Data Selection
Purpose
Why can a carefully selected 10 percent of a dataset match the accuracy of the full 100 percent?
The highest-impact optimization in machine learning operates upstream, before a single gradient is computed: on the data itself. Naive scaling assumes data is homogeneous, that every sample contributes equally to learning, but reality differs dramatically: in large-scale datasets, a tiny fraction of examples provides the majority of the gradient signal while the vast majority are redundant, noisy, or misaligned with the target distribution. This heterogeneity is not a statistical artifact but a systems optimization opportunity: data engineering established that data is the source code of ML systems, and data selection recognizes that not all source code is equally valuable. Where compressing models and accelerating hardware speed up the execution of work, data selection reduces the core workload itself, so a training run that takes a week on the full dataset might take a day on a strategically selected subset, and that savings compounds through every iteration of the development cycle, from faster experimentation to quicker response to distribution drift to lower barriers for teams with limited compute budgets. The shift is paradigmatic: from accumulating data as a massive liability to curating it as a precise resource, where every sample earns its place by contributing learning signal that no other sample provides. In D·A·M terms, that curation is a direct application of data-algorithm co-design: the dataset shaped deliberately to raise the statistical efficiency of the learning process.
Learning Objectives
- Explain data selection as data-algorithm co-design that reduces total operations before training begins
- Calculate information-compute ratio to decide whether additional examples improve learning per FLOP
- Compare deduplication, coreset selection, and quality pruning for reducing redundant pretraining data
- Design curriculum, active learning, or synthetic-data strategies for changing data value during training
- Apply the selection inequality to test whether selection overhead beats full-dataset training cost
- Evaluate distributed selection pipelines against storage locality, consistency, and GPU utilization constraints
- Select data-selection investments using ROI, amortization, and compute-optimal frontier diagnostics
Data Selection Fundamentals
Training pays the iron-law cost for every example it processes, but not every example returns learning signal worth that cost. Data selection gives a clean, well-engineered dataset a systems objective: keep the examples that contribute the most learning per unit of compute. Data engineering makes the dataset reliable through correct labels, consistent schemas, and governed records. Data selection optimizes the dataset’s value by extracting maximum learning from minimum samples, directly shrinking the total operations \((O)\) term in the iron law (principle 3). The distinction matters: quality asks whether data is correct, while value asks whether correct data is worth the compute spent processing it.

Compute supply can outrun high-quality data supply.
1 Scaling Laws: Jared Kaplan and colleagues at Johns Hopkins and OpenAI empirically demonstrated in 2020 that language model loss follows power-law relationships with model size, dataset size, and compute budget, each with predictable exponents. For data selection, the key consequence is quantitative: loss scales as \(\mathcal{L} \propto D^{-\alpha}\) with \(\alpha \approx 0.095\), meaning each doubling of data yields diminishing returns—making it possible to reason about when selection becomes more cost-effective than collection.
2 Data Wall: Unlike compute (which scales with capital expenditure) or algorithms (which improve through research), the stock of high-quality human-generated text grows slowly. Epoch AI’s 2022 projections estimated that, under the paper’s modeled consumption assumptions, high-quality language data could be exhausted within one to two decades of the 2022 publication date (Villalobos et al. 2022). The point for systems design is not a fixed calendar deadline; it is that data can become a supply constraint rather than merely an economic one. This constraint directly affects the total operations \((O)\) term: when quality data becomes scarce, additional compute yields diminishing returns regardless of hardware throughput.
Villalobos, Pablo, Anson Ho, Jaime Sevilla, Tamay Besiroglu, Lennart Heim, and Marius Hobbhahn. 2022. “Will We Run Out of Data? Limits of LLM Scaling Based on Human-Generated Data.” arXiv Preprint arXiv:2211.04325.
For decades, the dominant strategy was straightforward: more data, better models. Scaling laws1 (Kaplan et al. 2020; Hoffmann et al. 2022) confirmed that model performance improves predictably with dataset size, and teams responded rationally by scraping more web pages, labeling more images, and generating more synthetic examples. A critical asymmetry has since emerged. Accelerator fleets can expand usable compute faster than the supply of novel, high-quality human-generated text and images. Much of the easily accessible public web has already been incorporated into large training corpora, and expert labeling capacity grows slowly. This asymmetry is the Data Wall2, and it has inverted the optimization priority from “get more data” to “get more from existing data.” The engineering response is a selection discipline: static and dynamic methods choose which examples to train on, self-supervised and synthetic approaches manufacture value when labeled data runs short, and cost models determine when selection is worth its overhead.
GPU compute scales roughly 10× every 3 years, while high-quality labeled data grows far more slowly (table 1).
| Resource | Growth Rate | Implication |
|---|---|---|
| GPU Compute | ~10× / 3 years | Hardware throughput can rise quickly in a given era |
| Training Data (Web) | ~2× / 5 years | High-quality web text is finite; much already scraped |
| Labeled Data | ~1.5× / 5 years | Human annotation throughput is inherently bounded |
| Synthetic Data | Potentially large | Bounded by generator quality (models trained on model-generated data can degrade) |
Trace the trend line in figure 1: several foundation-model training datasets have grown toward the estimated stock of high-quality public text, with projections suggesting that unrestricted reuse of public human-generated text faces a finite supply. The exact exhaustion timeline depends on corpus definition, licensing, filtering, repetition policy, and synthetic-data practice; the systems lesson is that accessible high-quality data can become the binding resource even when compute remains available.

The gap between what compute can process and what accessible, high-quality data can support is therefore a systems variable, not a fixed law. Compute scales exponentially while accessible high-quality data does not (table 1), so in regimes where accelerator budgets outrun the corpus the system becomes compute-rich and data-constrained. Maintaining model relevance requires repeated refreshes of the training corpus as the world changes, and intelligent data selection becomes critical when data quality rather than accelerator time is the binding constraint.
The compute-data asymmetry can invert the optimization priority. When data is abundant and compute is scarce, the highest-leverage strategy is often algorithmic efficiency: squeeze more accuracy from limited GPU cycles. When compute is abundant and quality data is scarce, the highest-leverage strategy becomes data selection: squeeze more learning from each sample. Data selection operates upstream of all other optimizations. By pruning redundancy and selecting high-value samples, we reduce the workload before it ever enters the model or hits the hardware, directly shrinking the total operations \((O)\) term in the iron law. That is why the systems perspective treats selection as upstream workload reduction rather than a modeling heuristic. For teams whose accelerator budget exceeds their curated corpus, the bottleneck shifts from GPU access to the quality, legality, and diversity of the training data.
The engineering toolkit for intelligent data selection follows a deliberate optimization ordering: first ask whether a sample is worth processing, then ask how to process the remaining workload efficiently. Data selection puts the “largest return first” principle into practice by addressing whether work is necessary before asking how to simplify or accelerate it. The highest-return move comes first. Static pruning removes low-value samples before a single gradient is computed. Dynamic selection adapts the data diet during training through curriculum learning and active learning. Synthetic generation creates high-value samples through augmentation, simulation, or teacher-generated examples when real data runs short.
Each stage increases the information density of the data that reaches the model, and together they form a complementary toolkit: pruning reduces what the pipeline contains, selection focuses how the pipeline uses it, and synthesis expands what the pipeline can access. Before examining these techniques, we must formalize what “data selection” means, why it is inherently a systems problem, and how to measure its effectiveness.
Defining data selection
The three-stage pipeline needs a quantity that lets engineers compare samples before they spend accelerator time on them. A duplicated image, a mislabeled record, and a rare boundary case may all cost the same forward and backward pass, but they do not contribute the same learning signal. Data selection therefore starts by making sample value explicit relative to compute cost. We call that quantity the Information-Compute Ratio: learning signal gained per unit of training compute, formalized below.
Definition 1.1: Data selection
Data Selection is the process of maximizing the Information-Compute Ratio (ICR) of a training dataset.
- Significance: It identifies the smallest subset of data sufficient to define the decision boundary, reducing the total operations \((O)\) of the iron law by eliminating redundant or noisy samples from the dataset \(D\) before they consume GPU cycles.
- Distinction: Unlike data engineering, which focuses on the cleanliness and consistency of data, data selection focuses on the informativeness and diversity of the samples.
- Common pitfall: A frequent misconception is that more data is always better. In reality, it is the quality of the samples that matters: adding 10\(\times\) more low-quality data may yield less accuracy than 1.1\(\times\) carefully selected, high-quality data.
To make this concrete, consider training a model in the GPT-2/Llama Lighthouse family from Lighthouse roster: Model biographies, which spans the autoregressive large language model (LLM) family from GPT-2’s 1.5 billion parameters to Llama’s 7-70 billion parameter range, here using a 70-billion-parameter language model:
The compute budget (10,000 H100 GPUs for 3 months) represents roughly $86.4M at the chapter’s cloud-training price anchor and can process about 73.2T at 40 percent sustained MFU. Estimates of quality- and repetition-adjusted public human-generated text are on the order of 300T, far larger than a single curated web corpus. The practical bottleneck is narrower: how much of that stock is accessible, legally usable, high quality, deduplicated, and useful for the target distribution. If a team has only a 5T filtered corpus ready for use, the compute budget can already process it roughly 14.6× over. At that point, the team faces three options:
- Repeat epochs: The team can train on the same data for multiple epochs, but returns usually diminish after epochs 2–3.
- Lower quality thresholds: The team can include more data, but lower-quality tokens can degrade model quality.
- Invest in data selection: The team can improve filtering, curriculum design, and synthetic augmentation to extract more learning from each token.
Under these assumptions, the decision criterion favors selection over simply buying more accelerator time.
The data selection imperative applies across model architectures, though the bottlenecks differ. Unlike our compute-bound ResNet-50 Lighthouse, GPT-2/Llama models are memory bandwidth-bound during inference (though often compute-bound during training as well) and still benefit enormously from data selection during training. Each token processed requires the same forward/backward pass cost regardless of model bottleneck, so fewer tokens means fewer FLOPs. Because data selection benefits every architecture regardless of its dominant bottleneck, the appropriate framing is systemic rather than purely statistical.
Systems perspective
The data wall establishes why data selection matters; the systems perspective reveals how to approach it effectively. The conventional ML framing focuses on achieving the same accuracy with fewer samples, centering on statistical sample complexity and generalization theory. While valid, that framing misses the larger picture.
In this textbook, we adopt a data-selection systems framing that asks instead how to reduce the total cost of achieving target performance across the entire ML lifecycle. The shift moves attention from accuracy curves to resource consumption, as table 2 illustrates.
| ML Framing | Systems Framing |
|---|---|
| “Fewer samples for same accuracy” | “Fewer FLOPs for same accuracy” |
| “Better generalization” | “Lower training cost (time, money, energy)” |
| “Sample complexity bounds” | “End-to-end resource efficiency” |
| “Learning theory” | “Cost engineering” |
The systems framing reveals optimization opportunities invisible to the ML framing. To see why, consider how data selection interacts with the iron law introduced in Iron Law of ML Systems.
Systems Perspective 1.1: Data selection and the iron law
In the iron law of ML systems \((T = \frac{D_{\text{vol}}}{\text{BW}} + \frac{O}{R_{\text{peak}} \cdot \eta_{\text{hw}}} + L_{\text{lat}})\), data selection is the only technique that reduces the total operations term at its source. Later model-level optimizations reduce \(O\) per forward/backward pass, and machine-level optimizations increase \(R_{\text{peak}}\) (peak throughput) and \(\eta_{\text{hw}}\) (utilization). Data selection, by contrast, reduces the number of passes through the entire equation.
This makes data selection multiplicatively valuable in the iron law: when all three optimization layers act on the same bottleneck, a 2× reduction in dataset size with 2× fewer operations per sample and 2× higher effective throughput yields 8× total cost reduction, not 6×.
Consider training cost reduction: a 50 percent reduction in dataset size does not merely improve sample efficiency; it directly halves the number of forward passes, backward passes, and gradient updates. For a $100M training run, this translates to $50M in compute savings. The relationship is linear and immediate.
Compute savings cascade through the entire infrastructure stack. Large datasets consume petabytes of storage and saturate network bandwidth during distributed training; deduplication and coreset selection reduce storage costs while eliminating I/O bottlenecks that can idle expensive GPU clusters. The savings extend to labeling economics: expert labeling costs (from roughly 5 to more than 100 dollars per sample in domains like medical imaging) often exceed compute costs, and active learning and semi-supervised methods can substantially reduce labeling budgets in favorable regimes. The environmental implications compound further: for compute-dominated training runs, reducing the number of examples reduces energy consumption in proportion to the work avoided, provided the selected subset preserves accuracy. Smaller curated datasets also enable faster iteration velocity. A team that can iterate in hours rather than days has a compounding advantage in model development.
The cascading benefits illustrate a broader point: the ML researcher usually frames the problem as sample complexity, while the systems engineer frames it as cost-per-accuracy-point across the entire pipeline, from data acquisition through deployment. The systems engineer’s toolkit for that problem includes techniques to minimize total cost, metrics to quantify efficiency gains, and architectural patterns to implement data selection at scale.
Information-compute ratio
The systems framing established earlier calls for a quantitative metric. Data selection creates a frontier between accuracy and cost: keeping every example maximizes coverage but wastes compute on redundancy, while pruning too aggressively saves compute but loses signal. We need a way to measure where a sample sits on that frontier. The metric is the information each sample contributes to the model’s learning per unit of computation. We formalize it as the information-compute ratio.
Figure 2 recasts the D·A·M taxonomy as an optimization map, with data selection playing the role of input optimization: reducing total workload before it enters the model or hardware. The model side asks how much math each example requires. The machine side asks how quickly the hardware can execute that math. The data side asks whether the example should be processed at all. The three edges of the triangle capture the dominant bottlenecks: compute bound describes systems limited by arithmetic throughput, I/O bound describes systems limited by data movement, and sample efficiency describes systems limited by the information content of training data.

We can formalize this as the ICR, where \(I\) denotes information content: \[\text{ICR} = \frac{\Delta I}{\Delta \text{FLOPs}}\]
A higher ICR means each FLOP of training buys more learning; pushing it up is the goal of every technique in this chapter. The numerator is not directly observable in production, so engineers estimate it through proxies: validation improvement per unit compute, area under the learning curve, loss reduction on held-out data, uncertainty or gradient-based sample scores, and coverage checks on deployment-relevant slices. Those proxies are imperfect, but they make the systems question measurable before the training run spends its full budget.
The ICR frontier: When data becomes a tax

Past the frontier, data becomes a tax: compute climbs, learning stalls.
The Information-Compute Ratio is not constant; it follows a law of diminishing returns. We define the ICR Frontier as the point where the marginal learning signal from additional data drops toward zero.
Mathematically, let \(I(D)\) be the information content of a dataset of size \(D\). In a redundant dataset, \(I(D)\) often scales logarithmically (\(\log D\)) while the compute cost \(C(D)\) scales linearly with the per-sample operation count \(O_{\text{sample}}\): \(C(D) = O_{\text{sample}} \cdot D\). The resulting ICR follows equation 1: \[\text{ICR}(D) = \frac{\frac{d}{dD} I(D)}{\frac{d}{dD} C(D)} \approx \frac{1/D}{O_{\text{sample}}} = \frac{1}{O_{\text{sample}} \cdot D} \tag{1}\]
The \(1/(O_{\text{sample}} \cdot D)\) decay creates what we call the data wall. Beyond the frontier, adding more data yields near-zero learning but still costs linear compute. In this regime, data is no longer an asset; it is a data tax that inflates the \(O\) term of the iron law without improving the accuracy numerator of the RoC (return on compute, see The economic invariant: Return on compute (RoC)). A systems engineer’s goal is to keep the system operating at the “knee” of the ICR curve, where the learning signal per FLOP is maximized. The static and dynamic selection techniques that follow are designed to achieve exactly that.
The “Data selection and the iron law” callout shows that data selection turns the total operations \((O)\) term from a fixed constant into a variable. By maximizing ICR, we reduce the total FLOPs required to reach a target performance level. A 2\(\times\) improvement in ICR is mathematically equivalent to a 2\(\times\) improvement in hardware peak throughput \((R_{\text{peak}})\), but often much cheaper to achieve. ICR focuses specifically on compute; the cost-modeling framework in section 1.8 extends the same reasoning to acquisition, labeling, and storage costs.
A random batch of raw data often has low ICR: it contains redundant examples, noisy samples, or “easy” examples the model has already mastered, wasting GPU cycles on zero-information updates. High-efficiency data pipelines (figure 3) maximize ICR through three stages, static pruning before training, dynamic selection during training, and synthetic generation on demand, ensuring that every FLOP contributes to learning. To illustrate, consider computing ICR on a concrete coreset selection task: a deliberately selected subset intended to preserve the full dataset’s learning signal. Section 1.2.2 defines the EL2N and GraNd scoring methods used to build such subsets, and section 1.11 provides the complete measurement framework for evaluating these efficiency gains, including the compute-optimal frontier diagnostic that determines whether training is data-starved or compute-starved.

With the ICR framework established, we can verify understanding of its core mechanics.
Checkpoint 1.1: Data selection efficiency
The goal of data selection is to maximize the ICR.
Metric checks:
Pipeline check:
The practical question is how large the efficiency gap becomes on a real workload, where dataset size, model cost, and selection strategy interact with concrete FLOP budgets. A ResNet-50 training run on ImageNet provides the numbers: the dataset is large enough for coreset selection to matter, and the model’s compute-bound profile means that reducing dataset size translates almost linearly into reduced training FLOPs.
Napkin Math 1.1: Computing ICR: Coresets
Problem: Training the ResNet-50 Lighthouse model from Lighthouse roster: Model biographies on ImageNet for one epoch costs 1.58 × 10¹⁶ FLOPs. If an EL2N-based coreset (EL2N, or Error L2-Norm, scores each sample by how uncertain the model’s prediction is; defined formally in section 1.2.2) retains only 50 percent of the data, how much does the information-compute ratio improve over random selection? ResNet-50’s compute-bound nature (high arithmetic intensity, which The roofline model places firmly in the compute-bound regime) makes it an ideal candidate: reducing dataset size directly reduces training FLOPs with minimal I/O impact.
Setup:
- Dataset: ImageNet (1.28M)
- Model: ResNet-50 Lighthouse (~4.1 GFLOP per forward pass, roughly 12.3 GFLOP for a forward plus backward training step, depending on implementation)
- One epoch: 1.28M \(\times\) 12.3 GFLOP = 1.58 × 10¹⁶ FLOPs
- Accuracy improvement per epoch (early training): ~5 percentage points
Random selection (baseline):
- Process all 1.28M samples uniformly
- Accuracy gain: 5 percentage points
- \(\text{ICR}_{\text{random}}\) = 5 percentage points / (1.58 × 10¹⁶ FLOPs) = 3.2 × 10⁻¹⁶ per FLOP
EL2N coreset (50 percent of data):
- Process 640.6K high-uncertainty samples selected by EL2N scoring
- Coreset focuses on decision boundary samples
- Accuracy gain: 4.5 percentage points (90 percent of full data performance)
- Compute: 640.6K \(\times\) 12.3 GFLOP = 7.9 × 10¹⁵ FLOPs
- \(\text{ICR}_{\text{coreset}}\) = 4.5 percentage points / (7.9 × 10¹⁵ FLOPs) = 5.7 × 10⁻¹⁶ per FLOP
Systems insight: The coreset achieves 1.8× higher ICR, nearly twice the learning per FLOP, by eliminating low-information “easy” samples that contribute little to the decision boundary. The 0.5 percentage points accuracy difference is often acceptable given the 50 percent compute savings.
The three-stage optimization pipeline (static pruning, dynamic selection, and synthetic generation) provides the concrete techniques for maximizing ICR. Static pruning, the first stage, can reduce a dataset by 30 to 50 percent before training even begins.
Self-Check: Question
A team is deciding whether to invest engineering effort in curating their training corpus or in buying faster accelerators. Under the iron law of ML systems, which term of the equation does data selection most directly shrink?
- Peak throughput \(R_{\text{peak}}\), because curated data is processed at higher FLOP/s than raw data.
- Latency \(L_{\text{lat}}\), because shorter datasets eliminate data-loading orchestration overhead.
- Utilization \(\eta_{\text{hw}}\), because cleaner samples produce denser kernels with fewer memory stalls.
- Total Operations \(O\), because removing low-value samples reduces the number of forward and backward passes that must ever execute.
A 70-billion-parameter language-model team has enough H100 capacity to process tens of trillions of tokens in three months, but deduplicated high-quality tokens in their corpus total only about 5 trillion. Explain why buying twice as many H100s does not solve their problem, and identify what kind of investment closes the gap.
Two pretraining runs reach the same validation loss: Run X uses \(2\times 10^{22}\) FLOPs and Run Y uses \(4\times 10^{22}\) FLOPs. Under the Information-Compute Ratio framework, which statement is correct?
- Run Y has higher ICR because more FLOPs means the model saw more information.
- Run X has higher ICR because the same performance gain was delivered per half the compute.
- ICR is undefined because it requires the runs to share model architecture and batch size.
- Both runs have identical ICR because ICR measures final accuracy, independent of cost.
Order the following stages of the chapter’s three-stage data selection pipeline by the point in the training lifecycle at which each operates: (1) synthetic generation fills gaps where real data is scarce, (2) static pruning removes low-value samples before training begins, (3) dynamic selection adapts the data diet as the model learns.
True or False: A deduplicated, schema-validated, perfectly-labeled dataset is guaranteed to deliver high Information-Compute Ratio during training.
Static Pruning
The first stage of the pipeline acts entirely before training begins, removing low-value samples so that fewer of them ever reach the model. Static pruning and pretraining filtration reduce total computation without affecting, and sometimes improving, final model accuracy, all without modifying the training loop or model architecture.
The case for smaller datasets
The most counterintuitive finding in data selection is that training on less data often produces models just as accurate as training on the full dataset. Practitioners have long assumed that more data yields better performance, and while this holds in many scenarios, it obscures a critical reality: typical large-scale datasets contain massive redundancy. Empirical studies on coreset selection and data pruning have consistently demonstrated this redundancy across standard benchmarks.
On CIFAR-10, gradient-based selection methods (EL2N, GraNd) (Paul et al. 2021) have shown that training on 50 percent of carefully selected samples matches the accuracy of the full dataset, with aggressive pruning reaching 10–30 percent of samples while retaining over 90 percent of original performance. ImageNet-1K presents a harder challenge because it is less redundant: a representation-based prototype metric, later understood as a self-supervised approach, can discard 20 percent of ImageNet without sacrificing performance, with training on 80 percent of ImageNet approximating training on the full dataset (Sorscher et al. 2022). The pattern extends to language modeling: web-scraped corpora like The Pile3 and C44 have enough duplicate and templated content to make deduplication a systems issue. In datasets studied by Lee et al., approximate near-duplicate removal affected 3.04 percent of C4 and 13.63 percent of RealNews, and deduplicated training reduced memorization while preserving or improving perplexity (Lee et al. 2021).
Sorscher, Ben, Robert Geirhos, Shashank Shekhar, Surya Ganguli, and Ari S. Morcos. 2022. “Beyond Neural Scaling Laws: Beating Power Law Scaling via Data Pruning.” Advances in Neural Information Processing Systems 35 35: 19523–36. https://doi.org/10.52202/068431-1419.
3 The Pile: An 825 GB English text corpus aggregating twenty-two sub-datasets, including PubMed, ArXiv, GitHub, Project Gutenberg, Common Crawl, Stack Exchange, Wikipedia, and USPTO patents (Gao et al. 2020). Its multi-source design makes it a useful example of data diversity: each source family has a different duplication, quality, and domain-coverage profile, so selection pipelines must preserve coverage while removing redundant text.
Gao, Leo, Stella Biderman, Sid Black, Laurence Golding, Travis Hoppe, Charles Foster, Jason Phang, et al. 2020. “The Pile: An 800GB Dataset of Diverse Text for Language Modeling.” arXiv Preprint arXiv:2101.00027.
4 C4 (Colossal Clean Crawled Corpus): Applies aggressive filtering to Common Crawl data, removing pages with fewer than five sentences, deduplicating repeated three-sentence spans, and stripping boilerplate, JavaScript, and non-English content to produce approximately 750 GB of cleaned text (Raffel et al. 2020). C4 demonstrated that filtering web data at scale could match curated dataset quality, establishing the “large-scale-with-filters” paradigm. The systems trade-off is direct: the CPU cost of filtering is negligible compared to the GPU cost of training on the unfiltered equivalent, making quality pruning one of the highest-ROI pretraining investments.
Raffel, C., N. Shazeer, A. Roberts, K. Lee, S. Narang, M. Matena, Y. Zhou, W. Li, and P. J. Liu. 2020. “Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer.” Journal of Machine Learning Research 21 (140): 1–67.
The reported gains are benchmark-specific. Pruning effectiveness depends on the dataset’s intrinsic redundancy, the selection algorithm, and the model architecture; always validate on the specific task before deploying aggressive pruning in production. The key insight remains: not all data points provide equal value for training.
This heterogeneity follows from how neural networks learn decision boundaries. Most samples fall far from any class boundary: a picture of a dog in good lighting is unambiguously a dog. These “easy” examples provide diminishing returns after the first few epochs because the model has already mastered them. The informative samples cluster near boundaries where classes become ambiguous. Beyond sample redundancy, label quality also dramatically affects data requirements. A quick calculation quantifies the data quality multiplier: how label noise penalizes convergence.
Napkin Math 1.2: The data quality multiplier
Problem: How much more noisy data does it take to reach the same target error as clean data?
Math: Classical learning theory (for convex optimization with SGD) ties convergence rate to label noise, and while deep learning operates in a nonconvex regime, the qualitative relationship holds broadly. Clean data converges at \(\mathcal{O}(1/D)\), so halving the error needs 2\(\times\) data and the sample budget scales as \(D_{\text{clean}} \propto 1/\epsilon\). Noisy data converges at \(\mathcal{O}(1/\sqrt{D})\), so halving the error needs 4\(\times\) data and the budget scales as \(D_{\text{noisy}} \propto 1/\epsilon^2\). For target error \(\epsilon\) = 0.01 (1 percent):
- \(D_{\text{clean}}\) ≈ 100
- \(D_{\text{noisy}}\) ≈ 10,000
Result: Noisy data requires 100× more samples to reach the same target error, so one clean sample provides as much learning signal as 100 noisy ones.
Systems insight: Cleaning the dataset (removing label noise) is a 100× compute accelerator.
Coreset selection algorithms
The practical question then becomes how to identify which samples to keep. Coreset selection5 turns the static pruning decision into a coverage problem: keep the smallest subset that preserves the statistical properties of the entire dataset.
5 Coreset (Core Set): The method’s guarantee comes from computational geometry, where a small subset of points is proven to approximate geometric properties of the full set within a controlled error factor (Agarwal et al. 2005). In machine learning, this idea is adapted as a selection principle: preserve enough statistical structure that training on the retained subset approximates training on the full dataset. This provable-bound lineage is the critical distinction from random downsampling, which offers no such guarantee; it is what motivates trading much of the dataset for a fraction of the compute without accepting unbounded accuracy risk.
Agarwal, Pankaj K., Sariel Har-Peled, and Kasturi R. Varadarajan. 2005. “Geometric Approximation via Coresets.” In Combinatorial and Computational Geometry, edited by Jacob E. Goodman, János Pach, and Emo Welzl, vol. 52. MSRI Publications. Cambridge University Press. https://doi.org/10.1017/9781009701259.002.
The systems decision is where to spend the selection budget: on cheap coverage metrics that preserve distributional structure, or on costlier training-dynamics scores that better target the decision boundary. The decision also needs a guardrail before any score is applied: classes, demographic groups, time windows, and rare failure modes that matter at deployment require minimum representation, because the highest-average-ICR subset can still remove the examples that define production risk.
Geometry-based methods select samples that cover the data distribution without requiring any model training. The \(k\)-Center algorithm6, a facility-location-style coverage objective, selects samples that minimize the maximum distance from any point to its nearest selected center, ensuring coverage of the entire data manifold.
6 k-Center Algorithm: Its greedy strategy directly explains the coverage guarantee: it iteratively picks the point farthest from any existing center, forcing the selection to expand into uncovered regions of the data manifold. Sener and Savarese use this core-set framing for convolutional neural-network active learning (Sener and Savarese 2018). The geometric purity is also the weakness; by ignoring class labels, it can undersample rare but critical examples near a decision boundary, making its coverage approximation a poor proxy for downstream model accuracy.
Sener, Ozan, and Silvio Savarese. 2018. “Active Learning for Convolutional Neural Networks: A Core-Set Approach.” International Conference on Learning Representations.
Welling, Max. 2009. “Herding Dynamical Weights to Learn.” Proceedings of the 26th Annual International Conference on Machine Learning, 1121–28. https://doi.org/10.1145/1553374.1553517.
