Responsible Engineering
Purpose
Why is a system that does exactly what it was told to do often the most dangerous?
Operations ensures the system runs reliably: low latency, high availability, accurate predictions. Responsible engineering asks who that reliability serves. An ML system can meet every technical specification (latency, throughput, accuracy) while actively amplifying harm. The failure occurs not because the system is broken but because it is working efficiently to optimize a flawed specification. A loan approval system that correctly predicts default risk can encode historical discrimination, denying credit to qualified applicants from historically marginalized communities. A content recommendation system that accurately predicts engagement may amplify harmful content because outrage generates more clicks than nuance. A hiring algorithm that reliably identifies candidates similar to past hires may perpetuate workforce homogeneity, screening out the diversity that drives innovation. In each case the system is performing exactly as designed. The failure is in what was designed for. When mathematical optimization is confused with value alignment, the result is a system that is technically robust but socially fragile. The model faithfully reproduces whatever patterns exist in its training data, including historical injustice no one intended to encode. Building systems that work is an engineering achievement. Building systems that work for everyone requires treating unintended consequences not as edge cases but as system bugs: diagnosed, measured, and fixed with the rigor applied to latency or accuracy regressions. Responsible engineering is D·A·M co-design under a constraint the specification omits: data must be interrogated for the harms it encodes, algorithms must be bounded so they do not optimize those harms, and machine infrastructure must monitor, document, and enforce those boundaries in production.
Learning Objectives
- Explain how optimized ML systems can amplify harm through proxies, feedback loops, and distribution shift
- Apply data-algorithm-machine diagnosis to localize responsibility failures in data, algorithm objectives, or monitoring infrastructure
- Calculate fairness metrics from confusion matrices and compare trade-offs on the fairness-accuracy Pareto frontier
- Design disaggregated evaluation, stress testing, and monitoring to expose subgroup-specific failures before deployment
- Analyze total cost, inference dominance, and carbon impact as measurable responsibility constraints
- Construct model cards, datasheets, lineage records, and audit trails for accountability
- Evaluate privacy, access-control, and compliance designs against regulatory and human-review requirements
Responsibility as Systems Engineering
In 2014, Amazon built an AI recruiting tool1 that penalized resumes containing the word “women’s” (as in “women’s chess club captain”) and downgraded graduates of all-women’s colleges. The system optimized faithfully for its stated objective: identify candidates similar to those previously hired. The failure was not that the model malfunctioned, but that historical hiring patterns encoded gender bias, and the model reproduced that bias at scale.
1 Amazon Recruiting Tool: Developed starting in 2014 by Amazon’s Edinburgh engineering team to rate applicants on a 1–5 scale, the system trained on approximately a decade of resumes—overwhelmingly from male applicants reflecting the tech industry’s gender ratio. By 2015 the gender bias was identified; by 2017 the project was abandoned after repeated remediation attempts (Dastin 2018). The engineering cost was not the compute but the opportunity cost: a multi-year recruiting project failed because the objective encoded historical bias, making it a documented specification failure in ML tooling.
Dastin, Jeffrey. 2018. “Amazon Scraps Secret AI Recruiting Tool That Showed Bias Against Women.” Reuters.
National Aeronautics and Space Administration. 2016. NASA Systems Engineering Handbook. NASA/SP-2016-6105 Rev2. National Aeronautics; Space Administration.
If MLOps is the control loop for reliability, then Responsible Engineering is the control loop for safety. Where MLOps monitors system health and triggers retraining when performance degrades, responsible engineering monitors outcome quality and triggers intervention when systems cause harm. A model can optimize flawlessly for its stated objective and still cause systematic harm because the failure is not a bug in the code but a flaw in the specification. In systems engineering terms, a system can pass verification (it meets its stated requirements) while failing validation (it does not meet the user’s true needs) (National Aeronautics and Space Administration 2016).
Traditional software engineering assumes that bugs are local: a defect in one module rarely corrupts unrelated functionality. Machine learning systems violate this assumption. Data flows through shared representations, causing problems in one component to propagate unpredictably across the entire system. A biased training dataset does not produce a localized bug; it corrupts every prediction the system makes. The D·A·M Taxonomy formalizes the diagnostic framework that locates where such a failure originates, decomposing it along three axes: biased data, a misaligned algorithm, or inadequate infrastructure for monitoring outcomes. This makes responsibility an architectural concern, not an afterthought.
Engineering responsibility therefore expands what “correct” means for ML systems. Correctness in the traditional sense (reliable, performant, and maintainable) remains necessary, but ML systems must also be correct in a broader sense: fair across user groups, efficient in resource consumption, and transparent in their decision processes. Expanded correctness is engineering itself, applied to failure modes that conventional metrics do not capture. A latency regression is visible in dashboards; a fairness regression is invisible until it harms real users (principle 13). Both require systematic detection, measurement, and remediation.
Diagnosing, preventing, and mitigating these failures requires following the responsibility gap through the system. Concrete cases reveal the distance between technical performance and responsible outcomes, and the mechanisms (proxy variables, feedback loops, distribution shift) through which it manifests. That gap motivates repeatable engineering processes for impact assessment, model documentation, disaggregated testing, and incident response. The resource consumption quantified throughout this book (training compute, inference energy, carbon footprint) then becomes an ethical constraint as well as a performance constraint, because efficiency optimization serves responsibility as directly as it serves speed. Data governance and compliance infrastructure (access control, privacy protection, lineage tracking, and audit systems) make those practices enforceable at scale.
Self-Check: Question
A hiring model meets its latency SLA, maintains 99.9 percent availability, and reports 87 percent aggregate accuracy, yet it systematically rejects qualified applicants whose resumes contain the word “women’s.” Applying the section’s verification-versus-validation framing, which diagnosis best fits this outcome?
- The system passed verification but failed validation: it met every stated requirement while the requirement itself failed to capture the responsible outcome the organization needed.
- The system failed verification because any unfair outcome is by definition a technical defect of the implementation.
- The failure is primarily an operational reliability issue that responsible engineering practices address only after the serving pipeline becomes unstable.
- The root cause is insufficient model capacity, so scaling up parameters would remove the disparity without changing the specification.
A team argues that a one-time ethics review before launch is sufficient because their model achieves strong aggregate accuracy and passes all latency checks. Using the section’s MLOps analogy, explain why responsible engineering must instead be structured as a control loop, and give one specific measurement the one-time review would miss.
True or False: Because machine learning systems are built from modular software components, a fairness defect originating in the training data can be isolated to a single module and fixed without architectural change, the way a null-pointer exception can be patched in one function.
Engineering Responsibility Gap
A loan model that approves 95 percent of qualified majority-group applicants while rejecting 40 percent of equally qualified minority-group applicants meets its loss function perfectly. The responsibility gap between this technical correctness and responsible outcomes represents a central challenge in machine learning systems engineering, one that existing testing methodologies were not designed to address. The gap manifests through concrete mechanisms: proxy variables, feedback loops, and distribution shift, each producing harm through a distinct pathway that conventional monitoring leaves invisible.
When optimization succeeds but systems fail
The recruiting-tool failure turns this gap into a data problem rather than a code defect. A model trained on a decade of historical hiring data optimized faithfully for the objective it was given, but those historical patterns encoded gender bias that the system reproduced in candidate ratings (Dastin 2018).
Bolukbasi, Tolga, Kai-Wei Chang, James Y. Zou, Venkatesh Saligrama, and Adam Tauman Kalai. 2016. “Man Is to Computer Programmer as Woman Is to Homemaker? Debiasing Word Embeddings.” Advances in Neural Information Processing Systems (NeurIPS), 4349–57.
The technical mechanism behind this outcome is straightforward. The model learned token-level patterns from historical data. When most previously successful hires were men, resumes containing language associated with women’s activities or institutions appeared statistically less correlated with positive hiring decisions. The model correctly identified these patterns in the training data but learned the wrong lesson from correct pattern recognition. More generally, learned text representations can encode and amplify gender stereotypes, including in word embeddings (Bolukbasi et al. 2016).

The Amazon failure is a data-axis failure: biased historical signal.
2 Proxy Variable: The intractability is not in identifying that a proxy exists—it is that removing it often has no effect, because other correlated features (ZIP code, device type, browsing history) carry the same signal. Amazon’s case is typical: removing explicit gender left college names, activity descriptions, and career gap patterns to reconstruct gender from combinations the engineers never anticipated. Eliminating explicit protected attributes without eliminating their proxies produces a model that discriminates while appearing compliant—a failure mode called “fairness laundering”—making continuous per-group outcome monitoring the only reliable defense.
Amazon attempted remediation by removing explicit gender indicators and gendered terms from the training process. This intervention failed because the model had learned proxy variables—features that correlate with protected attributes without directly encoding them.2 In general, proxies arise whenever features carry indirect demographic signal: ZIP codes correlate with race due to residential segregation, first names correlate with gender and ethnicity, and healthcare utilization correlates with socioeconomic status. In Amazon’s case, college names revealed attendance at all-women’s institutions, activity descriptions encoded gender-associated language patterns, and career gaps suggested parental leave patterns that differed between genders. The model reconstructed protected attributes from these proxies without ever seeing gender labels directly. Removing protected attributes from training data is therefore insufficient. Fairness interventions generally operate in three places: constrain the training objective, remove protected-attribute signal from learned representations, or adjust decision thresholds after training.
The right intervention would have required multiple levels of change. Separate evaluation of resume scores for male-associated vs. female-associated candidates would have revealed the disparity quantitatively. Training with fairness constraints or adversarial debiasing techniques, where an auxiliary adversary tries to recover protected-attribute signal from the learned representation and the main model is penalized when that signal remains, could have prevented the model from learning gender-correlated patterns. Human-in-the-loop review for borderline cases would have provided a safeguard against systematic errors. Tracking actual hiring outcomes by gender over time would have enabled outcome monitoring beyond model metrics alone. Amazon eventually scrapped the project after determining that sufficient remediation was not feasible (Dastin 2018).
The Amazon case demonstrates how optimization objectives diverge from organizational values. The system found genuine statistical patterns in historical hiring decisions and optimized them faithfully. Those patterns, however, reflected biased historical practices rather than job-relevant qualifications.
The Amazon and COMPAS3 cases share a troubling pattern: each system achieved its stated objective while producing outcomes that conflicted with the values the system was intended to serve. Conventional engineering success, it turns out, can coexist with profound system failures. The pattern raises two design questions: whether the loss function is a defensible proxy for the system’s true goal, and whether error rates remain acceptable across the subgroups the system affects.
3 COMPAS (Correctional Offender Management Profiling for Alternative Sanctions): COMPAS achieved calibration (a given score meant the same re-offense probability for any group), but because recidivism base rates differed between populations, that choice made disparate error rates follow from the chosen fairness criterion (Chouldechova 2017; Kleinberg et al. 2016). No amount of testing for calibration alone would have surfaced this failure; the harm was encoded in the objective itself.
Kleinberg, Jon, Sendhil Mullainathan, and Manish Raghavan. 2016. “Inherent Trade-Offs in the Fair Determination of Risk Scores.” Innovations in Theoretical Computer Science Conference. https://doi.org/10.4230/LIPIcs.ITCS.2017.43.
War Story 1.1: The COMPAS recidivism algorithm audit
Context: COMPAS is a risk assessment tool used in US courtrooms to predict re-offending. Judges use these scores to inform bail and sentencing decisions.
Failure mode: A ProPublica investigation (Angwin et al. 2016) revealed that the system’s error rates were skewed:
- False Positives: Black defendants who did not re-offend were incorrectly flagged as high-risk at nearly twice the rate of White defendants (44.9 percent vs. 23.5 percent).
- False Negatives: White defendants who did re-offend were incorrectly labeled as low-risk far more often than Black defendants (47.7 percent vs. 28 percent).
Consequence: The result was not a runtime crash but a deployment mismatch: a system could be calibrated while still imposing unequal error burdens. Through the D·A·M taxonomy, COMPAS represents an algorithm-axis failure: the optimization objective (calibration) was misaligned with the deployment context’s fairness requirements (equalized odds). The data reflected real base-rate differences; the failure was in choosing which mathematical property to optimize. Contrast this with Amazon’s recruiting tool, a data-axis failure where biased historical hiring patterns corrupted the training signal itself.
Systems lesson: The system optimized for Calibration: a given score corresponded to the same observed re-offense probability across groups. It violated Equalized Odds: false positive and false negative rates did not match across groups. Formal fairness results show that common criteria such as calibration and error-rate parity can conflict when base rates differ between groups (Chouldechova 2017; Kleinberg et al. 2016; Hardt et al. 2016). This algorithmic bias shows why engineering responsibility requires explicitly choosing which fairness constraint matters for the domain; in criminal justice, false positives (wrongly jailing someone) are typically considered worse than false negatives. The worked fairness-metric section later computes these rates directly from confusion matrices.
Angwin, Julia, Jeff Larson, Surya Mattu, and Lauren Kirchner. 2016. “Machine Bias.” In Ethics of Data and Analytics. ProPublica investigation; Auerbach Publications. https://doi.org/10.1201/9781003278290-37.
Better testing would not catch these problems because they represent failures of problem specification, where the technical objective (minimizing prediction error on historical outcomes) diverges from the desired social objective (making fair and accurate predictions across demographic groups). Specification failures are difficult to detect precisely because the systems continue functioning normally by conventional engineering metrics. The deeper problem is clear: when a system appears healthy by every available metric, the harm it causes remains invisible to conventional monitoring.
Checkpoint 1.1: Responsible design
Responsibility is a system property, not a model property.
The Failure Modes
The Check
Silent failure modes

One upstream change; many silently affected.
Consider a hospital sepsis model that begins recommending aggressive treatments for low-risk patients after an electronic health record (EHR) workflow change alters how vital signs are recorded. No alarm triggers—the model’s confidence scores remain high, its latency stays within its service level agreement (SLA), and all system health checks pass green. The failure is silent: the input data distribution has shifted, but the monitoring pipeline has no mechanism to detect distributional drift.
This sepsis scenario illustrates a class of failure that traditional engineering is poorly equipped to handle. Traditional software fails loudly. A null pointer exception crashes the program, a network timeout returns an error code. These visible failures enable rapid detection and response. In contrast, ML systems fail silently because degraded predictions look like normal predictions. The primary mechanism behind this silent degradation is distribution shift.
Definition 1.1: Distribution shift
Distribution shift, introduced in Introduction and operationalized for drift detection in ML Operations, is the deployed-model violation of the stationarity assumption \((P_0 \neq P_t)\) that underpins supervised learning. Recalled here for its responsibility consequences, it is the umbrella term for a family of drift types: data drift occurs when \(p(x)\) shifts while \(p(y \mid x)\) remains stable; concept drift occurs when \(p(y \mid x)\) itself shifts.
- Significance: Accuracy degradation can be measured against divergence statistics such as Jensen-Shannon divergence \(\mathcal{D}_{\text{JS}}(P_t \lVert P_0)\), a bounded and symmetric distribution-distance measure used for the same drift-monitoring purpose as PSI and KL divergence in Data quality monitoring. Useful alert thresholds must be calibrated empirically for each task, representation, label process, and deployment environment. A \(\mathcal{D}_{\text{JS}}\) value of 0.1 may be harmless for one feature space and severe for another. This degradation occurs regardless of code quality, because the model is correct given its training distribution; the environment changed, not the code.
- Distinction: Unlike model error (which is a learning failure caused by the algorithm or data quality at training time), distribution shift is an environmental failure: the model’s learned mapping was correct at training time but is no longer representative of current reality.
- Common pitfall: A frequent misconception is that “data drift” and “distribution shift” are different concepts at the same level of the hierarchy. Distribution shift is the umbrella; data drift and concept drift are its two distinct subtypes. A system can experience data drift without concept drift (the inputs change, but the relationship holds), or concept drift without data drift (inputs are stable, but the correct output changes).
The stationarity assumption underpins all supervised learning: training and deployment distributions must match. Distribution shift is often unequal: a model’s accuracy on a minority subgroup can drop by over 30 percentage points while aggregate metrics barely change, masking the harm.

Past the knee, the proxy decouples from the goal.
Systems Perspective 1.1: The alignment gap
A model optimizes a proxy metric (Clicks) because the true metric (User Satisfaction) is unobservable, and the two can diverge sharply. Goodhart’s Law states that optimizing a proxy eventually decouples it from the goal. A system might begin with \(\text{Correlation}(\text{Clicks}, \text{Satisfaction}) = 0.8\); once a model is trained to maximize Clicks, it finds “Clickbait,” items with high clicks but low satisfaction, and \(\text{Correlation}(\text{Clicks}, \text{Satisfaction})\) drops to 0.2.
Conceptually, assuming normalized metrics on a common scale, equation 1 captures the gap: \[ \text{Gap} = \mathbb{E}[\text{Proxy}] - \mathbb{E}[\text{True}] \tag{1}\]
If the model increases Clicks by 20 percent but decreases Satisfaction by 5 percent, the alignment gap has widened.
Systems insight: Engineers cannot optimize what they cannot measure. If the true goal is unobservable, Counterfactual Evaluation (random holdouts) is required to periodically re-calibrate the proxy.
Distribution shift explains why models degrade over time (the operational detection and monitoring strategies for drift are covered in ML Operations). The failure is environmental: the world changed after the model was trained, and the model has no mechanism to notice. Retraining on fresh data can partially address this class of failure, but it cannot address a second mechanism for silent failure that operates even when the data distribution is perfectly stable. Metric misalignment occurs when the quantity the model optimizes diverges from the outcome the organization actually values. The dynamics of that divergence are made precise by Goodhart’s Law: once a proxy becomes the optimization target, it stops tracking the goal it was chosen to represent.
The alignment gap illustrates a failure that originates in the algorithm axis: the optimization objective is misspecified, so even a model that generalizes flawlessly to new data can drive outcomes that conflict with organizational or societal goals. Distribution shift, by contrast, originates in the data axis: the inputs changed, and the learned mapping no longer reflects reality. Both failures are silent, but they demand different remediations (better objectives vs. better monitoring), and conflating the two wastes engineering effort on the wrong fix. The D·A·M taxonomy introduced in Introduction maps each failure to the axis it originates from (Data · Algorithm · Machine), which The D·A·M Taxonomy defines in full.
Systems Perspective 1.2: The D·A·M taxonomy
When a system causes harm, use the D·A·M taxonomy to identify the root cause. Responsibility failures are rarely “algorithm bugs”; they are structural flaws along one of the three axes:
- Data (information): Does the training data reflect historical bias? (for example, Amazon’s recruiting tool learning from biased history). The failure is in the Fuel.
- Algorithm (logic): Does the objective function optimize a proxy for harm? (for example, optimizing “engagement” amplifies polarization). The failure is in the Blueprint.
- Machine (physics): Does the energy cost justify the societal benefit? (for example, training a massive model for a trivial task). The failure is in the Engine.
Locating the failure in the taxonomy identifies the correct remediation: better curation (Data), safer objectives (Algorithm), or greener infrastructure (Machine).
While the D·A·M taxonomy helps diagnose where failures originate, engineers also need a framework for understanding when and how different failure types manifest. Table 1 complements that diagnostic framework by categorizing failures by detection time, spatial scope, and remediation requirements. Crashes and performance degradation trigger immediate alerts through existing infrastructure. Data quality issues, distribution shifts, and fairness violations require specialized detection mechanisms because the system continues operating normally from a technical perspective while producing increasingly problematic outputs.
| Failure Type | Detection Time | Spatial Scope | Reversibility | Example |
|---|---|---|---|---|
| Crash | Immediate | Complete | Immediate | Out of memory error |
| Performance Degradation | Minutes | Complete | After fix | Latency spike from resource contention |
| Data Quality | Hours–days | Partial | Requires data correction | Corrupted inputs from upstream system |
| Distribution Shift | Days–weeks | Partial or all | Requires retraining | Population change due to new user segment |
| Fairness Violation | Weeks–months | Subpopulation | Requires redesign | Bias amplification in historical patterns |
The YouTube recommendation feedback loop (examined as a technical debt pattern in Production debt patterns) illustrates this pattern at scale (M. H. Ribeiro et al. 2020).4 M. H. Ribeiro et al. (2020) audited radicalization pathways on YouTube, finding migration from milder to more extreme channel categories and recommendation reachability between those categories. The broader systems lesson is that feedback loops can work exactly as designed while producing outcomes that conflict with societal values. From a responsibility perspective, the critical insight is that recommendation objectives must be tested against downstream harms, not only against engagement proxies.
Ribeiro, M. H., R. Ottoni, R. West, V. A. F. Almeida, and Jr. Meira Wagner. 2020. “Auditing Radicalization Pathways on YouTube.” Proceedings of the 2020 Conference on Fairness, Accountability, and Transparency, 131–41. https://doi.org/10.1145/3351095.3372879.
4 Goodhart’s Law: “When a measure becomes a target, it ceases to be a good measure” (Strathern’s generalization of Goodhart’s 1975 monetary policy observation) (Strathern 1997; Goodhart 1984). Recommendation feedback loops are the canonical ML manifestation: gradient descent optimizes watch-time proxies at a speed no human curator can match, and the system’s own outputs reshape the training distribution—users who consume extreme content generate data that reinforces extremity, decoupling the proxy from user welfare orders of magnitude faster than manual editorial processes ever could.
Strathern, Marilyn. 1997. “‘Improving Ratings’: Audit in the British University System.” European Review 5 (3): 305–21. https://doi.org/10.1002/(SICI)1234-981X(199707)5:3<305::AID-EURO184>3.0.CO;2-4.
Goodhart, Charles A. E. 1984. “Problems of Monetary Management: The UK Experience.” Monetary Theory and Practice, 91–121. https://doi.org/10.1007/978-1-349-17295-5_4.
Systems Perspective 1.3: News Feed proxy shifts
Context: In 2018, Facebook announced that News Feed ranking would shift toward posts that created more meaningful interactions among friends and family.
Failure mode: The change was a public example of a platform acknowledging that engagement proxies are incomplete. A system can optimize for relevance, clicks, or time spent while still producing passive consumption patterns that conflict with long-term user welfare. Facebook warned that pages could see reach, video watch time, and referral traffic decrease as the ranking objective changed.
Systems insight: Metrics are proxies for value, not value itself. Ranking systems need long-term health metrics and policy constraints, not only short-term engagement targets (Mosseri 2018).
Mosseri, Adam. 2018. Bringing People Closer Together. Meta Newsroom.
