Network Architectures
Purpose
Why is choosing a neural network architecture an infrastructure commitment rather than a modeling decision?
Selecting a neural network architecture is not a modeling decision but a contract with physics. A convolutional network commits the system to spatially local computation that parallelizes naturally across hardware cores. A transformer commits the system to attention mechanisms, token-to-token weighting operations, whose memory grows quadratically with sequence length. A recommendation model commits the system to enormous embedding tables that dominate memory and turn every training step into a bandwidth-bound lookup. These are not abstract trade-offs resolved during model selection; they are physical consequences that propagate through the entire system stack. The architecture determines whether the model fits in mobile device memory or requires a data center, whether training completes in days or months, whether inference meets millisecond latency targets, and whether deployment is economically viable at scale. More critically, the choice is irreversible in practice: data pipelines are built around the architecture’s input format, training infrastructure is provisioned for its compute profile, serving systems are optimized for its inference pattern, and monitoring dashboards are calibrated to its failure modes. Changing the architecture means rebuilding all of this, which is why architecture decisions made early in a project persist long after better alternatives emerge. The architecture is not what the model does but what the hardware must do, and every downstream engineering decision inherits the physical contract it imposes. In D·A·M terms, this contract is algorithm-machine co-design at its root: the structure of the mathematical graph permanently dictates how the hardware must allocate its memory and compute.
Learning Objectives
- Distinguish computational characteristics of MLPs, CNNs, RNNs, Transformers, and DLRM-style recommenders
- Explain how inductive biases exploit structure in different data types
- Analyze computational complexity and memory scaling across architectural families
- Identify building blocks such as skip connections, normalization, and gating that enable deep training
- Apply the architecture selection framework to match data characteristics with model designs
- Evaluate how compute, memory access, and data movement determine hardware mapping efficiency
- Critique architecture-selection fallacies under latency, bandwidth, and parallelization constraints
Architectural Principles
Matrix multiplication, activation functions, and gradient computation form the “verbs” of neural networks. Architectures assemble those verbs into computational graphs: specialized structures optimized for specific data types and computational constraints. Under the silicon contract (principle 4), every architecture makes an implicit agreement with hardware, trading computational patterns for efficiency on particular problem classes.
Every neural network architecture decides how computation should be structured to match the structure in the data. Images have spatial locality, language has sequential dependencies, and tabular records have no inherent structure at all. The architecture encodes assumptions about these patterns directly into the computational graph, and those assumptions determine everything from parameter count to hardware utilization to deployment feasibility. Architecture selection is therefore a systems engineering problem that directly determines the iron law terms: the number of operations \(O\) and the volume of data movement \(D_{\text{vol}}\). The structural assumptions that each architecture encodes are known as inductive biases1, and they serve as the unifying concept for this entire chapter.
1 Inductive Bias: From Latin inducere, “to lead into,” encoding a structural assumption “leads” the model toward a smaller solution space, which is why this concept unifies the entire chapter: every architecture discussed here—multilayer perceptron (MLP), convolutional neural network (CNN), recurrent neural network (RNN), and transformer—is defined by its choice of bias. A CNN’s locality bias cuts parameters by orders of magnitude vs. an equivalent MLP, directly shrinking the iron law’s \(O\) and \(D_{\text{vol}}\) terms, while a transformer’s lack of spatial bias demands quadratic memory in exchange for flexible long-range connectivity.

Inductive bias from strong (CNN) to weak (MLP): stronger prior, less data needed.
Definition 1.1: Inductive bias
Inductive Bias is a structural constraint built into a model architecture that restricts the hypothesis space, enabling generalization from finite data by encoding domain-specific assumptions (such as spatial locality or sequential ordering) directly into the computational graph.
- Significance: Inductive bias directly reduces the dataset size \((D)\) required for generalization. A CNN’s spatial locality bias reduces the hypothesis space from \(\mathcal{O}(N_{\text{pix}}^2)\) (fully connected) to \(\mathcal{O}(N_{\text{pix}} \cdot K^2)\) (local filters), where \(K \ll N_{\text{pix}}\): for a \(224{\times}224\) image, a \(3{\times}3\) CNN kernel needs roughly 5,575.1× fewer parameters than an equivalent dense input connection, cutting both the memory footprint and the data required to avoid overfitting by the same factor.
- Distinction: Unlike Regularization (which penalizes hypothesis complexity at training time via L1/L2 terms), Inductive Bias eliminates entire hypothesis classes at architecture design time: a CNN cannot represent arbitrary nonlocal functions regardless of training data, while regularization merely discourages them.
- Common pitfall: A frequent misconception is that stronger inductive bias is always better. A strong locality bias (CNN) excels on spatial data but fails to represent long-range dependencies in language, where a transformer’s lack of spatial bias–at the cost of \(\mathcal{O}(S^2)\) memory scaling for sequence length \(S\)–can be necessary to achieve high performance.
A convolutional neural network (CNN) encodes an inductive bias of spatial locality: nearby pixels matter more than distant ones. A transformer’s inductive bias is that any element may attend to any other, enabling flexible long-range relationships at the cost of quadratic memory scaling. These biases are not incidental design choices; they are the mechanism through which architectures achieve efficiency by restricting the space of functions they can represent. Without these biases, the hypothesis space is so large that learning even simple tasks would require effectively infinite data and compute. We formalize how inductive biases unify all architectural families in section 1.10.4, after examining how each architecture’s bias manifests in practice.

Architecture is the algorithm axis of D·A·M: it sets the operation-count budget.
Machine learning systems face a core engineering trade-off: representational power vs. computational efficiency. Under the iron law of ML systems (principle 3) (Iron Law of ML Systems), architectural choice is the primary determinant of the operation-count term \(O\). A transformer’s attention mechanism enables global relationships but scales as \(\mathcal{O}(S^2)\) operations with sequence length \(S\); a CNN exploits spatial locality to reduce operations to linear scaling in the number of spatial positions. Matching the right inductive biases to a workload’s data while setting a manageable operation-count budget defines the practice of neural architecture selection.
War Story 1.1: The ensemble Netflix did not ship
Context: Netflix launched the Netflix Prize in 2006, offering one million dollars to any team that could improve the root-mean-square error of its Cinematch rating predictor by 10 percent. After three years of competition, the team BellKor’s Pragmatic Chaos—Yehuda Koren, Bob Bell, Chris Volinsky, Andreas Toscher, Michael Jahrer, Martin Piotte, and Martin Chabbert—won in 2009 with a 10.06 percent improvement, blending more than a hundred component models into a single ensemble (Johnston 2012).
Failure mode: The offline metric improved, but the winning architecture was too expensive to deploy. Netflix engineers later wrote that the engineering effort required to put the ensemble into production was not justified by the additional accuracy it delivered, and by 2012 the product itself had shifted from rating-based DVD recommendations toward streaming personalization, where the rating signal mattered less. Netflix deployed earlier and simpler ideas from the competition but never shipped the Grand Prize ensemble.
Systems lesson: Architecture choice must be judged against the cost of running the model, not only the accuracy it achieves on a static benchmark. A network with more parameters and more layers can lose to a simpler one whose compute and memory budgets fit the system that has to keep it running.
Johnston, Casey. 2012. “Netflix Never Used Its $1 Million Algorithm Due to Engineering Costs.” Ars Technica, April.
Five architectural families define neural computation, each optimized for different data characteristics. Table 1 maps each family to its data domain, core innovation, and dominant system bottleneck. The bottleneck column is the decision column: CNNs concentrate reusable spatial work into compute throughput, MLPs stress memory bandwidth, RNNs expose sequential dependencies, and transformers and DLRM-style models push memory capacity through attention state or embedding tables. Each architectural choice creates distinct computational signatures that propagate through every level of the implementation stack.
| Architecture | Data Type | Core Innovation | System Bottleneck |
|---|---|---|---|
| MLPs | Tabular/Unstructured | Dense connectivity | Memory bandwidth |
| CNNs | Spatial (images) | Local filters + weight sharing | Compute throughput |
| RNNs | Sequential (time series) | Recurrent state | Sequential dependencies |
| Transformers | Relational (language) | Dynamic attention | Memory capacity \((S^2)\) |
| DLRM | Categorical (recommendations) | Embedding tables | Memory capacity (TB+) |
Throughout this book, we use five specific model architectures as recurring Lighthouse Models: consistent reference points that ground abstract concepts in concrete systems reality. These examples are concrete implementations of the Workload Archetypes (Compute Beast, Bandwidth Hog, etc.) introduced in Workload archetypes.
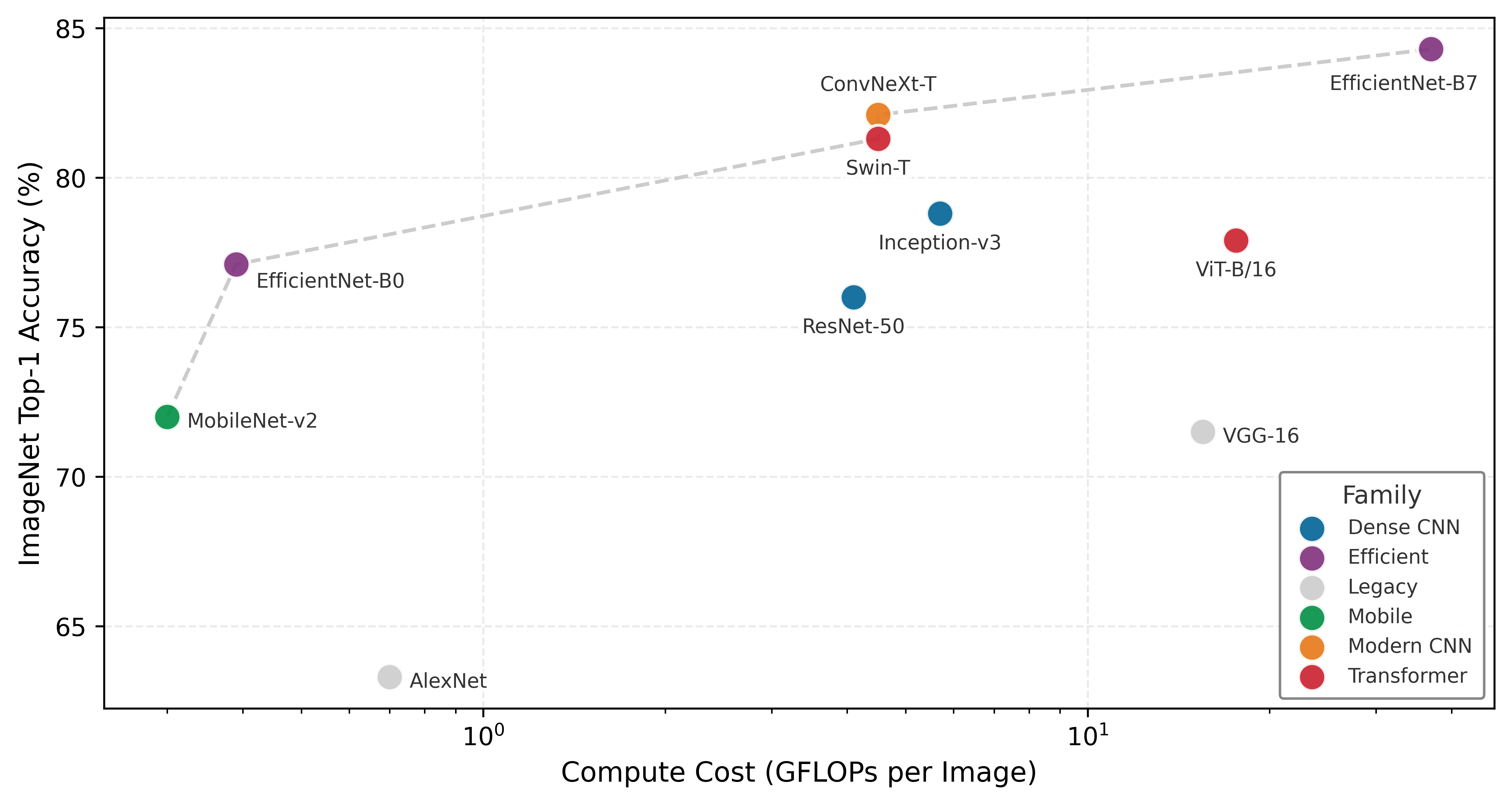
To understand why these specific models were chosen, consider the history of model evolution through the lens of the Pareto frontier (figure 1).
Szegedy, Christian, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, and Andrew Rabinovich. 2015. “Going Deeper with Convolutions.” 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 1–9. https://doi.org/10.1109/cvpr.2015.7298594.
Sandler, Mark, Andrew Howard, Menglong Zhu, Andrey Zhmoginov, and Liang-Chieh Chen. 2018. “MobileNetV2: Inverted Residuals and Linear Bottlenecks.” 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 4510–20. https://doi.org/10.1109/cvpr.2018.00474.
Tan, Mingxing, and Quoc V Le. 2019. “EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks.” International Conference on Machine Learning (ICML), 6105–14.
Liu, Ze, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. 2021. “Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows.” 2021 IEEE/CVF International Conference on Computer Vision (ICCV), 9992–10002. https://doi.org/10.1109/ICCV48922.2021.00986.
Liu, Zhuang, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, and Saining Xie. 2022. “A ConvNet for the 2020s.” 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 11966–76. https://doi.org/10.1109/CVPR52688.2022.01167.
These models serve as more than convenient examples; they form a set of canonical workloads for understanding system constraints. Each occupies a distinct position on the trade-off between accuracy and computational cost, as mapped in figure 1. The plotted frontier should be read as a historical map of representative architecture papers, not as a controlled benchmark table. It reveals three distinct eras of architectural thinking: the original dense CNNs that pushed accuracy at any cost, the efficiency revolution of MobileNets that minimized compute per unit accuracy, and transformer architectures that trade substantial computational cost for flexible long-range modeling. The architectural choices made at design time determine where a system lands on this frontier.
Lighthouse roster: Model biographies
Five models earn the lighthouse role because each isolates one system bottleneck that recurs repeatedly: compute (ResNet-50), memory bandwidth (GPT-2), memory capacity (DLRM), edge latency (MobileNetV2), and always-on power for keyword spotting (KWS). The biographies that follow trace each model’s historical context and why it became a useful reference.
ResNet-50 (He et al. 2016a) anchors the compute-intensive vision lighthouse. The Residual Network (ResNet) addressed the degradation problem in very deep plain networks: adding layers could increase training error despite sufficient capacity. By introducing “skip connections” that improve optimization and gradient flow, it enabled networks of 50, 100, or even 1000 layers. The ResNet architecture won the ImageNet 2015 competition (with very deep 152-layer models), and ResNet-50 has become a widely used backbone and benchmark workload for computer vision. From a systems perspective, it is a highly regular, compute-intensive workload composed almost entirely of dense convolutions, making it a useful test for GPU floating-point throughput.
Lighthouse 1.1: Canonical workloads
In computer architecture, the microprocessor without interlocked pipelined stages (MIPS) processor is often used to teach pipelining, not because it is the fastest available chip, but because it is the clearest embodiment of reduced instruction set computer (RISC) principles. Similarly, this book uses ResNet-50, GPT-2, DLRM, MobileNetV2, and KWS as canonical workloads. By studying these “Lighthouses,” we learn engineering principles about math, memory movement, and locality that remain valid even as the specific “State of the Art” model architectures evolve.
GPT-2 (Radford et al. 2019) anchors the bandwidth-bound language lighthouse. Generative Pre-trained Transformer 2 demonstrated that scaling up a simple decoder-only transformer architecture on massive datasets could produce coherent text generation. Unlike BERT, an encoder-style transformer that reads context in both directions, GPT-2 generates text sequentially (autoregressively2), creating a unique memory bandwidth bottleneck where the entire model must be loaded to generate just one token. It serves as our archetype for large language models (LLMs) such as Llama and ChatGPT.
2 [offset=-38mm] Autoregressive Generation: A decoding strategy where each output token is conditioned on all previously generated tokens, requiring a full model forward pass per token. For a 1.5B-parameter model in FP16, generating one token loads about 3 GB of weights from HBM yet performs only a matrix-vector multiply, yielding a work-to-byte ratio of about 1 FLOP/byte. This token-by-token serial dependency is what makes LLM inference fundamentally bandwidth bound rather than compute bound. During generation, serving systems also keep compact attention state from earlier tokens; the attention section later names this state the key-value cache.
DLRM (Naumov et al. 2019) anchors the sparse-recommendation lighthouse. Meta open-sourced DLRM to expose a workload that differs from CNNs and transformers in a critical way. While vision and language models are compute-heavy, recommendation systems are memory-heavy. They must look up user and item preferences in massive embedding tables that can reach terabytes in size, creating unique challenges for latency-critical serving (Model Serving). DLRM is a useful benchmark for memory capacity and sparse memory access patterns in the data center.
MobileNet (Howard et al. 2017) anchors the edge-efficiency lighthouse. MobileNet challenged the trend of ever-larger models by prioritizing efficiency. It popularized depthwise separable convolutions for efficient vision models, an architectural innovation that reduced computational cost (FLOPs) by 8–9\(\times\) for \(3{\times}3\) kernels with minimal accuracy loss. That smaller compute footprint made MobileNet a natural fit for compression and lower-precision deployment techniques [storing and computing with fewer bits per value] covered in Model Compression. It proved that model architecture could be co-designed with hardware constraints, becoming a reference family for running vision models on smartphones and embedded devices where battery life and latency are critical.
Warden, Pete. 2018. “Speech Commands: A Dataset for Limited-Vocabulary Speech Recognition.” arXiv Preprint arXiv:1804.03209, ahead of print. https://doi.org/10.48550/arXiv.1804.03209.
Warden, Pete, and Daniel Situnayake. 2020. TinyML: Machine Learning with TensorFlow Lite on Arduino and Ultra-Low-Power Microcontrollers. O’Reilly Media.
Banbury, Colby R, Chuteng Zhou, Igor Fedorov, Ramon Matas, Urmish Thakker, Dibakar Gope, Vijay Janapa Reddi, Matthew Mattina, and Paul N Whatmough. 2021. “MicroNets: Neural Network Architectures for Deploying TinyML Applications on Commodity Microcontrollers.” Proceedings of Machine Learning and Systems 3: 517–32.
Banbury, Colby, Vijay Janapa Reddi, Peter Torelli, Jeremy Holleman, Nat Jeffries, Csaba Kiraly, Pietro Montino, et al. 2021. “MLPerf Tiny Benchmark.” arXiv Preprint.
Keyword Spotting (KWS) (Warden 2018) anchors the always-on TinyML lighthouse. Keyword Spotting models (like those detecting “Hey Siri” or “Ok Google”) represent the extreme end of efficiency. Designed to run on “always-on” microcontrollers with kilobyte-scale memory and milliwatt power budgets, these models (often depthwise separable CNNs) exemplify the constraints of TinyML (Warden and Situnayake 2020; C. R. Banbury et al. 2021; C. Banbury et al. 2021). They force engineers to count every byte and cycle, motivating extreme quantization (INT8 and INT4) and specialized hardware. Together, these biographies establish why the lighthouses are not a model catalog: each one isolates a different bottleneck signature that the arithmetic-intensity analysis can quantify.
Workload signatures: The arithmetic intensity spectrum
ResNet-50 reuses convolutional weights across many pixels and images, while GPT-2/Llama decode streams large weight and KV-cache state for one token at a time. That contrast is the practical face of arithmetic intensity, the FLOP/byte ratio established in Neural Computation that determines whether a workload is compute bound or memory bound.

Arithmetic intensity spans ~80\(\times\): ResNet saturates compute, GPT-2 starves for bandwidth.
These bottlenecks are not accidental; they are the “signatures” of the underlying math. We quantify these signatures using arithmetic intensity \((I)\), defined as FLOP/byte: floating-point work divided by bytes moved from main memory. Computational complexity cheat sheet gives the per-operation FLOP and parameter formulas that supply the numerator of this ratio, so the intensity of any layer can be estimated before hardware is provisioned. Table 2 compares the signatures of our three primary Lighthouses, exposing the roughly 80.1× gap between ResNet and GPT-2.
| Model Family | Lighthouse | Intensity \((I)\) | Hardware Affinity |
|---|---|---|---|
| Dense CNN | ResNet-50 | ~40 FLOP/byte | Compute-Rich (GPUs/TPUs) |
| Efficient Vision | MobileNetV2 | ~21.4 FLOP/byte | Balanced (Mobile NPUs) |
| Transformer | GPT-2 (Inf) | ~0.50 FLOP/byte | Bandwidth-Rich (HBM3/H100) |
This table provides the quantitative justification for architecture selection: one chooses a transformer not because it is “better” in the abstract, but because the project can afford the bandwidth pressure implied by its low operation-to-byte ratio in exchange for its relational flexibility. Conversely, MobileNet is the right choice when the machine axis lacks the bandwidth to sustain a denser signature.
The “Bottleneck” column in table 3 deserves particular attention: it identifies which system resource (compute throughput, memory bandwidth, memory capacity, latency, or power) limits performance for each workload class. In iron law terms (Iron Law of ML Systems), the bottleneck identifies whether \(O\) (operations) or \(D_{\text{vol}}\) (data movement) dominates the runtime. These distinctions determine which optimization strategies prove effective, a theme we return to throughout subsequent chapters.
| Model | Domain | Params | FLOPs/Inf | Memory | Bottleneck | Role in Textbook |
|---|---|---|---|---|---|---|
| ResNet-50 | Vision | 25.6M | 4.1 GFLOP | 102.4 MB | Compute | Dense vision throughput |
| GPT-2 XL | Language | 1.5B | 3 GFLOP/token | 6 GB | Mem. Bandwidth | Token-by-token serving |
| DLRM | Recommender | 25B | Low | 100 GB | Mem. Capacity | Embedding tables and capacity planning |
| MobileNetV2 | Edge Vision | 3.5M | 300 MFLOP | 14 MB | Latency | Depthwise convolutions and efficiency |
| KWS (DS-CNN) | Audio | 200K | 20 MFLOP | 800 KB | Power | Always-on power budget |
Architecture selection is ultimately an engineering trade-off between math \((O)\) and memory movement \((D_{\text{vol}})\). The mechanisms behind the signatures in table 2 explain why each lighthouse sits where it does on the intensity spectrum. ResNet-50 earns its high intensity because convolutional layers reuse each weight many times across the spatial dimensions of an image (deeper bottleneck layers reach 100–200+ FLOP/byte), so its performance is limited by how fast the hardware can do math. GPT-2 sits at the opposite extreme: each generated token produces only a matrix-vector multiplication rather than the matrix-matrix operations of batch processing, so the system loads massive weights from memory for a single token’s math, and performance is limited by how fast memory can move bits. MobileNet lands between the two at the whole-model level, with individual depthwise layers falling lower once activation traffic is included: depthwise separable convolutions reduce total \(O\) but move more data relative to that work, which fits mobile hardware well yet often “starves” high-end GPUs optimized for dense math.
This spectrum determines whether the system needs a faster processor or faster memory to improve performance. The roofline model provides the analytical framework (the roofline model) for quantifying these limits on specific hardware, with applied examples in Hardware Acceleration. A concrete example: The A100 analysis works this intensity-to-bottleneck classification through a real accelerator specification, computing the ridge point of an A100 and showing how the same operation falls on either side of it.
The lighthouse signatures make the next step concrete: inspect each architecture family by the data pattern it targets, the computation it performs, the hardware mapping it induces, and the bottleneck it exposes. This four-part lens ensures that every architecture is evaluated for what it costs to run, not only for what it learns.
Checkpoint 1.1: Arithmetic intensity and architecture
Match the architectural choice to its systems implication:
Self-Check: Question
A team must choose between an MLP and a CNN for classifying 224-by-224 pixel medical images. A dense first layer would need 150,528 input weights per output unit, so a 1,000-unit layer would already carry roughly 150 million weights; the CNN uses filters with fewer than 10,000 weights shared across positions. Using the chapter’s framing of inductive bias, which statement best explains why the CNN is the better starting point?
- The CNN’s locality-and-weight-sharing assumption matches the spatial structure of images, which simultaneously reduces sample complexity and cuts per-layer memory traffic by orders of magnitude.
- The CNN is more expressive than the MLP, so it can fit any function the MLP can fit with fewer parameters.
- The MLP cannot represent image-classification functions at all, so the CNN is the only viable choice.
- The CNN eliminates the need for training entirely by using handcrafted filters, which avoids the gradient-descent cost of the MLP.
A dense MLP layer on a single-sample forward pass reports roughly 0.5 FLOP/byte, while a 3-by-3 convolution in ResNet-50 reuses each filter weight across more than 50,000 spatial positions. Using arithmetic intensity, explain why these two architectures sit in opposite regimes on the roofline and what that implies for which hardware upgrade helps each.
A team profiles a production workload and finds that a single model’s embedding tables occupy roughly 1 TB of DRAM, that each request performs a handful of random row lookups, and that matrix-multiply kernels use less than 5 percent of accelerator time. Which lighthouse model best represents this workload’s dominant bottleneck?
- ResNet-50, because the workload spends most of its time in convolution kernels that benefit from dense matrix hardware.
- GPT-2 XL, because autoregressive generation is the canonical example of a bandwidth-limited serving workload.
- DLRM, because the binding constraint is memory capacity for terabyte-scale embedding tables accessed via irregular sparse gathers.
- MobileNetV2, because the low compute utilization signature is diagnostic of depthwise-separable convolutions.
A 3-by-3 convolution filter in a ResNet layer is applied at more than 50,000 spatial positions in a single forward pass, while a dense matrix-vector multiply uses each weight exactly once per sample. The ratio of math done to bytes moved — the ____ — is what places these two workloads on opposite sides of the roofline and dictates whether faster HBM or more TFLOP/s is the correct hardware response.
Why does the chapter frame architecture selection as ‘signing a contract with physics’ rather than as a modeling preference?
- Because the chosen architecture fixes compute patterns (locality, quadratic attention, sparse lookups) that propagate into training-cluster provisioning, serving memory, and deployment feasibility — commitments that cannot be undone by clever optimization.
- Because the Python framework a team uses (PyTorch, TensorFlow, JAX) permanently binds a model to one vendor’s hardware.
- Because an architecture’s optimizer cannot be changed after the first training step without restarting training from scratch.
- Because the chapter’s theoretical analysis deliberately ignores real engineering constraints in favor of abstract mathematical results.
True or False: A stronger inductive bias is always preferable to a weaker one because it reduces the parameter count and the amount of data the model needs to learn from.
MLPs: Dense Pattern Processing
Consider a smartphone’s spam filter: given a set of features extracted from an email (sender reputation score, number of links, presence of certain keywords), the model must output a single probability: spam or not. This classification task, where every input feature connects to every output, is the domain of fully connected networks.
We begin with the simplest architecture in our spectrum. Multilayer perceptrons (MLPs)3 represent the fully-connected architectures introduced in Neural Computation, now examined through the four-part systems lens established earlier.
3 Perceptron: A portmanteau of “perception” and “electron,” coined by Frank Rosenblatt (Rosenblatt 1957) for the atomic unit of neural computation: a weighted sum followed by a nonlinear activation, extending the earlier McCulloch-Pitts neuron. MLPs are composed entirely of these units arranged in fully-connected layers, so the efficiency of this single operation, a multiply-accumulate, determines system throughput. Modern accelerators execute over \(10^{14}\) of these operations per second, making the perceptron the computational primitive that the entire ML hardware ecosystem is optimized around.
Rosenblatt, Frank. 1957. The Perceptron: A Perceiving and Recognizing Automaton. Report Nos. 85-460-1. Cornell Aeronautical Laboratory.
4 Universal Approximation Theorem (UAT): This theorem provides the mathematical guarantee for the MLP’s “no prior structure” inductive bias by proving a sufficiently wide network can approximate any continuous function. The systems-level catch is that “sufficiently wide” can require a number of neurons that grows exponentially with input dimensionality, rendering the theoretical guarantee practically unattainable for even moderately-sized inputs like a \(256{\times}256\) image.
Cybenko, George. 1989. “Approximation by Superpositions of a Sigmoidal Function.” Mathematics of Control, Signals, and Systems 2 (4): 303–14. https://doi.org/10.1007/bf02551274.
Hornik, Kurt, Maxwell Stinchcombe, and Halbert White. 1989. “Multilayer Feedforward Networks Are Universal Approximators.” Neural Networks 2 (5): 359–66. https://doi.org/10.1016/0893-6080(89)90020-8.
MLPs embody an inductive bias: they assume no prior structure in the data, allowing any input to relate to any output. This architectural choice enables maximum flexibility by treating all input relationships as equally plausible, making MLPs versatile but computationally intensive compared to specialized alternatives. Their computational power was established theoretically by the Universal Approximation Theorem (UAT)4 (Cybenko 1989; Hornik et al. 1989), which we encountered as a footnote in Neural Computation. This theorem states that a sufficiently large MLP with nonlinear activation functions can approximate any continuous function on a compact domain, given suitable weights and biases. That combination of theoretical universality and dense connectivity is the architectural concept captured by the multilayer perceptron.
Definition 1.2: Multilayer perceptrons
Multilayer Perceptrons are feed-forward neural network architectures that apply fully connected layers in sequence, where every neuron in one layer connects to every neuron in the next, encoding no structural assumption about the input domain.
- Significance: The lack of structural prior gives dense layers quadratic parameter scaling in layer width: a single layer mapping 1,024 inputs to 1,024 outputs requires 1,048,576 parameters and about 2.1 MB of weight memory in FP16. A 3 by 3 convolution mapping 1,024 input channels to 1,024 output channels has about 9.4M weights; convolution’s advantage for images comes from spatial weight sharing across positions, not from reducing the channel-mixing matrix itself. This makes MLPs inefficient for high-dimensional structured inputs like images.
- Distinction: Unlike Convolutional Neural Networks, which exploit spatial locality to reduce parameter count, MLPs treat all input elements symmetrically, making them the architecture of choice for tabular data where no spatial or sequential structure is present.
- Common pitfall: A frequent misconception is that MLPs are too simple to matter for complex tasks. Every other architecture (CNN, transformer) can be viewed as an MLP with additional structural constraints and weight sharing–the MLP is the universal baseline against which all inductive biases are measured.
In practice, the UAT explains why MLPs succeed across diverse tasks while revealing the gap between theoretical capability and practical implementation. The theorem guarantees that some MLP can approximate any function, yet provides no guidance on requisite network size or weight determination. While MLPs can theoretically solve any pattern recognition problem, doing so may demand impractically large networks or prohibitive computation. This theoretical power drives the selection of MLPs for tabular data, recommendation systems, and problems where input relationships are unknown. At the same time, these practical limitations motivated the development of specialized architectures that exploit data structure for computational efficiency, as the subsequent CNN, RNN, and transformer sections demonstrate.
Learnability gap
The UAT sounds definitive, yet a fundamental gap separates what MLPs can represent from what they can learn in practice. That gap traces to a critical distinction between what a network can represent and what it can learn.
Representation capacity refers to the functions an architecture can express given unlimited resources; the UAT established earlier guarantees MLPs have universal representation capacity. This capacity is particularly effective because of the manifold hypothesis5, which suggests that high-dimensional data actually occupies a much simpler structure. Learnability refers to whether gradient descent can find good weights given finite training samples and computational budgets. A function may be representable yet practically unlearnable.
5 Manifold Hypothesis: The assumption that high-dimensional data lies on a low-dimensional surface embedded within the full space. A \(256{\times}256\) image lives in a 65,536-dimensional space, but “valid cat images” occupy a tiny structured region. Deep networks progressively unfold this crumpled manifold into linearly separable representations. The systems consequence: if data truly occupied the full space, no architecture could learn from feasible dataset sizes; the manifold structure is what makes finite training budgets sufficient.
This distinction resolves the apparent paradox of universal approximation and architectural progress. Specialized architectures such as ResNets and transformers improve learnability by embedding inductive biases that match data structure, even when doing so restricts representational capacity.
Three factors create the learnability gap:
- Sample complexity: The UAT provides no bounds on training examples needed. For 28 by 28 images, an MLP treats 784 pixels independently, requiring exponentially many samples to learn spatial correlations. A CNN embeds locality bias, drastically reducing sample requirements. Mathematically, sample complexity can scale exponentially with input dimension for MLPs but polynomially for architectures matching data structure.
- Parameter efficiency: The UAT guarantees some width suffices, but provides no constructive bounds. Required width can be exponential in input dimension: approximating \(\sin(x_1) + \cdots + \sin(x_{d_{\text{in}}})\) may require \(\mathcal{O}(\exp(d_{\text{in}}))\) MLP neurons vs. \(\mathcal{O}(d_{\text{in}})\) for architectures processing dimensions independently.
- Optimization difficulty: Even when optimal weights exist, gradient descent may not find them. MLP loss surfaces exhibit complex topology without the regularizing effect of architectural constraints. Specialized architectures reduce the search space, introducing symmetries that gradient descent exploits.
The classic MNIST handwritten digit benchmark illustrates this gap between representation and learnability concretely.
Example 1.1: MNIST: Representation vs. learnability
Consider classifying \(28{\times}28\) MNIST digits (784 input pixels, 10 output classes).
MLP approach:
- Architecture: 784 → 4096 → 4096 → 10
- Parameters: \((784{\times}4096) + (4096{\times}4096) + (4096{\times}10)\) ≈ 20M parameters
- Training: 60,000 examples (standard MNIST training set)
- Test Accuracy: ~97–98 percent
- Rationale: Treats every pixel independently. Must learn all spatial correlations from data alone. No prior knowledge about spatial structure.
CNN approach:
- Architecture: Conv(32, \(3{\times}3\)) → Pool → Conv(64, \(3{\times}3\)) → Pool → FC(128) → 10
- Parameters: \((3{\times}3{\times}1{\times}32) + (3{\times}3{\times}32{\times}64) + (64{\times}7{\times}7{\times}128) + (128{\times}10)\) ≈ 421.4K parameters
- Training: 60,000 examples (same data)
- Test Accuracy: ~99 percent
- Rationale: Embeds locality bias (nearby pixels are related) and translation invariance (digit patterns are meaningful regardless of position). These structural assumptions reduce parameter count and improve generalization.
Systems insight:
- Parameter efficiency: CNN uses 47× fewer parameters
- Sample efficiency: CNN achieves better accuracy with the same training data
- Deployment implication: CNN requires 47× less memory, trains faster, and runs faster at inference
For this task, both architectures can represent an effective digit classifier. The difference is learnability: the CNN’s inductive bias matches the spatial structure of images, enabling efficient learning with limited data and compute while using a more constrained hypothesis space than an unconstrained MLP.
The learnability gap motivates the core design principle of this chapter: embed inductive biases that match data structure. Each architecture sacrifices theoretical generality for practical learnability. The No Free Lunch theorem6 (Wolpert 1996) formalizes this trade-off: the bias that helps one task may hurt another. CNN’s translation invariance aids image classification but hurts tasks where absolute position matters. Architecture selection is fundamentally the act of matching inductive bias to data structure.
6 No Free Lunch Theorem: Wolpert and Macready’s 1997 result proved that no optimization algorithm outperforms random search across all possible problems: averaged over every conceivable function, all algorithms are equivalent. The ML systems consequence: every inductive bias (locality, equivariance, attention) improves performance on problems matching that bias while necessarily degrading performance on problems that violate it, making architecture selection an irreversible engineering commitment to a problem class.
Wolpert, David H. 1996. “The Lack of a Priori Distinctions Between Learning Algorithms.” Neural Computation 8 (7): 1341–90. https://doi.org/10.1162/neco.1996.8.7.1341.
These theoretical insights translate directly into engineering decisions. Appropriate inductive biases reduce parameter counts (enabling edge deployment), accelerate convergence (reducing training costs), and produce structured computation patterns that map efficiently to specialized hardware (Hardware Acceleration). A 20M-parameter MLP infeasible for edge deployment becomes a 421.4K-parameter CNN that fits comfortably, a 47× reduction achieved by matching architecture to data structure. The next question is what specific pattern processing requirements dense architectures address.
Pattern processing needs
Deep learning models frequently encounter problems where any input feature may influence any output without inherent constraints. In financial market analysis, any economic indicator may affect any market outcome. In natural language processing, word meaning may depend on any other word in the sentence. These scenarios demand an architectural pattern capable of learning arbitrary relationships across all input features . The architecture must provide unrestricted feature interactions where each output can depend on any combination of inputs, learned feature importance where the system determines which connections matter rather than relying on prescribed relationships, and adaptive representation where the network reshapes internal representations based on the data itself.
The MNIST digit recognition task illustrates this uncertainty concretely. While humans might focus on specific parts of digits (loops in ‘six’ or crossings in ‘eight’), the pixel combinations critical for classification remain indeterminate. A ‘seven’ written with a serif may share pixel patterns with a ‘two’, and variations in handwriting mean discriminative features may appear anywhere in the image. This uncertainty about feature relationships requires a dense processing approach where every pixel can potentially influence the classification decision—an architectural commitment that leads directly to the mathematical foundation of MLPs.
Algorithmic structure
These pattern processing needs demand an architecture capable of relating any input to any output. MLPs solve this with complete connectivity between all nodes. This connectivity requirement manifests through a series of fully-connected layers, where each neuron connects to every neuron in adjacent layers, the “dense” connectivity pattern introduced in Neural Computation.
Dense connectivity translates directly into fully connected layers and matrix multiplication operations, the mathematical basis introduced in Matrix multiplication formulation that makes MLPs computationally tractable. Figure 2 shows how each layer transforms its input through this core operation.

