The dispatch tax: Python overhead vs. GPU reality
ML Frameworks
Purpose
Why does the framework silently constrain every decision that comes after it?
Neural networks are defined by mathematics (matrix multiplications, gradient computations, activation functions), but mathematics does not execute itself. Between the equations and the silicon lies a translation layer that decides how operations are scheduled on hardware, how memory is allocated across the compute hierarchy, and how gradients flow backward through the computational graph. The framework is this translation layer, and the translation is not neutral. A single tensor expression may become an immediate kernel launch, a captured graph, a fused operator, a recomputed activation, or an exported inference artifact depending on the framework’s execution model. Those choices shape not only speed but the engineering work itself: whether the model can be debugged step by step, whether the compiler can see enough context to eliminate memory traffic, whether gradients fit in device memory, whether custom operations survive conversion to a mobile runtime, and whether the chosen accelerator can run the model directly or falls back to a slow path. These execution-mode, compiler, and accelerator choices determine which optimizations are possible, which hardware is reachable, and which deployment targets can run the model. This abstraction creates both power and lock-in: once a project accumulates checkpoints, data pipelines, custom modules, distributed training scripts, serving formats, and team expertise around a framework, the framework becomes part of the system architecture rather than a replaceable library. In D·A·M terms, the framework is the mediator of algorithm-machine co-design: it turns mathematical intent into hardware behavior, making framework selection an infrastructure commitment that determines what the algorithm can do on its target machine.
Learning Objectives
- Explain how frameworks mediate algorithm-machine co-design through execution, differentiation, and hardware abstraction
- Compare execution strategies using dispatch overhead, compilation cost, and deployment constraints
- Analyze automatic differentiation and activation storage to choose recomputation or checkpointing
- Implement module abstraction patterns for parameter discovery, mode behavior, serialization, and hooks
- Calculate training-step FLOPs, memory traffic, and dispatch overhead to identify fusion and layout bottlenecks
- Select TensorFlow, PyTorch, JAX, or edge runtimes based on model, hardware, team, and deployment requirements
Three Framework Problems
An architecture is a graph of commitments: a transformer commits the system to attention, matrix multiplications, activation state, and memory traffic. The framework is the layer that turns that graph into work the machine can execute. A few calls such as logits = model(tokens), loss = criterion(logits, targets), and loss.backward() hide billions of floating-point operations across memory hierarchies, exact gradients through millions of parameters via automatic differentiation, thousands of GPU kernel launches, and gigabytes of intermediate state. The API looks simple because the framework is acting as a compiler for the silicon contract.
Architectures specify what computations neural networks perform, but knowing what to compute is entirely different from knowing how to compute it efficiently. A transformer’s attention mechanism requires coordinating computation across memory hierarchies and accelerator cores in patterns that naive implementations would execute 100\(\times\) slower than optimized ones. Implementing these operations from scratch for every model would make deep learning economically infeasible. ML frameworks exist to bridge this gap by translating high-level model definitions into hardware-specific execution plans that extract maximum performance from silicon.
A framework is to machine learning what a compiler is to traditional programming. A C compiler translates human-readable code into optimized machine instructions, managing register allocation, instruction scheduling, and memory layout. An ML framework translates high-level model definitions into hardware-specific execution plans, managing operator fusion, memory reuse, and device placement. This analogy is more than metaphor: modern frameworks literally include compilers.
Every ML framework, regardless of API or design philosophy, must solve three core problems. The first is the execution problem: deciding when and how computation runs. A framework can execute operations immediately as written (eager execution1) or build a complete description first—a computational graph2 (a structured representation of operations and their dependencies)—and optimize before executing (graph execution). This choice shapes debugging capability, optimization potential, and deployment flexibility.
1 Eager Execution: This mode executes each operation sequentially and immediately, which enables direct debugging with standard tools but sacrifices the global view needed for graph-level optimizations. Without seeing the full sequence of computations, the framework cannot fuse operations or preplan memory, forfeiting potential speedups of over 30 percent that compilers like torch.compile can provide.
2 Computational Graph: The “optimize before executing” distinction in the triggering sentence is the key design choice. By capturing the full program as a data structure (pioneered by Theano in 2007), the framework can fuse multiple operations into a single GPU kernel before any code runs, reducing overhead by over 10\(\times\). The engineering cost of this visibility is that the executed program differs from the source code, making debugging significantly harder, a trade-off every graph-based framework must justify against the performance gain.
Once execution has a shape, the framework must solve the differentiation problem: computing gradients automatically. As established in Neural Computation, training requires derivatives of a loss function with respect to millions or billions of parameters, and manual differentiation is error-prone at this scale. Frameworks therefore need automatic differentiation systems that compute exact gradients for arbitrary compositions of operations while managing the memory overhead of storing intermediate values.
The third problem is hardware abstraction: targeting diverse hardware from a single interface. The same model definition should be expressible across CPUs, GPUs, Tensor Processing Units (TPUs), and mobile devices, even though each target has different memory constraints and optimal execution patterns. Within the GPU slice of this problem, some framework ecosystems expose custom-kernel languages so advanced users can write high-performance kernels without dropping all the way to low-level CUDA (Tillet et al. 2019).
Tillet, Philippe, H. T. Kung, and David Cox. 2019. “Triton: An Intermediate Language and Compiler for Tiled Neural Network Computations.” Proceedings of the 3rd ACM SIGPLAN International Workshop on Machine Learning and Programming Languages, 10–19. https://doi.org/10.1145/3315508.3329973.
These three problems are deeply interconnected. The execution model determines when differentiation occurs and what optimizations are possible. The abstraction layer must support both execution styles across all hardware targets. Solving any one problem in isolation leads to frameworks that excel in narrow contexts but fail in broader deployment. Because these problems are ultimately about translating mathematics into efficient hardware execution, a useful perspective is to view frameworks not as libraries but as compilers.
Systems Perspective 1.1: The ML compiler
In the context of the iron law (Iron Law of ML Systems), a framework is a compiler for the silicon contract.
The “source code” is the model architecture (the \(O\) term). The framework’s job is to take this high-level math and compile it into a series of hardware-specific kernel launches that:
- Minimize Data Movement \((D_{\text{vol}})\) through techniques like kernel fusion.
- Maximize Utilization \((\eta_{\text{hw}})\) by matching operations to specialized hardware units like Tensor Cores.
- Minimize Overhead \((L_{\text{lat}})\) through efficient asynchronous dispatch and graph capture.
Choosing a framework means choosing the compiler that determines how efficiently a model uses hardware.
Precision matters: a definition that captures all three responsibilities separates genuine frameworks from numerical libraries that address only one.
Definition 1.1: Machine learning frameworks
Machine Learning Frameworks are software systems that translate high-level mathematical model definitions into hardware-optimized execution plans by managing the computational graph, automatic differentiation, kernel dispatch, and memory allocation across the hardware hierarchy.
- Significance: Frameworks directly determine the system efficiency \((\eta_{\text{hw}})\) term in the iron law. Compiler-backed operator fusion, for example, eliminates intermediate memory writes between consecutive elementwise operations: fusing a matrix multiplication, bias add, and rectified linear unit (ReLU) into a single kernel reduces the total data movement \((D_{\text{vol}})\) by 2–3\(\times\) compared with three separate kernel launches. The model has not changed; the framework has changed how the same math reaches hardware.
- Distinction: Unlike a numerical library such as NumPy, which executes each operation immediately (eager evaluation), an ML framework can defer execution to analyze the full computational graph and apply global optimizations: operator fusion, memory layout transformations, and parallel scheduling. These optimizations are impossible when operations are evaluated one at a time.
- Common pitfall: A frequent misconception is that frameworks are interchangeable API wrappers. Framework choice determines which compiler paths are available: PyTorch can recover graph-level optimization from eager code through
torch.compile(), PyTorch’s compiler path for eager programs, while TensorFlow and JAX commonly rely on XLA-backed compilation paths, with XLA serving as the graph compiler that lowers operations to target hardware. Moving from eager execution to a compiler path commonly changes throughput by 1.2–3\(\times\) on supported workloads, but the exact gain depends on model structure, shapes, and operator support.
The compiler metaphor is not decorative. An ML framework translates logical intent into physical execution under the constraints of the iron law, deciding how to partition computation across memory hierarchies, when to trade numerical precision for throughput, and how to schedule operations so that the dominant term (data movement, computation, or overhead) is minimized. The framework is where the governing physics developed throughout this book becomes executable code.
The scale of this translation is not obvious from the API surface. A single call to loss.backward() triggers operation recording, memory allocation for gradients, reverse-order graph traversal, and hardware-optimized kernel dispatch—machinery that would require hundreds of lines of manual calculus for even a three-layer network. For a contemporary language model, the framework additionally orchestrates billions of floating-point operations across accelerators, coordinating memory hierarchies, numerical precision, and, when the system grows beyond one device, communication libraries. Building this from scratch would be economically prohibitive for most organizations, which is why the history of ML frameworks is a history of progressively automating these layers.
The three problems—execution, differentiation, and abstraction—did not emerge simultaneously. Each arose as a response to scaling limitations in the previous generation of tools. Tracing this evolution reveals why modern frameworks are designed as they are and why the particular trade-offs they embody were, in hindsight, inevitable.
Self-Check: Question
A team reports that their model trains correctly on a CPU but produces wildly different tensor shapes when they switch to a GPU backend because some operators silently default to different memory layouts. Which of the three framework problems does this failure most directly belong to?
- The execution problem, because the operators are running eagerly instead of in a graph
- The differentiation problem, because the backward pass cannot handle layout changes
- The hardware abstraction problem, because one model interface must produce consistent behavior across diverse devices and memory layouts
- A data engineering problem unrelated to framework design
Explain why viewing a framework as a compiler, rather than as a numerical library like NumPy, changes what an engineer expects from framework choice.
True or False: Two frameworks that expose nearly identical tensor APIs and support the same target GPU will expose the same set of graph-level fusion and ahead-of-time compilation optimizations for that GPU.
A team trained a model in a research-focused framework that cannot export to their required edge deployment runtime. Applying the chapter’s infrastructure-commitment argument, what is the dominant systems lesson?
- The choice is easily reversible because model weights can be copied to any framework
- The real issue is the model architecture being too small for the edge target
- The failure is primarily about missing data preprocessing tools, not framework selection
- Framework selection silently constrains reachable hardware and deployment paths, so it functions as a long-lived infrastructure commitment whose reversal cost scales with how much of the serving stack has adopted it
The Ladder of Abstraction
In 1979, writing a matrix multiplication in Fortran that saturated the hardware required deep knowledge of cache lines, register scheduling, and vector units. By 2016, a single line of Python (torch.matmul(A, W)) achieved the same peak throughput without the programmer knowing anything about the silicon. That compression of effort did not happen in one step; it accumulated across four decades of abstraction, each layer solving a bottleneck that made the previous generation impractical for scaling. The result is a Ladder of Abstraction where each rung automates what the rung below exposed.
- Solving Performance (1979–1992): The original Basic Linear Algebra Subprograms (BLAS)3 standardized reusable low-level linear-algebra primitives (Lawson et al. 1979), while LAPACK4 (Bai et al. 2006) built higher-level numerical routines on top of that foundation. Together, these libraries solved the problem of hardware primitives: stable interfaces let frameworks delegate operations such as
C = A @ B5 to specialized implementations instead of hand-writing silicon-specific code. - Solving Usability (2006): NumPy6 solved the problem of developer velocity. By wrapping low-level BLAS routines in high-level Python (Harris et al. 2020), it allowed scientists to write code in a friendly language while executing it in optimized C/Fortran. This “Vectorization” pattern, where the slow language handles logic and the fast language handles loops, became a durable contract for scientific computing. Jupyter notebooks later extended this usability layer into readable, executable computational workflows for combining code, results, and explanations (Kluyver et al. 2016).
- Solving Differentiation (2007–present): Deep Learning Frameworks (Theano7, TensorFlow (Abadi et al. 2016), PyTorch (Paszke et al. 2019)) solved the problem of gradient computation. While NumPy required manual derivation of backpropagation gradients (error-prone and slow), these frameworks introduced automatic differentiation via the computational graph. This turned the chain rule into a software primitive, allowing researchers to define forward passes and get backward passes for free.
3 BLAS (Basic Linear Algebra Subprograms): The 1979 API specification that forms the bottom rung of the ladder described here. It standardized a fixed set of Fortran-callable vector operations, separating the public routine names from the machine-specific implementation decisions beneath them. Every framework above it inherits the broader version of this bargain: call a standard linear-algebra primitive from any language and let a tuned vendor library target the silicon. For modern GEMM on NVIDIA GPUs, that tuned path is cuBLAS rather than the 1979 BLAS specification itself (NVIDIA 2024a).
NVIDIA. 2024a. cuBLAS: CUDA Basic Linear Algebra Subprograms.
Lawson, Charles L., Richard J. Hanson, David R. Kincaid, and Fred T. Krogh. 1979. “Basic Linear Algebra Subprograms for Fortran Usage.” ACM Transactions on Mathematical Software 5 (3): 308–23. https://doi.org/10.1145/355841.355847.
4 LAPACK (Linear Algebra PACKage): Extends BLAS by providing a standard API for higher-level routines (SVD, eigendecomposition, least-squares) that vendors implement with chip-specific code layered on top of fast GEMM kernels. This layered design is the architectural pattern every ML framework inherits: high-level operations delegate downward to hand-tuned primitives, so a vendor-optimized LAPACK call can execute over 10\(\times\) faster than a naive implementation without the framework author writing a single line of hardware-specific code.
Bai, Zhaojun, James Demmel, Jack Dongarra, Julien Langou, and Jenny Wang. 2006. “LAPACK.” In Handbook of Linear Algebra. Chapman; Hall/CRC. https://doi.org/10.1201/9781420010572-75.
5 GEMM: The matrix-matrix primitive behind C = A @ B. Hardware vendors hand-tune GEMM for their specific chips because dense layers, attention projections, and convolution lowering all rely on matrix multiplication, making this one routine a performance floor for many frameworks above it on the ladder. Its high arithmetic intensity makes GEMM the operation most able to approach peak compute throughput, while small or misaligned shapes often fall back to much lower utilization.
6 NumPy (Numerical Python): In 2005, Travis Oliphant unified two competing Python array libraries (Numeric and Numarray) into a single package, giving the scientific computing community one BLAS-backed array standard at the moment it needed to scale. The “vectorization” contract this created (write logic in Python, execute loops in C/Fortran via BLAS) became the design template for every ML framework that followed: PyTorch tensors and TensorFlow arrays are direct descendants, extending the same \(n\)-dimensional array abstraction to GPUs. Python’s role in ML infrastructure inherits much of its shape from this consolidation decision.
Harris, Charles R., K. Jarrod Millman, Stéfan J. van der Walt, Ralf Gommers, Pauli Virtanen, David Cournapeau, Eric Wieser, et al. 2020. “Array Programming with NumPy.” Nature 585 (7825): 357–62. https://doi.org/10.1038/s41586-020-2649-2.
Kluyver, Thomas, Benjamin Ragan-Kelley, Fernando Pérez, Brian Granger, Matthias Bussonnier, Jonathan Frederic, Kyle Kelley, et al. 2016. “Jupyter Notebooks – a Publishing Format for Reproducible Computational Workflows.” In Positioning and Power in Academic Publishing: Players, Agents and Agendas, edited by Fernando Loizides and Birgit Schmidt. IOS Press. https://doi.org/10.3233/978-1-61499-649-1-87.
7 Theano: Developed at the Montreal Institute for Learning Algorithms (MILA) under Yoshua Bengio starting in 2007, Theano was an early and influential Python framework that compiled symbolic mathematical expressions into optimized CPU and GPU code via computational graphs (Bergstra et al. 2010; Team et al. 2016). Its key insight, that a Python-defined computation graph could be compiled to CUDA without the researcher writing GPU code, became the architectural template for TensorFlow (2015) and influenced PyTorch’s autograd design. Theano was retired in 2017, but every modern framework inherits its core abstraction.
Bergstra, James, Olivier Breuleux, Frédéric Bastien, Pascal Lamblin, Razvan Pascanu, Guillaume Desjardins, Joseph Turian, David Warde-Farley, and Yoshua Bengio. 2010. “Theano: A CPU and GPU Math Compiler in Python.” Proceedings of the Python in Science Conference 4: 18–24. https://doi.org/10.25080/majora-92bf1922-003.
Team, The Theano Development, Rami Al-Rfou, Guillaume Alain, Amjad Almahairi, Christof Angermueller, Dzmitry Bahdanau, Nicolas Ballas, et al. 2016. “Theano: A Python Framework for Fast Computation of Mathematical Expressions.” arXiv Preprint.
As figure 1 illustrates, this progression reveals a critical insight: frameworks exist to bridge the gap between mathematical intent and silicon reality. As we move up the ladder, we gain productivity but lose transparency: a trade-off explored in section 1.3.

Each generation abstracted away details that consumed engineering effort in the previous one, yet each abstraction introduced new trade-offs. BLAS hid assembly-level optimization but fixed the interface. NumPy hid memory management but required manual differentiation. Modern frameworks hide gradient computation but introduce the execution model choice we examine next. The deeper pattern is that every abstraction hides details by preserving a contract about shape, dtype, device, and sometimes units; when that contract becomes implicit, correct components can still compose into a wrong system.
With that contract risk in view, modern frameworks converge on the same three core problems: how to execute computation, how to differentiate it, and how to abstract across hardware. We begin with the most visible of these: the execution problem, because its resolution determines what optimizations the other two problems can exploit.
War Story 1.1: The interface that forgot its units
Context: NASA’s Mars Climate Orbiter depended on ground software, spacecraft software, navigation teams, and contractor interfaces all agreeing on the physical meaning of exchanged values (Mars Climate Orbiter Mishap Investigation Board 1999). The roughly $327M mission included a small-forces interface (SM_FORCES) that carried thruster-impulse measurements from ground operations into the navigation filter.
Failure mode: One piece of ground software, supplied by Lockheed Martin, computed the impulse from each Angular Momentum Desaturation event in pound-force seconds. The navigation software at the Jet Propulsion Laboratory (JPL) consumed the same numbers as newton-seconds—a 4.45\(\times\) unit mismatch. The code on both sides compiled, ran, and produced numerically reasonable values; only the implicit unit contract between them was wrong. On September 23, 1999, the trajectory error placed the orbiter at about 57 km above Mars rather than the intended 226 km. At that altitude the spacecraft was either destroyed in the atmosphere or skipped back into heliocentric space. Communication was permanently lost during orbit insertion.
Systems lesson: Framework abstractions are valuable because they carry contracts: shape, dtype, device placement, and sometimes units. If those contracts are implicit, two pieces of correct code can still compose into a wrong system.
Mars Climate Orbiter Mishap Investigation Board. 1999. Mars Climate Orbiter Mishap Investigation Board Phase i Report. National Aeronautics; Space Administration.
Self-Check: Question
NumPy gave scientists optimized BLAS performance through a Python API, but it did not solve the bottleneck that deep learning frameworks later closed. Which bottleneck did NumPy leave open, creating the opening for Theano, TensorFlow, and PyTorch?
- Saturating peak GEMM throughput on a single CPU
- Writing loops in Python rather than Fortran
- Hand-derived backpropagation gradients for multi-layer networks, which were error-prone and did not scale past toy models
- Storing arrays as n-dimensional tensors instead of flat buffers
Why does the chapter place BLAS at the bottom rung of the ladder rather than treating it as a minimal framework?
- BLAS runs only on CPUs, disqualifying it from modern ML workloads
- BLAS specifies hardware-optimized numerical primitives such as GEMM but does not provide gradient computation, graph-level execution planning, or hardware abstraction across device types
- BLAS is used exclusively for inference and never touches training code paths
- BLAS requires Python bindings to be useful to ML systems
Explain how each rung of the ladder (BLAS/LAPACK, NumPy, deep learning frameworks) addressed a different term of the iron law and why the rungs depend on each other rather than replacing each other.
True or False: Each higher rung of the ladder of abstraction hides more hardware detail from the programmer while still depending on the optimized primitives of lower rungs, meaning an inefficient lower rung places a ceiling on every framework above it.
Execution Problem
Consider two engineers writing the same neural network. The first debugs interactively, printing tensor shapes after each operation, inspecting intermediate values, and stepping through code with pdb. The second waits 30 seconds for compilation, then watches the model run 3\(\times\) faster with no ability to inspect any intermediate state. Both are correct; they have simply made different choices about the execution problem, the question of whether operations should execute immediately as written or be recorded for later execution. This choice creates a cascade of engineering trade-offs that shape every aspect of framework behavior, from debugging workflows to deployment options to peak hardware utilization.
Why execution strategy matters: The memory wall
To understand why execution strategy matters so much, return to the memory wall introduced in ML Systems: processor arithmetic has grown faster than memory bandwidth. Modern accelerators can perform arithmetic far faster than they can fetch data. Element-wise operations like ReLU use only a tiny fraction of peak compute capacity, not because the hardware is slow, but because they spend nearly all their time waiting for data. The roofline model formalizes this trade-off, showing exactly when operations are memory bound vs. compute bound.
The memory wall creates a critical classification: operations are either compute-bound (limited by arithmetic throughput, like large matrix multiplications) or memory-bound (limited by data movement, like activation functions and normalization). Most individual neural network operation types (activations, normalizations, element-wise operations) are memory bound, though the large matrix multiplications that dominate total compute time can be compute bound.
The key optimization for memory-bound operations is kernel fusion, combining multiple operations into a single GPU function (called a kernel)8 to avoid intermediate memory traffic. Fusing a sequence of normalization, dropout, and activation operations into one kernel can yield large speedups by eliminating intermediate writes between operations. Attention kernels9 use the same principle at larger scale: instead of materializing the full attention matrix in HBM, a fused implementation can keep tiles close to the compute units, cut HBM traffic by 10–20\(\times\), and produce 2–4\(\times\) wall-clock speedups (Dao et al. 2022).
8 Kernel (GPU): In GPU programming, a kernel is the function dispatched to execute in parallel across thousands of threads. Each kernel launch incurs 5–20 \(\mu\)s of CPU-side overhead for parameter assembly and GPU signaling, which means that small, unfused operations spend more time on launch overhead \((L_{\text{lat}})\) than on useful arithmetic. Reducing kernel count through fusion is therefore a direct attack on the overhead term of the iron law.
9 Fused Attention Kernel: A fused attention kernel combines the \(QK^T\) product, softmax, and value-weighted output into a tiled implementation that keeps intermediate values in on-chip memory rather than materializing the full attention matrix in HBM. FlashAttention is the canonical named example introduced in Network Architectures and reports 10–20\(\times\) lower HBM traffic with 2–4\(\times\) wall-clock speedups (Dao et al. 2022). The framework lesson is broader than the specific algorithm: fusion can shift an operation’s position on the Roofline Model from bandwidth-limited toward throughput-limited execution by reducing round-trips through external memory.
Dao, T., D. Y. Fu, S. Ermon, A. Rudra, and C. Ré. 2022. “FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness.” Advances in Neural Information Processing Systems 35 35: 16344–59. https://doi.org/10.52202/068431-1189.
A framework can only fuse operations it can see together. If operations execute immediately one at a time (eager execution), the framework cannot fuse them. If operations are recorded first into a graph (deferred execution), the framework can analyze and optimize the entire computation. This is why execution strategy matters so much: it determines what optimizations are even possible.
The computational graph
Kernel fusion is the key optimization for memory-bound operations, but fusion requires seeing multiple operations together. Frameworks make this visibility possible through the computational graph, a directed acyclic graph (DAG) where nodes represent operations and edges represent data dependencies. This graph is the framework’s internal model of the computation.
To ground this abstraction, examine figure 2: computing \(z = x \times y\) maps onto two input nodes (\(x\) and \(y\)), one operation node (multiplication), and one output node (\(z\)). The execution problem turns on when this graph is constructed and when it is executed.

Real machine learning models require much more complex graph structures. Figure 3 extends this representation to show a neural network computation graph alongside the system components that reason about it. In the left panel, notice how data flows through six operation nodes in a directed acyclic graph—each node’s output becomes the next node’s input. The right panel reveals what the framework gains by having this graph: it can query the structure to plan memory allocation for each tensor’s lifetime, and it can assign operations to devices based on data dependencies rather than execution order. The critical insight is that the graph exists independently of execution, enabling the framework to optimize before any arithmetic occurs.

This graph representation is more than a visualization; it is the data structure that enables both efficient execution and automatic differentiation. The answer to when this graph is constructed creates a design choice with cascading implications across four dimensions. Debugging benefits from visibility into intermediate values and step-through execution. Optimization benefits from seeing multiple operations at once, which enables fusion. Deployment benefits when execution no longer depends on the Python interpreter. Flexibility benefits when control flow can depend on computed tensor values.
No single execution model optimizes all these dimensions. Frameworks must choose their position in this trade-off space, and practitioners must understand these trade-offs to select appropriate tools and write efficient code. The three execution families that follow are different answers to the same systems question: how much graph visibility should the framework trade for immediate execution and debugging?
Three execution strategies
The computational graph representation enables global optimization, but it leaves a critical design choice unresolved: when the framework builds the graph. Consider a simple operation like y = x * 2. One approach performs the multiplication immediately, storing the result in y. This is natural and debuggable, but the framework sees only one operation at a time. The other approach defers execution, recording the intention to multiply and building a graph of operations that runs later when explicitly requested. This is less intuitive, but the framework sees the complete computation, which enables optimization.
Neither approach dominates; each embodies different trade-offs between flexibility and optimization potential. Modern frameworks have explored three primary execution strategies: eager execution with dynamic graphs, static computation graphs, and hybrid approaches that combine just-in-time (JIT) compilation with eager development. We examine each through its systems implications.
Eager execution with dynamic graphs
Eager execution evaluates each operation immediately as the program calls it, building the computation graph dynamically at runtime. A side-by-side comparison shows how this differs from graph-based execution at the code level.
Example 1.1: Eager vs. graph execution code comparison
PyTorch (eager execution):
import torch
x = torch.tensor([1.0, 2.0])
y = x * 2
print(f"Intermediate value: {y}") # Works immediately
z = y.sum()TensorFlow 1.x (static graph):
import tensorflow as tf
x = tf.placeholder(tf.float32)
y = x * 2
# print(y) -> Prints Tensor("mul:0"...), not value!
z = tf.reduce_sum(y)
with tf.Session() as sess:
result = sess.run(z, feed_dict={x: [1.0, 2.0]})Systems insight: Eager execution exposes intermediate values as ordinary runtime state, which makes debugging direct. Static graphs stage computation before execution, which enables whole-graph optimization but changes the debugging model.
Eager execution runs operations immediately as encountered, building the computation graph dynamically during execution. When a programmer writes y = x * 2, the multiplication happens instantly and the result is available for immediate use.
This provides the flexibility of normal programming: developers can print intermediate values, use conditionals based on computed results, and debug with standard tools. The framework records operations as they happen, constructing a dynamic graph that reflects the actual execution path taken.
For gradient computation, the framework records a history of operations in what is called an autograd tape10, a transient data structure built during execution. Each tensor operation creates a node that records: the operation performed, references to input tensors, and how to compute gradients. These nodes form a directed acyclic graph (DAG) of operations built during forward pass execution, not before. Listing 1 shows how PyTorch records operations as they execute in its default eager mode.
10 Autograd Tape: A transient data structure built during forward execution, where each node records the operation type, input tensor references, saved intermediate values, and the backward function for chain rule application. The tape’s memory cost scales linearly with network depth and is destroyed after the backward pass. For deep models, this transient graph can consume more memory than the model weights themselves, so frameworks sometimes store only selected activations and recompute the rest during the backward pass. This recomputation-for-memory trade-off is called activation checkpointing later in the chapter.
import torch
x = torch.tensor([1.0], requires_grad=True)
y = x * 2 # Executes immediately; records MulBackward node
z = y + 1 # Executes immediately; records AddBackward node
# The autograd tape exists NOW, built during executionAfter these two operations, the framework has constructed an autograd tape with two nodes: one for the multiplication and one for the addition. The tape records that z depends on y, and y depends on x.
Calling z.backward() traverses this tape in reverse topological order, applying the chain rule at each node:
- Compute \(\frac{\partial z}{\partial z} = 1\) (seed gradient)
- Call
AddBackward0.backward()\(\rightarrow \frac{\partial z}{\partial y} = 1\) - Call
MulBackward0.backward()\(\rightarrow \frac{\partial z}{\partial x} = 2\) - Accumulate gradient in
x.grad
After backward() completes, the autograd tape is destroyed to free memory. The next forward pass builds a completely new tape. This design enables memory-efficient training: the system pays for gradient computation storage only during the backward pass.
Example 1.2: In-place operations can break gradients
Scenario: An ML engineer implements a custom activation function in PyTorch. To save memory, they use an in-place operation such as
x += 1 instead of x = x + 1.
Failure mode: In-place operations modify the data directly in memory. However, the autograd tape often needs the original value of a tensor to compute gradients for previous layers. Modern PyTorch tracks tensor version counters and usually raises an error when a saved tensor has been modified before backward, because the original value needed for the chain rule is no longer available. The “memory optimization” failed at backward time rather than silently producing a trustworthy training run. The error message can be cryptic to new users, but it is an important safety mechanism: the framework refuses to compute a gradient when it cannot guarantee that the saved forward values are still valid.
Systems insight: Frameworks are graph construction engines, and in-place operations must respect the values saved for automatic differentiation. Writing x += 1 does not merely add a number: in PyTorch, it may invalidate the graph’s saved values, so PyTorch uses tensor versioning to detect unsafe mutation and report an error in those cases (PyTorch Contributors 2026a).
PyTorch Contributors. 2026a. PyTorch Autograd Mechanics.
Follow this “define-by-run” execution model step by step in figure 4. Notice the alternating pattern: define, execute, define, execute. Each operation completes entirely before the next begins, which is why standard Python debuggers work—a developer can set a breakpoint between any two operations and inspect the actual tensor values. This contrasts sharply with static graphs, where all operations must be defined before any execution occurs.

