The Edge Learning Paradigm
Edge Intelligence
Purpose
Why must intelligence adapt where it operates rather than remain frozen from distant training?
A model trained in a data center encounters a world it has never seen when deployed to a user’s device. The user’s vocabulary differs from training data. Local conditions (lighting, acoustics, usage patterns) diverge from the distributions that shaped the model’s parameters. Over time, the gap widens as user behavior evolves while the model remains static. On-device learning exists because centralized training cannot anticipate every context, personalize for every user, or adapt to continuous change. It also exists because data cannot always travel: privacy constraints, bandwidth limitations, and latency requirements may prohibit sending raw observations to distant servers. The alternative to on-device learning is accepting that deployed models grow stale, that personalization requires privacy sacrifice, and that disconnected operation means degraded intelligence. On-device learning rejects these compromises by bringing the learning process to where the data lives and where the adaptation matters. Edge intelligence turns adaptation into a C³ problem: compute moves onto the device, communication shrinks from raw observations to selective updates, and coordination must operate under power and memory budgets the data center never sees.
Learning Objectives
- Contrast centralized cloud training, on-device learning, and federated learning by analyzing their data flow, privacy properties, and operational trade-offs
- Quantify edge-device training overhead relative to inference-only deployment across memory, compute, and energy
- Select model adaptation strategies by comparing memory footprints, expressivity, and convergence for specific device capabilities
- Apply data-efficiency techniques (few-shot learning, experience replay, contrastive learning) to learn from limited local data without catastrophic forgetting
- Design federated learning systems that aggregate privacy-preserving updates while managing heterogeneous data, communication efficiency, and stragglers
- Explain the operational controls needed for on-device learning: device-aware deployment, distributed validation, privacy-preserving monitoring, and rollback across heterogeneous populations
Imagine a voice assistant trained on millions of generic audio samples in a cloud data center. When deployed, it struggles to understand a user’s heavy regional accent or specific household vocabulary. If the model cannot adapt locally on the device itself, it remains permanently frozen and becomes less useful as local usage diverges from the training distribution. Edge intelligence places inference, adaptation, and coordination on or near the devices that observe the data, so models can respond to local context under power, memory, privacy, and connectivity constraints. The edge learning paradigm shifts ML from a centralized factory model to a decentralized, continuously adapting network.
Data center ML systems assume a controlled environment where computational resources are abundant, network connectivity is reliable, and system behavior is predictable. Centralized inference is the clearest case of that assumption, and the edge breaks it.
A smartphone learning to predict user text input, a smart home device adapting to household routines, or an autonomous vehicle updating its perception models based on local driving conditions all demonstrate scenarios where traditional centralized training approaches prove inadequate. The smartphone encounters linguistic patterns unique to individual users that were not present in global training data. The smart home device must adapt to seasonal changes and family dynamics that vary dramatically across households. The autonomous vehicle faces local road conditions, weather patterns, and traffic behaviors that differ from its original training environment.
These scenarios require on-device learning, where models train and adapt directly on the devices where they operate.1 The consequence is a fundamental shift: machine learning moves from centralized training to distributed learning across millions of heterogeneous devices, each operating under unique constraints and local conditions. Within the fleet stack, distributed learning pushes the physical layer to its thermodynamic limits.
1 A11 Bionic (2017): Apple’s first SoC with a dedicated Neural Engine, rated up to 600 billion operations per second for machine-learning inference workloads. The systems consequence was establishing the mobile neural processing unit (NPU) as a distinct power domain: on-device adaptation becomes more practical when inference-optimized silicon frees thermal headroom for short local training or personalization bursts.
Local adaptation can only happen on hardware that already clears the inference floor, because a gradient update costs strictly more than the forward pass it builds on. Specialized accelerators set that floor: they determine whether an edge device has enough latency and energy margin to run intelligent workloads at all, and therefore whether any local training is even possible.
Systems Perspective 1.1: The silicon dividend of a dedicated NPU
The gap between running a model on a generic mobile CPU and on a dedicated Neural Processing Unit (NPU) is best understood as a “silicon dividend” rather than a marginal speedup. Published NPU profiles vary by silicon generation and workload, but for a MobileNet-class classifier the representative figures anchor the chapter’s argument: a dedicated NPU runs the forward pass on the order of 20× faster than the same model on a mobile CPU, and at roughly 60× better energy efficiency. The CPU baseline here is computed for MobileNetV2 at low utilization (1.711 ms per inference); the NPU figures are illustrative targets for this class of accelerator, not a measured profile.
What matters for system design is the kind of difference these ratios represent. Specialized hardware makes the model feasible, not merely faster: an energy gain of this magnitude is the difference between a workload that drains the battery in minutes and one that can run continuously in the background. On the edge, the CPU is for coordination and the NPU is for survival. Falling back to the CPU when the NPU target is missed does more than cost performance; it typically renders the application unusable through rapid battery drain and thermal throttling.
The transition to on-device learning introduces fundamental tension in machine learning systems design. While cloud-based architectures use abundant computational resources and controlled operational environments, edge devices must function within severely constrained resource envelopes. Memory is measured in megabytes rather than gigabytes; power budgets are measured in milliwatts rather than watts; and network connectivity may be intermittent or entirely absent. When a local model operates in a safety-critical loop, these constraints become life-safety engineering problems.
These constraints run through Archetype C (Federated MobileNet) (Archetype C (federated MobileNet)), where autonomy demands that learning happen on-device under severe resource limits. Archetype C represents the extreme end of this spectrum. Operating on milliwatt power budgets, it cannot afford the energy cost of transmitting raw data to the cloud. Data locality is therefore a physical necessity imposed by the power wall, not merely a privacy feature. Quantized training, sparse updates, and federated coordination are the survival strategies that allow Archetype C to exist.
Navigating this architectural tension requires the compression techniques carried over from inference, combined with algorithmic techniques, design patterns, and system principles that enable effective learning under extreme resource constraints. The challenge extends beyond conventional optimization of training algorithms: it requires rethinking the entire machine learning pipeline for deployment environments where traditional computational assumptions fail.
Definition 1.1: On-device learning
On-Device Learning is the local training or adaptation of machine learning models directly on deployed hardware without requiring server connectivity.
- Significance: It enables Hyper-Personalization and autonomous operation under severe resource constraints. Within the iron law, on-device learning must minimize the total energy consumed per update, because every gradient step draws on limited battery power and competes with other system tasks for the available compute throughput \((R_{\text{peak}})\).
- Distinction: Unlike Edge Inference, which only executes a fixed model, on-device learning involves a Local Optimization Loop (forward and backward passes) that requires significantly more memory and compute.
- Common pitfall: A frequent misconception is that on-device learning requires training from scratch. In reality, it is almost always On-Device Adaptation: fine-tuning a small subset of a pretrained base model’s parameters to fit the specific data distribution of a local environment.
The consequences reach beyond technical optimization into every phase of the machine learning lifecycle. Models transition from predictable versioning patterns to continuous divergence and adaptation trajectories. Performance evaluation shifts from centralized monitoring dashboards to distributed assessment across heterogeneous user populations. Privacy preservation becomes a core architectural requirement that shapes system design decisions rather than a downstream compliance concern.
Motivations and benefits
Machine learning systems have traditionally relied on centralized training pipelines. Models are developed and refined using large, curated datasets and cloud-based infrastructure (Dean et al. 2012). Once trained, these models are deployed to client devices for inference, creating a clear separation between the training and deployment phases. While this architectural separation has served many use cases well, it imposes significant limitations in applications where local data is dynamic, private, or highly personalized.
Dean, Jeffrey, Greg Corrado, Rajat Monga, Kai Chen 0010, Matthieu Devin, Quoc V. Le, Mark Z. Mao, et al. 2012. “Large Scale Distributed Deep Networks.” In Advances in Neural Information Processing Systems (NeurIPS), edited by Peter L. Bartlett, Fernando C. N. Pereira, Christopher J. C. Burges, Léon Bottou, and Kilian Q. Weinberger, vol. 25. Curran Associates.
2 [offset=-25mm] Privacy-Preserving (Differential Privacy): While federated learning avoids moving raw data, research has shown that raw gradients can be “inverted” to reconstruct input samples. Differential privacy adds calibrated noise to bound the privacy loss contributed by any one record or user under a stated adjacency definition; it reduces inference risk, but the strength of the guarantee depends on \(\varepsilon\), \(\delta\), composition, and implementation quality.
On-device learning challenges this established model by enabling systems to train or adapt directly on the device, without relying on constant connectivity to the cloud. The shift reflects changing application requirements and user expectations that demand responsive, personalized, and privacy-preserving2 machine learning systems.

On-device learning hits the memory wall before the compute wall.
Consider a smartphone keyboard adapting to a user’s unique vocabulary and typing patterns. To personalize predictions, the system must perform gradient updates on a compact language model using locally observed text input. A single gradient update for even a minimal language model requires 50 MB–100 MB of memory for activations and optimizer state. Smartphone operating systems often leave only 200 MB–300 MB for background applications like keyboards, with the exact budget varying by OS, device generation, and foreground workload. This razor-thin margin demonstrates the central engineering challenge of on-device learning: a single training step can consume 25 percent of available memory. The system must achieve meaningful personalization while operating within constraints so severe that traditional training approaches become architecturally infeasible. This quantitative reality drives the need for specialized techniques that make adaptation possible within extreme resource limitations.
Four key considerations motivate the shift from centralized to decentralized learning (Li et al. 2020): personalization, latency and availability, privacy, and infrastructure efficiency. Personalization represents the most compelling motivation, as deployed models often encounter usage patterns and data distributions that differ from their training environments. Local adaptation allows models to refine behavior in response to user-specific data, capturing linguistic preferences, physiological baselines, sensor characteristics, or environmental conditions. This capability is essential in applications with high inter-user variability, where a single global model cannot serve all users effectively.
Latency and availability constraints provide additional justification for local learning. In edge computing scenarios, connectivity to centralized infrastructure may be unreliable, delayed, or intentionally limited to preserve bandwidth or reduce energy consumption. On-device learning enables autonomous improvement of models even in fully offline or delay-sensitive contexts, where round-trip updates to the cloud are architecturally infeasible.
Privacy considerations provide a third compelling driver. Many applications involve sensitive or regulated data including biometric measurements, typed input, location traces, or health information. Local learning can reduce privacy exposure by keeping raw data on the device and limiting transmission to centralized systems. This can simplify compliance engineering, but it does not by itself establish adherence to regulations such as the General Data Protection Regulation (GDPR),3 the Health Insurance Portability and Accountability Act (HIPAA)4 (U.S. Department of Health and Human Services 2026), or region-specific data sovereignty laws.
3 GDPR (General Data Protection Regulation): Effective May 2018, GDPR requires a lawful basis, data minimization, purpose limitation, and rights-handling processes for personal-data processing. Explicit consent may be required in sensitive contexts, but it is not the only lawful basis. On-device learning can reduce the amount of personal data transferred to centralized systems and can simplify some cross-border and retention questions, but deployments still need consent, rights, and governance mechanisms appropriate to the data and use case.
4 HIPAA (Health Insurance Portability and Accountability Act): Requires covered entities and business associates to apply administrative, physical, and technical safeguards for protected health information (PHI). Cloud services that create, receive, maintain, or transmit electronic PHI on behalf of a covered entity or business associate generally require an appropriate Business Associate Agreement and Security Rule controls. On-device learning can reduce PHI transmission and vendor-management risk, but it does not remove HIPAA obligations for in-scope healthcare deployments.
U.S. Department of Health and Human Services. 2026. The HIPAA Security Rule. HHS.gov guidance.
Infrastructure efficiency provides economic motivation for distributed learning approaches. Centralized training pipelines require substantial backend infrastructure to collect, store, and process user data from potentially millions of devices. By shifting learning to the edge, systems reduce communication costs and distribute training workloads across the deployment fleet, relieving pressure on centralized resources while improving scalability.
Alternative approaches and decision criteria
On-device learning demands significant engineering investment that may not always be justified. Simpler alternatives can often achieve comparable results with lower operational overhead, and premature adoption introduces complexity without proportional value.
Table 1 compares three alternatives that often satisfy personalization and adaptation requirements without local training complexity.
| Alternative | Mechanism | When it fits |
|---|---|---|
| Feature-based personalization | Store user preferences, interaction history, and behavioral features locally, then feed those features into a static model rather than adapting model weights. | News recommendation systems can store topic preferences and reading patterns locally, then combine those features with a centralized content model. |
| Cloud-based fine-tuning with privacy controls | Centralize adaptation while processing user data in batches during off-peak hours with privacy-preserving techniques such as differential privacy, federated analytics, secure aggregation (Bonawitz et al. 2017), or combinations of these controls. | This approach often achieves higher accuracy than resource-constrained on-device updates while maintaining acceptable privacy properties for many applications. |
| User-specific lookup tables | Combine global models with personalized retrieval mechanisms by maintaining a lightweight table for frequently accessed local patterns. | Personalization benefits are needed with minimal computational and storage overhead. |
In the cloud-fine-tuning row, differential privacy5 is the mechanism that bounds information leakage while adding noise that can require more rounds or more data.
5 Differential Privacy (DP): A mathematical framework that bounds information leakage by adding calibrated noise to computations. In edge learning, that noise becomes a systems cost because noisier updates usually require more rounds or more data to reach the same utility. Security & Privacy develops the formal privacy-budget machinery.
The decision to implement on-device learning should be driven by quantifiable requirements that preclude these simpler alternatives. True data privacy constraints that legally prohibit cloud processing, genuine network limitations that prevent reliable connectivity, quantitative latency budgets that preclude cloud round-trips, or demonstrable performance improvements that justify the operational complexity represent legitimate drivers for on-device learning adoption.
For applications with critical timing requirements, network round-trip times make cloud-based alternatives architecturally infeasible. Camera processing under 33 ms, voice response under 500 ms, AR/VR motion-to-photon latency under 20 ms, or safety-critical control under 10 ms all face network round-trip times typically ranging from 50 to 200 ms. In such scenarios, on-device learning becomes necessary regardless of complexity considerations. Teams should thoroughly evaluate simpler solutions before committing to the significant engineering investment that on-device learning requires.
Knowledge transfer as the adaptation foundation
These motivations are grounded in the broader concept of knowledge transfer, where a pretrained model transfers useful representations to a new task or domain. This foundational principle makes on-device learning both feasible and effective, enabling sophisticated adaptation with minimal local resources. Figure 1 illustrates how knowledge transfer occurs between closely related tasks such as playing different board games or musical instruments, or across domains that share structure such as from riding a bicycle to driving a scooter. In on-device learning, a model pretrained in the cloud adapts efficiently to a new context using only local data and limited updates, allowing fast adaptation without relearning from scratch even when the new task diverges in input modality or goal.
This conceptual shift, enabled by transfer learning and adaptation, enables real-world on-device applications. Whether adapting a language model for personal typing preferences, adjusting gesture recognition to individual movement patterns, or recalibrating a sensor model in changing environments, on-device learning allows systems to remain responsive, efficient, and user-aligned over time.
Real-world application domains
The motivations for on-device learning manifest concretely across consumer technologies, healthcare, industrial systems, and embedded applications, each domain presenting scenarios where personalization, latency, privacy, and infrastructure efficiency become essential. Mobile input prediction is a well-documented example of on-device learning. In systems such as smartphone keyboards, predictive text and autocorrect features benefit substantially from continuous local adaptation. User typing patterns are highly personalized and evolve dynamically, making centralized static models insufficient for high-quality user experience. On-device learning allows language models to fine-tune their predictions directly on the device, achieving personalization while maintaining data locality. Google’s Gboard6, for instance, employs federated learning7 (each device shares model updates, never the underlying data) to improve shared models across a large population of users while keeping raw data local to each device (Hard et al. 2018).
6 Gboard (2017): One of the first widely reported commercial federated learning deployments at mobile scale. Published reports showed that keyboard models could improve from aggregated on-device updates while raw typed text remained local. The systems consequence is durable: compressed updates and privacy mechanisms make cross-fleet learning possible over constrained mobile networks without centralizing raw keystrokes.
7 Federated Learning: Named by direct analogy to a political federation (for example, the United States), where individual states (devices) maintain local autonomy over their data while participating in a global union to improve a shared model. This decentralization is one mechanism for reducing raw data movement and supporting data residency or regulated-data requirements, but legal compliance still depends on the deployment context, governance controls, and privacy guarantees around model updates.
Hard, Andrew, Kanishka Rao, Rajiv Mathews, Swaroop Ramaswamy, Françoise Beaufays, Sean Augenstein, Hubert Eichner, Chloé Kiddon, and Daniel Ramage. 2018. “Federated Learning for Mobile Keyboard Prediction.” arXiv Preprint arXiv:1811.03604.
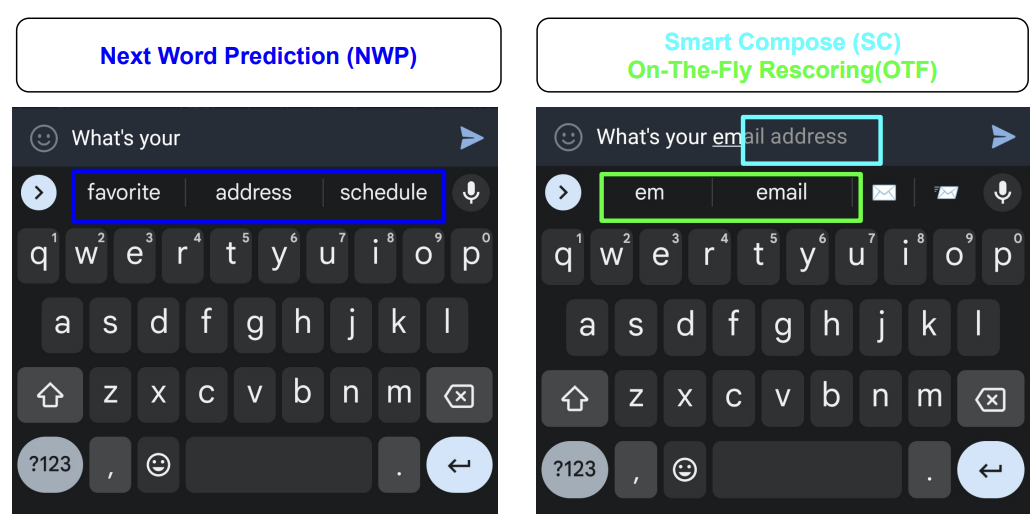
Figure 2 demonstrates how different prediction strategies enable local adaptation in real time. Next-word prediction suggests likely continuations based on prior text, while Smart Compose uses on-the-fly rescoring to offer dynamic completions. These techniques demonstrate the sophistication of local inference mechanisms.
Wearable and health monitoring devices present equally compelling use cases with additional regulatory constraints. These systems rely on real-time data from accelerometers, heart rate sensors, and electrodermal activity monitors to track user health and fitness. Physiological baselines vary dramatically between individuals, creating a personalization challenge that static models cannot address effectively. On-device learning allows models to adapt to these individual baselines over time, substantially improving the accuracy of activity recognition, stress detection, and sleep staging while meeting regulatory requirements for data localization.
Voice interaction technologies present another important application domain with unique acoustic challenges. Wake-word detection8 and voice interfaces in devices such as smart speakers and earbuds must recognize voice commands quickly and accurately even in noisy or dynamic acoustic environments.
8 Wake-Word Detection: Always-on keyword spotting commonly runs in a sub-milliwatt to low-milliwatt envelope, far below full speech recognition, using compact neural networks optimized for sub-100 ms latency and very low false-activation rates. This extreme power constraint defines the design space: the model must be small enough to run on a dedicated always-on processor, making on-device personalization critical for reducing false activations without increasing model size.
These systems face strict latency requirements. Voice interfaces must maintain end-to-end response times under 500 ms to preserve natural conversation flow, with wake-word detection requiring sub-100 ms response times to avoid user frustration. Local training allows models to adapt to the user’s unique voice profile and changing ambient context, reducing false positives and missed detections while meeting these demanding performance constraints. This adaptation is particularly valuable in far-field audio settings, where microphone configurations and room acoustics vary dramatically across deployments.
Beyond consumer applications, industrial IoT and remote monitoring systems demonstrate the value of on-device learning in resource-constrained environments. In applications such as agricultural sensing, pipeline monitoring, or environmental surveillance, connectivity to centralized infrastructure may be limited, expensive, or entirely unavailable. On-device learning allows these systems to detect anomalies, adjust thresholds, or adapt to seasonal trends without continuous communication with the cloud. This capability is necessary for maintaining autonomy and reliability in edge-deployed sensor networks, where system downtime or missed detections can have significant economic or safety consequences.
The most demanding applications emerge in embedded computer vision systems including robotics, AR/VR, and smart cameras. These combine complex visual processing with the tightest end of the latency budgets established in section 1.0.2: the 33 ms frame budget for 30 FPS cameras, the sub-20 ms motion-to-photon budget that prevents AR/VR nausea, and the sub-10 ms bound on safety-critical control. These systems also operate in novel or rapidly changing environments that differ substantially from their original training conditions. On-device adaptation allows models to recalibrate to new lighting conditions, object appearances, or motion patterns while meeting these critical latency budgets that fundamentally drive the architectural decision between on-device vs. cloud-based processing.
Each domain reveals a common pattern. Deployment environments introduce variation and context-specific requirements that cannot be anticipated during centralized training. These applications demonstrate how the motivational drivers manifest as concrete engineering constraints. Mobile keyboards face memory limitations for storing user-specific patterns. Wearable devices encounter energy budgets that restrict training frequency. Voice interfaces must meet sub-100 ms latency requirements that preclude cloud coordination. Industrial IoT systems operate in network-constrained environments that demand autonomous adaptation. This pattern illuminates the fundamental design requirement shaping all subsequent technical decisions. Learning must be performed efficiently, privately, and reliably under significant resource constraints. Section 1.1 analyzes these constraints systematically, section 1.2 presents techniques for adapting models within tight resource envelopes, and section 1.4 establishes protocols for privacy-preserving coordination across device populations.
Architectural trade-offs: Centralized vs. decentralized training
The diversity of these applications reveals how fundamentally on-device learning differs from traditional ML architectures, extending beyond deployment choices into a complete reimagining of the training lifecycle. Many machine learning systems follow a centralized learning paradigm: models train in data centers using large-scale, curated datasets aggregated from many sources, deploy to client devices in static form for inference without further modification, and receive updates periodically through offline retraining using newly collected or labeled data sent back from the field. This centralized model offers proven advantages, including high-performance computing infrastructure, access to diverse data distributions, and robust debugging and validation pipelines, but it also depends on assumptions that edge deployments often violate: reliable data transfer, trust in data custodianship, and infrastructure capable of managing global updates across device fleets.
On-device learning inverts these assumptions. Each device maintains its own model copy and adapts it locally using data unavailable to centralized infrastructure. Training occurs asynchronously under varying resource conditions driven by device usage patterns, battery levels, and thermal states. Raw data remains on the device, reducing privacy exposure but complicating coordination. Hardware capabilities, runtime environments, and usage patterns vary dramatically across devices, making the learning process heterogeneous and difficult to standardize.
Decentralization introduces a new class of systems challenges. Devices may operate with different model versions, leading to behavioral inconsistencies across the deployment fleet. Evaluation and validation grow more complex without a central point from which to measure performance (McMahan et al. 2017). Model updates must be carefully managed to prevent degradation, and safety guarantees become harder to enforce without centralized testing infrastructure.
Managing thousands of heterogeneous edge devices exceeds typical distributed systems complexity. Device heterogeneity extends beyond hardware differences to include varying operating system versions, security patches, network configurations, and power management policies. Large-scale federated systems must tolerate clients that fail eligibility checks, arrive late, or drop out during training rounds (Bonawitz et al. 2019). Others have been disconnected for weeks or months, creating persistent coordination challenges.
When disconnected devices reconnect, they require state reconciliation to avoid version conflicts. Update verification becomes critical as devices can silently fail to apply updates or report success while running outdated models. Robust systems implement multi-stage verification. Cryptographic signatures confirm update integrity, functional tests validate model behavior, and telemetry confirms deployment success. Rollback strategies must handle partial deployments where some devices received updates while others remain on previous versions. Maintaining system consistency during failure recovery requires sophisticated orchestration that draws on distributed systems principles while introducing edge-specific complexities.
Despite these challenges, decentralization enables deep personalization without centralized oversight, supports learning in disconnected or bandwidth-limited environments, and reduces the operational cost of model updates. The central question is how to coordinate learning across devices, and that question unfolds across three operational phases: centralized training, local adaptation, and federated coordination.
The traditional centralized paradigm begins with cloud-based training on aggregated data, followed by static model deployment to client devices. This approach works well when data collection is feasible, network connectivity is reliable, and a single global model can serve all users effectively. However, it breaks down when data becomes personalized, privacy-sensitive, or collected in environments with limited connectivity.
Once deployed, local differences begin to emerge as each device encounters its own unique data distribution. Devices collect data that reflects individual user patterns, environmental conditions, and usage contexts. This data is often non-i.i.d.9 and noisy, requiring local model adaptation to maintain performance. This transition marks the shift from global generalization to local specialization.
9 Non-IID (Not Independent and Identically Distributed): Data where samples are not drawn from a single common distribution, the default condition in federated learning where each device reflects a single user’s patterns. Non-IID label and feature distributions can sharply degrade federated averaging compared with IID baselines (Zhao et al. 2018), forcing systems to adopt techniques like local adaptation layers or clustered aggregation to maintain convergence.
Zhao, Yue, Meng Li, Liangzhen Lai, Naveen Suda, Damon Civin, and Vikas Chandra. 2018. “Federated Learning with Non-IID Data.” CoRR abs/1806.00582.
The final phase introduces federated coordination, where devices periodically synchronize their local adaptations through aggregated model updates rather than raw data sharing. This enables privacy-preserving global refinement while maintaining the benefits of local personalization.
Figure 3 traces this evolution from centralized training through local adaptation to federated coordination. Each phase increases coordination complexity while enabling capabilities impossible in purely centralized deployments.

Decentralized, continuous learning rewrites the rules of system design. We are no longer operating in climate-controlled data centers with effectively infinite power; we must confront the severe physical and algorithmic limits of edge devices.
Design Constraints
Attempting to fine-tune a neural network on a smartphone is a thermodynamic battle. A typical GPU training cluster consumes megawatts of power, while a smartphone must execute backpropagation on a 10 W thermal budget without burning the user’s hand or draining the battery in five minutes. These severe constraints force us to radically redesign our learning algorithms to be hyper-efficient in compute, memory, and data.
The constraints on parameters, operations, and data interact multiplicatively rather than additively, creating a constrained optimization problem far more challenging than inference-only deployment. The most important shift is in what compression is for: quantization shrinks bytes per weight, pruning removes unnecessary parameters, and knowledge distillation transfers behavior into a smaller architecture, and on-device learning turns these tools from optional optimizations into baseline feasibility requirements. This compression baseline, established here, is what later sections build on rather than re-derive.
On-device learning operates under the same efficiency constraints as inference but with training-specific amplifications that make optimization far more demanding. Where inference requires a single forward pass through the network, training demands forward propagation, gradient computation through backpropagation, and weight updates, increasing memory requirements by 4–12\(\times\) and computational costs by 2–3\(\times\) when activations, gradients, and optimizer state are included. These amplifications are why the compression baseline is non-negotiable at the edge: training within these device constraints would be impossible without it.
The fundamental engineering challenges that shape on-device learning implementation follow directly from these motivations. Enabling learning on the device requires completely rethinking conventional assumptions about where and how machine learning systems operate. In centralized environments, models are trained with access to extensive compute infrastructure, large and curated datasets, and generous memory and energy budgets. At the edge, none of these assumptions hold, creating a fundamentally different design space.
These constraints define a feasible region rather than a checklist. Model compression determines how little of the algorithm can change. Sparse, nonuniform data determines how much signal each local update can extract. Limited compute determines when training can run at all. The interaction among these dimensions sets the later choice among adaptation, data-efficiency, and federated-coordination techniques.
Quantifying training overhead on edge devices
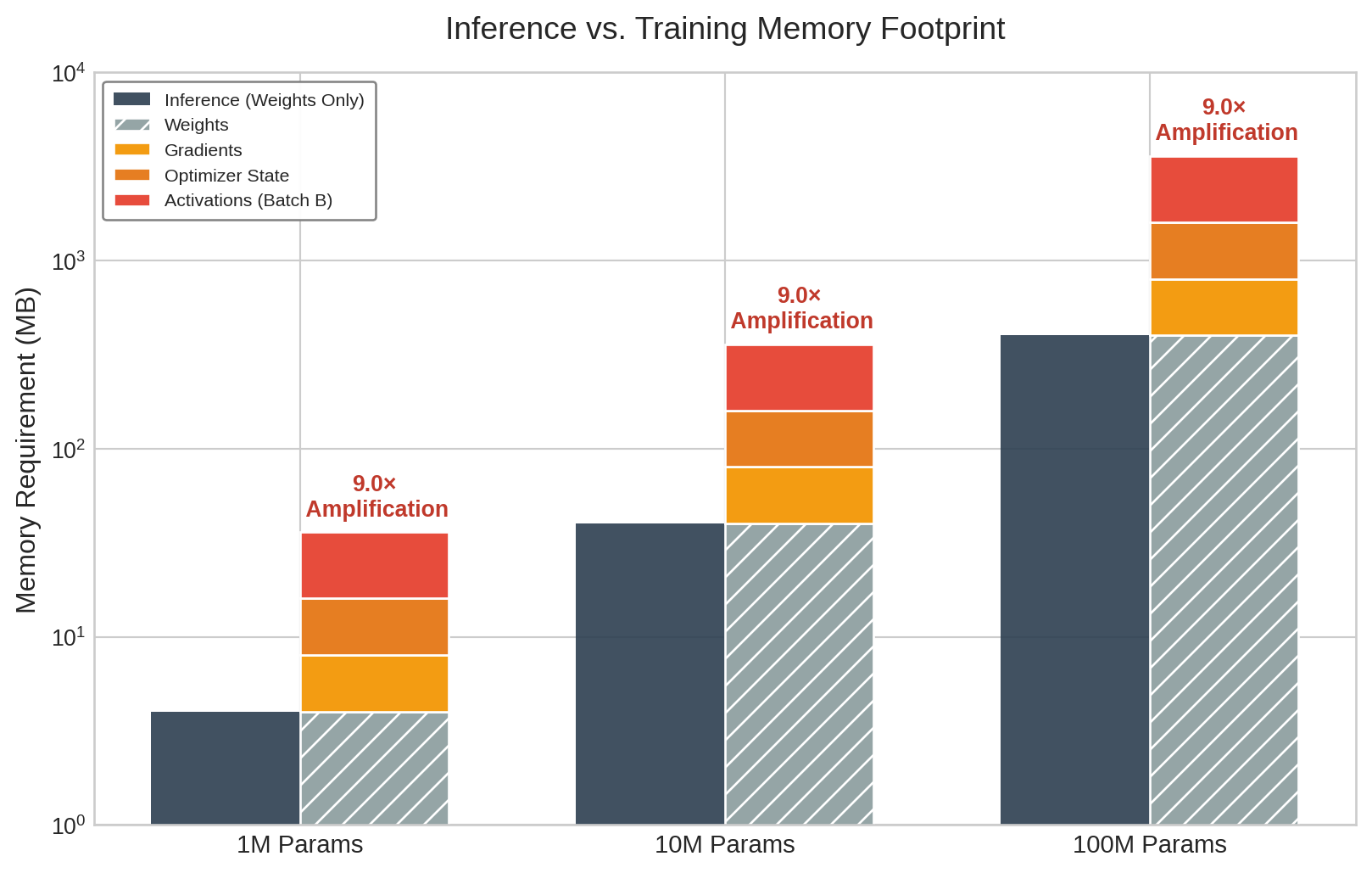
Beyond the compression baseline, training amplifies memory footprint, memory bandwidth, and hardware utilization pressures in ways that are specific to local adaptation, and these pressures compound rather than add. Table 2 quantifies how compute operations grow 2–3\(\times\) and energy consumption can balloon 10–50\(\times\), while figure 4 shows a representative 9\(\times\) Adam-style memory budget within that broader range.
| Constraint Dimension | Inference | Training Amplification | Impact on Design |
|---|---|---|---|
| Memory Footprint | Model weights + single activation map | Weights + full activation cache + gradients + optimizer state | 4–12\(\times\) increase; forces aggressive compression |
| Compute Operations | Forward pass only | Forward + backward + weight update | 2–3\(\times\) increase; limits model complexity |
| Memory Bandwidth | Sequential weight reads | Bidirectional data flow for gradients | 5–10\(\times\) increase; creates bottlenecks |
| Energy per Sample | Single inference operation | Multiple gradient steps with convergence | 10–50\(\times\) increase; requires opportunistic scheduling |
| Data Requirements | Precollected, curated datasets | Sparse, noisy, streaming local data | Necessitates sample-efficient methods |
| Hardware Utilization | Optimized for forward passes | Different access patterns for backprop | Inference accelerators may not help training |
As figure 4 shows, a representative Adam-style training budget can reach a 9\(\times\) memory footprint increase across model scales; the broader 4–12\(\times\) range depends on optimizer choice, batch size, activation checkpointing, and how many layers are updated.
Peak memory usage
Memory consumption during training is not static. It fluctuates dynamically, reaching a maximum during the backward pass when activations, gradients, and optimizer states must coexist. This peak memory usage determines whether a model can be trained on a device. For a 10M parameter model on a smartphone with 8 GB RAM, the 40 MB of FP32 weights might spike to over 200 MB during backpropagation as activations, gradients, and optimizer states accumulate—competing directly with the operating system and foreground applications for the device’s limited memory. Techniques like gradient checkpointing mitigate this by discarding intermediate activations during the forward pass and recomputing them on-demand during the backward pass (Chen et al. 2016). This approach trades extra computation for lower peak memory; the exact savings depend on which activations are checkpointed and how much recomputation the device can tolerate.
These amplifications explain why standard optimization techniques fail when applied to training workloads without modification. Each constraint category shapes on-device learning system design, requiring approaches that build on but extend beyond inference-focused methods.
Checkpoint 1.1: On-device training constraints
Verify your understanding of how training amplifies edge constraints:
Figure 5 illustrates how the complete training pipeline combines offline pretraining with online adaptive learning on resource-constrained IoT devices. The system first undergoes meta-training with generic data. During deployment, device-specific constraints such as data availability, compute, and memory shape the adaptation strategy by ranking and selecting layers and channels to update. This selective fine-tuning allows efficient on-device learning within limited resource envelopes.

