Model Compression
Purpose
Why do the models that win benchmarks rarely become the models that run in production?
Training produced a capable model, yet capability alone does not guarantee deployability. Cloud, Edge, Mobile, and TinyML each impose constraints that research benchmarks ignore: memory budgets measured in megabytes rather than gigabytes, latency targets measured in milliseconds rather than seconds, power envelopes measured in milliwatts rather than kilowatts. Research optimizes for accuracy on held-out test sets; production optimizes for accuracy per dollar, accuracy per watt, accuracy per millisecond, and the model that wins a benchmark typically does so by being larger, slower, and more resource-intensive than any production constraint permits. Bridging that gap requires a systematic discipline of compression: trading capabilities the deployment does not need for constraints it cannot violate. The key insight is that trained models are vastly over-specified for most production tasks, carrying more precision, more connections, and more capacity than the deployment context demands, and that surplus can be systematically removed without destroying what the deployment requires. Applied well, compression can reduce model size by one to two orders of magnitude, transforming a research artifact that runs only in a data center into a production asset that meets the physics of a phone, a sensor, or a microcontroller: the discipline is not about making models smaller but about making the right models possible for their physical environment. In D·A·M terms, compression is algorithm-machine co-design enacted on the model itself: the mathematical structure of the algorithm permanently rewritten to fit the physical constraints of the machine.
Learning Objectives
- Explain compression as algorithm-machine co-design that trades surplus capacity for memory, latency, and energy constraints
- Compare pruning, distillation, quantization, and architecture search by the resource constraint each relaxes
- Calculate parameter memory, precision, and sparsity reductions to estimate best-case compression gains
- Apply post-training, quantization-aware, and weight-only strategies under accuracy and hardware constraints
- Select structured pruning and operator choices that map to available accelerator kernels
- Design compression pipelines that order pruning, distillation, and quantization to preserve deployment accuracy
- Evaluate measured latency, energy, and accuracy on target hardware rather than relying on FLOP counts
Optimization Framework

Frontier weights dwarf phone and microcontroller memory; compression bridges the gap.
A 7-billion parameter language model requires 14 GB merely to store its weights in FP16. The deployment target is a smartphone with 8 GB of RAM shared across the operating system, applications, and the model. The math does not work. No amount of clever engineering changes this arithmetic: 14 GB cannot fit in 8 GB. Yet users expect the model to run: responsively, offline, without draining their battery in an hour. Every request has only a small time window in which to load data, run arithmetic, and return a result; the broader deployment gap also includes memory capacity, energy, and offline execution. That gap is not a minor inconvenience but a defining challenge of model compression.
Recall the silicon contract (principle 4), the implicit agreement every model makes with its hardware about which resource it will saturate. The three candidates are compute throughput, memory bandwidth, and memory capacity. During training, this contract is negotiated upward. Researchers select larger architectures, higher numerical precision, and deeper layers because the training environment, typically a GPU cluster with hundreds of gigabytes of memory, can afford those demands. In Mixed-precision training, mixed precision speeds training while maintaining the ability to learn. Here, we go further, reducing precision to INT8 and beyond for inference, where we trade the ability to update weights for massive gains in execution efficiency. Deployment reverses these priorities. The production environment is smaller, power-constrained, and latency-sensitive, yet the model was designed for an environment with none of those limitations. Where data selection optimized what the model learns from, compression optimizes what the trained model carries into that smaller environment. Model compression is the systematic process of renegotiating that contract for its new execution context, reducing memory footprint, computational cost, and energy consumption while preserving the model’s ability to perform its task.
The scale of this renegotiation makes model optimization an engineering discipline, not a collection of ad hoc tricks. A 175 billion parameter model consumes over 350 GB in FP16 representation alone, yet a smartphone provides 8 GB of RAM and a microcontroller offers 524.3 KB. Bridging six orders of magnitude requires systematic methods with predictable trade-offs, not trial and error. Every optimization technique removes something from the model (redundant parameters, numerical precision, or architectural complexity), and the engineer must understand exactly what is lost, what is preserved, and how these losses compose when techniques are combined.
Compression works along three complementary dimensions. Structural optimization removes redundancy from the model itself: pruning eliminates parameters that contribute little to output quality, knowledge distillation transfers a large model’s learned behavior into a smaller architecture, and neural architecture search discovers designs that are inherently efficient. Precision optimization reduces the numerical bit-width of weights and activations, for example converting 32-bit floating point values to 8-bit integers; on accelerators with dedicated low-precision matrix units such as Tensor Cores, that smaller representation can also accelerate arithmetic. Hardware-level optimization ensures that the resulting model executes efficiently on the target processor by fusing operations to reduce memory traffic and exploiting sparsity patterns that the hardware can accelerate. These dimensions are not alternatives but layers in an optimization stack. A practitioner deploying ResNet-50 to a mobile device might prune 50 percent of its filters, quantize the remaining weights to INT8, and fuse batch normalization into convolution, with each technique compounding the gains of the others. Tensor Cores later explains the accelerator mechanisms behind those low-precision paths.
Concrete systems keep those trade-offs measurable: ResNet-50 and MobileNetV2 (our Lighthouse Models from Lighthouse roster: Model biographies) for vision workloads, transformer-based language models for sequence tasks, DLRM for recommendation memory pressure (Naumov et al. 2019), and the DS-CNN, a depthwise-separable convolutional neural network (CNN), as the keyword spotter for TinyML deployment (Y. Zhang et al. 2017). Reusing these models lets us compare techniques under consistent conditions, making the trade-offs between accuracy, latency, memory, and energy tangible rather than abstract.
Definition 1.1: Model compression
Model Compression is a family of techniques that reduce a trained model’s computational cost and memory footprint by eliminating redundant parameters (pruning), reducing numerical precision (quantization), or transferring learned behavior into a smaller architecture (distillation), while preserving as much predictive accuracy as possible.
- Significance: Compression directly reduces the iron law’s data-movement and compute terms. INT8 quantization of a 175-billion-parameter large language model (LLM) cuts weight memory from 350 GB (FP16) to 175 GB, a 2× reduction in \(D_{\text{vol}}\), while dedicated low-precision matrix units can increase compute throughput when kernels and layouts use the supported INT8 path. Unstructured pruning to 50 percent sparsity theoretically halves \(O\), but hardware speedup only materializes when sparsity is structured (for example, a 2:4 pattern that keeps two weights in each group of four) to match accelerator capabilities.
- Distinction: Unlike post-training compression methods such as pruning and quantization, neural architecture search discovers efficient architectures from scratch by exploring a design space. Here, NAS is treated as a related structural optimization technique: it changes the representation before training rather than compressing a finished model post hoc.
- Common pitfall: A frequent misconception is that compression techniques compose without interference. In practice, applying quantization after pruning can amplify quantization error in near-zero weight regions that pruning left behind, causing accuracy degradation that neither technique produces alone.
The optimization stack moves from representation to numerics to execution. Deployment context determines which constraint binds first; structural methods change the computation, precision methods change the representation of each value, and architectural methods decide whether the compressed artifact actually maps to efficient hardware execution. Selection and composition follow from that constraint order rather than from a checklist of techniques.
Model optimization is not a single technique but a framework with three complementary dimensions, each addressing different bottlenecks. These dimensions form a natural hierarchy: we first decide what computations the model should perform (representation), then how precisely to perform them (numerics), and finally how efficiently to execute them on physical hardware (implementation). Tracing the stack in figure 1 from top to bottom reveals how each layer moves from pure software concerns toward hardware-level execution.

The top layer, efficient model representation, focuses on eliminating redundancy in the model structure. Techniques like pruning, knowledge distillation, and neural architecture search (NAS)1 reduce the number of parameters or operations required, addressing memory footprint and computational complexity at the algorithmic level.
1 Neural Architecture Search (NAS): Zoph and Le (2016) at Google Brain used reinforcement learning to learn the architecture itself at a cost of 22,400 GPU-days (800 GPUs for 28 days), equivalent to 537,600 GPU-hours. Weight-sharing approaches such as ENAS later reduced search cost by roughly 1,000× by sharing parameters across candidate architectures (Pham et al. 2018). Hardware-aware NAS and scaling methods then made the search output practical for deployable architecture families such as EfficientNet and MobileNetV3 (Tan and Le 2019; Howard et al. 2019).
Zoph, Barret, and Quoc V. Le. 2016. “Neural Architecture Search with Reinforcement Learning.” International Conference on Learning Representations 3.
Pham, Hieu, Melody Y. Guan, Barret Zoph, Quoc V. Le, and Jeff Dean. 2018. “Efficient Neural Architecture Search via Parameter Sharing.” Proceedings of the 35th International Conference on Machine Learning (ICML), Proceedings of machine learning research, vol. 80: 4095–104.
Howard, Andrew, Mark Sandler, Bo Chen, Weijun Wang, Liang-Chieh Chen, Mingxing Tan, Grace Chu, et al. 2019. “Searching for MobileNetV3.” 2019 IEEE/CVF International Conference on Computer Vision (ICCV), 1314–24. https://doi.org/10.1109/iccv.2019.00140.
The middle layer, efficient numerics representation, optimizes how numerical values are stored and processed. Quantization and mixed-precision training reduce the bit-width of weights and activations (for example, from 32-bit floating point to 8-bit integers), enabling faster execution and lower memory usage on specialized hardware.
The bottom layer, efficient hardware implementation, ensures operations run efficiently on target processors. Techniques like operator fusion, sparsity exploitation, and hardware-aware scheduling align computational patterns with hardware capabilities (memory hierarchy, vector units) to maximize utilization and throughput.
These dimensions are interdependent. Pruning reduces complexity but may require architectural changes for hardware efficiency. Quantization reduces precision but impacts execution logic. The most effective strategies combine techniques across all three layers. For practitioners seeking immediate guidance on which techniques to apply, section 1.6.2 provides a decision framework that maps deployment constraints to specific technique recommendations. The intervening sections provide the technical foundation needed to apply that framework effectively.
The relative importance of each dimension varies by deployment target. Cloud systems may tolerate larger models but demand throughput; mobile devices prioritize memory and energy; embedded systems face hard constraints on all resources simultaneously. Understanding these deployment contexts shapes which optimization dimensions to prioritize.
Self-Check: Question
The chapter’s optimization framework organizes compression along three dimensions that flow from pure software concerns toward hardware-level execution. Which ordering matches that stack?
- Efficient model representation → efficient numerics representation → efficient hardware implementation
- Efficient numerics representation → efficient model representation → efficient hardware implementation
- Efficient hardware implementation → efficient model representation → efficient numerics representation
- Efficient hardware implementation → efficient numerics representation → efficient model representation
A 7-billion parameter model in FP16 occupies 14 GB. The target device is a smartphone with 8 GB of shared RAM. Explain why quantization to INT4 simultaneously solves the memory-fit problem and improves autoregressive token throughput for this deployment.
True or False: When the binding deployment constraint is insufficient weight-memory capacity, operator fusion is a reasonable substitute for pruning or quantization because all three techniques remove the same resource bottleneck.
A 7-billion-parameter model quantized from FP16 to INT4 for autoregressive generation achieves approximately 4× higher token throughput on a bandwidth-limited accelerator. Which mechanism best explains the speedup?
- INT4 removes most of the attention computation, so compute rather than bandwidth becomes negligible
- INT4 makes the model’s reliance on the silicon contract disappear, so latency stops depending on memory traffic
- INT4 reduces the number of transformer layers evaluated per token, cutting the critical-path depth by 4×
- INT4 quarters the bytes that must be fetched per token from memory, so the bandwidth-bound critical path shrinks proportionally
The chapter frames compression as a systematic renegotiation of the model’s ____, the implicit agreement with hardware about which resource (compute throughput, memory bandwidth, or memory capacity) will be saturated at deployment.
A team deploying ResNet-50 to a mobile device applies three optimizations in sequence: it prunes 50 percent of filters, quantizes surviving weights to INT8, and fuses batch normalization into convolution. Why is this combination stronger than applying any single technique alone?
- Only pruning matters in practice; quantization and fusion are different names for the same parameter-count reduction
- Each technique acts on a distinct layer of the stack — representation, numerics, and execution — so the gains compose rather than overlap
- The sequence works because all three techniques raise training-time compute, which later reduces inference cost
- Pruning automatically converts the model into a NAS-discovered architecture, which is what delivers the compounded gain
Deployment Context
The preceding optimization framework identifies three dimensions of compression, but which dimensions matter most depends entirely on where the model will run. A data center GPU with 80 GB of HBM faces different binding constraints than a smartphone with shared RAM or a microcontroller with only a few hundred kilobytes of SRAM. Table 1 summarizes the key constraints across deployment environments.
| Context | Memory | Latency | Power | Primary Goal |
|---|---|---|---|---|
| Cloud | tens of GB | 10–100 ms | Flexible | Throughput, cost |
| Mobile/Edge | hundreds of MB to GB | 10–50 ms | W-scale | Size, latency |
| TinyML | KB–MB | 1–10 ms | mW | Size, energy |
Deployment scenarios
Cloud inference centers on throughput (requests/second/dollar), where quantization enables serving more concurrent requests and operator fusion reduces per-request latency (Choudhary et al. 2020; Dean et al. 2018). Mobile and edge deployments must fit device memory while meeting real-time targets. A camera app processing 30 fps has 33 ms per frame, so any optimization reducing inference below this threshold directly improves user experience.
Choudhary, Tejalal, Vipul Mishra, Anurag Goswami, and Jagannathan Sarangapani. 2020. “A Comprehensive Survey on Model Compression and Acceleration.” Artificial Intelligence Review 53 (7): 5113–55. https://doi.org/10.1007/s10462-020-09816-7.
Dean, Jeff, David Patterson, and Cliff Young. 2018. “A New Golden Age in Computer Architecture: Empowering the Machine-Learning Revolution.” IEEE Micro 38 (2): 21–29. https://doi.org/10.1109/mm.2018.112130030.
Banbury, Colby R., Vijay Janapa Reddi, Max Lam, William Fu, Amin Fazel, Jeremy Holleman, Xinyuan Huang, et al. 2020. “Benchmarking TinyML Systems: Challenges and Direction.” arXiv Preprint arXiv:2003.04821.
TinyML makes optimization existential, not optional. A microcontroller with a few hundred kilobytes of RAM cannot run a 100 MB model regardless of accuracy. The model must compress below hardware limits or deployment is impossible (Banbury et al. 2020). Even on mobile devices with comparatively generous resources, a single optimization technique can deliver a 4\(\times\) performance win that means the difference between a feature that ships and one that never leaves the prototype stage.
This deployment-time pressure is not new. The first major deep-learning success ran into the same memory wall during training itself, and the architecture itself carries the scar to this day.
War Story 1.1: AlexNet's two-GPU split (2012)
Context: In 2012, Alex Krizhevsky, Ilya Sutskever, and Geoffrey Hinton at the University of Toronto set out to train a convolutional network larger than anything previously attempted on ImageNet (Krizhevsky et al. 2012).
Failure mode: A single NVIDIA GTX 580 carried only 3 GB of memory—not enough to hold the planned 60-million-parameter network alongside its activations and gradients during training. The hardware wall stood directly between the team and the architecture they wanted to train.
Resolution: They split the network across two GTX 580s, placing half of the feature maps on each GPU and allowing cross-GPU communication only in selected layers. AlexNet’s two-tower structure was not a modeling choice driven by accuracy; it was a memory budget forced into the architecture. The split network won ImageNet 2012 by more than ten percentage points and kicked off the deep-learning era.
Systems lesson: Hardware memory has shaped deep learning since its first major success. Every model that runs on real silicon carries the fingerprints of the memory hierarchy it had to fit on, whether the constraint is met at training time (model splitting, gradient checkpointing) or at deployment time (pruning, quantization). Compression is not a finishing step layered onto a finished model; it is the same battle the field has been fighting since AlexNet.
Krizhevsky, Alex, Ilya Sutskever, and Geoffrey E. Hinton. 2012. “ImageNet Classification with Deep Convolutional Neural Networks.” Advances in Neural Information Processing Systems 25.
The same memory pressure that shaped AlexNet’s architecture appears in everyday product constraints when the model must run on commodity mobile hardware.
Example 1.1: An illustrative MobileNet win
Context: A mobile app wants to add real-time “Background Blur” to video calls. The feature requires a segmentation model running at 30 FPS.
Constraint: Suppose an unoptimized MobileNetV3-style FP32 segmentation model, descended from the mobile-efficient design line used by MobileNetV2 and MobileNetV3 (Howard et al. 2019), runs at 8 FPS on mid-tier Android phones. It is too slow to ship.
Optimization:
- Quantization: Converting weights to INT8 reduces size by 4\(\times\) and uses the phone’s DSP/NPU.
- Result: In the measured product profile, speed jumps to 35 FPS. Energy per frame drops by 3\(\times\).
Systems lesson: Compression can turn a nonviable prototype into a deployable feature. This scenario is an engineering profile, not a universal MobileNetV3 benchmark; the exact speedup would need to be remeasured on the target model, runtime, and phone.
Table 2 quantifies this mismatch using the Lighthouse models from Lighthouse roster: Model biographies. The gap between model requirements and device capabilities explains why compression is not optional for resource-constrained deployment: without it, the models cannot run.
As table 2 makes concrete, even aggressively optimized models like MobileNetV2 at INT8 precision exceed TinyML device memory by about 6.7×.
Balancing trade-offs
The accuracy-efficiency trade-off drives every optimization decision. Increasing model capacity generally enhances predictive performance while increasing computational cost, resulting in slower, more resource-intensive inference. The improvements introduce challenges related to memory footprint, inference latency, power consumption, and training efficiency.
| Model | Memory (Runtime) | Storage (Weights) | Cloud (~107 GB) | Mobile (~8 GB) | TinyML (~524.3 KB) |
|---|---|---|---|---|---|
| DLRM | 100 GB | 100 GB | ok | no (12.5×) | no (190734.9×) |
| GPT-2 XL | 6 GB | 6 GB | ok | ok | no (11444.1×) |
| ResNet-50 | 100 MB | 100 MB | ok | ok | no (190.7×) |
| MobileNetV2 | 14 MB | 14 MB | ok | ok | no (26.7×) |
| MobileNetV2 (INT8) | 3.5 MB | 3.5 MB | ok | ok | no (6.7×) |
| DS-CNN (KWS) | 500 KB | 500 KB | ok | ok | ok |
This tension manifests differently across deployment contexts. Training requires computational resources that scale with model size; inference demands strict latency and power constraints in real-time applications. Understanding where each optimization technique falls on the compression-accuracy Pareto frontier is essential for informed technique selection.
Systems Perspective 1.1: The compression-accuracy trade-off curve
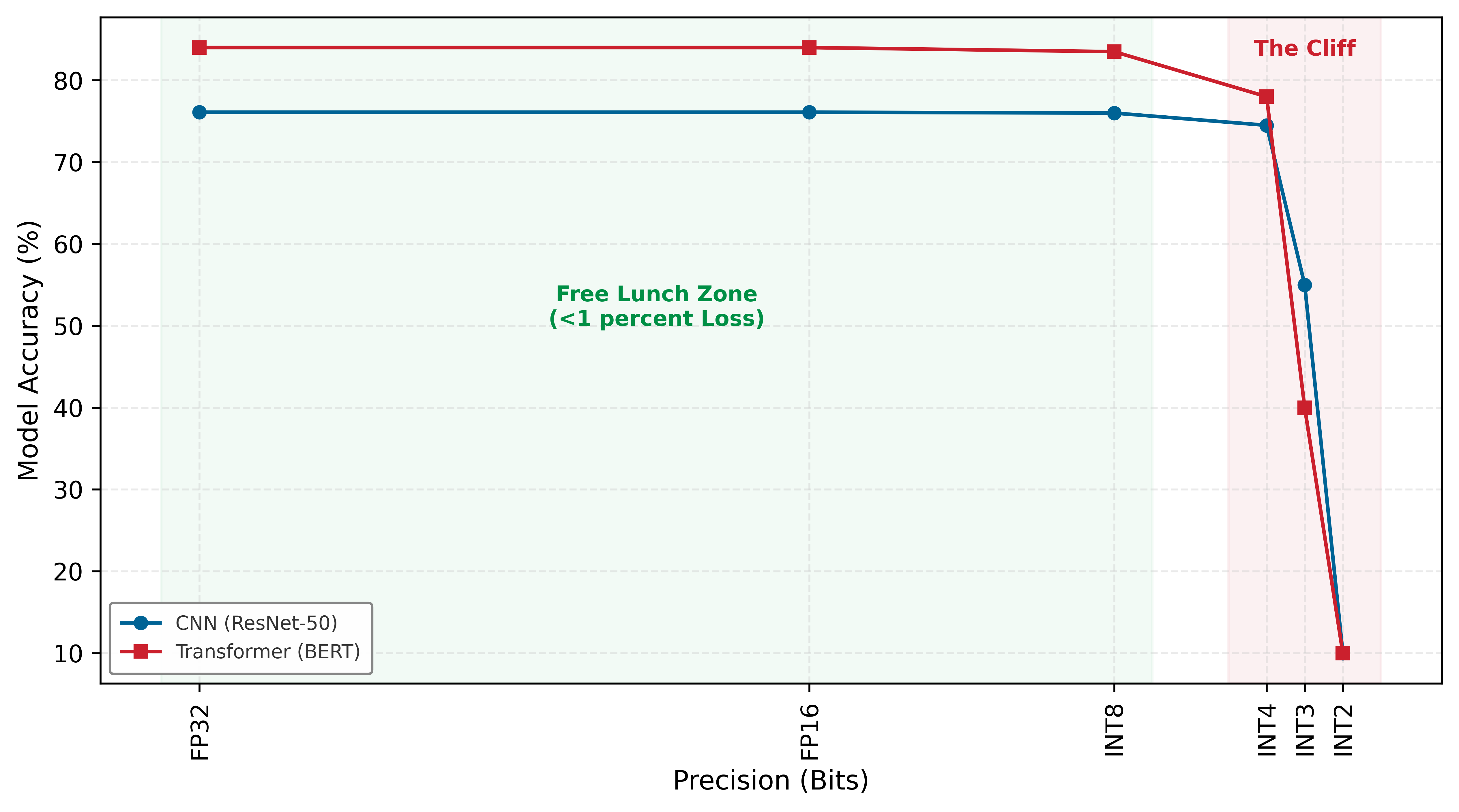
The frontier is not uniform: structure-preserving techniques sit near the top, exchanging little or no accuracy for real speedups, while aggressive structural surgery sits at the bottom, where each additional gain extracts a steepening accuracy penalty.
The engineering decision is where to stop. Compression should halt at the “knee” of the curve, the point where the marginal loss in accuracy first exceeds the marginal gain in efficiency. Past that knee, the model degrades faster than it accelerates.
Table 3 summarizes the key optimization techniques, their systems benefits, and their ML costs. These are empirical relationships—actual results depend on model architecture, task, and careful implementation.
| Technique | Systems Gain | ML Cost | Typical Impact | Region |
|---|---|---|---|---|
| Operator Fusion | 10–30% latency reduction | None | No accuracy loss | 1 |
| FP32 → BF16 | 2\(\times\) memory, ~2\(\times\) throughput | Minimal | <0.1% accuracy drop | 1 |
| FP16 → INT8 | 2\(\times\) memory, 2–4\(\times\) throughput | Quantization error | 0.5–1% accuracy drop | 2 |
| 50% Pruning | ~2\(\times\) smaller model | Capacity loss | 0.5–1% accuracy drop | 2 |
| Knowledge Distillation | 2–10\(\times\) smaller student | Capability ceiling | 1–3% accuracy drop | 2 |
| 4-bit Quantization | 4\(\times\) memory reduction | Significant error | 2–5% accuracy drop | 2–3 |
| 90% Pruning | ~10\(\times\) smaller model | Severe capacity loss | 5–15% accuracy drop | 3 |
| ↑ Batch Size (8\(\times\)) | Higher throughput, better GPU util | Generalization gap | Requires LR scaling | — |
The table reveals a pattern: techniques that preserve model structure (fusion, precision reduction) tend to be “free” or cheap, while techniques that alter structure (pruning, distillation) extract more savings but require careful tuning. Each deployment context imposes a binding constraint: memory capacity on mobile devices, latency on real-time systems, energy on battery-powered sensors. The optimization stack follows those constraints downward. Structural methods modify what computations occur, reducing the model’s parameter count and operation count to fit tighter memory and compute budgets. Precision techniques reduce how many bits represent each value, directly shrinking memory footprint and accelerating arithmetic. Architectural approaches improve how efficiently the remaining operations execute on physical hardware, closing the gap between theoretical savings and measured performance.
Checkpoint 1.1: The efficiency frontier
Optimization is about trading one resource for another.
Trade-offs
Self-Check: Question
Across the deployment contexts in this chapter, which one makes compression existential — that is, the model cannot run at all until it fits — rather than merely a throughput or latency optimization?
- Cloud inference, where throughput-per-dollar dominates the optimization budget
- Mobile and edge devices, where frame-rate targets bind but memory is usually generous
- TinyML, where KB-MB memory and mW power budgets create hard ceilings below which deployment is impossible
- Offline batch inference, where latency is irrelevant and storage never constrains deployment
A practitioner compares two candidates against the chapter’s 512 KB TinyML envelope: MobileNetV2 quantized to INT8 (roughly 3.5 MB) and a DS-CNN keyword spotter (roughly 500 KB at FP32, smaller at INT8). Using the chapter’s deployment-gap table, which outcome is most likely?
- Both models fit because INT8 quantization is always sufficient to land a mobile-class model on TinyML hardware
- Neither model fits because convolutional networks are inherently too expensive for microcontrollers
- MobileNetV2 INT8 fits only if the microcontroller clock rate is increased, while DS-CNN misses the RAM limit
- DS-CNN fits within the envelope while MobileNetV2 INT8 still exceeds TinyML memory by roughly 7×
The chapter’s compression-accuracy trade-off curve divides optimizations into three regions: free lunch, efficient trade, and danger zone. Explain what the ‘knee’ of this curve means quantitatively and what decision rule it gives the engineer.
True or False: Increasing batch size on a GPU should be treated as the same kind of compression move as pruning or quantization when locating a model on the chapter’s compression-accuracy trade-off curve.
A mobile video-call team needs 30 FPS background blur but FP32 MobileNetV3 runs at 8 FPS. INT8 quantization pushes the model to 35 FPS with a small accuracy drop and lower energy per frame. Which region of the chapter’s trade-off curve best describes this outcome?
- Region 1 (free lunch), because INT8 quantization carries zero accuracy cost of any kind
- Region 2 (efficient trade), because a small accuracy concession buys a large systems win that crosses the shipping threshold
- Region 3 (danger zone), because any deployment-driven optimization that changes the model is already a destructive move
- Outside the Pareto frontier, because once a model reaches 30 FPS the frontier no longer applies to it
Structural Optimization
Structural optimization addresses the first dimension of our framework, Efficient Model Representation, by modifying what the model computes. Modern neural networks are heavily overparameterized2: they carry far more parameters than any single task requires. This surplus is not a design flaw but a training necessity, since over-capacity helps optimization navigate complex loss landscapes. At deployment, however, every excess parameter translates directly into wasted memory, computation, and energy.
2 Overparameterization: C. Zhang et al. (2017) demonstrated that networks large enough to fit ImageNet can also memorize completely random labels, showing that training capacity can exceed the structure needed for natural labels. Pruning studies then show the deployment consequence: trained models often contain many parameters that can be removed or sparsified with modest task loss when pruning and fine-tuning are done carefully (Gale et al. 2019; Blalock et al. 2020). The redundancy is not a universal 10\(\times\) constant; it depends on architecture, dataset, sparsity pattern, and runtime support.
Zhang, Chiyuan, Samy Bengio, Moritz Hardt, Benjamin Recht, and Oriol Vinyals. 2017. “Understanding Deep Learning Requires Rethinking Generalization.” Communications of the ACM 64 (3): 107–15. https://doi.org/10.1145/3446776.
Gale, Trevor, Erich Elsen, and Sara Hooker. 2019. “The State of Sparsity in Deep Neural Networks.” arXiv Preprint arXiv:1902.09574.
Every technique in this chapter follows the same engineering heuristic: the conservation of complexity. Compression rarely destroys cost outright. It relocates cost between the Data, Algorithm, and Machine axes. Pruning may reduce parameters while asking the runtime to exploit sparse structure; distillation may reduce inference cost while adding a teacher-student training phase; quantization may reduce data movement while spending numerical precision. The engineer’s task is to move complexity to where the cost is lowest given deployment constraints.
The challenge is removing that surplus without removing what matters. Each technique relocates complexity to a different place: pruning moves it from parameters to the hardware’s ability to exploit sparse patterns: the model becomes simpler, but the system must now handle irregular memory access. Knowledge distillation moves complexity from inference compute to training compute: a smaller model at deployment, but a larger training budget to produce it. Neural architecture search moves complexity from human design effort to automated exploration: a more efficient architecture, but at the cost of a large search budget. Understanding where complexity should reside for a given deployment target3 is the central question of structural optimization.
3 Pareto Frontier: Named after Italian economist Vilfredo Pareto (1848–1923), who observed that 80 percent of Italy’s land was owned by 20 percent of the population. In multi-objective optimization, the Pareto frontier is the set of solutions where improving one objective (for example, speed) necessarily sacrifices another (for example, accuracy). EfficientNet traces this frontier concretely: B0 (77.1 percent accuracy, 390 million FLOPs) to B7 (84.4 percent, 37 billion FLOPs)—a 95\(\times\) compute increase for 7.3 percentage points of accuracy, quantifying how steep the trade-off becomes at the frontier’s edge (Tan and Le 2019).
Tan, Mingxing, and Quoc V Le. 2019. “EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks.” International Conference on Machine Learning (ICML), 6105–14.
Hutter, Frank, Lars Kotthoff, and Joaquin Vanschoren. 2019. Automated Machine Learning: Methods, Systems, Challenges. In Automated Machine Learning. The Springer Series on Challenges in Machine Learning. Springer International Publishing. https://doi.org/10.1007/978-3-030-05318-5.
These three techniques address the challenge through complementary approaches. Pruning eliminates low-impact parameters from an existing model. Knowledge distillation transfers a large model’s learned capabilities to a smaller architecture. NAS automates architecture design from the ground up, building optimized structures for specific constraints (Hutter et al. 2019). In practice, these techniques are often combined: a NAS-designed architecture, distilled from a large teacher, then pruned for final deployment. We start with pruning because it exposes the central structural trade-off most directly: removing parameters only helps if the resulting structure is something the runtime can exploit.
Pruning
As an illustrative deployment scenario, consider a MobileNet trained for image classification on a wearable health monitor. The trained model occupies 14 MB, but the target microcontroller offers only 2 MB of flash memory. Retraining a smaller architecture from scratch would require weeks of data collection and validation—time the product schedule does not allow. Suppose profiling shows that about 85.7 percent of the model’s weights are near zero and contribute little on the validation set. Removing those weights and fine-tuning the remainder for a few epochs could produce a model that fits in 2 MB with an acceptable accuracy loss. The numbers anchor the engineering trade-off rather than reporting a universal MobileNet benchmark.
Pruning4 directly addresses memory efficiency constraints by eliminating redundant parameters. Because neural networks carry far more weights than any single task demands (as established earlier), we can remove a significant fraction without substantial performance degradation. The central questions are what to prune (individual weights vs. entire structures), how to decide what is expendable (magnitude, gradients, or activations), and when to prune (after training, during training, or even at initialization). N:M structured sparsity mechanics explains the hardware side; the systems lesson here is that zeros become valuable only when the execution path can skip them.
4 Optimal Brain Damage: Introduced by LeCun et al. (1989), the method achieved 4\(\times\) parameter reduction—and proportional memory savings—in a handwriting recognizer by using second-derivative (Hessian) information to identify weights whose memory cost exceeded their accuracy contribution. The Hessian measures how much the loss increases when a weight is zeroed, directly ranking weights by their information-per-byte efficiency. However, Hessian computation costs \(\mathcal{O}(n^2)\) for \(n\) parameters, which is why magnitude-based pruning—despite its theoretical inferiority—became the practical standard at modern scale, where computing the Hessian itself would exceed the memory budget of the model it aims to compress.
LeCun, Yann, John S. Denker, and Sara A. Solla. 1989. “Optimal Brain Damage.” Advances in Neural Information Processing Systems 2 (NIPS 1989), 598–605.
Definition 1.2: Pruning
Pruning is a model-compression technique that sparsifies the parameter space by removing weights that contribute minimal information to the loss landscape.
- Significance: It converts dense matrices into sparse structures, reducing the memory footprint and the total data volume \((D_{\text{vol}})\) by as much as 10\(\times\) without significant accuracy loss.
- Distinction: Unlike quantization, which reduces the precision of every weight, pruning reduces the count of weights by identifying and eliminating redundancy.
- Common pitfall: A frequent misconception is that pruning “automatically” speeds up execution. In reality, without specialized sparse execution support, the resulting sparse matrices may actually run slower than dense ones due to irregular memory access patterns; a higher \(R_{\text{peak}}\) alone does not make an irregular sparse layout efficient.
The goal of pruning is to find a sparse version of the model parameters \(\hat{W}\) that minimizes the increase in prediction error (loss) while satisfying a fixed parameter budget \(k\). Framing this goal mathematically clarifies both the objective and why approximate solutions are necessary: \[ \min_{\hat{W}} \mathcal{L}(\hat{W}) \quad \text{subject to} \quad \|\hat{W}\|_0 \leq k \] where \(\|\hat{W}\|_0\) is the L0-norm (the count of nonzero parameters). Since minimizing the L0-norm is NP-hard, we use heuristics5 like magnitude-based pruning. Listing 1 demonstrates this approach, removing weights with small absolute values to transform a dense weight matrix into the sparse representation visualized in figure 2.
5 Heuristic: From Greek heuriskein (to discover), the same root as Archimedes’ “eureka.” In pruning, the dominant heuristic–larger magnitude means more important–works well empirically but creates a systems trap: magnitude-based pruning applied globally can remove most parameters from overparameterized layers while leaving critical bottleneck layers largely intact, giving the appearance of aggressive compression while preserving much of the compute and memory cost in the layers that matter (Blalock et al. 2020). This is why iterative prune-retrain cycles with per-layer budgets are often safer than naive global magnitude pruning: each cycle lets the network redistribute importance before the next cut.
Blalock, Davis, Jose Javier Gonzalez Ortiz, Jonathan Frankle, and John Guttag. 2020. “What Is the State of Neural Network Pruning?” Proceedings of Machine Learning and Systems 2: 129–46.
import torch
# Original dense weight matrix
weights = torch.tensor(
[[0.8, 0.1, -0.7], [0.05, -0.9, 0.03], [-0.6, 0.02, 0.4]]
)
# Simple magnitude-based pruning: keep only the 4 largest weights
threshold = 0.5
mask = torch.abs(weights) >= threshold
pruned_weights = weights * mask
print("Original:", weights)
print("Pruned (4 nonzeros):", pruned_weights)
Notice how the sparse matrix on the right retains only the high-magnitude values (colored cells) while the near-zero weights become exactly zero. This transformation reveals an important property: the “important” information in neural network weights is often concentrated in a small fraction of parameters, while most weights contribute little to the final output. This observation motivates magnitude-based pruning as a practical heuristic.
To make pruning computationally feasible, practical methods often replace the hard L0 constraint with soft regularization like L1-norm \((\lambda_{\text{L1}} \| \mathbf{W} \|_1)\), where \(\lambda_{\text{L1}}\) controls the strength of the sparsity penalty and \(\mathbf{W}\) denotes the weight tensor being regularized. This encourages small values that can later be thresholded to zero. Practitioners typically use iterative pruning, where parameters are removed in successive steps interleaved with fine-tuning to recover lost accuracy (Gale et al. 2019; Blalock et al. 2020).
Target structures
The choice of what to prune depends on the deployment target’s hardware constraints and which resource is the binding bottleneck. When memory capacity is the primary constraint, as in fully connected classifiers destined for mobile deployment, neuron pruning offers the most direct relief: removing entire neurons along with their associated weights and biases reduces the width of a layer, shrinking the parameter count proportionally. Because fully connected layers dominate memory in many architectures, targeting neurons addresses the largest contributor to model size.
When inference latency on commodity accelerators is the bottleneck, channel pruning (also called filter pruning) becomes the preferred approach. Eliminating entire channels or filters from convolutional layers reduces the depth of feature maps, which directly cuts the number of multiply-accumulate operations in subsequent layers. This reduction maps cleanly onto GPU and Tensor Processing Unit (TPU) execution patterns because the resulting model remains dense and regular, requiring no special sparse computation support. Channel pruning is therefore particularly effective for vision workloads where convolutional layers dominate computational cost.
When the most aggressive efficiency gains are required and the architecture has sufficient depth to absorb the loss, layer pruning removes entire layers from the network. This approach yields the largest per-operation reduction because it eliminates all computation within a layer, but it also carries the highest risk: removing a layer reduces the model’s representational depth, and the remaining layers must compensate for the lost capacity. Layer pruning therefore demands careful validation to ensure the model retains sufficient capacity to capture the patterns its task requires. The side-by-side comparison in figure 3 shows why the two choices have different implementation costs.

