Model Serving
Purpose
Why does serving invert every optimization priority that made training successful?
Training and serving demand opposite physics. Training maximizes throughput (samples per second): large batches and long epochs where latency spikes get absorbed invisibly. Serving minimizes latency, measured in milliseconds per request: individual requests answered fast enough that a single slow response is a broken product. Training amortizes hardware costs across billions of examples; serving pays a tax on every request, where small inefficiencies compound into operational debt. This inversion is why models that train beautifully often serve poorly: the batch-heavy architectures and memory-intensive optimizations designed to saturate accelerators during training are fundamentally ill-suited for the bursty, latency-critical, cost-sensitive reality of production traffic. Serving, however, is more than a latency problem. A serving system must handle traffic that varies by orders of magnitude between peak and trough, introduce new model versions without abruptly moving all users at once, degrade gracefully when upstream dependencies fail, and do all of this continuously, not for the duration of a training run but for the lifetime of the product. Every model that proved its value during training and survived compression and benchmarking eventually arrives at the serving layer—the deployment and integration stage of the ML lifecycle—where the question shifts from “does it work?” to “does it work reliably, at scale, under production conditions, every second of every day?” The serving infrastructure is where ML systems finally meet users, and the engineering that sustains that meeting is qualitatively different from the engineering that created the model. It is also where the trained algorithm meets live data within the machine’s latency budget: all three D·A·M constraints converge on every request.
Learning Objectives
- Explain serving inversion from training throughput to per-request latency, headroom, and tail behavior
- Decompose request latency across serialization, preprocessing, inference, queuing, postprocessing, and network overhead
- Apply queueing laws and simple queue models to plan capacity against percentile latency targets
- Diagnose training-serving skew and cold starts from mismatched preprocessing, model loading, or cache behavior
- Select batching, load shedding, autoscaling, and runtime strategies for traffic patterns and latency budgets
- Evaluate LLM serving bottlenecks using token latency, KV-cache memory, and continuous batching constraints
- Calculate cost per inference from precision, hardware utilization, replica count, and runtime throughput
Serving Paradigm
Serving begins where benchmarking stops: a model that performed under controlled measurement must now answer unpredictable live requests. Cloud, Edge, Mobile, and TinyML each impose distinct serving challenges, but all share the same inversion from throughput optimization to latency control. This serving inversion has concrete engineering implications that ripple through the whole stack. The iron law of ML systems undergoes a decisive shift: the latency term \((L_{\text{lat}})\), representing the irreducible overhead of request scheduling, network round-trips, and system orchestration, becomes the dominant constraint rather than a rounding error. Controlled benchmarks establish performance under known conditions; serving faces traffic patterns no benchmark can fully anticipate. Quantization can reduce model size; serving must confirm that such optimizations preserve accuracy under real traffic distributions. Together these revalidations flip the priorities of data, algorithm, and machine once requests arrive one at a time under a latency budget.
The D·A·M taxonomy makes the inversion visible. The data constraint shifts from volume to freshness: the system must process a live request immediately, not shuffle billions of examples over a training run. The algorithm constraint shifts from mutable to frozen: serving runs a fixed forward pass rather than updating weights through backpropagation. The machine constraint shifts from utilization to headroom: an accelerator held at 40 to 60 percent utilization can absorb traffic spikes, while a saturated accelerator turns small load changes into tail-latency failures. Serving therefore optimizes useful completed work under a latency promise rather than fully occupied hardware.
That promise ties the remaining parts of the serving stack together. Request routing, preprocessing, model execution, postprocessing, batching, caching, runtime selection, and capacity planning all compete for the same latency budget. The central engineering task is to decide which work belongs in the live request path, which work can move outside it, and how much headroom the system must reserve before useful throughput becomes fragile.
Self-Check: Question
A team moves a model from a training cluster to a serving cluster and notices that the new cluster intentionally runs at 40-60 percent average utilization while the training cluster ran at 90+ percent. Which statement best captures the systems reason for this inversion?
- Serving optimizes latency and especially p99 behavior, so the system keeps capacity headroom to absorb bursts and queueing growth rather than saturating hardware.
- Serving updates model weights continuously during inference, which forces utilization to stay below 60 percent to leave room for online learning.
- Serving must run exclusively on CPUs for predictable latency, which caps utilization well below what accelerators achieve during training.
- Serving relies on offline validation rather than monitoring, so nothing downstream can use the extra capacity when utilization exceeds 60 percent.
A photo organization app classifies a user’s existing library overnight, while a content moderation API must classify newly uploaded images immediately. Explain why the first workload favors static inference and the second favors dynamic inference.
A team wants to deploy the same vision model to a cloud API, a smartphone app, and a TinyML sensor node. Which deployment plan best matches the constraints the chapter lays out for each environment?
- Use one shared batching and memory strategy across all three so the model’s behavior stays identical in every environment.
- Cloud serving uses dynamic batching and concurrency, the smartphone serves at batch 1 to preserve responsiveness and battery, and the TinyML node pre-allocates memory statically and forgoes dynamic batching.
- The smartphone and TinyML deployments differ only in network protocol, and the smartphone and cloud share the same memory budget because both run the same model.
- Put the largest models on TinyML because firmware deployment avoids container cold starts.
True or False: If a load balancer keeps traffic evenly distributed across replicas and average utilization stays moderate, p99 latency should stay stable even without node-level isolation such as CPU pinning, memory locking, or interrupt steering.
Which operational change would most directly reduce p99 latency jitter on a single inference node serving a safety-critical workload?
- Drive average utilization toward 95 percent so the accelerator stays saturated and no cycles are wasted.
- Move health checks out of the load balancer and into the model code so the model owns its own liveness signal.
- Pin inference threads to dedicated cores, lock model weights and KV state in memory, and steer OS interrupts away from the inference cores.
- Replace gRPC with JSON over HTTP/1.1 so payloads are easier to inspect during incidents.
Serving Load, Latency, and Architecture
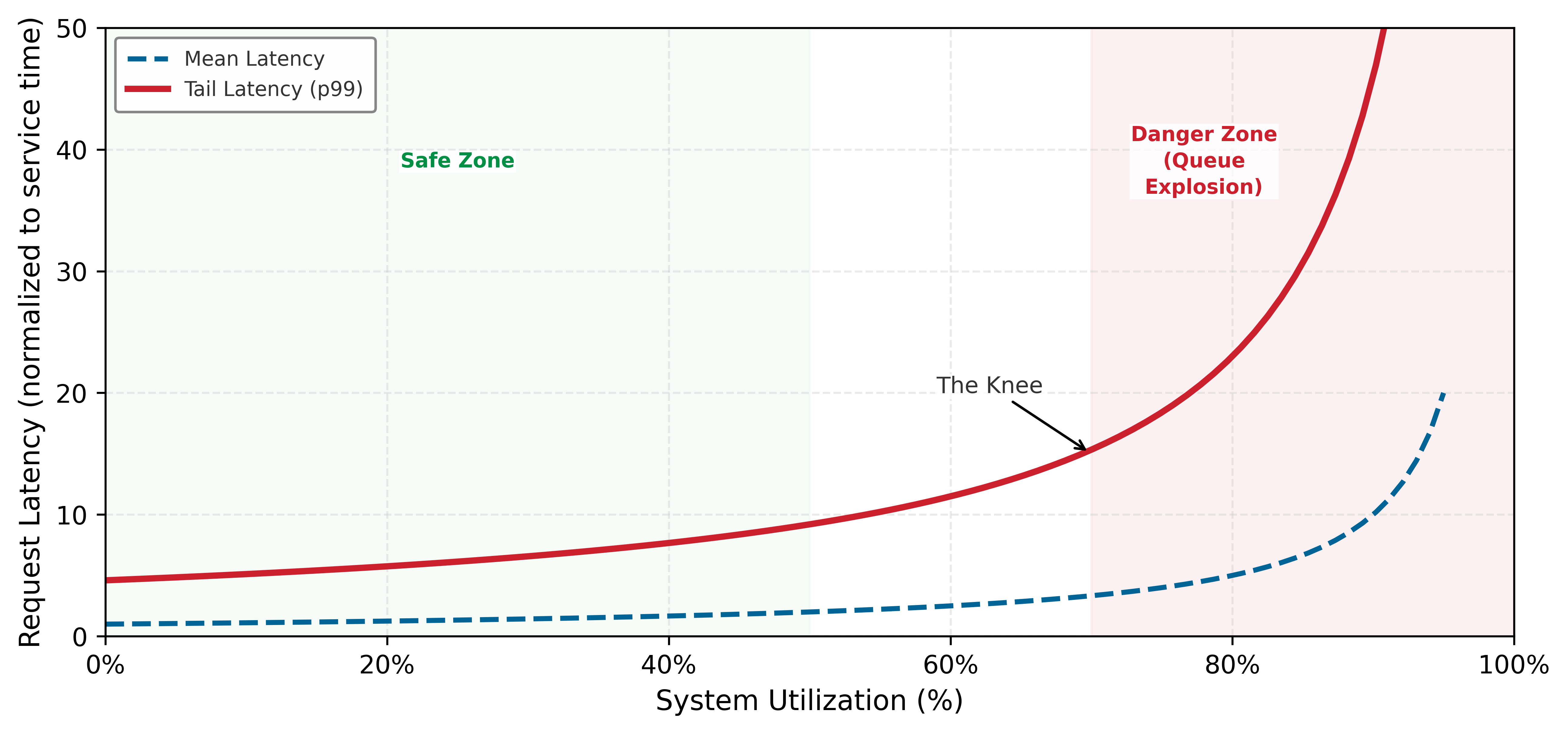
A single traffic spike that exceeds this margin can cascade into system-wide failure; the queueing curve in figure 1 makes that collapse visible.
Example 1.1: The 'Black Friday' traffic spike
Scenario: An e-commerce recommendation system runs comfortably at 50 ms with 1,000 QPS.
Failure mode: On Black Friday, traffic spikes 10× to 10,000 QPS. The system does not slow down 10×; it collapses. Latency hits 10 s, then requests start timing out. The servers are 100 percent loaded, but useful throughput drops to near zero because most completed requests have already timed out from the client’s perspective.
Physics: This previews the queueing theory formalized later in section 1.5. As utilization approaches 100 percent, queue lengths diverge nonlinearly rather than linearly. The system spends more time managing the queue (context switching, thrashing) than doing useful work.
Fix:
- Load shedding: Reject excess requests immediately to keep the queue short.
- Autoscaling: Use an operational control loop to spin up more serving replicas before utilization hits the “knee” of the curve.
- Degradation: Serve cached/dumber recommendations to reduce compute cost per query.
Systems lesson: High average throughput does not protect a serving system from collapse. Tail latency control requires keeping utilization below the queueing knee, honoring the machine constraint even if that means shedding load or serving a cheaper model.
Figure 1 shows that latency remains manageable at moderate utilization and then rises rapidly as the system approaches saturation; this is why production systems reserve headroom rather than planning for a permanently saturated accelerator (p99). Distributions and the long tail gives a mathematical treatment of long-tailed distributions and why p99 latency dominates the user experience at scale. The curve is a simple queueing approximation intended for intuition rather than a specific workload.
Beyond the technical limits of latency, the economics of serving have undergone a radical transformation. As models become more efficient and hardware becomes more specialized, the cost of “intelligence” is collapsing1. Facebook’s experience at fleet scale illustrates the magnitude of this serving cost problem.
1 Jevons Paradox: William Stanley Jevons observed in 1865 that efficiency improvements in coal-powered steam engines increased total coal consumption by making steam power economically viable for applications previously too costly (Jevons 1865). The same dynamic can apply to AI inference: each 10\(\times\) cost reduction opens application classes that were economically infeasible at the previous price point, expanding aggregate demand by more than the efficiency gain. This is why cheaper inference can increase, not decrease, total GPU fleet demand—efficiency and demand are often complements in AI, not substitutes.
Jevons, William Stanley. 1865. The Coal Question: An Inquiry Concerning the Progress of the Nation, and the Probable Exhaustion of Our Coal Mines. Macmillan; Co.
War Story 1.1: The inference tax at Facebook
Context: In 2018, Kim Hazelwood and Facebook’s AI Infrastructure team described a production ML workload that touched nearly every user-facing surface: News Feed ranking, Ads ranking, Search, image understanding (Lumos), face recognition (Facer), anomaly detection (Sigma), automated video captioning, and a Translate system serving roughly 4.5 billion translated post impressions per day across more than two thousand language pairs (Hazelwood et al. 2018).
Failure mode: The expensive part of ML had moved into serving. Inference ran on the order of tens of trillions of operations per day under strict tail-latency targets, where live request arrivals constrained batching and a one-hour-old ranking model measurably degraded News Feed quality—forcing aggressive retraining alongside aggressive serving.
Resolution: Facebook treated inference as a first-class data-center infrastructure problem, co-designing models, accelerators, memory systems, and serving platforms together rather than treating serving as an afterthought to training.
Systems lesson: Training creates the model; serving pays the recurring bill. At fleet scale, a model architecture that is cheap to train can still be too expensive, too memory-bound, or too variable in tail latency to serve.
Hazelwood, Kim, Sarah Bird, David Brooks, Soumith Chintala, Utku Diril, Dmytro Dzhulgakov, Mohamed Fawzy, et al. 2018. “Applied Machine Learning at Facebook: A Datacenter Infrastructure Perspective.” 2018 IEEE International Symposium on High Performance Computer Architecture (HPCA), 620–29. https://doi.org/10.1109/hpca.2018.00059.
OpenAI. 2023. Introducing ChatGPT and Whisper APIs.
OpenAI. 2024. GPT-4o Mini: Advancing Cost-Efficient Intelligence.
OpenAI, Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, et al. 2023. “GPT-4 Technical Report.” arXiv Preprint arXiv:2303.08774, ahead of print. https://doi.org/10.48550/arXiv.2303.08774.
OpenAI Developer Community. 2024. Announcing GPT-4o in the API.
Anthropic. 2024. Introducing the Next Generation of Claude.
Google Developers Blog. 2024. Gemini 1.5 Flash Price Drop with Tuning Rollout Complete, and More.
DeepSeek. 2024. Introducing DeepSeek-V3.
The same serving-economics pressure appears in public API prices. To grasp the speed of this cost collapse, examine the log-scale price trajectory in figure 2, which tracks representative public API list-price snapshots as a market proxy. Vendor prices change frequently, so these points should be read as historical provenance for the trend rather than as current purchasing guidance (OpenAI 2023, 2024; OpenAI et al. 2023; OpenAI Developer Community 2024; Anthropic 2024; Google Developers Blog 2024; DeepSeek 2024). Each order-of-magnitude drop changes which applications are feasible.
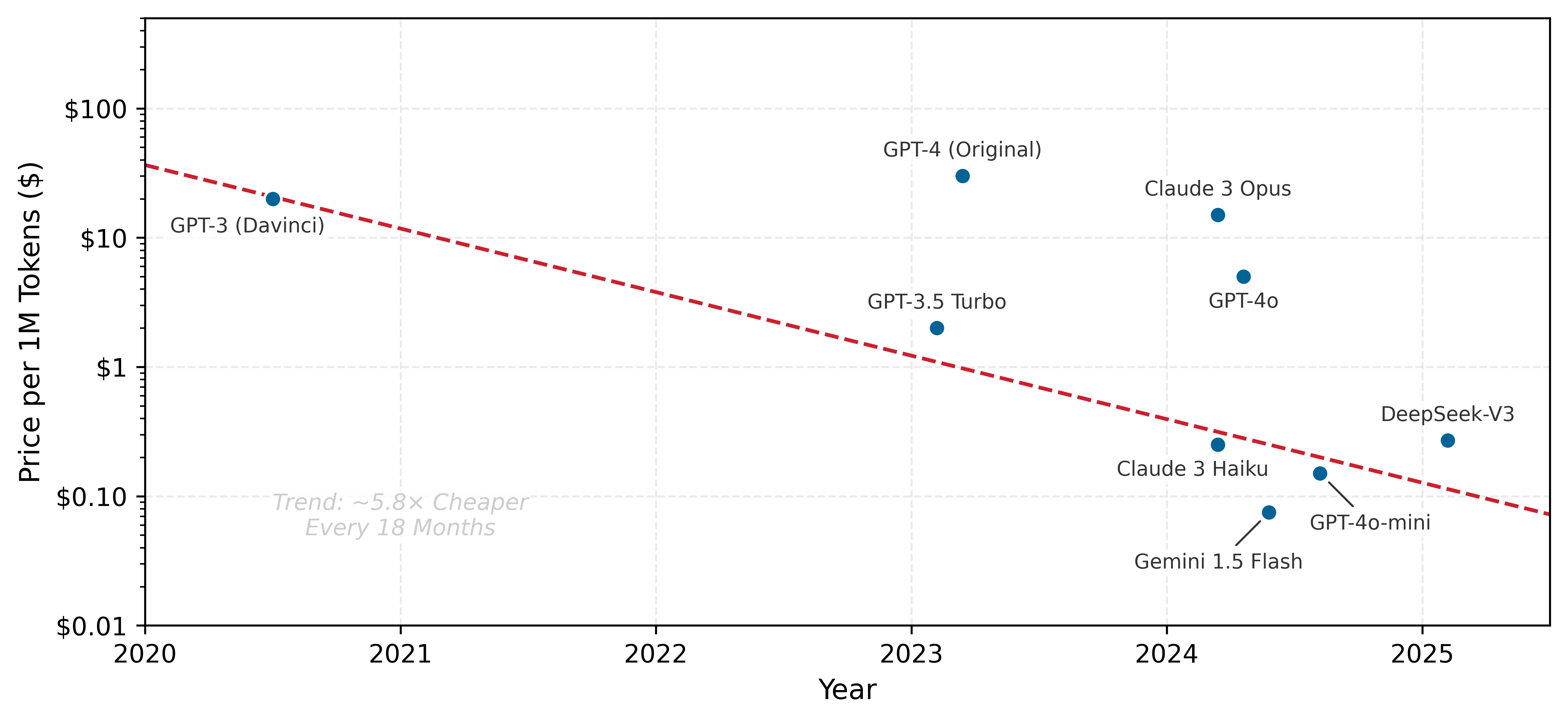
Two pressures now frame the serving problem: tail latency that explodes once utilization passes the queueing knee, and per-inference economics that fall by orders of magnitude as efficiency improves. Together they force a formal definition of serving built around latency rather than throughput.
Definition 1.1: Model serving
Model Serving is the operational phase that provides model predictions to end-users or downstream systems under strict latency constraints.
- Significance: It inverts the throughput priority (\(\eta_{\text{hw}}\)) of training into a latency constraint \((L_{\text{lat}})\), requiring an architectural stack designed to minimize the tail latency (p99) of individual inferences.
- Distinction: Unlike model training, which processes large, predictable batches of data, model serving must handle stochastic request patterns and unpredictable load.
- Common pitfall: A frequent misconception is that serving is “just the forward pass.” In reality, it is a distributed system problem: the model execution is only one component of a stack that includes request routing, load balancing, and data transformation.
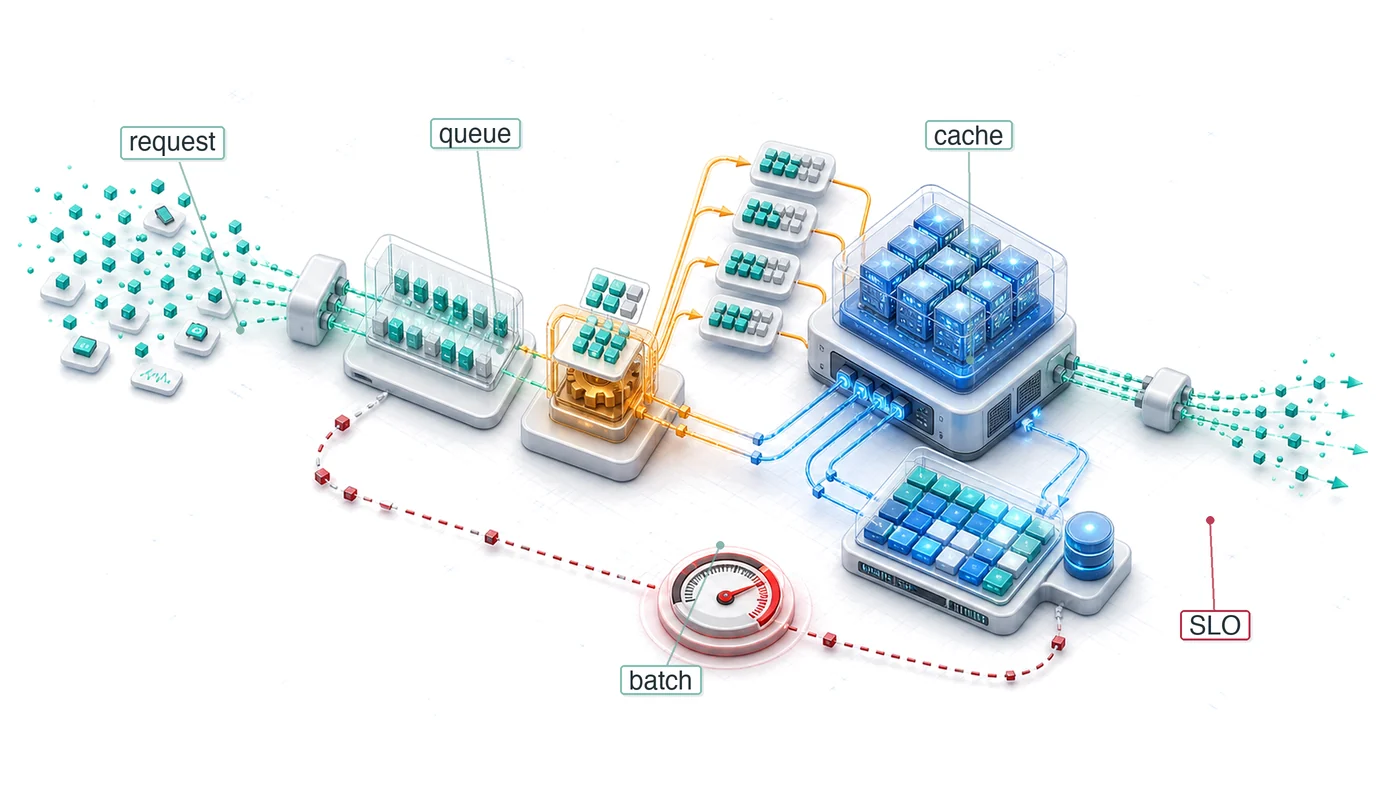
The SLO2 defines the latency target that shapes every architectural decision in the serving stack, including how the system budgets time across preprocessing, model execution, postprocessing, and transport. Serving systems must therefore execute a complete inference pipeline under latency constraints, not just the neural network computation. A common misconception is that “inference time” equals “serving time,” but the neural network is only one stage in a longer pipeline. Figure 3 shows that raw inputs pass through preprocessing (traditional computing), neural network inference (deep learning), and postprocessing (traditional computing) before producing final outputs. Any of these stages can become the latency bottleneck. Section 1.4.1 quantifies exactly where time goes, revealing a counterintuitive result about which stages dominate.
2 Service Level Objective (SLO) vs. Service Level Agreement (SLA): An SLO is an internal target (for example, “p99 latency under 50 ms”); an SLA is an external contractual commitment with financial penalties for violation. SLOs are set tighter than SLAs to provide a safety margin. For ML serving, both model accuracy and inference latency contribute to SLOs, creating multi-dimensional optimization targets where improving one dimension (for example, deploying a larger model for accuracy) can violate the other (latency).

The pipeline turns serving into an orchestration problem: preprocessing, model execution, postprocessing, and transport all compete for the same latency budget. Before optimizing any one stage, the system must decide whether predictions are computed ahead of time or on demand.
Static vs. dynamic inference
Before optimizing how to reduce inference latency, the system must decide when predictions are computed. The first architectural decision in any serving system is whether predictions happen before or during user requests (Google 2024). This choice shapes system design, cost structure, and capability boundaries.
Google. 2024. Static Vs. Dynamic Inference. Google Machine Learning Crash Course.
Static inference
Static inference (also called offline or batch inference) precomputes predictions for anticipated inputs and stores them for retrieval. Consider a recommendation system that generates predictions for all user-item pairs nightly. When a user requests recommendations, the system retrieves precomputed results from a lookup table rather than running inference. This approach moves compute out of the request path, enables offline quality checks, and can reduce serving costs for predictable inputs. However, static inference needs either a fallback online path or a refreshed batch computation when requests include unanticipated inputs or newly updated models.
Dynamic inference
Dynamic inference (also called online or real-time inference) computes predictions on demand when requests arrive. This handles any input, including rare edge cases and novel combinations, and immediately reflects model updates. The cost is strict latency requirements that constrain model complexity and demand robust monitoring infrastructure.
For our ResNet-50 image classifier, consider two deployment scenarios. A static approach suits a photo organization app that preclassifies all images in a user’s library overnight. With 10,000 photos and 5 ms inference each, batch processing takes ~50 s total, and users see instant classification when browsing. A dynamic approach suits a content moderation API that must classify user-uploaded images in real-time, with each image requiring the full preprocessing→inference→postprocessing pipeline and a 100 ms latency budget. Most production image classification systems use a hybrid approach: frequently requested images (popular products, known memes) are preclassified and cached, while novel uploads trigger dynamic inference.
The choice between static and dynamic serving has direct economic implications. Stricter latency requirements directly translate into higher infrastructure costs, and quantifying the cost of latency in dollar terms reveals how much infrastructure premium each millisecond of latency reduction demands.
Napkin Math 1.1: The cost of latency
Latency constraints directly dictate infrastructure costs. Consider a GPU server renting for $4/hour.
Scenario A (low latency): Batch size 1.
- Latency: 5 ms.
- Throughput: 200 req/s.
- Cost per million queries: $5.56.
Scenario B (high throughput): Batch size 8.
- Latency: 10 ms (doubled due to batching overhead).
- Throughput: 800 req/s (quadrupled due to parallel efficiency).
- Cost per million queries: $1.39.
Systems insight: Reducing latency from 10 ms to 5 ms increases the hardware bill by 300 percent. Engineers must quantify whether that speedup generates enough business value to justify the 4× cost increase.
Most production systems combine both approaches. Common queries hit a cache populated by batch inference while uncommon requests trigger dynamic computation. Understanding this spectrum matters because it determines which subsequent optimization strategies apply. Static inference optimizes for throughput during batch computation and storage efficiency for serving. Dynamic inference optimizes for per-request latency under concurrent load, which requires understanding where time goes within each request.
The static-vs.-dynamic decision is the first of several architectural choices that shape serving system design. Equally important is where the model executes, since deployment context constrains every subsequent optimization.
All of the cost analysis above assumes a traditional forward pass: a fixed computation graph that executes once per request and produces a result. A new class of models upends that assumption by deliberately increasing the amount of computation spent per query, trading latency for answer quality, and the serving cost implications are substantial.
Systems Perspective 1.1: Looking ahead: Deliberately spending more compute per query
Traditional serving optimizes for minimizing latency \((L_{\text{lat}} \to 0)\). Some inference-time-compute systems deliberately spend more compute cycles to improve answer quality. Individual token generation remains memory-bandwidth bound, but these systems may generate far more tokens per request, including intermediate reasoning or search tokens, increasing the total compute and energy spent per query. The aggregate effect can bring training-like compute budgets into the serving phase, even though each token is still governed by the memory wall.
Whether a system spends one forward pass or many reasoning steps per query, deployment context still determines the feasible latency and cost envelope. That context is the next variable.
The spectrum of serving architectures
Although “serving” often implies a networked server processing API requests, the architectural pattern varies drastically by deployment environment. Deployment Paradigm Framework introduced the four deployment paradigms (Cloud, Edge, Mobile, and TinyML) and the physical constraints (the light barrier, the power wall, and the memory wall) that give rise to them. Those constraints do not disappear at serving time; they intensify, because serving adds latency SLOs and cost pressure on top of the hardware limits that training could absorb through patience. The same model may require radically different serving strategies depending on where it executes.
Networked serving (cloud/data center)
In networked serving, the model runs as a standalone service (microservice), the deployment paradigm Cloud ML: Computational Power characterized as trading latency for larger pooled compute. The primary interface is the network through request protocols such as HTTP or gRPC, so the binding constraints are network bandwidth and serialization cost before the request even reaches the accelerator. Data-center hardware such as NVIDIA GPUs (V100, A100, H100), Google Tensor Processing Units (TPUs), and AWS Inferentia supports high-throughput batching and concurrency, but cold start can still stretch from seconds to minutes because container startup, model loading, and warmup sit outside the steady-state inference path.
Application-embedded serving (mobile/edge)
In application-embedded serving, the model runs within the user application process (for example, a smartphone app using CoreML or TensorFlow Lite), the embedded paradigm Edge ML: Latency and Privacy and Mobile ML: Offline Intelligence analyzed for its latency, privacy, and offline advantages. There is no “server.” The interface is a function call, so optimization focuses on energy and responsiveness (SingleStream) rather than shared-server throughput.
The central advantage is Zero-Copy Inference: when data moves through a system, each copy consumes CPU cycles and memory bandwidth. In cloud serving, a camera frame might be copied four times: from network buffer to application memory, then to a preprocessing buffer, then to GPU-accessible memory, and finally to GPU VRAM. Mobile NPUs can eliminate most of these copies by sharing memory directly with the camera hardware. The camera writes pixels into a buffer that the NPU reads directly, avoiding the CPU entirely. This reduces both latency (no copy operations) and energy (memory copies consume significant power). The mechanism requires hardware support: the camera, CPU, and NPU must share a unified memory architecture, as in mobile system on chip (SoC) designs such as Apple’s M-series and Qualcomm Snapdragon.
Typical hardware includes mobile NPUs (Apple Neural Engine, Qualcomm Hexagon) and embedded GPUs (Jetson). Cold start usually falls in milliseconds because the model is already in app memory, though first inference may trigger just-in-time (JIT) compilation (100–500 ms). The sustained power budget is 1–5 W, with thermal throttling after prolonged inference.
Bare-metal serving (TinyML)
In TinyML serving, the model is compiled into the firmware of a microcontroller, the extreme end of the deployment spectrum TinyML: Ubiquitous Sensing introduced as ubiquitous sensing at microwatt power budgets. There is no operating system or dynamic memory allocator. “Serving” is a tight loop reading sensors and invoking the interpreter. Optimization focuses on static memory usage (fitting in SRAM) because all memory is preallocated in the Tensor Arena and dynamic batching is impossible. Typical hardware includes ARM Cortex-M series, ESP32, and specialized TinyML accelerators. Cold start falls in microseconds because model weights live in flash and the tensor arena is preallocated, while the power budget ranges from microwatts to milliwatts for battery operation over months or years. Table 1 summarizes how these deployment contexts shape serving system design.
To make these architectural differences concrete, consider how a single model must adapt to each deployment context.
The same ResNet-50 architecture requires dramatically different serving strategies across deployment contexts. Table 2 compares the three tiers side by side: cloud serving runs the full FP16 engine at millisecond latency on a data center GPU; mobile serving compresses to INT8 and dispatches to an NPU at a fraction of the energy; TinyML cannot run ResNet-50 at all and instead serves a downsized MobileNetV2 in kilobytes of SRAM.
| Characteristic | Cloud/Data center | Mobile/Edge | TinyML |
|---|---|---|---|
| Latency Target | 10–100 ms | 20–50 ms | 1–100 ms |
| Batch Size | 1–128 (dynamic) | 1 (fixed) | 1 (fixed) |
| Memory | 16–80 GB VRAM | 2–8 GB shared | 256 KB–2 MB SRAM |
| Power | 300–700 W | 1–10 W | 1–100 mW |
| Update Mechanism | Container deploy | App store update | Firmware over-the-air (OTA) |
| Failure Mode | Retry/failover | Graceful degradation | Silent or reset |
| Monitoring | Full telemetry | Limited analytics | Heartbeat only |
Systems Perspective 1.2: ResNet-50 across the serving spectrum
Systems insight: The “same model” claim is misleading: each row of table 2 is a different optimization, and often a different architecture entirely. The cloud and mobile tiers share the ResNet-50 graph but diverge in precision, runtime, and memory by three to four orders of magnitude; the TinyML tier cannot run ResNet-50 at all and substitutes an architecture designed for the constraints from the start. Treating these as one model hides the work that makes each deployment possible.
| Dimension | Cloud | Mobile | TinyML |
|---|---|---|---|
| Model format | TensorRT FP16 engine (51.2 MB) | TensorFlow Lite INT8 (25.6 MB) | Not feasible (25.6 MB); alternative: MobileNetV2-0.35 INT8 (3.5 MB) |
| Inference (batch-1) | 1.4 ms (batch-16: 14 ms) | 12 ms (NPU), 45 ms (CPU) | 120 ms |
| Throughput | 1,143 img/s (batched) | ~80 img/s (single-stream) | ~8 img/s |
| Memory | 2 GB VRAM (batch-32) | 150 MB peak (shared with app) | 320 KB arena (fits in 512 KB SRAM) |
| Energy/inference | — | 0.8 mJ (NPU), 4.2 mJ (CPU) | 12 mJ |
The load balancer layer
When traffic exceeds what a single machine can handle, cloud and data center deployments that run multiple replicas of the same model require an additional infrastructure layer: the load balancer. Production serving systems place load balancers between clients and model servers, providing three essential functions for serving infrastructure.
Request distribution, the first function, routes incoming requests to available model replicas using algorithms like round-robin or least-connections. For latency-sensitive ML serving, algorithms that route away from slow or overloaded replicas improve tail latency. The second, health monitoring, continuously verifies that replicas are ready to serve, routing traffic away from unhealthy instances. For ML systems, health checks must verify both process liveness and model readiness, confirming that weights are loaded and warmup is complete. The third, deployment support, enables safe model updates by gradually shifting traffic between versions instead of treating release as an all-at-once switch. Model deployment later turns that basic traffic-shift idea into full deployment and validation strategies.
For single-machine serving with multiple model instances, such as running several Open Neural Network Exchange (ONNX) Runtime sessions, the framework and operating system handle request queuing. The full complexity of load balancing becomes necessary when scaling to distributed inference systems, where multiple machines serve the same model. The implementation details of request distribution algorithms and multi-replica architectures belong to that distributed context.
