Conclusion
Purpose
What does it mean to engineer intelligence when the unit of design is no longer a model, but a fleet?
The fleet stack is not only a sequence of topics; it is a working discipline. Physical infrastructure establishes the rates and limits; distributed protocols turn those limits into coordination costs; deployment systems convert trained models into services with latency, availability, and cost obligations; and governance constraints determine whether those services can remain secure, robust, sustainable, and accountable. The six principles form one structure so an engineer can reason across the whole fleet when the best local choice for one layer creates a constraint in another. In C³ terms, the professional habit is to identify whether compute, communication, or coordination is binding, then follow that constraint across layers until the fleet, not just the model, is the object being engineered.
Learning Objectives
- Synthesize the six principles into a constraint map for distributed ML systems
- Evaluate fleet designs using C³ terms, failure rates, serving obligations, and governance constraints
- Analyze how infrastructure, distributed training, inference, operations, and governance interact across the fleet stack
- Translate security, fairness, privacy, carbon, and reliability obligations into measurable design constraints
- Construct an engineering judgment that balances scale, sustainability, responsibility, and operational discipline
Synthesizing Distributed ML Systems
A frontier model becomes a production system only when thousands of accelerators, fabric links, storage tiers, schedulers, serving replicas, security controls, and governance checks act as one machine. Any one layer can bind the whole system:
- Storage bottleneck: A slow checkpoint can waste a training window.
- Fabric bottleneck: A congested fabric can erase scaling gains.
- Serving bottleneck: An underprovisioned serving pool can turn model quality into user-visible latency.
- Governance bottleneck: An unmeasured responsibility constraint can block deployment after the technical system works.
That integrated constraint is what separates foundational ML engineering from distributed ML engineering. Foundational ML engineering focuses on a single artifact: the weights of a neural network, optimized through training algorithms and architecture design on individual systems. Distributed ML engineering focuses on the infrastructure that enables that artifact to exist at scale: the data centers, distributed protocols, and governance frameworks that transform a static model file into a living global service. Six principles define that shift.
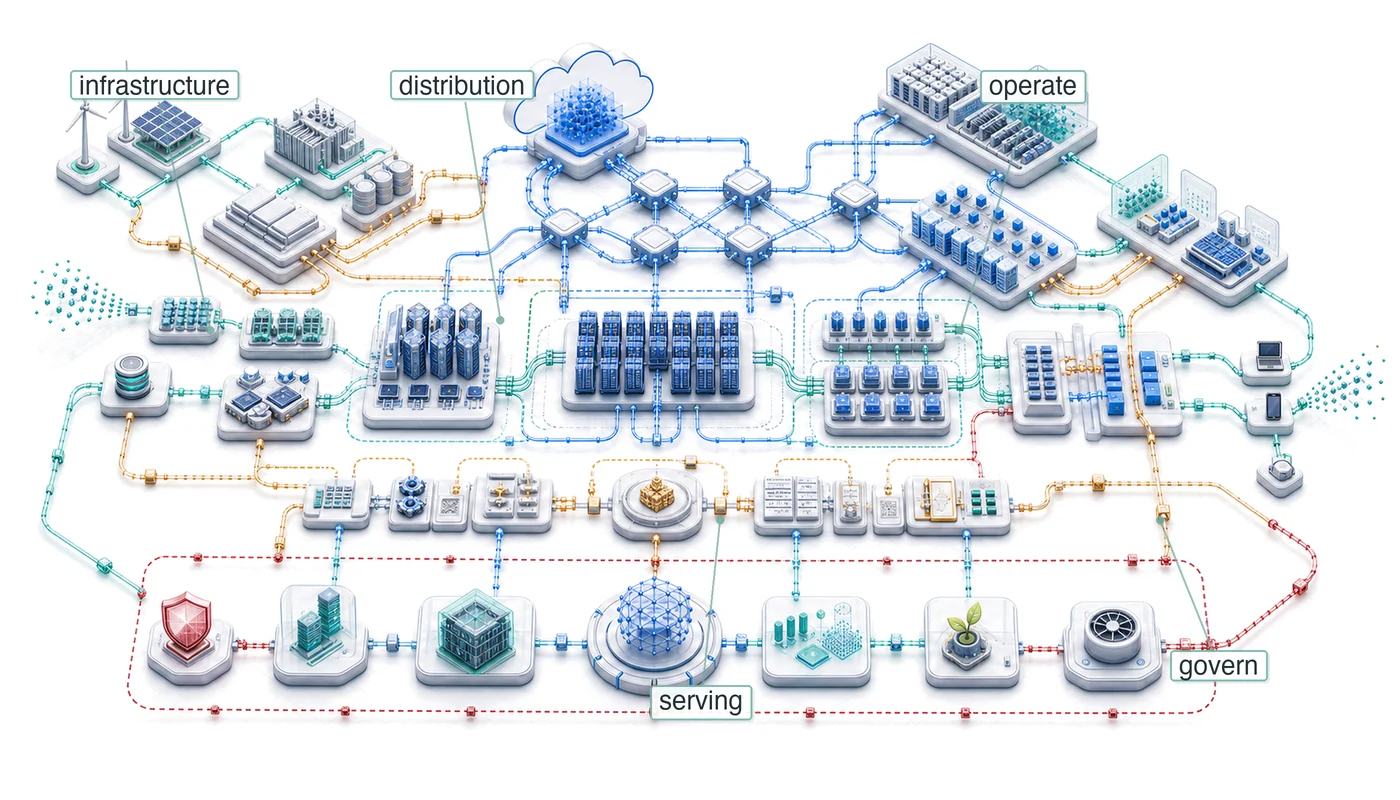
The fleet stack is deliberate. The opening layer built the physical substrate: the silicon, wires, and storage that make distributed ML possible. That substrate matters because every higher-level decision inherits its limits. A training strategy that ignores accelerator topology, a storage plan that ignores data-loading throughput, or a scheduling policy that ignores network contention will eventually collide with the physics underneath it.
The distribution layer then showed how those physical limits become system protocols. Partitioning work, synchronizing gradients, tolerating failure, and orchestrating resources are not separate concerns; they are the mechanisms that turn many machines into one useful training or serving system. The deployment layer carried the same logic outward, where inference, performance engineering, edge deployment, and operations convert a trained model into a service with latency, availability, and cost obligations. The responsible-fleet layer added the final constraint: technical capability must remain secure, robust, sustainable, and accountable. Together, these layers equip engineers to make informed decisions at every level, from algorithm selection through infrastructure design to governance frameworks.
Self-Check: Question
A team has a checkpoint that achieves 92 percent accuracy on a single workstation and decides to ship it as a global service answering 50,000 requests per second across three continents. Which set of engineering problems now becomes the dominant focus that did not exist in the single-machine version?
- Datacenter power and cooling budgets, inter-region network protocols, continuous failure recovery, and governance controls over who the model affects
- Choosing between supervised and self-supervised learning, since labels cannot cross region boundaries
- Running a larger architecture search, since single-machine weights rarely generalize to production traffic
- Tightening offline validation metrics, because production serving largely preserves the conditions seen during single-node development
Order the following Fleet Stack layers from the physical foundation upward to the highest-level constraint: (1) Deployment at Scale, (2) Governance, (3) Distributed ML, (4) Infrastructure.
An engineer ports a recommendation model that runs flawlessly on a single 8-GPU node to a 2,000-GPU cluster serving 10 million users, and the system immediately fails in ways that never appeared in the smaller deployment. Using the section’s argument, identify two specific assumptions the single-machine version relied on that no longer hold at scale, and describe one concrete engineering consequence for each.
Six Principles of Distributed ML Systems
The engineering practices that opened this volume—instrument first, design for headroom, co-design hardware with algorithms—become useful only when they name the constraint they are trying to move. The six principles below are those durable realities: each names a constraint, a governing question, and a metric that determines whether a distributed ML system can scale.
The single-node foundation is governed by strict mathematical constraints like the iron law, where performance is a matter of quantitative physics. Fleet-scale engineering shifts that foundation into probabilistic and operational realities: links contend, workers fail, schedulers make stale decisions, and policy constraints change what a technically feasible design may do. The bridge between these domains is the fleet law (\(T_{\text{step}}(N) = \frac{T_{\text{compute}}}{N} + T_{\text{comm}}(N) + T_{\text{sync}}(N) - T_{\text{overlap}}\)), derived in full in The Fleet Law and woven throughout the text. The fleet law acts as the distributed counterpart to the iron law, translating single-machine execution into the mechanics of networked collectives and driving the operational behaviors observed at scale. Its three terms map directly onto the C\(^3\) taxonomy that organizes this volume: \(T_{\text{compute}}/N\) is Compute, \(T_{\text{comm}}(N)\) is Communication, and \(T_{\text{sync}}(N)\) is Coordination.
