) perspective might justify spending an additional 2 million dollars on training infrastructure to improve the deployed model’s serving efficiency by 20 percent.
When training on preemptible cloud instances at a 70 percent discount, the ____ dictates economic viability: if the system must save state every 10 minutes to survive interruptions and each save takes 30 seconds, 5 percent of the cheaper compute is consumed by I/O overhead rather than forward progress.
True or False: Because ML accelerators are a massive capital expense, an organization with a fixed 300 kW power budget should continue running its 1,000 V100 GPUs for five to seven years to maximize return on investment before upgrading to a newer generation.
Order the following steps in the infrastructure planning methodology for a large training cluster: (1) design the network fabric and validate expected scaling, (2) perform workload characterization to determine the required compute budget and FLOP-hours, (3) translate the IT load through PUE to determine facility power and cooling requirements, (4) size the node by deciding how many accelerators share a host to satisfy memory constraints.
Multi-Model Management
Imagine an e-commerce platform where the search ranking model uses outputs from a user embedding model. If the embedding team silently pushes an updated model with a different dimensionality or scale, the search model will immediately begin producing garbage predictions. The maturity progression from single to multi-model operations hinges on managing precisely this kind of invisible entanglement.
Managing multiple machine learning models in production introduces coordination challenges absent from single-model operations. When models share features, feed predictions into one another, or compete for shared infrastructure resources, their individual behaviors become interdependent. Effective portfolio management therefore starts with registries, dependency tracking, and ensemble-aware deployment practices that make those relationships explicit.
Model registries at scale
Effective multi-model management begins by turning artifacts into governed interfaces. A model registry serves as the central catalog for all machine learning artifacts in an organization, but at enterprise scale the catalog must also expose the dependency graph that determines which downstream systems an update can break.
Core registry requirements
The registry can enforce dependency control only if four ordinary catalog capabilities are reliable. Table 11 summarizes the minimum interface: version identifiers let downstream consumers pin the exact artifact they validated; metadata exposes the training and deployment context needed for review; artifact storage turns registry entries into durable deployable assets; and access control keeps ownership boundaries explicit.
| Requirement | What it stores or enforces | Why it matters at scale |
|---|---|---|
| Version management | Unique artifact identifiers plus lineage for training data, hyperparameters, code commits, and evaluation metrics. | Downstream consumers can pin the exact artifact they validated. |
| Metadata storage | Training configuration, evaluation results, hardware requirements, serving configuration, and ownership. | Deployment and review decisions can be made without reverse-engineering the artifact. |
| Artifact storage | Durable model binaries with efficient retrieval and caching near serving locations. | Large models such as LLMs can exceed 100 GB and cannot rely on ad-hoc file distribution. |
| Access control | Read-write, administrative, and read-only permissions at team and dependency boundaries. | Model developers, platform operators, and dependent teams interact through governed APIs. |
Dependency tracking
Beyond these core requirements, the distinguishing feature of enterprise registries is explicit dependency tracking. Figure 4 illustrates how updates to an upstream model (such as a user embedding model) automatically trigger alerts and validation for all downstream consumers, including ranking and retrieval models. When Model A consumes features computed by Model B, this relationship must be recorded and enforced.

The key takeaway from figure 4 is that a single upstream update can silently invalidate every downstream consumer unless the registry enforces explicit dependency edges. The necessity of this tracking becomes clear when considering a recommendation system with four interdependent models:
- Embedding Model E produces user and item embeddings
- Retrieval Model R uses embeddings from E to generate candidates
- Ranking Models R1, R2, R3 score candidates using embeddings from E
- Ensemble Model M combines outputs from R1, R2, R3
The dependency graph must be explicit in the registry because the update approval process is graph traversal. When Embedding Model E is updated, the registry executes four graph-traversal steps:
- Identify all dependent models (R, R1, R2, R3, M)
- Trigger re-evaluation of dependent models with new embeddings
- Block deployment of the new E until compatibility is verified
- Coordinate deployment order if updates proceed
Without explicit dependency tracking, organizations discover dependencies through production failures when an upstream model change breaks downstream consumers.
Listing 1 illustrates how a single YAML entry captures artifact location, training provenance, and evaluation thresholds, giving the dependency tracker enough metadata to identify which downstream models must be re-evaluated when the upstream embedding changes.
model:
name: user_embedding_v3
version: "3.2.1"
type: embedding_model
domain: recommendation
artifact:
path: gs://models/user_embedding_v3/3.2.1/
format: tensorflow_savedmodel
size_bytes: 4294967296
training:
data_version: user_interaction_2024_01
code_commit: abc123def
started_at: 2024-01-15T10:00:00Z
duration_hours: 48
hardware: 8xA100-80 GB
evaluation:
metrics:
recall_at_100: 0.342
embedding_quality: 0.891
evaluation_set: eval_2024_01
dependencies:
upstream:
- feature_store/user_features_v2
- feature_store/interaction_features_v1
downstream:
- models/candidate_retrieval_v4
- models/ranking_ensemble_v2
serving:
min_replicas: 10
max_replicas: 100
latency_p99_target_ms: 5
memory_gb: 16
ownership:
team: recommendation-core
oncall: recsys-oncall-teamEnsemble management
Recommendation systems exemplify the multi-model management challenge because they operate as ensembles of 10–50 models per request. The platform must manage the ensemble as one production interface even when different teams own its components.
Why ensembles dominate recommendation
Modern recommendation systems use ensemble architectures because one model cannot simultaneously satisfy every latency, quality, and business constraint. Diverse objectives demand specialized models: engagement, diversity, freshness, inventory, and business constraints often pull in different directions, so separate models specialize in each objective and the ensemble combines their outputs. Staged filtering is the systems counterpart to that specialization. Processing enormous candidate sets with a single expensive model is computationally infeasible, so multi-stage architectures progressively filter candidates: retrieval produces a manageable candidate set, ranking scores that set with richer features, and later re-ranking or business-rule stages produce the final ordering (Covington et al. 2016; Liu et al. 2022).
Covington, Paul, Jay Adams, and Emre Sargin. 2016. “Deep Neural Networks for YouTube Recommendations.” Proceedings of the 10th ACM Conference on Recommender Systems, 191–98. https://doi.org/10.1145/2959100.2959190.
Liu, W., Y. Xi, J. Qin, F. Sun, B. Chen, W. Zhang, R. Zhang, and R. Tang. 2022. “Neural Re-Ranking in Multi-Stage Recommender Systems: A Review.” Proceedings of the Thirty-First International Joint Conference on Artificial Intelligence, 5512–20. https://doi.org/10.24963/ijcai.2022/771.
The same decomposition improves experimentation velocity because teams can update individual components without retraining the entire recommendation stack, but that independence creates version-compatibility obligations for the platform. It also changes risk management. Other ensemble components can sometimes compensate when one model fails or produces poor results, yet the platform must detect when compensation hides a regression rather than resolving it.
Ensemble deployment patterns
Deploying ensemble updates requires coordination that single-model deployments do not. Consider updating the fine ranking model within a recommendation ensemble. Table 12 breaks down the staged ensemble deployment pattern into four phases: shadow deployment (24–48 hours logging without serving), canary (1 percent traffic for 4–8 hours), staged rollout (5 percent to 100 percent over 24–72 hours), and soak (7–14 days monitoring for delayed effects).
| Deployment Stage | Actions | Duration | Rollback Trigger |
|---|---|---|---|
| Shadow | New model scores alongside production, results logged but not served | 24–48 hours | Quality metrics below threshold |
| Canary | 1% traffic receives new model results | 4–8 hours | Statistical significance of regression |
| Staged Rollout | 5% → 25% → 50% → 100% | 24–72 hours | Business metric degradation |
| Soak | Full traffic, extended monitoring | 7–14 days | Delayed effects emerge |
The extended timeline reflects the difficulty of detecting regressions in ensemble systems. A component change that improves its local metrics might degrade system-level performance through subtle interactions with other components.
Interaction effects
Ensemble components interact in ways that make local validation insufficient; three recurring patterns explain why the platform needs holdouts, intermediate logging, and long soak periods:
- Compensation effects: The retrieval model starts returning lower-quality candidates and the ranking model learns to compensate by upweighting quality signals; once retrieval is fixed, ranking can over-compensate and degrade results.
- Distribution shift propagation: An upstream model improves locally but changes the input distribution seen by downstream models trained on the old representation.
- Feedback loops: Ranking decisions affect which items users interact with, and those interactions become training data for future models over days to weeks.
Managing these interactions requires holdout groups that experience no changes and provide stable baselines, extensive logging of intermediate model outputs beyond final recommendations, long-term monitoring for feedback loop effects, and periodic ensemble reset experiments that retrain all components together.
Model lifecycle management
Lifecycle management exists to keep model dependencies from becoming permanent obligations: every promotion widens a model’s blast radius, and every retirement must migrate its consumers before the platform can reclaim resources. The stages below trace that progression from development to archive, each defined by the gates it imposes rather than by a status label.
Development → Staging → Canary → Production → Deprecation → ArchiveIn development, models exist as experimental artifacts. Operations requirements are intentionally light, but they are not optional: successful experiments must preserve results, version history, and enough reproducibility metadata to be challenged later. The operational concern is therefore transition readiness. A promising model should not move to staging until it has clear production-readiness criteria, automated evaluation against production-equivalent data, and documentation sufficient for review.
Staging turns that candidate into a deployable service without exposing users. A staged model should process production traffic in shadow mode, run against production feature pipelines, execute on production-equivalent hardware, and meet latency and throughput requirements. The promotion gate then combines automated checks, such as metric thresholds and latency requirements, with human review of model behavior and risk.
Production widens the blast radius from validation traffic to live traffic, so the model now requires continuous monitoring with alerting, capacity for traffic fluctuations, rollback procedures, and on-call support. Production is not a terminal state. Models still need retraining as data distributions shift, feature pipeline updates as upstream data changes, infrastructure updates as serving systems evolve, and periodic re-evaluation against newer baselines.
The lifecycle closes only when a model can be retired without breaking its consumers. Deprecation identifies dependent systems, provides migration paths and timelines, maintains the old model until migration completes, and archives artifacts for reproducibility and audit. Organizations often underinvest in this final stage, leading to accumulation of zombie models3 that consume resources but provide questionable value. Platform-level lifecycle enforcement helps address this pattern.
3 Zombie Models: Production models that continue serving despite being obsolete or superseded. Industry surveys estimate 20–40 percent of production models at mature organizations qualify as zombies, each consuming GPU memory, on-call attention, and monitoring budget while delivering negligible business value. The operational cost extends beyond wasted compute: zombie models inflate the dependency graph, making platform-wide upgrades and security patches slower and riskier.
Deployment patterns by model count
The appropriate deployment pattern depends on the number and interdependence of models being updated because each additional dependency widens the rollback unit. Table 13 categorizes deployment patterns by scale: single model deployments (monthly updates for isolated vision classifiers), pipeline deployments (weekly updates for 3–5 sequential NLP models), ensemble deployments (daily updates for 10–50 recommendation components), and platform deployments (continuous updates across hundreds of enterprise models).
| Pattern | Model Count | Update Frequency | Example |
|---|---|---|---|
| Single Model | 1 | Monthly | Vision classifier |
| Pipeline | 3-5 | Weekly | NLP processing pipeline |
| Ensemble | 10-50 | Daily | Recommendation system |
| Platform | 100s | Continuous | Enterprise ML platform |
For isolated models with no dependencies, standard deployment patterns suffice. Canary deployments, blue-green switches4, and gradual rollouts all work effectively because rollback means returning one model artifact to its previous version.
4 Blue-Green Deployment: A release pattern that uses two identical production environments (“Blue” and “Green”). Only one environment is live at a time. This enables zero-downtime rollouts and near-instant rollback if the new model fails, at the cost of doubling the required serving infrastructure \((C_{\text{infer}})\).
Pipelines introduce ordering constraints because models execute in sequence and each model’s output feeds the next. The deployment rule is compatibility before exposure: deploy upstream models before downstream consumers, validate each stage before proceeding, maintain version compatibility between stages, and roll back the pipeline as a unit if any stage fails.
Ensembles widen the coordination problem because multiple models may execute in parallel or in a graph. Different teams can update components on different schedules, partial updates may change only part of the ensemble, and the system behavior emerges from component interactions. Testing in isolation is therefore insufficient; integration testing becomes the deployment gate.
At platform scale, continuous deployment means some model is always being updated somewhere, so the platform must prevent individually safe changes from combining into an unsafe fleet state. Platform deployment requires automated rollout policies based on model risk classification, cross-model impact analysis before deployment approval, global rate limiting to prevent simultaneous high-risk deployments, and automated correlation of incidents with recent deployments.
Cross-model dependencies in practice
Example: E-commerce model ecosystem
The dependency-control argument becomes concrete in an e-commerce model graph, where a single embedding interface fans out into retrieval, ranking, and business logic. An e-commerce platform typically starts the graph with embedding models. A user embedding model generates user representations from behavior history, while a product embedding model represents products from attributes and interactions. Those embeddings are not final predictions; they are shared interfaces consumed by downstream services.
The next layer turns shared representations into candidate sets and business signals. A candidate retrieval model uses the embeddings to find relevant products, and a price sensitivity model estimates how strongly a user will respond to price changes. A ranking model then scores the candidate products using both embedding features and auxiliary signals, while a business rules model applies promotional and inventory constraints before results reach the user.
Figure 5 maps this dependency structure, showing how user and product embeddings flow through retrieval and price sensitivity models before converging in the ranking and business rules layers. This graph reveals critical operational implications.

As figure 5 makes visible, a single change to the User Embedding model propagates through two direct consumers and four transitive downstream nodes, including the final business rules layer. Operational procedures must therefore address four coordination requirements:
- Re-evaluate all downstream models with new embeddings before deployment
- Consider simultaneous deployment of related components
- Monitor both direct metrics (embedding quality) and downstream metrics (ranking performance)
- Maintain embedding version compatibility or coordinate synchronized updates
The example illustrates why multi-model management requires explicit dependency tracking and coordinated deployment procedures. Dependency graphs and registries, however, are static artifacts. Moving entangled models from a repository into a live production environment without causing cascading failures requires automated, verifiable deployment pipelines.
Self-Check: Question
A model registry that stored only artifact binaries and training metadata failed to prevent a production outage: an upstream embedding update silently changed output dimensionality, causing every downstream ranker to produce garbage. Which capability, present in an enterprise-scale registry, would have prevented this failure?
- Explicit tracking of upstream-downstream dependency edges so a dimensionality change triggers compatibility re-evaluation on all consumers before rollout.
- A larger binary store that retains more historical artifacts per model version.
- A permissions database that restricts which teams can view evaluation metrics.
- Automatic retraining of every downstream model on schedule, so stale-artifact failures never occur.
A recommendation system invokes 10-50 models per request across candidate generation, ranking, and filtering. Explain why the operational unit of management is the ensemble rather than any individual model, and give one concrete failure mode this principle prevents.
A recommendation ensemble’s ranking component retrains, improves NDCG by 2 percent offline, and ships. Within hours, production engagement drops 4 percent. Serving latency, checksums, and feature freshness are all healthy. Which explanation best fits the ensemble interaction pattern?
- A deployment artifact mismatch: the production ranker is serving a stale binary whose offline metrics no longer reflect runtime behavior.
- Downstream components were calibrated against the old ranker’s score distribution; the new distribution shifted inputs to diversity filters and business rules, removing compensatory behavior the system had adapted to.
- The retrained ranker exceeded its latency SLO, silently timing out and returning empty lists.
- The offline evaluation set drifted; the 2 percent NDCG gain is a measurement artifact and the model is identical.
True or False: Once a model passes its launch validation and reaches production, its lifecycle is essentially complete, with only archival and compliance tasks remaining until sunset.
Order the following steps for rolling out an upstream user-embedding model update that has 12 downstream consumers: (1) Trigger re-evaluation of every dependent model on the new embeddings, (2) Enumerate all dependent models from the registry’s dependency graph, (3) Block deployment until compatibility evidence confirms no consumer breaks, (4) Coordinate per-consumer rollout ordering based on risk and dependency depth.
CI/CD for ML at Scale
The dependency graphs and ensemble architectures examined in multi-model management do not deploy themselves. Each model update must navigate the dependency web: an embedding model update might require re-evaluation of four transitive downstream components, including the business rules layer, before any component can safely reach production. This coordination challenge transforms CI/CD from a per-model concern into a platform orchestration problem. Where software CI/CD validates code in isolation, ML CI/CD at scale must validate models within their operational context, ensuring upstream changes do not break downstream consumers and that deployment order respects the dependency graph.
Distributed Training detailed how data, tensor, and pipeline parallelism enable training models too large for single machines, producing artifacts that require validation and deployment at scale. Continuous integration and continuous deployment practices for machine learning differ from traditional software CI/CD along one axis: while software CI/CD focuses on code correctness and deployment reliability, ML CI/CD must additionally validate data, verify model performance, and manage the interactions between code, data, and learned parameters. At platform scale, these challenges multiply as pipelines must coordinate across hundreds of models with varying requirements.
Training pipeline automation
CI/CD for machine learning begins by making training a reproducible producer of deployable artifacts, not an artisanal job run. A well-designed training pipeline executes reproducibly, handles failures gracefully, and produces artifacts suitable for deployment validation.
Pipeline stages
A complete training pipeline includes data validation, training execution, model evaluation, registry registration, and canary deployment, each separated by quality gates that prevent defective artifacts from advancing (figure 6). The sequence matters because each stage protects a different fleet invariant.

- Data validation pins the data version and rejects schema, freshness, or distribution failures before they consume training capacity.
- Feature engineering preserves the feature contract between training and serving, so preprocessing changes do not become silent production regressions.
- Training records code, data, hyperparameters, hardware envelope, and random seeds so a promising artifact can be reproduced or challenged later.
- Evaluation compares the candidate with baselines, slice metrics, latency budgets, and task-specific gates before any user traffic is exposed.
- Artifact generation packages the model with its serving configuration, dependency versions, and rollback target.
- Registration records the artifact in the model registry with lineage, approvals, and deployment eligibility.
Each stage should be independently executable and idempotent. If the pipeline fails at evaluation, restarting should not re-execute data validation and feature engineering unless their inputs have changed.
Pipeline orchestration
Training pipelines require orchestration systems that make dependency order, resource allocation, and failure recovery explicit. The orchestrator represents the workflow as a directed acyclic graph (DAG), tracks dependencies between stages, retries transient failures without rerunning unaffected work, schedules scarce resources such as GPUs and memory, caches intermediate results when inputs are unchanged, and records logs and artifacts for later debugging.
Common orchestration choices include Kubeflow Pipelines5 (Bisong 2019), Airflow with ML extensions, and cloud-native solutions like Vertex AI Pipelines or SageMaker Pipelines. The choice depends on which dependency and resource contracts the platform must enforce, as well as existing infrastructure, team expertise, and scale requirements. Orchestration fixes the execution contract; parameterization fixes the variation contract, so the same graph can run against different data, models, and hardware envelopes without becoming a new program each time.
5 Kubeflow: An open-source ML platform released by Google in 2018 that couples pipeline orchestration to Kubernetes resource management. The key systems consequence: because Kubeflow DAGs express both computational dependencies and resource requests, the orchestrator can schedule GPU-intensive training steps only when accelerators are available, preventing the resource contention that makes manual scheduling of multi-model training fleets untenable.
Bisong, E. 2019. “Kubeflow and Kubeflow Pipelines.” Kubeflow and Kubeflow Pipelines in Building Machine Learning and Deep Learning Models on Google Cloud Platform. Apress. https://doi.org/10.1007/978-1-4842-4470-8_46.
Pipeline parameterization
Effective pipelines separate configuration from code, as illustrated in listing 2.
training_pipeline:
model_type: transformer_ranking
data:
train_path: gs://data/train/2024-01-*
eval_path: gs://data/eval/2024-01-15
schema_version: v3.2
features:
user_features: [embedding, history, demographics]
item_features: [embedding, attributes, popularity]
training:
epochs: 10
batch_size: 4096
learning_rate: 0.001
optimizer: adam
hardware: 4xA100
evaluation:
metrics: [ndcg_10, mrr, coverage]
baseline_model: ranking_v2.1.0The separation enables configuration-driven training because the platform can vary data versions, hyperparameter sweeps, reproducibility records, and environment-specific resource overrides without rewriting the pipeline code. A parameter file is also an audit artifact. When a candidate model later reaches a release gate, the platform can reconstruct exactly which data slice, feature set, hardware envelope, and threshold configuration produced it. That lineage turns validation from a one-time judgment into a reproducible contract.
Validation gates
Validation gates determine whether a trained model should proceed toward production. Effective gates balance thoroughness against deployment velocity. A release gate is an evidence bundle rather than a single score: model performance, latency, policy and fairness constraints, data quality, and operational readiness each answer a different failure mode before the model can safely receive traffic.
Performance gates
Performance validation compares the candidate model against absolute thresholds where the model must exceed minimum acceptable performance, relative baselines where the model must match or exceed current production performance, and historical trends where the model should not regress from recent performance trajectory. Listing 3 demonstrates this multi-criteria evaluation.
def evaluate_performance_gate(
candidate_metrics, production_metrics, thresholds
):
"""
Evaluate whether candidate model passes performance gates.
Returns tuple of (passed: bool, reasons: list)
"""
reasons = []
# Absolute threshold check
if candidate_metrics["ndcg_10"] < thresholds["min_ndcg"]:
reasons.append(
f"NDCG_10 {candidate_metrics['ndcg_10']:.4f} below minimum {thresholds['min_ndcg']}"
)
# Relative improvement check
relative_improvement = (
candidate_metrics["ndcg_10"] - production_metrics["ndcg_10"]
) / production_metrics["ndcg_10"]
if relative_improvement < thresholds["min_improvement"]:
reasons.append(
f"Improvement {relative_improvement:.2%} below minimum {thresholds['min_improvement']:.2%}"
)
# Regression check on secondary metrics
for metric in ["mrr", "coverage"]:
if candidate_metrics[metric] < production_metrics[metric] * (
1 - thresholds["max_regression"]
):
reasons.append(
f"{metric} regression exceeds {thresholds['max_regression']:.2%} tolerance"
)
return (len(reasons) == 0, reasons)Latency gates
Production models must meet latency requirements. Validation should measure inference latency on representative hardware, test at expected throughput levels, and account for batching effects if applicable. Table 14 specifies latency gate thresholds by model type: fraud detection demands the strictest requirements (5 ms p50, 20 ms p99 with instant blocking on violation), while LLMs accept broader bounds (500 ms p50, 2000 ms p99) reflecting their different operational constraints.
| Model Type | p50 Target | p99 Target | Gate Action if Exceeded |
|---|---|---|---|
| LLM | 500 ms | 2000 ms | Block deployment, require optimization |
| Recommendation | 10 ms | 50 ms | Block deployment |
| Fraud Detection | 5 ms | 20 ms | Block deployment, high priority |
| Vision | 50 ms | 200 ms | Warning, conditional approval |
Latency gates catch overt performance violations, but some regressions pass every gate and still degrade the product. The most dangerous failures are semantically silent: valid outputs built on corrupted inputs.
Example 1.2: Silent model regression
Scenario: A product ranking model passes offline validation gates but causes a measurable business regression after deployment.
Failure mode: The culprit is a silent failure in an upstream feature pipeline. A schema change causes a key behavioral feature to return null for a small slice of users. The model serving infrastructure, designed for robustness, automatically imputes these nulls as 0.0.
Consequence: Since 0.0 is a valid value in the feature space, no errors are logged. The model simply makes worse predictions for those users until a business metric monitor catches the regression.
Systems insight: Semantic silence is more dangerous than loud failure: syntactically valid feature values can hide production regressions until business metrics move.
Fairness gates
Fairness concepts become operational at release time when policy choices are encoded as thresholds. For models affecting users, fairness validation6 turns a policy commitment into a release gate. The platform cannot simply ask whether “the model is fair” because different contexts encode fairness differently. In operations, those definitions first appear as executable thresholds. Equation 3 expresses one operational choice: the probability of a positive prediction must differ by less than threshold \(\epsilon\) between protected groups \(a\) and \(b\). Equation 4 encodes a stricter choice from the equalized-odds family: prediction behavior must be similar across groups after conditioning on the true outcome (Hardt et al. 2016).
6 Fairness Validation in ML: Multiple fairness definitions exist – demographic parity, equalized odds, calibration – and satisfying them simultaneously is generally impossible under realistic conditions (Chouldechova 2017; Kleinberg et al. 2016). This forces a systems design choice: automated validation gates must encode which fairness definition the organization prioritizes, making the gate configuration itself a policy decision that cannot be delegated to a generic threshold.
Chouldechova, Alexandra. 2017. “Fair Prediction with Disparate Impact: A Study of Bias in Recidivism Prediction Instruments.” Big Data 5 (2): 153–63. https://doi.org/10.1089/big.2016.0047.
Kleinberg, Jon, Sendhil Mullainathan, and Manish Raghavan. 2016. “Inherent Trade-Offs in the Fair Determination of Risk Scores.” Innovations in Theoretical Computer Science Conference. https://doi.org/10.4230/LIPIcs.ITCS.2017.43.
Hardt, Moritz, Eric Price, and Nathan Srebro. 2016. “Equality of Opportunity in Supervised Learning.” Advances in Neural Information Processing Systems 29: 3315–23.
\[\text{Demographic Parity: } |\Pr(\hat{Y}=1 \mid A=a) - \Pr(\hat{Y}=1 \mid A=b)| < \epsilon \tag{3}\]
\[\text{Equalized Odds: } |\Pr(\hat{Y}=1 \mid Y=y, A=a) - \Pr(\hat{Y}=1 \mid Y=y, A=b)| < \epsilon \tag{4}\]
where \(A\) represents the protected attribute, \(\hat{Y}\) is the model prediction, and \(Y\) is the true outcome. The operational point is not that every gate should enforce every definition. The gate must record which definition the organization chose, compare the measured value against historical baselines as well as absolute thresholds, and route borderline cases to human review because a near-threshold fairness result is also a governance decision.
Data quality gates
Before training or deployment, data quality validation ensures that data meets expected properties (Caveness et al. 2020). Schema conformance verifies all required fields are present with correct types. Statistical properties ensure feature distributions remain within expected bounds. Freshness checks confirm data is not stale beyond acceptable thresholds. Completeness verification ensures missing data rates stay within tolerance.
Caveness, E., P. S. G. C., Z. Peng, N. Polyzotis, S. Roy, and M. Zinkevich. 2020. “TensorFlow Data Validation: Data Analysis and Validation in Continuous ML Pipelines.” Proceedings of the 2020 ACM SIGMOD International Conference on Management of Data, 2793–96. https://doi.org/10.1145/3318464.3384707.
These gates catch issues that would otherwise manifest as mysterious model degradation, completing the pre-release evidence bundle before deployment risk shifts from artifact validity to live-traffic exposure. The next control is no longer another offline score; it is the amount of production traffic allowed to test the artifact under real conditions.
Staged rollout strategies
Staged rollout is the mechanism that turns deployment risk into a controllable exposure budget. Traffic increases only after the model earns each larger blast radius through continued acceptable performance.
Napkin Math 1.6: The safety of staged rollouts
Problem: A team is deploying a new ranking model. A “Blue-Green” deployment (100 percent cutover) exposes all users to any potential bugs. A “Canary” deployment starts at 5 percent traffic. By how much does the canary approach reduce the deployment’s “Risk Exposure”?
Math: Risk exposure is proportional to the traffic percentage affected during the detection window.
- Blue-Green Exposure: 100 percent of users affected until rollback.
- Canary Exposure: 5 percent of users affected until rollback.
- Risk Mitigation: \(100 / 5 = 20\times\).
Systems insight: Staged rollouts are an insurance policy for model quality. Limiting initial exposure to 5 percent reduces the blast radius of a catastrophic failure by 20×. In the Machine Learning Fleet, where model behavior is probabilistic and hard to unit-test, gradual exposure is the only reliable way to ensure that “SOTA on paper” does not become “Broken in Production.”