Systems implications: Flexibility
The dynamic autograd tape enables capabilities impossible with static graphs. Conditionals and loops can depend on tensor values computed during execution, enabling algorithms like beam search, dynamic recurrent neural network (RNN) lengths, or adaptive computation that adjust their behavior based on intermediate results. Different iterations can process tensors of different sizes without redefining the computation—essential for natural language processing where sentence lengths vary. Because operations execute immediately in standard Python, developers can print tensors, inspect values, and use standard debuggers (pdb, breakpoints) to diagnose errors in the same way they would debug any Python program.
Systems implications: Overhead
This flexibility comes with performance costs that map directly to the iron law (Iron Law of ML Systems). Each forward pass rebuilds the autograd tape from scratch, adding Python object creation, reference counting, and node linking overhead to \(L_{\text{lat}}\) on every iteration. Every operation goes through Python dispatch—function lookup, argument parsing, type checking—costing approximately 10 μs per operation, which becomes significant for models with thousands of operations. Because the graph is built during execution, the framework cannot see across operations to fuse kernels, so each operation launches its own GPU kernel, increasing launch overhead \((L_{\text{lat}})\) and intermediate data movement \((D_{\text{vol}})\). The autograd tape itself stores references to all intermediate tensors and Function nodes, increasing memory consumption by 2–3\(\times\) compared to forward-only execution and adding pressure to \(D_{\text{vol}}\). Together, these costs create a performance ceiling that becomes visible as models grow smaller and dispatch overhead dominates computation. For a typical ResNet-50 forward pass, eager execution overhead adds approximately 5–10 ms compared to an optimized compiled version, with the majority spent in Python dispatch and tape construction rather than actual computation.
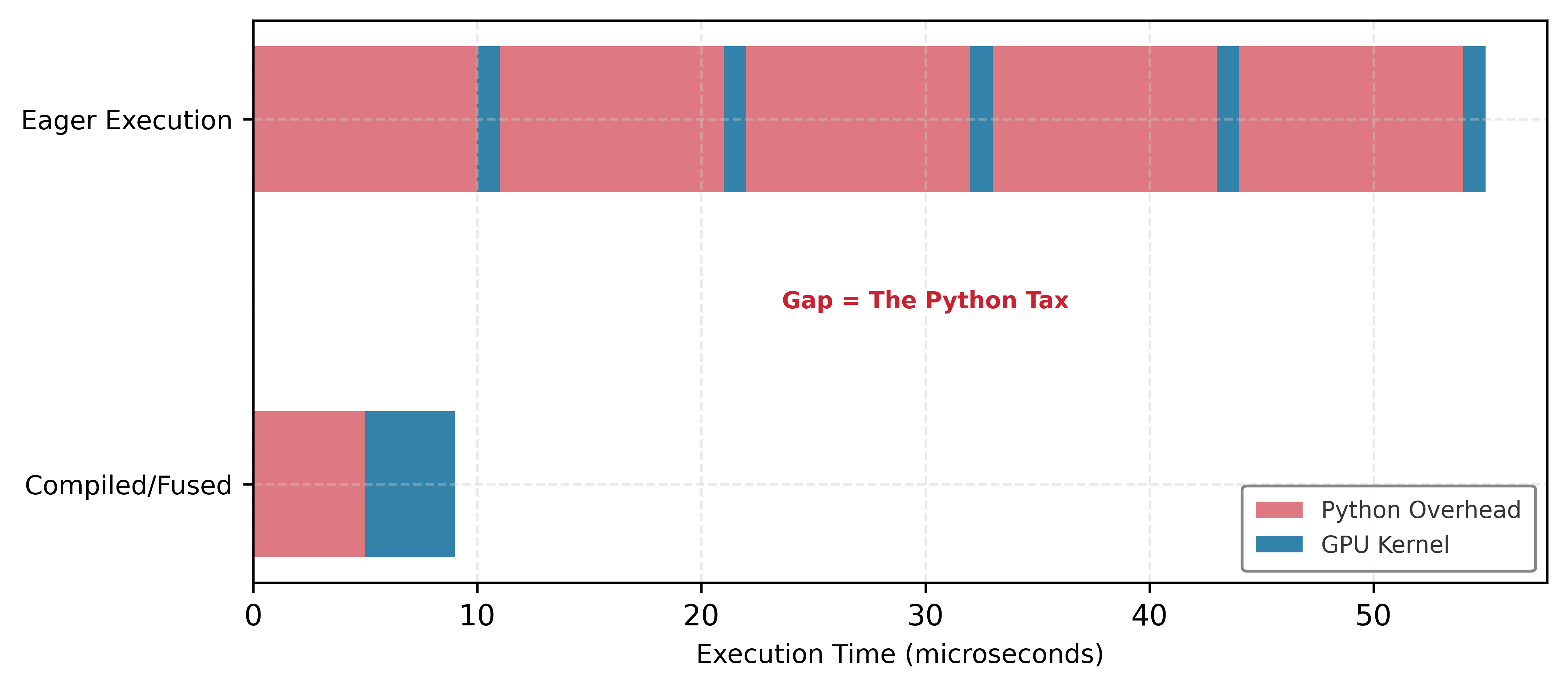
Eager execution’s performance ceiling is driven by a fundamental systems mismatch: the speed of the host-side interpreter vs. the speed of the device-side silicon. We quantify this using the dispatch tax, defined as the fraction of time spent in the host-side orchestration (Python) vs. actual device execution (GPU).

As work grows, useful compute outpaces fixed dispatch cost; the tax shrinks.
Every operation in an eager framework (like standard PyTorch) must pay a fixed “Tax” of approximately 15 \(\mu\)s for Python to look up the function, check tensor types, and launch the kernel. The relative weight of this tax depends entirely on operation size. For a small operation such as a ReLU on a small vector, the kernel might execute in only 1 \(\mu\)s, so the dispatch tax reaches 94 percent and the GPU spends the vast majority of its time waiting for the next command. For a large operation such as a large matrix multiply, the kernel executes for 100 \(\mu\)s, the dispatch tax drops to 13 percent, and the system becomes compute bound.
The dispatch tax explains why models with many small layers run significantly slower than their raw FLOP count predicts. Bottleneck diagnostic places this symptom in the bottleneck taxonomy, classifying a dispatch-dominated workload as latency-bound rather than compute-bound and showing which optimizations actually move it. To approach efficient execution, frameworks must move from kernel-by-kernel dispatch to graph-level execution, where the dispatch tax is paid once for the entire graph rather than per operation. The hybrid JIT and compilation strategies in section 1.3.3.3 exist precisely to address this overhead.
The overhead costs of eager execution motivate the opposite design: capturing the entire computation before executing any of it. This is precisely what static computation graphs provide.
Static computation graphs
Static graph execution defines the complete computational graph as a symbolic representation first, then executes it separately. This “define-then-run” execution model means the graph exists before any computation occurs, enabling aggressive ahead-of-time optimization. The key insight is that if the framework sees the entire computation before running it, the framework can analyze, transform, and optimize the graph globally—a visibility impossible when operations execute immediately one at a time. Operator fusion works through the canonical global transformation this enables: fusing a chain of \(k\) elementwise operations into one kernel cuts memory traffic from \(2kN\) to \(2N\) bytes, the round-trip savings that whole-graph optimization captures.
Two-phase execution
Static graphs implement a clear separation between graph construction and execution. Listing 2 illustrates the two phases using TensorFlow 1.x, which exemplified this approach. It deliberately runs the same x * 2 then + 1 computation shown under eager execution in listing 1, holding the arithmetic fixed so that the only thing that changes is when it executes: symbolic definition creates placeholders and operations without computation, while explicit execution triggers actual arithmetic.
# Phase 1: Graph Construction (symbolic, no computation)
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()
# Define graph symbolically
x = tf.placeholder(tf.float32, shape=[1]) # Just a placeholder
y = x * 2 # Not executed, just recorded
z = y + 1 # Still no execution
# At this point, nothing has been computed
# Phase 2: Graph Execution (actual computation)
with tf.Session() as sess:
result = sess.run(z, feed_dict={x: [1.0]})
# Now computation happens: result = [3.0]Compare this with the dynamic model by examining figure 5. Notice the clear boundary between phases: in the definition phase (left), the framework builds a complete blueprint without touching any data; in the execution phase (right), data flows through an already-optimized graph. This separation enables the framework to resolve questions during the definition phase that are unreachable operation-by-operation: which intermediate tensors can share memory, which operations can fuse into a single kernel, and what the total memory footprint will be. By the time execution begins, these optimizations are already baked in.
The key difference from eager execution is that during construction, x, y, and z are not tensors containing values but rather symbolic nodes in a graph. Operations like * and + add nodes to the graph definition without performing any arithmetic. The print(y) line in the code example would reveal this distinction—it would print tensor metadata, not a computed value. Execution is triggered explicitly through sess.run(), at which point the framework analyzes the complete graph, optimizes it, and executes the optimized version with the provided input data.