Herding takes a different approach, iteratively selecting samples whose features best approximate the mean of the full dataset, thereby maintaining distributional fidelity (Welling 2009). These methods are computationally attractive because they operate purely on feature representations, but they ignore label information entirely.
Gradient-based methods offer higher selection quality by using training dynamics to identify important samples, though they require training a proxy model first. GraNd (Gradient Normed) and EL2N (Error L2-Norm)7 score samples by gradient magnitude or prediction error early in training (Paul et al. 2021); high-scoring samples lie near the decision boundary and are most informative for learning. Crucially, these scores transfer across architectures: scores computed on a smaller model like ResNet-18 predict importance for larger models like ResNet-50, enabling inexpensive proxy-based selection. Forgetting Events8 tracks how often a sample is “forgotten” (correctly classified, then later misclassified) during training, identifying harder and more valuable examples (Toneva et al. 2019).
7 EL2N (Error L2-Norm) and GraNd (Gradient Normed): These methods score samples based on their error or gradient norm early in training, identifying samples the model finds most difficult. The practicality of this approach relies on transferability, where scores from a small proxy model can guide data selection for a much larger target model. For instance, a proxy trained for just five epochs can generate scores to curate a dataset for a full 90-epoch production training run.
Paul, Mansheej, Surya Ganguli, and Gintare Karolina Dziugaite. 2021. “Deep Learning on a Data Diet: Finding Important Examples Early in Training.” Advances in Neural Information Processing Systems 34: 20596–607.
8 Forgetting Events: This method identifies valuable examples by tracking when the model “forgets” them—transitioning from a correct to an incorrect classification during training. The central trade-off is the high cost of this analysis, which requires a full training run. However, the resulting importance scores transfer reliably from small proxy models to large target models (for example, ResNet-18 to ResNet-50), which is precisely what makes the “inexpensive proxy-based selection” strategy viable.
Toneva, Mariya, Alessandro Sordoni, Remi Tachet des Combes, Adam Trischler, Yoshua Bengio, and Geoffrey J Gordon. 2019. “An Empirical Study of Example Forgetting During Deep Neural Network Learning.” International Conference on Learning Representations.
Gradient-based approaches generally outperform geometry-based methods in selection quality but incur the overhead of proxy model training. Table 3 should be read as a selection-budget table: higher-quality scores buy more information per sample, but only if their scoring cost stays below the compute they save.
| Method | Compute Cost | Requires Training | Best For | Limitation |
|---|---|---|---|---|
| k-Center | \(\mathcal{O}(D^2)\) or \(\mathcal{O}(DK)\) | No | Coverage, exploration | Ignores label information |
| Herding | \(\mathcal{O}(DK)\) | No | Distribution matching | Assumes Gaussian-like |
| GraNd | \(\mathcal{O}(\text{epochs} \times D)\) | Yes (few epochs) | Decision boundaries | Requires proxy training |
| Forgetting | \(\mathcal{O}(\text{full training})\) | Yes (full) | Hard examples | Expensive to compute |
| EL2N | \(\mathcal{O}(\text{epochs} \times D)\) | Yes (few epochs) | Uncertainty sampling | Best with proxy model |
Each algorithm in table 3 occupies a different point in the ICR framework’s compute-vs.-information trade-off, determining how the selection budget is spent to maximize learning signal per FLOP. Figure 4 makes the core insight behind coreset methods concrete. Compare the two panels: random sampling (left) selects points uniformly across the feature space, capturing many samples deep within class regions where the model is already confident. Coreset selection (right) concentrates the selection budget on samples near the decision boundary, the dashed diagonal that separates the two classes, where the model’s predictions are most uncertain. The yellow band is the uncertainty margin straddling that boundary, and these boundary samples are precisely where additional training provides the most learning signal.

Given these trade-offs, most practitioners find that EL2N with a small proxy model offers the best balance of selection quality and computational cost. The approach is straightforward: train a lightweight model (for example, ResNet-18 instead of ResNet-50) for five to ten epochs, compute EL2N scores for all samples, then select the highest-scoring subset. The proxy does not need to be accurate; it only needs to identify which samples are hard. This upfront investment in proxy training typically yields substantial returns when the coreset reduces subsequent training by 50 percent or more. A concrete scenario illustrates this workflow.
Example 1.1: Coreset selection in practice
Context: A team has 1 million training images and wants to reduce to 100,000 (10 percent) for faster experimentation.
Insight: Random sampling loses rare classes and edge cases. Instead, a coreset approach focuses on the most informative samples:
- Train a small proxy model for 5 epochs
- Compute EL2N scores for all samples
- Select the 100,000 samples with highest uncertainty
- Train the full model on this coreset
Systems insight: The coreset often achieves higher accuracy than random sampling because it focuses on the decision boundary rather than redundant “easy” examples.
Listing 1 demonstrates how to compute EL2N scores and select a coreset using a lightweight proxy model. The mechanism spends a small amount of probe compute to identify high-uncertainty samples near the decision boundary, then trains the full model on the retained subset rather than on redundant easy examples.
compute_el2n_scores function trains a small model for a few epochs, then measures prediction confidence via L2 distance from one-hot labels. High scores indicate uncertain samples near decision boundaries. The select_coreset function retains only these informative samples, discarding redundant easy examples.
def compute_el2n_scores(model, dataloader, num_epochs=5):
"""Compute EL2N scores.
Returns L2 norm of (prediction - one_hot_label).
"""
# Train proxy model for a few epochs to get meaningful predictions
train_proxy(model, dataloader, num_epochs)
scores = []
model.eval()
for x, y in dataloader:
logits = model(x)
probs = softmax(logits, dim=1)
# One-hot encode labels
one_hot = zeros_like(probs).scatter_(1, y.unsqueeze(1), 1)
# EL2N score = L2 distance from confident prediction
el2n = (probs - one_hot).norm(dim=1) # High = uncertain
scores.extend(el2n.tolist())
return scores
def select_coreset(scores, dataset, fraction=0.1):
"""Select top-k highest-scoring (most uncertain) samples."""
k = int(len(dataset) * fraction)
# Sort by score descending (highest uncertainty first)
indices = argsort(scores, descending=True)[:k]
return Subset(dataset, indices)
# Usage: 10x data reduction with minimal accuracy loss
scores = compute_el2n_scores(proxy_model, full_loader)
coreset = select_coreset(scores, full_dataset, fraction=0.1)
train_full_model(model, coreset) # 10x faster trainingProxy scoring turns uncertainty into reusable selected indices: compute_el2n_scores measures which samples still confuse a briefly trained model, and select_coreset retains those high-information examples for the full training run.
Data deduplication
While coreset selection identifies which samples to keep based on their informativeness, a complementary approach targets duplicate samples that add compute without adding learning signal. Deduplication can provide immediate efficiency gains, especially for exact and near-duplicates, and requires no model training. This makes it one of the most accessible optimizations in data selection, but near-duplicate thresholds must be validated so the pipeline does not remove useful distributional signal.
The simplest form of deduplication (introduced as a data engineering pipeline stage in Systematic Data Processing, and here elevated to an optimization lever) uses hash-based methods for exact matches. By computing a cryptographic hash (MD5 or SHA-256) for each sample and removing those with identical hashes, practitioners can eliminate byte-for-byte duplicates that inevitably accumulate in large web-scraped corpora. This process is computationally cheap, scaling linearly with dataset size, and can be parallelized trivially.
Near-duplicate detection addresses the more subtle problem of semantically redundant content that differs at the byte level. For text, MinHash9 with Locality-Sensitive Hashing10 (LSH) approximates Jaccard similarity11 efficiently, detecting paraphrased or lightly edited content. The core idea is to create compact “fingerprints” of each document such that similar documents produce similar fingerprints with high probability, enabling fast approximate similarity detection without comparing every document pair.
9 MinHash: Invented by Broder (1997) to detect duplicate web pages for AltaVista, the algorithm creates compact “signatures” using random hash functions such that similar documents produce similar signatures with high probability. Each signature compresses a document to a fixed-size sketch (typically 128–256 hash values), enabling similarity estimation between any two documents in \(\mathcal{O}(1)\) time. For ML pretraining pipelines processing billions of documents, MinHash reduces deduplication storage from terabytes of raw text to gigabytes of signatures.
Broder, A. Z. 1997. “On the Resemblance and Containment of Documents.” Proceedings. Compression and Complexity of SEQUENCES 1997 (Cat. No.97TB100171), 21–29. https://doi.org/10.1109/sequen.1997.666900.
10 Locality-Sensitive Hashing (LSH): LSH works by hashing MinHash document fingerprints into buckets such that similar fingerprints are highly likely to collide. This probabilistic bucketing avoids the quadratic cost of comparing every document pair, directly enabling the efficiency described. The core trade-off is that tuning for higher recall (fewer missed duplicates) by using more hash functions increases computational cost, shifting the problem from an infeasible \(\mathcal{O}(D^2)\) complexity toward a manageable \(\mathcal{O}(D)\).
11 Jaccard Similarity: Defined as \(|A \cap B| / |A \cup B|\), ranging from 0 (disjoint) to one (identical). For deduplication, the metric’s set-based formulation naturally handles documents of different lengths without normalization. The practical threshold matters: setting Jaccard similarity above 0.8 catches near-duplicates while preserving legitimately similar-but-distinct content, but lowering it below 0.5 risks collapsing topically related documents and reducing dataset diversity.
12 CLIP (Contrastive Language-Image Pretraining): Pretrained on 400 million image-text pairs, CLIP maps visually distinct but semantically similar images to a shared embedding space, enabling semantic deduplication across visual concepts. This capability comes at a cost: generating an embedding requires a full forward pass through a large vision transformer, making it over 100\(\times\) more computationally expensive per sample than perceptual hashing.
Radford, Alec, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, et al. 2021. “Learning Transferable Visual Models from Natural Language Supervision.” International Conference on Machine Learning, 8748–63.
For images, perceptual hashing produces signatures robust to minor transformations like resizing and compression, identifying visually identical images stored in different formats. Embedding-based similarity offers the highest-fidelity detection by computing dense representations (CLIP12 (Radford et al. 2021) for images, sentence transformers for text) and clustering similar items, though this approach incurs higher computational overhead.
Foundation model pretraining now treats deduplication as essential. Studies on GPT-3 and LLaMA training demonstrate that deduplicated data improves both training efficiency and downstream performance by preventing memorization of repeated content. Deduplication delivers two gains: fewer wasted FLOPs on redundant samples, and better generalization because the model sees more diverse examples per training token.
Deduplication benefits extend beyond text corpora. The DLRM lighthouse presents a unique variant of this challenge centered on embedding deduplication.
Lighthouse 1.1: DLRM and embedding deduplication
Our DLRM Lighthouse model from Lighthouse roster: Model biographies is memory capacity-bound, with embedding tables consuming terabytes of storage for billions of user/item IDs. Much of this capacity is wasted on cold embeddings, IDs that appear rarely in training data.
Data selection for DLRM focuses on interaction deduplication (removing redundant user-item pairs) and embedding pruning (removing or sharing cold embeddings). A 20 percent reduction in unique interactions can reduce embedding table size by 30–40 percent, directly addressing DLRM’s primary bottleneck: memory capacity rather than compute.
Data pruning by quality
Deduplication removes redundant samples, but a third category of problematic data remains: samples that actively harm learning. Quality-based pruning eliminates samples that either contribute no meaningful signal or introduce contradictory information that confuses the optimization process.
Label error detection represents the most impactful form of quality pruning. Tools like Cleanlab identify samples where the assigned label is likely incorrect based on model confidence patterns across training. A sample that the model consistently predicts as class A but is labeled class B either represents a hard case near the decision boundary or, more commonly, an annotation mistake. Removing or correcting these mislabeled samples prevents the model from learning contradictory signals that degrade its decision boundary.
Outlier removal addresses a different pathology: samples far from any cluster center in feature space. While outliers might represent valuable edge cases, they more often indicate noise, annotation errors, or data corruption. The key is distinguishing between informative outliers (rare but valid examples of a class) and noise (samples that do not belong to any class). Conservative thresholds help avoid discarding genuinely rare examples.
Low-information filtering applies domain-specific heuristics to remove samples that lack sufficient signal for learning. For text corpora, this often means removing high-perplexity garbled text (perplexity is a language model’s measure of how surprising a text is, so high values flag incoherent strings) and, in some pipelines, very low-perplexity boilerplate or repetitive text. For image datasets, filtering targets blurry, corrupted, or near-uniform samples that provide little visual information.
Together, these three static pruning techniques—coreset selection, deduplication, and quality filtering—show that careful curation before training yields significant efficiency gains. The compute savings are multiplicative across the entire training process: a 50 percent dataset reduction means 50 percent fewer forward passes, backward passes, and gradient updates across all training epochs. For a model trained for 100 epochs, this translates to 50 epochs worth of saved compute, yielding substantial reductions in both training time and energy consumption.
Static pruning answers a question about what to keep, but it treats the answer as fixed. Once the pruned dataset is set, every epoch trains on the same subset. The optimal training samples, however, change as the model learns: examples that challenge an undertrained model become trivially easy after sufficient gradient updates. Dynamic selection techniques address this limitation by adapting the training data at each stage based on what the model has already mastered.
Self-Check: Question
Why can a 10 percent coreset of a modern vision dataset sometimes match the full dataset’s top-1 accuracy within one percentage point, despite training on a tenth of the samples?
- Because neural networks discard most examples after the first epoch, so any random 10 percent subset works equally well.
- Because smaller datasets eliminate overfitting regardless of the selection method used.
- Because pruning triggers an architecture change in modern frameworks that compensates for the reduced data volume.
- Because large datasets contain substantial easy-example redundancy and some noisy samples, while boundary and high-information examples dominate the learning signal.
A vision team wants the highest coreset quality for a 100M-image dataset and is willing to pay roughly 1 percent of full-target-model training cost on upfront scoring. Which selection method best matches this budget and quality target?
- Exact-match deduplication hashing alone, because hashes directly identify the decision-boundary samples that matter most for accuracy.
- k-Center geometric coverage without any training signal, because the method is the cheapest to run and treats all classes symmetrically.
- EL2N scores computed with a small proxy model early in training, because early-training error norms locate decision-boundary samples and transfer well to larger targets.
- Full-dataset forgetting-event analysis run on the target model itself, because only target-model dynamics give trustworthy importance scores.
The chapter argues that noisy-label convergence scales as \(\mathcal{O}(1/\sqrt{N})\) while clean-label convergence scales as \(\mathcal{O}(1/N)\). Using the chapter’s own order-of-magnitude figures, explain why investing engineering effort to remove label noise can save more compute than buying faster accelerators.
An engineering team wants immediate pretraining-cost savings with near-zero risk of hurting downstream accuracy. Which static-pruning technique matches that risk profile, and why?
- Deduplication, because removing exact and near-duplicate samples cuts wasted compute without altering the supervision distribution the model sees.
- Forgetting-events selection on the full training dynamics, because it produces the most-reliable per-sample scores.
- Aggressive outlier removal below the fifth percentile of embedding density, because rare samples tend to be noise.
- High-confidence pseudo-labeling on web-scraped unlabeled data, because pseudo-labels are always lower risk than real labels.
A fraud-detection dataset has 1 million benign transactions and 2,000 fraud transactions. A naive top-EL2N coreset at 10 percent produces a subset with only 60 fraud examples, and the deployed model’s recall on fraud collapses from 82 percent to 34 percent. Explain the failure and propose the corrected selection strategy.
Dynamic Selection
Early in training, a model benefits from broad, easy coverage that builds stable feature representations. Later, those same examples produce little new gradient signal, while harder samples near the decision boundary become more valuable for refinement. Dynamic selection exploits this changing information-compute ratio by adapting the data diet to the model’s current state.
Curriculum learning: Easy to hard
The first dynamic selection technique, curriculum learning13 (Bengio et al. 2009; Soviany et al. 2022), structures the order in which data is presented to the model. Instead of random shuffling, it starts with simpler examples and gradually introduces more complex ones, mirroring how humans learn by mastering basics before advancing to harder material.
13 Curriculum Learning: From Latin currere (“to run”), originally meaning “the course to be run”—a metaphor that maps directly to the technique: training data as a course run in deliberate order, easy stretches first. The key insight is that curriculum learning acts as a continuation method for nonconvex optimization: starting with easy examples smooths the loss landscape, helping the optimizer find better local minima. From a systems perspective, the ICR varies within a training run—easy samples have high ICR early but near-zero ICR later—which is precisely why presenting them first and phasing them out improves total compute efficiency.
Bengio, Yoshua, Jérôme Louradour, Ronan Collobert, and Jason Weston. 2009. “Curriculum Learning.” Proceedings of the 26th Annual International Conference on Machine Learning, 41–48. https://doi.org/10.1145/1553374.1553380.
Soviany, Petru, Radu Tudor Ionescu, Paolo Rota, and Nicu Sebe. 2022. “Curriculum Learning: A Survey.” International Journal of Computer Vision 130 (6): 1526–65. https://doi.org/10.1007/s11263-022-01611-x.
The effectiveness of curriculum learning stems from how neural networks respond to gradient signals at different training stages. Easy examples provide clear, consistent gradients that establish strong feature representations early in training, when the loss landscape is highly irregular. Hard examples introduced too early produce noisy gradient signals that slow convergence or cause the model to memorize outliers rather than learn general patterns. By sequencing examples from easy to hard, curriculum learning smooths the optimization trajectory.
Implementing a curriculum requires two components: a difficulty scorer that ranks samples, and a pacing function that controls how quickly hard samples are introduced. A common choice is linear pacing: \[ \text{samples}_{n_{\text{epoch}}} = \texttt{sort\_by\_difficulty}[:D \cdot \min(1, n_{\text{epoch}}/N_{\text{warmup}})] \] where \(n_{\text{epoch}}\) is the current epoch, \(D\) is the full dataset size, and \(N_{\text{warmup}}\) is the number of warmup epochs before the full dataset becomes available. Early epochs train on the easiest \(D \cdot (n_{\text{epoch}}/N_{\text{warmup}})\) fraction; after warmup, training proceeds on the full dataset.
The difficulty scorer is a systems choice because it trades probe-compute overhead against ordering quality, as table 4 shows. Loss and confidence scoring buy better ordering with extra inference, heuristics avoid compute but require domain knowledge, and self-paced scoring moves adaptation into the training loop itself.
| Strategy | Difficulty Score | Best For |
|---|---|---|
| Loss-Based | Loss from probe model (low = easy) | General-purpose; requires probe training |
| Confidence-Based | Teacher model confidence (high = easy) | When teacher available; distillation setups |
| Domain Heuristics | Sentence length, image complexity | No extra compute; domain knowledge required |
| Self-Paced | Current model’s loss (updated each epoch) | Adaptive; no probe needed |
Curriculum learning delivers 23.3 percent fewer training epochs on CIFAR-10 and 18.2 percent on CIFAR-100 (table 5).
| Dataset | Model | Pacing Strategy | Epochs to Target Acc. | Epoch Reduction |
|---|---|---|---|---|
| CIFAR-10 | ResNet-18 | Linear warmup | 115 vs. 150 baseline | 23.3% fewer epochs |
| CIFAR-100 | ResNet-32 | Self-paced | 180 vs. 220 baseline | 18.2% fewer epochs |
| ImageNet | ResNet-50 | Loss-based | 80 vs. 90 baseline | 11.1% fewer epochs |
| ImageNet | ResNet-50 | MentorNet (noisy) | 70 vs. 90 baseline | 22.2% fewer epochs |
The table reveals an important pattern: curriculum learning gains are inversely proportional to dataset quality. On highly curated datasets like ImageNet, the 11.1 percent epoch reduction is modest. On noisy or redundant data, reductions can exceed 20 percent. The optimal ordering is also task-dependent: anti-curriculum (hard examples first) can work when the decision boundary is complex and easy examples contribute little to defining it, while self-paced learning lets the model dynamically adjust difficulty based on its current loss, eliminating the need to predefine a curriculum. Empirically, self-paced methods often match or exceed hand-designed curricula.
Active learning: Human-in-the-loop
Curriculum learning optimizes the order in which samples are presented but assumes all samples are already labeled. This assumption breaks down in specialized fields such as medical diagnosis, autonomous driving, and scientific research, where labeling requires domain expertise and can cost $5–$100 or more per sample. Rather than labeling everything upfront, active learning14 (Settles 2012; Ren et al. 2021) shifts the optimization target: instead of choosing which labeled samples to train on, it chooses which unlabeled samples are worth labeling at all.
14 Active Learning: The “active” component is the learning algorithm itself selecting which unlabeled samples a human expert should label next. This reframes the problem from a computational optimization (training on given data) to a financial one: maximizing model improvement per dollar spent on expert labeling. Querying the most informative examples can substantially reduce labeling needs compared with random sampling, but the multiplier is task-, model-, and oracle-dependent.
Unlike static pruning, which discards samples permanently, active learning maintains an unlabeled pool and queries it strategically over time. Follow the cycle in figure 5: the model’s current uncertainty determines what gets labeled next, creating a feedback loop where each labeling round improves the model’s ability to identify what it still needs to learn.
The effectiveness of active learning depends critically on the query strategy used to select samples for annotation (Settles 2009, 2012; Ren et al. 2021). The simplest approach, uncertainty sampling, selects samples where the model is least confident, such as predictions near 0.5 probability for binary classification. This strategy is computationally cheap and effective in practice. Query-by-committee extends this idea by training multiple models and selecting samples where they disagree most, capturing epistemic uncertainty that a single model might miss.
Settles, Burr. 2009. Active Learning Literature Survey. Computer Sciences Technical Report 1648. University of Wisconsin-Madison.
Settles, Burr. 2012. Active Learning. Synthesis Lectures on Artificial Intelligence and Machine Learning. Springer Cham. https://doi.org/10.1007/978-3-031-01560-1.
Ren, Pengzhen, Yun Xiao, Xiaojun Chang, Po-Yao Huang, Zhihui Li, Brij B. Gupta, Xiaojiang Chen, and Xin Wang. 2021. “A Survey of Deep Active Learning.” ACM Computing Surveys 54 (9): 1–40. https://doi.org/10.1145/3472291.
For practitioners willing to invest more compute, expected model change selects samples that would cause the largest gradient update if labeled. This approach provides a theoretically grounded but expensive alternative. Diversity sampling complements uncertainty-based methods by selecting samples dissimilar from currently labeled data, ensuring the labeled set covers the full input space rather than clustering around ambiguous regions.
Active learning is particularly valuable in domains where labeling requires expertise. In medical imaging, for instance, an AI system diagnosing diseases from X-rays may be confident on common conditions but uncertain about rarer cases. By focusing human annotation on these ambiguous cases, active learning optimizes the use of expensive expert time while accelerating model improvement.

The economic implications are substantial. In production settings, labeling costs often dwarf compute costs because a specialist’s time is far more expensive than GPU hours. These query strategies drive each iteration of the active learning loop in figure 5, and a simple ROI calculation shows how the active learning ROI can exceed 10\(\times\).
Napkin Math 1.3: The active learning ROI
Problem: A hospital team is building a medical diagnostic AI. The pool contains 1 Million unlabeled scans. A specialist doctor charges $5/label. The team has a budget of $500,000 and a deadline of 1 month.
Scenario A: Naive Labeling
- Cost: Labeling all 1 Million scans would cost $5,000,000 (10× over budget).
- Time: The budget only covers labeling 100,000 random scans.
- Naive labeling outcome: The model misses rare pathologies because they were not in the random 10 percent.
Scenario B: Active Learning
- Strategy: The team uses uncertainty-based selection to pick the 50,000 “hardest” scans for the doctor to label.
- Cost: 50,000 \(\times\) $5/label = $250,000. (50 percent under budget).
- Training speed: With 20× less data, each training epoch is 20× faster.
- Active learning outcome: Empirical studies suggest that these 50,000 “high-information” samples often achieve higher accuracy than 100,000 random samples.
Systems insight: Data selection functions as a 20× compute accelerator and a $4.75 Million cost-saving measure, delivering gains that compound with every training iteration.
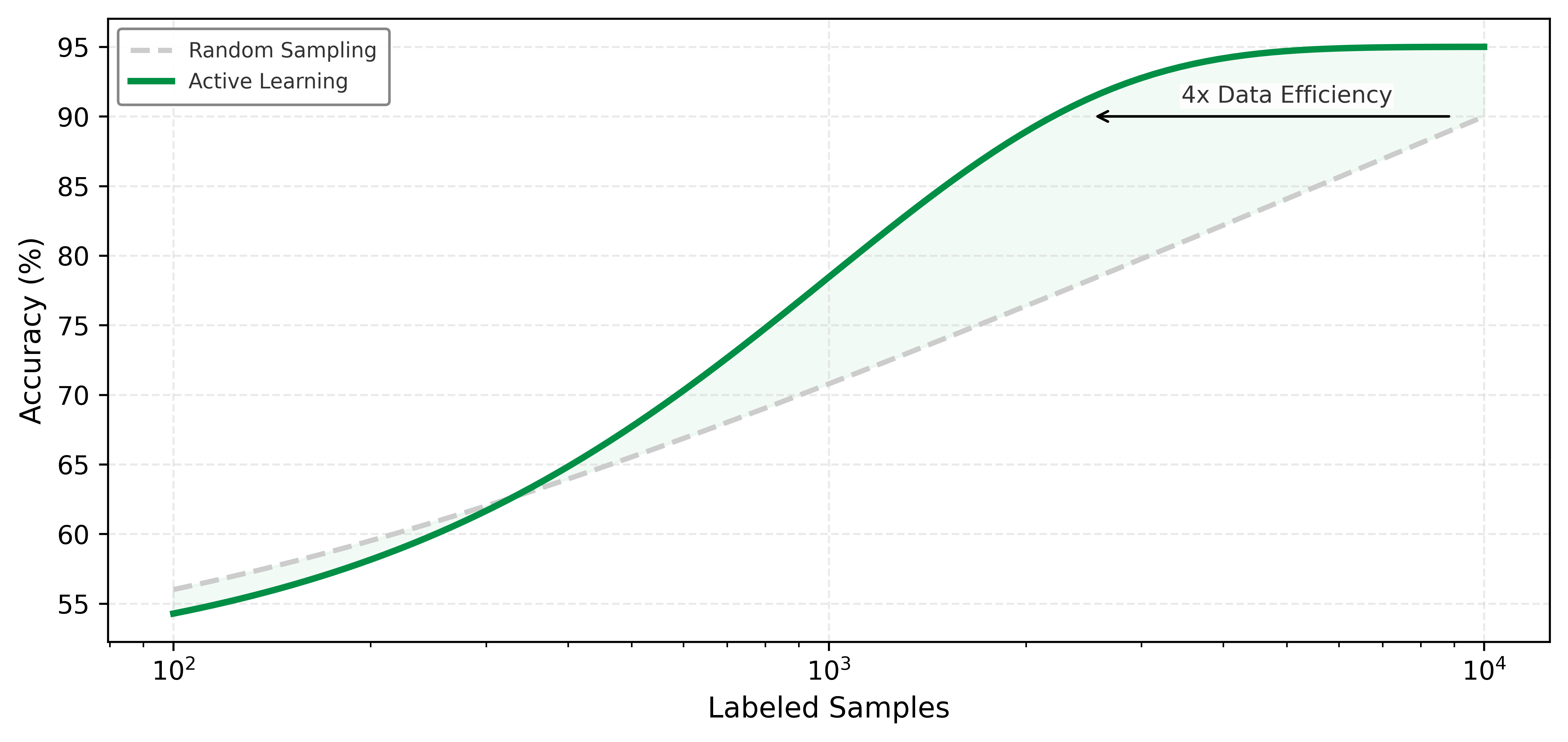
Compare the two curves in figure 6: active learning shifts the learning curve to the left, reaching roughly 90 percent accuracy with about 4\(\times\) fewer labeled samples than random selection, the gap marked by the figure’s data-efficiency annotation. The curves are illustrative to highlight the qualitative gap.
The figure tracks a different axis from the cost notebook above: active learning reaches the 90 percent accuracy threshold with roughly 4\(\times\) fewer labeled samples than random selection, a separate gain from the labeling dollars the notebook saved. That efficiency gap compounds across training iterations, because every epoch processes a smaller, higher-information dataset. The cost savings computed in the notebook above are therefore a lower bound; the real advantage grows as the model iterates and the selection oracle focuses labeling effort on the decision boundary.
Active learning yields more than cost savings: it directs the model toward precisely the examples that matter most.
Example 1.2: Hard negative mining in a smart doorbell
Context: The Smart Doorbell’s person detector faces a classic data selection challenge. Most of its video feed is empty (easy negatives) or shows people in unambiguous poses (easy positives), while the rare failures come from hard negatives such as statues, posters of people, or laundry piles that cast human-like shadows.
Insight: Random sampling will miss these rare failures. The Wake Vision team instead uses active learning to query the Oracle (human reviewers) on low-confidence predictions. If the model sees a statue and predicts “Person (51 percent)”, that sample is flagged for labeling.
