ML Operations
Purpose
Why can an ML system be perfectly available and perfectly wrong at the same time?
Traditional software fails loudly: a null pointer exception crashes the server, monitoring dashboards turn red, and engineers are paged within minutes. Machine learning systems fail silently. A model experiencing data drift continues serving predictions with full confidence while accuracy degrades week by week, triggering no alerts because every health check (latency, throughput, uptime) remains green. The serving infrastructure gets models into production; operations keeps them correct once they are there, and correctness is the harder problem. Unlike code, which degrades only when someone modifies it, models degrade simply because the world changes: customer behavior shifts, new product categories appear, seasonal patterns evolve, and the distribution the model learned from slowly diverges from the distribution it now faces. This is not an occasional failure mode but the default trajectory of every deployed model. Entropy is not a risk to be mitigated but a certainty to be managed. Managing it requires a fundamentally different operational discipline: continuous monitoring that tracks prediction quality alongside system health, automated retraining pipelines that detect drift and respond before accuracy degrades to unacceptable levels, and deployment strategies that validate new model versions against production traffic before full rollout. The gap between development and production is not a hurdle to be cleared once but a condition to be managed indefinitely. Machine learning operations exists because uptime without accuracy is a system that confidently delivers wrong answers at scale. It is D·A·M co-design made continuous: the data environment remains a moving target long after the initial model is deployed, so the alignment work never ends.
Learning Objectives
- Explain why ML systems can remain available while prediction quality silently degrades under distribution shift
- Diagnose technical debt across data-model, model-infrastructure, and production-monitoring interface boundaries
- Design feature stores, registries, and CI/CD pipelines that preserve training-serving consistency and reproducible rollback
- Apply the retraining staleness model to choose cost-aware retraining triggers and intervals
- Implement layered monitoring for drift, skew, degradation, business metrics, and data freshness
- Compare canary, blue-green, shadow, and rollback strategies for production model release risk
- Evaluate operational maturity and investment using model criticality, operational risk, and organizational readiness
MLOps Overview
After a model is built, optimized, benchmarked, and served, the system still has to remain correct. A benchmark establishes performance at a point in time; serving infrastructure answers requests in milliseconds. The team deploys to production, and week one looks excellent. The challenge begins in week two.
Data distributions shift, user behavior changes, and the world moves on from the conditions under which the model was trained. A large fraction of ML models that succeed in development never reach sustained production use, not because they were built incorrectly, but because no one watched them after deployment. The root cause is an operational mismatch: conventional monitoring tracks deterministic system health, including server uptime, request latency, and request success rates, while ML monitoring must track statistical health, including accuracy over time, input-distribution shift, and per-segment prediction quality. A model can degrade from 94 percent accuracy to 81 percent while throwing no exceptions, triggering no infrastructure alarms, and maintaining perfect uptime.
The discipline that makes these invisible failures visible is Machine Learning Operations (MLOps). MLOps synthesizes monitoring, automation, and governance into production architectures that detect degradation, trigger retraining, and maintain system health throughout a model’s operational lifetime. It inherits the automation and operations lineage of DevOps (Debois 2009), but the failure mode is different: conventional services can often be tested against deterministic code paths, while ML systems depend on training data distributions, learned parameters, and environmental conditions that shift continuously.
Debois, Patrick. 2009. DevOpsDays: The Birth of DevOps.
The week-two problem takes concrete shape in a specific deployment. Consider a demand prediction system for a ridesharing service. Initial measurements show 94 percent accuracy, 15 ms P99 latency, and strong performance across test segments. By week four, accuracy has dropped to 88 percent, but the infrastructure metrics show nothing wrong. By week eight, a product manager notices driver dispatch is inefficient; investigation reveals the model has not adapted to a competitor’s new promotion that shifted user behavior. The model needed retraining six weeks ago, but no system was watching for this degradation. MLOps provides the framework to detect such drift, trigger retraining, and validate new models before users experience the impact.
The operational mismatch connects directly to the book’s analytical foundations. If benchmarking provides the sensors for our system, MLOps is the complete control system. It closes the verification gap from equation by continuously recalibrating against a changing world. MLOps operationalizes the degradation equation in equation: accuracy decay is not a failure of the code, but an inevitable consequence of the distributional divergence between the world we trained on and the world we serve. It also formalizes interfaces and responsibilities across traditionally isolated domains (data science, machine learning engineering, and systems operations (Amershi et al. 2019)) through continuous retraining, A/B evaluation, graduated rollout, and standardized artifact tracking that makes every deployed model reproducible and auditable.
Deploying, monitoring, and maintaining a single ML system in production constitutes what we term single-model operations, the operational unit for the analysis that follows. This operational unit requires a dedicated term. We define the ML node, a complete system comprising data pipelines, feature computation, model training, serving infrastructure, and monitoring for a single machine learning application. Platform operations at larger scale (managing hundreds of models, cross-model dependencies, multi-region coordination, and organization-wide ML platform engineering) constitute advanced topics that build on these single-model foundations.
The lifecycle of one production ML node starts with the week-two control problem and follows the interfaces that make it observable. Technical debt explains why production ML becomes expensive after the first successful deployment; feature stores, CI/CD pipelines, and experiment tracking then define the infrastructure needed to reproduce data, code, parameters, and configuration. Once those artifacts can be reproduced, monitoring, drift detection, deployment strategy, and incident response keep the model healthy over time. Investment decisions and case studies then show how the same principles look different in an edge wearable and in clinical AI operations.
The single-model operational challenge decomposes into three distinct interfaces. The Data-Model Interface is the handoff between data infrastructure and model training; its goal is feature consistency, so training and serving pipelines compute features the same way. The Model-Infrastructure Interface is the transition from trained weights to scalable service; its challenge is environment parity, because a model that works in a notebook may fail in production due to version, dependency, or runtime mismatches. The Production-Monitoring Interface is the feedback loop that enables self-correction, returning statistical telemetry from production to training because ML systems fail silently through drift rather than crashes.
Those interfaces determine where the chapter’s infrastructure pieces belong. Feature stores stabilize feature computation at the data-model boundary. Model registries and deployment pipelines preserve the model-infrastructure handoff. Drift monitors, retraining triggers, and governance policies close the production-monitoring loop before silent degradation becomes a business failure.
The telemetry1 flowing through these interfaces provides the data needed for informed operational decisions. That operational scope makes the next task precise: distinguish MLOps from traditional DevOps, identify the foundational principles that govern production decisions, and expose the debt patterns that accumulate when those principles are ignored.
1 Telemetry: The only feedback path that makes model degradation visible before it becomes a business failure. Unlike traditional software, where crashes and error codes surface problems immediately, ML systems degrade silently: distribution shift can go undetected for weeks or months without statistical telemetry (feature distributions, prediction confidence, drift indicators). By that point the model has been making degraded predictions at full automation rate, accumulating compounding errors in downstream systems that no infrastructure metric would have flagged.
Self-Check: Question
A ridesharing demand model keeps 15 ms P99 latency, full uptime, and low error rates on its API, but dispatch quality worsens over several weeks after a competitor launches a promotion. Which operational gap is MLOps primarily meant to close in this situation?
- The gap between infrastructure health and predictive correctness
- The gap between CPU utilization and GPU utilization
- The gap between model size and serving throughput
- The gap between training speed and inference speed
True or False: If a deployed ML service maintains uptime, latency, and request-success SLOs, that is usually sufficient evidence that the model is still doing its job correctly in production.
Explain why the chapter describes MLOps as a control system rather than just a deployment practice.
Which scenario is the clearest failure of the Data-Model Interface described in the section?
- A new model version increases P99 latency because the container image is larger
- Training computes user_session_length as the rolling 7-day mean, while serving computes it as the last 24 hours
- A rollback takes 20 minutes because the previous model was not kept warm
- A drift alert reaches the team only after weekly business-review dashboards
A team operates a single production recommender with its own data pipeline, training job, serving cluster, and dashboards. Leadership wants to know whether the team should adopt ‘single ML node’ operations as described in the chapter or invest in platform-scale infrastructure. Identify two concrete signals from the chapter that would indicate the team has outgrown single-ML-node operations and must cross into platform-scale practice.
Principles and Foundations
A production ML release is no longer just a code diff: data distributions, learned parameters, evaluation slices, and monitoring feedback loops all become release objects that can change the system’s behavior. MLOps builds on DevOps but addresses these specific demands of ML system development and deployment (Kreuzberger et al. 2023; Amershi et al. 2019). Traditional CI/CD can usually reason about code, configuration, tests, and infrastructure as the primary release objects; ML operations must also manage artifacts whose validity depends on the data and environment that produced them.
Amershi, Saleema, Andrew Begel, Christian Bird, Robert DeLine, Harald Gall, Ece Kamar, Nachiappan Nagappan, Besmira Nushi, and Thomas Zimmermann. 2019. “Software Engineering for Machine Learning: A Case Study.” 2019 IEEE/ACM 41st International Conference on Software Engineering: Software Engineering in Practice (ICSE-SEIP), 291–300. https://doi.org/10.1109/icse-seip.2019.00042.
DevOps integrates and delivers deterministic software. MLOps must manage nondeterministic, data-dependent workflows spanning data acquisition, preprocessing, model training, evaluation, deployment, and continuous monitoring through an iterative cycle connecting design, model development, and operations. Trace the infinity-loop structure in figure 1 to see how these phases feed back into one another continuously; the loop gives the discipline its operating shape.
Definition 1.1: MLOps
Machine Learning Operations (MLOps) is the engineering discipline that closes the feedback loop between model behavior and data reality by automating retraining, validation, and deployment in response to measurable production drift (Kreuzberger et al. 2023).
- Significance: The cost of not closing this loop appears as stale predictions, delayed detection, and avoidable recovery work. Drift thresholds, retraining triggers, and mean time to recovery (MTTR) targets are deployment-specific quantities calibrated from the business value of predictions, label delay, validation risk, and retraining cost. The important quantitative habit is not a universal threshold but the control loop: measure distribution shift, estimate the cost of staleness, trigger retraining only when expected benefit exceeds validation and rollout risk, and verify the replacement model before promotion.
- Distinction: Unlike DevOps (which monitors system availability: uptime, error rates, latency, and succeeds as long as the service responds), MLOps must monitor predictive correctness, which can silently degrade to zero while every infrastructure health check stays green.
- Common pitfall: A frequent misconception is that retraining on new data solves distribution shift. In reality, retraining on shifted data without first diagnosing which distribution changed (input features (\(p(x)\)), label relationships (\(p(y \mid x)\)), or both) can entrench the shift rather than correct it. Data drift and concept drift require different interventions: fresh sampling fixes the former; relabeling under current ground-truth criteria is required for the latter.
Kreuzberger, Dominik, Niklas Kühl, and Sebastian Hirschl. 2023. “Machine Learning Operations (MLOps): Overview, Definition, and Architecture.” IEEE Access 11: 31866–79. https://doi.org/10.1109/access.2023.3262138.

The operational complexity and business risk of deploying machine learning without systematic engineering practices becomes clear when examining real-world failure patterns. Consider an illustrative retail deployment in which a recommendation model initially boosts sales by roughly 15 percent. Due to silent data drift, the model’s accuracy degrades over six months, eventually reducing sales by several percent compared to the original system. The problem goes undetected because monitoring focuses on system uptime rather than model performance metrics. By the time the issue is discovered during routine quarterly analysis, the cumulative revenue impact on a mid-size retailer can plausibly reach tens of millions of dollars. This scenario illustrates why MLOps is a business necessity, not an optional best practice, for organizations depending on machine learning systems for critical operations.
Foundational principles
That retail deployment illustrates a pattern: without systematic operational practices, even accurate models fail in production. Read the incident as a debugging sequence. When revenue drops, the first question is whether the team can reconstruct the deployed model, which requires reproducibility. The next question is whether the data pipeline, training job, serving path, and monitoring system have boundaries clear enough to isolate the fault, which requires separation of concerns. If the serving features no longer match the training features, consistency becomes the control that prevents the same incident from returning. If drift begins before users complain, observable degradation is the control that turns silent failure into an alert. Finally, if retraining is possible but expensive, cost-aware automation decides when intervention is worth the operational risk and compute cost. The enduring principles below name those controls in the order an operations team needs them.
Reproducibility
Every artifact2 that influences model behavior must be versioned and traceable. This principle extends beyond code versioning to encompass data, configurations, and environments. Equation 1 expresses this dependency formally: \[\text{Model Output} = f(\text{Code}_v, \text{Data}_v, \text{Config}_v, \text{Environment}_v) \tag{1}\] where each subscript \(v\) denotes a specific version. A model cannot be reproduced unless all four components are captured. Tools that implement this principle vary in implementation but share the common goal of enabling complete reproducibility. These include version control systems, data versioning platforms, and configuration managers.
2 Artifact: A model’s weights are the deterministic output of a function whose inputs (code, data, configuration) cannot be reverse-engineered from the resulting parameters. Consequently, versioning only the code is a critical failure mode, as a single-byte change in the input data can silently alter millions of parameters in the final model. Without versioning all four artifact classes (code, data, config, and environment), true reproducibility is impossible.
Separation of concerns
Separation of concerns decomposes MLOps systems into distinct functional layers that can evolve independently, as table 1 shows:
| Layer | Responsibility | Stability |
|---|---|---|
| Data Layer | Feature computation, storage, serving | Changes with data schema evolution |
| Training Layer | Model development, hyperparameter optimization | Changes with algorithm research |
| Serving Layer | Inference, scaling, latency management | Changes with traffic patterns |
| Monitoring Layer | Drift detection, performance tracking | Changes with business requirements |
Consistency imperative
The separation in table 1 enables teams to update serving infrastructure without retraining models, modify monitoring thresholds without redeploying, and evolve data pipelines while maintaining model compatibility. That independence is safe only when training and serving environments process data identically, making training-serving parity a consistency imperative. The financial impact of this inconsistency is captured in equation 2: \[\text{Skew Cost} = \text{Base Error Rate} \times \text{Query Volume} \times \text{Error Impact} \tag{2}\] where Base Error Rate is the fraction of queries affected by training-serving skew, Query Volume is the number of queries per time period, and Error Impact is the cost per erroneous prediction.
For a system serving 1,000,000 queries/day with 1 percent skew-induced errors costing $0.10 each, annual skew cost reaches $365,000. This quantifies why consistency mechanisms represent investments with measurable returns. These mechanisms include feature stores, shared preprocessing code, and validation checks.
Observable degradation
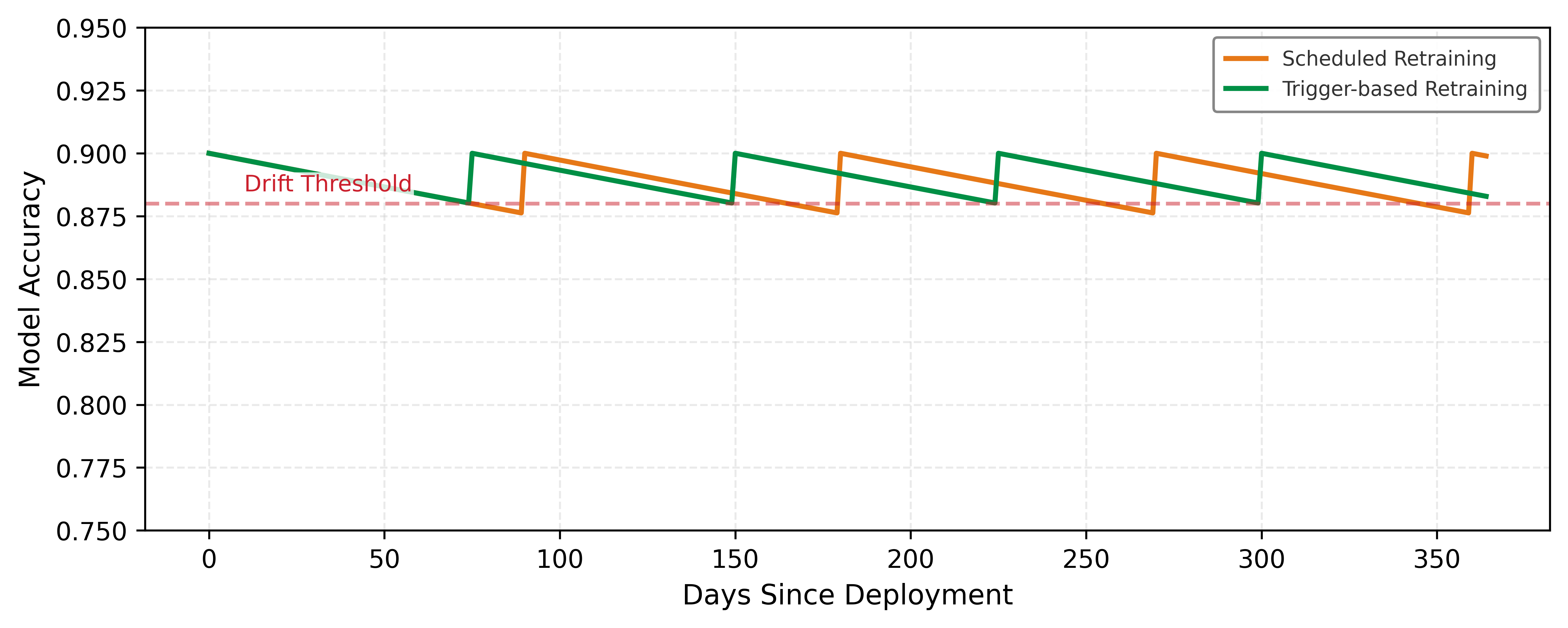
ML systems must make silent failures visible through continuous measurement. Model performance degrades along a continuum rather than failing discretely, and each failure mode has a distinct time signature that dictates both how it is detected and how the system should respond. Table 2 pairs each degradation type with the detector that catches it on its own timescale and the matching response: threshold alerts catch a sudden drop and trigger rollback, while slow trend analysis catches gradual drift and schedules retraining.
Cost-aware automation
Cost-aware automation should balance computational costs against accuracy improvements. Equation 3 models this trade-off: \[\text{Retrain if: } \Delta\text{Accuracy} \times \text{Value per Point} > \text{Training Cost} + \text{Deployment Risk} \tag{3}\]
| Degradation Type | Detection Mechanism | Response Strategy |
|---|---|---|
| Sudden accuracy drop | Threshold alerts | Immediate rollback |
| Gradual drift | Trend analysis | Scheduled retraining |
| Subgroup degradation | Cohort monitoring | Targeted data collection |
| Latency increase | Percentile tracking | Infrastructure scaling |
This principle guides the design of retraining triggers, validation thresholds, and deployment strategies examined throughout this chapter. The specific values vary by domain, but the framework for making principled trade-off decisions remains constant. Section 1.4.2.2.3 derives the complete economic model with worked examples showing how to calculate optimal retraining intervals. Once the causal chain is clear, the five principles can serve as a compact evaluation framework for tools and practices. The organizing claim of table 3 is that each principle is only operational once it is tied to a concrete measurable metric: pairing every principle with its key metric, from artifact hash to net retraining value, is what makes the framework auditable rather than aspirational.
| Principle | Core Insight | Key Metric |
|---|---|---|
| Reproducibility | Version all artifacts | Complete artifact hash |
| Separation of concerns | Independent layer evolution | Layer coupling score |
| Consistency | Training equals Serving | Feature skew rate |
| Observable degradation | Make failures visible | Time to detection |
| Cost-aware automation | Optimize total cost | Net retraining value |
How these principles manifest in practice depends on the workload. A recommendation system drifts daily as user preferences shift; a TinyML model deployed on embedded hardware may run unchanged for months. The monitoring strategy must match the archetype.
Lighthouse 1.1: Monitoring strategy by archetype
The dominant failure modes and monitoring priorities differ across workload archetypes. Table 4 compares four representative archetypes by drift pattern, monitoring metric, and example retraining trigger:
| Archetype | Dominant Drift Pattern | Primary Monitoring Metric | Example Retraining Trigger |
|---|---|---|---|
| ResNet-50 (Compute Beast) | Visual distribution shift (lighting, camera, new object classes) | Accuracy on holdout set (ground truth available) | Accuracy drops > 2% from baseline (\(\sim\)monthly for stable domains) |
| GPT-2 (Bandwidth Hog) | Vocabulary drift, topic shift, emerging entities | Perplexity on live traffic (no ground truth needed) | Perplexity increases > 10%; new vocabulary detected (\(\sim\)weekly for news domains) |
| DLRM (Sparse Scatter) | User behavior shift, item catalog churn, cold-start items | CTR/CVR delta vs. historical cohorts | Engagement drops > 5%; catalog refresh (\(\sim\)daily for e-commerce) |
| DS-CNN (Tiny Constraint) | Acoustic environment change (noise floor shift) | Duty cycle (wakeups/hour) + false positive rate | False wake rate > 1%; battery drain exceeds spec (\(\sim\)quarterly OTA update) |
Systems insight: Ground truth availability determines monitoring strategy. ResNet-50 (image classification) can use explicit labels; GPT-2 relies on proxy metrics (perplexity); DLRM uses implicit feedback (clicks); DS-CNN, a depthwise-separable convolutional neural network (CNN), monitors operational metrics (energy, false positives). The illustrative retraining cadence spans roughly two orders of magnitude, from daily recommendation updates to much slower embedded-device updates.
These principles respond to recurring challenges: data drift3, reproducibility failures (Schelter et al. 2018), and silent postdeployment degradation. These collectively motivate the specialized tools and workflows distinguishing MLOps from traditional DevOps. The divergence is driven by the silent failure problem introduced at the chapter’s opening: system health cannot be measured by uptime or latency alone. Operational discipline in ML requires monitoring the statistical properties of data distributions and model outputs, shifting the focus from “is the server running?” to “is the system still intelligent?”
3 Data Drift: Concept-drift and data-stream research formalized the problem that a model’s target relationship can change after deployment (Widmer and Kubat 1996; Gama et al. 2014). In adversarial domains such as spam, fraud, and abuse detection, the distribution can actively adapt in response to the model, making continuous monitoring and retraining a structural requirement rather than an operational luxury.
Widmer, Gerhard, and Miroslav Kubat. 1996. “Learning in the Presence of Concept Drift and Hidden Contexts.” Machine Learning 23 (1): 69–101. https://doi.org/10.1023/a:1018046501280.
Gama, João, Indrė Žliobaitė, Albert Bifet, Mykola Pechenizkiy, and Abdelhamid Bouchachia. 2014. “A Survey on Concept Drift Adaptation.” ACM Computing Surveys 46 (4): 1–37. https://doi.org/10.1145/2523813.
Schelter, Sebastian, Matthias Boehm, Johannes Kirschnick, Kostas Tzoumas, and Gunnar Ratsch. 2018. “Automating Large-Scale Machine Learning Model Management.” Proceedings of the 2018 IEEE International Conference on Data Engineering (ICDE), 137–48.
4 DVC (Data Version Control): DVC brings Git-like versioning to datasets and model artifacts (Iterative 2024), solving the artifact gap that equation 1 formalizes: without data versioning, the \(\text{Data}_v\) term is unrecoverable, and no combination of code commits can reconstruct the model that was deployed.
Iterative. 2024. Data Version Control (DVC).
Table 5 contrasts the objectives, methodologies, primary tools, and typical outcomes of DevOps and MLOps, illustrating how these ML-specific requirements demand distinct operational practices. MLOps coordinates a broader stakeholder ecosystem and introduces specialized practices such as data versioning4, model versioning, and model monitoring that extend beyond traditional DevOps scope.
| Aspect | DevOps | MLOps |
|---|---|---|
| Objective | Streamlining software development and operations processes | Optimizing the lifecycle of machine learning models |
| Methodology | Continuous Integration and Continuous Delivery (CI/CD) for software development | Similar to CI/CD but focuses on machine learning workflows |
| Primary Tools | Version control (Git), CI/CD tools (Jenkins, Travis CI), Configuration management (Ansible, Puppet) | Data versioning tools, Model training and deployment tools, CI/CD pipelines tailored for ML |
| Primary Concerns | Code integration, Testing, Release management, Automation, Infrastructure as code | Data management, Model versioning, Experiment tracking, Model deployment, Scalability of ML workflows |
| Typical Outcomes | Faster and more reliable software releases, Improved collaboration between development and operations teams | Efficient management and deployment of machine learning models, Enhanced collaboration between data scientists and engineers |
This expanded scope turns model operation into a feedback loop rather than a release pipeline.
Checkpoint 1.1: The MLOps loop
MLOps is not linear; it is circular.
The Feedback Cycle
The Artifacts
The evolution from DevOps to MLOps reflects a core truth: machine learning systems fail differently than traditional software. Where DevOps addresses deployment and scaling challenges for deterministic code, MLOps must contend with systems that accumulate hidden complexity through data dependencies, model interactions, and evolving requirements. These unique failure modes, collectively termed technical debt, form a diagnostic vocabulary that explains why MLOps requires specialized infrastructure. Understanding boundary erosion reveals why modular pipeline design is necessary. Recognizing correction cascades clarifies why versioning and rollback are essential. Identifying undeclared consumers justifies strict interface contracts. These patterns are the concrete failure modes motivating every infrastructure component we examine later.
Each iteration through the loop can introduce data dependencies, model interactions, and configuration drift invisible to standard software testing. Those accumulating costs are technical debt: a framework for converting silent ML failure modes into quantifiable engineering liabilities.
Self-Check: Question
A team versions code but not the training dataset, configuration, or runtime environment. Which foundational principle are they violating most directly?
- Observable degradation
- Reproducibility
- Separation of concerns
- Cost-aware automation
A system serves 1,000,000 queries per day, one percent of them are wrong because of training-serving skew, and each wrong prediction costs $0.10. Explain why the chapter treats consistency mechanisms as investments rather than engineering polish.
The chapter’s monitoring-archetype table pairs ResNet-50 with explicit accuracy labels, GPT-2 with perplexity, DLRM with click-through proxies, and DS-CNN (TinyML) with duty cycle and false-wake rate. What principle governs these different choices?
- Use only explicit accuracy labels for every deployment, because proxy metrics are too noisy to count
- Use the same drift threshold and retraining schedule for every archetype to simplify operations
- Match the monitoring signal to the archetype’s available ground truth and operational constraints
- Prioritize latency metrics over model-quality metrics across all archetypes
Per the section’s separation-of-concerns argument, order the following events in the lifecycle of a single production prediction so that each stage feeds the next without violating layer boundaries: (1) Serving layer returns a prediction to the client, (2) Data layer ingests and transforms a raw event, (3) Monitoring layer records the feature and prediction for drift analysis, (4) Training layer consumes versioned features to produce a model artifact the serving layer will load.
Why does the section argue that MLOps is not just DevOps plus periodic retraining?
- Because ML systems run on specialized accelerators rather than commodity servers
- Because ML deployment eliminates the need for testing once monitoring is in place
- Because ML systems are nondeterministic and data-dependent, so correctness must be monitored statistically over time
- Because ML teams always require larger organizations than software teams
Technical Debt
The silent failure modes established earlier manifest concretely as technical debt (Sculley et al. 2015): data changes, model interactions, and evolving requirements cause gradual degradation that compounds over time. Unlike code bugs that trigger stack traces, these failures accumulate invisibly across multiple system components, demanding engineering approaches designed specifically for probabilistic systems. Originally proposed in software engineering in the 1990s5, the technical debt metaphor compares shortcuts in implementation to financial debt, trading short-term velocity for ongoing interest payments in maintenance, refactoring, and systemic risk (Cunningham 1992). In ML, this debt extends beyond code to include “hidden” costs unique to statistical modeling and data dependencies. Systematic evaluation rubrics, such as the ML Test Score (Breck et al. 2017), provide frameworks for quantifying this debt and assessing production readiness across data, model, and infrastructure components.
5 Technical Debt: Ward Cunningham’s 1992 WyCash experience report introduced the debt metaphor for expedient code and delayed consolidation (Cunningham 1992). In ML, the debt compounds silently through data and model dependencies that conventional unit tests and code reviews cannot detect: a perfect pipeline degrades not because code changed but because the world did. The ML Test Score rubric (Breck et al. 2017) makes this debt explicit through 28 production-readiness tests grouped into data, model, infrastructure, and monitoring sections.
Cunningham, Ward. 1992. “The WyCash Portfolio Management System.” ACM SIGPLAN OOPS Messenger 4 (2): 29–30. https://doi.org/10.1145/157710.157715.
Breck, Eric, Shanqing Cai, Eric Nielsen, Michael Salib, and D. Sculley. 2017. “The ML Test Score: A Rubric for ML Production Readiness and Technical Debt Reduction.” Proceedings of the 2017 IEEE International Conference on Big Data (Big Data), 1123–32. https://doi.org/10.1109/bigdata.2017.8258038.
Definition 1.2: Technical debt in ML
Technical Debt in Machine Learning is the accumulating maintenance cost created by implicit data dependencies, entangled features, and undeclared consumers in ML systems, where the “interest” compounds as silent accuracy degradation rather than slower development velocity.
- Significance: Google’s analysis of production ML systems argues that model code is only a small fraction of the surrounding system; the larger operational surface includes data collection, feature extraction, configuration, serving infrastructure, monitoring, and process management (Sculley et al. 2015). ML-specific debt drivers compound this: changing one input feature can silently shift the learned representation of every other feature (entanglement), a model trained to correct another model’s errors creates a fragile dependency chain (correction cascades), and downstream systems consuming model outputs without explicit contracts become undeclared consumers that break silently when the model is updated.
- Distinction: Unlike software technical debt (which manifests as slower development velocity and is visible in code review), ML technical debt manifests as silent accuracy degradation that is invisible to unit tests, integration tests, and system health monitors. The system continues to run and respond correctly by every infrastructure metric while predictions quietly worsen.
- Common pitfall: A frequent misconception is that “better code” solves technical debt in ML. In reality, it is a systems architecture problem: the debt accumulates when the assumptions of the training distribution (feature ranges, label meanings, data freshness) are not enforced as runtime contracts at the system boundary.
The abstract notion of technical debt becomes concrete when we examine cost dynamics. Teams often resist automation investment because manual processes seem faster in the short term, but this intuition is systematically wrong. A break-even calculation makes that compounding concrete.

Cumulative manual work overtakes the one-time automation investment near week 20.
Figure 2 reveals the uncomfortable truth: the ML code itself represents only a small fraction of a production ML system’s complexity.
Napkin Math 1.1: The compound cost of manual operations
Problem: Why build automated pipelines when manual retraining is faster?
Physics: Manual work accumulates compound interest.
- Manual retrain: 4 hours of engineering per week.
- Pipeline build: 80 engineering hours (one-time).
Math:
- Break-even point: 20 weeks.
- Trap: This assumes the model never changes.
- Reality: Every new feature adds manual complexity. If feature count doubles, manual time doubles.
- Result: After 1 year, manual teams still spend 4 hours per week on maintenance. Pipeline teams spend 0 recurring hours.
Context: A central law of systems engineering is that the cost of maintaining a system over its lifetime can dominate the cost of building it. In ML, technical debt is especially dangerous because it is often data-driven rather than code-driven: a perfect piece of code can still fail if the data it processes shifts. Measurement is the management boundary: without telemetry, the team cannot tell whether maintenance work is reducing debt or merely hiding it.
Systems insight: Automation is fundamentally about capacity ceiling, not speed alone. A manual team hits a ceiling where they cannot deploy new models because they are drowning in the maintenance of old ones. MLOps is the engineering response: it replaces the manual “craft” of model maintenance with a systematic “factory” of observability and automation. Without monitoring infrastructure to make silent failures visible, the team is accumulating debt and building a system that is unmanageable by design.

