Benchmarking
Purpose
How can ML systems be compared fairly when hardware, models, data, and deployment all interact?
Benchmarking brings together decisions already developed across hardware targeting, model compression, data selection, and deployment behavior. Each decision improved one dimension (latency, accuracy, throughput, or energy), but an ML system is the product of all these dimensions simultaneously. A pruned model runs faster on one accelerator but slower on another. A larger batch size improves accelerator utilization but violates a latency service-level agreement. An edge device advertises peak throughput that thermal throttling halves under sustained workloads. The challenge is not whether individual optimizations work in isolation (they do) but how to measure their combined effect under conditions that actually matter. Benchmarking is the discipline of making such comparisons systematic rather than anecdotal. It requires defining what to measure (accuracy, latency, throughput, energy), at what granularity (a single kernel, a full model, an end-to-end pipeline), and under which conditions (batch size, input distribution, thermal state, concurrent load). Without this structure, teams compare numbers that were never measured on the same terms, and decisions that looked sound in a spreadsheet collapse under production workloads. Those chapters optimized the model, selected the data, and matched the hardware; benchmarking is where those optimizations are validated: where claims meet evidence, and where the gap between promise and delivery is quantified honestly or discovered painfully in production. In D·A·M terms, benchmarking is where co-design is held to account: the measurement discipline that reveals whether Data, Algorithm, and Machine were actually matched or merely assembled.
Learning Objectives
- Explain benchmarking as D·A·M validation that tests whether optimization claims hold under representative conditions
- Compare training and inference benchmarks using throughput, latency percentiles, energy, accuracy, and workload scope
- Select micro, macro, or end-to-end granularity based on the engineering decision being tested
- Apply standardized benchmark run rules to align datasets, metrics, hardware configuration, and reporting
- Design benchmark protocols that control power boundaries, input distributions, batch sizes, and statistical variance
- Evaluate model and data quality with calibration, robustness, representativeness, and slice-level metrics
- Diagnose benchmark-production gaps caused by drift, thermal throttling, dynamic load, and silent degradation
ML Benchmarking Framework
A model quantized to INT8 may benchmark 2\(\times\) faster on a synthetic workload but show no improvement under real traffic patterns with variable input sizes and concurrent requests. A pruned model may maintain accuracy on the test set but fail on edge cases the benchmark never covered. Every optimization arrives with a promise: data selection promises more efficient training, model compression promises smaller, faster models, and hardware acceleration promises higher throughput. Verifying that these claims hold in production is itself an engineering discipline.
Benchmarking is where the physical laws those chapters established (the iron law, the conservation of complexity, the memory wall) face empirical reality. The benchmark-production gap is not a failure of methodology but the measure of how much physical reality exceeds our models of it. Closing that gap by designing measurements that predict production behavior with quantitative fidelity is the core competency that distinguishes ML systems engineering from ML research. Benchmarking is the discipline’s truth-telling function: the practice that converts theoretical claims into verified engineering knowledge.
ML benchmarking operates across three interdependent dimensions that map directly to the components of any deployed system. System benchmarking measures whether the hardware delivers promised performance under realistic workloads or whether memory bandwidth saturation and software dispatch overhead erode the gains. Model benchmarking measures whether optimization techniques preserve model quality across the full input distribution, not just on curated test sets. Data benchmarking measures whether the model generalizes to real-world data with all its noise, bias, and distributional shift. Each dimension can independently reveal problems invisible to the others, and a system that passes all three provides far stronger deployment confidence than one evaluated along any single axis.
Definition 1.1: Machine learning benchmarking
Machine Learning Benchmarking is the empirical measurement of a system’s end-to-end performance on representative ML workloads, designed to decouple marketed peak specifications from the sustained throughput and latency achievable under realistic operating conditions.
- Significance: The gap between peak and sustained performance is large and structurally unavoidable. An A100 GPU delivers 312 TFLOP/s (BF16) at peak, but production transformer training runs typically sustain 93.6 TFLOP/s–156 TFLOP/s (30 percent–50 percent MFU), about a 2–3.5\(\times\) gap that exists even in optimally tuned systems due to memory stalls, pipeline bubbles, and kernel launch overhead. Benchmarking quantifies this \(\eta_{\text{hw}}\) gap; vendor spec sheets do not.
- Distinction: Unlike micro-benchmarks, which measure individual kernel performance such as a general matrix multiply (GEMM) at peak matrix dimensions, ML benchmarks measure the full stack: data loading, preprocessing, forward pass, gradient computation, optimizer step, and checkpoint I/O—exposing bottlenecks that individual-component benchmarks will never reveal.
- Common pitfall: A frequent misconception is that benchmark numbers are stable references. Both the workload (new model architectures) and the hardware (new GPU generations) evolve, so a result that leads a benchmark under one version often becomes the baseline under a later version, making year-over-year comparisons meaningful only when the benchmark version is held constant.
Unlike traditional systems where benchmarks represent fixed specifications, ML benchmarks capture only a snapshot of a shifting reality. The gap between peak and sustained performance documented above is not fixed either: it shifts as both workloads and hardware generations evolve, making any single benchmark result time-stamped rather than universal.
Systems Perspective 1.1: Benchmarks as moving targets
In traditional systems (for example, SPEC CPU), the benchmark is a rigid specification. A sorting algorithm is correct if it sorts the list. Correctness is absolute and unchanging. In ML systems, the benchmark is a soft specification: correctness is defined by a finite set of examples (ImageNet), and the world moves. A model that scores highly on ImageNet can still underperform on user photos taken years after the benchmark was created.
In computer architecture, engineers design for the benchmark because the benchmark represents the workload. In ML engineering, designing solely for the benchmark is overfitting. Robustness comes from acknowledging that the benchmark is only a proxy for a shifting reality.
To make this three-dimensional framework concrete, we ground it in a running example that threads through the entire chapter, returning to it repeatedly as we develop each dimension. MobileNetV2 deployment validation spans all three evaluation dimensions, illustrating how each reveals problems the others cannot.
Lighthouse 1.1: MobileNetV2 deployment validation
MobileNetV2 (introduced in Lighthouse roster: Model biographies) serves as the lighthouse example for validating the complete optimization pipeline. MobileNetV2 refines v1’s depthwise separable design with inverted residuals and linear bottlenecks while maintaining a similar parameter scale (Sandler et al. 2018). It exemplifies the deployment challenges where benchmarking determines success or failure: compression can reduce model size, hardware acceleration can reduce inference latency, and only benchmarking can determine whether those gains survive the full deployment pipeline.
- Model compression (Model Compression): INT8 quantization reduces this MobileNetV2 worked example from 14 MB to 3.5 MB (4× compression)
- Hardware acceleration (Hardware Acceleration): the illustrative EdgeTPU scenario uses 2 ms inference vs. 15 ms on CPU
- Benchmarking validation: Verify the pipeline delivers in practice
The sections that follow address one dimension of this validation stack at a time, building toward a systematic methodology that isolates EdgeTPU latency from preprocessing and data transfer overhead, confirms INT8 quantization preserves accuracy on edge cases such as unusual lighting, and checks that performance holds on real-world smartphone images rather than only ImageNet test images.
Before examining these dimensions in detail, we must establish the mindset that separates rigorous evaluation from misleading metrics. Three principles distinguish effective practitioners.
First, benchmarks are proxies, not truth. Every benchmark measures specific conditions that may not match the target deployment. A system can achieve high sample throughput in Offline mode (bulk throughput with all inputs available) and much lower QPS in Server mode (latency-constrained requests arriving over time). The critical question is always what the benchmark does not measure.
Second, Goodhart’s Law applies everywhere.1 “When a measure becomes a target, it ceases to be a good measure.” Teams that optimize for benchmark rankings often produce systems that excel in evaluation but fail in production. Benchmark-specific optimizations frequently degrade characteristics that matter for deployment: robustness, calibration, and efficiency.
1 Goodhart’s Law: Goodhart (1984) articulated the original 1975 Bank of England observation on monetary policy; Strathern (1997) generalized it into the form quoted above. The original context was macroeconomics: once a monetary aggregate became an official policy target, banks changed behavior to game the metric, destroying its predictive value. In ML, the same failure mode recurs structurally: BLEU rewards n-gram overlap (Papineni et al. 2002), ImageNet rewards performance on a fixed visual distribution (Deng et al. 2009; Recht et al. 2019), and benchmark leaderboards can incentivize test-set-specific tuning.
Goodhart, Charles A. E. 1984. “Problems of Monetary Management: The UK Experience.” Monetary Theory and Practice, 91–121. https://doi.org/10.1007/978-1-349-17295-5_4.
Strathern, Marilyn. 1997. “‘Improving Ratings’: Audit in the British University System.” European Review 5 (3): 305–21. https://doi.org/10.1002/(SICI)1234-981X(199707)5:3<305::AID-EURO184>3.0.CO;2-4.
Deng, Jia, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. 2009. “ImageNet: A Large-Scale Hierarchical Image Database.” 2009 IEEE Conference on Computer Vision and Pattern Recognition, 248–55. https://doi.org/10.1109/cvpr.2009.5206848.
Recht, Benjamin, Rebecca Roelofs, Ludwig Schmidt, and Vaishaal Shankar. 2019. “Do ImageNet Classifiers Generalize to ImageNet?” Proceedings of the 36th International Conference on Machine Learning (ICML), 5389–400.
Third, end-to-end beats component metrics. Vendors report component latency (5–10 ms for model inference), but production latency includes preprocessing, queuing, and postprocessing (50–100 ms total). A 3× inference speedup applied to a 10 ms model stage inside a 50 ms pipeline yields only about 1.2× end-to-end improvement, or worse if the optimization increases memory pressure. These principles reappear throughout the benchmarking methodology and are examined in depth in section 1.13.

Component speedup rarely survives as end-to-end benchmark speedup.
Knowing what to measure, however, is only half the problem. Measuring incorrectly (with the wrong workloads, biased baselines, or uncontrolled variables) produces numbers that feel precise but mislead decisions. The history of computing benchmarking is littered with examples of technically sound metrics applied with flawed methodology, from compiler-gamed Whetstone scores to cherry-picked GPU benchmarks that predict nothing about sustained workloads. Understanding how measurement methodology evolved, and where it failed, is essential for designing benchmarks that distinguish genuine improvements from measurement artifacts.
The historical foundations of benchmarking2 matter because they expose the validation failures that still recur in ML: optimized metrics that stop predicting real workloads, hardware numbers that ignore sustained operating state, and model scores that miss deployment cost. The same validation sequence governs modern practice: first verify that hardware delivers promised performance, then verify that the model and data optimizations built atop that hardware deliver their promised gains.
2 Benchmark: From surveying, where a “bench mark” was a horizontal cut in stone serving as a fixed elevation reference. The term entered computing in the 1970s to describe standardized comparison points, but the surveying metaphor carries a systems lesson: just as an elevation measurement is meaningless without a calibrated reference, an ML throughput number is meaningless without controlled workloads, thermal state, and precision settings.
Self-Check: Question
A team quantizes MobileNetV2 from FP32 to INT8, deploys it to an EdgeTPU that hits the advertised 2 ms inference time, and validates accuracy on ImageNet test data. After release, smartphone users in low-light conditions report 12 percent misclassification rates. Which benchmarking dimension most directly diagnoses this failure?
- System benchmarking, because 12 percent error indicates the EdgeTPU is not actually sustaining the 2 ms latency under load
- Model benchmarking, because quantization must have broken calibration even though aggregate accuracy looked fine
- Data benchmarking, because ImageNet test images do not represent the smartphone-user input distribution
- Power benchmarking, because thermal throttling on the EdgeTPU is the most likely cause
The chapter describes a 2–10\(\times\) benchmark-production gap as structural rather than as measurement error. Explain why no amount of careful instrumentation alone will close this gap, using the MobileNet EdgeTPU pipeline as a concrete example.
True or False: If a vendor demonstrates that model inference time dropped from 15 ms to 5 ms (a 3\(\times\) speedup), the deployed end-to-end application should see close to a 3\(\times\) end-to-end latency improvement.
A translation team improves BLEU score from 28 to 28.5 by expanding beam search from beam_size=1 to beam_size=10, tenfold increasing per-token candidate evaluation and moving inference from 50 ms to 200 ms. The team wins the leaderboard but users abandon the product. Which principle from the chapter most directly explains this outcome?
- Single-metric benchmark rankings reliably predict product quality when the metric is well-designed
- The team should have used synthetic translation kernels instead of real workloads
- Benchmark scores are meaningless unless reduced to a single scalar
- Once BLEU became the optimization target, improvements in the measured score decoupled from deployment-relevant quality like latency and user utility
Because any benchmark captures only a controlled slice of reality (fixed workload, thermal state, and input distribution), the chapter argues that benchmark results function as ____ for deployment behavior rather than as ground truth.
A team reports that MobileNetV2 on an EdgeTPU achieves the advertised 2 ms inference time after INT8 quantization and deployment. Explain why this result alone is insufficient to validate the full optimization pipeline, and name the additional measurements each of the three benchmarking dimensions would require.
Historical Foundations
In 1976, when Whetstone became one of the first standardized computing benchmarks, vendors immediately began optimizing their compilers specifically for its floating-point tests—producing impressive numbers that predicted nothing about real application performance. This gaming problem has plagued every generation of benchmarks since. Understanding why ML benchmarking requires our three-dimensional approach demands tracing how measurement methodologies evolved, and often failed, over decades of computing history. Each generation of benchmarks emerged from the limitations of its predecessors, teaching lessons that directly inform modern ML evaluation.
Before that history begins, one boundary condition matters: a benchmark is useful only when it names the layer whose claim it validates.
That cross-layer role explains why benchmark history matters: each generation of performance measurement advanced when practitioners discovered that the previous method failed to predict real-world behavior. The evolution from simple performance metrics to ML benchmarking reveals three methodological shifts.
Performance benchmarks
The earliest computing benchmarks revealed a problem that plagues evaluation to this day: benchmark gaming. Mainframe benchmarks like Whetstone (Curnow and Wichmann 1976) and LINPACK3 (Dongarra et al. 1979) measured isolated operations (floating-point throughput, matrix solve speed), and vendors quickly learned to optimize specifically for these narrow tests rather than for practical performance. The resulting numbers looked impressive on paper but predicted little about how systems performed on actual workloads. SPEC CPU (1989) broke this cycle by using a suite of portable, application-oriented programs rather than a single synthetic kernel (Dixit 1993). This lesson directly shapes ML benchmarking: optimization claims from Model Compression require validation on representative tasks, and MLPerf’s inclusion of real models like ResNet-50 and BERT ensures benchmarks capture deployment complexity rather than idealized test cases.
3 Whetstone and LINPACK: Whetstone (Curnow and Wichmann 1976) was named after the English Electric facility in Whetstone, Leicestershire, where the original ALGOL compiler was built; LINPACK (Dongarra et al. 1979) was Jack Dongarra’s benchmark for dense linear systems, later adopted by the Top500 list in 1993. Both measured a single operation type so narrowly that compilers could be tuned to game the result: Whetstone’s floating-point loops became a test of compiler optimization rather than hardware performance. ML benchmarking inherited the same vulnerability: single-model benchmarks can be gamed through model-specific kernel tuning, which is why MLPerf requires multiple workloads spanning vision, language, and recommendation (Dongarra et al. 2003).
Curnow, H. J., and B. A. Wichmann. 1976. “A Synthetic Benchmark.” The Computer Journal 19 (1): 43–49. https://doi.org/10.1093/comjnl/19.1.43.
Dongarra, J. J., J. R. Bunch, C. B. Moler, and G. W. Stewart. 1979. LINPACK Users’ Guide. SIAM. https://doi.org/10.1137/1.9781611971811.
Dongarra, Jack J., Piotr Luszczek, and Antoine Petitet. 2003. “The LINPACK Benchmark: Past, Present and Future.” Concurrency and Computation: Practice and Experience 15 (9): 803–20. https://doi.org/10.1002/cpe.728.
Dixit, Kaivalya M. 1993. “Overview of the SPEC Benchmarks.” In The Benchmark Handbook for Database and Transaction Systems, 2nd ed., edited by Jim Gray. Morgan Kaufmann.
As deployment contexts diversified, a second limitation emerged: single-metric evaluation proved inadequate. Graphics benchmarks began measuring rendering quality alongside frame rate; mobile benchmarks added battery life as a co-equal concern with performance. The multi-objective challenges from Introduction (balancing accuracy, latency, and energy) manifest directly in ML evaluation, where no single metric captures deployment viability.
A third shift occurred when distributed computing revealed that component-level optimization fails to predict system-level performance. A CPU benchmark cannot predict cluster throughput when network communication dominates. ML training similarly depends on the interplay of accelerator compute (Hardware Acceleration), data pipelines, gradient synchronization, and storage throughput. MLPerf evaluates complete workflows, recognizing that performance emerges from component interactions, not from components in isolation.
DAWNBench (Coleman et al. 2019) emerged as an early ML benchmark that pioneered time-to-accuracy evaluation, directly influencing MLPerf’s methodology for measuring training efficiency. These lessons culminate in MLPerf4 (2018), which synthesizes representative workloads, multi-objective evaluation, and integrated measurement while addressing ML-specific challenges (Mattson et al. 2020; Reddi et al. 2019).
Coleman, Cody, Deepak Narayanan, Daniel Kang, Tian Zhao, Jian Zhang, Luigi Nardi, Peter Bailis, Kunle Olukotun, Christopher Ré, and Matei Zaharia. 2019. “Analysis of DAWNBench, a Time-to-Accuracy Machine Learning Performance Benchmark.” ACM SIGOPS Operating Systems Review 53 (1): 14–25. https://doi.org/10.1145/3352020.3352024.
4 MLPerf: Founded in 2018 by researchers from Google, NVIDIA, Intel, Harvard, Stanford, and UC Berkeley, the name combines “ML” with “Perf” (performance), echoing SPEC’s benchmarking tradition. MLPerf’s design principles—representative workloads, full-system measurement, and open submission—directly address the gaming that plagued Whetstone and LINPACK: vendors who could previously report peak kernel throughput on cherry-picked problem sizes must now report end-to-end system performance on standardized tasks (Mattson et al. 2020; Reddi et al. 2019).
Energy benchmarks
The multi-objective evaluation paradigm naturally extended to energy efficiency as computing diversified beyond mainframes with less constrained power budgets. Mobile devices demanded battery life optimization, while warehouse-scale systems faced energy costs rivaling hardware expenses. This shift established energy as a first-class metric alongside performance, spawning benchmarks like SPEC Power5 for servers and Green5006 for supercomputers.
5 SPEC Power: Introduced in 2007, SPEC Power measures performance per watt across 11 load levels from idle (0 percent) through 100 percent in 10 percent increments (Lange 2009). This granularity matters for ML serving: inference workloads rarely sustain 100 percent load, and servers that are efficient at peak but wasteful at partial load inflate the energy cost of real-world deployment.
Lange, Klaus-Dieter. 2009. “Identifying Shades of Green: The SPECpower Benchmarks.” IEEE Computer 42 (3): 95–97. https://doi.org/10.1109/mc.2009.84.
6 Green500: Started in 2007 as a counterpart to the Top500, Green500 ranks systems by FLOP/s per watt rather than raw performance (Feng and Cameron 2007). Its lesson for ML systems is methodological: the most cost-effective training cluster is not necessarily the fastest one, but the system that delivers useful work per watt under the workload and measurement boundary that matter.
Feng, Wu-chun, and Kirk W. Cameron. 2007. “The Green500 List: Encouraging Sustainable Supercomputing.” Computer 40 (12): 50–55. https://doi.org/10.1109/MC.2007.445.
MLCommons. 2024b. MLPerf Power Measurement.
Diverse workload patterns and system configurations continue to challenge power benchmarking across computing environments. MLPerf Power (MLCommons 2024b) addresses this with specialized methodologies for measuring the energy impact of machine learning workloads, reflecting energy efficiency’s central role in AI system design.
Energy benchmarking extends beyond hardware power measurement to include algorithmic efficiency. Model compression techniques (pruning, quantization, knowledge distillation) can reduce energy by changing the work a system performs, not only by changing the hardware that performs it. MobileNet-family architectures use depthwise separable convolutions and related design choices to reduce computation relative to heavier CNN baselines such as ResNet (Howard et al. 2017; Sandler et al. 2018; He et al. 2016). These techniques, detailed in Model Compression, establish that energy-aware benchmarking must evaluate algorithmic efficiency alongside hardware power consumption; Energy costs quantifies the specific energy breakdown of INT8 vs. FP32. As AI systems scale, this lesson becomes central to sustainable computing practices.
Howard, A. G., M. Zhu, B. Chen, D. Kalenichenko, W. Wang, T. Weyand, M. Andreetto, and H. Adam. 2017. “MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications.” CoRR abs/1704.04861.
Domain-specific benchmarks
As computing diversified beyond general-purpose servers, generic benchmarks proved inadequate for specialized domains. Three categories of specialization drove this evolution, each exposing measurement dimensions that general-purpose benchmarks could not address.
Deployment constraints shape core metric priorities. Data center workloads optimize for throughput with rack- and cluster-scale power budgets, while mobile AI operates within tight device thermal envelopes, and IoT devices require milliwatt-scale operation. These constraints, rooted in efficiency principles from Introduction, determine whether benchmarks prioritize total throughput or energy per operation.
Application requirements then impose functional and regulatory constraints beyond raw performance. Healthcare AI demands interpretability metrics alongside accuracy; financial systems may require very low latency with audit compliance; autonomous vehicles need safety-critical reliability and formal functional-safety validation. These requirements extend evaluation beyond traditional performance metrics; Responsible Engineering later systematizes the responsible-engineering principles behind fairness, interpretability, and compliance.
Operational conditions determine real-world viability. Autonomous vehicles face wide temperature ranges and degraded sensor inputs; data centers handle large concurrent request volumes with network faults; industrial IoT endures long deployments without maintenance. The hardware capabilities from Hardware Acceleration only deliver value when validated under these conditions.
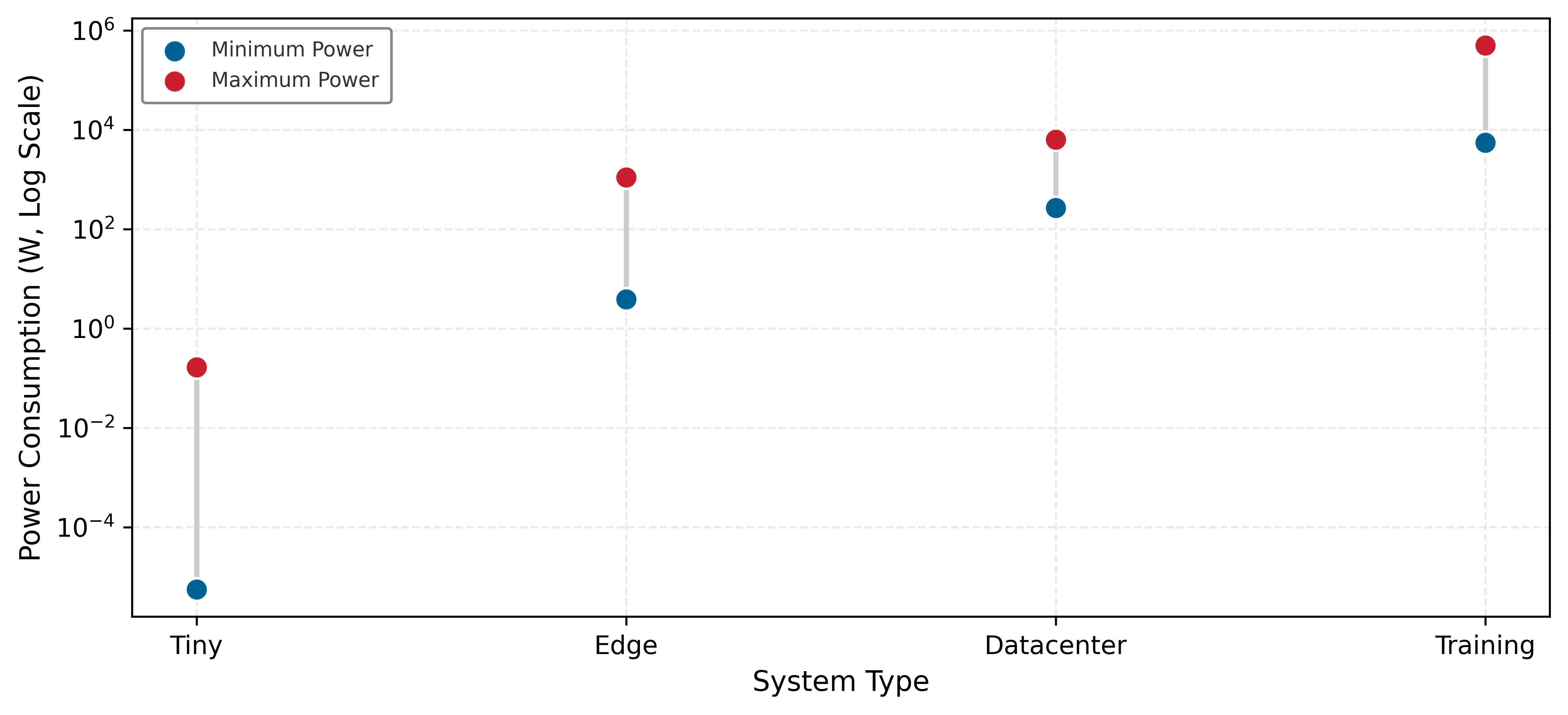
Machine learning exemplifies this transition to domain-specific evaluation. Traditional CPU and GPU benchmarks prove insufficient for assessing ML workloads, which involve complex interactions between computation, memory bandwidth, and data movement patterns. MLPerf provides standardized performance measurement for machine learning models across these categories: MLPerf Training addresses data center deployment constraints with multi-node scaling benchmarks (Mattson et al. 2020), MLPerf Inference evaluates latency-critical application requirements across server to edge deployments (Reddi et al. 2019), MLPerf Tiny assesses ultra-constrained operational conditions for microcontroller deployments (Banbury et al. 2021), and a cross-cutting MLPerf Power track measures energy efficiency under each of these regimes. Reading table 1 down its constraint column shows the binding limit tightening as deployment scale shrinks: multi-node interconnect bandwidth in the data center gives way to latency SLAs at the server and edge, then to ultra-low-power operation with kilobytes of memory at the microcontroller. The same three-category framework, applied to each scale, produces a suite whose metrics track what actually limits the system at that scale rather than a single universal score.
| MLPerf Variant | Target Domain | Key Constraints | Primary Metrics |
|---|---|---|---|
| MLPerf Training | Data center | Multi-node scaling, high bandwidth interconnects | Time-to-quality, throughput (samples/sec) |
| MLPerf Inference | Server/Edge | Latency SLAs, throughput requirements | QPS, latency percentiles, accuracy preservation |
| MLPerf Tiny | MCU/IoT | Ultra-low-power inference, limited memory | Latency, accuracy, energy per inference |
| MLPerf Power | Cross-cutting | Energy budgets, thermal constraints | Performance/W, energy per query |
MLPerf Power extends the same discipline to energy efficiency, where the benchmarked quantity is useful work per watt rather than raw throughput alone. Domain-specific benchmarks drive targeted hardware and software optimizations while ensuring that improvements translate to deployment success rather than narrow laboratory conditions.
This historical progression, from general computing benchmarks through energy-aware measurement to domain-specific evaluation frameworks, provides the foundation for understanding ML benchmarking challenges. The lessons learned (representative workloads over synthetic tests, multi-objective over single metrics, integrated systems over isolated components) directly shape AI system evaluation. Table 2 summarizes this progression and the key lessons each generation contributed.
| Benchmark | Year | Primary Focus | Key Metric(s) | Lesson for ML Benchmarking |
|---|---|---|---|---|
| Whetstone | 1976 | Synthetic floating-point operations | MWIPS | Gaming synthetic tests undermines evaluation validity |
| LINPACK | 1979 | Linear algebra (matrix operations) | FLOP/s | Isolated operations miss system-level complexity and bottlenecks |
| SPEC CPU | 1989 | Real application workloads | SPECrate, SPECspeed | Representative workloads reveal true deployment performance |
| SPEC Power | 2007 | Server energy efficiency | ssj_ops/W across load levels | Energy efficiency requires multi-load evaluation, not just peak performance |
| Green500 | 2007 | HPC energy efficiency | GFLOP/s per watt | Efficiency rankings complement raw performance rankings |
| MLPerf | 2018 | ML systems (training + inference) | Time-to-quality, QPS, latency, accuracy | Synthesizes all lessons: representative workloads + multi-objective + system |
These lessons culminate in ML benchmarking suites, yet ML systems face an additional challenge absent from traditional benchmarks: inherent probabilistic variability. Unlike traditional workloads with deterministic behavior, ML systems must satisfy all three historical lessons (representative workloads, multi-objective evaluation, integrated measurement) while also accounting for stochastic outcomes that vary with training data, weight initialization, and even operation ordering. This additional dimension of variability demands measurement methodologies that account for stochastic outcomes.
Individual organizations learned these lessons independently, often painfully, but isolated measurements cannot drive an industry. When one team measures inference latency including preprocessing and another excludes it, when accuracy benchmarks use different data splits, or when power measurements draw different system boundaries, the resulting numbers are incommensurable. The transition from ad-hoc measurement to standardized benchmarking suites transforms benchmarking from an internal validation exercise into a shared language that enables hardware procurement, architecture comparison, and deployment decisions across organizations.
Self-Check: Question
When Whetstone became standardized in 1976, vendors immediately tuned compilers specifically against its floating-point tests, producing strong numbers that did not predict real application performance. What methodological correction did SPEC CPU later introduce that directly addressed this failure mode?
- SPEC CPU replaced real application programs with more easily standardized synthetic inner loops
- SPEC CPU mandated vendor-specific compiler flags to make tuning results directly comparable
- SPEC CPU used suites of real compiled application programs so compiler optimizations had to improve actual workloads rather than a narrow synthetic target
- SPEC CPU restricted evaluation to energy-per-operation so compiler gaming could not affect the score
Explain why the rise of SPEC Power (2007) and Green500 (2007) changed the definition of a ‘winning’ system result, with specific reference to how warehouse-scale and mobile deployments made raw speed alone insufficient.
MLPerf splits into MLPerf Training, MLPerf Inference, MLPerf Tiny, and MLPerf Power rather than publishing one unified benchmark. Which historical lesson does this structural choice most directly encode?
- A single unchanging benchmark preserves cross-context comparability and should serve every deployment
- Energy benchmarking should wholly replace performance benchmarking now that modern accelerators are power-limited
- Microbenchmarks are sufficient for ML because full-application benchmarks vary too much to standardize across vendors
- Deployment regimes from microcontrollers to training clusters span nine orders of magnitude in power and memory, so the constraints that define ‘good’ differ enough that a single benchmark cannot be meaningful across them
True or False: The historical progression from performance to energy-aware to domain-specific benchmarks means raw throughput has been retired as a useful ML evaluation metric.
Order the following stages of computing-benchmark evolution from earliest to latest: (1) domain-specific ML benchmark suites like MLPerf, (2) narrow synthetic operation benchmarks like Whetstone and LINPACK, (3) representative whole-application benchmarks like SPEC CPU, (4) energy-first benchmarks like SPEC Power and Green500.
System Benchmarking Suites
A team evaluating edge deployment hardware needs to compare five different system on chip (SoC) designs for a smart camera product. Vendor A reports 8 TOPS at INT8; Vendor B reports 15 TOPS at INT4; Vendor C reports inference latency on a proprietary model; Vendor D cites MLPerf scores from two generations ago; Vendor E provides only peak throughput at maximum batch size. None of these numbers are comparable. The team cannot make a procurement decision because every vendor measured a different thing, under different conditions, using different definitions of “performance.” The problem is not a lack of data but a lack of commensurable data, and benchmarking suites exist to solve exactly this fragmentation.
Three lessons from benchmark history (representative workloads, multi-objective evaluation, and integrated measurement) converge with the challenge unique to ML: inherent probabilistic variability. Modern benchmarking suites encode these lessons into standardized frameworks that make the kind of cross-organization comparison our hardware procurement team needs possible.
ML benchmarks must evaluate the interplay between algorithms, hardware, and data, not merely computational efficiency alone. Early benchmarks focused on algorithmic performance (LeCun et al. 1998), but scaling demands expanded the focus to hardware efficiency (Jouppi et al. 2017), and high-profile deployment failures elevated data quality as a third evaluation dimension (Gebru et al. 2021). This probabilistic nature elevates accuracy to a first-class evaluation dimension alongside speed and energy consumption: the same ML system can produce different results depending on the data it encounters. Energy efficiency cuts across all three framework dimensions, since algorithmic choices affect computational complexity, hardware capabilities determine energy-performance trade-offs, and dataset characteristics influence training energy costs (Hernandez and Brown 2020).
Jouppi, Norman P., Cliff Young, Nishant Patil, David Patterson, Gaurav Agrawal, Raminder Bajwa, Sarah Bates, et al. 2017. “In-Datacenter Performance Analysis of a Tensor Processing Unit.” Proceedings of the 44th Annual International Symposium on Computer Architecture, ISCA ’17, 1–12. https://doi.org/10.1145/3079856.3080246.
Gebru, Timnit, Jamie Morgenstern, Briana Vecchione, Jennifer Wortman Vaughan, Hanna Wallach, Hal Daumé III, and Kate Crawford. 2021. “Datasheets for Datasets.” Communications of the ACM 64 (12): 86–92. https://doi.org/10.1145/3458723.
Hernandez, Danny, and Tom B. Brown. 2020. “Measuring the Algorithmic Efficiency of Neural Networks.” arXiv Preprint arXiv:2005.04305, ahead of print. https://doi.org/10.48550/arxiv.2005.04305.
ML measurement challenges
The unique characteristics of ML systems create measurement variability that many traditional benchmarks were not designed for. Unlike deterministic algorithms that produce identical outputs given the same inputs, ML systems exhibit inherent variability from multiple sources: algorithmic randomness from weight initialization and data shuffling, hardware thermal states affecting clock speeds, system load variations from concurrent processes, and environmental factors including network conditions and power management. This variability requires rigorous statistical methodology to distinguish genuine performance improvements from measurement noise.
To address this variability, effective benchmark protocols require multiple experimental runs with different random seeds. Running each benchmark 5–10 times and reporting statistical measures beyond simple means (including standard deviations or 95 percent confidence intervals) quantifies result stability and allows practitioners to distinguish genuine performance improvements from measurement noise.
Empirical studies have shown how inadequate statistical rigor can lead to misleading conclusions. Many reinforcement learning papers report improvements that fall within statistical noise (Henderson et al. 2018), while GAN comparisons often lack proper experimental protocols, leading to inconsistent rankings across different random seeds (Lucic et al. 2018). These findings underscore the importance of establishing measurement protocols that account for ML’s probabilistic nature.
Lucic, Mario, Karol Kurach, Marcin Michalski, Sylvain Gelly, and Olivier Bousquet. 2018. “Are GANs Created Equal? A Large-Scale Study.” Advances in Neural Information Processing Systems 31.
Representative workload selection determines benchmark validity. Synthetic microbenchmarks often fail to capture the complexity of real ML workloads where data movement, memory allocation, and dynamic batching create performance patterns not visible in simplified tests. Comprehensive benchmarking therefore requires workloads that reflect actual deployment patterns: variable sequence lengths in language models, mixed precision training regimes, and realistic data loading patterns that include preprocessing overhead.

