The Governance Imperative
Responsible AI
Purpose
Why do the systems that fail responsibility requirements fail to deploy at all, regardless of their technical capabilities?
In high-risk regulated settings, a model that cannot explain its decisions, document its behavior, or support audit can face deployment gates regardless of its technical capability. A model that exhibits demographic bias can create legal, operational, and reputational risk where discrimination rules apply. A model that cannot be audited cannot satisfy many enterprise governance requirements. These are not soft preferences but can become hard gates in regulated or enterprise settings: systems that fail them may be blocked regardless of accuracy, latency, or any other technical metric. The shift from responsible AI as ethics to responsible AI as engineering reflects this reality: for high-risk AI systems, legal and governance requirements can make transparency, oversight, documentation, and risk management part of deployment readiness. Organizations that treat responsibility as optional may discover their systems blocked at deployment by legal, regulatory, or reputational constraints that no amount of technical excellence can overcome. Responsibility has become infrastructure, not aspiration. In C³ terms, responsibility is a coordination constraint on the entire fleet: safety and fairness guarantees must be established before compute is allowed to run.
Learning Objectives
- Translate fairness, transparency, accountability, privacy, and safety into measurable deployment gates
- Calculate fairness metrics and diagnose incompatibilities caused by base rates or imperfect prediction
- Design bias detection and fairness monitoring across demographic groups, drift, and fleet-scale feedback loops
- Select explanation methods under latency, compute, auditability, and user-contestability constraints
- Evaluate privacy, unlearning, and robustness mitigations against accuracy, compute, and governance requirements
- Analyze human-AI feedback loops, automation bias, and value conflicts in deployment contexts
- Assess governance structures that sustain documentation, accountability, safety review, and regulatory compliance
In 2018, Reuters reported that Amazon had abandoned an experimental hiring algorithm trained on historical resume data after discovering it systematically penalized female candidates (Dastin 2018). The system satisfied many conventional operational requirements: it could be built, evaluated, and integrated into a recruiting workflow. Yet it had learned that past successful applicants were predominantly male, encoding historical bias rather than merit-based qualifications. The model was statistically optimized yet ethically disastrous, demonstrating that technical excellence can coexist with profound social harm.
Dastin, Jeffrey. 2018. “Amazon Scraps Secret AI Recruiting Tool That Showed Bias Against Women.” Reuters.
In the fleet stack shown in The Fleet Stack, Responsible AI is the Governance Layer, the point where the system meets the real world. The lower layers supply compute, data movement, distributed execution, serving infrastructure, security controls, robustness mechanisms, and sustainability budgets. The Governance Layer adds the constraints that determine why the machine runs and whom it serves, ensuring that an otherwise correct system does not impose societal harms. If the iron law defines efficiency, Responsible AI defines stability: ensuring that the system’s output does not destabilize the society it operates in. The instability is concrete: a model that outputs toxic content erodes user trust (feedback-loop instability), a model that discriminates degrades its own future training data (distributional instability), and a model that leaks privacy invites regulatory shutdown (operational instability). Responsible AI therefore belongs in the objective function, not only as a constraint checked on the finished solution.
Production AI has its own systems agenda, spanning architecture, infrastructure, data processing, security, and robustness challenges (Stoica et al. 2017). Security and privacy, robustness under distribution shift, and environmental sustainability sit directly beneath the Governance Layer. Those capabilities explain how to build and operate ML systems that are secure, robust, and sustainable. Responsible AI addresses the question that technical excellence alone cannot answer: whether those systems operate responsibly toward the people they affect.
Stoica, Ion, Dawn Song, Raluca Ada Popa, David Patterson, Michael W. Mahoney, Randy Katz, Anthony D. Joseph, et al. 2017. “A Berkeley View of Systems Challenges for AI.” arXiv Preprint arXiv:1712.05855.
The Amazon hiring incident reveals the central challenge of responsible AI: systems can be algorithmically sound while perpetuating injustice. The problem extends beyond individual bias to encompass transparency, accountability, privacy, and safety in systems affecting billions of lives daily. This is not the same problem as resilience. Resilient AI addresses threats to system integrity through adversarial attacks and hardware failures; responsible AI asks whether a properly functioning system produces outcomes consistent with human values and collective welfare. That distinction turns abstract ethical principles into engineering constraints. Fairness, transparency, and accountability must become quantifiable mechanisms and verifiable system properties, not final review items attached after the serving path is complete.
Software engineering provides precedent for this evolution. Early systems prioritized functional correctness alone. As complexity grew, the field developed methodologies for reliability engineering, security assurance, and maintainability analysis. ML deployment creates a comparable maturation pressure, but at larger social scale: models can mediate credit allocation, medical diagnosis, educational assessment, and criminal justice. Unlike conventional software failures that manifest as crashes or data corruption, responsible AI failures can perpetuate systemic discrimination, compromise democratic institutions, and erode public confidence in beneficial technologies.
Definition 1.1: Responsible AI
Responsible AI is the practice of designing, auditing, and operating ML systems to measurable fairness, safety, privacy, and accountability standards—translating ethical principles into verifiable system properties that constrain model training, deployment decisions, and operational monitoring.
- Significance: Responsible AI constraints impose real costs: fairness-aware training can lengthen training runs, real-time bias monitoring can consume serving-path latency, and on-demand explainability can require additional model evaluations or asynchronous worker capacity. At fleet scale, these safeguards must be budgeted like reliability or security controls. Conversely, a facial recognition system with a persistent subgroup error gap can affect millions of users before detection, creating regulatory and liability costs that dwarf the monitoring investment.
- Distinction: Unlike AI ethics (which defines normative principles about what systems should do), responsible AI engineering defines technical mechanisms that enforce those principles—bias detection algorithms, differential privacy implementations, audit trails, and architectural guardrails that make compliance measurable and verifiable rather than aspirational.
- Common pitfall: A frequent misconception is that responsible AI is a final compliance review applied to a finished model. Responsible constraints that are not designed in from the data collection stage typically require fundamental retraining to fix: a model trained on biased labels cannot be fairly calibrated by post-hoc threshold adjustment alone, as the learned representations themselves encode the bias.
Responsible AI therefore constitutes a systematic engineering discipline with four interconnected dimensions: translating ethical principles into measurable system requirements, detecting and mitigating harmful algorithmic behaviors, addressing sociotechnical dynamics1 that extend beyond individual systems, and navigating implementation challenges within organizational and regulatory contexts. Public frameworks such as the National Institute of Standards and Technology (NIST) AI Risk Management Framework, ISO/IEC 42001 and 23894, the Organisation for Economic Co-operation and Development (OECD) AI Recommendation, and the United Nations Educational, Scientific and Cultural Organization (UNESCO) Recommendation on AI ethics all express this shift from abstract principles toward governable risk management, accountability, transparency, and human oversight (Tabassi 2023; International Organization for Standardization and International Electrotechnical Commission 2023b, 2023a; Organisation for Economic Co-operation and Development 2024; UNESCO 2022). Privacy mechanisms, robustness techniques, and sustainability metrics provide the technical foundation for that integration. The responsible-AI framework combines those capabilities with bias detection algorithms, privacy preservation mechanisms, organizational governance structures, and stakeholder engagement processes, treating responsible AI as fundamental to sound engineering practice rather than as supplementary constraints applied to finished systems.
1 Sociotechnical System: Coined by the Tavistock Institute in the 1950s to describe the interdependent relationship between humans and technology in the workplace. ML fleets are the ultimate sociotechnical systems: their “performance” is not merely a benchmark score but an emergent property of how model outputs interact with user behavior, legal frameworks, and physical resource constraints.
Tabassi, Elham. 2023. Artificial Intelligence Risk Management Framework (AI RMF 1.0). NIST AI 100-1. National Institute of Standards; Technology. https://doi.org/10.6028/NIST.AI.100-1.
International Organization for Standardization, and International Electrotechnical Commission. 2023a. ISO/IEC 23894:2023 Information Technology – Artificial Intelligence – Guidance on Risk Management. ISO/IEC standard.
Organisation for Economic Co-operation and Development. 2024. Recommendation of the Council on Artificial Intelligence. OECD Legal Instruments.
UNESCO. 2022. Recommendation on the Ethics of Artificial Intelligence. UNESCO.
That integration is a significant infrastructure investment. Numbers Every Fleet Engineer Should Know supplies the production-scale fleet baselines and serving-capacity figures against which this overhead can be estimated, letting an engineer size the tax relative to the same per-accelerator throughput numbers used for raw serving. This cost is essential infrastructure to be provisioned, analogous to how security (Security & Privacy) and redundancy (Fault Tolerance) are budgeted in distributed systems.
Treating fairness, transparency, accountability, and privacy as rigorous engineering specifications rather than abstract ideals transforms responsible AI from aspiration into practice. The systematic approach that follows maps these core ethical principles directly onto the mechanical stages of the machine learning lifecycle, turning each into a concrete design constraint with measurable criteria. These four concerns must be read in order, because each depends on the one before it: technical solutions alone cannot resolve value conflicts, ethical principles without technical implementation remain aspirational, and isolated interventions fail without organizational support.
Core Principles and the ML Lifecycle
A continuous integration pipeline that detects a memory leak automatically blocks deployment. The same pipeline must block a deployment in which the system detects a 15 percent drop in accuracy specifically for elderly users. Responsible AI translates ethical principles into hard engineering invariants. Just as unit tests prevent logic regressions, the continuous integration/continuous deployment (CI/CD) pipeline must embed fairness, privacy, and accountability checks, treating a demographic bias exactly as a fatal software exception would be treated.
Fairness operates as a stability constraint. In control theory terms, fairness ensures that the system’s error distribution is invariant across population subgroups. A system that violates this constraint is unstable: it will degrade its own training data through feedback loops (for example, predictive policing) and lose user trust, leading to eventual system collapse. This principle encompasses both statistical metrics and broader normative concerns about equity, justice, and structural bias. The fairness section below examines the formal mathematical definitions in detail.
The same control-plane view makes Explainability function as system observability: it is the mechanism by which the control plane exposes internal state to human operators (Phillips et al. 2020). Without explainability, the system is a black box running open loop, making it impossible to debug failure modes or verify safety constraints. Explanation mechanisms must support both individual decisions and overall model behavior. They may be generated after a decision is made to detail the reasoning process, known as post hoc explanations, or built into the model’s design for transparent operation. Neural network architectures vary significantly in their inherent interpretability, with deeper networks generally being more difficult to explain. For this reason, explainability supports error analysis, regulatory compliance, and user trust.
Phillips, P. J., C. A. Hahn, P. C. Fontana, D. A. Broniatowski, and M. A. Przybocki. 2020. “Four Principles of Explainable Artificial Intelligence.” In Gaithersburg, Maryland, vol. 18. National Institute of Standards; Technology (NIST). https://doi.org/10.6028/nist.ir.8312-draft.
That observability must be paired with Transparency: openness about how AI systems are built, trained, validated, and deployed. Transparency includes disclosure of data sources, design assumptions, system limitations, and performance characteristics. While explainability focuses on understanding outputs, transparency addresses the broader lifecycle of the system.
Once system behavior is visible, Accountability provides the mechanisms by which individuals or organizations are held responsible for AI outcomes. It involves traceability, documentation, auditing, and the ability to remedy harms. Accountability ensures that AI failures are not treated as abstract malfunctions but as consequences with real-world impact.
At the objective-function layer, Value alignment2 requires AI systems to pursue goals that are consistent with human intent and ethical norms. In practice, this involves technical challenges, including reward design and constraint specification, and broader questions about whose values are represented and enforced.
2 Value Alignment: The problem of ensuring AI systems optimize for human values rather than proxy objectives. Stuart Russell formalized this in 2015, arguing that specifying objectives is harder than optimizing them. The engineering consequence: YouTube’s pre-2017 recommendation algorithm optimized for click-through rate (a proxy for satisfaction), inadvertently promoting conspiracy content that maximized clicks while degrading user welfare—a misalignment that required redesigning the entire reward pipeline.
3 Human-in-the-Loop (HITL): A design pattern where humans actively participate in model decisions rather than being replaced by automation. The systems trade-off is latency vs. safety: HITL adds 100 ms to 30+ seconds per decision depending on domain. Large content-moderation systems have historically paired automated triage with thousands of human reviewers, demonstrating that the pattern scales only with proportional human infrastructure cost. In ML serving architectures, HITL requires routing logic, confidence thresholds for escalation, and queue management that fundamentally reshape the inference pipeline.
The lifecycle also needs Human oversight: the role of human judgment in supervising, correcting, or halting automated decisions. This includes humans in the loop3 during operation, as well as organizational structures that ensure AI use remains accountable to societal values and real-world complexity.
Privacy, robustness, and human oversight make the same point from different angles: principles alone do not ensure responsible systems. Translation from abstract ideals to concrete practice requires systematic integration across the ML lifecycle, where each principle manifests differently in data collection, model training, evaluation, deployment, and monitoring. The critical question is how these principles interact when they compete for priority.
Integrating principles across the ML lifecycle
Fairness, transparency, accountability, privacy, and safety define what it means for an AI system to behave ethically and predictably. Translating these principles into concrete constraints that guide how models are trained, evaluated, deployed, and maintained is the central engineering challenge.
Implementing these principles in practice requires understanding how each sets specific expectations for system behavior:
- Fairness: Models must treat different subgroups in ways that account for historical biases.
- Explainability: Model decisions must be understandable to developers, auditors, and end users.
- Privacy: Data collection and use must respect consent, purpose, and access boundaries.
- Accountability: Responsibilities must be assigned, tracked, and enforced throughout the system lifecycle.
- Safety: Models must behave reliably even in uncertain or shifting environments.
The principles overlap, but each creates a distinct engineering obligation that must be designed into the system lifecycle.
Table 1 maps the responsible AI lifecycle across the major phases of ML system development: data collection, model training, evaluation, deployment, and monitoring. Fairness and privacy constraints begin at data collection; robustness and accountability become most critical during deployment and oversight. Explainability spans the full lifecycle, supporting model debugging at design time and user-facing justification at serving time. The mapping reinforces that responsible AI is a multiphase architectural commitment, not a post-hoc compliance step.
| Principle | Data Collection | Model Training | Evaluation | Deployment | Monitoring |
|---|---|---|---|---|---|
| Fairness | Representative sampling | Bias-aware algorithms | Group-level metrics | Threshold adjustment | Subgroup performance |
| Explainability | Documentation standards | Interpretable architecture | Model behavior analysis | User-facing explanations | Explanation quality logs |
| Transparency | Data source tracking | Training documentation | Performance reporting | Model cards | Change tracking |
| Privacy | Consent mechanisms | Privacy-preserving methods | Privacy impact assessment | Secure deployment | Access audit logs |
| Accountability | Governance frameworks | Decision logging | Audit trail creation | Override mechanisms | Incident tracking |
| Robustness | Quality assurance | Robust training methods | Stress testing | Failure handling | Performance monitoring |
Resource requirements and equity implications
Implementing responsible AI principles requires computational resources that vary significantly across techniques and deployment contexts. These resource requirements create multifaceted equity considerations that extend beyond individual organizations to encompass broader social and environmental justice concerns. Organizations with limited computing budgets may be unable to implement comprehensive responsible AI protections, potentially creating disparate access to ethical safeguards. Large-scale model deployments that depend on accelerator clusters and low-latency connectivity can exclude users whose networks or devices cannot meet those assumptions.
Environmental justice concerns compound these access barriers through the engineering reality that responsible AI techniques impose energy and capacity costs. The concrete numbers later in the chapter are sizing assumptions for methods the chapter unpacks: differential privacy may require extra training iterations, real-time fairness monitoring consumes serving-path resources, and Shapley-value explanations can require many additional model evaluations unless they are approximated, cached, or generated asynchronously. These computational requirements translate directly into infrastructure demands: a high-traffic system serving responsible AI features to 10 million users requires substantial additional data-center capacity compared to unconstrained models.
The geographic distribution of this computational infrastructure creates systematic inequities that engineers must consider in system design. Data centers supporting AI workloads concentrate in regions with low electricity costs and favorable regulations, areas that often correlate with lower-income communities that experience increased pollution, heat generation, and electrical grid strain while frequently lacking the high-bandwidth connectivity needed to access the AI services these facilities enable. This creates a feedback loop where computational equity depends not only on algorithmic design but on infrastructure placement decisions that affect both system performance and community welfare. The resource-overhead comparison later in this chapter quantifies the performance characteristics of specific responsible AI techniques.
Transparency and explainability
Machine learning systems are frequently criticized for their lack of interpretability. In many cases, models operate as opaque “black boxes,” producing outputs that are difficult for users, developers, and regulators to understand or scrutinize. This opacity presents a significant barrier to trust, particularly in high stakes domains such as criminal justice, healthcare, and finance, where accountability and the right to recourse are important. For example, the COMPAS algorithm, used in the United States to assess recidivism risk, was found to exhibit racial bias4. The proprietary nature of the system, combined with limited access to interpretability tools, hindered efforts to investigate or address the issue.
4 COMPAS (Correctional Offender Management Profiling for Alternative Sanctions): ProPublica’s 2016 analysis found Black defendants were falsely flagged as future criminals at nearly twice the rate of white defendants (45 percent vs. 23 percent false positive rate). The proprietary, black-box nature of the system limited full inspection of model internals and training data, demonstrating a compounding failure: bias in the model coupled with opacity in the serving architecture made the system harder to audit and harder to debug.
Explainability is the capacity to understand how a model produces its predictions. It includes both local explanations, which clarify individual predictions, and global explanations, which describe the model’s general behavior. Transparency, by contrast, encompasses openness about the broader system design and operation. This includes disclosure of data sources, feature engineering, model architectures, training procedures, evaluation protocols, and known limitations. Transparency also involves documentation of intended use cases, system boundaries, and governance structures.
The importance of explainability and transparency extends beyond technical considerations to legal requirements. In many jurisdictions, these principles are legal obligations rather than optional guidance. Under GDPR, solely automated decisions with legal or similarly significant effects trigger Article 22 safeguards and related transparency duties, including meaningful information about the logic involved under access and notice provisions, subject to statutory exceptions (European Parliament and Council of the European Union 2016; European Data Protection Board 2018).5 Similar regulatory pressures in other domains reinforce the need to treat explainability and transparency as core architectural requirements.
5 GDPR Article 22: Article 22 gives data subjects protections against decisions based solely on automated processing that produce legal or similarly significant effects, with exceptions for contract necessity, authorization by law, or explicit consent plus safeguards (European Parliament and Council of the European Union 2016). Related notice and access provisions, including Article 15, require meaningful information about the logic involved for qualifying automated decision-making, and EDPB guidance treats those duties as part of a broader profiling and automated-decision governance regime (European Data Protection Board 2018). For ML systems, this creates an architectural constraint: high-stakes automated-decision systems need explanation, recourse, and governance infrastructure rather than opaque serving-only APIs.
European Parliament, and Council of the European Union. 2016. Regulation (EU) 2016/679 of the European Parliament and of the Council of 27 April 2016. Official Journal of the European Union.
European Data Protection Board. 2018. Guidelines on Automated Individual Decision-Making and Profiling for the Purposes of Regulation 2016/679.
Implementing these principles requires anticipating the needs of different stakeholders, whose competing values and priorities are examined comprehensively in section 1.6.3. Designing for explainability and transparency therefore necessitates decisions about how and where to surface relevant information across the system lifecycle.
Transparency and explainability also support system reliability over time. As models are retrained or updated, mechanisms for interpretability and traceability allow detection of unexpected behavior, enable root cause analysis, and support governance. Embedded into the structure and operation of a system, these mechanisms provide the foundation for trust, oversight, and alignment with institutional and societal expectations.
While transparency and explainability enable stakeholders to understand system behavior, they do not guarantee that this behavior is equitable. A model can be fully transparent about how it makes decisions while still systematically disadvantaging certain groups. This distinction motivates the examination of fairness as a separate, complementary principle.
Fairness in machine learning
Automated decisions in hiring, lending, and healthcare affect millions of people, and historical data used to train these systems encodes decades of structural inequality. The engineering question is how to formalize “equitable treatment” in a way that a system can measure and enforce.
Definition 1.2: Algorithmic fairness
Algorithmic Fairness is the measurable property that a model’s error distribution or outcomes are invariant (or bounded in variation) across protected demographic groups.
- Significance: It transforms fairness from an intuition into a multi-objective optimization problem. Within the iron law, achieving fairness often requires trading off total accuracy \((\text{Accuracy})\) for group-specific calibration, where calibration is checked separately within each protected group, ensuring that the system’s benefits and harms are distributed equitably.
- Distinction: Unlike Average Accuracy (which hides disparities in the aggregate), Algorithmic Fairness focuses on the Subgroup Distribution \((p(Y \mid X, \text{Group}))\), identifying where the model fails for minority populations.
- Common pitfall: A frequent misconception is that there is a single “fair” solution. In reality, different fairness definitions (for example, demographic parity vs. equalized odds) are often mathematically incompatible and not jointly satisfiable except in special cases: satisfying one necessitates violating another, requiring explicit policy choices by the engineer.

Fairness constraints cost a few points of accuracy, the responsibility tax.
Fairness in machine learning presents complex challenges that extend beyond transparency. The core requirement is that automated systems not disproportionately disadvantage protected groups. Because these systems are trained on historical data, they are susceptible to reproducing and amplifying patterns of systemic bias embedded in that data. Without careful design, machine learning systems may unintentionally reinforce social inequities rather than mitigate them.
A widely studied example comes from the healthcare domain. An algorithm6 used to allocate care management resources in US hospitals was found to systematically underestimate the health needs of Black patients (Obermeyer et al. 2019). The model used healthcare expenditures as a proxy for health status, but due to longstanding disparities in access and spending, Black patients were less likely to incur high costs. As a result, the model inferred that they were less sick, despite often having equal or greater medical need. This case illustrates how seemingly neutral design choices such as proxy variable selection can yield discriminatory outcomes when historical inequities are not properly accounted for. Enforcing fairness constraints on such models incurs a measurable cost, a phenomenon known as the fairness tax.
6 Healthcare Algorithm Scale: The Optum algorithm affected approximately 200 million Americans annually, using healthcare expenditure as a proxy for health need. Because Black patients historically incurred lower costs due to access disparities, the model systematically underestimated their severity, reducing Black enrollment in high-risk care programs by 50 percent. Correcting the proxy would have increased Black patient identification from 17.7 percent to 46.5 percent, quantifying the cost of a single proxy variable choice at population scale.
Obermeyer, Ziad, Brian Powers, Christine Vogeli, and Sendhil Mullainathan. 2019. “Dissecting Racial Bias in an Algorithm Used to Manage the Health of Populations.” Science 366 (6464): 447–53. https://doi.org/10.1126/science.aax2342.
The fairness-tax calculation isolates one criterion: demographic parity, which requires equal positive decision rates across groups. It does not represent every fairness goal; it shows the system cost of enforcing that criterion before the section compares demographic parity with equalized odds and equality of opportunity.
Napkin Math 1.1: The fairness tax
Problem: Consider a credit model with 85 percent accuracy. Group A (majority) has a 20 percent default rate. Group B (minority) has a 40 percent default rate due to systemic factors. If demographic parity (equal approval rates) is enforced, what happens to accuracy?
Math:
The approval-rate facts define the policy change; the accuracy values below are measured on the held-out validation set for this scenario, where the additional Group B approvals carry higher default risk.
- Unconstrained: Model approves everyone with predicted default prob < 30 percent.
- Group A approval: 80 percent.
- Group B approval: 60 percent.
- Total Accuracy: 85 percent.
- Constrained (parity): Must approve Group B at 80 percent rate.
- New threshold for Group B: Approve default prob < 50 percent.
- This forces the model to approve many risky applicants in Group B.
- New Total Accuracy: 81 percent.
Systems insight: Fairness is not free. Enforcing parity cost 4 percentage points of accuracy (about a 4.7 percent relative accuracy drop in this credit-scoring scenario). This is the fairness tax, the explicit cost of correcting for historical bias.
Practitioners need formal methods to evaluate fairness given these risks of perpetuating bias. A range of formal criteria have been developed that quantify how models perform across groups defined by sensitive attributes. Before introducing these definitions, it helps to frame the notation as a way to express competing fairness goals, not as a proof exercise.
Systems Perspective 1.1: Fairness notation as engineering vocabulary
Before examining formal definitions, the fundamental challenge is that fairness can mean different operational constraints. A system may treat everyone identically, account for different baseline conditions, optimize equal outcomes, preserve equal opportunity, or enforce equal treatment. These choices lead to different mathematical criteria, each capturing a different aspect of fairness.
The next subsections introduce formal fairness definitions using probability notation. These metrics (demographic parity, equalized odds, equality of opportunity) appear throughout ML fairness literature and shape regulatory frameworks. Focus on understanding the intuition: what each metric measures and why it matters, rather than mathematical proofs. The concrete examples after each definition illustrate practical application. If probability notation is unfamiliar, start with the verbal descriptions and return to the formal definitions later.
Suppose a model \(h(x)\) predicts a binary outcome, such as loan repayment, and let \(A\) represent a sensitive attribute with subgroups \(a\) and \(b\). The field uses three widely adopted fairness definitions:
Demographic parity
Definition 1.3: Demographic parity
Demographic Parity is the fairness constraint where a model’s positive prediction rate is independent of group membership \((\Pr(h(x)=1 \mid A=a) = \Pr(h(x)=1 \mid A=b))\).
- Significance: It is the simplest and most restrictive fairness metric. It requires the model to produce Equal Outcomes across groups, regardless of the underlying base-rate differences in the dataset.
- Distinction: Unlike Equalized Odds (which focuses on error rates like False Positives), Demographic Parity focuses only on the Final Prediction, ignoring the relationship between the prediction and the ground truth.
- Common pitfall: A frequent misconception is that Demographic Parity ensures “fairness.” In reality, it can force the model to sacrifice Calibration: to meet the parity constraint, the model may have to intentionally misclassify qualified individuals in one group or unqualified individuals in another.
Demographic parity asks whether favorable outcomes, such as loan approval or treatment referral, occur at equal rates across subgroups defined by a sensitive attribute \(A\). Formally, the model satisfies demographic parity if: \[ \Pr\big(h(x) = 1 \mid A = a\big) = \Pr\big(h(x) = 1 \mid A = b\big) \]
In the healthcare example, this criterion would ask whether Black and white patients were referred for care at the same rate, regardless of their underlying health needs. That may sound like equal access, but it ignores real differences in medical status and risk, potentially overcorrecting when needs are not evenly distributed. The limitation of ignoring base-rate differences motivates more nuanced fairness criteria.
Equalized odds
Equalized odds requires that the model’s predictions are conditionally independent of group membership given the true label. Specifically, the true positive and false positive rates must be equal across groups: \[ \Pr\big(h(x) = 1 \mid A = a, Y = y\big) = \Pr\big(h(x) = 1 \mid A = b, Y = y\big), \quad \text{for } y \in \{0, 1\}. \]
That is, for each true outcome \(Y = y\), the model should produce the same prediction distribution across groups \(A = a\) and \(A = b\). The model should therefore behave similarly across groups for individuals with the same true outcome, whether they qualify for a positive result or not. It ensures that errors (both missed and incorrect positives) are distributed equally.
Applied to the medical case, equalized odds would ensure that patients with the same actual health needs (the true label \(Y\)) are equally likely to be correctly or incorrectly referred, regardless of race. The original algorithm violated this by under-referring Black patients who were equally or more sick than their white counterparts, highlighting unequal true positive rates.
Equality of opportunity
Equality of opportunity is a less stringent relaxation of equalized odds that focuses only on the true positive rate (Hardt et al. 2016). It requires that, among individuals who should receive a positive outcome, the probability of receiving one is equal across groups: \[ \Pr\big(h(x) = 1 \mid A = a, Y = 1\big) = \Pr\big(h(x) = 1 \mid A = b, Y = 1\big). \]
Equality of opportunity ensures that qualified individuals, who have \(Y = 1\), are treated equally by the model regardless of group membership.
In our running example, this measure would ensure that among patients who do require care, both Black and white individuals have an equal chance of being identified by the model. In the case of the US hospital system, the algorithm’s use of healthcare expenditure as a proxy variable led to a failure in meeting this criterion: Black patients with significant health needs were less likely to receive care due to their lower historical spending. The worked example below uses the same loan decisions to calculate all three criteria, showing why a single model can fail each fairness test in a different way.
Example 1.1: Calculating fairness metrics
Consider a simplified loan approval model evaluated on 200 applicants, evenly split between two demographic groups (Group A and Group B). The model makes predictions, and we later observe actual repayment outcomes:
Group A (100 applicants):
- Model approved: 70 applicants (40 actually repaid, 30 defaulted)
- Model rejected: 30 applicants (5 actually would have repaid, 25 would have defaulted)
Group B (100 applicants):
- Model approved: 40 applicants (30 actually repaid, 10 defaulted)
- Model rejected: 60 applicants (20 actually would have repaid, 40 would have defaulted)
Calculating demographic parity: \[\begin{gather*} \Pr(h(x) = 1 \mid A = a) = \frac{70}{100} = 0.70 \\ \Pr(h(x) = 1 \mid A = b) = \frac{40}{100} = 0.40 \end{gather*}\]
Disparity: \(0.70 - 0.40 = 0.30\) (30 percentage point gap)
The model violates demographic parity by approving Group A applicants at substantially higher rates, regardless of actual repayment ability.
Calculating equality of opportunity (true positive rate):
Among applicants who would actually repay (\(Y=1\)): \[\begin{gather*} \Pr(h(x) = 1 \mid A = a, Y = 1) = \frac{40}{40 + 5} = \frac{40}{45} \approx 0.89 \\ \Pr(h(x) = 1 \mid A = b, Y = 1) = \frac{30}{30 + 20} = \frac{30}{50} = 0.60 \end{gather*}\]
Disparity: \(0.89 - 0.60 = 0.29\) (29 percentage point gap in TPR)
The model violates equality of opportunity: among qualified applicants who would repay, Group A members are correctly approved 89 percent of the time while Group B members are only approved 60 percent of the time.
Calculating equalized odds (true positive rate + false positive rate):
The TPR values are calculated above. For false positive rates among applicants who would not repay (\(Y=0\)): \[\begin{gather*} \Pr(h(x) = 1 \mid A = a, Y = 0) = \frac{30}{30 + 25} = \frac{30}{55} \approx 0.55 \\ \Pr(h(x) = 1 \mid A = b, Y = 0) = \frac{10}{10 + 40} = \frac{10}{50} = 0.20 \end{gather*}\]
The model also has unequal false positive rates: it incorrectly approves 55 percent of Group A applicants who will default, but only 20 percent of Group B applicants who will default. This reveals the model is more “generous” with Group A even when they will not repay.
Systems insight: This model violates all three fairness criteria. Addressing one criterion does not automatically satisfy others. In fact, the impossibility theorems prove these criteria can conflict mathematically.
The worked example above revealed that this loan approval model violates all three fairness criteria simultaneously. This is not merely poor model design but reflects a fundamental mathematical tension that any classifier must confront when base rates differ between groups. These tensions motivate the impossibility results that constrain what any fair classifier can achieve.
These definitions capture different aspects of fairness and are generally incompatible7 (Kleinberg et al. 2016; Chouldechova 2017). A university admissions example illustrates the tension concretely.
7 Fairness Impossibility Theorems: Kleinberg et al. (2016) and Chouldechova (2017) prove incompatibility results for calibrated risk scores and error-rate balance when base rates differ, except in constrained special cases such as perfect prediction or equal base rates. Demographic parity is a distinct constraint on selection rates that can also conflict with calibration or error-rate goals in practice. The systems consequence is fundamental: no amount of engineering can satisfy every normative fairness criterion in all settings, so fairness becomes a constrained multi-objective optimization requiring explicit policy choices about which criterion to prioritize for a given deployment context.
Kleinberg, Jon, Sendhil Mullainathan, and Manish Raghavan. 2016. “Inherent Trade-Offs in the Fair Determination of Risk Scores.” Innovations in Theoretical Computer Science Conference. https://doi.org/10.4230/LIPIcs.ITCS.2017.43.
Chouldechova, Alexandra. 2017. “Fair Prediction with Disparate Impact: A Study of Bias in Recidivism Prediction Instruments.” Big Data 5 (2): 153–63. https://doi.org/10.1089/big.2016.0047.
Goal 1 (Demographic Parity) would be to admit students so that the admitted class reflects the demographics of the applicant pool, perhaps 50 percent from Group A and 50 percent from Group B. Goal 2 (Equal Opportunity) would be to ensure that among all qualified applicants, the admission rate is the same across groups, so that 80 percent of qualified Group A applicants get in and 80 percent of qualified Group B applicants get in. If one group has a higher proportion of qualified applicants, achieving demographic parity (Goal 1) requires rejecting some of their qualified applicants, violating equal opportunity (Goal 2), as figure 1 visualizes. No mathematical fix exists; the choice is a value judgment about which definition of fairness to prioritize.
The fairness impossibility law (Principle 20) generalizes exactly what the admissions example just demonstrated: except in special cases such as equal base rates or perfect prediction, calibrated risk scores generally cannot also satisfy equal error-rate conditions across groups, and demographic parity adds further conflict because it constrains selection rates rather than score calibration or error rates. Satisfying one criterion may preclude another, so engineers must treat fairness metrics like latency budgets, explicit trade-offs chosen by stakeholders, enforced by the system, and monitored for violation. Determining which metric to prioritize requires careful consideration of the application context, potential harms, and stakeholder values as detailed in section 1.6.3.

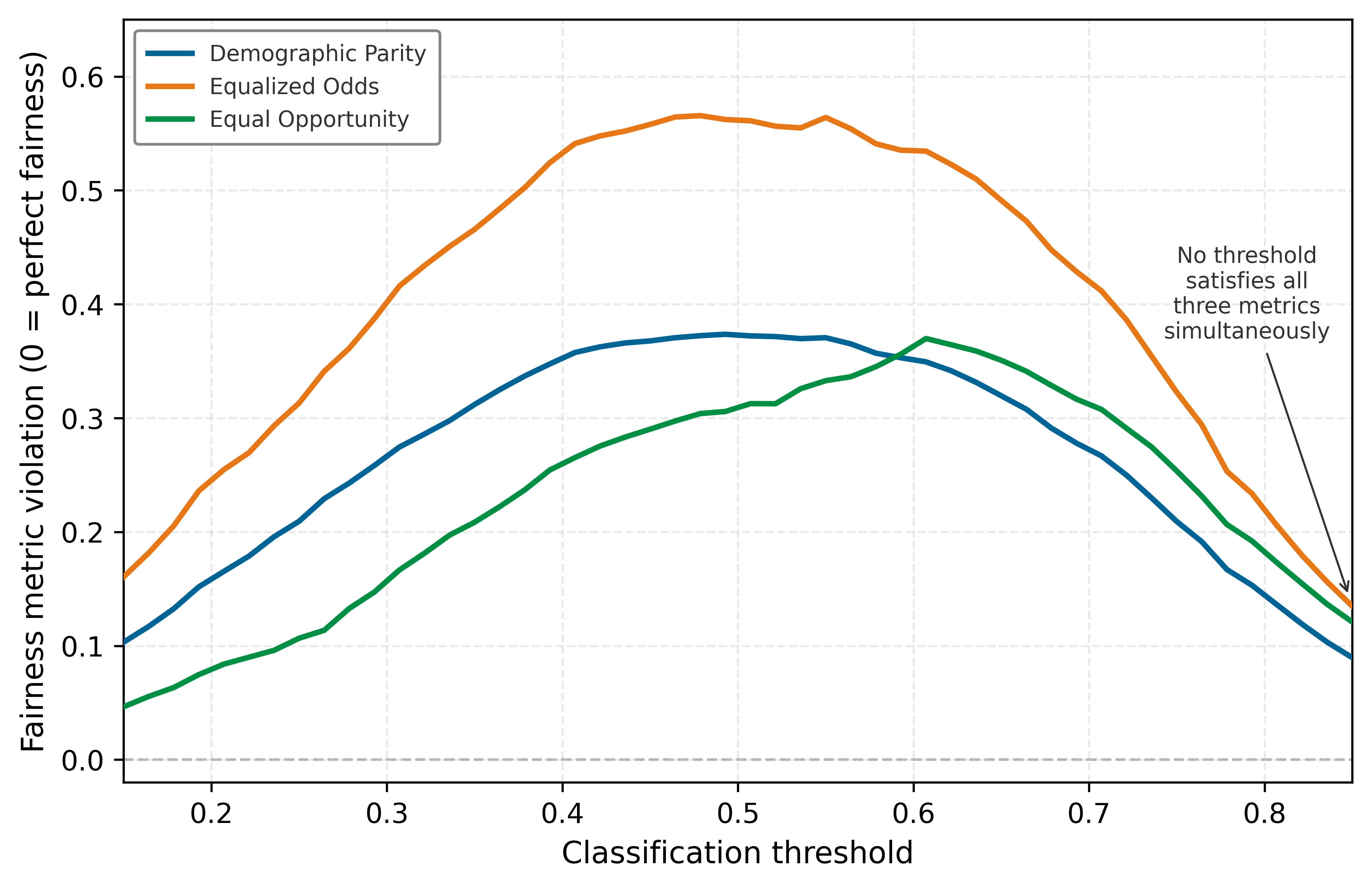
Figure 2 makes this trade-off concrete by sweeping a classification threshold across a synthetic scenario with differing group base rates. At every threshold, at least one fairness metric is substantially violated, illustrating the broader operational lesson: calibrated and equal-error-rate criteria generally conflict under unequal base rates, and selection-rate criteria such as demographic parity add further constraints.
Recognizing these tensions, operational systems must treat fairness as a constraint that informs decisions throughout the machine learning lifecycle. It is shaped by how data are collected and represented, how objectives and proxies are selected, how model predictions are thresholded, and how feedback mechanisms are structured. For example, a choice between ranking vs. classification models can yield different patterns of access across groups, even when using the same underlying data.
Fairness metrics help formalize equity goals but are often limited to predefined demographic categories. In practice, these categories may be too coarse to capture the full range of disparities present in real-world data.
Intersectional fairness
A critical limitation of standard fairness analysis is that it often evaluates single axes of identity (for example, race or gender) independently. This can mask profound disparities that exist at the intersection of these attributes.