Canary rollout cuts initial exposure by 20x.
Blue-green deployment
Blue-green deployment maintains two identical production environments. The current version (blue) serves traffic while the new version (green) is prepared. Once ready, traffic switches instantaneously to green.
The infrastructure cost of this duplication is qualitatively different for ML systems than for stateless web services. A recommendation or language model that requires multiple GPUs to hold its weights in VRAM cannot share that memory across environments: blue-green deployment for a large model means holding two complete copies of model weights across parallel accelerator allocations simultaneously. Loading model weights into GPU memory also takes measurable time (tens of seconds to minutes for multi-gigabyte checkpoints), so the “instant rollback” benefit assumes those weights remain warm in the standby environment throughout the deployment window. The effective cost is therefore not merely doubled serving infrastructure but doubled GPU memory reservation for the duration of the transition. Many organizations running large models treat blue-green deployment as a theoretical option and rely on canary or shadow deployment in practice because hardware capacity and cost make the duplicate allocation impractical.
Blue-green deployment offers a simple mental model and full testing in a production-equivalent environment before exposure. It also requires duplicate GPU and memory allocation during transition, provides no gradual exposure to detect subtle quality regressions, and relies on a binary switch that may miss issues emerging only at scale. The pattern fits low-risk changes to lightweight models where gradual rollout provides limited additional safety and the duplicate capacity cost is acceptable.
Canary deployment
Canary deployment7 routes a small percentage of traffic to the new version while monitoring for regressions. If metrics remain acceptable, traffic percentage increases until the new version serves all traffic.
7 Canary Deployment: Named after the coal-mining practice of using canaries to detect toxic gases – a small sacrifice that protects the whole. For ML systems, the analogy is precise: model regressions typically manifest as gradual accuracy degradation rather than crashes, making them invisible to health checks but detectable through statistical comparison of canary vs. control traffic. Without canary stages, a subtly degraded model can reach 100 percent traffic before anyone notices the loss.
A typical progression moves from 1 percent to 5 percent to 25 percent to 50 percent to 100 percent as evidence accumulates. Determining the duration of each stage is critical. Equation 5 relates stage duration to sample requirements, request rate, and traffic percentage, enabling precise calculation of minimum canary durations for statistical validity:
\[T_{\text{stage}} = \frac{n_{\text{samples needed}}}{r_{\text{requests}} \times p_{\text{stage}}} \tag{5}\]
where \(T_{\text{stage}}\) is the duration required at a given percentage, \(n_{\text{samples needed}}\) is the number of observations needed for statistical significance, \(r_{\text{requests}}\) is the request rate, and \(p_{\text{stage}}\) is the traffic percentage.
Worked example: Canary duration calculation
A model serves 1 million requests per hour. To detect a 1 percent change in click-through rate with 95 percent confidence requires approximately 10,000 samples per variant.
At 1 percent canary traffic: \(T_{1\%} = \frac{10,000}{1,000,000 \times 0.01} = 1\text{ hour}\). At 5 percent canary traffic: \(T_{5\%} = \frac{10,000}{1,000,000 \times 0.05} = 0.2\text{ hours} = 12\text{ minutes}\).
The organization might configure five rollout stages:
- 1 percent for 2 hours (2\(\times\) minimum for buffer)
- 5 percent for 30 minutes
- 25 percent for 30 minutes
- 50 percent for 1 hour
- 100 percent deployment
Total rollout: approximately 4 hours for a confident deployment.
Napkin Math 1.7: The cost of a delayed alert
Problem: A team deploys a recommendation model that has a silent bug: it reduces Click-Through Rate (CTR) by 0.5 percentage points (10 percent relative), from 5 percent to 4.5 percent. If the service handles 5,000 requests/s and each click is worth $0.50/click, how much revenue is lost if detection and remediation take 24 hours?
Math:
- Total Requests: 5,000 requests/s \(\times\) 86,400 s/day = 432,000,000 requests.
- Lost Clicks: 432,000,000 requests \(\times\) 0.005 = 2,160,000 lost clicks.
- Total Financial Loss: 2,160,000 lost clicks \(\times\) $0.50/click = $1,080,000.
Systems insight: A “minor” 0.5 percentage-point regression in a high-traffic model is a $1,080,000 daily disaster. MLOps is fundamentally economic risk management. Every hour shaved from “Time-to-Detection” via canary deployments and automated drift monitoring translates directly into saved revenue. In the fleet stack, monitoring is the “Insurance Policy” that protects model business value.
Multi-region deployment coordination
Fault Tolerance developed checkpointing, elastic training, and recovery mechanisms for handling failures within distributed training jobs. Multi-region deployment uses the same fault-tolerance idea [preserve useful work and state across failures] in the inference plane, where coordination across geographic regions introduces challenges absent from single-region operations. Model version consistency, traffic routing during transitions, and coordinated rollback require explicit protocol design to prevent mixed-version serving that can corrupt A/B test validity and user experience.
Coordination challenges
Multi-region ML deployment introduces two coordination burdens absent from stateless service rollouts. First, model artifacts are large: a production recommendation system’s ensemble of sparse and dense models may require tens to hundreds of gigabytes of checkpoint data, and a large language model serving inference may require hundreds of gigabytes per replica. Distributing those artifacts across wide-area networks before a region can serve traffic is a bandwidth-constrained scheduling problem, not a metadata-only configuration push. Second, most ML models do not carry their context in the request; they pull it from a feature store. If Region B has received the new model binary but its regional feature store has not yet synced the latest user embeddings, that region will serve degraded predictions despite a technically successful deployment. The readiness check for an ML region must therefore verify the model binary, feature-store consistency, and serving health as one coherent state.
Mixed-version serving is the failure mode that binds multi-region deployment. A rollout protocol must preserve a coherent version boundary even when clocks, traffic volume, routing, and rollback behavior differ by region.
Clock skew and timing coordination create ambiguity about canary phase boundaries. When a deployment starts at 2:00 PM UTC, Region A may begin its 1 percent canary while Region B, due to network delays or operational variation, still serves the old version. Defining deployment phases using wall-clock time leads to inconsistent user experiences as users crossing region boundaries encounter different model versions, so production systems need logical rollout states in addition to timestamps.
Regional traffic variation turns the same percentage into different statistical evidence. A 1 percent global canary might represent 5 percent of traffic in a low-volume region, enough for statistical significance, but only 0.3 percent in a high-volume region, potentially insufficient. Per-region sample sizes must be validated independently before the platform treats a canary as evidence.
Cross-region request routing then turns regional skew into user-visible inconsistency. Users may be routed to different regions based on latency, load balancing, or failover. A user whose requests span multiple regions during a deployment window may receive predictions from different model versions, violating the consistency assumptions underlying A/B test analysis.
Rollback is the final consistency test. Rolling back one region while others continue serving the new version creates the same mixed-version problem that careful deployment coordination was meant to prevent, so rollback must be part of the rollout protocol rather than an ad hoc emergency action.
Deployment strategies
Multi-region coordination chooses where to spend the rollout tax: longer deployment duration, stronger synchronization, or bounded regional skew. Three architectural approaches make different trade-offs:
- Sequential regional rollout: Regions deploy one at a time, completing the full canary progression in each region before the next begins. This maximizes safety by limiting blast radius to a single region, but extends total deployment duration proportionally to region count.
- Synchronized global rollout: All regions maintain identical deployment state simultaneously. A global coordination service transitions regions between canary phases at the same logical timestamp, giving users a consistent experience but making every regional issue part of the global deployment decision.
- Hybrid rollout: A deployment coordinator enforces minimum and maximum phase boundaries while allowing regions to progress independently within those bounds. Regions can accelerate through phases if local metrics are strong or pause if issues emerge, while global constraints prevent excessive version skew.
The right choice depends on whether the deployment values minimum blast radius, global consistency, or bounded regional independence most.
For a conservative sequential rollout across 5 regions, the typical progression is:
- Canary region (lowest traffic): Full canary cycle, 24 to 48 hours
- Early adopter regions (2 regions, 20 percent global traffic): Parallel deployment, 24 to 48 hours
- Majority regions (2 regions, 70 percent global traffic): Parallel deployment, 24 to 48 hours
- Final validation: Cross-region consistency check, 12 to 24 hours
Total deployment duration: 4 to 8 days for a conservative rollout.
Traffic management during transitions
Maintaining request consistency during deployment transitions requires three routing controls that keep the experiment and user experience coherent:
- Sticky routing: A user’s requests consistently route to the same region throughout the deployment window, typically through consistent hashing on user identifier. Users experience either the old version or new version consistently, never mixing within a session.
- Version pinning: Clients include a model version hash in the request, and the serving infrastructure routes to replicas serving that version. This supports gradual client migration independent of server-side deployment state.
- Request isolation: Cross-region traffic is disabled during critical deployment phases. During canary evaluation, this ensures metrics reflect single-region behavior rather than mixed routing patterns.
These controls preserve the statistical meaning of deployment metrics while users move through a changing fleet.
Consistency models for deployment
The choice of consistency model affects both deployment complexity and validity of deployment metrics. Table 15 compares deployment consistency models for multi-region systems: strong consistency guarantees identical versions across regions (essential for financial predictions) but requires high coordination overhead, while eventual consistency allows independent progression suitable for content recommendations at the cost of temporary version divergence:
| Model | Guarantee | Use Case | Coordination Overhead |
|---|---|---|---|
| Strong | All regions serve identical version | Financial predictions, safety-critical | High (global synchronization) |
| Eventual | Regions converge to same version | Content recommendations | Low (independent progression) |
| Bounded staleness | Regions within \(k\) versions of each other | Real-time ranking | Medium (version monitoring) |
For A/B testing validity, model serving typically requires strong consistency within treatment groups. If some users assigned to treatment receive old-version predictions due to deployment timing, the measured treatment effect is diluted. Eventual consistency across treatment groups is acceptable since each group is analyzed independently.
Rollback coordination
Rolling back a multi-region deployment requires careful coordination to prevent oscillation and mixed-version serving. The rollback protocol has two ordered phases:
- Stop traffic to the new version globally: The deployment coordinator broadcasts rollback intent, waits for every region to acknowledge that it has stopped routing new traffic to the new version, and lets in-flight requests complete. Regions that do not acknowledge before the timeout are marked unhealthy.
- Restore the old version globally: The coordinator confirms that all regions serve only the old version, re-enables normal traffic routing, clears deployment state, and prepares the system for a later re-attempt.
The protocol ensures that at no point do some regions serve the new version while others have rolled back, which would create inconsistent user experiences.
Partial rollback allows rolling back individual regions while others continue. This is appropriate when issues are region-specific (infrastructure problems, regional traffic patterns) rather than model-inherent. The deployment coordinator tracks per-region state and prevents inconsistent global decisions based on partial information.
Worked example: Multi-region coordination overhead
A recommendation system deploys across 5 regions with average inter-region latency of 80 ms. The coordination protocol requires five steps:
- Announce deployment intent (broadcast to all regions): 80 ms
- Receive acknowledgments (wait for slowest region): 80 ms
- Execute deployment phase (region-local): variable
- Confirm completion (broadcast): 80 ms
- Receive confirmations (wait for slowest region): 80 ms
Minimum coordination overhead per phase transition: 320 ms for the synchronization protocol itself. For a deployment with 5 canary phases, coordination adds 1.6 seconds to total deployment time, negligible compared to the hours spent in each phase.
However, the coordination service becomes a critical dependency. If the coordinator fails during a deployment, three behaviors are possible depending on the consistency model:
- With strong consistency: All regions freeze in current state until coordinator recovers
- With eventual consistency: Regions continue independent progression, potentially diverging
- With bounded staleness: Regions continue but coordinator failure triggers alerts if staleness exceeds bounds
Organizations deploying safety-critical models typically implement coordinator redundancy through consensus protocols (Raft, Paxos) that survive single-node failures while maintaining consistency guarantees.
Production experiment validation
Once rollout coordination preserves version boundaries, the next question is whether the candidate model is actually safe to expose. Shadow traffic, interleaving, A/B tests, and network-effect checks form an experiment ladder: each step buys stronger production evidence at higher operational cost.
Shadow deployment and traffic replay
Shadow deployment runs the new model in parallel with production, receiving the same inputs and logging outputs, but not affecting user-visible results (figure 7). This provides the highest fidelity testing environment short of actual production exposure, enabling detection of issues that escape offline validation.

Shadow deployment earns its duplicate infrastructure cost when it answers validation questions offline tests cannot. Operational load testing proves the new model can handle full production traffic volume without crashing, leaking memory, or violating latency service-level objectives (SLOs)8. A model that passes offline validation with small datasets may exhibit memory leaks, performance regressions, or resource contention when processing millions of requests per hour. Shadow deployment catches these operational issues before user impact.
8 SLO (Service Level Objective): A target reliability level. For a model-serving API, “three nines” (99.9 percent) availability allows only 8.7 hours of downtime per year. For latency, a P99 SLO of 200 ms means 99 percent of requests must complete faster than 200 ms. Meeting these targets at scale requires automated scaling and circuit breaking to handle load spikes.
Once the shadow path is isolated, the validation signal comes from comparing behavior under real traffic. Output comparison reveals distribution shifts, outlier behavior, and edge cases that aggregate offline metrics hide; for classification models, this might expose systematic shifts in confidence scores, while for recommendation systems it might expose changes in diversity or category distribution. Behavioral validation catches failures on long-tail inputs that appear infrequently in validation sets but thousands of times daily in production traffic. Performance characterization measures actual latency, throughput, and resource consumption, validating capacity assumptions before the model receives user-visible traffic.
Shadow deployment requires capturing and replaying production traffic, and the replay choice determines the trade-off among fidelity, cost, and freshness. Three architectural patterns address different operational requirements.
Live mirroring duplicates every production request to the shadow model in real time. The production model serves the response while the shadow model processes the same input in parallel, providing immediate validation at full production scale but requiring shadow infrastructure capable of handling 100 percent traffic load. To keep this validation path from becoming a production dependency, the serving system must invoke shadow requests asynchronously, enforce timeouts, shed shadow load when it falls behind, and isolate resources so shadow work cannot affect production responses.
Sampled replay mirrors a configurable percentage of production traffic to shadow models. This reduces infrastructure costs while maintaining statistical power for validation: a shadow model receiving 10 percent of traffic still processes hundreds of thousands of requests daily at scale, sufficient for detecting most issues. The sampling policy determines which failures remain visible at lower cost. Random sampling is simple and unbiased, stratified sampling preserves representation across user segments and request types, and adaptive sampling increases the rate for patterns where shadow and production outputs diverge.
Batch replay captures production traffic logs and replays them asynchronously against shadow models. This decouples shadow validation from production latency constraints, supports faster-than-real-time regression tests against historical traffic, and allows off-peak cost optimization. The same decoupling weakens the signal for freshness-sensitive systems: validation is delayed by hours or days, requires persistent logging infrastructure, may replay time-dependent features with stale context, and cannot validate real-time operational characteristics.
Effective shadow deployment requires quantitative comparison metrics beyond simple accuracy because the decision is whether the candidate behaves like production under real load. Output divergence measures how shadow predictions differ from production predictions: classification systems track disagreement rates, probability shifts, and class-specific concentration, while regression systems compute root mean square error (RMSE) between shadow and production outputs. Performance metrics compare latency distributions, throughput capability, and resource consumption; a shadow model with equivalent accuracy but 50 percent higher p99 latency requires infrastructure capacity adjustments before deployment.
The metric set must also separate operational failures from genuine model changes. Error-mode metrics count timeouts, exceptions, malformed outputs, and null predictions. A shadow model that times out on 0.1 percent of requests encounters 1,000 failures per day at 1M requests/day scale, and the request patterns that trigger those failures guide remediation. Statistical validation then determines whether observed differences represent genuine model changes or random variation. For a shadow model processing 100K requests with 1 percent disagreement rate and production model at 1.5 percent disagreement, a two-proportion z-test determines statistical significance:
\[z = \frac{0.015 - 0.010}{\sqrt{0.0125 \times 0.9875 \times (2/100000)}} = \frac{0.005}{0.000497} \approx 10.1\]
With \(z > 1.96\), this difference is statistically significant at \(\alpha_{\text{sig}} = 0.05\), indicating a genuine shift rather than sampling noise.
Worked example: Shadow deployment workflow
A fraud detection model processes 5 million transactions daily. The team develops a new model architecture expected to improve precision while maintaining recall. The shadow deployment workflow begins with a sampled-shadow phase that mirrors 10 percent of traffic for three days, so shadow infrastructure handles 500K requests per day. The observed recall is 94.2 percent for the shadow model vs. 94.5 percent in production, which is not statistically different, while precision improves from 82.3 percent to 87.1 percent with statistical significance. Shadow p99 latency reaches 45 ms vs. 38 ms in production, still acceptable under the 50 ms SLO, so the team proceeds to full shadow.
The full-shadow phase mirrors 100 percent of traffic for five days. This confirms that the precision improvement holds at full scale, but it also exposes an edge case: the shadow model flags 0.02 percent of transactions as errors due to an unexpected feature distribution, which is 1,000 transactions per day. The root cause is heightened sensitivity to outliers in transaction amount. After adjusting feature clipping thresholds and redeploying shadow, the error rate falls to 0.001 percent, clearing the gate for canary deployment.
Postdeployment validation then compares actual production metrics with the shadow predictions. Precision materializes at 87.3 percent in production vs. 87.1 percent in shadow, within expected variation. In this case, shadow deployment successfully predicted production behavior.
Shadow deployment infrastructure
Operating shadow deployments at scale requires infrastructure that preserves the validation signal without perturbing production. The traffic mirroring layer intercepts production requests and duplicates them to shadow environments, handling routing logic, sampling decisions, timeout enforcement, and error isolation so shadow failures cannot affect production. Logging and comparison infrastructure captures outputs from both production and shadow models, computes divergence metrics, and stores results for analysis; high-throughput systems can generate terabytes of comparison data, so storage and query design become part of the validation architecture.
The operational surface completes the loop. Alerting and dashboards surface statistically significant divergences, performance regressions, and elevated error rates to deployment decision makers, while drill-down views expose the request patterns that explain divergence. Resource isolation keeps shadow workloads from stealing production capacity through separate compute pools, network bandwidth allocation, and database capacity. Cloud deployments often achieve that isolation with separate clusters; on-premises deployments require explicit resource partitioning.
When shadow deployment is essential
Shadow deployment is most valuable when the cost of duplicate infrastructure is smaller than the cost of an undetected production regression:
- New model architectures where offline validation may miss production-specific failure modes
- High-stakes models (financial, medical, safety-critical) where production issues have severe consequences
- Models with complex dependencies on real-time features where offline replay cannot fully validate behavior
- Performance-sensitive deployments where latency or throughput regressions must be detected before user impact
- Regulatory environments requiring preproduction validation evidence
It is less critical when the deployment risk is bounded and rollback is cheap:
- Minor model updates (retraining with same architecture) where production behavior is well-understood
- Low-risk models where rapid rollback is acceptable
- Resource-constrained environments where shadow infrastructure costs exceed validation benefits
The decision is therefore economic as much as technical: pay for shadow validation when duplicate capacity buys risk information that offline tests and cheap rollback cannot provide.
Interleaving experiments
Interleaving experiments9 were developed for ranking and search evaluation (Chapelle et al. 2012) and are also used in recommender personalization experiments (Blog 2017). Rather than splitting users between variants, interleaving presents items from both variants to each user, then measures which items users engage with.
9 Interleaving Experiments: Originally developed for search engine evaluation, interleaving merges results from two rankers into one list shown to each user, then credits clicks to the originating ranker (Chapelle et al. 2012). It can require far fewer samples than A/B testing because each user provides a direct within-subject comparison rather than only a between-population signal. For fleet-scale recommendation systems iterating on many model variants, that sample-efficiency gain translates directly into faster experiment cycles and lower opportunity cost from suboptimal models in production.
Chapelle, Olivier, Thorsten Joachims, Filip Radlinski, and Yisong Yue. 2012. “Large-Scale Validation and Analysis of Interleaved Search Evaluation.” ACM Transactions on Information Systems 30 (1): 1–41. https://doi.org/10.1145/2094072.2094078.
The key insight is statistical efficiency. An interleaving experiment can require far fewer samples than A/B testing, and Netflix reports more than 100\(\times\) fewer users for some ranking experiments (Chapelle et al. 2012; Blog 2017), because each user provides direct comparison signals rather than contributing only to aggregate statistics.
Interleaving implementation:
- Both model variants score all candidates
- Results are interleaved using team draft or probabilistic interleaving
- User interactions attribute credit to the originating variant
- Statistical tests determine winning variant
Interleaving is essential for recommendation systems where detecting small engagement changes quickly enables rapid iteration, as figure 8 contrasts with traditional A/B testing.

A/B testing statistical foundations
The statistical challenges of experimentation multiply at platform scale. A/B testing provides rigorous frameworks for comparing model variants (Kohavi et al. 2009, 2020), but requires careful attention to statistical power10, significance thresholds, and multiple testing correction.
Kohavi, Ron, Roger Longbotham, Dan Sommerfield, and Randal M. Henne. 2009. “Controlled Experiments on the Web: Survey and Practical Guide.” Data Mining and Knowledge Discovery 18 (1): 140–81. https://doi.org/10.1007/s10618-008-0114-1.
Kohavi, Ron, Diane Tang, and Ya Xu. 2020. Trustworthy Online Controlled Experiments: A Practical Guide to A/B Testing. Cambridge University Press. https://doi.org/10.1017/9781108653985.
10 A/B Testing Power: The probability that an experiment correctly detects a true effect (\(1-\beta_{\text{stat}}\), typically set to 0.8). At fleet scale, the systems challenge is Statistical Power: if the expected improvement is small (for example, 0.1 percent), the experiment may require millions of samples to reach statistical significance, consuming substantial serving resources \((C_{\text{infer}})\) for weeks.
Sample size calculation
Improper statistical practices lead to false positives that waste engineering resources or false negatives that miss genuine improvements, so the required sample size for detecting an effect must be chosen from four parameters: significance level \((\alpha_{\text{sig}})\), statistical power \((1-\beta_{\text{stat}})\), baseline conversion rate \((p)\), and minimum detectable effect \((\delta)\). Equation 6 formalizes this relationship for comparing two proportions, showing that required samples scale inversely with the square of the minimum detectable effect:

Detecting smaller effects explodes the required sample size.
\[n_{\text{sample}} = \frac{(Z_{\alpha_{\text{sig}}} + Z_{\beta_{\text{stat}}})^2 \times 2p(1-p)}{\delta^2} \tag{6}\]
where \(Z_{\alpha_{\text{sig}}}\) is the critical value for significance level \(\alpha_{\text{sig}}\) (typically 1.96 for \(\alpha_{\text{sig}} = 0.05\)), \(Z_{\beta_{\text{stat}}}\) is the critical value for power (typically 0.84 for 80 percent power), \(p\) is the baseline rate, and \(\delta\) is the minimum detectable effect as an absolute difference.
Worked example: Sample size for recommendation model
A recommendation system has baseline CTR of 5 percent. The team wants to detect a 10 percent relative improvement (0.5 percentage points absolute) with 95 percent confidence and 80 percent power.
Parameters:
- \(Z_{\alpha_{\text{sig}}} = 1.96\) (95 percent confidence, two-tailed)
- \(Z_{\beta_{\text{stat}}} = 0.84\) (80 percent power)
- \(p = 0.05\) (baseline CTR)
- \(\delta = 0.005\) (0.5 percentage point improvement)
Calculation:
\[n_{\text{sample}} = \frac{(1.96 + 0.84)^2 \times 2 \times 0.05 \times 0.95}{0.005^2}\]
\[n_{\text{sample}} = \frac{7.84 \times 0.095}{0.000025} = \frac{0.7448}{0.000025} = 29,792\]
Each variant requires approximately 30,000 samples, totaling 60,000 observations. At 1 million requests per day, this experiment requires less than 2 hours. However, for a model with 1 percent baseline CTR detecting a 5 percent relative improvement (0.05 percentage points), the calculation yields:
\[n_{\text{sample}} = \frac{7.84 \times 2 \times 0.01 \times 0.99}{0.0005^2} = \frac{0.1552}{0.00000025} = 620,800\]
Now each variant needs approximately 621K samples. At 1M total requests/day split evenly between the two variants, the experiment requires about 30 hours. The lower the baseline rate and smaller the effect, the longer the experiment must run.
Statistical significance testing
Once data is collected, a two-proportion z-test determines if the observed difference is statistically significant. Equation 7 computes the test statistic as the difference in observed rates normalized by the pooled standard error:
\[z = \frac{\hat{p}_B - \hat{p}_A}{\sqrt{\hat{p}(1-\hat{p})(\frac{1}{m_A} + \frac{1}{m_B})}} \tag{7}\]
where \(\hat{p}_A\) and \(\hat{p}_B\) are the observed conversion rates for control and treatment, \(m_A\) and \(m_B\) are sample sizes, and \(\hat{p} = \frac{m_A\hat{p}_A + m_B\hat{p}_B}{m_A + m_B}\) is the pooled proportion. If \(|z| > Z_{\alpha_{\text{sig}}}\), reject the null hypothesis and conclude the variants differ significantly.
Multiple testing correction
Running multiple A/B tests simultaneously or sequentially without correction inflates the familywise error rate. With 20 independent tests at \(\alpha_{\text{sig}} = 0.05\), the probability of at least one false positive is:
\[\Pr(\text{at least one false positive}) = 1 - (1-\alpha_{\text{sig}})^k = 1 - 0.95^{20} = 0.642\]
The result is a 64 percent chance of falsely detecting an improvement. Three correction approaches address this problem.
Bonferroni correction adjusts the significance threshold to \(\alpha_{\text{sig}}' = \frac{\alpha_{\text{sig}}}{k}\) for \(k\) tests. This is conservative but simple. For 20 tests with \(\alpha_{\text{sig}} = 0.05\), use \(\alpha_{\text{sig}}' = 0.0025\) for each test. This controls the familywise error rate but reduces statistical power.
Šidák correction provides a less conservative adjustment. Equation 8 computes the per-test threshold that maintains the desired familywise error rate exactly, yielding slightly more statistical power than Bonferroni:
\[\alpha_{\text{sig}}' = 1 - (1-\alpha_{\text{sig}})^{1/k} \tag{8}\]
For 20 tests: \(\alpha_{\text{sig}}' = 1 - 0.95^{1/20} = 0.00256\), slightly more lenient than Bonferroni.
False Discovery Rate (FDR) control using Benjamini-Hochberg procedure allows a specified proportion of false positives among all rejections. This is appropriate when some false positives are acceptable. Order p-values from smallest to largest: \(p_{(1)} \leq p_{(2)} \leq \ldots \leq p_{(k)}\). Find the largest \(i\) such that:
\[p_{(i)} \leq \frac{i}{k} \times \alpha_{\text{sig}}\]
Reject all hypotheses \(H_{(1)}, \ldots, H_{(i)}\). This procedure yields higher statistical power than Bonferroni when running many tests.
Sequential testing and early stopping
Traditional A/B tests fix sample size in advance and evaluate once. Sequential testing allows monitoring results during data collection with principled early stopping rules. This can reduce experiment duration by 50 percent or more while controlling error rates.
The sequential probability ratio test (SPRT) evaluates the likelihood ratio after each observation:
\[\Lambda_m = \frac{p(X_1, \ldots, X_m \mid H_1)}{p(X_1, \ldots, X_m \mid H_0)}\]
Stop and reject \(H_0\) if \(\Lambda_m \geq \frac{1-\beta_{\text{stat}}}{\alpha_{\text{sig}}}\), stop and accept \(H_0\) if \(\Lambda_m \leq \frac{\beta_{\text{stat}}}{1-\alpha_{\text{sig}}}\), otherwise continue collecting data.
For large-scale A/B testing, group sequential methods divide the experiment into planned analysis stages. At each stage, compare test statistic to adjusted thresholds (computed using methods such as O’Brien-Fleming or Pocock boundaries) that maintain overall \(\alpha_{\text{sig}}\).
Practical implementation considerations
Real-world A/B testing faces complications beyond textbook statistics. Carryover effects occur when users exposed to treatment retain behavior changes after returning to control. This violates independence assumptions, so mitigation requires sufficient washout periods or cookie-based consistent assignment.
Network effects occur when treating user A affects user B’s behavior through interaction. This violates the stable unit treatment value assumption (SUTVA), so mitigation uses cluster randomization at network community level, though this reduces statistical power (Rubin 1980; Hudgens and Halloran 2008; Eckles et al. 2017).
Novelty effects occur when new model variants show artificial improvement because users respond to novelty, not genuine superiority. Mitigation extends experiment duration (typically 2–4 weeks) to observe steady-state behavior.
Metric selection can mislead when surrogate metrics (clicks, engagement) do not align with long-term objectives (retention, revenue). Mitigation tracks both short-term surrogate metrics and long-term guardrail metrics, even if the latter require longer observation periods.
Worked example: Multiple testing scenario
A platform team runs 30 A/B tests per quarter comparing candidate models. Using \(\alpha_{\text{sig}} = 0.05\) without correction, expect \(30 \times 0.05 = 1.5\) false positives per quarter. Over a year, expect approximately 6 models falsely identified as improvements, wasting engineering effort on deployments that provide no actual value.
Applying Bonferroni correction: \(\alpha_{\text{sig}}' = \frac{0.05}{30} = 0.00167\) per test. This requires larger sample sizes. For the recommendation model example above (5 percent baseline, 0.5pp effect), original requirement was 30K samples per variant. With a two-sided Bonferroni threshold, the critical value rises to about 3.14, increasing the requirement to roughly 60K samples per variant.
Using FDR control at \(q = 0.05\): Across repeated use, the Benjamini-Hochberg procedure controls the expected proportion of false discoveries among rejected hypotheses. If 10 of 30 tests are declared significant, the target is an expected false discovery proportion of 5 percent among those discoveries, not a hard maximum count in that single quarter. This provides better power than Bonferroni when running many tests.
The choice of correction method depends on consequences of false positives. For high-stakes decisions (financial models, safety-critical systems), use conservative Bonferroni correction. For exploratory analysis where missing true effects is costly, use FDR control.
Checkpoint 1.4: Family-wise error rate under multiple testing
The correction methods are Bonferroni, Šidák, and Benjamini-Hochberg. Apply the family-wise reasoning to a smaller platform.
SUTVA violations and network effects
The statistical results above rest on a fundamental assumption: independence between users. A treatment assigned to one user must not change another user’s outcome. If User A receives an improved recommendation algorithm, User B’s behavior should remain unaffected because User B never saw the new algorithm. This independence assumption underpins all the sample size calculations and significance tests presented so far.
Social platforms systematically violate this assumption. When User A receives better content recommendations, they share that content with their network, including User B in the control group. User B’s engagement changes despite never seeing the treatment. The control condition becomes contaminated, not through experimental error, but through the natural mechanics of networked products.
Formally, standard A/B testing relies on the Stable Unit Treatment Value Assumption (SUTVA): user \(i\)’s outcome \(Y_i(w)\) depends only on their own treatment assignment \(w\), not on the treatments assigned to other users (Rubin 1980). This assumption fails systematically in networked products and distributed ML systems, leading to biased effect estimates that can mislead deployment decisions (Hudgens and Halloran 2008; Eckles et al. 2017).
Rubin, Donald B. 1980. “Randomization Analysis of Experimental Data: The Fisher Randomization Test Comment.” Journal of the American Statistical Association 75 (371): 591–93. https://doi.org/10.2307/2287650.
Hudgens, Michael G., and M. Elizabeth Halloran. 2008. “Toward Causal Inference with Interference.” Journal of the American Statistical Association 103 (482): 832–42. https://doi.org/10.1198/016214508000000292.
Eckles, Dean, Brian Karrer, and Johan Ugander. 2017. “Design and Analysis of Experiments in Networks: Reducing Bias from Interference.” Journal of Causal Inference 5 (1): 1–23. https://doi.org/10.1515/jci-2015-0021.
Network effect categories
Network effects manifest in three primary forms, each requiring different detection and mitigation strategies:
- Direct network effects: User A’s treatment directly influences user B’s outcome through platform interactions. In a social feed ranking experiment, treatment users may share algorithmically optimized content with control users, biasing measured effects toward zero because control users partially receive the treatment through network propagation.
- Indirect network effects: Market-level mechanisms affect all users regardless of their individual treatment assignment. A ride-sharing pricing experiment that increases driver compensation in the treatment group can attract more drivers overall, causing control users to experience shorter wait times and making the measured treatment effect underestimate the true benefit.
- Spillover effects: Treatment effects spread across geographic or temporal boundaries. A local recommendation experiment can shift restaurant foot traffic and popularity signals in adjacent neighborhoods, changing recommendation quality for nearby control users.
In all three cases, the experiment no longer measures independent user-level treatment effects.
Quantifying SUTVA violations
The severity of network effect bias depends on network structure and outcome correlation. For cluster-randomized experiments, equation 9 gives a common design-effect approximation that quantifies how within-cluster correlation inflates the variance of treatment effect estimates, directly determining the sample size increase required for equivalent statistical power:
\[\text{DEFF} \approx 1 + (m - 1)\rho \tag{9}\]
where \(m\) is the average cluster size and \(\rho\) is the intra-cluster correlation of outcomes (how similar outcomes are within connected user groups). This factor indicates how much larger sample sizes must be to achieve equivalent statistical power. Network interference can also bias the estimated treatment effect itself, so variance inflation is only part of the correction.
Detection strategies
Detecting SUTVA violations requires explicit measurement of network exposure through three complementary checks:
- Ego-network analysis: Measure each control user’s exposure to treatment through their connections using \(e_i = |\{j \in \mathcal{N}_i : W_j = 1\}| / |\mathcal{N}_i|\), where \(\mathcal{N}_i\) is the connection set for control user \(i\) and \(W_j\) indicates treatment assignment for user \(j\). If control group outcomes correlate with \(e_i\), network effects are present; regression of control outcomes on exposure quantifies spillover magnitude.
- Interference tests: Compare outcomes for control users with high versus low treatment exposure. Under SUTVA, these groups should show identical outcomes, so significant differences indicate network contamination.
- Temporal analysis: Examine whether treatment effects propagate over time. If day-over-day control group metrics trend toward treatment group metrics, spillover is accumulating through the network.
Together, these checks turn spillover from a hidden assumption violation into a measurable experimental condition.
Mitigation approaches
When SUTVA violations are detected, four experimental design modifications can recover valid causal estimates:
- Graph cluster randomization: Treatment is assigned at the community level rather than the individual level. Graph partitioning algorithms such as Louvain or spectral clustering divide the user graph into clusters with dense internal connections and sparse cross-cluster edges, then randomize clusters so users primarily interact with others in the same condition. The trade-off is reduced statistical power: with \(k\) clusters, effective sample size becomes \(k\) rather than the total individual-user count.
- Ego-exclusion designs: Users whose network exposure exceeds a threshold are excluded from analysis. By analyzing only control users with minimal treatment connections, for example \(e_i < 0.05\), the control condition remains uncontaminated at the cost of sample size.
- Switchback experiments: All users alternate between treatment and control over time periods such as hours or days. Since all users receive both conditions, there is no cross-user contamination within periods, and analysis compares outcomes across time periods rather than across users.
- Geo-based experiments: Geographic boundaries act as natural barriers to network effects. For location-dependent services, city-level or region-level randomization eliminates most spillover pathways because users in different cities rarely interact directly.
The right design is the one that removes the dominant interference path without destroying statistical power.
Practical implementation
Implementing network-aware A/B testing requires infrastructure investment:
- Graph analysis pipelines that compute network statistics and cluster assignments
- Exposure calculation for every user based on their connections’ treatment status
- Modified statistical tests that account for clustered randomization
- Monitoring dashboards showing spillover indicators
For recommendation systems at scale, the engineering cost is justified by the magnitude of bias that network effects introduce. A system measuring +3 percent improvement when the true effect is +6 percent may incorrectly reject valuable model changes or incorrectly prioritize inferior alternatives.
Managing the edge fleet
The operational challenges examined thus far assume a controlled data center environment. However, Edge Intelligence demonstrated that federated learning and on-device ML extend the “Machine Learning Fleet” to millions of heterogeneous edge devices with constrained connectivity, power, and compute. Managing this distributed population introduces three distinct MLOps challenges.
The three constraints interact, so they should be handled as one operational design problem rather than as independent notes. Table 16 maps each constraint to the platform control it requires, including Hardware-in-the-Loop validation and Federated Analytics.
| Edge fleet constraint | Why it appears | Platform control |
|---|---|---|
| Extreme version skew | Rollouts can take weeks or months because devices are offline, on low battery, or on restricted networks. At any time, 50 model versions may remain active. | Maintain backward-compatible data pipelines and serving contracts for models deployed months earlier. |
| Device-aware validation | Accuracy gates do not reveal whether a model exceeds a 1 MB microcontroller memory budget or triggers thermal throttling on a smartphone system on chip (SoC). | Add Hardware-in-the-Loop (HIL) validation on physical or emulated target devices before promotion. |
| Privacy-limited telemetry | Raw predictions cannot stream back continuously because privacy rules and bandwidth costs constrain observability. | Use Federated Analytics: devices compute local statistics such as error rates or drift, then transmit only aggregated, anonymized health signals. |
Rollout risk management
Not all deployments carry equal risk. Effective CI/CD systems classify and handle deployments based on their risk profile. Table 17 provides risk-based rollout strategy selection, mapping four risk categories to appropriate rollout strategies: low-risk minor fixes proceed through fast canary, while critical core model changes require the full shadow deployment, human review, and staged rollout sequence.
Risk classification
Equation 10 formalizes deployment risk as the product of regression probability, impact severity, and exposure level, providing a quantitative foundation for risk-based rollout decisions:
\[R_{\text{rollout}} = p_{\text{regression}} \times I_{\text{regression}} \times E_{\text{exposure}} \tag{10}\]
where \(p_{\text{regression}}\) is the probability that the change causes a regression, \(I_{\text{regression}}\) is the impact severity if regression occurs, and \(E_{\text{exposure}}\) is the exposure level during the rollout period.
The rollout risk framework suggests three mitigation strategies:
- Reduce \(p_{\text{regression}}\): More thorough testing before deployment
- Reduce \(I_{\text{regression}}\): Architectural patterns that limit blast radius
- Reduce \(E_{\text{exposure}}\): Slower rollouts with lower initial traffic percentages
These levers turn the scalar risk formula into a rollout policy: each risk category chooses how much evidence to collect, how small the blast radius must remain, and how slowly exposure should grow.
Risk categories
The risk equation becomes actionable only when the platform maps measured risk to a rollout policy. Table 17 turns probability, impact, and exposure into deployment posture: low-risk changes can move through a fast canary, while safety-critical changes need shadow validation, human review, and slower traffic expansion.
| Category | \(p_{\text{regression}}\) | \(I_{\text{regression}}\) | Rollout Strategy |
|---|---|---|---|
| Low | Minor code fix | Limited user impact | Fast canary |
| Medium | Retrained model | Engagement effects | Standard canary |
| High | New architecture | Revenue impact | Extended shadow + slow canary |
| Critical | Core model change | Safety implications | Shadow + human review + staged |
Automated rollback triggers
Risk categories decide how cautiously traffic should expand, but rollback triggers decide when expansion must stop. The trigger configuration in listing 4 makes that stop condition executable by binding each monitored metric to a threshold, observation window, and minimum sample count.
rollback_config = {
"metrics": {
"engagement_rate": {
"threshold": -0.02, # 2% relative decline triggers rollback
"window_minutes": 15,
"min_samples": 1000,
},
"error_rate": {
"threshold": 0.01, # 1% absolute increase triggers rollback
"window_minutes": 5,
"min_samples": 500,
},
"latency_p99": {
"threshold": 1.5, # 50% relative increase triggers rollback
"window_minutes": 5,
"min_samples": 100,
},
},
"rollback_action": "immediate", # or 'gradual' for less severe issues
"notification": ["oncall", "model-owner"],
}Automated rollback must balance sensitivity against false triggers. The statistical significance requirements (minimum samples, window duration) prevent premature rollback from random fluctuation while enabling rapid response to genuine regressions.
CI/CD patterns by model type
Model type determines which CI/CD constraint binds: semantic quality, engagement power, adversarial urgency, or classification accuracy. Table 18 contrasts CI/CD patterns by model type: LLMs require quality-gated pipelines with human evaluation taking days to weeks, while fraud detection uses threshold-gated pipelines enabling hours-fast deployment with seconds-fast rollback to counter adversarial dynamics.
| Pattern | Model Type | Validation Focus | Rollout Speed | Rollback Speed |
|---|---|---|---|---|
| Quality-gated | LLM | Human eval, safety | Days to weeks | Hours |
| Metric-driven | Recommendation | Engagement metrics | Hours to days | Minutes |
| Threshold-gated | Fraud | Precision/recall | Hours | Seconds |
| Accuracy-focused | Vision | Classification metrics | Days | Minutes |
For LLMs, the binding constraint is semantic and safety quality, so the pipeline is deliberately slow. Automated benchmark evaluation on MMLU, HumanEval, and similar tasks narrows the candidate set; human evaluation checks sample outputs across capability categories; safety evaluation exercises red-teaming and toxicity cases; shadow deployment measures user-satisfaction signals; and a slow staged rollout gives the release an extended soak period. The full cycle may take 2–4 weeks from candidate model to full deployment because the main risk is a subtle regression that ordinary automated metrics miss.
Recommendation systems bind on freshness and engagement power, so the pipeline prioritizes rapid but statistically defensible comparison. Offline NDCG and recall screen candidate models, interleaving compares the candidate against the production baseline on the same requests, significance tests decide whether engagement moved, and a rapid canary promotes or rolls back automatically. Routine updates may complete in 24–48 hours because the cost of stale recommendations can exceed the cost of a carefully bounded experiment.
Fraud models bind on adversarial urgency. The pipeline still evaluates labeled fraud cases, validates the false-positive rate on legitimate traffic, and shadow-scores transactions to compare precision and recall, but it is designed around rapid deployment with instant rollback capability because attackers adapt while the rollout is still in progress. Routine updates may complete in 4–12 hours, and emergency updates may deploy in under 1 hour when new fraud patterns emerge.
A mature CI/CD pipeline ensures that only healthy, verified models reach production, completing the deployment cycle in hours rather than weeks. Deployment is not the finish line; it is the starting line. Once a model is safely deployed, the primary operational question is whether it continues to perform as expected under shifting conditions. Answering that question requires a monitoring architecture that scales alongside automated deployment.
Self-Check: Question
A training pipeline with six stages (data validation, feature computation, training, evaluation, registration, deployment) fails at the registration stage. With idempotent stage design, how does the pipeline recover, and why does this matter at fleet scale?
- Restart from the failed stage, because idempotence guarantees upstream outputs are reusable and downstream re-execution is deterministic.
- Restart from the beginning, because reproducibility in ML requires re-running every stage from scratch after any failure.
- Skip the failed stage and continue, because idempotent stages are optional and can be bypassed when they error.
- Switch orchestrators, because idempotence removes the need for systems like Kubeflow or Vertex AI Pipelines.
A fraud-detection model passes offline precision and recall targets but reports p99 latency of 28 ms on representative hardware. The section’s model-type latency gate for fraud detection is 20 ms p99. What should the CI/CD system do?
- Approve with a warning, because fraud models prioritize quality over latency.
- Block the deployment, because fraud detection runs inline in transaction flows and a 40 percent over-budget p99 translates to timeouts that worsen both user experience and the adversarial attack surface.
- Allow shadow deployment first, because hard latency gates apply only to LLMs.
- Ignore the latency result if rollback is fast, because seconds-level rollback masks any transient impact.
A ranking model serves 1 million requests per hour. A CTR A/B test needs roughly 10,000 samples in the treatment cohort to detect a meaningful lift. The rollout plan offers 1 percent and 5 percent canary stages. Compute the stage durations and explain the operational trade-off this imposes on rollout design.
A financial prediction service spanning five regions must never serve two different model versions to customers in the same currency zone because downstream settlement reconciles predictions. Which deployment-consistency model best matches this constraint?
- Strong consistency: all regions must serve the same version at every logical timestamp, because version divergence breaks settlement correctness.
- Eventual consistency: each region progresses independently, because financial models tolerate brief skew.
- Bounded staleness: regions may differ by up to k versions as long as rollback exists.
- Any model: sticky routing at the customer level removes the global coordination requirement.
True or False: Interleaving experiments are the preferred evaluation method for ranker comparisons because they expose different user populations to different rankers more cleanly than A/B testing does.
A team is about to deploy a new LLM backbone whose primary risks are subtle quality regressions on long-tail tasks and rare safety failures that automated metrics cannot reliably catch. Which CI/CD strategy best matches this risk profile?
- Threshold-gated rapid deployment with seconds-level rollback, because adversarial response time is the key metric.
- Quality-gated pipeline: benchmark suites, human evaluation, safety review, mandatory shadow period on live traffic, and slow staged rollout over days to weeks.
- Fast canary only, because online user feedback is a more reliable quality signal than offline evaluation for LLMs.
- Blue-green cutover, because duplicate environments remove the need for extended soak periods.
Monitoring at Scale
Application-layer drift detection depends on a healthy physical substrate. At fleet scale, a degraded NVLink connection or a thermally throttling GPU can masquerade as a software timeout. Monitoring therefore starts bottom-up with fleet telemetry, then climbs through alert aggregation, model-quality signals, dashboards, and cost observability so that operators can route a symptom to the layer that can actually repair it.
Fleet telemetry and hardware observability
Because failure is routine at pod scale, fleet monitoring and hardware observability are not operational conveniences but prerequisites for productive training. A 10,000-GPU cluster experiences hardware failures roughly once every five hours, and the difference between a 10-minute recovery and a multi-hour disruption depends on whether the operations team can detect degradation before it becomes failure. The monitoring system is itself a distributed system, collecting telemetry from every GPU, switch, and cooling component in the fleet.
The telemetry spans three physical levels. At the GPU level, the most diagnostic signals are junction temperature (which reveals cooling degradation), ECC error counts in HBM and SRAM (where a rising rate of correctable errors often precedes a crash-inducing uncorrectable error), and SM utilization (which distinguishes hardware faults from software inefficiencies). At the network level, packet retry rates on individual ports reveal failing cables or switches. At the facility level, coolant temperature deviations trigger automated load shedding before thermal damage occurs. The challenge is not collecting these signals individually but correlating them across spatial and temporal dimensions.
The most operationally valuable monitoring capability is correlation analysis across these telemetry streams. A single GPU showing elevated temperature might indicate a failing fan or a coolant flow restriction. If 8 GPUs in the same node simultaneously show elevated temperatures, however, the cause is more likely a node-level cooling issue. If all GPUs in a rack show elevated temperatures, the cause is probably a rack-level CDU problem. If GPUs across multiple racks show coordinated temperature changes, the cause is likely a facility-level event such as a chiller failure. The monitoring system must detect and classify these patterns at the correct spatial scale to direct operators to the actual root cause, rather than generating hundreds of independent alerts for what is a single underlying problem.
The scale of this telemetry is nontrivial. A 10,000-GPU cluster generates approximately 1 TB of metric data per day – junction temperatures sampled every second across 10,000 GPUs alone produce 864 million data points daily, before accounting for ECC counters, power readings, NVLink error rates, and network port statistics. Ingesting, indexing, and querying this firehose of time-series data with sub-second latency requires its own dedicated infrastructure. Organizations typically dedicate 1–2 percent of the cluster’s total compute and storage capacity to the monitoring stack itself: time-series databases (Prometheus, InfluxDB, or custom solutions), alerting engines, and dashboard systems. This operational overhead is the cost of visibility at scale; without it, the fleet is flying blind.
Before a training job is allocated to a set of nodes, the scheduler employs automated preflight checks to verify hardware health. The control plane runs a battery of short, intensive diagnostics: GEMM benchmarks to verify Tensor Core throughput, NCCL AllReduce tests to validate NVLink and InfiniBand bandwidth, and memory stress tests to catch weak HBM bit cells that might produce uncorrectable errors under sustained load. A node that underperforms on any diagnostic is automatically quarantined for repair, and a healthy replacement is substituted before the job launches. This validation process adds 5–10 minutes to job startup time, a negligible cost compared to the hours of wasted computation when a training run crashes mid-flight due to a degraded GPU that passed a simple power-on self-test but fails under sustained arithmetic load.