Systems lesson: Active learning turns the feedback loop from a random walk into a guided search for the decision boundary, reducing the data required to solve the “statue problem” by orders of magnitude compared to random collection.
Semi-supervised learning: Using unlabeled data
Consider a medical imaging dataset: a hospital has 50,000 chest X-rays, but only 500 have been reviewed and labeled15 by radiologists—a labeling rate of 1 percent. Training a supervised model on 500 examples yields poor accuracy, but the structural patterns in the remaining 49,500 unlabeled images contain information about what healthy and abnormal lungs look like. Semi-supervised learning exploits this abundant unlabeled data to improve the model trained on the scarce labeled examples.
15 Clinical Labeling Economics: A radiologist reviews approximately 50–80 chest X-rays per hour; labeling 500 scans from a pool of 50,000 requires 7–10 hours of specialist time at $150–300/hour—a $1,000–3,000 investment. Full supervised labeling of all 50,000 would cost $94,000–300,000 and require 625–1,000 radiologist-hours, or roughly 15.6–25 weeks of full-time work. Under this budget, the 1 percent labeling threshold is not a pedagogical convenience but a reflection of healthcare economics: semi-supervised learning becomes attractive when expert labels are expensive and the unlabeled pool matches the deployment distribution. This cost structure generalizes–any domain requiring credentialed specialists (legal, financial, scientific) faces the same arithmetic.
Active learning optimizes which samples to label but still requires human annotation for every selected example. Semi-supervised learning takes a more aggressive approach: rather than asking which samples to label, it asks whether we can extract learning signal from unlabeled data directly. It uses a small set of labeled examples to guide learning on a much larger unlabeled pool, typically achieving 80–95 percent of fully supervised accuracy with only 10–20 percent of the labels.
The core insight behind semi-supervised learning is that unlabeled data, while it cannot directly teach the mapping from inputs to outputs, contains structural information about the input distribution \(p(x)\) that constrains the hypothesis space. A decision boundary that cuts through dense regions of \(p(x)\) is unlikely to generalize well because it would assign different labels to similar inputs. Semi-supervised methods use unlabeled data to push decision boundaries toward low-density regions, where class transitions are more likely to occur naturally.
Three main techniques implement this insight. Pseudo-labeling16 takes the most direct approach: train on labeled data, use the model to generate “pseudo-labels” for high-confidence unlabeled predictions, then retrain on both. The confidence threshold is critical: setting it too low introduces label noise that degrades learning, while setting it too high wastes potentially useful data.
16 Pseudo-Labeling: Uses a trained model’s own confident predictions as ground-truth labels for unlabeled data. The technique’s effectiveness depends on a virtuous cycle: accurate predictions on easy unlabeled examples expand the training set, improving the model, which enables accurate predictions on harder examples. The failure mode is equally self-reinforcing: incorrect pseudo-labels reinforce errors through confirmation bias, making the confidence threshold a critical systems parameter. Setting it too low compounds label noise across training iterations; setting it too high wastes unlabeled data that could contribute learning signal.
17 Consistency Regularization: Rooted in the smoothness assumption: if two inputs \(x_1\) and \(x_2\) are close in input space, their labels should also be close. The training objective minimizes divergence between a model’s predictions on an input and its augmented version. This is conceptually distinct from data augmentation (which creates more training examples) because it explicitly enforces prediction consistency as a loss term, even for unlabeled data where the “correct” label is unknown. The systems consequence: consistency regularization extracts learning signal from unlabeled samples at the cost of doubling forward-pass compute per sample, a trade-off that favors GPU-rich, label-poor settings.
18 FixMatch: It generates a pseudo-label using a weakly augmented image and then trains the model to predict that same label for a strongly augmented version of the image. This consistency training is gated by a confidence threshold; a pseudo-label is only used if the model’s prediction on the weak augmentation is highly confident (for example, >0.95). This embodies a direct systems trade-off, exchanging roughly 5\(\times\) more GPU compute for a potential 200\(\times\) reduction in manual labeling cost.
Consistency regularization17 takes a different angle by enforcing that the model produces similar predictions for augmented versions of the same input. A robust classifier should be invariant to realistic perturbations like cropping, rotation, or color shifts. Methods like FixMatch18 combine both approaches, assigning pseudo-labels only to samples where the unaugmented prediction is confident but training the model to predict these labels on strongly augmented versions of the same images.
Label propagation offers a third paradigm through graph-based reasoning: construct a similarity graph over all samples and propagate labels from labeled nodes to their neighbors. This approach works particularly well when the feature space exhibits clear cluster structure.
Example 1.3: FixMatch on CIFAR-10
Context: FixMatch (Sohn et al. 2020) combines pseudo-labeling with consistency regularization to achieve high label efficiency (table 6). With only 250 labeled samples (25 per class), FixMatch achieves 94.9 percent accuracy, within 1.2 points of full supervision using 200× fewer labels. The technique works by generating pseudo-labels on weakly augmented unlabeled images (only when model confidence exceeds 0.95), then training to predict these labels on strongly augmented versions of the same images.
Systems insight: Semi-supervised learning trades labeled data for unlabeled data and compute. On CIFAR-10, training FixMatch requires ~5× more compute than supervised training (processing 50K unlabeled samples per epoch). Two baselines are in play. Against full supervision, the 250-label result in table 6 shows 200× fewer labels. The ROI calculation below instead compares against a 4,000-label supervised baseline, where FixMatch uses 16× fewer purchased labels; the resulting total-cost trade-off assumes labels cost $1 each and GPU hours cost $0.50:
- Supervised (4,000 labels): $4,000 labeling + $50 compute = $4,050
- FixMatch (250 labels): $250 labeling + $250 compute = $500
An 8.1× cost reduction for ~1.2 points of accuracy loss.
Sohn, Kihyuk, David Berthelot, Nicholas Carlini, Zizhao Zhang, Han Zhang, Colin A Raffel, Ekin Dogus Cubuk, Alexey Kurakin, and Chun-Liang Li. 2020. “FixMatch: Simplifying Semi-Supervised Learning with Consistency and Confidence.” Advances in Neural Information Processing Systems 33: 596–608.
The systems trade-off in semi-supervised learning is straightforward: it typically achieves the same accuracy as fully supervised training with 5–10\(\times\) fewer labels but requires more compute because training processes both labeled and unlabeled samples. Since labeling costs often dominate compute costs in production settings, this trade-off is usually favorable. A CIFAR-10 comparison makes this label efficiency concrete.
| Label Budget | Method | Accuracy | Label Efficiency |
|---|---|---|---|
| 50,000 (100%) | Fully Supervised | 96.1% | Baseline |
| 4,000 (8%) | FixMatch | 95.7% | 12.5× more efficient |
| 250 (0.5%) | FixMatch | 94.9% | 200× more efficient |
| 40 (0.08%) | FixMatch | 88.6% | 1250× more efficient |
The efficiency gains are substantial, but semi-supervised learning is not universally applicable. The technique assumes that unlabeled data comes from the same distribution as labeled data, and it struggles when unlabeled data contains out-of-distribution samples (the model confidently mislabels them), when class imbalance is severe (pseudo-labels amplify majority class bias), or when the labeled set does not cover all classes (preventing label propagation for unseen classes). Always validate on a held-out set with true labels to catch distribution mismatch.
Despite these limitations, semi-supervised learning reduces label requirements by 5–10\(\times\) while maintaining accuracy. The trajectory across techniques is clear: coreset selection and deduplication prune low-value samples before training; curriculum learning optimizes the order of presentation during training; active learning queries only the most informative samples for human annotation; and semi-supervised learning exploits unlabeled data to stretch those annotations further. Each technique has pushed the label requirement lower, but none has eliminated it. The progression raises a deeper possibility: that task-specific labels may not be necessary at all. The structure of data itself—that cat images resemble other cat images and coherent sentences follow grammatical patterns—may provide a sufficient supervision signal.
Self-Check: Question
What distinguishes dynamic selection from static pruning as an optimization strategy?
- Dynamic selection guarantees higher final accuracy because every sample is seen the same number of times over training.
- Dynamic selection is primarily a disk-footprint optimization that removes samples from storage as training progresses.
- Dynamic selection replaces human labels with self-supervised objectives during the training loop.
- Dynamic selection adapts which samples are emphasized to the model’s current state, recognizing that an example’s informativeness shifts as the model learns.
A team trains a vision model on a moderately noisy 50M-image dataset and wants to accelerate convergence by reshaping the per-epoch sample order. Which design is curriculum learning as the chapter describes it?
- Pseudo-label every unlabeled sample unconditionally to expand training volume as quickly as possible.
- Query the single most uncertain unlabeled sample each round and route it to a human annotator.
- Score samples by a difficulty metric, then introduce them using a pacing schedule that starts with the easiest fraction and gradually widens to include harder ones as training progresses.
- Randomly permute the dataset every epoch so the optimizer cannot exploit any ordering.
In the chapter’s medical-imaging example, active learning reaches a target accuracy with about 50,000 expert-labeled scans while the same labeling budget would buy roughly 100,000 random labels. Explain why active learning produces this 2\(\times\) budgeted-labeling advantage, and state one compute consequence beyond labeling cost.
From the chapter’s perspective, why is FixMatch a favorable systems trade-off for label-poor settings?
- It reduces both compute and labels simultaneously, making it strictly cheaper on every axis.
- It eliminates the need for any labeled examples, reducing labeling cost to zero.
- It trades additional compute on unlabeled data (two augmentation passes per unlabeled sample plus confidence gating) for a large reduction in manual labeling cost, typically at a small accuracy drop.
- It is robust to distribution mismatch between labeled and unlabeled pools because its augmentation step erases the difference.
True or False: If a team has 100\(\times\) more unlabeled data than labeled data, semi-supervised learning is almost guaranteed to improve accuracy regardless of whether the unlabeled pool was scraped from a different distribution than the labeled task data.
Self-Supervised Learning
GPT was trained to predict the next token in a sequence. BERT was trained to fill in masked tokens. Neither task required a single human label. Self-supervised learning19 generalizes this insight: by designing pretext tasks that derive supervision from the data’s inherent structure, models learn general-purpose representations from unlabeled data at scale. Where the progression from active learning to semi-supervised learning drove required labels downward, SSL changes the accounting by making unlabeled structure itself the supervision signal. In the three-stage map, this makes SSL less a fourth stage than the limiting case of dynamic selection, the point where the label requirement reaches zero and the question shifts from which labeled samples to train on to whether labels are needed at all. It is a direct response to the data wall formalized in section 1.1.4: rather than searching only for more high-quality labeled data in a finite pool, SSL redefines what counts as training data by extracting supervision from the structure of unlabeled corpora.
19 Self-Supervised Learning: The pretext task—predicting the next token (GPT) or a masked token (BERT)—provides a supervisory signal inherent to the unlabeled data itself, removing the human-labeling bottleneck. This reframes the system-building challenge from one of data acquisition to one of large-scale computational investment, where pretraining can cost >10,000\(\times\) more than a single downstream fine-tuning. The expense is amortized across thousands of downstream tasks.
The key insight is that labels represent just one form of supervision. Data structure itself provides rich learning signals that require no human annotation, as table 7 summarizes.
| Modality | Self-Supervised Task | Supervision Signal |
|---|---|---|
| Text | Masked language modeling | Predict [MASK] from context |
| Text | Next-token prediction | Predict next token in sequence |
| Images | Contrastive learning | Same image (augmented) vs. different images |
| Images | Masked autoencoding | Reconstruct masked patches |
| Multi-modal | CLIP-style alignment | Match image-text pairs |
Pretext tasks generate supervision signals automatically. A model trained to predict masked tokens necessarily learns grammar, semantics, and world knowledge; a model trained to predict the next token in a sequence learns continuation structure; and a model trained to distinguish augmented views of the same image learns visual features invariant to transformations. These approaches build on the CNN and transformer families examined in Network Architectures, but from a data selection perspective the systems implication is what matters: self-supervised pretraining moves the data cost off the critical path. Instead of waiting for labels before training begins, pretraining starts immediately on unlabeled data, often web-scale corpora of billions of samples. The separation of pretraining from task-specific labeling restructures the economics of machine learning.
The economics of amortization
Understanding why self-supervised learning became central to many foundation-model workflows requires examining its economic structure. A foundation model is a broadly pretrained reusable base model that can be adapted to many downstream tasks through fine-tuning. That shift translates into concrete cost savings through cost amortization, where expensive pretraining is performed once and reused across many applications (table 8).
| Approach | Labels per Task | Compute per Task | Data Acquisition |
|---|---|---|---|
| Train from scratch | 100K–1M labeled | 100% full training | Task-specific collection |
| Fine-tune foundation model | 100–1K labeled | 1–5% of full training | Reuse pretraining corpus |
To illustrate this economic transformation, consider a company building 10 specialized classifiers for tasks such as fraud detection, content moderation, and medical diagnosis. Training each classifier from scratch would require substantial investment in both labeling and compute. With 10 tasks each needing 100,000 labels at $1 per label, the total labeling cost reaches $1M. The compute burden amounts to 10,000 GPU-hours across all tasks, with each requiring its own data collection effort. From start to finish, each task takes six to twelve months to complete.
The fine-tuning approach restructures these costs. Pretraining requires a one-time investment of 10,000 GPU-hours on unlabeled data, but this cost is paid only once. Fine-tuning each task then requires just 1,000 labels ($10K total across all 10 tasks) and only 50 GPU-hours of compute. Each task reaches deployment in 1–2 weeks after pretraining completes.
The return on investment is substantial for labeling, marginal per-task compute, and time to deployment: labeling costs drop by 100× overall (from $1M to $10K), per-task marginal compute decreases by 20×, and time to deployment accelerates by 20–50\(\times\) per task. Total compute becomes favorable only after the pretraining cost is amortized across enough downstream tasks.
The cost structure explains why the fine-tuning paradigm dominates production ML. The pretraining cost is high but amortized across many downstream applications, while fine-tuning cost remains low on a per-task basis.
Contrast the two bar charts in figure 7 to see this cost structure in action. Training from scratch (left) incurs the full cost for each task independently. The foundation model approach (right) pays a large upfront pretraining cost but then fine-tunes each task at a fraction of the per-task cost.
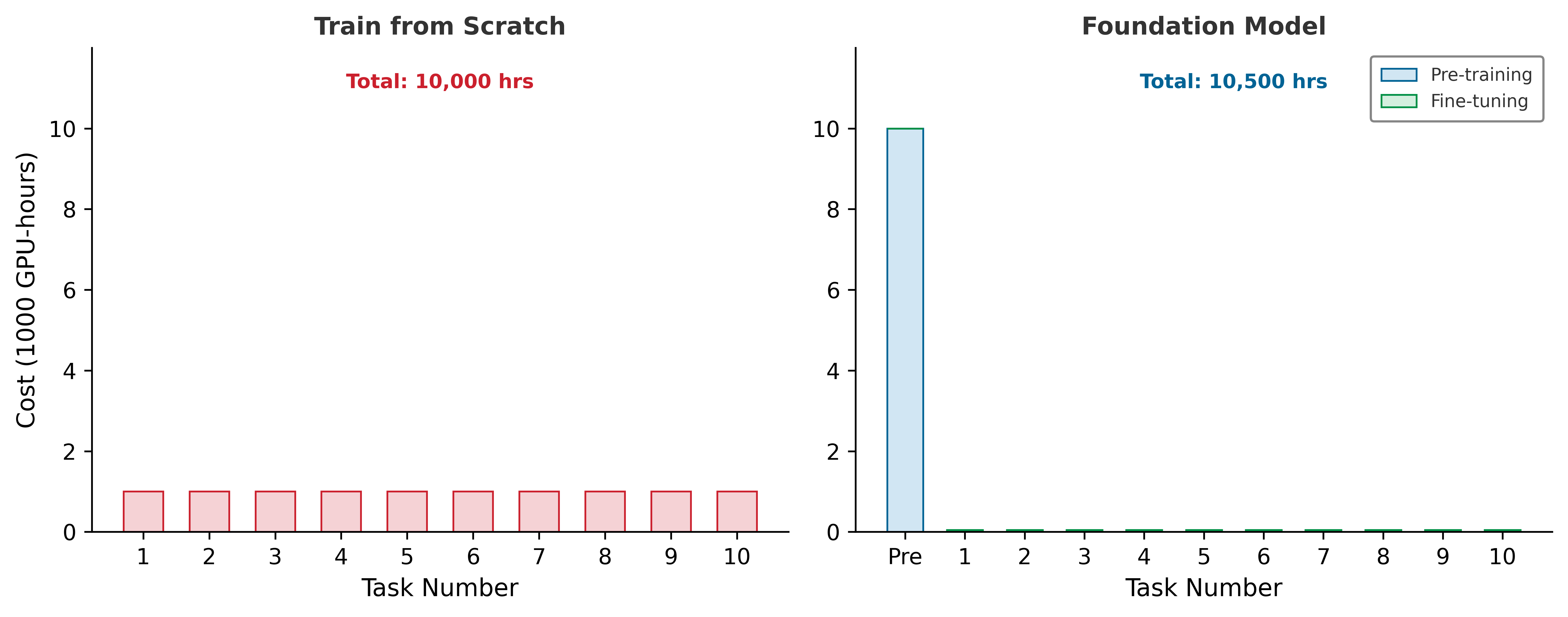
Foundation model paradigm
The amortization economics favor self-supervised learning broadly, though different SSL methods occupy different points on the cost-efficiency frontier. SimCLR-style contrastive learning (Chen et al. 2020) benefits from very large batches (4,096+ samples) and yields excellent downstream performance with minimal labeled data. MoCo (He et al. 2020) instead uses a queue-based dictionary and momentum encoder to decouple the number of negatives from the mini-batch, reducing the need for such large batches while preserving strong transfer performance. Masked modeling methods work with smaller batches at the cost of more training iterations. Generative pretraining follows empirical power-law scaling with data, parameters, and compute, making it attractive for foundation models where pretraining cost is amortized across thousands of tasks. These methods rely on architecture families introduced in Network Architectures; what matters for data selection is the shared conclusion: self-supervised pretraining can substantially increase the value of limited labeled data. Instead of labeling every task-specific example from scratch, practitioners fine-tune on hundreds or thousands of labeled samples while inheriting knowledge distilled from large unlabeled corpora.
Chen, Ting, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. 2020. “A Simple Framework for Contrastive Learning of Visual Representations.” Proceedings of the 37th International Conference on Machine Learning, ICML’20, vol. 119: 1597–607.
He, Kaiming, Haoqi Fan, Yuxin Wu, Saining Xie, and Ross Girshick. 2020. “Momentum Contrast for Unsupervised Visual Representation Learning.” 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 9726–35. https://doi.org/10.1109/cvpr42600.2020.00975.
20 Foundation Model: The name emphasizes that these models serve as a shared base for many downstream tasks, but this creates a single point of failure. Defects in the foundation model’s pretraining data (biases, factual errors, memorized private content) propagate to every application built upon it. From a systems perspective, this homogenization risk means that data selection quality during pretraining has an outsized blast radius: a curation error that would affect one task in the train-from-scratch paradigm now affects thousands of downstream deployments.
Bommasani, Rishi, Drew A. Hudson, Ehsan Adeli, Russ Altman, Simran Arora, Sydney von Arx, Michael S. Bernstein, et al. 2021. “On the Opportunities and Risks of Foundation Models.” arXiv Preprint arXiv:2108.07258.
The multiplicative advantage of SSL creates the foundation model paradigm20 (Bommasani et al. 2021) that defines modern ML systems. The data selection principles discussed throughout this chapter (coreset selection, curriculum learning, active learning) remain relevant within the foundation model paradigm. Pretraining corpus curation applies the same deduplication and quality filtering techniques at web scale, and fine-tuning data selection determines which labeled examples maximize downstream task performance.

One pretraining corpus defect propagates into many downstream tasks.
Self-supervised learning addresses the label bottleneck by learning from data structure rather than human annotation, yet it cannot solve data scarcity itself. Rare classes may have too few examples, edge cases may never appear in the wild, and privacy constraints may prevent collecting real samples. The third stage of our data selection pipeline addresses this gap: rather than selecting or curating existing data, we create new data on demand.
Self-Check: Question
What key bottleneck does self-supervised learning remove compared with active learning and semi-supervised learning, and what does it not remove?
- It removes the need for architecture choices because the pretext task determines the network automatically, and it eliminates compute cost as well.
- It removes the need for data curation because web-scale unlabeled corpora can be used directly without deduplication or filtering.
- It removes the compute cost of pretraining by making unlabeled training inherently cheaper than supervised training.
- It removes the need for task-specific human labels during pretraining by extracting supervision from data structure, but leaves curation and compute cost in place — often raising compute significantly.
A company plans to ship ten specialized models. One self-supervised pretraining run costs 10,000 GPU-hours; training each model from scratch requires 100,000 labels at $1 per label plus 1,000 GPU-hours of compute, while fine-tuning from the pretrained base requires 1,000 labels at $1 per label plus 50 GPU-hours. Analyze when the pretraining investment pays off and how the break-even shifts as the number of tasks grows.
Which statement best captures the chapter’s view of the foundation-model paradigm’s systemic implications for data selection?
- It makes coreset selection, deduplication, and fine-tuning curation obsolete because pretraining absorbs the responsibility for all data decisions.
- It replaces model compression as the primary mechanism for reducing inference cost on downstream tasks.
- It is useful only when every downstream task comes with millions of labeled examples.
- It creates a shared pretrained base whose data curation decisions have a large blast radius across every downstream application that inherits it.
An organization is deciding whether self-supervised pretraining is economically justified. Which situation most strongly tips the decision toward pretraining rather than per-task scratch training?
- A single specialized task with a fixed labeled budget and no plan to build additional models.
- Two related models that must ship within six weeks on tight hardware budgets.
- A multi-year roadmap of fifteen-plus related models across the organization’s domain, where each fine-tune inherits the same base.
- A one-off academic experiment that will not be redeployed or iterated.
Synthetic Data Generation
A robot fleet may need rare collision examples, a medical model may need cases a hospital cannot share, and a wake-word model may need thousands of noisy kitchens before the product exists. Static pruning removed redundancy before training. Dynamic selection focused compute on the most informative samples during training, and self-supervised pretraining drove its label requirement to zero, reframing what counts as training data rather than adding a stage. The third and final stage of the data selection pipeline, synthetic data generation, takes the opposite approach: rather than subtracting or selecting from existing data, it creates new high-value samples when real data is scarce, expensive, or lacks diversity. The strategy shifts from curation to creation.
Data augmentation: Transformation-based synthesis
Data augmentation is the lowest-cost form of synthetic generation: it expands a dataset by applying transformations to existing samples. Because many transformations preserve label semantics while creating novel inputs, augmentation effectively multiplies the diversity of a training set without requiring additional data collection.
For image data, augmentation should match the invariance the deployed model must learn (Shorten and Khoshgoftaar 2019). Geometric transformations such as rotation, flipping, cropping, and scaling introduce spatial variation that makes models robust to viewpoint changes. Photometric transformations adjust brightness, contrast, saturation, and hue to simulate different lighting conditions and camera characteristics. More advanced techniques like Cutout21 (which applies random rectangular masks), MixUp (Zhang et al. 2018) (which blends two images and their labels), and CutMix22 (which pastes patches between images) push augmentation further by creating entirely synthetic training examples that regularize learning.
Shorten, Connor, and Taghi M. Khoshgoftaar. 2019. “A Survey on Image Data Augmentation for Deep Learning.” Journal of Big Data 6 (1): 1–48. https://doi.org/10.1186/s40537-019-0197-0.
21 Cutout: Randomly masks square regions of input images during training, forcing the model to recognize objects from partial information rather than relying on any single discriminative region (DeVries and Taylor 2017). Unlike dropout (which zeroes neurons in feature space), Cutout operates in input space. The original Cutout experiments produced roughly 1–2 percentage-point gains on CIFAR-10/100 and strong gains on SVHN with negligible compute overhead, making it a high-ICR augmentation technique when occlusion-style invariance matches the task: more information per sample at near-zero additional cost to the pipeline.
DeVries, Terrance, and Graham W. Taylor. 2017. “Improved Regularization of Convolutional Neural Networks with Cutout.” arXiv Preprint arXiv:1708.04552.
Zhang, Hongyi, Moustapha Cisse, Yann N. Dauphin, and David Lopez-Paz. 2018. mixup: Beyond Empirical Risk Minimization. OpenReview.net.
22 CutMix: Replaces Cutout’s zeroed-out region with a patch from a different training image, mixing labels proportionally to patch area (30 percent of image A replaced by image B yields a 70/30 label split) (Yun et al. 2019). This addresses Cutout’s weakness: zeroed regions waste pixel information that could carry learning signal. The CutMix paper reports ImageNet top-1 improvements of 2.28 percentage points for ResNet-50 and 1.70 percentage points for ResNet-101, while also improving localization behavior. The method provides stronger regularization than either Cutout or MixUp alone with little additional data-pipeline cost.
Yun, Sangdoo, Dongyoon Han, Seong Joon Oh, Sanghyuk Chun, Junsuk Choe, and Youngjoon Yoo. 2019. “CutMix: Regularization Strategy to Train Strong Classifiers with Localizable Features.” 2019 IEEE/CVF International Conference on Computer Vision (ICCV), 6023–32. https://doi.org/10.1109/ICCV.2019.00612.
23 Back-Translation: Translates text to another language and back, producing paraphrases that preserve meaning while varying syntax and vocabulary (Sennrich et al. 2016). For low-resource NLP tasks, back-translation expands the training corpus by adding synthetic examples derived from monolingual text. The systems trade-off is latency: each augmented sample requires translation-model inference, making it far more expensive than token-level augmentations like synonym replacement. Production pipelines therefore precompute back-translations offline rather than generating them on the fly in the data loader.
Sennrich, Rico, Barry Haddow, and Alexandra Birch. 2016. “Improving Neural Machine Translation Models with Monolingual Data.” Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 86–96. https://doi.org/10.18653/v1/P16-1009.
Text augmentation presents different challenges because language is discrete rather than continuous. Back-translation23 offers one solution: translating text to another language and back generates paraphrases that preserve meaning while varying surface form. Simpler approaches include synonym replacement, which swaps words while preserving semantics, and random insertion or deletion, which adds noise that makes models robust to typos and informal input.
Rather than hand-designing these augmentation policies, AutoAugment24 uses reinforcement learning to discover optimal augmentation strategies for specific datasets, while RandAugment25 simplifies this by randomly sampling from a fixed set of transformations, achieving similar performance with less computation. Learned augmentation policies are particularly effective for resource-constrained models, where overfitting risk is highest. The MobileNetV2 lighthouse illustrates this principle: when model capacity is deliberately reduced for edge deployment, augmentation becomes the primary defense against overfitting.
24 [offset=-48mm] AutoAugment: Treats augmentation policy design as a reinforcement learning search problem: a controller selects operations (rotate, translate, shear, equalize), their magnitudes, and application probabilities to maximize validation accuracy (Cubuk et al. 2019). Learned policies transfer across datasets and architectures, but the search cost is prohibitive: 15,000 GPU-hours to find a single policy. This cost-quality trade-off explains why RandAugment displaced AutoAugment in production: the search overhead exceeded the accuracy gains for most practical training budgets.
Cubuk, Ekin D., Barret Zoph, Dandelion Mané, Vijay Vasudevan, and Quoc V. Le. 2019. “AutoAugment: Learning Augmentation Strategies from Data.” 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 113–23. https://doi.org/10.1109/cvpr.2019.00020.
25 RandAugment: Collapses AutoAugment’s policy search to two hyperparameters: transformation count \(N\) and shared magnitude \(M\) (Cubuk et al. 2020). That small search space recovers most AutoAugment gains at negligible cost, making it practical when 15,000 GPU-hours of policy search cannot be justified.
Cubuk, Ekin D., Barret Zoph, Jonathon Shlens, and Quoc V. Le. 2020. “Randaugment: Practical Automated Data Augmentation with a Reduced Search Space.” 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), 3008–17. https://doi.org/10.1109/cvprw50498.2020.00359.
Lighthouse 1.2: MobileNetV2 and aggressive augmentation
Our MobileNetV2 lighthouse model from Lighthouse roster: Model biographies exemplifies how data augmentation compensates for model capacity constraints. MobileNet-family depthwise separable convolutions reduce parameters by 8–9\(\times\) compared to standard convolutions, but this efficiency comes at a cost: smaller models are more prone to overfitting on limited data.
The solution is aggressive augmentation. MobileNetV2 training typically uses stronger augmentation than ResNet-50 training, including RandAugment with higher magnitude, more aggressive cropping, and longer training schedules. The augmentation effectively increases dataset diversity without increasing model capacity, allowing MobileNetV2 to achieve near-ResNet accuracy at a fraction of the parameter count. For edge deployment where both data collection and model size are constrained, augmentation is essential rather than optional.