A 1K test set cannot reliably see a one-point regression.
Napkin Math 1.1: The statistical confidence trap
Problem: A baseline image classifier has 95 percent accuracy. A “compressed” version is deployed and its accuracy measured on a 1,000-image test set, yielding 94 percent. Did the optimization cause a real regression, or is it noise?
Math:
Expected errors: At 95 percent accuracy, the test set produces 50 errors. At 94 percent, it produces 60 errors.
Standard Deviation \((\sigma_{\text{err}})\): Using the binomial distribution with \(N_{\text{test}}\) test examples and event probability \(p_{\text{err}} = \Pr(\text{err})\):
\[ \sigma_{\text{err}} \approx \sqrt{N_{\text{test}} \times p_{\text{err}} \times (1-p_{\text{err}})} = \sqrt{1000 \times 0.05 \times 0.95} \]
This yields approximately 7 errors.
Confidence interval (95 percent): 50 errors \(\pm\) 1.96 \(\times\) 7 errors \(\approx\) [36, 64].
Measurement implication: Both 50 errors and 60 errors fall inside the same confidence interval. A 1,000-sample test set cannot reliably detect a 1 percentage point accuracy drop. About 1,825 samples are enough to estimate a 95 percent accuracy rate with a 95 percent confidence interval of about ±1 percentage point; detecting a 1-point regression between two independently evaluated models requires a larger two-proportion power calculation.
Systems insight: Small benchmarks exhibit what amounts to a laboratory fallacy. The test set, viewed as a measurement instrument, must be sized to match the precision of the change it is meant to detect.
Beyond workload representativeness, the distinction between statistical significance and practical significance requires careful interpretation. A small performance improvement might achieve statistical significance across hundreds of trials but prove operationally irrelevant if it falls within measurement noise or costs exceed benefits. This creates what we call the statistical confidence trap, where seemingly rigorous evaluation still misleads.
Statistical confidence is a measurement-capacity problem: the benchmark may be pointed at the right quantity, but the test set is too small to resolve the change. A second failure mode is metric alignment. Here the measurement can be precise and reproducible, yet still reward behavior that violates the deployed system’s objective. The translation example makes that distinction concrete by showing how a BLEU improvement can come at the expense of latency.
Example 1.1: Goodhart's Law in action
Trap: Optimizing for a single metric often degrades others.
Scenario: A team optimizes a translation model for BLEU score, creating a Goodhart’s Law failure.
- Original model: BLEU = 28, Inference = 50 ms.
- Optimized model: BLEU = 28.5 (a 0.5-point gain), Inference = 200 ms (4× slower).
Analysis:
- The 0.5 BLEU gain comes from a larger beam search, which keeps the \(k\) most promising partial translations at each decoding step instead of one (beam_size = 10 vs. beam_size = 1).
- Cost: 10× more candidate evaluations per step.
- Result: The optimized model wins the leaderboard while violating the deployed system’s latency budget.
Systems lesson: Always constrain the optimization. Maximize Accuracy subject to Latency < 100 ms.
These measurement failures share a deeper limitation: a benchmark on a static dataset measures recognition under a fixed distribution, not the robustness to a shifting one that production demands. The data dimension of the framework developed later in this chapter confronts exactly that gap.
The preceding measurement challenges motivate evaluating each dimension of the three-dimensional framework (system, model, and data) with distinct methodologies. The bulk of this chapter focuses on system benchmarking (training benchmarks, inference benchmarks, and power measurement) because these form the foundation of standardized evaluation through MLPerf. Model and data benchmarking require different methodologies and are treated in detail in section 1.11 after we establish system evaluation foundations.
System benchmarks
System benchmarks measure the computational foundation that enables model capabilities, examining how hardware architectures, memory systems, and interconnects affect overall performance. This validation is critical because hardware specifications often describe theoretical peaks that real workloads never achieve. The discrepancy is common enough to make peak-performance claims misleading. System benchmarks reveal these gaps by running standardized ML workloads rather than synthetic microbenchmarks.
Systems Perspective 1.3: The fallacy of peak performance
Dave Patterson often refers to peak performance as “the performance the manufacturer guarantees you will not exceed.” For ML systems, that gap is especially wide because of the memory wall: a memory-bound model leaves most of the advertised FLOP/s unreachable no matter how fast the arithmetic units run. Standardized benchmarks like MLPerf are essential because they force systems to run real models on real data, revealing the true “sustained performance” that engineers can actually rely on.
The peak-vs.-sustained gap is structurally guaranteed by the memory wall, not an occasional anomaly that better engineering can avoid. Recognizing this structural nature reframes vendor evaluation from guesswork into a checklist of concrete criteria.
Checkpoint 1.1: Decoding vendor benchmark claims
When evaluating hardware or software based on vendor-reported benchmarks, check whether the claim identifies the workload, measurement boundary, and operating conditions.
Table 3 translates common marketing phrases into the technical caveats behind each.
| Vendor Claim | What It Often Means |
|---|---|
| “Up to 10,000 images/sec” | Peak throughput at maximum batch size, INT8, without preprocessing |
| “Sub-millisecond latency” | Accelerator compute only, excluding data transfer |
| “5\(\times\) more efficient” | Per-operation efficiency, not total system efficiency |
| “Optimized for AI” | May only accelerate specific operations or precisions |
The decision rule is to reject any benchmark claim whose workload boundary, precision, and excluded costs cannot be reconstructed. A headline throughput or latency number becomes useful only after the engineer can map it to the actual model, batch shape, data movement, sustained operating point, and power envelope.
The underlying hardware infrastructure (CPUs, GPUs, Tensor Processing Units (TPUs)7, and ASICs8) determines the speed, efficiency, and scalability of ML systems. System benchmarks establish standardized methodologies for evaluating hardware performance across AI workloads, measuring metrics including computational throughput, memory bandwidth, power efficiency, and scaling characteristics (Reddi et al. 2019; Mattson et al. 2020).
7 TPU (Tensor Processing Unit): Google’s custom ASIC for neural network workloads (architecture details in Hardware Acceleration). A TPU v4 pod (4,096 chips) delivers 1.1 exaFLOP/s peak BF16, but benchmarking TPUs requires caution: their systolic-array architecture favors regular tensor operations, so peak FLOP/s overstate performance on irregular workloads like sparse attention or dynamic control flow.
8 ASIC (Application-Specific Integrated Circuit): An ASIC’s peak TOPS number applies only to the specific operators it was designed for. A single unsupported layer forces fallback to a general-purpose processor, potentially negating the entire efficiency advantage. This makes operator coverage the first question in any ASIC benchmark: the gap between peak and achieved throughput is not a hardware limitation but a workload-compatibility limitation.
System benchmarks serve two functions. For practitioners, they enable informed hardware selection by providing comparative data across configurations. For manufacturers, they quantify generational improvements and guide accelerator development. The co-evolution has been dramatic: as GPU adoption grew, accuracy improved rapidly, demonstrating that hardware and algorithmic advances drive progress in tandem.
Effective benchmark interpretation requires knowing the performance characteristics of target hardware. Whether a specific AI workload is compute bound or memory-bound provides essential insight for optimization decisions. Computational intensity, measured as FLOP/byte9, determines performance limits. Consider an NVIDIA A100 GPU with 312 TFLOP/s of FP16 Tensor Core performance (FP32 is 19.5 TFLOP/s) and 2.04 TB/s memory bandwidth (SXM variant). Dividing peak compute by peak bandwidth yields an arithmetic intensity threshold of 153 FLOP/byte. Workloads below this threshold are bottlenecked by memory bandwidth, while those above are bottlenecked by compute capacity. The roofline model in Roofline Model provides the architectural foundation for interpreting these benchmark results. The roofline model derives the roofline equation and the ridge-point threshold from first principles, so the arithmetic intensity bound used here can be reconstructed for any accelerator.
9 FLOP/s (Floating-Point Operations Per Second): The gap between advertised peak FLOP/s and achieved FLOP/s is the central tension in hardware benchmarking. The A100 advertises 312 TFLOP/s FP16 Tensor Core, but real workloads achieve different fractions of peak depending on arithmetic intensity, memory access patterns, precision, and runtime overhead. Reporting peak FLOP/s without utilization context is the most common benchmarking distortion.
Definition 1.2: Machine learning system benchmarks
Machine Learning System Benchmarks are standardized evaluation protocols that hold the workload and quality target constant while varying the hardware-software stack, measuring \(\eta_{\text{hw}} = R_{\text{sustained}} / R_{\text{peak}}\) and \(L_{\text{lat}}\) to isolate infrastructure efficiency from algorithmic improvements.
- Significance: The same ResNet-50 model can deliver very different throughput across hardware stacks, precision formats, batch sizes, and compiler configurations, yet still report the same ImageNet Top-1 accuracy. System benchmarks capture this implementation gap, which is invisible to algorithmic benchmarks that only report accuracy.
- Distinction: Unlike algorithmic benchmarks (which vary model architectures and training procedures to improve convergence accuracy), system benchmarks hold the algorithm fixed and vary the implementation (kernel libraries, quantization formats, batch sizes, and hardware generations) to measure how efficiently the hardware-software stack executes the iron law’s \(O/(R_{\text{peak}} \cdot \eta_{\text{hw}})\) term.
- Common pitfall: A frequent misconception is that a system benchmark result generalizes across workloads. An accelerator that achieves high utilization on ResNet-50 (a compute-friendly vision workload) may achieve much lower utilization on a recommendation system (a memory-bandwidth-bound workload). System benchmarks are workload-specific; no single metric characterizes a hardware platform.
Roofline position10 depends on the workload. In this worked A100 example, high-intensity operations such as dense matrix multiplications in a ResNet-50 forward pass at large batch sizes reach arithmetic intensities around ~300 FLOP/byte, above the A100 ridge, and therefore behave as compute-bound kernels (He et al. 2016; Choquette et al. 2021). Low-intensity operations fall far below the ridge into the memory-bound regime: a BERT inference at batch size one, counting only weight-loading traffic, reaches only ~50 FLOP/byte arithmetic intensity and a small fraction of peak. Increasing the batch size moves that same workload across the ridge from memory-bound to compute-bound (Pope et al. 2023). A concrete example: The A100 analysis works the intensity-to-utilization calculation end to end on the A100, contrasting a compute-bound GEMM against a memory-bound element-wise operation, so the steps generalize to any model-hardware pair.
10 [offset=-25mm] Roofline Model: Williams et al. (2009) introduced the Berkeley model, named for the visual shape of its performance ceiling. Its ridge point (peak FLOP/s divided by peak bandwidth) separates memory-bound from compute-bound workloads, showing whether optimization should target data movement or arithmetic.
Williams, Samuel, Andrew Waterman, and David Patterson. 2009. “Roofline: An Insightful Visual Performance Model for Multicore Architectures.” Communications of the ACM 52 (4): 65–76. https://doi.org/10.1145/1498765.1498785.
Choquette, Jack, Wishwesh Gandhi, Olivier Giroux, Nick Stam, and Ronny Krashinsky. 2021. “NVIDIA A100 Tensor Core GPU: Performance and Innovation.” IEEE Micro 41 (2): 29–35. https://doi.org/10.1109/mm.2021.3061394.
Pope, Reiner, Sholto Douglas, Aakanksha Chowdhery, Jacob Devlin, James Bradbury, Jonathan Heek, Kefan Xiao, Shivani Agrawal, and Jeff Dean. 2023. “Efficiently Scaling Transformer Inference.” Proceedings of Machine Learning and Systems (MLSys) 5: 606–24.

Larger batches push transformer inference from memory-bound to compute-bound.
A worked BERT inference estimate shows how these roofline principles translate into concrete deployment predictions.
Napkin Math 1.2: Roofline analysis for BERT inference
Problem: BERT-Base must be deployed for inference on an A100 GPU. Management expects high GPU utilization. What performance should we predict, and how can we improve it?
Step 1: Hardware limits.
- Peak compute: 312 TFLOP/s (FP16 Tensor Core)
- Memory bandwidth: 2.04 TB/s
- Ridge point: 312 TFLOP/s ÷ 2.04 TB/s = 153 FLOP/byte
Any workload with arithmetic intensity below 153 FLOP/byte is memory bound; above is compute bound.
Step 2: BERT-base characteristics.
- Parameters: 110M = 440 MB (FP32)
- FLOPs per inference: ~22 GFLOP (forward pass with sequence length \(S=128\))
- Data movement: ~440 MB (must load all weights from memory)
- Arithmetic intensity: \((22 \times 10^{9}) \div (440 \times 10^{6})\) = 50 FLOP/byte (weights-only model; see note in main text)
Step 3: Performance prediction. Since 50 FLOP/byte < 153 FLOP/byte, BERT at batch = 1 is memory bound:
Achievable perf = 50 FLOP/byte \(\times\) 2.04 TB/s = 102 TFLOP/s
GPU utilization = 102 TFLOP/s ÷ 312 TFLOP/s = \(32.7\%\)
Step 4: Optimization via batching. Increase batch size to 32:
- Same 440 MB of weights, but 32× more compute
- New FLOPs: \(22 \times 10^{9} \times 32\) = 704 GFLOP
- New intensity: \((704 \times 10^{9}) \div (440 \times 10^{6})\) = 1600 FLOP/byte
Since 1600 FLOP/byte > 153 FLOP/byte, batch = 32 is compute bound:
Achievable perf ≈ \(85\%\) \(\times\) 312 TFLOP/s = 265.2 TFLOP/s \[\text{GPU utilization} \approx 85\%\]
Systems insight: Batch size transforms memory-bound inference (32.7 percent utilization) into compute-bound inference (85 percent utilization). Batching, however, increases latency because the system must wait to accumulate requests. This is the fundamental throughput-latency trade-off that MLPerf scenarios capture: SingleStream (batch = 1, latency-optimized) vs. Offline (maximum batch, throughput-optimized).
System benchmarks evaluate performance across scales, ranging from single-chip configurations to large distributed systems and covering AI workloads that include both training and inference tasks. This evaluation approach ensures that benchmarks accurately reflect real-world deployment scenarios and deliver insights that inform both hardware selection decisions and system architecture design. Figure 1 reveals the correlation between GPU adoption and ImageNet classification error rates from 2010 to 2014: as GPU entries surged from 0 to 110, top-5 error rates dropped from 28.2 percent to 7.3 percent (Russakovsky et al. 2015; Krizhevsky et al. 2012), illustrating how hardware capabilities and algorithmic advances can drive progress in tandem.

The ImageNet example demonstrates how hardware advances enable algorithmic breakthroughs. (We revisit this progression with model-specific architectural milestones in section 1.11.1.) Effective system benchmarking, however, requires understanding the relationship between workload characteristics and hardware utilization. Modern AI systems rarely achieve theoretical peak performance due to interactions between computational patterns, memory hierarchies, and system architectures. This gap between theoretical and achieved performance shapes how we design meaningful system benchmarks.
Realistic hardware utilization patterns are essential for actionable benchmark design. As the preceding roofline analysis demonstrated, GPU utilization varies dramatically with batch size and model architecture—from 85 percent for compute-bound workloads to 32.7 percent for memory-bound single-request inference. These patterns extend to memory bandwidth: parameter-heavy transformer inference and activation-heavy convolutional workloads stress different parts of the memory hierarchy, directly impacting achievable performance across different precision levels.
The consolidation across these factors is that effective system benchmarks must measure realistic utilization rather than peak theoretical capability, and several scope boundaries fall out of that requirement. Energy is one dimension: performance per watt varies by three orders of magnitude across platforms, and an underutilized accelerator consumes disproportionate power for its output, penalizing both operational cost and environmental impact. Distribution is another: multi-node training adds communication bottlenecks, network-topology effects, and coordination overhead that single-node benchmarks cannot capture and that warrant dedicated treatment beyond this book. Within the single-machine scope here, multi-GPU benchmarking instead focuses on intra-node communication, memory-bandwidth utilization across accelerators, and gradient-synchronization efficiency in shared-memory systems, where 4-8 GPUs on NVLink or PCIe deliver parallelism without the network challenges of multi-node clusters. Across all of these, a benchmark earns its value only when its operating point matches the deployment’s, not the datasheet’s.
Community-driven standardization
The hardware utilization insights are only useful for comparison when measured consistently, which requires community-driven standardization. When one team measures inference latency with preprocessing included and another excludes it, when accuracy benchmarks use different data splits, or when power measurements employ different system boundaries, meaningful comparison becomes impossible. Individual organizations cannot establish measurement standards alone; the proliferation of benchmarks across our three dimensions creates fragmentation that only coordinated effort can resolve.
The most successful benchmarks emerge through broad collaboration among academic institutions, industry partners, and domain experts. ImageNet’s lasting impact demonstrates how sustained community engagement through workshops, challenges, and open datasets establishes authority that corporate-driven benchmarks rarely achieve. This collaborative development creates a foundation for formal standardization: IEEE working groups (IEEE Standards Association 2024) and ISO/IEC technical committees (ISO 2024) codify community-developed methodologies into official standards (for example, IEEE 2416 (IEEE Standards Association 2019) for system power modeling), providing precise measurement specifications that enable reliable cross-institutional comparison. Projects that provide open-source reference implementations, containerized evaluation environments, and comprehensive validation suites further reduce barriers and ensure consistent interpretation across research groups.
IEEE Standards Association. 2024. IEEE Standards Association: Working Groups for AI and ML.
ISO. 2024. ISO/IEC JTC 1/SC 42 Artificial Intelligence.
IEEE Standards Association. 2019. IEEE 2416-2019: Standard for Power Modeling to Enable System-Level Analysis.
ML benchmarks must balance academic rigor with industry practicality, since theoretical advances must translate to practical improvements in deployed systems (Mattson et al. 2020; Reddi et al. 2019). Benchmarks that emerge from this balance, with transparent governance and regular evolution, become durable reference points; those developed in isolation struggle to gain traction regardless of technical sophistication. These evaluation methodology principles guide both training and inference benchmark design throughout this chapter.
Community standards ensure reproducibility, but they do not prescribe the level of detail at which measurements should be taken. A benchmark could time a single matrix multiplication or an entire training run—and each choice reveals different kinds of information. The depth of measurement, from individual operations to complete systems, determines what insights benchmarks can provide and which problems they can diagnose.
Self-Check: Question
A vendor advertises an accelerator at 300 TFLOP/s peak, but a BERT inference benchmark at batch size 1 achieves only 30 TFLOP/s (10 percent of peak). Apply the chapter’s roofline analysis to explain this gap.
- The benchmark is invalid because a correctly designed benchmark always drives the workload to peak FLOP/s
- The workload’s arithmetic intensity sits well below the accelerator’s ridge point, so memory bandwidth bounds the achievable rate rather than the compute ceiling
- The 10\(\times\) gap proves the advertised 300 TFLOP/s figure was falsified by the vendor
- The optimizer choice during inference is the primary factor limiting arithmetic throughput
Explain why the chapter requires 5-10 benchmark runs with confidence intervals rather than a single run, and describe a concrete scenario where a single-run result would mislead engineering decisions.
A vendor datasheet reports an accelerator delivering ‘10,000 images/second.’ According to the chapter’s guidance on interpreting such claims, which question is most essential to ask first?
- Which deep learning framework logo appears in the benchmark marketing materials
- What batch size, numerical precision, included pipeline stages, and thermal sustain conditions produced the number
- How many generations old the competitor hardware used for comparison was
- Whether the benchmark used the absolute latest compiler toolchain release
The chapter names the error of treating advertised peak TFLOP/s as a predictor of sustained ML workload rates the fallacy of peak ____, because memory stalls, kernel launch overhead, and software dispatch routinely leave real workloads far below the theoretical ceiling.
A procurement team evaluates five SoCs for an edge camera: Vendor A reports 8 TOPS at INT8, Vendor B reports 15 TOPS at INT4, Vendor C reports latency on a proprietary model, Vendor D cites MLPerf scores from two generations ago, and Vendor E reports only peak throughput at maximum batch size. Explain why community standardization is the only mechanism that can make these numbers commensurable for a real deployment decision.
Why does the chapter insist that no single benchmark result can characterize a hardware platform, even for a well-designed suite like MLPerf?
- Because benchmark-to-benchmark measurement variability makes any cross-benchmark comparison statistically impossible
- Because hardware efficiency is workload-dependent: an accelerator strong on compute-bound CNN training may be much weaker on memory-bound transformer inference or recommendation workloads
- Because every modern accelerator is tuned equally well for every ML workload category, rendering differentiation meaningless
- Because only energy metrics, not throughput metrics, carry meaningful information about hardware quality
Benchmarking Granularity
A GPU kernel that runs 3\(\times\) faster in isolation may deliver zero end-to-end speedup if the data pipeline cannot keep pace. This diagnostic failure illustrates a fundamental design choice: the level of detail at which evaluation occurs. Standardization specifies how measurement is consistent, while benchmarking granularity specifies what is measured. Each validation dimension can be assessed at different scales, from individual operations to complete workflows, with each granularity level revealing different kinds of problems:
- Micro benchmarks isolate individual components: kernel execution time, memory bandwidth utilization, single-layer accuracy. These diagnose where problems occur.
- Macro benchmarks evaluate subsystems: full model training convergence, inference pipeline throughput, dataset bias metrics. These reveal what problems exist.
- End-to-end benchmarks measure complete workflows: request-to-response latency including preprocessing, training time-to-accuracy including data loading, model performance on production data distributions. These show whether the system works.
The optimization techniques from Part III operate at different granularities (kernel fusion targets micro performance, pruning affects macro model behavior, data curation determines end-to-end generalization) and validation must match. A micro benchmark might show kernel speedup while a macro benchmark reveals memory bottlenecks that negate the gain; an end-to-end benchmark might expose data pipeline stalls invisible at any other level.
Figure 2 maps these granularity levels onto the ML stack by breaking the stack into four distinct evaluation scopes. Each scope progressively expands the measurement boundary: micro-benchmarks isolate neural network layers, macro-benchmarks encompass complete models, application benchmarks add supporting compute, and end-to-end benchmarks capture the full deployment context including non-AI components.

Micro benchmarks
While end-to-end benchmarks reveal overall system behavior, optimization requires pinpointing exactly which operations consume time and energy. Micro-benchmarks serve this diagnostic purpose by isolating individual tensor operations, the mathematical primitives whose hardware optimization we examined in Hardware Acceleration.
Consider debugging a slow inference pipeline: macro benchmarks might show unacceptable latency, but only micro-benchmarks reveal whether the bottleneck lies in convolutions, attention mechanisms, or memory copies. This diagnostic precision makes micro-benchmarks essential for the targeted optimization that transforms theoretical hardware capabilities into realized performance gains. These benchmarks isolate individual tasks to provide detailed insights into the computational demands of particular system elements, from neural network layers to optimization techniques to activation functions.
A key area of micro-benchmarking focuses on tensor operations, the computational core of deep learning. Libraries like cuDNN11 (Chetlur et al. 2014) by NVIDIA provide optimized primitives for core computations such as convolutions and matrix multiplications across different hardware configurations. Micro-benchmarks around these primitives help developers understand how their hardware handles the core mathematical operations that dominate ML workloads.
11 cuDNN (CUDA Deep Neural Network Library): Released by NVIDIA in 2014, cuDNN provides hand-tuned kernel implementations for convolutions, pooling, and normalization. The benchmarking implication: reported inference latencies depend heavily on which cuDNN version and algorithm autotuner settings were used, making cuDNN version a mandatory element of any reproducible benchmark specification.
Chetlur, Sharan, Cliff Woolley, Philippe Vandermersch, Jonathan Cohen, John Tran, Bryan Catanzaro, and Evan Shelhamer. 2014. “cuDNN: Efficient Primitives for Deep Learning.” arXiv Preprint arXiv:1410.0759.
Measuring these operations correctly requires discipline. A small set of measurement rules prevents common errors that can invalidate results entirely.
Systems Perspective 1.4: Micro-benchmarking rules
To avoid measuring hardware artifacts instead of kernel performance, follow the Systems Detective’s Rules:
- The warm-up rule: Do not measure cold-start iterations as steady-state performance. Modern hardware uses DVFS (dynamic voltage and frequency scaling) and Turbo Boost; caches, kernels, and clocks need warm-up before the measured loop represents sustained behavior.
- The variance rule: Report the Coefficient of Variation (CV) \((\text{CV} = \sigma_{\text{run}} / \mu_{\text{run}})\), where \(\sigma_{\text{run}}\) and \(\mu_{\text{run}}\) are the standard deviation and mean across repeated benchmark runs. If \(\text{CV} > 0.05\) (5 percent), the measurement is noisy. This usually indicates background OS jitter, thermal throttling, or memory contention.
- The “speed of light” (SOL) check: Compare the achieved throughput against the roofline. If a kernel achieves 10 TFLOP/s on an H100 (peak ~989 TFLOP/s FP16, or ~1,979 TFLOP/s FP8 dense), the diagnostic step is to identify the cause of low utilization (often kernel launch latency from too many small kernels) before optimizing the code itself.
- The flush rule: Memory bandwidth measurements must flush the L2 cache between runs; otherwise the reported “bandwidth” reflects cache speed (~5 TB/s–10 TB/s) rather than DRAM speed (~1 TB/s–2 TB/s).
A profiler turns these measurement rules into iron-law evidence by decomposing execution time into the terms introduced in Iron Law of ML Systems: data movement, compute throughput, and latency overhead.
Systems Perspective 1.5: Measuring the iron law terms
Moving from theory to trace means mapping the iron law equation from Iron Law of ML Systems onto a profiler timeline (like Nsight Systems or PyTorch Profiler).
Measuring the data term \(\left(\frac{D_{\text{vol}}}{\text{BW}}\right)\)
- Signal: Look for the “Memory Throughput” or “DRAM Bandwidth” line.
- Formula: \(\text{BW}_{\text{effective}} = \frac{D_{\text{vol}}}{T_{\text{kernel}}}\).
- Diagnosis: If \(\text{BW}_{\text{effective}} \approx \text{BW}_{\text{peak}}\) (for example, >1.6 TB/s on A100), the kernel is memory bound. Optimizing compute (\(O\)) will do nothing.
Measuring achieved compute throughput \((R_{\text{peak}} \cdot \eta_{\text{hw}})\)
- Signal: Look for “SM Active” or “Compute Throughput”.
- Formula: \(\text{Achieved TFLOP/s} = \frac{O}{10^{12}\,T_{\text{kernel}}}\).
- Diagnosis: If \(\text{Achieved TFLOP/s} \ll \text{Peak TFLOP/s}\) AND \(\text{BW}_{\text{effective}} \ll \text{BW}_{\text{peak}}\), the system is in the “Utilization Trap”: likely Latency Bound (kernels too small) or Grid Bound (not enough threads).
Measuring the latency term \((L_{\text{lat}})\)
- Signal: Look for gaps (empty space) between colored kernel bars on the timeline.
- Formula: \(\text{Overhead Ratio} = \frac{T_{\text{gap}}}{T_{\text{kernel}} + T_{\text{gap}}}\).
- Diagnosis: A “Sawtooth” pattern (Compute, Gap, Compute, Gap) indicates high software overhead. The solution is operator fusion, covered in Kernel fusion, or CUDA Graphs, which capture a repeated sequence of GPU launches so the runtime can replay it with less CPU dispatch overhead.
While benchmarks like MLPerf reveal how fast a system is, micro-benchmarking tools reveal why it is slow. To perform this diagnosis, engineers use kernel-level profilers that peer inside the execution of individual operations.
Framework profilers
Tools like PyTorch Profiler capture the logical execution flow of a training or inference step. They identify which layer dominates runtime, whether CPU and GPU work overlap or synchronize unnecessarily, and whether the data loader keeps the accelerator supplied. The diagnostic metric is the step-time breakdown across data loading, compute, and communication, because that breakdown tells the engineer which subsystem owns the next optimization.
Kernel profilers
Tools like NVIDIA Nsight Systems and Compute capture physical execution on the hardware. They determine whether a matrix multiplication is compute bound or memory bound, whether the Streaming Multiprocessors reach high occupancy, and whether memory accesses obey coalescing rules. The diagnostic metric is roofline position, because FLOP/s relative to memory bandwidth reveals whether more arithmetic throughput can help or whether the kernel is waiting on data movement.
The recommended workflow is to start with the Framework Profiler to find the slow layer (for example, “The Attention Block is slow”). Then, use the Kernel Profiler to diagnose the physics (for example, “The Softmax kernel is memory bound because it is reading too many bytes per FLOP”). This targeted approach avoids the “optimization without measurement” trap.
Micro-benchmarks also examine activation functions and neural network layers in isolation. This includes measuring the performance of various activation functions like the rectified linear unit (ReLU), Sigmoid, and Tanh under controlled conditions, and evaluating the computational efficiency of distinct neural network components such as LSTM cells or transformer blocks when processing standardized inputs.
DeepBench (Baidu Research 2016), developed by Baidu, was one of the first to demonstrate the value of comprehensive micro-benchmarking. It evaluates these core operations across different hardware platforms, providing detailed performance data that helps developers optimize their deep learning implementations. By isolating and measuring individual operations, DeepBench enables precise comparison of hardware platforms and identification of potential performance bottlenecks.
Baidu Research. 2016. DeepBench: Benchmarking Deep Learning Operations on Different Hardware.
These granular measurements enable precise optimization, but they cannot reveal how components interact when assembled into complete models. Macro-benchmarks address this gap.
Macro benchmarks
Micro-benchmarks confirm that individual convolution kernels run fast. Macro-benchmarks reveal whether the complete model works under realistic conditions. This shift from component-level to model-level assessment reveals how architectural choices and component interactions affect overall model behavior. For instance, while micro-benchmarks might show optimal performance for individual convolutional layers, macro-benchmarks reveal how these layers work together within a complete convolutional neural network.
Macro-benchmarks exist to serve one decision: choosing a model or architecture under standardized conditions. That decision needs the performance dimensions that emerge only at the model level: prediction accuracy, which shows how well the model generalizes to new data; memory consumption patterns across different batch sizes and sequence lengths; throughput under varying computational loads; and latency across different hardware configurations. These dimensions interact in ways a single-layer micro-benchmark cannot expose. A model that wins on accuracy may lose once its memory footprint at the target sequence length forces a smaller batch, collapsing the throughput that made it attractive, a coupling visible only when the complete model is measured as a unit.
The assessment of complete models occurs under standardized conditions using established datasets and tasks. For example, computer vision models might be evaluated on ImageNet (Deng et al. 2024), measuring both computational efficiency and prediction accuracy. Natural language processing models might be assessed on translation tasks, examining how they balance quality and speed across different language pairs.
Ignatov, Andrey, and Radu Timofte. 2024. AI Benchmark.
Several industry-standard benchmarks make model-level comparison reproducible across platforms. The MLPerf family (Inference, Mobile, Client, and Tiny) provides comprehensive testing suites adapted for computational environments from data center to microcontroller, detailed in section 1.8.4. For embedded systems, EEMBC’s MLMark emphasizes both performance and power efficiency, while the AI-Benchmark (Ignatov and Timofte 2024) suite specializes in mobile platforms.
End-to-end benchmarks
End-to-end benchmarks provide the most inclusive evaluation by encompassing the entire pipeline of an AI system, not just the model. This includes extract, transform, load (ETL) data processing, model inference, postprocessing of results, and critical infrastructure components like storage and network systems.
Data processing (extracting from source systems, transforming through cleaning and feature engineering, and loading into model-ready formats) forms the foundation of the pipeline. These preprocessing steps directly affect overall performance, and end-to-end benchmarks must assess standardized datasets through complete pipelines to ensure data preparation does not become a bottleneck. Postprocessing similarly affects real-world performance: a computer vision system must postprocess detection boundaries, apply confidence thresholds, and format results for downstream applications before the user sees a response.
Infrastructure components heavily influence overall performance beyond the AI workload itself. Storage solutions can dominate data retrieval times with large AI datasets, and network interactions in distributed systems can become performance bottlenecks. End-to-end benchmarks must evaluate these components under specified environmental conditions to ensure reproducible measurements of the entire system.
Public end-to-end benchmarks rarely account for data storage, network, and compute performance in one measurement. While MLPerf Training and Inference approach end-to-end evaluation, they primarily focus on model performance rather than real-world deployment scenarios. Nonetheless, they provide valuable baseline metrics for assessing AI system capabilities.
Given the inherent specificity of end-to-end benchmarking, organizations typically perform these evaluations internally by instrumenting production deployments. The sensitivity of these measurements means they rarely appear publicly, but their absence from the literature does not diminish their importance.
Granularity trade-offs and selection criteria
Table 4 reveals how different challenges emerge at different stages of an AI system’s lifecycle. Each benchmarking approach provides unique insights: micro-benchmarks help engineers optimize specific components like GPU kernel implementations or data loading operations, macro-benchmarks guide model architecture decisions and algorithm selection, while end-to-end benchmarks reveal system-level bottlenecks in production environments.
| Component | Micro Benchmarks | Macro Benchmarks | End-to-End Benchmarks |
|---|---|---|---|
| Focus | Individual operations | Complete models | Full system pipeline |
| Scope | Tensor ops, layers, activations | Model architecture, training, inference | ETL, model, infrastructure |
| Example | Conv layer performance on cuDNN | ResNet-50 on ImageNet | Production recommendation system |
| Advantages | Precise bottleneck identification, Component optimization | Model architecture comparison, Standardized evaluation | Realistic performance assessment, System-wide insights |
| Challenges | May miss interaction effects | Limited infrastructure insights | Complex to standardize, Often proprietary |
| Typical Use | Hardware selection, Operation optimization | Model selection, Research comparison | Production system evaluation |
Picking a single granularity level is rarely sufficient because a core tension exists between diagnostic precision and real-world fidelity. Figure 3 maps this trade-off, placing micro-benchmarks at the high-isolation end (precise but narrow) and end-to-end benchmarks at the high-representativeness end (realistic but harder to diagnose). No single point on this spectrum provides both: micro-benchmarks pinpoint exactly which kernel is slow but miss system-level bottlenecks, while end-to-end benchmarks capture production behavior but obscure root causes. The practical takeaway is that effective ML system evaluation requires combining insights from all three levels.

Component interaction often produces unexpected behaviors that single-level benchmarks miss. While micro-benchmarks might show excellent performance for individual operations and macro-benchmarks might demonstrate strong model accuracy, end-to-end evaluation can reveal that data preprocessing creates unexpected bottlenecks during high-traffic periods. These system-level insights remain hidden when components undergo isolated testing.
Choosing a granularity level, however, is only half the design problem. The other half is specifying the concrete ingredients every benchmark requires: the task, data, model, and metrics. Without those ingredients, even the right granularity level produces meaningless numbers. The components of a benchmark determine whether results translate into actionable engineering insight or merely generate impressive-looking numbers that collapse under scrutiny.
Self-Check: Question
A production inference service has mean latency of 80 ms. A profiler shows the softmax kernel alone takes 3 ms per request. The team suspects softmax is the bottleneck, but needs to confirm before optimizing. Which benchmarking approach best supports the diagnosis?
- Run only an end-to-end benchmark, since component-level tests never reveal root cause in isolation
- Run only a macro benchmark on the full model, since complete-model evaluation directly attributes latency to each layer
- Run a microbenchmark that isolates softmax under synthetic inputs to confirm the 3 ms figure, then an end-to-end benchmark to measure whether eliminating softmax would meaningfully change the 80 ms total
- Run only a power benchmark, since energy measurements inherently reveal both kernel and pipeline bottlenecks
Explain the trade-off between diagnostic precision and deployment representativeness across microbenchmarks, macrobenchmarks, and end-to-end benchmarks, with a concrete example where each level would reveal a different answer.
Which of the following is the best example of an end-to-end benchmark rather than a macro benchmark?
- Running ResNet-50 on ImageNet to compare full-model top-1 accuracy and throughput across accelerators
- Timing a single convolution kernel under different cuDNN autotuning settings
- Measuring a production recommendation pipeline that spans user-feature retrieval, candidate generation, model scoring, ranking, and response formatting
- Profiling the latency of a transformer attention block under fixed synthetic batch and sequence dimensions
True or False: If a GPU kernel runs 3\(\times\) faster in a microbenchmark, the deployed application will see roughly a 3\(\times\) speedup unless measurement noise is unusually high.
Order the following benchmark scopes from most isolated (narrowest measurement boundary) to most deployment-representative (broadest measurement boundary): (1) full production pipeline including data retrieval and response serialization, (2) single tensor operation under synthetic inputs, (3) complete model on a standardized dataset.
Benchmark Components
Choosing between micro, macro, and end-to-end granularity determines what a benchmark can diagnose, but every benchmark at every granularity must still specify the task, data, model, metrics, harness, system context, and run rules that make its result interpretable. Micro-benchmarks require synthetic inputs that isolate specific computational patterns; macro-benchmarks demand representative datasets like ImageNet; end-to-end benchmarks must incorporate real-world data with all its noise and distributional shift. Despite this variation, all benchmarks share a common implementation problem: each component must constrain the next one so the final number has a defensible meaning.
The essential components interconnect to form a complete evaluation pipeline. The workflow in figure 4 traces nine stages of an industrial audio anomaly detection benchmark, from problem definition through quantization to ARM embedded deployment. The serial dependency is the critical observation: the task definition constrains which datasets are valid, the dataset properties determine which model architectures are feasible, and the target hardware dictates quantization and compilation choices. Anomaly detection serves as an effective illustration precisely because it spans the full stack, coupling ML inference accuracy with embedded systems constraints such as memory footprint, power budget, and real-time latency. A benchmark that measured only classification accuracy or only inference speed would miss the interactions between these stages, where a decision at any point propagates forward and narrows every subsequent choice.