Reagen, Brandon, Robert Adolf, Paul Whatmough, Gu-Yeon Wei, and David Brooks. 2017. Deep Learning for Computer Architects. Synthesis Lectures on Computer Architecture. Springer International Publishing. https://doi.org/10.1007/978-3-031-01756-8.
The dense layer computation follows equation 1: \[ \mathbf{h}^{(\ell)} = f\big(\mathbf{h}^{(\ell-1)}\mathbf{W}^{(\ell)} + \mathbf{b}^{(\ell)}\big) \tag{1}\]
Recall that \(\mathbf{h}^{(\ell)}\) represents the layer \(\ell\) output (activation vector), \(\mathbf{h}^{(\ell-1)}\) represents the input from the previous layer, \(\mathbf{W}^{(\ell)}\) denotes the weight matrix for layer \(\ell\), \(\mathbf{b}^{(\ell)}\) denotes the bias vector, and \(f(\cdot)\) denotes the activation function; Nonlinear activation functions develops ReLU and related nonlinearities in detail. This layer-wise transformation, while conceptually simple, creates computational patterns whose efficiency depends critically on how we organize these operations for different problem structures.
The dimensions of these operations reveal the computational scale of dense pattern processing. The input vector \(\mathbf{h}^{(0)} \in \mathbb{R}^{d_{\text{in}}}\) (treated as a row vector in this formulation) represents all potential input features. Weight matrices \(\mathbf{W}^{(\ell)} \in \mathbb{R}^{d_{\text{in}} \times d_{\text{out}}}\) capture all possible input-output relationships. The output vector \(\mathbf{h}^{(\ell)} \in \mathbb{R}^{d_{\text{out}}}\) produces transformed representations. A four-pixel example turns this bookkeeping into arithmetic.
Example 1.2: Concrete computation example
Consider a simplified 4-pixel image processed by a 3-neuron hidden layer:
Input: \(\mathbf{h}^{(0)} = [0.8, 0.2, 0.9, 0.1]\) (4 pixel intensities)
Weight matrix: \[ \mathbf{W}^{(1)} = \begin{bmatrix} 0.5 & 0.1 & -0.2 \\ -0.3 & 0.8 & 0.4 \\ 0.2 & -0.4 & 0.6 \\ 0.7 & 0.3 & -0.1 \end{bmatrix}\quad (4{\times}3 \text{ matrix}) \]
Computation: \[\begin{gather*} \mathbf{z}^{(1)} = \mathbf{h}^{(0)}\mathbf{W}^{(1)} = \begin{bmatrix} 0.5{\times}0.8 + (-0.3)\times 0.2 + 0.2{\times}0.9 + 0.7{\times}0.1 \\ 0.1{\times}0.8 + 0.8{\times}0.2 + (-0.4)\times 0.9 + 0.3{\times}0.1 \\ (-0.2)\times 0.8 + 0.4{\times}0.2 + 0.6{\times}0.9 + (-0.1)\times 0.1 \end{bmatrix} = \begin{bmatrix} 0.59 \\ -0.09 \\ 0.45 \end{bmatrix} \end{gather*}\] After ReLU: \(\mathbf{h}^{(1)} = [0.59, 0, 0.45]\) (negative values zeroed)
Systems insight: Each hidden neuron combines all input pixels with different weights, demonstrating unrestricted feature interaction. Dense layers buy generality by paying the maximum connectivity cost.
The MNIST example makes this scale concrete. The 784-dimensional input connects to every neuron in the first hidden layer. A hidden layer with 100 neurons requires a \(784{\times}100\) weight matrix (78,400 parameters), where each weight represents a learnable relationship between an input pixel and a hidden feature. This single layer anchors the computational analysis throughout this chapter.
This algorithmic structure enables arbitrary feature relationships while creating specific computational patterns that computer systems must accommodate. Dense connectivity provides the universal approximation capability established earlier but introduces computational redundancy: while the theoretical power of MLPs enables modeling of any continuous function given sufficient width, this flexibility requires numerous parameters to learn relatively simple patterns. Every input feature influences every output, yielding maximum expressiveness at the cost of maximum computational expense. These trade-offs motivate later compression strategies that reduce computational demands while preserving model capability, and Hardware Acceleration explores hardware-specific implementations that exploit regular matrix operation structure.
Computational mapping
The preceding algorithmic structure defines what an MLP computes; computational mapping reveals how that computation translates to hardware operations. Listing 1 demonstrates how this mapping progresses from mathematical abstraction to computational reality.
def mlp_layer_matrix(X, W, b):
"""MLP forward pass using framework-level matrix operations."""
# X: input matrix (batch_size by num_inputs)
# W: weight matrix (num_inputs by num_outputs)
# b: bias vector (num_outputs)
# Single GEMM call: frameworks dispatch to optimized BLAS/cuBLAS
# For MNIST: 784 * 100 = 78,400 MACs per sample
H = activation(matmul(X, W) + b)
return HThe function mlp_layer_matrix directly mirrors the mathematical equation, employing high-level matrix operations (matmul) to express the computation in a single line while abstracting the underlying complexity. This implementation style characterizes deep learning frameworks, where optimized libraries manage the actual computation.
To understand the system implications of this architecture, we must look “under the hood” of the high-level framework call. The elegant one-line matrix multiplication output = matmul(X, W) is, from the hardware’s perspective, a series of nested loops that expose the true computational demands on the system. This translation from logical model to physical execution reveals critical patterns that determine memory access, parallelization strategies, and hardware utilization.
The second implementation in listing 2 exposes the actual computational pattern through nested loops, revealing what really happens when we compute a layer’s output: we process each sample in the batch, computing each output neuron by accumulating weighted contributions from all inputs. This translation from mathematical abstraction to concrete computation exposes how dense matrix multiplication decomposes into nested loops of simpler operations. The outer loop processes each sample in the batch, while the middle loop computes values for each output neuron. Within the innermost loop, the system performs repeated multiply-accumulate operations7, combining each input with its corresponding weight.
7 Multiply-Accumulate (MAC): The atomic operation of neural networks: multiply two values and add to a running sum. Data center accelerators sustain \(10^{14}\)–\(10^{15}\) MAC/s on dense kernels, while mobile chips reach \(10^{12}\)–\(10^{13}\) MAC/s. The critical systems insight: a MAC itself costs ~1 pJ, but fetching its operands from off-chip DRAM costs ~200 pJ, a 200\(\times\) energy gap that makes data movement, not arithmetic, the dominant constraint in ML system design.
def mlp_layer_compute(X, W, b):
"""Explicit loop structure exposing MLP computational patterns."""
# Loop 1: Process each sample independently (parallelizable)
for batch in range(batch_size):
# Loop 2: Compute each output neuron
for out in range(num_outputs):
Z[batch, out] = b[out] # Initialize with bias
# Loop 3: Accumulate weighted inputs (innermost loop)
# This is the MAC operation: result += input * weight
for in_ in range(num_inputs):
Z[batch, out] += X[batch, in_] * W[in_, out]
# Total per output: num_inputs MACs +
# num_inputs memory reads
H = activation(Z) # Element-wise nonlinearity
return HIn our reference MNIST layer, each output neuron requires 78,400 MACs divided by 100, or 784, multiply-accumulate operations and at least 1,568 memory accesses (784 for inputs, 784 for weights). Production implementations call optimized matrix libraries such as Basic Linear Algebra Subprograms (BLAS)8, but the same nested-loop pattern still determines the system design problem. The hardware architectures that accelerate these matrix operations, including GPU Tensor Cores9 and specialized AI accelerators, are covered in Hardware Acceleration.
8 BLAS (Basic Linear Algebra Subprograms): This standard API for matrix operations enables the use of highly optimized libraries (for example, cuBLAS) to accelerate the 784 multiply-accumulates per neuron. These libraries are tuned for large, square matrices and hit an “efficiency cliff” with the \(784{\times}100\) matrix of the MNIST example. This nonstandard shape fails to saturate the hardware’s parallel compute units, yielding utilization far below the 80–95 percent of peak throughput achieved in larger transformer layers.
9 Tensor Cores: Specialized units in NVIDIA GPUs that accelerate the thousands of multiply-accumulate operations described by fusing them into single, highly parallelized matrix instructions. Tensor Cores are most efficient when matrix dimensions meet datatype- and architecture-specific alignment multiples; modern cuBLAS/cuDNN can still use Tensor Cores for many nonaligned cases, often with lower efficiency or internal padding. The architectural lesson is vendor-independent: specialized matrix units reward dense, aligned GEMMs and penalize small, irregular shapes that cannot keep the units full.
System implications
The preceding computational mapping showed how MLP operations decompose into nested loops of multiply-accumulate operations. The system-level constraints that emerge from these patterns span three dimensions: memory requirements, computation needs, and data movement.
For dense pattern processing, the memory, compute, and data-movement costs all come from the same source: all-to-all connectivity. Memory usage is dominated by parameter storage. Our reference MNIST layer \((784{\times}100)\) requires only 78,400 parameters, but this \(\mathcal{O}(M \times N)\) scaling becomes prohibitive for high-dimensional inputs. A typical 2048-unit layer connected to a 2048-unit layer requires 4194304 parameters (16.8 MB at FP32). Since every weight is used exactly once per input vector, there is no opportunity for weight reuse within a single sample processing, making the workload heavily dependent on memory capacity and bandwidth.
The core computation is dense matrix-vector multiplication (GEMV), or matrix-matrix multiplication (GEMM) when batched. This computation is regular and parallelizable, but the arithmetic intensity (FLOP/byte) is low for small batch sizes (the batch size is the number of input samples processed together in one forward pass; larger batches amortize weight-loading cost over more computations). Modern processors optimize dense layers through specialized SIMD (Single Instruction, Multiple Data) units (for example, AVX-512 on CPUs) or systolic arrays (on Tensor Processing Units (TPUs)/GPUs) that amortize control overhead over massive blocks of parallel arithmetic.
The resulting bottleneck is data movement. To compute 100 hidden values from 784 inputs, the system must move \(784{\times}100\) weights from memory to the compute units. Applying the arithmetic intensity framework from section 1.1.2 to this layer yields roughly 0.5 FLOP/byte (assuming FP32) if batch size is one, as shown in equation 2: \[ \text{Intensity} \approx \frac{2 \cdot M \cdot N \text{ FLOPs}}{4 \cdot M \cdot N \text{ bytes}} = 0.5 \text{ FLOP/byte} \tag{2}\]
Since modern accelerators often require arithmetic intensities in the hundreds of FLOP/byte to saturate low-precision matrix units, dense layers are almost always memory bandwidth bound unless batch sizes exceed several hundred. This explains why “fully connected” layers are often the performance bottleneck in inference workloads, despite performing fewer total FLOPs than convolutional layers.

Weight sharing spares convolution the fully-connected parameter explosion.
Dense connectivity thus moves maximum data for minimum compute. For data with inherent structure, spatial locality in images or temporal order in sequences, specialized architectures can exploit that structure for both better accuracy and better efficiency. The most established such architecture is the convolutional neural network.
Self-Check: Question
A 2,048-unit dense layer connected to another 2,048-unit layer stores roughly 4.2 million weights, consuming about 16 MB in FP32 — and every weight is used exactly once per input sample. A team considering this layer as the front end of an image classifier asks why CNN-based classifiers typically use thousands of times fewer parameters for the same task. Which statement best captures the systems consequence of the MLP’s architectural assumption?
- The MLP treats every input feature as potentially relevant to every output feature, so it pays \(\mathcal{O}(M \times N)\) memory and \(\mathcal{O}(M \times N)\) bytes-moved per sample regardless of whether any spatial structure exists in the data.
- The MLP’s activation function is more expensive than a convolution, which is why its total memory footprint is higher.
- The MLP uses a fundamentally different optimizer that requires more state per parameter than a CNN’s optimizer.
- The MLP’s bias vector grows quadratically with input dimension, which dominates the parameter count.
A team cites the Universal Approximation Theorem to argue that a sufficiently wide MLP could solve any image classification task. They plan to train a 3-layer MLP on 224-by-224 ImageNet images. Explain why UAT does not justify this plan and what the practical learnability gap looks like in both statistical and systems terms.
A 2,048-to-2,048 dense layer processing a single FP32 input sample reports roughly 0.5 FLOP/byte on an A100, and the kernel runs at 4 percent of the advertised Tensor Core peak. Which optimization path is most directly aligned with the section’s analysis of this regime?
- Increase the batch size so weights are reused across many samples, raising arithmetic intensity above the ridge point and letting the Tensor Cores stay fed.
- Upgrade to an accelerator with 2\(\times\) the advertised TFLOP/s while keeping batch size 1, because the workload is compute-bound.
- Replace the matrix multiply with an element-wise activation to reduce total FLOPs to near zero.
- Disable the BLAS library and route the computation through a scalar Python loop to improve cache locality.
Order the following steps in a dense layer’s forward pass for one output neuron: (1) apply the activation function to the accumulated pre-activation, (2) initialize the output neuron with its bias value, (3) accumulate input-times-weight products across all input features.
A team ports an MNIST-style 784-by-100 dense layer to an A100 and measures throughput far below the advertised FP16 Tensor Core peak. The layer is small and has awkward dimensions for Tensor Core tiling. Which explanation is most consistent with the section’s discussion of Tensor Core alignment?
- Tensor Core peak assumes hardware-friendly tile shapes and enough work to amortize overhead; awkward small matrices may need padding or less efficient kernels, so their realized throughput can be far below peak.
- Small dense layers are never executed on GPUs and are silently dispatched to the CPU by the runtime.
- The activation function on a 100-dimensional output vector is the dominant cost and hides the GEMM’s throughput.
- The 784-by-100 layer has excessive arithmetic intensity that saturates memory and leaves compute units idle.
True or False: Because MLPs are universal approximators, they are the most practical architecture for any high-dimensional structured input such as a 224-by-224 image.
CNNs: Spatial Pattern Processing
The MLP’s assumption that all input features interact equally with all outputs proves particularly costly for spatially structured data like images. As the earlier MNIST comparison demonstrated, a CNN achieves higher accuracy with 47× fewer parameters by exploiting spatial locality rather than treating every pixel independently.
Convolutional neural networks (CNNs)10 emerged as the solution to this challenge (LeCun et al. 1998; Krizhevsky et al. 2012). Consider what happens when viewing a photograph: the visual system does not perceive every pixel simultaneously in relation to every other pixel. Instead, it detects local patterns (edges, textures, corners) and composes them into objects. CNNs encode this same insight architecturally.
10 Convolution: From Latin convolvere (“to roll together”), describing a filter that slides across an input, combining local elements at each position. This “rolling together” enforces a locality constraint that is the source of the operation’s efficiency: a single \(5{\times}5\) kernel reuses its 25 weights at every spatial position, reducing one feature detector for a 1-megapixel single-channel image from roughly 1,000,000 weights to 25, about 40,000\(\times\) fewer parameters than a fully connected detector.
Spatial locality produces two key innovations that enhance efficiency for spatially structured data. Parameter sharing allows the same feature detector to be applied across different spatial positions, reducing parameters from millions to thousands while improving generalization. Local connectivity restricts connections to spatially adjacent regions, reflecting the insight that spatial proximity correlates with feature relevance. Together, these innovations define convolutional neural networks as an architectural family.
Definition 1.3: Convolutional neural networks
Convolutional Neural Networks (CNNs) are architectures that exploit translation equivariance and spatial locality to share learned filters across all spatial positions, decoupling parameter count from input resolution.
- Significance: Weight sharing produces dramatic parameter reduction. A \(3{\times}3\) convolutional layer with 64 input and 64 output channels requires \(3 \times 3 \times 64 \times 64 \approx 37{,}000\) parameters regardless of whether the input image is \(224{\times}224\) or \(1024{\times}1024\). An equivalent fully connected layer on a \(224{\times}224{\times}64\) input would require \(224^2 \times 64 \times 64 \approx 205\) million parameters, a roughly 5,500\(\times\) difference. This constant-parameter scaling enables CNNs to process high-resolution inputs within the memory budget of a single accelerator.
- Distinction: Unlike MLPs, which connect every input element to every output element (global connectivity), CNNs restrict each output to a local spatial neighborhood, encoding the assumption that nearby pixels are more relevant than distant ones. This restriction eliminates entire hypothesis classes at architecture design time rather than penalizing them during training.
- Common pitfall: A frequent misconception is that CNNs are vision-only models. The convolution operation applies to any data with a grid-like topology: 1D convolutions process audio waveforms and time series, 2D convolutions process images and spectrograms, and 3D convolutions process video and volumetric data.
The trade-off is explicit: CNNs sacrifice the theoretical generality of MLPs for practical efficiency gains when data exhibits known structure. Where MLPs treat each input element independently, CNNs exploit spatial relationships to achieve both computational savings and improved accuracy on vision tasks.
Pattern processing needs
Spatial pattern processing addresses scenarios where the relationship between data points depends on their relative positions or proximity. Consider processing a natural image: a pixel’s relationship with its neighbors is important for detecting edges, textures, and shapes. These local patterns then combine hierarchically to form more complex features: edges form shapes, shapes form objects, and objects form scenes. The pipeline in figure 3 gives this hierarchy a concrete visual form.

This hierarchical processing appears across many domains: local pixel patterns forming edges that combine into objects (computer vision), nearby time-segment correlations identifying phonemes (speech), proximate sensor correlations (sensor networks), and tissue pattern recognition (medical imaging). The approach succeeds not because it mimics the brain, but because it mirrors the compositional structure of the data itself.
Focusing on image processing to illustrate these principles, if we want to detect a cat in an image, certain spatial patterns must be recognized: the triangular shape of ears, the round contours of the face, the texture of fur. These patterns maintain their meaning regardless of where they appear in the image. A cat is still a cat whether it appears in the top-left or bottom-right corner. This indicates two key requirements for spatial pattern processing: the ability to detect local patterns and the ability to recognize these patterns regardless of their position11. As figure 3 illustrates, convolutional neural networks meet both requirements through hierarchical feature extraction, where simple patterns compose into increasingly complex representations at successive layers. CNNs put these spatial processing principles into practice through parameter sharing, local connectivity, and translation equivariance12, the key innovations pioneered by Yann LeCun13 and LeCun et al. (1989).
11 ImageNet: The dataset that validated these two spatial processing requirements at scale. AlexNet’s 2012 victory in the ImageNet Large Scale Visual Recognition Challenge (ILSVRC) reduced top-5 error from 26.2 percent to 15.3 percent on the 1000-class ImageNet challenge with roughly 1.2 million training images; the broader ImageNet database contained more than 14 million images across over 20,000 synsets. The enduring systems lesson: every subsequent accuracy gain (VGG, ResNet, vision transformer (ViT)) required proportionally larger datasets and compute budgets, establishing the scaling relationship between architectural inductive bias and infrastructure cost.
12 Translation Equivariance: An inherent property of the convolution operation where shifting the input guarantees a corresponding spatial shift in the resulting feature map. This is distinct from true invariance, which is forced by a subsequent pooling layer that intentionally discards this precise positional data. The system design choice is stark: preserve equivariant data for segmentation or discard it via pooling, reducing downstream feature map size by 75 percent for classification.
13 Yann LeCun and LeNet: LeCun’s architecture directly addressed the intractable scaling of applying dense networks to images by enforcing the principles of local connectivity and parameter sharing. These constraints reduced the parameter count for an image-like input layer by over 95 percent, enabling LeNet-5 to achieve production-grade accuracy on commercial tasks like check reading with only ~60,000 total parameters.
LeCun, Yann, Bernhard Boser, John S. Denker, Donald Henderson, Richard E. Howard, Wayne Hubbard, and Lawrence D. Jackel. 1989. “Backpropagation Applied to Handwritten Zip Code Recognition.” Neural Computation 1 (4): 541–51. https://doi.org/10.1162/neco.1989.1.4.541.
Algorithmic structure
The core operation in a CNN can be expressed mathematically as equation 3: \[ \mathbf{H}^{(\ell)}_{i,j,k} = f\left(\sum_{m}\sum_{n}\sum_{c} \mathbf{W}^{(\ell)}_{m,n,c,k}\mathbf{H}^{(\ell-1)}_{i+m,j+n,c} + \mathbf{b}^{(\ell)}_k\right) \tag{3}\]
This equation describes how CNNs process spatial data. \(\mathbf{H}^{(\ell)}_{i,j,k}\) is the output at spatial position \((i,j)\) in channel \(k\) of layer \(\ell\). The triple sum iterates over the filter dimensions: \((m,n)\) scans the spatial filter size, and \(c\) covers input channels. \(\mathbf{W}^{(\ell)}_{m,n,c,k}\) represents the filter weights, capturing local spatial patterns. Unlike MLPs that connect all inputs to outputs, CNNs only connect local spatial neighborhoods.
Breaking down the notation further, \((i,j)\) corresponds to spatial positions, \(k\) indexes output channels, \(c\) indexes input channels, and \((m,n)\) spans the local receptive field14. Unlike the dense matrix multiplication of MLPs, this operation applies the same filter weights at each spatial position.
14 Receptive Field: The input region influencing a particular output neuron. With \(3{\times}3\) filters, receptive fields grow by 2 pixels per layer, so a neuron at layer 3 “sees” a \(7{\times}7\) region. This growth rate constrains architecture depth: detecting objects spanning 100+ pixels in a \(224{\times}224\) image requires either deep stacks of small filters (more layers, more memory for activations) or larger kernels (more parameters per layer), a fundamental depth-vs.-width trade-off in CNN design.
Wang, Zijie J., Robert Turko, Omar Shaikh, Haekyu Park, Nilaksh Das, Fred Hohman, Minsuk Kahng, and Duen Horng Polo Chau. 2021. “CNN Explainer: Learning Convolutional Neural Networks with Interactive Visualization.” IEEE Transactions on Visualization and Computer Graphics 27 (2): 1396–406. https://doi.org/10.1109/tvcg.2020.3030418.
Convolutional layers process local neighborhoods (typically \(3{\times}3\) or \(5{\times}5\)), reuse the same weights at each spatial position, and maintain spatial structure in the output. Study the mechanics in figure 4: a small filter slides over the input image, computing a dot product at each position to generate a feature map. This sliding window captures local structures while maintaining translation equivariance—the same filter detects the same pattern regardless of where it appears. For an interactive visual exploration of convolutional networks, the CNN Explainer (Wang et al. 2021) project provides an insightful demonstration of how these networks are constructed.

To illustrate, consider applying a CNN to the same MNIST images used in our MLP analysis. Each convolutional layer applies a set of filters (for example, \(3{\times}3\)) that slide across the \(28{\times}28\) input, computing local weighted sums. With 32 filters and padding to preserve dimensions, the layer produces a \(28{\times}28{\times}32\) output, where each spatial position contains 32 different feature measurements of its local neighborhood. This contrasts sharply with the MLP approach, where the entire image is flattened into a single vector before processing.
This algorithmic structure directly implements the requirements for spatial pattern processing, creating distinct computational patterns that influence system design. Unlike MLPs, convolutional networks preserve spatial locality, using the hierarchical feature extraction principles established earlier. These properties drive architectural optimizations in AI accelerators, where operations such as data reuse, tiling, and parallel filter computation are important for performance.
The property of translation equivariance is central to understanding why CNNs work effectively for spatial data: shifting the input shifts the output feature map correspondingly. We examine this property in four stages: the equivariance-invariance distinction, the mathematical formulation, the group theory generalization, and the systems implications for deployment.
Equivariance and invariance are related but distinct concepts that determine how architectures handle transformations. Equivariance means that transforming the input produces the same transformation in the output, as defined in equation 4: \[ f(\mathcal{T}(\mathbf{x})) = \mathcal{T}(f(\mathbf{x})) \tag{4}\]
For CNNs with translation \(\mathcal{T}_v\) (shift by vector \(v\)), under stride-1 convolution away from boundary effects (and before any pooling or strided downsampling), if the input shifts by five pixels right, the feature maps also shift by five pixels right. Position information is preserved through the transformation. Invariance, by contrast, means transforming the input does not change the output, as defined in equation 5: \[ f(\mathcal{T}(\mathbf{x})) = f(\mathbf{x}) \tag{5}\]
Global average pooling over an entire feature map exhibits translation invariance: shifting the input does not change the averaged output. Position information is discarded.
Equivariance matters for learning because it preserves information needed for structured representations. Consider spatial relationships: a feature detector responding to an eye at position \((x, y)\) will respond to the same eye at position \((x+5, y)\), but the response moves to reflect the new position. The network can learn spatial relationships like “eye above nose” that matter for face detection. Full invariance would lose this relational information, leaving only “eye and nose both present somewhere,” which proves insufficient for many tasks.
Object detection illustrates why equivariance is essential for localization. Detection outputs bounding boxes like “car at \((100, 200)\) with size \(50{\times}80\)”, requiring equivariant layers to track position through the network while invariant final layers determine class. This architectural choice matches task structure: equivariance for localization, invariance for classification.
Equivariance also supports hierarchical composition. Early layers detect edges equivariantly at all positions, middle layers combine edges into shapes while maintaining equivariance, and final layers may use partial invariance through pooling for classification. This hierarchy works precisely because intermediate features maintain spatial structure for composition.
These intuitions can be made formal. For a convolutional layer with filter \(\mathbf{w}\) and input \(\mathbf{x}\), the convolution is \[ (f * \mathbf{w})[i, j] = \sum_{m,n} \mathbf{w}[m, n] \cdot \mathbf{x}[i + m, j + n]. \] Applying translation \(\mathcal{T}_v\) (shift by \(v = (v_1, v_2)\)) to the input gives \((\mathcal{T}_v \mathbf{x})[i, j] = \mathbf{x}[i - v_1, j - v_2]\). Substituting into the convolution and re-indexing yields \[ (f * \mathbf{w})[\mathcal{T}_v \mathbf{x}][i, j] = (f * \mathbf{w})[\mathbf{x}][i - v_1, j - v_2] = \mathcal{T}_v((f * \mathbf{w})[\mathbf{x}])[i, j], \] which proves translation equivariance: \(f(\mathcal{T}_v \mathbf{x}) = \mathcal{T}_v(f(\mathbf{x}))\).
In practice, the contrast is stark: an equivariant convolutional layer tracks a shifted feature to its new position, preserving the spatial relationships (“whiskers near mouth,” “ears above eyes”) that recognition depends on, while an invariant global pooling layer returns the same scalar wherever the feature appears, discarding position entirely. The worked example that follows traces this tracking through actual matrices.
Example 1.3: Equivariance: Feature detection
Setup: Consider a \(7{\times}7\) image with a vertical edge at column 3: \[ \mathbf{x} = \begin{bmatrix} 0 & 0 & 1 & 0 & 0 & 0 & 0 \\ 0 & 0 & 1 & 0 & 0 & 0 & 0 \\ 0 & 0 & 1 & 0 & 0 & 0 & 0 \\ 0 & 0 & 1 & 0 & 0 & 0 & 0 \\ 0 & 0 & 1 & 0 & 0 & 0 & 0 \\ 0 & 0 & 1 & 0 & 0 & 0 & 0 \\ 0 & 0 & 1 & 0 & 0 & 0 & 0 \end{bmatrix} \]
Vertical edge detector filter: \[ \mathbf{w} = \begin{bmatrix} -1 & 0 & 1 \\ -1 & 0 & 1 \\ -1 & 0 & 1 \end{bmatrix} \]
Convolving original image:
Output feature map shows positive activation where the filter transitions from dark to bright (left side of edge) and negative activation where it transitions from bright to dark (right side): \[ f(\mathbf{x}) = \begin{bmatrix} 3 & 0 & -3 & 0 & 0 \\ 3 & 0 & -3 & 0 & 0 \\ 3 & 0 & -3 & 0 & 0 \\ 3 & 0 & -3 & 0 & 0 \\ 3 & 0 & -3 & 0 & 0 \end{bmatrix} \]
Shifted input (edge moved to column 5): \[ \mathcal{T}_2 \mathbf{x} = \begin{bmatrix} 0 & 0 & 0 & 0 & 1 & 0 & 0 \\ 0 & 0 & 0 & 0 & 1 & 0 & 0 \\ 0 & 0 & 0 & 0 & 1 & 0 & 0 \\ 0 & 0 & 0 & 0 & 1 & 0 & 0 \\ 0 & 0 & 0 & 0 & 1 & 0 & 0 \\ 0 & 0 & 0 & 0 & 1 & 0 & 0 \\ 0 & 0 & 0 & 0 & 1 & 0 & 0 \end{bmatrix} \]
Convolving shifted image: \[ f(\mathcal{T}_2 \mathbf{x}) = \begin{bmatrix} 0 & 0 & 3 & 0 & -3 \\ 0 & 0 & 3 & 0 & -3 \\ 0 & 0 & 3 & 0 & -3 \\ 0 & 0 & 3 & 0 & -3 \\ 0 & 0 & 3 & 0 & -3 \end{bmatrix} = \mathcal{T}_2(f(\mathbf{x})) \]
Systems insight: The feature activation shifts by the same amount as the input, demonstrating equivariance. The network knows the edge is at column 5 in the shifted image, not just that an edge exists somewhere.
Equivariance carries systems implications that extend beyond mathematical elegance. Parameter efficiency is the most immediate benefit: equivariance through parameter sharing produces dramatic reductions in model size. Consider processing a 224 by 224 RGB image. An MLP would require each hidden neuron to connect to all 150,528 input pixels input values. A CNN with a 3 by 3 filter needs only 27 parameters parameters per filter, reused across all 224 by 224 positions. This represents approximately 5,575.1× fewer parameters per feature detector, and the memory savings enable larger models and bigger batches on fixed hardware.
The computational structure created by equivariance proves equally valuable for systems optimization. The sliding window pattern applies the same operation at every spatial position, creating regular computation that hardware can exploit. Input pixels are used by multiple filter positions, enabling im2col optimizations that restructure data for efficient matrix operations. The resulting computation is inherently SIMD-friendly, as modern GPUs can execute identical instructions across spatial positions simultaneously. This structural regularity explains why TPUs and AI accelerators include specialized units for convolution: the operation maps efficiently to silicon precisely because equivariance creates predictable, parallelizable patterns.
Equivariance also improves sample efficiency in ways that benefit the entire training pipeline. When a network learns an edge detector at one position, equivariance ensures that same detector works at all positions automatically. Training no longer requires examples with edges at every possible location, providing a form of built-in data augmentation. The systems benefits cascade: less training data means reduced storage requirements, faster training, and lower bandwidth consumption during data loading.
Theorem 1.1: Group equivariance formulation
From a group theory perspective, convolution’s equivariance to translations represents one instance of a general principle. The translation group \((\mathbb{R}^2, +)\) consists of all 2D translations, closed under composition (translating by \(v\) then \(u\) equals translating by \(v + u\)). Convolution is equivariant to this group. Recent research extends this framework to other symmetry groups. Cohen and Welling (2016) developed Group-Equivariant CNNs that handle rotations and reflections by constructing filters equivariant to rotation groups. This allows learning rotation-invariant features for tasks like satellite imagery or medical imaging where orientation does not determine meaning.
The mathematical framework generalizes cleanly: for group \(G\) acting on input space \(X\) and output space \(Y\), a function \(f: X \to Y\) is \(G\)-equivariant if: \[ f(g \cdot \mathbf{x}) = g \cdot f(\mathbf{x}) \quad \forall g \in G, \mathbf{x} \in X \]
Standard CNNs are translation-equivariant, while rotation-equivariant networks extend this to rotation groups. The architectural principle generalizes: data symmetries should be embedded as equivariances in the architecture. For systems engineering, identifying data symmetries directly informs architecture choice: more constrained architectures with stronger symmetries often produce smaller models, and specialized equivariances may require custom operations like rotation convolutions that need either hardware support or efficient software implementations.
Cohen, Taco, and Max Welling. 2016. “Group Equivariant Convolutional Networks.” Proceedings of the 33rd International Conference on Machine Learning (ICML) 48: 2990–99.
In practice, perfect equivariance is often sacrificed for computational efficiency or training stability. Asymmetric padding at image boundaries breaks perfect translation equivariance, as does strided downsampling, which introduces quantization where a one-pixel shift in input produces a noninteger shift in output. Batch normalization, a later normalization layer that stabilizes activations using batch statistics, also breaks equivariance when those statistics are computed per position in some implementations. Modern networks accept these deviations as necessary trade-offs, and the slight loss of theoretical purity rarely impacts practical performance.
Checkpoint 1.2: Spatial inductive bias
CNNs succeed because they match the structure of image data. Verify you understand how:
Different tasks impose different requirements on where equivariance should be maintained vs. where invariance should be introduced. Image classification needs only the final class label to be invariant; intermediate layers benefit from staying equivariant to preserve spatial information for hierarchical feature learning. Object detection requires equivariance throughout the network because bounding box coordinates must track object positions. Semantic segmentation demands full equivariance to the output layer since per-pixel labels must align with input positions. Image generation similarly requires equivariance to maintain spatial structure in the output. The architectural decision of where to introduce invariance through pooling or global averaging vs. maintaining equivariance reflects these task requirements and directly shapes network design.
The preceding task-specific requirements illustrate the inductive bias principle defined in section 1.1: by restricting connectivity to local neighborhoods and sharing parameters across spatial positions, CNNs encode prior knowledge about the structure of visual data—that important features are local and translation-invariant. This architectural constraint reduces the hypothesis space that the network must search, enabling more efficient learning from limited data compared to fully connected networks.
CNNs naturally implement hierarchical representation learning (Bengio et al. 2013) through their layered structure. Early layers detect low-level features like edges and textures with small receptive fields, while deeper layers combine these into increasingly complex patterns with larger receptive fields. This hierarchical organization enables CNNs to build compositional representations: complex objects are represented as compositions of simpler parts. The mathematical foundation for this emerges from stacking convolutional layers, which creates a tree-like dependency structure where each deeper neuron depends on a progressively larger input region; with fixed small kernels, receptive-field side length grows roughly linearly with depth and receptive-field area grows roughly quadratically until it covers the image.
Bengio, Yoshua, Aaron Courville, and Pascal Vincent. 2013. “Representation Learning: A Review and New Perspectives.” IEEE Transactions on Pattern Analysis and Machine Intelligence 35 (8): 1798–828. https://doi.org/10.1109/tpami.2013.50.
The parameter sharing introduced earlier dramatically reduces complexity compared to MLPs. This sharing embodies the assumption that useful features can appear anywhere in an image, making the same feature detector valuable across all spatial positions.
Computational mapping
How much of this architectural efficiency survives in practice depends on how convolution’s sliding-window computation maps onto hardware. Convolution operations create computational patterns distinct from MLP dense matrix multiplication. While high-level frameworks abstract this as a sliding window, the underlying hardware implementation typically transforms the problem to exploit highly optimized matrix multiplication units.
The most common transformation is im2col (image-to-column), which rearranges the input image patches into columns of a large matrix, allowing the convolution to be executed as a single General Matrix Multiplication (GEMM). The computational-primitives discussion uses this transformation to connect CNN structure to matrix hardware.
The bridge between the logical model and physical execution becomes critical for understanding CNN system requirements. While listing 3 shows the framework-level abstraction as a simple function call, the hardware must orchestrate complex data movement patterns and exploit spatial locality for efficiency.
def conv_layer_spatial(input, kernel, bias):
"""Framework-level convolution.
Single call dispatches to optimized kernel (often via im2col + GEMM).
"""
# Convolution applies shared weights across all positions
# For a 3x3 kernel on 28x28 input (padded):
# 9 MACs per position x 784 positions
output = convolution(input, kernel) + bias
return activation(output)Listing 4 reveals the logical computational pattern: seven nested loops that process each spatial position. While functionally correct, this naive implementation is rarely used in practice due to poor memory locality. Instead, the im2col approach trades memory (duplicating overlapping input pixels) for computational regularity, converting the messy nested loops into a streamlined matrix multiplication that saturates hardware FP units.
The seven nested loops reveal different aspects of the computation. The loop structure divides into three groups: the outer loops manage position, determining which image and where in the image; the middle loop handles output features, computing different learned patterns; and the inner loops perform the actual convolution, sliding the kernel window across the input.
Examining this process in detail, the outer two loops (for y and for x) traverse each spatial position in the output feature map. At each position, values are computed for each output channel (for out_channel loop), representing different learned features or patterns: the 32 different feature detectors.
The inner 3 loops implement the actual convolution operation at each position. For each output value, we process a local \(3{\times}3\) region of the input (the ky and kx loops) across all input channels (for in_channel loop). This creates a sliding window effect, where the same \(3{\times}3\) filter moves across the image, performing multiply-accumulates between the filter weights and the local input values. Unlike the MLP’s global connectivity, this local processing pattern means each output value depends only on a small neighborhood of the input.
def conv_layer_compute(input, kernel, bias):
# Logical view of convolution (usually implemented via im2col +
# GEMM)
# Loop 1: Process each image in batch
for image in range(batch_size):
# Loop 2&3: Move across image spatially
for y in range(height):
for x in range(width):
# Loop 4: Compute each output feature
for out_channel in range(num_output_channels):
result = bias[out_channel]
# Loop 5&6: Move across kernel window
for ky in range(kernel_height):
for kx in range(kernel_width):
# Loop 7: Process each input feature
for in_channel in range(num_input_channels):
# ... MAC operations ...With \(3{\times}3\) filters and 32 output channels, each output position requires only nine multiply-accumulate operations per input channel, compared to 784 in the reference MLP layer. This operation repeats for every spatial position and every output channel.
While using fewer operations per output, the spatial structure creates different patterns of memory access and computation that systems must handle. These patterns influence system design, creating both challenges and opportunities for optimization. Understanding these system-level implications reveals why CNNs dominate computer vision despite their apparent simplicity.
System implications
The sliding window and im2col transformations described earlier reveal how CNNs compute; the system implications that follow reveal what that computation costs in memory, compute, and data movement.
Memory requirements
For convolutional layers, memory requirements center around two key components: filter weights and feature maps. Unlike MLPs that require storing full connection matrices, CNNs use small, reusable filters. For a typical CNN processing 224 by 224 ImageNet images, a convolutional layer with 64 filters of size 3 by 3 applied to a single input channel requires storing only 576 weight parameters; for multiple input channels, the same kernel and channel product remains dramatically smaller than the millions of weights needed for equivalent fully connected processing. The system must store feature maps for all spatial positions, creating a different memory demand. A 224 by 224 input with 64 output channels requires storing 3.2M activation values.
These memory access patterns suggest opportunities for optimization through weight reuse and careful feature map management. Processors optimize these spatial patterns by caching filter weights for reuse across positions while streaming feature map data. CPUs use their cache hierarchy to keep frequently used filters resident, while GPUs employ specialized memory architectures designed for the spatial access patterns of image processing. The detailed architecture design principles for these specialized processors are covered in Hardware Acceleration.
Computation needs
The core computation in CNNs involves repeatedly applying small filters across spatial positions. Each output value requires a local multiply-accumulate operation over the filter region. For ImageNet processing with 3 by 3 filters and 64 output channels, computing one spatial position involves 576 multiply-accumulates per input channel, and this must be repeated for all 50,176 spatial positions. While each individual computation involves fewer operations than an MLP layer, the total computational load remains large due to spatial repetition.
This computational pattern presents different optimization opportunities than MLPs. The regular, repeated nature of convolution operations enables efficient hardware utilization through structured parallelism. Modern processors exploit this pattern in various ways. CPUs use SIMD instructions15 to process multiple filter positions simultaneously, while GPUs parallelize computation across spatial positions and channels. The model optimization techniques that further reduce these computational demands, including specialized convolution optimizations and sparsity patterns, are detailed in Model Compression.
15 SIMD (Single Instruction, Multiple Data): CPU instructions that apply the same operation to multiple data elements simultaneously. AVX-512 processes 16 single-precision values per instruction, a 16\(\times\) speedup over scalar code. For CNN inference on edge CPUs without GPU access, SIMD utilization determines whether a model meets real-time latency targets. Frameworks like TFLite and Open Neural Network Exchange (ONNX) Runtime auto-vectorize convolution loops to exploit this, making SIMD width a first-order constraint in edge deployment planning.
Data movement
The sliding window pattern of convolutions creates a distinctive data movement profile. Unlike MLPs where each weight is used once per forward pass, CNN filter weights are reused many times as the filter slides across spatial positions. For ImageNet processing, each 3 by 3 filter weight is reused 50,176 times, once for each position in the 224 by 224 feature map. This creates a different challenge: the system must stream input features through the computation unit while keeping filter weights stable.
The predictable spatial access pattern enables strategic data movement optimizations. The CPU/GPU caching strategies described earlier apply directly to data movement: frameworks orchestrate computation to maximize 50,176 uses of each filter weight and minimize redundant feature map accesses, exploiting the same spatial locality that makes CNNs memory-efficient.
These memory, compute, and data-movement patterns converge in one model that serves as the chapter’s reference point for compute-bound vision workloads: the ResNet-50 architecture.
Lighthouse 1.2: ResNet-50 (vision lighthouse)
Why it matters: ResNet-50 is a reference point for regular, convolution-heavy vision workloads. Its architecture consists almost entirely of dense convolutional layers, making it highly regular and efficient on GPUs. Under batched execution with good data reuse, ResNet-50 performance is typically limited by floating-point throughput (FLOP/s), making it a useful lighthouse for explaining data parallelism, quantization, and batching strategies. Table 4 summarizes the quantitative properties and their system consequences:
| Property | Value | System Implication |
|---|---|---|
| Parameters | 25.6M | 102.4 MB model size at FP32; fits comfortably in GPU memory. |
| FLOPs/Image | 4.1 GFLOP \((224{\times}224)\) | \(3{\times}3\) convolutions are the largest single kernel class at roughly 48% of MACs. |
| Constraint | Compute-heavy when batched | Limited by peak FLOP/s when weight and activation reuse are high; small-batch inference can move toward the memory-bound regime. |
| Bottleneck | FP Throughput | Benefits maximally from specialized Matrix Units (Tensor Cores). |
| Profile | High effective arithmetic intensity under reuse | Arithmetic intensity depends on batch size, convolution algorithm, and materialized memory traffic. |
ResNet-50’s compute-bound profile assumes abundant hardware resources, yet most inference runs on devices with power budgets three orders of magnitude smaller than a data center GPU. MobileNetV2 demonstrates that architectural innovation can target this regime, achieving competitive accuracy with a fraction of the computational cost.
The ResNet-50 and MobileNetV2 profiles create a natural expectation: a model with 13.7× fewer FLOPs should execute proportionally faster. On mobile CPUs, where compute and memory bandwidth are roughly balanced, that expectation holds. On data center GPUs, where peak FLOP/s outpaces memory bandwidth by 10–20\(\times\), the relationship inverts: MobileNetV2’s low arithmetic intensity starves the hardware of useful work, and kernel launch overhead dominates the execution timeline.
Lighthouse 1.3: MobileNetV2 (efficiency lighthouse)
Why it matters: MobileNetV2 represents latency-constrained edge workloads. Its depthwise separable convolutions trade channel mixing capacity for speed, making it a useful baseline for mobile apps, embedded vision, and neural architecture search (NAS), automated search over model designs. Table 5 summarizes the efficiency lighthouse’s quantitative properties:
| Property | Value | System Implication |
|---|---|---|
| Parameters | 3.5M | 14 MB at FP32; 7.3× smaller than ResNet-50. |
| FLOPs/Image | 300 MFLOP | 13.7× fewer than ResNet-50 for similar accuracy. |
| Constraint | Latency Bound | Single-image inference speed is the priority. |
| Bottleneck | Overhead/Serial Ops | Kernel launch overhead often dominates actual compute. |
| Profile | Low Arithmetic Intensity | Memory access and control logic matter more than peak FLOP/s. |
With the hardware-mapping caveat in mind, the architectural efficiency of CNNs allows further optimization through specialized techniques like depthwise separable convolutions and pruning [removing low-value weights or channels], detailed in Model Compression. These optimization strategies build on spatial locality principles, with Hardware Acceleration detailing how modern processors exploit convolution’s inherent data reuse patterns.
Systems Perspective 1.1: Misconception: FLOPs equal speed
Fallacy: “MobileNetV2 has 13.7× fewer FLOPs than ResNet-50, so it must run 13.7× faster.”
Resolution: On high-end GPUs, MobileNetV2 often runs slower than ResNet-50 despite using far fewer operations. MobileNetV2’s depthwise separable convolutions have low arithmetic intensity: they move more data relative to computation. GPUs optimized for dense matrix operations (high arithmetic intensity) cannot saturate their compute units on MobileNetV2’s memory-bound kernels. FLOPs measure work; throughput depends on how well that work maps to hardware. This is why MobileNetV2 excels on mobile CPUs (where memory bandwidth matches compute) but underperforms on data center GPUs (where compute far exceeds bandwidth). We revisit this hardware-architecture mismatch as a general fallacy in section 1.11.
Efficient architectures: Keyword spotting
The system implications mentioned earlier assume standard CNN architectures with full convolutions. However, standard convolutions scale as \(\mathcal{O}(N \times K^2 \times C_{\text{in}} \times C_{\text{out}})\), a cost often prohibitive for the always-on edge devices introduced with our KWS Lighthouse. To bridge this gap, efficient architectures like Depthwise Separable CNNs (DS-CNN) decompose the standard convolution into two cheaper operations. This factorization, introduced by Sifre in the context of feature extraction (Sifre and Mallat 2014) and popularized by MobileNet (Howard et al. 2017), reduces cost by separating spatial and channel-wise computation. The depthwise convolution applies filters to each input channel independently (\(K \times K \times C_{\text{in}}\) parameters), and the pointwise convolution uses a \(1{\times}1\) convolution to project channels to the output dimension (\(1 \times 1 \times C_{\text{in}} \times C_{\text{out}}\) parameters).
Sifre, Laurent, and Stéphane Mallat. 2014. “Rigid-Motion Scattering for Image Classification.” arXiv Preprint arXiv:1403.1687, ahead of print. https://doi.org/10.48550/arXiv.1403.1687.
Howard, A. G., M. Zhu, B. Chen, D. Kalenichenko, W. Wang, T. Weyand, M. Andreetto, and H. Adam. 2017. “MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications.” CoRR abs/1704.04861.
This decomposition reduces parameter count and FLOPs by a factor of roughly \(1/C_{\text{out}} + 1/K^2\) (approximately \(1/K^2\) for large \(C_{\text{out}}\)), making real-time audio processing feasible on tiny hardware. KWS thus serves as the chapter’s TinyML lighthouse, illustrating power-constrained design at its most extreme.
Lighthouse 1.4: KWS (TinyML lighthouse)
Why it matters: Keyword Spotting models (like DS-CNN) represent the power-constrained end of the spectrum. Used in always-on applications like smart doorbells that wake a larger vision pipeline only after an audio trigger, these models must run on microcontrollers with milliwatt power budgets.
KWS forces engineers to count every byte and cycle. It is the lighthouse for extreme quantization (INT8/INT4, detailed in Model Compression) and specialized architectural primitives (Depthwise Separable Convolutions) that trade theoretical representational power for maximum efficiency per watt.
From ResNet-50’s compute-heavy standard convolutions through MobileNet’s efficient depthwise separable variants to KWS’s extreme power-constrained design, CNNs demonstrate how architectural constraints can transform computational challenges into efficiency gains for spatially structured data. Yet their core assumption, that nearby elements are most relevant, fails when patterns depend on temporal order rather than spatial proximity. The next architecture family addresses precisely this limitation.
Self-Check: Question
An MLP first layer connected to a 224-by-224 RGB image would need 150,528 weights per output neuron, so a 1,000-unit dense layer would have more than 150 million weights. A typical CNN first layer with 64 filters of size 3-by-3 applied to the same image uses roughly 1,728 weights total. Which statement best captures why the CNN achieves this compression?
- Each filter applies the same small set of learned weights at every one of the 50,176 spatial positions, so parameter count is governed by filter size and channel count rather than by input resolution.
- The CNN replaces learned filters with fixed hand-designed edge detectors, which is why it needs no per-pixel weights.
- The CNN processes only grayscale images, which reduces the parameter count by a factor of three versus RGB.
- The CNN removes all nonlinear activations, which allows adjacent layers to be merged and parameters to be dropped.
A vision team is building two models on the same backbone: one for whole-image classification and one for pedestrian bounding-box detection. Explain why the detection model must preserve translation equivariance deeper into the network than the classification model, and connect the distinction to what pooling and global averaging do to feature maps.
A designer wants a CNN whose top-layer neurons each respond to a 50-pixel-wide image region. A stack of 3-by-3 convolutions grows the receptive field by 2 pixels per layer. Which choice is the most consistent with the section’s reasoning about how to achieve that receptive-field target?
- Stack roughly 25 layers of 3-by-3 convolutions, because depth expands the receptive field while keeping per-layer parameter counts and arithmetic intensity favorable on accelerators.
- Use a single 50-by-50 convolution layer, because it reaches the target receptive field with one pass and therefore uses less compute than a deep stack.
- Replace the convolutions with a dense MLP layer that connects every pixel to every output, so receptive field becomes irrelevant.
- Use depthwise-separable convolutions exclusively, because they automatically expand the receptive field faster than standard convolutions.
A team deploys MobileNetV2 on a data-center A100 expecting roughly 14\(\times\) lower latency than ResNet-50 because MobileNetV2 uses about 14\(\times\) fewer FLOPs. Measurements show MobileNetV2 is actually slower than ResNet-50 on the same GPU. Which explanation best fits the section’s analysis?
- MobileNetV2’s depthwise-separable convolutions produce low-arithmetic-intensity kernels whose bytes-moved-per-FLOP ratio pushes the workload into the bandwidth-bound regime, so the A100’s Tensor Core throughput cannot be used.
- MobileNetV2 cannot be quantized, which forces it to run at higher precision and explains the worse latency.
- ResNet-50 has more parameters and is automatically compressed at runtime by the GPU driver, which makes it faster.
- Depthwise-separable convolutions force execution onto the CPU because GPUs do not implement depthwise kernels.
A smart-doorbell team must choose between ResNet-50 and a DS-CNN keyword-spotting model for always-on audio wake-word detection on a microcontroller with a 2 mW average power budget and 256 KB of SRAM. Explain why both models are convolutional yet only one is deployable, and what specific architectural choice closes the gap.
True or False: If two CNNs have the same total FLOP count, they will have the same inference latency on the same GPU.
RNNs: Sequential Pattern Processing
Convolutional networks exploit spatial structure: nearby pixels are more related than distant ones. Many real-world signals, however, have temporal structure instead: words in a sentence, samples in an audio stream, sensor readings over time. Processing sequences requires architectures that maintain state across time steps.
The limitation manifests concretely in domains such as natural language processing, where word meaning depends on sentential context, and time-series analysis, where future values depend on historical patterns. Sequential data presents a challenge distinct from spatial processing: patterns can span arbitrary temporal distances, rendering fixed-size kernels ineffective. Spatial convolution exploits the principle that nearby pixels are typically related, but temporal relationships operate differently because important connections may span hundreds or thousands of time steps with no correlation to proximity. Traditional feedforward architectures, including CNNs, process each input independently and cannot maintain the temporal context necessary for these long-range dependencies.
Classic recurrent neural networks, exemplified by Elman’s simple recurrent network and later gated variants such as LSTMs, address this architectural limitation (Elman 1990; Hochreiter and Schmidhuber 1997) by embodying a temporal inductive bias: they assume sequential dependence, where the order of information matters and the past influences the present. The assumption of sequential dependence guides the introduction of memory as a core component of the computational model. Rather than processing inputs in isolation, RNNs maintain an internal state that propagates information from previous time steps, allowing the network to condition its current output on historical context. This architecture embodies a distinctive trade-off: while CNNs sacrifice theoretical generality for spatial efficiency, recurrent neural networks introduce computational dependencies that challenge parallel execution in exchange for temporal processing capabilities.
Definition 1.4: Recurrent neural networks
Recurrent Neural Networks (RNNs) are sequence-processing architectures that maintain a hidden state \(\mathbf{h}_t = f(\mathbf{h}_{t-1}, \mathbf{x}_t)\) updated at each time step, encoding the assumption that the current output depends on all prior inputs through this fixed-size state vector.
- Significance: The fixed-size state provides \(\mathcal{O}(1)\) inference memory regardless of sequence length (processing a 10,000-token sequence requires the same memory as a 10-token sequence), but the sequential update rule creates a sequential bottleneck where all \(S\) steps must execute in order, directly contributing to the \(L_{\text{lat}}\) term of the iron law and making RNNs unable to exploit GPU parallelism across the time dimension during training.
- Distinction: Unlike Attention Mechanisms, which access the entire token history simultaneously with \(\mathcal{O}(S^2)\) memory cost, RNNs compress history into a bottleneck state, meaning gradient signal must propagate back through all \(S\) steps—causing \(\partial \mathcal{L} / \partial \mathbf{h}_0 \propto \prod_{t=1}^{S} \partial \mathbf{h}_t / \partial \mathbf{h}_{t-1}\), a product of \(S\) Jacobians that vanishes or explodes exponentially with sequence length.
- Common pitfall: A frequent misconception is that RNNs are obsolete. For streaming inference on resource-constrained hardware where \(\mathcal{O}(S^2)\) attention memory is prohibitive, such as keyword spotting on a microcontroller, an RNN’s \(\mathcal{O}(1)\) state size remains the systems-justified choice.

