Security & Privacy
DALL·E 3 Prompt: An illustration on privacy and security in machine learning systems. The image shows a digital landscape with a network of interconnected nodes and data streams, symbolizing machine learning algorithms. In the foreground, there’s a large lock superimposed over the network, representing privacy and security. The lock is semi-transparent, allowing the underlying network to be partially visible. The background features binary code and digital encryption symbols, emphasizing the theme of cybersecurity. The color scheme is a mix of blues, greens, and grays, suggesting a high-tech, digital environment.

Purpose
Why do privacy and security determine whether machine learning systems achieve widespread adoption and societal trust?
Machine learning systems require unprecedented access to personal data, institutional knowledge, and behavioral patterns to function effectively, creating tension between utility and protection that determines societal acceptance. Unlike traditional software that processes data transiently, ML systems learn from sensitive information and embed patterns into persistent models that can inadvertently reveal private details. This capability creates systemic risks extending beyond individual privacy violations to threaten institutional trust, competitive advantages, and democratic governance. Success of machine learning deployment across critical domains (healthcare, finance, education, and public services) depends entirely on establishing robust security and privacy foundations enabling beneficial use while preventing harmful exposure. Without these protections, even the most capable systems remain unused due to legal, ethical, and practical concerns. Understanding privacy and security principles enables engineers to design systems achieving both technical excellence and societal acceptance.
Distinguish between security and privacy concerns in machine learning systems using formal definitions and threat models
Analyze historical security incidents to extract principles applicable to ML system vulnerabilities
Classify ML threats across model, data, and hardware attack surfaces
Evaluate privacy-preserving techniques including differential privacy, federated learning, and synthetic data generation for specific use cases
Design layered defense architectures that integrate data protection, model security, and hardware trust mechanisms
Implement basic security controls including access management, encryption, and input validation for ML systems
Assess trade-offs between security measures and system performance using quantitative cost-benefit analysis
Apply the three-phase security roadmap to prioritize defenses based on organizational threat models and risk tolerance
Security and Privacy in ML Systems
The shift from centralized training architectures to distributed, adaptive machine learning systems has altered the threat landscape and security requirements for modern ML infrastructure. Contemporary machine learning systems, as examined in Chapter 14: On-Device Learning, increasingly operate across heterogeneous computational environments spanning edge devices, federated networks, and hybrid cloud deployments. This architectural evolution enables new capabilities in adaptive intelligence but introduces attack vectors and privacy vulnerabilities that traditional cybersecurity frameworks cannot adequately address.
Machine learning systems exhibit different security characteristics compared to conventional software applications. Traditional software systems process data transiently and deterministically, whereas machine learning systems extract and encode patterns from training data into persistent model parameters. This learned knowledge representation creates unique vulnerabilities where sensitive information can be inadvertently memorized and later exposed through model outputs or systematic interrogation. Such risks manifest across domains from healthcare systems that may leak patient information to proprietary models that can be reverse-engineered through strategic query patterns, threatening both individual privacy and organizational intellectual property.
The architectural complexity of machine learning systems, as detailed in Chapter 2: ML Systems, compounds these security challenges through multi-layered attack surfaces. Contemporary ML deployments include data ingestion pipelines, distributed training infrastructure, model serving systems, and continuous monitoring frameworks. Each architectural component introduces distinct vulnerabilities while privacy concerns affect the entire computational stack. The distributed nature of modern deployments, with continuous adaptation at edge nodes and federated coordination protocols, expands the attack surface while complicating comprehensive security implementation.
Addressing these challenges requires systematic approaches that integrate security and privacy considerations throughout the machine learning system lifecycle. This chapter establishes the foundations and methodologies necessary for engineering ML systems that achieve both computational effectiveness and trustworthy operation. We examine the application of established security principles to machine learning contexts, identify threat models specific to learning systems, and present comprehensive defense strategies that include data protection mechanisms, secure model architectures, and hardware-based security implementations.
Our investigation proceeds through four interconnected frameworks. We begin by establishing distinctions between security and privacy within machine learning contexts, then examine evidence from historical security incidents to inform contemporary threat assessment. We analyze vulnerabilities that emerge from the learning process itself, before presenting layered defense architectures that span cryptographic data protection, adversarial-robust model design, and hardware security mechanisms. Throughout this analysis, we emphasize implementation guidance that enables practitioners to develop systems meeting both technical performance requirements and the trust standards necessary for societal deployment.
Foundational Concepts and Definitions
Security and privacy are core concerns in machine learning system design, but they are often misunderstood or conflated. Both aim to protect systems and data, yet they do so in different ways, address different threat models, and require distinct technical responses. For ML systems, distinguishing between the two helps guide the design of robust and responsible infrastructure.
Security Defined
Security in machine learning focuses on defending systems from adversarial behavior. This includes protecting model parameters, training pipelines, deployment infrastructure, and data access pathways from manipulation or misuse.
Example: A facial recognition system deployed in public transit infrastructure may be targeted with adversarial inputs that cause it to misidentify individuals or fail entirely. This is a runtime security vulnerability that threatens both accuracy and system availability.
Privacy Defined
While security addresses adversarial threats, privacy focuses on limiting the exposure and misuse of sensitive information within ML systems. This includes protecting training data, inference inputs, and model outputs from leaking personal or proprietary information, even when systems operate correctly and no explicit attack is taking place.
Example: A language model trained on medical transcripts may inadvertently memorize snippets of patient conversations. If a user later triggers this content through a public-facing chatbot, it represents a privacy failure, even in the absence of an attacker.
Security versus Privacy
Although they intersect in some areas (encrypted storage supports both), security and privacy differ in their objectives, threat models, and typical mitigation strategies. Table 1 below summarizes these distinctions in the context of machine learning systems.
| Aspect | Security | Privacy |
|---|---|---|
| Primary Goal | Prevent unauthorized access or disruption | Limit exposure of sensitive information |
| Threat Model | Adversarial actors (external or internal) | Honest-but-curious observers or passive leaks |
| Typical Concerns | Model theft, poisoning, evasion attacks | Data leakage, re-identification, memorization |
| Example Attack | Adversarial inputs cause misclassification | Model inversion reveals training data |
| Representative Defenses | Access control, adversarial training | Differential privacy, federated learning |
| Relevance to Regulation | Emphasized in cybersecurity standards | Central to data protection laws (e.g., GDPR) |
Security-Privacy Interactions and Trade-offs
Security and privacy are deeply interrelated but not interchangeable. A secure system helps maintain privacy by restricting unauthorized access to models and data. Privacy-preserving designs can improve security by reducing the attack surface, for example, minimizing the retention of sensitive data reduces the risk of exposure if a system is compromised.
However, they can also be in tension. Techniques like differential privacy1 reduce memorization risks but may lower model utility. Similarly, encryption enhances security but may obscure transparency and auditability, complicating privacy compliance. In machine learning systems, designers must reason about these trade-offs holistically. Systems that serve sensitive domains, including healthcare, finance, and public safety, must simultaneously protect against both misuse (security) and overexposure (privacy). Understanding the boundaries between these concerns is essential for building systems that are performant, trustworthy, and legally compliant.
1 Differential Privacy Origins: Cynthia Dwork coined the term differential privacy at Microsoft Research in 2006, but the concept emerged from her frustration with the “anonymization myth” (the false belief that removing names from data guaranteed privacy). Her groundbreaking insight was that privacy should be mathematically provable, not just plausible, leading to the rigorous framework that now protects billions of users’ data in products from Apple to Google.
Learning from Security Breaches
Having established the conceptual foundations of security and privacy, we now examine how these principles manifest in real-world systems through landmark security incidents. These historical cases provide concrete illustrations of the abstract concepts we’ve defined, showing how security vulnerabilities emerge and propagate through complex systems. More importantly, they reveal universal patterns (supply chain compromise, insufficient isolation, and weaponized endpoints) that directly apply to modern machine learning deployments.
Valuable lessons can be drawn from well-known security breaches across a range of computing systems. Understanding how these patterns apply to modern ML deployments, which increasingly operate across cloud, edge, and embedded environments, provides important lessons for securing machine learning systems. These incidents demonstrate how weaknesses in system design can lead to widespread, and sometimes physical, consequences. Although the examples discussed in this section do not all involve machine learning directly, they provide important insights into designing secure systems. These lessons apply to machine learning applications deployed across cloud, edge, and embedded environments.