To see how these approaches differ in practice, compare the two sides of figure 3. When a channel is pruned, the model’s architecture must be adjusted to accommodate the structural change. Specifically, the number of input channels in subsequent layers must be modified, requiring alterations to the depths of the filters applied to the layer with the removed channel. In contrast, layer pruning removes all channels within a layer, necessitating more significant architectural modifications. In this case, connections between remaining layers must be reconfigured to bypass the removed layer. Regardless of the pruning approach, fine-tuning is important to adapt the remaining network and restore performance.
Unstructured pruning
Unstructured pruning removes individual weights while preserving the overall network architecture. Some connections become redundant during training, contributing little to the final output. Pruning these weak connections reduces memory requirements while preserving most of the model’s accuracy.
Formalizing this process, let \(W \in \mathbb{R}^{m \times n}\) represent a weight matrix in a given layer. Pruning removes a subset of weights by applying a binary mask \(M \in \{0,1\}^{m \times n}\), yielding a pruned weight matrix: \[ \hat{W} = M \odot W \] where \(\odot\) represents the element-wise Hadamard product. The mask \(M\) is constructed based on a pruning criterion, typically weight magnitude. A common approach is magnitude-based pruning, which removes a fraction \(\rho_{\text{sparse}}\) of the lowest-magnitude weights by defining a threshold \(\delta_{\text{prune}}\) such that: \[ M_{i,j} = \begin{cases} 1, & \text{if } |W_{i,j}| > \delta_{\text{prune}} \\ 0, & \text{otherwise} \end{cases} \] where \(\delta_{\text{prune}}\) is chosen to ensure that only the largest \((1 - \rho_{\text{sparse}})\) fraction of weights remain. This method assumes that larger-magnitude weights contribute more to the network’s function, making them preferable for retention.
The primary advantage of unstructured pruning is memory efficiency. By reducing the number of nonzero parameters, pruned models require less storage, which benefits deployment on embedded or mobile devices with limited memory.
Unstructured pruning does not necessarily improve computational efficiency on modern hardware, however. Standard accelerators are optimized for dense matrix multiplications, and a sparse weight matrix often cannot fully use hardware acceleration unless specialized sparse computation kernels are available. Unstructured pruning therefore primarily benefits model storage rather than inference acceleration.
Structured pruning
Where unstructured pruning removes individual weights, structured pruning (Li et al. 2017) eliminates entire computational units: neurons, filters, channels, or layers. This approach produces smaller dense models that map directly to modern machine learning accelerators. Because the resulting architecture remains fully dense, structured pruning leads to more efficient inference on general-purpose hardware than unstructured pruning, which requires specialized execution kernels to exploit its sparse weight matrices.
Li, Hao, Asim Kadav, Igor Durdanovic, Hanan Samet, and Hans Peter Graf. 2017. “Pruning Filters for Efficient ConvNets.” International Conference on Learning Representations (ICLR).
Neurons, filters, and layers vary dramatically in their contribution to a model’s predictions. Some units primarily carry redundant or low-impact information, and removing them does not significantly degrade model performance. Identifying which structures can be pruned while preserving accuracy remains the core challenge.
Hardware-aware pruning strategies, such as N:M structured sparsity6, enforce specific patterns (for example, ensuring 2 out of every 4 weights are zero) to align with specialized accelerator capabilities. This chapter uses the 2:4 pattern as the compression example; N:M structured sparsity mechanics later shows how sparse Tensor Cores exploit it.
6 N:M Structured Sparsity: Introduced commercially with NVIDIA’s A100 GPU (2020), the 2:4 pattern was chosen because it halves multiply-accumulate operations while keeping position metadata small enough for the sparse Tensor Core path (NVIDIA Corporation 2020; Choquette et al. 2021). This fixed ratio is a hardware constraint, not a mathematical optimum: the A100 Sparse Tensor Core path accelerates 2:4 sparse operands, yielding up to 2\(\times\) math-throughput speedup over dense execution when kernels and layouts satisfy the constraint. Other ratios are not accelerated by this specific hardware path, illustrating how silicon design constrains which sparsity patterns translate to actual speedup.
NVIDIA Corporation. 2020. NVIDIA A100 Tensor Core GPU Architecture. NVIDIA Whitepaper, V1.0.
Choquette, Jack, Wishwesh Gandhi, Olivier Giroux, Nick Stam, and Ronny Krashinsky. 2021. “NVIDIA A100 Tensor Core GPU: Performance and Innovation.” IEEE Micro 41 (2): 29–35. https://doi.org/10.1109/mm.2021.3061394.
To ground these distinctions, examine figure 4 from left to right. On the left, unstructured pruning removes individual weights (depicted as dashed connections), creating a sparse weight matrix. This can disrupt the original network structure, as shown in the fully connected network where certain connections have been randomly pruned. While this reduces the number of active parameters, the resulting sparsity requires specialized execution kernels to fully realize computational benefits.

Qi, Chen, Shibo Shen, Rongpeng Li, Zhifeng Zhao, Qing Liu, Jing Liang, and Honggang Zhang. 2021. “An Efficient Pruning Scheme of Deep Neural Networks for Internet of Things Applications.” EURASIP Journal on Advances in Signal Processing 2021 (1): 31. https://doi.org/10.1186/s13634-021-00744-4.
In contrast, structured pruning (depicted in the middle and right sections of figure 4) removes entire neurons or filters while preserving the network’s overall structure. In the middle section, a pruned fully connected network retains its fully connected nature but with fewer neurons. On the right, structured pruning is applied to a CNN by removing convolutional kernels or entire channels (dashed squares). This method maintains the CNN’s core convolutional operations while reducing the computational load, making it more compatible with hardware accelerators.
A common approach to structured pruning is magnitude-based pruning, where entire neurons or filters are removed based on the magnitude of their associated weights. The intuition is that parameters whose magnitude falls below the layer’s pruning threshold contribute negligibly to the model’s output, making them candidates for elimination. The importance of a neuron or filter is measured using a norm function, such as the \(\ell_1\)-norm or \(\ell_2\)-norm, applied to the weights associated with that unit. If the norm falls below a predefined threshold, the corresponding neuron or filter is pruned. This method is straightforward to implement and requires no additional computational overhead beyond computing norms across layers.
Another strategy is activation-based pruning, which evaluates the average activation values of neurons or filters over a dataset. Neurons that consistently produce low activations contribute less information to the network’s decision process and can be safely removed. This method captures the dynamic behavior of the network rather than relying solely on static weight values. Activation-based pruning requires profiling the model over a representative dataset to estimate the average activation magnitudes before making pruning decisions.
Gradient-based pruning uses information from the training process to identify less significant neurons or filters. Units with smaller gradient magnitudes contribute less to reducing the loss function, making them candidates for removal. By ranking neurons based on their gradient values, structured pruning can remove those with the least impact on model optimization. Unlike magnitude-based or activation-based pruning, which rely on static properties of the trained model, gradient-based pruning requires access to gradient computations and is typically applied during training rather than as a postprocessing step.
These three methods form a progression from static to dynamic assessment of parameter importance, and each presents distinct trade-offs. Magnitude-based pruning is computationally inexpensive and straightforward to implement, making it the default starting point, but it does not account for how neurons behave across different data distributions. Activation-based pruning captures more of this dynamic behavior by evaluating neurons over representative inputs, though it requires additional computation to estimate neuron importance. Gradient-based pruning exploits training dynamics most directly but may introduce prohibitive complexity for large-scale models. In practice, the choice depends on the specific constraints of the target deployment environment: magnitude-based methods suffice for most production scenarios, while gradient-based approaches justify their overhead only when accuracy preservation is paramount.
Dynamic pruning
Traditional pruning methods, whether unstructured or structured, involve static pruning: parameters are permanently removed after training or at fixed intervals during training, assuming that parameter importance is fixed. Dynamic pruning relaxes this assumption by adapting pruning decisions based on input data or training dynamics, allowing the model to adjust its structure in real time.
Dynamic pruning can be implemented using runtime sparsity techniques, where the model actively determines which parameters to use based on input characteristics. Activation-conditioned pruning exemplifies this approach by selectively deactivating neurons or channels that exhibit low activation values for specific inputs (Hu et al. 2023). This method introduces input-dependent sparsity patterns, effectively reducing the computational workload during inference without permanently modifying the model architecture.
Hu, Jie, Peng Lin, Huajun Zhang, Zining Lan, Wenxin Chen, Kailiang Xie, Siyun Chen, Hao Wang, and Sheng Chang. 2023. “A Dynamic Pruning Method on Multiple Sparse Structures in Deep Neural Networks.” IEEE Access 11: 38448–57. https://doi.org/10.1109/access.2023.3267469.
For instance, consider a convolutional neural network processing images with varying complexity. During inference of a simple image containing mostly uniform regions, many convolutional filters may produce negligible activations. Dynamic pruning identifies these low-impact filters and temporarily excludes them from computation, improving efficiency while maintaining accuracy for the current input. This adaptive behavior is particularly advantageous in latency-sensitive applications, where computational resources must be allocated judiciously based on input complexity. Benchmarking presents measurement strategies for evaluating such efficiency gains; at this point, the key requirement is to measure both speed and accuracy on the same target workload.
Another class of dynamic pruning operates during training, gradually introducing and adjusting sparsity throughout the optimization process. Methods such as gradual magnitude pruning start with a dense network and progressively increase the fraction of pruned parameters as training progresses. Instead of permanently removing parameters, these approaches allow the network to recover from pruning-induced capacity loss by regrowing connections that prove to be important in later stages of training.
Dynamic pruning offers several advantages over its static counterpart. By allowing models to adapt to different workloads, it improves efficiency while maintaining accuracy across a wider range of inputs. Where static pruning risks over-pruning and permanently degrading performance, dynamic pruning can selectively reactivate parameters when they prove necessary for a particular input. The cost of this flexibility is additional computational overhead, as pruning decisions must be made in real time during training or inference, making dynamic pruning harder to integrate into standard machine learning pipelines. Production deployments must also monitor how often the dynamic path changes behavior; ML Operations later develops those monitoring and rollback practices. These costs make dynamic pruning most appropriate for edge computing and efficient AI contexts where resource constraints and real-time efficiency requirements vary across inputs.
Pruning trade-offs
The three pruning approaches represent distinct positions on the regularity-vs.-compression trade-off. Unstructured pruning achieves the highest compression ratios because it can remove any individual weight, but the resulting irregular sparsity patterns are difficult for hardware to exploit: accelerators optimized for dense matrix operations cannot skip individual zero values without specialized sparse execution kernels. Structured pruning sacrifices some compression potential by removing entire channels, filters, or layers; the resulting dense sub-network runs efficiently on commodity hardware without sparse computation support. Dynamic pruning adapts pruning decisions to each input at runtime, offering the most flexibility at the cost of implementation complexity and computational overhead. Table 4 formalizes these comparisons across the dimensions that matter most for deployment.
| Aspect | Unstructured Pruning | Structured Pruning | Dynamic Pruning |
|---|---|---|---|
| What is removed? | Individual weights in the model | Entire neurons, channels, filters, or layers | Adjusts pruning based on runtime conditions |
| Model structure | Sparse weight matrices; original architecture remains unchanged | Model architecture is modified; pruned layers are fully removed | Structure adapts dynamically |
| Impact on memory | Reduces model storage by eliminating nonzero weights | Reduces model storage by removing entire components | Varies based on real-time pruning |
| Impact on computation | Limited; dense matrix operations still required unless specialized sparse computation is used | Directly reduces FLOPs and speeds up inference | Balances accuracy and efficiency dynamically |
| Hardware compatibility | Sparse weight matrices require specialized execution support for efficiency | Works efficiently with standard deep learning hardware | Requires adaptive inference engines |
| Fine-tuning required? | Often necessary to recover accuracy after pruning | More likely to require fine-tuning due to larger structural modifications | Adjusts dynamically, reducing the need for fine-tuning |
| Use cases | Memory-efficient model compression for cloud deployment | Real-time inference optimization, mobile/edge AI, and efficient training | Adaptive AI applications, real-time systems |
Pruning strategies
Beyond the broad categories of unstructured, structured, and dynamic pruning, different pruning workflows can impact model efficiency and accuracy retention. Two widely used pruning strategies are iterative pruning and one-shot pruning, each with distinct benefits and trade-offs.
Iterative pruning
Iterative pruning removes structure gradually through multiple cycles of pruning followed by fine-tuning. During each cycle, the algorithm removes a small subset of structures based on predefined importance metrics. The model then undergoes fine-tuning to adapt to these structural modifications before proceeding to the next pruning iteration. This gradual approach helps prevent sudden drops in accuracy while allowing the network to progressively adjust to reduced complexity. The workflow in figure 5 makes the key mechanism visible: each prune step creates a temporary accuracy drop, and each fine-tune step tests whether the compressed structure can recover.

Follow the three rows of figure 5 to see this gradual process in action on a convolutional neural network where six channels are pruned. Rather than removing all channels simultaneously, iterative pruning eliminates two channels per iteration over three cycles. Following each pruning step, the model undergoes fine-tuning to recover performance. The first iteration, which removes two channels, results in an accuracy decrease from 0.995 to 0.971, but subsequent fine-tuning restores accuracy to 0.992. After completing two additional pruning-tuning cycles, the final model achieves 0.991 accuracy, which represents only a 0.4 percent reduction from the original, while operating with 27 percent fewer channels. By distributing structural modifications across multiple iterations, the network maintains its performance capabilities while achieving improved computational efficiency.
One-shot pruning
One-shot pruning removes multiple architectural components in a single step, followed by an extensive fine-tuning phase to recover model accuracy. This aggressive approach compresses the model quickly but risks greater accuracy degradation, as the network must adapt to significant structural changes simultaneously.
Consider applying one-shot pruning to the same network from the iterative pruning example. Instead of removing two channels at a time over multiple iterations, one-shot pruning eliminates all six channels simultaneously. Compare the single-row workflow in figure 6 to the iterative case: removing 27 percent of the network’s channels simultaneously causes the accuracy to drop significantly, from 0.995 to 0.914. Even after fine-tuning, the network only recovers to an accuracy of 0.943, which is a 5 percent degradation from the original unpruned network. While both iterative and one-shot pruning ultimately produce identical network structures, the gradual approach of iterative pruning better preserves model performance.

The choice between strategies depends on three interrelated factors. First, the sparsity target: higher reduction targets often necessitate iterative approaches to maintain accuracy, while moderate goals may be achievable with one-shot methods. Second, available resources: iterative pruning demands significant compute for multiple fine-tuning cycles, whereas one-shot approaches trade accuracy for speed. Third, the deployment timeline and target platform: one-shot methods enable faster deployment, but certain hardware architectures better support specific sparsity patterns, making iterative approaches more advantageous when time permits.
Lottery ticket hypothesis
The pruning strategies in this chapter share a common assumption: we start with a trained network and then decide which parameters to remove. The relationship between network structure and trainability may run deeper than pruning strategies suggest: pruning may reveal inherently efficient subnetworks that were already hidden within the dense model, rather than merely deleting unnecessary weights after training.
This perspective leads to the Lottery Ticket Hypothesis7 (LTH), which challenges conventional pruning workflows by proposing that within large neural networks, there exist small, well-initialized subnetworks (“winning tickets”) that can achieve comparable accuracy to the full model when trained in isolation. Rather than viewing pruning as a post-training compression step, LTH suggests it can serve as a discovery mechanism to identify these efficient subnetworks early in training (Rachwan et al. 2022).
7 Lottery Ticket Hypothesis: Named for the intuition that training a large network is like buying many lottery tickets–most lose, but a few “winning tickets” (sparse subnetworks with favorable initializations) can train to comparable accuracy on their own. Frankle and Carbin (2019) established the hypothesis on smaller vision and fully connected networks; later work surveyed and extended the idea to larger settings (Rachwan et al. 2022). The systems implication is that some of the memory and compute spent training dense networks may be discoverable overhead, but the practical payoff depends on whether the winning subnetwork can be found before paying most of the original training cost.
Frankle, Jonathan, and Michael Carbin. 2019. “The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks.” International Conference on Learning Representations.
Rachwan, John, Daniel Zügner, Bertrand Charpentier, Simon Geisler, Morgane Ayle, and Stephan Günnemann. 2022. “Winning the Lottery Ahead of Time: Efficient Early Network Pruning.” International Conference on Machine Learning, 18293–309.
LTH is validated through an iterative pruning process. Trace the cycle in figure 7: a large network is first trained to convergence. The lowest-magnitude weights are then pruned, and the remaining weights are reset to their original initialization rather than being re-randomized. This process is repeated iteratively, gradually reducing the network’s size while preserving performance. After multiple iterations, the remaining subnetwork (the “winning ticket”) proves capable of training to the same or higher accuracy as the original full model.

The implications of the Lottery Ticket Hypothesis extend beyond conventional pruning. Instead of training large models and pruning them later, LTH suggests that compact, high-performing subnetworks could be trained directly from the start, eliminating the need for overparameterization. This insight challenges the traditional assumption that model size is necessary for effective learning. It also emphasizes the importance of initialization, as winning tickets only retain their performance when reset to their original weight values, raising deeper questions about how initialization shapes a network’s learning trajectory.
The hypothesis further reinforces the effectiveness of iterative pruning over one-shot pruning. Gradually refining the model structure allows the network to adapt at each stage, preserving accuracy more effectively than removing large portions of the model in a single step. This process aligns well with practical pruning strategies used in deployment, where preserving accuracy while reducing computation is important.
Despite its promise, applying LTH in practice remains computationally expensive because identifying winning tickets requires multiple cycles of pruning and retraining. Ongoing research explores whether winning subnetworks can be detected early without full training, potentially enabling more efficient sparse training. If such methods become practical, LTH could reshape model training, shifting the focus from pruning large networks after training to discovering and training only the important components from the beginning.
Pruning in practice
LTH presents a compelling theoretical perspective on pruning, but practical implementations must still produce runtime artifacts that deployment systems can exploit. Framework pruning is only useful when it produces a deployment artifact the runtime can exploit: a smaller dense model, a structured sparse model, or a sparse format with matching kernels. Training-time pruning often begins as mask application: the original tensor remains present, but a binary mask zeros selected weights during the forward pass. That mechanism can guide learning, yet by itself it does not guarantee lower latency or memory use. Deployment savings appear only after the masked structure is materialized into the artifact that the serving runtime actually loads.
This artifact boundary separates the pruning strategies. Unstructured pruning removes individual weights and needs sparse kernels plus an appropriate storage format to translate zeros into speed. Structured pruning removes whole channels, heads, neurons, or blocks, which can reshape tensors into smaller dense operations that ordinary accelerators already execute well. Gradual pruning during fine-tuning adds a training schedule: sparsity increases over time so the remaining weights can recover accuracy as capacity is removed. The systems audit is therefore concrete: identify what is pruned, identify the runtime format, and verify that the target hardware has kernels that make the sparsity useful.
These trade-offs become concrete when examining real-world deployments. Some model families reduce deployment cost through architecture rather than post-hoc pruning: MobileNet uses depthwise separable convolutions for mobile and embedded vision (Howard et al. 2017), while EfficientNet uses compound scaling to improve the accuracy-efficiency trade-off under resource constraints (Tan and Le 2019). Pruning remains a separate optimization lever. BERT-style transformers8 have been pruned by removing redundant attention heads or intermediate dimensions, while separate distillation methods such as DistilBERT and TinyBERT train smaller dense student models that retain much of BERT’s performance (Sanh et al. 2019).
8 BERT Pruning: Structured pruning succeeds here because BERT’s 12 attention heads per layer exhibit massive redundancy—Michel et al. (2019) showed that removing 40 percent of heads changes GLUE scores by only 1.2 percent. This redundancy is architectural, not accidental: overparameterization aids pretraining optimization, but at deployment, each unnecessary head consumes memory bandwidth for zero accuracy gain.
Michel, Paul, Omer Levy, and Graham Neumann. 2019. “Are Sixteen Heads Really Better Than One?” Advances in Neural Information Processing Systems.
Pruning has an inherent limitation: it starts with an existing architecture and carves away pieces. The pruned model inherits its structure from the original—same layer types, same connectivity patterns, just fewer parameters. The original architecture itself may be inefficient for deployment. A practitioner may need a model with a completely different structure, such as a six-layer transformer instead of a 12-layer one, that still captures the original model’s capabilities.
This limitation motivates knowledge distillation, a categorically different approach. Rather than modifying an existing model’s weights, distillation trains a new, compact “student” model to mimic the behavior of a larger “teacher” model. The student inherits the teacher’s learned knowledge without inheriting its computational overhead.
Knowledge distillation
A large language model achieves state-of-the-art accuracy on medical question-answering, but at hundreds of billions of parameters it cannot run on a hospital’s on-premise server constrained to a single GPU. Pruning alone cannot bridge this gap because a sparse variant is insufficient; the target architecture needs to be fundamentally different. Knowledge distillation addresses this class of problem by training a compact “student” model to replicate a larger “teacher” model’s behavior, often retaining much of the teacher’s task performance at a fraction of the inference cost (Hinton et al. 2015; Sanh et al. 2019). The term distillation borrows from chemistry, where the process extracts a concentrated essence from a larger mixture,9 and the systems insight is similar: the teacher’s predictions carry more information than the raw training labels.
9 Distillation: Borrowed from chemistry, where distillation separates mixtures by selective evaporation, extracting the essence while leaving impurities behind. Hinton et al. (2015) introduced temperature-scaled softmax to control how much “dark knowledge” about class relationships the student absorbs—the temperature parameter \(T_{\text{distill}}\) mirrors literal temperature in chemical distillation. The metaphor captures the systems trade-off precisely: distillation moves complexity from inference compute to training compute, producing a model 2–10\(\times\) smaller at the cost of a one-time training budget to generate the teacher’s soft targets.
Hinton, Geoffrey, Oriol Vinyals, and Jeff Dean. 2015. “Distilling the Knowledge in a Neural Network.” arXiv Preprint.
Definition 1.3: Knowledge distillation
Knowledge Distillation is a model-compression technique that trains a smaller student model to match the behavior of a larger, pretrained teacher model.
- Significance: Distillation moves cost from repeated inference to one-time training. A distilled student can be 2–10\(\times\) smaller than the teacher while retaining much of its task accuracy; DistilBERT, for example, retains up to 97 percent of BERT’s accuracy with 40 percent fewer parameters and 60 percent faster inference (Sanh et al. 2019). This trade-off is valuable when the training cost of producing soft targets is amortized across many deployed queries.
- Distinction: Unlike pruning, which removes parameters from an existing architecture, and quantization, which lowers numerical precision, distillation trains a new dense architecture. The student inherits behavior from the teacher’s output distribution or intermediate representations rather than inheriting the teacher’s full parameter count or layer structure.
- Common pitfall: A frequent misconception is that distillation is lossless compression. In reality, the student is bounded by its own capacity, the quality of the teacher, and the match between the distillation data and deployment distribution; a student can faithfully reproduce teacher errors as well as teacher knowledge.
A well-trained teacher provides a richer learning signal than simple ground-truth labels. While a hard label is binary (for example, \([1, 0, 0]\) for cat), a teacher’s probability distribution (for example, \([0.85, 0.10, 0.05]\)) provides soft labels and reveals inter-class similarity, showing that a cat shares more features with a dog than a fox. Notice in figure 8 how this “dark knowledge” embedded in the teacher’s probability distribution reveals inter-class relationships that guide the student to generalize better.

The distillation workflow, laid out in figure 9, trains the student model to minimize two loss functions. The distillation loss is typically the Kullback-Leibler (KL) divergence10 between the teacher’s softened output distribution and the student’s distribution, while the student loss is the standard cross-entropy loss against the ground-truth hard labels.
10 Kullback-Leibler (KL) Divergence: Introduced by Kullback and Leibler at the NSA in 1951 for cryptanalysis, \(\mathcal{D}_{\text{KL}}(p \lVert q)\) quantifies the extra bits needed to encode samples from distribution \(p\) using a code optimized for \(q\). The key asymmetric consequence: \(\mathcal{D}_{\text{KL}}(\text{teacher} \lVert \text{student})\) penalizes the student heavily for assigning zero probability to teacher-probable outputs, forcing the student to maintain broad coverage of the teacher’s distribution—including low-probability “soft labels” that carry the teacher’s learned uncertainty. This is why distillation transfers calibration as well as accuracy, while standard cross-entropy training against hard labels produces poorly calibrated models that are overconfident on ambiguous inputs.
Operationally, the workflow has four decisions before training begins: choose a teacher with the desired behavior, choose a student whose dense architecture fits the deployment target, run the teacher on calibration or task data to produce soft targets, and select the temperature and loss weight that balance teacher imitation against the hard labels. The validation step then checks more than accuracy. A successful distilled model must preserve calibration, subgroup behavior, and latency on the target hardware, because the student can inherit the teacher’s errors as easily as its useful uncertainty.

Distillation mathematics
Starting from the softmax normalization in Softmax, we use a temperature parameter11 \(T_{\text{distill}}\) to soften the probability distribution. The softmax output for class \(i\) becomes: \[ p_i^{(T_{\text{distill}})} = \frac{\exp(z_i/T_{\text{distill}})}{\sum_j \exp(z_j/T_{\text{distill}})} \]
11 Temperature (Softmax): Borrowed from statistical mechanics, where the Boltzmann distribution \(p_i \propto \exp(-E_i/kT_{\text{distill}})\) describes particle states at temperature \(T_{\text{distill}}\)—higher temperature means more uniform distribution across states. The analogy is load-bearing: at \(T_{\text{distill}}{=}1\) (standard softmax), the teacher’s output is a near-one-hot vector carrying almost no inter-class information; at \(T_{\text{distill}}{=}3\)–\(5\), the distribution softens enough to reveal which wrong classes the teacher considers plausible. This temperature tuning directly controls the bandwidth of information transferred from teacher to student, making it the primary hyperparameter governing distillation quality.
A higher \(T_{\text{distill}}\) (typically three to 5) produces a smoother distribution, allowing the student to learn from the “uncertainty” the teacher assigns to incorrect classes. The total loss \(\mathcal{L}_{\text{distill}}\) balances standard cross-entropy with the KL divergence: \[ \mathcal{L}_{\text{distill}} = (1 - \gamma_{\text{KD}}) \mathcal{L}_{\text{CE}}(\mathbf{p}_{\text{student}}, y) + \gamma_{\text{KD}} T_{\text{distill}}^2 \mathcal{D}_{\text{KL}}(\mathbf{p}_{\text{teacher}}^{(T_{\text{distill}})} \lVert \mathbf{p}_{\text{student}}^{(T_{\text{distill}})}) \]
Here \(\mathbf{p}_{\text{teacher}}^{(T_{\text{distill}})}\) and \(\mathbf{p}_{\text{student}}^{(T_{\text{distill}})}\) are the teacher and student probability distributions computed with \(T_{\text{distill}}\), \(y\) is the hard label, and \(\gamma_{\text{KD}} \in [0,1]\) weights the hard-label and distillation terms. The factor \(T_{\text{distill}}^2\) ensures that gradient scales remain consistent when \(T_{\text{distill}}\) is changed. This hybrid approach enables compact models (like DistilBERT) to achieve up to 97 percent of their teacher’s performance with a fraction of the memory and compute.
Efficiency gains and trade-offs
Distillation’s primary advantage over pruning is that it produces a dense model, not a sparse one. A distilled student runs efficiently on commodity hardware (accelerators, edge AI chips) without requiring specialized sparse execution kernels. Models such as DistilBERT12 retain up to 97 percent of the teacher’s accuracy with 40 percent fewer parameters and 60 percent faster inference, a compression level difficult to achieve through pruning alone (Sanh et al. 2019). The same dense-student principle can be paired with compact computer-vision architectures: MobileNet supplies a dense mobile-friendly architecture (Howard et al. 2017), while distillation supplies the teacher-supervision method (Hinton et al. 2015). The student may also inherit useful teacher behavior, but that inheritance has to be validated on the deployment distribution because it can transfer teacher errors as well as teacher knowledge.
12 DistilBERT: Achieves 97 percent of BERT-Base performance with 40 percent fewer parameters (66M vs. 110M) and 60 percent faster inference. The concrete deployment impact: memory drops from 1.35 GB to 0.81 GB (proportional to the 60 percent parameter scale) and latency from 85 ms to 34 ms, crossing the threshold for real-time NLP on mobile devices where BERT-Base cannot fit alongside the operating system.
Gordon, Mitchell, Kevin Duh, and Nicholas Andrews. 2020. “Compressing BERT: Studying the Effects of Weight Pruning on Transfer Learning.” Proceedings of the 5th Workshop on Representation Learning for NLP, 143–55. https://doi.org/10.18653/v1/2020.repl4nlp-1.18.
Distillation can also be combined with other compression techniques, but the evidence should be tied to the specific technique being used. For pruning, Gordon et al. (2020) show that BERT can be pruned during pretraining and then transferred to downstream tasks, rather than requiring a separate pruning pass for each task. Distilled students can also be paired with pruning or quantization in deployment pipelines, but those combinations need to be validated for the target task and hardware.
The limitations are real, however. Distillation requires training a new model, which means higher upfront computational cost than pruning (which modifies an existing model in place). The effectiveness depends on teacher quality—a poorly trained teacher transfers incorrect biases. Designing an appropriate student architecture requires care: overly small students lack the capacity to absorb the teacher’s knowledge, while overly large students defeat the purpose of compression. Benchmarking provides a broader evaluation framework; locally, the distillation decision should be judged by teacher-student accuracy, model size, latency, and training cost together.
Table 5 contrasts the key trade-offs between knowledge distillation and pruning across accuracy retention, training cost, inference speed, hardware compatibility, and implementation complexity. DistilBERT and MobileBERT demonstrate architecture redesign plus distillation; pruning can be combined with distillation in other optimization pipelines, but these models should be understood primarily as dense student-model examples.
| Criterion | Knowledge Distillation | Pruning |
|---|---|---|
| Accuracy retention | High – Student learns from teacher, better generalization | Varies – Can degrade accuracy if over-pruned |
| Training cost | Higher – Requires training both teacher and student | Lower – Only fine-tuning needed |
| Inference speed | High – Produces dense, optimized models | Depends – Structured pruning is efficient, unstructured needs special support |
| Hardware compatibility | High – Works on standard accelerators | Limited – Sparse models may need specialized execution |
| Ease of implementation | Complex – Requires designing a teacher-student pipeline | Simple – Applied post-training |
Knowledge distillation is frequently used alongside pruning and quantization for deployment-ready models. How distillation interacts with these complementary techniques determines the effectiveness of multi-stage optimization pipelines.
Pruning and distillation both reduce the number of parameters a model carries, but they take the parameter count as given and decide which parameters to keep or how to transfer their knowledge. Neither technique questions whether the model’s internal representations are efficiently organized. A \(4096{\times}4096\) weight matrix in a transformer layer may have an effective rank of only 128—meaning it can be approximated with only 6.25 percent as many parameters; the fraction of information retained depends on the singular-value spectrum. Structured approximation methods exploit exactly this mathematical redundancy.
Structured approximations
Structured approximation serves a different deployment decision from pruning or distillation: when a layer’s weights are mathematically redundant, it may be cheaper to represent that redundancy directly than to store the original dense tensor. These methods decompose large weight matrices and tensors into lower-dimensional components because high-dimensional representations often admit compact, low-rank approximations. Low-rank factorization and tensor decomposition offer complementary strategies for achieving this compression.
Low-rank factorization
Low-Rank Matrix Factorization (LRMF) approximates weight matrices with lower-rank representations. Given a matrix \(A \in \mathbb{R}^{m \times n}\), LRMF finds matrices \(U \in \mathbb{R}^{m \times k}\) and \(V \in \mathbb{R}^{k \times n}\) such that: \[ A \approx UV \] where \(k \ll m, n\) is the approximation rank. This is typically computed via singular value decomposition (SVD)13, retaining only the top \(k\) singular values.
13 Singular Value Decomposition (SVD): The Eckart-Young theorem (1936) proves that retaining the top \(k\) singular values yields the optimal rank-\(k\) approximation, minimizing information loss. The key systems trade-off is whether the high, one-time compute cost of this factorization—\(\mathcal{O}(mn \cdot \min(m,n))\)—is amortized by the memory and bandwidth savings from using the smaller model in repeated inference calls.
This factorization reveals a fundamental trade-off that recurs throughout systems design: spending more arithmetic to move less data, which is profitable whenever the original tensor was dominating memory bandwidth.
Napkin Math 1.1: The bandwidth-compute trade-off
Low-rank factorization reduces memory pressure by trading computation for bandwidth reduction. Storing a 4096 by 4096 matrix requires 67.1 MB (at FP32). Fetching this matrix for a single inference is a massive memory bandwidth hit, especially when limited by physical memory bandwidth constraints.
If we factorize it with rank \(k\) = 128, we store two matrices (4096 by 128 and 128 by 4096), totaling only 4.2 MB, a 16× reduction in data movement. When inference uses the two factors directly, matrix-vector compute also falls from \(\mathcal{O}(mn)\) to \(\mathcal{O}(k(m+n))\) for small \(k\). The system speedup is often dramatic because the processor moves much less data and performs fewer operations than with the original dense matrix. Explicitly materializing \(UV\) would add \(\mathcal{O}(mkn)\) work and defeat the purpose.
This bandwidth-compute trade-off is the local version of the memory wall: execution becomes bottlenecked by moving weights rather than multiplying them. Understanding the AI memory wall later examines the same phenomenon from the hardware side.