Model constraints
The structure and size of the machine learning model directly determine whether on-device training is possible. Cloud-deployed models can span billions of parameters and rely on multi-gigabyte memory budgets; models intended for on-device learning must conform to tight constraints on memory, storage, and computational complexity. These constraints tighten further during training, where gradient computation, parameter updates, and optimizer state management all demand additional resources beyond inference.
The scale of these constraints becomes concrete across the device spectrum. MobileNetV2, commonly used in mobile vision tasks, requires approximately 14 MB of storage in its standard configuration. While feasible for smartphones with gigabytes of available RAM, this far exceeds the 256 KB of SRAM and 1 MB of flash storage on microcontrollers such as the Arduino Nano 33 BLE Sense10. On such severely constrained platforms, even a single convolutional layer may exceed available RAM during training due to intermediate feature maps and gradient storage.
10 Arduino Nano 33 BLE Sense: With 256 KB SRAM, roughly 65,536× smaller than a flagship smartphone’s 16 GB, a single \(224{\times}224{\times}3\) RGB image occupies ~151 KB and consumes roughly 60 percent of available memory. Activation and gradient storage add several more live tensors, and optimizer state can push the training footprint far beyond the inference footprint. This means even a tiny convolutional neural network (CNN) layer can exceed total SRAM during backpropagation. This memory wall forces 8-bit or 4-bit quantization as a prerequisite, not an optimization.
The training process itself dramatically expands the effective memory footprint. Standard backpropagation caches activations for each layer during the forward pass, then reuses them during gradient computation in the backward pass. The constraint-amplification analysis established that this activation caching multiplies memory requirements compared to inference-only deployment. A seemingly modest 10-layer convolutional model processing \(64{\times}64\) images may require 1 to 2 MB, well beyond the SRAM capacity of most embedded systems.
Model complexity also directly affects runtime energy consumption and thermal limits. In smartwatches or battery-powered wearables, sustained model training can rapidly deplete energy reserves or trigger thermal throttling that degrades performance. Training a full model using floating-point operations on these devices is often infeasible from an energy perspective, even when memory constraints are satisfied. Ultra-lightweight benchmarks such as MLPerf Tiny provide small quantized inference targets for severely constrained devices (Banbury et al. 2021). On-device adaptation techniques then reduce training cost by freezing most parameters, reducing activation storage, or selecting sparse update sets (Cai et al. 2020; Kwon et al. 2024).
Banbury, Colby, Vijay Janapa Reddi, Peter Torelli, Jeremy Holleman, Nat Jeffries, Csaba Kiraly, Pietro Montino, et al. 2021. “MLPerf Tiny Benchmark.” arXiv Preprint.
The practical implications of battery and thermal constraints extend beyond just limiting training duration. Mobile devices must carefully balance training opportunities with user experience. Aggressive on-device training can cause noticeable device heating and rapid battery drain, leading to user dissatisfaction and potential app uninstalls. Smartphone ML workloads commonly operate within a sustained processing envelope of 2–3 W to prevent thermal discomfort, though they can burst to 5–10 W for brief periods before thermal throttling kicks in. Training even modest models can easily exceed these sustainable power limits. This reality necessitates intelligent scheduling strategies: training during charging periods when thermal dissipation is improved, using low-power cores for gradient computation when possible, and implementing thermal-aware duty cycling that pauses training when temperature thresholds are exceeded. Some systems even use device usage patterns, scheduling intensive adaptation only during overnight charging when the device is idle and connected to power.
These constraints demand that model architectures be designed for on-device learning from the outset. Large transformers and deep convolutional networks are simply not viable for on-device adaptation without partitioning, quantization, or offloading. Specialized lightweight architectures such as MobileNets11, SqueezeNet (Iandola et al. 2016), and EfficientNet (Tan and Le 2019) address resource-constrained inference through mechanisms such as depthwise separable convolutions12, bottleneck/fire modules, and compound model scaling. Quantization and selective updates are then separate deployment and adaptation choices layered on top of the architecture.
11 MobileNet (2017): Google’s architecture achieved 8–9\(\times\) FLOPs reduction over standard CNNs through depthwise separable convolutions. The systems consequence: MobileNetV2 runs ImageNet classification in approximately 75 ms on a Pixel phone vs. 1.8 seconds for ResNet-50, crossing the threshold where real-time on-device inference and adaptation become thermally sustainable within a smartphone’s 2–3 W power envelope.
Iandola, Forrest N., Song Han, Matthew W. Moskewicz, Khalid Ashraf, William J. Dally, and Kurt Keutzer. 2016. “SqueezeNet: AlexNet-Level Accuracy with 50x Fewer Parameters and <0.5MB Model Size.” ArXiv Preprint abs/1602.07360.
Tan, Mingxing, and Quoc V Le. 2019. “EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks.” International Conference on Machine Learning (ICML), 6105–14.
12 Depthwise Separable Convolutions: Decomposes a standard convolution into a per-channel depthwise filter followed by a \(1{\times}1\) pointwise combination. For a \(3{\times}3\) convolution with 512 input/output channels, this reduces parameters from 2.4 M to about 267 K, an 8.8\(\times\) reduction. The savings are not just theoretical: this decomposition is what makes real-time CNN inference possible on mobile CPUs, and it equally reduces the memory needed for activation caching during on-device training.
Howard, A. G., M. Zhu, B. Chen, D. Kalenichenko, W. Wang, T. Weyand, M. Andreetto, and H. Adam. 2017. “MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications.” CoRR abs/1704.04861.
Sandler, Mark, Andrew Howard, Menglong Zhu, Andrey Zhmoginov, and Liang-Chieh Chen. 2018. “MobileNetV2: Inverted Residuals and Linear Bottlenecks.” 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 4510–20. https://doi.org/10.1109/cvpr.2018.00474.
Modularity is a key design property. MobileNets (Howard et al. 2017) and MobileNetV2 (Sandler et al. 2018) can be configured with different width multipliers and resolution settings to balance performance and resource usage. A complete MobileNetV2 with width multiplier \(\alpha_{\text{width}}=1.0\) has approximately 3.5M parameters (14 MB in FP32). With \(\alpha_{\text{width}}=0.5\), the complete 1000-class model has approximately 2.0M parameters (7.9 MB), while a feature-extractor-only deployment with a small task-specific head can be as small as 0.69M parameters (2.8 MB), fitting within a 4 MB model budget.
Data constraints
Model architecture determines the memory and computational baseline for on-device learning, but data availability and quality introduce equally fundamental limitations that shape every aspect of the learning process. Data available to on-device ML systems differs dramatically from the large, curated datasets used in cloud-based training. At the edge, data is locally collected, temporally sparse, and often unstructured or unlabeled. The resulting challenges in volume, quality, and statistical distribution directly affect the reliability and generalizability of on-device learning.
Data volume is severely limited by both storage constraints and the sporadic nature of user interaction. A smart fitness tracker may collect motion data only during physical activity, generating relatively few labeled samples per day. If a user exercises for 30 minutes, only a few hundred data points might be available for training, compared to the thousands or millions required for effective supervised learning. The scarcity forces a shift from data-rich to data-efficient algorithms.
On-device data is also frequently non-IID (Zhao et al. 2018), creating statistical challenges that cloud-based systems rarely encounter. A voice assistant deployed across households encounters wide variation in accents, languages, speaking styles, and command patterns. Smartphone keyboards adapt to individual typing patterns, autocorrect preferences, and multilingual usage that varies widely between users. The heterogeneity complicates both model convergence and the design of update mechanisms that must generalize across devices while maintaining personalization.
Label scarcity compounds the distribution problem. Most edge-collected data is unlabeled by default, requiring systems to learn from weak or implicit supervision signals. A smartphone camera may capture thousands of images throughout the day, but only a few are associated with meaningful user actions (tagging, favoriting, or sharing) that could serve as implicit labels. In many applications, including anomaly detection in sensor data and gesture recognition adaptation, explicit labels may be entirely unavailable, making traditional supervised learning infeasible without alternative methods for weak supervision or unsupervised adaptation.
Data quality introduces further challenges. Embedded systems such as environmental sensors or automotive ECUs experience fluctuations in sensor calibration, environmental interference, or mechanical wear, leading to corrupted or drifting input signals over time. Without centralized validation systems to detect and filter these errors, they silently degrade learning performance.
Privacy and security concerns impose the most restrictive constraints, often making data sharing architecturally impossible rather than merely undesirable. Sensitive information such as health data, personal communications, or behavioral patterns must be protected from unauthorized access under legal and ethical requirements. On-device learning must therefore rely on techniques that enable local adaptation without ever exposing sensitive information, fundamentally reshaping how learning systems are designed and validated.
Compute constraints
The edge hardware landscape provides the computational substrate for machine learning, spanning from microcontrollers like STM32F4 and ESP32 at the most constrained end, to mobile-class processors with dedicated AI accelerators (Apple Neural Engine, Qualcomm Hexagon, Google Tensor) in the middle, and high-capability edge devices at the upper end. While these devices offer varying levels of inference capabilities (computational throughput, memory bandwidth, and energy efficiency when executing pretrained models), training workloads exhibit fundamentally different computational characteristics that reshape hardware utilization patterns.
On-device learning must operate within computational envelopes that differ from cloud-based training infrastructure by factors of hundreds or thousands in raw capacity. The key difference: backpropagation requires significantly higher memory bandwidth than inference due to gradient computation and activation caching, weight updates create write-heavy access patterns unlike inference’s read-only operations, and optimizer state management demands additional memory allocation. Hardware perfectly adequate for inference may prove entirely inadequate for adaptation, even when updating only a small parameter subset.
At the most constrained end, devices such as the STM32F413 or ESP3214 microcontrollers offer only a few hundred kilobytes of SRAM and limited compute and power budgets (Warden and Situnayake 2020). Although these families include single-precision floating-point support, practical ML deployments commonly rely on quantized or fixed-point kernels for efficiency. Libraries like CMSIS-NN (Lai et al. 2018) provide optimized neural network kernels for Arm Cortex-M processors, achieving 4.6\(\times\) runtime improvement through fixed-point arithmetic and single instruction, multiple data (SIMD) optimizations. These severe limitations preclude conventional deep learning libraries and require models designed for quantized arithmetic and minimal runtime memory allocation. Even simple models require quantization-aware training15 and selective parameter updates to execute training loops without exceeding memory or power budgets.
13 STM32F4 Microcontroller: With 192 KB SRAM, a 168 MHz clock speed, and a single-precision FPU, the main constraint is not the absence of floating point but the tiny memory and energy envelope. A dense layer with 1000 input features and 10 hidden units requires approximately 40.040 KB for weights and biases in FP32, consuming about 20.854 percent of total SRAM before accounting for activations or gradients. At approximately 100 mW active power, even simple gradient updates must be duty-cycled, and INT8 or fixed-point kernels remain preferable when accuracy allows.
14 ESP32: Provides 520 KB SRAM and dual-core 240 MHz processing with built-in Wi-Fi and Bluetooth, making it an inexpensive platform for experiments that combine local adaptation with federated coordination. Its CPU includes floating-point support, but fixed-point and 8-bit kernels are usually preferred for throughput, memory footprint, and energy efficiency; compact 8-bit models can fit in approximately 50 KB, enabling basic on-device adaptation for sensor anomaly detection.
15 Quantization-Aware Training (QAT): Simulates low-precision arithmetic during training so the model learns robust representations despite reduced precision, unlike post-training quantization which converts a trained FP32 model after the fact (Jacob et al. 2018; Krishnamoorthi 2018). The systems payoff is lower memory traffic and cheaper integer arithmetic: hardware energy models show that lower-precision arithmetic and memory movement can be much cheaper than FP32 computation (Horowitz 2014). Exact speed, energy, and accuracy outcomes depend on the processor, kernel implementation, model, and calibration data. On edge devices, QAT is often a prerequisite for fitting adaptation within thermal and memory budgets.
Jacob, Benoit, Skirmantas Kligys, Bo Chen, Menglong Zhu, Matthew Tang, Andrew Howard, Hartwig Adam, and Dmitry Kalenichenko. 2018. “Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference.” 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2704–13. https://doi.org/10.1109/cvpr.2018.00286.
Krishnamoorthi, Raghuraman. 2018. “Quantizing Deep Convolutional Networks for Efficient Inference: A Whitepaper.” arXiv Preprint arXiv:1806.08342 abs/1806.08342.
16 SGD (Stochastic Gradient Descent): Updates parameters from single-sample or small-batch gradients, storing only current parameters and their gradients. This minimal memory footprint is what makes SGD one of the few plausible optimizers on microcontrollers: Adaptive Moment Estimation (Adam) requires 3\(\times\) the memory of SGD for its per-parameter moment estimates, exceeding the SRAM budget on devices with $<$512 KB. The trade-off is slower convergence, requiring more gradient steps to reach comparable accuracy.
The practical implications are stark: while the STM32F4 microcontroller can run a simple linear regression model with a few hundred parameters, training even a small convolutional neural network would immediately exceed its memory capacity. In these severely constrained environments, neural updates are often limited to simple algorithms such as stochastic gradient descent (SGD)16, while non-neural adaptation may use \(k\)-means clustering to update centroids or thresholds for sensor anomaly detection. Both can be implemented using integer arithmetic and minimal memory overhead, representing a fundamental departure from data-center machine learning practice.
Moving up the computational hierarchy, mobile-class hardware represents improvement but still operates under severe constraints. Platforms including the Qualcomm Snapdragon, Apple Neural Engine17, and Google Tensor SoC18 provide significantly more compute power than microcontrollers, often featuring dedicated AI accelerators and optimized support for 8-bit or mixed-precision19 matrix operations. These accelerators offer dedicated matrix multiplication units, on-chip memory hierarchies, and power management features specifically designed for neural network inference, with varying support for local training workloads. While these platforms can support more sophisticated training routines, including full backpropagation over compact models, they still fall far short of the computational throughput and memory bandwidth available in centralized data centers. For instance, training a lightweight transformer20 on a smartphone is technically feasible but must be tightly bounded in both time and energy consumption to avoid degrading the user experience, highlighting the persistent tension between learning capabilities and practical deployment constraints.
17 Apple Neural Engine: From the A11 (0.6 TOPS) to flagship-class mobile NPUs around 35 TOPS, mobile neural acceleration improved by roughly two orders of magnitude across that device lineage. The systems consequence: fine-tuning a MobileNet classifier takes approximately 2 seconds on the neural accelerator vs. 45 seconds on CPU in this representative calculation, while consuming only approximately 500 mW additional power. This roughly 23\(\times\) speedup at minimal power cost is what makes on-device adaptation thermally feasible during normal phone usage, allowing compact personalization jobs to run as short accelerator-assisted bursts within strict thermal and battery policies.
18 Google Tensor SoC (2021): Integrates custom ML acceleration with Android and TensorFlow Lite tooling, making it a useful example of hardware-software co-design for on-device inference and federated workflows. The systems consequence is that accelerator capability alone is insufficient: local adaptation also depends on compiler support, runtime operators, power management, and update orchestration.
19 Mixed-Precision Training: Assigns different numerical precisions to different operations: FP16 for forward and backward passes, FP32 for parameter accumulation. This halves memory usage and doubles throughput on hardware with Tensor Cores. Mobile implementations go further, using INT8 for inference and FP16 for gradients, which reduces training memory by 4\(\times\) compared to full FP32 while keeping accumulation errors bounded through loss scaling.
20 Lightweight Transformers: Mobile-optimized architectures like MobileBERT achieve 4–6\(\times\) speedup over full models through knowledge distillation and attention head pruning, retaining 97 percent of BERT-base accuracy at approximately 40 ms inference on mobile CPUs vs. 160 ms for full BERT. The constraint that matters for on-device learning: even these compressed transformers require 50–200 MB for training activations, pushing against the 2–4 GB available on mid-range phones.
Published benchmark results from MLPerf Tiny and official vendor data make these hardware tiers concrete. Figure 6 plots inference latency against energy per inference for representative devices, revealing three distinct clusters separated by approximately 100\(\times\) in energy consumption. Dedicated neural processors such as the Syntiant Core 2 and STM32N6 NPU achieve keyword spotting in under 5 ms at 30 to 160 microjoules, while edge GPUs like the Jetson AGX Orin deliver sub-millisecond latency at 15 millijoules. The 100\(\times\) energy gap between tiers determines which devices can operate on battery power for months vs. hours, fundamentally shaping the feasible design space for on-device learning.
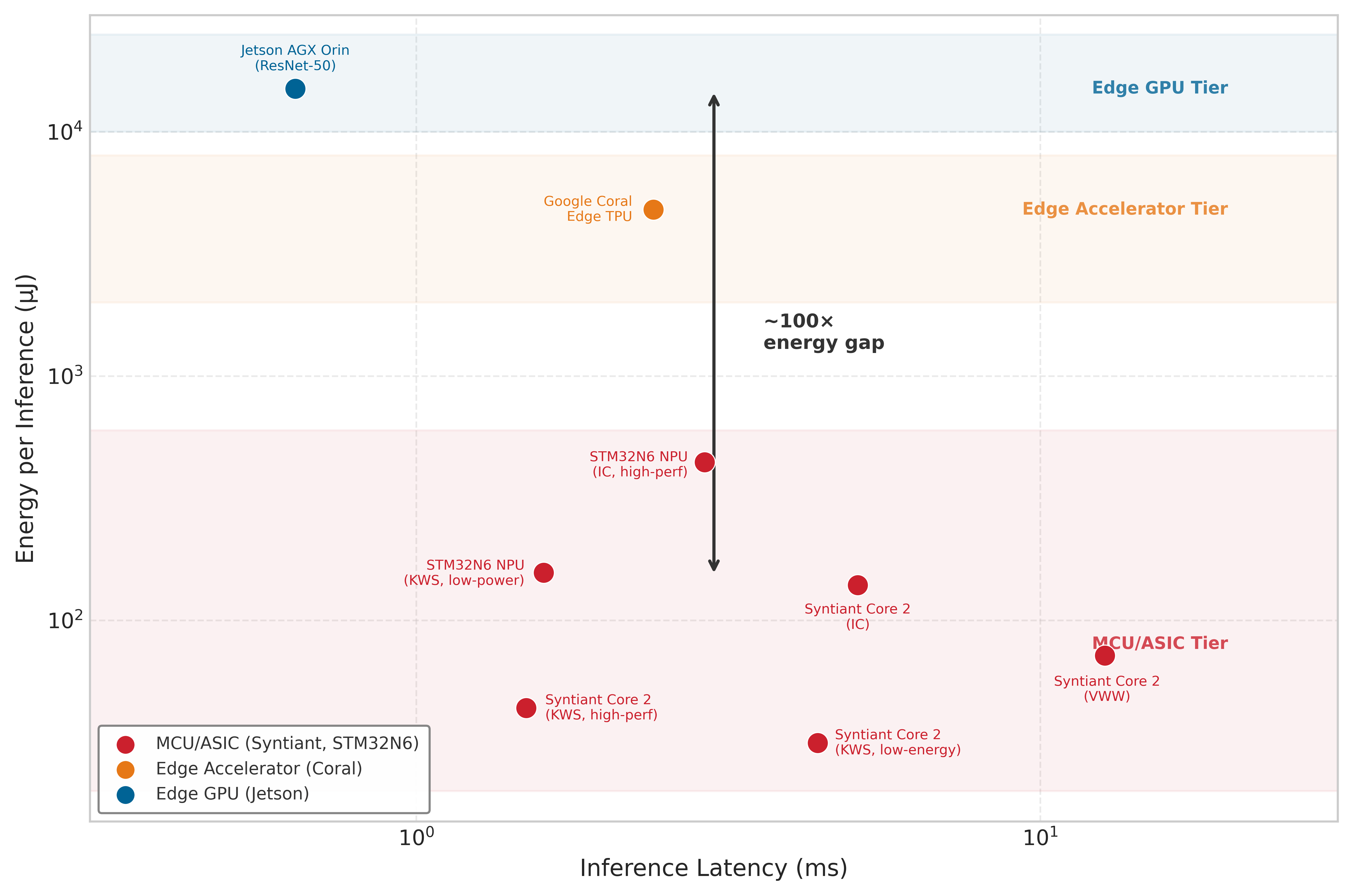
These computational limitations become especially acute in real-time or battery-operated systems, where the latency budgets established in section 1.0.2 turn into hard architectural constraints: they determine whether on-device adaptation is feasible at all or whether cloud-based alternatives become architecturally necessary. The harder constraint is that adaptation cannot have the device to itself. In a smartphone-based speech recognizer, on-device adaptation must seamlessly coexist with primary inference workloads without interfering with response latency or system responsiveness. Similarly, in wearable medical monitors, training must occur opportunistically during carefully managed windows (typically during periods of low activity or charging) to preserve battery life and avoid thermal management issues.
Beyond raw computational capacity, the architectural implications of these hardware constraints extend into fundamental system design choices. Training operations exhibit fundamentally different memory access patterns than inference workloads: backpropagation requires 3–5\(\times\) higher memory bandwidth due to gradient computation and activation caching, creating bottlenecks that pure computational metrics do not capture. Edge accelerator designs address these challenges through specialized hardware features. Adaptive precision datapaths allow dynamic switching between INT4 for forward passes and FP16 for gradient computation, optimizing both accuracy and efficiency within power budgets. Sparse computation units accelerate selective parameter updates by skipping zero gradients, a capability critical for efficient bias-only and structured low-rank updates (section 1.2.2.2). Near-memory compute architectures21 reduce data movement costs by performing gradient updates directly adjacent to weight storage, addressing the memory bandwidth bottleneck. However, many edge accelerators remain fundamentally optimized for inference workloads, creating hardware-software co-design opportunities for on-device training accelerators designed to handle the unique demands of local adaptation.
21 Near-Memory Computing: Places processing elements adjacent to or within memory arrays, reducing the data movement that often dominates arithmetic energy in conventional architectures (Horowitz 2014). Near-memory accelerator designs such as TensorDIMM illustrate how moving tensor operations closer to memory can improve throughput and energy behavior for memory-bound deep learning workloads (Kwon and Rhu 2018). For edge training, where gradient computation generates write-heavy access patterns that overwhelm cache hierarchies, this architectural shift could make some forms of on-device backpropagation more practical.
Horowitz, Mark. 2014. “1.1 Computing’s Energy Problem (and What We Can Do about It).” 2014 IEEE International Solid-State Circuits Conference Digest of Technical Papers (ISSCC), 10–14. https://doi.org/10.1109/isscc.2014.6757323.
Kwon, Youngeun, and Minsoo Rhu. 2018. “TensorDIMM: A Practical Near-Memory Processing Architecture for Embeddings and Tensor Operations in Deep Learning.” Proceedings of the 52nd Annual IEEE/ACM International Symposium on Microarchitecture, 740–53. https://doi.org/10.1145/3352460.3358284.
The mobile memory wall
While mobile NPUs deliver impressive TOPS, the “memory wall” that The Memory Wall examines becomes an impassable barrier for large-scale models on edge devices. The same bandwidth wall that limits training updates is easiest to see in mobile language-model decode: if weights and KV state cannot stream through memory fast enough, no advertised TOPS figure can rescue the workload. Recent analysis highlights how autoregressive decode shifts LLM inference pressure toward memory and interconnect rather than peak arithmetic throughput (Ma and Patterson 2026). The quantitative disparity is stark: data-center HBM3 on an H100 provides 3,350 GB/s, while flagship mobile systems such as A17 Pro or Snapdragon 8 Gen 3 devices sit near 64–100 GB/s of LPDDR5X bandwidth.
Ma, Xiaoyu, and David Patterson. 2026. Challenges and Research Directions for Large Language Model Inference Hardware. No. 5. Vol. 59. https://doi.org/10.1109/mc.2026.3652916.

Datacenter HBM outruns mobile memory bandwidth by about 34 times.
A 30–50\(\times\) bandwidth gap means that even if a model fits in mobile RAM, it will generate tokens 30–50\(\times\) slower than a data center GPU. On-device large language model (LLM) serving therefore requires aggressive quantization (INT4 or even INT2) as a bandwidth survival strategy, not just a capacity optimization. Reducing model size by 8\(\times\) effectively increases the relative bandwidth, making interactive generation speeds possible on mobile hardware.
Systems Perspective 1.2: Why bandwidth, not TOPS, is the binding constraint
The bandwidth gap binds because each generated token streams the model’s weights from memory to the compute units, so the iron law’s data term \((D_{\text{vol}} / \text{BW})\) dominates the compute term whenever weights exceed on-chip cache, which is the case for billion-parameter models on mobile-class silicon. That is also why quantization shrinks \(D_{\text{vol}}\) rather than arithmetic per token.
The practical corollary follows: when ranking edge accelerator options for transformer decoding, the figure of merit is the GB/s a chip can sustain to its on-package memory, not the peak TOPS on its spec sheet. The two can diverge by orders of magnitude on mobile-class silicon.
Edge hardware integration challenges
Beyond the individual constraints of models, data, and computation, on-device learning systems must navigate the underlying physics of mobile computing: power dissipation, thermal limits, and energy budgets. These physical constraints are fundamental design drivers that determine the entire feasible space of on-device learning algorithms.
Energy and thermal constraint analysis
Energy and thermal management represent the most challenging aspects of on-device learning system design, as they directly impact user experience and device longevity. Mobile devices operate under strict power budgets that fundamentally determine feasible model complexity and training schedules.
Napkin Math 1.1: Battery drain: The cost of edge learning
Problem: A team is designing a background fine-tuning job for a personalized voice assistant on a smartphone. The training job consumes 4.5 W and takes 30 minutes to complete. If the phone has a 15 Wh battery, how much of the user’s battery will this “invisible” update consume?
Math:
- Total energy: 4.5 W \(\times\) 0.5 h = 2.25 Wh.
- Battery Impact: 2.25 Wh/15 Wh = 15 percent.
Systems insight: Consuming 15 percent of a user’s battery for a background task is a severe violation of mobile UX principles—it is equivalent to losing an hour of screen-on time. This is why on-device training is typically restricted to Opportunistic Scheduling: it only runs when the device is plugged in, connected to Wi-Fi, and thermally stable. Designing for the edge means respecting the user’s energy budget as strictly as the model’s accuracy budget.
This battery calculation is the local edge-learning version of a broader energy constraint: training must fit the user’s energy budget, not only the model’s accuracy target. A production design therefore has to account for energy at scheduling time, compare local computation against communication cost, and defer learning when the user’s device cannot absorb the update.

Device memory spans about 15,000 times, phone to microcontroller.
Memory hierarchy optimization
Complementing the thermal and power challenges, memory hierarchy constraints create another fundamental bottleneck that shapes on-device learning system design. The constraint-amplification analysis shows that these limitations affect both static model storage and the dynamic memory requirements during training, often pushing systems beyond their practical limits.
The device memory hierarchy spans several orders of magnitude across different device classes, each presenting distinct constraints for on-device learning. A flagship phone provides about 8 GB total system memory, but only part of that remains available for application workloads after accounting for operating system requirements and background processes. Budget Android devices operate with about 4 GB total system memory, leaving roughly 1 GB–2 GB available for ML workloads after OS overhead consumes significant resources. IoT embedded systems provide 64 MB–1 GB total memory that must be shared between system tasks and application data, creating severe constraints for any learning algorithms. Microcontrollers offer only 256 KB–2 MB SRAM, requiring extreme optimization and careful memory management that fundamentally limits the complexity of models that can adapt on such platforms.
The memory expansion during training creates particularly acute challenges that often determine system feasibility. Standard backpropagation requires caching intermediate activations for each layer during the forward pass, which are then reused during gradient computation in the backward pass, creating substantial memory overhead. A MobileNetV2-scale model that fits comfortably for inference can exceed the available memory budget once activations, gradients, and optimizer state are included, making training impossible without aggressive optimization. Quantization, pruning, and distillation can each reduce model footprint or update cost (Jacob et al. 2018; Han et al. 2015; Hinton et al. 2015), but their gains are workload-specific and do not combine automatically. These techniques must be validated together to achieve the compression required for practical deployment.
Han, Song, Jeff Pool, John Tran, and William J. Dally. 2015. “Learning Both Weights and Connections for Efficient Neural Networks.” Advances in Neural Information Processing Systems 28 (NeurIPS 2015), 1135–43.
Hinton, Geoffrey, Oriol Vinyals, and Jeff Dean. 2015. “Distilling the Knowledge in a Neural Network.” arXiv Preprint.
Cache optimization therefore becomes critical for achieving acceptable performance with constrained memory pools. Modern mobile SoCs feature complex memory hierarchies with L1 cache (32–64 KB), L2 cache (1–8 MB), and system memory (4–16 GB) that exhibit 10–100\(\times\) latency differences between levels, creating severe performance cliffs when working sets exceed cache capacity. Training workloads that exceed cache capacity face dramatic performance degradation due to memory bandwidth bottlenecks that can slow training by orders of magnitude. Successful on-device learning systems must carefully design data access patterns to maximize cache hit rates, often requiring specialized memory layouts that group related parameters for spatial locality, carefully sized mini-batches that fit entirely within cache constraints, and sophisticated gradient accumulation strategies that minimize expensive memory bus traffic.
The memory bandwidth limitations become particularly acute during training. While inference workloads primarily read model weights sequentially, training requires bidirectional data flow for gradient computation and weight updates. This increased memory traffic can saturate the memory subsystem, creating bottlenecks that limit training throughput regardless of computational capacity. Advanced implementations employ techniques such as gradient checkpointing22 to trade computation for memory (Chen et al. 2016), and mixed-precision training to reduce bandwidth requirements while maintaining numerical stability.
22 Gradient Checkpointing: Trades computation for memory by recomputing selected intermediate activations during the backward pass instead of storing all of them. The general checkpointing result is sublinear activation memory at the cost of extra forward computation (Chen et al. 2016). On edge devices where memory is the binding constraint, this trade-off can make the difference between a model that fits in 2 GB RAM and one that requires 8 GB, but the exact memory and compute factors are architecture- and schedule-dependent.
Mobile AI accelerator optimization
Accelerator choice matters less as a peak-TOPS comparison than as a question of which training primitive the hardware can sustain. Fixed-precision inference engines favor inference-heavy adaptation, programmable vector units make compact backpropagation more plausible, and tight framework integration lowers federated coordination overhead. The architectural differences between these accelerators shape the design space for on-device training algorithms.
Flagship-class mobile accelerators should be read as different adaptation envelopes, not as a peak-TOPS ranking. Flagship-class mobile NPUs provide tens of TOPS of peak performance, with 35 TOPS serving here as a generic high-end reference point rather than a single named chip. Apple’s Neural Engine is optimized primarily for CoreML inference patterns with limited training support, making it well suited for inference-heavy adaptation techniques. Qualcomm’s Hexagon DSP in the Snapdragon 8 Gen 3 achieves 45 TOPS with flexible precision support and programmable vector units, enabling mixed-precision training workflows that can adapt precision dynamically based on training phase and memory constraints. Google’s Tensor TPU in the Pixel 8 is optimized specifically for TensorFlow Lite operations with strong INT8 performance and tight integration with federated learning frameworks, reflecting a software-stack focus on distributed learning scenarios. The energy-efficiency gap explains why dedicated neural processing units are essential: NPUs achieve 1–5 TOPS per watt vs. general-purpose CPUs at just 0.1-0.2 TOPS per watt, representing a 5–50\(\times\) efficiency advantage that makes the difference between feasible and infeasible on-device training.
Each accelerator implies different learning paradigms. Apple’s Neural Engine excels at fixed-precision inference but provides limited support for dynamic precision gradient computation, making it better suited for inference-heavy adaptation techniques like few-shot learning. Programmable DSPs offer greater training flexibility through vector units and mixed-precision arithmetic, enabling backpropagation on compact models when the software stack exposes the needed operators. Mobile TPU-class accelerators integrate tightly with framework runtimes and federated learning tooling, reducing the systems overhead of local training and update coordination.
These per-vendor envelopes inherit the same training-specific access patterns and hardware features discussed under section 1.1.4: the write-heavy gradient flow, the adaptive-precision datapaths, sparse-update units, and near-memory compute that distinguish a training-capable accelerator from an inference-only one. The consequence for design is that architecture selection here is not a peak-throughput choice; it influences everything from model quantization strategies and gradient computation approaches to federated communication protocols and thermal management policies.
Holistic resource management strategies
The constraint analysis above reveals three challenge categories that define the on-device learning design space, and each category drives a corresponding solution pillar. Resource amplification, where training increases memory requirements by 4–12\(\times\), computational costs by 2–3\(\times\), and energy consumption proportionally, necessitates Model Adaptation approaches that reduce the scope of parameter updates while preserving learning capability. Information scarcity, including limited local datasets, non-IID distributions, privacy restrictions on data sharing, and minimal supervision, drives data efficiency solutions that extract maximum learning signal from minimal examples. Coordination challenges, such as device heterogeneity, intermittent connectivity, distributed validation complexity, and scalability requirements, motivate federated coordination mechanisms that enable privacy-preserving collaboration across device populations.
Table 3 reveals how this on-device learning constraint-solution mapping creates a systematic engineering framework: Model Adaptation addresses memory and compute limits through selective parameter updates, Data Efficiency maximizes learning from scarce private samples, and Federated Coordination enables privacy-preserving collaboration. Rather than viewing these as independent techniques, robust systems orchestrate all three approaches to create coherent adaptive systems that operate effectively within edge constraints.
| Constraint Category | Key Challenges | Solution Approach |
|---|---|---|
| Resource Amplification | • Training workloads (4–12\(\times\) memory) • Memory limitations • Power constraints |
Model Adaptation • Parameter-efficient updates • Selective layer fine-tuning • Low-rank adaptations |
| Information Scarcity | • Limited local datasets • Non-IID distributions |
Data Efficiency |
| • Privacy restrictions | • Few-shot learning | |
| • Meta-learning • Transfer learning |
||
| Coordination Challenges | • Device heterogeneity • Intermittent connectivity • Distributed validation complexity • Scalability requirements |
Federated Coordination • Federated averaging and asynchronous aggregation • Secure aggregation and differential privacy • Client selection and stragglers handling |
Each solution pillar extends compression and distributed-systems tools to address a specific constraint category. No single pillar suffices on its own, but their integration creates systems capable of meaningful adaptation within the severe constraints of edge deployment environments.
Self-Check: Question
The chapter states that on-device training requires 4–12\(\times\) the memory of inference for the same model. What is the dominant mechanism behind this amplification?
- Backpropagation requires cached forward activations, per-parameter gradients, and optimizer state to coexist in memory alongside the weights, so the peak footprint scales as 4–12\(\times\) inference.
- Training duplicates the operating system image in RAM every epoch, which dominates memory use on phones.
- Inference compresses weights to zero during execution, but training has to restore them at full size.
- Training uses only sequential weight reads, so the memory increase comes mainly from longer runtimes rather than additional state.
A phone has 8 GB of advertised RAM, but an engineer hits out-of-memory errors trying to train a 100M-parameter model locally. Explain why total installed RAM is a misleading feasibility check, and name the measurement that actually determines feasibility.
True or False: Gradient checkpointing makes an attractive memory-compute trade-off on edge devices because it reduces peak memory at the cost of roughly 20-30 percent additional compute, which is usually the favorable direction when memory is the binding constraint.
A mobile NPU advertises 50 TOPS of peak integer throughput, yet a large language model still generates tokens far slower on the phone than on an H100. The chapter attributes this to a specific physical constraint. What is it?
- The phone’s CPU cannot compile the model graph quickly enough before each token is emitted.
- Mobile LPDDR5X delivers 64-100 GB/s of bandwidth while datacenter HBM3 delivers roughly 3,350 GB/s, a 30–50\(\times\) gap that makes autoregressive decode memory-bandwidth-bound rather than compute-bound.
- Token generation fails because mobile NPUs cannot perform integer arithmetic of the required precision.
- The bottleneck is that phones have too much on-chip cache, which lowers arithmetic intensity below the roofline ridge.
A background training job draws 4.5 W for 30 minutes on a phone with a 15 Wh battery. What systems conclusion best matches the chapter’s interpretation of this scenario?
- The job consumes about 15 percent of the battery (2.25 Wh / 15 Wh), which is unacceptable for an invisible background process and argues for scheduling training only during charging, Wi-Fi, and thermally stable windows.
- The cost is negligible, so background training should run whenever new data arrives.
- The job mainly stresses storage, not energy, because battery drain is dominated by flash writes.
- The drain is only acceptable if the model is larger than 100M parameters.
The chapter’s three-pillar framework pairs each design constraint category with a primary solution pillar. Order the following pillars according to the constraint category they address, starting with resource amplification, then information scarcity, then coordination: (1) Data Efficiency, (2) Model Adaptation, (3) Federated Coordination.
Model Adaptation
Personalizing a billion-parameter model on a smartwatch with 500 MB of total system memory is impossible without abandoning the goal of updating the complete model. The answer is that we do not update the whole model. We freeze the vast majority of the network and only train a tiny, strategically placed set of new parameters. This is the essence of resource-efficient model adaptation.