Manual operations hit a capacity ceiling, but the cost problem extends beyond engineering time. ML systems accumulate hidden complexity through specific debt patterns, each emerging from ML’s distinctive reliance on data rather than deterministic logic, statistical rather than exact behavior, and implicit dependencies through data flows rather than explicit interfaces.
Figure 3 maps these patterns into six categories. Notice how they span data concerns (quality issues, freshness), model concerns (feedback loops, correction cascades), and infrastructure concerns (configuration sprawl, pipeline fragmentation). We examine representative examples that illustrate the engineering responses each pattern demands.

Boundary erosion
The first and often most insidious debt pattern involves the dissolution of system boundaries. In traditional software, modularity and abstraction provide clear boundaries between components, allowing changes to be isolated and behavior to remain predictable. Machine learning systems blur these boundaries for a structural reason: model behavior depends on statistical properties of data flowing through the system rather than on explicit interfaces. A change to upstream data formatting might pass all unit tests while silently degrading downstream model accuracy. This implicit coupling through data, rather than code, creates tightly coupled interactions between data pipelines, feature engineering, model training, and downstream consumption.
This erosion produces entanglement: dependencies between components become so intertwined that local modifications require global understanding and coordination. The result is captured by the CACHE principle: Change Anything Changes Everything. When systems lack strong boundaries, adjusting a feature encoding, model hyperparameter, or data selection criterion can affect downstream behavior in unpredictable ways. For example, changing the binning strategy of a numerical feature may cause a previously tuned model to underperform, triggering retraining and downstream evaluation changes that ripple far beyond the original modification.
The primary defense against boundary erosion is architectural: modularity and encapsulation at the design level. Components with well-defined interfaces allow engineers to isolate faults, reason about changes, and reduce the risk of system-wide regressions. Explicit separation between data ingestion, feature engineering, and modeling logic introduces layers that can be independently validated, monitored, and maintained. Boundary erosion is often invisible in early development because the tight coupling only becomes apparent when a seemingly local change triggers a distant failure. Proactive design decisions that preserve abstraction, systematic testing, and interface documentation provide the most practical defenses against this creeping complexity.
Correction cascades
If boundary erosion describes how ML systems lose their structural integrity, correction cascades describe what happens when teams attempt repairs. A correction cascade occurs when fixing one component introduces problems elsewhere, requiring additional fixes that themselves cause further problems. In ML systems, these cascades are particularly severe because changes propagate through statistical dependencies rather than explicit code paths. Retraining a model to fix one failure mode may degrade performance on previously working cases. Adjusting thresholds to reduce false positives may increase false negatives. Adding features to address edge cases may introduce correlations that destabilize the entire system. Each correction triggers the need for more corrections, creating a cascade that can consume engineering resources far exceeding the original fix.
Figure 4 makes the cascade structure visible as a chain of dependent models. Each model is trained to correct the errors of the one before it: model B compensates for model A’s residual mistakes, model C compensates for model B’s, and so on down the chain. The arrangement holds until an upstream model changes. When model A is retrained to fix one failure mode, every downstream model that was tuned to its previous behavior is invalidated at once, and each must be re-corrected. The red arcs trace this propagation, showing how a repair that looked local reaches across the entire chain. A change near the top forces the most rework, while one near the bottom is nearly free. For an operations team, one change request can trigger a coordinated retraining of the chain.

Those arcs matter because they turn local repairs into lifecycle-wide dependencies. Sequential model development is one common source: reusing or fine-tuning existing models accelerates development for new tasks, but it also creates hidden assumptions that are difficult to unwind later. Assumptions embedded in earlier models become implicit constraints for future models, limiting flexibility and increasing the cost of downstream corrections.
Consider a team that fine-tunes a customer churn prediction model for a new product. The original model may embed product-specific behaviors or feature encodings that do not transfer to the new setting. As performance issues emerge, teams may attempt to patch the model, only to discover that the true problem lies several layers upstream in the original feature selection or labeling criteria.
To mitigate correction cascades, teams must balance reuse against redesign. For small, static datasets, fine-tuning may be appropriate; for large or rapidly evolving datasets, retraining from scratch provides greater control. Fine-tuning requires fewer computational resources but modifying foundational components later becomes extremely costly due to cascading effects.
The underlying mechanism is that when model A’s outputs influence model B’s training data, implicit dependencies emerge through data flows rather than explicit code interfaces. These dependencies are invisible to traditional dependency analysis tools. Preventing cascades requires architectural decisions that preserve system modularity: keeping models loosely coupled, maintaining clear version boundaries, and designing for independent evolution even when reusing components.
Interface and dependency challenges
Boundary erosion and correction cascades share a root cause: ML systems develop interface dependencies that bypass explicit interfaces. Traditional software dependencies are visible (import statements, API calls, configuration files) and can be analyzed by tools. ML dependencies hide in data. When model A’s predictions become features for model B, the dependency exists only in the data pipeline, invisible to code analysis. When a dashboard consumes model outputs to drive business decisions, no interface contract governs the relationship.
Two critical patterns illustrate these challenges. Undeclared consumers arise when model outputs serve downstream components without formal tracking or interface contracts. When models evolve, these hidden dependencies break silently. A credit scoring model’s outputs might feed an eligibility engine that influences future applicant pools and training data, creating untracked feedback loops that bias model behavior over time. Data dependency debt compounds this problem as ML pipelines accumulate unstable and underutilized data dependencies that become difficult to trace or validate. Feature engineering scripts, data joins, and labeling conventions lack the dependency analysis tools available in traditional software development. When data sources change structure or distribution, downstream models fail unexpectedly.
Mitigating these interface challenges requires systematic approaches: strict access controls for model outputs, formal interface contracts with documented schemas, data versioning and lineage tracking systems, and continuous monitoring of prediction usage patterns. The MLOps infrastructure patterns presented in subsequent sections provide concrete implementations of these solutions.
System evolution challenges
The preceding patterns describe debt from poor design. Even well-designed ML systems face evolution challenges that differ sharply from traditional software.
Feedback loops represent the most subtle evolution challenge: models influence their own future behavior through the data they generate. Recommendation systems exemplify this dynamic: suggested items shape user clicks, which become training data, potentially creating self-reinforcing biases. Operationally, the warning sign is a subgroup error gap that widens across retraining cycles: one cohort receives worse predictions, those predictions reshape future behavior or labels, and the next dataset amplifies the gap. The MLOps lesson is to monitor cohorts before aggregate metrics hide the loop. These loops undermine data independence assumptions and can mask performance degradation for months.
Pipeline and configuration debt accumulates as ML workflows evolve into “pipeline jungles” of ad hoc scripts and fragmented configurations. Without modular interfaces, teams build duplicate pipelines rather than refactor brittle ones, leading to inconsistent processing and growing maintenance burden. Compounding this, rapid prototyping encourages embedding business logic in training code and undocumented configuration changes. While these early-stage shortcuts are necessary for innovation, they become liabilities as systems scale across teams. Managing evolution requires architectural discipline: cohort-based monitoring for loop detection, modular pipeline design with workflow orchestration tools, and treating configuration as a first-class system component with versioning and validation.
Code and architecture debt
Data dependencies and system evolution create debt through implicit coupling. ML systems also accumulate code-level debt patterns that differ from traditional software. Sculley et al. (2015) identify several that deserve explicit attention.
Glue code dominates ML codebases: systems often require substantial integration code to connect general-purpose ML packages to specific data pipelines and serving systems, with the glue constituting up to 95 percent of the codebase while the actual ML code represents only 5 percent. This glue creates tight coupling between package APIs and the surrounding system, meaning that when packages update their interfaces, all glue code must be rewritten. Mitigation requires wrapping ML packages in stable internal APIs and treating external dependencies as substitutable components.
Dead experimental codepaths accumulate as ML development involves extensive experimentation, leaving behind conditional branches for abandoned approaches. Unlike traditional dead code that can be detected statically, experimental ML codepaths often remain “live” because they are controlled by configuration flags rather than compile-time conditions. Over time, these paths increase testing burden and create confusion about which code actually runs in production. Regular code audits with explicit deprecation timelines and feature flag hygiene help manage this debt.
Abstraction debt arises because traditional software engineering relies on well-defined abstractions like functions, classes, and modules, but ML systems lack mature abstractions for key concepts such as the right interface for a “feature” or the right encapsulation for “model behavior.” This absence forces teams to reinvent abstractions or, worse, avoid abstraction entirely. Common patterns such as feature stores (abstracting feature computation), model registries (abstracting model versioning), and prediction services (abstracting inference) reduce per-project abstraction debt when they fit the team’s workflow.
Beyond these patterns, Sculley et al. (2015) identify warning signs, or common smells, that indicate accumulating debt: the Plain-Old-Data Type Smell (using generic types like strings and floats instead of semantic types that encode meaning and constraints), the Multiple-Language Smell (systems spanning Python, SQL, C++, and shell scripts with inconsistent conventions), and the Prototype Smell (“temporary” research code that becomes permanent infrastructure without refactoring). Effective organizations track these smells in code reviews and allocate explicit time for debt reduction, treating technical debt paydown as a first-class engineering activity rather than an afterthought.
Technical debt in practice
The debt patterns described earlier are not theoretical constructs. They have played a critical role in shaping real-world machine learning systems. In practice, unseen dependencies and misaligned assumptions can accumulate quietly, only to become major liabilities over time.
Production debt patterns
The first pair exposes coupling through model behavior. YouTube’s recommendation system illustrates the feedback-loop version of this problem: large recommenders learn from the behavior they helped shape, so ranking objectives, delayed labels, and cohort-based evaluation become part of the system design rather than offline evaluation details (Covington et al. 2016). Zillow’s home valuation and purchasing workflow exposed the correction-cascade version during its iBuying venture6. Valuation and inventory assumptions propagated into purchasing decisions; later corrections then destabilized inventory and pricing decisions, forcing revalidation and eventually a full rollback when the company shut down the iBuying arm in 2021.
Covington, Paul, Jay Adams, and Emre Sargin. 2016. “Deep Neural Networks for YouTube Recommendations.” Proceedings of the 10th ACM Conference on Recommender Systems, 191–98. https://doi.org/10.1145/2959100.2959190.
6 Zillow iBuying Failure: Zillow reported a plan to wind down Zillow Offers in November 2021, including a Q3 inventory write-down and workforce reductions (Zillow Group 2021). The failure illustrates correction cascade debt at scale: pricing errors, purchasing decisions, and inventory feedback can reinforce one another, creating a loop that no single retraining cycle can break.
Zillow Group. 2021. Zillow Group Reports Third-Quarter 2021 Financial Results and Shares Plan to Wind down Zillow Offers Operations. Investor Relations Press Release.
National Transportation Safety Board. 2017. Collision Between a Car Operating with Automated Vehicle Control Systems and a Tractor-Semitrailer Truck Near Williston, Florida, May 7, 2016. HAR-17/02. National Transportation Safety Board.
Engineering, M. 2016. Introducing FBLearner Flow: Facebook’s AI Backbone. Engineering at Meta Blog.
Mosseri, Adam. 2018. Bringing People Closer Together. Meta Newsroom.
The second pair exposes coupling through ownership and configuration. Safety-critical driving automation illustrates the undeclared-consumer risk from a different direction: when automated-control outputs, driver expectations, and subsystem responsibilities are not specified clearly enough, operational failures can cross component boundaries rather than staying local (National Transportation Safety Board 2017). Facebook’s News Feed iterations show the configuration version of the same governance problem. Rapid experimentation and ranking changes require traceable settings and explicit objectives; otherwise behavioral changes become hard to audit after deployment (Engineering 2016; Mosseri 2018).
These examples are not cautionary tales from careless organizations. They are predictable consequences of deploying probabilistic or automated decision systems without infrastructure that makes coupling visible. YouTube, Zillow, safety-critical driving automation, and Facebook each expose a different debt pattern: feedback loops, correction cascades, undeclared consumers, and configuration sprawl.
Each debt pattern has a corresponding infrastructure solution: feature stores for data dependency debt, versioning systems for configuration debt, CI/CD pipelines for pipeline debt, monitoring systems for feedback loops. These are not arbitrary tooling choices but engineering responses to the failure modes diagnosed earlier.
Recognizing debt patterns, however, is only half the battle. The organizations in these case studies did not lack talented engineers; they lacked the systematic infrastructure to catch problems before they compounded. The transition from diagnosis to prevention requires examining each infrastructure component in detail: understanding what it does and, more critically, how it addresses the specific failure mode that motivated its creation.
Self-Check: Question
What makes technical debt in ML systems fundamentally different from ordinary software technical debt, according to the section?
- It mainly appears as lower developer productivity from unreadable code
- It mainly appears as hidden data and model dependencies that cause silent performance degradation
- It mainly appears because ML teams use too many programming languages
- It mainly appears because models are larger than traditional software binaries
A team changes the binning strategy for one numerical feature, and suddenly retraining, evaluation thresholds, and downstream business dashboards all need revision. Which debt pattern best describes this?
- Boundary erosion driven by CACHE-style entanglement
- Configuration debt from undocumented hyperparameters
- Dead experimental codepaths from abandoned branches
- Stateful rollback debt from incompatible caches
Explain why correction cascades are especially severe in ML systems compared with deterministic software pipelines.
Order the following stages to reflect the lifecycle path shown in the correction-cascade discussion: (1) Model deployment, (2) Data collection and labeling, (3) Model training, (4) Model evaluation.
Which mitigation best targets undeclared consumers and hidden data dependencies?
- Increase model size so downstream systems can tolerate noisier inputs
- Rely on unit tests over model code, since data dependencies are outside the codebase
- Use stricter output access controls, formal interface contracts, and lineage tracking
- Avoid versioning outputs so downstream teams can move faster without coordination
True or False: An ML team that rewrote their model code to pass strict linting, 95 percent unit-test coverage, and code-review checks has substantially reduced the kind of technical debt the chapter identifies as most dangerous.
Development Infrastructure
Development infrastructure turns the debt patterns diagnosed earlier into enforcement points. A feature schema that drifts upstream cannot be repaired by a dashboard alone; it needs a shared contract, a versioned artifact, and a deployment path that rejects incompatible changes before they reach production. The mapping in table 6 is direct: each component implements a foundational principle (section 1.2.1) and addresses a specific failure mode.
| Infrastructure Component | Principle Implemented | Debt Pattern Addressed |
|---|---|---|
| Feature stores | Consistency Imperative | Data dependency debt, training-serving skew |
| Versioning systems | Reproducibility Through Versioning | Configuration debt, correction cascades |
| CI/CD pipelines | Cost-Aware Automation | Pipeline debt, boundary erosion |
| Monitoring systems | Observable Degradation | Feedback loops, silent failures |
Figure 5 organizes these components across ML models, frameworks, orchestration, infrastructure, and hardware. Understanding how these layers interact enables practitioners to design systems that systematically address the technical debt patterns identified earlier while maintaining operational sustainability.

Data infrastructure and preparation
Reliable machine learning systems depend on structured, scalable, and repeatable data handling. From ingestion to inference, each stage must preserve quality, consistency, and traceability across initial development, continual retraining, auditing, and serving alike. These requirements demand systems that formalize data transformation and versioning throughout the ML lifecycle.
Data management
The technical debt patterns we examined stem largely from poor data management: unversioned datasets create boundary erosion, inconsistent feature computation causes correction cascades, and undocumented data dependencies breed hidden consumers. Data management infrastructure directly addresses these root causes. Building on the data engineering foundations from Data Engineering, data collection, preprocessing, and feature transformation become formalized operational processes. Where data engineering focuses on single-pipeline correctness, MLOps data management emphasizes cross-pipeline consistency, ensuring that training and serving compute identical features. Data management thus extends beyond initial preparation to encompass the continuous handling of data artifacts throughout the ML system lifecycle.
Three principles organize the infrastructure that addresses these root causes: consistency, freshness, and quality. Each principle motivates specific tooling rather than the reverse.
The first requirement is data consistency: every artifact influencing model behavior, from raw datasets to engineered features, must be versioned and reproducible. Without versioning, teams cannot trace which data produced which model, making debugging and rollback impossible. The implementation usually combines code versioning, dataset versioning, and durable object storage. DVC (Data Version Control) (Iterative 2024), Git (Torvalds and Hamano 2024), Amazon S3 (Amazon Web Services 2024a), and Google Cloud Storage (Google Cloud 2024b) are examples of that pattern, but the invariant is the important part: raw and processed artifacts must remain addressable by version. Section 1.4.1.3 examines implementation details including Git integration, metadata tracking, and lineage preservation. At the feature level, the feature store enforces consistency by computing features once and serving them identically to both training and serving pipelines. Uber’s Michelangelo platform popularized this pattern inside a large production ML platform, and Feast later made the pattern available as open-source feature-store infrastructure (Hermann and Del Balso 2017; Gojek and Google 2019). Section 1.4.1.2 details implementation patterns for training-serving consistency.
Amazon Web Services. 2024a. Amazon Simple Storage Service (S3).
Google Cloud. 2024b. Google Cloud Storage.
Apache Software Foundation. 2024. Apache Airflow.
dbt Labs. 2024. Dbt (Data Build Tool).
Consistency alone is insufficient if the underlying data is stale. Data freshness ensures that models train and serve on current data rather than outdated snapshots. Automated data pipelines maintain freshness by continuously transforming raw data into analysis-ready formats through structured stages: ingestion, schema validation, deduplication, transformation, and loading. Orchestration systems such as Apache Airflow (Apache Software Foundation 2024), Prefect (Prefect Technologies, Inc. 2024), and dbt (dbt Labs 2024) matter because they make those stages explicit, scheduled, and reviewable as code. Once the pipeline is managed this way, data flows can evolve with model requirements without losing versioning, modularity, or CI/CD integration.
The third pillar, data quality, governs whether the data reaching models is accurate, complete, and consistently labeled. In supervised learning pipelines, labeling quality directly determines model ceilings. Labeling tools such as Label Studio (HumanSignal 2024) support scalable, team-based annotation with integrated audit trails and version histories, capabilities that become essential when labeling conventions evolve over time or require refinement across multiple project iterations.
HumanSignal. 2024. Label Studio: Open Source Data Labeling Platform.
To illustrate how these three principles reinforce each other in practice, consider a predictive maintenance application in an industrial setting. A continuous stream of sensor data is ingested and joined with historical maintenance logs through a scheduled pipeline managed in Airflow (freshness). The resulting features, including rolling averages and statistical aggregates, are stored in a feature store for both retraining and low-latency inference (consistency). Schema validation, sensor-range checks, missingness tests, and label audits catch malformed or unreliable maintenance records before they reach training (quality), while versioning and model-registry integration preserve traceability from data to deployed model predictions. Data management, organized around these three principles, establishes the operational backbone for model reproducibility, auditability, and sustained deployment at scale.
Feature stores
The data dependency debt and training-serving skew patterns described in section 1.3 share a common root cause: inconsistent feature computation across pipeline stages. Consider what typically happens without a feature store: a data scientist computes user_session_length in Python for training, while an engineer reimplements the same calculation in Java for serving. Subtle differences emerge: one uses wall-clock time, the other processing time; one includes idle timeouts, the other does not. The model trains on one definition but serves using another, and accuracy degrades silently. Feature stores7 address this challenge by providing an abstraction layer between data engineering and machine learning, implementing the consistency imperative through a single source of truth for feature values. In conventional pipelines, feature engineering logic is duplicated or diverges across environments, introducing risks of training-serving skew, data leakage, and model drift.
7 Feature Store: Uber’s Michelangelo platform described a centralized feature store for sharing and serving features across production models (Hermann and Del Balso 2017). At that scale, the consistency guarantee must hold under an online latency budget: what distinguishes a feature store from a shared library of feature code is that the shared feature path also has to serve fresh features fast enough for real-time inference.
Hermann, Jeremy, and Mike Del Balso. 2017. Meet Michelangelo: Uber’s Machine Learning Platform. Uber Engineering Blog.
Feature stores manage both offline (batch) and online (real-time) feature access through a centralized repository. During training, features are computed and stored in a batch environment alongside historical labels. At inference time, the same transformation logic is applied to fresh data in an online serving system. This architecture ensures models consume identical features in both contexts, a property that becomes critical when deploying the optimized models discussed in Model Compression. The feature store is, in systems terms, the engineering mechanism that enforces the training-serving skew law: by centralizing feature definitions and serving them through a shared path, it reduces the pipeline divergence that otherwise causes silent production accuracy loss.
Beyond consistency, feature stores support versioning, metadata management, and feature reuse across teams. A fraud detection model and a credit scoring model may rely on overlapping transaction features that can be centrally maintained, validated, and shared. Integration with data pipelines and model registries enables lineage tracking: when a feature is updated or deprecated, dependent models are identified and retrained accordingly.
Training-serving skew: Diagnosis and prevention
Training-serving skew (defined formally in Training-serving skew) manifests operationally through feature store inconsistencies and pipeline divergence. Table 7 summarizes common causes and their detection methods:
| Skew Type | Example | Detection Method |
|---|---|---|
| Feature preprocessing | Normalization uses different statistics | Statistical comparison of feature distributions |
| Missing data handling | Training fills NaN with mean; serving uses 0 | Schema validation with explicit null handling |
| Time-dependent features | Features computed with different time cutoffs | Timestamp validation in feature pipelines |
| Library version drift | NumPy or Pandas version differences | Environment hash comparison |
Training-serving skew case study
A practical example illustrates how training-serving skew manifests in production systems. Consider a recommendation system that shows 8 percent accuracy degradation one month after deployment with no model-code changes. Feature distribution comparison reveals that user_session_length has a mean of 45 minutes in training but 12 minutes in serving. The root cause is feature-definition skew: the offline training pipeline computes wall-clock duration from the first event to the last event in a session, while the online serving path counts only foreground-active time after idle gaps are removed. As a result, the model learned thresholds tied to a feature definition that production never actually serves.
Feature stores (building on the data pipelines from Data Engineering) address this problem by computing features once and serving them consistently to both training and serving pipelines. Listing 1 demonstrates the invariant: training retrieves point-in-time historical features, serving retrieves current online features, and both calls resolve to the same versioned feature definition rather than duplicated code paths.
feature_definitions = registry.load(version="2026-06-01")
training_features = feature_definitions.materialize_historical(
entities=training_entities,
at_event_time=True,
names=["user.session_length", "user.purchase_history"],
)
serving_features = feature_definitions.lookup_online(
entities=[{"user_id": 12345}],
names=["user.session_length", "user.purchase_history"],
)
assert training_features.schema == serving_features.schema
assert (
training_features.definition_hash
== serving_features.definition_hash
)By computing session_length once in the feature pipeline, training and serving see identical values. Centralized feature stores also support feature reuse and metadata tracking, which makes skew easier to detect and correct when a feature definition changes (Hermann and Del Balso 2017; Gojek and Google 2019).
Gojek, and Google. 2019. Feast: An Open Source Feature Store for Machine Learning. Google Cloud Blog.
As the consistency imperative quantified (section 1.2.1.3), skew-induced errors at production scale translate to hundreds of thousands of dollars in annual cost. Feature stores transform this continuous leakage into a one-time infrastructure investment with measurable returns. Uber’s Michelangelo platform shows how those economics play out at scale.
Example 1.1: Uber Michelangelo feature store
Context: Uber’s Michelangelo platform helped establish the production feature-store pattern (Hermann and Del Balso 2017), addressing training-serving skew and reuse across many models and teams powering ride pricing, ETA prediction, and fraud detection.
Insight: Data scientists computed features in Spark for training, while engineers reimplemented the same logic in Java for serving. Michelangelo’s feature store moved feature computation into a shared system that served training through Hive and production through Cassandra, with feature definitions written once and compiled into batch and online implementations.
Systems lesson: Feature stores turn consistency from a team convention into infrastructure. Point-in-time correctness prevents leakage, feature versioning enables safe iteration, and a centralized catalog supports reuse across large model portfolios.
Skew detection in CI/CD
Automated pipelines should validate feature consistency before deployment. Listing 2 shows a function that compares training and serving feature distributions using the Kolmogorov-Smirnov test, rejecting deployment when any feature diverges beyond a threshold.
def validate_no_skew(
training_features, serving_features, threshold=0.1
):
"""Reject deployment if feature distributions diverge."""
for feature in training_features.columns:
ks_stat = ks_2samp(
training_features[feature], serving_features[feature]
)
if ks_stat.statistic > threshold:
raise SkewDetectedError(
f"{feature}: KS={ks_stat.statistic:.3f}"
)Versioning and lineage
Lineage tracking and versioning implement reproducibility (section 1.2.1), which requires all artifacts influencing model behavior to be versioned. Unlike traditional software, ML models depend on multiple changing artifacts: training data, feature engineering logic, trained model parameters, and configuration settings. MLOps practices enforce tracking of versions across all pipeline components to manage this complexity.
Data versioning allows teams to snapshot datasets at specific points in time and associate them with particular model runs, including both raw data and processed artifacts. Model versioning registers trained models as immutable artifacts alongside metadata such as training parameters, evaluation metrics, and environment specifications. Model registries8 provide structured interfaces for promoting, deploying, and rolling back model versions, with some supporting lineage visualization tracing the full dependency graph from raw data to deployed prediction (MLflow Project 2026; Cloud 2024b).
8 Model Registry: Prevents “registry bypass,” the failure mode where the undocumented production model diverges from the trained artifact through different preprocessing, stale serialization formats, or manual hotfixes applied directly to the serving endpoint. Without a registry enforcing versioned, immutable artifacts with queryable metadata and state, rollbacks require locating the correct weights from an ad-hoc artifact store under incident pressure.
MLflow Project. 2026. MLflow Model Registry.
These complementary practices form the lineage layer of an ML system. The lineage layer enables introspection, experimentation, and governance by preserving the chain of evidence needed to diagnose a degraded model: whether the input distribution matched training data, whether feature definitions changed, and whether the deployed model version matched the serving infrastructure. By elevating versioning and lineage to first-class citizens in the system design, MLOps enables teams to build and maintain reliable, auditable, and evolvable ML workflows at scale.
Continuous pipelines and automation
Feature stores and versioning systems address data consistency statically: they ensure that features are computed correctly at a point in time. Automation enables these systems to evolve continuously, synchronizing data preprocessing, training, evaluation, and release into integrated workflows that respond to new data, shifting objectives, and operational constraints (Orr et al. 2021).
Orr, Laurel, Atindriyo Sanyal, Xiao Ling, Karan Goel, and Megan Leszczynski. 2021. “Managing ML Pipelines: Feature Stores and the Coming Wave of Embedding Ecosystems.” Proceedings of the VLDB Endowment 14 (12): 3178–81. https://doi.org/10.14778/3476311.3476402.
CI/CD pipelines
Feature stores and versioning systems address the data side of consistency; CI/CD pipelines address the process side, ensuring that changes flow through validated stages rather than ad hoc deployments. ML CI/CD pipelines must handle complexity absent from traditional software: data dependencies, model training workflows, and artifact versioning that couple code changes to statistical behavior changes.
A typical ML CI/CD pipeline consists of coordinated stages: checking out updated code, preprocessing input data, training a candidate model, validating performance, packaging the model, and deploying to a serving environment. In some cases, pipelines also include triggers for automatic retraining based on data drift or performance degradation. By codifying these steps, CI/CD pipelines9 reduce manual intervention, enforce quality checks, and support continuous improvement of deployed systems.
9 Idempotency: This property ensures that rerunning a pipeline stage yields an identical result, but the training stage violates this by default due to sources of randomness like weight initialization. Without idempotency, a pipeline rerun after a validation or deploy failure would produce a slightly different model, invalidating the original performance metrics and making debugging unreliable. Production systems therefore enforce determinism by fixing all random seeds, often to a single integer like 42, as one of several controls (alongside deterministic kernels, fixed library versions, and controlled data ordering) needed for reproducibility.
CircleCI. 2024. CircleCI: Continuous Integration and Delivery Platform.
GitHub, Inc. 2024b. GitHub Actions.
Authors, Kubeflow. 2024. Kubeflow.
Netflix. 2024. Metaflow.
Prefect Technologies, Inc. 2024. Prefect: Workflow Orchestration Framework for Python.
ML-focused CI/CD layers two tiers of tooling for one reason. A general-purpose CI/CD orchestrator (Jenkins, CircleCI (2024), or GitHub Actions (GitHub, Inc. 2024b)) manages version-control events and execution logic, but the ML layer must additionally version data, gate on model metrics, and trigger retraining. Teams therefore add a domain-specific platform (Kubeflow (Authors 2024), Metaflow (Netflix 2024), or Prefect (Prefect Technologies, Inc. 2024)) that supplies higher-level abstractions for those ML-specific tasks.
Without this automation, model deployment degrades into a manual, error-prone process: an engineer retrains locally, copies artifacts to a staging server, and promotes to production with no guarantee that the data, code, or hyperparameters match what was validated. The cost of such ad hoc workflows compounds with team size and deployment frequency, producing configuration drift and silent regressions that surface only after the model has served incorrect predictions.
Figure 6 shows how a representative CI/CD pipeline addresses these risks, beginning with a dataset and feature repository from which data is ingested and validated. Validated data is then transformed for model training. A retraining trigger, such as a scheduled job or performance threshold, initiates this process automatically. Once training and hyperparameter tuning are complete, the resulting model undergoes evaluation against predefined criteria. If the model satisfies the required thresholds, it is registered in a model repository along with metadata, performance metrics, and lineage information. Finally, the model is deployed back into the production system, closing the loop and enabling continuous delivery of updated models.