To see why this matters, study figure 10: the matrix \(M\) can be approximated by the product of matrices \(U_k\) and \(V_k^T\). For intuition, most fully connected layers in networks are stored as a projection matrix \(M\), which requires \(m{\times}n\) parameters to be loaded during computation. However, by decomposing and approximating it as the product of two lower-rank matrices, we only need to store \(m \times k + k \times n\) parameters in terms of storage. Applying the factors directly costs \(\mathcal{O}(k(m+n))\) for a vector input, instead of \(\mathcal{O}(mn)\) for the original dense matrix; explicitly forming the dense product \(UV\) would cost \(\mathcal{O}(mkn)\) and should be avoided in inference (Denton et al. 2014).
Denton, Emily L, Soumith Chintala, and Rob Fergus. 2014. “Exploiting Linear Structure Within Convolutional Networks for Efficient Evaluation.” Advances in Neural Information Processing Systems (NeurIPS), 1269–77.
LRMF applies to fully connected layers (large weight matrices) and convolutional layers (via depthwise-separable convolutions). The key trade-off: storage reduces from \(\mathcal{O}(mn)\) to \(\mathcal{O}(mk + kn)\), but inference requires an additional matrix multiplication. Choosing rank \(k\) balances compression against information loss.
Tensor decomposition
Tensor decomposition extends factorization to multi-dimensional tensors common in convolutional layers and attention mechanisms, so the deployment decision becomes whether the storage saved by a low-rank tensor representation outweighs the reconstruction and inference overhead. Figure 11 breaks down a 3D tensor into its factor matrices, showing how each rank-one component contributes to the reconstruction. The choice among decomposition methods depends on tensor order, target rank, and inference overhead.

The main tensor-decomposition families differ in how they trade compression against inference overhead. CP decomposition expresses a tensor as a sum of rank-one components, \(\mathcal{X} \approx \sum_{r=1}^{k} u_r \otimes v_r \otimes w_r\), which can be compact but sensitive to rank choice. Tucker decomposition keeps a small core tensor with factor matrices, \(\mathcal{X} \approx \mathcal{G} \times _1 U \times _2 V \times _3 W\), making the retained interactions more explicit at the cost of a more complex representation. Tensor-Train (TT) factorizes high-dimensional tensors into a sequence of lower-rank factors, making it most attractive when the original tensor order is too large for a single matrix-like factorization to capture efficiently (Lebedev et al. 2015).
Lebedev, Vadim, Yaroslav Ganin, Maksim Rakhuba, Ivan Oseledets, and Victor Lempitsky. 2015. “Speeding up Convolutional Neural Networks Using Fine-Tuned CP-Decomposition.” 3rd International Conference on Learning Representations (ICLR).
Tensor decomposition applies to convolutional filters (approximating 4D weight tensors), attention mechanisms in transformers, and embedding layers in NLP models. The trade-offs mirror LRMF: compression vs. information loss, and the additional computational overhead of tensor contractions during inference. Table 6 compares LRMF and tensor decomposition across applicable data structure, compression mechanism, and computational cost.
| Feature | Low-Rank Matrix Factorization (LRMF) | Tensor Decomposition |
|---|---|---|
| Applicable Data Structure | Two-dimensional matrices | Multi-dimensional tensors |
| Compression Mechanism | Factorizes a matrix into two or more lower-rank matrices | Decomposes a tensor into multiple lower-rank components |
| Common Methods | Singular Value Decomposition (SVD), Alternating Least Squares (ALS) | CP Decomposition, Tucker Decomposition, Tensor-Train (TT) |
| Computational Complexity | Generally lower, often \(\mathcal{O}(mnk)\) for a rank-\(k\) approximation | Higher, due to iterative optimization and tensor contractions |
| Storage Reduction | Reduces storage from \(\mathcal{O}(mn)\) to \(\mathcal{O}(mk + kn)\) | Achieves higher compression but requires more complex storage representations |
| Inference Overhead | Requires additional matrix multiplication | Introduces additional tensor operations, potentially increasing inference latency |
| Primary Use Cases | Fully connected layers, embeddings, recommendation systems | Convolutional filters, attention mechanisms, multi-modal learning |
| Implementation Complexity | Easier to implement, often involves direct factorization methods | More complex, requiring iterative optimization and rank selection |
In practice, LRMF and tensor decomposition can be combined: fully connected layers compressed via LRMF while convolutional kernels use tensor decomposition. The choice depends on the model’s structure and whether memory or latency is the primary constraint.
The techniques explored so far (pruning, distillation, and factorization) all optimize existing architectures. Neural architecture search takes a different approach: discovering architectures that are efficient by construction.
Neural architecture search
Pruning, knowledge distillation, and other techniques explored in previous sections rely on human expertise to determine optimal model configurations. Selecting optimal architectures requires extensive experimentation, and even experienced practitioners may overlook more efficient designs (Elsken et al. 2019). Neural architecture search (NAS) automates this process by systematically exploring large spaces of possible architectures; early reinforcement-learning NAS optimized candidate architectures for validation accuracy (Zoph and Le 2016), weight-sharing methods reduced the cost of evaluating candidates (Pham et al. 2018), and later hardware-aware NAS work added device latency and platform efficiency to the search objective (Tan et al. 2019).
Elsken, Thomas, Jan Hendrik Metzen, and Frank Hutter. 2019. “Neural Architecture Search.” In The Springer Series on Challenges in Machine Learning, vol. 20. Springer International Publishing. https://doi.org/10.1007/978-3-030-05318-5_3.
14 Hardware-Aware NAS: Optimizes measured latency rather than FLOPs, which can diverge by 3–5\(\times\) when memory access or operator support dominates. Tan et al. (2019) fed device latency into search and found architectures 1.8\(\times\) faster than MobileNetV2 at higher accuracy.
Tan, Mingxing, Bo Chen, Ruoming Pang, Vijay Vasudevan, Mark Sandler, Andrew Howard, and Quoc V. Le. 2019. “MnasNet: Platform-Aware Neural Architecture Search for Mobile.” 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2815–23. https://doi.org/10.1109/cvpr.2019.00293.
The three-stage feedback loop in figure 12 captures the essence of how NAS works. NAS14 operates through three interconnected stages: defining the search space (architectural components and constraints), applying search strategies (reinforcement learning (Zoph and Le 2016), evolutionary algorithms, or gradient-based methods) to explore candidate architectures, and evaluating performance to ensure discovered designs satisfy accuracy and efficiency objectives. The key insight is that this feedback loop allows the search to learn from each evaluation, progressively focusing on promising regions of the architecture space. This automation enables the discovery of novel architectures that often match or surpass human-designed models while requiring substantially less expert effort.

The NAS optimization problem
The effectiveness of NAS depends on three design decisions: what architectures to search over (the search space), how to explore that space efficiently (the search strategy), and how to evaluate each candidate’s fitness for deployment. The optimization problem begins with a chicken-and-egg constraint: we cannot know how good an architecture is until we train it, but training is expensive. This creates two nested decisions: choosing which operations to include (the architecture) and finding the best parameters for those operations (the weights). The architecture defines what to optimize; the weights define how well that architecture can perform.
NAS is therefore a bi-level optimization problem15: the outer loop searches the architecture space \(\mathcal{A}\), while the inner loop trains candidate architectures to evaluate performance. Formally, we seek the optimal architecture \(\alpha^*\) that minimizes validation loss \(\mathcal{L}_{\text{val}}\) under constraints \(C\) (latency, memory): \[ \alpha^* = \operatorname{arg\,min}_{\alpha \in \mathcal{A}} \mathcal{L}_{\text{val}}(\theta^*(\alpha), \alpha) \quad \text{subject to} \quad C(\alpha) \leq C_{\text{max}} \] where \(\theta^*(\alpha)\) represents the optimal weights for architecture \(\alpha\), obtained by minimizing training loss: \[ \theta^*(\alpha) = \operatorname{arg\,min}_{\theta} \mathcal{L}_{\text{train}}(\theta, \alpha) \]
15 Bi-Level Optimization: A formulation where one optimization problem sits inside another. In NAS, the outer level selects an architecture while the inner level trains that candidate’s weights, so early methods paid a full training cost for every architecture evaluated. This nesting is why early NAS required 22,400 GPU-days; weight-sharing methods amortize one training run across many candidates, reducing search cost by roughly 1,000\(\times\).
The core challenge is the cost of the inner loop: evaluating each candidate requires expensive training. A search space with just 10 choices across 20 layers yields \(10^{20}\) architectures, making exhaustive search impossible. Efficient NAS methods address this by restricting the search space, using faster search strategies, or accelerating evaluation.
Search space design
The search space defines what architectures NAS can discover. Well-designed search spaces incorporate domain knowledge to focus search on promising regions while remaining flexible enough to discover novel patterns.
Rather than searching entire network architectures, many NAS systems search for reusable computational blocks, or cells, that can be stacked to form complete networks. A convolutional cell might choose from operations such as \(3{\times}3\) convolution, \(5{\times}5\) convolution, depthwise separable convolution, max pooling, or identity connections. A simplified cell with four nodes and two operations per edge yields roughly 10,000 possible cell designs, far more tractable than searching full architectures. NASNet exemplifies this approach, discovering reusable normal and reduction cells that can be stacked to form complete networks across different model sizes.
The same search-space decision can incorporate deployment constraints directly. Hardware-aware NAS treats latency, memory, or energy on the target platform as first-class objectives rather than optimizing only for accuracy and FLOPs (Zhang et al. 2020). MobileNetV3’s search space includes a latency prediction model that estimates inference time for each candidate architecture on Pixel phones without actually deploying them. This hardware-in-the-loop approach ensures discovered architectures run efficiently on real devices rather than just achieving low theoretical FLOP counts (Lei Yang et al. 2020).
Zhang, Li Lyna, Yuqing Yang, Yuhang Jiang, Wenwu Zhu, and Yunxin Liu. 2020. “Fast Hardware-Aware Neural Architecture Search.” 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). https://doi.org/10.1109/cvprw50498.2020.00354.
Yang, Lei, Zheyu Yan, Meng Li, Hyoukjun Kwon, Liangzhen Lai, Tushar Krishna, Vikas Chandra, Weiwen Jiang, and Yiyu Shi. 2020. “Co-Exploration of Neural Architectures and Heterogeneous ASIC Accelerator Designs Targeting Multiple Tasks.” arXiv Preprint, 523–87. https://doi.org/10.1002/9783527667703.ch67.
Search strategies
Search strategies determine how to explore the architecture space efficiently without exhaustive enumeration. Table 7 compares the trade-offs between search cost, architectural diversity, and optimality guarantees for each approach.
| Strategy | Search Efficiency | When to Use | Key Challenge |
|---|---|---|---|
| Reinforcement Learning | 400–1,000 GPU-days | Novel domains, unconstrained search | High computational cost |
| Evolutionary Algorithms | 200–500 GPU-days | Parallel infrastructure available | Requires large populations |
| Gradient-Based (DARTS) | 1–4 GPU-days | Limited compute budget | May converge to suboptimal local minima |
Reinforcement learning based NAS treats architecture search as a sequential decision problem where a controller generates architectures and receives accuracy as reward. The controller (typically an LSTM) learns to propose better architectures over time through policy gradient optimization. This approach discovered high-performing architectures like NASNet, but its inner loop is expensive because every reward requires training a candidate architecture; Zoph and Le (2016) evaluated 12,800–22,400 candidates, totaling 22,400 GPU-days. That cost explains why practical NAS work moved toward weight sharing and lower-cost performance predictors.
Real, Esteban, Alok Aggarwal, Yanping Huang, and Quoc V. Le. 2019. “Regularized Evolution for Image Classifier Architecture Search.” Proceedings of the AAAI Conference on Artificial Intelligence 33 (01): 4780–89. https://doi.org/10.1609/aaai.v33i01.33014780.
Evolutionary algorithms maintain a population of candidate architectures and iteratively apply mutations (changing operations, adding connections) and crossover (combining parent architectures) to generate offspring. Fitness-based selection retains high-performing architectures for the next generation, so useful components such as skip connections or depthwise separable convolutions can be recombined rather than rediscovered from scratch. AmoebaNet used evolution to achieve state-of-the-art results after 3,150 GPU-days (Real et al. 2019), showing both the value of population search and the continuing need for proxy tasks, weight sharing, or massive parallelism to control search cost.
Gradient-based methods like DARTS (Differentiable Architecture Search) (Liu et al. 2019) represent the search space as a continuous relaxation where all possible operations are weighted combinations. Rather than discrete sampling, DARTS optimizes architecture weights and model weights jointly using gradient descent. By making the search differentiable, DARTS reduces search cost from hundreds to just one to four GPU-days, though the continuous relaxation may miss discrete architectural patterns that discrete search methods discover.
Liu, Hanxiao, Karen Simonyan, and Yiming Yang. 2019. “DARTS: Differentiable Architecture Search.” International Conference on Learning Representations.
Hardware-aware NAS moves beyond FLOPs as a proxy for efficiency, directly optimizing for actual deployment metrics. MnasNet’s search incorporates a latency prediction model trained on thousands of architecture-latency pairs measured on actual mobile phones. The search objective combines accuracy and latency through a weighted product: \[ \text{Reward}(\alpha) = \text{Accuracy}(\alpha) \times \left(\frac{L_{\text{lat,target}}}{L_{\text{lat}}(\alpha)}\right)^\beta \] where \(L_{\text{lat}}(\alpha)\) is measured latency, \(L_{\text{lat,target}}\) is the latency constraint, and \(\beta\) controls the accuracy-latency trade-off. This formulation penalizes architectures that exceed latency targets while rewarding those that achieve high accuracy within the budget. MnasNet discovered that inverted residuals with varying expansion ratios achieve better accuracy-latency trade-offs than uniform expansion, a design insight that manual exploration likely would have missed.
When to use NAS
Neural architecture search can discover architectures that outperform hand-designed alternatives, but its significant computational cost demands careful consideration of when the investment is justified. NAS becomes worthwhile for novel hardware platforms with unique constraints (new accelerator architectures, extreme edge devices) where existing architectures are poorly optimized. It also makes sense at massive deployment scale (billions of inferences) where even 1–2 percent efficiency improvements justify the upfront search cost, or when multiple deployment configurations require architecture families (cloud, edge, mobile) that amortize one search across many variants.
Conversely, avoid NAS when working with standard deployment constraints (for example, ResNet-50 accuracy on NVIDIA GPUs) where well-optimized architectures already exist. If the compute budget is only a few GPU-days, avoid expensive RL or evolutionary NAS; differentiable or weight-sharing methods such as DARTS may be feasible, but should still be justified by deployment scale and validation cost. Rapidly changing requirements also make NAS impractical, as architecture selection may become obsolete before the search completes.
For most practitioners, starting with existing NAS-discovered or NAS-assisted architectures such as EfficientNet (Tan and Le 2019), MobileNetV3 (Howard et al. 2019), and MnasNet (Tan et al. 2019) provides better ROI than running NAS from scratch. These architectures are highly tuned and generalize well across tasks. Reserve custom NAS for scenarios with truly novel constraints or deployment scales that justify the investment.
Architecture examples
NAS-discovered architectures consistently demonstrate design insights that manual exploration would likely miss. EfficientNet discovered that depth, width, and resolution should scale with fixed compound coefficients rather than independently, a principle that achieves higher accuracy with fewer parameters across the entire model family from mobile to cloud deployment (Tan and Le 2019). MobileNetV3 optimized specifically for mobile hardware, using hardware-aware search and NetAdapt to improve accuracy-latency trade-offs on phones (Howard et al. 2019). FBNet extended this to real-time inference on mobile CPUs by incorporating device-specific latency constraints directly into the search objective (B. Wu et al. 2019).
Wu, Bichen, Kurt Keutzer, Xiaoliang Dai, Peizhao Zhang, Yanghan Wang, Fei Sun, Yiming Wu, Yuandong Tian, Peter Vajda, and Yangqing Jia. 2019. “FBNet: Hardware-Aware Efficient ConvNet Design via Differentiable Neural Architecture Search.” 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 10726–34. https://doi.org/10.1109/cvpr.2019.01099.
Beyond convolutional networks, NAS has been applied to transformer architectures: NAS-BERT discovers efficient structures that retain strong language understanding while reducing compute and memory overhead, and similar approaches design lightweight vision transformers with attention mechanisms tailored for edge deployment. The common thread is that encoding efficiency constraints directly into the search process produces architectures that are more computationally efficient and hardware-adapted than manual design.
The structural techniques covered so far (pruning, distillation, factorization, and NAS) all optimize what computations the model performs: which parameters exist, which connections remain, and how the architecture is structured. These techniques can dramatically reduce parameter counts and theoretical FLOPs. Even a perfectly pruned model with an optimal architecture, however, faces a fundamental constraint: every surviving weight and activation must be stored and processed at some numerical precision.
Checkpoint 1.2: Structural optimization checkpoint
Test your understanding of the structural optimization techniques covered so far:
This brings us to the second dimension of our optimization framework: the precision at which those computations are performed. Numerical precision directly determines memory footprint and arithmetic cost, two resources that structural optimization cannot touch. A 32-bit floating-point number uses 4 bytes of memory and requires expensive floating-point arithmetic; an 8-bit integer uses 1 byte and enables fast integer math. For bandwidth-bound inference, the smaller representation can reduce weight traffic by the same factor and unlock large latency gains when the runtime maps the model to efficient low-precision kernels. The accuracy cost can be small for well-calibrated INT8, especially in CNN inference settings, but it still has to be measured on the target model and hardware (Jacob et al. 2018; Gholami et al. 2021).
Quantization is often the highest-leverage optimization technique for deployment, especially for large language models. It requires no architectural changes, applies post-training in many cases, and turns a model-size problem into a precision, calibration, and hardware-mapping problem.
Self-Check: Question
A team prunes ResNet-50 to 50 percent sparsity using unstructured magnitude pruning, then benchmarks it on a commodity GPU and sees only a 1.1× speedup. Switching to structured channel pruning at the same 50 percent sparsity delivers roughly 1.8× speedup on the same GPU. Which explanation best captures why?
- Structured pruning removes whole channels that preserve dense execution patterns, while unstructured sparsity scatters zeros through memory and wastes standard compute units that cannot skip zeros without first loading them
- Structured pruning removes more parameters than unstructured pruning at the same nominal sparsity ratio, so the FLOP reduction is larger
- Unstructured pruning cannot reduce model storage at all, so only structured pruning shrinks the memory footprint
- Structured pruning works only because it eliminates the need for any fine-tuning after compression
Order the following stages of one Lottery Ticket Hypothesis iteration: (1) reset surviving weights to their original initialization values, (2) train the dense network to convergence, (3) prune the lowest-magnitude weights.
A team must compress a large transformer for deployment on standard GPUs that have no dedicated sparse-kernel support. The target architecture should be substantially smaller than the teacher. Which structural technique best fits these constraints?
- Unstructured pruning, because sparse matrix operations are always fastest on commodity GPUs
- Layer-wise magnitude pruning, because it preserves the original teacher architecture exactly
- Knowledge distillation, because it trains a smaller dense student that runs efficiently on ordinary hardware without requiring sparse kernels
- Low-rank factorization alone, because it avoids any additional training cost while guaranteeing no information loss
Low-rank factorization replaces one large weight matrix multiplication with two smaller ones, increasing the raw operation count. Explain why this can still accelerate inference on modern accelerators, using a concrete rank choice from the chapter.
An engineering team is choosing between running custom neural architecture search from scratch and adopting an existing NAS-discovered architecture such as EfficientNet or MobileNetV3. Which situation most strongly justifies custom NAS?
- Standard target hardware for which mature architectures already match the deployment constraints well
- Tight compute budget with fewer than 100 GPU-days available for the optimization effort
- Rapidly shifting product requirements where the architecture may be obsolete before a search finishes
- Novel hardware constraints or deployment scale so large that amortizing the search cost over deployed inferences produces a net win
A team compares one-shot pruning (remove 90 percent of weights in one step, then fine-tune) against iterative pruning (remove 10 percent, fine-tune, repeat nine times) on the same model to the same final sparsity. Why does iterative pruning typically recover higher accuracy?
- Iterative pruning uses more randomization, which hides the effect of removed parameters from the final accuracy measurement
- Iterative pruning interleaves smaller pruning steps with fine-tuning, letting surviving weights absorb each cut’s importance redistribution before the next is made
- One-shot pruning fails only when it removes structured units; iterative pruning avoids that by removing only unstructured weights
- Iterative pruning works because it avoids any temporary accuracy drop at any point in the compression process
Quantization and Precision
The framework section established the gap that compression must close: a 7-billion parameter language model in FP16 needs 14 GB, while the smartphone target offers only 8 GB of shared RAM. Structural optimization alone cannot bridge it, since even aggressive pruning rarely exceeds 50–70 percent parameter reduction. The remaining gains come from a different dimension entirely, reducing the number of bits used to represent each parameter, and the open question this section answers is how far precision can be cut before accuracy collapses. Quantization, the process of reducing numerical precision, offers one of the most impactful optimizations for deployment, because it trades bits for speed and efficiency with minimal accuracy loss.
Definition 1.4: Quantization
Quantization is a model-compression technique that reduces information fidelity by mapping high-precision continuous values to a lower-precision discrete set.
- Significance: It reduces the memory footprint and bandwidth demand by 4\(\times\) (FP32 to INT8) or more, exploiting the inherent robustness of neural networks to low-precision arithmetic.
- Distinction: Unlike pruning, which reduces the count of parameters, quantization reduces the bit depth of every parameter and activation in the system.
- Common pitfall: A frequent misconception is that quantization is just “rounding.” In reality, it is a lossy mapping that requires careful range estimation and, often, quantization-aware training (QAT) to minimize its impact on accuracy.
Quantization16 affects every neural network weight and activation stored at some numerical precision: FP32 (32 bits), FP16 (16 bits), INT8 (8 bits), or lower. The bit width therefore becomes a systems parameter, not just a numerical representation.
16 Quantization: Rooted in Shannon’s theory of representing continuous signals with discrete values (Shannon 1948), reducing FP32 to INT8 collapses over four billion representable values to just 256. Neural networks often tolerate this because trained weights concentrate information in relative magnitudes, not absolute precision: INT8 inference can stay close to the full-precision baseline with appropriate calibration or quantization-aware training, while INT4 and lower-bit methods become more architecture- and method-dependent (Jacob et al. 2018; Gholami et al. 2021; Shen et al. 2020; Lin et al. 2023). The systems consequence is that quantization viability must be validated per-model and per-task, not assumed from aggregate benchmarks.
Shannon, Claude E. 1948. “A Mathematical Theory of Communication.” Bell System Technical Journal 27 (3): 379–423. https://doi.org/10.1002/j.1538-7305.1948.tb01338.x.
Jacob, Benoit, Skirmantas Kligys, Bo Chen, Menglong Zhu, Matthew Tang, Andrew Howard, Hartwig Adam, and Dmitry Kalenichenko. 2018. “Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference.” 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2704–13. https://doi.org/10.1109/cvpr.2018.00286.
Gholami, Amir, Sehoon Kim, Zhen Dong, Zhewei Yao, Michael W. Mahoney, and Kurt Keutzer. 2021. “A Survey of Quantization Methods for Efficient Neural Network Inference.” arXiv Preprint arXiv:2103.13630 abs/2103.13630: 291–326. https://doi.org/10.1201/9781003162810-13.
Gupta, Suyog, Ankur Agrawal, Kailash Gopalakrishnan, and Pritish Narayanan. 2015. “Deep Learning with Limited Numerical Precision.” International Conference on Machine Learning, 1737–46.
Wang, Yu Emma, Gu-Yeon Wei, and David Brooks. 2019. “Benchmarking TPU, GPU, and CPU Platforms for Deep Learning.” arXiv Preprint arXiv:1907.10701.
This choice directly impacts three system properties. Memory shrinks because an INT8 model is 4\(\times\) smaller than FP32, enabling deployment on devices that could never hold the full-precision weights. Bandwidth demand drops proportionally: loading INT8 weights requires 4\(\times\) less memory traffic, directly accelerating the bandwidth-bound inference that dominates LLM generation. Compute cost falls as well, since INT8 arithmetic is faster and cheaper than FP32 on most hardware with dedicated low-precision units (Gupta et al. 2015; Wang et al. 2019).
The accuracy cost of reduced precision varies by model and technique. CNNs typically tolerate INT8 quantization with <1 percent accuracy loss; transformers may require more care. Three approaches in increasing complexity are: post-training quantization (PTQ) for rapid deployment, quantization-aware training (QAT) for production systems requiring minimal accuracy loss, and extreme quantization (INT4, binary) for the most constrained environments.
The viability of each approach depends on how much precision a model can shed before accuracy collapses. Figure 13 shows two distinct regimes: a “Free Lunch” zone where reducing precision has minimal impact on accuracy, and a “Cliff” where the model fails catastrophically.
Precision and energy
Precision is an energy decision as much as a storage decision. Efficient numerical representations reduce storage requirements, computation latency, and power usage, benefiting mobile AI, embedded systems, and cloud inference alike. Precision levels can be tuned to specific hardware capabilities, maximizing throughput on AI accelerators such as GPUs, TPUs, NPUs, and edge AI chips.
To understand why numerics matter so deeply, move from the algorithm to silicon-level energy and data movement. At that level, each bit is both a storage choice and an energy cost.
Systems Perspective 1.2: The physics of quantization
The energy-movement invariant \((E_{\text{move}} \gg E_{\text{compute}})\) means that, in the physics of silicon, every fetched bit carries an energy cost (Horowitz 2014). Numbers to Know collects the reference energy ratios, and Numerical Representations compares numerical format trade-offs.
According to the iron law \((T = \frac{D_{\text{vol}}}{\text{BW}} + \frac{O}{R_{\text{peak}} \cdot \eta_{\text{hw}}} + L_{\text{lat}})\), which decomposes execution time into data volume moved, operations performed, and fixed latency, reducing the bit-width of a weight has a roughly proportional effect on efficiency:
- Memory movement \((D_{\text{vol}} \times E_{\text{move}})\): Fetching a 32-bit float from DRAM costs ≈ 640 pJ. Fetching one 8-bit weight costs ≈ 160 pJ.
- Compute work \((O \times E_{\text{compute}})\): A 32-bit multiply-add costs ≈ 3.7 pJ/op. An INT8 multiply-add costs ≈ 0.2 pJ/op.
Table 8 normalizes these costs against an 8-bit integer add to expose the four-order-of-magnitude gap between arithmetic and DRAM access.
For inference workloads, moving from FP32 to INT8 saves 4× memory and can reduce the energy per inference by up to 20× on hardware with dedicated INT8 units. The size of that gain depends on whether the workload is mostly moving bytes or mostly doing arithmetic. The roofline model gives this relationship a formal shape: workloads with little arithmetic per byte are memory-bound, so shrinking data movement dominates; workloads with more arithmetic per byte are compute-bound, so arithmetic savings matter more. The practical impact is the difference between a battery lasting 1 hour or 20 hours.
These same physics apply at data center scale: distributed training systems use reduced precision to cut gradient communication overhead, a topic covered in Mixed-precision training. Hardware Acceleration returns to the silicon mechanisms that exploit these energy differences.
These savings explain why neural networks tolerate aggressive quantization: the energy cost of higher precision exceeds the accuracy benefit for most applications, and reduced precision turns capacity pressure into bandwidth relief on the target device. How much precision a model can shed before accuracy collapses, and how large the resulting speedup proves to be, are the questions the quantization section develops in full.
Energy costs
Table 8 established the canonical gap between arithmetic and data movement; precision granularity extends it. Figure 14 gives representative operation-level energy costs across more formats and across the SRAM hierarchy: a 32-bit integer addition costs 0.1 pJ/op, while an 8-bit integer addition is just 0.03 pJ/op. Floating-point arithmetic follows the same direction: a 32-bit floating-point addition consumes approximately 0.9 pJ/op, whereas a 16-bit floating-point addition requires 0.4 pJ/op. The chart’s headline is the gap between the two groups: even an on-chip SRAM read costs roughly two orders of magnitude more than the cheapest arithmetic operation, so where an operand lives matters more than how it is computed. DRAM access is more expensive still. These savings compound across large-scale models operating over billions of operations. Reducing a model’s energy footprint therefore contributes to sustainable and accessible AI deployment: it helps mitigate the environmental impact of large-scale ML training and inference as AI workloads scale (Patterson et al. 2021), and it expands the reach of machine learning into low-resource environments, from rural healthcare to autonomous systems operating in the field.
Patterson, David, Joseph Gonzalez, Quoc Le, Chen Liang, Lluis-Miquel Munguia, Daniel Rothchild, David So, Maud Texier, and Jeff Dean. 2021. “Carbon Emissions and Large Neural Network Training.” arXiv Preprint arXiv:2104.10350.
| Operation | Bit-Width | Relative Energy |
|---|---|---|
| Integer Add | 8-bit | 1\(\times\) |
| Float Add | 32-bit | 30× |
| DRAM Read | 32-bit | 21,333.3× |

The energy dividend: INT8 vs. FP32 reality
The memory reduction of quantization is often the primary motivation, but the Energy Dividend is the most significant systems consequence. While moving from FP32 to INT8 precision reduces the model’s footprint by exactly 4\(\times\), the energy required to perform the math drops much more precipitously.
The framework section’s energy hierarchy already exposed this asymmetry; here it becomes the dividend. Consider the energy per operation \((E_{\text{op}})\) for an addition, the backbone of the accumulators in matrix multiplication. An FP32 addition requires 0.9 pJ/op, while an INT8 addition requires only 0.03 pJ/op. The resulting efficiency gain is 30×. We call this the “Dividend” because the system pays a 4\(\times\) “price” in bits but receives a 30\(\times\) “return” in energy efficiency. For a battery-powered edge device or a megawatt-scale data center, quantization is often mandatory to stay within the power envelope even if a model could fit in memory at higher precision. This disparity reinforces why the machine axis of the D·A·M taxonomy has moved toward specialized INT8 and INT4 integer units rather than general-purpose floating-point hardware.