Generative synthesis: Creating new samples
Augmentation transforms existing samples; synthetic data generation goes further by creating entirely new examples using generative models. This capability becomes essential in three common scenarios:
- Privacy-sensitive data: Synthetic examples can reduce exposure when real records contain medical, financial, or otherwise sensitive information.
- Rare edge cases: Synthetic examples can cover failure modes, such as autonomous driving scenarios, that must be tested but seldom occur naturally.
- Expensive collection: Synthetic examples can supplement domains such as robotics or scientific experiments where each real sample requires physical resources.
The distribution sketch in figure 8 shows the central risk of that strategy: synthetic examples can be plentiful and still misaligned with deployment data.

The choice among generative approaches is a cost-fidelity decision. Generative Adversarial Networks (GANs) train a generator against a discriminator in an adversarial setup, producing realistic images through competition; StyleGAN, for instance, generates photorealistic faces that have augmented facial recognition datasets. Diffusion models use iterative denoising to produce high-quality images; systems like Stable Diffusion26 support targeted training example generation from natural language descriptions through text-to-image synthesis. Finally, simulation engines such as CARLA for autonomous driving or Unity and Unreal for robotics offer physics-based rendering that can generate large volumes of labeled scenarios with known simulator state, making them particularly valuable for safety-critical applications where edge case coverage is essential.
26 Stable Diffusion: Performs iterative denoising in a compressed latent space, enabling targeted text-to-image examples. Its cost is seconds per image rather than near-free geometric transforms, so it fits cases where novelty matters more than per-sample throughput.
Bridging the domain gap
Synthetic data’s greatest limitation is the domain gap,27 the statistical difference between generated and real-world data, as illustrated in figure 8. A model trained only on synthetic data learns a decision boundary optimized for the wrong distribution, potentially performing well on synthetic test data while failing on real deployment data.
27 Domain Gap: The statistical divergence between synthetic and real data distributions, measurable with metrics such as Maximum Mean Discrepancy (MMD) or Frechet Inception Distance (FID). For ML systems, the gap becomes training-serving skew: a simulator-trained model can validate well on synthetic data while failing silently on real deployment data.
28 Domain Randomization: Makes synthetic data deliberately varied by randomizing textures, colors, lighting, and physical properties. The goal is not photorealism; it is enough variation that the real world becomes one more sample from the training distribution, shifting the cost bottleneck from rendering fidelity to coverage.
Two complementary strategies address this distribution mismatch. Domain randomization28 takes an aggressive approach: rather than trying to match the real world precisely, it trains on wildly varied synthetic data by randomizing lighting, textures, backgrounds, and camera parameters during generation.
If the model encounters sufficient variation during training, the real world becomes “just another variation” within its learned distribution. This strategy produces strong results for robotics and autonomous driving, where simulation technology is mature enough to generate physically plausible variations across a wide range.
Domain adaptation takes the opposite approach by explicitly aligning synthetic and real distributions. Feature alignment methods train on synthetic data while simultaneously minimizing the distance between synthetic and real feature distributions, often using adversarial training to learn domain-invariant representations. Fine-tuning offers a simpler path: pretrain on abundant synthetic data to learn general features, then fine-tune on a small real dataset to adapt to deployment conditions. Self-training combines these ideas by using a synthetic-trained model to pseudo-label real unlabeled data, then retraining on the combined labeled set.
In practice, the best results often come from mixing synthetic and real data rather than relying on either source alone. Table 9 summarizes representative outcomes across different mixing ratios.
| Synthetic Fraction | Representative Outcome |
|---|---|
| 100% synthetic | Poor real-world generalization |
| 80% synthetic + 20% real | Good performance, significant cost savings |
| 50% synthetic + 50% real | Best performance in many domains |
| 100% real | Baseline (expensive) |
Example 1.4: KWS data selection
Context: The keyword spotting (KWS) DS-CNN lighthouse from Lighthouse roster: Model biographies represents the extreme end of data selection challenges. Building a wake-word detector (“Hey Device”) for a microcontroller with 256 KB SRAM (see TinyML: Ubiquitous Sensing for hardware constraints) requires a tiny model (~200 KB quantized weights before runtime buffers) and 10,000+ labeled audio samples to train it, samples that do not yet exist.
Insight:
- Recording 10,000 real utterances requires hundreds of speakers for diversity
- Professional recording costs $2–5/sample ($20K–50K total)
- Target deployment environment (noisy kitchen, car interior) differs from recording studio
The solution builds a usable dataset from almost nothing by layering five stages: seed recordings, augmentation, noise injection, hard-negative mining, and optional speech synthesis.
- Seed data (500 samples): Record 50 speakers at 10 utterances/speaker in controlled conditions
- Augmentation (5,000 samples): Apply pitch shift, time stretch, speed variation to 10× the seed data
- Noise injection (10,000 samples): Mix clean audio with environmental noise (kitchen appliances, HVAC, traffic) sampled from AudioSet
- Negative mining: Use acoustic similarity to find hard negatives (“Hey Siri”, “Hey Google”) from public datasets
- Simulation (optional): Text-to-speech synthesis with diverse voice models
Systems insight: When the target model is tiny, the data selection challenge shifts from “reduce terabytes to gigabytes” to “create a useful dataset from almost nothing.” Augmentation and simulation become essential rather than optional. 500 real recordings become 10,000+ training samples at 5 percent of the recording cost. The noise injection serves as domain randomization, improving deployment robustness.
The keyword-spotting deployment shows how augmentation, noise injection, and simulation can turn a tiny seed set into a deployable dataset, but the same creation strategy becomes riskier when synthetic samples come from ML models rather than simulators. In that setting, model collapse29 can amplify errors and reduce diversity over generations. This concern is particularly acute for foundation models, where synthetic data from earlier model generations may contaminate future training corpora. With appropriate safeguards, synthetic data generation remains an effective tool.
29 Model Collapse: Formally analyzed by Shumailov et al. (2024), this phenomenon occurs because generative models systematically underrepresent tail distributions – rare but important patterns that appear infrequently in training data. When generation \(n+1\) trains on output from generation \(n\), each successive generation further compresses the tails, producing increasingly homogeneous data. The degradation can be rapid in recursive training settings, which is why the Fallacies section of this chapter warns against pure synthetic training.
Shumailov, Ilia, Zakhar Shumaylov, Yiren Zhao, Nicolas Papernot, Ross Anderson, and Yarin Gal. 2024. “AI Models Collapse When Trained on Recursively Generated Data.” Nature 631 (8022): 755–59. https://doi.org/10.1038/s41586-024-07566-y.
Knowledge distillation: Compressing information
The preceding techniques create new input samples, but there is another form of synthesis that creates enhanced labels. Knowledge distillation30 (Hinton et al. 2015; Gou et al. 2021) trains a smaller “student” model from a larger “teacher” model’s outputs rather than from raw labels alone. From the data-selection perspective, the teacher’s outputs serve as enriched training data that carries more information per sample than hard labels. The same mechanism will later reappear from the model-efficiency perspective, where the student is valued because it is smaller and faster.
30 Knowledge Distillation: Hinton coined “dark knowledge” for the information in soft probability distributions: the teacher reveals not just which class is correct but which incorrect classes are most plausible. The temperature parameter controls how much dark knowledge is exposed: higher temperatures produce softer distributions that transfer more nuanced inter-class relationships. From a data selection perspective, distillation increases the information density per sample without changing the dataset, effectively boosting ICR by replacing low-entropy hard labels with high-entropy soft labels that carry richer gradient signal per forward pass.
Hinton, Geoffrey, Oriol Vinyals, and Jeff Dean. 2015. “Distilling the Knowledge in a Neural Network.” arXiv Preprint.
Gou, Jianping, Baosheng Yu, Stephen J. Maybank, and Dacheng Tao. 2021. “Knowledge Distillation: A Survey.” International Journal of Computer Vision 129 (6): 1789–819. https://doi.org/10.1007/s11263-021-01453-z.
The key insight is that the teacher’s soft predictions contain more information than hard labels, a form of dark knowledge: a teacher predicting [0.7, 0.2, 0.1] for three classes reveals inter-class relationships (classes one and two are more similar) that a hard label [1, 0, 0] obscures entirely. The richer supervision signal enables student models to learn more efficiently from the same data. From a systems perspective, distillation is particularly effective for creating synthetic labels at scale: run a large model (such as GPT-4) on unlabeled data to generate high-quality annotations, then train a smaller model on these synthetic labels. The smaller model inherits much of the teacher’s capability at a fraction of the inference cost, amortizing the expensive teacher computation across many student deployments.
Together, augmentation, generative synthesis, and distillation complete the third stage of our data selection pipeline. Where static pruning removes redundancy and dynamic selection focuses compute on high-value samples, synthetic generation fills gaps by creating samples that never existed. Selecting the right combination of techniques from these three pipeline stages requires a structured decision framework.
Self-Check: Question
Which workload most strongly favors transformation-based data augmentation over full generative synthesis?
- An autonomous-driving team that needs rare crash scenarios that never appeared in the collected fleet logs.
- A vision team with 500,000 labeled images that wants cheap label-preserving diversity via crops, flips, and color jitter to improve generalization.
- A medical-imaging team that wants to replace all real patient scans with synthetic-only training data for regulatory reasons.
- A robotics team that wants to avoid specifying any invariances by hand and outsource that choice to a generative model.
A perception model trained entirely on a high-fidelity simulator achieves 94 percent validation accuracy on synthetic test data but drops to 61 percent on real deployment data. Which mechanism best explains the failure?
- The simulator generated fewer labels per sample than the real dataset would have.
- Synthetic samples are too easy, so the model failed to build enough regularization against hard cases.
- The model learned a decision boundary tuned to the simulator’s distribution, and the deployment data differs enough on subtle features (texture statistics, sensor noise, lighting priors) that those features no longer fire the same way.
- Generative models cannot produce enough samples for modern architectures to converge.
A robotics team has a high-fidelity simulator capable of generating unlimited synthetic trajectories and 20,000 real-world logged trajectories. Propose a synthetic-real mixture for training and explain why pure synthetic and pure real are both worse than a mixture.
Viewed as a data-selection technique, what does knowledge distillation add beyond training on the same dataset with ordinary hard labels?
- It replaces the training set with fewer samples, so compute falls proportionally.
- It removes the need for any teacher inference, since soft labels can be derived from the student alone.
- It guarantees the student model matches the teacher model’s accuracy regardless of any capacity gap.
- It provides richer soft-target distributions that encode inter-class similarities, increasing the information carried per training sample.
True or False: If a simulator passes visual photorealism tests, it is safe to deploy a model trained 100 percent on that simulator without supplementing with real data.
Decision Framework
When labeling budget, redundancy, rare classes, privacy, and convergence speed all matter at once, the practitioner first has to identify which constraint is binding. Each stage raises the information-compute ratio by a different mechanism: pruning removes low-value samples before training, dynamic selection focuses compute on high-value samples during training, and synthesis creates new high-value samples on demand (table 10).
| Stage | When Applied | Techniques | Typical Gains |
|---|---|---|---|
| Static pruning | Before training | Coreset Selection, Deduplication, Quality Filtering | 30–50% dataset reduction |
| Dynamic selection | During training | Curriculum Learning, Active Learning, Semi-Supervised | 10–30% faster curricula; 2–100\(\times\) fewer labels |
| Synthetic generation | On-demand | Augmentation, Generative Models, Distillation | 2–10\(\times\) effective data expansion |
Once the dominant constraint is named, table 11 compares which technique changes that constraint and why.
| Constraint | Best Technique | Why |
|---|---|---|
| Limited labeling budget | Active Learning | Maximizes label ROI by selecting informative samples |
| High redundancy in data | Deduplication + Coreset | Removes waste before training begins |
| Rare classes or edge cases | Synthetic Generation | Creates samples that do not exist in raw data |
| Slow convergence | Curriculum Learning | Improves gradient quality in early training |
| Privacy requirements | Synthetic Data | Train on generated data, not real user data |
| Large model, small dataset | Knowledge Distillation | Use teacher model’s knowledge as “data” |
Table 11 maps individual constraints to techniques, but real projects face multiple constraints simultaneously. The decision tree in figure 9 structures the selection process hierarchically: start by identifying the primary bottleneck, then follow the branches to narrow the field.

Decision process
Each path requires a structured assessment because the same dataset symptom can point to different bottlenecks. Technique selection begins by naming the binding constraint, then checks whether the data, labels, and infrastructure needed by the chosen method actually exist.
Step 1: Assess the bottleneck
Identify which resource constraint most severely limits the training pipeline:
- Labeling cost: Label-efficiency techniques such as Active Learning, Semi-Supervised learning, and Self-Supervised learning maximize the value extracted from each human annotation.
- Compute cost: Dataset reduction through Coreset selection, Deduplication, and Curriculum Learning reduces the number of training iterations required.
- Data scarcity: Data creation through Augmentation, Synthesis, and Distillation expands the effective training set beyond what raw collection provides.
This diagnostic step keeps technique selection tied to the binding resource constraint rather than to the most familiar algorithm.
Step 2: Check prerequisites
With the bottleneck identified, verify that the corresponding techniques are feasible given the available infrastructure and data. Each approach carries specific requirements that must be met before implementation can begin (table 12).
| Technique | Prerequisites |
|---|---|
| Active Learning | Access to oracle, unlabeled pool, retraining infrastructure |
| Coreset Selection | Proxy model or embedding extractor, full dataset accessible |
| Curriculum Learning | Difficulty scoring method, pacing schedule |
| Semi-Supervised | Some labeled data, unlabeled data from same distribution |
| Self-Supervised | Large unlabeled corpus, pretraining compute budget |
| Augmentation | Domain knowledge of invariances, augmentation library |
| Synthetic Generation | Generative model or simulator, domain gap mitigation |
Step 3: Estimate ROI
Meeting the prerequisites is necessary but not sufficient. Before committing engineering resources, estimate the return on investment for each candidate technique: \[ \text{ROI} = \frac{\text{(Baseline Cost)} - \text{(Technique Cost + Implementation Cost)}}{\text{Technique Cost + Implementation Cost}} \]
A technique with high theoretical gains but high implementation cost may deliver lower ROI than a simpler approach. Deduplication, for example, often achieves the highest ROI because implementation cost is minimal and gains are immediate. Active Learning, by contrast, requires oracle access, retraining infrastructure, and selection algorithm development, so its ROI depends heavily on how many labeling cycles the team expects to amortize that investment across.
Step 4: Combine techniques
The techniques in this chapter are not mutually exclusive; in practice, the most effective pipelines combine multiple approaches. A typical production workflow begins by deduplicating the raw corpus for immediate gains at minimal cost. This cleaned dataset then undergoes coreset selection to identify the most informative samples. During training, curriculum learning orders these samples to optimize gradient quality, while data augmentation increases effective diversity at runtime. Finally, starting from a self-supervised foundation model rather than random initialization allows the pipeline to use knowledge learned from massive unlabeled corpora.
Each stage compounds the efficiency gains of previous stages, turning individual percentage improvements into multiplicative savings.
The preceding decision framework answers the what of data selection: which samples to prune, when to select dynamically, and how to synthesize new data. Understanding these algorithmic choices is essential, but algorithms alone do not translate into faster training. A perfectly designed coreset algorithm that takes 10 hours to select samples for a two-hour training run yields no practical benefit. Similarly, a curriculum learning strategy that requires scanning the entire dataset to determine difficulty rankings may idle GPUs while CPUs compute scores. The how of implementation matters as much as the what of algorithm choice.
The gap between algorithmic elegance and practical value raises several systems challenges: preventing selection overhead from negating theoretical gains, handling nonsequential I/O patterns that confuse prefetching logic, and coordinating selection decisions across distributed workers without introducing synchronization bottlenecks. The engineering patterns that follow bridge the gap between data selection theory and production reality.
Self-Check: Question
A pathology-AI team has 500,000 unlabeled slides, only 2,000 labeled slides, and a budget for approximately 3,000 expert-pathologist annotations. Using the chapter’s decision framework, which primary technique should they consider first?
- Active learning, because the binding bottleneck is expert labeling cost and the team has an oracle plus a large unlabeled pool — exactly the framework’s active-learning preconditions.
- Deduplication, because any labeling-constrained workload is fundamentally a redundancy problem.
- Knowledge distillation, because teacher outputs always substitute for human labels when labeling is expensive.
- Curriculum learning, because ordering the existing 2,000 labeled samples will produce enough signal to reach clinical accuracy.
Why does the framework insist on checking prerequisites before estimating ROI, rather than ranking techniques by expected gain alone?
A production team has a compute budget constraint, visible redundancy in its raw corpus, and a requirement for faster per-experiment iteration. Using the chapter’s framework, design a three-stage pipeline and justify why reordering the stages would lose gains.
Selection Engineering
Choosing the right data selection technique is necessary but not sufficient. Selection engineering begins where the decision framework ends: after identifying which algorithms to apply, we must ensure those algorithms actually deliver their promised speedups when deployed on real hardware with real data pipelines. A naive active learning loop that scans the entire dataset every epoch to select the “best” samples will turn a compute-bound training job into an I/O-bound bottleneck. The architectural patterns that prevent this and implement data selection in production are the subject of the following discussion.
The selection bottleneck
Dynamic data selection introduces a new bottleneck: selection latency. In standard training, the data loader reads the next batch sequentially. In active learning or curriculum learning, the system must evaluate a selection function \(f(x)\) over a large candidate pool to determine the next batch. Concretely, scoring a 1M dataset with a large model can take 2.8 hours, potentially negating the savings from a 10 percent coreset if not performed with a smaller proxy model.
For a selection strategy to be systems-efficient, it must satisfy the Selection Inequality expressed in equation 2: \[ T_{\text{selection}} + T_{\text{train}}(D_{\text{subset}}) < T_{\text{train}}(D_{\text{total}}) \tag{2}\]
Here \(T_{\text{selection}}\) is the time spent scoring the pool and \(T_{\text{train}}\) is the compute time. If \(f(x)\) requires a forward pass of a large model, the cost of selection can exceed the cost of training, producing negative ROI. A concrete scenario illustrates this trade-off.
Example 1.5: Selection inequality in practice
Scenario: Given 1M training images, the goal is to select a 100K coreset (10 percent) using EL2N scoring.
Option A: full-model selection:
- Score all 1M with the target ResNet-50: 1M \(\times\) 0.01 s/image = 10,000 s (2.8 h)
- Train on 100K coreset for 100 epochs: 100K \(\times\) 100 \(\times\) 0.01 s/image = 100,000 s (28 h)
- Total: 31 h
Option B: proxy-model selection:
- Score all 1M with a small proxy (ResNet-18): 1M \(\times\) 0.002 s/image = 2,000 s (0.6 h)
- Train on 100K coreset for 100 epochs: 100,000 s (28 h)
- Total: 28 h
Baseline: no selection:
- Train on the full 1M dataset for 100 epochs: 1M \(\times\) 100 \(\times\) 0.01 s/image =
Analysis:
- Option A saves 247 h vs. baseline (89 percent reduction) ✓
- Option B saves 249 h vs. baseline (89.8 percent reduction) ✓
- Option B beats Option A by 2 h. Proxy selection yields better ROI.
Trap: If selection required 50 h (for example, running a 7-billion-parameter model), the total would reach 78 h, still better than baseline, but the selection overhead equals 25 percent of the remaining net savings.
Systems insight: Selection time should stay below 10 percent of full-training time for good ROI, and it must remain smaller than the compute saved by discarding low-value samples.
The stacked bars in figure 10 demonstrate this trade-off: efficient selection (center) saves 55 percent of total compute in the figure’s normalized example, while expensive selection (right) consumes all the savings in overhead.
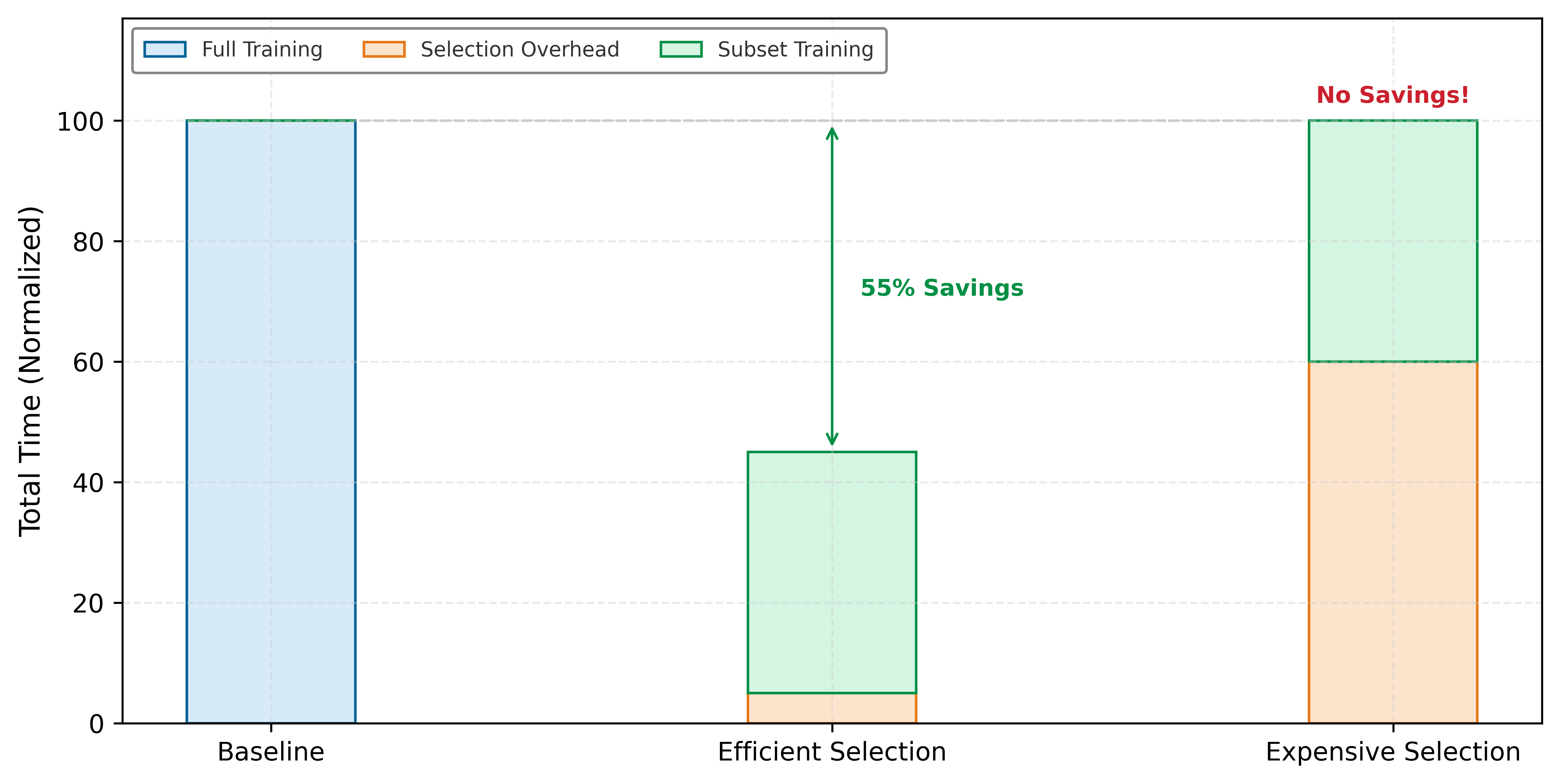
The lesson from figure 10 is unambiguous: selection overhead can negate the benefits of training on a smaller subset. The cost also compounds when selection runs every epoch instead of once: a per-epoch selection step that costs as much as one epoch of training spends as much compute on selection as on the subset itself, erasing any savings.
Hardware empathy: The random access penalty
The selection inequality addresses compute overhead, but data selection introduces a second, often overlooked cost: I/O pattern degradation. Data selection strategies like coresets or dynamic sampling often require random access to samples across the dataset, jumping to sample 47,231, then 892,104, then 3,417 based on selection scores. Standard training uses sequential reads that benefit from hardware readahead and OS page caching; random access patterns devastate throughput, especially on distributed filesystems or traditional hard drives. Table 13 quantifies this penalty across storage tiers.
High-efficiency systems mitigate this penalty through several techniques. Small proxy models (a 10-million-parameter “student” scoring on behalf of a 7-billion-parameter “teacher”) reduce selection cost by an order of magnitude while preserving ranking quality. Because proxy scoring is a pure inference workload, the inference runtime can execute it in lower-precision formats (INT8 or FP8) or dispatch it to inference-optimized runtimes, keeping the scoring pass well within the budget imposed by the selection inequality while the subsequent training pass retains the higher precision required for stable gradient updates. Embedding indices such as FAISS31 reduce selection from full linear scans to approximate nearest-neighbor searches whose cost depends on the index family and accuracy target. Both approaches share a common principle: decoupling selection from training enables independent optimization.
31 FAISS (Facebook AI Similarity Search): Provides GPU-accelerated similarity search using exact, approximate, and compressed-domain index designs (Johnson et al. 2019). Johnson, Douze, and Jegou report billion-vector graph construction on multiple GPUs, showing why vector-index infrastructure matters for web-scale selection. For data selection pipelines, FAISS-style indexing supports \(k\)-nearest-neighbor retrieval for coreset selection, embedding-based deduplication, and stratified clustering for balanced sampling. Without this infrastructure, embedding-based selection would often fall back to expensive full-corpus scans.
Johnson, Jeff, Matthijs Douze, and Hervé Jégou. 2019. “Billion-Scale Similarity Search with GPUs.” IEEE Transactions on Big Data 7 (3): 535–47. https://doi.org/10.1109/tbdata.2019.2921572.
| Storage Tier | Sequential Throughput | Random I/O (IOPS) | Random Throughput (approx) | Random Penalty |
|---|---|---|---|---|
| HDD (7.2k) | ~150 MB/s | ~100 IOPS | ~0.4 MB/s | 375× |
| SATA SSD | ~550 MB/s | ~10K IOPS | ~40 MB/s | 13.8× |
| NVMe SSD | ~3,500 MB/s | ~500K IOPS | ~2,000 MB/s | 1.75× |
| Cloud (S3) | ~100 MB/s (per conn) | ~10–50 ms (lat) | Very Low (per conn) | Extreme |
Data loaders also require architectural adaptation. Sharded dataset formats package many samples into sequentially readable chunks; WebDataset and FFCV are concrete examples. Shuffle buffers are a data-machine co-design: the loader reads large sequential shards into memory and samples randomly within the buffer, preserving sequential I/O throughput while achieving the statistical benefits of random sampling. In multi-accelerator training, each worker maintains its own shuffle buffer over a non-overlapping shard, so the randomization is local rather than global; rare classes or boundary cases that appear in only a few shards receive uneven coverage across workers unless the coreset is first stratified and shards are balanced before distribution.
Checkpoint 1.2: The selection inequality
Data selection is not free. It introduces a new term to the iron law and a new I/O cost.
Equation checks:
Systems implications:
Data echoing: Amortizing I/O costs
The optimizations discussed so far address I/O bandwidth, but modern data selection pipelines introduce another bottleneck: CPU computation. Synthetic data generation and heavy augmentation shift the constraint from disk speed to augmentation throughput. Heavy augmentations like 3D rotations and MixUp, or on-the-fly generative synthesis, can leave the GPU idle if the CPU cannot keep pace with sample production. When the data pipeline produces samples slower than the GPU can consume them, GPU utilization drops and training time extends, negating the efficiency gains from smarter data selection.
Data echoing32 (Choi et al. 2019) offers an elegant solution to this CPU-GPU imbalance. The technique reuses batches of data multiple times before fetching new samples, effectively trading sample diversity for GPU utilization. When the data pipeline (reading, decoding, augmenting) is slower than GPU processing, the GPU idles waiting for data. Data echoing fills this gap by “echoing” (repeating) each batch \(e\) times, applying different augmentations to each repetition so that the model still sees varied inputs.
32 Data Echoing: The key subtlety is where in the pipeline to insert the echo point. Echoing before augmentation (upstream echoing) applies different random augmentations to each repetition, preserving sample diversity; echoing after augmentation (downstream echoing) feeds identical tensors to the GPU, offering no diversity benefit. Upstream echoing with an echo factor of 2–4 typically matches standard training accuracy while recovering 50–75 percent of the GPU cycles lost to pipeline stalls.
The optimal echo factor depends on the ratio \(R\) of upstream processing time to downstream training time: \[ R = \frac{T_{\text{data pipeline}}}{T_{\text{GPU training}}} \]
If \(R > 1\) (data pipeline is the bottleneck), an echo factor \(e < R\) partially recovers idle GPU cycles, while \(e \geq R\) can fully use GPU capacity if echoed samples remain statistically useful. Increasing \(e\) beyond \(R\) no longer improves utilization and can reduce sample diversity. If \(R < 1\) (GPU is the bottleneck), data echoing provides no benefit. A realistic scenario makes these trade-offs concrete.

Data echoing helps only until the pipeline ratio threshold; beyond it, diversity falls.