Ahead-of-time optimization
Because the framework has the complete graph before execution, it can perform ahead-of-time optimization [optimizing the graph before runtime] impossible in eager mode. The kernel fusion opportunity introduced in section 1.3.1 becomes actionable here: because the framework sees y = x * 2 and z = y + 1 together in the graph, it can fuse them into z = x * 2 + 1, eliminating the intermediate y and halving memory traffic. With the full graph visible, the compiler can also calculate exact memory requirements for all tensors before execution, preallocating memory in a single pass and reusing buffers where lifetimes do not overlap. Tensor layouts can be transformed globally (for example, NCHW to NHWC) to match hardware preferences without runtime copying. Dead-code elimination (DCE)11 removes operations whose results are never consumed, and constant folding precomputes operations on constant values at graph construction time, so the cost is paid once rather than on every forward pass.
11 Dead Code Elimination (DCE): Removes graph nodes whose results are never consumed by any downstream operation. In ML graphs, dead code arises from debugging operations left in production (print nodes, assertions), unused conditional branches, and gradient computations for frozen layers. For large transformer models, DCE eliminates 5–15 percent of graph nodes, reducing both \(O\) (fewer operations) and \(L_{\text{lat}}\) (fewer kernel launches). The DAG structure makes this safe: the framework verifies no downstream node depends on a candidate before removing it.
These optimizations map directly to iron law terms: kernel fusion reduces \(D_{\text{vol}}\) by eliminating intermediate memory writes, constant folding reduces \(O\) by computing values once, memory preallocation reduces \(L_{\text{lat}}\) by avoiding runtime allocation overhead, and dead code elimination reduces both \(O\) and \(D_{\text{vol}}\). Concretely, in large transformer models, constant folding and dead code elimination can reduce total FLOPs by 5–10 percent before the first batch even arrives.
Compilation frameworks like XLA (Accelerated Linear Algebra)12 (Google 2025) take this further, compiling TensorFlow graphs to optimized executables for specific hardware. The benefit is not a fixed multiplier: XLA helps when it can fuse operations, specialize layouts and shapes, and reduce launch or memory overhead, so gains depend on graph structure, backend support, and input-shape stability.
12 XLA (Accelerated Linear Algebra): The “optimized machine code” in the triggering sentence means XLA can fuse subgraphs, specialize layouts, and lower high-level operations into backend-specific code. Fusion attacks both launch overhead \((L_{\text{lat}})\) and intermediate memory writes \((D_{\text{vol}})\), but the realized speedup depends on whether the graph contains enough fusible, memory-bound work for the compiler to remove. Large GEMM-heavy regions may already be compute bound, while chains of small elementwise operations can benefit more because fusion removes repeated trips through external memory.
Systems implications
Static graphs achieve high performance through ahead-of-time optimization. Kernel fusion reduces memory bandwidth requirements (often the bottleneck for ML workloads), and hardware-specific compilation enables near-peak utilization.
The cost of this performance is reduced flexibility. Standard Python control flow (if, for) cannot depend on computed tensor values in static graphs. TensorFlow provides graph-level control flow primitives (tf.cond and tf.while_loop) that support data-dependent conditions, but these require special syntax that diverges from standard Python, making code harder to write and reason about. Debugging is difficult because stack traces point to graph construction code, not execution code. Error messages often reference symbolic node names rather than the actual operations that failed.
Hybrid approaches: JIT compilation
JIT compilation pursues both eager debugging and graph optimization at once by capturing computation at runtime. The core trade-off is fidelity vs. generality. Tracing captures the exact execution path taken during a sample run, producing high fidelity to that specific input but missing branches not taken. Source-level compilation (scripting) analyzes the full program structure, preserving all control flow branches but requiring a restricted language subset. Both approaches produce an intermediate representation (IR)13 that enables the same ahead-of-time optimizations available to static graphs: operator fusion, constant folding, dead code elimination, and buffer reuse.
13 Intermediate Representation (IR): The “intermediate” captures this format’s architectural role: a language-independent layer that decouples the frontend (Python capture) from the backend (hardware code generation), exactly as LLVM IR decouples C/Rust/Swift frontends from x86/ARM backends. ML frameworks adopted this compiler pattern because it reduces the \(\mathcal{O}(M \times N)\) cost of supporting \(M\) frontends and \(N\) backends to \(\mathcal{O}(M + N)\): a single graph capture mechanism (TorchDynamo, tf2xla) can target multiple hardware backends without rewriting the capture logic.
The eager-vs.-compiled trade-off has a direct iron law consequence. JIT compilation amortizes the \(L_{\text{lat}}\) (dispatch overhead) across the compiled region. Longer compiled regions mean more overhead amortized per operation, which explains why graph breaks are performance-critical: each break forces a return to eager dispatch, resetting the amortization.
PyTorch’s TorchScript exemplifies both strategies (PyTorch Contributors 2026b). Tracing executes a function once with example inputs and records every tensor operation into a static computation graph. Listing 3 demonstrates the approach: the traced module becomes a compiled artifact that can be serialized, optimized, and executed independently of the Python interpreter:
import torch
def forward(x):
y = x * 2
z = y + 1
return z
# Trace the function by running it once
x_example = torch.tensor([1.0])
traced = torch.jit.trace(forward, x_example)
# traced is now a compiled TorchScript module
# Can serialize: torch.jit.save(traced, "model.pt")
# Can optimize: fusion, constant folding
# Can run without Python interpreterThe critical limitation of tracing reveals the fidelity-generality trade-off concretely. Because tracing records a single execution path, it cannot handle data-dependent control flow. Listing 4 illustrates a silent correctness failure.
def conditional_forward(x):
if x.sum() > 0: # Data-dependent condition
return x * 2
else:
return x * 3
traced = torch.jit.trace(conditional_forward, torch.tensor([1.0]))
# Tracing captures ONLY the x.sum() > 0 branch
# If input later has sum <= 0, traced version
# still executes x * 2 branchTracing records whichever branch executed during the example input. Subsequent executions always follow the traced path regardless of input values, silently producing incorrect results for inputs that would have taken the other branch. This failure mode is particularly dangerous because it produces no error, only wrong outputs. In production, such bugs can persist for months before anyone notices that a small fraction of inputs are being misclassified—and by then, debugging is a forensic exercise.
The alternative, scripting, achieves generality by analyzing Python source code directly and compiling it to TorchScript IR without executing (PyTorch Contributors 2026b). The scripting compiler parses the abstract syntax tree (AST), converts supported operations to IR operations, and preserves the branching structure so that both branches of a conditional exist in the compiled representation. The cost of this generality is a restricted Python subset: type annotations are required where inference fails, arbitrary Python objects and standard library modules are excluded, and dynamic metaprogramming is forbidden.
PyTorch Contributors. 2026b. TorchScript.
Tracing suits feed-forward models without conditionals (ResNet, VGG, Vision Transformer) and models where control flow depends only on hyperparameters fixed at trace time. Scripting suits models with data-dependent control flow (RNN variants, recursive networks, adaptive computation) and deployment to environments without a Python interpreter.
The key advantage of scripting appears when handling conditionals. Unlike tracing, which captures only one branch, scripting preserves both paths in the IR, as listing 5 shows.
@torch.jit.script
def conditional_forward(x: torch.Tensor) -> torch.Tensor:
if x.sum() > 0:
return x * 2
else:
return x * 3
# Both branches preserved in IR
# Correct branch executes based on runtime input valuesTo understand what the compiler produces, listing 6 inspects the generated intermediate representation directly, where the single Python expression has been lowered into explicit typed primitive operations the runtime can execute without the interpreter.
@torch.jit.script
def example(x: torch.Tensor) -> torch.Tensor:
return x * 2 + 1
# Inspect generated IR:
print(example.graph)
# graph(%x : Tensor):
# %1 : int = prim::Constant[value=2]()
# %2 : Tensor = aten::mul(%x, %1)
# %3 : int = prim::Constant[value=1]()
# %4 : Tensor = aten::add(%2, %3, %3)
# return (%4)However, scripting imposes constraints on what Python constructs are supported. Because TorchScript must statically analyze code that Python normally interprets dynamically, it accepts only a restricted Python subset. Function signatures and variables need explicit type annotations when type inference fails, and only tensor operations, numeric types, and standard containers (lists, dicts, tuples) are permitted—no arbitrary Python objects, no standard library modules like os or sys, and no dynamic class modification or metaprogramming, so an import numpy or an f-string inside a scripted function is a compile-time error. These constraints are the price of compilation: every feature that makes Python flexible also makes it unpredictable for a compiler. Table 1 summarizes the resulting decision rule: trace static feed-forward code when simplicity matters, and script conditional code when correctness requires preserving runtime branches.
The TorchScript IR represents operations using the aten namespace for core tensor operations, the prim namespace for primitives and control flow, static types for every value, and static single-assignment (SSA) form, where each variable is assigned exactly once to simplify compiler analysis. This IR enables optimizations independent of Python: operator fusion combines adjacent operations into single kernels, constant folding evaluates constant expressions at compile time, dead code elimination removes unused operations, and memory optimization reuses buffers when possible.
| Aspect | Tracing | Scripting |
|---|---|---|
| Input requirement | Example inputs needed | No inputs needed |
| Control flow | Cannot handle data-dependent | Supports data-dependent |
| Conversion ease | Simpler (just run function) | Harder (restricted Python) |
| Type annotations | Not required | Required when inference fails |
| Error detection | Runtime (wrong results) | Compile time (syntax errors) |
| Best for | Feed-forward models | Models with conditionals |
Modern compilation: Graph-capture JIT
The previous approaches force a choice: write flexible code (eager execution) or fast code (static graphs). Modern JIT compilation attempts to eliminate this trade-off by automatically compiling eager code into optimized graphs with minimal developer intervention.
Graph-capture JIT systems follow the same architectural pattern across frameworks. The first execution observes tensor operations, records a graph region guarded by assumptions about shapes, dtypes, layouts, and control flow, lowers that region into an intermediate representation, applies fusion and layout optimizations, and caches executable code for later calls that satisfy the same guards. Unsupported Python code does not disappear; it forms a graph boundary where execution returns to the eager runtime. PyTorch 2.0’s torch.compile (Ansel et al. 2024) is a concrete instance of this pattern, but the systems idea is broader than the API: compilation pays only when captured regions are long enough and stable enough to amortize capture, lowering, code generation, and cache-management costs.
Ansel, Jason, Edward Yang, Horace He, Natalia Gimelshein, Animesh Jain, Michael Voznesensky, Bin Bao, et al. 2024. “PyTorch 2: Faster Machine Learning Through Dynamic Python Bytecode Transformation and Graph Compilation.” Proceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2, 929–47. https://doi.org/10.1145/3620665.3640366.
This explains why compilation helps so much when it works. Dispatch costs that seem negligible for a single operation—a few microseconds here and there—compound dramatically across the thousands of operations in a forward pass. A simple fusion estimate makes the overhead concrete.
Napkin Math 1.1: The physics of software overhead
Iron law connection: The latency term \((L_{\text{lat}})\) in the iron law is dominated by software overhead: dispatching instructions from Python to the GPU. Each operation pays a Python dispatch cost of ~10 μs plus a kernel launch cost of ~5 μs, which together set the per-launch overhead the math below applies.
Scenario one: Eager Mode (The “Tiny Op” Trap) Consider a simple activation block: y = relu(x + bias).
- Operations: Two (Add, ReLU).
- Execution:
- Launch
AddKernel: 15 μs overhead. - Read/Write Memory: \(2N\) bytes.
- Launch
ReLUKernel: 15 μs overhead. - Read/Write Memory: \(2N\) bytes.
- Launch
- Total overhead: 30 μs.
- Total memory traffic: \(4N\) bytes.
Scenario two: Compiled Mode (Fusion) The compiler fuses this into one kernel: FusedAddRelu.
- Execution:
- Launch
FusedKernel: 15 μs overhead. - Read/Write Memory: \(2N\) bytes (intermediate result stays in registers).
- Launch
- Total overhead: 15 μs (2× speedup).
- Total memory traffic: 2N bytes (2× bandwidth efficiency).
Systems insight: Fusion wins on two fronts at once. Collapsing two launches into one halves the per-op dispatch overhead, and keeping the intermediate result in registers cuts memory traffic from \(4N\) to \(2N\) bytes. The bandwidth saving is the durable gain: for small, element-wise operations such as LayerNorm, Gaussian Error Linear Unit (GELU), and Add, the round-trip to memory between kernels, not the arithmetic, is what starves the hardware.
Figure 6 makes the dispatch tax visible: eager execution creates gaps where the GPU sits idle while Python dispatches the next kernel. The blue compute regions are short; the red dispatch regions are comparatively long. Compilation fuses these operations into a single kernel launch, replacing many dispatch gaps with one dispatch block and one fused compute block.
Automating this fusion is the design goal behind graph-capture compilers such as PyTorch 2.0’s torch.compile14. They capture eager tensor regions and compile them into fused kernels without requiring engineers to write custom CUDA15.
14 torch.compile: It is a 2020s PyTorch implementation of graph-capture JIT compilation: bytecode interception extracts tensor regions from eager programs, an intermediate representation carries those regions to compiler backends, and cached generated code is reused while guard conditions continue to hold.
15 CUDA (Compute Unified Device Architecture): NVIDIA’s parallel computing platform (2007) serving as the foundational layer between high-level Python operations and GPU silicon. When PyTorch executes torch.matmul(A, W), the call traverses the framework’s dispatcher, selects a cuBLAS kernel, and launches it on the GPU. Each launch incurs 5–20 \(\mu\)s of CPU-side overhead. For small operations, this dispatch overhead \((L_{\text{lat}})\) exceeds the useful compute time, which is why compilation (fusing \(N_{\text{ops}}\) operations into one kernel launch) yields speedups proportional to the reduction in launch count rather than the reduction in arithmetic.
The core engineering questions are therefore conceptual, not API-specific. A capture compiler needs a frontend that identifies graph regions in an eager program, an intermediate representation that separates the captured computation from Python, and a backend that lowers the region to hardware-specific code. It also needs a guard system: the compiled artifact is valid only while assumptions about tensor rank, dtype, layout, and control-flow path remain true. When a guard fails, the runtime must recompile or fall back to eager execution.
Graph breaks mark the boundary where compilation stops applying. Data-dependent Python control flow, unsupported library calls, I/O, custom Python objects, and highly variable shapes all shorten compiled regions. Each break reintroduces dispatch overhead and may require tensors to move between compiled code and the eager runtime. This is why graph-break analysis belongs in performance engineering: the relevant metric is not whether compilation is enabled, but how much of the hot path remains inside long, stable compiled regions.
Backends occupy different points on the flexibility-performance spectrum. A general JIT backend optimizes ordinary training and serving workloads with moderate compilation cost; a specialized inference backend can apply deeper fusion, precision lowering, and autotuning when the deployment target is fixed; an ahead-of-time mobile or embedded runtime removes even more flexibility to gain footprint and predictability. The same rule governs all of them: the narrower the target and the more stable the graph, the more optimization the compiler can safely perform.
The resulting workflow is a systems decision. Rapid prototyping favors eager execution because architecture changes and guard failures make recompilation cost visible. Long training runs and high-volume inference amortize compilation cost over many executions, provided the model has stable shapes and limited graph breaks. Debugging usually starts in eager mode because errors map directly to source code; compilation is reintroduced after the model behavior is correct and the performance bottleneck is measurable.
Comparison of execution models
Table 2 contrasts the three execution models across six dimensions, revealing that hybrid JIT compilation achieves most of static graph performance while preserving much of eager execution’s flexibility.
| Aspect | Eager + Autograd Tape (PyTorch default) | Static Graph (TensorFlow 1.x) | JIT Compilation (torch.compile) |
|---|---|---|---|
| Execution Model | Immediate | Deferred | Hybrid |
| Graph Construction | During forward pass | Before execution | First execution (cached) |
| Optimization | None (per-operation) | Ahead-of-time | JIT compilation |
| Dynamic Control Flow | Full support | Limited (static unroll) | Partial (graph breaks) |
| Debugging | Easy (standard Python) | Difficult (symbolic) | Moderate (mixed) |
| Performance | Baseline | High (optimized) | High (compiled regions) |
Eager mode’s primary value is in the iteration loop quantified in ML Lifecycle: it allows using standard Python debuggers (like PDB) to inspect variables mid-execution, whereas graph-mode debugging often requires specialized framework tools. This immediate feedback accelerates the prototyping phase of the ML lifecycle.
Beyond these core execution trade-offs, table 3 highlights additional systems-level distinctions between static and dynamic approaches.
| Aspect | Static Graphs | Dynamic Graphs |
|---|---|---|
| Memory Management | Precise allocation planning, optimized memory usage | Flexible but potentially less efficient |
| Hardware Utilization | Can generate highly optimized hardware-specific code | May sacrifice hardware-specific optimizations |
| Research Velocity | Slower iteration due to define-then-run requirement | Faster prototyping and model experimentation |
| Integration with Legacy Code | More separation between definition and execution | Natural integration with imperative code |
These trade-offs are not binary choices. Modern frameworks offer a spectrum of options, which raises the quantitative question of where on this spectrum a given project should operate.
Quantitative principles of execution
These execution models present a spectrum of trade-offs, but engineers need more than intuition to navigate them. Two quantitative principles formalize the decision. The Compilation Continuum Principle establishes when the performance gains from compilation justify its development cost, expressed as a ratio of production executions to development iterations. The Dispatch Overhead Law quantifies the per-operation cost of framework flexibility, revealing why small operations in eager mode can spend more time in Python overhead than in actual computation. Together, these principles transform framework selection from subjective preference into measurable engineering analysis.
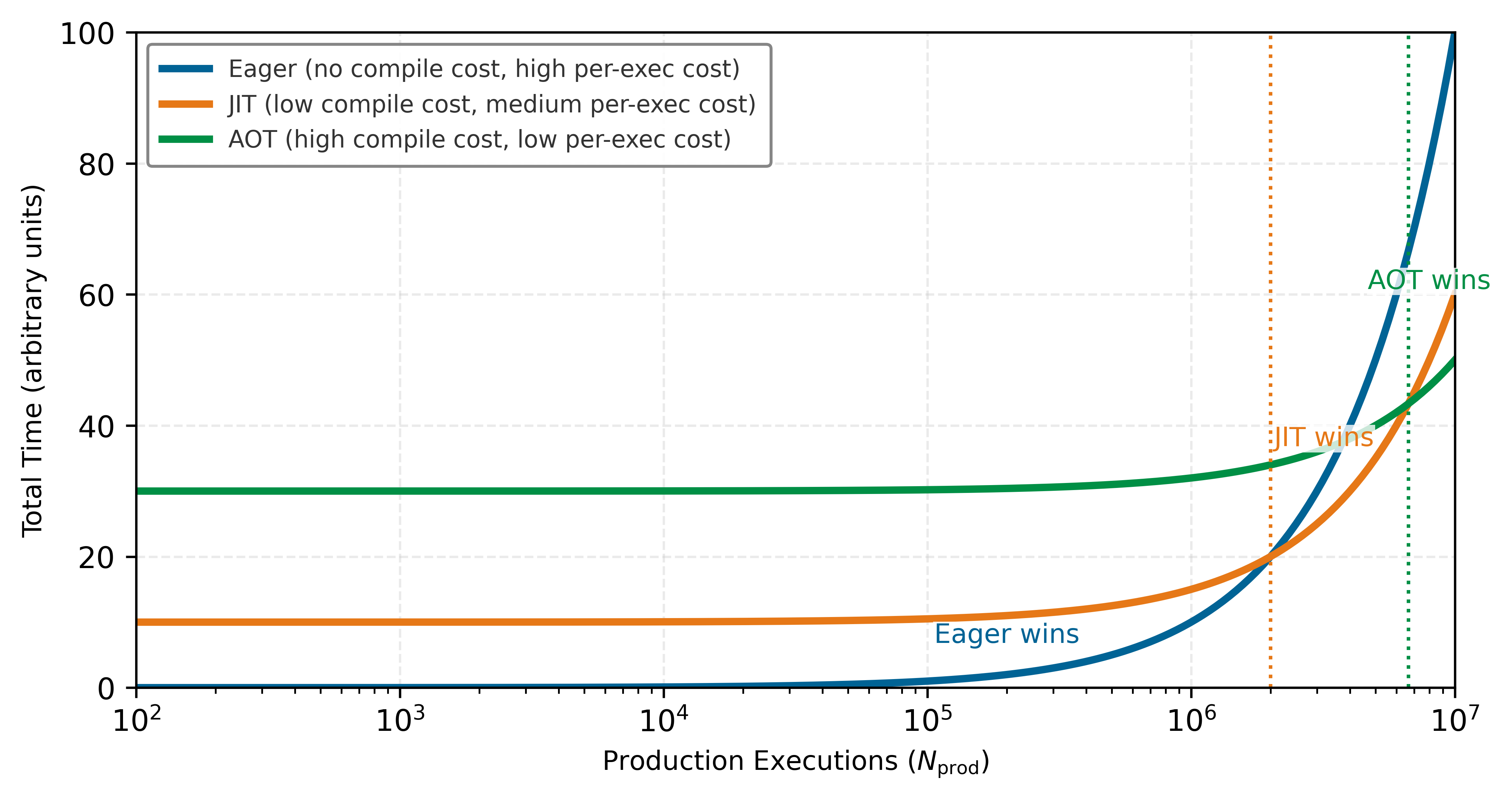
The compilation continuum principle
The execution problem demands a quantitative principle for when a project should compile. The execution models form a continuum from maximum flexibility to maximum optimization. Equation 1 lays out the four positions on that axis, and each labeled arrow names the mechanism that carries a project one step rightward toward hardware.
\[ \text{Eager} \xrightarrow{\text{tracing}} \text{JIT} \xrightarrow{\text{AOT}} \text{Static Graph} \xrightarrow{\text{synthesis}} \text{Custom Hardware} \tag{1}\]
Each step rightward sacrifices flexibility for performance. The practical question is where on this continuum a given project should operate. The optimal compilation strategy depends on the ratio of development iterations to production executions, defined in equation 2:
\[ \text{Compilation Benefit} = \frac{N_{\text{prod}} \cdot (T_{\text{eager}} - T_{\text{compiled}})}{T_{\text{compile}} + N_{\text{dev}} \cdot T_{\text{compile}}} \tag{2}\]
Where:
- \(N_{\text{prod}}\) = number of production executions (dimensionless count: inference requests, training steps)
- \(N_{\text{dev}}\) = number of development iterations requiring recompilation (dimensionless count)
- \(T_{\text{eager}}\) = time per execution in eager mode (seconds)
- \(T_{\text{compiled}}\) = time per execution in compiled mode (seconds)
- \(T_{\text{compile}}\) = one-time compilation cost (seconds)
The decision rule is to compile when \(\text{Compilation Benefit} > 1\). The ratio is dimensionless.
Table 4 provides representative throughput data across execution modes and model architectures:
| Model | Eager (examples/sec) | torch.compile (examples/sec) | TensorRT (examples/sec) | Compile Time (seconds) |
|---|---|---|---|---|
| ResNet-50 | 1,450 | 2,150 | 3,800 | 15–30 |
| BERT-Base | 380 | 520 | 890 | 30–60 |
| ViT-B/16 | 620 | 950 | 1,650 | 25–45 |
| GPT-2 (124M) | 180 | 260 | 420 | 45–90 |
These throughput differences across execution modes raise a practical question—which framework execution strategy best serves each workload archetype. The optimal strategy depends on which iron law term dominates the workload, and table 5 aligns each recurring archetype to its recommended execution strategy.
| Archetype | Dominant iron law Term | Optimal Framework Strategy | Rationale |
|---|---|---|---|
| ResNet-50 (Compute Beast) | \(\frac{O}{R_{\text{peak}} \cdot \eta_{\text{hw}}}\) (Compute) | Compiled dense kernels | Regular dense kernels benefit from layout selection, precision lowering, and backend specialization; fusion helps most in surrounding memory- or launch-bound regions |
| GPT-2 (Bandwidth Hog) | \(\frac{D_{\text{vol}}}{\text{BW}}\) (Memory Bandwidth) | Fused attention + graph compilation | Fused attention and compilation reduce HBM round-trips and improve cache reuse |
| DLRM (Sparse Scatter) | \(\frac{D_{\text{vol}}}{\text{BW}_{\text{random}}}+L_{\text{lat, network}}\) | Eager execution with specialized kernels | Embedding lookups are inherently irregular and dynamic; compilation gains are small |
| DS-CNN (Tiny Constraint) | \(L_{\text{lat}}\) (Overhead) | Ahead-of-time microcontroller runtime | Sub-ms inference; every microsecond of Python overhead is unacceptable |
Lighthouse 1.1: Framework strategy by archetype
The four recurring archetypes in table 5 trace one principle across the framework: compilation benefits scale with how much of the workload is optimizable.
Systems insight: Compute Beasts (table 4: ResNet-50 sees 2.6× speedup from TensorRT) benefit most because their dense kernels expose the most surface for layout selection, precision lowering, and fusion. Sparse Scatter workloads such as DLRM gain little because their bottleneck, irregular embedding lookups, leaves almost nothing for the compiler to optimize.
This principle has concrete implications across three regimes. In research prototyping (\(N_{\text{dev}} \gg N_{\text{prod}}\)), teams should stay eager. If the architecture changes every few minutes, compilation overhead dominates. A 30-second compile time with ten iterations/hour means five minutes lost to compilation per hour, often more than the runtime savings.
For training runs (\(N_{\text{prod}} \gg N_{\text{dev}}\)), compilation pays off. A typical training run executes millions of forward/backward passes, so even 60 seconds of compilation amortizes to microseconds per step. From table 4, torch.compile provides 48.3 percent higher throughput on ResNet-50 (2,150 img/s vs. 1,450 img/s). Using a 30 s compile cost, this pays off after the breakeven point in equation 3:
\[ N_{\text{breakeven}} = \frac{T_{\text{compile}}}{T_{\text{eager}} - T_{\text{compiled}}} \tag{3}\]
Evaluating equation 3 with the ResNet-50 table values gives approximately 134,000 images. For ImageNet (1.28M training images), compilation pays off within the first epoch.
For production inference (\(N_{\text{dev}} \approx 0\), \(N_{\text{prod}} \rightarrow \infty\)), teams should maximize compilation. With no development iterations and potentially millions of requests, every optimization matters. Aggressive autotuning can be worthwhile even when compilation takes much longer, because the cost is amortized over the deployment lifetime.
These three regimes create distinct regions in the compilation decision space. Figure 7 maps out these regions so engineers can identify where each strategy wins. Watch for the crossover points: the steep eager line (highest per-execution cost) eventually overtakes JIT’s moderate slope, while the gentlest compiled line (lowest per-execution cost but largest upfront investment) wins only after millions of executions. The slopes reveal per-execution cost; the vertical offsets reveal compilation overhead. A project’s position on the x-axis determines which line it should be on.
The dispatch overhead law
A second principle, the dispatch overhead law, emerges from equation 4, which identifies the regime in which framework overhead, rather than compute or memory, dominates execution time. Let \(N_{\text{ops}}\) be the number of operations (count), \(t_{\text{dispatch}}\) the per-operation dispatch overhead (seconds), and \(T_{\text{compute}}\) and \(T_{\text{memory}}\) the total compute and memory times (seconds). Framework overhead dominates when operations are small relative to dispatch cost:
\[ \text{Overhead Ratio} = \frac{N_{\text{ops}} \cdot t_{\text{dispatch}}}{T_{\text{compute}} + T_{\text{memory}}} \tag{4}\]
When Overhead Ratio \(> 1\), the model is overhead-bound. Compilation provides maximum benefit for overhead-bound workloads because it eliminates per-operation dispatch.
The training-step trace in section 1.10, at the end of this chapter, works this effect through end to end; the numbers that follow preview it.
Summed over \(N_{\text{ops}}\) operations, the per-operation dispatch cost \(t_{\text{dispatch}}\) accumulates into a per-call tax on execution. Whether that tax dominates depends on how the hardware execution time \(T_{\text{hw}}\) compares to the software overhead \(T_{\text{sw}}\) (both measured in seconds), and the regimes split sharply by model size.
Napkin Math 1.2: The dispatch tax
Problem: When does Python overhead kill performance?
Scenario one: Small multilayer perceptron (MLP) (Overhead Bound)
- Compute: 6 ops across small matrix/element-wise operations.
- Hardware time: \(T_{\text{hw}} \approx\) 2.6 μs (mostly memory latency).
- Software overhead: \(T_{\text{sw}} \approx\) 6 ops \(\times\) 5 μs/op = 30 μs.
- Ratio: 30 μs/2.6 μs ≈ 11.5.
- Small-model outcome: The system spends 92 percent of time in host-side dispatch and kernel-launch overhead. Compilation yields 12.5× speedup.
Scenario two: GPT-3 Layer (Compute Bound)
- Compute: Huge matrix multiplications.
- Hardware time: \(T_{\text{hw}} \approx\) 100 ms = 100000 μs.
- Software overhead: \(T_{\text{sw}} \approx 50.0 \, \mu s\).
- Ratio: 50 μs/100000 μs ≈ 0.0005.
- Large-model outcome: Python overhead is negligible. Compilation helps only via kernel fusion (memory bandwidth), not dispatch elimination.
Systems insight: Dispatch overhead is regime-dependent. Compilation removes host-side overhead for small-operation workloads, while large models benefit mainly from fused kernels and memory movement reductions.
The principle’s implication is that small models benefit disproportionately from compilation. A 100-parameter toy model might see 10\(\times\) speedup from torch.compile, while a 175B-parameter model sees only 1.3\(\times\). This explains why compilation matters most for efficient inference on smaller, deployed models.
The dispatch tax analysis reveals that small operations are overhead-bound regardless of hardware capability. This observation matters most at the extreme edge of the deployment spectrum, where the entire Python runtime is itself an unacceptable overhead.
Frameworks for the edge: TinyML and micro-runtimes
The compilation continuum reaches its extreme at the far edge. While cloud frameworks like PyTorch and TensorFlow 2.x prioritize flexibility through eager execution, TinyML16 systems operating on microcontrollers (MCUs) with kilobytes of memory cannot afford the overhead of a Python interpreter or a fully dynamic runtime.
16 TinyML: Systems designed for microcontrollers (MCUs) that cannot afford the memory or processing overhead of a Python interpreter. Instead of flexible eager execution, micro-runtimes use small C/C++ runtimes, fixed memory planning, and model-specific operator registration. In TensorFlow Lite Micro, inference is still interpreter-based: the application supplies a tensor arena, and the interpreter plans and reuses buffers without relying on heap allocation after setup. The hard requirement is predictable memory use, as a single malloc() failure on a device with just 256 KB of RAM is unrecoverable.
Lighthouse 1.2: Lighthouse example: KWS on TinyML
Scenario: Deploying the Smart Doorbell’s Keyword Spotting (KWS) model, the DS-CNN Tiny Constraint lighthouse, to an ARM Cortex-M4 microcontroller with 256 KB of RAM and 1 MB of Flash.
Constraint: A standard PyTorch runtime occupies ~500 MB. The Python interpreter itself occupies ~20 MB. Both are orders of magnitude larger than the entire device.
Framework solution: Micro-frameworks such as TensorFlow Lite Micro (TFLM) (David et al. 2021) solve this through a tiny interpreter-based runtime with a fixed memory discipline:
- Fixed memory arena: The application supplies a contiguous tensor arena, and the framework plans and reuses buffers from that arena rather than relying on dynamic allocation during inference.
- Kernel selection: Only the specific kernels used by the model (for example, Conv2D, DepthwiseConv) need to be linked or registered with the runtime.
- Compact interpreter execution: The MCU runs a small C/C++ interpreter over a flat model representation, with the model and arena bound at initialization rather than assembled dynamically at runtime.
Silicon contract: On TinyML devices, the contract is strictly memory-bound. The framework’s primary job is to ensure the model’s intermediate activations (the “working set”) fit within the MCU’s tiny SRAM.
David, Robert, Jared Duke, Advait Jain, Vijay Janapa Reddi, Nat Jeffries, Jian Li, Nick Kreeger, et al. 2021. “TensorFlow Lite Micro: Embedded Machine Learning for TinyML Systems.” Proceedings of Machine Learning and Systems 3: 800–811.
These micro-runtimes represent the most constrained endpoint of the continuum. By sacrificing most dynamic flexibility, they enable machine learning to run on devices consuming milliwatts of power because they keep data movement local to the chip.
The spectrum of execution strategies, from dynamic eager execution to static graph compilation and specialized micro-runtimes, requires developers to make deliberate trade-offs. Before turning to the second core problem, it is useful to collect the key execution-mode decisions in one place.
Checkpoint 1.1: Execution models
The choice of execution mode determines both developer velocity and model performance.
Debuggability vs. Speed
The Modern Compromise
The execution problem determines when computation happens and what optimizations are possible. Neural network training, however, requires a capability that no amount of clever scheduling can provide: the ability to compute gradients automatically.
Consider what training actually requires: for each of millions of parameters, compute how a tiny change would affect the loss. Doing this manually for even a simple three-layer network requires deriving and implementing dozens of partial derivatives. For a modern transformer with billions of parameters, manual differentiation is economically impossible. A framework that executes efficiently but cannot differentiate can run inference but cannot learn.
Self-Check: Question
A profile shows a sequence of LayerNorm, dropout, and activation kernels each do little arithmetic but repeatedly read and write large tensors to HBM. Why is kernel fusion especially valuable for this signature?
- These kernels are memory-bound and pay repeated kernel-launch overhead, so combining them reduces both HBM traffic and dispatch costs
- Fused kernels typically improve numerical accuracy by reducing floating-point rounding error
- Fusion lets the framework skip storing model weights in memory altogether
- Matrix multiplications cannot execute unless fused with surrounding element-wise operations
A model contains many tiny element-wise operations and runs far slower than its FLOP count suggests. Use the dispatch tax idea to explain what is happening and what compilation changes.
A developer traces a function using an example input whose tensor sum is positive, but at serving time inputs whose sums are negative also occur. What is the primary correctness risk introduced by tracing?
- Tracing inserts extra memory copies that make the model too slow to train
- Tracing captures only the branch taken by the example input, so data-dependent control flow can silently take the wrong path on unseen inputs
- Tracing forces every tensor to move back to CPU before execution
- Tracing prevents any form of operator fusion
Order the following phases in PyTorch 2.0’s compilation pipeline: (1) FX graph representation, (2) TorchInductor code generation, (3) TorchDynamo graph capture.
A research team iterates code changes many times per hour during development; a production team runs a fixed model millions of times per day. Applying the compilation continuum, which setting justifies moving rightward toward JIT or AOT compilation, and why?
A team is deploying keyword spotting on a microcontroller with 256 KB of RAM and no Python runtime. Explain why TinyML micro-runtimes represent the extreme AOT endpoint of the execution continuum, and what the team must give up to get there.
Differentiation Problem
The differentiation problem is the task of computing gradients17 automatically. Neural network training requires derivatives of a scalar loss \(\mathcal{L}\) with respect to millions or billions of parameters, making manual differentiation impractical. Because a single scalar loss depends on all parameters, reverse-mode automatic differentiation (AD)18 is the optimal strategy: one backward pass computes all parameter gradients simultaneously, while forward mode would require a separate pass for each parameter. All major ML frameworks therefore implement reverse-mode AD by default (Baydin et al. 2018).
17 Automatic Differentiation (AD): The “automatically” in the triggering sentence is the key word: AD mechanizes the chain rule as a graph traversal, eliminating the manual derivative computation that made scaling beyond toy networks impractical. The systems trade-off that makes this feasible is the choice of reverse mode, which exploits the many-to-one topology of training (many parameters, one scalar loss) to compute all gradients in a single backward pass. Forward mode would require one pass per parameter, making billion-parameter training computationally impossible.
18 Reverse-Mode AD: The \(\mathcal{O}(1)\)-vs.-\(\mathcal{O}(P)\) asymmetry mentioned earlier has a concrete price: reverse mode must store every intermediate value from the forward pass for use during the backward traversal. For a billion-parameter transformer, these stored activations can consume 3–4\(\times\) more memory than the weights themselves. This memory cost is the reason frameworks provide activation checkpointing and gradient accumulation, techniques that trade recomputation time for the memory that reverse-mode AD demands.
Baydin, Atilim Gunes, Barak A. Pearlmutter, Alexey Andreyevich Radul, and Jeffrey Mark Siskind. 2018. “Automatic Differentiation in Machine Learning: A Survey.” Journal of Machine Learning Research 18 (153): 1–43.
Building on the backpropagation algorithm introduced in Neural Computation (where we established that gradients flow backward through the computation graph via the chain rule), this section shifts focus from the mathematics to the systems engineering of differentiation: how frameworks represent computation graphs, manage memory for intermediate values, and orchestrate the backward pass efficiently across accelerators. The framework’s role is not to perform calculus but to manage the bookkeeping at scale, which is required for the training algorithms detailed in Model Training. Listing 7 illustrates the core idea with a simple three-operation function:
def f(x):
a = x * x # Square
b = sin(x) # Sine
c = a * b # Product
return cFrameworks decompose this function into elementary operations, each with a known local derivative, and then combine these local derivatives via the chain rule to compute gradients through arbitrary compositions. The systems challenge is implementing this efficiently: the framework must record the computation graph during the forward pass, store intermediate values, and execute the backward pass with minimal memory overhead. The rest of this section traces how production frameworks solve each of these problems.
Forward and reverse mode differentiation
Two primary approaches to automatic differentiation exist, and the choice between them (forward mode vs. reverse mode) determines whether gradient computation scales with the number of inputs or the number of outputs, a distinction that explains why neural network training universally uses one mode over the other. Forward mode is useful to understand first because it exposes the bookkeeping directly; reverse mode then appears as the systems response to the many-parameter, one-loss shape of neural network training.
Forward mode
Neural network training universally uses reverse mode (covered next), but forward mode illuminates why reverse mode is necessary. Forward mode automatic differentiation computes derivatives alongside the original computation, tracking how changes propagate from input to output. This approach mirrors manual derivative computation, making it intuitive to understand and implement.
Forward mode’s memory requirements are its strength: the method stores only the original value, a single derivative value, and temporary results. Memory usage stays constant regardless of computation depth, making forward mode particularly suitable for embedded systems, real-time applications, and memory-bandwidth-limited systems. However, this comes with a computational cost. Forward mode doubles the operation-count term \(O\) (in iron law terms) for each input parameter whose derivative is requested. For a model with \(P\) parameters, forward mode multiplies total computation by \(P\), because each parameter requires a separate forward pass. Reverse mode, by contrast, adds a constant factor of approximately 2–3\(\times\) regardless of \(P\). This asymmetry explains why forward mode is never used for training neural networks, where \(P\) ranges from millions to hundreds of billions. This combination of computational scaling with input count but constant memory creates a specific niche: forward mode excels in scenarios with few inputs but many outputs, such as sensitivity analysis, feature importance computation, and online learning with single-example updates.
To see the mechanism concretely, consider computing both the value and derivative of \(f(x) = x^2 \sin(x)\). Listing 8 shows how forward mode propagates derivative computations alongside every operation, applying the chain rule and product rule at each step:
def f(x): # Computing both value and derivative
# Step 1: x -> x²
a = x * x # Value: x²
da = 2 * x # Derivative: 2x
# Step 2: x -> sin(x)
b = sin(x) # Value: sin(x)
db = cos(x) # Derivative: cos(x)
# Step 3: Combine using product rule
result = a * b # Value: x² * sin(x)
dresult = a * db + b * da # Derivative: x²*cos(x) + sin(x)*2x
return result, dresultForward mode achieves this systematic derivative computation by augmenting each number with its derivative value, creating what mathematicians call a “dual number”. Listing 9 runs the same function at \(x = 2.0\), so the bookkeeping becomes concrete: each intermediate value carries its derivative alongside it through a single pass.
x, dx = 2.0, 1.0 # seed: track the derivative with respect to x
a = x * x # value: 4.0
da = 2 * x # derivative: 4.0
b = sin(x) # value: 0.9093
db = cos(x) # derivative: -0.4161
c = a * b # value: 3.637
dc = a * db + b * da # derivative: 1.973That paired execution is exactly the 2\(\times\) computational overhead per input: every arithmetic operation (multiply, sine, product rule combination) is performed twice, once for the value and once for the derivative. For this single-input function, the overhead is acceptable. For a neural network with \(P = 100{,}000{,}000\) parameters, computing all gradients would require 100 million such passes, which is why forward mode is restricted to the few-input applications described earlier.
Forward mode’s strength in single-input analysis becomes its fatal weakness for training. A neural network has one scalar loss but millions of parameters, and forward mode would require a separate pass for each one—an intractable \(\mathcal{O}(P)\) cost that explains why no production framework uses forward mode for training. Forward mode remains useful for targeted analyses such as sensitivity analysis (measuring how a single pixel change affects the prediction) and feature importance (ranking which input dimensions most influence the output), where the number of inputs of interest is small.
Given forward mode’s \(\mathcal{O}(P)\) scaling with parameter count, we need an entirely different approach for training. Reverse mode provides exactly this: by propagating gradients backward from output to input, it computes all \(P\) parameter gradients in a single pass.
Reverse mode
Every modern ML framework defaults to reverse mode for training because of computational asymmetry, one of the most consequential design decisions in machine learning software. A neural network has one scalar loss but millions of parameters. Forward mode computes one parameter’s gradient per pass, requiring \(P\) passes for \(P\) parameters. Reverse mode computes all \(P\) gradients in a single backward pass. For a model with 100 million parameters, that is the difference between 100 million forward passes and exactly one backward pass, a speedup proportional to the parameter count.
This asymmetry makes reverse mode the only viable option for training. Reverse mode runs on the same three-operation function \(f(x) = x^2\sin(x)\) from listing 7, where \(x\) reaches the output through two distinct paths: the square and the sine. Algorithm 1 states the general reverse-mode contract before the following worked trace makes one concrete input visible.
\begin{algorithm} \caption{Reverse-mode automatic differentiation} \begin{algorithmic} \Require directed acyclic graph with scalar output $y$; nodes $v_1,\dots,v_n$ in topological order; a local derivative rule for each node \Ensure adjoints $\bar{v}_i = \partial y / \partial v_i$ for the requested input or parameter nodes \For{$i = 1$ to $n$} \State compute $v_i$, store its value and parent edges \Comment{forward pass} \EndFor \State $\bar{v}_i \gets 0$ for all $i$; $\bar{y} \gets 1$ \For{$i = n$ down to $1$} \For{each parent $u$ of $v_i$} \State $\bar{u} \gets \bar{u} + \bar{v}_i \, \partial v_i / \partial u$ \Comment{accumulate via the chain rule} \EndFor \State release stored values once every rule that needs them has run \EndFor \State \Return the adjoints for the requested nodes \end{algorithmic} \end{algorithm}
The structure of algorithm 1 is also its cost. The forward pass retains every node value and parent edge until the reverse traversal consumes them, so reverse mode buys all \(P\) gradients in a single backward pass at the price of activation and graph memory proportional to the live forward state. That memory, not the arithmetic, is what the rest of this section must manage.
For the concrete function in listing 7 with \(x=2.0\), the forward pass stores \(a=x^2=4.0\), \(b=\sin(x)\approx0.9093\), and \(c=ab\approx3.637\). Seeding \(\bar{c}=1.0\), the reverse multiplication gives \(\bar{a}=0.9093\) and \(\bar{b}=4.0\); the square path contributes \(0.9093\cdot4.0\approx3.6372\) to \(\bar{x}\), and the sine path adds \(4.0\cos(2.0)\approx-1.6646\). The final derivative is \(\partial c/\partial x=\bar{x}\approx1.973\).
The critical observation is that this single backward pass computed \(\partial c/\partial x\) regardless of how many paths connect \(x\) to \(c\). In a neural network, each weight can affect the loss through thousands of paths across layers, and reverse mode handles them all in one traversal. This is why training a 175B-parameter model like GPT-3 is feasible at all: reverse mode’s \(\mathcal{O}(1)\) backward passes relative to parameter count keep gradient computation tractable.
Translating this mathematical elegance into a working system requires solving a concrete engineering problem: the backward pass needs values computed during the forward pass, so the framework must decide what to store, when to store it, and when to free it. Modern frameworks accomplish this through computational graphs and automatic gradient accumulation19.
19 Gradient Accumulation: A direct answer to the “when to free it” question: the framework breaks a large logical batch into smaller mini-batches processed sequentially, freeing activation memory after each mini-batch’s backward pass and accumulating only the small gradient tensors. This lets a system simulate a batch size of 4,096 using the memory footprint of a 64-sample batch, trading sequential compute time for a 64\(\times\) reduction in peak activation memory. Without this technique, many production training configurations would exceed accelerator memory on the first batch.
Listing 10 illustrates this with a two-layer network, showing both the forward computation that stores intermediate values and the backward pass that consumes them to produce gradients for every parameter simultaneously.
def simple_network(x, w1, w2):
hidden = x * w1 # First layer
activated = max(0, hidden) # ReLU activation
output = activated * w2 # Second layer
return output
# —Forward pass stores intermediates ---
# x=1.0, w1=2.0, w2=3.0
# hidden=2.0, activated=2.0, output=6.0
# —Backward pass consumes them ---
d_output = 1.0 # Seed gradient
d_w2 = activated # = 2.0
d_activated = w2 # = 3.0
d_hidden = d_activated * (1 if hidden > 0 else 0) # ReLU gate: 3.0
d_w1 = x * d_hidden # = 3.0
d_x = w1 * d_hidden # = 6.0Three implementation requirements emerge from this example. First, the framework must track dependencies between operations to determine the correct reverse traversal order. Second, intermediate values (hidden, activated) must persist in memory until the backward pass consumes them. Third, every operation needs both a forward implementation and a corresponding backward rule. These requirements define the engineering surface of any AD system, and the second requirement, memory persistence, turns out to be the dominant cost.
Memory management strategies
A 175B-parameter model in FP16 requires 350 GB just for weights, far exceeding any single GPU’s memory. Weights, however, are only the beginning: reverse mode AD also stores every intermediate activation from the forward pass for use during the backward pass. For a 100-layer network processing a batch of 64 images, these stored activations can consume 8–12 GB on top of the model weights, gradients, and optimizer state. Memory, not compute, is the binding constraint on what models a framework can train.
The problem scales linearly with depth. Listing 11 shows how each layer in a deeper network adds another activation tensor that must persist until the backward pass reaches that layer.
def deep_network(x, w1, w2, w3):
# Forward pass - must store intermediates
hidden1 = x * w1
activated1 = max(0, hidden1) # Store for backward
hidden2 = activated1 * w2
activated2 = max(0, hidden2) # Store for backward
output = activated2 * w3
return outputFrameworks attack this memory wall with two primary strategies. The first is activation checkpointing (also called gradient checkpointing): rather than storing every activation, the framework keeps selected boundary values and recomputes the missing intermediates during the backward pass. At this point, the important systems idea is the runtime contract, not the placement policy. The framework treats some activations as durable checkpoints and treats the rest as values that can be regenerated when the backward traversal reaches them; Activation checkpointing later examines how training systems choose the checkpoints. Listing 12 makes the runtime contract visible: the forward pass keeps only the segment boundaries, and the backward pass re-runs each segment to regenerate the activations it dropped rather than reading them back from memory.
# Standard backward: every forward activation stays resident
h1 = layer1(x) # kept for backward
h2 = layer2(h1) # kept for backward
out = layer3(h2) # kept for backward
# Checkpointed: keep only the boundary h1 and drop h2. The
# backward pass re-runs the wrapped segment to regenerate
# h2 on demand instead of holding it in memory.
h1 = layer1(x) # boundary: kept
out = checkpoint(
lambda a: layer3(layer2(a)), h1
) # h2 recomputed in backwardThe second strategy is operation fusion20. Rather than executing matrix multiplication, bias addition, and ReLU as three separate operations, each writing intermediate results to memory, frameworks fuse them into a single kernel. This eliminates intermediate memory allocations entirely and achieves 2–3\(\times\) speedup on modern GPUs by keeping data in registers and caches.
20 Operation Fusion: The 2–3\(\times\) speedup cited in the triggering sentence arises from a specific hardware fact: GPU registers and L1 cache deliver 10–100\(\times\) higher bandwidth than HBM. When matmul, bias, and ReLU execute as separate kernels, each writes its output to HBM and the next reads it back, a round-trip that dominates execution time for memory-bound operations. Fusing them into one kernel keeps intermediates in registers, converting three HBM round-trips into zero.
Chetlur, Sharan, Cliff Woolley, Philippe Vandermersch, Jonathan Cohen, John Tran, Bryan Catanzaro, and Evan Shelhamer. 2014. “cuDNN: Efficient Primitives for Deep Learning.” arXiv Preprint arXiv:1410.0759.
The backward pass itself benefits from hardware-specific optimization. Rather than directly translating the mathematical definition of a convolution gradient into code, frameworks implement specialized backward kernels that exploit memory access patterns and hardware capabilities of modern accelerators (Chetlur et al. 2014). These optimizations, checkpointing, fusion, and specialized kernels, work together to make training practical for architectures that would otherwise exhaust GPU memory in a single forward pass.
Framework implementation of automatic differentiation
Checkpointing, fusion, and specialized kernels solve the systems problems of AD. Practitioners, however, never interact with these mechanisms directly. Instead, frameworks expose AD through high-level APIs that hide the underlying machinery behind simple method calls. A PyTorch training loop—optimizer.zero_grad(), forward pass, loss.backward(), optimizer.step()—appears to be four function calls. Behind each call, however, the framework tracks all operations during the forward pass, builds and maintains the computation graph, manages memory for intermediate values, schedules gradient computations efficiently, and interfaces with hardware accelerators. The same graph machinery extends to advanced scenarios: nested torch.autograd.grad calls compute second-order derivatives for techniques like natural gradient descent, and mixed-precision contexts (autocast) select reduced-precision kernels for compute-intensive operations while maintaining FP32 for numerical stability.
PyTorch autograd internals
The autograd system is the framework component that solves the differentiation problem described in section 1.1. Three systems principles govern its design: the data structure that enables efficient gradient computation, the memory cost of maintaining that data structure, and the control mechanisms that production systems require. Understanding these principles explains why training consumes 100\(\times\) more memory than inference for the same model, and why frameworks provide specific mechanisms to manage that cost.
The reverse-linked graph structure
During the forward pass, the autograd system constructs a reverse-linked graph of Function nodes. Each node records the operation performed and stores references to the tensors it needs for gradient computation. This graph is the data structure that makes reverse-mode automatic differentiation possible: regardless of how many parameters a model has, a single backward pass through this graph computes all gradients. For a model with \(P\) parameters, reverse-mode AD requires \(\mathcal{O}(1)\) backward passes (compared to \(\mathcal{O}(P)\) for forward-mode), which is why every major framework implements this approach.
Concretely, every tensor produced by a differentiable operation stores a grad_fn attribute pointing to the Function that created it. Each Function links to its inputs through next_functions, forming a chain from the loss back to the leaf parameters. Listing 13 illustrates this structure for a simple computation:
grad_fn links to the Function that created it, forming a reverse chain from output to leaf parameters that enables \(\mathcal{O}(1)\) backward passes.
import torch
x = torch.tensor([2.0], requires_grad=True)
y = x * 3
z = y.pow(2)
# Traverse the reverse-linked graph
print(z.grad_fn) # PowBackward0
print(z.grad_fn.next_functions) # -> MulBackward0
print(
z.grad_fn.next_functions[0][0].next_functions
) # -> AccumulateGrad (leaf)The traversal reveals the chain: PowBackward0 (for z = y**2) links to MulBackward0 (for y = x * 3), which terminates at AccumulateGrad for the leaf tensor x. Leaf tensors are the endpoints of the graph where gradients accumulate into the .grad attribute rather than propagating further. The tuple format (Function, index) tracks which output of a multi-output operation each connection corresponds to.
A reverse-linked autograd structure has a critical systems implication: the entire graph must remain in memory from the time a tensor is created until the backward pass consumes it. The graph itself is lightweight (pointers and metadata), but the tensors it references are not, so memory consumption scales with model depth.
The memory-compute trade-off
Every activation saved for the backward pass persists in memory until consumed by gradient computation. This is the primary reason training memory dwarfs inference memory. Computing the gradient of most operations requires values from the forward pass: multiplication needs both inputs (\(\frac{\partial}{\partial x}(x \cdot y) = y\)), exponentiation needs the base (\(\frac{\partial}{\partial x}(x^2) = 2x\)), and softmax needs its output values. The autograd system stores these tensors in each Function node’s saved_tensors attribute.