One slow accelerator stalls every peer at the barrier.
The most insidious adversary in a large fleet is not the hard failure but the gray failure: a component that continues to function but at degraded performance. A single GPU with a partially failed HBM stack might operate at only 75 percent of its peak bandwidth. An NVLink with marginal signal integrity might force frequent link retraining, causing microsecond stalls that accumulate into seconds of lost time per training step. In a synchronous data-parallel workload, a single straggler slows the entire cluster, because every other GPU must wait for the slowest participant to complete its AllReduce contribution. These gray failures are invisible to simple “up/down” health checks and require continuous, fine-grained performance benchmarking to detect. The most effective approach is to run periodic micro-benchmarks on idle nodes (or during scheduled maintenance windows) and compare each node’s performance against the fleet baseline. A node whose GEMM throughput drops below 90 percent of the fleet median, or whose NVLink bandwidth drops below 85 percent, is flagged for investigation even though it has not experienced any hard error.
Systems Perspective 1.4: Proactive vs. reactive maintenance
Fleet operators have learned, often through costly experience, that proactive maintenance dramatically reduces the impact of hardware failures on training productivity. The three pillars of proactive maintenance are: predictive diagnostics (using models trained on historical telemetry to predict component failures 24–72 hours before they occur), scheduled burn-in testing (running benchmark workloads on newly installed nodes before assigning production work), and rolling maintenance windows (cycling 2–5 percent of nodes through health checks without reducing available capacity). Organizations that invest in proactive maintenance typically achieve 95–98 percent effective fleet utilization, compared to 80–90 percent for organizations that rely on reactive maintenance.
In multi-tenant clusters where multiple training jobs share the same physical infrastructure, the noisy neighbor problem introduces a performance hazard that is invisible to individual job metrics. While containerization strictly limits CPU and memory usage, the network fabric is often a shared resource susceptible to interference. If Job A initiates a massive AllReduce operation across the spine switches just as Job B attempts to fetch training data from networked storage, the resulting micro-bursts of packet contention can throttle Job B’s throughput by 30–40 percent. This interference is particularly pernicious in RDMA-enabled clusters where traffic bypasses the host CPU, rendering standard OS-level packet scheduling ineffective. Modern orchestration mitigates this via static rail alignment – physically dedicating specific InfiniBand subnets to specific jobs – or by deploying congestion notification protocols that throttle aggressive flows at the switch hardware level. For organizations running the 175B model training alongside smaller research experiments, the safest approach is to physically partition the cluster into isolated “islands” with dedicated network fabrics, accepting the utilization penalty of fragmentation in exchange for performance predictability.
Checkpoint cadence is the point where hardware telemetry becomes visible to ML operators rather than only to data-center technicians. A degraded node that forces frequent checkpoint recovery, or a storage path that lengthens checkpoint writes, turns directly into lost training throughput. The Young-Daly model derives the checkpoint-compute trade-off and the Young/Daly interval, which The Young-Daly law: Optimal checkpointing applies to checkpointing strategies; the operations responsibility here is to expose the telemetry those formulas depend on: write time, failure rate, straggler behavior, and recovery duration. Without that visibility, a platform may report that a job is “running” while useful learning has quietly collapsed behind retries and slow checkpoints.
With the physical substrate accounted for, monitoring returns to the deployed model fleet. Models that pass validation gates and survive canary deployment enter a production environment where gradual degradation, data drift, and emergent interactions can erode performance over weeks or months. The staged rollout strategies and rollback triggers examined in CI/CD detect acute failures during deployment; monitoring systems must detect chronic degradation during operation. At platform scale, where hundreds of models operate simultaneously, the naive approach of applying single-model monitoring practices to each model independently leads to alert fatigue, missed correlations, and operational chaos. Monitoring strategies appropriate for enterprise-scale ML platforms require hierarchical aggregation and systemic governance.
The alert fatigue problem
The mathematical reality of monitoring at scale exposes the limitations of per-model alerting. Consider the mathematics of monitoring 100 models with independent alerting. If each model has 10 monitored metrics, and each metric generates alerts at a 0.3 percent false positive rate (3-sigma thresholding), the expected number of false alerts is still substantial.

As tests multiply, false alerts become mathematically inevitable.
Napkin Math 1.8: The false alarm tax
Problem: Consider a system monitoring 100 models. Each model has 10 metrics (latency, accuracy, drift, and others). Alert thresholds are set at 3-sigma (99.7 percent specificity), and a control script re-evaluates every metric on a fixed interval. This configuration generates a massive volume of false alarms that the on-call engineer must address each day.
Math:
- Total Monitors: 100 models \(\times\) 10 metrics = 1,000 monitors.
- False Positive Rate: \(1 - 0.997 = 0.003\) (0.3 percent).
- Checks per day: Assume checks every 5 minutes (288 checks/day).
- Daily false alarms: \(1,000 \times 288 \times 0.003\) \(\approx\) 864 alerts/day.
Systems insight: Even with high-specificity (3-sigma) alerts, scale becomes problematic. It is not feasible to alert on raw metrics. One must use hierarchical aggregation (for example, “Cluster Health” instead of “Node Health”) to survive the false alarm tax.
Equation 11 reveals the mathematical inevitability of alert fatigue at scale: for a single metric with false positive rate \(\alpha_{\text{fp}}\), the probability of at least one false alert grows exponentially with the number of independent tests \(N_{\text{tests}}\):
\[\Pr(\text{at least one false alert}) = 1 - (1 - \alpha_{\text{fp}})^{N_{\text{tests}}} \tag{11}\]
With \(\alpha_{\text{fp}} = 0.05\) and \(N_{\text{tests}} = 1000\) (100 models \(\times\) 10 metrics):
\[\Pr(\text{false alert}) = 1 - (1 - 0.05)^{1000} = 1 - 0.95^{1000} \approx 1.0\]
The probability is essentially 100 percent. At this scale, the monitoring system will generate false alerts continuously. This creates a destructive dynamic: operators learn to ignore alerts because most are false, genuine issues get lost in the noise, and the monitoring system provides negative rather than positive value.
Worked example: Alert volume calculation
The 3-sigma analysis above already strains a team; loosening to the more common 2-sigma threshold (a 5 percent false positive rate) makes the load untenable. An ML platform monitors 100 models with the following configuration:
- 10 metrics per model (accuracy, latency p50, latency p99, throughput, error rate, data freshness, feature drift, memory usage, GPU utilization, request volume)
- Alert threshold at 2 standard deviations (approximately 5 percent false positive rate per metric)
- Metrics checked every 5 minutes
Expected daily false alerts: \(\text{Daily false alerts} = 100 \times 10 \times 0.05 \times \frac{24 \times 60}{5} = 14,400\).
Even if 99 percent of these are deduplicated or auto-resolved, the remaining 144 alerts daily overwhelm any on-call team. The monitoring system becomes useless despite (or rather, because of) comprehensive coverage.
Hierarchical monitoring architecture
The alert fatigue problem demands a fundamentally different approach. The solution is hierarchical monitoring (figure 9) that turns monitoring into an alert-routing system: broad signals decide whether the fleet is impaired, portfolio signals decide which model family or domain owns the incident, model signals support local diagnosis, and infrastructure signals route failures to the platform team. The hierarchy reduces alert volume while preserving the path from symptom to owner.