When capacity planning considers “the server” in this single-machine serving analysis, it means the machine’s model serving capacity. The queuing dynamics analyzed in section 1.5 apply to understanding single-machine behavior and determining when scaling to multiple machines becomes necessary.
While load balancers distribute requests across replicas, achieving predictable latency also requires controlling what happens within each machine. The operating system environment introduces its own sources of variability.
Deterministic latency and resource isolation

One noisy neighbor perturbs every workload sharing the node.
An inference server does not operate in isolation. On a single machine, the operating system manages multiple competing processes (logging agents, monitoring tools, and system interrupts) that can intermittently steal CPU cycles from the inference pipeline. These “noisy neighbors” are a primary source of latency jitter, where the time required to process identical requests varies significantly, causing the 99th percentile (P99) latency to spike even when the hardware is underused. The tail latency explosion from figure 1 illustrates the same spike, but here the trigger is resource contention rather than queuing.
Achieving deterministic performance on a single node requires reducing interference from the operating system’s normal resource-sharing behavior. Predictable serving systems such as Clockwork show that DNN inference can meet tight request-level SLOs when scheduling and execution are controlled carefully (Gujarati et al. 2020). CPU affinity (pinning) is one local isolation tool: it restricts the inference server’s threads to specific physical cores so latency-sensitive work is less exposed to thread migration and cache-locality loss. Pinning can reduce one source of latency jitter, but it is part of a broader resource-isolation strategy rather than a complete solution.
Memory locking (mlock) addresses a related but distinct source of jitter. By default, the OS can page any memory region to disk under memory pressure. If the GPU’s DMA engine begins reading model weights from a region that has been paged out, the transfer stalls until the data is faulted back into RAM, a penalty measured in milliseconds rather than microseconds. Locking model weights and KV caches in physical RAM guarantees consistent access times, though the trade-off is that pinned memory cannot be reclaimed by other processes.
The third technique, interrupt shielding, completes the isolation picture. Network and storage interrupts routed to inference cores can preempt GPU command submission at unpredictable moments. Steering these interrupts to noninference cores ensures that bursts of incoming traffic do not disrupt the GPU’s command stream, which is particularly important for maintaining stable tail latency under load.
These isolation principles transform a simple “model script” into a deterministic service, a transition essential for safety-critical applications like autonomous driving or real-time industrial control. The deployment spectrum, load balancing, and resource isolation define where models serve and what infrastructure supports them. The remaining question is how the serving software itself is organized, specifically what components comprise an inference server and how they coordinate to turn irregular user traffic into efficient hardware utilization.
Serving System Architecture
User requests arrive in unpredictable bursts, one millisecond apart, then five seconds of silence, while accelerators demand steady, uniformly-sized batches. Bridging this gap requires more than a Python script calling model.predict(); it requires a specialized software architecture that absorbs traffic variability, forms efficient batches, and keeps hardware saturated without violating latency SLOs.
Internal architecture and request flow
Model optimization focuses on the mathematical artifact, while model serving requires a specialized software architecture to manage high-frequency request streams and hardware utilization. An inference server3 (such as NVIDIA Triton, TensorFlow Serving, or TorchServe) is not a simple wrapper around a model script; it is a high-performance scheduler that manages concurrency, memory, and data movement.
3 Inference Server: Google’s TensorFlow Serving (Olston et al. 2017) helped establish the separation of model logic from serving infrastructure; NVIDIA’s Triton (NVIDIA 2024b) extends this pattern across multiple model frameworks and backends. The critical design insight is that a scheduler and dynamic batcher turn irregular single-request traffic into accelerator-friendly execution, improving utilization when latency budgets allow batching. Exact utilization gains depend on model, hardware, arrival rate, and the configured batching window.
Olston, Christopher, Noah Fiedel, Kiril Gorovoy, Jeremiah Harmsen, Li Lao, Fangwei Li, Vinu Rajashekhar, Sukriti Ramesh, and Jordan Soyke. 2017. “TensorFlow-Serving: Flexible, High-Performance ML Serving.” CoRR abs/1712.06139. https://doi.org/10.48550/arXiv.1712.06139.
NVIDIA. 2024b. NVIDIA Triton Inference Server.
The internal anatomy of these servers reveals how they bridge the gap between irregular user traffic and the highly regular, batch-oriented requirements of accelerators. Every request traverses a multi-stage pipeline designed to maximize hardware throughput while minimizing latency overhead. Figure 4 separates the six stages so each component’s role in absorbing traffic, queueing, batching, and accelerator execution is explicit.

This architecture serves three functions. First, concurrency management: servers use asynchronous event loops or thread pools to handle thousands of concurrent client connections without blocking, ensuring that network I/O wait times do not idle the accelerator. Second, request transformation: the server converts network payloads, such as JavaScript Object Notation (JSON) or Protobuf, into the specific tensor formats required by the optimized model runtime. Image tensors, for example, can be stored as NCHW4 (batch, channels, height, width) or NHWC (batch, height, width, channels). PyTorch and TensorRT prefer NCHW because it places channel data contiguously, enabling efficient convolution on GPUs. TensorFlow defaults to NHWC, which is more efficient on CPUs.
4 NCHW and NHWC (Tensor Memory Layouts): These acronyms encode the memory layout order of 4D image tensors: N (batch), C (channels), H (height), W (width). NCHW places all values for one channel contiguously, enabling vectorized convolution on GPUs; NHWC interleaves channels at each spatial position, aligning better with CPU single instruction, multiple data (SIMD) instructions. A format mismatch between client and server can produce incorrect tensors even when the shape appears valid, so serving code should make layout conversions explicit.
Third, model management: inference servers manage the lifecycle of loaded model artifacts, including loading weights into VRAM, tracking which artifact version is active, and completing warmup inferences before exposing the model to live traffic. Full registries (versioned artifact stores), release gates (checks before release), and rollback governance (rules for reverting a bad release) belong to ML Operations; the local serving concern is whether the right artifact is loaded and ready. Among these components, the scheduler deserves special attention because it embodies the core serving trade-off between throughput and latency.
The Scheduler is the “brain” of the inference server. It implements the dynamic batching logic discussed in section 1.7. The scheduler must decide whether to run a single request immediately to minimize its latency or wait five milliseconds for a second request and process them together to maximize throughput.
Systems designers use the Batching Window parameter to tune this trade-off. A window of 0 ms optimizes for pure latency (no batching), while a small bounded window lets the scheduler trade a controlled amount of waiting for higher accelerator utilization. This decision determines how busy the accelerator stays: whether the hardware spends its time computing or waiting for work.
Interface protocols and serialization
The mechanism used to transport data between client and server directly affects the latency budget. Model inference is often highly optimized, yet the cost of moving data into the model (serialization and network protocol overhead) can become the dominant bottleneck, especially for lightweight models where inference time is small.
The serialization bottleneck
ML serving payloads are fundamentally different from typical web API payloads: they consist of multi-dimensional float arrays (image tensors, embedding vectors, token ID sequences) that are dense, binary, and large. Text-based formats like JSON are ubiquitous but computationally expensive for this kind of data. Serialization overhead appears when parsing a JSON object requires reading every byte, validating syntax, and converting text representations into machine-native types. For tensor payloads, the cost compounds: floating-point values must first be encoded as ASCII digits (inflating a 4-byte float to 10–15 characters), and binary data such as image bytes requires Base64 encoding, which adds 33 percent size overhead before JSON parsing begins. For high-throughput systems, this consumes CPU cycles that could otherwise be used for request handling or preprocessing.
Binary formats like Protocol Buffers5 (Protobuf) or FlatBuffers6 reduce this bloat by using schema-aware binary encodings instead of text encodings. Native float arrays can transmit as compact IEEE 754 bytes with no ASCII conversion and no Base64 wrapper. FlatBuffers can also enable zero-copy access in supported cases, where the network buffer can be read without allocating a separate object graph.
5 Protocol Buffers (Protobuf): Protobuf uses a predefined schema (from a .proto file) to encode structured data into a compact binary format (Protocol Buffers Authors 2026). Because the schema carries field names and types, the wire payload need not repeat them as JSON does. Its wire format is still not identical to a C++ object’s in-memory layout, so it requires a parsing step and does not provide the same direct zero-copy access pattern that FlatBuffers targets.
Protocol Buffers Authors. 2026. Overview: Protocol Buffers.
6 FlatBuffers: The “flat” in the name describes the design: the binary buffer can serve as the serialized representation and the data structure being read, avoiding a separate parsing or unpacking phase for supported access patterns (FlatBuffers Authors 2026). For ML inference, this can enable zero-copy access to tensor metadata—the serving system reads tensor shapes and offsets directly from the buffer rather than allocating a second object representation.
FlatBuffers Authors. 2026. FlatBuffers Documentation.
REST vs. gRPC
Two common paradigms define serving interfaces, each with distinct system characteristics. REST (Representational State Transfer) typically uses HTTP/1.1 and JSON. It is widely supported, human-readable, and stateless, making it a common choice for public-facing APIs. However, REST’s statelessness forces re-sending context with every call; for LLM serving, where a conversation context can exceed 10 KB of token IDs, this per-request overhead compounds at high QPS. Standard HTTP/1.1 uses persistent TCP connections by default, but without HTTP/2-style multiplexing a client often needs multiple connections or careful connection pooling to avoid head-of-line blocking and handshake overhead after idle timeouts. JSON serialization also adds significant latency for numerical data like tensors.
In contrast, gRPC (gRPC Remote Procedure Call)7 uses HTTP/2 and commonly uses Protobuf. HTTP/2 enables multiplexing multiple requests over a single persistent TCP connection, reducing connection-management overhead and allowing efficient binary streaming. Protobuf provides typed schemas and efficient binary serialization, making gRPC a common choice for internal service-to-service communication where latency and typed interfaces matter.
7 gRPC (gRPC Remote Procedure Call): gRPC pairs HTTP/2 transport with an interface definition language and message format, most commonly Protocol Buffers (gRPC Authors 2026). The relevant serving advantage is the combination of typed contracts, persistent multiplexed connections, streaming support, and compact binary messages. The size and latency benefit over REST/JSON depends on payload shape, client/server implementation, and whether serialization is a meaningful share of the end-to-end latency budget.
gRPC Authors. 2026. Introduction to gRPC.
A concrete payload comparison shows how the serialization choice changes both wire size and parsing cost.
Napkin Math 1.2: JSON vs. Protobuf serialization
Consider a request payload containing 1,000 floating point numbers (for example, an embedding vector).
- JSON: Uses ~9 KB on the wire. Requires ~50 μs to parse.
- Protobuf: Uses ~4 KB on the wire. Requires ~5 μs to parse.
Math: Switching one request to the binary payload saves 50 μs − 5 μs = 45 μs of parse time. For this illustrative system processing 10,000 requests per second, the savings compound to 10,000 \(\times\) 45 μs = 0.45 s of CPU time reclaimed every wall-clock second, which is 45 percent of one core freed from serialization overhead alone.
Systems insight: This 10× scenario gain makes gRPC/Protobuf, FlatBuffers, or another binary protocol a strong candidate for high-throughput internal microservices when serialization is a visible part of the latency budget.
The system choice is constraint-dependent. REST/HTTP is common when public compatibility, debugging, and ecosystem reach dominate. gRPC/Protobuf, or another binary protocol, is favored when internal high-QPS tensor traffic, connection reuse, or streaming makes serialization a meaningful share of the latency and CPU budget.
The architectural components and protocols examined so far describe how serving systems are built. Understanding why certain configurations perform better requires analyzing what happens to individual requests as they traverse these components.
Self-Check: Question
Order the following inference-server stages for a typical online request: (1) Dynamic batcher, (2) Accelerator execution, (3) Network ingress, (4) Request queue.
An inference server sees traffic arriving in microbursts followed by silent gaps. Why is the scheduler described as the point ‘where throughput meets latency’?
- It decides whether to dispatch a request immediately or wait briefly to form a larger batch that raises accelerator efficiency, trading a small latency penalty for a large throughput gain.
- It chooses whether the model should train or serve on each request based on load.
- It performs NCHW-to-NHWC tensor-layout conversion inline so every framework sees a canonical layout.
- It replaces the need for cross-replica load balancing by handling all routing inside the node.
Explain why sending NHWC image tensors to a runtime expecting NCHW is often a silent serving failure rather than a loud crash, and what this implies for production monitoring.
A high-throughput internal microservice serves embedding vectors and spends a large fraction of CPU time parsing request payloads. Which interface choice best matches the chapter’s guidance for this workload?
- REST over HTTP/1.1 with larger JSON payloads, on the theory that bigger payloads amortize parsing cost automatically.
- REST over HTTP/1.1 with JSON, because human readability is the most important property for internal service communication.
- gRPC over HTTP/2 with Protobuf, because persistent multiplexed connections and binary serialization reduce both handshake and parsing overhead on the hot path.
- Flat text over raw TCP with no schema, because both services are internal and can agree on byte layouts informally.
A team serves an embedding model with a strict 20 ms p99 SLO. Requests carry 4 KB of JSON that takes 6 ms to parse and serialize end to end; the model itself takes 8 ms on the accelerator. Explain why switching to a binary format that supports near-zero-copy deserialization is a material optimization here, and when the same switch would not matter.
Request Lifecycle
A single HTTP request carrying a \(224{\times}224\) JPEG image arrives at an inference server. Between the moment the first byte enters the network stack and the moment the classification result leaves, that request traverses six pipeline stages, each consuming milliseconds that the user experiences as wait time. Understanding where time goes within each request is essential for effective optimization: one cannot improve what one does not measure.
The latency budget
For dynamic inference systems, the serving inversion established in section 1.1 creates a latency budget that shapes system design (Gujarati et al. 2020). A serving system with second-scale per-request latency may miss many interactive SLOs, even if it achieves excellent throughput.
Gujarati, Arpan, Reza Karimi, Safya Alzayat, Wei Hao, Antoine Kaufmann, Ymir Vigfusson, and Jonathan Mace. 2020. “Clockwork: Predictable and Scalable DNN Inference in the Cloud.” USENIX Symposium on Operating Systems Design and Implementation (OSDI), 443–62.
8 Tail Latency: Unlike averages, percentile latencies reveal the performance impact of system outliers common in ML serving, such as model cache misses or garbage collection pauses. These rare, high-latency requests disproportionately harm user satisfaction and directly impact revenue. Foundational studies at Google and Amazon quantified this relationship, finding that 100 ms of added latency cost ~1 percent in sales, establishing percentile targets (p95, p99) as the critical metrics for service quality.
Relevant metrics shift from aggregate throughput to latency distributions. Mean latency reveals little about user experience; p50, p95, and p99 latencies reveal how the system performs across the full range of requests. If the mean latency is 50 ms but p99 is two seconds, one in a hundred users waits 40× longer than average. For consumer-facing applications, these tail latencies often determine user satisfaction and retention.8
Managing these percentile constraints requires decomposing the total allowed response time into a latency budget that allocates time across each processing phase.
Definition 1.2: Latency budget
Latency Budget is the time capital allocated to an ML inference request, strictly bounded by the end-to-end service level objective (SLO).
- Significance: It acts as a zero-sum constraint system where any milliseconds consumed by serialization or network overhead directly reduce the latency budget \((L_{\text{lat}})\) available for model inference.
- Distinction: Unlike average latency, which hides variance, a latency budget is a hard bound that must be maintained for the slowest requests (for example, p99).
- Common pitfall: A frequent misconception is that the “model” has the entire budget. In reality, the model often has less than 50 percent of the total budget; the remainder is consumed by the request lifecycle (DNS, TLS, load balancing, serialization).
Before computing a full budget, this checkpoint sets the foundational latency-analysis skills every serving engineer needs.
Every serving request decomposes into three phases that each consume part of the latency budget. Preprocessing transforms raw input such as image bytes or text strings into model-ready tensors. Inference executes the model computation. Postprocessing transforms model outputs into user-facing responses.
Checkpoint 1.1: ResNet-50 latency analysis
Serving optimizes tail latency under load. Use this checkpoint to separate queueing and batching effects before choosing an optimization.

Inference is one slice of the latency budget; preprocessing rivals it.
Faster hardware does not automatically mean faster serving. In practice, preprocessing and postprocessing can dominate total latency when inference runs on optimized accelerators. Optimizing exclusively the inference phase yields diminishing returns if the surrounding pipeline remains bottlenecked by CPU operations.
Latency distribution analysis
Understanding where time goes requires instrumenting each phase independently. A ResNet-50 latency budget breakdown reveals exactly how each millisecond is spent when our classifier receives a JPEG image.
Systems Perspective 1.3: ResNet-50: Latency budget breakdown
Table 3 breaks a typical ResNet-50 serving request down per phase:
Table 3: ResNet-50 latency budget: Per-phase breakdown of a single serving request, showing that preprocessing and data transfer together rival the cost of the ResNet-50 forward pass itself. The percentages expose where engineering effort actually pays off, which is rarely in the model. Per-phase percentages are rounded to the nearest whole number and may not sum to exactly 100.
| Phase | Operation | Time | Percentage |
|---|---|---|---|
| Preprocessing | JPEG decode | 3 ms | 30% |
| Preprocessing | Resize to \(224{\times}224\) | 1 ms | 10% |
| Preprocessing | Normalize (mean/std) | 0.5 ms | 5% |
| Data Transfer | CPU→GPU copy | 0.5 ms | 5% |
| Inference | ResNet-50 forward pass | 5 ms | 50% |
| Postprocessing | Softmax + top-5 | 0.1 ms | ~1% |
| Total | 10.1 ms | 100% |
Systems insight: The ResNet-50 serving budget shows preprocessing consumes 44.6 percent of latency despite model inference being the computationally intensive phase. With TensorRT optimization reducing inference to 2 ms, preprocessing would dominate at 63.4 percent.
The ResNet example represents compute-bound inference where the forward-pass arithmetic dominates the latency budget. Applying the same framework to a different model architecture often reveals that the bottleneck shifts from compute to memory bandwidth, invalidating the optimization strategies that worked for vision models. Recommendation systems exhibit exactly this shift.
Lighthouse 1.1: Lighthouse example: DLRM serving
Scenario: Serving DLRM with a 10 ms P99 latency budget.
Table 4: DLRM serving latency: Per-phase breakdown of a recommendation request under a 10 ms p99 budget, contrasting DLRM’s memory-bandwidth-bound embedding lookups against ResNet-50’s compute-bound forward pass. Adding compute to the inference stage does not help once embedding-table bandwidth is the binding constraint.
Analysis: While ResNet-50’s model stage is dominated by convolutional neural network (CNN) compute, DLRM’s dominant model-stage cost is embedding-table memory access. End-to-end serving bottlenecks still require measuring the full path: preprocessing, inference, postprocessing, and data movement. Table 4 breaks the recommendation request down by phase:
| Phase | Operation | Time | Bottleneck |
|---|---|---|---|
| Input Parsing | Request parsing | 0.5 ms | CPU |
| Embedding Look | Fetch 100+ dense vectors | 6 ms | memory bandwidth |
| Inference | MLP forward pass | 1.5 ms | Compute |
| Postprocessing | Ranking & Filtering | 1 ms | CPU |
| Total | 9 ms |
Systems insight: In DLRM, the “Inference” multilayer perceptron (MLP) stage is only ~17 percent of the latency. The majority of time is spent in embedding lookups, retrieving massive 128-dim vectors from terabyte-scale tables. This is a memory-bandwidth and capacity-bound workload where adding more compute does not help unless the embedding tables can be served faster.
The two lighthouse cases illustrate the same general failure mode: straightforward optimization efforts target where ML expertise applies (model quantization, pruning) while the binding constraint sits elsewhere (image decoding on CPU for ResNet-50, embedding-table memory bandwidth for DLRM). The pattern generalizes: any serving system where the model accounts for less than half of total latency will see diminishing returns from model-only optimizations, regardless of how large those individual speedups are. Amdahl’s Law quantifies the ceiling. Adopting the quantitative approach to serving exposes these hidden bottlenecks before engineering effort is misallocated.
Napkin Math 1.3: The quantitative approach to serving
Amdahl’s Law at work (Amdahl's Law and Gustafson's Law provides the formal derivation): preprocessing (4.5 ms) and data transfer (0.5 ms) consume 49.5 percent of total latency. Optimizing the model 10\(\times\) faster (5 ms → 0.5 ms) yields only 1.8× end-to-end speedup (from 10.1 ms to 5.6 ms). This is why focusing exclusively on model optimization (quantization, pruning) often disappoints: the bottleneck is elsewhere.
DSA efficiency: General-purpose CPUs achieve only 1–2 percent of peak performance at batch-1 because instruction overhead dominates. DSAs like TPUs and Tensor Cores replace complex logic with dense multiply-accumulate (MAC) arrays, achieving 10–100\(\times\) higher arithmetic intensity. This makes hardware acceleration an economic requirement for many high-throughput or low-latency serving workloads.
Systems insight: Profile before optimizing. If preprocessing dominates, GPU-accelerated pipelines (NVIDIA DALI) may outperform model quantization.
Moving preprocessing closer to the accelerator can reduce avoidable CPU-GPU transfers, but the end-to-end gain is pipeline-specific. Effective optimization targets the largest time consumers first.
The serving tax bill
Beyond the model execution itself, every request pays a “tax” to the serving infrastructure. Table 5 gives representative overhead ranges for a high-performance inference request (for example, ResNet-50 classification).
The killer microseconds problem
Barroso, Patterson, and colleagues identified a critical gap in how systems handle latency at different time scales (Barroso et al. 2017). Operations in the microsecond range are too short for traditional OS scheduling (which operates at millisecond granularity) yet too long to simply spin-wait without wasting CPU cycles. This “killer microseconds” regime matters in modern serving workloads. Using the representative ranges in table 5, serialization at 50–500 μs, dispatch at 10–50 μs, and data copy at 100–500 μs are each individually small, but for a 5 ms inference service, these named microsecond-scale overheads collectively consume about 3.2 percent to 21 percent of the latency budget before network and queuing delays are counted. No single overhead justifies optimization in isolation, yet together they determine whether the system meets its SLO.
Barroso, Luiz, Mike Marty, David Patterson, and Parthasarathy Ranganathan. 2017. “Attack of the Killer Microseconds.” Communications of the ACM 60 (4): 48–54. https://doi.org/10.1145/3015146.
| Tax Component | Typical Cost | Scaling Behavior | Tax Evasion Strategy |
|---|---|---|---|
| Network I/O | 1-5 ms | Linear with payload | Compression, Region Colocation |
| Serialization | 50–500 \(\mu\text{s}\) | Linear with payload | gRPC/Protobuf (vs. JSON) |
| Queuing | 0.1-10 ms | Exponential w/ load | Dynamic Batching, Autoscaling |
| Dispatch | 10–50 \(\mu\text{s}\) | Constant per batch | Kernel Fusion (reduce launches) |
| Data Copy | 100–500 \(\mu\text{s}\) | Linear with tensor | Zero-Copy/Shared Memory |
The latency budget framework provides a systematic approach to this compound problem. Measurement comes first: without per-phase instrumentation, engineers cannot distinguish a preprocessing bottleneck from a serialization bottleneck, and optimization effort gets misallocated to the most visible component (the model) rather than the most expensive one. Once measurement reveals the true distribution of time, engineering effort should flow proportionally—a phase consuming 50 percent of latency deserves more attention than one consuming 5 percent, regardless of which feels more tractable. Architectural changes such as GPU-accelerated preprocessing or aggressive batching can shift work between phases entirely, sometimes eliminating a bottleneck rather than merely reducing it.
Resolution and input size trade-offs
Input resolution affects both preprocessing and inference latency, but the relationship differs depending on whether the system is compute bound (limited by arithmetic throughput) or memory-bound (limited by data movement). A compute-bound system slows proportionally to increased computation; a memory-bound system may show minimal slowdown if activation tensors still fit in fast memory. The roofline analysis in Roofline Model develops this distinction in depth, making it essential for informed resolution decisions.
For compute-bound models, equation 1 formalizes how throughput scales inversely with resolution squared: \[\frac{\text{Throughput}(r_2)}{\text{Throughput}(r_1)} = \left(\frac{r_1}{r_2}\right)^2 \tag{1}\]
Doubling resolution from 224 to 448 theoretically yields 4× slowdown (measured: 3.6× due to fixed overhead amortization). Higher resolution also shifts the compute-memory balance, but toward compute: every convolution weight is reused across more spatial positions, so FLOPs and activation traffic both grow quadratically while the fixed weight traffic is amortized, and arithmetic intensity rises further above the roofline ridge point. The serving costs of resolution are quadratic latency growth and quadratic activation-memory pressure, not a bandwidth bottleneck.
Table 6 quantifies this transition for ResNet-50.
| Resolution | Activation Size | Arith. Intensity | Bottleneck |
|---|---|---|---|
| \(224{\times}224\) | 12.5 MB | 32.2 FLOP/byte | Compute |
| \(384{\times}384\) | 36.7 MB | 68.5 FLOP/byte | Compute |
| \(512{\times}512\) | 65.3 MB | 91.9 FLOP/byte | Compute |
| \(640{\times}640\) | 102.0 MB | 109.2 FLOP/byte | Compute |
Resolution strategies in production
Different deployment contexts impose distinct resolution requirements shaped by their dominant constraints. Mobile applications often accept lower resolution (\(224{\times}224\)) for object detection in camera viewfinders, where latency and battery life outweigh marginal accuracy gains. Medical imaging sits at the opposite extreme, requiring \(512{\times}512\) or higher for diagnostic accuracy, with relaxed latency requirements that permit the additional compute. Autonomous vehicles split the difference by using multiple resolutions for different tasks: low resolution for rapid detection across wide fields of view and high-resolution crops for fine-grained recognition of detected objects. Cloud APIs face yet another challenge—they typically receive images at whatever resolution the client uploads and must handle the resulting range gracefully. This variability makes cloud APIs ideal candidates for adaptive resolution strategies, where the system selects resolution dynamically based on content characteristics.
Adaptive resolution
Adaptive resolution lets production systems select resolution dynamically based on content. One approach runs a lightweight classifier at \(128{\times}128\) to categorize content type, then selects task-appropriate resolution with documents at \(512{\times}512\), landscapes at \(224{\times}224\), and faces at \(384{\times}384\). This achieves 1.4× throughput improvement with 99.2 percent accuracy retention vs. fixed high resolution. This pattern trades preprocessing cost from running the lightweight classifier for inference savings on the main model.
The latency analysis so far has focused on sequential processing: one request completing before the next begins. The preprocessing, inference, and postprocessing stages use different hardware resources. This separation creates an opportunity to process multiple requests simultaneously.
Hardware utilization and request pipelining
Optimizing each request stage in isolation misses a critical opportunity: the stages use different hardware resources. The latency budget analysis in section 1.4.1 reveals that model inference is only one component of the request lifecycle. From a hardware perspective, the primary goal of a serving system is to maximize the duty cycle of the accelerator, the percentage of time the GPU is performing useful computation.
In a serialized serving system, the hardware sits idle during network I/O and CPU-based preprocessing. High-performance serving systems use Request Pipelining to overlap these stages, ensuring the GPU is fed a continuous stream of tensors.
Overlapping I/O and compute
The two timing diagrams in figure 5 illustrate the impact of pipelining. In the serial case (A), each request must complete its entire lifecycle (Network \(\rightarrow\) CPU Preprocessing \(\rightarrow\) GPU Inference \(\rightarrow\) Postprocessing) before the next request begins, and the grey idle gaps leave the GPU unused for more than 50 percent of the time. In the pipelined case (B), those gaps disappear.

Pipelining is enabled by asynchronous I/O and concurrency models. Instead of waiting for a GPU kernel to finish, the server’s CPU thread submits the work to the GPU’s command queue and immediately begins preprocessing the next incoming request.
The systems metric: Hardware duty cycle
In the “Quantitative Approach” to ML systems, we define system efficiency as the ability of a serving system to saturate the bottleneck resource. For most ML systems, this is the GPU’s compute cores or memory bandwidth. We quantify this in equation 2: \[\text{System Efficiency} = \frac{\sum T_{\text{compute}}}{\text{Wall Clock Time} \times \text{Resource Count}} \tag{2}\]
If a ResNet-50 request takes 10 ms total (5 ms GPU, 5 ms CPU), a serial system achieves only 50 percent efficiency. By pipelining just two requests, efficiency approaches 100 percent (assuming the CPU can keep up with the GPU). If the CPU is too slow to feed the GPU, the system becomes CPU-bound, and further model optimization provides zero throughput gain. This is Amdahl’s Law from Amdahl's Law and Gustafson's Law applied to serving: if preprocessing consumes 50 percent of latency, maximum speedup is 2\(\times\) regardless of how fast the model runs. The hardware trajectory makes this ceiling progressively tighter. Accelerator compute throughput (FLOPs) has grown far faster than CPU single-thread performance across successive hardware generations, so the inference portion of the pipeline shrinks while the CPU-bound preprocessing portion remains unchanged. A system that was compute-bound on an older accelerator may become CPU-bound after a hardware upgrade—not because preprocessing got slower, but because the model got dramatically faster while the CPU did not.
Postprocessing
The request lifecycle concludes with postprocessing, the phase that transforms model outputs into actionable results. A neural network produces raw tensors (floating-point arrays that carry no inherent meaning to applications or users). A 0.95 probability becomes a confident “dog” label only after postprocessing converts it; a sequence of token IDs becomes readable text; a bounding box tensor becomes a highlighted region in an image. Postprocessing significantly impacts both latency and the usefulness of predictions.
From logits to predictions
Classification models output logits or probabilities across classes. Converting these raw outputs to predictions involves several steps. The simplest is argmax selection, which returns the highest-probability class. Thresholding applies a confidence cutoff, returning predictions only when the model is sufficiently certain. Top-\(k\) extraction returns multiple high-probability classes with their scores, useful when applications need ranked alternatives. Calibration adjusts raw probabilities to better reflect true likelihoods, a step that adds computation but is essential when downstream systems make decisions based on confidence scores. For ResNet-50 image classification, listing 1 shows the full postprocessing path from raw logits to an API-ready response, including probability normalization, top-\(k\) extraction, label lookup, and response formatting.
For this example, total postprocessing time is approximately 0.1 ms, negligible compared to preprocessing and inference. Each step adds latency but improves response utility. Calibration in particular can add significant computation but is necessary when downstream systems make decisions based on confidence scores.
Output formatting
Production systems rarely return raw predictions. Outputs must conform to API contracts that specify JSON serialization schemas, confidence score formatting, and thresholding rules. Error handling must address edge cases: the system must define behavior when no prediction exceeds the confidence threshold or when the input appears out-of-distribution. Response metadata (model version, inference time, feature attributions) enables downstream monitoring and debugging.
# Transform raw logits to calibrated probabilities
# Input: logits tensor of shape (batch_size, 1000) - one score per
# ImageNet class
probs = torch.softmax(
logits, dim=-1
) # Normalize to sum=1; ~0.05 ms on GPU
# Extract top-5 predictions for multi-class response
# topk returns (values, indices) sorted by probability
top5_probs, top5_indices = probs.topk(5) # ~0.02 ms; GPU operation
top5_probs = top5_probs.squeeze(0).tolist()
top5_indices = top5_indices.squeeze(0).tolist()
# Map class indices to human-readable labels
# imagenet_labels: list of 1000 class names from synset mapping
labels = [
imagenet_labels[i] for i in top5_indices
] # ~0.01 ms; CPU lookup
# Format response with predictions and metadata for API contract
response = {
"predictions": [
{"label": label, "confidence": float(prob)}
for label, prob in zip(labels, top5_probs)
],
"model_version": "resnet50-v2.1", # Client-side version tracking
"inference_time_ms": 5.2, # Observability for latency monitoring
}The latency budget analysis reveals where time goes within a single request. Production systems, however, do not process requests in isolation: they must handle hundreds or thousands of concurrent requests competing for finite resources. Understanding this concurrency requires a different analytical framework.
Self-Check: Question
A ResNet-50 image-classification service on a GPU measures its end-to-end request latency after runtime optimization has reduced accelerator inference to roughly 2 ms. Based on the chapter’s breakdown, which phase is most likely to dominate the budget, and which other phase is the most realistic competitor if the team misreads the trace?
- JPEG decode and resize dominate; optimized GPU inference is the most realistic competitor because both remain visible millisecond-scale phases.
- Top-k postprocessing dominates; the network response path is the competitor because both run after the model.
- GPU inference dominates; JPEG decode is the competitor because neural network math is usually the longest single phase.
- HTTP ingress dominates; TLS handshake is the competitor because connection setup is almost always the primary cost for image workloads.
A team accelerates ResNet-50 inference from 5 ms to 0.5 ms on the accelerator but leaves JPEG decode, resize, normalization, and CPU-to-GPU transfer unchanged. Explain why the end-to-end speedup is nowhere near 10\(\times\), using the chapter’s Amdahl-style framing.
A vision service doubles input resolution from 224x224 to 448x448 and measures a slowdown of roughly 3\(\times\) rather than the 4\(\times\) a FLOPs-only argument predicts. Which explanation best fits the chapter?
- Latency is independent of input size once the model is JIT-compiled for the first request.
- Fixed preprocessing and transfer overheads are being amortized across more compute, and the kernel may shift between compute-bound and memory-bound regimes, so observed scaling departs from a pure FLOPs calculation.
- Postprocessing complexity drops as image size increases, which offsets model slowdown and produces sub-linear scaling.
- Higher-resolution inputs automatically improve batch formation efficiency and recover the difference.
True or False: Request pipelining can improve end-to-end serving throughput even when per-request model inference time on the accelerator stays unchanged.
Which deployment strategy best matches the chapter’s argument for adaptive resolution?
- Always use the maximum supported resolution because batching hides the added cost at scale.
- Always use the minimum supported resolution because preprocessing dominates the budget anyway.
- Pick one resolution at training time and never change it at serving time, so that train-and-serve inputs stay bit-identical.
- Use a lightweight first-stage classifier to route each input to a resolution appropriate for its complexity, trading a small extra preprocessing cost for higher aggregate throughput.