Supply Chain Compromise: Stuxnet
In 2010, security researchers discovered a highly sophisticated computer worm later named Stuxnet2, which targeted industrial control systems used in Iran’s Natanz nuclear facility (Farwell and Rohozinski 2011). Stuxnet exploited four previously unknown “zero-day”3 vulnerabilities in Microsoft Windows, allowing it to spread undetected through networked and isolated systems.
2 Stuxnet Discovery: Stuxnet was first detected by VirusBokNok, a small Belarusian antivirus company, when their client computers began crashing unexpectedly. What seemed like a routine malware investigation turned into one of the most significant cybersecurity discoveries in history: the first confirmed cyberweapon designed to cause physical destruction.
3 Zero-Day Term Origin: The term “zero-day” originated in software piracy circles, referring to the “zero days” since a program’s release when pirated copies appeared. In security, it describes the “zero days” defenders have to patch a vulnerability before attackers exploit it, representing the ultimate race between attack and defense.
4 Air-Gapped Systems: Air-gapped systems are networks physically isolated from external connections, originally developed for military systems in the 1960s. Despite seeming impenetrable, studies show 90% of air-gapped systems can be breached through supply chain compromise, infected removable media, or hidden channels (acoustic, electromagnetic, thermal) (Farwell and Rohozinski 2011).
5 USB Attacks: USB interfaces, introduced in 1996, became a primary attack vector for crossing air gaps. The 2008 Operation Olympic Games reportedly used infected USB drives to penetrate secure facilities, with some estimates suggesting 60% of organizations remain vulnerable to USB-based attacks (Farwell and Rohozinski 2011).
Unlike typical malware designed to steal information or perform espionage, Stuxnet was engineered to cause physical damage. Its objective was to disrupt uranium enrichment by sabotaging the centrifuges used in the process. Despite the facility being air-gapped4 from external networks, the malware is believed to have entered the system via an infected USB device5, demonstrating how physical access can compromise isolated environments.
The worm specifically targeted programmable logic controllers (PLCs), industrial computers that automate electromechanical processes such as controlling the speed of centrifuges. By exploiting vulnerabilities in the Windows operating system and the Siemens Step7 software used to program the PLCs, Stuxnet achieved highly targeted, real-world disruption. This represents a landmark in cybersecurity, demonstrating how malicious software can bridge the digital and physical worlds to manipulate industrial infrastructure.
The lessons from Stuxnet directly apply to modern ML systems. Training pipelines and model repositories face persistent supply chain risks analogous to those exploited by Stuxnet. Just as Stuxnet compromised industrial systems through infected USB devices and software vulnerabilities, modern ML systems face multiple attack vectors: compromised dependencies (malicious packages in PyPI/conda repositories), malicious training data (poisoned datasets on HuggingFace, Kaggle), backdoored model weights (trojan models in model repositories), and tampered hardware drivers (compromised NVIDIA CUDA libraries, firmware backdoors in AI accelerators).
A concrete ML attack scenario illustrates these risks: an attacker uploads a backdoored image classification model to a popular model repository, trained to misclassify specific patterns while maintaining normal accuracy on clean data. When deployed in autonomous vehicles, this backdoored model correctly identifies most objects but fails to detect pedestrians wearing specific patterns, creating safety risks. The attack propagates through automated model deployment pipelines, affecting thousands of vehicles before detection.
Defending against such supply chain attacks requires end-to-end security measures: (1) cryptographic verification to sign all model artifacts, datasets, and dependencies with cryptographic signatures; (2) provenance tracking to maintain immutable logs of all training data sources, code versions, and infrastructure used; (3) integrity validation to implement automated scanning for model backdoors, dependency vulnerabilities, and dataset poisoning before deployment; (4) air-gapped training to isolate sensitive model training in secure environments with controlled dependency management. Figure 1 illustrates how these supply chain compromise patterns apply across both industrial and ML systems.

Insufficient Isolation: Jeep Cherokee Hack
The 2015 Jeep Cherokee hack demonstrated how connectivity in everyday products creates new vulnerabilities. Security researchers publicly demonstrated a remote cyberattack on a Jeep Cherokee that exposed important vulnerabilities in automotive system design (Miller and Valasek 2015; Miller 2019). Conducted as a controlled experiment, the researchers exploited a vulnerability in the vehicle’s Uconnect entertainment system, which was connected to the internet via a cellular network. By gaining remote access to this system, they sent commands that affected the vehicle’s engine, transmission, and braking systems without physical access to the car.
This demonstration served as a wake-up call for the automotive industry, highlighting the risks posed by the growing connectivity of modern vehicles. Traditionally isolated automotive control systems, such as those managing steering and braking, were shown to be vulnerable when exposed through externally accessible software interfaces. The ability to remotely manipulate safety-critical functions raised serious concerns about passenger safety, regulatory oversight, and industry best practices.
The incident also led to a recall of over 1.4 million vehicles to patch the vulnerability6, highlighting the need for manufacturers to prioritize cybersecurity in their designs. The National Highway Traffic Safety Administration (NHTSA)7 issued guidelines for automakers to improve vehicle cybersecurity, including recommendations for secure software development practices and incident response protocols.
6 Automotive Cybersecurity Recalls: The Jeep Cherokee hack triggered the first-ever automotive cybersecurity recall in 2015. Since then, cybersecurity recalls have affected over 15 million vehicles globally, costing manufacturers an estimated $2.4 billion in remediation efforts and spurring new regulations.
7 NHTSA Cybersecurity Guidance: NHTSA, established in 1970, issued its first cybersecurity guidance in 2016 following the Jeep hack. The agency now mandates that connected vehicles include cybersecurity by design, affecting 99% of new vehicles sold in the US that contain 100+ onboard computers.
The Jeep Cherokee hack offers critical lessons for ML system security. Connected ML systems require strict isolation between external interfaces and safety-critical components, as this incident dramatically illustrated. The architectural flaw (allowing external interfaces to reach safety-critical functions) directly threatens modern ML deployments where inference APIs often connect to physical actuators or critical systems.
Modern ML attack vectors exploit these same isolation failures across multiple domains: (1) Autonomous vehicles where compromised infotainment system ML APIs (voice recognition, navigation) gain access to perception models controlling steering and braking; (2) Smart home systems where exploited voice assistant wake-word detection models provide backdoor access to security systems, door locks, and cameras; (3) Industrial IoT where compromised edge ML inference endpoints (predictive maintenance, anomaly detection) manipulate actuator control logic in manufacturing systems; (4) Medical devices where attacked diagnostic ML models influence treatment recommendations and drug delivery systems.
Consider a concrete attack scenario: a smart home voice assistant processes user commands through cloud-based NLP models. An attacker exploits a vulnerability in the voice processing API to inject malicious commands that bypass authentication. Through insufficient network segmentation, the compromised voice system gains access to the home security ML model responsible for facial recognition door unlocking, allowing unauthorized physical access.
Effective defense requires comprehensive isolation architecture: (1) network segmentation to isolate ML inference networks from actuator control networks using firewalls and VPNs; (2) API authentication requiring cryptographic authentication for all ML API calls with rate limiting and anomaly detection; (3) privilege separation to run inference models in sandboxed environments with minimal system permissions; (4) fail-safe defaults that design actuator control logic to revert to safe states (locked doors, stopped motors) when ML systems detect anomalies or lose connectivity; (5) monitoring that implements real-time logging and alerting for suspicious ML API usage patterns.
Weaponized Endpoints: Mirai Botnet
While the Jeep Cherokee hack demonstrated targeted exploitation of connected systems, the Mirai botnet revealed how poor security practices could be weaponized at massive scale. In 2016, the Mirai botnet8 emerged as one of the most disruptive distributed denial-of-service (DDoS)9 attacks in internet history (Antonakakis et al. 2017). The botnet infected thousands of networked devices, including digital cameras, DVRs, and other consumer electronics. These devices, often deployed with factory-default usernames and passwords, were easily compromised by the Mirai malware and enlisted into a large-scale attack network.