Example 1.6: Worked example: Data echoing ROI
Scenario: Training ResNet-50 on ImageNet with heavy augmentation (RandAugment + MixUp).
Measurements:
- Data pipeline throughput: 300 images/s (reading, decoding, augmenting on CPU)
- GPU training throughput: 800 images/s (forward + backward pass)
- Ratio \(R = T_{\text{pipeline}} / T_{\text{GPU}}\) = (1/300 images/s) / (1/800 images/s) = 800 images/s/300 images/s ≈ 2.67 (GPU waiting 62.5 percent of time)
Without echoing:
- Effective throughput: 300 images/s (limited by data pipeline)
- Training time for 90 epochs: \(90 \times 1.28\text{M}\) / 300 images/s = 384,350 seconds (106.8 hours)
- GPU utilization: ~38 percent
With echo factor: \(e\) = 2.
- Each batch is processed twice with different augmentations
- Effective throughput: 600 images/s (still below GPU capacity)
- Unique images per second: 300 images/s (unchanged)
- Training time: \(90 \times 1.28\text{M}\) / 600 images/s = 192,175 seconds (53.4 hours) if echoed data is equally valuable
Echoed data has diminishing returns: Repeated samples are not guaranteed to be as useful as fresh samples; the data echoing paper evaluates echo factor, insertion point, and shuffling because those choices determine whether reuse preserves predictive performance. Empirically, Choi et al. (2019) measured a 3.25\(\times\) speedup on ResNet-50 ImageNet training when reading data over a network, with minimal accuracy degradation.
Systems insight: Data echoing trades sample diversity for GPU utilization, and it pays off only when augmentation is diverse, the dataset contains redundant samples, and the echo factor \(e\) stays below the critical threshold (roughly 4\(\times\) for ImageNet). Above this threshold, the model starts memorizing and accuracy degrades.
Choi, Dami, Alexandre Passos, Christopher J. Shallue, and George E. Dahl. 2019. “Faster Neural Network Training with Data Echoing.” arXiv Preprint, ahead of print. https://doi.org/10.48550/arXiv.1907.05550.
Data echoing also interacts with batch normalization. When the same image appears multiple times in a batch (or across nearby batches), batch normalization statistics become less representative of the true data distribution. This correlation violates the independence assumption underlying batch normalization’s effectiveness. Practitioners address this by excluding consecutive echoes from the same batch or by maintaining separate batch normalization statistics for echoed samples.
The preceding engineering patterns provide production-ready implementations of data selection principles. Proxy selection reduces the computational cost of identifying valuable samples. Sharded formats and shuffle buffers reconcile random access algorithms with sequential storage hardware. Data echoing maximizes GPU utilization when the data pipeline becomes the bottleneck. Together, they transform data selection from an algorithmic idea into a deployable system.
Engineering patterns solve the how, but a more fundamental question remains: whether to invest in data selection at all. A deduplication pipeline that costs $50K to build but saves $10K per training run requires a cost model to justify. The next section provides the quantitative framework for these investment decisions.
Self-Check: Question
Under the Selection Inequality, when is a data selection method a positive-ROI systems optimization?
- When the subset is at least 10\(\times\) smaller than the original, regardless of scoring overhead.
- When the selection score is computed with the full target model so that every ranking is trustworthy.
- When the subset is regenerated every epoch to stay fresh as the model changes.
- When selection time plus subset-training time is less than full-dataset training time.
In the chapter’s ResNet-50 coreset example, scoring with a small ResNet-18 proxy produces slightly noisier importance rankings than scoring with the full ResNet-50, yet the proxy wins on total runtime. Explain why tolerating noisier rankings can be the correct engineering choice.
Why can coreset-based training degrade storage throughput even when the selected subset is much smaller than the full dataset?
- Because smaller datasets automatically disable prefetching and batching in the data loader.
- Because irregular sample selection breaks the sequential-read pattern that data loaders, filesystem readahead, and storage hardware are optimized for.
- Because all selection methods recompute gradients on the CPU before reading any data.
- Because deduplicated datasets compress poorly, expanding the bytes read per sample.
A ResNet-50 training job runs at 300 images/second end-to-end, but the GPU alone can process 800 images/second; profiling shows CPU-side decoding and augmentation dominate the pipeline. Which intervention from the section best matches this bottleneck signature?
- Use data echoing so each fetched and augmented batch is reused with different downstream augmentations, letting the GPU extract more updates per CPU-bound batch while the upstream pipeline remains the limiter.
- Precompute augmented batches offline and cache them to disk, which removes augmentation from the runtime pipeline and guarantees downstream speedup.
- Increase model size so the GPU stays busier per image and the data-pipeline bottleneck becomes irrelevant.
- Disable augmentation entirely to cut pipeline cost to zero.
Order the following steps in the chapter’s distributed coreset workflow: (1) compute EL2N scores on each worker’s locally-deduplicated shard, (2) build per-shard embeddings and run local deduplication, (3) merge local top-scoring candidates at a coordinator and broadcast the final global selection indices.
Cost Modeling
The systems framing of data selection demands cost modeling and quantitative answers. Practitioners must determine whether to label 10,000 more samples or buy more GPU hours, when active learning pays for itself, and what ROI a deduplication infrastructure investment delivers.
Quantifying data costs and ROI
Answering these questions requires understanding what training data actually costs. The total cost of data encompasses the full lifecycle of data acquisition, preparation, and utilization, extending well beyond storage fees. Table 14 breaks down the four cost components. Labeling is usually the component data selection can change most directly, while storage and processing tend to scale more mechanically with retained volume and training passes. \[ C_{\text{total}} = C_{\text{acquire}} + C_{\text{label}} + C_{\text{store}} + C_{\text{process}} \] where:
| Component | Formula | Typical Range |
|---|---|---|
| \(C_{\text{acquire}}\) | \(D \times c_{\text{sample}}\) | $0.001–$10/sample (web scrape vs. licensed) |
| \(C_{\text{label}}\) | \(D_{\text{labeled}} \times c_{\text{label}}\) | $0.10–$100/sample (crowd vs. expert) |
| \(C_{\text{store}}\) | \(D_{\text{vol,store}} \times c_{\text{storage}} \times T_{\text{months}}\) | $0.02–$0.10/GB/month |
| \(C_{\text{process}}\) | \(D \times N_{\text{epochs}} \times O_{\text{sample}} \times c_{\text{FLOP}}\) | Proportional to training FLOPs |
For a concrete example, consider training a vision model:
Example 1.7: Cost breakdown: ImageNet-scale training
Table 15 itemizes the acquisition, labeling, storage, and compute costs for a supervised training run at ImageNet scale. The ratio, where data costs dominate, is typical for supervised learning. It inverts for self-supervised learning on web-scraped data, where compute dominates.
Table 15: ImageNet-scale training cost breakdown: Itemized acquisition, labeling, storage, and compute costs for an ImageNet-scale supervised training run, showing that data costs dominate compute by a wide margin in this regime.
| Cost Component | Calculation | Amount |
|---|---|---|
| Raw data (1.2M) | Licensed dataset | $50,000 |
| Labels (1.2M \(\times\) $0.05/label) | Crowd annotation | $60,000 |
| Storage (150 GB \(\times\) 12 months) | Cloud storage | $200 |
| Training (100 epochs \(\times\) 8 A100s \(\times\) 24 h) | GPU compute | $25,000 |
| Total | $135,200 | |
| Data vs. Compute ratio | 81.5% data, 18.5% compute |
Systems insight: In supervised vision regimes, the expensive part is often not the GPU run but the acquisition and labeling pipeline that makes the run meaningful. A cost model that omits data cost will systematically overstate the ROI of additional training.
ROI framework for data selection techniques
Understanding total costs enables rational decisions about which efficiency techniques merit investment. Every technique carries both a cost (implementation effort, compute overhead) and a benefit (reduced data requirements, faster training). Comparing these trade-offs requires a common framework: Return on Investment (ROI). \[ \text{ROI} = \frac{\text{Savings} - \text{Investment}}{\text{Investment}} \times 100\% \]
The challenge lies in quantifying both sides accurately. Deduplication offers the lowest-risk entry point and active learning the highest potential savings, with coreset selection and augmentation occupying the middle ground (table 16).
| Technique | Investment (Cost) | Savings (Benefit) |
|---|---|---|
| Deduplication | One-time compute for hashing + infrastructure | Reduced storage, fewer epochs for same accuracy |
| Coreset Selection | Proxy model training + selection compute | Train on 10–50% of data with minimal accuracy loss |
| Active Learning | Inference on unlabeled pool + human-in-the-loop latency | 2–10\(\times\) reduction in labeling budget for same acc. |
| Data Augmentation | CPU/GPU cycles for transforms | Effective dataset size increase without new data acquisition |
Break-even analysis
ROI calculations assume that techniques deliver their promised benefits, but actual outcomes vary. For any technique, there exists a break-even point where investment equals savings. Below this threshold, the technique costs more than it saves; above it, the technique generates value. Identifying this threshold determines whether a technique makes sense for a given project.
Suppose labeling costs $10/sample, active learning starts from 1,000 labeled samples ($10,000), queries 100 queries per round at $50 inference cost, and the random-labeling baseline requires 5,000 samples for target accuracy. If active learning reaches target accuracy with only 2,000 labeled samples, the ROI follows from comparing labeling and compute costs.
Random labeling cost = 5,000 \(\times\) $10/sample = $50,000
Active learning cost = 2,000 \(\times\) $10/sample + 10 rounds \(\times\) $50 = $20,500
ROI = ($50,000 − $20,500) / $20,500 \(\times\) 100 = \(143.9\%\)
The break-even occurs when the labeling reduction equals the selection overhead. If active learning only reduces labeling by 20 percent, and selection overhead is high, ROI may be negative.
Amortization across training runs
Break-even analysis captures a snapshot in time, but many data selection investments span multiple projects. Techniques with high upfront costs yield significant returns when their benefits compound across repeated training runs. Amortized ROI accounts for this temporal dimension, as table 17 and table 18 illustrate for a deduplication pipeline: \[ \text{Amortized ROI} = \frac{N_{\text{runs}} \times \text{Per-Run Savings} - \text{One-Time Investment}}{\text{One-Time Investment}} \times 100\% \]
| Component | Cost |
|---|---|
| Build deduplication pipeline | $50,000 (engineering time) |
| Compute MinHash signatures (one-time) | $5,000 |
| Per-run savings (20% less data) | $10,000/run |
The ROI pattern in table 18 reveals which circumstances favor infrastructure investment. Data selection investments deliver the highest returns under three conditions:
- Repeated training runs: Hyperparameter search, model iterations, and scheduled retraining reuse the same selection infrastructure many times.
- Shared datasets: A cleaned or deduplicated corpus can support multiple teams or model architectures.
- Broadly reusable techniques: Methods such as deduplication transfer across models, whereas task-specific coresets may not.
| Number of Runs | Amortized ROI |
|---|---|
| 1 run | -81.8% (net loss) |
| 5 runs | -9.1% (near break-even) |
| 10 runs | +81.8% (positive) |
| 50 runs | +809.1% (highly profitable) |
Deduplication exemplifies a high-transfer investment because it benefits all models trained on the cleaned dataset. Task-specific coresets, by contrast, may not transfer across architectures, limiting their amortization potential. For one-off training runs, simple techniques like random sampling or basic augmentation often yield better ROI than sophisticated methods requiring substantial infrastructure investment.
The investment decision therefore reduces to a practical split between high-reuse, data-limited workflows and one-off, already-curated ones.
Systems Perspective 1.2: When to invest in data selection
High-ROI scenarios:
- Labeling is expensive (medical, legal, scientific domains)
- Dataset is large and redundant (web-scraped corpora)
- Training runs are repeated frequently (hyperparameter search, retraining)
- Iteration speed matters more than final accuracy
Low-ROI scenarios:
- Labeling is cheap or already done
- Dataset is small and curated
- Single training run (one-time cost)
- Accuracy matters more than efficiency
These ROI calculations all assume a single machine. Production ML training distributes data across many workers, introducing coordination overhead that can erode or amplify those returns: a coreset algorithm designed for a single GPU may behave very differently once its dataset is sharded across hundreds of workers.
Self-Check: Question
In a supervised-learning pipeline where expert annotation is required, which cost component is most likely to dominate total data cost?
- Acquisition cost, because once data is collected the labels are effectively free.
- Storage cost, because modern cloud object storage grows linearly with every experiment and usually dwarfs other expenses.
- Labeling cost, because expert time per sample can reach tens to hundreds of dollars in domains like medicine or law and scales linearly with sample count.
- Process cost, because data selection has no effect on training FLOPs once the dataset is fixed.
A team can reach target accuracy in two ways: (a) label 5,000 random samples at $20 per sample, or (b) active-learn with 2,000 labeled samples at the same rate plus about $15,000 in pool-scoring and coordination overhead. State the break-even condition and explain what shifts it in either direction.
A deduplication pipeline costs $50,000 to build and saves $8,000 per retraining run in downstream compute. Why can this be a sensible investment even though the first retraining run produces a −$42,000 ROI?
- Because deduplication guarantees higher model accuracy, making ROI math irrelevant after deployment.
- Because its one-time build cost is amortized across many future retraining runs, so cumulative ROI turns positive after roughly seven runs and keeps growing.
- Because amortization assumes hardware prices fall faster than engineering salaries rise, guaranteeing positive ROI.
- Because once built, the pipeline eliminates all future labeling costs as well as compute costs.
True or False: Between two techniques, the one with the highest theoretical efficiency gain should always be deployed first, even if its implementation cost is much higher than a simpler alternative.
A team evaluates a data-selection infrastructure investment with a one-time setup cost of $30,000 and per-run savings of $6,000. How does the economic picture change as the number of retraining runs grows, and when does it justify the investment?
- ROI worsens with each run because the initial overhead compounds, so the investment is never justified.
- ROI is flat across runs because per-run savings are offset by equal operational costs, so the decision is unaffected by run count.
- Cumulative ROI crosses zero at roughly five runs and grows linearly thereafter, so the investment is justified when the retraining roadmap commits to at least that many future runs.
- ROI only becomes positive if the team switches to a faster accelerator in parallel, because hardware progress is a prerequisite for amortization.
Distributed Selection
The preceding sections assumed centralized access to the full dataset: a single-machine view where one process can see the entire dataset, compute global statistics, and make coordinated selection decisions. This assumption simplifies algorithm design: coreset selection can rank all samples globally, curriculum learning can establish a universal difficulty ordering, and active learning can query the single most uncertain example. Production distributed training breaks this assumption. When data is sharded across hundreds of workers, each seeing only a local slice, two difficult problems arise: computing a global coreset when no single node sees all samples, and maintaining consistent curriculum difficulty rankings when the model updates asynchronously across workers.
Whether distributed selection stays faithful to the global dataset or collapses into local shard heuristics depends on how much cross-worker coordination each technique requires against the bandwidth available to sustain it. The selection problem therefore has to be evaluated at the boundary where statistical value meets sharding and locality.
Strategies for distributed selection
In standard distributed training, data parallelism is straightforward: shard the dataset across workers, each processes its shard independently. Data selection techniques, however, introduce selection dependencies (table 19):
| Technique | Single-Node Assumption | Distributed Challenge |
|---|---|---|
| Coreset Selection | Global view of dataset | Each worker sees only its shard |
| Active Learning | Centralized uncertainty scoring | Scoring requires model synchronization |
| Curriculum Learning | Global difficulty ordering | Workers may have different “hardest” samples |
| Deduplication | Hash table fits in memory | Distributed hash tables add latency |
The selection dependencies admit several architectural solutions, each navigating a different point in the consistency-scalability trade-off space. The most straightforward approach centralizes selection while distributing training. A coordinator node performs selection on the full dataset, then distributes selected indices to workers. This preserves selection quality but introduces a single bottleneck:
Coordinator: score_all_samples() → selected_indices
Broadcast: selected_indices → all workers
Workers: train on subset(local_shard, selected_indices)The semantics remain clean, but the coordinator becomes a single point of failure and a bandwidth bottleneck for large selections. For modest cluster sizes, this overhead is acceptable; for thousand-node deployments, it becomes prohibitive.
Hierarchical selection addresses this scalability limitation by distributing the selection computation itself. Each worker performs local selection on its shard, then a coordinator merges results:
Workers: local_selected = select_top_k(local_shard)
Coordinator: global_selected = merge_and_rerank(all local_selected)
Broadcast: final_indices → all workersShard-local selection reduces coordinator load substantially but introduces a quality trade-off: the system may miss globally important samples that appear unimportant within their local shard. A sample that is only moderately difficult on one worker might be the hardest example in the entire dataset when considered globally.
When even hierarchical approaches prove too expensive, approximate global selection offers a fallback. These methods trade exactness for scalability through distributed approximate algorithms. Distributed MinHash enables deduplication by having each worker compute MinHash signatures independently; signatures are then aggregated to find near-duplicates across shards without requiring any single node to see all the data. Similarly, distributed uncertainty sampling allows workers to compute local uncertainty scores, with a global threshold determined by score distribution statistics rather than exact ranking.
Consistency challenges in active learning
The approximate selection strategies assume static selection criteria, but active learning introduces an additional complication: the model changes during selection. Consider what happens when Worker A scores samples using the model at step \(t\) while Worker B simultaneously updates the model to step \(t+1\). Worker A’s scores are now stale and may select samples that the updated model would rank differently.
Several strategies mitigate this staleness problem, each with distinct overhead characteristics:
- Synchronous scoring: All workers pause training and score simultaneously, guaranteeing consistency but at substantial cost in GPU utilization.
- Periodic score refresh: Workers re-score every \(k\) epochs rather than every batch, trading freshness for reduced overhead.
- Checkpoint-robust selection: The system selects samples that exhibit high uncertainty under multiple model checkpoints, keeping selection decisions valid as the model evolves.
A distributed coreset scenario shows how these strategies combine in practice.
Example 1.8: Distributed coreset selection
Scenario: Select a 10 percent coreset from ImageNet (1.3M images) using 8 A100 workers, one GPU per worker.
Setup: Figure 11 shows the coordinator-worker topology.
Mechanism:
- Embedding phase (parallel): Each worker computes ResNet-18 embeddings for its shard → store in shared filesystem
- Deduplication phase (distributed): Coordinator builds FAISS index, workers query for near-duplicates → remove 15 percent duplicates
- Scoring phase (parallel): Each worker computes EL2N scores on its deduplicated shard using proxy model
- Selection phase (centralized): Coordinator collects top-20 percent scores from each worker, re-ranks globally, selects final 10 percent
- Broadcast: Selected indices distributed to all workers for training
Result (measured on 8\(\times\) A100 cluster):
- Embedding: 20 minutes (parallel)
- Deduplication: 15 minutes (distributed hash join)
- Scoring: 30 minutes (parallel, five epochs proxy training)
- Selection: 2 minutes (centralized)
- Total overhead: 67 minutes for 10\(\times\) training speedup
Systems insight: The 67 minutes selection overhead strictly pays for itself once full training exceeds about 1.25 hours under a 10\(\times\) speedup assumption. By the overhead-budgeting rule established earlier, it stays within the 10 percent of full-training time threshold once full training exceeds about twelve hours. For ImageNet with modern architectures, full training is around twenty-four hours, so coreset selection has clear positive ROI and comfortable overhead headroom.

local_scores to the coordinator.
The positive ROI can erode quickly when workers must coordinate frequently during training. Distributed data selection always incurs a coordination tax: the overhead of maintaining consistent selection across workers. The coordination tax must be smaller than the efficiency gains, or distributed selection yields negative ROI. As a rule of thumb, if selection overhead exceeds 10 percent of full-training time, simplify the selection strategy or increase the selection interval.
A further constraint arises from cluster network topology. During training, gradient synchronization via All-Reduce exploits the high-bandwidth intra-node interconnect and the dedicated collective-communication fabric provisioned for that workload. Data selection operations, by contrast, move a different kind of traffic: embedding vectors, score arrays, and coreset index broadcasts travel over the same standard network that also carries storage I/O and management traffic. Gathering a FAISS index or broadcasting selected indices across many workers stresses CPU-to-NIC bandwidth rather than the accelerator interconnect, and can saturate the general-purpose network before the first training epoch begins. Staging these transfers during idle periods, compressing embedding representations, and limiting coordinator broadcast frequency all help ensure that pretraining selection work does not become a hidden bottleneck in the cluster’s ordinary network fabric.
Real ML systems combine data selection with model-level efficiency, machine-level throughput, and distributed training simultaneously. These optimizations interact in ways that can amplify or undermine each other, and understanding these interactions is essential for designing efficient end-to-end pipelines.
Self-Check: Question
Why do centralized data-selection algorithms like coreset scoring or global curriculum learning become much harder to implement correctly when training is distributed across many workers?
- Because distributed training removes the need for global rankings by making every shard statistically identical to every other.
- Because only active learning is affected by sharding; coreset selection and curriculum learning are unchanged.
- Because data parallelism automatically provides exact cross-worker uncertainty synchronization at every step.
- Because each worker sees only a local shard, so algorithms that assumed a single global view (top-K selection, global difficulty ordering, global deduplication) now require coordination the single-node version did not.
Compare centralized and hierarchical distributed-selection architectures by the trade-off they make between selection quality and coordination cost, and state one realistic deployment signal that should push a team toward each.
True or False: In distributed active learning, as long as all workers share the same model architecture, local uncertainty rankings remain globally comparable and can be merged without further coordination.
Cross-Layer Interactions
Data selection does not exist in isolation. A coreset-trained model may later be simplified for deployment. A curriculum-learning pipeline will run on specialized accelerators. An actively-learned dataset will feed into distributed training. These cross-layer interactions can amplify gains or introduce unexpected conflicts. Understanding these interactions helps practitioners design end-to-end efficient systems rather than optimizing components independently.
Model-level efficiency
Model-level efficiency reduces the size or arithmetic cost of the trained model through techniques such as pruning, lower-precision representation, and distillation. Data selection affects that later simplification because the training corpus shapes which features the model learns and which redundancies compression can remove. Models trained on smaller, higher-quality datasets are often easier to simplify than those trained on larger, noisier ones; Model Compression and Hardware Acceleration return to the hardware consequences of that interaction.
Systems Perspective 1.3: The sparsity latency trap
Context: The compressibility advantage from data selection is counted in arithmetic operations, but model compression research repeatedly shows that pruning reduces those counts more easily than it reduces wall-clock latency.
Failure mode: FLOPs can decrease dramatically while inference latency stays flat or increases. Dense matrix multiplication hardware rewards regular layout and reuse, while sparse matrices require irregular memory access, metadata checks, and address jumps. Unless the sparsity pattern matches the execution substrate, the overhead of managing sparsity can outweigh the reduction in arithmetic.
Systems insight: FLOPs are not latency. A 99 percent reduction in operations can yield a 0 percent reduction in time if the remaining operations are memory bound or cache-inefficient. Optimization must target the hardware’s actual bottleneck, not just an abstract metric (Hoefler et al. 2021).
Hoefler, Torsten, Dan Alistarh, Tal Ben-Nun, Nikoli Dryden, and Alexandra Peste. 2021. “Sparsity in Deep Learning: Pruning and Growth for Efficient Inference and Training in Neural Networks.” Journal of Machine Learning Research 22 (241): 1–124.
The mechanism relates to how models encode information. A model trained on repetitive data can learn redundant features that pruning later removes. The training compute required to learn those features was wasted, only to be discarded during compression. By contrast, a model trained on diverse, informative samples may learn compact, nonredundant representations from the start, making subsequent compression easier to evaluate and sometimes easier to apply. Treat this as an engineering hypothesis to measure after curation rather than a guaranteed property of every selected dataset.
Data selection and model-level efficiency are therefore complementary. The techniques in this chapter can reduce both training cost and later simplification effort. When planning an efficiency pipeline, apply data selection first; the resulting model will often be easier to simplify.
Machine-level throughput
While model-level efficiency affects what work remains after training, machine-level throughput determines how efficiently training itself proceeds. Specialized accelerators, kernel optimization, and parallel execution increase effective throughput. Data selection affects which machine bottlenecks dominate, and this relationship is more nuanced than simple speedup calculations suggest, as table 20 illustrates.
| Scenario | Likely Bottleneck | Hardware Optimization |
|---|---|---|
| Large, sequential dataset | Memory bandwidth | Larger batch sizes, gradient accumulation |
| Small, curated dataset | Input-pipeline I/O latency | Faster data loaders, data echoing |
| Dynamic selection | Selection compute | Proxy models, cached embeddings |
Data selection can therefore shift the system from one bottleneck regime to another. A technique that reduces dataset size by 80 percent may expose input-pipeline latency, selection compute, or true GPU compute as the next bottleneck, requiring different optimizations in each case. Before applying aggressive data reduction, profile the system to understand which bottleneck is being targeted.
Distributed training
The preceding hardware bottleneck analysis assumes single-machine training. The interactions become more complex when scaling to multiple machines, because data selection affects different parallelism strategies in distinct ways.
Under strong scaling, where a fixed dataset is distributed across more workers, data selection reduces communication overhead by reducing gradient updates per epoch. Fewer samples means fewer synchronization points, and communication costs often dominate at large worker counts. Under weak scaling, where each worker processes more data as the cluster grows, data selection techniques can maintain accuracy while adding workers without proportionally increasing total data. This capability proves essential when data collection rather than compute is the bottleneck. Even within straightforward data parallelism, smaller curated datasets reduce per-worker shard sizes, potentially improving cache utilization and reducing I/O stalls on each node.
The benefits must be weighed against the distributed selection challenges discussed in section 1.9. A technique that works well on a single GPU may incur prohibitive coordination overhead across 1,000 workers, negating its efficiency gains.
The optimization stack
The preceding sections examined pairwise interactions, but production systems apply all these optimizations together. Trace the full optimization stack in figure 12, from data to deployment: each stage in this pipeline amplifies or attenuates the effects of others.

The pipeline in figure 12 reveals why data selection occupies a strategic position: it sits at the head of the optimization stack. Reducing the dataset by 50 percent through intelligent selection does not just halve data processing time; it propagates through each named downstream stage. It halves the training compute, lightens the compression stage that produces the compact model, and relaxes the hardware provisioning needed by the deployed system. Each downstream stage inherits the efficiency gains or quality losses from upstream decisions, so the multiplicative effect means that every FLOP saved in data processing is a FLOP that never needs to be executed, simplified, or accelerated. Conversely, poor data selection that degrades model quality forces downstream stages to compensate, whether through longer training, less aggressive simplification, or over-provisioned hardware.
Quantifying this multiplicative effect requires determining whether a 50 percent dataset reduction delivers 50 percent compute savings, or whether it has inadvertently degraded model quality in ways that surface only in production. Answering this question requires a rigorous measurement framework: metrics that capture both the efficiency gains and the quality costs of data selection decisions.
Self-Check: Question
Why can well-chosen upstream data selection make later model compression more effective rather than merely cheaper?
- Because curated training data produces more compact, less redundant internal representations, which quantize and prune with smaller accuracy loss than representations learned from redundant data.
- Because compression algorithms only succeed on models trained with synthetic data.
- Because reducing dataset size automatically repairs sparse-kernel hardware inefficiencies at inference time.
- Because compressed models never lose accuracy as long as the training set was filtered with EL2N.
A team aggressively reduces dataset size with a 10\(\times\) coreset and observes that the training job’s bottleneck has shifted: what used to be I/O-bound is now compute-bound. Explain why this shift is expected and what the team should do next.
A team argues that data selection should be treated as ‘just another independent optimization’ ranked alongside quantization, distillation, and better kernels. Why does the chapter place it at the head of the stack instead, and what is the compounding consequence?
Measurement Framework
The cross-layer stack makes a measurement framework unavoidable: every data selection technique claims to improve efficiency, but only rigorous measurement separates real savings from shifted costs or hidden quality loss. The metrics below tie sample reduction to accuracy, cost, and deployment coverage so that a smaller dataset is judged by what it preserves, not only by what it removes.
Core metrics
The core metrics connect sample reduction to model quality instead of reporting accuracy alone. They measure learning per sample, performance-per-data, and compression at a target accuracy.
Performance-per-data
The most direct metric, performance-per-data (PPD), measures accuracy gain per sample: \[ \text{PPD}(n) = \frac{\text{Accuracy}(n) - \text{Accuracy}(0)}{n} \] where \(n\) is the number of training samples. A higher PPD indicates more efficient use of data. The key insight is that PPD exhibits diminishing returns: the first 10,000 samples contribute far more to model performance than the next 10,000.
Area under the learning curve
Rather than comparing at a single point, the area under the learning curve (AULC) integrates performance across all dataset sizes: \[ \text{AULC} = \int_0^D \text{Accuracy}(n) \, dn \] where \(n\) is the dataset size and \(D\) is the total dataset size.
A data-efficient strategy has higher AULC because it achieves good accuracy faster. This metric is particularly useful for comparing coreset selection algorithms.