Google Cloud. 2026b. MLOps: Continuous Delivery and Automation Pipelines in Machine Learning.
To illustrate these concepts in practice, consider an image classification model under active development. When a data scientist commits changes to a GitHub (GitHub, Inc. 2024a) repository, a Jenkins pipeline is triggered. The pipeline fetches updated data, performs preprocessing, and initiates model training. Experiments are tracked using MLflow (Databricks 2024) which logs metrics and stores model artifacts. After passing automated evaluation tests, the model is containerized and deployed to a staging environment using Kubernetes (Cloud Native Computing Foundation 2024a). If the model meets validation criteria in staging, the pipeline orchestrates controlled deployment strategies such as canary testing (detailed in section 1.4.2.3), gradually routing production traffic to the new model while monitoring key metrics for anomalies. In case of performance regressions, the system can automatically revert to a previous model version.
CI/CD pipelines play a central role in enabling scalable, repeatable, and safe ML deployment. In mature MLOps environments, CI/CD is not optional but foundational, transforming ad hoc experimentation into structured, operationally sound development. Google’s TFX (TensorFlow Extended) platform exemplifies how these CI/CD principles scale to production.
Example 1.2: Google TFX production ML pipelines
Context: TensorFlow Extended (TFX) emerged from Google’s production ML infrastructure, providing reusable components for data validation, transformation, training, model analysis, and deployment (Baylor et al. 2017).
Insight: Before TFX, teams built bespoke pipelines for each ML project, repeatedly solving data validation, schema enforcement, model validation, and deployment gating. TFX standardized those steps through components such as ExampleGen, StatisticsGen, SchemaGen, ExampleValidator, Transform, Trainer, Evaluator, and Pusher.
Systems lesson: Production ML pipelines need artifact discipline, not just task orchestration. TFX makes each step produce versioned artifacts with metadata, so production issues can be traced back through the exact data, code, and configuration that produced the deployed model.
Baylor, Denis, Eric Breck, Heng-Tze Cheng, Noah Fiedel, Chuan Yu Foo, Zakaria Haque, Salem Haykal, et al. 2017. “TFX: A TensorFlow-Based Production-Scale Machine Learning Platform.” Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 1387–95. https://doi.org/10.1145/3097983.3098021.
Training pipelines
CI/CD pipelines orchestrate the overall workflow, but training itself requires specialized infrastructure. Model training, where algorithms are optimized to learn patterns from data, builds on the distributed training concepts covered in Model Training. Within MLOps, training activities become part of a reproducible, scalable, and automated pipeline supporting continual experimentation and reliable production deployment.
Frameworks such as TensorFlow (Abadi et al. 2016), PyTorch (Paszke et al. 2019), and Keras (Chollet et al. 2024) supply the modular components for building and training models, and the framework-selection principles from ML Frameworks carry into production unchanged. The operational question this section answers is different: which exploratory training logic graduates into a versioned, tested retraining job, and when.
Abadi, Martı́n, Paul Barham, Jianmin Chen, Zhifeng Chen, Andy Davis, Jeffrey Dean, Matthieu Devin, et al. 2016. “TensorFlow: A System for Large-Scale Machine Learning.” Proceedings of the 12th USENIX Symposium on Operating Systems Design and Implementation (OSDI), 265–83.
Paszke, Adam, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, et al. 2019. “PyTorch: An Imperative Style, High-Performance Deep Learning Library.” Advances in Neural Information Processing Systems 32: 8024–35.
Chollet, François et al. 2024. Keras.
Torvalds, Linus, and Junio Hamano. 2024. Git.
GitHub, Inc. 2024a. GitHub.
Project Jupyter. 2024. Project Jupyter.
Beyond scalability, reproducibility is a key objective. Training scripts and configurations are version-controlled using tools like Git (Torvalds and Hamano 2024) and hosted on platforms such as GitHub (GitHub, Inc. 2024a). Interactive development environments, including Jupyter (Project Jupyter 2024) notebooks, encapsulate data ingestion, feature engineering, training routines, and evaluation logic in a unified format. In production, notebooks should be treated as exploration harnesses: validated transformations, training code, and evaluation checks must be extracted into versioned, tested modules before they become scheduled retraining jobs.
Notebooks in production
CI/CD pipelines assume that code execution is reproducible, but Jupyter notebooks challenge this assumption in subtle ways. While notebooks excel for exploration and prototyping, using them directly in production pipelines introduces operational risks that require mitigation. These considerations are essential for teams transitioning from experimental workflows to production systems.
Reproducibility presents the first challenge. Notebook cells can be executed out of order, creating hidden state dependencies that make results nonreproducible. A common failure mode occurs when a data scientist runs cells one, three, two during development and the resulting model works, but a production pipeline running cells one, two, three fails.
Testing difficulties compound this challenge. Traditional unit testing frameworks do not integrate naturally with notebook structure. Cell-level testing is possible but rarely practiced, leaving notebooks less tested than equivalent Python modules.
Several mitigation strategies address these operational concerns. Papermill enables parameterization and programmatic execution of notebooks, treating them as configurable pipeline stages (Papermill Project 2026). The nbconvert tool converts validated notebooks to static formats including executable scripts for production execution (Project Jupyter 2026). Cell execution order enforcement tools execute all cells top-to-bottom, rejecting out-of-order dependencies.
Papermill Project. 2026. Papermill Documentation.
Project Jupyter. 2026. nbconvert: Convert Notebooks to Other Formats.
Napkin Math 1.2: The cost of silent failures
Problem: Is building an automated drift detection system worth the engineering effort?
Scenario: Consider a product recommendation engine generating $50M/year in revenue. Failure mode: A deployment bug causes training-serving skew, dropping recommendation quality by 5 percent. This degrades conversion rate proportionally.
Cost analysis:
- Manual ops (monthly review):
- Detection Time: ~4 weeks (28 days).
- Revenue Loss: $50M \(\times\) 0.05 \(\times\) 28 days/365 days ≈ $191,780.8.
- Automated MLOps (daily checks):
- Detection Time: 1 day.
- Revenue Loss: $50M \(\times\) 0.05 \(\times\) 1 day/365 days ≈ $6,849.3.
Systems insight: A single silent failure costs $184,931.5 more without MLOps. Under this scenario’s 4 incidents/year, MLOps saves nearly $739,726. The “expensive” infrastructure pays for itself by reducing the time-to-detection (TTD) for the silent failures the verification gap predicts.
The cost calculation makes the notebook-production boundary concrete. Notebooks remain useful for exploration and rapid iteration, but validated logic should move into tested Python modules before it enters production pipelines. The refactoring overhead pays off when it reduces time-to-detection for silent failures; leaving notebook state and preprocessing assumptions implicit turns exploratory convenience into operational risk.
Once training logic is reproducible, automation can standardize the steps around it. MLOps workflows incorporate techniques such as hyperparameter tuning (Ranjit et al. 2019; Li et al. 2017), neural architecture search (Elsken et al. 2019), and automatic feature selection (scikit-learn developers 2024a) to explore the design space efficiently. These tasks are orchestrated using CI/CD pipelines, which automate data preprocessing, model training, evaluation, registration, and deployment. For example, a Jenkins pipeline triggers a retraining job when new labeled data becomes available. The resulting model is evaluated against baseline metrics, and if performance thresholds are met, it is deployed automatically.
Ranjit, Mercy Prasanna, Gopinath Ganapathy, Kalaivani Sridhar, and Vikram Arumugham. 2019. “Efficient Deep Learning Hyperparameter Tuning Using Cloud Infrastructure: Intelligent Distributed Hyperparameter Tuning with Bayesian Optimization in the Cloud.” 2019 IEEE 12th International Conference on Cloud Computing (CLOUD), 520–22. https://doi.org/10.1109/cloud.2019.00097.
Li, Lisha, Kevin G. Jamieson, Giulia DeSalvo, Afshin Rostamizadeh, and Ameet Talwalkar. 2017. “Hyperband: A Novel Bandit-Based Approach to Hyperparameter Optimization.” Journal of Machine Learning Research 18: 185:1–52.
Elsken, Thomas, Jan Hendrik Metzen, and Frank Hutter. 2019. “Neural Architecture Search.” In The Springer Series on Challenges in Machine Learning, vol. 20. Springer International Publishing. https://doi.org/10.1007/978-3-030-05318-5_3.
scikit-learn developers. 2024a. Feature Selection — Scikit-Learn Documentation. Scikit-learn Documentation.
Gartner. 2024. Gartner Forecasts Worldwide Public Cloud End-User Spending to Total $679 Billion in 2024. Gartner, Inc.
10 Cloud ML Training Economics: GPT-3 training cost has been estimated in the millions of dollars when priced in V100 GPU-hours (Li 2020). Fine-tuning costs vary by model size, provider, dataset, and number of training steps. Spot instances and Spot VMs can reduce instance prices but introduce a trade-off: AWS Spot Instances and Google Cloud Spot VMs can be interrupted or preempted, requiring checkpoint-and-resume infrastructure for fault-tolerant training workloads (Amazon Web Services 2026; Google Cloud 2026c).
Li, Chengwei. 2020. Estimating the Training Cost of GPT-3.
Amazon Web Services. 2026. Amazon EC2 Spot Instances.
Google Cloud. 2026c. Spot VMs.
Cloud, Google. 2024a. Tune Models Overview.
OECD.AI. 2021. Measuring the Geographic Distribution of AI Computing Capacity. <Https://oecd.ai/en/policy-circle/computing-capacity>.
Growth in cloud infrastructure spending reflects how much training and serving work has moved into on-demand compute environments (Gartner 2024). This connects to the workflow orchestration patterns explored in ML Workflow, which provide the foundation for managing complex, multi-stage training processes across distributed systems. Cloud providers offer managed services that provision high-performance computing resources, including GPU and Tensor Processing Unit (TPU) accelerators, on demand10. Depending on the platform, teams construct their own training workflows or rely on fully managed services such as Vertex AI Fine Tuning (Cloud 2024a), which support automated adaptation of foundation models to new tasks. Hardware availability, regional access restrictions, and cost constraints remain important considerations when designing cloud-based training systems (OECD.AI 2021).
These practices converge on a single operational boundary. Exploratory training logic that proves out in a notebook, once it produces a validated model, is version-controlled and extracted into a scheduled retraining job triggered by data updates or performance monitoring. The exploration harness that made iteration fast is not what runs in production; the tested, versioned module is, and the discipline of that hand-off is what separates a reproducible pipeline from a fragile one. Through standardized workflows, versioned environments, and automated orchestration, MLOps transitions model training from ad hoc experimentation to robust, repeatable systems meeting production standards for reliability, traceability, and performance.
Retraining decision framework
Automated training pipelines introduce a critical decision regarding their execution frequency. Deciding when to retrain a model requires balancing accuracy maintenance against computational costs. Three common strategies exist, each with distinct trade-offs. Table 8 provides typical schedules across domains, from daily retraining for rapidly shifting ad click prediction to quarterly updates for stable medical imaging applications:
| Domain | Typical Schedule | Rationale |
|---|---|---|
| Ad click prediction | Daily | User interests shift rapidly |
| Fraud detection | Weekly | Attack patterns evolve continuously |
| Demand forecasting | Monthly | Seasonal patterns change slowly |
| Medical imaging | Quarterly | Disease presentations are stable |
Those schedules are starting points, not rules. Scheduled retraining runs on a fixed cadence, such as daily, weekly, or monthly, regardless of performance metrics. It is simple to implement and guarantees that recent data eventually enters the model, but it can waste compute when the distribution is stable or respond too slowly when a shift happens between calendar runs.
Triggered retraining ties the retraining decision to observed degradation. It optimizes compute cost by retraining only when monitoring detects performance loss or drift beyond thresholds, but it requires robust telemetry and careful calibration to avoid false positives or missed degradation. Listing 3 expresses the trigger as a decision function rather than a deployment-specific configuration file: retrain when the measured loss from staleness exceeds the cost and risk of a new training run. In the fraud-detection scenario used here, a 2 percent daily decay rate makes daily retraining the break-even point where retraining cost matches the loss from stale predictions.
Continuous retraining updates the model incrementally as labeled data arrives, either through online learning or periodic micro-updates. This keeps the model current with minimal latency, but it raises the validation burden because noisy labels or adversarial data can be incorporated before humans have reviewed the shift.
The operating choice therefore depends on four constraints: retraining cost, validation infrastructure, rollback capability, and label availability. Large models may cost tens of thousands of dollars per run; triggered retraining requires ground truth or reliable proxy labels; and every automated update path needs enough validation and rollback capacity to prove that the new model outperforms the baseline. Scheduled retraining suits stable domains, triggered retraining addresses gradual drift, and continuous retraining belongs to rapidly evolving distributions where waiting for a calendar interval would lose too much value.
quality_loss = baseline_accuracy - current_accuracy
feature_drift = max(population_stability_index(features))
prediction_shift = distribution_distance(
baseline_predictions, live_predictions
)
benefit = estimate_value_recovered(
quality_loss=quality_loss,
feature_drift=feature_drift,
prediction_shift=prediction_shift,
)
risk = retraining_cost + validation_cost + rollout_risk
if benefit > risk and validation_data_is_fresh():
schedule_retraining_run()Quantitative retraining economics
The decision to retrain a model is not a matter of intuition but an engineering optimization that balances the cost of System Entropy11 (accuracy decay) against the cost of infrastructure (retraining expense). We can think of model accuracy as a decaying quantity, analogous to radioactive decay, with a measurable rate of decline. In production, a model behaves like a radioactive isotope: it has a measurable Half-Life12 after which its predictive value becomes toxic to the business.
11 System Entropy: The decay rate \(\gamma\) varies by orders of magnitude across domains. Fast-moving domains (social media recommendations, financial fraud) exhibit half-lives of days to weeks; slower domains (medical imaging, industrial inspection) decay over months to years. This range determines the minimum infrastructure investment: a model with a three-day half-life requires continuous training infrastructure, not a scheduled batch job, while a model with a six-month half-life can retrain weekly at a fraction of the cost.
12 Half-Life (from nuclear physics, where it measures the time for half of a radioactive sample to decay): In ML operations, the metaphor is a mathematically convenient approximation, not a universal law. When historical performance supports an exponential decay fit, the fitted half-life turns “when should we retrain?” from a judgment call into a calculation; when decay is seasonal, abrupt, or adversarial, the model must be replaced by a richer drift process.
A simple half-life calculation turns retraining frequency into a measurable interval.
Napkin Math 1.3: The half-life of a model
Problem: How often should the team retrain the model to maximize profit?
Physics: Model accuracy \(\text{Accuracy}(t)\) decays at rate \(\gamma\) due to data drift.
- \(Q\): Daily Query Volume (Traffic).
- \(V\): Financial value per query for a unit change in accuracy fraction. With this convention, \(V = \$0.50\) means 1 percentage point of accuracy is worth \(\$0.005\) per query.
- \(C\): Fixed cost of a retraining run, including compute and operational overhead.
Formula: The approximation in equation 4 gives the optimal retraining interval \((T^*)\) that minimizes the sum of staleness losses and training costs: \[ T^* \approx \sqrt{\frac{2 \cdot C}{Q \cdot V \cdot \text{Accuracy}_0 \cdot \gamma}} \tag{4}\]
Math: Consider a lighthouse fraud model (\(\text{Accuracy}_0\) = 0.95):
- Traffic \((Q)\): 1,000,000 transactions/day.
- Utility \((V)\): $0.50/query for a unit accuracy change.
- Retraining Cost \((C)\): $5,000.
- Drift Rate \((\gamma)\): 2 percent per day.
\[ T^* \approx \sqrt{\frac{2 \times 5,000}{1,000,000 \times 0.50 \times 0.95 \times 0.02}} \approx \mathbf{1\text{ Day}} \]
Systems insight: If traffic is high and accuracy is valuable, the team cannot afford to wait. The pipeline must be automated. If \(T^*\) is less than the team’s manual deployment time, the system is in a state of permanent technical debt.
The same derivation can be formalized into a framework for calibrating monitoring thresholds based on measurable business impact. This quantitative framework transforms retraining from an ad hoc decision into an engineering optimization, implementing cost-aware automation (section 1.2.1).
The staleness cost function
Model accuracy typically degrades over time due to distribution drift, creating a staleness cost. While the mechanism of this degradation is the distributional divergence \(\mathcal{D}(P_t \lVert P_0)\) described by equation, for economic planning we can model the observable impact over time as an exponential decay process. In the canonical degradation equation, \(\lambda\) represents sensitivity to distributional divergence; here we use \(\gamma\) as a temporal decay rate, assuming drift accumulates steadily over time. The exponential model is a simplification that enables closed-form economic analysis. Let \(\text{Accuracy}(t)\) represent accuracy at time \(t\) since last training, and \(\text{Accuracy}_0\) represent initial accuracy. Equation 5 captures this degradation, where the rate \(\gamma\) depends on domain volatility: \[\text{Accuracy}(t) = \text{Accuracy}_0 \cdot e^{-\gamma t} \tag{5}\]
The cost of staleness accumulates based on query volume \(Q\) per time period and the value impact \(V\) of a unit change in accuracy fraction. Integrating the instantaneous accuracy loss \((\text{Accuracy}_0 - \text{Accuracy}(t))\) over the retraining interval \(T\) yields equation 6: \[ \begin{array}{>{\displaystyle}c} \text{Staleness Cost}(T) = \int_0^T Q \cdot V \cdot (\text{Accuracy}_0 - \text{Accuracy}(t)) \, dt = \\ Q \cdot V \cdot \text{Accuracy}_0 \cdot \left(T - \frac{1-e^{-\gamma T}}{\gamma}\right) \end{array} \tag{6}\]
The integral accumulates cost over time \(t\) from 0 to \(T\), and the closed form follows from substituting equation 5 for \(\text{Accuracy}(t)\).
The retraining cost function
Each retraining incurs fixed costs including compute, validation, and deployment overhead. Equation 7 decomposes these: \[\text{Retraining Cost} = C_{\text{compute}} + C_{\text{validation}} + C_{\text{deployment}} + C_{\text{risk}} \tag{7}\] where \(C_{\text{compute}}\) is the cost of the training run itself, \(C_{\text{validation}}\) is the cost of evaluating the new model before release, \(C_{\text{deployment}}\) is the cost of rolling it into production, and \(C_{\text{risk}}\) is the expected cost of potential regression from the new model.

Stretch retraining too far and staleness cost runs away.
Optimal retraining interval
The optimal retraining interval \(T^*\) minimizes total cost per unit time, as equation 8 shows: \[T^* = \operatorname{arg\,min}_T \frac{\text{Staleness Cost}(T) + \text{Retraining Cost}}{T} \tag{8}\]
For exponential decay, this yields the square-root law used in our earlier napkin math calculation. In fraud detection, these formulas translate directly into a retraining schedule: with the parameters in table 9, daily retraining is economically optimal because staleness cost accumulates faster than retraining cost.
| Parameter | Value | Description |
|---|---|---|
| \(Q\) | 1,000,000 | Transactions per day |
| \(V\) | $0.50/query | Value per query for a unit accuracy change |
| \(\text{Accuracy}_0\) | 0.95 | Initial accuracy |
| \(\gamma\) | 0.02 | Daily decay rate (2% per day) |
| Retraining Cost | $5,000 | Total retraining expense |
Sensitivity analysis
Because \(T^*\) scales with the square root of these parameters, large input swings produce only modest interval changes. Table 10 makes the damping concrete: a fourfold change in retraining cost, query volume, or decay rate moves the optimal interval only twofold, so retraining cadence stays robust to moderate uncertainty in any single parameter.
Model limitations
This framework provides a first-order approximation that enables principled decision-making, but practitioners should be aware of its assumptions:
- Predictable drift: The exponential decay model assumes drift occurs gradually at a known rate. Sudden distribution shifts (concept drift) require different detection and response mechanisms.
- Known value function: The model assumes each accuracy point has a quantifiable business value. In practice, this value may be nonlinear or context-dependent.
- Independent retraining cycles: The model treats each retraining decision independently, ignoring potential benefits from continuous learning or transfer across retraining cycles.
- Linear cost scaling: Retraining costs are assumed fixed. In practice, infrastructure costs may vary with compute availability and pricing dynamics.
| Change | Effect on \(T^*\) |
|---|---|
| 4\(\times\) retraining cost | 2\(\times\) longer interval |
| 4\(\times\) query volume | 2\(\times\) shorter interval |
| 4\(\times\) decay rate | 2\(\times\) shorter interval |
Despite these limitations, the framework provides a principled starting point for retraining decisions. Parameters improve with calibration against historical data and refinement as operational experience accumulates. By making cost-benefit trade-offs explicit and quantifiable, this framework implements cost-aware automation (section 1.2.1), enabling justified infrastructure investments and monitoring thresholds grounded in measurable business impact.
Model validation
Training pipelines produce model candidates; model validation determines which candidates merit production deployment. Unlike research evaluation, where a model that beats a benchmark on a static test set is considered successful, production validation must verify operational readiness: whether the model performs reliably under dynamic real-world conditions and continues to do so as data distributions shift.
The evaluation process begins with performance testing against a holdout test set sampled from the same distribution as production data. Core metrics such as accuracy, area under the curve (AUC), precision, recall, and F1 score (Rainio et al. 2024) are computed and tracked longitudinally to detect degradation from data drift (IBM 2024). The three aligned panels in figure 7 show this degradation pattern concretely. The top panel presents incoming data samples over time, color-coded by type. The middle panel reveals the underlying cause: a feature distribution (sales_channel) gradually shifting from predominantly online to predominantly offline transactions. The bottom panel shows the consequence: model accuracy declining in lockstep with the distribution shift. This visualization captures the core challenge of model validation: the need to monitor inputs alongside outputs to understand why performance changes.
Rainio, Oona, Jarmo Teuho, and Riku Klén. 2024. “Evaluation Metrics and Statistical Tests for Machine Learning.” Scientific Reports 14 (1): 6086. https://doi.org/10.1038/s41598-024-56706-x.
IBM. 2024. IBM Watson OpenScale: Data Drift Detection.