The hierarchy works because each level answers a different routing question. Table 19 maps each level to its signal, owner, and operational role.
| Level | Representative signals | Primary owner | Operational role |
|---|---|---|---|
| Business | Revenue or conversion attributed to recommendations, engagement indicators, automation rate, and human-review volume. | Incident lead | Few high-confidence alerts that indicate product or business impairment. |
| Portfolio | Engagement lift and diversity for recommendation, fraud caught and false-positive rate, or violation detection and appeal rate. | Domain team | Routes investigation to the model family or product area that owns the shared objective. |
| Model | Task quality, latency distributions, throughput, error rates, resource utilization, serving saturation, and recent deployment state. | Model owner | Supports local diagnosis after business or portfolio signals move. |
| Infrastructure | GPU cluster utilization and availability, feature store latency, training pipeline time, serving health, networking, and storage. | Platform team | Routes failures that require capacity, placement, networking, storage, or control-plane repair. |
Anomaly detection across the fleet
Rather than alerting on individual metric thresholds, fleet-wide anomaly detection identifies unusual patterns across the model portfolio. The detection stack proceeds from local statistical process control, to correlation across model families, to drift scores that explain why a metric moved. That ordering keeps alert volume low while preserving enough evidence to route the incident to the right owner.
Statistical process control
Statistical process control originated in industrial quality control (Shewhart 1931). When adapted for ML monitoring, control charts11 track whether metric distributions remain stable over time and complement drift-detection methods that watch for changing data distributions (Gama et al. 2014). The core idea is distinguishing common cause variation (normal fluctuation) from special cause variation (genuine anomalies).
11 Statistical Process Control (SPC): Shewhart (1931) established the control-chart framework for manufacturing quality control. Under a normal approximation, a 3-sigma control limit produces a false-alarm probability of only 0.27 percent for a stable process. For ML fleet monitoring, even small per-test false-alarm rates compound across many models and metrics, making alert-fatigue management an inherent constraint of applying SPC at platform scale.
Shewhart, Walter A. 1931. Economic Control of Quality of Manufactured Product. D. Van Nostrand Company.
Gama, João, Indrė Žliobaitė, Albert Bifet, Mykola Pechenizkiy, and Abdelhamid Bouchachia. 2014. “A Survey on Concept Drift Adaptation.” ACM Computing Surveys 46 (4): 1–37. https://doi.org/10.1145/2523813.
For a metric \(X\) with established mean \(\mu\) and standard deviation \(\sigma\), the upper control limit is \(\text{UCL} = \mu + 3\sigma\) and the lower control limit is \(\text{LCL} = \mu - 3\sigma\). Points outside control limits or systematic patterns, such as 7 consecutive points above or below the mean, trigger investigation.
Fleet-wide correlation
When multiple models exhibit similar anomalies simultaneously, the root cause is likely shared infrastructure or data rather than individual model issues. Correlation analysis across models enables three operational efficiencies:
- Automatic attribution of anomalies to likely causes (deployment, data issue, infrastructure)
- Deduplication of alerts that have common causes
- Prioritization based on breadth of impact
Listing 5 turns correlation into a triage rule. When the fraction of anomalous models crosses the fleet threshold, the incident changes from many local debugging tasks into one shared-cause investigation.
def detect_fleet_anomaly(model_metrics, threshold=0.6):
"""
Detect correlated anomalies across model fleet.
Returns list of (timestamp, affected_models, likely_cause) tuples.
"""
anomalies = []
for timestamp in model_metrics.timestamps:
# Identify models with anomalous metrics at this time
anomalous_models = []
for model in model_metrics.models:
if is_anomalous(model_metrics[model][timestamp]):
anomalous_models.append(model)
# Check if anomaly fraction exceeds correlation threshold
if (
len(anomalous_models) / len(model_metrics.models)
> threshold
):
# Many models affected -> likely shared cause
cause = attribute_to_shared_cause(
timestamp, anomalous_models
)
anomalies.append((timestamp, anomalous_models, cause))
return anomaliesThe threshold prevents the monitor from overreacting to isolated model noise while still catching platform-wide failures. Above the threshold, the right owner is usually the shared dependency, such as a deployment, feature pipeline, or infrastructure service, rather than each model team independently.
Drift detection
Data drift represents gradual shifts in input distributions that degrade model performance over time. Detecting drift requires distinguishing between two fundamental types.
Covariate shift occurs when the distribution of input features \(p(x)\) changes, but the relationship between inputs and outputs \(p(y \mid x)\) remains constant. This is detectable in real-time by monitoring input statistics such as mean, variance, and null rates without needing labels.
Concept drift occurs when the relationship \(p(y \mid x)\) changes, such as when users change their definition of spam or relevant content. This requires ground truth labels to detect, which are often delayed by minutes, days, or weeks.
Because labels are often delayed, most real-time monitoring systems use covariate shift as a leading indicator of possible performance degradation. A cheap drift score is valuable even when it is not a complete theory of robustness because it tells the operator where to investigate before outcome labels arrive.
For continuous features, the Population Stability Index (PSI)12 quantifies distribution shift (Yurdakul and Naranjo 2020). Equation 12 computes PSI as the sum of log-ratio weighted differences between actual and expected bucket proportions, yielding actionable thresholds: values below 0.1 indicate stability, while values at or above 0.25 demand immediate investigation. In this chapter, PSI plays a narrow operational role as an inexpensive alerting signal.
12 Population Stability Index (PSI): Originally developed in credit scoring to detect shifts in loan-applicant populations, where regulators mandated quantitative drift monitoring. The standard thresholds (\(\text{PSI} < 0.1\) stable, \(\text{PSI} \geq 0.25\) action required) were established empirically in financial services. For ML fleet monitoring, PSI’s advantage is computational cheapness – a single pass over bucketed histograms – making it feasible to track hundreds of features across hundreds of models without saturating the monitoring budget.
Yurdakul, Bilal, and Joshua Naranjo. 2020. “Statistical Properties of the Population Stability Index.” The Journal of Risk Model Validation 52. https://doi.org/10.21314/jrmv.2020.227.
\[\text{PSI} = \sum_{i=1}^{K_{\text{bucket}}} (A_i - E_i) \times \ln\left(\frac{A_i}{E_i}\right) \tag{12}\]
where \(A_i\) is the proportion in bucket \(i\) of the actual (current) distribution, \(E_i\) is the proportion in bucket \(i\) of the expected (reference) distribution, and \(K_{\text{bucket}}\) is the number of buckets.
The interpretation is deliberately coarse. PSI below 0.1 usually leaves the model in the normal monitoring path. Values between 0.1 and 0.25 create an investigation ticket. Values at or above 0.25 indicate enough shift that the platform should treat the model as potentially degraded even before labels confirm the outcome.
Napkin Math 1.9: Time-to-detection: The monitoring lag
Problem: A production model has a baseline accuracy of 95 percent. A data drift event causes accuracy to drop by 2 percent. If labeled outcomes arrive at 1000 samples/hour, how long is needed to statistically prove the model has degraded?
Math: Detection requires enough samples to distinguish the signal (the 2 percent drop) from the noise (random variance). A two-sample proportion test sets that sample count from the baseline and degraded accuracies (\(p_1\), \(p_2\)) and the confidence and power targets (\(z_{\alpha/2}\), \(z_{\beta}\)):
\[n \approx \frac{(z_{\alpha/2} + z_{\beta})^2 \left[ p_1(1 - p_1) + p_2(1 - p_2) \right]}{(p_1 - p_2)^2}\]
- Samples Required: At 95 percent confidence and 80 percent power, the standard normal quantiles are \(z_{\alpha/2} = 1.96,\ z_{\beta} = 0.84\), and plugging in gives \(n \approx (1.96 + 0.84)^2 \times \left[ 0.95(1 - 0.95) + 0.93(1 - 0.93) \right] / (0.95 - 0.93)^2 \approx 2,207\) samples.
- Detection Latency: 2,207 samples / 1000 samples/hour \(\approx\) 2.2 hours.
Systems insight: Monitoring is not instantaneous. For a 2 percent degradation, the model operates in a broken state for approximately 2.2 hours before there is enough data to trigger an alert. This is the monitoring lag. Reducing this lag requires either increasing the volume of labeled data (expensive) or monitoring “proxy” metrics like PSI (faster but noisier). In a high-stakes fleet, the alert triggers on input drift as a leading indicator rather than waiting for accuracy to drop.
Fleet-wide drift monitoring extends that signal across the portfolio. A PSI spike in one noncritical feature may be a local investigation, but simultaneous drift across shared features or multiple dependent models points to a data pipeline failure with a larger blast radius.
Model-type specific monitoring
Monitoring cadence follows failure cost. Compare the model-type monitoring parameters in table 20: recommendation systems demand real-time CTR monitoring with 5 percent degradation thresholds, while vision classifiers tolerate daily accuracy checks with dataset-specific thresholds reflecting their lower update frequency.
| Model Type | Primary Metrics | Alert Thresholds | Monitoring Frequency |
|---|---|---|---|
| Recommendation | CTR, engagement lift | 5% relative drop | Real-time |
| Fraud Detection | Precision, recall, fraud rate | 1% degradation | Real-time |
| LLM | Quality scores, safety metrics | Per-model calibration | Hourly |
| Vision | Accuracy by class | Dataset-specific | Daily |
| Search Ranking | NDCG, click position | 2% degradation | Real-time |
Recommendation monitoring is real-time because the product consequence is real-time. Click-through rate, dwell time, and conversion rate should be compared against time-matched historical baselines, control traffic when available, and the previous model version after a release. Those fast engagement metrics are not sufficient by themselves: diversity, catalog coverage, and filter-bubble indicators protect the long-term user experience, while revenue attribution and promotional-inventory metrics connect recommendation quality to business outcomes.
Fraud monitoring binds on adversarial urgency. Missed fraud creates immediate financial loss, but excessive false positives create customer friction and manual-review load. The monitoring surface therefore has to pair detection rate, prevented dollar amount, and detection latency with false-positive rate, blocked-legitimate-transaction events, manual-review volume, and adversarial indicators such as probing patterns or sudden shifts in fraudulent behavior.
LLM monitoring binds on semantic quality, which is difficult to measure from service metrics alone. Latency, token generation rate, error rate, and safety-classifier scores establish operational health; user satisfaction signals such as thumbs-up/thumbs-down rates, regeneration rate, and task-completion proxies add delayed quality evidence. Safety metrics such as toxicity detections, refusal rate, and hallucination indicators remain partial, so they should trigger review rather than claim complete coverage.
Standard monitoring cannot detect semantic safety failures such as persuasive misinformation or skilled manipulation. Here, red teaming is a production monitoring channel rather than a full adversarial-evaluation program: human evaluators or automated probes attempt jailbreaks before deployment, and a smaller continuous probe set verifies that production safety filters remain active. Sampling outputs for delayed human review closes the loop for failures that automated metrics do not observe.
Observability architecture
Effective monitoring requires observability infrastructure that preserves enough context to route an alert from symptom to owner. Each evidence channel answers a different operational question. Metrics show that a service property moved outside its envelope, traces show where a request spent time, logs explain which component emitted the abnormal event, and prediction logs connect system health back to model behavior. In multi-model systems, a single user request may traverse multiple models, so distributed tracing13, pioneered by Google’s Dapper system (Sigelman et al. 2010), becomes the only reliable way to decompose end-to-end latency across inference services. Table 21 summarizes the architecture as an evidence map rather than as a set of disconnected telemetry tools.
13 Distributed Tracing: Google’s 2010 Dapper paper established the pattern of propagating unique trace IDs across service boundaries. For multi-model ML pipelines, tracing is the only reliable way to attribute end-to-end latency to a specific model stage – without it, a 50 ms tail-latency spike in a 10-model pipeline requires investigating all 10 models independently. Dapper achieved this with less than 0.3 percent CPU overhead per host, setting the performance bar that makes always-on tracing feasible at fleet scale.
Sigelman, Benjamin H, Luiz André Barroso, Mike Burrows, Pat Stephenson, Manoj Plakal, Donald Beaver, Saul Jaspan, and Chandan Shanbhag. 2010. Dapper, a Large-Scale Distributed Systems Tracing Infrastructure. Dapper-2010-1. Google.
| Evidence Channel | Primary Question | What It Preserves | Typical Failure Revealed |
|---|---|---|---|
| Metrics | Which service property moved out of bounds? | Real-time streams for alerting and aggregated time series for trends | Drift, saturation, error-rate spikes, cost anomalies |
| Traces | Where did this request spend time? | Request IDs propagated across model invocations, timing, and resources | Cross-model latency, fan-out failures, hot stages |
| Logs | Which component emitted the abnormal event? | Structured events with consistent schemas and searchable indexes | New error classes, dependency failures, bad releases |
| Prediction logs | Did system health preserve model behavior? | Sampled inputs, outputs, features, and delayed labels | Accuracy regressions, bad cohorts, data gaps |
Prediction logging is the costliest evidence channel because it records model-facing data rather than compact service counters. Production systems therefore sample it deliberately, for example logging 1 percent of predictions or logging all predictions for specific users, so the fleet retains enough examples for offline accuracy assessment, training-data generation, and failure debugging without turning monitoring into a storage workload.
Dashboard design
A dashboard is the human attention surface of the monitoring hierarchy. It should answer the same routing questions without forcing every reader into the same debugging console: executives need to know whether the business is impaired, domain owners need to know which portfolio is failing, model owners need the evidence for their model, and incident responders need the trace from symptom to root cause. Table 22 shows that progression.
| View | Question Answered | Signals to Surface |
|---|---|---|
| Executive | Is the business impaired? | Platform health, business impact, active incidents, key trends |
| Portfolio | Which domain or model family is driving the impairment? | Model inventory, portfolio metrics, recent deployments, resource utilization and cost |
| Model | What changed for the responsible model? | Current metrics vs. baselines, deployment history, drift indicators, cost attribution |
| Investigation | Why did the change occur? | Cross-model correlations, time-series overlays, log search, request-level trace detail |
Cost monitoring and anomaly detection
Three structural properties of ML infrastructure make cost anomaly detection qualitatively harder than for general web services. First, GPU autoscaling is lumpy: adding one inference replica for a large model means provisioning an entire multi-GPU node, so a small traffic spillover triggers a step-function cost increase rather than smooth linear scaling. Second, distributed training jobs can misfire catastrophically: a misconfigured hyperparameter sweep, a DAG that does not honor spot-instance preemption, or an unbounded retry loop on a failed checkpoint can consume an entire cluster’s worth of GPU-hours before any alert fires. Third, zombie models (section 1.4) continue drawing GPU memory and serving capacity even when they carry negligible traffic, contributing a chronic baseline cost that compounds across the fleet. Cost anomalies in a model platform are therefore not usually caused by traffic spikes; they are caused by training job misconfigurations, autoscaling behavior on GPU-granularity boundaries, or model lifecycle failures. Effective anomaly detection must distinguish between these causes, not just flag that costs moved.
At scale, undetected cost anomalies can accumulate millions of dollars in unexpected charges before manual review catches them. A quantitative framework for cost anomaly detection balances sensitivity against false positive rates.
Cost anomaly detection metrics
The foundation of cost monitoring is statistical anomaly detection. For a cost time series with historical mean \(\mu\) and standard deviation \(\sigma\), the Z-score quantifies how unusual a current observation is:
\[Z = \frac{C_{\text{current}} - \mu}{\sigma}\]
where \(C_{\text{current}}\) is the observed cost for the current period. A Z-score of 3 indicates the current cost is 3 standard deviations above the historical mean, an event expected less than 0.3 percent of the time under normal operations.
Complementing Z-score analysis, percentage change detection captures sudden shifts regardless of historical variance, which makes it useful for catching step-function increases such as a misconfigured autoscaler that doubles instance count overnight:
\[\Delta\% = \frac{C_{\text{current}} - C_{\text{previous}}}{C_{\text{previous}}} \times 100\]
Alerting thresholds and false positive analysis
Effective alerting requires calibrating thresholds to balance detection sensitivity against operational burden. Two common configurations are a Z-score threshold, which alerts when \(|Z| > 3\) under the 3-sigma rule, and a percentage change threshold, which alerts when \(|\Delta\%| > 50\%\) day over day. The choice of thresholds determines false positive rates. For a normally distributed cost metric checked daily, a 3-sigma threshold produces:
\[\Pr(\text{false positive per day}) = 2 \times (1 - \Phi(3)) \approx 0.0027\]
Over a year of daily monitoring:
\[E[\text{false alerts per year}] = 365 \times 0.0027 \approx 1\]
This rate is operationally acceptable. Lowering the threshold to 2-sigma would increase annual false alerts to approximately 16, likely causing alert fatigue without meaningfully improving detection.
For percentage-based alerts, false positive rates depend on the underlying volatility of costs. Services with naturally variable demand may require higher thresholds (75 percent or 100 percent) to avoid excessive alerts, while stable baseline services can use tighter thresholds (25 percent or 30 percent).
Worked example: Detecting an inference cost spike
A recommendation service typically costs $100 per day for inference compute. The operations team receives an alert: today’s cost has reached $250 by end of day.
Historical data shows mean daily cost \(\mu = \$100\) with standard deviation \(\sigma = \$15\), so the first check is whether the alert is statistically plausible under normal operations: \(Z = \frac{\$250 - \$100}{\$15} = \frac{\$150}{\$15} = 10\).
A Z-score of 10 is extraordinarily unlikely under normal operations, but the team still confirms the billing data before treating the alert as real. After ruling out billing delays, double-counting, and pipeline errors, the investigation turns to the operating signal. Query volume is unchanged, so traffic did not cause the spike. P99 latency increased from 50 ms to 125 ms, which means each request now consumes roughly 2.5\(\times\) the GPU-seconds. A new model version deployed at 2:00 AM used a larger ranking model and additional features for quality improvements, while GPU utilization stayed near 95 percent and throughput per GPU dropped 60 percent. The root cause was therefore the model update, which increased computational cost per prediction: with unchanged traffic and a 2.5\(\times\) per-request cost, total cost rose from $100/day to $250/day. The platform decision is whether the quality improvement justifies the cost increase or whether optimization through quantization, smaller batches, or model distillation is required.
Root cause analysis framework
Table 23 groups cost anomaly root-cause categories into five classes, each with distinct investigation paths:
| Category | Indicators | Investigation Path |
|---|---|---|
| Traffic increase | QPS proportional to cost | Check upstream services, marketing campaigns, viral events |
| Efficiency regression | Cost up, QPS unchanged, latency up | Review recent deployments, model updates, infrastructure changes |
| Resource leak | Gradual cost growth, utilization stable | Check for orphaned resources, failed cleanup jobs, zombie processes |
| Pricing change | Cost up, all metrics stable | Verify cloud provider pricing, reserved instance expiration |
| Configuration error | Step-function cost increase | Audit autoscaling rules, instance types, replica counts |
Cost attribution by service and team
Effective cost management requires attributing costs to organizational units. Tag-based allocation assigns costs based on resource metadata, as shown in listing 6.
# Resource tagging schema for cost attribution
cost_allocation:
dimensions:
- team: "recommendation" # Organizational owner
- service: "ranking-model" # Specific service
- environment: "production" # prod/staging/dev
- model_type: "inference" # training/inference
- cost_center: "CC-4521" # Finance tracking
shared_cost_distribution:
# Platform infrastructure costs distributed by usage
- resource: "shared-gpu-cluster"
method: "proportional_gpu_hours"
- resource: "feature-store"
method: "proportional_query_volume"
- resource: "monitoring-infrastructure"
method: "equal_split"Shared infrastructure costs require allocation policies. Three common methods address this need:
- Proportional allocation: Distribute shared costs based on usage metrics (GPU-hours, storage bytes, API calls)
- Equal split: Divide costs equally among consuming teams (appropriate for fixed infrastructure)
- Marginal cost: Charge teams for the incremental cost their usage adds
The allocation policy determines whether a dashboard can assign action, not just describe spend.
Cost dashboards
Effective cost monitoring dashboards use the same attention-routing hierarchy as reliability dashboards. The executive view tracks total ML infrastructure cost, month-over-month trend, budget vs. actual, and cost efficiency metrics such as cost per prediction and cost per active user. The portfolio view then breaks cost down by domain and model type so the platform team can see whether recommendations, fraud, search, or another domain is driving the change. The service view exposes per-service cost, cost per inference, GPU utilization efficiency, and budget comparison. The investigation view adds deployment markers, operational metric correlations, and attribution detail so an anomaly can be tied to a specific change rather than treated as accounting noise.
Four key metrics govern ongoing cost monitoring:
- Cost per inference: The serving-unit economic metric formalized in the FinOps treatment below; track its trend here to detect efficiency regressions.
- Cost per active user: Infrastructure cost normalized by user base. Enables comparison across services with different scales.
- GPU utilization efficiency: Revenue or value generated per GPU-hour. Connects infrastructure cost to business outcomes.
- Budget burn rate: Current spending velocity relative to allocated budget. Enables proactive intervention before overruns.
Integrating cost monitoring with the hierarchical monitoring architecture ensures that cost anomalies receive appropriate attention alongside performance and quality metrics. Yet building these CI/CD pipelines and hierarchical monitoring systems for every individual product team is prohibitively expensive. To make these capabilities universally available without duplicating effort, organizations must elevate them into a unified internal product, a discipline known as platform engineering.
Self-Check: Question
A fleet of 100 models runs 10 independent metric checks each at a 1 percent per-check false-positive rate. The on-call team receives continuous pages and starts ignoring them. Which mechanism best explains why this alerting scheme collapses?
- Most ML metrics cannot be sampled more than once per day at fleet scale, so the alerts are stale.
- Across 1,000 independent checks with 1 percent false-positive rates, \(\Pr(\text{at least one false alert}) = 1 - 0.99^{1000}\), which is essentially 1, making continuous noise mathematically inevitable.
- Fleet-wide monitoring eliminates the need for per-model metrics, so these checks are unnecessary.
- Alert fatigue is caused primarily by telemetry storage cost rather than statistical compounding.
Explain why hierarchical monitoring is more effective than enumerating independent dashboards and alerts for each model, using a concrete failure scenario to illustrate.
A platform observes simultaneous anomalies across 80 percent of its recommendation models at the same timestamp. The models were trained independently and serve different regions. What conclusion is most consistent with the chapter’s fleet-wide anomaly analysis?
- Every model independently overfit at the same moment, so each team should debug locally.
- The correlated simultaneous signal indicates a shared cause (feature pipeline outage, ingestion schema change, or infrastructure issue), not 80 independent model regressions.
- Correlation analysis should be disabled because simultaneous alerts almost always reflect random coincidence.
- The issue is probably a CI/CD fairness-gate false positive rather than a runtime operational incident.
A platform must monitor feature drift across 10,000 continuous features at hourly cadence for 200 models. Explain why the Population Stability Index (PSI) is operationally preferable to waiting for delayed label-based metrics, and describe one failure mode PSI does not cover.
Order the following steps of the chapter’s cost-anomaly investigation workflow for a sudden inference-cost spike: (1) Perform root-cause checks on traffic, latency, model version, and utilization, (2) Confirm the billing data reflects real spend rather than a measurement artifact, (3) Compute anomaly severity (e.g., Z-score against the 30-day baseline), (4) Decide whether the driving quality gain justifies sustained higher cost or whether optimization is required.
Platform Engineering
Organizations where every data science team independently provisions GPU clusters, configures model registries, and wires up alerting dashboards pay a massive duplication tax on undifferentiated infrastructure work. Platform engineering solves this by treating the ML infrastructure itself as a product, providing paved roads that allow product teams to focus entirely on modeling rather than infrastructure plumbing.
Platform engineering for machine learning creates shared infrastructure that enables model teams to develop, deploy, and operate models without managing underlying complexity. Effective platforms balance self-service capabilities that accelerate development against governance requirements that ensure consistency and reliability.
Abstraction levels
The abstraction-level decision is how much operational judgment the platform should centralize on behalf of model teams. Too little abstraction leaves every team paying the same infrastructure tax; too much hides the controls that unusual workloads need. The four levels in table 24 sit on that flexibility-versus-convenience curve, distinguished by which concerns the platform owns and which it leaves to the model team.
| Level | Platform owns | Model team still owns | Best fit and risk |
|---|---|---|---|
| Level 1 | GPU capacity, storage volumes, network connectivity, and basic orchestration such as Kubernetes namespaces | Training code, serving stack, monitoring, and deployment path | Fits unusual workloads with strong infrastructure teams; becomes costly when many teams repeat the same operational work |
| Level 2 | Standardized containers, ML-aware Kubernetes integration, persistent volumes, and basic service-mesh support | Experiment structure, training jobs, serving releases, and monitoring workflows | Reduces packaging duplication; operational correctness still depends heavily on each team |
| Level 3 | ML-specific control loops such as topology-aware scheduling, hyperparameter tuning, distributed training, serving | Modeling judgment and workload-specific trade-offs | Absorbs failure modes that recur across teams; systems such as Kubeflow and Ray often sit near this level |
| Level 4 | Full lifecycle product: IDEs, feature stores, experiment tracking, registries, CI/CD, monitoring, cost, governance | Higher-level product and modeling intent, with less direct low-level control | Maximizes speed and consistency; the platform team accepts responsibility for policy, reliability, and economic visibility |
Managed and lifecycle platforms such as Vertex AI, SageMaker, TFX14 at Google (Baylor et al. 2017), and MLflow (Zaharia et al. 2018) represent the full-platform end of this spectrum. The trade-off is explicit: teams gain speed and consistency by giving up some low-level control, while the platform team accepts responsibility for policy, reliability, and economic visibility.
14 TensorFlow Extended (TFX): Google’s production ML platform. TFX’s key architectural insight is that data validation via TensorFlow Data Validation (TFDV) gates the pipeline before training begins, catching schema violations and distribution drift that would otherwise produce silently degraded models. This “fail before training” philosophy prevents the most expensive class of ML waste: GPU-hours spent training on corrupted data.
Baylor, Denis, Eric Breck, Heng-Tze Cheng, Noah Fiedel, Chuan Yu Foo, Zakaria Haque, Salem Haykal, et al. 2017. “TFX: A TensorFlow-Based Production-Scale Machine Learning Platform.” Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 1387–95. https://doi.org/10.1145/3097983.3098021.
Zaharia, Matei, Andrew Chen, Aaron Davidson, Ali Ghodsi, Sue Ann Hong, Andy Konwinski, Siddharth Murching, et al. 2018. “Accelerating the Machine Learning Lifecycle with MLflow.” IEEE Data Engineering Bulletin 41 (4): 39–45.
Self-service model deployment
Self-service deployment works only when the platform can let model teams move quickly while keeping risky choices inside governed boundaries. The design question is therefore which deployment decisions should remain team-owned and which invariants the platform must enforce before a model receives production traffic.
Deployment API design
A well-designed deployment API abstracts operational complexity by making the model team’s intent declarative. The platform lesson is not the shape of a particular YAML file; it is which invariants the platform must capture before it turns a model version into fleet traffic. The invariants in table 25 are the platform contract behind that declarative interface. Prometheus15 is one common operational sink for the telemetry side of that contract.
15 Prometheus: An open-source monitoring system now maintained under the CNCF umbrella, using a pull-based model to scrape metrics from exporters. For ML fleets, Prometheus is the standard for tracking operational health (CPU/GPU utilization, request rates), but its time-series model is poorly suited for tracking high-dimensional distribution drift, necessitating a two-tier monitoring architecture.
| Declared intent | Platform invariant |
|---|---|
| Model artifact and version | The serving system loads exactly the validated model from the registry. |
| Resource envelope | GPU, memory, and replica requests stay inside quota and scheduling constraints. |
| Traffic policy | Canary, shadow, and rollback controls bound blast radius before full promotion. |
| Quality gates | Error, latency, drift, and task-quality thresholds block unsafe promotion. |
| Telemetry sink | Operational metrics flow into operational monitoring, while model-quality signals flow into drift and slice monitors. |
| Approval boundary | Sensitive data access, budget overruns, and high-risk release windows require review. |
TensorFlow Serving provides model-serving lifecycle capabilities for loading, versioning, canarying, and rolling back models (Olston et al. 2017). A self-service platform adds the policy layer around those capabilities: model teams specify intent, and the platform translates it into scheduling, traffic routing, telemetry, and approval controls.
Olston, Christopher, Noah Fiedel, Kiril Gorovoy, Jeremiah Harmsen, Li Lao, Fangwei Li, Vinu Rajashekhar, Sukriti Ramesh, and Jordan Soyke. 2017. “TensorFlow-Serving: Flexible, High-Performance ML Serving.” CoRR abs/1712.06139. https://doi.org/10.48550/arXiv.1712.06139.
Resource management
Efficient resource utilization is essential for platform economics because shared capacity pays off only when training and serving workloads receive different controls. Training can trade time for utilization; serving trades capacity for tail-latency protection, so a single scheduler policy cannot optimize both.
Training resource management
Training workloads are batch-oriented, so their flexibility can be converted into higher utilization. Jobs have defined start and end times, GPU memory requirements are often known in advance, and many runs can be preempted and restarted if checkpointing limits lost work. A training scheduler uses priority queues, fair sharing, and deadline-aware placement to decide which jobs should wait, which should move, and which low-priority jobs can be preempted16 for urgent work. Spot/preemptible instances fit this control loop because automatic retry on preemption can preserve progress while reducing cost.
16 Job Preemption: The ability to terminate lower-priority workloads to free resources for urgent work. Cloud providers offer 60–90 percent discounts on preemptible/spot instances, but the trade-off is that ML training must support checkpoint-and-resume: without periodic checkpointing, a preempted 72-hour training run restarts from scratch, converting a 70 percent cost savings into a net loss. Checkpoint frequency itself is a trade-off between I/O overhead and wasted-compute risk.
Serving resource management
Serving workloads bind on latency rather than batch flexibility. Demand fluctuates with time of day, events, and seasonality, but a live request cannot be preempted without user impact. The serving control loop therefore starts from the latency SLO and asks how much capacity must be online before requests arrive.
Autoscaling adds horizontal capacity from request-rate, latency, or model-specific queue metrics, but it must account for model load time and GPU memory granularity. Resource isolation prevents one model from consuming another model’s budget, while cost optimization combines right-sized instances, reserved capacity for baseline demand, and spot instances only where overflow can tolerate interruption. The operational goal is not maximum utilization in isolation; it is the cheapest capacity plan that still protects tail latency.
Platform utilization metrics
Once training and serving controls are separated, the shared platform still needs an aggregate measure of whether capacity is being converted into useful work. Equation 13 defines platform efficiency as the capacity-weighted average utilization across all resources:
\[U_{\text{platform}} = \frac{\sum_{i} U_i \times \text{Cap}_i}{\sum_{i} \text{Cap}_i} \tag{13}\]
where \(U_i\) is the utilization of resource \(i\) and \(\text{Cap}_i\) is the capacity of resource \(i\). Weighting by capacity keeps the metric honest about where stranded work lives: an idle single GPU and an idle eight-GPU node are not equally wasteful, so a small underused resource should not drag the platform average down as hard as a large idle pool.
However, raw utilization is incomplete. Effective utilization must also consider utilization quality to determine whether GPUs are doing productive work or waiting on data, utilization fairness to assess whether utilization is distributed appropriately across teams, and utilization cost to evaluate efficiency in terms of cost per unit of ML output.
Worked example: GPU cluster efficiency
A platform operates a 100-GPU training cluster with average GPU utilization of 65 percent, memory utilization of 80 percent, four-hour average queue waits, and a cost of $2.50 per GPU-hour. The high memory utilization suggests jobs are generally sized correctly, while the lower compute utilization points to I/O-bound training steps. Queue waits show that demand already exceeds supply, so the platform decision is not simply whether to buy more GPUs. Daily cluster spend is fixed by provisioned capacity at \(100 \times 24 \times \$2.50 = \$6,000/day\), but only \(100 \times 24 \times 0.65 \times \$2.50 = \$3,900/day\) is currently converted into useful GPU work. If data-loading optimization raises compute utilization to 80 percent, useful work rises to \(100 \times 24 \times 0.80 \times \$2.50 = \$4,800/day\) before adding any capacity. The same measurements therefore support two different actions: remove the I/O bottleneck to recover stranded capacity, then use scheduling or expansion only for the remaining queue pressure.
Checkpoint 1.5: The annual cost of GPU cluster underutilization
Use daily cluster spend ($6,000/day) and productive GPU-hours ($3,900/day at 65 percent utilization) to extend the analysis to annual scale and compare against the platform ROI argument.
Advanced fleet metrics: ML productivity goodput (MPG)
While utilization metrics capture resource busyness, they often fail to reflect true engineering value. A GPU spinning at 100 percent utilization on a hyperparameter tuning job that eventually fails due to a configuration error is “efficient” in terms of hardware but “wasteful” in terms of productivity. To address this, ML Productivity Goodput (MPG) provides a comprehensive metric for fleet efficiency (Wongpanich et al. 2025).
Wongpanich, A., T. Oguntebi, J. Baiocchi Paredes, Y. E. Wang, P. M. Phothilimthana, R. Mitra, Z. Zhou, N. Kumar, and V. J. Reddi. 2025. Machine Learning Fleet Efficiency: Analyzing and Optimizing Large-Scale Google TPU Systems with ML Productivity Goodput.
Hennessy, J. L., and D. A. Patterson. 2011. Computer Architecture: A Quantitative Approach. Morgan Kaufmann.
MPG extends the fleet law introduced in The fleet law into the Iron Law of Machine Learning Fleet Efficiency. Just as the classic Iron Law of Processor Performance (Hennessy and Patterson 2011) decomposes CPU execution time, this formulation decomposes ML fleet efficiency into three orthogonal components:
\[\text{MPG} = \text{Scheduling Efficiency} \times \text{Runtime Efficiency} \times \text{Program Efficiency}\]
- Scheduling efficiency: This measures the platform’s ability to place jobs on available resources. It penalizes queuing delays and fragmentation where resources exist but cannot be assigned.
- Runtime efficiency: This captures the hardware utilization quality during execution. It penalizes “bad put” such as restart overheads from preemption, idle time due to data loading bottlenecks, and straggler effects in distributed training.
- Program efficiency: This assesses whether the code running on the hardware is optimized. It penalizes suboptimal kernels, excessive precision (FP32 where BF16 suffices), and redundant computations.
By tracking the iron law components, platform teams move beyond simple “utilization” to measuring “goodput”—the rate at which valid, useful model training work is completed. This shift often reveals that high-utilization clusters may have low MPG due to frequent failures or inefficient code, guiding optimization efforts toward the highest-impact bottlenecks.
Multi-tenancy and isolation
Enterprise platforms earn their sharing dividend only if multiple teams can share infrastructure without sharing failures. Multi-tenancy is therefore an isolation problem before it is an efficiency problem: the platform must bound performance interference, data exposure, and cost spillover at the same time.
Isolation requirements
Tenants need isolation at every boundary where one team’s workload, data, or cost can affect another team:
- Performance isolation: Resource limits, scheduling fairness, and network quality of service prevent one workload from degrading another during training spikes or serving bursts.
- Security isolation: Access controls, network segmentation, and encryption keep teams with different sensitivity levels from sharing data paths accidentally.
- Cost isolation: Metering and chargeback make each team’s usage attributable.
Together, the three boundaries make shared infrastructure safe enough for teams to use without negotiating every deployment by hand.
Namespace architecture
A typical multi-tenant architecture uses hierarchical namespaces:
Platform
├── Team A
│ ├── Development
│ ├── Staging
│ └── Production
├── Team B
│ ├── Development
│ ├── Staging
│ └── Production
└── Shared
├── Feature Store
├── Model Registry
└── MonitoringEach team receives dedicated namespaces with resource quotas, while shared services operate in common namespaces with appropriate access controls. Without controls, one team’s demanding workload can degrade performance for others, a failure mode known as the noisy neighbor problem17. Prevention requires controls at request, rate, priority, and budget boundaries.
17 Noisy Neighbor Problem: A multi-tenancy failure mode where one tenant’s workload degrades performance for co-located tenants. ML workloads are particularly prone to this because training jobs allocate GPU memory greedily – a single job requesting all available HBM on a shared node can starve co-located inference services, causing latency spikes that violate SLOs. Unlike CPU workloads, GPU memory cannot be overcommitted, making physical resource isolation the only reliable prevention.
Four controls prevent one tenant from overwhelming shared services:
- Request limits: Each request has a cap on the resources it can consume.
- Rate limiting: Each tenant has bounded request rates so shared services are not overwhelmed.
- Priority classes: Critical workloads receive resources even under contention.
- Burst budgets: Temporary resource overages are allowed while long-term fairness is preserved.
Together, these controls make fairness enforceable in the request path instead of relying on after-the-fact negotiation.
FinOps for ML platforms
Financial operations (FinOps) practices in traditional IT rarely account for the cost shape of ML workloads. GPU compute costs dominate ML budgets, with a single training run potentially costing tens of thousands of dollars. Serving infrastructure scales with traffic, creating variable costs that can swing by an order of magnitude between peak and trough. The experimental nature of ML development means many training runs produce no production value. Effective FinOps for ML requires specialized practices that account for these realities.
Definition 1.1: FinOps for ML
FinOps for ML is the practice of treating compute cost as a first-class engineering constraint (measured in real-time per experiment and model, and optimized jointly with model accuracy and latency) rather than accounting for it retrospectively through annual budget reconciliation.
- Significance: ML compute costs scale steeply with experimentation volume. A team running 1,000 GPU-hours/day at $3/GPU-hour spends $3,000/day ($1.1M/year) on training alone. With per-experiment cost visibility, an engineer can identify that 30 percent of runs are terminated early due to divergence (recoverable with better hyperparameter selection) and that spot instances provide 60–70 percent cost reduction for fault-tolerant workloads, reducing effective spend by 40–50 percent without changing output quality.
- Distinction: Unlike traditional IT budgeting (which allocates fixed annual compute budgets across departments), FinOps for ML operates at the per-run and per-model level with real-time feedback—enabling decisions like early stopping a $50K training run at step 1,000 when loss curves signal divergence, rather than discovering the waste after the full run completes.
- Common pitfall: A frequent misconception is that FinOps means minimizing compute spend. The goal is maximizing accuracy-per-dollar across the full lifecycle: a $500K training run producing a model serving 10B inferences at $0.0001/query may be far more cost-efficient than a $50K run producing a model that requires 10\(\times\) the inference compute to achieve the same accuracy at scale.
Cost components
ML platform cost breakdown spans multiple categories with different optimization strategies. Table 26 reveals that training compute dominates (40–60 percent of costs), driven by GPU hours and experiment volume, with spot instances and early stopping as primary optimization levers:
| Cost Category | Typical Share | Primary Drivers | Optimization Lever |
|---|---|---|---|
| Training compute | 40–60% | GPU hours, experiment volume | Spot instances, early stopping |
| Serving compute | 20–40% | Traffic volume, latency SLOs | Autoscaling, model optimization |
| Storage | 10–20% | Dataset size, checkpoint frequency | Tiered storage, retention policies |
| Network | 5–15% | Multi-region, data transfer | Caching, compression |
| Platform overhead | 5–10% | Team size, tooling | Automation, self-service |
Cost optimization strategies
Cost optimization is a risk-allocation decision, not a catalog of discounts. Interruptible compute pays off only when checkpointing bounds the work lost to preemption, serving autoscaling only within the latency budget, and instance right-sizing only against measured cost per step or per inference. Each lever below trades a specific risk for a specific saving.
Spot and preemptible instances
Cloud providers offer significant discounts (60–90 percent) for interruptible compute capacity. ML training workloads are well suited for spot instances because checkpointing enables recovery from interruptions, training jobs tolerate delays better than serving, and large batch jobs amortize instance acquisition overhead.
Effective spot usage requires three practices:
- Checkpoint frequency tuning: Balance checkpoint overhead against potential lost work. For a job costing $10/hour on spot instances, hourly checkpoints losing at most one hour of work ($10) far outweigh checkpoint storage costs.
- Instance diversification: Request capacity across multiple instance types and availability zones to reduce interruption probability.
- Fallback strategies: Automatically fall back to on-demand instances for time-sensitive jobs or when spot availability is low.
Together, these practices turn a cheap but unreliable resource into a bounded-risk training option.
Training Cost Comparison (100 GPU-hours):
├── On-demand: 100 × $3.00 = $300
├── Spot (70% discount): 100 × $0.90 = $90 (+ potential reruns)
├── Reserved (40% discount): 100 × $1.80 = $180 (requires commitment)
└── Actual spot with interruptions: ~$110 (accounting for 20% rerun overhead)The serving side allocates risk differently. Serving costs scale with traffic, but ML serving cannot autoscale like a stateless web application. Large models may take seconds or minutes to load, so purely reactive scaling arrives after the latency spike; the platform needs predictive scale-up before anticipated demand.
The capacity steps are also lumpy. Accelerator memory makes serving scale in jumps of 0, 1, 2, or 4 accelerators rather than smooth CPU fractions, and batching adds another coupling because waiting for a larger batch improves utilization but consumes latency budget. An autoscaling policy must therefore choose the least expensive capacity step that still protects the p99 latency SLO.
Instance selection then starts from the binding constraint rather than the newest instance type. Memory-bound training with large embedding tables prioritizes GPU memory capacity and bandwidth. Compute-bound dense training maximizes sustained FLOP/s per dollar.
Serving splits the decision again. Latency-sensitive serving minimizes cold start and single-request latency, while throughput-oriented serving maximizes requests per dollar through batching. Instance selection should therefore be benchmark-driven: compare cost per training step or cost per inference across instance types instead of assuming larger hardware is automatically more economical.
Cost visibility and attribution
Cost optimization requires granular visibility into spending because teams cannot optimize costs they cannot see or own. Attribution policy is an incentive design problem, not only an accounting problem. Direct metering charges teams exactly for resources consumed; it is the most accurate model but can encourage under-provisioning when teams optimize their bill instead of service health. Allocation-based attribution charges based on reserved capacity rather than actual usage, making budgets predictable while potentially hiding waste. Hybrid attribution combines a base charge for allocation with a variable charge for excess usage, balancing predictability with efficiency incentives.
For serving workloads, cost per inference provides the key unit economic metric. Equation 14 expresses this as total serving cost divided by inference count, enabling direct comparison of model efficiency and capacity planning:
\[\text{Cost per inference} = \frac{\text{Total serving cost}}{\text{Total inferences served}} \tag{14}\]
Cost per inference then becomes the bridge from infrastructure telemetry to product decisions. Teams can compare model versions by asking whether an accuracy gain justifies a 2\(\times\) inference cost, evaluate optimization work by measuring whether quantization reduced cost per inference by 40 percent, and forecast monthly serving cost under projected traffic. Tracking the metric by model, customer segment, and request type reveals which workload actually deserves optimization effort.
Effective chargeback closes the loop by making those costs actionable. It requires fine-grained resource metering, attribution rules that map resources to teams, dashboards that show cost by team, project, and model, forecasting tools that help teams plan budgets, and anomaly detection for unexpected cost increases.
Budget-aware development
FinOps extends beyond infrastructure optimization because cost feedback changes which experiments teams run and which models they ship. Unconstrained experimentation leads to runaway costs, but budget controls should make trade-offs visible before they block useful work: per-experiment limits cap individual training runs at a cost threshold, team budgets allocate monthly compute budgets with visibility into consumption, and approval workflows require review for experiments that exceed cost thresholds. These controls should inform rather than block. The goal is cost awareness, not prevention of valuable experiments.
Cost-quality trade-offs
Model selection should explicitly consider cost alongside accuracy. Table 27 illustrates cost-quality trade-off analysis: moving from small to medium model yields a 3 percentage-point accuracy gain for 10\(\times\) training cost increase, while medium to large yields only 1 additional percentage point for another 10\(\times\) cost, a pattern that should inform deployment decisions:
| Model | Accuracy | Training Cost | Serving Cost/1K | Value Judgment |
|---|---|---|---|---|
| Small | 92% | $500 | $0.10 | Baseline |
| Medium | 95% | $5,000 | $0.50 | 3 percentage points for 10× cost |
| Large | 96% | $50,000 | $2.00 | Additional 1 percentage point for 10× more |
For many applications, the marginal accuracy gain does not justify the cost increase. Making these trade-offs explicit prevents defaulting to the largest available model.
Efficiency metrics should be reviewed alongside model quality so the platform can identify waste that accuracy alone hides. Table 28 connects each metric to the operational question it answers.
| Metric | Waste Signal | Typical Action |
|---|---|---|
| Cost per accuracy point | Accuracy gains are bought with disproportionate spend | Revisit model size, feature set, or serving target before scaling up. |
| Experiments per production model | Many runs produce little deployable value | Improve experiment design, stopping rules, and promotion criteria. |
| GPU utilization | Capacity is reserved but not doing useful work | Right-size instances, improve batching, or profile inefficient code. |
| Spot utilization rate | Eligible workloads use expensive on-demand capacity | Move fault-tolerant jobs to spot instances with checkpoint support. |
Regular review of these metrics identifies systemic inefficiencies and guides platform improvements. The same visibility must extend to the knowledge layer of modern ML applications. Retrieval, fine-tuning, and total lifecycle ownership all look like model-quality choices from a notebook, but at fleet scale they become cost-placement decisions.
Retrieval-augmented generation vs. fine-tuning: The knowledge operations trade-off
Domain knowledge can live in a retrievable index, in model weights, or in adapter weights, and each placement creates a different operating cost surface. Retrieval-augmented generation (RAG) retrieves documents at inference time and places them in the prompt (Lewis et al. 2020). Fine-tuning stores adaptation in model weights or adapter weights: supervised fine-tuning (SFT) trains on curated input-output examples, while Low-Rank Adaptation (LoRA) stores small adapter-weight deltas (Hu et al. 2021). Both approaches can improve task behavior, but they move cost and failure risk to different places in the fleet.
Lewis, Patrick, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, et al. 2020. “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks.” Advances in Neural Information Processing Systems 33: 9459–74.
Hu, Edward J., Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2021. “LoRA: Low-Rank Adaptation of Large Language Models.” arXiv Preprint arXiv:2106.09685.
RAG chooses freshness and attribution over lower-cost inference. Updating a document index can change the system’s answers without retraining the model, and retrieved passages provide a concrete source trail for generated claims. The cost moves into the serving path: each query may carry a large payload of retrieved context, such as 10,000 extra tokens, increasing prefill attention work roughly quadratically with sequence length while growing the KV cache linearly with context length. FlashAttention reduces memory traffic and intermediate storage, but it does not remove the attention-compute or KV-cache footprint created by long context. Long contexts also introduce a quality risk because the model may underuse relevant evidence when the prompt contains too much retrieved material.
Fine-tuning chooses compact inference over fast knowledge updates. The platform pays for data curation, validation, training, and evaluation before deployment, but successful adaptation can shorten prompts and reduce per-query serving cost. Adapter-based fine-tuning changes the fleet problem rather than eliminating it: thousands of customer-specific LoRA adapters create a multi-tenant serving problem, while outdated or incorrect facts embedded in weights are harder to remove than documents in an index.
The decision boundary is where knowledge volatility, attribution requirements, latency budget, and adapter-management complexity cross. RAG fits volatile facts, strong attribution requirements, and moderate query volume because the index can change faster than a training pipeline. Fine-tuning fits specialized domain language, strict latency budgets, and stable behavior requirements because the model carries the adaptation without paying for 10,000 context tokens on every query. Many mature platforms use both: fine-tuning teaches the model how to use the organization’s tools and document style, while RAG supplies the facts that must remain fresh.
ML systems TCO framework
While FinOps practices provide operational cost visibility, strategic ML investment decisions require a comprehensive TCO framework that captures the complete economic picture across the ML lifecycle. Section 1.2 established the hardware total cost of ownership: the CapEx and OpEx of the physical fleet. The hardware lens now widens to the full ML lifecycle, where hardware underlies the training and inference cost terms and data and iteration costs complete the four-component model. Unlike traditional software where infrastructure costs dominate, ML systems exhibit a distinctive four-component cost structure that evolves differently with scale.
Definition 1.2: ML systems TCO
Total Cost of Ownership (TCO) for ML Systems is the complete economic accounting of developing, deploying, and operating machine learning capabilities across their full lifecycle.
- Significance: It captures the Cost Inversion of scale: while training costs are a one-time upfront operation, the cumulative Inference TCO grows linearly with user adoption and time, often exceeding development costs by 5\(\times\) to 10\(\times\) over a 3-year period.
- Distinction: Unlike traditional IT TCO (where hardware CapEx dominates), ML TCO is uniquely shaped by operating efficiency \((\eta_{\text{hw}})\), meaning the ability to serve predictions at the lowest possible energy and compute cost per query.
- Common pitfall: A frequent misconception is that the initial training bill is the primary financial risk. In reality, the data debt and maintenance overhead are the “silent interest rates” that can make an accurate model economically unsustainable in production.
The TCO equation
Equation 15 expresses the total cost of ownership as the sum of four distinct cost components, each with different scaling characteristics and optimization levers:
\[\text{TCO}_{\text{ML}} = C_{\text{train}} + C_{\text{infer}} + C_{\text{data}} + C_{\text{iter}} \tag{15}\]
Here, \(C_{\text{train}}\) is the one-time training and evaluation cost, \(C_{\text{infer}}\) is recurring serving cost, \(C_{\text{data}}\) covers data acquisition, storage, cleaning, and governance, and \(C_{\text{iter}}\) captures iteration costs such as retraining, validation, incident response, and maintenance.
As figure 10 illustrates, while GPU compute and storage are the visible costs, hidden operational costs often constitute fully half of the actual budget.
The decomposition reveals a critical insight: the dominant cost component shifts as organizations mature. Early-stage ML efforts are dominated by \(C_{\text{iter}}\) (experimentation), growth-stage by \(C_{\text{train}}\) (model development), and production-scale by \(C_{\text{infer}}\) (serving at volume). Optimization strategies must match the current cost structure.
Training cost model
Training costs encompass the compute required to develop and maintain models. Equation 16 formalizes training cost as a function of GPU count, training duration, non-energy accelerator-hour rates, data center energy overhead, and failure overhead:
\[C_{\text{train}} = N_{\text{GPU}} \times T_{\text{hours}} \times \left(R_{\text{GPU/hr}} + P_{\text{GPU}} \times R_{\$/\text{kWh}} \times \text{PUE}\right) \times (1 + F_{\text{fail}}) \tag{16}\]
where:
- \(N_{\text{GPU}}\) is the number of GPUs allocated
- \(T_{\text{hours}}\) is the training duration in hours
- \(R_{\text{GPU/hr}}\) is the non-energy accelerator-hour cost
- \(P_{\text{GPU}}\) is per-GPU power draw in kW
- \(R_{\$/\text{kWh}}\) is the electricity price
- \(\text{PUE}\) is the Power Usage Effectiveness multiplier applied to the energy term
- \(F_{\text{fail}}\) is the failure overhead factor (fraction of training lost to failures and restarts)
The PUE factor captures data center efficiency: a PUE of 1.2 means 20 percent additional power for cooling and infrastructure. It applies to energy consumption, not to the whole accelerator-hour rate. The failure overhead \(F_{\text{fail}}\) accounts for checkpoint-and-restart costs; at scale, Fault Tolerance established how component failures translate into checkpointing and restart overhead for long-running fleet jobs.
Worked example: Training cost calculation
Consider training a large language model:
- Configuration: 256 H100 GPUs for 14 days
- Base accelerator-hour rate: $3.50/GPU-hour
- Energy adder: 700 W at $0.07/kWh and PUE 1.15 adds $0.06/GPU-hour
- Effective rate: $3.56/GPU-hour
- Failure overhead: 15 percent (typical for multi-node training)
\(C_{\text{train}} = 256 \times (14 \times 24) \times (\$3.50 + \$0.06) \times 1.15 \approx \$352,150\)
If this model requires quarterly retraining, annual training cost reaches approximately $1.4M. However, training cost often represents a small fraction of total TCO for production systems serving millions of users.
Inference cost model

