Training Systems Fundamentals
Model Training
Purpose
Why does training a model cost millions while running it costs pennies?
Inference computes a single forward pass: data flows through the network, a prediction emerges. Training multiplies that cost at every level. Each example requires a forward pass plus a backward pass to compute gradients, plus an optimizer step that updates every parameter. The optimizer itself maintains momentum and variance estimates that can exceed the model’s own memory footprint. Then repeat across billions of examples, for multiple epochs, across dozens of hyperparameter configurations. The result is a million-to-one asymmetry between the cost of learning and the cost of using what was learned. This asymmetry is the primary gatekeeper to AI innovation: training a model costs orders of magnitude more than running it, a gap so large that it governs who can participate at all. A research lab that trains in three days iterates through ideas ten times faster than one that takes a month, and the compounding effect of faster iteration dominates any single architectural insight. For the systems engineer, training is the phase where hardware decisions matter most, where parallelism strategies determine feasibility, and where the ML workflow’s most expensive iteration loop either accelerates or stalls the entire project. In D·A·M terms, that iteration loop is where algorithm-machine co-design carries its highest cost: every parallelism and precision decision is a negotiation between the mathematics of optimization and the physics of the machine that executes it.
Learning Objectives
- Explain training cost asymmetry using forward, backward, optimizer-state, data, and iteration costs
- Calculate FLOPs, activation memory, optimizer state, and dollar cost for neural network training
- Compare SGD, Adam, and AdamW by convergence behavior, memory overhead, and compute cost
- Diagnose compute-, memory-, and data-bound training bottlenecks with roofline analysis and profiling evidence
- Apply mixed precision, checkpointing, gradient accumulation, and FlashAttention to fit accelerator memory and throughput limits
- Design single-machine training pipelines with prefetching, overlap, batching, and systematic re-profiling
- Evaluate when to scale beyond one machine using memory, duration, communication, energy, and cost constraints
Running a model once and training it from scratch live on opposite sides of the systems cost curve. Frameworks provide the execution substrate: computational graphs schedule operations, automatic differentiation computes gradients, and hardware abstractions target diverse accelerators. Those mechanisms make a single training step possible; training systems make it repeatable at scale. The same forward/backward/update loop must now run billions of times while retaining activations, feeding accelerators, and staying within practical memory, time, and budget limits.

Training cost stays flat across scale, then explodes past the large-scale knee.
1 [offset=8mm] Training Cost Scaling: The roughly 2,000\(\times\) increase in this chapter’s cost anchors from GPT-2–scale training to GPT-4–class training reflects three compounding factors: parameter counts, training-token budgets, and accelerator fleets all grew dramatically. OpenAI’s GPT-2 report documents the model and training setup but does not disclose training cost (Radford et al. 2019). Exact GPT-4 training details were also not disclosed, so the GPT-4-class figure is explicitly an industry-estimate anchor, supported by public reporting and independent infrastructure estimates (Knight 2023; SemiAnalysis 2023). Those estimates place GPT-4-class training in the regime of large accelerator fleets (tens of thousands of A100-class accelerators) for months, not single-node clusters, with widely cited nine-figure cost estimates. This trajectory made training one of the largest capital expenditures for organizations building models at that scale, exceeding the annual R&D budget of most universities.
Radford, Alec, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. 2019. Language Models Are Unsupervised Multitask Learners. OpenAI.
Knight, Will. 2023. OpenAI’s CEO Says the Age of Giant AI Models Is Already over. WIRED.
SemiAnalysis. 2023. GPT-4 Architecture, Infrastructure, Training Dataset, Costs, Vision, MoE. SemiAnalysis Blog.
Running GPT-2 once costs a fraction of a cent, while this chapter uses an order-of-magnitude 2019 cloud-cost anchor of approximately $50,000 for GPT-2-scale training. A GPT-4-class model may cost only a few cents to run once, yet public estimates place its training run near $100M1. This training cost asymmetry reflects the sheer volume of computation required: over a hundred billion forward passes, each followed by a backward pass, repeated across datasets measured in terabytes.
A single forward pass through GPT-2, using the architecture described in the GPT-2 technical report (Radford et al. 2019), requires roughly 3.00 × 10⁹ floating-point operations in this chapter’s accounting. Training requires over a hundred billion such passes, and each backward pass costs approximately twice as much as the forward pass, yielding a derived computational budget on the order of 1.50 × 10²¹ FLOPs. This asymmetry makes training systems engineering a distinct discipline and explains why access to training infrastructure increasingly determines who can participate in AI development.
Definition 1.1: Training systems
Machine Learning Training Systems are software-hardware systems that execute the iterative optimization loop (forward pass, loss computation, backward pass, and parameter update) to minimize a loss function over a training dataset.
- Significance: Training memory cost is 6× the inference memory cost per parameter when using the Adaptive Moment Estimation (Adam) optimizer: a 7B-parameter model requires 14 GB (FP16 weights) + 14 GB (FP16 gradients) + 56 GB (Adam first and second moments in FP32) = 84 GB at least, before accounting for activation storage. This multiplier is the primary reason a model that runs inference on one GPU requires multiple GPUs for training.
- Distinction: Unlike inference systems, which execute a single forward pass and discard intermediate activations, training systems must retain all intermediate activations from the forward pass for use during the backward pass, creating a memory footprint that grows linearly with model depth and batch size.
- Common pitfall: A frequent misconception is that training failures are compute problems. The most common training failure is out-of-memory (OOM) error, which is a memory management problem: the activation tensors from all \(N_L\) layers accumulate during the forward pass and must coexist in GPU memory simultaneously, causing OOM before the first gradient is computed.
Three characteristics distinguish training workloads from general-purpose computing:
- Computational intensity: The 1.50 × 10²¹ FLOPs budget spread over days of wall-clock time demands sustained PFLOP/s-scale throughput from hardware whose realized large-model throughput is often far below theoretical peak (Narayanan et al. 2021; Chowdhery et al. 2022).
- Memory pressure: Storing 1.5B weights requires 6 GB in FP32; the Adam optimizer adds two additional state tensors per parameter, consuming another 12 GB; and activation storage across 48 layers can double or triple this total, easily exceeding a single accelerator’s memory capacity.
- Data dependencies: Each gradient update depends on the result of the previous one, creating sequential bottlenecks that limit how much parallelism the system can exploit.
2 Gradient Checkpointing (Activation Checkpointing): The memory pressure described here arises because backpropagation requires every layer’s activations from the forward pass. Checkpointing breaks this requirement by saving activations at only \(\sqrt{N_L}\) strategic layers and recomputing the rest during the backward pass, trading roughly 33 percent additional compute for a large reduction in activation memory (Chen et al. 2016). Section 1.5.5.2 derives the optimal \(\sqrt{N_L}\) schedule and works the resulting memory–compute trade-off for GPT-2’s layer count.
Chen, Tianqi, Bing Xu, Chiyuan Zhang, and Carlos Guestrin. 2016. “Training Deep Nets with Sublinear Memory Cost.” arXiv Preprint arXiv:1604.06174.
3 Mixed-Precision Training: Uses half-precision (FP16 or BF16) for computation while maintaining FP32 “master weights” for accumulation, where rounding errors would otherwise compound. Loss scaling prevents gradient underflow in FP16’s limited dynamic range, often yielding roughly 2\(\times\) memory savings and 2–8\(\times\) throughput gains on Tensor Cores (Micikevicius et al. 2017). BF16 (“Brain Floating Point,” from Google Brain (Cloud 2019)) later eliminated loss scaling by matching FP32’s 8-bit exponent range, simplifying the dominant failure mode of half-precision training.
Micikevicius, Paulius, Sharan Narang, Jonah Alben, Gregory Diamos, Erich Elsen, David Garcia, Boris Ginsburg, et al. 2017. “Mixed Precision Training.” arXiv Preprint arXiv:1710.03740.
Cloud, Google. 2019. BFloat16: The Secret to High Performance on Cloud TPUs.
Each challenge points to a different kind of fix. Computational intensity pushes the system toward higher accelerator utilization and lower-precision arithmetic. Memory pressure calls for techniques such as gradient checkpointing2, a specific application of rematerialization (discarding and recomputing intermediate values to save memory, from ML Frameworks) that trades recomputation for reduced activation storage, and mixed-precision training3, which reduces the memory footprint of weights and activations. Data dependencies motivate pipeline designs that overlap computation with data movement, building directly on the data loading throughput optimized in Data Engineering so the accelerator never sits idle waiting for the next batch. The current chapter focuses on single-machine and single-node multi-GPU training; scaling to hundreds of machines across network boundaries introduces communication and fault tolerance challenges beyond our current scope.
The staged system pipeline: Identifying “accelerator bubbles”
A training system is not a single loop; it is a staged system pipeline. Reaching high accelerator utilization requires analyzing training as a factory floor where four distinct stages coordinate to keep the ALUs busy:
- Data Loading & Preprocessing (CPU/Storage): Fetching raw bits from Non-Volatile Memory Express (NVMe), decoding, and augmenting on CPU cores.
- Host-to-Device Transfer (PCIe): Moving the processed batch over the PCIe bus into GPU memory via DMA.
- Forward/Backward Pass (Accelerator): Propagating activations and gradients through layers on the GPU.
- Parameter Synchronization (NVLink): Exchanging gradients between GPUs over NVLink (900 GB/s) in multi-GPU configurations to update weights.
Any mismatch in the throughput of these stages creates accelerator bubbles—intervals of idle silicon where the machine axis of the D·A·M taxonomy sits at 0 percent utilization while waiting for the data axis to catch up. A systems engineer’s primary task during training is to eliminate these bubbles through asynchronous prefetching and pipeline overlapping, ensuring that the next batch is ready on the PCIe bus before the current backward pass completes. We develop the quantitative tools for measuring and fixing these bubbles in section 1.4.
The chapter follows that dependency chain. We begin with the iron law of training performance, a specialized application of the general iron law (Iron Law of ML Systems) that separates total operations, peak throughput, and utilization. That equation gives us the accounting system for the mathematical foundations that follow: neural-network computation as a workload, optimizer behavior, backpropagation mechanics, and arithmetic intensity. Once the costs are visible, the chapter turns to the training pipeline itself, where data loading, forward pass, backward pass, and parameter updates each constrain the next. The optimization sections then target the terms exposed by the accounting: mixed-precision training, FlashAttention, gradient accumulation, checkpointing, and data prefetching. Only after those single-machine levers are clear do we examine scaling beyond one accelerator, where communication overhead becomes the next bottleneck.
Before formalizing the iron law, consider how these constraints interact in practice. The theoretical framework matters because failures are expensive: a single gradient explosion can erase days of computation worth thousands of dollars.
War Story 1.1: The PaLM loss spikes (2022)
Context: During training of the 540B-parameter PaLM model, the largest run exhibited training-instability behavior that smaller runs did not show (Chowdhery et al. 2022).
Failure mode: The training loss spiked roughly 20 times despite gradient clipping. The spikes occurred irregularly, sometimes late in training, and were not explained by a simple “bad data batch” story.
Resolution: The practical mitigation was operational: restart from a checkpoint about 100 steps before the spike and skip roughly 200–500 data batches around the failure window. The mitigation avoided recurrence at the same point and showed that very large training runs require planned recovery paths alongside optimizer theory.
Systems lesson: Large-scale training stability is an operational problem as much as an optimization problem. Checkpoint cadence, automated loss-spike detection, batch skipping, and numerically robust formats such as BF16 are part of the training system, not afterthoughts.
Iron Law of Training Performance
PaLM’s loss spikes illustrate a broader point: instability at frontier scale is not a rare accident but a predictable consequence of pushing computational intensity, memory pressure, and data dependencies simultaneously. Each of those three characteristics is individually manageable, yet their interactions produce failure modes that operational recovery alone cannot prevent. Diagnosing which factor dominates a given failure, and quantifying the cost of each, requires a formal decomposition of training time into its physical constituents.
The iron law provides exactly that organizing framework: it decomposes training time so that every optimization technique maps to a specific term in the equation. This is a specialized application of the general iron law of ML systems introduced in Iron Law of ML Systems, focused specifically on maximizing computational throughput.
Definition 1.2: The iron law of training performance
The Iron Law of Training Performance is the simplified form of the general iron law that isolates the computational bottleneck of iterative optimization: \[T_{\text{train}} = \frac{O}{R_{\text{peak}} \times \eta_{\text{hw}}} \tag{1}\]
The simplification is valid when the pipeline is correctly staged: at training scale with large batches, data movement \((D_{\text{vol}}/\text{BW})\) is overlapped with compute via prefetching pipelines, and communication overhead \((L_{\text{lat}})\) is absorbed by gradient overlap strategies, leaving hardware utilization as the dominant remaining lever. When pipelines are poorly staged, \(D_{\text{vol}}/\text{BW}\) resurfaces as the bottleneck and the simplified form no longer applies.
- Significance: The three factors identify three distinct optimization levers: \(O\) (reducible by algorithmic changes, fewer training tokens, or later model-compression methods such as pruning and distillation), \(R_{\text{peak}}\) (improved by hardware and lower-precision tensor cores), and \(\eta_{\text{hw}}\) (the utilization fraction and primary engineering target; GPT-3 training achieved \(\eta_{\text{hw}} \approx 0.45\) (Narayanan et al. 2021), and well-tuned large training systems often target higher sustained utilization). Model Compression defines the compression techniques; here they serve only to show where such methods enter the accounting.
- Distinction: Unlike the general iron law, which models all three cost terms \((D_{\text{vol}}/\text{BW}, O/(R_{\text{peak}} \cdot \eta_{\text{hw}}), L_{\text{lat}})\), this simplified form assumes data movement and communication are not the binding constraint, an assumption that breaks for small-batch workloads or bandwidth-limited deployments.
- Common pitfall: A frequent misconception is that \(\eta_{\text{hw}}\) is fixed by hardware. System efficiency is a pipeline property: memory bandwidth saturation, kernel launch overhead, and synchronization barriers each reduce \(\eta_{\text{hw}}\) independently, and diagnosing which factor dominates requires profiling rather than reading hardware specs.

Training is compute-dominated: data and latency overlap away.
Equation 1 reveals three levers for improvement: reduce total operations through algorithmic innovation, increase peak throughput through hardware utilization, or improve utilization through better pipeline orchestration. Each optimization technique in this chapter pulls one or more of these levers, as summarized in table 1.
| Technique | Term Affected | Mechanism |
|---|---|---|
| Mixed Precision (FP16/BF16) | Peak Throughput ↑ | Tensor Cores operate at up to 16\(\times\) higher FLOP/s |
| Data Prefetching | Utilization ↑ | Reduces accelerator idle time waiting for data |
| Gradient Checkpointing | Total Operations ↑ | Adds recomputation, but enables larger models |
| Gradient Accumulation | Utilization ↑ | Maintains high batch parallelism efficiency |
| Operator Fusion | Utilization ↑ | Reduces memory bandwidth bottlenecks |
| FlashAttention | Memory Traffic ↓, Utilization ↑ | Same asymptotic FLOPs, much lower HBM IO; backward recomputation may add FLOPs |
A caveat: the iron law focuses on execution efficiency—how fast the hardware processes a given workload. It does not capture data-side factors such as data quality, dataset size, or curriculum design, which affect how many total operations \(O\) are needed to reach a target accuracy. A cleaner dataset or a better data mix can reduce the number of epochs required, shrinking \(O\) without touching hardware at all. In this chapter we hold the workload fixed and ask how to execute it as fast as possible.
The gap between theoretical peak performance and actual training speed is often 2–3\(\times\). Scaling to multiple accelerators introduces additional communication overhead that can erode these gains, a trade-off we examine in section 1.6.
Checkpoint 1.1: The physics of training
Training speed is governed by the utilization of hardware peaks.
The Utilization Gap
Precision Economics
The iron law provides a static framework for reasoning about training performance, but the history of deep learning reveals how the binding constraint has shifted over time as hardware and algorithms co-evolved. In 1986, backpropagation was formalized (Rumelhart et al. 1986), and training a three-layer network on toy datasets required days on CPU workstations—the bottleneck was raw compute throughput \((R_{\text{peak}})\). In 2012, AlexNet demonstrated GPU training (Krizhevsky et al. 2012), reducing ImageNet training from weeks to days and launching the deep learning era. By 2017, transformers (Vaswani et al. 2017) shifted attention toward large-scale sequence modeling and high-throughput accelerator kernels. GPT-3 in 2020 consumed about \(3.14 \times 10^{23}\) FLOPs (Brown et al. 2020), making utilization \((\eta_{\text{hw}})\) critical. By 2023, training efficiency improved through the techniques examined in this chapter: FlashAttention reduces memory traffic while improving \(\eta_{\text{hw}}\); gradient checkpointing trades additional \(O\) for memory capacity; mixed precision increases \(R_{\text{peak}}\). Each innovation was motivated by a specific iron law bottleneck.
Vaswani, Ashish, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. 2017. “Attention Is All You Need.” Advances in Neural Information Processing Systems 30: 5998–6008.
Running example: Training GPT-2
GPT-2 is large enough to expose real training bottlenecks yet small enough to reason about without trillion-parameter infrastructure. In inference, GPT-2 serves as the Bandwidth Hog lighthouse; in training, the same model exposes a different constraint mix: activation memory, accelerator utilization, and data-pipeline throughput. We use it as a recurring worked example so each optimization has a concrete model, dataset, and hardware target.
Lighthouse 1.1: Lighthouse example: Training GPT-2
Context: GPT-2 (1.5 billion parameters) serves as our primary case study for large-scale training because it sits at the “sweet spot” of systems complexity. It is large enough to require distributed training and serious memory optimizations, yet small enough to comprehend without the massive infrastructure complexity of trillion-parameter clusters. Table 2 maps each model property to the systems constraint it creates:
Table 2: GPT-2 (1.5 billion parameters) lighthouse model specifications: Parameter count, architecture depth, dataset size, and total training compute mapped to their systems implications. Each row pairs a model property with the engineering constraint it creates—memory footprint for weights, activation pressure from pipeline depth, I/O throughput requirements, and parallelization demand.
| Property | Specification | Systems Implication |
|---|---|---|
| Parameters | 1.5B (XL) | Requires ~3 GB (FP16) or ~6 GB (FP32) for weights alone. |
| Architecture | 48 Layers, 1600 Dim | Deep pipeline creates heavy activation memory pressure. |
| Dataset | OpenWebText (40 GB) | I/O throughput must match high-speed accelerator compute. |
| Compute | ~ 1.50 × 10²¹ FLOPs | Training takes days/weeks; demands parallelization. |
Challenge: Training GPT-2 is primarily memory-bound (due to activation storage) and compute-intensive (requiring massive matrix multiplications). It forces us to move beyond simple training loops to sophisticated pipelines that manage data movement as carefully as computation.
Not all training workloads are compute bound. Recommendation models like DLRM are dominated by massive embedding tables (100B to 10T parameters, mostly embeddings) that make them memory bandwidth bound rather than compute bound. For such workloads, the first scaling problem is often capacity: splitting the embedding tables across devices so the model fits at all. The remainder of this chapter focuses on dense, compute-intensive training using GPT-2 as the primary worked example.
Training systems occupy a critical position in the machine learning pipeline: they consume prepared data from upstream engineering (Data Engineering) and produce trained model artifacts that later systems must deploy and monitor. Data quality directly impacts training stability, while training efficiency determines iteration velocity during model development. The same pressure appears at three scales. At data scale, petabyte datasets require efficient I/O pipelines and distributed storage. At model scale, billion-parameter models force the system to decide whether to replicate the model across batches with data parallelism4 or split the model across devices with model parallelism5. At infrastructure scale, coordinating thousands of accelerators introduces communication overhead that can dominate training time. These challenges are why the workflow contracts from ML Workflow matter during training: orchestration decisions shape both scientific iteration and systems cost.
4 Data Parallelism: Replicates the full model on every device, splitting only the data. Each device computes gradients independently, then an AllReduce operation synchronizes them—adding communication volume proportional to model size at every step. This synchronization tax limits scaling efficiency: doubling accelerators rarely halves training time once communication becomes the bottleneck.
5 Model Parallelism: Partitions the model’s layers across devices when it exceeds single-device memory. Activations must transfer between devices at every partition boundary, and naive partitioning creates “pipeline bubbles” where downstream devices idle while waiting. Microbatch pipelining, as in GPipe and PipeDream, recovers much of this lost efficiency (Huang et al. 2019; Narayanan et al. 2019).
Narayanan, Deepak, Aaron Harlap, Amar Phanishayee, Vivek Seshadri, Nikhil R. Devanur, Gregory R. Ganger, Phillip B. Gibbons, and Matei Zaharia. 2019. “PipeDream: Generalized Pipeline Parallelism for DNN Training.” Proceedings of the 27th ACM Symposium on Operating Systems Principles, 1–15. https://doi.org/10.1145/3341301.3359646.
GPT-2’s 40 GB WebText corpus sits at the lower end of this data scale spectrum. Frontier models consume datasets that are two to three orders of magnitude larger, and the physics of data movement shifts qualitatively across that range. At the low end, the entire dataset fits in memory and the \(D_{\text{vol}}/\text{BW}\) term in the iron law is negligible; at the high end, sustained I/O throughput becomes the binding constraint, requiring dedicated prefetch workers, zero-copy transfer paths, and distributed storage backends to keep accelerators from starving between batches.
Systems Perspective 1.1: The 10 GB to 10 TB scale factor
In the memory-resident regime around 10 GB, the entire dataset often fits in system RAM. Data loading is a one-time startup cost, and disk bandwidth \((\text{BW})\) stops mattering after the first few seconds. In the streaming regime around 10 TB, the data becomes a continuous, high-pressure stream that the system can no longer simply load; it must orchestrate its movement. The \(D_{\text{vol}}\) term shifts from a storage bottleneck to a networking and I/O bottleneck, requiring zero-copy paths and multi-worker prefetching just to keep the accelerator from starving.
Scale therefore changes more than the amount of data; it transforms the system’s physics.
These scaling challenges translate into concrete workflow requirements. Training workflows consist of interdependent stages—data preprocessing, forward and backward passes, and parameter updates—extending the neural network concepts from Neural Computation. System constraints often dictate performance limits: accelerators with high compute-to-bandwidth ratios are frequently bottlenecked by memory bandwidth, where data movement between memory hierarchies is slower than the computations themselves (Patterson and Hennessy 2017). In distributed setups, synchronization across devices introduces additional latency, with interconnect performance (NVLink, InfiniBand) critically affecting throughput6.
Patterson, David A., and John L. Hennessy. 2017. Computer Architecture: A Quantitative Approach. 6th ed. Morgan Kaufmann.
6 Transformer Training Interconnect Sensitivity: Self-attention’s \(\mathcal{O}(S^2)\) memory and compute scaling amplifies the interconnect bottleneck mentioned here: each layer’s activation tensors must transfer between devices at every pipeline boundary, and gradient synchronization scales with the full parameter count. GPT-3 training across 1,024 V100 GPUs spent an estimated 30–40 percent of wall-clock time on inter-GPU communication, making the NVLink vs. InfiniBand bandwidth choice a first-order determinant of training cost.
The same hardware-software boundary that frameworks exposed in ML Frameworks is central here. Mixed-precision training emerged from recognizing that Tensor Core hardware could accelerate reduced-precision arithmetic. Gradient checkpointing arose from memory capacity constraints. Training systems engineering is the work of matching those algorithmic choices to the physical limits of the machine.
These scaling challenges share a common thread: every bottleneck traces back to the cost of specific mathematical operations—matrix multiplications that consume trillions of FLOPs, activation functions constrained by memory bandwidth, and optimizer states that triple the memory footprint. Before we can design effective systems to execute these operations at scale, we need to understand exactly what they cost (Goto and Geijn 2008).
Goto, Kazushige, and Robert A. van de Geijn. 2008. “Anatomy of High-Performance Matrix Multiplication.” ACM Transactions on Mathematical Software 34 (3): 1–25. https://doi.org/10.1145/1356052.1356053.
Self-Check: Question
A 1024-GPU training run has its prefetching pipeline well staged: PCIe is saturated overlapping with compute and gradient AllReduce is hidden behind the next forward pass. Profiling reports 38 percent MFU. Under the simplified iron law of training performance, which lever is the most actionable target for the next engineering investment, and why?
- Utilization \(\eta_{\text{hw}}\) — with data movement and communication already overlapped, the gap between 38 percent MFU and a 55–65 percent ceiling is composed of memory stalls, kernel-launch overhead, and synchronization slack that profiling can localize.
- Peak throughput \(R_{\text{peak}}\) — the only way to move 38 percent MFU is to procure newer accelerators with higher advertised TFLOP/s.
- Total operations \(O\) — reducing the FLOPs needed per step is the only term still movable when overlap is already achieved.
- Dataset size — shrinking the dataset is the equivalent of raising \(\eta_{\text{hw}}\) because both reduce wall-clock time per epoch.
A team enables Tensor Cores by switching from FP32 to mixed precision, leaving the model architecture, batch size, and dataset unchanged. Under the iron law of training performance, which term is this optimization most directly targeting?
- Utilization \(\eta_{\text{hw}}\), because mixed precision only removes data stalls.
- Peak throughput \(R_{\text{peak}}\), because reduced-precision execution raises the accelerator’s achievable FLOP/s ceiling.
- Total operations \(O\), because lower precision removes entire layers from the computational graph.
- Dataset size, because mixed precision reduces the number of examples needed for convergence.
Explain why the simplified iron law of training performance can fail to predict speedups for a small-batch debugging session even though it works well for a large-scale pretraining run on the same code.
True or False: Buying an accelerator with 2\(\times\) the advertised TFLOP/s roughly doubles realized training utilization \(\eta_{\text{hw}}\), because \(\eta_{\text{hw}}\) is proportional to the hardware’s peak capability.
Why did utilization \(\eta_{\text{hw}}\) become a more critical engineering concern by the GPT-3 era than in early CPU-era neural network training?
- Because training datasets became smaller, making total operations less important than utilization.
- Because modern training stopped depending on matrix multiplication and became dominated by symbolic reasoning kernels.
- Because peak throughput had become irrelevant once Tensor Cores were introduced.
- Because training routinely ran on thousands of accelerators, so each percentage point of inefficiency translated into millions of dollars and weeks of additional wall-clock time.
Mathematical Foundations
Matrix multiplication is just \(C = AB\) in notation, but training GPT-2 requires executing that operation billions of times with matrices too large to fit in fast memory. The activation function \(f(x) = \max(0, x)\) appears trivial, yet the choice between rectified linear unit (ReLU) and sigmoid determines whether Tensor Cores can accelerate computation. Neural Computation established what neural network operations compute and why they enable learning; the systems question is what they cost in FLOPs, memory, and bandwidth when those operations execute at scale.
Four dimensions structure this cost analysis:
- FLOP counts of the matrix operations that dominate dense neural-network training.
- Memory requirements for storing activations and optimizer states simultaneously.
- Bandwidth demands that determine whether operations are compute bound or memory bound.
- Arithmetic intensity classifications that guide optimization strategy selection.
Together, these dimensions provide the vocabulary for analyzing the computational intensity, memory pressure, and data dependencies introduced in Training Systems Fundamentals.
Neural network computation
Neural network training consists of repeated matrix operations and nonlinear transformations. These operations are conceptually simple but create the system-level challenges that dominate modern training infrastructure. The introduction of backpropagation7 by Rumelhart et al. (1986) and the development of efficient matrix computation libraries such as Basic Linear Algebra Subprograms (BLAS)8 (Dongarra et al. 1988) laid the groundwork for modern training architectures.
7 Backpropagation Provenance: The algorithm was independently derived by Linnainmaa (1970) for automatic differentiation of computer programs and by Werbos (1974) in a Harvard PhD thesis on economic modeling—over a decade before Rumelhart et al. (1986) popularized it for neural networks. This delay between derivation and broad adoption recurs in ML systems history: attention mechanisms predated transformers by decades, but the 2017 Transformer showed that attention-heavy models could train efficiently on contemporary GPU systems; later TPU and GPU clusters enabled much larger deployments. Every modern framework’s backward() call implements Linnainmaa’s reverse-mode AD, not textbook chain rule—the difference is that graph-reverse topological traversal enables parallel gradient computation across independent subgraphs.
Linnainmaa, Seppo. 1970. “The Representation of the Cumulative Rounding Error of an Algorithm as a Taylor Expansion of the Local Rounding Errors.” Master's thesis, University of Helsinki.
Werbos, Paul. 1974. “Beyond Regression: New Tools for Prediction and Analysis in the Behavioral Sciences.” PhD thesis, Harvard University.
Rumelhart, David E., Geoffrey E. Hinton, and Ronald J. Williams. 1986. “Learning Representations by Back-Propagating Errors.” Nature 323 (6088): 533–36. https://doi.org/10.1038/323533a0.
8 BLAS: The original BLAS specification standardized reusable Fortran-callable vector operations (Lawson et al. 1979). Later BLAS extensions added matrix-vector and matrix-matrix routines, giving the familiar Level 1, Level 2, and Level 3 hierarchy (Dongarra et al. 1988). Training is dominated by Level 3 operations precisely because their high arithmetic intensity—\(\mathcal{O}(n)\) FLOP/byte—saturates hardware compute units rather than starving on memory bandwidth. cuBLAS and oneDNN implement these as the kernel layer beneath every framework’s matrix multiplication.
Lawson, Charles L., Richard J. Hanson, David R. Kincaid, and Fred T. Krogh. 1979. “Basic Linear Algebra Subprograms for Fortran Usage.” ACM Transactions on Mathematical Software 5 (3): 308–23. https://doi.org/10.1145/355841.355847.
Dongarra, Jack J., Jeremy Du Croz, Sven Hammarling, and Richard J. Hanson. 1988. “An Extended Set of FORTRAN Basic Linear Algebra Subprograms.” ACM Transactions on Mathematical Software 14 (1): 1–17. https://doi.org/10.1145/42288.42291.
Mathematical operations in neural networks
Forward propagation, in its simplest case, involves two operations: matrix multiplication and activation function application. Matrix multiplication implements the linear transformation at each layer. At layer \(\ell\), the computation can be described as (following the row-vector convention established in Neural Computation): \[ \mathbf{A}^{(\ell)} = f\left(\mathbf{A}^{(\ell-1)}\mathbf{W}^{(\ell)} + \mathbf{b}^{(\ell)}\right) \] where:
- \(\mathbf{A}^{(\ell-1)}\) represents the activations from the previous layer (or the input layer for the first layer), with each row being a sample in the batch,
- \(\mathbf{W}^{(\ell)} \in \mathbb{R}^{n_{\ell-1} \times n_\ell}\) is the weight matrix at layer \(\ell\), which contains the parameters learned by the network,
- \(\mathbf{b}^{(\ell)}\) is the bias vector for layer \(\ell\),
- \(f(\cdot)\) is the activation function applied element-wise (for example, ReLU, sigmoid) to introduce nonlinearity.
Matrix operations
Matrix multiplication formulation established that forward propagation reduces to chains of matrix multiplications, and Core computational primitives catalogued the computational primitives—general matrix multiply (GEMM), convolution, and dynamic attention—that every architecture shares. Training amplifies these patterns: each operation executes not once but billions of times, and each forward pass is paired with a backward pass that roughly doubles the computational cost. Understanding which matrix operations dominate—and how their shapes change between forward and backward passes—reveals why specific system designs and optimizations emerged for training.
Matrix multiplication dominance has driven both algorithmic and hardware innovations. Early neural network implementations relied on standard CPU-based linear algebra libraries, but the scale of modern training demanded specialized optimizations. Strassen’s algorithm9 reduced the naive \(\mathcal{O}(n^3)\) complexity to approximately \(\mathcal{O}(n^{2.807})\) (Strassen 1969), and contemporary hardware-accelerated libraries like cuBLAS (NVIDIA 2024) continue pushing computational efficiency limits.
9 Strassen’s Algorithm: Achieves \(\mathcal{O}(n^{2.807})\) by replacing one of eight sub-multiplications with additions, but training systems rarely benefit. The recursion disrupts the regular memory-access patterns that Tensor Cores exploit, and accumulated rounding errors across billions of training iterations can destabilize convergence. In practice, mainstream GEMM libraries such as cuBLAS leave the dominant training matrix multiplications to highly optimized blocked \(\mathcal{O}(n^3)\) kernels with superior hardware utilization rather than recursive Strassen variants.
Strassen, Volker. 1969. “Gaussian Elimination Is Not Optimal.” Numerische Mathematik 13 (4): 354–56. https://doi.org/10.1007/bf02165411.
NVIDIA. 2024. cuBLAS: CUDA Basic Linear Algebra Subprograms.
This computational dominance has driven system-level optimizations: blocked matrix computations that parallelize across multiple units, and memory hierarchies designed for the access patterns of both forward and backward passes. As neural architectures grew, weight and activation matrices both had to remain accessible for backpropagation, and hardware evolved to serve these dense multiplication patterns within growing memory budgets. To illustrate the scale of these operations concretely, consider the attention layer computations in our GPT-2 Lighthouse Model.
A single GPT-2 layer makes the scale of these computations concrete.
Napkin Math 1.1: GPT-2 attention layer computation
Each GPT-2 layer performs attention computations that exemplify dense matrix multiplication demands. For one GPT-2 transformer layer (all heads combined) with batch size \(B\) = 32, sequence length \(S\) = 1024, and hidden dimension \(d\) = 1600:
Query, Key, Value Projections (the three linear transformations that create attention inputs—3 separate matrix multiplications): \[ \text{FLOPs} = 2 \times 3 \times (B \times S \times d \times d) \] \[ = 2 \times 3 \times (32 \times 1024 \times 1600 \times 1600) \approx 503 \text{ billion FLOPs} \]
Attention matmuls (Q \(\times\) K^T and Attn \(\times\) V): \[\begin{gather*} \text{FLOPs}_{QK} = 2 \times B \times N_{\text{heads}} \times S \times S \times d_{\text{head}} = 107 \text{ billion FLOPs} \\ \text{FLOPs}_{\text{Attn}\times V} = \text{FLOPs}_{QK};\quad \text{pair total} \approx 215 \text{ billion FLOPs} \end{gather*}\]
Output projection (attention output \(\rightarrow\) hidden): \[ \text{FLOPs} = 2 \times B \times S \times d \times d \approx 168 \text{ billion FLOPs} \]
Feed-Forward Network (Two linear transformations with expansion factor 4): \[ \text{FLOPs} \approx 16 \times B \times S \times d^2 \] Computation Scale
- Per-layer forward total (QKV 503 + attention 215 + output proj 168 + FFN): ~2228.01 GFLOP
- With 48 layers in GPT-2: ~320.8 TFLOP per training step
- At 50,000 steps training steps: ~16041.7 PFLOP total training computation
Systems insight: A V100 GPU (125 TFLOP/s peak with Tensor Cores, 15.7 TFLOP/s without) would require 2.6 s for the modeled attention-plus-FFN training-step estimate at 100 percent utilization (theoretical peak; practical throughput would be lower). Reaching a 180 to 220 ms training step is therefore already a multi-accelerator lower-bound problem: ideal arithmetic alone requires roughly 12 to 15 V100s, and practical systems need additional headroom for utilization losses, communication, and pipeline overhead.
These FLOP counts are not academic bookkeeping. They are the compute term of the iron law made concrete, and they explain why training cost scales as a predictable function of model architecture and sequence length rather than as an unpredictable emergent property.
Matrix-vector and batched operations
Not all operations in neural networks involve large matrix-matrix multiplications. Normalization layers, bias additions, and certain recurrent computations involve matrix-vector operations instead. Although computationally simpler than matrix-matrix multiplication, these operations present distinct system challenges: they exhibit lower hardware utilization due to their limited parallelization potential. A single vector provides insufficient work to keep thousands of accelerator cores busy simultaneously. This characteristic influences both hardware design and model architecture decisions, particularly in networks processing sequential inputs or computing layer statistics.
Recognizing the limitations of matrix-vector operations, the introduction of batching transformed matrix computation in neural networks. By processing multiple inputs simultaneously, training systems convert matrix-vector operations into more efficient matrix-matrix operations. This approach improves hardware utilization but increases memory demands for storing intermediate results. Modern implementations must balance batch sizes against available memory, leading to specific optimizations in memory management and computation scheduling.
The progression from matrix-vector to batched matrix-matrix operations explains the hardware design choices in modern accelerators. Hardware accelerators like Google’s TPU (Jouppi et al. 2017) reflect this evolution, incorporating specialized matrix units and memory hierarchies optimized for batched operations. These hardware adaptations enable training of large-scale models like GPT-3 (Brown et al. 2020) through efficient handling of the matrix-matrix multiplication patterns that batching produces.
Brown, Tom B., Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, et al. 2020. “Language Models Are Few-Shot Learners.” Advances in Neural Information Processing Systems 33: 1877–901. https://doi.org/10.48550/arxiv.2005.14165.
Systems Perspective 1.2: Why GPUs dominate training
The matrix operations described earlier directly explain data-center training hardware architecture. GPUs became central to large-scale training for three reasons:
- Matrix multiplication’s independent element calculations map well to thousands of GPU cores (NVIDIA A100 has 6,912 CUDA cores).
- Specialized hardware units like Tensor Cores accelerate matrix operations by 10–20\(\times\) through dedicated hardware for dense matrix workloads.
- Blocked matrix computation patterns enable efficient use of GPU memory hierarchy (L1/L2 cache, shared memory, global memory).
When GPT-2 examples later show why V100 GPUs achieve 2.4\(\times\) speedup with mixed precision, this acceleration comes from Tensor Cores executing the matrix multiplications we just analyzed. Matrix operation characteristics are prerequisite for appreciating why pipeline optimizations like mixed-precision training provide such substantial benefits.
Matrix multiplications dominate training compute, but neural networks require more than linear transformations. Between each layer’s matrix operations, activation functions introduce the nonlinearity that enables networks to learn complex patterns. These functions appear computationally trivial compared to matrix multiplication, yet their implementation characteristics affect training efficiency in ways that matter at scale.
Activation functions
Activation functions like sigmoid, tanh, ReLU, and softmax introduce nonlinearity, but their implementation characteristics also shape training system performance. From a systems perspective, the choice of activation function determines computational cost, hardware utilization, and memory access patterns during backpropagation.
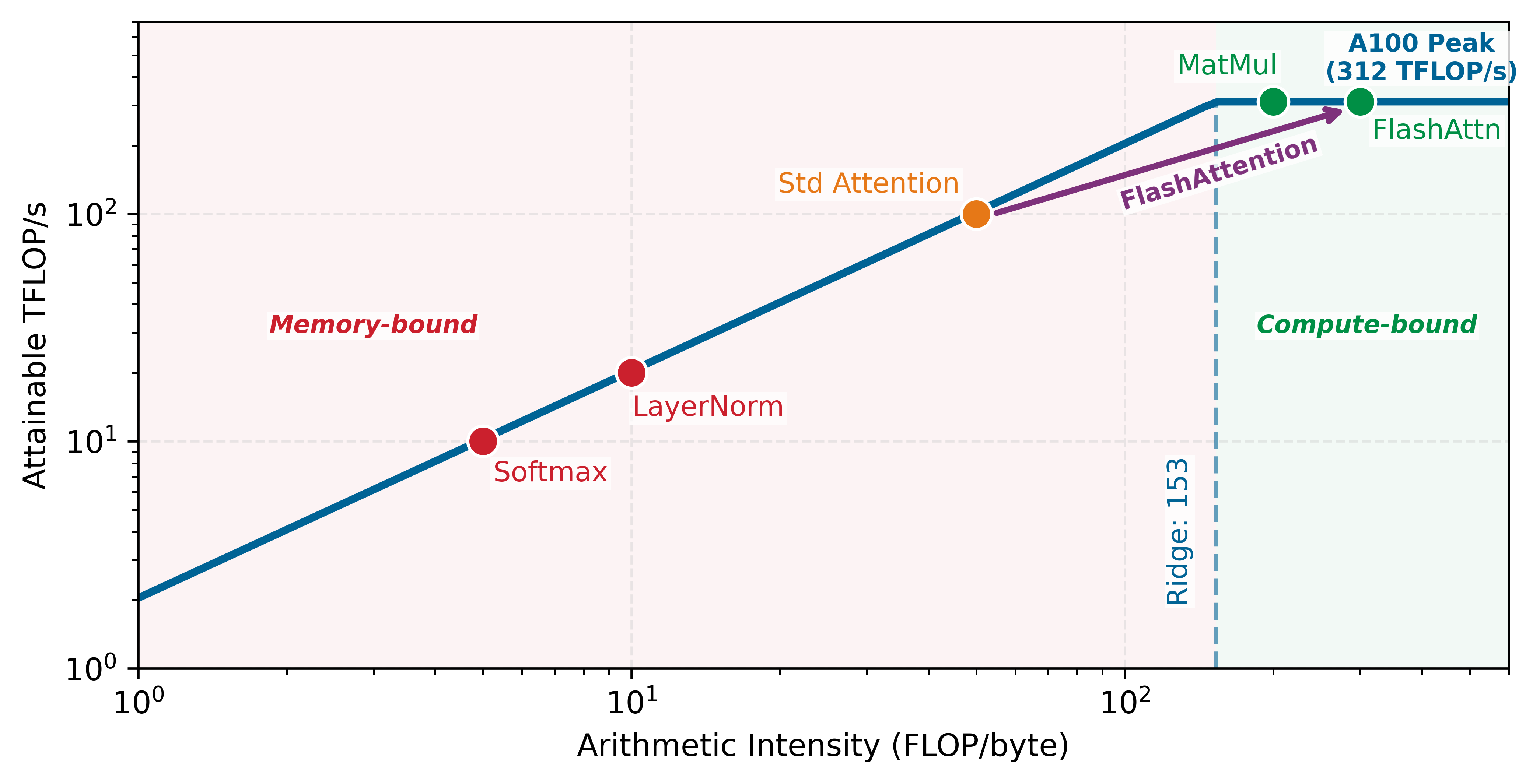
The critical question for ML systems engineers is not what these functions do mathematically, but how their cost behaves at scale. The benchmarks and trade-offs that follow build toward one systems thesis: because element-wise activations move many more bytes than they compute, the choice of activation is ultimately bounded by memory bandwidth rather than by arithmetic, so the per-operation differences below matter less than their magnitudes first suggest.
Because activation functions execute millions of times per training step, even small per-operation differences compound into significant training time impact. The selection of an activation function directly influences training throughput and hardware efficiency. Applied to the same fixed-size input tensor, figure 1 quantifies scalar CPU differences on Apple M2 hardware, revealing that Tanh executes in 0.61 s compared to Sigmoid’s 1.10 s, a 1.8× speedup. On accelerators, the same lesson must be translated through the roofline: activation kernels are often limited by memory traffic, fusion boundaries, and special-function throughput rather than by scalar instruction latency alone.