Beyond static evaluation, MLOps encourages controlled deployment strategies that simulate production conditions while minimizing risk. One widely adopted method is canary testing (Fowler 2014), in which a new model is deployed to a small fraction of users or queries. During this limited rollout, live performance metrics are monitored to assess system stability and user impact. For instance, an e-commerce platform deploys a new recommendation model to 5 percent of web traffic and observes metrics such as click-through rate, latency, and prediction accuracy. Only after the model demonstrates consistent and reliable performance is it promoted to full production.
Fowler, Martin. 2014. Canary Release. Martin Fowler’s Blog.
Weights & Biases, Inc. 2024. Weights & Biases: The AI Developer Platform.
Evaluating candidates under identical conditions is the prerequisite for a sound promotion decision, since a candidate that wins only because it was measured against different traffic, features, or time windows tells the team nothing. Cloud ML platforms support this through experiment logging, request replay, and synthetic test-case generation, and tooling such as Weights & Biases (Weights & Biases, Inc. 2024) captures the training artifacts, hyperparameter configurations, and metrics that make those comparisons reproducible and traceable across the training and deployment pipeline.
While automation is central to MLOps evaluation, human oversight remains essential. Automated tests may fail to capture nuanced performance issues such as poor generalization on rare subpopulations or shifts in user behavior. Teams combine quantitative evaluation with qualitative review, particularly for models deployed in high-stakes or regulated environments. This multi-stage evaluation process bridges offline testing and live system monitoring, ensuring models behave predictably under real-world conditions and completing the development infrastructure foundation necessary for production deployment.
Infrastructure integration
The development infrastructure examined earlier addresses two of the three critical interfaces introduced at the chapter’s opening. Feature stores and data versioning solve the Data-Model Interface by ensuring consistent, tracked feature access across training and serving. CI/CD pipelines, model registries, and validation gates address the Model-Infrastructure Interface by automating the transition from trained weights to containerized services with rollback capability.
These represent only two-thirds of the operational challenge, however. A model that passes all validation gates and deploys successfully can still fail silently in production as the world changes around it. The third critical interface, Production-Monitoring, requires a different set of practices focused not on building models but on keeping them healthy over time.
Self-Check: Question
What is the primary systems role of a feature store in the chapter’s development infrastructure?
- To centralize feature definitions so training and serving use the same computation path
- To replace model registries for rollback and artifact promotion
- To eliminate the need for data versioning because features are higher-level artifacts
- To maximize GPU utilization during training by caching activations
A team wants to run notebooks directly in production retraining because the notebook already works locally. Explain why the section treats this as risky and what mitigation it recommends.
A fraud model processes 1,000,000 transactions per day, has high value per accuracy point, and decays about two percent per day. According to the retraining economics section, what operational conclusion is most justified?
- Retraining should be rare because high-volume systems are too expensive to update
- The model should be retrained on a fixed quarterly schedule to reduce operational complexity
- The economics can justify very frequent retraining, potentially daily, because staleness costs dominate
- The team should ignore retraining frequency and focus only on offline benchmark quality
A team reruns the same training pipeline stage twice on identical inputs and gets two models with meaningfully different validation accuracy. Using the section’s reproducibility argument, diagnose the likely root causes and explain which engineering controls prevent this.
A team has strong feature-drift signals, expensive retraining jobs, and labels that arrive days later. Which retraining policy best matches the chapter’s framework?
- Continuous retraining on every new event regardless of whether the signal is noisy
- Triggered retraining when monitored drift or degradation thresholds are crossed
- No retraining until users complain, because delayed labels make monitoring useless
- A fixed daily retraining schedule even if the monitored inputs remain stable for weeks
Why does production model validation in this section go beyond beating a holdout benchmark?
Production Operations
A model that passes every validation gate still has a half-life. From the moment of deployment, the world begins to diverge from the training distribution: customers change behavior, competitors launch products, seasons shift, and new edge cases emerge that no test set anticipated. Production operations exist to make this inevitable decay visible and manageable, implementing the Production-Monitoring Interface through deployment strategies, monitoring, incident response, and governance. The requirements are demanding: handle variable loads, maintain consistent latency, recover gracefully from failures, and adapt to evolving data distributions, all without disrupting service. These practices implement observable degradation at runtime, transforming silent model drift into actionable alerts before users experience degradation.
Model deployment and serving
Once trained and validated, a model must be integrated into a production environment that delivers predictions at scale. Deployment transforms a static artifact into a live system component, and serving ensures accessibility, reliability, and efficiency in responding to inference requests. Together, these components bridge model development and real-world impact.
Model deployment
Consider a fraud detection model that achieves 99.2 percent precision in the development environment. An engineer exports the weights, copies them to a production server, and discovers the model predicts every transaction as legitimate—the production server runs a different version of the feature extraction library, producing inputs the model has never seen. This scenario, frustratingly common, illustrates why deployment is not a file transfer but a systems engineering problem. Packaging, testing, and tracking ML models for reliable production deployment requires treating the model, its dependencies, and its configuration as a single deployable unit. One common approach involves containerizing models using container technologies13, ensuring portability across environments.
13 Containerization for ML Deployment: Docker (Merkel 2014) packages code with dependencies into portable units; Kubernetes (Burns et al. 2016) orchestrates those units across clusters. For ML systems, containerization solves the \(\text{Environment}_v\) term in equation 1: a model that works in development but fails in production due to a library version mismatch is not a code bug but an environment parity failure. Containers make the environment a versioned, deployable artifact.
Merkel, Dirk. 2014. “Docker: Lightweight Linux Containers for Consistent Development and Deployment.” Linux Journal 2014 (239).
Burns, Brendan, Brian Grant, David Oppenheimer, Eric Brewer, and John Wilkes. 2016. “Borg, Omega, and Kubernetes.” Communications of the ACM 59 (5): 50–57. https://doi.org/10.1145/2890784.
Chen, Andrew, Andy Chow, Aaron Davidson, Arjun DCunha, Ali Ghodsi, Sue Ann Hong, Andy Konwinski, et al. 2020. “Developments in MLflow: A System to Accelerate the Machine Learning Lifecycle.” Proceedings of the Fourth International Workshop on Data Management for End-to-End Machine Learning, 1–4. https://doi.org/10.1145/3399579.3399867.
14 Staging Validation: The key difference from conventional software staging: conventional staging validates deterministic correctness (does the code produce the right output?), while ML staging validates probabilistic adequacy (is the model’s accuracy distribution acceptable given current data?). This makes ML staging fundamentally harder: a model can pass all unit tests and still fail in production because the test data does not reflect the deployment distribution, so rollout gates must compare prediction statistics, evaluation slices, and business guardrails against calibrated thresholds rather than rely on unit tests alone.
Production deployment requires frameworks that handle model packaging, versioning, and integration with serving infrastructure. Tools like MLflow and model registries manage these deployment artifacts (Chen et al. 2020), while serving-specific frameworks (detailed in Model Serving) handle the runtime optimization and scaling requirements. Before full-scale rollout, teams deploy updated models to staging or QA environments14 to rigorously test performance.
Techniques such as shadow deployments15, canary testing16, and blue-green deployment17 validate new models incrementally. These controlled deployment strategies enable safe model validation in production. Robust rollback procedures are essential to handle unexpected issues, reverting systems to the previous stable model version to ensure minimal disruption.
15 Shadow Deployment: Economically justified when the cost of a bad rollout (user-facing errors \(\times\) user count \(\times\) business impact per error) exceeds the cost of running shadow infrastructure for duplicated inference without serving results. The key insight is that shadow deployment’s value is asymmetric: it reduces catastrophic tail risk, not average-case error, making it useful for high-stakes models where a single bad rollout can cause irreversible damage.
16 Canary Deployment: Routes a small fraction of live traffic to a candidate model, using it as a sentinel for production health. The ML-specific challenge is that a “failure” is statistical degradation, not a deterministic crash: detecting a small accuracy difference with high confidence can require thousands of inferences, creating a tension between decision speed and statistical power that determines minimum canary duration.
17 Blue-Green Deployment: Maintains two comparable production environments, “blue” (serving current traffic) and “green” (running the candidate), then switches traffic in a routing change once the green environment passes validation. Because rollback is a traffic flip rather than a staged drain, recovery can be faster than a gradual canary for stateless services. The trade-off is extra infrastructure during the switch, so blue-green wins over canary when brief duplicate capacity is acceptable and per-segment statistical validation is expensive.
War Story 1.1: The Knight Capital error (2012)
Context: Knight Capital Group was a major market maker in US equities. In 2012, they deployed new software to seven of eight servers but missed the 8th (U.S. Securities and Exchange Commission 2013).
Failure mode: The new code repurposed an old flag (SMARS). On the seven updated servers, this worked correctly. On the 8th server running old code, activating SMARS triggered a dormant test function called “Power Peg” designed years earlier to buy stock aggressively for testing. In forty-five minutes, the defective router generated millions of erroneous orders, accumulated an unintended multi-billion-dollar portfolio, and ultimately cost Knight more than $460 million. The company needed emergency financing within days.
Systems lesson: Deployment is a systems problem that extends well beyond code. Configuration drift and partial rollouts are catastrophic failure modes in automated systems. ML deployments inherit the same risk surface: a model registry pointing at the wrong version, a feature schema drifting between training and serving, or a partial canary that wedges half the fleet on a stale routing rule each reproduce the Knight Capital shape with the model in place of the trading engine.
U.S. Securities and Exchange Commission. 2013. “Securities Exchange Act of 1934, Release No. 70694: Knight Capital Americas LLC.”
Avoiding the Knight Capital failure mode is exactly why ML deployments stage rollout rather than flip a switch, but staged rollout creates its own problem. When canary deployments reveal problems at partial traffic levels (issues appearing at 30 percent traffic but not at 5 percent), teams need systematic debugging strategies. Effective diagnosis requires correlating multiple signals: performance metrics from Benchmarking, data distribution analysis to detect drift, and feature importance shifts that might explain degradation. Teams maintain debug toolkits including A/B test analysis frameworks, feature attribution tools, and data slice analyzers that identify which subpopulations are experiencing degraded performance.
That diagnosis loop must connect directly to the release pipeline. CI/CD integration automates deployment and rollback, but only when rollback is designed as part of the rollout mechanism rather than treated as an emergency script.
Rollback strategies and safety mechanisms
Rollback18 capability is the safety net that enables confident deployment. Without reliable rollback, teams become deployment-averse and slow their iteration velocity. Effective rollback requires planning for three distinct scenarios:
18 Rollback (from Database Transaction Management): This “undo” action for deployments is complicated in ML by model-dependent state (for example, cached embeddings) which is often incompatible between model versions. The risk of this state-version mismatch (which can cause hours of downtime vs. seconds for a stateless service) is the direct cause of the deployment aversion and slow iteration velocity mentioned.
The fastest tier, immediate rollback, addresses critical failures detected right after deployment: serving errors, latency spikes, or obvious prediction failures. It requires keeping the previous model version loaded and warm so traffic can switch without cold-start delay. Rapid rollback handles performance degradation detected through canary metrics within the first hour, which requires model registry integration that keeps previous versions deployable with minimal configuration changes. Delayed rollback addresses subtle issues detected through business metrics or user feedback after full deployment, where rollback must account for model-dependent data such as personalization state or cached embeddings accumulated during the new model’s operation.
Table 11 summarizes implementation patterns for each rollback type:
| Rollback Type | Trigger | Implementation | State Handling |
|---|---|---|---|
| Immediate | Serving errors, crashes | Hot standby with instant switch | Stateless—no special handling |
| Rapid | Canary metric degradation | Registry-based redeployment | Clear caches, restart sessions |
| Delayed | Business metric decline | Full redeployment with migration | Migrate state, replay if needed |
Rollback testing
Rollback procedures that have never been tested will fail when needed, and the failure mode is particularly insidious: the team discovers the gap at 3:00 AM during an active incident, when cognitive load is highest and time pressure is greatest. Untested rollbacks fail for four distinct reasons, each corresponding to a different infrastructure gap. First, the mechanics of switching model versions often involve subtle configuration dependencies (environment variables, feature flag states, routing rules) that work differently under stress than in documentation. Monthly “fire drills” where teams practice rolling back to previous versions expose these gaps before they matter. Second, manual rollback decisions introduce dangerous latency; defining automated thresholds (for example, “if P99 latency exceeds 2\(\times\) baseline for 5 minutes, trigger rollback”) removes human reaction time from the critical path. Third, the rolled-back model must produce consistent behavior rather than corrupted predictions from stale caches or outdated feature values—a validation step that is trivial to skip in testing but catastrophic to miss in production. Finally, step-by-step runbook documentation ensures that the person executing the rollback need not be the person who designed it, a property that becomes essential as team sizes grow and on-call rotations widen.
Stateful vs. stateless rollback
ML systems vary in statefulness, affecting rollback complexity:
- Stateless models: Classification and regression rollback involves only switching model weights, because each prediction is independent.
- Stateful models: Sequential recommendation and conversational systems must consider accumulated user state, and rollback may require session resets or state migration.
- Models with feedback loops: Feedback-driven models may not restore previous behavior if training data was contaminated during the problematic deployment window.
For stateful systems, implement “rollback checkpoints” that capture consistent state snapshots at deployment boundaries, enabling clean restoration without user-visible disruption.
A/B testing for model validation
A/B testing provides the statistical foundation for deployment decisions by comparing model versions under controlled conditions. Unlike canary deployments (which validate operational stability), A/B tests measure whether a new model improves business outcomes with statistical confidence.
Experiment setup and decision rules
A valid A/B test starts with four controls that make the later deployment decision statistically meaningful. The Randomization Unit defines what gets randomly assigned to treatment vs. control. User-level randomization ensures consistent experience but requires larger sample sizes. Request-level randomization enables faster experiments but can confuse users seeing different results.
Sample size calculation: Determine required traffic before launch using equation 9: \[n = \frac{2(z_{\alpha/2} + z_{\beta})^2 \sigma^2}{\delta^2} \tag{9}\] where \(\delta\) is the minimum detectable effect, \(\sigma\) is outcome standard deviation, and \(z\) values depend on desired confidence (typically 95 percent) and power (typically 80 percent). For a 2 percent relative lift on a 5 percent baseline conversion rate (5 percent to 5.1 percent) and 80 percent power, expect roughly 745,644 users per variant; 25,000 users per variant would only detect a much larger lift, about 0.5 percentage points absolute.
Guardrail Metrics: Define metrics that must not degrade even if primary metric improves. A recommendation model improving click-through rate by 10 percent while increasing page load time by 500 ms may fail guardrail checks.
Runtime: Run tests until reaching statistical significance, typically 1–2 weeks minimum to capture weekly patterns. Avoid “peeking” at results and stopping early, as this inflates false positive rates.
Those controls establish the statistical envelope, but ML systems add failure modes that ordinary web experiments can hide. Conversion events may arrive days after prediction, creating delayed feedback: a recommendation shown Monday can drive a purchase Friday, so the attribution window must be part of the test design. Novelty effects can also inflate early performance as users engage with fresh recommendations, which is why mature experiments include a burn-in period before measurement.
Recommendation and ranking systems add interference effects because showing an item to one user can affect what remains available or salient for another, violating the independence assumption behind standard A/B analysis. Segment heterogeneity creates a second analysis problem: an overall neutral result may hide strong positive effects for one cohort and negative effects for another. These complications do not invalidate A/B testing, but they make guardrails, segment analysis, and preregistered decisions part of the experiment rather than after-the-fact interpretation.
Table 12 turns those constraints into a deployment decision:
| Primary Metric | Guardrails | Decision |
|---|---|---|
| Significant improvement | All pass | Ship new model |
| Significant improvement | Some fail | Investigate trade-offs, may need model iteration |
| No significant change | All pass | New model adds no value; keep current unless simplifying |
| Significant degradation | N/A | Do not ship; investigate root cause |
The table is only reliable when the analysis process is disciplined before launch. Teams should preregister expected effects before the test begins and choose the randomization unit, attribution window, guardrails, and minimum runtime before observing outcomes.
The same discipline has to continue during analysis. Sequential testing supports valid interim decisions by predefining when early stopping is statistically allowed, and variance-reduction techniques such as CUPED (Controlled-experiment Using Pre-Experiment Data) reduce metric noise by adjusting outcomes with pre-experiment covariates. Failed experiments should be archived because they encode negative evidence, and the analysis pipeline should be automated so manual spreadsheet work does not become a new source of deployment error.
An A/B decision only matters if the release machinery can promote, hold, or roll back the exact artifact that was tested. Model registries, such as Vertex AI’s model registry (Cloud 2024b), act as centralized repositories for storing and managing trained models and versions. Model catalogs serve a different role: Vertex AI Model Garden helps teams discover, test, customize, and deploy Google, partner, and selected open-source models (Google Cloud 2026a). Llama belongs in that model-family and model-catalog context, not in the registry lifecycle claim (Touvron et al. 2023).
Cloud, Google. 2024b. Vertex AI Model Registry.
Google Cloud. 2026a. Explore Models in Model Garden.
19 Serverless ML Inference: The cost-efficiency of this option stems from provisioning compute only upon request and scaling to zero when idle, eliminating the cost of a persistent endpoint. This creates a direct tension with performance targets, as the first request after an idle period incurs a “cold start” latency penalty while the model is loaded into memory. For large models, that delay can be long enough to violate real-time latency budgets unless the service keeps warm capacity or uses a runtime designed for fast loading.
Inference endpoints carry that tested artifact into live traffic. They typically expose the deployed model via REST APIs for real-time predictions. Depending on performance requirements, teams can configure resources, such as GPU accelerators, to meet latency and throughput targets. Some providers also offer flexible options like serverless19 or batch inference, eliminating the need for persistent endpoints and enabling cost-efficient, scalable deployments.
To maintain lineage and auditability, teams track model artifacts, including scripts, weights, logs, and metrics, using tools like MLflow20 (Databricks 2024). Together, registries, endpoints, lineage tracking, and distributed orchestration frameworks like Ray21 turn A/B outcomes into controlled production changes: the tested model can be promoted, observed, and reversed without losing provenance.
20 MLflow: Created by Databricks after observing that data scientists were tracking model results in spreadsheets and could never reproduce their best experiments. The “model registry” concept it popularized addresses the combinatorial explosion problem: with \(N\) hyperparameters, \(M\) data versions, and \(K\) code branches, manual tracking becomes intractable, and the inability to reproduce a deployed model becomes a governance and debugging liability.
Databricks. 2024. MLflow: An Open Source Platform for the Machine Learning Lifecycle.
21 Ray: A distributed computing framework from UC Berkeley (Moritz et al. 2018) that provides a unified task and actor interface, backed by a distributed scheduler and fault-tolerant store. The broader MLOps lesson is that fragmented infrastructure creates translation points where preprocessing logic, normalization constants, tokenizer versions, or artifact formats can diverge silently. Shared execution abstractions can reduce that fragmentation, but training-serving skew still requires explicit consistency checks across data, features, and serving code.
Moritz, Philipp, Robert Nishihara, Stephanie Wang, Alexey Tumanov, Richard Liaw, Eric Liang, Melih Elibol, et al. 2018. “Ray: A Distributed Framework for Emerging AI Applications.” Proceedings of the 13th USENIX Symposium on Operating Systems Design and Implementation (OSDI), 561–77.
Model format optimization
A PyTorch model that achieves top accuracy on a benchmark may serve predictions at 200 ms latency in production, ten times slower than the SLO requires. The gap between research frameworks and production serving is often substantial, and format optimization bridges it. Optimized formats can improve latency by converting models into representations tailored for specific hardware, but the gain is workload- and runtime-dependent. The inference runtimes and precision strategies detailed in Inference Runtime Selection and Precision selection for serving provide the technical foundations; this section focuses on the operational workflow.
The first operational boundary is representation. ONNX (Open Neural Network Exchange) is a widely used interchange format for model portability, but the choice of optimization framework determines both the hardware targets available and the performance ceiling reachable. Broader compatibility through ONNX Runtime comes at the cost of peak performance, while maximum throughput through TensorRT locks deployment to a single vendor, as table 13 summarizes. A typical workflow exports a PyTorch model to ONNX, runs graph-level cleanup (constant folding, dead-code elimination), applies operator fusion (such as Conv+BN+ReLU collapsed into a single op), and quantizes weights (FP32 to INT8) before deploying to the target runtime. Numerical equivalence to the source model must be validated at each step.
| Framework | Source Formats | Target Hardware | Key Optimizations |
|---|---|---|---|
| ONNX Runtime | PyTorch, TF, Keras, scikit | CPU, GPU, NPU | Graph optimization, operator fusion, quantization |
| TensorRT | ONNX, TF, PyTorch | NVIDIA GPU only | Kernel auto-tuning, precision calibration, layer fusion |
| OpenVINO | ONNX, TF, PyTorch, Caffe, MXNet | Intel CPU, GPU, VPU, FPGA | Model compression, async execution, caching |
| TF-TRT | TensorFlow | NVIDIA GPU | TensorRT integration within TensorFlow graph |
| Core ML | ONNX, TF, PyTorch | Apple Neural Engine, GPU, CPU | Unified format for Apple devices, on-device inference |
| TFLite | TensorFlow, Keras | Mobile CPU, GPU, Edge TPU | Quantization, delegate support, model compression |
The durable pattern is not the product list but the exchange it exposes: every gain in peak throughput is purchased with some degree of hardware or runtime commitment, so framework choice is a portability versus peak-performance decision before it is a feature comparison. Precision is the second boundary. Quantization reduces model size and increases throughput by using lower-precision arithmetic, but from an operational perspective the key deployment question is not whether INT8 is faster. It is whether the quantized model maintains accuracy under production traffic distributions, not merely calibration datasets. The mechanics of PTQ, QAT, and mixed-precision strategies are covered in Model Compression, with serving-specific precision selection (including dynamic per-request precision) detailed in Precision selection for serving.
Production deployment of optimized models therefore requires validation that targets the failure modes optimization can introduce silently. Consider a team that deploys an INT8-quantized model after verifying only throughput improvement: classification accuracy drops on rare but high-value edge cases, and the degradation goes undetected for weeks because aggregate metrics remain within SLO bounds. The first validation layer is numerical equivalence, comparing optimized outputs against the original model on a representative test set with application-specific divergence thresholds. That check is necessary but insufficient because rare inputs, out-of-distribution examples, and subgroup-specific cases can expose quantization artifacts that aggregate test metrics hide.
The second layer is operational validation. Memory footprint must be measured at peak runtime utilization, including dynamic allocations during inference, since some optimizations trade increased runtime memory for computational speed. Warm-up requirements matter because many optimized runtimes, including TensorRT and Accelerated Linear Algebra (XLA), require initial inference passes to compile kernels, creating a cold-start latency spike that deployment procedures and health checks must absorb. Runtime version compatibility then closes the loop: deployment configurations need explicit version pinning because even minor runtime changes can affect both performance characteristics and numerical correctness.
Inference serving
An optimized model sitting on disk generates zero value. It needs runtime infrastructure that accepts requests, executes inference, and returns predictions at scale. The serving architectures and service level agreement (SLA) and service level objective (SLO) frameworks detailed in Model Serving provide the technical foundation; this section focuses on the operational considerations for selecting and managing that infrastructure. In large-scale settings, serving systems process tens of trillions of inference queries per day (Wu et al. 2019), and the gap between a working serving system and a well-operated one determines whether SLOs are met consistently over months and years.
Wu, Carole-Jean, David Brooks, Kevin Chen, Douglas Chen, Sy Choudhury, Marat Dukhan, Kim Hazelwood, et al. 2019. “Machine Learning at Facebook: Understanding Inference at the Edge.” 2019 IEEE International Symposium on High Performance Computer Architecture (HPCA), 331–44. https://doi.org/10.1109/hpca.2019.00048.
Olston, Christopher, Noah Fiedel, Kiril Gorovoy, Jeremiah Harmsen, Li Lao, Fangwei Li, Vinu Rajashekhar, Sukriti Ramesh, and Jordan Soyke. 2017. “TensorFlow-Serving: Flexible, High-Performance ML Serving.” CoRR abs/1712.06139. https://doi.org/10.48550/arXiv.1712.06139.
NVIDIA. 2024. NVIDIA Triton Inference Server.
KServe Community. 2024. KServe: Highly Scalable and Standards-Based Model Inference Platform on Kubernetes.
Production-grade serving frameworks such as TensorFlow Serving (Olston et al. 2017), NVIDIA Triton Inference Server (NVIDIA 2024), and KServe (KServe Community 2024) provide standardized mechanisms for deploying, versioning, and scaling models. From an operational perspective, the key decision is which framework best fits the deployment context: TensorFlow Serving for TensorFlow-native workflows, Triton for multi-framework GPU serving, and KServe for Kubernetes-native environments requiring scale-to-zero.
Regardless of which serving paradigm is used (online, offline, or near-online, as detailed in The spectrum of serving architectures), a critical operational insight is that model inference time is often a minority of end-to-end latency. Decomposing the latency budget reveals where operational bottlenecks actually lie.
Systems Perspective 1.1: The latency budget
A service has a 100 ms P99 SLO, and the model inference budget is 45 ms; the remaining 55 ms must cover every other stage of the request path. Table 14 allocates the budget across the request lifecycle.
| Component | Budget Share | P99 Budget | Optimization Lever |
|---|---|---|---|
| Network RTT | 15% | 15 ms | Edge deployment, connection pooling |
| Feature retrieval | 25% | 25 ms | Feature caching, precomputation |
| Request parsing | 5% | 5 ms | Binary protocols (gRPC), schema optimization |
| Model inference | 45% | 45 ms | Quantization, batching, model distillation |
| Postprocessing | 5% | 5 ms | Async processing, result caching |
| Response serialization | 5% | 5 ms | Efficient formats (Protobuf, MessagePack) |
Systems insight: Model optimization alone often captures less than 50 percent of the latency opportunity. A model that runs 2× faster reduces this example from 100 ms to 77.5 ms, only 1.3× end-to-end improvement, because inference is 45 percent of total latency.
Systems thinking demands end-to-end analysis. Apply the D·A·M taxonomy to diagnose the root cause across Data (feature extraction overhead, serialization cost), Algorithm (too many layers, unoptimized graph), and Machine (memory bandwidth saturation, thermal throttling). Dave Patterson’s principle applies: “Measure everything, optimize the bottleneck.” If feature retrieval exceeds its budget, no amount of model optimization will achieve the SLO.
Beyond the latency budget, operationalizing serving requires selecting infrastructure techniques for the constraint the budget exposed. Table 15 summarizes representative strategies for ML-as-a-service infrastructure; the organizing question is whether the bottleneck lies in queueing delay, capacity, routing, orchestration overhead, or latency prediction.
| Technique | Description | Example System |
|---|---|---|
| Request Scheduling & Batching | Groups inference requests to improve throughput and reduce overhead | Clipper (Crankshaw et al. 2017) |
| Instance Selection & Routing | Dynamically assigns requests to model variants based on constraints | INFaaS (Romero et al. 2021) |
| Predictive Autoscaling | Adds capacity ahead of demand spikes to meet latency SLOs | MArk (Zhang et al. 2019) |
| Autoscaling | Adjusts model instances to match workload demands | INFaaS |
| Model Orchestration | Coordinates execution across model components or pipelines | AlpaServe (Li et al. 2023) |
| Execution Time Prediction | Forecasts latency to optimize request scheduling | Clockwork (Gujarati et al. 2020) |
Crankshaw, Daniel, Xin Wang, Guilio Zhou, Michael J. Franklin, Joseph E. Gonzalez, and Ion Stoica. 2017. “Clipper: A Low-Latency Online Prediction Serving System.” 14th USENIX Symposium on Networked Systems Design and Implementation (NSDI 17), 613–27.
Romero, Francisco, Qian Li, Neeraja J. Yadwadkar, and Christos Kozyrakis. 2021. “INFaaS: Automated Model-Less Inference Serving.” 2021 USENIX Annual Technical Conference (USENIX ATC 21), 397–411.
Zhang, Chengliang, Minchen Yu, Wei Wang, and Feng Yan. 2019. “MArk: Exploiting Cloud Services for Cost-Effective, SLO-Aware Machine Learning Inference Serving.” 2019 USENIX Annual Technical Conference (USENIX ATC 19), 1049–62.
Li, Zhuohan, Lianmin Zheng, Yinmin Zhong, Vincent Liu, Ying Sheng, Xin Jin, Yanping Huang, et al. 2023. “\(\{\)AlpaServe\(\}\): Statistical Multiplexing with Model Parallelism for Deep Learning Serving.” 17th USENIX Symposium on Operating Systems Design and Implementation (OSDI 23), 663–79.
Gujarati, Arpan, Reza Karimi, Safya Alzayat, Wei Hao, Antoine Kaufmann, Ymir Vigfusson, and Jonathan Mace. 2020. “Clockwork: Predictable and Scalable DNN Inference in the Cloud.” USENIX Symposium on Operating Systems Design and Implementation (OSDI), 443–62.
These strategies form the cloud-serving foundation. Edge deployment keeps the same operational goal but changes the constraints: rollback, telemetry, and update control must work on devices with limited power, memory, and connectivity.
Edge AI deployment
Consider a smoke detector with an ML model for distinguishing cooking smoke from fire. When this model degrades, an engineer cannot simply SSH into the device, roll back to a previous version, and restart. The device sits on someone’s ceiling with intermittent Wi-Fi, a coin-cell battery, and 256 KB of memory. Every operational assumption from cloud MLOps (instant rollback, centralized logging, real-time monitoring) must be reimagined.
Edge AI represents this shift: machine learning inference occurs at or near the data source rather than in centralized cloud infrastructure (Reddi et al. 2019). Workloads that require low latency, privacy-preserving local processing, intermittent connectivity, or tight energy budgets make edge deployment patterns essential knowledge for MLOps practitioners. The shift introduces three interrelated categories of operational challenges: resource constraints, deployment hierarchy, and update mechanisms.
Reddi, Vijay Janapa, Christine Cheng, David Kanter, Peter Mattson, Guenther Schmuelling, Carole-Jean Wu, Brian Anderson, et al. 2019. “MLPerf Inference Benchmark.” 2020 ACM/IEEE 47th Annual International Symposium on Computer Architecture (ISCA), 446–59. https://doi.org/10.1109/isca45697.2020.00045.
Warden, Pete, and Daniel Situnayake. 2020. TinyML: Machine Learning with TensorFlow Lite on Arduino and Ultra-Low-Power Microcontrollers. O’Reilly Media.
Resource constraints dominate edge deployment decisions. Edge devices require the aggressive model optimization techniques established in Model Compression (quantization, pruning, knowledge distillation) to meet the memory and power envelopes of microcontroller-class deployments (Warden and Situnayake 2020; David et al. 2021). Power budgets span four orders of magnitude, from milliwatts for IoT sensors to tens of watts in automotive systems, demanding power-aware inference scheduling and thermal management. Safety-critical applications impose deterministic timing targets requiring worst-case execution time (WCET) analysis under adverse conditions including thermal throttling and memory contention.

Edge power budgets span sensors, gateways, and vehicles across orders of magnitude.
These constraints shape a natural deployment hierarchy across three tiers. Sensor-level processing handles immediate data filtering and feature extraction on microcontroller-class devices consuming 1–100 mW. Edge gateway processing performs intermediate inference on application processors with 1–10 W power budgets. Cloud coordination manages model distribution, aggregated learning, and complex reasoning requiring GPU-class resources. This hierarchy enables system-wide optimization: computationally expensive operations migrate upward while latency-critical decisions remain local.
Two deployment contexts deserve specific attention. TinyML targets microcontroller-based inference under tight memory and milliwatt-class power constraints, requiring specialized engines such as TensorFlow Lite Micro and CMSIS-NN (David et al. 2021; Lai et al. 2018). Model architectures must be co-designed with hardware constraints, favoring compact operators, quantization, and pruning strategies whose aggressiveness depends on the device and accuracy target. Mobile AI extends edge deployment to smartphones with moderate compute, using NPUs and GPU compute shaders to meet interactive latency and battery-life constraints through power-aware scheduling.
David, Robert, Jared Duke, Advait Jain, Vijay Janapa Reddi, Nat Jeffries, Jian Li, Nick Kreeger, et al. 2021. “TensorFlow Lite Micro: Embedded Machine Learning for TinyML Systems.” Proceedings of Machine Learning and Systems 3: 800–811.
Lai, Liangzhen, Naveen Suda, and Vikas Chandra. 2018. “CMSIS-NN: Efficient Neural Network Kernels for Arm Cortex-M CPUs.” ArXiv Preprint abs/1801.06601.
Updates and monitoring complete the edge operational picture. Over-the-air (OTA) model updates enable maintenance for physically inaccessible systems. OTA pipelines must implement secure model distribution with cryptographic signatures and rollback mechanisms, using differential compression to transmit only parameter changes rather than complete model artifacts. Update scheduling must account for device connectivity patterns, power availability, and operational criticality.
Monitoring requires adaptation to resource-constrained environments: lightweight telemetry systems capture essential metrics (inference latency, power consumption, accuracy indicators) while minimizing overhead. Health monitoring tracks device-level conditions (thermal status, battery levels, connectivity quality) to predict maintenance needs. Edge-cloud coordination patterns enable adaptive offloading between tiers based on current load, network conditions, and latency requirements. Feature caching at edge gateways reduces redundant computation, while federated learning enables edge devices to contribute to model improvement without transmitting raw data.
Graceful degradation is the defining operational pattern for edge AI. When resources become constrained, systems must maintain essential functionality by reducing model complexity, inference frequency, or feature completeness. This design philosophy must be built in from the start, not bolted on as an afterthought.
Getting models into production is only half the challenge. A successfully deployed model can degrade through drift or data quality issues without triggering any alerts, precisely the silent failure modes that motivated this entire chapter. The monitoring, incident response, and on-call practices that follow close this loop.
Resource management and monitoring
Deployment and serving get models into production. Keeping them healthy requires two complementary disciplines: resource management (provisioning and scaling compute, storage, and networking) and monitoring (observing system behavior and detecting degradation before users notice).
Infrastructure management
A model that works in staging but fails in production because someone manually provisioned a different GPU type. A training job that crashes because a colleague’s experiment consumed all available memory. An inference service that cannot scale because its resource quotas were set via a Slack message six months ago. These failures share a root cause: infrastructure managed through manual processes rather than code.
Scalable, resilient infrastructure is foundational for operationalizing ML systems, and Infrastructure as Code (IaC) is the practice that makes it reliable. IaC treats infrastructure configuration as software (version-controlled, reviewed, tested, and automatically executed) rather than manually configured through graphical interfaces or command-line tools. This approach brings software engineering discipline to resource management: changes are tracked, configurations can be tested before deployment, and environments can be reliably reproduced.
The specific infrastructure tool matters less than the contract it enforces. Terraform (HashiCorp 2014), AWS CloudFormation (Amazon Web Services 2024d), and Ansible (Hatcher 2024) represent common ways to version infrastructure definitions alongside application code. In MLOps settings, that versioned definition is what lets a team reproduce the GPU type, network policy, storage permissions, and scaling limits used by a training or serving environment across AWS (Amazon Web Services 2024b), Google Cloud Platform (Google Cloud 2024a), Microsoft Azure (Microsoft 2024), or on-premises infrastructure.
HashiCorp. 2014. Terraform: Infrastructure as Code. Software available from https://www.terraform.io/.
Amazon Web Services. 2024d. AWS CloudFormation.
Hatcher, Blake Douglas. 2024. “Automating Server Deployments with Ansible: Utilizing Automation in DevOps.” Journal of Computing Sciences in Colleges 40 (3): 42–43.
Amazon Web Services. 2024b. Amazon Web Services (AWS).
Google Cloud. 2024a. Google Cloud Platform Documentation. Https://cloud.google.com/docs.
Microsoft. 2024. Microsoft Azure.
Infrastructure management spans the full ML lifecycle. During training, IaC scripts allocate compute instances with GPU or TPU accelerators, configure distributed storage, and deploy container clusters. Because infrastructure definitions are stored as code, they can be audited, reused, and integrated into CI/CD pipelines ensuring consistency across environments.
Containerization provides the same reproducibility boundary for runtime dependencies. Docker (Merkel 2014) packages the model, libraries, and serving code into an isolated unit, while orchestration systems such as Kubernetes (Cloud Native Computing Foundation 2024a) manage those units across clusters. The operational value is not the container name; it is the ability to deploy the same artifact repeatedly while resource allocation, scaling, and health management remain explicit.
Cloud Native Computing Foundation. 2024a. Kubernetes: Production-Grade Container Orchestration.
22 ML Autoscaling: Autoscaling adjusts capacity based on demand signals (Amazon Web Services 2024c), but ML serving adds constraints absent from stateless web services. Autoscaling decisions must account for model loading time (cold-start overhead), GPU memory fragmentation, and batching behavior in addition to CPU utilization. Scaling up too slowly violates latency SLOs; scaling down too aggressively forces repeated cold starts that degrade P99 latency.
Amazon Web Services. 2024c. AWS Auto Scaling.
To handle changes in workload intensity, including spikes during hyperparameter tuning and surges in prediction traffic, teams rely on cloud elasticity and autoscaling22. Cloud platforms support on-demand provisioning and horizontal scaling of infrastructure resources. Autoscaling mechanisms (Amazon Web Services 2024c) automatically adjust compute capacity based on usage metrics, enabling teams to optimize for both performance and cost-efficiency.
Infrastructure in MLOps is not limited to the cloud. Many deployments span on-premises, cloud, and edge environments, depending on latency, privacy, or regulatory constraints. A robust infrastructure management strategy must accommodate this diversity by offering flexible deployment targets and consistent configuration management across environments.
To illustrate, consider a scenario in which a team uses Terraform to provision a GPU serving node on Google Cloud Platform. The node hosts a containerized TensorFlow model that serves predictions via HTTP APIs, and an autoscaling group adds or removes identical replicas as request load varies. Meanwhile, CI/CD pipelines update the model container based on retraining cycles, and monitoring tools track latency and resource utilization. All infrastructure components, ranging from network configuration to compute quotas, are managed as version-controlled code, ensuring reproducibility and auditability. By adopting Infrastructure as Code, cloud-native orchestration, and automated scaling, MLOps teams can provision and maintain resources required for machine learning at production scale.
Infrastructure as Code addresses how to provision resources; the challenge remains deciding when and how much. ML workloads exhibit qualitatively different resource consumption patterns than stateless web applications: training jobs burst from zero to dozens of GPUs then return to minimal consumption, while inference maintains steady utilization under variable traffic. Training workloads demonstrate bursty requirements that create tension between resource utilization efficiency and time-to-insight. Inference workloads present steadier consumption patterns but with strict latency requirements under variable traffic.
Hardware utilization patterns
Provisioning resources is only the first half of the problem; using them efficiently means setting utilization targets that balance cost against reliability, and those targets depend on reading hardware metrics correctly rather than taking them at face value. Understanding hardware utilization patterns is essential for cost-effective ML operations. Unlike traditional web services where CPU utilization directly correlates with throughput, ML inference exhibits complex relationships between hardware metrics and actual performance.
GPU utilization metrics can mislead operators. A high utilization reading might be compute-bound (actively executing tensor operations, the ideal case), memory-bound (waiting for data transfers from GPU memory), or I/O-bound (stalled waiting for input data from CPU or network).
Table 16 distinguishes these patterns and their optimization strategies:
| Pattern | GPU Util | Memory bandwidth util. | Optimization Strategy |
|---|---|---|---|
| Compute-bound | >85% | <70% | Larger batch sizes, tensor parallelism within node |
| Memory-bound | 50–85% | >85% | Reduce model size, quantize, optimize memory access |
| I/O-bound | <50% | <50% | Improve data pipeline, prefetch inputs, use SSDs |
| Batch-starved | Variable (spiky) | Variable | Dynamic batching, request queuing on single server |
Utilization targets by workload
Representative utilization targets vary by workload characteristics, reflecting the different latency tolerances and cost sensitivities of each operational mode:
- Batch training: Target >80 percent GPU utilization. Lower utilization indicates data pipeline bottlenecks or suboptimal batch sizes. Monitor
gpu_util,memory_bandwidth_util, anddata_load_time. - Online inference: Target 50–70 percent GPU utilization at P50 load. Reserve headroom (30–50 percent) for traffic spikes. Higher sustained utilization risks latency SLA violations during bursts.
- Batch inference: Target >85 percent utilization. Unlike online serving, batch jobs can tolerate queuing delays, enabling maximum hardware efficiency.
Utilization targets are diagnostic starting points, not universal thresholds. The same utilization number can indicate a different bottleneck depending on whether the workload is latency-sensitive serving, throughput-oriented batch inference, or training.
Memory hierarchy effects
Model serving performance depends critically on memory hierarchy utilization. Data must flow through multiple memory levels with vastly different bandwidths (The memory hierarchy maps the full latency hierarchy across the storage spectrum), as table 17 quantifies. The roughly 400-fold bandwidth gap between L2 cache and NVMe is the binding constraint on where each serving artifact must live: hot weights belong in L2 and the full model in HBM precisely because they are touched on every token, while anything that spills to NVMe pays a swap penalty that dominates inference latency. Numbers to Know tabulates the current accelerator specifications and HBM bandwidths these serving numbers draw on, so the values below trace back to documented per-generation memory figures rather than illustrative estimates:
| Memory Level | Bandwidth | Typical Contents |
|---|---|---|
| L2 Cache (40 MB on A100) | ~3 TB/s | Hot weights |
| HBM2e GPU Memory (80 GB) | ~2 TB/s | Model |
| PCIe Gen4 x16 to CPU | ~32 GB/s | Activations |
| System RAM (512 GB) | ~200 GB/s | Batched inputs |
| NVMe SSD | ~7 GB/s | Model swap |
For large language model (LLM) serving on a single GPU or server, the KV-cache (storing attention keys and values for each token) often becomes the memory bottleneck; vLLM’s PagedAttention design was motivated by this serving pressure (Kwon et al. 2023). For a Llama 2 70-billion-parameter-style grouped-query attention model (Touvron et al. 2023) with 80 layers, 8 KV heads, a 4,096-token context, and FP16 cache entries, each active sequence stores about 1.3 GB of KV cache. Eight concurrent sequences therefore consume about 10.7 GB before scheduler headroom, fragmentation, or activations, limiting how many requests a single node can batch together. Monitoring KV-cache utilization on each serving node enables capacity planning: when KV-cache approaches GPU memory limits, additional requests queue rather than batch, degrading latency.
Kwon, Woosuk, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. 2023. “Efficient Memory Management for Large Language Model Serving with PagedAttention.” Proceedings of the 29th Symposium on Operating Systems Principles, 611–26. https://doi.org/10.1145/3600006.3613165.
Touvron, Hugo, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, et al. 2023. “Llama 2: Open Foundation and Fine-Tuned Chat Models.” arXiv Preprint arXiv:2307.09288.
Cost-per-inference tracking
Translate hardware metrics into business-relevant cost-per-inference metrics using equation 10: \[\text{Cost per 1K inferences} = \frac{\text{Hourly GPU cost} \times 1000}{\text{Inferences per hour}} \tag{10}\]
For a $3/hour A100 instance processing 50,000 inferences/hour, cost is $0.06/1K inferences. Track this metric over time; increases indicate efficiency degradation requiring investigation.
Model and infrastructure monitoring
Infrastructure management provisions resources; monitoring observes their behavior. This distinction matters because the verification gap means ML systems cannot be proven correct through unit tests—they can only be bounded statistically. Monitoring implements observable degradation (section 1.2.1), transforming this theoretical limitation into operational practice. Once monitoring surfaces a symptom—a latency SLA miss, throughput below target, or memory creep—Bottleneck diagnostic maps that symptom to its dominant D·A·M term and tells the operator which optimizations will move the binding constraint and which will be wasted on serving infrastructure. Without continuous monitoring, and the deeper observability23 it enables, a deployed model is a black box slowly drifting toward irrelevance.
23 [offset=-9mm]Observability (from control theory (Kalman 1960)): Measures how well a system’s internal states can be inferred from its external outputs. In MLOps, monitoring answers “is the system broken?” (high error rate) while observability answers “why is it broken?” by enabling inference of internal state (feature distributions, prediction confidence, neuron activations) from outputs alone. Without observability, a drifting model produces the same diagnostic signal as a healthy one: green dashboards and satisfied SLOs.
Kalman, Rudolf E. 1960. “On the General Theory of Control Systems.” IFAC Proceedings Volumes 1 (1): 491–502. https://doi.org/10.1016/S1474-6670(17)70094-8.
scikit-learn developers. 2024b. Sklearn.metrics.confusion_matrix — Scikit-Learn Documentation. Scikit-learn Documentation.
Effective monitoring spans both model behavior and infrastructure performance. On the model side, teams track metrics such as accuracy, precision, recall, and the confusion matrix (scikit-learn developers 2024b) using live or sampled predictions to detect whether performance remains stable or begins to drift. A critical constraint is the drift detection delay, which determines how quickly statistical monitoring can confirm that degradation has occurred. The speed of detection depends on traffic volume. A short sample-rate calculation makes that constraint visible.
The sample-rate calculation below exposes a fundamental asymmetry: statistical tests require enough labeled samples to achieve power, and low-traffic systems may wait days or weeks before accumulating sufficient evidence. This latency gap is not an engineering shortcut that better tooling can close; it is a consequence of finite sample rates colliding with the statistical power requirements of hypothesis testing. The practical implication is that monitoring systems must distinguish between drift that alters the input distribution (detectable without labels) and drift that changes the decision boundary itself (detectable only after ground truth arrives).