These principles form a layered architecture that mirrors the fleet stack synthesized in figure 1. At the physical foundation, infrastructure determines capability1 because hardware physics sets the hard limits. In the operational reality of the middle layers, communication dominates and failure is routine: these are the day-to-day dynamics of running distributed systems, driven directly by the fleet law’s network and synchronization terms. At the governance layer, two principles act as normative constraints on what may be built rather than what is merely possible: responsibility constrains design, and sustainability is a first-order cost. Emerging from this stack is the sixth principle: scale creates qualitative change.
1 Hardware Capability Ceiling: At fleet scale, the hardware sets the hard ceilings the software cannot argue with. Peak compute \((R_{\text{peak}})\), bisection bandwidth, and thermal design power are physical limits, not tuning knobs, so a workload that exceeds any one of them cannot run at all until the infrastructure changes. Systems engineering is the art of fitting the workload inside these physical limits rather than wishing them away.

Table 1 is therefore a decision map rather than a glossary: the six principles of distributed ML systems link each principle to the question, metric, and development context an engineer uses when diagnosing a fleet-scale design. The table and the walk that follows order the principles by what most often binds first at scale, beginning with communication, rather than from the foundation up as figure 1 layers them.
| Principle | Core Question | Key Metric | Chapter Reference |
|---|---|---|---|
| Communication dominates | What is the bottleneck? | Network bandwidth utilization | Collective Communication |
| Failure is routine | How do we recover? | Mean time between failures (MTBF), checkpoint overhead | Fault Tolerance |
| Infrastructure determines capability | What is possible? | FLOP/s, memory bandwidth | Compute Infrastructure |
| Responsibility constrains design | Who is affected? | Fairness metrics, audit trails | Responsible AI |
| Sustainability is a first-order cost | What is the cost? | kWh/training, carbon footprint | Sustainable AI |
| Scale creates change | What breaks at 1000\(\times\)? | Scaling efficiency | Distributed Training |
The first principle is that communication can become the binding term at scale (Jiang et al. 2024; Narayanan et al. 2021). In many synchronous training regimes, gradient synchronization and straggler effects dominate unless topology, overlap, and batching are designed around them. Production inference systems can also become latency-bound by tail effects2 (Dean and Barroso 2013), where the slowest worker determines response time regardless of how fast others complete.
2 Tail Latency: A standard fan-out estimate of the tail effects Inference at Scale analyzes: at the 99th percentile, a request touching 100 servers has a 63.4 percent chance of hitting at least one slow server.
3 Ring AllReduce: A collective that moves \(2(N-1)M/N\) bytes per worker for message size \(M\), giving \(T_{\text{allreduce}} \approx 2(N-1)\alpha + \frac{2(N-1)}{N}\frac{M}{\beta}\) under the \(\alpha\)-\(\beta\) communication model. The coefficient approaches 2\(\times\) message volume per worker as \(N\) grows, while remaining bandwidth-optimal for large messages. Detailed in Collective Communication.
4 Gradient Compression: Collective Communication explores techniques that reduce communication volume 10–100\(\times\) through sparsification, quantization, and error feedback, enabling bandwidth-limited distributed and federated training.
Distributed Training and Collective Communication develop this principle in detail, showing how Horovod-style Ring AllReduce3 (Sergeev and Balso 2018), gradient compression4, and overlapping computation with communication all address communication bottlenecks. For dense collective workloads, conventional oversubscribed fabrics often bottleneck, motivating high-bisection fabrics and transport choices matched to ML communication patterns. Recognizing when communication is the active constraint clarifies when algorithmic optimizations will help and when they merely shift work between equally constrained resources. The same communication fabric also exposes the second principle: a distributed system has many more components that can fail, and a single blocked rank or slow worker can stall the whole job.
The second principle follows directly: at distributed scale, component failures occur not occasionally but continuously. Meta’s experience training Llama 3 on 16,384 GPUs documented 419 unexpected interruptions over 54 days, averaging one interruption every 3.1 hours (Dubey et al. 2024). Hardware failures, network partitions, and service disruptions are routine occurrences that systems must handle without human intervention. The synchronous nature of large-scale ML training amplifies the cost of each failure: a single failed rank stalls every other rank in the collective, forcing the entire fleet to roll back to the last checkpoint. The computational loss from one event therefore scales linearly with cluster size, which is precisely why checkpoint cadence and recovery architecture are not afterthoughts but first-order design dimensions.
5 Elastic Training: Fault Tolerance describes elastic training, which enables dynamic worker membership: jobs continue with remaining workers after failures and seamlessly incorporate new resources when available.
Fault Tolerance establishes that architects must embed failure handling from the beginning. Checkpointing strategies balance recovery granularity against overhead. Elastic training5 dynamically adjusts to changing cluster membership, and graceful degradation maintains service quality as capacity diminishes. Systems that treat failure as exceptional do not survive production deployment.
Communication and failure together constitute the operational reality of distributed systems, the middle layer of the fleet stack. Both depend on the physical foundation beneath them, which makes infrastructure the third principle. Compute Infrastructure demonstrates that infrastructure determines which workloads are possible, not just how fast they run. Cluster-wide bisection bandwidth and chip-level power density set hard ceilings on the model and batch sizes a fleet can train at all, independent of how the training algorithm is tuned.
The memory wall makes this principle concrete: while compute (TFLOP/s) can be abundant, memory bandwidth (GB/s) remains the gating constraint for autoregressive decode. Inference at Scale and Sustainable AI quantify how the inability to move data fast enough from HBM to the processor makes autoregressive generation inherently inefficient. Mastering the fleet requires understanding these physical limits, from chip-level thermal density to cluster-wide bisection bandwidth. Once infrastructure determines what the system can do, governance determines what the system is allowed to do.

Decode sits memory-bound, left of the roofline ridge.
The fourth principle is responsible engineering. Responsible AI translates AI risk-management frameworks into engineering constraints (Tabassi 2023). Safety-specific risks such as reward hacking, distribution shift, and scalable oversight show why those constraints need implementation mechanisms (Amodei et al. 2016). Fairness, transparency, accountability, privacy, and safety are first-class requirements that shape system architecture throughout the ML lifecycle.
The fairness impossibility law (Responsible AI) shows why this is a systems constraint and not a tuning problem: when base rates differ across groups, no model can simultaneously satisfy calibration and error-rate balance (Kleinberg et al. 2016; Chouldechova 2017), so engineers must choose which criterion to prioritize and build the monitoring to hold it. Engineers must design for fairness from inception, with monitoring infrastructure detecting degradation across demographic groups. The engineering methods for responsible AI, from bias detection to explainability mechanisms, carry the same weight as performance optimization. Environmental responsibility extends that governance layer into the physical resource budget.
The fifth principle is sustainability. Sustainable AI reveals how the environmental impact of large-scale ML elevates resource efficiency to a primary engineering constraint (Strubell et al. 2019; Patterson et al. 2021). The Jevons Paradox of AI adapts Jevons’s resource-efficiency argument to explain why hardware efficiency gains alone do not eliminate power and carbon costs: cheaper computation expands deployment, so per-query savings are absorbed by usage growth unless absolute carbon budgets govern the fleet (Jevons 1865).
Sustainability thus transforms from environmental concern to engineering discipline. Energy costs can exceed model development budgets, thermal limits restrict hardware density, and power infrastructure requirements limit deployment locations. Carbon-aware scheduling, lifecycle assessment6, and efficiency optimization become essential engineering competencies alongside traditional performance metrics. These first five principles converge on the final insight: scale changes the behavior of the system itself.
6 Lifecycle Assessment: Sustainable AI introduces a method for evaluating environmental impact across a system’s entire lifespan, including embodied carbon in hardware manufacturing (often 20–50 percent of total impact).
The sixth principle captures this insight directly: systems that work at modest scale exhibit fundamentally different behaviors at production scale. A training job running on 8 GPUs may encounter communication bottlenecks, load imbalance, or synchronization overhead when scaled to 8,000 GPUs that did not manifest at smaller scale. A service with 100,000 concurrent user sessions can easily generate millions of daily request opportunities, so edge cases that occur one in a million times can still surface every day at production traffic volumes.
Scale is why distributed ML requires fundamentally different engineering approaches. The techniques that optimize single-machine performance, while necessary, prove insufficient. New phenomena emerge: stragglers7 that bottleneck clusters, network partitions that split training, and heterogeneity across hardware generations that complicates load balancing.
7 Stragglers: Workers completing tasks slower than peers that bottleneck synchronous training: a single straggler at 80 percent speed reduces cluster throughput by 20 percent. Examined in Fault Tolerance.
Self-Check: Question
A gradient-descent job on 8 GPUs shows 94 percent scaling efficiency; the same code on 8,000 GPUs shows 38 percent scaling efficiency, and the drop is attributed to stragglers, synchronization barriers, and load imbalance that no profiler flagged at the smaller scale. Which of the six principles best explains why the 8-GPU measurements failed to predict the 8,000-GPU behavior?