Adapters make per-user personalization cheap versus full model copies.
The engineering challenge centers on navigating a fundamental trade-off space: adaptation expressivity vs. resource consumption. At one extreme, updating all parameters provides maximum flexibility but exceeds edge device capabilities. At the other extreme, no adaptation preserves resources but fails to capture user-specific patterns. Effective on-device learning systems must operate in the middle ground, selecting adaptation strategies based on three key engineering criteria:
- Resource envelope determines which adaptation approaches are feasible. A tiny wearable-class device with 1 MB RAM requires fundamentally different strategies than a smartphone with 8 GB.
- User-specific variation determines how much adaptation complexity the system needs. Simple preference learning may require only bias updates, while complex domain shifts demand more sophisticated approaches.
- Systems integration determines whether the adaptation technique can fit existing inference pipelines, federated coordination protocols, and operational monitoring systems for model deployment and lifecycle management.
The selection of adaptation techniques follows the same logic, starting with lightweight approaches (section 1.2.1) and progressing to more expressive but resource-intensive methods (section 1.2.3). Each technique represents a different point in the engineering trade-off space.
On top of the compression baseline established in section 1.1, model adaptation adds a second move: complete model retraining is neither necessary nor feasible at the edge, so systems use pretrained representations strategically and adapt only the minimal parameter subset required to capture local variations: preserve what works globally, adapt what matters locally. Those three criteria turn adaptation into a device-matching decision. Weight freezing fits severe memory limits by updating only bias terms or final layers. Structured updates use low-rank and residual adaptations when the device can afford more expressiveness but not full fine-tuning. Sparse updates reserve scarce training capacity for the parameters with the highest adaptation value.
Weight freezing
The most direct approach to on-device learning is to freeze the majority of a model’s parameters and adapt only a minimal subset. Bias-only adaptation holds all weights fixed and updates only the bias terms (scalar offsets applied after linear or convolutional layers). The constraint reduces trainable parameters by 100–1000\(\times\), simplifies memory management during backpropagation, and helps mitigate overfitting when training data is sparse or noisy.
Consider a standard neural network layer: \[ y = W x + b \] where \(W \in \mathbb{R}^{m \times n}\) is the weight matrix, \(b \in \mathbb{R}^m\) is the bias vector, and \(x \in \mathbb{R}^n\) is the input. In full training, gradients are computed for both \(W\) and \(b\). In bias-only adaptation, we constrain: \[ \frac{\partial \mathcal{L}}{\partial W} = 0, \quad \frac{\partial \mathcal{L}}{\partial b} \neq 0 \] so that only the bias is updated via gradient descent: \[ b \leftarrow b - \eta \frac{\partial \mathcal{L}}{\partial b} \]
This reduces the number of stored gradients and optimizer states, enabling training to proceed under memory-constrained conditions. On embedded devices that lack floating-point units, this reduction enables on-device learning. Listing 1 makes the constraint explicit: all convolutional and fully connected weights remain frozen, while only bias terms adapt to local data.
# Freeze all parameters
for name, param in model.named_parameters():
param.requires_grad = False
# Enable gradients for bias parameters only
for name, param in model.named_parameters():
if "bias" in name:
param.requires_grad = TrueThis pattern ensures that only bias terms participate in the backward pass and optimizer update, simplifying the training process while maintaining adaptation capability. This is valuable when adapting pretrained models to user-specific or device-local data where the core representations remain relevant but require calibration.
The practical effectiveness of this approach is demonstrated by TinyTL (Cai et al. 2020), a framework explicitly designed to enable efficient adaptation of deep neural networks on microcontrollers and other severely memory-limited platforms. Rather than updating all network parameters during training (impossible on such constrained devices), TinyTL strategically freezes both the convolutional weights and the batch normalization statistics, training only the bias terms and, in some cases, lightweight residual components. This architectural constraint creates a profound shift in memory requirements during backpropagation, since the largest memory consumers (intermediate activations) no longer need to be stored for gradient computation across frozen layers.
Figure 7 visualizes this architectural impact by contrasting standard training with the TinyTL approach. Where conventional backpropagation requires storing activations across all layers, TinyTL freezes backbone weights and batch normalization statistics, training only the final classifier and lightweight bias modules. This eliminates the need to store activations for frozen layers, making adaptation possible within the severe memory constraints established earlier.

The memory reduction is useful only when the frozen backbone remains expressive enough for the downstream task. The bias terms allow for minor but meaningful shifts in model behavior, particularly for personalization tasks. When domain shift is more significant, TinyTL can optionally incorporate small residual adapters to improve expressivity, all while preserving the system’s tight memory and energy profile.
These design choices allow TinyTL to reduce training memory usage by 10\(\times\). For instance, adapting a MobileNetV2 model using TinyTL can reduce the number of updated parameters from over 3 million to fewer than 50,00023. Combined with quantization, this allows local adaptation on devices with only a few hundred kilobytes of memory, making on-device learning truly feasible in constrained environments.
23 TinyTL Memory Savings: The approximately 68× trainable-parameter reduction (3.4 M to 50 K) collapses MobileNetV2 training memory from approximately 20 MB (weights + activations in FP32) to approximately 600 KB, fitting within a 1 MB microcontroller budget. Real deployments on STM32H7 achieve 85 percent of full fine-tuning accuracy while completing updates in approximately 30 seconds vs. 8 minutes, demonstrating that bias-only adaptation trades expressivity for feasibility on the most constrained hardware.
Structured parameter updates
While weight freezing provides computational efficiency and clear memory bounds, it severely limits model expressivity by constraining adaptation to a small parameter subset. When bias-only updates prove insufficient for capturing complex domain shifts or user-specific patterns, residual and low-rank techniques provide a middle ground between the extreme efficiency of weight freezing and the full expressivity of unrestricted fine-tuning. Rather than modifying existing parameters, these methods extend frozen models by adding small trainable components, such as residual adaptation modules (Houlsby et al. 2019) or low-rank parameterizations (Hu et al. 2021). The main body of the network remains fixed, while only the added components are optimized, so the model can respond to new data without giving up the memory and compute bounds that make on-device adaptation feasible.
Houlsby, Neil, Andrei Giurgiu, Stanislaw Jastrzebski, Bruna Morrone, Chloé de Laroussilhe, Andrea Gesmundo, Mohammad Attariyan, and Sylvain Gelly. 2019. “Parameter-Efficient Transfer Learning for NLP.” International Conference on Machine Learning, 2790–99.
Adapter-based adaptation
A common implementation involves inserting residual adapters, which are small residual bottleneck layers, between existing layers in a pretrained model. Consider a hidden representation \(h\) passed between layers. A residual adapter introduces a transformation: \[ h' = h + A(h) \] where \(A(\cdot)\) is a trainable function, typically composed of two linear layers with a nonlinearity: \[ A(h) = W_2 \, \sigma(W_1 h) \] with \(W_1 \in \mathbb{R}^{r \times d}\) and \(W_2 \in \mathbb{R}^{d \times r}\), where \(r \ll d\). This bottleneck design ensures that only a small number of parameters are introduced per layer.
The adapters act as learnable perturbations on top of a frozen backbone. Because they are small and sparsely applied, they add negligible memory overhead, yet they allow the model to shift its predictions in response to new inputs.
Low-rank techniques
Another efficient strategy is to constrain weight updates themselves to a low-rank structure. Rather than updating a full matrix \(W\), the update is approximated as: \[ \Delta W \approx U V^\top \] where \(U \in \mathbb{R}^{m \times r}\) and \(V \in \mathbb{R}^{n \times r}\), with \(r \ll \min(m,n)\). This reduces the number of trainable parameters from \(mn\) to \(r(m + n)\).
The mathematical intuition behind this decomposition connects to fundamental linear algebra principles: any matrix can be expressed as a sum of rank-one matrices through singular value decomposition. Constraining updates to low rank (typically \(r = 4\) to \(16\)) captures a restricted set of variation modes while reducing parameters. For a typical transformer layer with dimensions \(768{\times}768\), full fine-tuning requires updating 589,824 parameters. With rank-4 decomposition, only $768{}4{}2 = $ 6,144 parameters are updated, a 99 percent reduction. Whether this retains most of the adaptation quality depends on the task, rank, and base model; Low-Rank Adaptation (LoRA) reports that low-rank adapters can match or approach full fine-tuning on several transformer adaptation benchmarks (Hu et al. 2021).
During adaptation, the new weight is computed as: \[ W_{\text{adapted}} = W_{\text{frozen}} + U V^\top \]
This formulation is commonly used in LoRA24, originally developed for transformer models (Hu et al. 2021) but broadly applicable across architectures. From a systems engineering perspective, LoRA makes the trainable adapter the artifact that can be stored, transmitted, scheduled, and rolled back separately from the frozen base model.
24 LoRA: Hu et al. (2021) learns rank-\(r\) decomposition matrices \(A\) and \(B\) instead of updating full weight matrices, reducing trainable parameters by 100–10,000\(\times\) while maintaining much of the adaptation quality. For on-device learning, this compression is decisive, but it affects adapter state rather than the full model footprint: a model with 7B parameters has about a 14 GB FP16 weight footprint before gradients, optimizer state, and activations, while rank 16 LoRA can reduce the trainable adapter parameters to tens or hundreds of megabytes. Practical phone deployment still requires storing, quantizing, or offloading the frozen base model.
Hu, Edward J., Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2021. “LoRA: Low-Rank Adaptation of Large Language Models.” arXiv Preprint arXiv:2106.09685.
Consider a mobile deployment where a language model with 7B parameters has a 14 GB FP16 weight footprint, before accounting for the additional gradients, optimizer states, and activations required by full fine-tuning. That footprint is impossible on smartphones with about 8 GB total memory unless the base model is aggressively quantized, partitioned, or offloaded. LoRA with rank 16 can reduce the trainable adapter parameters to tens or hundreds of megabytes, making local adaptation plausible only when the frozen base model is handled separately.
LoRA’s efficiency becomes critical in intermittent connectivity scenarios. A full model update over cellular networks would require a 14 GB download and corresponding data-plan cost, while the tier-profile adapter update is 50 MB. Small adapter updates can synchronize in under a minute on good mobile links; larger adapter updates typically require LTE or Wi-Fi for sub-minute coordination and may take minutes on 3G. This is still dramatically more practical than hours-long full model transfers.
A device-tiered deployment can use different adapter configurations based on device capabilities. Flagship phones use wider bottlenecks for higher expressivity, mid-range devices use moderate bottlenecks for balanced performance, and budget devices use narrow bottlenecks to stay within about 2 GB memory limits. These residual adapter modules can be implemented efficiently on edge devices, particularly when the down-projection and up-projection matrices are small and fixed-point representations are supported. Listing 2 implements this low-rank adapter pattern as a residual bottleneck, showing how a compact down/up projection adds trainable capacity without updating the frozen backbone.
Example 1.1: On-device keyboard learning
Scenario: Large-scale mobile keyboard systems are a canonical deployment pattern for federated and on-device learning.
Mechanism: A keyboard can adapt next-word prediction without uploading raw keystrokes, but only if training is strictly constrained: it runs during idle, charging, Wi-Fi-connected windows and transmits compressed updates rather than text. Large deployments can combine secure aggregation with privacy accounting or noise addition so that the server learns population-level update statistics, not individual typing histories.
Systems lesson: On-device learning is viable only when the training schedule, communication payload, and privacy boundary are engineered together. The model update is a systems protocol, not just a local optimization step.
Returning to the adapter mechanism, listing 2 shows the residual bottleneck that makes the memory savings concrete: the frozen backbone remains untouched, while only the down-projection and up-projection weights are trained.
class Adapter(nn.Module):
def __init__(self, dim, bottleneck_dim):
super().__init__()
# Project from full dimension to bottleneck (e.g., 768 -> 16)
self.down = nn.Linear(
dim, bottleneck_dim
) # W1: learns compression
# Project back to original dimension (e.g., 16 -> 768)
self.up = nn.Linear(
bottleneck_dim, dim
) # W2: learns expansion
self.activation = nn.ReLU()
def forward(self, x):
# Residual connection: original + low-rank adaptation
# Only adapter params trained; base model frozen
return x + self.up(self.activation(self.down(x)))This adapter adds a small residual transformation to a frozen layer. When inserted into a larger model, only the adapter parameters are trained.
Edge personalization
Adapters enable an efficient multi-tenant architecture for edge intelligence, where a single frozen backbone supports multiple personalized contexts. Consider a 10M parameter vision model deployed on a smartphone with 8 GB RAM. Full fine-tuning would require storing a separate 40 MB copy of the model weights for each personalization context (home, office, outdoor), rapidly consuming the device’s storage. A rank-64 adapter introduces only approximately 50,000 parameters (roughly 200 KB) per context—a 200\(\times\) reduction in storage. This efficiency allows the device to store dozens of specialized adapters that share the same frozen backbone, swapping them dynamically based on the user’s location or activity.
This adapter switching pattern transforms the smartphone from a static inference engine into a context-aware learning system. When the user enters a low-light environment, the system can load the appropriate adapter into the vision pipeline instead of replacing the entire backbone. The modularity extends naturally to federated learning: in the 10M-parameter example above, transmitting a 200 KB adapter is far cheaper than transmitting a 40 MB full-model update over a bandwidth-constrained cellular connection. Residual-adapter studies show that small trainable modules can adapt a shared visual backbone across multiple visual domains (Rebuffi et al. 2017), making them a useful design point between personalization quality and system resources. The frozen backbone helps preserve general visual representations, while adapters provide a bounded place for user- or context-specific updates without exposing the entire model to catastrophic forgetting, the loss of previously learned general behavior when new updates overwrite it (formalized in section 1.3.2 later in this chapter).
Rebuffi, Sylvestre-Alvise, Hakan Bilen, and Andrea Vedaldi. 2017. “Learning Multiple Visual Domains with Residual Adapters.” Advances in Neural Information Processing Systems 30.
In smartphone camera pipelines, environmental lighting, user preferences, and lens distortion vary between users. A shared model can be frozen and fine-tuned per-device using a few residual modules, allowing lightweight personalization without destabilizing the base model. In voice-based systems, adapter modules reduce word error rates in personalized speech recognition without retraining the full acoustic model. They also allow easy rollback or switching between user-specific versions—a critical operational capability when local adaptation occasionally degrades rather than improves performance.
Performance vs. resource trade-offs
Selecting the right adaptation strategy requires quantitative analysis of the resource-expressivity spectrum. For a 10M parameter model, the trade-offs are concrete. Bias-only updates are the most efficient, requiring just 50 KB of trainable parameters and negligible compute overhead, but they struggle to adapt to structural domain shifts like changing sensor geometries or new object categories. At the other extreme, full fine-tuning offers maximum expressivity but demands 40 MB or more of gradients and optimizer states, making it infeasible for background training on typical mobile devices. Low-rank techniques (LoRA) and residual adapters occupy the strategic middle ground: a rank-16 LoRA configuration requires approximately 2 MB of trainable memory, while a standard residual adapter needs approximately 5 MB.
The decision between LoRA and residual adapters often hinges on inference latency constraints. LoRA matrices can be mathematically merged into the frozen backbone weights during inference \((W_{\text{final}} = W_{\text{frozen}} + U V^\top)\), resulting in zero additional inference latency. This makes LoRA ideal for latency-critical paths like real-time video processing where every millisecond matters. Residual adapters, conversely, remain distinct modules (\(y = f(x) + \text{Adapter}(x)\)), adding 1–3 percent to inference latency due to the extra forward pass through the adapter layers. However, this separation enables the hot-swapping capability described earlier: switching adapters requires loading only the small adapter weights rather than recomputing merged matrices.
Implementing these adaptation techniques requires system-level support for dynamic computation graphs and the ability to selectively inject trainable parameters. Not all deployment environments or inference engines support such capabilities natively. TensorFlow Lite and Open Neural Network Exchange (ONNX) Runtime Mobile provide support for adapter-style architectures, but custom inference stacks on microcontrollers may require manual implementation of the adapter forward pass.
System architects should apply a device-tier framework to this decision. On flagship phones (Tier 1) with dedicated Neural Engines and 8+ GB RAM, residual adapters provide a strong balance of modularity and speed, enabling context-aware switching with minimal latency impact. On mid-range devices (Tier 2) with 4–8 GB RAM, LoRA is attractive because weight merging eliminates runtime overhead entirely. For ultra-constrained IoT endpoints (Tier 3) with less than 1 GB RAM, bias-only updates may be the only practical option. This tiered approach ensures that the adaptation mechanism matches the physical reality of the hardware, preventing thermal throttling while delivering meaningful personalization at each capability level.
Checkpoint 1.2: Edge personalization
Verify your understanding of efficient on-device adaptation:
Sparse updates
Sparse updates are the highest-expressivity end of the model adaptation hierarchy. Instead of adding new parameters or choosing a fixed subset in advance, the system dynamically identifies which existing parameters provide the greatest adaptation benefit for a specific task or user. This preserves more of full fine-tuning’s flexibility while keeping the update footprint small enough for edge deployment.
The sparse-update decision goes beyond updating fewer parameters. Training remains resource-intensive even after model-adaptation techniques restrict learning to a small subset. Sparse updating addresses the remaining cost by selecting only task-relevant parameters, reducing memory and compute while preserving meaningful personalization.
The key insight is that layers do not contribute equally to local performance gains. If the system can identify the minimal subset with the highest adaptation value, it can spend scarce training capacity where it changes the model’s behavior most.
Sparse update design
Let a neural network be defined by parameters \(\theta = \{\theta_1, \theta_2, \ldots, \theta_{N_L}\}\) across \(N_L\) layers. In standard fine-tuning, we compute gradients and perform updates on all parameters: \[ \theta_i \leftarrow \theta_i - \eta \frac{\partial \mathcal{L}}{\partial \theta_i}, \quad \text{for } i = 1, \ldots, N_L \]
In task-adaptive sparse updates, we select a small subset \(\mathcal{S} \subset \{1, \ldots, N_L\}\) such that only parameters in \(\mathcal{S}\) are updated: \[ \theta_i \leftarrow \begin{cases} \theta_i - \eta \frac{\partial \mathcal{L}}{\partial \theta_i}, & \text{if } i \in \mathcal{S} \\ \theta_i, & \text{otherwise} \end{cases} \]
The challenge lies in selecting the optimal subset \(\mathcal{S}\) given memory and compute constraints. A principled strategy is contribution analysis, an empirical method that estimates how much each layer contributes to downstream performance improvement. For example, one can measure the marginal gain from updating each layer independently:
- Freeze the entire model.
- Unfreeze one candidate layer.
- Finetune briefly and evaluate improvement in validation accuracy.
- Rank layers by performance gain per unit cost (e.g., per KB of trainable memory).
This layer-wise profiling yields a ranking from which \(\mathcal{S}\) can be constructed subject to a memory budget.
A concrete example is TinyTrain, a method designed to allow rapid adaptation on-device (Kwon et al. 2024). TinyTrain combines offline preparation with a task-adaptive sparse-update method that dynamically selects layers or channels to update using user data, memory limits, and compute limits. At runtime, the system updates only the selected subset rather than treating the whole network as trainable.
In implementation, selective layer updating turns the ranking into requires_grad decisions or equivalent graph masks. Listing 3 extends this pattern to profiling-driven layer selection, demonstrating how hardware profiling determines which layers to update based on contribution scores and memory constraints.
# Selective layer update based on contribution analysis
# Layers selected via profiling: conv2 and fc have highest
# accuracy-per-KB impact for this task
for name, param in model.named_parameters():
if "conv2" in name or "fc" in name:
param.requires_grad = True # Train high-impact layers
else:
param.requires_grad = False # Freeze low-impact layers
# Result: ~10% of params trainable, ~60% of adaptation quality
# Memory savings: gradient storage only for selected layersTinyTrain makes the runtime motivation concrete. Consider a scenario where a user wears an augmented reality headset that performs real-time object recognition. As lighting and environments shift, the system must adapt to maintain accuracy, but training must occur during brief idle periods or while charging. TinyTrain addresses this constraint through task-adaptive sparse updates: the deployment process selects a small update set that fits the device’s memory and compute budget. The approach keeps adaptation fast, energy-efficient, and memory-aware when the target task and device profile match the method’s assumptions.
Task-adaptive sparse updates still introduce system-level trade-offs. Contribution analysis has a nontrivial computational cost even when it occurs during pretraining or initial profiling, so the deployment pipeline must budget for it. Stability also requires attention: if too few parameters are selected for updating, the model may underfit the target distribution, so teams need validation thresholds for the selected subset before deployment. The selection policy must also account for hardware-specific execution costs because some parameters show high contribution scores but prove expensive to update on certain architectures. Despite these trade-offs, task-adaptive sparse updates provide a practical mechanism to scale adaptation across deployment contexts from microcontrollers to mobile devices (Diao et al. 2023).
Diao, Enmao, Jie Ding, and Vahid Tarokh. 2023. “Pruning and Sparse Training for on-Device Neural Network Optimization.” IEEE Transactions on Mobile Computing 22 (8): 4567–80.
Adaptation strategy comparison
Each adaptation strategy offers a distinct balance between expressivity, resource efficiency, and implementation complexity. Bias-only adaptation is the most lightweight approach, updating only scalar offsets in each layer while freezing all other parameters. This reduces memory requirements and computational burden, making it suitable for devices with tight memory and energy budgets. However, its limited expressivity means it is best suited to applications where the pretrained model already captures most of the relevant task features and only minor local calibration is required.
Residual adaptation, often implemented via adapter modules, introduces a small number of trainable parameters into the frozen backbone of a neural network. This allows for greater flexibility than bias-only updates, while still maintaining control over the adaptation cost. Because the backbone remains fixed, training can be performed efficiently and safely under constrained conditions. This method supports modular personalization across tasks and users, making it a favorable choice for mobile settings where moderate adaptation capacity is needed.
Task-adaptive sparse updates offer the greatest potential for task-specific finetuning by selectively updating only a subset of layers or parameters based on their contribution to downstream performance. While this method allows expressive local adaptation, it requires a mechanism for layer selection, through profiling, contribution analysis, or meta-training, which introduces additional complexity. Nonetheless, when deployed carefully, it allows for dynamic trade-offs between accuracy and efficiency, particularly in systems that experience large domain shifts or evolving input conditions. Table 4 contrasts adaptation strategy trade-offs across trainable parameters, memory overhead, expressivity, use-case suitability, and system requirements, revealing how the optimal choice depends on application domain, available hardware, latency constraints, and expected distribution shift.
| Technique | Trainable Parameters | Memory Overhead | Expressivity | Use Case Suitability | System Requirements |
|---|---|---|---|---|---|
| Bias-Only Updates | Bias terms only | Minimal | Low | Simple personalization; low variance | Extreme memory/compute limits |
| Residual Adapters | Adapter modules | Moderate | Moderate to High | User-specific tuning on mobile | Mobile-class SoCs with runtime support |
| Sparse Layer Updates | Selective parameter subsets | Variable | High (task-adaptive) | Real-time adaptation; domain shift | Requires profiling or meta-training |
While freezing weights and training adapters solves the memory bottleneck, it leaves us with a statistical problem. We have created a highly efficient learning mechanism, but edge devices rarely have the thousands of labeled examples required to properly train even these small adapters. We must now tackle the second pillar of on-device learning: data efficiency.
Self-Check: Question
Why is bias-only adaptation often the first viable adaptation strategy on extremely constrained devices?
- Biases capture all structural domain shifts, so bias-only adaptation is more expressive than full fine-tuning.
- Freezing every weight except biases collapses the set of trainable parameters by roughly two orders of magnitude, which proportionally shrinks gradient tensors, optimizer moments, and the activation cache needed to compute those gradients.
- It eliminates the need for a forward pass, so only backward computation remains.
- It requires more trainable state than LoRA but less runtime support from the software stack.
When a device cannot afford to train an entire weight matrix \(W \in \mathbb{R}^{d \times k}\), it can restrict the update to the product of two small matrices \(A \in \mathbb{R}^{d \times r}\) and \(B \in \mathbb{R}^{r \times k}\) with \(r \ll \min(d,k)\); this low-rank perturbation of frozen weights is commonly called ____.
A smartphone supports ten personalized contexts (home, office, gym, driving, etc.) with a 10M-parameter backbone. Explain why residual adapters are preferable to storing ten fully fine-tuned model copies, and quantify the approximate storage difference.
A real-time video pipeline has zero tolerance for additional inference latency after personalization is applied. Which adaptation method is the direct match according to the chapter’s inference-overhead analysis?
- Residual adapters, because the extra adapter forward pass improves latency predictability.
- Bias-only adaptation, because it always adapts deeper representations better than low-rank methods.
- Sparse layer updates, because profiling automatically removes all latency costs during inference.
- LoRA, because its low-rank update matrices can be merged into the frozen weights at deployment, producing a single weight tensor that adds essentially zero inference-time overhead.
Which strategy best captures the logic of task-adaptive sparse updates?
- Randomly select layers each round so every parameter eventually receives equal training attention.
- Always update the earliest layers because they are closest to the input distribution shift.
- Profile or meta-learn which layers deliver the most performance gain per unit of memory or compute, then spend the update budget on that subset.
- Freeze the model completely and rely on experience replay to simulate adaptation.
A deployment targets three device tiers: flagship phones (>6 GB RAM), mid-range phones (2-4 GB RAM), and ultra-constrained IoT devices (<1 GB RAM). Justify the adaptation method you would pick at each tier and name the binding constraint that makes each choice correct.
Data Efficiency
A user corrects their smartphone keyboard’s autocorrect perhaps three times a day. We cannot ask them to type 10,000 labeled sentences to train our language model. Data efficiency at the edge means learning aggressively from a sparse, noisy, and uncurated trickle of implicit user feedback, maximizing the signal extracted from each interaction.
The systems engineering challenge centers on a critical trade-off: data collection cost vs. adaptation quality. Edge devices face severe data acquisition constraints that reshape learning system design in ways not encountered in centralized training. Understanding and navigating these constraints requires systematic analysis of four interconnected engineering dimensions:
- Acquisition cost includes user friction, energy consumption, storage overhead, and privacy risk. A voice assistant learning from audio samples must balance improvement potential against battery drain and user comfort with always-on recording.
- Collection depth determines whether the system spends limited capacity on broad coverage or detailed examples. A mobile keyboard can collect many shallow typing patterns or fewer detailed interaction sequences, each strategy implying different learning approaches.
- Learning urgency determines whether the system must adapt from minimal examples immediately, as in emergency response scenarios, or can accumulate evidence over time, as in user preference learning.
- Lifecycle integration determines whether data efficiency techniques fit the model adaptation approaches from section 1.2, federated coordination (section 1.4), and operational monitoring for model deployment and lifecycle management.
These engineering constraints create a systematic trade-off space where different data efficiency approaches serve different combinations of constraints. Rather than choosing a single technique, successful on-device learning systems typically combine multiple approaches, each addressing specific aspects of the data scarcity challenge.
The strategy choice depends on which scarcity binds first. Few-shot learning fits cases where a few labeled or weakly labeled examples must drive personalization. Streaming updates fit settings where useful data arrives incrementally and cannot be batched in advance. Experience replay spends memory to stabilize continual updates by reusing scarce examples. Data compression reduces the storage cost of those histories so replay and lightweight training remain feasible within edge memory budgets.
Few-shot learning and data streaming
Together, these techniques turn data scarcity into an allocation problem: spend labels, memory, compute, and privacy budget where they produce the most reliable local signal. In conventional machine learning workflows, effective training typically requires large labeled datasets, carefully curated and preprocessed to ensure sufficient diversity and balance. On-device learning, by contrast, must often proceed from only a handful of local examples, collected passively through user interaction or ambient sensing, and rarely labeled in a supervised fashion. These constraints motivate two complementary adaptation strategies: few-shot learning, in which models generalize from a small, static set of examples, and streaming adaptation, where updates occur continuously as data arrives.
Few-shot adaptation is particularly relevant when the device observes a small number of labeled or weakly labeled instances for a new task or user condition (Wang et al. 2020). In such settings, it is often infeasible to perform full finetuning of all model parameters without overfitting. Instead, methods such as bias-only updates, adapter modules, or prototype-based classification are employed to make use of limited data while minimizing capacity for memorization. Let \(\mathcal{S} = \{(x_i, y_i)\}_{i=1}^K\) denote a \(K\)-shot dataset of labeled examples collected on-device. The model update is viable only if three constraints remain bounded:
Wang, Y., Q. Yao, J. T. Kwok, and L. M. Ni. 2020. “Generalizing from a Few Examples: A Survey on Few-Shot Learning.” ACM Computing Surveys 53 (3): 1–34. https://doi.org/10.1145/3386252.
- Gradient work stays small: \(K_{\text{steps}} \ll 100\).
- Updated state stays compact: \(\|\theta_{\text{updated}}\| \ll \|\theta\|\).
- Prior task knowledge remains preserved, avoiding catastrophic forgetting.
Keyword spotting (KWS) systems are a common target for data-efficient on-device adaptation; Speech Commands provides a standard dataset for training and evaluating limited-vocabulary KWS models under on-device constraints (Warden 2018). These models are used to detect fixed phrases, including phrases like “Hey Siri”25 or “OK Google”, with low latency and high reliability. A typical KWS model consists of a pretrained acoustic encoder (e.g., a small convolutional or recurrent network that transforms input audio into an embedding space) followed by a lightweight classifier. In commercial systems, the encoder is trained centrally using thousands of hours of labeled speech across multiple languages and speakers. However, supporting custom wake words (e.g., “Hey Jarvis”) or adapting to underrepresented accents and dialects is often infeasible via centralized training due to data scarcity and privacy concerns.
Warden, Pete. 2018. “Speech Commands: A Dataset for Limited-Vocabulary Speech Recognition.” arXiv Preprint arXiv:1804.03209, ahead of print. https://doi.org/10.48550/arXiv.1804.03209.
25 “Hey Siri” Power Budget: The always-on detector consumes $<$1 mW while monitoring audio continuously, using a compact acoustic model on a low-power always-on processor rather than the main application cores. The constraint envelope is extreme: $<$100 ms detection latency, $<$0.1 false activations per hour, and $>$95 percent true positive rate across accents and noise conditions. Few-shot personalization must improve accuracy within this fixed power and model-size budget, meaning adaptation can tune classifier weights but cannot expand the model.
Few-shot adaptation solves this problem by finetuning only the output classifier or a small subset of parameters, including bias terms, using just a few example utterances collected directly on the device. For example, a user might provide 5–10 recordings of their custom wake word. These samples are then used to update the model locally, while the main encoder remains frozen to preserve generalization and reduce memory overhead. This allows personalization without requiring additional labeled data or transmitting private audio to the cloud.
The approach is computationally efficient and aligned with privacy-preserving design principles. Because only the output layer is updated, often involving a single gradient step or prototype computation, the total memory footprint and runtime compute are compatible with mobile-class devices or even microcontrollers.
Beyond static few-shot learning, many on-device scenarios benefit from streaming adaptation, where models must learn incrementally as new data arrives (Hayes et al. 2020). Streaming adaptation generalizes this idea to continuous, asynchronous settings where data arrives incrementally over time. Let \(\{x_t\}_{t=1}^{\infty}\) represent a stream of observations. In streaming settings, the model must update itself after observing each new input, typically without access to prior data, and under bounded memory and compute. The computable loss may come from implicit feedback, pseudo-labels, self-supervised objectives, reconstruction error, or a task-specific proxy rather than explicit human labels. The model update can be written generically as: \[ \theta_{t+1} = \theta_t - \eta_t \nabla \mathcal{L}(x_t; \theta_t) \] where \(\eta_t\) is the learning rate at time \(t\). This form of adaptation is sensitive to noise and drift in the input distribution, and thus often incorporates mechanisms such as learning rate decay, meta-learned initialization, or update gating to improve stability.
Aside from KWS, practical examples of these strategies abound. In wearable health devices, a model that classifies physical activities may begin with a generic classifier and adapt to user-specific motion patterns using only a few labeled activity segments. In smart assistants, user voice profiles are fine-tuned over time using ongoing speech input, even when explicit supervision is unavailable. In such cases, local feedback, including correction, repetition, or downstream task success, can serve as implicit signals to guide learning.
Few-shot and streaming adaptation form the foundation for more advanced memory and replay strategies that address the stability challenges of continuous on-device learning.
Experience replay
Definition 1.2: Catastrophic forgetting
Catastrophic Forgetting is the phenomenon in which a neural network trained sequentially on new tasks or data distributions rapidly loses performance on previously learned tasks, because gradient updates that optimize the new objective overwrite weight configurations that supported the old ones.
- Significance: Without explicit mitigation, fine-tuning a deployed classifier on a new domain can sharply reduce prior-task accuracy, even when the new domain is closely related to the old one (Kirkpatrick et al. 2017). This is the central failure mode of on-device and federated learning: every device that adapts locally to its user’s recent data risks erasing the general capabilities the centralized training run paid for, and the loss is invisible until inference encounters out-of-recent-context inputs.
- Distinction: Unlike overfitting (a generalization failure on a single fixed task) and distribution shift (a deployment-time mismatch between training and inference data), forgetting is a training-time phenomenon caused by the sequential structure of the update stream itself; the model’s capacity is sufficient, but its weights cannot encode the new objective without disturbing the encoding of the old one.
- Common pitfall: A frequent misconception is that a small experience-replay buffer is sufficient protection. Naive replay of 100 to 1,000 stored samples can mask short-horizon forgetting on a held-out validation set yet still degrade rare-class or long-tail performance, because the buffer’s sampling distribution under-represents the tails. Production deployments require capacity-proportional buffers, prioritized replay, or weight-regularization methods such as elastic weight consolidation (section 1.6.2).