RNNs hold state memory fixed, but latency grows with sequence length.
Pattern processing needs
Sequential pattern processing addresses scenarios where current input interpretation depends on preceding information. Consider the word “bank”: in “river bank” it denotes a shoreline, but in “bank account” it denotes a financial institution. The correct interpretation depends not just on the word itself but on the words that came before it. This contextual dependency pervades natural language, speech recognition (where phoneme interpretation depends on surrounding sounds), and financial forecasting (where future values depend on historical patterns).
The challenge lies in maintaining and updating relevant context over time. Human text comprehension does not restart with each word; rather, a running understanding evolves as new information arrives. Time-series data compounds this challenge with patterns spanning different timescales, from immediate dependencies to long-term trends. An effective sequential architecture must therefore maintain state over time while updating it in response to new inputs: capturing temporal context in internal state, updating that state as new inputs arrive, and learning which historical information remains relevant for current predictions—all while accommodating variable-length sequences that MLPs and CNNs cannot naturally handle.
Algorithmic structure
The preceding pattern processing requirements demand an architecture that maintains and updates state over time. RNNs address this through recurrent connections, distinguishing them from MLPs and CNNs. Rather than merely mapping inputs to outputs, RNNs maintain an internal state updated at each time step, creating a memory mechanism that propagates information forward in time. This temporal dependency modeling capability was first explored by Elman (1990), who demonstrated RNN capacity to identify structure in time-dependent data. Basic RNNs suffer from the vanishing gradient problem, constraining their ability to learn long-term dependencies.
Elman, Jeffrey L. 1990. “Finding Structure in Time.” Cognitive Science 14 (2): 179–211. https://doi.org/10.1207/s15516709cog1402_1.
The core operation in a basic RNN can be expressed mathematically as equation 6: \[ \mathbf{h}_t = f(\mathbf{W}_{\text{hh}}\mathbf{h}_{t-1} + \mathbf{W}_{\text{hx}}\mathbf{x}_t + \mathbf{b}_h) \tag{6}\] where \(\mathbf{h}_t\) denotes the hidden state at time \(t\), \(\mathbf{x}_t\) denotes the input at time \(t\), \(\mathbf{W}_{\text{hh}}\) contains the recurrent weights, \(\mathbf{W}_{\text{hx}}\) contains the input weights, \(\mathbf{b}_h\) is the hidden-state bias vector, and \(f\) is the activation function. Compare the left and right panels of figure 5: the left panel shows the compact recurrent loop, while the right panel unfolds it across time steps, making explicit the temporal dependencies that this recurrence creates.

In word sequence processing, each word may be represented as a 100-dimensional vector \((\mathbf{x}_t)\), with a hidden state of 128 dimensions \((\mathbf{h}_t)\). At each time step, the network combines the current input with its previous state to update its sequential understanding, establishing a memory mechanism capable of capturing patterns across time steps.
This recurrent structure fulfills sequential processing requirements through connections that maintain internal state and propagate information forward in time. Rather than processing all inputs independently, RNNs process sequential data by iteratively updating a hidden state based on the current input and the previous hidden state. This architecture suits tasks including language modeling, speech recognition, and time-series forecasting.
RNNs implement a recursive algorithm where each time step’s function call depends on the result of the previous call. Analogous to recursive functions that maintain state through the call stack, RNNs maintain state through their hidden vectors. The mathematical formula \(\mathbf{h}_t = f(\mathbf{h}_{t-1}, \mathbf{x}_t)\) directly parallels recursive function definitions where f(n) = g(f(n-1), input(n)). This correspondence explains RNN capacity to handle variable-length sequences: just as recursive algorithms process lists of arbitrary length by applying the same function recursively, RNNs process sequences of any length by applying the same recurrent computation. This sequential dependency has a direct hardware consequence. Accelerators achieve high throughput by pipelining thousands of independent operations across their ALUs simultaneously; the recurrence imposes a barrier synchronization at every time step, because \(\mathbf{h}_t\) cannot begin until \(\mathbf{h}_{t-1}\) is complete. The \(\mathcal{O}(S)\) critical path through the computation graph serializes what could otherwise be parallel work, leaving the bulk of available ALUs idle for the duration of each time step. This is the structural reason RNN hardware utilization typically falls in the 30–50 percent range while compute-bound architectures like MLPs reach 80–90 percent on the same hardware.
Sequential processing creates computational bottlenecks but produces unique efficiency characteristics for memory usage. RNNs’ \(\mathcal{O}(d_{\text{hidden}})\) inference memory overhead (analyzed in detail in the following System Implications section) creates a distinctive advantage over transformers’ \(\mathcal{O}(S^2)\) scaling, allowing processing of sequences thousands of steps long on modest hardware. During training with backpropagation through time (BPTT), however, RNNs must store activations for all time steps, requiring \(\mathcal{O}(S \cdot d_{\text{hidden}})\) memory. The recurrent weight matrix often contains connections with minimal contribution to temporal dependencies, allowing significant compression through methods covered in Model Compression.
Computational mapping
RNN sequential processing creates computational patterns different from both MLPs and CNNs, extending the architectural diversity discussed in section 1.1. This implementation approach shows temporal dependencies translating into specific computational requirements.
Listing 5 demonstrates the single-time-step mechanism using framework-level matrix operations: combine the previous hidden state with the current input, add the bias, and apply the activation to produce the next hidden state. The code is intentionally local to one step because the systems cost is not the step itself, but the dependency chain that prevents parallel execution across time.
The function handles a single time step, taking the current input x_t and previous hidden state h_prev, along with two weight matrices: W_hh for hidden-to-hidden connections and W_hx for input-to-hidden connections. Through matrix multiplication operations (matmul), it merges the previous state and current input to generate the next hidden state.
def rnn_layer_step(x_t, h_prev, W_hh, W_hx, b):
# x_t: input at time t (batch_size × input_dim)
# h_prev: previous hidden state (batch_size × hidden_dim)
# W_hh: recurrent weights (hidden_dim × hidden_dim)
# W_hx: input weights (input_dim × hidden_dim)
h_t = activation(matmul(h_prev, W_hh) + matmul(x_t, W_hx) + b)
return h_tThe simple recurrence \(\mathbf{h}_t = \tanh(\mathbf{W}_{\text{hh}} \mathbf{h}_{t-1} + \mathbf{W}_{\text{hx}} \mathbf{x}_t + \mathbf{b})\) conceals a computational structure with unique challenges: sequential dependencies that prevent parallelization, memory access patterns that differ from feedforward networks, and state management requirements that affect system design. The detailed implementation in listing 6 reveals the computational reality beneath the mathematical abstraction. Its nested loop structure exposes how sequential processing creates both limitations and opportunities in system optimization.
def rnn_layer_compute(x_t, h_prev, W_hh, W_hx, b):
# Initialize next hidden state
h_t = np.zeros_like(h_prev)
# Loop 1: Process each sequence in the batch
for batch in range(batch_size):
# Loop 2: Compute recurrent contribution
# (h_prev × W_hh)
for i in range(hidden_dim):
for j in range(hidden_dim):
h_t[batch, i] += h_prev[batch, j] * W_hh[j, i]
# Loop 3: Compute input contribution (x_t × W_hx)
for i in range(hidden_dim):
for j in range(input_dim):
h_t[batch, i] += x_t[batch, j] * W_hx[j, i]
# Loop 4: Add bias and apply activation
for i in range(hidden_dim):
h_t[batch, i] = activation(h_t[batch, i] + b[i])
return h_tThe nested loops in rnn_layer_compute expose the core computational pattern of RNNs. Loop one processes each sequence in the batch independently, allowing for batch-level parallelism. Within each batch item, Loop two computes how the previous hidden state influences the next state through the recurrent weights \(\mathbf{W}_{\text{hh}}\). Loop three then incorporates new information from the current input through the input weights \(\mathbf{W}_{\text{hx}}\). Finally, Loop four adds biases and applies the activation function to produce the new hidden state.
For a sequence processing task with input dimension 100 and hidden state dimension 128, each time step requires two matrix multiplications: one \(128{\times}128\) for the recurrent connection and one \(100{\times}128\) for the input projection. While individual time steps can process in parallel across batch elements, the time steps themselves must execute sequentially, producing a computational pattern with fundamentally different parallelization characteristics than MLPs or CNNs.
System implications
RNNs introduce an inescapable system constraint: sequential dependency. Unlike MLPs and CNNs where parallelism scales with the number of neurons or pixels, RNN parallelism is limited by the sequence length. In iron law terms (Iron Law of ML Systems), neither increasing \(R_{\text{peak}}\) (peak compute rate) nor \(\text{BW}\) (memory bandwidth) can help—the bottleneck is latency along the sequential critical path.
The core computation \(\mathbf{h}_t = \tanh(\mathbf{W}_{\text{hh}}\mathbf{h}_{t-1} + \mathbf{W}_{\text{hx}}\mathbf{x}_t)\) creates a strict ordering. Time step \(t\) cannot begin until step \(t-1\) completes. If processing a document with 1,000 words, the system must execute 1,000 sequential matrix-vector multiplications. No amount of additional hardware (more GPUs, more cores) can accelerate this “critical path” along the time dimension. This limits the parallel width to the batch size, whereas CNNs can exploit parallelism across spatial dimensions, channels, and batches.
RNNs are uniquely memory-efficient for long sequences during inference. They maintain a fixed-size hidden state vector (for example, 2 KB for a 512-dim state) regardless of whether the sequence length is 10 or 10,000. This \(\mathcal{O}(d_{\text{hidden}})\) state scaling contrasts with attention, introduced next, which retains sequence state that grows with length: full transformer attention during training or prompt processing stores score interactions that scale as \(\mathcal{O}(S^2)\), while autoregressive transformer serving keeps an \(\mathcal{O}(S d_{\text{model}})\) key-value cache. The compression comes at a cost, however: the fixed-size state becomes an information bottleneck, forcing the network to compress arbitrary history into a small vector and leading to the vanishing gradient problems that motivated LSTMs and eventually transformers.
RNNs exhibit high temporal locality for weights (reused every step) but low locality for activations. The weight matrices \(\mathbf{W}_{\text{hh}}\) and \(\mathbf{W}_{\text{hx}}\) stay in the cache (or on-chip memory) for the entire duration of the sequence processing, achieving high arithmetic intensity if the batch size is large enough. However, the requirement to read and write the hidden state at every step creates a constant stream of low-intensity updates that can strain memory bandwidth if not carefully managed.
This tension between memory efficiency and sequential execution defined the pre-Transformer era. RNNs compress arbitrarily long histories into a fixed-size hidden state, which is memory efficient but creates two compounding problems: the sequential dependency prevents hardware from parallelizing across time steps, and the fixed-capacity state becomes an information bottleneck where early inputs fade as sequences grow (the vanishing gradient problem). Together, these limitations motivated architectures that could access any position in a sequence directly, without processing all intervening elements. That direct-access capability, developed in section 1.5, is the attention mechanism. Hardware strategies for managing sequential bottlenecks in RNN workloads that remain in production, including pipeline parallelism and operator fusion, are analyzed in Dataflow Optimization.
Self-Check: Question
What architectural feature lets a vanilla RNN process a 10-token input and a 10,000-token input using the same weight matrices and the same constant-sized hidden state?
- A recurrent update rule that applies the same learned transformation to produce a new hidden state from the previous hidden state and the current input, at every time step.
- A stored \(S \times S\) attention score matrix that captures all pairwise interactions between time steps.
- A spatial filter shared across all image locations that sweeps across the sequence like a CNN kernel.
- An input-independent decoder that ignores all prior inputs during inference.
True or False: A team whose RNN training job reports 40 percent GPU utilization and whose wall-clock time scales linearly with sequence length could recover most of the lost utilization by adding a second identical GPU in a data-parallel configuration.
A mobile-team engineer must choose between an RNN and a transformer for on-device streaming speech recognition on a phone with 4 GB of RAM. The input is an effectively unbounded audio stream. Walk through the memory trade-off between the RNN’s \(\mathcal{O}(1)\) hidden state and attention’s \(\mathcal{O}(S^2)\) score matrix, and justify which architecture the constraint favors.
Why does scaling from one to eight GPUs almost entirely remove the training-time bottleneck of a ResNet-50 data-parallel job but fail to similarly improve a vanilla-RNN training job on long sequences?
- Because the RNN’s binding constraint is the ordered dependency from \(\mathbf{h}_{t-1}\) to \(\mathbf{h}_t\) across time steps; extra parallel hardware shortens batch-wise work but cannot shorten the in-sequence dependency chain.
- Because recurrent layers cannot use matrix multiplication, so GPUs cannot accelerate them at all.
- Because the RNN’s hidden states are too large to fit in GPU memory, while ResNet’s activations are not.
- Because RNNs are primarily limited by random embedding-table lookups whose latency ignores compute throughput.
Order the following operations for one RNN time step producing \(\mathbf{h}_t\): (1) combine the current input with the input weights \(\mathbf{W}_{\text{hx}}\), (2) apply the nonlinear activation to produce the new hidden state \(\mathbf{h}_t\), (3) combine the previous hidden state \(\mathbf{h}_{t-1}\) with the recurrent weights \(\mathbf{W}_{\text{hh}}\).
A keyword-spotting deployment team must choose an architecture to run continuously on a microcontroller with a 1 MB working-memory budget for incoming audio. Which scenario best captures when an RNN is the systems-justified choice over an attention-based model, per the section’s argument?
- When streaming inference runs under tight memory limits and materializing even a modest attention matrix would breach the memory budget.
- When the task is image classification with strong translation invariance on large input resolutions.
- When the task requires quadratic pairwise attention over tens of thousands of tokens at once to meet accuracy targets.
- When throughput depends on maximizing batch-parallel sequence processing across a cluster of GPUs.
Attention: Dynamic Processing
The RNN bottlenecks analyzed earlier become concrete with a simple example. Consider the sentence “The cat, which was sitting by the window overlooking the garden, was sleeping.” Here, “cat” and “sleeping” are separated by multiple intervening words, yet they form the core subject-predicate relationship. An RNN would process all intervening elements sequentially, potentially losing this connection in its fixed-capacity hidden state. This limitation motivates an alternative: an architecture that directly computes the relevance between any two positions regardless of distance.
Attention mechanisms16 address precisely this challenge (Bahdanau et al. 2015) by introducing dynamic connectivity patterns that adapt based on input content. Rather than processing elements in predetermined order with fixed relationships, attention mechanisms compute the relevance between all pairs of elements and weight their interactions accordingly, replacing structural constraints with learned, data-dependent processing patterns.
16 Bahdanau Attention: This approach broke the “fixed-length vector” bottleneck of prior sequence-to-sequence models by allowing a decoder to dynamically query all input elements at each output step, creating the adaptive connectivity described. This replaced the structural constraint of a fixed-capacity channel with a learned, content-based weighting system. The core trade-off was accepting a linear, \(\mathcal{O}(S)\) memory cost to store all input states in exchange for overcoming the information loss inherent in a single vector.
17 Transformer: The founding paper, “Attention Is All You Need,” made the explicit systems claim that a parallel attention mechanism could fully replace sequential recurrent processing. This architectural trade eliminates an RNN’s \(\mathcal{O}(S)\) path length constraint on parallelism but introduces an \(\mathcal{O}(S^2)\) computational and memory cost, as every token must attend to every other. This quadratic growth is the bottleneck that limited GPT-3’s reported context window to 2048 tokens and continues to shape context-window engineering.
While attention mechanisms were initially used as components within recurrent architectures, their ability to connect any position to any other made the recurrent structure unnecessary for many sequence tasks. The transformer17 architecture (Vaswani et al. 2017) demonstrated that attention alone could entirely replace sequential processing. This architectural shift traded the RNN’s \(\mathcal{O}(S)\) sequential depth for \(\mathcal{O}(1)\) information flow between any two positions, enabling massive parallelization on high-throughput accelerators.
Definition 1.5: Attention mechanisms
Attention Mechanisms are neural network operations that compute a weighted sum of value vectors, where the weights are derived from learned similarity scores between a query vector and a set of key vectors, enabling dynamic, content-dependent information routing between any two positions in a sequence.
- Significance: Attention connects any two tokens in \(\mathcal{O}(1)\) depth, but the similarity matrix requires quadratic (\(S^2\)) memory: for a 4,096-token sequence with 16-bit scores, the attention matrix alone consumes 33.6 MB per layer per head (about 16.8M scores at 2 bytes each), a direct contribution to the \(D_{\text{vol}}\) and \(\text{BW}\) terms of the iron law that ultimately caps practical context window length.
- Distinction: Unlike RNNs, which compress all prior context into a single fixed-size state vector, attention mechanisms retain token representations and compute relevance scores directly. During training or full-sequence prefill, the initial pass that processes the whole prompt, score interactions grow quadratically with sequence length; during autoregressive serving, the stored KV cache, the saved key and value vectors from prior tokens, grows as \(\mathcal{O}(S d_{\text{model}})\) while each new token attends over prior keys and values.
- Common pitfall: A frequent misconception is that attention is a general-purpose weighting scheme that can be applied freely. Quadratic attention memory is a hard physical constraint: doubling the context window quadruples the attention memory, which is why FlashAttention and sparse attention variants exist—they recompute rather than store the attention matrix to break this memory wall.
The transformer architecture in section 1.6 inherits every important systems property from attention itself: dynamic routing, parallel sequence processing, and quadratic score construction. The next step is therefore to establish what kind of pattern-processing problem attention solves before treating the transformer as a full architecture.
Pattern processing needs
Dynamic pattern processing addresses scenarios where relationships between elements are not fixed by architecture but instead emerge from content. Language translation exemplifies this challenge: when translating “the bank by the river,” understanding “bank” requires attending to “river,” but in “the bank approved the loan,” the important relationship is with “approved” and “loan.” Unlike RNNs that process information sequentially or CNNs that use fixed spatial patterns, an architecture is required that can dynamically determine which relationships matter. The pronoun-resolution schematic in figure 6 makes that dynamic routing visible.

This requirement for dynamic processing extends well beyond language. In protein structure prediction, interactions between amino acids depend on their chemical properties and spatial arrangements rather than linear position in the chain. In graph analysis, node relationships vary based on graph structure and node features, typically modeled by graph convolutional networks (GCNs), neural networks that aggregate neighboring node features (Kipf and Welling 2017). Unlike CNNs, which access memory in regular spatial strides, or transformers, which work with dense sequence tensors, GCN neighbor aggregation follows the irregularly shaped adjacency structure of the input graph. Each gather step touches a different, unpredictable set of node embeddings, defeating cache prefetchers and preventing coalesced memory access. Irregular neighbor-gather access patterns bottleneck the workload on memory bandwidth and cache miss rate rather than compute throughput, a system constraint that persists regardless of graph size. In document analysis, connections between sections depend on semantic content rather than proximity.
Kipf, Thomas N, and Max Welling. 2017. “Semi-Supervised Classification with Graph Convolutional Networks.” International Conference on Learning Representations.
What unifies these domains is that the system must compute relationships between all pairs of elements, weigh those relationships based on content, and use the resulting weights to selectively combine information. Unlike architectures with fixed connectivity patterns, dynamic processing requires the flexibility to modify its computation graph based on the input itself. This capability defines the attention mechanism, the foundation of the transformer architecture.
When processing the pronoun “they” in the sentence, the attention mechanism must determine what “they” refers to. The attention weights (indicated by line thickness) emphasize “student” and “finish”: the model has learned to link pronouns with their referents and predicates across arbitrary distances, selectively weighting the most informative tokens in the sequence. This is precisely the kind of long-range dependency that RNNs struggle to capture.
Algorithmic structure
The pattern processing needs described earlier require computing relationships dynamically based on content. Attention mechanisms achieve this by computing weighted connections between elements based on their content (Bahdanau et al. 2015), processing relationships that emerge from the data itself rather than being fixed by architecture. At the core of an attention mechanism lies an operation that can be expressed mathematically as: \[ \text{Attention}(\mathbf{Q}, \mathbf{K}, \mathbf{V}) = \text{softmax} \left(\frac{\mathbf{Q}\mathbf{K}^T}{\sqrt{d_k}}\right)\mathbf{V} \]
18 Softmax: Named as a “soft” (differentiable) version of the argmax function, with mathematical roots in Boltzmann’s 1868 statistical mechanics. In transformer attention, softmax is a systems bottleneck: it requires a full pass over all \(S\) scores to compute the normalizing denominator, preventing streaming computation and forcing the entire \(S{\times}S\) attention matrix to be materialized (or carefully tiled, as FlashAttention does). This normalization dependency is the fundamental reason attention memory scales quadratically.
This equation shows scaled dot-product attention. \(\mathbf{Q}\) (queries) and \(\mathbf{K}\) (keys) are matrix-multiplied to compute similarity scores using the dot product; The dot product as similarity formalizes the dot product as a similarity measure. The scores are divided by \(\sqrt{d_k}\) (key dimension) for numerical stability, then normalized with softmax18 to produce attention weights. These weights are applied to \(\mathbf{V}\) (values) to produce the output. The result is a weighted combination where each position receives information from all relevant positions based on content similarity.
In this equation, \(\mathbf{Q}\) (queries), \(\mathbf{K}\) (keys), and \(\mathbf{V}\) (values)19 represent learned projections of the input. For a sequence of length \(S\) with dimension \(d\), this operation creates an \(S{\times}S\) attention matrix, determining how each position should attend to all others.
19 Query-Key-Value (QKV): The terminology is borrowed from information retrieval, explaining why the equation uses three distinct learned projections to calculate pairwise scores. Creating these projections requires three independent weight matrices, costing \(3 \times d_{\text{model}}^2\) parameters per layer. The direct systems consequence is the “KV cache” for autoregressive inference: all prior Key and Value vectors must be stored to generate the attention matrix for the next token, causing memory to grow linearly (\(\mathcal{O}(S)\)) with sequence length and dominating serving costs.
The attention operation involves several key steps. First, it computes query, key, and value projections for each position in the sequence. In figure 7, each cell in the \(S{\times}S\) attention matrix represents a query-key interaction, and the color intensity reveals which positions attend most strongly to which others. Finally, these attention weights combine value vectors to produce the output.

Unlike the fixed weight matrices found in previous architectures, attention weights are computed dynamically for each input. Follow the matrix dimensions in figure 8 to see this dynamic computation unfold: the embedding matrix multiplies with QKV weight matrices in a single batched operation, and the resulting projections change for every new input sequence.

Cho, Aeree, Grace C. Kim, Alexander Karpekov, Alec Helbling, Zijie J. Wang, Seongmin Lee, Benjamin Hoover, and Duen Horng (Polo) Chau. 2025. “TRANSFORMER EXPLAINER: Interactive Learning of Text-Generative Models.” Proceedings of the AAAI Conference on Artificial Intelligence 39 (28): 29625–27. https://doi.org/10.1609/aaai.v39i28.35347.
Computational mapping
Attention mechanisms create computational patterns that differ significantly from previous architectures. Listing 7 reveals how dynamic connectivity translates into specific computational requirements, exposing the nested loops that implement pairwise attention scoring.
def attention_layer_matrix(Q, K, V):
# Q, K, V: (batch_size × seq_len × d_model)
# Compute attention scores
scores = matmul(Q, K.transpose(-2, -1)) / sqrt(d_k)
weights = softmax(scores) # Normalize scores
output = matmul(weights, V) # Combine values
return output
def attention_layer_compute(Q, K, V):
# Initialize outputs
scores = np.zeros((batch_size, seq_len, seq_len))
outputs = np.zeros_like(V)
# Loop 1: Process each sequence in batch
for b in range(batch_size):
# Loop 2: Compute attention for each query position
for i in range(seq_len):
# Loop 3: Compare with each key position
for j in range(seq_len):
# Compute attention score
for d in range(d_model):
scores[b, i, j] += Q[b, i, d] * K[b, j, d]
scores[b, i, j] /= sqrt(d_k)
# Apply softmax to scores
for i in range(seq_len):
scores[b, i] = softmax(scores[b, i])
# Loop 4: Combine values using attention weights
for i in range(seq_len):
for j in range(seq_len):
for d in range(d_model):
outputs[b, i, d] += scores[b, i, j] * V[b, j, d]
return outputsThe translation from attention’s mathematical elegance to hardware execution reveals the computational price of dynamic connectivity. While the attention equation \(\text{Attention}(\mathbf{Q}, \mathbf{K}, \mathbf{V}) = \text{softmax}(\mathbf{Q}\mathbf{K}^T/\sqrt{d_k})\mathbf{V}\) appears as a straightforward matrix operation, the physical implementation requires orchestrating quadratic numbers of pairwise computations that create different system demands than previous architectures. The nested loops in attention_layer_compute expose this computational signature. The first loop processes each sequence in the batch independently. The second and third loops compute attention scores between all pairs of positions, creating the quadratic computation pattern that makes attention both powerful and computationally demanding. The fourth loop uses these attention weights to combine values from all positions, completing the dynamic connectivity pattern that defines attention mechanisms.
System implications
Attention mechanisms exhibit distinctive system-level patterns that differ from previous architectures through their dynamic connectivity requirements. In iron law terms (Iron Law of ML Systems), attention shifts the bottleneck from the latency-bound sequential path of RNNs toward quadratic score interactions and data movement. Naive implementations materialize an \(\mathcal{O}(S^2)\) attention matrix, while tiled algorithms such as FlashAttention avoid storing the full matrix by recomputing and streaming blocks through faster memory.
Memory requirements
Attention mechanisms require storage for attention weights, key-query-value projections, and intermediate feature representations. For a sequence length \(S\) and dimension \(d\), each attention layer must store an \(S{\times}S\) attention weight matrix for each sequence in the batch, three sets of projection matrices for queries, keys, and values (each sized \(d{\times}d\)), and input and output feature maps of size \(S{\times}d\). The dynamic generation of attention weights for every input creates a memory access pattern where intermediate attention weights become a significant factor in memory usage, producing a quadratic bottleneck that defines modern transformer scaling limits. A quick calculation shows how fast this memory wall appears at scale.