- Failure is routine, because the 8,000-GPU cluster is encountering more hardware faults per hour than the 8-GPU node
- Scale creates qualitative change, because new coordination dynamics among thousands of workers dominate once the worker count crosses several orders of magnitude
- Infrastructure determines capability, because the 8,000-GPU cluster must be using older accelerators than the 8-GPU node
- Sustainability is a first-order cost, because the larger cluster is thermally throttled in ways the smaller one is not
True or False: A distributed training run that holds steady at 78 percent scaling efficiency up to 512 GPUs but collapses to 31 percent efficiency at 4,096 GPUs is most plausibly diagnosed as compute-bound, because adding four thousand accelerators should have pushed the bottleneck away from arithmetic.
A team scales a training job from 8 GPUs to 8,000 GPUs and encounters stragglers, synchronization overhead, and load imbalance that were invisible at the smaller scale. Explain why the section treats this behavior as qualitatively different from a larger version of the small-cluster case, and describe one design practice that small-cluster validation cannot substitute for.
Meta’s Llama 3 training on 16,384 GPUs logged 419 unexpected failures over 54 days, or roughly one failure every three hours. What design conclusion does the section draw from this number?
- The cluster should be partitioned into smaller runs until the per-run failure rate is low enough that operators can intervene by hand
- Most failures at this scale originate in model code, so hardening optimizer and loss implementations is the primary response
- Failures are continuous and expected, so checkpointing cadence, elastic training, and graceful degradation must be architected from the start rather than treated as optional enhancements
- Improved next-generation hardware reliability will soon make explicit fault tolerance a secondary concern, so the priority is waiting for better GPUs
An inference team measures that its decode path on an H100 achieves only 12 percent of the advertised FP16 tensor-core throughput, while nvidia-smi reports 97 percent GPU utilization and the kernel mix is dominated by matrix-vector products. Given the chapter’s infrastructure principle, what engineering action is most directly supported by this evidence?
- Raise the batch size and sequence length together to drive arithmetic intensity above the HBM-bound regime, since utilization already indicates the compute units are saturated
- Replace the H100 with a higher-peak-TFLOP/s accelerator, since the gap between advertised throughput and realized throughput points to insufficient arithmetic capacity
- Reduce KV-cache pressure via paged attention, quantize weights to 8-bit, or shard across more devices, since the decode regime is bound by HBM bandwidth rather than by compute throughput
- Increase numerical precision from FP16 to FP32, since low realized throughput suggests the kernels are silently producing underflows that the accelerator is masking
A fleet design meets its throughput target by routing most work to a low-cost region, but the plan lacks subgroup monitoring and ignores the region’s carbon intensity. Which conclusion follows from the six-principles framework?
- The design is incomplete because responsible engineering and sustainability are governing constraints, not reviews that happen after throughput is optimized
- The design is acceptable because the infrastructure and distribution layers have already met the measurable performance target
- The design should be evaluated only after deployment because fairness and carbon effects cannot be measured before production traffic arrives
- The design can compensate for missing governance evidence by adding more accelerators and reducing queueing delay
The Complete Production System
Consider Archetype A, a frontier language model such as a GPT-4-class or Llama 3-class system, trained across thousands of accelerators and then shipped into a global serving fleet. The model first creates a storage problem: checkpoint bursts must land without starving the data loaders. Storage and network pressure then shape the training loop, because collective communication must finish before the next optimizer step idles the cluster. At that scale, failures are expected rather than exceptional, so checkpoint cadence must follow the Young-Daly checkpoint law from the observed failure rate (Young 1974; Daly 2006). Once the model ships, serving SLOs must leave headroom for rollback and fallback, and governance controls must decide which data, models, and outputs are allowed to reach users. These are not separate checklists. They are coupled rates, budgets, failure exposures, and policy constraints.
In production, no principle exists in isolation. The fleet stack reveals itself as a stack of interdependencies: physical foundations constrain operational possibilities, which in turn must satisfy governance requirements. Each principle creates requirements and constraints that ripple through the entire stack, and these principles sometimes conflict. Communication optimization may require synchronization patterns that increase failure exposure. Sustainability constraints may limit infrastructure choices that would maximize raw performance. Responsible AI requirements may add latency or compute overhead that strains serving SLOs and capacity budgets. The displacement of overhead guarantees these tensions cannot be eliminated, only relocated: the art of distributed ML engineering is to find designs that balance all six principles within acceptable trade-offs rather than to make the cost disappear.
The production system begins with physical capacity, but capacity matters only when the rates line up. Compute Infrastructure supplies accelerators, power, cooling, and fabric; Data Storage determines whether data can arrive fast enough; and Collective Communication determines whether workers can synchronize without turning the network into the bottleneck. These subsystems must be co-designed: storage bandwidth that exceeds communication capacity wastes resources, and communication paths that exceed storage throughput leave accelerators idle.

Storage and communication must be co-designed around matching rates.
Distributed Training then chooses a parallelization strategy that fits those physical rates and the expected failure pattern. Data parallelism, model parallelism, and pipeline parallelism are not interchangeable templates; each changes memory pressure, communication volume, checkpointing behavior, and scheduler complexity. Hybrid strategies become useful only when the surrounding storage, fabric, and recovery design can support the shape of the partition.
Serving turns the same stack outward. Inference at Scale and Performance Engineering convert model capability into latency, throughput, and cost targets, while ML Operations at Scale keeps those targets meaningful as traffic and distributions shift. Security & Privacy, Edge Intelligence, Robust AI, Responsible AI, and Sustainable AI add constraints that cannot be postponed: lowering latency cannot make the attack surface invisible, reducing energy cannot erase fairness observability, and increasing throughput cannot make recovery impossible. Together, these layers define the professional competencies required by the fleet stack: coordinating scale, operating live services, and governing consequences without treating any layer as independent.
The three workloads traced through the volume (Three systems archetypes) make the point that no single corner of the C\(^3\) taxonomy dominates. Table 2 compares which term binds first in each running archetype.
| Archetype | First binding term | Why it binds | Primary engineering reading |
|---|---|---|---|
| A: Frontier language model | Communication | Partitioning GPT-4-class or Llama 3-class models across thousands of accelerators makes gradient synchronization and activation transfer consume more wall-clock time than arithmetic | Read the fabric, collective, and checkpoint paths before adding compute |
| B: Recommendation at scale | Coordination | Sharding multi-terabyte DLRM embedding tables across hundreds of nodes makes sparse feature routing, shard placement, and request scheduling determine whether all-to-all traffic meets tail-latency budgets | Read placement, routing, and scheduler behavior before changing the model |
| C: Federated MobileNet on edge devices | Computation | Local training runs under a milliwatt power envelope, so each step is bound by device silicon rather than fleet-level bandwidth | Read the device power, memory, and duty-cycle limits before assuming cloud-scale remedies |
The same fleet law and the same six principles apply to all three; what changes is which term binds first, and the engineer’s job is to read that term off the workload rather than assume it.
The closing diagnostic is therefore procedural:
- Start with the observed symptom: Name the user-visible or operator-visible failure.
- Attach the metric: Choose the measurement that makes the symptom falsifiable.
- Map to C\(^3\): Identify whether compute, communication, or coordination is binding first.
- Locate the fleet-stack layer: Find the layer that owns the intervention.
- State the displaced cost: Describe what cost the proposed fix moves elsewhere.
- Preserve governance evidence: Keep the audit, safety, security, or responsibility evidence needed to justify the decision.
Low MFU may point to communication or coordination rather than insufficient computation. A fairness alert may point to missing labels, insufficient review capacity, or a serving-path threshold policy rather than model weights alone. A security incident may point to artifact provenance, tool permissions, or rollback evidence rather than network perimeter failure. The discipline is to follow the constraint until the responsible layer and trade-off are visible.
Self-Check: Question
A team upgrades its storage pipeline from 50 GB/s to 200 GB/s of sustained read bandwidth, but its inter-node interconnect tops out at 25 GB/s per worker and remains unchanged. Using the section’s co-design argument, why is this not a complete improvement to the training throughput of the cluster?
- Storage bandwidth that exceeds communication capacity is wasted because workers cannot exchange the gradients produced from the extra data; conversely, communication faster than storage throughput would leave accelerators idle waiting for input
- High storage throughput substitutes for most interconnect traffic because workers can re-read parameters from storage instead of exchanging them
- Collective communication matters mainly during online serving, so training throughput should not depend heavily on the interconnect fabric
- Once storage throughput crosses 100 GB/s, the remaining bottlenecks shift to fairness auditing and governance checks rather than to data movement
Give one concrete example from distributed ML where optimizing one of the six principles improves its dedicated metric but measurably worsens a different principle’s metric, and explain the mechanism that links the two.
A team builds a training cluster that achieves 68 percent MFU on a 4,096-GPU run, but its serving stack has no drift monitoring, no canary or shadow deployment capability, and its fairness auditing was skipped to hit a ship date. Using the section’s definition, explain why this cluster does not yet constitute a complete production system and identify which Fleet Stack layers the gaps fall into.
Competencies Mastered
The integrated production system just assembled defines competence as engineering judgment under constraint, not as a checklist of technologies. Mastery means recognizing which layer binds, which failure mode a design invites, and which trade-off must remain visible as the system scales.