Quantization pays off only when the machine axis has the right integer units.
These energy savings take on a different character for models where memory capacity, not compute, is the binding constraint.
The DLRM example shows quantization as a way to make a huge memory object placeable. The same logic reappears at the other end of the scale, where the object is small but the device is smaller still: the keyword spotting (KWS) DS-CNN lighthouse faces a TinyML deployment where compression becomes an existential requirement.
Lighthouse 1.1: DLRM and embedding quantization
The DLRM lighthouse (Sparse Architectures: RecSys) presents a compression challenge where memory capacity, rather than compute throughput or memory bandwidth, is the binding constraint (Naumov et al. 2019). Its embedding tables can reach terabytes in size, far exceeding GPU memory.
For DLRM, quantization is not about faster math; it is about storage density. Reducing embedding-table precision from FP32 to INT8 (or lower) can reduce memory footprint by 4–8\(\times\), allowing larger tables to fit on fewer GPUs when accuracy and lookup kernels tolerate the lower precision. This is a pure information-density optimization: we compress the lookup table so the machine (physics) can hold the algorithm (logic).
Naumov, Maxim, Dheevatsa Mudigere, Hao-Jun Michael Shi, Jianyu Huang, Narayanan Sundaraman, Jongsoo Park, Xiaodong Wang, et al. 2019. “Deep Learning Recommendation Model for Personalization and Recommendation Systems.” arXiv Preprint arXiv:1906.00091.
17 INT8 Energy Impact: The energy dominance of memory access is extreme: with the Horowitz constants used here, a single 32-bit DRAM read costs roughly 2,782.6× the energy of an INT8 multiply-accumulate (Horowitz 2014). Quantizing from FP32 to INT8 attacks this disparity on both fronts—4\(\times\) fewer bytes moved and cheaper arithmetic per operation. Representative MobileNetV2 INT8 measurements show multi-fold energy-per-inference reductions, with most savings coming from reduced memory traffic rather than cheaper arithmetic.
Horowitz, Mark. 2014. “1.1 Computing’s Energy Problem (and What We Can Do about It).” 2014 IEEE International Solid-State Circuits Conference Digest of Technical Papers (ISSCC), 10–14. https://doi.org/10.1109/isscc.2014.6757323.
Together, the two lighthouses separate the two reasons quantization matters. DLRM uses lower precision to make enormous tables fit; TinyML uses lower precision to keep every inference within a tiny energy and SRAM budget. Beyond direct compute savings, reducing numerical precision also lowers memory energy consumption, which often dominates total system power. Lower-precision representations reduce data storage requirements and memory bandwidth usage, leading to fewer and more efficient memory accesses. Accessing memory, particularly off-chip DRAM, is far more energy-intensive than performing arithmetic operations: the representative 32-bit DRAM read used in this chapter costs 640 pJ, compared with picojoule-scale cache and arithmetic operations. An instruction’s total energy can therefore be dominated by memory access patterns rather than computation17.
Lighthouse 1.2: The TinyML quantization imperative
The KWS (DS-CNN) lighthouse operates at the opposite extreme of the iron law from DLRM (Y. Zhang et al. 2017). A typical TinyML budget is roughly 512 KiB of SRAM, and even the purpose-built DS-CNN keyword spotter overshoots it in FP32: its weights occupy 800 KB. Quantized to INT8, the same network shrinks to 200 KB and fits with room for runtime buffers. A stricter smart-doorbell microcontroller with 256 KB SRAM leaves closer to 100 KB for model weights after runtime buffers, audio windows, and feature extraction state, motivating more aggressive INT4 or binary compression.
In FP32, even the compact DS-CNN architecture moves 4\(\times\) more weight bytes than in INT8, and the arithmetic path is also more expensive on hardware with efficient integer units. For an always-on device running on a coin cell battery, that first-order byte reduction can translate directly into longer battery life, but the measured gain still depends on sensor, wake-up, feature-extraction, and idle-power costs. Here, quantization reduces both the data-movement term and the compute term \((O / (R_{\text{peak}} \cdot \eta_{\text{hw}}))\) of the iron law.
Zhang, Yundong, Naveen Suda, Liangzhen Lai, and Vikas Chandra. 2017. Hello Edge: Keyword Spotting on Microcontrollers.
Reducing numerical precision thus improves efficiency on two fronts: faster computation and less data movement. This dual benefit is especially valuable for hardware accelerators and edge devices, where memory bandwidth and power efficiency are binding constraints.
Performance gains
The practical payoff of quantization becomes concrete in figure 15. Compare the orange (FP32) and blue (INT8) segments in each stacked bar to see the gains when moving from FP32 to INT8. The magnitude of the gain varies by model: Inception_v3 and ResNet_v2 see a 1.5–5\(\times\) reduction in both inference time and model size, while MobileNet_v1, designed for mobile-class INT8 hardware, sees an order-of-magnitude reduction. The pattern across architectures makes quantized models well suited for deployment in resource-constrained environments.

To make these gains concrete, consider the quantization savings when deploying a modern large language model at reduced precision.
Napkin Math 1.2: Quantization savings
Problem: Deploying Llama 3 8B requires storing 8B parameters on-device. How much memory does the model consume at FP16 vs. INT4, and does quantization shrink it enough to fit on a single consumer GPU?
FP16 (Half Precision)
- Size: 8 \(\times 10^9 \times\) 2 bytes (16-bit) = 16 GB
- Hardware requirement: Requires 24 GB GPU (for example, A10G, 3090, 4090).
INT4 (4-bit Quantization)
- Size: 8 \(\times 10^9 \times\) 0.5 bytes (INT4) = 4 GB
- Hardware requirement: Fits comfortably on 8 GB GPU (for example, T4, consumer laptops).
Systems insight: 4× compression allows deployment on commodity hardware instead of requiring a larger accelerator primarily for weight storage.
Beyond storage savings, quantization also accelerates computation through hardware parallelism. The speedup emerges from how modern processors pack more operations into the same hardware resources when working with smaller data types. A register-packing estimate makes that effect concrete.
Napkin Math 1.3: The SIMD multiplier
Problem: A compute-bound layer runs INT8 instead of FP32 on the same processor. Where does the speedup come from?
Mechanism: SIMD (Single Instruction, Multiple Data). A CPU or GPU core processes data in fixed-width vector registers (for example, AVX-512 is 512 bits wide).
Math:
- Register width: 512 bits.
- FP32 capacity: 512/32 = 16 elements per vector instruction.
- INT8 capacity: 512/8 = 64 elements per vector instruction.
Multiplier: Switching to INT8 packs 4× more elements into the same register. \(\text{Throughput Gain} = \text{INT8 elements/inst} / \text{FP32 elements/inst}\) = 64/16 = 4×
Systems insight: Quantization delivers up to 4× speedup on compute-bound layers from vector packing alone, on hardware whose INT8 vector instructions have comparable throughput to FP32, even before considering memory bandwidth savings.
Reducing numerical precision introduces trade-offs, however. Lower-precision formats can cause numerical instability and quantization noise, potentially affecting model accuracy. Figure 16 makes that risk concrete: most quantization error stays near zero, but tail errors can still perturb predictions when sensitive weights or activations land in the wrong bins. Some architectures, such as large transformer-based NLP models, tolerate quantization well, whereas others may experience significant degradation. Selecting the appropriate numerical precision therefore requires balancing accuracy constraints, hardware support, and efficiency gains.

To appreciate how precision loss manifests in practice, examine the representative quantization error distribution in figure 16: the bell-shaped curve centered near zero shows that most values quantize with minimal error, but the tails reveal outlier errors that can accumulate and influence model accuracy. Understanding this noise is essential, but practitioners ultimately care about end-to-end speedup, and the magnitude of the quantization speedup depends on whether a workload is compute bound or memory bound.
Napkin Math 1.4: The quantization speedup (compute bound)
Problem: A compute-bound matrix multiplication (for example, in a transformer multilayer perceptron (MLP) block) switches from FP16 to INT8. What is the expected speedup?
Math: On modern hardware with dedicated INT8 units:
- Integer throughput path: The reference A100-class accelerator rates its dedicated INT8 matrix units at 624 TOPS against 312 TFLOP/s on the FP16 path (NVIDIA Corporation 2020; Choquette et al. 2021). The peak throughput increase is that spec ratio: 624 TOPS ÷ 312 TFLOP/s ≈ 2×.
- Memory bandwidth: INT8 weights are half the size, so loading them from memory takes half the time.
- Combined effect: For compute-bound operations, the speedup is primarily from compute throughput: ~2× speedup.
Systems insight: The speedup from quantization depends on the bottleneck. Compute-bound operations (large batch sizes, high arithmetic intensity \(I\)) see ~2× from faster INT8 units, where the gain comes from the integer matrix path rather than reduced memory traffic. The bandwidth-bound case inverts this: halving the bytes moved (FP16 to INT8) yields up to 2×, and larger bit-width reductions scale the gain further, as the next worked example traces.
The complementary case is bandwidth bound, where the speedup tracks the reduction in bytes moved per token rather than peak arithmetic throughput.
The result is a bandwidth-driven speedup: fewer bits moved per token means more tokens/s.
Napkin Math 1.5: The quantization speedup
Problem: A deployment scenario calls for running a 7B-parameter LLM on a device with 16 GB RAM. The weights are FP16 (2 bytes).
Math:
- Model size: 7 \(\times 10^9 \times\) 2 bytes = 14 GB.
- KV cache: A 4,096-token FP16 KV cache uses two tensors (keys and values) across 32 layers, 32 KV heads, 128 dimensions per head, and 2 bytes per value, requiring approximately 2.1 GB.
- Total memory: 14 GB + 2.1 GB = 16.1 GB. This barely fits, leaving no room for OS or buffers.
- Bandwidth cost: Loading 14 GB at 50 GB/s takes 280 ms per token. That is 3.6 tokens/s, too slow for chat.
Fix (INT4):
- Quantization: Convert weights to INT4 (0.5 bytes).
- New size: 7 \(\times 10^9 \times\) 0.5 bytes = 3.5 GB.
- New speed: Loading 3.5 GB takes 70 ms. Speed jumps to 14 tokens/s.
Systems insight: Quantization makes the model fit and provides a 4× linear speedup because LLM generation is bandwidth bound.

Quantization speedup depends on whether memory bandwidth or compute throughput is binding.
Numerical format comparison
The format decision is to choose the numerical range and hardware path that preserve accuracy while reducing bytes moved, rather than to minimize bit width blindly. Table 9 compares commonly used numerical precision formats in machine learning, each exhibiting distinct trade-offs in storage efficiency, computational speed, and energy consumption. Formats such as FP8 and TF32 further optimize performance, especially on AI accelerators.
FP16 and BF16 formats provide moderate efficiency gains while preserving model accuracy. Many AI accelerators, such as NVIDIA Tensor Cores and TPUs, include dedicated support for FP16 computations, enabling 2\(\times\) faster matrix operations compared to FP32. BF16, in particular, retains the same 8-bit exponent as FP32 but with a reduced 7-bit mantissa, allowing it to maintain a similar dynamic range (~\(10^{-38}\) to \(10^{38}\)) while sacrificing precision. In contrast, FP16, with its 5-bit exponent and 10-bit mantissa, has a significantly reduced dynamic range (~\(10^{-5}\) to \(10^5\)), making it more suitable for inference rather than training. Since BF16 preserves the exponent size of FP32, it better handles extreme values encountered during training, whereas FP16 may struggle with underflow or overflow. This makes BF16 a more robust alternative for deep learning workloads that require a wide dynamic range.
| Precision Format | Bit-Width | Storage Reduction (vs. FP32) | Compute Speed (vs. FP32) | Power Consumption | Use Cases |
|---|---|---|---|---|---|
| FP32 (Single-Precision Floating Point) | 32-bit | Baseline (1\(\times\)) | Baseline (1\(\times\)) | High | Training & inference (general-purpose) |
| FP16 (Half-Precision Floating Point) | 16-bit | 2\(\times\) smaller | 2\(\times\) faster on FP16-optimized hardware | Lower | Accelerated training, inference (NVIDIA Tensor Cores, TPUs) |
| BF16 (Brain Floating Point) | 16-bit | 2\(\times\) smaller | Similar speed to FP16, better dynamic range | Lower | Training on TPUs, transformer-based models |
| TF32 (TensorFloat-32) | 19-bit | None (stored as FP32) | Up to 8\(\times\) faster on NVIDIA Ampere GPUs | Lower | Training on NVIDIA GPUs |
| FP8 (Floating-Point 8-bit) | 8-bit | 4\(\times\) smaller | Faster than INT8 in some cases | Significantly lower | Efficient training/inference (H100, AI accelerators) |
| INT8 (8-bit Integer) | 8-bit | 4\(\times\) smaller | 4–8\(\times\) faster than FP32 | Significantly lower | Quantized inference (Edge AI, mobile AI, NPUs) |
| INT4 (4-bit Integer) | 4-bit | 8\(\times\) smaller | Hardware-dependent | Extremely low | Ultra-low-power AI, experimental quantization |
| Binary/Ternary (1-bit/2-bit) | 1–2-bit | 16–32\(\times\) smaller | Highly hardware-dependent | Lowest | Extreme efficiency (binary/ternary neural networks) |
Compare the three bit layouts in figure 17 to see exactly where the bits go—and why the trade-off between precision and numerical range differs so sharply across formats.

INT8 precision offers more aggressive efficiency improvements for inference workloads. Many quantized models use INT8 for inference, reducing storage by 4\(\times\) while accelerating computation by 4–8\(\times\) on optimized hardware. INT8 is widely used in mobile and embedded AI, where energy constraints are significant.
Binary and ternary networks represent the extreme end of quantization, where weights and activations are constrained to one-bit (binary) or two-bit (ternary) values. This results in massive storage and energy savings, but model accuracy often degrades significantly unless specialized architectures are used. Our keyword-spotting lighthouse (Efficient architectures: Keyword spotting) lives precisely in this regime, where extreme compression is required just to fit the 256 KB SRAM device budget. INT8 is often just the starting point; engineers push toward INT4 or even binary weights, trading further accuracy for the microwatt-scale power budgets that always-on acoustic models demand.
The energy analysis completes the motivation for quantization: fewer bits reduce memory movement and lower arithmetic energy, but only when the target processor exposes the corresponding low-precision units. An INT8 operation, for example, uses roughly 20× less energy than its FP32 equivalent. Accelerators with Tensor Cores, FP8/INT8 units, TPUs, or NPUs can compound arithmetic savings with lower memory traffic, while general-purpose CPUs without efficient low-precision paths may lose much of the benefit to packing, dequantization, or scalar fallback. The practical implication is that precision is a model-hardware decision, not a software flag.
Precision reduction strategies
With the hardware condition established, the question becomes how to reduce precision without destroying model accuracy. Naive quantization introduces errors that degrade predictions, so practitioners need structured strategies that control where and how precision is reduced.
Three approaches form a complexity ladder. Post-training quantization (PTQ) reduces precision after training, requiring no retraining and minimal engineering effort. Quantization-aware training (QAT) incorporates quantization effects into the training loop, enabling models to adapt to lower precision and retain higher accuracy. Mixed-precision training assigns different precision levels to different operations, matching precision to each layer’s sensitivity. Figure 18 maps quantization techniques into three progressive tiers based on implementation complexity, resource requirements, and target use cases.

The roadmap is a deployment-ordering device rather than a taxonomy of numerical formats. PTQ belongs first because it changes representation with minimal training cost; QAT and mixed precision move into the production tier because they require training-loop or kernel support; INT4, binary, and ternary methods sit at the frontier because the accuracy and hardware assumptions become architecture-specific.
Post-training quantization
Post-training quantization (PTQ) reduces numerical precision after training, converting weights and activations from high-precision formats (FP32) to lower-precision representations (INT8 or FP16) without retraining (Jacob et al. 2018). This achieves smaller model sizes, faster computation, and reduced energy consumption, making it practical for resource-constrained environments such as mobile devices, edge AI systems, and cloud inference platforms (Wu et al. 2020).
PTQ’s key advantage is low computational cost: it requires no retraining and usually no labeled training set, although activation calibration typically needs a small representative calibration dataset. However, reducing precision introduces quantization error that can degrade accuracy, especially for tasks requiring fine-grained numerical precision. Machine learning frameworks such as TensorFlow Lite, Open Neural Network Exchange (ONNX) Runtime, and PyTorch provide built-in PTQ support.
The core mechanism of PTQ is uniform quantization, which maps floating-point values to discrete integer levels using a consistent scaling factor. Because the interval between each quantized value is constant, uniform quantization simplifies implementation and enables efficient hardware execution. The quantized value \(q\) is computed as: \[ q = \text{round} \left(\frac{x}{s} \right) \] where:
- \(q\) is the quantized integer representation,
- \(x\) is the original floating-point value,
- \(s\) is a scaling factor that maps the floating-point range to the available integer range.
Listing 2 demonstrates uniform quantization from FP32 to INT8, achieving 4\(\times\) memory reduction while measuring the resulting quantization error. Once a model is quantized, the runtime performs inference using integer arithmetic, which is significantly more efficient than floating-point operations on most hardware platforms (Gholami et al. 2021).
import torch
# Original FP32 weights
weights_fp32 = torch.tensor(
[0.127, -0.084, 0.392, -0.203], dtype=torch.float32
)
print(f"Original FP32: {weights_fp32}")
print(f"Memory per weight: 32 bits")
# Simple uniform quantization to INT8 (-128 to 127)
# Step 1: Find scale factor
max_val = weights_fp32.abs().max()
scale = max_val / 127 # 127 is max positive INT8 value
# Step 2: Quantize using our formula q = round(x/s)
weights_int8 = torch.round(weights_fp32 / scale).to(torch.int8)
print(f"Quantized INT8: {weights_int8}")
print(f"Memory per weight: 8 bits (reduced from 32)")
# Step 3: Dequantize to verify
weights_dequantized = weights_int8.float() * scale
print(f"Dequantized: {weights_dequantized}")
print(
f"Quantization error: "
f"{(weights_fp32 - weights_dequantized).abs().mean():.6f}"
)An alternative, nonuniform quantization, assigns finer-grained precision to numerical ranges that are more densely populated, which can preserve accuracy for models whose weight distributions concentrate around specific values. Nonuniform schemes require more complex calibration and are less common in production, but they can be effective for models particularly sensitive to precision changes.
PTQ works well for computer vision models, where CNNs often tolerate quantization without significant accuracy loss. Models that rely on small numerical differences, such as NLP transformers or speech recognition systems, may require quantization-aware training or nonuniform strategies to retain performance.
Calibration
An important aspect of PTQ is the calibration step, which selects the clipping range \([\alpha, \beta]\) for quantizing model weights and activations. The effectiveness of precision reduction depends heavily on this chosen range: without proper calibration, quantization may cause significant accuracy degradation. Calibration ensures that the chosen range minimizes information loss and preserves model performance.
Walk through the PTQ pipeline in figure 19 step by step. A calibration dataset, a representative subset of training or validation data, is passed through the pretrained model to estimate the numerical distribution of activations and weights. This distribution then defines the clipping range for quantization. In the algorithm, observers are lightweight runtime collectors that record tensor ranges, granularity is the scope over which one range is shared, and the zero-point is the integer value that represents real zero in an affine mapping. Algorithm 1 states the same deployment contract operationally: calibration produces fixed range metadata that the runtime will use when it executes the quantized model.
\begin{algorithm} \caption{Post-training quantization calibration} \begin{algorithmic} \Require pretrained model $f_\theta$; representative calibration set $C$; bit width $b$; granularity (layer/group/channel); method (max, entropy, percentile) \Ensure quantized weights and per-group range metadata $\{(\alpha_g, \beta_g, s_g, z_g)\}$ \State attach observers to weights and selected activation tensors, at the chosen granularity \For{each batch in $C$} \Comment{calibration pass} \State run $f_\theta$ in inference; record per-group value distributions \EndFor \For{each quantization group $g$} \State select clipping range $[\alpha_g, \beta_g]$ by the chosen method \State derive scale $s_g$, zero-point $z_g$ mapping $[\alpha_g, \beta_g]$ into the $b$-bit integer range \EndFor \State quantize static weights; export activation range metadata for inference \State if accuracy falls below the production threshold, widen ranges, change granularity, or move to QAT \end{algorithmic} \end{algorithm}
The single calibration pass over \(C\) avoids retraining, and FP32-to-INT8 weight quantization cuts stored weight bytes by 4\(\times\). The price is that the static activation ranges fixed in the loop risk saturation or wasted integer levels when the calibration data misses deployment tails. The quantization step then converts model parameters to the lower-precision format, producing the final quantized model.

For example, consider quantizing activations that originally range between -6 and six to 8-bit integers. Simply using the full integer range of \(-128\) to 127 might not be the most effective approach. Calibration passes a representative dataset through the model, observes the actual activation range, and uses that observed range to set a tighter quantization range, reducing information loss.
Common calibration methods include Max (uses maximum absolute value, simple but susceptible to outliers), Entropy (minimizes KL divergence between original and quantized distributions, TensorRT’s default), and Percentile (clips to a percentile, for example, 99 percent, avoiding outlier impact). Figure 20 shows why outlier handling matters: ResNet50 activations exhibit long tails where outliers can skew the quantization range.

Calibration ranges can be symmetric (equal positive and negative scaling) or asymmetric (different scaling factors for each side, useful when distributions are skewed). The choice of method and range significantly affects quantized model accuracy.
Tuning quantization ranges
A key challenge in post-training quantization is selecting the appropriate calibration range \([\alpha, \beta]\) to map floating-point values into a lower-precision representation. The choice of this range directly affects the quantization error and, consequently, the accuracy of the quantized model. Figure 21 contrasts the two primary calibration strategies: symmetric calibration and asymmetric calibration.

Compare the two mapping diagrams side by side in figure 21. Symmetric calibration (left) maps \([-1, 1]\) to \([-127, 127]\) with zero preserved, making it simpler to implement and well suited for zero-centered weight distributions. Asymmetric calibration (right) uses different ranges (\(\alpha = -0.5\), \(\beta = 1.5\)), better using the quantized range for skewed distributions at the cost of additional complexity. Most frameworks (TensorRT, PyTorch) support both modes. The conceptual difference is clear from the diagrams, but the actual computation of scale and zero-point parameters requires a concrete formula. A worked example makes those parameters explicit.
Granularity
After determining the clipping range, the next optimization step is adjusting the granularity of that range to retain as much accuracy as possible. In CNNs, the input activations of a layer undergo convolution with multiple filters, each of which may have a unique range of values. The quantization process must account for these differences to preserve model performance.
Example 1.2: Calculating scale and zero-point
The affine quantization formula: An affine map sends a floating-point range \([\alpha, \beta]\) to an integer range \([0, 2^b-1]\) (for example, UINT8) via the following construction.
Analysis: We need a linear mapping \(x \approx s(x_q - z)\), where \(s\) is the scale (step size) and \(z\) is the zero-point (integer value corresponding to real zero). The affine quantization process consists of three steps:
Calculate scale \((s)\): Divide the real range by the integer range using equation 1. \[s = \frac{\beta - \alpha}{2^b - 1} \tag{1}\]
Calculate zero-point \((z)\): Shift the range so that real zero maps to an integer using equation 2. \[z = \text{round}\left(\frac{-\alpha}{s}\right) \tag{2}\]
Quantize \((x \to x_q)\) using equation 3: \[x_q = \text{clamp}\left(\text{round}\left(\frac{x}{s} + z\right), 0, 2^b - 1\right) \tag{3}\]
Scenario: Suppose the activations range from \(\alpha\) = -1 to \(\beta\) = 3, and the target precision is UINT8 \((b=8)\).
- Range: \(\beta - \alpha\) = 4.
- Steps: \(2^8 - 1\) = 255.
- Scale: \(s\) = 4/255 \(\approx\) 0.0157.
- Zero-point: \(z = \text{round}(-(\alpha) / s)\) = round(-(-1)/\(\frac{4}{255}\)) = round(63.75) = 64.
Systems insight: The real value \(0.0\) is represented by the integer 64, which ensures that zero-padding (common in CNNs) is represented exactly, preventing “quantization drift” where padding introduces nonzero noise.
This variation is strikingly visible in figure 22: notice how the range for Filter one is significantly smaller than that for Filter 3. The two annotated columns contrast the strategies this variation motivates. A single shared layerwise range clips the narrow filters’ headroom to fit the widest one, while per-filter channelwise ranges fit each distribution independently, the difference the red and blue dashed bounds illustrate. The precision with which the clipping range \([\alpha, \beta]\) is determined becomes an important factor in effective quantization. This variability in ranges is why different granularity-based quantization strategies are employed.

Quantization granularity is the control knob that trades calibration overhead for accuracy: fewer shared ranges are cheaper, while more local ranges preserve more information when channels differ. The four levels run from one shared range per layer to a separate range within each filter, trading rising overhead for rising precision, as table 10 summarizes.
| Level | Range sharing | Trade-off |
|---|---|---|
| Layerwise | One range per layer | Simple but suboptimal when filter ranges vary widely |
| Groupwise | Filters grouped with shared ranges | Used in Q-BERT (Shen et al. 2020) for transformer attention layers |
| Channelwise | One range per filter | The current standard, balancing accuracy and efficiency |
| Sub-channelwise | Ranges within each filter | Maximum precision but significant overhead |
Channelwise quantization has become the dominant approach, providing significant accuracy improvements over layerwise quantization with minimal computational overhead. With granularity determined, the next consideration is what to quantize. Neural networks contain two primary numerical components: the static weights learned during training and the dynamic activations computed during inference. Each presents distinct quantization challenges.
Weights vs. activations
The granularity choice controls range sharing; the next decision is which tensors pay the quantization cost. Weight quantization involves converting the continuous, high-precision weights of a model into lower-precision values, such as converting FP32 weights to INT8 weights. In figure 23, focus on the violet quantization boxes that feed INT8 operands into the matrix multiplication; the red boxes show accumulator and output tensors after the multiply-accumulate path. This process significantly reduces the model size, decreasing both the memory required to store the model and the computational resources needed for inference. For example, a weight matrix in a neural network layer with FP32 weights like \([0.215, -1.432, 0.902,\ldots]\) might be mapped with a max-absolute INT8 scale to values such as \([19, -127, 80,\ldots]\), leading to a significant reduction in memory usage.

Activation quantization refers to the process of quantizing the activation values, or outputs of the layers, during model inference. This quantization can reduce the computational resources required during inference, particularly when targeting hardware optimized for integer arithmetic. It introduces challenges related to maintaining model accuracy, as the precision of intermediate computations is reduced. For instance, in a CNN, the activation maps (or feature maps) produced by convolutional layers, originally represented in FP32, may be quantized to INT8 during inference. This can significantly accelerate computation on hardware capable of efficiently processing lower-precision integers.
Activation-aware methods such as Activation-aware Weight Quantization (AWQ)18 compress and accelerate LLMs. This approach is particularly relevant for our GPT-2/Llama Lighthouse, which is memory-bandwidth bound. By protecting only a small fraction of the most salient weights (approximately 1 percent) based on activation magnitude, AWQ enables effective INT4 weight quantization. This reduces the memory traffic required to load the massive parameter set for every token generation, directly attacking the primary bottleneck of generative inference (Lin et al. 2023).
18 Activation-Aware Weight Quantization (AWQ): Salience is determined by activation magnitude, not weight magnitude–a distinction that matters because a small weight multiplied by a large activation produces a large output contribution. AWQ protects about 1 percent of salient weight channels through activation-aware scaling while quantizing most weights to low-bit formats, so a 7-billion-parameter FP16 weight set that would occupy about 14 GB can move toward an INT4-class weight footprint of about 3.5 GB before metadata, scales, and kernel-specific packing overheads (Lin et al. 2023).
Lin, Ji, Jiaming Tang, Haotian Tang, Shang Yang, Wei-Ming Chen, Wei-Chen Wang, Guangxuan Xiao, Xingyu Dang, Chuang Gan, and Song Han. 2023. “AWQ: Activation-Aware Weight Quantization for LLM Compression and Acceleration.” arXiv Preprint arXiv:2306.00978 abs/2306.00978.
Static vs. dynamic quantization
After determining the type and granularity of the clipping range, practitioners must decide when the clipping ranges are calculated. Two primary approaches exist for quantizing activations: static quantization and dynamic quantization.
In static quantization, the clipping range is precalculated and remains fixed during inference. This method introduces no additional computational overhead at runtime, making it efficient. The fixed range can, however, lead to lower accuracy compared to dynamic quantization. A typical implementation involves running calibration inputs to compute the typical activation range (Jacob et al. 2018; Yao et al. 2021).
Yao, Zhewei, Amir Gholami, Sheng Shen, Kurt Keutzer, and Michael W. Mahoney. 2021. “HAWQ-V3: Dyadic Neural Network Quantization.” Proceedings of the 38th International Conference on Machine Learning (ICML), 11875–86.
Dynamic quantization instead calculates the range for each activation map at runtime. This allows the quantization process to adjust based on the input, potentially yielding higher accuracy since the range is computed per activation. The trade-off is higher computational overhead, since the range must be recalculated at each step, which can be expensive at scale.
These timing and granularity decisions interact with the broader choice of quantization methodology. Table 11 compares post-training quantization, quantization-aware training, and dynamic quantization, each offering distinct strengths and trade-offs for different deployment scenarios.
| Method | Engineering effort | Accuracy preservation | Input adaptability | Reach for it when |
|---|---|---|---|---|
| Post-training quantization (PTQ) | Low: no retraining, applied in minutes | Lower: no mechanism to recover loss | Fixed calibration range | the accuracy budget tolerates 1–2% loss and the deadline is tight |
| Quantization-aware training (QAT) | High: retraining with quantization simulation | Highest: weights adapt to quantization noise | Fixed calibration range | accuracy must stay within roughly 1% and the training budget allows |
| Dynamic quantization | Moderate: ranges recomputed at runtime | High: range fits each input | Per-input range | activation ranges vary widely across inputs and runtime overhead is acceptable |
This comparison highlights the diverse strategies available for precision reduction. Before proceeding to advanced techniques, a quick checkpoint tests comprehension of these core quantization modes.
Checkpoint 1.3: The quantization gate
Precision reduction is the most impactful deployment optimization.
Quantization Modes
System Implications
PTQ in practice
The preceding subsections reveal PTQ’s core trade-off: simplicity vs. accuracy control. PTQ requires no retraining and can be applied to any pretrained model in minutes, making it the default starting point for deployment optimization. For rapid deployment scenarios with production deadlines under two weeks and acceptable accuracy loss of 1–2 percent, PTQ with appropriate calibration often provides a complete solution.
The limitation is that PTQ offers no mechanism to recover from accuracy loss. If the quantized model’s accuracy drops below the production threshold, a common outcome for transformer-based architectures where attention mechanisms amplify small numerical differences, the only recourse is to choose a less aggressive precision format, which sacrifices the efficiency gains that motivated quantization in the first place. This ceiling on PTQ’s accuracy preservation motivates a fundamentally different approach: rather than applying quantization as a post-hoc transformation, we can integrate precision constraints directly into the training process itself.
Quantization-aware training
QAT integrates quantization constraints directly into the training process, simulating low-precision arithmetic during forward passes to allow the model to adapt to quantization effects (Jacob et al. 2018). Production systems with tight accuracy budgets benefit most from this approach, which can recover accuracy through fine-tuning with quantization simulation at the cost of additional training time and implementation complexity. This approach is particularly important for models requiring fine-grained numerical precision, such as transformers used in NLP and speech recognition systems (Nagel et al. 2021). The QAT pipeline, outlined in figure 24, applies quantization to a pretrained model and then fine-tunes it so the weights learn to compensate for low-precision constraints.
Nagel, Markus, Marios Fournarakis, Rana Ali Amjad, Yelysei Bondarenko, Mart van Baalen, and Tijmen Blankevoort. 2021. “A White Paper on Neural Network Quantization.” arXiv Preprint arXiv:2106.08295.

In many cases, QAT can also build off PTQ (discussed in detail in the previous section). Trace the two-stage pipeline in figure 25: PTQ first produces an initial quantized model using only calibration data, requiring no gradient computation and completing in minutes rather than hours. QAT then fine-tunes this quantized model with training data, recovering accuracy lost during the initial quantization by allowing weights to adjust to low-precision constraints through backpropagation. The combined approach achieves higher accuracy than PTQ alone while requiring significantly less training time than running QAT from scratch on the full-precision model, because QAT starts from a weight configuration already close to the quantized optimum.