In production environments, modern hardware accelerators alter these relative characteristics, but the underlying cost hierarchy remains. Functions requiring transcendental operations are significantly more expensive than simple thresholding: in software, Gaussian Error Linear Unit (GELU) exp() evaluation takes 10–20 clock cycles compared to 1 cycle for basic arithmetic. Modern GPUs and TPUs mitigate this through lookup tables or piece-wise linear approximations, but even optimized hardware-based sigmoid/tanh remains 3–4× slower than ReLU. ReLU’s \(\max(0,x)\) requires only a single comparison and conditional set—a simple multiplexer checking the sign bit—enabling it to run at 95 percent+ of peak FLOP/s, while sigmoid achieves only 30 percent–40 percent hardware utilization. Beyond raw throughput, ReLU’s characteristic of producing roughly 50 percent zeros enables system-level sparsity optimizations—sparse matrix operations and gradient compression—that reduce memory bandwidth requirements, the primary bottleneck in large-scale training. In contrast, global normalization functions like Softmax10 require access to the entire input vector simultaneously to compute the denominator, preventing the independent element-wise parallelization possible with Sigmoid or ReLU.
10 Softmax: A “soft” (differentiable) approximation to the argmax function—returning a probability distribution rather than a hard one-hot vector. The systems cost is its global normalization: computing the denominator \(\sum e^{x_i}\) requires reading the entire input vector, preventing the element-wise parallelization that makes ReLU fast. This memory-access pattern is precisely what FlashAttention restructures via tiling.
Table 3 synthesizes these system-level trade-offs, showing how mathematical behavior translates into operational constraints.
| Function | Key Advantages | Key Disadvantages | System Implications |
|---|---|---|---|
| Sigmoid | Smooth gradients; bounded output in \((0, 1)\). | Vanishing gradients; nonzero-centered output. | Exponential computation adds overhead; LUT-based hardware implementation is required for efficiency. |
| Tanh | Zero-centered output in \((-1, 1)\). | Vanishing gradients at extremes. | Better convergence than sigmoid; similar computational cost due to exponential terms. |
| ReLU | Extremely efficient computation; avoids vanishing gradients for positive inputs. | Can suffer from “dying ReLU” (inactive neurons). | Single-instruction hardware implementation; enables sparsity-based optimizations. |
| Softmax | Outputs probability distribution over classes. | High computational cost; nonlocal dependencies. | Requires global normalization; memory-intensive due to dependencies across the entire input vector. |
In practice, ReLU is the default choice for large-scale networks due to its efficiency and scalability. Softmax remains indispensable for classification tasks requiring probabilistic outputs, despite its computational cost. Our GPT-2 Lighthouse Model illustrates these trade-offs through its use of GELU, the Gaussian Error Linear Unit.
Systems Perspective 1.3: The GELU activation choice
Beyond the foundational activation functions covered in Neural Computation (Sigmoid, Tanh, ReLU), modern architectures increasingly adopt smoother alternatives. GPT-2 uses a GELU activation (Radford et al. 2019), the Gaussian Error Linear Unit introduced by Hendrycks and Gimpel (2016) and often implemented with the common tanh-based approximation from that formulation. Its exact definition is: \[
\text{GELU}(x) = x \cdot \Phi(x) = x \cdot \frac{1}{2}\left[1 + \text{erf}\left(\frac{x}{\sqrt{2}}\right)\right]
\] where \(\Phi(x)\) is the cumulative distribution function of the standard normal distribution.
GELU earns its place in language modeling for reasons that are statistical rather than systems-driven. Its smoother response yields better-behaved gradients than ReLU and reduces the dying-neuron problem, its probabilistic gating acts like a built-in stochastic regularizer that drops inputs in proportion to their magnitude, and it consistently lowers perplexity on language tasks. The smoothness that helps optimization, however, is exactly what makes it more expensive to evaluate.
The system cost is real but bounded. Evaluating the erf function makes GELU roughly 2–4× more expensive than ReLU in raw arithmetic, while memory traffic is identical because both remain element-wise operations. Spread across GPT-2’s 48 layers, that arithmetic premium adds only about 10 percent to 20 percent to total forward-pass time, a price the lower perplexity comfortably offsets. Frameworks shrink it further with the fast tanh approximation (listing 1), which cuts the cost to approximately 1.5× ReLU while preserving GELU’s behavior. The activation choice is decided by model quality, not by compute budget, because the budget barely moves.
Hendrycks, Dan, and Kevin Gimpel. 2016. “Gaussian Error Linear Units (GELUs).” arXiv Preprint arXiv:1606.08415.
# Fast GELU approximation used in production systems
# Avoids expensive erf() computation while
# preserving activation properties
gelu_approx = (
0.5 * x * (1 + tanh(sqrt(2 / pi) * (x + 0.044715 * x**3)))
)The GELU approximation highlights a broader pattern: compute cost is not always the dominant concern. For activation functions, the real bottleneck is often memory bandwidth rather than arithmetic operations. This distinction between compute-bound and memory-bound operations directly affects optimization priorities and recurs throughout our analysis of training bottlenecks.
The distinction is quantifiable. A matrix multiplication in GPT-2’s attention layers performs hundreds of FLOPs per byte loaded, saturating the accelerator’s arithmetic units. An element-wise activation like ReLU or GELU performs one to three FLOPs per byte, finishing its arithmetic before the next cache line arrives from HBM. The arithmetic intensity gap between these two operation classes spans two orders of magnitude, which means that optimizing activation compute (for example, replacing GELU with a cheaper function) yields almost no wall-clock improvement because memory transfer time, not arithmetic time, determines how long the operation takes.
Systems Perspective 1.4: Memory bandwidth bottlenecks
Activation functions reveal a critical systems principle: not all operations are compute bound. While matrix multiplications saturate accelerator compute units, activation functions often become memory bandwidth bound for three reasons:
- Element-wise operations perform few calculations per memory access; ReLU performs one operation per load.
- Simple operations complete faster than memory transfer time, limiting parallelism benefits.
- Modern GPUs have 10–100\(\times\) more compute throughput than memory bandwidth.
This is why activation function choice matters less than expected. ReLU vs. sigmoid shows only 2–3\(\times\) difference despite vastly different computational complexity, because both are bottlenecked by memory access. The forward pass must carefully manage activation storage to prevent memory bandwidth from limiting overall training throughput.
Forward pass operations and their computational characteristics establish the workload that training systems must compute: matrix multiplications dominating FLOPs, activation functions constrained by memory bandwidth. A neural network that only computes predictions, however, learns nothing. Training requires updating model parameters so future predictions improve. The forward pass produces a loss value quantifying how wrong the current predictions are; the question now shifts from how much does computation cost to how do we use the result to improve.
Optimization algorithms
Optimization algorithms determine, given a loss value and the gradient information it produces, how each parameter should change to reduce future errors. These algorithms govern the learning trajectory, translating gradients into parameter updates that steer the model toward better performance, and their selection has direct system-level implications for computation efficiency, memory requirements, and scalability. The focus here is on the algorithms themselves during training: how they use gradients, how much state they retain, and how their update rules interact with the hardware budget.
Gradient-based optimization methods
In Parameter update algorithms, we introduced gradient descent as the fundamental optimization algorithm: iteratively adjusting parameters in the direction of steepest descent. That conceptual foundation assumed modest networks on single devices. Here, we examine how gradient descent and its variants interact with real hardware constraints. The same mathematical operation that elegantly adjusts weights becomes a significant systems challenge when models contain billions of parameters and training data spans terabytes.
Gradient descent
Gradient descent is the mathematical foundation of neural network training, iteratively adjusting parameters to minimize a loss function. In training systems, this mathematical operation translates into specific computational patterns. For each iteration, the system must execute four dependent operations:
- Compute forward pass activations
- Calculate loss value
- Compute gradients through backpropagation
- Update parameters using the gradient values
The computational demands of gradient descent scale with both model size and dataset size. Computing gradients requires storing intermediate activations during the forward pass for backpropagation. These activations consume memory proportional to the depth of the network and the number of examples being processed.
Traditional gradient descent processes the entire dataset before each parameter update. For a training set with one million examples, the system must compute an aggregate gradient over all examples before taking one step. Let \(B_{\text{micro}}\) denote the examples resident for one forward/backward pass; gradient accumulation composes multiple micro-batches into one larger effective batch. The peak-memory relation in equation 2 and the step-time relation in equation 3 capture the implementation distinction: \[ \text{Peak Activation Memory} \propto B_{\text{micro}} \times \text{Activation Memory per Example} \tag{2}\] \[ T_{\text{step}} \propto D \times T_{\text{forward+backward per example}} \tag{3}\]
This memory breakdown is formalized in the Algorithm Foundations appendix, which derives the full training memory equation including optimizer state overhead. Full-batch training does not require storing every example’s activations simultaneously if the dataset is streamed or microbatched; peak memory is governed by the examples held in memory at once. The systems problem is still severe: processing \(D=1{,}000{,}000\) examples before each update creates million-example iteration times, reducing the rate at which the model can learn from the data.
These system constraints led to the development of variants that better align with hardware capabilities. The key insight was that exact gradient computation, while mathematically appealing, is not necessary for effective learning. SGD11 represents a pivotal shift in optimization strategy, estimating gradients using individual training examples rather than the entire dataset. This approach drastically reduces memory requirements since only one example’s activations and gradients need storage at any time.
11 Stochastic Gradient Descent: “Stochastic” from Greek stochastikos (“able to guess”)—rather than computing exact gradients over all data, SGD estimates them from random samples. The systems payoff is enormous: memory drops from \(\mathcal{O}(D)\) (full dataset) to \(\mathcal{O}(B)\) (one mini-batch), and common mini-batch sizes of 32–512 strike the balance between gradient noise and hardware utilization that keeps accelerators in their compute-bound regime.
However, processing single examples creates new system challenges. Modern accelerators achieve peak performance through parallel computation, processing multiple data elements simultaneously. Single-example updates leave most computing resources idle, resulting in poor hardware utilization. The frequent parameter updates also increase memory bandwidth requirements, as weights must be read and written for each example rather than amortizing these operations across multiple examples.
Mini-batch processing
Mini-batch gradient descent emerges as a practical compromise between full-batch and stochastic methods, an algorithm-machine co-design that computes gradients over small batches of examples aligned with modern accelerator architectures (Dean et al. 2012). GPUs contain thousands of cores designed for parallel computation, and mini-batch processing allows these cores to simultaneously compute gradients for multiple examples. The batch size \(B\) becomes a key system parameter, influencing both computational efficiency and memory requirements.
Dean, Jeffrey, Greg Corrado, Rajat Monga, Kai Chen 0010, Matthieu Devin, Quoc V. Le, Mark Z. Mao, et al. 2012. “Large Scale Distributed Deep Networks.” In Advances in Neural Information Processing Systems (NeurIPS), edited by Peter L. Bartlett, Fernando C. N. Pereira, Christopher J. C. Burges, Léon Bottou, and Kilian Q. Weinberger, vol. 25. Curran Associates.
Definition 1.3: Batch processing
Batch Processing is the aggregation of multiple training examples into a single tensor operation to amortize fixed per-step overhead (kernel launch, optimizer update) across \(B\) examples, shifting the workload from memory bandwidth bound to compute bound as \(B\) increases.
- Significance: Throughput increases with batch size up to the critical batch size, beyond which additional examples provide diminishing gradient quality without proportional convergence benefit. For ResNet-50 on ImageNet, empirical studies find the critical batch size near \(B \approx 8{,}192\): at this batch size, throughput approaches \(R_{\text{peak}}\) while validation accuracy is preserved; larger batches require learning rate scaling (linear rule: \(\eta \propto B\)) to compensate for reduced update frequency.
- Distinction: Unlike stochastic gradient descent (\(B=1\)), which updates parameters after every example with maximum noise, mini-batch processing averages gradients over \(B\) examples, reducing the gradient noise (standard deviation of the mean gradient) by \(1/\sqrt{B}\)—lowering the data-movement volume \(D_{\text{vol}}\) per effective update while giving the hardware enough parallel work to reach compute-bound utilization.
- Common pitfall: A frequent misconception is that linear learning rate scaling (multiplying \(\eta\) by \(B/B_0\)) works at any batch size. The linear rule holds only up to the critical batch size; beyond it, the noise reduction from larger batches no longer compensates for the reduced number of updates per epoch, and validation accuracy degrades even with perfectly scaled learning rates.
The relationship between batch size and system performance follows clear patterns that reveal hardware-software trade-offs. Memory requirements scale linearly with batch size, but the specific costs vary dramatically by model architecture, as equation 4 shows: \[ \text{Memory Required} = \text{Parameter Memory} + \text{Gradient Memory} + B \times \text{Activation Memory} \tag{4}\]
Because the activation term scales with \(B\) while parameter and gradient memory stay fixed, doubling the batch doubles the activation working set, and a model that fits comfortably at a small batch can exhaust the 40–80 GB of HBM (High Bandwidth Memory) on a high-end training accelerator once the batch grows. Section 1.3.3.2 works this budget through layer by layer for
Larger batches enable more efficient computation through improved parallelism and better memory access patterns. Accelerator utilization efficiency demonstrates this trade-off: larger batches generally expose more parallel work to the accelerator, while very small batches can leave compute units underfilled. Linear scaling rules for large-batch training (scale learning rate proportionally to batch size increase) help maintain convergence speed (Goyal et al. 2017).
This establishes a central theme in training systems: the hardware-software trade-off between memory constraints and computational efficiency. Training systems must select batch sizes that maximize hardware utilization while fitting within available memory. The optimal choice often requires gradient accumulation when memory constraints prevent using efficiently large batches, trading micro-batch serialization and some overhead for the same effective batch size.
Adaptive and momentum-based optimizers
SGD computes correct gradients but struggles with ill-conditioned loss landscapes12 where some dimensions are steep (requiring small steps) while others are shallow (benefiting from large steps). A single learning rate13 either oscillates dangerously in steep dimensions or moves glacially in shallow ones. Each subsequent optimizer we examine solves a specific limitation of its predecessors: momentum smooths oscillations by averaging gradient history, RMSprop adapts step sizes per parameter, and Adam combines both strategies. Understanding this progression clarifies why Adam became the default choice for transformer training while revealing the system costs, specifically memory and computation, that each refinement introduces (Kingma and Ba 2014).
12 Loss Landscape Geometry: The “local minima” framing of neural network optimization is misleading at scale. For overparameterized networks (parameters >> training samples), the dominant challenge is saddle points—critical points where the gradient is zero but the Hessian has both positive and negative eigenvalues. In high-dimensional spaces, almost all local minima have approximately equivalent loss values, so avoiding bad minima is less important than maintaining gradient signal through saddle regions. This is why batch size, learning rate schedule, and normalization choices matter more than optimizer type for training stability: they govern how aggressively the optimizer escapes saddle points, not how carefully it descends to a minimum.
13 Learning Rate (\(\eta\)): The single most consequential hyperparameter—it controls step size along the gradient direction. Too large and the optimizer overshoots minima; too small and training stalls for days. Modern practice replaces fixed rates with schedules (warmup + cosine decay), and the linear scaling rule requires \(\eta\) to increase proportionally with batch size. Learning rate also interacts with numerical precision: FP16’s limited mantissa constrains the range of effective rates, creating a hidden coupling between hardware choice and convergence.
Kingma, Diederik P., and Jimmy Ba. 2014. “Adam: A Method for Stochastic Optimization.” ICLR in press.
Momentum-based methods
Momentum methods14 address SGD’s oscillation problem by accumulating a velocity vector across iterations, smoothing out noisy gradient directions. From a systems perspective, this smoothing comes at a cost: the training system must maintain a velocity vector with the same dimensionality as the parameter vector, effectively doubling the memory needed for optimization state.
14 Momentum: Borrowed from physics, where momentum (mass \(\times\) velocity) describes an object’s tendency to continue moving. The metaphor explains the design: accumulated velocity smooths noisy gradients, reducing the iteration count needed for convergence. The systems cost is an additional velocity vector per parameter (2\(\times\) optimizer state vs. SGD), the first step on the memory escalation that culminates in Adam’s 3\(\times\) overhead.
Adaptive learning rate methods
While momentum smooths gradient direction, it does not address the different scales of gradients across parameters. RMSprop15 solves this by maintaining a moving average of squared gradients for each parameter, automatically reducing step sizes for parameters with historically large gradients. This per-parameter adaptation requires storing the moving average \(s_t\), creating memory overhead similar to momentum methods. The element-wise operations in RMSprop also introduce additional computational steps compared to basic gradient descent.
15 RMSprop: Proposed by Geoffrey Hinton in Lecture 6e of his 2012 Coursera course—never published in a peer-reviewed paper, making it perhaps the most influential optimizer disseminated via a slide deck. RMSprop divides the learning rate by a running average of recent gradient magnitudes, adapting step sizes per parameter. This per-parameter adaptation is what Adam inherits as its second moment \(v_t\), directly contributing to Adam’s 3\(\times\) memory overhead described later.
Adam optimization
Adam16 combines the benefits of both momentum and RMSprop: momentum’s gradient smoothing addresses noisy updates, while RMSprop’s adaptive scaling handles parameter-specific step sizes. This combination maintains two moving averages for each parameter: \[\begin{gather*} m_t = \beta_1 m_{t-1} + (1-\beta_1)\nabla \mathcal{L}(\theta_t) \\ v_t = \beta_2 v_{t-1} + (1-\beta_2)\big(\nabla \mathcal{L}(\theta_t)\big)^2 \\ \hat{m}_t = \frac{m_t}{1-\beta_1^t}, \qquad \hat{v}_t = \frac{v_t}{1-\beta_2^t} \\ \theta_{t+1} = \theta_t - \eta \frac{\hat{m}_t}{\sqrt{\hat{v}_t} + \epsilon} \end{gather*}\]
16 Adam (Adaptive Moment Estimation): The two moving averages are the first moment (momentum) and second moment (uncentered variance) of the gradients, stored for every model parameter. For a 7B model, Adam’s FP32 moment tensors alone consume 56 GB; the full mixed-precision training state before activations is 84 GB once FP16 weights, FP16 gradients, and Adam moments are counted together.
The system implications of Adam are more substantial than previous methods. The optimizer must store two additional vectors (\(m_t\) and \(v_t\)) for each parameter, tripling the parameter-plus-optimizer-state footprint; for a 100M-parameter model, those auxiliary vectors alone add 800 MB beyond weight storage.
Optimization algorithm system implications
The choice of optimization algorithm creates specific patterns of computation and memory access that influence training efficiency. Optimizer auxiliary memory increases progressively from SGD (no auxiliary state) through Momentum (one velocity vector) to Adam (two moment vectors), as quantified in table 4. These memory costs must be balanced against convergence17 benefits. While Adam often requires fewer iterations to reach convergence, its per-iteration memory and computation overhead may impact training speed on memory-constrained systems. At GPT-2 scale, this overhead becomes a first-order memory constraint.
17 Convergence: Training converges when the loss stops decreasing meaningfully, typically after 50,000–500,000 iterations for large models. The systems consequence: faster convergence (fewer iterations) directly reduces wall-clock time and cost, but the optimizer that converges fastest (Adam) requires two FP32 auxiliary tensors beyond the parameters and gradients—a trade-off between time and memory that shapes every training budget.
18 AdamW (Adam with Decoupled Weight Decay): Decoupling weight decay from the gradient update corrects a flaw where standard Adam’s adaptive learning rates weaken regularization for parameters with large historical gradients (parameters with large second-moment estimates \(v_t\)). This directly improves generalization without adding to the 3\(\times\) per-parameter memory overhead, resolving the exact design tension between convergence speed and accelerator capacity mentioned in the text. The fix requires zero additional accelerator state, making it a memory-neutral upgrade and the default for training large transformer models.
Loshchilov, Ilya, and Frank Hutter. 2019. “Decoupled Weight Decay Regularization.” Proceedings of the International Conference on Learning Representations (ICLR).
The costs quantified in table 4 create a design tension: Adam’s 3\(\times\) memory overhead buys faster convergence, but that overhead determines maximum feasible model size and batch size on a given accelerator. Variants like AdamW18 (Loshchilov and Hutter 2019) decouple weight decay from the gradient update, improving generalization without increasing memory cost.
| Property | SGD | Momentum | RMSprop | Adam |
|---|---|---|---|---|
| Memory Overhead | None | Velocity terms | Squared gradients | Both velocity and squared gradients |
| Parameter + optimizer state | 1\(\times\) | 2\(\times\) | 2\(\times\) | 3\(\times\) |
| Access Pattern | Sequential | Sequential | Random | Random |
| Operations/Parameter | 2 | 3 | 4 | 5 |
| Hardware Efficiency | Low | Medium | High | Highest |
| Convergence Speed | Slowest | Medium | Fast | Fastest |
Napkin Math 1.2: GPT-2 optimizer memory requirements
A representative GPT-2 XL training configuration uses the Adam optimizer with five hyperparameters:
- β₁ = 0.9 (momentum decay)
- β₂ = 0.999 (second moment decay)
- Learning rate: Warmed up from 0 to 2.5e-4 over first 500 steps, then cosine decay
- Weight decay: 0.01
- Gradient clipping: Global norm clipping at 1.0
Memory Overhead Calculation
For GPT-2’s 1.5B parameters in FP32 (4 bytes each), the memory breaks down across four components:
- Parameters: 1.5B \(\times\) 4 bytes = 6 GB
- Gradients: 1.5B \(\times\) 4 bytes = 6 GB
- Adam State (m, v): 1.5B \(\times\) 8 bytes = 12 GB
- Total static memory: 24 GB
This explains why GPT-2’s 24 GB static training state alone approaches the 32 GB capacity of a V100 before activation storage is counted.
System Decisions Driven by Optimizer
- Mixed precision training (FP16) reduces operation precision but requires keeping FP32 master weights, maintaining the static memory footprint at ~24 GB.
- Gradient accumulation (splitting effective batches into smaller micro-batches) allows effective batch size \(B=512\) despite memory limits.
Adam’s memory overhead is a necessary trade-off for convergence. In this illustrative configuration, GPT-2 XL converges in ~50K steps vs. ~150K+ steps with SGD+Momentum, saving weeks of training time despite higher per-step cost.
Framework optimizer interface and scheduling
After optimizer memory is quantified, the framework interface matters because it fixes when that state is read, written, cleared, and preserved across steps. A training loop separates gradient computation from parameter updates so that the system can accumulate gradients, synchronize them, or defer updates without changing the optimizer equations. Listing 2 demonstrates where Adam optimization enters that cycle.
The optimizer.zero_grad() call marks the boundary between one update and the next. Gradients accumulate across calls to backward(), so clearing them explicitly prevents stale gradients from contaminating the next batch. The same accumulation behavior later becomes useful for large effective batch sizes, but only when the training loop manages the boundary deliberately.
import torch
import torch.nn as nn
import torch.optim as optim
# Initialize Adam optimizer with model parameters and learning rate
optimizer = optim.Adam(
model.parameters(), lr=0.001, betas=(0.9, 0.999)
)
loss_function = nn.CrossEntropyLoss()
# Standard training loop implementing the four-step optimization cycle
for epoch in range(num_epochs):
for batch_idx, (data, targets) in enumerate(dataloader):
# Step 1: Clear accumulated gradients from previous iteration
optimizer.zero_grad()
# Step 2: Forward pass - compute model predictions
predictions = model(data)
loss = loss_function(predictions, targets)
# Step 3: Backward pass - compute gradients via autodiff
loss.backward()
# Step 4: Parameter update - apply Adam optimization equations
optimizer.step()The optimizer.step() method is the other boundary: it consumes the current gradients and mutates persistent optimizer state. For Adam optimization, this call implements momentum estimation, squared gradient tracking, bias correction, and the parameter update. Algorithm 1 makes the hidden state explicit so the memory cost remains visible rather than disappearing behind an API call.

Adam state is the largest piece: 2\(\times\) the weights, half of training memory.
\begin{algorithm} \caption{Adam parameter update (one optimizer step)} \begin{algorithmic} \Require gradient $g_t = \nabla\mathcal{L}(\theta_t)$; step $t$; rate $\eta$; decays $\beta_1,\beta_2$; constant $\epsilon$ \Ensure updated parameter $\theta_{t+1}$; moment buffers $m_t, v_t$ carried to the next step \State $m_t \gets \beta_1 m_{t-1} + (1-\beta_1)\, g_t$ \Comment{first moment (momentum)} \State $v_t \gets \beta_2 v_{t-1} + (1-\beta_2)\, g_t^2$ \Comment{second moment (variance)} \State $\hat{m}_t \gets m_t / (1-\beta_1^{t})$; $\hat{v}_t \gets v_t / (1-\beta_2^{t})$ \Comment{bias correction} \State $\theta_{t+1} \gets \theta_t - \eta\, \hat{m}_t / (\sqrt{\hat{v}_t} + \epsilon)$ \Comment{parameter update} \end{algorithmic} \end{algorithm}
Steps 1 and 2 keep two persistent moment buffers per parameter, so parameters plus optimizer state reach roughly 3\(\times\) the parameter memory before gradients, activations, and FP32 master weights are counted. Framework implementations manage the allocator and access patterns for these optimizer states, but they do not remove the cost. Each Adam step reads the gradient, parameter, first moment, and second moment, then writes back the updated moments and parameter. The abstraction reduces implementation burden; the systems budget still pays for two extra tensors that must occupy memory and move through the hierarchy every step.
Learning rate scheduling integration
The framework’s learning rate scheduling hook changes the optimizer’s trajectory without adding per-parameter state. It adjusts the learning rate \(\eta\) during training, letting the system shape convergence behavior while leaving the underlying optimizer equations intact.
Schedules such as cosine annealing, exponential decay, or step-wise reductions implement that trajectory by changing the step size over time. Because the schedule is a state-free hook on \(\eta\), the framework reads the current step or epoch and overwrites the learning rate after each optimizer step, leaving the optimizer’s own update equations untouched; ML Frameworks covers the scheduler interface that wires this in. This separation lets the systems engineer combine base optimization algorithms (SGD, Adam) with scheduling strategies (cosine annealing, linear warmup) without reimplementing the update rule.
The preceding optimization algorithms specify how to update parameters given gradients, but they take those gradients as given. SGD, momentum, and Adam all assume gradient vectors arrive ready-made. In practice, computing gradients for a network with billions of parameters is itself a major computational and memory challenge. The cost of gradient computation, not the cost of the optimizer step, is what makes training so much more expensive than inference.
Backpropagation mechanics
Backpropagation solves the gradient computation problem by tracing error signals backward through the network, systematically attributing responsibility to each parameter for the final prediction error. Its memory and computational requirements reveal why training systems face such substantial resource constraints.
The backpropagation algorithm computes gradients by systematically moving backward through a neural network’s computational graph. In Gradient computation and backpropagation, we established the mathematical foundation: the chain rule breaks gradient computation into layer-by-layer operations, with each layer receiving adjustment signals proportional to its contribution to the final error. If terms like “computational graph” or “gradient flow” feel unfamiliar, the factory assembly line analogy in that section is worth revisiting.
Here, we shift focus from what backpropagation computes to what it costs to compute it at scale. The layer computations from section 1.2.1.1 produce activations that must be retained for the backward pass. Computing \(\frac{\partial \mathcal{L}}{\partial \mathbf{W}^{(\ell)}}\) requires access to these stored activations, creating the training memory equation that gradient checkpointing later exploits.
A simple three-layer network processing MNIST requires kilobytes of activation storage. GPT-2 processing a single batch requires over 71.7 GB, more than most accelerators can hold. That gap defines the engineering challenge this chapter addresses. The true cost of training memory derives how backpropagation drives these memory costs, including the full training memory equation (\(M_{\text{total}} = M_{\text{weights}} + M_{\text{gradients}} + M_{\text{optimizer}} + M_{\text{activations}}\)). Modern training systems use autodifferentiation (see ML Frameworks) to handle gradient computations automatically, but the underlying memory and computation patterns remain the systems engineer’s responsibility to manage.