Doubling the context quadruples attention memory: past the knee, the cost wall is unavoidable.
Napkin Math 1.1: The quadratic bottleneck
Problem: How much memory does the attention matrix of a single layer require at sequence length \(S =\) 100,000 (context window)?
Math:
- Matrix size: The attention score matrix \((\mathbf{Q}\mathbf{K}^T)\) has dimensions \(S{\times}S\) per head, across \(N_{\text{heads}}\) heads (12 heads in this example).
- Elements: 100,000 \(\times\) 100,000 \(\times\) 12 heads = 1.2 × 10¹¹ elements.
- Memory: At FP16 (2 bytes/element): 1.2 × 10¹¹ \(\times\) 2 bytes = 240 GB.
Systems insight: A single layer’s attention matrix consumes 240 GB of HBM. A 32-layer model would require 7,680 GB just for transient attention scores, far exceeding any single GPU’s capacity. This memory wall motivates two broad implementation strategies developed later: avoid materializing the full matrix by tiling the computation, or reduce the number of scores computed in the first place.
Computation and data movement
Attention computation divides into two main phases: generating attention weights and applying them to values. For each attention layer, the system performs many multiply-accumulate operations across multiple computational stages. The query-key interactions alone require \(S \times S \times d\) multiply-accumulates, with an equal number needed for applying attention weights to values. Additional computations are required for the projection matrices and softmax operations. This computational pattern differs from previous architectures due to its quadratic scaling with sequence length and the need to perform fresh computations for each input.
Checkpoint 1.3: Quadratic scaling intuition
Modern AI scaling is defined by the cost of Attention. Verify your intuition:
Data movement in attention mechanisms presents challenges distinct from all previous architectures. Each attention operation requires projecting and moving query, key, and value vectors for every position in the sequence, then storing and accessing the full \(S{\times}S\) attention weight matrix, and finally coordinating value vector movement during the weighted combination phase. These intermediate attention weights become a major factor in system bandwidth requirements. Unlike the predictable spatial access patterns of CNNs or the sequential access of RNNs, attention operations require frequent movement of dynamically computed weights across the memory hierarchy, a pattern that defeats simple caching strategies.
The distinctive memory, computation, and data movement characteristics of attention shape system design in fundamental ways—and raise the question of whether attention is effective enough to replace other architectural components entirely.
That scaling pressure was not hypothetical: early transformer deployments had to enforce short context windows because attention scores could exhaust memory long before model accuracy stopped improving.
Systems Perspective 1.2: The quadratic wall
Context: BERT-style transformer models set new accuracy records across NLP benchmarks, but common implementations fixed a short maximum input sequence length, often 512 tokens (Devlin et al. 2019).
Failure mode: This was not merely a product decision; it reflected a physics constraint. The self-attention mechanism’s memory requirement scales quadratically (\(\mathcal{O}(S^2)\)). Doubling the context from 512 to 1,024 would increase attention-score memory by 4×; increasing it to 4,096 (for a short article) would increase memory usage by 64×. Without practical input limits, a single long document can exhaust device memory during training or prefill. The “Quadratic Wall” made document chunking and shorter sequence windows common until sparse or low-rank attention variants and IO-aware optimizations such as FlashAttention reduced the memory pressure.
Systems insight: Big-O notation is not just theory; it becomes an infrastructure constraint. Vaswani et al.’s complexity analysis (2017) makes the quadratic cost of full self-attention explicit. Systems that expose long or unbounded sequences therefore need practical input limits or more efficient attention variants to avoid super-linear resource growth.
Despite these costs, attention’s ability to connect any position to any other in constant depth is too effective to serve merely as an add-on to recurrent architectures. Attention can bypass sequential processing entirely, eliminating the rationale for preserving recurrent structure. The question of whether attention can replace recurrence altogether produced a central architectural shift in deep learning systems.
Self-Check: Question
A sequence-modeling team finds that their model fails to resolve the sentence ‘The cat, which had been sitting on the windowsill overlooking the garden, was sleeping’ because the pronoun-predicate link between ‘cat’ and ‘was sleeping’ spans many intervening tokens. Why does an attention-based layer resolve this link more reliably than a stack of recurrent layers, and what is the systems cost of that guarantee?
- Attention directly computes a similarity-weighted mixture between ‘was sleeping’ and every prior token in a single step, so the long-range subject-predicate link does not have to survive traversal of every intervening hidden-state update; the cost is the \(S \times S\) score matrix that grows quadratically with context length.
- Attention eliminates the need for learned query, key, and value projections, which is why long-range dependencies are captured for free.
- Attention enforces strict left-to-right sequential processing like an RNN, which is why it reliably tracks long-range references.
- Attention replaces matrix multiplications with cheap element-wise operations, which is why it costs less than an RNN at long contexts.
Explain why attention succeeds at long-range dependencies that defeat recurrent layers, and give a concrete numeric example of the systems cost this capability introduces at typical transformer context lengths.
A team doubles the sequence length from 4,096 to 8,192 tokens while leaving model parameters unchanged, and the deployment suddenly runs out of accelerator memory. Which mechanism is most directly responsible?
- Self-attention materializes an \(S \times S\) score matrix, so doubling \(S\) quadruples the dominant attention-memory term — even though weight tensors stay exactly the same size.
- The Adam optimizer state doubles during autoregressive inference, overwhelming the accelerator.
- Softmax internally duplicates every weight matrix once per token, causing weight memory to grow linearly with sequence length.
- Query, key, and value projections become cubic in sequence length, which is the source of the memory explosion.
The attention mechanism’s \(S \times S\) score matrix must be fully materialized because the normalization step at its core requires a pass over all \(S\) scores to compute a shared denominator before any weight can be finalized. The specific operation whose denominator dependency forces this materialization — and whose tiled streaming form is what FlashAttention redesigns — is ____.
A team wants to extend transformer context length from 8,000 to 64,000 tokens but runs out of memory because the attention matrix consumes roughly 64\(\times\) more space. Which response is most aligned with the section’s analysis of this memory wall?
- Adopt FlashAttention or a sparse-attention variant that avoids materializing the full \(S \times S\) score matrix by tiling the softmax into on-chip memory or skipping most of its entries.
- Increase only FLOP throughput by upgrading to a faster accelerator, because attention is purely compute-bound and insensitive to memory bandwidth.
- Replace softmax with ReLU, which would make the attention matrix linear in sequence length while preserving the same functional form.
- Replace self-attention with convolutions, because convolutions preserve full pairwise token interactions at lower cost.
True or False: Attention’s main systems cost is the three linear projections that produce \(\mathbf{Q}\), \(\mathbf{K}\), and \(\mathbf{V}\); the subsequent similarity computation and value aggregation are nearly free.
Transformers: Parallel Sequence Processing
Attention provides the computational primitive of dynamic, content-dependent routing between positions, yet it was originally layered on top of recurrent architectures, inheriting their sequential bottleneck. The transformer architecture settles the question of whether attention can replace recurrence definitively: by building an entire architecture from attention alone, it eliminates sequential dependencies during training, enabling the massive parallelism that modern hardware demands while retaining dynamic connectivity. That trade also creates the system costs that dominate modern sequence models: quadratic attention memory, growing key-value state during serving, and high bandwidth pressure during autoregressive generation.
Definition 1.6: Transformers
Transformers are neural network architectures for sequence workloads that process all positions simultaneously through self-attention, eliminating recurrence and enabling full parallelization of the forward pass across the sequence dimension.
- Significance: Parallelism is the systems payoff. An RNN processing an \(S\)-token sequence executes \(S\) sequential steps, each dependent on the previous hidden state, leaving accelerator parallelism unused across the time dimension. A transformer processes all \(S\) tokens in \(\mathcal{O}(1)\) depth, converting the entire sequence into independent matrix multiplications that can saturate all compute units simultaneously. The cost is the \(\mathcal{O}(S^2)\) attention memory quantified in section 1.5, a ceiling that scales with sequence length, not model size.
- Distinction: Unlike attention used as a component inside a recurrent backbone, which inherits the host architecture’s \(\mathcal{O}(S)\) sequential depth, transformers make attention the only mixing operation between positions, so the architecture’s parallelism, memory scaling, and serving behavior are all set by attention alone.
- Common pitfall: A frequent misconception is that transformers have “infinite context.” Context length is bounded by two distinct memory costs: the attention-score matrix during training and prefill, and the KV cache that accumulates during autoregressive serving. At long contexts the cache alone can rival the model weights, which is why KV cache compression and related serving optimizations are active engineering areas rather than optional refinements.
Pattern processing needs
Attention mechanisms first appeared as additions to existing architectures, particularly RNN-based sequence-to-sequence tasks (Sutskever et al. 2014; Bahdanau et al. 2015). Those hybrids improved dynamic connectivity but kept the recurrent bottleneck: limited parallelism and difficulty with very long sequences. The transformer section begins from the architectural decision to remove that bottleneck entirely, then follows the cost of that decision through memory, bandwidth, and serving state.
Sutskever, Ilya, Oriol Vinyals, and Quoc V. Le. 2014. “Sequence to Sequence Learning with Neural Networks.” Advances in Neural Information Processing Systems 27: 3104–12.
Transformers, introduced in the “Attention Is All You Need” paper by Vaswani et al. (2017), embody a fundamentally different inductive bias: they assume no prior structure but allow the model to learn all pairwise relationships dynamically based on content. Rather than adding attention to RNNs, transformers built the entire architecture around attention mechanisms, introducing self-attention as the primary computational pattern. This architectural decision traded the parameter efficiency of CNNs and the sequential coherence of RNNs for maximum flexibility and parallelizability. The progression from MLPs that connect everything, to CNNs that connect locally, to RNNs that connect sequentially, to transformers that connect dynamically based on learned content relationships illustrates how each iteration refined the balance between flexibility and efficiency.
Algorithmic structure
The key innovation in transformers lies in their use of self-attention layers. In the self-attention mechanism used by transformers, the Query, Key, and Value vectors are all derived from the same input sequence. This is the key distinction from earlier attention mechanisms where the query might come from a decoder while the keys and values came from an encoder. By making all components self-referential, self-attention allows the model to weigh the importance of different positions within the same sequence when encoding each position. For instance, in processing the sentence “The animal did not cross the street because it was too wide,” self-attention allows the model to link “it” with “street,” capturing long-range dependencies that are challenging for traditional sequential models.
The self-attention mechanism differs from earlier attention in one critical respect: every query, key, and value is derived from the same input \(\mathbf{X}\), as equation 7 makes explicit: \[ \text{SelfAttention}(\mathbf{X}) = \text{softmax} \left(\frac{\mathbf{X}\mathbf{W}_Q(\mathbf{X}\mathbf{W}_K)^T}{\sqrt{d_k}}\right)\mathbf{X}\mathbf{W}_V \tag{7}\]
Here, \(\mathbf{X}\) is the input sequence, and \(\mathbf{W}_Q\), \(\mathbf{W}_K\), and \(\mathbf{W}_V\) are learned weight matrices for queries, keys, and values respectively. This formulation highlights how self-attention derives all its components from the same input, creating a dynamic, content-dependent processing pattern.
Building on this foundation, transformers employ multi-head attention, which extends the self-attention mechanism by running multiple attention functions in parallel. Each “head” involves a separate set of query/key/value projections that can focus on different aspects of the input, allowing the model to jointly attend to information from different representation subspaces. This multi-head structure provides the model with a richer representational capability, enabling it to capture various types of relationships within the data simultaneously.
Each head learns a separate projection into its own subspace, and their outputs are concatenated and linearly mixed, as equation 8 formalizes: \[ \text{MultiHead}(\mathbf{Q}, \mathbf{K}, \mathbf{V}) = \text{Concat}(\text{head}_1, \ldots, \text{head}_{N_{\text{heads}}})\mathbf{W}^O \tag{8}\] where each attention head is computed as: \[ \text{head}_i = \text{Attention}(\mathbf{Q}\mathbf{W}_i^Q, \mathbf{K}\mathbf{W}_i^K, \mathbf{V}\mathbf{W}_i^V) \]
A critical component in both self-attention and multi-head attention is the scaling factor \(\sqrt{d_k}\), which serves an important mathematical purpose. This factor prevents the dot products from growing too large, which would push the softmax function into regions with extremely small gradients. For queries and keys of dimension \(d_k\), their dot product has variance \(d_k\), so dividing by \(\sqrt{d_k}\) normalizes the variance to one, maintaining stable gradients and enabling effective learning.20
20 Attention Scaling \((\sqrt{d_k})\): This normalization directly counteracts the linear growth in variance \((d_k)\) of the query-key dot product, preventing the softmax function from saturating where gradients would otherwise vanish. The systems consequence is most acute in mixed-precision training: when activations grow large, unscaled dot products can produce logits that overflow the 16-bit float range, destabilizing or halting learning entirely.
Beyond the mathematical mechanics, attention mechanisms can be understood conceptually as implementing a form of content-addressable memory system. Like hash tables that retrieve values based on key matching, attention computes similarity between a query and all available keys, then retrieves a weighted combination of corresponding values. The dot product similarity \(\mathbf{q}_i \cdot \mathbf{k}_j\) functions like a hash function that measures how well each key matches the query. The softmax normalization ensures the weights sum to one, implementing a probabilistic retrieval mechanism. This connection explains why attention proves effective for tasks requiring flexible information retrieval: it provides a differentiable approximation to database lookup operations.
From an information-theoretic perspective, attention mechanisms implement smooth information aggregation under uncertainty. The attention weights represent uncertainty about which parts of the input contain relevant information for the current processing step. Softmax can be interpreted as choosing attention weights that maximize score-weighted utility plus an entropy regularizer, producing a smooth distribution rather than a hard argmax (Cover and Thomas 2006).
Cover, Thomas M., and Joy A. Thomas. 2006. Elements of Information Theory. 2nd ed. Wiley. https://doi.org/10.1002/0471200611.
Attention mechanisms exhibit significant redundancy (many heads learning similar patterns), and the softmax operation creates sensitivity to reduced precision. These properties create opportunities for optimization through pruning, factorization, sparse attention patterns, and specialized quantization, all covered in Model Compression.
This information-theoretic interpretation reveals why attention is effective for selective processing. The mechanism balances two competing objectives: focusing probability mass on high-scoring positions while preserving enough entropy to avoid a brittle hard selection. This smooth weighting helps transformers handle long sequences and complex dependencies.
Self-attention learns dynamic activation patterns across the input sequence. Unlike CNNs which apply fixed filters or RNNs which use fixed recurrence patterns, attention learns which elements should activate together based on their content. This creates a form of adaptive connectivity where the effective network topology changes for each input. Recent research has shown that attention heads in trained models often specialize in detecting specific linguistic or semantic patterns (Clark et al. 2019), suggesting that the mechanism naturally discovers interpretable structural regularities in data. The encoder-decoder diagram in figure 9 places this mechanism inside the residual, normalization, and feed-forward scaffolding that makes the full architecture trainable.
Clark, Kevin, Urvashi Khandelwal, Omer Levy, and Christopher D. Manning. 2019. “What Does BERT Look at? An Analysis of BERT’s Attention.” Proceedings of the 2019 ACL Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP, 276–86. https://doi.org/10.18653/v1/w19-4828.

The transformer architecture applies this self-attention mechanism within a broader structure that typically includes feed-forward layers, layer normalization, and residual connections. Figure 9 shows input tokens entering repeated attention and feed-forward blocks, each wrapped with residual connections and normalization, and emerging as contextualized representations. Because all positions can be processed in parallel rather than sequentially, the architecture trades recurrent state for large matrix operations that map well to accelerator training.
Computational mapping
While transformer self-attention builds upon the basic attention mechanism, it introduces distinct computational patterns that set it apart. Listing 8 presents a typical implementation, showing how self-attention derives queries, keys, and values from the same input sequence.
The preceding self-attention implementation shows how transformers process entire sequences in parallel. The picture changes at inference time, when the model generates tokens one at a time, a shift whose system consequences the next section quantifies through the GPT-2 XL lighthouse.
System implications
The quadratic bottleneck analyzed earlier manifests differently during training and inference, creating a bifurcation in system behavior defined by two distinct iron law regimes (Iron Law of ML Systems): training is dominated by \(O\) (compute), while inference is dominated by \(D_{\text{vol}}\) (data movement). The same attention mechanism therefore demands different optimizations depending on whether the system is learning from a full sequence or generating one token at a time.
def self_attention_layer(X, W_Q, W_K, W_V, d_k):
# X: input tensor (batch_size × seq_len × d_model)
# W_Q, W_K, W_V: weight matrices (d_model × d_k)
Q = matmul(X, W_Q)
K = matmul(X, W_K)
V = matmul(X, W_V)
scores = matmul(Q, K.transpose(-2, -1)) / sqrt(d_k)
attention_weights = softmax(scores, dim=-1)
output = matmul(attention_weights, V)
return output
def multi_head_attention(X, W_Q, W_K, W_V, W_O, num_heads, d_k):
outputs = []
for i in range(num_heads):
head_output = self_attention_layer(
X, W_Q[i], W_K[i], W_V[i], d_k
)
outputs.append(head_output)
concat_output = torch.cat(outputs, dim=-1)
final_output = matmul(concat_output, W_O)
return final_outputTraining: The quadratic compute wall
During training, all tokens are processed in parallel, making the \(\mathcal{O}(S^2)\) attention cost the dominant factor. For long sequences (for example, 32k tokens), materializing the \(32k{\times}32k\) attention matrix requires gigabytes of memory and massive compute. This compute-bound regime motivates optimizations like FlashAttention, which tiles computation to avoid materializing the full matrix in HBM. The hardware memory hierarchies (HBM, SRAM, register files) that make such tiling effective are detailed in Hardware Acceleration.
Inference: The memory bandwidth wall
Inference is autoregressive (generating one token at a time) and typically memory-bandwidth bound. To generate a single token, the system must complete three operations:
- Load all model weights (for example, 140 GB for a 70-billion-parameter model at FP16 precision).
- Perform matrix-vector multiplications.
- Read/write the KV Cache.
GPT-2 XL makes the cost of that first step concrete.
Lighthouse 1.5: GPT-2 XL (bandwidth lighthouse)
Why it matters: GPT-2 XL exemplifies memory-bandwidth-bound workloads. During autoregressive inference, the model must load all 6 GB of FP32 weights from HBM for every generated token, while performing only a single matrix-vector multiply per layer. The arithmetic intensity is about 0.5 FLOP/byte with FP32 weights in table 2, or about 1 FLOP/byte with FP16 weights, leaving compute cores idle while waiting for memory. This contrasts with ResNet-50 (compute bound, high weight reuse) and DLRM (capacity-bound, random access). Table 6 summarizes the bandwidth lighthouse’s quantitative properties:
| Property | Value | System Implication |
|---|---|---|
| Parameters | 1.5B | Weight loading dominates inference latency. |
| Model Size | 6 GB (FP32) | Fits on one GPU but saturates HBM bandwidth. |
| Compute | 3 GFLOP/token | Low per-token compute; bottleneck is data movement, not math. |
| Constraint | Memory Bandwidth | tokens/s \(\propto\) HBM bandwidth (for example, H100’s 3.35 TB/s). |
| Profile | Bandwidth-Bound (inference) | Training is compute bound; inference is bandwidth bound. |
The KV Cache21 grows linearly with sequence length (\(\mathcal{O}(N_L \times 2 \times N_{\text{heads}} \times S \times d_{\text{head}})\) per request, distinct from the \(\mathcal{O}(S^2)\) attention score matrix during training), storing the Key and Value vectors for all previous tokens to avoid recomputing them (Pope et al. 2023; Kwon et al. 2023). For long contexts, this cache becomes massive (for example, 100+ GB), forcing the system to fetch the full cache from HBM for every generated token. As the GPT-2 Lighthouse quantified earlier, the arithmetic intensity is about 0.5 FLOP/byte with FP32 weights or about 1 FLOP/byte with FP16 weights, explaining why serving LLMs requires massive HBM bandwidth (for example, H100’s 3.35 TB/s) rather than raw FLOP/s.
21 KV Cache Memory Scaling: For a 7-billion-parameter transformer in FP16, model weights consume ~14 GB. A single concurrent request’s KV cache requires: 32 layers \(\times\) 2 (K,V) \(\times\) 32 heads \(\times\) 2,048 positions at 128 dimensions per head \(\times\) 2 bytes ≈ 1.07 GB. At 8 concurrent users, KV cache alone (~8.6 GB) rivals the model weights—and grows linearly with both context length and concurrent users. Scaling serving throughput therefore forces memory-systems choices such as grouped-query attention (Ainslie et al. 2023), shorter context windows, or KV paging/offloading strategies (Kwon et al. 2023); none of these changes model quality, since the model is identical regardless of which memory strategy is chosen.
Ainslie, Joshua, James Lee-Thorp, Michiel de Jong, Yury Zemlyanskiy, Federico Lebron, and Sumit Sanghai. 2023. “GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints.” Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, 4895–901. https://doi.org/10.18653/v1/2023.emnlp-main.298.
Kwon, Woosuk, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. 2023. “Efficient Memory Management for Large Language Model Serving with PagedAttention.” Proceedings of the 29th Symposium on Operating Systems Principles, 611–26. https://doi.org/10.1145/3600006.3613165.
This implementation reveals three key computational characteristics. Self-attention enables parallel processing across all positions in the sequence, mapping efficiently to modern hardware during training. The quadratic complexity, however, creates a training bottleneck for long sequences. The autoregressive nature of inference creates a third constraint: a bandwidth bottleneck where memory speed, not compute speed, is the primary determinant of generation latency.
Despite these computational costs, the effectiveness of attention has driven sustained engineering effort to push context limits ever further. Figure 10 is a point-in-time schematic: early widely used transformer reports exposed context windows around 512–2K tokens for BERT, GPT-2, and GPT-3-style models (Devlin et al. 2019; Radford et al. 2019; Brown et al. 2020), while later product and technical announcements reported much larger windows such as GPT-4 Turbo (128K), Claude 2.1 (200K), and Gemini 1.5 (1M+) (OpenAI 2023; Anthropic 2023; Google 2024). Treat these product names as dated scale anchors: the durable systems lesson is that longer contexts trade external retrieval and chunking complexity for larger attention and KV-cache budgets. Techniques like FlashAttention (Dao et al. 2022), sparse attention, and architectural innovations make that trade-off less expensive but do not repeal the memory scaling.
Devlin, Jacob, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. “BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding.” Proceedings of the 2019 Conference of the North, 4171–86. https://doi.org/10.18653/v1/n19-1423.
Radford, Alec, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. 2019. Language Models Are Unsupervised Multitask Learners. OpenAI.
OpenAI. 2023. New Models and Developer Products Announced at DevDay.
Anthropic. 2023. Introducing Claude 2.1.
Google. 2024. Our Next-Generation Model: Gemini 1.5.
This examination of MLPs, CNNs, RNNs, attention mechanisms, and transformers reveals both their individual characteristics and their collective evolution. Each addresses distinct data patterns: dense feature interactions, spatial locality, sequential dependencies, and dynamic relational structure. While CNNs and transformers dominate academic attention, industrial AI workloads are driven by a structurally different architecture class.
A curious fact underscores this gap between research focus and industrial reality: recommendation systems account for a majority of AI inference cycles at companies like Meta, Google, and Amazon, yet receive a fraction of the academic attention devoted to language or vision models. The reason is architectural: recommendation systems face a bottleneck that neither CNNs nor transformers were designed to address—not compute, not bandwidth, but raw memory capacity. This final paradigm is the subject of section 1.7.
Self-Check: Question
What architectural change distinguishes transformers from recurrent sequence models and enables GPU-friendly parallelism during training?
- Transformers eliminate the time-step-by-time-step sequential recurrence and use self-attention to connect every sequence position directly, so all positions can be processed in parallel within one forward pass.
- Transformers replace learned projections with fixed, hand-designed feature extractors, reducing parameter count.
- Transformers retain recurrence but remove all normalization layers, which speeds up the per-step compute.
- Transformers process only image patches and cannot process token sequences.
A company runs the same transformer model in two environments: a distributed pretraining job on 1,024 GPUs and a single-GPU autoregressive serving endpoint generating one token at a time. Explain why the dominant bottleneck is different in the two settings and identify which iron-law term each setting stresses.
Why does multi-head attention use multiple independent attention heads instead of one monolithic attention computation with the same total parameter budget?
- Each head operates in a lower-dimensional subspace and learns to attend to a different relational pattern — syntactic, co-reference, positional — in parallel, and their concatenated outputs give the model access to multiple specialized relationships per layer.
- Multi-head attention removes the need for any \(\mathbf{Q}\), \(\mathbf{K}\), or \(\mathbf{V}\) projections entirely, replacing them with direct input routing.
- Multi-head attention forces every token to attend only to its immediate neighbors, which is why it is faster than single-head attention.
- Multi-head attention replaces the \(S \times S\) score matrix with a linear-in-\(S\) structure, eliminating the quadratic memory cost.
True or False: Because self-attention gives each token direct access to every other token, a transformer’s context window can be extended almost indefinitely with no systems consequences.
A serving team profiles a 30-billion-parameter GPT-style LLM and reports that each generated token requires only a modest amount of math relative to the accelerator’s peak FLOP/s, yet tokens-per-second falls far short of what peak FLOP/s would predict. Which diagnosis best fits the GPT-2 lighthouse analysis?
- The workload is memory-bandwidth-bound: each generated token must stream the model’s weight matrices plus read and update the KV cache, producing a low arithmetic-intensity kernel that starves the compute units regardless of advertised TFLOP/s.
- The workload is compute-bound because every token requires materializing a quadratic attention matrix over the entire training corpus.
- The bottleneck is image preprocessing on the CPU, which stalls the GPU before token generation can begin.
- Transformers cannot batch inference requests at all, so throughput is capped at one sample per GPU.
Growing transformer context windows from 2,048 tokens (GPT-3) to hundreds of thousands (recent long-context models) is widely called a ‘systems breakthrough’ rather than merely a bigger-model story. Explain what specifically had to change to make this possible and why naive transformer attention could not simply be scaled to long context.
Sparse Architectures: RecSys
When a user opens a streaming service, the system must select a handful of recommendations from a catalog of millions—in under 50 milliseconds. The fundamental challenge is representing both users and items as dense vectors in a shared embedding space, then computing similarity at scale.
Unlike the architectures examined so far, which are typically compute bound or bandwidth bound, recommendation models are uniquely memory-capacity-bound due to their reliance on massive embedding tables. This distinction explains why the same GPU that processes transformers efficiently may struggle with recommendation workloads.
Pattern processing needs
The core challenge in RecSys is handling high-cardinality categorical features. A model might need to process User IDs (billions of unique users) and Item IDs (millions of videos or products). Raw IDs carry no geometry: user 1042 is not “near” user 1043 in any meaningful sense, and a neural network cannot infer similarity from the integer itself.
Embeddings solve the representation problem by mapping each ID to a dense vector called an embedding22 (Mikolov et al. 2013). The systems cost is that every lookup becomes a random read into a potentially enormous table. Recommendation workloads therefore inherit a capacity and bandwidth problem before the dense neural network layers begin.
22 Embedding: From the mathematical concept of embedding one space into another: neural embeddings map discrete tokens (user IDs, words) into continuous vector spaces where semantic similarity becomes geometric proximity. The term entered ML via word2vec (2013). For systems, embedding tables create a distinctive memory access pattern: each lookup is a random read into a potentially terabyte-scale table, producing the sparse, bandwidth-bound workload that makes DLRM fundamentally different from compute-bound architectures like ResNet.
Mikolov, Tomas, Kai Chen, Greg Corrado, and Jeffrey Dean. 2013. “Efficient Estimation of Word Representations in Vector Space.” ICLR abs/1301.3781.
Algorithmic structure
The DLRM architecture (Naumov et al. 2019) standardizes this pattern as a four-stage pipeline split across dense and sparse regimes. Continuous features such as user age or time of day first flow through a bottom MLP, a compute-intensive but memory-light stage. The sparse stage then looks up categorical IDs in embedding tables, which is where the capacity wall appears:
Naumov, Maxim, Dheevatsa Mudigere, Hao-Jun Michael Shi, Jianyu Huang, Narayanan Sundaraman, Jongsoo Park, Xiaodong Wang, et al. 2019. “Deep Learning Recommendation Model for Personalization and Recommendation Systems.” arXiv Preprint arXiv:1906.00091.
Categorical features such as user ID or item ID are looked up in massive embedding tables. A table for one billion users with 128-dimensional vectors requires \(10^9 \times 128 \times 4\) bytes \(\approx\) 512 GB of memory, making this stage memory-intensive but compute-light because each lookup is essentially a memory copy. The interaction layer then combines dense vectors from the MLP with sparse embedding vectors, typically through dot products that capture user-item relationships. A top MLP finally processes the combined features to produce a probability such as click-through rate. This combination of dense and sparse computation makes DLRM the chapter’s recommendation lighthouse; the next section quantifies the capacity-bound profile that results.
Computational mapping and system implications
DLRM’s computational mapping splits into two regimes that stress different hardware subsystems. The dense MLPs are standard GEMM operations, identical to the MLP computational mapping discussed in section 1.2.4 and handled efficiently by Tensor Cores. The sparse embedding lookups, however, are qualitatively different: they are index-based memory copies (gather operations) with no arithmetic, making them entirely memory-bandwidth bound at the operation level. This is distinct from the capacity constraint described earlier: the total size of the embedding tables is what makes the model memory-capacity-bound, whereas the speed of each individual gather is what makes the lookup operations memory-bandwidth bound. Because each training sample accesses a different set of embedding rows, the access pattern is effectively random, defeating caching and prefetching strategies that benefit CNNs and MLPs.
Lighthouse 1.6: DLRM (recommendation lighthouse)
Why it matters: DLRM exemplifies memory-capacity-bound workloads. Its massive embedding tables often exceed the memory of a single accelerator or server, so the system must decide where those tables live before it can optimize arithmetic throughput. The interaction layer then gathers selected embedding vectors and combines them with dense features, making capacity and irregular data movement the dominant constraints. This contrasts sharply with CNNs (compute bound) and transformers (memory-bandwidth bound), requiring different hardware and deployment choices. Table 7 summarizes the recommendation lighthouse’s quantitative properties:
| Property | Value | System Implication |
|---|---|---|
| Embedding Parameters | 25B | Parameters \(\times\) 4 bytes; dominates total model size. |
| Model Size | 100 GB (FP32) | May exceed one device’s fast memory. |
| Constraint | Memory Capacity | Model size > Single GPU Memory. |
| Bottleneck | Irregular Data Movement | Gather operations dominate sparse feature processing. |
| Profile | Mixed (Sparse/Dense) | Combines memory-heavy lookups with compute-heavy MLPs. |
DLRM creates a unique systems challenge: the model is too big to fit on a single GPU. While a ResNet-50 (102.4 MB) or even GPT-3 (350 GB) might fit on a single node, industrial recommendation models can reach terabytes or petabytes due to massive embedding tables. In iron law terms (Iron Law of ML Systems), neither \(O\) nor \(D_{\text{vol}}\) is the binding constraint—it is raw memory capacity that limits the system, a regime the iron law was not designed to capture.

DLRM embedding lookups can depend on vectors stored outside the local memory partition.
The architecture therefore breaks the single-device assumption that worked for the earlier families. A designer has three broad options, and each changes a different part of the system:
- Shrink the tables: Compression, hashing, or pruning can reduce capacity pressure, but these techniques may lose information about rare users or items.
- Move the tables: Embeddings can live in CPU memory, host memory, or a storage-backed feature system, but every lookup then pays a data-movement cost.
- Partition the tables: Tables can be split across multiple memory resources so no one device stores the whole model, but each request may need vectors from several partitions.
This chapter only needs the architectural consequence: DLRM turns recommendation into a capacity-management problem before it becomes a compute-optimization problem. The corresponding execution strategies include training-time partitioning in Model Training and hardware support for fast data movement in Hardware Acceleration.
At 100 million IDs and 128 FP32 values per ID, one embedding table already consumes most of an 80 GB accelerator budget.