Training mathematics
During forward propagation, weights and activations are quantized and dequantized to mimic reduced precision. Let \(x\) be a full-precision value, \(s\) the scaling factor that maps floating-point values into a lower-precision range, and \(q\) the simulated quantized value. This process is typically represented as: \[ q = \text{round} \left(\frac{x}{s} \right) \times s \] where \(q\) represents the simulated quantized value, \(x\) denotes the full-precision weight or activation, and \(s\) is the scaling factor mapping floating-point values to lower-precision integers.
Although the forward pass uses quantized values, gradient calculations during backpropagation remain in full precision. The Straight-Through Estimator (STE) accomplishes this19, which approximates the gradient of the quantized function by treating the rounding operation as if it had a derivative of one. In effect, the STE pretends quantization is the identity function during backpropagation, allowing gradients to flow unchanged through otherwise nondifferentiable operations. This approach prevents the gradient from being obstructed due to the nondifferentiable nature of the quantization operation, thereby allowing effective model training (Bengio et al. 2013).
19 Straight-Through Estimator (STE): Proposed by Bengio et al. (2013), the STE substitutes the identity function for the true gradient of rounding, which is zero almost everywhere (rounding is piecewise constant). This approximation is correct in magnitude but wrong in direction for weights near quantization boundaries—a weight at 0.501 that rounds to 1.0 receives nearly the same gradient as one at 0.001 that rounds to 0.0, despite their opposite fates after rounding. QAT compensates by letting the model adapt to these systematic gradient errors during training, which is why QAT recovers accuracy that post-training quantization cannot.
Bengio, Yoshua, Nicholas Léonard, and Aaron Courville. 2013. “Estimating or Propagating Gradients Through Stochastic Neurons for Conditional Computation.” arXiv Preprint arXiv:1308.3432.
Krishnamoorthi, Raghuraman. 2018. “Quantizing Deep Convolutional Networks for Efficient Inference: A Whitepaper.” arXiv Preprint arXiv:1806.08342 abs/1806.08342.
Integrating quantization effects during training enables the model to learn weight and activation distributions that minimize numerical precision loss. The resulting model, when deployed using true low-precision arithmetic (for example, INT8 inference), maintains significantly higher accuracy than one that is quantized post hoc (Krishnamoorthi 2018).
Fake quantization nodes and implementation
QAT implementation relies on fake quantization operations that simulate quantization during forward propagation while maintaining full precision for gradient computation. These operations insert quantize-dequantize pairs into the computational graph, creating a training-time simulation of inference-time behavior.
A fake quantization node must preserve the same errors the inference runtime will see, so its three operations model the deployment path during training:
- Quantization: Map floating-point value to discrete quantization level
- Clipping: Enforce range constraints based on bit width
- Dequantization: Convert back to floating-point for subsequent operations
Mathematically, for symmetric quantization with bit width \(b\), given a floating-point input value \(x\): \[ \begin{aligned} q_{\text{level}} &= \text{clip}\left(\text{round}\left(\frac{x}{s}\right), -2^{b-1}, 2^{b-1} - 1\right) \\ x_{\text{fake}} &= q_{\text{level}} \times s \end{aligned} \] where \(s = \frac{\max(|x|)}{2^{b-1} - 1}\) is the scale factor computed from the input distribution, and \(x_{\text{fake}}\) represents the fake-quantized output that mimics INT8 values but remains in floating-point format.
For asymmetric quantization supporting unsigned integers: \[ \begin{aligned} s &= \frac{\max(x) - \min(x)}{2^b - 1} \\ z &= \text{round}\left(-\frac{\min(x)}{s}\right) \\ q_{\text{level}} &= \text{clip}\left(\text{round}\left(\frac{x}{s} + z\right), 0, 2^b - 1\right) \\ x_{\text{fake}} &= (q_{\text{level}} - z) \times s \end{aligned} \] where \(z\) is the zero-point offset enabling asymmetric range representation.
The following pseudocode demonstrates how frameworks simulate quantization during training while maintaining gradient flow. The forward pass applies quantization to both inputs and weights before convolution, mimicking INT8 inference behavior, while the training graph maintains floating-point precision so gradients can flow during backpropagation. Listing 3 demonstrates the computational graph for a quantized convolution layer, which contains fake quantization nodes for both weights and activations.
# Forward pass with fake quantization
def qat_conv_forward(x, weight):
# Fake quantize input activations
x_scale = compute_scale(x, bits=8, symmetric=False)
x_zero = compute_zero_point(x, x_scale, bits=8)
x_quant = fake_quantize(x, x_scale, x_zero, bits=8)
# Fake quantize weights (typically symmetric)
w_scale = compute_scale(weight, bits=8, symmetric=True)
w_quant = fake_quantize(weight, w_scale, zero=0, bits=8)
# Convolution with fake-quantized values
output = conv2d(x_quant, w_quant)
return outputThe critical aspect of fake quantization is gradient handling during backpropagation. The rounding and clipping operations are nondifferentiable, requiring gradient approximation through the Straight-Through Estimator: \[ \frac{\partial x_{\text{fake}}}{\partial x} = \begin{cases} 1 & \text{if } x \in [x_{\min}, x_{\max}] \\ 0 & \text{otherwise} \end{cases} \] This approximation treats the quantization function as identity within the valid range, allowing gradients to flow unchanged through the fake quantization nodes except for values that exceed clipping bounds. During backpropagation, the full-precision gradient \(\frac{\partial \mathcal{L}}{\partial x_{\text{fake}}}\) propagates directly to \(x\) for values within the quantization range. For weights and activations exceeding the range, gradients become zero, preventing further updates that would push values beyond representable limits. This gradient behavior encourages the model to learn weight distributions that naturally fit within quantization constraints.
In practice, frameworks like PyTorch and TensorFlow implement fake quantization as custom autograd operators whose forward pass performs the quantize-dequantize round trip while the backward pass applies the STE mask directly. Two implementation details deserve attention. First, scale factors should not remain static throughout training—as weight distributions evolve, scales must track these changes via exponential moving averages to prevent scale mismatch between training and deployment. Second, batch normalization layers require special handling: their running statistics must be computed on fake-quantized activations rather than full-precision values, ensuring that inference with true INT8 operations uses parameters calibrated for quantized distributions.
QAT trade-offs
QAT’s20 primary advantage is accuracy preservation under low-precision inference. By incorporating quantization noise during training, the model learns weight distributions that tolerate reduced precision, and AI processors with dedicated integer units (TPUs, NPUs, edge accelerators) can then exploit INT8 arithmetic for faster, lower-energy inference without significant accuracy degradation (Wu et al. 2020; Gholami et al. 2021). QAT particularly benefits quantization-sensitive architectures: transformers for NLP, speech recognition encoders, and high-resolution vision models where attention mechanisms amplify small numerical differences.
20 Quantization-Aware Training (QAT): QAT preserves accuracy by simulating low-precision integer arithmetic during the training process, forcing the model’s weight updates to adapt to quantization error from the start. BERT quantization studies report that training-aware or Hessian-aware methods can stay much closer to the full-precision GLUE baseline than simpler post-training routes (Zafrir et al. 2019; Shen et al. 2020). The exact gap is model- and task-dependent, but even a few percentage points often determine whether a model meets production accuracy requirements or must be served on more expensive, higher-precision hardware.
Zafrir, Ofir, Guy Boudoukh, Peter Izsak, and Moshe Wasserblat. 2019. “Q8BERT: Quantized 8Bit BERT.” 2019 Fifth Workshop on Energy Efficient Machine Learning and Cognitive Computing - NeurIPS Edition (EMC2-NIPS), 36–39. https://doi.org/10.1109/emc2-nips53020.2019.00016.
Shen, Sheng, Zhen Dong, Jiayu Ye, Linjian Ma, Zhewei Yao, Amir Gholami, Michael W. Mahoney, and Kurt Keutzer. 2020. “Q-BERT: Hessian Based Ultra Low Precision Quantization of BERT.” Proceedings of the AAAI Conference on Artificial Intelligence 34 (05): 8815–21. https://doi.org/10.1609/aaai.v34i05.6409.
Wu, Hao, Patrick Judd, Xiaojie Zhang, Mikhail Isaev, and Paulius Micikevicius. 2020. “Integer Quantization for Deep Learning Inference: Principles and Empirical Evaluation.” arXiv Preprint arXiv:2004.09602 abs/2004.09602.
Choukroun, Yoni, Eli Kravchik, Fan Yang, and Pavel Kisilev. 2019. “Low-Bit Quantization of Neural Networks for Efficient Inference.” 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), 3009–18. https://doi.org/10.1109/iccvw.2019.00363.
The cost is additional engineering complexity. QAT inserts simulated quantization into training, so teams must validate quantization schemes, scale behavior, and accuracy recovery on the target model. This overhead makes QAT less practical for models exceeding tens of billions of parameters, where training budgets are already constrained. Choukroun et al. (2019) illustrate the complementary post-training route: low-bit inference quantization for pretrained networks without full retraining.
In practice, the choice between PTQ and QAT follows a simple decision rule: start with PTQ and measure accuracy on the validation set. If accuracy meets the production threshold, ship it: the engineering cost of QAT is not justified. If PTQ falls short, invest in QAT to recover the gap. A hybrid approach, starting with PTQ calibration and applying QAT fine-tuning only for accuracy-critical layers, often provides the best balance.
Both PTQ and QAT typically target 8-bit or 4-bit precision while maintaining near-original accuracy. Some deployment scenarios, however, demand even more aggressive compression, pushing precision to the absolute limits of what neural networks can tolerate.
Extreme quantization
Extreme quantization is reserved for deployments where even INT8 or INT4 cannot meet the memory or energy budget. These techniques use binary representations with two values or ternary representations with three values, often packed into 2-bit storage, to achieve dramatic reductions in memory usage and computational requirements (Courbariaux et al. 2016). Binarization constrains weights and activations to two values (typically -1 and +1, or 0 and 1), drastically reducing model size and accelerating inference on specialized hardware for binary neural networks (Rastegari et al. 2016). However, this constraint severely limits model expressiveness, often degrading accuracy on tasks requiring high precision such as image recognition or natural language processing (Hubara et al. 2018).
Courbariaux, Matthieu, Yoshua Bengio, and Jean-Pierre David. 2016. “BinaryConnect: Training Deep Neural Networks with Binary Weights During Propagations.” Advances in Neural Information Processing Systems (NeurIPS) 28: 3123–31.
Choi, Jungwook, Zhuo Wang, Swagath Venkataramani, Pierce I-Jen Chuang, Vijayalakshmi Srinivasan, and Kailash Gopalakrishnan. 2018. “PACT: Parameterized Clipping Activation for Quantized Neural Networks.” arXiv Preprint.
Ternarization extends binarization by allowing three values (-1, 0, +1), providing additional flexibility that slightly improves accuracy over pure binarization (Zhu et al. 2017). The zero value enables greater sparsity while maintaining more representational power. Both techniques require gradient approximation methods like Straight-Through Estimator (STE) to handle nondifferentiable quantization operations during training (Bengio et al. 2013), with QAT integration helping mitigate accuracy loss (Choi et al. 2018).
Challenges and limitations
Despite enabling ultra-low-power machine learning for embedded systems and mobile devices, binarization and ternarization face significant challenges. Performance maintenance is difficult with such drastic quantization, requiring specialized hardware capable of efficiently handling binary or ternary operations (Umuroglu et al. 2017). Traditional processors lack optimization for these computations, necessitating custom hardware accelerators.
Umuroglu, Yaman, Nicholas J. Fraser, Giulio Gambardella, Michaela Blott, Philip Leong, Magnus Jahre, and Kees Vissers. 2017. “Finn: A Framework for Fast, Scalable Binarized Neural Network Inference.” Proceedings of the 2017 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, 65–74. https://doi.org/10.1145/3020078.3021744.
Rastegari, Mohammad, Vicente Ordonez, Joseph Redmon, and Ali Farhadi. 2016. “XNOR-Net: ImageNet Classification Using Binary Convolutional Neural Networks.” In Computer Vision – ECCV 2016. Springer. https://doi.org/10.1007/978-3-319-46493-0_32.
Hubara, Itay, Matthieu Courbariaux, Daniel Soudry, Ran El-Yaniv, and Yoshua Bengio. 2018. “Quantized Neural Networks: Training Neural Networks with Low Precision Weights and Activations.” Journal of Machine Learning Research 18 (187): 1–30.
Zhu, Chenzhuo, Song Han, Huizi Mao, and William J. Dally. 2017. “Trained Ternary Quantization.” International Conference on Learning Representations (ICLR) 4 (4): 1–16.
Accuracy loss remains a critical concern. These methods suit tasks where high precision is not critical or where QAT can compensate for precision constraints. Despite challenges, the ability to drastically reduce model size while maintaining acceptable accuracy makes binary and ternary methods attractive for edge AI and resource-constrained environments (Rastegari et al. 2016; Hubara et al. 2018; Zhu et al. 2017; Umuroglu et al. 2017). The operational rule follows from these constraints: reach for binary or ternary representations only when a KWS-class SRAM and energy budget leaves no other option, and only when specialized kernels exist to execute the resulting operations efficiently. Below that threshold, INT8 or INT4 retains accuracy that binary and ternary forfeit.
Before turning to architectural efficiency, the key engineering check is whether bit width, hardware arithmetic, and QAT/PTQ choice all trace back to deployment constraints.
Checkpoint 1.4: Quantization and precision checkpoint
Test your understanding of quantization before moving to architectural efficiency:
We have now covered two optimization dimensions: structural optimization (pruning, distillation, NAS) determines what to compute, and precision optimization (quantization) determines how precisely to compute it. Together, these techniques can reduce a model’s theoretical complexity by 80 percent or more—from removing half the parameters through pruning to compressing weights from 32-bit floats to 4-bit integers through quantization.
Yet practitioners often discover a frustrating gap between theory and practice: a model pruned to 50 percent parameters and quantized to INT8 has a back-of-envelope 8× speedup target, but may measure only about 1.5× on actual hardware. That is roughly 18.8 percent of the paper speedup. This theory-practice gap reveals that theoretical compression does not translate into proportional speedup. Optimization must extend beyond the model itself to how computations execute on physical hardware.
The gap arises from several sources. Sparse matrices stored in dense format waste memory bandwidth loading zeros—the hardware cannot skip what it does not know is zero. Operations that could run in parallel execute sequentially due to data dependencies the compiler cannot resolve. Simple inputs receive the same computational budget as complex ones because the model has no mechanism to exit early. Closing the gap between “optimized on paper” and “optimized in practice” is the domain of our third optimization dimension: architectural efficiency. This dimension ensures that structural and precision optimizations translate into real-world speedups by aligning computation patterns with hardware capabilities.
Self-Check: Question
The chapter reports that moving from FP32 to INT8 yields roughly a 30× energy improvement per addition operation, even though the storage reduction is exactly 4×. Which mechanism best explains why the energy gain exceeds the bit-width gain?
- INT8 eliminates all memory accesses, leaving only arithmetic energy, which scales superlinearly with bit-width
- Quantization reduces both bytes moved and the per-unit energy cost of arithmetic, and memory access already dominates arithmetic energy, so the savings compound across both fronts
- INT8 automatically prunes the lowest-magnitude weights during numerical conversion, removing entire multiplications from the compute graph
- FP32 values must be recomputed from training data at inference time, a cost that INT8 avoids entirely
In affine quantization, the integer value chosen to represent real zero exactly is the ____, without which padding and bias terms would map to nonzero integers and introduce artificial error.
A transformer model quantized with PTQ misses its production accuracy threshold, and the accuracy drop is concentrated in layers where small numerical differences matter most. According to the chapter, what is the appropriate next step?
- Drop to binary weights, because lower precision always restores the calibration lost at INT8
- Apply quantization-aware training so weights adapt to simulated low-precision noise during fine-tuning, which the chapter recommends whenever PTQ accuracy is insufficient
- Abandon quantization entirely, since PTQ failure implies the model cannot run below FP32 on any hardware
- Force a single global clipping range across every layer, so cross-layer consistency replaces per-layer fit
Weight-only INT4 quantization (INT4 weights with FP16 activations) is especially effective for autoregressive LLM generation but much less helpful for the training forward pass of the same model. Explain the mechanistic difference.
A calibration run for INT8 quantization of a CNN’s activations shows most values clustered near zero with a small set of rare outliers forming a long positive tail. Which calibration strategy is most likely to preserve effective resolution for the bulk of the activations?
- Max-absolute-value calibration, because outliers are always the most informative activations to preserve exactly
- Percentile or entropy-based calibration, which trims rare outliers’ influence on the chosen range so most INT8 levels land where the typical activations live
- Symmetric quantization with no clipping, because any clipping strictly increases quantization error
- A single global range shared across the entire model, because cross-layer consistency matters more than per-layer fit
A team quantizing a CNN finds that per-channel quantization preserves accuracy noticeably better than per-layer quantization at the same bit-width. Which mechanism best explains why?
- Each filter can have its own quantization range, so filters with very different value distributions no longer have to share one clipping range that fits none of them well
- Channelwise quantization eliminates scale factors and zero-points entirely, so no quantization error is introduced
- Layerwise quantization can be used only for weights, not activations, so it never provides full coverage
- Channelwise quantization always runs dynamically at inference time while layerwise is always static
Architectural Efficiency
Architectural efficiency starts from the execution trace. The preceding section quantified the gap between paper and measured speedup; a profiler explains where it goes: sparse tensors may still move through dense kernels, reduced-precision operators may require conversions the hardware cannot hide, and small layers may spend more time launching kernels and moving intermediates than doing arithmetic. The model has become smaller on paper, but the execution trace still asks the machine to perform an inefficient sequence of memory accesses and operations.
Where representation optimization determines what computations to perform and precision optimization determines how precisely to compute them, architectural efficiency determines how those computations fit the machine. Measured bottlenecks determine which architectural response is useful. Hardware-aware design changes the model before training so its layers match the deployment envelope. Sparsity exploitation makes removed weights visible to kernels that can skip them. Dynamic computation lets easy inputs leave early instead of paying for the worst case. Operator fusion reduces memory traffic when adjacent operations would otherwise write and reread the same tensors.
Hardware-aware design
Hardware-aware design begins before compression. If the target device cannot keep convolution kernels fed, cannot store activations without spilling, or cannot meet the power budget at the chosen input resolution, pruning and quantization only treat symptoms. The architecture itself must expose the kind of work the hardware can execute efficiently. That means choosing layer shapes, scaling rules, and operator patterns with memory bandwidth, parallelism, and energy as first-class constraints rather than post-hoc deployment checks.
Efficient design principles
The first design step is diagnostic: identify what the trace shows as the limiting resource. A model can miss its target because every layer is too expensive, because one convolution family dominates arithmetic, because activations or parameters do not fit the memory hierarchy, or because the candidate architecture ignores the platform’s preferred operators. Table 12 organizes the common responses by the bottleneck they address rather than by model family.
| Observed bottleneck | Architectural response | Example networks |
|---|---|---|
| Over-budget model scaling | Adjust depth, width, and resolution together so the model stays within the latency, memory, and power envelope. | EfficientNet, RegNet |
| Redundant computation | Replace expensive dense operations with factorized or grouped operations that preserve useful channel mixing at lower arithmetic cost. | MobileNet, ResNeXt |
| Memory pressure | Reduce parameter and activation storage, or reuse features so the working set fits the available cache, SRAM, or device memory. | DenseNet, SqueezeNet |
| Platform mismatch | Include measured device latency, operator support, and power behavior in the architecture search or design loop instead of optimizing FLOPs alone. | MobileNetV3, MnasNet |
These responses interact. Reducing convolutional FLOPs with depthwise separable convolutions21 helps only if the target runtime has efficient kernels for the resulting operators. Shrinking a model with parameter-reduction layers helps only if activation storage or memory traffic was part of the measured problem. Hardware-aware design therefore does not replace profiling; it moves profiling information earlier, into the architecture itself.
21 Depthwise Separable Convolutions: This technique directly reduces computation by factorizing a standard convolution into separate depthwise (per-channel) and pointwise \((1{\times}1)\) operations. This factorization underpins the core trade-off for on-device vision, allowing a model like MobileNetV2 to accept a 4-point accuracy drop on ImageNet in exchange for a \(13.7\times\) reduction in operations vs. a ResNet-50.
Scaling optimization
The first architectural response is global: when every stage of the profile is over budget, the problem is not one bad layer; the model is scaled incorrectly for the deployment envelope. The design task is then to distribute capacity across depth, width, and input resolution rather than choose a single parameter count. Depth increases sequential work and activation storage. Width exposes more parallel work but raises memory use. Resolution improves spatial detail while increasing the number of positions each convolution must process. The right balance depends on the machine: a highly parallel accelerator can often exploit width, while a small edge device may be dominated by memory capacity and energy per access.
Mathematically, the total FLOPs for a convolutional model can be approximated as: \[ \text{FLOPs} \propto N_L \cdot w^2 \cdot r^2, \] where \(N_L\) is depth (number of layers), \(w\) is width, and \(r\) is the input resolution. This expression shows why naive scaling fails: increasing width and resolution together multiplies work quickly, and the resulting model may exceed the memory bandwidth or power budget even when the parameter count appears reasonable.
Compound scaling turns this balancing act into a controlled design rule. Instead of adjusting depth, width, and resolution independently, compound scaling grows all three dimensions by fixed ratios \((\alpha, \beta, \gamma)\) relative to a base model: \[ N_L = \alpha^\phi N_{L,0}, \quad w = \beta^\phi w_0, \quad r = \gamma^\phi r_0 \] Here, \(\phi\) is a scaling coefficient, and \(\alpha\), \(\beta\), and \(\gamma\) are scaling factors determined from empirical accuracy and efficiency measurements. The rule matters because it prevents one dimension from consuming the budget before the others can contribute useful accuracy.
EfficientNet (section 1.3.4) validated this principle by using search to find a baseline architecture and then scaling it with balanced depth, width, and resolution coefficients (Tan and Le 2019). The lesson is not that every deployment should use EfficientNet. The systems lesson is that scaling is a resource-allocation decision: the same accuracy target can imply different depth-width-resolution trade-offs depending on which resource the target platform makes scarce. Later benchmarking material formalizes how to measure those trade-offs; here, the design principle is to scale the dimensions against the binding resource.
The same logic extends beyond convolutional models. Transformer layers, attention heads, sequence length, and embedding width play roles analogous to depth, width, and resolution: each increases capacity, but each stresses compute, memory bandwidth, or activation storage differently. Hardware-aware scaling keeps those dimensions tied to the measured bottleneck instead of treating model size as a single scalar.
Computation reduction
If the profile shows that a small set of convolutional operators dominates arithmetic, reducing the whole model uniformly is wasteful. The better response is to change the expensive operator. Modern efficient architectures do this by factorizing dense computations into cheaper pieces that preserve the representation needed for accuracy.
Depthwise separable convolutions, popularized by MobileNet, exemplify this approach by decomposing standard convolutions into two stages: depthwise convolution (applying separate filters to each input channel independently) and pointwise convolution (\(1{\times}1\) convolution mixing outputs across channels). The computational complexity of standard convolution with input size \(h{\times}w\), \(C_{\text{in}}\) input channels, and \(C_{\text{out}}\) output channels is: \[ \mathcal{O}(h w C_{\text{in}} C_{\text{out}} k^2) \] where \(k\) is kernel size. Depthwise separable convolutions reduce this to: \[ \mathcal{O}(h w C_{\text{in}} k^2) + \mathcal{O}(h w C_{\text{in}} C_{\text{out}}) \] eliminating the \(k^2\) factor from channel-mixing operations and often achieving 5–10\(\times\) FLOP reduction. The wall-clock benefit depends on kernel support and memory behavior: a mobile runtime with optimized depthwise kernels can convert much of this arithmetic reduction into latency savings, while a poorly supported backend may expose the factorized operations as many small, memory-bound kernels.
Other factorization patterns respond to the same diagnosis. Grouped convolutions, used in ResNeXt, partition feature maps into independent groups before merging them, reducing redundant cross-channel work. Bottleneck layers, used in ResNet, apply \(1{\times}1\) convolutions to reduce feature dimensionality before expensive operations. SqueezeNet uses the same \(1{\times}1\) idea to reduce parameters. These techniques improve efficiency when they reduce the operation that actually dominates the trace; they provide much less benefit when memory traffic, launch overhead, or unsupported kernels become the new bottleneck.
While reducing computation is essential, memory constraints often prove more limiting than compute capacity on resource-constrained devices. The next section addresses these memory bottlenecks directly.
Memory optimization
When the profile points to memory rather than arithmetic, the architecture must reduce the working set or the number of expensive memory accesses. Activations, feature maps, and parameters can exceed cache, SRAM, accelerator memory, or edge-device storage even when the FLOP count is acceptable. Memory-efficient architectures therefore try to preserve useful information while storing or moving less data.
DenseNet illustrates the feature-reuse response (Huang et al. 2017). In a traditional convolutional network, each layer computes a new set of feature maps, increasing the activation footprint as the network deepens. DenseNet connects layers so later computations can reuse earlier feature maps instead of relearning similar representations. In a standard convolutional network with \(N_L\) layers, if each layer generates \(g\) new feature maps, the total number of feature maps grows linearly: \[ \mathcal{O}(N_L g) \]
Huang, Gao, Zhuang Liu, Laurens Van Der Maaten, and Kilian Q. Weinberger. 2017. “Densely Connected Convolutional Networks.” 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2261–69. https://doi.org/10.1109/cvpr.2017.243.
DenseNet changes the growth pattern by making previously computed features available to later layers. The gain is not automatic compression; the architecture spends connectivity and bookkeeping to avoid recomputing or relearning information that is already present. Crucially, the benefit extends to memory traffic, not just parameter count: when a feature map produced by an earlier layer is reused by a later layer in the same forward pass, it may remain resident in the accelerator’s L2 cache or on-chip SRAM rather than being evicted and re-fetched from HBM. Each such cache hit avoids a round-trip to high-bandwidth memory, which—given the four-order-of-magnitude gap between on-chip and DRAM access energy summarized in table 8—can reduce both inference latency and energy consumption beyond what the parameter savings alone would suggest.
Activation checkpointing complements feature reuse by trading computation for memory during training. As established in Activation checkpointing, this technique stores only a subset of forward-pass activations and recomputes the rest during backpropagation, reducing peak memory from \(\mathcal{O}(A_{\text{total}})\) to \(\mathcal{O}\big(\sqrt{A_{\text{total}}}\big)\). In the compression context, checkpointing enables training of larger models within fixed memory budgets, which in turn provides more capacity for subsequent pruning or distillation to exploit.
Parameter reduction applies the same reasoning to storage. SqueezeNet uses \(1{\times}1\) convolutions to reduce the number of input channels before applying standard convolutions, making the expensive layer operate on a smaller representation (Iandola et al. 2016). The number of parameters in a standard convolutional layer is: \[ \mathcal{O}(C_{\text{in}} C_{\text{out}} k^2) \]
Iandola, Forrest N., Song Han, Matthew W. Moskewicz, Khalid Ashraf, William J. Dally, and Kurt Keutzer. 2016. “SqueezeNet: AlexNet-Level Accuracy with 50x Fewer Parameters and <0.5MB Model Size.” ArXiv Preprint abs/1602.07360.
By reducing \(C_{\text{in}}\) using \(1{\times}1\) convolutions, SqueezeNet reduces parameter count, achieving the paper’s AlexNet-level accuracy target with far fewer parameters than AlexNet. That trade is attractive when the deployment constraint is flash storage, model download size, or parameter bandwidth; it is less decisive when activation memory or operator overhead dominates.
Feature reuse, activation checkpointing, and parameter reduction are therefore not interchangeable recipes. Each changes a different part of the memory problem: reused features reduce redundant representations, checkpointing reduces training-time activation storage, and \(1{\times}1\) bottlenecks reduce parameter movement. The correct choice follows from which memory term the profile shows as binding.
Beyond reducing what data must be stored, substantial efficiency gains emerge from optimizing how operations access memory. The next technique addresses this by combining multiple operations to reduce memory traffic.
Operator fusion
Consider a typical neural network layer: convolution followed by batch normalization followed by rectified linear unit (ReLU). Without fusion, each operation writes its output to GPU global memory, then the next operation reads that output back. Three memory round-trips occur for what could be computed entirely in fast on-chip registers. By fusing these operations into a single kernel, compilers and inference engines eliminate the redundant memory transactions, improving both throughput and latency on memory-bound workloads (Chen et al. 2018; NVIDIA 2024).
Chen, Tianqi, Thierry Moreau, Ziheng Jiang, Lianmin Zheng, Eddie Q. Yan, Haichen Shen, Meghan Cowan, et al. 2018. “TVM: An Automated End-to-End Optimizing Compiler for Deep Learning.” Proceedings of the 13th USENIX Symposium on Operating Systems Design and Implementation (OSDI ’18), 578–94.
NVIDIA. 2024. NVIDIA TensorRT: Programmable Inference Accelerator.
Definition 1.5: Operator fusion
Operator Fusion is a compiler and runtime optimization that combines adjacent tensor operations into a single fused kernel so intermediate values remain in registers or on-chip memory instead of being written to and reread from accelerator global memory.
- Significance: For \(N\) unfused operations over an \(M\)-byte tensor, intermediate memory traffic scales as \(2NM\) because each operation reads and writes global memory. Fusion reduces this to approximately \(2M\) by reading the inputs once, computing the sequence locally, and writing only the final output. The savings directly reduce the \(D_{\text{vol}}/\text{BW}\) term and eliminate repeated kernel launch overhead.
- Distinction: Unlike pruning, quantization, or distillation, operator fusion does not change the model’s parameters, precision, or architecture. It changes the execution schedule of mathematically equivalent operations, preserving model outputs while improving latency and throughput on memory-bound workloads.
- Common pitfall: A frequent misconception is that more fusion is always better. Fusion is constrained by data dependencies, tensor shapes, register pressure, and cache capacity; over-fusing can reduce occupancy or force spills back to memory, erasing the benefit.
Modern neural networks consist of sequences of operations such as convolution, batch normalization, activation functions, and element-wise operations. When executed independently, each operation requires four steps:
- Loading input tensors from global memory
- Performing computation
- Writing output tensors back to global memory
- Launching the next kernel
The read-compute-write cycle creates memory bandwidth bottlenecks for operations with low arithmetic intensity (FLOP/byte). The memory traffic for \(N\) unfused operations operating on tensors of size \(M\) bytes is: \[ D_{\text{vol,unfused}} = 2NM \] where each operation reads (\(M\) bytes) and writes (\(M\) bytes) intermediate results. Operator fusion reduces this to: \[ D_{\text{vol,fused}} = 2M \] by reading inputs once, computing all operations in sequence, and writing final outputs once. Several fusion patterns in neural network inference optimize specific operation sequences that appear repeatedly in modern architectures.
Convolution-BatchNorm-ReLU fusion
This ubiquitous Conv-BN-ReLU fusion pattern, illustrated in listing 4, appears in nearly every modern CNN architecture and reduces three memory round-trips to a single kernel launch.
# === UNFUSED: 3 kernel launches, 6 memory transfers ===
conv_out = conv2d(input, weight)
bn_out = batch_norm(conv_out, ...)
relu_out = relu(bn_out)
# === FUSED: 1 kernel launch, 2 memory transfers ===
def conv_bn_relu_fused(input, weight, gamma, beta, mean, var):
# Read input and weight once
conv = conv2d(input, weight)
# Apply batch norm in registers (no memory write)
bn = gamma * (conv - mean) / sqrt(var + eps) + beta
# Apply ReLU in registers (no memory write)
output = max(bn, 0)
# Write final result once
return output
Operator fusion cuts memory transfers while arithmetic stays unchanged.
The arithmetic operations remain identical, but memory traffic drops from 6 transfers to 2 transfers (3× reduction). For a ResNet-50 layer with 256 channels and spatial size \(28{\times}28\), this eliminates \(4 \times 256 \times 28 \times 28 \times 4 \text{ bytes} \approx \text{3.2 MB}\) of intermediate memory traffic per layer.
The same principle extends beyond CNNs. General matrix multiply (GEMM) bias-activation fusion eliminates intermediate writes in transformer linear layers by computing element-wise operations in registers immediately after each matrix multiplication output element. Attention tiling, as in FlashAttention22, reduces HBM traffic from \(\mathcal{O}(S^2)\) to \(\mathcal{O}(S)\) for long-context transformers by processing attention in SRAM-sized tiles rather than materializing the full \(S{\times}S\) attention matrix, as detailed in Flash attention: IO-aware attention optimization.
22 FlashAttention: Demonstrates fusion’s power for memory-bound attention by tiling computation to SRAM, avoiding materialization of the full attention matrix, and reporting multi-fold speedups on long sequences (T. Dao et al. 2022). This exemplifies how operator fusion transforms memory-bound bottlenecks: the arithmetic is mathematically equivalent, but the memory access pattern changes, making longer-context attention feasible on hardware that could not otherwise afford the full intermediate matrix.
Dao, T., D. Y. Fu, S. Ermon, A. Rudra, and C. Ré. 2022. “FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness.” Advances in Neural Information Processing Systems 35 35: 16344–59. https://doi.org/10.52202/068431-1189.
Memory bandwidth analysis quantifies these fusion benefits concretely. Consider a Conv-BN-ReLU sequence operating on a \(28{\times}28{\times}256\) feature map (802.8 KB). Without fusion, each operation performs its own memory round-trip: Conv reads input (802.8 KB) plus weights (2.4 MB) and writes output (802.8 KB), totaling 4 MB. BN then reads that output, adds its parameters (2 KB), and writes again, for 1.6 MB. ReLU repeats the pattern for another 1.6 MB. The total unfused memory traffic is 7.2 MB. With fusion, the entire sequence reads input and weights once and writes the final output once, requiring only 4 MB—a 44.5 percent bandwidth reduction.
On a V100 GPU with 900 GB/s HBM bandwidth and 15.7 TFLOP/s FP32 compute, the unfused sequence takes approximately 8 microseconds (memory bound), while the fused version takes approximately 4.5 microseconds (1.80× speedup). The speedup comes entirely from reducing memory traffic, as the compute remains identical.
Fusion effectiveness varies by workload, as table 13 shows: memory-bound operations benefit most, while compute-bound operations see minimal improvement.
| Workload | Speedup | Why |
|---|---|---|
| Element-wise operations | 2–4\(\times\) | Highly memory bound, low arithmetic intensity |
| Conv-BN-Act patterns | 1.5–2\(\times\) | Mixed memory/compute characteristics |
| GEMM-based operations | 1.2–1.5\(\times\) | Compute bound; fusion reduces the memory-bound tail |
| Attention mechanisms | 2–4\(\times\) | Long sequences; quadratic memory scaling |
Fusion also reduces kernel launch overhead. Each CUDA kernel launch incurs microsecond-scale latency. For a ResNet-50 with fifty-three convolutional layers, unfused execution launches 159 kernels (Conv + BN + ReLU), while fused execution launches 53 kernels, saving repeated launch overhead in addition to memory traffic.
Fusion implementation spans the software stack, from framework-level pattern matching (PyTorch’s TorchScript, TensorFlow’s Grappler) through compiler-level optimization (Accelerated Linear Algebra (XLA), TVM, TensorRT) to runtime fusion that adapts to input shapes and hardware characteristics. This stack is made tractable by a structural property of ML frameworks: models are represented as declarative Directed Acyclic Graphs (DAGs) in which each node is a named tensor operation and each edge is a data dependency. Because the full computation is declared before any execution begins, a compiler can scan the graph, match patterns such as Conv→BN→ReLU, and rewrite them as single fused nodes without needing to reason about aliasing or pointer semantics—a transformation that is significantly harder to perform safely in general-purpose imperative code. Kernel fusion examines the compiler and hardware dimensions of fusion in detail, including register pressure constraints, graph pattern matching strategies, and platform-specific trade-offs across GPU, TPU, and edge accelerators.
Operator fusion optimizes how operations execute by reducing memory traffic between fixed computational steps. A complementary approach challenges the assumption that all computational steps must execute at all. This leads to adaptive computation methods that vary the amount of work performed based on input characteristics.
Adaptive computation methods
The preceding techniques (hardware-aware design and operator fusion) optimize models uniformly: every input receives the same computational treatment regardless of its complexity. Consider image classification: a photo of a cat against a plain white background requires less analysis than a cat partially hidden in a cluttered room. Adaptive inference challenges the uniform-computation assumption by turning inference into a control loop: measure confidence or context, route the input through only the needed computation, then pay the overhead of making that decision. This flexibility enables significant efficiency gains when many real-world inputs are simple enough to classify with a fraction of the full network, but it also introduces routing, batching, and evaluation costs that must be counted explicitly.
Dynamic schemes
When inputs vary in complexity, applying a uniform computational budget wastes resources on the simplest cases. Dynamic schemes address this inefficiency by modifying the computation graph at inference time so that average-case computation falls while worst-case accuracy remains available. The design question is what the controller is allowed to vary: the depth of one path, the path itself, the expert subnetwork, or a continuous compute budget.
The first control variable is depth. Early exit attaches lightweight classifiers to intermediate layers and stops once confidence is high enough (Teerapittayanon et al. 2017). BranchyNet implements this idea with multiple exit points, while multi-exit vision transformers attach the same decision rule to transformer layers. Simple inputs leave early and save power; difficult inputs continue deeper and pay the full cost.
Teerapittayanon, Surat, Bradley McDanel, and H. T. Kung. 2017. “BranchyNet: Fast Inference via Early Exiting from Deep Neural Networks.” 2016 23rd International Conference on Pattern Recognition (ICPR), 2464–69. https://doi.org/10.1109/icpr.2016.7900006.
Hu, Ting-Kuei, Tianlong Chen, Haotao Wang, and Zhangyang Wang. 2020. “Triple Wins: Boosting Accuracy, Robustness and Efficiency Together by Enabling Input-Adaptive Inference.” International Conference on Learning Representations (ICLR).
Chen, Yanxi, Xuchen Pan, Yaliang Li, Bolin Ding, and Jingren Zhou. 2024. “EE-LLM: Large-Scale Training and Inference of Early-Exit Large Language Models with 3D Parallelism.” Proceedings of the 41st International Conference on Machine Learning (ICML).
The systems trade-off depends on where those exits run. On mobile processors and edge accelerators, the power savings compound with lower latency (Hu et al. 2020). In GPU and TPU deployments, exit paths can sometimes be evaluated in parallel to recover throughput, but that benefit has to be balanced against routing overhead and batch fragmentation (Chen et al. 2024). Figure 26 traces the decision logic step by step: each layer refines the representation, the confidence estimator decides whether the answer is already reliable, and only low-confidence inputs continue to the next layer.