8 Mirai Botnet Scale: At its peak, Mirai controlled over 600,000 infected IoT devices, generating peak attacks of 1.2 Tbps (1,200 Gbps) against OVH hosting provider, making it one of the first terabit-scale DDoS attacks. The attack revealed that IoT devices with default credentials (admin/admin, root/12345) could be weaponized at unprecedented scale.
9 DDoS Attacks: Distributed Denial-of-Service (DDoS) attacks overwhelm targets with traffic from multiple sources, first demonstrated in 1999. Modern DDoS attacks can exceed 3.47 Tbps (terabits per second), enough to take down entire internet infrastructures and costing businesses $2.3 million per incident on average.
The Mirai botnet was used to overwhelm major internet infrastructure providers, disrupting access to popular online services across the United States and beyond. The scale of the attack demonstrated how vulnerable consumer and industrial devices can become a platform for widespread disruption when security is not prioritized in their design and deployment.
The Mirai botnet’s lessons apply directly to modern ML deployments. Edge-deployed ML devices with weak authentication become weaponized attack infrastructure at unprecedented scale, precisely as the Mirai botnet demonstrated with traditional IoT devices. Modern ML edge devices (smart cameras running object detection, voice assistants performing wake-word detection, autonomous drones with navigation models, industrial IoT sensors with anomaly detection algorithms) face identical vulnerability patterns but with amplified consequences due to their AI capabilities and access to sensitive data.
The attack escalation with ML devices differs significantly from traditional IoT compromises. Unlike simple IoT devices that provided only computing power for DDoS attacks, compromised ML devices offer sophisticated capabilities: (1) Data exfiltration where smart cameras leak facial recognition databases, voice assistants extract conversation transcripts, and health monitors steal biometric data; (2) Model weaponization where hijacked autonomous drones coordinate swarm attacks and compromised traffic cameras misreport vehicle counts to manipulate traffic systems; (3) AI-powered reconnaissance where compromised edge ML devices use their trained models to identify high-value targets (facial recognition for VIP identification, voice analysis for emotion detection) and coordinate sophisticated multi-stage attacks.
Consider a concrete attack scenario where attackers compromise 50,000 smart security cameras with default passwords, each running ML object detection models. Rather than traditional DDoS attacks, they use the compromised cameras to: (1) extract facial recognition databases from residential and commercial buildings; (2) coordinate physical surveillance of targeted individuals using distributed camera networks; (3) inject false object detection alerts to trigger emergency responses and create chaos; (4) use the cameras’ computing power to train adversarial examples against other security systems.
Comprehensive defense against such weaponization requires zero-trust edge security: (1) Secure manufacturing that eliminates default credentials, implements hardware security modules (HSMs) for device-unique keys, and enables secure boot with cryptographic verification; (2) Encrypted communications that mandate TLS 1.3+ for all ML API communications with certificate pinning and mutual authentication; (3) Behavioral monitoring that deploys anomaly detection systems to identify unusual inference patterns, unexpected network traffic, and suspicious computational loads; (4) Automated response that implements kill switches to disable compromised devices remotely and quarantine them from networks; (5) Update security that enforces cryptographically signed firmware updates with automatic security patching and version rollback capabilities.
Systematic Threat Analysis and Risk Assessment
The historical incidents demonstrate how fundamental security failures manifest across different computing paradigms. Supply chain vulnerabilities enable persistent compromise, insufficient isolation allows privilege escalation, and weaponized endpoints create attack infrastructure at scale. These patterns directly apply to machine learning deployments: compromised training pipelines and model repositories inherit supply chain risks, external interfaces to safety-critical ML components require strict isolation, and compromised ML edge devices can exfiltrate inference data or participate in coordinated attacks.
These historical incidents reveal universal security patterns that translate directly to ML system vulnerabilities. Supply chain compromise, as demonstrated by Stuxnet, manifests in ML through training data poisoning and backdoored model repositories. Insufficient isolation, exemplified by the Jeep Cherokee hack, appears in ML API access to safety-critical systems and compromised inference endpoints. Weaponized endpoints, illustrated by the Mirai botnet, emerge through hijacked ML edge devices capable of coordinated AI-powered attacks.
The key insight is that traditional cybersecurity patterns amplify in ML systems because models learn from data and make autonomous decisions. While Stuxnet required sophisticated malware to manipulate industrial controllers, ML systems can be compromised through data poisoning that appears statistically normal but embeds hidden behaviors. This characteristic makes ML systems both more vulnerable to subtle attacks and more dangerous when compromised, as they can make decisions affecting physical systems autonomously. Understanding these historical patterns helps recognize how familiar attack vectors manifest in ML contexts, while the unique properties of learning systems (statistical learning, decision autonomy, and data dependency) create new attack surfaces requiring specialized defenses.
Machine learning systems introduce attack vectors that extend beyond traditional computing vulnerabilities. The data-driven nature of learning creates new opportunities for adversaries: training data can be manipulated to embed backdoors, input perturbations can exploit learned decision boundaries, and systematic API queries can extract proprietary model knowledge. These ML-specific threats require specialized defenses that account for the statistical and probabilistic foundations of learning systems, complementing traditional infrastructure hardening.
Threat Prioritization Framework
With the wide range of potential threats facing ML systems, practitioners need a framework to prioritize their defensive efforts effectively. Not all threats are equally likely or impactful, and security resources are always constrained. A simple prioritization matrix based on likelihood and impact helps focus attention where it matters most.
Consider these threat priority categories:
High Likelihood / High Impact: Data poisoning in federated learning systems where training data comes from untrusted sources. These attacks are relatively easy to execute but can severely compromise model behavior.
High Likelihood / Medium Impact: Model extraction attacks against public APIs. These are common and technically simple but may only affect competitive advantage rather than safety or privacy.
Low Likelihood / High Impact: Hardware side-channel attacks on cloud-deployed models. These require sophisticated adversaries and physical access but could expose all model parameters and user data.
Medium Likelihood / Medium Impact: Membership inference attacks against models trained on sensitive data. These require some technical skill but mainly threaten individual privacy rather than system integrity.
This framework guides resource allocation throughout this chapter. We begin with the most common and accessible threats (model theft, data poisoning, and adversarial attacks) before examining more specialized hardware and infrastructure vulnerabilities. Understanding these priority levels helps practitioners implement defenses in a logical sequence that maximizes security benefit per invested effort.
Model-Specific Attack Vectors
Machine learning systems face threats spanning the entire ML lifecycle, from training-time manipulations to inference-time evasion. These threats fall into three broad categories: threats to model confidentiality (model theft), threats to training integrity (data poisoning10), and threats to inference robustness (adversarial examples11). Each category targets different vulnerabilities and requires distinct defensive strategies.
10 Data Poisoning Attacks: Data poisoning is an attack technique where adversaries inject malicious data during training, first formalized in 2012 (Biggio, Nelson, and Laskov 2012). Studies show that poisoning just 0.1% of training data can reduce model accuracy by 10-50%, making it a highly efficient attack vector against ML systems.
11 Adversarial Examples: Adversarial examples are inputs crafted to deceive ML models, discovered by Szegedy et al. (Szegedy et al. 2013). These attacks can fool state-of-the-art image classifiers with perturbations invisible to humans (changing <0.01% of pixel values), affecting 99%+ of deep learning models.
Understanding when and where different attacks occur in the ML lifecycle helps prioritize defenses and understand attacker motivations. Figure 2 maps the primary attack vectors to their target stages in the machine learning pipeline, revealing how adversaries exploit different system vulnerabilities at different times.
During Data Collection: Attackers can inject malicious samples or manipulate labels in training datasets, particularly in federated learning or crowdsourced data scenarios where data sources are less controlled.
During Training: This stage faces backdoor insertion attacks, where adversaries embed hidden behaviors that activate only under specific trigger conditions, and label manipulation attacks that systematically corrupt the learning process.
During Deployment: Model theft attacks target this stage because trained models become accessible through APIs, file downloads, or reverse engineering of mobile applications. This is where intellectual property is most vulnerable.
During Inference: Adversarial attacks occur at runtime, where attackers craft inputs designed to fool deployed models into making incorrect predictions while appearing normal to human observers.