At the distributed-systems layer, the governing question is how to make a workload larger than any single machine behave as one coordinated system. An engineer who has mastered this material can orchestrate training beyond single-machine memory or compute, analyze communication patterns (recognizing that, for a gradient of size \(M\), Ring AllReduce moves about \(2M\) bytes per worker in the bandwidth term as cluster size grows), and select network architectures appropriate to the workload.
That same engineer must also derive expected failure cadence from component MTBF and fleet size. At Llama 3-class cluster sizes, Meta reported unexpected interruptions every few hours rather than every few months (Dubey et al. 2024); the general lesson is to design for routine failure. The failure mode is treating scale as aggregate capacity alone; the trade-off is between parallel speedup, communication cost, and recovery overhead.
At the production-operations layer, the governing question is how a trained model keeps serving value under live traffic and shifting distributions. The serving tax, continuous batching, and monitoring for both performance and semantic drift matter because they prevent a working model from becoming an inefficient or semantically stale service.
At the governance layer, the governing question is who bears the costs and risks of the system’s decisions. Fairness, privacy, and sustainability are primary engineering constraints, and the ability to implement differential privacy, audit for bias, and schedule workloads for carbon efficiency distinguishes a systems engineer from a model developer because it treats social and environmental consequences as design requirements.
Self-Check: Question
An engineer tunes a 1,024-GPU ring AllReduce around the \(2(N-1)/N\) per-rank traffic coefficient, selects a fat-tree topology appropriate for the workload’s bisection-bandwidth demand, and designs a training loop that expects component failure every few hours. Which competency from the section does this combined skill set most directly reflect?
- Production operations
- Governance and ethics
- Distributed systems
- Model architecture research
True or False: A production recommendation service meets its p99 latency SLO of 80 ms every hour for a full quarter while click-through rate on its top-ranked items drifts downward by 12 percent; the section would regard this as successful production operations because the service-health metric is green.
Name one concrete architecture decision that changes when a team adds differential privacy, one that changes when it adds bias auditing across demographic groups, and one that changes when it adds carbon-aware scheduling. Use these to explain why the section treats governance and sustainability as competencies that reshape systems engineering rather than as add-ons after training is done.
The Fleet Stack as Discipline
These competencies matter because the binding constraint will keep moving. Mastery of a particular system generation is not enough; engineers must recognize when a new scaling regime changes the unit of design. Larger models run into systems limits: network fabrics constrain synchronization, memory systems constrain state residency, energy infrastructure constrains fleet growth, and governance constrains what may be deployed. Composition is one natural pressure point, because systems of models, tools, retrieval, and verification coordinate many specialized capabilities rather than only enlarging one model. The systems lesson is not a new law of capability; it is the same fleet-stack discipline applied at a new boundary. When useful work spans multiple components, the engineer must measure orchestration overhead, state movement, failure propagation, latency budgets, and governance evidence as part of the system itself.
The same point can be stated as a simple fleet-stack accounting problem. The calculation assumes a target 100× efficiency gain, then assigns part of that gain to hardware and algorithmic compression. The residual term is the orchestration improvement the fleet must supply.
Napkin Math 1.1: Fleet-stack efficiency accounting
Problem: Suppose a workload needs a 100× efficiency improvement over a large-cluster baseline. If a particular workload saw 4× from hardware and 2.5× from algorithmic compression, where would the remaining gain have to come from?
Math: Total system gain is the product of improvements across the fleet stack.
- Hardware (physics): 4× in this scenario.
- Algorithm (math): 2.5× from workload-compatible sparsity or distillation.
- Orchestration (systems): 100× / \((4.0 \times 2.5)\) = 10×.
Systems insight: Because silicon and math can hit diminishing returns, an aggressive 100× efficiency target cannot rely on one layer alone. Here, efficiency means useful task progress per fleet resource budget, not raw FLOP/s alone. In this illustrative scenario, the remaining 10× comes from system orchestration: reducing duplicate work, routing requests to appropriate components, reusing cached state, overlapping communication with computation, and validating outputs without exhausting the latency budget. Capability is not only in the model weights; it is also in the fleet logic.

Fleet efficiency needs hardware, algorithm, and orchestration gains together.
In the fleet-stack frame, capability emerges from specialized components coordinated through the machine learning operations (MLOps) pipelines established in ML Operations at Scale. The orchestration layer acts as a control plane that schedules model calls, retrieval, tool execution, and verification under latency, cost, and failure budgets, echoing the fleet orchestration studied in Fleet Orchestration.
Those orchestration gains still run on a physical fabric. Once software has reduced wasted model calls, duplicate retrieval, and avoidable coordination, the remaining frontier is the substrate that moves tokens, activations, and power through the fleet. The fleet-stack lens therefore also applies to research and deployment candidates beyond conventional transistor scaling. Technologies such as optical I/O, co-packaged optics, 3D integration, and novel computing substrates may change the physics of the fleet by reducing energy per bit, shortening communication paths, increasing bandwidth density, or moving memory closer to compute. The conclusion is not that any one substrate wins. The durable requirements remain the same: bandwidth optimization, fault tolerance, and responsible governance must hold even when the substrate changes.
Transformer models partitioned across thousands of accelerators create communication pressure through several mechanisms. Tensor parallelism uses frequent collectives across partitioned tensors, while mixture-of-experts routing uses all-to-all dispatch at MoE layers. At that scale, the energy cost of driving data electrically across data center-class distances can become comparable to the cost of useful arithmetic, which is why optical interconnects are a plausible fabric-efficiency lever. The scaling pressure is not generic; it originates directly from the collective communication patterns.
Napkin Math 1.2: The physics of better fabrics
Math: One communication-efficiency leap is moving part of the fabric from electrical to optical signaling.
- Electrical cost: 10 pJ/bit.
- Optical I/O scenario: 5 pJ/bit.
- Efficiency gain: 2×.
Systems insight: Scaling further by doing “more of the same” eventually runs into the energy wall. The wall is driven by the volume and frequency of collective operations: AllReduce for gradient synchronization and all-to-all dispatch for MoE layers grow with model and cluster size. Breaking that wall requires changing the physics of communication. Optical I/O is a meaningful fabric-efficiency lever, but this scenario illustrates single-digit energy improvements rather than orders-of-magnitude fabric-wide reductions. In the machine learning fleet, the principles of data locality and interconnect efficiency are thermodynamic requirements, not optional optimizations.
These fabric-level limits motivate one final efficiency sanity check: the machine fleet measured against the human brain. The comparison is not a biological analogy for its own sake; it tests whether orchestration, locality, and fabric efficiency are moving the engineered system toward a credible energy budget.
Self-Check: Question
A platform team improves serving latency by adding a cache, but the change increases state movement, invalidation failures, and missing audit evidence. What behavior best reflects the fleet stack as a professional discipline?
- Follow the active constraint across infrastructure, distribution, deployment, and governance until the system as a whole is the design object
- Treat the cache hit-rate improvement as sufficient because the local serving layer now meets its latency target
- Convert the fleet-stack principles into a checklist of technologies and mark the design complete once each layer has a named tool
- Postpone governance evidence until after the performance SLO is stable, because audit trails do not affect runtime behavior
The chapter’s notebook says a workload needs a 100\(\times\) efficiency improvement, with 4\(\times\) from hardware and 2.5\(\times\) from algorithmic compression. Compute what this implies about orchestration, and explain what happens if a team instead assumes additive rather than multiplicative gains.
Why does the section treat orchestration as a first-class fleet-stack budget rather than as implementation detail?
- Because general-purpose CPUs replace GPUs for model inference whenever composed services are used
- Because routing requests, reusing cached state, overlapping communication, and validating outputs consume latency, cost, failure, and governance budgets
- Because it eliminates the need for retrieval, tools, and verification by centralizing all logic in a single scheduler
- Because it guarantees that monolithic models will regain dominance once network bandwidth improves
Public optical I/O materials in the section describe moving from roughly 6–10 pJ/bit long-reach electrical signaling toward below 5 pJ/bit optical signaling. In the section’s simple 10 pJ/bit to 5 pJ/bit scenario, what is the strongest systems reason this lever matters for large fleets?
- Because reducing energy per bit by about 2\(\times\) relaxes communication power and cooling pressure, while leaving bandwidth optimization and locality as first-class design requirements
- Because lower energy-per-bit increases the peak arithmetic throughput of each accelerator, so the cluster finishes the same workload in fewer node-hours and therefore uses less total energy
- Because lower energy-per-bit eliminates the need for fault tolerance and checkpointing in the fleet, since cheaper communication reduces the probability that workers desynchronize
- Because lower energy-per-bit causes gradient synchronization to become numerically more accurate, which reduces the number of training steps needed to converge
True or False: Because the section’s post-silicon interconnect scenario gives about a 2\(\times\) communication-energy improvement, the chapter argues that bandwidth optimization drops from a first-class engineering concern to a secondary tuning parameter, even though fault tolerance and governance remain central.