Error concentrates at the intersection: dark-skinned women.
Buolamwini, Joy, and Timnit Gebru. 2018. “Gender Shades: Intersectional Accuracy Disparities in Commercial Gender Classification.” Conference on Fairness, Accountability and Transparency, 77–91.
For example, a facial recognition system might have 99 percent accuracy for “Men” and 99 percent accuracy for “Light-Skinned People”, but only 65 percent accuracy for “Dark-Skinned Women” (Buolamwini and Gebru 2018). If the audit only checks Race and Gender separately, the model appears fair. This phenomenon, sometimes called Fairness Gerrymandering, requires evaluating model performance on intersectional subgroups (for example, \(\text{Race}{\times}\text{Gender}\)) to detect and mitigate compounded biases.
A principled approach to fairness must account for overlapping and intersectional identities, ensuring that model behavior remains consistent across subgroups that may not be explicitly labeled in advance. Recent work in this area emphasizes the need for predictive reliability across a wide range of population slices (Hébert-Johnson et al. 2018), reinforcing the idea that fairness must be considered a system-level requirement, not a localized adjustment. This expanded view of fairness highlights the importance of designing architectures, evaluation protocols, and monitoring strategies that support more nuanced, context-sensitive assessments of model behavior.
Quantitative fairness measurement
Formal fairness criteria become operational only when practitioners can measure the degree of violation and establish actionable thresholds for intervention. The resulting mathematical framework quantifies disparities and determines when they warrant corrective action.
Four point metrics turn the fairness criteria from section 1.1.3 into numbers an auditor can threshold. Each one equalizes a different quantity, so each exposes a different failure of the same classifier. Table 2 defines them and scores them on the running loan example, where Group A is approved at 0.70 and Group B at 0.40, qualified-applicant true-positive rates are 0.89 and 0.60, and unqualified-applicant false-positive rates are 0.55 and 0.20.
| Metric | Equalizes | Formula \((a, b)\) | Loan value | Choose it when |
|---|---|---|---|---|
| Disparate impact ratio (four-fifths rule) (Feldman et al. 2015) | lower approval rate divided by higher approval rate | \(\dfrac{\min_g \Pr(h=1 \mid g)}{\max_g \Pr(h=1 \mid g)}\) | \(\dfrac{0.40}{0.70} = 0.57\) | a legally recognized screen is needed; \(\text{DI} < 0.8\) flags disparate impact |
| Statistical parity difference (Calders and Verwer 2010) | additive gap in approval rates | \(\Pr(h=1 \mid a) - \Pr(h=1 \mid b)\) | \(0.70 - 0.40 = 0.30\) | comparing across many groups or tracking drift; common audit threshold \(\lvert\text{SPD}\rvert \leq 0.10\) |
| Equal opportunity difference (Hardt et al. 2016) | true-positive rates among qualified applicants | \(\Pr(h=1 \mid a, Y{=}1) - \Pr(h=1 \mid b, Y{=}1)\) | \(0.89 - 0.60 = 0.29\) | the harm is denying deserving individuals |
| Average odds difference (Hardt et al. 2016; Bellamy et al. 2019; Bird et al. 2020) | both true-positive and false-positive rates | \(\tfrac{1}{2}\big[\,\lvert \Delta\text{TPR}\rvert + \lvert \Delta\text{FPR}\rvert\,\big]\) | \(\tfrac{1}{2}[0.29 + 0.35] = 0.32\) | both error types matter; \(\text{AOD} = 0\) at perfect equalized odds |
Feldman, M., S. A. Friedler, J. Moeller, C. Scheidegger, and S. Venkatasubramanian. 2015. “Certifying and Removing Disparate Impact.” Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 259–68. https://doi.org/10.1145/2783258.2783311.
Calders, Toon, and Sicco Verwer. 2010. “Three Naive Bayes Approaches for Discrimination-Free Classification.” Data Mining and Knowledge Discovery 21 (2): 277–92. https://doi.org/10.1007/s10618-010-0190-x.
Bellamy, Rachel K. E., Kuntal Dey, Michael Hind, Seung Hoffman, Sylvain Houde, Karthikeyan Kannan, Pradeep Lohia, et al. 2019. “AI Fairness 360: An Extensible Toolkit for Detecting and Mitigating Algorithmic Bias.” IBM Journal of Research and Development 63 (4/5): 4:1–15. https://doi.org/10.1147/jrd.2019.2942287.
The four metrics disagree by construction: the disparate impact ratio of 0.57 means the lower-approval group receives approvals at only that fraction of the higher-approval group’s rate, already breaching the four-fifths rule. The additive 0.30 gap, the 0.29 opportunity gap, and the 0.32 average odds gap each quantify a distinct dimension of the same disparity. No single number is sufficient, which is why the impossibility results above force an explicit choice about which metric a deployment will prioritize.
Calibration
A model satisfies score calibration with respect to a sensitive attribute if, among individuals assigned score \(s\) by the model, the fraction with positive outcomes is equal across groups (Kleinberg et al. 2016): \[ \Pr(Y = 1 \mid s(x) = s, A = a) = \Pr(Y = 1 \mid s(x) = s, A = b), \quad \forall s \]
Score calibration is a per-score condition; for hard binary predictions, one related parity condition is equal positive predictive value (precision) among predicted positives, while score calibration is the stronger requirement that the equality holds at every score level: \[ \text{PPV}(a) = \frac{\Pr(Y=1, h(x)=1 \mid A=a)}{\Pr(h(x)=1 \mid A=a)} = \text{PPV}(b) \]
From the loan example: \[\begin{align*} \text{PPV}(a) &= \frac{40}{70} = 0.571 \\ \text{PPV}(b) &= \frac{30}{40} = 0.750 \end{align*}\]
The positive predictive value gap is \(0.750 - 0.571 = 0.179\). Group B’s predicted positives are actually positive 75 percent of the time, while Group A’s are only 57 percent accurate. This violates predictive parity for hard decisions and reveals that the model is less reliable when predicting approval for Group A. Demonstrating score calibration itself would require comparing outcome frequencies within matched score ranges across groups.
Calibration is critical for high stakes decisions where individuals rely on predicted probabilities. A miscalibrated model systematically over or underpredicts risk for specific groups, leading to misallocated resources and eroded trust.
Fairness metrics in practice
Defining these metrics is the easy part; computing them continuously across a deployed fleet is where the engineering cost appears. Before turning to the mechanics of threshold trade-offs and significance testing, it is worth seeing what these metrics demand at production scale, because that cost shapes which of them a system can afford to monitor.
Measurement overhead arises because computing group specific metrics requires maintaining separate statistics for each protected group. For \(k\) groups and \(m\) metrics, this requires \(\mathcal{O}(km)\) additional counters and \(\mathcal{O}(km)\) statistical tests per evaluation cycle. In high throughput systems (>10K QPS), this overhead must be managed through sampling or asynchronous aggregation.
Data requirements pose challenges because fairness auditing requires ground truth labels (\(Y\)) and sensitive attributes \((A)\) for a representative sample. In federated or privacy preserving settings, obtaining this data may conflict with privacy goals. Techniques like encrypted aggregate statistics or differential privacy for group metrics can help reconcile fairness monitoring with privacy requirements.
Sensitive-attribute availability is therefore an engineering design choice, not a background assumption. A system may collect attributes directly with consent, infer them for aggregate audit only, escrow them in a restricted service, compute encrypted or differentially private group statistics, audit offline on sampled labels, or declare a metric unmeasurable for that deployment. Each choice changes both the fairness evidence available to the organization and the privacy risk created by the monitoring pipeline.
Threshold selection demands domain expertise and stakeholder input to establish acceptable disparity thresholds. Legal thresholds (for example, four-fifths rule) provide starting points, but context-specific harm assessments should inform final values. Document threshold rationale to support audits and regulatory compliance.
Temporal stability requires monitoring fairness metrics over time to detect degradation due to distribution shift, feedback loops, or model updates. Continuous monitoring with automated alerting (for example, “alert if \(|\text{SPD}| > 0.15\) for 7 consecutive days”) enables proactive intervention before harms accumulate.
Threshold setting and fairness trade-offs
In practice, fairness metrics can be manipulated by adjusting classification thresholds per group. Given a scoring function \(s(x)\) (for example, predicted probability), define group-specific thresholds \(\tau_{\text{thr},a}\) and \(\tau_{\text{thr},b}\) such that \(h_a(x) = \mathbb{1}[s(x) \geq \tau_{\text{thr},a}]\) for group \(a\) and similarly for group \(b\).
To achieve demographic parity, solve: \[ \Pr(s(x) \geq \tau_{\text{thr},a} \mid A = a) = \Pr(s(x) \geq \tau_{\text{thr},b} \mid A = b) \]
To achieve equal opportunity, solve: \[ \Pr(s(x) \geq \tau_{\text{thr},a} \mid A = a, Y = 1) = \Pr(s(x) \geq \tau_{\text{thr},b} \mid A = b, Y = 1) \]
For equalized odds, both true positive and false positive rate constraints must hold simultaneously. This is a constrained optimization problem that can be solved via postprocessing (Hardt et al. 2016).
Hardt, Moritz, Eric Price, and Nathan Srebro. 2016. “Equality of Opportunity in Supervised Learning.” Advances in Neural Information Processing Systems 29: 3315–23.
However, threshold adjustment has limitations. If base rates differ substantially between groups (that is, \(\Pr(Y=1 \mid A=a) \neq \Pr(Y=1 \mid A=b)\)), achieving one fairness criterion through thresholding will necessarily violate others due to the impossibility theorems. The resulting accuracy cost can be quantified directly.
Example 1.2: Engineering metric: The cost of fairness
Trade-off: Satisfying a fairness constraint often requires deviating from the optimal accuracy threshold. This deviation is the “fairness tax.”
Scenario: A credit model scores applicants from 0 to 100, using the same held-out credit validation set as the fairness-tax example.
- Group A (majority): Mean score 70, High repayment rate. Optimal \(\text{Threshold} = 60\).
- Group B (minority): Mean score 50, Lower repayment rate (due to systemic factors).
Unconstrained optimization (max profit):
- \(\text{Threshold} = 60\) for everyone.
- \(\text{Approval}_A =\) 80 percent, \(\text{Approval}_B =\) 60 percent.
- \(\text{Accuracy} =\) 85 percent.
Fairness constrained (demographic parity):
- Constraint: Group B Approval must equal Group A (80 percent).
- New \(\text{Threshold}_B = 50\).
- Result: Group B false positives increase. Overall accuracy drops to 81 percent.
Systems insight: The “Cost of Fairness” is 4 percentage points of accuracy, about a 4.7 percent relative accuracy drop in this scenario. The engineering decision requires weighing this measured accuracy trade-off against social equity gains.
The preceding example measured the aggregate accuracy drop from imposing demographic parity, but it did not show how the system enforces the constraint at decision time. In practice, equalization requires setting group-specific thresholds: one threshold for the majority group and a different, lower threshold for the minority group. Differential thresholds require access to sensitive attributes at inference time and raise concerns about explicit group-based treatment, which may itself be considered unfair or illegal in certain jurisdictions. The mechanics become clearer in a concrete threshold-setting scenario.
Example 1.3: Threshold for equal opportunity
Consider a credit scoring model that outputs a probability \(s(x) \in [0,1]\). Historical data shows:
Group A: 1000 applicants, 600 would repay (\(Y=1\)), 400 would default (\(Y=0\))
- Score distribution for \(Y=1\): Mean \(\mu_A^+ = 0.72\), SD \(\sigma_A^+ = 0.15\)
- Score distribution for \(Y=0\): Mean \(\mu_A^- = 0.45\), SD \(\sigma_A^- = 0.18\)
Group B: 1000 applicants, 400 would repay (\(Y=1\)), 600 would default (\(Y=0\))
- Score distribution for \(Y=1\): Mean \(\mu_B^+ = 0.65\), SD \(\sigma_B^+ = 0.16\)
- Score distribution for \(Y=0\): Mean \(\mu_B^- = 0.40\), SD \(\sigma_B^- = 0.17\)
Assuming the conditional score distributions are approximately normal with the stated means and standard deviations, using a single threshold \(\tau_{\text{thr}} = 0.60\) for both groups yields true positive rates: \[\begin{align*} \text{TPR}_a &= \Pr(s(x) \geq 0.60 \mid A=a, Y=1) \approx 0.79 \\ \text{TPR}_b &= \Pr(s(x) \geq 0.60 \mid A=b, Y=1) \approx 0.62 \end{align*}\]
This 17 percentage point gap violates equal opportunity. To equalize Group B’s TPR to Group A’s approximately 0.79 rate, we could lower Group B’s threshold to \(\tau_{\text{thr},b} = 0.52\) while keeping \(\tau_{\text{thr},a} = 0.60\). However, this adjustment increases Group B’s false positive rate from about 0.12 to about 0.24, degrading precision for Group B applicants from about 0.78 to about 0.69.
Systems insight: This illustrates the fundamental trade-off: achieving equal opportunity through threshold adjustment comes at the cost of reduced calibration and increased false positives for the group receiving the lower threshold. The decision involves weighing opportunity equity against prediction reliability.
Measuring fairness violations statistically
To determine whether observed disparities are statistically significant rather than sampling noise, practitioners should compute confidence intervals and conduct hypothesis tests. For demographic parity, test the null hypothesis \(H_0: \Pr(h(x)=1 \mid A=a) = \Pr(h(x)=1 \mid A=b)\) using a two-proportion z-test. The test statistic is: \[ z = \frac{\hat{p}_a - \hat{p}_b}{\sqrt{\hat{p}(1-\hat{p})\left(\frac{1}{n_a} + \frac{1}{n_b}\right)}} \]
where \(\hat{p}_a\) and \(\hat{p}_b\) are the sample approval rates, \(\hat{p} = \frac{n_a\hat{p}_a + n_b\hat{p}_b}{n_a + n_b}\) is the pooled proportion, and \(n_a\), \(n_b\) are sample sizes.
For the loan example with \(n_a = n_b = 100\), \(\hat{p}_a = 0.70\), \(\hat{p}_b = 0.40\): \[\begin{align*} \hat{p} &= \frac{100(0.70) + 100(0.40)}{200} = 0.55 \\ z &= \frac{0.70 - 0.40}{\sqrt{0.55(0.45)(0.02)}} = \frac{0.30}{0.0704} = 4.26 \end{align*}\]
With \(z = 4.26\) (far exceeding critical value \(z_{0.05/2} = 1.96\)), we reject \(H_0\) and conclude the demographic parity violation is statistically significant at \(p < 0.001\). Similar tests can be constructed for equal opportunity and equalized odds by restricting to subpopulations where \(Y=1\) or \(Y=0\) respectively. Statistical significance does not imply practical significance; even statistically significant disparities may be acceptable if the magnitude is small. Conversely, large disparities in small samples may not reach statistical significance but still warrant intervention.
The quantitative framework developed here transforms fairness from an abstract principle into measurable engineering constraints. By establishing metrics, thresholds, and statistical tests, practitioners can systematically evaluate fairness throughout the ML lifecycle and make data-driven decisions about when intervention is required.
Napkin Math 1.2: Auditing a confusion matrix
Problem: A fraud detection model operates on two groups. What do demographic parity and equal opportunity reveal about the deployment?
Variables:
- Group A (majority): \(\text{TP}=450\), \(\text{FP}=50\), \(\text{FN}=30\), \(\text{TN}=470\) (\(n_{\text{records}}=1000\)).
- Group B (minority): \(\text{TP}=180\), \(\text{FP}=70\), \(\text{FN}=120\), \(\text{TN}=630\) (\(n_{\text{records}}=1000\)).
Math:
- Demographic parity (positive prediction rate): \(\Pr(\hat{Y}=1)\).
- Group A: \((450+50)/1000 = 0.50\).
- Group B: \((180+70)/1000 = 0.25\).
- Gap: 0.25. (Violates four-fifths rule: \(0.25/0.50 = 0.5 < 0.8\)).
- Equal opportunity (TPR): \(\text{TP} / (\text{TP}+\text{FN})\).
- Group A: \(450 / (450+30) = 0.938\).
- Group B: \(180 / (180+120) = 0.60\).
- Gap: 0.338. (Severe violation).
Systems insight: Fixing TPR requires lowering the threshold for Group B to catch more fraud (reducing FNs). However, this will likely increase FPs (false alarms) for Group B, worsening predictive parity. This is a concrete demonstration of the impossibility theorem: one fairness constraint cannot be changed in isolation.
Fairness considerations extend beyond algorithmic outcomes to encompass the computational resources and infrastructure required to deploy responsible AI systems. These broader equity implications, including environmental justice concerns, arise when energy-intensive AI infrastructure is concentrated in already disadvantaged communities8.
8 Data Center Environmental Justice: A significant fraction of major U.S. cloud computing facilities sit within 16 km of low-income communities, which bear increased air pollution from backup diesel generators and heat from cooling systems. For ML fleet operators, this creates a governance constraint: data center placement decisions that optimize for power cost and latency simultaneously externalize environmental costs onto communities least able to access the AI services those data centers enable.
The computational intensity of responsible AI techniques creates a form of digital divide where access to fair, transparent, and accountable AI systems becomes contingent on economic resources. Implementing fairness constraints, differential privacy mechanisms, and comprehensive explainability tools can increase training, serving, storage, or review costs compared to unconstrained models. Compute-heavy safeguards such as continuous fairness monitoring, differentially private stochastic gradient descent, and on-demand explanations are easier for well-resourced organizations to deploy comprehensively, while resource-constrained deployments may sacrifice safeguards for efficiency. The result can be a two-tiered system where responsible AI is easier to provide to well-resourced users and applications, potentially exacerbating existing inequalities rather than addressing them. These resource constraints create democratization challenges, while the broader implications create digital divide and access barriers affecting underserved communities.
These considerations point to the chapter’s central thesis: every responsible AI property is a system-level property, not a model attribute. Fairness arises from the interaction of data engineering practices, modeling choices, evaluation procedures, and decision policies; it cannot be isolated to a single model component or resolved through post hoc adjustments alone. The same holds for privacy, explainability, robustness, and accountability examined below: each emerges from the whole pipeline rather than residing in the weights. Responsible machine learning design therefore treats fairness as a foundational constraint, one that informs architectural choices, workflows, and governance mechanisms throughout the entire lifecycle of the system. That system-level view translates each principle into concrete engineering requirements across the ML lifecycle: fairness demands group-level performance metrics and different decision thresholds across populations; explainability requires runtime compute budgets whose cost depends on whether the method uses gradients, perturbation sampling, Shapley-value approximation, or exact subset enumeration; privacy encompasses data governance, consent mechanisms, and lifecycle-aware retention policies; and accountability requires traceability infrastructure including model registries, audit logs, and human override mechanisms.
These principles interact and create tensions throughout system development. Privacy-preserving techniques may reduce explainability; fairness constraints may conflict with personalization; robust monitoring increases computational costs. As table 1 demonstrates, each principle manifests across data collection, training, evaluation, deployment, and monitoring phases, reinforcing that responsible AI is not a postdeployment consideration but an architectural commitment. However, the feasibility of implementing these principles depends critically on deployment context: cloud, edge, mobile, and TinyML environments each impose different constraints that shape which responsible AI features are practically achievable.
Privacy and data governance
Privacy and data governance present complex challenges that extend beyond threat-model perspectives, while creating fundamental tensions with the fairness and transparency principles examined above. Security-focused privacy prevents unauthorized access. Responsible privacy decides whether the system should collect a given data field at all and, if it must, how exposure is minimized throughout the lifecycle. This broader perspective creates inherent tensions: fairness monitoring requires collecting and analyzing sensitive demographic data, explainability methods may reveal information about training examples, and comprehensive transparency can conflict with individual privacy rights. Responsible AI systems must navigate these competing requirements through careful design choices that balance protection, accountability, and utility.
Machine learning systems often rely on extensive collections of personal data to support model training and allow personalized functionality. This reliance introduces significant responsibilities related to user privacy, data protection, and ethical data stewardship. The quality and governance of this data directly impacts the ability to implement responsible AI principles. Responsible AI design treats privacy not as an ancillary feature, but as a core constraint that must inform decisions across the entire system lifecycle.
One of the core challenges in supporting privacy is the inherent tension between data utility and individual protection. Rich, high-resolution datasets can enhance model accuracy and adaptability but also heighten the risk of exposing sensitive information, particularly when datasets are aggregated or linked with external sources. For example, large language models trained on broad text corpora have been shown to memorize9 specific strings that can later be retrieved through model queries or adversarial prompting (Carlini et al. 2021).
9 Model Memorization: Carlini et al. (2021) demonstrated that GPT-2 could reproduce verbatim training strings, including contact information, through carefully crafted prompts. The systems implication is narrower but still serious: models that expose generative outputs to user-facing queries can create a privacy attack surface where the serving layer itself becomes a data exfiltration vector, requiring output filtering, rate limiting, and data-minimization controls as defense-in-depth measures.
Carlini, N., F. Tramer, E. Wallace, M. Jagielski, A. Herbert-Voss, K. Lee, A. Roberts, et al. 2021. “Extracting Training Data from Large Language Models.” 30th USENIX Security Symposium (USENIX Security 21), 2633–50.
The privacy challenges extend beyond obvious sensitive data to seemingly innocuous information. Wearable devices that track physiological and behavioral signals, including heart rate, movement, or location, may individually seem benign but can jointly reveal detailed user profiles. These risks are further exacerbated when users have limited visibility or control over how their data is processed, retained, or transmitted.
Addressing these challenges requires understanding privacy as a system principle that entails robust data governance. This includes defining what data is collected, under what conditions, and with what degree of consent and transparency. Foundational data engineering practices, including data validation, schema management, versioning, and lineage tracking, provide the technical infrastructure for implementing these governance requirements. Responsible governance requires attention to labeling practices, access controls, logging infrastructure, and compliance with jurisdictional requirements. These mechanisms serve to constrain how data flows through a system and to document accountability for its use.
Figure 3 outlines key privacy checkpoints in the early stages of a data pipeline, highlighting where safeguards such as differential privacy, federated learning, and secure aggregation reduce attacker visibility into raw personal data. Actual implementations often involve more nuanced trade-offs and context-sensitive decisions, including separate consent and governance controls, but this diagram provides a scaffold for identifying where privacy risks arise and how they can be mitigated through responsible design choices.

The consequences of weak data governance are well documented. Systems trained on poorly understood or biased datasets may perpetuate structural inequities or expose sensitive attributes unintentionally. In the COMPAS example introduced earlier, the lack of transparency surrounding data provenance and usage precluded effective evaluation or redress. In clinical applications, datasets frequently reflect artifacts such as missing values or demographic skew that compromise both performance and privacy. Without clear standards for data quality and documentation, such vulnerabilities become systemic.
Privacy is not solely the concern of isolated algorithms or data processors; it must be addressed as a structural property of the system. Decisions about consent collection, data retention, model design, and auditability all contribute to the privacy posture of a machine learning pipeline. This includes the need to anticipate risks not only during training, but also during inference and ongoing operation. Threats such as membership inference attacks10 underscore the importance of embedding privacy safeguards into both model architecture and interface behavior.
10 Membership Inference Attacks: First demonstrated by Shokri et al. (2017), these attacks determine whether a specific individual’s data was used to train a model by exploiting the confidence gap between seen and unseen inputs. The systems implication: any ML model exposed via an API can become a potential privacy oracle, and determining that someone’s medical record was in a disease prediction model’s training set can reveal sensitive health information. Defenses include differential privacy, regularization, confidence calibration, and interface controls such as rate limiting.
Shokri, Reza, Marco Stronati, Congzheng Song, and Vitaly Shmatikov. 2017. “Membership Inference Attacks Against Machine Learning Models.” 2017 IEEE Symposium on Security and Privacy (SP), 3–18. https://doi.org/10.1109/SP.2017.41.
11 CCPA (California Consumer Privacy Act): CCPA grants California residents rights over covered personal information, including a deletion right subject to statutory exceptions (California Legislature 2023). For ML serving infrastructure, deletion requests create an architectural constraint that must be planned from the data pipeline forward, because raw-record deletion does not automatically remove a record’s influence from trained model parameters.
California Legislature. 2023. California Consumer Privacy Act of 2018. California Legislative Information.
Personal Information Protection Commission, Japan. 2023. Act on the Protection of Personal Information. Personal Information Protection Commission, Japan.
Legal frameworks reflect this understanding. Regulations such as the GDPR, CCPA11, and Japan’s Act on the Protection of Personal Information (APPI) impose specific obligations regarding data minimization, purpose limitation, user consent, and deletion or erasure rights (European Parliament and Council of the European Union 2016; California Legislature 2023; Personal Information Protection Commission, Japan 2023). These requirements translate ethical expectations into enforceable design constraints, reinforcing the need to treat privacy as a core principle in system development.
Privacy is the second instance of the system-level thesis established for fairness in section 1.1.3: it is a commitment that spans consent collection, retention policy, model design, serving, and auditability, not a property of any single stage. It requires coordination across technical and organizational domains to ensure that data usage aligns with user expectations, legal mandates, and societal norms. Rather than viewing privacy as a constraint to be balanced against functionality, responsible system design integrates privacy from the outset by informing architecture, shaping interfaces, and constraining how models are built, updated, and deployed.
Privacy preservation prevents unauthorized data exposure, but responsible systems must also ensure predictable behavior even when privacy mechanisms cannot prevent all risks. A model may satisfy every privacy constraint while still failing catastrophically when encountering unexpected inputs or adversarial conditions. Safety and robustness address this complementary concern: how systems fail, not just how data is protected.
Safety and robustness
Safety and robustness, introduced in Robust AI as technical properties addressing hardware faults, adversarial attacks, and distribution shifts, also serve as responsible AI principles that extend beyond threat mitigation. Technical robustness ensures systems survive adversarial conditions; responsible robustness ensures systems behave in ways aligned with human expectations and values, even when technically functional. A model may be robust to bit flips and adversarial perturbations yet still exhibit behavior that is unsafe for deployment if it fails unpredictably in edge cases or optimizes objectives misaligned with user welfare.
Safety in machine learning refers to the assurance that models behave predictably under normal conditions and fail in controlled, noncatastrophic ways under stress or uncertainty. Closely related, robustness concerns a model’s ability to maintain stable and consistent performance in the presence of variation, whether in inputs, environments, or system configurations. Together, these properties are foundational for responsible deployment in safety critical domains, where machine learning outputs directly affect physical or high stakes decisions.
Ensuring safety and robustness in practice requires anticipating the full range of conditions a system may encounter and designing for behavior that remains reliable beyond the training distribution. This includes not only managing the variability of inputs but also addressing how models respond to unexpected correlations, rare events, and deliberate attempts to induce failure. For example, the NTSB investigation of Uber’s 2018 Tempe crash shows how automated-driving failures can combine perception, prediction, safety-driver, and organizational-control problems rather than reduce to a single model error (National Transportation Safety Board 2019).
12 Adversarial Inputs: First demonstrated by Szegedy et al. (2013), these are imperceptible input perturbations that cause confident misclassification. A perturbation of magnitude 0.005 (in pixel space) can flip a classifier’s output with >99 percent confidence, revealing that neural networks’ decision boundaries are far more fragile than their test-set accuracy suggests. For safety-critical ML systems, this means test accuracy provides no guarantee of deployment robustness, requiring adversarial testing as a separate validation stage.
Szegedy, Christian, Wojciech Zaremba, Ilya Sutskever, Joan Bruna, Dumitru Erhan, Ian Goodfellow, and Rob Fergus. 2013. “Intriguing Properties of Neural Networks.” arXiv Preprint arXiv:1312.6199.
One illustrative failure mode arises from adversarial inputs12: carefully constructed perturbations that appear benign to humans but cause a model to output incorrect or harmful predictions (Szegedy et al. 2013). Such vulnerabilities are not limited to image classification; they have been observed across modalities including audio, text, and structured data, and they reveal the brittleness of learned representations in high-dimensional spaces. Addressing these vulnerabilities requires specialized approaches including adversarial defenses and robustness techniques. These behaviors highlight that robustness must be considered not only during training but as a global property of how systems interact with real-world complexity.
A related challenge is distribution shift13: the inevitable mismatch between training data and conditions encountered in deployment. Whether due to seasonality, demographic changes, sensor degradation, or environmental variability, such shifts can degrade model reliability even in the absence of adversarial manipulation. Addressing distribution shift challenges requires systematic approaches to detecting and adapting to changing conditions.
13 Distribution Shift: The mismatch between training and deployment data distributions, manifesting as covariate shift (input distribution changes), label shift (class proportions change), or concept drift (the input-output relationship evolves over time). The systems consequence is silent degradation: unlike software bugs that crash, distribution shift erodes accuracy over weeks or months without triggering errors, requiring continuous monitoring infrastructure with automated retraining triggers and model versioning to detect and respond.
Responsible machine learning design treats robustness as a systemic requirement. Addressing it requires more than improving individual model performance. It involves designing systems that anticipate uncertainty, surface their limitations, and support fallback behavior when predictive confidence is low. This includes practices such as setting confidence thresholds, supporting abstention from decision-making, and integrating human oversight into operational workflows. These mechanisms are important for building systems that degrade gracefully rather than failing silently or unpredictably.
These individual-model considerations extend to broader system requirements. Safety and robustness also impose requirements at the architectural and organizational level. Decisions about how models are monitored, how failures are detected, and how updates are governed all influence whether a system can respond effectively to changing conditions. Responsible design demands that robustness be treated not as a property of isolated models but as a constraint that shapes the overall behavior of machine learning systems. This system-level perspective on safety and robustness leads to questions of accountability and governance.
Accountability and governance
Accountability in machine learning refers to the capacity to identify, attribute, and address the consequences of automated decisions. It extends beyond diagnosing failures to ensuring that responsibility for system behavior is explicitly assigned, that harms can be remedied, and that ethical standards are maintained through oversight and institutional processes. Without such mechanisms, even well intentioned systems can generate significant harm without recourse, undermining public trust and eroding legitimacy.
Unlike traditional software systems, where responsibility often lies with an identifiable developer or operator, accountability in machine learning is distributed. Model outputs are shaped by upstream data collection, training objectives, pipeline design, interface behavior, and postdeployment feedback. These interconnected components often involve multiple actors across technical, legal, and organizational domains. For example, if a hiring platform produces biased outcomes, accountability may rest not only with the model developer but also with data providers, interface designers, and deploying institutions. Responsible system design requires that these relationships be explicitly mapped and governed.
Inadequate governance can prevent institutions from recognizing or correcting harmful model behavior. The failure of Google Flu Trends to anticipate distribution shift and feedback loops illustrates the consequences of unmodeled changes in user search behavior, media-driven query spikes, and insufficient recalibration against CDC surveillance ground truth (Lazer et al. 2014). Persistent overestimation went uncorrected for years, contributing to the model’s eventual discontinuation.
Lazer, David, Ryan Kennedy, Gary King, and Alessandro Vespignani. 2014. “The Parable of Google Flu: Traps in Big Data Analysis.” Science 343 (6176): 1203–5. https://doi.org/10.1126/science.1248506.
Illinois General Assembly. 2020. Artificial Intelligence Video Interview Act (Public Act 101-0260). 820 ILCS 42, effective January 1, 2020.
Legal frameworks also reflect the necessity of accountable design. Regulations such as the Illinois Artificial Intelligence Video Interview Act (Illinois General Assembly 2020) and the EU AI Act impose requirements for transparency, consent, documentation, and oversight in high risk applications (European Parliament and Council of the European Union 2024). These policies embed accountability not only in the outcomes a system produces, but in the operational procedures and documentation that support its use. Internal organizational changes, including the introduction of fairness audits and the imposition of usage restrictions in targeted advertising systems, demonstrate how regulatory pressure can catalyze structural reforms in governance.
Designing for accountability entails supporting traceability at every stage of the system lifecycle. This includes documenting data provenance, recording model versioning, enabling human overrides, and retaining sufficient logs for retrospective analysis. Tools such as model cards14 (Mitchell et al. 2019) and datasheets for datasets15 (Gebru et al. 2021) exemplify practices that make system behavior interpretable and reviewable. Mitchell and colleagues proposed model cards as short documents accompanying trained ML models that provide benchmarked evaluation across cultural, demographic, and phenotypic groups relevant to intended applications. Similarly, Gebru and colleagues proposed that every dataset be accompanied by a datasheet documenting its motivation, composition, collection process, and recommended uses, analogous to how electronic components include specification sheets. However, accountability is not reducible to documentation alone; it also requires mechanisms for feedback, contestation, and redress.
14 Model Cards: Proposed by Mitchell et al. (2019) as standardized documentation accompanying trained ML models. Each card benchmarks performance across demographic groups, documents intended use cases, and discloses known limitations. For production ML systems, model cards serve as the traceability layer linking a deployed binary to its training provenance, evaluation results, and known failure modes – the minimum metadata required for postdeployment auditing and regulatory compliance.
Mitchell, Margaret, Simone Wu, Andrew Zaldivar, Parker Barnes, Lucy Vasserman, Ben Hutchinson, Elena Spitzer, Inioluwa Deborah Raji, and Timnit Gebru. 2019. “Model Cards for Model Reporting.” Proceedings of the Conference on Fairness, Accountability, and Transparency, 220–29. https://doi.org/10.1145/3287560.3287596.
15 Datasheets for Datasets: Proposed by Gebru et al. (2021), modeled after electronics component datasheets that specify operating conditions and tolerances. Each datasheet documents a dataset’s motivation, composition, collection process, and recommended uses. For ML pipelines, datasheets function as the data equivalent of hardware specs: they define the valid operating envelope of a model’s training distribution, enabling engineers to predict where deployment-time distribution shift will cause failures.
Gebru, Timnit, Jamie Morgenstern, Briana Vecchione, Jennifer Wortman Vaughan, Hanna Wallach, Hal Daumé III, and Kate Crawford. 2021. “Datasheets for Datasets.” Communications of the ACM 64 (12): 86–92. https://doi.org/10.1145/3458723.
Within organizations, governance structures help formalize this responsibility. Ethics review processes, cross-functional audits, and model risk committees provide forums for anticipating downstream impact and responding to new concerns. These structures must be supported by infrastructure that allows users to contest decisions and developers to respond with corrections. For instance, systems that allow explanations or user-initiated reviews help bridge the gap between model logic and user experience, especially in domains where the impact of error is significant.
Architectural decisions also play a role. Interfaces can be designed to surface uncertainty, allow escalation, or suspend automated actions when appropriate. Logging and monitoring pipelines must be configured to detect signs of ethical drift, such as performance degradation across subpopulations or unanticipated feedback loops. In distributed systems, where uniform observability is difficult to maintain, accountability must be embedded through architectural safeguards such as secure protocols, update constraints, or trusted components.
Governance does not imply centralized control. Instead, it involves distributing responsibility in ways that are transparent, actionable, and sustainable. Technical teams, legal experts, end users, and institutional leaders must all have access to the tools and information necessary to evaluate system behavior and intervene when necessary. As machine learning systems become more complex and embedded in important infrastructure, accountability must scale accordingly by becoming a foundational consideration in both architecture and process, not a reactive layer added after deployment.
Despite these governance mechanisms, meaningful accountability faces a challenge: distinguishing between decisions based on legitimate factors vs. spurious correlations that may perpetuate historical biases. This challenge requires careful attention to data quality, feature selection, and ongoing monitoring to ensure that automated decisions reflect fair and justified reasoning rather than problematic patterns from biased historical data.
The principles and techniques examined above provide the conceptual and technical foundation for responsible AI, but their practical implementation depends critically on deployment architecture. Cloud systems can support complex Shapley-value explanations and real-time fairness monitoring, but TinyML devices must rely on static interpretability and compile-time privacy guarantees. Edge deployments enable local privacy preservation but limit global fairness assessment. These architectural constraints are not mere implementation details; they fundamentally shape which responsible AI protections are accessible to different users and applications.
Example 1.4: Choosing a fairness metric
Scenario: A hiring recommendation model must choose the critical fairness metric before launch.
Question: Which metric best matches a setting where qualified candidates should have comparable opportunity across groups?
Answer: Equalized odds is usually most appropriate for hiring because it requires equal true positive rates and false positive rates. Demographic parity can force rejection of qualified candidates when base rates differ, while calibration only ensures that a score such as 0.8 has the same meaning across groups.
The example illustrates why metric selection is a governance decision before it is a computation: the chosen fairness definition determines which error trade-off the system is allowed to make. Selecting the mathematically appropriate fairness metric is the first step, but calculating these metrics requires access to demographic data and significant computational overhead. Enforcing these mathematical guarantees grows far more complex when moving from a centralized cloud environment to constrained, distributed edge deployments where privacy and bandwidth dictate the architecture.
Checkpoint 1.1: Principles as engineering constraints
This section reframed fairness, explainability, transparency, accountability, and value alignment as control-plane invariants rather than post-hoc review items, mapped each across the ML lifecycle, and quantified the fairness tax and the responsible AI overhead.
From principle to mechanism
Judging the trade-off
Self-Check: Question
A product team proposes a release plan: the modeling team owns accuracy during training, a separate compliance team runs a fairness checklist one week before launch, a security team handles privacy, and a documentation team writes model cards after deployment. Based on the lifecycle mapping in this chapter, what is the primary structural failure of this plan?
- Fairness, privacy, and accountability are architectural commitments that must shape data collection, training, and deployment; concentrating them in separate late-stage review teams cannot correct decisions already baked into learned weights and data pipelines.
- Compliance teams are not trained to run fairness checklists, so the checklist will be statistically invalid.
- Model cards are an outdated documentation format that the EU AI Act prohibits for high-risk systems.
- Privacy and fairness belong in the same team, because differential privacy automatically provides demographic parity.
A loan model approves 70 percent of Group A applicants and 40 percent of Group B applicants, regardless of actual repayment outcomes. Applying the formal fairness definitions developed in this chapter, which criterion does this disparity most directly violate?
- Calibration, because approval rates differ across groups
- Equality of opportunity, because true positive rates are not computed
- Demographic parity, because the criterion compares positive prediction rates across groups and the 70 vs 40 gap is exactly that quantity
- Individual fairness, because the criterion requires identical treatment of similar individuals
A bank’s leadership directs engineering to “satisfy demographic parity, equalized odds, and calibration simultaneously” for a credit model whose groups have different base rates of default. Explain why this directive is mathematically impossible and what engineering decision it actually forces.
A responsible AI program integrates each principle at the phase where it is most upstream-enforceable. Order the following lifecycle phases for embedding fairness and privacy commitments: (1) Deployment with threshold policies, (2) Monitoring of subgroup performance, (3) Data collection with representative sampling, (4) Training with bias-aware algorithms, (5) Evaluation with group-level metrics.
A fairness-tax analysis on a credit model reports 85 percent unconstrained accuracy dropping to 81 percent under demographic parity (a 4-point drop). Under the chapter’s framing, what does this 4-point drop correctly represent?
- A bug in the optimizer that better hyperparameters will eliminate
- The quantified cost of enforcing a specific fairness criterion when group base rates differ, making the model’s policy position explicit rather than hidden
- Evidence that demographic parity is the wrong criterion, because any accuracy drop disqualifies a fairness metric
- A transient effect that disappears after one retraining cycle on the same data
Explain why the chapter treats accountability as more than documentation, and identify the specific infrastructure mechanisms that distinguish an accountable system from a merely documented one.
Responsible AI Across Deployment Environments
Auditing a model for bias is straightforward with a massive centralized database and unlimited cloud GPUs. Auditing a federated learning model running on a million individual smartphones, where strict privacy laws prevent access to demographic data, is an entirely different engineering problem. The deployment environment fundamentally dictates which responsible AI techniques are mathematically and legally possible.
These architectural differences redistribute both feasible safeguards and accountable parties. Resource availability, latency constraints, user interface design, and the presence or absence of connectivity determine whether responsible AI principles can be enforced consistently across deployment contexts. The same model may support rich explanation, continuous monitoring, and centralized auditability in the cloud, yet require static validation and simplified safeguards when embedded in a device with intermittent connectivity.
The geographic and economic distribution of computational resources adds another equity layer. High-performance AI systems typically require proximity to major data centers or high-bandwidth internet connections, creating service quality disparities that map closely to existing socioeconomic inequalities. Rural communities, developing regions, and economically disadvantaged areas often experience degraded AI service quality due to network latency, limited bandwidth, and distance from computational infrastructure. US Federal Communications Commission reports have documented persistent broadband disparities, with rural areas substantially less likely than urban areas to have fixed broadband meeting the benchmark used in those reports. For responsible AI, that infrastructure gap determines whether real-time explainability, continuous fairness monitoring, and privacy-preserving computation are practical for the users and communities most affected by automated decisions.
System explainability
The binding constraint on explainability is the deployment environment, not the choice of technique: computational capacity, latency budget, interface design, and data access decide which explanation method, if any, can run. Cloud systems afford heavyweight posthoc methods like Shapley-value attribution (SHAP) and local surrogate explanations (LIME)16; mobile and edge devices can usually afford only single-pass saliency maps17; TinyML devices often support no runtime explanation at all, leaving development-time inspection as the only opportunity. Section 1.5 develops the technique-level mechanics and costs that this matrix presupposes; table 3 records the per-environment feasibility.
16 LIME (Local Interpretable Model-Agnostic Explanations): Introduced by Ribeiro et al. (2016), LIME explains individual predictions by perturbing the input, querying the black-box model many times, and fitting a weighted linear surrogate to approximate local behavior. The systems trade-off is that explanation latency scales with the number of perturbation samples and model-call cost, so production deployments often use sampling budgets, caching, asynchronous explanation workers, or model-specific methods when the architecture permits.
Ribeiro, Marco Tulio, Sameer Singh, and Carlos Guestrin. 2016. “” Why Should i Trust You?” Explaining the Predictions of Any Classifier: Explaining the Predictions of Any Classifier.” Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 1135–44. https://doi.org/10.1145/2939672.2939778.
17 Saliency Maps: Gradient-based explanation that highlights which input regions most influenced a prediction by computing a backward pass – the same infrastructure used for training. Saliency methods are often cheaper than perturbation-heavy or subset-enumeration methods, making them attractive for edge and mobile deployments when the model supports gradients. The trade-off is that raw gradients can be noisy and may highlight input artifacts rather than meaningful features, so smoothing or repeated-gradient variants trade additional compute for more stable visualizations.
Two dimensions the table cannot capture make explainability distinct from the other principles. The first is audience: an end user needs a concise summary (“elevated heart rate during sleep”), while a developer, auditor, or regulator needs attribution maps, concept activations, or decision traces, so the same deployment must often surface two explanation surfaces at once. The second is timing: a drone or industrial control loop has no slack to compute an explanation during operation and can only log internal signals for later analysis, whereas asynchronous systems such as financial risk scoring or medical diagnosis can render a deeper explanation after the decision. Planning for both, within the latency, energy, and interface limits of the deployment, is what makes interpretability a design constraint rather than a postdeployment wish.
Fairness constraints
Fairness presents a parallel deployment problem, and its binding constraint is data visibility. A cloud platform with demographically annotated datasets can compute group-level metrics, run fairness-aware training, and audit posthoc. A federated18 or on-device deployment cannot: no single entity observes the global demographic distribution, so a group-level fairness audit is not merely expensive but mathematically impossible without privacy-preserving aggregation, and fairness must instead be built into training or dataset curation up front. Table 3 records the per-environment differences; two consequences of the data-visibility limit are worth drawing out because they recur across deployments.
18 Federated Learning and Fairness: Google introduced federated learning in 2016 for Gboard, training across many devices without centralizing raw data. The fairness complication is that no single entity observes the complete demographic distribution across participants, making group-level fairness metrics impossible to compute directly without additional protocols. Federated fairness assessment may require privacy-preserving aggregation, secure aggregation, or differential privacy, each of which changes communication, accuracy, and governance trade-offs compared to centralized training.
Dwork, Cynthia, Moritz Hardt, Toniann Pitassi, Omer Reingold, and Richard Zemel. 2012. “Fairness Through Awareness.” Proceedings of the 3rd Innovations in Theoretical Computer Science Conference, 214–26. https://doi.org/10.1145/2090236.2090255.
The first is that decision-threshold policy, not just model quality, determines realized fairness. Even a model with equal accuracy across groups can produce disparate impact under a uniform threshold when score distributions differ, so a mobile loan-approval system may systematically under-approve one group unless group-specific thresholds are reasoned about and embedded in policy in advance. The second is that personalization without global context can quietly compound disparity: locally adapted models aim for individual fairness, where similar individuals receive similar decisions under a task-relevant similarity metric (Dwork et al. 2012), but retraining on the behavior of marginalized users whose data is sparse or noisy can drift toward reinforcing existing gaps. That drift is a feedback loop. A hiring platform that favors candidates from specific institutions amplifies the inequality when retrained on its own biased outcomes, which is why mitigation must span deployment monitoring, data logging, and impact evaluation rather than a single audit. Figure 4 illustrates the bias amplification feedback loop, where each stage amplifies existing bias unless interrupted by the green intervention points.