Xin, Ji, Raphael Tang, Yaoliang Yu, and Jimmy Lin. 2021. “BERxiT: Early Exiting for BERT with Better Fine-Tuning and Extension to Regression.” In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume, edited by Paola Merlo, Jorg Tiedemann, and Reut Tsarfaty. Association for Computational Linguistics. https://doi.org/10.18653/v1/2021.eacl-main.8.
Early exits decide how far to proceed along one path. The next control variable is route. Conditional computation decides which path, layer, unit, or expert should run for a given input (Bengio et al. 2015). The control signal can skip work, change the computation being applied, or route representations through different structures; in every case, the model becomes an input-dependent execution graph rather than a fixed sequence of layers.
Bengio, Emmanuel, Pierre-Luc Bacon, Joelle Pineau, and Doina Precup. 2015. “Conditional Computation in Neural Networks for Faster Models.” arXiv Preprint arXiv:1511.06297.
Wang, Xin, Fisher Yu, Zi-Yi Dou, Trevor Darrell, and Joseph E. Gonzalez. 2018. “SkipNet: Learning Dynamic Routing in Convolutional Networks.” In Computer Vision – ECCV 2018. Springer. https://doi.org/10.1007/978-3-030-01261-8_25.
Jia, Xu, Bert De Brabandere, Tinne Tuytelaars, and Luc Van Gool. 2016. “Dynamic Filter Networks.” Advances in Neural Information Processing Systems 29.
Sabour, Sara, Nicholas Frosst, and Geoffrey E Hinton. 2017. “Dynamic Routing Between Capsules.” Advances in Neural Information Processing Systems 30.
Representative mechanisms make that range concrete. SkipNet uses a lightweight gate to skip CNN layers when the input is simple and to execute the full network when the input is difficult (Wang et al. 2018). Dynamic Filter Networks condition the filters themselves on the input, adapting feature extraction at runtime rather than merely skipping operations (Jia et al. 2016). Capsule Networks use routing to assign lower-level capsules to higher-level capsules based on agreement; in that case, routing supports part-whole representation learning rather than guaranteeing lower operation count (Sabour et al. 2017). The systems question is therefore not just whether routing is possible, but whether the routing decision saves more time and energy than it consumes.
At subnetwork scale, the route becomes an expert-selection decision. The mixture-of-experts (MoE) framework uses a gating network to select a small subset of expert subnetworks rather than activating the entire model (Shazeer et al. 2017). A question about mathematics and a question about history can use different experts while sharing the same overall model capacity. Google’s Switch Transformer23 instantiates this idea in transformers by replacing the dense feedforward layer with an expert-routed layer (Fedus et al. 2022). The benefit is parameter capacity without proportional per-token compute; the cost is that the full expert pool must still stay resident in memory even though only a fraction runs per token, on top of load balancing, routing overhead, and more complicated batching. While we introduce MoE principles here for single-system context, large-scale MoE deployments involving distributed expert placement [assigning expert subnetworks across machines] are explored in advanced coverage of large-scale systems.
Shazeer, Noam, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean. 2017. “Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer.” International Conference on Learning Representations.
23 Switch Transformer: Fedus et al. (2022) scales to 1.6 trillion parameters while activating only two billion per token (0.13 percent of total), achieving 7\(\times\) faster pretraining than dense T5 at equivalent FLOPs. Routing each token to a single expert (vs. top-\(k\)) reduces communication overhead, but training instability from load imbalance requires auxiliary loss terms, penalties that encourage even expert use, and capacity factors of 1.25–2\(\times\), extra expert slots reserved per batch to absorb routing variance. This trade-off—massive parameter capacity at low per-token compute cost, but with complex systems engineering for load balancing—defines the MoE design space.
Fedus, William, Barret Zoph, and Noam Shazeer. 2022. “Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity.” Journal of Machine Learning Research 23 (120): 1–39.
As figure 27 illustrates, the Switch Transformer replaces the traditional feedforward layer with a Switching FFN Layer. The left panel of the figure shows where this layer sits within the standard transformer block: after self-attention and layer normalization, tokens enter the Switching FFN Layer instead of a conventional feedforward network. The right panel expands this layer to reveal the routing mechanism: a gating network receives each token and computes a probability distribution over the available experts, activating only the single highest-probability expert per token. Because each forward pass engages one expert out of the full pool, the model scales its total parameter count without proportionally increasing per-token compute cost.

Gate-based conditional computation is effective for multi-task and transfer learning settings where inputs benefit from specialized processing pathways, but the gate is now part of the system’s critical path. Efficient deployment on GPUs, TPUs, or edge devices requires scheduling and batching expert activations so that specialization does not leave accelerator lanes idle (Lepikhin et al. 2021).
Lepikhin, Dmitry, HyoukJoong Lee, Yuanzhong Xu, Dehao Chen, Orhan Firat, Yanping Huang, Maxim Krikun, Noam Shazeer, and Zhifeng Chen. 2021. “GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding.” International Conference on Learning Representations.
Yang, Le, Yizeng Han, Xi Chen, Shiji Song, Jifeng Dai, and Gao Huang. 2020. “Resolution Adaptive Networks for Efficient Inference.” 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2366–75. https://doi.org/10.1109/cvpr42600.2020.00244.
Wu, Jian, Hao Cheng, and Yifan Zhang. 2019. “Fast Neural Networks: Efficient and Adaptive Computation for Inference.” Advances in Neural Information Processing Systems.
Early exit and conditional computation make discrete choices: exit or continue, activate this expert or that one. Adaptive inference treats computation more like a dial, continuously modulating depth and resource allocation based on confidence and task complexity (Le Yang et al. 2020). Fast Neural Networks adjust the number of active layers from a real-time complexity estimate (J. Wu et al. 2019), while dynamic layer scaling progressively increases depth when uncertainty remains high. The autonomous-driving example makes the trade-off concrete: lane detection may need a shallow path, while dense multi-object tracking may need deeper processing. The system gains only if the control signal is cheap, the routed paths preserve accuracy, and the runtime can still batch enough similar work to keep hardware busy.
Implementation challenges
The efficiency gains from dynamic computation come at the price of making the control loop itself correct, cheap, and hardware-aligned. Training is harder because discrete gating decisions cannot be optimized with standard backpropagation without reinforcement learning, continuous relaxations, or regularization that stabilizes gradients across different paths. Runtime overhead then becomes the practical test: a gate that saves one layer but adds synchronization, memory traffic, or queueing delay may lose to the dense baseline. Hardware utilization compounds the problem because modern accelerators favor regular, predictable batches; when each input follows a different path, some lanes sit idle unless the runtime regroups similar paths or uses specialized kernels. Dynamic kernel execution examines hardware-aware runtime strategies for these adaptive execution patterns.
The quality risks are equally important because the control policy decides which inputs receive computation. A poorly calibrated gate can underallocate work to rare but important inputs, creating biased predictions precisely where coverage matters most. If adversarial or malformed inputs can influence the gate, the same policy can become a denial-of-quality or denial-of-service lever by steering work toward cheap paths that miss hard cases or expensive paths that overload the service. Evaluation must therefore report more than average FLOPs: it must include path distributions, tail latency, accuracy by input difficulty, routing stability, and reproducibility under changing batches. Overcoming these challenges requires robust training techniques, hardware-aware execution strategies, and evaluation frameworks that account for adaptive scaling. Where dynamic computation decides whether to perform certain operations, sparsity exploitation addresses a complementary question: how to accelerate computation when many operands are zero.
Sparsity exploitation
Recall that pruning (from section 1.3.1) introduces zeros into weight matrices. Sparsity exploitation asks how to accelerate computation when those zeros are present. The distinction matters: Pruning reduces what we store, while sparsity exploitation reduces what we compute. Sparsity24 in machine learning refers to the condition where a significant portion of the elements within a tensor, such as weight matrices or activation tensors, are zero or nearly zero.
24 Sparsity: From Latin sparsus (scattered), past participle of spargere (to scatter). The mathematical concept dates to the 1950s when researchers studying linear systems noticed most real-world matrices had predominantly zero entries. In ML, L1 regularization (the lasso (Tibshirani 1996)) first exploited this by inducing exact zeros rather than merely small values. The persistent systems challenge: software can represent arbitrary sparsity patterns, but hardware acceleration requires structured patterns (for example, NVIDIA’s 2:4 sparsity), creating a gap between theoretical compression and realized speedup.
Tibshirani, Robert. 1996. “Regression Shrinkage and Selection via the Lasso.” Journal of the Royal Statistical Society: Series B (Methodological) 58 (1): 267–88. https://doi.org/10.1111/j.2517-6161.1996.tb02080.x.
More formally, for a sparse weight matrix \(\mathbf{W}_{\text{sparse}} \in \mathbb{R}^{m \times n}\), the sparsity ratio \(\rho_{\text{sparse}}\) can be expressed as: \[ \rho_{\text{sparse}} = \frac{\Vert \mathbf{1}_{\{(\mathbf{W}_{\text{sparse}})_{ij} = 0\}} \Vert_0}{m \times n} \] where \(\mathbf{1}_{\{(\mathbf{W}_{\text{sparse}})_{ij} = 0\}}\) is an indicator function that yields one if entry \((i,j)\) is zero and 0 otherwise, and \(\Vert \cdot \Vert_0\) represents the L0 norm, which counts the number of nonzero elements. Floating-point representations make exact zero an unreliable boundary, so we often extend this definition to include elements that are close to zero. The thresholded sparsity ratio becomes: \[ \rho_{\text{sparse},\epsilon} = \frac{\Vert \mathbf{1}_{\{|(\mathbf{W}_{\text{sparse}})_{ij}| < \epsilon\}} \Vert_0}{m \times n} \] where \(\epsilon\) is a small threshold value.
Sparsity can emerge naturally during training, often as a result of regularization techniques, or be deliberately introduced through methods like pruning, where elements below a specific threshold are forced to zero. Effectively exploiting sparsity leads to significant computational efficiency, memory savings, and reduced power consumption, which prove valuable when deploying models on devices with limited resources, such as mobile phones, embedded systems, and edge devices.
Sparsity types
The hardware decision begins with the pattern of zeros. Sparsity in neural networks falls into two broad categories: unstructured sparsity and structured sparsity.
Unstructured sparsity occurs when individual weights are set to zero without any specific pattern, typically through magnitude-based pruning. While highly flexible, unstructured sparsity is less efficient on hardware because it lacks a predictable structure25. Exploiting it requires specialized hardware or software optimizations.
25 Unstructured Sparsity and SIMD Waste: Modern CPUs and GPUs process data in vector or tensorized groups. Unstructured sparsity scatters nonzero elements irregularly through memory, so a vector load may bring back mostly zeros while still paying the full memory access cost. The processor cannot skip zero elements without first knowing where the nonzeros are, and the metadata needed to answer that question also consumes bandwidth. This is why structured sparsity can deliver speedups at lower sparsity levels than arbitrary unstructured sparsity, while unstructured sparsity often needs very high zero fractions and specialized kernels before arithmetic savings overcome indexing and lane-utilization overheads (Hoefler et al. 2021).
Hoefler, Torsten, Dan Alistarh, Tal Ben-Nun, Nikoli Dryden, and Alexandra Peste. 2021. “Sparsity in Deep Learning: Pruning and Growth for Efficient Inference and Training in Neural Networks.” Journal of Machine Learning Research 22 (241): 1–124.
Structured sparsity involves removing entire components of the network, such as filters, neurons, or channels. Because these removals produce predictable memory access patterns, structured sparsity is more efficient on hardware accelerators like GPUs or TPUs. It is the preferred approach when deployment requires predictable computational resource usage.
Sparsity utilization methods
A sparse model with 90 percent of weights zeroed may still run at nearly full computational cost on hardware not designed for irregular memory access. The critical question is how to translate theoretical zeros into actual speedup. The processor cannot skip a multiplication unless it knows the operand is zero—and discovering that requires loading the operand from memory in the first place. Bridging this gap requires specialized utilization methods and hardware support that can efficiently skip zero-valued computations (Hoefler et al. 2021). Han et al.’s pruning work (2015) is a canonical example of turning dense networks into sparse ones by removing unimportant connections, but accelerator speedups depend on whether the resulting sparsity pattern matches hardware-supported formats.
The simplest utilization method is sparse matrix operations, which skip zero elements during computation to significantly reduce arithmetic operations. Consider the difference: multiplying a dense \(4{\times}4\) matrix with a vector typically requires 16 multiplications, while a sparse-aware implementation computes only the six nonzero operations: \[ \begin{bmatrix} 2 & 0 & 0 & 1 \\ 0 & 3 & 0 & 0 \\ 4 & 0 & 5 & 0 \\ 0 & 0 & 0 & 6 \end{bmatrix} \begin{bmatrix} x_1 \\ x_2 \\ x_3 \\ x_4 \end{bmatrix} = \begin{bmatrix} 2x_1 + x_4 \\ 3x_2 \\ 4x_1 + 5x_3 \\ 6x_4 \end{bmatrix} \]
The deployment choice is therefore not a generic desire for fewer parameters; it is a choice between representations the runtime can execute efficiently. Low-rank approximation, covered earlier in section 1.3.3.1, replaces a dense matrix with smaller dense factors, while sparsity exploitation skips literal zero-valued weights. Sparsity-aware training and sparse gradient descent can help models learn or maintain zero patterns, but runtime speedup appears only when the deployed representation uses formats and kernels that skip zeros. That is why the next design question is not merely how sparse the matrix is, but what structure the zeros have.
Structured patterns
Achieving actual speedups from sparsity requires hardware that can efficiently skip zero-valued computations. Different processor architectures handle sparse patterns with varying effectiveness, a hardware topic taken up in Hardware Acceleration. Software libraries such as cuSPARSE can help bridge this gap by reformulating sparse computations into patterns that current hardware handles efficiently. For example, MegaBlocks (Gale et al. 2022) reformulates sparse Mixture of Experts training into block-sparse operations, grouping routed expert-token work into dense tiles so specialized kernels can maintain high accelerator utilization despite irregular sparsity patterns.
Gale, Trevor, Deepak Narayanan, Cliff Young, and Matei Zaharia. 2022. “MegaBlocks: Efficient Sparse Training with Mixture-of-Experts.” arXiv Preprint.
Dao, Tri, Beidi Chen, Nimit Sohoni, Arjun Desai, Michael Poli, Jessica Grogan, Alexander Liu, Aniruddh Rao, Atri Rudra, and Christopher Ré. 2022. “Monarch: Expressive Structured Matrices for Efficient and Accurate Training.” arXiv Preprint.
A sparse pattern earns hardware speedup only when it is regular enough for kernels to predict. Two prominent formats make that regularity explicit: block sparse matrices and N:M sparsity patterns. Block sparse matrices isolate blocks of zero and nonzero dense submatrices so that operations on the large sparse matrix can be re-expressed as a smaller number of dense operations on submatrices. This structure supports more efficient storage of dense submatrices while maintaining shape compatibility for matrix or vector products. For example, figure 28 shows how NVIDIA’s cuSPARSE (NVIDIA 2020) library supports sparse block matrix operations and storage. Several other works, such as Monarch matrices (Tri Dao et al. 2022), have built on this block-sparsity approach to strike an improved balance between matrix expressivity and compute/memory efficiency.

NVIDIA. 2020. Accelerating Matrix Multiplication with Block Sparse Format and NVIDIA Tensor Cores.
Similarly, the \(N\):\(M\) sparsity pattern is a structured sparsity format where, in every set of \(M\) consecutive elements (for example, weights or activations), exactly \(N\) are nonzero and the remaining \(M - N\) are zero (for 2:4 sparsity, the remaining two are zero) (Zhou et al. 2021). This deterministic pattern facilitates efficient hardware acceleration, as it allows for predictable memory access patterns and optimized computations. By enforcing this structure, models can achieve a balance between sparsity-induced efficiency gains and maintaining sufficient capacity for learning complex representations. Figure 29 compares accelerating dense vs. 2:4 sparsity matrix multiplication, a common sparsity pattern used in model training. Later works like STEP (Lu et al. 2023) have examined learning more general \(N\):\(M\) sparsity masks for accelerating deep learning inference under the same principles.
Zhou, Aojun, Yukun Ma, Junnan Zhu, Jianbo Liu, Zhijie Zhang, Kun Yuan, Wenxiu Sun, and Hongsheng Li. 2021. “Learning n:m Fine-Grained Structured Sparse Neural Networks from Scratch.” arXiv Preprint.
Lu, Yucheng, Shivani Agrawal, Suvinay Subramanian, Oleg Rybakov, Christopher De Sa, and Amir Yazdanbakhsh. 2023. “STEP: Learning n:m Structured Sparsity Masks from Scratch with Precondition.” arXiv Preprint.
At accelerator level, the same pattern-specific rule holds: hardware support is a contract between the sparse format and the execution path.

PyTorch. 2022. Accelerating Neural Network Training with Sparse Tensors.
GPUs with Sparse Tensor Cores (NVIDIA Ampere and later) accelerate structured sparsity patterns like 2:4, achieving up to 2\(\times\) speedup by skipping zero multiplications (NVIDIA Corporation 2020). However, this acceleration requires the sparsity pattern to match hardware expectations, and unstructured sparsity typically sees limited benefit (Hoefler et al. 2021). TPUs are useful contrast cases for dense systolic-array acceleration: the original TPU and later TPU generations emphasize high-throughput matrix units for neural-network workloads (Jouppi et al. 2021). Sparse acceleration on TPUs depends on the specific hardware and software path, so arbitrary pruned weight matrices should not be assumed to receive speedups. FPGAs offer the most flexibility: unlike GPUs and TPUs, they can be programmed to handle arbitrary sparse formats, making them suitable for unstructured pruning or application-specific patterns where general-purpose accelerators underperform.
Jouppi, Norman P., Doe Hyun Yoon, Matthew Ashcraft, Mark Gottscho, Thomas B. Jablin, George Kurian, James Laudon, et al. 2021. “Ten Lessons from Three Generations Shaped Google’s TPUv4i : Industrial Product.” 2021 ACM/IEEE 48th Annual International Symposium on Computer Architecture (ISCA) 64: 1–14. https://doi.org/10.1109/isca52012.2021.00010.
Across all platforms, sparse operations can reduce memory bandwidth requirements and energy consumption when the sparse representation and kernels actually skip data movement rather than only arithmetic. This benefit compounds with quantization: a sparse INT8 model can require less memory traffic than either technique alone when the format overhead is small enough (Hoefler et al. 2021; Gale et al. 2020).
Challenges and limitations

Unstructured sparsity pays off only past a 90 to 95 percent zero fraction.
The same format-hardware contract explains why sparsity often disappoints in practice. The central challenge is the gap between theoretical and practical speedups. Unstructured pruning removes individual weights based on importance, creating irregular patterns that hardware accelerators struggle to exploit. Most GPUs and TPUs optimize for structured data; without regular patterns, they cannot skip zero elements efficiently. Pruning algorithms themselves introduce overhead, as determining which weights to prune requires sophisticated importance estimation that can be computationally expensive for large models. Even when sparsity is achieved, sparse matrix storage formats add indexing overhead that can offset computational savings. Sparse matrix formats details the Compressed Sparse Row layout and quantifies how its per-nonzero metadata makes the memory payoff density-dependent, which is why a rule of thumb holds that sparsity typically must exceed 90–95 percent to be worthwhile for performance.
The accuracy-efficiency trade-off requires careful calibration. Aggressive sparsity can degrade accuracy beyond acceptable thresholds, and the relationship is often nonlinear: a model may tolerate one sparsity level with minimal impact and then collapse after a comparatively small additional pruning step. Finding the optimal operating point requires extensive experimentation.
Energy efficiency is not guaranteed. While sparse operations reduce arithmetic operations, the overhead of sparse indexing and irregular memory access can increase power consumption on hardware not optimized for sparse patterns. On edge devices with tight power budgets, these overheads may outweigh the benefits.
Finally, sparsity benefits vary by model type. Tasks requiring dense representations (image segmentation, some reinforcement learning) may not benefit from sparsity, and older hardware lacking sparse acceleration may see no improvement or even regression.
Combined optimizations
The techniques examined throughout this chapter (pruning, quantization, operator fusion, dynamic computation, and sparsity) do not exist in isolation. Production deployments rarely apply a single technique; instead, they compose multiple approaches to achieve compression ratios impossible with any individual method. While sparsity offers significant efficiency advantages on its own, it achieves its full potential when combined with other optimization techniques. These combinations introduce coordination challenges that require careful management (Hoefler et al. 2021).
Elsen, Erich, Marat Dukhan, Trevor Gale, and Karen Simonyan. 2020. “Fast Sparse ConvNets.” 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 14617–26. https://doi.org/10.1109/cvpr42600.2020.01464.
The interaction between sparsity and pruning is the most direct: pruning creates sparsity, but the pattern determines hardware efficiency. Structured pruning (entire filters or layers) produces regular sparsity that GPUs and TPUs accelerate efficiently. Unstructured pruning creates irregular patterns that may require specialized sparse matrix formats to realize speedups (Elsen et al. 2020; Gale et al. 2019).
Combining sparsity with quantization yields multiplicative compression but introduces its own complexity. GPUs with dedicated sparse tensor cores can accelerate supported structured sparsity patterns, while general-purpose CPUs often struggle with the combined overhead of sparse indexing and dequantization unless the sparsity pattern and kernel are chosen carefully (NVIDIA Corporation 2020; Hoefler et al. 2021; Gale et al. 2020).
Gale, Trevor, Matei Zaharia, Cliff Young, and Erich Elsen. 2020. “Sparse GPU Kernels for Deep Learning.” SC20: International Conference for High Performance Computing, Networking, Storage and Analysis 2020: 8955–67. https://doi.org/10.1109/sc41405.2020.00021.
Howard, A. G., M. Zhu, B. Chen, D. Kalenichenko, W. Wang, T. Weyand, M. Andreetto, and H. Adam. 2017. “MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications.” CoRR abs/1704.04861.
The recurring theme across all combinations is hardware alignment. Efficient model designs such as depthwise separable convolutions (Howard et al. 2017), dynamic computation, and sparsity help only when the target hardware supports the resulting operation patterns (Hoefler et al. 2021). Selecting technique combinations requires understanding target platform capabilities, as explored in Hardware Acceleration.
The coordination challenges inherent in combining sparsity with other techniques point to a broader principle: optimization techniques rarely succeed in isolation, and their effectiveness depends on sequencing decisions and hardware alignment.
Systems Perspective 1.3: The optimization composition problem
Unlike software functions that compose predictably, optimization techniques interact through shared physical resources: memory bandwidth, cache capacity, and arithmetic units. Pruning changes sparsity patterns that affect quantization’s dynamic range. Quantization changes numerical precision that affects fusion’s memory traffic assumptions. Operator fusion changes execution schedules that affect dynamic computation’s branching decisions. Effective optimization therefore requires treating the model-hardware pair as a coupled system rather than optimizing each dimension independently. This makes compression a systems engineering problem as well as a machine learning problem.
Self-Check: Question
A ResNet-50 pruned to 50 percent sparsity and quantized to INT8 has theoretical 6× speedup, yet measured wall-clock speedup on an unmodified GPU is closer to 1.5×. Architectural efficiency exists to close this gap. Which statement best describes its role?
- It reduces the training dataset so the model can be retrained more cheaply
- It guarantees that every optimized model becomes compute-bound rather than memory-bound
- It replaces pruning and quantization with a single universal optimization method
- It aligns execution patterns — scheduling, memory access, operator fusion, sparsity structure — with what the hardware can actually accelerate, converting theoretical savings into measured speedup
Operator fusion of Conv-BN-ReLU sequences often delivers significant speedup on CNN inference, even though the fused kernel performs exactly the same arithmetic as the three unfused kernels. Which mechanism explains the speedup?
- Fusion reduces the total number of learned parameters in the layer sequence
- Fusion retrains the model to use fewer output channels at inference time
- Fusion keeps intermediate activations in registers or on-chip SRAM rather than writing them to global memory between stages and reading them back, cutting HBM round-trips from six to two per sequence
- Fusion converts dense kernels into sparse kernels that skip zero multiplications
A compressed model reports a 50 percent reduction in FLOPs, but deployed end-to-end latency drops by only 10 percent. Using the chapter’s Amdahl’s-law framing, explain two distinct mechanisms that can produce this gap.
Which adaptive-computation strategy attaches multiple prediction points to a network and terminates inference for an input as soon as intermediate confidence exceeds a threshold?
- Low-rank factorization
- Operator fusion
- Block-sparse matrix execution
- Early-exit architectures
True or False: Once a weight matrix contains many zeros, modern SIMD hardware automatically delivers proportional speedup because vector lanes can cheaply skip the zeros without any specialized kernel or structure.
A deployment targets NVIDIA Ampere GPUs that accelerate 2:4 structured sparsity (exactly 2 nonzeros per group of 4 weights) but not arbitrary sparse patterns. Which compression choice best aligns with this hardware?
- Magnitude-based unstructured pruning with no pattern constraints, because it always maximizes usable speedup regardless of hardware support
- Structured sparsity that enforces the supported N:M pattern, because the accelerator is wired to skip operations only on that regular layout
- Knowledge distillation, because teacher-student training automatically generates 2:4 masks during student training
- Activation checkpointing, because recomputation during the backward pass is equivalent to structured sparsity at inference time
Technique Selection
Knowing how each technique works is necessary but not sufficient; the practical question is which techniques to apply for a given deployment target and how to sequence them. An engineer deploying a transformer model faces a concrete decision: the model exceeds the target device’s memory by 3\(\times\), inference latency is 4\(\times\) above the SLO, and the power budget allows no more than 2 W sustained. The choice of whether to quantize first, prune first, distill to a smaller architecture, or combine techniques depends on which constraint is binding, what accuracy loss is tolerable, and how much engineering time is available. The following framework structures that decision.
Before choosing a sequence, separate the major levers by what they change. Pruning changes the operation pattern and only becomes fast when the resulting structure maps to kernels. Quantization changes bit width and is usually the first memory and bandwidth lever. Distillation changes the model itself by training a smaller dense student. Table 14 summarizes the first-order trade-offs; the sections that follow then refine the choice by constraint, hardware support, and engineering budget.
| Technique | Primary Goal | Accuracy Impact | Training Cost | Hardware Dependency | Best For |
|---|---|---|---|---|---|
| Pruning | Reduce FLOPs/Size | Moderate | Low (fine-tuning) | High (for sparse ops) | Latency-critical apps |
| Quantization | Reduce Size/Latency | Low | Low (PTQ)/High (QAT) | High (INT8 support) | Edge/Mobile deployment |
| Distillation | Reduce Size | Low-Moderate | High (student training) | Low | Creating smaller, high-quality models |
Mapping constraints to techniques
The binding constraint should determine the optimization family before a team chooses a specific technique. Table 15 connects each system constraint to the representation, precision, or architectural dimension most likely to relieve it, so technique selection starts from the deployment bottleneck rather than from the most familiar compression method.
| System Constraint | Model Representation | Numerical Precision | Architectural Efficiency |
|---|---|---|---|
| Computational Cost | ✓ | △ | ✓ |
| Memory and Storage | ✓ | ✓ | ✗ |
| Latency and Throughput | ✓ | △ | ✓ |
| Energy Efficiency | ✓ | ✓ | ✓ |
| Scalability | ✓ | ✗ | ✓ |
Although each system constraint primarily aligns with one or more optimization dimensions, the relationships are not strictly one-to-one. Many optimization techniques affect multiple constraints simultaneously. Structuring model optimization along these three dimensions allows practitioners to analyze trade-offs more effectively and select optimizations that best align with deployment requirements.
Decision framework
The binding constraint of the deployment target determines which technique to reach for first, because each optimization addresses a different resource bottleneck. When model size is the primary constraint, as with over-the-air updates or storage-limited devices, quantization provides the most direct reduction. INT8 post-training quantization delivers a 4\(\times\) size reduction with minimal accuracy loss and requires no retraining, making it the natural first choice. When further reduction is needed, INT4 quantization doubles the compression to 8\(\times\) at the cost of 1–3 percent typical accuracy degradation. For applications where accuracy is paramount, combining knowledge distillation to a smaller architecture with subsequent quantization preserves quality while still achieving substantial compression.
When inference latency is the bottleneck, the optimization must reduce the actual number of operations executed rather than only the storage footprint. Structured pruning accomplishes this by removing entire channels or filters, directly cutting the FLOP count and producing dense sub-networks that run efficiently on commodity hardware. If the target hardware supports INT8 execution, adding quantization on top of structured pruning accelerates the arithmetic itself. For latency-critical applications with some accuracy flexibility, early-exit architectures offer an additional dimension by terminating computation early for easy inputs.
LLM generation presents a distinct bottleneck: autoregressive decoding is dominated by memory bandwidth rather than compute, because each token generation loads the entire weight matrix but performs relatively little arithmetic. Weight-only quantization (INT4 or INT8 weights with FP16 activations) therefore provides nearly linear speedup by reducing the bytes that must traverse the memory hierarchy.
When energy and power consumption drive the optimization, quantization again leads because it reduces both compute energy (cheaper arithmetic) and memory energy (fewer bytes transferred). Structured pruning complements quantization by reducing the total operation count. Combining both techniques yields multiplicative energy savings that neither achieves alone.
These choices also depend on the available engineering budget. When fine-tuning is feasible, QAT replaces PTQ for better accuracy at the same precision level, knowledge distillation enables maximum accuracy preservation, and NAS can discover hardware-specific architectures that outperform manual designs. When rapid deployment is required, PTQ with a calibration dataset can be completed in hours rather than days, and magnitude-based pruning with brief fine-tuning offers a practical middle ground. Techniques demanding large search budgets, such as NAS or full QAT, are best reserved for production systems with longer optimization timelines.
This decision framework provides starting points for individual technique selection. Validating that a chosen technique actually achieves its intended goal requires systematic profiling and measurement, which section 1.8 formalizes in detail. However, production deployments rarely rely on a single technique. Combining pruning with quantization, or distillation with hardware-aware design, introduces interaction effects that can either amplify benefits or create unexpected accuracy degradation. The following section addresses how to sequence and combine techniques effectively.
Self-Check: Question
When the binding deployment constraint is memory and storage capacity, which optimization dimensions should an engineer consider first?
- Model representation and numerical precision, because both directly reduce parameter footprint
- Architectural efficiency alone, because runtime execution patterns determine memory use
- Numerical precision and architectural efficiency, because arithmetic cost is the only relevant axis for capacity
- Model representation alone, because only structural changes can affect parameter count
A 13-billion-parameter language model exceeds device memory and autoregressive generation is memory-bandwidth bound. Which first optimization move best matches these binding bottlenecks?
- Structured pruning first, because cutting FLOPs is always the dominant fix for inference latency regardless of workload
- Weight-only INT4 or INT8 quantization, because reducing bytes streamed per token attacks both the memory-capacity gap and the bandwidth-bound generation path directly
- Operator fusion alone, because kernel-launch overhead is the primary cost during single-token decoding
- NAS from scratch, because novel architecture search is always the first response to deployment pressure
Two teams face the same bandwidth-bound LLM deployment bottleneck, but one has two days and one has two months before launch. Explain how available engineering time changes the recommended technique even when the diagnosed bottleneck is identical.
Optimization Strategies
The chapter’s illustrative BERT mobile pipeline compresses a BERT-Base-sized footprint from 440 MB to 28 MB, a 16× reduction, not through any single technique but through sequential application of pruning, distillation, and quantization. The largest optimization gains emerge when techniques target different resources: pruning changes the operation pattern, quantization changes numerical precision, distillation recovers behavior in a smaller dense student, and architecture search can produce designs that tolerate low-precision execution from the start.
Sequencing matters because these levers interact through the same weights and activations. Applying pruning first concentrates important weights into a smaller parameter set, making subsequent quantization less destructive. Distillation can then recover behavior that aggressive precision reduction or structural change would otherwise lose. The critical engineering question is therefore which sequence yields the greatest compression ratio with the least accuracy degradation. Figure 30 compares that trade-off: pruning combined with quantization (blue circles) achieves high compression ratios with minimal accuracy loss, while quantization alone (orange squares) provides a reasonable balance. In contrast, SVD (red diamonds) requires a larger model size to maintain accuracy, illustrating why complementary techniques compound while redundant ones stall.