Queuing Theory
In production, concurrent requests compete for finite resources, and queuing theory predicts how this competition affects latency. These principles explain the counterintuitive behavior that causes well-provisioned systems to violate latency SLOs when load increases modestly.
Little’s Law
Serving engineers routinely face a concrete capacity decision: given a latency SLO and an expected request rate, the system must determine how much in-flight work it has to hold before deciding how many GPUs to provision. Little’s Law (Little's Law) answers the first question by relating queue depth to throughput. The M/M/1 model later answers the second by predicting how latency degrades under load. Together, they provide the quantitative framework for capacity planning.
Serving engineers need a tool that connects observable metrics to capacity requirements. The most celebrated result in queuing theory is Little’s Law,9 which equation 3 expresses as a simple relationship between three quantities in any stable system: \[Q_{\text{req}} = \lambda_{\text{arr}} \cdot T_{\text{lat}} \tag{3}\] where \(Q_{\text{req}}\) is the average number of requests in the system, \(\lambda_{\text{arr}}\) is the arrival rate (requests per second), and \(T_{\text{lat}}\) is the average time each request spends in the system.
9 Little’s Law: John D. C. Little proved in 1961 that \(Q_{\text{req}} = \lambda_{\text{arr}} T_{\text{lat}}\) holds for any stable system regardless of arrival distribution, service distribution, or scheduling discipline. This universality is why it anchors ML capacity planning: the formula requires no assumptions about whether requests arrive in bursts, whether inference times vary, or whether the scheduler batches aggressively. The only requirement is stability \((\lambda_{\text{arr}} < \mu)\), and when that condition breaks, no amount of optimization prevents queue divergence.
Concretely, a server targeting 1000 QPS with a 50 ms SLO can translate that pair directly into the number of concurrent request slots it must hold in memory, the hard floor for activation storage on that node; the worked example below carries out that calculation.
Systems Perspective 1.4: Notation alert: L vs. latency
In queuing theory, \(T_{\text{lat}}\) denotes the response time or time in system per request; queue-only waiting time is \(W_q\). This book uses \(Q_{\text{req}}\) for the average in-system request count, \(\lambda_{\text{arr}}\) for arrival rate, and \(\rho_{\text{serv}}=\lambda_{\text{arr}}/\mu\) for serving utilization. The subscripts distinguish queueing notation from the degradation equation’s \(\lambda\) sensitivity parameter and keep serving utilization from occupying bare \(\rho\). In the latency-budget equations below, descriptive \(L_{\text{lat,*}}\) terms name components of the budget, such as waiting and compute. In the batching analysis that follows (section 1.7.3), \(L_{\text{lat,wait}}\) corresponds to the queueing wait component \(W_q\), and \(L_{\text{lat,compute}}\) includes inference time.
This relationship holds regardless of arrival distribution, service time distribution, or scheduling policy. A practical capacity calculation shows why this universality matters for serving memory.
Napkin Math 1.4: Little's Law capacity sizing
Problem: How much concurrent request capacity does a system need to serve 1,000 QPS?
Math: Little’s Law gives \(Q_{\text{req}} = \lambda_{\text{arr}} T_{\text{lat}}\), so concurrency equals throughput multiplied by latency (Little's Law derives the law).
Given:
- Throughput target \((\lambda_{\text{arr}})\): 1,000 QPS.
- Latency target \((T_{\text{lat}})\): 50 ms (0.05 s).
Math:
\(Q_{\text{req}}\) = 1,000 QPS \(\times\) 0.05 s = 50 concurrent requests
Systems insight: The server must have enough RAM to hold 50 requests simultaneously across batch and queue state. If the GPU runs out of memory at batch size 32, the system physically cannot hit 1,000 QPS at 50 ms latency; the only options are to reduce latency \((T_{\text{lat}})\) or add enough memory for a larger resident \(Q_{\text{req}}\).
Little’s Law has immediate practical implications. If an inference service averages 10 ms per request \((T_{\text{lat}} = 0.01 \text{ s})\) and the system shows 50 concurrent requests on average \((Q_{\text{req}} = 50)\), then the arrival rate must be \(\lambda_{\text{arr}} = Q_{\text{req}} / T_{\text{lat}} = 5000\) requests per second. Conversely, if the system must limit concurrent requests to 10 (perhaps due to GPU memory constraints) and the service time is 10 ms, it can sustain at most 1000 requests per second.
The batching tax: The latency-throughput frontier
While Little’s Law relates queue depth to throughput, it does not account for the Batching Tax: the deliberate delay introduced to maximize hardware utilization. In the tradition of quantitative systems, we analyze this as a queuing delay problem.
When an inference server batches requests, it introduces two distinct sources of latency. Batch formation delay \((L_{\text{lat,form}})\) is the time the first request in a batch waits for the last request to arrive. Inference inflation is the growth in inference time \(T_{\text{inf}}(B)\) when the GPU processes \(B\) samples instead of 1. The resulting latency-throughput Pareto frontier is the set of configurations where one cannot improve throughput without paying a “tax” in increased latency. We can quantify the total batched-request latency for a batch size \(B\) and arrival rate \(\lambda_{\text{arr}}\) as equation 4: \[ L_{\text{lat,total}} \approx \underbrace{ \frac{B-1}{2\lambda_{\text{arr}}} }_{\text{Formation delay}} + \underbrace{ T_{\text{inf}}(B) }_{\text{Inference time}} \tag{4}\]
This equation reveals the “cost of throughput.” Increasing \(B\) to saturate the GPU amortizes the hardware cost, but inflates the per-request latency. Concretely, at 500 QPS, moving from batch-1 to batch-32 increases wait-time from 0 ms to 31 ms, contributing to a 23× total latency penalty (2 ms → 46 ms). For a systems engineer, this tax is the primary regulator of economic efficiency: the engineer chooses the batch size that maximizes throughput (minimizing cost per query) without violating the latency SLO \((L_{\text{lat}})\).
The utilization-latency relationship
Little’s Law describes average system behavior, but it does not reveal how latency changes as load approaches capacity. To answer the critical question of how much spare capacity a serving system needs, we turn to the M/M/1 queue model (Harchol-Balter 2013).10 For a system with Poisson arrivals and exponential service times, equation 5 gives the average time in system: \[T_{\text{lat}} = \frac{1}{\mu - \lambda_{\text{arr}}} = \frac{\text{service time}}{1 - \rho_{\text{serv}}} \tag{5}\] where \(\lambda_{\text{arr}}\) is the arrival rate, \(\mu\) is the service rate (requests per second the server can handle), and \(\rho_{\text{serv}} = \lambda_{\text{arr}}/\mu\) is the utilization (fraction of time the server is busy).
10 M/M/1 Queue: Queuing theory originated with Agner Krarup Erlang’s 1909 analysis of the Copenhagen Telephone Exchange, where call arrivals genuinely were memoryless (Poisson). The M/M/1 model’s exponential service time assumption fit telephony well but overpredicts service-time variance for many fixed-shape ML inference workloads. This mismatch is useful for intuition: M/M/1 overestimates wait times by roughly 2\(\times\) compared with a deterministic-service model such as M/D/1, so capacity planning based on it tends to preserve more headroom.
11 Super-Linear Latency Divergence: The planning knee often appears well before full saturation. In the M/M/1 mean response-time equation, \(E[T] = \frac{1/\mu}{1-\rho_{\text{serv}}}\), where \(\rho_{\text{serv}} = \lambda_{\text{arr}}/\mu\) is utilization. The \((1-\rho_{\text{serv}})^{-1}\) term diverges as \(\rho_{\text{serv}} \to 1\): at \(\rho_{\text{serv}} = 0.7\), mean response time is already 3.3\(\times\) the base service time; at \(\rho_{\text{serv}} = 0.9\), it is 10\(\times\). The exact operating limit is a policy and workload choice, but trying to stretch a latency-sensitive queue toward saturation creates disproportionate latency growth.
This equation reveals why serving systems exhibit nonlinear behavior: small increases in load near capacity cause disproportionate latency increases11. Table 7 quantifies this relationship, showing how average time in system grows rapidly as utilization approaches 100 percent.
| Utilization \((\rho_{\text{serv}})\) | Latency Multiple | Example (5 ms service) |
|---|---|---|
| 50% | 2× | 10 ms |
| 70% | 3.3× | 17 ms |
| 80% | 5× | 25 ms |
| 90% | 10× | 50 ms |
| 95% | 20× | 100 ms |
The M/M/1 model assumes exponentially distributed service times, but ML inference typically has near-constant service time for fixed batch sizes, making the M/D/1 (deterministic service) model more accurate in practice. We use M/M/1 here because it yields closed-form solutions and produces conservative estimates. For M/D/1 queues, average wait time is approximately half of M/M/1 at the same utilization, which matters for capacity planning: M/M/1 analysis will slightly over-provision, erring on the side of meeting SLOs rather than violating them.12
12 Kendall Notation: In the A/S/c (Arrival/Service/servers) system, “M” signifies a Markovian (memoryless) process and “D” means deterministic. The text selects M/M/1 rather than the more realistic M/D/1 because M/M/1’s conservative bias is a feature for capacity planning: it overestimates wait times by roughly 2\(\times\) when service times are nearly deterministic, preserving margin against variance surprises. The cost of modest over-provisioning is often far lower than the cost of an SLA miss at the p99 tail when service time variance spikes unexpectedly.
Multi-server considerations
The preceding analysis focuses on a single serving node (one machine serving inference requests). This scope aligns with this book’s focus on mastering the basic unit of ML systems. Single-node queuing dynamics are prerequisite to effective scaling. Engineers cannot optimize a distributed system without first understanding the behavior of its components.
M/M/1 analysis remains the foundation for right-sizing individual nodes, identifying the scaling trigger, and avoiding premature scale-out. First, it determines whether one GPU can meet the latency SLO at expected traffic. Then it shows when arrival rate exceeds single-node capacity. Finally, it prevents teams from adding replicas before the bottleneck is actually node capacity rather than batching policy, preprocessing, cold start, or runtime configuration.
Once traffic truly exceeds single-node capacity, the next move is replica-level scale-out: multiple independent serving nodes sit behind a load balancer and each runs the same model. The M/M/c queuing model extends M/M/1 to \(c\) parallel servers, showing how replicas can improve latency when traffic is balanced across independent servers. The exact p99 improvement depends on arrival process, service-time variance, dispatch policy, and per-replica utilization. That replica model is still different from distributed inference, where one request is split across GPUs through model sharding, tensor parallelism, or pipeline parallelism. This chapter establishes the single-node and replica foundations; distributed inference adds coordination overhead and consistency challenges beyond this scope.
Tail latency
Production SLOs typically specify percentile targets (p95, p99) rather than averages because tail latency determines user experience for the slowest requests (Dean and Barroso 2013). For an M/M/1 queue, the p99 latency follows: \[T_{\text{lat},\text{p99}} \approx \frac{\text{service time}}{1 - \rho_{\text{serv}}} \cdot \ln\left(\frac{1}{1 - 0.99}\right) \approx \frac{4.6 \cdot \text{service time}}{1 - \rho_{\text{serv}}} \tag{6}\]
At 70 percent utilization, the M/M/1 p99 approximation is approximately 15 times the service time \((4.6/0.3 \approx 15.3)\), while average latency is only 3.3 times. For deterministic-service models such as M/D/1, tail values require model-specific calculation rather than a simple universal multiplier. The important point is unchanged: systems that seem healthy with low average latency can have unacceptable tail latency, since the average hides the experience of the unluckiest requests.
The tail at scale problem
Dean and Barroso’s analysis reveals why tail latency becomes critical as systems scale beyond single machines (Dean and Barroso 2013). When requests fan out to multiple servers, the probability of experiencing at least one slow response grows rapidly with server count. This “tail at scale” effect makes individual server tail latency critical for overall system performance.
For single-machine serving, this principle has two implications. First, tail latency on individual machines matters because it will compound when systems eventually scale. Second, the tail-tolerant techniques described later (hedging, graceful degradation) provide value even on single machines and become indispensable at scale.
Tail-tolerant techniques such as request hedging send redundant requests after a timeout, accepting whichever response arrives first. Backup requests and load balancing away from slow servers directly address latency variance. These techniques apply cleanly to multiple model replicas, and some single-node systems can approximate them with concurrent streams or instances when cancellation and resource isolation semantics permit it. They become essential when scaling to distributed inference systems.
The queuing model and tail latency analysis provide the inputs for capacity planning. A concrete deployment makes the trade-offs tangible.
Applying Little’s Law to ResNet-50 makes the capacity constraint concrete.
Napkin Math 1.5: ResNet-50 capacity planning
Consider designing a ResNet-50 serving system with these requirements:
- Target p99 latency: 50 ms
- Peak expected traffic: 5,000 QPS
- Service time (TensorRT FP16): 5 ms
Step 1: Find safe utilization. From equation 6, \(T_{\text{lat},\text{p99}} \approx\) 4.6 \(\times\) service time / \((1 - \rho_{\text{serv}})\). Setting \(T_{\text{lat},\text{p99}} \leq 50\) ms with 5 ms service time gives \(\rho_{\text{serv}} \leq 1 - (4.6 \times 5 ms)/50 ms = 0.54\) (54 percent maximum utilization). This uses the conservative M/M/1 p99 bound from the displayed equation rather than applying an average-wait M/D/1 adjustment to a tail-latency SLO.
Step 2: Calculate required service rate. \(\mu_{\text{required}} = 5,000 QPS / 0.54 = 9259.3 req/s\)
Step 3: Determine GPU count. Single V100 throughput at \(B = 16\): 1,143 img/s
GPUs needed = 9259.3 req/s / 1,143 img/s = 8.1 → 9 GPUs
Step 4: Add headroom for variance. Production systems add 30 percent headroom for traffic spikes and variance: final count = 9 \(\times\) 1.3 = 11.7, rounded up to 12.
Step 5: Verify fault tolerance. The 30 percent headroom addresses traffic variance, but production systems also need fault tolerance. With 12 GPUs, losing one leaves 11 GPUs handling 5,000 QPS. The postfailure utilization is (5,000 QPS / 1,143 img/s) / 11 = \(39.8\%\).
This remains well below the 54 percent safe utilization threshold, confirming N+1 redundancy is satisfied. For stricter fault tolerance requirements, N+2 redundancy (tolerating two simultaneous failures) would require 11 GPUs under the same safe-utilization threshold, or about 14 GPUs if the 30 percent headroom must remain after two simultaneous failures.
Result: Provision 12 V100 GPUs to serve 5,000 QPS at 50 ms p99 latency with N+1 fault tolerance.
The queuing analysis explains the capacity planning approach detailed in section 1.11.3 and connects directly to the MLPerf Server scenario. Server explains how MLPerf measures throughput only for requests meeting the latency SLO: a system achieving 10,000 QPS but violating the SLO on 5 percent of requests reports only 9,500 valid QPS.
Tail-tolerant techniques
Eliminating all sources of latency variability is often impractical. Production systems instead employ techniques that tolerate variability while still meeting SLOs (Dean and Barroso 2013; Dean 2012). The useful organization is by failure mode: a straggler replica calls for a race, fan-out calls for early detection, overload calls for admission control or graceful degradation, and retry amplification calls for coordinated shedding.
Dean, Jeffrey, and Luiz André Barroso. 2013. “The Tail at Scale.” Communications of the ACM 56 (2): 74–80. https://doi.org/10.1145/2408776.2408794.
Dean, Jeffrey. 2012. Achieving Rapid Response Times in Large Online Services. Berkeley AMPLab Cloud Seminar.
13 Hedging: The term is borrowed from finance, where an offsetting bet reduces risk; here, the redundant request is a bet against a slow server. This is not free: for ML systems, the losing hedged request may still occupy accelerator time if inference has already launched, because ordinary GPU kernels are not cheaply cancelled mid-execution. Thus, a hedging policy must budget duplicate work as well as the latency benefit.
For a straggler replica, the system can race the slow path. Under hedging, when a request has not completed within the expected time, the system sends a duplicate request to another server.13 The client uses whichever response arrives first and cancels the other. For ML serving, this means maintaining multiple model replicas and routing slow requests to alternative replicas. The overhead is modest: if the system hedges at the 95th percentile, only 5 percent of requests generate duplicates, increasing load by only 5 percent while dramatically reducing tail latency.
Ordinary launched inference kernels are not cheaply interrupted mid-execution. When a hedged request completes, the duplicate must be cancelled, but if inference has already begun on the GPU, cancellation approaches include checking a cancellation flag before launching inference, accepting wasted compute for the in-flight kernel, or using request prioritization to deprioritize the duplicate. Since hedging typically applies only to a small tail of requests, the overhead from occasional wasted compute can remain acceptable when the policy is tuned carefully.
Tied requests make the same race more aggressive by sending the request to multiple servers simultaneously, but include a tag allowing servers to cancel execution once another server begins processing. This eliminates the delay of waiting to detect a slow response before hedging. For inference servers with significant startup overhead from model loading and memory allocation, tied requests ensure at least one server begins immediately.
Fan-out systems need a different intervention point because one slow backend can stall the entire distributed request. Canary requests first send the request to a small subset of one to two servers.14 If these return within expected time, the system sends to the remainder. If the canary is slow, the system can retry elsewhere or use cached results before committing to the full fan-out. The technique turns a potential tail-latency amplification problem into an early warning signal.
14 Canary: Named for the coal mine practice (early 1900s–1980s) of using birds whose high metabolic rate made them sensitive to toxic gases before concentrations became lethal to humans. In ML serving, canary requests serve the same early-warning function for fan-out queries: by testing 1–2 backends before committing to the full fan-out, the system detects slow or failing replicas before a single straggler stalls the entire distributed inference request—a critical protection when fan-out width means tail latency grows with the maximum of all backend response times.
When the problem is overload rather than a single straggler, racing makes the system worse by adding duplicate work. The system instead has to protect user-visible responsiveness and admitted-request latency. Graceful degradation returns approximate results rather than timing out: classification systems can return cached predictions for similar inputs, generative models can return shorter outputs, and ensembles can return predictions from a subset of models. Reducing the number of active ensemble members during overload directly shortens service time (\(T_{\text{svc}}\)), which increases the server’s service rate \(\mu\) and brings utilization \(\rho_{\text{serv}} = \lambda_{\text{arr}} / \mu\) back below the queueing knee (figure 1)—trading a controlled accuracy reduction for SLO survival instead of an uncontrolled latency collapse. Admission control is stricter. When queue depth exceeds a threshold, it proactively rejects requests with immediate 503 responses rather than accepting work that is likely to time out. This sacrifices throughput to protect latency for admitted requests.
A practical starting point for setting the threshold is two to three times the number of workers (a queue of two to three service times’ worth of work). For a system with four workers, this yields a queue depth threshold of 8 to 12 requests. Adaptive admission control adjusts thresholds based on observed p99 latency, tightening when latency increases above target and relaxing when latency remains healthy. The M/D/1 property of ML inference—that compiled models executing a fixed batch size have near-constant, deterministic service times—gives ML admission controllers a precision advantage over general web server admission controllers. In a general web service, service time depends on database join complexity, cache state, and query structure, making it highly stochastic and difficult to predict. In ML inference, the forward pass time for a given batch size is often bounded tightly enough that an admission controller can estimate how many concurrent requests the system can absorb before the queue is likely to cause an SLO violation, rather than relying only on coarse conservative heuristics.
A subtle failure mode occurs when all replicas are overloaded simultaneously. If the load balancer retries rejected requests at other replicas that are also overloaded, retry traffic amplifies the overload. Coordinated load shedding addresses this by sharing load information across replicas, enabling system-wide decisions about which requests to accept. When global load exceeds capacity, replicas collectively reject the same fraction of requests rather than each rejecting independently and triggering retries.
These techniques become essential at scale when fan-out amplification makes individual server tail latency visible to users. Single-machine serving systems can implement hedged and tied requests across GPU streams or model replicas. The queuing analysis here assumes first-in-first-out (FIFO) processing, but production systems often implement priority scheduling such as deadline-aware or shortest-job-first approaches to further reduce tail latency for heterogeneous workloads (Harchol-Balter 2013).
Checkpoint 1.2: Queuing and SLO headroom
Latency SLOs are not enforced by “fast inference” alone; they are enforced by headroom.
The tail-tolerant techniques examined in this section optimize the flow of requests through a functioning serving system. The queuing analysis, however, assumes two critical preconditions: that models are loaded and ready to process requests, and that predictions match what was validated during development. In production, this assumption fails regularly: during deployments, new instances must load models from scratch; during scaling events, cold start latency affects the first requests to new replicas; and when preprocessing pipelines diverge from training, accuracy silently degrades. The next section examines these lifecycle challenges that must be solved before queuing optimization becomes relevant.
Self-Check: Question
A serving replica must sustain 1,000 QPS with a p99 end-to-end latency SLO of 50 ms. Each replica’s unloaded service time is 20 ms. A capacity planner uses Little’s Law at the SLO bound to estimate the minimum standing concurrency the fleet must support. Which interpretation is correct?
- Required concurrency is 20, because 1,000 QPS times 20 ms of service time gives the number of requests simultaneously executing.
- Required concurrency is 50, because 1,000 QPS times 50 ms (\(\lambda T_{\text{lat}}\) at the SLO bound) gives the standing population in the system, and real provisioning must exceed this because bursts push the realized \(T_{\text{lat}}\) above the mean.
- Required concurrency is 1,000, because one QPS equals one concurrent request under any SLO.
- Required concurrency is 5, because throughput divided by service time is the number of replicas needed.
At 500 QPS, a team moves from batch size 1 to batch size 32 and sees throughput rise while p99 latency increases sharply. What are the two components of the batching tax the chapter identifies?
- Larger batches reduce accelerator utilization and force spillover to the CPU, which adds two new latencies.
- The first request must wait for the rest of the batch to arrive before kernel launch, and inference time itself grows (super-linearly in some kernels) as the batch grows.
- Queueing theory stops applying at batch sizes above 16, and SLO violations become random.
- Larger batches eliminate the dynamic scheduler, so all requests become subject to static batch timeouts and always violate the SLO.
Explain why production serving systems target roughly 40 to 60 percent utilization instead of trying to run near 100 percent busy all the time, grounding your answer in the chapter’s queuing analysis.
Which statement best explains why p99 latency, not mean latency, is the headline metric for production-serving risk?
- Mean latency is usually equal to p99 once a service has been running long enough for caches to warm up.
- Percentile latency exposes the tail of slow requests that dominate real user experience, and tail latency amplifies in multi-component systems where one slow sub-request can dominate end-to-end response time.
- p99 measures only preprocessing and ignores queueing, so it is a cleaner signal of raw compute speed.
- Mean latency applies only to offline inference systems and is undefined in an online serving context.
A serving cluster is in overload: queue depth is growing faster than the workers can drain it, and projected p99 is climbing past the SLO. Which operator response best matches the chapter’s recommended tail-tolerant strategy?
- Keep accepting every request and raise the queue-depth limit so nothing is rejected; the queue will smooth out the burst.
- Extend the batching window to collect larger batches on the theory that bigger batches raise throughput and shrink the queue faster.
- Apply admission control or load shedding, rejecting or downgrading excess requests quickly so admitted requests still meet SLO rather than letting the whole fleet time out.
- Aggressively retry every request across multiple replicas so each user gets a response from whichever replica answers first.
Model Lifecycle Management
Queuing theory and tail-tolerant techniques optimize the steady-state flow of requests, but they cannot help if the system never reaches steady state. A newly deployed replica that takes 35 seconds to compile its TensorRT engine violates every SLO during that window. A model whose OpenCV-based serving pipeline resizes images differently than the PIL-based training pipeline silently drops 5 percentage points of accuracy—a degradation invisible to latency dashboards. These lifecycle failures are not edge cases; they occur at every deployment, every scaling event, and every framework migration. Addressing them requires engineering discipline in two areas: getting models ready to serve (cold start and initialization) and keeping predictions faithful to what was validated (training-serving skew).
Training-serving skew
A model that performed well during validation may silently degrade when deployed. This phenomenon, known as training-serving skew, represents one of the most subtle failure modes in production ML because it is invisible to latency monitoring and exception tracking (Sculley et al. 2015; Baylor et al. 2017).
Baylor, Denis, Eric Breck, Heng-Tze Cheng, Noah Fiedel, Chuan Yu Foo, Zakaria Haque, Salem Haykal, et al. 2017. “TFX: A TensorFlow-Based Production-Scale Machine Learning Platform.” Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 1387–95. https://doi.org/10.1145/3097983.3098021.
Definition 1.3: Training-serving skew
Training-Serving Skew is the distributional divergence between the training and inference environments caused by inconsistent logic or state.
- Significance: It violates the consistency imperative, causing silent accuracy degradation proportional to the difference in the transformation functions \((f_{\text{train}}(x) \neq f_{\text{serve}}(x))\).
- Distinction: Unlike data drift (which is an external shift in the environment), training-serving skew is an internal failure of the engineering stack.
- Common pitfall: A frequent misconception is that skew is “found” by looking for errors. In reality, it is invisible to exceptions: the system runs perfectly and the latency is low, but the predictions are statistically wrong.
ML Operations provides comprehensive coverage of skew diagnosis, monitoring, and organizational prevention strategies. Here we focus on the serving-specific manifestation: preprocessing divergence. This occurs when the real-time inference pipeline processes raw data differently than the batch training pipeline, a common failure mode when training uses Python/Pandas while serving uses C++/Java or optimized inference servers. Unlike data drift (which ML Operations addresses through monitoring), preprocessing divergence is deterministic and preventable through careful engineering.
Example 1.2: ResNet-50: Image preprocessing skew
Scenario: For ResNet-50 serving, three preprocessing choices commonly diverge between training and serving pipelines.
- Resize interpolation: Training uses PIL.BILINEAR while OpenCV defaults to cv2.INTER_LINEAR. These produce pixel-level differences that can shift accuracy by 0.5–1 percent.
- Color space handling: JPEG loading in different libraries may produce BGR vs. RGB ordering. If the model trained on RGB but serves BGR inputs, predictions are essentially random.
- Normalization constants: ImageNet normalization uses specific mean/std values. Using
mean=[0.5, 0.5, 0.5]instead ofmean=[0.485, 0.456, 0.406]shifts inputs out of the training distribution.
Systems lesson: The safest approach is to export the exact preprocessing code used during training and run it identically in serving, or use a framework like NVIDIA DALI that can help standardize preprocessing across training and serving environments.
Cold start and initialization dynamics
With preprocessing pipelines designed to avoid training-serving skew, the next challenge is getting models ready to serve. Before processing any request, models must load from storage into memory and prepare for inference (Romero et al. 2021). This initialization latency, known as cold start, affects system responsiveness during deployments, scaling events, and recovery from failures.
Romero, Francisco, Qian Li, Neeraja J. Yadwadkar, and Christos Kozyrakis. 2021. “INFaaS: Automated Model-Less Inference Serving.” 2021 USENIX Annual Technical Conference (USENIX ATC 21), 397–411.
Definition 1.4: Cold start
Cold Start is the initialization latency incurred when instantiating a new model replica.
- Significance: It represents the fixed cost of state hydration (loading weights, compiling graphs), which can take seconds or minutes, effectively blocking the system’s ability to scale elastically in response to traffic bursts.
- Distinction: Unlike inference latency \((L_{\text{lat}})\), which is a per-request cost, cold start is a per-replica cost that occurs only during deployment or scaling events.
- Common pitfall: A frequent misconception is that cold start is “just loading weights.” In reality, it includes graph compilation and memory allocation, which can often take longer than the bandwidth-limited data transfer itself \((D_{\text{vol}}/\text{BW})\).
Cold start dynamics determine whether systems meet latency requirements from the moment they begin serving traffic. Breaking a representative startup into phases reveals where each part contributes to total initialization latency.
Cold start latency compounds from multiple sources, each adding to the time between deployment and serving readiness. Weight loading reads model parameters from disk or network storage. Graph compilation performs just-in-time compilation of operations for the specific hardware. Memory allocation reserves GPU memory for activations and intermediate values. Warmup15 execution performs initial inferences that populate caches and trigger lazy initialization.
15 Warmup: Borrowed from JIT compilation, where initial executions compile hot paths into optimized machine code. For ML serving, warmup inferences trigger CUDA kernel compilation, cuDNN algorithm auto-tuning, and memory pool allocation that frameworks defer until first use. Without warmup, the first live request absorbs all of this setup and can be orders of magnitude slower than steady state. During autoscaling events, this means new replicas can violate SLOs for their first several seconds of traffic.
Systems Perspective 1.5: ResNet-50: Cold start timeline
Table 8 traces the per-phase duration of a ResNet-50 cold start:
Table 8: ResNet-50 cold start timeline: Per-phase durations for weight loading, CUDA context creation, TensorRT compilation, and warmup, with totals for the optimized local case and the first-deploy cloud case showing where the dominant cost lives.
| Phase | Duration | Notes |
|---|---|---|
| Weight loading (SSD) | 0.5 s | 98 MB FP32 weights from local storage |
| Weight loading (S3) | 3–5 s | Network latency dominates for cloud storage |
| CUDA context | 0.3–0.5 s | GPU driver initialization and memory setup |
| TensorRT compilation | 15–30 s | Converts PyTorch model to optimized engine |
| Warmup (10 inferences) | 0.2 s | Triggers remaining lazy initialization |
| Runtime overhead | 0.4 s | Process startup, framework hooks, and runtime setup |
| Total (local, optimized) | ~1.5 s | With precompiled TensorRT engine, warm container |
| Total (cloud, first deploy) | ~35 s | Including compilation from cold state |
Systems insight: Precompiling models and storing the optimized engine eliminates the 30-second compilation phase on subsequent deployments.
The CUDA context16 is the first cost in the cold start timeline. Before any GPU operation, the CUDA runtime must establish a context: a data structure that tracks memory allocations, loaded kernels, and device state. Creating a context requires communicating with the GPU driver and allocating GPU memory for internal bookkeeping. The 0.3–0.5 s value in table 8 is a scenario assumption for this cold-start budget, not a universal CUDA constant. CUDA lazy loading defers some module and kernel loading until first use, reducing apparent startup time but shifting some cost to the first inference (NVIDIA 2026a).
16 CUDA (Compute Unified Device Architecture): NVIDIA’s parallel computing platform (Nickolls et al. 2008), named for its goal of unifying diverse GPU shader models into a single general-purpose architecture. Before CUDA, GPU programming required disguising computations as graphics operations. The CUDA context—the data structure tracking memory allocations, loaded kernels, and device state—is the runtime’s per-process gateway to GPU resources; in serverless or rapidly scaling serving systems, context creation and lazy module loading can become visible parts of cold start latency (NVIDIA 2026a).
Nickolls, John, Ian Buck, Michael Garland, and Kevin Skadron. 2008. “Scalable Parallel Programming with CUDA: Is CUDA the Parallel Programming Model That Application Developers Have Been Waiting For?” Queue 6 (2): 40–53. https://doi.org/10.1145/1365490.1365500.
NVIDIA. 2026a. Lazy Loading: CUDA Programming Guide.
17 CUDA MPS (Multi-Process Service): MPS creates a control daemon that allows CUDA work from different processes to overlap on the GPU, which can improve utilization and reduce context-switching overhead when processes individually underuse the accelerator (NVIDIA 2026d). For multi-model serving, MPS can help replicas share GPU streaming multiprocessors efficiently. The trade-off is fault isolation: clients share MPS-managed GPU state, so hardware partitioning with Multi-Instance GPU (MIG) provides stronger isolation at the cost of fixed partition granularity.
NVIDIA. 2026d. NVIDIA CUDA Multi-Process Service.
CUDA MPS (Multi-Process Service)17 addresses GPU sharing for multi-process deployments. Normally, each process creates its own CUDA context, and the GPU may time-slice between contexts. MPS allows work from multiple processes to overlap on the GPU through a shared service, reducing context-switching overhead and improving utilization when individual processes underuse the device (NVIDIA 2026d). The trade-off is reduced isolation: a crash in one process can affect others sharing the MPS server.
Without warmup, the first real request triggers compilation and memory allocation mid-inference, often causing timeout failures. A request that normally takes 5 ms might require 500 ms during cold start, violating SLOs and degrading user experience.
Loading strategies
Different loading strategies trade off cold start duration against serving performance and memory efficiency. The simplest approach, full loading, reads the entire model into memory before serving begins. This maximizes inference speed since all weights are immediately available, but extends cold start duration and limits model size to available memory. The approach is appropriate when cold start latency is acceptable and models comfortably fit in memory.
When models are too large for immediate full loading, memory mapping offers an alternative by mapping model files directly into the address space and loading pages on demand as accessed. This reduces cold start time since inference can begin before the full model loads, but causes unpredictable latency as pages fault in during initial requests. Memory mapping works well for infrequently accessed model components but can cause latency spikes if critical weights are not preloaded.
A third strategy, lazy initialization, defers compilation and allocation until first use. This minimizes startup time but shifts latency to the first request. Production systems often combine lazy initialization with synthetic warmup requests to trigger initialization before real traffic arrives.
Model caching infrastructure
Production systems cache model weights at the infrastructure level to reduce cold start for common deployment scenarios. One approach, container image embedding, bundles model weights directly in the container image. This produces a single deployment artifact and eliminates network fetches at startup, but creates large images (often 10–50 GB) that slow container pulls and consume registry storage. This approach works best for models that rarely update.
For organizations with many models and frequent updates, a shared filesystem (EFS, GCS FUSE) containing model weights provides a more flexible alternative. Multiple replicas share cached weights, and updates propagate immediately without redeployment. The trade-off is that network latency affects cold start, and filesystem availability becomes a critical dependency.
When cold start latency is critical for high-traffic models, node-local SSD caching prepopulates local SSDs on inference nodes with frequently-used models. This approach provides fast loading from Non-Volatile Memory Express (NVMe) drives at 500 MB/s or more without network dependency, but requires cache management to handle model updates and capacity limits. The choice among these strategies depends on model update frequency: infrequent updates favor container embedding, frequent updates favor shared filesystem, and performance-critical deployments benefit from local caching with background refresh.
Multi-model serving
Production systems often serve multiple models from a single machine, whether different model versions for A/B testing, ensemble components, or entirely different models sharing infrastructure. GPU memory becomes the limiting resource, requiring careful management strategies.