This lifecycle perspective reveals that different threats require different defensive strategies. Data validation protects the collection phase, secure training environments protect the training phase, access controls and API design protect deployment, and input validation protects inference. By understanding which attacks target which lifecycle stages, security teams can implement appropriate defenses at the right architectural layers.

Machine learning models are not solely passive victims of attack; in some cases, they can be employed as components of an attack strategy. Pretrained models, particularly large generative or discriminative networks, may be adapted to automate tasks such as adversarial example generation, phishing content synthesis12, or protocol subversion. Open-source or publicly accessible models can be fine-tuned for malicious purposes, including impersonation, surveillance, or reverse-engineering of secure systems.
12 AI-Generated Phishing: Large language models can generate convincing phishing emails with 99%+ grammatical accuracy, compared to 19% for traditional phishing. Security firms report dramatic increases in AI-generated phishing attacks since 2022, with some studies citing 1,265% growth (though methodologies and baselines vary significantly), with some campaigns achieving 30%+ success rates. This dual-use potential necessitates a broader security perspective that considers models not only as assets to defend but also as possible instruments of attack.
Model Theft
The first category of model-specific threats targets confidentiality. Threats to model confidentiality arise when adversaries gain access to a trained model’s parameters, architecture, or output behavior. These attacks can undermine the economic value of machine learning systems, allow competitors to replicate proprietary functionality, or expose private information encoded in model weights.
Such threats arise across a range of deployment settings, including public APIs13, cloud-hosted services, on-device inference engines, and shared model repositories14. Machine learning models may be vulnerable due to exposed interfaces, insecure serialization formats15, or insufficient access controls, factors that create opportunities for unauthorized extraction or replication (Ateniese et al. 2015).
13 Machine Learning APIs: Machine learning APIs (Application Programming Interfaces) were popularized by Google’s Prediction API (2010). Today’s ML APIs handle billions of requests daily, with major providers processing billions of tokens monthly, creating vast attack surfaces for model extraction.
14 Model Repositories: Model repositories are centralized platforms for sharing ML models, led by Hugging Face (2016) which hosts 500,000+ models. While democratizing AI access, these repositories have become targets for supply chain attacks, with researchers finding malicious models in 5% of popular repositories (Oliynyk, Mayer, and Rauber 2023).
15 Model Serialization: Model serialization is the process of converting trained models into portable formats like ONNX (2017), TensorFlow SavedModel (2016), or PyTorch’s .pth files. Insecure serialization can expose model weights and enable arbitrary code execution, affecting 80%+ of deployed ML systems (Ateniese et al. 2015; Tramèr et al. 2016).
The severity of these threats is underscored by high-profile legal cases that have highlighted the strategic and economic value of machine learning models. For example, former Google engineer Anthony Levandowski was accused of stealing proprietary designs from Waymo, including critical components of its autonomous vehicle technology, before founding a competing startup. Such cases illustrate the potential for insider threats to bypass technical protections and gain access to sensitive intellectual property.
The consequences of model theft extend beyond economic loss. Stolen models can be used to extract sensitive information, replicate proprietary algorithms, or enable further attacks. The economic impact can be substantial: research estimates suggest that aspects of large language models can be approximated through systematic API queries at costs orders of magnitude lower than original training, though full model replication remains economically and technically challenging (Tramèr et al. 2016; Carlini et al. 2024). For instance, a competitor who obtains a stolen recommendation model from an e-commerce platform might gain insights into customer behavior, business analytics, and embedded trade secrets. This knowledge can also be used to conduct model inversion attacks16, where an attacker attempts to infer private details about the model’s training data (Fredrikson, Jha, and Ristenpart 2015).
16 Model Inversion Attacks: Model inversion attacks were first demonstrated in 2015 against face recognition systems, when researchers reconstructed recognizable faces from neural network outputs using only confidence scores. The attack revealed that models trained on 40 individuals could leak identifiable facial features, proving that “black-box” API access isn’t sufficient privacy protection.
17 Netflix Deanonymization: In 2008, researchers re-identified Netflix users by correlating the “anonymous” Prize dataset with public IMDb ratings. Using as few as 8 movie ratings with dates, they identified 99% of users, leading Netflix to cancel a second competition and highlighting the futility of naive anonymization.
In a model inversion attack, the adversary queries the model through a legitimate interface, such as a public API, and observes its outputs. By analyzing confidence scores or output probabilities, the attacker can optimize inputs to reconstruct data resembling the model’s training set. For example, a facial recognition model used for secure access could be manipulated to reveal statistical properties of the employee photos on which it was trained. Similar vulnerabilities have been demonstrated in studies on the Netflix Prize dataset17, where researchers inferred individual movie preferences from anonymized data (Narayanan and Shmatikov 2006).
Model theft can target two distinct objectives: extracting exact model properties, such as architecture and parameters, or replicating approximate model behavior to produce similar outputs without direct access to internal representations. Understanding neural network architectures helps recognize which architectural patterns are most vulnerable to extraction attacks. The specific architectural vulnerabilities vary by model type, as discussed in Chapter 4: DNN Architectures. Both forms of theft undermine the security and value of machine learning systems, as explored in the following subsections.
These two attack paths are illustrated in Figure 3. In exact model theft, the attacker gains access to the model’s internal components, including serialized files, weights, and architecture definitions, and reproduces the model directly. In contrast, approximate model theft relies on observing the model’s input-output behavior, typically through a public API. By repeatedly querying the model and collecting responses, the attacker trains a surrogate that mimics the original model’s functionality. The first approach compromises the model’s internal design and training investment, while the second threatens its predictive value and can facilitate further attacks such as adversarial example transfer or model inversion.

Exact Model Theft
Exact model property theft refers to attacks aimed at extracting the internal structure and learned parameters of a machine learning model. These attacks often target deployed models that are exposed through APIs, embedded in on-device inference engines, or shared as downloadable model files on collaboration platforms. Exploiting weak access control, insecure model packaging, or unprotected deployment interfaces, attackers can recover proprietary model assets without requiring full control of the underlying infrastructure.
These attacks typically seek three types of information. The first is the model’s learned parameters, such as weights and biases. By extracting these parameters, attackers can replicate the model’s functionality without incurring the cost of training. This replication allows them to benefit from the model’s performance while bypassing the original development effort.
The second target is the model’s fine-tuned hyperparameters, including training configurations such as learning rate, batch size, and regularization settings. These hyperparameters significantly influence model performance, and stealing them allows attackers to reproduce high-quality results with minimal additional experimentation.
Finally, attackers may seek to reconstruct the model’s architecture. This includes the sequence and types of layers, activation functions, and connectivity patterns that define the model’s behavior. Architecture theft may be accomplished through side-channel attacks18, reverse engineering, or analysis of observable model behavior.
18 ML Side-Channel Attacks: Side-channel attacks on ML were first demonstrated against neural networks in 2018, when researchers showed that power consumption patterns during inference could reveal sensitive model information. This extended traditional cryptographic side-channel attacks into the ML domain, creating new vulnerabilities for edge AI devices.
Revealing the architecture not only compromises intellectual property but also gives competitors strategic insights into the design choices that provide competitive advantage.
System designers must account for these risks by securing model serialization formats, restricting access to runtime APIs, and hardening deployment pipelines. Protecting models requires a combination of software engineering practices, including access control, encryption, and obfuscation techniques, to reduce the risk of unauthorized extraction (Tramèr et al. 2016).
Approximate Model Theft
While some attackers seek to extract a model’s exact internal properties, others focus on replicating its external behavior. Approximate model behavior theft refers to attacks that attempt to recreate a model’s decision-making capabilities without directly accessing its parameters or architecture. Instead, attackers observe the model’s inputs and outputs to build a substitute model that performs similarly on the same tasks.
This type of theft often targets models deployed as services, where the model is exposed through an API or embedded in a user-facing application. By repeatedly querying the model and recording its responses, an attacker can train their own model to mimic the behavior of the original. This process, often called model distillation19 or knockoff modeling, allows attackers to achieve comparable functionality without access to the original model’s proprietary internals (Orekondy, Schiele, and Fritz 2019).
19 Model Distillation: Model distillation is a knowledge transfer technique developed by (Hinton, Vinyals, and Dean 2015) where a smaller “student” model learns from a larger “teacher” model. While designed for model compression, attackers exploit this to create stolen models with 95%+ accuracy using only 1% of the original training data.