Drift detection speed is bounded by the sample rate.
Napkin Math 1.4: The drift detection delay
Problem: A model has 95 percent baseline accuracy. The goal is to detect a 5 percentage-point drop (to 90 percent) with 95 percent statistical confidence. The system handles 1 QPS. How long will it take to “prove” the model has drifted?
Math:
- Required samples: To distinguish 95 percent from 90 percent with high confidence, detection requires ≈ 1,000 labeled samples.
- Detection latency: 1,000 samples / 1 QPS = 1,000 seconds ≈ 16.7 minutes.
- Low-traffic case: If the model only processes 100 requests/day, detecting the same 5 percentage-point drift takes 10 days.
Systems insight: The sample rate of monitoring is physically limited by traffic volume. For low-traffic, high-stakes models (like medical diagnosis), drift detection can take days or weeks, leaving the system in a long-term silent-failure state. This is why high-stakes systems must supplement statistical monitoring with proactive model audits.
Production ML systems face two distinct forms of model drift24 that monitoring must distinguish. Concept drift25 occurs when the underlying relationship between features and targets evolves: the function \(p(y \mid x)\) changes even though the inputs look similar. During the COVID-19 pandemic, for example, purchasing behavior shifted dramatically, invalidating many previously accurate recommendation models. Data drift26, by contrast, refers to shifts in the input distribution \(p(x)\) itself. In applications such as self-driving cars, this may result from seasonal changes in weather, lighting, or road conditions, all of which alter the model’s inputs without changing the underlying physics of driving.
24 Drift Detection Lag: Feature drift (covariate shift on \(p(x)\)) is detectable immediately from input distributions, with no labels needed. Concept drift (\(p(y \mid x)\) changing) is invisible until ground truth arrives, which in high-stakes domains (medical diagnosis, fraud detection, legal decisions) can take days, weeks, or months. This asymmetry means the most dangerous drift is also the slowest to detect, requiring proxy metrics (prediction confidence distributions, output entropy) as imperfect early warning systems that trade false alarm rate for detection speed.
25 COVID-19 ML Impact: COVID-era behavior changes provide a canonical example of abrupt concept drift: demand patterns and user behavior shifted faster than any retraining pipeline could respond. Many recommendation and pricing systems required emergency manual intervention because their scheduled retraining cadences assumed gradual drift, not discontinuous distribution shifts, exposing a gap in cost-aware automation planning.
26 Covariate Shift: Shimodaira’s importance weighting correction (2000) assumes the support of the training distribution covers the deployment distribution: every deployment input could have appeared in training, just with different probability. When deployment contains genuinely out-of-distribution inputs (new product categories, new demographics, adversarial inputs), the correction fails entirely and the model produces confidently wrong outputs with no warning signal, making support coverage the hidden assumption that determines whether drift correction or full retraining is required.
Both forms of drift motivate a formal definition:
Definition 1.3: Data drift
Data drift is the specific subtype of distribution shift in which the input distribution \(p(x)\) changes while the decision boundary \(p(y \mid x)\) remains stable. The broader drift taxonomy from Data drift detection and response also includes concept drift, in which \(p(y \mid x)\) itself shifts.
- Significance: It represents a violation of the i.i.d. assumption (independent and identically distributed), causing accuracy to erode monotonically with the distributional divergence \((\mathcal{D}(P_t \lVert P_0))\), empirically modeled as \(\text{Accuracy}(t) \approx \text{Accuracy}_0 - \lambda \cdot \mathcal{D}(P_t \lVert P_0)\) with \(\lambda\) fit per deployment. Because \(p(y \mid x)\) is unchanged, retraining on fresh \(p(x)\) data can recover performance (when the new input distribution overlaps the original support), unlike concept drift, where the label relationship must also be re-learned.
- Distinction: Unlike model decay (which implies internal failure, where the algorithm or code degraded), data drift is an external force (market shifts, sensor aging, user behavior change) that invalidates the model’s learned mapping without any engineering error.
- Common pitfall: A frequent misconception is that drift is detectable by monitoring model outputs. By the time output drift is visible, the system has often already been serving degraded predictions for weeks. Monitoring input feature statistics (\(\mathcal{D}(P_t \lVert P_0)\) via PSI or KL divergence) provides earlier warning because input shift precedes output shift by the length of the ground-truth feedback loop.
Because of drift, a deployed model behaves less like software (which does not break unless changed) and more like inventory (which decays over time). This is the statistical drift invariant at work: the degradation equation \((\text{Accuracy}(t) \approx \text{Accuracy}_0 - \lambda \cdot \mathcal{D}(P_t \lVert P_0))\) predicts that accuracy erodes in proportion to the distributional divergence \(\mathcal{D}(P_t \lVert P_0)\), regardless of code quality. Every monitoring strategy in this chapter exists to detect this divergence before it compounds into business impact.
The Rotting Asset Curve plot (figure 8) puts this entropy into perspective by contrasting two maintenance strategies. The orange sawtooth pattern represents scheduled retraining: accuracy resets at a fixed interval, whether the model is still healthy or has already fallen below the drift threshold. This approach is simple but can be both wasteful and late because the calendar, not observed degradation, drives the update. The green line represents trigger-based retraining: accuracy is continuously monitored, and retraining fires when drift detection signals that the threshold has been crossed. The decay rate and intervals are illustrative, but the qualitative behavior is robust.
The two curves turn drift from an abstract statistical problem into an operations policy choice. Scheduled retraining is easy to plan but can retrain too early or too late; trigger-based retraining requires stronger telemetry but aligns intervention with observed degradation.
Layered monitoring and drift quantification
The statistical drift invariant established earlier tells us that accuracy decays in proportion to distributional divergence. Quantifying that decay requires two layers of telemetry: infrastructure metrics that reveal whether the serving system itself is the bottleneck, and distribution metrics such as PSI that reveal whether the data has moved. Gradual long-term degradation is particularly insidious because it can evade coarse detection thresholds: small day-to-day changes in a quality metric can compound into material degradation over a year without tripping monthly alerts. Seasonal patterns compound this complexity. A model trained in summer may perform well through autumn but fail in winter conditions it never observed. Detecting such gradual degradation requires multi-timescale monitoring: performance baselines across multiple time horizons (daily, weekly, quarterly), sliding window comparisons that detect slow trends, and seasonal performance profiles that account for cyclical patterns.
The first layer is infrastructure-level monitoring, which tracks indicators such as CPU and GPU utilization, memory and disk consumption, network latency, and service availability. Raw utilization alone is deceptively uninformative: as table 16 showed, identical 90 percent GPU-utilization readings can indicate compute-bound, memory-bound, or I/O-bound behavior, so a production dashboard must correlate GPU utilization with memory-bandwidth utilization to separate efficient tensor computation from a data-movement stall. Power-efficiency metrics (for example, inferences per joule or FLOP/s/W, depending on workload) add a cost-normalized view that enables mixed-workload scheduling for both economic and environmental impact.
Systems Perspective 1.2: Iron law in production monitoring
These utilization patterns map directly to the iron law of ML systems (Iron Law of ML Systems). Monitoring reveals which term dominates:
- Compute-bound (high GPU utilization, low memory bandwidth utilization): Limited by \(O/(R_{\text{peak}} \cdot \eta_{\text{hw}})\). Optimize kernels, use Tensor Cores, or upgrade hardware.
- Memory-bound (moderate GPU utilization, high memory bandwidth utilization): Limited by \(D_{\text{vol}}/\text{BW}\). Optimize with quantization, pruning, or batching.
- I/O-bound (low GPU utilization, low memory bandwidth utilization): Limited by data pipeline latency. Fix the DataLoader, not the model.
The iron law doubles as a diagnostic framework for production systems. When latency SLAs are violated, the monitoring dashboard indicates which term to investigate.
Thermal monitoring integrates into operational scheduling decisions, particularly for sustained high-utilization deployments where thermal throttling can degrade performance unpredictably. Modern MLOps monitoring dashboards incorporate thermal headroom metrics that guide workload distribution across available hardware, preventing thermal-induced performance degradation that can violate inference latency SLAs. Tools such as Prometheus27 (Cloud Native Computing Foundation 2024b), Grafana (Labs 2024), and Elastic (Elastic NV 2024) are widely used to collect, aggregate, and visualize these operational metrics. These tools often integrate into dashboards that offer real-time and historical views of system behavior.
27 Prometheus: Its pull-based model, where a central server scrapes metrics from target systems, is what enables the aggregated operational dashboard view described. For the thermal-aware scheduling mentioned, the critical trade-off is metric granularity; monitoring per-accelerator thermals allows precise workload routing but at high data cost, while cheaper server-level aggregates can mask the component-level throttling that violates latency SLAs. A typical scrape interval of 15–60 seconds dictates the system’s reaction time to a thermal event.
Cloud Native Computing Foundation. 2024b. Prometheus: Monitoring System and Time Series Database.
Labs, Grafana. 2024. Grafana.
Elastic NV. 2024. Elasticsearch: Distributed Search and Analytics Engine.
Collecting all of these signals at production scale introduces its own cost constraints. Those constraints force engineering teams to make deliberate trade-offs between monitoring granularity and infrastructure expense.
Napkin Math 1.5: The economics of observability
Trade-off: “Measure everything” is physically impossible at scale. Equation 11 shows that observability cost scales linearly with sampling frequency and metric cardinality: \[ \text{Cost} \approx \text{Frequency} \times \text{Metrics} \times (\text{Ingest Cost} + \text{Storage Cost}) \tag{11}\]
Frequency is measured in samples per unit time, Metrics is the count of emitted metric series after labels and cardinality expansion, and the cost terms are unit prices per ingested or retained data point. The product is an operating cost rate, not a one-time setup cost.
Both data volumes follow from the same two-step arithmetic. At full fidelity (1 s sampling), every request’s telemetry enters the stream: 1M req/s \(\times\) 1 KB of telemetry per request = 1 GB/s. Stretching the interval to 60 s spreads that same stream over a window 60× longer, so the sampled volume is 1 GB/s ÷ 60 \(\approx\) 16.7 MB/s. Table 18 places the two regimes side by side with their cost impact.
| Sampling | Granularity | Data Volume (1M req/s) | Cost Impact |
|---|---|---|---|
| 1 s | Micro-bursts | ~1 GB/s | High (Requires dedicated cluster) |
| 60 s | Trends | ~16.7 MB/s | Low (Standard sidecar) |
Recommendation: Use dynamic sampling. Sample 1 percent of successful requests but 100 percent of errors. Use high-frequency (1 s) monitoring only for aggregate counters (like error rate), but low-frequency (60 s) for high-cardinality data (like user-level distribution sketches). Section 1.5.3.1.4 provides worked examples for budgeting monitoring infrastructure.
The remaining question is how alerting mechanisms convert statistical signals into actionable responses before the cost of silent failure exceeds the cost of intervention. Proactive alerting mechanisms notify teams when anomalies or threshold violations occur. A sustained drop in model accuracy may trigger drift investigation; infrastructure alerts can signal memory saturation or degraded network performance. The design of these alerts determines the gap between when degradation begins and when an engineer acts on it, and that gap translates directly into business impact at scale.
Example 1.3: Recommendation monitoring at scale
Context: A large streaming recommendation service must monitor ranking quality while viewing patterns, content catalogs, and regional cohorts evolve.
Insight: Traditional infrastructure monitoring can miss ML-specific degradation as viewing patterns shift, content libraries change, and user cohorts evolve across regions. A stronger monitoring system combines statistical process control (control charts for detecting metric excursions), cohort-based monitoring (tracking subpopulations separately), counterfactual evaluation (estimating what would have happened under another ranking or policy), and interleaving experiments (mixing two rankers in one user experience to compare preference signals) to catch quality loss that aggregate metrics hide.
Systems lesson: Alerting is only useful when the monitored signal matches the failure mode. Recommendation systems need cohort and counterfactual signals because global averages can remain stable while specific user groups or content regions degrade.
Data quality monitoring
Model and infrastructure monitoring tracks outputs. By the time output metrics degrade, however, the underlying problem may have existed for days or weeks. Data quality monitoring catches issues before they propagate through the system. In production ML, monitoring inputs is often more important than monitoring outputs because data issues are a common source of model degradation. The first guardrail is executable input validation, as listing 4 shows: schema expectations reject malformed batches before inference, turning a data-quality assumption into a testable contract.
schema.require_column("user_id")
schema.require_type("timestamp", "datetime")
schema.require_non_null("feature_a")
schema.require_range("age", min_value=0, max_value=120)
schema.require_mean_between(
"purchase_amount", min_value=10, max_value=1000
)Input data validation
Schema28 validation catches structural problems before they reach the model. The common rule categories are column existence checks, type enforcement, null detection, and statistical bounds.
28 Schema Validation: The rules in listing 4 prevent silent data contract violations, such as a feature column changing from an integer to a float or a new category appearing that was absent during training. Without this input-level guardrail, downstream model monitoring cannot distinguish a data quality error from a true performance regression, masking the root cause. A schema mismatch in a critical feature can invalidate an otherwise well-formed prediction batch.
Feature distribution monitoring
Schema validation catches structural corruption (missing columns, wrong types, null values) but cannot detect the subtler failure mode where data arrives in the correct format but from a shifted distribution. A feature representing user age might pass every schema check while its mean silently migrates from 32 to 45 over three months as a marketing campaign attracts an older demographic. This distributional shift degrades model predictions long before any structural anomaly appears. Statistical distance measures quantify this divergence by comparing current feature distributions against training baselines. Table 19 specifies representative alert thresholds for three common metrics, with PSI suited for categorical features, KS statistics for continuous distributions, and Jensen-Shannon divergence for comparing full probability distributions with a symmetric, bounded KL-derived measure.
| Metric | Alert Threshold | Use Case |
|---|---|---|
| Population Stability Index (PSI) | PSI > 0.2 | Categorical and binned features |
| Kolmogorov-Smirnov statistic | KS > 0.1 | Continuous feature distributions |
| Jensen-Shannon divergence | JS > 0.1 | Probability distributions |
Understanding why we use these thresholds requires looking at the math. The Population Stability Index (PSI)29 quantifies distributional shift by comparing expected (training) vs. actual (serving) frequencies across bins (Measuring drift (divergence) develops the mathematical foundations of KL divergence, PSI, and information theory for systems monitoring). Equation 12 formalizes this: \[ \text{PSI} = \sum_{i=1}^{n} (\text{actual}_i - \text{expected}_i) \times \ln\left(\frac{\text{actual}_i}{\text{expected}_i}\right) \tag{12}\]
29 Population Stability Index (PSI): PSI is widely used in credit-risk scorecard monitoring to compare expected and observed binned populations; Yurdakul and Naranjo analyze its statistical properties (Yurdakul and Naranjo 2020). The common 0.1 and 0.2 bands are useful operational conventions, not universal statistical laws. ML operations adopted PSI because it works on binned categorical or continuous features and provides an interpretable drift score that non-specialists can review.
Yurdakul, Bilal, and Joshua Naranjo. 2020. “Statistical Properties of the Population Stability Index.” The Journal of Risk Model Validation 52. https://doi.org/10.21314/jrmv.2020.227.
For continuous distributions, Kullback-Leibler (KL) divergence offers a more sensitive alternative, though PSI’s symmetric properties often make it preferred for drift alerting. Equation 13 defines the local KL-specific notation \(\mathcal{D}_{\text{KL}}\); elsewhere in this volume, \(\mathcal{D}(P_t \lVert P_0)\) denotes a generic statistical divergence in the degradation equation: \[ \mathcal{D}_{\text{KL}}(p \lVert q) = \sum_{x} p(x) \log\left(\frac{p(x)}{q(x)}\right) \tag{13}\]
To see this in practice, consider a recommendation system monitoring user age. A shift from “younger” to “older” demographics might look subtle on a histogram but generates a clear PSI signal, decomposed bin by bin in table 20:
| Age Bin | Training | Serving | Difference | ln(Serving/Training) | Contribution |
|---|---|---|---|---|---|
| 18–25 | 15% | 12% | -0.03 | -0.223 | 0.0067 |
| 26–35 | 25% | 22% | -0.03 | -0.128 | 0.0038 |
| 36–45 | 20% | 18% | -0.02 | -0.105 | 0.0021 |
| 46–55 | 18% | 20% | +0.02 | +0.105 | 0.0021 |
| 56–65 | 12% | 15% | +0.03 | +0.223 | 0.0067 |
| 66+ | 10% | 13% | +0.03 | +0.262 | 0.0079 |
The total PSI is 0.029 (Stable). The training and serving columns are shown as percentages, while the difference column is expressed in proportion units, so a 3 percentage-point shift appears as \(\pm 0.03\). Even though specific bins shifted by 3 percentage points, the aggregate drift is well below the 0.1 warning threshold. This calculation prevents false alarms from minor fluctuations while remaining sensitive to systematic shifts.
Data freshness monitoring
Feature stores and data pipelines can become stale without triggering obvious errors. Data freshness monitoring catches that failure mode, and listing 5 shows a configuration that monitors feature freshness and triggers fallback behavior when data becomes stale.
user_purchase_history feature for staleness, alerting operations teams via PagerDuty and Slack and falling back to default values when the feature exceeds the maximum allowed age.
# Example freshness alert configuration
feature: user_purchase_history
max_staleness: 6h
alert_channels: [pagerduty, slack]
on_stale:
action: fallback_to_default
default_value: []Failures at different layers produce different symptoms and demand different responses.
Checkpoint 1.2: The monitoring stack
ML monitoring is layered, not monolithic. Can you diagnose which layer explains each symptom?
The same stack must watch the data sources that feed the ML system: database replication lag, API endpoint availability, and extract, transform, load (ETL) job completion status. In one representative incident pattern, a recommendation system detects a material shift in user_lifetime_value distribution within two days and traces the issue to a database migration that changed aggregation logic. Without data quality monitoring, this kind of issue can degrade recommendations for weeks before accuracy metrics detect the problem.
Monitoring cost model
Observability infrastructure incurs costs that scale with monitoring granularity. Understanding these costs enables rational decisions about monitoring depth vs. budget constraints.
Cost components
Monitoring costs break down into four categories, as equation 14 decomposes: \[\text{Monitoring Cost} = C_{\text{ingest}} + C_{\text{storage}} + C_{\text{compute}} + C_{\text{alert}} \tag{14}\]
The four \(C_*\) terms are cost components over the same accounting window: data ingestion, retained storage, query or dashboard compute, and alert-rule evaluation. Separating them matters because each scales with a different control knob.
Table 21 provides representative unit-cost assumptions for each component:
| Component | Typical Unit Cost | Scaling Factor |
|---|---|---|
| Metric Ingestion | $0.10–0.50 per million data points | \(\text{Number of metrics} \times \text{sample rate}\) |
| Log Storage | $0.50–2.00 per GB/month | \(\text{Log verbosity} \times \text{retention period}\) |
| Query Compute | $0.01–0.05 per query | \(\text{Dashboard refresh rate} \times \text{users}\) |
| Alert Evaluation | $0.001–0.01 per evaluation | \(\text{Number of alert rules} \times \text{check frequency}\) |
Translating these unit costs into a concrete budget estimate clarifies the real expense of monitoring even a single production model.
Example 1.4: Single-model monitoring budget
Scenario: Consider monitoring a single ML node (one production model) with:
- one model with 3 deployment variants (production, canary, staging), each emitting 50 metrics
- Metrics sampled every 15 seconds
- Retention requirement: 30 days
- 2 dashboards (model health, infrastructure), 3 team members, five-minute refresh
Metric ingestion:
- Data points per month: 3 \(\times\) 50 \(\times\) (4 samples/min \(\times\) 60 \(\times\) 24 \(\times\) 30 days) = 25.9M
- Cost at $0.30/million: $7.8/month
Storage:
- At 8 bytes/point compressed: 25.9M \(\times\) 8 bytes = 0.2 GB
- Cost at $1/GB: $0.21/month
Query compute:
- Queries per month: 2 dashboards \(\times\) 3 users \(\times\) (12 queries/hour \(\times\) 8 hours/day \(\times\) 22 days) = 12,672 queries/month
- Cost at $0.02/query: $253/month
Total: ~$261.4/month for a single ML node
Systems insight: This scales linearly. Platform teams managing fifty-plus models face additional constraints where query cost optimization becomes critical.
Cost optimization strategies
The dominant cost driver in monitoring infrastructure is metric cardinality: high-cardinality labels such as user_id or request_id create a combinatorial explosion in storage requirements that can dwarf compute costs. Addressing cardinality through sampling or aggregation for high-cardinality dimensions typically yields the largest immediate savings. The second major cost driver is temporal resolution: storing all metrics at 15-second granularity for 30 days is rarely necessary, yet it is the default in many monitoring systems. A tiered retention policy (high-resolution for recent incidents, downsampled data for longer history) preserves debugging fidelity while reducing storage. Dashboard query costs accumulate more subtly: each refresh triggers queries against the metrics backend, and default auto-refresh intervals across dozens of dashboards and users generate continuous query load even when no one is actively watching. Setting slower refresh intervals for noncritical dashboards and auto-pausing inactive tabs can reduce query costs. Finally, alert configuration affects both compute costs and operational effectiveness: consolidating related alerts into multi-condition rules reduces evaluation overhead while also reducing alert fatigue, aligning cost optimization with operational quality.
Cost-benefit framework
Justify monitoring investments against incident costs using the monitoring ROI formula in equation 15: \[\text{Monitoring ROI} = \frac{\text{Incidents Prevented} \times \text{Avg Incident Cost}}{\text{Annual Monitoring Cost}} \tag{15}\]
If average incident costs $50,000 (downtime + engineering time + reputation) and monitoring prevents 5 incidents annually at $50,000 monitoring cost:
\[ \text{ROI} = \frac{5 \times \$50,000}{\$50,000} = 5× \]
This framework helps justify monitoring investments and prioritize which metrics deserve fine-grained observation vs. coarse sampling. The monitoring systems themselves require resilience planning to prevent operational blind spots. When primary monitoring infrastructure fails (Prometheus experiencing downtime or Grafana becoming unavailable), teams risk operating blind during critical periods. Production-grade MLOps implementations therefore maintain redundant monitoring pathways: secondary metric collectors that activate during primary system failures, local logging that persists when centralized systems fail, and heartbeat checks that detect monitoring system outages.
Some organizations implement cross-monitoring where separate infrastructure monitors the monitoring systems themselves, ensuring that observation failures trigger immediate alerts through alternative channels such as PagerDuty or direct notifications. This defense-in-depth approach prevents the catastrophic scenario where both models and their monitoring systems fail simultaneously without detection. A circuit breaker30 adds a further safeguard, automatically routing traffic away from a failing service when its error rate exceeds a threshold. Coordinating these safeguards across many replicated services, with consensus-based alerting and cross-region metric aggregation, is a fleet-scale concern that arises once a model is replicated across regions, beyond the single-node scope here.
30 Circuit Breaker Pattern: Automatic failure detection that “opens” when error rates exceed configured thresholds, routing traffic away from failing services. In ML systems, the pattern requires a critical adaptation: prediction accuracy degradation demands different thresholds than service availability failures, because a model returning plausible but incorrect predictions triggers no error signal, leaving the circuit breaker blind to the most dangerous failure mode.
Incident response and operational practices
Monitoring and drift detection identify problems; the practices in this section resolve them and sustain operational health over time. Incident response, debugging, and on-call rotations form the human side of the Production-Monitoring Interface, ensuring that statistical signals translate into timely engineering action.
Incident response for ML systems
At 2:00 AM, an on-call engineer receives an alert: recommendation click-through rate has dropped 12 percent over the past hour. There is no stack trace, no error log, no crashed process, just a statistical signal that something has changed. The responder must distinguish among four candidate root causes: an upstream data-pipeline failure, model drift, a seasonal traffic pattern, or statistical noise. This ambiguity distinguishes ML incidents from traditional software incidents: symptoms manifest as accuracy degradation rather than explicit errors, and incident response must account for the probabilistic nature of the system.
Severity classification provides the foundation for prioritizing response in this ambiguous landscape. Table 22 defines four priority levels with associated response times, from P0 complete failures requiring 15-minute response to P3 minor anomalies allowing 24-hour investigation.
Once severity is assigned, the incident response process follows a structured checklist whose order narrows the search at each step:
- Detection determines which monitoring signal triggered the alert.
- Impact assessment quantifies what percentage of traffic is affected.
- Responders review recent changes to identify whether any models, features, or data pipelines were deployed.
- Mitigation options are evaluated, including rollback, fallback enablement, or traffic reduction.
- Root cause analysis determines whether the issue stems from the model, data, or infrastructure.
| Level | Criteria | Response Time | Example |
|---|---|---|---|
| P0 | Complete model failure, serving errors | 15 minutes | Model returns null predictions |
| P1 | Significant accuracy degradation (>10%) | 1 hour | Recommendation CTR drops 15% |
| P2 | Moderate drift, localized impact | 4 hours | One feature shows PSI > 0.3 |
| P3 | Minor anomalies, no user impact | 24 hours | Training pipeline delay |
For P0 and P1 incidents, postmortem documentation is required. These postmortems must include timeline, root cause, user impact, and preventive measures. ML-specific elements include identifying which monitoring gap allowed the issue to reach production and what validation would have caught it earlier.
Model debugging: From detection to diagnosis
Incident response triages and mitigates; model debugging identifies root causes. Monitoring detects that something is wrong; debugging determines why. ML debugging differs from traditional software debugging because failures are probabilistic rather than deterministic. A model producing incorrect predictions does not throw exceptions or generate stack traces, making systematic debugging approaches essential for resolving ML incidents efficiently.
The debugging decision tree
When model performance degrades, work through these diagnostic questions in order. For a systematic diagnostic matrix that maps symptoms to D·A·M (Data · Algorithm · Machine) axes, see Production Troubleshooting in the D·A·M appendix.