Learning the new task erodes accuracy on the old one.
Experience replay addresses catastrophic forgetting in continuous learning scenarios by maintaining a buffer of representative examples from previous learning episodes. This technique, originally developed for reinforcement learning (Mnih et al. 2015), proves essential in on-device learning where sequential data streams can cause models to overfit to recent examples. Here, experience replay addresses the immediate stability need; bio-inspired lifelong learning (section 1.6.2) addresses the same stability problem through local plasticity and consolidation mechanisms.
Unlike server-side replay strategies that rely on large datasets and extensive compute, on-device replay must operate with extremely limited capacity, often with tens or hundreds of samples, and must avoid interfering with user experience (Rolnick et al. 2019). Buffers may store only compressed features or distilled summaries, and updates must occur opportunistically (e.g., during idle cycles or charging). These system-level constraints reshape how replay is implemented and evaluated in the context of embedded ML.
Let \(\mathcal{M}\) represent a memory buffer that retains a fixed-size subset of training examples. At time step \(t\), the model receives a new data point \((x_t, y_t)\) and appends it to \(\mathcal{M}\). A replay-based update then samples a batch \(\{(x_i, y_i)\}_{i=1}^{k}\) from \(\mathcal{M}\) and applies a gradient step: \[ \theta_{t+1} = \theta_t - \eta \nabla_\theta \left[ \frac{1}{k} \sum_{i=1}^{k} \mathcal{L}(x_i, y_i; \theta_t) \right] \] where \(\theta_t\) are the model parameters, \(\eta\) is the learning rate, and \(\mathcal{L}\) is the loss function. Over time, this replay mechanism allows the model to reinforce prior knowledge while incorporating new information.
A practical on-device implementation might use a ring buffer to store a small set of compressed feature vectors rather than full input examples. Listing 4 implements this minimal replay buffer design, demonstrating how a circular storage mechanism enables efficient memory management while balancing historical knowledge retention with new information incorporation.
# Ring buffer for experience replay on memory-constrained devices
# Stores compressed features (not raw inputs) to minimize footprint
class ReplayBuffer:
def __init__(self, capacity):
self.capacity = capacity # Fixed size, e.g., 1000 examples
self.buffer = []
self.index = 0 # Circular write pointer
def store(self, feature_vec, label):
if len(self.buffer) < self.capacity:
self.buffer.append((feature_vec, label)) # Fill phase
else:
self.buffer[self.index] = (
feature_vec,
label,
) # Overwrite oldest
self.index = (self.index + 1) % self.capacity # Wrap around
def sample(self, k):
# Random sampling prevents recency bias during replay
return random.sample(self.buffer, min(k, len(self.buffer)))This implementation maintains a fixed-capacity cyclic buffer, storing compressed representations (e.g., last-layer embeddings) and associated labels. Such buffers are useful for replaying adaptation updates without violating memory or energy budgets.
In TinyML applications26, experience replay has been applied to problems such as gesture recognition, where devices must continuously improve predictions while observing a small number of events per day. Instead of training directly on the streaming data, the device stores representative feature vectors from recent gestures and uses them to finetune classification boundaries periodically. Similarly, in on-device keyword spotting, replaying past utterances can improve wake-word detection accuracy without the need to transmit audio data off-device.
26 TinyML Scale: Over 100 billion microcontrollers ship annually, but fewer than 1 percent support on-device learning due to memory ($<\(256 KB) and power (\)<$1 mW) constraints. The gap between deployed hardware and ML-capable hardware defines the engineering challenge: enabling experience replay and adaptation on chips costing under $1 requires algorithms designed for kilobytes, not gigabytes.
While experience replay improves stability in data-sparse or nonstationary environments, it introduces several trade-offs. Storing raw inputs may breach privacy constraints or exceed storage budgets, especially in vision and audio applications. Replaying from feature vectors reduces memory usage but may limit the richness of gradients for upstream layers. Write cycles to persistent flash memory, which are frequently necessary for long-term storage on embedded devices, can also raise wear-leveling concerns. These constraints require careful co-design of memory usage policies, replay frequency, and feature selection strategies, particularly in continuous deployment scenarios.
Data compression
In many on-device learning scenarios, the raw training data may be too large, noisy, or redundant to store and process effectively. This motivates the use of compressed data representations, where the original inputs are transformed into lower-dimensional embeddings or compact encodings that preserve salient information while minimizing memory and compute costs.
Compressed representations serve two complementary goals: they reduce the footprint of stored data, allowing devices to maintain longer histories or replay buffers under tight memory budgets (Hayes et al. 2020), and they simplify the learning task by projecting raw inputs into more structured feature spaces, often learned via pretraining or meta-learning, in which efficient adaptation is possible with minimal supervision.
Hayes, T. L., K. Kafle, R. Shrestha, M. Acharya, and C. Kanan. 2020. “REMIND Your Neural Network to Prevent Catastrophic Forgetting.” In Computer Vision – ECCV 2020. Springer. https://doi.org/10.1007/978-3-030-58598-3_28.
One common approach is to encode data points using a pretrained feature extractor and discard the original high-dimensional input. For example, an image \(x_i\) might be passed through a CNN to produce an embedding vector \(z_i = f(x_i)\), where \(f(\cdot)\) is a fixed feature encoder. This embedding captures visual structure (e.g., shape, texture, or spatial layout) in a compact representation, usually ranging from 64 to 512 dimensions, suitable for lightweight downstream adaptation.
Mathematically, training can proceed over compressed samples \((z_i, y_i)\) using a lightweight decoder or projection head. Let \(\theta\) represent the trainable parameters of this decoder model, which is typically a small neural network that maps from compressed representations to output predictions. As each example is presented, the model parameters are updated using gradient descent: \[ \theta_{t+1} = \theta_t - \eta \nabla_\theta \mathcal{L}\big(g(z_i; \theta), y_i\big) \] Six components define this update rule:
- \(z_i\) is the compressed representation of the \(i\)-th input,
- \(y_i\) is the corresponding label or supervision signal,
- \(g(z_i; \theta)\) is the decoder’s prediction,
- \(\mathcal{L}\) is the loss function measuring prediction error,
- \(\eta\) is the learning rate, and
- \(\nabla_\theta\) denotes the gradient with respect to the parameters \(\theta\).
This formulation highlights how only a compact decoder model, which has the parameter set \(\theta\), needs to be trained, making the learning process feasible even when memory and compute are limited.
Advanced approaches extend beyond fixed encoders when replay storage, rather than model compute, becomes the binding constraint. They learn discrete or sparse dictionaries: bases for recurring sensor-trace patterns that can be stored more compactly than raw replay examples. A dataset of sensor traces can be factorized as \(X \approx \Phi_{\text{dict}}C\), where \(\Phi_{\text{dict}}\) is a dictionary of basis patterns and \(C\) is a block-sparse coefficient matrix indicating which patterns are active in each example. By updating only a small number of dictionary atoms or coefficients, the model adapts with minimal replay-buffer overhead.
Compressed representations prove useful in privacy-sensitive settings, as they allow raw data to be discarded or obfuscated after encoding. Compression acts as an implicit regularizer, smoothing the learning process and mitigating overfitting when only a few training examples are available.
In practice, these strategies have been applied in domains such as keyword spotting, where raw audio signals are first transformed into Mel-frequency cepstral coefficients (MFCCs)27, a compact, lossy representation of the power spectrum of speech. These MFCC vectors serve as compressed inputs for downstream models, enabling local adaptation using only a few kilobytes of memory.
27 MFCCs (Mel-Frequency Cepstral Coefficients): Audio features that apply mel-scale frequency warping (emphasizing lower frequencies where speech concentrates) followed by cepstral analysis, reducing a 320-sample audio window (20 ms at 16 kHz) from 640 bytes to approximately 50 bytes in 12–13 coefficients. This 13\(\times\) compression preserves speech intelligibility while making on-device keyword spotting feasible in kilobytes of memory, a compression ratio that directly determines replay buffer capacity for few-shot voice adaptation.
Data efficiency strategy comparison
Few-shot learning, experience replay, and compressed data representations each address different facets of on-device adaptation when data is scarce or streaming. Their effectiveness depends on system-level factors: memory capacity, data availability, task structure, and privacy requirements.
Few-shot adaptation excels when a small but informative set of labeled examples is available, particularly when personalization or rapid task-specific tuning is required. It minimizes compute and data needs, but its effectiveness depends on the quality of pretrained representations and the alignment between the initial model and the local task.
Experience replay addresses continual adaptation by mitigating forgetting and improving stability, especially in nonstationary environments. It allows reuse of past data, but requires memory to store examples and compute cycles for periodic updates. Replay buffers may also raise privacy or longevity concerns, especially on devices with limited storage or flash write cycles.
Compressed data representations reduce the footprint of learning by transforming raw data into compact feature spaces. This approach supports longer retention of experience and efficient finetuning, particularly when only lightweight heads are trainable. Compression can introduce information loss, and fixed encoders may fail to capture task-relevant variability if they are not well-aligned with deployment conditions. Table 5 summarizes the on-device learning trade-offs across data requirements, memory overhead, and use case suitability for each technique.
| Technique | Data Requirements | Memory/Compute Overhead | Use Case Fit |
|---|---|---|---|
| Few-Shot Adaptation | Small labeled set (\(K\)-shots) | Low | Personalization, quick on-device finetuning |
| Experience Replay | Streaming data | Moderate (buffer & update) | Non-stationary data, stability under drift |
| Compressed Representations | Unlabeled or encoded data | Low to Moderate | Memory-limited devices; privacy-sensitive contexts |
In practice, these methods are not mutually exclusive. Many real-world systems combine them to achieve robust, efficient adaptation. For example, a keyword spotting system may use compressed audio features (e.g., MFCCs), finetune a few parameters from a small support set, and maintain a replay buffer of past embeddings for continual refinement.
Efficient adaptation and data strategies enable a single device to learn from its user. Millions of isolated devices learning individually, however, waste a massive opportunity to share their localized insights. Aggregating this decentralized intelligence without compromising user privacy requires the mathematics of federated learning.
Self-Check: Question
Why is few-shot adaptation a central technique for on-device learning specifically, as opposed to a general convenience?
- Edge devices usually receive abundant labeled local data, so the main challenge is avoiding too much supervision.
- Local data arrives in small, noisy, and often weakly-labeled amounts (a fitness tracker might yield only a few hundred samples from a 30-minute session), so adaptation must improve the model from a handful of examples without overfitting.
- Few-shot methods eliminate the need for pretrained representations on the device.
- Few-shot learning is mainly a networking technique for reducing federated bandwidth.
Explain how experience replay enables continual on-device adaptation without catastrophic forgetting, and name two system constraints that make replay harder on an edge device than in a datacenter.
True or False: Compressed feature representations on edge devices are useful only for reducing memory footprint; they have no effect on privacy posture or regularization behavior.
A user records 5-10 examples of a custom wake word on their phone. Which adaptation strategy is the direct fit given the chapter’s data-scarcity analysis?
- Few-shot adaptation of a lightweight classifier or small parameter subset on top of a frozen pretrained speech encoder.
- Full-model retraining from scratch so the encoder can relearn speech representations locally.
- Only federated aggregation, because local adaptation is impossible with so few examples.
- Accumulating large replay buffers of raw audio over months before any update is attempted.
Why do on-device replay buffers typically store compressed feature vectors rather than raw inputs?
- Raw inputs improve privacy because they are easier to anonymize than embeddings.
- Feature vectors remove the need for any trainable model on the device.
- Compressed features reduce storage and replay compute cost, though they limit how much upstream-layer adaptation can be driven by the replayed samples.
- Compressed buffers guarantee that catastrophic forgetting cannot occur.
A smart doorbell deployment faces three sequential data-efficiency challenges: rapid initial personalization from few labeled faces, stable continual adaptation as lighting and seasons change, and finally memory-bounded retention of past samples so the device can still learn after weeks of operation. Order these techniques to match the progression: (1) compressed representations for memory-limited retention, (2) few-shot adaptation from a tiny labeled support set, (3) experience replay for continual learning under drift.
Federated Learning: Algorithms
Suppose a hospital wants to train an AI on patient records to predict complications, but stringent privacy laws make it illegal to move the raw patient data to a central server. This is cross-silo federated learning: a small number of reliable institutions collaborate without centralizing their data. The challenge is to enable multiple hospitals to collaboratively train a global model without ever sharing their raw data. Federated learning solves this by moving the computation to the data, broadcasting the model to the edge, and only aggregating the resulting model updates.
Consider a voice assistant deployed to 10 million homes. This is cross-device federated learning: many unreliable, intermittently connected devices contribute small updates when local conditions permit. Each device adapts locally to its user’s voice, accent, and vocabulary. Device A learns that “data” is pronounced /ˈdeɪtə/, Device B learns /ˈdætə/. Device C encounters the rare phrase “machine learning” frequently (tech household), while Device D never sees it (nontech household). After six months of isolated local adaptation, four failure modes emerge:
- Each device excels at one user’s patterns but generalizes poorly beyond them.
- Rare vocabulary is learned on some devices and forgotten on others.
- Local biases accumulate without correction from the broader population.
- Valuable insights discovered on one device benefit no other devices.
Individual on-device learning, while effective for local personalization, faces fundamental limitations when devices operate in isolation. Each device observes only a narrow slice of the full data distribution, limiting generalization. Device capabilities vary dramatically, creating learning imbalances across the population. Valuable insights learned on one device cannot benefit others, reducing overall system intelligence. Without coordination, models may diverge or degrade over time due to local biases.
Federated learning addresses these coordination constraints through privacy-preserving collaboration: devices contribute to collective intelligence without sharing raw data. The approach transforms data locality from a limitation into a privacy feature, allowing systems to learn from population-scale data while keeping individual information secure. That promise only holds if the system treats gradients and participation metadata as sensitive outputs, because those signals can still reveal information about local users.
Definition 1.3: Federated learning
Federated Learning is a decentralized training paradigm where distributed devices collaboratively train a shared model using local data while exchanging only model updates (gradients or weights).
- Significance: It transforms the constraint of data locality into a privacy feature. Within the iron law, federated learning is constrained by the Wide-Area Bandwidth (\(\text{BW}\)) and the extreme Heterogeneity of the Fleet, where device-specific efficiency \((\eta_{\text{hw}})\) and availability can vary by orders of magnitude.
- Distinction: Unlike Centralized Training, where data is moved to the compute, federated learning moves compute to the data, ensuring that raw information never leaves the device.
- Common pitfall: A frequent misconception is that federated learning is “inherently private.” In reality, model updates themselves can leak information through Gradient Inversion attacks, requiring additional protections like differential privacy or secure aggregation.
The operational payoff is not abstract: moving compact model updates instead of private observations can shrink the bandwidth budget by orders of magnitude for camera-personalization workloads.

Federated learning ships updates, not raw data, cutting network load.
Napkin Math 1.3: Model updates vs. raw data
Problem: A team is designing a federated camera-personalization system that learns from 200 MB of compressed user images per week. Should the system upload the raw images to the cloud for training, or use federated learning to send model updates instead?
Math: Bandwidth efficiency is the ratio of raw data volume to model update size.
- Raw Data Upload: 200 MB/week.
- Federated Update: A compressed model update (5M params) is only 2.5 MB.
- Bandwidth Reduction: 200 MB/2.5 MB = 80× savings.
Systems insight: Federated learning is a network multiplier. For a user on a limited cellular plan, uploading 200 MB of raw data is expensive and slow. Uploading a 2.5 MB update is nearly invisible. Shifting compute to the data reduces network load by 80×, enabling continuous learning even in bandwidth-constrained environments. In the Machine Learning Fleet, this is how systems scale to large user populations without bankrupting the networking budget or violating user privacy.
The three-phase evolution introduced in figure 3 (local-only, centralized cloud, federated) now resolves into federated learning’s defining position. Figure 8 restates that comparison with the emphasis the algorithms section needs: offline learning trains centrally and deploys static models; on-device learning adapts locally but in isolation, sharing no insight across users; and federated learning bridges the two by coordinating updates globally while raw data stays local, so it benefits from distributed model improvements without centralizing the data that produced them.

Privacy-preserving collaborative learning
Across application domains such as Gboard’s keyboard personalization, wearable health monitoring, and voice interfaces, compact on-device updates solve only the data-movement side of the problem. Federated learning (FL) adds the coordination layer: it trains a shared model across a population of devices without transferring raw data to a central server (McMahan et al. 2017). Unlike traditional centralized training pipelines, which require aggregating all training data in a single location, federated learning distributes the training process itself. Each participating device computes updates based on its local data and contributes to a global model through an aggregation protocol, typically coordinated by a central server.
28 Non-IID Data: “Independently and Identically Distributed.” In the cloud, we shuffle data to ensure every batch represents the global distribution. On the edge, each user’s data is inherently biased (non-IID): a user in Tokyo mostly types Japanese, while a user in London types English. This bias creates gradient divergence, making standard FedAvg 2–5\(\times\) slower to converge than centralized SGD.
This shift aligns closely with mobile, edge, and embedded systems because it preserves data locality while still improving the shared model. However, the privacy and personalization benefits are real only if the system also handles client variability, communication efficiency, and non-i.i.d. data distributions28 through specialized protocols and coordination mechanisms.
Three areas define federated learning in on-device settings: the core learning protocols that govern coordination across devices, strategies for scheduling and communication efficiency, and approaches to personalization. Privacy mechanisms such as secure aggregation and differential privacy wrap these areas rather than replacing them: they determine what the server can infer from updates and how much noise the training loop must absorb.
Learning protocols
The protocols that make distributed coordination practical at scale must solve three engineering challenges simultaneously: ensuring that local training produces compatible updates despite non-IID data distributions, aggregating those updates efficiently despite bandwidth constraints, and coordinating timing across devices with heterogeneous availability patterns.
Local training
Local training is the point where privacy preservation becomes a systems boundary. Individual devices compute model updates from private data, but every local choice affects the validity of the aggregate: which base model the device starts from, which local examples it samples, how much optimization it performs, and what update it sends back. The loop is therefore useful to present as an ordered protocol rather than as an abstract definition:
- Model Initialization: Each device initializes its local model parameters, often by downloading the latest global model from the server.
- Local Data Sampling: The device samples a subset of its local data for training. This data may be non-IID, meaning that it may not be uniformly distributed across devices.
- Local Training: The device performs a number of training iterations on its local data, updating the model parameters based on the computed gradients.
- Model Update: After local training, the device computes a model update (e.g., the difference between the updated and initial parameters) and prepares to send it to the server.
- Communication: The device transmits the model update to the server, typically using a secure communication channel to protect user privacy.
- Model Aggregation: The server aggregates the updates from multiple devices to produce a new global model, which is then distributed back to the participating devices.
The process repeats iteratively, with devices periodically downloading the latest global model and performing local training. Update frequency varies based on system constraints, device availability, and communication costs.
Federated aggregation protocols
The central coordination mechanism in federated learning allows devices with small, local datasets to collaboratively train a shared model. Client devices perform local training and transmit model updates to a central server, which aggregates them into a refined global model and redistributes it for the next training round. The cyclical procedure decouples learning from centralized data collection, suiting environments where user data is private, bandwidth is constrained, and device participation is sporadic.
The most widely used baseline for this process is Federated Averaging (FedAvg)29, which has become a canonical algorithm for federated learning (McMahan et al. 2017). In FedAvg, each device trains its local copy of the model using stochastic gradient descent (SGD) on its private data.
29 FedAvg: McMahan et al. (2017) averages model weights instead of individual gradients, allowing each client to perform multiple local SGD steps (typically 1–20) before a single upload. This reduces communication by 10–100\(\times\) compared to distributed SGD, making federated learning viable over mobile networks where upload bandwidth is the binding constraint. The trade-off: more local steps improve communication efficiency but increase divergence on non-IID data, requiring careful tuning per deployment.
McMahan, Brendan, Eider Moore, Daniel Ramage, Seth Hampson, and Blaise Agüera y Arcas. 2017. “Communication-Efficient Learning of Deep Networks from Decentralized Data.” International Conference on Artificial Intelligence and Statistics (AISTATS), Proceedings of machine learning research, vol. 54: 1273–82.
Formally, let \(\mathcal{D}_k\) denote the local dataset on client \(k\), and let \(\theta_k^t\) be the parameters of the model on client \(k\) at round \(t\). Each client performs \(E\) epochs of SGD on its local data, yielding an update \(\theta_k^{t+1}\). The central server then aggregates these updates as: \[ \theta^{t+1} = \sum_{k=1}^{C} \frac{n_k}{n} \theta_k^{t+1} \] where \(n_k = |\mathcal{D}_k|\) is the number of samples on device \(k\), \(n = \sum_k n_k\) is the total number of samples across participating clients, and \(C\) is the number of active devices in the current round.
Straggler mitigation
In a fleet of millions of heterogeneous devices, waiting for every selected client to report its update is impractical. Network latency, battery depletion, or background process contention can cause some devices (“stragglers”) to take 10\(\times\) longer than average. At the level of round semantics, the consequence is direct: the weighted aggregation above cannot proceed until enough updates arrive, so the round duration is set by the slowest devices the server is still waiting on. The scheduling answer to this, over-selection, is a client-scheduling policy and is developed with the rest of client scheduling in section 1.5.1.
This cyclical coordination protocol forms the foundation of federated learning. Figure 9 breaks down the Federated Averaging protocol into four phases: client selection (with over-selection to handle stragglers), local training on private data, parameter upload with optional compression, and weighted aggregation that produces the updated global model.

This basic structure introduces a number of design choices and trade-offs. The number of local epochs \(E\) impacts the balance between computation and communication: larger \(E\) reduces communication frequency but risks divergence if local data distributions vary too much. The selection of participating clients affects convergence stability and fairness. In real-world deployments, not all devices are available at all times, and hardware capabilities may differ substantially, requiring robust participation scheduling and failure tolerance.
Federated learning convergence analysis
Whether federated learning converges and how fast it reaches acceptable accuracy are essential questions for system design. Unlike centralized training where convergence depends primarily on learning rate and batch size, federated learning convergence depends on the interplay between communication rounds, local computation, client participation, and data heterogeneity. These factors determine whether a federated deployment will reach target accuracy in hours, days, or never. Weak scaling at fleet scale develops the weak-scaling argument for why adding more participating devices grows total work faster than it shrinks wall-clock time, which sets the diminishing return that bounds how much client participation can accelerate convergence here.
Convergence rate fundamentals
A useful systems abstraction is to treat the product of participating clients, local epochs, and communication rounds as the effective amount of federated computation. McMahan et al. (2017) define FedAvg in terms of client participation, local minibatch/epoch work, and repeated communication rounds. For the chapter’s systems model, an idealized IID scaling heuristic summarizes the optimality gap as:
\[ \mathbb{E}[F(\theta^R) - F(\theta^\star)] \leq \mathcal{O}\left(\frac{1}{\sqrt{CER}}\right) \]
where \(F\) is the global objective, \(\theta^R\) is the model after \(R\) rounds, \(\theta^\star\) is the reference optimum of that objective, the expectation is over client sampling and stochastic local training, \(C\) is the number of clients participating per round, \(E\) is the number of local epochs each client performs, and \(R\) is the total number of communication rounds. Under this heuristic, convergence improves with the square root of total computation: doubling clients, local epochs, or rounds each provides diminishing returns. To halve the optimality gap, the system must quadruple total computation.
The product \(CER\) represents total client-epochs, the fundamental unit of federated computation. A system with 10 clients performing 5 local epochs over 100 rounds \((CER = 5000)\) achieves similar convergence to one with 50 clients performing 2 epochs over 50 rounds \((CER = 5000)\), assuming identical data distributions. This equivalence enables flexible resource allocation: bandwidth-constrained deployments can compensate with more local computation, while computation-constrained devices can rely on more frequent communication.
Non-IID data impact
The federated scaling heuristic assumes IID data across clients, an assumption that rarely holds in practice. Surveys and empirical studies identify non-IID data as a core federated-learning convergence challenge and quantify it with measures such as local dissimilarity, earth mover’s distance, or weight divergence (Li et al. 2020; Zhao et al. 2018). To reason about this systems effect, let \(\beta_{\text{het}}\) denote an abstract heterogeneity penalty that grows as local client objectives drift away from the global objective:
\[ \mathbb{E}[F(\theta^R) - F(\theta^\star)] \leq \mathcal{O}\left(\frac{1 + \beta_{\text{het}}}{\sqrt{CER}} + \frac{\beta_{\text{het}}^2 E^2}{R}\right) \]
Here, \(\beta_{\text{het}}\) is a compact way to represent client drift in the chapter’s systems model rather than a universal metric shared by all analyses. When data is close to IID, \(\beta_{\text{het}}\) is near zero and the bound reduces toward the standard \(\mathcal{O}(1/\sqrt{CER})\) rate. When data is highly heterogeneous, larger \(\beta_{\text{het}}\) values significantly slow convergence.
The second term \(\frac{\beta_{\text{het}}^2 E^2}{R}\) reveals a critical interaction: more local epochs \(E\) amplify the heterogeneity penalty. Each additional local step moves the local model further from the global optimum before aggregation, and these deviations compound across heterogeneous clients. This creates a communication-computation trade-off that depends on data distribution characteristics.
Quantifying heterogeneity in practice
Real-world federated deployments exhibit \(\beta_{\text{het}}\) values that vary dramatically by application domain. Keyboard prediction across users speaking the same language typically shows \(\beta_{\text{het}} \approx 0.3\)-\(0.8\), as vocabulary and typing patterns vary but share common linguistic structure. Cross-language keyboard prediction increases to \(\beta_{\text{het}} \approx 1.5\)-\(3.0\) due to fundamentally different character distributions and word patterns. Health monitoring with diverse patient populations can reach \(\beta_{\text{het}} \approx 2.0\)-\(5.0\) when physiological baselines vary dramatically across age groups, fitness levels, and medical conditions.
A production federated deployment with 100 clients makes the round-complexity trade-off concrete: 100 total clients in the population, \(C\) = 10 clients selected per round, \(E\) = 5 local epochs per round, target optimality gap \(\epsilon\) = 0.01, and two scenarios comparing IID data (\(\beta_{\text{het}}\) = 0) vs. moderately non-IID data (\(\beta_{\text{het}}\) = 1.5).
IID case \((\beta_{\text{het}} = 0)\): Using the convergence bound \(\epsilon \leq \frac{\sigma}{\sqrt{CER}}\) where \(\sigma\) captures gradient variance (typically \(\sigma \approx 1\) for normalized objectives), we solve for required rounds:
\[ R_{\text{IID}} \geq \frac{\sigma^2}{C \cdot E \cdot \epsilon^2} = \frac{1}{10 \cdot 5 \cdot 0.0001} = 200 \text{ rounds} \]
With 10 clients per round and 5 local epochs, this represents 200 \(\times\) 10 \(\times\) 5 = 10,000 total client-epochs of computation.
Non-IID case \((\beta_{\text{het}} = 1.5)\): The heterogeneity penalty requires satisfying both terms of the bound. With \(E=5\), the variance term requires 1,250 rounds, while the heterogeneity term dominates:
\[ \frac{\beta_{\text{het}}^2 E^2}{R} \leq \epsilon \implies R \geq \frac{\beta_{\text{het}}^2 E^2}{\epsilon} = \frac{2.25 \times 25}{0.01} = 5,625 \text{ rounds} \]
This represents a roughly 28.1× increase in communication rounds compared to the IID case. The non-IID scenario requires 5,625 \(\times\) 10 \(\times\) 5 = 281,250 client-epochs, demonstrating how data heterogeneity dominates convergence costs.
The quadratic dependence on \(E\) suggests reducing local computation when heterogeneity is high. With \(E = 2\) instead of \(E = 5\), the heterogeneity term shrinks to 900 rounds while the variance term grows to 3,125, so the variance term now dominates:
\[ R \geq \max\left(\frac{(1+\beta_{\text{het}})^2}{C \cdot E \cdot \epsilon^2}, \frac{\beta_{\text{het}}^2 E^2}{\epsilon}\right) = \max\left(\frac{2.5^2}{10 \cdot 2 \cdot 0.0001}, \frac{2.25 \times 4}{0.01}\right) = \max(3,125, 900) = 3,125 \text{ rounds} \]
This reduces total rounds by 1.80× at the cost of 2.5× more communication per unit of local computation. The total client-epochs become 3,125 \(\times\) 10 \(\times\) 2 = 62,500, a 4.5× reduction from the \(E\) = 5 non-IID case. This illustrates why adaptive local epoch selection based on estimated data heterogeneity significantly improves federated learning efficiency.
Communication-computation trade-off
The interaction between local epochs and communication rounds creates a fundamental design trade-off, visualized in figure 10. More local epochs reduce communication frequency (the computational pull) but increase client drift (the statistical penalty), while fewer local epochs maintain tighter synchronization at higher communication cost.

The optimal operating point depends on deployment-specific factors. Communication cost (bandwidth, energy) favors larger \(E\), while convergence speed under heterogeneity favors smaller \(E\). Practical systems often use adaptive strategies that start with small \(E\) and increase as the model approaches convergence and client drift diminishes.
When federated learning works
Federated learning achieves practical convergence only when several deployment conditions are favorable, a theme emphasized in surveys of federated-learning systems and open problems (Kairouz and McMahan 2021):
- Heterogeneity must remain bounded enough that client drift does not dominate training time. When populations are highly heterogeneous, clustering clients into more homogeneous groups or using personalization may be preferable to one global model.
- Client participation must be sufficient to provide stable aggregate updates. Very low participation makes gradient estimates noisy and exacerbates selection bias.
- Each participating client needs enough local data for meaningful update computation. Tiny local batches can contribute high-variance updates that destabilize training.
When these conditions are violated, alternative approaches become necessary. Severe heterogeneity suggests hierarchical federated learning with regional aggregation or fully personalized models without global aggregation. Very low participation rates indicate the need for asynchronous protocols that do not require synchronized rounds. Clients with minimal local data benefit from few-shot adaptation techniques rather than gradient-based training.
These mathematical aggregation protocols prove that decentralized learning is theoretically possible. Executing federated averaging across ten reliable nodes in a lab is trivial; executing it across ten million smartphones dropping on and off cellular networks is a different engineering problem. Robust federated systems must translate the algorithm into orchestration, scheduling, and failure-handling mechanisms that assume unreliable clients from the start.
Self-Check: Question
What is the defining architectural move of federated learning relative to centralized distributed training?
- Raw data is centralized in a datacenter, but inference is distributed to save latency.
- Each device trains completely independently forever, with no coordination or aggregation.
- A central server performs all gradient updates and sends only predictions back to clients.
- Compute is moved to where the data already lives, and devices exchange model updates rather than raw data.
True or False: Because federated learning keeps raw data on the device, it is structurally immune to data-privacy leaks — a participating client’s training data cannot be reconstructed from anything the protocol exposes.
Explain why increasing the number of local epochs per federated round is simultaneously helpful and harmful, and name the workload property that determines the optimal setting.
Production federated systems commonly invite more clients to a round than they need updates from (e.g., 1,500 invited for a 1,000-update target). What problem does this ‘over-selection’ solve?
- It guarantees every invited device contributes even if it is offline for weeks.
- It forces slower devices to train longer so their updates carry more weight.
- It lets the server close the round as soon as the first 1,000 successful responses arrive, bounding wall-clock round time by the 67th-percentile response rather than the slowest straggler.
- It makes aggregation independent of local dataset size.
In the section’s convergence analysis, why does non-IID client data inflate the number of communication rounds required by FedAvg?
- Because only IID data can be encrypted during secure aggregation.
- Heterogeneous local gradients add a variance-like penalty term to the convergence bound, and that penalty grows with both client drift and the number of local epochs per round.
- Because non-IID data reduces the number of model parameters, forcing smaller updates.
- Because the server must download all raw client data to estimate the true global distribution.
A federated deployment faces slow 3G mobile networks AND highly non-IID client data (each user’s data looks very different from the fleet average). A junior engineer proposes maximizing local epochs per round to minimize network usage. Justify whether this is correct and what configuration you would actually recommend.
Federated Learning: Systems at Scale
In a textbook algorithm, all 100 edge devices compute their updates perfectly and report back to the server exactly at the same time. In reality, a federated learning round spanning a million smartphones must deal with devices overheating, losing Wi-Fi, entering power-saving mode, or powering off. Building federated systems at scale means engineering an orchestrator that tolerates asynchronous dropouts and extreme stragglers as standard operating conditions.
Client scheduling
Federated learning operates under the assumption that clients, or devices that hold local data, periodically become available for participation in training rounds. In real-world systems, client availability is intermittent and variable. Devices may be turned off, disconnected from power, lacking network access, or otherwise unable to participate at any given time. As a result, client scheduling plays a central role in the effectiveness and efficiency of distributed learning.
At a baseline level, federated ML systems define eligibility criteria for participation. Devices must meet minimum requirements such as being plugged in, connected to Wi-Fi, and idle, to avoid interfering with user experience or depleting battery resources. These criteria determine which subset of the total population is considered “available” for any given training round.
Beyond these operational filters, devices also differ in their hardware capabilities, data availability, and network conditions. Some smartphones contain many recent examples relevant to the current task, while others have outdated or irrelevant data. Network bandwidth and upload speed may vary widely depending on geography and carrier infrastructure. As a result, selecting clients at random can lead to poor coverage of the underlying data distribution and unstable model convergence.
Availability-driven selection introduces participation bias. Clients with favorable conditions are more likely to participate repeatedly. These favorable conditions include frequent charging, high-end hardware, and consistent connectivity. Meanwhile, others are systematically underrepresented. This can skew the resulting model toward behaviors and preferences of a privileged subset of the population, raising both fairness and generalization concerns.
The severity of participation bias becomes apparent when examining real deployment statistics. Studies of federated learning deployments show that the most active 10 percent of devices can contribute to over 50 percent of training rounds, while the bottom 50 percent of devices may never participate at all. This creates a feedback loop: models become more strongly optimized for users with high-end devices and stable connectivity, potentially degrading performance for resource-constrained users who need adaptation the most. A keyboard prediction model might become biased toward the typing patterns of users with flagship phones who charge overnight, missing important linguistic variations from users with budget devices or irregular charging patterns.
To address these challenges, systems must balance scheduling efficiency with client diversity. A key approach involves using stratified or quota-based sampling to ensure representative client participation across different groups. Some systems implement “fairness budgets” that track cumulative participation and actively prioritize underrepresented devices when they become available. Others use importance sampling techniques to reweight contributions based on estimated population statistics rather than raw participation rates. For instance, asynchronous buffer-based techniques allow participating clients to contribute model updates independently, without requiring synchronized coordination in every round (Nguyen et al. 2021). This model has been extended to incorporate staleness awareness (Rodio and Neglia 2024) and fairness mechanisms (Ma et al. 2024), preventing bias from over-active clients who might otherwise dominate the training process.
Nguyen, John, Kshitiz Malik, Hongyuan Zhan, Ashkan Yousefpour, Michael Rabbat, Mani Malek, and Dzmitry Huba. 2021. “Federated Learning with Buffered Asynchronous Aggregation.” Proceedings of Machine Learning Research (AISTATS) 164.
Rodio, Angelo, and Giovanni Neglia. 2024. “FedStale: Leveraging Stale Client Updates in Federated Learning.” Frontiers in Artificial Intelligence and Applications (ECAI 2024) 78. https://doi.org/10.3233/faia240849.
Ma, Jeffrey, Alan Tu, Yiling Chen, and Vijay Janapa Reddi. 2024. “FedStaleWeight: Buffered Asynchronous Federated Learning with Fair Aggregation via Staleness Reweighting.” arXiv Preprint arXiv:2406.02877.
These fairness mechanisms sit alongside adaptive client selection strategies. Federated ML systems can prioritize clients with underrepresented data types, target geographies or demographics that are less frequently sampled, and use historical participation data to enforce fairness constraints. Predictive modeling can anticipate later client availability or success rates, improving training throughput.
Selected clients perform one or more local training steps on their private data and transmit their model updates to a central server. These updates are aggregated to form a new global model. Typically, this aggregation is weighted, where the contributions of each client are scaled, for example, by the number of local examples used during training, before averaging. This ensures that clients with more representative or larger datasets exert proportional influence on the global model.
Scheduling must also bound how long a round waits on its slowest participants. As established under section 1.4.2.3, stragglers can take 10\(\times\) longer than the median device, and the round cannot aggregate until enough updates arrive.