The News Feed case adds a twist the YouTube loop did not: a platform choosing to trade measured engagement for long-term welfare, direct evidence that engagement proxies are known to be incomplete even by those who optimize them. A distinct failure mode operates at the population level: proxy variables that appear neutral in the aggregate can encode systematic disparities across demographic groups. The distribution shift defined earlier also manifests as population mismatch, where models trained on one population perform differently on another without obvious indicators. The same proxy mechanism that let Amazon’s recruiting model reconstruct gender reappears in healthcare, where cost as a stand-in for need produced one of the most widely studied cases of algorithmic harm.
War Story 1.2: The proxy variable trap
Context: In 2019, Ziad Obermeyer and colleagues at UC Berkeley audited a commercial Optum algorithm used by health systems to enroll patients with complex needs into high-risk care management programs, examining roughly fifty thousand patients across one large academic hospital (Obermeyer et al. 2019).
Failure mode: The model predicted “future healthcare cost” as a proxy for “future health need.” The proxy was reasonable in the abstract—sicker people generally cost more—but the US healthcare system spends less on Black patients than on White patients with the same level of illness. The algorithm learned this pattern and assigned Black patients lower risk scores than White patients with comparable disease burdens. At any given risk score, Black patients carried substantially more chronic conditions than White patients with the same score. When the team reformulated the algorithm to predict illness markers directly rather than cost, the share of Black patients identified for the high-risk program rose from 17.7 percent to 46.5 percent. Optum subsequently adopted reformulations grounded in illness rather than spending.
Systems lesson: Optimizing for a proxy inherits the biases of the system that generated the proxy. The proxy-target relationship must be audited across every demographic subgroup the system serves.
Silent failure modes create profound testing challenges. Traditional software testing verifies deterministic behavior against specifications. ML systems produce probabilistic outputs learned from data, making correctness far more complex to define. The opening failures share a troubling pattern: each organization possessed the technical capability to prevent harm but lacked the disciplined processes to apply that capability. The same engineering capabilities can prevent these failures when organizations convert responsibility goals into structured practice.
When responsible engineering succeeds
Each documented success shares the same structural move: a vague responsibility goal becomes an engineering constraint that can be specified, tested, communicated, and, when necessary, used to stop deployment. Following the findings of Gender Shades, a 2018 audit that exposed severe error-rate disparities in commercial facial recognition (Buolamwini and Gebru 2018), Microsoft invested in improving facial recognition performance across demographic groups. Targeted data collection, model changes, and systematic disaggregated evaluation gave the team an explicit error-rate target, and Microsoft reported large error-rate reductions for darker-skinned subjects, bringing audited error rates below 2 percent (Raji and Buolamwini 2019). The company published these improvements transparently, turning external audit results into measurable engineering targets.
Yee, Kyra, Uthaipon Tantipongpipat, and Shubhanshu Mishra. 2021. “Image Cropping on Twitter: Fairness Metrics, Their Limitations, and the Importance of Representation, Design, and Agency.” Proceedings of the ACM on Human-Computer Interaction 5 (CSCW2): 1–24. https://doi.org/10.1145/3479594.
Twitter’s automatic image cropping system shows the same discipline under a different constraint. In 2020, users discovered racial bias in which faces appeared in preview thumbnails. Twitter characterized the problem quantitatively, published results for external review, and then removed automatic cropping entirely after determining that no technical solution could guarantee equitable outcomes across all contexts (Yee et al. 2021). In that case, responsible engineering meant recognizing that the safe system design was feature removal, not a better threshold.
Differential privacy makes the pattern formal: a privacy requirement becomes a mathematical guarantee rather than a policy aspiration (Dwork 2008).5 Systems that use differential privacy must calibrate noise to balance utility against privacy, track privacy budget across repeated analyses, and document the chosen privacy parameters. Spotify applied the same conversion at the user-interface layer, exposing why songs were recommended and giving users direct controls over recommendation behavior; transparency became a product mechanism rather than a compliance label.
Dwork, Cynthia. 2008. “Differential Privacy: A Survey of Results.” In Theory and Applications of Models of Computation. Springer Berlin Heidelberg. https://doi.org/10.1007/978-3-540-79228-4_1.
5 Differential Privacy: Introduced by Dwork et al. (2006), a mechanism satisfies \(\epsilon\)-differential privacy if any output’s probability changes by at most \(e^\epsilon\) when a single individual’s data is added or removed. The systems trade-off is utility rather than mere implementation complexity: stronger privacy generally requires more noise, and a finite privacy budget \((\epsilon)\) constrains repeated queries—forcing engineers to choose between richer analytics and stronger privacy guarantees.
Dwork, Cynthia, Frank McSherry, Kobbi Nissim, and Adam Smith. 2006. “Calibrating Noise to Sensitivity in Private Data Analysis.” In Theory of Cryptography Conference (TCC), edited by Shai Halevi and Tal Rabin, vol. 3876. Lecture Notes in Computer Science. Springer Berlin Heidelberg. https://doi.org/10.1007/11681878_14.
A common pattern unites the preceding cases: responsibility creates value only when technical interventions (improved data, better evaluation, architectural changes, formal guarantees, or user controls) combine with organizational commitments to transparency, long-term investment, and the willingness to remove features that cannot be made safe. Each success rested on systematic testing and evaluation practices, yet the nature of responsible testing differs fundamentally from traditional software verification.
The testing challenge
Traditional software testing verifies that systems behave correctly because correctness has clear definitions. The function should return the sum of its inputs, the database should maintain referential integrity. These properties can be expressed as testable assertions.
Responsible ML properties resist simple formalization. Fairness has multiple conflicting mathematical definitions that cannot all be satisfied simultaneously. What counts as fair depends on context, values, and trade-offs that technical systems cannot resolve alone. Individual fairness requires that similar individuals receive similar treatment, while group fairness requires equitable outcomes across demographic categories. These criteria can conflict, and choosing between them requires value judgments beyond the scope of optimization.
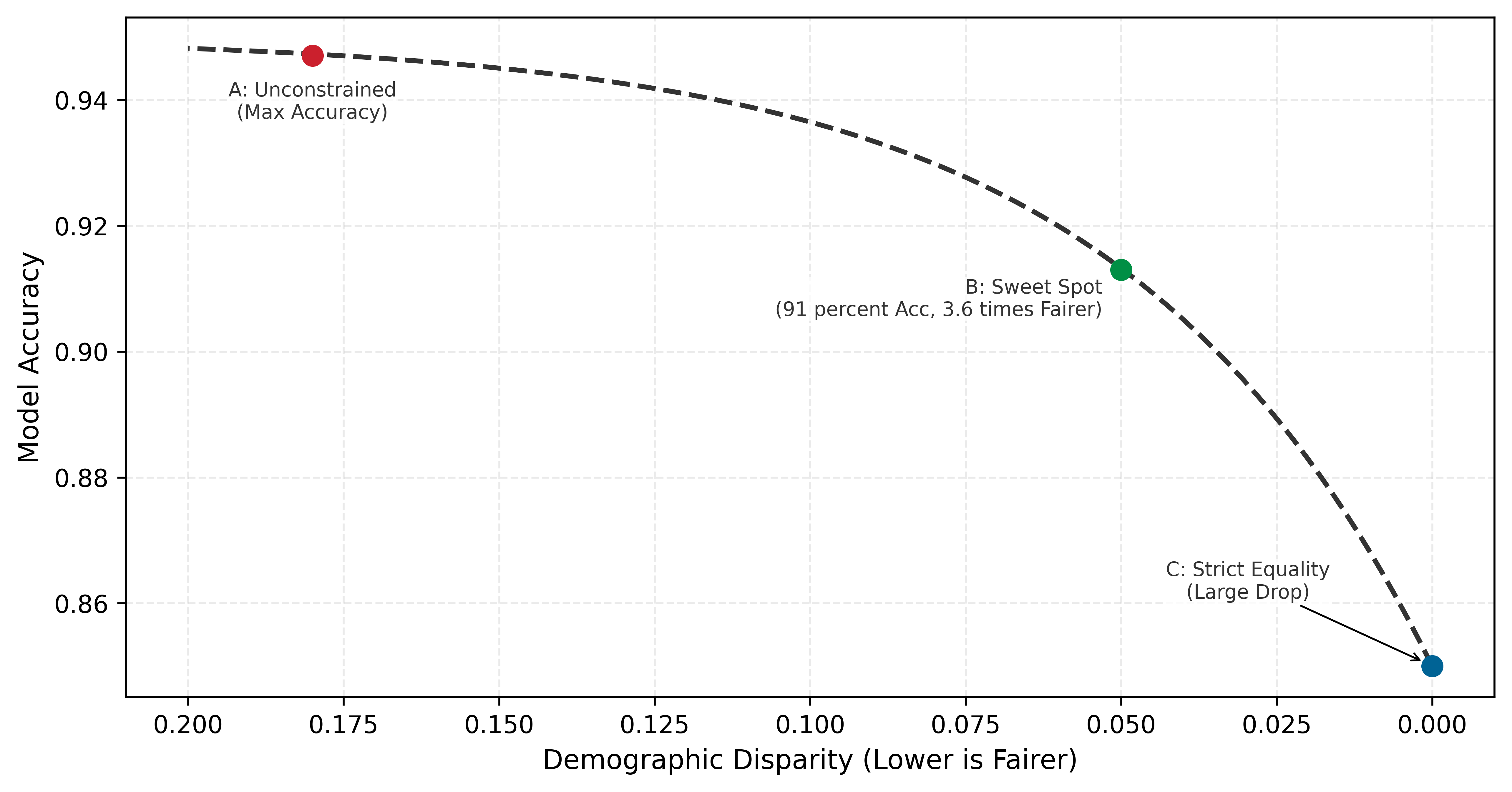
The trade-off between fairness and accuracy is not a sign that fairness is impractical; it is a fundamental property of constrained optimization that engineers must understand. A Pareto frontier represents the set of optimal configurations where improving one metric necessarily degrades another. Figure 1 visualizes this fairness-accuracy Pareto frontier. The curve is not linear: while perfect fairness (zero disparity) often requires a significant drop in accuracy, a “Sweet Spot” typically exists where large fairness gains can be achieved with minimal accuracy loss. The shape of the frontier explains why responsible engineering is feasible: in many practical settings, substantial fairness gains can be achieved with modest accuracy loss.
The frontier tells engineers what trade-off they may need to choose, but it cannot be plotted until subgroup performance is measured. Responsible properties become testable when engineers work with stakeholders to define criteria appropriate for specific applications. The Gender Shades project6 demonstrated how disaggregated evaluation across demographic categories reveals disparities invisible in aggregate metrics (Buolamwini and Gebru 2018), exposing the subgroup failures that responsibility monitoring must catch before deployment. Table 2 shows the dramatic error-rate differences that commercial facial recognition systems produced across demographic groups. Concretely, a 10,000-sample test set that suffices for the majority group provides only 100 samples for a minority subgroup representing 1 percent of the population—effectively requiring 100× more data than the majority group for high-confidence validation.
6 Gender Shades: A 2018 study by Joy Buolamwini and Timnit Gebru (MIT Media Lab) that audited facial recognition systems from Microsoft, IBM, and Face++ using the Fitzpatrick skin type scale—originally a dermatological classification developed by Thomas Fitzpatrick in 1975 for UV sensitivity and later validated for clinical use (Fitzpatrick 1988), repurposed here as a demographic benchmark for algorithmic auditing. The study established disaggregated evaluation as the standard, demonstrating that a single aggregate accuracy number can conceal 43\(\times\) error rate disparities across intersectional subgroups. Microsoft’s later reported reductions show how public audit results can motivate measurable remediation (Raji and Buolamwini 2019).
Fitzpatrick, Thomas B. 1988. “The Validity and Practicality of Sun-Reactive Skin Types i Through VI.” Archives of Dermatology 124 (6): 869. https://doi.org/10.1001/archderm.1988.01670060015008.
Raji, Inioluwa Deborah, and Joy Buolamwini. 2019. “Actionable Auditing: Investigating the Impact of Publicly Naming Biased Performance Results of Commercial AI Products.” Proceedings of the 2019 AAAI/ACM Conference on AI, Ethics, and Society, 429–35. https://doi.org/10.1145/3306618.3314244.
| Demographic Group | Error Rate (%) | Relative Disparity |
|---|---|---|
| Light-skinned males | 0.8% | Baseline (1.0\(\times\)) |
| Light-skinned females | 7.1% | 8.9× higher |
| Dark-skinned males | 12% | 15× higher |
| Dark-skinned females | 34.7% | 43.4× higher |
As table 2 quantifies, disaggregated evaluation revealed what aggregate accuracy scores concealed. Systems reporting high overall accuracy simultaneously achieved error rates as low as 0.8 percent for light-skinned males and as high as 34.7 percent for dark-skinned females (corresponding to accuracies of 99.2 percent and 65.3 percent respectively). The aggregate metric provided no indication of this 43.4× disparity in error rates.
No universal threshold defines acceptable disparity, but engineering teams should establish explicit bounds before deployment. Common industry practices include error rate ratios below 1.25\(\times\) between demographic groups for high-stakes applications, false positive rate differences under 5 percentage points for screening systems, and selection rate ratios of at least 0.8 relative to the highest group’s rate (the four-fifths rule from employment discrimination law).78 These thresholds serve as starting points for stakeholder discussion, not absolute standards. The key engineering discipline is defining measurable criteria before deployment rather than discovering problems after harm has occurred.
7 [offset=-110mm] Disparate Impact: A legal doctrine from Griggs v. Duke Power Co. (1971), where the US Supreme Court held that practices “fair in form, but discriminatory in operation” violate civil rights law even absent intent (Supreme Court of the United States 1971). The distinction between disparate impact (unintentional statistical harm) and disparate treatment (intentional discrimination) is critical for ML: models trained on historical data can produce disparate impact through proxy variables, creating legal risk even when engineers never encoded protected attributes.
Supreme Court of the United States. 1971. Griggs v. Duke Power Co., 401 U.S. 424. Legal decision.
8 [offset=-40mm] Four-Fifths Rule: Codified in the 1978 Uniform Guidelines on Employee Selection Procedures, used by the EEOC, Department of Labor, and Department of Justice (Equal Employment Opportunity Commission et al. 1978). A selection rate for any protected group below 80 percent of the highest group’s rate constitutes prima facie evidence of adverse impact—for example, if 60 percent of one group passes, at least 48 percent of any other group must pass. For ML systems, this translates to automated monitoring that alerts when per-group selection ratios fall below 0.8, providing a concrete threshold where most fairness metrics remain qualitative.
Equal Employment Opportunity Commission, Civil Service Commission, Department of Labor, and Department of Justice. 1978. Uniform Guidelines on Employee Selection Procedures. Code of Federal Regulations.
Despite the inherent challenges, several concrete testing approaches can surface responsibility issues before deployment:
- Slice-based evaluation: Partitions test data into meaningful subgroups and reports metrics separately for each slice, asking whether aggregate performance hides subgroup failure. A model may achieve 95 percent accuracy overall but only 78 percent accuracy on low-income applicants or users from rural areas, a disparity invisible in aggregate reporting.
- Invariance testing: Checks whether the model changes behavior for the wrong reasons. Replacing “John” with “Jamal” in a loan application should not change approval likelihood if the feature is not legitimate for the decision. Behavioral testing frameworks such as CheckList apply this idea by organizing tests around model capabilities and invariance-style expectations rather than accuracy alone (M. T. Ribeiro et al. 2020).
- Boundary and stress testing: Probes regions where ordinary validation sets are least informative. Boundary testing evaluates model behavior at the edges of input distributions (unusual ages, extreme values, rare categories) where training data may be sparse and predictions unreliable. Stress testing extends boundary testing to adversarial conditions: corrupted inputs, distribution shift, adversarial examples, and edge cases designed to probe failure modes systematically. Stakeholder red-teaming adds evidence from domain experts and affected community members, surfacing failure modes no automated test can discover because they require lived experience to imagine.
Ribeiro, Marco Tulio, Tongshuang Wu, Carlos Guestrin, and Sameer Singh. 2020. “Beyond Accuracy: Behavioral Testing of NLP Models with CheckList.” Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, 4902–12. https://doi.org/10.18653/v1/2020.acl-main.442.
Responsible testing strategies complement traditional software testing rather than replacing it. Each demands engineering judgment to select, configure, and interpret. A legal team cannot specify which demographic slices matter for a healthcare algorithm; a product manager cannot determine appropriate invariance tests for a loan model. The technical depth required to implement responsible testing points to a critical organizational truth: only engineers possess the knowledge to translate abstract fairness goals into measurable, testable properties. Responsibility ownership must therefore sit within engineering organizations, not outside them.
Engineering leadership on responsibility
By the time Amazon’s team tried to remediate the recruiting tool, the model had already learned proxy signals so deeply that the project was eventually scrapped. The intervention came too late because the technical decisions that created the problem, made months earlier by engineers, had already constrained every possible fix. Responsible AI engineering cannot be delegated exclusively to ethics boards or legal departments. These groups provide essential oversight but lack the technical access required to identify problems early in the development process.
Legal or ethics review can identify a problem near deployment, but it cannot recover design options the system has already foreclosed. If the team trained the model without fairness constraints, chose an architecture that cannot support interpretability requirements, or built a data pipeline without the demographic attributes needed for monitoring, review can only accept, reject, or demand expensive redesign. Engineers therefore occupy a critical position in the ML development lifecycle because their choices define the solution space for all subsequent interventions: architecture determines which fairness constraints can apply, the optimization objective determines which patterns the system learns, and the data pipeline determines whether disaggregated evaluation is possible.
Definition 1.2: Responsible AI engineering
Responsible AI Engineering is the engineering discipline of designing, deploying, and maintaining systems with probabilistic outputs by operationalizing societal and regulatory requirements as testable constraints on the D·A·M axes: permissible data contents, provenance, and composition; allowable model behavior and robustness properties; and infrastructure bounds such as latency, energy, compute budget, carbon emissions, and audit-log retention.
- Significance: Each D·A·M axis acquires concrete governance constraints: the data axis is bounded by privacy regulations such as the General Data Protection Regulation (GDPR), which limits which records, fields, and features can be collected; the algorithm axis is bounded by fairness and robustness metrics (for example, demographic parity within \(\varepsilon = 5\%\) across protected groups, meaning positive prediction rates must not differ by more than 5 percentage points, or accuracy degradation less than 2 percent under adversarial perturbation \(\|\delta\|_\infty \leq 0.01\), a worst-case input change bounded to 0.01 per normalized feature under the \(\ell_\infty\) norm); and the machine axis is bounded by resource and infrastructure budgets such as latency, energy per inference, carbon emissions, and audit-log retention. Violating these bounds is a system failure, not a research shortcoming.
- Distinction: Unlike AI ethics (which articulates aspirational values), responsible AI engineering translates those values into measurable, testable invariants that can be verified through automated testing and continuous monitoring, using the same lifecycle practices that enforce latency SLOs.
- Common pitfall: A frequent misconception is that responsibility is “added” at the end of development. The constraints imposed on the data axis (what data can be collected) propagate forward to constrain the algorithm axis (what biases will be encoded) and the machine axis (what audit trails must be kept), making late-stage remediation structurally impossible.
An engineering-centered approach does not diminish the importance of diverse perspectives in identifying potential harms. Product managers, user researchers, affected communities, and policy experts contribute essential knowledge about how systems fail socially despite technical success. Engineers translate these concerns into measurable requirements and testable properties that can be verified throughout the development lifecycle. Effective responsibility requires engineers who both listen to stakeholder concerns and possess the technical capability to implement appropriate safeguards.
Engineering teams do not operate in isolation. As figure 2 makes clear, engineering practices are nested within broader organizational, industry, and regulatory governance structures, each layer imposing constraints on the ones inside it. The key insight is that technical excellence at the innermost layer enables, but does not replace, compliance with requirements flowing inward from external governance.

Those governance layers define who owns responsibility, but they do not yet account for the costs that ordinary performance metrics omit.
Beyond ethical imperatives, responsible engineering delivers measurable business value through three reinforcing mechanisms. The most immediate is risk mitigation: ML system failures create legal and financial exposure that systematic responsibility practices reduce. Amazon’s recruiting tool cancellation represented years of development investment lost to inadequate fairness consideration, and COMPAS-related litigation has cost jurisdictions millions in legal fees and settlements. Organizations implementing disaggregated evaluation, documentation, and monitoring reduce the probability of costly failures and demonstrate due diligence if problems emerge.
Systems Perspective 1.4: The full cost of the iron law
The iron law of ML systems (principle 3) established in Iron Law of ML Systems holds that system performance depends on the interaction between data, compute, and system overhead. We have spent previous sections optimizing each term: compressing models (Model Compression), accelerating hardware (Hardware Acceleration), and automating operations (ML Operations). Yet every optimization has costs beyond those captured in benchmarks.
A model quantized for edge deployment consumes less energy, but also produces outputs that may differ across demographic groups. A recommendation system optimized for engagement maximizes a business metric, but may amplify harmful content. Responsible engineering extends our accounting to include these broader impacts: the carbon cost of computation, the fairness cost of optimization choices, and the societal cost of deployment at scale. The iron law governs how fast our systems run; responsible engineering governs how well they serve.
A second mechanism is regulatory compliance, driven by legal requirements that vary by jurisdiction and application risk. The EU AI Act, for example, classifies high-risk AI applications and mandates technical requirements including risk assessment, data governance, transparency, and human oversight. Organizations that build responsibility into engineering practice can demonstrate compliance through existing documentation and monitoring rather than expensive retrofitting; the engineering lesson is that proactive controls are usually cheaper than reconstructing evidence after deployment.
Competitive differentiation completes the business case. Trust can drive enterprise purchasing decisions for ML-powered services, and organizations that can demonstrate systematic responsibility practices through model cards, audit trails, and published evaluation results may qualify for deployments that competitors cannot. Apple’s privacy positioning, Microsoft’s responsible AI principles, and Anthropic’s safety research illustrate responsibility as a strategic investment rather than a purely defensive cost.
The quantization techniques from Model Compression reduce inference energy by 2–4\(\times\), directly supporting sustainable deployment. The monitoring infrastructure from ML Operations enables disaggregated fairness evaluation across demographic groups. Responsible engineering synthesizes these capabilities into disciplined practice through structured frameworks that translate principles into processes.
Every failure examined earlier could have been prevented by systematic processes applied at the right stage of development. The missing ingredient was not technical capability but disciplined practice: checklists, documentation standards, testing protocols, and monitoring infrastructure that translate responsibility principles into repeatable engineering workflows.
Self-Check: Question
Amazon’s engineers removed explicit gender indicators from the recruiting model’s features, retrained, and found the system still discriminated against resumes from all-women’s colleges. Which diagnosis best explains why the explicit-attribute removal did not fix the harm?
- The fix was sound in principle; the system only needed additional bias-mitigation training epochs for the gender signal to fade from the learned weights.