The section treats composition as a pressure point rather than as a new law of capability. Explain why orchestration must be measured as part of the system when a request passes through models, retrieval, tools, and verification.
Engineering Intelligence at Scale
The scale of large ML infrastructure invites comparison with a highly energy-efficient biological baseline: the human brain. A rough Fermi estimate frames that comparison without treating machine FLOP/s and synaptic activity as equivalent.
Napkin Math 1.3: The Fermi estimate of intelligence
Assumptions:
- Machine cluster: 25,000 H100 GPUs in a reference large-cluster scenario.
- Machine FLOP/s: \(25{,}000 \times \text{H100 FP16 tensor peak} \approx\) \(2.47 \times 10^{19}\) FLOP/s (rounded; H100 FP16 tensor peak is 989 TFLOP/s).
- Machine power: \(25,000 \times 700 \text{ W}\) \(\approx\) 17.5 MW.
- Brain synapses: \(10^{14}\) synapses (connections).
- Brain firing rate: illustrative average spike rate \(\approx 1 \text{ Hz}\); estimates vary by neuron type and brain region, and average cortical firing is far below the 100 Hz peak rates often used in casual comparisons.
- Brain synaptic operation rate: \(10^{14} \times 1 =\) \(1.0 \times 10^{14}\) synaptic ops/s.
Math:
The machine-to-brain raw operation-rate ratio is:
\[ \frac{\text{machine peak FLOP/s}}{\text{brain synaptic ops/s}} \approx 247,250× \]
Systems insight: The comparison is useful only as a caution, not as an equivalence. Machine FLOP/s are overwhelmingly dense matrix multiplications (GEMMs) mandated by Transformer architectures: structurally rigid, synchronous operations tightly orchestrated across thousands of accelerators. Biological synaptic operations are sparse, event-driven, and massively decentralized, with no equivalent of a global barrier or gradient step. The throughput ratio measures raw arithmetic volume, not intelligence, and the architectural gap between the two operation types is as significant as the numerical gap; any efficiency comparison between a \(20 \text{ W}\) brain and a 17.5 MW cluster depends on the operation model used for the brain.
The Fermi estimate is useful precisely because it refuses a simplistic equivalence between FLOP/s and intelligence. The fleet-stack framework has established the engineering principles for scale; the continuing challenge is efficiency, applying those principles within the energy, carbon, and economic envelopes that constrain further growth.

A data center draws megawatts; the brain runs on ~20 watts.
The fleet stack provides the professional framework for engineering intelligence as a system: infrastructure powers the fleet, distributed protocols coordinate work across thousands of devices, serving systems deliver intelligence to users, and governance mandates keep the fleet aligned with security, sustainability, accountability, and explicit human-impact constraints. Large-scale intelligent systems need engineers who understand these principles and can apply them under constraint. The agenda is therefore threefold: systems that scale, systems that endure, and systems whose social and environmental obligations are engineered into the operating path.
Self-Check: Question
The section’s Fermi estimate compares a hypothetical 25,000-H100 frontier cluster drawing roughly 17.5 MW and delivering about 2.47\(\times\) \(10^{19}\) peak FLOP/s with a rough brain estimate of \(10^{14}\) synaptic ops/s on 20 W. What does the section take as the main engineering conclusion of this comparison?
- Raw throughput is roughly matched between the brain and the cluster, so the remaining work should concentrate only on software reliability
- The cluster is now more energy efficient than the brain per useful operation, so energy has stopped being a meaningful systems constraint
- The cluster is slower than the brain in raw operation rate, which shows current silicon is far from useful intelligence
- The cluster has surpassed the rough brain estimate in raw peak operation rate, but the operations are not semantically equivalent and the megawatt-scale power draw keeps efficiency as the next frontier
True or False: Once ML clusters surpass the brain in raw operations per second, improving efficiency becomes secondary because the key scaling milestone has already been achieved.
An engineer asked to decide whether to deploy a new composed AI service reaches past a single performance metric and instead reasons across Infrastructure, Distribution, Deployment at Scale, and Governance before committing. Explain how this behavior exemplifies the Fleet Stack functioning as a professional framework in the sense this section uses the phrase, and describe one concrete failure mode that a purely single-layer decision process would miss.
Fallacies and Pitfalls
The closing mistakes all come from optimizing the wrong unit of design. A model can improve while the fleet becomes slower, less reliable, more expensive, or harder to govern.
Fallacy: A faster model is automatically a better system.
Raw model speed matters, but it is only one term in the fleet equation. A design that reduces kernel time while increasing checkpoint pressure, network contention, serving variance, or governance risk can make the total system worse. The systems question is whether the change improves useful throughput under the actual constraints: data movement, synchronization, failure recovery, power, latency, and accountability.
Pitfall: Optimizing one layer while hiding the constraint it creates in another.
A local improvement becomes dangerous when it moves cost to a layer that no one is measuring. Larger batches may raise accelerator utilization while worsening tail latency. Aggressive compression may reduce communication while increasing accuracy risk. Carbon-aware scheduling may lower emissions while requiring more slack in the service budget. Good engineering respects the displacement of overhead, keeping the transferred constraint visible so the system can choose deliberately rather than inheriting a hidden bottleneck.
Fallacy: Fleet-scale lessons are tied to today’s hardware and software stack.
Specific processors, frameworks, and serving engines will change, but the durable relationships remain. Data must reach compute at the required rate. Workers must communicate before synchronization stalls the job. Failures must be expected at large component counts. Serving systems must meet tail-latency budgets, and governance constraints must be engineered into the operating path. The technology names are examples; the rate, failure, and accountability relationships are the lesson.
Pitfall: Treating governance and sustainability as external reviews rather than system constraints.
Security, fairness, privacy, and carbon accounting are often postponed because they look less immediate than throughput or accuracy. At fleet scale, that postponement creates architectural debt. Retrofitting audit trails, demographic monitoring, access controls, deletion workflows, or carbon-aware placement after deployment is more expensive than budgeting for them when the serving path, data pipeline, and scheduler are designed.
Self-Check: Question
A team replaces a model kernel and reduces per-token compute time, but the new serving path increases checkpoint pressure, network contention, P99 variance, and missing audit evidence. Which conclusion best matches the chapter’s closing fallacy?
- The model is faster, so the system is automatically better unless accuracy drops.
- The change must be evaluated against useful throughput under data movement, synchronization, failure recovery, power, latency, and accountability constraints.
- The change should be accepted because local kernel speed is the only term that matters once a fleet is already deployed.
- The change should be judged only by governance teams because technical performance and accountability are separate decisions.
Explain why optimizing one layer while hiding the constraint it creates in another is a systems pitfall, using one example from the section.
True or False: Fleet-scale lessons are mostly tied to today’s processors, serving engines, and frameworks, so they should be expected to expire as the hardware and software stack changes.
Summary
At fleet scale, the central engineering object is no longer a model, accelerator, or serving endpoint in isolation. It is the coupled system that moves data, schedules work, survives failure, serves users, and satisfies governance obligations under real physical and organizational constraints. The same method recurs across the volume: identify the binding constraint, quantify the cost it imposes, and design the operating path so the constraint remains visible instead of being displaced into another layer.
Key Takeaways: Systems that scale, endure, and serve
- The fleet is the object: The volume’s six principles reduce to one habit: follow the binding constraint across infrastructure, communication, coordination, serving, and governance. The fleet, not any single model or component, is the unit you build, measure, and optimize.
- Scale changes the probability model: At the 99th percentile, touching 100 servers gives a 63.4 percent chance of a slow server, and Llama 3 saw 419 unexpected interruptions in 54 days. Fleet behavior is not single-node behavior repeated.
- Orchestration becomes capability: The illustrative 100× efficiency target cannot come from silicon or algorithms alone; after 4× hardware and 2.5× algorithm gains, the residual 10× must come from routing, reuse, overlap, and verification.
- Obligations belong in the path: Security, privacy, fairness, carbon, accessibility, and auditability are production constraints, not external reviews. The discipline is to design them into data pipelines, schedulers, serving paths, and operating procedures before scale makes the trade-off irreversible.
What’s Next: The discipline of ML systems
Prof. Vijay Janapa Reddi, Harvard University
Self-Check Answers
Self-Check: Answer
A team has a checkpoint that achieves 92 percent accuracy on a single workstation and decides to ship it as a global service answering 50,000 requests per second across three continents. Which set of engineering problems now becomes the dominant focus that did not exist in the single-machine version?
- Datacenter power and cooling budgets, inter-region network protocols, continuous failure recovery, and governance controls over who the model affects
- Choosing between supervised and self-supervised learning, since labels cannot cross region boundaries
- Running a larger architecture search, since single-machine weights rarely generalize to production traffic
- Tightening offline validation metrics, because production serving largely preserves the conditions seen during single-node development
Answer: The correct answer is A. The section contrasts single-node work centered on the weights themselves with distributed ML engineering centered on the datacenters, protocols, and governance that let the weights operate as a living global service. The self-supervised reframing confuses the learning paradigm with the deployment problem, the architecture-search answer conflates model research with system engineering, and the offline-metrics framing misses that production exposes new dominant constraints invisible on one machine.