Data compression ratio
For coreset methods, the Data Compression Ratio (DCR) measures how much data reduction is achieved at a target accuracy: \[ \text{DCR} = \frac{D_{\text{full}}}{D_{\text{coreset}}} \text{ at } \text{Accuracy}_{\text{target}} \]
A DCR of 5\(\times\) means the coreset achieves target accuracy with 20 percent of the data.
The compute-optimal frontier
The preceding metrics measure individual techniques, but a higher-level diagnostic is also needed: whether the overall training strategy is data-limited or compute-limited. Scaling laws provide that answer because research on neural scaling laws (Kaplan et al. 2020; Hoffmann et al. 2022) established that model performance follows predictable power laws with respect to compute, data, and model size. These laws provide more than theoretical interest: they offer a diagnostic framework for understanding whether training is limited by data quality or compute budget.
Kaplan, J., S. McCandlish, T. Henighan, T. B. Brown, B. Chess, R. Child, S. Gray, A. Radford, J. Wu, and D. Amodei. 2020. “Scaling Laws for Neural Language Models.” ArXiv Preprint abs/2001.08361.
Hoffmann, Jordan, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, et al. 2022. “Training Compute-Optimal Large Language Models.” Advances in Neural Information Processing Systems 35 35: 30016–30. https://doi.org/10.52202/068431-2176.
33 Chinchilla: A 70-billion-parameter language model whose central finding upended the “bigger is better” assumption: GPT-3 (175 billion parameters, 300 billion tokens) was significantly undertrained relative to its size. Chinchilla, with 70 billion parameters but 1.4 trillion tokens (4.7\(\times\) more data), outperformed GPT-3 on most benchmarks. The Chinchilla scaling law prescribes that model parameters and training tokens should scale roughly equally, redirecting the field from model scaling toward data scaling. For this chapter, the implication is direct: at the compute-optimal frontier, data quality and selection determine whether additional compute translates into better models or wasted FLOPs.
The Chinchilla study33 (Hoffmann et al. 2022) revealed a key insight: for any fixed compute budget, there exists an optimal balance between model size and training data. Training on too little data relative to model size wastes compute on an undertrained model; training on too much data with too small a model wastes data on a model that cannot absorb it.
The optimal balance defines a compute-optimal frontier: the best achievable performance at each compute budget when data and model size are properly balanced (figure 13).
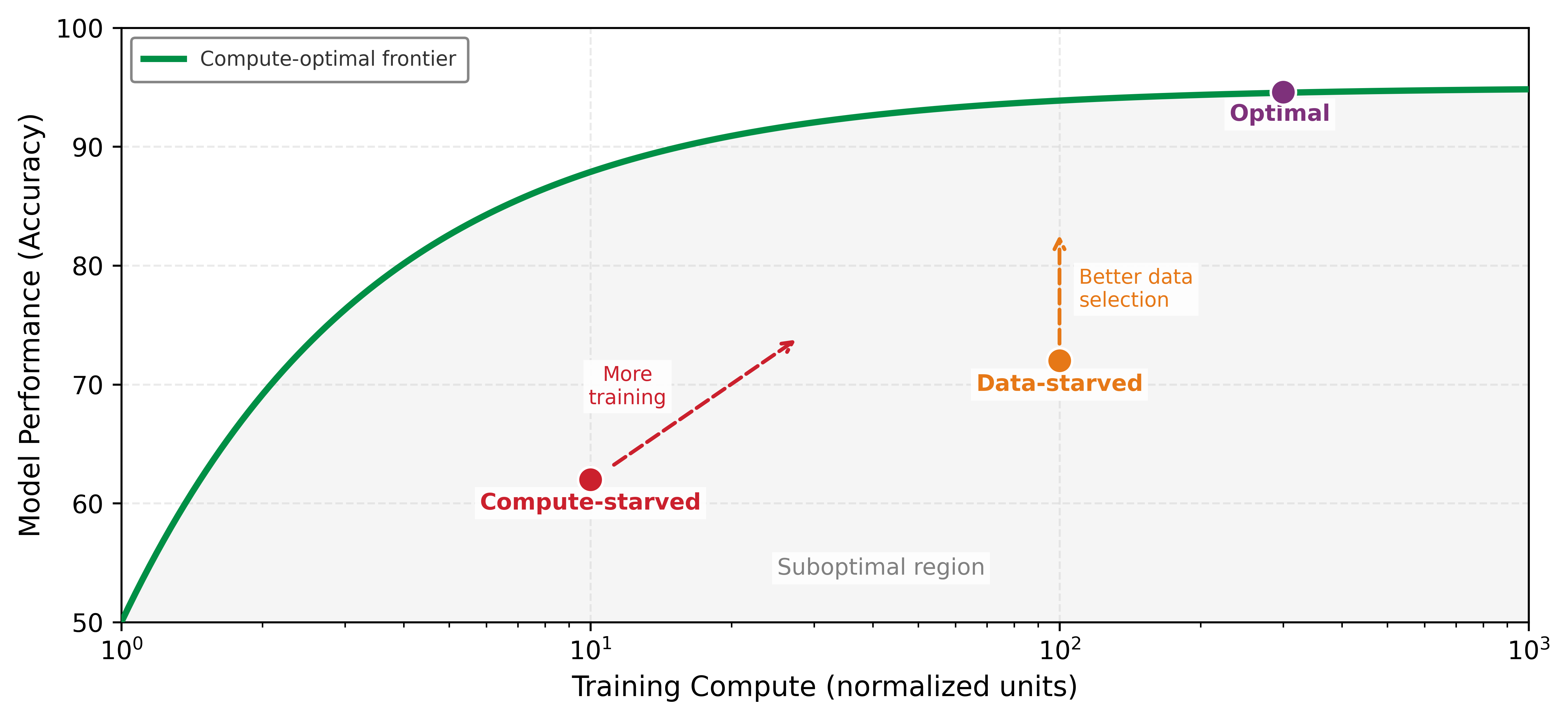
Once the point is plotted, the frontier diagnoses the intervention. A data-starved system has training compute available, but performance falls short of what the frontier predicts because data quality or quantity is limiting; the response is to apply the techniques from this chapter, such as deduplication, coreset selection, curriculum learning, or synthetic augmentation, to extract more learning per sample. A compute-starved system has high-quality data but cannot fully exploit it, so adding more data will not help until the training run gains effective throughput, longer duration, or more distributed capacity. Points on the frontier show that data and compute are balanced; further improvement requires increasing data quality and compute together.
The Chinchilla rule of thumb
In the compute-optimal regime described by the Chinchilla scaling laws34, training tokens and model parameters should scale together in a fixed ratio (roughly 20 per parameter). As a simplified consequence, when the model size is held proportional to its compute-optimal allocation, the number of training tokens grows roughly as \(D_{\text{opt}} \propto \sqrt{C}\); doubling the compute budget then implies about \(\sqrt{2} - 1\), or 41.4 percent, more tokens, not 100 percent. This explains why the data wall is so constraining: as compute grows exponentially, the demand for quality data grows roughly as its square root, but even that slower growth outpaces the supply of high-quality human-generated content.
34 [offset=-1mm] Chinchilla Ratio Diagnostic: The Chinchilla scaling law provides a practical data-starvation diagnostic: the \(D/P\) ratio (training tokens per model parameter). A ratio below 10 indicates severe data starvation; around 20 is compute-optimal; above 40 yields diminishing returns. For reference, GPT-3 trained at \(D/P \approx\) 1.7 (175 billion parameters, 300 billion tokens) was chronically undertrained, whereas LLaMA-2 70B at \(D/P \approx\) 28.6 is near-optimal. This single ratio is the fastest diagnostic for determining whether a training run is data-limited (add more tokens) or compute-limited (train a smaller model longer) before committing to an expensive run.
Applying the diagnostic
If a training run underperforms expectations, a simple diagnostic applies: train for 2\(\times\) longer. If performance improves substantially, the run was compute-starved. If it plateaus quickly, the run is data-starved and needs better data, not more training. The techniques in this chapter address the data-starved regime; more effective throughput, longer runs, and distributed training address the compute-starved regime.
In figure 14 the two curves diverge: a data-efficient selection strategy (blue) reaches the performance plateau much faster than random sampling (gray). The horizontal gap between the curves represents the efficiency opportunity (compute that could be saved), while the vertical gap marked by the red arrow represents the performance gained at a fixed dataset size.
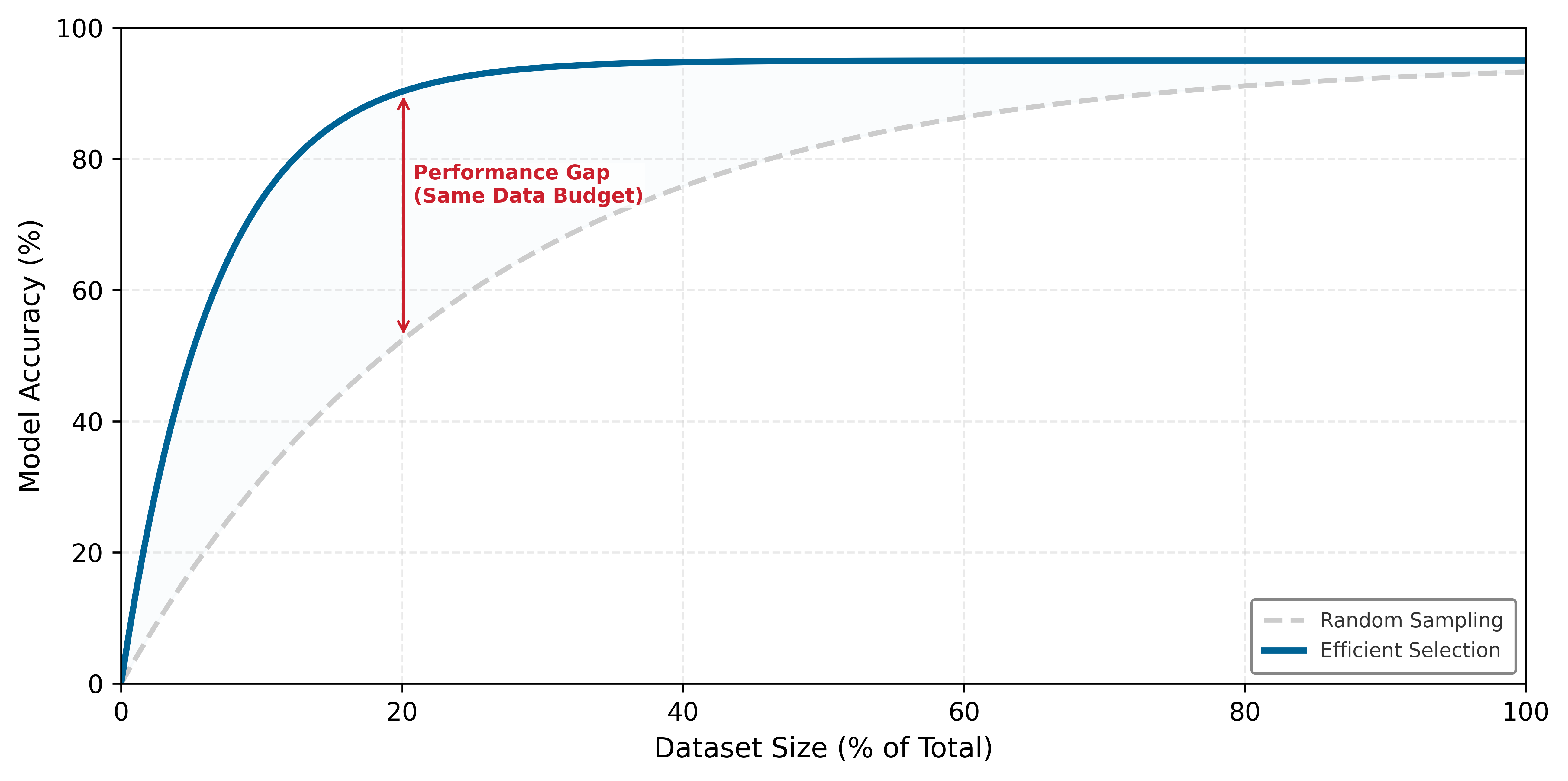
For practitioners, the metrics in this section answer a practical question: at what point to stop collecting data and start curating it, and when adding more samples wastes compute rather than improving accuracy. Knowing that a strategy is efficient, however, is not the same as confirming that a curated dataset preserved model quality.
Data selection techniques all make implicit claims about the value of different samples, and validating that a curated dataset actually preserves model quality requires systematic benchmarking across three dimensions. Coverage metrics validate that coreset selection preserved representation across classes and demographic groups. Distribution alignment metrics (such as KL divergence and PSI, which Measuring drift (divergence) defines) detect whether the curated training set drifted from the deployment distribution. Label quality metrics (inter-annotator agreement, confident learning) validate that active learning did not introduce systematic labeling errors. A 50 percent dataset reduction is only valuable if benchmarking confirms the model maintains target accuracy, calibration, and robustness. The benchmarking chapter later generalizes these ideas into broader model-and-data evaluation protocols; here, the point is narrower: a curated dataset must be validated against the task distribution, not only against its reduction ratio.
The validation target can itself be unreliable. A widely cited replication study shows how benchmark accuracy can overstate what a model has actually learned, which is why the evaluation set deserves the same scrutiny as the curated training set.
War Story 1.1: The benchmark replication gap
Context: ImageNet and CIFAR-10 were the gold standards for computer vision for nearly a decade, with researchers competing to squeeze every 0.1 percent accuracy gain. In 2019, a UC Berkeley team led by Benjamin Recht set out to test what those scores actually measured (Recht et al. 2019).
Failure mode: The Berkeley team built new CIFAR-10 and ImageNet test sets using the original collection methodology. Models that performed extremely well on the standard test sets dropped on the newly collected examples. Accuracy dropped by roughly 3–15 percentage points on the CIFAR-10 variants and 11–14 percentage points on ImageNetV2, depending on the model. The new test sets were slightly harder despite using the same broad data-generation process, showing that standard benchmark accuracy could overstate robustness to newly collected examples.
Systems lesson: Benchmark results are sensitive to the construction details of the evaluation set. Data leakage is one failure mode that requires train/test deduplication; distribution shift and example difficulty are another, as demonstrated by the ImageNet replication study.
Recht, Benjamin, Rebecca Roelofs, Ludwig Schmidt, and Vaishaal Shankar. 2019. “Do ImageNet Classifiers Generalize to ImageNet?” Proceedings of the 36th International Conference on Machine Learning (ICML), 5389–400.
The lesson carries directly to data selection: an efficiency gain measured against a single benchmark can evaporate on newly collected data, so a curated subset must hold up across multiple held-out distributions before its reduction ratio is trusted.
Lighthouse 1.3: Lighthouse data selection
Data selection principles apply to all five Lighthouse Models, though the dominant constraint determines the technique: compute-bound ResNet-50 benefits from coreset selection, memory-bound GPT-2/Llama from deduplication, and the tiny KWS model from augmentation and synthesis (table 21).
Table 21: Data selection priorities by lighthouse: Primary bottleneck and matching data-selection priority for each lighthouse workload, showing how the dominant resource constraint dictates which selection technique pays off.
| Lighthouse | Primary Bottleneck | Data Selection Priority |
|---|---|---|
| ResNet-50 | Compute | Coreset selection directly reduces training FLOPs |
| GPT-2/Llama | Memory bandwidth | Deduplication reduces corpus size; curriculum learning improves token efficiency |
| MobileNetV2 | Latency/Power | Aggressive augmentation compensates for reduced model capacity |
| DLRM | Memory capacity | Interaction deduplication and embedding pruning reduce table size |
| Keyword Spotting | Extreme constraints | Augmentation and synthesis create datasets from minimal seeds |
The common thread: data selection is not a single technique but a systems optimization tailored to whichever resource is most constrained.
The measurement tools and lighthouse examples demonstrate what data selection can achieve when applied correctly. The techniques, however, involve counterintuitive trade-offs, and practitioners frequently fall into predictable traps.
Self-Check: Question
A team wants a single number that answers ‘at our target accuracy, how many times smaller can our training set be?’ Which metric directly answers this question?
- Performance-per-data (PPD).
- Area under the learning curve (AULC).
- Data compression ratio (DCR).
- Return on investment (ROI).
A training run has 40 percent of its accelerator budget unused, yet doubling training time produces almost no further loss improvement. A plot against the compute-optimal frontier shows the run sitting well below the predicted achievable loss for its FLOP budget. What is the most likely diagnosis?
- On the frontier — no further optimization is possible.
- Compute-starved — the only fix is to rent faster accelerators and train for more hours.
- Data-starved — the binding constraint is insufficient information per sample, so more training on the same corpus cannot move loss further and better data (quality filtering, larger curated corpus) is the promising intervention.
- Inference-bound — training metrics are not useful for diagnosis.
A team compares two coreset selection methods. Method X wins by 0.4 points accuracy at 100 percent data, method Y wins by 1.2 points accuracy averaged over 10–100 percent data budgets. Explain why AULC is the better decision metric for this comparison than single-point accuracy.
True or False: Two runs on the same model and dataset both plateau at similar final loss; run A plateaus after 2 epochs while run B keeps improving through 10 epochs. Run A is almost certainly data-starved and run B is almost certainly compute-starved, so run A needs better data and run B needs more compute.
A run sits measurably below the compute-optimal frontier for its FLOP budget. Which interpretation matches the chapter’s diagnostic framework?
- The frontier applies only to toy models; real production runs cannot be compared to it.
- Being below the frontier is physically impossible; the measurement must be wrong.
- Below-frontier performance can only be fixed by buying more accelerators, since the frontier assumes optimal hardware.
- The run is wasting resources somewhere between the allocated compute and the realized loss: the hardware is capable of reaching frontier performance at this budget, so the gap points to correctable inefficiencies (data starvation, pipeline stalls, or suboptimal batch/model size balance).
Fallacies and Pitfalls
Data selection involves counterintuitive diminishing returns that contradict the “more is better” intuition from traditional machine learning. The following errors fall into three groups: conceptual fallacies about what data selection can achieve, implementation pitfalls that arise when correct strategies meet engineering realities, and transfer errors that occur when benchmark results are applied uncritically to new domains.
Fallacy: Data is the new oil, so more is always better.
Engineers assume linear returns from data scaling: 10× more data should yield proportional accuracy gains. In reality, the ICR framework (section 1.1.3) reveals severe diminishing returns. Scaling from 1M to 10M samples typically yields only 4 percentage points of accuracy gain while incurring 10× the compute cost. Table 1 quantifies the asymmetry: GPU compute grows 10× every 3 years while high-quality data grows only 2× every 5 years. A curated 100K dataset achieving 92 percent accuracy often outperforms a raw 1M dataset at 88 percent, despite 10× fewer samples. Teams that blindly scale data budgets waste compute on redundant samples that contribute near-zero gradient signal.
Pitfall: Replacing real-data validation with synthetic-only training data.
Engineers assume generative models can replace data collection with inexhaustible generated examples at marginal cost. Synthetic-only training can fail through two different mechanisms. First, section 1.5.3 and table 9 show the domain-gap problem: generated data can diverge from the real deployment distribution, causing the learned decision boundary in figure 8 to misclassify real-world inputs. Second, recursive training on model-generated data can cause model collapse: accuracy degrades from 95 percent to 78 percent after five generations of training on model-generated data, a 17 percentage-point drop. Optimal mixes are typically 50–80 percent synthetic, with the remainder real data; pure synthetic training fails catastrophically on deployment distributions.

Recursive synthetic-data training degrades accuracy across generations.
Fallacy: Data selection is just data cleaning.
Engineers conflate data quality (removing errors) with data value (maximizing ICR). A perfectly clean dataset can still be highly inefficient if filled with redundant, easy examples far from the decision boundary. Figure 4 illustrates the distinction: random sampling selects uniformly, wasting budget on samples deep within class regions. Coreset selection (section 1.2.2) prioritizes samples near the decision boundary where uncertainty is highest. EL2N and GraNd methods (table 3) achieve 1.8× higher ICR than random sampling by focusing on informative samples, not just clean ones. Cleaning addresses label errors; selection optimizes information content per FLOP.
Pitfall: Treating data selection as a budget-only tactic.
Practitioners view data selection as relevant only for TinyML or budget-limited startups. In reality, data selection applies wherever high-quality examples, not raw volume, constrain learning. A 10 percent efficiency gain on a $100M training run saves $10M. The data wall (figure 1) becomes especially visible at large scale: teams may have compute but lack enough high-quality data for the next useful training run. Section 1.8.4 shows that amortized ROI grows with reuse: deduplication infrastructure yielding $10K savings per run becomes highly profitable across 50 training runs. Organizations with large budgets adopt data selection because it addresses their true bottleneck: high-quality training data, not GPU hours.
Conceptual misunderstandings often lead to flawed strategies. Equally damaging are the implementation pitfalls that arise when correct strategies meet messy engineering realities.
Fallacy: Selection overhead is too small to change training economics.
A sophisticated coreset algorithm requiring 10 hours to select samples for a 2-hour training run has 5× overhead, yielding negative ROI. Section 1.7.1 establishes the Selection Inequality: \(T_{\text{selection}} + T_{\text{train}}(\text{subset}) < T_{\text{train}}(\text{full})\). If full training takes 8 hours, selection must remain under 10 percent of that time. Use lightweight proxy models (ResNet-18 for five epochs instead of ResNet-50 for 100) or cached embeddings: proxy-based EL2N scoring completes in 30 minutes (6.2 percent overhead), satisfying the inequality while achieving comparable selection quality.
Pitfall: Pruning rare classes into oblivion.
Aggressive coreset selection removes rare classes entirely because they contribute little to average loss. In a 1M dataset with 0.1 percent rare class samples (1,000 examples), a 10 percent coreset using uniform importance sampling retains only 100 rare examples on average, below the 150-sample minimum needed for reliable learning. Section 1.2.2 recommends stratified selection: set minimum samples per class before applying pruning, ensuring rare classes retain sufficient representation. Production models failing on rare cases despite excellent average accuracy often trace to this pitfall.
Fallacy: Deduplicating training data is enough to make evaluation reliable.
Some standard language-modeling datasets have measurable train-test overlap; a deduplication study reports overlap affecting over 4 percent of validation examples in evaluated datasets (Lee et al. 2021). Deduplicating only training data is therefore insufficient: evaluation sets must also be checked against the training corpus. Section 1.2.3 emphasizes joint deduplication for reliable evaluation. As noted in that section, deduplicated data can improve both efficiency and generalization, but teams should validate the effect because near-duplicate thresholds and domain distributions matter.
Lee, Katherine, Daphne Ippolito, Andrew Nystrom, Chiyuan Zhang, Douglas Eck, Chris Callison-Burch, and Nicholas Carlini. 2021. “Deduplicating Training Data Makes Language Models Better.” Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 8424–45. https://doi.org/10.18653/v1/2022.acl-long.577.
Pitfall: Active learning without considering annotation latency.
Active learning theory assumes instant oracle responses. In production annotation workflows, expert labels can require days or weeks in practice. With 14-day annotation latency, a model trained for 10 epochs between query rounds may have drifted significantly: samples selected as uncertain become irrelevant as the decision boundary shifts. Select larger batches (1,000 vs. 100 samples) to amortize latency and use diversity sampling to hedge against model drift. Active learning ROI therefore depends not only on label cost, as analyzed in section 1.8.3, but also on matching batch size to annotation turnaround time.
A subtler class of errors emerges when practitioners assume that benchmark results transfer directly to their specific domains and deployment contexts.
Fallacy: If a technique works on ImageNet, it will work on my dataset.
Benchmark papers report impressive results, but data selection effectiveness depends critically on dataset redundancy. CIFAR-10 is highly redundant: 50 percent coresets retain 98 percent accuracy. ImageNet has moderate redundancy: the same coreset retains 95 percent accuracy. Domain-specific datasets (medical imaging, satellite imagery) have near-zero redundancy: 50 percent coresets may retain only 72 percent accuracy because every sample captures unique diagnostic information. Section 1.11.2 and figure 14 show how the compute-optimal frontier varies by dataset structure. Start with conservative pruning (20–30 percent) and validate on held-out data before aggressive reduction; the “free lunch” ratios from benchmark papers rarely transfer directly.
Pitfall: Optimizing data selection metrics instead of deployment metrics.
A team creates a 10 percent coreset with excellent PPD and DCR scores, but the model fails catastrophically on production edge cases: 97 percent accuracy on majority classes but only 45 percent on rare subgroups. Section 1.11.1 defines efficiency metrics, but section 1.11 emphasizes that deployment success requires stratified evaluation. If the task demands 99.9 percent reliability on edge cases, the coreset must oversample those cases even at the cost of reduced average PPD. Include demographic subgroups, rare classes, and failure-mode coverage in selection optimization. The goal is deployment success, not benchmark efficiency.
Self-Check: Question
True or False: Once a large corpus has been deduplicated and label-validated, continuing to add more samples is a reliable way to improve training efficiency because the remaining data is all high quality.
A team deploys a sophisticated coreset-selection pipeline and observes that total end-to-end training time is 15 percent slower than the unselected baseline, despite the coreset being 4\(\times\) smaller. Which diagnosis matches the chapter’s framework?
- The sample efficiency improved so much that the optimizer converged too fast to measure the gains.
- Deduplication always forces the model to memorize harder examples, which slows convergence.
- Reducing training FLOPs typically increases wall-clock time on dense accelerators due to under-utilization penalties.
- The selection method violated the Selection Inequality: scoring, coordination, and I/O overhead consumed more time than the smaller subset saved in training.
A team reports 97 percent average validation accuracy after aggressive coreset pruning, but the deployed model misses 40 percent of critical fraud transactions and 55 percent of rare-disease indicators. Explain the measurement mistake and what evaluation suite would have caught it before deployment.
A team reads a paper reporting 90 percent coreset pruning on CIFAR-10 with no accuracy loss and applies the same 90 percent pruning ratio to a specialized medical-imaging dataset. Deployment accuracy drops 12 points. What does the chapter identify as the most likely cause?
- Medical datasets use different loss functions, which invalidates all coreset methods outside natural images.
- Redundancy levels differ by domain: benchmark datasets like CIFAR-10 contain high visual redundancy, while curated specialized corpora may have much less redundancy per sample, so a pruning ratio that is safe on the benchmark over-prunes in the specialized domain.
- Active learning is the only valid selection method outside of natural images.
- ImageNet-style results typically understate the pruning gains actually achievable on expert datasets.
True or False: A sufficiently strong generative model eliminates the risk of domain gap, making synthetic-only training safe for deployment-facing systems.
Summary
The preceding fallacies and pitfalls share a common thread: they arise when practitioners treat data selection as a purely algorithmic exercise divorced from the systems context in which it operates. Smaller, curated datasets sometimes outperform massive ones because data selection is a systems problem rather than a purely statistical one: it addresses the first question in the optimization ordering by reducing work before it begins. Traditional machine learning frames the problem as the number of samples needed to achieve target accuracy; the systems perspective frames it as minimizing total cost across the entire pipeline.
The reframing transforms how practitioners approach the ML development lifecycle. The shift introduced in the Purpose section, from accumulating data as a massive liability to curating it as a precise resource, becomes actionable through the ICR metric, the Selection Inequality, and the cost modeling framework. The goal is minimizing total cost across compute, storage, labeling, energy, and time, not merely maximizing accuracy.
The three-stage optimization pipeline addresses different phases of this cost equation: static pruning removes redundancy before training through coreset selection and deduplication, dynamic selection prioritizes informative examples during training through curriculum and active learning, and synthetic generation creates data where none exists through augmentation, simulation, and distillation. Together, these strategies address the “data wall,” the structural asymmetry between exponentially growing compute and slowly growing high-quality data.
The self-supervised learning paradigm represents the far end of the data-selection spectrum: pretraining shifts much of the learning signal into a reusable foundation model, so downstream tasks can often use far fewer task-specific labels through cost amortization. The structural transformation from “train from scratch” to “pretrain once, fine-tune many” has become the dominant approach in production ML precisely because of its superior data economics.
Translating these techniques into production requires systems engineering: the Selection Inequality \((T_{\text{selection}} + T_{\text{train}}(\text{subset}) < T_{\text{train}}(\text{full}))\) gates every technique, proxy models and shard-based data loaders reconcile selection algorithms with storage hardware, and data echoing maximizes GPU utilization when pipelines become the bottleneck. The cost modeling framework (total data cost, ROI analysis, and break-even thresholds) provides the quantitative tools to evaluate which techniques merit investment for a given workload, while core metrics (PPD, AULC, DCR) and the compute-optimal frontier diagnostic help practitioners determine whether their training is data-starved or compute-starved.
Key Takeaways: Curate, do not accumulate
- Selection optimizes system cost: The goal is reduced total cost across the entire pipeline (compute, storage, labeling, energy), not just “fewer samples for same accuracy.” The Information-Compute Ratio quantifies learning gained per FLOP spent, making selection mathematically equivalent to improving hardware throughput, but often cheaper to achieve.