Attackers may evaluate the success of behavior replication in two ways. The first is by measuring the level of effectiveness of the substitute model. This involves assessing whether the cloned model achieves similar accuracy, precision, recall, or other performance metrics on benchmark tasks. By aligning the substitute’s performance with that of the original, attackers can build a model that is practically indistinguishable in effectiveness, even if its internal structure differs.
The second is by testing prediction consistency. This involves checking whether the substitute model produces the same outputs as the original model when presented with the same inputs. Matching not only correct predictions but also the original model’s mistakes can provide attackers with a high-fidelity reproduction of the target model’s behavior. This poses particular concern in applications such as natural language processing, where attackers might replicate sentiment analysis models to gain competitive insights or bypass proprietary systems.
Approximate behavior theft proves challenging to defend against in open-access deployment settings, such as public APIs or consumer-facing applications. Limiting the rate of queries, detecting automated extraction patterns, and watermarking model outputs are among the techniques that can help mitigate this risk. However, these defenses must be balanced with usability and performance considerations, especially in production environments.
One demonstration of approximate model theft extracts internal components of black-box language models via public APIs. In their paper, Carlini et al. (2024), researchers show how to reconstruct the final embedding projection matrix of several OpenAI models, including ada, babbage, and gpt-3.5-turbo, using only public API access. By exploiting the low-rank structure of the output projection layer and making carefully crafted queries, they recover the model’s hidden dimensionality and replicate the weight matrix up to affine transformations.
The attack does not reconstruct the full model, but reveals internal architecture parameters and sets a precedent for future, deeper extractions. This work demonstrated that even partial model theft poses risks to confidentiality and competitive advantage, especially when model behavior can be probed through rich API responses such as logit bias and log-probabilities.
| Model | Size (Dimension Extraction) | Number of Queries | RMS (Weight Matrix Extraction) | Cost (USD) |
|---|---|---|---|---|
| OpenAI ada | 1024 ✓ | < 2 ^6$ | \(5 \cdot 10^{-4}\) | $1 / $4 |
| OpenAI babbage | 2048 ✓ | < 4 ^6$ | \(7 \cdot 10^{-4}\) | $2 / $12 |
| OpenAI babbage-002 | 1536 ✓ | < 4 ^6$ | Not implemented | $2 / $12 |
| OpenAI gpt-3.5-turbo-instruct | Not disclosed | < 4 ^7$ | Not implemented | $200 / ~$2,000 (estimated) |
| OpenAI gpt-3.5-turbo-1106 | Not disclosed | < 4 ^7$ | Not implemented | $800 / ~$8,000 (estimated) |
As shown in their empirical evaluation, reproduced in Table 2, model parameters could be extracted with root mean square errors as low as \(10^{-4}\), confirming that high-fidelity approximation is achievable at scale. These findings raise important implications for system design, suggesting that innocuous API features, like returning top-k logits, can serve as significant leakage vectors if not tightly controlled.
Case Study: Tesla IP Theft
In 2018, Tesla filed a lawsuit against the self-driving car startup Zoox, alleging that former Tesla employees had stolen proprietary data and trade secrets related to Tesla’s autonomous driving technology. According to the lawsuit, several employees transferred over 10 gigabytes of confidential files, including machine learning models and source code, before leaving Tesla to join Zoox.
Among the stolen materials was a key image recognition model used for object detection in Tesla’s self-driving system. By obtaining this model, Zoox could have bypassed years of research and development, giving the company a competitive advantage. Beyond the economic implications, there were concerns that the stolen model could expose Tesla to further security risks, such as model inversion attacks aimed at extracting sensitive data from the model’s training set.
The Zoox employees denied any wrongdoing, and the case was ultimately settled out of court. The incident highlights the real-world risks of model theft, especially in industries where machine learning models represent significant intellectual property. The theft of models not only undermines competitive advantage but also raises broader concerns about privacy, safety, and the potential for downstream exploitation.
This case demonstrates that model theft is not limited to theoretical attacks conducted over APIs or public interfaces. Insider threats, supply chain vulnerabilities, and unauthorized access to development infrastructure pose equally serious risks to machine learning systems deployed in commercial environments.
Data Poisoning
While model theft targets confidentiality, the second category of threats focuses on training integrity. Training integrity threats stem from the manipulation of data used to train machine learning models. These attacks aim to corrupt the learning process by introducing examples that appear benign but induce harmful or biased behavior in the final model.
Data poisoning attacks are a prominent example, in which adversaries inject carefully crafted data points into the training set to influence model behavior in targeted or systemic ways (Biggio, Nelson, and Laskov 2012). Poisoned data may cause a model to make incorrect predictions, degrade its generalization ability, or embed failure modes that remain dormant until triggered post-deployment.
20 Crowdsourcing Risks: Platforms like Amazon Mechanical Turk (2005) and Prolific democratized data labeling but introduced poisoning risks. Studies show 15-30% of crowdsourced labels contain errors or bias (Biggio, Nelson, and Laskov 2012; Oprea, Singhal, and Vassilev 2022), with coordinated attacks capable of poisoning entire datasets at costs under $1,000.
Data poisoning is a security threat because it involves intentional manipulation of the training data by an adversary, with the goal of embedding vulnerabilities or subverting model behavior. These attacks pose concern in applications where models retrain on data collected from external sources, including user interactions, crowdsourced annotations20, and online scraping, since attackers can inject poisoned data without direct access to the training pipeline.
These attacks occur across diverse threat models. From a security perspective, poisoning attacks vary depending on the attacker’s level of access and knowledge. In white-box scenarios, the adversary may have detailed insight into the model architecture or training process, enabling more precise manipulation. In contrast, black-box or limited-access attacks exploit open data submission channels or indirect injection vectors. Poisoning can target different stages of the ML pipeline, ranging from data collection and preprocessing to labeling and storage, making the attack surface both broad and system-dependent. The relative priority of data poisoning threats varies by deployment context as analyzed in Section 1.4.1.
Poisoning attacks typically follow a three-stage process. First, the attacker injects malicious data into the training set. These examples are often designed to appear legitimate but introduce subtle distortions that alter the model’s learning process. Second, the model trains on this compromised data, embedding the attacker’s intended behavior. Finally, once the model is deployed, the attacker may exploit the altered behavior to cause mispredictions, bypass safety checks, or degrade overall reliability.
To understand these attack mechanisms precisely, data poisoning can be viewed as a bilevel optimization problem, where the attacker seeks to select poisoning data \(D_p\) that maximizes the model’s loss on a validation or target dataset \(D_{\text{test}}\). Let \(D\) represent the original training data. The attacker’s objective is to solve: \[ \max_{D_p} \ \mathcal{L}(f_{D \cup D_p}, D_{\text{test}}) \] where \(f_{D \cup D_p}\) represents the model trained on the combined dataset of original and poisoned data. For targeted attacks, this objective can be refined to focus on specific inputs \(x_t\) and target labels \(y_t\): \[ \max_{D_p} \ \mathcal{L}(f_{D \cup D_p}, x_t, y_t) \]
This formulation captures the adversary’s goal of introducing carefully crafted data points to manipulate the model’s decision boundaries.
For example, consider a traffic sign classification model trained to distinguish between stop signs and speed limit signs. An attacker might inject a small number of stop sign images labeled as speed limit signs into the training data. The attacker’s goal is to subtly shift the model’s decision boundary so that future stop signs are misclassified as speed limit signs. In this case, the poisoning data \(D_p\) consists of mislabeled stop sign images, and the attacker’s objective is to maximize the misclassification of legitimate stop signs \(x_t\) as speed limit signs \(y_t\), following the targeted attack formulation above. Even if the model performs well on other types of signs, the poisoned training process creates a predictable and exploitable vulnerability.
Data poisoning attacks can be classified based on their objectives and scope of impact. Availability attacks degrade overall model performance by introducing noise or label flips that reduce accuracy across tasks. Targeted attacks manipulate a specific input or class, leaving general performance intact but causing consistent misclassification in select cases. Backdoor attacks21 embed hidden triggers, which are often imperceptible patterns, that elicit malicious behavior only when the trigger is present. Subpopulation attacks degrade performance on a specific group defined by shared features, making them particularly dangerous in fairness-sensitive applications.