Training memory dwarfs inference memory.
For a network with \(N_L\) layers, the system must save approximately \(N_L\) activation tensors, one per layer, for the entire batch. Consider a concrete example: ResNet-50 has 25.6M parameters (~102.4 MB in FP32) and processes batch size 64 with \(224{\times}224\) images. The memory breakdown reveals the scale of this trade-off. Forward activations alone consume approximately 8–12 GB (varying by implementation and checkpointing strategy). Parameter gradients add another ~102.4 MB (the same size as the parameters themselves), and Adaptive Moment Estimation (Adam) optimizer state contributes ~204.8 MB for its two momentum buffers per parameter. The total training footprint reaches 10 GB–15 GB, compared to just ~102.4 MB for inference alone.
This 97.7–146.5× ratio between training and inference memory quantifies why the Data Movement \((D_{\text{vol}})\) term dominates training latency in the iron law. During training, the framework must write all activations to memory during the forward pass and read them back during the backward pass, doubling the memory traffic compared to inference alone. The true cost of training memory derives the four-component training memory equation (\(M_{\text{total}} = M_{\text{weights}} + M_{\text{gradients}} + M_{\text{optimizer}} + M_{\text{activations}}\)) in full and works through examples at larger model scales.
Frameworks provide three primary mechanisms to manage this trade-off at the graph level. Gradient checkpointing (Chen et al. 2016) changes what the graph preserves: instead of saving all activations, the framework saves selected boundary values and rebuilds the missing intermediates during the backward pass. In iron law terms, checkpointing increases the \(O\) term (recomputation) to reduce the \(D_{\text{vol}}\) term (memory traffic). Tensor detachment provides a complementary mechanism: calling .detach() on a tensor changes which graph edges participate in differentiation, preventing the framework from saving activations through that path. This is essential for transfer learning, where pretrained layers should not accumulate gradients, and it reduces the \(D_{\text{vol}}\) term by eliminating unnecessary activation storage. Mixed-precision training offers a third approach: store selected activations and matrix operations in lower-precision formats so the framework reduces data movement while preserving numerically sensitive work in FP32. Model Training turns these graph mechanisms into sizing decisions.
Chen, Tianqi, Bing Xu, Chiyuan Zhang, and Carlos Guestrin. 2016. “Training Deep Nets with Sublinear Memory Cost.” arXiv Preprint arXiv:1604.06174.
Extensibility and control
Production training systems require fine-grained control over gradient flow that goes beyond the default backward pass. Three categories of control arise in practice. First, selective gradient computation: transfer learning and fine-tuning require freezing subsets of parameters, which the framework supports through requires_grad=False flags and the .detach() mechanism described earlier. Second, gradient inspection and modification: debugging vanishing or exploding gradients, implementing per-tensor gradient clipping, and logging gradient statistics all require intercepting gradients mid-computation, which frameworks expose through hook APIs. Third, custom differentiation rules: operations not in the framework’s built-in library (custom CUDA kernels, novel activation functions, domain-specific operations) require user-defined forward and backward implementations.
These control mechanisms share a common systems design: they are callback-based extensions that the autograd engine invokes at specific points during graph traversal, without modifying the core differentiation algorithm. This extensibility pattern allows the framework to maintain a single optimized backward pass while supporting arbitrarily complex gradient manipulation. In practice, this control appears through a few recurring PyTorch mechanisms: retained graphs, accumulated gradients, custom backward rules, hooks, and safe detachment. Table 6 maps each mechanism to what it controls and what it costs.
| Mechanism | What it controls | Cost or hazard |
|---|---|---|
retain_graph=True |
Keeps the graph alive for multiple backward passes (multi-loss objectives, higher-order derivatives) | Roughly doubles graph memory; by default backward() frees the graph after one use |
| Gradient accumulation | Successive backward passes sum into .grad until zero_grad() resets them, enabling large effective batches |
Forgetting the reset silently mixes gradients across optimization steps |
Custom autograd.Function |
User-defined forward and backward rules for operations outside the built-in library | Moves the differentiation contract (what to save, how to differentiate) to the implementer |
| Gradient hooks | Inspecting or modifying gradients mid-traversal (clipping, logging, debugging) | Runs arbitrary Python per registered tensor on every backward pass |
.detach() |
Cuts gradient flow at a chosen boundary (frozen layers, inference outputs) | The legacy .data attribute bypasses autograd and silently corrupts gradients; clone before in-place mutation |
One mechanism deserves a closer look because it exposes the differentiation contract most directly. Custom autograd functions move part of that contract from the framework to the implementer: the developer explicitly specifies what to save for the backward pass and how to compute gradients. Listing 14 shows the pattern.
These three principles connect directly to the framework’s role as a compiler for the silicon contract. The reverse-linked graph determines which operations the backward pass must execute (the \(O\) term). The memory-compute trade-off governs how much data the framework must move through the memory hierarchy (the \(D_{\text{vol}}\) term). The extensibility mechanisms, in turn, allow engineers to tune both terms for their specific workload. The interaction between autograd memory management and numerical precision leads naturally to mixed-precision training, which further reduces the \(D_{\text{vol}}\) term.
class MultiplyAdd(torch.autograd.Function):
@staticmethod
def forward(ctx, x, y, z):
# Save tensors needed for backward
ctx.save_for_backward(x, y)
return x * y + z
@staticmethod
def backward(ctx, grad_output):
# Retrieve saved tensors
x, y = ctx.saved_tensors
# Compute gradients using chain rule
grad_x = grad_output * y # ∂L/∂x = ∂L/∂out * ∂out/∂x
grad_y = grad_output * x # ∂L/∂y = ∂L/∂out * ∂out/∂y
grad_z = grad_output # ∂L/∂z = ∂L/∂out * 1
return grad_x, grad_y, grad_z
# Usage
x = torch.tensor([2.0], requires_grad=True)
y = torch.tensor([3.0], requires_grad=True)
z = torch.tensor([1.0], requires_grad=True)
output = MultiplyAdd.apply(x, y, z)
output.backward()
print(
x.grad, y.grad, z.grad
) # tensor([3.]), tensor([2.]), tensor([1.])Mixed-precision training support
Mixed precision exploits a hardware asymmetry to improve two iron law terms simultaneously: Tensor Cores execute FP16 matrix multiplications at higher throughput than FP32 CUDA cores (raising \(R_{\text{peak}}\) and reducing the compute term \(O/(R_{\text{peak}} \cdot \eta_{\text{hw}})\)), while FP16 activations halve the memory footprint (reducing \(D_{\text{vol}}\)). Improving both terms simultaneously is rare; most optimizations improve one at the expense of the other.
Frameworks exploit this through automatic mixed-precision APIs that select reduced precision for compute-intensive operations while maintaining FP32 where numerical stability demands it. Inside these APIs, frameworks automatically apply precision rules: matrix multiplications and convolutions use FP16 for bandwidth efficiency, while numerically sensitive operations like softmax and layer normalization remain in FP32. This selective precision maintains accuracy while achieving speedups on modern GPUs with specialized hardware units. Because FP16 has a narrower dynamic range than FP32, gradients can underflow to zero during backpropagation. Loss scaling addresses this by multiplying the loss by a large factor before the backward pass, then dividing gradients by the same factor afterward.
Frameworks also support multiple precision formats including FP16, BF1621, and TF32, NVIDIA’s Tensor Core format that keeps FP32-like exponent range while using lower mantissa precision for matrix multiply. Each format makes a different trade-off between range and precision. BF16 maintains FP32’s dynamic range, simplifying training by eliminating most gradient underflow issues and removing the need for loss scaling entirely. Mixed-precision training examines the mechanics of mixed-precision training in detail, including loss scaling algorithms, memory savings analysis, and numerical stability considerations. Listing 15 demonstrates PyTorch’s mixed precision API: the autocast context manager automatically selects FP16 for compute-intensive operations while GradScaler prevents gradient underflow by dynamically scaling loss values.
21 BF16 Design Rationale: Developed by Google Brain circa 2018 specifically for TPU training stability, BF16 preserves FP32’s eight-bit exponent range while halving memory footprint—an explicit trade-off of mantissa precision (7 bits vs. FP16’s 10) for dynamic range. The critical consequence is loss scaling elimination: FP16’s five-bit exponent causes gradient underflow for values below \(6 \times 10^{-5}\), requiring manual loss scaling to keep gradients in range. BF16’s FP32-matched exponent largely avoids this class of gradient underflow, eliminating the need for loss scaling in most workloads, which is why BF16 and FP16 are not interchangeable: BF16 is preferred when training stability matters; FP16 is preferred when numerical precision matters more than gradient stability.
import torch
from torch.amp import autocast, GradScaler
model = MyModel().cuda()
optimizer = torch.optim.Adam(model.parameters())
scaler = GradScaler("cuda")
for inputs, targets in dataloader:
inputs, targets = inputs.cuda(), targets.cuda()
optimizer.zero_grad()
# Framework automatically selects precision per operation
with autocast(device_type="cuda", dtype=torch.float16):
outputs = model(inputs)
loss = criterion(outputs, targets)
# GradScaler handles gradient scaling for numerical stability
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()BF16 training typically does not require loss scaling. Comparing listing 16 with listing 15 line for line, the GradScaler construction and its scale, step, and update calls all disappear: BF16’s FP32-matched exponent range removes the gradient underflow that forced loss scaling, so the loop collapses back to an ordinary backward pass.
# BF16 training typically does not require loss scaling
with torch.autocast(device_type="cuda", dtype=torch.bfloat16):
outputs = model(inputs)
loss = criterion(outputs, targets)
loss.backward() # No GradScaler needed
optimizer.step()Optimizer state and checkpointing
Resuming training after interruption requires restoring model weights and optimizer state together: momentum buffers, adaptive learning rates, and gradient statistics. For Adam, optimizer state adds about 4\(\times\) the FP16 weight memory (two FP32 states per parameter), so weights plus optimizer state require about 5\(\times\) the FP16 weight footprint. A 7-billion-parameter model therefore requires approximately 70 GB total (14 GB weights + 56 GB optimizer state). Checkpoint size therefore bounds recovery speed after failure, connecting fault tolerance directly to the iron law’s \(D_{\text{vol}}\) term.
Model Training covers optimizer memory requirements and optimization strategies for large-scale training, where checkpoint size becomes a binding constraint. Frameworks provide the state_dict() interface to access optimizer state for serialization (listing 17), and resuming training requires loading both model parameters and optimizer state (listing 18).
The mathematics of automatic differentiation were established decades before deep learning’s resurgence. What changed was the systems engineering. Before framework automation, implementing gradient computation for a single fully connected layer meant writing separate forward and backward functions, manually tracking intermediate values, and verifying mathematical correctness across dozens of operations. A modern transformer involves hundreds of operations with complex dependencies; manual gradient derivation for attention, layer normalization, and residual connections would require months of careful work per architecture variant.
import torch
import torch.nn as nn
import torch.optim as optim
model = nn.Linear(10, 5)
optimizer = optim.Adam(model.parameters(), lr=0.001)
# After training steps, optimizer accumulates state
loss = model(torch.randn(3, 10)).sum()
loss.backward()
optimizer.step()
# Access state for checkpointing
state = optimizer.state_dict()
# Contains: {'state': {...}, 'param_groups': [{'lr': 0.001, ...}]}# Saving checkpoint
checkpoint = {
"epoch": epoch,
"model_state_dict": model.state_dict(),
"optimizer_state_dict": optimizer.state_dict(),
}
torch.save(checkpoint, "checkpoint.pt")
# Resuming training
checkpoint = torch.load("checkpoint.pt")
model.load_state_dict(checkpoint["model_state_dict"])
optimizer.load_state_dict(checkpoint["optimizer_state_dict"])The breakthrough was turning this manual process into software infrastructure. A single matrix multiplication requires different gradient computations depending on which inputs require gradients, tensor shapes, hardware capabilities, and memory constraints. Autograd systems handle these variations transparently, which is why the rate of architectural innovation accelerated after frameworks matured. The mathematics did not change; software engineering made the mathematics practical to apply at scale.
Memory management in gradient computation
The memory strategies from section 1.4.1.2 (checkpointing, gradient accumulation) exist because reverse-mode differentiation requires preserving computational history. As listing 11 demonstrated, each layer adds an activation tensor that persists until the backward pass consumes it, creating a memory wave that peaks at the start of backpropagation and recedes as gradients are computed. Modern frameworks track the lifetime of each intermediate value automatically, freeing memory as soon as it is no longer needed. Even with precise lifetime tracking, however, a deeper problem remains: the cost of acquiring memory from the GPU in the first place.
The cost of raw GPU memory allocation provides a critical engineering lesson: production systems require memory abstraction. Requesting memory directly from a GPU is a high-latency operation that can synchronize the entire device, creating an allocation bottleneck that stalls computation. To solve this, modern frameworks implement caching allocators. Instead of communicating with the hardware for every new tensor, the framework requests large blocks of memory upfront and manages its own internal pool. This abstraction is critical because it prevents memory fragmentation, the scenario where free memory is available but scattered in pieces too small to hold a large tensor, allowing models to push the physical limits of the hardware without constant system-level overhead.
Systems Perspective 1.2: Caching allocator and utilization
The caching allocator is the framework’s primary mechanism for maximizing the hardware-utilization factor \(\eta_{\text{hw}}\) in the iron law. Without it, two factors degrade performance significantly:
- Allocation latency:
cudaMallocis a synchronous operation that costs 10–100 microseconds. In a training loop with thousands of operations per second, this latency would dominate execution time. The caching allocator pays this cost once, then serves subsequent requests in nanoseconds from its pool. - Fragmentation: A “Swiss cheese” memory pattern reduces effective capacity. If 10 GB is free but the largest contiguous block is 1 GB, a 2 GB tensor cannot be allocated. By binning allocations into standard sizes (powers of 2), the allocator ensures that freed memory can be reused for future requests, keeping utilization high.
When “OOM” (Out of Memory) errors appear despite nvidia-smi showing free memory, fragmentation is often the culprit. The allocator cannot find a contiguous block large enough for the requested tensor.
Production system integration challenges
A training iteration that takes 300 ms in profiling may take 500 ms in production because the AD system must coordinate with the memory allocator, the device manager, the operation scheduler, and the optimizer on every single step. Each gradient computation can trigger data movement between CPU and GPU, memory allocation for intermediate tensors, and kernel launches on accelerators. These system interactions dominate wall-clock time for small models and remain significant even at scale. The gap between what the programmer writes (a five-line training loop) and what the system executes (dozens of memory allocations, kernel launches, and synchronization points) is the central tension of AD system design.
The severity of this overhead depends on a deeper architectural choice: how the AD system records and replays computation in the first place. A framework that builds a dynamic trace at runtime pays per-operation bookkeeping on every forward pass, and its caching allocator must handle unpredictable allocation patterns because the graph shape is not known in advance. A framework that captures the entire computation as a static function, by contrast, can pre-plan memory pools and fuse allocations across the full backward pass, often cutting allocation overhead by an order of magnitude.
Systems Perspective 1.3: Tape-based vs. transform-based autodiff
PyTorch (tape-based): Records operations on a dynamic “tape” during the forward pass. This is flexible and easy to debug but makes it hard for a compiler to see the whole graph at once for global optimization.
JAX (transform-based): Treats automatic differentiation as a high-level function transformation (grad(f)). Because JAX sees the mathematical function before execution, it can easily chain other transformations like jit(grad(f)) or vmap(grad(f)), producing highly optimized, compiled kernels that often outperform dynamic frameworks on specialized hardware like TPUs.
Beyond sequential overhead, the AD system must also exploit concurrency. Modern networks frequently contain independent branches—two convolutional paths processing the same input before merging, as in Inception-style architectures. On a GPU with sufficient resources, the framework’s scheduler can execute both branch backward passes on separate CUDA streams, reducing backward pass time by up to 30–40 percent. The AD system therefore tracks dependencies for two purposes: correctness (computing the right gradients) and performance (scheduling independent computations concurrently). Frameworks hide this complexity behind loss.backward(), but the scheduling, memory allocation, and data movement decisions behind that call determine whether training runs at 40 percent or 80 percent of peak hardware utilization.
The memory and system integration challenges examined earlier (caching allocators, activation storage, and checkpoint overhead) affect all frameworks. Yet how frameworks implement automatic differentiation in the first place varies significantly, with consequences for both optimization potential and developer experience. The distinction between tape-based and transform-based autodiff captures this architectural divergence. JAX22 exemplifies the transform-based approach, where composable function transformations replace imperative tape recording.
22 JAX: The “transform-based” distinction matters because JAX’s grad, jit, and vmap are not library calls but algebraic transformations on pure functions, composable in any order. A chain like jit(grad(vmap(f))) compiles into a single XLA kernel because functional purity (no side effects, no mutation) lets the compiler reason about the entire program mathematically. The payoff is over 90 percent hardware utilization on TPUs; the cost is that any impurity (printing, mutation, unkeyed randomness) silently vanishes after the first trace.
How different frameworks implement AD
The execution models covered in section 1.3, namely eager, static graph, and hybrid, directly shape how each framework implements automatic differentiation:
- PyTorch (Paszke et al. 2019) builds its autograd tape dynamically during forward execution, providing immediate debugging at the cost of graph-level optimization. The
grad_fnchain mechanism detailed in section 1.4.2.1 enables flexible control flow but requires storing the complete graph until backward pass completion. - TensorFlow (Abadi et al. 2016) (in its 1.x incarnation) performed symbolic differentiation during graph construction, enabling ahead-of-time optimization. Modern TensorFlow 2.x uses eager execution by default but provides
tf.functionfor graph compilation when performance matters (TensorFlow Developers 2024). - JAX (Frostig et al. 2018) transforms functions rather than tracking operations. The
jax.grad()transformation returns a new function that computes gradients, enabling composition withjax.vmap()for vectorization andjax.jit()for compilation. This approach requires pure functions but enables composable program transformations that chain differentiation, vectorization, and compilation in a single expression.
Paszke, Adam, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, et al. 2019. “PyTorch: An Imperative Style, High-Performance Deep Learning Library.” Advances in Neural Information Processing Systems 32: 8024–35.
Abadi, Martı́n, Paul Barham, Jianmin Chen, Zhifeng Chen, Andy Davis, Jeffrey Dean, Matthieu Devin, et al. 2016. “TensorFlow: A System for Large-Scale Machine Learning.” Proceedings of the 12th USENIX Symposium on Operating Systems Design and Implementation (OSDI), 265–83.
Frostig, Roy, Matthew James Johnson, and Chris Leary. 2018. “Compiling Machine Learning Programs via High-Level Tracing.” Systems for Machine Learning.
Autodiff implementation differences determine how much debugging visibility, compiler optimization, and deployment portability a team can expect from each framework.
A recurring tension runs through every AD design decision: mathematical correctness demands storing computational history, but hardware imposes strict memory limits. Every framework resolves this tension differently, choosing which activations to checkpoint, which operations to fuse, and how aggressively to trade recomputation for memory. These choices determine which models can train on which hardware, making AD system design one of the most consequential engineering decisions in any framework.
Checkpoint 1.2: The systems cost of gradients
Training is inherently more expensive than inference because of Automatic Differentiation.
Computational Reality
Optimization Mechanics
The execution and differentiation problems together enable the training loop: the execution model determines when computation happens, while automatic differentiation computes the gradients that drive learning. Both problems, however, quietly assume something that cannot be taken for granted: that the same code can run across diverse hardware. A model trained on an NVIDIA A100 must serve inference on a mobile phone’s ARM CPU, a Google TPU, or a microcontroller with kilobytes of memory. The same torch.matmul call must dispatch to cuBLAS on one device and a hand-tuned ARM NEON kernel on another. This hardware diversity creates the third problem.
Self-Check: Question
Why do major ML frameworks default to reverse-mode AD rather than forward mode for neural network training?
- Reverse mode avoids storing any intermediate activations from the forward pass
- Training has a many-parameters-to-one-loss topology, so one reverse pass computes all parameter gradients, while forward mode would need one pass per parameter
- Forward mode cannot handle nonlinear operations such as ReLU or softmax
- Reverse mode is needed only for inference, not for training
Explain why training memory scales much more dramatically than inference memory on the same model under reverse-mode AD.
True or False: If you call backward() twice on the same output tensor without passing retain_graph=True, PyTorch will reuse the same autograd graph on the second call because gradient accumulation requires the graph to stay alive.
A transformer training run runs out of memory because saved activations dominate the footprint. Which change most directly trades extra computation for lower activation memory while preserving gradient correctness?
- Gradient checkpointing, which stores activations only at selected layer boundaries and recomputes the rest during the backward pass
- Pinned host memory, which reduces GPU activation storage by moving tensors into pageable host memory
- Data parallelism, which removes the need to store activations for the backward pass
- In-place edits via .data, which safely avoids saving prior tensor values
When PyTorch’s autograd traverses the computational graph during the backward pass, it follows the ____ attribute on each differentiable tensor to reach the backward Function that produced it.
Compare tape-based autodiff in PyTorch with transform-based autodiff in JAX, focusing on what each design makes easy and what it constrains.
Abstraction Problem
The hardware diversity described earlier is not merely inconvenient; it is architecturally fundamental. A GPU offers 1,000\(\times\) the parallelism of a CPU but has different memory semantics. A TPU provides higher throughput but requires static shapes. A microcontroller has kilobytes where a server has gigabytes. The abstraction problem is precisely this: frameworks must hide this complexity behind a single programming interface while still enabling efficient utilization of each target’s unique capabilities.
The problem decomposes into two interacting dimensions. The first is data representation: how frameworks encode tensors, parameters, and computational state in forms that work across hardware. The second is execution mapping: how high-level operations translate into hardware-specific implementations. These dimensions are not independent concerns. The way data is represented (memory layout, precision, device placement) directly affects what execution strategies are possible. A tensor stored in row-major format on a GPU requires different kernels than one in column-major format on a CPU. A model quantized to INT8 enables entirely different execution paths than FP32.
Solving the abstraction problem requires sophisticated software infrastructure: tensor representations that encode both mathematical semantics and hardware constraints, intermediate representations that enable hardware-specific compilation, and runtime systems that manage data movement across the memory hierarchy. To make this concrete, trace what must happen when a programmer writes model(input). The framework must resolve five decisions in rapid succession: data representation (tensor shape, memory layout, numeric precision), device placement (the bandwidth hierarchy connecting CPU, GPU, and accelerator memory), input delivery (data pipelines that sustain hundreds of MB/s to keep the accelerator fed), model organization (parameters, buffers, and submodules that must move together), and kernel execution (dispatch, scheduling, and resource optimization). The discussion follows those decisions in order, building from the data container up to the hardware execution layer. Distributed placement appears only as a preview of the same abstraction boundary: this chapter explains why frameworks expose placement scopes at all, while later chapters analyze the training algorithms and communication costs that make those scopes efficient.
Data structures and tensor abstractions
A ResNet-50 forward pass touches 25.6M parameters, produces intermediate activations at every layer, and must coordinate memory across CPU and GPU address spaces. Frameworks organize all of this data so that a single model(input) call executes millions of operations without the programmer managing a single pointer, by solving four problems in sequence: defining a universal data container (tensors), placing it on the right device (memory management), feeding data fast enough (data pipelines), and dispatching the right hardware kernel (core operations). We trace this path from data representation to hardware execution.
Computational graphs specify the logical flow of operations, but data structures determine how those operations access and manipulate data in physical memory. This distinction matters because the same mathematical operation can differ by an order of magnitude in throughput depending on whether data is contiguous in cache, pinned for DMA transfer, or scattered across pages.
The first step is the data container itself. Framework data structures must sustain memory bandwidth (hundreds of GB/s on modern GPUs), accommodate architectures from 1D sequences to 5D video tensors, and hide device management behind clean APIs. Tensors are the universal answer.
Tensors
At the foundation of every framework’s data representation lies a single abstraction: the tensor, an n-dimensional array that pairs numerical values with the information needed to interpret and place them.
Every computation in a neural network operates on tensors.23 Training batches, activation maps, parameter gradients, and optimizer states are all tensors. This unified representation lets frameworks optimize a single data structure for hardware rather than managing separate containers for each role.
23 Tensor: From Latin tendere (“to stretch”), coined in its mathematical sense by physicist Woldemar Voigt in 1898 for objects defined by how they transform under coordinate changes. ML inherited the term because framework tensors are similarly defined by transformation behavior: transposing changes strides but not data, reshaping changes metadata without moving bytes. This transformation-centric design is also the source of layout sensitivity: choosing NCHW when the target accelerator prefers NHWC (or vice versa) can halve computational throughput, because misaligned memory access patterns break hardware coalescing.
Definition 1.2: Tensor
Tensors are \(n\)-dimensional arrays with explicit shape, data type, and memory layout metadata that allow ML frameworks to map mathematical operations directly onto hardware vector units without intermediate data transformation.
- Significance: Tensor memory footprint is fully deterministic from its metadata: a contiguous FP32 tensor of shape \([1024, 1024]\) occupies \(1024{\times}1024{\times}4 = 4{,}194{,}304\) bytes (about 4.2 MB). Noncontiguous layouts (for example, from a transpose operation) require explicit
.contiguous()calls before certain CUDA kernels can execute, adding a memory-copy cost that can dominate the data movement term \((D_{\text{vol}}/\text{BW})\) for tensors under 1 MB. - Distinction: Unlike a Python list or generic NumPy array, a framework tensor carries device placement metadata (CPU vs. GPU), dtype (FP32, BF16, INT8), and stride information that enables zero-copy view operations and CUDA kernel dispatch without any runtime type checking or data movement.
- Common pitfall: A frequent misconception is that tensor operations are always in-place. Framework tensor operations return new tensors by default, allocating fresh GPU memory for each intermediate result. In a long computation graph, these intermediate allocations accumulate and can exhaust GPU memory before any weights are updated.
The tensor abstraction consumes far more memory than model weights alone suggest. Engineers who estimate memory from parameter count alone allocate accordingly and encounter out-of-memory errors that seem inexplicable. A quick memory accounting makes the hidden cost concrete: gradients, optimizer momentum, and stored activations accompany every weight tensor.
Napkin Math 1.3: The administrative tax
The memory breakdown for ResNet-50 in section 1.4.2.1.1 showed a concrete ~97.7–146.5× ratio between training and inference memory. Here we generalize that analysis to reveal the full administrative overhead at billion-parameter scale.
Problem: Why does GPU utilization drop when training small models?
Math:
- Model weights: 2 GB.
- Gradients: 2 GB (same size as weights).
- Optimizer states (Adam): 8 GB (\(4 \times\) FP16 weight memory for momentum and velocity stored in FP32).
- Activations: For a batch size of 32 and a 100-layer network, the framework must store every intermediate layer output for the backward pass. \[ \text{Activations} \approx B \times N_L \times S \times d_{\text{model}} \times n_{\text{saved}} \times 2 \text{ bytes} \] For a 1024-token sequence, 1024-wide hidden state, and 1 saved tensor per layer: \(32 \times 100 \times 1024 \times 1024 \times 1 \times 2 \approx \mathbf{6.7 GB}\). Materialized attention terms can add a separate \(B \times N_{\text{heads}} \times S^2\) component, which is why memory-efficient attention kernels matter.
Systems insight: A 2 GB model carries persistent training state before the first batch is processed (2 GB gradients + 8 GB optimizer state). During a training step, batch-dependent activations add another 6.7 GB, raising the peak “administrative tax” to ~16.7 GB beyond the weights. During training, data movement includes saving and retrieving these activations, which is why training is often 3–4\(\times\) slower than pure inference.
Tensor structure and dimensions
A tensor generalizes the familiar hierarchy of scalars (rank 0), vectors (rank 1), and matrices (rank 2) to arbitrary rank, with each rank adding one axis of organization; figure 8 compares the four lowest ranks side by side.

In ML data terms, a color image is a rank-3 tensor of height, width, and three color channels (figure 9), and a batch of \(B\) images is rank-4: \([B, 3, H, W]\) in PyTorch’s channel-first convention, \([B, H, W, 3]\) in channel-last layouts. That layout choice matters because every convolutional layer consumes and produces these rank-4 tensors, and the layout determines the memory access pattern the hardware sees.

Framework tensors carry more than raw numbers. Each tensor stores tensor metadata, runtime information used to validate operations and select fast execution paths: a shape tuple (for example, [64, 3, 224, 224] for a batch of images), a dtype (framework literals such as float32, float16, or int8), and a device tag (CPU, cuda:0). A matrix multiplication, for instance, checks shape compatibility at dispatch time and uses the dtype to route to the correct hardware kernel, whether a standard FP32 GEMM or a Tensor Core FP16 path.
Memory layout implementation introduces distinct challenges in tensor design. While tensors provide an abstraction of multi-dimensional data, physical computer memory remains linear. Stride patterns address this disparity by creating mappings between multi-dimensional tensor indices and linear memory addresses. These patterns significantly impact computational performance by determining memory access patterns during tensor operations. Figure 10 makes this concrete with a \(2{\times}3\) tensor: follow the same six values as they map into two different linear orderings—row-major and column-major—and note how the stride values change to compensate.

Stride choices become performance choices. Row-major layout (used by NumPy, PyTorch) stores elements row by row, making row-wise operations more cache-friendly. Column-major layout (used by some BLAS libraries) stores elements column by column, optimizing column-wise access patterns. The stride values encode this layout information: in row-major layout for a \(2{\times}3\) tensor, moving to the next row requires skipping three elements (stride[0]=3), while moving to the next column requires skipping one element (stride[1]=1).
These memory layout details have direct performance implications. When a convolution kernel accesses weight values, row-major layout means consecutive weights along the innermost (kernel-width) dimension are contiguous in memory—enabling efficient vectorized loads. Column-major layout would scatter those same weights across memory, forcing slower gather operations. Careful alignment of stride patterns with hardware memory hierarchies maximizes cache efficiency and memory throughput, with optimal layouts achieving 80–90 percent of theoretical memory bandwidth (1.5–3 TB/s on modern data-center GPUs like the A100 and H100) compared to suboptimal patterns that may achieve only 20–30 percent utilization.
The dtype is the tensor-level lever that trades numerical range against data movement. The standard choice in machine learning has been FP32 precision, exposed in frameworks through dtype literals such as float32, offering a balance of precision and efficiency. Modern frameworks extend this with multiple numeric types for different needs. Integer types support indexing and embedding operations. Reduced-precision types like FP16 enable efficient mobile deployment. INT8 precision allows fast inference on specialized hardware. The choice of numeric type affects both model behavior and computational efficiency: neural network training typically requires FP32 precision for critical accumulations to maintain stable gradient computations, while inference tasks can often use lower precision (framework dtype literals such as int8 or even int4, corresponding to INT8 and INT4), reducing memory usage and increasing processing speed. Mixed-precision training approaches combine these benefits by using FP32 for critical accumulations while performing most computations at lower precision.
Type conversions become another point where abstraction meets physics. Operating on tensors with different types demands explicit conversion rules to preserve numerical correctness. These conversions introduce computational costs and risk precision loss. Frameworks provide type casting capabilities but rely on developers to maintain numerical precision across operations.
Tensors answer the data-representation problem by encoding shape, layout, and precision into a single abstraction. A perfectly shaped tensor on the wrong device, however, or one that must cross a 60\(\times\) bandwidth gap to reach the GPU, can erase every layout optimization. The next problem is placement: where data lives and how it moves.
Device and memory management
Tensors and their memory layouts establish what the framework computes with. Where that data physically resides, and how it moves between locations, determines whether computation happens at full speed or crawls.
Frameworks as the operating system interface
While the high-level API focuses on math, the framework’s backend functions as the operating system of the Single-Machine Stack. It manages the two critical resources of a single node: compute scheduling and data movement.
The CUDA Runtime serves as this OS layer, providing the low-level primitives for launching kernels and managing device memory. The framework coordinates with this runtime to implement Direct Memory Access (DMA) over the PCIe bus. The bandwidth gap between the host (CPU) and device (GPU) is the primary “Data Loading Bottleneck”: Bandwidth vs. latency models this transfer, separating the two constraints, \(T = L_{\text{lat}} + D_{\text{vol}}/\text{BW}\), that determine whether a given data-loading strategy is limited by per-transfer latency or by sustained bandwidth. Frameworks mitigate this through pinned memory (page-locked memory) that allows the GPU to read directly from CPU RAM via DMA without interrupting the processor. This “HW/OS” interface is what makes high-throughput training loops possible on a single machine.
Every tensor resides on a specific device, and cross-device operations incur transfer costs that can dominate execution time. PCIe 4.0 delivers 32 GB/s between CPU and GPU, while HBM2e provides 2.04 TB/s within the GPU. This 63.7× bandwidth gap means a single misplaced tensor transfer can erase the entire speedup from GPU acceleration.