Three strategies address multi-model memory management. Time-multiplexing loads one model at a time and swaps based on request routing—simple but introduces swap latency. Memory sharing partitions GPU memory among models, limiting concurrent execution count but enabling more models to remain resident. Model virtualization, as implemented by frameworks like Triton, separates model lifecycle from application code through model repository and control APIs for loading, unloading, and versioning models (NVIDIA 2024b, 2026c, 2026b). The choice depends on request patterns: if models receive traffic evenly, concurrent loading works; if traffic is bursty and model-specific, time-multiplexing with explicit preloading reduces average latency while maximizing GPU utilization.
NVIDIA. 2026c. Model Repository: NVIDIA Triton Inference Server.
NVIDIA. 2026b. Model Management: NVIDIA Triton Inference Server.
Multi-stream execution
When multiple models or multiple instances of the same model must run concurrently on a single GPU, the hardware must partition resources between them. NVIDIA’s Multi-Instance GPU18 technology enables hardware-level isolation, dividing an A100 into up to seven independent GPU instances, each with dedicated memory and compute resources (NVIDIA 2026e). MIG is available on A100, A30 (up to four instances), H100, H200, and newer data center GPUs. For older GPUs such as V100 or T4, CUDA stream scheduling provides time-multiplexed sharing without hardware isolation. The choice depends on whether consistent latency with MIG or maximum utilization with shared streams is the priority.
18 MIG (Multi-Instance GPU): Introduced with NVIDIA’s A100 (NVIDIA Corporation 2020) and documented across supported data-center GPUs (NVIDIA 2026e), MIG partitions a single physical GPU into independent instances, each with dedicated compute and memory resources. Unlike software sharing (MPS or time-slicing), MIG provides hardware-level isolation between partitions. The trade-off is granularity—partitions must follow fixed profiles, so resources cannot be divided arbitrarily. For multi-model serving, MIG reduces noisy-neighbor risk on shared hardware, while per-model SLO guarantees still depend on scheduler policy, load, and the selected partition profile.
NVIDIA Corporation. 2020. NVIDIA A100 Tensor Core GPU Architecture. NVIDIA Whitepaper, V1.0.
NVIDIA. 2026e. NVIDIA Multi-Instance GPU User Guide.
Model swapping and host memory
When the aggregate size of all models exceeds GPU memory capacity, the serving system must swap models between host memory (DRAM) and device memory (VRAM) on demand. This introduces a new latency component determined by the PCIe bus bandwidth.
For a 10 GB model on PCIe Gen4 x16 (32 GB/s theoretical bandwidth), loading takes at least 312.5 ms before deserialization, graph setup, or warmup.

Model loading lands far outside a tight serving SLO.
To mitigate this, systems use pinned memory (page-locked host memory). By default, the operating system can move (“page”) any memory region to disk when RAM is under pressure. This creates a problem for GPU transfers: if the GPU’s DMA (Direct Memory Access) engine begins reading a memory region that gets paged out mid-transfer, the transfer fails or stalls. To avoid this, the CPU must first copy data to a temporary pinned buffer before the GPU can safely read it, adding both latency and CPU overhead.
Pinning memory instructs the OS to keep that region permanently in physical RAM. The GPU’s DMA engine can then transfer data directly from the pinned region without an extra pageable-to-pinned staging copy. The trade-off is that pinned memory reduces the RAM available for other processes and cannot be reclaimed under memory pressure. For model serving, the transfer-path improvement often justifies pinning model weights and frequently-used input buffers, while leaving less critical memory pageable.
The lifecycle management strategies examined so far ensure models are ready to serve: loaded into memory, warmed up, and producing predictions consistent with training. With these prerequisites satisfied, the queuing dynamics from section 1.5 become relevant. The next optimization opportunity lies in how requests are grouped for processing, which directly affects both the throughput and latency terms in our queuing equations.
Self-Check: Question
Which failure mode is the clearest example of training-serving skew rather than external data drift?
- User behavior changes seasonally and the model’s target distribution shifts gradually over several months.
- The serving pipeline uses OpenCV-resize on BGR images with one set of normalization constants, while training used PIL-resize on RGB with different constants.
- Holiday traffic produces a 5\(\times\) QPS spike and replica queue depth grows for several minutes before autoscaling catches up.
- A new GPU SKU enters the fleet and model loading time doubles during autoscaling events.
Explain why cold start is more than loading weights off disk, and why this matters for reactive autoscaling during a traffic surge.
A team serves a model through TensorRT and observes a 30-second graph compilation on every new replica during autoscaling. Which loading strategy best removes this cost from subsequent scale-outs?
- Store only the original training checkpoint and rely on just-in-time compilation at every deployment so the optimization always matches the runtime.
- Pre-compile the optimized engine once and deploy the compiled artifact, so new replicas load a ready-to-run graph and skip the heavy compilation step.
- Switch from binary weight files to JSON so weights load transparently and compilation becomes unnecessary.
- Raise the warmup batch size on every new replica so graph compilation amortizes across requests and disappears from visible latency.
A multi-model serving system cannot fit all models in GPU memory and swaps them from host DRAM over PCIe on demand. Why can this severely violate per-request latency SLOs?
- Host DRAM is faster than VRAM, so the swap itself is cheap and the problem is really a cache-locality issue.
- PCIe transfer of a multi-gigabyte model takes hundreds of milliseconds of pure I/O before inference can even begin, which on its own exceeds many online-serving SLOs.
- PCIe transfer time matters only during training, not during inference, so it is a provisioning issue rather than a latency issue.
- Model swapping improves tail latency by keeping caches diverse, so any latency increase is a monitoring artifact.
True or False: CUDA MPS primarily improves concurrency for co-tenant workloads, while MIG is the stronger choice when per-model isolation and predictable latency under contention matter most.
Throughput Optimization
Consider a representative ResNet-50 classifier scenario on a V100 GPU at batch size one: the GPU processes one image, then sits idle while the CPU fetches and preprocesses the next—achieving only 15 percent hardware utilization and 200 images per second. The same GPU processing 32 images at once reaches 95 percent utilization and 1,280 images per second, a 6.4\(\times\) throughput improvement on identical hardware because fixed costs are amortized across requests. The difference is batching, the core lever for improving serving economics. Batching19 differs sharply between training and serving (Crankshaw et al. 2017). Training batches maximize throughput by processing hundreds or thousands of samples together with no concern for individual sample latency. Serving batches must balance throughput against individual request latency, often processing small batches while ensuring no request waits too long. This adaptive approach is called dynamic batching because the system adjusts batch composition in real time based on arriving requests.
19 Batch: From Old French bache (a quantity baked at one time), entering computing in the 1950s for jobs processed together without human interaction. The ML serving usage preserves the original trade-off: grouping requests amortizes fixed costs (kernel launch, weight loading) across multiple inputs, but each request must wait for the batch to fill. In training, batches of 256–4096 are routine; in serving, batches above 8–32 typically violate latency SLOs, making the serving batch a fundamentally different optimization target.
Crankshaw, Daniel, Xin Wang, Guilio Zhou, Michael J. Franklin, Joseph E. Gonzalez, and Ion Stoica. 2017. “Clipper: A Low-Latency Online Prediction Serving System.” 14th USENIX Symposium on Networked Systems Design and Implementation (NSDI 17), 613–27.
Definition 1.5: Dynamic batching
Dynamic Batching is the ML serving optimization that trades Latency for Throughput under stochastic arrival patterns.
- Significance: By buffering requests into a batching window, the scheduler amortizes fixed overheads \((L_{\text{lat}})\) across multiple inputs, pushing the system away from the memory-bound regime \((\text{BW})\) toward the compute-bound regime \((R_{\text{peak}})\).
- Distinction: Unlike Static Batching, which is fixed during training, Dynamic Batching adaptively adjusts the batch size at Inference Time based on real-time traffic volume.
- Common pitfall: A frequent misconception is that batching “always helps.” In reality, there is a latency-throughput Pareto frontier: if the batching window is too large, the increased queuing delay may violate the system’s SLO before the throughput gains are realized.
Why batching helps
Modern accelerators achieve peak efficiency only at sufficient batch sizes (Shen et al. 2019). A single inference request leaves most compute units idle because GPUs are designed for parallel execution across thousands of threads. Batching amortizes fixed costs across multiple requests and enables parallel execution across the batch dimension.
Shen, Haichen, Lequn Chen, Yuchen Jin, Liangyu Zhao, Bingyu Kong, Matthai Philipose, Arvind Krishnamurthy, and Ravi Sundaram. 2019. “Nexus: A GPU Cluster Engine for Accelerating DNN-Based Video Analysis.” Proceedings of the 27th ACM Symposium on Operating Systems Principles, 322–37. https://doi.org/10.1145/3341301.3359658.
20 Kernel (GPU): CUDA borrowed this term from operating systems circa 2007 because GPU functions represent the computational “core” of parallel algorithms. Unlike OS kernels that run continuously, GPU kernels are discrete units of parallel work launched by the CPU. Each launch carries 5–20 \(\mu\)s of overhead independent of batch size—negligible for large training batches but dominant at batch-1 serving, where a 50-layer model accumulates 250–1000 \(\mu\)s of pure launch overhead per inference.
Two fixed costs dominate at small batch sizes. Kernel launch overhead20 is the time for the CPU to prepare and submit work to the GPU. Each layer in a neural network typically requires a separate kernel launch: the CPU must assemble kernel parameters, copy them to GPU-accessible memory, and signal the GPU to begin execution. This overhead is typically 5–20 μs per kernel, independent of batch size. ResNet-50 has approximately fifty layers, so kernel launch alone adds 250–1000 μs per inference. At batch size one, this overhead may exceed the actual compute time; at batch size thirty-two, the same overhead is amortized across thirty-two images. Weight loading reads model parameters from GPU memory (VRAM) to the compute units. At batch size one, the GPU reads all weights to process one image; at batch size thirty-two, the same weight read processes thirty-two images, achieving 32\(\times\) better memory efficiency. Measuring batching efficiency on a concrete model quantifies how these fixed costs amortize in practice.
Napkin Math 1.6: ResNet-50 batching efficiency
Table 9 illustrates the throughput-latency trade-off for a ResNet-50/V100 scenario across batch sizes one through thirty-two. The batch sizes, measured inference times, and GPU utilization are the scenario givens; the per-image compute and throughput columns are derived from them.
Table 9: ResNet-50 batching sweep: Per-image compute, throughput, and GPU utilization across batch sizes one through thirty-two on a V100. Throughput grows 6.4× from batch one to batch thirty-two as GPU utilization climbs from 15 percent to 95 percent, while pure inference time stretches from 5 ms to 25 ms.
Math: For the batch-8 row, per-image compute is the batch latency divided by the batch size, 9.1 ms ÷ 8 images ≈ 1.1 ms per image, and throughput is the batch size divided by the same latency, 8 images ÷ 9.1 ms ≈ 879 img/s. The same two divisions produce every derived row.
| Batch Size | Inference Time | Per-Image Compute | Throughput | GPU Util. |
|---|---|---|---|---|
| 1 | 5 ms | 5 ms | 200 img/s | 15% |
| 4 | 7.2 ms | 1.8 ms | 556 img/s | 42% |
| 8 | 9.1 ms | 1.1 ms | 879 img/s | 65% |
| 16 | 14 ms | 0.9 ms | 1,143 img/s | 85% |
| 32 | 25 ms | 0.8 ms | 1,280 img/s | 95% |
The times shown are pure inference time, excluding queue wait; section 1.7.6 analyzes how user-perceived latency includes batching-window wait.
Systems insight: Batch size thirty-two achieves 6.4× higher throughput than batch size 1. However, user-perceived latency includes both queue wait and inference time. With a 10 ms batching window and 25 ms inference, total latency reaches 35 ms vs. 5 ms at batch size 1.
The table reveals the throughput-latency trade-off in stark terms: larger batches dramatically improve hardware efficiency but increase per-request latency. In practice, the optimal batch size depends on both the latency Service Level Objective (SLO) and the arrival rate of requests. The question facing every serving engineer is therefore quantitative: determining the largest batch size that still meets a given latency SLO. In this scenario, batch size 8 with a 5 ms batching window has worst-case user latency of about 14 ms (5 ms wait plus 9 ms inference), below a 20 ms SLO budget. That earns nearly 3\(\times\) higher service throughput than batch-1 serving on the same hardware, provided sustained load is high enough to fill the batching window. Plotting the same trade-off in figure 6 reveals the knee where extra batching stops paying for its latency cost: throughput is already flattening while latency begins to spike, so batching beyond that point trades modest capacity gains for queueing delay.
The “knee” in figure 6 marks the point where the blue throughput curve begins to plateau just as the orange latency curve starts its sharp upward spike. This is the optimal operating point: push batch size beyond the knee and queuing delays dominate; staying below it leaves hardware capacity on the table. The numbers are representative rather than tied to a single benchmark.
The efficiency gains from batching come at a cost: requests must wait for the batch to form. This creates a direct tension between throughput optimization (larger batches) and latency minimization (immediate processing). The different batching strategies and their trade-offs govern how engineers tune this balance.
Static vs. dynamic batching
Static batching waits for a fixed batch size before processing, which is simple to implement but fragile under variable traffic: during low traffic, requests wait indefinitely for a full batch, and during high traffic, large batches increase per-request latency. Dynamic batching addresses this failure mode by collecting requests within a bounded time window and processing whatever has arrived when the window closes (Olston et al. 2017; NVIDIA 2024b). The window size becomes the tuning knob: shorter windows reduce latency but sacrifice throughput, longer windows improve throughput but increase latency, and latency-sensitive deployments tune both the time window and maximum batch size against arrival pattern, model shape, and SLO.
Dynamic batching latency-throughput trade-offs
Dynamic batching introduces a quantifiable tension between throughput optimization and latency constraints. Under overload, the mechanism is queue growth rather than slower inference, which enables systematic configuration decisions instead of trial-and-error tuning.
Systems Perspective 1.6: Why latency spikes under load
Recall from section 1.5.1: Little’s Law \((Q_{\text{req}} = \lambda_{\text{arr}} T_{\text{lat}})\) governs all stable queues. When hardware is saturated, the service rate \(\mu\) is maxed out; if the arrival rate \(\lambda_{\text{arr}}\) grows beyond that capacity, queue depth \((Q_{\text{req}})\) increases. Since \(\mu\) cannot grow, latency \((T_{\text{lat}})\) must grow with queue depth. This is why admission control (rejecting requests when \(T_{\text{lat}}\) exceeds a threshold) is the only way to preserve latency during overload.
Equation 7 decomposes the total user-perceived latency for a batched request into two components: \[L_{\text{lat}} = L_{\text{lat,wait}} + L_{\text{lat,compute}}(B) \tag{7}\] where \(L_{\text{lat,wait}}\) is the time spent waiting in the batching queue (corresponding to \(L_{\text{lat,queue}}\) in the overall latency budget) and \(L_{\text{lat,compute}}(B)\) is the inference time for batch size \(B\) (encompassing \(L_{\text{lat,infer}}\) plus portions of \(L_{\text{lat,pre}}\) and \(L_{\text{lat,post}}\)). The batching window \(T_{\text{window}}\) bounds wait time (\(L_{\text{lat,wait}} \leq T_{\text{window}}\)), while batch size affects compute time through GPU utilization characteristics.
Quantitative analysis of batching
For Poisson arrivals with rate \(\lambda_{\text{arr}}\) and batching window \(T_{\text{window}}\), requests arrive uniformly within the window. A request arriving at time \(t\) within the window waits \(T_{\text{window}} - t\) for the batch to close. Equation 8 shows that the average wait time is simply half the window: \[E[L_{\text{lat,wait}}] = \frac{T_{\text{window}}}{2} \tag{8}\]
This simple relationship has direct implications. A 20 ms batching window adds 10 ms average wait (up to 20 ms for the first arrival in a window; later arrivals wait less) regardless of batch size achieved. For a 50 ms mean latency SLO with 5 ms inference, the average wait consumes 20 percent of the latency budget before any computation begins; tail SLOs must budget the full window.
Batch size distribution
The number of requests collected during window \(T_{\text{window}}\) follows a Poisson distribution with mean \(\lambda_{\text{arr}} T_{\text{window}}\). Equation 9 formalizes this relationship: \[\Pr(\text{batch size} = k) = \frac{(\lambda_{\text{arr}} T_{\text{window}})^k e^{-\lambda_{\text{arr}} T_{\text{window}}}}{k!} \tag{9}\]
Table 10 quantifies this variability, showing how batch size fluctuates for different traffic levels with a fixed 10 ms window:
| Arrival Rate | Mean Batch | Std Dev | \(\Pr(\text{batch}=0)\) | \(\Pr(\text{batch} \ge 2 \times \text{mean})\) |
|---|---|---|---|---|
| 50 QPS | 0.5 | 0.7 | 61% | 39% |
| 200 QPS | 2 | 1.4 | 14% | 14% |
| 500 QPS | 5 | 2.2 | 0.7% | 3% |
| 1000 QPS | 10 | 3.2 | 0.005% | 0.3% |
Throughput maximization strategy
Throughput optimization requires separating per-request latency from saturated service capacity. A request waits for batch formation, then pays the service time of the formed batch. Under sustained load, however, batch formation can overlap with the previous batch’s execution, so capacity is governed by the ready-batch service time: \[\mu_{\text{eff}}(B) \approx \frac{B}{T_{\text{svc}}(B)}, \qquad \text{throughput} = \min(\lambda_{\text{arr}}, \mu_{\text{eff}}(B)) \tag{10}\]
In equation 10, \(\lambda_{\text{arr}}\) is the offered arrival rate and \(\mu_{\text{eff}}(B)\) is the saturated service capacity for batch size \(B\). The numerator increases linearly with batch size while service time often increases sub-linearly over a useful range because GPU parallelism is better utilized. The batching window still appears in request latency and in low-traffic regimes, where the expected batch size is limited by arrivals during the window, roughly \(\lambda_{\text{arr}} T_{\text{window}}\).
For ResNet-50 on a V100 GPU, service time approximately scales as \(T_{\text{svc}}(B) = 5 \text{ ms} + 0.6 B\) (5 ms fixed overhead plus 0.6 ms per image in the batch). This linear approximation captures the dominant trend; actual service times may deviate slightly due to memory hierarchy effects. With a \(T_{\text{window}} = 10 \text{ ms}\) batching window, table 11 extends the pure-inference sweep of table 9 by folding in the window wait, so its latency column reflects end-to-end cost rather than inference time alone:
| Batch Size | Service Time | Total Latency | Throughput | Efficiency |
|---|---|---|---|---|
| 1 | 5.6 ms | 15.6 ms | 64 img/s | Low |
| 4 | 7.4 ms | 17.4 ms | 230 img/s | Moderate |
| 8 | 9.8 ms | 19.8 ms | 404 img/s | Good |
| 16 | 14.6 ms | 24.6 ms | 650 img/s | High |
| 32 | 24.2 ms | 34.2 ms | 936 img/s | Maximum |
The throughput gains in table 11 trace directly back to the fixed-overhead term in the iron law established in Iron Law of Training Performance, where batching amortizes work across requests.
Napkin Math 1.7: The iron law of batching efficiency
Iron law connection: In serving, batching improves throughput by amortizing fixed per-batch work such as scheduling, kernel launch, and weight reads; queue wait remains a separate latency cost. The same iron-law decomposition from equation 11 shows why: \[ T = \frac{O}{R_{\text{peak}} \cdot \eta_{\text{hw}}} + L_{\text{lat}} \tag{11}\]
Deriving the sweet spot:
- Case 1 (batch 1): Overhead (5 ms) ≫ Compute (0.6 ms). Efficiency ≈ 10 percent. The GPU is mostly waiting.
- Case 2 (batch 32): Overhead (5 ms) ≪ Compute (19.2 ms). Efficiency ≈ 79 percent. The GPU is crunching numbers.
Golden rule: Increase batch size until fixed overhead becomes negligible (< 10 percent of total time) or the latency SLO blocks further waiting. Beyond this point, additional batching yields minimal throughput but imposes a linear queueing penalty.
These three results compose into one working model of dynamic batching: the window sets the average wait at half its length, Poisson arrivals make the realized batch size fluctuate around \(\lambda_{\text{arr}} T_{\text{window}}\), and the saturated service capacity \(\mu_{\text{eff}}(B)\) climbs with batch size until fixed overhead is amortized away. None of them yet enforces the latency SLO. The passes that follow add that missing constraint, working backward from a hard percentile budget to the largest batch the window may safely form.
Latency-constrained optimization
When latency SLOs provide the binding constraint, the optimization problem becomes finding the maximum batch size that meets the SLO. For a latency target \(L_{\text{lat,target}}\) and average wait time \(T_{\text{window}}/2\), equation 12 defines the maximum allowable batch size using a first-order average latency approximation: \[B_{\text{max}} = \max\left\{B : \frac{T_{\text{window}}}{2} + T_{\text{svc}}(B) \leq L_{\text{lat,target}}\right\} \tag{12}\]
Consider a 50 ms p95 latency SLO for ResNet-50 serving (using this mean-based approximation as a starting point):
Comparing a conservative batching window against an aggressive one isolates how the window choice trades wait time, inference budget, and throughput. Table 12 lays the two configurations side by side.
| Metric | Conservative (\(T_{\text{window}}\) = 5 ms) | Aggressive (\(T_{\text{window}}\) = 25 ms) |
|---|---|---|
| Average wait | 2.5 ms (max wait = 5 ms for the first request in a window) | 12.5 ms |
| Latency budget for inference | 47.5 ms (mean-latency planning; tail SLOs should budget the full window) | 37.5 ms |
| Batch size cap | 32 images (typical batch ≈ 5.7) | 48 (typical batch ≈ 32) |
| Achieved throughput | ~1,140 img/s | ~1,280 img/s |
The aggressive window achieves only 12.3 percent higher throughput but increases average latency by 10 ms and p99 latency by 20 ms. Examine table 11: for latency-sensitive applications, the conservative window provides better user experience at modest throughput cost.
SLO violation analysis
Batch size variability causes SLO violations even when mean latency appears safe. The p99 latency includes both worst-case wait time (full window) and worst-case batch size (governed by Poisson tail). Equation 13 captures this relationship: \[L_{\text{lat,p99}} \approx T_{\text{window}} + T_{\text{svc}}(B_{\text{p99}}) \tag{13}\] where \(B_{\text{p99}}\) is the 99th percentile batch size. For \(\lambda_{\text{arr}}\) = 500 QPS and \(T_{\text{window}}\) = 10 ms, the mean batch size is 5 while the Poisson tail pushes the p99 batch size to 11. That tail propagates into latency: the mean adds 5 ms of wait to 8 ms of service for 13 ms, whereas the p99 adds the full window of 10 ms to 11.6 ms of service for 21.6 ms.
The p99 latency is 1.66× the mean, reflecting both wait time variance and batch size variance. Systems that provision based on mean latency will experience SLO violations.
Systems Perspective 1.7: The latency-throughput trade-off
A single “inference speed” number is undefined until the batch size is named, because batch size selects which regime, and which bottleneck, the system operates in.
- Batch-1 regime: Latency-bound. The request path is dominated by Python overhead and memory bandwidth, since each request loads the weights for a single input. This regime governs real-time interaction such as typing helpers and robotics.
- Batch-N regime: Throughput-bound. Amortizing the weight load across a full batch shifts the bottleneck to compute (FLOP/s). This regime governs offline processing and high-traffic services.
The two regimes optimize opposite quantities, so a model that is “fast” at batch 1 may be far from peak throughput, and vice versa. Any latency or throughput figure must therefore specify whether it was measured at single-stream latency (batch 1) or maximum throughput (batch N).
Adaptive batching windows
The same batch-size dependence drives how the serving system shapes its batches in the first place. Fixed batching windows waste latency budget during high traffic when large batches form quickly. Listing 2 demonstrates how adaptive strategies adjust the window based on queue depth.
def adaptive_batching_window(
queue_depth, arrival_rate, slo_ms, service_ms, fixed_overhead_ms
):
"""Compute optimal batching window.
Based on current system state.
"""
target_batch_size = 16 # Optimal batch for GPU utilization
# Fast path: batch ready, close immediately to minimize latency
if queue_depth >= target_batch_size:
return 0
# Compute maximum allowable wait from the remaining p99 budget.
max_wait_ms = max(0, slo_ms - service_ms - fixed_overhead_ms)
# Estimate time to accumulate target batch at current arrival
# rate.
# arrival_rate is requests/second, so convert seconds to
# milliseconds.
if arrival_rate > 0:
requests_needed = target_batch_size - queue_depth
estimated_wait_ms = requests_needed / arrival_rate * 1000.0
# Return minimum of estimated wait and SLO-constrained maximum
return min(estimated_wait_ms, max_wait_ms)
return max_wait_ms # Low traffic: use remaining budget to accumulate batchThis approach reduces average wait time during high traffic while maintaining batch sizes. For traffic varying between 200–1000 QPS, a fixed 10 ms window produces 15 ms average latency at 650 img/s, while an adaptive window cuts average latency to 11 ms (27 percent reduction) and improves throughput to 680 img/s (5 percent improvement). The interplay between window size and batch limits creates a space of possible configurations, each representing a different balance between throughput and latency.
The batching configuration space forms a Pareto frontier where improving throughput requires accepting higher latency. Table 13 traces this frontier across five representative configurations:
| Window (ms) | Max Batch | Avg Latency | p99 Latency | Throughput | Configuration |
|---|---|---|---|---|---|
| 2 | 16 | 8 ms | 18 ms | 890 img/s | Ultra-low latency |
| 5 | 32 | 10 ms | 22 ms | 1,140 img/s | Balanced |
| 10 | 32 | 15 ms | 35 ms | 1,240 img/s | Moderate latency |
| 20 | 64 | 23 ms | 52 ms | 1,310 img/s | Throughput-optimized |
| 50 | 128 | 38 ms | 98 ms | 1,350 img/s | Maximum throughput |
Practical configuration guidelines
The Pareto frontier in table 13 illustrates why these guidelines matter: past the knee, widening the window buys steeply diminishing throughput for sharply rising tail latency. Principled batching configuration avoids this region of diminishing returns by working backward from the latency budget. Allocating twenty to 30 percent of the SLO to batching wait time leaves the remainder for inference and overhead, which bounds the maximum window at \(T_{\text{max}} = 0.3 \times L_{\text{lat,SLO}}\). The traffic estimate that feeds this calculation should use the p95 arrival rate rather than the average, because batching windows tuned for average traffic produce oversized batches during spikes—precisely when SLO headroom matters most. GPU memory imposes a hard ceiling on batch size independent of the latency constraint, since activation memory scales linearly with the batch dimension. Finally, monitoring the actual batch size distribution in production reveals whether initial traffic assumptions hold; high variance signals that the window needs adaptive tuning rather than a fixed configuration.
For ResNet-50 with 50 ms SLO and 500 QPS traffic:
The calculation turns the SLO and arrival-rate assumptions into two deployable knobs: the batching window and maximum batch size. Table 14 summarizes the resulting configuration and the predicted operating point.
| Quantity | Value | Engineering role |
|---|---|---|
| Latency budget for batching | 15 ms | Portion of the SLO available for queueing delay. |
| Maximum window | 15 ms | Upper bound implied by the latency budget. |
| Expected batch size | 6 | Average batch under the stated traffic. |
| p99 batch size | 12 | Burst size under Poisson arrivals. |
| Memory-limited maximum batch | 32 | Hard cap imposed by accelerator memory. |
| Selected configuration | \(T_{\text{window}}\) = 12 ms, \(B_{\text{max}}\) = 32 | Practical knob setting for deployment. |
| Predicted p99 latency | 24.2 ms | Confirms that the configuration stays within the SLO. |
| Predicted peak capacity | 1,176.9 img/s | Capacity if the selected batch cap is saturated. |
| Served throughput | 500 img/s | Arrival-limited load handled by the configuration. |
Continuous batching
Autoregressive models like language models generate outputs token by token—each new token depends on all previously generated tokens, so generation is inherently sequential. The dynamic batching examined in section 1.7 assumes fixed-length outputs. LLMs violate this assumption: if one sequence in a batch of eight finishes after ten tokens while others need 100 tokens, 90 percent of the compute for that sequence slot is wasted (Yu et al. 2022).
21 Continuous Batching: Also called “iteration-level batching” (Yu et al. 2022) and, in NVIDIA TensorRT-LLM, “in-flight batching” (NVIDIA 2026f). The key insight is scheduling granularity: traditional batching commits to a fixed batch for an entire generation sequence (potentially hundreds of iterations), while continuous batching reschedules at every token-generation step—analogous to preemptive OS process scheduling vs. run-to-completion. This finer granularity reduces the waste from variable-length sequences, where a batch slot occupied by a completed sequence sits idle until all other sequences finish.
Yu, Gyeong-In, Joo Seong Jeong, Geon-Woo Kim, Soojeong Kim, and Byung-Gon Chun. 2022. “Orca: A Distributed Serving System for Transformer-Based Generative Models.” 16th USENIX Symposium on Operating Systems Design and Implementation (OSDI 22), 521–38.
NVIDIA. 2026f. NVIDIA TensorRT-LLM.
Continuous batching21 (also called iteration-level batching) addresses this waste by allowing new requests to join a batch between generation steps and completed sequences to exit (Yu et al. 2022; Kwon et al. 2023). The system manages batch composition dynamically at each decoding iteration rather than forming static batches that persist for the entire generation process.
The mechanism works as follows: when a sequence generates its end-of-sequence token, its slot becomes immediately available. A waiting request can fill that slot for the next iteration rather than waiting for the entire batch to complete. Similarly, the system can add new requests to available slots without interrupting ongoing generation. This dynamic approach maintains high GPU utilization even when sequence lengths vary by 100\(\times\) or more.
Systems implementing continuous batching, such as vLLM22 and TensorRT-LLM, improve throughput by keeping decode slots occupied as sequences enter and exit (Kwon et al. 2023; NVIDIA 2026f). Sarathi-Serve refines this scheduler with chunked prefill and stall-free batching to reduce interference between prompt processing and token decoding (Agrawal et al. 2024). The improvement comes from two sources: reducing wasted compute on completed sequences and reducing average wait time for new requests. For production language model serving where response lengths vary from single tokens to thousands, continuous batching has become a central technique for cost-effective deployment.
22 vLLM (Virtual LLM): An open-source serving system that enables continuous batching via its PagedAttention algorithm (Kwon et al. 2023). Inspired by OS virtual memory, this technique reduces the severe KV-cache fragmentation and reservation waste that constrains static batching. By keeping KV-cache waste low, vLLM can serve larger effective batches on the same hardware.
Agrawal, Amey, Nitin Kedia, Ashish Panwar, Jayashree Mohan, Nipun Kwatra, Bhargav S. Gulavani, Alexey Tumanov, and Ramachandran Ramjee. 2024. “Taming Throughput-Latency Tradeoff in LLM Inference with Sarathi-Serve.” 18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24), 117–34.
Memory management adds complexity to continuous batching. As sequences enter and exit the batch, the key-value cache that stores attention context must be dynamically allocated and freed. Consider what happens when sequences of varying lengths share GPU memory: a 100-token sequence completes and releases its cache, but a new 150-token sequence cannot use that space because it needs a larger contiguous block. Over time, small unusable gaps accumulate between allocated regions, eventually preventing new sequences from starting even when total free memory appears sufficient. This memory fragmentation can waste 40 to 50 percent of available memory in naive implementations, severely limiting the concurrent batch size that determines throughput.
PagedAttention

PagedAttention recovers the KV-cache waste of contiguous allocation.
23 PagedAttention: The name directly references OS virtual memory paging, first implemented on the Atlas computer at Manchester (1962) to solve the same class of allocation problem—programs needed more memory than physically available, and contiguous allocation wasted space. Introduced at SOSP 2023, PagedAttention applies this six-decade-old abstraction to GPU KV-cache memory: before it, LLM serving systems wasted 60–80 percent of KV cache memory due to fragmentation and over-reservation. PagedAttention reduces waste to under 4 percent, enabling 2–4\(\times\) higher throughput on the same hardware (Kwon et al. 2023).
Kwon, Woosuk, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. 2023. “Efficient Memory Management for Large Language Model Serving with PagedAttention.” Proceedings of the 29th Symposium on Operating Systems Principles, 611–26. https://doi.org/10.1145/3600006.3613165.
PagedAttention,23 introduced in vLLM, solves this fragmentation problem by applying operating system virtual memory concepts to GPU memory (Kwon et al. 2023). Instead of allocating one contiguous block per sequence, PagedAttention divides the KV cache into fixed-size pages (typically 16 tokens each). A sequence’s cache consists of pointers to noncontiguous pages scattered across GPU memory. When a sequence completes, its pages return to a free list and can be reused by any new sequence, regardless of length. vLLM reports that this paging approach reduces KV-cache waste to below 4 percent while improving throughput relative to prior contiguous-allocation designs. The overhead is a page-table lookup during attention computation, making PagedAttention a standard reference point for production LLM serving.
The batching and memory techniques covered here establish the foundation for LLM serving, but several advanced topics warrant additional study.
Systems Perspective 1.8: LLM serving: Beyond the fundamentals
Language model serving introduces challenges beyond the batching and memory principles established here. The key-value cache that stores attention context scales with sequence length and batch size, often exceeding the model weights themselves in memory consumption. Techniques like speculative decoding use small draft models to propose multiple tokens that the target model verifies in parallel, achieving 2–3\(\times\) latency reduction for interactive applications (Leviathan et al. 2023). Weight-only quantization (such as INT4 weights with FP16 activations) is especially relevant for memory-bandwidth-bound LLM inference (Lin et al. 2023).
These LLM-specific optimizations build directly on the foundations this chapter establishes: queuing theory governs request scheduling, batching trade-offs determine throughput-latency curves, and precision selection follows the same accuracy-efficiency principles. The serving fundamentals apply universally; LLM serving adds domain-specific techniques atop this foundation. Advanced treatments provide detailed coverage of KV cache optimization, including techniques for multi-tenant serving, where one fleet shares capacity across users, and distributed inference, where one request may be split across machines.