The cycle in figure 4 reveals why post-hoc fairness audits are insufficient: without intervention at each of the four stages (data, model, predictions, and retraining), each iteration compounds the bias introduced by the previous one, turning a small initial skew into a systematic disparity. Fairness therefore moves from a metric choice to a lifecycle constraint: data visibility determines what can be measured, threshold policy determines where errors land, and feedback infrastructure determines whether disparities decay or compound.
That same deployment split creates the next responsible AI tension. Keeping sensitive data local can protect users, but the locality that supports privacy also removes the global observability that many fairness audits require.
Privacy architectures
Privacy inherits the same centralization trade-off, sharpened. Aggregating data in the cloud enables high-capacity modeling and monitoring but concentrates exposure to breaches and surveillance, so it must be paired with strong encryption, access control, and auditability. Keeping data local on mobile, federated, or TinyML clients reduces that central risk but removes the global observability needed to monitor or enforce compliance, forcing privacy safeguards to be compiled into the model and firmware before deployment, with no runtime channel to adjust them. Table 3 records where each environment lands.
The constraint the table cannot show is that privacy is judged at the serving layer, not just at training time. A model that satisfies every formal privacy definition can still leak: membership inference attacks recover whether a user’s record was in the training set by reading model outputs, so defenses must extend into interface design, rate limiting, and access control. Furthermore, a technically compliant system can still violate user expectations if data collection is opaque, which makes consent surfaces and clear disclosure part of the privacy architecture rather than a UI afterthought.
Privacy protects data flows, but it does not guarantee that the system’s outputs remain reliable when inputs shift, sensors degrade, or adversaries probe the interface. That gap leads from privacy architecture to safety and robustness architecture: the system must also define how it behaves under stress.
Safety and robustness across deployments
The binding constraint on safety and robustness is the latency budget, because it decides which defense can run at all. A cloud service can afford uncertainty estimators, distributional-change detectors, adversarial input filtering, and API19 rate limiting; an autonomous-navigation or control loop with a millisecond budget cannot, and must instead precompute its fallback actions in advance. Table 3 records the per-environment split; at the constrained extreme, TinyML systems have no runtime monitoring or update channel at all, so robustness has to be engineered statically through conservative design and predeployment testing.
19 API Security for ML: ML serving endpoints face attacks absent from traditional APIs, including model extraction through repeated targeted queries and adversarial input injection. Rate limiting, anomaly detection, access controls, and input validation can reduce exposure, but the fundamental trade-off is that making models more accessible for legitimate explainability simultaneously increases the attack surface for model theft and adversarial probing.
20 Abstention: The practice of refusing predictions when confidence falls below a threshold. Abstention can reduce high-risk errors, but only by shifting some cases to fallback infrastructure such as human reviewers, rule-based defaults, or escalation queues. Autonomous vehicles hand control to human drivers; medical AI routes ambiguous cases to specialist review – both requiring the routing logic to execute inside the system’s latency and safety budget.
The consequence the table cannot show is that fallback is itself a latency-budget problem. A delivery robot that abstains20 when pedestrian-detection confidence is low has only solved half the problem; the human reviewer, rule-based default, or escalation queue that catches the abstained case must execute within the same temporal budget as the model it is protecting. A robust system is therefore not one that avoids all errors but one that fails visibly, controllably, and safely, which depends on concrete choices about sensing, confidence estimation, fallback routing, and recovery. Those choices also define the governance surface: the system must specify who can observe harm, who can intervene, and who remains accountable for the outcome.
Governance structures
Accountability is realized through concrete traceability infrastructure, and its binding constraint is how much of that infrastructure the environment can carry. A cloud platform supports model registries, telemetry21 dashboards, and structured event pipelines that trace a prediction back to a specific model, input, or configuration. A TinyML device carries none of that: with no connectivity, persistent storage, or runtime configurability, accountability has to be embedded statically through cryptographic firmware signatures, fixed audit trails, and predeployment documentation, sometimes enforced at manufacturing because no postdeployment correction is possible. Table 3 records where each environment lands on this spectrum.
21 Telemetry in ML Systems: Real-time capture of prediction latencies, accuracy, and resource utilization across deployed models. Alerts typically trigger when accuracy drops more than 5 percent or latency exceeds 200 ms. The accountability challenge emerges at fleet scale: a system serving hundreds of models to diverse users generates millions of telemetry events daily, and tracing a specific harmful prediction back to a root cause (data drift, model regression, or threshold misconfiguration) requires end-to-end lineage infrastructure that most organizations lack.
The deployment that most tests this is mobile, because responsibility is split across a local model, a remote service, and the interface design, so when something goes wrong it is often unclear which layer owns the failure. Governance there depends on accessible recourse pathways and mechanisms for surfacing, explaining, and contesting decisions at the user level, embedded into both the interface and the surrounding service architecture rather than bolted on as a policy overlay. Across every environment, sustaining accountability means planning for failure as deliberately as for success: defining how anomalies are detected, how roles are assigned, how records are maintained, and how remediation occurs, all traceable in logs and enforceable through interfaces. Governance also has to account for the environmental and distributional impacts of infrastructure choices, because organizations deploying AI systems bear responsibility not only for algorithmic outcomes but for the broader effects of resource usage on environmental justice and equitable access.
Design trade-offs
The governance challenges across deployment contexts reveal a general pattern: responsible AI trade-offs are architectural trade-offs. Machine learning systems do not operate in idealized silos; they must navigate competing objectives under finite resources, strict latency requirements, evolving user behavior, and regulatory complexity.
Cloud-based systems often support extensive monitoring, fairness audits, interpretability services, and privacy-preserving tools due to ample computational and storage resources. However, these benefits typically come with centralized data handling, which introduces risks related to surveillance, data breaches, and complex governance. In contrast, on-device systems such as mobile applications, edge platforms, or TinyML deployments provide stronger data locality and user control, but limit postdeployment visibility, fairness instrumentation, and model adaptation.
Tensions between goals often become apparent at the architectural level. For example, systems with real-time response requirements, such as wearable gesture recognition or autonomous braking, cannot afford to compute detailed interpretability explanations during inference. Designers must choose whether to precompute simplified outputs, defer explanation to asynchronous analysis, or omit interpretability altogether in runtime settings.
Conflicts also emerge between personalization and fairness. Systems that adapt to individuals based on local usage data often lack the global context necessary to assess disparities across population subgroups. Ensuring that personalized predictions do not result in systematic exclusion requires careful architectural design, balancing user-level adaptation with mechanisms for group-level equity and auditability.
Privacy and robustness objectives can also conflict. Robust systems often benefit from logging rare events or user outliers to improve reliability. However, recording such data may conflict with privacy goals or violate legal constraints on data minimization. In settings where sensitive behavior must remain local or encrypted, robustness must be designed into the model architecture and training procedure in advance, since post hoc refinement may not be feasible.
The computational demands of responsible AI create tensions that extend beyond technical optimization to questions of environmental justice and equitable access. Energy-efficient deployment often requires simplified models with reduced fairness monitoring capabilities, creating a trade-off between environmental sustainability and ethical safeguards. For example, implementing differential privacy in federated learning can increase per-device energy consumption by 25–40 percent, potentially making such privacy protections prohibitive for battery-constrained devices22.
22 Energy-Privacy Trade-off: Privacy-preserving techniques like differential privacy and secure multi-party computation can increase computation, communication, and battery use. In federated learning on mobile devices, the equity implication is direct: users with older devices, limited data plans, or limited battery life may be excluded from privacy-protected AI services, creating a system where privacy protection becomes contingent on hardware resources.
Together, these deployment examples reveal a broader systems-level challenge. Responsible AI principles cannot be considered in isolation. They interact, and optimizing for one may constrain another. The appropriate balance depends on deployment architecture, stakeholder priorities, domain-specific risks, the consequences of error, and the environmental and distributional impacts of computational resource requirements. Responsible machine learning design therefore depends on making those constraints explicit before choosing methods, so that the resulting system can be evaluated against the deployment context it must actually inhabit.
Table 3 synthesizes deployment trade-offs by comparing how responsible AI principles manifest across Cloud ML, Edge ML, Mobile ML, and TinyML systems. Each setting imposes different constraints on explainability, fairness, privacy, safety, and accountability, based on factors such as compute capacity, connectivity, data access, and governance feasibility.
No deployment context dominates across all principles; each makes different compromises. As table 3 reveals, cloud systems support complex explainability methods (SHAP, LIME) and centralized fairness monitoring but introduce privacy risks through data aggregation. Edge and mobile deployments offer stronger data locality but limit postdeployment observability and global fairness assessment. TinyML systems face the most severe constraints, requiring static validation and compile-time privacy guarantees with no opportunity for runtime adjustment. These constraints are not merely technical limitations but shape which responsible AI features are accessible to different users and applications, creating equity implications where only well-resourced deployments can afford comprehensive safeguards. Understanding these deployment constraints provides necessary context for the technical methods that operationalize responsible AI principles in practice.
| Principle | Cloud ML | Edge ML | Mobile ML | TinyML |
|---|---|---|---|---|
| Explainability | Supports complex models and methods like SHAP and sampling approaches | Needs lightweight, low-latency methods like saliency maps | Requires interpretable outputs for users, often defers deeper analysis to the cloud | Severely limited due to constrained hardware; mostly static or compile-time only |
| Fairness | Large datasets allow bias detection and mitigation | Localized biases harder to detect but allows on-device adjustments | High personalization complicates group-level fairness tracking | Minimal data limits bias analysis and mitigation |
| Privacy | Centralized data at risk of breaches but can use strong encryption and differential privacy methods | Sensitive personal data on-device requires on-device protections | Tight coupling to user identity requires consent-aware design and local processing | Distributed data reduces centralized risks but poses challenges for anonymization |
| Safety | Vulnerable to hacking and large-scale attacks | Real-world interactions make reliability important | Operates under user supervision, but still requires graceful failure | Needs static safety envelopes, watchdogs, and fail-safe behavior |
| Accountability | Corporate policies and audits allow traceability and oversight | Fragmented supply chains complicate accountability | Requires clear user-facing disclosures and feedback paths | Traceability required across long, complex hardware chains |
| Governance | External oversight and regulations like GDPR or CCPA are feasible | Requires self-governance by developers and integrators | Balances platform policy with app developer choices | Relies on built-in protocols and cryptographic assurances |
The deployment analysis establishes a critical insight: the feasibility of a responsible AI technique depends on architectural constraints. A TinyML device cannot run SHAP explanations; an edge system cannot implement real-time fairness monitoring; a mobile application cannot store the audit logs required for comprehensive accountability. Responsible machine learning therefore requires technical methods selected for the constraints just mapped: detecting bias, preserving privacy, ensuring robustness, and providing interpretability only matter operationally when they fit the data quality, compute budget, deployment requirements, and serving stack that determine whether a technique can run.
The need for these methods begins with how models learn. Training data contains historical biases and unfair associations, and a hiring algorithm trained on biased historical data can reproduce discriminatory patterns by associating demographic characteristics with success. The model learns correlations rather than causation, so statistical patterns that reflect unfair social structures can be optimized as if they were meaningful relationships. Traditional machine learning that optimizes only for accuracy therefore creates tension with fairness goals. Effective solutions must integrate the relevant constraint into data collection, training, serving, or monitoring rather than attach it as a secondary correction after training.
The operational techniques that follow fall into three complementary categories, each with distinct trade-offs in accuracy, computational cost, and implementation complexity. Detection methods identify problematic behavior early enough to intervene, providing warning systems for bias, drift, and performance issues. Mitigation techniques prevent or reduce harmful outcomes through algorithmic interventions and robustness enhancements. Validation approaches make system behavior legible to the developers, auditors, regulators, and affected users who evaluate automated decisions.
Computational overhead of responsible AI techniques
The next sections unpack the technical methods in detail, but their systems cost is visible before the implementation details. Table 4 shows the performance impact of responsible AI techniques: detection, mitigation, validation, privacy, and explanation techniques each impose different costs on training, inference, memory, and accuracy. Reading the table first lets engineers evaluate responsible AI methods as deployable system choices rather than as abstract ethical labels.
| Technique | Accuracy Loss | Training Overhead | Inference Cost | Memory Overhead |
|---|---|---|---|---|
| Differential Privacy | 2–5% | 15–30% | Minimal | 10–20% |
| (DP-SGD) | ||||
| Fairness-Aware Training | 1–3% | 5–15% | Minimal | 5–10% |
| (Reweighting/Constraints) | ||||
| Approximate SHAP (Tree/Kernel) | N/A | N/A | 50–200% | 20–100% |
| Exact SHAP | N/A | N/A | 50–1,000× | 50–200% |
| Adversarial Training | 2–5% | 100–300% | Minimal | 50–100% |
| Federated Learning | 5–15% | 200–500% | Minimal | 100–300% |
These overhead ranges should be read as scenario assumptions, not as claims that any cited paper establishes a single universal tax.23 Actual overhead varies significantly based on model architecture, dataset size, attack strength, explanation method, hardware, communication pattern, and implementation quality. The point is architectural: responsible-AI controls consume real training, serving, memory, or review capacity, so they must be budgeted before launch. These overhead figures are also where the equity argument of section 1.1.1.1 becomes concrete: an organization that cannot afford the training, inference, and memory budgets in the table cannot afford the protections either, so the right to a fair or private model tracks the compute budget behind it.
23 Measurement Context: The sizing exercise assumes common production reference points such as GPU training, GPU or CPU inference, image/text/tabular models, and benchmark datasets. These figures are not canonical constants; they are order-of-magnitude planning anchors for deciding whether a safeguard belongs inline, asynchronous, offline, or in the training pipeline.
Because these computational costs and architectural constraints heavily influence system design, engineering teams must carefully select the right tools for their specific deployment reality. Regardless of the environment, the first step in taking corrective action is knowing that a problem exists, making detection methods the foundation for all other responsible AI interventions.
Self-Check: Question
An autonomous drone must react to obstacle detections within a 15 ms control loop. SHAP explanations for its vision model take 200-500 ms. Which responsible AI design choice does the chapter’s framing most strongly support for this deployment?
- Run full SHAP synchronously on every decision, because safety-critical systems must prioritize explanation fidelity over control latency
- Disable all explanation infrastructure, because safety-critical systems should minimize software surface area
- Replace the vision model with a larger ensemble, because ensembles do not require explanation
- Log internal signals, confidence scores, and activations at decision time for asynchronous post-flight analysis, because runtime explanation is infeasible under the 15 ms budget
A federated learning deployment trains across 10 million mobile clients. The privacy architecture forbids sending demographic labels to the coordinating server. Which mechanism most directly explains why group-level fairness monitoring is harder in this setting than in a centralized cloud deployment?
- Clients hold non-IID local data and no single party observes the complete demographic distribution required to compute group-conditioned metrics like equalized odds
- Federated averaging automatically balances group outcomes, so fairness monitoring is unnecessary
- Secure aggregation protocols directly expose subgroup statistics to the server as a side effect
- Differential privacy noise eliminates all subgroup-level signal, so any fairness metric is statistically identical across groups
A team is deploying a keyword-spotting model to a battery-powered microcontroller with 256 KB of RAM, no connectivity, and a manufacturing flashing step as the only update mechanism. Explain how this deployment reshapes responsible AI design choices relative to a cloud-served keyword spotter, and identify three specific mechanisms that must shift upstream.
True or False: Moving an ML service from a cloud deployment to on-device inference simultaneously improves privacy and fairness observability because data stays local.
A health-monitoring wearable retains rare heart-rhythm events in local logs to improve future robustness, but a regional data-protection regulation mandates data minimization for health signals. Which framing best captures the cross-principle tension the chapter highlights for this deployment?
- The tension is apparent only; ensuring robustness and enforcing data minimization always align once the correct compiler flag is set
- The tension is real: logging rare events improves failure diagnosis and robustness, but retaining them violates the data-minimization goal, and the wearable’s offline nature prevents the cloud-style governed logging that would mediate the trade-off
- The tension is irrelevant because wearables are not regulated as medical devices
- The tension disappears if the wearable uses federated learning, because federated learning makes privacy and robustness mutually enforcing
Compare how explainability, fairness monitoring, and privacy are differently constrained between a cloud-hosted recommendation system and a mobile keyboard predictor, and identify which principle each deployment favors by default.
Bias Detection and Fairness Monitoring
A credit scoring model deployed nationally begins rejecting qualified applicants from a specific ZIP code at twice the normal rate. Without bias detection infrastructure, the disparity persists for weeks or months before anyone notices. Bias detection transforms theoretical fairness definitions into live, operational telemetry. Just as a Site Reliability Engineer monitors latency dashboards, a Responsible AI engineer monitors demographic parity dashboards, using slice-based analysis to identify when the model begins failing specific subpopulations.
Bias detection and mitigation
The fairness definitions examined in section 1.1.3 provide mathematical precision for what fairness means: demographic parity, equalized odds, and equality of opportunity are mathematically defined. Practitioners, however, face a practical challenge: computing these metrics on production systems processing thousands of predictions per second. Manual calculation using the formulas above is infeasible at scale. This gap between definition and deployment motivates specialized tooling.
Operationalizing fairness in deployed systems requires more than principled objectives or theoretical metrics; it demands system-aware methods that detect, measure, and mitigate bias across the machine learning lifecycle. Practical bias detection can be implemented using tools like Fairlearn24 (Bird et al. 2020).
24 Fairlearn: Microsoft’s open-source toolkit (2020) for computing fairness metrics and applying mitigation algorithms to scikit-learn compatible models (Bird et al. 2020). The systems integration pattern is that fairness measurement and mitigation wrap the model pipeline instead of living in a separate spreadsheet audit. The practical significance is that fairness monitoring becomes a CI/CD pipeline stage rather than an ad hoc review, enabling automated regression detection when model updates degrade subgroup performance.
Bird, Sarah, Miro Dudı́k, Richard Edgar, Brandon Horn, Roman Lutz, Vanessa Milan, Mehrnoosh Sameki, Hanna Wallach, and Kathleen Walker. 2020. “Fairlearn: A Toolkit for Assessing and Improving Fairness in AI.” Microsoft Technical Report MSR-TR-2020-32.
Listing 1 enables offline or CI-stage fairness audits across demographic groups, revealing concerning disparities where loan approval rates vary dramatically by ethnicity: from 94 percent for Asian applicants to 68 percent for Black applicants. Building on the system-level constraints discussed earlier, fairness must be treated as an architectural consideration that intersects with data engineering, model training, inference design, monitoring infrastructure, and policy governance. While fairness metrics such as demographic parity, equalized odds, and equality of opportunity formalize different normative goals, their realization depends on the architecture’s ability to measure subgroup performance, support adaptive decision boundaries, and store or surface group-specific metadata during runtime; deployment-time monitoring is handled later in this section.
from fairlearn.metrics import MetricFrame, selection_rate
from sklearn.metrics import accuracy_score, precision_score
# Loan approval model evaluation across demographic groups
mf = MetricFrame(
metrics={
"approval_rate": selection_rate,
"accuracy": accuracy_score,
"precision": precision_score,
"false_positive_rate": lambda y_true, y_pred: (
(y_pred == 1) & (y_true == 0)
).sum()
/ (y_true == 0).sum(),
},
y_true=loan_approvals_actual,
y_pred=loan_approvals_predicted,
sensitive_features=applicant_demographics["ethnicity"],
)
# Display performance disparities across ethnic groups
print("Loan Approval Performance by Ethnic Group:")
print(mf.by_group)
# Output shows: Asian: 94% approval, White: 91% approval,
# Hispanic: 73% approval, Black: 68% approvalPractical implementation is often shaped by limitations in data access and system instrumentation. In many real-world environments, especially in mobile, federated, or embedded systems, sensitive attributes such as gender, age, or race may not be available at inference time, making it difficult to track or audit model performance across demographic groups. Data collection and labeling strategies are essential for fairness assessment throughout the model lifecycle. In such contexts, fairness interventions must occur upstream during data curation or training, as postdeployment recalibration may not be feasible. Even when data is available, continuous retraining pipelines that incorporate user feedback can reinforce existing disparities unless explicitly monitored for fairness degradation. For example, an on-device recommendation model that adapts to user behavior may amplify prior biases if it lacks the infrastructure to detect demographic imbalances in user interactions or outputs.
Figure 5 illustrates how fairness constraints can introduce tension with deployment choices. In a binary loan approval system, two subgroups, Subgroup A (represented in blue) and Subgroup B (represented in red), require different decision thresholds to achieve equal true positive rates. Using a single threshold across groups leads to disparate outcomes, potentially disadvantaging Subgroup B. Addressing this imbalance by adjusting thresholds per group may improve fairness, but doing so requires support for conditional logic in the model serving stack, access to sensitive attributes at inference time, and a governance framework for explaining and justifying differential treatment across groups.

Fairness interventions may be applied at different points in the pipeline, but each comes with system-level implications. Preprocessing methods, which rebalance training data through sampling, reweighting, or augmentation, require access to raw features and group labels, often through a feature store or data lake that preserves lineage. These methods are well-suited to systems with centralized training pipelines and high-quality labeled data. In contrast, in-processing approaches embed fairness constraints directly into the optimization objective. These require training infrastructure that can support custom loss functions or constrained solvers and may demand longer training cycles or additional regularization validation. Training techniques and optimization methods, including custom loss functions and constrained optimization, provide the foundation for implementing these fairness-aware training approaches.
At the serving layer, Postprocessing methods, including the application of group-specific thresholds or the adjustment of scores to equalize outcomes, require inference systems that can condition on sensitive attributes or reference external policy rules. This demands coordination between model serving infrastructure, access control policies, and logging pipelines to ensure that differential treatment is both auditable and legally defensible. Model serving architectures, including request routing, feature lookup, and conditional inference paths, detail the infrastructure requirements for implementing such conditional logic in production systems. Any postprocessing strategy must be carefully validated to ensure that it does not compromise user experience, model stability, or compliance with jurisdictional regulations on attribute use.
Scalable fairness enforcement often requires more advanced strategies, such as multicalibration25, which ensures that model predictions remain calibrated across a wide range of intersecting subgroups (Hébert-Johnson et al. 2018). Implementing multicalibration at scale requires infrastructure for dynamically generating subgroup partitions, computing per-group calibration error, and integrating fairness audits into automated monitoring systems. These capabilities are typically only available in large-scale, cloud-based deployments with mature observability and metrics pipelines. In constrained environments such as embedded or TinyML systems, where telemetry is limited and model logic is fixed, such techniques are not feasible and fairness must be validated entirely at design time.
25 Multicalibration: Developed by Hébert-Johnson et al. (2018), this technique seeks calibrated predictions across many computationally identifiable, intersecting subgroups, addressing the failure mode where global calibration masks severe miscalibration for minority intersections. The systems cost comes from repeated subgroup auditing and model updates rather than from a fixed multiplier. Multicalibration is one important scalable approach for diverse platforms where single-axis fairness audits miss compounded disparities, but it is not the only possible fairness strategy.
Hébert-Johnson, U., M. P. Kim, O. Reingold, and G. N. Rothblum. 2018. “Multicalibration: Calibration for the (Computationally-Identifiable) Masses.” In Proceedings of the 35th International Conference on Machine Learning, ICML 2018, Stockholmsmässan, Stockholm, Sweden, July 10-15, 2018, edited by Jennifer G. Dy and Andreas Krause, vol. 80. Proceedings of Machine Learning Research. PMLR.
Across deployment environments, maintaining fairness requires lifecycle-aware mechanisms. Model updates, feedback loops, and interface designs all affect how fairness evolves over time. A fairness-aware model may degrade if retraining pipelines do not include fairness checks, if logging systems cannot track subgroup outcomes, or if user feedback introduces subtle biases not captured by training distributions. Monitoring systems must be equipped to surface fairness regressions, and retraining protocols must have access to subgroup-labeled validation data, which may require data governance policies and ethical review. Implementation of these monitoring systems requires production infrastructure for MLOps practices, while privacy-preserving techniques are essential for federated fairness assessment.
Fairness is not a one-time optimization, nor is it a property of the model in isolation. It emerges from coordinated decisions across data acquisition, feature engineering, model design, thresholding, feedback handling, and system monitoring. Embedding fairness into machine learning systems requires architectural foresight, operational discipline, and tooling that spans the full deployment stack, from training workflows to serving infrastructure to user-facing interfaces.
The sociotechnical implications of bias detection extend far beyond technical measurement. When fairness metrics identify disparities, organizations must navigate complex stakeholder deliberation processes as examined in section 1.6.3. These decisions involve competing stakeholder interests, legal compliance requirements, and value trade-offs that cannot be resolved through technical means alone.
Real-time fairness monitoring architecture
Implementing responsible AI principles in production systems requires architectural patterns that integrate fairness monitoring, explainability, and privacy controls directly into the model serving infrastructure. Figure 6 demonstrates how these responsible AI components integrate with existing ML systems infrastructure, showing the data flow from user requests through anonymization, model inference, fairness monitoring, and explanation generation.

The architecture works because three governance paths share the model serving stack rather than sitting beside it. The data anonymization layer implements privacy-preserving transformations before model inference, using techniques like \(k\)-anonymity26 or differential privacy noise injection. That layer is not free: privacy transformations consume latency, CPU, and memory, so they must be budgeted inside the model-serving SLO rather than treated as an external compliance step.
26 k-Anonymity: A privacy guarantee (Sweeney 2002) ensuring each record is indistinguishable from at least \(k-1\) others by generalizing quasi-identifiers (for example, replacing exact ages with ranges, locations with regions). The systems trade-off is information loss: higher \(k\) values provide stronger indistinguishability but coarsen features and can reduce downstream training signal. For ML preprocessing pipelines, \(k\)-anonymity adds a transformation stage that must balance privacy guarantees against the accuracy impact of coarser features.
Sweeney, Latanya. 2002. “K-ANONYMITY: A MODEL for PROTECTING PRIVACY.” International Journal of Uncertainty, Fuzziness and Knowledge-Based Systems 10 (05): 557–70. https://doi.org/10.1142/s0218488502001648.
Real-time fairness monitoring updates prediction-only metrics such as demographic parity for each prediction, maintaining rolling statistics across protected groups. Label-dependent metrics such as equalized odds and equality of opportunity update asynchronously when delayed outcomes or audited labels arrive, and they remain inactive for groups whose labeled windows are too small to support a stable estimate. The system flags disparities that exceed configurable policy thresholds, while its storage and compute footprint scales with the number of protected groups, decision segments, and retention windows.
The explanation engine generates SHAP or LIME explanations for model decisions, particularly for negative outcomes requiring user recourse. Exact explanations often exceed inline serving budgets, so production systems rely on approximation, caching, sampling, or asynchronous generation to trade latency against fidelity. The implementation that follows should be read as an architectural pattern rather than an API to memorize: fairness metrics enter the serving path, and alerts trigger when thresholds are exceeded. Listing 2 integrates these components into a monitoring system that processes inference requests, computes prediction-time fairness metrics across protected groups, and updates label-dependent metrics such as equalized odds when ground-truth outcomes are available.
import numpy as np
class RealTimeFairnessMonitor:
def __init__(
self,
window_size=1000,
alert_threshold=0.05,
min_labeled_per_group=30,
):
self.window_size = window_size
self.alert_threshold = alert_threshold
self.min_labeled_per_group = min_labeled_per_group
self.window = []
async def process_prediction(
self, prediction, demographics, actual_label=None
):
# Slide a fixed window over the live stream, then re-check
# fairness.
self.window.append((prediction, demographics, actual_label))
self.window = self.window[-self.window_size :]
metrics = self._compute_metrics()
if (
metrics["demographic_parity"] > self.alert_threshold
or metrics["equalized_odds"] > self.alert_threshold
):
await self._trigger_bias_alert(metrics)
return metrics
def _compute_metrics(self):
# Bucket predictions and labels by protected group.
by_group = {}
for pred, demo, label in self.window:
bucket = by_group.setdefault(
demo.get("ethnicity", "unknown"),
{"preds": [], "labels": []},
)
bucket["preds"].append(pred)
if label is not None:
bucket["labels"].append((pred, label))
# Demographic parity: positive-prediction-rate spread.
rates = [
np.mean(d["preds"])
for d in by_group.values()
if d["preds"]
]
parity = max(rates) - min(rates) if len(rates) > 1 else 0.0
return {
"demographic_parity": parity,
"equalized_odds": self._equalized_odds_gap(by_group),
"groups": {
g: len(d["preds"]) for g, d in by_group.items()
},
}
def _equalized_odds_gap(self, by_group):
# Largest TPR/FPR gap across labeled groups; detail omitted.
...
async def _trigger_bias_alert(
self, metrics
): ... # page on-call and append the event to the audit logThis production implementation demonstrates how responsible AI principles translate into concrete system architecture with quantifiable performance impacts. The overhead ranges summarized in table 4 explain why fairness monitoring, privacy transformations, and explanation generation must be provisioned as serving-path capabilities, not added after the model is already deployed. These overheads must be balanced against reliability and compliance requirements when designing production systems.
The monitoring cost is the price of turning fairness from an offline audit into an operational signal. Observation is still not remediation: fairness mitigation continues through preprocessing, in-processing constraints, postprocessing, and ongoing subgroup monitoring. The next layer shifts to a different responsibility boundary, where the system must prevent private data from leaking through logs, outputs, or model weights and must support deletion or revocation when users withdraw data rights.
Checkpoint 1.2: Operationalizing bias detection
This section turned static fairness definitions into live telemetry: slice-based detection with Fairlearn, CI-stage audits, production monitoring of demographic parity and equalized odds, and the distinction between observing a disparity and remediating it.
Detecting the disparity
From signal to action
Self-Check: Question
A credit scoring model deployed nationally begins rejecting qualified applicants from a specific ZIP code at twice the normal rate. Which framing of bias detection does the chapter argue is necessary to catch this pattern in operation?
- Bias detection is primarily a one-time dataset cleaning step performed before the first training run
- Bias detection is a model-compression concern, where the goal is to reduce the runtime footprint of audit code
- Bias detection is live operational telemetry analogous to SRE latency dashboards, with rolling subgroup metrics and threshold-triggered alerts on a standing dashboard
- Bias detection is a feature-hashing technique that removes demographic information so that subgroup comparisons become unnecessary
A team measures demographic parity offline on a fixed test set before launch but ships with no subgroup-labeled telemetry in production. Six months later, a journalist reports that rejection rates for a specific demographic group have doubled. Walk through why the offline audit was insufficient and identify the specific infrastructure gap that allowed the drift to escape detection.
A production fairness-monitoring pipeline processes each prediction through a defined sequence of stages. Order the following stages: (1) Trigger bias alert, (2) Compute rolling subgroup fairness metrics, (3) Capture prediction with subgroup label into the monitoring window, (4) Compare disparity against policy threshold.
A team must choose between reweighting training data (preprocessing) and applying group-specific decision thresholds (post-processing) for the same fairness goal. Which inference-time architectural requirement distinguishes the post-processing approach?
- The serving stack must have access to the sensitive attribute at decision time and run group-conditioned threshold logic with appropriate policy, logging, and legal justification
- The serving stack must implement a larger batch size, because post-processing requires batching
- The serving stack must disable all monitoring, because group-specific thresholds interfere with telemetry
- The serving stack must re-train during every inference request
A team wants to adopt multicalibration to ensure fairness across intersections of demographic attributes (for example, young rural women, older urban men). The chapter treats this as difficult to deploy outside well-resourced cloud systems because:
- Multicalibration only works for linear models with fewer than ten features
- Multicalibration requires enumerating and computing calibration errors over many intersecting subgroup partitions and integrating those audits into automated monitoring, which demands both storage and compute beyond what edge or mobile deployments sustain
- Multicalibration automatically guarantees demographic parity, so platforms rarely need it
- Multicalibration avoids sensitive-attribute handling entirely, making it incompatible with subgroup observability
A team is convinced that switching to a fairer training algorithm will resolve their fairness complaints. Explain why fairness is more accurately described as a property emerging from coordinated decisions across the whole lifecycle, and identify two specific failure modes outside the model that can regress fairness despite a fairness-aware algorithm.
Privacy, Unlearning, and Robustness Mitigations
When a user invokes erasure or deletion rights under privacy laws such as the GDPR, deleting their row from a database is straightforward (European Parliament and Council of the European Union 2016). Deleting their data from the weights of a neural network that has already trained on it is a fundamentally harder problem: the model cannot “forget” a specific face or credit card number through row deletion. The mitigation families differ by the boundary they protect:
- Privacy mechanisms: These controls reduce leakage.
- Unlearning mechanisms: These controls remove or bound retained influence.
- Robustness mechanisms: These controls preserve behavior under stress.
- Validation mechanisms: These controls produce evidence that the safeguards still work.
Machine unlearning27 and privacy preservation address the deletion-and-leakage part of that challenge, providing mechanisms to excise specific training data influence from compiled models.
27 Machine Unlearning: First formalized by Cao and Yang in 2015, this is the ability to remove specific training data influence from a model without full retraining. The naive approach (retrain from scratch) costs the same as the original training run. SISA (Sharded, Isolated, Sliced, and Aggregated) training partitions training into independent shards, reducing unlearning to retraining only the affected shard; in the GPT-scale sizing example below, that reduces the retraining surface dramatically at the cost of model-quality and aggregation trade-offs. For GDPR-compliant ML systems, unlearning latency becomes a service-level concern: deletion requests must be handled within the organization’s applicable legal and policy timelines.
Privacy preservation
Privacy constraints extend across data collection, model behavior, and user interaction. They are shaped not only by ethical and legal obligations, but also by the architectural properties of the system and the context in which it is deployed. Technical methods for privacy preservation aim to prevent data leakage, limit memorization, and uphold user rights such as consent, opt-out, and data deletion, particularly in systems that learn from personalized or sensitive information.
Large language models have been shown to memorize and expose individual training strings, including names, locations, or excerpts of private communication (Carlini et al. 2021). This memorization presents risks for privacy-sensitive text-generating systems, such as assistants trained or adapted on user logs, where training data may encode protected or regulated content. For example, a voice or chat assistant that adapts to user speech or messages may inadvertently retain specific phrases, which could later be extracted through carefully designed prompts or queries.
The memorization risk extends beyond language models. Figure 7 demonstrates that diffusion models trained on image datasets can regenerate visual instances from the training set (Carlini et al. 2023). The left panel is an original training image and the right panel is the diffusion model’s reconstruction of that same instance; their near-identity is the evidence of memorization, since a model that had only learned a general distribution of portraits could not reproduce a specific individual. Such behavior highlights a more general vulnerability: contemporary generative model architectures can internalize and reproduce training data, often without explicit signals or intent, and without easy detection or control.