Effective benchmark design must account for the optimization techniques established in preceding chapters. Quantization and pruning affect model accuracy-efficiency trade-offs, requiring benchmarks that measure both speedup and accuracy preservation simultaneously. Hardware acceleration techniques influence arithmetic intensity and memory bandwidth utilization, necessitating roofline model analysis to interpret results correctly. Understanding these optimization foundations enables benchmark selection that validates claimed improvements rather than measuring artificial scenarios.
Problem definition
Every benchmark begins by specifying exactly what the system must do. The anomaly detection system in figure 4 processes audio signals to identify deviations from normal operation patterns, an industrial monitoring application that exemplifies how formal task specifications translate into practical implementations. While specific tasks vary widely by domain (natural language processing tasks include machine translation, question answering (Hirschberg and Manning 2015), and text classification; computer vision employs object detection and image segmentation (Everingham et al. 2009; Lin et al. 2014)), every benchmark task specification must define three essential elements: an input specification (what data the system processes), an output specification (what response the system must produce), and a performance specification (quantitative requirements for accuracy, speed, and resource utilization).
Hirschberg, Julia, and Christopher D. Manning. 2015. “Advances in Natural Language Processing.” Science 349 (6245): 261–66. https://doi.org/10.1126/science.aaa8685.
Everingham, Mark, Luc Van Gool, Christopher K. I. Williams, John Winn, and Andrew Zisserman. 2009. “The Pascal Visual Object Classes (VOC) Challenge.” International Journal of Computer Vision 88 (2): 303–38. https://doi.org/10.1007/s11263-009-0275-4.
Task design directly impacts the benchmark’s ability to evaluate AI systems. The audio anomaly detection example illustrates this through its specific requirements: processing continuous signal data, adapting to varying noise conditions, and operating within strict time constraints. These practical constraints create a framework for assessment that reflects real-world operational demands. Each subsequent phase of benchmark implementation, from dataset selection through deployment, builds directly upon these initial specifications.
Standardized datasets
A task definition is only as good as the data used to evaluate it. Standardized datasets ensure that all models undergo testing under identical conditions, enabling direct comparisons across different approaches—without them, every team would evaluate on private data, making cross-lab comparison impossible. In computer vision, ImageNet (Deng et al. 2024, 2009), COCO (Lin et al. 2014), and CIFAR-10 (Krizhevsky 2009) serve as reference standards; in natural language processing, SQuAD12 (Rajpurkar et al. 2016), GLUE13 (Wang et al. 2018), and WikiText (Merity 2016; Merity et al. 2016) fulfill similar roles, each encompassing a range of complexities and edge cases.
Deng, Jia, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. 2024. ImageNet.
Lin, Tsung-Yi, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C. Lawrence Zitnick. 2014. “Microsoft COCO: Common Objects in Context.” In Computer Vision – ECCV 2014. Springer. https://doi.org/10.1007/978-3-319-10602-1_48.
12 SQuAD (Stanford Question Answering Dataset): Introduced in 2016 with more than 100,000 question-answer pairs from Wikipedia (Rajpurkar et al. 2016). AI systems exceeded the SQuAD 1.1 human baseline of 91.2 percent F1 by 2018, but this “superhuman” result illustrates a benchmarking failure mode: the task’s extractive format (answers are text spans within the passage) makes it easier than open-ended question answering, inflating perceived capability relative to production NLP systems.
Rajpurkar, Pranav, Jian Zhang, Konstantin Lopyrev, and Percy Liang. 2016. “SQuAD: 100,000+ Questions for Machine Comprehension of Text.” Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, 2383–92. https://doi.org/10.18653/v1/d16-1264.
13 GLUE: GLUE’s saturation arc is a benchmark-obsolescence case study. Introduced in 2018 as a broad language-understanding benchmark (Wang et al. 2018), GLUE was quickly pressured by systems such as BERT (Devlin et al. 2019) and later models. This is Goodhart’s Law in action: once GLUE became a target, leaderboard optimization reduced its discriminating power. The pattern motivated harder follow-on evaluations such as SuperGLUE and BIG-bench.
Wang, Alex, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel R. Bowman. 2018. “GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding.” Proceedings of the 2018 EMNLP Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP, 353–55. https://doi.org/10.18653/v1/w18-5446.
Devlin, Jacob, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. “BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding.” Proceedings of the 2019 Conference of the North, 4171–86. https://doi.org/10.18653/v1/n19-1423.
Merity, Stephen. 2016. The WikiText Long Term Dependency Language Modeling Dataset.
Merity, Stephen, Caiming Xiong, James Bradbury, and Richard Socher. 2016. “Pointer Sentinel Mixture Models.” arXiv Preprint arXiv:1609.07843.
14 ToyADMOS: Developed by NTT Communications in 2019 for acoustic anomaly detection, containing audio recordings from toy car, toy conveyor, and related miniature-machine operating sounds (Koizumi et al. 2019). The “toy” prefix is intentional: the controlled environment enables reproducible benchmarking but can create a domain gap when models are moved to noisier industrial environments with different machines, sensors, vibration, and background sound.
Koizumi, Yuma, Shoichiro Saito, Hisashi Uematsu, Noboru Harada, and Keisuke Imoto. 2019. “ToyADMOS: A Dataset of Miniature-Machine Operating Sounds for Anomalous Sound Detection.” 2019 IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA), 313–17. https://doi.org/10.1109/waspaa.2019.8937164.
Dataset selection is the first place a benchmark can lose contact with deployment reality. In the audio anomaly detection example (figure 4), the dataset must include representative waveform samples of normal operation alongside comprehensive examples of anomalous conditions; domain-specific collections like ToyADMOS14 (Koizumi et al. 2019) for controlled anomaly-detection research and Google Speech Commands for general sound recognition address these requirements. Effective benchmark datasets must balance two competing demands: accurately representing real-world challenges while maintaining sufficient complexity to differentiate model performance. Simplified datasets like ToyADMOS are valuable for methodological development but may not capture the full complexity of production environments.
Model selection
With task and data specified, the benchmark must define which models to evaluate and what baselines to compare against. This choice is less straightforward than it appears: a benchmark’s model selection determines whether results reflect architectural innovation, implementation quality, or simply framework-specific optimizations. The selection process builds upon the architectural foundations established in Network Architectures and must account for the framework considerations discussed in ML Frameworks.
Baseline models serve as reference points spanning from basic implementations (linear regression, logistic regression) to advanced architectures with proven success in comparable domains. In NLP, models like BERT15 have emerged as standard baselines. Critically, the choice of baseline depends on the deployment framework: a PyTorch implementation may exhibit different performance characteristics than its TensorFlow equivalent due to framework-specific optimizations and operator implementations, meaning the benchmark must control for this variable.
15 BERT (Bidirectional Encoder Representations from Transformers): BERT-Large (340M parameters) became the default NLP baseline because its fixed-size encoder produces deterministic latency per input, unlike autoregressive models whose cost scales with output length. This predictability is precisely why MLPerf Inference adopted BERT as its NLP reference workload: a baseline must isolate hardware and software differences from model-inherent variability, and BERT’s constant-cost forward pass achieves that separation.
Once the architecture is selected, model development follows two parallel optimization paths that the benchmark must track. Training optimization focuses on achieving target accuracy within computational constraints. Inference optimization addresses the transition to production—particularly precision reduction from FP32 to INT8 or lower, which demands careful calibration to maintain accuracy while reducing resource requirements. The benchmark must specify requirements for both paths, because a model that trains efficiently but deploys poorly (or vice versa) fails the full evaluation. This dual optimization naturally demands quantitative evaluation metrics that span all three dimensions of our benchmarking framework.
Evaluation metrics
Evaluation metrics16 translate raw model behavior into numbers that can be compared, ranked, and used to make engineering decisions. The challenge is choosing the right numbers: a metric that captures accuracy but ignores latency may declare the winner to be a model too slow for production; one that rewards throughput but ignores energy may optimize for a deployment budget that does not exist.
16 Metric: In mathematics, a metric is a distance function satisfying strict axioms including the triangle inequality. ML borrows the term loosely for quantitative measures such as BLEU and perplexity, which are scoring rules rather than mathematical metrics. Leaderboard rankings can change when the evaluation protocol, dataset slice, or metric weighting changes, making the choice of metric an engineering decision that shapes which system wins, not just how we measure it.
Table 5 should be read as a decision aid: it categorizes metrics by the failure mode each exposes and the deployment context it serves.
| Category | Metric | Unit | Primary Use Case |
|---|---|---|---|
| Accuracy | Top-1/Top-5 Accuracy | Percentage | Classification |
| mAP (mean Average Precision) | 0-1 score | Object detection | |
| BLEU/ROUGE | 0-100 score | NLP generation | |
| Perplexity | Score (lower = better) | Language modeling | |
| Throughput | Samples/second | Samples/s | Batch inference |
| Token throughput | tokens/s | LLM inference | |
| Time-to-train | Hours/days | Training benchmarks | |
| Latency | p50 latency | Milliseconds | Median response time |
| p99 latency | Milliseconds | Tail latency (SLA) | |
| First-token latency | Milliseconds | LLM responsiveness | |
| Efficiency | Samples/second/watt | Samples/s/W | Energy efficiency |
| Accuracy/FLOP | percent/PFLOP | Algorithmic efficiency | |
| TCO per inference | $/inference | Economic efficiency |
Several distinctions within this taxonomy deserve emphasis. Throughput measures aggregate capacity (ideal for batch processing), while latency measures individual request timing (critical for interactive applications). These metrics frequently conflict: maximizing throughput through batching often increases per-request latency. Mean latency can hide problematic tail behavior—a system with 10 ms mean latency might have 500 ms p99 latency, failing SLA requirements. In production, percentiles (p50, p95, p99) are far more informative than means. Finally, compound metrics like samples/second/watt combine multiple dimensions into a single number, enabling quick comparisons but obscuring individual bottlenecks. Reporting both atomic and compound metrics provides a complete picture.
Metric choice must align with task objectives and deployment constraints, because the same raw model behavior can produce different scores across frameworks. The training methodologies from Model Training demonstrate how different frameworks handle loss computation and gradient accumulation differently, affecting reported metrics. Even small implementation differences, such as evaluation-mode batch-normalization handling, can shift measured accuracy enough to matter when benchmark deltas are small.
Task-specific metrics quantify a model’s performance on its intended function. For example, classification tasks employ metrics including accuracy (overall correct predictions), precision (positive prediction accuracy), recall (positive case detection rate), and F1 score (precision-recall harmonic mean) (Sokolova and Lapalme 2009). Regression problems use error measurements like Mean Squared Error (MSE) and Mean Absolute Error (MAE) to assess prediction accuracy. Domain-specific applications often require specialized metrics; for example, machine translation uses BLEU17 to measure modified n-gram precision against one or more human reference translations (Papineni et al. 2002).
17 BLEU (Bilingual Evaluation Understudy): Introduced by IBM in 2002, BLEU measures translation quality through modified n-gram precision with a brevity penalty against reference translations (Papineni et al. 2002). BLEU is a canonical example of Goodhart’s Law in ML: optimizing for n-gram matches can reward surface-level word overlap even when meaning, fluency, or deployment usefulness diverges from the target.
Papineni, Kishore, Salim Roukos, Todd Ward, and Wei-Jing Zhu. 2002. “Bleu: A Method for Automatic Evaluation of Machine Translation.” Proceedings of the 40th Annual Meeting on Association for Computational Linguistics - ACL ’02, 311–18. https://doi.org/10.3115/1073083.1073135.
Production deployment adds implementation metrics to task metrics. Model size, measured in parameters or memory footprint, directly affects deployment feasibility across different hardware platforms. Processing latency, typically measured in milliseconds per inference, determines whether the model meets real-time requirements. Energy consumption, measured in watts or joules per inference, indicates operational efficiency. These practical considerations reflect the growing need for solutions that balance accuracy with computational efficiency. The operational challenges of maintaining these metrics in production environments are explored in deployment strategies (ML Operations).
The benchmark therefore needs a metric set that matches both task requirements and deployment constraints. A single metric rarely captures all relevant aspects of performance in real-world scenarios. For instance, in anomaly detection systems, high accuracy alone may not indicate good performance if the model generates frequent false alarms. Similarly, a fast model with poor accuracy fails to provide practical value.
This multi-metric evaluation approach appears in our anomaly detection system, which reports performance across multiple dimensions: model size (270K parameters), processing speed (10.4 ms/inference), detection accuracy (0.86 AUC), and energy consumption (516 µJ per inference). This combination of metrics ensures the model meets both technical and operational requirements in real-world deployment scenarios.
Benchmark harness
Metrics define what to measure; the benchmark harness determines how to measure it. A harness is the test infrastructure that delivers inputs to the system under test, collects measurements, and ensures that the entire process is reproducible. Without a well-designed harness, even perfectly chosen metrics produce unreliable numbers.
Harness design must align with the intended deployment scenario. For server deployments, the harness generates request patterns that simulate real-world traffic, often using a Poisson distribution18 to model random but statistically consistent workloads, while managing concurrent requests and varying load intensities.
18 Poisson Distribution: Named after Siméon Denis Poisson, who formalized it in 1837 while modeling wrongful conviction rates in French courts. The distribution models independent events at a constant average rate \((\lambda_{\text{arr}})\), making it the standard assumption for server request arrivals. The benchmarking consequence: real ML serving traffic often violates the Poisson assumption due to bursty patterns (for example, viral content spikes), so benchmarks using Poisson arrivals systematically underestimate tail latency in production.
For embedded and mobile applications, the harness generates input patterns that reflect actual deployment conditions. This might involve sequential image injection for mobile vision applications or synchronized multi-sensor streams for autonomous systems. Such precise input generation and timing control ensures the system experiences realistic operational patterns, revealing performance characteristics that would emerge in actual device deployment.
The harness must also accommodate different throughput models. Batch processing scenarios require the ability to evaluate system performance on large volumes of parallel inputs, while real-time applications need precise timing control for sequential processing. In the embedded implementation phase, the harness must support precise measurement of inference time and energy consumption per operation.
Reproducibility demands that the harness maintain consistent testing conditions across different evaluation runs. This includes controlling environmental factors such as background processes, thermal conditions, and power states that might affect performance measurements. The harness must also provide mechanisms for collecting and logging performance metrics without measurably impacting the system under test.
System specifications
Complementing the harness that controls test execution, system specifications document the complete computational environment: the hardware and software stack on which the benchmark runs. Without precise specifications, a reported throughput number is meaningless: the same model can train much faster on a newer accelerator than on an older one, making the hardware context inseparable from the result.
On the hardware side, specifications must capture the processor type and clock rate, accelerator model and memory (GPU, TPU, or custom ASIC), system RAM, storage type, and network configuration for distributed setups. On the software side, they must record the operating system, framework versions (for example, PyTorch 2.1 vs. TensorFlow 2.14), compiler flags, and environment management tools such as Docker containers or virtual environments. This level of detail enables other researchers to replicate the benchmark environment with high fidelity and provides critical context for interpreting performance differences.
Many benchmarks include results across multiple hardware configurations, precisely because the trade-offs between model complexity, computational resources, and performance only become visible through comparative analysis. As the field increasingly prioritizes sustainability, specifications now extend to energy consumption metrics such as FLOP/s per watt and total power draw over training time, reflecting growing awareness that computational efficiency is an engineering requirement, not merely an environmental aspiration.
Run rules
System specifications describe what the benchmark runs on; run rules govern how it runs. These procedural constraints ensure that results can be reliably replicated, which is harder than it sounds in a field where stochastic processes (weight initialization, data shuffling, and dropout masks) mean that two identical runs on identical hardware can produce different numbers. Run rules tame this randomness by mandating fixed seeds, controlled data ordering, and systematic handling of every source of nondeterminism.
Hyperparameter documentation is equally critical. A learning-rate change can shift convergence and final accuracy, so benchmarks require exhaustive recording of every configuration setting. Similarly, benchmarks mandate the preservation and sharing of training and evaluation datasets; when privacy or licensing constraints prevent direct sharing, detailed preprocessing specifications enable construction of comparable datasets.
Code provenance completes the reproducibility chain. Contemporary benchmarks typically require publication of implementation code in version-controlled repositories—not just the model, but the full pipeline of preprocessing, training, and evaluation scripts. Advanced benchmarks distribute containerized environments that encapsulate all dependencies and configurations, while mandating detailed experimental logging: training metrics, model checkpoints, and documentation of any mid-experiment adjustments. Together, these protocols transform benchmarking from a one-time measurement into a verifiable, iterable scientific process.
Result interpretation
Producing benchmark numbers is the easy part; interpreting them correctly is where most engineers go wrong. A raw throughput figure or accuracy score is meaningless without understanding the conditions that produced it, the statistical confidence behind it, and the deployment context that determines whether the number matters.
Example 1.2: Benchmarking a vision model for edge deployment
Scenario: A team validates MobileNetV2 (Sandler et al. 2018) for a wildlife camera trap running on a Raspberry Pi 4.
Table 6: MobileNetV2 INT8 quantization trade-off: Latency, accuracy, and model size for FP32 and INT8 precisions on MobileNetV2.
The critical question is whether the accuracy cost of INT8 is acceptable for this deployment—table 6 shows that quantization trades a modest accuracy drop for dramatic latency and size improvements:
| Precision | Latency (ms) | Accuracy (Top-1) | Model Size |
|---|---|---|---|
| FP32 | 120 ms | 71.8% | 14 MB |
| INT8 | 35 ms | 70.9% | 3.5 MB |
Systems insight: The 3.4× speedup and 4× size reduction from quantization come at a cost of 0.9 percentage points of top-1 accuracy. For a battery-powered real-time system with this tolerance, INT8 is the clear choice, enabling about 28.6 FPS processing compared to about 8.3 FPS with FP32.
Before drawing conclusions from benchmark results, apply the vendor claim analysis framework introduced earlier (see the “Decoding Vendor Benchmark Claims” checklist) and extend it with two additional checks. First, the comparison must be fair: comparing ResNet-50 against MobileNet conflates architecture differences with optimization choices; precision differences (FP32 vs. INT8) alone can explain 2–4\(\times\) performance gaps, and batch size, hardware generation, and software framework must all be controlled. Second, the statistics must be meaningful: reliable results require multiple runs, reported variance with confidence intervals, clear handling of outliers, and steady-state operation rather than cold-start effects. Applying these questions to a representative vendor claim illustrates how incomplete specifications obscure real performance.
Beyond vendor claims, context determines which metrics matter most. A 1 percent accuracy improvement may be decisive for medical diagnostics but irrelevant for an application that prioritizes inference speed. Practitioners should also guard against benchmark overfitting, where models are excessively optimized for specific benchmark tasks at the expense of real-world generalization, by evaluating performance on related but distinct tasks and considering practical deployment scenarios.
Systems Perspective 1.6: Interpreting a benchmark claim
A vendor claims “Our system achieves 10,000 inferences/second on ResNet-50.” Taken alone, the number cannot support deployment planning because the conditions that determine its meaning are unstated.
Four unstated conditions determine what the claim means:
- Batch size: Large batches often achieve high throughput but can violate latency targets; batch 1 achieves low latency but lower throughput.
- Precision: INT8 is 2–4\(\times\) faster than FP32 on supported hardware but may have accuracy or calibration implications.
- Measurement boundary: The claim must state whether it covers pure inference or includes preprocessing.
- Accuracy: The claim must state whether the model matches the original 76.1 percent Top-1 or a degraded level.
A complete specification: “10,000 inferences/second on ResNet-50 at batch size 32, INT8 precision, 76 percent Top-1 accuracy, including JPEG decoding, on NVIDIA H100 at 700 W TDP.”
Systems insight: Understanding whether a performance difference is meaningful requires both statistical rigor and contextual validation. A benchmark number without these details is a marketing claim, not an engineering specification.
Example benchmark
To see how these components work together in practice, walk through the anomaly detection pipeline in figure 4 one more time, now focusing on the output stage. The benchmark produces three complementary measurements: a model size of 270K parameters with 10.4 ms per inference (computational resources), a detection accuracy of 0.86 AUC in distinguishing normal from anomalous audio patterns (task effectiveness), and an energy consumption of 516 µJ per inference (operational efficiency).
Which of these metrics matters most depends entirely on the deployment context. Energy consumption per inference is critical for battery-powered devices but irrelevant for always-on server racks. Model size constrains embedded devices with limited memory but barely registers for cloud deployments. Processing speed determines whether the system can operate in real-time or must batch inputs. These metrics also reveal inherent trade-offs: reducing model size from 270K parameters might improve speed and energy efficiency but degrade the 0.86 AUC detection accuracy. Whether these measurements constitute a “passing” benchmark depends on the deployment constraints—the framework provides structure for consistent evaluation, but acceptance criteria must come from the application requirements.
The components just enumerated define how to assemble any single benchmark. Two benchmark categories recur often enough across the optimization pipeline to warrant their own component checklists here: compression benchmarks, which a pruned or quantized model must pass before deployment, and mobile and edge benchmarks, which a power- and thermally-constrained target imposes. Each composes the task, data, model, metrics, harness, and run rules just defined while adding constraints the generic checklist does not. Both are previews of dimensions the chapter develops fully later: compression validation returns in section 1.11.1.3 with the full multi-metric protocol, and sustained-power behavior returns in section 1.9.
Compression benchmarks
Neural network compression (pruning, quantization, knowledge distillation, and architecture optimization) requires specialized benchmarks because compression reshapes the trade-off landscape: every byte saved or operation eliminated must be weighed against potential accuracy loss and hardware compatibility. The most basic compression metric is raw size reduction: parameter count, memory footprint in bytes, and compressed storage requirements. Size alone, however, is misleading. On ImageNet, MobileNetV2 achieves approximately 72 percent top-1 accuracy with 3.5M parameters vs. ResNet-50’s 76 percent accuracy with 25.6M parameters, about 7.3× fewer parameters at comparable accuracy, or roughly 6.9× more accuracy per parameter (Sandler et al. 2018; He et al. 2016).
Li, Hao, Asim Kadav, Igor Durdanovic, Hanan Samet, and Hans Peter Graf. 2017. “Pruning Filters for Efficient ConvNets.” International Conference on Learning Representations (ICLR).
Pruning benchmarks must distinguish between structured and unstructured approaches, because they produce qualitatively different results on real hardware. Structured pruning removes entire neurons or filters, yielding smaller dense operations that conventional kernels can exploit (Li et al. 2017). Unstructured pruning eliminates individual weights and can produce very sparse models, but realizing actual speedups requires specialized sparse computation support—meaning benchmark protocols must specify hardware platform and software implementation (Han et al. 2015; Gale et al. 2019).
Quantization benchmarks evaluate precision reduction across data types. INT8 delivers the 4\(\times\) memory reduction and 2–4\(\times\) inference speedup quantified for the MobileNetV2 lighthouse in table 6, with the precision-accuracy trade-off analyzed in section 1.8.2 and the energy implications in section 1.7.2.4. Mixed-precision approaches push further by applying different precision levels to different layers: critical layers retain FP16 while computation-heavy layers use INT8 or INT4, enabling fine-grained efficiency optimization. Knowledge distillation adds another dimension: a smaller student model can preserve much of a teacher’s behavior while reducing size and inference cost, but benchmarking must verify that the student generalizes rather than merely memorizing the teacher’s outputs (Hinton et al. 2015).
Critically, acceleration factors vary dramatically across hardware platforms: sparse models, reduced-precision models, and efficient architectures only deliver speedups when the target runtime has kernels, memory layouts, and accelerator support that exploit them. Current benchmark suites like MLPerf focus primarily on standardized reference models, while production deployments often use compressed or hardware-specific variants. This gap between what benchmarks measure and what production actually runs remains one of the field’s most consequential blind spots.
Mobile and edge benchmarks
Mobile and edge deployments face constraints radically different from cloud environments, requiring specialized benchmarking approaches that capture the unique trade-offs in resource-constrained settings. These constraints form an interdependent triangle of power consumption, inference latency, and model accuracy, where improving any two typically degrades the third. Edge deployment requires navigating trade-offs that cloud deployments can largely ignore, summarized in table 7.
| Constraint | Cloud Impact | Edge Impact |
|---|---|---|
| Power | Operational cost (~$0.10/kWh) | Hard limit (battery capacity) |
| Latency | User experience metric | Safety-critical deadline |
| Accuracy | Primary optimization target | Constrained by power/latency |
As a concrete example, a smartphone camera AI for real-time object detection may need to process video-rate inputs while staying inside a tight thermal envelope. In that setting, a MobileNet-family model can be the correct benchmark target even if a larger ResNet-family model reports higher accuracy in a cloud setting, because the edge benchmark must include sustained latency, power, and thermal behavior. A sustained edge benchmark exposes these gaps between marketed specifications and operational behavior. The peak-versus-sustained gap established in section 1.1 turns acute at the edge for a physical reason absent in the data center: a passively cooled device cannot shed the heat of continuous inference indefinitely, so burst-mode numbers can degrade under thermal throttling. That thermal mechanism, not measurement sloppiness, makes edge benchmarking a categorically different exercise than cloud benchmarking.
Example 1.3: Benchmarking the edge
Scenario: An engineering team is selecting a device for a smart doorbell. The vendor claims the chip runs “AI at 1 W.”
Setup: A continuous object detection loop is run.
Observation:
- Early burst: The chip runs quickly at the advertised power point.
- Heat buildup: Sustained inference raises junction temperature.
- Thermal throttling: The clock speed drops to stay inside the thermal envelope.
- Steady state: The chip stabilizes at a lower throughput than the burst result.
Systems insight: The peak result is not the product reality. A user experience designed around burst throughput is broken from the start. Always benchmark sustained performance, not just peak.
Thermal throttling in a constrained passive-cooling envelope can begin during sustained inference, making short burst benchmarks misleading for always-on applications. Any edge evaluation must therefore account for sustained power draw under thermal steady state, not burst-mode peaks, and must measure end-to-end latency including data transfer overhead.

Burst benchmark FPS collapses once thermal throttling sets in.
Systems Perspective 1.7: Edge benchmark reality check
When evaluating edge hardware claims, four factors determine whether vendor numbers translate to real-world performance:
- Peak vs. sustained: A vendor may advertise 45 TOPS peak throughput while a sustained thermal run delivers closer to 20 TOPS. Always benchmark under sustained workloads longer than 30 s.
- Power at idle vs. active: In this scenario, a device consuming 50 mW idle and 2 W active could report active draw for marketing, but if the application runs inference 1 percent of the time, effective power draw is ~69.5 mW, not 2 W.
- Thermal envelope: Edge devices often operate inside a narrow thermal design power (TDP) envelope. Exceeding it triggers throttling, so benchmark reports omitting thermal conditions are incomplete.
- End-to-end vs. accelerator-only: NPU benchmarks often exclude data transfer overhead. Moving image data from camera to NPU and back can exceed inference time for small models.
Heterogeneous processor coordination
Mobile SoCs integrate heterogeneous processors (CPU, GPU, DSP, NPU) requiring specialized benchmarking that captures workload distribution complexity while accounting for thermal and battery constraints. Effective processor coordination can deliver large gains when work is placed on the processor that matches its compute pattern. Each processor excels at different workload profiles: CPUs handle control flow, small batches, and sequential processing; GPUs accelerate parallel floating-point operations and general ML inference; DSPs excel at fixed-point signal processing and always-on detection tasks; and NPUs target specific neural network architectures with INT8/INT4 precision.
Benchmarks must evaluate workload placement decisions, not just individual processor performance. A voice assistant, for example, might use a low-power DSP for always-on wake-word detection, switch to an NPU for a short speech-recognition burst, and use the CPU for language understanding. Single-processor benchmarks miss these orchestration dynamics entirely.
Battery and thermal benchmarking
Battery impact varies dramatically by use case: computational photography can consume watts during active capture, while background AI for activity recognition may need to stay in a milliwatt-scale budget for acceptable all-day endurance. The challenge is that instantaneous power draw during inference tells only part of the story; what matters for battery life is the total energy budget across a realistic usage pattern.
The most important factor is the workload duty cycle: what fraction of time the system actually runs inference. A doorbell camera that processes occasional frames spends nearly all its time idle, making standby power the dominant concern. A real-time video analytics pipeline, by contrast, is inference-bound almost continuously, making per-inference energy the critical metric. Background power, the energy consumed when the model is loaded but waiting for input, bridges these extremes and often exceeds inference energy for intermittent workloads. Finally, sustained thermal behavior must be characterized over minutes rather than seconds, because edge devices that deliver impressive burst performance frequently throttle as junction temperatures rise, settling at substantially lower steady-state throughput.
Edge-cloud coordination
Mobile benchmarking must also evaluate 5G/Wi-Fi edge-cloud coordination, with URLLC19 emphasizing very low latency and high reliability for critical applications. This coordination introduces benchmarking dimensions absent from purely local evaluation. Network latency variability means that inference pipelines splitting work between device and cloud face unpredictable round-trip costs. Fallback behavior determines what happens when connectivity fails entirely: whether the device degrades gracefully to a smaller on-device model or queues requests until connectivity resumes. Workload splitting decisions (what computation runs locally vs. remotely) and privacy constraints (what data can be transmitted for cloud inference) further shape the benchmark design space. Each of these dimensions must be measured under realistic network conditions rather than idealized lab connectivity.
19 URLLC (Ultra-Reliable Low-Latency Communication): 5G service category requiring 99.999 percent reliability and <1 ms latency. These dual constraints force a systems trade-off: pushing compute closer to users reduces round-trip latency, but the edge hardware available at that location may be smaller and more power constrained than a centralized cloud cluster. URLLC benchmarking must therefore measure the entire chain: radio latency + compute latency + model accuracy at the constrained size.
Automotive deployments add ASIL validation, multi-sensor fusion, and wide-temperature environmental testing. These unique requirements necessitate comprehensive frameworks evaluating sustained performance under thermal constraints, battery efficiency across usage patterns, and connectivity-dependent behavior, extending beyond isolated peak measurements.
Whether benchmarking cloud servers or microcontrollers, however, a critical distinction cuts across all deployment contexts: the same neural network behaves entirely differently depending on whether it is learning or predicting. This distinction shapes what we measure, how we measure it, and which metrics matter—and it is so fundamental that separate benchmarking frameworks have emerged for each phase.
Self-Check: Question
A benchmark report claims excellent throughput but omits framework version, accelerator model, compiler flags, and driver stack. Which benchmark component is most directly missing?
- System specifications
- Problem definition
- Evaluation metrics
- Standardized datasets
A server inference harness uses sequential requests at fixed inter-arrival times, while real production traffic follows Poisson-like arrivals with occasional bursts. Explain how this harness choice shapes the benchmark result rather than just recording it, and what changes when the harness is corrected.
For an anomaly-detection model deployed on a battery-powered embedded device, which metric set best matches the chapter’s multi-metric guidance?
- Only AUC, with operational constraints evaluated after model selection is finalized
- Only parameter count, because model size determines all other embedded deployment constraints
- Only throughput, because real-time embedded systems are fundamentally throughput-limited rather than latency-sensitive
- AUC, latency per inference, and energy per inference, because deployment viability depends jointly on detection quality, response time, and sustained operation under battery constraints
To make stochastic training benchmarks reproducible, the chapter argues that benchmark ____ must specify random seed handling, data-ordering discipline, precision constraints, and the exact procedure for executing the workload, rather than leaving these choices to the submitter.
A compression report claims 10\(\times\) parameter reduction via unstructured pruning. Explain why size reduction alone is insufficient evidence that the compression delivers deployment value, using the chapter’s multi-dimensional compression benchmarking principle.
An edge hardware vendor advertises excellent burst inference performance on a vision model. Which omitted benchmark condition is most likely to make this number misleading for a smartphone-class deployment?
- Whether the benchmark dataset was public or proprietary
- Whether sustained thermal behavior was measured, since mobile silicon typically throttles under continuous load and steady-state performance can fall well below burst-mode peaks
- Whether the benchmark reported top-5 accuracy in addition to top-1 accuracy
- Whether the benchmark compared against one baseline model rather than two
Training vs. Inference
The same accelerator can fail in opposite ways: a training job may waste days because gradient synchronization dominates, while an inference service may miss its SLO because tail latency spikes under bursty traffic. Training and inference therefore create evaluation requirements so different that separate benchmarking frameworks emerged for each: MLPerf Training and MLPerf Inference (Mattson et al. 2020; Reddi et al. 2019). The critical question is whether theoretical TFLOP/s translate to practical time-to-train or queries-per-second. Training seeks optimal parameters through iterative refinement (Model Training), processing billions of examples over hours or days, stressing memory bandwidth, multi-GPU scaling, and sustained throughput. Inference applies those parameters to individual inputs in serving systems (Model Serving), often within millisecond deadlines, stressing latency consistency, cold-start time (model startup delay), and power efficiency; ML Operations connects those measurements to rollout and monitoring practice.
The differences cascade through every aspect of system design. Training involves bidirectional computation (forward and backward passes), while inference performs single forward passes with fixed parameters. Memory allocation diverges sharply: training requires simultaneous access to parameters, gradients, optimizer states, and activations, creating 3–4\(\times\) memory overhead compared to inference. Training employs mixed-precision computation and gradient compression to manage this overhead, while inference uses more aggressive precision reduction (detailed in section 1.8.2) and techniques like post-training quantization and knowledge distillation. Resource utilization patterns also contrast: training targets sustained GPU saturation, whereas inference contends with variable request patterns that leave hardware underutilized, as the roofline analysis in section 1.3.2 demonstrated.
Energy costs follow different patterns. Training energy costs are amortized across model lifetime and measured in total energy per trained model; estimates for large training runs can reach the scale of thousands of megawatt-hours (GPT-3 has been estimated at roughly 1,287 MWh) (Patterson et al. 2021). Inference energy costs accumulate per query and can become a dominant operational consideration at scale. A durable way to reason about per-query energy is the identity \(E_{\text{total}} = \text{Power} \times T\). For example, a 300 W accelerator running a 10 ms inference consumes \(300 W \times 0.01 s = 3 J\), which is about 0.0008 Wh; at 100 ms, that becomes about 0.0083 Wh.
The training-vs.-inference distinction guides benchmark design by highlighting which metrics matter most for each phase and how evaluation methodologies must differ. Training benchmarks emphasize convergence time and scaling efficiency; inference benchmarks prioritize latency consistency and resource efficiency across diverse deployment scenarios. We examine training benchmarks first, because the quality of the trained model sets the ceiling for everything inference can deliver.
Self-Check: Question
Why does the chapter argue that MLPerf Training and MLPerf Inference must be separate benchmark frameworks rather than one unified suite, even when they may run on identical accelerator hardware?
- Because training optimizes for time-to-convergence and sustained throughput across hours, while inference optimizes for per-request latency, tail behavior, and serving efficiency under unpredictable load, so the two phases are evaluated by different success criteria
- Because training and inference are implemented in different programming languages that cannot share hardware measurement
- Because inference never runs on accelerators while training always does
- Because only inference has power consumption worth reporting
Explain why memory requirements diverge sharply between training and inference for the same model, using the forward-only versus forward-plus-backward-plus-optimizer-state distinction.
True or False: Because training and inference can run on the same accelerator class, the primary performance metric should typically be identical across the two phases.
Training Benchmarks
In an illustrative procurement failure, a team purchases a larger GPU cluster expecting proportional training-speed gains, only to discover that communication overhead and memory bottlenecks limit the actual speedup. Training benchmarks exist to catch this kind of gap before procurement. They divide into three categories: convergence metrics that measure learning progress, throughput metrics that measure computational efficiency, and scalability metrics that measure distributed performance.
Training benchmarks validate whether hardware acceleration delivers promised training throughput. The GPU clusters, TPU pods, and distributed training strategies examined in Hardware Acceleration all claim dramatic speedups, and training benchmarks reveal which claims hold under realistic workloads. They evaluate how hardware configurations, data loading mechanisms, and distributed training strategies perform when training production-scale models. These benchmarks are vital because training represents the largest capital expenditure in ML systems, and only rigorous time-to-accuracy measurement reveals whether that capital delivers proportional value rather than dissipating into scaling inefficiencies, memory bottlenecks, or communication overhead.
For instance, large-scale models like OpenAI’s GPT-320 (Brown et al. 2020), which consists of 175B parameters trained on approximately 570 GB of filtered CommonCrawl text (from a ~45 TB raw dataset, combined with other sources to form 300B training tokens), highlight the immense computational demands of modern training. Standardized ML training benchmarks provide systematic evaluation of the underlying systems to ensure that hardware and software configurations can meet these unprecedented demands efficiently.
20 GPT-3: OpenAI’s 2020 language model (175B parameters, 300B training tokens) consumed an estimated 3,640 petaFLOP-days on 10,000 V100 GPUs (Patterson et al. 2021). This scale illustrates why training benchmarks are essential for predicting whether a planned training run is operationally viable before committing the compute.
Patterson, David, Joseph Gonzalez, Quoc Le, Chen Liang, Lluis-Miquel Munguia, Daniel Rothchild, David So, Maud Texier, and Jeff Dean. 2021. “Carbon Emissions and Large Neural Network Training.” arXiv Preprint arXiv:2104.10350.
Definition 1.3: ML training benchmarks
ML Training Benchmarks are machine learning system benchmarks that measure the time to reach a target quality metric (for example, a specified validation accuracy or loss threshold) on a fixed dataset and model, quantifying the rate of convergence per unit of resource.
- Significance: Training benchmarks reveal large gaps invisible to hardware specs. Holding the model and quality target fixed, the time to convergence can vary widely across hardware-software stacks because training performance depends on the full pipeline: data loading \((D_{\text{vol}}/\text{BW})\), compute utilization \((\eta_{\text{hw}})\), gradient synchronization \((L_{\text{lat}})\), and fault recovery overhead. A peak FLOP/s spec sheet captures none of these interactions.
- Distinction: Unlike inference benchmarks, which measure per-query latency and throughput under load, training benchmarks measure time-to-accuracy across the full optimization loop: data loading, forward pass, backward pass, gradient synchronization, and optimizer step. The binding constraint shifts from compute \((R_{\text{peak}})\) at small scale to communication \((\text{BW})\) at large scale.
- Common pitfall: A frequent misconception is that training benchmarks measure “how fast the GPU runs.” At large scale, interconnect bandwidth \((\text{BW})\) for gradient synchronization and fault tolerance overhead (checkpoint I/O, straggler mitigation) often dominate the benchmark result more than peak FLOP/s.
Training benchmark motivation
MLPerf Training (Mattson et al. 2020; MLCommons 2024c) provides the standardized framework for this kind of time-to-quality measurement, and its impact is striking: figure 5 demonstrates that performance improvements across successive MLPerf Training benchmark versions have consistently outpaced a Moore’s Law baseline, with some workloads showing very large multi-year speedups (Tschand et al. 2024). This exponential improvement illustrates a core principle: what gets measured gets improved. The standardized benchmarking framework creates competitive pressure that drives rapid optimization across the entire ML computing stack.