- College names, activity descriptions, and career-gap patterns remained as proxy variables that carried the same demographic signal the removed gender feature had carried.
- The problem was deployment-time distribution shift in the applicant pool rather than bias in the original training signal.
- The problem was an optimization-objective mismatch that a different gradient-descent variant would have corrected during convergence.
A hospital’s sepsis prediction model continues to emit confident recommendations after an EHR update changes how vital signs are recorded, yet clinicians observe deteriorating outcomes for a subset of patients. All dashboards stay green. Walk through why this is a silent failure, identify two specific monitoring signals that would have caught it, and state the systems consequence for how teams instrument production ML.
A recommendation team reports that engagement clicks rose 20 percent after deploying a new ranker, but month-over-month user satisfaction surveys dropped five percent and 30-day retention fell three percent. The team’s director asks how to detect or prevent this class of failure before it recurs. Which engineering intervention best fits the section’s alignment-gap framing?
- Scale the model two-fold: a larger model will learn a richer representation of satisfaction and close the gap automatically.
- Hold out a random counterfactual slice of users at deployment, measure true-outcome metrics (satisfaction, retention) on that slice periodically, and trigger rollback when the proxy-true gap widens beyond a preset threshold.
- Increase the weight of the clicks loss term: because the proxy correlates with the true goal initially, maximizing it harder will restore the lost correlation.
- Retrain on more data: with enough examples, gradient descent will discover the satisfaction signal implicitly even when it is not in the training labels.
A lending team generates paired test applications that differ only in the applicant’s first name (“John” vs “Jamal”) while holding income, credit history, and debt constant, then compares approval probabilities. Which responsible-testing method from the section are they applying, and what failure mode does it surface?
- Boundary testing, which probes behavior at the edges of the input distribution where training data is sparse.
- Slice-based evaluation, which partitions the test set into subgroups and reports per-slice aggregate accuracy.
- Stakeholder red-teaming, which relies on affected community members to propose adversarial scenarios.
- Invariance testing, which verifies that predictions remain stable when a feature the model should ignore is perturbed.
True or False: Once a model’s architecture, loss function, demographic-attribute collection, and monitoring pipeline have been fixed, a later ethics-board review can still implement equally effective fairness interventions as engineers could have at design time.
Responsible Engineering Checklist
Amazon’s recruiting tool could have been caught before deployment by a structured predeployment review. COMPAS’s error rate disparity would have surfaced through disaggregated testing. Both failures shared a common cause: responsibility was treated as a separate review stage rather than integrated into the development workflow. A responsible engineering checklist embeds assessment wherever engineering decisions create durable risk: before deployment, in documentation, during population-specific evaluation, at explanation and compliance boundaries, and after launch through monitoring. The stages build on one another: assessment identifies what to measure, documentation preserves the assumptions, fairness evaluation checks whether performance holds across groups, explainability and compliance translate decisions into obligations, and monitoring ensures violations trigger intervention.
Predeployment assessment
Before a loan approval model reaches production, a team must determine the provenance of the training data, identify who is represented and who is missing, anticipate failure modes, and define recourse for affected users. Table 3 structures this evaluation into five phases, distinguishing critical-path blockers from high-priority items that can proceed with documented risk acceptance.
| Phase | Priority | Key Questions | Documentation Required |
|---|---|---|---|
| Data | Critical Path | Where did this data come from? Who is represented? Who is missing? What historical biases might be encoded? | Data provenance records, demographic composition analysis, collection methodology documentation |
| Training | High | What are we optimizing for? What might we be implicitly penalizing? How do architecture choices affect outcomes? | Objective function specification, regularization choices, hyperparameter selection rationale |
| Evaluation | Critical Path | Does performance hold across different user groups? What edge cases exist? How were test sets constructed? | Disaggregated metrics by demographic group, edge case testing results, test set composition analysis |
| Deployment | Critical Path | Who will this system affect? What happens when it fails? What recourse do affected users have? | Impact assessment, stakeholder identification, rollback procedures, user notification protocols |
| Monitoring | High | How will we detect problems? Who reviews system behavior? What triggers intervention? | Monitoring dashboard specifications, alert thresholds, review schedules, escalation procedures |
Critical Path items are deployment blockers: the system must not go to production until these questions are answered. High Priority items should be addressed but may proceed with documented risk acceptance and a remediation timeline. The distinction enables teams to ship responsibly without requiring perfection on every dimension before initial deployment.
The Evaluation row in table 3 raises the critical concern of whether performance holds across different user groups. Answering this question requires statistically valid test sets for each group, which can create surprisingly stringent data requirements when representation is uneven.

Random sampling barely reaches small subgroups.
Napkin Math 1.1: The statistics of representation
Problem: An engineering team needs to verify that a Face ID model works for a minority group representing 1 percent of the user base. A worst-case binomial margin of error near 1 percentage point at 95 percent confidence requires roughly 10,000 images for this group.
Random Sampling: To get 10,000 images of a 1 percent group via random sampling, the team must collect and label: \(D_{\text{eval,total}}\) = 10,000 images / 0.01 = 1,000,000 images
Stratified Sampling: Specifically targeting this group (for example, via active learning or community outreach) requires only 10,000 images. Systems insight: Relying on “natural distribution” data for fairness is prohibitively expensive under random sampling. Validating the minority group effectively requires 100× more data than the majority group. Fairness requires intentional data engineering, not just more data.
Intentional data engineering addresses what the model sees during evaluation, but even a perfectly representative dataset cannot prevent harm at deployment if the system lacks adequate human oversight. The representation cost calculated above is a predeployment gate; the question that follows is what happens once the model is live and making decisions that affect people.
For high-stakes applications, the deployment phase should specify where human oversight is required. Human-in-the-loop (HITL) systems route uncertain, high-consequence, or flagged decisions to human reviewers rather than acting autonomously. Effective HITL design must specify four requirements: the review scope (which decisions require human review), the confidence thresholds that trigger escalation, the training reviewers receive, and the mechanisms for monitoring reviewer performance. HITL is not a catch-all solution: human reviewers can rubber-stamp automated decisions, introduce their own biases, or become overwhelmed by alert volume. Effective HITL design requires calibrating the human-machine boundary to the specific application risks and reviewer capabilities.
War Story 1.3: The automation paradox (2018)
Context: Uber’s Advanced Technologies Group (ATG) was testing self-driving cars in Arizona. The system was designed with a “safety driver” to take over if the AI failed (National Transportation Safety Board 2019).
Failure mode: The automated driving system detected the pedestrian but repeatedly changed its classification and did not correctly predict her path. Uber had also disabled automatic emergency braking while the developmental system was active, relying on the vehicle operator to intervene. The operator was visually distracted and did not take control in time. The pedestrian was killed. The “human-in-the-loop” safeguard failed because the human had been conditioned by the system’s reliability to disengage.
Systems lesson: Adding a human backup to an unreliable system does not make it reliable; it creates a new system with complex failure modes. If the AI is 99 percent reliable, the human will eventually trust it 100 percent, making the “backup” useless precisely when it is needed most.

As automation grows more reliable, human vigilance decays.
National Transportation Safety Board. 2019. Collision Between Vehicle Controlled by Developmental Automated Driving System and Pedestrian, Tempe, Arizona, March 18, 2018. HAR-19/03. National Transportation Safety Board.
The predeployment assessment framework parallels aviation preflight checklists, where pilots follow every item without exception to ensure comprehensive coverage of critical concerns despite time pressure. Production ML deployments require equivalent discipline and rigorous verification. Checklists ensure teams ask the right questions; documentation standards ensure the answers persist and travel with the model.
Model documentation standards
Consider inheriting a production model from a departed colleague: the model achieves 94 percent accuracy on its test set, but three pieces of information are missing. The identity of that test set, the data the model was trained on, and the populations it was validated against are unknown. Without those answers, deploying or updating the model is a gamble. Model cards solve this problem by providing a standardized documentation format for ML models9 (Mitchell et al. 2019). Originally developed at Google, model cards function as “nutrition labels” that capture information essential for responsible deployment and travel with the model throughout its lifecycle.
9 Model Cards: The primary failure mode model cards address is scope creep: gradual expansion from “it worked for case A” to “try it for case B” without revalidating intended use. In practice, cards are often written after deployment decisions are made, documenting observed behavior rather than constraining it. The companion “Datasheets for Datasets” (Gebru et al. 2021) applies the same principle to training data. Without both, the card becomes a historical record rather than a guard rail.
Gebru, Timnit, Jamie Morgenstern, Briana Vecchione, Jennifer Wortman Vaughan, Hanna Wallach, Hal Daumé III, and Kate Crawford. 2021. “Datasheets for Datasets.” Communications of the ACM 64 (12): 86–92. https://doi.org/10.1145/3458723.
Mitchell, Margaret, Simone Wu, Andrew Zaldivar, Parker Barnes, Lucy Vasserman, Ben Hutchinson, Elena Spitzer, Inioluwa Deborah Raji, and Timnit Gebru. 2019. “Model Cards for Model Reporting.” Proceedings of the Conference on Fairness, Accountability, and Transparency, 220–29. https://doi.org/10.1145/3287560.3287596.
A complete model card covers seven concerns that together enable responsible deployment. It begins with technical details (architecture, training procedures, hyperparameters) that enable reproducibility and auditing. Crucially, it specifies intended use alongside explicit exclusions, preventing the scope creep where models designed for photo organization get repurposed for security screening. The card then documents which factors (demographic groups, environmental conditions, instrumentation differences) might affect performance, guiding both evaluation strategy and monitoring protocols.
The remaining sections close the gap between what a model can do and what it should do. Performance metrics must include disaggregated results across the factors identified earlier, because aggregate accuracy alone conceals the disparities this chapter has documented. Training and evaluation data documentation enables assessment of potential encoded biases and provides essential context for interpreting results. Ethical considerations make implicit trade-offs explicit by documenting known limitations, potential harms, and mitigations implemented, while caveats and recommendations provide guidance on appropriate use and known failure modes.
A concrete MobileNetV2 model card makes these abstract categories operational: table 4 shows how each section addresses specific deployment concerns for edge deployment.
Datasheets for datasets provide analogous documentation for training data (Gebru et al. 2021). These documents capture data provenance, collection methodology, demographic composition, and known limitations that affect downstream model behavior. Documentation establishes what a model is designed to do; testing verifies whether it performs equitably across the populations it serves.
| Section | Content |
|---|---|
| Model Details | MobileNetV2 architecture with 3.5M parameters, trained on ImageNet using depthwise separable convolutions. INT8 quantized for edge deployment. |
| Intended Use | Real-time image classification on mobile devices with less than 50 ms latency requirement. Suitable for consumer applications including photo organization and accessibility features. |
| Factors | Performance varies with image quality (blur, lighting), object size in frame, and categories outside ImageNet distribution. |
| Metrics | 71.8% top-1 accuracy on ImageNet validation (full precision: 72.0%). Accuracy varies by category: 85% on common objects, 45% on fine-grained distinctions. |
| Ethical Considerations | Training data reflects ImageNet biases in geographic and demographic representation. Not validated for high-stakes applications (medical diagnosis, security screening). Performance may degrade on images from underrepresented regions. |
Testing across populations
The disaggregated evaluation that exposed the Gender Shades disparities (section 1.2.4) now becomes an operational release-gate task: selecting the slices, metrics, and thresholds that determine whether deployment is allowed. Aggregate performance metrics mask disparities across user populations, the Flaw of Averages (Savage 2009); responsible testing requires disaggregated evaluation that examines performance for each relevant subgroup.
Savage, Sam L. 2009. The Flaw of Averages: Why We Underestimate Risk in the Face of Uncertainty. John Wiley & Sons.
Systems Perspective 1.5: The flaw of averages
In systems engineering, we rarely design for the “average” case; we design for the tail cases and boundary conditions. A bridge that is “safe on average” but collapses under a heavy truck is a failure. Similarly, an ML system that is “accurate on average” but fails for a specific ethnic or gender group is an engineering failure. The same principle that drives us to measure tail latency (p99) for system reliability applies to fairness: we must use disaggregated evaluation to measure system fairness. Looking only at aggregate accuracy blinds the analysis to systemic failures occurring in the margins. Responsible engineering requires making these “tails” visible through granular, population-specific measurement.
The flaw of averages gives the testing principle: aggregate metrics are not enough. The next question is which tails to expose. That answer depends on the workload archetype, because each archetype creates different opportunities for bias to enter and different metrics for detecting it.
The table turns the flaw of averages into an engineering workflow: a vision model fails differently than a recommendation system, so the fairness metrics must match the failure mode and the subgroup slices must come from the application context. For healthcare applications, demographic factors like race, age, and gender are essential. For content moderation, language and cultural context matter. For financial services, protected categories under fair lending laws require specific attention.
Testing infrastructure should support stratified evaluation where performance metrics are computed separately for each relevant subgroup, enabling comparison of error rates and error types across populations. Intersectional analysis considers combinations of attributes because harms may concentrate at intersections not visible in single-factor analysis. Confidence intervals provide uncertainty quantification for subgroup metrics when small subgroup sizes may yield unreliable estimates. Temporal monitoring tracks subgroup performance over time, detecting drift that affects some populations before others.
Tool choice matters only after the team has named the fairness metric, subgroup slices, and alert thresholds. Open-source libraries such as Fairlearn (Bird et al. 2020), AI Fairness 360 (Bellamy et al. 2019), and Google’s What-If Tool (Wexler et al. 2020) lower the implementation cost of disaggregated and intersectional evaluation, but a library can only compute the metric the engineer asks for. It cannot decide which subgroup definition matters, which disparity threshold should page the team, or which fairness constraint is appropriate for the deployment context.
Bird, Sarah, Miro Dudı́k, Richard Edgar, Brandon Horn, Roman Lutz, Vanessa Milan, Mehrnoosh Sameki, Hanna Wallach, and Kathleen Walker. 2020. “Fairlearn: A Toolkit for Assessing and Improving Fairness in AI.” Microsoft Technical Report MSR-TR-2020-32.
Bellamy, Rachel K. E., Kuntal Dey, Michael Hind, Seung Hoffman, Sylvain Houde, Karthikeyan Kannan, Pradeep Lohia, et al. 2019. “AI Fairness 360: An Extensible Toolkit for Detecting and Mitigating Algorithmic Bias.” IBM Journal of Research and Development 63 (4/5): 4:1–15. https://doi.org/10.1147/jrd.2019.2942287.
Wexler, James, Mahima Pushkarna, Tolga Bolukbasi, Martin Wattenberg, Fernanda Viégas, and Jimbo Wilson. 2020. “The What-If Tool: Interactive Probing of Machine Learning Models.” IEEE Transactions on Visualization and Computer Graphics 26 (1): 56–65. https://doi.org/10.1109/TVCG.2019.2934619.
Lighthouse 1.1: Fairness concerns by archetype
The dominant fairness risks differ by workload archetype (introduced in ML Systems), requiring different evaluation strategies. Table 5 maps each archetype to its primary risk and evaluation metric.
Table 5: Fairness risk by ML archetype: Fairness risks vary by archetype’s data source and deployment context.
| Archetype | Primary Fairness Risk | Key Evaluation Metric | Real-World Example |
|---|---|---|---|
| ResNet-50 (Compute Beast) | Training data bias (underrepresentation of minority groups in ImageNet) | Disaggregated accuracy by demographic group | Gender Shades: 99.2% accuracy on light-skinned males, 65.3% on dark-skinned females (Buolamwini and Gebru 2018) |
| GPT-2 (Bandwidth Hog) | Corpus bias (overrepresentation of majority viewpoints in web text) | Toxicity rate by demographic prompt context; stereotype score | LLMs produce more toxic completions for prompts mentioning minority groups |
| DLRM (Sparse Scatter) | Feedback-loop amplification (popular items get more data) | Share of recommendation impressions by item category and supplier or creator group | Filter bubbles: the system recommends similar content to similar users, reducing discovery of niche creators |
| DS-CNN (Tiny Constraint) | Deployment-context mismatch (trained on clean audio, deployed in noisy real-world environments) | False positive rate by acoustic environment and speaker accent | Voice assistants perform worse on accented speech; wake-word triggers on TV audio in some languages |
Systems insight: Fairness evaluation must match the archetype’s failure mode. Vision models require demographic stratification of accuracy; large language models (LLMs) require toxicity and stereotype probing; recommendation systems require exposure audits; TinyML requires acoustic environment diversity testing. The Lighthouse keyword spotting (KWS) system introduced in ML Systems as the Tiny Constraint lighthouse faces exactly this challenge for its DS-CNN, a depthwise-separable convolutional neural network (CNN): trained on clean studio audio, it must perform equitably across accents, background noise levels, and speaker demographics in production homes—a governance challenge we examine in section 1.5.
Buolamwini, Joy, and Timnit Gebru. 2018. “Gender Shades: Intersectional Accuracy Disparities in Commercial Gender Classification.” Conference on Fairness, Accountability and Transparency, 77–91.
Worked example: Fairness analysis in loan approval
A loan approval model reports 85 percent accuracy on the majority group and 82.5 percent overall accuracy across the evaluated applicants—numbers that may satisfy a coarse aggregate dashboard. Table 6 and table 7 reveal what the aggregate conceals: loan approval outcomes for the same model evaluated separately on two demographic groups.
| Approved (pred) | Rejected (pred) | |
|---|---|---|
| Repaid (actual) | 4,500 (TP) | 500 (FN) |
| Defaulted (actual) | 1,000 (FP) | 4,000 (TN) |
| Approved (pred) | Rejected (pred) | |
|---|---|---|
| Repaid (actual) | 600 (TP) | 400 (FN) |
| Defaulted (actual) | 200 (FP) | 800 (TN) |
Three standard fairness metrics computed from the confusion matrices in table 6 and table 7 reveal significant disparities.10
10 Fairness Metric Incompatibility: The measured disparities in this worked example show how one set of confusion matrices can violate demographic parity, equal opportunity, and equalized odds. A separate impossibility theorem proves that when group base rates differ, multiple fairness criteria cannot generally be satisfied simultaneously (Chouldechova 2017). In those settings, optimizing for one metric, such as equal opportunity, can degrade another, such as predictive parity. A system designer must therefore make the trade-off explicit rather than assuming all guarantees can be achieved at once.
Chouldechova, Alexandra. 2017. “Fair Prediction with Disparate Impact: A Study of Bias in Recidivism Prediction Instruments.” Big Data 5 (2): 153–63. https://doi.org/10.1089/big.2016.0047.
The three metrics test different definitions of equal treatment:
- Demographic parity: Requires equal approval rates across groups. Group A receives approval at a rate of \((4,500 + 1,000) / 10,000 = 55\%\), while Group B receives approval at \((600 + 200) / 2,000 = 40\%\). The 15 percentage-point disparity indicates unequal treatment in approval decisions.
- Equal opportunity: Requires equal true positive rates among qualified applicants. Group A achieves a TPR of \(4,500 / (4,500 + 500) = 90\%\), meaning 90 percent of applicants who would repay receive approval. Group B achieves only \(600 / (600 + 400) = 60\%\). This 30 percentage-point disparity means qualified applicants from Group B face substantially higher rejection rates than equally qualified applicants from Group A.
- Equalized odds: Requires both equal true positive rates and equal false positive rates.11 Group A shows an FPR of \(1,000 / (1,000 + 4,000) = 20\%\), and Group B shows \(200 / (200 + 800) = 20\%\). While false positive rates are equal, the true positive rate disparity means equalized odds is violated.
11 Equalized Odds: Formalized by Hardt et al. (2016), requiring that both TPR and FPR be equal across protected groups. The weaker “equal opportunity” relaxes this to TPR alone. The practically important result: equalized odds can be achieved as a postprocessing step by adjusting prediction thresholds per group, requiring no model retraining—separating the fairness mechanism from the training pipeline and enabling fairness fixes without retraining cycles that cost thousands of GPU-hours.
Hardt, Moritz, Eric Price, and Nathan Srebro. 2016. “Equality of Opportunity in Supervised Learning.” Advances in Neural Information Processing Systems 29: 3315–23.
The metrics disagree because they encode different policy choices about which error rates matter most.
The pattern revealed by these metrics has a clear interpretation: the model rejects qualified applicants from Group B at a much higher rate (40 percent false negative rate vs. 10 percent) while maintaining similar false positive rates. The disparity pattern suggests the model has learned stricter approval criteria for Group B, potentially encoding historical discrimination in lending patterns where minority applicants faced higher scrutiny despite equivalent qualifications.
Production systems must automate these calculations across all protected attributes, triggering alerts when disparities exceed predefined thresholds. Listing 1 shows the core pattern: compute per-group metrics from confusion matrices, then flag disparities that exceed acceptable bounds.
def compute_fairness_metrics(confusion_matrix):
tp, fp, tn, fn = (
confusion_matrix[k] for k in ["TP", "FP", "TN", "FN"]
)
total = tp + fp + tn + fn
return {
# Demographic parity
"approval_rate": (tp + fp) / total,
# Equal opportunity
"tpr": tp / (tp + fn) if (tp + fn) else 0,
# Equalized odds (with TPR)
"fpr": fp / (fp + tn) if (fp + tn) else 0,
}
# Compare groups and flag disparities exceeding threshold
for metric in ["approval_rate", "tpr", "fpr"]:
disparity = abs(metrics_a[metric] - metrics_b[metric])
# e.g., 0.05 for high-stakes applications
if disparity > FAIRNESS_THRESHOLD:
trigger_alert(metric, disparity)Automated monitoring achieves what manual auditing cannot at scale: continuous tracking of fairness metrics with immediate alerting when disparities emerge. The 30 percentage-point TPR disparity far exceeds common industry thresholds of 5 percentage points for high-stakes applications, indicating the model requires fairness intervention before deployment. Table 8 reveals the pattern across the computed metrics and disparities.
| Metric | Group A | Group B | Disparity |
|---|---|---|---|
| Approval Rate | 55% | 40% | 15 pp |
| True Positive Rate | 90% | 60% | 30 pp |
| False Positive Rate | 20% | 20% | 0 pp |
To understand why aggregate metrics hide these disparities, look closely at figure 3. When a single threshold is applied to populations with different score distributions, the same decision boundary produces vastly different outcomes for each group (Barocas and Selbst 2016). The figure exposes a fundamental tension: any fixed threshold is simultaneously “correct” for the combined population while being systematically wrong for each subpopulation.
Barocas, Solon, and Andrew D. Selbst. 2016. “Big Data’s Disparate Impact.” California Law Review 104: 671–732. https://doi.org/10.2139/ssrn.2477899.

Several mitigation approaches exist, each with distinct trade-offs:
- Threshold adjustment: Lowers the approval threshold for Group B to equalize TPR but may increase false positives for that group.