At production scale, serving (infer) dominates total cost of ownership.
Inference costs dominate TCO for production ML systems at scale. Equation 17 expresses serving cost as a function of query volume, latency requirements, and utilization efficiency:
\[C_{\text{infer}} = \frac{Q_{\text{daily}} \times T_{\text{infer,avg}}}{U_{\text{GPU}} \times B_{\text{eff}}} \times R_{\text{GPU/hr}} \times 365 \tag{17}\]
where:
- \(Q_{\text{daily}}\) is the daily query volume
- \(T_{\text{infer,avg}}\) is the average latency per inference (in hours, so the numerator carries units of GPU-hours per day)
- \(U_{\text{GPU}}\) is the effective GPU utilization (typically 0.4-0.8)
- \(B_{\text{eff}}\) is the effective batch size (throughput multiplier from batching)
- \(R_{\text{GPU/hr}}\) is the hourly GPU cost
- The \(\times 365\) factor lifts daily GPU-hours into an annualized cost. The 24-hours-per-day factor is already absorbed into \(Q_{\text{daily}} \times T_{\text{infer,avg}}\) and must not be applied a second time.
The key insight is that inference cost scales linearly with query volume but sublinearly with optimization: improving utilization from 40 percent to 80 percent halves infrastructure requirements, and effective batching \((B_{\text{eff}} > 1)\) further reduces per-query costs.
Alternative formulation
For capacity planning, express inference cost in terms of required GPU-seconds per query:
\[C_{\text{infer}} = Q_{\text{annual}} \times \frac{T_{\text{infer}}}{U_{\text{GPU}}} \times \frac{R_{\text{GPU/hr}}}{3600}\]
where \(T_{\text{infer}}\) is the inference time in seconds. This formulation directly connects latency optimization to cost reduction.
Data cost model
Data costs exhibit superlinear scaling with user base due to storage growth, transfer volume, and processing requirements. Equation 18 decomposes data cost into three components that scale differently: storage cost \(C_{\text{storage}}\), egress cost \(C_{\text{egress}}\) for moving data out over the network, and processing cost \(C_{\text{process}}\):
\[C_{\text{data}} = C_{\text{storage}} + C_{\text{egress}} + C_{\text{process}} \tag{18}\]
Storage costs grow with data retention requirements: \[C_{\text{storage}} = D_{\text{vol,data}} \times R_{\text{storage/GB}} \times T_{\text{retention}}\]
where \(D_{\text{vol,data}}\) is data volume in GB, \(R_{\text{storage/GB}}\) is the monthly storage rate, and \(T_{\text{retention}}\) is retention period in months.
Egress costs scale with data transfer volume: \[C_{\text{egress}} = D_{\text{vol,transfer}} \times R_{\text{egress/GB}}\]
Cloud egress pricing ($0.08-0.12 per gigabyte) makes data transfer a significant cost driver for multi-region deployments and training data distribution.
Processing costs scale with compute requirements for extract, transform, load (ETL), feature engineering, and data validation: \[C_{\text{process}} = D_{\text{vol,processed}} \times R_{\text{process/GB}}\]
Data processing costs often surprise organizations: a feature engineering pipeline processing 10 terabytes daily at $0.02 per gigabyte costs $73,000 annually.
Iteration cost model
Development costs capture the engineering investment in experimentation and model improvement. Equation 19 formalizes this as the product of experiment count, experiment duration, and combined engineering and compute costs:
\[C_{\text{iter}} = N_{\text{exp}} \times T_{\text{exp}} \times (C_{\text{engineer}} + C_{\text{compute}}) \tag{19}\]
where:
- \(N_{\text{exp}}\) is the number of experiments conducted
- \(T_{\text{exp}}\) is the average experiment duration
- \(C_{\text{engineer}}\) is the engineering cost per experiment (time allocation)
- \(C_{\text{compute}}\) is the compute cost per experiment
A critical but often overlooked factor: failed experiments have real cost. If 90 percent of experiments do not improve production metrics, the effective cost per successful experiment is 10\(\times\) the nominal experiment cost. This motivates investment in experiment infrastructure that reduces \(T_{\text{exp}}\) and improves experiment success rates.
Worked example: Startup vs. production company TCO
Table 29 illustrates how cost structure evolves with scale by comparing two organizations. The startup operates 1 production model serving 100,000 daily users with monthly retraining, a 2-engineer team, and cloud-native infrastructure. The production company operates 50 models serving 10 million daily users with weekly retraining for high-velocity models, a dedicated 15-engineer ML platform team, and hybrid cloud/on-premise infrastructure.
| Cost Component | Startup | Production Company | Scaling Factor |
|---|---|---|---|
| Training | $5,000/month | $150,000/month | 30× (more models, larger) |
| Inference | $2,000/month | $400,000/month | 200× (100\(\times\) users, optimization) |
| Data | $500/month | $80,000/month | 160× (superlinear with users) |
| Iteration | $40,000/month | $350,000/month | 8.75× (team size, experiments) |
| Total TCO | $47,500/month | $980,000/month | 20.6× |
| Dominant Cost | Iteration (84%) | Inference (41%) |
The comparison reveals a structural shift in ML economics. Startups spend 84 percent on iteration through people and experimentation, while production companies spend 41 percent on inference infrastructure, so each stage demands different optimization strategies. TCO also scales sublinearly: a 100\(\times\) user increase yields only 20.6× TCO because inference economies of scale and amortized training costs absorb part of the growth. Data breaks that pattern by scaling 160× for 100\(\times\) users as storage requirements grow with user history and processing costs rise with feature complexity. Platform automation produces the final shift: the production company runs 10\(\times\) more experiments, but iteration cost grows only 8.75× because per-experiment overhead falls.
TCO sensitivity analysis
Understanding how TCO responds to key parameters enables strategic planning. Table 30 shows the impact of 2\(\times\) increases in key parameters on each cost component:
| Parameter | Change | Training | Inference | Data | Total Impact |
|---|---|---|---|---|---|
| Daily users | 2× | – | 100% | 120% | 45% |
| Model count | 2× | 100% | 100% | 50% | 85% |
| Queries per user | 2× | – | 100% | 80% | 40% |
| Model size | 2× | 150% | 120% | 30% | 55% |
| Retraining freq. | 2× | 100% | – | 40% | 25% |
The nonlinear effects explain why the total-impact column does not simply mirror the input change. User scaling makes data costs grow superlinearly (120 percent for 2× users) because user history accumulation and cross-user feature computation add state faster than headcount. Model size scaling pushes training cost up by 150 percent for 2× parameters because memory requirements can force multi-GPU configurations rather than a simple larger single-device run. Model count creates the broadest multiplicative effect because every additional model touches training, inference, data, monitoring, deployment, and governance at once, making portfolio growth the most expensive scaling dimension.
Decision framework: Speed vs. efficiency
TCO analysis enables principled decisions about when to optimize for development speed vs. operational efficiency. Equation 20 calculates the breakeven point for optimization investments:
\[T_{\text{breakeven}} = \frac{C_{\text{optimization}}}{C_{\text{save,monthly}}} \tag{20}\]
where \(C_{\text{optimization}}\) is the one-time cost of implementing an optimization and \(C_{\text{save,monthly}}\) is the monthly savings it produces.
The breakeven equation becomes useful only after the dominant cost component is known. Table 31 maps each cost structure to the optimization posture and payback threshold that should govern investment decisions.
| Dominant cost structure | Operating context | Optimization posture | Payback threshold |
|---|---|---|---|
| Iteration costs dominate (\(C_{\text{iter}} > 50\%\) of TCO) | Early stage | Optimize for development velocity, accept higher per-inference costs while experiments are still changing, and invest in experiment infrastructure that reduces \(T_{\text{exp}}\). Defer infrastructure efficiency work until the cost structure shifts. | Defer unless it directly accelerates iteration. |
| Training costs dominate (\(C_{\text{train}} > 40\%\) of TCO) | Growth stage | Invest in training efficiency through mixed precision, gradient checkpointing, spot instances with checkpoint-and-resume, and architecture changes that reduce training time. | 3–6 month payback is acceptable. |
| Inference costs dominate (\(C_{\text{infer}} > 40\%\) of TCO) | Scale stage | Prioritize serving optimization through quantization, batching, caching, and distillation because model optimization ROI is highest when every query repeats the savings. | 1–3 month payback is required. |
Worked example: Optimization investment decision
A production company \((C_{\text{infer}} = \$400K/\text{month})\) evaluates INT8 quantization:
- Implementation cost: $80,000 (engineering time + validation)
- Expected inference cost reduction: 40 percent
- Monthly savings: $400,000 \(\times\) 0.40 = $160,000
\(T_{\text{breakeven}} = \frac{\$80,000}{\$160,000/month} = 0.5 \text{ months}\)
Breakeven in 2 weeks makes this investment highly attractive. However, if the same company \((C_{\text{train}} = \$150K/\text{month})\) evaluates a training optimization:
- Implementation cost: $80,000
- Expected training cost reduction: 30 percent
- Monthly savings: $150,000 \(\times\) 0.30 = $45,000
\(T_{\text{breakeven}} = \frac{\$80,000}{\$45,000/month} = 1.8 \text{ months}\)
Still attractive, but lower priority than inference optimization due to longer payback and smaller absolute savings. That same payback logic generalizes into an optimization priority matrix. Table 32 maps the dominant cost structure to the optimization work that should come first:
| Dominant Cost | First Priority | Second Priority | Avoid |
|---|---|---|---|
| Iteration (>50%) | Experiment velocity | Developer tooling | Infrastructure optimization |
| Training (>40%) | Training efficiency | Spot/preemptible compute | Over-engineering serving |
| Inference (>40%) | Model optimization | Serving infrastructure | Excessive retraining |
| Data (>30%) | Storage tiering | Egress reduction | Premature feature expansion |
TCO-driven architecture decisions
TCO analysis should inform architectural choices alongside operational optimization. The utilization-driven build-vs.-buy analysis in section 1.2.2 applies per model: usage-based platform services may have lower TCO than self-managed infrastructure when a workload cannot sustain the utilization that amortizes owned capacity, especially where iteration costs dominate. Model architecture selection changes the same equation because a model requiring 2\(\times\) training cost but 0.5\(\times\) inference cost may have lower TCO at scale where inference dominates. Retraining frequency increases \(C_{\text{train}}\) and \(C_{\text{data}}\) but may reduce \(C_{\text{iter}}\) by catching drift earlier and avoiding emergency interventions. Feature complexity similarly increases \(C_{\text{data}}\) through storage and processing and \(C_{\text{train}}\) through longer training, but it may reduce \(C_{\text{iter}}\) by improving model performance faster.
The TCO framework transforms these architectural debates from opinion-based discussions into quantitative analyses with measurable outcomes. Among these investments, one particular component consistently emerges as both the most expensive to build and the most valuable to standardize. Because data represents the lifeblood of every model in the fleet, the platform must solve the persistent challenge of serving consistent features at scale.
Self-Check: Question
A platform team is deciding between providing a fully managed serving interface (‘deploy by pushing a model registry pointer’) and a bare Kubernetes cluster with no ML-specific conventions. What trade-off governs this abstraction decision?
- Higher abstraction delivers more self-service velocity and standardization, while lower abstraction preserves per-team flexibility and custom optimization paths at the cost of duplicated plumbing.
- Higher abstraction always reduces cost, latency, and governance overhead simultaneously with no downside.
- Lower abstraction is preferable only for teams lacking containerization skills; otherwise abstraction level does not affect operations.
- Abstraction level applies to training workloads only; serving, monitoring, and deployment are unaffected.
A 100-GPU training cluster shows 65 percent average GPU compute utilization, 80 percent memory utilization, and 4-hour average queue times. Diagnose the most likely bottleneck and recommend the highest-leverage intervention.
A platform reports 90 percent GPU busy time across its training fleet, but engineers observe that wall-clock time to train the same models barely improves quarter over quarter. Which statement best explains why ML productivity goodput (MPG) is a more useful metric than raw utilization in this situation?
- MPG ignores scheduling delays to focus purely on kernel efficiency, bypassing fleet-level waste.
- MPG measures whether hardware is busy regardless of whether the work is useful.
- MPG decomposes useful output into scheduling efficiency, runtime efficiency, and program efficiency, exposing failed jobs, recomputation, and inefficient code that raw ‘busy time’ masks.
- MPG is a FinOps-only metric used to allocate cloud bills, not an engineering diagnostic.
An LLM platform must choose between RAG and fine-tuning for a knowledge-heavy financial assistant whose source data changes hourly (market news, filings) and whose answers must include citations. Which choice does the chapter favor, and why?
- Fine-tuning, because the specialized financial domain language is the dominant concern.
- RAG, because high knowledge volatility and attribution requirements make retrieval-corpus updates the cheaper refresh mechanism, at the cost of higher per-query inference compute.
- Fine-tuning with thousands of per-customer adapters, to minimize operational complexity.
- RAG, because it eliminates context-window compute overhead entirely.
True or False: In mature production ML systems, the one-time training bill is the dominant long-run financial risk, and inference plus hidden operational costs remain secondary.
A production platform spends $400,000 per month on inference. An INT8 quantization project costs $80,000 to implement and is expected to cut inference cost by 40 percent. Using the chapter’s break-even framework, how should the team prioritize this optimization?
- Deprioritize: architecture changes should be avoided once serving is stable.
- Top priority: monthly savings are $160,000, so payback is about 0.5 months, making this optimization one of the highest-return investments available in an inference-dominated TCO.
- Medium priority: payback is about two months, behind training-efficiency work.
- Cannot evaluate: inference savings are only knowable after traffic doubles.
Feature Store Operations
Consider a fraud detection system that needs to know a user’s transaction volume over the last ten minutes. In production, this requires a sub-millisecond database lookup. During training, however, evaluating a year’s worth of historical data requires a massive distributed join across billions of rows. When the logic to compute “transaction volume” differs even slightly between the batch processing and the real-time lookup, the resulting training-serving skew will silently destroy the model’s performance.
The first design decision is the dual-store architecture: online stores serve low-latency feature lookups, while offline stores generate reproducible training data. Operating these systems at scale presents unique challenges in freshness, consistency, and performance. The core problem feature stores solve is the training-serving gap: features computed during training must be reproducible during serving, but the computational contexts differ fundamentally: batch vs. real-time, hours vs. milliseconds. That gap often manifests as training-serving skew, a critical failure mode where subtle differences in feature processing logic between batch training and real-time inference pipelines cause silent accuracy degradation.
Systems Perspective 1.5: Training-serving skew
At fleet scale, the concern shifts from detecting training-serving skew in a single model to controlling it as a platform-level property. A feature store reduces skew by making training and serving pipelines read from shared feature definitions and materialized feature values where possible, turning \(f_{\text{train}}(x) \equiv f_{\text{serve}}(x)\) into an architectural invariant that can be tested and monitored rather than a manual convention repeated by every team.
The guarantee has to hold across both computational contexts, which is why feature stores are an architectural boundary rather than a storage convenience. During training, features are computed in batch over historical data, where a pipeline can spend hours computing features over millions of examples and the priority is correctness and coverage. During serving, the same definitions must be available through low-latency lookups, where the priority is bounded tail latency for live requests.
Feature store architecture
The dual-store pattern (figure 11) resolves this conflict by separating the offline analytical store from the online key-value store, connected through a shared materialization layer.

A feature store is not merely a database; it is an architectural pattern designed to resolve the fundamental conflict between the data access patterns of model training and real-time serving. Training requires high-throughput analytical scans over massive historical datasets, while serving requires low-latency point lookups for individual prediction requests. No single database system can efficiently satisfy both constraints, forcing the adoption of a dual-store architecture composed of an offline store and an online store.
The offline store is the system of record for all historical feature data, often holding petabytes of information. It is optimized for the massive sequential reads characteristic of training data generation, where a single query might scan terabytes of data to build a feature set for millions of examples. The key metric is throughput, not latency. Systems like BigQuery, Snowflake, or data lakes built on S3 with formats like Apache Iceberg are common choices, designed to parallelize these large-scale analytical queries.
The online store is purpose-built for speed at serving time. When a prediction request arrives, the model needs its features within a strict latency budget—often a p99 of less than 10 milliseconds. For a platform serving 10,000 models, this can translate to millions of queries per second. This requires a key-value paradigm, using systems like Redis, DynamoDB, or Bigtable that are optimized for retrieving a small number of values for a specific entity key.
Features are loaded into these stores through a process called materialization. Batch computation pipelines, often running on Spark, execute daily or hourly to generate features from historical data. Streaming computation pipelines using Flink or Spark Streaming generate features in near-real-time from event streams like Kafka. On-demand computation calculates features at request time when freshness requirements exceed batch frequency. The central architectural challenge is ensuring consistency between the two stores during materialization. If the offline store contains a feature value for training that was not identically available in the online store at the time of prediction, it introduces a subtle form of data leakage that can lead to silent degradation of model performance in production—the training-serving skew problem formalized above.
For a platform managing over 10,000 models, this centralized dual-store architecture is not optional. It provides a governable contract between data production and model consumption, preventing thousands of independent, unmaintainable feature pipelines and ensuring that all models are built from a consistent, high-quality source of truth.
Freshness SLOs
Feature freshness represents the delay between real-world events and their reflection in feature values. Table 33 maps four feature types to their freshness requirements: static features like user demographics tolerate day-scale staleness with batch computation, while real-time features capturing the last user action demand seconds-scale freshness through streaming or on-demand computation.
The freshness requirement is particularly acute for recommendation systems, where stale features become a direct tax on engagement.
Lighthouse 1.2: Archetype B (DLRM at Scale): The staleness tax
Archetype B (DLRM at Scale), the DLRM workload, is uniquely sensitive to freshness. Unlike Archetype A (GPT-4/Llama-3), where grammar rules do not change, this archetype’s “ground truth” changes every second. If a user clicks a video about baking, and the feature store has a 10-minute lag, the next 100 recommendations will miss this new intent. This “staleness tax” directly degrades engagement, forcing DLRM systems to adopt expensive streaming pipelines over cheaper batch ones.
Feature freshness requirements by type set the SLOs that the monitoring and alerting system must enforce.
| Feature Type | Example | Freshness SLO | Computation Pattern |
|---|---|---|---|
| Static | User demographics | Days | Batch |
| Slowly changing | User preferences | Hours | Batch |
| Session-level | Current session context | Minutes | Streaming |
| Real-time | Last action | Seconds | Streaming/On-demand |
Freshness becomes operational only when the SLO turns into a measured quantity. Equation 21 defines feature staleness as the difference between current time and the most recent feature update, enabling direct comparison against the thresholds in table 33:
\[\text{Staleness} = t_{\text{current}} - t_{\text{feature\_update}} \tag{21}\]
The staleness scalar gives batch and streaming paths a shared alert rule. Streaming features should stay near zero except during pipeline disruption, while batch features increase predictably between scheduled updates; the monitoring system should therefore compare each feature against its own SLO rather than apply one global freshness threshold.
Worked example: Freshness impact on model quality
A recommendation system uses user interaction features with different freshness levels. Testing on historical data produces the engagement lift in table 34:
| Feature Freshness | Engagement Lift vs. Baseline |
|---|---|
| Real-time (< 1 min) | +12.3% |
| Near real-time (< 5 min) | +11.8% |
| Hourly | +10.2% |
| Daily | +8.1% |
The engagement difference between hourly and real-time features is 2.1 percentage points. If this translates to $10 million in annual engagement value, investing in real-time feature infrastructure may be justified if costs are below this value.
Checkpoint 1.6: Pricing the streaming and batch freshness decision
Table 34 shows that hourly-to-real-time features add 2.1 percentage points of engagement lift. Treat that lift as $10 million in annual engagement value and apply it to the choice between streaming and batch infrastructure.
Point-in-time correctness
Training data must use features as they existed at the time of each training example. Figure 12 illustrates the “time travel” problem: a batch job computing total_clicks_today at midnight produces a value of 10, but using this to train a model predicting behavior at noon introduces leakage since the true value at noon was only 4. Using current feature values to label historical events creates data leakage18 that inflates offline metrics but fails in production.
18 Data Leakage: An error where future information contaminates training data. The systems danger is that leakage produces models with spectacular offline metrics – sometimes 99 percent+ accuracy – that fail completely in production where future information is unavailable. At feature-store scale, leakage risk multiplies because batch-computed features may embed temporal information invisible to the model team but exploitable by the optimizer, making point-in-time correctness an infrastructure guarantee rather than a per-team responsibility.

The contrast in figure 12 is stark: the correct point-in-time value at noon is 4 clicks, but a naive batch join would supply the midnight value of 10, inflating the training signal by 2.5 times and producing a model that cannot generalize to production. This “time travel” failure is common because the feature value is valid in the database but invalid for the historical prediction moment: total_clicks_today really is 10 at midnight, but the noon prediction should only see the 4 clicks that existed by noon. Training on the midnight value leaks future information into the example, so the model learns to “cheat” with signals unavailable in production. The result can be spectacular offline metrics and catastrophic production failure when future data disappears.
Feature stores implement point-in-time joins that retrieve feature values as of specific timestamps, as shown in listing 7.
SELECT
e.user_id,
e.event_timestamp,
e.label,
f.feature_1,
f.feature_2
FROM events e
LEFT JOIN LATERAL (
SELECT feature_1, feature_2
FROM features f
WHERE f.user_id = e.user_id
AND f.feature_timestamp <= e.event_timestamp
ORDER BY f.feature_timestamp DESC
LIMIT 1
) f ON TRUEThis query retrieves the most recent feature values that existed before each event, ensuring training data reflects production reality.
Point-in-time correctness has a storage cost because the store must retain feature history rather than current values alone. The same guarantee that prevents leakage also multiplies retained state:
\[\text{Storage} = N_{\text{entities}} \times N_{\text{features}} \times \frac{T_{\text{retention}}}{T_{\text{update}}}\]
For 100 million users, 1000 features, 1 year retention, and updates every 1 hour, the history contains 876 trillion feature values. At 100 bytes per value, this represents approximately 87.6 PB before compression. Efficient feature stores use compression, columnar storage, and retention policies to manage this scale.
Feature versioning and lineage
Feature definitions are production interfaces, so changing one without versioning can break every dependent model. Versioning and lineage make this evolution governable rather than implicit.
A representative user_engagement_score incident makes the mechanics concrete. A platform team changes the feature from a 30-day z-score to a 7-day min-max scale. The output may still be a floating-point number, so schema validation alone can pass while the feature’s meaning changes completely. Versioning names the semantic change before it reaches production; lineage identifies every model trained or served with the old meaning; backfill recomputes historical values for the new meaning; and freshness and quality checks decide whether the rewritten history is safe to use. Without that chain, a feature migration becomes a silent multi-model regression.
A safe feature interface records both version dimensions and lineage fields. Table 35 keeps those fields tied to their operational use.
| Component | What It Records | Operational Use |
|---|---|---|
| Definition version | Computation logic for the feature | Blocks silent semantic changes when the formula changes but the type does not. |
| Data version | Source snapshot or stream contract | Distinguishes model changes from upstream data changes. |
| Schema version | Output type, shape, units, and nullability | Preserves API compatibility checks while still naming semantic shifts. |
| Consumer declaration | Exact feature versions each model consumes | Gives the platform a place to block unsafe updates before serving. |
| Source lineage | Source tables, streams, and their versions | Traces bad predictions back to the upstream data that produced them. |
| Transformation and runtime provenance | Transformation code, timestamp, and environment | Reproduces historical values for audit, debugging, and compliance. |
| Quality and freshness metrics | Validation results observed when the value was produced | Estimates blast radius and decides whether rewritten history is safe to use. |
Backfill procedures
A backfill is a production migration over history: changing a feature definition rewrites the training record for every model that depends on it, so the platform must bound the compute cost, validate that recomputed values match, and preserve a path back. Treating the backfill as a migration changes the operational question from whether the computation can run once to whether history can be rewritten without corrupting future training data.
At scale, historical data may have moved into cold storage, so recomputation first becomes a data-placement problem. The long historical window then competes with production workloads for compute. Even after the job finishes, the platform cannot simply trust the new values: it must compare overlapping periods against the original computation and coordinate with dependent pipelines so training jobs do not mix old and new semantics mid-run.
The practical pattern is incremental. Historical data is processed in date partitions, and each partition is validated before the next one starts. During a dual-write period, old and new computations run in parallel, which gives the platform overlapping values for comparison before cutover. Rollback remains possible because the previous feature version and its lineage stay available until dependent models have been retrained, evaluated, and redeployed.
Scale challenges
Feature stores at recommendation system scale face a coupled systems problem: request volume, latency budget, and storage history all bind at once.
The arithmetic behind a large recommender explains why feature stores become serving infrastructure rather than a metadata convenience. 1 billion daily recommendations with 100 features per recommendation produces 100 billion feature lookups per day. That average load is roughly 1.16M requests/s before peak traffic, which commonly reaches 5–10× the mean.
Feature retrieval must fit inside the overall latency budget because every extra lookup millisecond steals time from ranking. If the recommendation budget is 50 ms, the feature store may receive only 5–10 ms. Network overhead can consume 1–2 ms of that allocation, leaving roughly 3–8 ms for the store lookup itself. Meeting this budget requires in-memory storage, careful batching, and geographic placement close enough to the serving fleet that network latency does not dominate.
Production feature stores also carry two time horizons at once. The online path keeps current values for billions of entities and thousands of features per entity, usually in the terabyte range before replication. The offline path keeps enough historical state to reconstruct training examples, which can push retained feature history into petabytes. Multi-region replication then serves both availability and latency, but it also makes freshness and consistency visible operational concerns.
Data quality operations
Data quality issues are a major source of production ML problems (Polyzotis et al. 2017). While model monitoring detects symptoms, data quality monitoring prevents problems at their source. At scale, data quality operations become as critical as model quality operations, requiring systematic monitoring, validation, and incident response procedures.
Polyzotis, Neoklis, Sudip Roy, Steven Euijong Whang, and Martin Zinkevich. 2017. “Data Management Challenges in Production Machine Learning.” Proceedings of the 2017 ACM International Conference on Management of Data, 1723–26. https://doi.org/10.1145/3035918.3054782.
The first step is measurement: data quality must be quantified in dimensions that map directly to prevention gates. Completeness measures whether expected records and fields are present. A daily data pipeline expected to produce 10 million user events but delivering only 8.2 million user events is 82 percent complete, which usually indicates a pipeline failure or upstream data source issue rather than ordinary statistical variation. Consistency captures schema compliance and referential integrity: an age feature should fall between 0 and 120, while values such as 999 or -1 suggest sentinel leakage or data errors. Production systems often reject batches that fail more than 5 percent of validation rules because allowing corrupt data through is more expensive than delaying a batch.
Timeliness measures freshness against the SLO of the consuming model. Fraud detection may need features less than 100 milliseconds old, while demographic features can tolerate staleness measured in days; the alert threshold should therefore be tied to the feature’s use, not a global constant. Accuracy asks whether values remain correct within expected distributions. Sensor drift after calibration lapses, for example, can leave values well-typed but wrong. Statistical tests such as Kolmogorov-Smirnov for continuous features, chi-square for categorical features, and Maximum Mean Discrepancy for high-dimensional data turn those accuracy checks into recurring gates.
Validation then turns those measurements into a layered defense. Schema validation enforces expected column names, types, and constraints at ingestion; tools such as Great Expectations, TensorFlow Data Validation, and Pandera provide declarative schemas with automated checks. Distribution monitoring tracks feature distributions over time, catching drift that may not violate a type constraint but still indicates an upstream change likely to degrade model performance. Cross-field validation adds the business logic that neither schema nor marginal distributions can express: if country="USA", the zip_code should match US postal formats; if order_status="shipped", a shipping_date should exist; and age derived from birthdate should match any explicit age field.
Worked example: Debugging data quality incident
A recommendation model’s CTR drops 8 percent over 5 days. Initial hypothesis focuses on model drift, but data quality investigation reveals the root cause.