21 Backdoor Attacks: Backdoor attacks involve hidden triggers embedded in ML models during training, first demonstrated in 2017. These attacks achieve 99%+ success rates while maintaining normal accuracy, with triggers as subtle as single-pixel modifications. BadNets, the seminal backdoor attack, affected 100% of tested models.
22 Perspective API: Google’s Perspective API is a toxicity detection model launched in 2017, now processing 500+ million comments daily across platforms like The New York Times and Wikipedia. Despite sophisticated training, the API demonstrates how even billion-parameter models remain vulnerable to targeted poisoning attacks.
23 Perspective Vulnerability: After retraining, the poisoned model exhibited a significantly higher false negative rate, allowing offensive language to bypass filters. This demonstrates how poisoned data can exploit feedback loops in user-generated content systems, creating long-term vulnerabilities in content moderation pipelines.
A notable real-world example of a targeted poisoning attack was demonstrated against Perspective, Google’s widely-used online toxicity detection model22 that helps platforms identify harmful content (Hosseini et al. 2017). By injecting synthetically generated toxic comments with subtle misspellings and grammatical errors into the model’s training set, researchers degraded its ability to detect harmful content23.
Mitigating data poisoning threats requires end-to-end security of the data pipeline, encompassing collection, storage, labeling, and training. Preventative measures include input validation checks, integrity verification of training datasets, and anomaly detection to flag suspicious patterns. In parallel, robust training algorithms can limit the influence of mislabeled or manipulated data by down-weighting or filtering out anomalous instances. While no single technique guarantees immunity, combining proactive data governance, automated monitoring, and robust learning practices is important for maintaining model integrity in real-world deployments.
Adversarial Attacks
Moving from training-time to inference-time threats, the third category targets model robustness during deployment. Inference robustness threats occur when attackers manipulate inputs at test time to induce incorrect predictions. Unlike data poisoning, which compromises the training process, these attacks exploit vulnerabilities in the model’s decision surface during inference.
A central class of such threats is adversarial attacks, where carefully constructed inputs are designed to cause incorrect predictions while remaining nearly indistinguishable from legitimate data. As detailed in Chapter 16: Robust AI, these attacks highlight vulnerabilities in ML models’ sensitivity to small, targeted perturbations that can drastically alter output confidence or classification results.
These attacks create significant real-world risks in domains such as autonomous driving, biometric authentication, and content moderation. The effectiveness can be striking: research demonstrates that adversarial examples can achieve 99%+ attack success rates against state-of-the-art image classifiers while modifying less than 0.01% of pixel values, changes virtually imperceptible to humans (Szegedy et al. 2013; Goodfellow, Shlens, and Szegedy 2014). In physical-world attacks, printed adversarial patches as small as 2% of an image can cause autonomous vehicles to misclassify stop signs as speed limit signs with 80%+ success rates under varying lighting conditions (Eykholt et al. 2017).
Unlike data poisoning, which corrupts the model during training, adversarial attacks manipulate the model’s behavior at test time, often without requiring any access to the training data or model internals. The attack surface thus shifts from upstream data pipelines to real-time interaction, demanding robust defense mechanisms capable of detecting or mitigating malicious inputs at the point of inference.
The mathematical foundations of adversarial example generation and comprehensive taxonomies of attack algorithms, including gradient-based, optimization-based, and transfer-based techniques, are covered in detail in Chapter 16: Robust AI, which explores robust approaches to building adversarially resistant systems.
Adversarial attacks vary based on the attacker’s level of access to the model. In white-box attacks, the adversary has full knowledge of the model’s architecture, parameters, and training data, allowing them to craft highly effective adversarial examples. In black-box attacks, the adversary has no internal knowledge and must rely on querying the model and observing its outputs. Grey-box attacks fall between these extremes, with the adversary possessing partial information, such as access to the model architecture but not its parameters.
These attacker models can be summarized along a spectrum of knowledge levels. Table 3 highlights the differences in model access, data access, typical attack strategies, and common deployment scenarios. Such distinctions help characterize the practical challenges of securing ML systems across different deployment environments.
Common attack strategies include surrogate model construction, transfer attacks exploiting adversarial transferability, and GAN-based perturbation generation. The technical details of these approaches and their mathematical formulations are thoroughly covered in Chapter 16: Robust AI.
| Adversary Knowledge Level | Model Access | Training Data Access | Attack Example | Common Scenario |
|---|---|---|---|---|
| White-box | Full access to architecture and parameters | Full access | Crafting adversarial examples using gradients | Insider threats, open-source model reuse |
| Grey-box | Partial access (e.g., architecture only) | Limited or no access | Attacks based on surrogate model approximation | Known model family, unknown fine-tuning |
| Black-box | No internal access; only query-response view | No access | Query-based surrogate model training and transfer attacks | Public APIs, model-as-a-service deployments |
One illustrative example involves the manipulation of traffic sign recognition systems (Eykholt et al. 2017). Researchers demonstrated that placing small stickers on stop signs could cause machine learning models to misclassify them as speed limit signs. While the altered signs remained easily recognizable to humans, the model consistently misinterpreted them. Such attacks pose serious risks in applications like autonomous driving, where reliable perception is important for safety.
Adversarial attacks highlight the need for robust defenses that go beyond improving model accuracy. Securing ML systems against adversarial threats requires runtime defenses such as input validation, anomaly detection, and monitoring for abnormal patterns during inference. Training-time robustness methods (e.g., adversarial training) complement these strategies and are explored in Chapter 16: Robust AI. The training methodologies that support robust model development are detailed in Chapter 8: AI Training. These defenses aim to enhance model resilience against adversarial examples, ensuring that machine learning systems can operate reliably even in the presence of malicious inputs.
Case Study: Traffic Sign Attack
In 2017, researchers conducted experiments by placing small black and white stickers on stop signs (Eykholt et al. 2017). As shown in Figure 4, these stickers were designed to be nearly imperceptible to the human eye, yet they significantly altered the appearance of the stop sign when viewed by machine learning models. When viewed by a normal human eye, the stickers did not obscure the sign or prevent interpretability. However, when images of the stickers stop signs were fed into standard traffic sign classification ML models, they were misclassified as speed limit signs over 85% of the time.

This demonstration showed how simple adversarial stickers could trick ML systems into misreading important road signs. If deployed realistically, these attacks could endanger public safety, causing autonomous vehicles to misinterpret stop signs as speed limits. Researchers warned this could potentially cause dangerous rolling stops or acceleration into intersections.
This case study provides a concrete illustration of how adversarial examples exploit the pattern recognition mechanisms of ML models. By subtly altering the input data, attackers can induce incorrect predictions and pose significant risks to safety-important applications like self-driving cars. The attack’s simplicity demonstrates how even minor, imperceptible changes can lead models astray. Consequently, developers must implement robust defenses against such threats.
These threat types span different stages of the ML lifecycle and demand distinct defensive strategies. Table 4 below summarizes their key characteristics.
| Threat Type | Lifecycle Stage | Attack Vector | Example Impact |
|---|---|---|---|
| Model Theft | Deployment | API access, insider leaks | Stolen IP, model inversion, behavioral clone |
| Data Poisoning | Training | Label flipping, backdoors | Targeted misclassification, degraded accuracy |
| Adversarial Attacks | Inference | Input perturbation | Real-time misclassification, safety failure |
The appropriate defense for a given threat depends on its type, attack vector, and where it occurs in the ML lifecycle. Figure 5 provides a simplified decision flow that connects common threat categories, such as model theft, data poisoning, and adversarial examples, to corresponding defensive strategies. While real-world deployments may require more nuanced combinations of defenses as discussed in our layered defense framework, this flowchart serves as a conceptual guide for aligning threat models with practical mitigation techniques.

While ML models themselves present important attack surfaces, they ultimately run on hardware that can introduce vulnerabilities beyond the model’s control. The transition from software-based threats to hardware-based vulnerabilities represents a significant shift in the security landscape. Where software attacks target code logic and data flows, hardware attacks exploit the physical properties of the computing substrate itself.