Learning Objective: Distinguish the system-level problems that newly dominate when a single-machine model becomes a distributed production service from problems that belonged to single-machine training
Order the following Fleet Stack layers from the physical foundation upward to the highest-level constraint: (1) Deployment at Scale, (2) Governance, (3) Distributed ML, (4) Infrastructure.
Answer: The correct order is: (4) Infrastructure, (3) Distributed ML, (1) Deployment at Scale, (2) Governance. Infrastructure (compute, networking, storage) comes first because physical substrate sets what is possible; Distributed ML sits above it because partitioning, synchronization, and fault handling only exist once physical compute exists to coordinate; Deployment at Scale follows because a trained distributed model must still be served to users; and Governance sits at the top because it constrains what should be built from what can be built. Swapping Governance below Infrastructure would reverse the argument that physical possibility is necessary but not sufficient: a model that is technically serveable but violates fairness or privacy requirements is not a viable production system.
Learning Objective: Sequence the Fleet Stack layers from physical substrate through operational layers to governance constraints and justify why each layer depends on the one beneath it
An engineer ports a recommendation model that runs flawlessly on a single 8-GPU node to a 2,000-GPU cluster serving 10 million users, and the system immediately fails in ways that never appeared in the smaller deployment. Using the section’s argument, identify two specific assumptions the single-machine version relied on that no longer hold at scale, and describe one concrete engineering consequence for each.
Answer: First, the single-machine version assumed that coordination overhead is negligible: gradient exchange and parameter synchronization happen within a single PCIe or NVLink domain. At 2,000 GPUs across many nodes, communication becomes the dominant term in the iron law and the engineer must budget bandwidth like a first-class resource, selecting collective algorithms and overlap strategies to keep accelerators fed. Second, the single-machine version assumed component failure is exceptional and can be handled by restarting a process. At fleet scale, failures become continuous, so checkpointing cadence, elastic training membership, and graceful degradation must be designed in from the start rather than bolted on. The practical implication is that model quality alone no longer guarantees a viable system; the fleet architecture determines whether the model can actually run.
Learning Objective: Identify specific single-machine assumptions that break under distributed production and trace each to a concrete engineering response at fleet scale
Self-Check: Answer
A gradient-descent job on 8 GPUs shows 94 percent scaling efficiency; the same code on 8,000 GPUs shows 38 percent scaling efficiency, and the drop is attributed to stragglers, synchronization barriers, and load imbalance that no profiler flagged at the smaller scale. Which of the six principles best explains why the 8-GPU measurements failed to predict the 8,000-GPU behavior?
- Failure is routine, because the 8,000-GPU cluster is encountering more hardware faults per hour than the 8-GPU node
- Scale creates qualitative change, because new coordination dynamics among thousands of workers dominate once the worker count crosses several orders of magnitude
- Infrastructure determines capability, because the 8,000-GPU cluster must be using older accelerators than the 8-GPU node
- Sustainability is a first-order cost, because the larger cluster is thermally throttled in ways the smaller one is not
Answer: The correct answer is B. The scenario describes effects that are not present at 8 GPUs and cannot be extrapolated from the 8-GPU data: stragglers only matter when many workers synchronize, and synchronization overhead grows non-linearly with worker count. The failure-is-routine framing confuses hardware faults with the observed coordination effects, the infrastructure-age framing invents a hardware mismatch the scenario does not support, and the sustainability framing substitutes a thermal story for what the scenario explicitly attributes to coordination.
Learning Objective: Diagnose which of the six principles explains a qualitative shift in scaling efficiency between small-cluster and fleet-scale training
True or False: A distributed training run that holds steady at 78 percent scaling efficiency up to 512 GPUs but collapses to 31 percent efficiency at 4,096 GPUs is most plausibly diagnosed as compute-bound, because adding four thousand accelerators should have pushed the bottleneck away from arithmetic.
Answer: False. The collapse pattern is the signature of communication becoming dominant: gradient synchronization, all-reduce bandwidth demand, and tail effects grow with worker count, so adding GPUs can increase rather than decrease the bottleneck’s share of the step time. The section’s first principle names this directly: at scale, communication rather than arithmetic becomes the binding term in the distributed step-time budget, which is why adding FLOP/s fails to rescue the run.
Learning Objective: Evaluate whether a specific efficiency-collapse pattern is more consistent with communication limits than with insufficient aggregate compute
A team scales a training job from 8 GPUs to 8,000 GPUs and encounters stragglers, synchronization overhead, and load imbalance that were invisible at the smaller scale. Explain why the section treats this behavior as qualitatively different from a larger version of the small-cluster case, and describe one design practice that small-cluster validation cannot substitute for.
Answer: The behavior is qualitatively different because new coordination dynamics emerge only once thousands of workers must progress together: a single worker running at 80 percent of peer speed drags all 8,000 down to 80 percent throughput, and a sub-millisecond synchronization cost per step becomes a cluster-wide tax across billions of steps. These effects do not exist on 8 GPUs, so they cannot be measured, optimized, or even observed there. One design practice small-cluster validation cannot substitute for is chaos-style large-scale shakedown: intentionally running the full 8,000-GPU configuration under realistic failure rates and heterogeneity so stragglers, slow-node handling, and elastic recovery are exercised before the real training begins.
Learning Objective: Analyze how scale transforms performance problems qualitatively and identify at least one engineering practice that can only be validated at production scale
Meta’s Llama 3 training on 16,384 GPUs logged 419 unexpected failures over 54 days, or roughly one failure every three hours. What design conclusion does the section draw from this number?
- The cluster should be partitioned into smaller runs until the per-run failure rate is low enough that operators can intervene by hand
- Most failures at this scale originate in model code, so hardening optimizer and loss implementations is the primary response
- Failures are continuous and expected, so checkpointing cadence, elastic training, and graceful degradation must be architected from the start rather than treated as optional enhancements
- Improved next-generation hardware reliability will soon make explicit fault tolerance a secondary concern, so the priority is waiting for better GPUs
Answer: The correct answer is C. The section uses the Llama 3 failure rate to argue that at fleet scale the mean time between failures is shorter than any useful training job, so systems must recover without human intervention. The shrink-the-run response abandons the scale that justifies the fleet in the first place, the model-code-hardening response misattributes infrastructure failures to software defects, and the wait-for-better-hardware response ignores that failure rates scale with component count regardless of per-component reliability.
Learning Objective: Justify why the Llama 3 failure cadence forces checkpointing, elasticity, and graceful degradation to be first-class design primitives rather than optional optimizations
An inference team measures that its decode path on an H100 achieves only 12 percent of the advertised FP16 tensor-core throughput, while nvidia-smi reports 97 percent GPU utilization and the kernel mix is dominated by matrix-vector products. Given the chapter’s infrastructure principle, what engineering action is most directly supported by this evidence?
- Raise the batch size and sequence length together to drive arithmetic intensity above the HBM-bound regime, since utilization already indicates the compute units are saturated
- Replace the H100 with a higher-peak-TFLOP/s accelerator, since the gap between advertised throughput and realized throughput points to insufficient arithmetic capacity
- Reduce KV-cache pressure via paged attention, quantize weights to 8-bit, or shard across more devices, since the decode regime is bound by HBM bandwidth rather than by compute throughput
- Increase numerical precision from FP16 to FP32, since low realized throughput suggests the kernels are silently producing underflows that the accelerator is masking
Answer: The correct answer is C. The 12 percent of peak FP16 with matrix-vector-dominated kernels is the canonical signature of the memory wall regime the chapter names as the gating constraint on autoregressive decode: compute is idle because weights and KV state cannot be moved from HBM fast enough to feed it. The batch-up answer misreads high nvidia-smi utilization as compute saturation rather than memory-stall-induced busy waiting, the higher-peak-TFLOP/s answer throws more compute at a bandwidth problem, and the FP16-to-FP32 answer doubles memory traffic in exactly the regime where traffic is the bottleneck.
Learning Objective: Apply the infrastructure principle to translate a compute-versus-bandwidth diagnostic signature into the correct class of engineering remediation
A fleet design meets its throughput target by routing most work to a low-cost region, but the plan lacks subgroup monitoring and ignores the region’s carbon intensity. Which conclusion follows from the six-principles framework?
- The design is incomplete because responsible engineering and sustainability are governing constraints, not reviews that happen after throughput is optimized
- The design is acceptable because the infrastructure and distribution layers have already met the measurable performance target
- The design should be evaluated only after deployment because fairness and carbon effects cannot be measured before production traffic arrives
- The design can compensate for missing governance evidence by adding more accelerators and reducing queueing delay
Answer: The correct answer is A. The six-principles framework treats responsible engineering and sustainability as constraints that shape the architecture alongside communication, failure recovery, infrastructure, and scale. A plan that meets throughput while omitting fairness monitoring or carbon accounting has optimized one layer while leaving governing constraints unmeasured. The performance-only answer ignores the governance layer, the wait-until-production answer mistakes measurable design constraints for after-the-fact review, and the add-accelerators answer confuses queueing relief with accountability.