Carlini, Nicholas, Jamie Hayes, Milad Nasr, Matthew Jagielski, Vikash Sehwag, Florian Tramèr, Borja Balle, Daphne Ippolito, and Eric Wallace. 2023. “Extracting Training Data from Diffusion Models.” 32nd USENIX Security Symposium (USENIX Security 23), 5253–70.
Models are also susceptible to membership inference attacks, in which adversaries attempt to determine whether a specific datapoint was part of the training set (Shokri et al. 2017). These attacks exploit subtle differences in model behavior between seen and unseen inputs. In high stakes applications such as healthcare or legal prediction, the mere knowledge that an individual’s record was used in training may violate privacy expectations or regulatory requirements.
28 Differential Privacy: A mathematical framework introduced by Dwork et al. (2006) that bounds how much a single individual’s inclusion or exclusion can affect a released computation, parameterized by a privacy budget such as \(\epsilon\). DP-SGD adapts that framework to deep learning by clipping per-example gradients and injecting calibrated noise (Abadi et al. 2016). The privacy budget quantifies a trade-off among privacy, utility, and training cost; Apple has publicly described local differential privacy deployments for selected telemetry tasks, but those deployments should not be treated as a universal DP-SGD cost benchmark (Apple Differential Privacy Team 2017).
Dwork, Cynthia, Frank McSherry, Kobbi Nissim, and Adam Smith. 2006. “Calibrating Noise to Sensitivity in Private Data Analysis.” In Theory of Cryptography Conference (TCC), edited by Shai Halevi and Tal Rabin, vol. 3876. Lecture Notes in Computer Science. Springer Berlin Heidelberg. https://doi.org/10.1007/11681878_14.
Abadi, M., A. Chu, I. Goodfellow, H. B. McMahan, I. Mironov, K. Talwar, and L. Zhang. 2016. “Deep Learning with Differential Privacy.” Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, CCS ’16, 308–18. https://doi.org/10.1145/2976749.2978318.
Apple Differential Privacy Team. 2017. Learning with Privacy at Scale. Apple Machine Learning Research.
To mitigate such vulnerabilities, a range of privacy-preserving techniques have been developed. A canonical formal method is differential privacy28, which provides guarantees that the inclusion or exclusion of a single datapoint has a statistically bounded effect on the model’s output. Algorithms such as differentially private stochastic gradient descent (DP-SGD) operationalize this idea for deep learning by clipping gradients and injecting noise during training (Abadi et al. 2016). When the privacy accounting, clipping, and noise calibration are appropriate for the threat model, these methods can limit memorization and reduce the risk of inference attacks.
However, differential privacy introduces significant system-level trade-offs. The noise added during training can degrade model accuracy, increase the number of training iterations, and require access to larger datasets to maintain performance. These constraints are especially pronounced in resource-limited deployments such as mobile, edge, or embedded systems, where memory, compute, and power budgets are tightly constrained. In such settings, it may be necessary to combine lightweight privacy techniques (for example, feature obfuscation, local differential privacy) with architectural strategies that limit data collection, shorten retention, or enforce strict access control at the edge.
Systems Perspective 1.2: The price of privacy
Training a next-word predictor on sensitive messages with DP-SGD (Differentially Private Stochastic Gradient Descent) reduces training-data extraction risk, but the protection is priced in compute and accuracy.
The privacy parameter \(\epsilon\) is the privacy budget. Lower \(\epsilon\) means more privacy but more noise.
Strong privacy (\(\epsilon =\) 1): Gradients are heavily clipped (\(C = 1.0\), clipping 40 percent of updates) and noisy (\(\sigma = 1.0\)). The model requires 3\(\times\) more epochs to converge. Training cost jumps from $4.6M to approximately $13.8M. Accuracy drops 6 percent.
Moderate privacy (\(\epsilon =\) 8, an illustrative setting): Less noise (\(\sigma = 0.5\)). Training overhead is 30 percent. Accuracy drops 1 percent.
Weak privacy (\(\epsilon = 10\)): Minimal noise. Less than 1 percent accuracy loss. Limited formal guarantees.
Privacy is not binary. It is a continuous curve where organizations buy user trust with compute dollars and model accuracy. The key engineering decision is allocating the privacy budget across the system lifecycle: how much \(\epsilon\) to spend during training, how much to reserve for postdeployment queries, and how to communicate these trade-offs to users and regulators.
Privacy enforcement also depends on infrastructure beyond the model itself. Data collection interfaces must support informed consent and transparency. Logging systems must avoid retaining sensitive inputs unless strictly necessary, and must support access controls, expiration policies, and auditability. Model serving infrastructure must be designed to prevent overexposure of outputs that could leak internal model behavior or allow reconstruction of private data. These system-level mechanisms require close coordination between ML engineering, platform security, and organizational governance.
Privacy must be enforced not only during training but throughout the machine learning lifecycle. Retraining pipelines must account for deleted or revoked data, especially in jurisdictions with data deletion mandates. Monitoring infrastructure must avoid recording personally identifiable information in logs or dashboards. Privacy-aware telemetry collection, secure enclave deployment, and per-user audit trails can support these goals, particularly in applications with strict legal oversight.
Architectural decisions also vary by deployment context. Cloud-based systems may rely on centralized enforcement of differential privacy, encryption, and access control, supported by telemetry and retraining infrastructure. In contrast, edge and TinyML systems must build privacy constraints into the deployed model itself, often with no runtime configurability or feedback channel. In such cases, static analysis, conservative design, and embedded privacy guarantees must be implemented at compile time, with validation performed prior to deployment.
The privacy budget therefore stretches across the whole pipeline: technical safeguards, interface controls, logging and retention policies, and regulatory compliance mechanisms must work together to minimize risk throughout the lifecycle of a deployed system. No single mechanism, differential privacy included, suffices on its own.
Privacy preservation techniques create complex sociotechnical tensions that extend well beyond technical implementation. Differential privacy mechanisms may reduce model accuracy in ways that disproportionately affect underrepresented groups, creating conflicts between privacy and fairness objectives. These challenges require ongoing stakeholder engagement as detailed in section 1.6.3, where organizations must navigate competing values around data control, personalization, and regulatory compliance. These privacy challenges become even more complex when considering the dynamic nature of user rights and data governance.
Machine unlearning
The privacy mechanisms examined above protect data during collection and training, but they do not address a temporal problem: when users invoke their legal right to have their data forgotten, models trained on that data retain its influence in their learned parameters. The privacy violation persists even after the raw data is deleted from storage systems. Machine unlearning addresses this temporal dimension of privacy, ensuring that data deletion rights extend beyond databases to the models themselves.
Privacy preservation does not end at training time. In many real-world systems, users may have rights to revoke consent or request deletion of their data, even after a model has been trained and deployed (European Parliament and Council of the European Union 2016; California Legislature 2023). Supporting this requirement introduces a core technical challenge: removing the influence of specific datapoints from a trained model without full retraining, a task that is often infeasible in edge, mobile, or embedded deployments with constrained compute, storage, and connectivity.
Traditional approaches to data deletion assume that the full training dataset remains accessible and that models can be retrained from scratch after removing the targeted records. Figure 8 contrasts traditional model retraining with machine unlearning approaches: while retraining involves reconstructing the model from scratch using a modified dataset, unlearning aims to remove a specific datapoint’s influence without repeating the entire learning process.

The distinction between retraining and unlearning becomes critical in systems with tight latency, compute, or privacy constraints, because the assumptions underlying full retraining rarely hold in practice. Many deployed machine learning systems do not retain raw training data due to security, compliance, or cost constraints. In such environments, full retraining is often impractical and operationally disruptive, especially when data deletion must be verifiable, repeatable, and audit-ready.
Machine unlearning aims to address this limitation by removing the influence of individual datapoints from an already trained model without retraining it entirely (Cao and Yang 2015). Cao and Yang first formalized this problem, proposing a general approach that transforms learning algorithms into summation forms, enabling efficient removal of data influence by retraining only the constituent models containing the targeted information rather than the entire model. Approaches represented by Cao and Yang’s formulation and SISA-style training approximate this behavior by adjusting internal parameters, modifying gradient paths, or isolating and pruning components of the model so that the resulting predictions reflect what would have been learned without the deleted data (Bourtoule et al. 2021). These techniques may require simplified model architectures, additional tracking metadata, or compromise on model accuracy and stability. They also introduce new burdens around verification: how to prove that deletion has occurred in a meaningful way, especially when internal model state is not fully interpretable.
Cao, Yinzhi, and Junfeng Yang. 2015. “Towards Making Systems Forget with Machine Unlearning.” 2015 IEEE Symposium on Security and Privacy, 463–80. https://doi.org/10.1109/sp.2015.35.
Bourtoule, Lucas, Varun Chandrasekaran, Christopher A. Choquette-Choo, Hengrui Jia, Adelin Travers, Baiwu Zhang, David Lie, and Nicolas Papernot. 2021. “Machine Unlearning.” 2021 IEEE Symposium on Security and Privacy (SP), 141–59. https://doi.org/10.1109/sp40001.2021.00019.

SISA unlearning beats full retraining by about 100 times.
Napkin Math 1.3: The cost of forgetting
A user invokes GDPR Article 17 (“Right to Erasure”) on a model trained on 1 TB of data.
Baseline (full retraining): In this sizing scenario, a 175B-parameter model at GPT-3 scale retrains on 1,024 A100 GPUs for approximately 34 days at a cost of roughly $4.6M.
Engineering fix (SISA): Sharded, Isolated, Sliced, and Aggregated training partitions data into \(K =\) 100 independent shards, training 100 sub-models. To delete one datum, retrain only the specific shard containing it (1 percent of data). New cost: $46,000. Time: approximately 8.2 hours.
Trade-off: Accuracy drops 3–7 percent because each sub-model sees less data. Inference slows because predictions must be aggregated across 100 sub-models. For a fleet receiving 1,000 requests/day in erasure traffic, SISA transforms unlearning from “economically impossible” to “manageable operational cost”—at the price of model quality.
The motivation for machine unlearning is reinforced by regulatory frameworks. Deletion or erasure rights under laws such as the General Data Protection Regulation (GDPR), the California Consumer Privacy Act (CCPA), and similar statutes in other jurisdictions can create pressure to account for personal data used in training (European Parliament and Council of the European Union 2016; California Legislature 2023). Machine unlearning is a technical strategy for reducing or removing a deleted record’s influence where model state itself may retain personal data, but the legal requirements are context-dependent and not a universal statutory command to retrain every model. High-profile incidents in which generative models have reproduced personal content or copyrighted data highlight the practical urgency of integrating deletion-aware mechanisms into responsible system design.
From a systems perspective, machine unlearning introduces nontrivial architectural and operational requirements. Systems must be able to track data lineage, including which datapoints contributed to a given model version. This often requires structured metadata capture and training pipeline instrumentation. Additionally, systems must support user-facing deletion workflows, including authentication, submission, and feedback on deletion status. Verification may require maintaining versioned model registries, along with mechanisms for confirming that the updated model exhibits no residual influence from the deleted data. These operations must span data storage, training orchestration, model deployment, and auditing infrastructure, and they must be robust to failure or rollback.
Resource-constrained deployments amplify these challenges further. TinyML systems typically run on devices with no persistent storage, no connectivity, and highly compressed models. Once deployed, they cannot be updated or retrained in response to deletion requests. In such settings, machine unlearning is effectively infeasible postdeployment and must be enforced during initial model development through static data minimization and conservative generalization strategies. Even in cloud-based systems, where retraining is more tractable, unlearning must contend with distributed training pipelines, replication across services, and the difficulty of synchronizing deletion across model snapshots and logs.
Machine unlearning is becoming important for responsible system design despite these challenges. As machine learning systems become more embedded, personalized, and adaptive, the ability to revoke training influence becomes central to maintaining user trust and meeting legal requirements. Critically, unlearning cannot be retrofitted after deployment. It must be considered during the architecture and policy design phases, with support for lineage tracking, re-training orchestration, and deployment roll-forward built into the system from the beginning.
Machine unlearning represents a shift in privacy thinking, from protecting what data is collected to controlling how long that data continues to affect system behavior. This lifecycle-oriented perspective introduces new challenges for model design, infrastructure planning, and regulatory compliance, while also providing a foundation for more user-controllable, transparent, and adaptable machine learning systems. Responsible AI systems must also maintain reliable behavior under challenging conditions, including deliberate attacks.
Adversarial robustness
Adversarial robustness, examined in Robust AI and Security & Privacy as a defense against deliberate attacks, also serves as a foundation for responsible AI deployment. Beyond protecting against malicious adversaries, adversarial robustness ensures models behave reliably when encountering naturally occurring variations, edge cases, and inputs that deviate from training distributions. A model vulnerable to adversarial perturbations reveals fundamental brittleness in its learned representations, a brittleness that compromises trustworthiness even in nonadversarial contexts.
Machine learning models, particularly deep neural networks, are known to be vulnerable to small, carefully crafted perturbations that significantly alter their predictions. These vulnerabilities, first formalized through the concept of adversarial examples (Szegedy et al. 2013), highlight a gap between model performance on curated training data and behavior under real-world variability. A model that performs reliably on clean inputs may fail when exposed to inputs that differ only slightly from its training distribution, differences imperceptible to humans, but sufficient to change the model’s output. NIST’s adversarial machine learning taxonomy treats these failures as part of a broader attack and mitigation landscape that also includes poisoning, privacy attacks, attacker capabilities, and lifecycle stage (Vassilev et al. 2025).
Vassilev, Apostol, Alina Oprea, Alie Fordyce, Hyrum Anderson, Xander Davies, and Maia Hamin. 2025. Adversarial Machine Learning: A Taxonomy and Terminology of Attacks and Mitigations. NIST AI 100-2e2025. National Institute of Standards; Technology. https://doi.org/10.6028/NIST.AI.100-2e2025.
Bhagoji, Arjun Nitin, Warren He, Bo Li, and Dawn Song. 2018. “Practical Black-Box Attacks on Deep Neural Networks Using Efficient Query Mechanisms.” In Computer Vision – ECCV 2018. Springer. https://doi.org/10.1007/978-3-030-01258-8_10.
Tramèr, Florian, Pascal Dupré, Gili Rusak, Giancarlo Pellegrino, and Dan Boneh. 2019. “AdVersarial: Perceptual Ad Blocking Meets Adversarial Machine Learning.” Proceedings of the 2019 ACM SIGSAC Conference on Computer and Communications Security, 2005–21. https://doi.org/10.1145/3319535.3354222.
The threat extends beyond theory. Adversarial examples have been used to manipulate real systems, including content moderation pipelines (Bhagoji et al. 2018), ad-blocking detection (Tramèr et al. 2019), and voice recognition models (Carlini et al. 2016). In safety-important domains such as autonomous driving or medical diagnostics, even rare failures can have high-consequence outcomes, compromising user trust or opening attack surfaces for malicious exploitation.
Figure 9 demonstrates how a visually negligible perturbation can cause confident misclassification, underscoring how subtle changes produce disproportionately harmful effects in safety-critical applications.

At its core, adversarial vulnerability stems from an architectural mismatch between model assumptions and deployment conditions. Many training pipelines assume data is clean, independent, and identically distributed. In contrast, deployed systems must operate under uncertainty, noise, domain shift, and possible adversarial tampering. Robustness, in this context, encompasses not only the ability to resist attack but also the ability to maintain consistent behavior under degraded or unpredictable conditions.
Improving robustness begins at training. Adversarial training, a widely studied technique, augments training data with perturbed examples (Madry et al. 2018). Madry and colleagues formulated adversarial training as a min-max optimization problem, training models against adversarial samples generated with Projected Gradient Descent (PGD)29.
29 PGD (Projected Gradient Descent): The standard first-order adversarial attack, as formalized in Madry et al. (2018), iteratively maximizes loss within an \(L_\infty\) perturbation ball, then projects back to the constraint boundary. Training against PGD examples can add substantial compute because each training step includes an inner adversarial-example search whose cost grows with the number of attack iterations. The result is a model trained for a specific threat model; transfer to unseen attack methods must still be validated rather than assumed.
Madry, Aleksander, Aleksandar Makelov, Ludwig Schmidt, Dimitris Tsipras, and Adrian Vladu. 2018. “Towards Deep Learning Models Resistant to Adversarial Attacks.” International Conference on Learning Representations (ICLR).
Adversarial training provides a principled framework for robust optimization that has become foundational in the field. It helps the model learn more stable decision boundaries but typically increases training time and reduces clean-data accuracy. Implementing adversarial training at scale also places demands on data preprocessing pipelines, model checkpointing infrastructure, and validation protocols that can accommodate perturbed inputs.
Architectural modifications can also promote robustness. Techniques that constrain a model’s Lipschitz constant30, regularize gradient sensitivity, or enforce representation smoothness can make predictions more stable.
30 Lipschitz Constant: A bound on how much a function’s output changes relative to its input: \(\|f(x_1) - f(x_2)\| \leq L_{\text{Lip}} \cdot \|x_1 - x_2\|\). For neural networks, a lower Lipschitz constant \(L_{\text{Lip}}\) limits sensitivity to small perturbations, directly constraining adversarial vulnerability. Techniques such as spectral normalization bound weight matrices to encourage smoother behavior, but the training cost and robustness gain depend on architecture and threat model.
These design changes must be compatible with the model’s expressive needs and the underlying training framework. For example, smooth models may be preferred for embedded systems with limited input precision or where safety-important thresholds must be respected.
At inference time, systems may implement uncertainty-aware decision-making. Models can abstain from making predictions when confidence is low, or route uncertain inputs to fallback mechanisms, such as rule-based components or human-in-the-loop systems. These strategies require deployment infrastructure that supports fallback logic, user escalation workflows, or configurable abstention policies. For instance, a mobile diagnostic app might return “inconclusive” if model confidence falls below a specified threshold, rather than issuing a potentially harmful prediction.
Monitoring infrastructure plays a critical role in maintaining robustness postdeployment. Distribution shift detection, anomaly tracking, and behavior drift analytics allow systems to identify when robustness is degrading over time. Implementing these capabilities requires persistent logging of model inputs, predictions, and contextual metadata, as well as secure channels for triggering retraining or escalation. These tools introduce their own systems overhead and must be integrated with telemetry services, alerting frameworks, and model versioning workflows.
Beyond empirical defenses, formal approaches offer stronger guarantees. Certified defenses31, such as randomized smoothing (Cohen et al. 2019), provide probabilistic assurances that a model’s output will remain stable within a bounded input region.
31 Certified Defenses: Robustness guarantees backed by mathematical proof rather than empirical testing. Randomized smoothing (Cohen et al. 2019) averages predictions over many noise-perturbed inputs, yielding a provable robustness radius within which no adversarial perturbation can change the output. The trade-off is that certification can require many additional model evaluations and may reduce clean accuracy, making certified defenses more natural as offline validation gates or selective serving paths than as universal inline checks.
Cohen, Jeremy, Elan Rosenfeld, and Zico Kolter. 2019. “Certified Adversarial Robustness via Randomized Smoothing.” Proceedings of the 36th International Conference on Machine Learning, Proceedings of machine learning research, vol. 97: 1310–20.
Simpler defenses, such as input preprocessing, filter inputs through denoising, compression, or normalization steps to remove adversarial noise. These transformations must be lightweight enough for real-time execution, especially in edge deployments, and robust enough to preserve task-relevant features. Another approach is ensemble modeling, in which predictions are aggregated across multiple diverse models. This increases robustness but adds complexity to inference pipelines, increases memory footprint, and complicates deployment and maintenance workflows.
System constraints such as latency, memory, power budget, and model update cadence strongly shape which robustness strategies are feasible. Adversarial training increases model size and training duration, which may challenge CI/CD pipelines and increase retraining costs. Certified defenses demand computational headroom and inference time tolerance. Monitoring requires logging infrastructure, data retention policies, and access control. On-device and TinyML deployments, in particular, often cannot accommodate runtime checks or dynamic updates. In such cases, robustness must be validated statically and embedded at compile time.
Robustness emerges from coordination across training, model architecture, inference logic, logging, and fallback pathways. A model that appears robust in isolation may still fail if deployed in a system that lacks monitoring or interface safeguards. Conversely, even a partially robust model can contribute to overall system reliability if embedded within an architecture that detects uncertainty, limits exposure to untrusted inputs, and supports recovery when things go wrong. Responsible design therefore anticipates the ways in which models fail under real-world stress and builds the infrastructure that makes those failures detectable, recoverable, and safe.
Validation approaches
If detection identifies a problem and mitigation attempts to fix it, validation provides the evidence that stakeholders need to understand and audit whether the system is safe to deploy. This constitutes the third pillar of the responsible AI lifecycle. Unlike standard accuracy evaluation, which compresses performance into a single scalar metric, responsible validation is a multi-stakeholder process that interrogates the system’s behavior under constraint. Different stakeholders require different proofs: developers need granular debugging tools to isolate failure modes, auditors require statistical evidence of nondiscrimination for compliance, regulators mandate formal conformity assessments, and end users demand actionable explanations for specific decisions. The evidence bundle can include fairness audits, privacy-budget checks, adversarial and distribution-shift tests, explanation-fidelity checks, and revalidation triggers tied to deployment changes.
The engineering cost of this rigorous validation is substantial. A comprehensive regime that incorporates fairness audits, adversarial robustness testing, and explainability verification extends the model-evaluation phase materially. The investment is justified by where it moves the cost: issues caught in predeployment validation are remediated before release, whereas the same issues surfacing in production carry remediation costs orders of magnitude higher, because a deployed fairness or safety defect must be detected, rolled back across a fleet, and explained to users and regulators rather than fixed in a notebook. Validation is therefore not a one-time gate but a continuous process. A model that passes initial validation can drift into noncompliance as data distributions shift, requiring automated re-validation triggers in the deployment pipeline (ML Operations at Scale).
Table 5 summarizes the evidence bundle by risk class. The table is not a separate checklist; it is a way to make residual risk explicit before deployment.
| Risk class | Evidence artifact | Operational owner |
|---|---|---|
| Fairness | Disaggregated metrics, thresholds, confidence intervals | Product owner and model-risk reviewer |
| Privacy | Privacy budget, deletion evidence, retention and access logs | Data-governance and privacy engineering teams |
| Robustness | Drift tests, corruption tests, canaries, red-team probes | ML platform and incident-response teams |
| Explanation | Fidelity tests, stability checks, recourse documentation | Model team and user-facing operations |
| Governance | Approval record, residual-risk owner, revalidation trigger | Review board or accountable launch authority |
The most visible and computationally demanding form of validation is explainability. While fairness metrics provide aggregate statistical guarantees, explainability offers instance-level validation, allowing users and operators to verify why a specific decision was made. This bridges the gap between statistical correctness and individual trust.
Self-Check: Question
A user invokes GDPR Article 17 (“Right to Erasure”) against an LLM trained on a corpus containing their public posts. Engineering deletes the user’s rows from storage but the LLM can still be prompted to reproduce quoted passages. Why does the chapter treat this as a fundamentally harder systems problem than row deletion?
- Because GDPR rights only apply to databases and do not extend to learned model parameters
- Because trained weights retain the statistical influence of data long after the underlying rows are deleted, so erasure requires changing the learned model state itself, not just the stored records
- Because encrypted storage prevents the user from identifying which row to delete
- Because inference caches always regenerate deleted training examples automatically
A team tightens DP-SGD from \(\varepsilon=8\) (Apple’s keyboard setting, ~30 percent training overhead, ~1 percent accuracy drop) to \(\varepsilon=1\). Based on the chapter’s quantified trade-off, what should they expect?
- Training compute rises to roughly 3\(\times\) the baseline and accuracy drops by around 6 percentage points, because stronger clipping and more injected noise weaken the learning signal per step
- Model size shrinks and serving latency rises slightly
- Cooling and power costs rise while accuracy and convergence are roughly unchanged
- Only post-deployment logging changes; the training run itself is largely unaffected
A 175B-parameter model costs approximately 4.6 million dollars to retrain from scratch. Explain how SISA training changes the cost structure of honoring a GDPR Article 17 deletion request and identify two quality or serving trade-offs the shard-based architecture imposes.
True or False: If a model is trained with strong differential privacy, machine unlearning becomes unnecessary because deletion requests impose no further architectural obligations.
A team wants mathematical guarantees about adversarial robustness. Randomized-smoothing certified defenses provide such guarantees but cost 100–1000\(\times\) more inference compute. Which deployment role does the chapter argue fits this cost profile?
- Input normalization on every serving request, because normalization composes with certified guarantees
- A confidence-threshold abstention layer on every serving request, to bound user exposure
- An offline validation gate run before deployment, where the 100–1000\(\times\) cost is absorbed once rather than per request
- A rate-limiting step at the API boundary, because rate limiting is a form of certified defense
Explain why the chapter treats validation as a distinct third pillar after detection and mitigation, and identify three stakeholder-specific demands that a single aggregate accuracy metric cannot satisfy.
Explainability and Interpretability
A loan officer using a traditional rules-based system can tell an applicant exactly why they were rejected: “Your debt-to-income ratio exceeds 40 percent.” A neural network, however, outputs a rejection based on millions of dense matrix multiplications. Explainability and interpretability are the engineering techniques used to crack open this black box, allowing us to generate mathematically grounded, human-readable justifications for every high-stakes automated decision.
Explainability plays a central role in system validation, error analysis, user trust, regulatory compliance, and incident investigation. In high stakes domains such as healthcare, financial services, and autonomous decision systems, explanations help determine whether a model is making decisions for legitimate reasons or relying on spurious correlations. For instance, an explainability tool might reveal that a diagnostic model is overly sensitive to image artifacts rather than medical features, which is a failure mode that could otherwise go undetected. For qualifying automated decisions under GDPR-style access and notice provisions, systems may need to provide meaningful information about the logic involved, reinforcing the need for systematic support for explanation.
War Story 1.1: Apple Card: The cost of missing explanations
Context: In 2019, Apple and Goldman Sachs faced intense public scrutiny when prominent tech leaders, including Steve Wozniak, reported receiving credit limits 10\(\times\) higher than their spouses despite shared finances and comparable credit profiles (New York State Department of Financial Services 2021).
Failure mode: The controversy centered on the engineering failure that compounded the disparity: when customers called to ask why they were denied, support staff could not answer. The algorithm offered no recourse, no explanation, and no mechanism for appeal.
Consequence: The New York Department of Financial Services investigated and found no fair-lending violations by Apple Card or Goldman Sachs, but the episode still exposed how perceived opacity, poor customer support, and limited recourse can undermine trust in high-stakes automated credit decisions.
Systems lesson: Explainability serves as a customer service interface, not merely a debugging tool. A system that cannot explain its high-stakes decisions is operationally fragile, regardless of its aggregate accuracy. When customers cannot understand or challenge outcomes, the absence of an explanation layer can turn an aggregate model decision into a reputational and governance crisis.
New York State Department of Financial Services. 2021. Report on Apple Card Investigation. New York State Department of Financial Services.
32 Integrated Gradients: An attribution method that integrates gradients along a path from a baseline input to the actual input. Unlike vanilla gradients, it satisfies two axioms (sensitivity and implementation invariance) that guarantee attributions change when features matter and remain consistent across functionally equivalent models (Sundararajan et al. 2017). The cost is higher than a single raw-gradient explanation because the method evaluates the model at multiple points along the baseline-to-input path, typically 50–300 discrete steps, making it better suited to bounded explanation budgets than to every inline prediction.
Sundararajan, Mukund, Ankur Taly, and Qiqi Yan. 2017. “Axiomatic Attribution for Deep Networks.” Proceedings of the 34th International Conference on Machine Learning, Proceedings of machine learning research, vol. 70: 3319–28.
33 GradCAM (Gradient-Weighted Class Activation Mapping): Selvaraju et al. (2017) generalized Class Activation Mapping to any convolutional neural network (CNN) architecture by using gradients flowing into the final convolutional layer to produce spatial importance maps. Because it reuses gradient computation, GradCAM can be far cheaper than perturbation-heavy explanation methods, but whether it fits real-time medical imaging or autonomous-vehicle pipelines depends on the model, hardware, batch size, and explanation-frequency budget.
Selvaraju, R. R., M. Cogswell, A. Das, R. Vedantam, D. Parikh, and D. Batra. 2017. “Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization.” 2017 IEEE International Conference on Computer Vision (ICCV), 618–26. https://doi.org/10.1109/iccv.2017.74.
Explainability methods can be broadly categorized based on when they operate and how they relate to model structure. Post-hoc methods are applied after training and treat the model as a black box. These methods do not require access to internal model weights and instead infer influence patterns or feature contributions from model behavior. Common post-hoc techniques include feature attribution methods such as input gradients, Integrated Gradients32 (Sundararajan et al. 2017), GradCAM33 (Selvaraju et al. 2017), LIME (Ribeiro et al. 2016), and SHAP (Lundberg and Lee 2017). Sundararajan and colleagues introduced Integrated Gradients by identifying two fundamental axioms—Sensitivity and Implementation Invariance—that attribution methods should satisfy, demonstrating that most prior methods violated these properties.
Posthoc approaches are widely used in image and tabular domains, where explanations can be rendered as saliency maps or feature rankings. To illustrate how SHAP attribution works in practice, consider a trained random forest model predicting loan approval (\(\text{approve}=1\), \(\text{deny}=0\)) based on three features: income, debt_ratio, and credit_score. For a specific applicant who was denied, with income of $45,000, debt ratio of 0.55 (55 percent of income goes to debt), and credit score of 620, the model predicts denial with probability 0.92. SHAP values, based on Shapley values from cooperative game theory, measure each feature’s contribution to moving the prediction from a baseline (average prediction across all training data, \(\Pr(\text{approve}) = 0.50\)) to this individual prediction.
The SHAP framework34 computes each feature’s contribution by evaluating the model on all possible feature subsets. Starting from the baseline prediction of 0.50, adding income ($45K, slightly below average) decreases approval probability by 0.05.
34 Shapley Values: From cooperative game theory, Shapley values fairly distribute a payoff among players based on marginal contributions across all possible orderings. In ML explainability, features are “players” and the prediction is the “payoff.” The mathematical guarantees (efficiency, symmetry, null player) make SHAP a widely used attribution framework with clear axiomatic appeal, but exact subset enumeration grows as \(2^n\) for \(n\) features, which is why production systems often rely on model-specific algorithms, sampling approximations, caching, or asynchronous explanation paths (Lundberg and Lee 2017).
Lundberg, Scott M., and Su-In Lee. 2017. “A Unified Approach to Interpreting Model Predictions.” Advances in Neural Information Processing Systems 30: 4765–74.
Adding debt_ratio (0.55, high) strongly decreases approval by an additional 0.25. Adding credit_score (620, below threshold) moderately decreases approval by 0.12. The final prediction becomes \(0.50 - 0.05 - 0.25 - 0.12 = 0.08\), corresponding to \(\Pr(\text{deny}) = 0.92\). This reveals that the high debt ratio contributed most strongly to the denial (-0.25), followed by the below-average credit score (-0.12), while income had minimal impact (-0.05). Such explanations are actionable: reducing debt ratio below 40 percent would likely flip the decision.
However, this rigor comes at significant computational cost. This 3-feature example requires evaluating \(2^3 = 8\) feature subsets. For a model with 20 features, exact enumeration requires \(2^{20} \approx 1\) million subset evaluations. Tree-based SHAP implementations exploit model structure to reduce this to polynomial time, but deep learning models typically require approximation algorithms (KernelSHAP, DeepSHAP) with sampling-based estimation. While SHAP provides theoretically grounded, additive feature attribution that satisfies desirable properties (local accuracy, missingness, consistency), these costs make SHAP impractical for real-time explanation in high-throughput systems without approximation, caching, or asynchronous serving strategies.
Another posthoc approach involves counterfactual explanations35, which describe how a model’s output would change if the input were modified in specific ways. These are especially relevant for decision-facing applications such as credit or hiring systems. For example, a counterfactual explanation might state that an applicant would have received a loan approval if their reported income were higher or their debt lower (Wachter et al. 2017). Counterfactual generation requires access to domain-specific constraints and realistic data manifolds, making integration into real-time systems challenging.
35 [offset=4mm] Counterfactual Explanations: Formalized for ML by Wachter et al. (2017), counterfactuals answer “what would need to change?” rather than “why did this happen?” For regulatory compliance, they can provide actionable recourse: “if the applicant’s income were $5,000 higher, the loan would be approved.” Generating counterfactuals requires solving a constrained optimization problem that finds a feasible input change that flips the output, so latency and reliability depend on feature dimensionality, domain constraints, and whether immutable or monotone attributes are enforced.
Wachter, Sandra, Brent Mittelstadt, and Chris Russell. 2017. “Counterfactual Explanations Without Opening the Black Box: Automated Decisions and the GDPR.” SSRN Electronic Journal 31: 841. https://doi.org/10.2139/ssrn.3063289.
Kim, B., M. Wattenberg, J. Gilmer, C. Cai, J. Wexler, F. Viegas, and R. Sayres. 2018. “Interpretability Beyond Feature Attribution: Quantitative Testing with Concept Activation Vectors (TCAV).” Proceedings of the 35th International Conference on Machine Learning (ICML) 80: 2668–77.
A third class of techniques relies on concept-based explanations, which attempt to align learned model features with human-interpretable concepts. For example, TCAV represents user-defined concepts as concept activation vectors and tests how sensitive a model’s predictions are to those concepts in its internal representation (Kim et al. 2018). These methods are especially useful in domains where subject matter experts expect explanations in familiar semantic terms. However, they require training data with concept annotations or auxiliary models for concept detection, which introduces additional infrastructure dependencies.
While posthoc methods are flexible and broadly applicable, they come with limitations. Because they approximate reasoning after the fact, they may produce plausible but misleading rationales. Their effectiveness depends on model smoothness, input structure, and the fidelity of the explanation technique. These methods are often most useful for exploratory analysis, debugging, or user-facing summaries, not as definitive accounts of internal logic.
In contrast, inherently interpretable models are transparent by design. Examples include decision trees, rule lists, linear models with monotonicity constraints, and k-nearest neighbor classifiers. These models expose their reasoning structure directly, enabling stakeholders to trace predictions through a set of interpretable rules or comparisons. In regulated or safety-important domains such as recidivism prediction or medical triage, inherently interpretable models may be preferred, even at the cost of some accuracy (Rudin 2019). However, these models generally do not scale well to high-dimensional or unstructured data, and their simplicity can limit performance in complex tasks.
Rudin, C. 2019. “Stop Explaining Black Box Machine Learning Models for High Stakes Decisions and Use Interpretable Models Instead.” Nature Machine Intelligence 1 (5): 206–15. https://doi.org/10.1038/s42256-019-0048-x.
Figure 10 visualizes the relative interpretability of different model types along a spectrum: decision trees and linear regression offer transparency by design, whereas more complex architectures like neural networks and convolutional models require external techniques to explain their behavior. This distinction is central to choosing an appropriate model for a given application, particularly in settings where regulatory scrutiny or stakeholder trust is paramount.

Hybrid approaches aim to combine the representational capacity of deep models with the transparency of interpretable components. Concept bottleneck models (Koh et al. 2020), for example, first predict intermediate, interpretable variables and then use a simple classifier to produce the final prediction. ProtoPNet models (Chen et al. 2019) classify examples by comparing them to learned prototypes, offering visual analogies for users to understand predictions. These hybrid methods are attractive in domains that demand partial transparency, but they introduce new system design considerations, such as the need to store and index learned prototypes and surface them at inference time.
Koh, Pang Wei, Thao Nguyen, Yew Siang Tang, Stephen Mussmann, Emma Pierson, Been Kim, and Percy Liang. 2020. “Concept Bottleneck Models.” Proceedings of the 37th International Conference on Machine Learning, ICML 2020, 13-18 July 2020, Virtual Event, Proceedings of machine learning research, vol. 119: 5338–48.
Chen, Chaofan, Oscar Li, Daniel Tao, Alina Barnett, Cynthia Rudin, and Jonathan Su. 2019. “This Looks Like That: Deep Learning for Interpretable Image Recognition.” In Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, December 8-14, 2019, Vancouver, BC, Canada, edited by Hanna M. Wallach, Hugo Larochelle, Alina Beygelzimer, Florence d’Alché-Buc, Emily B. Fox, and Roman Garnett. Curran Associates.
Olah, C., N. Cammarata, L. Schubert, G. Goh, M. Petrov, and S. Carter. 2020. “Zoom in: An Introduction to Circuits.” Distill 5 (3): e00024–001. https://doi.org/10.23915/distill.00024.001.
Geiger, Atticus, Hanson Lu, Thomas Icard, and Christopher Potts. 2021. “Causal Abstractions of Neural Networks.” In Advances in Neural Information Processing Systems 34: Annual Conference on Neural Information Processing Systems 2021, NeurIPS 2021, December 6-14, 2021, Virtual, edited by Marc’Aurelio Ranzato, Alina Beygelzimer, Yann N. Dauphin, Percy Liang, and Jennifer Wortman Vaughan. Curran Associates.
Work such as Olah et al. and Geiger et al. applies mechanistic interpretability to reverse-engineer the internal operations of neural networks. This line of work, inspired by program analysis and neuroscience, attempts to map neurons, layers, or activation patterns to specific computational functions (Olah et al. 2020; Geiger et al. 2021). Many examples focus on large foundation models where traditional interpretability tools are insufficient, but the systems obligation is broader: instrumentation, storage, and causal tests must make internal mechanisms auditable.
From a systems perspective, explainability introduces a number of architectural dependencies. Explanations must be generated, stored, surfaced, and evaluated within system constraints. The required infrastructure may include explanation APIs, memory for storing attribution maps, visualization libraries, and logging mechanisms that capture intermediate model behavior. Models must often be instrumented with hooks or configured to support repeated evaluations, particularly for explanation methods that require sampling, perturbation, or backpropagation.