Interconnect bandwidth spans ~64\(\times\): HBM far above NVLink, NVLink far above PCIe.
Device placement matters for framework design because the framework must track where every tensor lives and enforce that operations only combine tensors on the same device. When data must move, the framework must decide whether to block execution or overlap the transfer with other work. These decisions, invisible to most users, determine whether a training loop achieves 30 percent or 80 percent of theoretical hardware throughput.
Three systems principles govern effective device and memory management: understanding the bandwidth hierarchy that constrains data movement, overlapping computation with communication to hide transfer latency, and using fine-grained synchronization to maintain correctness without sacrificing concurrency. The remainder of this section develops each principle, with quantitative analysis grounded in the iron law’s data movement term.
The device bandwidth hierarchy
The cost of moving data between devices varies by orders of magnitude depending on the interconnect.24 Before examining optimization strategies, we need to understand these costs quantitatively. Table 7 shows transfer times for a \(1000{\times}1000\) float32 tensor (4 MB)—roughly the size of a typical activation tensor in a moderately sized model. The numbers reveal why careless device placement can erase any speedup from GPU acceleration.
24 NVLink: NVIDIA’s high-bandwidth GPU-to-GPU interconnect (see Hardware Acceleration), providing 600 GB/s bidirectional bandwidth (NVLink 3.0 on A100) compared to 64 GB/s for PCIe 4.0 x16. This ~10\(\times\) bandwidth advantage determines whether tensor parallelism, splitting one large tensor computation across multiple GPUs, is practical for a given model size: GPUs connected only by PCIe can make the \(D_{\text{vol}}/\text{BW}\) communication term dominate total training time, erasing the benefit of additional compute.
| Interconnect | Bandwidth | Transfer Time | Relative to Compute |
|---|---|---|---|
| PCIe 3.0 x16 | 15.8 GB/s | 0.254 ms | 10\(\times\) slower than GPU compute |
| PCIe 4.0 x16 | 32 GB/s | 0.125 ms | 5\(\times\) slower than GPU compute |
| NVLink 3.0 | 300 GB/s per direction (600 GB/s bidirectional) | 0.013 ms | Comparable to GPU compute |
| GPU Memory | 2039 GB/s | 0.002 ms | Optimal |
These numbers connect directly to the iron law of performance. Every cross-device transfer inflates the data movement term \((D_{\text{vol}}/\text{BW})\) at a fraction of the available on-device bandwidth. A PCIe 4.0 transfer at 32 GB/s means moving a 1 GB activation tensor adds approximately 31.2 ms to the data movement cost, equivalent to roughly 9.8 TFLOP operations on a GPU delivering 312 TFLOP/s. For a model forward pass taking 0.5 ms on GPU, transferring inputs and outputs over PCIe 3.0 doubles the total latency. When batches are small or models are lightweight, transfer overhead can exceed computation time entirely.
The systems implication is clear: every tensor should reside on the device where it will be consumed, and transfers should occur only when unavoidable. Frameworks track device placement for every tensor and raise errors when operations attempt to combine tensors from different devices, enforcing this discipline at the API level.
Overlapping computation and communication
When transfers are unavoidable, the next optimization is to hide their latency by executing them concurrently with computation. Modern GPUs contain independent hardware units for computation (SM clusters) and data transfer (copy engines), enabling true simultaneous execution. The framework abstraction that exposes this hardware parallelism is the CUDA stream: an independent execution queue where operations execute sequentially within a stream but concurrently across streams.
Without explicit concurrency control, the GPU serializes all operations on a single default stream, leaving execution units idle while data transfers complete. By placing data transfers on one stream and computation on another, the effective latency approaches the theoretical minimum of \(\max(\text{compute\_time}, \text{transfer\_time})\) rather than their sum. Stream-based overlap effectively hides the \(D_{\text{vol}}/\text{BW}\) penalty when computation is the longer operation (see listing 19):

Overlapping copy and compute costs max(copy, compute), not their sum.
compute_stream = torch.cuda.Stream()
transfer_stream = torch.cuda.Stream()
# Transfer next batch while computing current batch
with torch.cuda.stream(transfer_stream):
next_batch = next_batch_cpu.to("cuda", non_blocking=True)
with torch.cuda.stream(compute_stream):
output = model(current_batch)
loss = criterion(output, labels)
# Pinned memory enables non_blocking transfers
x_pinned = torch.randn(1000, 1000).pin_memory()
x_gpu = x_pinned.to("cuda", non_blocking=True) # Asynchronous
# Regular memory requires blocking transfer
y_regular = torch.randn(1000, 1000)
y_gpu = y_regular.to("cuda", non_blocking=True) # Still blocksThe non_blocking=True flag enables asynchronous transfers that return immediately without waiting for completion. This works only when the source tensor uses pinned memory (page-locked memory that enables DMA transfers). Without pinned memory, the transfer blocks even when non_blocking=True is specified, because the GPU’s copy engine cannot initiate a DMA transfer from pageable host memory.
The same synchronization pattern appears when model stages overlap across microbatches. Listing 20 shows each stage running on its own stream, with events enforcing only the producer-consumer dependencies needed for correctness.
# Pipeline parallelism: overlap stages across microbatches
stages = [Stage1().cuda(), Stage2().cuda(), Stage3().cuda()]
streams = [torch.cuda.Stream() for _ in stages]
events = [
[torch.cuda.Event() for _ in range(num_microbatches)]
for _ in stages
]
for mb in range(num_microbatches):
for stage_idx, (stage, stream) in enumerate(zip(stages, streams)):
with torch.cuda.stream(stream):
if stage_idx > 0:
# Wait for previous stage to complete this microbatch
events[stage_idx - 1][mb].wait()
output = stage(inputs[stage_idx][mb])
events[stage_idx][mb].record()This overlap principle extends naturally to model-stage overlap within a single node. Different model stages on separate GPUs can process different microbatches concurrently, with each stage’s computation overlapping the next stage’s data reception (see listing 20). Model Training later names and analyzes the distributed-training strategies built from this scheduling pattern; here, the single-node implementation is enough to expose the synchronization principle that survives at larger scale. Once computation and communication overlap, the remaining challenge is ensuring correctness when operations complete out of order.
Synchronization and correctness
Concurrent execution introduces ordering constraints. When one stream’s output becomes another stream’s input, the system must enforce a happens-before relationship without unnecessarily serializing independent work. Two synchronization mechanisms exist, with dramatically different performance implications.
Full device synchronization (torch.cuda.synchronize()) blocks all streams and the CPU until every queued operation completes. This creates a global serialization point that eliminates all overlap benefits. CUDA events provide the alternative: fine-grained synchronization that blocks only the dependent stream, allowing other streams and the CPU to continue execution (see listing 21):
# Create streams and event
stream1 = torch.cuda.Stream()
stream2 = torch.cuda.Stream()
event = torch.cuda.Event()
# Stream 1: producer
with torch.cuda.stream(stream1):
result1 = expensive_computation(data1)
event.record() # Mark completion point
# Stream 2: consumer (waits only for stream1's event)
with torch.cuda.stream(stream2):
event.wait() # Block stream2 until event is recorded
result2 = dependent_computation(result1) # Safe to use result1The performance difference between these approaches is not incremental but categorical. Full synchronization after every operation converts a concurrent pipeline into a sequential one, entirely negating the hardware parallelism that streams expose. Event-based synchronization preserves the concurrent execution model while enforcing only the dependencies that correctness requires.
Device placement discipline protects the bandwidth hierarchy from accidental PCIe traffic. Every tensor carries a device attribute, and frameworks enforce a strict invariant: operations can only combine tensors on the same device. A RuntimeError results from mixing cuda:0 and cuda:1 tensors, preventing silent cross-device transfers.
The movement mechanism is explicit. The .to() method moves tensors between devices with copy-on-write semantics: calling .to("cuda") on a tensor already on the GPU returns the same object without copying. A module-level .to() recursively moves all parameters and buffers, ensuring the entire model hierarchy lands on a single device.
The performance discipline follows from the bandwidth gap: allocate tensors on the target device from the start rather than creating them on CPU and transferring them, reuse GPU memory across iterations rather than reallocating it, and colocate inputs, labels, and model parameters on the same device to eliminate implicit transfers. At 32 GB/s, violating any of these principles inserts PCIe transfers into the critical path that can dominate a training iteration that otherwise runs at 2.04 TB/s on-device.
The same synchronization discipline has one operational trap: debug code often leaves torch. cuda.synchronize() in the hot path, turning an overlapped pipeline into a serialized one. When overlap remains poor, profiling must separate scheduling stalls from kernel inefficiency. NVIDIA Nsight Systems (nsys profile) shows CPU activity, GPU kernels, and memory transfers on one timeline. NVIDIA Nsight Compute (ncu) then explains kernel behavior with hardware counters.
Table 8 is the diagnostic map for that second step. SM means streaming multiprocessor, the GPU block that schedules groups of threads; a warp is one scheduled thread group.
| Metric | Meaning | Optimization Target |
|---|---|---|
| SM Occupancy | Active warps/maximum warps | Increase parallelism if low |
| Memory Throughput | Achieved/peak bandwidth | Optimize memory access patterns |
| Compute Throughput | Achieved/peak FLOP/s | Reduce memory bottlenecks |
| Tensor Core Active | Time in Tensor Core ops | Verify mixed-precision utilization |
Data pipelines and loading

Each DataLoader knob relieves a specific input bottleneck.
Streams and events address placement and movement by overlapping transfers with computation so that the GPU rarely stalls on a single tensor. Scheduling alone, however, cannot help if data arrives too slowly in the first place. The next constraint is input delivery: data must arrive fast enough to sustain throughput. The core systems principle is straightforward: the data pipeline must sustain the accelerator’s consumption rate. A GPU processing 1,000 images per second at 224 by 224 resolution requires approximately 150.5 MB/s of sustained raw uint8 image throughput. If the pipeline cannot maintain this rate, the accelerator idles and the effective utilization term in the iron law drops below 1.
Frameworks address this throughput requirement through three mechanisms. The first is parallel worker processes: the DataLoader spawns multiple CPU processes, each independently loading and preprocessing samples. Because data loading involves disk I/O and CPU-bound transformations (decoding, augmentation, normalization), a single process cannot saturate a modern GPU. Multiple workers overlap I/O wait times with preprocessing computation, collectively sustaining throughput that no single process could achieve. When num_workers > 0, the DataLoader distributes sample indices across workers through a shared queue, and workers push completed samples to a data queue that the main process assembles into batches.
The second mechanism is prefetching. The prefetch_factor parameter (default 2) controls how many batches each worker prepares in advance. With four workers and prefetch_factor=2, the pipeline maintains eight batches in flight, ensuring the GPU never stalls waiting for data. While the model processes batch \(N\) on the GPU, workers simultaneously load and preprocess batch \(N+1\) through \(N+8\) on CPUs, effectively hiding data loading latency behind computation. The cost is memory consumption proportional to batch size times prefetch depth.
The third mechanism is pinned memory for DMA transfers. The pin_memory=True option allocates batch data in page-locked (pinned) host memory rather than pageable memory. Pageable memory can be swapped to disk by the operating system, forcing the CUDA runtime to first copy data to a temporary pinned buffer before initiating the GPU transfer. Pinned memory bypasses this intermediate copy, enabling direct memory access (DMA) transfers where the GPU’s memory controller reads directly from host memory while the CPU continues other work. For a batch of 64 images at \(224{\times}224{\times}3\) in FP32 (38.5 MB), pinned memory transfer takes approximately 1.2 ms over PCIe 4.0 x16 (32 GB/s) compared to ~3 ms with pageable memory, a 2–3\(\times\) speedup. The cost is reduced available system memory, as pinned pages cannot be swapped.
The DataLoader configuration is useful only when each parameter is tied to a bottleneck. In listing 22, num_workers enables parallel loading, prefetch_factor controls pipeline depth, and pin_memory enables DMA transfers. The worker count is a throughput/memory trade-off, not a universal constant. A practical starting point is setting num_workers equal to the number of available CPU cores, then adjusting based on whether loading is I/O-bound or CPU-bound. For I/O-bound workloads such as reading images from network storage, more workers overlap disk latency and improve throughput. For CPU-bound workloads involving heavy augmentation, the benefit saturates once all cores are in use. Too many workers waste memory, since each maintains a copy of the Dataset object.
Once throughput is high enough, worker process management becomes a correctness constraint. Because workers are separate processes, random number generators used in data augmentation must be explicitly seeded per worker via worker_init_fn to ensure reproducibility. Without proper seeding, workers may produce identical augmentation sequences, reducing effective data diversity. Shared state between workers presents a separate challenge: each worker has its own memory space, so modifications to global variables in one worker do not propagate to others or to the main process. For large datasets where caching matters, memory-mapped files or shared memory regions that persist across processes are the standard solution.
from torch.utils.data import DataLoader
loader = DataLoader(
dataset,
batch_size=64,
shuffle=True,
num_workers=4, # Parallel worker processes (mechanism 1)
prefetch_factor=2, # Batches prepared ahead per worker (mechanism 2)
pin_memory=True, # Page-locked memory for DMA (mechanism 3)
worker_init_fn=seed_worker, # Reproducible augmentation per worker
)
# Pipeline effect: while GPU processes batch N,
# 4 workers load batches N+1..N+8 into pinned memory,
# ready for DMA transfer when the GPU finishes.The Dataset choice is another throughput decision because it determines how samples can be scheduled. PyTorch supports two dataset paradigms. Map-style datasets implement __len__ and __getitem__, enabling random access to samples by index—this pattern works well for datasets that fit in memory or support efficient random access on disk. Iterable-style datasets implement __iter__ instead, yielding samples sequentially for streaming data sources where random access is impractical. The choice between paradigms determines whether the DataLoader can shuffle samples (map-style only) or must process them in arrival order (iterable-style).
Collation is the final place where representation choices affect throughput. The collate_fn parameter determines how individual samples are combined into batches. The default collation stacks tensors along a new batch dimension, which works when all samples have identical shapes. For variable-length data such as text sequences, custom collation handles padding, sorting by length, or creating attention masks—directly affecting both memory usage and training throughput.
DataLoaders, Datasets, and collation functions solve input delivery by sustaining accelerator-rate throughput through parallelism, prefetching, and DMA. These structures, however, handle only ephemeral data: samples flow through the pipeline once per epoch and are discarded. The next framework responsibility is persistent state, especially the model’s own weights when those weights exceed the memory of any single device.
Parameter structures
A GPT-3 scale model stores 175B parameters, occupying 350 GB in FP16. Managing these parameters across devices, keeping gradients synchronized, and maintaining optimizer state (Adam state alone can add about 4\(\times\) the FP16 weight memory, as the Administrative Tax notebook showed) is a core framework responsibility. Because parameters persist throughout training and inference, frameworks organize them into compact structures that minimize memory while enabling fast read and write access. During multi-GPU training, frameworks may replicate parameters across devices for parallel computation while keeping a synchronized master copy; parameter-server systems are one communication-efficient design for workers to read and write globally shared parameters (Li et al. 2014). Synchronizing multi-billion parameter models can require transferring tens of GB of gradients per step, which is why frameworks expose communication backends that can synchronize tensors efficiently. Model Training later names the specific collective operations and scaling strategies.
Li, Mu, David G. Andersen, Jun Woo Park, Alexander J. Smola, Amr Ahmed, Vanja Josifovski, James Long, Eugene J. Shekita, and Bor-Yiing Su. 2014. “Communication Efficient Distributed Machine Learning with the Parameter Server.” Advances in Neural Information Processing Systems 27: 19–27.
Parameter structures must also adapt to varying precision requirements. Training typically uses FP32 for gradient stability, but inference and large-scale training increasingly use FP16 or INT8. Frameworks implement type casting and mixed-precision management to enable these optimizations without compromising numerical accuracy.
Distributed execution contexts
The computational graph defines what to compute, but where and how that computation runs across devices is the job of execution contexts. On a single node, execution contexts manage CUDA streams and events (introduced in section 1.5.1.3) to overlap computation and data transfer across GPUs.
When training scales beyond a single machine, these same abstractions extend to named groups of devices. Frameworks use constructs like ProcessGroup (PyTorch) or Mesh (JAX) to describe which tensors and operations belong together, leaving the runtime to map that logical scope onto devices, streams, and communication libraries. The important framework idea is the abstraction boundary: user code names placement relationships, and the framework preserves those relationships while the hardware path changes underneath.
These concepts appear here because they shape framework API design even before the book asks the reader to reason about distributed-training algorithms. The details of gradient synchronization, communication topologies, and fault tolerance build on these foundations later. For now, the only point needed is placement expressiveness: when models exceed single-device memory, frameworks must give the training system more than one way to place work. A GPT-3 scale model, for instance, cannot fit on a single GPU—its 175B parameters alone require 350 GB in FP16, far exceeding any GPU’s memory. Figure 11 previews the framework placement idea without requiring the full distributed-training machinery yet: a system can split work across layer groups, across replicated batches, or within very large tensors. Scaling Training Systems later formalizes these dimensions as training strategies and analyzes their communication costs.

The data structures examined so far—tensors, device managers, data pipelines, parameter structures, and distributed execution contexts—define what data a framework manages and where it lives. The remaining abstraction problem is execution: what actually runs on the hardware.
Core operations
When an engineer writes y = torch.matmul(x, w), the gap between Python and the GPU is larger than it appears. The gap between a single line of Python and thousands of parallel GPU threads is bridged by three groups of operations working in coordination. Figure 12 shows the full stack: hardware abstraction operations manage platform-specific execution, basic numerical operations implement mathematical computation, and system-level operations coordinate scheduling, memory, and resources across the graph. The prose follows that build-up from the hardware-specific kernel path toward system orchestration.

Hardware abstraction operations
The hardware abstraction layer isolates framework code from platform-specific details. It solves three concrete problems: selecting the right compute kernel, moving data through the memory hierarchy, and coordinating execution across processing units.
Compute kernel management
The kernel manager dispatches each operation to the fastest available implementation for the current hardware. When a framework encounters a matrix multiplication, it selects among optimized CPU BLAS backends such as Intel oneMKL or OpenBLAS (Intel Corporation 2026; OpenBLAS Project 2026), cuBLAS on NVIDIA GPUs (NVIDIA 2024a), or dedicated tensor processing instructions on AI accelerators. The dispatch decision depends on input dimensions, data layout, and hardware capabilities. A \(4096{\times}4096\) GEMM on an A100 GPU can route to cuBLAS Tensor Core kernels whose published A100 peak is represented here by 312 TFLOP/s (Choquette et al. 2021; NVIDIA Corporation 2020). The same operation on a CPU takes a CPU BLAS/vectorized path rather than the Tensor Core path. When no specialized kernel exists, the manager falls back to a generic implementation rather than failing.
NVIDIA Corporation. 2020. NVIDIA A100 Tensor Core GPU Architecture. NVIDIA Whitepaper, V1.0.
Memory system abstraction
The memory abstraction layer moves tensors between device types (CPU registered memory, GPU pinned memory, unified memory) and transforms data layouts to match hardware preferences. A convolutional layer, for example, may store activations in NCHW format (batch, channels, height, width) on NVIDIA GPUs but convert to NHWC for Apple’s Metal backend. Alignment requirements vary from 4 bytes on CPUs to 128 bytes on some accelerators, and misaligned access can halve effective memory bandwidth. The layer also enforces cache coherency when multiple execution units read and write the same tensor, preventing silent data corruption during concurrent operations.
Execution control
The execution controller coordinates work across multiple processing units and memory spaces. On a modern GPU, graph runtimes or explicit stream use can overlap independent kernels when dependency analysis proves they are ready and the kernels leave enough resources unused to run concurrently. Eager default-stream execution often serializes this work instead. The controller inserts synchronization barriers where data dependencies require them, tracks event completions to trigger dependent operations, and routes hardware errors (ECC failures, timeout watchdogs) to the framework’s error handling path.
Basic numerical operations
With hardware abstraction managing the platform-specific details, frameworks build a layer of mathematical operations on top. General Matrix Multiply (GEMM) dominates ML computation. General matrix multiply (GEMM) derives how GEMM arithmetic intensity scales with matrix dimension, predicting whether a given layer is compute bound or memory bound before any profiler runs. The operation \(C = \alpha A W + \beta C\) accounts for the vast majority of arithmetic in neural networks: a single ResNet-50 forward pass performs approximately 4.1 GFLOP, nearly all of which reduce to GEMM. Frameworks optimize GEMM through cache-aware tiling (splitting matrices into blocks that fit in L1/L2 cache), loop unrolling for instruction-level parallelism, and shape-specific kernels. Fully connected layers use standard dense GEMM, while convolutional layers use im2col transformations that reshape input patches into matrix columns, converting convolution into GEMM.
Beyond GEMM, frameworks implement BLAS operations (AXPY for vector addition, GEMV for matrix-vector products) and element-wise operations (activation functions, normalization). Element-wise operations are individually cheap but collectively expensive due to memory bandwidth. Each operation reads and writes the full tensor, so a sequence of five element-wise operations on a 100 MB tensor moves 1 GB of data. Fusing those five operations into a single kernel reduces memory traffic to 200 MB, a 5\(\times\) bandwidth savings that directly translates to faster execution.
Numerical precision adds another dimension. Training in FP32 uses 4 bytes per parameter; quantizing to INT8 reduces this to 1 byte, cutting memory by 4\(\times\) and enabling 2–4\(\times\) throughput improvements on hardware with INT8 acceleration. Training typically keeps numerically sensitive accumulations in higher precision, while inference can often run many operations in FP16 or INT8 with little quality loss. Frameworks maintain separate kernel implementations for each precision format and handle workflows where different layers operate at different bit widths within a single forward pass.
System-level operations
Hardware abstraction and numerical operations provide the building blocks; system-level operations orchestrate them. The system layer ties scheduling, memory management, and resource optimization into a coherent execution engine.
The operation scheduler analyzes the computational graph to find parallelism while respecting data dependencies. In a static graph, the scheduler sees the full dependency structure before execution begins and can plan an optimal ordering. In a dynamic graph, dependencies emerge at runtime, forcing the scheduler to make greedy decisions. Concretely, when a ResNet block produces two independent branch outputs, the scheduler launches both branches simultaneously rather than serializing them, reducing idle cycles on the GPU’s streaming multiprocessors.
The memory manager allocates and reclaims GPU memory across the computational graph’s lifetime. Model parameters (a 7-billion-parameter model consumes approximately 14 GB in FP16) persist for the entire training run, while activation tensors live only until the backward pass consumes them. PyTorch’s caching allocator maintains a memory pool, subdividing and reusing freed blocks without returning them to CUDA, which avoids repeated cudaMalloc calls that can cost tens of microseconds and may be worse when they synchronize the device. For models that exceed GPU memory, the manager can apply checkpointing by discarding selected activations during the forward pass and recomputing them during the backward pass. The policy question—which activations to keep, and how much recomputation to tolerate—belongs to the training pipeline; the framework abstraction is what makes that policy executable.
The resource optimizer integrates these scheduling and memory decisions. When two matrix multiplications with different shapes are ready to execute, it selects the algorithm variant, such as Winograd, Strassen, or standard tiled GEMM, that best fits each shape and the current memory pressure. These alternatives trade arithmetic count, memory access, and numerical behavior rather than being interchangeable speedups. A poorly scheduled graph wastes compute; a poorly managed memory pool triggers out-of-memory errors on hardware that theoretically has capacity to spare.
Checkpoint 1.3: Hardware abstraction
The abstraction problem is the bridge between portable code and efficient execution.
The preceding sections examined what happens beneath the API surface: tensors manage data layout, streams overlap computation with communication, and kernel dispatch routes operations to hardware. These mechanisms operate at the level of individual tensors and operations—the raw materials of machine learning computation. Practitioners, however, rarely write code at this level. A ResNet-50 has 25.6M parameters organized into dozens of layers; manually tracking each tensor, registering it with an optimizer, and handling device placement would be error-prone and tedious. The abstraction problem is not fully solved by hardware-level mechanisms alone; it also requires a programming model that organizes these low-level primitives into the clean APIs that practitioners actually use.
Individual operations—matrix multiplications, activations, normalizations—are the atoms of deep learning computation. Building models from individual operations, however, would be like building a house from individual atoms. Frameworks need an organizational abstraction that lets engineers compose operations into reusable, nestable building blocks. That abstraction is the module.
Self-Check: Question
A framework dispatches a matrix multiplication to one of several backend kernels (cuBLAS, cuDNN, a TPU path, or a CPU GEMM). Which combination of tensor metadata does the runtime actually need to make that dispatch decision correctly?
- Value range and loss contribution of the tensor
- Shape, dtype, device placement, and memory layout (including strides)
- Optimizer state associated with the tensor
- Training accuracy, validation accuracy, and batch size
Why can a single unnecessary CPU-GPU tensor transfer erase much of the benefit of GPU acceleration, even when the GPU kernel itself is fast?
A GPU training job shows idle gaps between batches even though preprocessing is cheap. Why does setting pin_memory=True on the dataloader typically close those gaps?
- It makes every tensor contiguous in GPU memory automatically
- It allocates page-locked host memory so DMA transfers to the GPU can proceed asynchronously and be overlapped with compute on another stream
- It eliminates the need for batching because each sample now transfers faster
- It moves preprocessing from the CPU to the GPU kernel scheduler
Two CUDA streams produce data that a third stream consumes, and the producer ordering must be respected. Which synchronization strategy preserves the most overlap while enforcing the required ordering?
- Call torch.cuda.synchronize() between stages, because it guarantees correctness
- Record a CUDA event on each producer stream at the relevant point and have the consumer stream wait on those events, leaving unrelated work free to run concurrently
- Disable all streams and run every kernel on the default stream
- Use Python threading locks to serialize the producers
Order the following questions in the sequence the section uses to unpack what happens when a programmer writes model(input): (1) What actually runs on the hardware?, (2) What is the data?, (3) Where does it live?, (4) How does it arrive fast enough?, (5) How does it scale beyond one device?
Explain why the section separates core framework operations into hardware abstraction operations, basic numerical operations, and system-level operations rather than treating everything as math kernels.
nn.Module Abstraction
The hardware-facing half of the abstraction problem—tensors, kernels, streams, and memory managers—makes individual operations fast on diverse silicon. A ResNet-50, however, contains fifty layers, each with multiple parameter tensors, buffers, and mode-dependent behaviors. Manually wiring each tensor to the correct device, registering it with an optimizer, toggling dropout behavior between training and inference, and serializing state for checkpointing—for every layer—would drown practitioners in bookkeeping that has nothing to do with model design. The upper layer of the abstraction problem is organizational: composing thousands of low-level primitives into the clean, composable APIs that practitioners actually use.
Every major framework answers this question through a module abstraction that bundles parameters, forward computation, and state management into a single reusable unit. PyTorch’s nn.Module25 provides an instructive case study because its design patterns recur across frameworks: Keras uses similar layer abstractions (Chollet 2018), JAX’s Flax employs analogous module structures, and TensorFlow’s functional API shares conceptual parallels. Rather than catalog its API, we extract three enduring design principles that every framework must address regardless of its syntax or programming paradigm.
25 nn.Module: The “design patterns recur” claim holds because nn.Module solves a universal organizational problem: it automatically registers any assigned submodule or parameter into a hierarchical tree, enabling a single .to('cuda') call to recursively place millions of parameters onto a GPU. Keras layers, JAX Flax modules, and TensorFlow’s tf.Module all implement the same tree-walking pattern. Without it, managing model state would require manual bookkeeping that scales linearly with architectural depth, a cost that grows prohibitive for models with hundreds of layers.
Chollet, François. 2018. Deep Learning with Python. Manning Publications.
Automatic parameter discovery
A modern neural network may contain millions of trainable parameters spread across dozens of layers. Without automation, a programmer would need to enumerate every parameter tensor and pass it to the optimizer manually, an error-prone process that scales poorly with model complexity. Frameworks solve this through automatic parameter discovery: the system walks the module tree, collecting every parameter tensor so the optimizer can update them in a single call.
This is a graph traversal problem at its core. When a developer assigns an nn.Parameter as a class attribute, the framework’s metaclass machinery intercepts the assignment and registers the tensor in an internal dictionary. A call to .parameters() then performs a recursive depth-first traversal of the module tree, yielding every registered parameter. The same pattern appears in every major framework: Keras layers maintain a trainable_weights list, JAX’s Flax modules use init() to return a nested parameter dictionary, and TensorFlow’s tf.Module provides trainable_variables. The mechanism differs but the principle is universal.
The systems consequence is significant. Automatic parameter discovery gives the optimizer a complete parameter set or parameter groups, enabling grouped, foreach, or fused update paths when the framework and backend support them. The important efficiency win is avoiding manual per-parameter Python bookkeeping; without this abstraction, each parameter update would require a separate Python function call, and the interpreter overhead alone would dominate training time for large models. Listing 23 demonstrates the core mechanism: attribute assignment triggers registration, and .parameters() returns all discovered tensors.
The distinction between parameters and buffers illustrates a subtlety of the discovery mechanism. Parameters carry requires_grad=True and participate in gradient computation. Buffers, registered through register_buffer(), travel with the model during device transfers but remain excluded from gradient updates. This separation is essential for normalization layers, where running statistics must persist across batches but must not receive gradients. The same dual-track design appears in Keras (via non_trainable_weights) and Flax (via state vs. params).
import torch
import torch.nn as nn
class CustomLayer(nn.Module):
def __init__(self, input_size, output_size):
super().__init__()
self.weight = nn.Parameter(
torch.randn(output_size, input_size)
)
self.bias = nn.Parameter(torch.randn(output_size))
self.register_buffer("running_mean", torch.zeros(output_size))
def forward(self, x):
return torch.matmul(x, self.weight.t()) + self.bias
layer = CustomLayer(10, 20)
# Framework discovers both parameters automatically:
for name, param in layer.named_parameters():
print(f"{name}: shape {param.shape}")Table 9 shows how the same principle manifests differently across frameworks. Despite syntactic differences, all frameworks solve the same problem: enabling optimizers to discover and update trainable parameters while preserving nontrainable state across forward passes.
| Framework | Parameter Access | Nontrainable State |
|---|---|---|
| PyTorch | model.parameters() |
register_buffer() |
| Keras | layer.trainable_weights |
layer.non_trainable_weights |
| JAX/Flax | params = model.init(key, x) |
Separate state dict |
| TensorFlow | module.trainable_variables |
module.non_trainable_variables |
Across all four rows, the durable pattern is the same: a trainable-parameter accessor for the optimizer and a separate nontrainable-state channel for values that must persist but must not receive gradients.
Mode-dependent behavior
Training and inference require different computational behavior from the same model graph. During training, dropout layers randomly zero elements with probability \(p_{\text{drop}} = \Pr(\text{drop})\) to regularize the network, while during inference those same layers must perform identity mapping to produce deterministic outputs. Batch normalization uses per-batch statistics during training but switches to accumulated running statistics during inference. If these behavioral changes are left to the programmer, forgetting a single mode switch produces silently incorrect predictions in production.
Frameworks solve this with a state flag that propagates through the module hierarchy. A single call to .eval() on the root module recursively sets self.training = False on every descendant, and each layer queries this flag to select its behavior. This is an instance of a broader systems principle: the same computation graph must produce different execution behavior depending on context. Compilers face the same challenge when the same source code must produce debug builds (with bounds checking and symbol tables) vs. release builds (with aggressive optimization). The flag-propagation pattern ensures correctness by centralizing the mode decision at the root rather than requiring per-layer coordination.
This principle extends to parameter freezing for transfer learning. Setting requires_grad=False on specific parameters excludes them from gradient computation, effectively creating a third behavioral mode where some parameters train while others remain fixed. Selective freezing achieves computational savings by pruning the backward pass graph: frozen parameters need no gradient storage, reducing memory consumption proportionally.
Hierarchical composition and serialization
Complex models compose from reusable submodules, creating a tree structure. A ResNet is not implemented as a monolithic block of operations but as a hierarchy: the root module contains a sequence of residual blocks, each block contains convolution layers and normalization layers, and each layer contains parameter tensors. This hierarchical composition must support two critical operations made concrete in listing 24: recursive parameter collection for training and state serialization for checkpointing and deployment.
import torch
import torch.nn as nn
class ResidualBlock(nn.Module):
def __init__(self, channels):
super().__init__()
self.conv1 = nn.Conv2d(channels, channels, 3, padding=1)
self.bn1 = nn.BatchNorm2d(channels)
self.conv2 = nn.Conv2d(channels, channels, 3, padding=1)
self.bn2 = nn.BatchNorm2d(channels)
def forward(self, x):
residual = x
x = torch.relu(self.bn1(self.conv1(x)))
x = self.bn2(self.conv2(x))
return torch.relu(x + residual)
class ResNet(nn.Module):
def __init__(self, num_blocks, channels=64):
super().__init__()
self.conv_in = nn.Conv2d(3, channels, 7, padding=3)
self.blocks = nn.ModuleList(
[ResidualBlock(channels) for _ in range(num_blocks)]
)
self.fc = nn.Linear(channels, 10)
def forward(self, x):
x = self.conv_in(x)
for block in self.blocks:
x = block(x)
x = x.mean(dim=[2, 3]) # Global average pooling
return self.fc(x)
model = ResNet(num_blocks=4)
total = sum(p.numel() for p in model.parameters())
print(f"Total parameters: {total}")
# state_dict() flattens the tree: 'blocks.0.conv1.weight', etc.
print(list(model.state_dict().keys())[:4])Hierarchical composition mirrors the hardware memory hierarchy in a systems-relevant way: each submodule’s parameters can be loaded independently, enabling placement across devices. When a model is too large for a single GPU, the framework can assign different subtrees of the module hierarchy to different devices, with the tree structure providing natural partition boundaries.
The state_dict() method produces a flat key-value mapping of the full module tree, where dotted path names (for example, blocks.0.conv1.weight) encode the hierarchy. This flat structure enables efficient serialization: a 7-billion-parameter model’s approximately 14 GB FP16 checkpoint can be written as a sequential byte stream, maximizing storage bandwidth utilization. The inverse operation, load_state_dict(), reconstructs the hierarchy from the flat mapping, enabling checkpoint recovery within the same framework. Cross-framework exchange is a separate mechanism: it requires exporting graph structure plus weights through an interchange format such as ONNX, introduced in the deployment-target discussion. Listing 24 demonstrates how the module tree enables both recursive parameter access and hierarchical state serialization.
The hierarchical structure also enables module-level traversal for systematic operations. Methods like .named_modules() iterate the entire tree, supporting bulk transformations such as replacing all BatchNorm layers with GroupNorm or applying Xavier initialization to every Linear layer. These traversal operations depend on the same tree structure that enables parameter discovery, illustrating how a single design decision propagates benefits across multiple use cases.
These three principles, automatic parameter discovery, mode-dependent behavior, and hierarchical composition with serialization, are not PyTorch-specific. Every framework must solve them. Keras layers, JAX’s Flax modules, and even functional approaches all address the same problems of parameter management, state tracking, and compositional design. The differences lie not in what problems they solve but in how they prioritize among competing solutions. Two practical patterns show how the principles become system controls: selective parameter freezing reduces unnecessary gradient work for transfer learning (listing 25), and module hooks provide noninvasive inspection (listing 26).
from torchvision.models import ResNet18_Weights, resnet18
# Freeze all parameters in a pretrained model
pretrained_model = resnet18(weights=ResNet18_Weights.DEFAULT)
for param in pretrained_model.parameters():
param.requires_grad = False
# Replace final layer with trainable parameters
pretrained_model.fc = nn.Linear(512, 10) # New layer is trainable
# Only fc.parameters() will receive gradients during training
optimizer = torch.optim.Adam(
filter(lambda p: p.requires_grad, pretrained_model.parameters()),
lr=0.001,
)Module hooks are the inspection counterpart to parameter freezing: they intercept intermediate computations without modifying model code, enabling gradient flow diagnosis and activation monitoring. Listing 26 illustrates both hook types.
Together, these patterns—parameter discovery, freezing, and hooks—demonstrate how the three principles translate into practical APIs. The preceding nn.Module patterns illustrate PyTorch’s approach to the abstraction problem. PyTorch, however, is only one of several major frameworks, and its choices (mutable state, class inheritance, eager execution by default) are not the only valid design points. TensorFlow centralizes state differently, and JAX avoids mutable state entirely. These are not superficial API differences; they reflect deeply different answers to the three problems we examined at the chapter’s start.
Self-Check: Question
What organizational problem does automatic parameter discovery in nn.Module primarily solve for the optimizer?
- It lets the optimizer recursively find every trainable tensor in a model tree without the programmer manually enumerating them, so new submodules are automatically included
- It removes the need for gradients by replacing backpropagation with fixed update rules
- It forces every parameter onto CPU so serialization is simpler
- It guarantees that all models can be exported to ONNX without conversion issues
Why do frameworks need explicit train() and eval() modes instead of treating the forward pass as identical in all contexts?
When a framework flattens a nested module tree into named parameter-and-buffer entries such as blocks.0.conv1.weight for checkpoint save and restore, the resulting artifact is called the model’s ____.
Why is hierarchical composition in nn.Module more than just a code-organization convenience?
- Because it guarantees every submodule uses the same activation function
- Because the module tree is the structure that powers recursive parameter traversal, .to(device) movement, hook registration, and named state serialization across large models
- Because it eliminates the need for optimizer state during training
- Because it automatically converts dynamic graphs into static graphs
Framework Platform Analysis
A team that prototypes quickly but cannot deploy the resulting model, or deploys reliably but cannot debug training failures, has run into a framework design trade-off rather than a missing API call. Each major framework represents a distinct point in the design space defined by the three core problems: TensorFlow prioritizes the Abstraction Problem through its comprehensive deployment ecosystem, PyTorch prioritizes the Execution Problem through its dynamic graph approach, and JAX reframes the Differentiation Problem through composable function transformations. These differences are architectural, reflecting fundamental capability trade-offs that determine what each framework can and cannot do well.
import torch
import torch.nn as nn
model = nn.Sequential(nn.Linear(10, 20), nn.ReLU(), nn.Linear(20, 5))
# Forward hook to inspect activations
def forward_hook(module, input, output):
print(
f"Layer: {module.__class__.__name__}, "
f"Output shape: {output.shape}, "
f"mean={output.mean():.3f}, "
f"std={output.std():.3f}"
)
# Backward hook to inspect gradients
def backward_hook(module, grad_input, grad_output):
print(f"Gradient norm: {grad_output[0].norm():.3f}")
# Register hooks on specific layer
handle_fwd = model[0].register_forward_hook(forward_hook)
handle_bwd = model[0].register_full_backward_hook(backward_hook)
# Execute forward and backward pass
x = torch.randn(32, 10)
y = model(x)
loss = y.sum()
loss.backward()
# Remove hooks when done
handle_fwd.remove()
handle_bwd.remove()
Each framework optimizes for a different system bottleneck.
TensorFlow: The graph-first production machine
TensorFlow’s architecture reflects a comprehensive solution to the Abstraction Problem: targeting diverse hardware, from cloud TPUs to microcontrollers, through a single interface. Google’s production environment demanded this breadth because the same model often needed to serve predictions on TPU pods in the data center, on Android phones via TensorFlow Lite, and in web browsers through TensorFlow.js. This deployment diversity drove the choice of a static graph (or “Define-and-Run”) design. By requiring the model to be represented as a complete computational graph before execution, TensorFlow enables ahead-of-time (AOT) compilation and optimization for each target platform.
The graph-first approach prioritizes the deployment spectrum: because the framework sees the entire graph, it can perform aggressive optimizations like constant folding, operator fusion, and memory layout optimization before the first byte of data is processed. TensorFlow’s production-oriented design traces directly to this ahead-of-time optimization capability. Figure 13 maps the full training-to-deployment pipeline—trace how a model flows from data preprocessing through distributed training on the left, then fans out through SavedModel export, TensorFlow’s serialized graph-and-weights package, to TensorFlow Serving, the server runtime for loading and swapping model versions, mobile (TF Lite), browser (TF.js), and language bindings on the right.