Continuous batching is the dominant technique for LLM serving, yet not all deployment scenarios benefit from batching. The sophisticated techniques examined so far (from dynamic batching windows to PagedAttention) optimize for high-throughput server workloads. These techniques introduce complexity and latency overhead that may not be justified for all deployment contexts. The practical question is when batching hurts rather than helps.
Some scenarios require single-request processing. Ultra-low latency requirements, where p99 latency must stay under 10 ms, make any batching delay unacceptable. Highly variable request sizes create padding overhead that wastes compute, since the smallest input in a batch must be padded to match the largest. Memory constraints also become binding when models already consume most GPU memory, since batch activations scale linearly with batch size and can trigger out-of-memory errors.
Session affinity constraints
When requests from the same user or session should route to the same replica, batching becomes constrained. Session affinity, also called sticky sessions, matters for three main reasons.
The most impactful case is KV-cache reuse in conversational AI, where the key-value cache from previous turns can materially speed up multi-turn conversations. Routing a follow-up request to a different replica forfeits this cached context, forcing the system to recompute or reload prefix state for long conversations.
A second driver is user-specific models: some systems serve personalized models or adapters per user, and routing requests to the replica that has already loaded that user’s adapter avoids repeated loading overhead. Similarly, stateful preprocessing that maintains tokenizer caches or session-specific normalization requires rebuilding state when requests route to a different replica.
The tension with batching is clear since strict affinity constrains which requests can be batched together, potentially reducing batch sizes and GPU utilization. Production systems often implement soft affinity where requests prefer their assigned replica but can overflow to others when that replica is overloaded. This preserves most affinity benefits while maintaining load balance.
Traffic patterns and batching strategy
The optimal batching strategy depends critically on how requests arrive. Different deployment contexts exhibit distinct arrival patterns, each requiring different batching approaches. The MLPerf inference benchmark codifies these patterns into four scenarios that directly map to real-world deployments, as MLPerf execution scenarios explains in detail.
Server traffic (poisson arrivals)
The MLPerf Server scenario models cloud/API-like inference traffic with Poisson arrivals (Reddi et al. 2019).24 Under that model, arrivals are independent and uniformly distributed over time. Equation 14 expresses the expected batch size for Poisson arrivals with rate \(\lambda_{\text{arr}}\) and batching window \(T_{\text{window}}\): \[E[\text{batch size}] = \lambda_{\text{arr}} \cdot T_{\text{window}} \tag{14}\]
Reddi, Vijay Janapa, Christine Cheng, David Kanter, Peter Mattson, Guenther Schmuelling, Carole-Jean Wu, Brian Anderson, et al. 2019. “MLPerf Inference Benchmark.” 2020 ACM/IEEE 47th Annual International Symposium on Computer Architecture (ISCA), 446–59. https://doi.org/10.1109/isca45697.2020.00045.
24 Poisson Process: Named after French mathematician Simeon Denis Poisson (1781–1840), this stochastic model describes events occurring continuously and independently at a constant average rate. The key property for serving: variance equals the mean, so batch sizes fluctuate significantly at moderate traffic—with \(\lambda_{\text{arr}}=200\) req/s and a 10 ms window, expected batch size is two but roughly 14 percent of windows will be empty (wasted GPU cycles). This variance is why batching windows must be tuned probabilistically rather than set from average traffic alone.
The variance equals the mean (a property of Poisson distributions), so batch sizes fluctuate significantly at moderate traffic. With \(\lambda_{\text{arr}} = 200\) requests/second and \(T_{\text{window}} = 10\) ms, expected batch size is two, but roughly 14 percent of windows will have zero requests (wasted compute cycles) while others may have four or more.
A useful heuristic for the batching window balances waiting cost against throughput benefit. Equation 15 expresses one such rule: \[T_{\text{window}} \approx \min\left(L_{\text{lat,SLO}} - T_{\text{svc}}, \sqrt{\frac{T_{\text{svc}}}{\lambda_{\text{arr}}}}\right) \tag{15}\] where \(L_{\text{lat,SLO}}\) is the latency SLO, \(T_{\text{svc}}\) is the service time (in seconds), and \(\lambda_{\text{arr}}\) is the arrival rate (in requests per second), making the second term dimensionally consistent in seconds. The square-root form is a local cost-model heuristic: it balances a fixed per-batch benefit against a waiting cost that grows with the arrival interval. It is not a closed-form optimum for ML serving specifically; production systems calibrate the window empirically against observed traffic. A counterintuitive result emerges from this equation: as traffic increases, the optimal window decreases while achieved batch sizes still grow. Table 15 demonstrates this phenomenon across four traffic levels.

As QPS rises, the batching window shrinks while batch size grows.
| Arrival Rate | Optimal Window | Avg Batch Size | Approx. Latency |
|---|---|---|---|
| 100 QPS | 15.8 ms | 1.6 | 40.8 ms |
| 500 QPS | 7.1 ms | 3.5 | 32.1 ms |
| 1,000 QPS | 5 ms | 5 | 30 ms |
| 5,000 QPS | 2.24 ms | 11.2 | 27.2 ms |
Single-user traffic (sequential arrivals)
Streaming traffic correlates arrivals by sensor synchronization, making batch size and deadline externally fixed. At the opposite end of the spectrum, mobile and embedded applications face no batching opportunity at all. The optimization target shifts from synchronization budget against a hard frame deadline to per-request latency against energy consumption under a thermal power envelope.
Mobile and embedded applications serve one user at a time; the MLPerf SingleStream scenario captures this sequential-serving shape. For ResNet-50 on a phone, the dominant costs shift from batch formation to per-request latency and energy.
Napkin Math 1.8: ResNet-50: Mobile serving
Table 17 decomposes per-phase latency and energy for a single-user mobile vision inference:
| Phase | Duration | Energy | Notes |
|---|---|---|---|
| Camera buffer read | 8 ms | 0.08 mJ | System API |
| JPEG decode (CPU) | 15 ms | 1.5 mJ | Single-threaded |
| Resize + Normalize | 5 ms | 0.4 mJ | CPU preprocessing |
| NPU inference | 12 ms | 0.8 mJ | 82% utilization |
| Postprocess + UI | 5 ms | 0.2 mJ | Result rendering |
| Total | 45 ms | 2.98 mJ | 22 FPS sustained |
The mobile serving node is governed by four metrics:
- Energy per inference: 2.98 mJ enables ~12.1M inferences per 10 Wh battery (typical smartphone)
- Thermal budget: At 2.98 mJ / 45 ms = 66 mW sustained, indefinite operation without throttling
- NPU vs. CPU trade-off: CPU fallback replaces the 12 ms, 0.8 mJ NPU inference stage with a 45 ms, 4.2 mJ CPU stage; the full pipeline would rise from 45 ms and 2.98 mJ to about 78 ms and 6.4 mJ before additional system overhead.
- Memory footprint: 150 MB peak (model + activations), competing with app memory
Systems insight: Even at batch size one, the mobile NPU achieves 82 percent utilization because its compute capacity matches single-image workloads. This differs from data center GPUs, which achieve only 15 percent utilization at batch size one because their massive parallelism requires larger batches to saturate.
Mobile serving constraints
Unlike cloud serving where cost dominates, mobile serving faces three related constraints that shape optimization strategy. The first is an energy budget that throughput targets ignore, because each inference depletes battery. In the modeled pipeline, 2.98 mJ at 22 FPS draws about 66 mW for the inference path alone, before camera, display, ISP, and OS overhead add to that total in a full photo app, so the optimization target shifts from throughput to energy-per-inference. Thermal throttling compounds this limit, since sustained high-power operation triggers thermal management: once the SoC reaches its thermal ceiling (typically 45 °C junction), the OS reduces NPU frequency by 30–50 percent, degrading both latency and throughput, which is why bursty workloads that allow cooling between bursts outperform sustained maximum throughput. Memory constraints close the set, because mobile devices share limited RAM across applications. A model consuming 500 MB may be evicted during background operation, forcing a reload (cold start) that adds 200–500 ms of latency, and even a 150 MB footprint becomes problematic when the model must coexist with other app components. Memory-efficient quantization improves user experience through faster model restoration, and memory-mapped model loading (section 1.6.3) helps further by loading pages on demand rather than requiring the full model in memory.
These constraints make mobile serving optimization qualitatively different from cloud optimization. The goal is not maximum throughput but sustainable performance, maintaining acceptable latency without thermal throttling or excessive battery drain.
Traffic pattern summary
Traffic-adaptive batching adjusts the batching window as queue depth and request rate change. Table 18 maps the four MLPerf scenarios to their deployment contexts and optimal batching strategies, providing a decision framework for serving system design.
| Scenario | Context | Strategy | Focus |
|---|---|---|---|
| Server | Cloud APIs, web services | Dynamic batching with timeout | Window tuning, utilization-latency curve |
| MultiStream | Autonomous driving, video analytics | Synchronized sensor fusion | Jitter handling, deadline guarantees |
| SingleStream | Mobile apps, embedded devices | No batching (\(B = 1\)) | Preprocessing, power efficiency |
| Offline | Batch processing, data pipelines | Maximum batch size | Throughput, hardware utilization |
The MLPerf Server scenario captures cloud API traffic, MultiStream captures synchronized sensor workloads, and Offline inference captures batch processing where throughput dominates latency.
Checkpoint 1.3: Batching and traffic patterns
Batching is the primary lever for serving economics, but the optimal strategy depends on context.
The batching strategies examined so far share a critical assumption: each request produces a single, fixed-size output—one classification label, one bounding box, one embedding vector. This assumption governs the queuing math, the Pareto frontier analysis, and the traffic-adaptive window tuning. The fastest-growing category of serving workloads, however, violates this assumption entirely. Large language models generate outputs token by token, with each token depending on every previous one. A single request may produce hundreds or thousands of tokens over seconds of elapsed time, yet must feel responsive from the first token onward. This fundamental shift from fixed-output to variable-length, streaming-output serving builds directly on the continuous batching and KV-cache paging already established for autoregressive generation. What it adds are phase-split metrics for prefill and decode, decoding strategies that trade output quality against per-token cost, and memory tactics such as prefix reuse and offloading that exploit shared context.
Self-Check: Question
Why does increasing batch size from 1 to moderate values (say 8-32) often improve serving throughput dramatically on GPUs?
- Larger batches remove the need for preprocessing and postprocessing by combining them into the kernel launch.
- Batching amortizes fixed per-call costs such as kernel launch overhead and a single pass of weight reads from HBM across many requests, raising the effective arithmetic intensity and hardware utilization.
- Larger batches make queuing theory irrelevant once the accelerator is saturated, so mean latency stops mattering.
- The model’s parameter count effectively shrinks as batch size grows because the runtime dedupes repeated weights.
A public API sees 50 QPS overnight and 800 QPS during peak hours. Why is dynamic batching with a time window generally preferable to waiting for a fixed full batch?
- A time-bounded window caps per-request wait time even when traffic is low, while static-full-batch policies force early arrivers to wait indefinitely for enough requests during off-peak hours.
- Static batching cannot be used with GPUs; they require a scheduler to form every batch at runtime.
- Dynamic batching guarantees that every batch has exactly the same size, which makes kernel tuning easier.
- Static batching always delivers worse throughput than batch 1, so the question is just which dynamic strategy to use.
A service has a 50 ms latency SLO. Explain why allocating roughly 20 to 30 percent of that budget (10-15 ms) to a batching window is a reasonable starting configuration, and what breaks if the window is pushed to 40 ms.
Why does continuous batching matter far more for LLM serving than for fixed-output models such as image classifiers?
- Language models are trained online while image classifiers are not, so only LLM batches must be recomputed continuously.
- LLM requests generate variable-length sequences, so in static batching a completed sequence leaves its slot idle until the longest sequence finishes, wasting a growing fraction of capacity; continuous batching refills those slots on each decode step.
- Continuous batching eliminates the need for a KV cache, which is why it is reserved for LLMs.
- Image classification cannot benefit from any form of batching, so any batching innovation is automatically LLM-only.
A naive LLM server allocates the KV cache as one contiguous region per request. Under continuous batching with variable-length sequences, why does this allocation strategy severely limit the achievable concurrent batch size, and what does PagedAttention change?
- Contiguous allocation is bandwidth-bound rather than capacity-bound, and PagedAttention rewrites attention kernels to use a slower but more predictable memory path.
- As sequences of different lengths enter and leave, free memory accumulates in unusable gaps (external fragmentation). A new long sequence cannot find a single contiguous block even when total free memory looks sufficient, so 40-50 percent of VRAM can sit unused and concurrency falls well below what capacity alone would predict. PagedAttention divides the KV cache into fixed-size pages that can be allocated non-contiguously, pushing utilization above 90 percent.
- Contiguous allocation is a software bug that has already been fixed in the CUDA driver; PagedAttention is a fallback for older drivers.
- Contiguous allocation is fine in principle, but PagedAttention moves the KV cache to CPU RAM to bypass VRAM limits entirely.
Which batching strategy best matches a mobile SingleStream deployment such as on-device image classification in a smartphone app?
- Large dynamic batches with 20-50 ms windows to maximize on-device GPU utilization across background queries.
- Synchronized multi-sensor batching with fixed camera-frame groups pulled from a hardware trigger.
- No batching (batch 1), prioritizing immediate responsiveness, low peak power, and thermal stability over aggregate throughput.
- Offline maximum-batch processing because a single user generates a predictable request stream.
LLM Serving
Large language models introduce three properties absent from traditional serving: autoregressive generation25 (each token depends on all previous tokens, making output inherently sequential), variable-length output (response length is unknown at request time, invalidating fixed-batch assumptions), and stateful memory (the key-value cache grows with each generated token, creating dynamic memory pressure that traditional models never face). Together, these properties create a qualitatively different serving challenge. The p50, p95, and p99 metrics that govern classification serving still matter, but they apply to different phases of the request—the initial prompt processing and the subsequent token generation. The foundational principles of queuing theory, batching trade-offs, and latency budgets apply universally; LLM serving adds domain-specific techniques atop this foundation.
25 Autoregressive: From Greek auto- (self) and Latin regressus (a going back)—the output “regresses” on itself. George Udny Yule introduced autoregressive models in 1927 for analyzing sunspot cycles. In language modeling, each output token conditions on all previously generated tokens, creating a serial dependency that prevents the parallelism exploited during training. This serial bottleneck explains why LLM serving is memory-bandwidth-bound rather than compute bound: the model weights must be read from memory once per token, regardless of available compute capacity.
Performance metrics: TTFT and TPOT

TTFT and TPOT live in different bottleneck regimes.
Generative models produce a stream of tokens rather than a single output tensor. This streaming nature requires dedicated LLM performance metrics that reflect the internal state transition from “prefill” (processing input) to “decode” (generating output). The two key measures are Time to First Token (TTFT) and Time Per Output Token (TPOT), which capture responsiveness and fluidity respectively.
Definition 1.6: LLM performance metrics
LLM Performance Metrics are the two-dimensional measurements of latency for streaming autoregressive generation.
- Significance: They decompose user-perceived latency into Time to First Token (TTFT) (governed by the compute-bound Prefill Phase) and Time Per Output Token (TPOT) (governed by the memory-bandwidth-bound Decode Phase).
- Distinction: Unlike Fixed-Output Metrics (for example, end-to-end latency), LLM metrics measure the Fluidity of Generation, acknowledging that the user experience depends on the rhythm of token arrival.
- Common pitfall: A frequent misconception is that a “fast model” has a low TTFT. In reality, a model can have a fast TTFT but a sluggish TPOT (if the memory wall \((\text{BW})\) is the bottleneck), leading to a frustrating user experience where the answer starts quickly but “stutters” thereafter.
These two metrics capture distinct user experience aspects, and production systems set separate SLO targets for each.
Systems Perspective 1.9: LLM serving latency targets
Interactive LLM services usually need separate SLOs for responsiveness, generation fluidity, and fleet throughput. The values below are illustrative targets rather than universal requirements:
- TTFT: < 500 ms (for a 1000-token prompt)
- TPOT: < 50 ms (equivalent to ~20 tokens/s, faster than human reading speed)
- Throughput: > 1000 tokens/s aggregate across active serving replicas
The systems point is that a single “latency” number hides the prefill/decode split: TTFT is the blank-screen budget, TPOT is the reading-flow budget, and aggregate service throughput, measured as tokens/s summed across active serving replicas, determines whether those targets hold under shared load.
Decoding strategies
Meeting these TPOT targets depends on more than memory bandwidth alone: the algorithm used to select each token also affects per-token latency and output quality. Generative models require decoding strategies that trade off quality, diversity, and latency. The choice of decoding strategy dramatically affects both output quality and computational cost.
The simplest approach, greedy decoding, selects the highest-probability token at each step at the cost of one model pass per token. It is fast but often produces repetitive outputs because it cannot recover from early mistakes. Beam search improves quality by maintaining multiple candidate sequences and selecting the highest-scoring complete sequence, but it multiplies per-token compute by the beam width. Sampling with temperature, top-\(k\), and top-\(p\) (also called nucleus sampling) injects controlled randomness for diversity at negligible extra compute (Holtzman et al. 2020); its serving cost lies less in arithmetic than in output-length variance, which widens the spread of sequence lengths that continuous batching must absorb. These costs compound at the per-token level (Meister et al. 2020): beam search with width five runs roughly 5\(\times\) the compute of greedy decoding for every token, which is why interactive, latency-sensitive deployments rarely use it and instead reach for greedy or sampling.
Holtzman, Ari, Jan Buys, Li Du, Maxwell Forbes, and Yejin Choi. 2020. “The Curious Case of Neural Text Degeneration.” Proceedings of the 8th International Conference on Learning Representations (ICLR 2020).
Meister, Clara, Ryan Cotterell, and Tim Vieira. 2020. “If Beam Search Is the Answer, What Was the Question?” Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2173–85. https://doi.org/10.18653/v1/2020.emnlp-main.170.
Production LLM systems return tokens as they are produced rather than waiting for complete generation. This streaming response transforms the user experience: a two-second total generation feels responsive when tokens stream continuously, but feels broken when users stare at a blank screen for two seconds. Streaming requires infrastructure support for chunked HTTP responses and client-side incremental rendering. The latency profile shifts accordingly: TTFT determines when output starts appearing (responsiveness), while TPOT determines the perceived generation speed (fluidity). Once generation is streamed token by token, the serving bottleneck shifts from one prediction request to a stateful sequence whose memory footprint grows on every step.
Memory and KV cache
Generative inference requires managing the KV Cache26, a stateful memory structure that grows with sequence length. Unlike traditional models where memory usage is constant per batch, LLM memory usage is dynamic. Each generated token adds to the context window, consuming additional GPU memory through state accumulation, and variable-length sequences can lead to memory fragmentation if not managed explicitly.
26 KV Cache (Key-Value Cache): To avoid redundant work, the system caches the Key and Value vectors from previous tokens, which remain valid throughout generation. This design choice is the direct cause of the dynamic memory growth described; the cache’s size grows linearly with every generated token, making memory management, not computation, the primary constraint. For the 70-billion-parameter-class grouped-query-attention sizing example in this section, the FP16 KV cache is about 0.31 MB per token per sequence; grouped-query attention (GQA), used in Llama-family models such as Llama 3, shares key/value heads across multiple query heads, reducing the cache relative to full multi-head attention (Dubey et al. 2024). A batch of 32 requests at an 8,000-token context therefore requires roughly 80 GB just for KV cache, several times larger still without grouped-query or multi-query attention.
Dubey, Abhimanyu, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, et al. 2024. The Llama 3 Herd of Models. arXiv preprint arXiv:2407.21783.
Prefix caching and memory offloading
The continuous batching and PagedAttention techniques covered in section 1.7.4 address request scheduling and cache paging; the remaining memory pressure can be further mitigated through architectural strategies that exploit request patterns. Prefix Caching stores the KV cache of common instruction prefixes (such as a 2,000-token system prompt or a shared retrieval-augmented generation (RAG) context), allowing many independent requests to reuse the same precomputed hidden states. For \(N\) requests sharing a prefix of \(S_{\text{prefix}}\) tokens, the saved prefill work is roughly \((N-1)S_{\text{prefix}}\) token steps, plus the avoided reads and writes of the prefix KV state. For multi-turn conversations, this “caching of the past” allows the system to process only the new tokens in each turn.
When the aggregate KV cache exceeds GPU VRAM, systems can employ KV Cache Offloading. This strategy spills inactive or low-priority context windows to host CPU RAM or NVMe SSD, freeing VRAM for active generation. The reload cost is bounded below by bytes moved divided by PCIe or NVMe bandwidth, before software overhead and queueing are added. Offloading therefore prevents Out-of-Memory (OOM) failures and enables larger context windows, but it also creates affinity, invalidation, and hot-decode latency risks that must be budgeted explicitly. Advanced techniques including speculative decoding27 and distributed parallelism, where one request is split across multiple devices or machines, are covered in specialized treatments of large-scale systems.
27 Speculative Decoding: A small “draft” model generates \(k\) candidate tokens autoregressively; the large target model then verifies the proposed block in parallel (Leviathan et al. 2023). When the draft model’s proposals are accepted at rate \(\alpha\), effective throughput can scale with the number of accepted tokens per verification step. This breaks the serial autoregressive bottleneck at the runtime layer, not the architecture layer.
Leviathan, Yaniv, Matan Kalman, and Yossi Matias. 2023. “Fast Inference from Transformers via Speculative Decoding.” Proceedings of the 40th International Conference on Machine Learning, 19274–86.
The computational intensity of managing KV caches across concurrent requests raises a broader question about the energy cost of each token generated. Unlike classification models where energy per inference is constant, LLM energy consumption scales with response length—every generated token requires reading the entire model from memory. Energy and carbon accounting translate these hardware demands into metrics that make the environmental impact concrete.
Napkin Math 1.9: The carbon cost of a chat
Problem: How much energy does an H100-backed chat service spend per generated token and for a response with 500 tokens?
As LLMs scale, joules per token becomes a first-class operational metric alongside latency. For this scenario using an H100 GPU (700 W TDP), the energy footprint follows from throughput and power (Choquette 2023):
- Throughput: 114 concurrent requests \(\times\) 8 tokens/s per request ≈ 912 tokens/s.
- Power: 700 W (GPU) + 300 W (Host/Overhead) = 1000 W.
- Energy per token: 1000 W / 912 tokens/s ≈ 1.0965 J/token
Systems insight: A typical response of 500 tokens consumes ≈ 548.2 J.
- For comparison, charging a smartphone consumes ≈ 40000 J.
- Boiling a cup of water consumes ≈ 100000 J.
The primary way to reduce J/token is to increase hardware utilization and eliminate redundant compute. If the GPU sits at 10 percent utilization due to poor batching, the idle power is still ~300 W, causing the energy per token to rise to >3.3 J/token. Architectural optimizations like prefix caching also skip the energy-intensive prefill phase for shared context, directly reducing the energy footprint of retrieval-augmented generation (RAG) and chat applications. The serving lesson is that efficiency is not only a latency or cost metric; it also determines how much energy each useful token consumes.
Energy efficiency depends on the same batching, memory, and prefix-cache mechanisms that govern LLM latency, so the useful summary is a constraint checklist rather than a single scalar metric.
Checkpoint 1.4: LLM serving fundamentals
LLM serving introduces constraints absent from traditional model serving.
Self-Check: Question
Which pairing correctly matches the two main LLM serving metrics with the user experience they capture?
- TTFT measures sustained generation fluidity, while TPOT measures startup responsiveness.
- TTFT measures how long the user waits for the first token to appear, while TPOT measures the rhythm of successive tokens once generation has begun.
- TTFT and TPOT both measure the same quantity sampled at different percentiles.
- TTFT measures model accuracy while TPOT measures serving cost.
Why is the decode phase of LLM serving described as memory-bandwidth bound rather than compute bound?
- Each new token requires re-reading the model weights and the growing KV state per layer, and per-token arithmetic intensity is low enough that HBM transfer time dominates kernel time.
- Decoding always runs on CPUs rather than GPUs, which have lower compute but higher bandwidth.
- Beam search removes most memory traffic, leaving only arithmetic work, which is why decode is bandwidth-bound in practice.
- Prefill and decode have identical hardware bottlenecks, so both are bandwidth-bound by definition.
Explain why returning tokens incrementally can make a 2-second LLM response feel much better to a user than returning the entire response at the end.
Many production LLM requests share the same long system prompt or the same retrieved context prefix. Which change most directly reduces the redundant prefill work across such requests?
- Raise temperature so the model explores a wider output distribution and reuses less computation per request.
- Enable prefix caching so the KV states for the shared prompt prefix are computed once and reused across requests that share that prefix.
- Disable the KV cache entirely so requests are memory-independent and cannot interfere with one another.
- Switch from sampling to greedy decoding so prefill disappears and only decode remains.
A team serving a 70-billion-parameter-class LLM can afford exactly one GPU upgrade. Option X doubles peak FP16 TFLOP/s while HBM bandwidth stays roughly flat. Option Y holds peak TFLOP/s roughly flat but increases HBM bandwidth by 60 percent. Assuming typical long-output chat traffic where decode dominates the budget, which option improves TPOT more, and why?
- Option X, because more compute always lowers per-token latency regardless of where the bottleneck sits.
- Option Y, because decode is memory-bandwidth bound: each token requires moving weights and KV state through HBM, so faster HBM directly shrinks per-token kernel time while extra FLOP/s sits idle.
- Neither option changes TPOT; per-token time depends only on model architecture, not hardware.
- Both options improve TPOT equally, because TPOT scales with the geometric mean of compute and bandwidth.
Inference Runtime Selection
The batching strategies and LLM-specific techniques determine how requests are grouped and processed. These strategies assume an underlying execution engine that actually runs the model computations—an assumption that matters enormously. The token generation relationship formalized later in this chapter and the latency budgets established earlier are achievable only if the runtime efficiently maps operations to hardware. The inference runtime, the software layer that orchestrates tensor operations and manages hardware resources, can vary by an order of magnitude in performance for identical models. Runtime work therefore has two phases: selection chooses the execution engine, and configuration tunes that engine for the target model, hardware, and latency distribution.
Runtime ecosystem and configuration
Selection should start with the binding constraint rather than the framework used during training. When deployment speed and compatibility dominate, PyTorch and TensorFlow models can serve directly using their native runtimes. This approach maximizes compatibility (any model that trains will serve) and simplifies the deployment pipeline (no export or conversion step). Framework runtimes include training functionality that adds overhead, and default execution paths may not exploit hardware-specific optimizations.
TorchScript and TensorFlow SavedModel formats enable ahead-of-time compilation and graph optimization, improving over eager execution while maintaining framework compatibility. These formats represent the first step toward deployment optimization without abandoning the familiar framework ecosystem.
General-purpose optimization
When portability across hardware is the binding constraint, ONNX Runtime28 provides a hardware-agnostic optimization layer (Microsoft 2024). Models export to ONNX format, then ONNX Runtime applies graph optimizations and selects execution providers for the target hardware. This enables single-format deployment across CPUs, GPUs, and specialized accelerators.
28 ONNX Runtime: Microsoft’s inference engine acts as a hardware abstraction layer: the same ONNX model runs on CPUs, NVIDIA GPUs, AMD GPUs, or custom accelerators through pluggable “execution providers.” ONNX Runtime applies framework-agnostic graph optimizations—constant folding, redundant node elimination, operator fusion—that benefit all targets. This cross-platform capability avoids maintaining separate optimization pipelines per hardware target, accepting a 5–15 percent throughput loss vs. TensorRT for vision models, offset by the ability to retarget the same .onnx artifact across CPU/GPU/NPU without recompilation—a flexibility premium that matters most in heterogeneous device fleets where recompiling per-target is measured in engineer-days.
Microsoft. 2024. ONNX Runtime: Cross-Platform Inference and Training Machine-Learning Accelerator. GitHub.
Specialized inference engines
When latency or hardware cost binds more tightly than portability, TensorRT29 (NVIDIA GPUs), OpenVINO30 (Intel hardware), and similar engines optimize specifically for their target hardware (NVIDIA 2024a; Intel Corporation 2026; Chen et al. 2018). They apply aggressive optimizations that framework-native runtimes cannot safely perform.
29 TensorRT: It abandons the portability of general-purpose frameworks by requiring a build phase that optimizes the model for a target GPU architecture (for example, an H100) (NVIDIA 2024a). This hardware lock-in allows aggressive optimizations like layer fusion and precision selection that are unsafe for a framework that must run on any hardware. The resulting nonportable engine can materially reduce latency and therefore the number of GPUs required to meet a throughput target.
NVIDIA. 2024a. NVIDIA TensorRT: Programmable Inference Accelerator.
30 OpenVINO (Open Visual Inference and Neural Network Optimization): An Intel-oriented inference toolkit that converts, optimizes, and runs models across Intel CPU, GPU, and NPU targets (Intel Corporation 2026). This direct hardware targeting is an “aggressive” optimization because it abandons some portability that framework-native runtimes must guarantee, allowing it to exploit target-specific kernels and precision choices. The resulting performance gain is workload- and hardware-dependent, but it can make dedicated CPU or edge serving economically viable for smaller and latency-sensitive models.
Intel Corporation. 2026. OpenVINO Documentation.
Chen, Tianqi, Thierry Moreau, Ziheng Jiang, Lianmin Zheng, Eddie Q. Yan, Haichen Shen, Meghan Cowan, et al. 2018. “TVM: An Automated End-to-End Optimizing Compiler for Deep Learning.” Proceedings of the 13th USENIX Symposium on Operating Systems Design and Implementation (OSDI ’18), 578–94.
31 Layer Fusion: Analogous to loop fusion in compiler optimization, where adjacent loops over the same array are combined to reduce memory traffic. Kernel fusion applies the identical principle to GPU operations: sequential kernels that write and re-read intermediate tensors from HBM are merged into a single kernel that keeps data in registers. The savings compound—a typical ResNet-50 has ~35 fusible operation pairs, and each eliminated HBM round-trip saves 1–3 \(\mu\)s at 3.35 TB/s bandwidth, converting memory-bound chains into compute-bound fused kernels.
Layer fusion31 combines multiple sequential operations into a single GPU kernel. Consider a common pattern: convolution → batch normalization → rectified linear unit (ReLU) activation. Without fusion, this requires three kernel launches, three round-trips to GPU memory (write conv output, read for batchnorm, write batchnorm output, read for ReLU), and three sets of intermediate tensors. Fusion combines all three into one kernel that reads inputs once, computes the combined result in registers, and writes final outputs once. This eliminates kernel launch overhead (15–60 μs saved per fusion) and reduces memory traffic by 2–3\(\times\). TensorRT automatically detects and fuses common patterns; a typical ResNet-50 reduces from ~50 kernels to ~15 after fusion.
Kernel auto-tuning selects the fastest algorithm for each operation on the specific GPU. A single convolution can be implemented using dozens of algorithms such as direct, fast Fourier transform (FFT) based, Winograd, and various tiling strategies, each optimal for different input sizes and GPU architectures. Auto-tuning benchmarks each candidate and caches the winner, trading compilation time for runtime performance.
These optimizations typically achieve 2–5\(\times\) speedup over framework-native serving but require explicit export and may not support all operations. A runtime comparison on a standard model quantifies these gains across the optimization spectrum.
Systems Perspective 1.10: ResNet-50: Runtime comparison
Table 19 compares ResNet-50 inference latency and speedup across runtimes on a V100 GPU at batch size one:
Table 19: Inference runtime comparison: Latency and speedup for ResNet-50 (batch size one) across PyTorch eager, TorchScript, ONNX Runtime, and TensorRT in three precisions on a V100. Each step down the table trades portability for raw speed, exposing the optimization-compatibility trade-off that defines runtime selection.
| Runtime | Latency | Speedup | Notes |
|---|---|---|---|
| PyTorch (eager) | 8.5 ms | 1× | Baseline, no optimization |
| TorchScript | 6.2 ms | 1.4× | JIT compilation |
| ONNX Runtime | 5.1 ms | 1.7× | Cross-platform |
| TensorRT FP32 | 2.8 ms | 3× | NVIDIA-specific |
| TensorRT FP16 | 1.4 ms | 6.1× | Tensor Core acceleration |
| TensorRT INT8 | 0.9 ms | 9.4× | Requires calibration |
Systems insight: The 9.4× speedup from TensorRT INT8 comes at the cost of: (1) quantization calibration data, (2) potential accuracy loss (<1 percent for ResNet-50), and (3) NVIDIA-specific deployment.
The optimization-compatibility trade-off is inherent. More aggressive optimization yields better performance yet increases deployment complexity and may introduce numerical differences from training. The choice depends on latency requirements, deployment constraints, and available engineering resources.
After the runtime is chosen, configuration applies the same constraint-first logic. Thread pool sizing controls parallelism for CPU inference: too few threads leave cores idle, while too many cause contention. Memory allocation strategies (preallocated buffers vs. dynamic allocation) trade startup cost against flexibility. Execution provider selection prioritizes which hardware backends handle each operation, and graph optimization level trades compilation time for runtime performance. These settings are not a separate checklist after selection; they are how the selected runtime is made honest under production traffic. Production deployments therefore measure configuration impact on latency distributions rather than relying on defaults.
Precision selection for serving
A team deploying ResNet-50 on V100 GPUs faces a concrete constraint: their 30-GPU cluster costs $90/hour, and business growth requires 3\(\times\) more throughput without expanding the fleet. Switching from FP32 to INT8 inference achieves exactly this—the same model on the same hardware serves 3\(\times\) more requests per second, reducing the effective cost per inference by two-thirds, at a cost of less than 0.4 percentage points of accuracy. This example illustrates the direct connection between numerical precision and infrastructure economics. Precision selection connects to the quantization techniques covered in Quantization and Precision. Numerical Representations compares the numerical formats (FP32, FP16, BF16, FP8, INT8) and their precision-range trade-offs, and Integer quantization details the mechanics of symmetric and asymmetric integer quantization. Serving adds runtime concerns such as calibration data availability, layer sensitivity under production inputs, and dynamic precision selection.