Every minute of delayed detection compounds the cost.
The investigation starts with the model symptom and then works backward through the data path. Model metrics confirm that CTR declined from 4.2 percent to 3.87 percent, but freshness checks show that features still arrive within the 1-hour SLO. That rules out a stale pipeline and points to semantic change. Distribution analysis then shows the user_engagement_score mean shifting from 0.42 to 0.31, a 26 percent decline, and lineage tracking ties the shift to an upstream pipeline version deployed 5 days earlier. The root cause is not model drift but a feature computation bug in the new pipeline version.
The quantitative impact is the relative CTR loss multiplied by weekly revenue and the fraction of the week exposed: 8 percent of $15M/week over 5 days produces $857K in lost revenue. Distribution monitoring with automated alerts would detect the shift within 4 hours, reducing impact by 97 percent. The resolution is to roll back the pipeline to the previous version, redeploy models with correctly computed features, and add a distribution validation gate to prevent future pipeline deployments with feature shifts exceeding the 10 percent threshold.
Operational integration
Data quality operations integrate into production systems by turning checks into enforceable contracts. Data contracts establish formal agreements between data producers and consumers, specifying schema requirements, freshness SLOs, quality thresholds for completeness and accuracy, and escalation procedures for violations. When a data producer changes schema or computation logic, the contract forces explicit negotiation with consumers rather than allowing a silent interface change.
The contract becomes operational through continuous validation and incident response. Preingestion validation rejects bad source data before accepting it, posttransformation checks verify that computation logic still produces expected values, and final validation prevents corrupted features from reaching models. When quality degrades anyway, automated alerts page the on-call team with severity and affected systems, circuit breakers keep known-bad data out of serving, fallback paths use last-known-good data or cached features, and bad batches are quarantined for forensic analysis. Root-cause analysis then repairs the pipeline rather than only clearing the current alert.
At enterprise scale with thousands of features, monitoring must aggregate by likely shared failure mode. Individual feature monitoring creates alert fatigue, while hierarchical monitoring preserves signal by grouping features along operational boundaries. Source-system grouping catches shared upstream failures, such as a payment-processing outage that affects all payment-related features simultaneously. Computation-pipeline grouping catches errors in transformation code or dependencies. Update-frequency grouping separates streaming features from daily batch features because staleness thresholds and alert sensitivity vary by update pattern. Business-domain grouping then routes user demographic, product catalog, and interaction-feature alerts to the teams that understand the affected models.
Freshness monitoring applies the same aggregation rule to time. For 10,000 features updated at different frequencies, continuous freshness checking generates substantial overhead, so efficient implementations reduce the number of checks without losing systemic signal. Sampling 1 percent of representative entities rather than every feature value is usually enough to detect systemic freshness failures. Pipeline-level aggregation is even cheaper when one pipeline updates 500 features, because the pipeline update timestamp captures the freshness state of the group. Threshold stratification reserves per-feature monitoring for revenue-critical features and uses aggregated monitoring for features whose staleness has lower immediate impact. The resulting overhead scales with the number of distinct features, not the volume of feature values, so efficient implementations maintain \(\mathcal{O}(F)\) overhead even when feature values scale to billions of entities.
Self-Check: Question
A team proposes replacing a feature store’s dual-store architecture with a single high-performance analytical database on the claim that one system can serve both training scans and real-time lookups. What is the strongest argument for keeping the split?
- Training requires high-throughput sequential scans over terabytes while serving requires sub-10ms point lookups at millions of QPS; no single engine optimizes both access patterns well without severe cost penalties.
- Online stores exist only for compliance logging; offline stores exist only for billing.
- Dual-store guarantees that streaming features are always fresher than batch features.
- A single database cannot support versioning or lineage metadata.
A recommendation team powers its ‘user latest action’ feature from a daily batch pipeline, arguing that batch processing is simpler and cheaper. What operational consequence does the chapter predict, and why?
- Lower infrastructure cost with no meaningful product impact, because recent actions are redundant with long-term preferences.
- A staleness tax: session-level intent can shift within seconds, so a batch latency of 12-24 hours means the recommender serves yesterday’s intent, and streaming pipelines show a 10-20 percent engagement lift for exactly this reason.
- Improved reproducibility, because slower feature updates eliminate streaming validation needs.
- Reduced need for point-in-time joins, because daily aggregates are already time-aligned with training data.
A training set is built by joining user events with a user_total_clicks_today feature. The feature table holds end-of-day totals. Explain why this produces leakage and what point-in-time correctness requires instead.
True or False: If an online feature store is fresh (seconds-scale updates) and low-latency (single-digit milliseconds), training-serving skew is no longer a meaningful risk.
A platform backfills a revised feature definition across 12 months of historical data that drives training for 40 models. Which procedure best matches the chapter’s recommended practice?
- Immediately overwrite historical values and retrain all dependent models in parallel to minimize storage overhead.
- Process historical data in date partitions, validate each partition before proceeding, run old and new computations in parallel for an overlap window, and preserve rollback capability to the prior feature version.
- Skip overlap validation if the new definition passes schema checks, because backfill errors are almost always type mismatches.
- Backfill only the online store first, because serving correctness matters more than retraining reproducibility.
Organizational Patterns
Feature stores resolved who owns a shared feature; the broader question is who owns the shared platform itself. Technical infrastructure alone is insufficient for ML operations at scale: organizational structure determines whether platform capabilities become shared infrastructure or another bottleneck. The central question is where an organization places invariants. Deployment safety, observability, compliance, cost control, and feature consistency can either be enforced once by a platform team or rediscovered differently by every model team.
Centralized platform team
A centralized ML platform team maximizes consistency by building and maintaining shared infrastructure while model teams focus on model development. Figure 13 places that pattern alongside embedded and hybrid alternatives, each trading off consistency against velocity.