One embedding table fits an 80 GB A100; a second breaches the capacity wall.
Napkin Math 1.2: The capacity wall
Problem: Consider a recommendation system for a store with 100M items using an embedding size of 128. How much memory does the item table alone require?
Math:
- Table entries: 100M items.
- Vector size: 128 elements.
- Precision: FP32 (4 bytes per element).
- Table size: 100M items \(\times\) 128 \(\times\) 4 bytes ≈ 51.2 GB.
Systems insight: A single embedding table for one feature (Items) already consumes 64 percent of an 80 GB A100 GPU. Adding a User table of the same size means the embedding tables no longer fit on a single 80 GB, motivating either smaller tables, off-device memory, or partitioning across memory resources. DLRM is capacity bound: the first question is not how many FLOPs the accelerator can deliver, but where the embedding state can physically reside.
Once those tables no longer fit on one device, the bottleneck shifts from storing embeddings to moving sparse embedding lookups across memory and network boundaries. Partitioning an embedding table means that one request may need rows owned by several devices; the local dense MLP cannot continue until those remote rows have been gathered. In a single node, that exchange stresses the accelerator interconnect. Across nodes, the same pattern becomes a many-device exchange problem because each device may need different sparse rows at the same time. For a foundational understanding, we need only the architectural consequence: DLRM is not merely “large”; its memory layout determines the communication pattern any serving or training system must pay. Later at fleet scale, this becomes a distributed coordination challenge.
Checkpoint 1.4: DLRM and sparse scatter
Recommendation systems stress a different part of the machine than CNNs or transformers.
The five architecture families examined earlier (MLPs, CNNs, RNNs, transformers, and DLRM-style sparse models) appear to differ fundamentally, yet they share a striking convergence: many modern deep variants reuse a small set of primitives such as dense projections, normalization, skip connections, and gating. Every transformer block contains a feedforward MLP, and gating, invented for RNNs, reappears in mixture-of-experts routing. These building blocks are portable: they originated in one architecture family but migrated broadly because the problems they solve (gradient flow, activation stability, signal routing) recur across data types and inductive biases. For systems engineers, this portability is critical because it reveals which hardware optimizations transfer across workloads and which remain architecture-specific.
Self-Check: Question
A recommendation system must represent 500 million unique user IDs and 100 million unique item IDs as inputs to a neural network that accepts dense vectors. Which property of embedding tables makes them the standard bridge between these high-cardinality categorical IDs and dense-network computation?
- Each discrete ID indexes a row of learned dense floats, so every ID becomes a trainable vector whose dimensions the downstream network can process like any other dense input — at the cost of a table whose row count equals the cardinality of the ID space.
- Embeddings remove all memory accesses from inference, because once trained, the table is no longer consulted.
- Embeddings convert recommendation workloads from memory-bound to compute-bound, eliminating the need for specialized memory hardware.
- Embeddings are only valid in language models and are copied into RecSys without change or justification.
A DLRM with 500 million user embeddings at 128 dimensions in FP32 already requires about 256 GB for user embeddings alone, before item embeddings or any MLP weights. Explain why the section calls DLRM ‘capacity-bound’ rather than compute-bound or bandwidth-bound and what that diagnosis forces on the infrastructure.
Why do embedding-table lookups in a production DLRM resist the cache-and-prefetch optimizations that accelerate CNN convolutions or dense MLP layers?
- Each request gathers a different set of embedding rows determined by the user’s and items’ IDs, so the access pattern is effectively random across a terabyte-scale table: hardware prefetchers cannot predict it, and caches cannot hold enough rows to exploit reuse.
- Embedding tables are always smaller than the L1 cache and therefore bypass the memory hierarchy entirely.
- Recommendation models do not use matrix operations anywhere, so the memory system cannot be optimized for them.
- Sparse embedding access inherits the translation-equivariance properties of CNNs, which blocks caching.
Order the following high-level stages of a DLRM forward pass on one user-item example: (1) interaction layer combines dense and sparse representations, (2) bottom MLP processes continuous numerical features, (3) top MLP produces the final click-probability score, (4) embedding-table lookup retrieves vectors for categorical IDs.
A recommendation team finds that their DLRM’s combined embedding tables total 600 GB, exceeding any single 80 GB accelerator. Which distributed-memory strategy does the section identify as the required response?
- Shard the embedding tables across multiple accelerators so each holds a disjoint subset of rows, then use all-to-all communication at lookup time to fetch each batch’s required rows from wherever they reside.
- Replicate every embedding table fully on every accelerator and rely solely on data parallelism for scaling.
- Replace the embedding tables with convolutions so the model becomes spatially local and fits on one device.
- Move the model to a single CPU because CPUs do not have memory-capacity limits.
True or False: In a sharded DLRM deployment, interconnect bandwidth can become a first-order bottleneck because each GPU’s forward pass may require rows from embeddings stored on many other GPUs.
Shared Building Blocks
A transformer block reuses several ideas born elsewhere: dense projections from MLPs, residual paths from deep CNNs, normalization for activation stability, and gating-like routing in later variants. The five architecture families differ in their data assumptions, but many of their engineering problems recur, so the practical question is which building blocks and optimizations transfer. Table 8 shows how these primitives accumulated as architectures grew more complex: each era inherited the tools of its predecessors while adding a mechanism for the next bottleneck.
Those portable building blocks were shaped by the hardware available at the time. LeNet-5 (LeCun et al. 1998) trained on CPUs with networks small enough to fit in megabytes of memory. AlexNet (Krizhevsky et al. 2012) required GPU parallelism: its 60 million parameters and billions of floating-point operations per image were infeasible on CPUs of that era, but mapped naturally to GPU architectures designed for graphics workloads with similar parallel structure. ResNet-152 (He et al. 2016a) became trainable because residual connections and batch normalization improved optimization at depth, using available GPU training infrastructure rather than a specific memory-capacity threshold. Transformers (Vaswani et al. 2017) became practical on contemporary GPUs and later scaled dramatically as GPU/TPU memory bandwidth and distributed training infrastructure improved. This pattern continues: each building block exploits newly available computational resources while pushing against the limits of existing systems.
LeCun, Yann, Léon Bottou, Yoshua Bengio, and Patrick Haffner. 1998. “Gradient-Based Learning Applied to Document Recognition.” Proceedings of the IEEE 86 (11): 2278–324. https://doi.org/10.1109/5.726791.
Krizhevsky, Alex, Ilya Sutskever, and Geoffrey E. Hinton. 2012. “ImageNet Classification with Deep Convolutional Neural Networks.” Advances in Neural Information Processing Systems 25.
Vaswani, Ashish, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. 2017. “Attention Is All You Need.” Advances in Neural Information Processing Systems 30: 5998–6008.
| Building Block | Born In | Problem Solved | Now Used In |
|---|---|---|---|
| Dense Matrix Ops (GEMM) | MLPs | Universal function approximation | All architectures (feedforward layers) |
| Parameter Sharing | CNNs | Spatial efficiency | Transformers (shared projections), RNNs (weight reuse across time) |
| Skip Connections | ResNets (CNNs) | Gradient flow at depth | Transformers, DenseNets, U-Nets, many modern deep networks |
| Normalization | CNNs (BatchNorm) | Activation stability | LayerNorm (Transformers), RMSNorm (root-mean-square normalization), GroupNorm (grouped channels) |
| Gating | LSTMs (RNNs) | Selective signal routing | Transformers (mixture-of-experts routing), GRUs, highway networks |
Dense operations: The universal baseline
The dense matrix multiply (GEMM) is the one primitive shared by every architecture in this chapter. While section 1.2 examined MLPs as dense pattern processors, the systems engineering legacy of GEMM extends far beyond MLPs. It is the feedforward layer inside every transformer block, the \(1{\times}1\) pointwise convolution in MobileNets, the input and recurrent projections inside every RNN cell, and the bottom MLP in every DLRM.
MLPs introduced the GEMM-dominated computation profile that led GPU vendors to develop Tensor Cores. The backpropagation algorithm’s23 memory access patterns, with its alternating forward and backward passes storing intermediate activations, influenced accelerator memory hierarchies. The batch processing paradigm pioneered for MLP training established the data-center-scale throughput optimization that defines modern ML infrastructure. These foundational patterns (dense matrix operations, gradient-based optimization, batch-oriented processing) appear in every architecture examined in this chapter, even when obscured by domain-specific terminology.
23 Backpropagation: Rumelhart, Hinton, and Williams showed in 1986 how to efficiently apply the chain rule to train multi-layer networks. The algorithm remains virtually unchanged, but its systems consequence is permanent: backpropagation requires storing all intermediate activations from the forward pass, meaning training memory scales linearly with network depth. This activation storage, not the weight matrices, is often the binding memory constraint that determines maximum feasible batch size on a given accelerator.
Dense connectivity also established the cost baseline that every subsequent architecture navigates. At \(\mathcal{O}(n^2)\) parameters and operations for layers of width \(n\), GEMM sets the reference point against which specialized architectures demonstrate efficiency gains. CNNs achieve spatial processing with \(\mathcal{O}(k^2)\) parameters per location (where \(k\) is kernel size), transformers trade parameter efficiency for dynamic computation with \(\mathcal{O}(S^2)\) attention complexity, and sparse architectures like DLRM exploit embedding lookups to handle categorical dimensions that would explode dense layer sizes. Each innovation represents a different strategy for escaping the dense connectivity baseline, but none escapes GEMM itself—it reappears inside every architecture as the workhorse of feature transformation.
Skip connections: Solving the depth problem
Parameter sharing (born in CNNs) made deep networks efficient, but efficiency alone could not solve the challenges of training them. As practitioners attempted to build deeper CNNs for more complex tasks, they encountered a barrier that now confronts every deep architecture: the gradient flow problem. The mathematical foundation for skip connections starts with the failure modes of depth: vanishing gradients, exploding gradients, the limitations of ReLU, and the residual solution that enabled networks exceeding 100 layers.
The problem of depth
Backpropagation through \(N_L\) layers applies the chain rule repeatedly; Gradient computation and backpropagation gives the formal derivation of backpropagation and the chain rule. For a deep network with layers \(f_1, f_2, \ldots, f_{N_L}\), the gradient of the loss \(\mathcal{L}\) with respect to the weights in layer 1 is: \[ \frac{\partial \mathcal{L}}{\partial W_1} = \frac{\partial \mathcal{L}}{\partial a_{N_L}} \cdot \frac{\partial a_{N_L}}{\partial z_{N_L}} \cdot \frac{\partial z_{N_L}}{\partial a_{N_L-1}} \cdot \ldots \cdot \frac{\partial z_2}{\partial a_1} \cdot \frac{\partial a_1}{\partial z_1} \cdot \frac{\partial z_1}{\partial W_1} \] where \(z_\ell\) represents the preactivation and \(a_\ell = \sigma(z_\ell)\) the postactivation output of layer \(\ell\). The gradient becomes a product of \(N_L\) terms, each depending on the activation function derivative \(\sigma'(z_\ell)\).
Vanishing gradients create a silent training failure in deep architectures. For sigmoid activation functions, the derivative is \(\sigma'(z) = \sigma(z)(1 - \sigma(z))\), with maximum value \(\sigma'(0) = 0.25\). Through \(N_L\) layers, the gradient magnitude is multiplied by approximately \((0.25)^{N_L}\). With such extreme attenuation, early layers receive infinitesimal gradient signals. Weight updates become negligible, effectively preventing these layers from training.
Exploding gradients are the catastrophic counterpart to vanishing gradients. If activation function derivatives exceed one, gradients grow exponentially through the layers. Consider a network where each layer’s Jacobian has eigenvalues around 1.5. This exponential growth causes numerical overflow producing not a number (NaN) values, extreme parameter updates, and training divergence. Unlike vanishing gradients which silently prevent learning, exploding gradients cause immediate training failure.
Quantitative analysis: Plain deep networks
Consider training a deep plain convolutional network on CIFAR-10 without architectural interventions. Even with ReLU activations, which have derivative one for positive inputs, optimization can degrade as depth increases. The original ResNet paper reported that a 56-layer plain network had substantially worse CIFAR-10 test error than a 20-layer plain network (about 13.6 percent vs. 8.8 percent), demonstrating that simply adding layers can make optimization worse despite greater representational capacity (He et al. 2016a).
This “degradation problem” is not overfitting. Deeper networks train worse than shallow ones, contradicting the intuition that more layers should provide more representational capacity.
Why ReLU helps but is not sufficient
ReLU activation (\(\text{ReLU}(z) = \max(0, z)\)) has derivative: \[ \text{ReLU}'(z) = \begin{cases} 1 & \text{if } z > 0 \\ 0 & \text{if } z \leq 0 \end{cases} \]
Through active paths \((z > 0)\), the derivative equals 1, avoiding gradient decay from the activation function. This represents significant improvement over sigmoid, enabling training of networks with 10–20 layers.
However, ReLU introduces a different problem: dead neurons. When \(z \leq 0\), the gradient is exactly zero, permanently blocking gradient flow through that path. A poorly initialized neuron or large gradient update can push a ReLU unit into the negative regime across all training examples, causing it to “die” and never recover. ReLU does not solve gradient flow issues arising from weight matrices themselves. If weight matrices have eigenvalues far from 1, gradients still vanish or explode regardless of activation function.
The residual solution
ResNet blocks introduce residual learning through skip connections that transform gradient flow. A residual block computes equation 9: \[ \mathbf{y} = \mathcal{F}(\mathbf{x}) + \mathbf{x} \tag{9}\] where \(\mathcal{F}(\mathbf{x})\) represents the residual function (typically two convolutional layers with batch normalization and ReLU) and \(\mathbf{x}\) is the identity skip connection.
During backpropagation, the gradient flows through this addition: \[ \frac{\partial \mathcal{L}}{\partial \mathbf{x}} = \frac{\partial \mathcal{L}}{\partial \mathbf{y}} \cdot \frac{\partial \mathbf{y}}{\partial \mathbf{x}} = \frac{\partial \mathcal{L}}{\partial \mathbf{y}} \cdot \frac{\partial (\mathcal{F}(\mathbf{x}) + \mathbf{x})}{\partial \mathbf{x}} \]
Applying the chain rule: \[ \frac{\partial \mathcal{L}}{\partial \mathbf{x}} = \frac{\partial \mathcal{L}}{\partial \mathbf{y}} \cdot \left(\frac{\partial \mathcal{F}(\mathbf{x})}{\partial \mathbf{x}} + \mathbf{I}\right) = \frac{\partial \mathcal{L}}{\partial \mathbf{y}} \cdot \mathcal{F}'(\mathbf{x}) + \frac{\partial \mathcal{L}}{\partial \mathbf{y}} \]
This equation reveals the critical insight: the gradient divides into two paths. The residual path, \(\frac{\partial \mathcal{L}}{\partial \mathbf{y}} \cdot \mathcal{F}'(\mathbf{x})\), can vanish if \(\mathcal{F}'(\mathbf{x}) \to 0\), whereas the identity path, \(\frac{\partial \mathcal{L}}{\partial \mathbf{y}}\), always flows unimpeded. The identity term ensures that even if the residual function produces vanishing gradients, the gradient signal \(\frac{\partial \mathcal{L}}{\partial \mathbf{y}}\) flows directly to earlier layers.
Gradient flow through multiple blocks
Through \(N_L\) residual blocks, the gradient becomes: \[ \frac{\partial \mathcal{L}}{\partial \mathbf{x}_0} = \frac{\partial \mathcal{L}}{\partial \mathbf{x}_{N_L}} \cdot \prod_{\ell=1}^{N_L} \left(\mathcal{F}'_\ell(\mathbf{x}_\ell) + \mathbf{I}\right) \]
Each factor \((\mathcal{F}'_\ell + \mathbf{I})\) contains the identity term, preserving a direct gradient component even when the residual-branch Jacobian is small. Unlike plain networks where gradients multiply arbitrary layer Jacobians, ResNets multiply factors that maintain a stable identity path. This mathematical property allows training of networks with 100+ layers.
Theorem 1.2: Residual Jacobian conditioning
Analysis: Consider the network as a composition of functions \(\mathbf{x}_{\ell+1} = f_\ell(\mathbf{x}_\ell)\). By the chain rule, the gradient at the input is the product of layer Jacobians \(\mathbf{J}_\ell = \frac{\partial f_\ell}{\partial \mathbf{x}_\ell}\): \[
\frac{\partial \mathcal{L}}{\partial \mathbf{x}_0} = \frac{\partial \mathcal{L}}{\partial \mathbf{x}_{N_L}} \cdot \prod_{\ell=1}^{N_L} \mathbf{J}_\ell
\]
For plain networks, \(\mathbf{J}_\ell\) is arbitrary. If its spectral radius (largest eigenvalue magnitude) \(\rho(\mathbf{J}_\ell) < 1\), gradients vanish exponentially \((\rho^{N_L} \to 0)\). If \(\rho(\mathbf{J}_\ell) > 1\), gradients explode \((\rho^{N_L} \to \infty)\). Balancing hundreds of matrices on this “edge of chaos” is numerically impossible.
For ResNets, the layer function is \(\mathbf{x}_{\ell+1} = \mathbf{x}_\ell + \mathcal{F}(\mathbf{x}_\ell)\), so the Jacobian is: \[ \mathbf{J}_\ell = \mathbf{I} + \frac{\partial \mathcal{F}}{\partial \mathbf{x}_\ell} \] where \(\mathbf{I}\) is the identity matrix. The eigenvalues of \(\mathbf{J}_\ell\) are \(1 + \lambda_i\), where \(\lambda_i\) are the eigenvalues of the residual branch \(\mathcal{F}'\). Since the residual branch is initialized with small weights, \(\lambda_i \approx 0\), meaning the total eigenvalues cluster around 1. This structure creates a “gradient highway” where signals propagate with unit gain, solving the vanishing gradient problem by construction rather than by tuning.
Empirical validation: 50-Layer comparison
The ResNet CIFAR-10 experiments provide the empirical contrast: residual networks avoided the degradation seen in deeper plain networks and achieved lower training and test error as depth increased. In the same family of experiments, a 56-layer residual network reached about 7.0 percent test error, improving over the deeper plain network rather than degrading with depth (He et al. 2016a). The critical difference appears in gradient flow and optimization: identity shortcuts give later layers a direct path to refine earlier representations rather than forcing every layer to learn a complete transformation from scratch.
He, Kaiming, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2016a. “Deep Residual Learning for Image Recognition.” 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 770–78. https://doi.org/10.1109/cvpr.2016.90.
While skip connections solve gradient flow, they introduce system-level costs. Memory overhead increases because skip connections require storing the input to each residual block for the addition operation during the forward pass and for backpropagation. For a ResNet-50 with batch size 32 processing \(224{\times}224\) RGB images, this adds approximately 20 percent memory overhead compared to a plain network. The computational cost of the addition operation (\(\mathbf{y} = \mathcal{F}(\mathbf{x}) + \mathbf{x}\)) is computationally trivial, adding negligible compute time. The primary cost is the residual function \(\mathcal{F}(\mathbf{x})\) itself.
Better gradient flow accelerates convergence and reduces total training time. ResNet-50 typically converges in 90 epochs on ImageNet, while plain 50-layer networks may not converge at all. The per-epoch cost increases by approximately 10 percent due to memory overhead, but total training time decreases dramatically because the network actually learns.
These empirical results establish a systems constraint: depth requires architectural support for gradient flow. The relationship is quantitative. Networks with fewer than 20 layers can train without skip connections, as demonstrated by architectures like VGG-16 (Simonyan and Zisserman 2015). Between 20 and 100 layers, skip connections become necessary, which is why ResNet-50 and ResNet-101 incorporate them. Beyond 100 layers, skip connections alone prove insufficient; pre-activation residual variants such as ResNet-v2 require skip connections plus careful normalization to maintain trainability (He et al. 2016b).
Simonyan, Karen, and Andrew Zisserman. 2015. “Very Deep Convolutional Networks for Large-Scale Image Recognition.” arXiv Preprint.
He, Kaiming, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2016b. “Identity Mappings in Deep Residual Networks.” Computer Vision – ECCV 2016, 630–45. https://doi.org/10.1007/978-3-319-46493-0_38.
This constraint shapes architecture selection: if the task benefits from depth (and empirically, most vision and language tasks do), the architecture must incorporate mechanisms to maintain gradient flow. Skip connections are a necessity, not an optional optimization.
The gradient flow improvements from skip connections solved one critical training challenge, but revealed another: controlling activation distributions across layers. Even with skip connections ensuring gradient flow, poorly conditioned activations can destabilize training. Skip connections guarantee gradients reach early layers; normalization ensures those gradients have stable magnitude. That distinction explains why modern architectures universally include normalization alongside skip connections.
Normalization: Stabilizing activations at depth
Skip connections ensure gradients reach early layers; normalization ensures those gradients have stable magnitude. Like skip connections, normalization is a portable building block: it was born as batch normalization in CNNs24 (Ioffe and Szegedy 2015), evolved into layer normalization for transformers, and most recently simplified into RMSNorm25 for efficient LLMs. Every modern architecture deeper than ~10 layers uses some variant. Understanding the mathematics of normalization reveals why these layers are not merely optimization tricks but essential components enabling deep network training.
24 Batch Normalization (BatchNorm): The original normalization layer (Ioffe and Szegedy 2015), which stabilizes training by re-scaling activations using per-mini-batch statistics, enabling higher learning rates that cut ImageNet training time by 14\(\times\). Its batch-size dependency and training-serving skew (switching from batch statistics to running averages at inference) are the systems limitations that drove the subsequent evolution: LayerNorm removed batch dependency for transformers, and RMSNorm further halved the normalization cost for LLMs.
Ioffe, Sergey, and Christian Szegedy. 2015. “Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift.” Proceedings of the 32nd International Conference on Machine Learning (ICML) 37: 448–56.
25 RMSNorm (Root Mean Square Normalization): Introduced by Zhang and Sennrich (2019) at NeurIPS, RMSNorm simplifies LayerNorm by normalizing with the root mean square alone, dropping the mean-centering step. This eliminates one full reduction pass over the feature dimension, reducing per-layer normalization latency by 7–64 percent depending on model size. LLaMA-family and Mixtral-style transformer reports use RMSNorm (Touvron, Lavril, et al. 2023; Touvron, Martin, et al. 2023; Jiang et al. 2024), illustrating why one reduction pass can matter for transformer inference latency.
Zhang, Biao, and Rico Sennrich. 2019. “Root Mean Square Layer Normalization.” Advances in Neural Information Processing Systems (NeurIPS).
Touvron, Hugo, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, et al. 2023. “LLaMA: Open and Efficient Foundation Language Models.” arXiv Preprint arXiv:2302.13971.
Touvron, Hugo, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, et al. 2023. “Llama 2: Open Foundation and Fine-Tuned Chat Models.” arXiv Preprint arXiv:2307.09288.
Jiang, A. Q., A. Sablayrolles, A. Roux, A. Mensch, B. Savary, C. Bamford, D. S. Chaplot, et al. 2024. “Mixtral of Experts.” arXiv Preprint arXiv:2401.04088.
Batch normalization: Definition and formulation
Batch normalization normalizes activations using statistics computed over the mini-batch for each feature or channel during training. For fully connected activations, the averaging axis is the batch. For convolutional activations, implementations typically compute per-channel statistics over both the batch and spatial positions. For a mini-batch \(\mathcal{B} = \{x_1, \ldots, x_B\}\) of activations at a particular layer, the transformation proceeds in two stages.
First, compute the batch statistics: \[ \mu_{\mathcal{B}} = \frac{1}{B}\sum_{i=1}^{B} x_i \qquad \sigma_{\mathcal{B}}^2 = \frac{1}{B}\sum_{i=1}^{B} (x_i - \mu_{\mathcal{B}})^2 \]
Then, over the batch, normalize and apply learnable scale and shift. The normalization step in equation 10 centers and scales activations, while equation 11 applies learnable parameters that allow the network to recover the identity transformation if optimal: \[ \hat{x}_i = \frac{x_i - \mu_{\mathcal{B}}}{\sqrt{\sigma_{\mathcal{B}}^2 + \epsilon}} \tag{10}\] \[ y_i = \gamma \hat{x}_i + \beta \tag{11}\]
The parameters \(\gamma\) (scale) and \(\beta\) (shift) are learned during training, while \(\epsilon\) (typically \(10^{-5}\)) prevents division by zero. This formulation ensures the network can represent the identity transformation if optimal (\(\gamma = \sqrt{\sigma_{\mathcal{B}}^2 + \epsilon}\), \(\beta = \mu_{\mathcal{B}}\)), preserving representational capacity.
Theorem 1.3: Normalization Jacobian conditioning
Analysis: The mathematical insight into why normalization aids training lies in how it conditions the Jacobian matrix of the layer. For the current batch, consider the gradient of the normalized output with respect to the input: \[
\frac{\partial \hat{x}_i}{\partial x_j} = \frac{1}{\sqrt{\sigma_{\mathcal{B}}^2 + \epsilon}} \left( \delta_{ij} - \frac{1}{B} - \frac{(x_i - \mu_{\mathcal{B}})(x_j - \mu_{\mathcal{B}})}{B(\sigma_{\mathcal{B}}^2 + \epsilon)} \right)
\] where \(\delta_{ij}\) is the Kronecker delta. The critical observation is that this Jacobian has bounded eigenvalues. Without normalization, the Jacobian of a linear layer with weight matrix \(\mathbf{W}\) can have eigenvalues spanning orders of magnitude (empirically, 0.01 to 100 in deep networks). With batch normalization, the effective Jacobian eigenvalues are constrained to a much narrower range, typically within \([0.5, 2.0]\).
This constraint prevents both vanishing gradients (eigenvalues \(\ll 1\)) and exploding gradients (eigenvalues \(\gg 1\)) through the normalization layer itself. The quantitative impact on training stability is substantial: without normalization, gradient norms can vary by factors of \(10^4\) across layers, but with batch normalization, gradient norms typically vary by only factors of two to four across layers.
Normalization enables significantly higher learning rates. Networks with batch normalization commonly train with learning rates 10 to 30 times larger than unnormalized networks, directly accelerating convergence.
Layer normalization: Architecture independence
While batch normalization enabled training of much deeper CNNs, it introduced a problematic dependency on batch statistics. This creates issues for small batch sizes (noisy statistics), varying sequence lengths (incompatible batch dimensions), and inference (requires running mean/variance estimation). Layer normalization addresses these limitations by normalizing across features rather than across the batch (Ba et al. 2016).
For an input vector \(\mathbf{x} \in \mathbb{R}^{d_{\text{model}}}\) with \(d_{\text{model}}\) features: \[ \mu_{\text{LN}} = \frac{1}{d_{\text{model}}}\sum_{i=1}^{d_{\text{model}}} x_i \qquad \sigma_{\text{LN}}^2 = \frac{1}{d_{\text{model}}}\sum_{i=1}^{d_{\text{model}}} (x_i - \mu_{\text{LN}})^2 \]
Equation 12 defines the complete layer normalization operation, where \(\odot\) denotes element-wise multiplication: \[ \text{LayerNorm}(\mathbf{x}) = \frac{\mathbf{x} - \mu_{\text{LN}}}{\sqrt{\sigma_{\text{LN}}^2 + \epsilon}} \odot \boldsymbol{\gamma} + \boldsymbol{\beta} \tag{12}\]
Layer normalization normalizes each sample independently, making the operation invariant to batch size and suitable for autoregressive models where per-sample independence is required (batch statistics would leak information across samples). This architectural difference explains why transformers universally adopt layer normalization: the self-attention mechanism processes sequences of varying length, and autoregressive generation requires each position to be normalized independently of batch composition.
Comparative analysis: When to use each variant
The choice between normalization variants depends on computational context. Table 9 summarizes the key trade-offs. BatchNorm typically stores learned scale/shift parameters plus nonlearned running mean/variance buffers; LayerNorm computes per-sample statistics at runtime and typically stores learned scale/shift parameters but no running-statistic buffers.
| Characteristic | BatchNorm | LayerNorm | RMSNorm |
|---|---|---|---|
| Normalization Axis | Batch and, for CNNs, spatial positions | Feature dimension | Feature dimension |
| Batch Size Dependency | High (noisy for small batches) | None | None |
| Typical Use Case | CNNs, vision models | Transformers, RNNs | LLaMA, efficient Transformers |
| Computation Cost | Higher (mean + variance) | Higher (mean + variance) | Lower (RMS only) |
| Training/Inference | Different (running stats) | Identical | Identical |
Batch size constraints emerge because batch normalization requires sufficiently large batches for stable statistics. Empirically, batch sizes below 16 degrade performance noticeably, and sizes below 8 can cause training instability. This constraint impacts memory-limited scenarios such as high-resolution images or billion-parameter models.
The computational cost of computing mean and variance adds \(\mathcal{O}(B \times d_{\text{model}})\) operations per batch normalization layer for batch size \(B\) and feature dimension \(d_{\text{model}}\). For layer normalization, the cost is \(\mathcal{O}(d_{\text{model}})\) per sample. RMSNorm reduces this further by eliminating the mean computation.
Operational differences between training vs. inference require explicit mode switching for batch normalization, which exhibits different behavior between training (batch statistics) and inference (running statistics). Incorrect mode handling is a common source of training-serving skew. Layer normalization behaves identically in both modes, simplifying deployment.
Skip connections and normalization solve depth-related problems—gradient flow and activation stability, respectively. The third portable building block, gating, solves a different problem entirely: selectively routing information through the network.
Gating: Controlling information flow
Gating mechanisms were born in RNNs, where early sequence models hit a “temporal barrier”: gradients vanished or exploded through long sequences, revealing that simple recurrence was insufficient for long-term dependencies. LSTMs26 (Hochreiter and Schmidhuber 1997) and GRUs27 (Cho et al. 2014) solved this by introducing gates: small MLPs that learn to control the flow of information through the network, acting as differentiable valves that selectively protect, forget, or route signals.
26 LSTM (Long Short-Term Memory): Invented by Hochreiter and Schmidhuber in 1997, LSTMs introduced a “Constant Error Carousel,” a gated cell state that protects error signals from exponential decay during backpropagation through time. The systems cost of this solution: a standard LSTM computes input, forget, and output gates plus a candidate cell update, giving roughly four affine transformations per time step vs. one in a vanilla RNN. This compute overhead explains why transformers, which solve long-range dependencies through parallelizable attention, replaced LSTMs in many large-scale language workloads.
Hochreiter, Sepp, and Jürgen Schmidhuber. 1997. “Long Short-Term Memory.” Neural Computation 9 (8): 1735–80. https://doi.org/10.1162/neco.1997.9.8.1735.
27 GRU (Gated Recurrent Unit): Cho et al. (2014) describes a gated hidden unit for encoder-decoder translation that uses reset and update gates to control how the hidden state is updated. Relative to an LSTM’s input, forget, and output gates plus candidate cell update, this gives a simpler gated recurrence. The broader systems lesson: architectural simplification can reduce state and matrix operations when it preserves task performance, a principle that recurs in efficiency-oriented designs from MobileNet to distilled transformers.
Cho, Kyunghyun, Bart van Merrienboer, Dzmitry Bahdanau, and Yoshua Bengio. 2014. “On the Properties of Neural Machine Translation: Encoder-Decoder Approaches.” Proceedings of SSST-8, Eighth Workshop on Syntax, Semantics and Structure in Statistical Translation, 103–11. https://doi.org/10.3115/v1/w14-4012.
Bahdanau, Dzmitry, Kyunghyun Cho, and Yoshua Bengio. 2015. “Neural Machine Translation by Jointly Learning to Align and Translate.” International Conference on Learning Representations (ICLR).
The key insight is that gating is not an RNN-specific technique. It is a general principle of using one learned signal to modulate another learned signal. Highway Networks applied the idea to feedforward layers, letting the network decide whether to transform an input or pass it through, which made them an important precursor to skip connections. Attention uses the same principle at the sequence level: encoder-decoder attention (Bahdanau et al. 2015), originally introduced for machine translation, learns which source positions should influence each output position. In transformers, the softmax attention weights become the routing signal that controls how much each position contributes to the output, while later large-scale variants extend the same idea to explicit expert routing. The portability of gating reinforces the central theme: the building blocks that matter most are not tied to any single architecture but solve universal problems—in this case, the problem of selectively routing information through deep, complex networks.
Synthesis: How transformers recombine everything
The transformer is not a new invention so much as a masterful recombination of every building block discussed earlier. A full transformer block combines the residual-path idea illustrated in figure 11 with dense projections, normalization, and attention gating. Dense GEMM operations in MLP-style feedforward networks process features between attention layers. Residual paths wrap every sub-layer, enabling gradient flow through 100+ layer stacks. LayerNorm, evolved from the same stabilization problem that BatchNorm addressed in CNNs, stabilizes activations at each sub-layer (Ba et al. 2016). Softmax attention weights then gate how much each position contributes, while MoE variants extend the same routing idea to explicit expert selection.
Ba, Jimmy Lei, Jamie Ryan Kiros, and Geoffrey E. Hinton. 2016. “Layer Normalization.” arXiv Preprint arXiv:1607.06450.

This recombination is not accidental. The transition from RNNs to transformers represents a decisive engineering shift from sequential to parallel state management. By replacing time-step dependencies with global, data-dependent routing (attention), we moved from \(\mathcal{O}(S)\) sequential complexity to \(\mathcal{O}(1)\) sequential steps for information flow between any two positions, enabling full use of accelerator parallelism. The other building blocks, however, carried over unchanged: GEMM, skip connections, and normalization remain essential across all families.
This portability is the central lesson. Recent innovations continue the same pattern: Vision Transformers28 adapt the transformer to images while maintaining all four building blocks (Dosovitskiy et al. 2021). GPT-3, for example, scales up these transformer patterns and uses alternating dense and locally banded sparse attention while still relying on the same core primitives (Brown et al. 2020). Practical implementation challenges and optimizations are explored in Model Compression.
28 Vision Transformers (ViTs): Google’s 2020 ViT paper split \(224{\times}224\) images into \(16{\times}16\) patches (196 “tokens”) and applied standard Transformer attention. The systems trade-off: ViTs replace CNN’s efficient local convolutions with \(\mathcal{O}(S^2)\) global attention over patch tokens, requiring 3–5\(\times\) more training data and compute to match CNN accuracy on ImageNet. ViTs become most competitive when pretraining budgets are large enough to compensate for weaker spatial inductive bias, illustrating how inductive bias and compute budget are substitutes.
Dosovitskiy, Alexey, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, et al. 2021. “An Image Is Worth 16x16 Words: Transformers for Image Recognition at Scale.” International Conference on Learning Representations.
Brown, Tom B., Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, et al. 2020. “Language Models Are Few-Shot Learners.” Advances in Neural Information Processing Systems 33: 1877–901. https://doi.org/10.48550/arxiv.2005.14165.
Table 10 makes this synthesis concrete. Transformers retain the core GEMM operations common to all architectures but introduce content-dependent all-to-all reductions through attention, blending the broadcast operations of MLPs with the gather and reduce operations of more dynamic architectures.
| Primitive Type | MLP | CNN | RNN | Transformer |
|---|---|---|---|---|
| Computation | Dense GEMM | Convolution | Sequential GEMM | GEMM + Attention |
| Memory Access | Sequential | Strided | Sequential + State | Tiled QKV streams |
| Data Movement | Broadcast | Sliding window | Temporal broadcast | Gather + Reduce |
| Parallelism | High | High | Low (time deps) | High (positions) |
For systems engineers, this building-block perspective separates portable optimizations from architecture-specific ones. GEMM tiling and mixed-precision compute benefit every architecture. Skip connection memory management applies to any residual network. Normalization kernel fusion helps CNNs and transformers alike. Attention-specific optimizations remain tied to attention’s memory pattern, but even those build on the same underlying GEMM and memory-access primitives. ML Frameworks shows how software frameworks encapsulate these building blocks as composable layer abstractions, while Hardware Acceleration details how hardware exploits their shared computational patterns.
Self-Check: Question
Pre-2015 CNNs could not be trained beyond roughly 20 layers without training loss stagnating or diverging. Which portable architectural primitive resolved this depth ceiling and subsequently became standard in transformers, U-Nets, and most deep architectures?
- Skip (residual) connections, which add an identity path from a block’s input to its output so the gradient can propagate through the identity alongside the learned transformation.
- Embedding tables, which replaced raw inputs with learned dense vectors and eliminated the need for deep networks.
- The softmax activation applied uniformly to every hidden layer, which rescaled gradients at every depth.
- Depthwise-separable convolutions, which reduced depth by factoring each layer into two cheaper operations.
Explain why the identity path in a residual block produces a well-behaved gradient in a very deep network where a plain stack of layers does not. Make the mechanism explicit, not just the empirical result.
A serving team is deploying a transformer that performs autoregressive generation one token at a time with an effective batch size of 1 per request. Which normalization choice is most appropriate and why?
- Layer normalization, because it normalizes using per-sample statistics computed across the feature dimension and is independent of batch composition, which matters when each inference request is a single sample.
- Batch normalization, because it always outperforms layer normalization on GPU inference regardless of batch size.
- No normalization at all, because normalization is only required during training.
- Layer normalization, because it eliminates the quadratic cost of self-attention.
Modern large language models often replace standard layer normalization with a variant that drops the mean-centering step and normalizes by the root-mean-square of the activations, saving one reduction pass and a subtraction per token. This efficient normalization variant is called ____.
What is the section’s main argument about gating as a cross-architecture primitive?
- Gating is a general mechanism for selectively routing information, and variants of the same idea appear in LSTM cells, attention weights, mixture-of-experts routers, and gated linear units — making it a portable primitive rather than an LSTM-specific trick.
- Gating is confined to LSTMs and has no analog in attention-based or mixture-of-experts architectures.
- Gating always reduces total parameter count by a fixed factor regardless of the architecture that uses it.
- Gating replaces the need for normalization layers entirely, which is why it appears in every modern architecture.
Explain why the chapter frames transformers as a recombination of earlier architectural building blocks rather than a complete break from prior designs, and give two concrete primitives the transformer inherits.
Computational Primitives
Portable building blocks still lower to a smaller set of operations; those primitives determine what hardware must execute. A ResNet-50 forward pass executes billions of multiply-accumulate operations; a transformer attention layer moves gigabytes through memory hierarchies; a DLRM lookup scatters random reads across terabyte-scale tables. Despite their architectural differences, all three reduce to a small set of computational primitives that hardware and software must actually execute. Synthesizing the per-architecture system implications from earlier sections into a unified view reveals common optimization opportunities.
Each primitive represents an operation that cannot be decomposed further while maintaining its essential characteristics. Understanding these operations reveals where performance bottlenecks arise on specific hardware and guides the optimization strategies detailed in Hardware Acceleration.
Core computational primitives
The core primitive question is which execution pattern an architecture forces the system to optimize: dense tensor math, repeated local reuse, or input-dependent routing. Matrix multiplication, sliding window operations, and dynamic computation recur across the families because each preserves a distinct performance profile when lowered to hardware. They are primitive in the engineering sense: decomposing them further would erase the performance characteristics a system must optimize.
Matrix multiplication is the dense tensor-math path. Multiplying a matrix of inputs by a matrix of weights computes weighted combinations, the core operation of neural networks (recall the reference MLP layer from section 1.2.3). This path appears everywhere: MLPs use it directly for layer computations, CNNs reshape convolutions into matrix multiplications, and transformers use it extensively in their attention mechanisms. Figure 12 shows why this path is so useful: a convolution over \(3{\times}3\) input feature maps becomes a matrix operation when each sliding window position unfolds into a column of the transformed matrix.

Structured and unstructured sparsity are treated in Pruning; hardware-aware sparse execution and algorithm-hardware co-design are treated in Hardware Acceleration.
The im2col29 (image to column) technique is the bridge that turns sliding-window locality into the matrix-multiply path. It unfolds overlapping image patches into columns of a matrix (figure 12). Each sliding window position in the convolution becomes a column in the transformed matrix, while the filter kernels are arranged as rows. This allows the convolution operation to be expressed as a standard GEMM (general matrix multiply) operation.
29 im2col (Image to Column): Rather than being a new learning algorithm, im2col-style lowering is an implementation technique used by CNN frameworks and libraries such as Caffe and cuDNN (Jia et al. 2014; Chetlur et al. 2014): it converts convolutions into standard GEMM calls by unfolding overlapping patches into matrix columns. The trade-off is memory: in a simple fully materialized stride-1 \(K{\times}K\) transform, interior input elements can appear in up to \(K^2\) columns (9 times for \(3{\times}3\) filters), though borders, stride, padding, tiling, and direct-convolution algorithms reduce the realized expansion. This memory-for-simplicity exchange explains why mobile frameworks (TFLite, NNAPI) prefer direct convolution, while data center GPUs with abundant HBM may use GEMM-oriented lowering when it improves throughput.
Jia, Yangqing, Evan Shelhamer, Jeff Donahue, Sergey Karayev, Jonathan Long, Ross Girshick, Sergio Guadarrama, and Trevor Darrell. 2014. “Caffe: Convolutional Architecture for Fast Feature Embedding.” Proceedings of the 22nd ACM International Conference on Multimedia, 675–78. https://doi.org/10.1145/2647868.2654889.
Chetlur, Sharan, Cliff Woolley, Philippe Vandermersch, Jonathan Cohen, John Tran, Bryan Catanzaro, and Evan Shelhamer. 2014. “cuDNN: Efficient Primitives for Deep Learning.” arXiv Preprint arXiv:1410.0759.
The optimization trade-off is pragmatic: im2col spends memory to buy mature GEMM throughput. Decades of engineering effort have produced extraordinarily optimized GEMM implementations (cuBLAS, MKL, OpenBLAS), while convolution-specific code would need to be written from scratch for each target. The transformation duplicates data where windows overlap, but it enables CNNs to use these mature BLAS libraries and achieve 5–10\(\times\) speedups on CPUs. In deployed systems, these matrix multiplications map to specific hardware and software implementations. Data center accelerators can deliver on the order of hundreds of TFLOP/s on mixed-precision matrix operations, and software frameworks automatically lower high-level convolution operations to optimized matrix libraries that exploit available hardware capabilities.
Sliding window operations are the local-reuse path. They compute local relationships by applying the same operation to chunks of data. A \(3{\times}3\) convolution filter slides across the input, generating one output per window position (for example, \(26{\times}26\) windows for a \(28{\times}28\) input with stride 1). Modern hardware accelerators implement this through specialized memory access patterns and data buffering schemes that optimize data reuse. For example, TPUs use systolic arrays30 where data flows systematically through processing elements, allowing each input value to be reused across multiple computations without repeatedly accessing off-chip memory.
30 Systolic Array: Named for the heart’s rhythmic contraction, the array’s lockstep “pulse” of data through a grid of processors directly implements the efficient data reuse required by sliding window operations. By passing input values between neighboring processors, an expensive round-trip to off-chip DRAM is avoided for every single multiplication in the convolution. This is critical for efficiency, as a single off-chip memory access can cost over 100\(\times\) more energy than a floating-point multiply-accumulate, and still more relative to low-precision arithmetic.
Dynamic computation is the adaptive-routing path. The operation itself depends on the input data, a capability that emerged prominently with attention mechanisms but applies to adaptive processing more broadly. In transformer attention, each query dynamically determines its interaction weights with all keys; for a sequence of length 512, 512 different weight patterns must be computed on the fly. Unlike fixed patterns where the computation graph is known in advance, dynamic computation requires runtime decisions. This creates specific implementation challenges: hardware must provide flexible data routing and support variable computation patterns, while software frameworks require efficient mechanisms for handling data-dependent execution paths.
Real architectures combine these paths, which is why primitive-level reasoning is a design tool rather than a taxonomy. A transformer layer processing a sequence of 512 tokens uses matrix multiplications for feature projections (\(512{\times}512\) operations implemented through Tensor Cores), may employ sliding windows for efficient attention over long sequences (using specialized memory access patterns for local regions), and requires dynamic computation for attention weights (computing \(512{\times}512\) attention patterns at runtime). The interaction between primitives creates specific demands on system design, from memory hierarchy organization to computation scheduling.
The preceding building blocks explain why certain hardware features exist (Tensor Cores for matrix multiplication) and why software frameworks organize computations in particular ways (batching similar operations together). Computational primitives, however, tell only part of the story: the way operations access memory often determines real-world performance more than the operations themselves.
Memory access primitives
The next optimization decision is whether the primitive can feed the compute units predictably. Memory access often constitutes the primary bottleneck in ML systems: even a matrix multiplication unit capable of thousands of operations per cycle will remain idle if data is not available in time. Accessing data from DRAM typically requires hundreds of cycles, while on-chip computation requires only a few, making data movement a first-order energy constraint.
The relevant access patterns are sequential access, strided access, and random access because they determine how much of the memory stream the system can predict and reuse. Each pattern creates different demands on the memory system and offers different opportunities for optimization. Critically, each incurs vastly different energy costs based on the preceding principle.
Systems Perspective 1.3: The energy cost of data movement
A core systems principle: moving data costs more than computing on it. A floating-point multiply-accumulate operation consumes approximately 1–5 pJ depending on process node (for example, ~4.6 pJ at 45 nm (Horowitz 2014)), while fetching a 32-bit operand from off-chip DRAM costs hundreds of pJ in the same reference model. Even conservative estimates put off-chip DRAM access tens to hundreds of times above arithmetic, explaining why memory access patterns, not just FLOP counts, determine real-world efficiency.
Revisit the preceding architectures through this energy lens: MLPs have low data reuse (each weight loaded once per sample) and are therefore energy-dominated by DRAM traffic. CNNs reuse filter weights across spatial positions, amortizing load cost over \(H \times W\) applications; the very locality that makes them compute-bound also makes them energy-efficient. RNNs reuse weights across time steps (high temporal reuse) but pay repeated hidden-state read/write costs at each step. Transformers exhibit the worst case: attention matrices require fresh loads of unique key-value pairs at every position, making long-sequence attention both compute-quadratic and energy-quadratic. These energy profiles directly track the bottleneck column in table 3.
This principle underlies later optimization strategies: Quantization and Precision shows how quantization reduces bits moved per value, pruning eliminates unnecessary data movement, and tiling keeps working sets in faster, lower-energy caches.
Sequential access is the simplest, most efficient pattern, and the most energy-favorable. Consider an MLP performing matrix multiplication: it accesses weight matrices and input vectors in contiguous order. This pattern maps well to modern memory systems; DRAM can operate in burst mode for sequential reads (reaching on the order of hundreds of GB/s in modern GPUs), and hardware prefetchers can effectively predict and fetch upcoming data. Software frameworks optimize for this by ensuring data is laid out contiguously in memory and aligning data to cache line boundaries.
Strided access appears prominently in CNNs, where each output position needs to access a window of input values at regular intervals. Each output position requires accessing nine input values (for a \(3{\times}3\) filter) with a stride matching the input width. While less efficient than sequential access, hardware supports this through pattern-aware caching strategies and specialized memory controllers. Software frameworks often transform these strided patterns into sequential access through data layout reorganization, where the im2col transformation in deep learning frameworks converts convolution’s strided access into efficient matrix multiplications.
Random access poses the greatest challenge for system efficiency. Sparse embedding lookups in recommendation models are the canonical example: each request may touch a different set of table rows, defeating predictable streaming and causing cache misses or irregular memory latency. Dense transformer attention is different. Its weights are content-dependent, but Q, K, and V are stored in contiguous tensors and optimized kernels tile those tensors through SRAM/registers while reducing over the sequence. The systems challenge for attention is therefore quadratic data movement and reduction structure, not arbitrary address-random fetches.
Table 11 quantifies how these different memory access patterns contribute to the overall memory requirements of each architecture, comparing MLPs, CNNs, RNNs, and transformers across parameter storage, activation storage, and scaling behavior.
| Architecture | Input Dependency | Parameter Storage | Activation Storage | Scaling Behavior |
|---|---|---|---|---|
| MLP | Linear | \(\mathcal{O}(N_{\text{in}} \times d_{\text{width}})\) | \(\mathcal{O}(B \times d_{\text{width}})\) | Predictable |
| CNN | Constant w.r.t. resolution | \(\mathcal{O}(K^2 C_{\text{in}} C_{\text{out}})\) | \(\mathcal{O}(B \times H_{\text{img}} \times W_{\text{img}} \times C)\) | Efficient |
| RNN | Linear | \(\mathcal{O}(d_{\text{hidden}}^2)\) | \(\mathcal{O}(B \times S \times d_{\text{hidden}})\) | Challenging |
| Transformer | Quadratic attention | \(\mathcal{O}(d_{\text{model}}^2 + d_{\text{model}} d_{\text{ff}})\) per block | \(\mathcal{O}(B \times S^2)\) attention, plus \(\mathcal{O}(B S d_{\text{model}})\) activations | Problematic |
Where:
- \(N_{\text{in}}\): Input size
- \(d_{\text{width}}\): Layer width
- \(B\): Batch size
- \(K\): Kernel size
- \(C\): Number of channels
- \(C_{\text{in}}, C_{\text{out}}\): Input and output channels
- \(H_{\text{img}}\): Height of input feature map (CNN)
- \(W_{\text{img}}\): Width of input feature map (CNN)
- \(d_{\text{hidden}}\): RNN hidden-state dimension
- \(S\): Sequence length
- \(d_{\text{model}}\): Transformer model dimensionality
Table 11 captures where data lives and how access patterns scale. The complementary table 12 that follows captures how much computation each architecture demands, including forward-pass FLOPs, parallelization potential, and the resulting bottleneck. Together, the two tables answer the systems questions “how much work?” and “how does the memory system handle it?”, providing a resource profile that informs design decisions such as choosing memory hierarchy configurations and developing memory optimization strategies.
| Architecture | Parameters | Forward Pass | Memory | Parallelization | Bottleneck |
|---|---|---|---|---|---|
| MLPs | \(\mathcal{O}(d_{\text{in}} \times d_{\text{out}})\) per layer | \(\mathcal{O}(d_{\text{in}} \times d_{\text{out}})\) per layer | \(\mathcal{O}(d_{\text{in}}d_{\text{out}})\) weights \(\mathcal{O}(B d_{\text{out}})\) activations | Excellent Matrix ops parallel | Memory bandwidth |
| CNNs | \(\mathcal{O}(k^2 \times c_{\text{in}} \times c_{\text{out}})\) per layer | \(\mathcal{O}(H_{\text{img}} \times W_{\text{img}} \times k^2 \times c_{\text{in}} \times c_{\text{out}})\) | \(\mathcal{O}(H_{\text{img}} \times W_{\text{img}} \times c)\) features \(\mathcal{O}(k^2 \times c^2)\) weights | Good Spatial independence | Often compute throughput; bandwidth for depthwise or small-batch cases |
| RNNs | \(\mathcal{O}(d_{\text{hidden}}^2+d_{\text{hidden}} \times d_{\text{in}})\) total | \(\mathcal{O}(S \times d_{\text{hidden}}^2)\) for \(S\) time steps | \(\mathcal{O}(d_{\text{hidden}})\) hidden state (constant) | Poor Sequential deps | Sequential deps |
| Transformers | \(\mathcal{O}(d_{\text{model}}^2)\) QKV/O projections plus \(\mathcal{O}(d_{\text{model}}d_{\text{ff}})\) feed-forward layers | \(\mathcal{O}(S^2 \times d_{\text{model}} + S \times d_{\text{model}}^2)\) per layer | \(\mathcal{O}(S^2)\) attention \(\mathcal{O}(S \times d_{\text{model}})\) sequences | Excellent (positions) Limited by memory | Memory \((S^2)\) |
The impact of these patterns becomes clear when we consider data reuse opportunities. In CNNs, each input pixel participates in multiple convolution windows (typically nine times for a \(3{\times}3\) filter), making effective data reuse necessary for performance. Modern GPUs provide multi-level cache hierarchies (L1, L2, shared memory) to capture this reuse, while software techniques like loop tiling ensure data remains in cache once loaded.
Working set size, the amount of data needed simultaneously for computation, varies dramatically across architectures. An MLP layer might need only a few hundred KB (weights plus activations), while a transformer processing long sequences can require several MB just for storing attention patterns. These differences directly influence hardware design choices, like the balance between compute units and on-chip memory, and software optimizations like activation checkpointing, which saves memory by recomputing selected activations during backpropagation instead of storing all of them, or attention approximation techniques.
Understanding these memory access patterns is essential as architectures evolve. The shift from CNNs to transformers, for instance, has driven the development of hardware with larger on-chip memories and more advanced caching strategies to handle increased working sets and more dynamic access patterns. Future architectures will likely continue to be shaped by their memory access characteristics as much as their computational requirements.
Data movement primitives
Memory access patterns describe where data resides, but a complementary dimension determines system performance: the flow of information between components. Data movement primitives characterize these flows. As established in the preceding energy callout, data movement often dominates both time and energy budgets, making these flow patterns critical optimization targets.
The data-movement decision is fan-out and fan-in: whether one value must reach many consumers, many values must converge, or different values must be routed to different destinations. Figure 13 separates the four recurring patterns: broadcast, scatter, gather, and reduction. Broadcast operations send the same data to multiple destinations simultaneously. In matrix multiplication with batch size 32, each weight must be broadcast to process different inputs in parallel. Modern hardware supports this through specialized interconnects and hardware multicast capabilities, with bandwidth on the order of hundreds of GB/s in high-end accelerator interconnects, while some accelerators also use dedicated on-chip broadcast fabrics. Software frameworks optimize broadcasts by restructuring computations (like matrix tiling) to maximize data reuse.

Scatter operations distribute different elements to different destinations. When parallelizing a \(512{\times}512\) matrix multiplication across accelerator cores, each core receives a subset of the computation. This parallelization is important for performance but challenging, as memory conflicts and load imbalance can reduce efficiency substantially. Hardware provides flexible high-bandwidth interconnects (often in the hundreds of GB/s class within a node), while software frameworks employ specialized work distribution algorithms to maintain high utilization. In large language models, Mixture of Experts (MoE) architectures expose a far more demanding scatter pattern: a learned gating network routes each token to a small subset of expert sub-networks distributed across accelerators, requiring all-to-all communication that scales with the number of devices. Unlike the predictable tile-to-core scatter in matrix tiling, MoE routing is data-dependent, so load imbalance across experts is common and can leave most accelerator capacity idle while a handful of hot experts become bottlenecks. This communication cost is a primary constraint on scaling MoE models to hundreds of experts.
Gather operations collect data from multiple sources. In transformer attention with sequence length 512, each query must gather information from 512 different key-value pairs. These irregular access patterns are challenging: random gathering can be 10\(\times\) slower than sequential access, and the energy cost compounds due to the DRAM access penalty established earlier. Hardware supports this through high-bandwidth interconnects and large caches, while software frameworks employ techniques like attention pattern pruning to reduce gathering overhead.
Reduction operations combine multiple values into a single result through operations like summation. When computing attention scores in transformers or layer outputs in MLPs, efficient reduction is essential. Hardware implements tree-structured reduction networks (reducing latency from \(\mathcal{O}(n)\) to \(\mathcal{O}(\log n)\)), while software frameworks use optimized parallel reduction algorithms that can achieve near-theoretical peak performance.
In practice, these patterns combine in layered ways. For each sequence and attention head in a transformer attention operation with sequence length 512 and batch size 32, the computation involves broadcasting query vectors (\(512{\times}64\) elements), gathering relevant keys and values (\(512{\times}512{\times}64\) elements), and reducing attention scores (\(512{\times}512\) elements). The batch dimension multiplies each of these counts by 32.
The evolution from CNNs to transformers has increased reliance on gather and reduction operations, driving hardware innovations like more flexible interconnects and larger on-chip memories. As models grow (some now exceeding 100 billion parameters), efficient data movement becomes an architecture constraint rather than an implementation afterthought, leading to innovations like near-memory processing and targeted data flow optimizations.
System design impact
The computational, memory access, and data movement primitives explored earlier become system design constraints when they force resources to be allocated in silicon and software. Matrix-heavy workloads justify tensor units; random and gather-heavy workloads justify memory hierarchy and interconnect investment. The way these primitives influence hardware design, create common bottlenecks, and drive trade-offs turns architecture selection into infrastructure planning.
The most visible result is specialized hardware. The prevalence of matrix multiplications and convolutions in deep learning has led to the development of tensor processing units (TPUs)31 and Tensor Cores in GPUs, which are specifically designed to perform these operations efficiently. Hardware Acceleration examines how these specialized units map architectural primitives to silicon, from systolic arrays for GEMM to dataflow engines for convolution.
31 TPU (Tensor Processing Unit): Google’s response to the prevalence of matrix multiplications across all neural network architectures. The TPU maps GEMM onto a large systolic array, executing thousands of multiply-accumulate operations per clock cycle while sacrificing general-purpose flexibility (caches, complex control flow) for domain-specific efficiency. The first-generation TPU v1 (2017) delivered 92 TOPS (vendor-reported INT8 tera-operations/s) at 40 W, compared to an NVIDIA K80’s ~8.7 TFLOP/s (FP32) at 300 W, about 79.3× higher peak operations per watt from the quoted specifications. That peak comparison mixes INT8 TOPS with FP32 TFLOP/s, so application throughput-per-watt must still be measured on the structured matrix workloads that dominate neural network inference. Hardware has continued to co-evolve with the dominant primitives: subsequent accelerator generations added dedicated transformer-oriented features, such as dynamic precision switching between lower-precision formats to accelerate attention and feed-forward layers at reduced numerical cost, a concrete instance of the same design principle—dedicating silicon to a dominant primitive can outperform general-purpose flexibility.
Memory systems have also been profoundly influenced by the demands of deep learning primitives. The need to support both sequential and random access patterns efficiently has driven the development of multi-level memory hierarchies. High-bandwidth memory (HBM)–3D-stacked DRAM delivering 2–3 TB/s of bandwidth, over 20\(\times\) standard server RAM–has become common in AI accelerators to support the massive data movement requirements, especially for operations like attention mechanisms in transformers. On-chip memory hierarchies have grown in complexity, with multiple levels of caching and scratchpad memories–programmer-controlled SRAM that trades cache convenience for explicit data movement and predictable locality–to support the diverse working set sizes of different neural network layers.
The data movement primitives have particularly influenced the design of interconnects and on-chip networks. The need to support efficient broadcasts, gathers, and reductions has led to the development of more flexible and higher-bandwidth interconnects. Some AI chips now feature specialized networks-on-chip designed to accelerate common data movement patterns in neural networks.
The system implications of these primitives span hardware, software, and performance considerations. Table 13 turns the primitive-to-system mapping into a design checklist: each row links an architectural primitive to the hardware support, software optimization, and bottleneck it tends to create. Despite the specialized hardware that these primitives have motivated, several bottlenecks persist. Memory bandwidth often remains a key limitation, particularly for models with large working sets or those that require frequent random access. The energy cost of data movement, especially between off-chip memory and processing units, continues to be a significant concern. For large-scale models, the communication overhead in distributed training can become a bottleneck, limiting scaling efficiency.
| Primitive | Hardware Impact | Software Optimization | Key Challenges |
|---|---|---|---|
| Matrix Multiplication | Tensor Cores | Batching, GEMM libraries | Parallelization, precision |
| Sliding Window | Specialized datapaths | Data layout optimization | Stride handling |
| Dynamic Computation | Flexible routing | Dynamic graph execution | Load balancing |
| Sequential Access | Burst mode DRAM | Contiguous allocation | Access latency |
| Random Access | Large caches | Memory-aware scheduling | Cache misses |
| Broadcast | Specialized interconnects | Operation fusion | Bandwidth |
| Gather/Scatter | High-bandwidth memory | Work distribution | Load balancing |
The same primitive mapping also determines energy budgets. Each architectural pattern exhibits distinct energy characteristics that inform deployment decisions and optimization strategies for data center and edge systems.