Activation memory spans MNIST toys to GPT-scale training.
Activation memory requirements
Training systems must maintain intermediate values (activations) from the forward pass to compute gradients during the backward pass. This requirement compounds the memory demands of optimization algorithms. For each layer \(\ell\), the system must store four values:
- Input activations from the forward pass
- Output activations after applying layer operations
- Layer parameters being optimized
- Computed gradients for parameter updates
Consider a batch of training examples passing through a network. The forward pass computes and stores: \[\begin{gather*} \mathbf{Z}^{(\ell)} = \mathbf{A}^{(\ell-1)}\mathbf{W}^{(\ell)} + \mathbf{b}^{(\ell)} \\ \mathbf{A}^{(\ell)} = f(\mathbf{Z}^{(\ell)}) \end{gather*}\]
Both \(\mathbf{Z}^{(\ell)}\) and \(\mathbf{A}^{(\ell)}\) must be cached for the backward pass. This creates a multiplicative effect on memory usage: each layer’s memory requirement is multiplied by the batch size, and the optimizer’s memory overhead (discussed in the previous section) applies to each parameter. Quantifying these costs for our GPT-2 Lighthouse Model reveals the scale of the activation memory challenge. For GPT-2, the calculation decomposes that pressure into per-layer attention, feed-forward, and training-state costs.
Napkin Math 1.3: GPT-2 activation memory breakdown
For GPT-2 with batch size \(B\) = 8, sequence length \(S\) = 1024, hidden dimension \(d\) = 1600, and 48 layers:
Per-Layer Activation Memory.
- Attention activations: \(B \times S \times d \times 4\) (Q, K, V, output) = 8 \(\times\) 1024 \(\times\) 1600 \(\times\) \(4 \times 2\) bytes (FP16) = 104.9 MB
- FFN activations: \(B \times S \times (4d)\) (intermediate expansion) = 8 \(\times\) 1024 \(\times\) 6400 \(\times\) 2 bytes = 104.9 MB
- Attention scores: \(5 \times N_{\text{heads}} \times S^2 \times B\) bytes for the \(S{\times}S\) score, softmax, and dropout buffers. With 25 heads, this term reaches 1048.6 MB per layer—the dominant term, quadratic in sequence length, and exactly what selective recomputation discards
- Layer norm states: Minimal (~10 MB per layer)
- Total per layer: ~1268.3 MB (attention + FFN + attention scores + layer norm states)
Full Model Activation Memory.
- Total activation memory (library estimate, includes residual-stream and framework buffers beyond the line items above): 71.7 GB
- Parameters (FP16): 3 GB
- Gradients: 3 GB
- Optimizer state (Adam, FP32): 12 GB
- Peak memory during training: ~89.7 GB
This exceeds a single V100’s 32 GB capacity.
System Solutions Applied.
- Gradient checkpointing: Recompute activations during backward pass, reducing activation memory by 75 percent (to ~17.9 GB) at cost of 33 more compute
- Activation CPU offloading: Store some activations in CPU RAM, transfer during backward pass
- Mixed precision: FP16 activations (already applied) vs. FP32 (would be 143.4 GB)
- Reduced batch size: Use batch size \(B=16\) per accelerator + gradient accumulation over two steps = effective batch size \(B=32\)
Most GPT-2 implementations use a training configuration of gradient checkpointing and batch size \(B=16\) per accelerator, fitting comfortably in 32 GB V100s while maintaining training efficiency.
This breakdown illustrates the practical engineering decisions required when accelerator memory falls short. The same trade-off between stored activations, recomputation, and batch size drives the memory-computation analysis that follows.
Checkpoint 1.2: The memory-compute trade-off
Training large models requires managing the memory wall (the bandwidth bottleneck introduced in Neural Computation and revisited in Why execution strategy matters: The memory wall).
The Bottleneck
Scaling Limits
Memory-computation trade-offs
Training systems must balance memory usage against computational efficiency. Each forward pass through the network generates a set of activations that must be stored for the backward pass. For a neural network with \(N_L\) layers, let \(s_\ell\) represent the size of intermediate computations (like \(\mathbf{Z}^{(\ell)}\)) and \(a_\ell\) represent the activation outputs at layer \(\ell\). Processing a batch of \(B\) examples requires storing the memory specified by equation 5:
\[ \text{Memory per batch} = B \times \sum_{\ell=1}^{N_L} (s_\ell + a_\ell) \tag{5}\]
This memory requirement compounds with the weights, gradients, and optimizer memory discussed in the previous section. Equation 6 gives the full training memory footprint: \[ \text{Total Memory} = \text{Memory}_{\text{weights}} + \text{Memory}_{\text{gradients}} + \text{Memory}_{\text{optimizer}} + \text{Memory per batch} \tag{6}\]
To manage these substantial memory requirements, training systems use several sophisticated strategies. Gradient checkpointing is a basic approach, strategically recomputing some intermediate values during the backward pass rather than storing them. While this increases computational work, it can significantly reduce memory usage, enabling training of deeper networks or larger batch sizes on memory-constrained hardware (Chen et al. 2016). Algorithm 2 makes the trade explicit: the forward pass keeps activations at only a sparse set of checkpoint layers, and the backward pass recomputes the rest on demand.
\begin{algorithm} \caption{Gradient checkpointing (activation recomputation)} \begin{algorithmic} \Require $N_L$-layer network; checkpoint set $\mathcal{C} \subseteq \{1,\dots,N_L\}$ (e.g. every $\sqrt{N_L}$ layers) \Ensure parameter gradients, at reduced peak activation memory \For{$\ell = 1$ to $N_L$} \State forward layer $\ell$; store its activation only if $\ell \in \mathcal{C}$ \Comment{drop the rest} \EndFor \For{$\ell = N_L$ down to $1$} \If{the activation of layer $\ell$ was dropped} \State recompute the forward segment from the nearest stored checkpoint through layer $\ell$ \EndIf \State compute the layer's gradient; free the activation \EndFor \State \Return the accumulated gradients \end{algorithmic} \end{algorithm}
Spacing checkpoints every \(\sqrt{N_L}\) layers can drop peak activation memory from \(\mathcal{O}(N_L)\) to \(\mathcal{O}(\sqrt{N_L})\), paid for by extra forward work over checkpoint segments during the backward pass. That is the lever that fits a network too large to train within accelerator memory, trading the iron law’s operation term for activation capacity.
The efficiency of these memory management strategies depends heavily on the underlying hardware architecture. Accelerator systems, with their high computational throughput but limited memory bandwidth, often encounter different bottlenecks than CPU systems. Memory bandwidth limitations on accelerators mean that even when sufficient storage exists, moving data between memory and compute units can become the primary performance constraint (Jouppi et al. 2017).
Jouppi, Norman P., Cliff Young, Nishant Patil, David Patterson, Gaurav Agrawal, Raminder Bajwa, Sarah Bates, et al. 2017. “In-Datacenter Performance Analysis of a Tensor Processing Unit.” Proceedings of the 44th Annual International Symposium on Computer Architecture, ISCA ’17, 1–12. https://doi.org/10.1145/3079856.3080246.
Paszke, Adam, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, et al. 2019. “PyTorch: An Imperative Style, High-Performance Deep Learning Library.” Advances in Neural Information Processing Systems 32: 8024–35.
These hardware considerations guide the implementation of backpropagation in modern training systems. Specialized memory-efficient algorithms for operations like convolutions compute gradients in tiles or chunks, adapting to available memory bandwidth. Dynamic memory management tracks the lifetime of intermediate values throughout the computation graph, deallocating memory as soon as tensors become unnecessary for subsequent computations (Paszke et al. 2019).
The mathematical operations we have examined (forward propagation, gradient computation, and parameter updates) define what training systems must compute. However, knowing the cost of each operation individually does not tell us where the system actually stalls. Matrix multiplications are compute bound; activation functions are memory bound; optimizer updates are somewhere in between. To determine which resource limits a given operation, we need one more analytical tool: arithmetic intensity.
Arithmetic intensity
Arithmetic intensity captures this distinction—the ratio of computation to data movement that reveals whether an operation is limited by compute throughput or memory bandwidth: \[ \text{Arithmetic Intensity} = \frac{\text{FLOPs}}{\text{bytes moved}} \]
Operations with high arithmetic intensity are compute bound: their performance is limited by the processor’s computational throughput. Operations with low arithmetic intensity are memory bound: they spend more time moving data than computing. The roofline model gives the formal definition of the roofline model and shows how to compute a hardware’s ridge point19.
19 Ridge Point and Precision: The roofline ridge point—the arithmetic intensity threshold separating memory-bound from compute-bound operations—shifts with numerical precision. On the same accelerator, a lower-precision Tensor Core path can expose much more arithmetic throughput at roughly the same memory bandwidth, raising the ridge point substantially. Switching from TF32-style execution to BF16 mixed precision can therefore change which optimization technique yields returns, making precision selection inseparable from roofline analysis.
Consider table 5: dense matrix multiplication achieves \(\mathcal{O}(n)\) FLOP/byte (compute bound), while activation functions operate at just 0.50 FLOP/byte (memory bound), explaining why optimization strategies must differ between these operation types.
| Operation | Arithmetic Intensity | Classification |
|---|---|---|
| Dense MatMul (large) | \(\mathcal{O}(n)\) FLOP/byte | Compute-bound |
| Activation functions | 0.50 FLOP/byte (FP16) | Memory-bound |
| LayerNorm/BatchNorm | ~10 FLOP/byte | Memory-bound |
| Attention softmax | ~5 FLOP/byte | Memory-bound |
The roofline view in figure 2 turns that table into a hardware diagnostic: the same operation classification now appears relative to a concrete ridge point.
To build intuition for these relationships, study the roofline diagram in figure 2, the standard diagnostic tool for understanding hardware utilization. The ridge point marks the “knee” where the sloped memory-bound region meets the flat compute-bound ceiling. Operations falling left of this point, including attention softmax, are starved for data: the accelerator could compute faster, but memory bandwidth cannot deliver operands quickly enough. Operations to the right are compute bound: adding more memory bandwidth would not help because the arithmetic units themselves limit throughput. Notice how GPT-2’s training operations distribute across this landscape.
Consider a GPT-2 attention layer that materializes the \(S{\times}S\) attention-score matrix. For each head, the \(QK^\top\) product costs approximately \(2S^2d_{\text{head}}\) FLOPs, while writing the FP16 score matrix and reading it back for softmax traffic moves about \(4S^2\) bytes. The arithmetic intensity of this materialized score path is therefore \(d_{\text{head}}/2\). For GPT-2 Small (\(d_{\text{model}}=\) 768 across 12 heads, so \(d_{\text{head}}=\) 64), this yields 32 FLOP/byte, below the A100’s ridge point, making standard materialized attention memory bound. Scaling the hidden dimension raises projection intensity, but it does not remove the \(\mathcal{O}(S^2)\) score-matrix traffic that FlashAttention targets.
Accelerators have characteristic hardware ridge points where operations transition from memory-bound to compute bound. A representative data-center accelerator has a ridge point high enough that low-intensity operations such as materialized attention softmax remain memory bound even when large matrix multiplications are compute bound. Operations below the ridge point are memory bound; above it, they are compute bound.
Systems Perspective 1.5: Peak FLOP/s vs. sustained performance
Hardware vendors often market “Peak TFLOP/s,” but for a systems engineer, this number is often a theoretical limit that is rarely reached. The intensity gap reveals that most neural network operations, especially in the backward pass, have arithmetic intensities well below the hardware’s ridge point. When an operation is memory bound (like LayerNorm or Softmax), doubling the hardware’s peak TFLOP/s does nothing for performance. This is why mixed-precision training with FP16/BF16 is so effective: beyond enabling faster arithmetic, it halves the bytes moved per operation, effectively doubling the data supply rate and allowing the system to reach a much higher percentage of its peak computational capability. Successful optimization is the art of increasing arithmetic intensity through kernel fusion and reducing data movement through precision management.
Batch size directly influences arithmetic intensity. With batch = 1, many operations fall below the ridge point and become memory bound. With batch=32 or higher, most matrix operations exceed the ridge point and become compute bound. This explains why larger batches improve hardware utilization: they shift operations into the compute-bound regime where accelerators excel.
This analysis guides optimization strategy selection. For memory-bound operations, reducing data movement through operator fusion, reduced precision, or algorithmic improvements like FlashAttention provides the largest gains. For compute-bound operations, increasing throughput through Tensor Cores and parallel execution matters more. The distinction is practical: the first case asks how to move fewer bytes, while the second asks how to keep more arithmetic units busy.
In figure 2, standard attention sits in the memory-bound region while FlashAttention20 shifts the same workload into the compute-bound region, which captures the core insight of IO-aware algorithm design. By never materializing the full \(S{\times}S\) attention matrix in HBM and instead processing tiles that fit in fast SRAM (on-chip static RAM), FlashAttention reduces attention activation memory from \(\mathcal{O}(S^2)\) to \(\mathcal{O}(S)\) and sharply reduces HBM traffic, achieving 2–4\(\times\) speedups (Dao et al. 2022). The algorithm, its implementation, and the conditions under which it applies are examined in detail in section 1.5.4.
20 FlashAttention: The core mechanism is processing the attention calculation in small tiles that fit within the accelerator’s fast, on-chip SRAM, which avoids writing the full intermediate \(S{\times}S\) matrix to slower HBM. The exact HBM IO bound depends on tile size and SRAM capacity, but the practical effect is a large reduction in memory traffic and activation storage. The result is the 2–4\(\times\) end-to-end speedup mentioned in the text.
The preceding arithmetic intensity analysis reveals which operations constrain training performance and why: matrix multiplications are compute bound while normalization and activation functions are memory bound, each requiring different optimization strategies. FlashAttention exemplifies how understanding these bottlenecks enables algorithmic solutions that shift operations from one regime to another.
Optimizing individual operations is necessary but insufficient. A perfectly tuned matrix multiplication achieves nothing if the accelerator sits idle waiting for the next batch of data. The preceding mathematical foundations quantified the cost of each piece—matrix multiplications consuming trillions of FLOPs, activation functions bottlenecked by memory bandwidth, optimizer states tripling memory requirements. The next question is how to orchestrate these pieces into a pipeline where no stage starves the others.
Self-Check: Question
Why do batched matrix-matrix operations dominate modern training accelerator design more than matrix-vector operations do, even though the underlying mathematics is similar?
- Because matrix-matrix operations eliminate the need to store activations for backpropagation, reducing the training memory footprint.
- Because matrix-vector operations require more total memory than matrix-matrix operations for the same model, exhausting accelerator capacity faster.
- Because matrix-matrix operations expose much more parallel work per byte loaded — their high arithmetic intensity lets accelerators with thousands of compute units approach peak throughput, while matrix-vector workloads starve the same units on memory traffic.
- Because matrix-vector operations cannot run on GPUs without CPU coordination at every step.
A team is training a 7-billion-parameter model on accelerators with 80 GB of HBM each. Weights, gradients, and activations together occupy 64 GB per accelerator at the planned batch size. Using the section’s optimizer-memory accounting, explain the systems trade-off between choosing SGD and Adam for this run.
Why do activations often dominate the memory budget during training even when model weights already occupy several gigabytes on the accelerator?
- Because activations from every layer must remain resident from the forward pass until the backward pass consumes them, so total activation memory scales with depth and batch size while parameter memory is largely fixed for a given model.
- Because activations are stored in FP64 even when weights are kept in FP16 or FP32, doubling their byte count.
- Because activations include the raw training dataset, which grows with the number of epochs.
- Because the optimizer’s state vectors are accounted for as activations during the backward pass.
Order the following components of one standard training step: (1) backward pass computes gradients, (2) optimizer updates parameters, (3) forward pass computes predictions and loss.
On an A100 with a ridge point near 156 FLOP/byte, a fused LayerNorm-plus-attention-softmax kernel measures roughly 5 FLOP/byte from weight and activation movement. Which optimization family is most likely to move this workload closer to the roofline, and why?
- Replacing the A100 with a newer accelerator advertising 2\(\times\) the peak FP16 TFLOP/s.
- Reducing data movement through fusion, tiling, or lower-precision weights so arithmetic intensity increases for each byte loaded into on-chip SRAM.
- Doubling the batch size while leaving every kernel unchanged, because larger batches always move operations across the ridge point.
- Switching the optimizer from Adam to SGD while keeping every kernel unchanged.
Pipeline Architecture
A training step is not a single operation but a sequence of dependent stages—data must be loaded before computation can begin, forward passes must complete before backward passes start, and gradients must be computed before parameters can update. The speed of the slowest stage determines the speed of the entire system.
The system-level pipeline coordinates these stages across real hardware with finite memory and bandwidth constraints. ML Frameworks introduced how frameworks like PyTorch and TensorFlow provide APIs for defining models and executing forward passes; here those API calls become part of a larger architecture of data loading, preprocessing, accelerator transfers, and parameter updates—a unified pipeline rather than isolated operations.
This orchestration is not a single monolithic process but rather three interconnected subsystems, each with distinct responsibilities and resource demands. Figure 3 traces how these subsystems connect: the data pipeline handles ingestion and preprocessing, the training loop executes forward passes, backward passes, and parameter updates, and the evaluation pipeline periodically assesses model quality. The flow between these components is where bottlenecks emerge—the interconnection points expose the binding constraints.

Architectural overview
A single training iteration involves three subsystems executing in sequence: a data pipeline that ingests, transforms, and batches raw data; a training loop that performs the forward pass, gradient computation, and parameter update; and an evaluation pipeline that measures model quality against held-out data. This subsystem sequence frames the chapter’s training pipeline, while figure 4 details the forward, backward, and update interactions inside the training loop. Understanding each subsystem’s role clarifies where performance bottlenecks arise and where system-level optimizations have their greatest impact.
A training system is easiest to reason about from its boundaries inward. The data pipeline loads raw records from storage, applies transformations such as resizing, augmentation, and normalization, and assembles the resulting examples into batches; input normalization is a long-standing training aid (LeCun et al. 2012). The evaluation pipeline sits at the other boundary. At configurable intervals, it runs held-out validation data through the current model, computes metrics such as accuracy or loss, and exposes convergence problems such as overfitting, where training loss improves while validation loss degrades. Because evaluation consumes accelerator time, its cadence trades finer-grained feedback against training throughput.
LeCun, Yann, Leon Bottou, Genevieve B. Orr, and Klaus-Robert Müller. 2012. “Efficient BackProp.” In Neural Networks: Tricks of the Trade, vol. 7700. Lecture Notes in Computer Science. Springer Berlin Heidelberg. https://doi.org/10.1007/978-3-642-35289-8_3.
The training loop is the computational core of the pipeline, where the model learns from the prepared data. The data path in figure 4 traces how this process unfolds through three sequential steps on a single accelerator: the forward pass generates predictions from input data, gradient computation propagates error signals backward through the network, and parameter updates apply the optimizer to minimize the loss function.

Each iteration executes the forward pass, loss computation, backward pass, and parameter update cycle established in section 1.2. The systems question is not what these operations compute (covered earlier) but how they interact as a pipeline, where the bottleneck in any one stage limits overall throughput.
This process repeats across batches and epochs, gradually refining the model to improve its predictive accuracy. The loop is tightly coupled to the stages around it: data preparation can overlap with computation by preprocessing the next batch while the current batch trains, while evaluation temporarily pauses gradient updates to measure validation quality. The integration minimizes idle time for system resources, but any imbalance, such as a slow data pipeline or an overly frequent evaluation schedule, propagates as reduced overall throughput.
Data pipeline
The architectural overview identified the data pipeline as the first component in the training system. Its efficiency directly determines whether expensive accelerator resources remain fully engaged or sit idle waiting for data. The systems aspects of data movement and preprocessing are the focus here; the upstream data engineering practices are covered in Data Engineering.
The data pipeline running on the CPU bridges raw data storage and accelerator computation. Figure 5 breaks down this architecture into three distinct zones.

These zones matter because each can become the slowest stage. Storage supplies raw examples from disk, typically image files for computer vision or text files for natural language processing. CPU preprocessing then converts formats, applies resizing, normalization, or data augmentation, and batches examples into tensors the accelerator can consume.
The GPU training zone consumes those preprocessed batches across multiple accelerators for parallel computation. Format conversion, processing, and batching are therefore not housekeeping steps; they are throughput gates. If any one runs slower than the training loop, expensive accelerator resources idle while the data pipeline catches up.
Core components
The data pipeline’s throughput is ultimately limited by how fast training data can be retrieved from storage. The data engineering practices from Data Engineering, including data format selection (Parquet, TFRecord, Arrow), partitioning strategies, and data locality optimization, directly impact these storage characteristics. Here we examine how storage constraints propagate through the training system.
Storage throughput is bounded by the slower of two hardware constraints, expressed in equation 7: \[R_{\text{storage}} =\min(\text{BW}_{\text{disk}}, \text{BW}_{\text{network}}) \tag{7}\] where \(\text{BW}_{\text{disk}}\) is the physical disk bandwidth and \(\text{BW}_{\text{network}}\) represents the network bandwidth for distributed storage systems. In practice, training workloads rarely achieve this theoretical maximum because they require data shuffling—randomly sampling examples to prevent the model from learning spurious ordering effects. This random access pattern dramatically reduces the effective storage throughput to \(R_{\text{storage,eff}} = R_{\text{storage}} \times F_{\text{access}}\), where \(F_{\text{access}} \approx 0.1\) for typical training workloads. Storage systems optimized for sequential reads deliver only 10 percent of their peak bandwidth under random access. This order-of-magnitude penalty explains why data pipeline engineering matters: without careful prefetching and buffering, an accelerator costing thousands of dollars per hour sits idle waiting for a storage device costing hundreds.
Preprocessing
Once data arrives from storage, preprocessing transforms raw inputs into model-ready tensors. This process builds on the data pipeline patterns established in Data Engineering, typically implemented through extract, load, transform (ELT) pipelines where raw data is loaded first and transformed on-demand during training. Preprocessing throughput scales with parallelism, as expressed in equation 8: \[R_{\text{preprocessing}} = \frac{N_{\text{workers}}}{T_{\text{transform}}} \tag{8}\] where \(N_{\text{workers}}\) parallel processing threads each perform transformations requiring \(T_{\text{transform}}\) seconds. Training architectures employ multiple workers to ensure preprocessing keeps pace with accelerator consumption rates—a single thread performing image augmentation at 30 ms per batch cannot feed an accelerator that computes a forward pass in 10 ms.
Preprocessed data must then transfer to the accelerator before computation can begin. The overall training throughput is therefore constrained by the slowest of three stages, as equation 9 makes explicit: \[R_{\text{training}} =\min(R_{\text{preprocessing}}, \text{BW}_{\text{GPU\_transfer}}, R_{\text{compute}}) \tag{9}\] where \(R_{\text{compute}}\) is the accelerator’s realized compute throughput for the forward-backward pass, distinct from the transfer bandwidth that feeds it.
This min-of-three relationship is the governing principle of training pipeline design: the system’s throughput equals its bottleneck’s throughput. An accelerator with 312 TFLOP/s of compute capacity delivers zero useful work while waiting for data. Conversely, a perfectly optimized data pipeline provides no benefit if the accelerator is already compute-saturated. Balanced pipeline design aligns preprocessing capacity, transfer bandwidth, and compute throughput so that no single stage dominates iteration time. Applying this throughput analysis to our GPT-2 Lighthouse Model reveals where the data pipeline bottleneck lies for language model training.
Example 1.1: GPT-2 language model data pipeline
Scenario: Training language models like GPT-2 requires a data pipeline whose main question is not whether the text can be read from disk, but whether CPU tokenization can keep the accelerator supplied with complete batches.
Stage trace:
- Raw text storage: The OpenWebText corpus contributes about 40 GB of raw text. Sequential reads from an NVMe SSD can reach 7 GB/s, but language-model training samples across documents, so the effective random-access bandwidth falls to roughly 0.70 GB/s when the effective-access factor is about 0.1.
- Tokenization: A BPE tokenizer with a 50,257 vocabulary converts raw text into subword token IDs, so a word such as “unbreakable” becomes the sequence [“un”, “break”, “able”]. With global batch size \(B=32\) across the cluster and sequence length \(S=1024\), each training step needs 32.8K tokens; at 500K tokens/s per CPU core, one core spends 65.5 ms preparing a batch.
- Batching and padding: The pipeline pads sequences to a uniform length and packs them into an int64 tensor with 32 sequences by 1,024 tokens, for 262.1 KB per batch.
- PCIe transfer: Moving that tensor across a Gen3 x16 link with 15.75 GB/s of theoretical bandwidth takes only 0.017 ms, so optimizing the copy would not materially improve this pipeline.
Systems insight: At GPT-2 scale, storage and PCIe movement are not the binding terms; CPU tokenization is already close to the 84.4 ms accelerator training step. The useful intervention is to parallelize and overlap tokenization: 8 CPU workers reduce the tokenization service time to about 8.2 ms, while prefetching prepares the next batch during the current accelerator step. The result is accelerator utilization above 95 percent and a cluster-wide throughput of 379 global samples per second on 32 V100 GPUs.
Data pipeline throughput is not the only flow that can starve the accelerator. Multi-GPU training adds a second stream of traffic, the gradient synchronization required after every step, and once synchronization time exceeds compute time, communication becomes the limiting wall. Section 1.6.2 quantifies that network wall at the point where training crosses the node boundary.
System implications
The data pipeline and compute engine form a coupled system whose throughput equals the slower of the two, as equation 10 states: \[R_{\text{system}} =\min(R_{\text{pipeline}}, R_{\text{compute}}) \tag{10}\]
This simple relationship has profound consequences. When \(R_{\text{pipeline}} < R_{\text{compute}}\), the accelerator sits idle waiting for data, and accelerator utilization drops proportionally, as equation 11 shows: \[\text{Accelerator Utilization} = \frac{R_{\text{pipeline}}}{R_{\text{compute}}} \times 100\% \tag{11}\]
A ResNet-50 model on modern accelerator hardware can process 1,000 images per second, but if the data pipeline delivers only 200 images per second, accelerator utilization drops to 20 percent—the accelerator is idle 80 percent of the time. Crucially, upgrading to faster hardware does not help; an accelerator capable of 2,000 images per second would achieve only 10 percent utilization with the same pipeline. Balanced system design matters precisely here: the most expensive component in the system (the accelerator) must never be the one waiting.
Data flows
Training data traverses three memory tiers on its way from disk to accelerator, and the bandwidth gap between these tiers, spanning three orders of magnitude, is the central challenge of data pipeline design. The effective transfer rate through the hierarchy is bounded by its slowest link, as equation 12 shows: \[R_{\text{memory}} =\min(\text{BW}_{\text{storage}}, \text{BW}_{\text{system}}, \text{BW}_{\text{accelerator}}) \tag{12}\]

Bandwidth steps up the storage to DRAM to HBM hierarchy.
Storage devices provide 1–2 GB/s, system memory delivers 50–100 GB/s, and accelerator HBM achieves 900 GB/s or higher. Each tier is orders of magnitude faster than the one below it, which means data that flows freely within accelerator memory creates a severe bottleneck when it must be fetched from disk. This cascading bandwidth hierarchy explains why the iteration time of a well-pipelined system is governed by the maximum of its component latencies rather than their sum, as equation 13 shows: \[T_{\text{iteration}} =\max(T_{\text{fetch}}, T_{\text{process}}, T_{\text{transfer}}) \tag{13}\]
When pipeline stages overlap correctly (fetching the next batch from storage while preprocessing the current one and transferring the previous one to the accelerator), the iteration time equals the duration of the slowest stage rather than the sum of all stages. This overlap is exactly what prefetching achieves, turning a serial bottleneck into a parallel pipeline where each tier operates concurrently on different batches.
Practical architectures
These throughput relationships become concrete when applied to real storage hardware. An NVMe storage device with 7 GB/s theoretical bandwidth typically sustains only about half of that, approximately 3.50 GB/s in practice (\(R_{\text{practical}} \approx 0.5 \times \text{BW}_{\text{theoretical}}\)), and random access patterns for data shuffling reduce effective throughput by another 90 percent.
To keep accelerators fed despite this bandwidth reduction, pipeline architectures maintain multiple data buffers simultaneously—prefetch buffers loading future batches, processing buffers holding data under transformation, and transfer buffers staging data for accelerator consumption. The total host memory required scales with the per-batch memory footprint \(M_{\text{batch}}\) according to equation 14: \[M_{\text{required}} = (N_{\text{prefetch}} + N_{\text{processing}} + N_{\text{transfer}}) \times M_{\text{batch}} \tag{14}\]
The critical design constraint is that preprocessing must complete faster than accelerator computation, as equation 15 states. When this inequality is violated, expensive accelerators idle while CPUs finish transforming data: \[T_{\text{preprocessing}} < T_{\text{compute}} \tag{15}\]
For image classification pipelines where resizing, augmentation, and normalization consume 20–40 ms per batch on a single CPU thread, while a modern GPU completes the forward-backward pass in 10–15 ms, satisfying this inequality requires parallel preprocessing with four to eight worker threads. This is exactly the configuration that section 1.5.2 optimizes.
Forward pass
Prepared batches enter the training loop through the forward pass, where input data propagates through the model to generate predictions. The conceptual flow follows the layer-by-layer transformation \(\mathbf{A}^{(\ell)} = f\left(\mathbf{A}^{(\ell-1)}\mathbf{W}^{(\ell)} + \mathbf{b}^{(\ell)}\right)\) established earlier, but the system-level implementation must schedule kernels, move activations, and preserve enough state for backpropagation.
Compute operations
The forward pass orchestrates the computational patterns introduced in section 1.2.1.2, optimizing them for specific neural network operations. Building on the matrix multiplication foundations, the system must efficiently execute the \(N \times M \times B\) multiply-accumulate operations required for each layer, where typical layers with dimensions of \(512 \times 1024\) processing batches of 64 samples execute about 33.6 million MACs, or about 67.1 MFLOP under the two-FLOPs-per-MAC convention.
Modern neural architectures extend beyond these basic matrix operations to include specialized computational patterns. Convolutional networks, for instance, perform systematic kernel operations across input tensors. Consider a typical input tensor of dimensions \(64 \times 224 \times 224 \times 3\) (batch size \(\times\) height \(\times\) width \(\times\) channels) processed by \(7 \times 7\) kernels. Each position requires 147 multiply-accumulate operations, and with 64 filters operating across \(218 \times 218\) spatial dimensions, the computational demands become substantial.
Transformer architectures introduce attention mechanisms (see Network Architectures), which compute similarity scores between sequences. These operations combine matrix multiplications with softmax normalization, requiring efficient broadcasting and reduction operations across varying sequence lengths. The computational pattern here differs significantly from convolutions, demanding flexible execution strategies from hardware accelerators.
Throughout these networks, element-wise operations play a supporting role. Activation functions like ReLU and sigmoid transform values independently and, as established in section 1.2.4, are memory-bandwidth-bound rather than compute bound. Batch normalization presents similar challenges, computing statistics and normalizing values across batch dimensions while creating synchronization points in the computation pipeline.
Modern hardware accelerators, particularly GPUs, optimize these diverse computations through massive parallelization. Achieving peak performance requires careful attention to hardware architecture. GPUs process data in fixed-size blocks of threads called warps21 (in NVIDIA architectures) or wavefronts (in AMD architectures). Peak efficiency occurs when matrix dimensions align with these hardware-specific sizes. For instance, NVIDIA GPUs typically achieve optimal performance when processing matrices aligned to \(32{\times}32\) dimensions. This fixed-size execution model creates a subtle but consequential effect that practitioners frequently overlook.
21 Warp: From textile weaving, where a “warp” is the set of threads held taut on a loom while a shuttle weaves across them. NVIDIA adopted the term because GPU threads within a warp execute the same instruction in lockstep, analogous to parallel threads moving together on the loom. The fixed warp size of 32 threads is a hardware constant that creates the wave quantization effect analyzed below: when matrix dimensions are not multiples of 32, partial warps execute with idle lanes, silently wasting silicon.
Systems Perspective 1.6: Wave quantization and tail effects
A common mistake in ML systems is treating batch size as a continuous variable. In reality, GPU execution is quantized into “waves” of work.
Table 6: Wave quantization tax on NVIDIA GPUs: Batch sizes that straddle the 32-thread warp boundary launch additional partially-filled warps, dropping utilization sharply while leaving step time nearly unchanged. A batch of 33 launches the same two warps as a batch of 64 but uses only half the hardware; the next quantum boundary repeats at 65. This is why batch sizes should be multiples of 32 or 64, not values that look “close enough.”
The wave effect: An NVIDIA GPU executes work in warps of 32 threads. With a batch size of 32, all 32 threads are busy. With a batch size of 33, the GPU must launch a second warp to process the single remaining sample. This second warp uses only 1/32 (3 percent) of its potential compute power, but takes just as long to execute as the first.
Tail effects at scale: On a large GPU like the H100 with 132 Streaming Multiprocessors (SMs), where each SM schedules groups of warps, the hardware can process thousands of threads in one “wave.” If the total workload is just slightly over a wave boundary (e.g., 1.01 waves), the hardware must wait for a nearly empty wave to finish before the next task begins.
Table 6 quantifies the cost: batch sizes that straddle the 32-thread boundary launch additional partially filled warps and collapse utilization while leaving step time nearly unchanged.
| Batch Size | Warps Needed | Utilization | Relative Time |
|---|---|---|---|
| 32 | 1 | 100% | 1\(\times\) |
| 33 | 2 | 51.6% | ~2× |
| 64 | 2 | 100% | 1\(\times\) |
| 65 | 3 | 67.7% | ~1.5× |
Engineering rule: Always choose batch sizes and hidden dimensions that are powers of two or multiples of 8/32/64 to avoid this “quantization tax.” A batch of 32 is often faster than 33, and a batch of 64 is often just as fast as 33.
Understanding these tail effects is the difference between a practitioner who tunes by trial-and-error and an engineer who designs for the hardware.
Libraries like cuDNN (Chetlur et al. 2014) address these challenges by providing optimized implementations for each operation type. These systems dynamically select algorithms based on input dimensions, hardware capabilities, and memory constraints. The selection process balances computational efficiency with memory usage, often requiring empirical measurement to determine optimal configurations for specific hardware setups. These hardware utilization patterns reinforce the batch-size–utilization relationship established in section 1.2.2.1.2: the tension between larger batch sizes (better utilization) and memory constraints (forcing smaller batches) permeates all levels of training system design.
Chetlur, Sharan, Cliff Woolley, Philippe Vandermersch, Jonathan Cohen, John Tran, Bryan Catanzaro, and Evan Shelhamer. 2014. “cuDNN: Efficient Primitives for Deep Learning.” arXiv Preprint arXiv:1410.0759.
Memory management
Memory management is particularly important during the forward pass, when intermediate activations must be stored for subsequent backward propagation. Before examining how frameworks manage forward-pass memory, it is useful to estimate the total VRAM required for training. A concrete 7-billion-parameter-on-24 GB case shows how weights, gradients, optimizer state, and activations combine.
Napkin Math 1.4: Estimating VRAM requirements
Problem: Will a 7B-parameter model fit on a 24 GB GPU for training?
Given: 7B parameters, mixed-precision training (FP16 weights/gradients, FP32 optimizer), Adam optimizer, 24 GB GPU memory.
Math:
- Weights (FP16): 7B \(\times\) 2 bytes = 14 GB.
- Gradients (FP16): Same size as weights = 14 GB.
- Optimizer (Adam, FP32): Stores momentum & variance. 7B \(\times\) 8 bytes = 56 GB.
- Subtotal (before activations): 14 GB + 14 GB + 56 GB = 84 GB. Already exceeds a 24 GB GPU.
- Activations: Scale with batch size. A simplified transformer estimate is Batch \(\times\) SeqLen \(\times\) Hidden \(\times\) Layers \(\times\) Bytes \(\times\) an activation factor for retained attention, MLP, and normalization intermediates. Example: Batch = 1, Seq = 2048, Hidden = 4096, 32 layers, activation factor \(\approx\) 57× gives 30.6 GB additional.
Systems insight: The “administrative tax” (gradients + optimizer states) is 4–6\(\times\) larger than model weights. Training a 7B model on a single 24 GB GPU requires changing representation or placement: INT4 quantization stores values in four-bit form, while parameter sharding splits weights, gradients, and optimizer state across GPUs, with Fully Sharded Data Parallel (FSDP) and ZeRO as common implementations.
The total memory scales linearly with batch size (as established in equation 5), which means the practical complexity lies not in the scaling law itself but in how these costs interact across layers.
Consider a representative large model like ResNet-50 (a widely-used image classification architecture) processing images at 224 \(\times\) 224 resolution with a batch size of 32. The initial convolutional layer produces activation maps of dimension 112 \(\times\) 112 \(\times\) 64; per image at single-precision (4 bytes), this requires approximately 3.2 MB. As the network progresses through 50 layers, the cumulative memory demands grow substantially: the complete forward pass activations total approximately 8 GB, the backward pass adds another 4 GB of activation working set (empirical total, not stored parameter gradients), and model parameters consume 102.4 MB. This 12.1 GB total represents about 14.1 percent of an A100 GPU’s 80 GB memory capacity for a single batch.
The memory scaling patterns reveal critical hardware utilization trade-offs. Doubling the batch size to 64 increases forward activation memory to 16 GB and the backward activation working set to 8 GB, totaling 24.1 GB and reducing the memory headroom available for deeper models, larger inputs, and optimizer state. Training larger models at the scale of GPT-3 (175B parameters, representing current large language models) requires approximately 700 GB just for parameters in FP32 (350 GB in FP16), necessitating distributed memory strategies across multiple high-memory nodes.
GPUs typically provide 40 GB–80 GB of memory in high-end training configurations, which must accommodate activations, model parameters, gradients, and optimization states. Two techniques address this constraint directly: activation checkpointing trades recomputation for reduced activation storage, and mixed-precision training halves memory per value by using FP16 instead of FP32. Both are examined in detail in section 1.5; here, the key insight is that memory capacity, not compute throughput, often determines the maximum feasible batch size and model depth. Practitioners frequently start with large batch sizes during initial development on smaller networks, then adjust downward when scaling to deeper architectures or memory-constrained hardware.
The backward pass reverses this flow, computing gradients at approximately twice the forward pass cost (as established in section 1.2.3). The per-layer memory costs accumulate rapidly across the full network: deeper in ResNet-50, mid-network convolutional layers use 256 filters rather than the initial 64, but smaller spatial maps offset some activation memory while convolutional work depends on kernel size and both input and output channels. Across 50 layers, peak backward-pass working set can reach approximately 3.2 GB before accounting for optimizer state and parameter updates. Each layer’s backward step depends on gradients from the layer above, so the GPU processes layers sequentially; activation buffers for the current layer are freed as soon as that layer’s backward step finishes, but peak memory is set by the widest layer in the chain.
Parameter updates and optimizers
Once the backward pass computes gradients, the system must allocate and manage memory for both parameters and gradients, then perform the update computations. The choice of optimizer determines the mathematical update rule and the system resources required for training. Listing 3 demonstrates the backward/update portion of the parameter update cycle in PyTorch: after the forward pass computes predictions and the loss function quantifies error, loss.backward() populates gradient tensors and optimizer.step() applies the update rule to all parameters based on the configured optimizer (Adam, SGD, etc.).
loss.backward() # Compute gradients
optimizer.step() # Update parametersThese operations initiate a sequence of memory accesses and computations. The system must load parameters from memory, compute updates using the stored gradients, and write the modified parameters back to memory. Different optimizers vary in their memory requirements and computational patterns, directly affecting system performance and resource utilization.
Optimizer memory in the training loop
The optimizer memory hierarchy established in table 4 manifests concretely during each training iteration. Each parameter update involves reading current values, accessing gradients, computing the update rule, and writing modified parameters back to memory. For Adam, this includes updating and accessing the momentum and variance buffers, creating substantial memory traffic for large models.
At billion-parameter scale, optimizer state dominates the memory budget. As quantified in the GPT-2 worked example (section 1.2.2.3), a 1.5B model requires 12 GB for Adam optimizer state alone in FP32, in addition to parameters and gradients, before accounting for activations. This challenge has motivated memory-efficient optimizer variants. Adafactor factorizes second-moment state (Shazeer and Stern 2018), 8-bit optimizers quantize optimizer statistics (Dettmers et al. 2022), and GaLoRE computes updates in a low-rank space. Compare the memory bars in figure 6 to see how GaLoRE attacks this constraint: by computing updates in a compressed space (Zhao et al. 2024), the technique reduces the memory footprint dominated by optimizer states to a fraction of its original size, enabling training of larger models on fixed hardware.
Shazeer, Noam, and Mitchell Stern. 2018. “Adafactor: Adaptive Learning Rates with Sublinear Memory Cost.” Proceedings of the 35th International Conference on Machine Learning, Proceedings of machine learning research, vol. 80: 4596–604.
Dettmers, Tim, Mike Lewis, Sam Shleifer, and Luke Zettlemoyer. 2022. “8-Bit Optimizers via Block-Wise Quantization.” International Conference on Learning Representations.
Zhao, Jiawei, Zhenyu Zhang, Beidi Chen, Zhangyang Wang, Anima Anandkumar, and Yuandong Tian. 2024. “GaLore: Memory-Efficient LLM Training by Gradient Low-Rank Projection.” arXiv Preprint.