Han, Song, Huizi Mao, and William J. Dally. 2016. “Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization and Huffman Coding.” arXiv Preprint.
A mobile BERT pipeline makes that sequencing dependency concrete.
This example illustrates why sequencing matters: pruning first concentrates important weights into smaller ranges, making subsequent quantization more effective. Applying quantization before pruning reduces numerical precision available for importance-based pruning decisions, degrading final accuracy. Effective combination requires understanding these dependencies and developing application sequences that maximize cumulative benefits.
Example 1.3: BERT-Base mobile deployment pipeline
Scenario: An illustrative BERT-Base mobile deployment pipeline that combines published compression patterns rather than reproducing one paper’s exact experiment (Sanh et al. 2019; Jiao et al. 2020; Zafrir et al. 2019).
Mechanism: Stage one applies structured architectural pruning: removing 30 percent of attention heads, trimming 40 percent of intermediate FFN dimensions, and reducing depth and hidden width to a compact BERT variant. In this scenario, the structural recipe yields a 75 percent parameter reduction, with accuracy dropping from 76.2 percent to 75.1 percent. Stage two uses knowledge distillation from the original teacher to recover accuracy to 75.9 percent. Stage three applies quantization-aware training with INT8 quantization, achieving 4× additional memory reduction with final accuracy of 75.6 percent.
Systems insight: The combined impact is 16× memory reduction (440 MB to 28 MB), 12× inference speedup on mobile CPU, and only 0.6 percent final accuracy loss vs. 2.1 percent if quantization had been applied before pruning. The ordering of compression techniques changes the final deployment trade-off.
Jiao, Xiaoqi, Yichun Yin, Lifeng Shang, Xin Jiang, Xiao Chen, Linlin Li, Fang Wang, and Qun Liu. 2020. “TinyBERT: Distilling BERT for Natural Language Understanding.” Findings of the Association for Computational Linguistics: EMNLP 2020, 4163–74. https://doi.org/10.18653/v1/2020.findings-emnlp.372.
With dozens of techniques across three optimization dimensions, rigorous measurement is essential for validating that optimizations achieve their intended goals. A practitioner who prunes, quantizes, and fuses without profiling the actual impact on target hardware is optimizing blindly.
Self-Check: Question
The chapter reports BERT compressed from 440 MB to 28 MB (roughly 16×) by sequencing pruning, distillation, and quantization. Why does this combination compound rather than substitute when pruning and quantization are both applied?
- They target the same resource in the same way, so the second technique merely reinforces the first without changing what it reduces
- Pruning reduces parameter count while quantization reduces bits-per-parameter, so the techniques operate on orthogonal resource axes and their reductions multiply
- Quantization automatically converts any pruned model into a distilled student network, which is where the extra gain comes from
- The two techniques compose well only when operator fusion is applied as a mandatory first step
The chapter states that applying pruning before quantization on BERT achieves 0.6 percent final accuracy loss, while reversing the order (quantizing first, then pruning) produces 2.1 percent loss. Explain the mechanism that makes sequencing this sensitive.
Efficiency Measurement
Section 1.5 traced the gap between a compression ratio on paper and the speedup a model actually realizes. That gap now becomes a measurement obligation: a model quantized to INT8 should be 4\(\times\) smaller and roughly 3\(\times\) faster, but only profiling on target hardware confirms how much of that the deployment keeps. Real speedups depend on memory hierarchy effects, kernel implementations, and hardware utilization patterns that theory alone cannot predict, so translating compression ratios into measurable improvements requires systematic profiling and evaluation. Three questions structure this analysis: where optimization efforts should focus, how to measure whether optimizations achieve their intended goals, and how to validate that combined techniques deliver expected benefits.
Profiling and opportunity analysis
Optimization begins with profiling to identify which components consume the most computational resources and offer the greatest optimization potential. The critical first step is determining whether model optimization will actually improve system performance, since model computation often represents only a fraction of total system overhead in production environments.
Modern machine learning models exhibit heterogeneous resource consumption: specific layers, operations, or data paths contribute disproportionately to memory usage, computational cost, or latency. Understanding these patterns is essential for prioritizing optimization efforts and achieving maximum impact with minimal accuracy degradation.
Effective profiling begins with establishing baseline measurements across relevant performance dimensions. Memory consumption, both static (model parameters and buffers) and dynamic allocation during inference, determines whether a model fits on the target device at all. Computational bottlenecks, measured in both FLOPs and actual wall-clock execution time, reveal which layers dominate the inference budget. For battery-powered and edge deployments, power consumption profiles determine operational feasibility: a model that drains a phone battery in an hour is unusable regardless of its accuracy. End-to-end latency measurements identify which operations contribute most to inference delay, often revealing that memory-bound operations like layer normalization consume disproportionate wall-clock time relative to their FLOP count.
A critical caveat applies when translating profiling metrics into optimization estimates.

Compression hits an end-to-end ceiling once non-model work dominates the pipeline.
Consider profiling a Vision Transformer (ViT) for edge deployment. Using PyTorch Profiler reveals three key findings: attention layers consume 65 percent of total FLOPs (highly amenable to structured pruning), layer normalization consumes 8 percent of latency despite only 2 percent of FLOPs (a memory-bound operation), and the final classification head consumes 1 percent of computation but 15 percent of parameter memory. This profile suggests a clear priority ordering: first, apply magnitude-based pruning to attention layers for high FLOP reduction; second, quantize the classification head to INT8 for large memory savings with minimal accuracy impact; third, fuse layer normalization operations to reduce the memory bandwidth bottleneck.
Systems Perspective 1.4: FLOPs reduction is not proportional speedup
Reducing a model’s FLOPs by 50 percent does not guarantee 50 percent latency reduction. Memory-bound operations (common in LLM inference and normalization layers) see minimal benefit from compute reduction because they are bottlenecked by data movement, not arithmetic. Critically, Amdahl’s Law applies at the system level (Amdahl's Law and Gustafson's Law derives its strong-scaling form): if model inference accounts for only 20 percent of end-to-end latency (with the remaining 80 percent spent on data loading, preprocessing, and postprocessing), then even perfect model optimization yields at most 1.25× overall speedup. In language model serving, CPU-bound tokenization and network round-trip time frequently dominate that non-model fraction; in computer vision pipelines, JPEG decoding and image augmentation (resize, crop, normalize) on the CPU often consume the remainder. Always profile on target hardware before estimating optimization benefits.
Beyond these baseline measurements, modern optimization requires understanding model sensitivity to different types of modifications. Not all parameters contribute equally to accuracy. Layer-wise sensitivity analysis reveals which network components are most important for maintaining accuracy, guiding decisions about where to apply aggressive pruning or quantization and where to use conservative approaches.
Measuring optimization effectiveness
Optimization requires rigorous measurement frameworks that go beyond simple accuracy metrics to capture the full impact of optimization decisions. Effective measurement considers multiple objectives simultaneously: accuracy preservation, computational efficiency gains, memory reduction, latency improvement, and energy savings. Balancing these often-competing objectives requires careful trade-off analysis.
The measurement framework should establish clear baselines before applying any optimizations. Accuracy baselines must go beyond top-line classification accuracy to include calibration (whether confidence matches observed correctness), slice-level performance across important input or user groups, and robustness to input variations. Efficiency baselines capture computational cost (FLOPs, memory bandwidth), execution time across hardware platforms, peak memory consumption, and energy consumption profiles.

INT8 quantization: size collapses about 4 times, accuracy holds.
Quantizing ResNet-50 from FP32 to INT8 should be evaluated as a before-and-after system profile, not as an accuracy number alone. Table 16 compares the baseline artifact against the quantized one across the resource dimensions that determine deployment feasibility.
| Metric | FP32 baseline | INT8 result | Deployment reading |
|---|---|---|---|
| Top-1 accuracy | 76.1% | 75.8% (0.3 pp drop) | Aggregate accuracy mostly holds, but subgroup checks still matter. |
| V100 latency | 1.04 ms | 0.26 ms | GPU latency improves when the runtime maps INT8 to fast kernels. |
| Model size | 102.4 MB | 25.6 MB (4×) | The artifact becomes easier to cache, transmit, and deploy on edge. |
| Energy/inference | 0.15 J | 0.04 J (4×) | Lower precision reduces both arithmetic and memory-movement energy. |
| Calibration error | 2.1% | 3.4% | Confidence calibration can drift even when accuracy looks acceptable. |
The aggregate numbers make INT8 look almost free, but the diagnostic measurements explain why validation still matters. Per-class accuracy degradation spans 0.1–1.2 percentage points, with the highest impact on fine-grained categories, and the latency gain is hardware-dependent: this profile shows 4× on GPU but only 1.2× on CPU.
With these comprehensive baselines in place, the measurement framework must track optimization impact systematically. Rather than evaluating techniques in isolation, applying our three-dimensional framework requires understanding how different approaches interact when combined. Sequential application can lead to compounding benefits or unexpected interactions that diminish overall effectiveness. Compression validation: The efficiency-quality frontier later expands this into a full efficiency-quality evaluation framework.
Rigorous measurement tells practitioners whether their optimizations succeeded, but the measurements themselves require tooling to perform. Profiling, quantization, pruning, and deployment all depend on software frameworks that automate otherwise prohibitively complex workflows.
Self-Check: Question
A Vision Transformer profile shows that attention dominates FLOPs (65 percent), layer normalization consumes 8 percent of wall-clock time despite only 2 percent of FLOPs, and the classification head is 1 percent of compute but 15 percent of parameter memory. What is the most important lesson this profile teaches?
- All layers should receive the same optimization because fairness across layers matters more than impact
- Optimization should target only the largest FLOP contributor, because latency and memory naturally track FLOPs
- Different bottlenecks demand different responses: prune attention for FLOPs, fuse LayerNorm for bandwidth, quantize the classification head for memory — one-size-fits-all tactics ignore the profile
- Profiling is unnecessary once parameter count is known, because model size predicts all deployment behavior
A team reports that its INT8-quantized ResNet-50 preserves top-1 accuracy within 0.3 percent of FP32. Explain why this single number is insufficient to conclude the optimization succeeded, naming at least three additional measurement axes the chapter requires.
Implementation Tools
Quantizing a 175-billion-parameter model by hand, inserting scale factors at every layer boundary, managing mixed-precision accumulation, and calibrating activation ranges would require modifying thousands of lines of model code. Without framework tooling, even straightforward INT8 post-training quantization demands manual insertion of quantization operations throughout the network, while pruning requires direct manipulation of weight tensors. Both become prohibitively complex as models scale.
Tool choice should follow the layer that owns the transformation. Framework APIs are useful while the model is still being trained, calibrated, or pruned because they can see weights, activations, gradients, and training state. Compiler and runtime tools become necessary after export, when the optimized graph must match a specific accelerator. This boundary is the practical reason software infrastructure matters: it records the calibration data, pruning schedule, quantization settings, and runtime libraries that produced the artifact, instead of leaving compression as an unrepeatable sequence of manual edits.
The resulting software infrastructure transforms theoretical optimization techniques into practical tools for production environments. For this chapter, the operational requirement is reproducibility. ML Operations later expands the same requirement into model versioning, monitoring, artifact management, and rollback procedures; here, the narrower point is that a compressed model must be traceable from training checkpoint to calibrated export to runtime artifact.
Model optimization APIs and tools
At the model-development layer, framework APIs are most useful for transformations that need access to training state, calibration data, or weight tensors before export. TensorFlow, PyTorch, and MXNet expose different APIs, but the systems role is the same: insert quantization behavior into the graph, mutate or mask weights for pruning, and preserve enough metadata to reproduce the optimized artifact. ML Frameworks examines the frameworks themselves; this section only needs the compression-facing boundary.
Quantization-aware training is the clearest example because it must change the training graph without changing the mathematical objective. The transformation inserts quantization and dequantization behavior around selected tensors, lets gradients continue to flow through the simulated low-precision path, and records the configuration needed for later conversion. Listing 5 demonstrates the mechanism without depending on a specific framework API.
choose target precision and calibration policy
insert quantize/dequantize boundaries around selected tensors
train with simulated low-precision values while keeping gradient flow intact
record scales, zero points, accumulator precision, and unsupported operations
export the calibrated graph and metadata as one reproducible artifactThe same transformation pattern applies to pruning. The optimization pass owns the weight tensor, applies a mask or structured removal rule, and records which parameters were removed so that subsequent fine-tuning and export operate on the intended model. Listing 6 illustrates the artifact boundary for both unstructured and structured pruning.
choose pruning granularity: individual weights, channels, blocks, or attention heads
score candidate parameters by magnitude, sensitivity, or validation loss impact
remove or mask the selected structure according to the hardware-compatible rule
fine-tune the compressed model against the original validation target
export weights, masks, sparsity pattern, and calibration evidence togetherThe engineering value is repeatability rather than the API call itself. Built-in optimization APIs provide standardized control points for experimentation: teams can vary pruning amount, quantization mode, calibration data, and fine-tuning schedule while keeping the rest of the training pipeline fixed. That repeatability is what lets practitioners compare strategies rather than debug one-off graph rewrites.
Hardware-specific optimization libraries
After the model leaves the training framework, hardware-specific libraries own the final translation step: converting a pruned, quantized, or fused graph into kernels the target platform can execute efficiently. Libraries like TensorRT, Accelerated Linear Algebra (XLA), OpenVINO, and TVM perform this translation for target platforms. Hardware Acceleration explains the accelerator features these tools target; the local point is that compression is incomplete until the exported graph maps to kernels the device can actually run well.
The runtime layer checks whether the apparent compression is executable compression. A pruned model needs sparsity-aware kernels or it may still run as dense arithmetic. A quantized model needs INT8 or INT4 kernels, scale handling, and layouts that the device supports. A fused model needs an operator pattern the compiler can legally combine without changing numerical behavior. These requirements explain why framework integration is not enough by itself: the artifact must survive conversion into a hardware-specific execution plan.
Diagnostic visualization
The toolchain boundary is therefore clear: framework APIs create and calibrate the compressed model, hardware optimization libraries adapt that model to the execution substrate, and diagnostic visualization asks whether the optimization damaged the model rather than only whether it shrank. The benchmarking and MLOps chapters later show how to validate and operate the exported artifact at system scale; within this chapter, the local diagnostic question is whether quantization, pruning, or sparsity changed the internal distributions in a way that threatens accuracy.
Quantization error histograms reveal whether quantization errors are Gaussian or contain problematic outliers. Activation visualizations help detect overflow and saturation issues. Figure 31 shows color-mapped first-layer convolutional kernels grouped by the pattern type each filter has learned, functioning as a sparsity heat map for the learned filters. The diagnostic payoff is in the uniform, near-blank kernels: a filter that learned no structure is dead capacity and a prime pruning candidate, so the engineer reads the heat map to find weights worth removing rather than simply to admire the learned features. TensorFlow’s Quantization Debugger, PyTorch’s FX Graph Mode, and TensorRT Inspector provide these capabilities.

Sparsity diagnostics answer a deployment question: which layers actually became sparse enough for the runtime to exploit? Heat maps show sparsity distribution across layers (figure 32), with darker regions indicating more removed weights, while trend plots track sparsity progression across pruning iterations. TensorBoard, Netron, and SparseML provide these tools.