Centralization works when the same operational mistakes would otherwise recur across the organization. A shared team can enforce consistent deployment, monitoring, and governance practices; invest once in training, serving, and observability infrastructure; and concentrate deep ML systems expertise that would be hard to replicate across many product teams. It also gives infrastructure engineers a visible career path rather than scattering them as one-person support functions.
The same structure can become a queue. If every platform request routes through one team, model teams wait on prioritization decisions they do not control. Distance from product context can also produce abstractions that are technically elegant but poorly matched to the consuming team’s constraints. Centralization is therefore strongest when common invariants dominate local variation, and weakest when model teams need rapid domain-specific changes.
Embedded ML engineers
The embedded pattern chooses proximity over uniformity by placing ML infrastructure expertise inside model teams, with coordination through communities of practice rather than a single reporting line. The benefit is responsiveness: the infrastructure engineer sees the team’s data, model behavior, release pressure, and incident history directly, so local changes do not wait for cross-team scheduling.
The cost appears later, when each team has solved deployment, monitoring, and feature management slightly differently. Fragmentation wastes engineering effort, complicates integration, and makes platform quality depend on the skill and bandwidth of whoever happens to be embedded with a given team. Embedded teams therefore work best when local speed matters more than cross-team consistency, and worst when every team is reimplementing the same platform substrate.
Hybrid models
Most mature organizations adopt hybrid approaches because neither pure centralization nor pure embedding handles both shared infrastructure and domain-specific needs well. The core platform team owns compute, storage, networking, common training and serving systems, monitoring, security, compliance, and cost controls. Domain platform engineers then stay close to recommendation, language, vision, fraud, or search teams, where workload-specific requirements change faster than the shared substrate should.
A federated version of the same idea distributes implementation work without giving up architectural control. Major contributing teams help maintain platform components, but standards, ownership boundaries, and prioritization are coordinated explicitly. This works only when governance has real authority: otherwise federation degenerates into embedding with more meetings.
Organizational pattern selection
The appropriate organizational pattern depends on where standardization creates more value than local autonomy. Table 36 summarizes the organizational pattern decision factors: higher model counts, stricter regulatory requirements, and immature infrastructure favor centralized platforms, while heterogeneous model portfolios and smaller organizations may benefit from distributed expertise:
| Factor | Favors Centralized | Favors Distributed |
|---|---|---|
| Model count | Higher (100+) | Lower (10–20) |
| Model similarity | Homogeneous | Heterogeneous |
| Organization size | Larger | Smaller |
| Regulatory requirements | Stricter | Lighter |
| Infrastructure maturity | Earlier stage | Later stage |
The selection logic becomes clearer in a concrete organization. A technology company with 50 ML engineers across 8 teams operates 80 production models across recommendation, fraud, search, and ads. Each team maintains its own deployment and monitoring, which has created duplicated infrastructure work and inconsistent integration practices. The model count is high enough that shared platform investment should pay off, but the domain diversity is real enough that a purely centralized team would struggle to understand every workload.
The resulting design is hybrid. A central platform team of roughly 12–15 engineers owns core infrastructure, while domain-specific platform leads remain embedded with the largest model teams. A community of practice coordinates standards and a shared contribution model lets domain teams upstream reusable components instead of maintaining permanent forks.
By establishing shared contribution models and domain-specific platform leads, organizations can standardize the shared control plane without turning every domain-specific request into a platform bottleneck. The same platform engineering, feature management, and governance trade-offs become more concrete in the hyper-scale systems built by large technology companies.
Case Studies
The platform cases instantiate the operations trade-offs developed above: standardization vs. team-local velocity, abstraction vs. control, freshness vs. cost, and governance vs. autonomy. Each case shows a different way to keep a multi-model fleet repeatable without turning every model into bespoke infrastructure.
Uber Michelangelo
Uber’s Michelangelo platform shows why repeatability becomes the first platform requirement at company scale (Hermann and Del Balso 2017). This case embodies the first operations trade-off in the platform sequence: standardization vs. team-local velocity. Before Michelangelo, Uber faced a “dual implementation” problem: data scientists developed models in Python, but engineering teams had to rewrite feature pipelines for production, creating delay and logic divergence. The platform combined model training, deployment, serving, workflow management, and feature management for use cases including ETA prediction, fraud detection, and recommendations. Its feature store centralized reusable features such as trip-distance aggregates, reducing duplicated feature engineering and addressing training-serving consistency.
Hermann, Jeremy, and Mike Del Balso. 2017. Meet Michelangelo: Uber’s Machine Learning Platform. Uber Engineering Blog.
The operational challenge at Uber was not just model count, but the need to make model development repeatable across many product teams. Michelangelo provided a “Golden Path” for common workflows: teams could train models, create offline training datasets, serve predictions online or in batch, and reuse platform-managed feature pipelines. This standardization improved automation across training, evaluation, deployment, and monitoring while still requiring product teams to own model behavior and business-specific validation.
A critical evolution in platforms like Michelangelo is the move from batch-centric training toward fresher online features and lower-latency serving. Early platform designs commonly pair offline stores for training data with online stores for serving precomputed or recently computed features. Real-time products such as food delivery and fraud detection then introduce consistency challenges: the same feature definition must produce compatible values for offline training sets and online inference requests. The lesson is durable even when implementation details vary: centralized ML platforms must provide shared abstractions for features, training, serving, experimentation, and monitoring without turning every model into bespoke infrastructure.
Meta FBLearner Flow
Meta’s FBLearner Flow shows how democratizing ML infrastructure requires hiding resource management without hiding workflow structure (Engineering 2016). Facebook reported that more than 25 percent of its engineering organization used FBLearner Flow, that the system had trained more than one million models, and that its online prediction service made more than six million predictions per second. The primary operational challenge was the “N-models problem”: many teams needed repeatable model workflows without hand-building infrastructure for every ranking, ads, recommendation, or integrity model. FBLearner addressed this by treating the training pipeline as a DAG that abstracts away the underlying infrastructure. An engineer defines the workflow in code, and the platform handles resource allocation, dependency management, and fault tolerance.
Engineering, M. 2016. Introducing FBLearner Flow: Facebook’s AI Backbone. Engineering at Meta Blog.
A defining characteristic of large social ML platforms is feature freshness. For products like feed ranking, the value of a feature (for example, “user just clicked ‘like’ on a similar video”) can decay quickly. This pushes platforms toward stream processing, online feature computation, and monitoring that tracks data distributions as well as service health. Standard metrics like CPU usage are insufficient to detect silent failures in feature streams; production ML systems need checks for missing features, distribution shifts, and training-serving skew.
To manage deployment risk, platforms at this scale commonly use Shadow Mode (or dark launching), canary releases, and online evaluation before broad promotion. Candidate models can run alongside the current production model, receiving live traffic while their outputs are logged but not shown to users. This phase verifies operational integrity (latency, memory usage, error rates) and helps build comparison data before a model affects user experience.
Netflix ML infrastructure
Netflix’s ML infrastructure shows how personalization platforms manage fan-out cost under a strict latency budget (Gomez-Uribe and Hunt 2015). Rather than one model making one decision, the recommendation system combines multiple ranking and personalization algorithms for tasks such as page generation, row selection, search, “continue watching,” and artwork personalization. The operational challenge is fan-out cost: every additional online ranker or feature dependency consumes latency budget. Production systems therefore separate candidate generation, offline model training, online ranking, and caching so the homepage can remain personalized without executing an unbounded number of expensive models per request.
Gomez-Uribe, Carlos A., and Neil Hunt. 2015. “The Netflix Recommender System: Algorithms, Business Value, and Innovation.” ACM Transactions on Management Information Systems 6 (4): 1–19. https://doi.org/10.1145/2843948.
A specific problem Netflix tackles aggressively is the “Cold Start”—the inability to recommend content to a new user with no history, or to recommend a brand new show with no viewing data. Their infrastructure solves this using “online learning” bandits that dynamically balance exploration and exploitation. When a new show launches, the system allocates a small “budget” of impressions to test the title on different user cohorts, rapidly converging on an effective audience. This requires an infrastructure capable of updating serving policies, exploration budgets, and recommendation state in near real-time, rather than waiting for the traditional daily batch training cycle. The system must also handle the “feedback loop” latency, ensuring that a user’s interaction with a new title is immediately reflected in their subsequent recommendations, a requirement that pushed Netflix to move key parts of their feature engineering into the serving layer itself.
To validate these complex interactions, Netflix moved beyond standard A/B testing (Blog 2017) to “Interleaving.” In a traditional A/B test, Group A sees Ranking 1 and Group B sees Ranking 2. This requires huge sample sizes and long durations to detect small improvements. Interleaving mixes the results of Ranking 1 and Ranking 2 into a single list for the same user, tracking which source the user actually clicks. This method cancels out user-level variance and creates a direct head-to-head comparison. The infrastructure supports this by allowing the serving layer to merge ranked lists on the fly and log attribution data with high fidelity. While this increases the complexity of the logging and attribution pipelines, the quantitative outcome is substantial: Netflix can detect statistically significant improvements with 100\(\times\) fewer users than traditional A/B testing, allowing them to iterate on ranking algorithms at a velocity that traditional testing frameworks could not support.
Blog, Netflix Technology. 2017. Innovating Faster on Personalization Algorithms at Netflix Using Interleaving. Netflix Tech Blog.
Google Vertex AI
Google Vertex AI illustrates the managed-platform abstraction problem: the platform must remove glue code while preserving enough control for custom workloads. Google aimed to solve the “glue code” problem—where 95 percent of ML code is infrastructure boilerplate—by providing a unified control plane that spans data labeling, training, and serving. A key architectural decision was the integration of AutoML as a first-class citizen alongside custom training. This allows the platform to perform neural architecture search (NAS) to find an effective model structure for a given budget. The operational trade-off here is “compute for human time”: rather than an engineer spending weeks tuning hyperparameters, the platform spins up hundreds of parallel trials. This requires a multi-tenant scheduler capable of managing “burst capacity,” allowing high-priority production jobs to preempt experimental AutoML trials without losing state, effectively maximizing cluster utilization.
For the serving layer, Vertex AI addresses the “noisy neighbor” problem inherent in multi-tenant environments. When thousands of customers deploy models to the same underlying fleet of Tensor Processing Units (TPUs) and GPUs, resource contention can cause unpredictable latency spikes. Google solves this with a strict containerization strategy and a “prediction sidecar” architecture. Every model runs in an isolated container, but a shared sidecar proxy handles logging, monitoring, and request batching. This separation allows the platform to enforce strict resource quotas (CPU, RAM, Accelerator RAM) and provide auto-scaling that reacts to custom metrics like “request queue depth” alongside CPU load. The quantitative benefit is a more predictable latency tail; hard isolation boundaries reduce the chance that a heavy batch job from one tenant degrades the real-time inference performance of another.
Vertex also tackles the feature store problem with a focus on consistency and compliance. Managed feature serving and point-in-time retrieval let training pipelines request only the feature values that existed at the timestamp of each training example. A common operational failure in ML is temporal data leakage—using feature values that were not available at prediction time. Managed feature serving also controls the training-serving skew developed in section 1.7 by standardizing feature definitions and serving paths across both contexts. These design decisions add storage and lineage overhead, but they eliminate entire classes of silent bugs. Combined with cost and utilization controls around training and serving, managed platforms can help teams manage total cost of ownership rather than just providing raw compute.
Spotify ML platform
Spotify’s ML platform shows how personalization infrastructure balances exploration against exploitation at the scale of 500 million users. The core operational challenge is that optimizing strictly for immediate clicks (exploitation) creates “filter bubbles” that degrade long-term user retention. To counter this, the platform supports counterfactual evaluation and contextual bandit algorithms, methods for estimating outcomes and allocating exploration traffic under partial feedback, directly in the serving path. The architecture separates the “candidate generation” phase (retrieving 1,000 potential songs) from the “ranking” phase (ordering the top 10). The candidate generators are diverse—some are collaborative filtering models (Koren et al. 2009) updated daily, while others are “algotorial” heuristics updated in real-time. This decoupling allows the platform to mix-and-match retrieval strategies without rewriting the heavy ranking logic, facilitating rapid experimentation with new content types like podcasts and audiobooks.
Koren, Yehuda, Robert Bell, and Chris Volinsky. 2009. “Matrix Factorization Techniques for Recommender Systems.” Computer 42 (8): 30–37. https://doi.org/10.1109/mc.2009.263.
Engineering, S. 2019. The Winding Road to Better Machine Learning Infrastructure Through TensorFlow Extended and Kubeflow. Spotify Engineering Blog.
A central component of their architecture is the “Paved Road” for model orchestration (Engineering 2019). Spotify describes a platform path built around TensorFlow Extended, Kubeflow Pipelines, metadata tracking, and centralized Kubeflow clusters so teams can move from experiments to repeatable production workflows. The operational lesson is lineage rather than cryptography: model artifacts, datasets, code, and pipeline metadata must remain connected enough that an engineer can trace a silent regression back to the data or workflow state that produced it. Canary deployment and rollback remain necessary release controls, but they are platform policies layered on top of that metadata substrate rather than claims established by the Spotify source itself.
Latency constraints at Spotify are nonnegotiable; playback must feel instantaneous. This forces a design trade-off where complex inference is often precomputed. For the “Discover Weekly” playlist, the platform runs massive batch inference jobs on weekends, storing the results in a low-latency key-value store. However, for the “Home” screen, which must react to the song just listened to, they employ a hybrid approach. User embeddings are updated in near real-time using a streaming pipeline, but the heavy item-item similarity matrices are computed offline. This split architecture allows them to achieve sub-100 ms latency for the Home screen while still incorporating the user’s immediate history. The systems lesson is that latency constraints determine where personalization work runs: precompute what can be stale, stream what must be fresh, and reserve online inference for what the user must experience immediately.
Strict latency requirements explain why mature personalization platforms precompute as much work as possible, but precomputation does not remove operational risk. The same shared registries, feature stores, and orchestrators that make platforms efficient also create control planes whose failures require disciplined incident response.
Self-Check: Question
Reading across Uber Michelangelo, Meta FBLearner, Netflix, Google Vertex, and Spotify, which systems lesson emerges as the shared signature of ML operations at hyper-scale?
- Each team independently optimizes its own stack; standardization actively harms product-team velocity.
- Hyper-scale ML operations must be treated as a platform problem with shared abstractions for lineage, deployment, monitoring, feature serving, and rollout, while product teams still own model behavior and business-specific validation.
- Batch-only pipelines dominate at scale because real-time coordination cost exceeds personalization benefits.
- Quality gains primarily come from replacing shared feature stores with application-specific per-team pipelines.
Meta’s shadow mode and Netflix’s interleaving both reduce deployment risk but solve different problems. Explain what each mechanism optimizes for and why a mature platform uses both rather than choosing one.
True or False: The case studies imply that once a shared ML platform exists, product teams no longer need to own model behavior or business-specific validation.
Production Debugging and Incident Response
At 3:00 AM, PagerDuty alerts the on-call engineer that revenue from the core recommendation system has dropped 15 percent in the last hour. The servers are healthy, the latency is normal, and there are no exception logs. In traditional software, a silent failure of this magnitude is rare; in machine learning systems, it is the expected reality. Debugging production ML systems requires fundamentally different investigative frameworks because the failures reside in data and mathematics as much as in code.
When production debugging consumes a large share of engineering attention, platform scale multiplies the complexity because failures may originate in data pipelines, model code, infrastructure, or emergent interactions between components that no single team owns end to end. Effective incident response therefore needs a diagnostic order: classify the incident, attribute the failure to the right dependency, mitigate the blast radius, and then convert the incident into a stronger platform control.
War Story 1.1: The control plane that disappeared
Context: Meta’s global services depended on a backbone network that connected data centers and carried the internal control traffic needed to operate Facebook, Instagram, WhatsApp, and related systems (Janardhan 2021).
Failure mode: On October 4, 2021, a command intended to assess backbone capacity unintentionally disconnected Facebook data centers from each other. The resulting routing withdrawal also broke access to the DNS and internal tools needed for remote recovery.
Consequence: Major services were unavailable globally for hours while teams restored connectivity through constrained operational paths.
Systems lesson: Platform-scale operations must treat the control plane as a dependency with its own blast radius. Runbooks, out-of-band access, and staged network changes matter because the tools used to fix an outage can depend on the system that is down. ML platforms expose the same trap at fleet scale: training schedulers, model registries, feature stores, and inference routers often share the auth, DNS, and network plane an incident takes down, so recovery requires explicit isolation between the control plane and the ML systems that depend on it.
Janardhan, Santosh. 2021. More Details about the October 4 Outage. Meta Engineering postmortem.
Incident classification
Incident classification is the first routing decision in an outage: the category tells responders which telemetry to inspect first, which owner to page, and whether the likely control is a rollback, a data repair, or infrastructure isolation. The categories below are organized around that first diagnostic signal.
Data incidents involve problems with input data: pipeline failures that prevent fresh data from reaching models, schema changes that break downstream consumers, data quality degradation from missing values or distribution shifts, and feature staleness exceeding SLO thresholds. These incidents often manifest as accuracy degradation across multiple models that share data sources, making data pipeline health the first diagnostic checkpoint.
Model incidents involve problems with model behavior, including accuracy degradation beyond acceptable thresholds, latency spikes indicating computational issues, memory exhaustion from growing state (KV cache, buffers), and prediction bias shifts detected by fairness monitoring. Model incidents typically affect individual models. If multiple unrelated models degrade simultaneously, suspect a shared data or infrastructure issue rather than independent model problems.
Infrastructure incidents involve problems with the serving platform: GPU failures causing request errors, network partitions between model shards, load balancer misconfigurations routing traffic poorly, and container orchestration issues affecting deployments. These incidents tend to produce error rate spikes and timeout patterns rather than gradual accuracy degradation.
Business metric incidents involve unexpected changes to downstream KPIs, such as engagement drops without clear model or data cause, revenue anomalies during normal model operation, and user behavior shifts that affect model efficacy. These incidents are the hardest to attribute because they may stem from external factors (competition, seasonality, marketing campaigns) rather than ML system problems.
Attribution analysis
Attribution analysis protects diagnostic order: determine the root cause before implementing fixes. Temporal correlation analysis traces the degradation backward through recent changes:
Symptom: Recommendation engagement dropped 5% in past hour
Step 1: Check recent deployments
→ No model deployments in past 4 hours
→ Eliminate model change as cause
Step 2: Check feature freshness SLOs
→ user_features: 3 hours stale (SLO: 1 hour)
→ Feature pipeline delayed
Step 3: Check feature pipeline status
→ Kafka consumer lag: 10M events (normal: 10K)
→ Data ingestion bottleneck
Step 4: Investigate Kafka cluster
→ Broker disk 95% full on partition 7
→ Root cause identifiedWhen a model’s accuracy drops, the critical distinction is whether the root cause lies in the data or the model. The attribution flow separates four failure classes:
- Data drift: Input distribution shifted (new user demographics, seasonal patterns)
- Feature staleness: Pipeline delays causing stale predictions
- Model decay: Concept drift where true relationships changed
- Upstream model change: A model this model depends on was updated
The diagnostic sequence then tests the highest-probability shared causes before local model defects:
- Compare current input distribution to training distribution
- Check feature freshness across all input features
- Examine performance on stable evaluation sets
- Trace dependency graph for recent changes
Example 1.3: Feature pipeline cascade
Scenario: A platform team updates the normalization logic for a shared “User Engagement Score” feature, switching from a 30-day z-score to a 7-day min-max scale to better capture trends. They update the feature store definition and backfill the data.
Failure mode: Multiple downstream models, owned by different teams, suffer significant accuracy degradation because they all consumed the feature as an implicit interface.
Consequence: Without explicit lineage tracking, each team debugs its own model architecture and recent deployments before noticing the shared feature change.
Systems insight: Shared features need immutable versions (for example, engagement_score_v2) because feature semantics are production interfaces, not implementation details.
At platform scale, failures often span multiple models, so the affected set becomes a diagnostic signal. Cross-model correlation patterns reveal the likely root cause, as table 37 shows:
| Pattern | Likely Cause |
|---|---|
| All RecSys models degraded | Feature store issue |
| All vision models degraded | Image preprocessing pipeline |
| Single model degraded | Model-specific issue |
| Geographic pattern | Regional infrastructure |
| Time-based pattern | Batch job scheduling |
Runbook development
A runbook earns its place when it preserves diagnostic order under time pressure. For ML systems, the correct diagnostic order is the opposite of what infrastructure instincts suggest: ML systems fail silently. When a feature pipeline stalls, feature values become stale, and the model continues processing those stale features while returning HTTP 200 responses with normal latency—prediction quality degrades invisibly and infrastructure checks appear green. An ML runbook must therefore begin with data and semantic health: verifying feature freshness, confirming that input distributions are consistent with training data, and checking whether a model version changed recently. Only after confirming that data and model behavior are intact should the runbook descend to infrastructure checks. If latency and error rates are nominal but business KPIs have dropped, the runbook must immediately direct the responder to feature freshness and distribution drift before any infrastructure investigation. That ordering starts from the user-visible symptom, tests data and semantic dependencies before infrastructure, and names escalation thresholds before the incident begins, so a responder under stress always knows the next test to run rather than only the system to inspect.
The reusable structure is a diagnostic flow, not a document template. For a recommendation engagement drop, the responder should move through the same control loop every time. Table 38 names the control questions that preserve that order under pressure.
| Step | Question | Example evidence |
|---|---|---|
| Detect user impact | Which product or cohort is degraded? | CTR, conversion, retention, revenue, or complaint rate |
| Localize dependency | Did a shared service change for many models? | Feature freshness, model registry, regional health |
| Bound blast radius | Can traffic be reduced, shadowed, or rolled back? | Canary metrics, rollback target, serving saturation |
| Escalate by evidence | Which team owns the failed control? | Data pipeline, platform, serving, or model owner |
| Learn from the gap | Which missing signal would have caught it sooner? | Freshness gate, slice alert, deployment guardrail |
Runbook anti-patterns break diagnostic order in three common ways. A too-specific instruction such as “If BERT model fails, restart container” encodes one historical fix rather than a reusable investigation. A vague instruction such as “Investigate the issue” transfers all judgment back to the responder at the worst possible time. An outdated runbook is worse than no runbook when it points responders toward deprecated systems, dead dashboards, or obsolete contacts.
Post-incident reviews
Post-incident reviews (PIRs) transform incidents into organizational learning only when they turn one failure into a stronger platform control. The incident record should connect duration and user impact to the timeline of detection, attribution, mitigation, and recovery. Root causes should identify the control that failed or did not exist, and corrective actions should name owners and deadlines so the review changes the platform rather than only documenting the outage.
The useful PIR fields are the ones that force a control decision. Duration and impact quantify severity; the timeline exposes detection and attribution latency; root causes name missing controls; and corrective actions assign ownership for the next platform change. In a feature-freshness incident, the most important observation is not that a disk filled up, but that no freshness gate caught the stalled feature pipeline before engagement metrics moved. The questions in table 39 turn that timeline into platform work.
| PIR question | Control decision it should force |
|---|---|
| How long was user impact visible? | Whether detection latency or mitigation latency dominated the incident. |
| Which dependency failed first? | Whether the missing control belongs to data, platform, serving, or model code. |
| Which signal arrived too late? | Whether a new freshness, slice, saturation, or canary guard is needed. |
| What would have bounded impact? | Whether rollback, traffic shadowing, admission control, or fallback was absent. |
| Who owns the next control? | Whether the review changes the platform rather than only recording blame. |
Effective PIRs require psychological safety and a systems frame rather than individual blame. The review should identify which systems allowed the incident, not which person caused it. It should ask which signal would have detected the failure earlier, not why an individual missed it. It should prevent the class of failure, not only the exact failure that occurred.
Debugging distributed ML systems
Distributed training and inference shift debugging from a single failing process to a coordinated set of ranks, devices, and network paths. Operator triage localizes the failing rank, collective, or resource so the right specialist can act; deep performance debugging then uses NCCL logs, per-rank memory traces, and profilers to explain the mechanism.
Distributed failure diagnostics
Communication is the first failure class to rule out because a single blocked rank can stall the whole distributed job. NCCL19 collective operations can fail silently or hang indefinitely, and listing 8 shows how debug logging identifies blocked ranks.
19 NVIDIA Collective Communications Library (NCCL): NCCL implements AllReduce, AllGather, and ReduceScatter with topology-aware algorithms that exploit NVLink, NVSwitch, and InfiniBand. Debugging NCCL failures is notoriously difficult because collective hangs are deadlocks by another name: one rank waits for data another never sent, producing no error message and no crash – just silence. At fleet scale with thousands of GPUs, identifying the single blocked rank requires correlating logs across all participants.
# Enable NCCL debug logging
export NCCL_DEBUG=INFO
export NCCL_DEBUG_SUBSYS=ALL
# Identify slow/failed ranks
# Look for: "Waiting for" messages indicating a rank is blocking othersWhen a collective hangs, the diagnostic sequence identifies the blocked rank before inspecting local causes:
- Identify which ranks completed vs. blocked
- Check network connectivity between problematic ranks
- Examine GPU memory pressure on blocked ranks
- Look for asymmetric workloads causing timing differences
Once communication has been checked, the same rank-aware discipline applies to model state and memory state. Training instabilities at scale often manifest as gradient issues, each with a distinct diagnostic path, as table 40 summarizes:
| Symptom | Likely Cause | Diagnostic |
|---|---|---|
| Loss NaN | Gradient explosion | Log gradient norms |
| Loss stuck | Vanishing gradients | Check per-layer norms |
| Slow convergence | Learning rate mismatch | Compare to single-GPU baseline |
| Rank divergence | Nondeterminism | Compare rank-specific losses |
OOM errors require the same per-rank view because aggregate memory usage hides the device that actually crossed the limit. Listing 9 tracks memory across devices.
# Memory tracking per rank
for rank in range(world_size):
if torch.distributed.get_rank() == rank:
print(f"Rank {rank}:")
print(
f" Allocated: {torch.cuda.memory_allocated() / BILLION:.2f} GB"
)
print(
f" Reserved: {torch.cuda.memory_reserved() / BILLION:.2f} GB"
)
print(
f" Max allocated: {torch.cuda.max_memory_allocated() / BILLION:.2f} GB"
)
torch.distributed.barrier()Memory leaks in distributed training usually trace to retained state that should have been released:
- Gradient accumulation buffers not freed
- Communication buffers retained across iterations
- Activation checkpointing not releasing properly
Profiling closes the loop by showing which rank limits throughput after communication and memory failures have been ruled out. Listing 10 records per-rank profiles with synchronization.
# Per-rank profiling with synchronization
with torch.profiler.profile() as prof:
# Training iteration
...
# Gather profiles from all ranks
all_profiles = gather_profiles(prof)
# Identify slowest rank and operationThe slowest rank determines overall throughput, so straggler diagnosis must inspect hardware, network, data, and degradation causes:
- Thermal throttling on specific GPUs
- Network congestion on particular switches
- Uneven data loading across ranks
- GPU hardware degradation
Those diagnoses become operational only when the on-call path routes each failure class to the owner who can act on it quickly.
On-call practices for ML teams
ML systems require specialized on-call practices because prediction quality, data freshness, and dependency graphs join uptime as reliability concerns. The debugging sections above explain why an incident can begin as a business metric anomaly and end in a feature pipeline, a model registry, or an NCCL collective. On-call design has to make that diagnostic burden sustainable, building on established Site Reliability Engineering (SRE)20 principles (Beyer et al. 2016).
20 Site Reliability Engineering (SRE): Founded by Ben Treynor Sloss at Google in 2003, SRE introduced error budgets and SLOs as quantitative reliability contracts. For ML systems, classical SRE must be extended: traditional services fail in binary (up/down), but models degrade probabilistically – accuracy can drop 5 percent over weeks without triggering any health check. This demands drift-aware SLOs that treat prediction quality alongside uptime as a reliability metric.
Beyer, Betsy, Chris Jones, Jennifer Petoff, and Niall Richard Murphy. 2016. Site Reliability Engineering: How Google Runs Production Systems. O’Reilly Media.
A structural challenge specific to ML on-call is that the expertise required to resolve an incident is rarely concentrated in one engineer. A single ML production incident may require an ML platform engineer to diagnose the Kubernetes GPU scheduler, a data engineer to trace a stale feature pipeline, and a modeling scientist to interpret whether a distribution shift is a bug or an expected concept drift. Traditional single-role on-call rotations are poorly suited to this because the symptom (a degraded recommendation metric) is entirely decoupled from the root cause domain (an upstream Kafka topic schema change). Mature ML organizations address this by structuring on-call as a tiered or domain-matrixed system: a primary responder owns initial triage and escalation, with clear escalation paths to data engineering, model development, and platform infrastructure as domain specialists. The primary’s role is to route the incident to the correct domain within the first 15 to 30 minutes, not to be capable of resolving every failure class in isolation.
Rotation design determines whether the team can sustain that diagnostic burden. Table 41 lists guidelines that reflect industry practice. The pattern is bounded continuity with redundancy: short rotations limit burnout, secondary coverage handles multi-domain incidents, and handoff overlap preserves context.
| Aspect | Recommendation |
|---|---|
| Rotation length | 1 week (shorter causes context switching, longer causes burnout) |
| Primary + secondary | Always have backup; ML incidents often require multiple experts |
| Handoff overlap | 30 min overlap for incident context transfer |
| Follow-the-sun | For global teams, hand off with timezone; 8-hour shifts maximum |
Alert fatigue poses a persistent risk to on-call effectiveness. Signs include on-call engineers ignoring alerts, assuming false positives, increasing time to acknowledge, and alerts auto-resolving without investigation. Mitigation must reduce pages that do not lead to ML-specific action:
- Tune drift, freshness, latency, and business-metric thresholds quarterly based on false positive rate.
- Deduplicate related model, feature-store, serving, and infrastructure alerts into one incident page.
- Attach runbooks that identify the likely owner and the first diagnostic query for each alert.
- Track alert-to-action ratio; aim for >80 percent.
Beyond general SRE skills, ML on-call requires interpreting model quality metrics, understanding data pipeline dependencies, distinguishing model bugs from data drift, and making rollback vs. investigate decisions under pressure. Toil reduction is equally critical because recurring manual tasks consume the capacity needed to improve the platform. Track time spent on recurring manual tasks, targeting less than 25 percent of on-call time on toil.
Common ML toil usually accumulates at the model-platform boundary:
- Manually restarting failed training jobs
- Manually approving routine deployments
- Investigating alerts that require no action
- Generating recurring reports
Automation is the durable response to recurring toil. Every hour of automation development that saves 10 minutes per incident per on-call pays back within a quarter. Despite these operational tools, common misconceptions consistently lead engineering teams astray when attempting to scale their ML operations.
Self-Check: Question
At 3 AM, a recommendation system’s revenue drops 15 percent in one hour. Serving latency, CPU, memory, and exception logs are all nominal. Which incident class should the on-call engineer investigate first, per the chapter’s debugging logic?
- Data incident: silent feature staleness, schema change, or pipeline degradation can degrade quality without any traditional software-outage signature.
- Infrastructure incident: healthy logs usually mean the failure is hidden inside the cluster network.
- Model incident only: engagement drops cannot originate upstream once a model is in production.
- Security incident: unexplained KPI drops are usually adversarial by default.
A platform with 200 models sees three recommendation models degrade simultaneously. Explain how cross-model correlation accelerates root-cause attribution and why this is more valuable at fleet scale than at single-model scale.
Which characteristic most distinguishes an effective post-incident review for an ML system from an effective post-incident review for a traditional software outage?
- Identifying the individual who missed the earliest warning signal and recording corrective counseling.
- Narrowing the scope strictly to the failed model artifact to avoid diluting conclusions.
- Emphasizing systemic causes, detection delays, and class-of-failure prevention over blame, with explicit treatment of silent data and model-quality failures that have no stack traces.
- Restricting the review format to infrastructure outages only, since silent data incidents cannot be systematically analyzed.
Order the attribution steps for a sudden recommendation engagement drop: (1) Check feature freshness SLOs, (2) Inspect recent deployments for model or pipeline changes, (3) Investigate the specific pipeline or ingestion bottleneck once freshness is violated, (4) Eliminate model change as the primary cause if no recent deployment is found.
A 512-GPU pretraining job appears to hang 40 minutes into a step: no crash, no exception, training simply stops advancing. Why does the chapter identify NCCL collective hangs as especially hard to debug relative to single-process failures?
- Collective failures always crash every rank immediately, leaving too little state to inspect.
- A single blocked rank silently halts progress on every other rank waiting on the collective, producing deadlock-like behavior with no error message and requiring cross-rank inspection to localize the originating rank.
- NCCL runs only on CPUs, so GPU telemetry is irrelevant during diagnosis.
- Memory pressure cannot affect collectives once communication has started.
Fallacies and Pitfalls
Operating machine learning systems at scale involves counterintuitive complexity growth that causes common misconceptions. Engineers often assume that operational practices scale linearly with model count, when in reality the interactions between models create combinatorial complexity that demands fundamentally different platform architectures. These fallacies and pitfalls capture errors that waste millions in operational costs, cause cascading production failures across model fleets, and prevent organizations from deploying machine learning effectively beyond initial prototypes.
Fallacy: Operational complexity grows linearly with model count.
In production, complexity grows superlinearly due to inter-model dependencies: 100 models introduce dense dependency graphs where Model A depends on features from Pipeline B using embeddings from Model C, making isolated updates impossible. The monitoring burden alone is telling: 100 models with 10 metrics each at 5 percent false positive rate generate 14,400 false alerts daily. A platform supporting 40 models with per-model operational practices requires 1,600 engineer-hours monthly ($2.88M annually at $150/hour). Per-model CI/CD, monitoring, and deployment patterns do not compose at scale.
Pitfall: Applying independent alerts to every model and metric.
Comprehensive per-model alerting guarantees alert fatigue. Equation 11 establishes that for \(N_{\text{tests}}=1000\) independent tests (100 models \(\times\) 10 metrics) at \(\alpha_{\text{fp}}=0.05\), \(\Pr(\text{at least one false alert}) = 1 - 0.95^{1000} \approx 1.0\). Operators learn to ignore the noise, and genuine incidents disappear. The solution is hierarchical monitoring: business metrics trigger executive attention, portfolio metrics aggregate across related models, and model-specific metrics serve investigation rather than primary alerting.
Fallacy: Platform investment can wait until the organization reaches 100+ models.
Figure 2 shows platform ROI becomes positive at 20–50 models, not 100+. Technical debt from fragmented practices compounds rapidly: 40 models maintaining 847-line YAML files with no validation schema cause 35 percent of deployment delays; 23 preprocessing scripts with 62 percent duplication require 12 engineer-hours weekly to debug. By the time organizations reach 100 models, migration cost exceeds the cost of building the platform initially by 3–5\(\times\). With 50 models requiring 40 hours monthly operational work each, a $2M platform investment pays for itself within 12 months.
Pitfall: Treating all deployments with uniform procedures regardless of risk profile.
Applying the same staged rollout to every model update either over-burdens low-risk changes or under-protects high-risk ones. Table 8 demonstrates that fraud detection requires hourly updates with seconds-fast rollback, while LLMs require monthly staged rollouts with hours-to-days rollback windows. A fraud model that cannot redeploy within one hour provides an exploitable window; an LLM deployed without multi-day shadow testing risks safety violations across millions of queries. Risk-based policies should match section 1.4 patterns: instant rollback for adversarial models, canary deployments for recommendations, shadow deployments for LLMs.
Fallacy: Per-model metrics, such as loss and accuracy, are sufficient at scale.
In multi-model platforms, system-level metrics matter more than individual model performance. A recommendation ensemble invoking 10–50 models can experience 30 percent latency degradation when one upstream retrieval model slows by 20 ms, even though all accuracy metrics remain nominal. Upstream embedding drift can degrade 12 downstream models simultaneously, a failure mode invisible in per-model accuracy tracking. Section 1.5 establishes that platform observability requires business metrics at the top, portfolio metrics for coordination, model metrics for investigation, and infrastructure metrics at the foundation.
Pitfall: Defaulting to batch pipelines for all features to simplify architecture.
Batch pipelines with daily feature updates ignore the quantitative impact of staleness. The freshness formula \(T_{\text{freshness}} = T_{\text{available}} - T_{\text{event}}\) shows daily batch processing yields \(T_{\text{freshness}} \approx 12\text{--}24 \text{ hours}\); streaming pipelines achieve \(T_{\text{freshness}} \approx 1\text{--}5 \text{ seconds}\). The recommendation-system example in table 34 quantifies the engagement lift from fresher features, and for fraud detection, day-old features give adversaries a 24-hour exploitation window. A recommendation platform generating $15M weekly with 10 percent from ML that improves 15 percent with real-time features gains $225K weekly, easily covering streaming infrastructure costs.
Fallacy: Technical debt is inevitable at scale and should be addressed only when it blocks critical work.
The premise misunderstands technical debt economics. Section 1.1.3.2 establishes quantitative thresholds: deployment velocity exceeding 2 weeks (healthy: $<$1 day) indicates configuration complexity, incident rates exceeding 20 per 1,000 deployments (healthy: $<$5) indicate testing debt, and toil exceeding 50 percent of capacity (healthy: $<$20 percent) indicates automation debt. Monitoring debt alone, with mean-time-to-detect of 4.2 hours, costs $50K per incident \(\times\) 15 incidents yearly = $750K annually. Organizations that treat debt as inevitable watch toil consume 70–80 percent of engineering capacity, creating a death spiral where teams can only maintain existing systems.
Pitfall: Letting debt metrics remain qualitative until toil consumes the team.
Teams that accept growing deployment times and expanding toil as the inevitable “cost of growth” miss the operational signal that the platform boundary has failed. Debt must be measured while it is still small enough to redirect: deployment lead time, incident frequency, alert noise, rollback delay, and toil share are all leading indicators. Recognizing these pitfalls completes the management layer of the AI fleet before the discussion moves to security.
Self-Check: Question
Which of the following is a fallacy the chapter explicitly rejects about scaling ML operations?
- Operational complexity grows roughly linearly with model count, so teams can scale by replicating single-model practices.
- Shared infrastructure improves utilization when model workloads have non-coincident demand peaks.
- Feature freshness matters more for recommendation than for static demographic models.
- Technical debt can be measured using deployment velocity, toil percentage, and incident rate.
True or False: A platform with 200 production models, each monitored on 10 independent metrics with a 1 percent per-metric false-alarm rate, can safely keep the alerting default of ‘page on-call whenever any metric fires’ if the team simply trains operators to filter false positives in real time.
Leadership argues that platform investment should wait until the organization hits 100+ models. The organization currently has 25 models with fragmented CI/CD, per-team monitoring, and 60 percent toil across the platform group. Explain why this ‘wait for 100’ heuristic is usually a mistake, using the chapter’s quantitative arguments.
Summary
ML operations at scale is the “nervous system” of the Machine Learning Fleet. The surrounding arc has moved from physical fleet foundations, to distributed training and serving mechanisms, to the operational and governance layers that keep global services reliable. This chapter developed the management layer required to sustain that architecture across hundreds of models and billions of devices.
The transition from managing a single model to operating an organizational platform represents a qualitative shift in complexity. Per-model operational practices do not compose; they create combinatorial debt that can only be resolved through platform abstractions like centralized registries, ensemble-aware CI/CD, and hierarchical monitoring.
Operational cadences must match model risk profiles, from the staged, weeks-long rollouts of LLMs to the seconds-fast rollbacks of adversarial fraud detection. The TCO framework \((\text{TCO}_{\text{ML}} = C_{\text{train}} + C_{\text{infer}} + C_{\text{data}} + C_{\text{iter}})\) provides quantitative foundations for strategic investment decisions, revealing how cost structure shifts from iteration-dominated (early stage) to inference-dominated (production scale) and how optimization priorities must evolve accordingly. Finally, the MLOps vision extends to the edge, addressing the “Fleet Version Skew” and “Hardware-in-the-Loop” validation requirements essential for managing intelligence on millions of heterogeneous devices.
The central lesson of this chapter is that managing one model differs qualitatively from managing hundreds. A single model can be operated through manual processes, ad hoc monitoring, and bespoke deployment scripts. At organizational scale, these practices collapse under combinatorial weight: 200 models with independent CI/CD pipelines, individual alert configurations, and separate cost tracking create thousands of operational surfaces that no team can maintain. Platform abstractions are the only viable response, transforming per-model toil into shared infrastructure where each additional model incurs marginal rather than linear operational cost.
The practitioner who internalizes this lesson gains a strategic advantage. Understanding TCO economics enables quantitative arguments for infrastructure investment, demonstrating why a $2M platform investment can pay for itself within 12 months at 50 models by eliminating redundant pipelines and reducing incident response costs. Mastering hierarchical monitoring turns fleet-wide observability from an aspiration into an engineering discipline, surfacing cross-model failures that per-model dashboards cannot detect. Quantifying platform ROI in terms of deployment velocity, incident rates, and toil ratios provides the evidence that leadership requires before committing resources. Without these skills, operational debt accumulates silently until it paralyzes the organization, consuming engineering capacity in maintenance while competitors build the platforms that let them iterate faster.
Key Takeaways: Platforms, not pipelines
- One model is not the unit: At portfolio scale, the operational object becomes the dependency graph of models, features, pipelines, alerts, and owners. Registries, lineage, and ensemble-aware CI/CD prevent a local update from silently breaking downstream consumers.
- Platforms turn toil marginal: The summary’s 50-model, $2M platform example shows why shared infrastructure pays back when repeated pipelines, incident response, and manual coordination are removed. The economic gain is not elegance; each added model costs less to deploy and maintain.
- Ownership cost chooses the target: The cost-of-ownership equation separates training, inference, data, and iteration costs, and the dominant term changes over a system’s life. Early fleets should buy velocity; mature high-traffic fleets should buy serving efficiency, utilization, and cost attribution.
- Monitoring must aggregate signal: Per-model dashboards and alerts scale into noise when 100 models each emit independent failures. Hierarchical telemetry, fleet-wide anomaly detection, and feature-quality gates make common-cause incidents visible before alert fatigue hides them.
- Operations reaches the edge: Model fleets do not end at the data center. Weeks-long rollouts, hardware-in-the-loop validation, version skew, and heterogeneous device failures make edge deployment part of the same platform discipline that governs cloud CI/CD.
The surprising claim of this chapter is that operations does not scale, at least not for free. The reason is combinatorial: a fleet’s burden is driven less by any one model than by the interactions among all of them, so effort grows faster than the model count unless something breaks that coupling. A platform is that something. By making the fleet rather than the model the unit that is built, watched, and paid for, it turns each new model from a fixed tax into a marginal one. Without it, the toil compounds until maintenance consumes the very capacity that was meant to build the next thing, and an organization can be at the technical frontier while paralyzed operationally.
What’s Next: A governed fleet is still an attack surface
The operational machinery is now in place. Platform economics, fleet monitoring, edge deployment, and FinOps governance keep hundreds of models reliable and observable. Reliability and observability, however, say nothing about adversaries. Every model endpoint the fleet exposes can be probed for extraction or evasion, every shared pipeline can be poisoned, and every training corpus and telemetry stream is a privacy liability. Security & Privacy takes up that exposure, asking how a fleet defends its models, its data, and its users once it operates at scale.
Self-Check: Question
Two organizations each operate 80 production models. Organization X runs dedicated per-team CI/CD, per-model alerting, and per-team GPU reservations, with platform spend at 10 percent of total ML budget. Organization Y runs a shared CI/CD plane, hierarchical monitoring, a centralized feature store, and pools GPUs, with platform spend at 30 percent of total ML budget. Both have the same headcount. Which organization better embodies the chapter’s operational thesis, and why?
- Organization X, because lower platform spend implies higher fraction of headcount on product work.
- Organization Y, because the chapter’s superlinear-complexity argument implies that fragmented per-team practices accumulate operational debt that eventually paralyzes product teams, while platform investment (even at a higher fraction) is the only mechanism that keeps marginal cost per additional model roughly flat.
- Neither: the chapter is agnostic between the two structures at this scale.
- Organization X, because the 10 percent platform spend indicates the team has successfully kept infrastructure lean.
A team is running a production inference service with \(C_{\text{infer}} = \$500K\) per month, \(C_{\text{train}} = \$50K\) per month, and \(C_{\text{iter}} = \$40K\) per month. They have engineering capacity to pursue one optimization next quarter: a serving quantization project (3-week payback), a training-time compression project (3-month payback), or a new experimentation platform (6-month payback). Using the chapter’s TCO logic, justify a single priority and explain when the team’s answer should change.
Self-Check Answers
Self-Check: Answer
An organization trains one 175B-parameter model per year, requiring 1,000 H100 GPUs for four weeks, and leaves the GPUs idle for the remaining 48 weeks. Under the utilization invariant, which deployment strategy minimizes total cost of ownership (TCO) and why?
- On-premises ownership, because avoiding the cloud provider’s hourly margin over 48 weeks yields the lowest total lifecycle cost.
- Cloud rental, because the organization only pays for the active four weeks and avoids amortizing massive CapEx and continuous facility OpEx over the idle months.
- A hybrid architecture, because the platform can run the steady-state baseline on owned hardware while bursting to the cloud for the four-week training run.
- On-premises ownership with a delayed refresh cycle, because retaining the hardware for five to seven years fully amortizes the facility costs regardless of utilization.