The bars make the ranking concrete: BF16 Adam alone pushes past the single-GPU budget line, Adafactor and 8-bit Adam bring optimizer state back within it, and 8-bit GaLoRE leaves the most headroom of all by computing its updates in a low-rank space.
Batch size and parameter updates
The batch size–utilization relationship established in section 1.2.2.1.2 showed that larger batches improve accelerator utilization by shifting operations into the compute-bound regime. However, batch size also affects the parameter update process in ways that become critical at scale. A larger batch provides a more accurate estimate of the true gradient, allowing for larger learning steps. However, increasing the batch size without adjusting the learning rate22 leads to the linear scaling failure. The loss curves in figure 7 show the failure mode and its correction before we formalize the rule.
22 Hyperparameter: While weights are learned during training, hyperparameters (learning rate, batch size, layer count) are set before training and control the learning process itself. Each hyperparameter choice has direct systems consequences: batch size determines memory footprint, learning rate interacts with numerical precision, and layer count multiplies activation storage. Tuning them typically requires multiple full training runs, multiplying total compute cost.
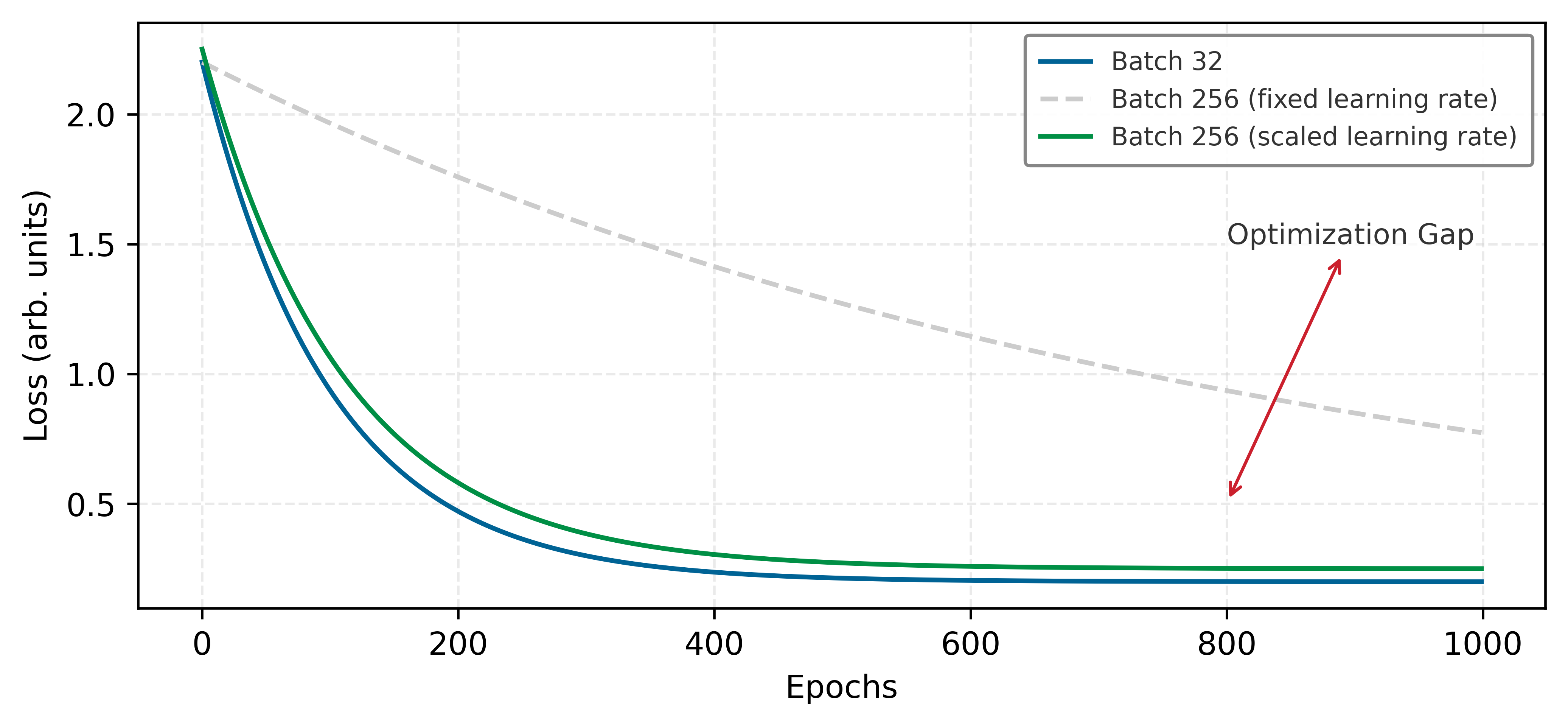
Doubling the batch size halves the number of updates per epoch. If the learning rate remains constant, the model effectively travels “half the distance” in weight space, causing underfitting. Figure 7 reveals this failure, which contrasts the generalization gap against the correction from the linear scaling rule (\(\eta_{\text{new}} = k \times \eta_{\text{base}}\)); the loss curves are normalized for intuition.
Beyond the convergence effects, batch size interacts with distributed training strategies: larger batches reduce the frequency of gradient synchronization across devices (fewer optimizer steps per epoch), but each synchronization transfers more data. In distributed settings, batch size often determines the degree of data parallelism, impacting how gradient computations and parameter updates are distributed. Gradient accumulation (section 1.5.5) decouples the effective batch size from memory constraints, enabling optimal batch sizes without requiring the memory to hold all samples simultaneously.
Every batch-size and precision decision so far has aimed at wall-clock time; at scale, that time is denominated in dollars. The compute cost itself becomes a binding constraint that shapes every training decision, from hardware selection to cluster sizing. The calculation here turns that cost into a rental-versus-purchase decision for a realistic training run.
Napkin Math 1.5: The utility bill
Problem: Is it cheaper to rent an H100 or buy it for training a Llama 2 70-billion-parameter model?
Math:
- Workload: Llama 2 70B model (70B parameters, 2T tokens).
- Compute required: \(6 \times 70 \times 10^9 \times 2 \times 10^{12} \approx 8.4 \times 10^{23}\) FLOPs. The leading factor of 6 follows from the chapter’s accounting: about 2 FLOPs per parameter per token in the forward pass (two FLOPs per multiply-accumulate), tripled once the backward pass, which costs roughly twice the forward pass, is included.
- Hardware: NVIDIA H100 (Peak: 989 TFLOP/s FP16). Assumed Utilization: 50 percent (494.5 TFLOP/s).
- Time: \(8.4 \times 10^{23} / (494.5 \times 10^{12}) \approx 1.70 \times 10^{9}\) seconds ≈ 53.8 years (on one GPU).
- Cluster: On 1,024 GPUs → 19.2 days.
The economics:
- Rental ($3/hr): 1,024 GPUs \(\times\) 24 hrs \(\times\) 19.2 days \(\times\) $3/hr ≈ $1.42M.
- Purchase ($30,000 per GPU): 1,024 GPUs \(\times\) $30,000 = $30.7M.
Systems insight: A team must train 21.7 models before buying becomes cheaper than renting. Cloud economics favors bursty workloads like training; on-premise favors steady-state workloads like inference.
The preceding pipeline architecture established the structural what of training systems, and the mathematical foundations quantified the FLOPs, memory, and bandwidth each stage demands. Yet understanding what must happen does not reveal where the system currently underperforms. A training pipeline is only as fast as its slowest stage: if data loading takes 50 ms and computation takes 100 ms, optimizing computation by 20 percent saves 20 ms, but if the bottleneck were data loading, those same engineering hours would save nothing. Before reaching for optimization techniques, we need diagnostic tools that identify which constraint actually limits performance.
Self-Check: Question
Which set of subsystems best describes the chapter’s high-level training-system architecture, and what is the engineering value of organizing the system this way?
- Data pipeline, training loop, and evaluation pipeline — each subsystem has distinct resource demands (CPU/IO, accelerator compute, periodic validation), so bottlenecks can be diagnosed at the subsystem boundary instead of inside a monolithic training script.
- Storage controller, compiler pass, and inference server — a layering that separates data placement from computation graph optimization.
- Optimizer state manager, scheduler daemon, and checkpoint restorer — a service decomposition that mirrors how cloud training platforms expose APIs.
- Tokenizer, hyperparameter tuner, and deployment gateway — a workflow decomposition centered on model-development tooling.
A profile shows preprocessing delivering batches at 4 GB/s, host-to-device transfer at 32 GB/s, and the GPU consuming the equivalent of 12 GB/s during forward and backward passes. According to the pipeline throughput model, what determines end-to-end training throughput, and what does the answer imply for the team’s next move?
- The average of the three rates, so the team should look for small simultaneous gains across all stages.
- The transfer rate alone, because every byte must traverse PCIe before being used.
- The GPU compute rate alone, because compute always dominates training cost.
- The minimum of the three rates — 4 GB/s at preprocessing — so total throughput is capped by the data pipeline, and the team should parallelize preprocessing before optimizing compute.
Explain why CPU tokenization can become a hidden bottleneck for language-model training even on a system whose host-to-device transfer time is well under a millisecond.
A team measures iteration time for two configurations of the same training run on the same hardware: batch size 32 yields 92 percent GPU utilization, while batch size 33 yields 71 percent utilization. Based on the pipeline architecture section’s discussion of hardware execution granularity, what is the most likely cause?
- Batch size 33 exceeded the L2 cache capacity, forcing every operation to spill activations to HBM.
- The optimizer automatically switched to FP32 accumulation at the larger batch, halving effective compute throughput.
- Crossing a fixed warp or wave boundary at batch 33 launches a partially filled additional execution unit, leaving GPU lanes idle and lowering effective utilization.
- Larger batches always reduce gradient accuracy enough that the framework inserts extra synchronization barriers.
A team scales an existing training run from batch size 512 to 4096 on an 8-GPU node, leaving every other hyperparameter unchanged. Per-step GPU utilization rises from 61 percent to 88 percent, but validation loss after 10,000 steps is worse than the 512-batch run at the same wall clock. What is the most likely explanation under the chapter’s batch-size analysis?
- Larger batches changed the dtype of gradients from FP16 to FP32 automatically, slowing each step.
- Each epoch now contains 8\(\times\) fewer gradient updates, and the unchanged learning rate under-utilizes the available weight-space travel per epoch — the system is throughput-healthy but optimization-starved.
- Larger batches removed the need for backward propagation, so the optimizer had no gradient information to update weights.
- Larger batches always increase per-epoch communication volume linearly with batch size and no change in update frequency.
Identifying Bottlenecks
Blueprint knowledge is not diagnosis. Knowing that attention operations consume 50 percent of FLOPs and data loading takes 25 percent of wall-clock time does not reveal which constraint to attack first; that depends on which resource is actually saturated during execution.
The diagnostic methodology that transforms blueprint knowledge into actionable optimization decisions begins with a meaningful measure of training efficiency. Raw accelerator utilization percentages can be misleading because they include overhead from recomputation and padding. A more precise metric captures only the useful training work performed per second. That metric is Model FLOPs Utilization (MFU)23, the fraction of peak hardware throughput spent on useful training work rather than lost to stalls and overhead.
23 Model FLOPs Utilization (MFU): Introduced in the PaLM paper (Chowdhery et al. 2022) as a hardware-agnostic efficiency metric. Unlike raw accelerator utilization, which counts all cycles including overhead, MFU measures only the FLOPs that contribute to model convergence. PaLM’s 540-billion-parameter run reported 46.2 percent MFU on 6,144 TPU v4 chips—meaning over half the theoretical compute was lost to memory stalls, communication, and pipeline bubbles.
Chowdhery, Aakanksha, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, et al. 2022. “PaLM: Scaling Language Modeling with Pathways.” arXiv Preprint arXiv:2204.02311.
Definition 1.4: Model FLOPs utilization (MFU)
Model FLOPs Utilization (MFU) is the efficiency metric \(\text{MFU} = O_{\text{model}} / (R_{\text{peak}} \cdot T_{\text{step}})\), where \(O_{\text{model}}\) is the useful per-step model FLOP count (forward plus backward, excluding rematerialization) and \(T_{\text{step}}\) is the measured wall-clock time per training step, expressing what fraction of peak hardware throughput is doing useful model computation.
- Significance: MFU is the \(\eta_{\text{hw}}\) term in the iron law made concrete. For a 7B-parameter transformer processing 1,024 tokens per step on an A100 (312 TFLOP/s FP16/BF16 Tensor Core peak), a 1.2-second step gives useful model FLOPs divided by the available peak-rate FLOP budget of approximately 0.11 (11.5 percent), meaning 88.5 percent of peak compute is lost to memory stalls, communication, and scheduling overhead. Production systems typically reach 30–50 percent MFU; values below 30 percent indicate a specific addressable bottleneck.
- Distinction: Unlike hardware utilization reported by profilers (which counts all cycles where the compute units are active, including gradient checkpointing recomputation and padding FLOPs), MFU counts only the FLOPs that directly advance the model toward convergence—providing a hardware-agnostic efficiency score that is comparable across different accelerator generations.
- Common pitfall: A frequent misconception is that 100 percent MFU is achievable. Memory bandwidth is always a finite resource: even a perfectly compute-bound kernel must load weights from DRAM, and the resulting stalls impose a ceiling well below 100 percent. The practical upper bound for most transformer training runs is 55–65 percent MFU, achievable only with FlashAttention and carefully tuned batch sizes.
Training bottlenecks fall into three categories that map directly to the D·A·M taxonomy (Data, Algorithm, Machine; The D·A·M Taxonomy provides the full diagnostic framework, troubleshooting matrix, and D·A·M Scorecard). Table 7 connects each D·A·M axis to the corresponding training bottleneck, its observable symptoms, and the optimization techniques that address it.
| D·A·M Axis | Bottleneck | Symptoms | Primary Solutions |
|---|---|---|---|
| Algorithm | compute-bound | accelerator utilization >90%; low memory bandwidth usage; arithmetic units are the limiting factor | FlashAttention, mixed precision, faster hardware |
| Machine | memory-bound | accelerator utilization 50–80%; high memory bandwidth usage; arithmetic units idle waiting for data from memory | Operator fusion, memory-efficient attention, reduced precision formats |
| Data | data-bound | periodic accelerator utilization drops to near-zero; CPU fully busy during gaps; pipeline cannot feed GPU fast enough | Prefetching, pipeline overlap, faster storage, DataLoader parallelism |
The data-bound category is the most commonly misdiagnosed bottleneck in practice. A training job with 40 percent MFU and a GPU utilization trace full of idle gaps looks like a hardware problem, but the root cause is often a software serialization bottleneck in the input pipeline. When the CPU-side data loader cannot prepare batches faster than the accelerator consumes them, no amount of GPU tuning can close the gap.
Example 1.2: The GIL-locked GPU
Scenario: A team writes its data loading pipeline in standard Python, using a simple loop to read images, augment them, and feed the GPU.
Failure mode: Python expert David Beazley demonstrated that the Global Interpreter Lock (GIL) ensures only one thread executes Python bytecode at a time (Beazley 2010). In this illustrative failure mode, the data loader runs as a serialized CPU bottleneck: it processes one image, the GPU consumes it quickly, and then the GPU waits for the next item. The CPU can appear busy on one core while the accelerator fleet spends long intervals idle. The accelerator trace shows white space: the GPU is healthy, but it is starved by the input pipeline.
Systems insight: Amdahl’s Law is brutal. A serial data pipeline renders a parallel accelerator useless. High-performance training requires multiprocessing to bypass Python-side serialization or offloading preprocessing to the accelerator, as in systems such as NVIDIA DALI, to keep the compute units fed.
Beazley, David. 2010. “Understanding the Python GIL.” PyCon US 2010 PyCon US 2010.
Profiling tools reveal which bottleneck dominates a given workload. Figure 8 captures the data-bound pathology from the callout: the gaps in GPU activity (white regions between compute blocks) show the device waiting for input data while utilization drops to zero during loading phases.
Four tools integrated into machine learning frameworks provide detailed bottleneck analysis. Table 8 separates framework-level timeline tools from GPU-level execution tools, because each exposes a different failure signature.
| Tool | Scope | Best signal |
|---|---|---|
PyTorch Profiler (torch.profiler) |
Framework-level operation trace | Time spent in each operation, memory allocation patterns, and GPU kernel execution |
| TensorFlow Profiler | Framework-level training timeline | Input pipeline bottlenecks and device placement |
| NVIDIA Nsight Systems | System-level GPU trace | Kernel execution, memory transfers, and synchronization points |
| NVIDIA Nsight Compute | Kernel-level GPU analysis | Arithmetic intensity, memory throughput, and occupancy |
The profiling workflow follows a systematic pattern: run a representative training iteration with profiling enabled, examine the timeline for gaps (data-bound), check memory bandwidth utilization (memory-bound vs. compute bound), and identify the dominant bottleneck before selecting an optimization technique.
In practice, the characteristic signatures from table 7 are directly visible in profiler traces: accelerator utilization levels, memory bandwidth saturation, and CPU vs. GPU activity ratios each point to a specific bottleneck class. These signatures map to specific optimization techniques: prefetching for data bottlenecks, mixed precision and operator fusion for memory bottlenecks, and algorithmic improvements or hardware upgrades for compute bottlenecks. With a diagnostic framework in hand, the next step is to examine each optimization technique in detail: what it does, which iron law term it targets, and when profiling results indicate it should be applied.
Self-Check: Question
Why is Model FLOPs Utilization (MFU) a more informative metric than the raw accelerator-busy percentage reported by a vendor profiler when diagnosing training efficiency?
- Because MFU equals peak hardware throughput expressed in percent and so always sits at 100 percent on healthy hardware.
- Because MFU is measured from CPU activity, so it isolates the data-loading pipeline automatically.
- Because MFU ignores wall-clock time and therefore removes timing noise from profile traces.
- Because MFU counts only the FLOPs that directly advance the model toward convergence, while raw busy time also charges padding FLOPs, gradient-checkpointing recomputation, and stalled kernels that do no useful model work.
A profiler trace shows repeated white gaps where GPU activity drops nearly to zero for tens of milliseconds at a time, while CPU-side data loading shows sustained activity during those same intervals and HBM bandwidth utilization sits low. Which D·A·M class most likely dominates this trace, and how does the signature distinguish it from an adjacent class?
- Compute-bound — the GPU is saturated on arithmetic units; the trace would show this regardless of CPU activity.
- Memory-bound — the GPU is stalled on HBM bandwidth, with the compute units idle waiting for data from device memory.
- Data-bound — the input pipeline cannot deliver batches fast enough; the discriminating signal is the GPU dropping to near zero rather than merely stalling on memory traffic.
- Communication-bound — inter-GPU synchronization is consuming the wall-clock budget.
A team profiles two training runs. Run A shows GPU utilization at 92 percent with HBM bandwidth saturated and CPU near idle. Run B shows GPU utilization at 18 percent with periodic drops to zero, CPU pinned, and HBM bandwidth low. Use the D·A·M taxonomy to assign each run to a bottleneck class and name the optimization family the chapter prescribes for each.
Order the following stages of the chapter’s profile-diagnose-fix-reprofile workflow: (1) apply a targeted fix to the dominant bottleneck, (2) profile the training run to gather evidence, (3) re-profile and iterate, (4) identify the dominant bottleneck from the profile.
Pipeline Optimizations
Profiling reveals where the training system underperforms; the D·A·M taxonomy (The D·A·M Taxonomy) classifies what kind of bottleneck limits throughput. The remaining question is how to close the gap. Four optimization techniques, each targeting a specific bottleneck category, together with a systematic framework for composing them, provide the answer.
Even well-designed pipeline architectures rarely achieve optimal performance without targeted optimization. Published large-model training reports show the gap between theoretical hardware capability and realized throughput: GPUs advertised at 312 TFLOP/s may deliver only 93.6 TFLOP/s–156 TFLOP/s for training workloads (Narayanan et al. 2021; Chowdhery et al. 2022). Systems such as SuperNeurons show one version of this problem: memory-management bottlenecks can prevent larger networks from training efficiently unless the runtime actively optimizes activation storage and transfer (Wang et al. 2018). This efficiency gap stems from systematic bottlenecks that optimization techniques can address. Table 9 extends the D·A·M-based bottleneck classification from table 7 by mapping each bottleneck to the specific optimization technique that addresses it.
Narayanan, Deepak, Mohammad Shoeybi, Jared Casper, Patrick LeGresley, Mostofa Patwary, Vijay Korthikanti, Dmitri Vainbrand, et al. 2021. “Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM.” Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, 1–15. https://doi.org/10.1145/3458817.3476209.
Wang, Linnan, Jinmian Ye, Yiyang Zhao, Wei Wu, Ang Li, Shuaiwen Leon Song, Zenglin Xu, and Tim Kraska. 2018. “SuperNeurons: Dynamic GPU Memory Management for Training Deep Neural Networks.” Proceedings of the 23rd ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming, 41–53. https://doi.org/10.1145/3178487.3178491.
| Bottleneck | Primary Solution(s) |
|---|---|
| Data Movement Latency | Prefetching & Pipeline Overlapping |
| Compute Throughput | Mixed-Precision Training |
| Memory Capacity | Gradient Accumulation & Activation Checkpointing |
| Memory Bandwidth (Attn.) | FlashAttention (IO-aware tiling) |
These bottlenecks manifest differently across system scales (a 100 GB model faces different constraints than a 1 GB model), but identification and mitigation follow consistent principles. Data movement latency emerges when training batches cannot flow from storage through preprocessing to compute units fast enough to keep accelerators in use. Computational throughput limitations occur when mathematical operations execute below hardware peak performance due to suboptimal precision choices or kernel inefficiencies. Memory capacity constraints restrict both the model sizes and batch sizes we can process, directly limiting model complexity and training efficiency.
These bottlenecks interact, illustrating the conservation of complexity thesis from Part I: eliminating a bottleneck inevitably shifts load elsewhere. When data loading becomes a bottleneck, GPUs sit idle waiting for batches. When computation is suboptimal, memory bandwidth goes underutilized. When memory is constrained, we resort to smaller batches that reduce GPU efficiency. Consider GPT-2: profiling reveals memory-bound attention operations (50 percent of time), data loading overhead (25 percent), and compute-bound matrix multiplications (25 percent)—requiring a composition of mixed precision, prefetching, and gradient checkpointing to address all three constraints. The optimization challenge involves identifying which bottleneck currently limits performance, then selecting techniques that address that specific constraint without introducing new bottlenecks elsewhere.
Systematic optimization framework
The profile example shows why optimization must start from evidence rather than preference. Effective optimization follows a systematic methodology that applies regardless of system scale or model architecture: profile to identify bottlenecks, select appropriate techniques for the identified constraints, and compose solutions that address multiple bottlenecks simultaneously without creating conflicts.
The profiling phase employs tools like PyTorch Profiler, TensorFlow Profiler, or NVIDIA Nsight Systems to reveal where time is spent during training iterations. These are the same profiling approaches introduced in the overview, now applied systematically to quantify which bottleneck dominates. A profile might show 40 percent of time in data loading, 35 percent in computation, and 25 percent in memory operations, indicating data loading as the primary target for optimization.
The selection phase matches optimization techniques to identified bottlenecks. Each technique we examine targets specific constraints: prefetching addresses data movement latency, mixed-precision training tackles both computational throughput and memory constraints, and gradient accumulation manages memory limitations. Selection requires understanding the bottleneck type alongside the characteristics of the hardware, model architecture, and training configuration that influence technique effectiveness.
The composition phase combines multiple techniques to achieve cumulative benefits. Prefetching and mixed-precision training complement each other (one addresses data loading, the other computation and memory), allowing simultaneous application. However, some combinations create conflicts: aggressive prefetching increases memory pressure, potentially conflicting with memory-constrained configurations. Successful composition requires understanding technique interactions and dependencies.
This systematic framework (profile, select, compose) applies to the four core optimization techniques covered next. Prefetching targets data movement latency. Mixed-precision training addresses both throughput and memory constraints. FlashAttention eliminates the memory-bandwidth bottleneck in attention layers. Gradient accumulation manages batch-memory limits by serializing micro-batches, while checkpointing trades recomputation for lower activation storage. In practice, high-impact, low-complexity optimizations like data prefetching should be implemented first, while complex optimizations such as gradient checkpointing require cost-benefit analysis that accounts for development effort and debugging complexity.
Figure 9 provides a decision tree that operationalizes this systematic framework. The branches lead from profiling results through bottleneck identification to technique selection, ensuring optimization effort targets the actual constraint rather than perceived issues.

The flowchart embodies a critical insight: optimization is iterative. After applying a technique, re-profiling often reveals that a different bottleneck has become dominant. A data-bound system that implements prefetching may become memory bound, requiring the next technique in the decision tree. This iterative refinement continues until profiling shows balanced resource utilization or acceptable training throughput.
Data prefetching and overlapping
Prefetching and overlapping techniques illustrate the systematic framework in action, targeting data movement latency bottlenecks by coordinating data transfer with computation. This optimization proves most effective when profiling reveals that computational units remain idle while waiting for data transfers to complete.
Training machine learning models involves significant data movement between storage, memory, and computational units. The data pipeline consists of sequential transfers: from disk storage to CPU memory, CPU memory to GPU memory, and through the GPU processing units. In ML training, a “Read” operation is rarely a simple disk fetch: for image workloads it encompasses JPEG decoding, random crops, and color jitter applied on CPU cores before the tensor is ready to transfer; for language workloads it encompasses tokenization, subword encoding, and sequence padding. Figure 10 exposes the inefficiency of sequential data transfer: the GPU remains idle during file operations (Open 1, Open 2), and training steps cannot begin until these read and preprocessing operations complete, leaving expensive compute resources underutilized for significant portions of each epoch.
Prefetching addresses these inefficiencies by loading data into memory before its scheduled computation time. During the processing of the current batch, framework data pipelines such as tf.data load and prepare subsequent batches, maintaining a consistent supply of ready data (Murray et al. 2021).
Murray, Derek G., Jiřı́ Šimša, Ana Klimovic, and Ihor Indyk. 2021. “Tf.data: A Machine Learning Data Processing Framework.” Proceedings of the VLDB Endowment 14 (12): 2945–58. https://doi.org/10.14778/3476311.3476374.
Overlapping builds upon prefetching by coordinating multiple pipeline stages to execute concurrently. The system processes the current batch while simultaneously preparing future batches through data loading and preprocessing operations. Compare figure 10 with figure 11: the optimized pipeline completes two epochs in approximately 55 s compared to 105 s with sequential fetching, a 47.6 percent reduction in wall-clock time achieved by overlapping read and train operations within each time slice.


Prefetching mechanics
Prefetching only pays off when the profile shows data movement on the critical path. Training data still passes through retrieval, transformation, and model execution; the optimization changes when those stages run. An unoptimized pipeline serializes them, leaving the GPU idle during data fetching and preprocessing. Data loaders avoid that stall by preparing the next batch in separate threads or processes while the current batch trains.
Overlapping extends the same idea across the full pipeline. As the GPU processes one batch, preprocessing begins on the next batch, while data fetching starts for the subsequent batch. The goal is constant activity at each stage so the slowest stage no longer leaves the others waiting.
Machine learning frameworks (introduced in ML Frameworks) expose the control variables for this trade-off. Listing 4 demonstrates PyTorch’s DataLoader configuration, where num_workers=4 sets preprocessing parallelism and prefetch_factor=2 maintains a buffer of 8 batches ready for accelerator consumption.
loader = DataLoader(
dataset, batch_size=32, num_workers=4, prefetch_factor=2
)The parameters num_workers and prefetch_factor are not generic performance toggles. They determine CPU parallelism and buffer depth, which means they shift pressure from accelerator idle time to host memory and CPU scheduling.
Buffer management is the main trade-off. A buffer that is too small causes the GPU to wait for data preparation, reintroducing the idle time prefetching was meant to remove. An overly large buffer consumes memory that could otherwise store model parameters or larger batches. The right configuration coordinates CPU preparation, storage I/O, and GPU computation so each resource has work ready at the moment it can use it. These techniques yield the greatest benefit when storage access is slow, preprocessing is complex, or datasets are large.
Practical considerations
Prefetch buffers and overlap depth are tunable, so the same machinery adapts to whichever stage binds, whether slow storage, limited network bandwidth, or computational throughput. Prefetching and overlapping deliver the greatest gains when preprocessing is computationally expensive relative to model computation. A typical image classification pipeline involving random cropping (10 ms), color jittering (15 ms), and normalization (5 ms) adds 30 ms of delay per batch without prefetching; overlapping these operations with the previous batch’s accelerator computation eliminates this stall entirely. NLP workloads similarly benefit when tokenization and subword processing would otherwise block the training loop.
The primary trade-off is memory: prefetch buffers consume GPU or host memory proportional to the buffer depth and batch size. With batch size 256 high-resolution images (\(1024\times 1024\) pixels), one buffered batch requires approximately 3.2 GB. With num_workers= num_workers=4 and prefetch_factor= prefetch_factor=2, the 8-batch prefetch window can hold about 25.8 GB. Tuning num_workers and prefetch_factor requires empirical testing, as excessive worker threads contend for CPU resources while insufficient buffering reintroduces data stalls. A practical starting point is setting num_workers equal to the number of available CPU cores, then profiling to verify that data loading no longer appears as idle GPU time. When storage bandwidth already exceeds compute demand, prefetching adds complexity without measurable throughput improvement.
Mixed-precision training
While prefetching optimizes data movement, mixed-precision training addresses both computational throughput limitations and memory capacity constraints. It uses lower-precision arithmetic where possible while keeping numerically sensitive accumulations in safer formats. Numerical Representations compares FP32, FP16, BF16, FP8, and INT8 precision-range trade-offs. Mixed-precision is most effective when profiling reveals that training is constrained by GPU memory capacity or when computational units are underutilized due to memory bandwidth limitations. Mixed-precision training combines FP32, 16-bit floating-point (FP16), and BF16 formats to reduce memory and accelerate computation while preserving accuracy (Micikevicius et al. 2017; Cloud 2019) (Kalamkar et al. 2019).
Kalamkar, Dhiraj, Dheevatsa Mudigere, Naveen Mellempudi, Dipankar Das, Kunal Banerjee, Sasikanth Avancha, Dharma Teja Vooturi, et al. 2019. A Study of BFLOAT16 for Deep Learning Training.
A neural network trained in FP32 requires 4 bytes per parameter, while both FP16 and BF16 use 2 bytes. For a model with \(10^9\) parameters, this reduction cuts memory usage from 4 GB to 2 GB. This memory reduction enables larger batch sizes and deeper architectures on the same hardware.
The numerical precision differences between these formats shape their use cases. Table 10 reveals that BF16’s 8-bit exponent matches FP32’s dynamic range \((\pm1.18 \times 10^{-38} \text{ to } \pm3.4 \times 10^{38})\), while FP16’s 5-bit exponent gives a minimum normal value of about \(6.1 \times 10^{-5}\). Although FP16 subnormal values extend toward \(6 \times 10^{-8}\), many accelerators flush subnormals to zero, explaining why small gradients can underflow without loss scaling. FP32 represents numbers from approximately \(\pm1.18 \times 10^{-38}\) to \(\pm3.4 \times 10^{38}\) with 7 decimal digits of precision. FP16 ranges from \(\pm6.10 \times 10^{-5}\) to \(\pm65{,}504\) with 3-4 decimal digits of precision. BF16, developed by Google Brain, maintains the same dynamic range as FP32 \((\pm1.18 \times 10^{-38} \text{ to } \pm3.4 \times 10^{38})\) but with reduced precision (3-4 decimal digits). This range preservation makes BF16 particularly suited for deep learning training, as it handles large and small gradients more effectively than FP16.
| Property | FP32 | FP16 | BF16 |
|---|---|---|---|
| Exponent bits | 8 | 5 | 8 |
| Mantissa bits | 23 | 10 | 7 |
| Min normal value | \(10^{-38}\) | \(6.1 \times 10^{-5}\) | \(10^{-38}\) |
| A100 peak throughput ratio | 1\(\times\) | 16× | 16× |
The choice between formats depends on model characteristics. Models with gradient outliers, common in transformer architectures, generally benefit from BF16’s wider dynamic range. Models with well-conditioned gradients may prefer FP16’s greater mantissa precision. Regardless of the reduced-precision format chosen for forward and backward passes, certain operations require FP32 precision: loss accumulation, softmax denominators, normalization variance computation, and optimizer state. These requirements stem from the numerical sensitivity of these operations rather than arbitrary convention.
Figure 12 traces the data flow through mixed-precision training’s six-step cycle: FP32 master weights convert to FP16 for the forward pass (step 1), the forward pass computes FP16 loss (step 2), loss is scaled to prevent gradient underflow (step 3), backpropagation computes scaled FP16 gradients (step 4), gradients are copied to FP32 and unscaled (step 5), and FP32 gradients update the master weights (step 6), completing the cycle that enables Tensor Core acceleration while preserving numerical stability through strategic precision management.