Beyond charting that progress, training benchmarks uncover the inefficiencies that systematic evaluation makes visible: slow data loading, underutilized accelerators, excessive memory overhead, and communication bottlenecks that erode scaling efficiency. The theoretical hardware capabilities established in Hardware Acceleration (for example, GPU TFLOP/s, TPU tensor throughput) only translate to actual training speedups when benchmarks verify them under realistic conditions.
Training benchmarks serve four interconnected functions. First, they enable hardware and software optimization by providing vendor-neutral comparisons across accelerator architectures and frameworks (TensorFlow, PyTorch) on standardized tasks, guiding hardware selection for data centers and cloud environments. Software optimizations including mixed-precision training21 and memory-efficient data loading are similarly quantified. Second, they evaluate scalability: adding GPUs should reduce training time proportionally, but communication overhead, synchronization latency, and memory bottlenecks limit scaling efficiency in practice. Training benchmarks quantify these losses, revealing whether infrastructure investments deliver proportional returns. Third, they provide cost and energy accountability: with large-scale training runs consuming thousands of megawatt-hours, benchmarks that track cost per training run and power consumption per unit of progress help organizations balance computational power with sustainability goals. Finally, they ensure fair, reproducible comparison through standardized evaluation criteria, controlled randomness, and strict submission guidelines that guarantee performance results reflect genuine system capabilities rather than implementation-specific tuning.
21 Mixed-Precision Training: Uses lower precision for most arithmetic while preserving higher-precision accumulation where needed (Micikevicius et al. 2017). The benchmarking consequence: mixed-precision and full-precision runs are not directly comparable because reduced memory traffic and larger feasible batch sizes can change convergence dynamics. MLPerf addresses this by fixing the accuracy target, making time-to-accuracy the comparable quantity regardless of precision strategy.
Micikevicius, Paulius, Sharan Narang, Jonah Alben, Gregory Diamos, Erich Elsen, David Garcia, Boris Ginsburg, et al. 2017. “Mixed Precision Training.” arXiv Preprint arXiv:1710.03740.
Training metrics
From a systems perspective, training benchmarks assess how efficiently a model reaches a predefined accuracy threshold. Metrics like throughput and scalability are only meaningful relative to whether the model achieves its target accuracy; without this constraint, optimizing raw speed may be misleading. MLPerf Training codifies this by defining specific accuracy targets per task: a system that trains quickly but misses the target is invalid, and one that converges accurately but too slowly is impractical. Effective benchmarking balances speed, efficiency, and accuracy convergence.
Time and throughput
One of the primary metrics for evaluating training efficiency is the time required to reach a predefined accuracy threshold. Training time \((T_{\text{train}})\) measures how long a model takes to converge to an acceptable performance level, reflecting the overall computational efficiency of the system. Let \(\text{Accuracy}(t)\) be the model’s accuracy at training time \(t\), and let target accuracy be the benchmark-specific threshold (for example, 75.9 percent top-1 accuracy for ResNet-50 on ImageNet in MLPerf). Equation 1 formally defines this metric, keeping the benchmark focused on how quickly a system achieves meaningful results:
\[T_{\text{train}} = \operatorname{arg\,min}_{t} \big\{ \text{Accuracy}(t) \geq \text{target accuracy} \big\} \tag{1}\]
Throughput22, often expressed as the number of training samples processed per second, provides an additional measure of system performance. Let \(N_{\text{samples}}\) be the total number of training samples processed and \(T_{\text{train}}\) the training time from equation 1. Equation 2 shows: \[\text{Throughput} = \frac{N_{\text{samples}}}{T_{\text{train}}} \tag{2}\]
22 Throughput: From manufacturing, where it measured units passing through a production line per unit time. The term entered computing in the 1960s batch-processing era. The manufacturing origin carries a systems lesson: throughput and latency are inherently opposed, because batching increases throughput (more units per hour) at the cost of individual item wait time. In ML serving, this manifests as the batch-size trade-off: larger batches improve GPU utilization but increase per-request latency.
MLCommons. 2024c. MLPerf Training Benchmark.
Throughput alone does not guarantee meaningful results, as a model may process a large number of samples quickly without necessarily reaching the desired accuracy. For example, MLPerf Training specifies workload-specific quality targets; a ResNet-50 result on ImageNet must reach a top-1 accuracy target of 75.9 percent to be valid (Mattson et al. 2020; MLCommons 2024c). A hypothetical system that processes many images per second but fails to reach the target is not a valid benchmark result, while a slower system that converges efficiently can be preferable. This highlights why throughput should be evaluated in relation to time-to-accuracy rather than as an independent performance measure.
Scalability and parallelism
Scalability measures how effectively training performance improves as resources are added. Ideally, doubling GPU count should halve training time. In practice, communication overhead, memory bandwidth limits, and parallelization inefficiencies constrain scaling well below linear.
When training large-scale models such as GPT-3, OpenAI employed a large cluster of NVIDIA V100 GPUs in a distributed training setup (Brown et al. 2020; Patterson et al. 2021). Google’s TPU v4 systems demonstrate the same distributed-systems lesson at data center scale: adding computational resources provides more raw power, but performance and resiliency depend on network communication, topology, and operational management (Jouppi et al. 2023; Zu et al. 2024). Benchmarks such as MLPerf quantify how well a system scales across multiple accelerators, providing insights into where inefficiencies arise in distributed training.
Brown, Tom B., Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, et al. 2020. “Language Models Are Few-Shot Learners.” Advances in Neural Information Processing Systems 33: 1877–901. https://doi.org/10.48550/arxiv.2005.14165.
Jouppi, Norm, George Kurian, Sheng Li, Peter Ma, Rahul Nagarajan, Lifeng Nai, Nishant Patil, et al. 2023. “TPU v4: An Optically Reconfigurable Supercomputer for Machine Learning with Hardware Support for Embeddings.” Proceedings of the 50th Annual International Symposium on Computer Architecture, 1–14. https://doi.org/10.1145/3579371.3589350.
Zu, Y., A. Ghaffarkhah, H.-V. Dang, B. Towles, S. Hand, S. Huda, A. Bello, et al. 2024. “Resiliency at Scale: Managing Google’s TPUv4 Machine Learning Supercomputer.” 21st USENIX Symposium on Networked Systems Design and Implementation (NSDI 24), 761–74.
Parallelism in training is categorized into data parallelism, model parallelism, and pipeline parallelism (see Model Training), each presenting distinct challenges. Data parallelism, the most commonly used strategy, involves splitting the training dataset across multiple compute nodes. The efficiency of this approach depends on synchronization mechanisms and gradient communication overhead. In contrast, model parallelism partitions the neural network itself, requiring efficient coordination between processors. Benchmarks evaluate how well a system manages these parallelism strategies without degrading accuracy convergence. A key metric for evaluating parallelism is scaling efficiency, which quantifies how much of the added computational capacity translates into actual speedup.
Napkin Math 1.3: Scaling efficiency calculation
Problem: A team trains ResNet-50 on ImageNet. Single-GPU training takes 24 hours. With 8 GPUs, training takes 4 hours. Is this good scaling? Where did the efficiency go?
Table 8: Scaling Efficiency Loss Sources: Illustrative decomposition of the missing efficiency budget into measurable overhead categories and the corresponding measurement signal used to attribute each loss. Actual percentages depend on model, interconnect, storage, batch schedule, and framework implementation.
Step 1: Define scaling efficiency. For strong scaling (fixed problem size, more processors), let \(T(1)\) be the training time on a single GPU, \(T(N_{\text{GPU}})\) the training time on \(N_{\text{GPU}}\) GPUs, and \(N_{\text{GPU}}\) the GPU count. Equation 3 defines efficiency: \[\text{Eff}_{\text{scaling}} = \frac{T(1)}{N_{\text{GPU}} \times T(N_{\text{GPU}})} \times 100\% \tag{3}\]
Step 2: Calculate efficiency. \(\text{Eff}_{\text{scaling}}(8) = \frac{24\,\text{hours}}{8 \times 4\,\text{hours}} \times 100\%\) = 24/32 = 75 percent
With perfect scaling, 8 GPUs would complete in 3 hours (24 hours/8 GPUs). The actual 4 hours represents 75 percent efficiency.
Step 3: Account for the efficiency loss. Table 8 decomposes the “missing” 25 percent into measurable overhead categories—gradient synchronization, memory copy, load imbalance, and batch-size effects—each measurable through a distinct profiling signal.
| Source | Example Contribution | Measurement |
|---|---|---|
| Gradient synchronization | 10-15% | AllReduce time per step |
| Memory copy (CPU↔︎GPU) | 3-5% | Data transfer profiling |
| Load imbalance | 2-5% | Per-GPU step time variance |
| Batch size effects | 2-5% | Larger batches converge differently |
Step 4: The systems insight. Scaling efficiency decreases as \(N_{\text{GPU}}\) grows because communication overhead scales with GPU count while per-GPU compute shrinks. In this worked example, eight GPUs reach 75 percent efficiency; at larger scales, the same arithmetic makes clear why sophisticated communication and input-pipeline optimization become necessary.
MLPerf reports both raw performance and scaling efficiency for this reason: a system achieving 2\(\times\) throughput at 50 percent efficiency may be worse than 1.5\(\times\) throughput at 90 percent efficiency, depending on cost constraints.
Resource utilization
The efficiency of machine learning training depends not only on speed and scalability but also on how well available hardware resources are used. Compute utilization measures the extent to which processing units, such as GPUs or TPUs, are actively engaged during training. Low utilization may indicate bottlenecks in data movement, memory access, or inefficient workload scheduling.
For instance, when training BERT on a TPU cluster, input-pipeline inefficiencies can limit overall throughput even when the accelerators have high raw compute power. If storage retrieval or preprocessing cannot keep up, the system fails to keep the TPUs fully busy. Profiling resource utilization identifies the bottleneck, and optimizations such as prefetching, caching, and more parallel input processing can improve sustained performance.
Memory bandwidth is another critical factor, as deep learning models require frequent access to large volumes of data during training. If memory bandwidth becomes a limiting factor, increasing compute power alone will not improve training speed. Benchmarks assess how well models use available memory, ensuring that data transfer rates between storage, main memory, and processing units do not become performance bottlenecks.
I/O performance also plays a direct role in training efficiency, particularly when working with large datasets that cannot fit entirely in memory. Benchmarks evaluate the efficiency of data loading pipelines, including preprocessing operations, caching mechanisms, and storage retrieval speeds. Systems that fail to optimize data loading can experience large slowdowns, regardless of computational power.
Energy efficiency and cost
Training large-scale machine learning models requires substantial computational resources, leading to considerable energy consumption and financial costs. Energy efficiency metrics quantify the power usage of training workloads, helping identify systems that optimize computational efficiency while minimizing energy waste. The increasing focus on sustainability has led to the inclusion of energy-based benchmarks, such as those in MLPerf Training, which measure power consumption per training run. The same power accounting governs inference, where precision becomes the dominant energy lever; section 1.9 works through why INT8 quantization cuts per-inference energy by attacking both memory traffic and arithmetic cost.
Training GPT-3 was estimated to consume 1,287 MWh of electricity (Patterson et al. 2021). If a system can achieve the same accuracy with fewer training iterations, it directly reduces energy consumption. Energy-aware benchmarks help guide the development of hardware and training strategies that optimize power efficiency while maintaining accuracy targets.
Cost considerations extend beyond electricity usage to include hardware expenses, cloud computing costs, and infrastructure maintenance. Training benchmarks provide insights into the cost-effectiveness of different hardware and software configurations by measuring training time in relation to resource expenditure. Organizations can use these benchmarks to balance performance and budget constraints when selecting training infrastructure.
Fault tolerance and robustness
Training workloads often run for extended periods, sometimes spanning days or weeks, making fault tolerance an essential consideration. A resilient system must handle unexpected failures (hardware malfunctions, network disruptions, and memory errors) without compromising accuracy convergence.
In large-scale cloud-based training, node failures are an operational reality. If a GPU node in a distributed cluster fails, training must continue without corrupting the model. Production training systems use checkpointing for fault tolerance, where models periodically save their progress so that failures do not require restarting the entire training process. For large language model training, however, checkpointing is itself a systems bottleneck: a single checkpoint must write model weights plus optimizer states to network storage, which at 100-billion-parameter scale can mean hundreds of gigabytes written before training resumes. During that write, accelerators can stall, degrading time-to-accuracy by extending the effective iteration time. Production LLM training systems address this by overlapping checkpoint I/O with the next training step (asynchronous checkpointing) or by using high-bandwidth parallel file systems that reduce idle time. MLPerf Training itself primarily measures time-to-quality under standardized workloads and does not benchmark failure recovery directly, but checkpoint overhead is a material component of any real sustained-throughput number.
Reproducibility and standardization
Reproducibility studies have repeatedly shown that modest benchmark gains can disappear when random seeds, hardware, framework versions, or implementation details change (Henderson et al. 2018). This failure mode illustrates a pervasive problem: training benchmarks involve stochastic processes (weight initialization, data shuffling, dropout masks) that interact with hardware-specific behaviors (floating-point rounding, memory layout, compiler optimizations) to produce results that can vary meaningfully across environments.
Henderson, Peter, Riashat Islam, Philip Bachman, Joelle Pineau, Doina Precup, and David Meger. 2018. “Deep Reinforcement Learning That Matters.” Proceedings of the AAAI Conference on Artificial Intelligence 32 (1): 3207–14. https://doi.org/10.1609/aaai.v32i1.11694.
A deeper layer of non-determinism comes from the parallel hardware itself. Operations such as parallel atomic additions, used during gradient accumulation for sparse embeddings in models like Graph Neural Networks, execute in non-deterministic order across threads when concurrent updates target the same memory location. The resulting floating-point summation order changes across runs, producing bit-for-bit different gradients even with identical inputs and seeds. Enforcing bit-exact reproducibility in these cases requires disabling the parallel accumulation paths, which reduces training throughput—a direct trade-off between reproducibility and performance that benchmark protocols must explicitly address. Without explicit controls for all these sources of variability, benchmark numbers reflect a specific confluence of conditions rather than a system’s genuine capability.
MLPerf Training addresses this by enforcing strict reproducibility requirements: fixed random seeds, standardized data preprocessing, and submission rules that demonstrate result stability across accepted runs (Mattson et al. 2020). The point is not merely to produce a fast run, but to show that the reported performance reflects system capability rather than a favorable combination of stochastic factors.
For a training benchmark, reproducibility is therefore the full run envelope, not just the random seed. A credible report must preserve the model commit, dataset checksum, preprocessing pipeline, seed plan, framework and compiler versions, precision policy, batch schedule, hardware topology, thermal and power limits, and checkpoint behavior. It must also report the distribution of accepted runs rather than a single best run. Only then can the benchmark separate a real system improvement from a favorable interaction among software version, hardware state, and stochastic training path.
Training performance evaluation
A comprehensive training benchmark considers multiple dimensions of system behavior because each dimension identifies a different way hardware investment can fail to become convergence. Table 9 summarizes the core categories and associated metrics commonly used to benchmark system-level training performance, providing a framework for understanding how training systems behave under different workloads and configurations.
| Category | Key Metrics | Example Benchmark Use |
|---|---|---|
| Training Time and Throughput | Time-to-accuracy (seconds, minutes, hours); Throughput (samples/sec) | Comparing training speed across different GPU architectures |
| Scalability and Parallelism | Scaling efficiency (percent of ideal speedup); Communication overhead (latency, bandwidth) | Analyzing distributed training performance for large models |
| Resource Utilization | Compute utilization (percent GPU/TPU usage); Memory bandwidth (GB/s); I/O efficiency (data loading speed) | Optimizing data pipelines to improve GPU utilization |
| Energy Efficiency and Cost | Energy consumption per run (MWh, kWh); Training throughput per watt (FLOP/s/W) | Evaluating energy-efficient training strategies |
| Fault Tolerance and Robustness | Checkpoint overhead (time per save); Recovery success rate (percent) | Assessing failure recovery in cloud-based training systems |
| Reproducibility and Standardization | Variance across runs (percent difference in accuracy, training time); Framework consistency (TensorFlow vs. PyTorch vs. JAX) | Ensuring consistency in benchmark results across hardware |
The dimensions in table 9 interact in ways that tables cannot capture. Higher throughput from reduced precision (for example, TF32) is meaningless if it increases the iterations required to reach target accuracy, making time-to-accuracy the essential corrective metric. Scaling efficiency can look nearly linear at small node counts but taper as gradient synchronization costs dominate. Resource utilization metrics reveal why: a BERT pretraining task with moderate GPU utilization may be bottlenecked by its data pipeline, not its accelerators. Checkpointing for fault tolerance introduces its own overhead, requiring balance between resilience and performance.
Across all dimensions, measurement accuracy depends on controlling for hardware variability. GPU boost clock23 behavior and thermal throttling24 can shift results enough to swamp small claimed gains, making repeated runs and statistical rigor (as established earlier) essential for distinguishing genuine performance differences from noise.
23 GPU Boost Clock: Dynamic frequency scaling raises clocks above base when thermal and power headroom permit. The benchmarking trap: short benchmark runs can capture boost-clock performance, but sustained ML training may settle to lower steady-state frequencies as junction temperature rises. Reporting burst-phase results overstates the throughput a production workload can sustain.
24 Thermal Throttling: Frequency reduction triggered when junction temperature exceeds safe limits. For edge devices without active cooling, throttling can begin during sustained inference, meaning peak throughput numbers from short benchmarks may misrepresent steady-state performance.
Despite the availability of well-defined benchmarking methodologies, misleading conclusions recur when teams treat one training metric as a substitute for the whole optimization loop. The following pitfalls show where the benchmark must keep speed, convergence, scaling, and reproducibility tied together.
Training benchmark failures usually start when throughput is treated as the objective rather than as one part of the learning process. A system can increase examples per second by using lower numerical precision, reducing synchronization, or even bypassing certain computations, but those changes only help if convergence is preserved. A TF32 run may outpace FP32 per step and still lose overall if numerical instability increases the number of iterations required to reach the target accuracy. The benchmark therefore has to report throughput in relation to time-to-accuracy, ensuring that speed optimizations do not come at the expense of convergence efficiency.
Scaling creates a second trap because a small-node result can look linear until communication and synchronization dominate. The earlier eight-GPU calculation shows why small-node results cannot be extrapolated linearly once synchronization becomes the binding term.
As the preceding scaling efficiency calculation demonstrated (where 8 GPUs achieved only 75 percent efficiency), extrapolating single-node results to clusters is a common error. Google’s experience with 4,096-node TPU v4 clusters shows this effect at extreme scale, where synchronization challenges become the dominant performance factor. Proper benchmarking should measure scaling efficiency explicitly rather than assuming linear improvement.
The same discipline applies to failures and interference. Many benchmarks assume idealized conditions where hardware failures, network instability, and workload interference do not occur, even though those events are routine at scale. Effective benchmarking accounts for checkpointing overhead, failure recovery efficiency, and resource contention rather than reporting only best-case performance.
Reproducibility adds a different threat. Results must reproduce across hardware and software stacks: a TensorFlow run with Accelerated Linear Algebra (XLA) optimizations may exhibit different convergence behavior than the same model trained in PyTorch with Automatic Mixed Precision (AMP), because floating-point arithmetic, memory layouts, and optimization strategies can all shift training time and accuracy.
Avoiding these pitfalls requires evaluating throughput in relation to accuracy convergence, assessing scaling efficiency holistically, and accounting for real-world failures rather than assuming idealized conditions. A model trained efficiently, however, still requires validation of its deployment performance, which shifts the evaluation framework entirely.
Self-Check: Question
Why does the chapter treat time-to-accuracy as the primary training benchmark metric rather than raw samples per second?
- Because throughput alone rewards systems that process data quickly but fail to converge to the required accuracy target, while time-to-accuracy combines throughput and convergence into a single deployment-relevant quantity
- Because samples-per-second is impossible to measure consistently across hardware platforms
- Because time-to-accuracy ignores convergence behavior and focuses only on wall-clock runtime cost
- Because throughput is relevant only to inference workloads, not to training
A training run takes 24 hours on 1 GPU and 4 hours on 8 GPUs. Using strong-scaling efficiency, what is the scaling result and what does the missing efficiency typically indicate?
- Perfect scaling, because 8 GPUs reduced wall-clock time by 6\(\times\)
- Invalid benchmark, because any multi-GPU scaling below 90 percent efficiency should be discarded
- 75 percent scaling efficiency (24 / (8 * 4) = 0.75), with the remaining 25 percent typically attributable to gradient synchronization, data-movement overhead, and load imbalance across workers
- Proof that the workload is compute-bound rather than communication-bound
A team reports that switching from FP32 to mixed precision raised training throughput from 180 samples/second to 420 samples/second (2.3\(\times\)). Explain why this throughput win does not automatically prove mixed precision was the right deployment choice for this training run.
During BERT pretraining, GPU utilization stays around 45 percent even though the cluster has substantial raw compute headroom and no out-of-memory errors. Which diagnosis aligns with the chapter’s resource-utilization discussion?
- A non-compute stage (input pipeline, gradient synchronization, or host-to-device transfer) is likely starving the accelerators, so adding peak FLOP/s without addressing the binding bottleneck will not meaningfully improve throughput
- The benchmark proves the BERT architecture is fundamentally defective and should be replaced
- The benchmark should drop utilization reporting entirely and report only top-line training time
- Any utilization below 95 percent invalidates the benchmark result and the run should be rejected
True or False: Because training benchmarks are run under controlled conditions, they can safely ignore failures, checkpoint overhead, and recovery time when reporting results for GPT-3-scale training runs.
Explain why the chapter insists on reproducibility controls such as fixed seeds, standardized preprocessing, and multi-run submissions for training benchmarks, with reference to the sources of variation that make a single impressive run untrustworthy.
Inference Benchmarks
Training benchmarks measure how quickly a system learns; inference benchmarks measure how reliably it serves. This shift changes nearly every aspect of evaluation. Training tolerates variable iteration times as long as convergence proceeds; inference requires consistent latency because users experience every slow response. Training optimizes for aggregate throughput across hours; inference must handle unpredictable request patterns with millisecond-level guarantees. Training runs on dedicated high-performance hardware; inference spans environments from data center GPUs to mobile phones to microcontrollers.
This is where the optimization chapters converge: the accelerated hardware from Hardware Acceleration runs compressed models from Model Compression to deliver real-time predictions. Inference benchmarks reveal whether those theoretical speedups become actual latency reductions under realistic deployment conditions.
Definition 1.4: ML inference benchmarks
ML Inference Benchmarks are machine learning system benchmarks that quantify the system’s ability to meet latency constraints \((L_{\text{lat}})\) at specified throughput levels, measuring tail latency (p99), throughput (queries per second), and power efficiency across representative serving scenarios.
- Significance: Inference benchmarks expose the gap between unconstrained throughput and throughput while meeting a service-level objective (SLO), such as a p99 latency target. A system’s peak queries per second under no latency constraint (offline mode) can be 2–3\(\times\) higher than its sustainable rate under a p99 latency SLO (server mode), because queuing delays push tail latency above the target at high load. This gap is invisible without a benchmark that enforces latency targets at each throughput level.
- Distinction: Unlike training benchmarks, which measure time-to-accuracy over a fixed dataset, inference benchmarks measure per-query response time under realistic load patterns, capturing queuing effects, batching trade-offs, and cold-start overhead that determine real-world serving economics.
- Common pitfall: A frequent misconception is that average latency is a sufficient benchmark. A system with low average latency but a long p99 tail can violate production SLOs for the slowest 1 percent of requests; at high request rates, that small percentage becomes a large number of affected users. Tail latency is therefore the operationally relevant metric.
Inference benchmark motivation
Unlike training, which runs on dedicated data center hardware, inference must be optimized for dramatically diverse deployment scenarios—from real-time applications like autonomous driving and conversational AI to mobile devices, IoT systems, and embedded processors. This diversity extends to hardware: while GPUs and TPUs dominate training, inference workloads often require specialized accelerators like NPUs, FPGAs, and dedicated inference chips such as Google’s Edge TPU25. Inference benchmarks evaluate how well hardware selection, model optimization, and data pipeline design work together across these deployment environments.
25 Edge TPU: Google’s fixed-function edge AI accelerator. It illustrates a benchmarking constraint specific to fixed-function accelerators: its headline throughput applies only to quantized TensorFlow Lite models with supported operator types, so models requiring unsupported operators fall back to the host CPU or need graph rewrites before the accelerator result is meaningful.
Scaling inference workloads across cloud servers, edge platforms, mobile devices, and TinyML systems introduces additional complexity. Figure 6 reveals the staggering power consumption differentials among these systems—spanning over ten orders of magnitude from microwatts in tiny embedded devices to hundreds of kilowatts in data center training clusters. The ranges are representative rather than exhaustive. This spread explains why no single benchmark can serve all deployment contexts: a metric meaningful for data center optimization (kilowatts per rack) becomes irrelevant for battery-powered edge devices (milliwatts per inference). Inference benchmarks must evaluate the trade-offs between latency, cost, and energy efficiency within each scale to assist organizations in making informed deployment decisions.
These deployment differences create the practical motivation for inference benchmarks: they evaluate the bottlenecks that emerge when models transition from development to production serving. The motivating factors parallel those for training (hardware optimization, scalability, cost, fair comparison) but differ in specifics. Software optimization frameworks apply inference-specific techniques such as operator fusion (see Model Compression and Hardware Acceleration), precision calibration, and kernel tuning, whose impact on latency, throughput, and power efficiency must be measured under realistic conditions to confirm they deliver real improvements without degrading accuracy. Auto-tuning compilers add a hidden variable: the compiler itself can require hours of optimization per model-hardware pair, meaning benchmark results reflect the tuning budget as much as the hardware capability, and comparing results across submissions requires normalizing for compiler optimization time.
Scalability concerns also shift character. Training scales by adding GPUs to reduce time-to-accuracy on a fixed workload, whereas inference must scale dynamically in response to fluctuating user demand, handling traffic spikes without violating latency guarantees. Cold-start performance, the time required for a model to load and begin processing queries, becomes a distinct inference concern with no training analog. Applications that load models on demand, such as serverless AI deployments, are particularly sensitive to this overhead.
The cost and energy profile of inference differs sharply from training. Training costs are incurred once and amortized over the model’s lifetime, while inference costs accumulate continuously as models serve production traffic. Running an inefficient model at scale can multiply cloud compute expenses, and on battery-powered devices, excessive computation directly impacts usability. Benchmarks that measure cost per inference request and efficiency per watt help organizations optimize for both performance and sustainability across deployment platforms.
MLPerf Inference extends the standardized comparison principles established for training benchmarks to deployment scenarios, defining evaluation criteria for tasks such as image classification, object detection, and speech recognition across different hardware platforms. This ensures that inference performance comparisons remain meaningful and reproducible while accounting for deployment-specific constraints like latency requirements and energy efficiency (Reddi et al. 2019).
Inference metrics
For example, a voice assistant must respond quickly enough that users do not perceive lag, while a recommendation engine must score enough candidates to keep pace with user scrolling. These constraints (latency and throughput) define the performance envelope within which all serving optimizations must operate. Inference metrics formalize these real-world demands into measurable quantities, and they differ from training metrics in kind, not just degree, because the optimization target shifts from “how fast can we learn?” to “how reliably can we serve?” Training cares about throughput and time-to-accuracy; inference cares about latency consistency, resource efficiency, and deployment practicality, spanning cloud data centers handling millions of requests to edge devices operating under strict power constraints.
Latency and tail latency
Latency (introduced in ML Systems) measures the time for an inference system to process an input and produce a prediction. Average latency is useful, but it does not capture worst-case delays that degrade reliability in high-demand scenarios.
To account for this, benchmarks often measure tail latency26, which reflects the worst-case delays in a system. These are typically reported as the 95th percentile (p95) or 99th percentile (p99) latency, meaning that 95 percent or 99 percent of inferences are completed within a given time. For applications such as autonomous driving or real-time trading, maintaining low tail latency is essential to avoid unpredictable delays that could lead to catastrophic outcomes.
26 Tail Latency: The 95th or 99th percentile response time, which determines production SLA compliance. Dean and Barroso (2013) showed that in fan-out architectures (common in recommendation systems), even 1 percent slow responses compound: a request touching 100 backend shards has a 63 percent chance that at least one shard hits its 1 percent tail, making p99 latency the effective average. Benchmarks reporting only mean latency hide this failure mode.
Dean, Jeffrey, and Luiz André Barroso. 2013. “The Tail at Scale.” Communications of the ACM 56 (2): 74–80. https://doi.org/10.1145/2408776.2408794.
These measurements form the basis for Service Level Objectives (SLOs) and Service Level Agreements (SLAs), which formalize performance expectations.
Definition 1.5: SLOs and SLAs
SLOs and SLAs are performance commitment specifications for production ML serving systems: a Service Level Objective (SLO) is the internal engineering target that the team optimizes toward, while a Service Level Agreement (SLA) is the external contractual threshold whose breach triggers financial penalties.
- Significance: SLOs directly constrain the \(L_{\text{lat}}\) term in the iron law by setting a hard latency ceiling that the serving system must satisfy at a given percentile. A representative production setup might set the internal SLO tighter than the external SLA, leaving headroom that functions as an error budget for transient spikes, maintenance windows, and cascading failures.
- Distinction: An SLO is violated internally (triggering a paging alert and an engineering response), while an SLA breach is a contract violation (triggering customer credits or penalties). The SLO must be tighter than the SLA; setting them equal leaves no headroom for measurement variance, deploy windows, or incident response time.
- Common pitfall: A frequent misconception is that meeting average latency satisfies an SLO. SLOs are defined at tail percentiles (p99, p99.9), not means. A system can have an excellent mean while still violating its tail-latency commitment for the slowest requests.
The distinction matters in practice: engineering teams optimize toward SLOs while the business commits to SLAs. Choosing the wrong metric to optimize wastes engineering effort or violates customer guarantees.
Tail latency’s connection to user experience at scale becomes critical in production systems serving millions of users. Even small P99 latency degradations create compounding effects across large user bases: if 1 percent of requests experience 10\(\times\) latency (for example, 1000 ms instead of 100 ms), this affects 10,000 users per million requests, potentially leading to timeout errors, poor user experience, and customer churn. Search engines and recommendation systems demonstrate this sensitivity: Google’s search-latency experiments found measurable reductions in daily searches per user after 100–400 ms server-side delays (Brutlag 2009), which is why interactive services often treat sub-100 ms response times as a practical design target.
Brutlag, Jake. 2009. Speed Matters for Google Web Search. Google Research Blog.
Checkpoint 1.2: Metric selection
The metric shapes the optimization.
Apply three rules before finalizing your metric selection:
Service level objectives (SLOs) in production systems therefore focus on tail latency rather than mean latency to ensure consistent user experience. Interactive services often define percentile-based latency objectives because occasional slow responses have disproportionate impact on user satisfaction. Large-scale systems may track even deeper tails, such as p99.9, when traffic spikes and infrastructure variation affect reliability.
The challenge of meeting these tail latency targets is that the source of the tail is often architectural, not algorithmic. A garbage-collected runtime, a shared kernel driver, or a priority-inversion bug in the serving stack can inject latency spikes that no model optimization will remove.
War Story 1.1: The tail latency death
Context: Discord, a real-time chat platform supporting millions of concurrent users, originally implemented its Read States service in Go. The service tracks which channels and messages each user has read and is accessed on every connection, every message sent, and every read event, making it one of the platform’s hottest data paths (Howarth 2020).
Failure mode: Engineers observed latency spikes every two minutes that matched Go’s forced minimum garbage-collection interval. The LRU cache held tens of millions of Read States across millions of users with hundreds of thousands of updates per second, so every “stop-the-world” GC pass had to scan an enormous heap. Tuning the GC Percent setting and partitioning the cache across servers made no difference: the spikes were structural, not configurable.
Resolution: In 2019, Discord rewrote Read States in Rust, which has no garbage collector. Average response time dropped from milliseconds to microseconds, and the periodic latency spikes disappeared.
Systems lesson: Average latency is a vanity metric; tail latency is the user experience. Language-runtime choices (managed GC vs. ownership-based memory management) set a floor on the tail that no amount of tuning can lower. This failure mode is structurally embedded in ML serving stacks: feature stores that serve real-time embeddings for DLRM-style recommendation models are commonly implemented in Java or Go, and their garbage-collector pauses inflate the p99 latency of every downstream inference request that waits for a retrieved embedding. No model optimization closes that gap, because the bottleneck is in the retrieval path, not the model itself. The Discord incident is the clearest documented example of this mechanism: a managed-runtime GC pause defines the tail just as decisively for an ML inference pipeline as it did for a chat service.
Howarth, Jesse. 2020. “Why Discord Is Switching from Go to Rust.”
End-to-end vs. component latency
A critical distinction in inference benchmarking is between component latency (time spent in model computation) and end-to-end latency (total time from request arrival to response delivery). Many benchmarks report only model inference time, obscuring the remaining overhead that determines actual user experience. The overhead is not marginal: serialization, network hops, and queue wait time can dominate total request time, making model-only optimizations yield diminishing returns.
Example 1.4: The JSON serialization trap
Scenario: Researchers at Berkeley developed Clipper, a low-latency model serving system. Their evaluation highlighted that prediction serving overhead can dominate simple models.
Failure mode: For simple models like linear regression or small convolutional neural networks (CNNs), API overhead from serialization, deserialization, and language/runtime boundaries can consume more CPU time than the actual inference. The system’s throughput was capped not by the model’s math, but by the text processing of the input data. The GPU sat idle while the CPU parsed JSON strings.
Systems insight: Text protocols (JSON/HTTP) are CPU-bound bottlenecks for high-throughput ML. Binary protocols such as gRPC over Protobuf reduce parsing overhead by sending compact typed messages, while shared-memory formats such as Apache Arrow avoid repeated serialization when processes run on the same host. For high-performance serving, the “wrapper” often costs more than the “gift” (Crankshaw et al. 2017).
Crankshaw, Daniel, Xin Wang, Guilio Zhou, Michael J. Franklin, Joseph E. Gonzalez, and Ion Stoica. 2017. “Clipper: A Low-Latency Online Prediction Serving System.” 14th USENIX Symposium on Networked Systems Design and Implementation (NSDI 17), 613–27.
Table 10 gives an illustrative latency breakdown for an inference request. The model inference stage that vendors report as their “benchmark” number spans 5 to 100 ms, yet the queue wait time it sits behind ranges from 0 to over 1,000 ms: under load, the single component a benchmark measures is dwarfed by one it never sees, so the reported number can be a small slice of what the user actually experiences.
| Component | Example Range | Notes |
|---|---|---|
| Network round-trip | 10–100 ms | Varies by region |
| Request parsing | 0.1–1 ms | JSON/protobuf |
| Input preprocessing | 1–50 ms | Tokenization, image resize |
| Queue wait time | 0–1000+ ms | Load-dependent |
| Model inference | 5–100 ms | The “benchmark” |
| Output postprocessing | 0.5–10 ms | Decoding, format |
| Response serialization | 0.1–1 ms | JSON/protobuf |
These component-level contributions explain why optimizing any single stage yields diminishing returns on end-to-end performance, an optimization ceiling formalized by Amdahl’s Law.
Napkin Math 1.4: Amdahl's Law: optimization ceiling
Problem: A vision pipeline spends 8 ms on preprocessing (JPEG decode, resize, normalize) and 10 ms on inference. If inference alone is optimized by 5×, how much does end-to-end latency actually improve?
Math: Optimizing inference from 10 ms to 2 ms reduces total latency from 18 ms to only 10 ms, a 1.8× improvement rather than 5×. Amdahl’s Law formalizes this ceiling: if preprocessing consumes fraction \(f\) of total latency, then even infinitely fast inference yields at most \(1/f\) speedup. With preprocessing at 44.4 percent of latency (\(f \approx\) 0.44), the maximum achievable speedup is \(1/f \approx\) 2.25× regardless of model optimization.
Systems insight: Aggressive model optimization yields disappointing end-to-end results whenever the nonmodel fraction dominates. A 3\(\times\) inference speedup reported in isolation might translate to only 1.5\(\times\) end-to-end improvement in production. Comprehensive benchmarks must either include preprocessing in measurements or state explicitly that reported speedups apply only to the inference component.
Amdahl’s ceiling highlights why rigorous benchmarking methodology matters. Comprehensive latency reporting requires specifying which components are included, measuring under realistic load conditions, and distinguishing component from end-to-end metrics. Before interpreting any benchmark result, verify that the measurement approach itself is sound.
Checkpoint 1.3: Benchmarking methodology
Bad benchmarks optimize the wrong things.
Three practices distinguish rigorous benchmarks from misleading ones:
Throughput and batch efficiency measure whether a serving system can use available hardware without violating latency constraints. Throughput counts how many inference requests a system processes per second, typically expressed as queries per second (QPS) or frames per second (FPS). Single-instance systems process each input independently on arrival; batch systems process multiple inputs in parallel, exploiting hardware parallelism for higher efficiency.
For example, cloud-based services handling millions of queries per second benefit from batch inference, where large groups of inputs are processed together to maximize computational efficiency. In contrast, applications like robotics, interactive AI, and augmented reality require low-latency single-instance inference, where the system must respond immediately to each new input. Benchmarks must consider both single-instance and batch throughput to provide a comprehensive understanding of inference performance across different deployment scenarios.
Speed alone is insufficient because inference optimizations can change model behavior. Reducing numerical precision accelerates computation while cutting memory and energy, the 2–4\(\times\) speedup the MobileNetV2 lighthouse measured (table 6), but lower-precision calculations can introduce accuracy degradation. Inference benchmarks therefore evaluate how well models perform under different numerical settings, such as FP32, FP16, and INT827. Many modern AI accelerators support mixed-precision inference, allowing systems to dynamically adjust numerical representation based on workload requirements. Model compression techniques28 further improve efficiency, but their impact on model accuracy varies depending on the task and dataset. Benchmarks help determine whether these optimizations are viable for deployment, ensuring that improvements in efficiency do not come at the cost of unacceptable accuracy loss.
27 INT8 (8-Bit Integer): INT8 sits at the aggressive end of the precision hierarchy (FP32 baseline, FP16 halves memory, INT8 quarters it), and each step demands increasing care to preserve accuracy. The benchmarking catch: INT8 requires posttraining calibration using a representative dataset, and accuracy preservation (typically 95–99 percent of FP32) depends on the calibration data’s similarity to deployment data. INT8 benchmarks without specifying the calibration dataset and procedure are not reproducible.
28 Model Compression Benchmarking: Compression impact must be measured across four dimensions simultaneously: accuracy degradation, inference speedup, memory reduction, and energy savings. A technique achieving 10\(\times\) size reduction with 1 percent accuracy loss may still be unsuitable if latency does not improve proportionally; unstructured pruning, for example, reduces parameter count but rarely improves latency on dense hardware because sparse operations lack efficient hardware support on most GPUs.
29 Serverless AI: Deployment paradigm where models scale from zero instances on demand. The benchmarking trap: serverless providers report inference latency excluding cold-start time, but for intermittent workloads, cold starts (100 ms for small models, 10+ seconds for large language models (LLMs)) dominate the user-perceived latency. Benchmark results from warm instances systematically understate real-world latency for workloads with low request rates.
Memory footprint and model load time define whether the model can start, stay resident, and respond within the deployment envelope. Unlike training, where models can span multiple accelerators, inference often runs within strict memory budgets. Total model size determines storage requirements, RAM usage reflects working memory during execution, and memory bandwidth can bottleneck data transfer between processing units. Cold-start performance becomes critical when models are loaded on demand rather than kept resident in memory. In serverless AI environments29, where resources scale dynamically with incoming requests, the time from idle to active execution determines whether users experience acceptable response times.
Model load time refers to the duration required to load a trained model into memory before it can process inputs. In some cases, particularly on resource-limited devices, models must be reloaded frequently to free up memory for other applications. The time taken for the first inference request is also an important consideration, as it reflects the total delay users experience when interacting with an AI-powered service. Benchmarks help quantify these delays, ensuring that inference systems can meet real-world responsiveness requirements.
Deployment-scale metrics extend the same logic from one request to a workload. Cloud services must handle millions of concurrent users efficiently, allocating resources dynamically as demand fluctuates without compromising latency; mobile devices must manage multiple simultaneous AI models without overloading the system. Scalability measures how well inference performance improves when additional computational resources are allocated. In some cases, adding more GPUs or TPUs increases throughput proportionally, but in other scenarios, bottlenecks such as memory bandwidth limitations or network latency may limit scaling efficiency. Benchmarks also assess how well a system balances multiple concurrent models in real-world deployment, where different AI-powered features may need to run at the same time without interference.
Energy consumption closes the loop because inference workloads run continuously in production. Mobile and edge devices face the most acute constraints, where battery life and thermal limits restrict available computational resources. Even in large-scale cloud environments, power efficiency directly impacts operational costs and sustainability goals. The energy required for a single inference is often measured in joules per inference, reflecting how efficiently a system processes inputs while minimizing power draw. In cloud-based inference, efficiency is commonly expressed as queries per second per watt (QPS/W) to quantify how well a system balances performance and energy consumption. For mobile AI applications, optimizing inference power consumption extends battery life and allows models to run efficiently on resource-constrained devices. Reducing energy use also plays a key role in making large-scale AI systems more environmentally sustainable, ensuring that computational advancements align with energy-conscious deployment strategies.
Inference performance evaluation
Unlike training, inference systems must process inputs and deliver predictions efficiently across diverse deployment scenarios. Latency, throughput, memory usage, and energy efficiency provide the structured measures for evaluating this performance.
Table 11 should be read as a deployment filter: each metric identifies a constraint that can dominate a different serving environment. Tail latency (p99, p99.9) is the binding metric for a safety-critical real-time system, where a single slow request fails the deadline, while queries per second per watt governs a battery-bound mobile deployment, where the same model is judged on endurance rather than peak speed. Trade-offs between metrics, including speed vs. accuracy and throughput vs. power consumption, are common, and understanding these trade-offs is essential for effective system design.
| Category | Key Metrics | Example Benchmark Use |
|---|---|---|
| Latency and Tail Latency | Mean latency (ms/request); Tail latency (p95, p99, p99.9) | Evaluating real-time performance for safety-critical AI |
| Throughput and Efficiency | Queries per second (QPS); Frames per second (FPS); Batch throughput | Comparing large-scale cloud inference systems |
| Numerical Precision Impact | Accuracy degradation (FP32 vs. INT8); Speedup from reduced precision | Balancing accuracy vs. efficiency in optimized inference |
| Memory Footprint | Model size (MB/GB); RAM usage (MB); Memory bandwidth utilization | Assessing feasibility for edge and mobile deployments |
| Cold-Start and Load Time | Model load time (s); First inference latency (s) | Evaluating responsiveness in serverless AI |
| Scalability | Efficiency under load; Multi-model serving performance | Measuring robustness for dynamic, high-demand systems |
| Power and Energy Efficiency | Power consumption (W); Performance per W (QPS/W) | Optimizing energy use for mobile and sustainable AI |
These metrics interact through unavoidable trade-offs. Optimizing for high throughput via large batch sizes increases latency, making a system unsuitable for real-time applications. Reducing numerical precision improves power efficiency and speed but may degrade accuracy. The deployment environment determines which trade-offs are acceptable: cloud systems prioritize scalability and throughput, while edge devices are dominated by memory and power constraints. Evaluating inference performance holistically, rather than fixating on a single metric, ensures that systems meet their functional, resource, and performance goals in context.
Deployment scenario determines the priority order among those metrics. The operational constraints and success criteria vary dramatically across contexts, so metric priorities help engineers focus benchmarking effort and interpret results within the right decision framework. Table 12 illustrates how performance priorities shift across five major deployment contexts, revealing the systematic relationship between operational constraints and optimization targets.
| Deployment Context | Primary Priority | Secondary Priority | Tertiary Priority | Key Design Constraint |
|---|---|---|---|---|
| Real-Time Applications | Latency (p95 < 50 ms) | Reliability (99.9%) | Memory Footprint | User experience demands immediate response |
| Cloud-Scale Services | Throughput (QPS) | Cost Efficiency | Average Latency | Business viability requires massive scale |
| Edge/Mobile Devices | Power Consumption | Memory Footprint | Latency | Battery life and resource limits dominate |
| Training Workloads | Training Time | GPU Utilization | Memory Efficiency | Research velocity enables faster experimentation |
| Scientific/Medical | Accuracy | Reliability | Explainability | Correctness cannot be compromised for performance |
The key insight from table 12 is that the same metric can be primary in one context and irrelevant in another. Latency ranks first for real-time applications (autonomous vehicles must process sensor data within strict timing deadlines) but tertiary for cloud services (which accept higher latency in exchange for cost efficiency per query). A smartphone AI assistant that improves throughput by 50 percent but increases power consumption by 30 percent represents a net regression since battery life directly impacts user satisfaction. Medical diagnostic systems prioritize accuracy as nonnegotiable—achieving 99.2 percent accuracy at 10 ms latency provides superior value compared to 98.8 percent at 5 ms. This context-dependence means that a 2\(\times\) throughput improvement represents substantial value for cloud deployments but minimal benefit for battery-powered edge devices, where 20 percent power reduction delivers superior operational impact.
Even with well-defined metrics, inference evaluations fail when the benchmark ignores the deployment constraint that dominates the serving system. The following pitfalls show where average latency, memory, energy, cold starts, and scaling assumptions can each invalidate an otherwise plausible result.
Inference benchmark failures begin when the benchmark averages away the event users actually notice. Tail latency (p95, p99) determines production reliability, not mean latency; a conversational AI system that misses its tail-latency target will produce unacceptable response delays even if its average response time looks healthy. Resource constraints create the same kind of mismatch. A model with excellent cloud throughput may still be unusable on a phone or edge device if its memory footprint or power draw exceeds the deployment budget, so practical inference benchmarks must include memory and energy alongside latency.
Serverless and on-demand serving add a separate first-request constraint. Cold-start latency30 measures the time required to initialize a model and process the first request, so excluding model load time creates unrealistic expectations for responsiveness. Evaluating both model load time and first-inference latency ensures that systems are designed for the conditions they will actually face.
30 Cold-Start Latency: The initialization time from idle state, dominated by model weight loading from storage to accelerator memory. For a 7B-parameter model in FP16 (~14 GB), cold start on PCIe 4.0 (25 GB/s effective) takes ~560 ms for weight transfer alone, plus framework initialization overhead. This physical lower bound means that cold-start mitigation (model caching, speculative loading) is a systems design requirement, not just an operational convenience.
Inference benchmarks also become misleading when one metric is optimized in isolation. Maximizing batch throughput can degrade latency, while aggressive precision reduction can reduce accuracy. A precision example makes the comparability problem concrete.
Numerical precision optimization exemplifies this challenge particularly well. Individual accelerator benchmarks show INT8 operation throughput31 reaching about 4\(\times\) the FP32 floating-point throughput on the same accelerator, creating compelling performance narratives. Those narratives are only valid when the benchmark also checks accuracy, supported operator coverage, and whether the reported operations are comparable across devices.
31 TOPS (Tera Operations Per Second): A measure of raw computational throughput (trillions of operations/second). The H100 delivers 1979 TOPS INT8 vs. the Apple M2 Neural Engine at 15.8 TOPS and Edge TPU at 4 TOPS, but these numbers conflate different operation types—multiply-accumulate (MAC) vs. accumulate vs. activation. TOPS comparisons across vendors are meaningful only when the operation definition, precision, and sparsity assumptions are identical, conditions rarely met in vendor specifications.
Scaling and application fit require the same skepticism. The linear scaling pitfall discussed for training benchmarks applies equally to inference, though the bottlenecks differ: training scaling is often limited by gradient synchronization, while inference scaling encounters memory bandwidth saturation, thermal throttling under sustained load, and request-routing overhead, the extra time spent assigning requests to model replicas in distributed serving. As discussed in Hardware Acceleration, these limitations arise from physical hardware constraints and interconnect architectures. A cloud-optimized benchmark can therefore be irrelevant for an edge deployment where energy and memory dominate, so benchmark selection has to follow the application requirement rather than the most convenient leaderboard.
Finally, inference results need the same statistical discipline as training results. Following the evaluation methodology principles established earlier, MLPerf addresses measurement variability by requiring multiple benchmark runs and reporting percentile-based metrics rather than single measurements (Reddi et al. 2019). MLPerf Inference, for instance, reports 99th percentile latency alongside mean performance, capturing both typical behavior and worst-case scenarios that single-run measurements might miss. This approach recognizes that system performance naturally varies due to factors such as thermal throttling, memory allocation patterns, and background processes.
MLPerf inference benchmarks
Avoiding these pitfalls requires treating inference benchmarking as a process of balancing multiple priorities (latency, throughput, memory, energy, and accuracy) rather than optimizing for any single metric in isolation; MLPerf Inference operationalizes that balance through deployment-specific scenarios. MLPerf Inference matters because deployment context changes what a result means. The benchmark, developed by MLCommons32, provides a standardized framework for evaluating machine learning inference performance across a range of deployment environments. MLPerf began with training benchmarks in 2018; MLPerf Inference was added later to standardize deployment-time evaluation across scenarios. As machine learning systems expanded into diverse applications, it became clear that a one-size-fits-all inference benchmark was insufficient. The resulting family of MLPerf inference benchmarks maps each benchmark to a deployment setting, so a score can be interpreted against the latency, throughput, memory, and power constraints the system will face.
32 MLCommons: Nonprofit consortium launched in 2020 from the earlier MLPerf effort, with members from industry, academia, startups, and nonprofits (MLCommons 2026a). MLPerf itself began in 2018. MLCommons addresses benchmark credibility by requiring open submissions with full system specifications, preventing the cherry-picking that plagued earlier benchmarks. Published results reveal large performance differences between vendors on identical workloads, making MLCommons the closest the field has to SPEC-style apples-to-apples hardware comparison.
MLCommons. 2026a. MLCommons: About Us.
MLPerf Inference
MLPerf Inference (Reddi et al. 2019) serves as the baseline inference benchmark, defining standardized scenarios for deployment-time evaluation across data-center and edge settings. It assesses performance across deep learning workloads such as image classification, object detection, natural language processing, and recommendation systems. This version of MLPerf is a widely used reference point for comparing AI accelerators, GPUs, TPUs, and CPUs when the submission rules and workload scenario match the intended deployment environment.
33 DLRM: Facebook’s 2019 recommendation architecture combines embedding tables for categorical features with multilayer perceptrons (MLPs) for continuous features (Naumov et al. 2019). DLRM stresses benchmarks differently than vision or language models: its embedding tables can be large enough that memory capacity and bandwidth dominate compute throughput. That makes DLRM a useful memory-bound recommendation workload in MLPerf-style inference evaluation, revealing hardware limitations invisible to compute-bound benchmarks (Reddi et al. 2019).
Naumov, Maxim, Dheevatsa Mudigere, Hao-Jun Michael Shi, Jianyu Huang, Narayanan Sundaraman, Jongsoo Park, Xiaodong Wang, et al. 2019. “Deep Learning Recommendation Model for Personalization and Recommendation Systems.” arXiv Preprint arXiv:1906.00091.
Reddi, Vijay Janapa, Christine Cheng, David Kanter, Peter Mattson, Guenther Schmuelling, Carole-Jean Wu, Brian Anderson, et al. 2019. “MLPerf Inference Benchmark.” 2020 ACM/IEEE 47th Annual International Symposium on Computer Architecture (ISCA), 446–59. https://doi.org/10.1109/isca45697.2020.00045.
Major technology companies regularly reference MLPerf results for hardware procurement decisions. When evaluating hardware for recommendation systems infrastructure, MLPerf benchmark scores on DLRM33 workloads can inform choices between different accelerator generations. Across generations, benchmark results often show substantial throughput improvements, although the magnitude depends on workload, software stack, and system configuration. This illustrates how standardized benchmarks can translate into consequential infrastructure decisions.
These standardized evaluations provide invaluable comparisons, but the cost of comprehensive benchmarking limits who can participate and how thoroughly systems are evaluated.
Systems Perspective 1.8: The cost of comprehensive benchmarking
Submitting to MLPerf can require dedicated engineering effort, hardware access, tuning, validation, and careful documentation across the relevant configurations. The cost depends heavily on workload and scope, but it is high enough that submissions are dominated by major technology companies and hardware vendors, while smaller organizations rely on published results rather than conducting their own comprehensive evaluations. That barrier motivates the need for more lightweight, internal benchmarking practices that organizations can use to make informed decisions without the expense of full-scale standardized benchmarking.
The rest of the MLPerf inference family narrows that baseline by deployment context. MLPerf Mobile (MLCommons 2024a) evaluates whether a model can remain responsive within smartphone power and memory limits (Janapa Reddi et al. 2022), measuring real-time AI tasks such as camera-based scene detection, speech recognition, and augmented reality. MLPerf Client (MLCommons 2026b) addresses the local-computing decision: whether consumer devices can run AI workloads directly rather than relying on cloud inference. Its current emphasis on local generative-AI and LLM workloads makes CPUs, discrete GPUs, and integrated Neural Processing Units (NPUs) part of the benchmarked system rather than incidental host hardware. MLPerf Tiny (Banbury et al. 2021) tests the extreme constraint case: embedded and ultra-low-power AI systems, such as IoT devices, wearables, and microcontrollers. These variants preserve the same benchmark discipline while changing the binding resource from data center throughput to client responsiveness, mobile power, or microcontroller memory.
MLCommons. 2024a. MLPerf Mobile Benchmark.
Janapa Reddi, Vijay et al. 2022. “MLPerf Mobile V2. 0: An Industry-Standard Benchmark Suite for Mobile Machine Learning.” Proceedings of Machine Learning and Systems 4: 806–23.
MLPerf execution scenarios
The same hardware can report dramatically different benchmark numbers depending on how requests arrive—a fact that explains why vendor claims often fail to predict production performance. Classic MLPerf Inference defines four execution scenarios that characterize distinct traffic patterns, each requiring different optimization strategies (Reddi et al. 2019). Current client and generative-AI benchmark variants also include interactive measurements for latency-sensitive LLM workloads, where metrics such as time-to-first-token and time-per-output-token become central (MLCommons 2026b).
MLCommons. 2026b. MLPerf Client Benchmark.
SingleStream
SingleStream processes one request at a time, measuring latency for sequential inference. This scenario models mobile and embedded applications where a single user interacts with the device: a smartphone camera app classifying images, a voice assistant processing speech, or a wearable detecting gestures. The key metric is per-request latency, and batching provides no benefit since requests arrive only after the previous result is consumed. Optimization focuses on preprocessing efficiency and power consumption rather than throughput.
MultiStream
MultiStream processes multiple synchronized input streams simultaneously, modeling scenarios like autonomous vehicles with multiple cameras that must be processed together for spatial fusion. Unlike SingleStream’s sequential requests, MultiStream requires processing frames from all sensors within tight video-rate deadlines. The key distinction from Server mode is that MultiStream inputs arrive in lockstep, while Server requests arrive independently and unpredictably. The key constraint is synchronization: all streams must complete before the planning module can act. Optimization focuses on jitter handling and meeting hard deadlines rather than average throughput.
Server
Server generates requests following a Poisson distribution, simulating cloud API traffic where requests arrive independently and unpredictably. This scenario models web services handling millions of queries from different users. Unlike SingleStream’s guaranteed sequential arrival, Server traffic creates queuing dynamics where multiple requests compete for resources. The key metrics are throughput (queries per second) and tail latency (p99), and dynamic batching can improve efficiency by grouping requests that arrive within a time window. Optimization balances throughput against latency SLOs.
Offline
Offline provides all inputs upfront, measuring maximum throughput when latency constraints are removed. This scenario models batch processing pipelines: overnight data processing, scientific computing, or precomputing recommendations. With no latency requirement, systems can use maximum batch sizes to saturate hardware utilization. The key metric is pure throughput (samples per second), and optimization focuses entirely on hardware efficiency.
Table 13 maps the classic execution scenarios, plus the newer Interactive LLM-oriented case, to their deployment contexts and optimization strategies.
| Scenario | Context | Strategy | Focus |
|---|---|---|---|
| SingleStream | Mobile apps, embedded devices | No batching (batch = 1) | Preprocessing, power efficiency |
| MultiStream | Autonomous driving, video analytics | Synchronized sensor fusion | Jitter handling, deadline guarantees |
| Server | Cloud APIs, web services | Dynamic batching with timeout | Throughput-latency trade-off tuning |
| Offline | Batch processing, data pipelines | Maximum batch size | Throughput, hardware utilization |
| Interactive | Chat, agents, local generative AI | Token streaming, KV-cache management | Time-to-first-token, time-per-output-token |
The scenarios explain why the same hardware can report dramatically different benchmark numbers. In an illustrative comparison, an accelerator with high Offline throughput can sustain much lower Server-mode throughput once p99 latency constraints and queuing overhead are enforced, because Server mode cannot always use maximum batch sizes. When evaluating hardware for a specific application, selecting the appropriate scenario ensures benchmark results predict production performance. To make scenario-based validation concrete, we return to the MobileNetV2 lighthouse on EdgeTPU.
Lighthouse 1.2: MobileNetV2 on EdgeTPU
Completing our MobileNetV2 lighthouse example, we validate the hardware acceleration claims from Hardware Acceleration using the scenario discipline that MLPerf applies to latency-focused edge inference (Reddi et al. 2019; Banbury et al. 2021).
Table 14: EdgeTPU vs. Cortex-M7 MobileNetV2 validation: SingleStream-scenario measurements comparing inference latency, end-to-end latency, power, and energy per inference for INT8 MobileNetV2, showing how preprocessing overhead narrows the headline accelerator speedup.
Hardware acceleration claim: In this illustrative edge-accelerator scenario, the accelerator achieves ~2 ms inference for INT8 MobileNetV2, approximately 7.5× speedup over a Cortex-M-class CPU (~15 ms). Actual results depend on operator coverage, clock frequency, thermal state, and implementation.
Table 14 reports the validation protocol under the SingleStream scenario.
| Metric | CPU (Cortex-M7) | EdgeTPU | Claimed | Validated? |
|---|---|---|---|---|
| Inference latency | ~15 ms | ~2 ms | 7.5× faster | ✓ |
| End-to-end latency | ~18 ms | ~6 ms | — | ~3× faster |
| Power consumption | ~120 mW | ~500 mW | — | ~4.2× higher |
| Energy per inference | ~1.8 mJ | ~1 mJ | — | ~1.8× more efficient |
What this reveals: The 7.5× inference speedup is real, but end-to-end improvement is only ~3× because preprocessing (image capture, resize, normalize) runs on the CPU in both cases. EdgeTPU consumes more power but completes faster, yielding better energy efficiency per inference.
Deployment decision: For battery-powered devices running infrequently, the active inference calculation alone favors EdgeTPU, but total battery impact depends on sleep power, wake-up energy, host-transfer overhead, and whether the accelerator adds idle leakage while the system waits. For continuous video operation, EdgeTPU’s lower active energy per inference is much more likely to dominate.
The SingleStream result illustrates why benchmarking requires matching the MLPerf scenario to the deployment context: SingleStream validates mobile applications, while Offline benchmarks would give different conclusions optimized for throughput rather than latency.
Banbury, Colby, Vijay Janapa Reddi, Peter Torelli, Jeremy Holleman, Nat Jeffries, Csaba Kiraly, Pietro Montino, et al. 2021. “MLPerf Tiny Benchmark.” arXiv Preprint.
Training benchmarks measure learning speed; inference benchmarks measure serving speed. Yet both measures share a critical blind spot: they say nothing about how much energy the system consumes to achieve that speed. A system that sets throughput records while consuming kilowatts of power may be economically unsustainable or physically impossible to deploy at the edge. Completing the evaluation picture requires power measurement: measuring the energy cost of performance.
Self-Check: Question
For an interactive user-facing ML service that fans out to multiple backend models per request, why does the chapter elevate p99 latency over mean latency as the primary benchmark metric?
- Because mean latency can only be improved by changing numerical precision while p99 can only be improved by batching
- Because p99 latency is easier to instrument accurately than mean latency
- Because mean latency is relevant only to training workloads rather than inference
- Because the user experience is determined by the slowest requests, and a fan-out request completing only when its slowest subrequest returns makes even a 1 percent tail dominate perceived reliability
An inference benchmark reports that model execution takes 5 ms. Production monitoring later shows end-to-end request latency averages 80 ms. Explain how this gap emerges and what the benchmark should have measured instead for deployment planning.
A vision inference pipeline spends 8 ms in preprocessing and 10 ms in model inference. If the team optimizes the model alone to achieve a 5\(\times\) speedup, what does Amdahl’s Law predict about end-to-end latency and what is the main lesson?
- End-to-end latency should also improve by approximately 5\(\times\) if the model was the most optimized component
- The optimization is wasted because preprocessing is non-zero
- End-to-end latency drops from 18 ms to only 10 ms (1.8\(\times\) speedup), because preprocessing now dominates and bounds further component-only gains
- Amdahl’s Law applies only to distributed training, not to inference serving
Which MLPerf inference scenario best matches a cloud API that receives independent, unpredictable user requests and must satisfy latency SLOs under variable load?
- SingleStream
- MultiStream
- Server
- Offline
In a serverless inference deployment, long delays on the first request after an idle period are typically dominated by ____ latency: the one-time cost of loading weights, initializing runtime state, and warming caches before any prediction can begin.
A mobile device benchmark reports that the NPU achieves 2 ms accelerator-only inference on a vision model. Explain why this number may not predict user-perceived speed or battery life in actual deployment.
Power Measurement Techniques
A chip vendor advertises “10 TOPS at 0.5 W,” but under sustained inference load, thermal throttling drops actual throughput to 3 TOPS at 2 W. Without standardized power measurement, this 13.3× efficiency gap between the datasheet and reality goes undetected until deployment.
This third dimension is critical because Hardware Acceleration established TOPS/W as a primary design objective alongside raw TOPS. Power benchmarks validate whether efficiency-optimized accelerators deliver their promised energy savings. TOPS/W is particularly susceptible to gaming precisely because it is a ratio of two separately quotable peaks: a vendor can read the numerator (operations) at the batch size and precision that maximize throughput and the denominator (watts) at a near-idle operating point, so the advertised efficiency describes a state the chip never occupies under real load. Power benchmarks close that loophole by fixing the workload and the measurement window, forcing the numerator and denominator to be read at the same operating point.