Learning Objective: Apply the responsible-engineering and sustainability principles as design constraints rather than post-deployment reviews
Self-Check: Answer
A team upgrades its storage pipeline from 50 GB/s to 200 GB/s of sustained read bandwidth, but its inter-node interconnect tops out at 25 GB/s per worker and remains unchanged. Using the section’s co-design argument, why is this not a complete improvement to the training throughput of the cluster?
- Storage bandwidth that exceeds communication capacity is wasted because workers cannot exchange the gradients produced from the extra data; conversely, communication faster than storage throughput would leave accelerators idle waiting for input
- High storage throughput substitutes for most interconnect traffic because workers can re-read parameters from storage instead of exchanging them
- Collective communication matters mainly during online serving, so training throughput should not depend heavily on the interconnect fabric
- Once storage throughput crosses 100 GB/s, the remaining bottlenecks shift to fairness auditing and governance checks rather than to data movement
Answer: The correct answer is A. The section frames storage and communication as coupled throughput constraints that must be co-designed: the maximum useful data rate is the minimum of the two, and widening one without the other converts the improvement into idle capacity. The storage-substitutes-for-network answer confuses dataset ingestion with gradient synchronization, the serving-only answer ignores that distributed training depends on frequent all-reduce exchanges, and the fairness-auditing answer swaps a throughput argument for a governance argument with no mechanism connecting them.
Learning Objective: Compare storage throughput and communication capacity as co-dependent throughput constraints and diagnose when a one-sided upgrade fails to improve end-to-end performance
Give one concrete example from distributed ML where optimizing one of the six principles improves its dedicated metric but measurably worsens a different principle’s metric, and explain the mechanism that links the two.
Answer: Tightening communication efficiency via larger synchronization groups (for example, moving from 256-worker to 4,096-worker all-reduce rings) improves bandwidth utilization and reduces gradient exchange time per step, but it worsens the failure-is-routine principle: a single slow or failed worker now stalls 4,096 peers rather than 256, so the expected wall-clock cost per failure and the effective recovery time both grow. The mechanism is that synchronization fate-shares all participants, so expanding the group size amplifies the blast radius of every component failure. The practical implication is that engineers must tune synchronization group size against the measured failure rate, not purely against bandwidth efficiency, which is exactly the cross-principle trade-off the section names as the art of distributed ML engineering.
Learning Objective: Analyze a concrete case where local optimization of one principle exerts measurable pressure on another and name the mechanism that couples them
A team builds a training cluster that achieves 68 percent MFU on a 4,096-GPU run, but its serving stack has no drift monitoring, no canary or shadow deployment capability, and its fairness auditing was skipped to hit a ship date. Using the section’s definition, explain why this cluster does not yet constitute a complete production system and identify which Fleet Stack layers the gaps fall into.
Answer: A complete production system integrates infrastructure, distributed training, serving, operations, security, and governance so that the trained model can be delivered to users reliably, evolved safely, and held accountable. The scenario solves the Infrastructure and Distributed ML layers well (strong MFU indicates both the physical substrate and the distribution logic are working), but the missing drift monitoring and canary capability are gaps in the Deployment at Scale layer, and the skipped fairness auditing is a gap in the Responsible Fleet (governance) layer. Without the upper two layers the team may produce capable models, but it cannot detect when production behavior diverges from training, cannot safely roll out updates, and cannot demonstrate accountability, so the system fails the section’s test that capability must also serve human welfare.
Learning Objective: Evaluate whether a specific stack satisfies the cross-layer requirements of a complete production ML system and locate each gap at the correct Fleet Stack layer
Self-Check: Answer
An engineer tunes a 1,024-GPU ring AllReduce around the \(2(N-1)/N\) per-rank traffic coefficient, selects a fat-tree topology appropriate for the workload’s bisection-bandwidth demand, and designs a training loop that expects component failure every few hours. Which competency from the section does this combined skill set most directly reflect?
- Production operations
- Governance and ethics
- Distributed systems
- Model architecture research
Answer: The correct answer is C. The section defines the distributed-systems competency precisely in terms of communication-pattern analysis, network-architecture selection, and design for routine failure at cluster scale, all of which the scenario exercises simultaneously. Production operations centers on serving behavior, monitoring, and continuous batching rather than on AllReduce efficiency; governance and ethics centers on fairness, privacy, and sustainability constraints rather than on fabric choice; and model architecture research centers on weights and loss functions rather than on fleet-level coordination.
Learning Objective: Classify concrete distributed-systems tasks (bandwidth-efficient collectives, topology selection, failure-aware design) under the correct competency area
True or False: A production recommendation service meets its p99 latency SLO of 80 ms every hour for a full quarter while click-through rate on its top-ranked items drifts downward by 12 percent; the section would regard this as successful production operations because the service-health metric is green.
Answer: False. The section explicitly scopes production operations to include monitoring for both performance and semantic drift: a 12 percent downward drift in click-through rate is the exact semantic signal the competency is defined to catch, regardless of whether latency SLOs are met. A production operations team that treats a green latency dashboard as sufficient is ignoring half of its mandate, which is why the chapter names drift monitoring alongside performance monitoring as core to the skill.
Learning Objective: Evaluate whether meeting service-health SLOs alone satisfies the section’s definition of successful production operations when semantic drift is present
Name one concrete architecture decision that changes when a team adds differential privacy, one that changes when it adds bias auditing across demographic groups, and one that changes when it adds carbon-aware scheduling. Use these to explain why the section treats governance and sustainability as competencies that reshape systems engineering rather than as add-ons after training is done.
Answer: Differential privacy forces the training loop to add calibrated gradient noise and privacy accounting, which changes the optimizer, batch size, and convergence budget; bias auditing across demographic groups forces the operational stack to retain per-group labels and evaluation slices through the entire serving path, which changes logging, storage, and the serving API; carbon-aware scheduling forces the fleet orchestrator to treat grid carbon intensity as a first-class scheduling signal, which changes when and where jobs run and couples workload placement to regional energy markets. Each of these rewrites part of the architecture rather than decorating it, so the section treats the capability to implement all three as the dividing line between a systems engineer and a model developer: the systems engineer is responsible for the design choices these constraints force, not only for the weights.
Learning Objective: Justify why privacy, fairness, and sustainability constraints change concrete architecture and operations decisions rather than functioning as post-hoc checks on a finished model
Self-Check: Answer
A platform team improves serving latency by adding a cache, but the change increases state movement, invalidation failures, and missing audit evidence. What behavior best reflects the fleet stack as a professional discipline?
- Follow the active constraint across infrastructure, distribution, deployment, and governance until the system as a whole is the design object
- Treat the cache hit-rate improvement as sufficient because the local serving layer now meets its latency target
- Convert the fleet-stack principles into a checklist of technologies and mark the design complete once each layer has a named tool
- Postpone governance evidence until after the performance SLO is stable, because audit trails do not affect runtime behavior
Answer: The correct answer is A. The section argues that mastery is not a checklist of technologies; it is the habit of following the active constraint across layers until the fleet, not a single model or component, becomes the design object. The single-machine answer abandons the scale that motivated the fleet stack, the labeling answer misreads hardware limits as a reason to ignore serving, and the manual-operation answer inverts the section’s claim that orchestration and MLOps become more central as component interactions grow.
Learning Objective: Identify the fleet-stack discipline as cross-layer constraint following rather than isolated layer optimization
The chapter’s notebook says a workload needs a 100\(\times\) efficiency improvement, with 4\(\times\) from hardware and 2.5\(\times\) from algorithmic compression. Compute what this implies about orchestration, and explain what happens if a team instead assumes additive rather than multiplicative gains.
Answer: Because total gain multiplies across the stack, the required orchestration gain is \(100/(4 \times 2.5)=10\times\); hardware and algorithmic compression together deliver 10\(\times\), so orchestration must supply the remaining order of magnitude. If the team instead assumed the sources added, hardware and compression would deliver \(4 + 2.5 = 6.5\times\) and the orchestration budget would balloon to roughly 93.5\(\times\). The practical implication is that the accounting only works when the layers compose without canceling one another; for example, an algorithmic compression gain must not introduce enough communication overhead to erase the hardware gain.
Learning Objective: Apply fleet-stack efficiency accounting to compute the required orchestration gain and evaluate additive versus multiplicative assumptions
Why does the section treat orchestration as a first-class fleet-stack budget rather than as implementation detail?