Modern hardware architectures are specifically designed to accelerate reduced precision computations. NVIDIA Tensor Cores were introduced for FP16 mixed-precision operations (NVIDIA 2017), and later A100-class Tensor Cores added BF16 support (NVIDIA Corporation 2020). Google’s TPUs natively support BF16, as this format was specifically designed for machine learning workloads (Cloud 2019). These architectural optimizations typically enable substantially higher computational throughput for reduced precision operations compared to FP32, making mixed-precision training particularly efficient on modern hardware.
NVIDIA. 2017. Training with Mixed Precision.
NVIDIA Corporation. 2020. NVIDIA A100 Tensor Core GPU Architecture. NVIDIA Whitepaper, V1.0.
Mixed-precision training turns those hardware capabilities into a split numerical contract: the fast path and the stable path use different formats. Matrix multiplications, convolutions, and activation functions run primarily in FP16 because their tensor-heavy arithmetic dominates training cost and maps directly to Tensor Core fast paths. Storing and moving those tensors at half precision also reduces activation and gradient traffic, so the performance gain comes from both arithmetic throughput and memory movement. FP32 remains in the update path because the optimizer is where small numerical errors accumulate across many steps. Master weights, gradient accumulation, and weight updates use higher precision to avoid underflow, overflow, and accumulated rounding error. The system therefore does not simply train in FP16; it uses FP16 where the hardware gains are largest and keeps FP32 where convergence is most fragile.
Loss scaling
One of the key challenges with FP16 is its reduced dynamic range24, which increases the likelihood of gradient values becoming too small to be represented accurately. Loss scaling addresses this issue by temporarily amplifying gradient values during backpropagation. Specifically, the loss value is scaled by a large factor (e.g., \(2^{10}\)) before gradients are computed, ensuring they remain within the representable range of FP16.
24 FP16 (Half-Precision Floating-Point): Its reduced dynamic range stems from using only 5 exponent bits, vs. 8 in FP32. As a result, it cannot represent values smaller than \(6.1 \times 10^{-5}\), causing gradients that fall below this threshold to be flushed to zero. The loss scaling operation described explicitly counters this by amplifying gradients, ensuring they remain above this hardware-imposed floor.
Machine learning frameworks provide built-in support for mixed-precision training. PyTorch’s torch.cuda.amp (Automatic Mixed Precision) library automates the process of selecting which operations to perform in FP16 or FP32, as well as applying loss scaling when necessary.
Mixed-precision benefits
Mixed-precision benefits manifest across three dimensions that compound in practice:
- Memory consumption: Decreases by approximately 50 percent. A one billion parameter transformer requires 4 GB in FP32 but only 2 GB in FP16 for weights alone, enabling larger batch sizes or deeper architectures.
- Computational throughput: Increases dramatically as Tensor Cores achieve 2–3\(\times\) speedup for matrix multiplications, as detailed in section 1.5.3.3.
- Communication bandwidth: Decreases proportionally when halving tensor sizes reduces inter-device communication requirements in distributed training.
These benefits compound: a practitioner might simultaneously double batch size (memory savings), accelerate each iteration (Tensor Core throughput), and reduce gradient synchronization time (smaller tensors). On GPT-2, the combined effect is visible in both the memory budget and the training throughput.
Napkin Math 1.6: GPT-2 mixed precision memory savings
Problem: Can GPT-2 XL (1.5B parameters) be trained on a single V100 GPU, and what does mixed precision plus gradient checkpointing buy us in memory footprint?
FP32 baseline:
- Parameters and gradients (FP32): 12 GB (6 GB parameters + 6 GB gradients)
- Activations (batch = 4): ~71.7 GB
- Optimizer states (Adam m, v in FP32): 12 GB
- Total: ~95.7 GB (exceeds any single GPU)
FP16 mixed precision:
- Parameters (FP16): 1.5B parameters at 2 bytes each = 3 GB
- Activations (FP16): ~35.9 GB
- Gradients (FP16): 3 GB
- FP32 master weights: 6 GB (for precise optimizer updates)
- Optimizer states (Adam m, v in FP32): 12 GB
- Total: ~59.9 GB (still tight, but manageable with optimizations)
Mixed precision + gradient checkpointing:
- Activations reduced to ~9 GB (recompute during backward)
- Total: ~33 GB → fits in 32 GB V100
Systems insight: Mixed precision halves the parameter and gradient footprint; gradient checkpointing then trades a backward-pass recompute for an additional activation-memory cut. Together they bring GPT-2 XL at batch size 4 within V100 capacity, turning an out-of-memory configuration into a trainable one. The relief is bounded, because activations grow linearly with batch size: at batch 32, the same recipe still requires ~95.7 GB, beyond any single accelerator, which is where the scaling techniques later in this chapter take over.
Memory savings alone do not guarantee correct or stable training. FP16’s limited dynamic range demands specific implementation choices to keep gradients representable and weight updates nonzero.
Three implementation details make mixed precision viable:
- Loss scaling: Multiplies the loss by a factor, typically starting at \(2^{15}\) and dynamically halved when overflow is detected, so that small gradients land in FP16’s representable range. Attention-layer gradients can span \(10^{-6}\) to \(10^{3}\), and without scaling the smallest of these would underflow to zero.
- FP32 master weights: Preserve tiny optimizer updates that would otherwise round to zero when a small learning rate (2.5e-4) is multiplied by an FP16 gradient.
- Selective FP32 computation: Keeps LayerNorm and Softmax in FP32 because variance computation needs high precision and exponentials need the full FP32 range, while every other operation runs in FP16.
With these stability mechanisms in place, the gains from mixed precision are measurable in throughput and dollars.
The throughput and cost win does not make mixed precision automatic. The primary limitation is FP16’s restricted dynamic range of \(\pm65{,}504\). Gradient values below \(6 \times 10^{-5}\) underflow to zero. Loss scaling factors, typically \(2^{8}\) to \(2^{14}\), keep gradients within the representable range. Recurrent architectures with long sequences are particularly susceptible to accumulated numerical errors. NaN values in gradients or activations, the telltale sign of precision failures, appear more frequently in FP16 workflows and may manifest differently than in FP32, complicating debugging. BF16 eliminates many of these issues by preserving FP32’s dynamic range, though at the cost of reduced mantissa precision. For models under 10M parameters, the overhead of configuring mixed precision may exceed the performance benefit.
Napkin Math 1.7: GPT-2 mixed precision throughput and cost
Problem: For the same GPT-2 XL training job on V100 Tensor Cores, how much faster and how much cheaper does mixed precision make training compared to FP32?
V100 throughput (Tensor Cores enabled):
- FP32 throughput: ~90 samples/s
- FP16 throughput: ~220 samples/s
- Speedup: 220 samples/s ÷ 90 samples/s ≈ 2.4× faster training
Cost impact on a cluster of 32 GPUs:
- Assumed FP32 billing: $50,000 for 2 weeks
- Assumed FP16 billing: $28,000 for 1.2 weeks
- Wall-clock gain: 2 weeks ÷ 1.2 weeks ≈ 1.7×, below the 2.4× throughput speedup, since the assumed schedule includes work the FP16 kernels do not accelerate
- Time saved: 2 weeks − 1.2 weeks = 0.8 weeks (5.6 days)
- Cost saved: $50,000 − $28,000 = $22,000
Quality impact: minimal. GPT-2 perplexity stays within 0.5 percent of the FP32 baseline, well within noise margin.
Systems insight: Mixed precision converts the same cluster of 32 GPUs from a job of 2 weeks and $50,000 into one of 1.2 weeks and $28,000 with no measurable convergence cost—a quality-neutral speedup that pays for itself in 5.6 days of saved wall-clock time.
Mixed-precision hardware support
Understanding how modern hardware implements reduced-precision arithmetic explains why mixed precision changes wall-clock time, not only memory capacity. The performance gains from FP16 and BF16 computation come from specialized hardware units designed for low-precision tensor operations25. Those units trade numerical range or precision for much higher matrix throughput, while the training recipe keeps numerically sensitive accumulations in safer formats.
25 Tensor Core: The specialized hardware unit behind the FP16/BF16 speedups described here. Each Tensor Core performs a fused \(4{\times}4\) matrix multiply-accumulate in a single cycle, achieving 8–16\(\times\) the throughput of standard CUDA cores. The catch: input matrices must align to multiples of 8 or 16 for peak utilization, meaning misaligned tensor dimensions in a training workload silently forfeit most of this hardware advantage.
NVIDIA introduced Tensor Cores in their Volta architecture (2017) as dedicated matrix multiplication units optimized for mixed-precision workloads. Unlike standard CUDA cores that process scalar or small vector operations, Tensor Cores perform \(4{\times}4\) matrix multiply-accumulate operations in a single clock cycle. For FP16 inputs, a single Tensor Core executes: \[ \mathbf{D}_{\text{tc}} = \mathbf{A}_{\text{tc}} \times \mathbf{B}_{\text{tc}} + \mathbf{C}_{\text{acc}} \] where \(\mathbf{A}_{\text{tc}}\) and \(\mathbf{B}_{\text{tc}}\) are \(4{\times}4\) FP16 matrices, \(\mathbf{C}_{\text{acc}}\) is an FP32 accumulator, and \(\mathbf{D}_{\text{tc}}\) is the FP32 result. This accumulation in higher precision prevents catastrophic cancellation errors that would occur if intermediate products were stored in FP16.
The peak numbers make the upper bound concrete. An NVIDIA A100 GPU exposes 19.5 TFLOP/s of FP32 throughput on standard CUDA cores and 312 TFLOP/s of FP16 or BF16 Tensor Core throughput, a 16× peak ratio. H100-class accelerators add FP8 Tensor Cores at 1,979 TFLOP/s without sparsity, about 2× the H100 FP16/BF16 Tensor Core rate. These figures are hardware ceilings, not end-to-end training promises: matrix multiplications map naturally to Tensor Cores, but data movement, non-Tensor-Core kernels, communication, loss scaling, and optimizer work remain. A transformer’s attention mechanism computing \(\mathbf{Q}\mathbf{K}^T\) for a tensor shaped by batch size \(B\), number of heads \(N_{\text{heads}}\), sequence length \(S\), and head dimension \(d_{\text{head}}\) requires \(2 \times B \times N_{\text{heads}} \times S^2 \times d_{\text{head}}\) FLOPs; this portion can accelerate dramatically, while the rest of the step determines the realized speedup.
Brain Float 16 (BF16) maintains FP32’s 8-bit exponent while reducing the mantissa to 7 bits. This design choice prioritizes dynamic range preservation over precision, which matters for gradient-based learning where values span many orders of magnitude. Google’s TPUs natively support BF16, while NVIDIA’s Ampere architecture (A100) and newer provide full hardware support.
The hardware advantage of BF16 over FP16 emerges in gradient summation scenarios. Consider summing 1000 gradients with values around \(10^{-4}\). FP16’s smallest normal value is \(6.1 \times 10^{-5}\), while its theoretical subnormal floor extends to approximately \(6 \times 10^{-8}\).26 In practice, hardware that flushes subnormals can discard values below the normal threshold. BF16’s smallest positive normal value is approximately \(10^{-38}\), matching FP32’s normal exponent range, so no underflow occurs in the regime where FP16 would already have lost those values. FP32 has full range but computes 2\(\times\) slower. For transformer training where attention gradients vary from \(10^{-10}\) to \(10^3\), BF16’s range prevents the loss scaling complexity required for FP16, simplifying implementation without sacrificing throughput.
26 FP16 Subnormal Flushing: To accelerate computation, hardware often flushes any FP16 value smaller than the minimum normal value (\(6.1 \times 10^{-5}\)) to zero. This flushing is the direct cause of the underflow described in the gradient summation scenario, as any gradient between the hardware floor and the theoretical limit of \(6 \times 10^{-8}\) is discarded. This creates a practical precision gap where values are abruptly lost, a gap that does not exist for the BF16 format.
NVIDIA’s Hopper architecture (H100) introduces FP8 support with two formats. E4M3 uses four exponent bits and three mantissa bits (prioritizing precision for forward pass weights and activations), while E5M2 uses five exponent bits and two mantissa bits (prioritizing dynamic range for backward pass gradients).
FP8 training doubles Tensor Core throughput again (1.98 PFLOP/s on H100 dense vs. 0.99 PFLOP/s for FP16 dense, without sparsity). However, FP8’s severely limited precision requires per-tensor scaling factors maintained in higher precision, adding algorithmic complexity. Table 11 summarizes when each precision is appropriate:
| Precision | When to Use | Hardware Requirement |
|---|---|---|
| FP8 | Maximum throughput on H100, with careful scaling | H100 or newer |
| BF16 | Default for transformers, wide dynamic range | A100, TPU v4+ |
| FP16 | Computer vision, controlled gradients | V100, A100 |
| FP32 | Numerical stability critical, small models | All GPUs |
The decision rule is workload first, hardware second. FP8 is a Hopper-throughput choice when scaling can be validated, BF16 is the transformer default because range failures are expensive, FP16 remains practical for controlled-gradient vision workloads, and FP32 is the fallback when stability matters more than throughput.
Reduced precision accelerates computation and alleviates memory bandwidth bottlenecks. Modern GPUs are increasingly compute-bound rather than bandwidth-bound for large matrix operations, but data movement still limits performance for smaller operations. A100’s specifications illustrate this:
- HBM2e bandwidth: 2,039 GB/s
- FP32 throughput (19.5 TFLOP/s): worst-case demand is 78 TB/s if every FLOP needs new data
- Actual requirement (with data reuse): Much lower, but bandwidth-limited for operations with low arithmetic intensity
FP16 halves memory traffic for the same computation, effectively doubling available bandwidth. For operations like layer normalization (arithmetic intensity approximately 1 FLOP/byte), this bandwidth doubling directly translates to speedups even without Tensor Core involvement.
Modern frameworks abstract hardware complexity through automatic operation routing, as discussed in ML Frameworks. The framework runtime determines which operations benefit from reduced precision and which require FP32 for numerical stability. PyTorch’s automatic mixed precision manages precision selection and loss scaling transparently, as listing 5 illustrates.
import torch
from torch.cuda.amp import autocast, GradScaler
model = TransformerModel().cuda()
optimizer = torch.optim.Adam(model.parameters(), lr=1e-4)
scaler = GradScaler() # Handles loss scaling automatically
for batch in dataloader:
optimizer.zero_grad()
# Automatic precision selection per operation
with autocast(dtype=torch.float16): # or torch.bfloat16
output = model(batch)
loss = criterion(output, target)
# Scale loss to prevent gradient underflow
scaler.scale(loss).backward()
# Unscale gradients before optimizer step
scaler.step(optimizer)
scaler.update() # Adjust scaling factor dynamicallyThe autocast context routes matrix multiplications and convolutions to FP16 or BF16 while keeping softmax, layer normalization, and loss computation in FP32. This selective precision maximizes hardware utilization while maintaining numerical stability, but the best precision policy still depends on hardware support. Table 12 summarizes the recommended precision strategy for each GPU generation, reflecting the evolution from FP16-only support on Volta to native FP8 on Hopper.
| Architecture | Recommended Precision | Key Considerations |
|---|---|---|
| V100 (Volta) | FP16 with loss scaling | No BF16 support; gradient clipping essential |
| A100 (Ampere) | BF16 for transformers; FP16 for CNNs | TF32 mode provides automatic 2–3\(\times\) speedup for legacy FP32 code |
| H100 (Hopper) | FP8 via TransformerEngine | Requires FP8-aware training recipes; 1,979 TFLOP/s peak throughput |
The performance impact across generations appears in the throughput numbers: training our lighthouse GPT-2 model (1.5B) on a single GPU illustrates how hardware and precision co-evolve: V100 achieves 18 samples/s in FP32 and 45 samples/s in FP16 (2.5× speedup), A100 reaches 165 samples/s in BF16 (9.2× over V100 FP32), and H100 delivers 380 samples/s in FP8 (21.1× over V100 FP32). These speedups compound with reduced-precision memory savings, enabling both faster iteration and larger models. The hardware-software co-design principle is evident: algorithmic techniques like mixed precision unlock specialized hardware capabilities, while hardware features like Tensor Cores make certain algorithms practical.
Flash attention: IO-aware attention optimization
Mixed-precision training addresses two bottlenecks: compute throughput, because Tensor Cores operate faster on FP16, and memory capacity, because each value uses fewer bytes. For transformer models during training, however, a third bottleneck often dominates: memory bandwidth. The attention mechanism’s quadratic intermediate matrices must be repeatedly loaded and stored during the forward pass and accessed again during backpropagation. Even with reduced precision, the sheer volume of memory traffic can leave compute units idle while the processor waits for data.
FlashAttention27 (Dao et al. 2022) addresses this bandwidth bottleneck by optimizing how data flows between memory hierarchies. By processing attention in small tiles that fit in fast on-chip SRAM, FlashAttention avoids materializing the full \(S{\times}S\) attention matrix in slow HBM. This algorithmic restructuring achieves 2–4\(\times\) training speedups while enabling training on sequences that would otherwise cause out-of-memory errors.
27 FlashAttention: Introduced by Dao et al. (2022), achieving 2–4\(\times\) wall-clock speedups without changing the mathematical output of attention. The key insight was treating attention as an IO problem rather than a compute problem: by never materializing the \(S{\times}S\) score matrix in HBM and instead computing in SRAM-sized tiles, the algorithm shifted the operation from memory-bound to compute-bound on the roofline model. FlashAttention-2 (Dao 2023) further improved throughput to 50–73 percent of theoretical peak on A100.
Dao, T., D. Y. Fu, S. Ermon, A. Rudra, and C. Ré. 2022. “FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness.” Advances in Neural Information Processing Systems 35 35: 16344–59. https://doi.org/10.52202/068431-1189.
Dao, Tri. 2023. “FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning.” arXiv Preprint arXiv:2307.08691.
The standard attention memory bottleneck
As detailed in Network Architectures, standard self-attention computes relationships between all positions in a sequence. For an input sequence of length \(S\), the mechanism computes an \(S{\times}S\) attention matrix according to equation 16:
\[ \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V \tag{16}\]
Here, \(Q\), \(K\), and \(V\) are the query, key, and value matrices for the sequence, and \(d_k\) is the key-vector dimension used to scale the dot products before softmax. The \(QK^T\) term is the source of the \(S{\times}S\) score matrix, which is why attention becomes an I/O problem even when the arithmetic itself maps well to Tensor Cores.
The memory bottleneck emerges from materializing the \(S{\times}S\) intermediate matrices for scores and probabilities. For a sequence length of 4,096 with embedding dimension 64 (typical for a single attention head), the attention score matrix alone requires \(4,096^2 \times 4\) bytes = 67.1 MB in FP32. With 16 heads, this grows to 1.1 GB just for intermediate attention matrices, not including the keys, queries, values, or output tensors.
Modern GPU memory hierarchy exacerbates this bottleneck. HBM provides 40–80 GB capacity with 1–2 TB/s bandwidth, while SRAM provides only 20–40 MB capacity but delivers 20+ TB/s bandwidth (10\(\times\) faster). Standard attention stores these large matrices in slow HBM and repeatedly loads them during the backward pass. For GPT-2 scale models processing 2048-token sequences, attention operations spend 70–80 percent of execution time waiting for memory transfers rather than computing, leaving expensive tensor cores underutilized.
The backward pass compounds this problem. Computing \(\frac{\partial \mathcal{L}}{\partial \mathbf{Q}}\), \(\frac{\partial \mathcal{L}}{\partial \mathbf{K}}\), and \(\frac{\partial \mathcal{L}}{\partial \mathbf{V}}\) requires access to the attention probability matrix \(\mathbf{A}_{\text{attn}} = \text{softmax}(\mathbf{Z}_{\text{attn}})\) and the raw scores \(\mathbf{Z}_{\text{attn}} = \mathbf{Q}\mathbf{K}^T/\sqrt{d_k}\) from the forward pass. Differentiating through softmax couples every element of \(\mathbf{A}_{\text{attn}}\) to every element of \(\mathbf{Z}_{\text{attn}}\), so the full \(S{\times}S\) matrices must be stored: \[ \frac{\partial \mathcal{L}}{\partial \mathbf{Q}} = \frac{1}{\sqrt{d_k}} \cdot \text{dsoftmax}\!\left(\frac{\partial \mathcal{L}}{\partial \mathbf{A}_{\text{attn}}},\, \mathbf{A}_{\text{attn}}\right) \cdot \mathbf{K} \] where \(\text{dsoftmax}\) denotes the Jacobian-vector product of softmax, which itself depends on the stored \(\mathbf{A}_{\text{attn}}\) matrix. Analogous expressions for \(\frac{\partial \mathcal{L}}{\partial \mathbf{K}}\) and \(\frac{\partial \mathcal{L}}{\partial \mathbf{V}}\) also require \(\mathbf{A}_{\text{attn}}\) and \(\mathbf{Z}_{\text{attn}}\). Storing both for all layers in HBM during the forward pass doubles memory requirements and creates multiple round-trips between HBM and compute units during backpropagation.
IO-aware attention through tiling
FlashAttention eliminates the need to materialize full \(S{\times}S\) attention matrices in HBM by computing attention incrementally through tiling. Instead of computing the entire attention matrix at once, the algorithm partitions \(Q\), \(K\), and \(V\) into tiles small enough to fit in fast SRAM, computes attention scores for these tiles, and incrementally accumulates results.
The key algorithmic insight relies on the mathematical structure of softmax attention. Standard attention computes: \[ \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V \]
Algorithm 3 decomposes this computation by partitioning the queries and the keys/values into tiles small enough to fit in SRAM, then streaming over the key/value tiles while maintaining the running softmax statistics needed to assemble each output tile, without ever forming the full score matrix.

FlashAttention swaps the full attention matrix for small SRAM tiles.
\begin{algorithm} \caption{FlashAttention: tiled attention with online softmax} \begin{algorithmic} \Require queries $Q$, keys $K$, values $V$ for a length-$S$ sequence; tile size $b$ \Ensure attention output $Y$, without materializing the $S\times S$ score matrix \For{each query tile $Q_i$} \State in SRAM: $Y_i^{\text{acc}} \gets \mathbf{0}$, $m_i \gets -\infty$, $l_i \gets 0$ \For{each key/value tile $(K_j, V_j)$} \State load $Q_i, K_j, V_j$ into SRAM; $Z_{ij} \gets Q_i K_j^\top / \sqrt{d_k}$ \State $m_i' \gets \max(m_i,\operatorname{rowmax}(Z_{ij}))$ \Comment{new stable max} \State $Y_i^{\text{acc}} \gets Y_i^{\text{acc}}\odot e^{m_i-m_i'} + e^{Z_{ij}-m_i'}V_j$ \State $l_i \gets l_i\odot e^{m_i-m_i'} + \operatorname{rowsum}(e^{Z_{ij}-m_i'})$; $m_i \gets m_i'$ \State discard $Z_{ij}$ \Comment{never written to HBM} \EndFor \State $Y_i \gets Y_i^{\text{acc}} / l_i$; write $Y_i$ to HBM \EndFor \end{algorithmic} \end{algorithm}
No \(S{\times}S\) matrix ever exists in HBM. The largest intermediate tensor is \(b{\times}b\) (typically \(b = 128\)), requiring only 64 KB for a \(128{\times}128\) FP32 matrix compared to 64 MB for the full \(4096{\times}4096\) matrix.
The online softmax algorithm enables this decomposition. Traditional softmax requires knowing all inputs before computing any output: \(\text{softmax}(x)_i = e^{x_i} / \sum_j e^{x_j}\). FlashAttention uses an incremental formulation that updates softmax statistics as new blocks arrive, tracking the running maximum \(m\) (for numerical stability) and denominator \(l\) as each block is processed, then rescaling accumulated outputs accordingly.
Memory and IO complexity analysis
FlashAttention improves both activation memory and memory IO, which are the limiting costs in bandwidth-bound attention. Standard attention requires \(\mathcal{O}(S^2)\) memory to store score matrices \(\mathbf{Z}_{\text{attn}}\) and attention-probability matrices \(A_{\text{attn}}\) across all sequence positions. FlashAttention reduces the stored activation footprint to \(\mathcal{O}(S)\) by keeping only input and output tensors \((Q, K, V, Y)\) plus a small SRAM buffer for the current tile.
For \(S = 4096\), \(d_{\text{head}} = 64\): Standard attention requires \(4096^2 \times 4\) bytes = 67.1 MB per head. FlashAttention requires only \((3 \times 4096{\times}64) \times 4\) bytes ≈ 3.1 MB per head, a 21.3× reduction.
The IO pattern changes for the same reason. Standard attention reads \(Q\), \(K\), and \(V\) from HBM, writes score, probability, and output matrices during the forward pass, then rereads those stored matrices during the backward pass before writing \(dQ\), \(dK\), and \(dV\). The resulting HBM traffic includes the same \(\mathcal{O}(S^2)\) term that made the activation footprint large. FlashAttention forms score and probability blocks in SRAM and never writes the full \(S \times S\) tensors to HBM. In the backward pass, it recomputes the needed blocks rather than reading stored full matrices. The exact HBM IO complexity depends on tile size and available SRAM because key and value blocks are streamed repeatedly across query blocks, so the bound is not simply \(\mathcal{O}(S \cdot d)\).
For large sequence lengths, FlashAttention reduces HBM traffic by avoiding writes and rereads of the \(S \times S\) score and probability matrices. With \(S = 4096\) and \(d_{\text{head}} = 64\), the activation memory footprint falls from hundreds of MB per head for stored attention matrices to a few MB for tiled inputs and outputs, while the precise bandwidth reduction depends on hardware and kernel tiling.
Both approaches require the same \(\mathcal{O}(S^2 d)\) asymptotic FLOPs for attention computation. FlashAttention’s backward pass recomputes attention activations from the saved \(Q, K, V\) rather than storing the full score and probability matrices, trading a small amount of recomputation for dramatically reduced HBM traffic. By converting the workload from bandwidth-bound to compute-bound, FlashAttention achieves net speedups since modern GPUs have abundant compute capacity but limited memory bandwidth.
Implementation and hardware utilization
FlashAttention’s performance gains materialize through careful exploitation of GPU memory hierarchy. Modern frameworks integrate these optimizations transparently, automatically selecting the most efficient attention implementation based on hardware capabilities and input characteristics. Listing 6 contrasts standard and optimized attention implementations.
import torch
import torch.nn.functional as F
# Standard attention (materializes n-by-n matrix)
def standard_attention(q, k, v):
# q, k, v: [batch, heads, seq_len, head_dim]
scores = torch.matmul(q, k.transpose(-2, -1)) / (
q.size(-1) ** 0.5
)
attn = F.softmax(scores, dim=-1) # n-by-n matrix in HBM
output = torch.matmul(attn, v)
return output
# FlashAttention (no n-by-n materialization)
def flash_attention(q, k, v):
# Automatically uses FlashAttention if available
output = F.scaled_dot_product_attention(q, k, v)
return output
# Explicit FlashAttention 2 (flash-attn library)
from flash_attn import flash_attn_func
def flash_attn_2(q, k, v):
# q, k, v: [batch, seq_len, heads, head_dim]
# Different layout for optimized memory access
output = flash_attn_func(q, k, v)
return outputBenchmark results
The benefits of FlashAttention become concrete when measured on real hardware. Dao et al. (2022) reports end-to-end GPT-style training speedups and separate attention-kernel benchmarks showing that IO-aware attention reduces memory traffic and improves runtime. Table 13 uses an illustrative A100-style scenario to show the same systems pattern; its timings and memory values are representative chapter numbers, not values reported verbatim by Dao et al.
| Sequence Length | Standard Forward | Flash Forward | Standard Backward | Flash Backward | Memory (Standard) | Memory (Flash) |
|---|---|---|---|---|---|---|
| 512 | 12 ms | 8 ms | 35 ms | 18 ms | 4.2 GB | 2.8 GB |
| 2048 | 45 ms | 15 ms | 120 ms | 35 ms | 18 GB | 6 GB |
| 4096 | OOM | 32 ms | OOM | 85 ms | >40 GB | 12 GB |
| 8192 | OOM | 68 ms | OOM | 180 ms | >80 GB | 24 GB |
In this illustrative 40 GB A100-style scenario, standard attention runs out of memory beyond 2048 tokens, while FlashAttention fits sequences up to 8192 tokens. Even at 2048 tokens where both fit, FlashAttention achieves 3× forward pass speedup and 3.4× backward pass speedup.
Subsequent versions have continued improving performance: FlashAttention-2 (Dao 2023) achieved 1.5–2\(\times\) additional speedup through better parallelism and register allocation, while FlashAttention-3 (Shah et al. 2024) exploits FP8 tensor cores and asynchronous memory operations on Hopper GPUs and reports reaching approximately 740 TFLOP/s on H100, around 75 percent of theoretical peak.
Shah, Jay, Ganesh Bikshandi, Ying Zhang, Vijay Thakkar, Pradeep Ramani, and Tri Dao. 2024. “FlashAttention-3: Fast and Accurate Attention with Asynchrony and Low-Precision.” Advances in Neural Information Processing Systems 37 (NeurIPS), 68658–85. https://doi.org/10.52202/079017-2193.
When to use flash attention
For transformer training with long sequences, FlashAttention is usually the first attention implementation to test. It often becomes essential once sequence length pushes standard attention into an HBM-capacity or HBM-bandwidth bottleneck, especially around the multi-thousand-token regime where the \(S{\times}S\) attention matrices dominate memory. A100- and H100-class GPUs with fast on-chip SRAM benefit most. The returns diminish for short sequences where tiling overhead is not worthwhile, on older GPU architectures without comparable SRAM bandwidth, and for nonattention architectures such as convolutional neural networks (CNNs) and multilayer perceptrons (MLPs).
In practice, deep learning frameworks handle much of FlashAttention’s integration, but the decision still depends on layout, precision, and memory budget. PyTorch 2.0+ automatically selects FlashAttention when available and appropriate. Three practical checks determine whether FlashAttention is appropriate:
- Ensure tensor layouts match library expectations (contiguous memory, correct dimension ordering)
- Use FP16 or BF16 for maximum speedup (FlashAttention optimized for mixed precision)
- Combine with gradient checkpointing for further memory savings (4–8\(\times\) larger models trainable)
The integration is often a single-line change—swapping a manual attention call for F.scaled_dot_product_attention (as shown in listing 6). The engineering decision is still the same one established by the roofline analysis: use the optimized primitive when the bottleneck is HBM traffic, and let the library manage the tiling and SRAM scheduling needed to remove it.
Systems implications and broader principles
FlashAttention exemplifies a fundamental systems engineering principle: IO-aware algorithm design. The core insight recognizes that many accelerators are compute-abundant relative to their memory bandwidth. An algorithm’s runtime is determined not by FLOP count but by memory traffic.
This principle extends beyond attention. In IO-aware matrix multiplication, tiling algorithms like those in CUTLASS minimize DRAM traffic by maximizing data reuse in fast caches. A naive \(m{\times}m\) matrix multiply performs \(\mathcal{O}(m^3)\) FLOPs with \(\mathcal{O}(m^2)\) memory traffic, while blocked algorithms maintain \(\mathcal{O}(m^3)\) FLOPs but reduce cache misses through locality optimization.
The same byte-movement principle reappears in communication-efficient distributed training, where gradient compression trades extra computation (compression/decompression) for reduced network bandwidth consumption. Low-power edge devices with limited memory bandwidth benefit even more from IO-aware algorithms, where a 10 percent increase in FLOPs that halves memory traffic yields 3–5\(\times\) energy savings. This section establishes the IO-aware heuristic; distributed and edge deployment settings reuse the same byte-movement logic.
FlashAttention transforms practical model training capabilities. By eliminating the \(\mathcal{O}(S^2)\) memory bottleneck, FlashAttention enables three capabilities:
- Longer sequences: Enables 4\(\times\) context length on the same hardware, moving GPT-2 on A100 from 2K to 8K context.
- Larger batch sizes: Doubles batch size through freed memory, improving convergence behavior.
- Deeper models: Reduces activation memory so more layers fit in the same memory budget.
For a 7-billion-parameter model training on A100 GPUs, FlashAttention can transform the memory feasibility calculation from OOM at a 2K context to an 8K-context run with room for batch size 32 under the chapter’s scenario assumptions.
The technique demonstrates that algorithmic innovation at the systems level, exploiting hardware characteristics like memory hierarchy, can provide order-of-magnitude improvements that hardware scaling alone would not deliver. Treating memory bandwidth as the primary constraint and compute as abundant is a recurring pattern in ML performance optimization.
FlashAttention addresses memory bandwidth bottlenecks during computation, but another class of memory constraints exists: the sheer capacity required to store activations and optimizer states simultaneously. When models or batch sizes exceed GPU memory capacity, two complementary techniques trade computation for memory.
Gradient accumulation and checkpointing
Training large models requires substantial memory for storing activations, gradients, and model parameters simultaneously. When GPU memory constrains the batch size or model complexity, gradient accumulation28 and activation checkpointing address these limitations by trading computation for memory. These techniques exploit the efficiency principles formalized by the iron law in Iron Law of ML Systems and become standard tools when memory is the binding constraint.
28 Gradient Accumulation: Enables effective batch sizes of 2,048+ on single GPUs with only 32–64 micro-batch capacity, essential for transformer training where convergence requires large batches. The technique sums gradients across \(k\) micro-batches before a single optimizer step, trading 10–15 percent wall-clock overhead from micro-batch serialization, synchronization, and gradient-buffer management for \(k\times\) lower activation memory. BERT-Large training achieved 99.5 percent of full-batch performance using an effective batch size of 256 accumulated over eight steps.
Gradient accumulation and checkpointing mechanics
Gradient accumulation and activation checkpointing operate on distinct principles, but both aim to optimize memory usage during training by modifying how forward and backward computations are handled. Gradient accumulation changes how many examples contribute to one update; checkpointing changes which activations remain resident between the forward and backward passes.
Gradient accumulation
Gradient accumulation simulates larger batch sizes by splitting a single effective batch into smaller “micro-batches.” Follow the data flow in figure 13 to see this in action: three independent batches (green, red, blue) each compute their own loss (\(\mathcal{L}_1\), \(\mathcal{L}_2\), \(\mathcal{L}_3\)) and gradients (\(\delta_1\), \(\delta_2\), \(\delta_3\)), which then sum to produce the combined gradient \(\delta_1+\delta_2+\delta_3\) used for a single parameter update. This approach achieves the same gradient as training with a batch three times larger, without requiring the memory to hold all samples simultaneously.