Precision-throughput relationship
For memory-bandwidth-bound operations, reducing precision proportionally increases throughput by reducing data movement. Equation 16 quantifies the theoretical maximum speedup from precision reduction: \[ \frac{\text{Throughput}_{\text{INT8}}}{\text{Throughput}_{\text{FP32}}} = \frac{32}{8} = 4\times \text{ (theoretical maximum)} \tag{16}\]
In practice, GPU compute pipelines and Tensor Core alignment effects limit achieved speedup to 2.5–3.5\(\times\) for INT8 vs. FP32. Tensor Core kernels are most efficient when matrix dimensions are aligned, such as INT8 multiples of 16 elements and FP16 multiples of 8 elements on many paths. Modern cuBLAS and cuDNN can still use Tensor Cores for many other dimensions, though often less efficiently or with internal padding. Hardware Acceleration provides the detailed Tensor Core architecture that explains these alignment constraints. The precision trade-offs for a standard vision model illustrate how these theoretical limits manifest in practice.
Systems Perspective 1.11: ResNet-50: Precision trade-offs on V100
Table 20 compares latency, memory, accuracy, and Tensor Core utilization across FP32, FP16, and two INT8 paths for ResNet-50:
Table 20: Precision trade-offs on V100: Latency, memory footprint, accuracy, and Tensor Core utilization for ResNet-50 in FP32, FP16, and INT8 (PTQ and QAT). FP16 is a near-free 2× speedup over FP32, while INT8 reaches 3.1× over FP32 (1.6× beyond FP16) at the cost of calibration data and a fraction of a percentage point in accuracy.
| Precision | Latency | Memory | Accuracy | Tensor Core Util. | Calibration |
|---|---|---|---|---|---|
| FP32 | 2.8 ms | 98 MB | 76.13% | 0% | None |
| FP16 | 1.4 ms | 49 MB | 76.13% | 85% | None |
| INT8 (PTQ) | 0.9 ms | 25 MB | 75.80% | 92% | 1,000 samples |
| INT8 (QAT) | 0.9 ms | 25 MB | 76.05% | 92% | Full retraining |
Systems insight: INT8 achieves 3.1× speedup but loses 0.33 percentage points of accuracy with post-training quantization (PTQ). Quantization-aware training (QAT) recovers most accuracy but requires retraining. FP16 provides 2× speedup with no accuracy loss for most models.
Precision selection constraints
Precision selection is constrained by layer sensitivity, calibration data, and runtime policy. Not all layers tolerate reduced precision equally. Empirically, quantization error for a layer scales with weight magnitude and gradient sensitivity, captured by the following proportionality in equation 17: \[\epsilon_{\text{quant}} \propto \kappa_{\text{quant}} \cdot \|W\|_2 \cdot 2^{-b} \tag{17}\] where \(\kappa_{\text{quant}}\) is a layer-specific sensitivity coefficient (determined empirically or via Fisher information), \(\|W\|_2\) is the weight L2 norm, and \(b\) is the bit width. This explains observed patterns where first convolutional layers with high gradients and large sensitivity coefficients are precision-sensitive and often kept at FP16, middle layers with stable gradients and low sensitivity coefficients tolerate INT8 well, and final classification layers with small weights but high task sensitivity benefit from FP16 or higher precision.
Post-training quantization adds a data constraint. The calibration dataset determines the scale factors used for INT8 conversion, so it must represent actual serving traffic rather than merely reuse convenient training or validation data. A model calibrated on ImageNet-style validation images can lose several percentage points when served on wildlife camera images with different lighting and backgrounds, a failure mode revisited in section 1.12.
Advanced serving systems turn precision into a runtime policy. If the system is ahead of its latency SLO, it can use higher precision for better accuracy. For low-confidence INT8 results, it can recompute at FP16. Different customer tiers may receive different precision levels. This pattern enables adaptive quality-latency trade-offs while maximizing throughput during normal operation.
The precision decision has direct infrastructure consequences: INT8 inference achieves roughly 3\(\times\) higher throughput than FP32, meaning a workload requiring 30 GPUs at FP32 needs only 10 at INT8. This 3\(\times\) reduction in hardware translates directly to a 3\(\times\) reduction in operating costs. The connection between model-level optimization and infrastructure economics is why precision selection cannot be treated as purely a model concern.
Runtime selection and precision tuning operate at the model level: they determine what computation runs and at what numerical format. Between the model and the silicon, however, lies another optimization layer encompassing the mechanics of graph compilation to kernels, byte movement from disk to memory, and CPU-GPU coordination. These node-level techniques often yield the final 2–5\(\times\) that separates a functional prototype from a production-grade serving node.
Self-Check: Question
Why might a team choose ONNX Runtime instead of TensorRT for a production service?
- ONNX Runtime is usually the absolute fastest option on NVIDIA GPUs for any given model.
- ONNX Runtime preserves training functionality needed for online gradient updates during serving.
- ONNX Runtime offers cross-platform deployment flexibility across CPUs, GPUs, and other accelerators from a single exported model, at the cost of some target-specific peak performance.
- ONNX Runtime removes the need for any graph optimization pass before deployment.
What is the main systems benefit of layer fusion in an optimized serving runtime?
- It lets the model retrain itself online during inference without exposing gradient state.
- It merges sequential operations so intermediate activations stay in on-chip SRAM across stages, reducing kernel launches and the number of round trips through HBM.
- It converts dynamic batching into static batching automatically.
- It guarantees zero numerical difference from the original training framework.
A deployment team can use FP16 with no measurable accuracy loss, or INT8 with additional calibration work and a small possible accuracy drop. Explain why this should be framed as a serving economics decision rather than a numerical-format decision.
Why must calibration data for post-training INT8 quantization resemble real serving traffic rather than convenient training examples?
- Calibration determines activation scale factors; mismatched data produces poor scale estimates that clip or overflow in production and silently degrade accuracy.
- Tensor Cores refuse to execute INT8 kernels unless calibration used live production samples.
- Representative calibration data eliminates the need for any ongoing monitoring.
- Calibration only affects cold-start latency, not model predictions.
A serving team runs an INT8 model that returns a confidence score per prediction. Low-confidence outputs are automatically re-run in FP16 before returning a final answer. Explain the latency-cost trade-off this dynamic-precision scheme creates and when it is worth it.
Node-Level Optimization
Consider an image classifier whose model benchmark promises millisecond inference but whose production trace shows a slower request path. Node-level optimization identifies which boundary is wasting time on that machine. The trace usually points to one of four recurring diagnostic boundaries:
- Graph-to-kernel boundary: The computation graph has to become a small number of efficient kernels rather than a long sequence of launch overheads.
- CPU execution boundary: CPU-side work has to exploit vector units, locality, and runtime libraries rather than scalar Python.
- Load boundary: Model bytes have to move from disk into memory fast enough that cold starts do not dominate scale-up events.
- Host-accelerator boundary: The host has to keep the accelerator scheduled without gaps caused by preprocessing, transfers, or synchronization.
These are not independent tricks. They are places where a measured trace can explain why a request path is slower than the model benchmark promised.
Runtime graph compilation
Inference engines like TensorRT were introduced in section 1.9. These engines achieve 2–5\(\times\) speedups because serving changes the compiler problem. Training computation graphs are dynamic and mutable, whereas serving graphs are usually static. Once shapes and operators are fixed, the compiler can spend deployment-time work to remove runtime work.
The first gain is operator fusion, the same kernel-merging optimization section 1.9.1.2 applied to TensorRT. What the static serving graph adds is when the fusion happens: because operators and shapes are fixed before any request arrives, the compiler can discover and commit the fused kernels ahead of time rather than rediscovering them at runtime, so no request pays for the analysis.
The same static graph also enables constant folding. If a subexpression depends only on fixed weights or constants, such as x * (sqrt(2) / 2), the compiler replaces it with the precomputed multiplication x * 0.707.... This removes work from every request without changing the model’s mathematical output.
Memory planning applies the same idea to allocation rather than arithmetic. Since the tensor lifetimes are known, the runtime can precalculate memory offsets and reuse buffers instead of allocating reactively during the request. The result is not just fewer operations, but a more predictable serving path with fewer allocator stalls and less memory fragmentation.
These optimizations lead to a deployment choice. Just-in-time compilation adapts to the shapes observed at runtime, but the first request pays the compilation penalty. Ahead-of-time compilation removes that startup spike by shipping an optimized artifact, but the deployment must explicitly cover every shape profile the service will accept.
Systems Perspective 1.12: Compilation timing trade-off
Just-in-time compilation waits until the graph is first executed and can specialize to the shapes it observes. That specialization is useful for variable traffic, but it moves compiler work into the serving path and creates a cold-request latency spike.
Ahead-of-time compilation performs the compiler work before deployment. It gives the service a fixed graph and avoids startup compilation latency, at the cost of defining all dynamic shapes explicitly or compiling multiple profiles.
The systems choice is where to pay compilation cost: JIT pays it in the serving path and risks a first-request latency spike, while AOT pays it before deployment and requires tighter control over input shapes.
CPU inference optimization
The JIT vs. AOT choice governs GPU compilation strategy; CPU inference faces its own optimization landscape, where vectorization and quantization replace graph compilation as the primary levers. GPUs dominate the narrative, yet CPUs remain the workhorse for many inference workloads, especially small models, latency-insensitive batch jobs, and cost-constrained environments. CPU optimization starts from a different machine model. Modern CPUs32 (Intel Xeon, AMD EPYC) contain vector units such as AVX-512 and AMX, but a scalar Python loop cannot use them. Specialized runtimes like OpenVINO or Intel Extension for PyTorch (IPEX) map neural network operators directly to these vector instructions, substantially improving performance over naive scalar implementations (Intel Corporation 2026).
32 SIMD (Single Instruction, Multiple Data): From Michael Flynn’s 1966 taxonomy of computer architectures, SIMD enables one instruction to operate on multiple data elements simultaneously. Intel’s AVX-512 processes 512 bits (16 floats) per instruction; AMX extends this to matrix tile operations. For CPU inference, SIMD exploitation is the primary optimization lever: naive scalar matrix multiplication achieves ~1 percent of theoretical peak, while SIMD-optimized kernels approach 80–90 percent utilization—a gap that determines whether CPU-only serving is economically viable.
33 NUMA (Non-Uniform Memory Access): Accessing memory local to a CPU socket is faster than accessing memory attached to a different socket. Pinning an inference thread to a core is insufficient if its required memory is allocated remotely, forcing every weight access across the slower inter-socket link. This failure to co-locate threads and data imposes a ~60 percent latency overhead, as remote access takes ~130 ns vs. ~80 ns for local. The penalty is compounded for ML workloads because model weights, which can range from hundreds of megabytes to gigabytes, exceed L3 cache capacity entirely—ensuring that cross-socket fetches occur on every inference pass rather than only on cache misses.
The next CPU boundary is locality. On multi-socket servers33, accessing memory attached to a different CPU socket (NUMA) adds significant latency. An inference server must therefore be NUMA-aware: threads should be pinned to specific cores, and the model weights and input buffers those threads touch should be allocated on the same socket. ML model weights—hundreds of megabytes for a mid-sized network, gigabytes for a large language model—massively exceed the capacity of a CPU’s L3 cache, so the NUMA penalty is persistent rather than occasional. Every inference pass must read the full weight tensor; the working set never fits in cache, producing guaranteed cache thrashing and forcing constant fetches from main RAM across the slower inter-socket link.
This is why CPUs often outperform GPUs at batch size one for small models. Launching a GPU kernel (~10 \(\mu\)s) and transferring data (~50 \(\mu\)s) can exceed the compute time for a tiny dense layer. For models under 50 MB serving single requests, a well-optimized CPU runtime can deliver lower latency than a GPU because it avoids the accelerator handoff entirely.
Model serialization and fast loading
Autoscaling systems are operational control loops that add or remove serving replicas based on load. In those systems, the time to spin up a new node is critical. A major component of “Cold Start” (section 1.6.2) is simply reading the model weights from disk into memory. The choice of serialization format determines how quickly this loading can occur.
The standard PyTorch torch.load() uses Python’s pickle format. This approach is inefficient because it requires the CPU to unpickle objects one by one, copy them into memory, and then often copy them again to the GPU. The memory mapping introduced for on-demand loading in section 1.6.3 offers a faster path here for a different reason: if the serialized bytes already match the in-memory tensor layout, the mapped file needs no parsing or copying at all.
Building on this zero-copy principle, Safetensors34 is a tensor format designed specifically for fast loading. It stores tensors as raw bytes with a minimal JSON header. This enables zero-copy loading: the raw bytes on disk are mapped directly into the tensor’s memory buffer.
34 Safetensors: The name emphasizes safety: unlike Python’s pickle format, safetensors cannot execute arbitrary code during deserialization, eliminating a class of security vulnerabilities where malicious model files could compromise a serving system (Hugging Face 2026). The format stores tensors as contiguous raw bytes with a minimal JSON header, enabling memory-mapped loading; in the local example above, that path is 10× faster than pickle. For autoscaling serving fleets, this loading speed directly reduces cold start latency: the difference between a load that takes 15 s and one that takes 1.5 s determines whether new replicas can absorb traffic spikes before SLOs are violated.
Hugging Face. 2026. Safetensors Documentation.
Example 1.4: Loading speed: Safetensors vs. Pickle
Scenario: A cold-start replica has to load a 5 GB Stable Diffusion v1.5 checkpoint before it can absorb traffic.
Analysis:
- Pickle path: The PyTorch pickle-based loader takes 15 s in this scenario because Python has to reconstruct objects before tensors are usable.
- Safetensors path: The same weights stored with Safetensors load in 1.5 s, a 10× improvement.
Systems insight: With memory-mapped Safetensors files, loading speed becomes limited mainly by the disk’s read speed—for example 3.5 GB/s on local Gen3 NVMe—rather than by CPU parsing overhead.
Profiling the serving node
Optimization without measurement is guesswork. The system efficiency metric defined in equation 2 provides the target: maximizing the fraction of wall-clock time the accelerator spends on useful computation. Timeline profiling tools like PyTorch Profiler or NVIDIA Nsight Systems (nsys) make that target visible by showing the exact sequence of events on the CPU and GPU.
A useful trace reading is bottleneck-first. Empty spaces in the GPU bar mean idle hardware, usually because the GPU is waiting for CPU preprocessing or disk I/O. Thousands of tiny GPU slivers indicate excessive kernel launches and point toward operator fusion or graph compilation. MemcpyHtoD blocks expose host-to-device movement; the diagnostic question is whether those transfers overlap with computation or block it. The timeline therefore converts a vague complaint about slow serving into a concrete boundary in the request path.
Example 1.5: The profiling loop
Scenario: A serving node has high P99 latency even though average accelerator utilization looks acceptable, and a trace of warm requests shows large blank regions in the accelerator timeline between short kernels.
Approach:
- Setup: Run a warmup, then capture ten to fifty representative requests in Chrome Tracing, Nsight, or the runtime’s profiler.
- Diagnosis: Find the largest idle gap or longest blocking event in the trace.
- Fix: Apply the smallest targeted fix, such as fusion for kernel-launch fragmentation, pinning for CPU locality, zero-copy loading for startup, or scheduling changes for host-device stalls.
- Verification: Capture the trace again and confirm that the targeted gap disappeared or moved.
Systems lesson: Profiling is credible only when the next trace changes in the expected direction. The loop prevents optimization from becoming a list of tricks detached from measured bottlenecks.
Table 21 is a decision aid rather than a checklist: choose the technique whose target metric matches the measured bottleneck, not the row with the largest typical gain.
| Technique | Target Metric | Typical Gain | Implement. Cost | Best For |
|---|---|---|---|---|
| Operator Fusion | Latency & Throughput | 2–5\(\times\) | Medium (Compiler) | Memory-bound layers |
| INT8 Quantization | Throughput | 3–4\(\times\) | High (Calibration) | Inference-heavy nodes |
| Graph Compilation | Latency | 1.5–3\(\times\) | Low (One-line) | Static graph models |
| Zero-Copy Loading | Startup Time | 10–50\(\times\) | Low (File format) | Autoscaling/Cold Start |
| CPU Pinning | Tail Latency (P99) | 20-50% reduction | Low (Config) | Latency-critical apps |
This hierarchy of impact guides where to invest engineering effort. A layered checkpoint keeps that prioritization tied to the serving stack, from request transport down to fused kernels.
Checkpoint 1.5: The optimization hierarchy
Optimizing inference follows the request path from the outside in.
The stack has four levels.
The optimization techniques examined so far (batching, runtime selection, precision tuning, graph compilation) collectively determine how much useful work a single serving node extracts from its hardware. The next step is economic: determining how much infrastructure is required and at what total cost.
Self-Check: Question
Why can serving graphs be optimized more aggressively than training graphs?
- Serving graphs have fixed weights and a stable execution structure, so the compiler can fuse ops, fold constants, and pre-plan memory with assumptions that would be unsafe while gradients still flow through the graph.
- Serving graphs always run on a single hardware target with zero runtime variability, so every optimization applies unconditionally.
- Training graphs cannot contain constants, so there is nothing for a constant-folding pass to work with.
- Graph compilation matters only for CPU inference and has no effect on accelerator performance.
When can a CPU beat a GPU on serving latency?
- Never; GPUs dominate latency because they have more parallel hardware.
- When the model is small and batch size is 1, so that GPU kernel-launch overhead plus host-to-device transfer exceed the actual arithmetic time and an optimized CPU path runs the kernel faster end to end.
- Only when the CPU is retraining the model in parallel, which gives it priority on the serving path.
- Only when the GPU lacks Tensor Cores, so its FP16 throughput collapses.
Explain why thread pinning without NUMA-aware memory placement can still leave a CPU serving system slow.
Why do memory-mapped formats such as safetensors reduce cold-start time compared with Python pickle-based loading?
- They compress weights more aggressively than all other formats.
- They map raw tensor bytes directly into the process address space with minimal parsing, so load time becomes limited by disk bandwidth rather than Python object reconstruction.
- They automatically quantize weights to INT8 during load.
- They eliminate the need to transfer weights to accelerator memory.
A profiler trace shows frequent idle gaps on the GPU timeline while the CPU is busy decoding images and preparing tensors. What is the most defensible immediate conclusion?
- The model is compute-bound and needs more Tensor Cores.
- The GPU is being starved by an upstream CPU or I/O bottleneck rather than being limited by the model kernels themselves; the next optimization target is preprocessing or transfer, not the model.
- The runtime has fused too many operators and is bottlenecking on fused-kernel complexity.
- The node is suffering from quantization error, which is causing the GPU to stall waiting for retries.
Economics and Planning
Every optimization technique examined so far (batching, precision tuning, operator fusion, graph compilation) reduces a single number: the cost of one inference on one machine. Production deployment, however, requires answering a different question: how many machines, of what type, at what total cost. A team that achieves 1,200 images/second on a V100 still needs to know whether 8 V100s at $3/hour each or 24 T4s at $0.53/hour each yields lower total cost of ownership for their 5,000 QPS target. Serving costs scale with request volume, unlike training costs that scale with dataset size and model complexity (Zhang et al. 2019). The public API price compression shown in figure 2 illustrates this pressure: as per-token prices fall, the margin on each inference shrinks, making infrastructure efficiency a primary lever for economic viability.
Zhang, Chengliang, Minchen Yu, Wei Wang, and Feng Yan. 2019. “MArk: Exploiting Cloud Services for Cost-Effective, SLO-Aware Machine Learning Inference Serving.” 2019 USENIX Annual Technical Conference (USENIX ATC 19), 1049–62.
Cost per inference
Cost per inference decomposes into four components: compute time (GPU or CPU cycles consumed per inference), memory (accelerator memory required to hold model weights and activations), data transfer (network bandwidth for request and response payloads), and orchestration overhead (container runtime, load balancing, and monitoring). For GPU inference, the dominant cost component shifts with utilization. At high utilization, compute time dominates because the GPU stays busy processing requests. At low utilization, memory cost dominates because the GPU is reserved and billed even while idle. This distinction matters for cost optimization: improving throughput reduces compute cost per inference, while improving utilization reduces the memory waste of idle hardware. Applying the framework to ResNet-50 shows how hourly price and sustained throughput combine into cost per inference.
Napkin Math 1.10: ResNet-50: Cost analysis
Table 22 compares hourly cost, throughput, and per-million-image cost for serving ResNet-50 on AWS (US-East, on-demand pricing in 2026):
Table 22: ResNet-50 cloud inference cost comparison: AWS hourly cost, sustained throughput, and resulting cost per one million images for CPU, T4, and V100 instances in this scenario, showing how a higher hourly rate can still yield lower cost per inference when throughput rises enough.
| Instance Type | Cost/Hour | Throughput | Cost per 1M Images |
|---|---|---|---|
| c5.xlarge (CPU) | $0.17 | 50 img/s | $0.94 |
| g4dn.xlarge (T4 GPU) | $0.53 | 400 img/s | $0.37 |
| p3.2xlarge (V100 GPU) | $3.06 | 1,200 img/s | $0.71 |
Systems insight: The T4 GPU instance achieves the lowest cost per inference despite higher hourly cost, because GPU throughput dramatically exceeds CPU throughput. The V100 is only cost-effective at very high sustained traffic where its higher throughput justifies the 5.8× price increase. Cloud pricing varies by region and changes over time; consult current pricing for production planning.
GPU vs. CPU economics
In the worked AWS example above, GPU instances cost more per hour but deliver much higher parallel throughput. The crossover point depends on model characteristics and latency requirements.
CPU inference makes economic sense for small models with few parameters and simple operations, when latency requirements are relaxed (hundreds of milliseconds acceptable), when request volume is low or highly variable (making GPU reservation wasteful), or when the model’s operations do not parallelize well. GPU inference is attractive when models are large with parallel-friendly operations, latency requirements are strict (tens of milliseconds), request volume is high and consistent enough to sustain utilization, and batching can amortize the per-inference overhead of GPU kernel launches.
Beyond steady-state costs, startup time affects scaling economics. CPU instances typically start in 30–60 seconds while GPU instances take 2–5 minutes including driver initialization, model loading, and warmup. For variable traffic patterns, this startup latency can be more important than cost per inference. If traffic spikes arrive faster than GPU instances can scale, latency SLOs will be violated despite having sufficient eventual capacity.
This asymmetry suggests different scaling strategies where CPU instances enable reactive scaling by responding to current demand while GPU instances often require predictive scaling by provisioning based on anticipated demand. For bursty workloads, a hybrid approach uses always-on GPU capacity for baseline load plus CPU overflow capacity for spikes, trading higher per-inference cost during spikes for better responsiveness. This GPU+CPU hybrid is one instance of the broader hybrid architecture patterns cataloged in Hybrid Architectures, where the train-serve split and hierarchical processing patterns also combine paradigms to balance cost, latency, and capability.
Capacity planning
The GPU vs. CPU decision establishes the cost per inference, but determining how much infrastructure to provision requires combining cost analysis with the queuing theory foundations from section 1.5. Capacity planning translates three inputs into infrastructure specifications: traffic patterns (peak request rate, daily/weekly cycles, growth projections), latency SLOs (p50, p95, p99 targets), and model characteristics (inference time distribution at various batch sizes) (Harchol-Balter 2013).
Harchol-Balter, Mor. 2013. Performance Modeling and Design of Computer Systems: Queueing Theory in Action. Cambridge University Press. https://doi.org/10.1017/cbo9781139226424.
The worked example in section 1.5 demonstrates the complete workflow: starting from a 50 ms p99 SLO and 5,000 QPS target, deriving the conservative M/M/1 safe utilization threshold of 54 percent from equation 6, and determining GPU count with headroom of 12 V100s. Production systems typically provision for peak load plus 30 percent headroom, using autoscaling to reduce costs during low-traffic periods while meeting latency objectives during peaks; ML Operations develops the operational policy layer around these serving calculations. The key insight from capacity planning is that throughput numbers are meaningful only when coupled with latency guarantees: as the valid-QPS accounting in section 1.5 established, capacity must be sized for requests that actually meet the SLO, not for raw request volume.
Production case study: Serving 8-billion-parameter Llama 3
The dominant cost in serving a large language model is not compute but KV-cache memory, and figure 7 shows why. Plotted at 70-billion-parameter scale to amplify the effect, the cache grows linearly with context length and batch size until long contexts push even an H100 into its out-of-memory zone. The 8-billion-parameter Llama 3 profile analyzed in the rest of this section obeys the same physics with more headroom, making it a workload an engineer can fit on one GPU and reason about end to end.
The linear growth of the KV cache with sequence length forces a hard trade-off: to support longer contexts (32k+), we must reduce batch size, which in turn kills throughput efficiency.
Workload profile
The fixed workload assumptions below define the reference case used throughout the latency, memory, and economics calculations in this section; together, they bound the analyses that follow.
- Model: 8-billion-parameter Llama 3 (quantized to 4-bit using activation-aware weight quantization (AWQ); see Model Compression for quantization techniques) (Dubey et al. 2024; Lin et al. 2023).
- Hardware: 1\(\times\) NVIDIA H100 SXM5 GPU (80 GB HBM3, 3.35 TB/s bandwidth) (Choquette 2023).
- Request characteristics: 1,000-token input prompt (Prefill), 256-token generated response (Decode).
- Target SLOs: TTFT \(<\) 200 ms, TPOT \(<\) 20 ms.
Lin, Ji, Jiaming Tang, Haotian Tang, Shang Yang, Wei-Ming Chen, Wei-Chen Wang, Guangxuan Xiao, Xingyu Dang, Chuang Gan, and Song Han. 2023. “AWQ: Activation-Aware Weight Quantization for LLM Compression and Acceleration.” arXiv Preprint arXiv:2306.00978 abs/2306.00978.
Choquette, Jack. 2023. “NVIDIA Hopper H100 GPU: Scaling Performance.” IEEE Micro 43 (3): 9–17. https://doi.org/10.1109/mm.2023.3256796.
These assumptions make the case study narrow enough to calculate while preserving the two serving constraints that matter most: the prefill budget for time to first token and the decode budget for each generated token.
Latency deconstruction
The end-to-end request latency is governed by the two-phase execution model of autoregressive transformers, applying the TTFT and TPOT metrics defined in section 1.8.1. Prefill determines whether the user sees a prompt response quickly; decode determines whether the generated stream keeps moving after it starts.
Prefill phase (time to first token)
The model processes the 1,000-token prompt in parallel. In this scenario, the H100 prefill rate is set to approximately 10,000 tokens/s: \(T_{\text{prefill}} =\) 1000 tokens ÷ 10,000 tokens/s = 100 ms. Accounting for 20 ms of system overhead (network ingress, tokenization), the TTFT is 120 ms, comfortably within the 200 ms SLO.
Decode phase (time per output token)
The model generates 256 tokens sequentially. This phase is memory-bandwidth bound—the same IO-bound pattern seen in the DLRM embedding lookups (section 1.4.2), but at a larger scale: the system must read the entire 3.5 GB weight tensor from VRAM to generate a single token.
Systems Perspective 1.13: The physics of token generation
Recall the energy-movement invariant quantified in Energy cost of moving vs. computing on a bit: moving a bit is 100–1,000\(\times\) more expensive than computing on it. In the Decode Phase, this law determines the physical “cost per word.”
Physics: Because the decode phase has an arithmetic intensity of \(\approx 1\) FLOP/byte (we must read every weight just to generate one token), performance is strictly limited by memory bandwidth \((\text{BW})\), not compute. This relationship is captured in equation 18: \[ T_{\text{token}} \approx \frac{D_{\text{vol}}}{\text{BW}_{\text{memory}}} \tag{18}\]
Implication: Every token generation pays a massive “energy tax” to move the model’s logic from HBM into compute registers. For comparison, on an A100 80 GB (2.04 TB/s HBM2e), an 8-billion-parameter Llama 3 model (4.1 GB INT4) generates tokens at \(\approx\) 2.0 ms per token. When decode remains bandwidth-bound, adding more compute cores yields little latency improvement; faster memory (Physics), smaller models (Algorithm), or better batching and cache management change the bound.
Reading the 4.1 GB weight tensor at 3.35 TB/s sets the theoretical floor: \(T_{\text{token}} \approx\) 1.2 ms. Accounting for kernel launch overhead, attention computation, and a conservative production safety margin, the realized \(T_{\text{token}}\) is approximately 1.53 ms. Generating all 256 tokens therefore takes 256 tokens \(\times\) 1.53 ms = 0.39 s, and the resulting TPOT of 1.53 ms sits well within the 20 ms “fluidity” SLO.
Memory and throughput
With 4-bit weights occupying 4.1 GB, the remaining ~75 GB is available for the KV Cache, which PagedAttention allocates with near-zero fragmentation. Each token requires approximately 0.033 MB of INT4 KV cache in the 8-billion-parameter Llama 3 configuration, since Grouped Query Attention reduces KV-head storage relative to full multi-head attention at FP16. Dividing the 72 GB of cache by that per-token cost yields capacity for ≈ 2.2 million tokens, so at 1,256 tokens the GPU can hold a concurrent batch size of ~1749 requests.
Unit economics
Consider a representative H100 SXM5 rental cost of approximately $3/hour. Prefill-limited admissions come to 10,000 tokens/s divided by 1,000 tokens = 10 req/s. This is below the KV-residency limit of 1749 requests / 0.44 s ≈ 3931 req/s, so full-request throughput is 10 req/s \(\times\) 3,600 s/hr \(\times\) 1,256 tokens ≈ 45.2 million tokens/hour. Dividing the hourly cost by that throughput gives a cost per million tokens of $3/hour / 45.2 million tokens/hour ≈ $0.066/million tokens.
This analysis highlights that for LLMs, memory capacity (the size of the KV cache) determines the maximum concurrent residency, while prefill compute and decode bandwidth determine realized token throughput and cost under a specific traffic mix. Memory bandwidth remains the primary determinant of decode latency.
This case study applies the core principles developed throughout this chapter: latency budgets decompose into prefill and decode phases, queuing theory governs batch sizing and capacity planning, and hardware constraints in the form of memory bandwidth and capacity determine achievable performance and cost. The quantitative framework established here enables principled engineering decisions, but only when applied correctly. Common misconceptions cause even experienced engineers to misapply these principles in practice.
Self-Check: Question
Why can a more expensive GPU instance have a lower cost per inference than a cheaper CPU instance?
- Cloud providers charge less for idle GPU time than for idle CPU time.
- Cost per inference equals price divided by sustained throughput; a GPU’s much higher throughput can more than offset its higher hourly price, making it cheaper per successful request under the same latency SLO.
- Serving costs ignore latency and only count memory footprint.
- GPUs eliminate all orchestration overhead, which collapses fixed costs to zero.
Explain why a throughput number alone is meaningless for capacity planning unless it is paired with a percentile latency guarantee.
Why might a hybrid scaling strategy keep baseline traffic on GPUs but route overflow traffic to CPUs during spikes?
- CPUs are always cheaper and faster than GPUs for all models.
- GPU instances scale up instantly while CPUs have long startup delays.
- GPU cold-start and spin-up times can exceed the burst duration itself, so reactive scaling misses the window; CPUs come online much faster and can absorb the burst at worse per-request efficiency, which is acceptable precisely because the overflow is temporary.
- Hybrid systems eliminate the need for load balancing.
A team serving a quantized 70-billion-parameter-class LLM can pick between two single-GPU upgrades on the same $/hour. Upgrade P keeps VRAM at 80 GB but raises HBM bandwidth by 50 percent. Upgrade Q keeps HBM bandwidth roughly flat but raises VRAM to 140 GB. For a workload with long-running conversations and significant KV-cache demand, how should the team decide, and why?
- Upgrade P, because bandwidth always dominates both latency and cost in LLM serving.
- Upgrade P lowers TPOT and improves per-user latency, while Upgrade Q lifts the concurrency ceiling (more KV cache fits, so more conversations run side-by-side) and directly increases throughput and lowers cost per token. If the service is latency-constrained, pick P; if it is throughput or unit-cost constrained, pick Q.
- Upgrade Q, because memory capacity always dominates both latency and cost in LLM serving.
- The two upgrades are interchangeable for LLM workloads and the team should pick based on vendor preference.
In the 8-billion-parameter Llama 3 case study’s traffic mix, once the model weights are already quantized and loaded, which resource primarily determines realized full-request throughput and therefore cost per token?
- Prefill compute throughput, because the case study’s 10 requests/s prefill admission rate is below the KV-residency ceiling.
- FLOP count alone, because autoregressive decoding is compute-bound.
- Network bandwidth, because prompt tokens dominate end-to-end economics.
- KV-cache memory capacity alone, because concurrency always dominates throughput and cost for every traffic mix.
Fallacies and Pitfalls
Serving inverts training priorities in ways that violate intuitions from batch processing. The nonlinear relationship between utilization and latency, the hidden costs of preprocessing, and the silent failure modes of training-serving skew cause violated SLOs, wasted optimization effort, and accuracy degradation invisible to standard monitoring.
Fallacy: Reducing model inference latency proportionally reduces user-perceived latency.
Engineers who optimize model inference expect proportional improvement in user-perceived latency, but serving systems introduce latency sources absent from offline benchmarks. Under load, queuing delay dominates: equation 5 shows that at 80 percent utilization with 5 ms service time, average wait time is 20 ms before inference even begins. Reducing inference from 5 ms to 2 ms changes service time but also shifts utilization from 80 percent to 32 percent, reducing queuing wait from 20 ms to 0.9 ms, a 21.2× queuing improvement that dwarfs the 3 ms inference gain. This nonlinear interaction between inference speed and queuing behavior means the system-level speedup (25 ms → 2.9 ms, or 8.5×) far exceeds the model-level speedup (5 ms → 2 ms, or 2.5×). Conversely, teams that reduce inference by only 20 percent at high utilization see negligible user-facing improvement because queuing still dominates. Serving optimization requires analyzing the complete latency budget, including serialization, queuing, preprocessing, and postprocessing, under realistic load conditions rather than profiling inference latency in isolation.
Pitfall: Running serving infrastructure at high utilization to maximize cost efficiency.
Teams target 90 percent utilization to minimize idle capacity. In production, latency degrades nonlinearly as utilization approaches capacity. Equation 5 shows that at 90 percent utilization, average time in system reaches 10× service time. Moving from 70 percent to 90 percent utilization cuts infrastructure costs by 22.2 percent but triples average latency. For a 5 ms inference service, p99 latency jumps from ~76.7 ms to ~230 ms (M/M/1 model). Systems provisioned for average load violate SLOs precisely when traffic increases during business-critical periods. Production systems targeting 60 to 70 percent utilization at peak load maintain the latency headroom needed to absorb traffic spikes.