While TensorFlow 2.0 introduced eager execution to bridge the gap between research and production, TensorFlow 2.x still exposes tf.function as the graph-conversion path for performance-sensitive code (TensorFlow Developers 2024). Its core strength remains the robust, compiled path from research to global-scale deployment. Model Training and Model Serving later examine the scaling and production infrastructure that use these export paths.
TensorFlow Developers. 2024. Better Performance with tf.function.
PyTorch: The eager research standard
Where TensorFlow’s graph-first approach prioritizes production optimization, PyTorch makes the opposite trade-off: it prioritizes developer experience. PyTorch’s architecture represents a sharply different answer to the Execution Problem, built on dynamic graphs (or “Define-by-Run”). Instead of building a blueprint before execution, PyTorch builds the computational graph on-the-fly as the code runs. Facebook AI Research (FAIR) adopted this design because researchers need immediate feedback when experimenting with novel architectures; the define-then-run cycle of static graphs introduced a compilation delay that slowed the rapid prototyping essential to research workflows.
PyTorch’s approach fits exploratory research for the same reason: it treats deep learning as standard Python programming. Developers can use Python loops, conditionals, and debuggers (like pdb) directly within a model’s forward pass, with no special syntax, no separate compilation step, and no waiting to see if the code works. Eager execution enables rapid iteration and intuitive model design, which is essential when architectures and training objectives are still changing.
PyTorch’s answer to the Differentiation Problem is the tape-based autograd system examined in section 1.4.2.1: flexible and debuggable, but harder to optimize globally because the tape is rebuilt each iteration. Its answer to the Abstraction Problem is more pragmatic than comprehensive: strong GPU support through cuBLAS and cuDNN, but deployment to mobile, edge, and browser environments requires exporting through ONNX or specialized runtimes rather than a native path.
The trade-off is therefore a more fragmented deployment path. Because the graph is dynamic, the framework cannot easily perform global optimizations before execution. A model that works perfectly in development may hit performance walls in production when dispatch overhead dominates small operations. To bridge this research-to-production gap, PyTorch introduced graph-capture and compilation paths, from TorchScript historically to torch.compile and export workflows, which allow developers to capture a dynamic model and turn it into an optimized representation for deployment. This evolution shows how an eager framework can move toward the production end of the compilation continuum while preserving the interactive experience that motivated the design.
JAX: The functional transformation engine
PyTorch’s eager execution and TensorFlow’s graph compilation represent two points on a spectrum, yet both share an imperative programming heritage where computation proceeds as a sequence of stateful operations. JAX represents a radically different user-facing approach, one built on functional programming principles and composable program transformations rather than object-level tapes or user-authored graph APIs (Bradbury et al. 2018). Developed by Google Research, JAX is especially useful for work requiring custom differentiation, advanced optimization research, and large-scale distributed training.
Bradbury, James, Roy Frostig, Peter Hawkins, Matthew James Johnson, Chris Leary, Dougal Maclaurin, George Necula, et al. 2018. JAX: Composable Transformations of Python+NumPy Programs.
JAX’s architecture reframes the Differentiation Problem entirely. Google Research built JAX on a key observation: if functions are pure (no side effects, no mutable state), the compiler can safely reorder, fuse, and parallelize any operation, because outputs depend only on inputs. This constraint, borrowed from functional programming, is what makes JAX’s composable transformations possible. Rather than implementing automatic differentiation as a tape-based system (PyTorch) or a graph transformation pass (TensorFlow), JAX treats differentiation as one of several composable function transformations. The jax.grad function does not compute gradients directly; it returns a new function that computes gradients. This subtle distinction enables arbitrary compositions: differentiating a differentiated function yields higher-order derivatives, vectorizing a gradient computation (vmap(grad(f))) parallelizes across examples, and compiling a vectorized gradient to XLA (jit(vmap(grad(f)))) eliminates Python overhead entirely.
JAX’s functional paradigm requires a genuine mental shift from “tracking state through objects” to “transforming pure functions.” While PyTorch and TensorFlow expose autograd primarily through dynamic tapes or graph-compilation paths, JAX asks users to write pure Python functions and then applies transformations to those functions. The core insight is that automatic differentiation, vectorization, and JIT compilation are all program transformations that can compose. Listing 27 demonstrates this composable approach.
import jax
import jax.numpy as jnp
def loss_fn(params, x, y):
pred = jnp.dot(x, params["w"]) + params["b"]
return jnp.mean((pred - y) ** 2)
# Transform: compute gradients
grad_fn = jax.grad(loss_fn)
# Transform: vectorize over batch dimension
batched_grad = jax.vmap(grad_fn, in_axes=(None, 0, 0))
# Transform: compile to XLA
fast_batched_grad = jax.jit(batched_grad)
# Compose all three: fast, batched gradient computationThis functional approach requires pure functions (no side effects) and immutable data (arrays cannot be modified in place). These constraints may seem restrictive coming from PyTorch’s mutable object model, but they enable formal guarantees: the compiler can safely reorder, fuse, and parallelize operations because function outputs depend only on inputs. The restriction is the feature; purity is what makes transformation composition possible.
JAX’s power emerges from composition. Start with a loss function f and apply jax.grad to obtain a new function that computes gradients—unlike PyTorch’s tape-based autograd, grad returns a function, not a value, supporting both forward-mode (jacfwd) and reverse-mode (jacrev) differentiation. Wrap that gradient function in jax.jit and JAX traces it once, compiles to optimized XLA machine code, caches the result, and eliminates Python overhead on subsequent calls. Apply jax.vmap to the compiled gradient function and it automatically vectorizes across a batch dimension, transforming single-example code into batched code without manual reshaping. Finally, jax.pmap maps the vectorized, compiled gradient function across multiple GPUs or TPUs, automatically handling inter-device communication. The result—pmap(jit(vmap(grad(f))))—expresses distributed, compiled, batched gradient computation as a single composed expression, making transformation order part of the programming interface rather than a sequence of separate framework features.
The same minimalist core delegates neural network abstractions to companion libraries (Flax, Haiku, Equinox) and optimization to Optax. This separation reflects the functional philosophy: the core provides transformations, while libraries build conventional abstractions on top. The trade-off is that production readiness depends not only on the transformation model, but also on the maturity of the surrounding libraries, export paths, and operational tooling for the target environment.
The functional constraints that JAX imposes become advantages in specific domains. Custom differentiation—higher-order gradients, custom vector-Jacobian product (VJP) and Jacobian-vector product (JVP) rules—composes cleanly because pure functions make differentiation rules predictable. Research on optimization algorithms benefits from transformations that let researchers manipulate gradient computation as naturally as they manipulate data. Compilation-heavy accelerator workloads use XLA to extract more utilization when the program can be expressed in this functional style. Scientific computing with AD requirements benefits from functional purity that enables mathematical reasoning about code. JAX requires more upfront investment than PyTorch: the functional paradigm has a learning curve, state management requires explicit patterns, and debugging compiled code is harder than eager execution. Teams should choose JAX when its strengths align with project requirements, not as a default.
Framework trade-offs under measurement
The preceding sections described each framework’s design philosophy in qualitative terms: graph-first vs. eager-first, stateful vs. functional. The useful comparison is not which framework is fastest in the abstract, because that answer changes with model shape, batch size, hardware backend, and compiler configuration. The useful comparison is what each design lets the system see and optimize. Table 10 therefore maps TensorFlow, PyTorch, and JAX back to the three framework problems: execution visibility, differentiation model, and hardware abstraction path.
| Aspect | TensorFlow | PyTorch | JAX |
|---|---|---|---|
| Graph Type | Static roots, dynamic front end in 2.x | Dynamic | Functional transformations |
| Programming Model | Imperative front end, graph capture path | Imperative | Functional |
| Core Data Structure | Tensor with framework-managed state | Tensor with framework-managed state | Immutable array |
| Execution Mode | Eager by default, graph for optimization | Eager by default | Trace and just-in-time compilation |
| Automatic Differentiation | Reverse mode over captured computation | Reverse mode over an eager tape | Forward and reverse transformations |
| Hardware Abstraction | Broad deployment runtimes and XLA paths | Native GPU path plus export/compile runtimes | XLA-centered accelerator compilation |
| Optimization Risk | Graph capture and operator coverage | Graph breaks after eager development | Purity, shape stability, and tracing |
The measurement implication is straightforward: profile the constraint each framework makes most visible. In PyTorch, check whether eager dispatch or graph breaks dominate. In TensorFlow, check whether the captured graph covers the operators and deployment target. In JAX, check whether shapes and purity let XLA compile the program actually executed. A framework-level comparison or leaderboard can orient a decision, but it cannot replace profiling the specific workload on the target hardware.
The same simple network exposes how each design philosophy shapes the code. Listing 28 implements one neural network, a single linear layer mapping ten inputs to one output, across all three frameworks:
# PyTorch - Dynamic, Pythonic
import torch.nn as nn
class SimpleNet(nn.Module):
def __init__(self):
super().__init__()
self.fc = nn.Linear(10, 1)
def forward(self, x):
return self.fc(x)
# TensorFlow/Keras - High-level API
import tensorflow as tf
model = tf.keras.Sequential(
[tf.keras.layers.Dense(1, input_shape=(10))]
)
# JAX - Functional approach
import jax.numpy as jnp
from jax import random
def simple_net(params, x):
return jnp.dot(x, params["w"]) + params["b"]
key = random.PRNGKey(0)
params = {
"w": random.normal(key, (10, 1)),
"b": random.normal(key, (1)),
}These three implementations solve the same mathematical problem but reveal distinct answers to the Three Problems. The differences are not cosmetic; they shape debugging workflows, deployment options, and optimization potential.
PyTorch binds state and computation together through class inheritance (nn.Module), solving the Execution Problem through eager evaluation: the graph builds as Python runs, making standard debuggers and control flow work naturally. The cost is that no optimizer sees the full computation before execution begins.
TensorFlow/Keras inverts this priority through the Sequential API, which declares structure without executing it, solving the Abstraction Problem first: the same declaration compiles to server GPUs, mobile NPUs, or browser WebGL backends. Eager mode (default in TensorFlow 2.x) recovers some of PyTorch’s debugging flexibility, but production deployment still relies on graph capture for optimization.
JAX makes the most radical trade-off by treating the model as a pure function26 with immutable data and no internal state. This functional purity solves the Differentiation Problem most elegantly: grad, vmap (automatic vectorization), and jit (just-in-time compilation27) are composable transformations on stateless functions, not infrastructure bolted onto an object system. The cost is explicit parameter management and a programming model unfamiliar to most engineers.
26 Pure Function: Has no side effects and always returns the same output for the same inputs. In JAX, purity is not a style preference but a compiler requirement: jax.jit traces the function once and caches the compiled result, so any side effect (printing, modifying global state, random number generation without explicit key threading) would execute only during the first trace and silently vanish from subsequent calls. This constraint is the cost JAX pays for composable, whole-program optimization.
27 Just-in-Time (JIT) Compilation: Translates high-level code into optimized machine code at runtime, specializing for the actual data shapes and hardware present. The trade-off is compilation latency: the first execution pays a one-time cost (5–30 seconds for transformer models) while subsequent calls with the same shapes execute cached compiled code with microsecond dispatch overhead. Shape changes trigger recompilation, which is why dynamic sequence lengths in language models can degrade JIT performance unless the framework pads to fixed shape buckets.
No framework optimizes all three problems simultaneously, and the ten-line program makes the trade visible in source code rather than buried in compiler internals: where state lives, when the graph exists, and what the compiler is allowed to see. The underlying currency is compiler visibility vs. human iteration latency. Graph capture and ahead-of-time compilation reduce runtime overhead and intermediate data movement; eager evaluation shortens the human iteration loop, outside the iron-law runtime equation, at the cost of compiler visibility until a graph-capture path is used; functional purity gives XLA the freedom to fuse, reorder, and parallelize when the traced program is stable. Each philosophy also shapes code syntax, team workflows, debugging practices, and deployment pipelines, which is why framework migration costs are measured in engineer-months rather than engineer-days.
Runtime constraint map
The same principle extends beyond the three general-purpose frameworks. Runtime families differ because they remove different degrees of flexibility in exchange for compiler visibility, smaller binaries, or hardware-specific execution. Table 11 is therefore a constraint map: each row shows what the runtime gives up, what optimization path that enables, and which failure mode to test before committing.
| Runtime family | Where it fits | Scale anchor | Optimization path | Constraint to test |
|---|---|---|---|---|
| PyTorch eager | Research and iteration | Baseline latency; full Python/runtime footprint | Dynamic graphs, eager debugging | Dispatch overhead and missing graph view |
| Compiled PyTorch/TensorFlow | Server training and serving | Often 1.2–3\(\times\) speedup when graph capture is clean | Graph capture, fusion, layout planning | Operator coverage and graph breaks |
| TensorFlow Lite/Core ML | Mobile and edge inference | Commonly targets tens of ms latency and MB-scale model packages | Quantization, static graphs, NPU delegates | Target-specific conversion constraints |
| TF Lite Micro/microTVM | Microcontroller inference | KB-scale RAM budgets, often <256 KB for small TinyML deployments | Static allocation, INT8 kernels | Small operator set and fixed memory arena |
| ONNX Runtime | Cross-framework serving | Backend-dependent; can match native runtimes for supported graphs | Standard graph format, execution providers | Export gaps and custom-operator fallbacks |
| TensorRT/TVM | Hardware-specialized inference | Often 2–10\(\times\) latency gains over untuned eager baselines | Kernel fusion, precision lowering, autotuning | Narrower target and conversion assumptions |
The map reveals one systems pattern rather than a product ranking. Each move toward a narrower runtime trades flexibility for a more predictable execution plan. Specialized inference runtimes such as TensorRT and TVM can deliver multi-fold latency gains, often in the 2–10\(\times\) range, when the model can be converted cleanly and the deployment target is known. Mobile and microcontroller runtimes reduce footprint by removing training machinery and relying on static graphs, quantization, platform delegates, or fixed memory arenas. A delegate is a runtime plugin that routes supported operators to a target accelerator and falls back when the operator is unsupported. The engineering question is always what was removed to make the optimization possible, because unsupported operators, dynamic shapes, or graph breaks can erase the expected advantage.
These efficiency gaps, significant in the data center, become existential as we move beyond the server room. A 2–10\(\times\) latency gap between eager execution and a specialized inference engine is an optimization opportunity on a cloud GPU; on a microcontroller with 256 KB of RAM, a framework that requires a full training runtime simply cannot run at all. The selection criterion shifts from raw latency to whether the framework fits inside the memory and runtime envelope at all.
Self-Check: Question
A team needs to train a mid-size model now but must also serve it across cloud, Android, and browser with minimal graph-rewriting work, and they value aggressive ahead-of-time graph optimization across those targets. Which framework’s architectural commitments fit the scenario most directly?
- PyTorch, because eager execution is the dominant need
- JAX, because composable pure-function transforms are the dominant need
- TensorFlow, because its graph-first architecture and broad deployment stack (mobile, browser, XLA-style compilation) are built around exactly this multi-target optimization and deployment requirement
- NumPy, because the same array API is available everywhere
What is the architectural commitment that most distinguishes JAX from both PyTorch and TensorFlow as presented in this section?
- It relies on mutable tensors to make state updates easier to debug
- It treats differentiation, vectorization, and compilation (grad, vmap, jit, and related operations) as composable transformations on pure functions, so each transform is an algebraic operation on the program
- It avoids compilation entirely in favor of always-eager execution
- It was designed only for edge inference and not for training
Compare why PyTorch became the research standard while TensorFlow held stronger footing in production deployment.
True or False: Exporting a stable production model from a general-purpose framework to a specialized inference runtime such as TensorRT typically yields only single-digit percent improvements in latency and hardware utilization, because both execute the same model.
A team needs maximum NVIDIA GPU inference throughput for a stable production model and is choosing between staying inside their general-purpose training framework and exporting to a specialized runtime. Using the chapter’s quantitative analysis, what should they expect and what do they give up?
Deployment Targets
As ML models move from cloud servers to edge devices, the efficiency gaps measured earlier transform from optimization opportunities into hard deployment constraints. Framework selection must reweight the three core problems dramatically at the edge. The execution problem shifts from choosing between eager and graph execution to fitting computation inside 10 ms latency and 50 KB memory budgets. The differentiation problem often disappears entirely, since edge devices run inference only. The abstraction problem intensifies: targeting ARM vs. x86, mobile NPUs vs. edge TPUs, microcontrollers with kilobytes of memory.
Table 12 continues the same constraint map across the cloud-to-edge spectrum: each row identifies the runtime assumptions that fit the target envelope.
| Environment | Runtime assumptions that usually fit | Optimization lever | Binding constraint |
|---|---|---|---|
| Cloud/Server | Full training/serving frameworks | Graph compilation, batching, lower precision | Throughput, cost |
| Edge | Static graph or portable serving runtime | Static graphs, lower-precision kernels | Latency <10 ms, limited memory |
| Mobile | App-integrated runtime with delegates | Accelerator delegates, compact model formats | Battery, thermal, app size limits |
| Microcontroller (TinyML) | Tiny runtime with fixed allocation | Static allocation, small integer kernels | <256 KB RAM, no dynamic memory |
Table 12 shows why deployment target is a hard constraint rather than a late packaging step. The Smart Doorbell KWS model from section 1.3.5 exemplifies the microcontroller tier: a runtime with a fixed memory arena and compact C/C++ footprint is not a preference but a condition for fitting the device. This constraint creates the practical framework problem that ONNX addresses: organizations often train in one environment but deploy into another whose runtime assumptions are stricter.
The Open Neural Network Exchange (ONNX)28 format addresses this fragmentation by enabling model portability across many runtimes (ONNX Contributors 2019): train in PyTorch, export through ONNX, and deploy through ONNX Runtime or a hardware-specific backend. TensorFlow Lite has its own conversion path rather than being a direct ONNX target in typical workflows. Standard interchange formats reduce manual conversion work when moving between development and production environments, but they do not eliminate compatibility testing, operator coverage gaps, or custom-kernel work. Figure 14 captures this hub-and-spoke interoperability model—notice how ONNX sits at the center, accepting models from common training frameworks on the left and dispatching them to ONNX Runtime and other compatible runtimes on the right. The compression and serving choices in Model Compression and Model Serving sit on top of this export boundary.
28 ONNX: The “fragmentation” ONNX addresses is that the framework used for model development may not match the runtime best suited to the deployment target. ONNX defines a hardware-agnostic graph representation that decouples the two, reducing the engineer-months of manual model conversion that would otherwise be required each time a deployment target changes. The accepted trade-off is that ONNX export can lose framework-specific optimizations or custom operators, requiring fallback implementations.
ONNX reduces the cost of framework fragmentation, but it does not eliminate the initial selection decision. With the deployment landscape mapped and interoperability options understood, we can now ask how to choose a framework for a specific project’s constraints.
Self-Check: Question
Which deployment tier most strongly forces frameworks toward extreme ahead-of-time compilation, tiny binaries, and no dynamic memory allocation?
- Hyperscale cloud training clusters
- Microcontroller TinyML deployments with kilobytes of RAM and no OS-level runtime
- Browser-based visualization dashboards
- Offline data labeling pipelines
Explain why the three core framework problems are reweighted on inference-only edge and mobile targets, and what framework consequence that implies.
What practical role does ONNX play in the deployment landscape described here?
- It replaces quantization by automatically reducing every model to INT8
- It provides an interchange format that lets models move from a training framework to a deployment runtime, reducing fragmentation across train-and-deploy pipelines while not eliminating all operator-compatibility issues
- It guarantees that every framework-specific custom operator will run unchanged on every target
- It eliminates the need to choose a framework at project start
Framework Selection
Framework selection is a constrained optimization problem across the same three framework problems. The question is not which framework is “best”; it is which execution model, differentiation system, and abstraction path survive the project’s constraints.
The framework selection trade-off space
Framework selection involves three interconnected tensions. The first is between development velocity and production performance: eager execution prioritizes iteration speed, while graph compilation prioritizes runtime optimization. Research teams that need to test ten architecture variants per day cannot afford minutes of compilation between experiments; production teams that deploy a single model for months cannot afford the throughput penalty of eager dispatch. The optimal point shifts as a project moves through its lifecycle.
This velocity-performance tension leads directly to the second: flexibility vs. optimization depth. Dynamic graphs enable the arbitrary control flow that makes eager development fast, but they limit the compiler’s scope. Static graphs constrain expressiveness but enable aggressive fusion and hardware-specific code generation. As table 3 demonstrated, this trade-off cascades through memory management, utilization, and debugging workflows—it is not a single design decision but a system-wide constraint.
The flexibility-optimization tension, in turn, exposes a third: ecosystem breadth vs. specialization. General-purpose frameworks cover broad operation sets but often underperform specialized runtimes on workloads those runtimes can optimize deeply. TensorRT, TVM, and similar systems optimize for narrower deployment targets through fusion, precision selection, and hardware-specific scheduling (NVIDIA 2024b; Chen et al. 2018). ONNX bridges part of this gap through standardized interchange (ONNX Contributors 2019). Runtime specialization still has to be evaluated separately: the more a runtime specializes, the more it depends on conversion coverage, supported operators, and fallback behavior.
NVIDIA. 2024b. NVIDIA TensorRT: Programmable Inference Accelerator.
Chen, Tianqi, Thierry Moreau, Ziheng Jiang, Lianmin Zheng, Eddie Q. Yan, Haichen Shen, Meghan Cowan, et al. 2018. “TVM: An Automated End-to-End Optimizing Compiler for Deep Learning.” Proceedings of the 13th USENIX Symposium on Operating Systems Design and Implementation (OSDI ’18), 578–94.
ONNX Contributors. 2019. ONNX: Open Neural Network Exchange.
Systems Perspective 1.4: Framework selection constraints
Rather than seeking the “best” framework, effective selection first eliminates candidates that cannot satisfy hard constraints: deployment target, required operations, compiler path, and team expertise. Only then should soft preferences such as performance, development speed, and ecosystem rank the survivors.
The TensorFlow ecosystem illustrates how these axes interact concretely. Its three variants (TensorFlow, TensorFlow Lite, TensorFlow Lite Micro) trace a single design philosophy across progressively tighter constraints, a pattern that generalizes to any framework family. Table 13 quantifies the trade-offs.
The principle is progressive constraint leading to progressive optimization: fewer supported operations enable smaller binaries, tighter memory budgets, and native lower-precision execution. Three dimensions structure this analysis: model requirements define the supported operations, software dependencies define the runtime environment, and hardware constraints define the physical limits.
| TensorFlow | TensorFlow Lite | TensorFlow Lite for Microcontrollers | |
|---|---|---|---|
| Training | Yes | No | No |
| Inference | Yes (but inefficient on edge) | Yes (and efficient) | Yes (and even more efficient) |
| How Many Ops | ~1400 | ~130 | ~50 |
| Native Lower-Precision Tooling | No | Yes | Yes |
Framework selection criteria
Three dimensions structure systematic framework evaluation: what the model requires (supported operations and graph semantics), what the software environment provides (OS, memory management, accelerator delegation), and what the hardware physically permits (compute, memory, power). Each dimension acts as a filter: hard constraints eliminate candidates, and soft preferences rank the survivors.
Model requirements
The first question is whether a framework can express the models a project requires. Examine table 13: notice how operator count drops from approximately \(10^3\) (full TensorFlow) to \(10^2\) (TensorFlow Lite) to \(10^1\) (TensorFlow Lite Micro). Each reduction eliminates training capability and general-purpose operations while adding native lower-precision tooling. The engineering principle is that algorithmic expressiveness and machine efficiency trade against each other: fewer supported operations enable tighter code generation, smaller binaries, and hardware-specific optimization paths. This progressive constraint model applies to any framework family, not just TensorFlow. Layered on top of operator count is a separate axis with its own trade-off: when the graph is captured statically before execution versus assembled dynamically at runtime.
Systems Perspective 1.5: Dynamic vs. static computational graphs
The static-vs.-dynamic graph distinction (examined in section 1.3) has direct implications for model requirements analysis. Static graphs constrain which operations are expressible but enable ahead-of-time optimization for deployment. Dynamic graphs support arbitrary Python control flow but require explicit compilation steps (for example,
torch.compile, tf.function) to recover optimization potential.
Software dependencies
Once model requirements are satisfied, the framework must integrate with the target software environment. Table 14 reveals how operating system requirements, memory management, and accelerator support vary across TensorFlow variants.
| TensorFlow | TensorFlow Lite | TensorFlow Lite for Microcontrollers | |
|---|---|---|---|
| Needs an OS | Yes | Yes | No |
| Memory Mapping of Models | No | Yes | Yes |
| Delegation to accelerators | Yes | Yes | No |
The key distinctions follow the same progressive constraint pattern. TensorFlow Lite Micro eliminates the OS requirement entirely, enabling bare-metal execution on microcontrollers (though it integrates with RTOSes like FreeRTOS and Zephyr when available). Both Lite variants support memory-mapped model access from flash storage, avoiding the RAM overhead of loading full models. Accelerator delegation drops out at the microcontroller tier, where specialized hardware is rarely available. Each software dependency removed is a deployment target gained.
Hardware constraints
Software compatibility alone does not guarantee deployment; the framework must fit within physical hardware limits. Table 15 quantifies this final constraint dimension.
| TensorFlow | TensorFlow Lite | TensorFlow Lite for Microcontrollers | |
|---|---|---|---|
| Base Binary Size | A few MB (varies by platform and build configuration) | Tens to hundreds of KB | On the order of 10 KB |
| Base Memory Footprint | Several MB (minimum runtime overhead) | Hundreds of KB | Tens of KB |
| Optimized Architectures | X86, TPUs, GPUs | Arm Cortex A, x86 | Arm Cortex M, DSPs, MCUs |
Binary size spans three orders of magnitude: from MB (full TensorFlow) to tens of KB (TensorFlow Lite Micro). Memory footprint follows the same pattern. Processor architecture support shifts correspondingly from x86/GPU/TPU (data center) through Arm Cortex-A (mobile/edge) to Arm Cortex-M, DSPs, and MCUs (embedded). These are not arbitrary engineering tiers—they mirror the physical constraints (Light Barrier, power wall, memory wall) that carve the deployment spectrum into distinct paradigms (Physical Constraints: Why Paradigms Exist). The engineering lesson generalizes beyond TensorFlow: every framework family that spans deployment tiers makes analogous trade-offs between capability and resource footprint, and the framework’s job is to make those trade-offs navigable rather than invisible.
Production-ready evaluation factors
Beyond this expressiveness-efficiency trade-off, technical specifications establish necessary but not sufficient conditions for selection. Production deployments also require evaluating operational factors: migration cost (typically three to six engineer-months for production systems), maintenance burden, and deployment success rates.
These hardware constraints cascade into performance trade-offs that are tightly coupled. Inference latency (tens of milliseconds for mobile image classification, sub-millisecond for industrial control), memory footprint (MB for full TensorFlow down to tens of KB for TF Lite Micro), power consumption, and hardware utilization (operator fusion improving achieved FLOP/s from 10–20 percent to 60–80 percent of peak) are not independent dimensions. Lower-precision execution can reduce memory, latency, and energy at the cost of numerical margin, and framework selection determines which of these optimization levers are available in the first place. Scalability introduces a further concern: consistent deployment from microcontrollers to servers, smooth prototype-to-production transitions, and version management across deployed fleets all depend on the framework’s deployment toolchain. The three-dimension methodology illustrated here—model requirements, software dependencies, hardware constraints—applies to any framework ecosystem, not just TensorFlow.
Development support and long-term viability assessment
Framework viability over a five-year production deployment depends on whether the ecosystem keeps the chosen execution, differentiation, and abstraction paths maintainable. Community composition matters because it determines which problems receive engineering attention: research-heavy ecosystems tend to improve experimentation and reproducibility first, production-heavy ecosystems tend to improve serving, monitoring, and compatibility first, and smaller specialized ecosystems tend to advance narrower mathematical or compiler capabilities faster than broad deployment tooling.
A framework’s practical utility often depends more on these surrounding paths than on the core tensor API. Model hubs, experiment trackers, serving runtimes, cloud ML services, and interchange formats can reduce lock-in or deepen optimization, but each also adds a dependency that must be maintained. These compounding effects make framework migration progressively harder: CI/CD pipelines, monitoring infrastructure, cloud integrations, and custom operators turn an API choice into an operational commitment. The measurable indicators of viability are therefore contributor diversity, backward compatibility track record, available hiring pool, and the cost of preserving an exit path through standardized formats such as ONNX, framework-agnostic data pipelines, and documented customizations.
The three core problems have so far appeared in isolation: execution, differentiation, and abstraction examined one at a time, with framework choices and selection criteria layered on top. A single training step is where the three problems collide. Tracing one end-to-end reveals how the machinery developed across this chapter operates as one integrated system.
Self-Check: Question
A team is choosing a framework for a product whose edge deployment target is fixed, whose operator set is unusual, and whose engineering org is small. Applying the chapter’s framing, which description best captures how they should approach the decision?
- Pick the framework that is universally best across all workloads and move on
- Treat the decision as constrained optimization: deployment target, required operators, hardware, and org reality act as hard filters that eliminate candidates, then rank the survivors by softer preferences like ergonomics and community
- Choose whichever framework has the largest community, since ecosystem size dominates
- Choose by syntax preference, since the choice rarely affects deployment
Why does the chapter insist on evaluating the deployment target before committing to a training framework?
Which evaluation dimension in the chapter’s selection framework answers the question: can this framework even express the operations and graph semantics the model requires?
- Long-term viability assessment
- Software dependencies
- Model requirements (representational and operator compatibility)
- Community branding
True or False: Once a framework runs the current model fast enough, ecosystem health and long-term viability can be safely deprioritized because technical fit dominates over a production system’s lifetime.