Over-selection closes the round on the first K updates.
To prevent the global model update from stalling, production FL systems employ Over-Selection. The server selects a candidate pool size \(K_{\text{candidates}}\) larger than the target number of updates \(K_{\text{target}}\) (typically \(K_{\text{candidates}} \approx 1.3 \times K_{\text{target}}\)). The server aggregates updates from the first \(K_{\text{target}}\) responders and discards the rest. This approach bounds the round duration by the speed of the \(K_{\text{target}}\)-th fastest device rather than the absolute slowest, dramatically accelerating convergence wall-clock time.
These scheduling decisions directly impact convergence rate, model generalization, energy consumption, and overall user experience. Poor scheduling results in excessive stragglers, overfitting to narrow client segments, or wasted computation. Client scheduling is therefore a core component of system design in federated learning, demanding both algorithmic insight and infrastructure-level coordination.
Checkpoint 1.3: Federated system design
You are architecting a federated learning system for a fleet of 10 million mobile devices. The data is highly non-IID (users have distinct, clustered typing patterns), and the network environment is constrained (1-10 Mbps). Before choosing optimizations for this scenario, classify the local bottlenecks and state which system constraint dominates each decision.
Consider three design decisions:
- Aggregation: Select plain FedAvg, reduced local epochs, or personalization/clustering for the non-IID population, and justify how the choice controls client drift.
- Privacy: Decide whether the deployment needs formal differential-privacy noise or whether secure aggregation and data minimization are sufficient for the stated threat model; explain the expected convergence-time cost qualitatively.
- Communication: Choose between gradient quantization (e.g., 8-bit) and structured sparsity under constrained bandwidth, and justify the bandwidth/accuracy trade-off.
Bandwidth-aware update compression
Update compression is a bottleneck diagnosis before it is a technique choice: if each round transmits full model weights or gradients, mobile bandwidth and battery budgets determine convergence before the optimizer does30. The design decision is which information can be quantized, sparsified, or kept local while preserving enough gradient fidelity for FedAvg to converge.
30 Wireless Upload Asymmetry: LTE uploads average 5–10 Mbps vs. 50+ Mbps downloads, creating the asymmetric bottleneck that dominates federated learning design. Transmitting a 50 MB model update consumes approximately 100 mAh (2–3 percent of battery) and takes 40–80 seconds over LTE. Low-power protocols are far worse: LoRaWAN maxes at 50 kbps with 1 percent duty cycle, making uncompressed updates physically impossible. This asymmetry is why gradient compression is not optional but architecturally required.
31 Gradient Quantization: Converts FP32 gradients to lower precision (INT8, INT4, or 1-bit) before transmission. Techniques like QSGD and signSGD show that quantized or sign-only updates can greatly reduce communication while relying on stochastic quantization or error compensation to preserve convergence behavior (Alistarh et al. 2017; Bernstein et al. 2018). The achieved byte reduction and accuracy impact depend on the optimizer, model, data heterogeneity, and residual-handling scheme.
Alistarh, Dan, Demjan Grubic, Jerry Li 0001, Ryota Tomioka, and Milan Vojnovic. 2017. “QSGD: Communication-Efficient SGD via Gradient Quantization and Encoding.” Advances in Neural Information Processing Systems 30: 1709–20.
Bernstein, Jeremy, Yu-Xiang Wang, Kamyar Azizzadenesheli, and Animashree Anandkumar. 2018. “signSGD: Compressed Optimisation for Non-Convex Problems.” Proceedings of the 35th International Conference on Machine Learning 80: 560–69.
32 Gradient Sparsification: Transmits only the top 1–10 percent of gradients by magnitude, exploiting the observation that most gradient elements are near-zero and contribute minimally to convergence. Local gradient accumulation stores the untransmitted residuals until they grow large enough to send, achieving 10–100\(\times\) compression while preserving training quality, a pattern used in sparsified SGD and deep gradient compression (Stich et al. 2018; Lin et al. 2018). The trade-off: aggressive sparsification can bias updates toward frequently active parameters, potentially reducing personalization for rare user patterns.
Stich, S. U., J.-B. Cordonnier, and M. Jaggi. 2018. “Sparsified SGD with Memory.” Advances in Neural Information Processing Systems 31.
Lin, Yujun, Song Han, Huizi Mao, Yu Wang, and William J Dally. 2018. “Deep Gradient Compression: Reducing the Communication Bandwidth for Distributed Training.” International Conference on Learning Representations.
The compression decision separates into three levers, each changing a different part of the communication bottleneck: model compression reduces bits per update, selective sharing reduces which parameters travel, and architectural partitioning keeps private state local. Model compression methods aim to reduce the size of transmitted updates through quantization31, sparsification, or subsampling, as figure 12 illustrates. Instead of sending full-precision gradients, a client transmits 8-bit quantized updates or communicates only the top-\(k\) gradient elements32 with highest magnitude.
Selective update sharing further reduces communication by transmitting only subsets of model parameters or updates. In layer-wise selective sharing, clients update only certain layers, typically the final classifier or adapter modules, while keeping the majority of the backbone frozen. This reduces both upload cost and the risk of overfitting shared representations to nonrepresentative client data.
Split models and architectural partitioning divide the model into a shared global component and a private local component. Clients train and maintain their private modules independently while synchronizing only the shared parts with the server. This allows for user-specific personalization with minimal communication and privacy leakage.
All of these approaches operate within the FedAvg aggregation protocol (section 1.4.2.2): compression changes what each client transmits, not how the server combines updates. While figure 11 illustrates the fundamental trade-off between local computation and network bandwidth, other communication-efficient updates introduce their own trade-offs. Compression may degrade gradient fidelity, selective updates can limit model capacity, and split architectures may complicate coordination. As a result, effective federated learning requires careful balancing of bandwidth constraints, privacy concerns, and convergence dynamics, a balance that depends heavily on the capabilities and variability of the client population. Compression Economics works the compression break-even threshold through a worked example, quantifying when the bandwidth saved by a given compression ratio outweighs the accuracy lost to reduced gradient fidelity.
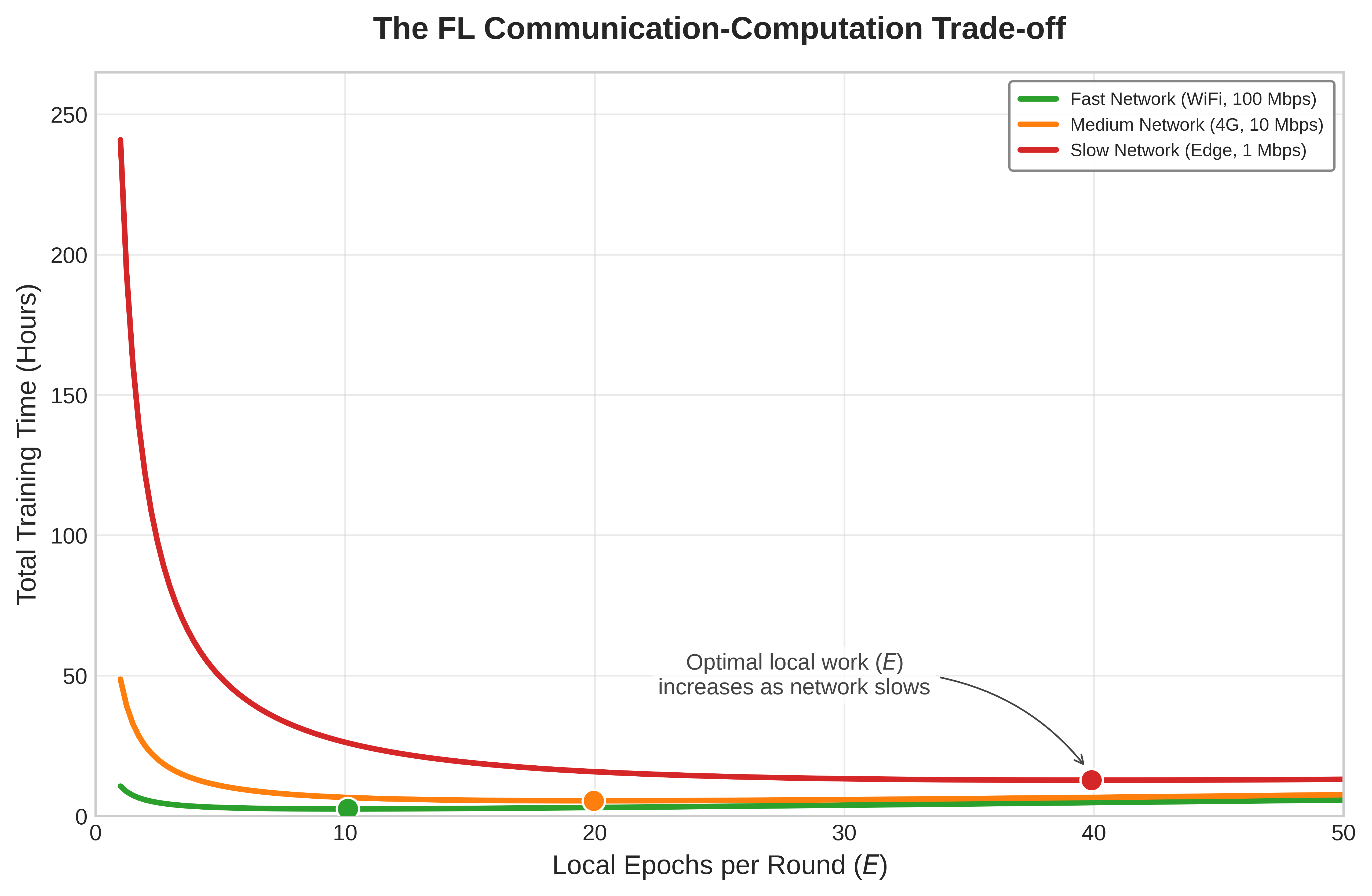
Once the system chooses how much local work to perform, update compression determines how much each round must transmit.

Federated personalization
While compression and communication strategies improve scalability, they do not address an important limitation of the global federated learning paradigm, its inability to capture user-specific variation. In real-world deployments, devices often observe distinct and heterogeneous data distributions. A one-size-fits-all global model may underperform when applied uniformly across diverse users. This motivates the need for personalized federated learning, where local models are adapted to user-specific data without compromising the benefits of global coordination.
Let \(\theta_k\) denote the model parameters on client \(k\), and \(\theta_{\text{global}}\) the aggregated global model. For \(K\) clients, traditional FL seeks to minimize a global objective: \[ \min_\theta \sum_{k=1}^K w_k \mathcal{L}_k(\theta) \] where \(\mathcal{L}_k(\theta)\) is the local loss on client \(k\), and \(w_k\) is a weighting factor (e.g., proportional to local dataset size). However, this formulation assumes that a single model \(\theta\) can serve all users well. In practice, local loss landscapes \(\mathcal{L}_k\) often differ significantly across clients, reflecting non-IID data distributions and varying task requirements.
Personalization modifies this objective to allow each client to maintain its own adapted parameters \(\theta_k\), optimized with respect to both the global model and local data: \[ \min_{\theta_1, \ldots, \theta_K} \sum_{k=1}^K \left( \mathcal{L}_k(\theta_k) + \lambda_{\text{reg}} \cdot \mathcal{R}(\theta_k, \theta_{\text{global}}) \right) \]
Here, \(\mathcal{R}\) is a regularization term that penalizes deviation from the global model, and \(\lambda_{\text{reg}}\) controls the strength of this penalty. This formulation allows local models to deviate as needed, while still benefiting from global coordination.
Real-world use cases illustrate the importance of this approach. Consider a wearable health monitor that tracks physiological signals to classify physical activities. While a global model may perform reasonably well across the population, individual users exhibit unique motion patterns, gait signatures, or sensor placements. Personalized finetuning of the final classification layer or low-rank adapters allows improved accuracy, particularly for rare or user-specific classes.
Several personalization strategies have emerged to address the trade-offs between compute overhead, privacy, and adaptation speed. One widely used approach is local finetuning, in which each client downloads the latest global model and performs a small number of gradient steps using its private data. While this method is simple and preserves privacy, it may yield suboptimal results when the global model is poorly aligned with the client’s data distribution or when the local dataset is extremely limited.
Another effective technique involves personalization layers, where the model is partitioned into a shared backbone and a lightweight, client-specific head, typically the final classification layer (Arivazhagan et al. 2019). Only the head is updated on-device, reducing memory usage and training time. This approach is particularly well-suited for scenarios in which the primary variation across clients lies in output categories or decision boundaries.
Arivazhagan, Manoj Ghuhan, Vinay Aggarwal, Aaditya Kumar Singh, and Sunav Choudhary. 2019. “Federated Learning with Personalization Layers.” CoRR abs/1912.00818.
Clustered federated learning offers an alternative by grouping clients according to similarities in their data or performance characteristics, and training separate models for each cluster. This strategy can enhance accuracy within homogeneous subpopulations but introduces additional system complexity and may require exchanging metadata to determine group membership.
Finally, meta-learning approaches, such as Model-Agnostic Meta-Learning (MAML)33, aim to produce a global model initialization that can be quickly adapted to new tasks with just a few local updates (Finn et al. 2017). This technique is especially useful when clients have limited data or operate in environments with frequent distributional shifts.
33 MAML: Finn et al. (2017) optimizes for a model initialization from which one or a few gradient steps can yield good performance on a new task, with experiments including one-shot and few-shot settings. Meta-training is more expensive than ordinary finetuning because it differentiates through the adaptation process, but deployment adaptation can be limited to a small number of local updates. This makes MAML relevant for edge scenarios where inference compute is cheap but training data is scarce.
Finn, Chelsea, Pieter Abbeel, and Sergey Levine. 2017. “Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks.” Proceedings of the 34th International Conference on Machine Learning (ICML).
Each of these strategies reflects a different point in the personalization trade-off space. Examine table 6 to see how compute overhead, privacy guarantees, and adaptation latency vary across local finetuning, personalization layers, clustered federated learning, and meta-learning approaches.
| Strategy | Personalization Mechanism | Compute Overhead | Privacy Preservation | Adaptation Speed |
|---|---|---|---|---|
| Local Finetuning | Gradient descent on local loss postaggregation | Low to Moderate | High (no data sharing) | Fast (few steps) |
| Personalization Layers | Split model: shared base + user-specific head | Moderate | High | Fast (train small head) |
| Clustered FL | Group clients by data similarity, train per group | Moderate to High | Medium (group metadata) | Medium |
| Meta-Learning | Train for fast adaptation across tasks/devices | High (meta-objective) | High | Very Fast (few-shot) |
Selecting the appropriate personalization method depends on deployment constraints, data characteristics, and the desired balance between accuracy, privacy, and computational efficiency. Figure 13 contrasts three architectural approaches: full fine-tuning offers maximum expressivity at high compute cost, head-only adaptation provides low-cost but limited adaptation, and adapter-based methods balance efficiency with deep representation adaptation through small trainable modules.

Federated privacy
The critical distinction figure 13 reveals is the trade-off between adaptation expressivity and compute cost: full fine-tuning updates every parameter but demands resources unavailable on most edge devices, while adapter-based methods achieve deep representation adaptation at a fraction of the memory and compute budget. While federated learning is often motivated by privacy concerns, as it involves keeping raw data localized instead of transmitting it to a central server, the paradigm introduces its own set of security and privacy risks. Although devices do not share their raw data, the transmitted model updates (such as gradients or weight changes) can inadvertently leak information about the underlying private data. Techniques such as model inversion attacks34 and membership inference attacks35 demonstrate that adversaries may partially reconstruct or infer properties of local datasets by analyzing these updates.
34 Model Inversion Attack: Reconstructs training data from model outputs or gradients by optimizing inputs that maximize confidence scores (Fredrikson et al. 2015; Zhu et al. 2019). In federated learning, gradient updates can leak more information than model outputs alone because they expose training-step information directly. Defenses such as gradient perturbation, secure aggregation, and differential privacy add protocol, utility, communication, or compute trade-offs whose magnitude depends on the threat model and deployment.
Fredrikson, Matt, Somesh Jha, and Thomas Ristenpart. 2015. “Model Inversion Attacks That Exploit Confidence Information and Basic Countermeasures.” Proceedings of the 22nd ACM SIGSAC Conference on Computer and Communications Security, 1322–33. https://doi.org/10.1145/2810103.2813677.
Zhu, Ligeng, Zhijian Liu, and Song Han. 2019. “Deep Leakage from Gradients.” Advances in Neural Information Processing Systems 32: 17–31. https://doi.org/10.1007/978-3-030-63076-8_2.
35 Membership Inference Attack: Determines whether specific data points were used to train a model by exploiting the confidence gap between training data (high confidence, low loss) and unseen data (Shokri et al. 2017). Published attacks can perform substantially above chance on overfitted models. In federated learning on personal data, this means an adversary could infer whether a specific patient’s records trained a health model, making regularization and differential privacy architecturally important whenever the threat model includes training-data disclosure.
Shokri, Reza, Marco Stronati, Congzheng Song, and Vitaly Shmatikov. 2017. “Membership Inference Attacks Against Machine Learning Models.” 2017 IEEE Symposium on Security and Privacy (SP), 3–18. https://doi.org/10.1109/SP.2017.41.
36 Secure Aggregation: Cryptographic protocol where client pairs exchange random masks that cancel in the server-side sum, revealing only the aggregate gradient without exposing individual contributions (Bonawitz et al. 2017). Production-scale federated systems such as Gboard combine secure aggregation with eligibility checks, drop-out handling, and round scheduling (Bonawitz et al. 2019). The communication expansion and minimum-participation requirements depend on protocol parameters and the security model, so aggregation systems must wait for enough eligible devices before releasing a round.
Bonawitz, Keith, Vladimir Ivanov, Ben Kreuter, Antonio Marcedone, H. Brendan McMahan, Sarvar Patel, Daniel Ramage, Aaron Segal, and Karn Seth. 2017. “Practical Secure Aggregation for Privacy-Preserving Machine Learning.” Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, 1175–91. https://doi.org/10.1145/3133956.3133982.
37 Differential Privacy (DP): A mathematical framework that bounds information leakage by adding calibrated noise to computations. In edge learning, that noise becomes a systems cost because noisier updates usually require more rounds or more data to reach the same utility. Security & Privacy develops the formal privacy-budget machinery.
To mitigate such risks, federated ML systems can employ protective measures. Secure aggregation36 protocols ensure that individual model updates are encrypted and aggregated in a way that the server only observes the combined result, not any individual client’s contribution. Differential privacy37 techniques inject carefully calibrated noise into updates to mathematically bound the information that can be inferred about any single client’s data.
While these techniques enhance privacy, they introduce additional system complexity and trade-offs between model utility, communication cost, and robustness. Figure 14 illustrates the secure aggregation protocol, showing how pairs of clients exchange shared random masks that cancel out during server-side summation, revealing only the aggregate gradient without exposing individual contributions.

Large-scale device orchestration
That algebraic cancellation is what makes secure aggregation composable with differential privacy for layered defense: the protocol hides individual contributions first, then privacy noise can bound what the aggregate still reveals. Federated learning transforms machine learning into a massive distributed systems challenge that extends far beyond traditional algorithmic considerations. Coordinating thousands or millions of heterogeneous devices with intermittent connectivity requires sophisticated distributed systems protocols that handle Byzantine failures [clients sending arbitrary or malicious updates], network partitions [temporary loss of connectivity between participants], and communication efficiency at unprecedented scale. These challenges fundamentally differ from the controlled environments of data center distributed training, where high-bandwidth networks and reliable infrastructure enable straightforward coordination protocols.
Network and bandwidth optimization
The communication bottleneck represents the primary scalability constraint in federated learning systems. Quantifying the actual transfer requirements exposes the design constraints on model architectures, update compression strategies, and client participation policies that determine system viability.
The federated communication hierarchy reveals the severe bandwidth constraints under which distributed learning must operate. Full model synchronization can require tens to hundreds of megabytes per training round for common deep models, which is a poor fit for intermittent mobile uplinks. Federated-optimization work therefore studies communication reduction through structured updates, quantization, sparsification, and selective transmission (Konečný et al. 2016; McMahan et al. 2017). Practical deployments often push this further by transmitting only adapters, heads, or compressed update summaries rather than complete model states. Communication frequency introduces a critical trade-off between model update freshness, where more frequent updates enable faster adaptation to changing conditions, and network efficiency constraints that limit sustainable bandwidth consumption.
Network infrastructure constraints directly impact participation rates and overall system viability. Mobile upload capacity varies sharply by geography, carrier, radio generation, congestion, and whether the device remains idle long enough to complete the transfer. A multi-megabyte update may be tolerable for a high-end device on a stable connection but impractical for a low-end device on a congested uplink. This variance in network capability necessitates adaptive communication strategies that optimize for lowest-common-denominator connectivity while enabling high-capability devices to contribute more effectively.
The relationship between communication requirements and participation rates exhibits sharp threshold effects. Large model transfers sharply reduce sustained client participation because devices must remain idle, connected, sufficiently charged, and willing to spend upload bandwidth for the whole transfer window. Keeping updates small, often through adapter-only sharing or aggressive compression, increases the eligible device pool and shortens round duration. This communication efficiency directly translates to model quality improvements: higher participation rates provide better statistical diversity and more robust gradient estimates for global model updates. The compression techniques that make these small updates possible (gradient quantization, sparsification, and top-\(k\) selection with error accumulation) are the same ones established in section 1.5.2; here they serve the participation argument rather than the bandwidth argument, because shrinking the update is what widens the eligible device pool.
Asynchronous device synchronization
Federated learning operates at the complex intersection of distributed systems and machine learning, inheriting fundamental challenges from both domains while introducing unique complications that arise from the mobile, heterogeneous, and unreliable nature of edge devices. Federated learning must contend with Byzantine fault tolerance requirements that extend beyond typical distributed systems challenges. Device failures occur frequently as clients crash, lose power, or disconnect during training rounds due to battery depletion or network connectivity issues, far more common than server failures in traditional distributed training. Malicious updates present security concerns as adversarial clients can provide corrupted gradients deliberately designed to degrade global model performance or extract private information from the aggregation process. Robust aggregation protocols implementing Byzantine-resilient averaging preserve useful model updates despite compromised or unreliable participants, though these protocols introduce significant computational overhead. The coordination problem is not consensus in the Paxos or Raft sense; it is deciding which client updates are eligible, how stale updates are weighted, and which aggregation rule can tolerate faulty participants without letting them steer the global model.
Network partitions pose particularly acute challenges for federated coordination protocols. Unlike traditional distributed systems operating within reliable data center networks, federated learning must gracefully handle prolonged client disconnection events where devices may remain offline for hours or days while traveling, in poor coverage areas, or simply powered down. Asynchronous coordination protocols enable continued training progress despite missing participants, but must carefully balance staleness (accepting potentially outdated contributions) against freshness (prioritizing recent but potentially sparse updates).
Fault recovery and resilience strategies form an essential layer of federated learning infrastructure. Checkpoint synchronization through periodic global model snapshots enables recovery from server failures and provides rollback points when corrupted training rounds are detected, though checkpointing large models across millions of devices introduces substantial storage and communication overhead. Partial update handling ensures systems gracefully handle incomplete training rounds when significant subsets of clients fail or disconnect mid-training, requiring careful weighting strategies to prevent bias toward more reliable device cohorts. State reconciliation protocols enable clients rejoining after extended offline periods, potentially days or weeks, to efficiently resynchronize with the current global model while minimizing communication overhead that could overwhelm bandwidth-constrained devices. Dynamic load balancing addresses uneven client availability patterns that create computational hotspots, requiring intelligent load redistribution across available participants to maintain training throughput despite time-varying participation rates.
The asynchronous nature of federated coordination introduces additional complexity in maintaining training convergence guarantees. Traditional synchronous training assumes all participants complete each round, but federated systems must handle stragglers38 and dropouts gracefully.
38 Straggler Problem: In data center training, stragglers slow synchronous progress; in federated learning, the problem is amplified by heterogeneous hardware, intermittent connectivity, and eligibility windows (Bonawitz et al. 2019; Kairouz and McMahan 2021). Solutions like asynchronous aggregation and bounded staleness (ignoring updates older than \(k\) rounds) improve throughput but introduce a fairness trade-off: aggressive straggler mitigation biases models toward users with high-end devices, potentially degrading performance for the most constrained users who need personalization most.
Managing million-device heterogeneity
Million-device orchestration is a tiering decision: the system must decide which clients can train, which can only report lightweight updates, and how much bias that selection introduces. The difficulty is that hardware capabilities, network conditions, data distributions, and availability patterns vary simultaneously, challenging traditional distributed machine learning assumptions about homogeneous participants operating under similar conditions.
Real-world federated learning deployments face multi-dimensional device heterogeneity that creates extreme variation across every system dimension. Computational variation spans about 1,166.7× differences in processing power between flagship smartphones running at 35 TOPS and IoT microcontrollers operating at just 0.03 TOPS, fundamentally limiting what models can train on different device tiers. Memory constraints exhibit even more dramatic differences in available RAM across device categories, up to roughly 65,536× between 256 KB microcontrollers and 16 GB premium smartphones, determining whether devices can perform any local training at all or must rely purely on inference. Energy limitations force training sessions to be carefully scheduled around charging patterns, thermal constraints, and battery preservation requirements: background adaptation often targets roughly 500–1000 mW, even though phones may sustain 2–3 W for foreground ML workloads and burst higher briefly. Network diversity introduces orders-of-magnitude performance differences as Wi-Fi, 4G, 5G, and satellite connectivity exhibit vastly different bandwidth (ranging from 1 Mbps to 1 Gbps), latency (10 ms to 600 ms), and reliability characteristics that determine feasible update frequencies and compression requirements.
Adaptive coordination protocols address this heterogeneity through sophisticated tiered participation strategies that optimize resource utilization across the device spectrum. High-capability devices such as flagship smartphones can perform complex local training with large batch sizes and multiple epochs, while resource-constrained IoT devices contribute through lightweight updates, specialized subtasks, or even simple data aggregation. This creates a natural computational hierarchy where powerful devices act as “super-peers” performing disproportionate computation, while edge devices contribute specialized local knowledge and coverage.
The scale challenges extend far beyond device heterogeneity to fundamental coordination overhead limitations. Traditional distributed consensus algorithms such as Raft or PBFT are designed for dozens of nodes in controlled environments, but federated learning requires coordination among millions of participants across unreliable networks. This necessitates hierarchical coordination architectures where regional aggregation servers reduce communication overhead by performing local consensus before contributing to global aggregation. Edge computing infrastructure provides natural hierarchical coordination points, enabling federated learning systems to use existing content delivery networks (CDNs) and mobile edge computing (MEC) deployments for efficient gradient aggregation.
Federated systems can implement sophisticated client selection strategies that balance statistical diversity with practical constraints. Random sampling ensures unbiased representation but may select many low-capability devices, while capability-based selection improves training efficiency but risks statistical bias. Hybrid approaches use stratified sampling across device tiers, ensuring both statistical representativeness and computational efficiency. These selection strategies must also consider temporal patterns: office workers’ devices may be available during specific hours, while IoT sensors provide continuous but limited computational resources.
With robust orchestration managing the heterogeneity and intermittency of millions of devices, the individual components for decentralized AI are in place. Each pillar so far has been treated as a discrete capability a device invokes, but a deployed edge model does not adapt once and stop; it keeps learning for the lifetime of the deployment, which is where the three pillars stop being separable.
Self-Check: Question
Why is naive random client selection often inadequate in production federated learning, even when the randomness is statistically unbiased?
- Random selection guarantees identical data distributions across participants, which reduces personalization.
- The pool of eligible clients at any moment is itself filtered by availability (charging, Wi-Fi, idle, adequate battery), so random-within-available systematically overrepresents flagship devices on fast networks and underrepresents users with older hardware or constrained connectivity.
- Random selection prevents secure aggregation from masking individual updates.
- Random selection always picks too few clients for weighted averaging to work.
Explain why update compression in federated learning is not merely an optimization but an architectural requirement on large mobile deployments, and quantify the bandwidth savings typical of production systems.
A federated deployment needs per-user adaptation while still benefiting from global coordination. Client memory budgets are tight, and analysis shows most user variation lives in the output decision boundary rather than in the shared representation. Which personalization design is the direct match?
- Personalization layers with a shared backbone and a lightweight client-specific head.
- Full-model fine-tuning on every client after each round.
- Elimination of the global model in favor of isolated local models only.
- Clustered federated learning with dozens of client clusters, because local heads cannot express any user variation.
What specific privacy property does secure aggregation provide in a federated round, and what is it not?
- It proves that no differential-privacy noise is ever needed.
- It lets the server inspect every client’s gradient individually and then decide which ones to keep.
- It ensures only the aggregate update is revealed at the server, because pairwise masks between clients cancel in the sum — but it does not by itself defend against reconstruction of aggregates over time, which is why differential privacy is often layered on top.
- It eliminates the need for a minimum client count per round.
True or False: Aggressive straggler mitigation that drops slow or stale clients speeds up federated round times but can simultaneously introduce a fairness problem by systematically underrepresenting constrained devices.
Order the following concerns as they logically build from round-local execution to fleet-wide governance when scaling federated learning from prototype to production: (1) client scheduling, (2) update compression, (3) million-device orchestration.
Continual Adaptation Under Edge Budgets
Continual adaptation on edge devices has to fit inside power, memory, and communication budgets that leave little room for waste. The model adaptation, data efficiency, and federated coordination pillars each attack one slice of that budget, but a model that keeps learning after deployment must respect all of them at once. The human brain operates at approximately 20 watts while continuously learning from limited supervision without catastrophic forgetting39. This comparison does not make biology a deployment recipe; it explains why edge systems keep returning to sparsity, replay, and opportunistic updates.
39 Brain Power Efficiency: At 20 W, the brain processes approximately \(10^{15}\) operations per second, equivalent to about 50 TOPS/W under this coarse operation-counting model. Compared with the 1–5 TOPS/W mobile-NPU range used earlier in this chapter, that is roughly 10–50× higher energy efficiency, though biological synaptic events and digital operations are only an approximate analogy. This efficiency derives from extreme sparsity (only 1–2 percent of 86 billion neurons active simultaneously) and event-driven processing that activates computation only on input change. These two principles directly inform edge ML design: sparse activation patterns and opportunistic training scheduling are not heuristics but attempts to approach biological efficiency limits.
Biological analogies are useful only when they clarify engineering choices. Sparse representations mirror the selective parameter updates that keep mobile adaptation low cost. Replay buffers parallel memory-consolidation mechanisms that stabilize continual learning. Local-global coordination echoes the need for individual adaptation without abandoning population-level improvement. The point is to recognize why the same constraints keep producing similar design patterns.
For edge systems, the useful comparison is not the neuron count; it is the budget discipline. A 20 W learning system, with roughly 10 W available for active learning and memory consolidation, sits in the same order of magnitude as the power a mobile device can allocate during charging. Sparse, distributed representations reduce memory traffic because only 1–2 percent of neurons activate during a cognitive task. Few-shot learning and continual consolidation point to the same systems target: adapt from little local evidence without overwriting the representation that still serves the original task. Hierarchical processing adds the final lesson, because reusable features reduce the amount of work each new local context must perform.
Two implementation pressures follow from that comparison. Sparse representations map naturally to selective parameter updates and pruned architectures, which keep mobile adaptation within memory and energy limits. Event-driven processing maps to opportunistic scheduling, where the device spends energy on learning only when new input, idle time, power state, and thermal headroom make the update worth running. The analogy is useful only because it sharpens these engineering constraints.
Unlabeled data exploitation strategies
Unlabeled sensor streams turn the efficiency argument into a storage and scheduling decision. Mobile devices continuously collect visual data from cameras, temporal patterns from accelerometers, spatial patterns from GPS, and interaction patterns from touchscreen usage, all of which can support self-supervised learning. The engineering question is which traces encode stable structure and which should expire before they crowd out model state, replay buffers, or user-facing storage.
The scale of mobile sensor data makes that decision concrete across four common stream types:
- Visual streams from cameras operating at 30 frames per second provide approximately 2.6 million frames daily, offering abundant data for contrastive learning approaches that learn visual representations by comparing augmented versions of the same image40.
- Motion streams from accelerometers sampling at 100 Hz generate 8.6 million data points daily, capturing temporal patterns suitable for learning representations of human activities and device movement.
- Location traces from GPS sensors enable spatial representation learning and behavioral prediction by capturing movement patterns and frequently visited locations without requiring explicit labels.
- Interaction patterns from touch events, typing dynamics, and app usage sequences create rich behavioral embeddings that reveal user preferences and habits, enabling personalized model adaptation without manual annotation.
40 Mobile Sensor Data Scale: A typical smartphone generates 2–4 GB of sensor data daily: cameras (1–2 GB), accelerometers (approximately 50 MB), GPS (approximately 10 MB), and touch events (approximately 5 MB). Contrastive learning can extract useful representations from a small retained sample of this data, making self-supervised on-device learning feasible without labels or cloud processing. The constraint becomes storage policy, not data availability: deciding what to retain and what to discard before memory fills.
41 Contrastive Learning: Self-supervised technique that learns representations by distinguishing similar (positive) from dissimilar (negative) pairs without labels. SimCLR (Chen et al. 2020) demonstrates that large batches of augmented views can learn strong visual representations without human labels. For edge devices, the transferable systems idea is to use unlabeled sensor streams for representation learning or pretraining, then spend scarce labels only on lightweight local adaptation; the exact label savings depend on the task, retention policy, and compute budget.
Chen, Ting, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. 2020. “A Simple Framework for Contrastive Learning of Visual Representations.” Proceedings of the 37th International Conference on Machine Learning, ICML’20, vol. 119: 1597–607.
Contrastive learning41 from temporal correlations offers particularly promising opportunities for exploiting this sensor data. Consecutive frames from mobile cameras or augmented views of the same frame naturally provide positive pairs for visual representation learning. Negative examples come from different frames, other devices’ samples, or replay/memory queues that represent dissimilar scenes.
The biological inspiration extends to continual learning without forgetting. Brains continuously integrate new experiences while retaining decades of memories through mechanisms like synaptic consolidation and replay. On-device systems must implement analogous mechanisms: elastic weight consolidation42 (Kirkpatrick et al. 2017) prevents catastrophic forgetting by protecting weights important for previous tasks, experience replay maintains stability during adaptation by interleaving new training with replayed examples from previous tasks, and progressive neural architectures allocate new capacity for new tasks rather than forcing all knowledge into fixed-capacity networks (Rusu et al. 2016). That last option is attractive when interference is severe, but it consumes additional memory and therefore fits only devices with enough spare capacity.
42 EWC (Elastic Weight Consolidation): Estimates per-parameter importance for previous tasks using the Fisher Information Matrix, then penalizes changes to important parameters during new learning. This adds only 10–15 percent computation per training step but requires storing one importance score per parameter (4 bytes each), roughly doubling weight memory. The trade-off vs. replay buffers is explicit: EWC trades memory proportional to model size for memory proportional to data history, favoring large-model-small-data edge scenarios.
Kirkpatrick, J., R. Pascanu, N. Rabinowitz, J. Veness, G. Desjardins, A. A. Rusu, K. Milan, et al. 2017. “Overcoming Catastrophic Forgetting in Neural Networks.” Proceedings of the National Academy of Sciences 114 (13): 3521–26. https://doi.org/10.1073/pnas.1611835114.
Rusu, A. A., N. C. Rabinowitz, G. Desjardins, H. Soyer, J. Kirkpatrick, K. Kavukcuoglu, R. Pascanu, and R. Hadsell. 2016. “Progressive Neural Networks.” arXiv Preprint arXiv:1606.04671.
Lifelong adaptation without forgetting
Real-world on-device deployment demands continual adaptation to changing environments, user behavior, and task requirements. This presents the fundamental challenge of the stability-plasticity trade-off: models must remain stable enough to preserve existing knowledge while plastic enough to learn new patterns.
Continual learning on edge devices faces several interconnected challenges that compound the difficulty of distributed adaptation:
- Catastrophic forgetting occurs when new learning overwrites previously acquired knowledge, causing models to lose performance on earlier tasks as they adapt to new ones. The problem is particularly severe when devices cannot access historical training data.
- Task interference emerges when multiple learning objectives compete for limited model capacity, forcing difficult trade-offs between different capabilities that the model must maintain simultaneously.
- Data distribution shift manifests as deployment environments differ significantly from training conditions, requiring models to adapt to new patterns while maintaining performance on the original distribution.
- Resource constraints limit the available solutions, as limited memory prevents storing all historical data for replay-based approaches that work well in centralized settings but exceed edge device capabilities.
Meta-learning approaches address these challenges by learning algorithms themselves rather than just learning specific tasks. Model-Agnostic Meta-Learning (MAML) trains models to quickly adapt to new tasks with minimal data, exactly the capability required for personalized on-device adaptation where collecting large user-specific datasets is impractical. Few-shot learning techniques enable rapid specialization from small user-specific datasets, allowing models to personalize based on just a handful of examples while maintaining general capabilities learned during pretraining.
The theoretical foundation points to a compact design rule: durable on-device learning minimizes the adaptation footprint while preserving enough plasticity to track local change. Sparse model architectures reduce memory and compute requirements, self-supervised objectives use abundant unlabeled sensor data, and meta-learning enables efficient personalization from limited user interactions.
That rule first changes what the device is allowed to update. Full-model fine-tuning is typically infeasible on edge platforms, so localized update strategies, including bias-only optimization, residual adapters, and lightweight task-specific heads, keep model specialization within resource constraints while reducing the risk of overfitting or instability. When personalization is required, restricting updates to lightweight components constrains catastrophic forgetting, reduces memory overhead, and accelerates adaptation without destabilizing core model representations. The feasibility of this strategy depends critically on the strength of offline pretraining (Bommasani et al. 2021): pretrained models must encapsulate generalizable features so the device spends its limited energy specializing behavior rather than relearning representations from scarce local data.
Bommasani, Rishi, Drew A. Hudson, Ehsan Adeli, Russ Altman, Simran Arora, Sydney von Arx, Michael S. Bernstein, et al. 2021. “On the Opportunities and Risks of Foundation Models.” arXiv Preprint arXiv:2108.07258.
Once the update footprint is bounded, the runtime must decide when the update can execute and whether it should be shared. Opportunistic scheduling defers local updates to periods when the device is idle, connected to external power, and operating on a reliable network, minimizing the impact of background training on latency, battery consumption, and thermal performance. In decentralized or federated learning contexts, the same budget pressure applies to communication: quantized gradient updates, sparsified parameter sets, and selective model transmission allow large heterogeneous fleets to coordinate without overwhelming bandwidth or energy budgets (Konečný et al. 2016).
Stability then becomes a state-management problem. Replay buffers, support sets, adaptation logs, and model update metadata must be protected against unauthorized access or tampering because they encode the local evidence that shaped the model. Lightweight encryption or hardware-backed secure storage can reduce that exposure, but security controls do not prove that adaptation remains beneficial. Lightweight validation techniques, including confidence scoring, drift detection heuristics (Gama et al. 2014), and shadow model evaluation, monitor adaptation dynamics and can trigger rollback before severe degradation occurs. Robust rollback procedures require a trusted baseline checkpoint that can be restored quickly, especially in safety-important and regulated domains where failure recovery must be provable.
Gama, João, Indrė Žliobaitė, Albert Bifet, Mykola Pechenizkiy, and Abdelhamid Bouchachia. 2014. “A Survey on Concept Drift Adaptation.” ACM Computing Surveys 46 (4): 1–37. https://doi.org/10.1145/2523813.
Privacy and compliance requirements close the loop. User consent, data minimization, retention limits, and the right to erasure must be designed into the adaptation pipeline rather than added after deployment. Meeting regulatory obligations at scale demands on-device learning workflows that preserve auditable autonomy: the model can adapt in place, but the system still retains enough control to explain, bound, and reverse that adaptation when necessary.
Consider figure 15 for a systematic decision framework: the flowchart guides practitioners through key decision points about adaptation complexity, compute availability, and data sharing requirements, mapping these choices to concrete implementation strategies from bias-only updates to full federated learning with privacy measures.