The specialized computing infrastructure that powers machine learning workloads creates a layered attack surface that extends far beyond traditional software vulnerabilities. This includes the processors that execute instructions, the memory systems that store data, and the interconnects that move information between components. Understanding these hardware-level risks is essential because they can bypass conventional software security mechanisms and remain difficult to detect. These risks are addressed through the hardware-based security mechanisms detailed in Section 1.8.7.
In the next section, we examine how adversaries can target the physical infrastructure that executes machine learning workloads through hardware bugs, physical tampering, side channels, and supply chain risks.
Hardware-Level Security Vulnerabilities
As machine learning systems move from research prototypes to large-scale, real-world deployments, their security depends on the hardware platforms they run on. Whether deployed in data centers, on edge devices, or in embedded systems, machine learning applications rely on a layered stack of processors, accelerators, memory, and communication interfaces. These hardware components, while essential for enabling efficient computation, introduce unique security risks that go beyond traditional software-based vulnerabilities.
Unlike general-purpose software systems, machine learning workflows often process high-value models and sensitive data in performance-constrained environments. This makes them attractive targets not only for software attacks but also for hardware-level exploitation. Vulnerabilities in hardware can expose models to theft, leak user data, disrupt system reliability, or allow adversaries to manipulate inference results. Because hardware operates below the software stack, such attacks can bypass conventional security mechanisms and remain difficult to detect.
Understanding hardware security threats requires considering how computing substrates implement machine learning operations. At the hardware level, CPU components like arithmetic logic units, registers, and caches execute the instructions that drive model inference and training. Memory hierarchies determine how quickly models can access parameters and intermediate results. The hardware-software interface, mediated by firmware and bootloaders, establishes the initial trust foundation for system operation. The physical properties of computation—including power consumption, timing characteristics, and electromagnetic emissions—create observable signals that attackers can exploit to extract sensitive information.
Hardware threats arise from multiple sources that span the entire system lifecycle. Design flaws in processor architectures, exemplified by vulnerabilities like Meltdown and Spectre, can compromise security guarantees. Physical tampering enables direct manipulation of components and data flows. Side-channel attacks exploit unintended information leakage through power traces, timing variations, and electromagnetic radiation. Supply chain compromises introduce malicious components or modifications during manufacturing and distribution. Together, these threats form a critical attack surface that must be addressed to build trustworthy machine learning systems. For readers focusing on practical deployment, the key lessons center on supply chain verification, physical access controls, and hardware trust anchors, while the defensive strategies in Section 1.8 provide actionable guidance regardless of deep architectural expertise.
Table 5 summarizes the major categories of hardware security threats, describing their origins, methods, and implications for machine learning system design and deployment.
| Threat Type | Description | Relevance to ML Hardware Security |
|---|---|---|
| Hardware Bugs | Intrinsic flaws in hardware designs that can compromise system integrity. | Foundation of hardware vulnerability. |
| Physical Attacks | Direct exploitation of hardware through physical access or manipulation. | Basic and overt threat model. |
| Fault-injection Attacks | Induction of faults to cause errors in hardware operation, leading to potential system crashes. | Systematic manipulation leading to failure. |
| Side-Channel Attacks | Exploitation of leaked information from hardware operation to extract sensitive data. | Indirect attack via environmental observation. |
| Leaky Interfaces | Vulnerabilities arising from interfaces that expose data unintentionally. | Data exposure through communication channels. |
| Counterfeit Hardware | Use of unauthorized hardware components that may have security flaws. | Compounded vulnerability issues. |
| Supply Chain Risks | Risks introduced through the hardware lifecycle, from production to deployment. | Cumulative & multifaceted security challenges. |
Hardware Bugs
The first category of hardware threats stems from design vulnerabilities. Hardware is not immune to the pervasive issue of design flaws or bugs. Attackers can exploit these vulnerabilities to access, manipulate, or extract sensitive data, breaching the confidentiality and integrity that users and services depend on. One of the most notable examples came with the discovery of Meltdown and Spectre24—two vulnerabilities in modern processors that allow malicious programs to bypass memory isolation and read the data of other applications and the operating system (Kocher et al. 2019a, 2019b).
24 Meltdown/Spectre Impact: Disclosed in January 2018, these vulnerabilities affected virtually every processor made since 1995 (billions of devices). The disclosure triggered emergency patches across all major operating systems, causing 5-30% performance degradation in some workloads, and led to a core rethinking of processor security.
25 Speculative Execution: Introduced in the Intel Pentium Pro (1995), this technique executes instructions before confirming they’re needed, improving performance by 10-25%. However, it creates a 20+ year attack window where speculated operations leak data through cache timing, affecting ML accelerators that rely on similar optimizations.
These attacks exploit speculative execution25, a performance optimization in CPUs that executes instructions out of order before safety checks are complete. While improving computational speed, this optimization inadvertently exposes sensitive data through microarchitectural side channels, such as CPU caches. The technical sophistication of these attacks highlights the difficulty of eliminating vulnerabilities even with extensive hardware validation.
Further research has revealed that these were not isolated incidents. Variants such as Foreshadow, ZombieLoad, and RIDL target different microarchitectural elements, ranging from secure enclaves to CPU internal buffers, demonstrating that speculative execution flaws are a systemic hardware risk. This systemic nature means that while these attacks were first demonstrated on general-purpose CPUs, their implications extend to machine learning accelerators and specialized hardware. ML systems often rely on heterogeneous compute platforms that combine CPUs with GPUs, TPUs, FPGAs, or custom accelerators. These components process sensitive data such as personal information, medical records, or proprietary models. Vulnerabilities in any part of this stack could expose such data to attackers.
For example, an edge device like a smart camera running a face recognition model on an accelerator could be vulnerable if the hardware lacks proper cache isolation. An attacker might exploit this weakness to extract intermediate computations, model parameters, or user data. Similar risks exist in cloud inference services, where hardware multi-tenancy increases the chances of cross-tenant data leakage.
Such vulnerabilities pose concern in privacy-sensitive domains like healthcare, where ML systems routinely handle patient data. A breach could violate privacy regulations such as the Health Insurance Portability and Accountability Act (HIPAA)26, leading to significant legal and ethical consequences. Similar regulatory risks apply globally, with GDPR27 imposing fines up to 4% of global revenue for organizations that fail to implement appropriate technical measures to protect EU citizens’ data.
26 HIPAA Violations: Since enforcement began in 2003, HIPAA has generated over $130 million in fines, with individual penalties reaching $16 million. The largest healthcare data breach affected 78.8 million patients at Anthem Inc. in 2015, highlighting the massive scale of exposure when ML systems handling medical data are compromised.
27 General Data Protection Regulation (GDPR): Enacted by the EU in 2018, GDPR imposes fines up to 4% of global revenue (€20+ million) for privacy violations. Since enforcement began, over €4.5 billion in fines have been levied, including €746 million against Amazon in 2021, driving massive investment in privacy-preserving ML technologies.
These examples illustrate that hardware security is not solely about preventing physical tampering. It also requires architectural safeguards to prevent data leakage through the hardware itself. As new vulnerabilities continue to emerge across processors, accelerators, and memory systems, addressing these risks requires continuous mitigation efforts, often involving performance trade-offs, especially in compute- and memory-intensive ML workloads. Proactive solutions, such as confidential computing and trusted execution environments (TEEs), offer promising architectural defenses. However, achieving robust hardware security requires attention at every stage of the system lifecycle, from design to deployment.
Physical Attacks
Beyond design flaws, the second category involves direct physical manipulation. Physical tampering refers to the direct, unauthorized manipulation of computing hardware to undermine the integrity of machine learning systems. This type of attack is particularly concerning because it bypasses traditional software security defenses, directly targeting the physical components on which machine learning depends. ML systems are especially vulnerable to such attacks because they rely on hardware sensors, accelerators, and storage to process large volumes of data and produce reliable outcomes in real-world environments.
While software security measures, including encryption, authentication, and access control, protect ML systems against remote attacks, they offer little defense against adversaries with physical access to devices. Physical tampering can range from simple actions, like inserting a malicious USB device into an edge server, to highly sophisticated manipulations such as embedding hardware trojans during chip manufacturing. These threats are particularly relevant for machine learning systems deployed at the edge or in physically exposed environments, where attackers may have opportunities to interfere with the hardware directly.