A company expects its models to be maintained for years across CI/CD pipelines, monitoring, and evolving deployment targets. Explain why the chapter treats framework lock-in as an engineering risk, not merely a switching inconvenience.
Anatomy of a Training Step
The concepts developed throughout this chapter—eager vs. graph execution, reverse-mode autodiff, tensor abstractions, kernel dispatch—remain abstract until we see them interact inside a real execution. To solidify understanding, we trace a single training step through the PyTorch stack, revealing how seven executable Python statements trigger the execution, differentiation, and abstraction machinery simultaneously.
Listing 29 presents a minimal training iteration for a two-layer multilayer perceptron. Though only seven executable statements, this code exercises the entire framework stack: tensor allocation, kernel dispatch, autograd recording, gradient computation, and parameter updates. Tracing each phase reveals the three problems in action and connects the quantitative principles developed earlier to concrete execution.
# Single training step for a 2-layer MLP
x = torch.randn(32, 784, device="cuda") # Input batch
y = torch.randint(0, 10, (32), device="cuda") # Labels
# Forward pass
h = torch.relu(x @ W1 + b1) # Hidden layer
logits = h @ W2 + b2 # Output layer
loss = F.cross_entropy(logits, y)
# Backward pass
loss.backward()
# Parameter update
optimizer.step()Phase 1: Forward pass (solving the execution problem)
When h = torch.relu(x @ W1 + b1) executes, PyTorch’s eager execution triggers immediate computation:
- Python dispatch: The Python interpreter calls
torch.matmul, which routes through PyTorch’s dispatcher to select the CUDA backend, adding microseconds-scale overhead before device work begins. - Kernel selection: cuBLAS selects an optimized GEMM kernel based on matrix dimensions (32 \(\times\) 784 \(\times\) 256). For these dimensions, it might choose a tiled algorithm optimized for L2 cache.
- Kernel launch: The selected kernel is queued to the GPU’s command buffer, adding a few microseconds of launch overhead while the CPU continues immediately through asynchronous execution.
- GPU execution: The kernel loads W1 from HBM29 to L2 cache, performs the matrix multiply in tensor cores when available, and writes the result back to HBM; for this small GEMM, the workload usually still lasts only microseconds.
- Autograd recording: Simultaneously, PyTorch’s autograd engine records a
MmBackwardnode on the tape, storing references toxandW1for gradient computation.
29 HBM (High Bandwidth Memory): Provides 2–3 TB/s bandwidth on modern GPUs, making it the memory tier that most directly feeds accelerator arithmetic. HBM bandwidth determines whether operations are memory bound or compute bound, and its 80 GB capacity on an A100 sets the hard ceiling on model size: weights, activations, gradients, and optimizer state must all fit simultaneously during training. When they do not, the framework must resort to offloading, selective recomputation, or placement across devices, each adding complexity to what the programmer perceives as a single loss.backward() call.
The bias addition and ReLU follow similar patterns, each adding a node to the autograd tape.
Phase 2: Backward pass (solving the differentiation problem)
Calling loss.backward() triggers a three-stage backward pass:
- Tape Traversal: The autograd engine traverses the recorded graph in reverse topological order.
- Gradient Computation: For each node, it calls the registered backward function, where \(W_1\) and \(W_2\) are layer weight matrices that form part of the model weights \(\theta\). Traversing in reverse,
CrossEntropyBackwardcomputes \(\frac{\partial \mathcal{L}}{\partial \text{logits}}\) using the softmax derivative;MmBackwardfor \(W_2\) computes \(\frac{\partial \mathcal{L}}{\partial W_2} = h^T \cdot \frac{\partial \mathcal{L}}{\partial \text{logits}}\) along with \(\frac{\partial \mathcal{L}}{\partial h}\);ReluBackwardapplies the ReLU derivative mask (zero where \(h \leq 0\)); andMmBackwardfor \(W_1\) computes \(\frac{\partial \mathcal{L}}{\partial W_1}\) and \(\frac{\partial \mathcal{L}}{\partial x}\). - Gradient Accumulation: Gradients are accumulated into
.gradattributes of leaf tensors. - Memory Management: After each backward node completes, its saved tensors are freed, allowing memory reuse.
Together, these backward-pass stages turn the recorded forward graph into gradients while releasing intermediate state as soon as it is no longer needed.
Phase 3: Memory traffic analysis (the physics at work)
Applying equation 4 to this step, table 16 breaks down the FLOPs, memory traffic, and arithmetic intensity for each operation:
| Component | FLOPs | Memory Traffic | Arithmetic Intensity |
|---|---|---|---|
| MatMul (x @ W1) | \(2 \times 32 \times 784{\times}256\) = 12.8 MFLOP | 0.9 MB | 13.7 FLOP/byte |
| ReLU | \(32{\times}256\) = 8.2 KFLOP | 65.5 KB | 0.125 FLOP/byte |
| MatMul (h @ W2) | \(2 \times 32 \times 256{\times}10\) = 163.8 KFLOP | 44.3 KB | 3.7 FLOP/byte |
| Cross-entropy | ~0.96 KFLOP | 2.6 KB | 0.4 FLOP/byte |
| Backward (2\(\times\) forward) | ~26 MFLOP | 3.1 MB | 8.3 FLOP/byte |
The arithmetic-intensity column is the diagnostic column. Matrix multiplications reuse operands enough to move toward the compute roof, while ReLU and cross-entropy move too little work per byte to escape the memory and launch-overhead regime. This is why fusion and dispatch reduction matter even when the model is written in high-level tensor code.
Total: ~39.1 MFLOP, ~4.2 MB memory traffic. On an A100:
- \(T_{\text{compute}} \approx\) 39.1 MFLOP/312 TFLOP/s ≈ 0.1 μs
- \(T_{\text{memory}} \approx\) 4.2 MB/2.0 TB/s ≈ 2.1 μs
- \(T_{\text{overhead}} \approx\) 6 ops \(\times\) 5 μs ≈ 30 μs
The training step is overhead-bound. For small models, Python dispatch and kernel launch dominate, which drives three common production practices:
torch.compileprovides 2–3\(\times\) speedup by fusing operations and reducing kernel launches- Batch size increases help amortize per-batch overhead
- Production training uses much larger models where compute dominates
All three responses reduce the dispatch term rather than changing the model’s mathematical work.
Phase 4: Hardware abstraction (solving the abstraction problem)
The same Python code runs on different hardware through abstraction layers, each pairing a backend library with a hardware-specific execution mechanism, as table 17 summarizes.
| Hardware | Backend library | Execution mechanism |
|---|---|---|
| CUDA GPU | cuBLAS (NVIDIA 2024a; Choquette et al. 2021) | GEMM kernels and CUDA streams for async execution |
| CPU | Intel oneMKL or OpenBLAS (Intel Corporation 2026; OpenBLAS Project 2026) | Thread-level parallelism around optimized kernels |
| TPU | XLA (Google 2025) | Compilation to TPU-specific high-level optimizer (HLO) operations |
| Apple Silicon | Metal Performance Shaders | MPS backend |
Choquette, Jack, Wishwesh Gandhi, Olivier Giroux, Nick Stam, and Ronny Krashinsky. 2021. “NVIDIA A100 Tensor Core GPU: Performance and Innovation.” IEEE Micro 41 (2): 29–35. https://doi.org/10.1109/mm.2021.3061394.
Intel Corporation. 2026. Intel oneAPI Math Kernel Library.
OpenBLAS Project. 2026. OpenBLAS: An Optimized BLAS Library.
Google. 2025. XLA: Optimizing Compiler for Machine Learning.
Each backend implements the same tensor operations with hardware-specific optimizations. The framework’s abstraction layer (section 1.5) ensures identical numerical results (within floating-point tolerance) across platforms. This is the abstraction problem solved: a single loss.backward() call triggers completely different code paths depending on hardware, yet produces mathematically equivalent gradients.
Systems Perspective 1.6: The three problems in action
This trace reveals the three problems in concrete terms:
- Execution: Eager mode enables line-by-line debugging but incurs dispatch overhead
- Differentiation: Autograd tape records operations during forward, replays in reverse during backward
- Abstraction: Same code runs on GPU/CPU/TPU through backend-specific kernel implementations
Understanding this flow enables informed optimization: fuse operations to reduce overhead, use appropriate batch sizes, and match model scale to hardware capabilities.
This detailed trace through a single training step demonstrates how deeply the three core problems interact. Even simple code exercises the full framework stack, and seemingly minor decisions—device placement, batch size, compilation mode—cascade through execution, differentiation, and abstraction layers in ways that are difficult to predict without systems-level understanding. The pitfalls that follow are the common failure modes when that systems view is missing.
Self-Check: Question
During the forward expression h = torch.relu(x @ W1 + b1), what happens simultaneously with the numerical computation that becomes essential later?
- The framework records autograd nodes (grad_fn links to the producing operations) that the later backward pass will traverse
- The optimizer immediately updates W1 and b1 before the loss is even computed
- The model checkpoint is automatically serialized to disk
- The framework disables asynchronous execution to simplify debugging
Why is a toy MLP training step on an A100 overhead-bound rather than compute-bound, and which framework mechanism mitigates this?
What does the hardware abstraction layer contribute during a standard training step?
- It guarantees the same low-level kernel binary runs unchanged on CPU, GPU, and TPU
- It maps the same high-level tensor operations to backend-specific implementations (for example cuBLAS on NVIDIA GPUs, Intel MKL or OpenBLAS on CPUs, and XLA-compiled paths on TPUs) while preserving the mathematical semantics
- It removes the need for backward passes on non-GPU hardware
- It ensures all backends have identical memory bandwidth and latency characteristics
Explain how execution, differentiation, and abstraction all appear within a single forward-backward-optimizer iteration.
Fallacies and Pitfalls
Framework selection involves subtle trade-offs where intuitions from conventional software engineering fail. The memory wall, kernel fusion constraints, and deployment target diversity create pitfalls that waste months of engineering effort and cause production systems to miss latency targets by 10\(\times\) or more.
Fallacy: “All frameworks provide equivalent performance for the same model architecture.”
Engineers assume that ResNet-50 yields identical performance across frameworks since the mathematics is the same, forgetting that performance is an emergent property of algorithm-machine co-design. In production, framework implementation matters enormously: compiled execution can improve supported eager workloads by 1.2–3\(\times\), and hardware-specialized inference engines such as TensorRT or TVM often deliver 2–10\(\times\) latency gains over untuned eager baselines when conversion is clean. The difference arises from kernel fusion depth, graph optimization strategies, memory access patterns, precision support, and backend libraries that vary dramatically between frameworks. Organizations that assume equivalence can miss latency service level agreements (SLAs) and require costly last-minute framework migrations.
Pitfall: Choosing frameworks based on popularity rather than project requirements.
Engineers assume the most popular framework works for any project. In reality, deployment constraints dominate. A mobile runtime such as ExecuTorch or TensorFlow Lite and a microcontroller runtime such as TensorFlow Lite Micro make different assumptions about memory allocation, operator coverage, and hardware delegates; the former targets phones with GB-scale memory, while the latter often targets devices with hundreds of KB of RAM, commonly below 256 KB for small TinyML deployments. Teams that prototype edge applications without checking the final runtime can face memory bloat that exceeds device capacity or a late framework migration after development completes. Evaluate deployment targets per section 1.8 before selecting a training framework.
Fallacy: “Framework abstractions eliminate the need for systems knowledge.”
Engineers assume high-level APIs handle all optimization automatically. The Roofline Model (The roofline model) proves otherwise: element-wise operations like ReLU achieve arithmetic intensity of 0.125 FLOP/byte, using under 0.1 percent of an A100’s peak compute regardless of framework sophistication. Section 1.3.1 explains why: memory bandwidth, not compute, is the bottleneck for most operations. Engineers who lack this understanding leave 80–90 percent of hardware capacity unused, directly translating to 5–10\(\times\) higher inference costs at production scale.
Pitfall: Ignoring vendor lock-in from framework-specific formats.
Engineers assume framework migration is straightforward since models are “just math.” Converting TensorFlow SavedModel to PyTorch can require rewriting custom operations, validating numerical equivalence across large test suites, and retraining when operations lack exact equivalents—typically three to six engineer-months for production systems. ONNX (section 1.8) improves portability, but custom operators, dynamic shapes, and backend-specific optimizations can still require manual work. Organizations that ignore this during initial framework selection face costly migrations when deployment requirements change or better frameworks emerge.
Fallacy: Training framework choice is independent of production infrastructure.
Engineers assume training framework choice is independent of deployment infrastructure. In practice, framework-infrastructure mismatches can impose substantial operational overhead. Some serving stacks provide atomic model swaps, while others require a process or container restart unless the deployment architecture adds version routing around them. Some frameworks and runtimes expose monitoring hooks directly; others require custom instrumentation. These are preview consequences of the serving and operations layers developed in Model Serving and ML Operations; the local lesson is to evaluate the complete deployment stack during framework selection, including serving infrastructure, monitoring, and operational tooling.
Pitfall: Increasing batch size without modeling activation memory.
Engineers assume that if memory is available, larger batches always improve throughput. Larger mini-batches can amortize fixed dispatch overhead, but they also scale the activation memory that must remain live during training. A 7-billion-parameter model in FP16 consumes 14 GB, leaving 71.9 GB on an 80 GB A100. Increasing batch size from 8 to 32 quadruples the batch-dependent activation footprint; transformer attention adds a large \(\mathcal{O}(S^2)\) term in sequence length that makes each sample expensive. The resulting memory pressure can trigger recomputation strategies that reduce throughput by 20–30 percent despite the larger batch. Teams that blindly maximize batch size often achieve lower throughput than smaller batches that avoid these memory management pathways; Mini-batch processing formalizes the throughput target.
Fallacy: Compilation overhead is negligible.
Engineers assume compilation overhead is a one-time cost that pays off quickly. Table 4 shows torch.compile achieves 48.3 percent higher ResNet-50 throughput, but the same table also assigns ResNet-50 a compile window of 15 s to 30 s per graph change. For a 10,000-image experiment with 10 code changes: Eager completes in 6.9 s, whereas Compiled requires 304.7 s (including 10 \(\times\) 30 s recompilation overhead), making the compiled workflow about 44.2× slower in this rapid-prototyping scenario. Teams that enable compilation during rapid prototyping can waste minutes waiting for recompilations that negate any throughput gains.
Pitfall: Using one execution policy for exploration and production.
The right framework mode depends on the loop being optimized. During exploration, eager execution and smaller tests often shorten the human feedback loop because they avoid repeated graph captures and recompilations. During production serving or long training runs, compilation can amortize its setup cost across enough requests or samples to pay back. Teams that use the same execution policy in both phases either slow research iteration or leave production throughput on the table.
Self-Check: Question
True or False: If two frameworks implement the same model architecture and run on the same GPU, production latency and hardware utilization should land within single-digit percent of each other because the underlying mathematics is identical.
Why is choosing a framework primarily on popularity a risky default for edge or embedded projects?
A research team modifies model code dozens of times per day and is considering enabling torch.compile on every experiment for faster runs. Why might this make them slower overall even though each compiled execution is faster once it starts?
- Because compilation removes access to GPUs and forces CPU execution
- Because each code change triggers recompilation, and when the number of recompiles is high relative to production executions the compile cost dominates the wall-clock savings, per the compilation continuum
- Because compiled models cannot compute gradients correctly during training
- Because compilation always increases memory use so much that batch size must be one
Summary
Machine learning frameworks exist to solve three fundamental problems that would otherwise make deep learning impractical. The first is execution: deciding when and how computation runs. Frameworks navigate the trade-off between eager execution (immediate, debuggable, flexible) and graph execution (deferred, optimizable, deployable), while modern hybrid approaches like torch.compile attempt to provide both flexibility during development and optimization for production. The second is differentiation: computing gradients automatically. Frameworks implement reverse-mode automatic differentiation that computes exact gradients for arbitrary operation compositions, transforming the mathematical chain rule into a software primitive that can train billions of parameters with a single loss.backward() call. The third is abstraction: targeting diverse hardware from a single interface. Frameworks provide tensor abstractions, intermediate representations, and runtime systems that hide hardware complexity while enabling efficient utilization across CPUs, GPUs, TPUs, and specialized accelerators.
These problems are interconnected and constrained by the iron law of performance (Iron Law of ML Systems): execution strategy determines dispatch overhead \((L_{\text{lat}})\), differentiation determines memory traffic \((D_{\text{vol}})\), and abstraction determines hardware utilization \((\eta_{\text{hw}})\). The memory wall makes data movement often more expensive than computation, explaining why frameworks invest in kernel fusion, selective recomputation, lower-precision execution, and compilation pipelines.
Understanding framework internals transforms how practitioners approach performance debugging and optimization. When a training job runs slower than expected, engineers who understand execution graphs can identify whether the bottleneck lies in eager-mode overhead, insufficient kernel fusion, or suboptimal memory layout. When deployment fails on target hardware, the compilation pipeline reveals whether the issue is operator support, quantization compatibility, or runtime configuration. This knowledge is essential for diagnosing and resolving performance issues in production systems.
Key Takeaways: The layer between math and hardware
- Three problems define every framework: Execution (how to run), differentiation (how to train), and abstraction (how to express). TensorFlow prioritizes abstraction for deployment breadth, PyTorch prioritizes execution for research velocity, and JAX reframes differentiation through composable function transformations. These are infrastructure commitments, not tooling preferences.
- The memory wall drives optimization: Compute capacity has grown far faster than memory bandwidth for decades, widening the cumulative gap that bounds data movement. Kernel fusion, selective recomputation, lower-precision execution, and data layout optimizations all target the data movement term \((D_{\text{vol}})\) in the iron law, not the compute term.
- Compilation pays off only at scale: The compilation continuum principle in equation 2 quantifies when compilation benefits exceed costs. Research prototyping favors eager mode; production training and inference favor progressive compilation from JIT to AOT. The dispatch overhead law in equation 4 explains why small models benefit disproportionately.
- Module abstractions are widely adopted: Automatic parameter discovery, mode-dependent behavior, and hierarchical composition with serialization appear across major frameworks, enabling million-parameter optimization in a single optimizer step regardless of API syntax.
- Framework choice constrains deployment by orders of magnitude: Specialized inference engines, mobile runtimes, and microcontroller runtimes make different trade-offs about operator coverage, memory allocation, compilation, and hardware delegates. A 2–10\(\times\) latency gap between untuned eager execution and specialized inference, or the gap between GB-scale server runtimes and <256 KB microcontroller budgets, is not an implementation detail. The deployment target must be evaluated before framework selection.
A framework presents itself as a convenience, a cleaner way to write a model, and that is exactly what makes its influence easy to miss. Its real work is to translate mathematics into machine operations, and no translation is free: every choice it makes (eager or graph execution, when to fuse kernels, what precision to keep, how much to compile) shifts cost between the terms of the iron law rather than removing it. What looks like an API is therefore a standing decision about where the system will spend, made mostly before the engineer arrives. The framework cannot lighten the load the iron law names; it can only decide which of the three terms will carry it.
What’s Next: From control room to power plant
Frameworks are the software substrate that translates abstract architectures into executable kernels. Computational graphs, autograd tapes, and kernel dispatch pipelines are the control room instruments: they give engineers visibility into and control over the training process. The machinery is built, but every budget decision it exposes remains unmade: which activations to checkpoint when memory runs short, how large a batch the hardware allows, and at what point a single device stops being enough. Model Training is where those bills come due, scaling this chapter’s execution, differentiation, and memory-management machinery into the training systems that power modern AI.
Self-Check: Question
Which of the following best captures how the chapter wants engineers to think about framework choice in terms of the iron law?
- The framework is a syntax preference and does not meaningfully affect iron-law terms
- The framework is the compiler for the silicon contract: it decides how much the data-movement and overhead terms can be reduced and how close the execution gets to peak throughput under the utilization term
- The framework controls dataset quality and size, and therefore dictates accuracy
- The framework’s only role is ergonomics; performance depends entirely on hardware choice
Explain why the memory wall, rather than raw FLOP count, drives many of the framework optimizations the chapter discussed.
A new engineer asks why the team spent weeks choosing between frameworks for a multi-year production system. Applying the chapter’s integrative argument, what is the concrete systems consequence of that choice that justifies the investment?
Self-Check Answers
Self-Check: Answer
A team reports that their model trains correctly on a CPU but produces wildly different tensor shapes when they switch to a GPU backend because some operators silently default to different memory layouts. Which of the three framework problems does this failure most directly belong to?
- The execution problem, because the operators are running eagerly instead of in a graph
- The differentiation problem, because the backward pass cannot handle layout changes
- The hardware abstraction problem, because one model interface must produce consistent behavior across diverse devices and memory layouts
- A data engineering problem unrelated to framework design
Answer: The correct answer is C. The chapter defines hardware abstraction as the problem of making one model definition behave correctly across CPUs, GPUs, TPUs, and mobile devices despite their different memory constraints and optimal execution patterns; a silent layout divergence is a textbook failure of that abstraction. An explanation blaming the execution model confuses when operations run with which device executes them. Blaming the backward pass misreads the failure entirely: the gradient code never got a chance to misbehave because forward shapes were already wrong.
Learning Objective: Classify a concrete framework failure into the execution, differentiation, or hardware abstraction problem
Explain why viewing a framework as a compiler, rather than as a numerical library like NumPy, changes what an engineer expects from framework choice.
Answer: A numerical library executes each operation immediately in isolation, so switching libraries with similar APIs mostly changes syntax. A compiler translates a high-level program into a physical execution plan, so switching compilers changes which optimizations are possible, which hardware targets are reachable, and how much of the iron law’s data and overhead terms the framework can actually attack. For example, a framework that can fuse matmul, bias-add, and ReLU into one kernel reduces memory traffic in ways an eager library cannot. The consequence is that framework choice sets a ceiling on achievable utilization, not just developer ergonomics.
Learning Objective: Explain how the compiler analogy changes the engineer’s expectations of what framework choice determines
True or False: Two frameworks that expose nearly identical tensor APIs and support the same target GPU will expose the same set of graph-level fusion and ahead-of-time compilation optimizations for that GPU.
Answer: False. The chapter’s argument is that API similarity is not the same as compiler similarity: one framework may support whole-program fusion and ahead-of-time lowering to the accelerator while another provides only eager dispatch on the same hardware, producing throughput gaps that can exceed 2\(\times\) on identical GPUs.
Learning Objective: Evaluate the misconception that matching tensor APIs imply matching graph-level optimization capabilities
A team trained a model in a research-focused framework that cannot export to their required edge deployment runtime. Applying the chapter’s infrastructure-commitment argument, what is the dominant systems lesson?
- The choice is easily reversible because model weights can be copied to any framework
- The real issue is the model architecture being too small for the edge target
- The failure is primarily about missing data preprocessing tools, not framework selection
- Framework selection silently constrains reachable hardware and deployment paths, so it functions as a long-lived infrastructure commitment whose reversal cost scales with how much of the serving stack has adopted it
Answer: The correct answer is D. The chapter emphasizes that framework decisions constrain which optimizations, accelerators, and deployment routes remain available, and that migration cost touches checkpoints, serving systems, CI/CD, and team workflows. A weight-copy answer misreads the problem as pure data portability; a model-size explanation invents a mechanism the scenario does not describe.
Learning Objective: Analyze why framework selection functions as a long-term infrastructure commitment rather than a reversible tooling choice
Self-Check: Answer
NumPy gave scientists optimized BLAS performance through a Python API, but it did not solve the bottleneck that deep learning frameworks later closed. Which bottleneck did NumPy leave open, creating the opening for Theano, TensorFlow, and PyTorch?
- Saturating peak GEMM throughput on a single CPU
- Writing loops in Python rather than Fortran
- Hand-derived backpropagation gradients for multi-layer networks, which were error-prone and did not scale past toy models
- Storing arrays as n-dimensional tensors instead of flat buffers
Answer: The correct answer is C. The chapter’s ladder shows NumPy solved performance (via BLAS) and usability, but researchers still wrote backpropagation gradients by hand, and this was the bottleneck automatic differentiation frameworks later removed. The GEMM-saturation option was already solved at the BLAS rung below NumPy; the loops-in-Python answer describes what NumPy itself did, not what it left undone; the tensor-storage answer is a NumPy feature, not a missing one.
Learning Objective: Analyze which scaling bottleneck NumPy left open for the next rung of the ladder to close
Why does the chapter place BLAS at the bottom rung of the ladder rather than treating it as a minimal framework?
- BLAS runs only on CPUs, disqualifying it from modern ML workloads
- BLAS specifies hardware-optimized numerical primitives such as GEMM but does not provide gradient computation, graph-level execution planning, or hardware abstraction across device types
- BLAS is used exclusively for inference and never touches training code paths
- BLAS requires Python bindings to be useful to ML systems
Answer: The correct answer is B. The chapter presents BLAS as the performance primitive layer whose scope is kernel-level throughput for matrix operations, while a full framework must additionally solve differentiation, graph execution, and device abstraction. The CPU-only claim is historically wrong (cuBLAS is the GPU implementation); the inference-only claim mischaracterizes a library that serves both training and inference; the Python-requirement claim inverts the dependency direction.
Learning Objective: Compare the scope of BLAS primitives with the broader responsibilities of a full ML framework
Explain how each rung of the ladder (BLAS/LAPACK, NumPy, deep learning frameworks) addressed a different term of the iron law and why the rungs depend on each other rather than replacing each other.
Answer: BLAS and LAPACK attack peak throughput by hand-tuning matrix kernels to the hardware, raising the ceiling that the utilization term can approach. NumPy attacks developer overhead by wrapping those primitives in Python, so programs reach the ceiling without hardware-specific code. Deep learning frameworks attack gradient bookkeeping and data movement by introducing computational graphs and operator fusion. Each higher rung still calls BLAS underneath, so a PyTorch matmul ultimately lands in a cuBLAS kernel: the inheritance is the point, not replacement.
Learning Objective: Explain how successive ladder rungs addressed different iron-law terms while inheriting the primitives of lower rungs
True or False: Each higher rung of the ladder of abstraction hides more hardware detail from the programmer while still depending on the optimized primitives of lower rungs, meaning an inefficient lower rung places a ceiling on every framework above it.
Answer: True. The chapter’s point is that a PyTorch matmul ultimately calls cuBLAS, so framework performance is bounded below by BLAS-kernel quality; the higher rungs cannot escape an inefficient primitive they inherit from.
Learning Objective: Analyze why the ladder creates inheritance dependencies that cap higher-rung performance at lower-rung quality
Self-Check: Answer
A profile shows a sequence of LayerNorm, dropout, and activation kernels each do little arithmetic but repeatedly read and write large tensors to HBM. Why is kernel fusion especially valuable for this signature?
- These kernels are memory-bound and pay repeated kernel-launch overhead, so combining them reduces both HBM traffic and dispatch costs
- Fused kernels typically improve numerical accuracy by reducing floating-point rounding error
- Fusion lets the framework skip storing model weights in memory altogether
- Matrix multiplications cannot execute unless fused with surrounding element-wise operations
Answer: The correct answer is A. The profile signature (low arithmetic, repeated large-tensor reads/writes) identifies a memory-bound regime; fusion keeps intermediates in on-chip SRAM across the sequence and amortizes dispatch, directly attacking the memory-wall bottleneck. An accuracy-improvement answer conflates performance with numerics, and a weights-elimination answer invents a mechanism that does not exist.
Learning Objective: Analyze why kernel fusion is especially effective for memory-bound operation sequences
A model contains many tiny element-wise operations and runs far slower than its FLOP count suggests. Use the dispatch tax idea to explain what is happening and what compilation changes.
Answer: In eager mode, each small operation pays Python-side dispatch and kernel-launch overhead that can exceed the actual GPU work, so wall-clock time is dominated by per-op fixed costs rather than by arithmetic, making the workload overhead-bound. Compiling the region fuses the small operations into fewer kernels and amortizes dispatch over the whole graph. The practical consequence is that throughput improves substantially even though the total FLOPs have barely changed.
Learning Objective: Analyze how dispatch overhead can dominate execution time for small operations and how compilation amortizes it
A developer traces a function using an example input whose tensor sum is positive, but at serving time inputs whose sums are negative also occur. What is the primary correctness risk introduced by tracing?
- Tracing inserts extra memory copies that make the model too slow to train
- Tracing captures only the branch taken by the example input, so data-dependent control flow can silently take the wrong path on unseen inputs
- Tracing forces every tensor to move back to CPU before execution
- Tracing prevents any form of operator fusion
Answer: The correct answer is B. The chapter’s tracing example shows that the recorded graph reflects one realized execution path, not the full branching structure, so a later input that would have taken a different branch silently follows the traced one and can produce wrong outputs without raising an error. A CPU-transfer claim fabricates behavior tracing does not have; a no-fusion claim mistakes tracing for an optimization ban rather than a fidelity issue.
Learning Objective: Evaluate the correctness risks of tracing models that contain data-dependent control flow
Order the following phases in PyTorch 2.0’s compilation pipeline: (1) FX graph representation, (2) TorchInductor code generation, (3) TorchDynamo graph capture.
Answer: The correct order is: (3) TorchDynamo graph capture, (1) FX graph representation, (2) TorchInductor code generation. The runtime first captures Python execution into a graph (TorchDynamo), then the graph is expressed in the FX intermediate representation so transforms can analyze it, and only then does TorchInductor lower that IR to backend-specific optimized code. Swapping graph capture with code generation would leave the compiler with nothing structured to compile, and skipping the FX step would force code generation to operate on unanalyzable Python bytecode.
Learning Objective: Sequence the major phases of the torch.compile pipeline from capture through backend code generation
A research team iterates code changes many times per hour during development; a production team runs a fixed model millions of times per day. Applying the compilation continuum, which setting justifies moving rightward toward JIT or AOT compilation, and why?
Answer: The production setting justifies the move, because the compilation continuum weighs a one-time compile cost against repeated runtime savings. When the number of production executions greatly exceeds the number of development recompilations, amortizing fusion, layout selection, and kernel tuning across millions of calls dominates any per-session build time. The research workflow sits at the opposite end: frequent code changes trigger frequent recompilation, so eager execution’s zero build time and direct debuggability remain the better operating point until the model stabilizes.
Learning Objective: Apply the compilation continuum to decide when repeated execution justifies compilation overhead
A team is deploying keyword spotting on a microcontroller with 256 KB of RAM and no Python runtime. Explain why TinyML micro-runtimes represent the extreme AOT endpoint of the execution continuum, and what the team must give up to get there.