In PyTorch, gradient accumulation is usually implemented by dividing each microbatch loss by the number of accumulation steps and calling optimizer.step() only after processing the entire effective batch. Under that averaging convention, no learning-rate adjustment is needed solely because of accumulation. The implementation follows five steps:
- Perform the forward pass for a micro-batch.
- Compute the gradients during the backward pass.
- Accumulate the gradients into a buffer without updating the model parameters.
- Repeat steps 1–3 for all micro-batches in the effective batch.
- Update the model parameters using the accumulated gradients after all micro-batches are processed.
Gradient accumulation can reproduce the gradient of a larger batch under controlled assumptions. For an effective batch size \(B = k \times b\) where \(k\) is the number of accumulation steps and \(b\) is the micro-batch size, equation 17 confirms that the accumulated gradient equals the true batch gradient: \[ \nabla \mathcal{L}_B = \frac{1}{B}\sum_{i=1}^{B} \nabla \mathcal{L}_i = \frac{1}{k}\sum_{j=1}^{k}\left(\frac{1}{b}\sum_{i \in \mathcal{B}_j} \nabla \mathcal{L}_i\right) \tag{17}\]
This equivalence holds when each example’s computation is identical and the loss is averaged consistently. The right-hand side shows that averaging \(k\) micro-batch gradients (each computed over \(b\) examples) produces the same result as computing the gradient over all \(B = kb\) examples at once. Stateful layers such as BatchNorm, stochastic operations such as dropout and data augmentation, finite-precision accumulation order, and step-indexed schedules can break exact equivalence, so large-batch accumulation still requires validation.
Gradient accumulation exchanges memory capacity for computation time. Table 14 separates the memory benefit from the compute and scheduling costs that remain.
| Dimension | Effect |
|---|---|
| Memory | \(\mathcal{O}(b)\) instead of \(\mathcal{O}(B)\), yielding a \(k\times\) reduction in activation memory |
| Computation | Unchanged total FLOPs, as all \(B\) examples are still processed |
| Time | \(k\) forward and backward passes execute before each optimizer step, introducing synchronization overhead |
The time overhead per accumulation step is typically 2–5 percent, arising from the additional synchronization and gradient buffer management. For \(k\) accumulation steps with micro-batch time \(T_{\text{micro}}\) and synchronization overhead \(T_{\text{sync}}\), equation 18 gives the effective time per update: \[ T_{\text{effective}} = k \times T_{\text{micro}} + (k-1) \times T_{\text{sync}} \tag{18}\]
In practice, this overhead is small compared to the memory savings. Training BERT-Large with effective batch size 256 using eight accumulation steps of micro-batch 32 reduces activation memory by 8\(\times\) while adding only 10–15 percent to wall-clock time.
When gradient accumulation is combined with distributed data parallelism across multiple machines, additional considerations arise for gradient synchronization timing and effective batch size calculation across the cluster. Advanced distributed systems texts treat these patterns in depth.
Activation checkpointing
Activation checkpointing reduces memory usage during the backward pass by discarding and selectively recomputing activations. In standard training, activations from the forward pass are stored in memory for use in gradient computations during backpropagation. However, these activations can consume gigabytes of memory, particularly in deep networks.
With checkpointing, only a subset of the activations is retained during the forward pass. The two-pass structure in figure 14 illustrates this memory-compute trade-off: during the forward pass (top row), only checkpoint nodes (green, solid) are retained while intermediate nodes (white, dashed) are discarded. During the backward pass (bottom row), these discarded activations are recomputed on demand (orange nodes) from the nearest checkpoint, trading approximately 33 percent additional compute for memory savings that can exceed 70 percent in deep networks.

The implementation keeps the capacity trade-off explicit. The system splits the model into segments, retains activations only at segment boundaries during the forward pass, and recomputes intermediate activations during the backward pass when needed.
Frameworks like PyTorch provide tools such as torch.utils.checkpoint to simplify this process, but the recompute cost remains. Checkpointing is most effective for deep architectures with dozens or hundreds of layers, such as transformers or large convolutional networks, where activation storage exceeds the GPU’s capacity before arithmetic throughput is exhausted.
The synergy between gradient accumulation and checkpointing enables training of larger, more complex models. Gradient accumulation manages memory constraints related to batch size, while checkpointing optimizes memory usage for intermediate activations. Together, these techniques expand the range of models that can be trained on available hardware.
Optimal checkpoint placement strategy
For a network with \(N_L\) layers, each storing \(A\) bytes of activations, table 15 quantifies how the number and placement of checkpoints determines the memory-compute trade-off. Sub-linear checkpointing strategies can reduce memory consumption from \(\mathcal{O}(N_L)\) to \(\mathcal{O}(\sqrt{N_L})\) with only a fractional increase in total compute time, enabling the training of much deeper models on existing hardware.
| Strategy | Memory Cost | Recompute Cost |
|---|---|---|
| No checkpointing | \(N_L \times A\) | 0 forward ops |
| Checkpoint every layer | \(A\) | \((N_L-1)\) forward ops |
| k checkpoints | \(k\times A + (N_L/k)\times A\) | \((N_L-k)\) forward ops |
Setting the derivative of total memory cost \((k \times A + (N_L/k) \times A)\) to zero yields \(k_{\text{optimal}} = \sqrt{N_L}\). In the common \(\sqrt{N_L}\) checkpointing scheme, this gives roughly one-third extra forward compute in exchange for the minimum memory footprint under this simplified model. For GPT-2 with forty-eight transformer layers, the contrast is stark: without checkpointing, memory equals \(48 \times A\) (full activation storage). Optimal checkpointing (\(\sqrt{48}\) approximately equals seven checkpoints) requires memory of \(7 \times A + (48/7) \times A\) approximately equals \(14 \times A\), achieving 71 percent memory savings with approximately 33 percent compute overhead.
Not all operations are equally expensive to recompute, which motivates selective checkpointing. Table 16 compares where activation memory is large enough to justify recomputation.
| Layer type | Memory cost | Recompute cost | Checkpointing strategy |
|---|---|---|---|
| Attention layers | High: \(3 \times B \times S \times d_{\text{model}}\) for QKV projections | High: three matrix multiplications | Checkpoint before attention layers when memory saved justifies recompute |
| Feed-forward layers | High: \(2 \times B \times S \times 4d_{\text{model}}\) | Lower: two matrix multiplications | Often skip FFN checkpoints because recompute is relatively fast |
| LayerNorm | Low | Very low | Avoid checkpointing normalization layers |
The practical rule is to spend recomputation on high-memory layers, not on operations whose activations are already cheap to retain.
Memory and computational benefits
Gradient accumulation simulates larger batch sizes without increasing memory requirements for storing the full batch. Larger batch sizes improve gradient estimates, leading to more stable convergence and faster training. This flexibility proves particularly valuable when training on high-resolution data where even a single batch may exceed available memory.
Activation checkpointing significantly reduces the memory footprint of intermediate activations during the forward pass, allowing training of deeper models. By discarding and recomputing activations as needed, checkpointing frees up memory for larger models, additional layers, or higher resolution data. This is especially important in advanced architectures like transformers that require substantial memory for intermediate computations.
Both techniques improve scalability by reducing the memory required before adding hardware. Returning to our GPT-2 Lighthouse Model, gradient accumulation is essential for achieving the target batch size within V100 memory constraints.
Napkin Math 1.8: GPT-2 gradient accumulation strategy
GPT-2’s training configuration demonstrates the essential role of gradient accumulation.
Memory Constraints
- V100 32 GB with gradient checkpointing: Can fit batch size \(B=16\) (as shown in activation memory example)
- Desired effective batch size \(B=512\) (optimal for transformer convergence)
- Problem: 512 ÷ 16 = 32 GPUs needed just for batch size
Gradient Accumulation Solution
Instead of 32 GPUs, use 8 GPUs with gradient accumulation:
Configuration:
- Per-GPU micro-batch: 16
- Accumulation steps: 4
- Effective batch per accelerator: 16 \(\times\) 4 = 64
- Global effective batch: 8 GPUs \(\times\) 64 = 512 ✓
In listing 7, notice that the no_sync() context manager suppresses AllReduce during the first three micro-batches, so the expensive gradient synchronization fires only once per effective batch rather than once per micro-batch.
Performance Impact
Without Accumulation (naive approach):
- 32 GPUs \(\times\) batch size \(B=\) 16 = 512 effective batch
- Gradient sync: 32 GPUs → high communication overhead
- Cost: $16/hour \(\times\) 32 GPUs = $512/hour
With Accumulation (actual GPT-2 approach):
- 8 GPUs \(\times\) (16 \(\times\) 4 steps accumulation) = 512 effective batch
- Gradient sync: Only every 4 steps steps, only 8 GPUs
- Cost: $16/hour \(\times\) 8 GPUs = $128/hour
- Savings: $384/hour = 75 percent cost reduction
Trade-off Analysis
- Wall-clock overhead: 4 serialized micro-batches per update = ~8 percent slower (pipeline overlap hides some overhead)
- Memory overhead: Gradient accumulation buffer = negligible (gradients already needed)
- Communication benefit: Sync frequency reduced by 4 steps\(\times\) → communication time drops by 75 percent
- Cost benefit: Training two weeks on 8 GPUs = $43K vs. 32 GPUs = $172K
Convergence Quality
- Effective batch 512 with accumulation: Perplexity 18.3
- True batch 512 without accumulation: Perplexity 18.2
- Difference: 0.5 percent (within noise margin)
Why this works: Gradient accumulation is mathematically equivalent to larger batches because gradients are additive. Each accelerator first accumulates a local gradient over its 64 examples: \[ \frac{1}{4}\sum_{j=1}^{4} \left[\frac{1}{16}\sum_{k=1}^{16} \nabla \mathcal{L}(x_{jk})\right] \]
AllReduce then averages those local gradients across 8 GPUs accelerators, producing the global effective batch: \[ \frac{1}{8}\sum_{g=1}^{8} \nabla \mathcal{L}_{\text{local}}^{(g)}, \qquad B_{\text{global}} = 8 \times 64 = 512 \]
Systems insight: For memory-bound models like GPT-2, gradient accumulation + moderate GPU count is more cost-effective than scaling to many GPUs with small batches.
optimizer.zero_grad()
for step in range(4): # Accumulation steps
micro_batch = next(dataloader) # 16 samples
loss = model(micro_batch) / 4 # Scale loss
loss.backward() # Accumulate gradients
# Now gradients represent 64 samples
all_reduce(gradients) # Sync across 8 GPUs
optimizer.step() # Update with effective batch=512Practical considerations
Gradient accumulation is most valuable when optimal batch sizes exceed GPU memory capacity. Transformer language models often use effective batches of hundreds of thousands to millions of tokens; if memory only permits a smaller number of sequences per device, accumulation bridges the gap without requiring additional hardware. Activation checkpointing complements this by enabling deeper architectures: models like GPT-3 and T5 rely on checkpointing to fit within accelerator memory budgets, as do dual-network configurations such as GANs.
Both techniques introduce explicit trade-offs. Activation checkpointing adds approximately 33 percent compute overhead from recomputation; in a 12-layer transformer with checkpoints every four layers, each intermediate activation is recomputed up to three times during the backward pass. Gradient accumulation reduces parameter update frequency: each optimizer step processes \(k\) micro-batches sequentially before updating. When using loss division by \(k\) (as shown in listing 7), gradients are already correctly averaged, so the learning rate needs no adjustment. When gradients are summed without division, the learning rate must be reduced by \(k\times\) to compensate. The choice of convention matters—frameworks and codebases differ, making this a common source of subtle bugs. For models that do not require large batch sizes or have shallow architectures with modest activation memory, the added implementation complexity may not be justified.
Optimization technique comparison
Table 17 synthesizes three of the four core optimization strategies, contrasting their primary goals, mechanisms, and trade-offs. FlashAttention (section 1.5.4) complements these by addressing memory-bandwidth bottlenecks in attention layers through IO-aware tiling, achieving 2–4\(\times\) speedups while reducing memory from \(\mathcal{O}(S^2)\) to \(\mathcal{O}(S)\). Selecting an appropriate strategy depends on the specific bottleneck identified through profiling.
These four techniques (prefetching, mixed precision, FlashAttention, and gradient accumulation) form the core optimization toolkit for single-machine training. Each targets a specific bottleneck: prefetching addresses data starvation, mixed precision accelerates computation and reduces memory, FlashAttention eliminates attention’s memory-bandwidth bottleneck, and gradient accumulation enables effective batch sizes that would otherwise exceed memory capacity. Applied systematically using the profiling methodology established earlier, they can dramatically extend the capabilities of a single device. The practical question is how a profile selects the subset that composes for a specific bottleneck trace.
| Aspect | Prefetching and Overlapping | Mixed-Precision Training | Gradient Accumulation and Checkpointing |
|---|---|---|---|
| Primary Goal | Minimize data transfer delays and maximize accelerator utilization | Reduce memory consumption and computational overhead | Overcome memory limitations during backpropagation and parameter updates |
| Key Mechanism | Asynchronous data loading and parallel processing | Combining FP16 and FP32 computations | Simulating larger batch sizes and selective activation storage |
| Memory Impact | Increases memory usage for prefetch buffer | Reduces memory usage by using FP16 | Reduces memory usage for activations and gradients |
| Computation Speed | Improves by reducing idle time | Accelerates computations using FP16 | May slow down due to recomputations in checkpointing |
| Scalability | Highly scalable, especially for large datasets | Enables training of larger models | Allows training deeper models on limited hardware |
| Hardware Requirements | Benefits from fast storage and multi-core CPUs | Requires GPUs with FP16 support (for example, Tensor Cores) | Works on standard hardware |
| Implementation Complexity | Moderate (requires tuning of prefetch parameters) | Low to moderate (with framework support) | Moderate (requires careful segmentation and accumulation) |
| Main Benefits | Reduces training time, improves hardware utilization | Faster training, larger models, reduced memory usage | Enables larger batch sizes and deeper models |
| Primary Challenges | Tuning buffer sizes, increased memory usage | Potential numerical instability, loss scaling needed | Increased computational overhead, slower parameter updates |
| Ideal Use Cases | Large datasets, complex preprocessing | Large-scale models, especially in NLP and computer vision | Deep networks (50+ layers), memory-constrained environments |
The table compares techniques in isolation; the GPT-2 walkthrough shows how those techniques combine when one model must fit in memory, run fast enough, and stay within a realistic cost envelope.
GPT-2 optimization walkthrough
To answer that question, let us walk through the memory-feasibility path for GPT-2 (1.5 billion parameters) training on a single V100 GPU, then summarize the time, energy, and cost implications for a 32-V100 training run.
Example 1.3: GPT-2 optimization on V100
Step 1: Establish the baseline memory footprint.
Table 18: GPT-2 optimization final profile: Batch-4 memory figures from the walkthrough (95.7 GB → 33 GB); table 19 reports batch-32 totals.
The trace starts with GPT-2 XL with 1.5 billion parameters, batch size 4, sequence length 1024, FP32 tensors throughout, and a single-threaded synchronous data loader. This is a deliberately constrained configuration: small enough to discuss on one V100, but large enough that the first failure is immediate and unambiguous. This walkthrough uses batch size 4, the same configuration as the mixed-precision callout earlier; table 19 reports the batch-32 equivalents (597.8 GB FP32 baseline, 95.7 GB optimized), which exceed a single GPU even after optimization. At batch size 4, the FP32 baseline requires 95.7 GB, so the run fails the machine constraint on a 32 GB V100 before throughput matters.
Step 2: Apply mixed precision.
The first intervention targets memory feasibility, not speed. Mixed precision changes the first term in the memory budget and reduces the footprint to 59.9 GB, a 37.5 percent reduction, but it still does not fit.
Step 3: Add gradient checkpointing.
Gradient checkpointing changes a different term by storing fewer activations and recomputing them during backpropagation. Checkpointing every four layers reduces activation storage by 4× and brings total memory to 33 GB, which fits at the cost of 33 percent additional compute.
Step 4: Profile for throughput bottlenecks.
Fitting the model is only the first diagnostic pass. The next profile asks whether the accelerator is doing useful work once the run can start. The answer is no:
- Accelerator utilization: 45 percent
- Data loading: 40 percent of iteration time
- Compute: 35 percent of iteration time
- Memory transfers: 25 percent of iteration time
The profile moves the bottleneck from machine capacity to the data axis in D·A·M terms, so additional memory optimization would not improve wall-clock time.
Step 5: Apply prefetching and data pipeline optimization.
The targeted fix is to overlap input preparation with accelerator execution: configuring the data loader with eight workers, pinned memory, and a prefetch factor of 2 changes the pipeline schedule rather than the model. Data loading becomes mostly hidden behind computation, accelerator utilization rises to 85 percent, and the remaining overhead is dominated by synchronization, loss scaling, memory transfers, and kernel launch latency rather than batch starvation.
Table 18 contrasts the naive baseline against the optimized configuration:
| Metric | Naive | Optimized | Improvement |
|---|---|---|---|
| Memory | 95.7 GB | 33 GB | 2.9× reduction |
| Accelerator utilization | N/A | 85% | Trainable |
| Throughput | N/A | 1,200 tokens/s | — |
| Time per epoch | N/A | 8.3 hours | — |
Systems insight: The final profile is compute-bound, an algorithm constraint in D·A·M terms, which is the desired endpoint for this single-device exercise. The run is now limited by useful training work rather than by avoidable memory capacity or input-pipeline failures.
The case study illustrates why training optimization is an iterative diagnostic discipline rather than a menu of tricks. Each intervention answers the bottleneck exposed by the previous measurement: mixed precision reduces tensor storage but does not solve capacity alone, checkpointing accepts 33 percent additional compute to gain 2.9× memory reduction, and prefetching matters only after the model can run and profiling reveals data starvation. The systematic loop of profile, identify the bottleneck, apply a targeted technique, and re-profile transforms optimization from trial-and-error into engineering practice.
Optimization impact summary
The GPT-2 case study demonstrates how targeted techniques compose to transform infeasible training requirements into practical configurations. In this trace, mixed precision and gradient checkpointing solve the memory problem, and data prefetching improves throughput after profiling reveals data starvation. The cumulative impact spans memory, time, energy, and cost for the same optimized configuration.
Table 19 compiles the cluster-level impact of applying mixed-precision training, gradient checkpointing, and the data-pipeline utilization gains from the walkthrough to GPT-2.
| Metric | FP32 Baseline | Optimized | Technique Applied |
|---|---|---|---|
| Parameters | 6 GB | 3 GB | Mixed precision (FP16) |
| Gradients | 6 GB | 3 GB | Mixed precision (FP16) |
| Master Weights | 0 GB | 6 GB | AMP Overhead |
| Optimizer State (Adam) | 12 GB | 12 GB | Unchanged (FP32 moments) |
| Activations (batch=32) | 573.8 GB | 71.7 GB | Gradient checkpointing + FP16 |
| Total Memory | 597.8 GB | 95.7 GB | — |
| Training Time (32 V100s) | 14 days | 8.4 days | Data prefetching + utilization |
| Energy Consumption | 3,914 kWh | 2,348 kWh | Reduced time + improved efficiency |
| Electricity Cost ($0.10/kWh) | $391.4 | $234.8 | — |
| Carbon Footprint | 1.7 t | 1.01 t | Regional grid average (0.43 kg/kWh) |
As table 19 shows, this 6× memory reduction, combined with 1.7× computational speedup and 40 percent energy reduction, exemplifies how systematic optimization transforms hardware constraints into engineering design parameters. The same optimizations that improve throughput also reduce energy consumption and operational cost.
The single-machine optimization toolkit needed for this chapter is now exhausted. Mixed precision extracts maximum throughput from Tensor Cores. FlashAttention reduces bandwidth consumption to near-theoretical minimums. Gradient checkpointing trades compute for memory at favorable ratios. Prefetching hides data loading latency. A well-optimized single GPU can train GPT-2 scale models in days rather than weeks.
Yet some models simply will not fit, and some training runs would take years even on perfectly optimized hardware. When every single-machine technique has been applied and training still exceeds acceptable time or memory budgets, a fundamentally different approach becomes necessary: spreading the computation across multiple devices. This transition from single-machine to multi-device training introduces new bottlenecks, including communication overhead, synchronization costs, and fault tolerance requirements, that demand their own set of engineering solutions.
Self-Check: Question
A profile shows 40 percent of iteration time in data loading, 35 percent in compute, and 25 percent in memory operations on a single-GPU training run. According to the section’s systematic optimization framework, what should be optimized first, and why does this choice matter more than picking the most familiar technique?
- Data prefetching and pipeline overlap, because the dominant bottleneck is on the data path — optimizing compute or memory first leaves the GPU starved regardless of how fast the accelerator becomes.
- Gradient checkpointing, because memory is always the safest first target for memory-constrained training.
- Mixed precision, because compute is still a large fraction of time and Tensor Cores are the highest-leverage lever.
- FlashAttention, because attention is usually the slowest kernel in transformers.
Explain why prefetching can reduce iteration time from roughly the sum of fetch, preprocess, and transfer stages to roughly the maximum of those stages, and identify what condition must hold for that benefit to materialize.
Why does mixed-precision training keep certain quantities — such as master weights and select reductions — in FP32 even though the bulk of the forward and backward passes runs in FP16 or BF16?
- Because FP16 and BF16 cannot run on Tensor Cores without an FP32 mirror of every activation tensor existing alongside.
- Because reduced precision increases memory bandwidth demand, so FP32 is reserved for traffic-heavy paths to lower bandwidth pressure.
- Because storing part of the model in FP32 is required for data parallelism but not for single-GPU training.
- Because numerically sensitive accumulations and parameter updates can lose precision or underflow if held in reduced precision, while bulk matrix multiplies tolerate FP16/BF16; selective FP32 storage protects stability where it matters and exploits faster low-precision compute everywhere else.
What is the core systems mechanism that makes FlashAttention faster and more memory-efficient than the standard attention implementation, even though both compute the same mathematical result?
- It tiles the attention computation so intermediate score and probability blocks stay in on-chip SRAM across the softmax-mask-matmul stages, never materializing the full \(S \times S\) attention matrix in HBM.
- It replaces softmax with ReLU so attention becomes element-wise and compute-bound.
- It reduces sequence length during training so the attention matrix never exceeds cache capacity.
- It stores the full \(S \times S\) attention matrix in HBM once and reuses it across all backward-pass calls.
A model converges best with an effective batch size of 512, but each accelerator’s memory budget admits only a micro-batch of 16 once activations and Adam optimizer state are accounted for. Which combination most directly emulates the 512 batch while also reducing activation pressure?
- FlashAttention plus weight decay.
- Data prefetching plus operator fusion.
- Gradient accumulation plus activation checkpointing — accumulation simulates the 512 batch by summing gradients over 32 micro-batches before stepping the optimizer, while checkpointing recomputes activations selectively to lower per-step activation memory.
- AdamW plus cosine annealing.
A team applies mixed precision to a transformer training run and sees compute time drop by 38 percent. They are about to declare the run optimized. Using the chapter’s iterative optimization principle, explain what they should do next and what new dominant bottleneck is most plausible after a compute-side win like this.
Scaling Training Systems
The single-device optimization toolkit (mixed precision, FlashAttention, gradient checkpointing, and data prefetching) can transform an infeasible training configuration into a practical one on a single machine. The GPT-2 walkthrough demonstrated this at batch size 4, bringing a 1.5-billion-parameter model to 33 GB and within reach of a single V100 GPU (32 GB). The same toolkit has limits that batch size makes visible: at batch 32, memory falls from 597.8 GB to 95.7 GB, a substantial reduction that still exceeds what any single accelerator provides. Some models still will not fit, no matter how aggressively these techniques are applied. A 70-billion-parameter model requires about 140 GB for FP16 weights alone, which exceeds the 80 GB configurations of A100 and H100 SXM accelerators and leaves little or no room even on higher-capacity variants like the H100 NVL (94 GB) and H200 (141 GB) once gradients, optimizer state, and activations are included. Even when a model does fit, training on a single device may take years rather than weeks.

Some models exceed single-GPU memory before anything else matters.
When single-machine optimization has been exhausted, the only remaining option is to spread computation across multiple devices. Multi-device training provides three capabilities unavailable to a single GPU: aggregate memory capacity, aggregate compute throughput, and aggregate storage bandwidth. Scaling beyond a single device begins with multi-GPU configurations inside one machine, then reaches the threshold where distributed systems become necessary. The key parallelism strategies and their trade-offs are introduced here as a bridge from single-node training to the next frontier: scale; the implementation details of multi-node distributed training (collective communication primitives, fault tolerance, and elastic scheduling) are beyond our current scope.
Not all workloads benefit equally from adding more GPUs. The relationship between compute intensity and communication overhead determines whether scaling helps or hurts. This is the conservation of complexity (introduced in section 1.5) at the system level: eliminating single-machine bottlenecks through parallelism introduces new communication bottlenecks across devices. The scaling curves in figure 15 quantify this trade-off: compute-bound workloads like image classification (blue) maintain high efficiency as GPU count grows, balanced workloads like LLM training with high-speed interconnects (green) show moderate degradation, while bandwidth-bound workloads (red) suffer the full communication tax as synchronization overhead accumulates with cluster size. An arrow indicates this tax: the gap between theoretical linear scaling and actual achieved throughput. Here, \(r\) denotes the fraction of step time spent on communication and the curves are illustrative.
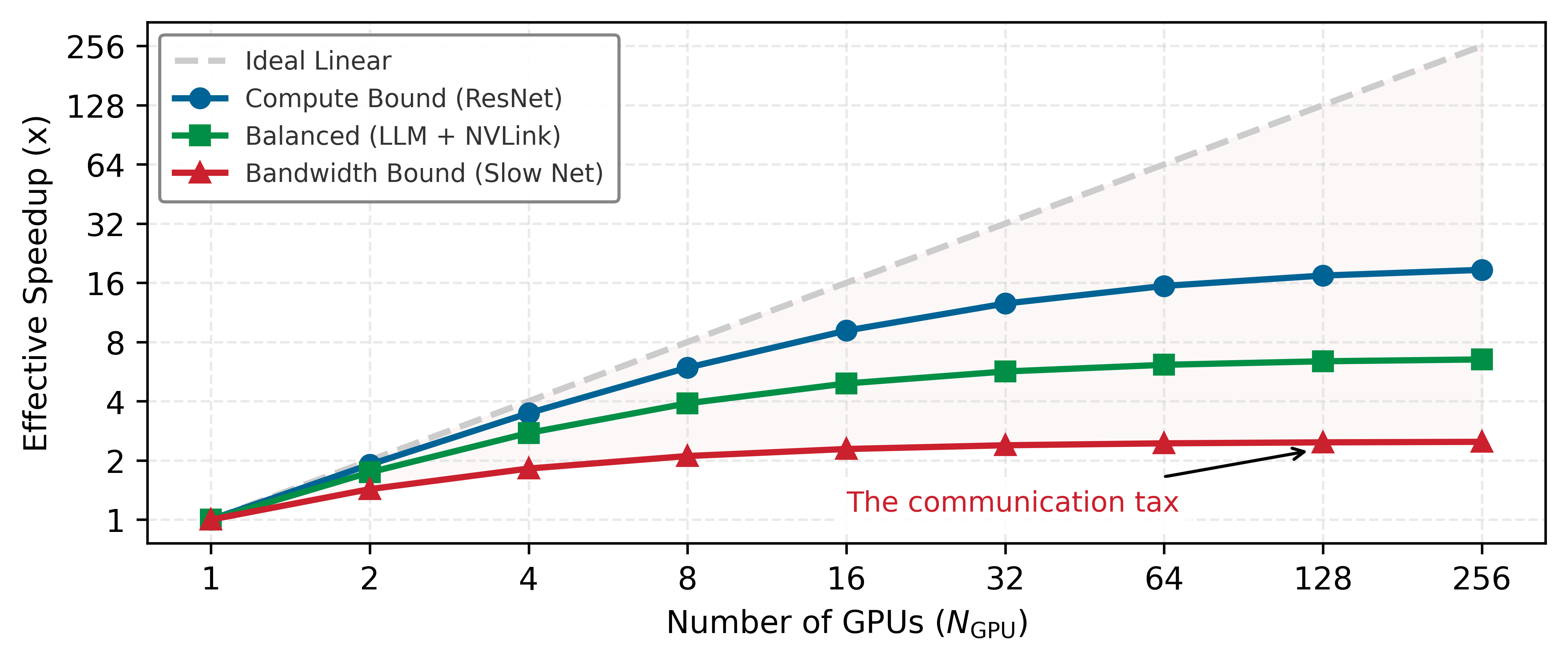
The red curve’s widening gap from the dashed ideal is the communication tax made visible; shrinking that gap is what every distributed strategy below exists to do.
Single-node multi-GPU training
Multi-GPU training within a single node, the scope of this book, predates large-scale distributed systems. AlexNet29 (Krizhevsky et al. 2012) famously split its model across two GTX 580 GPUs—not because the model was too large, but because the 3 GB memory per GPU could not hold both the model and the batch activations. This single-node, multi-GPU configuration remains a useful entry point because it introduces the core parallelism strategies without the complexity of network communication.
29 AlexNet (2012): The model’s 60M parameters (~240 MB) fit on one GPU, but the large intermediate feature maps (activations) produced during training did not. This forced a model-parallel design where specific layers communicated across GPUs, a workaround dictated entirely by the memory ceiling of a single 3 GB GTX 580.
Krizhevsky, Alex, Ilya Sutskever, and Geoffrey E. Hinton. 2012. “ImageNet Classification with Deep Convolutional Neural Networks.” Advances in Neural Information Processing Systems 25.
The two foundational strategies, data parallelism and model parallelism, represent fundamentally different partitioning choices: data parallelism replicates the model and partitions data, while model parallelism partitions model state or computation. This distinction determines memory requirements, communication patterns, and scaling behavior.
Data parallelism
Data parallelism replicates the entire model on each GPU, with each processing different batches. After computing gradients locally, GPUs synchronize via gradient averaging. Figure 16 shows the data flow: input data splits into nonoverlapping batches, each accelerator computes forward and backward passes independently, then gradients aggregate before updating the shared model.

Data parallelism’s appeal lies in its simplicity and efficiency. Each GPU runs the identical forward-backward computation, just on different data. The only coordination required is averaging gradients at the end of each step—a single synchronization point per iteration. This makes data parallelism the natural first strategy to evaluate when models fit in GPU memory. Frameworks like PyTorch’s DistributedDataParallel and TensorFlow’s MirroredStrategy automate the gradient synchronization, making multi-GPU data parallelism nearly as simple as single-GPU training.
However, data parallelism has a hard constraint: every GPU must hold a complete copy of the model. For a 7-billion-parameter model in FP16, that amounts to 14 GB just for weights—before gradients, optimizer states, or activations. When models exceed available GPU memory, a different strategy becomes necessary.
Model parallelism
Model parallelism partitions the model itself across GPUs, which becomes necessary when the model exceeds single-GPU memory. AlexNet used a simple form: certain layers resided on GPU 1, others on GPU 2, with activations passing between them. Figure 17 shows the forward and backward paths: data moves through model partitions on different devices, with gradients flowing backward during training.

In practice, model parallelism typically partitions by layers. Consider the concrete example in figure 18, where a 24-layer transformer is distributed across four devices: Device one handles blocks 1–6, Device two handles blocks 7–12, and so forth. This layer-wise partitioning minimizes cross-device communication to the boundaries between partitions.

Model parallelism’s challenge is idle time. While Device one computes layers 1–6, Devices 2–4 sit idle waiting for activations. During the backward pass, the problem reverses: Device four computes first while others wait. This “pipeline bubble” means naive model parallelism can waste much of the available accelerator time even with careful partitioning. Pipeline parallelism addresses this inefficiency, as the discussion of distributed strategies demonstrates.
Within a single node, GPUs communicate via high-bandwidth interconnects like NVLink30 (up to 900 GB/s on H100-class systems), making gradient synchronization and activation transfers fast. Data parallelism transfers gradients, which are proportional to model size. Model parallelism transfers activations, proportional to batch size times hidden dimension, at every partition boundary. The 10–50\(\times\) bandwidth advantage of NVLink over PCIe makes both strategies practical within a node. This intra-node parallelism forms the building block for larger distributed systems. Choosing between data and model parallelism requires comparing how each splits compute, memory, and communication.
30 NVLink: NVIDIA’s proprietary, direct GPU-to-GPU interconnect that bypasses the general-purpose PCIe bus. The bandwidth advantage quantified in the text (10–50\(\times\) over PCIe) is what determines whether intra-node parallelism is practical: data parallelism must transfer gradient tensors proportional to model size every iteration, and model parallelism must transfer activations at every layer boundary. If either transfer takes longer than the computation it overlaps, the parallelism strategy yields negative returns.
Systems Perspective 1.7: Data vs. model parallelism
A model that is too big or too slow for a single device must be split across multiple devices. For a model with parameters \(P\) and batch size \(B\) trained across \(N_{\text{GPU}}\) GPUs, the split can divide either the batch or the weights.
Data parallelism (split the batch): Compute \((O)\) splits by \(N_{\text{GPU}}\), with each GPU processing \(1/N_{\text{GPU}}\) of the batch, but the memory footprint is replicated: every GPU must hold the full model weights \(\theta\) (\(P\) parameters). Communication consists of gradients, with size \(\propto P\), exchanged at the end of the backward pass. The bottleneck arrives when the model size \(P\) exceeds a single GPU’s memory.
Model parallelism (split the weights): Compute \((O)\) again splits by \(N_{\text{GPU}}\), with each accelerator computing part of the layer, and the memory footprint splits with it: each GPU holds a shard of \(\theta\) containing approximately \(P/N_{\text{GPU}}\) parameters. Communication consists of activations, with size \(\propto B \times d\), exchanged at every layer boundary. The bottleneck arrives when the activation size is large, because the communication frequency is high.
Systems insight: Use data parallelism when the model fits in memory but training is too slow; use model parallelism when the model is too big to fit in a single GPU’s memory.
Scaling beyond a single node
When single-node multi-GPU training remains insufficient, distributed training extends across multiple machines. This introduces network communication bottlenecks (typically 1.25–12.5 GB/s, or 10–100 Gbps, between nodes vs. 900 GB/s within a node) and fault tolerance requirements absent from single-node setups. The bandwidth gap matters because synchronization turns every gradient update into a data-movement problem.
Within a single node, NVLink provides enough bandwidth to overlap gradient synchronization with computation, keeping the \(L_{\text{lat}}\) term in the iron law small relative to the compute term. Crossing the node boundary collapses that ratio: inter-node Ethernet or InfiniBand bandwidth is 10–50\(\times\) lower than NVLink, and every AllReduce31 operation, a collective that aggregates gradients across devices, must traverse this slower fabric. The communication overhead that was negligible at four GPUs can dominate total step time at 64 nodes, making the physical cost of moving gradients the central engineering constraint of distributed training.
31 AllReduce: A collective communication primitive that sums data across all devices and distributes the result back to each device. Ring AllReduce is one common implementation: devices pass gradient shards around a logical ring so each participant sends and receives bounded chunks rather than a full copy of every gradient tensor at once. This is the communication primitive that makes large data-parallel training practical, but its detailed cost model belongs with distributed training.
Systems Perspective 1.8: The physics of synchronization
Recall the energy-movement invariant from Data Engineering: moving data is 100–1,000\(\times\) more expensive than computing on it. In distributed training, this physical law manifests as the communication tax.
Synchronizing gradients across a fleet of GPUs means moving megabytes of data across a network or PCIe bus for every few milliseconds of computation. If the energy required for communication (\(E_{\text{move}}\) across the network) exceeds the energy for computation (\(E_{\text{compute}}\)), system efficiency \((\eta_{\text{hw}})\) collapses. Techniques like mixed precision (section 1.5.3) and gradient compression, which reduces communicated gradient bytes through sparsity, quantization, or encoding, address this directly by managing the physical limits of distributed scaling.
A short calculation shows how quickly the inter-node fabric becomes the binding constraint.
Napkin Math 1.9: The network wall
Problem: A team scales training to 8 GPUs, one per node, connected by a 100 Gbps fabric. Is the network the bottleneck?
Math: For a 7B-parameter model with FP16 gradients:
- Gradient size (FP16): 14 GB per step.
- AllReduce cost: Ring AllReduce passes gradient shards around a logical ring, so each worker ends up sending nearly two full copies of the gradient: \(2(N_{\text{GPU}}-1)/N_{\text{GPU}}\), which equals 1.75× for 8 GPUs. That gives 1.75 \(\times\) 14 GB = 24.5 GB total.
- Network time: At 12.5 GB/s across the inter-node fabric (100 Gbps): 24.5 GB / 12.5 GB/s = 1.96 s.
- Compute time: If forward + backward takes \(1 \text{ s}\), network is the bottleneck.
Systems insight: The network becomes a wall when \(T_{\text{communication}} > T_{\text{computation}}\). Solutions include gradient compression, which sends fewer or lower-precision gradient bytes while checking convergence impact; overlapping computation with communication, as implemented in Horovod (Sergeev and Balso 2018); and keeping the most frequent communication on faster links (NVLink at 900 GB/s within a node vs. 12.5 GB/s between nodes).
Sergeev, Alexander, and Mike Del Balso. 2018. “Horovod: Fast and Easy Distributed Deep Learning in TensorFlow.” CoRR abs/1802.05799.
32 GPipe (2019): GPipe implements the described microbatching strategy, staggering execution to fill the idle “bubbles” in naive model parallelism and thus boost utilization (Huang et al. 2019). The key trade-off it manages is increased memory for storing the activations of multiple in-flight microbatches. It preserves large-batch training dynamics by accumulating gradients before the weight update, achieving 80–93 percent hardware efficiency when scaling across 2–4 accelerators.
Huang, Y., Y. Cheng, A. Bapna, O. Firat, D. Chen, M. X. Chen, H. Lee, et al. 2019. “GPipe: Efficient Training of Giant Neural Networks Using Pipeline Parallelism.” Advances in Neural Information Processing Systems 32: 103–12.
Once training crosses the node boundary, the strategy must match communication frequency to available bandwidth. Pipeline parallelism addresses the idle time problem in model parallelism through microbatching. Instead of processing one batch and waiting for it to traverse all devices, the system splits each batch into smaller microbatches and overlaps their execution. While one device processes the second microbatch, the next device can process the first. This interleaving keeps devices busy, substantially improving utilization compared with naive layer partitioning. The memory constraint is more severe than in CPU instruction pipelining: unlike a CPU instruction that completes and leaves the pipeline, each microbatch’s activations must remain resident in memory on their assigned device until the backward pass traverses the pipeline in reverse order, so every in-flight microbatch adds a full activation footprint to the device’s memory budget. The trade-off is this increased memory usage from multiple microbatches in flight and higher implementation complexity. GPipe32 and PipeDream pioneered these techniques for training models too large for single GPUs while maintaining reasonable efficiency (Huang et al. 2019; Narayanan et al. 2019).
Tensor parallelism takes a finer-grained approach: rather than assigning whole layers to devices, it splits individual operations across devices. Consider a transformer’s feed-forward layer with a large matrix multiplication \(Y = XW\). Tensor parallelism splits the weight matrix \(W\) column-wise across GPUs, so each accelerator computes a portion of the output. The results are then gathered to form the complete output. This strategy is particularly effective for the massive attention and feed-forward layers in large transformers, where a single operation may involve matrices too large for one GPU’s memory. Megatron-LM demonstrated that tensor parallelism enables training models with billions of parameters by distributing individual attention heads and feed-forward blocks across devices (Shoeybi et al. 2019).
Shoeybi, Mohammad, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper, and Bryan Catanzaro. 2019. “Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism.” arXiv Preprint arXiv:1909.08053.
Hybrid strategies combine these approaches because each has different scaling characteristics. Table 20 shows the usual hierarchy: use the fastest links for the most frequent communication and reserve slower network tiers for less frequent synchronization.
| Strategy | Typical placement | Communication pattern |
|---|---|---|
| Tensor parallelism | Within a node | Frequent communication that exploits NVLink’s high bandwidth |
| Pipeline parallelism | Across nodes within a rack | Moderate communication at layer boundaries |
| Data parallelism | Across racks | Gradient synchronization once per iteration |
The placement rule is not arbitrary; it maps communication frequency to the fastest available bandwidth tier.
Data-parallel systems also rely on collective operations such as AllReduce to combine gradients across devices. The implementation details of collective algorithms, parameter-server and peer-to-peer communication patterns, fault tolerance mechanisms, and scaling-efficiency analysis for training runs spanning thousands of GPUs constitute a specialized domain that builds on the foundations established here.
The evolution of training infrastructure
The parallelism strategies above are one endpoint of a longer infrastructure progression. Training systems took this form because computing infrastructure evolved through four distinct eras, each shaped by dominant workloads. Figure 19 and the computing eras table that follows show the durable pattern: new application demands expose architectural limitations, triggering innovations that eventually become standardized infrastructure.
Neural network training combines requirements from multiple predecessors while adding unique demands. Like HPC, training requires massive floating-point throughput for matrix operations. Like warehouse-scale computing, training at scale requires fault tolerance across many machines. The critical distinction lies in synchronization: warehouse-scale systems such as MapReduce were designed around independent parallel tasks that require minimal coordination, and a worker’s failure simply retries its shard without affecting others. Neural network training, by contrast, requires a synchronous AllReduce collective operation at the end of every backward pass to average gradients across all participating workers before any worker can advance to the next step. This mandatory, globally synchronizing communication pattern at every iteration is what warehouse-scale infrastructure was never designed to support efficiently, and it is the defining requirement that forced the evolution to AI hypercomputing, characterized by specialized accelerators (GPUs, TPUs), high-bandwidth interconnects (NVLink, InfiniBand) capable of sustaining low-latency AllReduce at scale, and software stacks optimized for gradient-based learning.