Deployment power spans ten orders of magnitude, µW to kW.
Henderson, Peter, Jieru Hu, Joshua Romoff, Emma Brunskill, Dan Jurafsky, and Joelle Pineau. 2020. “Towards the Systematic Reporting of the Energy and Carbon Footprints of Machine Learning.” CoRR abs/2002.05651 (248): 1–43. https://doi.org/10.48550/arxiv.2002.05651.
However, measuring power consumption in machine learning systems presents challenges distinct from measuring time or throughput. Power varies with temperature, workload phase, and system configuration in ways that performance metrics do not. Table 15 quantifies how energy demands of ML models vary dramatically across deployment environments, spanning multiple orders of magnitude from TinyML devices consuming mere microwatts to data center racks requiring kilowatts. This wide spectrum illustrates the central challenge in creating standardized benchmarking methodologies (Henderson et al. 2020).
Creating a unified methodology across this ten-orders-of-magnitude range requires careful consideration of each scale’s unique characteristics: microwatt-level TinyML measurements demand different instrumentation than kilowatt-scale server rack monitoring. A comprehensive framework must accommodate these scales while maintaining consistency, fairness, and reproducibility.
| Category | Device Type | Power Consumption |
|---|---|---|
| Tiny | Neural Decision Processor (NDP) | 150 µW |
| Tiny | M7 Microcontroller | 25 mW |
| Mobile | Raspberry Pi 4 | 3.5 W |
| Mobile | Smartphone | 4 W |
| Edge | Smart Camera | 10-15 W |
| Edge | Edge Server | 65-95 W |
| Cloud | ML Server Node | 300-500 W |
| Cloud | ML Server Rack | 4-10 kW |
Power measurement boundaries
To address these measurement challenges, we must understand how power consumption is measured at different system scales, from TinyML devices to full-scale data center inference nodes. Figure 7 lays out the distinct measurement boundaries for each scenario: components in green fall inside the energy accounting boundary, while components with red dashed outlines are explicitly excluded from power measurements. This distinction matters because where the boundary is drawn determines what counts as “efficient.”

The diagram is organized into three categories, Tiny, Inference, and Training examples, each reflecting different measurement scopes based on system architecture and deployment environment. In TinyML systems, the entire low-power SoC, including compute, memory, and basic interconnects, typically falls within the measurement boundary. Inference nodes introduce more complexity, incorporating multiple SoCs, local storage, accelerators, and memory, while often excluding remote storage and off-chip components. Training deployments span multiple racks, where only selected elements, including compute nodes and network switches, are measured, while storage systems, cooling infrastructure, and parts of the interconnect fabric are often excluded.
Where the boundary falls determines what counts as energy, but within any boundary the dominant term is rarely arithmetic. Decomposing inference energy into its physical sources shows why precision, not raw operation count, is the primary energy lever, and why a power benchmark that ignores data movement measures the wrong thing.
Napkin Math 1.5: Why INT8 saves energy
Recall from Hardware Acceleration that moving data costs far more energy than computing on it (the energy-movement invariant formalized in Data Engineering and quantified by Horowitz’s energy estimates (Horowitz 2014)). Understanding why quantization reduces energy consumption requires decomposing energy into its physical sources. Two dominant factors determine inference energy: compute operations and memory access.
Narrower datatypes generally require less switching and storage energy per operation, so table 16 reveals an 18× gap between FP32 and INT8 multiply-accumulate cost:
| Precision | Multiplier Energy | Relative Cost |
|---|---|---|
| FP32 | ~3.7 pJ/FLOP | 1× |
| FP16 | ~1.1 pJ/FLOP | 0.3× |
| INT8 | ~0.2 pJ/FLOP | 0.05× |
An 8-bit multiplier uses ~18× less energy than a 32-bit floating-point multiplier in this energy model because narrower arithmetic reduces switching and storage work (Horowitz 2014). Numbers to Know catalogs the canonical per-operation energy figures behind these ratios and shows why the FP32-to-INT8 and data-movement-to-compute gaps stay stable across hardware generations.
Table 17 extends the picture to memory access, with energy cost per byte across each tier of the hierarchy:
| Memory Level | Energy per Byte | Relative Cost |
|---|---|---|
| Register | ~0.01 pJ | 1× |
| L1 Cache | ~0.5 pJ | 50× |
| L2 Cache | ~2 pJ | 200× |
| DRAM | ~160 pJ/byte | 16,000× |
Memory access dominates: reading one byte from DRAM costs over 16,000× more energy than a register access.
Table 18 combines the two effects for a MobileNetV2 inference, decomposing per-inference energy into model-load and compute terms at FP32 vs. INT8:
| Component | FP32 (14 MB) | INT8 (3.5 MB) | Savings |
|---|---|---|---|
| Model load from DRAM | 2243 µJ | 561 µJ | 4× |
| Compute (300 MFLOP) | 1,110 µJ | 60 µJ | 18.5× |
| Total | 3,353 µJ | 621 µJ | 5.4× |
Systems insight: Memory access dominates FP32 energy consumption (~2.2 mJ vs. 1.1 mJ compute). INT8 quantization provides 4× memory energy reduction and ~18.5× compute energy reduction. The combined effect explains why quantized models on edge devices can improve battery life: they attack the dominant memory bottleneck while simultaneously accelerating compute.
Horowitz, Mark. 2014. “1.1 Computing’s Energy Problem (and What We Can Do about It).” 2014 IEEE International Solid-State Circuits Conference Digest of Technical Papers (ISSCC), 10–14. https://doi.org/10.1109/isscc.2014.6757323.
Boroumand, Amirali, Saugata Ghose, Youngsok Kim, Rachata Ausavarungnirun, Eric Shiu, Rahul Thakur, Daehyun Kim, et al. 2018. “Google Workloads for Consumer Devices: Mitigating Data Movement Bottlenecks.” Proceedings of the Twenty-Third International Conference on Architectural Support for Programming Languages and Operating Systems, ASPLOS ’18, 316–31. https://doi.org/10.1145/3173162.3173177.
System-level power measurement offers a more holistic view than measuring individual components in isolation. While component-level metrics (for example, accelerator or processor power) are valuable for performance tuning, real-world ML workloads involve intricate interactions between compute units, memory systems, and supporting infrastructure. For instance, analysis of Google’s TensorFlow Mobile workloads shows that data movement accounts for 57.3 percent of total inference energy consumption (Boroumand et al. 2018), highlighting how memory-bound operations can dominate system power usage.
Shared infrastructure presents additional challenges. In data centers, resources such as cooling systems and power delivery are shared across workloads, complicating attribution of energy use to specific ML tasks. Cooling alone can account for 20–30 percent of total facility power consumption, making it a major factor in energy efficiency assessments (Barroso et al. 2019). Even at the edge, components like memory and I/O interfaces may serve both ML and non-ML functions, further blurring measurement boundaries.
Kim, Wonyoung, Meeta S. Gupta, Gu-Yeon Wei, and David Brooks. 2008. “System Level Analysis of Fast, Per-Core DVFS Using on-Chip Switching Regulators.” IEEE International Symposium on High-Performance Computer Architecture (HPCA), HPCA ’08, 123–34. https://doi.org/10.1109/hpca.2008.4658633.
Within a single Transformer forward pass, the compute profile shifts sharply between feed-forward layers—dense matrix multiplications that saturate arithmetic throughput and draw peak power—and attention layers, which are memory-bandwidth-bound with lower arithmetic intensity and correspondingly lower power draw. Modern ML accelerators respond to this oscillation through dynamic voltage and frequency scaling (DVFS), which adjusts processor voltage and clock frequency based on workload demands. Advanced DVFS implementations using on-chip switching regulators can achieve meaningful energy savings (Kim et al. 2008), causing power consumption for the same ML model to vary with system load and concurrent activity. This rapid toggling between power states within a single Transformer forward pass creates a thermal and measurement challenge that generic server workloads do not exhibit: low-rate power sampling can alias across the compute-to-memory phase boundary, producing an averaged reading that misrepresents both the peak draw and the low-power dwell time. This variability affects not only the compute components but also the supporting infrastructure, as reduced processor activity can lower cooling requirements and overall facility power draw.
Support infrastructure, particularly cooling systems, is a major component of total energy consumption in large-scale deployments. Data centers must maintain operational temperatures, typically between 20–25 °C, to ensure system reliability. Cooling overhead is captured in the Power Usage Effectiveness (PUE) metric, which ranges from 1.1 in highly efficient facilities to over 2.0 in less optimized ones (Barroso et al. 2019). The interaction between compute workloads and cooling infrastructure creates complex dependencies; for example, power management techniques like DVFS not only reduce direct processor power consumption but also decrease heat generation, creating cascading effects on cooling requirements. Even edge devices require basic thermal management.
Barroso, Luiz André, Urs Hölzle, and Parthasarathy Ranganathan. 2019. The Datacenter as a Computer: Designing Warehouse-Scale Machines. Synthesis Lectures on Computer Architecture. Springer International Publishing. https://doi.org/10.1007/978-3-031-01761-2.
Computational efficiency vs. power consumption
The relationship between computational performance and energy efficiency is a central trade-off in modern ML system design. As systems push for higher performance, they often encounter diminishing returns in energy efficiency due to physical limitations in semiconductor scaling and power delivery (Koomey et al. 2011). This relationship is particularly evident in processor frequency scaling: higher frequency often requires higher voltage, so dynamic power can rise faster than delivered throughput, reflecting the voltage-frequency-power relationship that underlies DVFS and its diminishing returns (Le Sueur and Heiser 2010).
Koomey, Jonathan, Stephen Berard, Marla Sanchez, and Henry Wong. 2011. “Implications of Historical Trends in the Electrical Efficiency of Computing.” IEEE Annals of the History of Computing 33 (3): 46–54. https://doi.org/10.1109/mahc.2010.28.
Le Sueur, Etienne, and Gernot Heiser. 2010. “Dynamic Voltage and Frequency Scaling: The Laws of Diminishing Returns.” Proceedings of the 2010 International Conference on Power Aware Computing and Systems, 1–8.
Wu, Hao, Patrick Judd, Xiaojie Zhang, Mikhail Isaev, and Paulius Micikevicius. 2020. “Integer Quantization for Deep Learning Inference: Principles and Empirical Evaluation.” arXiv Preprint arXiv:2004.09602 abs/2004.09602.
Gholami, Amir, Sehoon Kim, Zhen Dong, Zhewei Yao, Michael W. Mahoney, and Kurt Keutzer. 2021. “A Survey of Quantization Methods for Efficient Neural Network Inference.” arXiv Preprint arXiv:2103.13630 abs/2103.13630: 291–326. https://doi.org/10.1201/9781003162810-13.
In deployment scenarios with strict energy constraints, particularly battery-powered edge devices and mobile applications, optimizing this performance-energy trade-off becomes essential for practical viability. Model optimization techniques offer promising approaches to achieve better efficiency without material accuracy degradation. Numerical precision optimization techniques, which reduce computational requirements while maintaining model quality, demonstrate this trade-off effectively. Integer quantization studies show that reduced-precision computation can often preserve model quality while improving inference speed, memory traffic, and energy efficiency, although the realized gain depends on model, calibration method, and hardware support (Jacob et al. 2018; Wu et al. 2020; Gholami et al. 2021).
Optimization strategies span three interconnected dimensions: accuracy, computational performance, and energy efficiency. Advanced optimization methods enable fine-tuned control over this trade-off space. Similarly, model optimization and compression techniques require careful balancing of accuracy losses against efficiency gains. The optimal operating point among these factors depends heavily on deployment requirements and constraints; mobile applications typically prioritize energy efficiency to extend battery life, while cloud-based services might optimize for accuracy even at higher power consumption costs, benefiting from economies of scale and dedicated cooling infrastructure.
Energy efficiency metrics now occupy a central position in AI system evaluation. Power measurement standards such as MLPerf Power (Tschand et al. 2024) provide standardized frameworks for comparing energy efficiency across hardware platforms and deployment scenarios. These standards enable engineers to systematically balance performance, power consumption, and environmental impact when selecting hardware and optimization strategies.
Standardized power measurement
Power measurement techniques like SPEC Power have long served general computing (Lange 2009), but ML workloads expose a fundamental difficulty: instantaneous power consumption during a single inference can shift rapidly between compute-intensive matrix multiplication and memory-stall phases. MLPerf Power formalizes this problem for ML systems by specifying measurement boundaries, instrumentation, and reporting rules across a wide power range (Tschand et al. 2024). This volatility means that any single-point measurement is misleading, and the act of measurement itself (instrumentation overhead, sampling-induced delays) can perturb the very power profile being characterized.
The core challenge is therefore temporal: characterizing a quantity that fluctuates faster than many measurement instruments can sample. Dense matrix operations in transformer layers create short, intense power spikes that require high-frequency sampling to capture accurately, while CNN inference tends toward more consistent power draw amenable to lower sampling rates. The measurement window must also account for ML-specific warm-up periods, where initial inferences consume more power due to cache population and pipeline initialization. Sliding-window averages over repeated inferences smooth these fluctuations into actionable efficiency numbers, but the window size itself becomes a design parameter that can hide or reveal different aspects of the power profile.
Memory access patterns compound the measurement problem because ML systems often spend more energy moving data than computing on it. Recommendation models like DLRM, for example, can consume more energy on memory access than computation—a pattern that traditional compute-focused power measurement misses entirely. Capturing both compute and memory subsystem power consumption requires instrumenting the full data path, not just the processor.
Heterogeneous accelerator configurations introduce further complexity. GPUs, TPUs, and NPUs each maintain independent power management schemes, and modern SoCs dynamically switch between compute resources based on workload characteristics. Accurate system-level measurement requires synchronized power capture across all active compute units—a challenge that scales with system size. Multi-GPU configurations must account for gradient synchronization energy alongside computation, and multi-node deployments add nontrivial network infrastructure power. At the other extreme, edge deployments must capture the energy cost of model updates and data preprocessing alongside inference itself.
Batch size creates a nonlinear relationship with power consumption that single-point measurements cannot characterize. Larger batches improve compute efficiency (better amortization of memory loads) but increase memory pressure and peak power requirements, meaning the most efficient batch size for throughput may differ from the most efficient batch size for energy. Measurement across multiple batch sizes is essential for a complete efficiency profile. System idle states deserve equal attention, particularly for intermittent edge workloads: a wake-word detection TinyML system that actively processes audio for only a small fraction of operating time may be dominated by idle power consumption rather than inference energy. Finally, sustained ML workloads can cause temperature increases that trigger thermal throttling and alter power consumption patterns—an effect particularly acute in edge devices, where thermal constraints limit sustained performance and make extended benchmarking runs essential for realistic characterization.
MLPerf power case study
MLPerf Power (Tschand et al. 2024) turns power measurement from a device-specific reading into a comparable efficiency claim: how many useful inferences a system delivers per watt under a defined boundary. The methodology applies standardized evaluation principles across data center, edge, and tiny inference settings, where the relevant decision changes from rack operating cost to battery life to microwatt-scale endurance.
Boundary-aware standardization matters because the same hardware family can look efficient or wasteful depending on boundary and workload. By adapting the protocol to CPUs, accelerators, and heterogeneous systems while preserving measurement integrity, MLPerf Power makes cross-platform comparisons meaningful across different computing scales.
The benchmark has accumulated many reproducible measurements submitted by industry organizations, demonstrating submitted hardware capabilities and the sector-wide focus on energy-efficient AI technology. The data-center panel in figure 8 shows how normalized energy efficiency has evolved across successive MLPerf Inference versions. The gains are not uniform across workloads: established vision, language, recommendation, and speech benchmarks improve modestly after their early releases, while newer generative-model workloads show larger jumps as systems mature.
Analysis of the data-center MLPerf Power trends reveals two notable patterns. First, energy efficiency improvements for established ML workloads, including image classification, language understanding, recommendation, and recurrent neural network (RNN) based speech recognition (specifically ResNet, BERT, DLRM, RetinaNet, and RNN-T), have plateaued after initial gains; the low-hanging fruit of optimization has been harvested. Second, large generative-model workloads show much larger recent efficiency increases, reflecting rapid optimization as researchers and system builders tune newer, larger models (Tschand et al. 2024). This dichotomy suggests that established workloads can reach optimization maturity while newer model classes still offer substantial efficiency headroom, a pattern likely to repeat as each architecture matures.
Tschand, Arya, Arun Tejusve Raghunath Rajan, Sachin Idgunji, Anirban Ghosh, Jeremy Holleman, Csaba Kiraly, Pawan Ambalkar, et al. 2024. “MLPerf Power: Benchmarking the Energy Efficiency of Machine Learning Systems from \(\mu\)Watts to MWatts for Sustainable AI.” 2025 IEEE International Symposium on High Performance Computer Architecture (HPCA), 1201–16. https://doi.org/10.1109/hpca61900.2025.00092.
Timing protocols and power instrumentation provide the raw data for benchmarking. Raw data alone, however, does not guarantee sound conclusions. Converting measurements into meaningful comparisons requires understanding the systematic sources of error, bias, and misalignment that can make even carefully collected benchmark numbers misleading.
Self-Check: Question
A vendor advertises an accelerator at ‘10 TOPS at 0.5 W,’ but under sustained inference load the chip throttles to 3 TOPS at 2 W, a 13.3\(\times\) efficiency gap. Why does the chapter emphasize defining the power measurement boundary as the fix for this kind of gaming?
- Because a power claim is only interpretable when the measured components (accelerator, off-chip memory, cooling, voltage regulators) and operating conditions (burst vs. sustained) are specified consistently; otherwise two systems report different numbers simply because one includes more of the real power draw
- Because measurement boundary choices affect latency but not energy efficiency
- Because standardizing boundaries matters only for TinyML devices and not for server-class accelerators
- Because power benchmarks should always exclude memory to isolate compute efficiency
Explain why instantaneous power samples are misleading for ML workloads and describe a concrete workload phase pattern that requires sustained sampling with a carefully chosen averaging window.
A system gains approximately 5 percent more throughput by raising clock frequency but draws roughly 50 percent more power as a result. What broader lesson does the chapter draw from this kind of non-linear trade-off?
- Higher clock frequency is always worth it because power scales linearly with throughput
- Performance gains can hit severe diminishing returns in energy efficiency, so the fastest operating point can be an expensive deployment choice, especially under power-capped or thermally-constrained environments
- The result proves the benchmark instrumentation is malfunctioning because real silicon does not exhibit such trade-offs
- Only cloud deployments care about energy trade-offs; edge devices are compute-limited rather than power-limited
True or False: Standardized ML power measurement can focus primarily on compute units because memory access energy is usually a small correction relative to arithmetic energy.
The chapter’s power table spans from 150 µW TinyML devices to 10 kW server racks, a range of nearly eight orders of magnitude. Explain why MLPerf Power remains valuable across this range even though a microwatt sensor and a kilowatt rack cannot share physical instrumentation.
Benchmarking Best Practices
An inference stack that passes a steady-state lab run can still miss latency targets when production traffic arrives in bursts, or when the input mix shifts toward expensive examples. Training throughput, inference latency, and power efficiency each have established measurement protocols validated through MLPerf, but knowing what to measure is insufficient without understanding what benchmarks cannot capture and why this gap has derailed countless deployments.
Every benchmark makes simplifying assumptions that enable standardized comparison but diverge from production reality. Training benchmarks assume fixed datasets and reproducible random seeds; production data drifts continuously. Inference benchmarks assume steady-state operation; production traffic spikes unpredictably. Power benchmarks assume controlled thermal environments; real hardware throttles under sustained load. Four categories of limitations (statistical, deployment-related, system design, and organizational) determine whether benchmark results translate to deployment success.
Statistical and methodological issues
Benchmark results are only as reliable as the measurements that produce them. Three pervasive issues undermine this reliability if left unaddressed.
Incomplete problem coverage represents one of the most pervasive limitations. Many benchmarks, while useful for controlled comparisons, fail to capture the full diversity of real-world applications. Common image classification datasets such as CIFAR-10 (Krizhevsky 2009) contain a limited variety of images. Models that perform well on these datasets may struggle when applied to more complex, real-world scenarios with greater variability in lighting, perspective, and object composition. This gap between benchmark tasks and real-world complexity means strong benchmark performance provides limited guarantees about practical deployment success.
Krizhevsky, Alex. 2009. Learning Multiple Layers of Features from Tiny Images. University of Toronto.
Statistical insignificance arises when benchmark evaluations are conducted on too few data samples or trials, and it is most acute in settings where the evaluation medium itself introduces variance. Large language model evaluation exemplifies this problem: whether scoring a new LLM against a reference using human preference ratings or an LLM-as-judge protocol, the evaluation signal carries high variance because judges respond differently to prompt phrasing, ordering effects, and response length. A reported two-point preference win can disappear entirely across a different judge configuration or prompt template. Rigorous LLM benchmarking therefore requires statistical methods—bootstrap confidence intervals or paired significance tests—applied across enough prompts and response pairings to separate a genuine capability improvement from evaluation noise. Without sufficient trials and diverse input distributions, benchmarking results will mislead: reported differences reflect evaluation noise rather than genuine capability. The statistical confidence intervals around benchmark scores often go unreported, obscuring whether measured differences represent genuine improvements or measurement noise.
Reproducibility represents a major ongoing challenge. Benchmark results can vary measurably depending on factors such as hardware configurations, software versions, and system dependencies. Small differences in compilers, numerical precision, or library updates can lead to inconsistent performance measurements across different environments. To mitigate this issue, MLPerf addresses reproducibility by providing reference implementations, standardized test environments, and strict submission guidelines. Even with these efforts, achieving true consistency across diverse hardware platforms remains an ongoing challenge. The proliferation of optimization libraries, framework versions, and compiler flags creates a vast configuration space where slight variations produce different results.
Laboratory-to-deployment performance gaps
Statistical rigor ensures that benchmark measurements are accurate. Accurate measurements of the wrong thing, however, still lead to deployment failures. Benchmarks must also align with practical deployment objectives.
Misalignment with real-world goals occurs when benchmarks emphasize metrics such as speed, accuracy, and throughput, while practical AI deployments require balancing multiple objectives including power efficiency, cost, and robustness. A model that achieves top-line accuracy on a benchmark may be impractical for deployment if it consumes excessive energy or requires expensive hardware. Similarly, optimizing for average-case performance on benchmark datasets may neglect tail-latency requirements that determine user experience in production systems. The multi-objective nature of real deployment, encompassing resource constraints, operational costs, maintenance complexity, and business requirements, extends far beyond the single-metric optimization that most benchmarks reward.
System design challenges
Statistical methodology and deployment alignment address how we measure and what we optimize for. A third category of limitations emerges from the physical systems being measured. Hardware behavior depends on environmental conditions, architectural compatibility, and operational context in ways that complicate fair comparison.
Environmental conditions affect benchmarks in measurable ways. Benchmark results depend on physical conditions (ambient temperature, humidity, altitude) and operational context (background processes, network load, power supply stability) in subtle but measurable ways. Elevated temperatures trigger thermal throttling that reduces computational speed; background processes compete for resources and alter performance characteristics. Ensuring valid benchmarks requires controlling these factors to the extent possible (temperature-controlled environments, standardized system states, documented background loads) and, when full control is impractical (as in distributed or cloud-based benchmarking), detailed reporting of conditions so that others can account for potential variations when interpreting results.
The hardware lottery34 (Hooker 2021) presents another critical issue. The success of a machine learning model is often dictated not only by its architecture and training data but also by how well it aligns with the underlying hardware. Some models perform exceptionally well not because they are inherently superior but because they map naturally onto GPU or TPU parallel processing capabilities. Other promising architectures may be systematically overlooked because they do not fit dominant hardware platforms.
34 Hardware Lottery: Coined by Hooker (2021) to describe how algorithmic success depends on alignment with available hardware. The transformer succeeded partly because its dense matrix multiplications map well to GPU Tensor Cores, while graph neural networks and sparse mixture-of-experts models can be harder to evaluate when available silicon and software stacks favor dense kernels. For benchmarking, this means hardware-specific leaderboards systematically favor hardware-aligned architectures, potentially obscuring algorithms that would perform better under different hardware assumptions.
Hooker, Sara. 2021. “The Hardware Lottery.” Communications of the ACM 64 (12): 58–65. https://doi.org/10.1145/3467017.
Hardware compatibility dependence introduces subtle but significant biases into benchmarking results. A model that is highly efficient on a specific GPU may perform poorly on a CPU or a custom AI accelerator. Figure 9 makes this hardware dependence concrete by comparing model performance across different platforms. On the CPU uint8 and GPU configurations, the multi-hardware models track the “MobileNetV3 Large min” baseline closely, reaching roughly 77 percent top-1 ImageNet accuracy where the baseline reaches about 75 percent. On the EdgeTPU and DSP hardware the same multi-hardware models sustain that 77 percent at substantially lower latency, while a model tuned only for the CPU would forfeit those gains. This reveals that the “best” model depends entirely on deployment target: a conclusion impossible to reach from single-platform benchmarks.

Chu, Grace, Okan Arikan, Gabriel Bender, Weijun Wang, Achille Brighton, Pieter-Jan Kindermans, Hanxiao Liu, Berkin Akin, Suyog Gupta, and Andrew Howard. 2021. “Discovering Multi-Hardware Mobile Models via Architecture Search.” 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), 3016–25. https://doi.org/10.1109/cvprw53098.2021.00337.
Without careful benchmarking across diverse hardware configurations, the field risks favoring architectures that “win” the hardware lottery rather than selecting models based on their intrinsic strengths. This bias can shape research directions, influence funding allocation, and impact the design of next-generation AI systems. In extreme cases, it may even stifle innovation by discouraging exploration of alternative architectures that do not align with current hardware trends.
Organizational and strategic issues
The preceding limitations arise from technical challenges: statistical noise, deployment misalignment, environmental variance, and hardware compatibility. A fourth category emerges from human factors—and these may be the hardest to mitigate because they involve incentives rather than instrumentation. Competitive pressures and research incentives create systematic biases in how benchmarks are used and interpreted. These organizational dynamics require governance mechanisms and community standards to maintain benchmark integrity.
Benchmark engineering
While the hardware lottery is an unintended consequence of hardware trends, benchmark engineering is an intentional practice where models or systems are explicitly optimized to excel on specific benchmark tests. This practice can lead to misleading performance claims and results that do not generalize beyond the benchmarking environment.
Benchmark engineering occurs when AI developers fine-tune hyperparameters, preprocessing techniques, or model architectures specifically to maximize benchmark scores rather than improve real-world performance. The distinction between legitimate optimization and benchmark engineering is often blurry, sitting at the threshold where tuning for a specific benchmark crosses into overfitting to it. For example, an object detection model might be carefully optimized to achieve record-low latency on a benchmark but fail when deployed in dynamic, real-world environments with varying lighting, motion blur, and occlusions. Similarly, a language model might be tuned to excel on benchmark datasets but struggle when processing conversational speech with informal phrasing and code-switching.
The pressure to achieve high benchmark scores is often driven by competition, marketing, and research recognition. Benchmarks are frequently used to rank AI models and systems, creating an incentive to optimize specifically for them. While this can drive technical advancements, it also risks prioritizing benchmark-specific optimizations at the expense of broader generalization—precisely the Goodhart’s Law dynamic introduced in section 1.1 and illustrated with the BLEU-score example in section 1.3.1.
Bias and over-optimization
The practitioner consuming a benchmark result must determine whether a number reflects legitimate optimization or benchmark engineering. Several practices make that distinguishable, and each catches a specific failure at a specific cost. Transparency is the first line of defense: a submission that documents every optimization applied lets a reader separate general improvement from benchmark-specific tuning, at the cost of exposing techniques a vendor may prefer to keep proprietary. Reporting both benchmark and real-world deployment results closes the same gap from the other side. Diversified evaluation across multiple, continuously updated benchmarks raises the cost of overfitting to any single test set, because a model engineered to win one cannot easily win them all; its cost is the engineering effort of maintaining many benchmarks.
Standardization and third-party verification raise the bar further. Independent audits catch results that fail to reproduce across settings, and the existence proof for this mechanism appears two sections later in MLPerf’s reference-vs-submission validation (section 1.10.5), which disqualifies any submission that cannot hit the reference accuracy target. Application-specific testing catches the failure controlled benchmarks structurally cannot: an autonomous-driving model must be exercised across the weather, lighting, and urban settings it will actually meet, not judged solely on a curated dataset. Multi-hardware testing catches the last case, performance that is really hardware-lottery alignment rather than model quality, by confirming that a result does not depend on compatibility with one platform.
Benchmark evolution
A persistent challenge in benchmarking is that benchmarks are rarely static. As AI systems evolve, so must the benchmarks that evaluate them. A performance target that discriminates well under one generation of models, hardware, and applications may lose relevance under another. While benchmarks are essential for tracking progress, they can also become outdated, leading to over-optimization for old metrics rather than real-world performance improvements.
This evolution is evident in the history of AI benchmarks. Early model benchmarks, for instance, focused heavily on image classification and object detection, as these were some of the first widely studied deep learning tasks. However, as AI expanded into natural language processing, recommendation systems, and generative AI, it became clear that these early benchmarks no longer reflected the most important challenges in the field. In response, new benchmarks emerged to measure language understanding (Wang et al. 2018, 2019) and generative AI (Liang et al. 2022).
Wang, Alex, Yada Pruksachatkun, Nikita Nangia, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel R. Bowman. 2019. “SuperGLUE: A Stickier Benchmark for General-Purpose Language Understanding Systems.” arXiv Preprint arXiv:1905.00537.
Benchmark evolution extends beyond the addition of new tasks to encompass new dimensions of performance measurement. While traditional AI benchmarks emphasized accuracy and throughput, deployed applications demand evaluation across multiple criteria: fairness, robustness, scalability, and energy efficiency. Figure 10 makes these disparate requirements concrete by mapping scientific applications across data rate and computation time. The visualization reveals a striking pattern: Large Hadron Collider sensors must process data at rates approaching \(10^{14}\) bytes per second with nanosecond-scale computation times, while mobile applications operate at \(10^{4}\) bytes per second with longer computational windows—a span of 10 orders of magnitude on each axis. This range of requirements necessitates specialized benchmarks. For example, edge AI applications benefit from benchmarks like MLPerf that evaluate performance under resource constraints, and scientific application domains need their own “Fast ML for Science” benchmarks (Duarte et al. 2022).