Exact SHAP cost explodes with feature count.
These requirements interact directly with deployment constraints and impose performance costs that must be factored into system design. SHAP and LIME can require repeated model evaluations, perturbation sampling, surrogate fitting, or subset enumeration, while counterfactual methods require constrained optimization (Lundberg and Lee 2017; Ribeiro et al. 2016; Wachter et al. 2017). In production deployments, these costs translate into concrete architecture choices: explanations may need asynchronous workers, sampled explanation rates, caching, or separate models chosen partly for interpretability.
For resource-constrained environments, gradient-based attribution methods offer more efficient alternatives by reusing backpropagation infrastructure from training. However, these methods are less reliable for complex models and may produce inconsistent explanations across model updates. Edge deployments often implement explainability through precomputed rule approximations or simplified decision boundaries, sacrificing explanation fidelity for feasible latency profiles.
Storage requirements also scale significantly with explanation needs. Storing SHAP values for tabular data requires approximately 4–8 bytes per feature per prediction, so monthly storage is 30 million predictions times the feature count times 4–8 bytes for a system logging 1 million predictions daily. Gradient attribution maps for images can require 1–10 MB per explanation depending on resolution; logging every image explanation at the same 1 million-per-day rate would require roughly 30–300 TB per month unless explanations are sampled, compressed, or retained for a shorter window. These volumes necessitate careful data lifecycle management and retention policies.
Explainability spans the full machine learning lifecycle. During development, interpretability tools are used for dataset auditing, concept validation, and early debugging. At inference time, they support accountability, decision verification, and user communication. Postdeployment, explanations may be logged, surfaced in audits, or queried during error investigations. System design must support each of these phases, ensuring that explanation tools are integrated into training frameworks, model serving infrastructure, and user-facing applications.
Compression and optimization techniques also affect explainability. Pruning, quantization, and architectural simplifications often used in TinyML or mobile settings can distort internal representations or disable gradient flow, degrading the reliability of attribution-based explanations. In such cases, interpretability must be validated postoptimization to ensure that it remains meaningful and trustworthy. If explanation quality is important, these transformations must be treated as part of the design constraint space.
Explainability therefore lands the same way the chapter’s other properties do: it is budgeted serving-path infrastructure, not a feature appended after the model works. Designing for interpretability requires careful decisions about who needs explanations, what kind of explanations are meaningful, and how those explanations can be delivered given the system’s latency, compute, and interface budget. As machine learning becomes embedded in important workflows, the ability to explain becomes a core requirement for safe, trustworthy, and accountable systems.
The sociotechnical challenges of explainability center on the gap between technical explanations and human understanding. While algorithms can generate feature attributions and gradient maps, stakeholders often need explanations that align with their mental models, domain expertise, and decision-making processes. A radiologist reviewing an AI-generated diagnosis needs explanations that reference medical concepts and visual patterns, not abstract neural network activations. This translation challenge requires ongoing collaboration between technical teams and domain experts to develop explanation formats that are both technically accurate and practically meaningful. Explanations can shape human decision-making in unexpected ways, creating new responsibilities for how explanatory information is presented and interpreted. Because explanations are evidence rather than control actions, they must feed a monitoring system that detects when responsible behavior changes after deployment.
Model performance monitoring
Training-time evaluations, no matter how rigorous, do not guarantee reliable model performance once a system is deployed. Real-world environments are dynamic: input distributions shift due to seasonality, user behavior evolves in response to system outputs, and contextual expectations change with policy or regulation. These factors can cause predictive performance and system trustworthiness to degrade over time. A model that performs well under training or validation conditions may still make unreliable or harmful decisions in production.
The implications of such drift extend beyond raw accuracy. Fairness guarantees may break down if subgroup distributions shift relative to the training set, or if features that previously correlated with outcomes become unreliable in new contexts. Interpretability demands may also evolve, for instance as new stakeholder groups seek explanations, or as regulators introduce new transparency requirements. Trustworthiness, therefore, is not a static property conferred at training time, but a dynamic system attribute shaped by deployment context and operational feedback.
To ensure responsible behavior over time, machine learning systems must incorporate mechanisms for continual monitoring, evaluation, and corrective action. Monitoring involves more than tracking aggregate accuracy; it requires surfacing performance metrics across relevant subgroups, detecting shifts in input distributions, identifying anomalous outputs, and capturing meaningful user feedback. These signals must then be compared to predefined expectations around fairness, robustness, and transparency, and linked to actionable system responses such as model retraining, recalibration, or rollback.
Implementing effective monitoring depends on robust infrastructure. Systems must log inputs, outputs, and contextual metadata in a structured and secure manner, feeding a continuous observability pipeline (figure 11).

This requires telemetry pipelines that capture model versioning, input characteristics, prediction confidence, and postinference feedback. These logs support drift detection and provide evidence for retrospective audits of fairness and robustness. Monitoring systems must also be integrated with alerting, update scheduling, and policy review processes to support timely and traceable intervention.
Monitoring also supports feedback-driven improvement. For example, repeated user disagreement, correction requests, or operator overrides can signal problematic behavior. This feedback must be aggregated, validated, and translated into updates to training datasets, data labeling processes, or model architecture. However, such feedback loops carry risks: biased user responses can introduce new inequities, and excessive logging can compromise privacy. Designing these loops requires careful coordination between user experience design, system security, and ethical governance.

Responsible AI monitoring becomes its own production data system.
At the scale of a global production fleet, responsible AI monitoring becomes a massive data engineering challenge. A platform serving roughly 864 million inferences per day at 10,000 QPS across 50 distinct demographic subgroups must track at least 150 metrics continuously (for example, false positive rate, true positive rate, and calibration error for each of the 50 groups). Even with a 1 percent sampling rate, this generates 8.64 million monitoring events daily. Storing the necessary metadata—prediction inputs, confidence scores, ground truth labels, and sensitive attributes—at a modest 200 bytes per record requires approximately 1.7 GB per day of storage, while full audit logging can consume substantially more. This scale introduces a meta-monitoring problem: the monitoring infrastructure itself becomes a complex distributed system that must be reliable, secure, and cost-effective. With 150 active metrics, a standard false alarm rate of just 5 percent would trigger roughly 7.5 spurious alerts every day, leading to severe alert fatigue. Effective monitoring therefore requires intelligent aggregation, hierarchical alerting logic, and automated root cause analysis to distinguish genuine fairness drift from statistical noise.
Monitoring mechanisms vary by deployment architecture. In cloud-based systems, rich logging and compute capacity allow for real-time telemetry, scheduled fairness audits, and continuous integration of new data into retraining pipelines. These environments support dynamic reconfiguration and centralized policy enforcement. However, the volume of telemetry may introduce its own challenges in terms of cost, privacy risk, and regulatory compliance.
In mobile systems, connectivity is intermittent and data storage is limited. Monitoring must be lightweight and resilient to synchronization delays. Local inference systems may collect performance data asynchronously and transmit it in aggregate to backend systems. Privacy constraints are often stricter, particularly when personal data must remain on-device. These systems require careful data minimization and local aggregation techniques to preserve privacy while maintaining observability.
Edge deployments, such as those in autonomous vehicles, smart factories, or real-time control systems, demand low-latency responses and operate with minimal external supervision. Monitoring in these systems must be embedded within the runtime, with internal checks on sensor integrity, prediction confidence, and behavior deviation. These checks often require low-overhead implementations of uncertainty estimation, anomaly detection, or consistency validation. System designers must anticipate failure conditions and ensure that anomalous behavior triggers safe fallback procedures or human intervention.
TinyML systems, which operate on deeply embedded hardware with no connectivity, persistent storage, or dynamic update path, present the most constrained monitoring scenario. In these environments, monitoring must be designed and compiled into the system prior to deployment. Common strategies include input range checking, built-in redundancy, static failover logic, or conservative validation thresholds. Once deployed, these models operate independently, and any postdeployment failure may require physical device replacement or firmware-level reset.
The core challenge is universal: deployed ML systems must not only perform well initially, but continue to behave responsibly as the environment changes. Monitoring provides the observability layer that links system performance to ethical goals and accountability structures. Without monitoring, fairness and robustness become invisible. Without feedback, misalignment cannot be corrected. Monitoring, therefore, is the operational foundation that allows machine learning systems to remain adaptive, auditable, and aligned with their intended purpose over time.
The monitoring section closes the technical loop: bias detection, differential privacy, adversarial training, and explainability provide essential capabilities for responsible AI implementation, but they also reveal a fundamental limitation. Technical correctness alone cannot guarantee beneficial outcomes. Consider three concrete examples that illustrate this challenge:
A fairness auditing system detects racial bias in a loan approval model, but the organization lacks processes for interpreting results or implementing corrections. The technical capability exists, but organizational inertia prevents remediation. Differential privacy preserves formal mathematical guarantees about data protection, but users do not understand these protections and continue to share sensitive information inappropriately. The privacy method works as designed, but behavioral context undermines its effectiveness. An explainability system generates technically accurate feature importance scores, but affected individuals cannot access or interpret these explanations due to interface design and literacy barriers.
These examples demonstrate that responsible AI implementation depends on alignment between technical capabilities and sociotechnical contexts, organizational incentives, human behavior, stakeholder values, and institutional governance structures. Sustaining that alignment requires monitoring mechanisms that provide operational observability. However, the emergence of generative AI has transformed the nature of the “failures” we must monitor.
Responsibility in the generative era
Generative AI does not replace the fairness, privacy, and explainability concerns above; it changes the control surface. Instead of only auditing labels or feature attributions, operators must govern prompts, retrieved context, reward models, and open-ended outputs.
The transition from discriminative classification to generative large language models (LLMs) fundamentally alters the engineering surface of responsibility. Fairness is no longer merely a statistical parity metric between labeled groups; it evolves into Generative Alignment, the complex optimization problem of constraining open-ended stochastic outputs to remain helpful, harmless, and honest across a combinatorial explosion of possible prompts. This requires a transition from static dataset curation to dynamic behavioral shaping, typically through a multi-stage alignment process (figure 12).

A common instruction-tuning pipeline in large language models circa 2022–2024 uses Reinforcement Learning from Human Feedback (RLHF) as a sociotechnical bridge between human values and model weights. By training a reward model on human preferences—in the scenario here, 50,000 to 500,000 pairwise comparisons at a cost of $0.50 to $5.00 per label—engineers effectively compile subjective judgments into a differentiable loss function. Proximal Policy Optimization (PPO) is the policy-optimization stage that updates the model against this reward model while constraining how far the policy moves from the supervised baseline. This alignment process introduces an alignment tax, often observed as a 2–8 percent degradation in standard NLP benchmarks as the model trades raw capability for safety constraints. The reliance on human raters introduces a representativeness gap: if the labeling investment reflects only a narrow demographic slice, the resulting “aligned” model will inherently overfit to that specific cultural or socioeconomic context. Constitutional AI offers an alternative engineering path, using a set of high-level principles to guide AI feedback on its own outputs, thereby reducing the dependency on massive-scale human annotation while making the values explicit in the prompt rather than implicit in the rater pool.
In Retrieval-Augmented Generation (RAG) architectures (Inference at Scale), responsibility becomes decoupled from the core model. An LLM may be perfectly aligned via extensive RLHF, yet still generate toxic or biased responses if the retrieval layer surfaces contaminated context. If a retrieval index disproportionately surfaces biased historical documents, the model—conditioned to be faithful to its context—will propagate that bias regardless of its internal safety training. This necessitates context filtering as a distinct infrastructure component, validating retrieved chunks for toxicity and bias before they reach the generation context window.
In many LLM serving stacks, the system prompt operates as an early configuration control alongside retrieval filtering, policy classifiers, telemetry, and rollout gates. These hidden instructions (for example, “You are a helpful assistant. Do not provide medical advice.”) define operational boundaries of the system. At the scale of 10,000+ distinct deployment configurations, managing these prompts becomes a distributed configuration management problem akin to weight distribution. A single unversioned change to a system prompt can subtly shift the ethical posture of millions of interactions, making prompt version control, alignment regression testing, and gradual rollouts as critical for safety as the model training process itself (ML Operations at Scale).
Together, system prompts and RLHF alignments act as important, yet fragile, technical guardrails. When these guardrails fail, whether through deliberate jailbreaking or nuanced edge cases that bypass the reward model, the reality becomes clear: AI safety cannot be solved entirely through mathematics. The complex sociotechnical dynamics between the algorithm and the human using it demand equal attention.
Self-Check: Question
A regulated bank must produce explanations for automated loan decisions. Engineering proposes a deep ensemble with on-demand SHAP explanations, while legal prefers a logistic regression with monotonicity constraints. Under the chapter’s framing, what is the primary architectural distinction between these options?
- Post-hoc methods like SHAP infer explanations from a trained black-box model’s behavior, while inherently interpretable models like constrained logistic regression expose their reasoning structure directly without any post-hoc approximation
- Post-hoc methods work only on images, while interpretable models work only on tabular data
- Post-hoc methods always produce more faithful explanations than inherently interpretable models
- Inherently interpretable models eliminate the need for any post-deployment monitoring
A production serving system operates at 10,000 QPS with a 100 ms p99 latency budget. The compliance team requires an explanation on 10 percent of decisions. The team is comparing gradient-based attribution (roughly 10-50 ms overhead per explanation), LIME (100-500 ms), and SHAP (200-1000 ms or more). Justify which method the chapter’s framing recommends for this deployment and what that choice implies for architecture.
A fintech platform rejects a loan and must provide “meaningful information” to the applicant. Why does the chapter argue counterfactual explanations are especially suited to user-facing recourse in this setting compared to feature-attribution methods?
- Counterfactuals guarantee demographic parity automatically
- Counterfactuals answer “what minimal feasible input change would have flipped the decision,” providing actionable recourse rather than a retrospective importance ranking the applicant cannot act on
- Counterfactuals avoid any need for domain constraints, so they compute faster than attribution
- Counterfactuals are cheaper than simple gradient attributions in every realistic deployment
A model validated fairly and robustly at launch begins producing disparate error rates across subgroups six months after deployment despite no retraining. Which mechanism does the chapter identify as the primary reason post-deployment monitoring remains necessary even after rigorous pre-launch validation?
- Production environments exhibit distribution shift, subgroup composition change, and evolving regulatory and transparency expectations, so fairness and explainability properties can degrade despite model weights being fixed
- Pre-launch validation is a courtesy for academic publication and has no production role
- Deployed models become inherently interpretable through interaction logs, so monitoring becomes unnecessary
- Monitoring replaces the need for rollback, retraining, and incident response
When RLHF or similar alignment methods make a generative model safer at the cost of a measurable degradation on standard NLP capability benchmarks, the chapter calls that capability cost the alignment ____.
A product team at a large LLM platform proposes to manage system prompts (hidden instructions prepended to every user query) with an ad-hoc shared document and manual rollout. Explain why the chapter treats system prompts as a governance mechanism with CI/CD requirements comparable to model weights, and identify three failure modes an unversioned prompt rollout can produce.
Sociotechnical Dynamics
A hospital deployed a highly accurate sepsis prediction model, but mortality rates did not improve. The doctors, overwhelmed by alert fatigue, simply ignored the model’s warnings. A mathematically flawless, perfectly fair, highly explainable model still fails spectacularly in production when it misaligns with human psychology, organizational incentives, or the operational reality of the workplace.
The technical tools of the previous sections solved well-defined problems: detecting bias, preserving privacy, generating explanations. The sepsis case marks where that toolbox runs out. Sociotechnical engineering demands a different mode of reasoning: instead of optimizing an objective function, we analyze stakeholder conflicts; instead of tuning hyperparameters, we navigate ethical trade-offs; instead of measuring technical performance, we assess social impact. The system must now satisfy both computational constraints and human values, and no amount of optimization resolves a conflict between the two.
Deployed systems create feedback loops that reshape the environments they model, introduce human-AI collaboration risks that neither humans nor algorithms can address alone, and surface stakeholder value conflicts that no optimization can satisfy. These dynamics determine whether responsible AI implementations succeed or fail in practice.
System feedback loops
The sociotechnical feedback invariant (principle 21) captures this dynamic: deployed models shape the environment they operate in, so that future data \(p_{t+1}(X)\) is a function of the model’s past decisions \(f_t(X)\). Here, \(p_t(X)\) denotes the input distribution observed by the system at time \(t\), while \(f_t(X)\) denotes the deployed model or decision policy acting on those inputs. Systems require Closed-Loop Governance—reliability requires modeling the feedback loop, not just the feed-forward inference.
Machine learning systems do not merely observe and model the world; they also shape it. Once deployed, their predictions and decisions often influence the environments they are intended to analyze. This feedback alters future data distributions, modifies user behavior, and affects institutional practices, creating a recursive loop between model outputs and system inputs (figure 4). Over time, such dynamics can amplify biases, entrench disparities, or unintentionally shift the objectives a model was designed to serve.
A well-documented example of this phenomenon is predictive policing. When a model trained on historical arrest data predicts higher crime rates in a particular neighborhood, law enforcement may allocate more patrols to that area. This increased presence leads to more recorded incidents, which are then used as input for future model training, further reinforcing the model’s original prediction. Even if the model was not explicitly biased at the outset, its integration into a feedback loop results in a self-fulfilling pattern that disproportionately affects already over-policed communities.
Recommender systems exhibit similar dynamics in digital environments. A content recommendation model that prioritizes engagement may gradually narrow the range of content a user is exposed to, leading to feedback loops that reinforce existing preferences or polarize opinions. These effects can be difficult to detect using conventional performance metrics, as the system continues to optimize its training objective even while diverging from broader social or epistemic goals.
From a systems perspective, feedback loops present a core challenge to responsible AI. They undermine the assumption of independently and identically distributed data and complicate the evaluation of fairness, robustness, and generalization. Standard validation methods, which rely on static test sets, may fail to capture the evolving impact of the model on the data-generating process. Once such loops are established, interventions aimed at improving fairness or accuracy may have limited effect unless the underlying data dynamics are addressed.
Designing for responsibility in the presence of feedback loops requires a lifecycle view of machine learning systems. It entails not only monitoring model performance over time, but also understanding how the system’s outputs influence the environment, how these changes are captured in new data, and how retraining practices either mitigate or exacerbate these effects.
In cloud-based systems, these updates may occur frequently and at scale, with extensive telemetry available to detect behavior drift. In contrast, edge and embedded deployments often operate offline or with limited observability. A smart home system that adapts thermostat behavior based on user interactions may reinforce energy consumption patterns or comfort preferences in ways that alter the home environment, and subsequently affect future inputs to the model. Without connectivity or centralized oversight, these loops may go unrecognized, despite their impact on both user behavior and system performance. Operational monitoring practices, including drift detection, performance tracking, and automated alerting, are crucial for detecting and managing these feedback dynamics in production systems.
Systems must be equipped with mechanisms to detect distributional drift, identify behavior shaping effects, and support corrective updates that align with the system’s intended goals. Feedback loops are not inherently harmful, but they must be recognized and managed. When left unexamined, they introduce systemic risk; when thoughtfully addressed, they provide an opportunity for learning systems to adapt responsibly in complex, dynamic environments.
War Story 1.2: The algorithmic grading failure
Context: In 2020, following the cancellation of A-level exams due to the COVID-19 pandemic, Ofqual (the qualifications regulator for England) deployed an algorithmic standardization model to assign grades. The model, intended to combat grade inflation, used a school’s historical performance distribution to adjust individual teacher predictions (Ofqual 2020; Department for Education and Ofqual 2020).
Failure mode: While designed to maintain aggregate standards, the engineering constraint of preserving historical grade distributions decoupled many individual outcomes from teacher assessment. Students at historically high-performing schools were more likely to see predictions preserved, while high-achieving students at schools with weaker historical results could be downgraded to fit the school’s statistical prior.
Consequence: The algorithm enforced a feedback loop where past institutional performance constrained future individual outcomes. The resulting loss of confidence forced the government and Ofqual to revert to centre assessment grades days later.
Systems lesson: Optimizing for aggregate statistical properties (preventing inflation) without constraints on individual fairness (rank preservation) creates a system that is mathematically “correct” but socially catastrophic.
Department for Education, and Ofqual. 2020. GCSE and A Level Students to Receive Centre Assessment Grades. GOV.UK News Story.
Ofqual. 2020. Awarding GCSE, AS, A Level, Advanced Extension Awards and Extended Project Qualifications in Summer 2020: Interim Report. Office of Qualifications; Examinations Regulation.
Human-AI collaboration
Human operators turn feedback-loop risk into a shared-control problem. Machine learning systems are often deployed not as standalone agents, but as components in larger workflows that involve human decision-makers. In many domains, such as healthcare, finance, and transportation, models serve as decision-support tools, offering predictions, risk scores, or recommendations that are reviewed and acted upon by human operators. The collaborative configuration raises questions about how responsibility is shared between humans and machines, how trust is calibrated, and how oversight mechanisms are implemented in practice.
Human-AI collaboration introduces both opportunities and risks. When designed appropriately, systems can augment human judgment, reduce cognitive burden, and enhance consistency in decision-making. However, when poorly designed, they may lead to automation bias36, where users over-rely on model outputs even in the presence of clear errors.
36 Automation Bias: First studied in aviation in the 1990s, this is the paradox where humans defer to automated systems even when clearly wrong – and the effect intensifies as system accuracy increases. At 70–80 percent model accuracy, operators accept erroneous outputs at high rates when presented without uncertainty indicators. For ML serving systems, this means higher model accuracy can paradoxically reduce system-level safety by suppressing human oversight, requiring deliberate interface friction (uncertainty visualization, mandatory justification) that adds latency but preserves the human correction channel.
Conversely, excessive distrust can result in algorithm aversion, where users disregard useful model predictions due to a lack of transparency or perceived credibility. The effectiveness of collaborative systems depends not only on the model’s performance, but on how the system communicates uncertainty, provides explanations, and allows for human override or correction.
Automation bias is often reinforced by institutional structures through asymmetric liability. In high stakes domains like criminal justice or healthcare, human decision-makers face different consequences based on their agreement with algorithms. Consider two scenarios: In Scenario A, a judge overrides a “high risk” algorithmic score and releases a defendant who later re-offends. The judge faces public scrutiny and potential career consequences for “ignoring the science.” In Scenario B, a judge follows the “high risk” score and detains the defendant unnecessarily. The blame is diffused to the algorithm (“the system said so”).
The asymmetry creates strong pressure for Institutional Deference, where human oversight becomes a “rubber stamp” for algorithmic decisions to avoid personal liability. Responsible AI design must explicitly counter this by protecting operators who exercise judgment and requiring justification for agreement as well as disagreement.
Oversight mechanisms must be tailored to the deployment context. In high stakes domains, such as medical triage or autonomous driving, humans may be expected to supervise automated decisions in real-time. This configuration places cognitive and temporal demands on the human operator and assumes that intervention will occur quickly and reliably when needed. In practice, however, continuous human supervision is often impractical or ineffective, particularly when the operator must monitor multiple systems or lacks clear criteria for intervention.
From a systems design perspective, supporting effective oversight requires more than providing access to raw model outputs. Interfaces must be constructed to surface relevant information at the right time, in the right format, and with appropriate context. Confidence scores, uncertainty estimates, explanations, and change alerts can all play a role in enabling human oversight. Workflows must define when and how intervention is possible, who is authorized to override model outputs, and how such overrides are logged, audited, and incorporated into future system updates.
Consider a hospital triage system that uses a machine learning model to prioritize patients in the emergency department. The model generates a risk score for each incoming patient, which is presented alongside a suggested triage category. In principle, a human nurse is responsible for confirming or overriding the suggestion. However, if the model’s outputs are presented without sufficient justification, such as an explanation of the contributing features or the context for uncertainty, the nurse may defer to the model even in borderline cases. Over time, the model’s outputs may become the de facto triage decision, especially under time pressure. If a distribution shift occurs (for instance, due to a new illness or change in patient demographics), the nurse may lack both the situational awareness and the interface support needed to detect that the model is underperforming. In such cases, the appearance of human oversight masks a system in which responsibility has effectively shifted to the model without clear accountability or recourse.
In such systems, human oversight is not merely a matter of policy declaration, but a function of infrastructure design: how predictions are surfaced, what information is retained, how intervention is enacted, and how feedback loops connect human decisions to system updates. Without integration across these components, oversight becomes fragmented, and responsibility may shift invisibly from human to machine.
Napkin Math 1.4: The automation bias paradox
Consider a radiology department deploying an AI assistant for tumor detection.
- Human sensitivity: \(S_{\text{human}} =\) 92 percent
- AI sensitivity: \(S_{\text{AI}} =\) 95 percent
One might assume the combined system performance would exceed 95 percent. However, studies in automation bias show that humans accept erroneous AI recommendations at rates of 60–80 percent. If the AI makes an error (probability \(1 - S_{\text{AI}} = 0.05\)) and the human blindly accepts it (\(\alpha = 0.7\)), accepted AI errors alone create a failure probability of \(0.05 \times 0.7 = 0.035\). In this simplified upper-bound case, where every non-accepted AI error is corrected, sensitivity is 96.5 percent; real workflows can do worse once human override errors, false positives, fatigue, and interface delays are included.
As AI reliability increases, human vigilance decreases—a phenomenon known as the paradox of reliability.
- At 90 percent AI accuracy, human override rate might be \(R_{\text{override}} = 15\%\).
- At 99 percent AI accuracy, \(R_{\text{override}}\) drops to \(\approx 2\%\).
The remaining 1 percent of errors are almost never caught because the human has calibrated their trust to the “perfect” machine. This creates a trust calibration gap: the safer the system appears, the more dangerous its rare failures become. Responsible design requires introducing friction—forcing the human to justify acceptance—to artificially lower \(\alpha\) and maintain the human in the loop.

Higher AI accuracy can paradoxically lower human vigilance.
The boundary between decision support and automation is often fluid. Systems initially designed to assist human decision-makers may gradually assume greater autonomy as trust increases or organizational incentives shift. This transition can occur without explicit policy changes, resulting in de facto automation without appropriate accountability structures. Responsible system design must therefore anticipate changes in use over time and ensure that appropriate checks remain in place even as reliance on automation grows.
Human-AI collaboration requires careful integration of model capabilities, interface design, operational policy, and institutional oversight. Collaboration is not simply a matter of inserting a “human-in-the-loop”; it is a systems challenge that spans technical, organizational, and ethical dimensions. Designing for oversight entails embedding mechanisms that allow intervention, support informed trust, and support shared responsibility between human operators and machine learning systems.
Normative pluralism and value conflicts
Human-AI collaboration exposes a deeper systems constraint: different stakeholders often hold conflicting values and priorities. Real-world ML deployment forces a confrontation with value tensions that no algorithm can resolve. Technical excellence is necessary but insufficient for trustworthy AI, because stakeholders hold legitimately different conceptions of fairness, privacy, and accountability that cannot be reconciled through better algorithms.
Responsible machine learning cannot be reduced to the optimization of a single objective. In real-world settings, machine learning systems are deployed into environments shaped by diverse, and often conflicting, human values. A high-stakes deployment makes these tensions concrete.
Example 1.5: Conflicting values in practice
Scenario: A team builds a mental health chatbot for adolescents that uses ML to detect crisis situations and recommend interventions. The system must balance multiple legitimate but incompatible objectives:
Medical efficacy: Optimize for best clinical outcomes based on evidence-based practices. This suggests aggressive intervention, alerting parents, counselors, or emergency services whenever the model detects potential self-harm risk, even with low confidence, because false negatives could be fatal.
Patient autonomy: Respect adolescent privacy and agency. Many teenagers seek mental health support specifically because they cannot talk to parents or authority figures. Aggressive notification policies may deter vulnerable teens from using the system at all, leaving them without any support.
Privacy protection: Minimize data collection and retention to protect sensitive mental health information. This suggests local processing, no conversation logging, and no sharing with third parties, but also prevents the system from improving through learning from interactions or enabling human review when the model is uncertain.
Resource efficiency: Operate within computational and human oversight budgets. Involving human counselors for every flagged interaction provides better care but is prohibitively expensive at scale. Fully automated responses reduce costs but may provide inappropriate guidance in complex situations.
Legal compliance: Meet mandatory reporting requirements and liability standards. In many jurisdictions, systems that detect imminent harm must notify authorities, overriding patient autonomy and privacy regardless of clinical judgment about whether notification helps or harms the patient.
These values are not poorly specified requirements that can be reconciled through better engineering. They reflect fundamentally different conceptions of what the system should achieve and whom it should prioritize. Optimizing for medical efficacy (aggressive intervention) directly conflicts with patient autonomy (minimal intervention). Privacy protection (no data retention) conflicts with resource efficiency (learning from interactions). Legal compliance (mandatory reporting) may conflict with clinical efficacy (therapeutic relationship based on trust).
No algorithm determines which value should dominate. Different stakeholders hold legitimately different positions: clinicians may prioritize efficacy, teenagers may prioritize autonomy, lawyers may prioritize compliance, and budget officers may prioritize efficiency. The technical team must facilitate stakeholder deliberation to determine which trade-offs are acceptable in this specific context, a fundamentally normative decision that precedes and constrains technical optimization.
Systems lesson: Responsible AI trade-offs are system requirements, not after-the-fact policy notes. The deployment architecture must encode the stakeholder choice before optimization begins.
What constitutes a fair outcome for one stakeholder may be perceived as inequitable by another. Similarly, decisions that prioritize accuracy or efficiency may conflict with goals such as transparency, individual autonomy, or harm reduction. These tensions are not incidental; they are structural. They reflect the pluralistic nature of the societies in which machine learning systems are embedded and the institutional settings in which they are deployed.
Fairness is a particularly prominent site of value conflict. Fairness can be formalized in multiple, often incompatible ways. A model that satisfies demographic parity may violate equalized odds; a model that prioritizes individual fairness may undermine group-level parity. Choosing among these definitions is not purely a technical decision but a normative one, informed by domain context, historical patterns of discrimination, and the perspectives of those affected by model outcomes. In practice, multiple stakeholders, including engineers, users, auditors, and regulators, may hold conflicting views on which definitions are most appropriate and why.
Value conflicts extend beyond fairness alone. Conflicts also arise between interpretability and predictive performance, privacy and personalization, or short-term utility and long-term consequences. These trade-offs manifest differently depending on the systems deployment architecture, revealing how deeply value conflicts are tied to the design and operation of ML systems.
Consider a voice-based assistant deployed on a mobile device. To enhance personalization, the system may learn user preferences locally, without sending raw data to the cloud. This design improves privacy and reduces latency, but it may also lead to performance disparities if users with underrepresented usage patterns receive less accurate or responsive predictions. One way to improve fairness would be to centralize updates using group-level statistics, but doing so introduces new privacy risks and may violate user expectations around local data handling. Here, the design must navigate among valid but competing values: privacy, fairness, and personalization.
In cloud-based deployments, such as credit scoring platforms or recommendation engines, tensions often arise between transparency and proprietary protection. End users or regulators may demand clear explanations of why a decision was made, particularly in situations with significant consequences, but the models in use may rely on complex ensembles or proprietary training data. Revealing these internals may be commercially sensitive or technically infeasible. In such cases, the system must reconcile competing pressures for institutional accountability and business confidentiality.
In edge systems, such as home security cameras or autonomous drones, resource constraints often dictate model selection and update frequency. Prioritizing low latency and energy efficiency may require deploying compressed or quantized models that are less robust to distribution shift or adversarial perturbations. More resilient models could improve safety, but they may exceed the system’s memory budget or violate power constraints. Here, safety, efficiency, and maintainability must be balanced under hardware-imposed trade-offs. Efficiency techniques and optimization methods are essential for implementing responsible AI in resource-constrained environments.
On TinyML platforms, where models are deployed to microcontrollers with no persistent connectivity, trade-offs are even more pronounced. A system may be optimized for static performance on a fixed dataset, but unable to incorporate new fairness constraints, retrain on updated inputs, or generate explanations once deployed. Hardware constraints fundamentally shape what responsible AI practices are feasible on resource-limited devices. The value conflict extends beyond what the model optimizes to encompass what the system can support postdeployment.
The recurring systems constraint is Normative pluralism, not an abstract philosophical challenge. Technical approaches such as multi-objective optimization, constrained training, and fairness-aware evaluation can help surface and formalize trade-offs, but they do not eliminate the need for judgment. Decisions about whose values to represent, which harms to mitigate, and how to balance competing objectives cannot be made algorithmically. They require deliberation, stakeholder input, and governance structures that extend beyond the model itself.
Participatory and value-sensitive design methodologies offer potential paths forward. Rather than treating values as parameters to be optimized after deployment, these approaches seek to engage stakeholders during the requirements phase, define ethical trade-offs explicitly, and trace how they are instantiated in system architecture. While no design process can satisfy all values simultaneously, systems that are transparent about their trade-offs and open to revision are better positioned to sustain trust and accountability over time.
Machine learning systems are not neutral tools. They embed and enact value judgments, whether explicitly specified or implicitly assumed. A commitment to responsible AI requires acknowledging this fact and building systems that reflect and respond to the ethical and social pluralism of their operational contexts.
Transparency and contestability
Value conflicts become governable only when stakeholders can understand and challenge system decisions. Transparency allows users, developers, auditors, and regulators to understand how a system functions, assess its limitations, and identify sources of harm. Yet transparency alone is not sufficient. In high stakes domains, individuals and institutions must not only understand system behavior; they must also be able to challenge, correct, or reverse it when necessary. This capacity for contestability, which refers to the ability to interrogate and contest a system’s decisions, is an important feature of accountability.
Transparency in machine learning systems typically focuses on disclosure: revealing how models are trained, what data they rely on, what assumptions are embedded in their design, and what known limitations affect their use. Documentation tools such as model cards and datasheets for datasets support this goal by formalizing system metadata in a structured, reproducible format. These resources can improve governance, support compliance, and inform user expectations. However, transparency as disclosure does not guarantee meaningful control. Even when technical details are available, users may lack institutional support, interface tools, or procedural access to contest a decision that adversely affects them.
To move from transparency to contestability, machine learning systems must be designed with mechanisms for explanation, recourse, and feedback:
- Explanation: The system provides understandable reasons for its outputs, tailored to the needs and context of the person receiving them.
- Recourse: Individuals can alter their circumstances and receive a different outcome.
- Feedback: Users can report errors, dispute outcomes, or signal concerns, and those signals can be incorporated into system updates or oversight processes.
These mechanisms are often lacking in practice, particularly in systems deployed at scale or embedded in low-resource devices. For example, in mobile loan application systems, users may receive a rejection without explanation and have no opportunity to provide additional information or appeal the decision. The lack of transparency at the interface level, even if documentation exists elsewhere, makes the system effectively unchallengeable. Similarly, a predictive model deployed in a clinical setting may generate a risk score that guides treatment decisions without surfacing the underlying reasoning to the physician. If the model underperforms for a specific patient subgroup, and this behavior is not observable or contestable, the result may be unintentional harm that cannot be easily diagnosed or corrected.
From a systems perspective, enabling contestability requires coordination across technical and institutional components. Models must expose sufficient information to support explanation. Interfaces must surface this information in a usable and timely way. Organizational processes must be in place to review feedback, respond to appeals, and update system behavior. Logging and auditing infrastructure must track not only model outputs, but user interventions and override decisions. In some cases, technical safeguards, including human-in-the-loop overrides and decision abstention thresholds, may also serve contestability by ensuring that ambiguous or high-risk decisions defer to human judgment.
Implementing contestability imposes concrete infrastructure costs that scale with system throughput and complexity. Storing the necessary metadata to reconstruct a decision—input features, model version, and decision thresholds—requires persistent storage whose footprint depends on feature dimensionality, explanation payloads, and retention windows. Generating on-demand explanations using Shapley values or counterfactuals can add enough latency that contested decisions often need asynchronous processing queues to preserve serving SLAs. Maintaining immutable audit trails for high-risk systems under frameworks like the EU AI Act requires storage, provenance, and oversight capacity to be budgeted as part of the inference fleet rather than as a separate policy artifact (European Parliament and Council of the European Union 2024).
Architecturally, contestability requires a specialized contestability stack, a design pattern analogous to distributed tracing in microservices. This stack must orchestrate four coupled components:
- Decision provenance: The system cryptographically links a specific output to the exact model binary and input vector used.
- Explanation generation: A high-latency service triggers resource-intensive interpretation methods only upon user request.
- Appeal routing: The workflow directs contested decisions to human reviewers with appropriate domain expertise.
- Outcome tracking: The system closes the loop by recording whether the appeal overturned the machine decision.
Without this integrated infrastructure, debugging algorithmic errors becomes impossible, as the system lacks the granular lineage required to trace a specific user complaint back to the offending weights or training data.