- Reweighting: Increases the weight of Group B samples during training to give the model stronger signal about this population but may reduce overall accuracy.12
- Adversarial debiasing: Trains with an adversary that prevents the model from learning group membership but adds training complexity.13
12 Reweighting: A preprocessing technique rooted in importance sampling from statistics: samples from an underrepresented group receive higher loss weights during training, amplifying their influence on gradient updates without removing any data. Kamiran and Calders (2012) showed that appropriately chosen weights can reduce disparate impact from training data. The systems trade-off is application-specific: reweighting shifts the loss landscape and may reduce performance on other slices, so the cost must be evaluated against the Pareto frontier for the application.
Kamiran, Faisal, and Toon Calders. 2012. “Data Preprocessing Techniques for Classification Without Discrimination.” Knowledge and Information Systems 33 (1): 1–33. https://doi.org/10.1007/s10115-011-0463-8.
13 Adversarial Debiasing: The key differentiating property is representation pressure: the adversary discourages the primary model from encoding protected-attribute information, which can reduce protected-attribute leakage and help satisfy selected fairness criteria under the evaluated distribution (Zhang et al. 2018). It does not provide a general fairness guarantee under arbitrary deployment shift; guarantees depend on assumptions about invariance, labels, causal structure, and the type of shift. Postprocessing methods such as threshold adjustment may also be appropriate under different assumptions but must be revalidated when deployment demographics or label processes change. The cost is additional training, hyperparameter tuning, and slice-level validation rather than a universal percentage overhead.
Zhang, Brian Hu, Blake Lemoine, and Margaret Mitchell. 2018. “Mitigating Unwanted Biases with Adversarial Learning.” Proceedings of the 2018 AAAI/ACM Conference on AI, Ethics, and Society, 335–40. https://doi.org/10.1145/3278721.3278779.
The choice among these approaches requires stakeholder input about which trade-offs are acceptable in the specific application context. Engineers present these trade-offs effectively by making them explicit and quantifiable.
Checkpoint 1.2: Fairness criteria
Fairness is not a single metric; it is a constrained design choice.
Quantifying the fairness-accuracy trade-off
The impossibility result in Kleinberg et al. (2016) establishes that fairness criteria can conflict, and figure 1 turns that conflict into an engineering trade-off. However, knowing the trade-off exists is insufficient: engineers must quantify the practical cost of fairness constraints to inform stakeholder decisions. A compact hiring scenario makes that cost concrete, distinct from the preceding loan approval example and with different disparity magnitudes to illustrate a different point.
Napkin Math 1.2: The price of fairness
Problem: Stakeholders demand elimination of a 20 percentage-point True Positive Rate (TPR) disparity in a hiring model. What is the “Price of Fairness” in terms of hiring quality?
Physics: TPRs can be equalized by adjusting the classification threshold \((\gamma_{\text{cls}})\) for the disadvantaged group.
- Original state: Group A (\(\text{TPR} =\) 90 percent), Group B (\(\text{TPR} =\) 70 percent). Aggregate Accuracy = 85 percent.
- Intervention: Lower \(\gamma_{\text{cls},g=B}\) until \(\text{TPR}_{g=B} =\) 90 percent.
- The cost: Lowering the threshold increases false positives (hiring candidates who do not meet the bar).
Math:
- Closing the 20 percentage-point TPR gap requires accepting a 15 percentage-point increase in False Positives for the disadvantaged group: near the original threshold most remaining candidates do not meet the bar, so each additional qualified hire admits several unqualified ones.
- If the value of a successful hire is $100,000 and the cost of a bad hire is $50,000, both sides of the intervention must be counted:
- \(\Delta\text{Utility} = \Delta\text{TPR} \times \text{Base Rate} \times \text{Hire Value} - \Delta\text{FPR} \times (1 - \text{Base Rate}) \times \text{Bad Hire Cost}\).
- \(\text{Aggregate Utility Tax} = \frac{-\Delta\text{Utility}}{\text{Baseline Utility}} \times \text{Group Share}\).
- Under the assumption that the disadvantaged group is 30 percent of the applicant pool and that the base rate of qualified applicants is 20 percent, the added bad-hire cost outweighs the added hire value and the aggregate utility loss is 6 percent.
Systems insight: The “Price of Fairness” in this system is a 6 percent utility tax under the stated assumptions, a system constraint, not a bug. The tax is not automatic: when a TPR gap reflects a miscalibrated threshold, closing it can even raise net utility. It appears precisely when the baseline threshold is already near the utility optimum, so the marginal admits skew unqualified; the engineer’s job is to present the Pareto frontier to stakeholders so they can choose the Utility/Fairness trade-off that aligns with organizational values.
The calculation gives stakeholders a way to choose a point on the fairness-accuracy frontier, but it still does not explain any particular decision. When a loan applicant receives a rejection, stating that “the model’s true positive rate for your demographic group is 60 percent compared to 90 percent for other groups” provides no actionable information. The applicant needs to know why the application was rejected and what could be changed. These questions require explainability, which is the ability to articulate which input features drove specific predictions.
Explainability requirements
A loan applicant denied credit by an algorithmic system has a right to know why, not in aggregate statistical terms but in terms specific to her application. Explainability14 provides this capability: it enables human oversight of automated decisions, supports debugging when problems emerge, and satisfies regulatory requirements for decision transparency.
14 Explainability vs. Interpretability: Interpretability is an intrinsic model property—the degree to which a human can understand internal mechanics (linear regression is interpretable; a 100-layer network is not). Explainability is a post-hoc capability added without changing the model (LIME, SHAP). The systems implication: interpretable models constrain architecture selection (simpler models, fewer features), while post-hoc explanations add a separate computation path whose cost depends on the method, model, and serving workflow. Regulations like the EU AI Act demand “meaningful information about the logic involved” without specifying which approach, leaving the latency-vs.-architecture trade-off to engineering teams.
The level of explainability required varies by application context and regulatory environment. Table 9 maps common deployment scenarios to their explainability needs.
| Application Domain | Explainability Level | Typical Requirements |
|---|---|---|
| Credit decisions | Individual explanation required | Specific factors contributing to denial must be disclosed to applicant |
| Medical diagnosis | Clinical reasoning support | Explanation must support physician decision-making, not replace it |
| Content moderation | Appeal-supporting | Sufficient detail for users to understand and contest decisions |
| Recommendation | Transparency optional | “Because you watched X” sufficient for most contexts |
| Fraud detection | Internal audit only | Detailed explanations may enable adversarial gaming |
Engineering teams should select explainability approaches based on these domain requirements:
- Post-hoc explanation methods: Generate feature importance scores for individual predictions without requiring model architecture changes.15
- Inherently interpretable models: Provide explanations as part of their structure through linear models, decision trees, or attention mechanisms, but may sacrifice predictive performance.
- Concept-based explanations: Map model behavior to human-understandable concepts rather than raw features.
15 LIME and SHAP: LIME (Ribeiro et al. 2016) fits a local interpretable model around each prediction—fast but potentially inconsistent across nearby inputs. SHAP (Lundberg and Lee 2017) adapts Shapley values from cooperative game theory to compute feature contributions under a unified additive framework. Exact Shapley-value computation can be expensive, so practical SHAP implementations rely on approximations or model-specific algorithms. The systems trade-off is that explanation fidelity, latency, and implementation complexity must be budgeted explicitly rather than treated as free.
Ribeiro, Marco Tulio, Sameer Singh, and Carlos Guestrin. 2016. “” Why Should i Trust You?” Explaining the Predictions of Any Classifier: Explaining the Predictions of Any Classifier.” Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 1135–44. https://doi.org/10.1145/2939672.2939778.
Lundberg, Scott M., and Su-In Lee. 2017. “A Unified Approach to Interpreting Model Predictions.” Advances in Neural Information Processing Systems 30: 4765–74.
The choice involves trade-offs between explanation fidelity, computational cost, and model flexibility.
War Story 1.4: The hospital shortcut (2018)
Context: A team at Mount Sinai’s Icahn School of Medicine trained deep learning models for pneumonia detection on chest X-rays from their own hospital and tested them against scans from the National Institutes of Health and Indiana University (Zech et al. 2018).
Failure mode: Models that appeared strong on internal data performed worse on external hospitals. The problem was not simply architecture quality: hospital-specific prevalence, acquisition patterns, and dataset artifacts created shortcuts that did not transfer cleanly across sites. A model could appear clinically useful in one hospital’s data while failing when moved to another institution. That is precisely the dangerous form of shortcut learning: the model has learned the data-generating process, not necessarily the disease process.
Systems lesson: Neural networks exploit the easiest statistical signal available. External validation identifies the site-transfer failure; interpretability work on Clever Hans predictors shows how saliency maps can expose shortcut features (Lapuschkin et al. 2019). Both are quality-assurance gates, not presentation polish.
Lapuschkin, Sebastian, Stephan Wäldchen, Alexander Binder, Grégoire Montavon, Wojciech Samek, and Klaus-Robert Müller. 2019. “Unmasking Clever Hans Predictors and Assessing What Machines Really Learn.” Nature Communications 10 (1): 1–8. https://doi.org/10.1038/s41467-019-08987-4.
Zech, John R., Marcus A. Badgeley, Manway Liu, Anthony B. Costa, Joseph J. Titano, and Eric Karl Oermann. 2018. “Variable Generalization Performance of a Deep Learning Model to Detect Pneumonia in Chest Radiographs: A Cross-Sectional Study.” PLOS Medicine 15 (11): e1002683. https://doi.org/10.1371/journal.pmed.1002683.
The hospital shortcut shows why interpretability is a systems requirement rather than presentation polish: teams need enough visibility to catch shortcuts before deployment. Figure 4 arranges the resulting trade-offs along a single axis. On the left side, decision trees and linear regression offer direct auditability: an engineer can inspect every coefficient or branching rule that produced a prediction, at the cost of limited representational capacity. On the right side, deep neural networks and convolutional architectures achieve higher accuracy on complex tasks but resist human inspection, requiring post-hoc tools like LIME or SHAP to approximate explanations.

The choice depends on the application’s accountability requirements: high-stakes credit decisions subject to adverse action notice laws demand models near the interpretable end, while large-scale recommendation systems that face no per-decision regulatory scrutiny can tolerate opaque architectures. The spectrum does not imply “simple is always better,” because a highly interpretable model that makes wrong predictions serves no one. The engineering challenge is selecting the most interpretable model that meets accuracy requirements for the application.
The explainability requirements outlined earlier carry the force of law, not merely of engineering best practice. The EU AI Act, which entered into force on August 1, 2024 and applies in phases, imposes documentation, transparency, human-oversight, and risk-management obligations for high-risk systems (European Parliament and Council of the European Union 2024). US regulators also require adverse action notices in lending contexts, including when algorithmic tools contribute to credit decisions (Consumer Financial Protection Bureau 2022). Regulations transform explainability from a design choice into a compliance requirement with concrete penalties for failure, making the technical mechanisms just described prerequisites for legal operation.
The regulatory landscape
Regulation changes responsible engineering from a best-practice argument into architecture constraints. Imagine a credit model denies an applicant and the applicant asks why, contests the decision, and later requests access to the data used about her. The system must do more than report an accuracy score. It must produce an explanation tied to the specific decision, preserve the model and data lineage that led to that output, route the dispute to a substantive human review path, retain audit logs, and support deletion or access workflows where data rights apply. Responsible engineering now operates within explicit regulatory frameworks that turn transparency, oversight, and accountability into technical requirements.
Regulation first enters the architecture through risk classification. The EU AI Act establishes a comprehensive framework, classifying AI systems by risk level and mandating requirements accordingly.16 The Act entered into force on August 1, 2024 and applies in phases: prohibited-practice rules began applying in 2025, while high-risk and other operator obligations phase in by system category and implementation guidance. Article 99 sets maximum fines of EUR 35 million or 7 percent of global turnover for prohibited AI practices, while many other operator obligations are capped at EUR 15 million or 3 percent (European Parliament and Council of the European Union 2024).
16 EU AI Act (Regulation 2024/1689): The first comprehensive AI legal framework, defining four risk tiers with penalties that vary by infringement category. Prohibited AI-practice violations can reach EUR 35 million or 7 percent of global turnover; many other obligations, including many high-risk operator obligations, are capped at EUR 15 million or 3 percent. The Act has extraterritorial reach: non-EU organizations may need to comply when they place systems on the EU market or when system outputs are used in the EU. Systems engineering implications are concrete: high-risk AI requires logging infrastructure for audit trails, human oversight mechanisms built into the architecture, and CE marking—all capabilities that must be designed in from inception, not retrofitted after deployment.
European Parliament and Council of the European Union. 2024. Regulation (EU) 2024/1689 of the European Parliament and of the Council of 13 June 2024 Laying down Harmonised Rules on Artificial Intelligence (AI Act). Official Journal of the European Union, L 2024/1689.
17 High-Risk AI (EU AI Act Annex III): Risk classification is not subjective—Annex III enumerates eight specific domains: biometric identification, critical infrastructure, education and vocational training, employment and worker management, essential services access (credit, insurance), law enforcement, migration and border control, and justice administration. A system falls under high-risk requirements based on deployment context, not model architecture: a logistic regression approving loans faces the same compliance burden as a transformer, because the Act regulates what decisions are made, not how they are computed.
For engineers, the important point is not the fine schedule but the capabilities the law demands. High-risk systems17, including those used in employment, credit, education, and critical infrastructure, must implement risk management, data governance, technical documentation, transparency, human oversight, and accuracy, robustness, and security requirements. A credit-decision system therefore needs auditability from inception: model versions, training data provenance, validation evidence, human-oversight design, logging, and postdeployment monitoring must be part of the architecture rather than documents assembled after launch.
Contestability adds a second architectural requirement. GDPR moves the same applicant workflow into data-subject rights. Article 22 grants EU data subjects the right not to be subject to decisions based solely on automated processing that produce legal or similarly significant effects, subject to specified exceptions and safeguards.18 Article 15(1)(h) separately gives data subjects access to meaningful information about the logic involved in automated decision-making referred to in Article 22. While legal interpretation varies, engineering teams should assume that every high-stakes automated decision requires both an explainability capability and a human review mechanism where required. That review path must be operationally staffed and supported by summaries, provenance, and audit tools; otherwise the right exists on paper but cannot be exercised at production scale.
18 GDPR (General Data Protection Regulation) Articles 15 and 22: Article 22 restricts certain solely automated decisions with legal or similarly significant effects and, for specified exceptions, requires safeguards including human intervention, the ability to express a point of view, and the ability to contest the decision. Article 15(1)(h) contains the access right to meaningful information about the logic involved in such automated decision-making (European Parliament and Council of the European Union 2016). The European Data Protection Board’s guidance emphasizes that required human oversight must be substantive and not merely a “rubber-stamping” exercise (European Data Protection Board 2018). A system making 1M daily decisions with a 0.1 percent error rate requiring substantive review would generate 1,000 cases/day, an operational load that is untenable without built-in summarization and audit tools.
European Data Protection Board. 2018. Guidelines on Automated Individual Decision-Making and Profiling for the Purposes of Regulation 2016/679.
Consumer Financial Protection Bureau. 2022. Consumer Financial Protection Circular 2022-03: Adverse Action Notification Requirements in Connection with Credit Decisions Based on Complex Algorithms. Consumer Financial Protection Circular 2022-03.
US sectoral law reaches the same capabilities through domain-specific evidence requirements. These regulations are less unified than the EU AI Act, but they force the same engineering posture through domain-specific duties. In the credit example, the Equal Credit Opportunity Act (ECOA) and its implementing Regulation B require specific reasons for adverse credit decisions even when complex algorithms contribute to the decision (Consumer Financial Protection Bureau 2022). If consumer-report information or credit scores influence the decision, the Fair Credit Reporting Act (FCRA) adds notice obligations; if the same scoring machinery is used for housing, the Fair Housing Act (FHA) adds a discrimination-prohibition constraint. The technical consequence is practical rather than abstract: the system must connect model scores to reason codes, preserve the data sources used in the decision, support review, and monitor subgroup outcomes rather than relying on aggregate accuracy alone.
Healthcare regulations, including the Health Insurance Portability and Accountability Act (HIPAA)19 and FDA guidance, impose the same pattern with different artifacts: protected-health-information controls, validation records, audit logs, and incident response. Employment systems likewise require evidence that automated screening does not reproduce discriminatory hiring practices. Across domains, the task is to translate each obligation into a concrete capability: explanation, human review, lineage, access control, deletion, monitoring, or incident response. The deployment checkpoint that follows is therefore not a US-sectoral checklist; it is the common production contract implied by the regulatory landscape.
19 HIPAA (Health Insurance Portability and Accountability Act): Enacted in 1996, with Privacy Rule and Security Rule requirements establishing standards for protected health information (United States Congress 1996; U.S. Department of Health and Human Services 2003, 2005). ML-specific constraints are stringent: training data containing PHI must be de-identified, model outputs that could re-identify patients may constitute PHI themselves, and security-rule documentation retention must be reflected in audit and evidence design. Civil money penalties are tiered and inflation-adjusted by regulation (U.S. Department of Health and Human Services 2026), making a poorly governed ML pipeline a material compliance risk.
United States Congress. 1996. Health Insurance Portability and Accountability Act of 1996. Public Law 104-191.
U.S. Department of Health and Human Services. 2003. “Summary of the HIPAA Privacy Rule.”
U.S. Department of Health and Human Services. 2026. Annual Civil Monetary Penalties Inflation Adjustment. Federal Register.
Checkpoint 1.3: Ethical deployment
Deployment is the point of no return.
The Safety Net
The Monitoring Plan
The engineering response to these regulatory requirements is proactive architectural design. Teams that build documentation, monitoring, explainability, and human oversight into systems from inception demonstrate compliance efficiently. Teams that must retrofit these capabilities face expensive redesign or deployment constraints. The foundation established here, that responsibility is an engineering requirement rather than a legal afterthought, enables more targeted compliance strategies as regulatory frameworks mature. Yet regulatory readiness still covers only the planned path; even well-designed systems can fail, making incident response preparation essential.
Monitoring and incident response
Zillow reported a $304 million20 Q3 2021 Homes-segment inventory write-down after buying homes at prices above revised estimates of future selling prices (Zillow Group 2021). A systems diagnosis can interpret the failure as a combination of forecasting uncertainty, distribution shift, operational capacity limits, and insufficient circuit breakers. Planning for system failures before they occur is a core responsible engineering practice. Incident response and monitoring require preparation before the system fails. Building on the incident severity classification and response framework from Incident response for ML systems, table 10 adapts that general framework to responsible deployment, where detection must surface fairness violations and demographic-slice degradation alongside ordinary outages. The five components are largely the standard incident-response arc; what makes the table actionable is its second column. The requirements state what each component must do, but the predeployment-verification column states what must be proven before launch: an alert threshold that has been tested, a rollback path that has been exercised, a contact list that is current. A requirement without a verified control is an intention, not a safeguard, so this column is the gate that decides whether the system is ready to deploy.
20 Zillow’s D·A·M Failure: Zillow’s 2021 write-down is a useful systems case because the documented business failure combined forecast uncertainty with operational execution (Zillow Group 2021). A D·A·M diagnosis interprets the data axis as the mismatch between historical home-sale data and pandemic-era price volatility, the algorithm axis as the difficulty of pricing homes with reliable uncertainty estimates, and the machine axis as an automated iBuying pipeline that needed stronger capacity limits and circuit breakers. This is an engineering interpretation of Zillow’s public disclosure, not a claim that Zillow identified one root technical cause.
Zillow Group. 2021. Zillow Group Reports Third-Quarter 2021 Financial Results and Shares Plan to Wind down Zillow Offers Operations. Investor Relations Press Release.
| Component | Requirements | Predeployment Verification |
|---|---|---|
| Detection | Monitoring systems that identify anomalies, degraded performance, and fairness violations | Alert thresholds tested, on-call rotation established, escalation paths documented |
| Assessment | Procedures for evaluating incident scope and severity | Severity classification defined, impact assessment templates prepared |
| Mitigation | Technical capabilities to reduce harm while investigation proceeds | Rollback procedures tested, fallback systems operational, kill switches functional |
| Communication | Protocols for stakeholder notification | Contact lists current, message templates prepared, approval chains defined |
| Remediation | Processes for permanent fixes and system improvements | Root cause analysis procedures, change management integration |
ML systems create unique maintenance challenges and technical debt (Sculley et al. 2015). Models degrade silently, dependencies shift unexpectedly, and feedback loops amplify small problems into large ones. Incident response planning must account for these ML-specific failure modes, and effective response depends on continuous monitoring infrastructure that detects problems in the first place. The monitoring infrastructure from ML Operations provides the foundation for responsible system operation, extending traditional operational metrics to include outcome quality measures.
Responsible monitoring extends along several interconnected dimensions:
- Performance stability tracking: Detects gradual prediction quality degradation that might not trigger immediate alerts. Slow accuracy decay that accumulates over weeks is far more dangerous than a sudden crash because it evades threshold-based alarms.
- Subgroup parity monitoring: Adds a fairness lens to temporal tracking, comparing error rates across demographic groups to detect emerging disparities before they cause significant harm.
- Input distribution monitoring: Catches population shifts and potential adversarial manipulation at the data layer before they surface as outcome failures.
- Outcome monitoring: Validates whether predictions translate to intended real-world results, not merely whether model scores remain stable.
- User feedback systems: Surface complaints and corrections that reveal problems invisible to any automated metric, including harms that only affected users can articulate.
Together, these dimensions connect model-level metrics, data-layer shifts, real-world outcomes, and human reports into one monitoring surface.
Effective monitoring requires both data collection infrastructure and disciplined review processes. Dashboards that no one examines provide no protection, so engineering teams must establish regular review cadences with clear ownership and escalation procedures.
The frameworks established in this section address one dimension of responsible engineering: ensuring systems work fairly and reliably across user populations. Fairness is not the only cost that conventional engineering metrics overlook. Every model training run, every inference request, every monitoring dashboard consumes electricity that translates into carbon emissions and dollar costs. A system can be perfectly fair across demographic groups while consuming orders of magnitude more resources than the task requires, harming not specific user populations but the broader environment and the organizations paying the bills. Responsible engineering must therefore extend beyond who the system serves to encompass what it costs to serve them.
Self-Check: Question
A team needs a statistically valid test set of 10,000 face images for a subgroup that makes up 1 percent of the user base to detect a one-percent performance gap with 95 percent confidence. Using the section’s representation statistics, what total sample collection does random sampling require, and what does this imply for the fairness evaluation workflow?
- About 100,000 total images, because confidence intervals shrink roughly linearly with the combined dataset size regardless of subgroup prevalence.