Duarte, Javier, Nhan Tran, Ben Hawks, Christian Herwig, Jules Muhizi, Shvetank Prakash, and Vijay Janapa Reddi. 2022. “FastML Science Benchmarks: Accelerating Real-Time Scientific Edge Machine Learning.” arXiv Preprint arXiv:2207.07958.
The need for evolving benchmarks also presents a challenge: stability vs. adaptability. On the one hand, benchmarks must remain stable for long enough to allow meaningful comparisons over time. If benchmarks change too frequently, it becomes difficult to track long-term progress and compare new results with historical performance. On the other hand, failing to update benchmarks leads to stagnation, where models are optimized for outdated tasks rather than advancing the field. Striking the right balance between benchmark longevity and adaptation is an ongoing challenge for the AI community.
Evolving benchmarks remains essential for meaningful progress measurement. Without updates, benchmarks become detached from real-world needs, and researchers optimize for artificial test cases rather than practical challenges. The transition from ImageNet-era accuracy benchmarks to multi-dimensional evaluations spanning fairness, robustness, and energy efficiency illustrates this evolution in practice.
MLPerf synthesis and benchmark gaming
Benchmark gaming begins when a compiler, runtime, or hardware stack optimizes for the benchmark artifact rather than the workload it is supposed to represent. MLPerf counters that risk by synthesizing the principles discussed throughout this chapter into a single evolving framework: reference implementations and strict submission rules enforce reproducibility, deployment-specific suites (Inference, Mobile, Client, Tiny) align with the three-dimensional evaluation framework, and regular task updates (including generative AI and energy-efficient computing) prevent benchmark stagnation. In the Hennessy & Patterson tradition of quantitative systems, we must acknowledge that benchmarks are not just measurements; they are targets. The Goodhart dynamic introduced in section 1.1 applies here in full force. In the high-stakes world of AI hardware, it manifests as benchmark gaming: optimizing hardware or compilers specifically for the benchmark’s unique characteristics, rather than for real-world performance.
Submitters chasing leaderboard position commonly reach for three gaming techniques:
- Precision Dropping: Compilers may silently reduce precision (for example, from FP32 to BF16) only during the benchmark run to inflate throughput, even if the user did not request it.
- Operator Removal: A compiler might identify that a benchmark only cares about top-1 accuracy and “optimize out” the activation functions or layer norms if they do not affect that specific metric, yielding unrealistic speedups.
- Weight Preloading: Hardcoding the benchmark model’s weights into the chip’s on-chip SRAM, bypassing the “memory wall” bottlenecks that real production models must face.
MLPerf prevents this gaming through its Reference vs. Submission validation. Every submitter must run the exact same model structure and reach a verifiable accuracy target (for example, 75.9 percent on ImageNet) to qualify. A compiler that drops precision or removes operators fails the accuracy check, and the result is disqualified. This accuracy guardrail transforms a simple speed test into a rigorous engineering benchmark, forcing vendors to optimize for the silicon contract rather than gaming the numbers.
Yet even the most rigorous system benchmarks validate only one dimension of deployment readiness. A system achieving record throughput and efficiency on MLPerf says nothing about whether the model it runs is accurate on real-world inputs, or whether the data it was trained on represents the population it will serve. Hardware that delivers promised TFLOP/s is necessary but insufficient; the model running on that hardware must preserve the quality users depend on, and the data that shaped that model must represent the world it will encounter. Completing the validation stack requires turning from hardware to the model and data dimensions of our three-dimensional framework.
Self-Check: Question
An image classifier trained and tested on CIFAR-10 achieves 95 percent accuracy but fails to 70 percent accuracy on real-world photos with natural lighting and occlusion. Which limitation category from the chapter’s taxonomy does this most directly illustrate?
- Incomplete problem coverage: the benchmark dataset does not span the diversity of lighting, perspective, and composition present in deployment inputs
- Perfect reproducibility: the benchmark can be repeated on many systems with identical results
- Fault-tolerance overhead: checkpointing adds latency to the training loop
- Benchmark stability: benchmarks change too frequently over time to support longitudinal comparison
Explain why a statistically rigorous benchmark measurement, complete with confidence intervals and multiple runs, can still be the wrong basis for a deployment decision.
What does the chapter mean by the ‘hardware lottery,’ the concept coined by Sara Hooker in 2021?
- A benchmark protocol that randomly assigns hardware to submissions to eliminate vendor bias
- A power-management feature that unpredictably changes clock frequency during benchmark runs
- A ranking system that rewards vendors whose benchmark submissions use more hardware than competitors
- The tendency for a model or algorithm to appear superior mainly because its computation pattern aligns well with currently dominant hardware (for example, dense matrix multiplies on GPU Tensor Cores) rather than because the algorithm is intrinsically best
Which practice best reflects the chapter’s recommended defense against benchmark engineering and over-optimization?
- Adopting a single static benchmark so results remain easy to compare over many years
- Reporting only the highest-performing run, since that best represents the system’s potential capability
- Evaluating systems across multiple and evolving benchmarks, and reporting deployment-relevant outcomes (robustness, calibration, energy efficiency) alongside leaderboard scores
- Removing accuracy guardrails from benchmark submissions so implementations can innovate more freely
The chapter uses the phrase hardware ____ to describe how a model family can look superior mainly because it maps efficiently onto currently dominant accelerator silicon, leaving alternative architectures systematically underexplored.
Explain why the chapter argues benchmarks must evolve over time, even though frequent changes complicate longitudinal comparison.
Model and Data Evaluation
A compressed model running on accelerated hardware can still fail if it was trained on biased data. System benchmarks can confirm that hardware delivers promised training throughput, inference latency, and power efficiency, but hardware validation alone cannot ensure deployment success. The optimization pipeline from Part III also included model compression (Model Compression) and data selection (Data Selection), each requiring its own validation. The remaining two dimensions of the framework address this gap: model benchmarks verify that compression preserved accuracy and critical model properties, while data benchmarks verify that training data enables robust generalization.
Model benchmarking
Model benchmarks validate whether compression techniques from Model Compression preserved the properties that matter for deployment. This extends beyond top-line accuracy. A pruned model might maintain ImageNet accuracy while losing robustness to adversarial inputs. A quantized model might preserve average-case performance while degrading on rare but critical edge cases. A distilled model might match the teacher’s accuracy while losing calibration. Historically, benchmarks focused almost exclusively on accuracy, but compression makes multi-dimensional evaluation essential.
ImageNet links model benchmarking to the hardware story from figure 1: error rates fell as GPU-enabled architectures became practical. Figure 11 adds the architectural milestones to that same progression, tracing error reduction from 28.2 percent in 2010 to 3.57 percent on the ImageNet Large Scale Visual Recognition Challenge (ILSVRC) (Russakovsky et al. 2015). The introduction of AlexNet35 reduced the error rate from 25.8 percent to 16.4 percent. Subsequent models like ZFNet, VGGNet, GoogLeNet, and ResNet36 continued this trend, with ResNet achieving 3.57 percent (He et al. 2016). This progression established the baselines against which model compression techniques are evaluated: a pruned ResNet must demonstrate how much accuracy it sacrifices for a given efficiency gain.
35 AlexNet: The eight-layer CNN (60M parameters) that cut ImageNet top-5 error from 25.8 percent to 16.4 percent in 2012, trained on two GTX 580 GPUs with 3 GB memory each (Krizhevsky et al. 2012). AlexNet established a benchmarking paradigm that still informs vision evaluation: accuracy on a fixed dataset as the primary metric, with hardware configuration as a secondary specification. Later ImageNet results inherited this baseline comparison structure.
Krizhevsky, Alex, Ilya Sutskever, and Geoffrey E. Hinton. 2012. “ImageNet Classification with Deep Convolutional Neural Networks.” Advances in Neural Information Processing Systems 25.
36 ResNet: Introduced by He et al. (2016), skip connections enabled 152+ layer networks and achieved 3.57 percent top-5 ImageNet error (ensemble), surpassing the estimated human error rate reported in the ImageNet challenge context (Russakovsky et al. 2015). ResNet-50 became a common MLPerf Training reference workload because its moderate size (25.6M parameters) and well-understood compute profile (4.1 GFLOP per image) make it sensitive to both hardware and software optimizations without requiring multi-node setups (Mattson et al. 2020).
He, Kaiming, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2016. “Deep Residual Learning for Image Recognition.” 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 770–78. https://doi.org/10.1109/cvpr.2016.90.
Russakovsky, Olga, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, et al. 2015. “ImageNet Large Scale Visual Recognition Challenge.” International Journal of Computer Vision 115 (3): 211–52. https://doi.org/10.1007/s11263-015-0816-y.
Mattson, Peter, Christine Cheng, Cody Coleman, Greg Diamos, Paulius Micikevicius, David Patterson, Hanlin Tang, et al. 2020. “MLPerf Training Benchmark.” Proceedings of Machine Learning and Systems (MLSys) 2: 336–49.
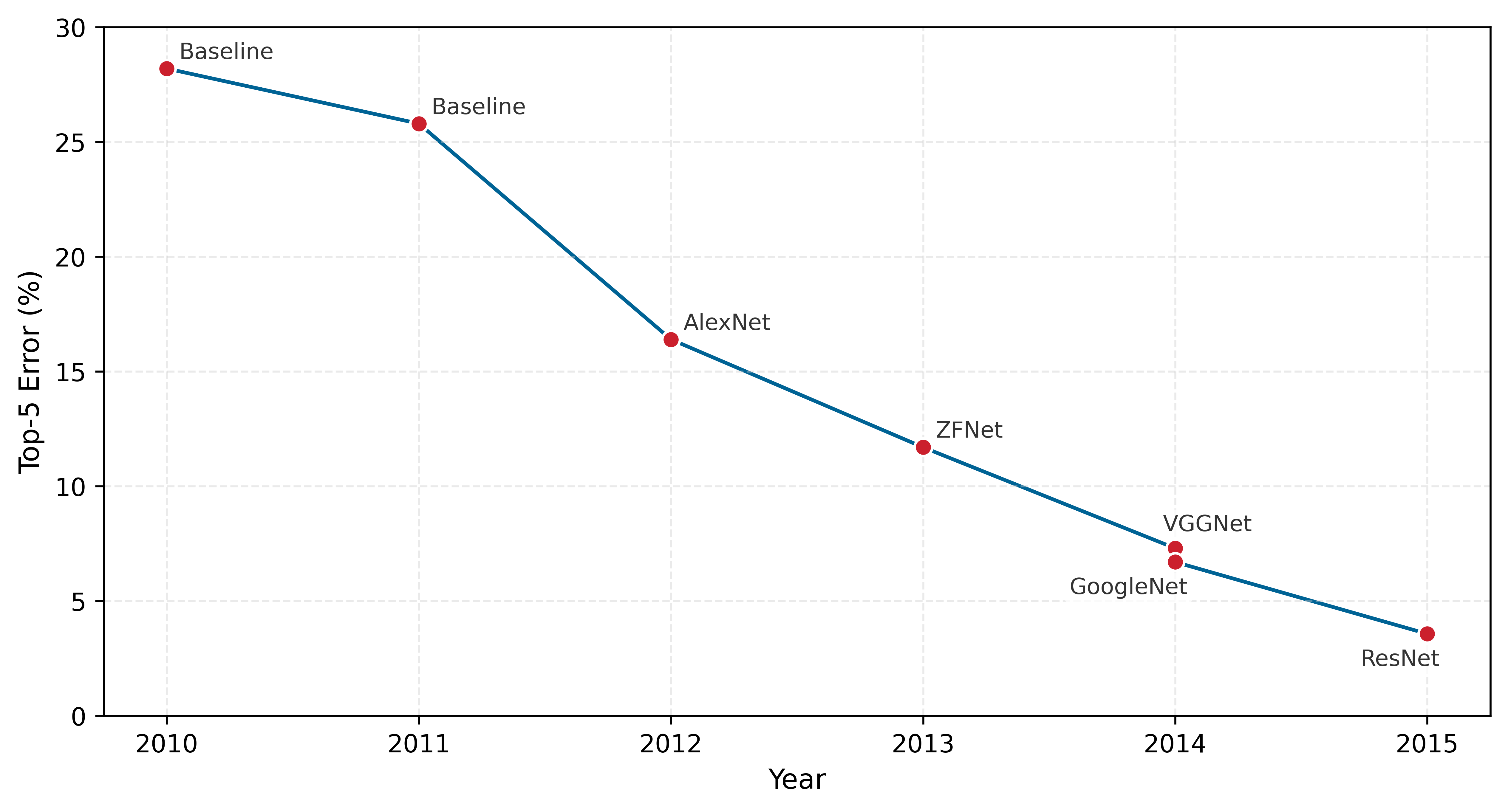
Accuracy metrics and their blind spots
The most common model metrics (accuracy, precision, recall, F1) each reveal different aspects of model behavior while hiding others, and understanding their blind spots is essential for compression validation. Top-\(k\) accuracy measures whether the correct label appears in the model’s top-\(k\) predictions. Top-1 accuracy is strict; top-5 is lenient. The gap between them reveals model uncertainty: a model with 75 percent top-1 but 95 percent top-5 accuracy “knows” the answer is among a few candidates but struggles to commit. For deployment, the acceptable gap depends on whether downstream systems can use ranked predictions or require single answers.
Precision and recall matter when classes are imbalanced or errors have asymmetric costs (Sokolova and Lapalme 2009). A fraud detection model with 99 percent accuracy might have 10 percent recall on actual fraud (catching only one in 10 fraudulent transactions), a catastrophic failure despite high accuracy. Precision (of predicted positives, how many are correct?) and recall (of actual positives, how many were found?) expose these failures that accuracy hides.
Sokolova, Marina, and Guy Lapalme. 2009. “A Systematic Analysis of Performance Measures for Classification Tasks.” Information Processing &Amp; Management 45 (4): 427–37. https://doi.org/10.1016/j.ipm.2009.03.002.
Buolamwini, Joy, and Timnit Gebru. 2018. “Gender Shades: Intersectional Accuracy Disparities in Commercial Gender Classification.” Conference on Fairness, Accountability and Transparency, 77–91.
Most insidiously, aggregate metrics hide subgroup failures. A model achieving 95 percent overall accuracy might achieve 60 percent on a critical demographic subgroup. The Gender Shades project (Buolamwini and Gebru 2018) revealed commercial gender-classification systems for facial analysis performing substantially worse on darker-skinned women than on lighter-skinned men, a disparity invisible to aggregate benchmarks. Disaggregated evaluation across deployment-relevant subgroups is essential; Responsible Engineering examines fairness evaluation systematically.
Calibration: When confidence scores matter
For many deployment scenarios, how confident the model is matters as much as what it predicts. A well-calibrated37 model’s confidence scores correspond to actual correctness probability: when it says “90 percent confident,” it should be correct 90 percent of the time.
37 Calibration: From Arabic qalib (a mold for casting metal) via Latin calibrare, originally describing the adjustment of measuring instruments against known standards. In ML, calibration ensures predicted probabilities match empirical frequencies; Guo et al. formalize this concern for modern neural networks and show that temperature scaling is a simple effective post-hoc correction (Guo et al. 2017). The etymology is apt: just as an uncalibrated instrument produces precise but inaccurate measurements, an uncalibrated model produces confident but unreliable predictions, causing downstream systems that threshold on confidence scores to make systematically wrong decisions.
Guo, Chuan, Geoff Pleiss, Yu Sun, and Kilian Q. Weinberger. 2017. “On Calibration of Modern Neural Networks.” Proceedings of the 34th International Conference on Machine Learning (ICML) 70: 1321–30.
Compression can shift calibration even when preserving accuracy, a critical concern when validating quantization techniques from Quantization and Precision. A quantized model might maintain headline accuracy while becoming overconfident on examples it gets wrong. This matters because post-hoc calibration techniques such as temperature scaling can only correct the problem if calibration is measured explicitly (Guo et al. 2017).
Calibration failures create downstream problems. An overconfident model triggers unnecessary human review (predicted 95 percent confidence but wrong 30 percent of the time). An underconfident model fails to automate decisions it could handle (predicted 70 percent confidence but correct 95 percent of the time). Expected Calibration Error (ECE) measures the gap between confidence and accuracy across confidence bins; reliability diagrams visualize this correspondence.
Compression validation: The efficiency-quality frontier
Model compression (Model Compression) trades model capacity for efficiency. Validation must determine whether compression achieved an acceptable trade-off or damaged capabilities that matter.
Pareto frontier38 evaluation determines whether a compressed model represents a good trade-off. Plotting accuracy against the target efficiency metric (latency, model size, energy) reveals the trade-off frontier. Models on the Pareto frontier cannot improve one metric without degrading the other; models below the frontier are dominated by better alternatives.
38 Pareto Frontier: Named after economist Vilfredo Pareto (Pareto 1896), the frontier contains all solutions where improving one objective requires degrading another. In compression benchmarking, the frontier’s shape carries diagnostic information: a steep region means efficiency gains come cheaply (prune here), while a flat region means further compression costs disproportionate accuracy (stop here). Points below the frontier are strictly dominated and represent wasted capacity.
Pareto, Vilfredo. 1896. Cours d’économie Politique. F. Rouge.

A dominated model loses on both axes of the Pareto frontier.
Han, Song, Jeff Pool, John Tran, and William J. Dally. 2015. “Learning Both Weights and Connections for Efficient Neural Networks.” Advances in Neural Information Processing Systems 28 (NeurIPS 2015), 1135–43.
Gale, Trevor, Erich Elsen, and Sara Hooker. 2019. “The State of Sparsity in Deep Neural Networks.” arXiv Preprint arXiv:1902.09574.
Hinton, Geoffrey, Oriol Vinyals, and Jeff Dean. 2015. “Distilling the Knowledge in a Neural Network.” arXiv Preprint.
Different compression techniques fail in different ways. Quantization (reducing numerical precision) can preserve average-case performance while changing calibration or behavior near decision boundaries (Jacob et al. 2018; Guo et al. 2017). Pruning (removing weights or structures) can lose capacity for rare features, potentially fine for common cases but risky for tail scenarios (Han et al. 2015; Gale et al. 2019). Distillation (training smaller models to mimic larger ones) can match top-line accuracy while changing softer properties such as confidence and calibration (Hinton et al. 2015). Validation must probe these specific failure modes, not just measure aggregate accuracy.
Calibration is the failure mode aggregate accuracy hides most completely, and expected calibration error (ECE) is the metric that exposes it. ECE measures whether predicted confidence matches actual accuracy: when a model reports a prediction as 90 percent confident, it should be correct 90 percent of the time. Three thresholds govern interpretation. An \(\text{ECE} < 0.05\) is well-calibrated, with confidence scores reliable for threshold-based decisions; an \(\text{ECE}\) between 0.05 and 0.10 is moderately calibrated, where confidence scores should be used with caution; and an \(\text{ECE} > 0.10\) is poorly calibrated, where confidence scores are unreliable. Compression can leave top-1 accuracy intact while pushing ECE across these thresholds, which is why a compression protocol measures it directly.
Acceptable degradation depends on deployment context. A 2 percent accuracy drop might be acceptable for a recommendation system (users tolerate imperfect suggestions) but unacceptable for medical diagnosis (each error has significant consequences). Define accuracy thresholds before compression, then validate against them. The MobileNetV2 lighthouse makes the complete INT8 validation protocol concrete.
Lighthouse 1.3: MobileNetV2 INT8 compression
Returning to our MobileNetV2 lighthouse example, consider a complete validation protocol for INT8 quantization, grounded in MobileNetV2’s architecture (Sandler et al. 2018) and post-training quantization practice (Jacob et al. 2018):
Precompression baseline: MobileNetV2 achieves 71.8 percent top-1 accuracy on ImageNet at 3.5M parameters (14 MB FP32).
Notice in table 19 that aggregate accuracy barely changes after INT8 quantization to 3.5 MB, but calibration error and edge-case accuracy tell a different story. The INT8 model’s ECE of 0.089 lands in the borderline band: confidence scores are becoming unreliable for automated decision thresholds.
| Metric | FP32 | INT8 | Acceptable? |
|---|---|---|---|
| Top-1 accuracy | 71.8% | 70.9% | ✓ (0.9 pp drop; below 1 percentage-point threshold) |
| Top-5 accuracy | 91% | 90.4% | ✓ |
| Calibration ECE | 0.031 | 0.089 | ⚠ (degraded) |
| Edge-case accuracy | 68.2% | 61.4% | ⚠ (drop of 6.8 pp) |
Edge-case definition: Images with >50 percent occlusion, <100 lux lighting, or >30° rotation from training distribution (approximately 5 percent of real-world inputs).
What this reveals: Average-case accuracy looks acceptable (0.9 percentage-point drop), but calibration degraded significantly and edge-case accuracy dropped 6.8 percentage points. If the deployment context uses confidence thresholds (for example, “only act if confidence > 85 percent”) or encounters many edge cases (unusual lighting, partial occlusions), INT8 MobileNetV2 may fail despite passing aggregate benchmarks.
Fix: Apply temperature scaling post-hoc to restore calibration (Guo et al. 2017). Temperature scaling learns a single scalar \(T_{\text{cal}}\) to divide logits before softmax: \(\text{softmax}(z_i/T_{\text{cal}})\). In parallel, add edge-case examples to the test set to monitor that specific failure mode continuously.
Jacob, Benoit, Skirmantas Kligys, Bo Chen, Menglong Zhu, Matthew Tang, Andrew Howard, Hartwig Adam, and Dmitry Kalenichenko. 2018. “Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference.” 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2704–13. https://doi.org/10.1109/cvpr.2018.00286.
Sandler, Mark, Andrew Howard, Menglong Zhu, Andrey Zhmoginov, and Liang-Chieh Chen. 2018. “MobileNetV2: Inverted Residuals and Linear Bottlenecks.” 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 4510–20. https://doi.org/10.1109/cvpr.2018.00474.
Frankle, Jonathan, and Michael Carbin. 2019. “The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks.” International Conference on Learning Representations.
The Lottery Ticket Hypothesis (Lottery ticket hypothesis) provides concrete benchmarking data illustrating what Pareto-efficient compression looks like. Through iterative pruning, Frankle and Carbin (2019) found sparse subnetworks (“winning tickets”) in fully connected and convolutional networks that could match the original network’s test accuracy when trained in isolation.
The Lottery Ticket results reveal the shape of compression trade-offs: aggressive pruning can preserve accuracy for some architectures and tasks, but the acceptable sparsity point is empirical rather than universal. Compression validation should establish similar trade-off curves for each specific model and task, identifying where the model sits on the Pareto frontier and whether further compression yields meaningful efficiency gains or merely degrades quality.
Large language model benchmarks
The compression evaluation framework applies cleanly when the task has a stable label: classification accuracy, detection mAP, segmentation IoU. Large language models break that pattern. A team can choose a model because it scores well on a public benchmark, then discover in deployment that the model recognizes multiple-choice facts but cannot generate a grounded answer, responds too slowly for an interactive product, or produces confident unsafe text that the benchmark never stressed. LLM benchmarking therefore starts by naming the deployment failure that a score is meant to rule out.
The useful LLM metric taxonomy in table 20 is therefore a decision aid, not a leaderboard. Its rows use Massive Multitask Language Understanding (MMLU)39, HELM (Holistic Evaluation of Language Models)40, and perplexity41 as examples of scores that answer different deployment questions:
39 MMLU (Massive Multitask Language Understanding): Introduced by Hendrycks et al. (2020) with 15,908 multiple-choice questions across fifty-seven subjects. MMLU’s benchmarking limitation is its format: multiple-choice recognition is not the same task as open-ended generation, so an MMLU score should not be read as direct evidence that a model can produce grounded free-form answers in production.
Hendrycks, Dan, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. 2020. “Measuring Massive Multitask Language Understanding.” arXiv Preprint.
40 HELM (Holistic Evaluation of Language Models): Stanford’s 2022 evaluation framework tested a broad set of models across seven dimensions (accuracy, calibration, robustness, fairness, bias, toxicity, efficiency) (Liang et al. 2022). HELM’s contribution is methodological: by evaluating models that score similarly on accuracy but diverge on calibration or toxicity, it demonstrates that single-metric leaderboards systematically hide failure modes that matter for production deployment.
Liang, Percy, Rishi Bommasani, Tony Lee, Dimitris Tsipras, Dilara Soylu, Michihiro Yasunaga, Yian Zhang, et al. 2022. “Holistic Evaluation of Language Models.” arXiv Preprint arXiv:2211.09110.
41 Perplexity: From Latin perplexus (entangled); in information theory, \(2^{H(p)}\) where \(H\) is entropy. A perplexity of 10 means the model is “10-way confused” on average. The systems consequence is interpretive rather than direct memory accounting: perplexity measures held-out next-token prediction on a corpus, while serving memory pressure is governed by context length, batch size, model shape, and decoding state; KV-cache management is a separate serving problem (Kwon et al. 2023).
Kwon, Woosuk, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. 2023. “Efficient Memory Management for Large Language Model Serving with PagedAttention.” Proceedings of the 29th Symposium on Operating Systems Principles, 611–26. https://doi.org/10.1145/3600006.3613165.
| Deployment failure to rule out | Metric or benchmark family | What the score reveals | What the score cannot prove |
|---|---|---|---|
| The model recognizes facts poorly | MMLU (Massive Multitask Language Understanding) | Broad factual and disciplinary knowledge across fifty-seven subjects, with scores interpretable against chance-level multiple-choice performance | Whether the model can generate grounded open-ended answers rather than choose among multiple-choice options |
| The model is capable but unsafe | HELM (Holistic Evaluation of Language Models) | Accuracy alongside calibration, robustness, fairness, bias, toxicity, and efficiency | Whether one aggregate score captures the deployment risk; a model can be strong on accuracy and weak on calibration, safety, cost, or prompt stability |
| The model predicts its corpus well | Perplexity | Held-out next-token prediction on the same corpus; a perplexity of 10 means the model is “10-way confused” on average | Whether generated answers are helpful, safe, or grounded outside that corpus |
| The model feels slow in use | First-token latency, inter-token latency, and token throughput | Prompt-processing delay before generation starts and decode speed after generation begins | Whether a single throughput number hides poor interactive responsiveness, especially when batching improves throughput but worsens first-token latency |
The responsiveness row deserves a concrete timing anchor because LLM benchmarks often report a single throughput number even though users experience generation in phases. A model can look efficient in tokens per second while still feeling slow if the first token arrives late, or it can improve first-token latency while producing the rest of the answer too slowly for an interactive workflow. The small calculation below turns those token-rate metrics into user-visible wall-clock time.
Token throughput turns that trade-off into wall-clock time. For a response of about 750 tokens, 25 tokens/s means 30 seconds of generation, while 100 tokens/s means 7.5 seconds. Time-to-first-token and inter-token latency must therefore be reported together: one captures responsiveness at the start of the exchange, and the other captures the rate at which the answer arrives.
The final failure is that a score may measure memory rather than capability. Benchmark contamination is a unique LLM risk because models trained on web-scale corpora may encounter benchmark questions during pretraining, inflating scores through memorization rather than skill (Xu et al. 2024). Leakage detection reframes this risk as something benchmark designers can test for rather than merely suspect. Temporal holdouts use content published after the training cutoff, dynamic benchmarks generate fresh instances continuously, and contamination tests ask whether the model recalls exact benchmark phrasing. These techniques keep the benchmark aligned with the deployment question instead of rewarding exposure to the test set.
Xu, Ruijie, Zengzhi Wang, Run-Ze Fan, and Pengfei Liu. 2024. “Benchmarking Benchmark Leakage in Large Language Models.” arXiv Preprint arXiv:2404.18824.
Data benchmarking
Model benchmarks validate whether compression preserved model quality. Model quality, however, depends entirely on the data used to train and evaluate it, and this dependency creates the most insidious failure mode in ML deployment. A perfectly preserved model trained on biased or unrepresentative data will still fail in production. Data benchmarks validate whether the efficiency strategies from Data Selection (active learning, curriculum design, data augmentation, and synthetic data generation) produced training sets that enable reliable deployment. This is often the last validation to fail and the hardest to diagnose: a model achieving excellent accuracy on held-out test data may collapse on production inputs that the training data never adequately represented.
Contemporary AI development reveals that data quality often determines performance boundaries more than model architecture. This recognition elevated data benchmarking from afterthought to critical discipline.
A data benchmark therefore starts with a protocol before it starts with a score. Define the deployment slice the model must serve, reserve a leakage-resistant holdout, verify duplicate and near-duplicate separation across partitions, set minimum coverage for rare classes and subgroups, audit label quality, and establish drift thresholds that determine when the benchmark no longer represents production. Only after those gates are explicit do aggregate metrics become interpretable.
Coverage metrics
The first question data benchmarking must answer is whether the training data represents the inputs the model will encounter. A model cannot learn patterns it has never seen, and the ways training data can fail to represent deployment reality are often subtle.
Consider class balance: a fraud detection dataset with 99 percent legitimate transactions and 1 percent fraud might produce a model that achieves 99 percent accuracy by simply labeling everything legitimate. The model is useless, but the accuracy metric looks excellent. Severe imbalance often requires mitigation through oversampling, class weighting, or threshold adjustment. More insidious is subgroup imbalance within classes: a dataset might have balanced positive and negative examples overall, but negative examples might be drawn predominantly from one demographic group, creating disparities invisible to aggregate class balance metrics.
Feature coverage presents an even harder challenge because it requires domain knowledge about what variations matter. A computer vision model trained exclusively on daytime images will fail on nighttime inputs; a natural language model trained on formal text will fail on colloquial language. Unlike class balance, which can be computed from labels alone, feature coverage requires understanding the deployment context. The lighting conditions the camera will encounter, the dialects users will speak, and the edge cases that exist in production but never appear in test sets all fall outside what labels alone can predict. These questions have no algorithmic answer; they demand collaboration between ML engineers and domain experts who understand the deployment environment.
For applications affecting people, demographic representation becomes a coverage dimension with ethical implications. Training data must represent the deployment population across relevant dimensions: age, gender, ethnicity, geography, language. A facial recognition system trained predominantly on one demographic group will systematically underperform on others, even if aggregate accuracy metrics look acceptable. The challenge is that demographic metadata is often unavailable or unreliable, making representation gaps difficult to detect and measure.
Quality metrics
Even when training data covers the right inputs, the labels themselves may be unreliable. Studies consistently find 3–6 percent label error rates in major datasets, including ImageNet (Northcutt et al. 2021). These errors are not merely noise—they become learned ground truth. A model trained on data where wolves are occasionally labeled as dogs will learn the false rule that some wolves are dogs. The benchmark will report this as correct behavior because the model matches the (incorrect) labels.
Northcutt, Curtis G., Anish Athalye, and Jonas Mueller. 2021. “Pervasive Label Errors in Test Sets Destabilize Machine Learning Benchmarks.” arXiv Preprint arXiv:2103.14749 34: 19075–90. https://doi.org/10.48550/arxiv.2103.14749.
For small datasets, manual audit of a random sample can estimate label accuracy. For large datasets, confident learning techniques identify likely mislabeled examples by finding cases where model predictions systematically disagree with labels. The intuition is that when a model confidently predicts a different label than the ground truth, either the model has learned something incorrect or the label is wrong. Detection, however, is only the first step; correction requires human review, and scaling human review to millions of examples presents its own challenges.
Inter-annotator agreement provides a different lens on label quality by measuring consistency across human labelers. Cohen’s kappa or Fleiss’ kappa quantify agreement beyond what chance would produce (Cohen 1960; Fleiss 1971). When agreement falls below conventional thresholds for tasks with clear ground truth, something is wrong: either the labeling guidelines are ambiguous, the task is inherently subjective, or labeler quality varies significantly. Landis and Koch’s qualitative kappa bands are widely cited as a rough interpretive guide, though they should not replace domain judgment (Landis and Koch 1977).
Cohen, Jacob. 1960. “A Coefficient of Agreement for Nominal Scales.” Educational and Psychological Measurement 20 (1): 37–46. https://doi.org/10.1177/001316446002000104.
Fleiss, Joseph L. 1971. “Measuring Nominal Scale Agreement Among Many Raters.” Psychological Bulletin 76 (5): 378–82. https://doi.org/10.1037/h0031619.
Landis, J. Richard, and Gary G. Koch. 1977. “The Measurement of Observer Agreement for Categorical Data.” Biometrics 33 (1): 159–74. https://doi.org/10.2307/2529310.
The distinction between random and systematic errors matters enormously for their downstream effects. Random label noise partially averages out during training: if different examples are mislabeled in different directions, the model learns the central tendency. Systematic errors (consistently mislabeling a particular subclass), in contrast, are learned as ground truth. A dataset where all wolves photographed in snow are labeled “dogs” will produce a model that calls snowy wolves dogs, and no amount of additional data fixes this without correcting the systematic error at its source.
Distribution alignment
The final category of data benchmarking asks whether models will generalize from training conditions to deployment reality. This train-to-production alignment question is where the gap between benchmark performance and production performance most frequently emerges.
The standard assumption underlying held-out evaluation, that test data comes from the same distribution as training data, is routinely violated in practice. Test sets constructed years after training data may reflect distribution drift as the world changes. Test sets from different geographic regions may reflect population shift. A model with strong held-out accuracy can drop sharply when deployed to a region or time period the test set did not represent. Standard held-out evaluation overestimates deployment performance whenever the i.i.d. (independent and identically distributed) assumption fails.
The true test is train-to-production alignment, and this is far harder to measure because production data differs from training data in ways that held-out test sets often fail to capture. Production images come from different cameras with different characteristics. Production users come from different populations with different behaviors. Production inputs include edge cases that curated test sets systematically exclude. The WILDS42 benchmark (Koh et al. 2021) was designed specifically to evaluate models under realistic distribution shifts: hospital systems with different patient populations, wildlife cameras at different locations, satellite imagery from different time periods. The results reveal a stark reality: models achieving 90 percent+ accuracy on in-distribution test sets may drop to 60 percent under these realistic shifts.
42 WILDS: Stanford’s 2021 benchmark of ten datasets with real-world distribution shifts: hospital patient population changes (Camelyon17), wildlife camera location shifts (iWildCam), and satellite imagery temporal drift (PovertyMap). WILDS quantifies the deployment gap: models achieving 97 percent in-distribution accuracy can drop to 70 percent under these realistic shifts, demonstrating that standard held-out evaluation systematically overestimates production performance when the i.i.d. assumption fails.
Koh, Pang Wei, Shiori Sagawa, Henrik Marklund, Sang Michael Xie, Marvin Zhang, Akshay Balsubramani, Weihua Hu, et al. 2021. “WILDS: A Benchmark of in-the-Wild Distribution Shifts.” In Proceedings of the 38th International Conference on Machine Learning, ICML 2021, 18-24 July 2021, Virtual Event, edited by Marina Meila and Tong Zhang, vol. 139. Proceedings of Machine Learning Research. PMLR.
Berger, V. W., and Y. Zhou. 2014. “Wiley StatsRef: Statistics Reference Online.” In Wiley Statsref: Statistics Reference Online. Wiley. https://doi.org/10.1002/9781118445112.stat06558.
Gretton, Arthur, Karsten M. Borgwardt, Malte J. Rasch, Bernhard Schölkopf, and Alexander Smola. 2012. “A Kernel Two-Sample Test.” Journal of Machine Learning Research 13 (25): 723–73.
Given these challenges, shift detection methods become essential for production monitoring. Statistical tests like the Kolmogorov-Smirnov test (Berger and Zhou 2014) or kernel-based two-sample tests such as Maximum Mean Discrepancy (MMD) (Gretton et al. 2012) can detect covariate shift—when the distribution of inputs changes even if the relationship between inputs and outputs remains stable. Monitoring model confidence distributions can detect when the model encounters inputs unlike anything in training. The goal is early detection: identifying distribution shift before it causes catastrophic performance degradation, enabling intervention through model updates, data collection, or deployment constraints.
Distribution alignment challenges highlight a persistent tension in ML development between two paradigms: fixing the data and iterating on models, or fixing the model and iterating on data. Figure 12 places these two paradigms side by side, revealing exactly where the feedback loop differs. In the model-centric diagram, the iteration cycle targets the architecture while the data remains static; in the data-centric diagram, the architecture stays fixed while the cycle targets data quality. Research increasingly demonstrates that methodical dataset enhancement can yield superior performance gains compared to model refinements alone—challenging the conventional emphasis on architectural innovation.

Data-centric AI reflects an important shift in understanding that challenges the “more data is always better” assumption: better datasets, not just larger ones, produce more reliable and generalizable AI systems. Initiatives like DataPerf (Mazumder et al. 2023) and DataComp43 have emerged to systematically evaluate how dataset improvements affect model performance. For instance, DataComp (Gadre et al. 2023) demonstrated that models trained on a carefully curated 30 percent subset of data achieved better results than those trained on the complete dataset, challenging the assumption that more data automatically leads to better performance.
Mazumder, Mark, Colby Banbury, Xiaozhe Yao, Bojan Karlaš, et al. 2023. “DataPerf: Benchmarks for Data-Centric AI Development.” Advances in Neural Information Processing Systems 36.
43 DataComp: Introduced in 2023, DataComp inverts the standard benchmark by fixing the model and training code, letting participants compete on dataset curation alone. Results showed that a carefully filtered 30 percent subset matched models trained on 10\(\times\) larger unfiltered data, quantifying a systems insight: for many workloads, engineering the data pipeline yields greater performance gains per dollar than scaling compute.
Gadre, Samir Yitzhak, Gabriel Ilharco, Alex Fang, Jonathan Hayase, Georgios Smyrnis, Thao Nguyen, Ryan Marten, et al. 2023. “DataComp: In Search of the Next Generation of Multimodal Datasets.” Advances in Neural Information Processing Systems 36 36: 27092–112. https://doi.org/10.52202/075280-1179.
A persistent challenge in data benchmarking emerges from dataset saturation. When models achieve near-perfect accuracy on benchmarks like ImageNet, practitioners must distinguish whether performance gains represent genuine capability advances or merely optimization to existing test sets. As the timeline in figure 13 illustrates, widely tracked AI benchmarks have repeatedly crossed reported human baselines, making each corresponding benchmark less useful as a differentiator (Maslej et al. 2024).