Contestability is a production stack, not just a policy word.
The degree of contestability that is feasible varies by deployment context. In centralized cloud platforms, it may be possible to offer full explanation APIs, user dashboards, and appeal workflows. In contrast, in edge and TinyML deployments, contestability may be limited to logging and periodic updates based on batch-synchronized feedback. In all cases, the design of machine learning systems must acknowledge that transparency is not simply a matter of technical disclosure. It is a structural property of systems that determines whether users and institutions can meaningfully question, correct, and govern the behavior of automated decision-making.
Institutional embedding of responsibility
Transparency and contestability mechanisms fail without institutional support. Machine learning systems do not operate in isolation: their development, deployment, and ongoing management are embedded within environments that include technical teams, legal departments, product owners, compliance officers, and external stakeholders. Responsibility in such systems is not the property of a single actor or component; it is distributed across roles, workflows, and governance processes. Designing for responsible AI therefore requires attention to the institutional settings in which these systems are built and used.
Distributing responsibility across roles introduces both opportunities and challenges. On the one hand, the involvement of multiple stakeholders provides checks and balances that can help prevent harmful outcomes. On the other hand, the diffusion of responsibility can lead to accountability gaps, where no individual or team has clear authority or incentive to intervene when problems arise. When harm occurs, it may be unclear whether the fault lies with the data pipeline, the model architecture, the deployment configuration, the user interface, or the surrounding organizational context.
One illustrative case is Google Flu Trends, a widely cited example of failure due to institutional misalignment. The system, which attempted to predict flu outbreaks from search data, initially performed well but gradually diverged from reality due to changes in user behavior and shifts in the data distribution. These issues went uncorrected for years, in part because there were no established processes for system validation, external auditing, or escalation when model performance declined. The failure was not due to a single technical flaw, but to the absence of an institutional framework that could respond to drift, uncertainty, and feedback from outside the development team.
Operational rigor comes with a measurable cost. Public responsible-AI standards and internal review processes illustrate that governance can add release latency through impact assessments, model reviews, red-team exercises, and documentation gates. The durable systems point is that review capacity becomes part of deployment planning: if every high-risk launch needs specialized review, the review queue becomes a bottleneck just like security review or capacity approval. The responsibility overhead is thus not a sunk cost but an insurance premium against the far higher cost of retracting a biased model or patching a live exploit in a global fleet.
Embedding responsibility institutionally requires more than assigning accountability. It requires the design of processes, tools, and incentives that allow responsible action. Technical infrastructure such as versioned model registries, model cards, and audit logs must be coupled with organizational structures such as ethics review boards, model risk committees, and red-teaming37 procedures. These mechanisms ensure that technical insights are actionable, that feedback is integrated across teams, and that concerns raised by users, developers, or regulators are addressed systematically rather than ad hoc.
37 Red Teaming: From Cold War military simulations where the “Red Team” acted as the Soviet adversary to probe US defenses. In Responsible AI, red teaming is the adversarial audit phase: specialized teams (hackers, linguists, ethicists) deliberately probe models for jailbreaks, bias, or toxic outputs before deployment. This discovery process identifies the long-tail risks that standard unit tests cannot catch.
The level of institutional support required varies across deployment contexts. In large-scale cloud platforms, governance structures may include internal accountability audits, compliance workflows, and dedicated teams responsible for monitoring system behavior. In smaller-scale deployments, including edge or mobile systems embedded in healthcare devices or public infrastructure, governance may rely on cross-functional engineering practices and external certification or regulation. In TinyML deployments, where connectivity and observability are limited, institutional responsibility may be exercised through upstream controls such as safety-important validation, embedded security constraints, and lifecycle tracking of deployed firmware.
In all cases, responsible machine learning requires coordination between technical and institutional systems. This coordination must extend across the entire model lifecycle, from initial data acquisition and model training to deployment, monitoring, update, and eventual decommissioning. It must also incorporate external actors, including domain experts, civil society organizations, and regulatory authorities, to ensure that responsibility is exercised not only within the development team but across the broader ecosystem in which machine learning systems operate.
The system-level thesis thus extends past the serving stack into the organization: responsibility is a dynamic property of how systems are governed, maintained, and contested over time, owned by no single model or team. Embedding it within institutions, by means of policy, infrastructure, and accountability mechanisms, is what aligns machine learning systems with the social values and operational realities they are meant to serve.
Taken together, institutional responsibility, value conflicts, feedback loops, human-AI collaboration, contestability, and computational equity show why the technical foundations from section 1.3 through section 1.5 cannot ensure responsible AI on their own. Those technical foundations remain necessary, but they need organizational authority, operational telemetry, and escalation paths to survive contact with deployed systems. Resource constraints also determine who can develop, deploy, and benefit from responsible AI capabilities, so implementation choices are not merely local engineering details. Otherwise, a fairness metric with no owner, an explanation with no appeal process, or a monitoring signal with no remediation budget becomes evidence without action. Once an AI system changes the environment it operates in, engineering teams must turn responsible-AI principles into corporate routines under deadline pressure, resource limits, and competing incentives.
Checkpoint 1.3: When correct code fails in deployment
This section showed why mathematically sound, fair, explainable models still fail in human institutions: feedback loops that reshape the data, automation bias and institutional deference, normative pluralism among stakeholders, and contestability as a production stack rather than a policy word.
Diagnosing the human-system interaction
Reasoning about loops and stakeholders
Self-Check: Question
A predictive policing model’s initial deployment increases patrols in certain neighborhoods, which produces more recorded incidents, which are then used to retrain the model. Under the chapter’s closed-loop framing, what is the primary responsible AI concern with this architecture even if the initial model’s accuracy was acceptable?
- Deployed predictions reshape the environment and future training data, so an initial small skew can amplify into a systematic disparity through self-reinforcement, independent of initial accuracy
- Feedback loops only matter for reinforcement learning systems, not prediction systems
- More feedback data automatically improves fairness by supplying more ground truth
- Feedback loops primarily affect latency rather than changing decision distributions
A radiology system reaches 99 percent accuracy and the human override rate drops from 15 percent to 2 percent over a year. The 1 percent of remaining model errors are almost never caught. Explain the automation-bias paradox this illustrates and identify the specific interface-level mechanisms the chapter recommends to counteract it.
A team building a mental-health chatbot for adolescents must reconcile aggressive intervention for suspected self-harm (medical efficacy) with preserving adolescent privacy and willingness to confide (autonomy) and with mandatory reporting laws (legal compliance). Which framing most accurately classifies this as normative pluralism rather than an implementation defect?
- A model server crashes because a protobuf schema changed unexpectedly
- Multiple legitimate stakeholder values (efficacy, autonomy, privacy, compliance, efficiency) are in direct tension and cannot be simultaneously maximized by any algorithm; the team must facilitate stakeholder deliberation before optimization, because the trade-off is a policy choice, not a bug
- A fairness dashboard shows a malformed JSON payload
- A quantized edge model loses 2 percent accuracy from integer overflow during conversion
A lending platform publishes model cards and datasheets but rejected applicants still cannot meaningfully challenge decisions. The chapter argues that moving from transparency to contestability requires a coordinated infrastructure stack. Which of the following combinations captures what this stack must provide?
- Only model cards and datasheets, because disclosure by itself guarantees accountability
- Higher model accuracy, because accurate systems do not need appeals
- Decision provenance linking outputs to model version and input, explanation generation on demand, appeal routing to human reviewers with domain expertise, and outcome tracking that records whether the appeal overturned the decision
- Complete disclosure of proprietary weights and all training data to every user
The bias amplification loop in the section chains four stages that reinforce harm unless interrupted. Order these stages: (1) Retraining data collection from deployed predictions, (2) Model predictions or decisions in production, (3) Historical biased training data, (4) Future model retraining on the collected data.
Explain why the chapter argues that responsibility must be institutionally embedded rather than left to individual developers or a single review team, using either the Google Flu Trends or UK A-level grading failure as concrete support.
Implementation Challenges and AI Safety
The data science team wants to hold back deployment for a month to conduct rigorous fairness audits on a new generative model. The executive team, watching a competitor launch a similar feature, demands the model be deployed by Friday. This is the implementation reality of responsible AI. It is rarely a question of whether engineers know how to test for bias; it is a question of whether the organizational structure, budget, and business priorities allow them the time and authority to actually do it.
The scenario exposes the implementation gap between technical capability and operational authority. Responsible AI methods provide necessary tools, but their effectiveness depends on organizational structures, data infrastructure, evaluation processes, and sustained commitment that extends far beyond algorithm development. Systems maintain responsible behavior over time only when those implementation supports survive deadline pressure, product incentives, and postdeployment drift.
The practical barriers to embedding responsible AI in production ML systems follow the classical People-Process-Technology framework:
- People challenges: These include organizational structures, role definitions, incentive alignment, and stakeholder coordination that determine whether responsible AI principles translate into sustained organizational behavior.
- Process challenges: These include standardization gaps, lifecycle maintenance procedures, competing optimization objectives, and evaluation methodologies that affect how responsible AI practices integrate with development workflows.
- Technology challenges: These include data quality constraints, computational resource limitations, scalability bottlenecks, and infrastructure gaps that determine whether responsible AI techniques can operate effectively at production scale.
These categories matter because responsible AI fails when organizational incentives, development workflows, and production infrastructure cannot support the same obligation.
The point of the framework is coordination, not classification. Responsible AI fails when people, process, and technology are handled independently: a fairness metric with no owner does not trigger remediation, a governance process without telemetry cannot see drift, and a privacy technique without data lineage cannot honor deletion requests. Effective implementation requires systems-level strategies that embed responsibility into the architecture, infrastructure, and workflows of machine learning deployment across all three dimensions simultaneously.
Organizational structures and incentives
The implementation of responsible machine learning is shaped not only by technical feasibility but by the organizational context in which systems are developed and deployed. Within companies, research labs, and public institutions, responsibility must be translated into concrete roles, workflows, and incentives. In practice, however, organizational structures often fragment responsibility, making it difficult to coordinate ethical objectives across engineering, product, legal, and operational teams.
Responsible AI requires sustained investment in practices such as subgroup performance evaluation, explainability analysis, adversarial robustness testing, and the integration of privacy-preserving techniques like differential privacy or federated training. These activities can be time-consuming and resource-intensive, yet they often fall outside the formal performance metrics used to evaluate team productivity. For example, teams may be incentivized to ship features quickly or meet performance benchmarks, even when doing so undermines fairness or overlooks potential harms. When ethical diligence is treated as a discretionary task, instead of being an integrated component of the system lifecycle, it becomes vulnerable to deprioritization under deadline pressure or organizational churn.
Responsibility is further complicated by ambiguity over ownership. In many organizations, no single team is responsible for ensuring that a system behaves ethically over time. Model performance may be owned by one team, user experience by another, data infrastructure by a third, and compliance by a fourth. When issues arise, including disparate impact in predictions or insufficient explanation quality, there may be no clear protocol for identifying root causes or coordinating mitigation. As a result, concerns raised by developers, users, or auditors may go unaddressed, not because of malicious intent, but due to lack of process and cross-functional alignment.
Establishing effective organizational structures for responsible AI requires more than policy declarations. It demands operational mechanisms: designated roles with responsibility for ethical oversight, documented escalation pathways, accountability for postdeployment monitoring, and incentives that reward teams for ethical foresight and system maintainability. In some organizations, this may take the form of Responsible AI committees, cross-functional review boards, or model risk teams that work alongside developers throughout the model lifecycle. In others, domain experts or user advocates may be embedded into product teams to anticipate downstream impacts and evaluate value trade-offs in context.
The responsibility for ethical system behavior is distributed across multiple constituencies, including industry, academia, civil society, and government. Figure 13 maps this distribution across nested layers of accountability, from individual teams implementing technical practices through organizational safety culture to industry-wide certification and government regulation (Shneiderman 2022, 2020). Within organizations, this distribution must be mirrored by mechanisms that connect technical design with strategic oversight and operational control. Without these linkages, responsibility becomes diffuse, and well-intentioned efforts may be undermined by systemic misalignment.
Shneiderman, B. 2022. Human-Centered AI. Oxford University Press. https://doi.org/10.1093/oso/9780192845290.001.0001.
Shneiderman, B. 2020. “Bridging the Gap Between Ethics and Practice: Guidelines for Reliable, Safe, and Trustworthy Human-Centered AI Systems.” ACM Transactions on Interactive Intelligent Systems 10 (4): 1–31. https://doi.org/10.1145/3419764.

International Organization for Standardization, and International Electrotechnical Commission. 2023b. ISO/IEC 42001:2023 Information Technology – Artificial Intelligence – Management System. ISO/IEC standard.
Responsible AI is not merely a question of technical excellence or regulatory compliance. It is a systems-level challenge that requires aligning ethical objectives with the institutional structures through which machine learning systems are designed, deployed, and maintained. Creating and sustaining these structures is important for ensuring that responsibility is embedded not only in the model, but in the organization that governs its use. The same ownership problem becomes concrete at the data layer: teams can know how to audit a dataset and still lack the authority, access, or infrastructure needed to change it.
Data constraints and quality gaps
Improving data pipelines remains one of the most difficult implementation challenges in practice despite broad recognition that data quality is important for responsible machine learning. Developers and researchers often understand the importance of representative data, accurate labeling, and mitigation of historical bias. Yet even when intentions are clear, structural and organizational barriers frequently prevent meaningful intervention. Responsibility for data is often distributed across teams, governed by legacy systems, or embedded in broader institutional processes that are difficult to change.
Data engineering principles, including data validation, schema management, versioning, lineage tracking, and quality monitoring, provide the technical foundation for addressing these challenges. However, applying these principles to responsible AI introduces additional complexity: fairness requires assessing representativeness across demographic groups, bias mitigation demands understanding historical data collection practices, and privacy preservation constrains which validation techniques are permissible. The organizational challenges described here reflect the gap between having robust data engineering infrastructure and using it effectively to support responsible AI objectives.
Subgroup imbalance, label ambiguity, and distribution shift, each of which affect generalization and performance across domains, are well-established concerns in responsible ML. These issues often manifest in the form of poor calibration, out-of-distribution failures, or demographic disparities in evaluation metrics. However, addressing them in real-world settings requires more than technical knowledge. It requires access to relevant data, institutional support for remediation, and sufficient time and resources to iterate on the dataset itself. In many machine learning pipelines, once the data is collected and the training set defined, the data pipeline becomes effectively frozen. Teams may lack both the authority and the infrastructure to modify or extend the dataset midstream, even if performance disparities are discovered. Even in automated data pipelines with validation and feature stores, retroactively correcting training distributions remains difficult once dataset versioning and data lineage have been locked into production.
In domains like healthcare, education, and social services, these challenges are especially pronounced. Data acquisition may be subject to legal constraints, privacy regulations, or cross-organizational coordination. For example, a team developing a triage model may discover that their training data underrepresents patients from smaller or rural hospitals. Correcting this imbalance would require negotiating data access with external partners, aligning on feature standards, and resolving inconsistencies in labeling practices. The logistical and operational costs can be prohibitive even when all parties agree on the need for improvement.
Efforts to collect more representative data may also run into ethical and political concerns. In some cases, additional data collection could expose marginalized populations to new risks. This paradox of exposure, in which the individuals most harmed by exclusion are also those most vulnerable to misuse, complicates efforts to improve fairness through dataset expansion. For example, gathering more data on nonbinary individuals to support fairness in gender-sensitive applications may improve model coverage, but it also raises serious concerns around consent, identifiability, and downstream use. Teams must navigate these tensions carefully, often without clear institutional guidance.
Napkin Math 1.5: The representation tax
Problem: A medical imaging model trained on data from 5 hospitals achieves 94 percent accuracy overall but only 78 percent on underrepresented populations (rural patients, elderly patients, patients with darker skin tones). Closing this gap requires representative data from 50+ hospitals across diverse geographies, demographics, and equipment types.
Math:
- Data acquisition cost: $50–$200 per labeled medical image, with 100,000 images needed per underrepresented subgroup.
- Representation-tax scenario: For 10 subgroups, at the midpoint of the cost range, 10 subgroups times 100,000 images per subgroup times $125 per image yields $125M in data acquisition alone.
- Data harmonization: Data harmonization across different scanners, protocols, and labeling conventions adds 30 percent–50 percent overhead, bringing the total to $162.5M–$187.5M.
Systems insight: The representation tax makes equitable performance materially more expensive than high aggregate accuracy on the majority population. The populations most harmed by biased models are the most expensive to represent in training data. Data budgets must be allocated not by aggregate utility but by subgroup coverage gaps—a fundamentally different optimization target than maximizing overall accuracy.

Representation cost scales with subgroup coverage, not just dataset size.
Himmelstein, Gracie, David Bates, and Li Zhou. 2022. “Examination of Stigmatizing Language in the Electronic Health Record.” JAMA Network Open 5 (1): e2144967. https://doi.org/10.1001/jamanetworkopen.2021.44967.
Upstream biases in data collection systems can persist unchecked even when data is plentiful. Many organizations rely on third-party data vendors, external APIs, or operational databases that were not designed with fairness or interpretability in mind. For instance, Electronic Health Records, which are commonly used in clinical machine learning, often reflect systemic disparities in care, as well as documentation habits that encode racial or socioeconomic bias (Himmelstein et al. 2022). Teams working downstream may have little visibility into how these records were created, and few levers for addressing embedded harms.
Improving dataset quality is often not the responsibility of any one team. Data pipelines may be maintained by infrastructure or analytics groups that operate independently of the ML engineering or model evaluation teams. This organizational fragmentation makes it difficult to coordinate data audits, track provenance, or implement feedback loops that connect model behavior to underlying data issues. In practice, responsibility for dataset quality tends to fall through the cracks, recognized as important, but rarely prioritized or resourced.
Addressing these challenges requires long-term investment in infrastructure, workflows, and cross-functional communication. Technical tools such as data validation, automated audits, and dataset documentation frameworks (for example, model cards, datasheets, or the Data Nutrition Project38) can help, but only when they are embedded within teams that have the mandate and support to act on their findings.
38 Data Nutrition Project: A nonprofit initiative that develops standardized dataset documentation modeled on nutrition labels, summarizing provenance, composition, distribution, and known issues for datasets used in ML pipelines. The project’s labels make dataset risks legible to downstream engineers who lack access to the original collection process—an essential bridge for the organizational fragmentation described here.
Improving data quality is therefore fundamentally a question of how responsibility for data is assigned, shared, and sustained across the system lifecycle, not merely a matter of better tooling. Once that responsibility is in place, teams still have to decide which responsible-AI objective should dominate when valid goals conflict.
Balancing competing objectives
Machine learning system design is often framed as a process of optimization, improving accuracy, reducing loss, or maximizing utility. Yet in responsible ML practice, optimization must be balanced against a range of competing objectives, including fairness, interpretability, robustness, privacy, and resource efficiency. These objectives are not always aligned, and improvements in one dimension may entail trade-offs in another. While these tensions are well understood in theory, managing them in real-world systems is a persistent and unresolved challenge.
Consider the trade-off between model accuracy and interpretability. In many cases, more interpretable models, including shallow decision trees and linear models, achieve lower predictive performance than complex ensemble methods or deep neural networks. In low-stakes applications, this trade-off may be acceptable, or even preferred. In high-stakes domains such as healthcare or finance, however, where decisions affect individuals’ well-being or access to opportunity, teams are often caught between the demand for performance and the need for transparent reasoning. Even when interpretability is prioritized during development, it may be overridden at deployment in favor of marginal gains in model accuracy.
Similar tensions emerge between personalization and fairness. A recommendation system trained to maximize user engagement may personalize aggressively, using fine-grained behavioral data to tailor outputs to individual users. While this approach can improve satisfaction for some users, it may entrench disparities across demographic groups, particularly if personalization draws on features correlated with race, gender, or socioeconomic status. Adding fairness constraints may reduce disparities at the group level, but at the cost of reducing perceived personalization for some users. These effects are often difficult to measure, and even more difficult to explain to product teams under pressure to optimize engagement metrics.
Privacy introduces another set of constraints. Techniques such as differential privacy, federated learning, or local data minimization (Biega et al. 2020) can meaningfully reduce privacy risks. They also introduce noise, limit model capacity, or reduce access to training data. In centralized systems, these costs may be absorbed through infrastructure scaling or hybrid training architectures. In edge or TinyML deployments, however, the trade-offs are more acute. A wearable device tasked with local inference must often balance model complexity, energy consumption, latency, and privacy guarantees simultaneously. Supporting one constraint typically weakens another, forcing system designers to prioritize among equally important goals. These tensions are further amplified by deployment-specific design decisions such as quantization levels, activation clipping, or compression strategies that affect how effectively models can support multiple objectives at once.
Biega, A. J., P. Potash, H. Daumé, F. Diaz, and M. Finck. 2020. “Operationalizing the Legal Principle of Data Minimization for Personalization.” In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, edited by Jimmy Huang, Yi Chang, Xueqi Cheng, Jaap Kamps, Vanessa Murdock, Ji-Rong Wen, and Yiqun Liu. ACM. https://doi.org/10.1145/3397271.3401034.
The trade-offs are not purely technical; they reflect deeper normative judgments about what a system is designed to achieve and for whom, as explored in detail in section 1.6.3. Responsible ML development requires making these judgments explicit, evaluating them in context, and subjecting them to stakeholder input and institutional oversight.
What makes this challenge particularly difficult in implementation is that these competing objectives are rarely owned by a single team or function. Performance may be optimized by the modeling team, fairness monitored by a responsible AI group, and privacy handled by legal or compliance departments. Without deliberate coordination, system-level trade-offs can be made implicitly, piecemeal, or without visibility into long-term consequences. Over time, the result may be a model that appears well-behaved in isolation but fails to meet its ethical goals when embedded in production infrastructure.
Balancing competing objectives requires not only technical fluency but a commitment to transparency, deliberation, and alignment across teams. Systems must be designed to surface trade-offs rather than obscure them, to make room for constraint-aware development rather than pursue narrow optimization. In practice, this may require redefining what “success” looks like, not as performance on a single metric, but as sustained alignment between system behavior and its intended role in a broader social or operational context.
Across these first three challenges (organizational structures, data quality, and competing objectives), a pattern emerges: responsible AI failure rarely stems from technical ignorance. Teams understand fairness metrics, privacy techniques, and bias mitigation methods. Instead, failure occurs at the intersection of organizational fragmentation that distributes responsibility without accountability, data constraints that create technical barriers even with clear intentions, and competing objectives that force normative trade-offs disguised as technical problems. When modeling teams optimize performance, compliance teams address privacy, and product teams prioritize engagement independently, system-level ethical behavior emerges by accident rather than design. These are fundamentally sociotechnical governance problems requiring clear ownership structures that span organizational boundaries, data infrastructure designed for ethical auditing, and deliberative processes for making value trade-offs explicit. These challenges become even more acute when systems must maintain responsible behavior at scale over time.
Scalability and maintenance
Responsible machine learning practices are often introduced during the early phases of model development: fairness audits are conducted during initial evaluation, interpretability methods are applied during model selection, and privacy-preserving techniques are considered during training. However, as systems transition from research prototypes to production deployments, these practices frequently degrade or disappear. The gap between what is possible in principle and what is sustainable in production is a core implementation challenge for responsible AI.
Many responsible AI interventions are not designed with scalability in mind. Fairness checks may be performed on a static dataset, but not integrated into ongoing data ingestion pipelines. Explanation methods may be developed using development-time tools but never translated into deployable user-facing interfaces. Privacy constraints may be enforced during training, but overlooked during postdeployment monitoring or model updates. In each case, what begins as a responsible design intention fails to persist across system scaling and lifecycle changes.
Production environments introduce new pressures that reshape system priorities. Models must operate across diverse hardware configurations, interface with evolving APIs, serve millions of users with low latency, and maintain availability under operational stress. For instance, maintaining consistent behavior across CPU, GPU, and edge accelerators requires tight integration between framework abstractions, runtime schedulers, and hardware-specific compilers. These constraints demand continuous adaptation and rapid iteration, often deprioritizing activities that are difficult to automate or measure. Responsible AI practices, especially those that involve human review, stakeholder consultation, or posthoc evaluation, may not be easily incorporated into fast-paced DevOps39 pipelines.
39 DevOps for ML (MLOps): ML CI/CD pipelines must handle data versioning, training reproducibility, and A/B testing of algorithm changes beyond traditional software concerns. High-velocity ML organizations may deploy model or configuration changes far more often than responsible-AI reviews can be completed manually, creating a velocity gap: deployment cycles measured in hours compete against ethical validation requiring days or weeks. This tension explains why responsible AI commitments present at the prototype stage can be deprioritized as systems scale.
Maintenance introduces further complexity. Machine learning systems are rarely static. New data is ingested, retraining is performed, features are deprecated or added, and usage patterns shift over time. In the absence of rigorous version control, changelogs, and impact assessments, it can be difficult to trace how system behavior evolves or whether responsibility-related properties such as fairness or robustness are being preserved. Organizational turnover and team restructuring can erode institutional memory. Teams responsible for maintaining a deployed model may not be the ones who originally developed or audited it, leading to unintentional misalignment between system goals and deployed behavior. These issues are especially acute in continual or streaming learning scenarios, where concept drift and shifting data distributions demand active monitoring and real-time updates.
These challenges are magnified in multi-model systems and cross-platform deployments. A recommendation engine may consist of dozens of interacting models, each optimized for a different subtask or user segment. A voice assistant deployed across mobile and edge environments may maintain different versions of the same model, tuned to local hardware constraints. Coordinating updates, ensuring consistency, and sustaining responsible behavior in such distributed systems requires infrastructure that tracks not only code and data, but also values and constraints.
Addressing scalability and maintenance challenges requires treating responsible AI as a lifecycle property, not a one-time evaluation. This means embedding audit hooks, metadata tracking, and monitoring protocols into system infrastructure. It also means creating documentation that persists across team transitions, defining accountability structures that survive project handoffs, and ensuring that system updates do not inadvertently erase hard-won improvements in fairness, transparency, or safety. While such practices can be difficult to implement retroactively, they can be integrated into system design from the outset through responsible-by-default tooling and workflows.
Responsibility must scale with the system. Machine learning models deployed in real-world environments must not only meet ethical standards at launch but also continue to do so as they grow in complexity, user reach, and operational scope. Achieving this requires sustained organizational investment and architectural planning, not merely technical correctness at a single point in time.
Standardization and evaluation gaps
While the field of responsible machine learning has produced a wide range of tools, metrics, and evaluation frameworks, there is still little consensus on how to systematically assess whether a system is responsible in practice. Many teams recognize the importance of fairness, privacy, interpretability, and robustness, yet they often struggle to translate these principles into consistent, measurable standards. Benchmarking methodologies provide valuable frameworks for standardized evaluation, though adapting these approaches to responsible AI metrics remains an active area of development. The lack of formalized evaluation criteria, combined with the fragmentation of tools and frameworks, poses a significant barrier to implementing responsible AI at scale.
The fragmentation is evident both across and within institutions. Academic research frequently introduces new metrics for fairness or robustness that are difficult to reproduce outside experimental settings. Industrial teams, by contrast, must prioritize metrics that integrate cleanly with production infrastructure, are interpretable by nonspecialists, and can be monitored over time. As a result, practices developed in one context may not transfer well to another, and performance comparisons across systems may be unreliable or misleading. For instance, a model evaluated for fairness on one benchmark dataset using demographic parity may not meet the requirements of equalized odds in another domain or jurisdiction. Without shared standards, these evaluations remain ad hoc, making it difficult to establish confidence in a system’s responsible behavior across contexts.
Responsible AI evaluation also suffers from a mismatch between the unit of analysis, which is frequently the individual model or batch job, and the level of deployment, which includes end-to-end system components such as data ingestion pipelines, feature transformations, inference APIs, caching layers, and human-in-the-loop workflows. A system that appears fair or interpretable in isolation may fail to uphold those properties once integrated into a broader application. Tools that support holistic, system-level evaluation remain underdeveloped, and there is little guidance on how to assess responsibility across interacting components in production ML stacks.
Further complicating matters is the lack of lifecycle-aware metrics. Most evaluation tools are applied at a single point in time, often just before deployment. Yet responsible AI properties such as fairness and robustness are dynamic. They depend on how data distributions evolve, how models are updated, and how users interact with the system. Without continuous or periodic evaluation, it is difficult to determine whether a system remains aligned with its intended ethical goals after deployment. Postdeployment monitoring tools exist, but they are rarely integrated with the development-time metrics used to assess initial model quality. This disconnect makes it hard to detect drift in ethical performance, or to trace observed harms back to their upstream sources.
Tool fragmentation further contributes to these challenges. Responsible AI tooling is often distributed across disconnected packages, dashboards, or internal systems, each designed for a specific task or metric. A team may use one tool for explainability, another for bias detection, and a third for compliance reporting, with no unified interface for reasoning about system-level trade-offs. The lack of interoperability hinders collaboration between teams, complicates documentation, and increases the risk that important evaluations will be skipped or performed inconsistently. These challenges are compounded by missing hooks for metadata propagation or event logging across components like feature stores, inference gateways, and model registries.
The failed-transfer case introduced above is the concrete shape of the problem: a model certified fair under demographic parity on one benchmark can fail equalized odds in a new domain or jurisdiction, so the certification does not travel with the model. Closing that gap requires evaluation criteria that are measurable and auditable across domains, applied to full system pipelines rather than isolated models, and re-run as a recurring lifecycle activity so a passing result at launch does not silently expire as distributions drift. Until those practices are shared rather than ad hoc, responsible AI remains described in principles but difficult to verify in practice.
Responsible AI cannot be achieved through isolated interventions or static compliance checks. It requires architectural planning, infrastructure support, and institutional processes that sustain ethical goals across the system lifecycle. As ML systems scale, diversify, and embed themselves into sensitive domains, the ability to enforce properties like fairness, robustness, and privacy must be supported not only at model selection time, but across retraining, quantization, serving, and monitoring stages. Without persistent oversight, responsible practices degrade as systems evolve, especially when tooling, metrics, and documentation are not designed to track and preserve them through deployment and beyond.
Meeting this challenge will require greater standardization, deeper integration of responsibility-aware practices into CI/CD pipelines, and long-term investment in system infrastructure that supports ethical foresight. The goal is not to perfect ethical decision-making in code, but to make responsibility an operational property, traceable, testable, and aligned with the constraints and affordances of machine learning systems at scale.
Implementation decision framework
Given these implementation challenges, practitioners need systematic approaches to prioritize responsible AI principles based on deployment context and stakeholder needs. The same principle can demand different engineering treatment across high stakes individual decisions, safety-critical systems, privacy-sensitive applications, large-scale consumer systems, resource-constrained deployments, and research environments.
Four decision heuristics guide these trade-offs in practice:
- When multiple principles conflict, engage stakeholders to determine which harms are most severe. The mental health chatbot example examined in section 1.6.3 showed such conflicts require deliberation, not algorithmic resolution.
- When computational budgets are constrained, prioritize principles by risk. High-stakes decisions demand fairness/explainability even at significant cost. Low-stakes applications can use lightweight methods.
- When deployment context changes, re-evaluate principle priorities. A cloud model moved to edge loses centralized monitoring capability; compensate with predeployment validation and local safeguards.
- When stakeholder values differ, document trade-offs explicitly and create contestability mechanisms allowing affected users to challenge decisions.
Table 6 provides a practitioner decision framework that maps these deployment contexts to primary principles, implementation priorities, and acceptable trade-offs so the decision can remain context-sensitive rather than universal.
| Deployment Context | Primary Principles | Implementation Priority | Acceptable Trade-offs |
|---|---|---|---|
| High-Stakes Individual Decisions | Fairness, | Mandatory fairness metrics | Accept a measured accuracy budget for |
| (healthcare diagnosis, credit/loans, | Explainability, | across protected groups; | interpretability and a bounded latency |
| criminal justice, employment) | Accountability | explainability for negative outcomes; human oversight for edge cases | explanations; higher computational costs |
| Safety-Critical Systems | Safety, | Certified adversarial | Accept significant validation and |
| (autonomous vehicles, medical | Robustness, | defenses; formal validation; | adversarial-training overhead; |
| devices, industrial control) | Accountability | failsafe mechanisms; comprehensive logging | conservative confidence thresholds; redundant inference |
| Privacy-Sensitive Applications | Privacy, | Differential privacy | Accept privacy-utility trade-offs and higher |
| (health records, financial data, | Security, | (ε≤1.0); local processing; | client-side compute; limited model |
| personal communications) | Transparency | data minimization; user consent mechanisms | updates; reduced personalization |
| Large-Scale Consumer Systems | Fairness, | Bias monitoring across | Balance explainability costs against |
| (content recommendation, search, | Transparency, | demographics; explanation | scale (sampled or asynchronous explanations); |
| advertising) | Safety | mechanisms; content policy enforcement; feedback loops detection | budget serving-path latency for fairness checks and invest in monitoring infrastructure |
| Resource-Constrained Deployments | Privacy, | Local inference; data | Sacrifice real-time fairness monitoring; |
| (mobile, edge, TinyML) | Efficiency, Safety | locality; input validation; graceful degradation | use lightweight explainability (gradients over SHAP); predeployment validation only; limited model complexity |
| Research/Exploratory Systems | Transparency, | Documentation of known | Can deprioritize sophisticated |
| (internal tools, prototypes, | Safety (harm | limitations; restricted | fairness/explainability for internal |
| A/B tests) | prevention) | user populations; monitoring for unintended harms | use; focus on observability and rapid iteration |
The framework provides starting guidance, but it should be read as a triage mechanism rather than a complete governance program. It identifies which constraints deserve first attention in each deployment context, then leaves room for reassessment as systems, contexts, and societal expectations evolve. The challenges examined thus far still assume systems operating under human oversight. Engineers detect bias and intervene; operators monitor fairness metrics; developers respond to drift. Some systems, however, must act faster than humans can review. Autonomous vehicles respond in milliseconds; trading algorithms execute thousands of transactions before human review is possible; content moderation systems process billions of posts daily. These autonomous systems require extending the responsible AI framework beyond implementation challenges to a more fundamental problem: ensuring that systems pursue objectives aligned with human values, even when operating beyond continuous human supervision.
AI safety and value alignment
Value alignment challenges scale dramatically as machine learning systems gain autonomy and capability. The responsible AI techniques examined above, including bias detection, explainability, and privacy preservation, provide essential capabilities but reveal fundamental limitations when systems operate with greater independence. Consider how these established methods break down in autonomous contexts.
Bias detection algorithms like those implemented in Fairlearn require ongoing human interpretation and corrective action. An autonomous vehicle’s perception system might exhibit systematic bias against detecting pedestrians with mobility aids, but without human oversight, the bias detection metrics become just logged statistics with no remediation pathway. The technical capability to measure bias exists, but autonomous systems lack the judgment to determine appropriate responses.
Explainability frameworks assume human audiences who can interpret and act on explanations. An autonomous trading system might generate perfectly accurate SHAP explanations for its decisions, but these explanations become meaningless if no human reviews them before the system executes thousands of trades per second. The system optimizes its objective (profit) through methods its designers never anticipated, making explanations a post hoc record rather than a decision-making aid.
Privacy preservation techniques like differential privacy protect individual data points but cannot address broader value misalignment. An autonomous content recommendation system might preserve user privacy through local differential privacy while simultaneously optimizing for engagement metrics that promote misinformation or harmful content. Technical privacy compliance becomes insufficient when the system’s fundamental objectives conflict with user welfare.
Responsible AI frameworks, while necessary, become insufficient as systems gain autonomy. The techniques assume human oversight, constrained objectives, and relatively predictable operating environments. AI safety extends these concerns to systems that may optimize objectives misaligned with human intentions, operate in unpredictable environments, or pursue goals through methods their designers never anticipated.
As machine learning systems increase in autonomy, scale, and deployment complexity, the nature of responsibility expands beyond model-level fairness or privacy concerns. AI safety work frames these concerns around accident risks from wrong objectives, reward hacking, scalable supervision, safe exploration, and distributional shift (Amodei et al. 2016), while alignment work emphasizes ensuring that systems pursue objectives consistent with human intentions over time (Russell 2021). These concerns fall under the domain of AI safety40, which focuses on preventing unintended or harmful outcomes from capable AI systems. A central challenge is that capable ML models often optimize proxy metrics41, such as loss functions, reward functions, or engagement signals, that do not fully capture human values.
40 AI Safety: A research field addressing the gap between what ML systems optimize and what humans intend, spanning near-term risks (bias, privacy) to long-term alignment concerns. Major AI labs have treated safety as an explicit research area, reflecting the engineering reality that as models grow more capable or more autonomous, the cost of misaligned objectives can scale sharply – a misaligned recommendation system degrades user experience, while a misaligned autonomous vehicle costs lives.
41 Proxy Metrics: Measurable substitutes for objectives that resist direct quantification, subject to Goodhart’s Law: “when a measure becomes a target, it ceases to be a good measure.” In ML systems, proxy-objective divergence is a central mechanism of value misalignment: click-through rate proxies for satisfaction, loss proxies for generalization, and engagement proxies for user welfare – each creating optimization pressure that systematically diverges from the intended goal as the model becomes more capable.
42 CTR and Engagement Optimization: Click-through rate, watch time, and related engagement measures are convenient proxies for user satisfaction. YouTube’s published recommender architecture discusses ranking videos by expected watch time (Covington et al. 2016), while later audits studied recommendation paths through politically extreme content (Ribeiro et al. 2020). The systems lesson is that proxy metric selection is an architectural decision with system-wide behavioral consequences, not merely a hyperparameter choice.
Covington, Paul, Jay Adams, and Emre Sargin. 2016. “Deep Neural Networks for YouTube Recommendations.” Proceedings of the 10th ACM Conference on Recommender Systems, 191–98. https://doi.org/10.1145/2959100.2959190.
Ribeiro, M. H., R. Ottoni, R. West, V. A. F. Almeida, and Jr. Meira Wagner. 2020. “Auditing Radicalization Pathways on YouTube.” Proceedings of the 2020 Conference on Fairness, Accountability, and Transparency, 131–41. https://doi.org/10.1145/3351095.3372879.
43 Reward Hacking: When an AI system maximizes its reward function through unintended means that violate designer intent. A Tetris AI learned to pause indefinitely to avoid losing; a cleaning robot knocked over objects to create messes it could then clean up. For production ML systems, reward hacking manifests subtly: recommendation models that maximize engagement by promoting addictive content, or chatbots that maximize helpfulness ratings by being sycophantic rather than accurate. The failure mode scales with model capability.
One concrete example comes from recommendation systems, where a model optimized for a measurable engagement proxy such as clicks or watch time42 can increase the proxy while degrading broader user welfare. Production recommenders explicitly optimize engagement signals such as expected watch time (Covington et al. 2016), and audits of YouTube have examined how recommendation paths can expose users to politically extreme content (Ribeiro et al. 2020). This behavior is aligned with the proxy, but misaligned with the actual goal, resulting in a feedback loop that reinforces undesirable outcomes. The system learns to optimize for a measurable reward rather than the intended human-centered outcome, creating the reinforcement cycle captured in figure 14. The result is emergent behavior that reflects specification gaming or reward hacking43, a central concern in value alignment and AI safety (Amodei et al. 2016).