- About 1,000,000 total images, because subgroup confidence depends on subgroup sample count, so random collection requires a 100\(\times\) multiplier relative to the target and makes intentional stratified collection an engineering prerequisite.
- About 10,000 total images, because the target test-set size is already fixed and subgroup composition is handled automatically by the model’s training procedure.
- Sample-size reasoning applies only to training data; evaluation confidence scales with the number of gradient-update steps, not with the subgroup sample count.
A team argues they will write their model card after launch so it can accurately reflect observed behavior. Explain why the section calls this a guard-rail failure, and describe one specific scope-creep scenario that a predeployment model card would have blocked but a post-launch card would not.
In the loan-approval worked example, Group A (majority) has a true positive rate of 90 percent and Group B (minority) has a true positive rate of 60 percent, while both groups share the same false positive rate of 20 percent. Evaluating each fairness criterion against these numbers, which statement is correct?
- Demographic parity is satisfied because the false positive rates match across groups.
- Equal opportunity is violated by the 30-point true-positive-rate gap, and equalized odds is also violated because equalized odds requires both true-positive-rate and false-positive-rate equality, so matching false positive rates alone is not sufficient.
- Equalized odds is satisfied because one of its two component rates matches across groups.
- Only calibration is implicated, because true-positive-rate disparities affect model accuracy rather than fairness.
Stakeholders ask a hiring team to close a 20-percentage-point true-positive-rate gap between two groups by lowering the decision threshold for the disadvantaged group. Using the Pareto-frontier framing and the price-of-fairness calculation from the section, analyze what the team should present to stakeholders and why threshold adjustment alone is a design choice, not a technical fix.
A European lender plans to deploy a deep neural network that automates credit decisions affecting hundreds of thousands of applicants per year. Given EU AI Act high-risk classification and GDPR Article 22 obligations as described in the section, which architectural consequence follows most directly?
- Because deeper models are more accurate, explainability engineering can be deferred until after legal approval closes.
- Aggregate fairness metrics alone are sufficient because individual applicant explanations are irrelevant in financial decisions.
- The deployment architecture must be designed at inception to support per-applicant explanations, substantive human review of automated decisions, and audit-trail logging, because adverse-action and Article 22 substantive-review obligations are enforced as technical requirements with penalties up to 15M EUR or 3 percent of global turnover for high-risk operator violations.
- EU regulation applies primarily to foundation models, so a loan classifier with fewer than a billion parameters can be deployed without explainability infrastructure.
Environmental and Cost Awareness
In 2019, researchers estimated that development-scale training and architecture search for a large NLP model could emit as much carbon as five cars over their entire lifetimes (Strubell et al. 2019). Later analysis showed that the most quoted architecture-search estimate was highly sensitive to proxy-task, hardware, data-center efficiency, and grid carbon-intensity assumptions (Patterson et al. 2021). The correction sharpened the responsible-engineering point rather than weakening it: training runs consume megawatt-hours of electricity, inference at scale multiplies per-request inefficiencies into measurable environmental impact, and resource-intensive models exclude organizations that lack large compute budgets. The optimization techniques developed in Model Compression, Hardware Acceleration, and Benchmarking therefore serve double duty as instruments of responsible engineering, connecting computational efficiency to environmental sustainability, economic accessibility, and long-term scalability.
Strubell, Emma, Ananya Ganesh, and Andrew McCallum. 2019. “Energy and Policy Considerations for Deep Learning in NLP.” Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 3645–50. https://doi.org/10.18653/v1/p19-1355.
Patterson, David, Joseph Gonzalez, Quoc Le, Chen Liang, Lluis-Miquel Munguia, Daniel Rothchild, David So, Maud Texier, and Jeff Dean. 2021. “Carbon Emissions and Large Neural Network Training.” arXiv Preprint arXiv:2104.10350.
Efficiency as responsibility
Training a single large language model consumes thousands of GPU hours and energy measured in megawatt-hours. Much of this expense, however, is not intrinsic to the learning task but represents accidental complexity: training from scratch when fine-tuning would suffice, using larger models than tasks require, and running hyperparameter searches that explore redundant configurations. Computational cost is largely a function of engineering discipline, not just model physics. Green AI treats that efficiency as a primary metric rather than an afterthought.21
21 Green AI: Schwartz et al. (2020) contrasted “Red AI” (performance at any cost) with “Green AI” (efficiency as primary metric). The compute-growth anchor comes from AI and Compute’s 2012–2018 trend analysis, which reported a 300,000\(\times\) increase in compute used in the largest AI training runs (Amodei and Hernandez 2018). The Green AI proposal—reporting FLOPs alongside accuracy for every published result—reframes efficiency from an engineering preference into a scientific reporting obligation, making the resource cost of marginal accuracy gains visible and comparable across research groups.
Schwartz, Roy, Jesse Dodge, Noah A. Smith, and Oren Etzioni. 2020. “Green AI.” Communications of the ACM 63 (12): 54–63. https://doi.org/10.1145/3381831.
Amodei, Dario, and Danny Hernandez. 2018. “AI and Compute.” OpenAI Blog 6.
Resource efficiency and responsible engineering are directly linked through three interconnected channels:
- Environmental impact: A model that requires 4\(\times\) more compute than necessary generates 4\(\times\) more carbon emissions, so the efficiency techniques from Model Compression that enable edge deployment also reduce the environmental footprint of cloud inference.
- Accessibility: Resource-efficient models can run on less expensive hardware, democratizing access to ML capabilities. A quantized model that runs on a smartphone enables users who cannot afford cloud API costs.
- Sustainability at scale: Systems serving millions of users multiply inefficiencies across every request, so a 10 ms latency reduction per query translates to thousands of GPU-hours saved annually.
These channels make optimization a responsibility requirement rather than a narrow performance exercise.
The optimization techniques directly serve responsibility goals. Quantization (Model Compression) reduces compute by 2–4\(\times\) with minimal accuracy impact. Pruning removes 50–90 percent of parameters. Knowledge distillation typically achieves 5–20\(\times\) compression while retaining 90–95 percent of the original accuracy. Hardware acceleration (Hardware Acceleration) achieves 10–100\(\times\) better energy efficiency than general-purpose processors.
Responsible engineers apply these techniques as design requirements, not afterthoughts. The question shifts from maximizing accuracy alone to maximizing accuracy within efficiency constraints.
Efficiency engineering in practice
Acknowledging that efficiency matters is the easy part; the harder engineering challenge is translating that principle into measurable targets. The goal is selecting the smallest model that meets task requirements, then applying methodical optimization to reduce resource consumption further. Edge deployment scenarios make these constraints concrete because they impose hard physical limits that cannot be negotiated away.
Edge deployment scenarios make efficiency requirements concrete. When a wearable device has a 500 mW power budget and must run inference continuously for 24 hours on a small battery, abstract efficiency discussions become engineering constraints with measurable consequences. table 11 quantifies these constraints across four deployment contexts, from smartphones with 5 W budgets to IoT sensors operating at 100 mW.
| Deployment Context | Power Budget | Latency Requirement | Typical Use Cases |
|---|---|---|---|
| Smartphone | 5 W | 100 ms | Photo enhancement, voice assistants |
| IoT Sensor | 100 mW | 1 second | Anomaly detection, environmental monitoring |
| Embedded Camera | 1 W | 30 FPS (33 ms) | Real-time object detection, surveillance |
| Wearable Device | 500 mW | 500 ms | Health monitoring, activity recognition |
The benchmarks in table 12 provide actionable guidance for efficiency optimization. Techniques that enable deployment on power-constrained platforms (quantization, pruning, and efficient architectures) directly reduce environmental impact per inference regardless of deployment context. Power savings at inference time translate directly to financial savings when aggregated across millions of requests.
| Model | Parameters | Inference Power | Latency | Fits Smartphone? | Fits IoT? |
|---|---|---|---|---|---|
| MobileNetV2 | 3.5M | 1.2 W | 40 ms | Yes | No |
| EfficientNet-B0 | 5.3M | 1.8 W | 65 ms | Yes | No |
| ResNet-50 | 25.6M | 4.5 W | 180 ms | No | No |
| TinyML Model | 200K | 50 mW | 200 ms | No | Yes |
For the wearable budget in table 11, the TinyML model leaves a 10× power margin, while MobileNetV2 exceeds the same power budget by 2.4× before accounting for sustained thermals. Fitting the device envelope is necessary but not sufficient: per-inference power compounds into lifetime serving cost once the model runs continuously at production scale.
Total cost of ownership
A team spends $3,200 training a recommendation model and celebrates the modest cost. Six months later, they discover they are spending $500,000 per year serving it. The surprise exposes a structural asymmetry in total cost of ownership22: power budgets translate directly to financial costs (a model that consumes 2 W instead of 4 W cuts electricity expenses in half), and for successful production systems, inference costs typically exceed training costs by ten to 1,000 times depending on traffic volume. Inference cost dominance dictates where optimization efforts should focus.
22 [offset=-25mm] Total Cost of Ownership (TCO): ML TCO includes labeling, monitoring, retraining, remediation, carbon, audits, and compliance. Repeated inference usually dominates the one-time training bill, so upfront compute is a poor proxy for lifetime cost.

At production scale, recurring inference can dominate lifetime cost.
Consider a concrete example of a recommendation system serving 10M users daily. Training costs appear considerable: data preparation consumes 100 GPU-hours at approximately $4/hour ($400), hyperparameter search across multiple configurations requires 500 GPU-hours ($2,000), and the final training run uses 200 GPU-hours ($800). Total training cost reaches approximately $3,200.
Inference costs dominate. With 10M users each receiving 20 recommendations per day, the system serves 200M inferences daily. Assuming 10 milliseconds per inference on GPU hardware, the system requires approximately 23.1 GPUs running continuously. At $2.50/GPU-hour, annual GPU costs reach $506,944.
Over a three-year operational period, quarterly retraining produces total training costs of approximately $38,400, while inference costs over the same period total $1.5M. The 40:1 ratio between inference and training costs is typical for production systems, directing optimization effort toward inference latency and serving efficiency rather than training speed.
Per-query optimization becomes essential when serving billions of requests. Reducing inference latency by ten milliseconds per query translates to measurable reductions in required hardware across billions of queries despite appearing negligible for individual requests. Hardware selection between CPU, GPU, and Tensor Processing Unit (TPU) deployment changes costs and carbon footprint by factors of ten or more. Model compression through quantization and pruning delivers immediate return on investment for high-volume systems because inference cost reduction compounds across every subsequent query.
Total cost of ownership encompasses additional dimensions beyond computation. Operational costs include monitoring, maintenance, retraining, and incident response, all of which scale with system complexity and the rate of distribution shift in the application domain. Opportunity costs reflect that resources consumed by ML systems cannot be used for other purposes. Wasteful resource consumption in one project constrains what other projects can attempt.
Engineers should evaluate return on investment: whether the value an ML system delivers justifies its resource consumption. A recommendation system that increases engagement by 1 percent might not justify millions of dollars in computational costs, while a medical diagnosis system that saves lives does. Explicit trade-offs enable responsible resource allocation.23
23 ML Return on Investment: The 10:1 deployment-to-training cost ratio emerges from the composition of monitoring (continuous), retraining (periodic), infrastructure (ongoing), and incident response (unpredictable), each of which scales with deployment duration and data volume rather than with the initial development effort. A model deployed for three years accumulates roughly 10–15\(\times\) its development cost in operational overhead. Responsible engineering practices that reduce incident frequency and severity therefore yield ROI proportional to deployment lifetime, explaining why a logistic regression at 1 percent of the cost often represents the correct engineering decision when the TCO difference compounds over years.
TCO calculation methodology
Quantifying environmental impact requires converting compute hours into carbon emissions, making carbon a first-class engineering metric alongside dollar cost. Engineers can estimate three-year total cost of ownership using a structured approach that separates training, inference, and operational costs into ledgers. Training is usually a one-time or periodic expense, inference recurs with every user request, and operations accumulate through monitoring, retraining, and incident response. The ledger methodology applies that structure to the recommendation system example in this section.
Napkin Math 1.3: The carbon cost of compute
Problem: The TCO ledgers must convert “compute hours” into “kg CO2eq”. What carbon factor does one GPU-hour carry under the scenario baseline?
Variables:
- Power: 400 W per GPU (scenario baseline).
- Intensity: 0.4 kg/kWh CO2eq (rounded grid baseline).
Math: Equation 2 captures the standard conversion: \[ \text{Carbon} = \text{Energy (kWh)} \times \text{Carbon Intensity (kg/kWh)} \tag{2}\]
Applying the baseline assumptions: \[\text{% (0.4 kW $\times$ 1 hour) $\times$ 0.4 kg/kWh = 0.16 kg CO~2~eq per GPU-hour. }\]
Systems insight: This conversion factor lets the ledgers track “Carbon Cost” alongside “Dollar Cost”, making emissions a first-class engineering metric across the downstream TCO tables.
Training costs
Training costs include both initial development and ongoing retraining. Table 13 breaks down these costs, showing how quarterly retraining cycles accumulate over a three-year operational period.
| Cost Component | Calculation | Financial Cost | Carbon (kg CO2) |
|---|---|---|---|
| Initial data preparation | hours \(\times\) rate | 100 GPU-hr \(\times\) $4 = $400 | 16 kg |
| Hyperparameter search | experiments \(\times\) cost/experiment | 50 \(\times\) $40 = $2,000 | 80 kg |
| Final training | hours \(\times\) rate | 200 GPU-hr \(\times\) $4 = $800 | 32 kg |
| Subtotal per training cycle | $3,200 | 128 kg | |
| Retraining frequency | cycles/year \(\times\) years | 4/year \(\times\) 3 years = 12 | same multiplier (12 cycles) |
| Total training cost | subtotal \(\times\) cycles | $38,400 | 1,536 kg |
Inference costs
Table 14 walks the conversion chain that turns traffic into cost: daily queries become GPU-seconds, GPU-seconds become GPU-hours, and GPU-hours convert into both dollars and carbon. Carbon attaches only once the workload is expressed in GPU-hours, so the query and GPU-second rows leave the carbon column blank by design rather than omitting data. Following the chain to the bottom row shows why inference, not training, dominates total cost of ownership for production systems.
| Cost Component | Calculation | Financial Cost | Carbon (kg CO2) |
|---|---|---|---|
| Daily queries | users \(\times\) queries/user | 10M \(\times\) 20 = 200M | - |
| GPU-seconds/day | queries \(\times\) latency | 200M \(\times\) 0.01 s = 2M sec | - |
| GPU-hours/day | seconds ÷ SEC_PER_HOUR | 556 GPU-hr | 88.9 kg |
| Annual GPU cost | hours \(\times\) 365 \(\times\) rate | 556 \(\times\) 365 \(\times\) $2.50 = $507K | 32,444.4 kg |
| 3-year inference cost | annual \(\times\) 3 | $1.52M | 97,333.3 kg |
Operational costs
Operational costs encompass infrastructure, personnel, and incident response. ML systems generate operational burdens that traditional software does not: “incident response” frequently means debugging silent failures (data drift, feature corruption, or distribution shifts) rather than binary service outages, and “monitoring infrastructure” must continuously track statistical anomalies in model predictions across demographic slices, not merely service availability. Table 15 itemizes these ongoing expenses, which often surprise teams focused primarily on compute costs.
| Cost Component | Annual Estimate | 3-Year Total |
|---|---|---|
| Monitoring infrastructure | $50K | $150K |
| On-call engineering (0.5 FTE) | $100K | $300K |
| Incident response (estimated) | $20K | $60K |
| Total operational | $510K |
The stark breakdown in table 16 answers where the money goes: inference at 73.5 percent, operations at 24.6 percent, and training at only 1.9 percent.
| Category | 3-Year Cost | Percentage | Carbon Impact |
|---|---|---|---|
| Training | $38K | 1.9% | 1.5 t |
| Inference | $1.52M | 73.5% | 97.3 t |
| Operations | $510K | 24.6% | - |
| Total TCO | $2.07M | 100% | ~98.9 t |
Those proportions turn efficiency from a tuning preference into a responsibility check.
Checkpoint 1.4: Efficiency as responsibility
Total cost of ownership reveals where responsible optimization has the most leverage.
Environmental impact
The preceding TCO analysis captures costs that appear on invoices, but computational resources carry costs that no invoice reflects. Environmental impact follows from computational efficiency: the same optimization techniques that reduce TCO also reduce carbon emissions. The optimization techniques from Hardware Acceleration and Model Compression reduce energy consumption per inference, directly lowering carbon footprint. Data-center electricity use makes cloud-region selection, workload timing, and model efficiency part of responsible engineering: the same ML workload can have different carbon footprints depending on power draw, runtime, and grid carbon intensity (Henderson et al. 2020). Engineers can reduce this impact by selecting lower-carbon cloud regions, applying model efficiency techniques such as quantization, and scheduling intensive workloads during periods of abundant renewable energy. The magnitude becomes clearer in a scale calculation for training a large foundation model.
Henderson, Peter, Jieru Hu, Joshua Romoff, Emma Brunskill, Dan Jurafsky, and Joelle Pineau. 2020. “Towards the Systematic Reporting of the Energy and Carbon Footprints of Machine Learning.” CoRR abs/2002.05651 (248): 1–43. https://doi.org/10.48550/arxiv.2002.05651.

Training one model can rival a car’s annual carbon.
Napkin Math 1.4: The carbon cost of scale
Problem: A foundation model is being trained at the scale of GPT-3, consuming 1,287 MWh (Megawatt-hours) of electricity. What is the environmental impact?
Math:
- Energy consumption: 1,287 MWh = 1,287,000 kWh.
- Carbon intensity: The average US grid emits \(\approx\) 429 g/kWh CO2 (0.429 kg/kWh).
- Total emissions: 1,287,000 kWh \(\times\) 0.429 kg/kWh = 552,123 kg CO2 (552 t).
- Comparison: A typical passenger car emits ≈ 4.6 t CO2 per year.
Systems insight: Under the training-energy scenario above, the carbon footprint is equivalent to the annual emissions of 120 cars. At this scale, efficiency transforms from a technical preference into a responsibility constraint. Every 1 percent improvement in the efficiency \((\eta_{\text{hw}})\) of the training pipeline removes the equivalent of about 1.2 cars’ annual emissions from the calculation.
The key insight is that efficiency optimization and environmental responsibility align: the techniques that reduce inference costs also reduce carbon emissions per prediction. More granular carbon accounting methodologies build on this foundation for organizations requiring detailed environmental impact analysis: lifecycle assessment tracks impacts across the system’s full life, scope 1/2/3 emissions separate direct emissions, purchased electricity, and supply-chain or use-phase emissions, and carbon-aware scheduling shifts work toward lower-carbon times or regions.
The same physical invariants that govern performance also govern responsibility. The energy-movement invariant determines both chip-level computational efficiency and data-center-level carbon footprints. The physics is identical; only the unit of cost changes from joules per inference to metric tons of CO2 per year. The Pareto frontier governs data-algorithm accuracy-fairness trade-offs with the same mathematical force as algorithm-machine accuracy-latency trade-offs: improving one metric without sacrificing another requires moving to a strictly superior architecture, not reweighting an objective. Responsible engineering is the same constrained optimization problem this book has been teaching, evaluated over a wider set of objectives that include societal impact alongside throughput and latency.
The checklists, fairness metrics, explainability mechanisms, and efficiency analyses developed in previous sections tell engineering teams what to measure and how to act. A natural follow-up concern is what infrastructure ensures that answers are recorded, costs are audited, and violations trigger automated intervention rather than relying on human vigilance. The answer lies in data governance—the engineering discipline that transforms policy intentions into enforceable technical controls.
Self-Check: Question
A team can deploy either a full-precision model or a quantized version that preserves task accuracy while cutting inference compute by roughly 4\(\times\). According to the section, why does this efficiency choice count as a responsibility decision rather than purely a performance decision?
- Quantization is primarily a responsibility tool because it automatically reduces fairness disparities by making all user groups equally cheap to serve.
- Quantization reduces compute per inference, which simultaneously shrinks carbon emissions in proportion, lowers serving dollar cost, and lowers hardware barriers so smaller organizations and edge devices can deploy the model.
- Quantization is a pure performance optimization that should be evaluated separately from responsibility, because fairness, carbon, and cost belong to distinct engineering layers with different owners.
- Quantization matters mainly for training-time energy: production inference is usually a minor fraction of lifecycle resource use, so the responsibility payoff is small.
A wearable device has a 500 mW sustained power budget and a 500 ms end-to-end inference latency requirement. Using the section’s deployment-comparison data (TinyML at roughly 50 mW / 200 ms, MobileNetV2 at roughly 1.2 W / 40 ms, EfficientNet-B0 at roughly 1.8 W, ResNet-50 much larger), which model selection is the correct responsible-engineering choice, and why?
- ResNet-50, because larger models achieve better energy efficiency per accuracy point once their throughput is amortized through batching.
- MobileNetV2, because 1.2 W is close enough to the 500 mW target that the gap is operationally negligible on modern battery-management hardware.
- TinyML model, because its 50 mW power draw fits 10\(\times\) under the budget and its 200 ms latency fits under the 500 ms requirement, so it is the only option that satisfies both constraints simultaneously.
- EfficientNet-B0, because its smartphone-grade footprint guarantees it also fits wearable constraints once the form factor is reduced.
Using the section’s three-year TCO breakdown (training ~2 percent, inference ~73 percent, operations ~25 percent for a recommendation system serving 200M daily queries), a team proposes two optimization options: Proposal 1 is a 50 percent reduction in training wall-clock time, and Proposal 2 is a 20 percent reduction in per-query inference latency via quantization. Explain which proposal has higher leverage on both dollar cost and carbon, and give the rough dollar-savings ratio between them.
True or False: For an identical model and serving workload, migrating deployment from a carbon-intensive cloud region to one powered by abundant renewable energy can reduce inference emissions more than a one-time modest algorithmic efficiency improvement.
Training GPT-3 consumed roughly 1,287 MWh of electricity. At a US-grid average carbon intensity of roughly 0.429 kg CO2 per kWh, what does the section identify as the dominant responsible-engineering lever for reducing the footprint of future foundation-model training runs?
- Reducing model size to under one billion parameters, accepting the corresponding accuracy loss, because parameter count is the only significant driver of training energy.
- Improving accelerator utilization \(\eta_{\text{hw}}\) during training so that the same 1,287 MWh produces more useful FLOPs, combined with carbon-aware scheduling that runs intensive jobs when renewable supply is abundant and selecting regions with lower grid-carbon intensity.
- Deferring all training until grid carbon intensity reaches zero, since any non-zero intensity produces emissions that cannot be justified ethically.
- Switching the entire training pipeline from FP32 to FP16 without other changes, because numerical precision alone accounts for the bulk of training energy use.