Answer: At 256 KB of RAM, even an interpreter and a dynamic allocator are unaffordable, so the model must be compiled ahead of time into a fixed C or C++ execution plan with static memory placement and the unused operator library stripped. TensorFlow Lite Micro pre-plans every tensor address and emits only the kernels the specific model calls. The trade-off is that eager debugging, dynamic shapes, and flexible operator coverage all disappear in exchange for fitting within strict memory and latency budgets.
Learning Objective: Justify why TinyML runtimes represent the extreme AOT endpoint of the execution continuum and what flexibility is surrendered
Self-Check: Answer
Why do major ML frameworks default to reverse-mode AD rather than forward mode for neural network training?
- Reverse mode avoids storing any intermediate activations from the forward pass
- Training has a many-parameters-to-one-loss topology, so one reverse pass computes all parameter gradients, while forward mode would need one pass per parameter
- Forward mode cannot handle nonlinear operations such as ReLU or softmax
- Reverse mode is needed only for inference, not for training
Answer: The correct answer is B. The chapter’s framing is that reverse mode exploits the scalar-loss structure of training, giving a single backward pass that produces every parameter’s gradient; forward mode’s cost would scale linearly with parameter count, making billion-parameter training infeasible. The no-intermediates option inverts reality: reverse mode’s defining systems cost is precisely that it retains activations. The nonlinearity and inference claims invent constraints the chapter never argues.
Learning Objective: Explain why reverse-mode AD is the practical default for neural network training given the many-to-one loss structure
Explain why training memory scales much more dramatically than inference memory on the same model under reverse-mode AD.
Answer: Inference holds weights and transient outputs, but reverse-mode training must additionally preserve every layer’s forward-pass activations until backpropagation reaches them, maintain a gradient tensor for every parameter, and often keep optimizer state such as Adam’s first and second moments. In a deep transformer this can make stored activations three to four times larger than the weights themselves. The consequence is that memory, not raw compute, frequently becomes the binding limit on trainable model size.
Learning Objective: Explain how reverse-mode AD inflates training memory relative to inference for the same model
True or False: If you call backward() twice on the same output tensor without passing retain_graph=True, PyTorch will reuse the same autograd graph on the second call because gradient accumulation requires the graph to stay alive.
Answer: False. Gradients accumulate into leaf .grad tensors, but the intermediate computation graph is freed after the first backward pass to reclaim activation memory; a second backward on the same output raises an error unless the first call used retain_graph=True. The chapter distinguishes gradient accumulation from graph retention precisely to head off this confusion.
Learning Objective: Distinguish gradient accumulation (in .grad) from computation-graph retention after a backward pass
A transformer training run runs out of memory because saved activations dominate the footprint. Which change most directly trades extra computation for lower activation memory while preserving gradient correctness?
- Gradient checkpointing, which stores activations only at selected layer boundaries and recomputes the rest during the backward pass
- Pinned host memory, which reduces GPU activation storage by moving tensors into pageable host memory
- Data parallelism, which removes the need to store activations for the backward pass
- In-place edits via .data, which safely avoids saving prior tensor values
Answer: The correct answer is A. Checkpointing reduces peak activation memory by discarding selected forward activations and rebuilding them during the backward pass, which the chapter describes as increasing the \(O\) term (recomputation) to reduce the \(D_{\text{vol}}\) term (memory traffic). A pinned-memory answer confuses host-device transfer mechanics with activation storage; a data-parallelism answer misattributes memory savings to a technique that replicates activations across ranks; the .data option is presented in the chapter as dangerous because it can silently corrupt gradient computation.
Learning Objective: Analyze how gradient checkpointing trades recomputation time for activation memory
When PyTorch’s autograd traverses the computational graph during the backward pass, it follows the ____ attribute on each differentiable tensor to reach the backward Function that produced it.
Answer: grad_fn. This attribute links the tensor into the reverse-linked autograd graph so the backward traversal can chain derivatives from the loss all the way to the leaf parameters without a separately stored graph structure.
Learning Objective: Identify the autograd attribute that enables backward graph traversal in PyTorch
Compare tape-based autodiff in PyTorch with transform-based autodiff in JAX, focusing on what each design makes easy and what it constrains.
Answer: PyTorch records operations dynamically onto a tape as they execute, which makes dynamic control flow natural and debugging feel like standard Python but limits whole-program optimization because the compiler sees each graph only after the fact. JAX transforms pure functions with operations like grad, vmap, and jit so composition and global optimization are algebraic, but it requires functional purity and explicit state management. The trade-off is ergonomics and dynamism versus compile-time visibility and composable transforms.
Learning Objective: Compare tape-based and transform-based autodiff architectures and their consequences for optimization and programming style
Self-Check: Answer
A framework dispatches a matrix multiplication to one of several backend kernels (cuBLAS, cuDNN, a TPU path, or a CPU GEMM). Which combination of tensor metadata does the runtime actually need to make that dispatch decision correctly?
- Value range and loss contribution of the tensor
- Shape, dtype, device placement, and memory layout (including strides)
- Optimizer state associated with the tensor
- Training accuracy, validation accuracy, and batch size
Answer: The correct answer is B. The chapter argues that kernel selection, layout reasoning, and device-aware execution all hinge on shape, numeric type, device, and layout metadata carried by each tensor; without them the runtime cannot pick a backend or lay out memory correctly. Answers centered on optimizer state or accuracy metrics conflate model-training bookkeeping with the tensor abstraction the runtime uses to dispatch operations.
Learning Objective: Identify the tensor metadata a framework runtime needs to dispatch kernels and reason about memory
Why can a single unnecessary CPU-GPU tensor transfer erase much of the benefit of GPU acceleration, even when the GPU kernel itself is fast?
Answer: On-device GPU memory bandwidth sits in the thousand-gigabyte-per-second range, while PCIe between host and GPU tops out at tens of gigabytes per second; a cross-device transfer can therefore take longer than the kernel that consumes the data. For a large activation, the PCIe copy alone can exceed the GPU compute budget for the step. The practical implication is that frameworks enforce device-placement discipline and overlap unavoidable transfers with computation via streams rather than letting them land on the critical path.
Learning Objective: Explain how the device bandwidth hierarchy makes data placement a first-order performance concern
A GPU training job shows idle gaps between batches even though preprocessing is cheap. Why does setting pin_memory=True on the dataloader typically close those gaps?
- It makes every tensor contiguous in GPU memory automatically
- It allocates page-locked host memory so DMA transfers to the GPU can proceed asynchronously and be overlapped with compute on another stream
- It eliminates the need for batching because each sample now transfers faster
- It moves preprocessing from the CPU to the GPU kernel scheduler
Answer: The correct answer is B. Pinned (page-locked) host memory is a precondition for true asynchronous DMA: the GPU can pull bytes without the kernel faulting them in, and combined with non_blocking=True copies the transfer overlaps the current batch’s compute, keeping the GPU fed. A contiguous-GPU-memory claim confuses host pinning with device layout; a no-batching claim rewrites the scheduling model; a CPU-to-GPU-preprocessing move invents a capability pin_memory does not provide.
Learning Objective: Analyze how pinned host memory enables asynchronous DMA and keeps the GPU pipeline fed
Two CUDA streams produce data that a third stream consumes, and the producer ordering must be respected. Which synchronization strategy preserves the most overlap while enforcing the required ordering?
- Call torch.cuda.synchronize() between stages, because it guarantees correctness
- Record a CUDA event on each producer stream at the relevant point and have the consumer stream wait on those events, leaving unrelated work free to run concurrently
- Disable all streams and run every kernel on the default stream
- Use Python threading locks to serialize the producers
Answer: The correct answer is B. CUDA events enforce exactly the producer-consumer dependency required, so other independent kernels on other streams keep running. A device-wide synchronize is a sledgehammer that blocks every stream and destroys overlap; collapsing to the default stream eliminates concurrency entirely; Python locks do not control GPU ordering at all since kernel launches are already asynchronous.
Learning Objective: Compare event-based and device-wide synchronization in terms of overlap preserved versus ordering enforced
Order the following questions in the sequence the section uses to unpack what happens when a programmer writes model(input): (1) What actually runs on the hardware?, (2) What is the data?, (3) Where does it live?, (4) How does it arrive fast enough?, (5) How does it scale beyond one device?
Answer: The correct order is: (2) What is the data?, (3) Where does it live?, (4) How does it arrive fast enough?, (5) How does it scale beyond one device?, (1) What actually runs on the hardware? The chapter builds from tensor representation outward: the data’s shape and dtype, where it is placed, how the pipeline keeps it flowing, how scaling distributes it across devices, and only then which kernels actually execute. Reversing the order would commit to a kernel before the placement and transport constraints that determine which kernel is even feasible are known.
Learning Objective: Sequence the abstraction questions from tensor representation through distributed scaling to hardware execution
Explain why the section separates core framework operations into hardware abstraction operations, basic numerical operations, and system-level operations rather than treating everything as math kernels.
Answer: Mathematical primitives like GEMM deliver peak throughput only when something else has already picked the right backend, laid out memory correctly, scheduled the kernel launch, and managed concurrency and memory reuse. Separating hardware abstraction operations (dispatch, device placement) from numerical operations (matmul, convolution) from system-level operations (allocation, streams, synchronization) makes clear that end-to-end performance is an orchestration property, not a kernel property. The practical consequence is that a fast GEMM alone does not make a fast training step; the three layers must cooperate.
Learning Objective: Explain how the three-layer operations stack separates mathematical primitives from runtime orchestration and hardware dispatch
Self-Check: Answer
What organizational problem does automatic parameter discovery in nn.Module primarily solve for the optimizer?
- It lets the optimizer recursively find every trainable tensor in a model tree without the programmer manually enumerating them, so new submodules are automatically included
- It removes the need for gradients by replacing backpropagation with fixed update rules
- It forces every parameter onto CPU so serialization is simpler
- It guarantees that all models can be exported to ONNX without conversion issues
Answer: The correct answer is A. Recursive parameter registration lets optimizers operate over deep module trees without bookkeeping that becomes error-prone the moment a submodule is added; drop in a new block and optimizer.step() continues to update it. A gradient-elimination answer rewrites the learning algorithm; a CPU-placement claim invents behavior; and an ONNX-export guarantee is unrelated to the discovery mechanism.
Learning Objective: Explain the organizational problem automatic parameter discovery solves for optimizer construction
Why do frameworks need explicit train() and eval() modes instead of treating the forward pass as identical in all contexts?
Answer: Certain layers must behave differently between training and inference: dropout should randomize only during training, and batch normalization must switch from per-batch statistics to stored running statistics at inference to produce deterministic, well-calibrated outputs. A single root-level mode switch propagates that context recursively through the module tree, so every dropout and batchnorm layer flips at once. The practical consequence is that evaluation remains numerically consistent without the engineer tracking mode on each layer by hand.
Learning Objective: Explain why module mode propagation is a systems requirement for numerically correct inference
When a framework flattens a nested module tree into named parameter-and-buffer entries such as blocks.0.conv1.weight for checkpoint save and restore, the resulting artifact is called the model’s ____.
Answer: state_dict. It provides a portable, Python-object-free snapshot of parameters and buffers keyed by dotted names, enabling checkpoint save and restore without serializing the module class hierarchy itself.
Learning Objective: Identify the serialization structure that captures hierarchical model state for portable checkpointing
Why is hierarchical composition in nn.Module more than just a code-organization convenience?
- Because it guarantees every submodule uses the same activation function
- Because the module tree is the structure that powers recursive parameter traversal, .to(device) movement, hook registration, and named state serialization across large models
- Because it eliminates the need for optimizer state during training
- Because it automatically converts dynamic graphs into static graphs
Answer: The correct answer is B. The chapter presents the module tree as the structural substrate for every cross-cutting operation a framework performs on a model: collecting parameters, migrating them to a device, attaching hooks, and serializing named state. Answers claiming the tree eliminates optimizer state or automatically changes the execution model conflate software organization with unrelated runtime concerns.
Learning Objective: Analyze how hierarchical composition supports cross-cutting framework operations beyond readability
Self-Check: Answer
A team needs to train a mid-size model now but must also serve it across cloud, Android, and browser with minimal graph-rewriting work, and they value aggressive ahead-of-time graph optimization across those targets. Which framework’s architectural commitments fit the scenario most directly?
- PyTorch, because eager execution is the dominant need
- JAX, because composable pure-function transforms are the dominant need
- TensorFlow, because its graph-first architecture and broad deployment stack (mobile, browser, XLA-style compilation) are built around exactly this multi-target optimization and deployment requirement
- NumPy, because the same array API is available everywhere
Answer: The correct answer is C. The chapter frames TensorFlow as the graph-first production machine whose deployment breadth across servers, mobile, and browsers and whose ahead-of-time compilation story make it the match for a multi-target deployment scenario. A PyTorch-first answer misreads the scenario’s deployment emphasis as a research-workflow preference; a JAX answer privileges transformation composition over the deployment stack the scenario actually demands; NumPy lacks the deployment and compilation machinery entirely.
Learning Objective: Classify a workload scenario against the architectural commitments of major frameworks
What is the architectural commitment that most distinguishes JAX from both PyTorch and TensorFlow as presented in this section?
- It relies on mutable tensors to make state updates easier to debug
- It treats differentiation, vectorization, and compilation (grad, vmap, jit, and related operations) as composable transformations on pure functions, so each transform is an algebraic operation on the program
- It avoids compilation entirely in favor of always-eager execution
- It was designed only for edge inference and not for training
Answer: The correct answer is B. JAX’s defining idea is that grad, vmap, jit, and related functions are composable transformations on pure functions, giving the programmer an algebra over programs rather than a framework-specific API. The mutable-state answer inverts JAX’s insistence on functional purity; the never-compile answer contradicts jit; the edge-only answer misstates the framework’s scope.
Learning Objective: Explain the composable transformation model that differentiates JAX architecturally
Compare why PyTorch became the research standard while TensorFlow held stronger footing in production deployment.
Answer: PyTorch won researchers with eager execution, direct debugging, and natural control flow, so model code reads like normal Python and iteration is fast. TensorFlow’s graph-first architecture made whole-program optimization, multi-target deployment, and server-to-mobile-to-browser serving easier to ship at scale, even though the debugging story was harder. The consequence is that the right framework depends on which constraint binds: iteration velocity versus deployment breadth.
Learning Objective: Compare the workflow and deployment trade-offs that drove PyTorch and TensorFlow to different niches
True or False: Exporting a stable production model from a general-purpose framework to a specialized inference runtime such as TensorRT typically yields only single-digit percent improvements in latency and hardware utilization, because both execute the same model.
Answer: False. The chapter’s quantitative tables report large gaps, with specialized runtimes achieving materially lower latency and materially higher utilization than general-purpose frameworks on identical GPUs because they apply more aggressive fusion, precision lowering, and hardware-specific tuning than a general-purpose runtime will attempt.
Learning Objective: Evaluate the misconception that specialized inference runtimes deliver only marginal gains over general-purpose frameworks
A team needs maximum NVIDIA GPU inference throughput for a stable production model and is choosing between staying inside their general-purpose training framework and exporting to a specialized runtime. Using the chapter’s quantitative analysis, what should they expect and what do they give up?
Answer: They should expect a specialized runtime like TensorRT to deliver substantially lower latency and higher utilization through aggressive fusion, precision lowering (FP16 or INT8), and hardware-specific kernel tuning the general-purpose framework will not attempt by default. The cost is reduced flexibility and narrower assumptions: the specialized runtime targets a fixed deployment shape, so model changes typically require re-export and revalidation. In production with a stable model, that narrower specialization is frequently the exact lever that moves the workload onto the accelerator’s roofline.
Learning Objective: Use the chapter’s quantitative platform analysis to recommend a runtime for high-throughput production inference
Self-Check: Answer
Which deployment tier most strongly forces frameworks toward extreme ahead-of-time compilation, tiny binaries, and no dynamic memory allocation?
- Hyperscale cloud training clusters
- Microcontroller TinyML deployments with kilobytes of RAM and no OS-level runtime
- Browser-based visualization dashboards
- Offline data labeling pipelines
Answer: The correct answer is B. Microcontroller deployments operate under RAM and runtime budgets so tight that only stripped-down AOT execution with statically planned memory is viable. Hyperscale cloud clusters prioritize throughput and distributed coordination rather than tiny binaries; browser dashboards care about network and rendering, not bare-metal execution; offline labeling has no latency or memory pressure at all.
Learning Objective: Match deployment tier constraints to the framework style they force at the edge of the spectrum
Explain why the three core framework problems are reweighted on inference-only edge and mobile targets, and what framework consequence that implies.
Answer: On inference-only devices the differentiation problem largely falls away because no gradient computation is needed, while the execution and hardware abstraction problems become dominant under strict latency, memory, and power budgets. A microcontroller for keyword spotting cares far more about static memory planning, fused kernels, and a tiny operator set than about flexible training APIs. The consequence is that framework choice at the edge narrows from research generality toward specialized inference runtimes engineered for exactly that reweighted problem mix.
Learning Objective: Explain how deployment context reweights execution, differentiation, and abstraction for inference-only targets
What practical role does ONNX play in the deployment landscape described here?
- It replaces quantization by automatically reducing every model to INT8
- It provides an interchange format that lets models move from a training framework to a deployment runtime, reducing fragmentation across train-and-deploy pipelines while not eliminating all operator-compatibility issues
- It guarantees that every framework-specific custom operator will run unchanged on every target
- It eliminates the need to choose a framework at project start
Answer: The correct answer is B. The chapter positions ONNX as a portability mechanism that reduces framework fragmentation for the train-in-one, deploy-in-another workflow; it does not automate quantization, does not guarantee custom-operator portability, and does not remove the need for an initial framework decision.
Learning Objective: Identify the role and limits of ONNX as an interchange format across deployment targets
Self-Check: Answer
A team is choosing a framework for a product whose edge deployment target is fixed, whose operator set is unusual, and whose engineering org is small. Applying the chapter’s framing, which description best captures how they should approach the decision?
- Pick the framework that is universally best across all workloads and move on
- Treat the decision as constrained optimization: deployment target, required operators, hardware, and org reality act as hard filters that eliminate candidates, then rank the survivors by softer preferences like ergonomics and community
- Choose whichever framework has the largest community, since ecosystem size dominates
- Choose by syntax preference, since the choice rarely affects deployment
Answer: The correct answer is B. The chapter’s claim is that framework choice is a constrained optimization whose hard filters come from deployment target, operator coverage, hardware, and team capacity; only after those eliminate the infeasible candidates do softer preferences like convenience and community differentiate the survivors. A single-universal-best answer denies the scenario dependence the chapter emphasizes; a popularity-first or syntax-first answer ignores the systems and lifecycle constraints the chapter makes load-bearing.
Learning Objective: Apply the hard-filter-then-soft-preference structure of framework selection to a concrete scenario
Why does the chapter insist on evaluating the deployment target before committing to a training framework?
Answer: Deployment constraints can invalidate an otherwise convenient training choice when runtime memory, supported operators, or platform tooling differ by orders of magnitude between the research environment and the production target. For example, an edge or microcontroller target may require a lightweight inference runtime that a research-first framework cannot reach without a painful export path, and some operators may not exist in the target runtime at all. The practical consequence is that deferring deployment analysis to the end of the project typically forces an expensive framework migration after substantial code and checkpoint investment.
Learning Objective: Justify why deployment requirements must be evaluated before committing to a training framework
Which evaluation dimension in the chapter’s selection framework answers the question: can this framework even express the operations and graph semantics the model requires?
- Long-term viability assessment
- Software dependencies
- Model requirements (representational and operator compatibility)
- Community branding
Answer: The correct answer is C. Model requirements act as the first filter in the chapter’s framework: before deployment tooling, dependencies, or ecosystem can matter, the candidate framework must support the operations and graph behavior the model actually needs. Dependencies and viability apply to survivors of this first filter but do not rescue a framework that cannot represent the model correctly at all.
Learning Objective: Identify which selection criterion checks representational and operator compatibility
True or False: Once a framework runs the current model fast enough, ecosystem health and long-term viability can be safely deprioritized because technical fit dominates over a production system’s lifetime.
Answer: False. The chapter stresses that contributor diversity, tooling, hiring alignment, and migration cost materially shape a framework’s suitability over a multi-year lifecycle, and a framework that is a technical fit today can still become a liability when its community stalls or its integration surface with CI/CD, monitoring, and serving tools decays.
Learning Objective: Evaluate the role of ecosystem health and long-term viability in framework selection
A company expects its models to be maintained for years across CI/CD pipelines, monitoring, and evolving deployment targets. Explain why the chapter treats framework lock-in as an engineering risk, not merely a switching inconvenience.
Answer: Framework choices get embedded in checkpoints, serving formats, cloud integrations, monitoring hooks, and team expertise, so a later migration requires months of coordinated re-serialization, re-validation, and retraining of staff; cross-framework tools reduce but do not eliminate this surface area. The lifecycle risk compounds as more services depend on the framework’s output formats and APIs. The consequence is that selection must account for future portability and organizational fit, not just today’s benchmark numbers.
Learning Objective: Analyze why framework lock-in is a strategic engineering risk over a production system’s lifetime
Self-Check: Answer
During the forward expression h = torch.relu(x @ W1 + b1), what happens simultaneously with the numerical computation that becomes essential later?
- The framework records autograd nodes (grad_fn links to the producing operations) that the later backward pass will traverse
- The optimizer immediately updates W1 and b1 before the loss is even computed
- The model checkpoint is automatically serialized to disk
- The framework disables asynchronous execution to simplify debugging
Answer: The correct answer is A. Eager execution produces the value and, in parallel, records the autograd graph nodes required for the backward pass via each tensor’s grad_fn, so that loss.backward() later has a graph to traverse. Optimizer updates occur only after gradients exist; no automatic checkpointing happens per step; and kernel launches remain asynchronous during the forward pass.
Learning Objective: Identify what autograd records during the forward pass of a training step
Why is a toy MLP training step on an A100 overhead-bound rather than compute-bound, and which framework mechanism mitigates this?
Answer: The toy model’s total FLOPs and HBM traffic per step are tiny compared with what an A100 can sustain, yet every operation still pays Python dispatch and CUDA launch overhead, so a handful of small kernels leaves software overhead dominating wall-clock time. Compilation mechanisms such as torch.compile fuse multiple operations into fewer kernels and amortize dispatch across the graph. The practical consequence is that throughput improves even though the arithmetic work is essentially unchanged.
Learning Objective: Analyze why a small training step can be dominated by software overhead and how compilation amortizes it
What does the hardware abstraction layer contribute during a standard training step?
- It guarantees the same low-level kernel binary runs unchanged on CPU, GPU, and TPU
- It maps the same high-level tensor operations to backend-specific implementations (for example cuBLAS on NVIDIA GPUs, Intel MKL or OpenBLAS on CPUs, and XLA-compiled paths on TPUs) while preserving the mathematical semantics
- It removes the need for backward passes on non-GPU hardware
- It ensures all backends have identical memory bandwidth and latency characteristics
Answer: The correct answer is B. The point of the abstraction layer is that one API call expands into different optimized backend paths depending on the device, while the mathematical intent is preserved. Claims about identical binaries or identical hardware characteristics misunderstand the abstraction: the implementations differ precisely because the machines differ. The idea that it removes the need for backward passes confuses hardware execution with the mathematical requirement of backpropagation.
Learning Objective: Explain how hardware abstraction preserves one API while dispatching to backend-specific execution paths
Explain how execution, differentiation, and abstraction all appear within a single forward-backward-optimizer iteration.
Answer: Execution appears when each operation dispatches eagerly to a kernel launched asynchronously on the device. Differentiation appears when autograd records grad_fn links during the forward pass and traverses them backward from the loss to produce parameter gradients. Abstraction appears because the same code maps to different backend implementations depending on whether the tensors live on CPU, GPU, or TPU. The practical consequence is that these are coordinated layers of one iteration, not independent subsystems, meaning a few Python lines necessarily expand into a full systems pipeline.
Learning Objective: Synthesize how execution, differentiation, and abstraction interact within one training iteration
Self-Check: Answer
True or False: If two frameworks implement the same model architecture and run on the same GPU, production latency and hardware utilization should land within single-digit percent of each other because the underlying mathematics is identical.
Answer: False. The chapter shows that kernel fusion, graph-level optimization, memory layout, and runtime specialization create large latency and utilization gaps on identical hardware, so the same math can execute with markedly different efficiency depending on how the framework compiles and schedules it.
Learning Objective: Reject the misconception that identical model math implies equivalent framework performance
Why is choosing a framework primarily on popularity a risky default for edge or embedded projects?
Answer: Popularity does not guarantee that the runtime fits the deployment target’s memory budget, binary size, or operator set. A framework beloved in research may still be unusable on a tiny device, forcing a painful mid-project migration after significant investment in training loops and checkpoints. The practical consequence is that deployment requirements must be evaluated before popularity can become a tiebreaker among frameworks that all meet the hard constraints.
Learning Objective: Explain why popularity is an insufficient substitute for deployment-driven evaluation on edge projects
A research team modifies model code dozens of times per day and is considering enabling torch.compile on every experiment for faster runs. Why might this make them slower overall even though each compiled execution is faster once it starts?
- Because compilation removes access to GPUs and forces CPU execution
- Because each code change triggers recompilation, and when the number of recompiles is high relative to production executions the compile cost dominates the wall-clock savings, per the compilation continuum
- Because compiled models cannot compute gradients correctly during training
- Because compilation always increases memory use so much that batch size must be one
Answer: The correct answer is B. The chapter’s compilation-continuum argument is that compile cost pays off only when amortized over many executions; during fast iteration, frequent recompiles can erase any throughput gain. Claims that compilation loses GPU access or disables gradients invent limitations the chapter never argues; a forced batch-size-of-one claim rewrites the memory behavior of compilation.
Learning Objective: Analyze when compilation overhead outweighs per-run throughput gains during rapid prototyping
Self-Check: Answer
Which of the following best captures how the chapter wants engineers to think about framework choice in terms of the iron law?
- The framework is a syntax preference and does not meaningfully affect iron-law terms
- The framework is the compiler for the silicon contract: it decides how much the data-movement and overhead terms can be reduced and how close the execution gets to peak throughput under the utilization term
- The framework controls dataset quality and size, and therefore dictates accuracy
- The framework’s only role is ergonomics; performance depends entirely on hardware choice
Answer: The correct answer is B. The chapter positions frameworks as the layer that translates model math into hardware-specific execution plans whose fusion, dispatch, and layout choices directly attack the data-movement and overhead terms and determine how close real execution gets to the utilization ceiling. A syntax-preference view denies the performance implications the chapter grounded in quantitative examples; dataset and hardware-only views misplace the framework’s actual role.
Learning Objective: Synthesize how framework choice maps to specific iron-law terms
Explain why the memory wall, rather than raw FLOP count, drives many of the framework optimizations the chapter discussed.
Answer: Modern accelerators can execute arithmetic faster than they can move bytes across the memory hierarchy, so sequences of small, memory-bound operations become HBM-traffic-bound and overhead-bound long before they become compute-bound. Optimizations such as kernel fusion, operator fusion across sequences, and precision lowering attack data movement and per-op cost directly; keeping intermediates in registers or on-chip SRAM can matter more than shaving FLOPs. The practical consequence is that effective framework optimization usually means attacking bandwidth and dispatch, not only compute.
Learning Objective: Explain why memory movement dominates many framework optimization decisions relative to arithmetic count
A new engineer asks why the team spent weeks choosing between frameworks for a multi-year production system. Applying the chapter’s integrative argument, what is the concrete systems consequence of that choice that justifies the investment?
Answer: The framework fixes which execution strategies, autodiff behaviors, and deployment runtimes are reachable, and those choices propagate into checkpoints, serving formats, monitoring, and team expertise across the system’s lifetime. Reaching a specific latency budget on a specific accelerator may simply be infeasible once the wrong commitments are baked in, and migration cost scales with every downstream service that has already adopted them. The consequence is that a framework decision silently determines throughput, portability, and lifecycle cost for years after the choice is made.
Learning Objective: Justify, with specific lifecycle consequences, why framework choice deserves deliberate investment for long-lived systems