The diagnostic value is the nonuniformity, not the exact shade of any one cell. If later layers are much sparser than early feature extractors, the pruning policy is concentrating compression where representations are more redundant; if early layers darken first, the policy may be destroying low-level features before the model has enough depth to compensate.
Implementation tools make compression repeatable, but they do not make the trade-offs disappear. In practice, quantization is often applied after pruning or distillation to achieve compound compression benefits: initial pruning reduces parameter count, quantization optimizes numerical representation, and fine-tuning through distillation principles recovers accuracy loss. Sequential application can enable compression ratios of 10–50\(\times\) while maintaining competitive accuracy across diverse deployment scenarios, but only if the interactions are measured rather than assumed.
Self-Check: Question
An engineer is evaluating TensorFlow Model Optimization Toolkit and PyTorch’s quantization and pruning APIs for a production pipeline that must compress hundreds of models per quarter. What is the main systems value these toolkits provide?
- They eliminate the need to understand accuracy-vs-efficiency trade-offs, because the API chooses the trade-off automatically
- They automate the insertion and management of compression workflows — QAT observer placement, sparsity masks, calibration scheduling — that would be error-prone and prohibitively complex to implement manually at scale
- They guarantee that every optimized model will run optimally on every hardware target without any additional runtime conversion
- They replace profiling and validation by embedding the correct deployment choice directly in the API
A model has already been pruned and quantized inside PyTorch’s training framework, yet it still does not achieve the expected speedup when deployed. Explain why hardware-specific runtime libraries such as TensorRT, XLA, or TVM remain necessary at this stage.
Fallacies and Pitfalls
The most instructive lessons in model compression often come not from what works but from what fails. The numerical claims that follow (specific BERT GLUE retention rates, ResNet-50 accuracy under INT8/INT4, distillation gaps between in-training and post-hoc setups) are characteristic of the magnitudes reported across the BERT, ResNet-50, pruning, distillation, and quantization-aware-training literature rather than reproductions of a single paper (Zafrir et al. 2019; Shen et al. 2020; Gale et al. 2019; Han et al. 2015; Hinton et al. 2015; Sanh et al. 2019). Treat them as calibrated order-of-magnitude landmarks: precise values depend on architecture variant, calibration set, and target hardware, and the engineering decisions that follow survive small shifts in the exact numbers.
Han, Song, Jeff Pool, John Tran, and William J. Dally. 2015. “Learning Both Weights and Connections for Efficient Neural Networks.” Advances in Neural Information Processing Systems 28 (NeurIPS 2015), 1135–43.
Sanh, Victor, Lysandre Debut, Julien Chaumond, and Thomas Wolf. 2019. “DistilBERT, a Distilled Version of BERT: Smaller, Faster, Cheaper and Lighter.” arXiv Preprint arXiv:1910.01108, ahead of print. https://doi.org/10.48550/arXiv.1910.01108.
Model optimization involves counterintuitive interactions between techniques that appear independent. Engineers often assume strategies compose linearly and that theoretical metrics predict deployment performance, and those assumptions waste optimization effort, degrade accuracy, or miss deployment requirements despite substantial investment.
Fallacy: Optimization techniques can be applied independently without considering their interactions.
Engineers assume optimization strategies compose additively: 50 percent pruning plus 4× quantization yields combined benefits. In reality, techniques interact nonlinearly and compound losses. In a representative BERT-style compression scenario, pruning to 70 percent sparsity may preserve most task performance, but applying INT8 quantization afterward can lose more accuracy than QAT on the pruned model. Knowledge distillation from heavily pruned teachers can also transfer degenerate attention patterns that reduce student accuracy compared with distilling from dense teachers. As section 1.7 demonstrates, successful optimization requires coordinated application where techniques are sequenced together. Organizations that apply aggressive combinations without measuring interactions waste weeks recovering lost accuracy.
Pitfall: Optimizing for theoretical metrics rather than actual deployment performance.
Teams reduce FLOPs by 60 percent and celebrate efficiency gains without profiling deployment hardware. A pruned model with 40 percent fewer parameters shows irregular sparsity patterns that prevent vectorization, achieving only 12 percent latency reduction instead of the expected 40 percent on ARM processors. INT8 quantization reduces a transformer from 440 MB to 110 MB, but dequantization overhead on GPUs lacking low-precision acceleration increases latency by 15 percent despite the 4× size reduction. As shown in section 1.8.1, memory bandwidth, cache behavior, and instruction-level parallelism determine actual performance, not operation counts. Production deployments require measuring wall-clock latency on target hardware.
Fallacy: Aggressive quantization maintains model performance with minimal accuracy loss.
Engineers assume quantization scales uniformly: if INT8 loses 1 percent, then INT4 loses 2 percent. In practice, precision reduction exhibits threshold effects where models collapse catastrophically. ResNet-50 quantized to INT8 maintains 76.1 percent vs. 76.2 percent FP32 accuracy, but naive INT4 quantization drops accuracy by 5–15 percent depending on the method. Binary weights achieve only ~51 percent on ImageNet. BERT with INT8 weights retains 99.1 percent of FP32 GLUE performance, but INT4 attention mechanisms cause numerical instability reducing scores by 8–12 percent. LayerNorm and Softmax require FP16 minimum precision; quantizing them to INT8 causes divergence. As section 1.4.4 demonstrates, mixed-precision approaches maintain accuracy where uniform quantization fails.
Pitfall: Defaulting to FP32 everywhere to avoid quantization risk.
Engineers default to FP32 to avoid quantization risk, but for deep learning FP32 often hurts performance without improving convergence. FP32 consumes 2\(\times\) the memory bandwidth of BF16 and roughly 4\(\times\) the arithmetic energy of FP16-class tensor compute. Because neural networks are resilient to noise in the mantissa, the extra precision bits typically model random variance rather than signal: BERT and ResNet-50 retain over 99 percent of FP32 accuracy at FP16 or BF16 with no algorithmic intervention, and the speed and energy gains are immediate. The right framing is not “what precision is safe” but “what is the lowest precision that preserves accuracy on my evaluation distribution,” with FP16/BF16 as the default starting point and FP32 reserved for the layers (LayerNorm, Softmax, accumulators) that empirically need it.
Fallacy: Posttraining optimization is enough when accuracy drops are small.
Teams apply post-training quantization (PTQ) to avoid retraining and accept a modest task-specific accuracy gap. However, quantization-aware training (QAT) can recover part of that gap through learned quantization parameters. Similarly, posttraining pruning and post-hoc distillation can underperform training-aware compression schedules when the target sparsity or bit width is aggressive. As detailed in section 1.4.4, even small accuracy improvements from training-aware methods often determine whether models meet production thresholds.
Pitfall: Assuming compression ratios translate directly into proportional deployment gains.
Teams achieve 4× model size reduction through INT8 quantization and expect 4× memory savings in deployment. In practice, runtime overhead erodes compression gains. Dequantization kernels add 15 percent latency overhead converting INT8 weights back to FP16. Pruned models with irregular sparsity achieve only 12 percent latency reduction despite 40 percent parameter removal because hardware cannot skip zeroed weights efficiently. As section 1.8.1 demonstrates, a BERT model pruned to 50 percent sparsity and quantized to INT8 achieves only a 28 percent end-to-end improvement, or about 1.28\(\times\) throughput, rather than the expected 8× theoretical speedup, because unstructured sparsity creates irregular memory access. Production workflows must profile deployed latency on target hardware, not extrapolate from compression ratios.
Fallacy: Sparse matrices always save memory.
Sparse formats add index-array metadata that erodes the savings at moderate densities. With FP32 values and INT32 indices, CSR storage breaks even at roughly 50 percent density and COO at roughly 33 percent density before row-pointer overhead is counted. The performance break-even is even stricter: generic sparse kernels typically need to exceed 90–95 percent sparsity to outrun dense kernels, because irregular index traversal defeats the regular memory access patterns that hardware optimizes for. Specialized formats like NVIDIA’s 2:4 structured sparsity sidestep this by encoding sparsity in fixed-ratio bitmasks rather than explicit indices, but unstructured pruning that does not clear the density threshold delivers neither memory nor latency savings on commodity hardware (see section 1.8.1).
Pitfall: Choosing sparse storage before checking the density threshold.
Teams sometimes convert tensors to sparse formats as soon as pruning creates visible zeros. That conversion can make the system slower and larger if metadata, gather/scatter overhead, and poor cache locality outweigh the saved values. A production compression pass should measure the realized density, choose a sparse format only after the break-even point is crossed, and prefer structured sparsity when the target hardware has kernels that can exploit it.
Self-Check: Question
Which statement best captures the chapter’s warning about combining optimization techniques?
- Compression techniques compose linearly, so the combined gain is the sum of the individual gains
- Techniques interact through shared resources (bandwidth, cache, numerical range) and shared accuracy budgets, so sequencing and joint evaluation matter
- Only quantization interacts meaningfully with other methods; pruning and distillation can be analyzed independently
- Once a model has been compressed by any one method, applying a second method is pointless because the accuracy margin is already exhausted
True or False: If a model’s parameter count falls 4× after compression on modern hardware, deployed end-to-end latency should also improve by roughly 4×.
Summary
Model compression is not a bag of tricks but an engineering discipline built on three complementary dimensions: structural optimization determines what the model computes, precision optimization determines how precisely it computes, and architectural optimization determines how efficiently those computations execute on physical hardware. The most important lesson of this chapter is that these dimensions compose multiplicatively. Pruning alone might achieve 2\(\times\) compression; quantization alone might achieve 4\(\times\); but pruning, distillation, and quantization applied together can achieve the illustrative pipeline’s 16× footprint reduction from 440 MB to 28 MB. The second lesson is equally important: theoretical compression ratios lie. A 4\(\times\) reduction in parameters translates to 4\(\times\) latency improvement only when the optimization aligns with the hardware’s execution model. Unstructured sparsity on hardware that lacks sparse kernels achieves almost nothing; INT8 quantization on hardware without INT8 units achieves even less. Profile on target hardware, not paper metrics.
Combined with the data selection techniques from Data Selection, these model-centric optimizations complete the model-side efficiency toolkit: data selection maximizes learning from available examples, while model compression minimizes resources required for deployment. Whether those savings become real speedups still depends on the hardware and runtime that execute the compressed model.
Key Takeaways: From benchmark winner to production model
- Compression spends surplus capacity: Production models trade unused parameters, precision, and capacity for latency, memory, power, or cost limits the deployment cannot violate. The right target is not minimum size, but the smallest artifact that preserves the behavior the context actually needs.
- Savings multiply only when aligned: Structural pruning, distillation, quantization, and architecture changes can compound, as the BERT mobile pipeline’s 16× footprint reduction shows. The gain becomes real only when the resulting operators match the target runtime and accelerator.
- Precision is a deployment contract: INT8 post-training quantization offers a strong first move because it can deliver 4\(\times\) storage reduction without retraining, while QAT, distillation, or mixed precision buy back accuracy when calibration or layer sensitivity exposes unacceptable error.
- Hardware sets the exchange rate: Unstructured sparsity and theoretical FLOP cuts rarely help commodity GPUs unless kernels and memory layouts can exploit them. The chapter’s warning that an 8\(\times\) paper speedup can collapse to about 1.5\(\times\) makes target-hardware profiling mandatory.
- End-to-end latency caps model wins: Compression is valuable only on the critical path. When inference is 20 percent of total request latency, Amdahl’s Law caps even perfect model acceleration at 1.25\(\times\), so preprocessing, dispatch, and data movement may be the true optimization target.
The techniques in this chapter differ in almost every detail, yet one rule runs beneath all of them. Each buys a smaller, faster, or cooler model by spending something else: pruning spends capacity, quantization spends numerical precision, distillation spends training compute, and where the model holds no surplus to spend, the bill is paid in accuracy. Compression does not make the work disappear; it moves the cost from one part of the system to another, and the hardware sets the exchange rate, which is why a technique that pays off on a phone can be worthless on a data-center GPU. This is the conservation-of-complexity heuristic at the level of a single model. The surplus an over-built network carries can be stripped away, but the constraint it was meeting cannot be, only relocated. A benchmark winner refuses to make that trade, optimizing accuracy as if the machine were free; a production model is the same algorithm, rewritten until the trade balances against the silicon that has to run it.
What’s Next: From math to physics
We have compressed the model’s logic, reducing the work the algorithm asks the machine to perform. Logic, however, must eventually run on physics. Hardware Acceleration examines how GPUs, TPUs, and NPUs are designed to exploit these optimizations and execute compressed models at maximum throughput.
Self-Check: Question
Which statement best summarizes the chapter’s central engineering lesson about deploying compressed models?
- Quantization is sufficient on its own, so structural and architectural techniques are secondary details in practice
- Model compression is best treated as a single technique chosen once per deployment target and applied uniformly
- The strongest deployment gains come from composing structural, precision, and architectural optimizations multiplicatively, while validating each gain on target hardware rather than trusting paper metrics
- Theoretical compression ratios are reliable enough that target-hardware profiling can be deferred to later operational phases
Explain why the chapter frames model compression as the bridge between benchmark-winning models and deployable systems, using the chapter’s own quantitative anchors to ground the argument.
Self-Check Answers
Self-Check: Answer
The chapter’s optimization framework organizes compression along three dimensions that flow from pure software concerns toward hardware-level execution. Which ordering matches that stack?
- Efficient model representation → efficient numerics representation → efficient hardware implementation
- Efficient numerics representation → efficient model representation → efficient hardware implementation
- Efficient hardware implementation → efficient model representation → efficient numerics representation
- Efficient hardware implementation → efficient numerics representation → efficient model representation
Answer: The correct answer is A. The stack first decides what computations exist (pruning, distillation, architecture), then how many bits represent each value (quantization), then how those operations actually execute on silicon (fusion, sparsity exploitation). An ordering that starts with hardware implementation inverts the stack and confuses downstream execution alignment with the architectural decisions that must be made first. Placing numerics before representation misses that quantization operates on whatever parameters structural optimization leaves behind.
Learning Objective: Identify the ordered layers of the chapter’s three-part optimization framework
A 7-billion parameter model in FP16 occupies 14 GB. The target device is a smartphone with 8 GB of shared RAM. Explain why quantization to INT4 simultaneously solves the memory-fit problem and improves autoregressive token throughput for this deployment.
Answer: INT4 stores each weight in 4 bits rather than 16, cutting the weight footprint from 14 GB to roughly 3.5 GB and bringing the model under the 8 GB RAM ceiling shared with the operating system. Because autoregressive generation is memory-bandwidth bound — each token loads the entire weight matrix but performs little arithmetic per byte — fetching one-quarter as many bytes per token yields roughly 4× higher throughput. The systems consequence is that quantization is simultaneously a capacity fix that enables deployment and a latency optimization that attacks the binding bandwidth bottleneck.
Learning Objective: Apply bandwidth-bound reasoning to explain why reduced precision solves capacity and latency constraints together
True or False: When the binding deployment constraint is insufficient weight-memory capacity, operator fusion is a reasonable substitute for pruning or quantization because all three techniques remove the same resource bottleneck.
Answer: False. Fusion reduces intermediate activation traffic and kernel-launch overhead during execution but does not shrink the stored weights or lower their bit-width. When the binding problem is that the weights do not fit, fusion leaves the capacity problem untouched while pruning reduces parameter count and quantization reduces bit-width per parameter.
Learning Objective: Distinguish execution-scheduling optimizations from those that reduce parameter count or bit-width
A 7-billion-parameter model quantized from FP16 to INT4 for autoregressive generation achieves approximately 4× higher token throughput on a bandwidth-limited accelerator. Which mechanism best explains the speedup?
- INT4 removes most of the attention computation, so compute rather than bandwidth becomes negligible
- INT4 makes the model’s reliance on the silicon contract disappear, so latency stops depending on memory traffic
- INT4 reduces the number of transformer layers evaluated per token, cutting the critical-path depth by 4×
- INT4 quarters the bytes that must be fetched per token from memory, so the bandwidth-bound critical path shrinks proportionally
Answer: The correct answer is D. Autoregressive decoding is dominated by the cost of streaming weights through the memory hierarchy once per token, so cutting bytes-per-weight from 16 bits to 4 bits directly shrinks the critical path by roughly the same factor. An answer based on fewer attention operations misidentifies the workload as compute-bound; an answer claiming the silicon contract vanishes misreads quantization as a change of physics rather than a change in bytes moved; and nothing about INT4 removes layers from the computational graph.
Learning Objective: Apply bandwidth-bound reasoning to predict quantization speedup for autoregressive LLM inference
The chapter frames compression as a systematic renegotiation of the model’s ____, the implicit agreement with hardware about which resource (compute throughput, memory bandwidth, or memory capacity) will be saturated at deployment.
Answer: silicon contract. This term carries the book’s argument that compression is not about making a model smaller in the abstract, but about changing which physical resource the model saturates to match what the deployment device can actually supply.
Learning Objective: Identify the hardware-resource framing the chapter uses to motivate compression decisions
A team deploying ResNet-50 to a mobile device applies three optimizations in sequence: it prunes 50 percent of filters, quantizes surviving weights to INT8, and fuses batch normalization into convolution. Why is this combination stronger than applying any single technique alone?
- Only pruning matters in practice; quantization and fusion are different names for the same parameter-count reduction
- Each technique acts on a distinct layer of the stack — representation, numerics, and execution — so the gains compose rather than overlap
- The sequence works because all three techniques raise training-time compute, which later reduces inference cost
- Pruning automatically converts the model into a NAS-discovered architecture, which is what delivers the compounded gain
Answer: The correct answer is B. Filter pruning changes what is computed (parameter count), INT8 quantization changes how values are represented (bit-width per operand), and Conv-BN fusion changes how operations execute on silicon (eliminated intermediate memory round-trips). Because each lever acts on a different resource axis, their benefits multiply rather than overlap. Framing them as duplicate parameter-count reductions ignores that fusion preserves arithmetic and quantization changes bit-width not count, and nothing about pruning performs an architecture search.
Learning Objective: Analyze why combining optimizations across representation, numerics, and execution layers produces multiplicative compression gains
Self-Check: Answer
Across the deployment contexts in this chapter, which one makes compression existential — that is, the model cannot run at all until it fits — rather than merely a throughput or latency optimization?
- Cloud inference, where throughput-per-dollar dominates the optimization budget
- Mobile and edge devices, where frame-rate targets bind but memory is usually generous
- TinyML, where KB-MB memory and mW power budgets create hard ceilings below which deployment is impossible
- Offline batch inference, where latency is irrelevant and storage never constrains deployment
Answer: The correct answer is C. TinyML microcontrollers enforce absolute RAM ceilings measured in hundreds of kilobytes and milliwatt power envelopes; a model that does not compress below these limits cannot run regardless of accuracy. Cloud workloads still reward optimization but are bounded by cost and throughput rather than an impossibility of fitting at all, and the ‘generous memory’ framing of mobile misreads why 30-FPS real-time targets still push compression from optional to essential.
Learning Objective: Identify which deployment context makes compression a feasibility requirement rather than a performance optimization
A practitioner compares two candidates against the chapter’s 512 KB TinyML envelope: MobileNetV2 quantized to INT8 (roughly 3.5 MB) and a DS-CNN keyword spotter (roughly 500 KB at FP32, smaller at INT8). Using the chapter’s deployment-gap table, which outcome is most likely?
- Both models fit because INT8 quantization is always sufficient to land a mobile-class model on TinyML hardware
- Neither model fits because convolutional networks are inherently too expensive for microcontrollers
- MobileNetV2 INT8 fits only if the microcontroller clock rate is increased, while DS-CNN misses the RAM limit
- DS-CNN fits within the envelope while MobileNetV2 INT8 still exceeds TinyML memory by roughly 7×
Answer: The correct answer is D. The chapter’s deployment-gap table shows MobileNetV2 INT8 at 3.5 MB is still roughly 7× the 512 KB TinyML envelope, while the purpose-built DS-CNN keyword spotter fits within it. The ‘INT8 always fits’ framing ignores the scale mismatch between mobile-class and TinyML-class models, and nothing about clock rate changes whether a static model footprint fits in RAM.
Learning Objective: Compare model-device fit across deployment targets using the chapter’s deployment-gap arithmetic
The chapter’s compression-accuracy trade-off curve divides optimizations into three regions: free lunch, efficient trade, and danger zone. Explain what the ‘knee’ of this curve means quantitatively and what decision rule it gives the engineer.
Answer: The knee marks the point where the slope of the curve steepens sharply: each additional unit of efficiency gain beyond it costs disproportionately more accuracy than the same gain cost before it. The chapter’s numbers make this concrete — moving from FP32 to INT8 costs roughly 0.5 percent accuracy for a 4× speedup (pre-knee), but pushing pruning from 50 percent to 90 percent can cost 5-15 percent accuracy for a further 5× size reduction (post-knee). The decision rule is to stop compressing when marginal accuracy loss exceeds marginal systems benefit; continuing past the knee sacrifices more quality than it buys efficiency.
Learning Objective: Explain how the Pareto-frontier knee gives engineers a quantitative stopping rule for compression
True or False: Increasing batch size on a GPU should be treated as the same kind of compression move as pruning or quantization when locating a model on the chapter’s compression-accuracy trade-off curve.
Answer: False. Batch-size scaling changes training and serving throughput but leaves the model’s structure, parameter count, and numerical representation unchanged, so the chapter explicitly separates it from compression techniques that reshape what the model stores or computes.
Learning Objective: Distinguish throughput-scaling adjustments from structural compression on the efficiency frontier
A mobile video-call team needs 30 FPS background blur but FP32 MobileNetV3 runs at 8 FPS. INT8 quantization pushes the model to 35 FPS with a small accuracy drop and lower energy per frame. Which region of the chapter’s trade-off curve best describes this outcome?
- Region 1 (free lunch), because INT8 quantization carries zero accuracy cost of any kind
- Region 2 (efficient trade), because a small accuracy concession buys a large systems win that crosses the shipping threshold
- Region 3 (danger zone), because any deployment-driven optimization that changes the model is already a destructive move
- Outside the Pareto frontier, because once a model reaches 30 FPS the frontier no longer applies to it
Answer: The correct answer is B. The chapter’s efficient-trade region is defined by a modest quality cost buying a dramatic speedup, and this is the canonical case — a 4× throughput jump enables a feature that otherwise cannot ship. Calling INT8 quantization free ignores that quantization introduces real (if small) numerical error, and the danger-zone framing applies to aggressive pruning or binary quantization, not INT8. The ‘outside the frontier’ framing misreads the frontier as a function of absolute performance rather than the shape of the accuracy-efficiency trade.
Learning Objective: Classify a concrete production optimization within the chapter’s compression-accuracy trade-off regions
Self-Check: Answer
A team prunes ResNet-50 to 50 percent sparsity using unstructured magnitude pruning, then benchmarks it on a commodity GPU and sees only a 1.1× speedup. Switching to structured channel pruning at the same 50 percent sparsity delivers roughly 1.8× speedup on the same GPU. Which explanation best captures why?
- Structured pruning removes whole channels that preserve dense execution patterns, while unstructured sparsity scatters zeros through memory and wastes standard compute units that cannot skip zeros without first loading them
- Structured pruning removes more parameters than unstructured pruning at the same nominal sparsity ratio, so the FLOP reduction is larger
- Unstructured pruning cannot reduce model storage at all, so only structured pruning shrinks the memory footprint
- Structured pruning works only because it eliminates the need for any fine-tuning after compression
Answer: The correct answer is A. Standard accelerators fetch contiguous blocks of operands, so unstructured zeros scattered through a matrix still consume memory bandwidth and compute slots without yielding arithmetic savings; structured pruning removes whole channels or filters, which preserves the dense execution pattern the accelerator is designed for. The ‘more parameters at same sparsity’ framing confuses the structural axis with the absolute count. The claim that unstructured pruning cannot reduce storage ignores that both methods remove parameters; only the speedup pattern differs. And structured pruning routinely requires fine-tuning to recover accuracy — its advantage is execution alignment, not zero retraining.
Learning Objective: Compare structured and unstructured pruning in terms of hardware-realizable speedup on commodity accelerators
Order the following stages of one Lottery Ticket Hypothesis iteration: (1) reset surviving weights to their original initialization values, (2) train the dense network to convergence, (3) prune the lowest-magnitude weights.
Answer: The correct order is: (2) train the dense network to convergence, (3) prune the lowest-magnitude weights, (1) reset surviving weights to their original initialization values. Training first reveals which weights matter by letting magnitudes diverge; pruning uses those magnitudes as importance signals; only then does resetting to the original initialization test whether the surviving subnetwork can retrain on its own. Resetting before pruning would erase the magnitude evidence needed to identify the winning ticket, and pruning a randomly initialized network would remove weights by accident rather than by learned importance.
Learning Objective: Sequence the iterative workflow used to identify winning-ticket subnetworks under the Lottery Ticket Hypothesis
A team must compress a large transformer for deployment on standard GPUs that have no dedicated sparse-kernel support. The target architecture should be substantially smaller than the teacher. Which structural technique best fits these constraints?
- Unstructured pruning, because sparse matrix operations are always fastest on commodity GPUs
- Layer-wise magnitude pruning, because it preserves the original teacher architecture exactly
- Knowledge distillation, because it trains a smaller dense student that runs efficiently on ordinary hardware without requiring sparse kernels
- Low-rank factorization alone, because it avoids any additional training cost while guaranteeing no information loss
Answer: The correct answer is C. Distillation produces a compact dense student that inherits teacher behavior without relying on sparse-kernel support, which directly matches the stated constraint of commodity GPUs lacking specialized sparse execution. The unstructured-pruning framing contradicts the earlier section’s warning that irregular sparsity often fails to translate into speedup on such hardware, and the claim that low-rank factorization guarantees no information loss misreads the compression-accuracy trade — factorization is a lossy approximation whose rank choice directly controls the accuracy loss.
Learning Objective: Select knowledge distillation when the deployment requires a dense student that runs on hardware without sparse-kernel support
Low-rank factorization replaces one large weight matrix multiplication with two smaller ones, increasing the raw operation count. Explain why this can still accelerate inference on modern accelerators, using a concrete rank choice from the chapter.
Answer: The chapter shows a 4096×4096 matrix factored at rank 128 stores roughly 16× fewer parameters, so far fewer bytes must traverse the memory hierarchy even though two multiplications replace one. On memory-bound layers — which dominate transformer linear layers and LLM generation — time is gated by bytes moved per operation, not arithmetic count, so a small increase in FLOPs combined with a large reduction in memory traffic reduces end-to-end latency. The systems consequence is that trading cheap arithmetic for expensive memory movement is often the right direction when the workload is bandwidth-bound.
Learning Objective: Analyze why low-rank factorization can improve inference efficiency despite raising the raw arithmetic count
An engineering team is choosing between running custom neural architecture search from scratch and adopting an existing NAS-discovered architecture such as EfficientNet or MobileNetV3. Which situation most strongly justifies custom NAS?
- Standard target hardware for which mature architectures already match the deployment constraints well
- Tight compute budget with fewer than 100 GPU-days available for the optimization effort
- Rapidly shifting product requirements where the architecture may be obsolete before a search finishes
- Novel hardware constraints or deployment scale so large that amortizing the search cost over deployed inferences produces a net win
Answer: The correct answer is D. Custom NAS is justified when the target hardware’s constraints are not represented in existing NAS-discovered designs or when deployment volume is large enough that even small per-inference efficiency gains repay the search cost. Standard hardware with mature off-the-shelf designs makes the search redundant, limited compute cannot fund the search in the first place, and rapidly shifting requirements render the discovered architecture obsolete before it ships.
Learning Objective: Evaluate when custom NAS is worth its search cost versus reusing a NAS-discovered architecture
A team compares one-shot pruning (remove 90 percent of weights in one step, then fine-tune) against iterative pruning (remove 10 percent, fine-tune, repeat nine times) on the same model to the same final sparsity. Why does iterative pruning typically recover higher accuracy?
- Iterative pruning uses more randomization, which hides the effect of removed parameters from the final accuracy measurement
- Iterative pruning interleaves smaller pruning steps with fine-tuning, letting surviving weights absorb each cut’s importance redistribution before the next is made
- One-shot pruning fails only when it removes structured units; iterative pruning avoids that by removing only unstructured weights
- Iterative pruning works because it avoids any temporary accuracy drop at any point in the compression process
Answer: The correct answer is B. Each iterative cycle imposes a smaller structural shock the network can compensate for during fine-tuning, so importance-bearing weight patterns can reorganize across the remaining parameters rather than being destroyed all at once. One-shot pruning forces the model to absorb a 90-percent cut in a single step, which often destroys capacity faster than fine-tuning can recover it. The randomization framing invents a mechanism that does not exist in magnitude pruning, and the ‘avoids any drop’ framing contradicts the well-documented recovery curve after each iterative cut.
Learning Objective: Explain why iterative pruning better preserves model accuracy than one-shot pruning at the same final sparsity
Self-Check: Answer
The chapter reports that moving from FP32 to INT8 yields roughly a 30× energy improvement per addition operation, even though the storage reduction is exactly 4×. Which mechanism best explains why the energy gain exceeds the bit-width gain?
- INT8 eliminates all memory accesses, leaving only arithmetic energy, which scales superlinearly with bit-width
- Quantization reduces both bytes moved and the per-unit energy cost of arithmetic, and memory access already dominates arithmetic energy, so the savings compound across both fronts
- INT8 automatically prunes the lowest-magnitude weights during numerical conversion, removing entire multiplications from the compute graph
- FP32 values must be recomputed from training data at inference time, a cost that INT8 avoids entirely
Answer: The correct answer is B. Quantization attacks data movement (fewer bytes per weight on every access) and arithmetic (cheaper INT8 units than FP32 units) simultaneously, and because memory access is already the more expensive axis — the chapter’s Horowitz constants put a DRAM read thousands of times above an INT8 MAC — the compound reduction yields more than a bit-width-proportional improvement. The ‘eliminates all memory access’ framing is physically wrong; quantization never automatically prunes weights; and FP32 weights are never recomputed from training data at inference.
Learning Objective: Explain why quantization energy savings exceed what the raw bit-width reduction alone predicts
In affine quantization, the integer value chosen to represent real zero exactly is the ____, without which padding and bias terms would map to nonzero integers and introduce artificial error.
Answer: zero-point. The zero-point shifts the integer range so that the real value 0 maps to an exact integer, which is critical in convolutional networks where zero padding must remain exactly zero after quantization.
Learning Objective: Identify the affine-quantization parameter that preserves exact representation of zero
A transformer model quantized with PTQ misses its production accuracy threshold, and the accuracy drop is concentrated in layers where small numerical differences matter most. According to the chapter, what is the appropriate next step?
- Drop to binary weights, because lower precision always restores the calibration lost at INT8
- Apply quantization-aware training so weights adapt to simulated low-precision noise during fine-tuning, which the chapter recommends whenever PTQ accuracy is insufficient
- Abandon quantization entirely, since PTQ failure implies the model cannot run below FP32 on any hardware
- Force a single global clipping range across every layer, so cross-layer consistency replaces per-layer fit
Answer: The correct answer is B. QAT is the chapter’s designated escalation when PTQ is too inaccurate: the model simulates quantization during training so weights and activations adapt to reduced-precision effects, closing most of the gap PTQ leaves. Binary quantization moves in the wrong direction (much harsher precision regime with far greater accuracy risk), abandoning quantization confuses one method’s failure with the technique’s general viability, and forcing a single global range strictly worsens accuracy by wasting range on layers whose distributions diverge.
Learning Objective: Choose quantization-aware training rather than more aggressive PTQ when post-training quantization misses the accuracy target
Weight-only INT4 quantization (INT4 weights with FP16 activations) is especially effective for autoregressive LLM generation but much less helpful for the training forward pass of the same model. Explain the mechanistic difference.
Answer: Autoregressive generation is memory-bandwidth bound: each new token requires streaming the entire weight matrix through the memory hierarchy while performing only modest arithmetic per byte, so cutting weight bit-width from 16 to 4 reduces fetched bytes per token nearly 4× and throughput scales proportionally. Training forward passes batch many examples through each weight fetch, pushing arithmetic intensity high enough that the workload becomes compute-bound; once compute is the binding resource, reducing bytes-per-weight yields a much smaller speedup, and the extra dequantization work for gradients and activations adds overhead. The practical implication is that the same quantization lever delivers dramatically different returns depending on which Iron Law term is binding at each stage of the lifecycle.
Learning Objective: Analyze why weight-only quantization helps bandwidth-bound inference far more than it helps compute-bound training
A calibration run for INT8 quantization of a CNN’s activations shows most values clustered near zero with a small set of rare outliers forming a long positive tail. Which calibration strategy is most likely to preserve effective resolution for the bulk of the activations?
- Max-absolute-value calibration, because outliers are always the most informative activations to preserve exactly
- Percentile or entropy-based calibration, which trims rare outliers’ influence on the chosen range so most INT8 levels land where the typical activations live
- Symmetric quantization with no clipping, because any clipping strictly increases quantization error
- A single global range shared across the entire model, because cross-layer consistency matters more than per-layer fit
Answer: The correct answer is B. Percentile and entropy-based calibration deliberately ignore or down-weight rare tail values so the 256 INT8 levels distribute across the activations that actually occur most often, preserving typical-case resolution. Max-abs calibration stretches the range to cover rare outliers and leaves most levels unused in the dense center of the distribution. The ‘no clipping’ framing misreads the trade-off — unclipped range is what wastes resolution here — and a single global range conflates cross-layer uniformity with in-layer effective precision.
Learning Objective: Compare calibration strategies for skewed activation distributions with long-tailed outliers
A team quantizing a CNN finds that per-channel quantization preserves accuracy noticeably better than per-layer quantization at the same bit-width. Which mechanism best explains why?
- Each filter can have its own quantization range, so filters with very different value distributions no longer have to share one clipping range that fits none of them well
- Channelwise quantization eliminates scale factors and zero-points entirely, so no quantization error is introduced
- Layerwise quantization can be used only for weights, not activations, so it never provides full coverage
- Channelwise quantization always runs dynamically at inference time while layerwise is always static
Answer: The correct answer is A. Different channels in a convolution often carry distributions with very different magnitudes, so a single layerwise range must either clip the narrow-channel values or under-utilize the wide-channel range; giving each channel its own range preserves effective precision on both. The claim that channelwise quantization removes scale factors contradicts how affine quantization is defined, the restriction of layerwise quantization to weights is invented, and the static-vs-dynamic distinction is independent of granularity.
Learning Objective: Explain why finer quantization granularity improves accuracy preservation in convolutional models
Self-Check: Answer
A ResNet-50 pruned to 50 percent sparsity and quantized to INT8 has theoretical 6× speedup, yet measured wall-clock speedup on an unmodified GPU is closer to 1.5×. Architectural efficiency exists to close this gap. Which statement best describes its role?
- It reduces the training dataset so the model can be retrained more cheaply
- It guarantees that every optimized model becomes compute-bound rather than memory-bound
- It replaces pruning and quantization with a single universal optimization method
- It aligns execution patterns — scheduling, memory access, operator fusion, sparsity structure — with what the hardware can actually accelerate, converting theoretical savings into measured speedup
Answer: The correct answer is D. The section defines architectural efficiency as the layer that ensures structural and precision gains actually materialize on silicon by matching sparsity patterns, memory access, and kernel fusion to hardware capabilities. The ‘guarantees compute-bound’ framing invents a property architectural efficiency does not claim, the ‘replaces the other dimensions’ framing contradicts its role as a complementary layer in the stack, and nothing about architectural efficiency touches training data.
Learning Objective: Explain the purpose of architectural efficiency as the layer that translates theoretical compression into measured hardware speedup
Operator fusion of Conv-BN-ReLU sequences often delivers significant speedup on CNN inference, even though the fused kernel performs exactly the same arithmetic as the three unfused kernels. Which mechanism explains the speedup?
- Fusion reduces the total number of learned parameters in the layer sequence
- Fusion retrains the model to use fewer output channels at inference time
- Fusion keeps intermediate activations in registers or on-chip SRAM rather than writing them to global memory between stages and reading them back, cutting HBM round-trips from six to two per sequence
- Fusion converts dense kernels into sparse kernels that skip zero multiplications
Answer: The correct answer is C. Fusion preserves the same mathematical operations but keeps intermediate tensors in fast on-chip storage and eliminates redundant kernel-launch overhead, which is the dominant cost when the sequence is memory-bound. The parameter-reduction framing misreads fusion as structural compression, the ‘retrains to fewer channels’ claim describes a different technique, and fusion does not create sparsity — it preserves dense arithmetic.
Learning Objective: Analyze how operator fusion accelerates Conv-BN-ReLU sequences by eliminating memory traffic rather than reducing arithmetic
A compressed model reports a 50 percent reduction in FLOPs, but deployed end-to-end latency drops by only 10 percent. Using the chapter’s Amdahl’s-law framing, explain two distinct mechanisms that can produce this gap.
Answer: First, Amdahl’s law at the system level bounds the achievable gain: if model inference is only 20 percent of end-to-end latency while data loading, preprocessing, and postprocessing consume the rest, even a perfect 2× model speedup yields at most 1.25× overall. Second, within the model itself, FLOP reduction targets arithmetic while many layers are memory-bound — layer normalization, activation functions, and attention at long context lengths pay in bytes moved, not in arithmetic, so cutting FLOPs on those layers leaves wall-clock time largely unchanged. The systems consequence is that FLOP counts predict latency only when the workload is arithmetic-bound and the model dominates the end-to-end pipeline, which must be verified on target hardware rather than assumed.
Learning Objective: Explain why compute-reduction metrics overpredict latency gains through Amdahl’s law and memory-bound layers
Which adaptive-computation strategy attaches multiple prediction points to a network and terminates inference for an input as soon as intermediate confidence exceeds a threshold?
- Low-rank factorization
- Operator fusion
- Block-sparse matrix execution
- Early-exit architectures
Answer: The correct answer is D. Early-exit architectures such as BranchyNet explicitly insert intermediate classifiers and terminate computation for easy inputs whose confidence clears a threshold, delivering input-proportional compute savings. Low-rank factorization restructures weight matrices but does not skip layers per-input, operator fusion optimizes execution of fixed computation graphs, and block-sparse execution accelerates sparse matmul but does not make per-input stopping decisions based on confidence.
Learning Objective: Identify early-exit architectures as the technique that allocates compute per-input based on confidence
True or False: Once a weight matrix contains many zeros, modern SIMD hardware automatically delivers proportional speedup because vector lanes can cheaply skip the zeros without any specialized kernel or structure.
Answer: False. SIMD lanes fetch and process contiguous blocks of operands; without structured sparsity or dedicated sparse kernels, a 16-wide vector register may carry only 1-2 nonzeros but still pay the full memory access and lane-utilization cost, so unstructured sparsity below roughly 90 percent often delivers little or no speedup on commodity hardware.
Learning Objective: Reject the misconception that unstructured sparsity automatically translates into SIMD-accelerated speedup
A deployment targets NVIDIA Ampere GPUs that accelerate 2:4 structured sparsity (exactly 2 nonzeros per group of 4 weights) but not arbitrary sparse patterns. Which compression choice best aligns with this hardware?
- Magnitude-based unstructured pruning with no pattern constraints, because it always maximizes usable speedup regardless of hardware support
- Structured sparsity that enforces the supported N:M pattern, because the accelerator is wired to skip operations only on that regular layout
- Knowledge distillation, because teacher-student training automatically generates 2:4 masks during student training
- Activation checkpointing, because recomputation during the backward pass is equivalent to structured sparsity at inference time
Answer: The correct answer is B. When hardware accelerates a fixed N:M pattern, the model must match that pattern for the sparse-execution path to engage — otherwise the accelerator treats the matrix as dense. Unstructured pruning may reach higher nominal sparsity but, as the section warns, produces an irregular layout that wastes accelerator capability. Distillation is a separate technique that does not generate hardware masks, and activation checkpointing trades compute for training memory rather than inducing sparsity at inference.
Learning Objective: Match sparsity structure to the hardware patterns required for actual acceleration on N:M-capable accelerators
Self-Check: Answer
When the binding deployment constraint is memory and storage capacity, which optimization dimensions should an engineer consider first?
- Model representation and numerical precision, because both directly reduce parameter footprint
- Architectural efficiency alone, because runtime execution patterns determine memory use
- Numerical precision and architectural efficiency, because arithmetic cost is the only relevant axis for capacity
- Model representation alone, because only structural changes can affect parameter count
Answer: The correct answer is A. Memory-and-storage constraints tie primarily to model representation (pruning, distillation) and numerical precision (quantization), because both directly reduce the bytes occupied by weights. The ‘architectural efficiency alone’ choice is incorrect because while it matters for runtime performance, it does not itself shrink stored parameters when the immediate problem is that the model does not fit. Precision alone misses that structural optimization can deliver larger capacity reductions when combined, and representation alone discards the quantization lever that often contributes more than half of the compression in practice.
Learning Objective: Map a deployment bottleneck to the optimization dimensions most likely to relieve it.
A 13-billion-parameter language model exceeds device memory and autoregressive generation is memory-bandwidth bound. Which first optimization move best matches these binding bottlenecks?
- Structured pruning first, because cutting FLOPs is always the dominant fix for inference latency regardless of workload
- Weight-only INT4 or INT8 quantization, because reducing bytes streamed per token attacks both the memory-capacity gap and the bandwidth-bound generation path directly
- Operator fusion alone, because kernel-launch overhead is the primary cost during single-token decoding
- NAS from scratch, because novel architecture search is always the first response to deployment pressure
Answer: The correct answer is B. Weight-only quantization shrinks the stored weights (fixing capacity) and reduces bytes fetched per token (fixing bandwidth-bound throughput) — exactly the two binding constraints the scenario names. Pruning first misidentifies the bottleneck as arithmetic; operator fusion cannot close a capacity gap or shrink weight-fetch bandwidth; and running NAS from scratch is a poor first move for a targeted deployment decision due to its massive search cost.
Learning Objective: Select weight-only quantization as the appropriate first optimization for bandwidth-bound LLM deployment.
Two teams face the same bandwidth-bound LLM deployment bottleneck, but one has two days and one has two months before launch. Explain how available engineering time changes the recommended technique even when the diagnosed bottleneck is identical.
Answer: With only two days, post-training quantization (PTQ) or simple magnitude-based pruning are optimal because both can be applied with a calibration set and no full retraining cycle, usually landing within a few percentage points of the target accuracy. With two months, quantization-aware training (QAT) becomes viable because simulating quantization noise during fine-tuning recovers most of the PTQ accuracy gap, and distillation from a larger teacher can further narrow any remaining loss. The practical consequence is that technique selection is jointly constrained by the model, the hardware, and the optimization timeline — the same bottleneck justifies PTQ, QAT, or even NAS depending on how much fine-tuning the schedule permits.
Learning Objective: Explain how engineering budget and retraining time shape which technique within a dimension to deploy.
Self-Check: Answer
The chapter reports BERT compressed from 440 MB to 28 MB (roughly 16×) by sequencing pruning, distillation, and quantization. Why does this combination compound rather than substitute when pruning and quantization are both applied?
- They target the same resource in the same way, so the second technique merely reinforces the first without changing what it reduces
- Pruning reduces parameter count while quantization reduces bits-per-parameter, so the techniques operate on orthogonal resource axes and their reductions multiply
- Quantization automatically converts any pruned model into a distilled student network, which is where the extra gain comes from
- The two techniques compose well only when operator fusion is applied as a mandatory first step
Answer: The correct answer is B. Compression_total = (parameter ratio) × (bits ratio), and the two ratios are independent controls: 50 percent pruning plus 4× INT8 quantization multiplies to 8× storage reduction that neither achieves alone. Framing them as the same kind of optimization ignores that pruning removes weights and quantization shrinks each surviving weight, distillation is a separate technique quantization does not invoke, and nothing about fusion is prerequisite to composing pruning with quantization.
Learning Objective: Explain why orthogonal optimization techniques yield multiplicative rather than additive compression
The chapter states that applying pruning before quantization on BERT achieves 0.6 percent final accuracy loss, while reversing the order (quantizing first, then pruning) produces 2.1 percent loss. Explain the mechanism that makes sequencing this sensitive.
Answer: Pruning selects which weights to remove based on magnitude or importance scores computed from the trained weight distribution. Applying quantization first collapses that distribution onto discrete levels, so the importance signal pruning relies on — the relative magnitudes of near-threshold weights — is distorted, and the pruner removes weights whose quantized rank does not reflect their true importance. Pruning first concentrates capacity into the surviving set, whose full-precision magnitudes retain their informativeness, and quantization then operates on a smaller, better-separated parameter set. The systems consequence is that sequencing is not just a scheduling convenience but changes the information each downstream technique has available to make its decisions.
Learning Objective: Analyze how ordering pruning before quantization preserves the importance signals that downstream compression depends on
Self-Check: Answer
A Vision Transformer profile shows that attention dominates FLOPs (65 percent), layer normalization consumes 8 percent of wall-clock time despite only 2 percent of FLOPs, and the classification head is 1 percent of compute but 15 percent of parameter memory. What is the most important lesson this profile teaches?
- All layers should receive the same optimization because fairness across layers matters more than impact
- Optimization should target only the largest FLOP contributor, because latency and memory naturally track FLOPs
- Different bottlenecks demand different responses: prune attention for FLOPs, fuse LayerNorm for bandwidth, quantize the classification head for memory — one-size-fits-all tactics ignore the profile
- Profiling is unnecessary once parameter count is known, because model size predicts all deployment behavior
Answer: The correct answer is C. The profile exposes three distinct bottlenecks — compute-bound attention, memory-bound LayerNorm, memory-capacity-bound classification head — each requiring a different intervention (pruning, fusion, quantization respectively). The ‘same optimization everywhere’ framing ignores the profile entirely, the ‘only FLOPs matter’ framing contradicts the LayerNorm data point where 2 percent of FLOPs becomes 8 percent of latency, and the ‘parameter count predicts everything’ framing contradicts the classification head’s outsized memory share at 1 percent compute.
Learning Objective: Use a heterogeneous profile to prioritize layer-specific optimizations rather than a single global tactic
A team reports that its INT8-quantized ResNet-50 preserves top-1 accuracy within 0.3 percent of FP32. Explain why this single number is insufficient to conclude the optimization succeeded, naming at least three additional measurement axes the chapter requires.
Answer: Top-1 accuracy can be preserved while calibration, latency, memory, or energy targets fail: the chapter’s own ResNet-50 numbers show 3.2× speedup on GPU but only 1.8× on CPU, calibration error rising from 2.1 percent to 3.4 percent, and per-class degradation ranging from 0.1 to 1.2 percent that disproportionately hits fine-grained categories. A complete evaluation must report wall-clock latency on target hardware, peak memory and model size, energy per inference, calibration-and-fairness metrics across subgroups, and hardware-specific variation (GPU vs. CPU vs. NPU). The practical implication is that compressed-model success is a systems outcome measured across multiple objectives, not an aggregate-accuracy number.
Learning Objective: Explain why compressed-model evaluation requires multi-objective measurement beyond top-line accuracy
Self-Check: Answer
An engineer is evaluating TensorFlow Model Optimization Toolkit and PyTorch’s quantization and pruning APIs for a production pipeline that must compress hundreds of models per quarter. What is the main systems value these toolkits provide?
- They eliminate the need to understand accuracy-vs-efficiency trade-offs, because the API chooses the trade-off automatically
- They automate the insertion and management of compression workflows — QAT observer placement, sparsity masks, calibration scheduling — that would be error-prone and prohibitively complex to implement manually at scale
- They guarantee that every optimized model will run optimally on every hardware target without any additional runtime conversion
- They replace profiling and validation by embedding the correct deployment choice directly in the API
Answer: The correct answer is B. The chapter’s case for these APIs is that quantization and pruning at production scale demand thousands of correctly-placed observer nodes, mask operations, and calibration runs per model; the framework encapsulates that mechanical work. Nothing about the API removes the engineer’s responsibility to understand trade-offs, to revalidate after optimization, or to match the output to hardware-specific runtime libraries — all three remain explicit next steps in the pipeline.
Learning Objective: Explain why framework optimization APIs are essential for scaling compression workflows without removing the engineer’s trade-off judgment
A model has already been pruned and quantized inside PyTorch’s training framework, yet it still does not achieve the expected speedup when deployed. Explain why hardware-specific runtime libraries such as TensorRT, XLA, or TVM remain necessary at this stage.
Answer: Framework APIs produce models in a hardware-neutral representation: quantized weights and sparse masks exist in the graph, but the kernels that actually execute them must be generated for the target device. Hardware-specific libraries lower the model onto supported accelerator capabilities — INT8 matmul paths on Tensor Cores, 2:4 structured-sparsity kernels on Ampere, or fused operator kernels for TPUs — and without that lowering step, a quantized or sparse model often runs through a generic dense kernel that ignores the compression. The practical implication is that compression and deployment optimization are separate stages in the pipeline, and a model that ships only through the framework layer will leave most of its theoretical speedup on the table.
Learning Objective: Explain the role of hardware-specific runtime libraries in converting compressed-model representations into actual deployment speedup
Self-Check: Answer
Which statement best captures the chapter’s warning about combining optimization techniques?
- Compression techniques compose linearly, so the combined gain is the sum of the individual gains
- Techniques interact through shared resources (bandwidth, cache, numerical range) and shared accuracy budgets, so sequencing and joint evaluation matter
- Only quantization interacts meaningfully with other methods; pruning and distillation can be analyzed independently
- Once a model has been compressed by any one method, applying a second method is pointless because the accuracy margin is already exhausted
Answer: The correct answer is B. The chapter’s fallacies section and BERT example together show that combined-technique accuracy depends on sequencing (pruning-then-quantization beats the reverse by 1.5 percentage points) and that techniques share resources — quantization after pruning can amplify error in near-zero regions pruning leaves. Linear-composition framing contradicts the repeated examples of compound loss, the ‘only quantization interacts’ claim picks one technique arbitrarily when all three interact, and the ‘second method is pointless’ framing ignores that orthogonal techniques produce multiplicative compression gains.
Learning Objective: Recognize that optimization techniques interact nonlinearly and must be evaluated jointly rather than additively
True or False: If a model’s parameter count falls 4× after compression on modern hardware, deployed end-to-end latency should also improve by roughly 4×.
Answer: False. The chapter documents multiple mechanisms that decouple compression ratio from latency ratio: dequantization kernels add roughly 15 percent overhead on GPUs lacking INT8 units, unstructured sparsity wastes SIMD lanes so 40-percent pruning delivers only about 12 percent speedup on ARM, and Amdahl’s law at the pipeline level caps end-to-end gain when preprocessing and data loading dominate.
Learning Objective: Reject the misconception that parameter-count reduction translates directly into proportional deployment speedup
Self-Check: Answer
Which statement best summarizes the chapter’s central engineering lesson about deploying compressed models?
- Quantization is sufficient on its own, so structural and architectural techniques are secondary details in practice
- Model compression is best treated as a single technique chosen once per deployment target and applied uniformly
- The strongest deployment gains come from composing structural, precision, and architectural optimizations multiplicatively, while validating each gain on target hardware rather than trusting paper metrics
- Theoretical compression ratios are reliable enough that target-hardware profiling can be deferred to later operational phases
Answer: The correct answer is C. The summary reinforces both the multiplicative-composition thesis (BERT’s 16× compression required all three techniques) and the measurement discipline (theoretical ratios lie without hardware-aware validation). Framing quantization as sufficient ignores the 16×-vs-4× evidence directly, treating compression as a single lever contradicts the three-dimensional framework the chapter builds, and deferring profiling is the exact failure mode the Fallacies section warned against.
Learning Objective: Identify the chapter’s synthesis thesis combining multiplicative composition with on-target validation
Explain why the chapter frames model compression as the bridge between benchmark-winning models and deployable systems, using the chapter’s own quantitative anchors to ground the argument.
Answer: Benchmark winners are sized for research environments: a 7-billion-parameter FP16 LLM needs 14 GB of weights alone, yet a smartphone provides 8 GB of shared RAM, so without renegotiating the silicon contract the model simply cannot run. Compression systematically trades unneeded capacity for fit, latency, and energy — pruning removes surplus parameters, quantization reduces bit-width per parameter, and architectural efficiency aligns execution with hardware, together producing the 10× to 50× reductions the chapter demonstrates on BERT and MobileNet. The practical implication is that deployment viability is a systems outcome, not an accuracy outcome: a model that wins a benchmark but misses its latency, memory, or power envelope has zero utility until compression makes it fit the physical environment it must run in.
Learning Objective: Explain how model compression converts benchmark-grade models into deployable systems by renegotiating the silicon contract