Maslej, Nestor, Loredana Fattorini, C. Raymond Perrault, Vanessa Parli, Anka Reuel, Erik Brynjolfsson, John Etchemendy, et al. 2024. “Artificial Intelligence Index Report 2024.” In CoRR, abs/2405.19522. https://doi.org/10.48550/ARXIV.2405.19522.
Dataset saturation and dynamic benchmarks
Figure 13 raises a critical methodological problem: when models surpass human performance on benchmarks, the result may reflect either genuine capability advances or optimization to static evaluation sets, and the two are difficult to distinguish from leaderboard scores alone. MNIST, introduced through the classic handwritten-digit recognition work of LeCun and colleagues (LeCun et al. 1998), illustrates the concern: static test images can contain dataset-specific artifacts that models learn to exploit. The question “Are we done with ImageNet?” (Beyer et al. 2020) generalizes this concern.
44 Dynabench: Facebook AI Research’s 2021 platform for dynamic benchmark generation, where humans craft adversarial inputs that fool current best models. Dynabench addresses the saturation problem, where very high accuracy on static benchmarks may reflect test-set familiarity rather than robust capability, but introduces its own trade-off: dynamic benchmarks are harder to compare across time because the evaluation set changes. Static and dynamic benchmarks serve complementary diagnostic roles.
Kiela, Douwe, Max Bartolo, Yixin Nie, Divyansh Kaushik, Atticus Geiger, Zhengxuan Wu, Bertie Vidgen, et al. 2021. “Dynabench: Rethinking Benchmarking in NLP.” Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies 9: 4110–24. https://doi.org/10.18653/v1/2021.naacl-main.324.
Dynamic benchmarking approaches like Dynabench44 (Kiela et al. 2021) address saturation by continuously evolving test data based on model performance, ensuring that benchmarks remain challenging as capabilities improve. However, dynamic benchmarks complement rather than replace the coverage, quality, and distribution metrics described earlier: they prevent saturation but do not diagnose its causes.
Holistic system-model-data evaluation
Passing system, model, and data benchmarks independently is not enough. A system benchmark can validate hardware performance, a model benchmark can verify that compression preserved quality, and a data benchmark can assess training set representativeness, yet the deployed system can still fail because the three dimensions interact. Real-world AI performance emerges from that interaction, and optimizing one dimension can expose weaknesses in another.
Consider a concrete failure cascade: a team achieves excellent MLPerf Inference scores by deploying an INT8-quantized model on optimized hardware. System benchmarks pass. The quantized model, however, was validated only on ImageNet-distributed test data; deployment reveals accuracy degradation on factory-floor images with different lighting characteristics. Model quality benchmarks would have caught the quantization sensitivity. Further investigation shows the training data contained no images with industrial lighting—a data quality gap that no amount of system or model optimization can address.
This interdependence means that benchmark results from one dimension can be invalidated by failures in another:
- System success + Model failure: Hardware delivers promised throughput, but compression degraded accuracy below deployment thresholds
- System success + Data failure: Fast inference on representative inputs, but training data bias causes failures on demographic subgroups
- Model success + System failure: Accurate predictions, but latency variance under load violates SLA requirements
- Model success + Data failure: High accuracy on held-out test set, but distribution shift in production causes silent degradation
This interdependence is precisely the AI Triad introduced in Introduction (The D·A·M Taxonomy): System corresponds to Machine, Model corresponds to Algorithm, and Data remains Data. Holistic evaluation requires not just passing benchmarks in each dimension, but verifying that assumptions made in one dimension hold across the others. The Part III optimization pipeline (data → model → hardware) creates implicit dependencies that benchmarking must validate explicitly.
The D·A·M taxonomy provides a diagnostic framework for systematically identifying which axis limits performance. Diagnostic Summary maps each axis to its binding physical constraint and the optimization pathway that relieves it, giving the first diagnostic step when a benchmark reveals underutilization. Table 21 formalizes this approach by crossing each D·A·M axis with the three fundamental bottleneck types; The D·A·M Taxonomy gives the full diagnostic guide, including profiling utilities and efficiency grading rubrics.
| Component | Compute-Bound | Memory-Bound | I/O-Bound |
|---|---|---|---|
| Data | Preprocessing too slow (augmentation, tokenization) | Dataset exceeds RAM (spills to disk) | Storage cannot feed GPU (disk throughput limit) |
| Algorithm | Model too large for hardware (FLOPs exceed capacity) | Activations exceed memory (batch size limited) | Gradient sync slower than compute (distributed training) |
| Machine | GPU utilization saturated (need faster accelerator) | Memory bandwidth saturated (need more HBM bandwidth) | Network/PCIe bandwidth saturated (need faster links) |
The diagnostic power of this matrix becomes clear when benchmarks reveal unexpected results—particularly when performance falls short of expectations. If system benchmarks show low GPU utilization despite adequate hardware, the bottleneck likely lies elsewhere. For example, a team observing only 30 percent GPU utilization during training might initially suspect an inefficient model architecture (Algorithm row), but profiling reveals that image augmentation runs on CPU and cannot keep up with GPU consumption (Data row, Compute-Bound column: “Preprocessing too slow”). Systematic diagnosis using this matrix prevents the common mistake of optimizing the wrong component.
Yet validation under controlled laboratory conditions differs profoundly from validation under production reality. In the laboratory, data distributions stay fixed, request patterns remain uniform, and systems run in isolation. In production, all three assumptions break simultaneously—data drifts, traffic spikes unpredictably, and system components interact in ways that isolated benchmarks cannot capture. The final dimension of benchmarking asks whether systems validated in the lab survive contact with the real world.
Self-Check: Question
A quantized model preserves FP32 top-1 accuracy within 0.3 percent, but downstream automation that relies on confidence thresholds starts making incorrect routing decisions after deployment. Which model-benchmarking metric most directly surfaces this failure?
- Expected Calibration Error, because it measures whether predicted confidence probabilities match actual correctness rates
- Top-5 accuracy, because it reveals whether the correct label appears among several guesses when top-1 is wrong
- Throughput, because faster models tend to be systematically less calibrated than slower models
- Parameter count, because smaller compressed models always lose confidence reliability in proportion to their size reduction
Explain why compression validation should be framed as an efficiency-quality Pareto frontier rather than a single before-and-after accuracy comparison, using a concrete example where a technique that loses 1 percent accuracy is still the correct deployment choice.
A sepsis-prediction model performs excellently on a held-out test split from Hospital A’s training data but fails badly when deployed to Hospital B in a different geography. Which data-benchmarking failure most directly explains this pattern?
- Low parameter efficiency in the model architecture
- Excessively high arithmetic intensity in the model kernels
- Distribution misalignment between training/test data and the deployment population (different patient demographics, protocols, sensor calibrations)
- Over-calibration of the confidence scores
True or False: If a system benchmark and a model benchmark both pass with flying colors, data benchmarking is largely redundant because deployment-relevant failures should already be visible in those two dimensions.
Why are large language model benchmarks structurally harder to design than image classification benchmarks?
- Because language models cannot be evaluated on hardware metrics at all, so benchmarks must abandon quantitative measurement entirely
- Because open-ended generation requires joint evaluation across multiple dimensions (factuality, calibration, safety, reasoning, instruction-following) rather than a single fixed-label answer, and these dimensions can trade off against each other
- Because all LLM benchmarks are inherently contaminated by training data and therefore uninformative
- Because language models do not experience distribution shift and so benchmark design is less urgent
A team deploys a compressed MobileNet to an EdgeTPU for defect detection on a factory floor. MLPerf Inference scores look excellent in the lab, but the system misclassifies 8 percent of parts once deployed. Walk through how the chapter’s holistic system-model-data view diagnoses this kind of failure.
Production Considerations
A system that passes all three benchmark categories can still fail in production. The three-dimensional framework validated hardware performance, model quality, and data representativeness under controlled conditions—but production violates those conditions continuously. This gap between benchmark success and deployment success motivates a final benchmarking concern: validating systems under conditions that match operational reality.
From laboratory to production
Laboratory benchmarks establish what a system is capable of under ideal conditions. Production validation determines whether that system is performing correctly right now, under real conditions.
This distinction matters because laboratory benchmarks assume conditions that production systematically violates. Silent degradation poses the most insidious challenge: models can produce plausible but incorrect outputs without obvious error signals, and a recommendation system returning “reasonable” but suboptimal suggestions has no built-in error indicator. Dynamic workloads present a different failure mode: a system benchmarked at steady 1,000 QPS may fail when flash traffic events spike to 10,000 QPS, revealing that benchmark “throughput” assumed uniform request arrival rather than bursty production patterns. Data distribution shift compounds these problems over time, as production data evolves and diverges from training distributions—an image classifier trained on professional photos degrades gradually as users submit smartphone images with different lighting, angles, and compression artifacts. Finally, production imposes multi-objective constraints that benchmarks treat independently: accuracy, latency, cost, and resource utilization must all be satisfied simultaneously, and optimizing any one at the expense of others leads to deployment failure.
Bridging benchmark to deployment
Before deployment, validate benchmarking conclusions against production-representative conditions. Table 22 names the benchmark assumption, the production reality that violates it, and the validation step that closes the gap; the checkpoint that follows turns those rows into release-readiness actions.
| Benchmark Assumption | Production Reality | Validation Approach |
|---|---|---|
| Uniform request arrival | Bursty traffic patterns | Load test with production trace replay |
| Clean, preprocessed inputs | Variable quality inputs | Evaluate on production data sample |
| Warm system state | Cold starts, cache misses | Measure cold-start performance |
| Isolated execution | Resource contention | Benchmark under realistic system load |
| Fixed model version | A/B testing, gradual rollout | Establish baseline for comparison |
Checkpoint 1.4: Predeployment benchmark checklist
Before deploying a model based on benchmark results:
Production monitoring as continuous benchmarking
Production monitoring extends benchmarking from a one-time gate to a continuous process. The same principles apply (standardized metrics, reproducible measurement, statistical rigor) but the context shifts from “will this work?” to “is this working?”
Once a model is live, benchmarking becomes a rolling comparison against the baselines just established. The immediate checks stay concrete: whether the input distribution remains close to the benchmark distribution, whether latency and throughput stay inside the measured envelope, and whether model quality moves outside the expected range. Answering those checks requires the same measurement discipline as the offline benchmark, but now the measurements arrive continuously and under live traffic.
The MLOps chapter later turns this measurement loop into release and recovery machinery: staged rollouts, shadow evaluation [running the new model beside production without serving its outputs], continuous validation, and rollback. At this point, the handoff is narrower. Benchmarking defines the baselines and failure thresholds; operations keeps measuring against them after deployment.
The same gap between benchmark conditions and production conditions explains why otherwise careful teams still make predictable mistakes. The final section names the misconceptions that turn benchmark success into deployment failure.
Self-Check: Question
Which benchmark assumption is most directly violated when a production service experiences Black-Friday-style traffic bursts rather than the steady request rate used during evaluation?
- Uniform request arrival (Poisson or steady rate)
- Fixed model version across requests
- Clean labels in the input data
- Constant arithmetic intensity across batches
Explain why replaying production traces during predeployment validation is a stronger check than relying on the benchmark throughput number, and describe a concrete failure mode trace replay surfaces that benchmarks miss.
True or False: Once a model passes predeployment benchmarks, production monitoring is primarily an alerting convenience rather than a continuation of benchmarking.
Fallacies and Pitfalls
Benchmarking creates false confidence when standardized measurement obscures deployment realities. Teams assume controlled evaluations predict production performance, but real systems face variability, resource constraints, and multi-objective trade-offs that benchmarks cannot capture, wasting engineering effort on systems optimized for evaluation rather than deployment.
Fallacy: Benchmark performance directly translates to real-world application performance.
The seductive clarity of benchmark rankings leads teams to select systems as though leaderboard position predicts production behavior. It rarely does. As section 1.3.1 demonstrates, ML systems exhibit inherent variability from data quality issues, distribution shifts, and resource constraints absent in controlled evaluation. In a representative failure scenario, a language model achieving 92 percent benchmark accuracy drops to 78–82 percent accuracy in production when processing user-generated text with spelling errors, informal language, and domain-specific terminology. An inference system with 15 ms mean latency on MLPerf experiences 150–200 ms p99 latency in production (10–13.3× degradation) due to concurrent load, garbage collection pauses, and network variability. Teams relying solely on benchmark rankings systematically underestimate deployment complexity, leading to failed launches and costly re-engineering.