This architectural progression illuminates why traditional computing systems proved insufficient for neural network training. The co-evolution in table 21 shows that while HPC systems provided the foundation for parallel numerical computation and warehouse-scale systems demonstrated distributed processing at scale, neither fully addressed the computational patterns of model training. Modern neural networks combine intensive parameter updates, complex memory access patterns, and coordinated distributed computation in ways that demanded new architectural approaches.
The practical consequence: when configuring a multi-GPU training job, the practitioner implicitly chooses from parallelism strategies that evolved to address these distinct computational patterns. Understanding these strategies, their trade-offs, their communication costs, and their failure modes, enables informed decisions about when additional hardware will help and when it will merely add complexity.
| Era | Primary Workload | Memory Patterns | Processing Model |
|---|---|---|---|
| Mainframe | Sequential batch processing | Simple memory hierarchy | Single instruction stream |
| HPC | Scientific simulation | Regular array access | Synchronized parallel |
| Warehouse-scale | Internet services | Sparse, irregular access | Independent parallel tasks |
| AI Hypercomputing | Neural network training | Parameter-heavy, mixed access | Hybrid parallel, distributed |
When to scale: The physical ceiling
With this vocabulary of parallelism strategies (data, model, pipeline, tensor, and hybrid), knowing how to scale is different from knowing when to scale. Distributed training introduces substantial complexity—debugging becomes harder, experiments take longer to iterate, and infrastructure costs multiply. Before accepting this complexity, practitioners should exhaust four single-machine optimizations in order:
- Mixed-precision training: Apply mixed precision (section 1.5.3) to reduce memory by ~50 percent.
- Gradient accumulation: Use accumulation (section 1.5.5) to simulate larger batch sizes.
- Activation checkpointing: Implement checkpointing (section 1.5.5.1.2) to trade compute for memory.
- Data pipeline optimization: Optimize data pipelines (section 1.5.2) to eliminate I/O bottlenecks.
Table 22 turns this principle into a lookup keyed on scale. A model under one billion parameters stays on a single GPU where every optimization still fits; the one to ten billion range moves to a single multi-GPU node so that model parallelism rides the fast intra-node interconnect rather than the network; and only past ten billion parameters, or ten terabytes of data, does the memory or I/O requirement force a multi-node cluster.
| Scale | Typical Approach | Rationale |
|---|---|---|
| <1 billion parameters, <100 GB | Single GPU | All optimizations fit; fastest iteration |
| 1-10 billion parameters, <1 TB | Single node (1-8 GPUs) | Model parallelism within node avoids network |
| >10 billion parameters | Multi-node cluster | Memory requirements exceed single-node capacity |
| >10 TB dataset | Multi-node + streaming | I/O bandwidth requires distributed storage |
Only when profiling reveals persistent bottlenecks despite these optimizations should multi-device approaches be considered. Every hardware device has a physical ceiling: a workload requiring \(10^{24}\) FLOPs cannot be completed on a single accelerator within a practical training schedule, no matter how carefully that accelerator is tuned. The transition to multi-device training becomes necessary when one of three hard limits is reached:
- Memory exhaustion: The model weights, gradients, optimizer states, and activations exceed the VRAM of a single GPU. A 70-billion-parameter model requires approximately 140 GB in FP16 for weights alone, exceeding the 80 GB configurations of A100 and H100 SXM accelerators and leaving little or no headroom on higher-capacity variants like the H100 NVL (94 GB) and H200 (141 GB) once training state is included.
- Training wall-clock time: The estimated time to convergence on a single device exceeds the project’s timeline (typically > two weeks). At \(10^{15}\) FLOP/s sustained on one H100-class accelerator, a model requiring \(10^{24}\) FLOPs would take about 32 years at perfect utilization and longer at realistic utilization.
- Dataset scale: The time required to stream the dataset from storage to a single node creates an insurmountable IO bottleneck. Training on petabyte-scale datasets requires distributed storage systems with aggregate bandwidth exceeding any single node’s capacity.
These three limits are technical, but scaling carries a cost beyond complexity and capacity. Adding devices amplifies the energy consumption and environmental impact of training, so efficiency optimization becomes an environmental concern as much as a performance one.
Napkin Math 1.10: The carbon footprint of training
Scenario: Training large models is a massive energy sink as well as a compute challenge. The physical ceiling appears in the energy corollary to the iron law, which lets us quantify the environmental impact of scaling training:
- Workload: Training a 7 billion-parameter model for 1 trillion tokens.
- Compute: ≈ \(4.2 \times 10^{22}\).
- Efficiency: 156 TFLOP/s sustained on A100 (400 W TDP).
- Time: ≈ 3.04 days on 1024 GPUs.
- Energy: (1024 GPUs \(\times\) 400 W + 128 hosts \(\times\) 200 W) \(\times\) 73 hours ≈ 31,784.2 kWh
Systems insight: This single training run consumes as much electricity as an average US household uses in 35.3 months.
- The optimization dividend: Improving utilization from 30 percent to 60 percent halves the compute time; it saves ~15,892.1 kWh of energy and reduces the carbon footprint by over 6.8 t (assuming average grid intensity).
- The true cost: Training systems engineering is a primary lever for sustainable AI because utilization gains reduce wall-clock time, energy use, and carbon emissions on the same hardware fleet.
Scaling changes the binding constraint rather than removing it: data parallelism buys throughput, model parallelism buys memory capacity, pipeline parallelism buys utilization, and tensor parallelism buys layer-scale feasibility, but each adds communication and coordination cost. The implementation details of multi-node distributed training, including collective communication primitives, fault tolerance mechanisms, and elastic scheduling, build directly on the single-machine principles covered throughout this chapter and are treated in depth in advanced distributed systems texts.
Checkpoint 1.3: Scaling decisions
Scaling trades compute bottlenecks for communication bottlenecks.
When to Scale
How to Scale
Self-Check: Question
A 1.5-billion-parameter model fits within a single accelerator’s memory with batch size 32 and Adam optimizer state, but per-epoch wall clock is 14 hours and the team needs results in under 4 hours per epoch. They have access to 8 identical accelerators on the same node. Comparing the section’s parallelism strategies, which choice is the most appropriate first step, and why does the alternative fail this scenario?
- Model parallelism — partition the layers across the 8 accelerators so each one holds a smaller working set; this is the right choice because layer partitioning increases per-step throughput proportionally to the number of devices.
- Switch from Adam to SGD on a single accelerator to reclaim optimizer-state memory; this is the right choice because parallelism complexity should be avoided when memory is not the binding constraint.
- Pipeline parallelism with naive layer assignment — split forward and backward passes across the 8 devices, accepting whatever bubble overhead this introduces.
- Data parallelism — replicate the model on each accelerator and split the batch into 8 micro-batches with one AllReduce per step; this is preferred because the model already fits, so the per-step gradient synchronization is a smaller cost than the pipeline bubbles model parallelism would introduce.
Why does naive model parallelism often deliver poor utilization — the section quotes 25 to 50 percent — even though it is the technique that lets larger models fit at all?
- Because each GPU must still store the full optimizer state for all partitions, exhausting memory before training begins.
- Because partitioning the model by layers introduces sequential dependencies, so downstream devices sit idle waiting for upstream activations to arrive — these pipeline bubbles dominate utilization until microbatched pipelining (GPipe, PipeDream) interleaves work across them.
- Because model parallelism removes the need for batching, lowering arithmetic intensity to the memory-bound regime.
- Because model parallelism requires storing the entire dataset in each node’s RAM.
Explain the communication tax in distributed training and why it can erase expected speedups even when individual GPUs become more efficient. Describe one quantitative regime where the tax becomes the binding constraint.
A team plans to train a 70-billion-parameter model in FP16. Weights alone require approximately 140 GB, while the largest available single accelerator has 80 GB of HBM. Which hard limit identified by the section is forcing the move beyond single-device training, and what does this imply about the order in which they should explore optimizations?
- Memory exhaustion — the weights alone exceed single-device capacity, so single-machine optimizations cannot fit the model and the team must move to model or tensor parallelism regardless of throughput considerations.
- Wall-clock time only — the team should procure a faster single accelerator before rearchitecting.
- Dataset scale — the team should first attempt distributed storage tuning before considering parallelism.
- Numerical precision — the team should switch to FP32 master weights to handle the larger model.
According to the section’s scaling guidance, when should a team seriously consider multi-device training?
- Immediately, because distributed training is usually more cost-efficient than single-node optimization.
- Whenever the model uses Adam rather than SGD, because Adam’s optimizer state always forces multi-GPU training.
- As soon as GPU utilization exceeds 60 percent on a single device, because further single-node gains become difficult.
- Only after mixed precision, gradient accumulation, activation checkpointing, and data-pipeline optimization have been applied and a hard limit (memory exhaustion, wall-clock budget, or dataset scale) still remains.
Fallacies and Pitfalls
The journey from single-GPU optimization through multi-device parallelism reveals a consistent pattern: every technique involves trade-offs, and every optimization introduces new constraints. The systematic approach developed throughout this chapter (quantifying costs through the iron law, diagnosing bottlenecks through profiling, applying targeted optimizations, and scaling only when necessary) provides a principled framework for training system design. Yet even experienced practitioners fall into traps that waste compute resources, delay research progress, and cause production training failures. The following fallacies and pitfalls capture the most consequential of these errors.
Fallacy: Larger models always yield better performance.
Teams treat scale as a monotonic lever: if a 7B-parameter model works well, a 20B-parameter model must work better. In practice, scaling model capacity without proportionally increasing data causes severe overfitting. A 20B model requires approximately 320 GB of nonactivation training state (40 GB FP16 parameters + 40 GB FP16 gradients + 80 GB FP32 master weights + 160 GB Adam states) yet delivers worse accuracy than a 7B model when trained on datasets under 100 million training examples. Beyond critical thresholds, doubling model size while holding data constant typically degrades validation accuracy by 5 percent–10 percent due to overfitting. Model capacity must match dataset size, as established in section 1.2. Teams that pursue scale without commensurate data budgets waste months of compute on models that underperform smaller variants.
Pitfall: Assuming distributed training automatically accelerates development.
More accelerators should mean faster training—but the communication tax (section 1.6) often eats the gains. Small models on 8 GPUs spend 30–50 percent of time synchronizing gradients, achieving only 4–6× speedup instead of the ideal 8×. A well-optimized single A100 completing training in 24 hours can outperform a poorly configured cluster of 8 GPUs taking 36 hours. The overhead of debugging distributed configurations, managing gradient synchronization, and handling stragglers often exceeds the time saved. Always profile and exhaust single-machine optimizations before distributing.
Fallacy: Hyperparameters transfer directly from small-scale experiments to large-scale training.
A learning rate that works at batch size 512 does not work at batch size 4,096. The linear scaling rule (Goyal et al. 2017) requires multiplying the learning rate by the batch size ratio: scaling from 512 to 4,096 means increasing the learning rate from 0.1 to 0.8. Ignoring this relationship causes training instability or divergence, typically manifesting 3–5 days into a multi-week run—after substantial compute has already been consumed. Large-scale training also requires warmup schedules and adjusted momentum to maintain convergence, as discussed in section 1.5.
Goyal, Priya, Piotr Dollár, Ross Girshick, Pieter Noordhuis, Lukasz Wesolowski, Aapo Kyrola, Andrew Tulloch, Yangqing Jia, and Kaiming He. 2017. “Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour.” arXiv Preprint arXiv:1706.02677 abs/1706.02677.
Pitfall: Treating mixed precision training as a simple toggle without validation.
Mixed precision achieves 2.4× speedup in this illustrative V100 profile but requires loss scaling to prevent gradient underflow (see section 1.5.3; Micikevicius et al. (2017)). A language model training for 48 hours can diverge at step 10,000 due to accumulated numerical errors. Always validate mixed precision convergence on representative workloads before deploying at scale.
Fallacy: Memory and computation can be optimized independently.
Memory and compute are coupled: in this illustrative profile, accelerator utilization drops from 90 percent at batch 256 to 60–70 percent at batch 16. Gradient accumulation (effective batch 512, physical batch 64) trades 5 percent efficiency for 8× memory reduction. Tuning these parameters independently extends training time by 20–40 percent (see section 1.5.5).
Pitfall: Budgeting training memory as if it only contains model weights.
Engineers size training clusters by parameter count and discover out-of-memory errors midway through their first run. For a model with \(P\) parameters trained with Adam in mixed precision, the nonactivation overhead alone is roughly 2 bytes (FP16 weights) + 2 bytes (FP16 gradients) + 8–12 bytes (FP32 master weights + Adam moments) = 12–16 bytes per parameter, before activations are counted. Activations themselves scale with batch size and sequence length and routinely exceed the weight footprint by 10–50\(\times\) for transformer training. As section 1.2 derives, sizing a cluster around the 2-byte FP16 weight footprint underestimates the actual memory requirement by 6–8\(\times\) before activations enter the picture. The GPT-2 walkthrough earlier in this chapter showed how gradient checkpointing, mixed precision, and gradient accumulation compose to fit training within these bounds.
Fallacy: The accelerator is always the training bottleneck.
Data loading often creates idle time, yet teams optimize computation first. In this illustrative profile, prefetching with pipeline overlap reduces wall-clock time by 47 percent (105 s to 55 s) by overlapping data loading with computation (see section 1.5.2). Profile before assuming the GPU is the bottleneck.
Pitfall: Optimizing kernels before profiling the input pipeline.
Kernel-level tuning is attractive because GPU utilization is easy to inspect, but a starved accelerator can look like an inefficient accelerator. Before changing precision, rewriting kernels, or adding GPUs, measure dataloader throughput, host preprocessing time, storage wait, and host-to-device transfer overlap. If the accelerator is waiting for batches, the fastest optimization is to feed it reliably rather than make its kernels marginally faster.
Self-Check: Question
A team has a 7-billion-parameter model performing well on a 100-million-example dataset. They scale up to a 20-billion-parameter model on the same dataset, expecting better validation performance. Which outcome does the section identify as most likely, and what is the underlying mechanism?
- Validation performance improves linearly with parameter count, because larger models always extract more signal from a fixed dataset.
- Validation performance degrades by 5–10 percent due to overfitting, because the larger model has the capacity to memorize idiosyncrasies of the fixed 100M-example dataset rather than learn generalizable patterns — and it pays roughly 3\(\times\) the memory and compute cost to do so.
- Validation performance is unchanged, because parameter count and data size are independent levers in the training equation.
- Validation performance improves only if the optimizer is changed from Adam to SGD.
Which scenario best illustrates why distributed training does not automatically speed up development, even when more accelerators are added?
- A cluster trains faster per step, which always means faster experimentation regardless of debugging complexity.
- A large model uses BF16 instead of FP16, so data parallelism cannot be used at all and the team is forced into model parallelism.
- A small communication-heavy model spends 30–50 percent of each step in gradient AllReduce, so adding more GPUs increases the synchronization fraction faster than it adds useful compute and the team observes only a 4–6\(\times\) speedup on 8 GPUs instead of the expected 8\(\times\).
- A model uses activation checkpointing, which prevents any gradient communication from occurring across devices.
Explain why copying hyperparameters directly from a small-batch experiment (batch 512, learning rate 0.1) to a much larger-batch training run (batch 4,096, same learning rate) can waste days of compute and end in failure.
Which mistake does the chapter identify as especially common when teams focus only on accelerator-side optimization (kernels, mixed precision, FlashAttention) and skip end-to-end profiling?
- Computing LayerNorm in FP32 during mixed-precision training.
- Choosing AdamW instead of SGD for a transformer.
- Using gradient accumulation to emulate larger effective batches.
- Assuming the input pipeline is fine and only later discovering that the GPU is idle 30–50 percent of the time waiting for data, even though every kernel-level optimization succeeded.
Summary
Training represents the computational heart of machine learning systems: the phase where mathematical algorithms, memory management, and hardware acceleration converge to transform raw data into capable models. What appears conceptually simple, iterative parameter optimization, becomes a serious engineering challenge at scale. Forward and backward propagation transform into orchestrations of matrix operations, memory allocations, and gradient computations that must be carefully balanced against hardware constraints and performance requirements.
Single-machine training optimization demonstrates how computational bottlenecks drive innovation rather than simply limiting capabilities. Techniques like data prefetching, mixed-precision training, FlashAttention, gradient accumulation, and activation checkpointing illustrate how training systems optimize memory usage, computational throughput, and convergence stability simultaneously. The interplay between these strategies reveals that effective training system design requires deep understanding of both algorithmic properties and hardware characteristics to achieve optimal resource utilization. When single-machine limits are reached, distributed approaches such as data parallelism, model parallelism, pipeline parallelism, and tensor parallelism provide pathways to further scaling, though with increased system complexity.
This co-design principle, where algorithms, software frameworks, and hardware architectures evolve together, shapes large-scale training infrastructure. Matrix operation patterns drove GPU Tensor Core development, which frameworks exposed through mixed-precision APIs, enabling algorithmic techniques like FP16 training that further influenced next-generation hardware design. The chapter’s FLOP and memory accounting provides the quantitative basis for comparing optimizers, estimating training cost at scale, and deciding when more hardware will help rather than merely move the bottleneck.
The practitioners who internalize the iron law can look at a slow training job and immediately classify the bottleneck: compute-bound (increase batch size, enable mixed precision), memory-bound (activate checkpointing, reduce model size), or communication-bound (adjust gradient accumulation, rethink parallelism strategy). This diagnostic discipline distinguishes engineers who solve problems from those who throw hardware at symptoms. Treating training as a black box leads to wasted GPU-months on misdiagnosed problems: hardware upgrades for algorithmic bottlenecks, more GPUs for data pipeline starvation, precision reduction for communication-bound workloads. As training runs scale to millions of dollars and months of calendar time, the ability to profile, diagnose, and apply targeted optimizations determines whether organizations can iterate fast enough to remain competitive.
Key Takeaways: Why training costs millions
- Training cost is an iron-law budget: \(T_{\text{train}} = \frac{O}{R_{\text{peak}} \times \eta_{\text{hw}}}\) makes every optimization accountable: reduce work, raise effective throughput, or improve utilization. A change that misses the dominant term only moves cost around the training loop.
- Memory determines whether convergence matters: Adam can reach good solutions in roughly one-third the iterations of SGD, but its per-parameter state costs 3\(\times\) extra memory before activations enter the budget. Optimizer choice and batch-size-dependent activations often decide whether training fits at all.
- Profiles choose the remedy: The loop is profile, diagnose, fix, and re-profile. Compute-bound jobs benefit from larger batches and mixed precision; memory-bound jobs need checkpointing or smaller state; data- and communication-bound jobs need pipeline or parallelism changes.
- Precision and IO-aware kernels shift bottlenecks: FP16 with FP32 accumulation can deliver about 2\(\times\) throughput and memory reduction, while FlashAttention avoids materializing the full \(S{\times}S\) matrix in HBM and can yield 2–4\(\times\) speedups when attention IO dominates.
- Checkpointing buys memory with recompute: Storing fewer activations and recomputing them during backpropagation cuts activation memory 3–4\(\times\) in the walkthrough, from 35.9 GB to 9 GB at batch 4. Use it when memory, not compute, binds.
- Composed optimizations postpone scale-out: Mixed precision, checkpointing, and prefetching together turn 95.7 GB into 33 GB for the GPT-2 walkthrough. Exhaust these local levers before paying distributed-training communication, reliability, energy, and cost overheads.
Training costs millions because it pays, in full and up front, for a search that inference later replays for pennies. The chapter is a tour of that bill and of where it can be made to sit. Mixed precision relieves compute and loads memory; checkpointing relieves memory and reloads compute; scaling out relieves both and summons communication. The iron law names the three terms the bill is written in, and the discipline is to read which one dominates right now and spend only against it, because an engineer who adds hardware to a memory-bound or communication-bound job buys nothing but a larger invoice. Training is where the iron law stops being a definition and becomes a daily instrument: the work is fixed, and the engineering is all in choosing which term to pay down next.
What’s Next: From training to data selection
Training produces the model artifact: billions of learned parameters that encode patterns extracted from data, at a cost paid once but paid steeply. A run that demanded 33 GB of memory spent compute on every example it ingested, yet not every example earned that price. Before optimizing how the trained model runs, the optimization journey turns upstream, to the workload itself. Data Selection asks how much of the training data is actually necessary, showing that a carefully chosen subset can match the accuracy of the full dataset while cutting the cost of every training iteration that follows.
Self-Check: Question
Which statement best captures the chapter’s main approach to improving training performance?
- Keep adding GPUs until wall-clock time is acceptable, then tune the data pipeline afterward.
- Use the iron law to identify whether total operations, peak throughput, or utilization is the binding lever; profile to confirm; apply targeted optimizations to that lever; then re-profile to handle the new dominant bottleneck.
- Prefer optimizer changes over systems changes, because convergence dominates all hardware effects.
- Reduce model size first, because system optimization rarely changes the feasible training regime.
Why does the chapter recommend exhausting single-machine optimizations before scaling to multi-device training? Name two single-machine techniques the chapter places ahead of distribution and explain what they buy.
A team improves a 1024-GPU training run’s MFU from 30 percent to 60 percent through better pipeline overlap and a FlashAttention swap, with no change to the iron law’s \(R_{\text{peak}}\) or the dataset. Under the chapter’s framework, what is the most accurate description of how this single utilization gain propagates through the system’s runtime, energy, and operating cost?
- Wall-clock time roughly halves, but energy use is unchanged because the accelerators draw similar power per second whether or not they are doing useful model work.
- Wall-clock time, energy, and cost all stay the same, because MFU is an efficiency metric that does not affect physical resource use.
- Wall-clock time roughly halves, energy use drops in proportion because the run finishes faster on the same hardware drawing similar instantaneous power, and operating cost (cloud rental and electricity) drops along with energy — a single \(\eta_{\text{hw}}\) win compounds across all three downstream quantities.
- Wall-clock time stays the same, but energy and cost double because the accelerators are running ‘harder.’
Self-Check Answers
Self-Check: Answer
A 1024-GPU training run has its prefetching pipeline well staged: PCIe is saturated overlapping with compute and gradient AllReduce is hidden behind the next forward pass. Profiling reports 38 percent MFU. Under the simplified iron law of training performance, which lever is the most actionable target for the next engineering investment, and why?
- Utilization \(\eta_{\text{hw}}\) — with data movement and communication already overlapped, the gap between 38 percent MFU and a 55–65 percent ceiling is composed of memory stalls, kernel-launch overhead, and synchronization slack that profiling can localize.
- Peak throughput \(R_{\text{peak}}\) — the only way to move 38 percent MFU is to procure newer accelerators with higher advertised TFLOP/s.
- Total operations \(O\) — reducing the FLOPs needed per step is the only term still movable when overlap is already achieved.
- Dataset size — shrinking the dataset is the equivalent of raising \(\eta_{\text{hw}}\) because both reduce wall-clock time per epoch.
Answer: The correct answer is A. The simplified law’s three levers are \(O\), \(R_{\text{peak}}\), and \(\eta_{\text{hw}}\); once overlap removes the data and communication terms from the binding constraint, the actionable variable for engineering work is utilization. The chapter explicitly notes that \(\eta_{\text{hw}}\) is a pipeline property determined by memory stalls and kernel-launch overhead, both of which a profiler can localize. The ‘reduce \(O\)’ answer treats algorithmic change as the only remaining lever, but the question states the team wants the next engineering investment within the existing workload — not a model rewrite. The ‘newer accelerators’ answer confuses raising \(R_{\text{peak}}\) (which doubles the ceiling but not the gap) with raising the realized fraction of that ceiling. The dataset-size claim invents an equivalence the law does not endorse: dataset shrinkage changes \(O\), not \(\eta_{\text{hw}}\).
Learning Objective: Apply the simplified iron law of training performance to identify which term is the actionable engineering lever given a measured utilization and a well-overlapped pipeline.
A team enables Tensor Cores by switching from FP32 to mixed precision, leaving the model architecture, batch size, and dataset unchanged. Under the iron law of training performance, which term is this optimization most directly targeting?
- Utilization \(\eta_{\text{hw}}\), because mixed precision only removes data stalls.
- Peak throughput \(R_{\text{peak}}\), because reduced-precision execution raises the accelerator’s achievable FLOP/s ceiling.
- Total operations \(O\), because lower precision removes entire layers from the computational graph.
- Dataset size, because mixed precision reduces the number of examples needed for convergence.
Answer: The correct answer is B. Tensor Cores execute reduced-precision matrix multiplies at a higher FLOP/s ceiling than the FP32 path; the chapter’s iron-law-mapping table explicitly assigns mixed precision to the peak-throughput lever. The ‘only removes data stalls’ explanation misses that the hardware ceiling itself has changed — \(\eta_{\text{hw}}\) is how close the system gets to \(R_{\text{peak}}\), but \(R_{\text{peak}}\) is what has just increased. The ‘removes entire layers’ claim is a structural misreading: precision affects how each operation executes, not which operations exist. A convergence-based dataset-size claim invents an effect mixed precision does not have on the optimizer’s sample efficiency.
Learning Objective: Classify mixed-precision training by which term of the iron law of training performance it most directly affects.
Explain why the simplified iron law of training performance can fail to predict speedups for a small-batch debugging session even though it works well for a large-scale pretraining run on the same code.
Answer: The simplified law collapses the general iron law’s three terms into one because data movement and communication are assumed to be overlapped behind compute. That assumption requires the workload to have enough parallel work per kernel launch to hide transfer and synchronization latency — a property large batches provide and small batches do not. At batch size 4 with no prefetching, the kernel-launch overhead and PCIe transfer of each tiny batch resurface as the binding constraint, so the workload’s wall-clock time is dominated by the data term, not by the compute term \(O/(R_{\text{peak}} \cdot \eta_{\text{hw}})\). The practical implication is that a team chasing a faster accelerator for a debug regime is solving the wrong term: the fix is restoring overlap, not raising \(R_{\text{peak}}\).
Learning Objective: Identify the conditions under which the simplified form of the iron law of training performance is a valid approximation and explain the failure mode when those conditions are violated.
True or False: Buying an accelerator with 2\(\times\) the advertised TFLOP/s roughly doubles realized training utilization \(\eta_{\text{hw}}\), because \(\eta_{\text{hw}}\) is proportional to the hardware’s peak capability.
Answer: False. Utilization \(\eta_{\text{hw}}\) is a pipeline property determined by memory stalls, kernel-launch overhead, and synchronization — not a property of the silicon. Doubling \(R_{\text{peak}}\) raises the ceiling but can leave \(\eta_{\text{hw}}\) unchanged or even lower it if the software cannot feed the faster compute, so the team ends up with more peak and similar wall clock.
Learning Objective: Distinguish hardware peak capability from realized utilization in the iron law of training performance.
Why did utilization \(\eta_{\text{hw}}\) become a more critical engineering concern by the GPT-3 era than in early CPU-era neural network training?
- Because training datasets became smaller, making total operations less important than utilization.
- Because modern training stopped depending on matrix multiplication and became dominated by symbolic reasoning kernels.
- Because peak throughput had become irrelevant once Tensor Cores were introduced.
- Because training routinely ran on thousands of accelerators, so each percentage point of inefficiency translated into millions of dollars and weeks of additional wall-clock time.
Answer: The correct answer is D. At GPT-3 scale (over 1,024 V100 GPUs spending 30–40 percent of wall clock on inter-GPU communication, by the chapter’s footnote), the cost of a percentage point of inefficiency multiplied by the fleet size and run length becomes a first-order budget item. A claim that matrix multiplication stopped mattering inverts the chapter’s argument: dense compute still dominates, which is exactly why keeping it busy is the optimization target. A peak-throughput-irrelevance answer misreads Tensor Cores, which raised \(R_{\text{peak}}\) and thereby made the gap between theoretical peak and realized throughput more expensive, not less. The shrinking-dataset claim contradicts the historical record GPT-3 sat in.
Learning Objective: Analyze why utilization becomes increasingly important as training scales to large accelerator fleets.
Self-Check: Answer
Why do batched matrix-matrix operations dominate modern training accelerator design more than matrix-vector operations do, even though the underlying mathematics is similar?
- Because matrix-matrix operations eliminate the need to store activations for backpropagation, reducing the training memory footprint.
- Because matrix-vector operations require more total memory than matrix-matrix operations for the same model, exhausting accelerator capacity faster.
- Because matrix-matrix operations expose much more parallel work per byte loaded — their high arithmetic intensity lets accelerators with thousands of compute units approach peak throughput, while matrix-vector workloads starve the same units on memory traffic.
- Because matrix-vector operations cannot run on GPUs without CPU coordination at every step.
Answer: The correct answer is C. The matrix-operations subsection traces the systems consequence directly: matrix-matrix kernels do \(\mathcal{O}(n)\) FLOP/byte and saturate compute, while matrix-vector kernels do \(\mathcal{O}(1)\) FLOP/byte and fall on the memory-bound side of the roofline, leaving most of an accelerator’s parallel hardware idle. The ‘eliminate activation storage’ claim conflates compute structure with backpropagation’s memory requirement — activations are stored regardless of which matrix shape produces them. The CPU-coordination claim is mechanically wrong: GPUs execute matrix-vector ops natively but inefficiently. The total-memory claim inverts the actual arithmetic; matrix-matrix work uses more memory per call, not less.
Learning Objective: Identify why batched matrix-matrix operations align better with accelerator hardware than matrix-vector operations by reference to arithmetic intensity.
A team is training a 7-billion-parameter model on accelerators with 80 GB of HBM each. Weights, gradients, and activations together occupy 64 GB per accelerator at the planned batch size. Using the section’s optimizer-memory accounting, explain the systems trade-off between choosing SGD and Adam for this run.
Answer: Adam typically converges in fewer iterations than SGD because its first- and second-moment estimates adapt the per-parameter step size, but it stores those moments at FP32 — 4 bytes for each — adding roughly \(2 \times 4 \times 7\) billion = 56 GB of optimizer state on top of the 64 GB already in use. Adam’s optimizer memory alone would push the per-accelerator footprint past 80 GB and force a smaller batch, gradient checkpointing, or more devices. SGD’s near-zero state cost preserves the existing memory budget at the price of more steps to the same loss — a wall-clock penalty rather than a feasibility one. The system consequence is that optimizer choice near the memory ceiling is a feasibility question, not a pure convergence-rate question.
Learning Objective: Compare SGD and Adam in terms of optimizer-state memory, convergence speed, and training-system feasibility at a given memory budget.
Why do activations often dominate the memory budget during training even when model weights already occupy several gigabytes on the accelerator?
- Because activations from every layer must remain resident from the forward pass until the backward pass consumes them, so total activation memory scales with depth and batch size while parameter memory is largely fixed for a given model.
- Because activations are stored in FP64 even when weights are kept in FP16 or FP32, doubling their byte count.
- Because activations include the raw training dataset, which grows with the number of epochs.
- Because the optimizer’s state vectors are accounted for as activations during the backward pass.
Answer: The correct answer is A. The backpropagation discussion shows that gradients are computed by walking the chain rule backward through every saved layer activation, so each layer’s output tensor must persist across the full forward-backward arc. Doubling depth or batch size doubles the activation footprint while leaving parameter count untouched — which is why deep transformers exceed weight-only budgets. The FP64-activation claim contradicts the actual storage convention (typically FP16 or BF16 in mixed precision). The ‘raw dataset’ claim confuses pipeline data-loading memory with model-internal state. Optimizer state and activations are tracked as separate budgets in the chapter’s training-memory equation.
Learning Objective: Explain why activation storage scales with depth and batch size and can exceed parameter memory during training.
Order the following components of one standard training step: (1) backward pass computes gradients, (2) optimizer updates parameters, (3) forward pass computes predictions and loss.
Answer: The correct order is: (3) forward pass computes predictions and loss, (1) backward pass computes gradients, (2) optimizer updates parameters. The sequence is necessary because gradients are defined only with respect to a computed loss, so the forward pass must finish first; the optimizer then needs the freshly computed gradients before it can step the parameters. Swapping the last two would mean updating weights from whichever stale gradients remained from a prior step, which destroys the link between the current minibatch and the current update.
Learning Objective: Sequence the three sub-steps of one training iteration and justify why the ordering is causally necessary.
On an A100 with a ridge point near 156 FLOP/byte, a fused LayerNorm-plus-attention-softmax kernel measures roughly 5 FLOP/byte from weight and activation movement. Which optimization family is most likely to move this workload closer to the roofline, and why?
- Replacing the A100 with a newer accelerator advertising 2\(\times\) the peak FP16 TFLOP/s.
- Reducing data movement through fusion, tiling, or lower-precision weights so arithmetic intensity increases for each byte loaded into on-chip SRAM.
- Doubling the batch size while leaving every kernel unchanged, because larger batches always move operations across the ridge point.
- Switching the optimizer from Adam to SGD while keeping every kernel unchanged.
Answer: The correct answer is B. With arithmetic intensity at 5 FLOP/byte against a 156 FLOP/byte ridge point, the kernel is firmly memory-bound and the gap closes only by reducing bytes moved per useful FLOP — the exact effect of operator fusion, tiling, and reduced precision. The ‘newer accelerator’ answer raises \(R_{\text{peak}}\) but leaves the kernel still starved for bytes, so most of the new FLOPs go unused. The ‘double the batch’ answer overgeneralizes: batch scaling helps for compute-bound kernels with high parallel work, but cannot raise the FLOP/byte ratio of a memory-bound op whose data movement scales with the same batch. The optimizer-swap answer is unrelated to the kernel’s memory pattern.
Learning Objective: Apply arithmetic-intensity analysis and ridge-point reasoning to select the optimization family that will move a memory-bound kernel closer to the roofline.
Self-Check: Answer
Which set of subsystems best describes the chapter’s high-level training-system architecture, and what is the engineering value of organizing the system this way?
- Data pipeline, training loop, and evaluation pipeline — each subsystem has distinct resource demands (CPU/IO, accelerator compute, periodic validation), so bottlenecks can be diagnosed at the subsystem boundary instead of inside a monolithic training script.
- Storage controller, compiler pass, and inference server — a layering that separates data placement from computation graph optimization.
- Optimizer state manager, scheduler daemon, and checkpoint restorer — a service decomposition that mirrors how cloud training platforms expose APIs.
- Tokenizer, hyperparameter tuner, and deployment gateway — a workflow decomposition centered on model-development tooling.