Data Governance and Compliance
Recommendation and targeting models are the primary consumers of user data at scale, which means a governance failure in the data pipeline is simultaneously a failure in the ML system’s data ingestion and validation infrastructure. Governance is the enforcement layer that makes accountability possible: fairness metrics, model cards, and impact assessments only matter at scale if the system can prove what data it used, who accessed it, which legal basis allowed processing, and whether deletion or contestability rights were honored.
The Meta fines make the governance question concrete: a system must prove why it is allowed to process data as well as show that data remained secure. In January 2023, the Irish Data Protection Commission issued separate EUR 210M and EUR 180M fines (totaling EUR 390M) against Meta Ireland for relying on contractual necessity as the legal basis for personalized advertising on Facebook and Instagram—penalties that stemmed not from a data breach but from insufficient governance infrastructure to demonstrate lawful processing (Data Protection Commission 2023).
Data Protection Commission. 2023. Data Protection Commission Announces Conclusion of Two Inquiries into Meta Ireland. Regulatory press release.
The storage architectures examined in Data Engineering are governance enforcement mechanisms that determine who accesses data, how usage is tracked, and whether systems comply with regulatory requirements. Every architectural decision, from acquisition strategies through processing pipelines to storage design, carries governance implications that manifest when systems face regulatory audits, privacy violations, or ethical challenges. Data governance transforms from abstract policy into concrete engineering: access control systems that enforce who can read training data, audit infrastructure that tracks every data access for compliance, privacy-preserving techniques that protect individuals while enabling model training, and lineage systems that document how raw audio recordings become production models.
Data governance encompasses four interconnected domains that make security, privacy, compliance, and lineage mutually dependent enforcement constraints:
- Security infrastructure: Protects data assets through access control and encryption, establishing the perimeter within which all other governance operates.
- Privacy mechanisms: Determine what information is exposed even to authorized users, respecting individual rights while enabling model training.
- Compliance frameworks: Translate jurisdiction-specific regulatory requirements into architectural constraints that shape how data flows through the system.
- Lineage and audit systems: Create the accountability trails that make the first three domains verifiable. Without them, security policies, privacy guarantees, and compliance claims are unenforceable assertions rather than demonstrable properties.
Principle 1: Compliance as Engineering Constraint
Invariant: Data governance obligations are engineering requirements, not optional policy overlays.
Implication: Systems that process regulated data must implement access control, erasure, contestability, audit, and lineage mechanisms from the outset. The EU General Data Protection Regulation (GDPR), the California Consumer Privacy Act (CCPA), Brazil’s General Data Protection Law (LGPD), and China’s Personal Information Protection Law (PIPL) differ by jurisdiction, but they all turn compliance into concrete requirements for data pipelines, storage architectures, and model training workflows.
The Lighthouse KWS system, the keyword-spotting voice assistant introduced in ML Systems as the Tiny Constraint lighthouse, illustrates how the fairness risks identified in table 5 intensify at the governance level. Always-listening devices continuously process audio in users’ homes, feature stores maintain voice pattern histories across millions of users, and edge storage caches models derived from population-wide training data. These capabilities create governance obligations around consent management, data minimization, access auditing, and deletion rights.
For the KWS system, the four domains become concrete enforcement questions. Security determines who may reach data through encryption at rest and in transit, role-based access controls, and audit logging of every query against the feature store. Privacy determines what the system may retain beyond its immediate training purpose through differential privacy and data minimization. Compliance determines which regulatory duties constrain data flow, translating GDPR and CCPA requirements into erasure pipelines and consent management APIs. Lineage and audit determine how the system proves what happened through documentation of data provenance, model lineage, and decision audit trails. Figure 5 shows the broader operating model that supports these domains: organization, policies, data catalogs, data sourcing, data quality, data operations, data security, and shared definitions. The domains and this broader operating model must work together because a failure in any one undermines the others: encrypted data with no access controls is still vulnerable, and compliant storage without verifiable audit trails cannot survive a regulatory audit. In the context of the D·A·M taxonomy, governance provides the structural integrity for the data axis, ensuring that the fuel for our systems remains safe, compliant, and reliable across the entire data lifecycle.

Security and access control architecture
Consider a data scientist querying a feature store for training data. She can read aggregated voice features but cannot access the raw audio recordings from which they were derived. The serving pipeline can read online features for inference but cannot write to the training dataset. Neither can modify source data. The separation is intentional: it reflects a layered security architecture where governance requirements translate into enforceable technical controls at each pipeline stage. Feature stores can implement role-based access control (RBAC) that maps organizational policies into database permissions, preventing unauthorized access. These controls operate across storage tiers: object storage like S3 enforces bucket policies, data warehouses implement column-level security that hides sensitive fields, and feature stores maintain separate read/write paths with different permission requirements.
Access control mechanisms remain incomplete without encryption, which protects data throughout its lifecycle even when access controls are bypassed or misconfigured. Training data stored in data lakes uses server-side encryption with keys managed through dedicated key management services (AWS KMS, Google Cloud KMS) that enforce separation. Feature stores implement encryption both at rest (storage encrypted using platform-managed keys) and in transit (TLS 1.3 for all communication). For Lighthouse KWS edge devices, model updates require end-to-end encryption and code signing that verifies model integrity, preventing adversarial model injection that could compromise device security or user privacy.
Model artifacts (serialized weights, ONNX exports, and checkpoint files) require the same protection as training data. Weights represent substantial intellectual property and are a vulnerability surface: an attacker who injects a backdoored model into a registry can corrupt every downstream deployment, an attacker who retrieves weights can probe whether particular records were in training (Shokri et al. 2017), and model-extraction attacks can steal model behavior through prediction APIs (Tramèr et al. 2016). Model registries therefore require version-pinned access controls, cryptographic signatures that verify artifact integrity before serving, and write-protected promotion gates so that only pipeline-validated checkpoints can overwrite production slots. Training pipelines themselves must be protected from data poisoning attacks, where adversarially crafted samples inserted into the training corpus cause the learned model to exhibit targeted misbehavior at inference time.
Tramèr, Florian, Fan Zhang, Ari Juels, Michael K Reiter, and Thomas Ristenpart. 2016. “Stealing Machine Learning Models via Prediction APIs.” 25th USENIX Security Symposium (USENIX Security 16), 601–18.
Access control and encryption establish who can reach data and how it is protected in transit and at rest. Controlling access is only half the problem: even authorized users can compromise individual privacy if the data itself is insufficiently protected.
Technical privacy protection methods
A data scientist with legitimate access to training data does not need, and should not see, individual user records when aggregate statistics suffice. Privacy-preserving techniques24 address this gap by determining what information systems expose even to authorized users, adding a second layer of protection beyond access control. Differential privacy provides formal mathematical guarantees that individual training examples do not leak through model behavior. Implementing differential privacy in production requires careful engineering: adding calibrated noise during model development, tracking privacy budgets across all data uses, and validating that deployed models satisfy privacy guarantees through testing infrastructure that attempts to extract training data through membership inference attacks.25
24 Privacy-Preserving Techniques: Before differential privacy, the field relied on syntactic guarantees: k-anonymity (Sweeney 2002) ensures each record is indistinguishable from \(k-1\) others, l-diversity adds attribute variety within equivalence classes (Machanavajjhala et al. 2007), and t-closeness bounds distribution distance (Li et al. 2007). These syntactic methods do not by themselves protect against all ML-specific leakage: a model trained on de-identified data can still memorize examples or reveal membership signal under some conditions (Shokri et al. 2017). Differential privacy’s semantic guarantee (\(\epsilon\)-bounded influence per record) is stronger against arbitrary side information, explaining why it displaced syntactic methods for many ML training settings despite its utility cost.
Sweeney, Latanya. 2002. “K-ANONYMITY: A MODEL for PROTECTING PRIVACY.” International Journal of Uncertainty, Fuzziness and Knowledge-Based Systems 10 (05): 557–70. https://doi.org/10.1142/s0218488502001648.
Li, Ninghui, Tiancheng Li, and Suresh Venkatasubramanian. 2007. “t-Closeness: Privacy Beyond k-Anonymity and l-Diversity.” 2007 IEEE 23rd International Conference on Data Engineering, 106–15. https://doi.org/10.1109/ICDE.2007.367856.
25 Membership Inference Attack: The attack exploits a model’s higher prediction confidence on examples from its training set, a direct signal of overfitting (Shokri et al. 2017). Membership inference provides a validation method for the privacy engineering described: if an attacker can determine that a specific record was used for training, the privacy guarantee is violated, even if the record’s content is not exposed. The attack’s measured success depends on overfitting, model access, data distribution, and defense assumptions.
Shokri, Reza, Marco Stronati, Congzheng Song, and Vitaly Shmatikov. 2017. “Membership Inference Attacks Against Machine Learning Models.” 2017 IEEE Symposium on Security and Privacy (SP), 3–18. https://doi.org/10.1109/SP.2017.41.
KWS systems face particularly acute privacy challenges because the always-listening architecture requires processing audio continuously while minimizing data retention and exposure. Production systems implement privacy through three architectural choices:
- On-device processing: Ensures that wake word detection runs entirely locally, with audio never transmitted unless the wake word is detected.
- Federated learning: Allows devices to train on local audio and improve wake word detection while sharing only aggregated model updates, never raw recordings.26
- Automatic deletion policies: Ensure that detected wake word audio is retained only briefly for quality monitoring before being permanently removed from storage. Data lakes can implement lifecycle policies that delete voice samples after a stated retention period unless explicitly tagged for approved longer-term use, and feature stores can implement time-to-live (TTL) fields that cause user voice patterns to expire and be purged from online serving stores.
26 Federated Learning: From Latin foedus (treaty, covenant)—the name describes independent entities collaborating while retaining autonomy. McMahan et al. (2017) introduced Federated Averaging (FedAvg): each device trains locally and shares only gradient updates, never raw data. The etymology explains the design: federated learning provides “data minimization by architecture.” However, gradient updates can leak training data through reconstruction attacks (Zhu et al. 2019), motivating the combination of federated learning with differential privacy—a defense-in-depth pattern where neither mechanism alone suffices.
McMahan, Brendan, Eider Moore, Daniel Ramage, Seth Hampson, and Blaise Agüera y Arcas. 2017. “Communication-Efficient Learning of Deep Networks from Decentralized Data.” International Conference on Artificial Intelligence and Statistics (AISTATS), Proceedings of machine learning research, vol. 54: 1273–82.
Zhu, Ligeng, Zhijian Liu, and Song Han. 2019. “Deep Leakage from Gradients.” Advances in Neural Information Processing Systems 32: 17–31. https://doi.org/10.1007/978-3-030-63076-8_2.
Together, these choices minimize what leaves the device, what the server can reconstruct, and how long sensitive traces persist.
Architecting for regulatory compliance
When a European user invokes the “right to erasure” under GDPR, the voice assistant must determine which recordings, derived features, and downstream artifacts are in scope and execute deletion workflows within the regulation’s response deadlines (European Parliament and Council of the European Union 2016). The requirement is not a policy aspiration; it is an engineering specification with a deadline. Compliance requirements transform from legal obligations into system architecture constraints that shape pipeline design, storage choices, and operational procedures. GDPR’s data minimization principle requires limiting collection and retention to what is necessary for stated purposes. For KWS systems, data minimization requires justifying why voice samples need retention beyond training, documenting retention periods in system design documents, and implementing automated deletion once periods expire. The “right to access” requires systems to retrieve all data associated with a user, consolidating results from distributed storage systems.
Pushkarna, Mahima, Andrew Zaldivar, and Oddur Kjartansson. 2022. “Data Cards: Purposeful and Transparent Dataset Documentation for Responsible AI.” Proceedings of the 2022 ACM Conference on Fairness, Accountability, and Transparency (FAccT), 1776–826. https://doi.org/10.1145/3531146.3533231.
Voice assistants operating globally face overlapping regulatory regimes because compliance requirements vary by jurisdiction and apply differently based on user age and data sensitivity. European requirements for cross-border data transfer restrict storing EU users’ voice data on servers outside designated countries unless specific safeguards exist, driving architectural decisions about regional data lakes, feature store replication strategies, and processing localization. Standardized documentation frameworks like data cards (Pushkarna et al. 2022) translate these compliance requirements into operational artifacts. Examine the data card template in figure 6 to see how this structured format turns abstract compliance obligations into concrete, machine-checkable fields. Training pipelines check that input datasets have valid data cards before processing, and serving systems enforce that only models trained on compliant data can deploy to production.

Building data lineage infrastructure
Data-card fields become operational checks once they enter the pipeline: provenance, intended use, risk, and retention metadata determine which datasets can train which models and which artifacts must be traced during an audit. Compliance obligations are only as credible as the infrastructure that demonstrates them. When a regulator asks “which training data produced this model?” or a user invokes their right to erasure, the organization must answer with engineering precision, not manual investigation. Data lineage provides this capability, transforming compliance documentation into operational infrastructure that powers governance across the ML lifecycle. Modern lineage systems like Apache Atlas and DataHub27 integrate with pipeline orchestrators (Airflow, Kubeflow) to automatically capture relationships: when an Airflow directed acyclic graph (DAG) reads audio files from S3 and transforms them into spectrograms, the lineage system records each step, creating a graph that traces any feature back to its source audio file. Automated tracking proves essential for deletion requests. When a user invokes GDPR rights, the lineage graph identifies all derived artifacts (extracted features, computed embeddings, trained model versions) that must be removed or retrained.
27 Data Lineage Systems: Apache Atlas and LinkedIn’s DataHub capture metadata about data flows automatically from pipeline execution logs, creating directed graphs where nodes are datasets and edges are transformations. GDPR Article 30 requires detailed records of processing activities (European Parliament and Council of the European Union 2016), making automated lineage tracking essential: when a user invokes the right to erasure, the lineage graph identifies candidate derived artifacts—features, embeddings, and trained model versions—that require deletion, retraining, or legal review, a task that is infeasible manually at production scale.
European Parliament, and Council of the European Union. 2016. Regulation (EU) 2016/679 of the European Parliament and of the Council of 27 April 2016. Official Journal of the European Union.
Production KWS systems implement lineage tracking across all stages of the data engineering lifecycle. Source audio ingestion creates lineage records linking each audio file to its acquisition method, enabling verification of consent requirements. Processing pipeline execution extends lineage graphs as audio becomes features and embeddings, and each transformation adds nodes that record code versions and hyperparameters. Training jobs create lineage edges from feature collections to model artifacts, recording which data versions trained which model versions. When a voice assistant device downloads a model update, lineage tracking records the deployment, enabling recall if training data is later discovered to have quality or compliance issues. Lineage captures provenance, but accountable operation also requires access history: who touched the data, when, and under which authority.
Audit infrastructure and accountability

Audit logs grow without bound as decisions are retained.
28 Audit Trail: The append-only requirement (audit entries can be added but never modified or deleted) forces write-once storage architectures, typically implemented as append-only columnar stores (Apache Iceberg, Delta Lake) or cryptographic hash chains. A large platform may log billions of events daily; HIPAA’s Security Rule also imposes multi-year documentation-retention obligations for required policies and procedures (U.S. Department of Health and Human Services 2005). Storage cost therefore grows with deployment lifetime and retained decision volume, making audit-retention planning a first-class concern at deployment time, not an afterthought.
U.S. Department of Health and Human Services. 2005. “Summary of the HIPAA Security Rule.”
Lineage tracks what data exists and how it transforms through the pipeline. Governance also requires knowing who accessed data and when: the accountability dimension that lineage alone cannot provide. Audit systems record these access events, creating accountability trails required by regulations like HIPAA and SOX28. Production ML systems generate enormous audit volumes, necessitating specialized infrastructure: immutable append-only storage that prevents tampering with historical records, efficient indexing that enables querying specific user or dataset accesses, and automated analysis that detects anomalous patterns indicating potential security breaches or policy violations.
KWS systems implement multi-tier audit architectures that balance granularity against performance and cost:
- Edge devices: Log critical events locally, with logs periodically uploaded to centralized storage for compliance retention.
- Feature stores: Log every query with request metadata: which service requested features, which user IDs were accessed, and what features were retrieved.
- Training infrastructure: Logs dataset access, recording which jobs read which data partitions and implementing the accountability needed to demonstrate that deleted user data no longer appears in new model versions.
The tiers split audit work according to where evidence is generated, while preserving enough context to reconstruct access and deletion claims.
Regulatory requirements extend audit responsibility to prediction-time behavior. Answering “why was this specific applicant denied a loan?” requires logs that capture not only who queried the model but the exact feature vector presented at inference time and the resulting prediction score or decision. Without inference-time logging, audit trails answer data-access questions but cannot reconstruct the causal chain from input features to a specific decision, which is exactly the chain that adverse-action notice laws and GDPR Article 22 contestability rights demand. Production audit infrastructure must therefore capture the full prediction context: input feature values, model version, decision threshold, and output, stored immutably and indexed by the entity identifier so that per-decision reconstruction is a query, not a manual investigation.
Together, the four governance domains—security, privacy, compliance, and audit—form the enforcement layer that makes every other practice in this chapter durable. Data governance ensures that measurements are captured, actions are recorded, and commitments are verifiable under regulatory scrutiny. Without this infrastructure, responsible engineering remains aspirational; with it, responsibility becomes a demonstrable system property.
Self-Check: Question
In 2023 Meta received a 390M EUR fine not for a data breach but for insufficient governance infrastructure to demonstrate lawful processing. Which diagnosis best captures why the section frames data governance as an enforcement mechanism rather than a policy document?
- Governance replaces the need for model monitoring once regulators sign off on the data pipeline, because certification transfers ongoing responsibility to the certifier.
- Governance is primarily about publishing external-facing datasheets and model cards so that readers outside the organization can assess the system.
- Policy claims become demonstrable only when access controls, privacy mechanisms, lineage tracking, and audit logs make each requirement technically enforceable across the data lifecycle — otherwise compliance is an assertion rather than evidence.
- Governance applies only to raw storage, since derived features, model artifacts, and deployment workflows are downstream and fall outside the data lifecycle.
A European user of a voice-assistant service invokes GDPR Article 17 right-to-erasure. Explain why a manual search across storage systems is both unreliable and too slow to satisfy the request, and describe what automated infrastructure the compliance architecture must instead provide.
The Lighthouse KWS system is an always-listening keyword-spotting voice assistant deployed in users’ homes. Which architectural combination best reflects the section’s privacy-by-design approach for this deployment, and why?
- Stream all ambient audio to a cloud service that applies strong centralized privacy controls after collection, since centralized processing allows more sophisticated mechanisms than any edge device can run.
- Run wake-word detection on-device, transmit only aggregated or federated updates rather than raw recordings, and enforce automatic retention and deletion policies on any audio that must be retained, so the system minimizes the personal data exposed in the first place.
- Retain raw audio indefinitely on secure cloud storage, because the future retraining value of long-horizon voice data outweighs privacy concerns when access is properly encrypted.
- Rely on role-based access control as the sole privacy mechanism, since privacy concerns reduce to limiting who can query the data and RBAC solves exactly that problem.
A teammate argues that security, privacy, and audit are essentially the same concern because each restricts data access. Using the section’s governance stack, distinguish the operational role of each and give one concrete failure mode that would not be caught if the other two were fully implemented but that mechanism were missing.
True or False: Because GDPR Article 17 (right-to-erasure) penalties are capped at modest administrative amounts, an ML team can reasonably defer building automated lineage infrastructure until the first deletion request arrives.
Fallacies and Pitfalls
Teams can still fail after assembling assessment frameworks, fairness metrics, explainability mechanisms, efficiency analyses, and governance infrastructure. A team may retrofit fairness after benchmark success, trust aggregate accuracy, or treat compliance evidence as paperwork rather than system behavior, drawing on intuitions from traditional software engineering where bugs are local and testing is deterministic. Recognizing these failure patterns early, before a fallacy shapes a design decision, is far cheaper than discovering it after deployment.
Fallacy: Responsibility can be addressed after the system achieves technical objectives.
Teams assume fairness constraints can be retrofitted once models demonstrate strong benchmark performance. In production, early architectural decisions constrain what interventions remain feasible. Amazon’s recruiting tool (see section 1.2.1) illustrates this trap: remediation failed because the model had learned proxy signals, leading to project cancellation after considerable investment. Organizations deferring responsibility face expensive redesign, deployment with documented risks, or cancellation. Integrating fairness constraints at system inception is usually cheaper than retrofitting them after data contracts, monitoring, and release gates are already fixed.
Pitfall: Relying on aggregate metrics to assess fairness.
Engineers assume high overall accuracy indicates the system works well for all users. The Flaw of Averages (section 1.3.3) reveals this intuition fails: aggregate metrics conceal disparities exceeding 40\(\times\) between demographic groups (section 1.2.4). The loan approval analysis in section 1.3.3.1 showed a 30 percentage-point TPR gap, meaning qualified minority applicants faced 4× higher rejection rates. These disparities persist for months undetected because standard monitoring tracks only aggregates. Production systems require disaggregated evaluation with alerts when subgroup disparity exceeds 1.25\(\times\) error rate ratio or 5 percentage point TPR difference.
Fallacy: Removing sensitive attributes from training data eliminates bias.
Teams remove gender, race, and protected attributes expecting this ensures fairness. Models reconstruct protected attributes through proxy variables that correlate with sensitive characteristics. ZIP codes, purchase patterns, browsing history, college names, and language choices can all carry indirect demographic signal. Amazon’s system (see section 1.2.1) learned gender from college names and activity descriptions despite explicit removal. Healthcare algorithms excluded race but encoded unequal access through cost history; a population-health study found that correcting the bias would increase the share of Black patients receiving additional help from 17.7 percent to 46.5 percent (Obermeyer et al. 2019). Feature removal without causal analysis creates false confidence while bias persists.
Obermeyer, Ziad, Brian Powers, Christine Vogeli, and Sendhil Mullainathan. 2019. “Dissecting Racial Bias in an Algorithm Used to Manage the Health of Populations.” Science 366 (6464): 447–53. https://doi.org/10.1126/science.aax2342.
Pitfall: Treating documentation as sufficient accountability.
Teams invest effort in model cards, then consider responsibility requirements satisfied. Documentation provides transparency (section 1.3.2) but not enforcement. A model card specifying “not validated for high-stakes decisions” has no effect when the system is repurposed for loan approvals without technical restrictions. Accountability requires operational integration: monitoring dashboards, documented subgroup-disparity alert thresholds, incident response procedures, and access controls preventing deployment beyond validated use cases.
Fallacy: Responsible AI is primarily a legal compliance issue.