Answer: The correct answer is B. Cloud rental is cheaper for highly bursty workloads because it avoids amortizing the massive upfront CapEx and continuous facility and staffing OpEx over 11 idle months. An answer based on avoiding the cloud provider’s margin misses the fundamental utilization invariant: owning is only cheaper when high, continuous utilization amortizes the fixed costs. The hybrid answer describes a different workload pattern (a steady baseline plus bursts), not a purely episodic workload. The delayed refresh answer fails because older hardware becomes too expensive to operate per unit of computation due to power inefficiency.
Learning Objective: Apply the utilization invariant to evaluate the build-vs-buy decision for a bursty training workload.
A team spends 5 million dollars to train a model that will serve 10 million queries per day. Explain how the total value of ownership (TVO) perspective might justify spending an additional 2 million dollars on training infrastructure to improve the deployed model’s serving efficiency by 20 percent.
Answer: Training is a bounded, one-time capital expense, whereas serving is an ongoing operational cost that accumulates indefinitely and often dominates the model’s lifecycle budget. If the base model costs 3.6 million dollars per year to serve, a 20 percent efficiency improvement saves 720,000 dollars annually, recovering the extra 2 million dollar training investment in under three years. The practical consequence is that organizations should optimize training infrastructure to enable better architecture search or compression, treating higher training costs as an investment in lowering the continuous serving tax.
Learning Objective: Justify why infrastructure decisions must account for the economic inversion where ongoing serving costs exceed one-time training costs over a model’s lifecycle.
When training on preemptible cloud instances at a 70 percent discount, the ____ dictates economic viability: if the system must save state every 10 minutes to survive interruptions and each save takes 30 seconds, 5 percent of the cheaper compute is consumed by I/O overhead rather than forward progress.
Answer: checkpoint tax. This metric captures the I/O overhead required to limit data loss from frequent preemptions, and there is a break-even point where this overhead makes spot instances more expensive in wall-clock time than reserved capacity.
Learning Objective: Infer the checkpoint tax from a scenario describing the I/O overhead required to survive frequent preemptions on spot instances.
True or False: Because ML accelerators are a massive capital expense, an organization with a fixed 300 kW power budget should continue running its 1,000 V100 GPUs for five to seven years to maximize return on investment before upgrading to a newer generation.
Answer: False. Newer generations deliver multiplicatively more throughput per watt, meaning upgrading to a fraction as many H100s can match the old throughput at much lower power, or maxing out the 300 kW budget can deliver an order of magnitude more performance. The electricity savings and throughput gains per watt drive a rapid three to four year depreciation cycle, making older hardware too expensive to operate per unit of useful computation.
Learning Objective: Analyze how the trajectory of power efficiency drives rapid depreciation and hardware refresh cycles for ML accelerators.
Order the following steps in the infrastructure planning methodology for a large training cluster: (1) design the network fabric and validate expected scaling, (2) perform workload characterization to determine the required compute budget and FLOP-hours, (3) translate the IT load through PUE to determine facility power and cooling requirements, (4) size the node by deciding how many accelerators share a host to satisfy memory constraints.
Answer: The correct order is: (2) perform workload characterization to determine the required compute budget and FLOP-hours, (4) size the node by deciding how many accelerators share a host to satisfy memory constraints, (1) design the network fabric and validate expected scaling, (3) translate the IT load through PUE to determine facility power and cooling requirements. The planning is a causal chain from workload to facility: the model and dataset fix the compute budget, the model state fixes the node’s memory architecture, the cluster size fixes the network fabric needed to connect them, and the sum of all IT equipment fixes the facility’s power and cooling. Swapping node sizing and workload characterization would mean designing hardware without knowing the memory pressure or compute target.
Learning Objective: Sequence the stages of infrastructure planning from workload characterization to facility power and justify the causal chain of constraints.
Self-Check: Answer
A model registry that stored only artifact binaries and training metadata failed to prevent a production outage: an upstream embedding update silently changed output dimensionality, causing every downstream ranker to produce garbage. Which capability, present in an enterprise-scale registry, would have prevented this failure?
- Explicit tracking of upstream-downstream dependency edges so a dimensionality change triggers compatibility re-evaluation on all consumers before rollout.
- A larger binary store that retains more historical artifacts per model version.
- A permissions database that restricts which teams can view evaluation metrics.
- Automatic retraining of every downstream model on schedule, so stale-artifact failures never occur.
Answer: The correct answer is A. Enterprise registries differ from artifact catalogs by modeling the dependency graph as a first-class data structure: a dimensionality change on an embedding becomes an automatically discoverable compatibility break on every registered consumer. Storing more binaries does not itself connect consumers to producers. A permissions database solves access control, not coordination. Scheduled blind retraining multiplies cost and would still not detect the silent contract break, because retraining does not validate interface compatibility.
Learning Objective: Identify the dependency-graph capability that distinguishes enterprise model registries from simple artifact catalogs.
A recommendation system invokes 10-50 models per request across candidate generation, ranking, and filtering. Explain why the operational unit of management is the ensemble rather than any individual model, and give one concrete failure mode this principle prevents.
Answer: Because each request traverses many models whose outputs feed each other, system behavior emerges from component interaction, not from any single component’s metric. Downstream rankers are often calibrated to compensate for upstream quirks; improving a retrieval model in isolation can silently remove behavior that ranking depends on, dropping end-to-end engagement even when local offline precision goes up. The consequence is that integration tests, holdout cohorts, and coordinated rollout matter more than isolated per-model validation, and deployment approval must be gated on ensemble-level metrics (engagement, conversion) rather than on component-level accuracy.
Learning Objective: Explain why ensembles are the atomic unit of operational management and what failure mode this prevents.
A recommendation ensemble’s ranking component retrains, improves NDCG by 2 percent offline, and ships. Within hours, production engagement drops 4 percent. Serving latency, checksums, and feature freshness are all healthy. Which explanation best fits the ensemble interaction pattern?
- A deployment artifact mismatch: the production ranker is serving a stale binary whose offline metrics no longer reflect runtime behavior.
- Downstream components were calibrated against the old ranker’s score distribution; the new distribution shifted inputs to diversity filters and business rules, removing compensatory behavior the system had adapted to.
- The retrained ranker exceeded its latency SLO, silently timing out and returning empty lists.
- The offline evaluation set drifted; the 2 percent NDCG gain is a measurement artifact and the model is identical.
Answer: The correct answer is B. Inside an ensemble, one component’s score distribution is another component’s input distribution; a local NDCG improvement that shifts score calibration can break downstream filters tuned to the old distribution, the classic compensation-effect failure. The checksum and freshness signals would have surfaced an artifact mismatch, ruling out the stale-binary explanation. The latency explanation contradicts the healthy-latency observation. The ‘identical model’ explanation ignores that the score distribution shift is itself the mechanism, not a measurement artifact.
Learning Objective: Analyze how compensation effects inside ensembles produce system-level regressions despite local model improvements.
True or False: Once a model passes its launch validation and reaches production, its lifecycle is essentially complete, with only archival and compliance tasks remaining until sunset.
Answer: False. The section treats production as an ongoing lifecycle stage requiring continuous monitoring, scheduled retraining against drift, infrastructure updates as platforms evolve, and formal deprecation planning. Teams that treat production as terminal accumulate zombie models: unowned artifacts whose feature pipelines still run, whose compute costs accrue, and whose outputs no one validates, the single largest contributor to operational debt at scale.
Learning Objective: Evaluate why production is an ongoing operational stage rather than a terminal state in the model lifecycle.
Order the following steps for rolling out an upstream user-embedding model update that has 12 downstream consumers: (1) Trigger re-evaluation of every dependent model on the new embeddings, (2) Enumerate all dependent models from the registry’s dependency graph, (3) Block deployment until compatibility evidence confirms no consumer breaks, (4) Coordinate per-consumer rollout ordering based on risk and dependency depth.
Answer: The correct order is: (2) Enumerate all dependent models from the registry’s dependency graph, (1) Trigger re-evaluation of every dependent model on the new embeddings, (3) Block deployment until compatibility evidence confirms no consumer breaks, (4) Coordinate per-consumer rollout ordering based on risk and dependency depth. Enumeration must precede re-evaluation because you cannot re-evaluate consumers you have not yet identified. Re-evaluation must precede the block/unblock decision because that decision consumes the compatibility evidence. Coordination is last because it operates on the set of compatible consumers; sequencing rollout before the compatibility gate would ship breaking changes to 12 systems simultaneously.
Learning Objective: Sequence the steps of dependency-aware rollout for an upstream update with downstream consumers.
Self-Check: Answer
A training pipeline with six stages (data validation, feature computation, training, evaluation, registration, deployment) fails at the registration stage. With idempotent stage design, how does the pipeline recover, and why does this matter at fleet scale?
- Restart from the failed stage, because idempotence guarantees upstream outputs are reusable and downstream re-execution is deterministic.
- Restart from the beginning, because reproducibility in ML requires re-running every stage from scratch after any failure.
- Skip the failed stage and continue, because idempotent stages are optional and can be bypassed when they error.
- Switch orchestrators, because idempotence removes the need for systems like Kubeflow or Vertex AI Pipelines.
Answer: The correct answer is A. Idempotent stages produce the same output given the same input, so upstream results can be reused and only the failed stage forward needs rerunning. At fleet scale, restarting from scratch would waste hours of training compute every time a late-stage registration or deployment step has a transient failure. The ‘restart from beginning’ answer confuses reproducibility (deterministic outputs) with wasteful re-execution. The ‘skip and continue’ answer would deploy an unregistered artifact, violating governance. The ‘no orchestrator’ answer conflates idempotent stage design with DAG scheduling, retries, and resource management, which remain necessary.
Learning Objective: Explain how idempotent stage design bounds failure-recovery cost in ML CI/CD pipelines.
A fraud-detection model passes offline precision and recall targets but reports p99 latency of 28 ms on representative hardware. The section’s model-type latency gate for fraud detection is 20 ms p99. What should the CI/CD system do?
- Approve with a warning, because fraud models prioritize quality over latency.
- Block the deployment, because fraud detection runs inline in transaction flows and a 40 percent over-budget p99 translates to timeouts that worsen both user experience and the adversarial attack surface.
- Allow shadow deployment first, because hard latency gates apply only to LLMs.
- Ignore the latency result if rollback is fast, because seconds-level rollback masks any transient impact.
Answer: The correct answer is B. Fraud detection has the tightest latency gate in the chapter’s table (20 ms p99 blocking) because it runs synchronously in the payment path: a 28 ms p99 is 8 ms, or 40 percent, over budget. At 1000 TPS, even counting the overage only against the slowest 1 percent of requests gives \(8 \text{ ms} \times 10 \text{ requests/s} \times 86{,}400 \text{ s} = 6.9\) million extra milliseconds of tail wait per day, creating a window adversaries can exploit by timing transactions to force timeouts. Treating latency as secondary to quality inverts the fraud risk profile. Restricting blocking gates to LLMs misreads the table. Fast rollback cannot erase the transaction failures already suffered during the breach window.
Learning Objective: Apply model-type-specific latency gates to deployment decisions on adversarially-constrained workloads.
A ranking model serves 1 million requests per hour. A CTR A/B test needs roughly 10,000 samples in the treatment cohort to detect a meaningful lift. The rollout plan offers 1 percent and 5 percent canary stages. Compute the stage durations and explain the operational trade-off this imposes on rollout design.
Answer: Stage duration equals samples-needed divided by (requests \(\times\) canary fraction). At 1 percent, canary rate is 10,000 req/hr, yielding a full cohort in roughly 1 hour. At 5 percent, the canary rate is 50,000 req/hr, yielding the cohort in about 12 minutes. The trade-off is that lower percentages reduce blast radius (fewer users exposed to a regression) but delay the statistical decision, while higher percentages accelerate the decision but expose more users to any defect. The practical consequence is that rollout plans combine small early stages (safety margin) with larger later stages (decision speed); holding an unsafe model in a 1 percent stage for the full 10-sample-multiple is itself a cost, because rollback after detection still leaves traffic exposed during the measurement window.
Learning Objective: Quantify the canary-percentage vs. decision-speed trade-off and justify a staged rollout schedule.
A financial prediction service spanning five regions must never serve two different model versions to customers in the same currency zone because downstream settlement reconciles predictions. Which deployment-consistency model best matches this constraint?
- Strong consistency: all regions must serve the same version at every logical timestamp, because version divergence breaks settlement correctness.
- Eventual consistency: each region progresses independently, because financial models tolerate brief skew.
- Bounded staleness: regions may differ by up to k versions as long as rollback exists.
- Any model: sticky routing at the customer level removes the global coordination requirement.
Answer: The correct answer is A. Strong consistency is the section’s prescription for financial and safety-critical services where cross-version divergence produces incorrect results in downstream systems, not just inconsistent user experience. Eventual consistency and bounded staleness trade coordination cost for temporary skew, which is acceptable for some recommendation workloads but not for settlement reconciliation where two different model versions produce two different ground truths. Sticky routing solves per-user consistency but does nothing for a cross-customer settlement reconciliation that joins predictions across users.
Learning Objective: Select a deployment-consistency model appropriate to an application’s correctness constraints.
True or False: Interleaving experiments are the preferred evaluation method for ranker comparisons because they expose different user populations to different rankers more cleanly than A/B testing does.
Answer: False. Interleaving works precisely the opposite way: it blends outputs from both rankers into a single list presented to the same user, using within-user variance reduction to detect differences with roughly 100\(\times\) fewer users than split-population A/B testing. The sample-efficiency gain is the mechanism that makes it the Netflix-style default for ranker comparisons.
Learning Objective: Distinguish the within-user comparison mechanism of interleaving from the between-user comparison of A/B testing.
A team is about to deploy a new LLM backbone whose primary risks are subtle quality regressions on long-tail tasks and rare safety failures that automated metrics cannot reliably catch. Which CI/CD strategy best matches this risk profile?
- Threshold-gated rapid deployment with seconds-level rollback, because adversarial response time is the key metric.
- Quality-gated pipeline: benchmark suites, human evaluation, safety review, mandatory shadow period on live traffic, and slow staged rollout over days to weeks.
- Fast canary only, because online user feedback is a more reliable quality signal than offline evaluation for LLMs.
- Blue-green cutover, because duplicate environments remove the need for extended soak periods.
Answer: The correct answer is B. The section characterizes LLM CI/CD as quality-gated and slow precisely because the failure modes (subtle regressions, rare safety events) are invisible to automated metrics over short windows; shadow deployment and human evaluation are the only reliable detectors. The fraud-style threshold-gated approach confuses adversarial reactivity (short rollback matters most) with quality-risk reactivity (detection lag matters most). Relying on user feedback alone skips the human-eval and safety layers. Blue-green cutover accelerates rollback but provides zero additional quality signal during the switch, which is the binding constraint here.
Learning Objective: Design a CI/CD process that matches an LLM deployment’s quality and safety risk profile.
Self-Check: Answer
A fleet of 100 models runs 10 independent metric checks each at a 1 percent per-check false-positive rate. The on-call team receives continuous pages and starts ignoring them. Which mechanism best explains why this alerting scheme collapses?
- Most ML metrics cannot be sampled more than once per day at fleet scale, so the alerts are stale.
- Across 1,000 independent checks with 1 percent false-positive rates, \(\Pr(\text{at least one false alert}) = 1 - 0.99^{1000}\), which is essentially 1, making continuous noise mathematically inevitable.
- Fleet-wide monitoring eliminates the need for per-model metrics, so these checks are unnecessary.
- Alert fatigue is caused primarily by telemetry storage cost rather than statistical compounding.
Answer: The correct answer is B. The binomial compounding of independent tests makes the probability of at least one false positive rise to essentially 1 as the number of checks grows, regardless of individual check rigor. Per-model metrics remain valuable for investigation; the failure mode is alerting on each one independently, not measuring them. The sampling-cadence explanation confuses alert noise with metric freshness. The storage-cost answer attributes the problem to infrastructure when it is a statistical consequence of independent test multiplication.
Learning Objective: Analyze why false-positive compounding across independent per-model alerts makes naive alerting unsustainable at fleet scale.
Explain why hierarchical monitoring is more effective than enumerating independent dashboards and alerts for each model, using a concrete failure scenario to illustrate.
Answer: Hierarchical monitoring surfaces a small number of high-signal business and portfolio indicators first, then lets operators drill down into model and infrastructure detail only when an aggregated signal warrants it. Concretely, if portfolio CTR drops 3 percent across the recommendation fleet, a hierarchical system raises one business-level alert and the operator immediately sees that the drop is fleet-wide, directing investigation toward a shared upstream (feature pipeline, embedding service) rather than 40 separate ‘engagement degraded’ alerts. The practical consequence is that attribution collapses from \(\mathcal{O}(N_{\text{models}})\) per-model dashboards to a single cause, reducing time-to-mitigation and preventing alert fatigue from destroying response quality.
Learning Objective: Explain how hierarchical aggregation improves attribution speed and alert quality in fleet-scale monitoring.
A platform observes simultaneous anomalies across 80 percent of its recommendation models at the same timestamp. The models were trained independently and serve different regions. What conclusion is most consistent with the chapter’s fleet-wide anomaly analysis?
- Every model independently overfit at the same moment, so each team should debug locally.
- The correlated simultaneous signal indicates a shared cause (feature pipeline outage, ingestion schema change, or infrastructure issue), not 80 independent model regressions.
- Correlation analysis should be disabled because simultaneous alerts almost always reflect random coincidence.
- The issue is probably a CI/CD fairness-gate false positive rather than a runtime operational incident.
Answer: The correct answer is B. When a high fraction of independent models degrade at the same timestamp, the probability this reflects independent causes is vanishingly small; the only hypotheses that remain plausible are shared-cause events in the data pipeline, feature store, or infrastructure. Treating each as an independent failure is exactly the per-model debugging trap hierarchical fleet monitoring is designed to avoid. Disabling correlation analysis would eliminate the only signal that can distinguish shared from independent causes. CI/CD fairness gates fire at deployment time, not as runtime fleet-correlated signals.
Learning Objective: Attribute correlated fleet-wide anomalies to likely shared operational causes rather than independent model failures.
A platform must monitor feature drift across 10,000 continuous features at hourly cadence for 200 models. Explain why the Population Stability Index (PSI) is operationally preferable to waiting for delayed label-based metrics, and describe one failure mode PSI does not cover.
Answer: Label-based drift metrics wait until ground truth arrives (often hours to days), by which point the model has already served degraded predictions to users. PSI is a cheap bucketed divergence statistic between current and reference feature distributions; it can run at hourly cadence on 10,000 features without human labels, flagging distribution shift in near-real-time so the team can pause retraining or enable rollback before quality degrades measurably downstream. Its limitation is that PSI detects covariate shift only, not concept drift: the relationship between features and the label can change while marginal feature distributions stay constant, and PSI will see nothing. The practical consequence is that PSI belongs in a multi-layer monitoring stack with both feature drift and label-based metrics, used as a fast early warning rather than a complete drift detector.
Learning Objective: Justify selecting a distribution-divergence statistic for scalable feature-drift monitoring and identify the drift mode it misses.
Order the following steps of the chapter’s cost-anomaly investigation workflow for a sudden inference-cost spike: (1) Perform root-cause checks on traffic, latency, model version, and utilization, (2) Confirm the billing data reflects real spend rather than a measurement artifact, (3) Compute anomaly severity (e.g., Z-score against the 30-day baseline), (4) Decide whether the driving quality gain justifies sustained higher cost or whether optimization is required.
Answer: The correct order is: (3) Compute anomaly severity against the 30-day baseline, (2) Confirm the billing data is real and not a measurement artifact, (1) Perform root-cause checks on traffic, latency, model version, and utilization, (4) Decide whether the quality gain justifies sustained higher cost or whether optimization is required. Severity first establishes whether the spike exceeds the noise floor and warrants further work. Verification rules out billing-pipeline artifacts that would waste engineering hours. Root-cause then attributes the spike to a specific driver (traffic surge, version change, utilization drop). Only after the driver is known can the team make the product decision in step 4; swapping the decision before root-cause forces teams to accept or optimize a cost they do not yet understand.
Learning Objective: Apply the chapter’s structured workflow for detecting, verifying, attributing, and deciding on ML cost anomalies.
Self-Check: Answer
A platform team is deciding between providing a fully managed serving interface (‘deploy by pushing a model registry pointer’) and a bare Kubernetes cluster with no ML-specific conventions. What trade-off governs this abstraction decision?
- Higher abstraction delivers more self-service velocity and standardization, while lower abstraction preserves per-team flexibility and custom optimization paths at the cost of duplicated plumbing.
- Higher abstraction always reduces cost, latency, and governance overhead simultaneously with no downside.
- Lower abstraction is preferable only for teams lacking containerization skills; otherwise abstraction level does not affect operations.
- Abstraction level applies to training workloads only; serving, monitoring, and deployment are unaffected.
Answer: The correct answer is A. Platform abstraction is a convenience-versus-flexibility decision: paved-road platforms accelerate the median team by standardizing deployment, monitoring, and rollout but constrain teams whose workloads do not fit the standard template. Bare infrastructure preserves control but forces every team to rebuild the same plumbing. The ‘no downside’ answer contradicts the trade-off central to the section. The ‘only for non-containerized teams’ answer mistakes a historical accident for the principle. The ‘training only’ answer ignores that the abstraction decision is platform-wide, spanning deployment, monitoring, and governance.
Learning Objective: Compare ML platform abstraction levels by the trade-off between velocity and flexibility.
A 100-GPU training cluster shows 65 percent average GPU compute utilization, 80 percent memory utilization, and 4-hour average queue times. Diagnose the most likely bottleneck and recommend the highest-leverage intervention.
Answer: The signature says the cluster is not over-provisioned and jobs are correctly memory-sized (80 percent memory utilization), yet compute utilization is moderate and queues are 4 hours deep. Running jobs are not consuming the GPUs they hold, which typically points to upstream data-loading stalls or scheduling gaps between jobs: the GPUs wait while queued jobs wait for them. The highest-leverage next step is to profile data-loading and scheduling, not to buy more hardware: fixing a data-loading stall or tightening scheduler handoff can raise compute utilization from 65 percent to 85 percent, unlocking effectively 30 percent more cluster capacity without capital spend. Adding GPUs before diagnosing this would worsen the cost structure while leaving the queue problem untouched.
Learning Objective: Diagnose training-cluster bottlenecks from utilization and queue signals and prioritize interventions before capacity expansion.
A platform reports 90 percent GPU busy time across its training fleet, but engineers observe that wall-clock time to train the same models barely improves quarter over quarter. Which statement best explains why ML productivity goodput (MPG) is a more useful metric than raw utilization in this situation?
- MPG ignores scheduling delays to focus purely on kernel efficiency, bypassing fleet-level waste.
- MPG measures whether hardware is busy regardless of whether the work is useful.
- MPG decomposes useful output into scheduling efficiency, runtime efficiency, and program efficiency, exposing failed jobs, recomputation, and inefficient code that raw ‘busy time’ masks.
- MPG is a FinOps-only metric used to allocate cloud bills, not an engineering diagnostic.
Answer: The correct answer is C. Goodput was introduced because a GPU can be 90 percent busy on restarted failed jobs, gradient recomputation, or poorly-vectorized kernels, and none of that busyness produces useful model training. MPG decomposes usefulness into its three determinants so the team can see that a 90/90 utilization reading hides a 50 percent waste ratio. The ‘ignores scheduling’ answer inverts the decomposition. The ‘busy regardless of useful’ answer describes raw utilization, not MPG. The ‘FinOps-only’ answer reduces an engineering diagnostic to a billing label.
Learning Objective: Explain why goodput decomposes raw utilization into useful-work components that busy-time cannot surface.
An LLM platform must choose between RAG and fine-tuning for a knowledge-heavy financial assistant whose source data changes hourly (market news, filings) and whose answers must include citations. Which choice does the chapter favor, and why?
- Fine-tuning, because the specialized financial domain language is the dominant concern.
- RAG, because high knowledge volatility and attribution requirements make retrieval-corpus updates the cheaper refresh mechanism, at the cost of higher per-query inference compute.
- Fine-tuning with thousands of per-customer adapters, to minimize operational complexity.
- RAG, because it eliminates context-window compute overhead entirely.
Answer: The correct answer is B. The section maps RAG to high-volatility + high-attribution scenarios: the financial assistant’s knowledge changes every hour, so retraining weights nightly is both expensive and still hours stale, while updating the retrieval corpus propagates in minutes. The citation requirement also favors retrieval, because grounding text can be surfaced as the source. The fine-tuning-for-language answer conflates domain vocabulary (which fine-tuning handles) with factual volatility (which it does not). The ‘thousands of adapters’ option invents operational complexity. The ‘RAG eliminates context compute’ answer inverts the cost model; RAG’s trade-off is that it moves cost to inference via longer prompts.
Learning Objective: Evaluate the RAG-versus-fine-tuning trade-off for an LLM application based on knowledge volatility, attribution, and cost structure.
True or False: In mature production ML systems, the one-time training bill is the dominant long-run financial risk, and inference plus hidden operational costs remain secondary.
Answer: False. The TCO framework shows that as user volume grows, continuous inference and hidden operational costs (engineering labor, monitoring, compliance, data pipelines) typically dominate lifetime spend; the initial training bill and later retraining are only part of the full cost structure. The chapter’s ‘iceberg’ framing warns that teams focused only on the visible training bill miss much of the TCO that sits underwater.
Learning Objective: Evaluate how dominant cost components shift from training to inference and hidden ops as ML systems mature.
A production platform spends $400,000 per month on inference. An INT8 quantization project costs $80,000 to implement and is expected to cut inference cost by 40 percent. Using the chapter’s break-even framework, how should the team prioritize this optimization?
- Deprioritize: architecture changes should be avoided once serving is stable.
- Top priority: monthly savings are $160,000, so payback is about 0.5 months, making this optimization one of the highest-return investments available in an inference-dominated TCO.
- Medium priority: payback is about two months, behind training-efficiency work.
- Cannot evaluate: inference savings are only knowable after traffic doubles.
Answer: The correct answer is B. Monthly savings are $400,000 \(\times\) 0.40 = $160,000, and $80,000 / $160,000 = 0.5 months payback. When inference dominates TCO (>40 percent), serving-side optimizations typically carry the shortest payback periods in the portfolio, and a two-week recoup is exceptional. The ‘avoid architecture changes’ answer confuses operational stability with optimization paralysis. The ‘two-month payback’ answer miscomputes the break-even. The ‘need more traffic’ answer misreads the formula; the savings are already realizable at current volume.
Learning Objective: Apply the break-even formula to prioritize platform optimizations under an inference-dominated TCO.
Self-Check: Answer
A team proposes replacing a feature store’s dual-store architecture with a single high-performance analytical database on the claim that one system can serve both training scans and real-time lookups. What is the strongest argument for keeping the split?
- Training requires high-throughput sequential scans over terabytes while serving requires sub-10ms point lookups at millions of QPS; no single engine optimizes both access patterns well without severe cost penalties.
- Online stores exist only for compliance logging; offline stores exist only for billing.
- Dual-store guarantees that streaming features are always fresher than batch features.
- A single database cannot support versioning or lineage metadata.
Answer: The correct answer is A. The dual-store split is forced by fundamentally different access patterns: analytical engines (BigQuery, data lakes on S3) optimize scans via columnar layout and distributed joins, while serving engines (Redis, DynamoDB, Bigtable) optimize point lookups via key-value indexing and in-memory residency. Trying to serve both on one engine costs either throughput (during scans) or latency (during lookups) by one to two orders of magnitude. Compliance, freshness guarantees, and metadata capabilities are present in many single-engine systems and are not the binding reason for the split.
Learning Objective: Explain why conflicting training vs. serving access patterns force the dual-store feature architecture.
A recommendation team powers its ‘user latest action’ feature from a daily batch pipeline, arguing that batch processing is simpler and cheaper. What operational consequence does the chapter predict, and why?
- Lower infrastructure cost with no meaningful product impact, because recent actions are redundant with long-term preferences.
- A staleness tax: session-level intent can shift within seconds, so a batch latency of 12-24 hours means the recommender serves yesterday’s intent, and streaming pipelines show a 10-20 percent engagement lift for exactly this reason.
- Improved reproducibility, because slower feature updates eliminate streaming validation needs.
- Reduced need for point-in-time joins, because daily aggregates are already time-aligned with training data.
Answer: The correct answer is B. The chapter quantifies the freshness-engagement gradient: hourly features give +10.2 percent vs. +8.1 percent for daily, and real-time features give +12.3 percent. The Archetype B (DLRM) callout frames the same phenomenon as the ‘staleness tax’ on session-level intent. The ‘no impact’ answer confuses cheaper plumbing with no cost. The reproducibility answer conflates determinism with currency. The point-in-time answer misreads the problem: batch daily features still require point-in-time joins, they are just stale point-in-time values.
Learning Objective: Analyze how feature-freshness choices impose a measurable staleness tax on session-driven recommendation quality.
A training set is built by joining user events with a user_total_clicks_today feature. The feature table holds end-of-day totals. Explain why this produces leakage and what point-in-time correctness requires instead.
Answer: An event at noon with a click outcome is being paired with the end-of-day total of 10 clicks, but at prediction time (noon) the user had only made 4 clicks. The training signal encodes 10 when production can ever only see 4, so the model learns to rely on future information that will never arrive in serving. Point-in-time correctness requires joining events with the feature value that existed at the event timestamp, using a lateral join that selects the most recent feature record whose feature_timestamp is <= event_timestamp. The practical consequence is spectacular offline metrics (99 percent-type accuracy on ‘easy’ future-leaked signals) followed by catastrophic production failure, which is why feature stores make time-aware joins an infrastructure guarantee rather than a per-team convention.
Learning Objective: Explain why naive feature joins leak future information and what point-in-time correctness mechanically requires.
True or False: If an online feature store is fresh (seconds-scale updates) and low-latency (single-digit milliseconds), training-serving skew is no longer a meaningful risk.
Answer: False. Skew arises from any divergence between the computation performed during training and the computation performed during serving, independent of freshness. A Python script in training and a C++ implementation in serving, a different null-handling rule, or a subtly different aggregation window can all produce silent skew while both paths are fast and fresh. Feature stores address skew by making training and serving read from the same materialized values (\(f_{\text{train}}(x) \equiv f_{\text{serve}}(x)\) as an architectural invariant), not by speeding the online path.
Learning Objective: Evaluate why latency and freshness alone do not eliminate training-serving skew.
A platform backfills a revised feature definition across 12 months of historical data that drives training for 40 models. Which procedure best matches the chapter’s recommended practice?
- Immediately overwrite historical values and retrain all dependent models in parallel to minimize storage overhead.
- Process historical data in date partitions, validate each partition before proceeding, run old and new computations in parallel for an overlap window, and preserve rollback capability to the prior feature version.
- Skip overlap validation if the new definition passes schema checks, because backfill errors are almost always type mismatches.
- Backfill only the online store first, because serving correctness matters more than retraining reproducibility.
Answer: The correct answer is B. The recommended procedure combines incremental partitioned backfill (contain blast radius), dual-write overlap (compare new and old computations on the same period), and rollback readiness (revert if overlap diverges). Immediate overwrite removes the rollback option the moment anything unexpected appears. Schema-only validation misses semantic bugs (unit errors, windowing changes) that schemas cannot catch. Online-first backfill breaks the training-serving consistency the feature store exists to guarantee, because models trained on old offline values would now serve against new online values.
Learning Objective: Apply safe operational procedures for feature-definition changes and historical backfills.
Self-Check: Answer
Reading across Uber Michelangelo, Meta FBLearner, Netflix, Google Vertex, and Spotify, which systems lesson emerges as the shared signature of ML operations at hyper-scale?
- Each team independently optimizes its own stack; standardization actively harms product-team velocity.
- Hyper-scale ML operations must be treated as a platform problem with shared abstractions for lineage, deployment, monitoring, feature serving, and rollout, while product teams still own model behavior and business-specific validation.
- Batch-only pipelines dominate at scale because real-time coordination cost exceeds personalization benefits.
- Quality gains primarily come from replacing shared feature stores with application-specific per-team pipelines.
Answer: The correct answer is B. The five case studies share a repeating pattern: shared platform abstractions for lineage, deployment, monitoring, feature serving, experimentation, and rollout let product teams avoid rebuilding the same infrastructure while still owning model behavior and domain-specific validation. Celebrating fragmentation inverts the central lesson. The batch-dominance claim contradicts the emphasis on feature freshness, shadow mode, interleaving, and hybrid streaming/batch designs. The ‘replace feature stores’ claim inverts the feature-store and managed-serving lessons in the case studies.
Learning Objective: Synthesize the shared platformization lesson across large-scale ML case studies while recognizing the boundary between platform ownership and product-team validation.
Meta’s shadow mode and Netflix’s interleaving both reduce deployment risk but solve different problems. Explain what each mechanism optimizes for and why a mature platform uses both rather than choosing one.
Answer: Shadow mode runs a candidate model on live traffic without showing outputs to users, validating operational properties (latency, memory, reliability, resource contention) and producing behavioral comparisons against the incumbent without product risk. It solves ‘will this model survive production at all’. Interleaving mixes ranker outputs into a single list for the same user and measures which source the user clicks; it solves ‘is the new ranker statistically better on quality’ with roughly 100\(\times\) fewer users than split-population A/B testing. The two mechanisms operate on orthogonal dimensions: shadowing answers operational viability before any quality signal is collected, and interleaving answers quality improvement efficiently after operational viability is established. The practical consequence is that mature platforms pipe candidate models through shadow first (gating on latency and error rates), then into interleaving (gating on quality lift), rather than treating them as substitutes.
Learning Objective: Compare shadow deployment and interleaving experiments by what each mechanism validates and why both are needed.
True or False: The case studies imply that once a shared ML platform exists, product teams no longer need to own model behavior or business-specific validation.
Answer: False. The case studies show the opposite boundary: shared platforms provide reusable infrastructure for features, training, serving, experimentation, deployment, and monitoring, but product teams still own whether model behavior satisfies domain-specific and business-specific requirements. Uber’s platform, for example, standardizes common workflows while still requiring product teams to validate model behavior. The durable lesson is shared plumbing plus local accountability, not centralized ownership of every model decision.
Learning Objective: Evaluate the boundary between shared platform responsibilities and product-team model ownership in large ML organizations.
Self-Check: Answer
At 3 AM, a recommendation system’s revenue drops 15 percent in one hour. Serving latency, CPU, memory, and exception logs are all nominal. Which incident class should the on-call engineer investigate first, per the chapter’s debugging logic?
- Data incident: silent feature staleness, schema change, or pipeline degradation can degrade quality without any traditional software-outage signature.
- Infrastructure incident: healthy logs usually mean the failure is hidden inside the cluster network.
- Model incident only: engagement drops cannot originate upstream once a model is in production.
- Security incident: unexplained KPI drops are usually adversarial by default.
Answer: The correct answer is A. The chapter’s attribution framework identifies silent data failures (stale features, schema drift, pipeline degradation) as the dominant ML incident class because they produce KPI-level symptoms without the infrastructure-level signatures traditional monitoring relies on. The infrastructure-first answer ignores that healthy telemetry is the diagnostic clue pointing away from infrastructure. The model-only answer contradicts the framework’s explicit insistence that model artifacts are often downstream victims. Defaulting to ‘adversarial’ over-weights a low-base-rate cause and wastes the first investigation hour on security when the feature pipeline is far more likely.
Learning Objective: Classify silent production degradations using the ML incident taxonomy.
A platform with 200 models sees three recommendation models degrade simultaneously. Explain how cross-model correlation accelerates root-cause attribution and why this is more valuable at fleet scale than at single-model scale.
Answer: Cross-model correlation asks: are multiple models failing the same way at the same time? If three recommendation models share the same feature pipeline and all degrade together, the correlation points to a shared upstream (feature store outage, ingestion schema break, embedding-service failure) rather than three independent model bugs. At single-model scale this question is meaningless because there is nothing to correlate with; at fleet scale, correlated signals are the only mechanism that distinguishes systemic causes from local ones. The practical consequence is faster attribution (minutes instead of hours), alert deduplication (one shared-cause incident instead of three per-model pages), and correct escalation (the feature-platform team owns the fix, not the individual model teams), directly reducing MTTR and preventing the per-model dashboard explosion that makes fleet incidents unmanageable.
Learning Objective: Explain how cross-model correlation improves attribution at fleet scale and why single-model debugging lacks this lever.
Which characteristic most distinguishes an effective post-incident review for an ML system from an effective post-incident review for a traditional software outage?
- Identifying the individual who missed the earliest warning signal and recording corrective counseling.
- Narrowing the scope strictly to the failed model artifact to avoid diluting conclusions.
- Emphasizing systemic causes, detection delays, and class-of-failure prevention over blame, with explicit treatment of silent data and model-quality failures that have no stack traces.
- Restricting the review format to infrastructure outages only, since silent data incidents cannot be systematically analyzed.
Answer: The correct answer is C. Effective ML post-incident reviews emphasize psychological safety and systemic learning because many ML failures (distribution drift, feature staleness, silent data corruption) produce no stack trace and no single ‘did wrong’ moment, so blame-oriented reviews discourage reporting and narrow artifact-focused analysis misses the shared-cause pattern. Blame-centered reviews chill reporting and push future incidents underground. Artifact-narrow reviews miss the upstream data pipeline that is actually at fault. Excluding silent-quality incidents from review eliminates the category ML systems disproportionately suffer.
Learning Objective: Evaluate post-incident review practices that convert ML-specific silent failures into organizational learning.
Order the attribution steps for a sudden recommendation engagement drop: (1) Check feature freshness SLOs, (2) Inspect recent deployments for model or pipeline changes, (3) Investigate the specific pipeline or ingestion bottleneck once freshness is violated, (4) Eliminate model change as the primary cause if no recent deployment is found.
Answer: The correct order is: (2) Inspect recent deployments, (4) Eliminate model change as the primary cause if no recent deployment is found, (1) Check feature freshness SLOs, (3) Investigate the specific pipeline or ingestion bottleneck once freshness is violated. The sequence follows the chapter’s attribution flow: obvious recent changes are ruled out first because they are the cheapest signal to check and the highest-base-rate cause. Once model change is eliminated, attention shifts to the shared data path starting at the SLO boundary. Only after a freshness violation is confirmed does the team dive into pipeline forensics; going straight to deep pipeline diagnosis before checking deployments and freshness wastes the first hour on a low-probability subsystem and delays mitigation.
Learning Objective: Apply the chapter’s structured attribution workflow to a production recommendation incident.
A 512-GPU pretraining job appears to hang 40 minutes into a step: no crash, no exception, training simply stops advancing. Why does the chapter identify NCCL collective hangs as especially hard to debug relative to single-process failures?
- Collective failures always crash every rank immediately, leaving too little state to inspect.
- A single blocked rank silently halts progress on every other rank waiting on the collective, producing deadlock-like behavior with no error message and requiring cross-rank inspection to localize the originating rank.
- NCCL runs only on CPUs, so GPU telemetry is irrelevant during diagnosis.
- Memory pressure cannot affect collectives once communication has started.
Answer: The correct answer is B. Collectives synchronize all participating ranks; if one rank stalls (OOM, network fault, kernel stuck), every other rank waits indefinitely at the collective barrier with no fault signal. Debugging requires inspecting every rank’s state to find the one that diverged, which is fundamentally different from single-process debugging where a traceback names the failure site. The ‘immediate crash’ answer contradicts the observed silent hang. The ‘CPU-only’ answer misrepresents NCCL, which coordinates GPU communication. The memory-pressure answer contradicts the real mechanism: late-step OOMs on one rank are precisely how collective hangs start.
Learning Objective: Analyze why distributed collective communication failures require cross-rank debugging rather than single-process inspection.
Self-Check: Answer
Which of the following is a fallacy the chapter explicitly rejects about scaling ML operations?
- Operational complexity grows roughly linearly with model count, so teams can scale by replicating single-model practices.
- Shared infrastructure improves utilization when model workloads have non-coincident demand peaks.
- Feature freshness matters more for recommendation than for static demographic models.
- Technical debt can be measured using deployment velocity, toil percentage, and incident rate.
Answer: The correct answer is A. The chapter repeatedly argues that dependencies, monitoring load, and organizational coordination create superlinear complexity; scaling by replication fails because dependency graph density grows as \(\mathcal{O}(N_{\text{models}}^2)\) not \(\mathcal{O}(N_{\text{models}})\). The other statements align with the chapter’s positive claims about multiplexing, freshness-sensitive workloads, and quantified debt metrics.
Learning Objective: Identify and reject the linear-scaling fallacy that drives failed scaling attempts in ML operations.
True or False: A platform with 200 production models, each monitored on 10 independent metrics with a 1 percent per-metric false-alarm rate, can safely keep the alerting default of ‘page on-call whenever any metric fires’ if the team simply trains operators to filter false positives in real time.
Answer: False. With \(200 \times 10 = 2000\) independent checks at a 1 percent false-alarm rate, the expected number of false alerts is roughly 20 per evaluation cycle and the probability of at least one false alert across all checks is essentially 1. If those checks run repeatedly through the day, this becomes a constant noise floor. The operator-filtering strategy fails mathematically: real alerts are lost among false positives, response latency grows as operators debate which alerts to trust, and the monitoring system eventually has negative value. Hierarchical aggregation and correlation analysis are the only sustainable responses at this scale.
Learning Objective: Evaluate why exhaustive independent alerting fails quantitatively at fleet scale regardless of operator skill.
Leadership argues that platform investment should wait until the organization hits 100+ models. The organization currently has 25 models with fragmented CI/CD, per-team monitoring, and 60 percent toil across the platform group. Explain why this ‘wait for 100’ heuristic is usually a mistake, using the chapter’s quantitative arguments.
Answer: The chapter’s ROI analysis places the platform break-even between 20 and 50 models: at 25 models, this organization is already past the break-even point for a typical $2M-$5M platform investment. The 60 percent toil rate is itself a quantitative signal (above the 50 percent threshold that flags unsustainable infrastructure debt), meaning platform engineering capacity is already consumed by maintenance rather than improvement. Waiting until 100 models compounds two costs: every month of fragmented CI/CD, configuration, and monitoring adds dependencies that must later be migrated, and duplicated tooling becomes harder to unwind as teams specialize around their bespoke stacks. The practical consequence is that deferred investment converts an affordable greenfield build into a painful migration under operational stress, often with the original trigger being a large production incident rather than strategic planning.
Learning Objective: Justify earlier platform investment using the ROI threshold and toil-ratio evidence from the chapter.
Self-Check: Answer
Two organizations each operate 80 production models. Organization X runs dedicated per-team CI/CD, per-model alerting, and per-team GPU reservations, with platform spend at 10 percent of total ML budget. Organization Y runs a shared CI/CD plane, hierarchical monitoring, a centralized feature store, and pools GPUs, with platform spend at 30 percent of total ML budget. Both have the same headcount. Which organization better embodies the chapter’s operational thesis, and why?
- Organization X, because lower platform spend implies higher fraction of headcount on product work.
- Organization Y, because the chapter’s superlinear-complexity argument implies that fragmented per-team practices accumulate operational debt that eventually paralyzes product teams, while platform investment (even at a higher fraction) is the only mechanism that keeps marginal cost per additional model roughly flat.
- Neither: the chapter is agnostic between the two structures at this scale.
- Organization X, because the 10 percent platform spend indicates the team has successfully kept infrastructure lean.
Answer: The correct answer is B. At 80 models, Organization X has crossed the break-even point but has not yet paid down operational debt: fragmented CI/CD, alerting, and GPU allocation mean each additional model adds roughly full operational cost, and cross-model incidents must be debugged per-team. Organization Y has front-loaded the platform investment, so each additional model contributes marginal rather than linear operational cost, cross-model incidents attribute faster through hierarchical monitoring, and GPU pools sustain higher utilization. The lower-platform-spend organizations typically have higher total costs masked as product-team expenses rather than platform expenses. The ‘agnostic’ answer contradicts the chapter’s explicit thesis. The ‘lean is better’ answer confuses absolute spend with total cost structure.
Learning Objective: Synthesize the chapter’s platform thesis by comparing two operational structures at the same scale.
A team is running a production inference service with \(C_{\text{infer}} = \$500K\) per month, \(C_{\text{train}} = \$50K\) per month, and \(C_{\text{iter}} = \$40K\) per month. They have engineering capacity to pursue one optimization next quarter: a serving quantization project (3-week payback), a training-time compression project (3-month payback), or a new experimentation platform (6-month payback). Using the chapter’s TCO logic, justify a single priority and explain when the team’s answer should change.
Answer: Inference dominates at roughly $500K/$590K total = 85 percent of monthly TCO, so the serving quantization project is the correct top priority: it attacks the dominant cost component, and its 3-week payback exceeds the typical 1-3 month breakeven threshold required when inference dominates. Training and iteration each contribute under 10 percent of monthly spend, so even large percentage wins there produce small absolute savings relative to the quantization. The priority should change if usage drops or batching improvements already squeezed the inference bill (shifting dominance back to training or iteration), or if the team enters a new product phase where rapid experimentation drives revenue (iteration-dominated), at which point a 6-month-payback experimentation platform could become the right answer. The meta-lesson is that optimization priority follows the dominant TCO component, not engineering fashion.
Learning Objective: Prioritize iteration, training, or inference optimization by identifying the dominant TCO component in a given operational scenario.