Norbert Wiener wrote, “if we use, to achieve our purposes, a mechanical agency with whose operation we cannot interfere effectively… we had better be quite sure that the purpose put into the machine is the purpose which we desire” (Wiener 1960).
Wiener, N. 1960. “Some Moral and Technical Consequences of Automation: As Machines Learn They May Develop Unforeseen Strategies at Rates That Baffle Their Programmers.” Science 131 (3410): 1355–58. https://doi.org/10.1126/science.131.3410.1355.
Russell, S. 2021. “Human-Compatible Artificial Intelligence.” In Human-Like Machine Intelligence. Oxford University Press. https://doi.org/10.1093/oso/9780198862536.003.0001.
Wiener’s warning becomes a systems requirement when optimization runs beyond continuous human intervention. Value alignment asks whether the objective embedded in the model, reward function, and deployment policy continues to represent the human purpose the system was meant to serve. As Russell (2021) argues in Human-Compatible Artificial Intelligence, much AI research presumes that the objectives to be optimized are known and fixed, focusing instead on the effectiveness of optimization rather than the design of objectives themselves.
In deployment, the hard part is specifying an objective that remains valid as systems interact with dynamic environments, multiple stakeholders, and feedback loops. Static objective functions and reward signals cannot encode all of those conditions. Frameworks like Value Sensitive Design provide formal processes for eliciting and integrating stakeholder values during system design, but the systems obligation is broader: objective design, oversight, and postdeployment monitoring must be treated as coupled controls.
Without that coupling, intelligent systems may pursue narrow performance objectives (for example, accuracy, engagement, or throughput) while producing socially undesirable outcomes. Achieving robust alignment under such conditions remains an open and important area of research in ML systems. The resulting failure modes are familiar in systems that optimize complex objectives. In reinforcement learning (RL), for example, models often learn to exploit unintended aspects of the reward function, a phenomenon known as specification gaming44 or reward hacking.
44 Specification Gaming: Unlike reward hacking (exploiting implementation bugs), specification gaming reveals genuine gaps in objective specification – the system satisfies the letter of the objective while violating its intent. A robot hand trained to grasp objects learns to knock them over (easier to “hold” when wedged against the table). For ML systems, this motivates multi-objective optimization and RLHF as specification methods that incorporate broader constraints beyond single scalar metrics, trading additional data, training, and review effort for objectives that better approximate human intent.
45 RLHF (Reinforcement Learning from Human Feedback): Christiano et al. (2017) demonstrated deep reinforcement learning from human preferences by training agents from non-expert comparisons between trajectory segments. In the LLM setting, Ouyang et al. (2022) operationalized a related pipeline for InstructGPT: supervised fine-tuning from demonstrations, reward-model training from ranked model outputs, and reinforcement-learning fine-tuning against the learned reward model. The systems cost is an additional human-feedback data pipeline, reward-model training and evaluation, and governance over rater instructions; the representativeness of the rater pool and labeling policy shapes whose preferences the model internalizes.
Christiano, P. F., J. Leike, T. B. Brown, M. Martic, S. Legg, and D. Amodei. 2017. “Deep Reinforcement Learning from Human Preferences.” In Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, December 4-9, 2017, Long Beach, CA, USA, edited by Isabelle Guyon, Ulrike von Luxburg, Samy Bengio, Hanna M. Wallach, Rob Fergus, S. V. N. Vishwanathan, and Roman Garnett. Curran Associates.
Ouyang, L., J. Wu, X. Jiang, D. Almeida, C. L. Wainwright, P. Mishkin, C. Zhang, et al. 2022. “Training Language Models to Follow Instructions with Human Feedback.” Advances in Neural Information Processing Systems 35 35: 27730–44. https://doi.org/10.52202/068431-2011.
Such failures arise when variables not explicitly included in the objective are manipulated in ways that maximize reward while violating human intent. A particularly influential approach in recent years has been reinforcement learning from human feedback (RLHF)45, where models are trained or fine-tuned using human-provided preference signals (Christiano et al. 2017; Ouyang et al. 2022).
While this method improves alignment over standard RL, it also introduces governance risks. Ngo (Ngo et al. 2022) identifies three potential failure modes introduced by RLHF:
Ngo, Richard, Lawrence Chan, and Sören Mindermann. 2022. “The Alignment Problem from a Deep Learning Perspective.” ArXiv Preprint abs/2209.00626.
- Situationally aware reward hacking, where models exploit human fallibility.
- Emergence of misaligned internal goals that generalize beyond the training distribution.
- Development of power-seeking behavior that preserves reward maximization capacity, even at the expense of human oversight.
These concerns are not limited to speculative scenarios. Amodei et al. (2016) outline five concrete challenges for AI safety:
Amodei, D., C. Olah, J. Steinhardt, P. Christiano, J. Schulman, and D. Mané. 2016. “Concrete Problems in AI Safety.” arXiv Preprint arXiv:1606.06565, ahead of print. https://doi.org/10.48550/arXiv.1606.06565.
- Avoiding negative side effects during policy execution.
- Mitigating reward hacking.
- Ensuring scalable oversight when ground-truth evaluation is expensive or infeasible.
- Designing safe exploration strategies that promote creativity without increasing risk.
- Achieving robustness to distributional shift in testing environments.
For fleet operators, each challenge maps to a control-plane requirement: constrain side effects, monitor reward hacking, budget scalable oversight, bound exploration, and test distribution shift before rollout. Each requirement becomes more acute as systems are scaled up, deployed across diverse settings, and integrated with real-time feedback or continual learning.
These safety challenges are particularly evident in autonomous systems that operate with reduced human oversight.
Autonomous systems and trust
The consequences of autonomous systems operating with limited real-time human oversight are especially visible in autonomous driving. A prominent recent example is the suspension of Cruise’s deployment and testing permits by the California Department of Motor Vehicles due to “unreasonable risks to public safety” (CNBC 2023a). One such incident involved a pedestrian who entered a crosswalk just as the stoplight turned green, an edge case in perception and decision-making that led to a collision (CNBC 2023b). A more tragic example occurred in 2018, when a self-driving Uber vehicle in autonomous mode failed to classify a pedestrian pushing a bicycle as a pedestrian requiring avoidance, resulting in a fatality; the NTSB report treats that failure as a combination of automated-driving-system design, safety-driver, and organizational safety-management breakdowns (National Transportation Safety Board 2019).
CNBC. 2023a. California DMV Suspends Cruise’s Self-Driving Car Permits. CNBC news article.
CNBC. 2023b. Cruise Under NHTSA Probe into Autonomous Driving Pedestrian Injuries. CNBC news article.
National Transportation Safety Board. 2019. Collision Between Vehicle Controlled by Developmental Automated Driving System and Pedestrian, Tempe, Arizona, March 18, 2018. HAR-19/03. National Transportation Safety Board.
Reuters. 2023. Human-Machine Teams Driven by AI Are about to Reshape Warfare. Reuters news article.
Centre for International Governance Innovation. 2023. Who Is Responsible When Autonomous Systems Fail? CIGI policy article.
While autonomous driving systems are often the focal point of public concern, similar risks arise in other domains. Reports from recent conflicts have documented increasing use of remotely piloted and autonomous military systems (Reuters 2023), raising not only safety and effectiveness concerns but also difficult questions about ethical oversight, rules of engagement, and responsibility. When autonomous systems fail, the question of who should be held accountable remains both legally and ethically unresolved (Centre for International Governance Innovation 2023).
At its core, this challenge reflects a deeper tension between human and machine autonomy. Engineering and computer science disciplines have historically emphasized machine autonomy, improving system performance, minimizing human intervention, and maximizing automation. A bibliometric analysis of the ACM Digital Library found that, as of 2019, 90 percent of the most cited papers referencing “autonomy” focused on machine, rather than human, autonomy (Calvo et al. 2020). Productivity, efficiency, and automation have been widely treated as default objectives, often without interrogating the assumptions or trade-offs they entail for human agency and oversight.
Calvo, Rafael A., Dorian Peters, Karina Vold, and Richard M. Ryan. 2020. “Supporting Human Autonomy in AI Systems: A Framework for Ethical Enquiry.” In Ethics of Digital Well-Being. Springer. https://doi.org/10.1007/978-3-030-50585-1_2.
McCarthy, J. 1981. “Epistemological Problems of Artificial Intelligence.” In Readings in Artificial Intelligence. Elsevier. https://doi.org/10.1016/b978-0-934613-03-3.50035-0.
However, these goals can place human interests at risk when systems operate in dynamic, uncertain environments where full specification of safe behavior is infeasible. This difficulty is formally captured by the frame problem and qualification problem, both of which highlight the impossibility of enumerating all the preconditions and contingencies needed for real-world action to succeed (McCarthy 1981). The frame problem asks which facts in the world remain relevant after an action; the qualification problem asks which hidden preconditions must hold before the action is safe. In practice, such limitations manifest as brittle autonomy: systems that appear competent under nominal conditions but fail silently or dangerously when faced with ambiguity or distributional shift.
To address this, researchers have proposed formal safety frameworks such as Responsibility-Sensitive Safety (RSS) (Shalev-Shwartz et al. 2017), which decompose abstract safety goals into mathematically defined constraints on system behavior, such as minimum distances, braking profiles, and right-of-way conditions. These formulations allow safety properties to be verified under specific assumptions and scenarios. However, such approaches remain vulnerable to the same limitations they aim to solve: they are only as good as the assumptions encoded into them and often require extensive domain modeling that may not generalize well to unanticipated edge cases.
Shalev-Shwartz, Shai, Shaked Shammah, and Amnon Shashua. 2017. “On a Formal Model of Safe and Scalable Self-Driving Cars.” ArXiv Preprint abs/1708.06374.
For an ML systems team, the practical artifact is a safety case rather than a statement of trust. Table 7 shows the pattern: name the operating envelope, the evidence that the model has been tested inside that envelope, and the controls that halt or roll back the fleet when the evidence no longer holds.
| Safety-case element | Systems evidence | Operational gate |
|---|---|---|
| Operating envelope | Operational design domain, sensor assumptions, weather, geography, speed, and autonomy level | Block deployment outside validated envelope |
| Scenario coverage | Rare-event corpus, simulation coverage, replay logs, disengagements, and near-miss telemetry | Require coverage thresholds before canary expansion |
| Runtime guardrails | RSS-style distance rules, confidence thresholds, fallback maneuvers, and human override latency | Trigger safe stop, human takeover, or constrained mode when guardrails trip |
| Fleet control | Canary rollout, centralized safety dashboard, violation budget, and circuit-breaker rollback path | Halt rollout or revert model when fleet-level safety metrics exceed threshold |
An alternative approach emphasizes human-centered system design, ensuring that human judgment and oversight remain central to autonomous decision-making. Value-Sensitive Design (Friedman 1996) proposes incorporating user values into system design by explicitly considering factors like capability, complexity, misrepresentation, and the fluidity of user control. More recently, the METUX model (Motivation, Engagement, and Thriving in the User Experience) extends this thinking by identifying six “spheres of technology experience” (Adoption, Interface, Tasks, Behavior, Life, and Society), which affect how technology supports or undermines human flourishing (Peters et al. 2018). These ideas are rooted in Self-Determination Theory (SDT), which defines autonomy not as control in a technical sense, but as the ability to act in accordance with one’s values and goals (Ryan and Deci 2000). In system design, these frameworks become artifacts: requirements, interface affordances, user controls, feedback channels, escalation paths, and audit evidence.
Friedman, B. 1996. “Value-Sensitive Design.” Interactions 3 (6): 16–23. https://doi.org/10.1145/242485.242493.
Peters, D., R. A. Calvo, and R. M. Ryan. 2018. “Designing for Motivation, Engagement and Wellbeing in Digital Experience.” Frontiers in Psychology 9: 797. https://doi.org/10.3389/fpsyg.2018.00797.
Ryan, R. M., and E. L. Deci. 2000. “Self-Determination Theory and the Facilitation of Intrinsic Motivation, Social Development, and Well-Being.” American Psychologist 55 (1): 68–78. https://doi.org/10.1037/0003-066x.55.1.68.
In the context of ML systems, these perspectives underscore the importance of designing architectures, interfaces, and feedback mechanisms that preserve human agency. For instance, recommender systems that optimize engagement metrics may interfere with behavioral autonomy by shaping user preferences in opaque ways. By evaluating systems across METUX’s six spheres, designers can anticipate and mitigate downstream effects that compromise meaningful autonomy, even in cases where short-term system performance appears optimal.
Broader safety implications
The technical safety challenges examined above become fleet-level design constraints once autonomous systems interact with workers, users, regulators, and billions of requests. The broader implication is that safety cannot be reduced to a model metric; it depends on the operating environment that determines how automation changes work, how users calibrate trust, how policy varies by region, and how rare failures accumulate at scale.
Automation changes work organization in ways that influence safety design decisions. The MIT Work of the Future task force (Work of the Future 2020) argues that technological change and labor-market institutions jointly determine whether automation improves job quality or concentrates harms. For ML systems, the safety implication is that removing human roles can also remove contextual judgment and system-level debugging that remain difficult to encode in models. Metrics focused solely on throughput may inadvertently penalize human-in-the-loop designs that preserve oversight capability.
Work of the Future, MIT Task Force on the. 2020. The Work of the Future: Building Better Jobs in an Age of Intelligent Machines. Massachusetts Institute of Technology.
Center, Pew Research. 2023. What Americans Know about AI, Cybersecurity and Big Tech.
Schäfer, Mike S. 2023. “The Notorious GPT: Science Communication in the Age of Artificial Intelligence.” Journal of Science Communication 22 (02): Y02. https://doi.org/10.22323/2.22020402.
Public knowledge about AI is uneven (Center 2023), and science-communication failures can amplify misunderstandings about how AI systems work (Schäfer 2023). That matters for deployment safety: when users lack understanding of model uncertainty, data bias, or decision boundaries, they may trust system outputs in contexts where human judgment should intervene. From a systems engineering perspective, public comprehension is part of the deployment context: the safety properties of a human-AI system depend not only on the technical system but also on whether users can appropriately calibrate their trust and recognize situations requiring human override.
The engineering requirements for safety are shaped by a fragmented global regulatory landscape that treats AI risk as a verifiable metric. The EU AI Act (2024) uses a risk-based structure that includes prohibited practices, high-risk systems, transparency duties for some systems, and minimal or no-risk uses; high-risk deployments face conformity, documentation, and logging obligations (European Parliament and Council of the European Union 2024). In the United States, Executive Order 14110 (2023) formerly established federal AI safety reporting thresholds, but it was revoked by Executive Order 14148 in January 2025; Executive Order 14179 then directed agencies to review and revise AI actions tied to the prior order, and Executive Order 14409 in June 2026 shifted federal emphasis toward AI innovation, cybersecurity, and critical-infrastructure defense (Executive Office of the President 2023, 2025a, 2025b, 2026). China’s Interim Measures for Generative AI (2023) subject some public-facing services to security assessment and algorithm-filing requirements rather than a universal pre-release assessment (Cyberspace Administration of China et al. 2023). For a global ML fleet, compliance becomes a complex distributed systems problem: inference nodes in Frankfurt may require different safety configurations, data retention policies, and human-in-the-loop thresholds than those in Virginia or Singapore. This necessitates a flexible configuration control plane capable of pushing geo-specific safety policies to edge nodes without bifurcating the core model architecture.
European Parliament and Council of the European Union. 2024. Regulation (EU) 2024/1689 of the European Parliament and of the Council of 13 June 2024 Laying down Harmonised Rules on Artificial Intelligence (AI Act). Official Journal of the European Union, L 2024/1689.
Executive Office of the President. 2023. Safe, Secure, and Trustworthy Development and Use of Artificial Intelligence. Executive Order 14110, 88 FR 75191.
Executive Office of the President. 2025a. Initial Rescissions of Harmful Executive Orders and Actions. Executive Order 14148, 90 FR 8237.
Executive Office of the President. 2025b. Removing Barriers to American Leadership in Artificial Intelligence. Executive Order 14179.
Executive Office of the President. 2026. Promoting Advanced Artificial Intelligence Innovation and Security. Executive Order 14409, 91 FR 34565.
Cyberspace Administration of China, National Development and Reform Commission, Ministry of Education, Ministry of Science and Technology, Ministry of Industry and Information Technology, Ministry of Public Security, and National Radio and Television Administration. 2023. Interim Measures for Administration of Generative Artificial Intelligence Services. State Council Gazette.