Production debugging starts on the data axis of D·A·M.
- Is it the data? Check for upstream data pipeline failures, schema changes, missing values, or distribution shifts. Data is often the first place to look because many production ML failures originate in changing inputs, labels, or feature pipelines.
- Is it training-serving skew? Compare feature distributions between training and production. Use the KS statistic or PSI to identify divergent features.
- Is it a specific subpopulation? Slice performance by key dimensions (geography, device type, user segment). Degradation localized to one slice suggests a data coverage or labeling issue.
- Is it temporal? Plot performance over time. Sudden drops indicate deployment or data issues; gradual decline suggests concept drift.
- Is it the model? Only after eliminating data issues, examine model behavior through prediction analysis and feature attribution.
This sequence makes slice analysis the first deepening step once a global degradation has been detected, because it tests whether the apparent system-wide problem is actually concentrated in a subpopulation.
Slice analysis
Performance metrics aggregated across all traffic can mask significant problems in subpopulations. Slice analysis exposes that masking, and table 23 illustrates how overall accuracy can hide severe degradation in specific segments.
Feature attribution for debugging
When slice analysis identifies a problematic segment, feature attribution techniques help identify which features drive incorrect predictions. Listing 6 demonstrates a workflow that uses SHAP values, feature-attribution scores that estimate how much each input feature contributed to an individual prediction, to analyze mispredictions within a specific slice.
| User Segment | Traffic % | Accuracy | Impact |
|---|---|---|---|
| Desktop users | 45% | 94% | Nominal |
| Mobile (iOS) | 30% | 92% | Nominal |
| Mobile (Android) | 20% | 88% | Minor degradation |
| Tablet users | 5% | 62% | Severe—investigate |
| Overall | 100% | 91% | Masks tablet problem |
# SHAP-based debugging workflow
import shap
# Select mispredicted examples from problematic slice
errors = predictions[
(predictions.actual != predictions.predicted)
& (predictions.device_type == "tablet")
]
# Compute SHAP values for error cases
explainer = shap.Explainer(model)
shap_values = explainer(errors[feature_columns])
# Identify features with high attribution for errors
shap.summary_plot(shap_values, errors[feature_columns])Common findings from feature attribution debugging include: stale features (feature store not updating for specific segments), missing feature coverage (features undefined for edge cases), and feature distribution shift (feature semantics changed in production).
Systems Perspective 1.3: Zombie features
Long-lived production models often accumulate features whose original owners, semantics, or intended use have faded. A feature can be deprecated in application code while still flowing through a feature store, training dataset, or serialized model input contract. The model may learn to ignore it, split signal across a duplicate, or depend on a preprocessing artifact that nobody still owns. Removing such a feature is therefore no longer a local cleanup: it becomes a compatibility change that can affect retraining, serving, monitoring, and downstream analysis.
Features in ML systems do not disappear just because code owners stop thinking about them. Without explicit deprecation policies and feature-store governance, models accumulate “dead code” that consumes resources and complicates debugging (Sculley et al. 2015).
Zombie features show that attribution can reveal what a model should no longer depend on. For individual mispredictions, counterfactual analysis adds the complementary view: the minimal change that would flip a single decision.
Counterfactual analysis
For individual mispredictions, counterfactual analysis identifies the minimal change that would flip the prediction: if session_duration were 45 seconds instead of 12 seconds, the model would predict “engaged” instead of “churned.” This reveals which feature boundaries drive decisions and whether those boundaries make semantic sense. Counterfactuals that require implausible changes (“user age would need to be -5 years”) often indicate feature engineering problems.
These techniques (decision trees, slice analysis, feature attribution, and counterfactuals) form a debugging toolkit. To apply them consistently, teams codify the process.
Debugging checklist
Systematic debugging follows a six-phase debugging checklist that mirrors the scientific method: observe, isolate, hypothesize, test, confirm, and generalize. The ordering is deliberate because each phase narrows the search space for the next. Reproduction comes first because an ML failure that cannot be reproduced on held-out data is often data-dependent, an insight that redirects investigation toward the D·A·M taxonomy’s data layer. Once reproduced, isolation identifies the minimal input set that triggers the failure, transforming a diffuse “the model is wrong” complaint into a specific, testable condition.
Bisection then exploits version history: if the failure correlates with a recent deployment, comparing model versions pinpoints which change introduced the regression. Feature attribution applies the interpretability techniques from the preceding sections to identify which input factors drive the erroneous behavior. Validation closes the causal loop by confirming that the hypothesized root cause, when corrected, actually resolves the failure, distinguishing genuine fixes from coincidental improvements.
The final phase, prevention, converts each resolved incident into a monitoring rule or validation check, systematically closing the gap between detection and recurrence. This cumulative hardening explains why mature ML systems experience fewer novel failure modes over time: each incident permanently strengthens the observability infrastructure.
Debugging ML systems requires both systematic methodology and domain expertise. The most effective debugging often comes from engineers who understand both the model architecture and the business context of the predictions.
On-call practices for ML systems
The preceding debugging techniques work when an engineer is actively investigating an issue during business hours. Production systems, however, fail at 3:00 AM on weekends, and the person responding may not be the one who built the model. Debugging resolves individual incidents; on-call practices sustain operational health over time by ensuring that someone with appropriate expertise is always available and equipped to respond. On-call rotation for ML systems requires specialized practices beyond traditional software operations because ML incidents often manifest as gradual degradation rather than hard failures. A traditional software engineer responding to an alert can typically trace a stack trace to a root cause within minutes. An ML engineer facing a 3 percent accuracy drop must first determine whether the change represents statistical noise, legitimate concept drift, or a critical failure requiring immediate rollback. This distinction demands statistical context rather than simple log analysis.
This ambiguity compounds with delayed impact visibility. Unlike latency spikes that surface immediately in dashboards, ML degradation may take hours or days to manifest in business metrics. A recommendation model that began serving slightly worse suggestions on Monday might not produce measurable revenue impact until Friday, by which time the window for easy diagnosis has closed. Cross-system dependencies further complicate response: ML issues often originate in upstream data systems owned by different teams, requiring coordination across organizational boundaries during incident response. The deepest challenge is that effective response demands understanding model behavior, not infrastructure health alone. A database administrator can restart a crashed service without understanding its business logic, but an ML engineer cannot meaningfully debug accuracy degradation without understanding the model’s feature dependencies and expected behavior patterns.
These challenges motivate tiered escalation structures that match expertise to incident complexity. Table 24 illustrates a recommended on-call structure for ML teams, where primary responders handle routine issues using standardized runbooks while escalation paths connect to specialists capable of deeper investigation. The parallel data on-call role deserves particular attention. Since data issues cause the majority of ML incidents, having a data engineer available alongside the ML on-call dramatically reduces time-to-resolution for upstream problems. Without this parallel structure, ML engineers waste hours investigating model behavior only to discover that the root cause lies in a data pipeline they cannot access or modify.
| Tier | Responder | Responsibility |
|---|---|---|
| Tier 1 (Primary) | ML Engineer | Initial triage, standard runbooks, escalation decisions |
| Tier 2 (Escalation) | Senior ML Engineer/Data Scientist | Complex debugging, cross-system investigation, model-specific issues |
| Tier 3 (Critical) | ML Platform Lead | Architecture decisions, major incidents, vendor escalation |
| Data On-Call (Parallel) | Data Engineer | Data pipeline issues, feature store problems, upstream dependencies |
Effective on-call depends heavily on runbook quality. Every production ML model should have documentation covering the model’s purpose, ownership, and business criticality alongside its normal operating parameters—expected latency, throughput, and accuracy ranges that define healthy behavior. Historical incidents and their resolutions provide templates for common failure patterns, while diagnostic commands enable rapid health assessment: how to check recent predictions, feature distributions, and model confidence scores. Critically, runbooks must specify escalation criteria (when to wake up Tier 2 vs. when to rollback without approval) and rollback procedures with step-by-step instructions and expected recovery times. Runbooks written during calm periods save critical minutes during 3:00 AM incidents.
Even well-designed monitoring can generate excessive alerts that erode on-call effectiveness. Alert fatigue, the tendency to ignore or dismiss alerts after experiencing too many false positives, represents a significant operational risk. Teams combat fatigue through consolidation, grouping related alerts so that multiple features drifting simultaneously generate a single notification rather than dozens. Adaptive thresholds that account for weekly and seasonal patterns prevent predictable variations from triggering unnecessary pages. Measuring alert actionability provides empirical guidance: alerts acted upon less than 10 percent of the time should be retired or recalibrated. When temporary silencing is necessary, accountability mechanisms (requiring a follow-up ticket before snoozing) prevent alerts from being permanently ignored.
Shift handoffs represent another critical practice that distinguishes mature operations. Incoming on-call engineers need context about active incidents and their current status, recent deployments that might cause delayed issues, upcoming scheduled changes such as data migrations or model updates, and any alerts that were suppressed along with the reasoning. Without structured handoffs, context is lost between shifts, and incoming engineers waste time rediscovering information their predecessors already gathered.
Sustainable on-call practices must also address burnout. ML on-call carries particular stress due to incident ambiguity: the uncertainty of not knowing whether an alert represents a real problem demands constant vigilance. Organizations mitigate burnout by limiting consecutive on-call days, providing compensatory time off after high-severity incidents, conducting regular rotation reviews to balance load across team members, and investing in automation that reduces toil. The goal is to make on-call rotations sustainable over years of operation, not to staff them as an afterthought.
Technical monitoring capabilities alone do not ensure operational success. The most sophisticated dashboards fail if no one is responsible for acting on alerts, and the most detailed runbooks languish if team structures do not support their use. Production ML operations require organizational infrastructure paralleling the technical: clear governance, defined roles, and communication patterns that enable cross-functional coordination.
Governance and team coordination
On-call practices address operational emergencies, but production ML also requires proactive governance and cross-functional collaboration. Governance encompasses the policies and practices ensuring that ML models operate transparently, fairly, and in compliance with ethical and regulatory standards. Without it, deployed models may produce biased or opaque decisions, creating legal, reputational, and societal risks. Governance focuses on three core objectives: transparency (interpretable, auditable models), fairness (equitable treatment across user groups), and compliance (alignment with legal and organizational policies). The specific interpretability methods, fairness metrics, and bias detection techniques that operationalize these objectives are examined in Responsible Engineering; MLOps provides the infrastructure to enforce these checks continuously throughout the deployment lifecycle.
What makes ML governance uniquely challenging is its lifecycle scope. Unlike traditional software compliance, which can be verified at release time, ML governance must span development, deployment, and operation. During development, teams must document model assumptions and training data provenance. At deployment, prerelease audits evaluate fairness and robustness. Postdeployment, the monitoring systems discussed in the previous section must track not only performance degradation but also fairness drift, where concept drift disproportionately affects specific user subgroups. Governance policies encoded into automated pipelines ensure that these checks are applied consistently rather than relying on ad hoc human review.
Concretely, a model registry promotion gate might require a signed feature contract, a recorded training-data lineage hash, subgroup metrics above policy thresholds, a canary SLO with rollback criteria, and a named artifact owner before the model can move from staging to production. That gate turns governance from a meeting into a release invariant enforced by the same CI/CD machinery that deploys the model.
Governance establishes policies, but cross-functional collaboration implements them. Machine learning systems are developed and maintained by multidisciplinary teams, and the boundaries between roles create the most failure-prone points in the entire lifecycle. Shared experiment tracking, model registries, and standardized documentation provide the connective tissue that enables reproducibility and eases handoff between specialists. Equally important is shared understanding of data semantics: glossaries, schema references, and lineage documentation ensure that all stakeholders interpret features, labels, and statistics consistently.
While titles vary across organizations, five core ML team roles emerge consistently. Table 25 maps these roles to their primary responsibilities:
| Role | Primary Focus | Key Deliverables | Collaboration Points |
|---|---|---|---|
| Data Scientist | Model development, experimentation, algorithm selection | Trained models, experiment results, performance benchmarks | Hands off to ML Engineer for productionization |
| ML Engineer | Production ML systems, training pipelines, serving infrastructure | Deployed models, training pipelines, serving systems | Receives from Data Scientist; works with Platform Engineer on infrastructure |
| Data Engineer | Data pipelines, feature engineering, data quality | Feature pipelines, data quality systems, feature stores | Provides data to Data Scientist; maintains feature store for ML Engineer |
| Platform Engineer | MLOps infrastructure, tooling, automation | CI/CD pipelines, monitoring systems, compute infrastructure | Enables ML Engineer; maintains shared infrastructure |
| DevOps/SRE | Reliability, incident response, system health | SLOs/SLAs, on-call procedures, runbooks | Supports all roles; owns production health |
Clear role definitions matter most at handoff points, where work transitions between specialists. The most failure-prone handoff occurs between Data Scientists and ML Engineers: a model that performs well in a Jupyter notebook may fail in production due to undocumented preprocessing steps, hardcoded file paths, or environment dependencies. Similarly, the handoff from ML Engineers to SREs (Beyer et al. 2016) requires verified monitoring dashboards, configured alerting rules, documented runbooks, and tested rollback procedures. Data Engineers hand off to the broader ML team through feature contracts, formal specifications of schema, freshness SLOs, and quality guarantees that prevent silent pipeline changes from surfacing as mysterious model degradation weeks later. Organizations mitigate these handoff risks through standardized model interfaces, required documentation, and reproducibility requirements that must be verified before each transition.
Beyer, Betsy, Chris Jones, Jennifer Petoff, and Niall Richard Murphy. 2016. Site Reliability Engineering: How Google Runs Production Systems. O’Reilly Media.
Stakeholder communication
Effective MLOps extends beyond internal team coordination to the broader communication challenges that arise when technical teams interface with business stakeholders. Cross-functional collaboration addresses coordination within technical teams; stakeholder communication bridges technical and business domains. Effective MLOps bridges these domains by translating machine learning realities into terms stakeholders can act on. Unlike deterministic software, machine learning systems exhibit probabilistic performance, data dependencies, and degradation patterns that stakeholders often find counterintuitive.
The most common communication challenge emerges from oversimplified improvement requests. Product managers frequently propose “make the model more accurate” without understanding underlying trade-offs. Effective communication reframes such requests by presenting concrete options: improving accuracy from 85 percent to 87 percent might require substantially more labeled data and a slower model that violates the latency budget. Articulating specific constraints transforms vague requests into informed business decisions.
Translating technical metrics into business impact requires consistent frameworks connecting model performance to operational outcomes. A 5 percent accuracy improvement appears modest in isolation, but contextualizing this as “reducing false fraud alerts from 1,000 to 800 daily customer friction incidents” provides actionable business context.
This connection is not linear. Figure 9 exposes this nonlinearity: the optimal operating point for a model is rarely the point of highest accuracy. It is the point where the combined cost of False Positives (for example, blocking a legitimate user) and False Negatives (for example, missing fraud) is minimized.
Incident communication presents another critical challenge. When models degrade or require rollbacks, maintaining stakeholder trust depends on clear categorization: temporary performance fluctuations as normal variation, data drift as planned maintenance requirements, and system failures demanding immediate rollback. Regular performance reporting cadences preemptively address reliability concerns.
Resource justification requires translating technical requirements into business value. Rather than requesting “eight A100 GPUs for model training,” effective communication frames investments as “infrastructure to reduce experiment cycle time from weeks to days, enabling faster feature iteration.” Timeline estimation must account for realistic proportions: data preparation and deployment integration often dominate the schedule, while model development is only one part of the work.
Consider a fraud detection team implementing model improvements. When stakeholders request enhanced accuracy, the team responds with a structured proposal: increasing detection rates from 92 percent to 94 percent requires integrating external data sources, extending training duration by two weeks, and accepting 30 percent higher infrastructure costs, but would prevent an estimated $1 million in annual fraud losses while reducing false positive alerts affecting 50,000 customers monthly.
Through disciplined stakeholder communication, MLOps practitioners maintain organizational support while establishing realistic expectations about system capabilities. This communication competency is as essential as technical expertise for sustaining successful ML operations.
ML test score
A release-readiness assessment needs a shared inventory of the debt patterns that can make a model unsafe to deploy even when its offline metrics look acceptable. Table 26 consolidates the patterns discussed throughout this chapter, providing the reference that the assessment rubric below builds on.
| Debt Pattern | Primary Cause | Key Symptoms | Mitigation Strategies |
|---|---|---|---|
| Boundary Erosion | Tightly coupled components, unclear interfaces | Changes cascade unpredictably, CACHE principle violations | Enforce modular interfaces, design for encapsulation |
| Correction Cascades | Sequential model dependencies, inherited assumptions | Upstream fixes break downstream systems, escalating revisions | Careful reuse vs. redesign trade-offs, clear versioning |
| Undeclared Consumers | Informal output sharing, untracked dependencies | Silent breakage from model updates, hidden feedback loops | Strict access controls, formal interface contracts, usage monitoring |
| Data Dependency Debt | Unstable or underutilized data inputs | Model failures from data changes, brittle feature pipelines | Data versioning, lineage tracking, leave-one-out analysis |
| Feedback Loops | Model outputs influence future training data | Self-reinforcing behavior, hidden performance degradation | Cohort-based monitoring, canary deployments, architectural isolation |
| Pipeline Debt | Ad hoc workflows, lack of standard interfaces | Fragile execution, duplication, maintenance burden | Modular design, workflow orchestration tools, shared libraries |
| Configuration Debt | Fragmented settings, poor versioning | Irreproducible results, silent failures, tuning opacity | Version control, validation, structured formats, automation |
| Prototype Debt | Rapid prototyping shortcuts, tight code-logic coupling | Inflexibility as systems scale, difficult team collaboration | Flexible foundations, intentional debt tracking, planned refactoring |
With those debt patterns in one place, awareness alone is insufficient; teams need a systematic technical debt assessment rubric that transforms subjective “is this system ready?” conversations into quantifiable evaluations. The ML Test Score (Breck et al. 2017) provides a systematic rubric for evaluating production readiness across four categories: data tests, model tests, ML infrastructure tests, and monitoring tests. The paper defines 28 tests in total, seven per section, with partial or full credit for each test. Readiness is tracked by section rather than by a simple grand-total maturity band: a system with strong model tests but weak monitoring still carries production risk. Table 27 summarizes representative tests practitioners should implement:
- Data section: Validates feature expectations, privacy controls, and whether each feature is beneficial relative to its operational cost.
- Model section: Validates reviewed model specifications, hyperparameter discipline, staleness limits, and offline-online metric alignment.
- Infrastructure section: Validates reproducible training, rollback, training-serving consistency, and deployment gates.
- Monitoring section: Validates alerts for dependency changes, data invariants, skew, and model staleness.
| Category | Test | Implementation Example |
|---|---|---|
| Data Tests | Feature expectations are captured in schema | Great Expectations, TFX Data Validation |
| All features are beneficial (no unused features) | Feature importance analysis, ablation studies | |
| No feature’s cost exceeds its benefit | Latency/accuracy trade-off analysis | |
| Data pipeline has appropriate privacy controls | PII detection, access logging | |
| Model Tests | Model spec is reviewed and checked into version control | Git-tracked model configs |
| Offline and online metrics are correlated | A/B test validation of offline improvements | |
| All hyperparameters are tuned | Automated HPO with tracked results | |
| Model staleness is measured and bounded | Performance decay monitoring | |
| Infrastructure Tests | Training is reproducible | Fixed seeds, versioned data, locked dependencies |
| Model can be rolled back to previous version | Model registry with versioning | |
| Training and serving code paths are tested for consistency | Feature store integration tests | |
| Model quality is validated before serving | Automated validation gates in CI/CD | |
| Monitoring Tests | Dependency changes result in alerts | Data schema monitoring |
| Data invariants hold in training and serving | Distribution comparison tests | |
| Training and serving features are not skewed | Training-serving skew detection | |
| Model staleness triggers retraining | Automated retraining pipelines |
Quarterly audits against this rubric, prioritizing tests that address the most frequent incident types, reveal where operational investments will yield the highest reliability gains. Checking boxes is necessary but not sufficient. Production readiness requires understanding how practices integrate into a coherent system and how organizations evolve their capabilities over time.
Self-Check: Question
A team wants to validate a high-risk new model on real production traffic without exposing users to its predictions. Which deployment pattern best matches that goal?
- Shadow deployment, mirroring live traffic to the candidate model while users continue to receive the incumbent’s responses
- Blue-green deployment, switching all user-visible traffic between two fully warm environments at cutover
- Canary deployment, routing one percent of live user-visible traffic to the new model first
- Immediate full rollout, replacing the incumbent in a single atomic cutover
A service has a 100 ms P99 SLO. Network takes 15 ms, feature retrieval 25 ms, request parsing 5 ms, inference 45 ms, post-processing 5 ms, and response serialization 5 ms. If the team makes the model itself 2\(\times\) faster, what is the main lesson from the chapter’s latency-budget analysis?
- End-to-end latency will also improve by 2\(\times\), because inference is the ML-specific component
- The SLO will remain impossible because feature retrieval dominates all budgets
- The system improves only modestly overall because inference is less than half of total latency
- The optimization is wasted because only network RTT matters in production
Explain why low-traffic, high-stakes models can remain in a silent-failure state much longer than high-traffic models even when monitoring is in place.
Order the ML incident response flow described in the section: (1) Review recent model, feature, or pipeline changes, (2) Detect the triggering signal, (3) Evaluate mitigation such as rollback or fallback, (4) Assess traffic and user impact, (5) Perform root-cause analysis.
A GPU serving cluster reports moderate GPU utilization, very high memory-bandwidth utilization, and poor throughput. Which diagnosis and response best fits the chapter’s monitoring guidance?
- Compute-bound workload; add tensor parallelism before changing the model
- Memory-bound workload; reduce model size or use quantization to cut data movement
- I/O-bound workload; the request router is starved, so add more replicas without touching the model
- Healthy workload; high bandwidth utilization always indicates efficient serving
Which statement best captures how the ML Test Score should be used operationally?
- As a replacement for monitoring, because a high score proves the model will remain correct in production
- As a production-readiness rubric spanning data, model, infrastructure, and monitoring practices
- As a benchmark of model architecture quality independent of pipelines and operations
- As a measure of whether the team can skip human review during deployment
Design and Maturity Framework
An organization deploying its initial ML model might rely on a hand-run Jupyter notebook, a scheduled cron job, and minimal monitoring. A mature enterprise runs thousands of models through automated pipelines with drift detection, canary deployments, and continuous validation. Both are doing “MLOps,” yet the gap between them spans orders of magnitude in reliability, cost efficiency, and engineering velocity. Deployment case studies show that practical challenges appear across the ML deployment workflow (Paleyes et al. 2022). This chapter uses operational maturity as a systems lens for that progression: organizations evolve from ad hoc experimentation toward fully automated operations, and understanding where a team stands on this continuum is as important as knowing the technical components themselves. Identifying what investments yield the highest returns at each stage guides resource allocation more effectively than adopting tools indiscriminately.
Paleyes, Andrei, Raoul-Gabriel Urma, and Neil D. Lawrence. 2022. “Challenges in Deploying Machine Learning: A Survey of Case Studies.” ACM Computing Surveys 55 (6): 1–29. https://doi.org/10.1145/3533378.
Maturity levels
The ML Test Score assesses individual practices. Operational maturity captures something broader: the systemic integration of those practices into a coherent whole. The key distinction is not which tools a team has adopted but how well infrastructure, automation, monitoring, governance, and collaboration work together across the ML lifecycle. Lifecycle tools such as MLflow address parts of that workflow (Zaharia et al. 2018), but maturity is the organizational ability to make the pieces work together. Although operational maturity exists on a continuum, distinguishing broad maturity levels helps illustrate how ML systems evolve from research prototypes to production-grade infrastructure.
Zaharia, Matei, Andrew Chen, Aaron Davidson, Ali Ghodsi, Sue Ann Hong, Andy Konwinski, Siddharth Murching, et al. 2018. “Accelerating the Machine Learning Lifecycle with MLflow.” IEEE Data Engineering Bulletin 41 (4): 39–45.
At the lowest level, ML workflows are ad hoc: experiments run manually, models train on local machines, and deployment involves hand-crafted scripts. As maturity increases, workflows become structured: teams adopt version control, automated training pipelines, and centralized model storage. At the highest levels, systems are fully integrated with infrastructure-as-code, continuous delivery pipelines, and automated monitoring that support large-scale deployment and rapid experimentation.
The distinguishing marker at each stage is not which tools a team adopts but how tightly infrastructure, automation, and monitoring integrate across the lifecycle—table 28 shows that the leap from ad hoc to scalable is primarily an architectural shift from isolated scripts to a cohesive system.
| Maturity Level | System Characteristics | Typical Outcomes |
|---|---|---|
| Ad Hoc | Manual data processing, local training, no version control, unclear ownership | Fragile workflows, difficult to reproduce or debug |
| Repeatable | Automated training pipelines, basic CI/CD, centralized model storage, some monitoring | Improved reproducibility, limited scalability |
| Scalable | Fully automated workflows, integrated observability, infrastructure-as-code, governance | High reliability, rapid iteration, production-grade ML |
Consider how a fraud detection system evolves across these maturity levels:
- Ad hoc: A data scientist trains a model in a Jupyter notebook, exports it as a pickle file, and hands it to an engineer who deploys it to a single server. When accuracy drops, the data scientist retrains manually by running the notebook again with fresh data. Debugging requires the original data scientist because no one else understands the preprocessing steps.
- Repeatable: The training script is version-controlled, with a scheduled Jenkins job that retrains monthly. Features are computed in a SQL script that engineering maintains separately. The model is deployed via container, with basic accuracy monitoring. When the feature SQL changes, the data scientist must manually verify the model still works.
- Scalable: Training and serving use the same feature store, eliminating skew. A CI/CD pipeline automatically retrains when drift exceeds PSI > 0.2, validates the new model against the baseline, and deploys via canary release. Monitoring tracks per-merchant accuracy, triggering investigation when specific segments degrade. The entire lineage from raw data to production prediction is auditable.
The investment required to move between levels is substantial and often spans months of engineering effort, but the reduction in incident frequency and debugging time can justify the cost for production-critical systems.
These maturity levels provide a systems lens through which to evaluate ML operations, not in terms of specific tools adopted, but in how reliably and cohesively a system supports the full machine learning lifecycle. Understanding this progression prepares practitioners to identify design bottlenecks and prioritize investments that support long-term system sustainability.
System design implications
Maturity levels describe organizational stages; system design implications describe the architectural consequences. At each level, the system architecture evolves in response to new expectations around modularity, automation, monitoring, and fault tolerance.
In low-maturity environments, ML systems are monolithic: data processing logic embedded in model code, configurations managed informally, and deployments handled through ad hoc scripts. These architectures enable rapid experimentation but lack the separation of concerns needed for maintainability or safe iteration. As maturity increases, modular abstractions emerge: feature engineering decouples from model logic, pipelines become declarative, and system boundaries are enforced through APIs. At high maturity, ML systems exhibit properties of production-grade software (stateless services, contract-driven interfaces, environment isolation, and observable execution) where data, models, and infrastructure co-evolve through closed feedback loops.
Figure 10 captures this architectural reality as an iceberg. What stakeholders see (uptime, the visible tip) represents only a fraction of what must work correctly beneath the surface. The hidden mass below the waterline shows the threats that can sink a system even when it appears healthy: data drift, concept drift, broken pipelines, schema changes, model bias, and underperforming segments. Operational maturity must address all three domains (data health, model health, service health) simultaneously.