Fallacy: Training accuracy guarantees serving accuracy.
Engineers assume identical model weights preserve validation set performance. In production, preprocessing differences silently shift inputs outside the training distribution. Section 1.6.1 shows how training-serving skew causes accuracy degradation despite identical weights: PIL vs. OpenCV resize interpolation alone can shift accuracy by 0.5–1 percentage points, FP64 vs. FP32 normalization produces different values, or feature computation timing changes. A model achieving 95 percent validation accuracy drops to 90 percent in production from these preprocessing mismatches, a 5 percentage-point loss invisible to latency monitoring. Standard monitoring checking exceptions and latency violations fails to detect this silent degradation. Production systems require either identical preprocessing code for training and serving, or statistical monitoring comparing input distributions to catch drift before accuracy degrades.
Pitfall: Using average latency to evaluate serving system performance.
Engineers monitor average latency because it trends smoothly and is simple to compute. In production, averages hide the slowest requests that determine user satisfaction. As section 1.5.5 demonstrates, at 70 percent utilization with 5 ms service time, average latency is 16.7 ms but p99 reaches 76.7 ms, a 4.6× gap invisible to mean-based monitoring. Teams optimizing average latency miss the tail that determines user satisfaction: the 1 percent of users experiencing 76.7 ms delays often generate the most valuable transactions. Production SLOs specify percentile targets (p95, p99) precisely because averages mask tail behavior.
Fallacy: Larger serving batches always improve throughput without affecting latency SLOs.
Engineers maximize batch size assuming GPU saturation improves cost efficiency under production load. In serving systems, however, batching introduces a latency-throughput trade-off governed by queuing dynamics absent from offline benchmarks. Accumulating requests into larger batches increases wait time for early arrivals: a batch window of 10 ms means the first request waits 10 ms before inference begins, directly adding to p99 latency. In the representative ResNet-50/V100 scenario used earlier, increasing batch size from 16 to 32 improves throughput only 12 percent but nearly doubles per-batch inference time from 14 ms to 25 ms, and variable input sizes within a batch can create padding overhead that wastes compute on padding tokens. Section 1.7.3 shows why, for tight p99 targets, larger batch sizes can violate SLOs when batch formation delay plus increased per-batch inference time exceeds the latency budget. Serving batch optimization requires jointly tuning batch size, batch timeout, and concurrency against latency SLOs under realistic traffic patterns, not maximizing throughput in isolation.
Pitfall: Calibrating quantized models with training data rather than production traffic.
Teams calibrate with training data because it is readily available and produced validation accuracy. In production, traffic distribution often differs from training data, making calibration scale factors suboptimal. Post-training quantization determines INT8 scale factors by measuring activation ranges on calibration data, but this assumes production inputs match the calibration distribution. One production system achieving 76.1 percent accuracy on ImageNet-calibrated INT8 dropped to 72.9 percent, a 3.2 percentage-point loss, when serving wildlife camera images with different lighting and backgrounds. Model Compression shows quantization error scales with activation range: miscalibration amplifies errors precisely on out-of-distribution inputs where activations exceed calibrated ranges. Effective quantization is data-algorithm co-design: the compressed model must be calibrated against representative samples of actual serving traffic, not convenience data.
Fallacy: Cold start latency only matters for the first request.
Engineers optimize steady-state latency assuming most requests hit warm instances. In production, cold starts compound during the events that matter most: traffic spikes requiring scale-up, deployments rolling out new versions, and recovery from instance failures. Section 1.6.2 details the anatomy of cold start: TensorRT compilation alone takes 30 s per instance. During a traffic spike requiring 10 new instances, aggregate cold-start work reaches 300 instance-seconds; if the instances warm in parallel, new capacity becomes useful after about 30 s. Worse, requests hitting cold instances experience 500 ms latency vs. 5 ms steady-state, a 100× degradation that violates SLOs precisely when traffic is highest. Systems ignoring cold start meet SLOs during steady state but fail during scale-up events and deployment windows when reliability matters most.
Pitfall: Scaling without a warm-pool or staged-loading budget.
Autoscaling policies that count only steady-state replicas underestimate the capacity needed during traffic spikes and deployments. Serving systems need warm pools (pre-initialized spare replicas), staged model loading, or admission control so that new replicas become useful before user requests depend on them. The budget should include compilation, weight loading, cache initialization, and health-check time, because those steps determine whether scale-out adds capacity or adds another source of tail latency.
Self-Check: Question
A team makes model inference 2.5\(\times\) faster on the accelerator. The service was previously running at 70 percent utilization on replicas whose end-to-end budget was split evenly between model inference and everything else. Compared to the original, what should happen to end-to-end p99 user latency?
- It should improve by exactly 2.5\(\times\), matching the model speedup one-to-one.
- It should improve by much less than 2.5\(\times\) in nominal load (because the non-model half of the budget is unchanged), and under the same traffic it may improve even more than 2.5\(\times\) because lower per-request service time also lowers utilization and shrinks the queueing term.
- It should stay exactly the same because latency is determined only by network overhead.
- It should get worse because faster inference destabilizes batching.
Why is pushing serving infrastructure to 90 percent utilization usually a mistake even when it looks more cost-efficient on paper?
- GPUs become less numerically accurate above 70 percent utilization.
- Queueing delay grows nonlinearly as utilization approaches saturation, so modest cost savings from higher utilization are paid for by disproportionately large p99 latency increases and SLO violations during normal traffic variation.
- Model loading stops working once average utilization exceeds 80 percent.
- High utilization prevents the dynamic batcher from running at all.
Which single monitoring approach, relied on by itself, is the most dangerous for a production serving system?
- Monitoring p95 and p99 latency distributions under load.
- Comparing serving preprocessing against the training preprocessing for skew.
- Tracking only average latency, on the assumption that the average represents user experience.
- Validating quantized-model accuracy on representative production-like traffic.
Explain why calibrating an INT8 model on convenient training data rather than representative serving traffic can silently damage production accuracy.
Which statement best captures the chapter’s warning about cold starts?
- Cold start matters only for the very first request a new service ever handles.
- Cold start is mainly a logging artifact with minimal effect on user latency.
- Cold start recurs on every scale-out, redeployment, and replica replacement, so its cost is paid precisely when traffic is surging or the fleet is churning, not just at first launch.
- Cold start disappears automatically once dynamic batching is enabled.
Summary
Serving marks the transition from model development to production deployment, where the optimization priorities that governed training must be inverted. The shift from throughput maximization to latency minimization transforms every system design decision. The queuing theory foundations established here reveal why this inversion is not merely a change in metrics but a change in the governing mathematics. The nonlinear relationship between utilization and latency means that systems behaving well at moderate load can suddenly violate SLOs when traffic increases modestly. Little’s Law and the M/M/1 wait time equations provide the quantitative foundation for capacity planning, replacing intuition-based provisioning with engineering rigor.
Effective serving optimization requires understanding the complete request path rather than focusing exclusively on model inference. Interface protocols like gRPC and efficient serialization formats minimize the “tax” of data movement, while preprocessing often consumes 45 to 70 percent of total latency when inference runs on optimized accelerators. The microsecond-scale overheads identified by Barroso, Patterson, and colleagues explain why serving latency often exceeds the sum of its measured parts, and why system-level optimization matters as much as model optimization. Training-serving skew represents another dimension of this complexity, silently degrading accuracy when preprocessing logic differs between training and production environments in ways that traditional testing cannot detect.
The traffic pattern analysis reveals how the deployment paradigm selected in ML Systems shapes every serving decision downstream. Server workloads with Poisson arrivals optimize dynamic batching windows, autonomous vehicles with streaming sensor data require synchronized batch formation, and mobile applications with single-user patterns eliminate batching entirely. Each pattern is a direct consequence of the physical constraints (power wall, memory wall, light barrier) that created the four paradigms in the first place. The MLPerf scenarios codify these patterns for standardized benchmarking, connecting the serving principles established here to the measurement frameworks explored in Benchmarking.
Node-level optimization techniques (graph compilation, operator fusion, and systematic profiling) bridge the gap between model-level decisions and hardware execution, often yielding 2–5\(\times\) additional speedup through better utilization of the accelerator’s duty cycle. Precision selection and runtime optimization extend the quantization techniques from Model Compression and Tensor Core capabilities from Hardware Acceleration into the serving domain. The translation of these technical metrics into unit economics, as shown by the Llama-3 case study, demonstrates how engineering decisions regarding batching, precision, and hardware selection directly determine the financial viability of deployment, a pressure illustrated by the public API price compression in figure 2.
Key Takeaways: Inverting every training priority
- Serving is latency economics: Training rewards throughput over long runs, but serving spends a fixed per-request budget across serialization, preprocessing, queuing, inference, postprocessing, and the network. Optimizing only model latency misses the stages users actually wait on.
- Utilization turns into waiting: Queuing theory makes capacity planning nonlinear: at 80 percent utilization, average time in system is 5\(\times\) service time; at 90 percent, it reaches 10\(\times\). Cost-efficient headroom keeps modest traffic surges from becoming SLO failures.
- Fast models reveal pipeline taxes: Once inference falls to roughly 5 ms, image decode, tokenization, and other preprocessing can consume 45–70 percent of total latency. The binding optimization becomes the request path, not the neural network kernel.
- Batching follows traffic, not habit: Poisson web arrivals can use dynamic batching, synchronized sensors need aligned batches, and single-user mobile workloads often cannot batch at all. The right batching window converts slack into throughput without spending the latency budget.
- Skew breaks accuracy without errors: Resize methods, normalization order, calibration data, or feature definitions that differ between training and serving shift live inputs outside the learned distribution. Reusing identical code paths and monitoring production slices prevents silent degradation.
- LLM serving is memory management: Decode often reads weights from VRAM for every generated token, so token latency is bandwidth-bound unless batching changes the constraint. KV-cache layout, PagedAttention, continuous batching, precision, and runtime choice determine both concurrency and cost per token.
- Runtime choices become infrastructure bills: Precision, graph compilation, operator fusion, and serving runtime translate directly into replica count and cost per inference. Quantization and specialized runtimes can materially reduce required serving capacity when they preserve accuracy and fit the target hardware.
The serving principles established here (queuing theory for capacity planning, preprocessing optimization, batching strategy selection, and training-serving skew prevention) form the foundation for building production ML systems that meet real-world SLAs. Whether deploying a recommendation system serving millions of users or a medical AI where every millisecond affects patient outcomes, these principles translate mathematical understanding into engineering decisions that determine whether systems succeed or fail under load.
Training is judged by how much work it completes; serving is judged by whether the work finishes in time, and that single change of question inverts everything. A latency budget is fixed from the outside, by the user and the contract, and every stage of a request spends against the same envelope: serialization, preprocessing, the queue, the model, the response. The trained algorithm, the live data, and the machine all meet inside that envelope, and the queue is what makes it treacherous, because waiting time climbs nonlinearly with load and a system comfortably within budget at moderate traffic can blow through it on a small surge. Nothing in serving removes work from the request; it only decides how the fixed budget is divided, which is why the goal is no longer speed but the guarantee that every request, every time, lands inside the line.
What’s Next: From node to factory
This chapter engineered the single serving node. On its own, however, that node is fragile. Models drift as the world changes, updates must reach users without interrupting service, and scaling events require many replicas to behave like one dependable system. In ML Operations, we scale our perspective from the single request to the production factory: CI/CD (automated build, test, and release pipelines) decides which model artifact may ship, model registries (versioned model artifact stores) and feature stores (shared serving/training feature repositories) keep serving aligned with training, observability (telemetry for behavior and health) detects latency and accuracy drift, and rollback machinery (tools for reverting a bad release) keeps failures from becoming permanent outages.
Self-Check: Question
Which statement best summarizes why serving requires a different systems design than training?
- Serving and training share the same optimization objective and differ mainly in framework choice.
- Serving prioritizes per-request latency, tail behavior, and operational reliability under stochastic traffic, while training prioritizes aggregate throughput and high utilization over long runs; this inversion reshapes batching, headroom, scheduling, and failure handling simultaneously.
- Serving differs from training primarily because model weights are smaller after deployment.
- Serving is mostly a postprocessing problem because the model has already been fully optimized.
Explain why a serving team that optimizes only the model, ignores queueing headroom, and never checks preprocessing consistency is likely to fail in production even if offline benchmarks look strong.
What is the most important additional constraint that makes LLM serving different from traditional fixed-output model serving?
- LLMs eliminate the need for batching because outputs are text rather than tensors.
- LLMs replace latency concerns with accuracy concerns only.
- LLMs introduce autoregressive, variable-length generation with a KV cache whose memory and bandwidth demands grow over a request, so memory bandwidth, cache management, and scheduling at token granularity become central bottlenecks rather than secondary concerns.
- LLMs are easier to serve because each request has exactly one output size.
Self-Check Answers
Self-Check: Answer
A team moves a model from a training cluster to a serving cluster and notices that the new cluster intentionally runs at 40-60 percent average utilization while the training cluster ran at 90+ percent. Which statement best captures the systems reason for this inversion?
- Serving optimizes latency and especially p99 behavior, so the system keeps capacity headroom to absorb bursts and queueing growth rather than saturating hardware.
- Serving updates model weights continuously during inference, which forces utilization to stay below 60 percent to leave room for online learning.
- Serving must run exclusively on CPUs for predictable latency, which caps utilization well below what accelerators achieve during training.
- Serving relies on offline validation rather than monitoring, so nothing downstream can use the extra capacity when utilization exceeds 60 percent.
Answer: The correct answer is A. The Iron Law time-in-system blows up nonlinearly as utilization approaches one, so serving deliberately reserves headroom to preserve tail latency under bursts. The online-weight-updates framing confuses serving with training, and the CPU-only claim ignores the existence of cloud GPU serving entirely.
Learning Objective: Distinguish the serving objective from the training objective by analyzing how latency, utilization, and headroom shift when a model moves from training to production.
A photo organization app classifies a user’s existing library overnight, while a content moderation API must classify newly uploaded images immediately. Explain why the first workload favors static inference and the second favors dynamic inference.
Answer: The photo app serves predictable, bounded inputs, so predictions can be computed in advance and served from a lookup table, eliminating user-visible inference latency entirely. Content moderation receives unpredictable novel uploads and must classify each one before the upload is allowed to propagate, so predictions must be computed on demand. The practical consequence is that the moderation system must provision for p99 latency and burst capacity, while the photo pipeline can trade freshness for dramatically lower serving cost by amortizing compute across off-peak hours.
Learning Objective: Compare how input predictability and freshness requirements drive the choice between static and dynamic inference in a production system.
A team wants to deploy the same vision model to a cloud API, a smartphone app, and a TinyML sensor node. Which deployment plan best matches the constraints the chapter lays out for each environment?
- Use one shared batching and memory strategy across all three so the model’s behavior stays identical in every environment.
- Cloud serving uses dynamic batching and concurrency, the smartphone serves at batch 1 to preserve responsiveness and battery, and the TinyML node pre-allocates memory statically and forgoes dynamic batching.
- The smartphone and TinyML deployments differ only in network protocol, and the smartphone and cloud share the same memory budget because both run the same model.
- Put the largest models on TinyML because firmware deployment avoids container cold starts.
Answer: The correct answer is B. Cloud, mobile, and TinyML occupy different points in the power, memory, and batch-size regime, so each forces a different serving design for the same weights. A one-strategy plan ignores the mobile thermal envelope and the TinyML memory ceiling; the ‘protocol-only’ framing pretends the smartphone and TinyML share budgets when their RAM differs by two to three orders of magnitude; and the TinyML-for-large-models idea inverts the entire deployment spectrum.
Learning Objective: Classify how cloud, mobile, and TinyML constraints force different batching and memory strategies for the same model weights.
True or False: If a load balancer keeps traffic evenly distributed across replicas and average utilization stays moderate, p99 latency should stay stable even without node-level isolation such as CPU pinning, memory locking, or interrupt steering.
Answer: False. Replica-level balancing cannot remove intra-node jitter caused by thread migration, paging, or OS interrupts hitting the inference cores. The chapter argues that load balancing and node-level determinism solve different problems: one distributes load across nodes, the other preserves deterministic service time within a node, and a production system needs both for stable tail latency.
Learning Objective: Distinguish replica-level load distribution from node-level resource isolation when reasoning about tail-latency stability.
Which operational change would most directly reduce p99 latency jitter on a single inference node serving a safety-critical workload?
- Drive average utilization toward 95 percent so the accelerator stays saturated and no cycles are wasted.
- Move health checks out of the load balancer and into the model code so the model owns its own liveness signal.
- Pin inference threads to dedicated cores, lock model weights and KV state in memory, and steer OS interrupts away from the inference cores.
- Replace gRPC with JSON over HTTP/1.1 so payloads are easier to inspect during incidents.
Answer: The correct answer is C. Pinning eliminates cache-warmth loss from thread migration, memory locking prevents page-fault stalls during DMA, and interrupt steering prevents the kernel from preempting inference cores for network or disk work. Pushing utilization toward 95 percent worsens queueing and makes p99 explode under bursts, and the JSON switch adds parsing overhead without addressing any of the real jitter sources.
Learning Objective: Select the node-level isolation mechanisms that reduce p99 jitter on a latency-critical serving node.
Self-Check: Answer
Order the following inference-server stages for a typical online request: (1) Dynamic batcher, (2) Accelerator execution, (3) Network ingress, (4) Request queue.
Answer: The correct order is: (3) Network ingress, (4) Request queue, (1) Dynamic batcher, (2) Accelerator execution. Requests must pass through the network stack and be decoded before the server can hold them. The queue is where the batcher finds candidates to group, so the batcher cannot run before the queue has buffered arrivals. Only once a batch is formed does the runtime dispatch tensors to the accelerator. Swapping the batcher and the queue would remove the staging area the scheduler needs to amortize kernel launches, and swapping the accelerator and the batcher would dispatch batch-1 work on every arrival and defeat the throughput benefit.
Learning Objective: Sequence the stages inside an inference server and justify why each stage must precede the next.
An inference server sees traffic arriving in microbursts followed by silent gaps. Why is the scheduler described as the point ‘where throughput meets latency’?
- It decides whether to dispatch a request immediately or wait briefly to form a larger batch that raises accelerator efficiency, trading a small latency penalty for a large throughput gain.
- It chooses whether the model should train or serve on each request based on load.
- It performs NCHW-to-NHWC tensor-layout conversion inline so every framework sees a canonical layout.
- It replaces the need for cross-replica load balancing by handling all routing inside the node.
Answer: The correct answer is A. The scheduler owns the batching-window policy, which is the single knob that exchanges per-request latency for accelerator throughput. Tensor-layout conversion is a separate concern handled by the runtime, and intra-node scheduling does not substitute for balancing traffic across replicas.
Learning Objective: Explain how scheduler policy mediates the throughput-latency trade-off under bursty request arrivals.
Explain why sending NHWC image tensors to a runtime expecting NCHW is often a silent serving failure rather than a loud crash, and what this implies for production monitoring.
Answer: A reshaped tensor is still a valid block of numbers: the runtime reads the bytes in channel-first order even though they were written channel-last, so no shape exception fires and no process crashes. The convolutions run normally but interpret spatial structure as channel structure, producing confident predictions from scrambled inputs. For a monitoring system that tracks only uptime, error rates, and latency percentiles, nothing looks broken even while accuracy drops by tens of percentage points. The operational consequence is that serving monitoring must include input-distribution and accuracy-shadow checks, not just infrastructure health.
Learning Objective: Analyze how tensor-layout mismatches silently corrupt serving outputs without process failures, and derive the monitoring implication.
A high-throughput internal microservice serves embedding vectors and spends a large fraction of CPU time parsing request payloads. Which interface choice best matches the chapter’s guidance for this workload?
- REST over HTTP/1.1 with larger JSON payloads, on the theory that bigger payloads amortize parsing cost automatically.
- REST over HTTP/1.1 with JSON, because human readability is the most important property for internal service communication.
- gRPC over HTTP/2 with Protobuf, because persistent multiplexed connections and binary serialization reduce both handshake and parsing overhead on the hot path.
- Flat text over raw TCP with no schema, because both services are internal and can agree on byte layouts informally.
Answer: The correct answer is C. HTTP/2 multiplexing removes the head-of-line blocking of HTTP/1.1, and Protobuf binary framing cuts the per-request parsing cost that the profile identified as the bottleneck. JSON readability is a public-API property, not a latency property, and stacking larger payloads makes parsing worse rather than better. Schemaless TCP trades present-day observability for brittle long-term evolution and is not what the chapter recommends for latency-critical internal paths.
Learning Objective: Select a serving interface protocol by comparing serialization and transport overheads on a latency-critical internal path.
A team serves an embedding model with a strict 20 ms p99 SLO. Requests carry 4 KB of JSON that takes 6 ms to parse and serialize end to end; the model itself takes 8 ms on the accelerator. Explain why switching to a binary format that supports near-zero-copy deserialization is a material optimization here, and when the same switch would not matter.
Answer: Serialization is consuming 6 of the 20 ms budget, or 30 percent of the SLO, and it is paid on every request regardless of model speed. A binary format whose wire buffer is layout-compatible with in-memory tensors removes most of the parse and allocate cost, reclaiming roughly 4-5 ms of headroom that can go to the model or to queue wait. The same switch would not matter for a workload whose latency budget is dominated by model execution, say a 200 ms LLM decode or a 150 ms vision pipeline, where shaving 4 ms off deserialization is in the noise and the engineering cost is not repaid. The systems lesson is that serialization-format choice is a latency-budget decision, not a default.
Learning Objective: Evaluate when zero-copy binary deserialization materially improves end-to-end serving latency and when the change is not worth its engineering cost.
Self-Check: Answer
A ResNet-50 image-classification service on a GPU measures its end-to-end request latency after runtime optimization has reduced accelerator inference to roughly 2 ms. Based on the chapter’s breakdown, which phase is most likely to dominate the budget, and which other phase is the most realistic competitor if the team misreads the trace?
- JPEG decode and resize dominate; optimized GPU inference is the most realistic competitor because both remain visible millisecond-scale phases.
- Top-k postprocessing dominates; the network response path is the competitor because both run after the model.
- GPU inference dominates; JPEG decode is the competitor because neural network math is usually the longest single phase.
- HTTP ingress dominates; TLS handshake is the competitor because connection setup is almost always the primary cost for image workloads.
Answer: The correct answer is A. After TensorRT-style optimization, the chapter’s ResNet-50 example has about 4.5 ms of preprocessing against roughly 2 ms of accelerator inference, so JPEG decode and resize become the dominant budget terms. A team can still plausibly over-focus on the optimized inference slice because it is the model stage, but the measured path says the CPU-side image pipeline is now the larger target. Top-k postprocessing is tiny in the chapter’s numbers, and HTTP/TLS is not the primary cost for this persistent image-serving path.
Learning Objective: Identify which phase actually dominates a measured ResNet-50 serving latency budget, and which adjacent phase is the most realistic source of diagnostic confusion.
A team accelerates ResNet-50 inference from 5 ms to 0.5 ms on the accelerator but leaves JPEG decode, resize, normalization, and CPU-to-GPU transfer unchanged. Explain why the end-to-end speedup is nowhere near 10\(\times\), using the chapter’s Amdahl-style framing.
Answer: Most of the original budget sits outside the model, so accelerating inference shrinks only one term in the Iron Law sum. In the chapter’s ResNet-50 budget, the original path is about 10.1 ms: 5 ms of inference plus 5.1 ms of preprocessing, transfer, and postprocessing. Cutting inference to 0.5 ms produces about 5.6 ms end-to-end latency, or roughly a 1.8\(\times\) speedup despite a 10\(\times\) kernel speedup. The practical implication is that the next optimization target must be chosen by profiling the full request path; doubling down on the model returns less and less as the non-model terms come to dominate the denominator.
Learning Objective: Analyze why model-only acceleration yields sub-proportional end-to-end gains once other latency-budget terms dominate, and derive the next optimization target from the profile.
A vision service doubles input resolution from 224x224 to 448x448 and measures a slowdown of roughly 3\(\times\) rather than the 4\(\times\) a FLOPs-only argument predicts. Which explanation best fits the chapter?
- Latency is independent of input size once the model is JIT-compiled for the first request.
- Fixed preprocessing and transfer overheads are being amortized across more compute, and the kernel may shift between compute-bound and memory-bound regimes, so observed scaling departs from a pure FLOPs calculation.
- Postprocessing complexity drops as image size increases, which offsets model slowdown and produces sub-linear scaling.
- Higher-resolution inputs automatically improve batch formation efficiency and recover the difference.
Answer: The correct answer is B. Quadratic compute scaling is the naive starting point, but real kernels carry a per-request fixed cost (decode, resize, transfer) that is independent of resolution, and the operating point on the roofline can shift as activation memory grows. The ‘independent of input size’ and ‘postprocessing shrinks’ framings contradict the chapter’s measured behavior, and adaptive batch formation is not what’s driving the sub-4\(\times\) slowdown in this scenario.
Learning Objective: Interpret why observed resolution scaling can fall below the simple FLOP-based prediction on a real serving node.
True or False: Request pipelining can improve end-to-end serving throughput even when per-request model inference time on the accelerator stays unchanged.
Answer: True. Pipelining overlaps CPU-side preprocessing and host-to-device transfer for one request with accelerator execution for another, raising the accelerator’s duty cycle. The gain comes from shrinking idle gaps between kernel launches, not from making any single kernel faster, so per-request model time stays constant while aggregate requests-per-second rises.
Learning Objective: Explain how overlapping pipeline stages improves aggregate throughput without changing per-request model compute time.
Which deployment strategy best matches the chapter’s argument for adaptive resolution?
- Always use the maximum supported resolution because batching hides the added cost at scale.
- Always use the minimum supported resolution because preprocessing dominates the budget anyway.
- Pick one resolution at training time and never change it at serving time, so that train-and-serve inputs stay bit-identical.
- Use a lightweight first-stage classifier to route each input to a resolution appropriate for its complexity, trading a small extra preprocessing cost for higher aggregate throughput.
Answer: The correct answer is D. Adaptive resolution pays a small upfront compute cost to avoid high-resolution inference on easy inputs, which raises throughput without changing the accuracy target on hard inputs. The always-maximum framing ignores that maximum-resolution inference taxes every request regardless of difficulty, always-minimum discards accuracy where it was needed, and freezing resolution at training time collapses the whole optimization by removing the knob the strategy depends on.
Learning Objective: Select an adaptive-resolution strategy that balances accuracy and throughput across heterogeneous inputs.
Self-Check: Answer
A serving replica must sustain 1,000 QPS with a p99 end-to-end latency SLO of 50 ms. Each replica’s unloaded service time is 20 ms. A capacity planner uses Little’s Law at the SLO bound to estimate the minimum standing concurrency the fleet must support. Which interpretation is correct?
- Required concurrency is 20, because 1,000 QPS times 20 ms of service time gives the number of requests simultaneously executing.
- Required concurrency is 50, because 1,000 QPS times 50 ms (\(\lambda T_{\text{lat}}\) at the SLO bound) gives the standing population in the system, and real provisioning must exceed this because bursts push the realized \(T_{\text{lat}}\) above the mean.
- Required concurrency is 1,000, because one QPS equals one concurrent request under any SLO.
- Required concurrency is 5, because throughput divided by service time is the number of replicas needed.
Answer: The correct answer is B. Little’s Law applied at the SLO bound gives \(N_{\text{req}} = \lambda T_{\text{lat}} = 1,000 \times 0.050 = 50\) requests standing in the system across the fleet. That is the arithmetic floor; in practice the planner provisions above 50 because p99 is not the mean, arrival processes are bursty, and headroom is what keeps queueing delay from collapsing the SLO. The service-time-based framing confuses ‘in service’ with ‘in system’ (it ignores queue wait), and both the 1,000 and 5 answers misapply the law to unrelated quantities.
Learning Objective: Apply Little’s Law at a tail-latency SLO bound to compute minimum standing concurrency for a serving fleet, and explain why the arithmetic floor is not the provisioned capacity.
At 500 QPS, a team moves from batch size 1 to batch size 32 and sees throughput rise while p99 latency increases sharply. What are the two components of the batching tax the chapter identifies?
- Larger batches reduce accelerator utilization and force spillover to the CPU, which adds two new latencies.
- The first request must wait for the rest of the batch to arrive before kernel launch, and inference time itself grows (super-linearly in some kernels) as the batch grows.
- Queueing theory stops applying at batch sizes above 16, and SLO violations become random.
- Larger batches eliminate the dynamic scheduler, so all requests become subject to static batch timeouts and always violate the SLO.
Answer: The correct answer is B. The batching tax has two additive parts: formation delay, where the first-arriving request waits for 31 more before the kernel launches, and inflated inference time, because the batched kernel on the accelerator runs longer per call. The utilization-drops-to-CPU framing inverts the chapter’s argument (batching usually raises utilization), and the other options invent failure modes the chapter never describes.
Learning Objective: Explain the two components of batching-induced latency under online arrivals.
Explain why production serving systems target roughly 40 to 60 percent utilization instead of trying to run near 100 percent busy all the time, grounding your answer in the chapter’s queuing analysis.
Answer: The M/M/1-style wait formula has time-in-system growing as \(1/(1 - \rho)\), so as utilization \(\rho\) approaches 1 the delay term blows up nonlinearly even if mean service time is unchanged. A modest 10 percent traffic spike at 85 percent utilization can push p99 latency many times above service time, while the same spike at 50 percent utilization barely moves the curve. The practical consequence is that the ‘wasted’ 40-60 percent of capacity is not waste at all: it is the margin that converts the nonlinear latency-vs-utilization curve into a workable SLO. Planners provision for tail behavior, not mean throughput, and the headroom is the single biggest lever for keeping tails bounded under bursts and partial failures.
Learning Objective: Justify conservative utilization targets using the nonlinear latency behavior of M/M/1-style queues.
Which statement best explains why p99 latency, not mean latency, is the headline metric for production-serving risk?
- Mean latency is usually equal to p99 once a service has been running long enough for caches to warm up.
- Percentile latency exposes the tail of slow requests that dominate real user experience, and tail latency amplifies in multi-component systems where one slow sub-request can dominate end-to-end response time.
- p99 measures only preprocessing and ignores queueing, so it is a cleaner signal of raw compute speed.
- Mean latency applies only to offline inference systems and is undefined in an online serving context.
Answer: The correct answer is B. Tail latency captures the unlucky requests users remember, and in a service where a response depends on N parallel sub-requests the probability that at least one falls in the tail grows with N, so a 1-in-100 tail per hop becomes visible to most users in a 10-hop fan-out. The mean-equals-p99 framing ignores the long-tail distributions serving systems actually produce, and the other options misdescribe what p99 measures.
Learning Objective: Analyze why percentile latency rather than mean latency governs production-serving risk, including the fan-out amplification effect.
A serving cluster is in overload: queue depth is growing faster than the workers can drain it, and projected p99 is climbing past the SLO. Which operator response best matches the chapter’s recommended tail-tolerant strategy?
- Keep accepting every request and raise the queue-depth limit so nothing is rejected; the queue will smooth out the burst.
- Extend the batching window to collect larger batches on the theory that bigger batches raise throughput and shrink the queue faster.
- Apply admission control or load shedding, rejecting or downgrading excess requests quickly so admitted requests still meet SLO rather than letting the whole fleet time out.
- Aggressively retry every request across multiple replicas so each user gets a response from whichever replica answers first.
Answer: The correct answer is C. Admission control bounds queue growth and protects the latency of admitted work; without it, hopeless requests pile up, drive p99 through the SLO, and often collapse useful throughput. Raising the queue limit converts latency pressure into more waiting, stretching batching windows under load pays the same cost with a different name, and aggressive cross-replica retries amplify the effective load and push an overloaded fleet further into collapse.
Learning Objective: Select an overload-control policy that protects admitted-request latency during queue growth, and reject operator responses that convert overload into collapse.
Self-Check: Answer
Which failure mode is the clearest example of training-serving skew rather than external data drift?
- User behavior changes seasonally and the model’s target distribution shifts gradually over several months.
- The serving pipeline uses OpenCV-resize on BGR images with one set of normalization constants, while training used PIL-resize on RGB with different constants.
- Holiday traffic produces a 5\(\times\) QPS spike and replica queue depth grows for several minutes before autoscaling catches up.
- A new GPU SKU enters the fleet and model loading time doubles during autoscaling events.
Answer: The correct answer is B. Training-serving skew is an internal implementation inconsistency: the serving pipeline computes features differently than the training pipeline did, so identical weights see different inputs. Seasonal target drift is an external distribution shift, traffic spikes are a capacity problem, and a slower-loading SKU is a cold-start problem, none of which are skew.
Learning Objective: Distinguish internal preprocessing mismatches from external distribution shift, capacity, and cold-start failures in production.
Explain why cold start is more than loading weights off disk, and why this matters for reactive autoscaling during a traffic surge.
Answer: A cold replica has to create the CUDA context, compile or deserialize the execution graph, allocate and pin memory, and complete any first-request warmup the runtime defers, in addition to reading weights from storage. On a TensorRT-style engine these steps can dominate total startup time, putting a new replica tens of seconds away from being ready. In a reactive-autoscaling regime, the replica is not usable during the burst it was created to absorb, so p99 latency spikes precisely when demand is rising. The operational consequence is that engines should be pre-compiled, weights pre-staged, and warmup traffic issued before the load balancer marks the replica healthy.
Learning Objective: Explain how multiple initialization phases beyond weight loading shape autoscaling responsiveness, and derive the preconditions for reactive scaling to keep its SLO.
A team serves a model through TensorRT and observes a 30-second graph compilation on every new replica during autoscaling. Which loading strategy best removes this cost from subsequent scale-outs?
- Store only the original training checkpoint and rely on just-in-time compilation at every deployment so the optimization always matches the runtime.
- Pre-compile the optimized engine once and deploy the compiled artifact, so new replicas load a ready-to-run graph and skip the heavy compilation step.
- Switch from binary weight files to JSON so weights load transparently and compilation becomes unnecessary.
- Raise the warmup batch size on every new replica so graph compilation amortizes across requests and disappears from visible latency.