- Start with deduplication: Exact deduplication is often the lowest-risk data selection technique and can deliver immediate storage and compute savings. Near-duplicate and semantic deduplication should precede expensive selection methods only after thresholds are validated against downstream quality metrics.
- The selection inequality gates every technique: \(T_{\text{selection}} + T_{\text{train}}(\text{subset}) < T_{\text{train}}(\text{full})\). Selection overhead should stay below 10 percent of full-training time. Proxy models and cached embeddings keep \(T_{\text{selection}}\) low; expensive selection algorithms can consume all the savings they promise.
- Dynamic selection adapts the data diet as the model learns: Curriculum learning (easy-to-hard ordering) and active learning (uncertainty-guided labeling) exploit the insight that the optimal training distribution changes during training, improving convergence speed and label efficiency respectively.
- Self-supervised pretraining amortizes labels: Pretraining once and fine-tuning many times spreads expensive label and compute costs across downstream tasks; the worked example delivers a 100\(\times\) labeled-data multiplier and a 20\(\times\) marginal-compute reduction. The amortization is strongest when the pretrained foundation is reused across teams and training runs.
- Synthetic data is a supplement, not a replacement: Mixing 50–80 percent synthetic with 20–50 percent real data typically yields the best results. Pure synthetic training risks model collapse and domain gap degradation.
- Data selection sits upstream of every later optimization: Savings from data selection are multiplicative with downstream model and machine improvements. Every FLOP eliminated upstream is a FLOP that never needs to be simplified or accelerated.
The techniques explored throughout this chapter (deduplication, coreset selection, curriculum learning, active learning, and synthetic generation) provide practitioners with a systematic toolkit for breaking through the data wall. Organizations that master these techniques gain compound advantages: reduced labeling budgets, faster iteration cycles, lower storage costs, and models that generalize better because they learn from higher-quality examples rather than redundant noise.
The answer to the chapter’s opening question is that most data is not where the learning is. A dataset can often shed 90 percent of its examples with no loss because they carried cost without carrying complexity: redundant examples consume compute, storage, and labeling budget while teaching the model nothing it did not already hold. Selection is the discipline of telling the two apart, keeping the examples that carry real signal and refusing the ones that carry only volume. Through D·A·M, this is data-algorithm co-design working upstream of everything else, because a sample that never enters training is a cost no optimization downstream ever has to fight. The most efficient computation a system can perform is the one that selection proves it never needed.
What’s Next: From data to algorithms
With high-quality data in hand, we have optimized the source of the system. Even the best data, however, cannot make an inefficient model run fast on constrained hardware. In Model Compression, we move from optimizing what the system learns to optimizing how it represents that knowledge, applying pruning, quantization, and knowledge distillation to reduce the computational cost of the model artifact itself.
Self-Check: Question
Which statement best captures the chapter’s central systems claim about data selection?
- Data selection is primarily a statistical variance-reduction trick with little effect on end-to-end system cost.
- Data selection is an upstream workload-reduction lever whose gains compound with every downstream algorithmic and hardware optimization because every removed sample is one that never loads, never computes, never synchronizes, and never compresses.
- Data selection matters only when labels are expensive; compute-rich teams can safely ignore it.
- Data selection should be applied after model compression so the final deployment artifact is smaller.
In one integrated explanation, relate the Information-Compute Ratio, the Selection Inequality, and the chapter’s three-stage pipeline to each other.
Why is the next chapter on model compression a natural continuation of this chapter, and how do the two differ in what they optimize?
Self-Check Answers
Self-Check: Answer
A team is deciding whether to invest engineering effort in curating their training corpus or in buying faster accelerators. Under the iron law of ML systems, which term of the equation does data selection most directly shrink?
- Peak throughput \(R_{\text{peak}}\), because curated data is processed at higher FLOP/s than raw data.
- Latency \(L_{\text{lat}}\), because shorter datasets eliminate data-loading orchestration overhead.
- Utilization \(\eta_{\text{hw}}\), because cleaner samples produce denser kernels with fewer memory stalls.
- Total Operations \(O\), because removing low-value samples reduces the number of forward and backward passes that must ever execute.
Answer: The correct answer is D. Data selection acts upstream of every compute stage: a sample that is never selected never contributes a forward or backward pass, so Total Operations falls at the source. An \(R_{\text{peak}}\) explanation confuses data with hardware capability — peak throughput is a property of silicon, not the data it processes. The utilization-efficiency framing misidentifies where data selection acts: \(\eta_{\text{hw}}\) depends on how code feeds the accelerator, not on which examples were chosen.
Learning Objective: Classify data selection as a Total Operations reduction within the iron law of ML systems.
A 70-billion-parameter language-model team has enough H100 capacity to process tens of trillions of tokens in three months, but deduplicated high-quality tokens in their corpus total only about 5 trillion. Explain why buying twice as many H100s does not solve their problem, and identify what kind of investment closes the gap.
Answer: The cluster is already compute-capable of many more tokens than the ready-to-use data supply can fill, so the binding constraint is data availability, not compute capacity — this is the Data Wall regime. Doubling the H100 count doubles a resource that is already in surplus; training longer on the same 5T tokens hits diminishing returns within two to three epochs as the model saturates on the available information. The investment that closes the gap is per-token information density: stricter quality filtering, curriculum design that re-weights informative samples, synthetic augmentation, or distillation from stronger teacher models.
Learning Objective: Diagnose a Data Wall regime from a stated compute-to-data ratio and prescribe the correct class of intervention.
Two pretraining runs reach the same validation loss: Run X uses \(2\times 10^{22}\) FLOPs and Run Y uses \(4\times 10^{22}\) FLOPs. Under the Information-Compute Ratio framework, which statement is correct?
- Run Y has higher ICR because more FLOPs means the model saw more information.
- Run X has higher ICR because the same performance gain was delivered per half the compute.
- ICR is undefined because it requires the runs to share model architecture and batch size.
- Both runs have identical ICR because ICR measures final accuracy, independent of cost.
Answer: The correct answer is B. ICR is performance-gain per unit compute, so halving the FLOPs at equal performance doubles the ratio by construction. The interpretation that more compute implies more information inverts the metric’s purpose — ICR exists precisely to distinguish efficient learning from wasteful processing. The claim that ICR depends on final accuracy alone ignores the ‘per unit compute’ denominator, which is the entire point of the metric.
Learning Objective: Apply the Information-Compute Ratio to compare the data-efficiency of two training runs.
Order the following stages of the chapter’s three-stage data selection pipeline by the point in the training lifecycle at which each operates: (1) synthetic generation fills gaps where real data is scarce, (2) static pruning removes low-value samples before training begins, (3) dynamic selection adapts the data diet as the model learns.
Answer: The correct order is: (2) static pruning removes low-value samples before training begins, (3) dynamic selection adapts the data diet as the model learns, (1) synthetic generation fills gaps where real data is scarce. Static pruning runs once offline so every subsequent stage operates on a smaller corpus; dynamic selection then adapts sample emphasis during training based on model state that only exists once training is underway; synthetic generation is applied last when the remaining real-data distribution shows coverage gaps the first two stages cannot fix. Swapping pruning and dynamic selection would force the trainer to re-rank the full raw corpus every epoch, wasting the cheap one-time reduction; putting synthesis first manufactures samples before eliminating obvious redundancy in the real corpus.
Learning Objective: Sequence the three stages of the data selection pipeline across the training lifecycle and justify why each must follow the prior.
True or False: A deduplicated, schema-validated, perfectly-labeled dataset is guaranteed to deliver high Information-Compute Ratio during training.
Answer: False. The chapter separates data correctness (the data-engineering guarantee) from data value (the data-selection target). A perfectly clean corpus can still be dominated by samples the model has already mastered, so each additional sample adds compute cost but little learning signal — a low-ICR regime despite flawless quality. Correctness is necessary but not sufficient for value.
Learning Objective: Distinguish data correctness from data value in the ICR framework.
Self-Check: Answer
Why can a 10 percent coreset of a modern vision dataset sometimes match the full dataset’s top-1 accuracy within one percentage point, despite training on a tenth of the samples?
- Because neural networks discard most examples after the first epoch, so any random 10 percent subset works equally well.
- Because smaller datasets eliminate overfitting regardless of the selection method used.
- Because pruning triggers an architecture change in modern frameworks that compensates for the reduced data volume.
- Because large datasets contain substantial easy-example redundancy and some noisy samples, while boundary and high-information examples dominate the learning signal.
Answer: The correct answer is D. The chapter’s argument is that large web-scale datasets are information-redundant: thousands of near-duplicate cat photos each contribute almost nothing once the first few have been seen, while the samples near the decision boundary carry most of the gradient signal. A random-subset-works-equally-well answer contradicts the chapter’s explicit finding that selection quality matters, especially for rare classes. The overfitting-elimination framing confuses regularization with sample-information density.
Learning Objective: Explain why informative-sample concentration allows coresets to approximate full-dataset accuracy.
A vision team wants the highest coreset quality for a 100M-image dataset and is willing to pay roughly 1 percent of full-target-model training cost on upfront scoring. Which selection method best matches this budget and quality target?
- Exact-match deduplication hashing alone, because hashes directly identify the decision-boundary samples that matter most for accuracy.
- k-Center geometric coverage without any training signal, because the method is the cheapest to run and treats all classes symmetrically.
- EL2N scores computed with a small proxy model early in training, because early-training error norms locate decision-boundary samples and transfer well to larger targets.
- Full-dataset forgetting-event analysis run on the target model itself, because only target-model dynamics give trustworthy importance scores.
Answer: The correct answer is C. EL2N uses proxy-model training dynamics to rank samples by boundary-informativeness, and the chapter emphasizes that these rankings transfer from small proxies to larger targets at roughly 1 percent of target training cost. Deduplication hashing removes redundancy but does not rank by informativeness, so it cannot concentrate on boundary samples by itself. k-Center achieves geometric coverage but ignores label-informed difficulty, and full-target forgetting analysis blows the 1 percent budget by orders of magnitude because it requires a complete training run.
Learning Objective: Compare coreset selection methods by selection quality versus scoring cost under a stated budget.
The chapter argues that noisy-label convergence scales as \(\mathcal{O}(1/\sqrt{N})\) while clean-label convergence scales as \(\mathcal{O}(1/N)\). Using the chapter’s own order-of-magnitude figures, explain why investing engineering effort to remove label noise can save more compute than buying faster accelerators.
Answer: At the 1 percent target error rate, the two scaling regimes diverge by roughly two orders of magnitude in the samples needed — about 100 clean labels versus about 10,000 noisy ones for the same target. Because the training-FLOPs bill is roughly linear in samples processed, a 100\(\times\) sample gap translates into a 100\(\times\) compute gap that faster accelerators cannot erase: a 2\(\times\) speedup still leaves a 50\(\times\) effective cost disadvantage against the clean-data baseline. The practical consequence is that a mislabeling-rate audit and a label-correction pipeline are higher-ICR investments than the next-generation hardware refresh for noise-limited workloads.
Learning Objective: Analyze how label noise changes the sample-count requirement and quantify the compute implication.
An engineering team wants immediate pretraining-cost savings with near-zero risk of hurting downstream accuracy. Which static-pruning technique matches that risk profile, and why?
- Deduplication, because removing exact and near-duplicate samples cuts wasted compute without altering the supervision distribution the model sees.
- Forgetting-events selection on the full training dynamics, because it produces the most-reliable per-sample scores.
- Aggressive outlier removal below the fifth percentile of embedding density, because rare samples tend to be noise.
- High-confidence pseudo-labeling on web-scraped unlabeled data, because pseudo-labels are always lower risk than real labels.
Answer: The correct answer is A. Deduplication removes samples that carry no new information by definition — the remaining corpus still covers the same label distribution — so the downside risk to accuracy is essentially zero. A forgetting-events approach requires a full training run to compute, so it pays the cost the team wants to avoid. Aggressive outlier removal risks deleting rare but valid examples (minority classes, edge cases) that the model needs, and indiscriminate pseudo-labeling injects label noise whose downstream impact is unpredictable.
Learning Objective: Identify the lowest-risk static-pruning entry point for immediate production gains.
A fraud-detection dataset has 1 million benign transactions and 2,000 fraud transactions. A naive top-EL2N coreset at 10 percent produces a subset with only 60 fraud examples, and the deployed model’s recall on fraud collapses from 82 percent to 34 percent. Explain the failure and propose the corrected selection strategy.
Answer: Global top-EL2N scoring is dominated by the majority class: the 1 million benign transactions supply most of the score mass, and a 10 percent global cut keeps proportionally few fraud examples — often too few to learn the minority decision boundary. The 60-to-2,000 drop reveals that the rare class was treated as an afterthought by a class-blind selector. The corrected strategy is stratified selection: partition the dataset by class first, then apply coreset scoring within each stratum with a minimum-per-class floor (for example, retain at least 80 percent of fraud examples and apply aggressive EL2N pruning only to the benign majority). This preserves the rare-class signal while still reducing the majority redundancy.
Learning Objective: Design a stratified pruning strategy that preserves rare-class signal under severe class imbalance.
Self-Check: Answer
What distinguishes dynamic selection from static pruning as an optimization strategy?
- Dynamic selection guarantees higher final accuracy because every sample is seen the same number of times over training.
- Dynamic selection is primarily a disk-footprint optimization that removes samples from storage as training progresses.
- Dynamic selection replaces human labels with self-supervised objectives during the training loop.
- Dynamic selection adapts which samples are emphasized to the model’s current state, recognizing that an example’s informativeness shifts as the model learns.
Answer: The correct answer is D. The section’s central claim is that the most informative samples early in training (easy, clear-gradient examples) differ from the most informative samples later (hard, boundary-region examples), so a static selection made before training cannot be optimal throughout. The equal-exposure framing contradicts the whole premise of adapting the data diet. The self-supervision claim confuses dynamic selection with the next section’s topic, and the storage framing misidentifies what dynamic selection is for.
Learning Objective: Explain why the informativeness of training samples changes over the course of learning.
A team trains a vision model on a moderately noisy 50M-image dataset and wants to accelerate convergence by reshaping the per-epoch sample order. Which design is curriculum learning as the chapter describes it?
- Pseudo-label every unlabeled sample unconditionally to expand training volume as quickly as possible.
- Query the single most uncertain unlabeled sample each round and route it to a human annotator.
- Score samples by a difficulty metric, then introduce them using a pacing schedule that starts with the easiest fraction and gradually widens to include harder ones as training progresses.
- Randomly permute the dataset every epoch so the optimizer cannot exploit any ordering.
Answer: The correct answer is C. Curriculum learning pairs a difficulty scorer with a pacing function so early gradient updates come from clear, easy-to-learn examples and the distribution shifts toward harder examples as the model improves. The human-query option describes active learning, which addresses labeling cost rather than sample ordering. Unconditional pseudo-labeling ignores the confidence gating that semi-supervised methods require, and per-epoch random permutation is exactly the ordering-agnostic baseline curriculum learning departs from.
Learning Objective: Apply the curriculum-learning design pattern to a concrete training scenario.
In the chapter’s medical-imaging example, active learning reaches a target accuracy with about 50,000 expert-labeled scans while the same labeling budget would buy roughly 100,000 random labels. Explain why active learning produces this 2\(\times\) budgeted-labeling advantage, and state one compute consequence beyond labeling cost.
Answer: Active learning concentrates the expert’s limited time on samples the current model is uncertain about, which carry the most gradient information per label; random sampling spreads the same labeling budget across obvious easy cases where the model is already confident and gains little from extra supervision. In the medical scenario this means 50,000 strategically chosen scans are compared against 100,000 budgeted random labels. The compute consequence beyond labeling is a proportionally shorter training wall clock — a 2\(\times\) smaller labeled set means a 2\(\times\) smaller per-epoch FLOP count for the labeled subset — so each iteration of the active-learning loop finishes faster, compounding the budget advantage.
Learning Objective: Analyze the labeling-ROI advantage of active learning and identify its downstream compute consequence.
From the chapter’s perspective, why is FixMatch a favorable systems trade-off for label-poor settings?
- It reduces both compute and labels simultaneously, making it strictly cheaper on every axis.
- It eliminates the need for any labeled examples, reducing labeling cost to zero.
- It trades additional compute on unlabeled data (two augmentation passes per unlabeled sample plus confidence gating) for a large reduction in manual labeling cost, typically at a small accuracy drop.
- It is robust to distribution mismatch between labeled and unlabeled pools because its augmentation step erases the difference.
Answer: The correct answer is C. FixMatch’s entire value proposition is a compute-for-labels exchange: the unlabeled pool drives extra forward passes and augmentations, which cost accelerator cycles, but those cycles substitute for expensive annotation work. The zero-label claim is incorrect: FixMatch still requires a labeled seed set to drive confident pseudo-labeling. The strictly-cheaper framing misses the trade entirely — compute rises, not falls. The distribution-match claim ignores a real failure mode the chapter highlights: confident wrong pseudo-labels under domain shift.
Learning Objective: Evaluate the compute-for-labels trade-off underlying FixMatch-style semi-supervised learning.
True or False: If a team has 100\(\times\) more unlabeled data than labeled data, semi-supervised learning is almost guaranteed to improve accuracy regardless of whether the unlabeled pool was scraped from a different distribution than the labeled task data.
Answer: False. Semi-supervised methods rely on the unlabeled pool matching the task distribution so that high-confidence pseudo-labels concentrate near the correct decision boundary. Out-of-distribution samples can receive confidently wrong pseudo-labels, which the self-training loop then reinforces — more unlabeled volume amplifies the poisoning rather than curing it.
Learning Objective: Identify the distributional assumption that must hold for semi-supervised learning to help rather than hurt.
Self-Check: Answer
What key bottleneck does self-supervised learning remove compared with active learning and semi-supervised learning, and what does it not remove?
- It removes the need for architecture choices because the pretext task determines the network automatically, and it eliminates compute cost as well.
- It removes the need for data curation because web-scale unlabeled corpora can be used directly without deduplication or filtering.
- It removes the compute cost of pretraining by making unlabeled training inherently cheaper than supervised training.
- It removes the need for task-specific human labels during pretraining by extracting supervision from data structure, but leaves curation and compute cost in place — often raising compute significantly.
Answer: The correct answer is D. The pretext task (next-token prediction, masked reconstruction) manufactures labels from the data itself, which is why human-labeling bottlenecks disappear at pretraining. But the chapter explicitly notes that pretraining often multiplies compute cost by one to two orders of magnitude, and that pretraining-scale deduplication and quality filtering remain essential. The architecture-determination claim invents a mechanism SSL does not provide. The cheaper-compute framing inverts the actual cost picture. The no-curation-needed option directly contradicts the chapter’s warning that web-scale data still requires aggressive filtering.
Learning Objective: Explain which bottleneck self-supervised learning removes and which constraints persist.
A company plans to ship ten specialized models. One self-supervised pretraining run costs 10,000 GPU-hours; training each model from scratch requires 100,000 labels at $1 per label plus 1,000 GPU-hours of compute, while fine-tuning from the pretrained base requires 1,000 labels at $1 per label plus 50 GPU-hours. Analyze when the pretraining investment pays off and how the break-even shifts as the number of tasks grows.
Answer: Training ten models from scratch costs $1M in labels (100,000 labels at $1 per label per task) plus 10,000 GPU-hours of compute. Pretraining plus ten fine-tunes costs $10K in labels plus 10,500 GPU-hours (10,000 one-time pretrain plus 10$\(50 fine-tune). Labeling savings are 100\)\(; per-task marginal compute drops 20\)$. Total compute is comparable at ten tasks (10,000 vs. 10,500 GPU-hours), but the crossover favoring pretraining on compute alone occurs around 10.5 tasks: below that, scratch is cheaper because the 10,000 GPU-hour pretraining bill cannot be amortized; above that, every additional task widens the gap on marginal per-task cost. The practical implication is that the foundation-model strategy is a bet on task count: justified when the organization is confident it will ship many related specialized models, overkill when only two or three are planned.
Learning Objective: Analyze how the break-even task count for self-supervised pretraining depends on scratch-training and fine-tuning cost ratios.
Which statement best captures the chapter’s view of the foundation-model paradigm’s systemic implications for data selection?
- It makes coreset selection, deduplication, and fine-tuning curation obsolete because pretraining absorbs the responsibility for all data decisions.
- It replaces model compression as the primary mechanism for reducing inference cost on downstream tasks.
- It is useful only when every downstream task comes with millions of labeled examples.
- It creates a shared pretrained base whose data curation decisions have a large blast radius across every downstream application that inherits it.
Answer: The correct answer is D. The foundation-model paradigm concentrates data-selection decisions at one point — the pretraining corpus — and then propagates the consequences (both capabilities and biases) to every downstream fine-tune that reuses the base. This amplifies the importance of pretraining-stage curation rather than eliminating it. The obsolete-curation framing directly contradicts the chapter’s emphasis that deduplication, filtering, and fine-tuning selection all still matter. The compression-replacement claim confuses different parts of the D·A·M stack. The millions-of-labels framing inverts the actual use case, which is label-poor downstream tasks.
Learning Objective: Evaluate the systemic blast-radius implications of the foundation-model paradigm for upstream data curation.
An organization is deciding whether self-supervised pretraining is economically justified. Which situation most strongly tips the decision toward pretraining rather than per-task scratch training?
- A single specialized task with a fixed labeled budget and no plan to build additional models.
- Two related models that must ship within six weeks on tight hardware budgets.
- A multi-year roadmap of fifteen-plus related models across the organization’s domain, where each fine-tune inherits the same base.
- A one-off academic experiment that will not be redeployed or iterated.
Answer: The correct answer is C. Amortization economics reward task count directly: the large upfront pretraining bill becomes attractive only when spread across enough downstream fine-tunes that each inherits a much cheaper label and compute cost. A multi-year fifteen-model roadmap is exactly the regime the chapter highlights as the foundation-model sweet spot. Single-task, two-task-on-tight-timelines, and one-off experimental scenarios all lack the task count needed to pay back the pretraining investment; in those cases scratch training stays competitive or wins outright.
Learning Objective: Apply amortization reasoning to decide when self-supervised pretraining is economically justified.
Self-Check: Answer
Which workload most strongly favors transformation-based data augmentation over full generative synthesis?
- An autonomous-driving team that needs rare crash scenarios that never appeared in the collected fleet logs.
- A vision team with 500,000 labeled images that wants cheap label-preserving diversity via crops, flips, and color jitter to improve generalization.
- A medical-imaging team that wants to replace all real patient scans with synthetic-only training data for regulatory reasons.
- A robotics team that wants to avoid specifying any invariances by hand and outsource that choice to a generative model.
Answer: The correct answer is B. Augmentation’s value is expanding diversity from existing labeled samples via transformations that preserve the label — crops, flips, color jitter — at near-zero marginal cost per epoch. The rare-crash-scenario workload needs entirely novel inputs that augmentation cannot manufacture; that regime is what generative simulation targets. Synthetic-only replacement is exactly the overreach the chapter flags, and the no-invariance-specification framing confuses augmentation (which requires the engineer to pick which transformations preserve the label) with an automatic property augmentation does not have.
Learning Objective: Select between augmentation and generative synthesis based on the workload’s diversity requirements and cost constraints.
A perception model trained entirely on a high-fidelity simulator achieves 94 percent validation accuracy on synthetic test data but drops to 61 percent on real deployment data. Which mechanism best explains the failure?
- The simulator generated fewer labels per sample than the real dataset would have.
- Synthetic samples are too easy, so the model failed to build enough regularization against hard cases.
- The model learned a decision boundary tuned to the simulator’s distribution, and the deployment data differs enough on subtle features (texture statistics, sensor noise, lighting priors) that those features no longer fire the same way.
- Generative models cannot produce enough samples for modern architectures to converge.
Answer: The correct answer is C. This is the domain-gap failure the chapter warns about: a simulator’s statistical signature — however photorealistic it looks to humans — differs from the real sensor stream on features the model actually relies on, so a boundary that works on synthetic data misfires on deployment data. The label-count explanation confuses volume with distribution match. The too-easy-samples framing touches regularization but misses the central issue of distribution mismatch. The sample-volume claim contradicts the observed 94 percent synthetic accuracy, which is only possible if the model converged.
Learning Objective: Analyze the domain-gap mechanism behind synthetic-to-real transfer failure.
A robotics team has a high-fidelity simulator capable of generating unlimited synthetic trajectories and 20,000 real-world logged trajectories. Propose a synthetic-real mixture for training and explain why pure synthetic and pure real are both worse than a mixture.
Answer: A typical design is roughly 80 percent synthetic and 20 percent real per batch, which uses the simulator for cheap coverage of rare edge cases (collisions, sensor failures, weather variation) while anchoring the model to the real deployment distribution via the 20 percent real share. Pure synthetic training maximizes coverage but leaves the domain gap unbridged, producing the sim-to-real accuracy drop demonstrated in the prior question. Pure real training eliminates the domain gap but loses the simulator’s cheap edge-case diversity and is limited to the 20,000 samples available. The mixture captures both benefits; as real data grows, the ratio should shift toward real data to close the remaining gap.
Learning Objective: Design a synthetic-real training mixture and justify why neither pure strategy is optimal.
Viewed as a data-selection technique, what does knowledge distillation add beyond training on the same dataset with ordinary hard labels?
- It replaces the training set with fewer samples, so compute falls proportionally.
- It removes the need for any teacher inference, since soft labels can be derived from the student alone.
- It guarantees the student model matches the teacher model’s accuracy regardless of any capacity gap.
- It provides richer soft-target distributions that encode inter-class similarities, increasing the information carried per training sample.
Answer: The correct answer is D. Distillation replaces one-hot hard labels with the teacher’s full probability distribution, which encodes similarity structure among classes (the student sees that ‘truck’ is closer to ‘car’ than to ‘cat’). The chapter frames this as higher information density per sample, which is precisely an ICR improvement. The dataset-size explanation misidentifies the mechanism — distillation does not shrink the dataset, it enriches each sample’s supervision. The accuracy-guarantee claim ignores capacity gaps, and the no-teacher-inference option contradicts the mechanism itself.
Learning Objective: Reframe knowledge distillation as an information-density optimization within the data-selection framework.
True or False: If a simulator passes visual photorealism tests, it is safe to deploy a model trained 100 percent on that simulator without supplementing with real data.
Answer: False. Photorealism to human eyes is not the same as statistical match to the model’s internal features — subtle texture, sensor-noise, and lighting-prior differences can still produce a measurable domain gap. The chapter’s recommendation is to mix synthetic with real data for precisely this reason, using real samples to anchor the learned boundary to deployment conditions even when synthetic quality looks excellent.
Learning Objective: Assess the misconception that high-fidelity synthetic alone is sufficient for deployment-bound training.
Self-Check: Answer
A pathology-AI team has 500,000 unlabeled slides, only 2,000 labeled slides, and a budget for approximately 3,000 expert-pathologist annotations. Using the chapter’s decision framework, which primary technique should they consider first?
- Active learning, because the binding bottleneck is expert labeling cost and the team has an oracle plus a large unlabeled pool — exactly the framework’s active-learning preconditions.
- Deduplication, because any labeling-constrained workload is fundamentally a redundancy problem.
- Knowledge distillation, because teacher outputs always substitute for human labels when labeling is expensive.
- Curriculum learning, because ordering the existing 2,000 labeled samples will produce enough signal to reach clinical accuracy.
Answer: The correct answer is A. The framework’s active-learning gate is: expensive oracle labels plus a large unlabeled pool plus retraining infrastructure — the team satisfies all three, and the 3,000-query budget is exactly what active learning is designed to allocate for maximum accuracy gain. Deduplication addresses a different bottleneck (redundancy, not labeling cost) and would save little on a 2,000-sample labeled corpus. Distillation requires a strong teacher model in the target domain, which the team does not have. Curriculum learning only reorders existing labels and cannot compensate for the absolute shortage of 2,000 labeled samples at clinical scale.
Learning Objective: Apply the decision framework to map a stated bottleneck and resources to the correct technique.
Why does the framework insist on checking prerequisites before estimating ROI, rather than ranking techniques by expected gain alone?
Answer: A technique with strong theoretical ROI still delivers zero practical gain if its required infrastructure is missing or expensive to build. Active learning needs an oracle, a large unlabeled pool, and a retraining loop that can accept new labels frequently; coreset selection needs access to the full dataset plus either a proxy model or an embedding extractor; distillation needs a teacher that is already strong on the target task. A team without these components would spend the ROI window building infrastructure rather than realizing gains, and the simpler alternative with looser prerequisites may win on real-world wall-clock. The framework therefore gates ROI estimation on feasibility: an unmet prerequisite converts a high-ROI technique into a zero-ROI one at the time the decision is made.
Learning Objective: Justify the prerequisite-gating step in the decision framework and explain how it changes technique ranking.
A production team has a compute budget constraint, visible redundancy in its raw corpus, and a requirement for faster per-experiment iteration. Using the chapter’s framework, design a three-stage pipeline and justify why reordering the stages would lose gains.