A design rule and a decision flowchart describe what a single device should do. Running that adaptation across a fleet, on a release cadence, with monitoring and rollback, is a separate discipline: it turns these continual-learning choices into operations that must survive CI/CD, versioning, and the absence of centralized labels.
Production Integration
It is one thing to write a proof-of-concept script that fine-tunes an adapter on a Raspberry Pi. It is an entirely different discipline to ship that capability to 50 million devices within a strict CI/CD pipeline, ensuring that a bad gradient update does not brick the app. Production integration is where the theoretical elegance of edge intelligence collides with the unforgiving realities of mobile software engineering.
MLOps integration challenges
Integrating on-device learning into MLOps changes what operations must validate: a hierarchy of backbones, adapters, policies, and local states spread across heterogeneous devices, in place of a single model artifact in one controlled environment. Traditional continuous integration pipelines, model versioning systems, and monitoring infrastructure provide essential foundations, but they assume centralized data access, controlled deployment environments, and unified monitoring. Edge learning breaks those assumptions, requiring operational practices that preserve reliability while privacy-preserving coordination and local adaptation continue after deployment.
Deployment pipeline transformations
Traditional MLOps deployment pipelines release one validated model artifact into uniform infrastructure. On-device learning turns that artifact into a policy bundle because device class determines what safe adaptation means. Microcontrollers receive bias-only updates, mid-range phones use LoRA adapters, and flagship devices perform selective layer updates. The deployable unit includes adaptation policies, initial model weights, and device-specific optimization configurations, so CI/CD must validate the policy that selects among them, not only the weights.
That shift also changes versioning. While centralized systems maintain a single model version, on-device learning systems must simultaneously track multiple versioning dimensions. The pretrained backbone distributed to all devices represents the base model version, which serves as the foundation for all local adaptations. Different update mechanisms deployed per device class constitute adaptation strategies, varying from simple bias adjustments on microcontrollers to full layer fine-tuning on flagship devices. Local model states naturally diverge from the base as devices encounter unique data distributions, creating device-specific checkpoints that reflect individual adaptation histories. Federated learning rounds that periodically synchronize device populations establish aggregation epochs, marking discrete points where distributed knowledge converges into updated global models. A robust deployment implements tiered versioning schemes where base models evolve slowly, often through scheduled updates, while local adaptations occur continuously, creating a hierarchical version space rather than the linear version history familiar from traditional deployments.
Monitoring system evolution
Traditional monitoring practices aggregate metrics from centralized inference servers. On-device learning monitoring must operate within fundamentally different constraints that reshape how systems observe, measure, and respond to model behavior across distributed device populations.
Privacy-preserving telemetry represents the first fundamental departure from traditional monitoring. Collecting performance metrics without compromising user privacy requires federated analytics where devices share only aggregate statistics or differentially private summaries. Systems cannot simply log individual predictions or training samples as centralized systems do. Instead, devices report distribution summaries such as mean accuracy and confidence histograms rather than per-example metrics. When formal privacy guarantees are required, reported statistics need differential privacy mechanisms that bound information leakage through carefully calibrated noise addition. Secure aggregation protocols prevent the server from observing individual device contributions, reducing the risk that the aggregation process itself reconstructs private information from any single device’s data.
Drift detection presents additional challenges without access to ground truth labels. Traditional monitoring compares model predictions against labeled validation sets maintained on centralized infrastructure. On-device systems must detect drift using only local signals available during deployment:
- Confidence calibration tracks whether predicted probabilities match empirical frequencies, detecting degradation when the model’s confidence estimates become poorly calibrated to actual outcomes.
- Input distribution monitoring detects when feature distributions shift from training data through statistical techniques that require no labels.
- Task performance proxies use implicit feedback such as user corrections or task abandonment as quality signals that indicate when the model fails to meet user needs.
- Shadow baseline comparison runs a frozen base model alongside the adapted model to measure divergence, flagging cases where local adaptation degrades rather than improves performance relative to the known-good baseline.
Heterogeneous performance tracking addresses a third critical challenge: global averages mask critical failures when device populations exhibit high variance. Monitoring systems must segment performance across multiple dimensions to identify systematic issues that affect specific device cohorts:
- Capability-based performance gaps reveal when flagship devices achieve substantially better results than budget devices, indicating that adaptation strategies may need adjustment for resource-constrained hardware.
- Regional bias issues surface when models perform well in some geographic markets but poorly in others, potentially reflecting data distribution shifts or cultural factors not captured during initial training.
- Temporal patterns emerge when performance degrades for devices running stale base models that have not received recent updates from federated aggregation.
- Participation inequality becomes visible when comparing devices that adapt frequently against those that rarely participate in training, revealing potential fairness issues in how learning benefits are distributed across the user population.
These slices keep cohort-specific failures visible instead of letting strong devices hide weak-device regressions inside a global average.
Continuous training orchestration
Traditional continuous training executes scheduled retraining jobs on centralized infrastructure with predictable resource availability and coordinated execution. On-device learning transforms this into continuous distributed training where millions of devices train independently without global synchronization, creating orchestration challenges that require fundamentally different coordination strategies.
Asynchronous device coordination represents the first major departure from centralized training. Millions of devices train independently on their local data, but the orchestration system cannot rely on synchronized participation. In a representative mobile deployment, only a minority of devices may be available in any training round because of network connectivity limitations, battery constraints, and varying usage patterns. The system must exhibit straggler tolerance, ensuring that slow devices on limited hardware or poor network connections cannot block faster devices from progressing with their local adaptations. Devices often operate on different base model versions simultaneously, creating version skew that the aggregation protocol must handle gracefully without forcing all devices to maintain identical model states. State reconciliation becomes necessary when devices reconnect after extended offline periods, potentially days or weeks, requiring the system to integrate their accumulated local adaptations despite having missed multiple federated aggregation rounds.
Resource-aware scheduling ensures that training respects both device constraints and user experience:
- Orchestration policies implement opportunistic training windows that execute adaptation only when the device is idle, charging, and connected to Wi-Fi, avoiding interference with active user tasks or consuming metered cellular data.
- Thermal budgets suspend training when device temperature exceeds manufacturer-specified thresholds, preventing user discomfort and hardware damage from sustained computational loads.
- Battery preservation policies limit training energy consumption to less than 5 percent of battery capacity per day, ensuring that on-device learning does not noticeably impact device runtime from the user’s perspective.
- Network-aware communication compresses model updates aggressively when devices must use metered connections, trading computational overhead for reduced bandwidth consumption to minimize user data charges.
Convergence assessment without global visibility poses the final orchestration challenge. Traditional training monitors loss curves on centralized validation sets, providing clear signals about training progress and convergence. Distributed training must assess convergence through indirect signals aggregated across the device population:
- Federated evaluation aggregates validation metrics from devices that maintain local held-out sets, providing approximate measures of global model quality despite incomplete device participation.
- Update magnitude tracking monitors how much local gradients change the global model in each aggregation round, with diminishing update sizes signaling potential convergence.
- Participation diversity ensures broad device representation in aggregated updates, preventing convergence metrics from reflecting only a narrow subset of the deployment environment.
- Temporal consistency detects when model improvements plateau across multiple aggregation rounds, indicating that the current adaptation strategy has exhausted its potential gains and may require adjustment.
Together, these signals substitute population-level progress checks for the centralized loss curves unavailable in federated settings.
Validation strategy adaptation
Traditional validation approaches assume access to held-out test sets and centralized evaluation infrastructure where model quality can be measured directly against known ground truth. On-device learning requires distributed validation that respects privacy and resource constraints while still providing reliable quality signals across heterogeneous device populations.
Shadow model evaluation provides a validation mechanism by maintaining multiple model variants on each device and comparing their behavior. Devices simultaneously run a baseline shadow model, a frozen copy of the last known-good base model that provides a stable reference point, alongside the locally-adapted version that reflects recent on-device training. Some systems also maintain the recent federated aggregation result as a global model variant, enabling comparison between individual device adaptations and the collective knowledge aggregated from the entire device population. By comparing predictions across these variants on incoming data streams, systems detect when local adaptation degrades performance relative to established baselines. This comparison occurs continuously during normal operation, requiring no additional labeled validation data. When the adapted model consistently underperforms the baseline shadow, the system triggers automatic rollback to the known-good version, preventing performance degradation from persisting in production.
Confidence-based quality gates provide an additional validation signal when labeled validation data is unavailable. Without ground truth labels, systems use prediction confidence as a quality proxy that correlates with model performance. Well-calibrated models should exhibit high confidence on in-distribution samples that resemble their training data, with confidence scores that accurately reflect the probability of correct predictions. Confidence drops indicate either distributional shift, where input data no longer matches training distributions, or model degradation from problematic local adaptations. Threshold-based gating implements this validation mechanism by continuously monitoring average prediction confidence and suspending adaptation when confidence falls below baseline levels established during initial deployment. This approach catches many failure modes without requiring labeled validation data, though it cannot detect all performance issues since overconfident but incorrect predictions can maintain high confidence scores.
Federated A/B testing enables validation of new adaptation strategies or model architectures across distributed device populations. To validate proposed changes, systems implement distributed experiments that randomly assign devices to treatment and control groups while maintaining statistical balance across device tiers and usage patterns. Both groups collect federated metrics using privacy-preserving aggregation protocols that prevent individual device data from being exposed while enabling population-level comparisons. The system compares adaptation success rates, measuring how frequently local adaptations improve over baseline models, along with convergence speed that indicates how quickly devices reach optimal performance, and final performance metrics that reflect ultimate model quality after adaptation completes. Successful strategies demonstrating clear improvements in treatment groups are rolled out gradually across the device population, starting with small percentages and expanding only after confirming that benefits generalize beyond the experimental cohort.
These operational transformations necessitate new tooling and infrastructure that systematically extends traditional MLOps practices. The CI/CD pipelines, monitoring dashboards, A/B testing frameworks, and incident response procedures established for centralized deployments form the foundation for on-device learning operations. The federated learning protocols presented in section 1.4 provide the coordination mechanisms for distributed training, while section 1.9.3 addresses the observability gaps created by decentralized adaptation. The shadow validation approach operates as a continuous comparison pipeline running on each device (figure 16), where incoming data flows through both a frozen baseline and the locally adapted model before an arbiter decides whether to accept or roll back adaptations.

Successful on-device learning deployments build on proven MLOps methodologies while adapting them to the unique challenges of distributed, heterogeneous learning environments. This evolutionary approach ensures operational reliability while enabling the benefits of edge learning. With the pillars built and the operational scaffolding in place, the remaining question is how the three fit together in a single fleet rather than as separate techniques.
Self-Check: Question
How does on-device learning fundamentally change model versioning relative to a traditional centralized deployment where a single artifact ships to every replica?
- Versioning disappears because local models should never be tracked once deployed.
- Versioning becomes hierarchical: the system must simultaneously track a shared backbone version, an adaptation-strategy version, the per-device adapted state, and the federated aggregation epoch.
- A single linear version number still suffices because all devices receive identical updates at the same time.
- Only the optimizer version matters, because local model parameters are too dynamic to record.
Explain how privacy-preserving telemetry changes what a production monitoring system can observe in on-device learning deployments, and name two concrete metrics that remain safe to report at the fleet level.
A production on-device learning system adds a shadow validation mechanism. What specific function does shadow validation serve?
- It increases training speed by running two adapting models in parallel and averaging their gradients.
- It eliminates the need for device-side monitoring by outsourcing validation to a server.
- It guarantees that local adaptation always improves accuracy for every user.
- It runs a frozen known-good baseline in parallel with the adapting model and compares their behavior on the same inputs, giving the device a labels-free drift signal that can trigger rollback.
A team debates when on-device training should actually run on consumer phones. Which scheduling policy matches the chapter’s resource-aware recommendation?
- Avoid any ML-aware policy and let the OS’s default process scheduler decide training timing.
- Train immediately whenever new local data arrives, because adaptation quality should dominate UX concerns.
- Train only during opportunistic windows when the device is idle, charging, thermally stable, and typically on Wi-Fi.
- Train continuously during active use so adaptation reflects the freshest user context.
True or False: The chapter invokes biological learning mainly as a metaphor for intuition-building, not as a source of concrete design principles that show up in actual edge-learning systems.
Why is strong offline pretraining especially important before deploying lightweight local adaptation methods such as bias-only updates or adapters? Explain the feature-learning division of labor this creates.
Putting the Pillars Together
The integration is concrete: rather than deploy one adaptation policy everywhere, bound the risks by matching each pillar to device capability. Consider a production voice assistant deployment across 50 million devices, where each layer constrains what the others are allowed to do.
The chapter built three pillars separately: model adaptation, data efficiency, and federated coordination. Treated as isolated techniques, each one solves a local constraint but leaves the others free to misbehave. The production voice assistant shows the central payoff: integrate all three by device tier, so the policy that decides how much a device may adapt is the same policy that decides how much it may remember and how it may participate in the fleet.
The model adaptation layer stratifies techniques by device capability, matching sophistication to available resources. Flagship phones representing the top 20 percent of the deployment use LoRA adapters of rank 32 that enable sophisticated voice pattern learning through high-dimensional parameter updates. Mid-tier devices comprising 60 percent of the fleet employ adapters of rank 16 that balance adaptation expressiveness with the tighter memory constraints typical of mainstream smartphones. Budget devices making up the remaining 20 percent rely on bias-only updates that stay comfortably within 1 GB memory limits while still enabling basic personalization.
The data efficiency layer implements adaptive strategies across the entire device population while respecting individual resource constraints. All devices implement experience replay43, but with device-appropriate buffer sizes, 10 MB on budget devices vs. 100 MB on flagship models, ensuring that memory-constrained devices can still benefit from replay-based learning. Few-shot learning enables rapid adaptation to new users within their first 5–10 interactions, reducing the cold-start problem44 that plagues systems requiring extensive training data. Streaming updates accommodate continuous voice pattern evolution as users’ speaking styles naturally change over time or as they use the assistant in new acoustic environments.
43 [offset=-15mm] Experience Replay: Borrowed from reinforcement learning (Mnih et al. 2015), stores past input-output pairs in a buffer and interleaves them with new training data to reduce catastrophic forgetting in continual learning (Rolnick et al. 2019). Memory-efficient edge implementations may store compressed embeddings or summaries rather than raw inputs, reducing storage and privacy pressure at the cost of less complete gradient information. Buffer size, sampling policy, and representation choice jointly determine the stability-memory trade-off: too small and old tasks can degrade, too large and the buffer competes with model weights for scarce edge memory.
Mnih, Volodymyr, Koray Kavukcuoglu, David Silver, Andrei A. Rusu, Joel Veness, Marc G. Bellemare, Alex Graves, et al. 2015. “Human-Level Control Through Deep Reinforcement Learning.” Nature 518 (7540): 529–33. https://doi.org/10.1038/nature14236.
Rolnick, David, Arun Ahuja, Jonathan Schwarz, Timothy Lillicrap, and Greg Wayne. 2019. “Experience Replay for Continual Learning.” Advances in Neural Information Processing Systems (NeurIPS).
44 [offset=-38mm] Cold-Start Problem: New users or devices have no local data for personalization, so early predictions must rely on a global model, coarse context, or explicit user input. Meta-learned initializations (MAML) or privacy-preserving population statistics can bootstrap personalization, but the fundamental trade-off remains: faster cold-start requires more information from the global model, which may not represent the new user’s distribution. Few-shot adaptation from 5–10 interactions offers one balance of speed and local relevance.
The federated coordination layer orchestrates privacy-preserving collaboration across the device population. Devices participate in federated training rounds opportunistically based on connectivity status and battery level, ensuring that coordination does not degrade user experience. LoRA adapters aggregate efficiently with just 50 MB per update compared to 14 GB for full model synchronization, making federated learning practical over mobile networks. Privacy-preserving aggregation protocols ensure that individual voice patterns never leave devices while still enabling population-scale improvements in accent recognition and language understanding that benefit all users.
These layers only work as a system when the integration policy protects against capability mismatch, component failure, resource conflicts, and untested emergent behavior. Table 7 maps edge-learning integration controls for each system risk: hierarchical capability matching, graceful degradation, explicit priority policy, and performance validation.
| Integration risk | Control | Why it matters |
|---|---|---|
| Capability mismatch | Hierarchical capability matching | Deploys more sophisticated techniques on capable devices while preserving basic functionality across the full device spectrum. |
| Component failure | Graceful degradation | Keeps local adaptation useful when connectivity is poor or battery constraints force the system into a minimal adaptation mode. |
| Resource conflict | Explicit priority policy | Prevents model adaptation and replay buffers from competing for the same memory, energy, or latency budget without a predefined owner. |
| Emergent behavior | Performance validation | Tests combinations of device tier, network state, and adaptation policy because integrated systems fail in ways individual techniques do not expose. |
This integrated approach transforms on-device learning from a collection of techniques into a coherent systems capability that provides robust personalization within real-world deployment constraints. A tiered adaptation strategy (figure 17) maps these techniques to device capabilities.