Answer: The correct answer is B. The chapter’s cold-start example shows that pre-compiling the optimized engine converts a 30-second per-replica cost into a one-time build-pipeline cost, which is the largest single lever for autoscaling responsiveness. Just-in-time compilation keeps the cost on the hot path, JSON is slower for weight loading rather than faster, and warmup batching does not change how long graph compilation itself takes.
Learning Objective: Select a deployment-artifact strategy that removes repeated runtime compilation from autoscaling events.
A multi-model serving system cannot fit all models in GPU memory and swaps them from host DRAM over PCIe on demand. Why can this severely violate per-request latency SLOs?
- Host DRAM is faster than VRAM, so the swap itself is cheap and the problem is really a cache-locality issue.
- PCIe transfer of a multi-gigabyte model takes hundreds of milliseconds of pure I/O before inference can even begin, which on its own exceeds many online-serving SLOs.
- PCIe transfer time matters only during training, not during inference, so it is a provisioning issue rather than a latency issue.
- Model swapping improves tail latency by keeping caches diverse, so any latency increase is a monitoring artifact.
Answer: The correct answer is B. The section quantifies swap time for a multi-gigabyte model as hundreds of milliseconds under realistic PCIe bandwidth, which already exceeds many online SLOs even before any inference runs. The DRAM-faster-than-VRAM framing reverses the memory hierarchy, and the claims that PCIe applies only during training or that swapping improves tails contradict the section’s entire argument.
Learning Objective: Analyze why host-to-device model swapping can dominate latency in multi-model serving.
True or False: CUDA MPS primarily improves concurrency for co-tenant workloads, while MIG is the stronger choice when per-model isolation and predictable latency under contention matter most.
Answer: True. CUDA MPS reduces per-context overhead and lets multiple processes time-share a GPU more efficiently, but clients still share an execution context and can interfere with each other’s tail behavior. MIG partitions the GPU at the hardware level, giving each tenant its own memory bandwidth and compute slice, so per-model latency is protected against noisy neighbors at the cost of some peak utilization.
Learning Objective: Compare CUDA MPS and MIG by separating concurrency benefits from hardware isolation guarantees.
Self-Check: Answer
Why does increasing batch size from 1 to moderate values (say 8-32) often improve serving throughput dramatically on GPUs?
- Larger batches remove the need for preprocessing and postprocessing by combining them into the kernel launch.
- Batching amortizes fixed per-call costs such as kernel launch overhead and a single pass of weight reads from HBM across many requests, raising the effective arithmetic intensity and hardware utilization.
- Larger batches make queuing theory irrelevant once the accelerator is saturated, so mean latency stops mattering.
- The model’s parameter count effectively shrinks as batch size grows because the runtime dedupes repeated weights.
Answer: The correct answer is B. At batch 1, each call pays the same kernel-launch overhead and pulls the full weight matrix from HBM to deliver very little arithmetic, leaving the accelerator memory-bound. At batch 32, the same weight read is amortized across 32 requests, arithmetic intensity rises, and the kernel moves toward the compute-bound regime. The other options either eliminate costs that are still paid or redefine what batching does to the model itself.
Learning Objective: Explain why batching raises accelerator efficiency by amortizing fixed serving overheads and shifting the operating point on the roofline.
A public API sees 50 QPS overnight and 800 QPS during peak hours. Why is dynamic batching with a time window generally preferable to waiting for a fixed full batch?
- A time-bounded window caps per-request wait time even when traffic is low, while static-full-batch policies force early arrivers to wait indefinitely for enough requests during off-peak hours.
- Static batching cannot be used with GPUs; they require a scheduler to form every batch at runtime.
- Dynamic batching guarantees that every batch has exactly the same size, which makes kernel tuning easier.
- Static batching always delivers worse throughput than batch 1, so the question is just which dynamic strategy to use.
Answer: The correct answer is A. The failure mode of static-full-batch at low traffic is unbounded wait for the last slots to fill; a time window converts that into a hard ceiling on formation delay, trading a small per-batch efficiency loss for a much better tail under bursty or sparse arrivals. Dynamic batching does not guarantee identical batch sizes (the section emphasizes that size is stochastic), and the other framings are incorrect about GPU scheduling and static-batching throughput.
Learning Objective: Compare dynamic and static batching under variable arrival rates, focusing on how the time window bounds tail formation delay.
A service has a 50 ms latency SLO. Explain why allocating roughly 20 to 30 percent of that budget (10-15 ms) to a batching window is a reasonable starting configuration, and what breaks if the window is pushed to 40 ms.
Answer: Batching pays for throughput in latency-budget milliseconds, and every millisecond spent waiting is charged against the SLO before any computation occurs. A 10-15 ms window leaves the remaining 35-40 ms for inference, serialization, transfer, and queueing, preserving enough headroom for the rest of the Iron Law budget while capturing most of the batching gain (the throughput-vs-window curve flattens well before 30 ms in typical workloads). Pushing the window to 40 ms leaves only 10 ms for everything else, which is not enough for inference plus the other phases, so p99 will cross the SLO even when average latency looks acceptable. The practical principle is to budget the batching window as a fraction of the SLO, not as a separate knob.
Learning Objective: Justify a batching-window budget by balancing end-to-end latency constraints against throughput gains.
Why does continuous batching matter far more for LLM serving than for fixed-output models such as image classifiers?
- Language models are trained online while image classifiers are not, so only LLM batches must be recomputed continuously.
- LLM requests generate variable-length sequences, so in static batching a completed sequence leaves its slot idle until the longest sequence finishes, wasting a growing fraction of capacity; continuous batching refills those slots on each decode step.
- Continuous batching eliminates the need for a KV cache, which is why it is reserved for LLMs.
- Image classification cannot benefit from any form of batching, so any batching innovation is automatically LLM-only.
Answer: The correct answer is B. Variable decode length is the structural problem: a static batch of 32 requests runs at the rate of the slowest generator, and the completed sequences waste their slots until the whole batch unwinds. Continuous batching reschedules at every token step, so completed slots immediately accept new work. The KV-cache-elimination framing is incorrect (continuous batching makes KV management more complex, not less), and image classifiers do benefit from static batching.
Learning Objective: Analyze why variable-length generation makes continuous batching essential for LLM throughput while fixed-output workloads are well served by static batching.
A naive LLM server allocates the KV cache as one contiguous region per request. Under continuous batching with variable-length sequences, why does this allocation strategy severely limit the achievable concurrent batch size, and what does PagedAttention change?
- Contiguous allocation is bandwidth-bound rather than capacity-bound, and PagedAttention rewrites attention kernels to use a slower but more predictable memory path.
- As sequences of different lengths enter and leave, free memory accumulates in unusable gaps (external fragmentation). A new long sequence cannot find a single contiguous block even when total free memory looks sufficient, so 40-50 percent of VRAM can sit unused and concurrency falls well below what capacity alone would predict. PagedAttention divides the KV cache into fixed-size pages that can be allocated non-contiguously, pushing utilization above 90 percent.
- Contiguous allocation is a software bug that has already been fixed in the CUDA driver; PagedAttention is a fallback for older drivers.
- Contiguous allocation is fine in principle, but PagedAttention moves the KV cache to CPU RAM to bypass VRAM limits entirely.
Answer: The correct answer is B. External fragmentation is the binding constraint: the allocator cannot find a contiguous region even when cumulative free memory is large, so the scheduler has to cap concurrency well below the capacity-only limit. PagedAttention borrows OS virtual-memory paging, allocating the KV cache in fixed-size pages that need not be contiguous, which drives fragmentation-induced waste toward zero and lets more sequences run concurrently on the same hardware. The other options misattribute the bottleneck (bandwidth, a driver bug, or offloading to CPU RAM) and none describe what PagedAttention actually does.
Learning Objective: Analyze why contiguous KV-cache allocation fragments memory under continuous batching, and how paged allocation restores concurrency.
Which batching strategy best matches a mobile SingleStream deployment such as on-device image classification in a smartphone app?
- Large dynamic batches with 20-50 ms windows to maximize on-device GPU utilization across background queries.
- Synchronized multi-sensor batching with fixed camera-frame groups pulled from a hardware trigger.
- No batching (batch 1), prioritizing immediate responsiveness, low peak power, and thermal stability over aggregate throughput.
- Offline maximum-batch processing because a single user generates a predictable request stream.
Answer: The correct answer is C. A SingleStream mobile workload has a single user whose next query depends on the previous result, so any batching window directly delays the user. Mobile silicon is also thermally constrained, so running larger batches at higher peak power shortens sustained performance. Large dynamic windows describe cloud serving, synchronized multi-sensor batching describes a MultiStream deployment, and offline batch processing forfeits the interactive use case the mobile app exists for.
Learning Objective: Match batching policy to a SingleStream mobile serving workload where responsiveness and thermal stability dominate throughput.
Self-Check: Answer
Which pairing correctly matches the two main LLM serving metrics with the user experience they capture?
- TTFT measures sustained generation fluidity, while TPOT measures startup responsiveness.
- TTFT measures how long the user waits for the first token to appear, while TPOT measures the rhythm of successive tokens once generation has begun.
- TTFT and TPOT both measure the same quantity sampled at different percentiles.
- TTFT measures model accuracy while TPOT measures serving cost.
Answer: The correct answer is B. Time-to-first-token captures the prefill-dominated startup phase and shapes whether the service feels alive; time-per-output-token captures the decode-phase steady state and shapes whether the response feels fluent. Collapsing them to one quantity loses the chapter’s entire two-phase framing, and the accuracy-vs-cost pairing bears no relation to either metric.
Learning Objective: Differentiate startup responsiveness from streaming fluidity using TTFT and TPOT.
Why is the decode phase of LLM serving described as memory-bandwidth bound rather than compute bound?
- Each new token requires re-reading the model weights and the growing KV state per layer, and per-token arithmetic intensity is low enough that HBM transfer time dominates kernel time.
- Decoding always runs on CPUs rather than GPUs, which have lower compute but higher bandwidth.
- Beam search removes most memory traffic, leaving only arithmetic work, which is why decode is bandwidth-bound in practice.
- Prefill and decode have identical hardware bottlenecks, so both are bandwidth-bound by definition.
Answer: The correct answer is A. Per-token decode has low FLOP/byte arithmetic intensity from weight and KV state moved through HBM, so the roofline places the kernel well below the ridge point and the HBM traffic is the binding resource. The CPU-only framing is empirically wrong, beam search does not eliminate the per-token weight read, and the chapter’s entire section exists to contrast prefill (compute-bound) with decode (bandwidth-bound).
Learning Objective: Explain why token generation is limited primarily by memory movement rather than raw compute.
Explain why returning tokens incrementally can make a 2-second LLM response feel much better to a user than returning the entire response at the end.
Answer: Perceived responsiveness is dominated by how long the user waits before seeing anything; streaming converts the interaction from ‘frozen screen for 2 seconds’ to ‘system started answering within TTFT and keeps producing at TPOT’. The total generation time is the same, but the user’s mental model shifts from failure to progress, and they can begin reading while later tokens are still being generated. The systems implication is that serving infrastructure must support chunked or incremental responses end to end (reverse proxies, client libraries, buffering policies) so the TTFT benefit is not absorbed somewhere between the model and the user.
Learning Objective: Explain how incremental token streaming improves perceived responsiveness even when total latency is unchanged, and identify what the serving stack must support.
Many production LLM requests share the same long system prompt or the same retrieved context prefix. Which change most directly reduces the redundant prefill work across such requests?
- Raise temperature so the model explores a wider output distribution and reuses less computation per request.
- Enable prefix caching so the KV states for the shared prompt prefix are computed once and reused across requests that share that prefix.
- Disable the KV cache entirely so requests are memory-independent and cannot interfere with one another.
- Switch from sampling to greedy decoding so prefill disappears and only decode remains.
Answer: The correct answer is B. Prefix caching stores the hidden states for the shared prefix and reuses them for any request with a matching start, cutting both compute and HBM traffic proportional to the prefix length. Raising temperature changes output diversity, not prefill work; disabling the KV cache removes the mechanism by which decode itself stays tractable; and greedy decoding changes sampling semantics but does not eliminate the prefill phase.
Learning Objective: Select a serving optimization that reuses shared prompt computation across requests, and reject alternatives that confuse decoding policy with prefill amortization.
A team serving a 70-billion-parameter-class LLM can afford exactly one GPU upgrade. Option X doubles peak FP16 TFLOP/s while HBM bandwidth stays roughly flat. Option Y holds peak TFLOP/s roughly flat but increases HBM bandwidth by 60 percent. Assuming typical long-output chat traffic where decode dominates the budget, which option improves TPOT more, and why?
- Option X, because more compute always lowers per-token latency regardless of where the bottleneck sits.
- Option Y, because decode is memory-bandwidth bound: each token requires moving weights and KV state through HBM, so faster HBM directly shrinks per-token kernel time while extra FLOP/s sits idle.
- Neither option changes TPOT; per-token time depends only on model architecture, not hardware.
- Both options improve TPOT equally, because TPOT scales with the geometric mean of compute and bandwidth.
Answer: The correct answer is B. The section’s decode analysis places per-token work well below the roofline ridge, so the kernel is HBM-traffic-bound and doubling compute leaves TPOT essentially unchanged. Option Y lifts the binding resource directly, so per-token latency drops roughly in proportion to the bandwidth increase. The ‘compute always wins’ framing ignores the roofline, and the ‘neither changes TPOT’ and ‘both improve equally’ framings ignore which of the two hardware axes is actually the bottleneck.
Learning Objective: Analyze two concrete GPU upgrade options and select the one that improves TPOT under a decode-bound workload, justifying the choice with roofline reasoning.
Self-Check: Answer
Why might a team choose ONNX Runtime instead of TensorRT for a production service?
- ONNX Runtime is usually the absolute fastest option on NVIDIA GPUs for any given model.
- ONNX Runtime preserves training functionality needed for online gradient updates during serving.
- ONNX Runtime offers cross-platform deployment flexibility across CPUs, GPUs, and other accelerators from a single exported model, at the cost of some target-specific peak performance.
- ONNX Runtime removes the need for any graph optimization pass before deployment.
Answer: The correct answer is C. The section positions ONNX Runtime as a portability layer that trades a small amount of NVIDIA-specific peak performance for the ability to deploy the same exported graph across CPU, GPU, and other accelerator targets. TensorRT is typically faster on NVIDIA GPUs specifically, so an ‘always fastest’ claim is wrong; ONNX Runtime does not support online gradient updates, and it still performs graph optimization during engine build.
Learning Objective: Compare runtime choices by weighing cross-platform flexibility against target-specific peak performance.
What is the main systems benefit of layer fusion in an optimized serving runtime?
- It lets the model retrain itself online during inference without exposing gradient state.
- It merges sequential operations so intermediate activations stay in on-chip SRAM across stages, reducing kernel launches and the number of round trips through HBM.
- It converts dynamic batching into static batching automatically.
- It guarantees zero numerical difference from the original training framework.
Answer: The correct answer is B. Fusing ops keeps intermediate tensors in fast on-chip memory instead of writing them back to HBM and reading them again, which removes per-op launch overhead and cuts memory traffic. Neither property implies online retraining or exact bit-for-bit numerical identity, and fusion has nothing to do with static versus dynamic batching.
Learning Objective: Explain how layer fusion reduces launch overhead and memory traffic in serving runtimes.
A deployment team can use FP16 with no measurable accuracy loss, or INT8 with additional calibration work and a small possible accuracy drop. Explain why this should be framed as a serving economics decision rather than a numerical-format decision.
Answer: Lower precision raises throughput and cuts per-request memory footprint, which directly changes the number of accelerators the fleet needs to meet a given QPS and SLO. FP16 is the easiest ‘free lunch’ because it holds accuracy and halves memory traffic; INT8 can push fleet cost further down by another large factor but pays a calibration tax and a small accuracy risk. The decision is therefore a joint function of latency margin, fleet size at projected traffic, and the business cost of a 0.5-1 percent accuracy regression, not an aesthetic choice about numerical format. For a high-volume service where the fleet is expensive, INT8 often pays for itself; for a small-fleet service where accuracy is brand-critical, FP16 usually wins.
Learning Objective: Evaluate precision choices in terms of fleet size, latency, and acceptable accuracy loss.
Why must calibration data for post-training INT8 quantization resemble real serving traffic rather than convenient training examples?
- Calibration determines activation scale factors; mismatched data produces poor scale estimates that clip or overflow in production and silently degrade accuracy.
- Tensor Cores refuse to execute INT8 kernels unless calibration used live production samples.
- Representative calibration data eliminates the need for any ongoing monitoring.
- Calibration only affects cold-start latency, not model predictions.
Answer: The correct answer is A. Calibration computes per-activation ranges that the INT8 scheme will clip or map, and mismatched data underrepresents the tails actually produced in serving, so scale factors end up too tight or too loose and prediction quality drops quietly. The other framings misdescribe what calibration does: it does not gate hardware execution, it does not substitute for monitoring, and it affects inference accuracy rather than startup time.
Learning Objective: Analyze why representative traffic is required for reliable post-training quantization calibration.
A serving team runs an INT8 model that returns a confidence score per prediction. Low-confidence outputs are automatically re-run in FP16 before returning a final answer. Explain the latency-cost trade-off this dynamic-precision scheme creates and when it is worth it.
Answer: Most requests stay on the fast INT8 path and pay one inference, but a fraction f of requests take two inferences, the second at higher FP16 latency; expected per-request latency rises roughly by f times the FP16 time, and per-request cost rises by the same factor on the small minority that is reprocessed. The scheme is worth it when INT8 is accurate enough on easy inputs but loses a business-material amount of accuracy on hard ones, and when the fraction f is small enough that the added latency still meets the SLO. A retail-recommendation service at low f can double its fleet efficiency without moving p99, while a safety-critical service where INT8 accuracy is never acceptable should just run FP16 everywhere rather than bet on the low-confidence trigger.
Learning Objective: Evaluate when dynamic per-request precision selection improves fleet economics and when it adds latency without payoff.
Self-Check: Answer
Why can serving graphs be optimized more aggressively than training graphs?
- Serving graphs have fixed weights and a stable execution structure, so the compiler can fuse ops, fold constants, and pre-plan memory with assumptions that would be unsafe while gradients still flow through the graph.
- Serving graphs always run on a single hardware target with zero runtime variability, so every optimization applies unconditionally.
- Training graphs cannot contain constants, so there is nothing for a constant-folding pass to work with.
- Graph compilation matters only for CPU inference and has no effect on accelerator performance.
Answer: The correct answer is A. The key difference is mutability: during training, weights and intermediate activations change every step, so the compiler cannot fuse or fold across them without either recomputing every step or breaking the backward pass. At serving time the weights are frozen and the activation pattern is fixed, so the same transformations become safe and often free. The ‘no runtime variability’ framing is too strong (input shapes and batch sizes still vary), training graphs absolutely can contain constants, and graph compilation improves accelerator performance through fusion and memory planning.
Learning Objective: Explain why static inference graphs enable compiler optimizations unavailable or unsafe during training.
When can a CPU beat a GPU on serving latency?
- Never; GPUs dominate latency because they have more parallel hardware.
- When the model is small and batch size is 1, so that GPU kernel-launch overhead plus host-to-device transfer exceed the actual arithmetic time and an optimized CPU path runs the kernel faster end to end.
- Only when the CPU is retraining the model in parallel, which gives it priority on the serving path.
- Only when the GPU lacks Tensor Cores, so its FP16 throughput collapses.
Answer: The correct answer is B. For small models at batch 1, the CPU has no launch or transfer tax, and cache-resident weights can run the kernel in microseconds, while the GPU pays tens of microseconds of dispatch plus any host-to-device copy before doing any math. The ‘GPU always wins’ framing ignores exactly the low-batch regime the section centers on, and the other options invent failure modes.
Learning Objective: Identify the low-batch workload regime where CPU inference outperforms GPU serving.
Explain why thread pinning without NUMA-aware memory placement can still leave a CPU serving system slow.
Answer: Pinning keeps threads on specific cores, but if their model weights or per-request activations live in memory attached to a different NUMA socket, every access goes through the cross-socket interconnect, which can be several times slower than local DRAM. The cores look well-behaved in configuration dashboards but are quietly waiting on far memory on each request. The practical fix is to co-locate threads and data: allocate model weights on the socket where the serving threads run, ideally interleaved per-socket for multi-socket serving, so locality covers both halves of the problem at once.
Learning Objective: Analyze how NUMA locality and thread affinity must work together to reduce CPU serving latency.
Why do memory-mapped formats such as safetensors reduce cold-start time compared with Python pickle-based loading?
- They compress weights more aggressively than all other formats.
- They map raw tensor bytes directly into the process address space with minimal parsing, so load time becomes limited by disk bandwidth rather than Python object reconstruction.
- They automatically quantize weights to INT8 during load.
- They eliminate the need to transfer weights to accelerator memory.
Answer: The correct answer is B. mmap-style formats keep the on-disk layout compatible with the in-memory layout, so the runtime skips the Python-object construction that makes pickle loading slow and expensive. The storage layout lets disk bandwidth become the bottleneck, which is fast and parallelizable. The other options invent features the format does not provide, and accelerator transfer is a separate subsequent step.
Learning Objective: Explain how serialization format choice affects model-loading time during cold start.
A profiler trace shows frequent idle gaps on the GPU timeline while the CPU is busy decoding images and preparing tensors. What is the most defensible immediate conclusion?
- The model is compute-bound and needs more Tensor Cores.
- The GPU is being starved by an upstream CPU or I/O bottleneck rather than being limited by the model kernels themselves; the next optimization target is preprocessing or transfer, not the model.
- The runtime has fused too many operators and is bottlenecking on fused-kernel complexity.
- The node is suffering from quantization error, which is causing the GPU to stall waiting for retries.
Answer: The correct answer is B. Idle GPU combined with busy CPU is the canonical GPU-starvation signature: the accelerator is ready but the host has not delivered the next batch. The first move is to attack the upstream pipeline (multi-worker preprocessing, overlapped transfer, larger prefetch) rather than the model kernel. Quantization error is an accuracy issue with no direct relation to timeline idle regions, and over-fusion does not produce this pattern.
Learning Objective: Interpret timeline traces to distinguish GPU starvation from true model-kernel bottlenecks, and pick the appropriate next optimization.
Self-Check: Answer
Why can a more expensive GPU instance have a lower cost per inference than a cheaper CPU instance?
- Cloud providers charge less for idle GPU time than for idle CPU time.
- Cost per inference equals price divided by sustained throughput; a GPU’s much higher throughput can more than offset its higher hourly price, making it cheaper per successful request under the same latency SLO.
- Serving costs ignore latency and only count memory footprint.
- GPUs eliminate all orchestration overhead, which collapses fixed costs to zero.
Answer: The correct answer is B. Unit economics is price normalized by throughput, so the pricier GPU wins per inference whenever its throughput ratio exceeds its price ratio, which the chapter’s CPU-T4-V100 comparison shows is the common case for cloud image classification. The idle-pricing, memory-only, and zero-overhead framings misrepresent both cloud pricing and the serving cost equation.
Learning Objective: Evaluate hardware options using normalized cost per inference instead of hourly rental price alone.
Explain why a throughput number alone is meaningless for capacity planning unless it is paired with a percentile latency guarantee.
Answer: A system can quote a very high QPS by allowing latency to drift arbitrarily: running saturated and letting p99 cross the SLO increases the advertised throughput but delivers fewer successful requests to real users. Only throughput delivered under the SLO counts as useful capacity, and that quantity can be a small fraction of the unconstrained number when the system is near saturation. The practical consequence is that capacity plans must be built from SLO-constrained benchmarks (throughput at p99 ≤ target) rather than from peak throughput, and provisioning needs explicit headroom above the constrained number to absorb bursts.
Learning Objective: Justify why capacity planning must combine throughput measurements with percentile latency SLOs.
Why might a hybrid scaling strategy keep baseline traffic on GPUs but route overflow traffic to CPUs during spikes?
- CPUs are always cheaper and faster than GPUs for all models.
- GPU instances scale up instantly while CPUs have long startup delays.
- GPU cold-start and spin-up times can exceed the burst duration itself, so reactive scaling misses the window; CPUs come online much faster and can absorb the burst at worse per-request efficiency, which is acceptable precisely because the overflow is temporary.
- Hybrid systems eliminate the need for load balancing.
Answer: The correct answer is C. The argument is about scaling time scales, not steady-state efficiency: CPUs can be provisioned in seconds while GPU replicas can take tens of seconds to hundreds for full warmup, and a burst may be half over before new GPUs are ready. The worse CPU cost per inference during the burst is the premium paid for responsiveness; it does not imply CPUs are globally cheaper or that load balancing becomes unnecessary.
Learning Objective: Analyze when CPU overflow capacity is economically useful despite worse steady-state efficiency.
A team serving a quantized 70-billion-parameter-class LLM can pick between two single-GPU upgrades on the same $/hour. Upgrade P keeps VRAM at 80 GB but raises HBM bandwidth by 50 percent. Upgrade Q keeps HBM bandwidth roughly flat but raises VRAM to 140 GB. For a workload with long-running conversations and significant KV-cache demand, how should the team decide, and why?
- Upgrade P, because bandwidth always dominates both latency and cost in LLM serving.
- Upgrade P lowers TPOT and improves per-user latency, while Upgrade Q lifts the concurrency ceiling (more KV cache fits, so more conversations run side-by-side) and directly increases throughput and lowers cost per token. If the service is latency-constrained, pick P; if it is throughput or unit-cost constrained, pick Q.
- Upgrade Q, because memory capacity always dominates both latency and cost in LLM serving.
- The two upgrades are interchangeable for LLM workloads and the team should pick based on vendor preference.
Answer: The correct answer is B. The case study separates the two hardware axes cleanly: bandwidth governs per-token speed (TPOT and therefore user-perceived latency) while capacity governs how much KV cache and therefore how much concurrency the device can hold (throughput and cost-per-token). Collapsing either axis to ‘always dominates’ hides the actual choice, and the interchangeability framing ignores that the two knobs affect disjoint system objectives.
Learning Objective: Analyze a two-knob LLM hardware-upgrade decision by mapping each knob to latency and throughput objectives separately.
In the 8-billion-parameter Llama 3 case study’s traffic mix, once the model weights are already quantized and loaded, which resource primarily determines realized full-request throughput and therefore cost per token?
- Prefill compute throughput, because the case study’s 10 requests/s prefill admission rate is below the KV-residency ceiling.
- FLOP count alone, because autoregressive decoding is compute-bound.
- Network bandwidth, because prompt tokens dominate end-to-end economics.
- KV-cache memory capacity alone, because concurrency always dominates throughput and cost for every traffic mix.
Answer: The correct answer is A. The case study separates residency from realized throughput: remaining VRAM bounds the maximum concurrent KV-cache residency, but the worked traffic mix admits only 10 requests/s from prefill while the KV-residency ceiling is much higher. Cost per token in this example is therefore computed from prefill-limited full-request throughput. Treating decode as compute-bound misses the memory-bandwidth argument, network bandwidth is not the binding quantity in the arithmetic, and saying KV capacity always dominates collapses a concurrency ceiling into a throughput claim.
Learning Objective: Distinguish KV-cache concurrency limits from the prefill-limited realized throughput used in LLM serving unit economics.
Self-Check: Answer
A team makes model inference 2.5\(\times\) faster on the accelerator. The service was previously running at 70 percent utilization on replicas whose end-to-end budget was split evenly between model inference and everything else. Compared to the original, what should happen to end-to-end p99 user latency?
- It should improve by exactly 2.5\(\times\), matching the model speedup one-to-one.
- It should improve by much less than 2.5\(\times\) in nominal load (because the non-model half of the budget is unchanged), and under the same traffic it may improve even more than 2.5\(\times\) because lower per-request service time also lowers utilization and shrinks the queueing term.
- It should stay exactly the same because latency is determined only by network overhead.
- It should get worse because faster inference destabilizes batching.
Answer: The correct answer is B. End-to-end latency is an Iron Law sum, so halving only the model term cannot halve the total; on the other hand, lower per-request service time also pushes the utilization \(\rho\) down, which can shrink the queueing term more than proportionally at moderate-to-high load. The 1:1 mapping confuses model speedup with end-to-end speedup, the ‘exactly the same’ framing ignores the entire chapter, and faster inference does not destabilize batching as a matter of course.
Learning Objective: Evaluate why model-speed improvements do not translate one-to-one into end-to-end latency gains, and why queueing can amplify or damp the model-level change.
Why is pushing serving infrastructure to 90 percent utilization usually a mistake even when it looks more cost-efficient on paper?
- GPUs become less numerically accurate above 70 percent utilization.
- Queueing delay grows nonlinearly as utilization approaches saturation, so modest cost savings from higher utilization are paid for by disproportionately large p99 latency increases and SLO violations during normal traffic variation.
- Model loading stops working once average utilization exceeds 80 percent.
- High utilization prevents the dynamic batcher from running at all.
Answer: The correct answer is B. The chapter’s queueing analysis makes the \(1/(1 - \rho)\) curve explicit: the move from 50 percent to 90 percent utilization saves a chunk of fleet cost but multiplies the queueing term, and any traffic variability near saturation produces SLO-breaking tails. Accuracy does not degrade with utilization, model loading is unaffected, and batching runs regardless of utilization.
Learning Objective: Analyze why high apparent hardware efficiency is incompatible with latency SLOs in queueing-limited regimes.
Which single monitoring approach, relied on by itself, is the most dangerous for a production serving system?
- Monitoring p95 and p99 latency distributions under load.
- Comparing serving preprocessing against the training preprocessing for skew.
- Tracking only average latency, on the assumption that the average represents user experience.
- Validating quantized-model accuracy on representative production-like traffic.
Answer: The correct answer is C. Mean latency can look healthy while p99 is catastrophic, because a few percent of requests pulled far into the tail barely move the mean but dominate real user experience and fan-out amplification. The other three choices are the checks the chapter explicitly recommends for catching tail latency, silent skew, and calibration regressions.
Learning Objective: Identify why average-only latency monitoring misses the serving failures users actually experience.
Explain why calibrating an INT8 model on convenient training data rather than representative serving traffic can silently damage production accuracy.
Answer: Calibration fixes per-layer activation scale factors to the ranges it observed during calibration, and those ranges determine which values get clipped or rounded when the model is executed in INT8. If the calibration set under-represents the tails of the production activation distribution, the scale factors are too tight and production inputs get clipped or quantized aggressively, degrading outputs with no exception and no latency signal. The model continues to meet its SLO and run at expected cost while predictions drift silently, which is the worst class of failure because dashboards look healthy. The operational fix is to calibrate on traffic captured from production and to maintain ongoing accuracy shadow-monitoring after every re-calibration.
Learning Objective: Explain how misaligned calibration data creates silent production regressions in quantized serving.
Which statement best captures the chapter’s warning about cold starts?
- Cold start matters only for the very first request a new service ever handles.
- Cold start is mainly a logging artifact with minimal effect on user latency.
- Cold start recurs on every scale-out, redeployment, and replica replacement, so its cost is paid precisely when traffic is surging or the fleet is churning, not just at first launch.
- Cold start disappears automatically once dynamic batching is enabled.
Answer: The correct answer is C. The section emphasizes that cold start is a property of every new replica, not of the service’s lifetime, so every autoscaling event, canary rollout, or replica replacement re-pays the initialization cost. The ‘first request only’ and ‘logging artifact’ framings trivialize a latency source that can dominate tail behavior during bursts, and dynamic batching does not change initialization time.
Learning Objective: Analyze why cold-start effects recur during deployments and scale-out events rather than only at first launch.
Self-Check: Answer
Which statement best summarizes why serving requires a different systems design than training?
- Serving and training share the same optimization objective and differ mainly in framework choice.
- Serving prioritizes per-request latency, tail behavior, and operational reliability under stochastic traffic, while training prioritizes aggregate throughput and high utilization over long runs; this inversion reshapes batching, headroom, scheduling, and failure handling simultaneously.
- Serving differs from training primarily because model weights are smaller after deployment.
- Serving is mostly a postprocessing problem because the model has already been fully optimized.
Answer: The correct answer is B. The chapter’s synthesis argument is that latency, tail behavior, and reliability under stochastic arrivals are the dominant design constraints on the serving side, and that training’s throughput-and-utilization optimum is an anti-goal for a latency-sensitive serving fleet. The other options reduce that inversion to either a naming change or a single pipeline stage.
Learning Objective: Compare how throughput, headroom, and reliability requirements change system design between training and serving, and explain why the resulting inversion touches every pipeline stage.
Explain why a serving team that optimizes only the model, ignores queueing headroom, and never checks preprocessing consistency is likely to fail in production even if offline benchmarks look strong.
Answer: Offline benchmarks measure the accelerator kernel in isolation, which the chapter shows can be a small fraction of real end-to-end latency once preprocessing, transfer, queueing, and serialization are included. A fleet run near saturation for efficiency will trip the \(1/(1 - \rho)\) queueing curve on the first traffic burst, and a preprocessing pipeline that diverges from training will produce confident but wrong predictions that infrastructure dashboards cannot detect. The combined failure mode is a service that looks fast on the bench, violates SLOs the first time traffic spikes, and silently drifts on accuracy the whole time; passing any one of latency, tail, or correctness is not enough when a production deployment demands all three.
Learning Objective: Integrate latency, headroom, and correctness concerns into a production-serving evaluation that spans the full chapter.
What is the most important additional constraint that makes LLM serving different from traditional fixed-output model serving?
- LLMs eliminate the need for batching because outputs are text rather than tensors.
- LLMs replace latency concerns with accuracy concerns only.
- LLMs introduce autoregressive, variable-length generation with a KV cache whose memory and bandwidth demands grow over a request, so memory bandwidth, cache management, and scheduling at token granularity become central bottlenecks rather than secondary concerns.
- LLMs are easier to serve because each request has exactly one output size.
Answer: The correct answer is C. Sequential token generation with a growing KV cache makes decode memory-bandwidth bound, fragments memory under continuous batching, and forces token-level scheduling, none of which appear in fixed-output serving. The other options either deny the batching and memory constraints the chapter spends a section on or assume fixed-size outputs, which is the exact property LLM serving does not have.
Learning Objective: Summarize the additional memory and scheduling constraints introduced by autoregressive LLM serving.