Moving a value from DRAM costs far more energy than a MAC.
Horowitz, Mark. 2014. “1.1 Computing’s Energy Problem (and What We Can Do about It).” 2014 IEEE International Solid-State Circuits Conference Digest of Technical Papers (ISSCC), 10–14. https://doi.org/10.1109/isscc.2014.6757323.
Large batched GEMMs in MLPs can achieve excellent arithmetic intensity, but small-batch MLP inference often has low reuse and spends most of its energy on data movement. The reference FP32 compute cost is approximately 3.7 pJ/FLOP, while data movement from DRAM costs 640 pJ per 32-bit value (Horowitz 2014), about 173× higher. Given this energy ratio, typical MLP inference spends the majority of its energy budget on data movement rather than computation, making memory bandwidth optimization critical for energy efficiency. This energy gap has driven a structural response in accelerator design: maximizing on-chip SRAM capacity keeps weights and activations closer to compute units, avoiding the DRAM penalty on the most frequently accessed data. Architectures that can fit their entire working set on-chip—whether through large tiled SRAM banks on conventional accelerators or through wafer-scale integration that replaces off-chip DRAM with on-chip memory for the largest models—reduce the energy cost of inference by eliminating the dominant term in the energy budget.
Convolutional operations reduce energy consumption through data reuse but exhibit variable efficiency depending on implementation. Im2col-based convolution implementations trade memory for simplicity; a fully materialized lowering can multiply temporary storage and memory traffic, up to \(K^2\) for stride-1 \(K{\times}K\) filters away from the borders. Direct convolution implementations can achieve substantially better energy efficiency by eliminating redundant data movement, particularly for larger kernel sizes where im2col duplication is most severe.
Sequential processing in RNNs creates energy efficiency opportunities through temporal data reuse. The constant memory footprint of RNN hidden states allows aggressive caching strategies that can dramatically reduce DRAM access energy for long sequences by keeping the recurrent state in on-chip SRAM. The sequential dependencies limit parallelization opportunities, often resulting in suboptimal hardware utilization and higher energy per operation.
Attention mechanisms in transformers can exhibit high energy consumption per operation due to irregular memory access patterns and the need to store attention matrices (the quadratic bottleneck from section 1.5.4). The irregular access patterns of self-attention can result in significantly higher energy per useful FLOP compared to standard matrix multiplication, making long-sequence processing expensive without architectural modifications such as FlashAttention.
These energy profiles make primitive support a deployment trade-off. Optimizing for the dense matrix operations common in MLPs and CNNs might come at the cost of flexibility needed for the more dynamic computations in attention mechanisms. Supporting large working sets for transformers might require sacrificing energy efficiency.
The right balance depends on the target workloads and deployment scenarios. Understanding the nature of each primitive guides the development of both hardware and software optimizations in ML systems, allowing designers to make informed decisions about system architecture and resource allocation.
The analysis of architectural patterns, computational primitives, and system implications provides the conceptual foundation for understanding how architectures work and what they cost. The practical selection problem is to choose an architecture for a specific problem under specific deployment constraints. This selection process must consider not only algorithmic performance but also the deployment constraints covered in ML Systems and the lifecycle requirements introduced in ML Workflow.
Self-Check: Question
A deep-learning framework converts a convolution on a 224-by-224 input with a 3-by-3 kernel into a GEMM call via im2col, producing an unrolled matrix roughly 9\(\times\) larger than the original input tensor. Why does this memory-expanding transformation routinely improve end-to-end speed?
- im2col reshapes the irregular sliding-window access pattern of convolution into a regular dense matrix multiply, which lets the runtime dispatch the work to highly tuned BLAS/cuBLAS kernels and Tensor Core hardware paths that would not fire on the original layout.
- im2col preserves the original convolution’s memory footprint exactly and therefore costs nothing, which is why it is always profitable.
- im2col eliminates the need for filter weights entirely by expressing the convolution as a purely data-driven transformation.
- im2col is required because convolution is mathematically impossible to implement on GPUs without this transformation.
The section notes that a MAC operation costs roughly 1 pJ while fetching an operand from off-chip DRAM costs roughly 200 pJ. Explain why this 200\(\times\) energy gap makes data movement rather than arithmetic the dominant systems concern in neural network execution, and give a concrete design implication.
Which memory-access pattern is hardest for hardware caches and prefetchers to exploit, and therefore most likely to starve the compute units of a neural-network workload?
- Random access, because the next address depends on input data (for example, an ID-dependent embedding row), so neither prefetch prediction nor spatial-locality-based caching can help.
- Sequential access through a contiguous tensor, because each element is predictable and burst-friendly.
- Contiguous burst reads across a large array, because DRAM row-open costs are amortized over many reads.
- Regularly strided access with high reuse, because stride prefetchers and cache blocking are designed for exactly this shape.
Order the following categories from the section’s conceptual organization, moving from the lowest-level building blocks outward to their system-design consequences: (1) memory access primitives, (2) system design impact, (3) core computational primitives, (4) data movement primitives.
In a data-parallel training job on 64 GPUs, the framework replicates each layer’s weight tensor to every GPU at the start of the step so all workers can compute forward passes on different micro-batches simultaneously. Which data-movement primitive matches this one-source-to-many-destinations transfer, and why is it the appropriate choice?
- Broadcast, because the same weight tensor must arrive intact at many destinations; broadcast trees exploit network bandwidth in \(\mathcal{O}(\log N)\) rounds rather than \(\mathcal{O}(N)\) repeated unicasts.
- Gather, because the operation aggregates activations from many sources into one target device.
- Reduction, because the workers must compute a weighted sum of their inputs before proceeding.
- Scatter, because the weight tensor is partitioned into distinct slices sent to different devices.
True or False: Upgrading only the arithmetic compute units on an accelerator — doubling FLOP/s while leaving memory hierarchy, interconnect, and software scheduling unchanged — would resolve most neural-network performance problems.
Architecture Selection Framework
A wildlife monitoring sensor may need to classify audio continuously on solar power, while a recommendation service may need to retrieve terabyte-scale embeddings under a millisecond budget. Those deployment constraints immediately rule out many otherwise accurate architectures. The families examined earlier embody specific assumptions about data structure and computational patterns: MLPs assume arbitrary feature relationships, CNNs exploit spatial locality, RNNs capture temporal dependencies, and transformers model complex relational patterns. The selection problem is to match those assumptions to a specific use case before optimizing the model.
Successful architecture selection requires understanding principles rather than following trends: matching data characteristics to architectural strengths, evaluating computational constraints against system capabilities, and balancing accuracy requirements with deployment realities. The framework presented here draws upon the computational patterns and system implications explored in this chapter, together with the deployment paradigms from ML Systems and the lifecycle constraints from ML Workflow. The same selection logic also governs Data Selection and ML Operations, where data curation and production operations add their own constraints.
Data-to-architecture mapping
The first step in systematic architecture selection involves data-to-architecture mapping: understanding how different data types align with architectural strengths. The architectural families introduced in section 1.1 provide the foundation: MLPs for tabular data with arbitrary relationships, CNNs for spatial data with local patterns, RNNs for sequential data with temporal dependencies, transformers for complex relational data where any element might influence any other, and sparse embedding architectures such as DLRM for high-cardinality categorical recommendation data.
This alignment is not coincidental; it reflects fundamental computational trade-offs. Architectures that match data characteristics can exploit natural structure for efficiency, while mismatched architectures must work against their design assumptions, leading to poor performance or excessive resource consumption.
In practice, MLPs excel for financial modeling, medical measurements, and structured prediction where feature relationships are unknown a priori. CNNs dominate image recognition, 2D sensor processing, and signal analysis where spatial locality matters. RNNs remain useful for time-series forecasting and simple sequential tasks where memory across time is essential. Transformers have become the architecture of choice for language understanding, machine translation, and complex reasoning tasks (Wei et al. 2022) requiring long-range dependencies. DLRM-style sparse architectures are the natural starting point for recommendation systems with user IDs, item IDs, and other high-cardinality categorical features whose embedding tables dominate memory capacity.
Wei, Jason, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V. Le, and Denny Zhou. 2022. “Chain-of-Thought Prompting Elicits Reasoning in Large Language Models.” Advances in Neural Information Processing Systems 35 35: 24824–37. https://doi.org/10.52202/068431-1800.
Beyond data type matching, computational constraints often determine final feasibility. Understanding the scaling behavior of each architecture allows realistic resource planning and prevents costly architectural mismatches during deployment.
Computational complexity considerations
Architecture selection must account for computational and memory trade-offs that determine deployment feasibility. Each architecture exhibits distinct scaling behaviors that create different bottlenecks as problem size increases, and understanding these patterns allows realistic resource planning.
The preceding sections analyzed each architecture through the four-part lens of pattern processing needs, algorithmic structure, computational mapping, and system implications. As table 12 showed earlier alongside table 11, examining these architectures from both computational scaling and memory access perspectives reveals different optimization opportunities and system design considerations.
Scalability and production considerations
Production deployment introduces constraints beyond algorithmic performance: latency requirements, memory limitations, energy budgets, and fault tolerance needs. These are not four independent scorecards. Each family’s production behavior traces back to the single structural property that defined it: dense connectivity, spatial locality, sequential dependence, or all-to-all attention. The same property that set a family’s accuracy also governs how it parallelizes, how its latency scales, and how much memory it consumes.
MLPs and CNNs occupy the easier operational corner because they are largely stateless across examples and can scale when independent inputs are split across devices. Their latency and memory behavior still differ. MLP latency is usually predictable from layer size, which helps with strict service level agreement (SLA) requirements, while CNN latency depends more on implementation strategy, convolution algorithm, and hardware support, with optimized implementations reaching sub-millisecond inference. MLPs require fixed memory proportional to model size; CNNs add feature-map memory that grows with input resolution.
RNNs and transformers create harder production regimes for opposite reasons. RNNs keep a compact hidden state, but time step \(t\) depends on time step \(t-1\), so additional hardware cannot remove the sequence’s critical path and temporal state complicates recovery. Transformers parallelize well across sequence positions and deliver high throughput for batches, but the quadratic attention bottleneck (section 1.5.4) limits effective batch size, single-request latency, and checkpoint practicality as model scale grows. This structural split also explains typical hardware-efficiency ranges in optimized deployments: MLPs can reach 80–90 percent of peak performance on specialized tensor units, CNNs reach 60–75 percent depending on layer configuration, RNNs often remain at 30–50 percent due to sequential constraints, and transformers can reach 70–85 percent for large batches but drop sharply for small batches. Model Training later formalizes the corresponding scaling strategies as data, model, pipeline, and tensor parallelism.
Hardware mapping and optimization strategies
Different architectural patterns require distinct optimization strategies for efficient hardware mapping, so performance tuning starts by matching the operation shape to the hardware path. Dense matrix operations in MLPs map naturally to tensor processing units and GPU Tensor Cores (Hardware Acceleration details how these map to specific silicon implementations). These operations benefit from three recurring optimizations: matrix tiling keeps active blocks close to the compute units, often with tile sizes such as \(64{\times}64\) for L1 cache, \(256{\times}256\) for L2 cache, and \(16{\times}16\) Tensor Core blocks on Volta-class GPUs; mixed-precision computation increases useful operations per second when accuracy allows it; and operation fusion reduces memory traffic by combining adjacent steps. ML Frameworks later examines how frameworks translate these high-level operations into optimized kernel launches on specific hardware.
CNNs benefit from specialized convolution algorithms and data layout optimizations that differ significantly from dense matrix operations. Im2col transformations convert convolutions to matrix multiplication but can multiply temporary storage and memory traffic, up to \(K^2\) for fully materialized stride-1 \(K{\times}K\) filters away from the borders. Winograd algorithms32 reduce arithmetic complexity by 2.25× for \(3{\times}3\) convolutions at the cost of numerical stability. Direct convolution with custom kernels achieves optimal memory efficiency but requires architecture-specific tuning.
32 Winograd Algorithm: This method achieves its 2.25× arithmetic reduction for \(3{\times}3\) convolutions by trading 9 expensive multiplications for 4 in the Winograd domain, plus a larger number of cheaper additions. The intermediate mathematical transforms required for this trade, however, amplify rounding errors. This loss of numerical precision makes Winograd unsuitable for FP16 training, creating a direct trade-off between arithmetic throughput and model stability.
RNNs require different optimization approaches because, as section 1.4.4 established, their sequential critical path cannot be shortened by adding hardware, so the available levers attack the overhead around that path instead. Loop unrolling removes per-step control overhead, shaving the latency term at the cost of larger code size and activation memory. State vectorization batches multiple independent sequences through the same step, recovering SIMD throughput without shortening any single sequence’s critical path. Wavefront parallelization exploits the independence of forward and backward passes in bidirectional models, roughly doubling utilization where the model structure permits it. None of these removes the sequential dependency; they amortize or sidestep it.
Transformer attention demands specialized optimizations that reduce memory usage and complexity. The common theme is to keep attention scores close to the compute units or to avoid computing scores that the model structure does not need. Flash attention: IO-aware attention optimization examines FlashAttention33 as a concrete tiling example, while sparse attention patterns remain a model-structure optimization.
33 FlashAttention: An IO-aware algorithm (Dao et al. 2022) that avoids materializing the full \(S{\times}S\) attention matrix in HBM by fusing computation into a single kernel tiled to fit in SRAM. The result: 2–4\(\times\) wall-clock speedup and memory reduction from \(\mathcal{O}(S^2)\) to \(\mathcal{O}(S)\), enabling training on sequences 4–16\(\times\) longer than standard attention. FlashAttention demonstrates that algorithmic optimization of data movement \((D_{\text{vol}})\) can yield larger speedups than increasing raw compute \((R_{\text{peak}})\) – a concrete validation of the iron law’s data term.
Dao, T., D. Y. Fu, S. Ermon, A. Rudra, and C. Ré. 2022. “FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness.” Advances in Neural Information Processing Systems 35 35: 16344–59. https://doi.org/10.52202/068431-1189.
The complexity patterns detailed in each architecture’s System Implications section define optimal domains. MLPs excel when parameter efficiency is not critical, CNNs dominate for moderate-resolution spatial data, RNNs remain viable for very long sequences where memory is constrained, and transformers excel for complex relational tasks where their computational cost is justified through superior performance. With these quantitative foundations established, we can construct a systematic decision framework for architecture selection.
Decision framework
Effective architecture selection requires balancing multiple competing factors: data characteristics, computational resources, performance requirements, and deployment constraints. In practice, teams often make this choice based on familiarity (“we always use transformers”) or trend-following (“new papers use X”), leading to architectures that are either overpowered for the problem (wasting resources) or underpowered (failing to meet requirements). While data patterns provide initial guidance and complexity analysis establishes feasibility bounds, final architectural choices often involve nuanced trade-offs demanding systematic evaluation.
The decision flowchart in figure 14 proceeds from top to bottom: identify the data type, follow the branches to candidate dense architectures (Transformers, RNNs, CNNs, or MLPs), then check each constraint diamond. High-cardinality recommendation workloads sit outside this flowchart: route them to the sparse embedding/DLRM family described earlier, then apply the same memory, compute, speed, accuracy, and deployment checks. If any check fails, the “No” path loops back for reconsideration. This iterative structure ensures consideration of all relevant factors while avoiding selection based on novelty or perceived sophistication.