- Because general-purpose CPUs replace GPUs for model inference whenever composed services are used
- Because routing requests, reusing cached state, overlapping communication, and validating outputs consume latency, cost, failure, and governance budgets
- Because it eliminates the need for retrieval, tools, and verification by centralizing all logic in a single scheduler
- Because it guarantees that monolithic models will regain dominance once network bandwidth improves
Answer: The correct answer is B. The section treats orchestration as load-bearing because coordination consumes the same budgets the rest of the fleet stack must satisfy: latency, cost, failure recovery, state movement, and governance evidence. The CPU-replaces-GPU answer takes hardware literally, the single-scheduler answer conflates coordination with consolidation, and the monolithic-return answer ignores the section’s point that no single layer removes cross-layer constraints.
Learning Objective: Interpret orchestration as a measurable fleet-stack budget rather than an implementation detail
Public optical I/O materials in the section describe moving from roughly 6–10 pJ/bit long-reach electrical signaling toward below 5 pJ/bit optical signaling. In the section’s simple 10 pJ/bit to 5 pJ/bit scenario, what is the strongest systems reason this lever matters for large fleets?
- Because reducing energy per bit by about 2\(\times\) relaxes communication power and cooling pressure, while leaving bandwidth optimization and locality as first-class design requirements
- Because lower energy-per-bit increases the peak arithmetic throughput of each accelerator, so the cluster finishes the same workload in fewer node-hours and therefore uses less total energy
- Because lower energy-per-bit eliminates the need for fault tolerance and checkpointing in the fleet, since cheaper communication reduces the probability that workers desynchronize
- Because lower energy-per-bit causes gradient synchronization to become numerically more accurate, which reduces the number of training steps needed to converge
Answer: The correct answer is A. The section’s notebook computes the simple scenario as \(10/5=2\times\), then uses that result to make a systems point: total communication power scales with bits moved times energy per bit, so lowering the energy cost of signaling relaxes power and cooling pressure. The peak-FLOP/s answer confuses arithmetic throughput with communication energy, which is orthogonal to the wattage question; the fault-tolerance-disappears answer invents a causal link that the section explicitly rejects when it argues core principles endure across substrates; and the numerical-accuracy answer conflates signaling energy with numerical precision, two unrelated properties of the interconnect.
Learning Objective: Apply energy-per-bit reasoning to the section’s 10 pJ/bit to 5 pJ/bit scenario and rule out common confusions with throughput, fault tolerance, or numerical precision
True or False: Because the section’s post-silicon interconnect scenario gives about a 2\(\times\) communication-energy improvement, the chapter argues that bandwidth optimization drops from a first-class engineering concern to a secondary tuning parameter, even though fault tolerance and governance remain central.
Answer: False. The section explicitly lists bandwidth optimization alongside fault tolerance and responsible governance as enduring requirements that persist across substrate transitions. Cheaper per-bit energy raises the affordable bit count rather than removing the need to use those bits efficiently: larger workloads can saturate whatever interconnect the substrate affords. The section is careful that public co-packaged optics and optical-I/O claims support single-digit energy improvements in the scenario rather than orders-of-magnitude fabric-wide reductions.
Learning Objective: Evaluate whether bandwidth optimization is retired by the section’s post-silicon interconnect scenario while distinguishing quantitative relaxation from qualitative retirement of a principle
The section treats composition as a pressure point rather than as a new law of capability. Explain why orchestration must be measured as part of the system when a request passes through models, retrieval, tools, and verification.
Answer: Composition increases capability by coordinating specialized components, but every added component consumes latency, moves state, creates another failure surface, and produces evidence that governance may need to audit. Orchestration is therefore not glue code outside the system; it is the control plane that spends the same budgets the fleet stack tracks. The practical implication is that useful work must be measured across model calls, retrieval, tool execution, verification, cache reuse, and failure handling, not only inside the largest model.
Learning Objective: Analyze why composed services make orchestration overhead and state movement part of the measured fleet-stack design
Self-Check: Answer
The section’s Fermi estimate compares a hypothetical 25,000-H100 frontier cluster drawing roughly 17.5 MW and delivering about 2.47\(\times\) \(10^{19}\) peak FLOP/s with a rough brain estimate of \(10^{14}\) synaptic ops/s on 20 W. What does the section take as the main engineering conclusion of this comparison?
- Raw throughput is roughly matched between the brain and the cluster, so the remaining work should concentrate only on software reliability
- The cluster is now more energy efficient than the brain per useful operation, so energy has stopped being a meaningful systems constraint
- The cluster is slower than the brain in raw operation rate, which shows current silicon is far from useful intelligence
- The cluster has surpassed the rough brain estimate in raw peak operation rate, but the operations are not semantically equivalent and the megawatt-scale power draw keeps efficiency as the next frontier
Answer: The correct answer is D. The section’s local calculation shows machine peak FLOP/s far above the rough synaptic-activity estimate, while explicitly warning that the two operation rates are not semantically equivalent. It then names efficiency, not additional raw scale, as the next frontier under energy, carbon, and economic constraints. The equal-throughput answer contradicts the stated ratios; the machine-is-more-efficient answer inverts the power comparison and ignores the 20 W versus 17.5 MW gap; and the slower-than-brain answer denies the section’s explicit claim that machine throughput has already surpassed the brain.
Learning Objective: Interpret the Fermi estimate’s dual comparison (raw throughput and energy efficiency) and identify which of the two the section names as the next engineering frontier
True or False: Once ML clusters surpass the brain in raw operations per second, improving efficiency becomes secondary because the key scaling milestone has already been achieved.
Answer: False. The section states that surpassing the rough brain estimate in raw throughput still leaves the energy and efficiency problem unaddressed, and explicitly names efficiency as the next-generation challenge. Framing the throughput milestone as the decisive one confuses one dimension of the comparison for its conclusion; raw operation-rate superiority does not retire scaling concerns, but it makes efficiency under energy, carbon, and economic constraints central.
Learning Objective: Evaluate whether raw throughput superiority is sufficient to make efficiency a secondary engineering concern given the Fermi estimate’s efficiency gap
An engineer asked to decide whether to deploy a new composed AI service reaches past a single performance metric and instead reasons across Infrastructure, Distribution, Deployment at Scale, and Governance before committing. Explain how this behavior exemplifies the Fleet Stack functioning as a professional framework in the sense this section uses the phrase, and describe one concrete failure mode that a purely single-layer decision process would miss.
Answer: The Fleet Stack as a professional framework means the engineer treats cross-layer reasoning as the standard operating procedure rather than as a post-hoc check: infrastructure feasibility, distribution efficiency, deployment reliability, and governance acceptability are all required simultaneously, and a decision that optimizes one layer while silently breaking another is considered incomplete. A concrete failure mode a single-layer process would miss is a retrieval-augmented generation system that shows excellent infrastructure utilization and strong distributed training behavior, passes offline accuracy benchmarks, and yet exhibits demographic disparities in retrieval relevance that are only detectable from a governance perspective; a purely performance-oriented review would ship the system, while a Fleet Stack review catches the governance gap before deployment. The practical implication is that professional ML systems work requires cross-layer judgment, not isolated technical expertise.
Learning Objective: Explain how the Fleet Stack supports professional cross-layer decision making and identify a concrete failure mode that single-layer evaluation would fail to catch
Self-Check: Answer
A team replaces a model kernel and reduces per-token compute time, but the new serving path increases checkpoint pressure, network contention, P99 variance, and missing audit evidence. Which conclusion best matches the chapter’s closing fallacy?
- The model is faster, so the system is automatically better unless accuracy drops.
- The change must be evaluated against useful throughput under data movement, synchronization, failure recovery, power, latency, and accountability constraints.
- The change should be accepted because local kernel speed is the only term that matters once a fleet is already deployed.
- The change should be judged only by governance teams because technical performance and accountability are separate decisions.
Answer: The correct answer is B. The fallacy is treating a faster model as automatically better than the system it runs inside. A kernel improvement can still make the fleet worse if it shifts cost into checkpointing, network contention, tail latency, power, or governance evidence. The speed-only answers ignore transferred constraints, while the governance-only answer separates obligations from the operating path the chapter insists must carry them.
Learning Objective: Evaluate a local model-speed improvement against fleet-level system constraints
Explain why optimizing one layer while hiding the constraint it creates in another is a systems pitfall, using one example from the section.
Answer: A local optimization is dangerous when it moves cost to a layer no one is measuring. Larger batches can raise accelerator utilization while worsening tail latency; aggressive compression can reduce communication while increasing accuracy risk; carbon-aware scheduling can lower emissions while requiring more slack in the service budget. The engineering requirement is to keep the transferred constraint visible so the system chooses the trade-off deliberately instead of inheriting a hidden bottleneck.
Learning Objective: Explain why transferred constraints must remain visible across fleet-stack layers
True or False: Fleet-scale lessons are mostly tied to today’s processors, serving engines, and frameworks, so they should be expected to expire as the hardware and software stack changes.
Answer: False. The section states that technology names are examples, while the durable relationships are the lesson: data must reach compute at the required rate, workers must communicate before synchronization stalls the job, failures must be expected at large component counts, serving systems must meet tail-latency budgets, and governance constraints must be engineered into the operating path.
Learning Objective: Distinguish durable fleet-scale systems relationships from current implementation names