Teams treat responsibility as external oversight rather than engineering practice. Engineering decisions made months before legal review constrain the solution space more than any compliance assessment. Architecture selection determines what fairness interventions are feasible, while data pipeline design establishes whether disaggregated evaluation is even possible. As section 1.2.5 establishes, systems designed with responsibility as an engineering objective enable efficient validation; systems where responsibility is added at late-stage review face redesign or deployment with documented risks.
Pitfall: Measuring the environmental impact of training but not inference.
Public discourse focuses on the carbon cost of training runs, and engineers naturally follow this framing when assessing environmental responsibility. The TCO analysis in section 1.4.3 reveals why this focus is misplaced: inference-to-training cost ratios can exceed 40:1 over a model’s operational lifetime. A model trained once but served millions of times daily has its environmental footprint dominated by inference, not training. For the recommendation system analyzed in table 16, training accounts for just 1.9 percent of three-year costs while inference accounts for 73.5 percent. The carbon ratio is even more lopsided in this example, with inference emitting about 63 times as much CO2 as training. Engineers who optimize training efficiency while ignoring per-query inference costs address the smaller term in a lopsided equation, leaving the dominant source of environmental impact unexamined.
Fallacy: Model weights are exempt from data governance and deletion requests.
Teams often assume that once training data has been compiled into model weights, the data is gone and compliance obligations no longer apply. This assumption is wrong on technical grounds and risky on legal grounds. Models can memorize training data: membership inference attacks (section 1.5.2) demonstrate that an attacker may determine whether a specific record appeared in the training set (Shokri et al. 2017), meaning model artifacts can carry privacy-relevant signal. When a user invokes the right to erasure under GDPR, a system that deletes the source records but leaves affected model artifacts unanalyzed may still have an unresolved governance obligation. The engineering response is to track which user data contributed to which model versions and to evaluate retraining, targeted machine unlearning, or compensating controls when deletion requests propagate through the artifact graph (Cao and Yang 2015; Bourtoule et al. 2021). Teams that treat model artifacts as outside the data governance perimeter create a compliance gap that grows with every deployment and cannot be closed after the fact.
Cao, Yinzhi, and Junfeng Yang. 2015. “Towards Making Systems Forget with Machine Unlearning.” 2015 IEEE Symposium on Security and Privacy, 463–80. https://doi.org/10.1109/sp.2015.35.
Bourtoule, Lucas, Varun Chandrasekaran, Christopher A. Choquette-Choo, Hengrui Jia, Adelin Travers, Baiwu Zhang, David Lie, and Nicolas Papernot. 2021. “Machine Unlearning.” 2021 IEEE Symposium on Security and Privacy (SP), 141–59. https://doi.org/10.1109/sp40001.2021.00019.
Self-Check: Question
A deployed loan-approval model reports 85 percent aggregate accuracy, but disaggregated evaluation shows qualified applicants from one demographic group have a true-positive rate 30 percentage points lower than another group. Which pitfall from the section does this outcome most directly illustrate?
- The mistaken belief that fairness can be assessed from aggregate metrics alone, because strong overall accuracy masks the subgroup disparity that only disaggregated evaluation surfaces.
- The mistaken belief that documentation automatically enforces deployment constraints, so a written model card prevents misuse even when no technical control blocks it.
- The mistaken belief that removing sensitive attributes from training data always eliminates bias, so explicit-attribute exclusion guarantees proxy-free predictions.
- The mistaken belief that training costs dominate lifecycle cost, which leads teams to over-optimize training at the expense of inference.
A team proposes removing race and gender features from their model, then deploying without further fairness evaluation because “the model cannot discriminate on attributes it does not see.” Drawing on the Amazon recruiting and Optum healthcare-cost cases from the chapter, explain why this reasoning creates false confidence rather than eliminating bias, and identify the specific engineering work still required.
True or False: Because a well-written model card explicitly states intended use and excluded use cases, teams that publish comprehensive model cards can treat deployment-scope compliance as handled without additional technical controls.
True or False: For most successful production ML systems, reporting the carbon emissions from training runs accurately characterizes the system’s long-term environmental burden.
Summary
Responsible engineering is ML systems engineering done completely, not a separate discipline. The chapter traced a path from failure diagnosis through prevention to enforcement, beginning with the responsibility gap (the distance between technical performance and responsible outcomes) and demonstrating how proxy variables, feedback loops, and distribution shift cause systems to harm users while meeting every conventional metric. The engineering response includes checklists that systematize predeployment assessment, fairness metrics that make disparities measurable, explainability mechanisms that satisfy regulatory and stakeholder requirements, and monitoring infrastructure that detects silent failures before they accumulate harm.
The key insight unifying these tools is that translating responsibility concerns into measurable properties makes them tractable. “Fairness gap <5 percent across groups” is actionable; “be fair” is not. This translation extends beyond fairness: efficiency becomes carbon accounting and TCO analysis, where a 20 percent latency reduction through quantization saves $304K and eliminates 19 t of CO2. Documentation becomes model cards with explicit intended use and known limitations. Governance becomes access control, lineage tracking, and audit infrastructure that makes compliance demonstrable rather than aspirational. At every level, the same pattern holds: abstract ethical obligations become concrete engineering requirements that can be specified, tested, monitored, and enforced.
The responsible engineering practices developed in this chapter are integral components of complete engineering, not external constraints layered onto technical work. Systems that ignore fairness, efficiency, transparency, or governance are technically incomplete. The same rigor applied to latency budgets and memory constraints must extend to demographic parity, environmental impact, and regulatory compliance. Engineers who integrate these considerations from system inception build systems that are not only more ethical but more robust, more maintainable, and more likely to succeed in production.
Key Takeaways: Reliable for whom?
- Aggregate correctness hides harm: A model can report 95 percent accuracy while producing 43.4× error-rate disparities across demographic groups. Responsible evaluation therefore starts with disaggregated and intersectional slices, not aggregate accuracy alone.
- Responsibility becomes testable through thresholds: “Be fair” is not testable, but bounded disparity, documented intended use, and explainability requirements are. Translating values into measurable constraints lets teams place fairness, accuracy, latency, and cost on the same reviewable Pareto frontier.
- Efficiency is a social constraint: A 4\(\times\) more efficient model uses 4\(\times\) less energy, costs 4\(\times\) less, and broadens who can deploy it. Because inference dominates total cost by 40:1 over training, per-query optimization is responsible engineering.
- Monitoring must watch outcomes: Bias and privacy failures can continue with green uptime dashboards because harmful predictions look operationally normal. Production monitoring must track subgroup outcomes, data lineage, feedback loops, and incident paths with the same rigor as latency regressions.
- Governance has to be built in: Model cards, datasheets, access controls, erasure workflows, human-review paths, and audit trails are technical infrastructure. Regulations such as GDPR require capabilities that cannot be retrofitted after a pipeline is already serving decisions.
A system that does exactly what it was told is dangerous precisely because the telling is never complete. Every objective a model is given is a specification with gaps, and an optimizer is a machine for finding the gaps: it will reproduce the bias latent in its data, chase the proxy instead of the goal, and call the result success, because nothing in the objective said otherwise. Responsible engineering is the discipline of writing back in what the specification left out, bounding the algorithm so it cannot optimize its way into the harms its data already encodes. The constraint is the same kind the rest of the book imposed in latency and memory, except that here it protects people the objective never named, and a model that is fast and accurate while wrong about whom it serves has not failed less than one that crashes, only more quietly.
What’s Next: From technique to philosophy
The chapter closes a circle that began with the iron law of ML systems (principle 3). The optimizations developed in Model Compression, Hardware Acceleration, and ML Operations were motivated by performance, but here they serve a second master: responsibility. Efficiency reduces carbon emissions. Compression democratizes access. Monitoring detects silent bias. The techniques are identical; only the lens changes. In Conclusion, we assemble these pieces into a coherent philosophy of engineering excellence. Where this chapter addressed whether systems serve everyone fairly and justify their resource consumption, the conclusion takes on the broadest concern of all: what it means to build ML systems well, in every dimension that the word encompasses.
Self-Check: Question
After reading the chapter, which statement best captures the summary’s claim about how responsible engineering relates to traditional systems engineering?
- Responsible engineering is primarily a legal and ethical overlay that engineering teams apply after the technical system is feature-complete.
- Responsible engineering is a specialty concern that matters only for high-risk regulated domains such as healthcare and criminal justice.
- Responsible engineering is ML systems engineering done completely: a system that ignores fairness, efficiency, transparency, or governance is technically incomplete, not merely ethically imperfect.
- Responsible engineering replaces performance optimization with ethical review, so teams adopting it trade throughput and latency for fairness and transparency.
The summary argues that responsibility concerns become tractable only when translated into measurable engineering invariants. Explain what this means by contrasting a vague principle with a specific invariant, and describe how the invariant integrates into an existing monitoring workflow.
The summary argues that earlier optimization techniques taught in the book serve a “second master” beyond performance. Which pairing most precisely reflects that dual-purpose claim?
- Monitoring primarily detects latency regressions, so fairness monitoring requires entirely separate infrastructure that does not share code paths with reliability monitoring.
- Hardware acceleration improves throughput and energy efficiency at the chip level, but grid-scale carbon impact depends purely on regulatory-policy decisions that engineers cannot influence through technical choices.
- Quantization yields sustainability benefits (lower energy per inference) but those benefits are independent of accessibility, since cheaper hardware deployment is a product-management concern rather than a consequence of compute reduction.
- Quantization, pruning, and monitoring improve throughput and latency while simultaneously reducing carbon per query, broadening deployment to lower-cost hardware, and surfacing silent subgroup disparities — the same techniques serve performance and responsibility through shared mechanisms.
Self-Check Answers
Self-Check: Answer
A hiring model meets its latency SLA, maintains 99.9 percent availability, and reports 87 percent aggregate accuracy, yet it systematically rejects qualified applicants whose resumes contain the word “women’s.” Applying the section’s verification-versus-validation framing, which diagnosis best fits this outcome?
- The system passed verification but failed validation: it met every stated requirement while the requirement itself failed to capture the responsible outcome the organization needed.
- The system failed verification because any unfair outcome is by definition a technical defect of the implementation.
- The failure is primarily an operational reliability issue that responsible engineering practices address only after the serving pipeline becomes unstable.
- The root cause is insufficient model capacity, so scaling up parameters would remove the disparity without changing the specification.
Answer: The correct answer is A. The model satisfied its loss function and its availability targets, so verification succeeded in the systems-engineering sense, but the requirement itself encoded historical bias rather than the organization’s true hiring goal. The capacity-based answer makes the wrong diagnosis: a larger model would optimize the same flawed objective more faithfully, not less. The reliability-based answer conflates outage response with specification correctness, which is exactly the category error the section warns against.
Learning Objective: Classify a concrete ML deployment failure as verification-success-with-validation-failure and distinguish it from reliability or capacity issues.
A team argues that a one-time ethics review before launch is sufficient because their model achieves strong aggregate accuracy and passes all latency checks. Using the section’s MLOps analogy, explain why responsible engineering must instead be structured as a control loop, and give one specific measurement the one-time review would miss.
Answer: MLOps is the control loop for reliability because model performance degrades as data distributions drift; responsible engineering is the control loop for safety because outcome quality degrades as downstream populations and proxies drift, and both degradations are silent to the dashboards engineers already watch. A specific signal the one-time review misses is subgroup-level outcome disparity over time: a model reviewed at launch with 87 percent aggregate accuracy can develop a 30-point true-positive-rate gap for a minority subgroup months later without moving any latency or availability metric. The practical consequence is that responsibility requires the same ongoing measurement, feedback, and intervention infrastructure as latency SLOs, not a sign-off meeting that closes the loop.
Learning Objective: Explain the MLOps-to-responsibility control-loop parallel and identify a specific fairness measurement a one-time review cannot provide.
True or False: Because machine learning systems are built from modular software components, a fairness defect originating in the training data can be isolated to a single module and fixed without architectural change, the way a null-pointer exception can be patched in one function.
Answer: False. The section’s central structural point is that ML data flows through shared representations, so a biased training signal propagates through every prediction the system makes rather than remaining local. Unlike a null-pointer bug, the defect is encoded in the learned weights themselves, so fixing it requires data-pipeline, objective, and evaluation changes across the D·A·M axes, not a localized patch.
Learning Objective: Distinguish localized software bugs from architecture-level ML failures and justify why specification-induced harm propagates across shared representations.
Self-Check: Answer
Amazon’s engineers removed explicit gender indicators from the recruiting model’s features, retrained, and found the system still discriminated against resumes from all-women’s colleges. Which diagnosis best explains why the explicit-attribute removal did not fix the harm?
- The fix was sound in principle; the system only needed additional bias-mitigation training epochs for the gender signal to fade from the learned weights.
- College names, activity descriptions, and career-gap patterns remained as proxy variables that carried the same demographic signal the removed gender feature had carried.
- The problem was deployment-time distribution shift in the applicant pool rather than bias in the original training signal.
- The problem was an optimization-objective mismatch that a different gradient-descent variant would have corrected during convergence.
Answer: The correct answer is B. Protected attributes can be reconstructed from correlated features even when the explicit label is absent, so a model trained on a dataset containing college names and activity descriptions recovers gender indirectly and preserves the original discriminatory pattern. The deployment-drift answer misidentifies the failure mode: Amazon’s harm is a biased training signal that predates deployment, not an environmental shift. The optimizer-choice answer is a category error because changing the optimizer does not remove the information content of the proxy features from the training set.
Learning Objective: Analyze how proxy variables preserve discrimination after explicit protected-attribute removal and distinguish this failure mode from deployment-time drift.
A hospital’s sepsis prediction model continues to emit confident recommendations after an EHR update changes how vital signs are recorded, yet clinicians observe deteriorating outcomes for a subset of patients. All dashboards stay green. Walk through why this is a silent failure, identify two specific monitoring signals that would have caught it, and state the systems consequence for how teams instrument production ML.
Answer: The failure is silent because the model’s confidence scores, latency, and uptime dashboards all rely on the output distribution looking the same as training, but an EHR change shifts the input distribution, so the model emits normal-looking predictions on inputs that are effectively out-of-distribution. Two specific signals that would have caught this: input-feature drift detection (for example, Jensen-Shannon divergence between training and current feature distributions crossing a 0.1 threshold) would have flagged the EHR change, and disaggregated outcome monitoring against ground-truth sepsis diagnoses would have shown the subgroup-level accuracy collapse before the aggregate moved. The systems consequence is that production responsibility monitoring must instrument the input pipeline and per-subgroup outcomes, not just confidence and latency, because dashboards that track only the system’s self-reported health cannot see distribution-shift failures.
Learning Objective: Analyze a distribution-shift silent failure on a concrete clinical scenario and specify the monitoring signals that distinguish environmental failures from healthy operation.
A recommendation team reports that engagement clicks rose 20 percent after deploying a new ranker, but month-over-month user satisfaction surveys dropped five percent and 30-day retention fell three percent. The team’s director asks how to detect or prevent this class of failure before it recurs. Which engineering intervention best fits the section’s alignment-gap framing?
- Scale the model two-fold: a larger model will learn a richer representation of satisfaction and close the gap automatically.
- Hold out a random counterfactual slice of users at deployment, measure true-outcome metrics (satisfaction, retention) on that slice periodically, and trigger rollback when the proxy-true gap widens beyond a preset threshold.
- Increase the weight of the clicks loss term: because the proxy correlates with the true goal initially, maximizing it harder will restore the lost correlation.
- Retrain on more data: with enough examples, gradient descent will discover the satisfaction signal implicitly even when it is not in the training labels.
Answer: The correct answer is B. The section’s alignment-gap analysis is a Goodhart-style decoupling between a measurable proxy (clicks) and an unobservable true goal (satisfaction); the only way to detect the decoupling is to periodically re-calibrate the proxy against the true outcome using a counterfactual holdout. Scaling up the model or reweighting the clicks loss makes the proxy-true gap worse by optimizing the proxy more aggressively. Retraining on more data does not help because the training labels do not contain satisfaction information, so more examples cannot surface a signal the loss function was never given.
Learning Objective: Apply the alignment-gap mechanism to a concrete recommender scenario and select the engineering intervention that re-anchors a proxy metric to its unobservable true goal.
A lending team generates paired test applications that differ only in the applicant’s first name (“John” vs “Jamal”) while holding income, credit history, and debt constant, then compares approval probabilities. Which responsible-testing method from the section are they applying, and what failure mode does it surface?
- Boundary testing, which probes behavior at the edges of the input distribution where training data is sparse.
- Slice-based evaluation, which partitions the test set into subgroups and reports per-slice aggregate accuracy.
- Stakeholder red-teaming, which relies on affected community members to propose adversarial scenarios.
- Invariance testing, which verifies that predictions remain stable when a feature the model should ignore is perturbed.
Answer: The correct answer is D. Invariance testing explicitly checks whether predictions change under a perturbation of an irrelevant attribute while holding task-relevant features fixed, which is precisely the counterfactual-pair construction the lending team is using. Slice-based evaluation answers a different question — per-subgroup aggregate metrics — and cannot isolate the causal effect of the name change. Boundary testing probes sparse regions of the input space, not counterfactual invariance. Red-teaming identifies scenarios to test but does not define the test construction itself.
Learning Objective: Classify responsible-testing methods by their construction and the specific failure mode each is designed to expose.
True or False: Once a model’s architecture, loss function, demographic-attribute collection, and monitoring pipeline have been fixed, a later ethics-board review can still implement equally effective fairness interventions as engineers could have at design time.
Answer: False. The section shows that each early architectural decision forecloses remediation options downstream: a loss function chosen without fairness constraints cannot be retrained without starting over, an architecture chosen without interpretability cannot be explained post hoc, and a data pipeline that omits demographic attributes cannot support disaggregated evaluation at all. By review time, the ethics board’s choices collapse to accept, reject, or rebuild — which is why Amazon’s review required cancelling the project rather than patching it.
Learning Objective: Evaluate why late-stage review cannot substitute for engineering-time responsibility decisions, grounded in the D·A·M architectural-foreclosure mechanism.
Self-Check: Answer
A team needs a statistically valid test set of 10,000 face images for a subgroup that makes up 1 percent of the user base to detect a one-percent performance gap with 95 percent confidence. Using the section’s representation statistics, what total sample collection does random sampling require, and what does this imply for the fairness evaluation workflow?
- About 100,000 total images, because confidence intervals shrink roughly linearly with the combined dataset size regardless of subgroup prevalence.
- About 1,000,000 total images, because subgroup confidence depends on subgroup sample count, so random collection requires a 100\(\times\) multiplier relative to the target and makes intentional stratified collection an engineering prerequisite.
- About 10,000 total images, because the target test-set size is already fixed and subgroup composition is handled automatically by the model’s training procedure.
- Sample-size reasoning applies only to training data; evaluation confidence scales with the number of gradient-update steps, not with the subgroup sample count.
Answer: The correct answer is B. Dividing the target 10,000 subgroup samples by the 0.01 prevalence yields 1,000,000 total samples — the 100\(\times\) multiplier the section derives — which makes natural-distribution sampling infeasible at production scale and forces intentional stratified collection through targeted outreach or active learning. A 100,000-image estimate ignores that subgroup confidence intervals scale with subgroup sample count, not overall dataset size. Claiming evaluation escapes the constraint confuses training data with test data: the subgroup confidence interval is purely a statistical property of the held-out test set.
Learning Objective: Apply representation statistics to derive the 100\(\times\) data multiplier and justify stratified collection as a fairness-evaluation engineering requirement.
A team argues they will write their model card after launch so it can accurately reflect observed behavior. Explain why the section calls this a guard-rail failure, and describe one specific scope-creep scenario that a predeployment model card would have blocked but a post-launch card would not.
Answer: A model card written before deployment constrains what the system is allowed to do by specifying intended use, excluded use cases, and the demographic factors under which performance was validated, so it operates as an enforcement artifact that downstream teams must satisfy before repurposing the model. Written after launch, the card becomes a historical summary that records whatever the deployment already does, which cannot prevent scope creep that has already occurred. A concrete scenario: a vision model validated only for consumer photo organization with a card specifying “not validated for high-stakes screening” can be automatically blocked from reuse in a security application, whereas a card written six months into the security deployment would merely describe the security use case rather than prevent it. The systems consequence is that the estimated 40 to 60 percent of deployments that exceed their documented scope do so through gradual expansion that only an up-front card can arrest.
Learning Objective: Explain why model-card timing determines whether it functions as a deployment constraint or a retrospective record, and identify a concrete scope-creep scenario this timing controls.
In the loan-approval worked example, Group A (majority) has a true positive rate of 90 percent and Group B (minority) has a true positive rate of 60 percent, while both groups share the same false positive rate of 20 percent. Evaluating each fairness criterion against these numbers, which statement is correct?
- Demographic parity is satisfied because the false positive rates match across groups.
- Equal opportunity is violated by the 30-point true-positive-rate gap, and equalized odds is also violated because equalized odds requires both true-positive-rate and false-positive-rate equality, so matching false positive rates alone is not sufficient.
- Equalized odds is satisfied because one of its two component rates matches across groups.
- Only calibration is implicated, because true-positive-rate disparities affect model accuracy rather than fairness.
Answer: The correct answer is B. Equal opportunity requires equal true-positive rates among qualified applicants, so a 30-point gap violates it directly — qualified minority applicants face a 30-point higher rejection rate than equally qualified majority applicants. Equalized odds requires both true-positive-rate and false-positive-rate equality, and the shared false-positive rate cannot rescue the criterion when the true-positive-rate component is violated. Demographic parity is about equal approval rates, not equal error rates, so matching false-positive rates is not its criterion. The calibration-only framing misreads the problem: true-positive-rate disparities are fairness violations regardless of their aggregate-accuracy effect.
Learning Objective: Diagnose equal-opportunity and equalized-odds violations directly from confusion-matrix statistics and distinguish them from demographic parity and calibration.
Stakeholders ask a hiring team to close a 20-percentage-point true-positive-rate gap between two groups by lowering the decision threshold for the disadvantaged group. Using the Pareto-frontier framing and the price-of-fairness calculation from the section, analyze what the team should present to stakeholders and why threshold adjustment alone is a design choice, not a technical fix.
Answer: Lowering the threshold for the disadvantaged group increases that group’s true-positive rate but also its false-positive rate, which in the section’s hiring example translates to roughly a 5-percentage-point rise in false positives and about a 1.4-percent aggregate utility loss under the stated assumptions: $100k successful-hire value, $50k bad-hire cost, a 50-percent qualified-applicant base rate, and a disadvantaged group that is 30 percent of the applicant pool. The team should present the Pareto frontier to stakeholders: each candidate threshold traces out a specific (accuracy, disparity) point, and no reweighting can move the system off the frontier — only choosing where on the frontier to sit. The practical consequence is that threshold adjustment is a values decision expressed through engineering, not a technical patch: the engineer’s job is to make the trade-off quantitative and legible so stakeholders can pick the point aligned with organizational priorities rather than discovering the trade-off after deployment.