When constraints require scaling down, the model compression techniques in Model Compression provide systematic approaches for reducing memory, compute, and latency while preserving accuracy. The framework applies through four ordered steps:
- Data analysis: Pattern types in data provide the strongest initial signal. Spatial data naturally aligns with CNNs, sequential data with RNNs.
- Progressive constraint validation: Each constraint check (memory, computational budget, inference speed) acts as a filter. Failing any constraint requires either scaling down the current architecture or considering a fundamentally different approach.
- Iterative trade-off handling: When accuracy targets remain unmet, additional model capacity may be needed, requiring a return to constraint checking. If deployment hardware cannot support the chosen architecture, reconsidering the entire architectural approach may be necessary.
- Multiple iterations: Practitioners should anticipate several passes, as real projects typically cycle through this framework before reaching an optimal balance between data fit, computational feasibility, and deployment requirements.
The preceding decision framework provides practical guidance for architecture selection, but the entire process rests on a deeper unifying principle: diverse architectures differ in the inductive biases they encode.
Inductive bias hierarchy
The five architectural families, practical selection framework, and computational primitives examined throughout this chapter share a common theoretical foundation: inductive bias, introduced in section 1.1. Rather than re-defining each architecture’s bias, we focus here on the hierarchy and systems implications that emerge when comparing them.
Different architectures form a hierarchy of decreasing inductive bias. CNNs exhibit the strongest constraints through local connectivity, parameter sharing, and translation equivariance, dramatically reducing the parameter space while limiting flexibility to spatial data. RNNs demonstrate moderate bias through sequential processing and shared temporal weights. MLPs maintain minimal architectural bias, requiring more data to learn structure that other architectures encode explicitly. Transformers represent adaptive inductive bias, dynamically adjusting based on data through learned attention patterns.
All successful architectures implement hierarchical representation learning, but through different mechanisms: CNNs through progressive receptive field expansion (section 1.3), RNNs through hidden state evolution (section 1.4), and transformers through multi-head attention (section 1.5). This hierarchical organization reflects a general principle: complex patterns can be efficiently represented through composition of simpler components. For systems engineering, computational patterns must efficiently compose lower-level features into higher-level abstractions, memory hierarchies must align with representational hierarchies to minimize data movement, parallelization strategies must respect hierarchical dependency structure, and hardware accelerators must efficiently support the matrix operations implementing feature composition.
Architecture selection in practice
A complete architecture selection exercise synthesizes the chapter’s concepts. We walk through the full decision process an ML systems engineer would follow, using a real-time wildlife monitoring scenario as the integrating case study. First, a back-of-the-napkin calculation reveals the throughput ceiling that drives the hardware selection.
Napkin Math 1.3: The throughput ceiling
Problem: A real-time application must process 30 FPS of video with ResNet-50. What sustained compute throughput is required?
Math:
- Model cost: ResNet-50 requires ~4.1 GFLOP per \(224{\times}224\) image.
- Frame rate: 30 FPS required.
- Sustained throughput: 30 FPS \(\times\) 4.1 GFLOP = 123 GFLOP/s.
Systems insight: A mid-range GPU delivering 10 TFLOP/s theoretical peak achieves ~50–60 percent utilization in this planning scenario, yielding 5 TFLOP/s–6 TFLOP/s effective. For ResNet-50 at 30 FPS, the system has 40.7× headroom. Switching to an object detection model at 100 GFLOP per frame, however, requires 3 TFLOP/s sustained, leaving only 1.7× headroom. Batch size constraints or multi-stream processing quickly push the system toward the compute ceiling. ResNet-50 is compute-bound, but the margin depends on the accelerator and utilization achieved.
The throughput ceiling converts an abstract compute requirement into a concrete hardware utilization percentage. A real-world deployment adds physical constraints the ceiling alone does not capture.
Worked example: Real-time wildlife monitoring
The task is to design an ML system that identifies wildlife species from camera trap images in a national park. The system must process images locally with no cloud connectivity, operate on battery power for six months, and achieve 90 percent accuracy on 50 target species. The decision process below walks through five steps: characterizing the data, analyzing the constraints, evaluating candidate architectures, validating against hardware limits, and assessing deployment risk.
The first step is data characterization. The input is spatial data (images from camera traps, typically \(1920{\times}1080\) resolution, downsampled to \(224{\times}224\) for processing). The task requires recognizing visual patterns (fur textures, body shapes, distinctive markings) that are:
- Spatially local: Species identification relies on local features (ear shape, stripe patterns)
- Translation invariant: A deer in the top-left is still a deer in the bottom-right
- Hierarchical: Low-level edges combine into textures, then body parts, then whole animals
These three properties (spatial locality, translation invariance, and hierarchical structure) point directly to a CNN, whose inductive bias matches them.
Constraint analysis comes next. Table 14 catalogs the five deployment constraints and the architectural choices each forces:
| Constraint | Requirement | Implication |
|---|---|---|
| Connectivity | None (offline) | All inference must run on-device |
| Power | ~2 W average (solar + battery) | Rules out GPUs; must use low-power MCU or edge NPU |
| Latency | <500 ms per detection | Allows batch size 1, no real-time streaming |
| Memory | 512 MB RAM, 2 GB storage | Model must fit in ~100 MB after lower-precision storage |
| Accuracy | 90%+ on 50 species | Requires sufficient model capacity |
With the constraints fixed, the third step evaluates candidate architectures against the chapter’s lighthouse models:
- ResNet-50 (25.6M params, 4.1 GFLOP): Too compute- and power-heavy for this device. At 102.4 MB FP32, it is also marginal against the 100 MB model budget before lower-precision weights, activations, and runtime buffers. The main blockers are its GFLOP cost and power draw, not raw storage alone.
- MobileNetV1 (4.2M params, 569 MFLOP): Promising. It needs 16.8 MB at FP32, or 4.2 MB when each weight is stored as an 8-bit integer (INT8). Its depthwise separable convolutions are power-efficient.
- KWS DS-CNN (200K params, 20 MFLOP): Too small. Designed for 12-class audio, insufficient capacity for 50 visual species.
This points to a MobileNetV2 variant with width multiplier 0.75 as the chosen model. It carries ~2.2M (8.8 MB FP32, 2.2 MB with INT8 weights) and costs ~150 MFLOP at \(224{\times}224\). It offers sufficient capacity for the 50-class problem, fits the memory budget with margin, and its depthwise separable convolutions are power-efficient.
The fourth step validates that choice against the hardware. The memory budget checks out: \[ \text{$\underbrace{\text{2.2 MB}}_{\text{Model}} + \underbrace{224 \times 224 \times 64 \times 4 \approx \text{12.8 MB}}_{\text{Activations}} + \underbrace{\text{50 MB}}_{\text{OS/Buffers}} = \text{65 MB} \ll \text{512 MB}~\checkmark$} \]
The compute budget holds on the target device, an ARM Cortex-A53 at 1.2 GHz with NEON SIMD (~2 GOPS INT8): \(\frac{150 \times 10^6 \text{ INT8 ops}}{0.002 \times 10^12 \text{ INT8 ops/s}} = 75 ms \text{ latency} \ll 500 ms \text{ target}~\checkmark\)
Power is the final check. Estimated inference power is ~200 mW for 75 ms, or 15 mJ per inference. At 100 inferences/day, that is 1.5 J/day, negligible against the sleep power budget \(\checkmark\).
The fifth step is risk assessment. Table 15 pairs the top accuracy, thermal, and species-coverage risks with the engineering mitigation chosen for each:
| Risk | Mitigation |
|---|---|
| 90% accuracy not achieved | Train on augmented dataset; consider EfficientNet-Lite if MobileNet insufficient |
| Thermal throttling in enclosure | Add passive heatsink; reduce inference frequency in high-temperature conditions |
| New species added postdeployment | Reserve 10% model capacity; plan for over-the-air (OTA) update mechanism |
The resolution is therefore MobileNetV2 (0.75× width) with INT8 weight storage, deployed on a Cortex-A53 system on chip (SoC) with 512 MB RAM. The systems insight is that this architecture meets the accuracy target while operating within the 2 W power envelope, processing images in about 75 ms under the stated throughput assumption and leaving sufficient memory headroom for system operations. The decision was driven by matching the CNN inductive bias to the spatial data characteristics, then validating against hardware constraints with quantitative analysis.
This worked example demonstrates the systematic approach that transforms architectural knowledge into practical engineering decisions. Yet even with systematic methodology, practitioners routinely make costly mistakes because architecture selection involves counterintuitive trade-offs. A model with fewer FLOPs can run slower on certain hardware. A more expressive architecture can deliver worse accuracy on problems that do not match its inductive bias. An architecture that performs beautifully in the lab can likewise fail catastrophically when deployed to production hardware with different memory hierarchies. The most common errors are catalogued next, each grounded in the systems principles developed throughout this chapter.
Self-Check: Question
A data-science team must model loan-default risk from a 47-feature tabular dataset with no known structural relationships among features — features are demographic, financial, and behavioral attributes with no obvious ordering or spatial arrangement. Using the chapter’s data-to-architecture mapping, which architecture is the default starting candidate?
- MLP, because the data carries no spatial or temporal structure and the feature-interaction pattern is unknown a priori; a no-structural-prior architecture is the appropriate starting point.
- CNN, because convolutions always improve accuracy regardless of whether spatial structure exists in the inputs.
- RNN, because tabular features must be processed in strict order to preserve their causal relationships.
- Transformer, because transformers always outperform simpler architectures and should be the default for any tabular problem.
Explain why the chapter’s architecture-selection process is iterative rather than a one-shot mapping from data type to model family. Illustrate with a case where the data-type mapping would point one way but deployment constraints force a different final choice.
In the wildlife-monitoring case study, the team must classify 50 bird species from trail-camera images under a 2 W power budget and sub-second latency on a Raspberry-Pi-class device. Why was a MobileNetV2-class CNN chosen over both a full ResNet-50 and a much smaller DS-CNN keyword-spotting-style model?
- MobileNetV2 preserves the spatial-locality prior that matches image inputs while using depthwise-separable convolutions to fit the device’s power, latency, and memory budget; ResNet-50 exceeds the budget, and a KWS-scale DS-CNN lacks the representational capacity for 50-class fine-grained species discrimination.
- MobileNetV2 was chosen because transformers physically cannot process image inputs.
- MobileNetV2 was chosen because KWS-class DS-CNN architectures are always less accurate than any MobileNet on every vision task in every regime.
- MobileNetV2 was chosen because the device has unlimited memory but requires minimizing FLOPs at all costs.
Three architectures are candidates for a well-structured image-classification task: a dense MLP, a standard CNN, and a vision transformer (ViT). From strongest to weakest built-in structural assumption, which ordering is correct — and which architecture would the chapter’s framework therefore prefer as the first candidate for a dataset of only 50,000 labeled images?
- CNN > ViT > MLP; the CNN is preferred because its locality-and-weight-sharing prior lets it generalize from limited data without the ViT’s large-data appetite or the MLP’s no-prior cost.
- MLP > CNN > ViT; the MLP is preferred because having no prior is the most flexible choice with limited labels.
- ViT > CNN > MLP; the ViT is preferred because attention’s all-pairs capability gives it the strongest structural assumption about image inputs.
- All three impose equally strong priors; the choice is arbitrary.
Which consideration most directly explains why an architecture with the best published benchmark accuracy may nevertheless be rejected during the framework’s selection process?
- The model may hit the accuracy target but fail memory, latency, or hardware-mapping constraints in the intended deployment environment, which together determine whether accuracy is usable.
- All papers report accuracy on synthetic data that has no bearing on production performance.
- Benchmark accuracy is evidence of overfitting, so high-accuracy models are always worse in practice.
- The newest architecture is always unsupported by mature software frameworks and therefore unusable.
A team proposes a transformer for a task with 50-token inputs, a 100 ms edge-device latency budget, and dependencies that are mostly local. Using the framework, critique this choice and propose a more appropriate alternative.
Fallacies and Pitfalls
Architecture choice is a systems decision, not a leaderboard selection. The common mistakes in this section arise when teams treat architecture families as interchangeable accuracy tools while ignoring inductive bias, memory traffic, hardware mapping, and deployment state.
Fallacy: More complex architectures always perform better than simpler ones.
Engineers often assume that transformers outperform simpler architectures on all tasks. In production, architectural sophistication must match problem complexity: the algorithm must fit both the structure of the data and the cost of the machine. The learnability-gap analysis in section 1.2.1 demonstrates the scale of this mismatch: a CNN achieves 99 percent accuracy on MNIST with 421.4K parameters while an MLP requires 20.0M parameters for 98 percent accuracy—a 47× parameter reduction with higher accuracy. For problems with spatial locality, CNNs exploit inductive biases that MLPs cannot match. Teams defaulting to transformers for tabular data or small-image classification waste 5–10\(\times\) resources. A $1,000 training job becomes $10,000 with no accuracy benefit.
Pitfall: Selecting architectures based solely on accuracy metrics without analyzing computational requirements.
Practitioners choose architectures from papers reporting top-line accuracy, ignoring computational implications. As shown in section 1.10.2, RNNs achieve only 30–50 percent of peak hardware performance vs. 80–90 percent for MLPs due to sequential constraints. Transformers face the quadratic memory scaling detailed in section 1.6.4: sequence length 2,048 requires 16× more attention-score memory than length 512 because attention memory scales with the square of sequence length. Production systems ignoring these characteristics miss latency SLAs (100 ms target becomes 500 ms), exceed memory budgets (8 GB becomes 32 GB), or achieve 25 percent hardware efficiency instead of the expected 80 percent. These mismatches can add months to deployment timelines.
Fallacy: Architecture performance transfers uniformly across different hardware platforms.
Engineers assume GPU benchmarks predict edge device performance. In reality, hardware-architecture alignment determines efficiency. As discussed in section 1.10.2, CNNs achieve 60–75 percent of peak throughput on matrix acceleration units, while RNNs’ irregular memory access yields only 30–50 percent. A transformer running at 50 ms on an A100 may require 2000 ms on a mobile SoC—a 40\(\times\) slowdown due to lack of high-bandwidth memory and tensor cores. This gap renders the model unusable for interactive applications requiring sub-200 ms response. Organizations benchmarking only on training hardware discover these gaps late, forcing architecture redesigns that delay launches by quarters.
Pitfall: Combining architectural patterns without analyzing interaction effects at the system level.
Engineers add attention to CNNs or convolutions to transformers expecting additive benefits. Each pattern creates distinct memory access characteristics: CNNs exploit spatial locality through sliding windows, while attention requires all-to-all communication. Naive combinations create bandwidth conflicts—attention layers flush CNN feature maps from cache, eliminating locality benefits. A ResNet achieving 250 images/second can drop to 80 images/second when attention disrupts the cache-optimized pipeline, a 3\(\times\) throughput reduction requiring tripled infrastructure to maintain capacity. Adding recurrent connections to transformers reintroduces sequential dependencies that eliminate parallelization advantages. Successful hybrids require profiling memory access and cache behavior before combining patterns.
Fallacy: Architecture wins on training hardware transfer directly to deployment hardware.
Teams design for high-end GPU clusters, then discover deployment failures on target hardware. An architecture exploiting 8\(\times\) A100 GPUs (640 GB total memory) cannot deploy to a representative edge node such as the NVIDIA Jetson Orin NX (16 GB system memory)—a 40× gap that requires architectural changes, not merely smaller weight formats. As section 1.10.3 emphasizes, architecture selection must analyze the full system stack. Edge deployment compounds constraints: models must fit 10–100 MB storage, execute in 50–200 ms, and operate within 2–5 W power. Organizations deferring deployment considerations to “optimize later” encounter mismatches requiring costly redesigns that delay products by months.
Pitfall: Ignoring KV cache growth when estimating transformer serving costs.
Teams budget transformer deployment based on model weight memory alone, overlooking the key-value (KV) cache that self-attention requires during autoregressive generation (Pope et al. 2023; Kwon et al. 2023). The KV cache scales as \(\mathcal{O}(B \times N_L \times 2 \times N_{\text{heads}} \times S \times d_{\text{head}})\), where \(B\) is the number of concurrent sequences resident in the batch, \(N_{\text{heads}}\) is the number of attention heads, \(S\) is the sequence length, and \(d_{\text{head}}\) is the per-head dimension; for large models this overhead dominates serving memory. For the 32-layer, 32-head configuration of a 7-billion-parameter transformer, whose cache arithmetic section 1.6.4.2 works through step by step (128-dimensional heads, sequences of length 2,048, FP16), each concurrent request holds \(\approx\) 1 GB of KV cache. At even modest concurrency of 2–4 users, the KV cache alone consumes 2 GB–4 GB, a nontrivial memory budget before batching, allocator overhead, or longer contexts. As the quadratic memory analysis in section 1.6.4 establishes, attention memory grows with sequence length, making the KV cache the binding constraint on serving throughput. Teams that size infrastructure based solely on weight memory discover at deployment that halving the batch size or truncating context length is the only way to fit within device memory, degrading either throughput or output quality.
Pope, Reiner, Sholto Douglas, Aakanksha Chowdhery, Jacob Devlin, James Bradbury, Jonathan Heek, Kefan Xiao, Shivani Agrawal, and Jeff Dean. 2023. “Efficiently Scaling Transformer Inference.” Proceedings of Machine Learning and Systems (MLSys) 5: 606–24.
The preceding cautionary notes reinforce a recurring theme: architectural decisions are infrastructure commitments. The key concepts from this chapter’s systematic tour of architectural families, shared building blocks, computational primitives, and selection methodology follow.
Self-Check: Question
A team deploys MobileNetV2 on the same A100 serving rack that runs ResNet-50 in production. MobileNetV2 uses roughly 14\(\times\) fewer FLOPs than ResNet-50, yet per-request latency ends up roughly matching ResNet-50 rather than dropping 14\(\times\). Using the fallacies section, which explanation best diagnoses the gap?
- MobileNetV2’s depthwise-separable kernels have far lower arithmetic intensity than ResNet-50’s standard convolutions, so on a data-center GPU with abundant FP16 Tensor Cores the workload becomes bandwidth-bound rather than compute-bound; FLOP reduction does not translate into latency reduction when the A100 is not the limiting resource.
- MobileNetV2 cannot be quantized on A100 hardware, so it is forced to FP32 execution and loses the expected speedup.
- ResNet-50 is automatically compressed by the CUDA driver at load time, which erases the FLOP advantage MobileNetV2 would otherwise enjoy.
- The A100 secretly converts depthwise convolutions into sequential CPU operations, which explains the missing speedup.
Which scenario best captures the pitfall of optimizing architecture only for training hardware without analyzing the deployment environment?
- A team develops on an 8-GPU A100 node (687 GB total memory), then discovers at launch that the model cannot fit the 4 GB edge device it must actually run on — a 172\(\times\) memory reduction that cannot be closed by quantization alone and forces architectural redesign that delays release by a quarter.
- A team applies data augmentation during training and sees improved generalization on the validation set.
- A team benchmarks three candidate models on held-out test data before picking one.
- A team selects a CNN for a vision task because the data’s spatial locality matches the architecture’s inductive bias.
A team plans to serve a 7 billion parameter transformer (14 GB of FP16 weights) on an 80 GB A100. They assume that since model weights are 14 GB and one A100 has 80 GB, they have 66 GB of serving headroom per replica. Using the section’s KV-cache pitfall, walk through what they are missing for a 32-layer model with 32 attention heads, head dimension 128, context length 2,048 at FP16 with concurrency 8, and state what that means for the throughput plan.
Summary
Architecture is infrastructure. The choice between MLPs, CNNs, RNNs, transformers, and DLRM determines the physical viability of the system: its memory footprint, latency floor, power envelope, and scaling limit. Each architecture was analyzed through the same four-part lens (pattern processing needs, algorithmic structure, computational mapping, and system implications), revealing that even architectures with fundamentally different inductive biases create analogous engineering challenges.
The five Lighthouse Models established at the chapter opening (ResNet-50, GPT-2, DLRM, MobileNetV2, KWS) reveal distinct system bottlenecks: compute, bandwidth, capacity, latency, and power respectively. These lighthouses demonstrate that no single “best” architecture exists. CNNs fit spatial perception but fail at relationships; transformers model long-range dependencies but consume quadratic memory; DLRM-style architectures demonstrate a regime where neither compute nor bandwidth but raw memory capacity becomes the binding constraint, forcing explicit capacity planning before arithmetic optimization. The engineer’s role is not to pick the “newest” architecture, but to match the inductive bias of the model to the structure of the data and the physics of the hardware.
Key Takeaways: Architecture is infrastructure
- Inductive bias is the unifying concept: Every architecture encodes structural assumptions: locality for CNNs, sequence for RNNs, global context for transformers. These biases trade generality for sample efficiency and determine which problems an architecture can solve efficiently.
- Arithmetic intensity determines the bottleneck: High-intensity workloads (CNNs with weight reuse) are compute bound; low-intensity workloads (embedding lookups, autoregressive generation) are memory bound. Matching architecture to hardware requires knowing which regime the workload occupies.
- Quadratic costs are permanent constraints: Transformer attention scales as \(\mathcal{O}(S^2)\) in memory with sequence length. This is a fundamental property that constrains deployment contexts, not an implementation detail to optimize away.
- Lighthouse models isolate distinct bottlenecks: ResNet-50 (compute), GPT-2 (bandwidth), DLRM (capacity), MobileNetV2 (latency), KWS (power). These archetypes diagnose which physical constraint dominates a given system.
- Depth requires architectural support: Skip connections and normalization layers are not optimizations but prerequisites for training networks beyond ~20 layers. These building blocks, born in CNNs, transfer to many deep architectures, including transformers.
- FLOPs do not equal speed: MobileNetV2 uses 13.7× fewer FLOPs than ResNet-50 but can run slower on data center GPUs because its low arithmetic intensity starves compute units. Architecture-hardware alignment, not operation count, determines throughput.
- Architecture selection is deployment selection: Choosing a transformer over a CNN determines memory requirements, latency floors, hardware utilization, and infrastructure costs. The architecture is the system constraint.
The chapter-opening question now has a concrete answer: architecture determines the physical contract a system signs with hardware. A CNN commits to spatial locality and weight reuse; a transformer commits to quadratic memory scaling; an RNN commits to sequential dependencies that limit parallelization. These commitments cannot be renegotiated through clever optimization—they are baked into the mathematics. Engineers who understand these architectural contracts can predict system behavior before writing code, diagnose performance problems by tracing them to structural causes, and select architectures that match both the data’s structure and the deployment’s constraints.
An architecture is chosen like a model and paid for like infrastructure. The inductive bias that lets a network learn efficiently is the same bias that fixes, permanently, what it will demand of memory, bandwidth, and parallelism. A quadratic attention cost cannot be optimized into a linear one, and a sequential dependency cannot be parallelized away, no matter how the system beneath is built. This is the silicon contract signed at the level of architecture: the structure of the graph names in advance how the machine must spend its memory and compute, and nothing downstream is permitted to renegotiate the terms.
What’s Next: From blueprints to construction
How does an architectural blueprint become an executable system? The architecture has decided what the hardware must do; the framework decides how. ML Frameworks examines how PyTorch, TensorFlow, and JAX translate these high-level architectural graphs into the low-level kernels that run on silicon, the layer where the demands fixed here are turned into instructions the machine can execute.
Self-Check: Question
A product team is deciding how to allocate engineering effort for a new feature. Which decision best reflects the chapter’s thesis that ‘architecture is infrastructure’?
- Before picking the model family, profile the target deployment’s memory budget, latency SLO, and interconnect bandwidth, because the architecture’s memory footprint, attention cost, and data-access pattern will determine which hardware and infrastructure the team must provision.
- Pick the newest architecture from the latest paper and postpone all deployment analysis until the model is fully trained, because architecture choice does not affect infrastructure.
- Train multiple architectures identically and select whichever has the highest validation accuracy, because accuracy alone determines production viability.
- Always use a transformer for every task because transformers have the most capacity and will generalize best across any deployment environment.
Explain how inductive bias and arithmetic intensity together form a joint selection framework for choosing between architecture families, using a specific contrast from the chapter to ground the explanation.
Which pairing correctly matches a lighthouse model to its dominant system bottleneck, per the chapter’s synthesis?
- GPT-2: memory bandwidth, because autoregressive generation streams billions of weight bytes per low-intensity token step and is limited by HBM throughput, not peak FLOP/s.
- ResNet-50: memory capacity, because its deep stack of convolutional layers forces terabyte-scale storage.
- DLRM: compute throughput, because its matrix multiplies dominate all other costs at scale.
- MobileNetV2: quadratic attention memory, because its efficient-CNN design still incurs \(\mathcal{O}(S^2)\) serving cost.
Self-Check Answers
Self-Check: Answer
A team must choose between an MLP and a CNN for classifying 224-by-224 pixel medical images. A dense first layer would need 150,528 input weights per output unit, so a 1,000-unit layer would already carry roughly 150 million weights; the CNN uses filters with fewer than 10,000 weights shared across positions. Using the chapter’s framing of inductive bias, which statement best explains why the CNN is the better starting point?
- The CNN’s locality-and-weight-sharing assumption matches the spatial structure of images, which simultaneously reduces sample complexity and cuts per-layer memory traffic by orders of magnitude.
- The CNN is more expressive than the MLP, so it can fit any function the MLP can fit with fewer parameters.
- The MLP cannot represent image-classification functions at all, so the CNN is the only viable choice.
- The CNN eliminates the need for training entirely by using handcrafted filters, which avoids the gradient-descent cost of the MLP.
Answer: The correct answer is A. Inductive bias is the architecture’s built-in assumption about data structure: the CNN assumes nearby pixels are more related than distant ones, which lets it share a single small filter across every spatial position. That match between prior and data simultaneously collapses the parameter count and raises weight reuse, which improves both learnability and memory behavior. The ‘CNN is more expressive’ framing inverts the relationship — CNNs are less expressive than MLPs but more learnable on structured data. The ‘MLP cannot represent image functions’ claim contradicts universal approximation. The ‘handcrafted filters’ claim is wrong because CNN filters are still learned by gradient descent.
Learning Objective: Apply the inductive bias concept to justify a CNN-over-MLP architecture choice on structured spatial data and explain how the bias reduces both sample complexity and memory traffic.
A dense MLP layer on a single-sample forward pass reports roughly 0.5 FLOP/byte, while a 3-by-3 convolution in ResNet-50 reuses each filter weight across more than 50,000 spatial positions. Using arithmetic intensity, explain why these two architectures sit in opposite regimes on the roofline and what that implies for which hardware upgrade helps each.
Answer: Arithmetic intensity is the ratio of FLOPs performed to bytes moved; a modern accelerator needs roughly 100 FLOP/byte to saturate its compute units. The dense MLP layer at batch size 1 uses each weight exactly once, so 2 FLOPs per weight divided by 4 bytes of FP32 weight gives 0.5 FLOP/byte — hundreds of times below the ridge point, which puts the workload firmly in the bandwidth-bound regime. The ResNet-50 convolution reuses each filter across tens of thousands of positions, pushing intensity well above the ridge point and into the compute-bound regime. The practical consequence is that faster HBM (not more TFLOP/s) helps the MLP, while a higher peak-FLOP/s accelerator (not wider memory) helps ResNet-50. Same operation family, opposite hardware requirements.
Learning Objective: Analyze how arithmetic intensity determines which side of the roofline a workload occupies and select the hardware upgrade that targets its actual bottleneck.
A team profiles a production workload and finds that a single model’s embedding tables occupy roughly 1 TB of DRAM, that each request performs a handful of random row lookups, and that matrix-multiply kernels use less than 5 percent of accelerator time. Which lighthouse model best represents this workload’s dominant bottleneck?
- ResNet-50, because the workload spends most of its time in convolution kernels that benefit from dense matrix hardware.
- GPT-2 XL, because autoregressive generation is the canonical example of a bandwidth-limited serving workload.
- DLRM, because the binding constraint is memory capacity for terabyte-scale embedding tables accessed via irregular sparse gathers.
- MobileNetV2, because the low compute utilization signature is diagnostic of depthwise-separable convolutions.
Answer: The correct answer is C. A 1 TB embedding table that does not fit on any single accelerator, combined with sparse random access and idle compute units, is the defining fingerprint of DLRM: the workload is capacity-bound, not compute-bound or bandwidth-bound. The autoregressive framing describes GPT-2’s signature (low intensity with weight streaming), not terabyte-scale table storage. The ResNet-50 framing confuses a compute-dense dense-matrix workload with this sparse-lookup regime. The MobileNetV2 diagnosis is wrong because depthwise-separable kernels stress bandwidth on a data-center GPU; they do not produce the terabyte-capacity signature.
Learning Objective: Classify a production workload by matching its profile signature (table size, access pattern, compute utilization) to the correct lighthouse archetype.
A 3-by-3 convolution filter in a ResNet layer is applied at more than 50,000 spatial positions in a single forward pass, while a dense matrix-vector multiply uses each weight exactly once per sample. The ratio of math done to bytes moved — the ____ — is what places these two workloads on opposite sides of the roofline and dictates whether faster HBM or more TFLOP/s is the correct hardware response.
Answer: arithmetic intensity. It is the single quantity the roofline model uses to classify a workload as memory-bound or compute-bound, and in this chapter it is the diagnostic that explains why the same accelerator can be compute-starved on one architecture (dense MLP at low batch) and bandwidth-starved on another (autoregressive transformer).
Learning Objective: Infer the arithmetic-intensity metric from a description of weight reuse versus data movement and apply it to explain opposite roofline placements for CNN and MLP kernels.
Why does the chapter frame architecture selection as ‘signing a contract with physics’ rather than as a modeling preference?
- Because the chosen architecture fixes compute patterns (locality, quadratic attention, sparse lookups) that propagate into training-cluster provisioning, serving memory, and deployment feasibility — commitments that cannot be undone by clever optimization.
- Because the Python framework a team uses (PyTorch, TensorFlow, JAX) permanently binds a model to one vendor’s hardware.
- Because an architecture’s optimizer cannot be changed after the first training step without restarting training from scratch.
- Because the chapter’s theoretical analysis deliberately ignores real engineering constraints in favor of abstract mathematical results.
Answer: The correct answer is A. The chapter’s argument is that structural choices (a CNN’s locality, a transformer’s all-pairs attention, DLRM’s sparse lookups) determine the physical cost structure — memory footprint, bandwidth demand, scaling profile — that downstream teams must build infrastructure around. These costs are baked into the mathematics, not implementation details. The framework-lock-in answer confuses portability with physics: PyTorch models run on many vendors; the ‘contract’ is with memory and compute limits, not vendor APIs. The optimizer answer misreads what is permanent: optimizers are changeable, but attention’s quadratic memory scaling is not. The ‘theoretical analysis ignores constraints’ framing reverses the chapter’s actual argument.
Learning Objective: Analyze how architectural choice propagates through training infrastructure, serving memory, and deployment viability to justify framing architecture selection as an infrastructure commitment.
True or False: A stronger inductive bias is always preferable to a weaker one because it reduces the parameter count and the amount of data the model needs to learn from.
Answer: False. A stronger bias wins only when it matches the data’s structure. A CNN’s locality prior is a superpower on images but a cage on language, where important dependencies span hundreds of tokens that no local filter can see. In that regime, a more expensive architecture like attention — which pays \(\mathcal{O}(S^2)\) memory to reach across the sequence — is the systems-justified choice. The correct framing is match, not strength.
Learning Objective: Evaluate when a stronger inductive bias helps and when it blocks the cross-element interactions a task requires.
Self-Check: Answer
A 2,048-unit dense layer connected to another 2,048-unit layer stores roughly 4.2 million weights, consuming about 16 MB in FP32 — and every weight is used exactly once per input sample. A team considering this layer as the front end of an image classifier asks why CNN-based classifiers typically use thousands of times fewer parameters for the same task. Which statement best captures the systems consequence of the MLP’s architectural assumption?
- The MLP treats every input feature as potentially relevant to every output feature, so it pays \(\mathcal{O}(M \times N)\) memory and \(\mathcal{O}(M \times N)\) bytes-moved per sample regardless of whether any spatial structure exists in the data.
- The MLP’s activation function is more expensive than a convolution, which is why its total memory footprint is higher.
- The MLP uses a fundamentally different optimizer that requires more state per parameter than a CNN’s optimizer.
- The MLP’s bias vector grows quadratically with input dimension, which dominates the parameter count.
Answer: The correct answer is A. The dense layer’s ‘no structural assumption’ bias is exactly what forces the \(\mathcal{O}(M \times N)\) weight matrix: with no prior that nearby inputs matter more than distant ones, every input-output pair must have its own learnable parameter. On a 2,048-to-2,048 layer that is 4.2 million weights used once each, which is both the memory cost and the bytes-moved-per-sample cost. The activation-cost framing inverts the dominant term: element-wise activations are trivial next to matrix multiplication. The optimizer framing is wrong because optimizer state is a training-time overhead on top of the weights, not the cause of the parameter count. The bias-vector framing is arithmetically wrong — the bias is linear in output dimension.
Learning Objective: Apply the MLP’s unrestricted-interaction assumption to explain why parameter count and bytes-moved-per-sample both scale as \(\mathcal{O}(M \times N)\), and connect that scaling to its bandwidth behavior.
A team cites the Universal Approximation Theorem to argue that a sufficiently wide MLP could solve any image classification task. They plan to train a 3-layer MLP on 224-by-224 ImageNet images. Explain why UAT does not justify this plan and what the practical learnability gap looks like in both statistical and systems terms.
Answer: UAT guarantees that some MLP of sufficient width represents the target function; it says nothing about whether gradient descent can find that MLP with finite data or whether the resulting footprint is physically realizable. On 224-by-224 RGB inputs a single first-layer neuron already connects to 150,528 input values, so a modest hidden width quickly reaches hundreds of millions or billions of weights that the model must both store and learn. Statistically, the absence of a locality prior forces sample complexity to grow with that unstructured parameter count, so the data and compute required to converge become impractical. Systemically, the dense matrix is used once per sample and drags the workload into the 0.5 FLOP/byte regime, far below the ridge point of any modern accelerator. The engineering consequence is that CNNs do not win because MLPs cannot represent the function; they win because gradient descent on a locality-sharing architecture actually converges within the budget an accelerator provides.
Learning Objective: Analyze the gap between UAT’s representational guarantee and practical trainability, and connect both the statistical (sample complexity) and systems (memory-bandwidth) failure modes of a naive dense-MLP image classifier.
A 2,048-to-2,048 dense layer processing a single FP32 input sample reports roughly 0.5 FLOP/byte on an A100, and the kernel runs at 4 percent of the advertised Tensor Core peak. Which optimization path is most directly aligned with the section’s analysis of this regime?
- Increase the batch size so weights are reused across many samples, raising arithmetic intensity above the ridge point and letting the Tensor Cores stay fed.
- Upgrade to an accelerator with 2\(\times\) the advertised TFLOP/s while keeping batch size 1, because the workload is compute-bound.
- Replace the matrix multiply with an element-wise activation to reduce total FLOPs to near zero.
- Disable the BLAS library and route the computation through a scalar Python loop to improve cache locality.
Answer: The correct answer is A. The signature — 0.5 FLOP/byte, 4 percent of peak — is memory-bound: each weight is used once per sample, so more compute cannot help a kernel already starved for bytes. Batching reuses the same weight matrix across many samples, lifting arithmetic intensity past the ridge point and letting Tensor Cores amortize their loads. Doubling peak TFLOP/s is the classic compute-first mistake that misreads the profile. Replacing the matmul with an activation is not an optimization; it removes the operation the layer exists to perform. Disabling BLAS runs the same arithmetic with far worse hardware utilization, not better.
Learning Objective: Diagnose a batch-1 dense-layer kernel as bandwidth-bound from a FLOP/byte signature and select batching as the intensity-raising fix rather than a compute upgrade.
Order the following steps in a dense layer’s forward pass for one output neuron: (1) apply the activation function to the accumulated pre-activation, (2) initialize the output neuron with its bias value, (3) accumulate input-times-weight products across all input features.
Answer: The correct order is: (2) initialize the output neuron with its bias value, (3) accumulate input-times-weight products across all input features, (1) apply the activation function to the accumulated pre-activation. The bias sets the starting pre-activation so the subsequent MAC loop adds into a defined value; the loop then builds the weighted sum; only after the sum is complete does the nonlinearity transform it into the final output. Applying the activation before accumulation would pass each individual product through a nonlinearity and destroy the linearity of the inner loop — the layer would no longer be the operation the mathematics defines.
Learning Objective: Sequence the three sub-steps of a dense-layer forward pass and identify the failure mode that arises if the activation is applied before accumulation completes.
A team ports an MNIST-style 784-by-100 dense layer to an A100 and measures throughput far below the advertised FP16 Tensor Core peak. The layer is small and has awkward dimensions for Tensor Core tiling. Which explanation is most consistent with the section’s discussion of Tensor Core alignment?
- Tensor Core peak assumes hardware-friendly tile shapes and enough work to amortize overhead; awkward small matrices may need padding or less efficient kernels, so their realized throughput can be far below peak.
- Small dense layers are never executed on GPUs and are silently dispatched to the CPU by the runtime.
- The activation function on a 100-dimensional output vector is the dominant cost and hides the GEMM’s throughput.
- The 784-by-100 layer has excessive arithmetic intensity that saturates memory and leaves compute units idle.
Answer: The correct answer is A. The A100’s Tensor Core path is shape-aware: peak throughput assumes matrix dimensions and batch sizes that map cleanly onto hardware tiles and keep the pipeline full. Modern libraries can often still use Tensor Cores for non-ideal shapes, but padding, edge tiles, launch overhead, and low reuse can make a 784-by-100 batch-1 layer run far below advertised peak. The ‘always on CPU’ claim is false — GPUs execute small dense layers routinely, just inefficiently. The activation-dominance claim inverts the cost ratio — matmul dominates, activations are trivial. The excessive-intensity explanation is backwards: the problem is insufficient hardware-friendly geometry and reuse, not saturating memory.
Learning Objective: Analyze how matrix shape, tile alignment, and problem size determine whether a dense layer reaches Tensor Core peak, and diagnose an awkward small matrix as a likely cause of underperformance.
True or False: Because MLPs are universal approximators, they are the most practical architecture for any high-dimensional structured input such as a 224-by-224 image.
Answer: False. Universal approximation guarantees that some MLP represents the target function; it does not guarantee that gradient descent finds it with finite data, nor that the network fits on any realizable accelerator. On a 224-by-224 RGB image, dense connectivity alone requires 150,528 input weights per first-layer output unit, so practical hidden widths can push the first layer into hundreds of millions of weights. UAT is a statement about representability, not about learnability or feasibility.
Learning Objective: Distinguish representational power from practical learnability and feasibility when evaluating an MLP for high-dimensional structured inputs.
Self-Check: Answer
An MLP first layer connected to a 224-by-224 RGB image would need 150,528 weights per output neuron, so a 1,000-unit dense layer would have more than 150 million weights. A typical CNN first layer with 64 filters of size 3-by-3 applied to the same image uses roughly 1,728 weights total. Which statement best captures why the CNN achieves this compression?
- Each filter applies the same small set of learned weights at every one of the 50,176 spatial positions, so parameter count is governed by filter size and channel count rather than by input resolution.
- The CNN replaces learned filters with fixed hand-designed edge detectors, which is why it needs no per-pixel weights.
- The CNN processes only grayscale images, which reduces the parameter count by a factor of three versus RGB.
- The CNN removes all nonlinear activations, which allows adjacent layers to be merged and parameters to be dropped.
Answer: The correct answer is A. The CNN’s structural assumptions — local receptive fields plus weight sharing across spatial positions — decouple parameter count from input resolution. A 3-by-3 filter has 9 weights regardless of whether the image is 224-by-224 or 4K; multiplying by channels and filter count gives the entire layer’s parameter budget. The ‘fixed hand-designed filters’ framing is wrong because CNN filters are still learned by gradient descent; locality is the prior, learning is still end-to-end. The grayscale and ‘no-activations’ framings are both factually wrong and unrelated to the reason parameters compress.
Learning Objective: Explain how local receptive fields and weight sharing together decouple a CNN’s parameter count from input resolution, and quantify the compression versus a comparable dense layer.
A vision team is building two models on the same backbone: one for whole-image classification and one for pedestrian bounding-box detection. Explain why the detection model must preserve translation equivariance deeper into the network than the classification model, and connect the distinction to what pooling and global averaging do to feature maps.
Answer: Translation equivariance means shifting the input shifts the feature map in the same way, which preserves where features occur. Translation invariance means the output is unchanged after a shift — the ‘where’ is collapsed, only the ‘what’ remains. Classification wants invariance: a cat is a cat regardless of where it appears in the frame, so global average pooling or aggressive pooling late in the network is an asset. Detection wants equivariance through most of the network: a bounding box is defined by location, so collapsing spatial information too early erases the very signal the detection head must regress. The systems consequence is that detection networks keep feature maps spatially resolved deeper into the stack and pay the activation-memory cost of doing so, while classification networks can afford aggressive spatial reduction.
Learning Objective: Distinguish equivariance from invariance and apply the distinction to justify different feature-map-preservation strategies for classification versus detection.
A designer wants a CNN whose top-layer neurons each respond to a 50-pixel-wide image region. A stack of 3-by-3 convolutions grows the receptive field by 2 pixels per layer. Which choice is the most consistent with the section’s reasoning about how to achieve that receptive-field target?
- Stack roughly 25 layers of 3-by-3 convolutions, because depth expands the receptive field while keeping per-layer parameter counts and arithmetic intensity favorable on accelerators.
- Use a single 50-by-50 convolution layer, because it reaches the target receptive field with one pass and therefore uses less compute than a deep stack.
- Replace the convolutions with a dense MLP layer that connects every pixel to every output, so receptive field becomes irrelevant.
- Use depthwise-separable convolutions exclusively, because they automatically expand the receptive field faster than standard convolutions.
Answer: The correct answer is A. Receptive field is the region of the input that influences one output activation; stacking many small-kernel convolutions compounds receptive fields additively (or multiplicatively for dilated variants) while keeping each layer small enough to enjoy weight sharing and map cleanly onto accelerator primitives. A single 50-by-50 kernel has 2,500 weights per input channel — orders of magnitude more than a 3-by-3 filter — and produces an irregular shape that maps poorly to optimized GEMM paths, so depth-via-small-kernels is both cheaper and better for hardware. The dense-MLP framing discards the weight sharing that makes CNNs efficient on images. The depthwise-separable claim confuses an efficiency technique (decomposing a standard conv) with receptive-field geometry — DS convolutions do not automatically grow the receptive field faster.
Learning Objective: Apply the receptive-field concept to justify deep stacks of small kernels over single large-kernel designs and connect the decision to both parameter count and hardware mapping.
A team deploys MobileNetV2 on a data-center A100 expecting roughly 14\(\times\) lower latency than ResNet-50 because MobileNetV2 uses about 14\(\times\) fewer FLOPs. Measurements show MobileNetV2 is actually slower than ResNet-50 on the same GPU. Which explanation best fits the section’s analysis?
- MobileNetV2’s depthwise-separable convolutions produce low-arithmetic-intensity kernels whose bytes-moved-per-FLOP ratio pushes the workload into the bandwidth-bound regime, so the A100’s Tensor Core throughput cannot be used.
- MobileNetV2 cannot be quantized, which forces it to run at higher precision and explains the worse latency.
- ResNet-50 has more parameters and is automatically compressed at runtime by the GPU driver, which makes it faster.
- Depthwise-separable convolutions force execution onto the CPU because GPUs do not implement depthwise kernels.
Answer: The correct answer is A. Depthwise-separable convolutions decompose one standard conv into two cheaper operations (depthwise plus pointwise), but each component has far less weight reuse per byte than a standard conv: depthwise convs touch one input channel at a time, and pointwise 1-by-1 convs move large feature maps per modest flop count. The result is low arithmetic intensity, which leaves a data-center GPU’s compute units underfed even though total FLOPs are down 14\(\times\). The quantization-support framing is factually wrong (MobileNet is highly quantizable). The driver-compression framing invents a runtime mechanism GPUs do not perform. The CPU-fallback claim is wrong — GPUs execute depthwise kernels, just with poor intensity.
Learning Objective: Diagnose why MobileNetV2’s FLOP reduction does not translate to A100 latency reduction and identify low arithmetic intensity as the cause.
A smart-doorbell team must choose between ResNet-50 and a DS-CNN keyword-spotting model for always-on audio wake-word detection on a microcontroller with a 2 mW average power budget and 256 KB of SRAM. Explain why both models are convolutional yet only one is deployable, and what specific architectural choice closes the gap.
Answer: Both are convolutional — both exploit local structure and weight sharing — but their computational footprints differ by orders of magnitude. ResNet-50’s standard convolutions scale as K-squared times the product of input and output channels, giving millions of parameters and gigaflops per inference that no microcontroller power envelope can sustain. DS-CNN’s depthwise-separable decomposition splits one K-by-K-by-C-in-by-C-out convolution into a K-by-K-by-C-in depthwise step plus a 1-by-1-by-C-in-by-C-out pointwise step, reducing parameters and FLOPs by roughly 1/K-squared plus 1/C-out. For K equals 3 and typical channel counts, that is nearly an order-of-magnitude cost cut at each layer. The systems consequence is that DS-CNN fits the microcontroller’s storage and energy budget while retaining the locality prior; ResNet-50’s standard convolutions simply cannot run inside a milliwatt power envelope, regardless of accuracy.
Learning Objective: Compare standard and depthwise-separable convolutions by parameters, FLOPs, and deployability, and justify the architectural choice for an always-on microcontroller keyword spotter.
True or False: If two CNNs have the same total FLOP count, they will have the same inference latency on the same GPU.
Answer: False. Latency depends on arithmetic intensity and kernel-to-hardware mapping, not FLOP count alone. A standard-convolution CNN and a depthwise-separable CNN can have matching FLOPs but very different bytes-moved-per-FLOP ratios, placing them on opposite sides of the roofline on the same accelerator and producing a latency gap that FLOP-counting cannot predict.
Learning Objective: Evaluate why equal FLOP counts do not imply equal latency for two CNN variants on the same hardware.
Self-Check: Answer
What architectural feature lets a vanilla RNN process a 10-token input and a 10,000-token input using the same weight matrices and the same constant-sized hidden state?
- A recurrent update rule that applies the same learned transformation to produce a new hidden state from the previous hidden state and the current input, at every time step.
- A stored \(S \times S\) attention score matrix that captures all pairwise interactions between time steps.
- A spatial filter shared across all image locations that sweeps across the sequence like a CNN kernel.
- An input-independent decoder that ignores all prior inputs during inference.
Answer: The correct answer is A. The recurrent update rule \(\mathbf{h}_t = f(\mathbf{W}_{\text{hh}}\mathbf{h}_{t-1} + \mathbf{W}_{\text{hx}}\mathbf{x}_t + \mathbf{b}_h)\) applies the same weights at every time step, which is exactly what allows arbitrary-length sequences to share parameters and lets the hidden state carry history forward at constant per-step cost. The \(S \times S\) attention matrix framing belongs to attention-based models, not RNNs. The spatial-filter framing imports CNN machinery that does not exist in a recurrent layer. The ‘ignores prior inputs’ framing contradicts the definition of a recurrent network.
Learning Objective: Identify the recurrent update rule that enables variable-length sequence processing with a fixed-size hidden state and shared weights.
True or False: A team whose RNN training job reports 40 percent GPU utilization and whose wall-clock time scales linearly with sequence length could recover most of the lost utilization by adding a second identical GPU in a data-parallel configuration.
Answer: False. The 30-50 percent utilization signature is a consequence of the sequential Jacobian chain over time, not a shortage of arithmetic hardware. Adding a second GPU in data parallelism speeds up gradient computation across the batch but does nothing to shorten the within-sequence dependency path. Each step still must wait for the previous one’s hidden state, so per-sample latency is unchanged and per-step utilization stays similarly low. The remediation is algorithmic (truncated BPTT, attention) or architectural (pipeline-style scheduling) — not more accelerators.
Learning Objective: Analyze why the RNN utilization wall is caused by the temporal dependency chain and cannot be closed by adding data-parallel hardware.
A mobile-team engineer must choose between an RNN and a transformer for on-device streaming speech recognition on a phone with 4 GB of RAM. The input is an effectively unbounded audio stream. Walk through the memory trade-off between the RNN’s \(\mathcal{O}(1)\) hidden state and attention’s \(\mathcal{O}(S^2)\) score matrix, and justify which architecture the constraint favors.
Answer: The RNN’s recurrence compresses arbitrary history into a fixed-size hidden state — typically hundreds of floats — so inference memory is independent of how long the audio stream has been running. A transformer’s self-attention retains all \(S\) prior token representations and materializes an \(S \times S\) score matrix, so memory grows quadratically with context: at 10,000 frames and 16-bit scores, the attention matrix alone consumes roughly 200 MB per layer per head, quickly overwhelming a 4 GB device running multiple layers and heads. On streaming speech specifically, the transformer’s richer long-range access does not compensate for breaching the memory budget, so the RNN’s \(\mathcal{O}(1)\) state is the systems-justified choice despite its sequential latency cost. The deeper point: the chapter explicitly cites streaming and resource-constrained inference as the regime where recurrence remains advantageous.
Learning Objective: Analyze the \(\mathcal{O}(1)\) hidden state versus \(\mathcal{O}(S^2)\) attention memory trade-off and justify an architecture choice for a streaming-inference memory budget.
Why does scaling from one to eight GPUs almost entirely remove the training-time bottleneck of a ResNet-50 data-parallel job but fail to similarly improve a vanilla-RNN training job on long sequences?
- Because the RNN’s binding constraint is the ordered dependency from \(\mathbf{h}_{t-1}\) to \(\mathbf{h}_t\) across time steps; extra parallel hardware shortens batch-wise work but cannot shorten the in-sequence dependency chain.
- Because recurrent layers cannot use matrix multiplication, so GPUs cannot accelerate them at all.
- Because the RNN’s hidden states are too large to fit in GPU memory, while ResNet’s activations are not.
- Because RNNs are primarily limited by random embedding-table lookups whose latency ignores compute throughput.
Answer: The correct answer is A. ResNet-50 is batch-parallel: each sample’s forward-and-backward pass is independent, so adding GPUs multiplies throughput almost linearly. A vanilla RNN’s training critical path is the \(S\)-step chain of dependencies within a sequence — \(\mathbf{h}_t\) depends on \(\mathbf{h}_{t-1}\), which depends on \(\mathbf{h}_{t-2}\), and so on — and no number of parallel accelerators shortens that path. The ‘RNNs cannot use matmul’ framing is wrong because each recurrent step is itself a matmul; the problem is their sequential composition. The ‘hidden states too large’ framing reverses the RNN’s defining property, which is \(\mathcal{O}(1)\) state. The ‘embedding lookups’ framing imports DLRM machinery that is not the RNN’s bottleneck.
Learning Objective: Diagnose why data-parallel scaling does not close the RNN latency wall and identify the sequential-dependency chain as the binding constraint.
Order the following operations for one RNN time step producing \(\mathbf{h}_t\): (1) combine the current input with the input weights \(\mathbf{W}_{\text{hx}}\), (2) apply the nonlinear activation to produce the new hidden state \(\mathbf{h}_t\), (3) combine the previous hidden state \(\mathbf{h}_{t-1}\) with the recurrent weights \(\mathbf{W}_{\text{hh}}\).
Answer: The correct order is: (3) combine the previous hidden state \(\mathbf{h}_{t-1}\) with the recurrent weights \(\mathbf{W}_{\text{hh}}\), (1) combine the current input with the input weights \(\mathbf{W}_{\text{hx}}\), (2) apply the nonlinear activation to produce the new hidden state \(\mathbf{h}_t\). The recurrent and input contributions are both summed into the same pre-activation state, so either can be computed first but both must be completed before the nonlinearity. The activation must trail the accumulation because applying it mid-sum would change the equation \(\mathbf{h}_t = f(\mathbf{W}_{\text{hh}}\mathbf{h}_{t-1} + \mathbf{W}_{\text{hx}}\mathbf{x}_t + \mathbf{b}_h)\) — pushing the nonlinearity inside the addition changes the recurrence the model has learned and destroys gradient flow during training.
Learning Objective: Sequence the core sub-steps of one recurrent time step and justify why the activation must follow the full accumulation.
A keyword-spotting deployment team must choose an architecture to run continuously on a microcontroller with a 1 MB working-memory budget for incoming audio. Which scenario best captures when an RNN is the systems-justified choice over an attention-based model, per the section’s argument?
- When streaming inference runs under tight memory limits and materializing even a modest attention matrix would breach the memory budget.
- When the task is image classification with strong translation invariance on large input resolutions.
- When the task requires quadratic pairwise attention over tens of thousands of tokens at once to meet accuracy targets.
- When throughput depends on maximizing batch-parallel sequence processing across a cluster of GPUs.
Answer: The correct answer is A. The section explicitly names streaming inference on resource-constrained hardware — where the attention matrix’s \(\mathcal{O}(S^2)\) memory is prohibitive — as the regime where the RNN’s \(\mathcal{O}(1)\) hidden state remains systems-justified. Classification with translation invariance points toward CNNs, not RNNs. Quadratic pairwise attention over many tokens is the regime where transformers win, not RNNs. Maximizing batch-parallel sequence throughput is the transformer’s strength, not the RNN’s — the RNN’s sequential dependency prevents exactly that parallelism.