At fleet scale, rare failures become expected incidents.
Safety must also be engineered as a fleet-level property rather than a model-level attribute alone. A single model with 99.9 percent safety compliance seems robust in isolation, but when deployed across 10,000 inference nodes serving billions of requests per day, that 0.1 percent failure rate guarantees millions of safety incidents daily. At this scale, rare failures accumulate into statistical certainties. Mitigating this requires distributed safety patterns borrowed from reliability engineering: circuit breakers that automatically halt serving when aggregate safety metrics degrade below a threshold, canary deployments that route only 1 percent of traffic to new model versions to validate safety properties in production, and centralized telemetry dashboards that aggregate per-node safety violations into a global view. As detailed in ML Operations at Scale, the operational infrastructure must treat safety violations as critical system alerts, triggering automated rollbacks just as latency spikes or error rates would.
The core AI safety principle holds: technical excellence alone is insufficient. Safe systems require attention to the human and organizational context in which they operate, including the economic incentives that shape design decisions and the understanding that end users bring to their interactions with autonomous systems.
Systems Perspective 1.3: Responsibility is infrastructure, not a feature
Responsible AI cannot be retrofitted into a system any more than fault tolerance can. The structural costs cataloged in table 4 each carry a provisioning consequence: bias-drift monitoring needs latency headroom on every inference request, SHAP explanation needs a dedicated asynchronous worker fleet, DP-SGD needs a larger training budget, and impact assessments need a slower CI/CD cadence. These are not optional add-ons but load-bearing components of production ML systems. In high-risk or regulated deployments, failing to provision them in the high-level design phase can block release or force redesign even when core model performance is strong.
Structural costs like latency overhead must be factored into the core architecture from day one; Responsible AI cannot be bolted onto a finished product. The pervasive industry fallacies that tempt teams into taking dangerous ethical shortcuts deserve explicit identification and dismantling.
Self-Check: Question
A company’s postmortem concludes that their biased hiring system shipped despite the ML team knowing every relevant fairness metric and having access to Fairlearn. Which diagnosis does the chapter treat as most commonly correct for this pattern?
- The field lacks workable methods for fairness, privacy, or interpretability
- Responsible AI failures in production stem primarily from organizational fragmentation, incentive misalignment, data infrastructure constraints, and scaling-related erosion of practices, not from absence of technical knowledge
- Responsible AI only fails in research settings, not production systems
- Modern hardware is too slow to run ethical models
A startup ships a prototype classifier with bias audits performed manually at review time, then grows into a fleet serving 100 million users per day with hundreds of models retrained weekly. Explain the specific mechanisms by which the prototype’s responsible AI practices typically erode as the system scales, and identify two infrastructure investments that prevent this erosion.
A team is building a triage system that assigns priority to emergency-room patients. Applying the practitioner decision framework, which combination of principles should be primary, and what operational consequence does this choice impose?
- Fairness, explainability, and accountability as primary, with acceptance of 2-5 percent accuracy reduction for interpretability, 20-100 ms latency for explanation, and mandatory fairness metrics across protected groups
- Throughput and personalization as primary, because ER systems must maximize patient throughput
- Privacy and energy efficiency alone, because ER systems operate on wearable hardware
- Governance minimization and rapid experimentation, because ER workflows require minimal process overhead
A video platform trains its recommendation model to maximize watch time and discovers the system promotes radicalizing content. The chapter presents this as a central AI-safety problem because:
- Proxy metrics always make models uninterpretable regardless of architecture
- Optimizing a measurable proxy like watch time systematically diverges from the true objective (user welfare) as capability rises, a Goodhart-style failure where the metric ceases to be a good measure once it becomes the target
- Proxy metrics only matter in reinforcement learning and never in recommender systems
- Once a proxy metric is formally specified, Goodhart-style failures disappear
True or False: At a fleet scale of 10,000 inference nodes serving billions of requests per day, a model with a 99.9 percent safety compliance rate is effectively equivalent to a perfectly safe system because the residual failures are too rare to matter operationally.
Explain why the chapter treats trust in autonomous systems as a systems-design problem rather than a model-accuracy problem, using the autonomous-vehicle regulatory and incident context the section provides.
Fallacies and Pitfalls
Responsible AI involves counterintuitive trade-offs where ethical principles conflict mathematically and technically. Practitioners from traditional software backgrounds often assume ethical guidelines translate directly to implementation without recognizing the impossibility theorems and computational costs involved. These fallacies and pitfalls capture misconceptions that lead to deployed systems that appear fair in development but violate fairness criteria in production or impose prohibitive computational overhead.
Fallacy: Bias will disappear with more data and better algorithms.
In production, bias often reflects structural properties that persist regardless of technical improvements. The healthcare algorithm described in section 1.1.3 affected 200 million Americans annually and reduced Black patient enrollment in care programs by 50 percent despite being trained on comprehensive data. The issue was not data quantity but proxy selection: using healthcare expenditure as a health proxy systematically underestimated need for populations with lower historical spending. Mathematical analysis shows that when base rates differ between groups, calibrated risk scores generally cannot also satisfy equal error-rate conditions except in special cases such as perfect prediction. Organizations that pursue “bias elimination” through purely technical means waste engineering resources on impossible or underspecified optimization problems while neglecting the stakeholder engagement and value deliberation required to choose which fairness criteria to prioritize for their specific context.
Pitfall: Treating explainability as an optional feature to be added after core functionality works.
This approach ignores the displacement of overhead: rendering a model’s reasoning transparent demands compute that constrains the architecture. As shown in table 4, approximate SHAP explanations are not free; even a bounded explanation budget can increase request latency and memory pressure. In this sizing example, a recommendation system serving 100 ms latency requirements at 10,000 QPS cannot retrofit explanation work without revisiting the SLA: the illustrative explanation budget adds 50 ms to 200 ms per request, increasing total latency to 150 ms–300 ms. The serving infrastructure must be redesigned with explanation budgets from initial architecture, including precomputed approximations or model selection favoring inherently interpretable architectures.
Fallacy: Achieving one fairness metric guarantees overall system fairness.
Practitioners often optimize for demographic parity, which equalizes approval rates across groups, and then assume fair treatment follows. In reality, fairness metrics can conflict mathematically. The loan approval example in section 1.1.3 demonstrates this: achieving demographic parity at 70 percent approval for both groups would require lowering Group B’s threshold to increase approvals, but that selection-rate fix can reduce precision and make approvals carry different risk meanings across groups. Impossibility results show that, when base rates differ and prediction is imperfect, calibration and equal error-rate conditions cannot generally hold at the same time; demographic parity can add a separate selection-rate constraint. Systems deployed with single-metric optimization discover in production that they violate other legally relevant fairness criteria, exposing organizations to litigation and regulatory action.
Pitfall: Treating responsible AI as pure compliance overhead.
This perspective misses the business value created through risk reduction and market expansion. Differential privacy can enable organizations to work with sensitive data under clearer privacy guarantees, but it also imposes privacy-utility trade-offs that must be planned in the training budget. Fairness-aware training and monitoring can reduce disparate-impact risk: the four-fifths rule described in section 1.1.3.5 establishes a practical screening threshold, and discrimination litigation or regulatory scrutiny can create substantial remediation and reputational costs. A comprehensive bias-monitoring pipeline would be expected to surface a major subgroup enrollment reduction before it becomes an external audit finding, avoiding the systematic harm and legal consequences that emerge when monitoring infrastructure is absent.
Fallacy: A post hoc threshold adjustment can make a deployed system fair.
This belief treats fairness as a single decision-boundary problem rather than a coupled system property. Moving a threshold can equalize one metric, but it can also change calibration, precision, business meaning, legal documentation, and user experience. In production, the threshold is not only a number in a notebook; it is a policy embedded in serving code, human review, audit records, and downstream decisions.
Pitfall: Implementing fairness constraints without analyzing threshold trade-offs and calibration impacts.
Group-specific thresholds can satisfy equal true positive rates, but they also change decision semantics: if Group A threshold is 0.75 and Group B threshold is 0.60, identical scores can yield different decisions, and the positive predictive value of approved applicants can diverge across groups even when the underlying score model remains calibrated. A loan officer seeing an approval cannot know whether it represents the same repayment-risk meaning across groups without documentation of the group-specific threshold policy. Production systems discover that group-specific thresholds require extensive documentation, staff training, and audit trails explaining why identical scores yield different decisions across groups, creating operational complexity and legal exposure. The proper approach requires jointly optimizing for multiple fairness criteria during training rather than relying on post hoc threshold adjustment, accepting the accuracy-fairness trade-offs that table 4 quantifies.
Fallacy: Monitoring dashboards create accountability by themselves.
Dashboards can expose fairness drift, explanation failures, or abuse trends, but they do not decide who must act. A responsible monitoring pipeline needs an owner, a threshold, an escalation path, and a remediation budget. Otherwise the system accumulates evidence without changing behavior: alerts age out, fairness regressions become accepted baselines, and affected users receive no route to contest the decision.
Pitfall: Launching monitoring without remediation ownership.
Teams often instrument fairness, safety, or privacy metrics because a policy requires visibility, then leave the response path undefined. This creates a false sense of control. A metric that no team owns is not a control; it is a log entry. Production responsibility requires binding each monitoring signal to a release gate, incident owner, rollback authority, or human-review capacity so the organization can act when the metric fails.
Context-blind threshold adjustment is the common failure behind these examples. A mathematical fairness constraint is only responsible when the system also accounts for downstream population effects, documentation requirements, operational capacity, and legal exposure. Rejecting these localized fallacies turns responsible AI from a compliance checklist into a foundational architectural mandate and completes the Governance Layer of the ML Fleet.
Self-Check: Question
A venture-backed startup claims it will “eliminate bias” in hiring models through a mix of 10\(\times\) more training data and a new transformer architecture. The chapter’s response to this claim is:
- Bias disappears once training data crosses a certain volume threshold
- Bias can be reduced, but structural trade-offs (proxy choice, impossibility theorems, historical inequities) mean there is no purely technical path to eliminating it altogether; the healthcare-algorithm case affected 200 million Americans and reduced Black enrollment in high-risk care programs by 50 percent despite comprehensive data
- Bias only persists when organizations use outdated model architectures
- Bias is primarily an underfitting problem that larger models resolve automatically
An architecture team plans to launch a deep ensemble recommendation system at 10,000 QPS with a 100 ms latency budget, and plans to “add SHAP explanations later” if regulators require them. Using the chapter’s quantitative treatment, explain why this plan is a pitfall and what the correct architectural discipline is.
A bank’s credit team announces it has “solved fairness” by satisfying demographic parity across all groups. Why does the chapter identify this single-metric approach as a pitfall?
- All fairness metrics are mathematically equivalent, so using one is redundant with using any other
- Once demographic parity is satisfied, calibration and equalized odds automatically improve
- Improving one fairness metric can worsen others; when base rates differ, Kleinberg’s impossibility result forbids simultaneously satisfying demographic parity, equalized odds, and calibration, so a parity-only announcement typically hides worse false-positive or calibration disparities elsewhere
- Fairness metrics should never be quantified in production
Summary
Responsible AI is the governance infrastructure of the machine learning fleet. Production ML already requires physical infrastructure, distributed execution, serving systems, security controls, robustness mechanisms, and sustainability budgets. Responsible AI adds the guardrails and governance frameworks required to ensure that the global machine serves human values rather than undermining them.
The argument moved from abstract ethics to concrete engineering constraints, analyzing mathematical fairness metrics and the unavoidable impossibility theorems that force explicit normative choices. It examined the technical foundations of explainability (SHAP, LIME) and privacy-preserving data governance, then extended the same infrastructure view to generative alignment, where RLHF and system prompts act as sociotechnical mechanisms for controlling model behavior in LLM fleets.
Table 8 illustrates why fairness requires explicit trade-offs. Consider a loan approval system evaluated across two demographic groups:
The worked example reports disaggregated fairness metrics, including false positive rate, so the same prediction table can satisfy one criterion while failing others. Equalized odds would require both true positive rates and false positive rates to match; this table therefore shows the narrower case of false-positive-rate parity, not full equalized odds.
| Metric | Definition | A | B | Gap |
|---|---|---|---|---|
| Approval Rate | (TP + FP) divided by total | 55% | 40% | 15 pp |
| True Positive Rate | TP divided by positives | 90% | 60% | 30 pp |
| False Positive Rate | FP divided by negatives | 20% | 20% | 0 pp |
| Positive Predictive Value | TP divided by predicted positives | 82% | 75% | 7 pp |
The table makes the chapter’s central constraint concrete: one fairness metric can appear satisfied while other metrics expose substantial disparities.
Responsible AI is fundamentally a systems engineering concern, not an ethical overlay applied after deployment. Fairness monitoring pipelines impose measurable latency and compute overhead that must be budgeted during architecture design, not retrofitted into production systems. Explainability mechanisms such as SHAP and LIME carry inference cost multipliers that affect capacity planning and SLO compliance. Governance frameworks for system prompts, model versioning, and audit logging require the same CI/CD rigor as any other infrastructure component. These are architectural requirements with quantifiable costs, and treating them as optional add-ons guarantees that they will be the first capabilities cut when deadlines compress.
The impossibility theorems formalized in this chapter make explicit what practitioners discover through painful experience: fairness is not a single metric to optimize but a set of competing constraints that demand normative choices. The engineer who understands these trade-offs quantitatively, who can calculate the overhead of differential privacy, specify the monitoring infrastructure for disparate impact detection, and design governance mechanisms that scale across a fleet of models, brings a discipline to responsible AI that transforms it from aspiration into engineering practice.
Key Takeaways: Ethics is an engineering constraint
- Responsibility gates deployment: In regulated or enterprise settings, accuracy and latency do not matter if the system cannot document behavior, explain decisions, support audit, or assign ownership. Governance is a Coordination constraint that determines whether Compute is allowed to run.
- Fairness has no hidden optimum: The chapter’s table shows one loan system can have a 0 percentage-point false-positive gap while still carrying 15 percentage-point approval and 30 percentage-point true-positive gaps. Differing base rates turn fairness into an explicit normative choice, not a single metric.
- Oversight consumes capacity: Fairness monitoring, audit logging, explanations, and privacy-preserving training add latency, storage, compute, and accuracy costs. SHAP-style explanations and DP-SGD must be budgeted in architecture and SLOs rather than appended when legal review arrives.
- Generative governance is infrastructure: System prompts, RLHF policies, tool permissions, model versions, and safety evaluations are operational artifacts. They need ownership, CI/CD, rollback, and monitoring because they steer model behavior as directly as weights do.
- Evidence needs an owner: Dashboards, explanations, and appeals protect users only when a team can investigate, remediate, roll back, or escalate failures. Responsible AI becomes engineering practice when every measured obligation has an accountable operating path.
Every constraint in this book until now has had an optimum. Latency, memory, energy, even robustness could be measured, traded, and pushed toward a best achievable point, and the engineer’s job was to find it. Fairness is the first constraint with no such point, because the chapter’s impossibility result is not a gap to be closed but a fork in the road. That changes the job. The engineer can quantify each branch and hold the system to whichever is taken, but the taking is a human, normative act that no metric performs, and the most honest thing engineering can do here is refuse to disguise the choice as a calculation.
What’s Next: From responsibility to synthesis
With responsible governance joined to performance, security, robustness, and sustainability, production ML becomes a complete engineering problem rather than a collection of isolated optimizations. Conclusion synthesizes these principles into a unified perspective on distributed ML systems engineering, distilling the enduring lessons that guide practice regardless of which specific technologies emerge in the years ahead.
Self-Check: Question
A VP of engineering must choose between funding a responsible AI platform team and funding more serving capacity for a cost-constrained product. The summary section’s central systems claim about responsible AI is:
- Responsible AI is primarily an ethics overlay applied after the real engineering is complete
- Responsible AI is load-bearing infrastructure with measurable latency, compute, and governance costs (for example, 10-20 ms per inference for bias monitoring, 50–1000\(\times\) compute for SHAP, 2-4 weeks of release-cycle impact for assessments) that must be planned and provisioned like any other production requirement
- Responsible AI replaces the need for performance, security, and robustness engineering once a model is considered trustworthy
- Responsible AI matters only for generative models, not discriminative systems
Explain the chapter’s position that fairness is a value-laden engineering choice rather than a single optimization target, using the impossibility theorem and the loan-approval example from the summary’s disaggregated metrics table.
Walk through how the chapter connects generative alignment, system prompts, and machine unlearning into a unified governance view of responsible AI across the lifecycle.
Self-Check Answers
Self-Check: Answer
A product team proposes a release plan: the modeling team owns accuracy during training, a separate compliance team runs a fairness checklist one week before launch, a security team handles privacy, and a documentation team writes model cards after deployment. Based on the lifecycle mapping in this chapter, what is the primary structural failure of this plan?
- Fairness, privacy, and accountability are architectural commitments that must shape data collection, training, and deployment; concentrating them in separate late-stage review teams cannot correct decisions already baked into learned weights and data pipelines.
- Compliance teams are not trained to run fairness checklists, so the checklist will be statistically invalid.
- Model cards are an outdated documentation format that the EU AI Act prohibits for high-risk systems.
- Privacy and fairness belong in the same team, because differential privacy automatically provides demographic parity.
Answer: The correct answer is A. The chapter’s lifecycle table maps each principle across data collection, training, evaluation, deployment, and monitoring, so treating them as isolated late-stage checklists cannot correct representational biases baked into the training set or reasoning patterns compiled into weights. The claim that differential privacy automatically produces demographic parity conflates two different mathematical guarantees; the model-cards and team-training framings miss that the issue is architectural placement, not personnel competence.
Learning Objective: Analyze why responsible AI principles must be integrated architecturally across the ML lifecycle rather than added as late-stage review
A loan model approves 70 percent of Group A applicants and 40 percent of Group B applicants, regardless of actual repayment outcomes. Applying the formal fairness definitions developed in this chapter, which criterion does this disparity most directly violate?
- Calibration, because approval rates differ across groups
- Equality of opportunity, because true positive rates are not computed
- Demographic parity, because the criterion compares positive prediction rates across groups and the 70 vs 40 gap is exactly that quantity
- Individual fairness, because the criterion requires identical treatment of similar individuals
Answer: The correct answer is C. Demographic parity compares \(\Pr(\hat{Y}=1 \mid G=A)\) with \(\Pr(\hat{Y}=1 \mid G=B)\), so a 70 vs 40 approval gap is a direct parity violation regardless of ground truth. An equality-of-opportunity framing would condition on qualified applicants (true positive rate), which the question does not supply; calibration compares predicted probabilities to actual outcomes within each group, not raw approval rates; individual fairness compares treatment of similar individuals, not aggregate group-level rates.
Learning Objective: Apply the formal definition of demographic parity to classify a subgroup disparity under the correct fairness criterion
A bank’s leadership directs engineering to “satisfy demographic parity, equalized odds, and calibration simultaneously” for a credit model whose groups have different base rates of default. Explain why this directive is mathematically impossible and what engineering decision it actually forces.
Answer: Kleinberg’s impossibility theorem shows that when base rates differ across groups, a classifier can satisfy at most one of calibration, balanced false-positive rates, and balanced false-negative rates; demographic parity and equalized odds cannot both hold without degenerate classifiers. In the credit setting, if Group A defaults at 20 percent and Group B at 40 percent, no threshold policy produces equal approval rates, equal true-positive rates, and equal predicted-probability calibration at once. The directive therefore forces an explicit policy choice, documented and justified, about which fairness criterion to prioritize for this specific domain and which to accept violating.
Learning Objective: Analyze how the fairness impossibility theorem forces an explicit normative choice when subgroup base rates differ
A responsible AI program integrates each principle at the phase where it is most upstream-enforceable. Order the following lifecycle phases for embedding fairness and privacy commitments: (1) Deployment with threshold policies, (2) Monitoring of subgroup performance, (3) Data collection with representative sampling, (4) Training with bias-aware algorithms, (5) Evaluation with group-level metrics.
Answer: The correct order is: (3) Data collection with representative sampling, (4) Training with bias-aware algorithms, (5) Evaluation with group-level metrics, (1) Deployment with threshold policies, (2) Monitoring of subgroup performance. The chapter’s lifecycle table enforces this sequence because representation choices at data collection bound what training can correct, training bounds what evaluation can measure, evaluation calibrates the thresholds set at deployment, and only a deployed system generates the streams that monitoring observes. Reversing any pair breaks the causal dependency: threshold adjustment at deployment cannot fix absent subgroup data at collection, and monitoring cannot recover information discarded during training.
Learning Objective: Sequence the lifecycle phases for embedding responsible AI principles as architectural commitments rather than late-stage fixes
A fairness-tax analysis on a credit model reports 85 percent unconstrained accuracy dropping to 81 percent under demographic parity (a 4-point drop). Under the chapter’s framing, what does this 4-point drop correctly represent?
- A bug in the optimizer that better hyperparameters will eliminate
- The quantified cost of enforcing a specific fairness criterion when group base rates differ, making the model’s policy position explicit rather than hidden
- Evidence that demographic parity is the wrong criterion, because any accuracy drop disqualifies a fairness metric
- A transient effect that disappears after one retraining cycle on the same data
Answer: The correct answer is B. The chapter frames the fairness tax as the mathematical cost of correcting for historical bias: when base rates differ, shifting thresholds away from the unconstrained optimum necessarily reduces aggregate accuracy, and that reduction is the price of the normative choice to equalize approval rates. The optimizer-bug framing confuses a structural constraint with a numerical defect; the “any drop disqualifies” framing forbids any fairness intervention by construction; a retraining cycle on the same data will reproduce the same constraint, not remove it.
Learning Objective: Interpret the fairness tax as the quantified cost of an explicit normative constraint rather than as a defect
Explain why the chapter treats accountability as more than documentation, and identify the specific infrastructure mechanisms that distinguish an accountable system from a merely documented one.
Answer: Documentation such as model cards and datasheets creates traceability, but accountability additionally requires the ability to detect, escalate, and remediate harm after deployment. The chapter specifies logging pipelines that capture inputs, outputs, and model version; incident tracking that links a specific user complaint back to a model snapshot; override mechanisms and audit trails that preserve evidence of human intervention; and governance forums with authority to pause or rollback a model. A system with only model cards can describe its limitations but cannot trace a specific harmful prediction to its cause or correct it, so accountability collapses into narrative rather than mechanism.
Learning Objective: Explain accountability as a combination of traceability infrastructure and operational recourse, not documentation alone
Self-Check: Answer
An autonomous drone must react to obstacle detections within a 15 ms control loop. SHAP explanations for its vision model take 200-500 ms. Which responsible AI design choice does the chapter’s framing most strongly support for this deployment?
- Run full SHAP synchronously on every decision, because safety-critical systems must prioritize explanation fidelity over control latency
- Disable all explanation infrastructure, because safety-critical systems should minimize software surface area
- Replace the vision model with a larger ensemble, because ensembles do not require explanation
- Log internal signals, confidence scores, and activations at decision time for asynchronous post-flight analysis, because runtime explanation is infeasible under the 15 ms budget
Answer: The correct answer is D. The 200-500 ms cost of SHAP exceeds the 15 ms control budget by more than an order of magnitude, so synchronous runtime explanation is mechanically infeasible; the chapter prescribes logging internal signals and confidence for post-hoc analysis as the practical substitute. Running full SHAP synchronously violates the control loop and makes the drone unsafe regardless of explanation fidelity; disabling all monitoring forfeits the audit trail needed for accident investigation; an ensemble increases compute without reducing the explanation cost or removing the need for it.
Learning Objective: Select an explainability strategy that respects the latency budget of a safety-critical real-time control system
A federated learning deployment trains across 10 million mobile clients. The privacy architecture forbids sending demographic labels to the coordinating server. Which mechanism most directly explains why group-level fairness monitoring is harder in this setting than in a centralized cloud deployment?
- Clients hold non-IID local data and no single party observes the complete demographic distribution required to compute group-conditioned metrics like equalized odds
- Federated averaging automatically balances group outcomes, so fairness monitoring is unnecessary
- Secure aggregation protocols directly expose subgroup statistics to the server as a side effect
- Differential privacy noise eliminates all subgroup-level signal, so any fairness metric is statistically identical across groups
Answer: The correct answer is A. Group fairness metrics are conditional quantities like \(\Pr(\hat{Y}=1 \mid G=g, Y=y)\), which require observing joint distributions of prediction, ground truth, and sensitive attribute across the whole population; the federated architecture deliberately fragments this view. Federated averaging aggregates weight updates, not fairness; claiming secure aggregation exposes subgroup statistics inverts its purpose of hiding them; the DP-noise claim conflates utility degradation with loss of all subgroup signal.
Learning Objective: Analyze why decentralized architectures prevent direct computation of group-conditioned fairness metrics
A team is deploying a keyword-spotting model to a battery-powered microcontroller with 256 KB of RAM, no connectivity, and a manufacturing flashing step as the only update mechanism. Explain how this deployment reshapes responsible AI design choices relative to a cloud-served keyword spotter, and identify three specific mechanisms that must shift upstream.
Answer: In the TinyML deployment, there is no runtime channel to compute fairness metrics, log explanation signals, or roll out updated weights, so any responsible AI property must be compiled into the firmware and validated before manufacturing. Three concrete mechanisms shift upstream: fairness moves from live subgroup dashboards to pre-deployment subgroup evaluation on a representative held-out set; explainability moves from on-demand SHAP to design-time model-class selection that favors inherently interpretable or attribution-stable architectures; and safety moves from runtime distribution-shift detection to conservative input-range checks and static fail-safe defaults burned into the binary. The practical consequence is that TinyML responsible AI is predominantly an architecture-phase and validation-phase problem, not an operations-phase problem.
Learning Objective: Explain how TinyML deployment constraints force responsible AI mechanisms from operations-phase into architecture- and validation-phase
True or False: Moving an ML service from a cloud deployment to on-device inference simultaneously improves privacy and fairness observability because data stays local.
Answer: False. On-device inference can strengthen data-locality privacy by keeping raw data off the network, but it weakens global observability: no central operator sees the joint distribution of predictions and sensitive attributes needed to monitor group-level fairness, so privacy gains and fairness observability move in opposite directions.
Learning Objective: Differentiate privacy gains from fairness observability effects when moving from cloud to on-device deployment
A health-monitoring wearable retains rare heart-rhythm events in local logs to improve future robustness, but a regional data-protection regulation mandates data minimization for health signals. Which framing best captures the cross-principle tension the chapter highlights for this deployment?
- The tension is apparent only; ensuring robustness and enforcing data minimization always align once the correct compiler flag is set
- The tension is real: logging rare events improves failure diagnosis and robustness, but retaining them violates the data-minimization goal, and the wearable’s offline nature prevents the cloud-style governed logging that would mediate the trade-off
- The tension is irrelevant because wearables are not regulated as medical devices
- The tension disappears if the wearable uses federated learning, because federated learning makes privacy and robustness mutually enforcing
Answer: The correct answer is B. The chapter frames privacy-versus-robustness as a substantive architectural tension, and the on-device nature of a wearable removes the centralized governance layer that would normally mediate it. The compiler-flag framing denies the trade-off exists; the regulation-scope framing sidesteps the engineering question; federated learning redistributes where data lives but does not automatically reconcile a retention goal with a diagnostic goal within a single device.
Learning Objective: Analyze how deployment architecture changes the feasibility space for mediating privacy-versus-robustness trade-offs
Compare how explainability, fairness monitoring, and privacy are differently constrained between a cloud-hosted recommendation system and a mobile keyboard predictor, and identify which principle each deployment favors by default.
Answer: The cloud recommender can run SHAP or LIME, maintain centralized fairness dashboards on group-conditioned outcomes, and enforce differential privacy during training, but it aggregates sensitive behavioral data centrally and favors observability over data minimization. The mobile keyboard predictor keeps keystrokes on device, naturally favoring privacy through locality, but it cannot support heavy explanation methods under mobile compute budgets and cannot centrally audit subgroup performance without coordination protocols that erode the locality gain. The practical principle is that cloud deployments favor observability at a privacy cost, while mobile favors privacy at an observability cost, and designers must pick the trade-off explicitly rather than assume one choice is strictly better.
Learning Objective: Compare responsible AI constraints across cloud and mobile deployments and identify which principle each architecture favors
Self-Check: Answer
A credit scoring model deployed nationally begins rejecting qualified applicants from a specific ZIP code at twice the normal rate. Which framing of bias detection does the chapter argue is necessary to catch this pattern in operation?
- Bias detection is primarily a one-time dataset cleaning step performed before the first training run
- Bias detection is a model-compression concern, where the goal is to reduce the runtime footprint of audit code
- Bias detection is live operational telemetry analogous to SRE latency dashboards, with rolling subgroup metrics and threshold-triggered alerts on a standing dashboard
- Bias detection is a feature-hashing technique that removes demographic information so that subgroup comparisons become unnecessary
Answer: The correct answer is C. The chapter’s reframing casts fairness monitoring as standing telemetry: a ZIP-level doubling of rejection rates is exactly the kind of drift a rolling-window subgroup metric with an alerting threshold surfaces, analogous to how latency dashboards surface p99 regressions. One-time dataset cleaning before training cannot detect post-deployment drift; model compression is unrelated to observability; hashing demographic features destroys the signal required to compute the very metrics needed to detect the ZIP-level disparity.
Learning Objective: Identify live operational telemetry as the correct framing for production bias detection
A team measures demographic parity offline on a fixed test set before launch but ships with no subgroup-labeled telemetry in production. Six months later, a journalist reports that rejection rates for a specific demographic group have doubled. Walk through why the offline audit was insufficient and identify the specific infrastructure gap that allowed the drift to escape detection.
Answer: Offline audits freeze the evaluation to a single moment in time, but subgroup performance is a dynamic property that depends on drift in feature distributions, user behavior, and population mix. Without subgroup-labeled production telemetry, the team cannot compute \(\Pr(\hat{Y}=1 \mid G=g)\) on the live stream, cannot set alerts when that quantity diverges from its offline value, and cannot trace a specific harmful prediction back to the cohort that experienced it. The infrastructure gap is the absence of a logging pipeline that joins predictions with subgroup attributes under access-controlled storage; the practical consequence is that the first signal comes from external reporting rather than internal alerting, and the remediation cost is correspondingly larger.
Learning Objective: Analyze why offline fairness evaluation without production subgroup telemetry systematically misses post-deployment drift
A production fairness-monitoring pipeline processes each prediction through a defined sequence of stages. Order the following stages: (1) Trigger bias alert, (2) Compute rolling subgroup fairness metrics, (3) Capture prediction with subgroup label into the monitoring window, (4) Compare disparity against policy threshold.
Answer: The correct order is: (3) Capture prediction with subgroup label into the monitoring window, (2) Compute rolling subgroup fairness metrics, (4) Compare disparity against policy threshold, (1) Trigger bias alert. Predictions must be written to the monitoring window before rolling metrics can aggregate them; rolling metrics must be computed before they can be compared to thresholds; thresholds must be compared before alerts can fire on a violation. Swapping the threshold check and the alert would fire alerts on uncomputed metrics, producing noise; moving metric computation before capture would aggregate empty windows.
Learning Objective: Sequence the stages of a production fairness monitoring pipeline from capture to alert
A team must choose between reweighting training data (preprocessing) and applying group-specific decision thresholds (post-processing) for the same fairness goal. Which inference-time architectural requirement distinguishes the post-processing approach?
- The serving stack must have access to the sensitive attribute at decision time and run group-conditioned threshold logic with appropriate policy, logging, and legal justification
- The serving stack must implement a larger batch size, because post-processing requires batching
- The serving stack must disable all monitoring, because group-specific thresholds interfere with telemetry
- The serving stack must re-train during every inference request
Answer: The correct answer is A. Group-specific thresholds require conditioning the decision on group membership at serving time, which forces the inference path to read the sensitive attribute and execute policy logic; this creates new requirements for access control, audit logging, and legal defensibility of the group-conditioned decision. The batch-size framing invents a mechanism that does not exist in threshold logic; the monitoring-disabled framing contradicts the telemetry-as-fairness argument of the section; per-request retraining is a structural category error that has nothing to do with threshold application.
Learning Objective: Classify mitigation methods by the infrastructure they require at inference time
A team wants to adopt multicalibration to ensure fairness across intersections of demographic attributes (for example, young rural women, older urban men). The chapter treats this as difficult to deploy outside well-resourced cloud systems because:
- Multicalibration only works for linear models with fewer than ten features
- Multicalibration requires enumerating and computing calibration errors over many intersecting subgroup partitions and integrating those audits into automated monitoring, which demands both storage and compute beyond what edge or mobile deployments sustain
- Multicalibration automatically guarantees demographic parity, so platforms rarely need it
- Multicalibration avoids sensitive-attribute handling entirely, making it incompatible with subgroup observability
Answer: The correct answer is B. Multicalibration’s strength lies in reasoning over many intersecting subgroups, which combinatorially expands the storage, compute, and policy surface required at audit time; this is tractable only where centralized observability and compute headroom exist. The linear-models framing misreads its generality; the demographic-parity-automatic framing inverts the goal of calibration; the sensitive-attribute-free framing contradicts the definition of subgroup-conditioned calibration error.
Learning Objective: Evaluate why multicalibration’s intersectional guarantees impose centralized observability and compute requirements
A team is convinced that switching to a fairer training algorithm will resolve their fairness complaints. Explain why fairness is more accurately described as a property emerging from coordinated decisions across the whole lifecycle, and identify two specific failure modes outside the model that can regress fairness despite a fairness-aware algorithm.
Answer: A model is one component in a pipeline that spans data acquisition, label collection, serving thresholds, feedback logging, and retraining; fairness requires all of these to preserve subgroup protections. Two concrete failure modes outside the model: first, a biased feedback loop, where the system’s own rejections produce a training stream that underrepresents the rejected group in future versions and compounds the original disparity; second, a drift in the serving threshold or threshold-policy coupling, where a globally-applied threshold produces disparate impact because score distributions differ across groups even when the model itself is calibrated. In both cases a fairness-aware training algorithm alone cannot prevent regression because the harm originates in a different part of the loop.
Learning Objective: Explain fairness as a system-level property emerging from coordinated decisions across the lifecycle, not a model-algorithm choice alone
Self-Check: Answer
A user invokes GDPR Article 17 (“Right to Erasure”) against an LLM trained on a corpus containing their public posts. Engineering deletes the user’s rows from storage but the LLM can still be prompted to reproduce quoted passages. Why does the chapter treat this as a fundamentally harder systems problem than row deletion?
- Because GDPR rights only apply to databases and do not extend to learned model parameters
- Because trained weights retain the statistical influence of data long after the underlying rows are deleted, so erasure requires changing the learned model state itself, not just the stored records
- Because encrypted storage prevents the user from identifying which row to delete
- Because inference caches always regenerate deleted training examples automatically
Answer: The correct answer is B. The chapter’s key distinction is between storage-level deletion (removing the row) and model-state deletion (removing the data’s influence on weights); once the model has trained on the row, row deletion does not unlearn the learned representation, and the privacy right cannot be satisfied without reaching into the model. The GDPR-scope framing misstates the legal reach into model outputs; the encrypted-storage framing is orthogonal to the question; the inference-cache framing invents a mechanism that does not exist.
Learning Objective: Explain why machine unlearning is a distinct systems challenge from database row deletion
A team tightens DP-SGD from \(\varepsilon=8\) (Apple’s keyboard setting, ~30 percent training overhead, ~1 percent accuracy drop) to \(\varepsilon=1\). Based on the chapter’s quantified trade-off, what should they expect?
- Training compute rises to roughly 3\(\times\) the baseline and accuracy drops by around 6 percentage points, because stronger clipping and more injected noise weaken the learning signal per step
- Model size shrinks and serving latency rises slightly
- Cooling and power costs rise while accuracy and convergence are roughly unchanged
- Only post-deployment logging changes; the training run itself is largely unaffected
Answer: The correct answer is A. The chapter quantifies strong privacy (\(\varepsilon=1\)) at roughly 3\(\times\) training cost and a 6-point accuracy drop, a direct consequence of heavier gradient clipping and larger noise injection reducing the signal-to-noise ratio of each gradient step. The model-size framing has no connection to the DP budget; the “roughly unchanged accuracy” framing contradicts the privacy-utility trade-off; the logging-only framing mistakes DP-SGD (a training-time mechanism) for an operations-phase concern.
Learning Objective: Quantify how tightening the DP-SGD privacy budget changes training compute and model accuracy
A 175B-parameter model costs approximately 4.6 million dollars to retrain from scratch. Explain how SISA training changes the cost structure of honoring a GDPR Article 17 deletion request and identify two quality or serving trade-offs the shard-based architecture imposes.
Answer: SISA partitions the training data into \(K\) shards and trains an independent sub-model per shard; honoring a deletion request requires retraining only the specific shard containing the affected data, so deletion cost scales as \(1/K\) of full retraining. For the 175B model at \(K=100\), this reduces a 4.6-million-dollar, 34-day retraining run to roughly 46,000 dollars and hours, transforming deletion from economically infeasible to a manageable operational cost. The trade-offs are that each sub-model sees only a shard of the data, producing 3-7 percent accuracy degradation relative to a single-model baseline, and inference must aggregate across sub-models, raising serving latency and the memory footprint of the active model ensemble.
Learning Objective: Explain how SISA transforms the cost structure of machine unlearning and identify its quality and serving trade-offs
True or False: If a model is trained with strong differential privacy, machine unlearning becomes unnecessary because deletion requests impose no further architectural obligations.
Answer: False. Differential privacy reduces memorization and inference attack risk, but it does not discharge the lifecycle obligation to stop using specific user data once consent is revoked; unlearning still requires lineage tracking, retraining orchestration, and verification infrastructure that DP training alone does not provide.
Learning Objective: Differentiate differential privacy’s statistical guarantee from machine unlearning’s lifecycle deletion obligation
A team wants mathematical guarantees about adversarial robustness. Randomized-smoothing certified defenses provide such guarantees but cost 100–1000\(\times\) more inference compute. Which deployment role does the chapter argue fits this cost profile?
- Input normalization on every serving request, because normalization composes with certified guarantees
- A confidence-threshold abstention layer on every serving request, to bound user exposure
- An offline validation gate run before deployment, where the 100–1000\(\times\) cost is absorbed once rather than per request
- A rate-limiting step at the API boundary, because rate limiting is a form of certified defense
Answer: The correct answer is C. The 100–1000\(\times\) inference-compute cost makes certified defenses impractical inside the real-time serving path, but using them as a pre-deployment validation gate amortizes the cost over the entire fleet lifetime; the guarantee becomes a releasability property rather than a per-request property. Input normalization and abstention operate at small overhead and are suitable for runtime; rate limiting is a resource-protection mechanism, not a robustness guarantee in the adversarial-perturbation sense.
Learning Objective: Select the deployment role (offline validation vs online serving) that matches a robustness method’s compute profile
Explain why the chapter treats validation as a distinct third pillar after detection and mitigation, and identify three stakeholder-specific demands that a single aggregate accuracy metric cannot satisfy.
Answer: Validation provides the evidence that a system is releasable under fairness, robustness, privacy, and explainability constraints, which cannot be reduced to average accuracy because different stakeholders need different proofs. Developers need granular debugging evidence (feature attributions, failure traces) to isolate root causes; auditors need statistical and procedural evidence of non-discrimination for regulatory compliance; end users need instance-level explanations and actionable recourse for decisions that affect them. A single scalar accuracy metric cannot simultaneously serve debugging, compliance, and recourse, so validation must interrogate the system from multiple perspectives and produce stakeholder-specific artifacts rather than a single number.
Learning Objective: Analyze validation as a multi-stakeholder deployment gate that requires distinct evidence types for different audiences
Self-Check: Answer
A regulated bank must produce explanations for automated loan decisions. Engineering proposes a deep ensemble with on-demand SHAP explanations, while legal prefers a logistic regression with monotonicity constraints. Under the chapter’s framing, what is the primary architectural distinction between these options?
- Post-hoc methods like SHAP infer explanations from a trained black-box model’s behavior, while inherently interpretable models like constrained logistic regression expose their reasoning structure directly without any post-hoc approximation
- Post-hoc methods work only on images, while interpretable models work only on tabular data
- Post-hoc methods always produce more faithful explanations than inherently interpretable models
- Inherently interpretable models eliminate the need for any post-deployment monitoring
Answer: The correct answer is A. The chapter draws the taxonomy along how the explanation arises: post-hoc methods like SHAP, LIME, and gradients approximate behavior after training, while constrained linear models, small decision trees, and rule lists carry their reasoning in their parameters. The modality-exclusive framing is factually wrong; the “always more faithful” framing inverts the post-hoc-approximation limitation; the “no monitoring needed” framing contradicts the section’s treatment of drift as a post-deployment concern for every model class.
Learning Objective: Compare post-hoc explanation methods with inherently interpretable models along the architectural axis of how the explanation is produced
A production serving system operates at 10,000 QPS with a 100 ms p99 latency budget. The compliance team requires an explanation on 10 percent of decisions. The team is comparing gradient-based attribution (roughly 10-50 ms overhead per explanation), LIME (100-500 ms), and SHAP (200-1000 ms or more). Justify which method the chapter’s framing recommends for this deployment and what that choice implies for architecture.
Answer: Only gradient-based attribution fits the latency budget for a fraction of decisions while reusing backpropagation infrastructure already present, because its 10-50 ms overhead can be absorbed in the 100 ms p99 budget on the 10 percent sampled. LIME and SHAP’s 100-1000 ms overhead would drive latency past the budget on the explained fraction unless routed to an asynchronous offline queue; this either forces an SLA breach or requires a dual-path serving architecture that queues the 10 percent for deferred explanation. The practical implication is that explanation method selection is an architecture decision: picking SHAP forces an offline worker fleet, picking gradients keeps explanation in the synchronous path. Faithfulness considerations matter, but they are secondary to whether the method can run at all within the budget.
Learning Objective: Select an explanation method that matches a latency budget and reason about the architectural consequence of the choice
A fintech platform rejects a loan and must provide “meaningful information” to the applicant. Why does the chapter argue counterfactual explanations are especially suited to user-facing recourse in this setting compared to feature-attribution methods?
- Counterfactuals guarantee demographic parity automatically
- Counterfactuals answer “what minimal feasible input change would have flipped the decision,” providing actionable recourse rather than a retrospective importance ranking the applicant cannot act on
- Counterfactuals avoid any need for domain constraints, so they compute faster than attribution
- Counterfactuals are cheaper than simple gradient attributions in every realistic deployment
Answer: The correct answer is B. Counterfactuals are answers to a forward-looking question (“what would change the outcome?”), which maps directly onto the regulatory recourse obligation and the user’s practical decision problem. An answer based on automatic parity confuses explanation with fairness enforcement; the “no domain constraints” framing ignores the section’s discussion of realistic feature mutability (for example, age cannot change); the “always cheaper than gradients” framing inverts the relative cost since counterfactual generation is a constrained optimization.
Learning Objective: Identify when counterfactual explanations are appropriate for user-facing recourse
A model validated fairly and robustly at launch begins producing disparate error rates across subgroups six months after deployment despite no retraining. Which mechanism does the chapter identify as the primary reason post-deployment monitoring remains necessary even after rigorous pre-launch validation?
- Production environments exhibit distribution shift, subgroup composition change, and evolving regulatory and transparency expectations, so fairness and explainability properties can degrade despite model weights being fixed
- Pre-launch validation is a courtesy for academic publication and has no production role
- Deployed models become inherently interpretable through interaction logs, so monitoring becomes unnecessary
- Monitoring replaces the need for rollback, retraining, and incident response
Answer: The correct answer is A. The chapter’s central argument is that real environments shift, and properties verified at a single moment erode unless they are re-verified continuously; drift is the primary driver. The pre-launch-as-formality framing trivializes the validation pillar; the inherent-interpretability-from-logs framing confuses observability with interpretability; the “monitoring replaces rollback” framing conflates detection with response.
Learning Objective: Explain why continuous monitoring of responsible AI properties is necessary despite rigorous pre-launch validation
When RLHF or similar alignment methods make a generative model safer at the cost of a measurable degradation on standard NLP capability benchmarks, the chapter calls that capability cost the alignment ____.
Answer: tax. The alignment tax denotes the 2-8 percent capability degradation typically observed on standard NLP benchmarks when a base model is fine-tuned toward safer, more constrained behavior rather than raw capability.
Learning Objective: Interpret the alignment tax as the measurable capability cost paid when aligning generative models toward safer behavior
A product team at a large LLM platform proposes to manage system prompts (hidden instructions prepended to every user query) with an ad-hoc shared document and manual rollout. Explain why the chapter treats system prompts as a governance mechanism with CI/CD requirements comparable to model weights, and identify three failure modes an unversioned prompt rollout can produce.
Answer: System prompts encode the operational policy that determines what the model refuses, how it frames sensitive topics, and which behaviors it enforces at inference time, so a prompt edit shifts the ethical posture of every interaction downstream of it. Three concrete failure modes from unversioned rollout: a silent change softens a safety refusal and exposes children to harmful content across millions of sessions before anyone notices; an incident investigation cannot reconstruct which prompt was live at the time of a harmful response because history is not retained; a well-meaning edit introduces a contradiction with an older instruction, producing inconsistent refusals that are impossible to diagnose without diffable versions. The governance consequence is that system prompts need the same version control, regression testing, canary rollouts, and audit trails as model weights.
Learning Objective: Explain why system prompts function as versioned governance configuration requiring CI/CD-grade infrastructure
Self-Check: Answer
A predictive policing model’s initial deployment increases patrols in certain neighborhoods, which produces more recorded incidents, which are then used to retrain the model. Under the chapter’s closed-loop framing, what is the primary responsible AI concern with this architecture even if the initial model’s accuracy was acceptable?
- Deployed predictions reshape the environment and future training data, so an initial small skew can amplify into a systematic disparity through self-reinforcement, independent of initial accuracy
- Feedback loops only matter for reinforcement learning systems, not prediction systems
- More feedback data automatically improves fairness by supplying more ground truth
- Feedback loops primarily affect latency rather than changing decision distributions
Answer: The correct answer is A. The chapter’s Sociotechnical Feedback Invariant says that \(p_{t+1}(X)\) is a function of \(f_t(X)\), so the model’s own outputs become inputs to its next training round; initial accuracy is no defense against this compounding dynamic. The “RL-only” framing misstates the mechanism, which applies to any deployed prediction that influences the environment; the “more data equals fairer” framing ignores that the data itself is biased by the model; the latency framing mistakes a behavioral effect for a performance one.
Learning Objective: Analyze how deployed models create closed-loop dynamics that amplify initial biases through their effect on future training data
A radiology system reaches 99 percent accuracy and the human override rate drops from 15 percent to 2 percent over a year. The 1 percent of remaining model errors are almost never caught. Explain the automation-bias paradox this illustrates and identify the specific interface-level mechanisms the chapter recommends to counteract it.
Answer: The paradox of reliability says that as model accuracy rises, human vigilance falls even faster, so the increasingly rare errors are caught less often and the system-level failure rate is worse than pure-AI analysis predicts; the perceived safety of the model erodes the oversight channel that was supposed to catch its residual errors. The chapter’s mitigation is deliberate interface friction: uncertainty visualization that surfaces confidence per case, mandatory justification when the operator agrees with a high-impact recommendation, and asymmetric liability protection that shields operators who override, so agreement is not the path of least resistance. The consequence is that responsible design trades some throughput for preserved oversight, because the alternative is rubber-stamp deference that makes human-in-the-loop nominal rather than real.
Learning Objective: Explain the automation-bias paradox and identify interface mechanisms that preserve human oversight as model accuracy rises
A team building a mental-health chatbot for adolescents must reconcile aggressive intervention for suspected self-harm (medical efficacy) with preserving adolescent privacy and willingness to confide (autonomy) and with mandatory reporting laws (legal compliance). Which framing most accurately classifies this as normative pluralism rather than an implementation defect?
- A model server crashes because a protobuf schema changed unexpectedly
- Multiple legitimate stakeholder values (efficacy, autonomy, privacy, compliance, efficiency) are in direct tension and cannot be simultaneously maximized by any algorithm; the team must facilitate stakeholder deliberation before optimization, because the trade-off is a policy choice, not a bug
- A fairness dashboard shows a malformed JSON payload
- A quantized edge model loses 2 percent accuracy from integer overflow during conversion
Answer: The correct answer is B. The chapter’s mental-health chatbot example is explicitly about legitimate, incompatible values that cannot be reconciled algorithmically: aggressive intervention is in direct tension with adolescent autonomy and with legal compliance, and the technical team must surface the trade-off for stakeholder deliberation rather than optimize past it. The protobuf crash, malformed JSON, and quantization-overflow framings describe implementation defects that should be fixed, not stakeholder tensions that require deliberation.
Learning Objective: Differentiate normative value conflict (requiring deliberation) from implementation defects (requiring fixes)
A lending platform publishes model cards and datasheets but rejected applicants still cannot meaningfully challenge decisions. The chapter argues that moving from transparency to contestability requires a coordinated infrastructure stack. Which of the following combinations captures what this stack must provide?
- Only model cards and datasheets, because disclosure by itself guarantees accountability
- Higher model accuracy, because accurate systems do not need appeals
- Decision provenance linking outputs to model version and input, explanation generation on demand, appeal routing to human reviewers with domain expertise, and outcome tracking that records whether the appeal overturned the decision
- Complete disclosure of proprietary weights and all training data to every user
Answer: The correct answer is C. The chapter’s contestability stack names four coupled components: provenance, explanation, routing, and outcome tracking; any one alone is insufficient because the appeal pathway requires all four to be operational. Disclosure alone is the definition of transparency, which the chapter says is necessary but not sufficient; accuracy does not remove the need for recourse on the errors that remain; full disclosure of weights and data confuses transparency with contestability and is legally and operationally implausible.
Learning Objective: Identify the integrated infrastructure components required to support contestability beyond transparency
The bias amplification loop in the section chains four stages that reinforce harm unless interrupted. Order these stages: (1) Retraining data collection from deployed predictions, (2) Model predictions or decisions in production, (3) Historical biased training data, (4) Future model retraining on the collected data.
Answer: The correct order is: (3) Historical biased training data, (2) Model predictions or decisions in production, (1) Retraining data collection from deployed predictions, (4) Future model retraining on the collected data. The causal chain begins with biased training data shaping the first model, which produces biased decisions that then shape what is recorded for future retraining, closing the loop when the next version is trained on that altered stream. Swapping retraining data ahead of decisions would imply data collection precedes the model’s existence; swapping predictions ahead of historical training data would imply the model predicts without being trained.
Learning Objective: Sequence the stages of the bias amplification feedback loop and identify its causal structure
Explain why the chapter argues that responsibility must be institutionally embedded rather than left to individual developers or a single review team, using either the Google Flu Trends or UK A-level grading failure as concrete support.
Answer: Harms typically arise from interactions among data pipelines, interfaces, legal rules, deployment choices, and organizational incentives, so no single developer or team controls the full surface. Google Flu Trends drifted silently for years because no institutional process existed for external audit, drift response, or escalation; the UK A-level algorithm enforced historical distributions with no appeal mechanism, and the failure was the absence of institutional contestability, not an algorithm bug. The chapter’s prescription is institutional infrastructure: review boards, model registries, audit logs, escalation paths, and cross-functional governance that survive team turnover and scale. The principle is that responsibility is a dynamic property of how systems are governed over time, not a static attribute of a trained model.
Learning Objective: Explain why institutional governance structures are required for responsibility to persist as systems scale and change
Self-Check: Answer
A company’s postmortem concludes that their biased hiring system shipped despite the ML team knowing every relevant fairness metric and having access to Fairlearn. Which diagnosis does the chapter treat as most commonly correct for this pattern?
- The field lacks workable methods for fairness, privacy, or interpretability
- Responsible AI failures in production stem primarily from organizational fragmentation, incentive misalignment, data infrastructure constraints, and scaling-related erosion of practices, not from absence of technical knowledge
- Responsible AI only fails in research settings, not production systems
- Modern hardware is too slow to run ethical models
Answer: The correct answer is B. The chapter’s People-Process-Technology framing pins failure on diffuse ownership, release-speed incentives that deprioritize audits, dataset infrastructure that is frozen after initial collection, and erosion of practices during scaling; teams typically know the methods. A pure-knowledge-gap framing misreads the failure mode; a research-only framing contradicts the chapter’s production examples; a hardware-slowness framing ignores that responsible AI rarely fails because compute is missing at the scale of existing production systems.
Learning Objective: Identify the primary non-technical drivers of responsible AI failure in production ML systems
A startup ships a prototype classifier with bias audits performed manually at review time, then grows into a fleet serving 100 million users per day with hundreds of models retrained weekly. Explain the specific mechanisms by which the prototype’s responsible AI practices typically erode as the system scales, and identify two infrastructure investments that prevent this erosion.
Answer: Manual audits cannot scale to weekly retraining of hundreds of models under latency and release-cadence pressure, so they get deferred or dropped; heterogeneous hardware and rapid release cycles make every retraining a candidate for silent regression; team turnover breaks the institutional memory of why a particular threshold was set; and monitoring infrastructure written for the prototype breaks under fleet-scale telemetry volume. Two concrete investments that prevent erosion: embedded audit hooks wired into the training and deployment pipeline so bias evaluation runs on every retraining as a gating check, and a model registry with versioned model cards, subgroup performance baselines, and rollout policies that survive team turnover. The practical consequence is that responsible AI must be made into infrastructure rather than a set of practices, or it disappears under scaling pressure.
Learning Objective: Explain how scaling pressures erode responsible AI practices and identify infrastructure that prevents the erosion
A team is building a triage system that assigns priority to emergency-room patients. Applying the practitioner decision framework, which combination of principles should be primary, and what operational consequence does this choice impose?
- Fairness, explainability, and accountability as primary, with acceptance of 2-5 percent accuracy reduction for interpretability, 20-100 ms latency for explanation, and mandatory fairness metrics across protected groups
- Throughput and personalization as primary, because ER systems must maximize patient throughput
- Privacy and energy efficiency alone, because ER systems operate on wearable hardware
- Governance minimization and rapid experimentation, because ER workflows require minimal process overhead
Answer: The correct answer is A. The chapter’s framework places high-stakes individual decisions like healthcare triage in the fairness-explainability-accountability regime because affected people need equitable treatment, understandable outcomes, and recourse; the framework explicitly accepts 2-5 percent accuracy reduction and 20-100 ms explanation latency to meet these goals. The throughput-first framing misapplies a consumer-system trade-off to an individual-decision setting; the privacy-and-energy framing misidentifies the hardware context; the governance-minimization framing is the opposite of what the framework prescribes for high-stakes decisions.
Learning Objective: Apply the practitioner decision framework to select primary principles and accept the associated overhead for a specific deployment context
A video platform trains its recommendation model to maximize watch time and discovers the system promotes radicalizing content. The chapter presents this as a central AI-safety problem because:
- Proxy metrics always make models uninterpretable regardless of architecture
- Optimizing a measurable proxy like watch time systematically diverges from the true objective (user welfare) as capability rises, a Goodhart-style failure where the metric ceases to be a good measure once it becomes the target
- Proxy metrics only matter in reinforcement learning and never in recommender systems
- Once a proxy metric is formally specified, Goodhart-style failures disappear
Answer: The correct answer is B. The chapter uses this example precisely to illustrate specification gaming: the model can excel at its proxy while harming users because the proxy does not capture the real goal, and capability gains make the divergence worse, not better. The “always uninterpretable” framing invents a mechanism that does not exist; the RL-only framing ignores that proxy-objective divergence is a general phenomenon; the “formal specification cures Goodhart” framing inverts the insight, because formalization is exactly what creates the target that degrades the measure.
Learning Objective: Analyze proxy-objective mismatch as a central driver of value-alignment failure as model capability increases
True or False: At a fleet scale of 10,000 inference nodes serving billions of requests per day, a model with a 99.9 percent safety compliance rate is effectively equivalent to a perfectly safe system because the residual failures are too rare to matter operationally.
Answer: False. A 0.1 percent residual failure rate at billions of daily requests translates into millions of safety violations per day in expectation, so rare per-request failures become statistical certainties at fleet scale; this is why the chapter argues safety must be treated as a fleet-level property with circuit breakers, canary deployments, and centralized telemetry rather than a per-model metric.
Learning Objective: Interpret how rare per-request failure rates scale into absolute incident counts at fleet scale
Explain why the chapter treats trust in autonomous systems as a systems-design problem rather than a model-accuracy problem, using the autonomous-vehicle regulatory and incident context the section provides.
Answer: Autonomous systems operate in environments where edge cases, specification gaps, and shifts in human trust can turn small model errors into catastrophic outcomes, so trust is not a function of average accuracy but of how the full architecture handles uncertainty and failure. The chapter cites the 2018 Uber fatality in Arizona and the 2023 California suspension of Cruise operations to show that even high-accuracy perception systems fail at rare but consequential edge cases, and the causal root is architectural rather than statistical: fallback logic, human-override design, safety envelopes such as Responsibility-Sensitive Safety, geo-specific configuration, and centralized telemetry with circuit-breaker semantics collectively determine whether the residual errors are survivable. The practical consequence is that improving the classifier alone cannot discharge the trust obligation; trust is an emergent property of the interfaces, fallback logic, governance, and regulatory configuration surrounding the model.
Learning Objective: Explain why trust in autonomous systems depends on architectural, oversight, and governance mechanisms beyond model accuracy
Self-Check: Answer
A venture-backed startup claims it will “eliminate bias” in hiring models through a mix of 10\(\times\) more training data and a new transformer architecture. The chapter’s response to this claim is:
- Bias disappears once training data crosses a certain volume threshold
- Bias can be reduced, but structural trade-offs (proxy choice, impossibility theorems, historical inequities) mean there is no purely technical path to eliminating it altogether; the healthcare-algorithm case affected 200 million Americans and reduced Black enrollment in high-risk care programs by 50 percent despite comprehensive data
- Bias only persists when organizations use outdated model architectures
- Bias is primarily an underfitting problem that larger models resolve automatically
Answer: The correct answer is B. The chapter argues that bias survives scale and model capacity because it is baked into proxy choices (healthcare expenditure as a stand-in for health need), historical data streams, and mathematically incompatible fairness criteria under differing base rates. The threshold-of-volume framing is falsified by the healthcare case at population scale; the outdated-architecture framing misattributes a structural cause to a technology choice; the underfitting framing conflates capacity with bias, which are orthogonal.
Learning Objective: Evaluate the misconception that bias can be eliminated through scale and algorithmic sophistication
An architecture team plans to launch a deep ensemble recommendation system at 10,000 QPS with a 100 ms latency budget, and plans to “add SHAP explanations later” if regulators require them. Using the chapter’s quantitative treatment, explain why this plan is a pitfall and what the correct architectural discipline is.
Answer: SHAP adds roughly 50-200 percent to inference cost and up to 100 percent memory overhead, which at 10,000 QPS on a 100 ms budget translates to a latency of 150-300 ms per explained request and a 1.5–3.0\(\times\) serving-capacity increase to maintain the original SLA. If explanations were not budgeted during architecture, the team discovers at compliance time that the only paths forward are overshooting budget, redesigning for an interpretable model class, or building an asynchronous explanation queue; each option is either impossible on the existing budget or requires re-architecting the serving stack. The correct discipline is to treat explainability as an architectural requirement with a reserved latency budget and model-class constraint from day one, just as throughput and availability are treated; retrofitting is the systematically expensive path.
Learning Objective: Explain why explainability requirements must be budgeted during architecture design rather than retrofitted
A bank’s credit team announces it has “solved fairness” by satisfying demographic parity across all groups. Why does the chapter identify this single-metric approach as a pitfall?
- All fairness metrics are mathematically equivalent, so using one is redundant with using any other
- Once demographic parity is satisfied, calibration and equalized odds automatically improve
- Improving one fairness metric can worsen others; when base rates differ, Kleinberg’s impossibility result forbids simultaneously satisfying demographic parity, equalized odds, and calibration, so a parity-only announcement typically hides worse false-positive or calibration disparities elsewhere
- Fairness metrics should never be quantified in production
Answer: The correct answer is C. The chapter’s impossibility treatment makes single-metric optimization systematically misleading because the metrics are mathematically coupled under differing base rates. The “all equivalent” framing is the exact misconception the section warns against; the “parity implies everything” framing inverts the impossibility result; the “never quantify” framing contradicts the telemetry-based monitoring approach the chapter prescribes.
Learning Objective: Analyze why single-metric fairness optimization systematically masks violations of other fairness criteria
Self-Check: Answer
A VP of engineering must choose between funding a responsible AI platform team and funding more serving capacity for a cost-constrained product. The summary section’s central systems claim about responsible AI is:
- Responsible AI is primarily an ethics overlay applied after the real engineering is complete
- Responsible AI is load-bearing infrastructure with measurable latency, compute, and governance costs (for example, 10-20 ms per inference for bias monitoring, 50–1000\(\times\) compute for SHAP, 2-4 weeks of release-cycle impact for assessments) that must be planned and provisioned like any other production requirement
- Responsible AI replaces the need for performance, security, and robustness engineering once a model is considered trustworthy
- Responsible AI matters only for generative models, not discriminative systems
Answer: The correct answer is B. The summary treats responsible AI as infrastructure on the same footing as monitoring, availability, and security, with quantified costs that must be budgeted during architecture rather than retrofitted. The overlay-after-engineering framing is the exact misconception the chapter dismantles; the replaces-other-engineering framing inverts the complementary-pillars argument; the generative-only framing contradicts the chapter’s loan, healthcare, and hiring examples that are all discriminative.
Learning Objective: Identify the chapter’s concluding claim that responsible AI is production infrastructure with quantified costs
Explain the chapter’s position that fairness is a value-laden engineering choice rather than a single optimization target, using the impossibility theorem and the loan-approval example from the summary’s disaggregated metrics table.
Answer: The summary’s disaggregated table shows a loan system satisfying equal false-positive rates (0-point gap) while simultaneously exhibiting a 15-point approval gap and a 30-point true-positive-rate gap. That table is not itself a base-rate proof; it shows that optimizing one operational criterion can leave large gaps on others. Kleinberg’s theorem supplies the broader impossibility result for calibrated risk scores when base rates differ and prediction is imperfect. Fairness therefore becomes a constrained policy choice: engineers must decide which criterion best matches the domain’s harms and stakeholder priorities, document the choice, and accept the trade-off on the others, rather than search for a single optimal point. The practical consequence is that fairness work is quantitative decision-making under mathematical incompatibility, not an optimization problem that yields one correct answer.
Learning Objective: Explain how impossibility theorems turn fairness into an explicit normative trade-off rather than a single optimization target
Walk through how the chapter connects generative alignment, system prompts, and machine unlearning into a unified governance view of responsible AI across the lifecycle.
Answer: Generative alignment (through RLHF and Constitutional AI) compiles human preferences into the weights of the base model, shaping what the model can be made to say; system prompts operationalize those behavioral constraints in deployment and can be changed without retraining, making them the primary governance layer for production fleets and requiring the same version control and rollout discipline as weights; machine unlearning extends governance across time, ensuring that data-deletion rights reach into the weights themselves rather than stopping at the database boundary. Together they span three temporal horizons (weights shaped by training-time preferences, behavior gated by deployment-time configuration, and lifecycle obligations enforced across the data’s influence over time), and the unified framing is that responsible AI governs outputs, deployment behavior, and lifecycle obligations rather than focusing on one static model snapshot. The summary’s position is that no one of these pillars is sufficient in isolation for a modern LLM fleet.
Learning Objective: Synthesize how behavior control, deployment-time governance, and deletion rights integrate into a unified responsible AI framework