The three threat categories in the iceberg map to distinct failure mechanisms. Data health threats (drift, staleness, and schema changes) erode the statistical assumptions a model was trained on, often without any change to the model itself. Model health threats (accuracy degradation, bias amplification, and feedback loops) compound silently because the model continues to produce outputs that appear well-formed even as their quality decays. Infrastructure health threats (configuration sprawl, pipeline fragmentation, and stale dependencies) undermine reproducibility and recoverability. None of these categories triggers a traditional server-down alert, which is precisely why they persist undetected in low-maturity environments.
Design patterns and anti-patterns
The most sophisticated infrastructure fails without the organizational patterns to operate it effectively. A feature store cannot prevent training-serving skew if no one owns the feature definitions; automated monitoring cannot catch drift if alerts route to the wrong team. As ML systems grow in complexity, organizational patterns must evolve to match.
In mature environments, organizational design emphasizes clear ownership and interface discipline. Platform teams may take responsibility for shared infrastructure and CI/CD pipelines while domain teams focus on model development and business alignment. Interfaces between teams (feature definitions, data schemas, and deployment targets) are well-defined and versioned.
One effective pattern is a centralized MLOps team providing shared services to multiple model development groups. Such structures promote consistency and reduce duplicated effort. Alternatively, some organizations adopt a federated model, embedding MLOps engineers within product teams while maintaining a central architectural function for system-wide integration.
Anti-patterns emerge when responsibilities are fragmented. The tool-first approach (adopting infrastructure tools without first defining processes and roles) results in fragile pipelines and unclear handoffs. Siloed experimentation, where data scientists operate in isolation from production engineers, leads to models that are difficult to deploy or retrain effectively.
Organizational drift presents another challenge: as teams scale, undocumented workflows become entrenched and coordination costs increase. Organizational maturity must co-evolve with system complexity through communication patterns, role definitions, and accountability structures that reinforce modularity, automation, and observability.
These organizational patterns must be supported by technical architectures handling the unique reliability challenges of ML systems. MLOps inherits distributed systems challenges but adds complications through learning components requiring adaptations for probabilistic behavior. Traditional fault tolerance assumes failures are obvious: a service either responds or it does not. ML systems introduce a third state: responding incorrectly, with no error signal to distinguish bad predictions from good ones.
Circuit breaker patterns must account for model-specific failure modes, where prediction accuracy degradation requires different thresholds than service availability failures. Bulkhead patterns31 become critical when isolating experimental model versions from production traffic. These patterns require resource partitioning strategies that prevent resource exhaustion in one model from affecting others. The Byzantine fault tolerance32 problem takes on new characteristics in MLOps environments, where “Byzantine” behavior includes models producing plausible but incorrect outputs rather than obvious failures.
31 Bulkhead Pattern: This pattern partitions system resources to contain failures within isolated zones. For isolating experimental models, a bulkhead dedicates a fixed compute and memory budget to the new version. This resource partition ensures that a catastrophic failure in the experiment, such as a memory leak, cannot exhaust all available resources and cause a system-wide production outage.
32 Byzantine Fault Tolerance: In ML systems, the classic Byzantine failure model shifts from arbitrary node failures to “semantic failures,” where models produce plausible but incorrect predictions that pass health checks. Unlike a system crash, these semantic failures do not trigger availability-focused circuit breakers, silently corrupting application outcomes. The strict Byzantine fault-tolerance result requires \(3f+1\) replicas to tolerate \(f\) arbitrary faults (Lamport et al. 1982); ML ensembles are only an analogy because model errors can be correlated rather than independent.
Lamport, Leslie, Robert Shostak, and Marshall Pease. 1982. “The Byzantine Generals Problem.” The Byzantine generals problem in Concurrency: The Works of Leslie Lamport, vol. 4. Association for Computing Machinery. https://doi.org/10.1145/3335772.3335936.
Traditional consensus algorithms focus on agreement among correct nodes, but ML systems require consensus about model correctness when ground truth may be delayed or unavailable. These reliability patterns form the theoretical foundation distinguishing robust MLOps implementations from fragile ones.
Contextualizing MLOps
Best practices are rarely deployed in pristine environments. Every ML system operates within a specific context that shapes how practices are implemented: physical constraints (edge compute, power budgets), regulatory requirements (healthcare, finance), or organizational realities (team size, skill distribution). A standard CI/CD pipeline may be infeasible without direct host access; monitoring may require indirect signals or on-device anomaly detection; data collection may be limited by privacy regulations. These adaptations are expressions of maturity under constraint, not departures from the principles.
At the highest levels of operational maturity, the single-model practices established here become building blocks for larger organizational capabilities. Organizations operating many ML nodes simultaneously often consolidate into platform architectures that provide shared infrastructure, centralized governance, and economies of scale. The transition from individual ML nodes to platform-scale infrastructure introduces qualitatively different challenges (cross-model resource allocation, system-level observability, fault tolerance for interdependent AI systems) that extend beyond our single-model scope. The key insight is that solid ML node practices are prerequisite to platform success: every gap in single-model monitoring, testing, or deployment becomes multiplied across the model portfolio.
MLOps investment economics
The operational benefits of MLOps become persuasive only when the investment matches the model’s production value. For a single ML node, the decision is whether deployment speed, incident reduction, and monitoring coverage justify the operational spend; for a portfolio, the same economics compound into platform investment.
Single-model MLOps investment
For a single production ML system, the first threshold is the annual cost of making the node observable, deployable, and recoverable. Table 29 summarizes the main cost categories:
| Component | Typical Cost | Justification |
|---|---|---|
| CI/CD pipeline setup | $10–30K one-time | Reduces deployment time from days to hours |
| Monitoring and alerting | $2–10K/year | Catches degradation before user impact |
| Feature store (basic) | $5–20K/year | Eliminates training-serving skew |
| Model registry | $0–5K/year | Enables rollback, audit trails |
| Engineering time | 1–2 FTE-months setup | Initial automation and integration |
Single-model ROI calculation
The return threshold then depends on model criticality: a revenue-facing model can justify more operational spend because avoided incidents and deployment-time savings have measurable value. Equation 16 formalizes that single-node calculation: \[\text{Annual ROI} = \frac{\text{Incidents Avoided} \times \text{Avg Incident Cost} + \text{Time Savings} \times \text{Hourly Cost}}{\text{Annual MLOps Investment}} \tag{16}\] where Incidents Avoided is the count of production failures the tooling prevents per year and Avg Incident Cost is the loss per failure, so their product is the value of avoided incidents; Time Savings is the engineer-hours that automation reclaims per year and Hourly Cost is the loaded labor rate, so their product is the value of recovered labor; the denominator is the annual cost of the tooling itself. The ratio expresses every dollar of investment in dollars returned.
For a model generating $1M annual revenue with:
- 4 incidents/year avoided (at $25K each) = $100K saved
- 20 hours/month deployment time saved (at $150/hr) = $36K saved
- MLOps investment of $30K/year
\[ \text{ROI} = \frac{\$100K + \$36K}{\$30K} = 4.5× \]
When to invest more
The 4.5× return means the investment is not justified by tooling elegance; it is justified because the model is expensive enough that preventing incidents and shortening deployments outweigh the annual platform spend. The returns from single-model MLOps practices compound when teams add additional models. The transition from operating several independent ML nodes to building a centralized platform involves different economics entirely, including shared infrastructure amortization, platform team overhead, and cross-model coordination costs.
For single-model operations, the key insight is: invest in MLOps proportional to model criticality. A model driving $10M in annual revenue justifies more operational rigor than an internal analytics model. Start with monitoring and CI/CD (highest ROI), then add feature stores and automated retraining as the model matures.
The preceding technical infrastructure and economic framework provide the foundation; the case studies that follow demonstrate how these elements combine in production systems. Each case demonstrates specific implementations of the five foundational principles, identifying where reproducibility appears, how observable degradation is achieved, and what triggers automation.
Self-Check: Question
Which description best fits the ‘Repeatable’ maturity level in the chapter’s framework?
- Manual local training, no version control, and unclear ownership
- Automated retraining on drift with integrated observability, feature-store consistency, and canary release
- Basic automation such as training pipelines, centralized model storage, and some monitoring, but limited scalability
- Centralized platform operations for a large multi-model fleet with full cross-region coordination
Explain the architectural lesson of the uptime iceberg in the section.
Which organizational pattern is presented as effective when many teams need shared ML infrastructure but also domain-specific model ownership?
- A centralized MLOps function providing shared services, or a federated model with embedded MLOps engineers and central architecture
- Keeping data scientists isolated from production engineers so experimentation stays fast
- Letting every product team invent its own pipeline and registry choices to maximize flexibility
- Deferring role definitions until after tooling is deployed, since tools create process naturally
True or False: An organization that owns a feature store, a model registry, a CI/CD pipeline, and a monitoring platform has, by the chapter’s framework, effectively reached the scalable maturity level.
A single production model is business-critical, but the team has limited budget for its first MLOps investments. According to the investment-economics section, which sequence is most justified?
- Start with monitoring and CI/CD because they usually provide the highest ROI, then add feature stores and automated retraining as the model matures
- Build a full platform-scale fleet management system before improving single-model operations
- Prioritize feature stores first for every model, even when skew has not been observed and deployment is still manual
- Delay all MLOps investment until multiple incidents prove the model is already unstable
Case Studies
A battery-powered sleep-tracking ring and AI/ML-based medical software governed by FDA lifecycle expectations (U.S. Food and Drug Administration 2021) face different operational constraints. The principles, patterns, and infrastructure examined throughout this chapter converge differently depending on the deployment context. We examine two cases: the Oura Ring, where pipeline debt and configuration management challenge resource-constrained edge environments, and ClinAIOps, where feedback loops and governance requirements drive specialized healthcare operations. The comparison starts with the shared principles, because the domains differ most in how those principles are implemented.
U.S. Food and Drug Administration. 2021. Artificial Intelligence/Machine Learning (AI/ML)-Based Software as a Medical Device (SaMD) Action Plan. U.S. Department of Health; Human Services.
Table 30 lays out how the two environments implement the five foundational MLOps principles. Domain constraints (edge hardware, clinical regulation) reshape how each principle is realized without changing which principles matter. In the Oura case, polysomnography (PSG) refers to the clinical sleep-study measurements used as the reference labels.
| Principle | Oura Ring | ClinAIOps |
|---|---|---|
| Reproducibility | Versioned synchronized wearable and PSG datasets | Audit trails, decision provenance |
| Separation of concerns | Independent data, training, and serving layers with edge-specific deployment pipeline | Distinct clinical validation and deployment stages with regulatory compliance isolation |
| Consistency | PSG-aligned preprocessing across training and on-device inference | Standardized clinical data pipelines ensuring training-serving parity |
| Observable degradation | On-device anomaly detection, limited telemetry | Cohort-specific monitoring, outcome tracking |
| Cost-aware automation | Battery-aware retraining triggers, CI/CD for edge balancing accuracy and resource cost | Automated model updates with human-in-loop gates balancing update cost and patient risk |
The principles stay stable, but their implementation changes with the deployment regime. Edge systems spend the automation budget on battery, telemetry, and constrained updates; clinical systems spend it on auditability, validation gates, and accountable human control. The two case studies that follow trace how each environment earns those entries.
Oura Ring case study
The Oura Ring exemplifies MLOps practices applied to consumer wearable devices, where embedded ML must operate under strict resource constraints while delivering accurate health insights. This case study traces the full operational lifecycle—from the clinical data collection that established ground truth, through the model development process that improved sleep stage classification, to the over-the-air deployment pipeline and iterative refinement cycle that sustains the system in production. The constraints imposed by a battery-powered ring with limited compute make every MLOps decision visible in a way that cloud-scale systems can obscure.
Context and motivation
The Oura Ring is a consumer-grade wearable monitoring sleep, activity, and physiological recovery through embedded sensing and computation. By measuring motion, heart rate, and body temperature, the device estimates sleep stages and delivers personalized feedback. Unlike traditional cloud-based systems, much of the data processing and inference occurs directly on the device.
The central objective was improving sleep stage classification accuracy to align more closely with polysomnography (PSG)33, the clinical gold standard. Initial evaluations showed 57 percent four-stage sleep classification accuracy for an accelerometer-only model, compared with 79 percent for models that included autonomic nervous system and circadian features. Published human PSG inter-scorer reliability is about 82 percent to 83 percent, framing the remaining gap between wearable inference and expert clinical scoring. The 22 percentage-point gain closes roughly 84.6–88 percent of the baseline-to-human-agreement gap, so the remaining improvement target is real but bounded by the noisiness of the clinical reference itself. This discrepancy prompted an effort to re-evaluate data collection, preprocessing, and model development workflows.
33 Polysomnography (PSG): A multi-parameter sleep study that provides the clinical ground truth data for this classification task. This ‘truth’ is inherently noisy; expert human scorers interpreting the same PSG recordings agree with each other at about 82 percent–83 percent reliability. This inter-rater agreement establishes a practical accuracy ceiling, framing the Oura study’s 57 percent accelerometer-only baseline and 79 percent enhanced model as a meaningful but still imperfect approach to clinical sleep staging.
Altini, Marco, and Hannu Kinnunen. 2021. “The Promise of Sleep: A Multi-Sensor Approach for Accurate Sleep Stage Detection Using the Oura Ring.” Sensors 21 (13): 4302. https://doi.org/10.3390/s21134302.
To overcome performance limitations, the Oura team constructed a diverse dataset grounded in clinical standards through a study involving 106 participants from three continents (Altini and Kinnunen 2021). Each participant wore the Oura Ring while simultaneously undergoing PSG, yielding 440 nights of data and 3,444 hours of time-synchronized recordings that aligned wearable sensor data with validated sleep annotations. The scale and diversity of the collection captured physiological variation as well as environmental and behavioral factors critical for generalizing across a real-world user base.
The study consolidated synchronized accelerometer, temperature, heart-rate, heart-rate-variability, and PSG data from research Oura rings, then resolved temporal alignment and preprocessing requirements for downstream model development. These workflows address data dependency debt patterns by emphasizing robust versioning and lineage tracking, avoiding unstable dependencies that commonly plague embedded ML systems.
With high-quality data in place, the next operational question was whether extra sensing justified its cost on the device. The team developed models classifying sleep stages under the ring’s limited memory and compute budget, so model design had to prioritize efficiency alongside predictive accuracy. The team explored two configurations: one using only accelerometer data for minimal energy consumption, and another incorporating heart rate variability and body temperature to capture autonomic nervous system activity and circadian rhythms. Through 5-fold cross-validation against PSG annotations and iterative tuning, the enhanced models achieved 79 percent four-stage classification accuracy, a significant improvement from the 57 percent accelerometer-only baseline toward the clinical benchmark. These gains reflect the broader impact of an MLOps approach integrating data collection, reproducible training pipelines, and disciplined evaluation: structured documentation and version control of model parameters avoided the fragmented settings that often undermine embedded ML deployments, while requiring close collaboration among data scientists, ML engineers, and DevOps engineers.
Following validation, deployment shifted the problem from model quality to update safety. An Oura-like edge deployment must decide which parts of the model run continuously on-device, which richer signals can be used under looser memory and battery budgets, and how model updates reach devices already in the field. To keep that split maintainable, the operational toolchain needs reproducible model conversion, versioned artifacts, and over-the-air (OTA)34 update procedures that preserve consistency across devices in the field.
34 Over-the-Air (OTA) Updates: The mechanism used to deploy optimized models to devices already in the field, bypassing the need for physical access. The small footprint from quantization and pruning matters because constrained edge networks may need to transmit only changed model artifacts rather than complete application bundles. This process makes consistency a critical concern; a failed update can corrupt the on-device model, breaking the ML pipeline until a future connectivity window allows for a fix.
The operational lesson is that edge MLOps is not governed by accuracy alone; it is governed by accuracy under battery, privacy, telemetry, and weak ground truth constraints. Consider the DS-CNN (Tiny Constraint) archetype from table 4, where monitoring relies on operational metrics such as duty cycle and false positive rate rather than continuous ground-truth labels, and retraining occurs quarterly through OTA updates. The transition from 57 percent accelerometer-only accuracy to 79 percent multi-sensor accuracy required systematic configuration management across data collection, feature sets, model architectures, and deployment targets.
Those constraints explain how the foundational principles appear without repeating them as a checklist. Versioned wearable and PSG datasets make each model traceable to the evidence used to train it. Modular tiered architectures keep data collection, model training, and on-device serving separate enough that quantization, pruning, and fallback policies can change without destabilizing the whole pipeline. PSG-aligned preprocessing preserves consistency between training and on-device inference, while privacy-preserving telemetry makes degradation observable through duty cycle, battery impact, inference failures, confidence, anomaly rates, and periodic labeled studies. OTA deployment then becomes the cost-aware automation boundary: updates must justify their accuracy gain against battery impact, validation burden, and the risk of changing software on a device worn continuously by users.
This case exemplifies how MLOps principles adapt to domain-specific constraints. When machine learning moves into clinical applications, additional complexity emerges, requiring frameworks that address regulatory compliance, patient safety, and clinical decision-making.
ClinAIOps case study
Healthcare ML deployment presents challenges extending beyond resource constraints. Traditional MLOps frameworks often fall short in domains requiring extensive human oversight, domain-specific evaluation, and ethical governance. Continuous therapeutic monitoring (CTM)35 exemplifies a domain where MLOps must evolve to meet clinical integration demands.
35 Continuous Therapeutic Monitoring (CTM): Healthcare approach using wearable sensors for real-time physiological data collection and personalized treatment adjustments. CTM forces MLOps to confront constraints absent in typical deployments: feedback loops must include human-in-the-loop approval for safety-critical decisions, retraining requires clinician-validated labels rather than implicit signals, and model updates must satisfy regulatory compliance before deployment. These constraints reshape every MLOps principle, making CTM a stress test for operational maturity.
CTM uses wearable sensors to collect real-time physiological and behavioral data from patients. AI systems must be integrated into clinical workflows, aligned with regulatory requirements, and designed to augment rather than replace human decision-making. The traditional MLOps paradigm does not adequately account for patient safety, clinician judgment, and ethical constraints.
ClinAIOps (Chen et al. 2023), a framework for operationalizing AI in clinical environments, shows how MLOps principles must evolve for regulatory and human-centered requirements. Unlike conventional MLOps, ClinAIOps directly addresses feedback loop challenges by designing them into the system architecture. The framework’s structured coordination between patients, clinicians, and AI developers represents practical implementation of governance and collaboration principles.
Standard MLOps falls short in clinical environments because healthcare requires coordination among diverse human actors, clinical decision-making hinges on personalized care and shared accountability, and health data must comply with strict privacy regulations. ClinAIOps presents a framework that balances technical rigor with clinical utility and operational reliability with ethical responsibility.
Feedback loops
Three interlocking feedback loops enable safe, adaptive integration of machine learning into clinical practice. Figure 11 maps these loops as a circular flow among three stakeholders. Patients contribute continuous monitoring data from wearable sensors and receive bounded AI-assisted guidance. Clinicians receive AI-generated summaries, alerts, and recommendations, then apply clinical judgment by setting therapy regimens and approval limits. AI developers receive continuous feedback from patients and clinicians, using real-world performance and workflow signals to improve models and deployment processes. The outer loop connecting all three stakeholders represents the full governance cycle.

Each feedback loop plays a distinct yet interconnected role:
- The patient treatment loop captures real-time physiological data and uses bounded AI outputs to support patient self-management.
- The clinician oversight loop ensures AI-assisted recommendations are reviewed, limited, and refined under professional supervision.
- The developer feedback loop gives AI developers continuous feedback from patients and clinicians so models, interfaces, and monitoring workflows can improve.
Together, these loops enable adaptive personalization, maintain clinician control, and promote continuous model improvement based on real-world feedback.
Patient treatment loop
The patient treatment loop enables personalized therapy optimization through continuous physiological data from wearable devices. Patients wear sensors such as continuous glucose monitors or ECG-enabled wearables that passively capture health signals.
The AI system analyzes these data streams alongside clinical context from electronic medical records, generating individualized recommendations for treatment adjustments. Treatment suggestions are tiered: minor adjustments within clinician-defined safety thresholds may be acted upon directly by the patient, while significant changes require clinician approval. This structure maintains human oversight while enabling high-frequency, data-driven adaptation.
Clinician oversight loop
The clinician oversight loop introduces human oversight into AI-assisted decision-making. The AI generates treatment recommendations with interpretable summaries of patient data including longitudinal trends and sensor-derived metrics.
For example, an AI model might recommend reducing antihypertensive medication for a patient with consistently below-target blood pressure. The clinician reviews the recommendation in context and may accept, reject, or modify it, and this feedback refines model alignment with clinical practice. Clinicians also define operational boundaries that ensure only low-risk adjustments are automated, preserving clinical accountability while integrating machine intelligence.
Developer feedback and patient-clinician coordination
Developer feedback and patient-clinician coordination shift clinical interactions from routine data collection to higher-level interpretation, shared decision-making, and model improvement. With AI handling data aggregation and trend analysis, clinicians engage more meaningfully: reviewing patterns, contextualizing insights, and setting personalized health goals.
For example, in diabetes management, a clinician may use AI-summarized data to guide discussions on dietary habits and physical activity. Visit frequency adjusts dynamically based on patient progress rather than fixed intervals. This positions the clinician as coach and advisor, interpreting data through the lens of patient preferences and clinical judgment. Feedback from these interactions gives AI developers evidence about model behavior, interface usability, and workflow fit.
Hypertension case example
Hypertension management illustrates how the three ClinAIOps loops work in practice. Because it affects a large share of adults and requires individualized, ongoing therapy adjustments, it is an ideal candidate for continuous therapeutic monitoring.
Data infrastructure
Research systems estimate systolic blood pressure indirectly from ECG, photoplethysmography (PPG)36, pulse-transit-time, and heart-rate features (Zhang et al. 2017). In a deployed hypertension workflow, those signals may be augmented by accelerometer data for activity context and self-reported medication adherence logs. Accuracy depends on validation, calibration, and regulatory authorization; consumer wrist or ring claims should not be treated as clinically reliable without such evidence. When validated for the intended population and setting, this multimodal data stream, integrated with electronic health records, can form the foundation for personalized AI recommendations.
36 Photoplethysmography (PPG): Optical technique detecting blood volume changes by measuring light absorption variations through green LEDs. For ML operations, PPG introduces a data quality challenge absent in controlled environments: motion artifacts from wrist movement corrupt the signal, creating a data drift pattern where the same physiological state produces different input distributions depending on user activity. Models must either filter corrupted windows before inference or learn to be robust to motion noise, and monitoring must distinguish genuine physiological changes from artifact-induced distribution shift.
Zhang, Qingxue, Dian Zhou, and Xuan Zeng. 2017. “Highly Wearable Cuff-Less Blood Pressure and Heart Rate Monitoring with Single-Arm Electrocardiogram and Photoplethysmogram Signals.” BioMedical Engineering OnLine 16 (1): 23. https://doi.org/10.1186/s12938-017-0317-z.
Loop implementation
Figure 12 shows how two of the three feedback loops manifest in hypertension management, with each panel highlighting one loop. The left panel illustrates the patient treatment loop, where the patient monitors blood pressure and receives bounded titration recommendations that the AI system can issue within clinician-defined safety thresholds; significant changes require explicit approval. The center panel depicts the clinician oversight loop, where longitudinal trend summaries flow from the AI system to the clinician, and the clinician sets approval limits and receives alerts for clinical risk events such as persistent hypotension or hypertensive crisis. The right panel captures the patient-clinician coordination that emerges once routine data collection moves to the AI loop: appointments shift to higher-level discussions of lifestyle factors and shared decision-making. The third loop (developer feedback) is not depicted in the figure; it is described in the prose above as the channel by which real-world workflow signals from both patients and clinicians inform model and interface improvements.