Answer: The correct answer is A. The pipeline architecture section organizes training as three interconnected subsystems with distinct resource profiles — ingest and preprocess on the data pipeline, forward/backward/update on the training loop, and periodic validation on the evaluation pipeline — explicitly because their interconnection points are where bottlenecks emerge. The storage-controller-and-compiler-pass grouping describes infrastructure layers, not the training architecture’s stages. The optimizer-state-manager grouping lists implementation modules, not subsystems. The tokenizer-and-tuner grouping mixes a data-pipeline component with model-development tooling and ignores the runtime training loop entirely.
Learning Objective: Identify the major subsystems in the chapter’s training pipeline architecture and justify why subsystem-level decomposition supports bottleneck diagnosis.
A profile shows preprocessing delivering batches at 4 GB/s, host-to-device transfer at 32 GB/s, and the GPU consuming the equivalent of 12 GB/s during forward and backward passes. According to the pipeline throughput model, what determines end-to-end training throughput, and what does the answer imply for the team’s next move?
- The average of the three rates, so the team should look for small simultaneous gains across all stages.
- The transfer rate alone, because every byte must traverse PCIe before being used.
- The GPU compute rate alone, because compute always dominates training cost.
- The minimum of the three rates — 4 GB/s at preprocessing — so total throughput is capped by the data pipeline, and the team should parallelize preprocessing before optimizing compute.
Answer: The correct answer is D. The pipeline throughput model the chapter introduces says end-to-end rate is bounded by the slowest stage, so the 4 GB/s preprocessor caps the system regardless of how much faster the other stages can run. Buying a faster GPU or fatter PCIe link does not help when the producer is starved — only adding preprocessing parallelism (multi-worker DataLoader, prefetching) does. Averaging the rates hides the bottleneck behavior and overstates achievable throughput. The ‘compute always dominates’ interpretation is the operations-manual fallacy the chapter warns about. The ‘transfer dominates’ answer mistakes presence on the path for being the binding stage.
Learning Objective: Apply the pipeline bottleneck model to determine end-to-end training throughput and select the stage to optimize first.
Explain why CPU tokenization can become a hidden bottleneck for language-model training even on a system whose host-to-device transfer time is well under a millisecond.
Answer: For a language model, each batch of 1 million tokens can take tens of milliseconds of single-threaded Python tokenization, while the resulting integer-tensor transfer over PCIe takes well under a millisecond and forward/backward compute takes 150–220 ms. Pipeline throughput is bounded by the slowest stage, so if tokenization runs at 60 ms while compute runs at 200 ms, the GPU is fed at the tokenizer’s rate and shows the gap as periodic idle intervals between batches. The system consequence is that adding more GPU throughput (a faster accelerator, mixed precision) cannot help: the binding constraint is on the CPU. The fix is multi-worker tokenization with prefetching, sized so the slowest worker still produces a batch faster than the longest downstream stage.
Learning Objective: Analyze why CPU-side preprocessing can starve GPU compute in a staged training pipeline despite low transfer latency.
A team measures iteration time for two configurations of the same training run on the same hardware: batch size 32 yields 92 percent GPU utilization, while batch size 33 yields 71 percent utilization. Based on the pipeline architecture section’s discussion of hardware execution granularity, what is the most likely cause?
- Batch size 33 exceeded the L2 cache capacity, forcing every operation to spill activations to HBM.
- The optimizer automatically switched to FP32 accumulation at the larger batch, halving effective compute throughput.
- Crossing a fixed warp or wave boundary at batch 33 launches a partially filled additional execution unit, leaving GPU lanes idle and lowering effective utilization.
- Larger batches always reduce gradient accuracy enough that the framework inserts extra synchronization barriers.
Answer: The correct answer is C. The chapter’s wave-quantization discussion explains that GPU execution is quantized into fixed-size warps or waves, so a batch one element past a multiple of that boundary launches an additional partially filled wave whose unused lanes dilute realized throughput — exactly the 92 → 71 percent pattern observed. The ‘optimizer switched to FP32’ explanation invents a mechanism PyTorch and TensorFlow do not implement at batch boundaries. The ‘L2 cache spill’ answer would manifest as a sustained drop tied to working-set size, not a one-element step change. The ‘extra synchronization barriers’ claim contradicts the framework’s actual behavior, which does not insert barriers based on gradient-accuracy heuristics.
Learning Objective: Diagnose hardware-execution-granularity effects (wave quantization) on training utilization from a paired batch-size measurement.
A team scales an existing training run from batch size 512 to 4096 on an 8-GPU node, leaving every other hyperparameter unchanged. Per-step GPU utilization rises from 61 percent to 88 percent, but validation loss after 10,000 steps is worse than the 512-batch run at the same wall clock. What is the most likely explanation under the chapter’s batch-size analysis?
- Larger batches changed the dtype of gradients from FP16 to FP32 automatically, slowing each step.
- Each epoch now contains 8\(\times\) fewer gradient updates, and the unchanged learning rate under-utilizes the available weight-space travel per epoch — the system is throughput-healthy but optimization-starved.
- Larger batches removed the need for backward propagation, so the optimizer had no gradient information to update weights.
- Larger batches always increase per-epoch communication volume linearly with batch size and no change in update frequency.
Answer: The correct answer is B. Total epoch work is bounded by dataset size, so an 8\(\times\) larger batch means 8\(\times\) fewer gradient updates per epoch. With the learning rate held constant, each update covers more examples but the optimizer still moves the same distance in weight space — the system is throughput-healthy but optimization-starved, exactly the chapter’s warning about copying small-batch hyperparameters to large-batch runs. The ‘gradient dtype switch’ answer invents a mechanism that does not exist in the training stack. The ‘backprop disappears’ answer contradicts the chapter’s description of larger batches as a grouping change, not a structural one. The communication claim misidentifies what scales: per-epoch communication volume stays roughly constant; per-step communication grows.
Learning Objective: Analyze why batch-size scaling interacts with learning-rate selection to create an optimization-starved regime despite improved hardware utilization.
Self-Check: Answer
Why is Model FLOPs Utilization (MFU) a more informative metric than the raw accelerator-busy percentage reported by a vendor profiler when diagnosing training efficiency?
- Because MFU equals peak hardware throughput expressed in percent and so always sits at 100 percent on healthy hardware.
- Because MFU is measured from CPU activity, so it isolates the data-loading pipeline automatically.
- Because MFU ignores wall-clock time and therefore removes timing noise from profile traces.
- Because MFU counts only the FLOPs that directly advance the model toward convergence, while raw busy time also charges padding FLOPs, gradient-checkpointing recomputation, and stalled kernels that do no useful model work.
Answer: The correct answer is D. The MFU definition the chapter introduces explicitly excludes recomputation, padding, and idle-busy time from the numerator — it counts only the forward-pass FLOPs the model actually needs against the accelerator’s advertised peak. That is precisely why MFU diagnoses overhead that hardware-busy time hides: a kernel can be ‘busy’ redoing recomputation a checkpointer scheduled, and a vendor profiler will count that as utilized while MFU correctly does not. A CPU-based interpretation confuses where the metric is collected with what it measures — MFU is computed from accelerator throughput, not host activity. An MFU that ‘ignores wall-clock time’ contradicts the formula \(T_{\text{step}} \cdot R_{\text{peak}}\) in the denominator. A ‘100 percent MFU on healthy hardware’ claim contradicts the chapter’s stated 55–65 percent practical ceiling.
Learning Objective: Explain why MFU distinguishes useful model computation from hardware-busy time and identify the overhead sources that raw utilization conflates with productive work.
A profiler trace shows repeated white gaps where GPU activity drops nearly to zero for tens of milliseconds at a time, while CPU-side data loading shows sustained activity during those same intervals and HBM bandwidth utilization sits low. Which D·A·M class most likely dominates this trace, and how does the signature distinguish it from an adjacent class?
- Compute-bound — the GPU is saturated on arithmetic units; the trace would show this regardless of CPU activity.
- Memory-bound — the GPU is stalled on HBM bandwidth, with the compute units idle waiting for data from device memory.
- Data-bound — the input pipeline cannot deliver batches fast enough; the discriminating signal is the GPU dropping to near zero rather than merely stalling on memory traffic.
- Communication-bound — inter-GPU synchronization is consuming the wall-clock budget.
Answer: The correct answer is C. The D·A·M table maps near-zero GPU utilization with active CPU input work to data-bound — the input pipeline cannot keep the accelerator fed, so it stops doing anything between batches. The discriminating signal is the GPU dropping to near zero: a memory-bound kernel still keeps the GPU’s execution units active and HBM bandwidth saturated, just stalled on memory traffic rather than completely starved for input. A compute-bound interpretation contradicts the low HBM utilization the trace also shows. A communication-bound interpretation requires multi-GPU traces showing collective-operation kernels in the gaps, not idle gaps with active CPU.
Learning Objective: Classify a training trace as data-bound versus memory-bound by reading GPU utilization, CPU activity, and HBM bandwidth signatures together.
A team profiles two training runs. Run A shows GPU utilization at 92 percent with HBM bandwidth saturated and CPU near idle. Run B shows GPU utilization at 18 percent with periodic drops to zero, CPU pinned, and HBM bandwidth low. Use the D·A·M taxonomy to assign each run to a bottleneck class and name the optimization family the chapter prescribes for each.
Answer: Run A’s signature — GPU near saturation, HBM bandwidth saturated — places it on the Algorithm axis as compute-bound: the arithmetic units themselves limit throughput. The chapter prescribes algorithmic and precision-reducing fixes here — FlashAttention to lower the FLOP count of the dominant kernel, mixed precision to raise \(R_{\text{peak}}\) through Tensor Cores, or simply faster hardware. Run B’s signature — low GPU utilization with periodic drops to zero, pinned CPU, low HBM — is the data-bound pattern on the Data axis: the input pipeline cannot feed the accelerator. The chapter’s prescription is prefetching and pipeline overlap, faster storage, and DataLoader parallelism. The system consequence is that swapping the techniques would waste effort: Run A needs algorithmic compute reduction, while Run B needs producer-side parallelism.
Learning Objective: Apply the D·A·M taxonomy to assign two contrasting profile signatures to bottleneck classes and select the corresponding optimization family for each.
Order the following stages of the chapter’s profile-diagnose-fix-reprofile workflow: (1) apply a targeted fix to the dominant bottleneck, (2) profile the training run to gather evidence, (3) re-profile and iterate, (4) identify the dominant bottleneck from the profile.
Answer: The correct order is: (2) profile the training run to gather evidence, (4) identify the dominant bottleneck from the profile, (1) apply a targeted fix to the dominant bottleneck, (3) re-profile and iterate. The sequence is causal: without an initial profile there is no evidence on which to build a diagnosis; without a diagnosis a ‘fix’ is just a guess that may target a non-bottleneck; and without re-profiling the team cannot detect that removing one bottleneck has revealed a new dominant one elsewhere. Skipping any earlier step leaves a later step working from invented or stale information — the exact failure mode the iterative loop exists to prevent.
Learning Objective: Sequence the profile-diagnose-fix-reprofile workflow for training optimization and justify why each step depends on the prior one.
Self-Check: Answer
A profile shows 40 percent of iteration time in data loading, 35 percent in compute, and 25 percent in memory operations on a single-GPU training run. According to the section’s systematic optimization framework, what should be optimized first, and why does this choice matter more than picking the most familiar technique?
- Data prefetching and pipeline overlap, because the dominant bottleneck is on the data path — optimizing compute or memory first leaves the GPU starved regardless of how fast the accelerator becomes.
- Gradient checkpointing, because memory is always the safest first target for memory-constrained training.
- Mixed precision, because compute is still a large fraction of time and Tensor Cores are the highest-leverage lever.
- FlashAttention, because attention is usually the slowest kernel in transformers.
Answer: The correct answer is A. The framework prescribes profiling, identifying the dominant bottleneck, and targeting that constraint first; here data loading at 40 percent dominates. Jumping directly to mixed precision or FlashAttention optimizes a non-bottleneck and produces no speedup at the system level, because the slowest pipeline stage caps end-to-end throughput. The ‘memory is always the safest first target’ framing replaces evidence with habit — a memory fix on a data-bound run yields nothing. The ‘attention is usually slowest’ answer overgeneralizes from common transformer profiles to a workload whose own profile says otherwise.
Learning Objective: Apply the systematic profile-driven framework to select the optimization technique whose target matches the measured dominant bottleneck.
Explain why prefetching can reduce iteration time from roughly the sum of fetch, preprocess, and transfer stages to roughly the maximum of those stages, and identify what condition must hold for that benefit to materialize.
Answer: Prefetching overlaps stages across consecutive batches: the next batch’s fetch and preprocessing run on the CPU while the current batch’s transfer and compute run on the accelerator. Without overlap, every iteration pays each stage’s latency in series, so iteration time is the sum; with overlap, the system pays only the slowest stage’s latency per iteration, so iteration time approaches the maximum. The condition for the benefit is that the pipeline buffer is deep enough and the producer stages run on hardware independent of the consumer — typically a multi-worker DataLoader on CPU plus a queue sized so the next batch is ready when the current one finishes. The system consequence is much higher accelerator utilization without changing the model itself.
Learning Objective: Explain how overlapping pipeline stages transforms serial latency into the maximum-stage latency and identify the buffering condition required for the transformation.
Why does mixed-precision training keep certain quantities — such as master weights and select reductions — in FP32 even though the bulk of the forward and backward passes runs in FP16 or BF16?
- Because FP16 and BF16 cannot run on Tensor Cores without an FP32 mirror of every activation tensor existing alongside.
- Because reduced precision increases memory bandwidth demand, so FP32 is reserved for traffic-heavy paths to lower bandwidth pressure.
- Because storing part of the model in FP32 is required for data parallelism but not for single-GPU training.
- Because numerically sensitive accumulations and parameter updates can lose precision or underflow if held in reduced precision, while bulk matrix multiplies tolerate FP16/BF16; selective FP32 storage protects stability where it matters and exploits faster low-precision compute everywhere else.
Answer: The correct answer is D. The mixed-precision design isolates the small subset of operations whose dynamic-range or precision requirements would otherwise destabilize training (master weight updates, certain reductions) and keeps them in FP32, while letting the large dense matrix multiplies run on Tensor Cores at FP16/BF16. The ‘FP32 mirror of every activation’ claim contradicts the actual implementation — only weights and select accumulators stay FP32. The ‘data parallelism only’ claim is mechanically wrong: mixed precision applies identically on a single GPU. The bandwidth claim inverts the direction of the actual benefit, since reduced precision halves bytes moved — keeping FP32 anywhere increases bandwidth, not decreases it.
Learning Objective: Explain why mixed-precision training selectively retains FP32 for numerically sensitive quantities and why that selectivity is the source of its training stability.
What is the core systems mechanism that makes FlashAttention faster and more memory-efficient than the standard attention implementation, even though both compute the same mathematical result?
- It tiles the attention computation so intermediate score and probability blocks stay in on-chip SRAM across the softmax-mask-matmul stages, never materializing the full \(S \times S\) attention matrix in HBM.
- It replaces softmax with ReLU so attention becomes element-wise and compute-bound.
- It reduces sequence length during training so the attention matrix never exceeds cache capacity.
- It stores the full \(S \times S\) attention matrix in HBM once and reuses it across all backward-pass calls.
Answer: The correct answer is A. FlashAttention’s mechanism is I/O-aware: it processes attention in tiles small enough to fit in on-chip SRAM, fusing softmax, masking, and matmul stages so intermediates never spill to HBM. That cuts the dominant memory traffic from \(\mathcal{O}(S^2)\) to \(\mathcal{O}(S)\), which is exactly what shifts attention from the memory-bound side of the roofline to the compute-bound side. The ‘shorten sequence length’ claim describes a different intervention (truncation) that changes the model output and is not what FlashAttention does. The softmax-replacement claim describes a different algorithm class (linear attention). The ‘store full matrix in HBM’ description is the standard attention pattern FlashAttention exists to avoid.
Learning Objective: Identify the IO-aware tiling mechanism that lets FlashAttention reduce HBM traffic and shift attention from memory-bound to compute-bound.
A model converges best with an effective batch size of 512, but each accelerator’s memory budget admits only a micro-batch of 16 once activations and Adam optimizer state are accounted for. Which combination most directly emulates the 512 batch while also reducing activation pressure?
- FlashAttention plus weight decay.
- Data prefetching plus operator fusion.
- Gradient accumulation plus activation checkpointing — accumulation simulates the 512 batch by summing gradients over 32 micro-batches before stepping the optimizer, while checkpointing recomputes activations selectively to lower per-step activation memory.
- AdamW plus cosine annealing.
Answer: The correct answer is C. Gradient accumulation lets the system emulate a larger effective batch by holding only one micro-batch’s worth of activations at a time and summing gradients over multiple micro-batches before each optimizer step — the section’s exact prescription for the 512/16 mismatch. Activation checkpointing then recomputes a chosen subset of forward activations during backprop to free their storage, addressing the activation pressure that would otherwise bind even at micro-batch 16. Prefetching plus fusion helps data starvation and memory traffic but neither emulates a larger batch nor frees activation memory. FlashAttention-plus-weight-decay mixes a kernel optimization with a regularizer; neither addresses the batch-size or activation-storage problem. AdamW-plus-cosine-annealing changes the optimizer and learning-rate schedule, neither of which affects per-step memory.
Learning Objective: Compose memory-capacity optimization techniques to satisfy a target effective batch size on a memory-constrained accelerator while reducing activation pressure.
A team applies mixed precision to a transformer training run and sees compute time drop by 38 percent. They are about to declare the run optimized. Using the chapter’s iterative optimization principle, explain what they should do next and what new dominant bottleneck is most plausible after a compute-side win like this.
Answer: The team should re-profile before declaring victory: removing one bottleneck typically reveals another, because the staged-pipeline rate is set by whichever stage is now the slowest. After mixed precision cuts compute time substantially, the data pipeline often becomes the new dominant stage — a CPU tokenizer or single-worker DataLoader that was previously masked by 200 ms of compute now appears as periodic GPU idle gaps. Memory-bandwidth-bound activation kernels can also surface as the new ceiling, since reduced precision halves bytes moved per op but does not change how many tiny activation kernels execute serially. The system consequence is that the next optimization — prefetching, multi-worker loading, or operator fusion — should be selected from a fresh profile, not from the optimization that worked last round.
Learning Objective: Justify why optimization is iterative by predicting which class of bottleneck most plausibly becomes dominant after a successful compute-side win.
Self-Check: Answer
A 1.5-billion-parameter model fits within a single accelerator’s memory with batch size 32 and Adam optimizer state, but per-epoch wall clock is 14 hours and the team needs results in under 4 hours per epoch. They have access to 8 identical accelerators on the same node. Comparing the section’s parallelism strategies, which choice is the most appropriate first step, and why does the alternative fail this scenario?
- Model parallelism — partition the layers across the 8 accelerators so each one holds a smaller working set; this is the right choice because layer partitioning increases per-step throughput proportionally to the number of devices.
- Switch from Adam to SGD on a single accelerator to reclaim optimizer-state memory; this is the right choice because parallelism complexity should be avoided when memory is not the binding constraint.
- Pipeline parallelism with naive layer assignment — split forward and backward passes across the 8 devices, accepting whatever bubble overhead this introduces.
- Data parallelism — replicate the model on each accelerator and split the batch into 8 micro-batches with one AllReduce per step; this is preferred because the model already fits, so the per-step gradient synchronization is a smaller cost than the pipeline bubbles model parallelism would introduce.
Answer: The correct answer is D. Data parallelism is the natural fit when each device can hold a full model copy: it splits the batch across replicas and synchronizes gradients once per step via AllReduce, scaling throughput nearly linearly until communication becomes the bottleneck. Model parallelism is the tool for memory overflow, not throughput — layer partitioning forces sequential dependencies across devices and introduces pipeline bubbles that cost utilization. Naive pipeline parallelism makes the same mistake without microbatching. Switching to SGD addresses memory — not the binding constraint here — and gives up Adam’s convergence advantage to solve a problem the team does not have.
Learning Objective: Choose between data parallelism and model parallelism for a memory-fits-but-too-slow training run and justify the choice by reference to which constraint the workload actually has.
Why does naive model parallelism often deliver poor utilization — the section quotes 25 to 50 percent — even though it is the technique that lets larger models fit at all?
- Because each GPU must still store the full optimizer state for all partitions, exhausting memory before training begins.
- Because partitioning the model by layers introduces sequential dependencies, so downstream devices sit idle waiting for upstream activations to arrive — these pipeline bubbles dominate utilization until microbatched pipelining (GPipe, PipeDream) interleaves work across them.
- Because model parallelism removes the need for batching, lowering arithmetic intensity to the memory-bound regime.
- Because model parallelism requires storing the entire dataset in each node’s RAM.
Answer: The correct answer is B. Layer-by-layer partitioning makes device N’s forward computation depend on device N-1’s output, so after the first device starts, every subsequent device idles until the activations have propagated — the pipeline bubble. The chapter’s footnote names microbatched pipelining (GPipe, PipeDream) as the technique that recovers most of this lost efficiency by overlapping multiple in-flight microbatches. The ‘full optimizer state for all partitions’ claim contradicts how model parallelism actually shards optimizer state. The ‘removes the need for batching’ claim invents a mechanism: minibatch execution remains essential. The ‘entire dataset in each node’s RAM’ claim is the data-parallelism failure mode, misapplied here.
Learning Objective: Explain why naive model parallelism suffers from pipeline-bubble idleness and identify the technique class that recovers most of the lost efficiency.
Explain the communication tax in distributed training and why it can erase expected speedups even when individual GPUs become more efficient. Describe one quantitative regime where the tax becomes the binding constraint.
Answer: Distributed training adds synchronization and gradient-exchange overhead that does not shrink in proportion to per-device compute: doubling the device count typically doubles the data each device must exchange (gradient AllReduce) without halving the per-step compute by the same factor. As GPU count rises, communication becomes a larger fraction of each step, so beyond some point doubling devices stops doubling throughput. The chapter’s transformer-training footnote gives a concrete regime: GPT-3 across 1,024 V100 GPUs spent an estimated 30–40 percent of wall-clock time on inter-GPU communication, making the NVLink vs InfiniBand bandwidth choice a first-order determinant of training cost. The system consequence is that scaling helps only when the workload’s compute intensity is high enough relative to communication overhead — small or communication-heavy workloads see scaling efficiency collapse first.
Learning Objective: Analyze why communication overhead limits scaling efficiency in distributed training and identify a quantitative regime where it dominates wall-clock time.
A team plans to train a 70-billion-parameter model in FP16. Weights alone require approximately 140 GB, while the largest available single accelerator has 80 GB of HBM. Which hard limit identified by the section is forcing the move beyond single-device training, and what does this imply about the order in which they should explore optimizations?
- Memory exhaustion — the weights alone exceed single-device capacity, so single-machine optimizations cannot fit the model and the team must move to model or tensor parallelism regardless of throughput considerations.
- Wall-clock time only — the team should procure a faster single accelerator before rearchitecting.
- Dataset scale — the team should first attempt distributed storage tuning before considering parallelism.
- Numerical precision — the team should switch to FP32 master weights to handle the larger model.
Answer: The correct answer is A. The chapter lists three hard limits that justify multi-device training: memory exhaustion, wall-clock time, and dataset scale. With 140 GB of FP16 weights against an 80 GB ceiling, the system has hit the capacity limit before considering gradients, optimizer state, or activations — single-machine optimizations like mixed precision and checkpointing reduce activations and optimizer state, but they cannot shrink weights below the precision floor. Wall-clock time may also matter, but it is not the first blocking constraint. The dataset-scale claim does not match the scenario, which describes a parameter-count problem, not an I/O problem. Switching to FP32 makes the situation worse, doubling weight memory.
Learning Objective: Identify memory exhaustion as the binding hard limit forcing scaling beyond a single device and explain why single-machine optimizations cannot resolve it for weight-dominated cases.
According to the section’s scaling guidance, when should a team seriously consider multi-device training?
- Immediately, because distributed training is usually more cost-efficient than single-node optimization.
- Whenever the model uses Adam rather than SGD, because Adam’s optimizer state always forces multi-GPU training.
- As soon as GPU utilization exceeds 60 percent on a single device, because further single-node gains become difficult.
- Only after mixed precision, gradient accumulation, activation checkpointing, and data-pipeline optimization have been applied and a hard limit (memory exhaustion, wall-clock budget, or dataset scale) still remains.
Answer: The correct answer is D. The section is explicit that teams should exhaust the single-machine optimization toolkit before accepting distributed complexity — mixed precision, accumulation, checkpointing, and pipeline optimization typically remove the binding constraint more cheaply than adding nodes. A 60 percent utilization threshold alone is not enough; the decision depends on whether one of the three hard limits persists. The ‘distributed is always cheaper’ framing contradicts the chapter’s communication-tax analysis. The ‘Adam forces multi-GPU’ claim overgeneralizes: Adam’s 3\(\times\) optimizer state is significant but is reducible via 8-bit Adam or offloading before reaching for distribution.
Learning Objective: Evaluate when the complexity of multi-device training is justified by reference to the single-machine optimization toolkit and the three hard limits.
Self-Check: Answer
A team has a 7-billion-parameter model performing well on a 100-million-example dataset. They scale up to a 20-billion-parameter model on the same dataset, expecting better validation performance. Which outcome does the section identify as most likely, and what is the underlying mechanism?
- Validation performance improves linearly with parameter count, because larger models always extract more signal from a fixed dataset.
- Validation performance degrades by 5–10 percent due to overfitting, because the larger model has the capacity to memorize idiosyncrasies of the fixed 100M-example dataset rather than learn generalizable patterns — and it pays roughly 3\(\times\) the memory and compute cost to do so.
- Validation performance is unchanged, because parameter count and data size are independent levers in the training equation.
- Validation performance improves only if the optimizer is changed from Adam to SGD.
Answer: The correct answer is B. The section’s first fallacy explicitly warns that scaling capacity without matching data can worsen validation performance through overfitting; with parameter count growing 3\(\times\) against unchanged data, the model memorizes dataset noise rather than learning the underlying distribution. The compute and memory costs scale with the model, so the team pays significantly more wall-clock time and dollars for a worse result. The ‘linear improvement’ answer ignores the data-capacity coupling the chapter’s scaling-laws material formalizes. The ‘unchanged’ answer treats the levers as independent, which they are not. The optimizer-change answer misattributes the failure mode to optimizer choice rather than data-capacity mismatch.
Learning Objective: Predict the validation outcome of scaling model capacity against a fixed dataset and explain the overfitting mechanism that produces it.
Which scenario best illustrates why distributed training does not automatically speed up development, even when more accelerators are added?
- A cluster trains faster per step, which always means faster experimentation regardless of debugging complexity.
- A large model uses BF16 instead of FP16, so data parallelism cannot be used at all and the team is forced into model parallelism.
- A small communication-heavy model spends 30–50 percent of each step in gradient AllReduce, so adding more GPUs increases the synchronization fraction faster than it adds useful compute and the team observes only a 4–6\(\times\) speedup on 8 GPUs instead of the expected 8\(\times\).
- A model uses activation checkpointing, which prevents any gradient communication from occurring across devices.
Answer: The correct answer is C. The communication-tax pitfall the section identifies plays out exactly this way: for small or communication-heavy workloads, synchronization overhead dominates and erodes the linear speedup distributed training would otherwise deliver. The BF16-blocks-data-parallelism claim is mechanically wrong: data parallelism works identically across precisions. The ‘faster per step always means faster experimentation’ framing ignores debugging and infrastructure complexity, which the section explicitly warns about. The activation-checkpointing-eliminates-communication claim conflates a memory-reduction technique with distributed synchronization, which still happens regardless of checkpointing.
Learning Objective: Identify how communication overhead can negate expected gains from distributed training and recognize the workload signature that surfaces this pitfall.
Explain why copying hyperparameters directly from a small-batch experiment (batch 512, learning rate 0.1) to a much larger-batch training run (batch 4,096, same learning rate) can waste days of compute and end in failure.
Answer: Large batches change optimization dynamics: per epoch, the 4,096 batch run does 8\(\times\) fewer gradient updates than the 512 batch run, so the same learning rate moves the optimizer through 8\(\times\) less weight space per epoch. The run can appear healthy for thousands of steps — loss decreases, GPU utilization is high — then either fail to converge to the small-batch baseline or diverge unstably once the unscaled learning rate interacts with the larger gradient noise floor. The chapter’s pitfall scenario notes that such failures typically surface 3 to 5 days into a multi-day run, after substantial compute is spent. The system consequence is that hyperparameters need re-tuning — typically the linear scaling rule (\(\eta\) proportional to batch size) up to the critical batch size — whenever training scale changes substantially.
Learning Objective: Explain why hyperparameter transfer from small-batch to large-batch training can fail late in a run and identify the corrective rule the chapter prescribes.
Which mistake does the chapter identify as especially common when teams focus only on accelerator-side optimization (kernels, mixed precision, FlashAttention) and skip end-to-end profiling?
- Computing LayerNorm in FP32 during mixed-precision training.
- Choosing AdamW instead of SGD for a transformer.
- Using gradient accumulation to emulate larger effective batches.
- Assuming the input pipeline is fine and only later discovering that the GPU is idle 30–50 percent of the time waiting for data, even though every kernel-level optimization succeeded.
Answer: The correct answer is D. The section warns that neglected input pipelines can leave accelerators idle for 30 to 50 percent of training time, so optimizing compute kernels first risks attacking a non-bottleneck. Even a perfectly tuned attention kernel cannot help when the GPU sits waiting for the next batch. Choosing AdamW over SGD is a standard design decision the chapter neither flags as a pitfall nor ties to pipeline neglect. Gradient accumulation is a recommended technique, not a pitfall. Keeping LayerNorm in FP32 during mixed precision is the chapter’s prescribed selective-FP32 stability practice.
Learning Objective: Recognize data-pipeline neglect as the most common operational pitfall when accelerator-side optimization succeeds without end-to-end profiling.
Self-Check: Answer
Which statement best captures the chapter’s main approach to improving training performance?
- Keep adding GPUs until wall-clock time is acceptable, then tune the data pipeline afterward.
- Use the iron law to identify whether total operations, peak throughput, or utilization is the binding lever; profile to confirm; apply targeted optimizations to that lever; then re-profile to handle the new dominant bottleneck.
- Prefer optimizer changes over systems changes, because convergence dominates all hardware effects.
- Reduce model size first, because system optimization rarely changes the feasible training regime.
Answer: The correct answer is B. The chapter’s central discipline is profile-driven optimization guided by the iron law and the D·A·M taxonomy, with iteration after each fix. The hardware-first approach ignores the chapter’s repeated warning that non-compute bottlenecks — especially memory and data flow — dominate training performance more often than compute alone. The ‘optimizer-changes-dominate’ framing inverts the chapter’s framing of optimizer choice as a memory-versus-convergence trade-off, not a hardware-effect dominator. The ‘reduce model size first’ claim reverses the chapter’s actual sequence, in which system optimization (mixed precision, checkpointing, accumulation) is exactly what changes the feasible training regime.
Learning Objective: Synthesize the chapter’s profile-driven, iron-law-guided method for improving training performance.
Why does the chapter recommend exhausting single-machine optimizations before scaling to multi-device training? Name two single-machine techniques the chapter places ahead of distribution and explain what they buy.
Answer: Single-machine optimizations like mixed precision, gradient checkpointing, gradient accumulation, FlashAttention, and prefetching often remove the binding constraint at far lower complexity cost than distribution: distribution adds communication overhead, debugging difficulty, and infrastructure spend that all compound failure probability. Mixed precision halves bytes moved and roughly doubles Tensor-Core throughput, raising \(R_{\text{peak}}\); activation checkpointing trades roughly 33 percent additional compute for large activation-memory savings (about 70 percent in the chapter’s simplified GPT-2 example), often eliminating the memory exhaustion that would otherwise force scale-out. The system consequence is that a well-optimized single node can match or beat a poorly optimized cluster while preserving faster iteration cycles — distribution should be reached for only after profiling shows a hard limit (memory, wall clock, or dataset scale) the single-node toolkit cannot resolve.
Learning Objective: Justify the single-machine-before-scale-out principle and connect two single-machine techniques to the iron-law levers they target.
A team improves a 1024-GPU training run’s MFU from 30 percent to 60 percent through better pipeline overlap and a FlashAttention swap, with no change to the iron law’s \(R_{\text{peak}}\) or the dataset. Under the chapter’s framework, what is the most accurate description of how this single utilization gain propagates through the system’s runtime, energy, and operating cost?
- Wall-clock time roughly halves, but energy use is unchanged because the accelerators draw similar power per second whether or not they are doing useful model work.
- Wall-clock time, energy, and cost all stay the same, because MFU is an efficiency metric that does not affect physical resource use.
- Wall-clock time roughly halves, energy use drops in proportion because the run finishes faster on the same hardware drawing similar instantaneous power, and operating cost (cloud rental and electricity) drops along with energy — a single \(\eta_{\text{hw}}\) win compounds across all three downstream quantities.
- Wall-clock time stays the same, but energy and cost double because the accelerators are running ‘harder.’
Answer: The correct answer is C. Doubling \(\eta_{\text{hw}}\) in the iron law’s denominator roughly halves \(T_{\text{train}}\) at fixed \(O\) and \(R_{\text{peak}}\); on the same hardware drawing similar instantaneous power, finishing in half the wall clock cuts total energy roughly in half, and cloud-rental cost (charged per accelerator-second) drops with it. The chapter’s carbon-footprint perspective makes this propagation explicit: a 30 percent → 60 percent MFU improvement saves substantial kWh and tons of CO2 on a fleet-scale run. The ‘energy unchanged’ answer ignores that a shorter run draws power for fewer seconds. The ‘no propagation’ answer contradicts the iron law’s structure. The ‘energy doubles’ answer inverts the relationship: working harder per unit time but for half as long roughly halves total energy when instantaneous power is similar.
Learning Objective: Analyze how a utilization improvement propagates through wall-clock time, energy use, and operating cost via the iron law of training performance.