Learning Objective: Select the deployment regime (streaming inference under tight memory limits) in which a recurrent architecture remains preferable to attention-based models.
Self-Check: Answer
A sequence-modeling team finds that their model fails to resolve the sentence ‘The cat, which had been sitting on the windowsill overlooking the garden, was sleeping’ because the pronoun-predicate link between ‘cat’ and ‘was sleeping’ spans many intervening tokens. Why does an attention-based layer resolve this link more reliably than a stack of recurrent layers, and what is the systems cost of that guarantee?
- Attention directly computes a similarity-weighted mixture between ‘was sleeping’ and every prior token in a single step, so the long-range subject-predicate link does not have to survive traversal of every intervening hidden-state update; the cost is the \(S \times S\) score matrix that grows quadratically with context length.
- Attention eliminates the need for learned query, key, and value projections, which is why long-range dependencies are captured for free.
- Attention enforces strict left-to-right sequential processing like an RNN, which is why it reliably tracks long-range references.
- Attention replaces matrix multiplications with cheap element-wise operations, which is why it costs less than an RNN at long contexts.
Answer: The correct answer is A. In an RNN, the ‘cat’-to-‘was sleeping’ signal must survive \(S\) Jacobian products through the hidden-state chain, where it typically decays or explodes; attention’s query-against-all-keys operation creates an \(\mathcal{O}(1)\)-depth path between any two tokens so the information does not have to traverse intervening states. The systems price is the \(S \times S\) score matrix that self-attention must compute and (unless tiled) store. The projection-free framing is wrong — attention requires \(\mathbf{Q}\), \(\mathbf{K}\), and \(\mathbf{V}\) projections. The sequential framing inverts attention’s defining property, which is parallel all-pairs access. The element-wise-operations framing is factually wrong and contradicts the quadratic cost structure.
Learning Objective: Apply attention’s \(\mathcal{O}(1)\) information-flow depth and \(\mathcal{O}(S^2)\) memory cost to a long-range dependency scenario and trade off the two against an RNN’s hidden-state chain.
Explain why attention succeeds at long-range dependencies that defeat recurrent layers, and give a concrete numeric example of the systems cost this capability introduces at typical transformer context lengths.
Answer: Attention connects any two positions in \(\mathcal{O}(1)\) information-flow depth: the query at position \(i\) is matched against all \(S\) keys and the softmax-weighted combination of values arrives in one step, regardless of how far apart positions \(i\) and \(j\) are. That removes the RNN’s bottleneck where a signal must survive a chain of \(S\) Jacobian products through intermediate hidden states. The trade is the \(S \times S\) attention score matrix, which scales quadratically with sequence length. At \(S = 4{,}096\) with 16-bit scores, the matrix alone consumes roughly 32 MB per layer per head before the value aggregation and before accounting for batch or multi-head concurrency. Doubling context to 8,192 quadruples this to roughly 128 MB per layer per head, which is exactly why long-context inference falls off a memory cliff.
Learning Objective: Explain attention’s reduction of sequential depth from \(\mathcal{O}(S)\) to \(\mathcal{O}(1)\) and quantify the \(\mathcal{O}(S^2)\) memory price at typical transformer context lengths.
A team doubles the sequence length from 4,096 to 8,192 tokens while leaving model parameters unchanged, and the deployment suddenly runs out of accelerator memory. Which mechanism is most directly responsible?
- Self-attention materializes an \(S \times S\) score matrix, so doubling \(S\) quadruples the dominant attention-memory term — even though weight tensors stay exactly the same size.
- The Adam optimizer state doubles during autoregressive inference, overwhelming the accelerator.
- Softmax internally duplicates every weight matrix once per token, causing weight memory to grow linearly with sequence length.
- Query, key, and value projections become cubic in sequence length, which is the source of the memory explosion.
Answer: The correct answer is A. Self-attention compares every position against every other, so the dominant score structure is an \(S \times S\) matrix; doubling \(S\) from 4,096 to 8,192 quadruples that matrix. Parameter tensors (weights, biases, projection matrices) are independent of sequence length, so they do not grow at all. The Adam-state framing invents a training-time structure that does not appear during inference. The softmax-duplicates-weights framing fabricates a mechanism that does not exist. The ‘cubic projections’ framing is arithmetically wrong — \(\mathbf{Q}\), \(\mathbf{K}\), and \(\mathbf{V}\) projections are each linear in \(S\) (producing \(\mathcal{O}(S d)\) output tensors), not cubic.
Learning Objective: Diagnose quadratic attention-memory growth as the cause of sudden out-of-memory failure when sequence length doubles and rule out parameter-duplication mechanisms.
The attention mechanism’s \(S \times S\) score matrix must be fully materialized because the normalization step at its core requires a pass over all \(S\) scores to compute a shared denominator before any weight can be finalized. The specific operation whose denominator dependency forces this materialization — and whose tiled streaming form is what FlashAttention redesigns — is ____.
Answer: softmax. Its exponentiate-then-normalize structure requires the sum of exp-scores across a full row before any individual weight is valid, which prevents streaming computation and forces the whole row (and thus the whole matrix) to be present in memory at once. FlashAttention’s contribution is a tiled online algorithm that keeps a running max and sum so the same softmax result can be produced without materializing the whole \(S \times S\) matrix at once.
Learning Objective: Infer the softmax operation from its normalization-dependency property and connect that dependency to the quadratic memory wall and FlashAttention’s remediation.
A team wants to extend transformer context length from 8,000 to 64,000 tokens but runs out of memory because the attention matrix consumes roughly 64\(\times\) more space. Which response is most aligned with the section’s analysis of this memory wall?
- Adopt FlashAttention or a sparse-attention variant that avoids materializing the full \(S \times S\) score matrix by tiling the softmax into on-chip memory or skipping most of its entries.
- Increase only FLOP throughput by upgrading to a faster accelerator, because attention is purely compute-bound and insensitive to memory bandwidth.
- Replace softmax with ReLU, which would make the attention matrix linear in sequence length while preserving the same functional form.
- Replace self-attention with convolutions, because convolutions preserve full pairwise token interactions at lower cost.
Answer: The correct answer is A. The memory wall comes from storing the full \(S \times S\) score matrix; the section explicitly points to FlashAttention (tiled softmax keeps activations in on-chip SRAM) and sparse-attention variants (skip most entries) as the response. Upgrading compute cannot help a kernel whose bottleneck is memory traffic, not FLOPs. Replacing softmax with ReLU does not change the \(S \times S\) structure — the matrix is still \(S \times S\); softmax’s specific issue is the normalization dependency, not its magnitude. Replacing attention with convolutions discards the all-pairs interaction that is precisely the capability the long-context goal requires.
Learning Objective: Evaluate architecture-level responses to the attention memory wall and select FlashAttention or sparse attention over compute-first or structure-destroying alternatives.
True or False: Attention’s main systems cost is the three linear projections that produce \(\mathbf{Q}\), \(\mathbf{K}\), and \(\mathbf{V}\); the subsequent similarity computation and value aggregation are nearly free.
Answer: False. The \(\mathbf{Q}\), \(\mathbf{K}\), and \(\mathbf{V}\) projections are each \(\mathcal{O}(S d_{\text{model}}^2)\) — linear in sequence length — while the subsequent \(\mathbf{Q}\mathbf{K}^T\) similarity and the softmax-weighted value aggregation both produce and consume an \(\mathcal{O}(S^2)\) score matrix. At long context the score matrix dominates memory and bandwidth, not the projections. Treating attention’s cost as ‘projections plus a cheap weighted sum’ is exactly the mental model the section’s memory-wall analysis disproves.
Learning Objective: Distinguish the linear projection cost from the quadratic all-pairs similarity cost in attention and identify which term dominates at long context.
Self-Check: Answer
What architectural change distinguishes transformers from recurrent sequence models and enables GPU-friendly parallelism during training?
- Transformers eliminate the time-step-by-time-step sequential recurrence and use self-attention to connect every sequence position directly, so all positions can be processed in parallel within one forward pass.
- Transformers replace learned projections with fixed, hand-designed feature extractors, reducing parameter count.
- Transformers retain recurrence but remove all normalization layers, which speeds up the per-step compute.
- Transformers process only image patches and cannot process token sequences.
Answer: The correct answer is A. The defining shift is replacing the \(\mathbf{h}_t = f(\mathbf{h}_{t-1}, \mathbf{x}_t)\) chain — whose \(S\)-step dependency blocks parallelism — with self-attention, which produces all \(S\) output positions in one forward pass because every position attends to every other simultaneously. The fixed-feature-extractor framing is wrong; transformers use learned \(\mathbf{Q}\), \(\mathbf{K}\), and \(\mathbf{V}\) projections. The ‘retain recurrence’ framing reverses the shift. The image-patches-only framing confuses one application (ViT) with the architecture’s generality.
Learning Objective: Identify the elimination of sequential recurrence as the architectural change that enables transformer training parallelism.
A company runs the same transformer model in two environments: a distributed pretraining job on 1,024 GPUs and a single-GPU autoregressive serving endpoint generating one token at a time. Explain why the dominant bottleneck is different in the two settings and identify which iron-law term each setting stresses.
Answer: During pretraining, the model processes thousands of tokens per forward pass in parallel: all \(S\) query-key-value pairs can be computed simultaneously, and the \(S\)-by-\(S\) attention matrix plus value aggregation is the dominant cost. Compute and quadratic-attention memory bite — the training regime is compute-bound on modern accelerators, stressing the iron law’s compute term \(O / (R_{\text{peak}} \cdot \eta_{\text{hw}})\). During autoregressive serving, tokens are generated one at a time: each new token requires reloading the full weight matrix and the growing KV cache to compute a single query’s attention, giving very low arithmetic intensity per token. Weight streaming and KV-cache reads dominate, making serving bandwidth-bound — the iron law’s data term \(D_{\text{vol}} / \text{BW}\) is the binding constraint. The same model, therefore, is limited by compute at scale-up and by memory bandwidth at scale-out. This is why serving throughput often tracks HBM bandwidth more closely than advertised TFLOP/s.
Learning Objective: Analyze why training and autoregressive inference stress different iron-law terms in the same transformer, and map each regime to its dominant resource.
Why does multi-head attention use multiple independent attention heads instead of one monolithic attention computation with the same total parameter budget?
- Each head operates in a lower-dimensional subspace and learns to attend to a different relational pattern — syntactic, co-reference, positional — in parallel, and their concatenated outputs give the model access to multiple specialized relationships per layer.
- Multi-head attention removes the need for any \(\mathbf{Q}\), \(\mathbf{K}\), or \(\mathbf{V}\) projections entirely, replacing them with direct input routing.
- Multi-head attention forces every token to attend only to its immediate neighbors, which is why it is faster than single-head attention.
- Multi-head attention replaces the \(S \times S\) score matrix with a linear-in-\(S\) structure, eliminating the quadratic memory cost.
Answer: The correct answer is A. The point of multiple heads is parallel subspace specialization: each head projects the input into a smaller \(\mathbf{Q}\)/\(\mathbf{K}\)/\(\mathbf{V}\) space and learns its own attention pattern, so one head can capture syntactic agreement while another tracks pronoun resolution while a third tracks positional locality — all within the same layer. The ‘no projections’ framing is wrong because each head has its own projection matrices. The ‘immediate neighbors only’ framing confuses multi-head attention with sliding-window attention. The ‘eliminates quadratic memory’ framing is wrong because the quadratic cost is per head; multi-head adds a factor of \(N_{\text{heads}}\) without changing the \(S^2\) scaling.
Learning Objective: Explain multi-head attention as parallel subspace specialization and distinguish it from architectural variants that change attention’s locality or cost structure.
True or False: Because self-attention gives each token direct access to every other token, a transformer’s context window can be extended almost indefinitely with no systems consequences.
Answer: False. Direct access is algorithmically useful, but two physical costs grow with context length: training-time attention-matrix memory scales as \(\mathcal{O}(S^2)\) per head per layer, and inference-time KV cache scales linearly with context and concurrent requests. Both walls bite well before ‘almost indefinite’ context. The \(\mathcal{O}(1)\) information-flow-depth benefit is a statement about connectivity, not about resource cost.
Learning Objective: Evaluate why transformer context length is bounded by physical memory costs (quadratic attention matrix during training, linear KV cache during inference) even though information-flow depth is constant.
A serving team profiles a 30-billion-parameter GPT-style LLM and reports that each generated token requires only a modest amount of math relative to the accelerator’s peak FLOP/s, yet tokens-per-second falls far short of what peak FLOP/s would predict. Which diagnosis best fits the GPT-2 lighthouse analysis?
- The workload is memory-bandwidth-bound: each generated token must stream the model’s weight matrices plus read and update the KV cache, producing a low arithmetic-intensity kernel that starves the compute units regardless of advertised TFLOP/s.
- The workload is compute-bound because every token requires materializing a quadratic attention matrix over the entire training corpus.
- The bottleneck is image preprocessing on the CPU, which stalls the GPU before token generation can begin.
- Transformers cannot batch inference requests at all, so throughput is capped at one sample per GPU.
Answer: The correct answer is A. The GPT-2 lighthouse signature is exactly this: low FLOP/byte per generated token because the model must stream billions of weight bytes through the compute units for each step of generation, and the KV cache read/write adds further memory traffic. More TFLOP/s does not help a kernel whose bottleneck is bandwidth. The quadratic-matrix-over-training-corpus framing is wrong on two counts: attention is over the current sequence, not the training corpus, and decoding does not rematerialize the full attention during each step. The preprocessing framing imports CV pipeline machinery that does not apply to LLM serving. The ‘no batching’ framing is wrong — batching is supported, just with different dynamics than image models.
Learning Objective: Diagnose autoregressive transformer serving as bandwidth-bound from the low-FLOPs-per-token signature and identify weight streaming plus KV-cache traffic as the mechanism.
Growing transformer context windows from 2,048 tokens (GPT-3) to hundreds of thousands (recent long-context models) is widely called a ‘systems breakthrough’ rather than merely a bigger-model story. Explain what specifically had to change to make this possible and why naive transformer attention could not simply be scaled to long context.
Answer: Naive self-attention materializes an \(S \times S\) score matrix per layer per head. At \(S = 100{,}000\) with 16-bit scores, that matrix alone consumes roughly 20 GB per layer per head — multiplied by tens of layers and multiple heads, it exceeds any single accelerator’s memory many times over. Simply buying more compute would not help; the memory wall is the binding constraint. The breakthroughs that unlocked long context were algorithmic-systems co-design: FlashAttention’s tiled online softmax that keeps intermediates in on-chip SRAM rather than HBM, sparse attention and architectural innovations that skip or approximate most of the score matrix, and KV offloading strategies that fit the serving-time footprint. The systems consequence is that long-context models reason over entire codebases and documents without chunking — a capability that scaling compute alone would not have delivered.
Learning Objective: Analyze why long-context transformers required algorithmic-systems co-design (tiled softmax, sparse attention, KV offloading) rather than peak-FLOP/s scaling to break the quadratic-attention memory wall.
Self-Check: Answer
A recommendation system must represent 500 million unique user IDs and 100 million unique item IDs as inputs to a neural network that accepts dense vectors. Which property of embedding tables makes them the standard bridge between these high-cardinality categorical IDs and dense-network computation?
- Each discrete ID indexes a row of learned dense floats, so every ID becomes a trainable vector whose dimensions the downstream network can process like any other dense input — at the cost of a table whose row count equals the cardinality of the ID space.
- Embeddings remove all memory accesses from inference, because once trained, the table is no longer consulted.
- Embeddings convert recommendation workloads from memory-bound to compute-bound, eliminating the need for specialized memory hardware.
- Embeddings are only valid in language models and are copied into RecSys without change or justification.
Answer: The correct answer is A. Embeddings are a lookup-as-representation: each ID selects a dense vector (typically 32 to 256 dimensions) from a table whose total memory is vocabulary_size * dimension * bytes_per_float. That gives the dense network something it can process while preserving learned similarity structure among IDs. The ‘removes memory accesses’ framing is the opposite of the truth — the lookup is the memory access, and it is the defining bottleneck of the DLRM architecture. The ‘compute-bound’ framing is wrong because the section explicitly argues RecSys becomes memory-capacity-bound. The ‘only LLMs use embeddings’ framing is historically wrong; embeddings predate modern LLMs and are foundational to recommendation.
Learning Objective: Explain why embedding tables are the canonical mechanism for converting high-cardinality categorical features into dense vectors for neural-network consumption.
A DLRM with 500 million user embeddings at 128 dimensions in FP32 already requires about 256 GB for user embeddings alone, before item embeddings or any MLP weights. Explain why the section calls DLRM ‘capacity-bound’ rather than compute-bound or bandwidth-bound and what that diagnosis forces on the infrastructure.
Answer: The defining issue is not how fast compute happens or how fast bytes move, but whether the model fits at all. A 256 GB user table cannot reside on any single 40-to-80 GB accelerator, so the usual compute/bandwidth optimizations are irrelevant until the model is physically placed. DLRM is capacity-bound because memory size — not throughput — is the binding constraint. The forced infrastructure response is model parallelism at the embedding layer: the table must be sharded across many accelerators, and at lookup time the request must find and fetch the relevant rows from wherever they live. That turns what looked like a local memory access into a distributed-memory problem, which in turn makes interconnect bandwidth (all-to-all bisection bandwidth) a first-order design parameter. Throughput tuning begins only after sharding makes the model placeable.
Learning Objective: Analyze why DLRM’s binding constraint is memory capacity rather than compute or bandwidth, and identify embedding sharding as the required distributed-memory response.
Why do embedding-table lookups in a production DLRM resist the cache-and-prefetch optimizations that accelerate CNN convolutions or dense MLP layers?
- Each request gathers a different set of embedding rows determined by the user’s and items’ IDs, so the access pattern is effectively random across a terabyte-scale table: hardware prefetchers cannot predict it, and caches cannot hold enough rows to exploit reuse.
- Embedding tables are always smaller than the L1 cache and therefore bypass the memory hierarchy entirely.
- Recommendation models do not use matrix operations anywhere, so the memory system cannot be optimized for them.
- Sparse embedding access inherits the translation-equivariance properties of CNNs, which blocks caching.
Answer: The correct answer is A. Each user-and-item pair generates an ID-dependent lookup into a table large enough that no realistic cache can hold the working set, and the lookups are scattered across the table’s address space with little reuse between consecutive requests. Hardware prefetchers rely on predictable sequential or strided access; random gather defeats them. The ‘smaller than L1 cache’ framing is reversed — the table is gigabytes to terabytes, not kilobytes. The ‘no matrix operations’ framing is factually wrong; DLRM contains MLPs. The translation-equivariance framing imports CNN terminology that does not describe embedding access.
Learning Objective: Analyze why the random, ID-dependent gather pattern of embedding lookups defeats cache and prefetch optimizations designed for predictable dense-matrix access.
Order the following high-level stages of a DLRM forward pass on one user-item example: (1) interaction layer combines dense and sparse representations, (2) bottom MLP processes continuous numerical features, (3) top MLP produces the final click-probability score, (4) embedding-table lookup retrieves vectors for categorical IDs.
Answer: The correct order is: (2) bottom MLP processes continuous numerical features, (4) embedding-table lookup retrieves vectors for categorical IDs, (1) interaction layer combines dense and sparse representations, (3) top MLP produces the final click-probability score. The bottom MLP and the embedding lookup operate on independent feature types and can in principle run concurrently; both must complete before the interaction layer can combine them, because the interaction explicitly consumes outputs from both. The top MLP then scores the example using the combined representation. Swapping the interaction and top MLP would score raw feature channels that have not yet been fused; swapping embeddings and interaction would try to combine vectors that do not yet exist.
Learning Objective: Sequence the four DLRM stages and justify why the interaction layer depends on both dense and sparse inputs completing first.
A recommendation team finds that their DLRM’s combined embedding tables total 600 GB, exceeding any single 80 GB accelerator. Which distributed-memory strategy does the section identify as the required response?
- Shard the embedding tables across multiple accelerators so each holds a disjoint subset of rows, then use all-to-all communication at lookup time to fetch each batch’s required rows from wherever they reside.
- Replicate every embedding table fully on every accelerator and rely solely on data parallelism for scaling.
- Replace the embedding tables with convolutions so the model becomes spatially local and fits on one device.
- Move the model to a single CPU because CPUs do not have memory-capacity limits.
Answer: The correct answer is A. Sharding splits the table across devices — typical schemes partition by row (row-wise) or by embedding dimension (column-wise) — and each forward pass gathers the needed rows via an all-to-all exchange whose volume scales with batch size and embedding dimension. This is the canonical capacity-bound response. Full replication requires that every accelerator hold the full 600 GB, which is exactly the constraint sharding exists to break. Replacing embeddings with convolutions discards the categorical representation the model actually needs. The ‘CPU has no limits’ framing is factually wrong — host memory is also bounded, and CPU bandwidth and compute cannot serve the target request rate.
Learning Objective: Select embedding sharding with all-to-all communication as the capacity-bound response required when tables exceed single-accelerator memory.
True or False: In a sharded DLRM deployment, interconnect bandwidth can become a first-order bottleneck because each GPU’s forward pass may require rows from embeddings stored on many other GPUs.
Answer: True. Sharded embeddings induce all-to-all communication at every lookup, so bisection bandwidth on the cluster fabric determines how fast a batch’s required rows can arrive. Once compute units are not the binding resource, the interconnect is — which is why recommendation systems at scale are designed around the network fabric (NVLink domains, InfiniBand, fat-tree topologies) as much as around the accelerators themselves.
Learning Objective: Evaluate why sharded embedding lookups make cluster interconnect bandwidth a first-order performance determinant in distributed recommendation systems.
Self-Check: Answer
Pre-2015 CNNs could not be trained beyond roughly 20 layers without training loss stagnating or diverging. Which portable architectural primitive resolved this depth ceiling and subsequently became standard in transformers, U-Nets, and most deep architectures?
- Skip (residual) connections, which add an identity path from a block’s input to its output so the gradient can propagate through the identity alongside the learned transformation.
- Embedding tables, which replaced raw inputs with learned dense vectors and eliminated the need for deep networks.
- The softmax activation applied uniformly to every hidden layer, which rescaled gradients at every depth.
- Depthwise-separable convolutions, which reduced depth by factoring each layer into two cheaper operations.
Answer: The correct answer is A. The ResNet skip connection creates \(\mathbf{y} = \mathbf{x} + \mathcal{F}(\mathbf{x})\), giving the gradient two paths backward: through the residual branch’s Jacobian and through the identity. That identity term guarantees gradient signal reaches early layers even when the learned Jacobian shrinks, which is why arbitrarily deep networks (50, 101, 152, and beyond) become trainable. Embedding tables solve categorical representation, not depth. Softmax-everywhere is wrong on multiple counts (softmax is a final-layer operation, not a per-layer activation, and it does not solve depth). Depthwise-separable convolutions target efficiency, not depth stability.
Learning Objective: Identify skip connections as the portable primitive that solved the depth-training problem and became the prerequisite for training networks beyond roughly 20 layers.
Explain why the identity path in a residual block produces a well-behaved gradient in a very deep network where a plain stack of layers does not. Make the mechanism explicit, not just the empirical result.
Answer: In a plain deep stack, the gradient of the loss with respect to an early hidden state must traverse the product of every intermediate Jacobian: \(\partial \mathcal{L}/\partial \mathbf{h}_0\) is proportional to the product of \(\partial \mathbf{h}_t/\partial \mathbf{h}_{t-1}\) across all layers. If each Jacobian has spectral norm less than 1, this product decays exponentially (vanishing gradient); if greater than 1, it explodes. In a residual block \(\mathbf{y} = \mathbf{x} + \mathcal{F}(\mathbf{x})\), the local derivative \(\partial \mathbf{y}/\partial \mathbf{x} = \mathbf{I} + \partial \mathcal{F}/\partial \mathbf{x}\), so the gradient backward through the block is identity-plus-learned-term, and the identity contribution adds a constant-magnitude channel that cannot vanish. Across many layers, the gradient remains the sum of all learned-path products plus the straight identity path, which guarantees an unattenuated signal reaches the earliest layers. The practical consequence is that ResNet-152 trains successfully where VGG-30 does not, and the same identity-path idea carries directly into transformers, U-Nets, and most modern deep stacks.
Learning Objective: Analyze the gradient-flow mechanism of residual connections, contrasting the identity-plus-learned Jacobian chain with the product-only chain of plain deep stacks.
A serving team is deploying a transformer that performs autoregressive generation one token at a time with an effective batch size of 1 per request. Which normalization choice is most appropriate and why?
- Layer normalization, because it normalizes using per-sample statistics computed across the feature dimension and is independent of batch composition, which matters when each inference request is a single sample.
- Batch normalization, because it always outperforms layer normalization on GPU inference regardless of batch size.
- No normalization at all, because normalization is only required during training.
- Layer normalization, because it eliminates the quadratic cost of self-attention.
Answer: The correct answer is A. LayerNorm computes the mean and variance across the features of one sample and normalizes each sample independently; BatchNorm averages across the batch and breaks when batch size equals 1 or when statistics drift between training (over large batches) and serving (over single requests). Autoregressive serving at batch 1 is the paradigm case for LayerNorm. The ‘BatchNorm always wins’ framing inverts the actual comparison on this deployment profile. The ‘no normalization’ framing ignores normalization’s training-and-inference role in stabilizing very deep networks. The ‘eliminates quadratic attention cost’ framing is wrong — normalization affects stability, not the \(\mathcal{O}(S^2)\) cost structure of self-attention.
Learning Objective: Justify LayerNorm over BatchNorm for variable-batch or single-sample autoregressive serving and distinguish normalization’s stabilizing role from attention’s cost structure.
Modern large language models often replace standard layer normalization with a variant that drops the mean-centering step and normalizes by the root-mean-square of the activations, saving one reduction pass and a subtraction per token. This efficient normalization variant is called ____.
Answer: RMSNorm (root mean square normalization). It preserves LayerNorm’s per-sample, batch-independent behavior while eliminating the mean-centering pass, which reduces per-token overhead in autoregressive inference where every saved microsecond multiplies across long generations.
Learning Objective: Infer the RMSNorm variant from its described mechanism (drop mean-centering, normalize by RMS) and explain why the saved work matters most at inference time.
What is the section’s main argument about gating as a cross-architecture primitive?
- Gating is a general mechanism for selectively routing information, and variants of the same idea appear in LSTM cells, attention weights, mixture-of-experts routers, and gated linear units — making it a portable primitive rather than an LSTM-specific trick.
- Gating is confined to LSTMs and has no analog in attention-based or mixture-of-experts architectures.
- Gating always reduces total parameter count by a fixed factor regardless of the architecture that uses it.
- Gating replaces the need for normalization layers entirely, which is why it appears in every modern architecture.
Answer: The correct answer is A. The section’s argument is that gating — computing a scalar or vector in [0, 1] that modulates a signal’s pass-through — is a fundamental information-routing primitive that reappears in many disguises: LSTM’s input/forget/output gates, attention’s softmax weights (a learned gate over positions), MoE’s expert-selection router (a learned gate over experts), and GLU-style activations in feed-forward blocks. The ‘LSTM-only’ framing contradicts the section’s portability claim. The ‘always reduces parameters’ framing is a factual error. The ‘replaces normalization’ framing confuses two independent mechanisms.
Learning Objective: Analyze gating as a portable information-routing primitive whose variants span LSTMs, attention, MoE, and GLU-style activations.
Explain why the chapter frames transformers as a recombination of earlier architectural building blocks rather than a complete break from prior designs, and give two concrete primitives the transformer inherits.
Answer: The transformer’s novel idea is removing sequential recurrence in favor of parallel all-pairs attention; the rest of the architecture is borrowed. \(\mathbf{Q}\), \(\mathbf{K}\), and \(\mathbf{V}\) projections and the output projection are dense matrix multiplications — the same GEMM primitive that MLPs and CNN 1x1 convolutions already depend on. Residual (skip) connections wrap every attention block and every feed-forward block, directly inherited from ResNet-era CNN design, and they are what make many-layer transformers trainable. Normalization (LayerNorm, later RMSNorm) also carries over from prior work, adjusted for variable-length and single-sample serving. The systems consequence is that the low-level kernel inventory developed for earlier architectures — optimized GEMM libraries, fused residual-plus-norm kernels, mixed-precision execution paths — transfers directly to transformers, which is why hardware designed for dense linear algebra was ready to execute them the moment they appeared.
Learning Objective: Analyze transformers as a recombination of inherited primitives (dense GEMM, skip connections, normalization) around the novel self-attention core and explain why earlier kernel and hardware work transferred.
Self-Check: Answer
A deep-learning framework converts a convolution on a 224-by-224 input with a 3-by-3 kernel into a GEMM call via im2col, producing an unrolled matrix roughly 9\(\times\) larger than the original input tensor. Why does this memory-expanding transformation routinely improve end-to-end speed?
- im2col reshapes the irregular sliding-window access pattern of convolution into a regular dense matrix multiply, which lets the runtime dispatch the work to highly tuned BLAS/cuBLAS kernels and Tensor Core hardware paths that would not fire on the original layout.
- im2col preserves the original convolution’s memory footprint exactly and therefore costs nothing, which is why it is always profitable.
- im2col eliminates the need for filter weights entirely by expressing the convolution as a purely data-driven transformation.
- im2col is required because convolution is mathematically impossible to implement on GPUs without this transformation.
Answer: The correct answer is A. Convolution’s sliding-window access is irregular, which limits how well vendor BLAS and Tensor Core pipelines can be exercised. im2col duplicates input patches into columns so the operation becomes a single large GEMM — the most heavily tuned primitive in every linear-algebra library — at the price of extra memory for the unrolled input. The trade is memory for regularity, and the regularity win on optimized hardware typically dominates the memory cost. The ‘preserves footprint exactly’ framing directly contradicts the section, which emphasizes patch duplication. The ‘eliminates filter weights’ framing is wrong — filters are still learned. The ‘mathematically impossible’ framing is false — direct convolution kernels exist; im2col wins on throughput, not feasibility.
Learning Objective: Explain the memory-for-regularity trade in im2col and justify why converting convolution to GEMM accelerates execution on accelerators with mature matrix-multiplication paths.
The section notes that a MAC operation costs roughly 1 pJ while fetching an operand from off-chip DRAM costs roughly 200 pJ. Explain why this 200\(\times\) energy gap makes data movement rather than arithmetic the dominant systems concern in neural network execution, and give a concrete design implication.
Answer: A 200\(\times\) energy ratio between arithmetic and memory access means that running the same FLOPs with poor data reuse spends hundreds of times more energy on bytes moved than on math performed. Since neural-network kernels routinely move gigabytes per forward pass, end-to-end energy and often end-to-end latency are governed by memory traffic, not compute. A fast FPU cannot help when it spends most cycles waiting for operands, and the energy budget of an edge device is exhausted long before compute becomes the limiter. The concrete design implication is that optimization strategies that raise reuse — operator fusion (keep intermediates in SRAM across stages), tiling (fit working sets into on-chip memory), quantization (fewer bytes per operand), and arithmetic-intensity-aware layer design — typically produce far larger wins than simply adding more FLOP/s. This is why accelerator design focuses as much on memory hierarchy, interconnect, and placement as on arithmetic throughput.
Learning Objective: Analyze the 200\(\times\) MAC-to-DRAM-access energy gap and derive design implications (fusion, tiling, quantization, intensity-aware layers) that target data movement rather than arithmetic.
Which memory-access pattern is hardest for hardware caches and prefetchers to exploit, and therefore most likely to starve the compute units of a neural-network workload?
- Random access, because the next address depends on input data (for example, an ID-dependent embedding row), so neither prefetch prediction nor spatial-locality-based caching can help.
- Sequential access through a contiguous tensor, because each element is predictable and burst-friendly.
- Contiguous burst reads across a large array, because DRAM row-open costs are amortized over many reads.
- Regularly strided access with high reuse, because stride prefetchers and cache blocking are designed for exactly this shape.
Answer: The correct answer is A. Caches exploit spatial and temporal locality; prefetchers exploit predictable (sequential or strided) patterns. A random gather, such as a sparse embedding lookup, violates both: addresses are input-dependent and rarely revisit recent lines. Sequential access is the easy case because it is burst-friendly. Contiguous burst reads amortize DRAM row-open overhead across many elements. Regularly strided access with high reuse is exactly what stride prefetchers and cache-blocked algorithms exist to optimize.
Learning Objective: Rank memory access patterns by hostility to cache and prefetch hardware and identify random access as the pattern most likely to starve compute units.
Order the following categories from the section’s conceptual organization, moving from the lowest-level building blocks outward to their system-design consequences: (1) memory access primitives, (2) system design impact, (3) core computational primitives, (4) data movement primitives.
Answer: The correct order is: (3) core computational primitives, (1) memory access primitives, (4) data movement primitives, (2) system design impact. The section first identifies the arithmetic operations the workload performs (MAC, GEMM, elementwise), then describes how those operations touch memory (strided, gathered, cached), then how data flows between components (broadcast, gather, reduce, scatter), and only after establishing those three layers does it synthesize the consequences for hardware and software design. Swapping computation and memory access would describe access patterns before naming the operations that produce them; ending on anything other than system-design impact would leave the chain without its engineering payload.
Learning Objective: Sequence the section’s four analytical layers (computation, memory access, data movement, system-design impact) and justify why the layering proceeds from primitive to consequence.
In a data-parallel training job on 64 GPUs, the framework replicates each layer’s weight tensor to every GPU at the start of the step so all workers can compute forward passes on different micro-batches simultaneously. Which data-movement primitive matches this one-source-to-many-destinations transfer, and why is it the appropriate choice?
- Broadcast, because the same weight tensor must arrive intact at many destinations; broadcast trees exploit network bandwidth in \(\mathcal{O}(\log N)\) rounds rather than \(\mathcal{O}(N)\) repeated unicasts.
- Gather, because the operation aggregates activations from many sources into one target device.
- Reduction, because the workers must compute a weighted sum of their inputs before proceeding.
- Scatter, because the weight tensor is partitioned into distinct slices sent to different devices.
Answer: The correct answer is A. Broadcast is exactly the one-to-many transfer of identical content: one source device owns the weight tensor and every other device needs a full copy. Tree-structured broadcast algorithms complete in log N communication rounds, amortizing bandwidth across the fabric. Gather aggregates many sources into one destination — the opposite direction. Reduction combines values from many sources into a single reduced result (sum, mean, max), which is what gradient synchronization uses after the backward pass, not weight distribution before the forward pass. Scatter partitions one tensor into slices and sends each slice to a different device — this fits embedding-table distribution, not weight replication.
Learning Objective: Classify a distributed weight-replication transfer as a broadcast operation and distinguish it from gather, scatter, and reduce by the direction and content of the data movement.
True or False: Upgrading only the arithmetic compute units on an accelerator — doubling FLOP/s while leaving memory hierarchy, interconnect, and software scheduling unchanged — would resolve most neural-network performance problems.
Answer: False. The section argues that neural-network performance depends on the interaction among compute, memory-access, and data-movement primitives. Most modern workloads are memory- or bandwidth-bound (dense MLPs at low batch, autoregressive decoding, sparse embedding lookups), so doubling arithmetic capacity while leaving bytes-per-second and kernel-launch overhead unchanged typically leaves the binding constraint in place and the new compute units idle.
Learning Objective: Evaluate why neural-network system design requires co-optimization of compute, memory, and communication primitives rather than arithmetic-only upgrades.
Self-Check: Answer
A data-science team must model loan-default risk from a 47-feature tabular dataset with no known structural relationships among features — features are demographic, financial, and behavioral attributes with no obvious ordering or spatial arrangement. Using the chapter’s data-to-architecture mapping, which architecture is the default starting candidate?
- MLP, because the data carries no spatial or temporal structure and the feature-interaction pattern is unknown a priori; a no-structural-prior architecture is the appropriate starting point.
- CNN, because convolutions always improve accuracy regardless of whether spatial structure exists in the inputs.
- RNN, because tabular features must be processed in strict order to preserve their causal relationships.
- Transformer, because transformers always outperform simpler architectures and should be the default for any tabular problem.
Answer: The correct answer is A. The mapping is structural: MLPs for tabular or weakly-structured data, CNNs for spatial data, RNNs for sequences, transformers for long-range relational data. Tabular features with no known relationships are exactly the MLP’s home ground because the architecture’s ‘any feature may relate to any feature’ assumption does not impose a false prior. Using a CNN on unordered features encodes a locality assumption that does not exist and wastes the model’s capacity on a constraint that is not real. RNNs impose a temporal order that is not in the data. Defaulting to transformers for tabular data is the exact overapplication the chapter warns against — the quadratic-attention cost is unjustified when there is no long-range structure to capture.
Learning Objective: Apply the data-to-architecture mapping to choose an initial architecture candidate for tabular data and justify why stronger structural priors mismatch the data.
Explain why the chapter’s architecture-selection process is iterative rather than a one-shot mapping from data type to model family. Illustrate with a case where the data-type mapping would point one way but deployment constraints force a different final choice.
Answer: Data-type mapping produces a first candidate, but deployment constraints — memory budget, latency SLO, power envelope, hardware affinity — can invalidate that candidate before it ships. The process iterates: pick the candidate, check feasibility, revise. Concrete example: spatial image-classification data points to a CNN, but if the deployment target is a milliwatt-class microcontroller with 256 KB of SRAM, a ResNet-50 simply does not fit. The iteration step does not abandon the CNN family; it switches to a depthwise-separable variant (MobileNet, DS-CNN) that keeps the locality prior while cutting parameters and FLOPs by roughly an order of magnitude. If the device is even more constrained, the team may trade resolution for feasibility (smaller input size, fewer channels) or, at the extreme, accept that the chosen data-to-architecture match cannot run on the target hardware at all and must move off-device. The practical consequence is that architecture selection is a two-dimensional search — structural fit and deployment fit — not a one-dimensional lookup.
Learning Objective: Analyze why architecture selection must iterate between problem structure and deployment feasibility, with a concrete example where the deployment target forces a within-family revision.
In the wildlife-monitoring case study, the team must classify 50 bird species from trail-camera images under a 2 W power budget and sub-second latency on a Raspberry-Pi-class device. Why was a MobileNetV2-class CNN chosen over both a full ResNet-50 and a much smaller DS-CNN keyword-spotting-style model?
- MobileNetV2 preserves the spatial-locality prior that matches image inputs while using depthwise-separable convolutions to fit the device’s power, latency, and memory budget; ResNet-50 exceeds the budget, and a KWS-scale DS-CNN lacks the representational capacity for 50-class fine-grained species discrimination.
- MobileNetV2 was chosen because transformers physically cannot process image inputs.
- MobileNetV2 was chosen because KWS-class DS-CNN architectures are always less accurate than any MobileNet on every vision task in every regime.
- MobileNetV2 was chosen because the device has unlimited memory but requires minimizing FLOPs at all costs.
Answer: The correct answer is A. The case study balances the structural match (spatial locality points to CNNs) with deployment constraints (milliwatts, hundreds of milliseconds, hundreds of MB at most). ResNet-50 is structurally a fit but exceeds the power and memory budgets. A KWS-class DS-CNN designed for keyword spotting (2-to-10 classes) has too little representational capacity for 50-way fine-grained species classification. MobileNetV2’s depthwise-separable blocks keep the locality prior while cutting cost by roughly an order of magnitude — the right trade for this deployment. The ‘transformers cannot process images’ framing is factually wrong (ViT exists). The ‘KWS-class DS-CNN always less accurate’ framing is too strong — the accuracy gap is task-dependent. The ‘unlimited memory but FLOPs-only’ framing inverts the actual constraints.
Learning Objective: Evaluate the wildlife-monitoring architecture choice by combining data-to-architecture match with deployment constraints and rejecting both under- and over-capacity alternatives.
Three architectures are candidates for a well-structured image-classification task: a dense MLP, a standard CNN, and a vision transformer (ViT). From strongest to weakest built-in structural assumption, which ordering is correct — and which architecture would the chapter’s framework therefore prefer as the first candidate for a dataset of only 50,000 labeled images?
- CNN > ViT > MLP; the CNN is preferred because its locality-and-weight-sharing prior lets it generalize from limited data without the ViT’s large-data appetite or the MLP’s no-prior cost.
- MLP > CNN > ViT; the MLP is preferred because having no prior is the most flexible choice with limited labels.
- ViT > CNN > MLP; the ViT is preferred because attention’s all-pairs capability gives it the strongest structural assumption about image inputs.
- All three impose equally strong priors; the choice is arbitrary.
Answer: The correct answer is A. The CNN encodes the strongest image-specific prior — local receptive fields and translation equivariance — which narrows its hypothesis class dramatically and improves sample efficiency on structured visual data. ViT’s patch-and-attention design is a weaker visual prior: it is permutation-sensitive via positional embeddings but does not assume locality per se, which is why vanilla ViTs typically need far more labeled data than CNNs to reach comparable accuracy. The MLP has essentially no structural prior on images, which is why it needs the most data. At 50,000 labels, the CNN’s stronger prior is the asset the framework calls for. The MLP-preferred ordering reverses the sample-efficiency argument. The ViT-strongest framing misreads attention as an image-specific prior. ‘Equal priors’ contradicts the explicit hierarchy the framework builds on.
Learning Objective: Apply the inductive-bias hierarchy to rank CNN, ViT, and MLP by structural-assumption strength and select the strongest-prior candidate for a label-limited task.
Which consideration most directly explains why an architecture with the best published benchmark accuracy may nevertheless be rejected during the framework’s selection process?
- The model may hit the accuracy target but fail memory, latency, or hardware-mapping constraints in the intended deployment environment, which together determine whether accuracy is usable.
- All papers report accuracy on synthetic data that has no bearing on production performance.
- Benchmark accuracy is evidence of overfitting, so high-accuracy models are always worse in practice.
- The newest architecture is always unsupported by mature software frameworks and therefore unusable.
Answer: The correct answer is A. The framework’s repeated argument is that accuracy is necessary but not sufficient: a model that misses latency SLOs, exceeds memory budgets, or maps poorly to the target accelerator is unusable regardless of how it ranks on a leaderboard. Real deployments routinely reject state-of-the-art architectures for exactly these reasons and accept a small accuracy penalty in exchange for feasibility. ‘Papers always use synthetic data’ is factually wrong. ‘High accuracy implies overfitting’ confuses benchmark saturation with generalization. ‘Newest architecture is unsupported’ overstates framework-lag; modern architectures typically have strong software support within months.
Learning Objective: Analyze why deployment feasibility (memory, latency, hardware mapping) filters paper-benchmark accuracy in the architecture-selection framework.
A team proposes a transformer for a task with 50-token inputs, a 100 ms edge-device latency budget, and dependencies that are mostly local. Using the framework, critique this choice and propose a more appropriate alternative.
Answer: The framework flags this as a classic over-reach: the transformer’s flexibility exists to capture long-range, content-dependent relationships, but the task describes short, local-dependency inputs. The model pays the \(\mathcal{O}(S^2)\) attention cost and the KV-cache overhead without any accuracy compensation because the long-range connectivity it offers is not needed. At the edge, those costs translate directly into memory pressure and per-token latency that is hard to squeeze under 100 ms on modest hardware. A more appropriate alternative is a small 1D CNN or a compact RNN: the 1D CNN encodes local co-occurrence structure via weight sharing, matches the data’s locality bias, and maps cleanly to edge accelerators at fixed low memory; the RNN keeps \(\mathcal{O}(1)\) inference memory and is well-suited to strictly sequential short inputs. Either choice typically delivers similar accuracy at a fraction of the memory and latency cost. The principle: match inductive bias to data structure, and prefer the simplest sufficient architecture when deployment is constrained.
Learning Objective: Critique a transformer-at-edge architecture choice for a task with short local dependencies and propose a better-matched alternative using the chapter’s selection framework.
Self-Check: Answer
A team deploys MobileNetV2 on the same A100 serving rack that runs ResNet-50 in production. MobileNetV2 uses roughly 14\(\times\) fewer FLOPs than ResNet-50, yet per-request latency ends up roughly matching ResNet-50 rather than dropping 14\(\times\). Using the fallacies section, which explanation best diagnoses the gap?
- MobileNetV2’s depthwise-separable kernels have far lower arithmetic intensity than ResNet-50’s standard convolutions, so on a data-center GPU with abundant FP16 Tensor Cores the workload becomes bandwidth-bound rather than compute-bound; FLOP reduction does not translate into latency reduction when the A100 is not the limiting resource.
- MobileNetV2 cannot be quantized on A100 hardware, so it is forced to FP32 execution and loses the expected speedup.
- ResNet-50 is automatically compressed by the CUDA driver at load time, which erases the FLOP advantage MobileNetV2 would otherwise enjoy.
- The A100 secretly converts depthwise convolutions into sequential CPU operations, which explains the missing speedup.
Answer: The correct answer is A. The fallacy is that FLOPs measure runtime; the section argues that latency depends on arithmetic intensity and hardware-architecture alignment. Depthwise-separable convolutions move many bytes per FLOP — each depthwise kernel touches one input channel, and each pointwise 1-by-1 handles large feature maps for modest flop count — so the A100’s Tensor Cores stay underfed. ResNet-50’s standard convolutions have the reuse profile the hardware expects and run near peak. The quantization framing is factually wrong (MobileNet is highly quantizable). The driver-compression framing invents a mechanism that does not exist. The ‘CPU fallback’ framing is wrong — depthwise kernels run on GPUs, just with low intensity.
Learning Objective: Diagnose the FLOPs-versus-latency fallacy on a concrete MobileNet-versus-ResNet-50 contrast on a data-center GPU and identify low arithmetic intensity as the mechanism.
Which scenario best captures the pitfall of optimizing architecture only for training hardware without analyzing the deployment environment?
- A team develops on an 8-GPU A100 node (687 GB total memory), then discovers at launch that the model cannot fit the 4 GB edge device it must actually run on — a 172\(\times\) memory reduction that cannot be closed by quantization alone and forces architectural redesign that delays release by a quarter.
- A team applies data augmentation during training and sees improved generalization on the validation set.
- A team benchmarks three candidate models on held-out test data before picking one.
- A team selects a CNN for a vision task because the data’s spatial locality matches the architecture’s inductive bias.
Answer: The correct answer is A. The pitfall is the mismatch between development and deployment environments — the section explicitly cites the 172\(\times\) memory gap between an 8-GPU training node and a 4 GB edge device as the canonical example, with quantization insufficient to close it. The other options describe healthy practices (augmentation, benchmarking, structural alignment), not pitfalls.
Learning Objective: Identify the training-to-deployment hardware mismatch pitfall from a scenario where architectural assumptions exceed target-device memory.
A team plans to serve a 7 billion parameter transformer (14 GB of FP16 weights) on an 80 GB A100. They assume that since model weights are 14 GB and one A100 has 80 GB, they have 66 GB of serving headroom per replica. Using the section’s KV-cache pitfall, walk through what they are missing for a 32-layer model with 32 attention heads, head dimension 128, context length 2,048 at FP16 with concurrency 8, and state what that means for the throughput plan.
Answer: The serving team is missing the KV cache, which stores all prior key and value vectors so self-attention can attend to the growing context without recomputing. Per-request KV memory is 2 (K and V) times layers times heads times context times head-dim times bytes = 2 * 32 * 32 * 2048 * 128 * 2 bytes per request, or roughly 1.1 GB per concurrent request. At concurrency 8, that is 8.5 GB of KV cache — a substantial fraction of the 66 GB headroom. Doubling context to 4,096 doubles per-request KV to 2.2 GB, and 16 concurrent users alone reaches 35 GB. Without explicit KV budgeting, the team will discover at peak load that the device runs out of memory, and the only short-term fixes are halving concurrency, truncating context, or evicting sessions — each of which misses the throughput or quality target. The deeper lesson is that transformer serving memory is driven by KV cache as much as by weights; a capacity plan based on weights alone will underestimate real serving memory by 2\(\times\) or more at typical concurrency.
Learning Objective: Analyze how KV-cache growth changes the serving-memory budget of a transformer and compute its size from layer count, head count, context length, and concurrency to refute a weights-only capacity plan.
Self-Check: Answer
A product team is deciding how to allocate engineering effort for a new feature. Which decision best reflects the chapter’s thesis that ‘architecture is infrastructure’?
- Before picking the model family, profile the target deployment’s memory budget, latency SLO, and interconnect bandwidth, because the architecture’s memory footprint, attention cost, and data-access pattern will determine which hardware and infrastructure the team must provision.
- Pick the newest architecture from the latest paper and postpone all deployment analysis until the model is fully trained, because architecture choice does not affect infrastructure.
- Train multiple architectures identically and select whichever has the highest validation accuracy, because accuracy alone determines production viability.
- Always use a transformer for every task because transformers have the most capacity and will generalize best across any deployment environment.
Answer: The correct answer is A. The chapter’s thesis is that architecture determines the physical cost structure of the system — memory footprint, bandwidth demand, scaling profile, deployment feasibility — so selection must happen in dialog with the target infrastructure, not after it. The ‘pick newest, postpone analysis’ framing is the exact failure mode the chapter’s pitfalls section names: architectures often land at deployment and turn out to exceed memory or latency budgets after months of training. The ‘accuracy alone’ framing is the benchmark-filtering pitfall. The ‘always transformer’ framing contradicts the chapter’s inductive-bias-match principle and the explicit argument that transformers pay a quadratic memory tax that makes them the wrong choice for short-input, edge-constrained tasks.
Learning Objective: Apply the ‘architecture is infrastructure’ thesis to a concrete engineering-allocation decision and distinguish it from accuracy-first or trend-following alternatives.
Explain how inductive bias and arithmetic intensity together form a joint selection framework for choosing between architecture families, using a specific contrast from the chapter to ground the explanation.
Answer: Inductive bias answers whether the architecture’s structural assumptions match the data — whether locality, sequence, or all-pairs relational structure is present — and therefore governs sample efficiency and generalization. Arithmetic intensity answers how the chosen architecture will stress the target hardware — whether the workload lands compute-bound or bandwidth-bound on a given accelerator — and therefore governs latency, throughput, and energy. A good choice satisfies both. Concrete contrast: ResNet-50 and MobileNetV2 share the locality bias that matches image data, but ResNet-50’s standard convolutions hit roughly 100+ FLOP/byte and sit compute-bound on a data-center GPU, while MobileNetV2’s depthwise-separable convolutions have low intensity and sit bandwidth-bound on the same GPU. Same bias, different regimes: the GPU is the natural home for ResNet-50 but underfed by MobileNetV2; for MobileNetV2, a mobile NPU with narrower peak compute but tighter memory is the better physical host. The two criteria together, not either alone, produce a defensible selection.
Learning Objective: Synthesize inductive bias (data match) and arithmetic intensity (hardware match) into a joint selection framework and apply it to distinguish ResNet-50’s and MobileNetV2’s target deployments.
Which pairing correctly matches a lighthouse model to its dominant system bottleneck, per the chapter’s synthesis?
- GPT-2: memory bandwidth, because autoregressive generation streams billions of weight bytes per low-intensity token step and is limited by HBM throughput, not peak FLOP/s.
- ResNet-50: memory capacity, because its deep stack of convolutional layers forces terabyte-scale storage.
- DLRM: compute throughput, because its matrix multiplies dominate all other costs at scale.
- MobileNetV2: quadratic attention memory, because its efficient-CNN design still incurs \(\mathcal{O}(S^2)\) serving cost.
Answer: The correct answer is A. GPT-2 is the bandwidth lighthouse precisely because each generated token performs modest math relative to the weight and KV bytes it must stream, so HBM bandwidth sets the throughput ceiling. ResNet-50 is the compute lighthouse — its dense-convolution arithmetic intensity is high enough to saturate Tensor Cores, and its model memory is measured in tens of MB, not terabytes. DLRM is the capacity lighthouse — terabyte-scale embedding tables force model parallelism and make memory size (not throughput) the binding constraint. MobileNetV2 is the latency lighthouse driven by hardware mismatch for edge devices, not quadratic attention — attention is not part of its architecture.
Learning Objective: Match each of the chapter’s five lighthouse workloads to its dominant bottleneck and refute three common lighthouse-mismatch errors.