Checkpoint 1.4: Integrating the three pillars across device tiers
The chapter built three pillars for on-device learning: model adaptation (bias-only updates, adapters, full fine-tuning), data efficiency (few-shot, experience replay, contrastive), and federated coordination (aggregation, secure aggregation, drift handling). Figure 17 maps each technique to device-class capability. Test whether you can integrate the three pillars across the same deployment.
The hardest edge-learning failures appear when model adaptation, data efficiency, and federated coordination interact rather than when any one pillar fails alone. The techniques above solve individual constraints, but they also create interaction failures in real deployments: an adapter can fit memory yet overfit sparse local data, a replay buffer can stabilize learning yet leak sensitive history, and a federated round can improve the global model while amplifying participation bias. These limits provide critical context for deciding when on-device learning is appropriate and when a simpler strategy is safer.
That interaction is what separates edge learning from conventional centralized training. Controlled training environments can standardize hardware, curate data, and validate updates before release. Edge deployments inherit heterogeneous devices, fragmented data, and limited visibility at the same time, so the next design question is how each source of variation changes the boundaries of the adaptation strategies, data efficiency methods, and coordination mechanisms developed earlier in the chapter.
Engineering Challenges and Mitigations
A billion-user predictive text model that learns from live keyboard inputs can be poisoned if a coordinated group of malicious users repeatedly types a specific slur and those local updates enter the global federated aggregate. The tiered integration policy bounds where each pillar may act, but it does not erase the failure surfaces that exposing an adapting model to the real world creates: device and data heterogeneity, non-IID distributions, limited observability, resource contention, silent failures, and the security and compliance risks of post-release adaptation. The remainder of this section works through those challenges and the engineering mitigations each one demands, beginning with the variation that is hardest to design around because it is present from the first rollout.
Device and data heterogeneity management
Heterogeneity is not background variation; it determines which devices can train, which can validate, and which can only contribute lightweight signals. The quantitative spread established in section 1.5.5.3 gives the resource envelope. Here the management problem is reproducibility: a single rollout must behave consistently across smartphones, wearables, IoT sensors, and microcontrollers whose hardware tiers, software stacks, network connectivity, and power availability differ sharply.
Hardware tiers still shape the execution path. ARM Cortex-M-class devices, mobile-class A-series CPUs, and phones with dedicated NPUs45 may all participate in the same federated population, but each tier supports a different adaptation envelope. The system must therefore assign model formats, training algorithms, validation duties, and update frequencies by device class rather than treating the fleet as uniform.
45 ARM Cortex Spectrum: Representative endpoints span nearly six orders of magnitude, from Cortex-M-class devices around 48 MHz, 32 KB RAM, and 10 µW power to mobile-class devices around 3 GHz, 16 GB RAM, and 5 W (Warden and Situnayake 2020; Lai et al. 2018). Federated-learning surveys and production-system reports identify this kind of client heterogeneity and availability skew as a core systems challenge (Kairouz and McMahan 2021; Bonawitz et al. 2019). The design consequence is tiering: quantized inference on the smallest microcontrollers, lightweight bias-only updates on larger embedded or wearable tiers, and fuller adapter or backpropagation loops only on mobile-class SoCs.
Warden, Pete, and Daniel Situnayake. 2020. TinyML: Machine Learning with TensorFlow Lite on Arduino and Ultra-Low-Power Microcontrollers. O’Reilly Media.
Lai, Liangzhen, Naveen Suda, and Vikas Chandra. 2018. “CMSIS-NN: Efficient Neural Network Kernels for Arm Cortex-M CPUs.” ArXiv Preprint abs/1801.06601.
Kairouz, P., and H. B. McMahan. 2021. “Advances and Open Problems in Federated Learning.” Foundations and Trends in Machine Learning 14 (1-2): 1–210. https://doi.org/10.1561/2200000083.
Bonawitz, K., H. Eichner, W. Grieskamp, D. Huba, A. Ingerman, V. Ivanov, C. Kiddon, et al. 2019. “Towards Federated Learning at Scale: System Design.” Proceedings of Machine Learning and Systems 3.
46 TensorFlow Lite: Google’s mobile inference runtime, optimized for ARM with specialized 8-bit and 16-bit kernels that achieve 3\(\times\) faster inference than full TensorFlow. TFLite Micro extends to microcontrollers with $<$1 MB memory. The systems consequence for federated learning: runtime differences between TFLite and other frameworks can cause numerically different gradient updates from identical models, introducing aggregation noise that compounds across heterogeneous device fleets.
47 ONNX Runtime Mobile: Microsoft’s cross-platform inference engine using the vendor-neutral Open Neural Network Exchange format, enabling training in one framework and deployment across iOS, Android, and embedded Linux. The mobile variant achieves 2–3\(\times\) faster inference than TFLite on some models through operator fusion. For federated learning, ONNX’s portability reduces the numerical divergence problem: a single model representation across heterogeneous devices produces more consistent gradient updates during aggregation.
Software heterogeneity compounds the challenge. Devices may run different versions of operating systems, kernel-level drivers, and runtime libraries. Some environments support optimized ML runtimes like TensorFlow Lite46 Micro or ONNX Runtime Mobile47, while others rely on custom inference stacks or restricted APIs. These discrepancies can lead to subtle inconsistencies in behavior, especially when models are compiled differently or when floating-point precision varies across platforms.
Connectivity and uptime add the scheduling dimension. Some devices are intermittently connected, plugged in only occasionally, or operating under strict bandwidth constraints. Others have continuous power and reliable networking, but still prioritize user-facing responsiveness over background learning. These differences complicate coordinated learning because update eligibility changes with the device’s current state, not only with its hardware tier.
System fragmentation closes the loop by making reproducibility and testing a fleet property rather than a lab property. With such a wide range of execution environments, consistent model behavior is difficult to guarantee and failures are difficult to reproduce. Monitoring, validation, and rollback therefore become more important, while also becoming harder to implement uniformly across the fleet.
The consequence is visible in a federated learning deployment for mobile keyboards. A high-end smartphone might feature 8 GB of RAM, a dedicated AI accelerator, and continuous Wi-Fi access. In contrast, a budget device may have just 2 GB of RAM, no hardware acceleration, and rely on intermittent mobile data. These disparities influence how long training runs can proceed, how frequently models can be updated, and even whether training is feasible at all. To support such a range, the system must dynamically adjust training schedules, model formats, and compression strategies, ensuring equitable model improvement across users while respecting each device’s limitations.
Non-IID data distribution challenges
In centralized machine learning, data can be aggregated, shuffled, and curated to approximate independent and identically distributed (IID) samples, a key assumption underlying many learning algorithms. On-device and federated learning systems fundamentally challenge this assumption, requiring algorithms that can handle highly fragmented and non-IID data across diverse devices and contexts.
The statistical implications of this fragmentation create cascading challenges throughout the learning process. Gradients computed on different devices may conflict, slowing convergence or destabilizing training. Local updates risk overfitting to individual client idiosyncrasies, reducing performance when aggregated globally. The diversity of data across clients also complicates evaluation, as no single test set can represent the true deployment distribution.
Operationally, non-IID data is a control problem as much as a statistical one. Clustered federated learning, personalization layers, stratified client sampling, per-cohort validation, importance weighting, and adaptive aggregation schemes provide partial controls, but the optimal mix depends on which population slices are underrepresented and which update conflicts are destabilizing the global model.
Distributed system observability
Observability is the control plane that keeps local adaptation from becoming invisible. Traditional centralized MLOps monitors collect prediction, label, and performance telemetry in one place; that approach becomes impractical when devices operate intermittently connected and data cannot be centralized. Edge systems still need drift detection and performance monitoring, but those techniques must work through privacy-preserving summaries, local gates, and partial population signals.
The visibility shift matters because on-device models keep changing after release. In centralized systems, model updates can be evaluated against held-out validation sets before promotion. In on-device systems, internal updates may proceed inside highly diverse and disconnected environments, creating the central safety question for edge observability: whether local adaptation is improving the model or silently moving it away from the intended behavior.
A core difficulty lies in the absence of centralized validation data. In traditional workflows, models are trained and evaluated using curated datasets that serve as proxies for deployment conditions. On-device learners, by contrast, adapt in response to local inputs, which are rarely labeled and may not be systematically collected. As a result, the quality and direction of updates, whether they enhance generalization or cause drift, are difficult to assess without interfering with the user experience or violating privacy constraints.
The risk of model drift is especially pronounced in streaming settings, where continual adaptation may cause a slow degradation in performance. For instance, a voice recognition model that adapts too aggressively to background noise may eventually overfit to transient acoustic conditions, reducing accuracy on the target task. Without visibility into the evolution of model parameters or outputs, such degradations can remain undetected until they become severe.
Mitigating this problem requires mechanisms for on-device validation and update gating. The shadow-model and checkpoint-rollback mechanisms introduced in section 1.7.1.4 are the practical answer to this observability gap: compare the adapted model against a stable baseline, suspend adaptation when confidence falls below the deployment threshold, and retain a known-good state that can be restored when local learning degrades behavior. The observability challenge is deciding which lightweight signals are trustworthy enough to trigger those gates without collecting the raw user data that would make validation straightforward.
In some cases, federated validation offers a partial solution. Devices can share anonymized model updates or summary statistics with a central server, which aggregates them across users to identify global patterns of drift or failure. While this preserves some degree of privacy, it introduces communication overhead and may not capture rare or user-specific failures.
Update monitoring and validation in on-device learning require rethinking traditional evaluation practices. Instead of centralized test sets, systems must rely on implicit signals, runtime feedback, and conservative adaptation policies to ensure robustness. The absence of global observability reflects a deeper systems challenge: aligning local adaptation with global reliability.
Performance evaluation in dynamic environments
Systematic approaches for measuring ML system performance include inference latency, throughput, energy efficiency, and accuracy metrics. These benchmarking methodologies provide foundations for characterizing model performance, but they were designed for static inference workloads. On-device learning requires extending these metrics to capture adaptation quality and training efficiency through training-specific benchmarks.
Beyond traditional inference metrics, adaptive systems require measures that explain whether local learning is worth the resource cost. Adaptation efficiency measures how much accuracy improves per training sample consumed. A system that gains 2 percent accuracy from 100 local samples is more useful on a device than one that needs 500 samples for the same improvement, because fewer samples mean faster personalization, less local storage, and fewer training windows competing with user-facing work.
Device-envelope fit measures whether the improvement stays inside resource budgets. Memory-constrained convergence evaluates validation loss under a fixed RAM budget, such as “convergence within 512 KB training footprint,” while energy-per-update measures millijoules consumed per gradient step; background adaptation commonly budgets 500–1000 mW, translating to roughly 1.8–3.6 kJ/hour of adaptation before noticeably affecting battery life. Time-to-adaptation extends the same idea to scheduling by measuring wall-clock time from new data to measurable improvement, including waiting for idleness, charging status, and thermal headroom rather than only raw accelerator throughput.
Personalization quality measures whether adaptation improves the right behavior without damaging the base model. Per-user performance delta compares the adapted model against the global baseline on user-specific holdout data, and deployments typically need statistically significant gains, often above 2 percent accuracy, before accepting the compute and energy overhead. Personalization-privacy trade-off measures accuracy gain per unit of local data exposure, while catastrophic forgetting rate measures degradation on the original task after local adaptation; many systems target less than 5 percent accuracy loss on the original task so personalization does not erase general capability.
When devices coordinate through the federated protocols examined in section 1.4, the metrics shift from one device to the population. Communication efficiency measures accuracy improvement per byte transmitted, capturing whether gradient compression and selective updates make mobile deployment practical; compressed-update designs can greatly reduce transmitted bytes, but accuracy retention depends on the model, optimizer, data heterogeneity, and compression rule (Konečný et al. 2016; Kairouz and McMahan 2021). Straggler impact measures convergence delay caused by slow or unreliable devices, while aggregation quality tracks global model performance as participation rate changes. Together, these metrics reveal the deployment-specific minimum viable participation threshold below which federated learning becomes unstable.
Konečný, J., H. B. McMahan, D. Ramage, and P. Richtárik. 2016. “Federated Optimization: Distributed Machine Learning for on-Device Intelligence.” CoRR abs/1610.02527.
These training-specific benchmarks complement inference metrics including latency, throughput, and accuracy, creating complete performance characterization for adaptive systems. Practical benchmarking must measure both dimensions: a system that achieves fast inference but slow adaptation, or efficient adaptation but poor final accuracy, fails to meet real-world requirements. The integration of inference and training benchmarks enables holistic evaluation of on-device learning systems across their full operational lifecycle.
Resource management
On-device learning introduces resource contention modes absent in conventional inference-only deployments. At deployment time, feasibility is no longer abstract; the runtime question is how to arbitrate scarce resources while the user is still interacting with the device. Many edge devices are provisioned to run pretrained models efficiently but are rarely designed with training workloads in mind. Local adaptation therefore competes for scarce resources, including compute cycles, memory bandwidth, energy, and thermal headroom, with other system processes and user-facing applications.
The most direct constraint is compute availability. Training involves additional forward and backward passes through the model, which can exceed the cost of inference. Even when only a small subset of parameters is updated, for instance, in bias-only or head-only adaptation, backpropagation must still traverse the relevant layers, triggering increased instruction counts and memory traffic. On devices with shared compute units (for example, mobile SoCs or embedded CPUs), this demand can delay interactive tasks, reduce frame rates, or impair sensor processing.
Energy consumption compounds this problem. Adaptation typically involves sustained computation over multiple input samples, which taxes battery-powered systems and may lead to rapid energy depletion. For instance, performing a single epoch of adaptation on a microcontroller-class device can consume several millijoules48, an appreciable fraction of the energy budget for a duty-cycled system operating on harvested power. This necessitates careful scheduling, such that learning occurs only during idle periods, when energy reserves are high and user latency constraints are relaxed.
48 Microcontroller Power Budget: A microcontroller drawing 10 mW during training consumes 36 J per hour, so a small 200 mAh coin-cell battery (about 2,200 J of usable energy at 3 V) sustains roughly 60 hours of continuous compute. Indoor energy harvesting provides only 10–100 \(\mu\)W continuously, two to three orders of magnitude below the training draw, so real deployments duty-cycle: training 10 seconds per hour consumes only about 0.1 J per session and limits adaptation to a few hundred gradient steps per session. This energy ceiling, not compute throughput, is the binding constraint that determines which algorithms are feasible on harvested-power devices.
49 Activation Caching: Forward pass activations must be stored or recomputed for backpropagation, and for many CNNs this activation memory can exceed the model-weight footprint. On devices with $<$512 KB RAM, activation storage alone can exceed total memory, precluding multi-layer adaptation entirely unless gradient checkpointing (Chen et al. 2016), low-rank updates, or sparse-update methods are employed.
Chen, Tianqi, Bing Xu, Chiyuan Zhang, and Carlos Guestrin. 2016. “Training Deep Nets with Sublinear Memory Cost.” arXiv Preprint arXiv:1604.06174.
Cai, Han, Chuang Gan, Ligeng Zhu, and Song Han. 2020. “TinyTL: Reduce Activations, Not Trainable Parameters for Efficient on-Device Learning.” Advances in Neural Information Processing Systems 33: 11285–97.
Kwon, Y. D., R. Li, S. I. Venieris, J. Chauhan, and N. D. Lane. 2024. “TinyTrain: Resource-Aware Task-Adaptive Sparse Training of DNNs at the Data-Scarce Edge.” Proceedings of the 41st International Conference on Machine Learning (ICML).
From a memory perspective, training incurs higher peak usage than inference, especially because backpropagation must retain or recompute intermediate activations49; efficient on-device training systems reduce this activation burden and limit the amount of trainable state (Cai et al. 2020; Kwon et al. 2024).
These resource demands must also be balanced against quality of service (QoS)50 goals. Users expect edge devices to respond reliably and consistently, regardless of whether learning is occurring in the background. Any observable degradation, including dropped audio in a wake-word detector or lag in a wearable display, can erode user trust.
50 QoS (Quality of Service) for Edge ML: Latency guarantees that on-device training must not violate: voice assistants, video applications, and wearables each have tight interactive response budgets. Background training that noticeably increases latency, drops frames, or delays sensor processing can damage user trust. Systems enforce this through priority scheduling where inference preempts training, and resource governors throttle learning when QoS metrics approach deployment-specific thresholds.
51 Cloudlet: A small-scale compute tier located close to users, often near access networks or enterprise sites, provides lower-latency offload than a distant cloud region. This intermediate tier enables hybrid on-device learning: time-sensitive inference runs locally while aggregation, validation, or heavier adaptation work can offload nearby when the network and trust model allow it. The trade-off is deployment complexity: cloudlets add an orchestration layer that must decide per-update whether to compute locally, offload nearby, or defer to cloud.
In some deployments, adaptation is further gated by cost constraints imposed by networked infrastructure. For instance, devices may offload portions of the learning workload to nearby gateways or cloudlets51, introducing bandwidth and communication trade-offs.
The cost of on-device learning is not solely measured in FLOPs or memory usage. It manifests as a complex interplay of system load, user experience, energy availability, and infrastructure capacity. Addressing these challenges requires co-design across algorithmic, runtime, and hardware layers, ensuring that adaptation remains unobtrusive, efficient, and sustainable under real-world constraints.
Identifying and preventing system failures
Those same constraints also make failures hard to see: system failures in on-device learning emerge slowly, locally, and often without centralized evidence. Based on documented challenges in federated learning research (Kairouz and McMahan 2021) and known risks in adaptive systems, several categories of failures warrant careful consideration.
The most fundamental risk in on-device learning is unbounded adaptation drift, where continuous learning without constraints causes models to gradually diverge from their intended behavior. Consider a hypothetical keyboard prediction system that learns from all user inputs, including corrections. It might begin incorporating typos as valid suggestions, leading to progressively degraded predictions. This risk becomes acute in health monitoring applications where gradual changes in user baselines could be learned as “normal,” potentially causing the system to miss important anomalies that would have been detected by a static model. The insidious nature of this drift is that it occurs slowly and locally, making detection difficult without proper monitoring infrastructure.
Beyond individual device drift, federated learning systems face the challenge of participation bias amplification at the population level. Devices with reliable power and connectivity participate more frequently in federated rounds (Li et al. 2020). This uneven participation creates scenarios where models become more strongly optimized for users with high-end devices while performance degrades for those with limited resources. The resulting feedback loop exacerbates digital inequality: better-served users receive better models, while underserved populations experience declining performance, reducing their engagement and further diminishing their representation in training rounds (Wang et al. 2021). These fairness and bias amplification concerns highlight the ethical implications of distributed learning systems.
Wang, Jianyu, Zachary Charles, Zheng Xu, Gauri Joshi, H. Brendan McMahan, Blaise Aguera y Arcas, Maruan Al-Shedivat, et al. 2021. “A Field Guide to Federated Optimization.” arXiv Preprint arXiv:2107.06917.
These systematic biases interact with data quality issues to create autocorrection feedback loops, particularly in text-based applications. When systems cannot distinguish between intended inputs and corrections, they may develop unexpected behaviors. Frequently corrected domain-specific terminology might be incorrectly learned as errors, leading to inappropriate suggestions in professional contexts. This problem compounds the drift issue: not only do models adapt to individual quirks, but they may also learn from their own mistakes when users accept autocorrections without realizing the system is learning from these interactions.
The interconnected nature of these failure modes, from individual drift to population bias to data quality degradation, underscores the importance of implementing comprehensive safety mechanisms. Successful deployments require bounded adaptation ranges to prevent unbounded drift, stratified sampling to address participation bias, careful data filtering to avoid learning from corrections as ground truth, and shadow evaluation against static baselines to detect degradation. While specific production incidents are rarely publicized due to competitive and privacy concerns, the research community has identified these patterns as critical areas requiring systematic mitigation strategies (Li et al. 2020; Kairouz and McMahan 2021).
Li, Tian, Anit Kumar Sahu, Ameet Talwalkar, and Virginia Smith. 2020. “Federated Learning: Challenges, Methods, and Future Directions.” IEEE Signal Processing Magazine 37 (3): 50–60. https://doi.org/10.1109/msp.2020.2975749.
Production deployment risk assessment
The deployment of adaptive models on edge devices introduces challenges that extend beyond technical feasibility. In domains where compliance, auditability, and regulatory approval are necessary, including healthcare, finance, and safety-important systems, on-device learning poses a core tension between system autonomy and control.
In traditional machine learning pipelines, all model updates are centrally managed, versioned, and validated. The training data, model checkpoints, and evaluation metrics are typically recorded in reproducible workflows that support traceability. When learning occurs on the device itself, however, this visibility is lost. Each device may independently evolve its model parameters, influenced by unique local data streams that are never observed by the developer or system maintainer.
This autonomy creates a validation gap. Without access to the input data or the exact update trajectory, it becomes difficult to verify that the learned model still adheres to its original specification or performance guarantees. This is especially problematic in regulated industries, where certification depends on demonstrating that a system behaves consistently across defined operational boundaries. A device that updates itself in response to real-world usage may drift outside those bounds, triggering compliance violations without any external signal.
The lack of centralized oversight complicates rollback and failure recovery. If a model update degrades performance, it may not be immediately detectable, particularly in offline scenarios or systems without telemetry. By the time failure is observed, the system’s internal state may have diverged significantly from any known checkpoint, making diagnosis and recovery more complex than in static deployments. Recovery therefore depends on robust safety mechanisms, such as conservative update thresholds, rollback caches, or dual-model architectures that retain a verified baseline.
In addition to compliance challenges, on-device learning introduces new security vulnerabilities. Because model adaptation occurs locally and relies on device-specific, potentially untrusted data streams, adversaries may attempt to manipulate the learning process by tampering with stored data, such as replay buffers, or by injecting poisoned examples during adaptation, to degrade model performance or introduce vulnerabilities. Any locally stored adaptation data, such as feature embeddings or few-shot examples, must be secured against unauthorized access to prevent unintended information leakage.
Maintaining model integrity over time is particularly difficult in decentralized settings, where central monitoring and validation are limited. Autonomous updates could, without external visibility, cause models to drift into unsafe or biased states. These risks are compounded by compliance obligations such as the GDPR’s right to erasure: if user data subtly influences a model through adaptation, tracking and reversing that influence becomes complex.
The same local-state problem becomes safety-critical when perception and control loops rely on local models. A human fallback is not a safety mechanism unless the fallback itself is engineered as part of the system.
War Story 1.1: The edge model with a human fallback
Context: A 2015 Tesla Model S operating with Traffic-Aware Cruise Control and Autosteer performed perception and control decisions locally on the vehicle, with the human driver expected to supervise (National Transportation Safety Board 2017).
Failure mode: In the May 7, 2016 Williston, Florida crash, the automation operated outside a safety envelope that reliably ensured driver engagement. The NTSB found the driver’s overreliance on automation contributed to the fatal collision.
Consequence: The incident became a reference case for operational design domains, driver-monitoring requirements, and the limits of treating human takeover as a generic fallback for edge autonomy.
Systems lesson: Edge intelligence is a closed-loop system in a physical environment. Latency, perception, user attention, and handoff design must be engineered together; local inference alone does not make a deployment safe.
National Transportation Safety Board. 2017. Collision Between a Car Operating with Automated Vehicle Control Systems and a Tractor-Semitrailer Truck Near Williston, Florida, May 7, 2016. HAR-17/02. National Transportation Safety Board.
The immediate design obligation is to treat model state, replay buffers, and adaptation triggers as security-sensitive assets. Edge learning cannot rely on central inspection after the fact; it needs local integrity checks, protected storage, and conservative update policies before adaptation begins.
Privacy regulations also interact with on-device learning in nontrivial ways. While local adaptation can reduce the need to transmit sensitive data, it may still require storage and processing of personal information, including sensor traces or behavioral logs, on the device itself. These privacy considerations require careful attention to security frameworks and regulatory compliance. Depending on jurisdiction, this may invoke additional requirements for data retention, user consent, and auditability. Systems must be designed to satisfy these requirements without compromising adaptation effectiveness, which often involves encrypting stored data, enforcing retention limits, or implementing user-controlled reset mechanisms.
Lastly, the emergence of edge learning raises open questions about accountability for debugging and failure analysis in decentralized training systems (Kairouz and McMahan 2021). When a model adapts autonomously, the question of who is responsible for detecting and correcting its behavior remains unresolved. If an adapted model makes a faulty decision, such as misdiagnosing a health condition or misinterpreting a voice command, the root cause may lie in local data drift, poor initialization, or insufficient safeguards. Without standardized mechanisms for capturing and analyzing these failure modes, root-cause analysis can be difficult.
Addressing these deployment and compliance risks requires tooling, protocols, and design practices that support auditable autonomy, the ability of a system to adapt in place while still satisfying external requirements for traceability, reproducibility, and user protection. For any deployment that permits post-release adaptation, these challenges are central to both system architecture and governance frameworks.
Engineering challenge synthesis
The deployment risks, failure modes, and compliance concerns compound the technical challenges discussed throughout this chapter. These interconnected issues, from drift and bias amplification to validation gaps and accountability questions, represent the full range of challenges that on-device learning systems must navigate. Effective system design depends on how these challenges interact across hardware heterogeneity, data fragmentation, observability limitations, and regulatory compliance requirements.
System heterogeneity complicates deployment and optimization by introducing variation in compute, memory, and runtime environments. Non-IID data distributions challenge learning stability and generalization, especially when models are trained on-device without access to global context. The absence of centralized monitoring makes it difficult to validate updates or detect performance regressions, and training activity must often compete with core device functionality for energy and compute. Finally, postdeployment learning introduces complications in model governance, from auditability and rollback to privacy assurance.
These on-device learning challenges are not isolated; they interact in ways that influence the viability of different adaptation strategies. Table 8 synthesizes these interconnected issues, mapping each challenge category to its root cause and system-level implications for on-device learning deployments.
| Challenge | Root Cause | System-Level Implications |
|---|---|---|
| System Heterogeneity | Diverse hardware, software, and toolchains | Limits portability; requires platform-specific tuning |
| Non-IID and Fragmented Data | Localized, user-specific data distributions | Hinders generalization; increases risk of drift |
| Limited Observability and Feedback | No centralized testing or logging | Makes update validation and debugging difficult |
| Resource Contention and Scheduling | Competing demands for memory, compute, and battery | Requires dynamic scheduling and budget-aware learning |
| Deployment and Compliance Risk | Learning continues postdeployment | Complicates model versioning, auditing, and rollback |
Foundations for robust AI systems
The operational challenges and failure modes reveal vulnerabilities that extend beyond deployment concerns into fundamental system reliability. Poisoning, inversion, drift, and validation failures also exist in centralized ML systems, but local adaptation and federated coordination amplify them by making failures harder to observe, attribute, and roll back across millions of heterogeneous devices.
Local failures can propagate silently across device populations, unlike failures in centralized systems where errors are usually localized and observable. A corrupted adaptation on one device, if aggregated through federated learning, can poison the global model. Hardware faults that would trigger errors in centralized infrastructure may silently corrupt gradients on edge devices with minimal error detection capabilities.
Federated coordination mechanisms create new attack surfaces while enabling collaborative learning. Adversarial clients can inject poisoned gradients52 designed to degrade global model performance. Model inversion attacks can extract private information from shared updates despite aggregation. The distributed nature of on-device learning makes these attacks both easier to execute, because client devices can be compromised, and harder to detect, because no centralized validation set sees every update.
52 Byzantine Fault Tolerance in FL: Named after the Byzantine Generals Problem (Lamport et al. 1982), this property enables useful aggregation despite malicious or faulty participants. Krum’s original analysis requires conditions such as \(2f + 2 < n\) (Blanchard et al. 2017), while coordinate-wise median and trimmed-mean aggregators use different robustness assumptions; the tolerated Byzantine fraction depends on the aggregation rule, dimensionality, and statistical model. These defenses can increase communication and compute overhead because they require extra validation, robust statistics, or redundant participation. That overhead is the price of trust in open federated systems where any client device could be compromised.
Lamport, Leslie, Robert Shostak, and Marshall Pease. 1982. “The Byzantine Generals Problem.” The Byzantine generals problem in Concurrency: The Works of Leslie Lamport, vol. 4. Association for Computing Machinery. https://doi.org/10.1145/3335772.3335936.
Blanchard, Peva, El Mahdi El Mhamdi, Rachid Guerraoui, and Julien Stainer. 2017. “Machine Learning with Adversaries: Byzantine Tolerant Gradient Descent.” Advances in Neural Information Processing Systems, 119–29.
On-device systems must handle distribution shifts and environmental changes without access to labeled validation data. Models may confidently drift into failure modes, adapting to local biases or temporary anomalies. The non-IID data distributions across devices mean that local drift on individual devices may not trigger global alarms, allowing silent degradation.
These reliability threats demand systematic approaches that keep local adaptation bounded even when devices are faulty, malicious, or operating under environmental shift. The local lesson is that robust aggregation, drift checks, conservative update policies, secure aggregation, and differential privacy are part of the edge-learning architecture, not optional add-ons after deployment; the broader treatment of adversarial robustness as its own discipline is deferred to a later chapter. What remains, and what the next chapter takes up, is the operational problem these safeguards leave open: sustaining the adaptation, monitoring, and lifecycle of a heterogeneous fleet at scale, day after day.
Self-Check: Question
Why does the chapter argue that a single uniform adaptation algorithm across a heterogeneous deployment fleet is a structural failure rather than an optimization problem?
- All devices should eventually converge to the same local training loop once enough data is collected.
- Device capabilities span orders of magnitude in RAM, compute, and energy, so an adaptation loop that fits on a flagship will exceed the RAM, thermal, or battery budget on a low-end device — the same code path fails on one tier while working on another.
- Federated learning requires every client to update the same number of parameters each round.
- Low-end devices are better at full fine-tuning than flagship phones due to lower thermal output.
A team deploys on-device learning and discovers that debugging a single user’s accuracy regression takes weeks, whereas centralized deployments resolve similar issues in hours. Explain the observability asymmetry and name two specific signals the team can still use.
Which challenge most directly captures why federated learning can fail to converge even when every participating client is honest and well-resourced?
- Non-IID and fragmented data make locally-useful gradients point in conflicting directions, producing aggregated updates that hurt global generalization rather than help it.
- Secure aggregation forces all clients to share raw data before updates can be averaged.
- Model rollback is impossible once any local adaptation has occurred.
- Client scheduling removes all statistical bias because only idle devices participate.
A keyboard team lets their model learn continuously from every local correction without bounds, checkpoints, or rollback triggers. Which failure mode from the section is most likely?
- Perfect personalization, because every local correction is guaranteed to be reliable supervision.
- Complete elimination of participation bias, because learning is now fully local.
- Immediate memory savings, because continual adaptation reduces checkpointing needs.
- Unbounded adaptation drift, where the model progressively learns from noisy or misleading signals (accidental taps, autocorrect acceptances the user intended to reject, one-off contexts) and degrades over weeks.
True or False: Because local learning reduces dependence on cloud infrastructure, the deployment’s compliance, auditability, and rollback properties also become simpler than those of a centralized ML system.
Why does the chapter connect on-device learning to broader robust-AI concerns such as Byzantine resilience, drift detection, and adversarial manipulation? Explain why these techniques become mandatory architectural layers rather than optional hardening.
Fallacies and Pitfalls
A team attempts to port their massive cloud-based recommendation engine directly to a mobile app, assuming a flagship smartphone chip can handle a few epochs of backpropagation. The app instantly crashes from out-of-memory errors, and the phone’s battery plummets by 20 percent. This disaster highlights how applying data center intuition to the edge leads directly to catastrophic failure, bringing us to the domain’s most common fallacies and pitfalls.
Fallacy: On-device learning provides the same adaptation capabilities as cloud-based training.
Teams expect local learning to match centralized training’s model improvements, ignoring fundamental resource constraints. On-device learning amplifies resource needs by 4–12\(\times\) compared to inference-only deployment due to activation caching, gradient storage, optimizer state, and bidirectional memory traffic (section 1.2). Local datasets are typically small, biased, and nonrepresentative, while compute budgets remain orders of magnitude below cloud GPUs. A smartphone with 8 GB RAM and 5 W power budget cannot replicate the adaptation achieved by data center systems with terabytes of memory and kilowatts of power. Effective on-device learning requires designing adaptation strategies that provide meaningful improvements within these constraints rather than attempting to replicate cloud-scale learning capabilities.
Pitfall: Assuming federated learning automatically preserves privacy without additional safeguards.
Practitioners believe that keeping data on local devices inherently provides privacy protection, ignoring what can be inferred from model updates. Gradient and parameter updates leak significant information about local training data through various inference attacks, while device participation patterns reveal sensitive information about users and activities. Stronger privacy preservation requires additional mechanisms: differential privacy provides a tunable probabilistic bound on how much the output distribution can change because of one individual’s data, while secure aggregation protocols prevent parameter inspection during coordination (Bonawitz et al. 2017) (as figure 14 illustrates with cryptographic masking). Data locality alone is insufficient for privacy protection.
Fallacy: Resource-constrained adaptation always produces better personalized models than generic models.
This belief assumes that any local adaptation is beneficial regardless of the quality or quantity of local data available. On-device learning with insufficient, noisy, or biased local data can actually degrade model performance compared to well-trained generic models (section 1.3). Small datasets may not provide enough signal for meaningful learning, while adaptation to local noise can harm generalization. Effective on-device learning systems must include mechanisms to detect when local adaptation is beneficial and fall back to generic models when local data is inadequate for reliable learning.
Pitfall: Ignoring heterogeneity across different device types and capabilities.
Teams design on-device learning systems assuming uniform hardware capabilities across deployment devices. Real-world deployments span diverse hardware with varying computational power, memory capacity, energy constraints, and networking capabilities. Edge device capabilities span nearly six orders of magnitude in memory and power, and four orders in CPU throughput: from 32 KB RAM microcontrollers to 16 GB smartphones, 48 MHz Cortex-M-class processors (~10 MIPS) to 3 GHz mobile-class processors (~100,000 MIPS), and 10 µW sensor nodes to 5 W flagship phones (Warden and Situnayake 2020; Lai et al. 2018). A learning algorithm that works well on high-end smartphones may fail catastrophically on resource-constrained IoT devices. Federated learning algorithms must account for heterogeneous clients and availability (Kairouz and McMahan 2021; Bonawitz et al. 2019), using selective participation, compression, and tiered aggregation strategies when the deployment spans 10,000× performance differences.
Fallacy: Coordinating edge learning is just scaling up an aggregation server.
This belief treats coordination as a stateless averaging problem, as if local updates arrive regularly, represent comparable device populations, and can be merged without operational context. At fleet scale, the aggregation server is only one component in a larger control loop: it must know which devices are eligible, which model version they hold, whether their power and network state can support participation, and whether the resulting update is safe to promote.
Pitfall: Underestimating the complexity of coordinating learning across distributed edge systems.
Many teams focus on individual device optimization without considering the system-level challenges of coordinating learning across thousands or millions of edge devices. Edge systems orchestration (section 1.5.5) must handle intermittent connectivity, varying power states, different time zones, and unpredictable device availability patterns that create complex scheduling and synchronization challenges. Device clustering, federated rounds coordination, model versioning across diverse deployment contexts, and handling partial participation from unreliable devices require sophisticated infrastructure beyond simple aggregation servers. Additionally, real-world edge deployments involve multiple stakeholders with different incentives, security requirements, and operational procedures that must be balanced against learning objectives. Effective edge learning systems require robust orchestration frameworks that can maintain system coherence despite constant device churn, network partitions, and operational disruptions.
Self-Check: Question
A senior engineer proposes: ‘Modern phones have dedicated NPUs and successfully run inference, so local training should just be a scaled-down version of cloud training.’ What is wrong with this reasoning?
- Training on the phone faces the 4–12\(\times\) memory amplification over inference, a 30–50\(\times\) bandwidth gap to datacenter HBM, a ~10 W thermal ceiling, and intermittent connectivity — these are qualitatively different physics, not smaller versions of datacenter physics.
- Mobile deployment can safely use the same training intuition as a datacenter because modern NPUs close the gap.
- Only model accuracy matters when moving from cloud to edge; systems constraints are secondary details.
- If a model serves correctly on a phone, local training will usually be feasible with only a small extra cost.
True or False: In a federated learning deployment, keeping raw data on-device is sufficient by itself to guarantee that no information about a user’s training data can be recovered by the aggregation server.
A team deploys on-device personalization assuming every local update will improve the user’s experience. Explain two concrete mechanisms by which local personalization can actively degrade model behavior, and name the guardrail that prevents each.
A deployment targets phones ranging from a 6 GB flagship down to a 1 GB entry-level device, and the team proposes a single federated training loop for the entire fleet. What is the primary risk the chapter identifies?
- All devices will eventually match the flagship’s performance once enough federated rounds have passed.
- Heterogeneity matters only for inference latency, not for adaptation or federated training.
- Low-end devices usually contribute better gradients than high-end devices due to simpler workloads.
- A loop that fits comfortably on the 6 GB flagship can exceed RAM, thermal, or battery limits on the 1 GB entry-level device, producing crashes, throttling, or silent participation dropouts that bias the resulting model toward flagship users.
Summary
Avoiding these pitfalls, from ignoring thermal throttling to underestimating the chaos of federated orchestration, is essential to architecting edge systems that survive the real world. Edge intelligence is the physics-limited boundary of the Machine Learning Fleet. Data center infrastructure and global serving systems assume abundant power, memory, and connectivity; edge deployments invert those assumptions with sensors that operate under microwatt power budgets, microcontrollers with kilobyte memory, and smartphones facing the mobile memory wall.
Three design levers make learning possible under those constraints. Model adaptation reduces the update footprint by freezing most of the network or using small adapters. Data efficiency extracts useful signal from few local samples or streaming experience. Federated coordination lets a population improve a shared model without centralizing raw data. Success at the edge requires more than algorithmic cleverness; it demands co-design between the software’s mathematical requirements and the hardware’s thermal, energy, and bandwidth realities.
Many devices run inference workloads locally, from keyboard prediction on smartphones to anomaly detection on industrial sensors. Edge intelligence addresses requirements that no amount of data center scaling can satisfy: latency-critical applications where cloud round-trips introduce unacceptable delays, privacy-sensitive domains where raw data must never leave the device, and connectivity-constrained environments where network access is intermittent or absent. As on-device capabilities advance through hardware specialization and algorithmic efficiency, the boundary between what requires cloud infrastructure and what can execute locally can shift, but the co-design principles remain central to production ML system architecture.
Key Takeaways: Physics sets the budget
- The edge reverses the fleet: Data centers fight to keep many accelerators busy; edge devices fight to learn under batteries, kilobytes, thermal throttling, and intermittent links. The same Compute, Communication, Coordination constraints produce a different discipline when scarcity, not scale, is binding.
- Bandwidth beats advertised TOPS: On-device LLMs are limited by mobile memory bandwidth, not NPU peak compute. The 30–50\(\times\) gap between mobile RAM and data-center HBM makes quantization and locality survival requirements for interactive decode.
- Learning multiplies the footprint: On-device training needs activations, gradients, optimizer state, and bidirectional traffic, raising resources 4–12\(\times\) over inference-only deployment. Adaptation strategies must shrink the update, not merely compress the deployed model.
- Adaptation needs three levers: Bias-only updates, LoRA, sparse layers, few-shot data reuse, and experience replay each spend different memory, energy, and privacy budgets. Federated coordination adds population learning only when protocols handle non-IID data and client dropout.
- Heterogeneity is normal operation: Edge fleets span microcontrollers, phones, gateways, and NPUs with uneven availability and performance. Federated systems must treat stragglers, participation bias, rollback, and privacy-preserving observability as protocol design constraints, not deployment cleanup.
Everything in this volume so far has pushed in one direction, outward, toward more accelerators, more bandwidth, more power, the data center swelling into a single machine. The edge is that same physics read backward. The constraints have not changed identity, only sign: where the data center fights to keep ten thousand accelerators busy, the edge fights to do anything at all inside a battery and a few kilobytes. That sign flip is why a phone is not a small data center and a sensor is not a slow GPU; when scarcity rather than scale sets the terms, the techniques that win are the ones that get more from less. The same laws, run at the opposite extreme, produce a different discipline.
What’s Next: From devices to operations
Edge intelligence pushes models to the boundary where hardware diversity, battery budgets, intermittent connectivity, and local autonomy all become first-order constraints. Deploying models across this spectrum, from data center GPUs to edge sensors, is only the beginning. Sustaining these deployments at production scale demands systematic operational practices. ML Operations at Scale examines the platform engineering, monitoring, and lifecycle management frameworks required to keep the entire Machine Learning Fleet running reliably.
Self-Check: Question
Which triple of ideas is the chapter’s three-pillar framework for edge intelligence?
- Model Sharding, Autoscaling, and Batch Inference.
- Model Adaptation, Data Efficiency, and Federated Coordination.
- Hyperparameter Search, Data Labeling, and GPU Scheduling.
- Full Fine-Tuning, Unlimited Replay, and Centralized Logging.
Explain why the chapter frames the mobile memory wall as a physical limit, not a software optimization problem, and connect the 30–50\(\times\) bandwidth gap to a specific serving consequence.
True or False: The chapter’s final takeaway is that edge deployment is essentially cloud deployment with smaller models — the same engineering discipline, just scaled down.
Self-Check Answers
Self-Check: Answer
The chapter states that on-device training requires 4–12\(\times\) the memory of inference for the same model. What is the dominant mechanism behind this amplification?
- Backpropagation requires cached forward activations, per-parameter gradients, and optimizer state to coexist in memory alongside the weights, so the peak footprint scales as 4–12\(\times\) inference.
- Training duplicates the operating system image in RAM every epoch, which dominates memory use on phones.
- Inference compresses weights to zero during execution, but training has to restore them at full size.
- Training uses only sequential weight reads, so the memory increase comes mainly from longer runtimes rather than additional state.
Answer: The correct answer is A. The backward pass requires activations from the forward pass (to compute local gradients), gradients themselves, and optimizer moments (e.g., Adam’s two moment vectors) to all reside in memory concurrently with the weights — this composition produces the 4–12\(\times\) multiplier. The OS-duplication claim invents a mechanism that does not exist; the ‘weights compressed to zero’ idea is nonsense in any standard inference runtime; and the sequential-read explanation confuses time with space, missing that the multiplier is a peak-footprint property.
Learning Objective: Explain the mechanism by which backpropagation inflates memory by 4–12\(\times\) over inference on edge devices.
A phone has 8 GB of advertised RAM, but an engineer hits out-of-memory errors trying to train a 100M-parameter model locally. Explain why total installed RAM is a misleading feasibility check, and name the measurement that actually determines feasibility.
Answer: The 8 GB figure is shared across the OS, foreground apps, and background services, so only a fraction is available to the training process even on an idle device. Worse, training-time memory peaks during the backward pass when weights (~400 MB at FP32), activations, per-parameter gradients, and Adam optimizer state (another 800 MB of moments) must coexist, easily producing a multi-gigabyte spike for a 100M-parameter model. The feasibility check that matters is peak backward-pass memory — measured at the synchronization boundary between the forward activation cache, gradient tensors, and optimizer moments — not the device’s nominal RAM capacity.
Learning Objective: Analyze why peak backward-pass memory, not installed RAM, determines on-device training feasibility.
True or False: Gradient checkpointing makes an attractive memory-compute trade-off on edge devices because it reduces peak memory at the cost of roughly 20-30 percent additional compute, which is usually the favorable direction when memory is the binding constraint.