Chen, Emma, Shvetank Prakash, Vijay Janapa Reddi, David Kim, and Pranav Rajpurkar. 2023. “A Framework for Integrating Artificial Intelligence for Clinical Care with Continuous Therapeutic Monitoring.” Nature Biomedical Engineering 9 (4): 445–54. https://doi.org/10.1038/s41551-023-01115-0.
The three panels make the accountability boundary explicit: routine monitoring can be automated only inside clinician-defined limits, while escalation, adverse-event review, and treatment trade-offs remain human responsibilities. That boundary is the point where ordinary MLOps practices need the additional clinical coordination summarized next.
MLOps vs. ClinAIOps comparison
The hypertension case illustrates the ClinAIOps-MLOps comparison: traditional MLOps frameworks are often insufficient for high-stakes clinical domains. Conventional MLOps excels at technical lifecycle management but lacks constructs for coordinating human decision-making and ensuring ethical accountability.
ClinAIOps extends beyond technical infrastructure to support complex sociotechnical systems, embedding machine learning into contexts where clinicians, patients, and stakeholders collaboratively shape treatment decisions. Table 31 contrasts these approaches across eight dimensions.
| Traditional MLOps | ClinAIOps | |
|---|---|---|
| Focus | ML model development and deployment | Coordinating human and AI decision-making |
| Stakeholders | Data scientists, IT engineers | Patients, clinicians, AI developers |
| Feedback loops | Model retraining, monitoring | Patient treatment, clinician oversight, developer feedback |
| Objective | Operationalize ML deployments | Optimize patient health outcomes |
| Processes | Automated pipelines and infrastructure | Integrates clinical workflows and oversight |
| Data considerations | Building training datasets | Privacy, ethics, protected health information |
| Model validation | Testing model performance metrics | Clinical evaluation of recommendations |
| Implementation | Focuses on technical integration | Aligns incentives of human stakeholders |
The table’s central distinction is that clinical deployment changes who owns the risk. Technical performance remains necessary, but it is not sufficient when a recommendation affects care decisions. The ClinAIOps framework therefore changes the governing constraint from device efficiency to clinical accountability. The model participates in care, but it cannot own the clinical decision. Every recommendation must be reproducible from input data, model version, confidence score, and clinician action; otherwise the system cannot support audit, review, or outcome analysis. Separation of concerns becomes a safety mechanism rather than only a software design preference: automated data collection from wearables, AI recommendations, clinician diagnosis, treatment decisions, and developer workflow improvement each need explicit boundaries and human gates at critical decision points.
The same accountability requirement changes monitoring. Standardized clinical data pipelines preserve training-serving parity, but clinical validation also has to compare recommendations against standard-of-care outcomes, prospective evidence, and cohort-specific effects. Observable degradation is measured through blood pressure control, adverse events, clinician overrides, and subgroup outcomes, not just model metrics. Feedback loops are therefore not technical debt in this setting; patient treatment, clinician oversight, and developer feedback loops are intentional mechanisms that improve care while keeping authority with humans. Cost-aware automation operates inside those gates: updates can be automated only when their expected benefit justifies validation cost and patient risk, and conservative recommendations or uncertainty flags must route low-confidence cases back to clinical review.
Case study synthesis
The Oura Ring and ClinAIOps cases separate stable MLOps principles from the deployment constraints that reshape their implementation. Oura is a resource-envelope case: the operational system must preserve reproducibility, consistency, and observable degradation while battery, telemetry, and weak ground truth limit what can be measured and updated on the device. ClinAIOps is an accountability-envelope case: the same principles apply, but validation, audit trails, and human gates dominate because the model influences clinical action.
The shared engineering lesson is that MLOps maturity is not tool accumulation. It is the ability to identify the governing constraint, choose the operational controls that match it, and preserve evidence when the model changes. Production ML systems more commonly fail when teams import intuitions from deterministic software into probabilistic systems, which is why the chapter closes by naming the fallacies and pitfalls that these two case studies help expose.
Self-Check: Question
What did the Oura Ring case most directly demonstrate about implementing MLOps under edge constraints?
- Edge deployments can ignore graceful degradation because failures are localized to the device
- The main operational challenge is maximizing cloud GPU utilization for retraining
- Edge constraints force proactive design for resource-aware degradation, OTA updates, and tight preprocessing consistency
- Battery-powered devices remove the need for lineage tracking because the system is physically constrained
Explain why ClinAIOps treats feedback loops differently from the technical-debt framing earlier in the chapter.
Which comparison between the two case studies is most consistent with the chapter?
- Oura Ring emphasizes resource-constrained deployment mechanics, while ClinAIOps emphasizes regulation, auditability, and human-in-the-loop safety
- Oura Ring needs human oversight at every prediction, while ClinAIOps is mostly fully automated once deployed
- Both cases show that the five MLOps principles are replaced by domain-specific rules
- ClinAIOps focuses mainly on hardware quantization, while Oura Ring focuses mainly on cross-functional clinical governance
The Oura team moved four-stage sleep classification accuracy against polysomnography (PSG) from 57 percent to 79 percent, while the inter-rater agreement among expert human PSG scorers sits at 82 to 83 percent. Explain how the chapter uses these numbers to drive operational decisions about validation targets, retraining triggers, and when further model investment stops paying back.
Why is clinician override a central cost-aware automation mechanism in the ClinAIOps case rather than evidence that automation failed?
- Because healthcare models cannot be versioned or audited after deployment
- Because patient-risk cost dominates, so automation must operate within clinician-approved safety bounds
- Because clinical data drift is impossible to monitor directly
- Because automated recommendations are meant only for offline research, not real workflows
Fallacies and Pitfalls
These fallacies and pitfalls capture common errors that waste engineering resources, trigger production incidents, and cause silent accuracy degradation. Each connects to specific sections detailing the underlying mechanisms and solutions.
Fallacy: MLOps is just applying traditional DevOps practices to machine learning models.
Engineers assume standard CI/CD pipelines transfer directly to ML, but production ML requires specialized infrastructure. As section 1.4.2.1 showed, ML pipelines add data validation, model training, performance evaluation, artifact registration, and deployment gates that make them slower and more stateful than conventional software pipelines. Traditional DevOps can release deterministic services frequently; ML systems without specialized tooling often slow down because retraining and validation are stateful. Standard CI/CD tools do not by themselves handle feature stores, model registries, or drift detection. A recommendation system deployed using conventional DevOps can lose accuracy because the pipeline lacks training-serving consistency checks. Organizations that adopt DevOps without ML adaptations optimize the computational reliability of their infrastructure while neglecting the statistical behavior of their models, encountering silent model degradation, training-serving skew, and data quality failures that evade conventional testing.
Pitfall: Treating model deployment as a one-time event rather than an ongoing process.
Teams view deployment as a terminal milestone analogous to shipping software releases, but models degrade continuously due to data drift and distribution shift. Section 1.5.3.1 establishes PSI as one useful distribution-shift signal whose thresholds must be calibrated to the feature and business risk. A fraud detection model can move from below the warning threshold to above the review threshold within months, turning initially acceptable accuracy into material degradation. The optimal retraining interval follows \(T^* \approx \sqrt{\frac{2C}{Q \cdot V \cdot \text{Accuracy}_0 \cdot \gamma}}\) from section 1.4.2.2.3, where high-volume systems require more frequent retraining than low-drift domains. Production ML requires continuous monitoring of feature distributions, performance metrics, and automated retraining triggers throughout the operational lifecycle.
Fallacy: Automated retraining ensures optimal model performance without human oversight.
Engineers assume automated pipelines handle all maintenance scenarios, yet automation cannot detect all failure modes. Automated retraining can perpetuate biases in corrupted training data, trigger updates during peak traffic, or deploy models that pass aggregate validation but degrade edge cases. A news recommendation system retrained on weekend data might exhibit lower weekday engagement because user behavior differs sharply across weekday vs. weekend contexts. Effective MLOps requires escalation protocols for anomalous validation results, manual approval for unusual metric patterns, and override capabilities when automation produces questionable outcomes.
Pitfall: Focusing on technical infrastructure while neglecting organizational and process alignment.
Organizations invest in MLOps platforms expecting tooling to solve deployment problems, but sophisticated infrastructure fails without cultural transformation. MLOps demands coordination between data scientists optimizing for accuracy, engineers prioritizing latency, and business stakeholders focused on impact. A retail company may deploy feature stores and model registries yet maintain a slow deployment cadence because data scientists and engineers operate in isolation. Successful MLOps requires cross-functional teams with unified objectives, shared on-call rotations building empathy across roles, and incentive structures rewarding production reliability alongside model performance.
Fallacy: Training and serving environments automatically remain consistent once pipelines are established.
Teams assume that feature computation produces identical values across training and serving after initial pipeline setup, but training-serving skew emerges from subtle inconsistencies in preprocessing logic, timezone handling, or dependency versions. Section 1.4.1.2 demonstrates how a feature store reduces this risk by centralizing feature definitions and comparing feature distributions across environments. An e-commerce ranking model that computes session_length using wall-clock time in training but processing time in serving can suffer material accuracy loss that persists until someone compares feature distributions directly. Without centralized feature stores and automated consistency validation, skew detection can take weeks as degradation gradually becomes visible in aggregate metrics.
Pitfall: Assuming comprehensive monitoring prevents all production incidents.
Engineers believe sufficient metrics and dashboards eliminate surprise failures, but monitoring creates blind spots when teams track outputs without validating inputs. Section 1.5.3.1 establishes that input validation detects issues before they degrade predictions, yet many ML systems in practice monitor only accuracy and latency. A recommendation system can track click-through rate while ignoring feature staleness, missing embeddings that are hours out of date due to database replication lag. This can create engagement degradation before accuracy monitoring triggers alerts. Systems monitoring only outputs can detect failures late; adding data quality monitoring can reduce time to detection. Production ML requires layered monitoring with explicit SLAs for data freshness, schema validation, feature distributions, model outputs, and business metrics. Monitoring infrastructure itself needs redundancy to prevent blind operation during platform failures.
Fallacy: Accuracy is the first production signal to monitor.
Teams instrument production with accuracy dashboards and assume degradation will appear there first. Accuracy is a lagging indicator. A model’s accuracy can remain stable even as the input distribution drifts, because the model continues to memorize enough of the old distribution to maintain aggregate metrics on the slice it has seen before. By the time accuracy visibly degrades, the drift may have been accumulating for weeks. Monitoring input distributions with PSI or KL divergence (section 1.5.3.1) catches drift earlier and allows proactive retraining before accuracy crosses the SLO.
Pitfall: Routing leading-indicator alerts to a different channel than accuracy alerts.
Teams that do instrument drift and freshness signals often wire them to a dashboard or a low-priority queue separate from the on-call path that handles accuracy regressions, so the early warning fires but no one is paged. A leading indicator only buys time if it reaches the same response machinery, with the same severity classification and runbooks, that an accuracy drop would trigger; otherwise detection improves while time-to-response does not. The operational goal is to make accuracy the confirmation signal rather than the first sign of trouble, which holds only when the earlier signals are acted on with equal urgency.
Self-Check: Question
True or False: Once an ML pipeline is deployed and basic CI/CD is in place, training and serving will usually stay consistent unless engineers make an obvious code change.
Which pitfall best reflects the chapter’s warning about organizational alignment?
- Using shared on-call rotations to build empathy across roles
- Investing in tooling while data scientists, engineers, and business stakeholders still operate with fragmented objectives and handoffs
- Defining clear feature contracts between data and ML teams
- Starting with monitoring and CI/CD before adding more specialized infrastructure
Why is ‘treating deployment as a one-time event’ a dangerous operational mindset for ML systems?
Summary
MLOps exists because machine learning systems fail differently than traditional software. Where a crashed server throws exceptions and turns dashboards red, a degrading model continues serving predictions with full confidence while accuracy erodes invisibly. This fundamental difference (probabilistic systems that decay rather than crash) explains why the operational practices developed for deterministic software prove insufficient for ML, and why the discipline of machine learning operations emerged to close this observability gap.
The five foundational principles introduced at the chapter’s opening (section 1.2.1) provide an evaluation framework that applies regardless of scale or domain. Reproducibility through versioning addresses the root cause of many production incidents: untracked artifacts including data versions, configuration changes, and environment drift that make debugging impossible and rollbacks unreliable. Separation of concerns contains the blast radius when changes are required, preventing the boundary erosion and correction cascades that transform local fixes into system-wide regressions. The consistency imperative targets training-serving skew, the silent accuracy killer that appears when feature computation diverges between pipelines; feature stores implement this principle by computing features once and serving them everywhere. Observable degradation transforms the abstract “silent failure” problem into actionable alerts through layered monitoring that tracks data freshness, feature distributions, model outputs, and business metrics. Cost-aware automation replaces arbitrary retraining schedules with principled economics, using the staleness cost function \((T^* \approx \sqrt{\frac{2C}{Q \cdot V \cdot \text{Accuracy}_0 \cdot \gamma}})\) to quantify when accuracy decay justifies retraining expense.
The infrastructure components examined throughout the chapter directly implement these principles across the three critical interfaces introduced at the chapter’s opening. Feature stores and data versioning address the Data-Model Interface by ensuring training-serving consistency. CI/CD pipelines and model registries address the Model-Infrastructure Interface by enforcing reproducibility and enabling rollback. Monitoring systems, incident response frameworks, and on-call practices address the Production-Monitoring Interface by making degradation observable and actionable. The retraining decision framework enables cost-aware automation by connecting drift detection to economic thresholds. The case studies demonstrated that domain constraints reshape how principles are implemented without changing which principles matter: Oura Ring showed how edge constraints force proactive graceful degradation design, with the 57 percent to 79 percent accuracy improvement coming from systematic data management and feature integration rather than algorithmic innovation alone. ClinAIOps showed how regulatory requirements transform graceful degradation from optional to mandatory, with human-in-the-loop governance serving as the primary safety mechanism and the three feedback loops (patient treatment, clinician oversight, developer feedback) functioning as architectural patterns rather than operational overhead.
Key Takeaways: Perfectly available, perfectly wrong
- ML systems fail silently, and the degradation equation quantifies why: Unlike software that crashes, ML degrades gradually as the distributional divergence \(\mathcal{D}(P_t \lVert P_0)\) grows. A model can maintain perfect uptime while accuracy falls. Outcome monitoring is essential, not uptime tracking alone.
- Training-serving skew is a silent accuracy killer: Feature stores reduce skew by computing features once and serving them to both training and production, transforming continuous accuracy leakage into a one-time infrastructure investment.
- Retraining is an engineering optimization, not a guess: The staleness cost function \((T^* \approx \sqrt{2C/(Q \cdot V \cdot \text{Accuracy}_0 \cdot \gamma)})\) transforms retraining frequency from intuition into quantitative economics. High-volume systems may require daily retraining; stable domains sustain monthly intervals.
- Deploy through graduated rollout with pretested rollback: Canary, blue-green, and shadow deployments match risk profiles, with tiered rollback strategies that must be tested regularly through fire drills.
- Stage the investment: Monitoring and continuous integration/deployment typically provide the highest return on investment. A $10M model justifies more rigor than internal analytics. Add feature stores when training-serving skew becomes measurable; add automated retraining as the model matures.
- The five principles apply universally: Reproducibility (version everything), Separation of Concerns (modular layers), Consistency (feature stores), Observable Degradation (layered monitoring), and Cost-Aware Automation (retraining economics). Domain constraints change how each principle is implemented, not whether it is required.
- Operational maturity is staged and organizational: Managing one model differs qualitatively from managing many. The principles scale, but complexity grows superlinearly with fleet size, and shared on-call rotations and unified incentives are as critical as tooling.
The operational discipline examined in this chapter distinguishes production ML systems from development prototypes. The practitioners who internalize these principles can diagnose a degrading model and immediately identify whether the problem is data drift (check feature distributions), training-serving skew (compare preprocessing paths), configuration debt (audit recent changes), or feedback loop contamination (analyze temporal patterns). Those who treat production ML as “deploy and forget” discover their models have been silently wrong for months, eroding user trust and business value while dashboards showed green. As ML systems become critical infrastructure powering decisions from loan approvals to medical diagnoses, this operational discipline determines whether organizations can deploy AI responsibly at scale.
A traditional system can be perfectly available and therefore correct, because it breaks against its own code, and code does not move. A model breaks against the world. Its code can stay byte-for-byte identical while the data it was trained on drifts out from under it, so a system at full uptime can be confidently, silently wrong. That is why operations for ML cannot be inherited from software: the match between model and world is not a state reached once but a cost paid continuously, the data axis of D·A·M never holding still. Reliability here is measured in outcomes, not uptime, and the most dangerous state an ML system can occupy is a green dashboard resting on a drifting model.
What’s Next: From reliability to responsibility
We have built a system that is efficient, scalable, and reliable. A system can achieve 99.9 percent uptime and sub-10 ms latency, however, while still causing harm by amplifying bias or leaking data. In Responsible Engineering, we face the final and most difficult constraint: aligning our technical optimization with human values, ensuring that what we build serves the world we want to live in.
Self-Check: Question
Which pairing correctly matches an infrastructure component to the critical interface it primarily supports in the chapter’s summary?
- Feature stores -> Data-Model Interface
- Feature stores -> Production-Monitoring Interface
- Canary rollback drills -> Data-Model Interface
- Model registries alone -> Organizational governance interface
The chapter’s optimal retraining interval follows \(T^* \approx \sqrt{2C/(QVA_0\gamma)}\), where \(C\) is retraining cost, \(Q\) is query volume, \(V\) is value per accuracy point, \(A_0\) is current accuracy, and \(\gamma\) is temporal decay rate. A recommender suddenly faces a 4\(\times\) spike in query volume and a 4\(\times\) jump in decay rate while retraining cost and value per point stay fixed. What happens to the optimal retraining interval?
- It stays roughly the same because the two changes cancel out
- It shrinks by roughly 4\(\times\) because both factors push retraining more often
- It shrinks by roughly 2\(\times\) because the interval scales with the inverse square root of the product of Q and decay rate
- It grows by roughly 4\(\times\) because higher traffic makes retraining more expensive in absolute terms
Explain the chapter’s central warning captured by the phrase ‘perfectly available, perfectly wrong.’
Self-Check Answers
Self-Check: Answer
A ridesharing demand model keeps 15 ms P99 latency, full uptime, and low error rates on its API, but dispatch quality worsens over several weeks after a competitor launches a promotion. Which operational gap is MLOps primarily meant to close in this situation?
- The gap between infrastructure health and predictive correctness
- The gap between CPU utilization and GPU utilization
- The gap between model size and serving throughput
- The gap between training speed and inference speed
Answer: The correct answer is A. MLOps exists because infrastructure metrics can stay green while model quality degrades silently as the world changes. A hardware-utilization explanation misses the point: the core failure is not resource saturation but invisible statistical performance loss that no uptime or latency probe will surface.
Learning Objective: Identify why silent failures distinguish ML operations from traditional software operations
True or False: If a deployed ML service maintains uptime, latency, and request-success SLOs, that is usually sufficient evidence that the model is still doing its job correctly in production.
Answer: False. The chapter’s core point is that ML systems can keep serving successfully while predictive quality degrades because the world changed. Operational health therefore has to include drift and accuracy-oriented signals, not just availability metrics.
Learning Objective: Distinguish service health from predictive health in a deployed ML system
Explain why the chapter describes MLOps as a control system rather than just a deployment practice.
Answer: MLOps closes the loop between production behavior and future model updates, rather than treating deployment as the end of the lifecycle. For example, drift telemetry from a recommendation system can trigger retraining and staged rollout. The practical consequence is that production monitoring becomes part of model correctness, not a separate ops concern.
Learning Objective: Explain how production telemetry feeds retraining and deployment decisions in an ML control loop
Which scenario is the clearest failure of the Data-Model Interface described in the section?
- A new model version increases P99 latency because the container image is larger
- Training computes user_session_length as the rolling 7-day mean, while serving computes it as the last 24 hours
- A rollback takes 20 minutes because the previous model was not kept warm
- A drift alert reaches the team only after weekly business-review dashboards
Answer: The correct answer is B. The Data-Model Interface is about feature consistency between data infrastructure and model training/serving, so divergent feature computation across the two paths is the textbook failure the interface exists to prevent. The rollback scenario belongs to the Model-Infrastructure Interface, and delayed drift alerting belongs to the Production-Monitoring Interface.
Learning Objective: Classify operational failures by the three critical MLOps interfaces
A team operates a single production recommender with its own data pipeline, training job, serving cluster, and dashboards. Leadership wants to know whether the team should adopt ‘single ML node’ operations as described in the chapter or invest in platform-scale infrastructure. Identify two concrete signals from the chapter that would indicate the team has outgrown single-ML-node operations and must cross into platform-scale practice.
Answer: The chapter frames the ML node as the operational unit for one data pipeline, feature computation, training, serving, and monitoring stack. A team has outgrown it when it must coordinate many models with cross-model feature or label dependencies, or when deployments span multiple regions with organization-wide platform concerns like shared registries and multi-team governance. For example, a second recommender that wants to reuse the first model’s feature transforms introduces a multi-model dependency the single-node abstraction does not cover. The practical consequence is that platform engineering (shared feature stores across many nodes, multi-region coordination) begins once any of these dependencies appear; until then, the lighter single-ML-node discipline is the correct investment.
Learning Objective: Apply the ML node definition to judge when single-model operations no longer suffice and platform-scale investment is warranted
Self-Check: Answer
A team versions code but not the training dataset, configuration, or runtime environment. Which foundational principle are they violating most directly?
- Observable degradation
- Reproducibility
- Separation of concerns
- Cost-aware automation
Answer: The correct answer is B. Reproducibility requires versioning all artifacts that determine model behavior: code, data, configuration, and environment. An observability-focused answer confuses detecting production decay with reconstructing how a particular model was produced.
Learning Objective: Identify which foundational principle is violated by incomplete artifact versioning
A system serves 1,000,000 queries per day, one percent of them are wrong because of training-serving skew, and each wrong prediction costs $0.10. Explain why the chapter treats consistency mechanisms as investments rather than engineering polish.
Answer: At that scale, a one percent skew-induced error rate creates a large recurring business loss, not a minor technical imperfection. In the chapter’s example, the annual cost reaches $365,000, so feature stores and shared preprocessing code pay back by eliminating a persistent revenue leak. The system consequence is that consistency work belongs in ROI calculations, not just code quality discussions.
Learning Objective: Apply skew-cost reasoning to justify feature-consistency infrastructure
The chapter’s monitoring-archetype table pairs ResNet-50 with explicit accuracy labels, GPT-2 with perplexity, DLRM with click-through proxies, and DS-CNN (TinyML) with duty cycle and false-wake rate. What principle governs these different choices?
- Use only explicit accuracy labels for every deployment, because proxy metrics are too noisy to count
- Use the same drift threshold and retraining schedule for every archetype to simplify operations
- Match the monitoring signal to the archetype’s available ground truth and operational constraints
- Prioritize latency metrics over model-quality metrics across all archetypes
Answer: The correct answer is C. The section argues that monitoring depends on workload archetype and especially on whether ground truth is available. A one-size-fits-all drift threshold ignores that recommendation systems, language models, and TinyML devices expose different operational signals, and demanding explicit labels everywhere ignores that devices like DS-CNN cannot ship labeled telemetry home at all.
Learning Objective: Compare monitoring strategies across workload archetypes based on available ground-truth signals
Per the section’s separation-of-concerns argument, order the following events in the lifecycle of a single production prediction so that each stage feeds the next without violating layer boundaries: (1) Serving layer returns a prediction to the client, (2) Data layer ingests and transforms a raw event, (3) Monitoring layer records the feature and prediction for drift analysis, (4) Training layer consumes versioned features to produce a model artifact the serving layer will load.
Answer: The correct order is: (2) Data layer ingests and transforms a raw event, (4) Training layer consumes versioned features to produce a model artifact the serving layer will load, (1) Serving layer returns a prediction to the client, (3) Monitoring layer records the feature and prediction for drift analysis. Separation of concerns requires that versioned features feed the training layer before any serving layer can load an artifact; placing monitoring earlier would let it observe inputs before the serving boundary exists, and placing serving before training would require deploying a model that has not yet been produced.
Learning Objective: Order the operational layers so that each respects the section’s separation-of-concerns contract
Why does the section argue that MLOps is not just DevOps plus periodic retraining?
- Because ML systems run on specialized accelerators rather than commodity servers
- Because ML deployment eliminates the need for testing once monitoring is in place
- Because ML systems are nondeterministic and data-dependent, so correctness must be monitored statistically over time
- Because ML teams always require larger organizations than software teams
Answer: The correct answer is C. The durable distinction is that ML correctness depends on shifting data distributions and learned behavior, not only on whether software responds. The accelerator-based explanation is incidental hardware context, not the reason a separate operational discipline is needed.
Learning Objective: Compare DevOps and MLOps in terms of system assumptions and operational obligations
Self-Check: Answer
What makes technical debt in ML systems fundamentally different from ordinary software technical debt, according to the section?
- It mainly appears as lower developer productivity from unreadable code
- It mainly appears as hidden data and model dependencies that cause silent performance degradation
- It mainly appears because ML teams use too many programming languages
- It mainly appears because models are larger than traditional software binaries
Answer: The correct answer is B. The section emphasizes implicit dependencies, entanglement, and silent degradation as the high-interest debt unique to ML systems. A productivity-only framing is too narrow because ML debt often manifests first as correctness loss rather than slower coding.
Learning Objective: Identify the defining characteristics of ML-specific technical debt
A team changes the binning strategy for one numerical feature, and suddenly retraining, evaluation thresholds, and downstream business dashboards all need revision. Which debt pattern best describes this?
- Boundary erosion driven by CACHE-style entanglement
- Configuration debt from undocumented hyperparameters
- Dead experimental codepaths from abandoned branches
- Stateful rollback debt from incompatible caches
Answer: The correct answer is A. Boundary erosion means local changes propagate globally because system boundaries are weak and components are coupled through data. Configuration sprawl may coexist, but it does not explain why one feature change ripples unpredictably across many downstream components.
Learning Objective: Classify change-propagation failures as boundary erosion
Explain why correction cascades are especially severe in ML systems compared with deterministic software pipelines.
Answer: Corrections in ML propagate through statistical relationships, not only explicit code paths, so fixing one failure mode can quietly degrade previously working cases. For example, lowering a fraud threshold may reduce false negatives but increase false positives and alter future training data. The operational consequence is that teams need clear version boundaries and modular architectures before they can safely iterate.
Learning Objective: Explain why statistical dependencies make ML corrections cascade across the system
Order the following stages to reflect the lifecycle path shown in the correction-cascade discussion: (1) Model deployment, (2) Data collection and labeling, (3) Model training, (4) Model evaluation.
Answer: The correct order is: (2) Data collection and labeling, (3) Model training, (4) Model evaluation, (1) Model deployment. Data must exist before training, evaluation happens before release, and deployment is the final operational step. Swapping evaluation and deployment would let regressions reach users before the system checks whether the fix actually worked.
Learning Objective: Order the main stages across which correction cascades propagate
Which mitigation best targets undeclared consumers and hidden data dependencies?
- Increase model size so downstream systems can tolerate noisier inputs
- Rely on unit tests over model code, since data dependencies are outside the codebase
- Use stricter output access controls, formal interface contracts, and lineage tracking
- Avoid versioning outputs so downstream teams can move faster without coordination
Answer: The correct answer is C. Hidden consumers and data dependency debt arise because relationships exist in pipelines and downstream usage without explicit contracts. Simply testing model code or relaxing governance misses the problem: the system needs visibility into who consumes what and under which schema guarantees.
Learning Objective: Select infrastructure responses appropriate for undeclared consumers and data dependency debt
True or False: An ML team that rewrote their model code to pass strict linting, 95 percent unit-test coverage, and code-review checks has substantially reduced the kind of technical debt the chapter identifies as most dangerous.
Answer: False. The chapter’s most dangerous debt lives in data dependencies, feedback loops, undeclared consumers, and feature-pipeline entanglement, not in the model’s source file. Hardening the code alone leaves every silent-degradation failure mode intact because those failures are system-shape problems, not code-quality problems.
Learning Objective: Distinguish code-quality improvements from system-level debt mitigation in ML
Self-Check: Answer
What is the primary systems role of a feature store in the chapter’s development infrastructure?
- To centralize feature definitions so training and serving use the same computation path
- To replace model registries for rollback and artifact promotion
- To eliminate the need for data versioning because features are higher-level artifacts
- To maximize GPU utilization during training by caching activations
Answer: The correct answer is A. Feature stores implement the consistency imperative by preventing duplicated feature logic across environments. A rollback-oriented answer confuses model registries with feature infrastructure, and caching activations is a training optimization rather than the reason feature stores exist.
Learning Objective: Identify how feature stores prevent training-serving skew
A team wants to run notebooks directly in production retraining because the notebook already works locally. Explain why the section treats this as risky and what mitigation it recommends.
Answer: Notebooks can hide state and execution-order dependencies, so a pipeline that runs cells top-to-bottom may behave differently from a scientist’s interactive session. A notebook that worked after running cells out of order can fail reproducibility and validation in production. The recommended mitigation is to use notebooks for exploration, then refactor validated logic into tested Python modules or strictly parameterized notebook stages.
Learning Objective: Analyze notebook-specific reproducibility risks in production ML pipelines
A fraud model processes 1,000,000 transactions per day, has high value per accuracy point, and decays about two percent per day. According to the retraining economics section, what operational conclusion is most justified?
- Retraining should be rare because high-volume systems are too expensive to update
- The model should be retrained on a fixed quarterly schedule to reduce operational complexity
- The economics can justify very frequent retraining, potentially daily, because staleness costs dominate
- The team should ignore retraining frequency and focus only on offline benchmark quality
Answer: The correct answer is C. The square-root-law analysis shows that high traffic, high value, and fast decay shorten the optimal retraining interval substantially. A quarterly schedule ignores the cost of stale predictions, which the section frames as an economic loss rather than just a modeling inconvenience.
Learning Objective: Apply the retraining-staleness model to choose retraining cadence
A team reruns the same training pipeline stage twice on identical inputs and gets two models with meaningfully different validation accuracy. Using the section’s reproducibility argument, diagnose the likely root causes and explain which engineering controls prevent this.
Answer: The pipeline is not idempotent: repeated execution on the same inputs does not produce the same model, which undermines every downstream validation signal. The chapter attributes this to uncontrolled randomness (unpinned seeds), nondeterministic GPU kernels, unversioned data snapshots, or floating-point nondeterminism across reruns. For example, a pipeline that resamples training shards on each run silently produces different training sets. The operational controls are pinned seeds, deterministic kernel flags, versioned immutable data snapshots, and environment pinning; together they make each stage produce the same artifact when rerun, so a failed run can be retried without invalidating its validation results.
Learning Objective: Diagnose non-idempotent training behavior and prescribe the controls required for reproducible automation
A team has strong feature-drift signals, expensive retraining jobs, and labels that arrive days later. Which retraining policy best matches the chapter’s framework?
- Continuous retraining on every new event regardless of whether the signal is noisy
- Triggered retraining when monitored drift or degradation thresholds are crossed
- No retraining until users complain, because delayed labels make monitoring useless
- A fixed daily retraining schedule even if the monitored inputs remain stable for weeks
Answer: The correct answer is B. Triggered retraining is designed for cases where measurable drift can guide updates without paying compute cost continuously. Continuous updates can amplify noise, and a rigid daily schedule ignores the chapter’s cost-aware argument that retraining frequency should respond to observed system change rather than calendar habit alone.
Learning Objective: Select a retraining strategy that balances drift signals, delayed labels, and compute cost
Why does production model validation in this section go beyond beating a holdout benchmark?
Answer: Production validation must test whether a candidate model remains safe and useful under live distributions, deployment conditions, and rollout risk, not just whether it wins offline. For example, a model may beat a static test set yet fail canary checks because latency rises or one user segment degrades badly. The practical result is that staging, canary testing, and guardrails are part of validation, not separate afterthoughts.
Learning Objective: Explain why production validation requires operational as well as offline performance checks
Self-Check: Answer
A team wants to validate a high-risk new model on real production traffic without exposing users to its predictions. Which deployment pattern best matches that goal?
- Shadow deployment, mirroring live traffic to the candidate model while users continue to receive the incumbent’s responses
- Blue-green deployment, switching all user-visible traffic between two fully warm environments at cutover
- Canary deployment, routing one percent of live user-visible traffic to the new model first
- Immediate full rollout, replacing the incumbent in a single atomic cutover
Answer: The correct answer is A. Shadow deployment duplicates live traffic to the candidate while keeping user-visible responses on the current system, which is the only listed pattern where no user ever receives the candidate’s predictions. Blue-green and canary both expose real users to the candidate (all of them at cutover, or a slice of them respectively), and immediate full rollout exposes everyone at once.
Learning Objective: Compare deployment patterns by the type of production risk they control
A service has a 100 ms P99 SLO. Network takes 15 ms, feature retrieval 25 ms, request parsing 5 ms, inference 45 ms, post-processing 5 ms, and response serialization 5 ms. If the team makes the model itself 2\(\times\) faster, what is the main lesson from the chapter’s latency-budget analysis?
- End-to-end latency will also improve by 2\(\times\), because inference is the ML-specific component
- The SLO will remain impossible because feature retrieval dominates all budgets
- The system improves only modestly overall because inference is less than half of total latency
- The optimization is wasted because only network RTT matters in production
Answer: The correct answer is C. The section emphasizes that model inference is only 45 percent of this end-to-end budget, so a 2\(\times\) model speedup reduces total latency from 100 ms to about 77.5 ms, or roughly 1.3\(\times\) end-to-end. An answer centered only on feature retrieval overstates one bottleneck instead of applying the full budget decomposition.
Learning Objective: Analyze end-to-end latency budgets rather than optimizing model inference in isolation
Explain why low-traffic, high-stakes models can remain in a silent-failure state much longer than high-traffic models even when monitoring is in place.
Answer: Statistical drift detection needs enough labeled samples to separate real degradation from noise, and low-traffic systems collect evidence slowly. A model serving 100 requests per day may need days or weeks to confirm a five percentage-point accuracy drop that a 1 QPS system could detect in minutes. The operational consequence is that high-stakes low-volume systems need audits and proxy monitoring, not confidence in traffic-driven detection alone.
Learning Objective: Analyze how traffic volume constrains the time-to-detection of model degradation
Order the ML incident response flow described in the section: (1) Review recent model, feature, or pipeline changes, (2) Detect the triggering signal, (3) Evaluate mitigation such as rollback or fallback, (4) Assess traffic and user impact, (5) Perform root-cause analysis.
Answer: The correct order is: (2) Detect the triggering signal, (4) Assess traffic and user impact, (1) Review recent model, feature, or pipeline changes, (3) Evaluate mitigation such as rollback or fallback, (5) Perform root-cause analysis. Teams first need to know what alert fired and how much traffic is affected before searching for recent changes and deciding whether to mitigate immediately. Root-cause analysis comes after stabilization, not before.
Learning Objective: Order the major steps in structured ML incident response
A GPU serving cluster reports moderate GPU utilization, very high memory-bandwidth utilization, and poor throughput. Which diagnosis and response best fits the chapter’s monitoring guidance?
- Compute-bound workload; add tensor parallelism before changing the model
- Memory-bound workload; reduce model size or use quantization to cut data movement
- I/O-bound workload; the request router is starved, so add more replicas without touching the model
- Healthy workload; high bandwidth utilization always indicates efficient serving
Answer: The correct answer is B. The chapter distinguishes memory-bound behavior by high memory-bandwidth pressure with non-maximal compute utilization, suggesting the model spends time moving data rather than doing arithmetic. Treating this as a pure routing problem ignores the hardware signature, and calling it healthy misses that the utilization pattern itself indicates an optimization target.
Learning Objective: Diagnose hardware bottlenecks from combined utilization and bandwidth signals
Which statement best captures how the ML Test Score should be used operationally?
- As a replacement for monitoring, because a high score proves the model will remain correct in production
- As a production-readiness rubric spanning data, model, infrastructure, and monitoring practices
- As a benchmark of model architecture quality independent of pipelines and operations
- As a measure of whether the team can skip human review during deployment
Answer: The correct answer is B. The ML Test Score is a structured readiness rubric covering reproducibility, rollback, skew checks, staleness monitoring, and related operational practices. A score cannot replace runtime monitoring because drift and production change still occur after deployment.
Learning Objective: Interpret the ML Test Score as an operational readiness framework
Self-Check: Answer
Which description best fits the ‘Repeatable’ maturity level in the chapter’s framework?
- Manual local training, no version control, and unclear ownership
- Automated retraining on drift with integrated observability, feature-store consistency, and canary release
- Basic automation such as training pipelines, centralized model storage, and some monitoring, but limited scalability
- Centralized platform operations for a large multi-model fleet with full cross-region coordination
Answer: The correct answer is C. The repeatable level sits between ad hoc and scalable: it has some automation and reproducibility but not the fully integrated, closed-loop operational system described at the highest level. The fully automated drift-triggered pipeline belongs to the scalable stage instead.
Learning Objective: Classify organizational ML practice into the chapter’s maturity levels
Explain the architectural lesson of the uptime iceberg in the section.
Answer: Visible uptime is only the tip of operational health; beneath it sit hidden failures like data drift, schema changes, broken pipelines, and subgroup degradation. A system can look healthy to service dashboards while its model quality decays underneath. The system consequence is that mature architectures must monitor data health and model health alongside service health, not just availability.
Learning Objective: Explain why uptime alone is an incomplete measure of ML system reliability
Which organizational pattern is presented as effective when many teams need shared ML infrastructure but also domain-specific model ownership?
- A centralized MLOps function providing shared services, or a federated model with embedded MLOps engineers and central architecture
- Keeping data scientists isolated from production engineers so experimentation stays fast
- Letting every product team invent its own pipeline and registry choices to maximize flexibility
- Deferring role definitions until after tooling is deployed, since tools create process naturally
Answer: The correct answer is A. The section presents both centralized shared services and federated embedded models as viable patterns when ownership boundaries are clear. The siloed and tool-first approaches are explicitly identified as anti-patterns because they create fragile handoffs and duplicated infrastructure.
Learning Objective: Compare organizational patterns for scaling MLOps responsibilities across teams
True or False: An organization that owns a feature store, a model registry, a CI/CD pipeline, and a monitoring platform has, by the chapter’s framework, effectively reached the scalable maturity level.
Answer: False. The scalable level is defined by integrated practices (drift-triggered retraining, canary validation, closed-loop monitoring feeding updates, per-segment degradation tracking) not by tool ownership. A team that owns every tool but runs them as disconnected islands stays at a lower maturity because the pieces do not form a control loop.
Learning Objective: Distinguish operational maturity from tool adoption
A single production model is business-critical, but the team has limited budget for its first MLOps investments. According to the investment-economics section, which sequence is most justified?
- Start with monitoring and CI/CD because they usually provide the highest ROI, then add feature stores and automated retraining as the model matures
- Build a full platform-scale fleet management system before improving single-model operations
- Prioritize feature stores first for every model, even when skew has not been observed and deployment is still manual
- Delay all MLOps investment until multiple incidents prove the model is already unstable
Answer: The correct answer is A. The section explicitly recommends starting with monitoring and CI/CD, then investing proportionally to model criticality as needs mature. Building platform-scale machinery first or waiting for repeated failures both ignore the chapter’s cost-aware, staged-investment framing.
Learning Objective: Prioritize MLOps investments using the chapter’s ROI-oriented maturity guidance
Self-Check: Answer
What did the Oura Ring case most directly demonstrate about implementing MLOps under edge constraints?
- Edge deployments can ignore graceful degradation because failures are localized to the device
- The main operational challenge is maximizing cloud GPU utilization for retraining
- Edge constraints force proactive design for resource-aware degradation, OTA updates, and tight preprocessing consistency
- Battery-powered devices remove the need for lineage tracking because the system is physically constrained
Answer: The correct answer is C. The Oura case shows that battery, memory, and connectivity constraints make graceful degradation, OTA deployment, and consistent preprocessing central design concerns. Treating edge failures as harmless or lineage as unnecessary ignores the section’s emphasis on reproducibility and update safety.
Learning Objective: Identify how edge constraints reshape implementation of core MLOps principles
Explain why ClinAIOps treats feedback loops differently from the technical-debt framing earlier in the chapter.
Answer: Earlier sections warned that feedback loops can create hidden coupling and degraded learning, but ClinAIOps intentionally designs patient-AI, clinician-AI, and patient-clinician loops as governed system components. For example, clinician approval bounds prevent the AI from autonomously making unsafe medication changes. The operational implication is that high-stakes domains must transform risky feedback into explicit, human-supervised architecture.
Learning Objective: Analyze how healthcare operations converts risky feedback loops into governed design features
Which comparison between the two case studies is most consistent with the chapter?
- Oura Ring emphasizes resource-constrained deployment mechanics, while ClinAIOps emphasizes regulation, auditability, and human-in-the-loop safety
- Oura Ring needs human oversight at every prediction, while ClinAIOps is mostly fully automated once deployed
- Both cases show that the five MLOps principles are replaced by domain-specific rules
- ClinAIOps focuses mainly on hardware quantization, while Oura Ring focuses mainly on cross-functional clinical governance
Answer: The correct answer is A. Oura is the edge case where battery, memory, OTA updates, and limited telemetry dominate, whereas ClinAIOps adds patient safety, provenance, clinician oversight, and regulatory accountability. The other pairings invert the domains or wrongly imply the core principles no longer apply.
Learning Objective: Compare how domain constraints change the implementation of shared MLOps principles
The Oura team moved four-stage sleep classification accuracy against polysomnography (PSG) from 57 percent to 79 percent, while the inter-rater agreement among expert human PSG scorers sits at 82 to 83 percent. Explain how the chapter uses these numbers to drive operational decisions about validation targets, retraining triggers, and when further model investment stops paying back.
Answer: PSG is the clinical ground truth that gives Oura an objective validation target, but the 82 to 83 percent human agreement establishes a practical ceiling: the chapter treats it as a consistency upper bound no wearable model can reliably exceed. A jump from 57 to 79 percent therefore closes roughly 85 to 88 percent of the baseline-to-human-agreement gap, while pushing toward 83 percent implies diminishing returns that may no longer justify the engineering cost. The operational consequence is that PSG both grounds retraining-threshold choices (regression below 79 percent triggers investigation) and sets an economic stopping rule for further accuracy investment, turning a clinical measurement into an MLOps control knob.
Learning Objective: Analyze how a high-fidelity ground-truth reference shapes validation targets, retraining triggers, and investment stopping rules in an edge-health ML pipeline
Why is clinician override a central cost-aware automation mechanism in the ClinAIOps case rather than evidence that automation failed?
- Because healthcare models cannot be versioned or audited after deployment
- Because patient-risk cost dominates, so automation must operate within clinician-approved safety bounds
- Because clinical data drift is impossible to monitor directly
- Because automated recommendations are meant only for offline research, not real workflows
Answer: The correct answer is B. The chapter frames cost-aware automation as balancing value against risk, and in healthcare the cost of an unsafe action is high enough that human review is an intentional control, not a defect. Saying recommendations are only for research contradicts the case study’s whole purpose of operational deployment.
Learning Objective: Evaluate why human-in-the-loop controls can be part of optimal automation design in high-stakes domains
Self-Check: Answer
True or False: Once an ML pipeline is deployed and basic CI/CD is in place, training and serving will usually stay consistent unless engineers make an obvious code change.
Answer: False. The chapter repeatedly argues that subtle preprocessing, feature, dependency, and environment mismatches can create training-serving skew without any obvious failure signal.
Learning Objective: Identify why training-serving consistency cannot be assumed after initial deployment
Which pitfall best reflects the chapter’s warning about organizational alignment?
- Using shared on-call rotations to build empathy across roles
- Investing in tooling while data scientists, engineers, and business stakeholders still operate with fragmented objectives and handoffs
- Defining clear feature contracts between data and ML teams
- Starting with monitoring and CI/CD before adding more specialized infrastructure
Answer: The correct answer is B. The chapter argues that tooling alone does not solve production ML if roles, incentives, and handoffs remain fragmented. Shared rotations, contracts, and staged investment are presented as remedies rather than pitfalls.
Learning Objective: Recognize organizational misalignment as a root cause of MLOps failure
Why is ‘treating deployment as a one-time event’ a dangerous operational mindset for ML systems?
Answer: Because ML systems continue to decay after launch as data distributions shift, so correctness is a moving target rather than a property frozen at release time. A model that was validated at deployment can become wrong weeks later without any code change. The practical consequence is that retraining, drift monitoring, and rollback planning are part of deployment, not postscript tasks.
Learning Objective: Explain why ML deployment must be managed as an ongoing operational process
Self-Check: Answer
Which pairing correctly matches an infrastructure component to the critical interface it primarily supports in the chapter’s summary?
- Feature stores -> Data-Model Interface
- Feature stores -> Production-Monitoring Interface
- Canary rollback drills -> Data-Model Interface
- Model registries alone -> Organizational governance interface
Answer: The correct answer is A. The summary explicitly links feature stores and data versioning to the Data-Model Interface by enforcing training-serving consistency. Rollback drills belong to deployment and production operations, not the feature-consistency boundary.
Learning Objective: Match infrastructure components to the chapter’s three critical interfaces
The chapter’s optimal retraining interval follows \(T^* \approx \sqrt{2C/(QVA_0\gamma)}\), where \(C\) is retraining cost, \(Q\) is query volume, \(V\) is value per accuracy point, \(A_0\) is current accuracy, and \(\gamma\) is temporal decay rate. A recommender suddenly faces a 4\(\times\) spike in query volume and a 4\(\times\) jump in decay rate while retraining cost and value per point stay fixed. What happens to the optimal retraining interval?
- It stays roughly the same because the two changes cancel out
- It shrinks by roughly 4\(\times\) because both factors push retraining more often
- It shrinks by roughly 2\(\times\) because the interval scales with the inverse square root of the product of Q and decay rate
- It grows by roughly 4\(\times\) because higher traffic makes retraining more expensive in absolute terms
Answer: The correct answer is B. The formula places Q and decay rate under the square root in the denominator, so a 4\(\times\) increase in query volume and a 4\(\times\) increase in decay rate create a combined 16\(\times\) increase in staleness pressure. The interval therefore scales by \(1/\sqrt{16} = 1/4\), shrinking by roughly 4\(\times\). The ‘stay the same’ answer mistakes the effects as canceling, the 2\(\times\) answer applies only one of the two changes, and the ‘grows 4\(\times\)’ answer inverts the economics because higher traffic raises the cost of staleness.
Learning Objective: Apply the retraining-economics formula to reason about how the optimal interval responds to changes in traffic and decay rate
Explain the chapter’s central warning captured by the phrase ‘perfectly available, perfectly wrong.’
Answer: An ML system can satisfy uptime and latency objectives while silently producing degraded or harmful predictions because the world has drifted away from the training distribution. For example, stale features or concept drift can erode accuracy with no red infrastructure dashboard. The operational consequence is that production correctness requires observability, retraining logic, and governance rather than availability metrics alone.
Learning Objective: Explain the chapter’s core operational risk in production ML systems