Learning Objective: Quantify the price-of-fairness trade-off for a concrete threshold-adjustment scenario and justify why Pareto-frontier presentation is the correct engineering deliverable to stakeholders.
A European lender plans to deploy a deep neural network that automates credit decisions affecting hundreds of thousands of applicants per year. Given EU AI Act high-risk classification and GDPR Article 22 obligations as described in the section, which architectural consequence follows most directly?
- Because deeper models are more accurate, explainability engineering can be deferred until after legal approval closes.
- Aggregate fairness metrics alone are sufficient because individual applicant explanations are irrelevant in financial decisions.
- The deployment architecture must be designed at inception to support per-applicant explanations, substantive human review of automated decisions, and audit-trail logging, because adverse-action and Article 22 substantive-review obligations are enforced as technical requirements with penalties up to 15M EUR or 3 percent of global turnover for high-risk operator violations.
- EU regulation applies primarily to foundation models, so a loan classifier with fewer than a billion parameters can be deployed without explainability infrastructure.
Answer: The correct answer is C. Credit decisions are high-risk under EU AI Act Annex III regardless of model size, and Article 22 requires substantive human review for automated decisions with significant effects, so the architecture must ship from day one with per-applicant explanation capabilities (to satisfy adverse-action notice requirements), human-oversight interfaces, and logging infrastructure that supports audit. Aggregate fairness metrics do not discharge the per-applicant recourse obligation, which is individual-level by construction. The size-based framing misreads Annex III: risk classification is based on deployment context, not model architecture, so a logistic regression deciding credit carries the same obligations as a large transformer.
Learning Objective: Analyze how high-stakes regulatory obligations translate into specific architectural capabilities that must be engineered in at system inception rather than retrofitted.
Self-Check: Answer
A team can deploy either a full-precision model or a quantized version that preserves task accuracy while cutting inference compute by roughly 4\(\times\). According to the section, why does this efficiency choice count as a responsibility decision rather than purely a performance decision?
- Quantization is primarily a responsibility tool because it automatically reduces fairness disparities by making all user groups equally cheap to serve.
- Quantization reduces compute per inference, which simultaneously shrinks carbon emissions in proportion, lowers serving dollar cost, and lowers hardware barriers so smaller organizations and edge devices can deploy the model.
- Quantization is a pure performance optimization that should be evaluated separately from responsibility, because fairness, carbon, and cost belong to distinct engineering layers with different owners.
- Quantization matters mainly for training-time energy: production inference is usually a minor fraction of lifecycle resource use, so the responsibility payoff is small.
Answer: The correct answer is B. The section’s efficiency-as-responsibility argument is that a single intervention (reducing compute per inference) pays out simultaneously across three channels — carbon (4\(\times\) fewer emissions per query), dollar cost (4\(\times\) lower serving bill), and accessibility (the model fits cheaper hardware or devices that would otherwise be priced out). The “separate layers” answer is the misconception the section exists to correct: splitting efficiency from responsibility misses the unification. The fairness-automation answer conflates cost-per-query with fairness, which the section explicitly keeps distinct. The training-dominance answer contradicts the 40:1 inference-to-training ratio in the TCO analysis.
Learning Objective: Justify why efficiency interventions serve environmental, economic, and accessibility responsibilities simultaneously rather than being a separable performance concern.
A wearable device has a 500 mW sustained power budget and a 500 ms end-to-end inference latency requirement. Using the section’s deployment-comparison data (TinyML at roughly 50 mW / 200 ms, MobileNetV2 at roughly 1.2 W / 40 ms, EfficientNet-B0 at roughly 1.8 W, ResNet-50 much larger), which model selection is the correct responsible-engineering choice, and why?
- ResNet-50, because larger models achieve better energy efficiency per accuracy point once their throughput is amortized through batching.
- MobileNetV2, because 1.2 W is close enough to the 500 mW target that the gap is operationally negligible on modern battery-management hardware.
- TinyML model, because its 50 mW power draw fits 10\(\times\) under the budget and its 200 ms latency fits under the 500 ms requirement, so it is the only option that satisfies both constraints simultaneously.
- EfficientNet-B0, because its smartphone-grade footprint guarantees it also fits wearable constraints once the form factor is reduced.
Answer: The correct answer is C. Only the TinyML model satisfies both the 500 mW power ceiling (at 50 mW, a 10\(\times\) margin) and the 500 ms latency ceiling (at 200 ms); every other option exceeds the power budget by at least 2\(\times\). The MobileNetV2 answer misreads the power constraint — a wearable cannot sustain 1.2 W without thermal throttling and rapid battery depletion, so “close enough” is quantitatively wrong by a factor of 2.4. The smartphone-to-wearable extrapolation is the common mistake the section warns against: wearable budgets are an order of magnitude tighter than smartphones on sustained draw. Batching arguments do not rescue ResNet-50 on a device that serves one query at a time.
Learning Objective: Apply edge-deployment power and latency constraints to select a model architecture that satisfies both budgets and reject the smartphone-to-wearable extrapolation.
Using the section’s three-year TCO breakdown (training ~2 percent, inference ~73 percent, operations ~25 percent for a recommendation system serving 200M daily queries), a team proposes two optimization options: Proposal 1 is a 50 percent reduction in training wall-clock time, and Proposal 2 is a 20 percent reduction in per-query inference latency via quantization. Explain which proposal has higher leverage on both dollar cost and carbon, and give the rough dollar-savings ratio between them.
Answer: The inference latency reduction has higher leverage in both dimensions because inference dominates lifecycle cost at roughly 73 percent of the 3-year total while training sits at only 2 percent. A 20 percent cut on the 73 percent term saves roughly 14.6 percent of total cost, whereas a 50 percent cut on the 2 percent term saves only about 1 percent of total cost, giving a dollar-savings ratio near 15-to-1 in favor of inference optimization. The carbon ratio is even more lopsided in this scenario: the same 20 percent inference reduction saves about 25 times as much CO2 as the 50 percent training-time reduction because inference consumes far more GPU-hours over the deployment lifetime. The practical consequence is that on inference-dominated workloads, per-query optimization is the highest-leverage responsibility intervention available and should capture the majority of engineering investment.
Learning Objective: Compare two optimization proposals using TCO framing to quantify which intervention has higher leverage on dollar cost and carbon for inference-dominated production systems.
True or False: For an identical model and serving workload, migrating deployment from a carbon-intensive cloud region to one powered by abundant renewable energy can reduce inference emissions more than a one-time modest algorithmic efficiency improvement.
Answer: True. The section notes cloud region choice can yield roughly a 5\(\times\) carbon reduction while typical algorithmic tweaks fall in the low-percent range, so when the algorithmic gain is modest the infrastructure choice dominates emissions. Carbon intensity of the underlying grid is therefore a first-class infrastructure parameter engineers must surface alongside compute efficiency, not a post-hoc accounting detail.
Learning Objective: Evaluate how grid-carbon-intensity infrastructure choices can outweigh algorithmic efficiency gains in overall emissions for the same workload.
Training GPT-3 consumed roughly 1,287 MWh of electricity. At a US-grid average carbon intensity of roughly 0.429 kg CO2 per kWh, what does the section identify as the dominant responsible-engineering lever for reducing the footprint of future foundation-model training runs?
- Reducing model size to under one billion parameters, accepting the corresponding accuracy loss, because parameter count is the only significant driver of training energy.
- Improving accelerator utilization \(\eta_{\text{hw}}\) during training so that the same 1,287 MWh produces more useful FLOPs, combined with carbon-aware scheduling that runs intensive jobs when renewable supply is abundant and selecting regions with lower grid-carbon intensity.
- Deferring all training until grid carbon intensity reaches zero, since any non-zero intensity produces emissions that cannot be justified ethically.
- Switching the entire training pipeline from FP32 to FP16 without other changes, because numerical precision alone accounts for the bulk of training energy use.
Answer: The correct answer is B. The section’s quantitative analysis identifies two stackable infrastructure levers: hardware efficiency (\(\eta_{\text{hw}}\) improvements so more of the 1,287 MWh becomes useful FLOPs rather than memory stalls) and carbon-aware scheduling and region selection (which can yield roughly 5\(\times\) reductions independent of the algorithm). Parameter reduction is one lever but not the only one, and treating it as sole driver ignores that utilization dominates effective energy per useful FLOP. The zero-carbon answer is a category mistake — it is a moral absolutism, not an engineering intervention. The FP16-only answer overstates precision’s share of energy: precision matters, but the section places it alongside utilization and grid selection, not above them.
Learning Objective: Identify the dominant infrastructure-layer responsibility levers (efficiency and carbon-aware scheduling) for large-scale training energy and reject single-lever framings.
Self-Check: Answer
In 2023 Meta received a 390M EUR fine not for a data breach but for insufficient governance infrastructure to demonstrate lawful processing. Which diagnosis best captures why the section frames data governance as an enforcement mechanism rather than a policy document?
- Governance replaces the need for model monitoring once regulators sign off on the data pipeline, because certification transfers ongoing responsibility to the certifier.
- Governance is primarily about publishing external-facing datasheets and model cards so that readers outside the organization can assess the system.
- Policy claims become demonstrable only when access controls, privacy mechanisms, lineage tracking, and audit logs make each requirement technically enforceable across the data lifecycle — otherwise compliance is an assertion rather than evidence.
- Governance applies only to raw storage, since derived features, model artifacts, and deployment workflows are downstream and fall outside the data lifecycle.
Answer: The correct answer is C. Meta’s fine demonstrates the section’s structural point: governance that exists only as policy cannot withstand audit because the organization cannot produce evidence of enforcement. The architecture must record who accessed data, what transformations produced each feature, and which model versions derived from which training runs — policy without these technical controls is unverifiable. The certification-handoff answer is wrong because regulatory certification does not transfer ongoing compliance. The datasheet-only answer confuses documentation with enforcement; model cards are necessary but do not control access. The raw-storage-only answer contradicts the section’s explicit scope: governance spans features, models, and deployment workflows, not just raw data.
Learning Objective: Explain why data governance must be implemented through enforceable technical infrastructure and distinguish this framing from documentation-only or raw-storage-only views.
A European user of a voice-assistant service invokes GDPR Article 17 right-to-erasure. Explain why a manual search across storage systems is both unreliable and too slow to satisfy the request, and describe what automated infrastructure the compliance architecture must instead provide.
Answer: Satisfying Article 17 requires locating not only the user’s raw audio recordings but also every derived artifact that depended on that data — feature-store entries, embedding caches, fine-tuned model checkpoints, and audit logs — across storage layers, feature stores, training jobs, and deployed model versions. A distributed ML pipeline fans data across systems that a manual trace cannot visit reliably within regulatory time limits, and any missed artifact is itself a compliance failure. The architecture must instead provide an automated lineage graph that links every source record to its downstream derivations and a deletion workflow that traverses this graph to remove or invalidate each dependent artifact. The practical consequence is that compliance is an infrastructure problem: teams that rely on ad-hoc search either miss artifacts (risking fines) or take weeks to respond (violating the regulation’s timeline), whereas a lineage-backed deletion pipeline makes the request a routine automated operation.
Learning Objective: Analyze why distributed ML pipelines make manual deletion infeasible and identify the lineage-and-automation infrastructure that right-to-erasure compliance requires.
The Lighthouse KWS system is an always-listening keyword-spotting voice assistant deployed in users’ homes. Which architectural combination best reflects the section’s privacy-by-design approach for this deployment, and why?
- Stream all ambient audio to a cloud service that applies strong centralized privacy controls after collection, since centralized processing allows more sophisticated mechanisms than any edge device can run.
- Run wake-word detection on-device, transmit only aggregated or federated updates rather than raw recordings, and enforce automatic retention and deletion policies on any audio that must be retained, so the system minimizes the personal data exposed in the first place.
- Retain raw audio indefinitely on secure cloud storage, because the future retraining value of long-horizon voice data outweighs privacy concerns when access is properly encrypted.
- Rely on role-based access control as the sole privacy mechanism, since privacy concerns reduce to limiting who can query the data and RBAC solves exactly that problem.
Answer: The correct answer is B. The section’s privacy-by-design architecture combines three complementary moves — on-device processing (raw audio never leaves the device in the common case), federated-style minimization (only aggregated signals cross the network), and retention limits (any retained audio has a bounded lifetime) — so the attack surface is small by construction rather than by policy. Centralized cloud collection inverts the principle: it maximizes the data exposed before applying any protection, so a breach or insider access exposes more. Indefinite retention treats future training value as a blank check, which the section explicitly rejects. RBAC-only misreads the threat model: RBAC limits who can query data, but privacy also requires limiting what even authorized actors can learn about individuals, which is a separate problem that techniques like differential privacy and data minimization address.
Learning Objective: Identify the privacy-by-design architectural pattern for always-listening systems and distinguish privacy minimization from access-control mechanisms.
A teammate argues that security, privacy, and audit are essentially the same concern because each restricts data access. Using the section’s governance stack, distinguish the operational role of each and give one concrete failure mode that would not be caught if the other two were fully implemented but that mechanism were missing.
Answer: Security answers who can reach the data at all: access controls, authentication, and encryption define the perimeter within which all other mechanisms operate. Privacy answers what information authorized actors can learn about individuals: differential privacy, minimization, and aggregation limit inference even when access is legitimate. Audit answers who actually did what: logs of access and transformation events create the accountability trail that makes the other two verifiable under scrutiny. A system with strong security and privacy but no audit cannot respond to a regulatory subpoena that asks which employee accessed which records on which date — the access happened legitimately, the data was appropriately anonymized, but the organization cannot prove either claim and fails the audit. Symmetrically, strong security plus audit without privacy still leaks individual-level information to every authorized data scientist, and strong privacy plus audit without security lets unauthorized actors bypass the whole stack. The mechanisms are complementary accountability layers, not redundant restrictions.
Learning Objective: Distinguish the operational roles of security, privacy, and audit mechanisms in the governance stack and identify a concrete failure mode specific to each missing mechanism.
True or False: Because GDPR Article 17 (right-to-erasure) penalties are capped at modest administrative amounts, an ML team can reasonably defer building automated lineage infrastructure until the first deletion request arrives.
Answer: False. The section’s Meta example (390M EUR in 2023) demonstrates that governance-infrastructure deficiencies — not data breaches — drive penalties that are far from modest. Deferring lineage infrastructure until a request arrives makes timely compliance across distributed artifacts infeasible.
Learning Objective: Evaluate the quantitative regulatory risk that makes up-front lineage infrastructure a prerequisite rather than an optional engineering investment.
Self-Check: Answer
A deployed loan-approval model reports 85 percent aggregate accuracy, but disaggregated evaluation shows qualified applicants from one demographic group have a true-positive rate 30 percentage points lower than another group. Which pitfall from the section does this outcome most directly illustrate?
- The mistaken belief that fairness can be assessed from aggregate metrics alone, because strong overall accuracy masks the subgroup disparity that only disaggregated evaluation surfaces.
- The mistaken belief that documentation automatically enforces deployment constraints, so a written model card prevents misuse even when no technical control blocks it.
- The mistaken belief that removing sensitive attributes from training data always eliminates bias, so explicit-attribute exclusion guarantees proxy-free predictions.
- The mistaken belief that training costs dominate lifecycle cost, which leads teams to over-optimize training at the expense of inference.
Answer: The correct answer is A. The 30-percentage-point true-positive-rate gap under 85 percent aggregate accuracy is the canonical flaw-of-averages failure: the aggregate is a weighted average that hides the minority-group disparity, which only disaggregated evaluation reveals. The documentation-enforcement answer describes a different pitfall about deployment scope creep, not aggregate-metric concealment. The attribute-removal answer is also real but refers to why fairness persists after explicit-attribute removal, which is the next fallacy in the section and does not explain the metric mechanic here. The training-cost answer addresses environmental accounting, not fairness metric reporting.
Learning Objective: Identify the aggregate-metric pitfall when strong overall performance conceals substantial subgroup disparity and distinguish it from other fallacies in the section.
A team proposes removing race and gender features from their model, then deploying without further fairness evaluation because “the model cannot discriminate on attributes it does not see.” Drawing on the Amazon recruiting and Optum healthcare-cost cases from the chapter, explain why this reasoning creates false confidence rather than eliminating bias, and identify the specific engineering work still required.
Answer: Protected attributes remain inferable through correlated proxies that carry the same demographic signal: Amazon’s system reconstructed gender from college names, activity descriptions, and career-gap patterns despite explicit gender removal, and Optum’s system encoded race through healthcare-cost history because unequal system access made cost a de-facto race proxy; correcting the bias would have increased the share of Black patients receiving additional help from 17.7 percent to 46.5 percent. Research shows models recover protected attributes with 70 to 90 percent accuracy from supposedly neutral features like ZIP codes, purchase patterns, and browsing history. The engineering work still required includes causal analysis of which features carry demographic signal, fairness constraints during training (adversarial debiasing or constrained optimization), per-group outcome monitoring in production, and the disaggregated-metric reporting this chapter develops — attribute removal alone is necessary but insufficient, and teams that stop there deploy a model that discriminates while appearing compliant.
Learning Objective: Explain why proxy variables undermine naive attribute-removal approaches and specify the causal-analysis, fairness-constraint, and monitoring work required for actual bias mitigation.
True or False: Because a well-written model card explicitly states intended use and excluded use cases, teams that publish comprehensive model cards can treat deployment-scope compliance as handled without additional technical controls.
Answer: False. The section’s documentation-as-accountability pitfall is exactly this assumption: studies show 40 to 60 percent of production models operate outside their documented scope within 18 months, and a model card specifying “not validated for high-stakes decisions” has no enforcement power when the system is repurposed without access-control or deployment-gate restrictions. Documentation provides transparency but requires paired operational controls — monitoring dashboards, subgroup-disparity alerts, and deployment gates tied to the card’s intended use — to function as enforcement.
Learning Objective: Evaluate why documentation without enforcement fails under scope creep and identify the operational controls that must pair with model cards.
True or False: For most successful production ML systems, reporting the carbon emissions from training runs accurately characterizes the system’s long-term environmental burden.
Answer: False. The section’s TCO analysis shows inference-to-training compute ratios reaching 40:1 over a three-year operational lifetime, so a model trained once and served millions of times daily has its carbon footprint dominated by inference energy, not training. Training-only reporting addresses the smaller term in a lopsided equation, leaving the dominant source of environmental impact unmeasured and unaddressed.
Learning Objective: Evaluate why training-only environmental accounting is misleading for production ML systems and quantify the inference-dominance ratio that drives the misclassification.
Self-Check: Answer
After reading the chapter, which statement best captures the summary’s claim about how responsible engineering relates to traditional systems engineering?
- Responsible engineering is primarily a legal and ethical overlay that engineering teams apply after the technical system is feature-complete.
- Responsible engineering is a specialty concern that matters only for high-risk regulated domains such as healthcare and criminal justice.
- Responsible engineering is ML systems engineering done completely: a system that ignores fairness, efficiency, transparency, or governance is technically incomplete, not merely ethically imperfect.
- Responsible engineering replaces performance optimization with ethical review, so teams adopting it trade throughput and latency for fairness and transparency.
Answer: The correct answer is C. The chapter’s closing thesis is that correctness in ML must extend beyond latency and accuracy to encompass fairness, efficiency, transparency, and governance as measurable properties of a complete system, applied from inception. The legal-overlay answer inverts the chapter’s argument: the Amazon and COMPAS cases show that late-stage review cannot fix architecturally foreclosed problems. The specialty-domain answer is contradicted by the efficiency and TCO material, which applies to every production system regardless of regulatory classification. The replacement framing misreads the chapter: earlier optimization techniques (quantization, pruning, hardware acceleration) serve both masters simultaneously rather than being traded off.
Learning Objective: Identify the summary’s thesis that responsibility is engineering completeness and distinguish it from overlay, specialty-domain, and replacement framings.
The summary argues that responsibility concerns become tractable only when translated into measurable engineering invariants. Explain what this means by contrasting a vague principle with a specific invariant, and describe how the invariant integrates into an existing monitoring workflow.
Answer: A vague principle such as “be fair” gives engineers nothing to implement, test, or monitor, whereas an invariant such as “per-group true-positive-rate disparity <5 percentage points, measured hourly, with automatic rollback if exceeded for 15 minutes” is a concrete target that slots directly into existing SLO infrastructure. The engineering consequence is that responsibility invariants integrate into monitoring the same way latency SLOs do: the fairness dashboard sits next to the p99-latency dashboard, the same alerting and on-call rotations cover both, and the same rollback mechanisms that fire on latency regressions can fire on fairness regressions. The practical implication is that responsibility becomes actionable and auditable only at this level of specification; at the principle level, compliance claims cannot be verified and interventions cannot be triggered.
Learning Objective: Explain how concrete measurable invariants make responsibility concerns actionable by integrating into existing SLO and monitoring workflows.
The summary argues that earlier optimization techniques taught in the book serve a “second master” beyond performance. Which pairing most precisely reflects that dual-purpose claim?
- Monitoring primarily detects latency regressions, so fairness monitoring requires entirely separate infrastructure that does not share code paths with reliability monitoring.
- Hardware acceleration improves throughput and energy efficiency at the chip level, but grid-scale carbon impact depends purely on regulatory-policy decisions that engineers cannot influence through technical choices.
- Quantization yields sustainability benefits (lower energy per inference) but those benefits are independent of accessibility, since cheaper hardware deployment is a product-management concern rather than a consequence of compute reduction.
- Quantization, pruning, and monitoring improve throughput and latency while simultaneously reducing carbon per query, broadening deployment to lower-cost hardware, and surfacing silent subgroup disparities — the same techniques serve performance and responsibility through shared mechanisms.
Answer: The correct answer is D. The chapter’s synthesis is that a single technique often pays out along multiple dimensions because the underlying mechanism (fewer bytes moved, fewer cycles spent, faster subgroup-metric computation) simultaneously reduces energy per query, lowers the hardware cost floor for deployment, and makes real-time fairness monitoring feasible. The monitoring-as-separate-infrastructure answer contradicts the chapter’s argument that subgroup-disparity dashboards extend existing reliability monitoring rather than replacing it. The sustainability-separated-from-accessibility answer misses the three-channel unification: reducing compute per inference directly lowers the hardware cost floor. The policy-only carbon answer misreads the chapter’s efficiency-as-responsibility argument — grid carbon intensity matters, but chip-level efficiency multiplies against it rather than being irrelevant to it.
Learning Objective: Analyze how prior optimization and monitoring techniques serve both performance and responsibility objectives through shared mechanisms rather than through separable work.