Answer: True. The technique stores only a subset of forward activations and recomputes the rest during the backward pass, exchanging FLOPs for memory. Because edge training is almost always memory-bound rather than compute-bound, paying 20-30 percent more compute for roughly 2–5\(\times\) lower peak memory, often 3–4\(\times\) in practical examples, is the correct direction of trade.
Learning Objective: Evaluate gradient checkpointing as a compute-for-memory trade-off under edge memory constraints.
A mobile NPU advertises 50 TOPS of peak integer throughput, yet a large language model still generates tokens far slower on the phone than on an H100. The chapter attributes this to a specific physical constraint. What is it?
- The phone’s CPU cannot compile the model graph quickly enough before each token is emitted.
- Mobile LPDDR5X delivers 64-100 GB/s of bandwidth while datacenter HBM3 delivers roughly 3,350 GB/s, a 30–50\(\times\) gap that makes autoregressive decode memory-bandwidth-bound rather than compute-bound.
- Token generation fails because mobile NPUs cannot perform integer arithmetic of the required precision.
- The bottleneck is that phones have too much on-chip cache, which lowers arithmetic intensity below the roofline ridge.
Answer: The correct answer is B. Autoregressive decode reads the entire weight matrix per token with near-zero reuse, so throughput is bounded by memory bandwidth, not by peak TOPS — and mobile memory sits roughly 30–50\(\times\) below datacenter memory. The graph-compilation explanation describes a startup cost, not the steady-state bottleneck; claiming mobile NPUs cannot do integer arithmetic contradicts the workload they are literally designed for; and ‘too much cache lowering arithmetic intensity’ inverts the actual relationship between cache and reuse.
Learning Objective: Analyze why memory bandwidth, not advertised peak compute, limits large-model edge serving.
A background training job draws 4.5 W for 30 minutes on a phone with a 15 Wh battery. What systems conclusion best matches the chapter’s interpretation of this scenario?
- The job consumes about 15 percent of the battery (2.25 Wh / 15 Wh), which is unacceptable for an invisible background process and argues for scheduling training only during charging, Wi-Fi, and thermally stable windows.
- The cost is negligible, so background training should run whenever new data arrives.
- The job mainly stresses storage, not energy, because battery drain is dominated by flash writes.
- The drain is only acceptable if the model is larger than 100M parameters.
Answer: The correct answer is A. Computing the energy: 4.5 W \(\times\) 0.5 h = 2.25 Wh, which is 15 percent of the 15 Wh battery — a massive user-visible impact for a process the user did not initiate. The chapter’s prescription is opportunistic scheduling (idle + charging + cool + Wi-Fi) rather than unconditional execution. The ‘negligible cost’ answer ignores the arithmetic; the ‘storage stress’ claim misattributes the dominant energy cost, which for training is compute and memory traffic, not flash writes; and making acceptability depend on model size inverts the actual relationship between model complexity and energy cost.
Learning Objective: Apply quantitative energy analysis to justify opportunistic scheduling of on-device training.
The chapter’s three-pillar framework pairs each design constraint category with a primary solution pillar. Order the following pillars according to the constraint category they address, starting with resource amplification, then information scarcity, then coordination: (1) Data Efficiency, (2) Model Adaptation, (3) Federated Coordination.
Answer: The correct order is: (2) Model Adaptation, (1) Data Efficiency, (3) Federated Coordination. Resource amplification (memory, compute, energy) is addressed first by Model Adaptation, which shrinks what gets updated via bias-only updates, LoRA, and sparse layers. Information scarcity (few labels, weak supervision) is addressed next by Data Efficiency techniques that extract more signal from fewer examples. Coordination across heterogeneous devices is addressed last by Federated Coordination, which presupposes that individual devices can already adapt feasibly. Swapping the first two conflates memory limits with data scarcity, while placing coordination before local feasibility attempts fleet-wide collaboration on devices that cannot yet adapt alone.
Learning Objective: Organize the chapter’s constraint-to-solution framework into its causal progression from local feasibility to fleet-wide coordination.
Self-Check: Answer
Why is bias-only adaptation often the first viable adaptation strategy on extremely constrained devices?
- Biases capture all structural domain shifts, so bias-only adaptation is more expressive than full fine-tuning.
- Freezing every weight except biases collapses the set of trainable parameters by roughly two orders of magnitude, which proportionally shrinks gradient tensors, optimizer moments, and the activation cache needed to compute those gradients.
- It eliminates the need for a forward pass, so only backward computation remains.
- It requires more trainable state than LoRA but less runtime support from the software stack.
Answer: The correct answer is B. Because biases are roughly 1 percent of a transformer’s parameters, restricting updates to them makes the gradient, optimizer, and activation-cache footprints collapse, which is exactly the set of quantities that caused the 4–12\(\times\) memory amplification in the first place. Claiming bias-only adaptation is more expressive than full fine-tuning reverses the actual expressivity ordering; claiming it eliminates the forward pass misunderstands the algorithm (the forward pass always runs); and the ‘more state than LoRA’ framing is numerically wrong since LoRA has more trainable parameters.
Learning Objective: Explain why bias-only adaptation’s memory savings come from shrinking gradients, optimizer state, and activation caches, not just the weight count.
When a device cannot afford to train an entire weight matrix \(W \in \mathbb{R}^{d \times k}\), it can restrict the update to the product of two small matrices \(A \in \mathbb{R}^{d \times r}\) and \(B \in \mathbb{R}^{r \times k}\) with \(r \ll \min(d,k)\); this low-rank perturbation of frozen weights is commonly called ____.
Answer: LoRA. The method represents the weight update as a low-rank factorization whose two skinny matrices contain far fewer parameters than the original weight matrix, letting the device train a small subset while preserving most of the benefit of full fine-tuning.
Learning Objective: Identify the parameter-efficient adaptation method that factorizes weight updates into a low-rank product.
A smartphone supports ten personalized contexts (home, office, gym, driving, etc.) with a 10M-parameter backbone. Explain why residual adapters are preferable to storing ten fully fine-tuned model copies, and quantify the approximate storage difference.
Answer: Residual adapters add small bottleneck modules between frozen backbone layers, so ten contexts share one backbone and differ only by adapter weights. In the chapter’s FP32 example, a 10M-parameter backbone occupies about 40 MB per full copy, so ten fine-tuned copies cost about 400 MB; ten 200 KB adapter sets add about 2 MB plus the single shared 40 MB backbone, for roughly 42 MB total. The systems consequence is a roughly 9.5\(\times\) total storage reduction and a 200\(\times\) lower marginal cost per new context.
Learning Objective: Quantify the storage-efficiency argument for adapter-based multi-context personalization against per-context full fine-tuning.
A real-time video pipeline has zero tolerance for additional inference latency after personalization is applied. Which adaptation method is the direct match according to the chapter’s inference-overhead analysis?
- Residual adapters, because the extra adapter forward pass improves latency predictability.
- Bias-only adaptation, because it always adapts deeper representations better than low-rank methods.
- Sparse layer updates, because profiling automatically removes all latency costs during inference.
- LoRA, because its low-rank update matrices can be merged into the frozen weights at deployment, producing a single weight tensor that adds essentially zero inference-time overhead.
Answer: The correct answer is D. LoRA’s defining structural advantage on the inference path is mergeability: \(W + AB\) becomes a single weight tensor with the original shape, so inference latency after personalization matches the unmodified backbone. Residual adapters cannot merge because they introduce new modules between existing layers, so each forward pass pays extra compute and memory traffic. Bias-only adaptation has low overhead but adapts a much weaker function class, and sparse updates operate on training paths and do not automatically eliminate the inference-time cost of the updated parameters.
Learning Objective: Select the adaptation method whose structural form permits zero inference-time overhead after deployment.
Which strategy best captures the logic of task-adaptive sparse updates?
- Randomly select layers each round so every parameter eventually receives equal training attention.
- Always update the earliest layers because they are closest to the input distribution shift.
- Profile or meta-learn which layers deliver the most performance gain per unit of memory or compute, then spend the update budget on that subset.
- Freeze the model completely and rely on experience replay to simulate adaptation.
Answer: The correct answer is C. Sparse update methods allocate a scarce training budget to the parameters that return the most accuracy per memory or compute unit, typically using sensitivity profiling or a meta-learned importance signal. Random layer selection wastes capacity by ignoring the observed heterogeneity in per-layer adaptation payoff; the ‘always early layers’ heuristic contradicts findings that late layers often carry most task-specific adaptation; and using replay without updating any parameters is not adaptation at all — the model never changes.
Learning Objective: Analyze how sparse update methods allocate a limited training budget to high-impact parameters.
A deployment targets three device tiers: flagship phones (>6 GB RAM), mid-range phones (2-4 GB RAM), and ultra-constrained IoT devices (<1 GB RAM). Justify the adaptation method you would pick at each tier and name the binding constraint that makes each choice correct.
Answer: Flagship phones can run residual adapters because their memory budget absorbs the extra adapter modules at both training and inference time, and the modularity lets them switch personalization contexts cheaply. Mid-range phones favor LoRA because its mergeable low-rank update avoids adapter runtime overhead while keeping trainable state small; memory pressure is the binding constraint, and LoRA’s inference-path equivalence to the backbone keeps UX stable. Ultra-constrained IoT devices need bias-only updates because even LoRA’s training-time activation cache exceeds their RAM; here the binding constraint is peak backward-pass memory, and collapsing trainable parameters to biases is the only path to feasibility. The systems consequence is that adaptation strategy must be selected per tier against the specific binding constraint, not as a uniform fleet-wide algorithm.
Learning Objective: Design a tiered adaptation policy by naming the binding constraint that selects each method.
Self-Check: Answer
Why is few-shot adaptation a central technique for on-device learning specifically, as opposed to a general convenience?
- Edge devices usually receive abundant labeled local data, so the main challenge is avoiding too much supervision.
- Local data arrives in small, noisy, and often weakly-labeled amounts (a fitness tracker might yield only a few hundred samples from a 30-minute session), so adaptation must improve the model from a handful of examples without overfitting.
- Few-shot methods eliminate the need for pretrained representations on the device.
- Few-shot learning is mainly a networking technique for reducing federated bandwidth.
Answer: The correct answer is B. The section grounds the argument in a concrete scarcity — a fitness tracker collecting data only during activity windows produces hundreds of samples per day, orders of magnitude below the millions typical of centralized training sets — which makes few-shot generalization a functional requirement, not a luxury. The ‘abundant labeled local data’ framing inverts the section’s premise; the ‘no pretrained representations needed’ claim ignores that few-shot methods are most effective precisely when a strong backbone exists; and reframing few-shot learning as a networking technique confuses data efficiency with communication compression.
Learning Objective: Explain why data scarcity on edge devices makes few-shot learning a structural requirement, not an optimization.
Explain how experience replay enables continual on-device adaptation without catastrophic forgetting, and name two system constraints that make replay harder on an edge device than in a datacenter.
Answer: Experience replay interleaves stored representative examples from past interactions with new incoming samples during each update, so the model’s loss surface is pinned to both past and present distributions rather than chasing the latest batch. A keyword spotter, for example, replays compressed embeddings from last week’s utterances while learning from today’s. Two edge-specific constraints compound this: flash endurance (each stored example costs a write cycle against a bounded-endurance medium) and privacy (replay buffers of raw inputs expand the attack surface for on-device or cross-tenant leakage). The systems consequence is that edge replay typically stores compressed representations in RAM-backed queues rather than long-lived raw-sample caches on flash.
Learning Objective: Analyze how replay mitigates forgetting and name the specific edge constraints that constrain its implementation.
True or False: Compressed feature representations on edge devices are useful only for reducing memory footprint; they have no effect on privacy posture or regularization behavior.
Answer: False. Compression serves three simultaneous roles: it reduces memory, it discards raw sensitive inputs once the embedding is stored (shrinking the privacy-relevant attack surface), and it acts as an implicit regularizer by forcing downstream adaptation to work with a lower-dimensional representation, which can reduce overfitting when local data is scarce.
Learning Objective: Evaluate how compressed representations simultaneously address memory, privacy, and overfitting in edge learning.
A user records 5-10 examples of a custom wake word on their phone. Which adaptation strategy is the direct fit given the chapter’s data-scarcity analysis?
- Few-shot adaptation of a lightweight classifier or small parameter subset on top of a frozen pretrained speech encoder.
- Full-model retraining from scratch so the encoder can relearn speech representations locally.
- Only federated aggregation, because local adaptation is impossible with so few examples.
- Accumulating large replay buffers of raw audio over months before any update is attempted.
Answer: The correct answer is A. The 5-10 sample regime is exactly where few-shot adaptation on top of a centrally-trained encoder shines: the encoder supplies the general speech representation, and the lightweight classifier or low-rank head captures the user-specific wake-word pattern. Retraining a full speech encoder from 10 samples is statistically hopeless; waiting for federated aggregation means the user’s wake word does not work until the server releases a new model; and delaying updates until months of raw audio accumulate defeats both the privacy contract and the personalization latency the feature promises.
Learning Objective: Apply few-shot learning to a realistic wake-word personalization scenario and reject mismatched alternatives.
Why do on-device replay buffers typically store compressed feature vectors rather than raw inputs?
- Raw inputs improve privacy because they are easier to anonymize than embeddings.
- Feature vectors remove the need for any trainable model on the device.
- Compressed features reduce storage and replay compute cost, though they limit how much upstream-layer adaptation can be driven by the replayed samples.
- Compressed buffers guarantee that catastrophic forgetting cannot occur.
Answer: The correct answer is C. Storing post-encoder embeddings shrinks per-sample storage by roughly the ratio of input dimensionality to embedding dimensionality, and replay through the frozen encoder becomes trivial. The trade-off is that gradients computed from replayed embeddings only flow into layers above the encoder, so representation-level adaptation from replay is limited. The ‘raw inputs improve privacy’ claim reverses the actual privacy direction (raw audio is the sensitive asset); the ‘no trainable model needed’ claim contradicts the entire premise of replay-based adaptation; and no storage technique eliminates forgetting by construction.
Learning Objective: Evaluate the storage-vs-adaptation-richness trade-off in replay-buffer representation choice.
A smart doorbell deployment faces three sequential data-efficiency challenges: rapid initial personalization from few labeled faces, stable continual adaptation as lighting and seasons change, and finally memory-bounded retention of past samples so the device can still learn after weeks of operation. Order these techniques to match the progression: (1) compressed representations for memory-limited retention, (2) few-shot adaptation from a tiny labeled support set, (3) experience replay for continual learning under drift.
Answer: The correct order is: (2) few-shot adaptation from a tiny labeled support set, (3) experience replay for continual learning under drift, (1) compressed representations for memory-limited retention. Few-shot adaptation addresses the cold-start problem first — the device must personalize from 5-10 family-member photos before any continual learning matters. Experience replay then handles the ongoing drift from lighting and seasonal changes, requiring a stored sample history. Compressed representations come last because they are an enabling technique for sustainable long-horizon replay: once the device has been deployed for weeks, raw samples exceed storage, and compressed embeddings let replay continue indefinitely. Reversing the order would attempt storage optimization before the learning problem it serves has emerged.
Learning Objective: Organize data-efficiency techniques according to the temporal progression of problems they address in a real deployment.
Self-Check: Answer
What is the defining architectural move of federated learning relative to centralized distributed training?
- Raw data is centralized in a datacenter, but inference is distributed to save latency.
- Each device trains completely independently forever, with no coordination or aggregation.
- A central server performs all gradient updates and sends only predictions back to clients.
- Compute is moved to where the data already lives, and devices exchange model updates rather than raw data.
Answer: The correct answer is D. Federated learning inverts the classical data-gravity pattern: instead of pulling data toward compute, it pushes compute toward data and exchanges the far smaller model updates across the network. The ‘centralize raw data for training’ framing describes traditional distributed training, which is exactly what federated learning rejects; ‘isolated training forever’ is not federated learning (no coordination); and ‘server does all updates, clients get predictions’ describes centralized inference, not learning at all.
Learning Objective: Identify the core architectural principle that distinguishes federated learning from centralized distributed training.
True or False: Because federated learning keeps raw data on the device, it is structurally immune to data-privacy leaks — a participating client’s training data cannot be reconstructed from anything the protocol exposes.
Answer: False. Gradient and parameter updates encode enough information about local data that model-inversion and membership-inference attacks can reconstruct training samples or determine whether a specific record participated. This is exactly why production federated systems layer secure aggregation and differential privacy on top of locality — the locality itself is necessary but not sufficient.
Learning Objective: Reject the misconception that federated data locality alone provides privacy guarantees.
Explain why increasing the number of local epochs per federated round is simultaneously helpful and harmful, and name the workload property that determines the optimal setting.
Answer: More local epochs amortize the communication cost of each round over more gradient steps, which is attractive on slow mobile networks where the round trip dominates wall-clock time. But under non-IID data, each additional local epoch pushes the client further toward its own local optimum, widening the drift between clients and increasing the heterogeneity penalty in the aggregation step — which raises the number of global rounds required for convergence. The binding workload property is the degree of client heterogeneity: high non-IID-ness favors fewer local epochs to limit drift, while near-IID workloads favor many local epochs to hide communication cost. The practical consequence is that the optimal local-epoch count is an adaptive function of both bandwidth and data heterogeneity, not a fixed hyperparameter.
Learning Objective: Analyze the communication-computation trade-off and identify heterogeneity as the property that selects the operating point.
Production federated systems commonly invite more clients to a round than they need updates from (e.g., 1,500 invited for a 1,000-update target). What problem does this ‘over-selection’ solve?
- It guarantees every invited device contributes even if it is offline for weeks.
- It forces slower devices to train longer so their updates carry more weight.
- It lets the server close the round as soon as the first 1,000 successful responses arrive, bounding wall-clock round time by the 67th-percentile response rather than the slowest straggler.
- It makes aggregation independent of local dataset size.
Answer: The correct answer is C. Over-selection is a tail-latency mitigation tactic: mobile clients fail, drop, or slow down arbitrarily, so waiting for a specific device to complete is a bet against a heavy-tailed distribution. Inviting surplus clients lets the server accept the first 1,000 completions and drop the remaining stragglers, converting an open-ended wait into a bounded one. The ‘guarantees universal contribution’ answer contradicts the mechanism (it specifically tolerates dropouts), and the weighting and size-independence explanations describe unrelated aggregation-logic properties.
Learning Objective: Explain how over-selection bounds federated round time by substituting completion-rate targeting for individual-client waiting.
In the section’s convergence analysis, why does non-IID client data inflate the number of communication rounds required by FedAvg?
- Because only IID data can be encrypted during secure aggregation.
- Heterogeneous local gradients add a variance-like penalty term to the convergence bound, and that penalty grows with both client drift and the number of local epochs per round.
- Because non-IID data reduces the number of model parameters, forcing smaller updates.
- Because the server must download all raw client data to estimate the true global distribution.
Answer: The correct answer is B. The section’s convergence bound decomposes into a standard SGD-like term plus a heterogeneity penalty that scales with how far apart client-local optima are and with how many local steps each client takes before aggregation — the penalty is the mathematical form of the drift problem. The encryption claim invents a constraint that does not exist; the ‘fewer parameters’ claim reverses causality (non-IID data does not alter model size); and ‘server downloads all raw client data’ contradicts the federated architecture itself.
Learning Objective: Analyze how data heterogeneity enters the convergence bound and interacts with the local-epoch setting.
A federated deployment faces slow 3G mobile networks AND highly non-IID client data (each user’s data looks very different from the fleet average). A junior engineer proposes maximizing local epochs per round to minimize network usage. Justify whether this is correct and what configuration you would actually recommend.
Answer: The junior engineer is optimizing the wrong quantity. Slow networks do favor more local work per round to amortize communication cost, but at high non-IID-ness each extra local epoch multiplies client drift into the heterogeneity penalty term, potentially exploding the total number of global rounds required by 2–10\(\times\). The net wall-clock time can worsen even though per-round communication time improves. The correct configuration is an adaptive local-epoch count — roughly 2-3 epochs at high heterogeneity rather than 10+ — combined with compression of each uploaded update to recover the bandwidth savings without paying the drift penalty. The practical implication is that the communication-computation operating point must be jointly tuned against both bandwidth and heterogeneity, not optimized for one dimension in isolation.
Learning Objective: Justify a federated training configuration under simultaneous bandwidth and heterogeneity constraints, and reject the single-dimension optimization.
Self-Check: Answer
Why is naive random client selection often inadequate in production federated learning, even when the randomness is statistically unbiased?
- Random selection guarantees identical data distributions across participants, which reduces personalization.
- The pool of eligible clients at any moment is itself filtered by availability (charging, Wi-Fi, idle, adequate battery), so random-within-available systematically overrepresents flagship devices on fast networks and underrepresents users with older hardware or constrained connectivity.
- Random selection prevents secure aggregation from masking individual updates.
- Random selection always picks too few clients for weighted averaging to work.
Answer: The correct answer is B. The bias enters before the randomness acts: the pool of ‘available’ clients is not a random sample of the user population but a self-selected subset with systematic hardware and connectivity advantages. Training a model on this pool and deploying it fleet-wide produces worse service quality for exactly the users who were filtered out, which is a fairness and generalization problem. The ‘identical distributions’ claim contradicts the core non-IID premise of federated data; the secure-aggregation and weighted-averaging explanations invent mechanisms that do not depend on selection strategy.
Learning Objective: Analyze how availability-based eligibility filtering creates participation bias independent of whether sampling within the filtered pool is random.
Explain why update compression in federated learning is not merely an optimization but an architectural requirement on large mobile deployments, and quantify the bandwidth savings typical of production systems.
Answer: Mobile uploads are slow (typically 1-10 Mbps on cellular), highly asymmetric with downloads, and energy-expensive per byte transmitted. A full-precision update for a 10M-parameter model is ~40 MB at FP32, which takes 30-300 seconds to upload on a cellular link and costs measurable battery. Quantization to 8 bits plus sparsification of small-magnitude entries typically compresses updates by one to two orders of magnitude (10–100\(\times\)), turning 40 MB into 0.4-4 MB and uploads into manageable background traffic. The systems consequence is that without compression, round duration is dominated by upload tail latency, client participation rates collapse because users close apps during slow uploads, and the federated round cadence becomes unsustainable at scale.
Learning Objective: Explain why upload asymmetry makes compression architectural rather than optional and quantify the achievable reduction.
A federated deployment needs per-user adaptation while still benefiting from global coordination. Client memory budgets are tight, and analysis shows most user variation lives in the output decision boundary rather than in the shared representation. Which personalization design is the direct match?
- Personalization layers with a shared backbone and a lightweight client-specific head.
- Full-model fine-tuning on every client after each round.
- Elimination of the global model in favor of isolated local models only.
- Clustered federated learning with dozens of client clusters, because local heads cannot express any user variation.
Answer: The correct answer is A. When variation concentrates in the output mapping, a shared backbone captures the common representation (which benefits from all clients’ data) while the client-specific head captures the user-particular decision boundary — at a fraction of the memory and compute cost of full fine-tuning. Full fine-tuning on every client blows the memory budget the question already flagged as tight. Eliminating the global model discards the cross-client learning signal that made federated worthwhile. Clustered federated learning solves a different problem (dense subpopulations with distinct distributions) and is not required when per-user variation is narrow.
Learning Objective: Select a personalization architecture that matches where variation lives in the model and respects client resource constraints.
What specific privacy property does secure aggregation provide in a federated round, and what is it not?
- It proves that no differential-privacy noise is ever needed.
- It lets the server inspect every client’s gradient individually and then decide which ones to keep.
- It ensures only the aggregate update is revealed at the server, because pairwise masks between clients cancel in the sum — but it does not by itself defend against reconstruction of aggregates over time, which is why differential privacy is often layered on top.
- It eliminates the need for a minimum client count per round.
Answer: The correct answer is C. Secure aggregation’s contract is precisely that: individual updates are masked, the masks cancel when summed, and the server learns only the aggregate. Crucially, it does not replace differential privacy — observing aggregates over many rounds can still leak information about clients who participate repeatedly, which is why production systems combine the two. The ‘no DP needed’ claim overstates the guarantee; the ‘server inspects individual gradients’ claim contradicts the mechanism entirely; and in practice secure aggregation protocols require a minimum number of participants for the masking algebra to work, not fewer.
Learning Objective: Explain exactly what secure aggregation guarantees and what it does not, relative to differential privacy.
True or False: Aggressive straggler mitigation that drops slow or stale clients speeds up federated round times but can simultaneously introduce a fairness problem by systematically underrepresenting constrained devices.
Answer: True. The mechanism is direct: dropping slow and stale updates biases the aggregation toward devices with stronger hardware, faster networks, and more consistent availability. Round throughput improves, but the trained model disproportionately reflects the experience of privileged users — the same fairness failure mode as availability-biased client selection, just expressed in the aggregation step rather than the selection step.
Learning Objective: Evaluate the fairness cost of throughput-oriented straggler mitigation in federated aggregation.
Order the following concerns as they logically build from round-local execution to fleet-wide governance when scaling federated learning from prototype to production: (1) client scheduling, (2) update compression, (3) million-device orchestration.
Answer: The correct order is: (1) client scheduling, (2) update compression, (3) million-device orchestration. Scheduling determines which devices enter a round and on what fairness contract — a precondition for everything that follows. Compression then makes each selected client’s participation affordable on real mobile networks, without which scheduling decisions cannot actually produce completed updates. Million-device orchestration finally coordinates the machinery across the full fleet: asynchronous participation, versioned global checkpoints, failure recovery, hierarchical aggregation. Swapping any pair skips a foundational layer — for example, compressing updates for devices that scheduling bias excluded produces a fast but unfair system.
Learning Objective: Organize federated-systems concerns from round-level participation through fleet-scale orchestration.
Self-Check: Answer
How does on-device learning fundamentally change model versioning relative to a traditional centralized deployment where a single artifact ships to every replica?
- Versioning disappears because local models should never be tracked once deployed.
- Versioning becomes hierarchical: the system must simultaneously track a shared backbone version, an adaptation-strategy version, the per-device adapted state, and the federated aggregation epoch.
- A single linear version number still suffices because all devices receive identical updates at the same time.
- Only the optimizer version matters, because local model parameters are too dynamic to record.
Answer: The correct answer is B. Centralized MLOps can describe the deployed model as a single immutable artifact with one version string, but edge deployments mix a fleet-wide backbone, an adaptation mechanism (LoRA, adapter, bias-only) that can itself be versioned, per-device state that diverges continuously, and a federated round counter that describes the aggregation epoch. All four dimensions interact during rollback and debugging. Claiming versioning disappears would make rollback impossible; claiming ‘one linear version’ ignores continuous local divergence; and reducing to optimizer version alone drops every other dimension the system must trace.
Learning Objective: Explain why edge deployments require multidimensional version tracking rather than a single artifact version.
Explain how privacy-preserving telemetry changes what a production monitoring system can observe in on-device learning deployments, and name two concrete metrics that remain safe to report at the fleet level.
Answer: Centralized monitoring can log every prediction, every input, and every error case; on-device learning forbids all of these at the raw level because the data never legitimately leaves the device. Monitoring must therefore rely on aggregated, differentially-private, or securely-aggregated summaries rather than per-example traces. Two safe fleet-level metrics are confidence-score histograms (distributions of predictive confidence across a device cohort, which can be summed securely) and model drift indicators computed locally (e.g., KL divergence between current and reference prediction distributions, reported as a scalar). The systems consequence is that observability becomes indirect and coarse, so validation, rollback triggers, and alerting must be designed around noisy aggregate signals rather than precise per-example introspection.
Learning Objective: Analyze how privacy constraints force observability to shift from per-example logs to aggregate statistics, and name specific safe metrics.
A production on-device learning system adds a shadow validation mechanism. What specific function does shadow validation serve?
- It increases training speed by running two adapting models in parallel and averaging their gradients.
- It eliminates the need for device-side monitoring by outsourcing validation to a server.
- It guarantees that local adaptation always improves accuracy for every user.
- It runs a frozen known-good baseline in parallel with the adapting model and compares their behavior on the same inputs, giving the device a labels-free drift signal that can trigger rollback.
Answer: The correct answer is D. Shadow validation is a labels-free regression detector: because the device rarely has ground truth, it cannot directly measure accuracy — but it can measure divergence between the adapting model and a known-safe baseline on the same input stream. Large divergence flags suspected regression and triggers rollback to the frozen baseline. The ‘gradient averaging’ explanation describes a different technique entirely; outsourcing validation to a server contradicts the privacy constraint; and guaranteeing universal improvement misrepresents what any validation mechanism can deliver.
Learning Objective: Explain how shadow validation provides a labels-free regression signal for safe edge adaptation.
A team debates when on-device training should actually run on consumer phones. Which scheduling policy matches the chapter’s resource-aware recommendation?
- Avoid any ML-aware policy and let the OS’s default process scheduler decide training timing.
- Train immediately whenever new local data arrives, because adaptation quality should dominate UX concerns.
- Train only during opportunistic windows when the device is idle, charging, thermally stable, and typically on Wi-Fi.
- Train continuously during active use so adaptation reflects the freshest user context.
Answer: The correct answer is C. Opportunistic scheduling simultaneously protects the three budgets the chapter quantifies: battery (training under charging uses grid energy rather than the 15 percent battery hit), thermal (idle devices are cool enough that sustained training does not throttle the SoC), and UX (background training during active use competes with the foreground app for compute and bandwidth). Immediate-on-data training ignores all three constraints; continuous-during-use training is the worst case for UX; and deferring to the OS scheduler surrenders the model-aware guardrails that make adaptation safe.
Learning Objective: Apply the chapter’s opportunistic scheduling rule and name which budgets each condition protects.
True or False: The chapter invokes biological learning mainly as a metaphor for intuition-building, not as a source of concrete design principles that show up in actual edge-learning systems.
Answer: False. The bio-inspired subsection translates biological efficiency into three concrete edge-design principles: sparse activation patterns (inspired by neural firing sparsity) that reduce compute per step, self-supervised use of abundant unlabeled sensor data (modeling how biological systems learn predominantly without explicit labels), and continual-learning mechanisms (modeling mammalian consolidation) that let models update without catastrophic forgetting. These are specific architectural levers, not decorative metaphors.
Learning Objective: Evaluate whether the chapter’s bio-inspired section produces concrete design levers or only metaphorical framing.
Why is strong offline pretraining especially important before deploying lightweight local adaptation methods such as bias-only updates or adapters? Explain the feature-learning division of labor this creates.
Answer: Lightweight local adaptation modifies too few parameters to learn rich new representations from scratch — a bias vector or a low-rank adapter cannot restructure the feature geometry the frozen backbone encodes. Adaptation therefore works only when the deployed backbone already contains transferable features that generalize to the user’s domain. The division of labor is clear: cloud pretraining absorbs the hard, data-hungry, compute-intensive feature-learning work, and local adaptation does the cheap, low-data, personalization work on top of those features. The systems consequence is that edge-learning success is gated by the quality of the centrally-trained backbone — skimping on pretraining shifts difficulty onto the device that cannot afford it, and the deployment fails.
Learning Objective: Justify why edge adaptation depends on a strong centrally-trained backbone and describe the resulting division of labor.
Self-Check: Answer
Why does the chapter argue that a single uniform adaptation algorithm across a heterogeneous deployment fleet is a structural failure rather than an optimization problem?
- All devices should eventually converge to the same local training loop once enough data is collected.
- Device capabilities span orders of magnitude in RAM, compute, and energy, so an adaptation loop that fits on a flagship will exceed the RAM, thermal, or battery budget on a low-end device — the same code path fails on one tier while working on another.
- Federated learning requires every client to update the same number of parameters each round.
- Low-end devices are better at full fine-tuning than flagship phones due to lower thermal output.
Answer: The correct answer is B. The chapter treats heterogeneity as a physical-constraint fact, not a tuning choice: 512 MB of RAM cannot hold the activation cache that 6 GB of RAM holds, full stop. A uniform algorithm becomes a reliability bug because correctness on one tier does not imply correctness on another. The ‘eventual convergence to one loop’ answer denies the constraint spread; the federated-parity claim confuses aggregation with local compute; and the thermal-throttling inversion directly contradicts the physics — lower-end devices have weaker thermals, not better fine-tuning headroom.
Learning Objective: Justify capability-matched adaptation strategies by framing heterogeneity as a physical-constraint spread rather than a tuning parameter.
A team deploys on-device learning and discovers that debugging a single user’s accuracy regression takes weeks, whereas centralized deployments resolve similar issues in hours. Explain the observability asymmetry and name two specific signals the team can still use.
Answer: Centralized training can reproduce any prediction from stored inputs, compare against held-out labels, and inspect the exact training trajectory — all of which depend on raw data the team is contractually and technically forbidden from touching on-device. For example, a voice model’s regression on one user might be triggered by a specific acoustic pattern that is never logged. The team must fall back on indirect signals: (1) locally computed drift indicators (e.g., change in prediction-confidence distribution, reported as a scalar per device) and (2) shadow-validation divergence scores comparing the adapted model against a frozen baseline. The systems consequence is that debugging shifts from root-cause investigation to aggregate-statistical triage, and rollback checkpoints become the primary recovery mechanism because forward-debugging is often impossible.
Learning Objective: Analyze the observability asymmetry between centralized and edge deployments and identify usable indirect signals.
Which challenge most directly captures why federated learning can fail to converge even when every participating client is honest and well-resourced?
- Non-IID and fragmented data make locally-useful gradients point in conflicting directions, producing aggregated updates that hurt global generalization rather than help it.
- Secure aggregation forces all clients to share raw data before updates can be averaged.
- Model rollback is impossible once any local adaptation has occurred.
- Client scheduling removes all statistical bias because only idle devices participate.
Answer: The correct answer is A. This is the purely statistical failure mode: even with perfect infrastructure, honest clients with sharply different local distributions compute gradients that work for their own data but disagree fleet-wide. The averaged update captures none of the individual improvements and can regress on the global distribution. The secure-aggregation claim inverts the mechanism (it specifically avoids raw-data sharing), the rollback claim contradicts production designs that maintain versioned checkpoints, and scheduling does not eliminate selection bias — it is one of its sources.
Learning Objective: Identify non-IID gradient conflict as the statistical failure mode that persists even in ideal infrastructure conditions.
A keyboard team lets their model learn continuously from every local correction without bounds, checkpoints, or rollback triggers. Which failure mode from the section is most likely?
- Perfect personalization, because every local correction is guaranteed to be reliable supervision.
- Complete elimination of participation bias, because learning is now fully local.
- Immediate memory savings, because continual adaptation reduces checkpointing needs.
- Unbounded adaptation drift, where the model progressively learns from noisy or misleading signals (accidental taps, autocorrect acceptances the user intended to reject, one-off contexts) and degrades over weeks.
Answer: The correct answer is D. The chapter’s warning is explicit: local corrections are weak, noisy supervision, not clean ground truth. Without bounds, checkpoints, or rollback, the model accumulates noise in the direction of whatever signal is most frequent — which is often a mix of genuine corrections and accidental inputs the user did not intend as labels. The ‘perfect personalization’ and ‘bias elimination’ answers treat weak signals as reliable; the ‘memory savings from fewer checkpoints’ claim confuses drift (a model-quality problem) with storage (an infrastructure problem) and sacrifices the primary recovery mechanism.
Learning Objective: Identify unconstrained adaptation drift as the primary failure mode of continual local learning without guardrails.
True or False: Because local learning reduces dependence on cloud infrastructure, the deployment’s compliance, auditability, and rollback properties also become simpler than those of a centralized ML system.
Answer: False. Local autonomy makes those properties harder, not simpler: models evolve continuously after deployment without centralized visibility, so auditing ‘what the system predicted and why at time T’ requires reconstructing per-device adaptation state the central operator cannot inspect. Rollback must propagate to millions of devices through code paths that may be offline. Regulatory traceability (e.g., GDPR’s explanation requirements) now applies to a moving target rather than a fixed artifact. The governance surface expands substantially.
Learning Objective: Evaluate why post-deployment local adaptation expands rather than reduces compliance and rollback complexity.
Why does the chapter connect on-device learning to broader robust-AI concerns such as Byzantine resilience, drift detection, and adversarial manipulation? Explain why these techniques become mandatory architectural layers rather than optional hardening.
Answer: When learning runs on millions of devices rather than a single trusted datacenter, every failure mode that was once a local bug becomes a distributed reliability risk. A malicious client can inject crafted gradients that steer global aggregation (Byzantine attack); a subset of devices can experience correlated drift from a seasonal data shift with no labels to reveal the regression; adversarial inputs can manipulate the adapted model’s decision boundary at scale. For example, a coordinated set of compromised phones can poison the next federated round if no Byzantine-resilient aggregation is in place, and honest devices can silently drift if no statistical drift detector is running. The systems consequence is that robust-AI mechanisms — Byzantine-resilient aggregators, on-device drift detectors, input validation — become mandatory architectural layers because the attack surface and failure surface are structurally larger than in centralized learning, and no downstream mitigation can recover what corrupted learning already absorbed.
Learning Objective: Synthesize why robust-AI mechanisms shift from optional hardening to mandatory architecture in distributed edge-learning systems.
Self-Check: Answer
A senior engineer proposes: ‘Modern phones have dedicated NPUs and successfully run inference, so local training should just be a scaled-down version of cloud training.’ What is wrong with this reasoning?
- Training on the phone faces the 4–12\(\times\) memory amplification over inference, a 30–50\(\times\) bandwidth gap to datacenter HBM, a ~10 W thermal ceiling, and intermittent connectivity — these are qualitatively different physics, not smaller versions of datacenter physics.
- Mobile deployment can safely use the same training intuition as a datacenter because modern NPUs close the gap.
- Only model accuracy matters when moving from cloud to edge; systems constraints are secondary details.
- If a model serves correctly on a phone, local training will usually be feasible with only a small extra cost.
Answer: The correct answer is A. The chapter’s central thesis is that the constraint regime flips at the edge: training peak memory scales multiplicatively over inference, mobile memory bandwidth is ~30–50\(\times\) below datacenter HBM, thermal budgets cap sustainable power at about 10 W versus kilowatts in a rack, and connectivity can vanish for hours. Any one of these qualitative differences would invalidate the ‘scaled-down cloud’ analogy; together they make edge training a fundamentally different engineering discipline. The other answers restate the fallacy in progressively naive forms — trusting NPUs to close a 30–50\(\times\) physics gap, dismissing systems constraints, or assuming inference feasibility implies training feasibility — all of which the chapter explicitly refutes.
Learning Objective: Reject the ‘edge is scaled-down cloud’ fallacy by naming the specific physics that break the analogy.
True or False: In a federated learning deployment, keeping raw data on-device is sufficient by itself to guarantee that no information about a user’s training data can be recovered by the aggregation server.
Answer: False. Gradient and model-update exchanges leak enough information to enable model-inversion attacks (reconstructing training samples) and membership-inference attacks (determining whether a specific record participated). Privacy-in-practice requires secure aggregation (so the server sees only sums, not individual updates) AND differential privacy (so even the sums cannot be backed out over rounds) — locality alone is one necessary layer among three.
Learning Objective: Reject the misconception that data locality alone delivers federated privacy.
A team deploys on-device personalization assuming every local update will improve the user’s experience. Explain two concrete mechanisms by which local personalization can actively degrade model behavior, and name the guardrail that prevents each.
Answer: The first mechanism is overfitting to noisy or transient signals: a keyboard that adapts to autocorrect acceptances the user intended to reject, or a voice assistant that adapts to one cold-afflicted day of speech, will degrade under normal conditions. The guardrail is confidence gating — rejecting updates when the supervision signal’s estimated reliability is low. The second mechanism is bias amplification: a user whose narrow slice of behavior (e.g., only formal emails) dominates the local data will drive the model away from its broader generalization, degrading on any out-of-slice input. The guardrail is shadow validation against a frozen backbone, which detects divergence and triggers rollback to the last known-good state. The practical implication is that personalization is not automatically monotonic in quality — it requires architectural guardrails for every pathway by which local signal can be weaker than the pretrained prior.
Learning Objective: Identify mechanisms by which local adaptation degrades model quality and name the specific guardrails for each.
A deployment targets phones ranging from a 6 GB flagship down to a 1 GB entry-level device, and the team proposes a single federated training loop for the entire fleet. What is the primary risk the chapter identifies?
- All devices will eventually match the flagship’s performance once enough federated rounds have passed.
- Heterogeneity matters only for inference latency, not for adaptation or federated training.
- Low-end devices usually contribute better gradients than high-end devices due to simpler workloads.
- A loop that fits comfortably on the 6 GB flagship can exceed RAM, thermal, or battery limits on the 1 GB entry-level device, producing crashes, throttling, or silent participation dropouts that bias the resulting model toward flagship users.
Answer: The correct answer is D. A 6\(\times\) spread in RAM alone guarantees that any training algorithm tuned for the upper tier will blow the budget on the lower tier. The failure mode is twofold: entry-level devices either crash or silently drop out of rounds, and the aggregation then trains on a flagship-dominated sample, encoding flagship behavior as the fleet model. The ‘eventual matching through rounds’ answer contradicts the physics (RAM does not grow by running federated rounds); ‘heterogeneity only matters for inference latency’ dismisses the training dimension entirely; and ‘low-end devices contribute better gradients’ invents a property that does not exist.
Learning Objective: Evaluate why hardware heterogeneity creates a dual failure mode (crashes on constrained devices + bias toward privileged devices) in uniform fleet training.
Self-Check: Answer
Which triple of ideas is the chapter’s three-pillar framework for edge intelligence?
- Model Sharding, Autoscaling, and Batch Inference.
- Model Adaptation, Data Efficiency, and Federated Coordination.
- Hyperparameter Search, Data Labeling, and GPU Scheduling.
- Full Fine-Tuning, Unlimited Replay, and Centralized Logging.
Answer: The correct answer is B. The chapter’s pillars are: Model Adaptation (shrink the update footprint via bias-only, LoRA, adapters, or sparse updates), Data Efficiency (extract more signal from scarce local data via few-shot learning, replay, and compressed representations), and Federated Coordination (share knowledge across devices without sharing raw data). The other sets describe cloud-serving concerns (sharding, autoscaling, batch inference), centralized training operations (hyperparameter search, GPU scheduling), or explicit anti-patterns (unlimited replay, centralized logging of on-device events) that the chapter spends its pages rejecting.
Learning Objective: Identify the chapter’s three-pillar framework for edge intelligence.
Explain why the chapter frames the mobile memory wall as a physical limit, not a software optimization problem, and connect the 30–50\(\times\) bandwidth gap to a specific serving consequence.
Answer: Mobile NPUs advertise strong peak compute (50 TOPS on a flagship NPU), but autoregressive decode reads the entire weight matrix per token with near-zero reuse, so throughput is bounded by memory bandwidth rather than by TOPS. The 30–50\(\times\) gap between flagship mobile LPDDR5X (64-100 GB/s) and datacenter HBM3 (~3,350 GB/s) directly translates to proportionally slower token generation — a model that decodes at 100 tokens/second on H100 decodes at 2-3 tokens/second on the phone, even though the phone’s advertised compute peak would suggest otherwise. The practical consequence is that techniques like aggressive quantization become survival strategies imposed by the physics of memory bandwidth, not optional compression tricks.
Learning Objective: Connect the 30–50\(\times\) mobile-to-datacenter bandwidth gap to its concrete serving consequence for autoregressive generation.
True or False: The chapter’s final takeaway is that edge deployment is essentially cloud deployment with smaller models — the same engineering discipline, just scaled down.
Answer: False. The closing synthesis insists that edge is a qualitatively distinct engineering discipline defined by thermal throttling on ~10 W budgets, intermittent connectivity, finite battery, hardware heterogeneity spanning orders of magnitude, and weak observability under privacy constraints. None of these are cloud concerns at smaller scale; they are different physics that require different architectures.
Learning Objective: Assess the chapter’s closing claim that edge ML is qualitatively, not quantitatively, different from cloud ML.