Answer: A sensible pipeline is: (1) deduplication first for an immediate low-risk 10–20 percent reduction in corpus size; (2) coreset selection next to remove low-information samples from the deduplicated corpus, concentrating training compute on boundary-informative examples; (3) curriculum learning during training to accelerate convergence on the curated subset by pacing samples from easy to hard. The order matters because each stage operates on the previous stage’s output: deduplication running on a coreset would re-score fewer samples than necessary and miss the cheap redundancy wins; coreset scoring before deduplication wastes scoring effort on near-duplicates; curriculum learning before the corpus is curated sequences low-value samples alongside high-value ones, diluting the pacing signal. The consequence is multiplicative: each stage compounds the efficiency of the prior stages rather than duplicating their work.
Learning Objective: Design a staged data-selection pipeline and justify the ordering by how each stage’s output enables the next.
Self-Check: Answer
Under the Selection Inequality, when is a data selection method a positive-ROI systems optimization?
- When the subset is at least 10\(\times\) smaller than the original, regardless of scoring overhead.
- When the selection score is computed with the full target model so that every ranking is trustworthy.
- When the subset is regenerated every epoch to stay fresh as the model changes.
- When selection time plus subset-training time is less than full-dataset training time.
Answer: The correct answer is D. The Selection Inequality is the systems-level ROI check: the total end-to-end wall clock (scoring plus selection plus subset training) must be strictly less than the baseline (full-dataset training) for the method to pay off. The subset-size framing ignores scoring cost, which is the exact trap the Selection Inequality exists to expose. The full-target-model framing often violates the inequality by spending more on scoring than it saves in training, and per-epoch regeneration inflates scoring cost without guaranteeing matching training savings.
Learning Objective: Apply the Selection Inequality to determine whether a selection method is a net systems win.
In the chapter’s ResNet-50 coreset example, scoring with a small ResNet-18 proxy produces slightly noisier importance rankings than scoring with the full ResNet-50, yet the proxy wins on total runtime. Explain why tolerating noisier rankings can be the correct engineering choice.
Answer: Scoring cost is dominated by the model used to compute it: ResNet-50 scoring can exceed the training-time savings from the resulting coreset, while the concrete ResNet-18 proxy example is roughly 5\(\times\) cheaper and still produces rankings that correlate well with the target-model’s true difficulty. Under the Selection Inequality, total runtime is scoring plus subset training; a slightly noisier but much cheaper ranking keeps more of the training-time savings intact. The practical consequence is that selection quality matters only up to the point where it passes the inequality — beyond that threshold, further ranking refinement erases the wall-clock advantage rather than adding to it.
Learning Objective: Analyze the cost-quality trade-off for proxy-model scoring under the Selection Inequality.
Why can coreset-based training degrade storage throughput even when the selected subset is much smaller than the full dataset?
- Because smaller datasets automatically disable prefetching and batching in the data loader.
- Because irregular sample selection breaks the sequential-read pattern that data loaders, filesystem readahead, and storage hardware are optimized for.
- Because all selection methods recompute gradients on the CPU before reading any data.
- Because deduplicated datasets compress poorly, expanding the bytes read per sample.
Answer: The correct answer is B. Modern storage stacks (SSDs, object stores, parallel filesystems) deliver their peak throughput on sequential or predictable-stride access because readahead, caching, and device-level queueing all assume it. A coreset sampled as scattered indices forces random-access I/O, whose latency per read is dominated by seek overhead and cache miss rate rather than raw bandwidth — the smaller dataset can end up slower to load than the full sequential baseline. The prefetching-disabled framing invents a mechanism that does not exist; framework batching does not depend on dataset size. The CPU-gradient option misidentifies the bottleneck, and the compression claim is orthogonal to access-pattern behavior.
Learning Objective: Explain the random-access I/O penalty that scattered sample selection imposes on storage throughput.
A ResNet-50 training job runs at 300 images/second end-to-end, but the GPU alone can process 800 images/second; profiling shows CPU-side decoding and augmentation dominate the pipeline. Which intervention from the section best matches this bottleneck signature?
- Use data echoing so each fetched and augmented batch is reused with different downstream augmentations, letting the GPU extract more updates per CPU-bound batch while the upstream pipeline remains the limiter.
- Precompute augmented batches offline and cache them to disk, which removes augmentation from the runtime pipeline and guarantees downstream speedup.
- Increase model size so the GPU stays busier per image and the data-pipeline bottleneck becomes irrelevant.
- Disable augmentation entirely to cut pipeline cost to zero.
Answer: The correct answer is A. Data echoing is the chapter’s specific fix for the pipeline-bound training pattern: when the CPU cannot produce batches fast enough to saturate the GPU, reusing each produced batch for multiple gradient updates recovers otherwise-idle accelerator cycles without waiting for the pipeline to catch up. The offline-precompute option is a plausible-sounding distractor that partially addresses the symptom but incurs large disk I/O and storage costs, loses per-epoch augmentation diversity, and may not fit for terabyte-scale corpora — the chapter does not frame it as the canonical fix. Making the model larger attacks the wrong term: the bottleneck is upstream of the GPU, so more compute work makes the imbalance worse. Removing augmentation entirely throws away regularization signal, hurting final accuracy while engineering around the wall-clock limit.
Learning Objective: Select the pipeline intervention that matches a CPU-bound data-loading bottleneck signature.
Order the following steps in the chapter’s distributed coreset workflow: (1) compute EL2N scores on each worker’s locally-deduplicated shard, (2) build per-shard embeddings and run local deduplication, (3) merge local top-scoring candidates at a coordinator and broadcast the final global selection indices.
Answer: The correct order is: (2) build per-shard embeddings and run local deduplication, (1) compute EL2N scores on each worker’s locally-deduplicated shard, (3) merge local top-scoring candidates at a coordinator and broadcast the final global selection indices. Deduplication must precede scoring so that workers do not spend compute ranking near-identical samples whose scores would double-count. EL2N scoring must precede the global merge because the coordinator’s job is to rerank across workers’ candidate sets, which requires per-candidate scores to exist first. Reversing steps 1 and 2 wastes scoring effort on redundant samples; reversing steps 1 and 3 would force the coordinator to merge without meaningful rankings, collapsing the global selection to a purely geometric coverage or random sample.
Learning Objective: Sequence the main stages of a distributed coreset workflow and justify the data dependencies that fix the order.
Self-Check: Answer
In a supervised-learning pipeline where expert annotation is required, which cost component is most likely to dominate total data cost?
- Acquisition cost, because once data is collected the labels are effectively free.
- Storage cost, because modern cloud object storage grows linearly with every experiment and usually dwarfs other expenses.
- Labeling cost, because expert time per sample can reach tens to hundreds of dollars in domains like medicine or law and scales linearly with sample count.
- Process cost, because data selection has no effect on training FLOPs once the dataset is fixed.
Answer: The correct answer is C. The chapter’s cost decomposition emphasizes that expert-annotation unit cost is typically one to three orders of magnitude above storage or compute per sample, and scales with sample count, so total labeling cost dominates for any meaningful labeled-corpus size. Cloud storage is cheap per terabyte and grows slowly compared to labeling. The acquisition-dominant framing is wrong by construction for supervised pipelines where labels are the scarce resource. The process-cost option misidentifies data selection as orthogonal to training FLOPs when the chapter’s central claim is that it reduces them.
Learning Objective: Identify the dominant cost component in annotation-heavy supervised pipelines.
A team can reach target accuracy in two ways: (a) label 5,000 random samples at $20 per sample, or (b) active-learn with 2,000 labeled samples at the same rate plus about $15,000 in pool-scoring and coordination overhead. State the break-even condition and explain what shifts it in either direction.
Answer: Option (a) costs $100,000 and option (b) costs $40,000 labeling plus $15,000 overhead = $55,000, so active learning is break-even favorable by about $45,000 in this scenario. The break-even condition is: overhead must be less than the labeling savings, i.e.
overhead < (N_random - N_active) * cost_per_label. Active learning becomes more attractive as per-label cost rises (medical/legal experts at $200 per sample dominate any reasonable overhead) or as the active-learning sample-count advantage grows. It becomes less attractive when scoring cost scales with pool size (e.g. repeated expensive forward passes on 10M unlabeled samples) or when coordination across query rounds inflates engineering time, because those costs scale with pool size rather than with the label savings.Learning Objective: Analyze the break-even conditions that make active learning economically favorable versus random labeling.
A deduplication pipeline costs $50,000 to build and saves $8,000 per retraining run in downstream compute. Why can this be a sensible investment even though the first retraining run produces a −$42,000 ROI?
- Because deduplication guarantees higher model accuracy, making ROI math irrelevant after deployment.
- Because its one-time build cost is amortized across many future retraining runs, so cumulative ROI turns positive after roughly seven runs and keeps growing.
- Because amortization assumes hardware prices fall faster than engineering salaries rise, guaranteeing positive ROI.
- Because once built, the pipeline eliminates all future labeling costs as well as compute costs.
Answer: The correct answer is B. Amortized ROI spreads the $50,000 fixed cost across every retraining run that inherits the pipeline: at $8,000 in per-run savings, cumulative ROI crosses zero at run 7 and grows linearly thereafter. Teams retraining monthly realize roughly $46,000 per year in net savings after the first year, which justifies the upfront spend even though any single run looks unprofitable. The accuracy-guarantee framing invents a benefit deduplication does not provide. The hardware-price-versus-salary claim invokes a trend unrelated to the amortization mechanism. The eliminates-labeling-costs option overclaims — deduplication removes duplicate compute work, not labeling work.
Learning Objective: Evaluate infrastructure investments using amortized ROI across repeated retraining runs.
True or False: Between two techniques, the one with the highest theoretical efficiency gain should always be deployed first, even if its implementation cost is much higher than a simpler alternative.
Answer: False. The chapter prioritizes realized ROI (theoretical gain minus implementation and operational overhead) over theoretical gain alone. A simpler method like deduplication often outperforms a more sophisticated coreset approach when the coreset’s scoring, coordination, and debugging overhead exceeds the extra savings it produces.
Learning Objective: Distinguish theoretical efficiency gain from realized ROI in technique selection.
A team evaluates a data-selection infrastructure investment with a one-time setup cost of $30,000 and per-run savings of $6,000. How does the economic picture change as the number of retraining runs grows, and when does it justify the investment?
- ROI worsens with each run because the initial overhead compounds, so the investment is never justified.
- ROI is flat across runs because per-run savings are offset by equal operational costs, so the decision is unaffected by run count.
- Cumulative ROI crosses zero at roughly five runs and grows linearly thereafter, so the investment is justified when the retraining roadmap commits to at least that many future runs.
- ROI only becomes positive if the team switches to a faster accelerator in parallel, because hardware progress is a prerequisite for amortization.
Answer: The correct answer is C. With a $30,000 setup cost and $6,000 per-run savings, cumulative ROI reaches breakeven at run 5 ($6,000 \(\times\) 5 = $30,000) and grows by $6,000 every run afterward. The decision reduces to a retraining-count forecast: if the team will retrain at least five times, the investment pays back; if fewer, it does not. The worsening-ROI framing misreads amortization as if overhead were recurring rather than fixed. The flat-ROI claim invents a phantom operational cost not described in the section. The hardware-prerequisite framing confuses amortization with an unrelated mechanism.
Learning Objective: Analyze how cumulative ROI for a fixed-cost selection investment evolves with the number of retraining runs.
Self-Check: Answer
Why do centralized data-selection algorithms like coreset scoring or global curriculum learning become much harder to implement correctly when training is distributed across many workers?
- Because distributed training removes the need for global rankings by making every shard statistically identical to every other.
- Because only active learning is affected by sharding; coreset selection and curriculum learning are unchanged.
- Because data parallelism automatically provides exact cross-worker uncertainty synchronization at every step.
- Because each worker sees only a local shard, so algorithms that assumed a single global view (top-K selection, global difficulty ordering, global deduplication) now require coordination the single-node version did not.
Answer: The correct answer is D. The central finding of the section is that sharding partitions the corpus across workers, so every algorithm that originally said ‘pick the top K globally’ or ‘rank all samples by difficulty’ now requires a coordination step to reconstruct the global view — and that coordination itself has cost, staleness, and consistency risks. The identical-shards framing invents a property sharding does not guarantee. The automatic-synchronization claim contradicts the coordination tax the section explicitly describes. The only-active-learning option is wrong: all three algorithm families are affected.
Learning Objective: Explain how sharding breaks the global-view assumptions of centralized selection methods.
Compare centralized and hierarchical distributed-selection architectures by the trade-off they make between selection quality and coordination cost, and state one realistic deployment signal that should push a team toward each.
Answer: Centralized selection routes all candidate samples or scores to a single coordinator that ranks globally — quality is high because the coordinator sees the full problem, but the coordinator becomes a throughput bottleneck and a single point of failure at scale. Hierarchical selection lets each worker rank locally and escalates only top candidates, dramatically cutting coordination traffic and eliminating the single choke point — but a sample that is globally informative yet not a standout within its shard may be missed. Push toward centralized when the cluster is small (tens of workers), global ranking quality is critical, and the coordinator has headroom; push toward hierarchical when the cluster is large (hundreds-to-thousands of workers), coordinator bandwidth is the binding constraint, and minor quality loss is acceptable.
Learning Objective: Compare centralized versus hierarchical distributed-selection architectures and match each to a deployment regime.
True or False: In distributed active learning, as long as all workers share the same model architecture, local uncertainty rankings remain globally comparable and can be merged without further coordination.
Answer: False. Shared architecture is not sufficient because workers score against slightly different checkpoint weights (different optimizer states, different gradient histories), so ‘uncertainty’ means different things on different workers. The section prescribes synchronous-checkpoint scoring, periodic weight synchronization, or checkpoint-robust uncertainty estimators; relying on architecture match alone produces silently miscalibrated global rankings.
Learning Objective: Identify why shared architecture alone does not make local uncertainty rankings globally comparable.
Self-Check: Answer
Why can well-chosen upstream data selection make later model compression more effective rather than merely cheaper?
- Because curated training data produces more compact, less redundant internal representations, which quantize and prune with smaller accuracy loss than representations learned from redundant data.
- Because compression algorithms only succeed on models trained with synthetic data.
- Because reducing dataset size automatically repairs sparse-kernel hardware inefficiencies at inference time.
- Because compressed models never lose accuracy as long as the training set was filtered with EL2N.
Answer: The correct answer is A. The chapter’s argument is that redundant or noisy training data teaches the model redundant or noisy internal features, which compression methods must later try to remove; curated training data yields leaner representations from the start, so pruning and quantization preserve more accuracy per bit of compression. The synthetic-data claim invents a dependency that does not exist. The sparse-kernel framing conflates dataset size with a hardware inference issue they do not govern. The no-accuracy-loss option overclaims the guarantee that EL2N provides.
Learning Objective: Analyze how upstream data curation affects downstream model compressibility.
A team aggressively reduces dataset size with a 10\(\times\) coreset and observes that the training job’s bottleneck has shifted: what used to be I/O-bound is now compute-bound. Explain why this shift is expected and what the team should do next.
Answer: Data reduction changes workload shape, and changing the shape moves the bottleneck: fewer samples mean less I/O volume per epoch, so the storage-to-compute ratio drops and the compute stage — which was previously under-utilized waiting for I/O — now dominates wall clock. The system was never ‘optimized’; it was rebalanced, and the binding constraint moved. The practical next step is to re-profile from scratch and redirect optimization effort at the new bottleneck: compute-term optimizations like mixed precision, kernel fusion, or larger batch sizes. Assuming the I/O optimization effort from before the reduction is still relevant would waste engineering time on a non-binding constraint.
Learning Objective: Evaluate bottleneck shifts caused by aggressive data reduction and prescribe the re-profiling response.
A team argues that data selection should be treated as ‘just another independent optimization’ ranked alongside quantization, distillation, and better kernels. Why does the chapter place it at the head of the stack instead, and what is the compounding consequence?
Answer: Data selection operates upstream of every downstream optimization: a sample removed at the data-selection stage is a sample that never forces a forward pass, never loads weights from HBM, never synchronizes gradients across the cluster, and never forces a compression or acceleration engineer to compensate for it later. Upstream savings therefore propagate and compound: a 2\(\times\) data reduction multiplies with a 2\(\times\) algorithmic speedup and a 2\(\times\) hardware acceleration to deliver 8\(\times\) end-to-end, not 2+2+2 additive. Treating data selection as one more peer optimization would miss this multiplicative leverage and leave downstream engineers fighting an unnecessarily large workload — every inefficient sample translates into effort at every later stage.
Learning Objective: Explain how upstream data curation propagates into downstream training, compression, and deployment costs to produce multiplicative stack-wide gains.
Self-Check: Answer
A team wants a single number that answers ‘at our target accuracy, how many times smaller can our training set be?’ Which metric directly answers this question?
- Performance-per-data (PPD).
- Area under the learning curve (AULC).
- Data compression ratio (DCR).
- Return on investment (ROI).
Answer: The correct answer is C. DCR is defined as the ratio of full-dataset size to minimum subset size at a fixed target accuracy — it directly states the compression factor the team is asking about. PPD measures accuracy gained per sample added, which is a marginal-rate metric; AULC integrates performance across data budgets; ROI is an economic metric spanning compute and labor. None of these three answer the compression-factor question directly.
Learning Objective: Match data-selection measurement metrics to the specific evaluation question each is designed to answer.
A training run has 40 percent of its accelerator budget unused, yet doubling training time produces almost no further loss improvement. A plot against the compute-optimal frontier shows the run sitting well below the predicted achievable loss for its FLOP budget. What is the most likely diagnosis?
- On the frontier — no further optimization is possible.
- Compute-starved — the only fix is to rent faster accelerators and train for more hours.
- Data-starved — the binding constraint is insufficient information per sample, so more training on the same corpus cannot move loss further and better data (quality filtering, larger curated corpus) is the promising intervention.
- Inference-bound — training metrics are not useful for diagnosis.
Answer: The correct answer is C. The diagnostic signature is exactly data-starved: idle compute plus a training-time plateau plus below-frontier performance together mean the model has extracted roughly all the information the current corpus contains. Compute-starved would show the opposite signature (fully-utilized accelerators plus continued loss improvement from more training time). On-the-frontier would be inconsistent with the run sitting below the frontier line. Inference-bound misidentifies a training-time measurement as an inference-time concern.
Learning Objective: Diagnose a data-starved operating regime from the conjunction of idle compute, loss plateau, and below-frontier performance.
A team compares two coreset selection methods. Method X wins by 0.4 points accuracy at 100 percent data, method Y wins by 1.2 points accuracy averaged over 10–100 percent data budgets. Explain why AULC is the better decision metric for this comparison than single-point accuracy.
Answer: Single-point accuracy at 100 percent data rewards methods that happen to win at the saturation budget, but real production runs live at many budgets: experiments at 10 percent for quick iteration, 30 percent for validation ablations, 100 percent for final training. AULC integrates performance across the full budget range and therefore captures which method is better on average across the decisions the team actually makes. Method X’s 0.4-point saturation advantage fails to compensate for method Y’s 1.2-point average advantage across budgets; choosing X on single-point data would select the worse method for most of the team’s real workflows. The practical consequence is that AULC aligns the metric with the decision: iterative, budget-constrained training demands a metric that rewards efficiency across budgets, not a single endpoint.
Learning Objective: Justify choosing AULC over single-point accuracy when comparing selection methods under variable data budgets.
True or False: Two runs on the same model and dataset both plateau at similar final loss; run A plateaus after 2 epochs while run B keeps improving through 10 epochs. Run A is almost certainly data-starved and run B is almost certainly compute-starved, so run A needs better data and run B needs more compute.
Answer: True. The chapter’s diagnostic contrast is exactly this: rapid plateau with no further gains from more training indicates the model has extracted the available information and the binding constraint is data quality or volume; continued improvement from more training at the same data corpus indicates the model still has signal to extract and the binding constraint is compute budget. Run A’s short-epoch plateau fits the data-starved signature; run B’s 10-epoch improvement fits the compute-starved signature, and the prescribed interventions differ accordingly.
Learning Objective: Diagnose data-starved versus compute-starved regimes from contrasting loss-curve plateau behavior.
A run sits measurably below the compute-optimal frontier for its FLOP budget. Which interpretation matches the chapter’s diagnostic framework?
- The frontier applies only to toy models; real production runs cannot be compared to it.
- Being below the frontier is physically impossible; the measurement must be wrong.
- Below-frontier performance can only be fixed by buying more accelerators, since the frontier assumes optimal hardware.
- The run is wasting resources somewhere between the allocated compute and the realized loss: the hardware is capable of reaching frontier performance at this budget, so the gap points to correctable inefficiencies (data starvation, pipeline stalls, or suboptimal batch/model size balance).
Answer: The correct answer is D. The compute-optimal frontier is the best achievable loss at a given FLOP budget when model size and data are properly balanced; a run below the frontier is under-performing for its budget and the gap identifies a fixable mismatch — typically data starvation (too few tokens for the model size), pipeline inefficiency (idle accelerators), or model-data-size imbalance (the run is not following scaling-law-optimal ratios). The impossibility framing misreads the frontier as a physical lower bound rather than a best-practice target. The more-accelerators framing prescribes the wrong fix; the frontier assumes optimal use of existing compute. The toy-models-only claim contradicts the chapter’s use of the frontier as a production diagnostic.
Learning Objective: Interpret below-frontier operating points as a diagnostic for correctable inefficiencies in training-system balance.
Self-Check: Answer
True or False: Once a large corpus has been deduplicated and label-validated, continuing to add more samples is a reliable way to improve training efficiency because the remaining data is all high quality.
Answer: False. The chapter argues that even correct, deduplicated data hits diminishing ICR past the information plateau: additional samples add linear compute cost while contributing little new learning signal, because the model has already extracted most of the information the distribution contains. Past that frontier, more volume is more cost without more value.
Learning Objective: Evaluate the misconception that quality-controlled volume growth automatically yields efficiency gains.
A team deploys a sophisticated coreset-selection pipeline and observes that total end-to-end training time is 15 percent slower than the unselected baseline, despite the coreset being 4\(\times\) smaller. Which diagnosis matches the chapter’s framework?
- The sample efficiency improved so much that the optimizer converged too fast to measure the gains.
- Deduplication always forces the model to memorize harder examples, which slows convergence.
- Reducing training FLOPs typically increases wall-clock time on dense accelerators due to under-utilization penalties.
- The selection method violated the Selection Inequality: scoring, coordination, and I/O overhead consumed more time than the smaller subset saved in training.
Answer: The correct answer is D. This is the canonical Selection Inequality failure: a method that looks better in isolation (4\(\times\) smaller subset) can be worse end-to-end once scoring cost, random-access I/O penalty, and coordination overhead are added to the total wall clock. The converged-too-fast framing invents an unrealistic regime that does not match the 15 percent slowdown signature. The reduce-FLOPs-increases-wall-clock claim inverts how hardware utilization works. The deduplication-forces-memorization option invents a mechanism the chapter does not describe.
Learning Objective: Diagnose Selection Inequality violations from end-to-end wall-clock signatures.
A team reports 97 percent average validation accuracy after aggressive coreset pruning, but the deployed model misses 40 percent of critical fraud transactions and 55 percent of rare-disease indicators. Explain the measurement mistake and what evaluation suite would have caught it before deployment.
Answer: The team optimized and evaluated on aggregate accuracy, a metric dominated by the majority class: the 97 percent figure is nearly entirely driven by correctly classifying abundant benign or healthy cases, while the rare-but-critical classes contributed almost nothing to the aggregate score. Pruning made the problem worse by further underrepresenting rare classes in the coreset. The evaluation that would have caught this is a stratified deployment metrics suite: per-class accuracy (or recall) with a floor on rare-class performance, subgroup coverage checks, calibration at the decision threshold used in production, and robustness tests on failure-mode scenarios. The practical fix is to treat average accuracy as a necessary but insufficient metric and add subgroup gates that can fail a coreset regardless of how well it optimizes the aggregate.
Learning Objective: Evaluate deployment-relevant measurement choices for data-selection pipelines under class imbalance.
A team reads a paper reporting 90 percent coreset pruning on CIFAR-10 with no accuracy loss and applies the same 90 percent pruning ratio to a specialized medical-imaging dataset. Deployment accuracy drops 12 points. What does the chapter identify as the most likely cause?
- Medical datasets use different loss functions, which invalidates all coreset methods outside natural images.
- Redundancy levels differ by domain: benchmark datasets like CIFAR-10 contain high visual redundancy, while curated specialized corpora may have much less redundancy per sample, so a pruning ratio that is safe on the benchmark over-prunes in the specialized domain.
- Active learning is the only valid selection method outside of natural images.
- ImageNet-style results typically understate the pruning gains actually achievable on expert datasets.
Answer: The correct answer is B. The chapter’s warning about benchmark transfer is that pruning ratios are calibrated to the redundancy level of the source dataset: CIFAR-10 has many visually similar samples, so 90 percent can be removed without losing distinct information, but a small, carefully curated medical dataset may have far less redundancy per sample, so the same ratio removes genuinely informative examples. The different-loss-functions framing invokes an unrelated mechanism. The active-learning-only claim is an overreach; the chapter presents multiple methods as applicable outside natural images. The understates-gains option inverts the direction of the transfer failure.
Learning Objective: Analyze why pruning ratios calibrated on benchmark datasets may not transfer to specialized domains.
True or False: A sufficiently strong generative model eliminates the risk of domain gap, making synthetic-only training safe for deployment-facing systems.
Answer: False. The chapter identifies domain gap and model collapse as persistent risks even with powerful generators: the synthetic distribution’s statistical signature rarely matches the deployment distribution exactly, and training purely on synthetic samples can also cause the student model to inherit and amplify the generator’s blind spots. The chapter’s prescription is to treat synthetic data as a supplement that works best mixed with real deployment-relevant samples, not as a drop-in replacement.
Learning Objective: Assess the misconception that generator quality alone makes synthetic-only training deployment-safe.
Self-Check: Answer
Which statement best captures the chapter’s central systems claim about data selection?
- Data selection is primarily a statistical variance-reduction trick with little effect on end-to-end system cost.
- Data selection is an upstream workload-reduction lever whose gains compound with every downstream algorithmic and hardware optimization because every removed sample is one that never loads, never computes, never synchronizes, and never compresses.
- Data selection matters only when labels are expensive; compute-rich teams can safely ignore it.
- Data selection should be applied after model compression so the final deployment artifact is smaller.
Answer: The correct answer is B. The chapter’s governing argument is that upstream reduction propagates through the entire stack: the Iron Law’s Total Operations term falls at the source, and every downstream layer (compression, distribution, deployment) operates on a smaller base — multiplicative leverage, not additive. The variance-reduction framing misidentifies data selection as statistical rather than systems-level. The compute-rich-teams-can-ignore-it claim contradicts the Data Wall argument that compute surplus makes data quality the binding constraint. The after-compression ordering inverts the D·A·M stack the chapter structures.
Learning Objective: Explain how upstream data curation compounds with downstream algorithm and hardware optimizations across the D·A·M stack.
In one integrated explanation, relate the Information-Compute Ratio, the Selection Inequality, and the chapter’s three-stage pipeline to each other.
Answer: ICR defines what good data selection aims for — maximum learning per unit of compute — making it the chapter’s quality metric. The three-stage pipeline (static pruning, dynamic selection, synthetic generation) is the toolkit that raises ICR by removing redundancy, concentrating on informative samples, and creating high-value samples when real data is scarce. The Selection Inequality is the systems-level feasibility gate: any technique that raises ICR is only worthwhile if the end-to-end wall clock (scoring plus coordination plus subset training) is less than the baseline. The three concepts interlock: the pipeline produces candidate selection strategies, ICR ranks them by information efficiency, and the Selection Inequality filters out those whose overhead erases the ICR gain in practice — so a strong data-selection decision is simultaneously information-efficient and systems-efficient.
Learning Objective: Integrate ICR (the quality metric), the Selection Inequality (the feasibility gate), and the three-stage pipeline (the technique taxonomy).
Why is the next chapter on model compression a natural continuation of this chapter, and how do the two differ in what they optimize?
Answer: This chapter optimizes the workload itself — what data reaches the model at all — reducing Total Operations at the source. Model compression optimizes the algorithm’s cost of processing whatever data does reach it — reducing FLOPs per sample via pruning, quantization, or distillation, and reducing memory footprint of the weights themselves. The sequence is deliberate: curating the data first shrinks the surface area that compression must later handle, so every FLOP saved by compression is multiplied by the sample-count reduction achieved by data selection. Together they are the ‘D’ and ‘A’ halves of the D·A·M stack: the data chapter removes unnecessary inputs, the algorithm chapter makes each remaining computation cheaper, and their gains compound rather than duplicate.
Learning Objective: Compare data selection’s workload-reduction role with model compression’s algorithm-cost-reduction role within the D·A·M optimization stack.