Mean benchmark latency understates the production tail by an order of magnitude.
Pitfall: Optimizing exclusively for benchmark metrics without considering broader system requirements.
Benchmark leaderboards incentivize aggressive optimization, but the optimizations that climb rankings often degrade the very characteristics production demands. As discussed in section 1.10.4, this exemplifies Goodhart’s Law: when benchmark scores become optimization targets, they cease to be meaningful measures of system quality. In one illustrative scenario, a team reduces inference latency from 12 ms to 8 ms through aggressive quantization, improving MLPerf ranking by 15 positions while degrading calibration such that prediction confidence scores become unreliable for downstream decision-making. Another team improves ImageNet accuracy by 2.1 percent through extensive hyperparameter tuning but the optimized model consumes 40 percent more energy and exhibits 25 percent worse performance on out-of-distribution images from production cameras. Organizations rewarding benchmark rankings over deployment success systematically produce systems that excel in evaluation but fail in production.
Fallacy: Single-metric evaluation provides sufficient insight into system performance.
A single number is seductively simple: this system is “94 percent accurate” or “1,200 QPS fast.” But production success requires balancing multiple competing objectives that any single metric obscures. As established in section 1.8.2, modern inference systems demand evaluation across accuracy, latency, throughput, energy, and robustness dimensions. In an illustrative trade-off, a recommendation model achieving 94 percent accuracy with 180 ms p99 latency fails service-level objectives requiring p99 < 100 ms despite excellent accuracy. Conversely, a system optimized for 1,200 QPS throughput achieves this rate while consuming 4.2 W vs. 1.8 W for a slightly slower system at 1,000 QPS (2.3× power difference). For battery-powered edge devices, the 17 percent throughput loss enables 2.3× longer operation time. Different stakeholders prioritize different metrics: ML engineers focus on accuracy, infrastructure teams on throughput and cost, product managers on latency percentiles. Single-metric optimization systematically produces systems that excel on one dimension while failing deployment requirements on others.
Pitfall: Using outdated benchmarks that no longer reflect deployment challenges and requirements.
Benchmarks have inertia: teams continue reporting on established benchmarks long after those benchmarks cease to provide meaningful discrimination. Saturation occurs when multiple approaches achieve near-identical performance, eliminating useful comparison. ImageNet top-5 classification error decreased from 28.2 percent in 2010 to 3.57 percent by 2015, with the competition ending in 2017, at which point 29 teams of 38 teams exceeded 95 percent accuracy (Russakovsky et al. 2015; Beyer et al. 2020); further optimization beyond this threshold provides marginal value for most applications. Similarly, MNIST became saturated enough that improvements at the third decimal place are rarely deployment-relevant (LeCun et al. 1998). As discussed in section 1.10.1, statistical confidence intervals around these measurements often exceed the claimed improvements. Changing deployment contexts compound the problem: benchmarks designed for server hardware become misleading for edge devices with 10× less memory and 100× lower power budgets. Effective benchmarking requires retiring saturated benchmarks and developing evaluation frameworks matching target deployment realities.
Beyer, Lucas, Olivier J. Hénaff, Alexander Kolesnikov, Xiaohua Zhai, and Aäron van den Oord. 2020. “Are We Done with ImageNet?” arXiv Preprint arXiv:2006.07159.
LeCun, Yann, Léon Bottou, Yoshua Bengio, and Patrick Haffner. 1998. “Gradient-Based Learning Applied to Document Recognition.” Proceedings of the IEEE 86 (11): 2278–324. https://doi.org/10.1109/5.726791.
Fallacy: Research benchmarks predict production behavior under real traffic.
Research benchmarks exist to compare algorithms under controlled conditions; production systems exist to serve users under chaotic ones. Applying the former to evaluate the latter systematically overestimates performance, because research benchmarks often assume ample computational resources, optimal data quality, and idealized conditions absent in production. As established in section 1.10.2, production systems face concurrent user loads, varying input quality, network latency, and system failures that degrade performance. A system achieving 800 QPS throughput in isolated benchmarks sustains only 400–500 QPS under production load with 90 percent utilization (37.5–50 percent degradation) due to queue contention and garbage collection pauses. Research benchmarks report model inference time (5–10 ms) while production end-to-end latency includes preprocessing, queuing, and postprocessing overhead totaling 50–100 ms. Production systems require 99.9 percent availability (43 minutes downtime per month) and graceful degradation under failures, characteristics research benchmarks ignore. Effective production evaluation requires operational metrics: sustained throughput under load, recovery time from failures, and complete latency breakdown.
Pitfall: Using research benchmarks as production release gates.
Teams sometimes promote a model because it passes the research benchmark, then discover only after launch that the benchmark never exercised the operational path. A release gate for a serving system must include load tests, tail-latency measurements, data-quality checks, failure drills, and rollback criteria. Research benchmarks remain useful for comparing algorithms, but production gates must measure the deployed system under the traffic, hardware, and failure conditions it will actually face.
Self-Check: Question
True or False: A system that ranks near the top of a benchmark leaderboard will usually maintain a similar relative advantage once deployed to production, provided the benchmark itself was measured carefully with proper statistical controls.
A team improves a benchmark from 1,000 QPS at 1.8 W to 1,200 QPS at 4.2 W (20 percent throughput gain, 133 percent power increase). Which lesson from the chapter best applies?
- The faster system is automatically better because throughput dominates every deployment concern
- Single-metric evaluation can mislead: a 20 percent throughput gain purchased at 2.3\(\times\) power cost is a poor trade for any deployment with energy, thermal, or cost constraints, and may be negative value in absolute terms
- The result proves the lower-throughput system is defective and should be discarded
- Power consumption should be ignored unless the deployment is in a data center
Explain why the chapter warns against using saturated benchmarks (such as MNIST or long-mature ImageNet) as primary evidence of system progress, and describe what should replace them.
What is the core mistake in applying research-style benchmark results directly to production system evaluation?
- Research benchmarks usually run on excessive hardware, so they systematically underestimate production performance
- Research benchmarks evaluate algorithms under controlled conditions with narrow metrics, while production systems must satisfy end-to-end operational requirements (tail latency under load, fault tolerance, multi-objective constraints, drift resilience) that research evaluations deliberately exclude
- Research benchmarks always omit accuracy measurements entirely
- Production systems should never consult benchmark data under any circumstances
Explain how Goodhart’s Law manifests in the pitfall of optimizing exclusively for benchmark rankings, using a concrete scenario where chasing the metric degrades deployment quality.
Summary
Benchmarking completes Part III’s optimization pipeline by validating whether the efficiency gains from data selection (Data Selection), model compression (Model Compression), and hardware acceleration (Hardware Acceleration) deliver in practice. Working backward through the optimization stack (hardware first, then model quality, then data representativeness), the three-dimensional framework catches failures at each layer before they cascade to production.
The validation sequence reflects how problems manifest: hardware issues surface immediately (wrong throughput, thermal throttling), model quality issues emerge under evaluation (accuracy degradation, calibration loss), and data issues often reveal themselves only in production (distribution shift, demographic bias). System benchmarks like MLPerf Training and Inference validate hardware claims with standardized workloads. Model quality benchmarks verify that compression preserved critical properties beyond top-line accuracy. Data benchmarks expose representativeness gaps that no amount of hardware optimization can compensate for.
Rigorous benchmarking is what distinguishes engineering claims from guesses. Practitioners who validate their optimizations rigorously, by measuring wall-clock latency rather than trusting FLOP counts, profiling tail latencies rather than averages, and testing on production-representative data rather than convenient benchmarks, build systems that perform as expected when deployed. As AI systems become increasingly influential in critical applications, this measurement rigor determines whether optimization claims translate into real-world impact.
Key Takeaways: Measuring what matters
- Benchmarks validate co-design: System, model, and data benchmarks expose different failures: hardware underdelivery, compression quality loss, and distribution mismatch. A system that passes only one axis can still fail when Data, Algorithm, and Machine constraints meet under production load.
- Proxy numbers need boundaries: Standardized run rules make comparisons honest, but fixed workloads are still proxies. Batch size, thermal state, input distribution, concurrency, and service-deadline windows decide whether a lab result survives the benchmark-production gap.
- Granularity trades diagnosis for realism: Micro-benchmarks isolate kernels, macro-benchmarks expose model-level costs, and end-to-end benchmarks capture user-visible behavior. Effective measurement stacks all three so teams can see both the symptom and the layer that caused it.
- Tail latency is the benchmark: Interactive systems fail at p95 and p99 before averages move. Reporting percentile latency under representative load prevents a benchmark from approving a system whose mean passes while its worst-served requests violate the SLO.
- Amdahl caps every optimization claim: A faster model cannot outrun the rest of the pipeline; if preprocessing is 50 percent of latency, an infinitely fast model yields only a 2\(\times\) system improvement. Benchmark the whole request path before celebrating kernel speedups.
- Efficiency still needs quality evidence: INT8 may cut memory 4\(\times\) and reduce MobileNet inference energy by about 5.4×, but calibration, subgroup robustness, and edge-case behavior decide whether the compressed model is deployable.
Every chapter in this part promised a gain of fewer FLOPs, a smaller model, or higher throughput. Benchmarking is where those promises are made to face the system that will keep or break them. The gap between a claimed improvement and a measured one is not noise but structure, the place where Data, Algorithm, and Machine turn out to have been merely assembled rather than matched: Amdahl’s Law shows why a model made infinitely fast still leaves a pipeline bounded by everything outside it, and the tail shows why an average can pass while the worst-served request fails. This is co-design held to account. An ML system is engineered, not asserted, and only measurement on the real workload can tell the two apart.
What’s Next: From lab to live
What does a system that passes every benchmark fail to predict? Production reality is what static benchmarks cannot capture: traffic bursts, data drift, and cascading failures that emerge only under contact with live workloads. Part IV leaves the controlled environment of the benchmark for that chaotic reality, beginning with Model Serving, where systems must survive contact with the real world.
Self-Check: Question
Which statement best summarizes the chapter’s final view of benchmarking in ML systems engineering?
- Benchmarking is mainly a mechanism for ranking hardware vendors by a single standardized throughput metric
- Benchmarking is the empirical validation layer that tests whether system, model, and data optimizations deliver their promised gains in deployment-representative conditions, converting optimization claims into measured engineering evidence
- Benchmarking matters mostly during research and becomes less useful once systems enter production
- Benchmarking replaces the need for production monitoring provided the benchmark is comprehensive enough
Explain why the chapter frames practitioners who measure tail latency, wall-clock end-to-end behavior, and production-representative data distributions as doing something fundamentally different from practitioners who rely on component benchmarks alone.
Which takeaway from the chapter most directly explains why a 3\(\times\) model inference speedup may produce only about a 1.2\(\times\) end-to-end latency improvement in a typical serving pipeline?
- Benchmarks are moving targets
- The tail determines the user experience
- Amdahl’s Law bounds total system improvement by the unoptimized fraction of the pipeline (preprocessing, queueing, postprocessing), so component-only optimization hits a ceiling set by what was not optimized
- Precision is a distinct energy lever
Self-Check Answers
Self-Check: Answer
A team quantizes MobileNetV2 from FP32 to INT8, deploys it to an EdgeTPU that hits the advertised 2 ms inference time, and validates accuracy on ImageNet test data. After release, smartphone users in low-light conditions report 12 percent misclassification rates. Which benchmarking dimension most directly diagnoses this failure?
- System benchmarking, because 12 percent error indicates the EdgeTPU is not actually sustaining the 2 ms latency under load
- Model benchmarking, because quantization must have broken calibration even though aggregate accuracy looked fine
- Data benchmarking, because ImageNet test images do not represent the smartphone-user input distribution
- Power benchmarking, because thermal throttling on the EdgeTPU is the most likely cause
Answer: The correct answer is C. Data benchmarking asks whether the training and test distributions match the deployed input distribution; low-light smartphone photos differ systematically from curated ImageNet validation images, so the failure is distributional coverage, not a hardware or model-quality regression. The system-latency framing misreads accuracy failures as throughput failures, and the calibration framing would predict confidence-reliability issues rather than a specific lighting-correlated error pattern.
Learning Objective: Classify a field-observed deployment failure by which of the three benchmarking dimensions would have caught it
The chapter describes a 2–10\(\times\) benchmark-production gap as structural rather than as measurement error. Explain why no amount of careful instrumentation alone will close this gap, using the MobileNet EdgeTPU pipeline as a concrete example.
Answer: The gap is structural because benchmarks intentionally abstract a controlled slice of reality (fixed batch sizes, synthetic inputs, steady thermal state) while production adds variable request patterns, preprocessing and queueing delays, thermal throttling, and distributional shift that the benchmark elides by design. A quantized MobileNet that hits 2 ms on an EdgeTPU benchmark can still experience 12 ms end-to-end under real smartphone traffic once image decode, resize, and result serialization are included. The engineering consequence is that benchmarks must be designed to predict production behavior with quantitative fidelity, not assumed to transfer directly; otherwise every optimization claim inherits this unobserved 2–10\(\times\) error band.
Learning Objective: Explain why the benchmark-production gap is an artifact of abstraction rather than a measurement defect
True or False: If a vendor demonstrates that model inference time dropped from 15 ms to 5 ms (a 3\(\times\) speedup), the deployed end-to-end application should see close to a 3\(\times\) end-to-end latency improvement.
Answer: False. End-to-end latency is the sum of preprocessing, queueing, model inference, postprocessing, and data movement, so a 3\(\times\) gain on only the inference component is bounded by Amdahl’s Law. In the chapter’s concrete 10 ms model stage inside a 50 ms pipeline, the realistic end-to-end improvement is only about 1.2\(\times\).
Learning Objective: Analyze why component speedups do not propagate to end-to-end gains when non-model stages dominate the critical path
A translation team improves BLEU score from 28 to 28.5 by expanding beam search from beam_size=1 to beam_size=10, tenfold increasing per-token candidate evaluation and moving inference from 50 ms to 200 ms. The team wins the leaderboard but users abandon the product. Which principle from the chapter most directly explains this outcome?
- Single-metric benchmark rankings reliably predict product quality when the metric is well-designed
- The team should have used synthetic translation kernels instead of real workloads
- Benchmark scores are meaningless unless reduced to a single scalar
- Once BLEU became the optimization target, improvements in the measured score decoupled from deployment-relevant quality like latency and user utility
Answer: The correct answer is D. Goodhart’s Law predicts that when a measure becomes a target, the optimization pressure diverges from what made the measure useful: here, 0.5 BLEU points of gain cost 4\(\times\) inference slowdown, destroying the product even as the leaderboard improved. The synthetic-kernel framing repeats an older benchmark failure mode unrelated to Goodhart, and collapsing to a single score would make the problem worse by hiding the latency-quality trade-off.
Learning Objective: Analyze how benchmark-targeted optimization can degrade deployment-relevant qualities through Goodhart’s Law
Because any benchmark captures only a controlled slice of reality (fixed workload, thermal state, and input distribution), the chapter argues that benchmark results function as ____ for deployment behavior rather than as ground truth.
Answer: proxies. The term captures that benchmark numbers stand in for deployment performance under assumptions that the benchmark necessarily simplifies, so every benchmark result must be interpreted in light of what its controlled conditions leave out.
Learning Objective: Interpret the chapter’s framing of benchmark results as proxy measurements whose validity depends on the assumptions they encode
A team reports that MobileNetV2 on an EdgeTPU achieves the advertised 2 ms inference time after INT8 quantization and deployment. Explain why this result alone is insufficient to validate the full optimization pipeline, and name the additional measurements each of the three benchmarking dimensions would require.
Answer: The 2 ms number validates only the system axis at a single operating point: it does not reveal whether preprocessing and data transfer add 10 ms of hidden overhead, whether INT8 quantization preserved calibration and edge-case accuracy, or whether the model generalizes to real smartphone photos rather than ImageNet test images. Full validation requires end-to-end system measurement under realistic traffic (including thermal sustain), model-quality evaluation that separates top-1 accuracy from calibration and robustness on shifted distributions, and data benchmarking against production input distributions with lighting and composition variation. The practical consequence is that single-axis success routinely masks deployment failure along the other two axes.
Learning Objective: Evaluate why deployment validation requires independent measurement along the system, model, and data dimensions
Self-Check: Answer
When Whetstone became standardized in 1976, vendors immediately tuned compilers specifically against its floating-point tests, producing strong numbers that did not predict real application performance. What methodological correction did SPEC CPU later introduce that directly addressed this failure mode?
- SPEC CPU replaced real application programs with more easily standardized synthetic inner loops
- SPEC CPU mandated vendor-specific compiler flags to make tuning results directly comparable
- SPEC CPU used suites of real compiled application programs so compiler optimizations had to improve actual workloads rather than a narrow synthetic target
- SPEC CPU restricted evaluation to energy-per-operation so compiler gaming could not affect the score
Answer: The correct answer is C. By running a portfolio of real applications, SPEC CPU forced any compiler optimization that improved the benchmark to also improve realistic workloads, which is exactly what Whetstone’s narrow synthetic loops failed to do. The synthetic-loop framing describes the problem SPEC CPU was solving, not its solution, and energy-focused benchmarking emerged decades later in response to a different pressure.
Learning Objective: Identify the specific methodological shift from synthetic to representative-workload benchmarking and how it addressed vendor gaming
Explain why the rise of SPEC Power (2007) and Green500 (2007) changed the definition of a ‘winning’ system result, with specific reference to how warehouse-scale and mobile deployments made raw speed alone insufficient.
Answer: Once deployments were either power-capped (mobile, battery-powered edge) or economically bounded by energy cost (warehouse-scale data centers), a faster system that consumed disproportionately more power could lose on total cost of ownership or simply fail to fit the operating envelope. A server efficient only near 100 percent load, for example, wastes energy at the 20-50 percent utilization typical of production serving, so performance-per-watt and energy-per-query became first-class metrics alongside throughput. The practical implication is that benchmark design must admit multi-objective reporting rather than assuming a single speed score characterizes a system’s deployment fitness.
Learning Objective: Explain how power and thermal constraints forced benchmarking to become multi-objective rather than speed-only
MLPerf splits into MLPerf Training, MLPerf Inference, MLPerf Tiny, and MLPerf Power rather than publishing one unified benchmark. Which historical lesson does this structural choice most directly encode?
- A single unchanging benchmark preserves cross-context comparability and should serve every deployment
- Energy benchmarking should wholly replace performance benchmarking now that modern accelerators are power-limited
- Microbenchmarks are sufficient for ML because full-application benchmarks vary too much to standardize across vendors
- Deployment regimes from microcontrollers to training clusters span nine orders of magnitude in power and memory, so the constraints that define ‘good’ differ enough that a single benchmark cannot be meaningful across them
Answer: The correct answer is D. The chapter argues that constraints differ so sharply across data center training, data center inference, edge devices, and microcontrollers that a meaningful ‘benchmark result’ in one regime would be uninterpretable in another. Using one benchmark everywhere repeats the Whetstone-era mistake of hiding context-dependent constraints; treating energy as the sole metric conflicts with the historical move toward multi-objective evaluation.
Learning Objective: Identify why deployment-specific constraints drive the domain-specific structure of modern ML benchmark suites
True or False: The historical progression from performance to energy-aware to domain-specific benchmarks means raw throughput has been retired as a useful ML evaluation metric.
Answer: False. Throughput remained a core metric across every transition; the shift was to surround it with energy, latency, and domain constraints rather than discard it. Benchmarks became additive in what they measured, not substitutive.
Learning Objective: Distinguish adding metrics to a benchmark suite from replacing a metric as the primary evaluation signal
Order the following stages of computing-benchmark evolution from earliest to latest: (1) domain-specific ML benchmark suites like MLPerf, (2) narrow synthetic operation benchmarks like Whetstone and LINPACK, (3) representative whole-application benchmarks like SPEC CPU, (4) energy-first benchmarks like SPEC Power and Green500.
Answer: The correct order is: (2) narrow synthetic operation benchmarks like Whetstone and LINPACK, (3) representative whole-application benchmarks like SPEC CPU, (4) energy-first benchmarks like SPEC Power and Green500, (1) domain-specific ML benchmark suites like MLPerf. The progression moves from measuring narrow operations (gameable by compilers), to whole-application suites that resist gaming, to multi-objective energy-aware evaluation driven by warehouse-scale and mobile constraints, and finally to workload-specific ML suites once no single benchmark could span the nine-orders-of-magnitude deployment range. Swapping the middle stages loses the causal chain from validity, to efficiency, to domain specialization.
Learning Objective: Sequence the major historical transitions in benchmark design and justify why each stage responded to the limits of its predecessor
Self-Check: Answer
A vendor advertises an accelerator at 300 TFLOP/s peak, but a BERT inference benchmark at batch size 1 achieves only 30 TFLOP/s (10 percent of peak). Apply the chapter’s roofline analysis to explain this gap.
- The benchmark is invalid because a correctly designed benchmark always drives the workload to peak FLOP/s
- The workload’s arithmetic intensity sits well below the accelerator’s ridge point, so memory bandwidth bounds the achievable rate rather than the compute ceiling
- The 10\(\times\) gap proves the advertised 300 TFLOP/s figure was falsified by the vendor
- The optimizer choice during inference is the primary factor limiting arithmetic throughput
Answer: The correct answer is B. Batch-size-1 transformer inference has low FLOP/byte arithmetic intensity from weight movement, placing it far left of the roofline’s ridge point where memory bandwidth, not arithmetic throughput, is the binding constraint. The fallacy-of-peak framing explicitly covers this case: peak TFLOP/s predicts sustained performance only for compute-bound workloads, and inference workloads with low arithmetic intensity are the canonical memory-bound counterexample. The optimizer framing confuses training phases with the inference pattern described.
Learning Objective: Apply roofline reasoning to diagnose why peak-FLOP/s claims diverge from sustained ML workload performance
Explain why the chapter requires 5-10 benchmark runs with confidence intervals rather than a single run, and describe a concrete scenario where a single-run result would mislead engineering decisions.
Answer: ML measurements vary from random seeds, thermal state, background processes, and hardware power management, so a single observation conflates signal with noise. For example, a reinforcement learning experiment on a single seed can show a 5 percent apparent improvement that entirely disappears when averaged over ten seeds, yet empirical surveys have shown many RL papers report exactly this kind of unreplicable gain. The engineering consequence is that benchmark claims need sample-variance evidence (standard deviations or 95 percent confidence intervals) before they can justify procurement or architectural decisions, otherwise the discipline confuses lucky draws for real improvements.
Learning Objective: Explain why statistical replication is a prerequisite for trustworthy ML benchmark claims
A vendor datasheet reports an accelerator delivering ‘10,000 images/second.’ According to the chapter’s guidance on interpreting such claims, which question is most essential to ask first?
- Which deep learning framework logo appears in the benchmark marketing materials
- What batch size, numerical precision, included pipeline stages, and thermal sustain conditions produced the number
- How many generations old the competitor hardware used for comparison was
- Whether the benchmark used the absolute latest compiler toolchain release
Answer: The correct answer is B. The chapter argues that a throughput number is uninterpretable without the workload configuration: batch 1 versus batch 256, FP32 versus INT8, model-only versus end-to-end, and burst versus sustained thermal operation can produce numbers that differ by an order of magnitude on the same hardware. Tool versions and competitor-generation framing may matter at the margin, but the core measurement is ambiguous before those concerns even apply.
Learning Objective: Identify the minimum workload-configuration context required to interpret a vendor throughput claim
The chapter names the error of treating advertised peak TFLOP/s as a predictor of sustained ML workload rates the fallacy of peak ____, because memory stalls, kernel launch overhead, and software dispatch routinely leave real workloads far below the theoretical ceiling.
Answer: performance. The term captures the mismatch between hardware’s theoretical maximum throughput and the rate a real ML workload actually sustains, a roughly 2–3.5\(\times\) gap visible in the A100’s 312 TFLOP/s peak versus 90-155 TFLOP/s (30-50 percent MFU) typical of production transformer training.
Learning Objective: Interpret the fallacy-of-peak-performance framing that distinguishes theoretical hardware capability from sustained workload throughput
A procurement team evaluates five SoCs for an edge camera: Vendor A reports 8 TOPS at INT8, Vendor B reports 15 TOPS at INT4, Vendor C reports latency on a proprietary model, Vendor D cites MLPerf scores from two generations ago, and Vendor E reports only peak throughput at maximum batch size. Explain why community standardization is the only mechanism that can make these numbers commensurable for a real deployment decision.
Answer: Each vendor technically measured something correctly but under different workloads, precisions, model definitions, and pipeline scopes, so the numbers cannot be compared without ambiguous assumptions that will be wrong. A shared specification (MLPerf-style run rules, reference models, accuracy floors, measurement boundaries, and submission review) forces every vendor to report the same quantity on the same conditions, converting five incomparable numbers into a single ranked comparison that admits honest engineering evaluation. The system consequence is that standardization is not a style preference; it is the only way to make vendor-supplied data actionable for procurement without running every benchmark in-house.
Learning Objective: Explain how community benchmarking standards convert incomparable vendor numbers into commensurable evidence for procurement decisions
Why does the chapter insist that no single benchmark result can characterize a hardware platform, even for a well-designed suite like MLPerf?
- Because benchmark-to-benchmark measurement variability makes any cross-benchmark comparison statistically impossible
- Because hardware efficiency is workload-dependent: an accelerator strong on compute-bound CNN training may be much weaker on memory-bound transformer inference or recommendation workloads
- Because every modern accelerator is tuned equally well for every ML workload category, rendering differentiation meaningless
- Because only energy metrics, not throughput metrics, carry meaningful information about hardware quality
Answer: The correct answer is B. The roofline framework explains why: the same silicon can achieve 90 percent of peak on a compute-bound training workload and 10 percent on a memory-bound inference workload, so a single result exposes only one point on a multi-dimensional capability surface. The measurement-variability framing would make all comparison impossible (which is false, given confidence intervals), and the claim that all accelerators are equally tuned contradicts observable differentiation across MLPerf categories.
Learning Objective: Analyze why hardware evaluation requires workload-specific benchmarks rather than a single summary number
Self-Check: Answer
A production inference service has mean latency of 80 ms. A profiler shows the softmax kernel alone takes 3 ms per request. The team suspects softmax is the bottleneck, but needs to confirm before optimizing. Which benchmarking approach best supports the diagnosis?
- Run only an end-to-end benchmark, since component-level tests never reveal root cause in isolation
- Run only a macro benchmark on the full model, since complete-model evaluation directly attributes latency to each layer
- Run a microbenchmark that isolates softmax under synthetic inputs to confirm the 3 ms figure, then an end-to-end benchmark to measure whether eliminating softmax would meaningfully change the 80 ms total
- Run only a power benchmark, since energy measurements inherently reveal both kernel and pipeline bottlenecks
Answer: The correct answer is C. Microbenchmarking confirms whether softmax is genuinely slow in isolation, while an end-to-end benchmark reveals whether the 3 ms softmax stage is on the critical path or parallelizable with other work; together they prevent the common mistake of optimizing a local bottleneck that happens to be masked end-to-end. The end-to-end-only framing sacrifices diagnostic precision, the macro-only framing conflates layer effects with surrounding infrastructure, and power benchmarks are a different diagnostic dimension entirely.
Learning Objective: Select complementary benchmark granularities to diagnose root cause and verify systemic impact
Explain the trade-off between diagnostic precision and deployment representativeness across microbenchmarks, macrobenchmarks, and end-to-end benchmarks, with a concrete example where each level would reveal a different answer.
Answer: Microbenchmarks isolate single operations under synthetic inputs, maximizing diagnostic precision (a fused attention kernel that doubles its isolated FLOP/s is immediately attributable) but missing interactions with data loading, framework overhead, and pipeline scheduling. Macrobenchmarks like ResNet-50 on ImageNet include model-wide effects and framework behavior but still exclude production surrounding infrastructure. End-to-end benchmarks capture real deployment behavior including ETL, queueing, and network but make root-cause attribution harder because many components interact simultaneously. A kernel optimization that doubles isolated throughput (microbenchmark wins) may leave macro throughput unchanged (memory bandwidth unchanged) and reduce end-to-end latency by only 3 percent (preprocessing dominates), so effective practice combines all three levels rather than claiming one as universal.
Learning Objective: Compare the diagnostic and representativeness properties of micro, macro, and end-to-end benchmarks
Which of the following is the best example of an end-to-end benchmark rather than a macro benchmark?
- Running ResNet-50 on ImageNet to compare full-model top-1 accuracy and throughput across accelerators
- Timing a single convolution kernel under different cuDNN autotuning settings
- Measuring a production recommendation pipeline that spans user-feature retrieval, candidate generation, model scoring, ranking, and response formatting
- Profiling the latency of a transformer attention block under fixed synthetic batch and sequence dimensions
Answer: The correct answer is C. End-to-end benchmarks span the full deployment pipeline including surrounding infrastructure and non-model components, not just the model. ResNet-50 on ImageNet evaluates a whole model but stops at model-output scoring (a macro benchmark), while single-kernel and attention-block profiling operate at the microbenchmark level where only one operation is measured.
Learning Objective: Classify specific benchmark scenarios by granularity level
True or False: If a GPU kernel runs 3\(\times\) faster in a microbenchmark, the deployed application will see roughly a 3\(\times\) speedup unless measurement noise is unusually high.
Answer: False. The chapter’s opening scenario for this section makes exactly this point: a kernel running 3\(\times\) faster in isolation may deliver zero end-to-end speedup if the data pipeline cannot keep pace, because the overall system rate is bounded by the slowest stage rather than by the optimized kernel.
Learning Objective: Analyze why isolated microbenchmark gains do not automatically propagate to end-to-end application performance
Order the following benchmark scopes from most isolated (narrowest measurement boundary) to most deployment-representative (broadest measurement boundary): (1) full production pipeline including data retrieval and response serialization, (2) single tensor operation under synthetic inputs, (3) complete model on a standardized dataset.
Answer: The correct order is: (2) single tensor operation under synthetic inputs, (3) complete model on a standardized dataset, (1) full production pipeline including data retrieval and response serialization. Single operations maximize isolation and diagnostic precision, complete-model tests add inter-layer and framework interactions, and full-pipeline benchmarks additionally include surrounding infrastructure and real deployment overheads. Reversing any two adjacent stages collapses a distinction the chapter explicitly preserves: isolation buys diagnostic clarity, representativeness buys deployment prediction, and the two trade off monotonically across this ordering.
Learning Objective: Sequence benchmark scopes along the isolation-versus-representativeness spectrum
Self-Check: Answer
A benchmark report claims excellent throughput but omits framework version, accelerator model, compiler flags, and driver stack. Which benchmark component is most directly missing?
- System specifications
- Problem definition
- Evaluation metrics
- Standardized datasets
Answer: The correct answer is A. System specifications document the hardware and software stack (accelerator, framework version, compiler settings, driver, thermal configuration) that make a throughput result interpretable and reproducible. The task, metric, and dataset can all be specified correctly, but without the execution environment a reader cannot compare against or replicate the claim.
Learning Objective: Identify which benchmark component captures the computational environment required for reproducibility
A server inference harness uses sequential requests at fixed inter-arrival times, while real production traffic follows Poisson-like arrivals with occasional bursts. Explain how this harness choice shapes the benchmark result rather than just recording it, and what changes when the harness is corrected.
Answer: Sequential fixed-interval requests eliminate queueing entirely, so the harness measures only service time and fails to expose the tail-latency effects that dominate production behavior under realistic load. Replacing it with Poisson arrivals reveals queueing dynamics: occasional bursts create short queues that drive p99 latency substantially above the mean even when mean service time is unchanged, which is exactly the signal a serving benchmark exists to surface. The practical implication is that harness design is a semantic choice, not a technical detail; a weak harness can make a rigorously measured number systematically misleading about deployment fitness.
Learning Objective: Explain how harness design shapes benchmark validity and what it captures about production behavior
For an anomaly-detection model deployed on a battery-powered embedded device, which metric set best matches the chapter’s multi-metric guidance?
- Only AUC, with operational constraints evaluated after model selection is finalized
- Only parameter count, because model size determines all other embedded deployment constraints
- Only throughput, because real-time embedded systems are fundamentally throughput-limited rather than latency-sensitive
- AUC, latency per inference, and energy per inference, because deployment viability depends jointly on detection quality, response time, and sustained operation under battery constraints
Answer: The correct answer is D. The chapter frames embedded ML benchmarking as inherently multi-metric: an anomaly detector that achieves high AUC but draws too much power or misses latency budgets fails in deployment, so detection quality, speed, and energy must be reported together. Parameter count is a crude proxy for these, and throughput misses the real-time per-event response requirement that defines embedded anomaly detection.
Learning Objective: Select deployment-relevant benchmark metrics for a resource-constrained embedded ML task
To make stochastic training benchmarks reproducible, the chapter argues that benchmark ____ must specify random seed handling, data-ordering discipline, precision constraints, and the exact procedure for executing the workload, rather than leaving these choices to the submitter.
Answer: run rules. These procedural constraints convert nominally identical benchmarks into actually-reproducible measurements by fixing the sources of variability that would otherwise let two legitimate submissions produce materially different numbers from the same workload.
Learning Objective: Interpret which benchmark component constrains the execution procedure so stochastic runs can be compared across submitters
A compression report claims 10\(\times\) parameter reduction via unstructured pruning. Explain why size reduction alone is insufficient evidence that the compression delivers deployment value, using the chapter’s multi-dimensional compression benchmarking principle.
Answer: Unstructured pruning removes individual weights irregularly, so dense accelerator hardware (GPUs, most NPUs) still executes the full matrix multiplication and gains little or no latency reduction, even as the parameter count drops by 10\(\times\). Meaningful compression evaluation must jointly report size, measured latency on the target hardware, accuracy preservation, and hardware-pattern compatibility; otherwise the size reduction is a paper win that produces zero wall-clock improvement in production. The engineering consequence is that compression benchmarks must include the deployment hardware and expose the latency-versus-compression Pareto front, not just the compression ratio.
Learning Objective: Evaluate why compression benchmarking requires joint measurement across size, latency, accuracy, and hardware compatibility
An edge hardware vendor advertises excellent burst inference performance on a vision model. Which omitted benchmark condition is most likely to make this number misleading for a smartphone-class deployment?
- Whether the benchmark dataset was public or proprietary
- Whether sustained thermal behavior was measured, since mobile silicon typically throttles under continuous load and steady-state performance can fall well below burst-mode peaks
- Whether the benchmark reported top-5 accuracy in addition to top-1 accuracy
- Whether the benchmark compared against one baseline model rather than two
Answer: The correct answer is B. Burst-mode numbers capture brief peak performance before thermal headroom is exhausted; smartphones and edge devices with limited cooling throttle under sustained load, so a deployment sized around burst performance fails once the device heats up and the governor reduces clock. The baseline-model and dataset-provenance framings matter for accuracy comparison but do not explain why the performance number itself would not hold in deployment.
Learning Objective: Analyze why sustained thermal measurement is essential for interpreting edge device benchmark claims
Self-Check: Answer
Why does the chapter argue that MLPerf Training and MLPerf Inference must be separate benchmark frameworks rather than one unified suite, even when they may run on identical accelerator hardware?
- Because training optimizes for time-to-convergence and sustained throughput across hours, while inference optimizes for per-request latency, tail behavior, and serving efficiency under unpredictable load, so the two phases are evaluated by different success criteria
- Because training and inference are implemented in different programming languages that cannot share hardware measurement
- Because inference never runs on accelerators while training always does
- Because only inference has power consumption worth reporting
Answer: The correct answer is A. The metrics themselves diverge: training cares about time-to-accuracy and scaling efficiency over long runs, while inference cares about p99 latency, cold-start behavior, and throughput under SLO constraints. A unified benchmark would either report the wrong metric for one phase or report two different metrics under the same label, defeating the purpose of standardization. The framing that inference does not use accelerators contradicts EdgeTPU, NPU, and data center inference accelerators discussed elsewhere in the chapter.
Learning Objective: Compare the benchmark objectives that distinguish training and inference systems
Explain why memory requirements diverge sharply between training and inference for the same model, using the forward-only versus forward-plus-backward-plus-optimizer-state distinction.
Answer: Inference runs only the forward pass with fixed weights, so memory footprint is essentially parameters plus per-request activations. Training additionally stores activations for backpropagation, gradients for every parameter, and optimizer state (roughly 2 extra bytes per parameter for Adam’s moments), which multiplies memory pressure by a factor of four or more over inference. A 7-billion-parameter model that fits comfortably for inference on a 16 GB accelerator can require gradient checkpointing, model sharding, or a 40+ GB accelerator for training, so an ‘it fits’ result in one phase does not predict feasibility in the other. The system consequence is that benchmark results are phase-specific: hardware procurement decisions must be evaluated separately for training and inference even when the same model and accelerator are involved.
Learning Objective: Explain why training and inference impose different memory pressures on the same model and hardware
True or False: Because training and inference can run on the same accelerator class, the primary performance metric should typically be identical across the two phases.
Answer: False. Even on identical hardware, training is evaluated by convergence metrics like time-to-accuracy and scaling efficiency, while inference is evaluated by tail latency, throughput under serving constraints, and energy per query. The hardware is shared; the workload success criteria are not.
Learning Objective: Distinguish workload metrics from hardware identity when selecting evaluation criteria for ML systems
Self-Check: Answer
Why does the chapter treat time-to-accuracy as the primary training benchmark metric rather than raw samples per second?
- Because throughput alone rewards systems that process data quickly but fail to converge to the required accuracy target, while time-to-accuracy combines throughput and convergence into a single deployment-relevant quantity
- Because samples-per-second is impossible to measure consistently across hardware platforms
- Because time-to-accuracy ignores convergence behavior and focuses only on wall-clock runtime cost
- Because throughput is relevant only to inference workloads, not to training
Answer: The correct answer is A. Training value is defined by reaching a model that meets an accuracy target, so a system that moves billions of samples per second but never converges is worthless, while a slightly slower system that converges in half the wall-clock time is superior. Time-to-accuracy captures this coupling explicitly, which is why MLPerf Training uses it as the headline metric rather than throughput.
Learning Objective: Explain why the training benchmark primary metric must couple throughput to convergence quality
A training run takes 24 hours on 1 GPU and 4 hours on 8 GPUs. Using strong-scaling efficiency, what is the scaling result and what does the missing efficiency typically indicate?
- Perfect scaling, because 8 GPUs reduced wall-clock time by 6\(\times\)
- Invalid benchmark, because any multi-GPU scaling below 90 percent efficiency should be discarded
- 75 percent scaling efficiency (24 / (8 * 4) = 0.75), with the remaining 25 percent typically attributable to gradient synchronization, data-movement overhead, and load imbalance across workers
- Proof that the workload is compute-bound rather than communication-bound
Answer: The correct answer is C. Strong-scaling efficiency is (single-GPU time) / (N * N-GPU time) = 24 / (8 * 4) = 0.75, or 75 percent. The chapter emphasizes that this gap is exactly what training benchmarks are designed to expose: communication tax on AllReduce, data-pipeline imbalance, and synchronization barriers account for the missing efficiency in typical runs. The invalid-below-90-percent framing is arbitrary and not in the chapter; the compute-bound framing misreads the direction the efficiency drop implies.
Learning Objective: Calculate and interpret strong-scaling efficiency and identify the system overheads that produce sub-linear scaling
A team reports that switching from FP32 to mixed precision raised training throughput from 180 samples/second to 420 samples/second (2.3\(\times\)). Explain why this throughput win does not automatically prove mixed precision was the right deployment choice for this training run.
Answer: Mixed precision can change convergence dynamics: the reduced numerical precision may increase the number of iterations to hit the target accuracy, produce occasional loss scaling failures requiring backoff, or reach a slightly different final accuracy. If 2.3\(\times\) throughput is paired with 2.5\(\times\) more iterations to convergence, the total wall-clock time is worse than FP32. The correct evaluation reports time-to-accuracy at the target accuracy floor, not samples-per-second in isolation, because only time-to-accuracy captures the interaction between numerical behavior and optimization progress that determines whether the precision change was net-positive.
Learning Objective: Analyze why throughput gains from precision changes must be validated against convergence behavior via time-to-accuracy
During BERT pretraining, GPU utilization stays around 45 percent even though the cluster has substantial raw compute headroom and no out-of-memory errors. Which diagnosis aligns with the chapter’s resource-utilization discussion?
- A non-compute stage (input pipeline, gradient synchronization, or host-to-device transfer) is likely starving the accelerators, so adding peak FLOP/s without addressing the binding bottleneck will not meaningfully improve throughput
- The benchmark proves the BERT architecture is fundamentally defective and should be replaced
- The benchmark should drop utilization reporting entirely and report only top-line training time
- Any utilization below 95 percent invalidates the benchmark result and the run should be rejected
Answer: The correct answer is A. Low GPU utilization in the presence of memory headroom is the canonical signature of a non-compute bottleneck: the pipeline’s bottleneck rate is set by the slowest stage, and if tokenization, gradient AllReduce, or PCIe transfer cannot keep up, GPUs idle. Scaling peak FLOP/s without removing this bottleneck wastes money, which is why training benchmarks report utilization alongside wall-clock time. The architecture-defective and throw-out-the-benchmark framings overreact to what is a routine profiling finding.
Learning Objective: Diagnose how non-compute bottlenecks limit training throughput on well-provisioned accelerator hardware
True or False: Because training benchmarks are run under controlled conditions, they can safely ignore failures, checkpoint overhead, and recovery time when reporting results for GPT-3-scale training runs.
Answer: False. A GPT-3-scale run on 10,000 V100s across weeks experiences node failures as statistical certainties, and checkpoint save/restore overhead can consume a material fraction of wall-clock time, so realistic training benchmarks must report fault-tolerance behavior and recovery cost rather than assume ideal uptime.
Learning Objective: Recognize fault-tolerance overhead as a first-class component of realistic large-scale training benchmarks
Explain why the chapter insists on reproducibility controls such as fixed seeds, standardized preprocessing, and multi-run submissions for training benchmarks, with reference to the sources of variation that make a single impressive run untrustworthy.
Answer: Training outcomes depend on stochastic initialization, shuffling order, dropout masks, and hardware-level floating-point non-determinism, so a single submission can reflect lucky seeds rather than system capability. Empirical studies of reinforcement learning and GAN benchmarks have shown that unreported seed variance routinely produces rankings that reverse when runs are replicated. The engineering consequence is that a credible training benchmark reports statistics (standard deviation or confidence intervals) across multiple runs with fixed seeds, standardized preprocessing, and identical software stacks, so that a reported improvement reflects genuine system performance rather than a favorable draw.
Learning Objective: Explain why training benchmark validity depends on explicit control of stochastic and software-dependent variation
Self-Check: Answer
For an interactive user-facing ML service that fans out to multiple backend models per request, why does the chapter elevate p99 latency over mean latency as the primary benchmark metric?
- Because mean latency can only be improved by changing numerical precision while p99 can only be improved by batching
- Because p99 latency is easier to instrument accurately than mean latency
- Because mean latency is relevant only to training workloads rather than inference
- Because the user experience is determined by the slowest requests, and a fan-out request completing only when its slowest subrequest returns makes even a 1 percent tail dominate perceived reliability
Answer: The correct answer is D. In a fan-out system, one slow subrequest stalls the whole response, so the probability of hitting the tail grows with request count: a 1 percent p99 tail becomes 9.6 percent expected-slow at 10 fan-outs. The chapter’s ‘tail at scale’ framing explicitly warns that mean latency can look healthy while the tail violates SLOs and degrades user experience. The measurement-ease framing is backwards (p99 requires more samples than the mean), and the training-only framing contradicts the section’s focus.
Learning Objective: Explain why tail latency (p99) is the primary metric for interactive and fan-out inference services
An inference benchmark reports that model execution takes 5 ms. Production monitoring later shows end-to-end request latency averages 80 ms. Explain how this gap emerges and what the benchmark should have measured instead for deployment planning.
Answer: Model execution is only one stage of a multi-stage request path: the full pipeline includes request parsing, input preprocessing (decode, resize, tokenize), queueing on the accelerator, model inference, postprocessing, and response serialization. With 5 ms model time and 75 ms of other stages, a deployment-focused benchmark should have measured end-to-end request latency under realistic load patterns (Poisson arrivals, variable input sizes, concurrent requests) rather than model-only timing, because the 5 ms figure is actionable for kernel optimization but useless for capacity planning. The practical consequence is that component-latency benchmarks systematically overestimate the end-to-end payoff of model optimizations when preprocessing and queueing dominate.
Learning Objective: Distinguish component latency from end-to-end latency and explain why deployment planning requires the latter
A vision inference pipeline spends 8 ms in preprocessing and 10 ms in model inference. If the team optimizes the model alone to achieve a 5\(\times\) speedup, what does Amdahl’s Law predict about end-to-end latency and what is the main lesson?
- End-to-end latency should also improve by approximately 5\(\times\) if the model was the most optimized component
- The optimization is wasted because preprocessing is non-zero
- End-to-end latency drops from 18 ms to only 10 ms (1.8\(\times\) speedup), because preprocessing now dominates and bounds further component-only gains
- Amdahl’s Law applies only to distributed training, not to inference serving
Answer: The correct answer is C. Applying Amdahl’s Law: model time goes from 10 ms to 2 ms, so total becomes 8 + 2 = 10 ms, yielding 18 / 10 = 1.8\(\times\) end-to-end speedup versus the claimed 5\(\times\) model speedup. The lesson is that component optimization hits a ceiling set by the unoptimized fraction; without also addressing preprocessing, further model optimization yields diminishing returns. The ‘wasted effort’ framing is too strong (1.8\(\times\) is still real value), and Amdahl’s Law is domain-general.
Learning Objective: Apply Amdahl’s Law quantitatively to predict the end-to-end ceiling of component-only inference optimization
Which MLPerf inference scenario best matches a cloud API that receives independent, unpredictable user requests and must satisfy latency SLOs under variable load?
- SingleStream
- MultiStream
- Server
- Offline
Answer: The correct answer is Server. Server mode models Poisson-like request arrivals with latency SLOs, exposing queueing dynamics and the throughput-latency trade-off of interactive cloud serving. SingleStream processes requests strictly sequentially one at a time (suited to a phone typing-prediction scenario), MultiStream evaluates synchronized parallel inputs (suited to sensor-fusion pipelines), and Offline removes latency constraints to maximize batch throughput for precomputation workloads.
Learning Objective: Select the MLPerf inference scenario that matches a given deployment context
In a serverless inference deployment, long delays on the first request after an idle period are typically dominated by ____ latency: the one-time cost of loading weights, initializing runtime state, and warming caches before any prediction can begin.
Answer: cold-start. This term names the initialization overhead incurred when a function spins up from idle; the chapter emphasizes that cold-start latency has no training analog and can dominate user-perceived latency for on-demand serving where models are not kept resident.
Learning Objective: Identify the inference metric that captures initialization overhead in on-demand serverless serving
A mobile device benchmark reports that the NPU achieves 2 ms accelerator-only inference on a vision model. Explain why this number may not predict user-perceived speed or battery life in actual deployment.
Answer: On-device inference includes image capture and decode, memory copies between CPU and NPU address spaces, preprocessing that may run on CPU or GPU, the NPU kernel, postprocessing, and result delivery to the app; any of these can exceed the 2 ms accelerator time. Additionally, sustained use triggers thermal throttling that drops NPU frequency, and battery state affects power management, so the 2 ms number applies only to cold-state single-inference conditions. The practical implication is that mobile benchmarking must measure end-to-end duty cycles under realistic thermal and battery states, not accelerator kernels in isolation.
Learning Objective: Analyze why accelerator-only results fail to predict mobile inference performance under realistic duty cycles
Self-Check: Answer
A vendor advertises an accelerator at ‘10 TOPS at 0.5 W,’ but under sustained inference load the chip throttles to 3 TOPS at 2 W, a 13.3\(\times\) efficiency gap. Why does the chapter emphasize defining the power measurement boundary as the fix for this kind of gaming?
- Because a power claim is only interpretable when the measured components (accelerator, off-chip memory, cooling, voltage regulators) and operating conditions (burst vs. sustained) are specified consistently; otherwise two systems report different numbers simply because one includes more of the real power draw
- Because measurement boundary choices affect latency but not energy efficiency
- Because standardizing boundaries matters only for TinyML devices and not for server-class accelerators
- Because power benchmarks should always exclude memory to isolate compute efficiency
Answer: The correct answer is the one describing component consistency and operating conditions. The 10 TOPS/0.5 W number implies 20 TOPS/W in burst mode with memory excluded; the sustained 3 TOPS/2 W number is 1.5 TOPS/W with memory and cooling included, a 13.3\(\times\) efficiency gap. A defined measurement boundary forces consistent accounting so vendor comparisons are honest. The latency-not-energy framing misreads the consequence, the TinyML-only framing contradicts MLPerf Power’s cross-scale scope, and the exclude-memory framing would make the gaming worse by blessing it as a standard.
Learning Objective: Explain why explicit power-measurement boundaries are essential for fair energy-efficiency comparisons
Explain why instantaneous power samples are misleading for ML workloads and describe a concrete workload phase pattern that requires sustained sampling with a carefully chosen averaging window.
Answer: ML workloads alternate rapidly between compute-heavy phases (matrix multiplies saturating Tensor Cores) and memory-heavy or idle phases (waiting for HBM reads, gradient synchronization), producing power draws that can swing by 2–3\(\times\) within milliseconds. A transformer training step, for example, shows a brief forward-pass compute burst, a backward-pass burst, and a communication valley during AllReduce; an instantaneous sample captures whichever phase the probe hit, neither of which represents the average. Accurate measurement requires sustained sampling (at kHz or higher) with an averaging window that spans at least one full training step or inference cycle, so the reported power reflects the actual workload rhythm rather than a snapshot artifact.
Learning Objective: Explain why time-varying workload phases require sustained power sampling rather than instantaneous measurement
A system gains approximately 5 percent more throughput by raising clock frequency but draws roughly 50 percent more power as a result. What broader lesson does the chapter draw from this kind of non-linear trade-off?
- Higher clock frequency is always worth it because power scales linearly with throughput
- Performance gains can hit severe diminishing returns in energy efficiency, so the fastest operating point can be an expensive deployment choice, especially under power-capped or thermally-constrained environments
- The result proves the benchmark instrumentation is malfunctioning because real silicon does not exhibit such trade-offs
- Only cloud deployments care about energy trade-offs; edge devices are compute-limited rather than power-limited
Answer: The correct answer is B. The cubic relationship between voltage, frequency, and power means the last 5 percent of performance routinely costs disproportionate energy; the chapter argues benchmarks must report performance and power jointly because ‘fastest’ can be far from ‘most deployable.’ The linear-scaling framing denies the physics, the instrumentation-broken framing misattributes a real effect to measurement error, and the cloud-only framing ignores that battery-powered edge devices face this trade-off most sharply.
Learning Objective: Analyze why performance-per-watt is a more actionable design metric than peak performance under power or thermal constraints
True or False: Standardized ML power measurement can focus primarily on compute units because memory access energy is usually a small correction relative to arithmetic energy.
Answer: False. The chapter emphasizes that memory movement frequently dominates total energy, especially for memory-bound workloads such as recommendation models and batch-1 transformer inference where HBM and DRAM access can consume 60-80 percent of per-inference energy. Compute-only accounting systematically underestimates real energy use.
Learning Objective: Recognize memory movement as a first-class contributor to ML workload energy consumption
The chapter’s power table spans from 150 µW TinyML devices to 10 kW server racks, a range of nearly eight orders of magnitude. Explain why MLPerf Power remains valuable across this range even though a microwatt sensor and a kilowatt rack cannot share physical instrumentation.
Answer: MLPerf Power’s value is methodological consistency, not instrument uniformity: each deployment scale specifies measurement boundaries, sampling procedures, sustained-load conditions, and reporting formats appropriate to its regime, so every reported efficiency number means the same thing within its class even though the sensors differ. A TinyML developer choosing between two 150 µW sensors can compare fairly under the TinyML rules, and a data center operator comparing two 10 kW racks can compare fairly under the rack rules, and neither comparison depends on the absolute power scale being the same. The engineering consequence is that energy efficiency becomes an actionable engineering quantity rather than a marketing slogan, even across nearly eight orders of magnitude of deployment regimes in the representative table.
Learning Objective: Explain how standardized methodology enables meaningful power benchmarking across heterogeneous deployment scales
Self-Check: Answer
An image classifier trained and tested on CIFAR-10 achieves 95 percent accuracy but fails to 70 percent accuracy on real-world photos with natural lighting and occlusion. Which limitation category from the chapter’s taxonomy does this most directly illustrate?
- Incomplete problem coverage: the benchmark dataset does not span the diversity of lighting, perspective, and composition present in deployment inputs
- Perfect reproducibility: the benchmark can be repeated on many systems with identical results
- Fault-tolerance overhead: checkpointing adds latency to the training loop
- Benchmark stability: benchmarks change too frequently over time to support longitudinal comparison
Answer: The correct answer is A. Incomplete problem coverage is the canonical limitation where benchmark success fails to predict deployment performance because the benchmark distribution is narrower than the deployment distribution. Reproducibility is a virtue, not a failure; fault tolerance and benchmark stability are real concerns but address different categories of limitation than the lighting/occlusion gap described.
Learning Objective: Identify incomplete benchmark coverage as the limitation category for deployment failures driven by distributional narrowness
Explain why a statistically rigorous benchmark measurement, complete with confidence intervals and multiple runs, can still be the wrong basis for a deployment decision.
Answer: Statistical rigor ensures that a measurement is precise; it does not ensure the measurement is of the quantity that determines deployment success. A benchmark can produce tight confidence intervals around average latency while the production SLO depends on p99 tail latency; or it can measure accuracy on a held-out set that does not represent the operating distribution. Worse, rigorous measurement of the wrong objective gives false confidence that the decision is well-grounded. The practical consequence is that measurement quality cannot substitute for benchmark-to-deployment task alignment: engineers must evaluate both axes (valid measurement AND valid target) before acting on benchmark results.
Learning Objective: Critique benchmark validity along both the statistical-rigor and deployment-alignment axes
What does the chapter mean by the ‘hardware lottery,’ the concept coined by Sara Hooker in 2021?
- A benchmark protocol that randomly assigns hardware to submissions to eliminate vendor bias
- A power-management feature that unpredictably changes clock frequency during benchmark runs
- A ranking system that rewards vendors whose benchmark submissions use more hardware than competitors
- The tendency for a model or algorithm to appear superior mainly because its computation pattern aligns well with currently dominant hardware (for example, dense matrix multiplies on GPU Tensor Cores) rather than because the algorithm is intrinsically best
Answer: The correct answer is D. The hardware lottery describes how transformer-style dense matrix multiplications win partly because they map well to GPU silicon, while graph neural networks and sparse mixture-of-experts architectures remain underexplored because they map poorly. The random-assignment and ranking framings are unrelated to the concept; the clock-frequency framing describes a different phenomenon (thermal throttling) entirely.
Learning Objective: Explain how hardware-algorithm alignment can bias benchmark outcomes and research directions
Which practice best reflects the chapter’s recommended defense against benchmark engineering and over-optimization?
- Adopting a single static benchmark so results remain easy to compare over many years
- Reporting only the highest-performing run, since that best represents the system’s potential capability
- Evaluating systems across multiple and evolving benchmarks, and reporting deployment-relevant outcomes (robustness, calibration, energy efficiency) alongside leaderboard scores
- Removing accuracy guardrails from benchmark submissions so implementations can innovate more freely
Answer: The correct answer is C. Diversified evaluation (multiple benchmarks, multiple metrics, deployment-relevant reporting) prevents Goodhart-style gaming of any single target while still allowing comparison. A single static target is exactly what enables over-optimization; reporting only peak runs hides variance and reliability; removing accuracy floors makes gaming easier rather than harder by decoupling innovation from quality.
Learning Objective: Evaluate strategies for reducing benchmark overfitting and leaderboard gaming
The chapter uses the phrase hardware ____ to describe how a model family can look superior mainly because it maps efficiently onto currently dominant accelerator silicon, leaving alternative architectures systematically underexplored.
Answer: lottery. The term captures Sara Hooker’s 2021 observation that apparent algorithmic superiority often reflects alignment with available hardware rather than a deeper algorithmic advantage across all possible platforms, with transformers-on-GPUs as the canonical recent example.
Learning Objective: Interpret the term for hardware-driven benchmark advantage and its systemic effect on research direction
Explain why the chapter argues benchmarks must evolve over time, even though frequent changes complicate longitudinal comparison.
Answer: Static benchmarks eventually saturate: once models cluster near the ceiling, small score gains reflect test-set artifact exploitation rather than meaningful capability improvements, and the benchmark stops discriminating between useful and gimmicky techniques. ImageNet’s journey from 50 percent top-5 accuracy to 97 percent is a canonical example where late-stage gains tell us little about current deployment challenges like energy, robustness, or out-of-distribution generalization. The engineering consequence is that benchmark design must balance stability (for longitudinal comparison and trend-tracking) with adaptation (introducing harder tasks, new metrics, or new deployment conditions) so the benchmark keeps rewarding real progress on current constraints rather than historical ones.
Learning Objective: Explain the trade-off between benchmark stability and benchmark evolution
Self-Check: Answer
A quantized model preserves FP32 top-1 accuracy within 0.3 percent, but downstream automation that relies on confidence thresholds starts making incorrect routing decisions after deployment. Which model-benchmarking metric most directly surfaces this failure?
- Expected Calibration Error, because it measures whether predicted confidence probabilities match actual correctness rates
- Top-5 accuracy, because it reveals whether the correct label appears among several guesses when top-1 is wrong
- Throughput, because faster models tend to be systematically less calibrated than slower models
- Parameter count, because smaller compressed models always lose confidence reliability in proportion to their size reduction
Answer: The correct answer is A. Expected Calibration Error measures the gap between reported confidence and empirical correctness at that confidence level; quantization can preserve top-1 accuracy while miscalibrating confidences (a prediction reported as 90 percent confident becomes correct only 75 percent of the time), breaking any system that thresholds on confidence. Top-5 accuracy may stay unchanged while calibration degrades. Throughput and parameter count are not calibration diagnostics.
Learning Objective: Identify Expected Calibration Error as a distinct model-quality dimension that aggregate accuracy alone does not capture
Explain why compression validation should be framed as an efficiency-quality Pareto frontier rather than a single before-and-after accuracy comparison, using a concrete example where a technique that loses 1 percent accuracy is still the correct deployment choice.
Answer: Compression changes multiple quantities simultaneously: size, latency, energy, robustness, and calibration can all shift in different directions, so a scalar accuracy delta hides whether the combined trade-off is favorable. Consider a pruned model with 1 percent lower accuracy but 3\(\times\) smaller memory footprint and 2.5\(\times\) lower inference energy: the Pareto comparison must check whether any other compressed model is simultaneously better on size, energy, and accuracy (no technique dominates it), and if not, this Pareto-efficient point is the right choice for energy-constrained deployment. The engineering consequence is that compression benchmarking must expose the full multi-objective trade-off surface, not headline accuracy numbers, because single-axis comparisons produce misleading selection decisions.
Learning Objective: Evaluate compression results using multi-objective Pareto-frontier reasoning rather than single-metric deltas
A sepsis-prediction model performs excellently on a held-out test split from Hospital A’s training data but fails badly when deployed to Hospital B in a different geography. Which data-benchmarking failure most directly explains this pattern?
- Low parameter efficiency in the model architecture
- Excessively high arithmetic intensity in the model kernels
- Distribution misalignment between training/test data and the deployment population (different patient demographics, protocols, sensor calibrations)
- Over-calibration of the confidence scores
Answer: The correct answer is C. Held-out splits drawn from the same source distribution as training data cannot detect covariate shift to a new deployment population; Hospital B’s patient mix, intake protocols, and sensor baselines differ systematically from Hospital A’s, so the model’s learned statistical assumptions break. Parameter efficiency, arithmetic intensity, and calibration are unrelated to this specific inter-site generalization failure.
Learning Objective: Analyze how distribution shift between training and deployment populations undermines apparently strong benchmark performance
True or False: If a system benchmark and a model benchmark both pass with flying colors, data benchmarking is largely redundant because deployment-relevant failures should already be visible in those two dimensions.
Answer: False. Biased, unrepresentative, or shifted training and evaluation data can still produce deployment failure even when hardware performs well and the model preserves benchmarked accuracy on the evaluated distribution, because data-dimension failures are invisible to system and model axes that evaluate against the same flawed data.
Learning Objective: Recognize data evaluation as a necessary and independent axis in the three-dimensional benchmarking framework
Why are large language model benchmarks structurally harder to design than image classification benchmarks?
- Because language models cannot be evaluated on hardware metrics at all, so benchmarks must abandon quantitative measurement entirely
- Because open-ended generation requires joint evaluation across multiple dimensions (factuality, calibration, safety, reasoning, instruction-following) rather than a single fixed-label answer, and these dimensions can trade off against each other
- Because all LLM benchmarks are inherently contaminated by training data and therefore uninformative
- Because language models do not experience distribution shift and so benchmark design is less urgent
Answer: The correct answer is B. Open-ended generation has no unique ground-truth label per input, so evaluation must span multiple interacting quality axes; a model that hallucinates less may reason worse, and a safer model may be less helpful, making single-number comparison structurally inadequate. Contamination is real but not universal; claiming LLMs escape distribution shift contradicts every serving observation; abandoning hardware metrics is a false conclusion (serving cost matters as much for LLMs).
Learning Objective: Explain why generative model evaluation requires multi-dimensional assessment rather than single-label scoring
A team deploys a compressed MobileNet to an EdgeTPU for defect detection on a factory floor. MLPerf Inference scores look excellent in the lab, but the system misclassifies 8 percent of parts once deployed. Walk through how the chapter’s holistic system-model-data view diagnoses this kind of failure.
Answer: Holistic diagnosis asks three separate questions. On the system axis: does the EdgeTPU sustain its benchmarked latency under factory-floor thermal conditions and dust exposure, or does throttling and sensor variability introduce error? On the model axis: did INT8 quantization preserve calibration and robustness on edge cases, or does confidence on ambiguous parts now exceed the deployment threshold? On the data axis: does the training data span the factory-floor lighting, camera angles, part variations, and occlusion patterns, or does it reflect a narrower curated distribution? A benchmark pass on one dimension means little if another fails: MLPerf may score the hardware correctly while ignoring that the model was never tested on factory-floor lighting or that quantization ruined calibration for ambiguous parts. The practical consequence is that deployment readiness requires validating interactions across all three dimensions rather than passing each independently on convenient conditions.
Learning Objective: Synthesize the three-dimensional framework to diagnose a deployment failure that no single axis would have surfaced
Self-Check: Answer
Which benchmark assumption is most directly violated when a production service experiences Black-Friday-style traffic bursts rather than the steady request rate used during evaluation?
- Uniform request arrival (Poisson or steady rate)
- Fixed model version across requests
- Clean labels in the input data
- Constant arithmetic intensity across batches
Answer: The correct answer is A. The benchmark assumed request arrivals followed a smooth distribution, but bursty traffic creates queue buildup and latency spikes that the steady-rate harness could not expose; queueing theory predicts that the tail latency under bursts can be orders of magnitude worse than under the benchmark’s smooth arrival pattern. The fixed-version, clean-label, and arithmetic-intensity framings describe different assumptions that may or may not hold but do not directly describe the traffic-pattern mismatch.
Learning Objective: Identify how production traffic patterns invalidate the arrival-rate assumptions embedded in benchmark harnesses
Explain why replaying production traces during predeployment validation is a stronger check than relying on the benchmark throughput number, and describe a concrete failure mode trace replay surfaces that benchmarks miss.
Answer: Trace replay drives the system with the actual arrival pattern, input size distribution, and burst structure it will face, so it tests whether benchmark conclusions survive under realistic load rather than under the smooth synthetic load the benchmark harness used. A system that benchmarks at 10,000 QPS steady-state with 50 ms p99 can reveal, under trace replay, that the real workload has a 2-minute morning burst producing 3\(\times\) the benchmark rate and p99 latency of 450 ms. The engineering consequence is that trace replay bridges the benchmark-production gap quantitatively for a specific deployment, letting teams catch SLO violations before users do rather than after.
Learning Objective: Explain how trace replay converts benchmark results into deployment-specific predeployment validation
True or False: Once a model passes predeployment benchmarks, production monitoring is primarily an alerting convenience rather than a continuation of benchmarking.
Answer: False. The chapter explicitly frames production monitoring as continuous benchmarking: the same system must continue to be validated against shifting data distributions, changing workloads, and evolving operational conditions after deployment, because the factors that made the predeployment benchmark pass may no longer hold a month later.
Learning Objective: Recognize production monitoring as an ongoing extension of benchmark validation rather than a separate alerting function
Self-Check: Answer
True or False: A system that ranks near the top of a benchmark leaderboard will usually maintain a similar relative advantage once deployed to production, provided the benchmark itself was measured carefully with proper statistical controls.
Answer: False. Production adds noisy inputs, variable load, resource contention, distribution shift, and multi-objective constraints the benchmark did not evaluate, so even a rigorously measured leaderboard rank may reverse in deployment; the chapter argues careful measurement is necessary but far from sufficient for predicting production outcomes.
Learning Objective: Critique the assumption that benchmark rank transfers directly to production success
A team improves a benchmark from 1,000 QPS at 1.8 W to 1,200 QPS at 4.2 W (20 percent throughput gain, 133 percent power increase). Which lesson from the chapter best applies?
- The faster system is automatically better because throughput dominates every deployment concern
- Single-metric evaluation can mislead: a 20 percent throughput gain purchased at 2.3\(\times\) power cost is a poor trade for any deployment with energy, thermal, or cost constraints, and may be negative value in absolute terms
- The result proves the lower-throughput system is defective and should be discarded
- Power consumption should be ignored unless the deployment is in a data center
Answer: The correct answer is B. QPS-per-watt dropped from 556 to 286 (49 percent efficiency loss), so the ‘improvement’ is a net regression on efficiency; for edge, mobile, or cost-sensitive data center deployment, accepting 2.3\(\times\) power for 20 percent throughput is a bad trade. The faster-is-better framing denies the joint evaluation the chapter teaches; calling the original system defective inverts the comparison; ignoring power under data center deployment contradicts TCO economics.
Learning Objective: Analyze why throughput-only benchmark wins can be deployment losses once energy and cost are included
Explain why the chapter warns against using saturated benchmarks (such as MNIST or long-mature ImageNet) as primary evidence of system progress, and describe what should replace them.
Answer: Once many systems cluster near the ceiling of a benchmark, small score changes more often reflect test-set artifact exploitation, seed variation, or irrelevant refinements than genuine capability gains; MNIST at 99.8 percent accuracy, for example, tells almost nothing about modern vision system quality or robustness to deployment conditions. Evaluation should shift to benchmarks that still discriminate on the constraints that matter (energy-per-inference on edge hardware, robustness to distribution shift, tail latency under load) and should include deployment-relevant dimensions like calibration and out-of-distribution generalization. The practical implication is that benchmark choice is itself a research decision: running a saturated benchmark produces decision-relevant noise, while running a discriminating benchmark produces actionable evidence.
Learning Objective: Explain why saturated benchmarks stop serving as reliable progress signals and what should replace them
What is the core mistake in applying research-style benchmark results directly to production system evaluation?
- Research benchmarks usually run on excessive hardware, so they systematically underestimate production performance
- Research benchmarks evaluate algorithms under controlled conditions with narrow metrics, while production systems must satisfy end-to-end operational requirements (tail latency under load, fault tolerance, multi-objective constraints, drift resilience) that research evaluations deliberately exclude
- Research benchmarks always omit accuracy measurements entirely
- Production systems should never consult benchmark data under any circumstances
Answer: The correct answer is B. Research benchmarks isolate algorithmic properties under ideal conditions by design; production systems operate under a superset of concerns (queueing, failures, uptime targets, full-pipeline latency) that research evaluations explicitly abstract away. The difference is scope, not quality. The under-estimation framing reverses the direction; claiming research omits accuracy is false; saying production should ignore benchmarks overcorrects a real problem (misuse) with an unworkable policy.
Learning Objective: Distinguish research benchmarking scope from production evaluation requirements
Explain how Goodhart’s Law manifests in the pitfall of optimizing exclusively for benchmark rankings, using a concrete scenario where chasing the metric degrades deployment quality.
Answer: Goodhart’s Law predicts that once a benchmark score becomes the explicit target, teams make changes that improve the measured number even when those changes degrade correlated deployment-relevant qualities. A vision team that chases top-1 accuracy on ImageNet through aggressive post-training quantization may climb from 76.2 to 76.5 percent while destroying confidence calibration, so downstream automation based on confidence thresholds now routes wrongly; the model improved on the tracked metric but regressed on the deployment-critical property. The system consequence is that benchmark success and production quality can become anti-correlated when optimization is single-axis and the incentives are misaligned: the only defense is multi-metric evaluation that penalizes gains accompanied by regressions on deployment-relevant dimensions.
Learning Objective: Explain how benchmark-targeted optimization can distort engineering priorities through Goodhart’s Law
Self-Check: Answer
Which statement best summarizes the chapter’s final view of benchmarking in ML systems engineering?
- Benchmarking is mainly a mechanism for ranking hardware vendors by a single standardized throughput metric
- Benchmarking is the empirical validation layer that tests whether system, model, and data optimizations deliver their promised gains in deployment-representative conditions, converting optimization claims into measured engineering evidence
- Benchmarking matters mostly during research and becomes less useful once systems enter production
- Benchmarking replaces the need for production monitoring provided the benchmark is comprehensive enough
Answer: The correct answer is B. The chapter’s thesis is that benchmarking is the discipline’s truth-telling function: it validates the optimization pipeline across all three dimensions, so every claimed improvement is tested rather than assumed. Single-metric vendor ranking captures only a slice of the framework; the research-only and benchmark-replaces-monitoring framings directly contradict the production-considerations section.
Learning Objective: Synthesize the chapter’s overall view of benchmarking as the empirical validation discipline for ML systems
Explain why the chapter frames practitioners who measure tail latency, wall-clock end-to-end behavior, and production-representative data distributions as doing something fundamentally different from practitioners who rely on component benchmarks alone.
Answer: Component benchmarks evaluate proxies (isolated kernels, mean latency, clean datasets) that can satisfy benchmarks while deployment fails silently, so acting on those numbers amounts to engineering by assumption. Measuring tail latency, wall-clock end-to-end, and real input distributions closes the benchmark-production gap directly: these measurements confirm that optimization claims survive the physical and operational constraints of deployment rather than trusting that they will. The practical consequence is that disciplined benchmarking converts optimization from plausible speculation into verified engineering; the difference between about 1.2\(\times\) and 3\(\times\) end-to-end improvement is the difference between a real system and a benchmark artifact.
Learning Objective: Explain why rigorous benchmarking is constitutive of dependable ML systems engineering rather than an optional check
Which takeaway from the chapter most directly explains why a 3\(\times\) model inference speedup may produce only about a 1.2\(\times\) end-to-end latency improvement in a typical serving pipeline?
- Benchmarks are moving targets
- The tail determines the user experience
- Amdahl’s Law bounds total system improvement by the unoptimized fraction of the pipeline (preprocessing, queueing, postprocessing), so component-only optimization hits a ceiling set by what was not optimized
- Precision is a distinct energy lever
Answer: The correct answer is C. The chapter’s 10 ms model time inside a 50 ms end-to-end latency is the canonical Amdahl situation: optimizing the model component cannot move the preprocessing, queueing, and postprocessing work around it. The moving-target, tail, and precision framings are real chapter points but do not explain this specific component-to-end-to-end attenuation.
Learning Objective: Apply Amdahl’s Law to interpret the ceiling on system-level improvement from component optimization