To understand how such attacks affect ML systems in practice, consider the example of an ML-powered drone used for environmental mapping or infrastructure inspection. The drone’s navigation depends on machine learning models that process data from GPS, cameras, and inertial measurement units. If an attacker gains physical access to the drone, they could replace or modify its navigation module, embedding a hidden backdoor that alters flight behavior or reroutes data collection. Such manipulation not only compromises the system’s reliability but also opens the door to misuse, such as surveillance or smuggling operations.
These threats extend across application domains. Physical attacks are not limited to mobility systems. Biometric access control systems, which rely on ML models to process face or fingerprint data, are also vulnerable. These systems typically use embedded hardware to capture and process biometric inputs. An attacker could physically replace a biometric sensor with a modified component designed to capture and transmit personal identification data to an unauthorized receiver. This creates multiple vulnerabilities including unauthorized data access and enabling future impersonation attacks.
In addition to tampering with external sensors, attackers may target internal hardware subsystems. For example, the sensors used in autonomous vehicles, including cameras, LiDAR, and radar, are important for ML models that interpret the surrounding environment. A malicious actor could physically misalign or obstruct these sensors, degrading the model’s perception capabilities and creating safety hazards.
Hardware trojans pose another serious risk. Malicious modifications introduced during chip fabrication or assembly can embed dormant circuits in ML accelerators or inference chips. These trojans may remain inactive under normal conditions but trigger malicious behavior when specific inputs are processed or system states are reached. Such hidden vulnerabilities can disrupt computations, leak model outputs, or degrade system performance in ways that are extremely difficult to diagnose post-deployment.
Memory subsystems are also attractive targets. Attackers with physical access to edge devices or embedded ML accelerators could manipulate memory chips to extract encrypted model parameters or training data. Fault injection techniques, including voltage manipulation and electromagnetic interference, can further degrade system reliability by corrupting model weights or forcing incorrect computations during inference.
Physical access threats extend to data center and cloud environments as well. Attackers with sufficient access could install hardware implants, such as keyloggers or data interceptors, to capture administrative credentials or monitor data streams. Such implants can provide persistent backdoor access, enabling long-term surveillance or data exfiltration from ML training and inference pipelines.
In summary, physical attacks on machine learning systems threaten both security and reliability across a wide range of deployment environments. Addressing these risks requires a combination of hardware-level protections, tamper detection mechanisms, and supply chain integrity checks. Without these safeguards, even the most secure software defenses may be undermined by vulnerabilities introduced through direct physical manipulation.
Fault Injection Attacks
Building on physical tampering techniques, fault injection represents a more sophisticated approach to hardware exploitation. Fault injection is a powerful class of physical attacks that deliberately disrupts hardware operations to induce errors in computation. These induced faults can compromise the integrity of machine learning models by causing them to produce incorrect outputs, degrade reliability, or leak sensitive information. For ML systems, such faults not only disrupt inference but also expose models to deeper exploitation, including reverse engineering and bypass of security protocols (Joye and Tunstall 2012).
Attackers achieve fault injection by applying precisely timed physical or electrical disturbances to the hardware while it is executing computations. Techniques such as low-voltage manipulation (Barenghi et al. 2010), power spikes (Hutter, Schmidt, and Plos 2009), clock glitches (Amiel, Clavier, and Tunstall 2006), electromagnetic pulses (Agrawal et al. 2007), temperature variations (S. Skorobogatov 2009), and even laser strikes (S. P. Skorobogatov and Anderson 2003) have been demonstrated to corrupt specific parts of a program’s execution. These disturbances can cause effects such as bit flips, skipped instructions, or corrupted memory states, which adversaries can exploit to alter ML model behavior or extract sensitive information.
For machine learning systems, these attacks pose several concrete risks. Fault injection can degrade model accuracy, force incorrect classifications, trigger denial of service, or even leak internal model parameters. For example, attackers could inject faults into an embedded ML model running on a microcontroller, forcing it to misclassify inputs in safety-important applications such as autonomous navigation or medical diagnostics. More sophisticated attackers may target memory or control logic to steal intellectual property, such as proprietary model weights or architecture details.
The practical viability of these attacks has been demonstrated through controlled experiments. One notable example is the work by Breier et al. (2018), where researchers successfully used a laser fault injection attack on a deep neural network deployed on a microcontroller. By heating specific transistors, as shown in Figure 6. they forced the hardware to skip execution steps, including a ReLU activation function.
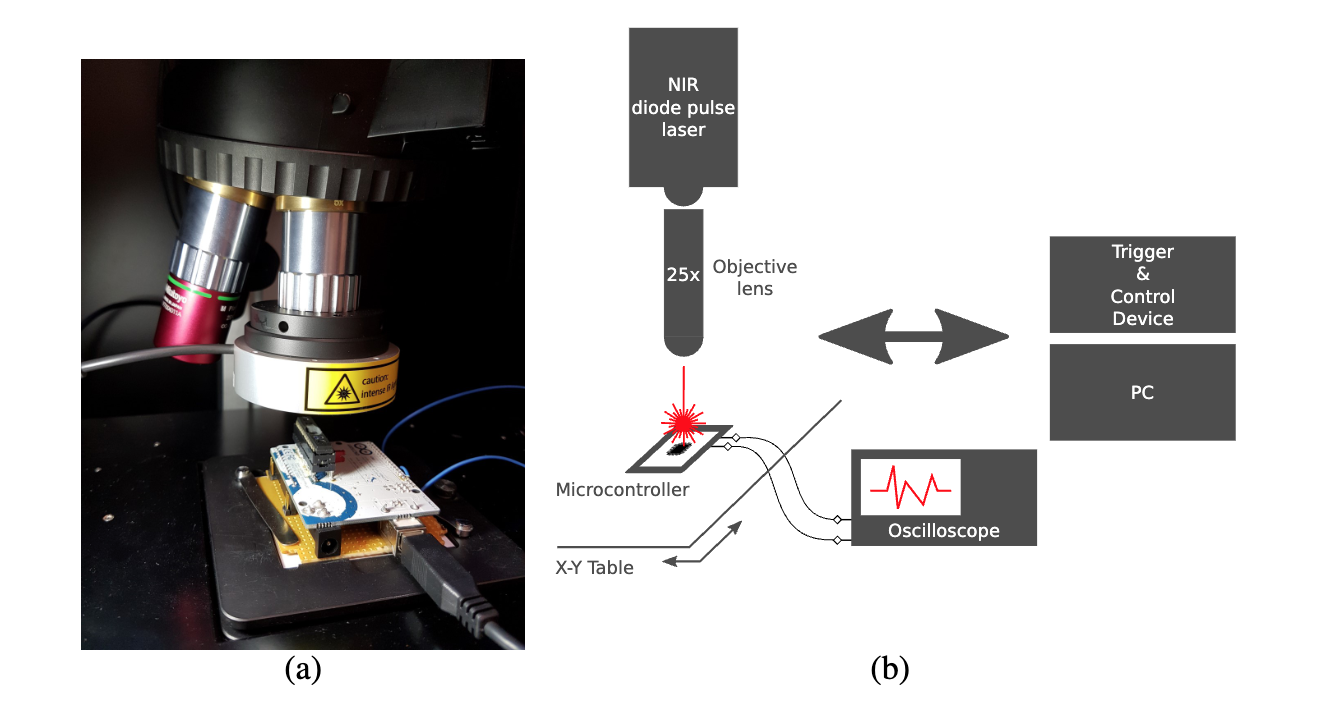
This manipulation is illustrated in Figure 7, which shows a segment of assembly code implementing the ReLU activation function. Normally, the code compares the most significant bit (MSB) of the accumulator to zero and uses a brge (branch if greater or equal) instruction to skip the assignment if the value is non-positive. However, the fault injection suppresses the branch, causing the processor to always execute the “else” block. As a result, the neuron’s output is forcibly zeroed out, regardless of the input value.

Fault injection attacks can also be combined with side-channel analysis, where attackers first observe power or timing characteristics to infer model structure or data flow. This reconnaissance allows them to target specific layers or operations, such as activation functions or final decision layers, maximizing the impact of the injected faults.
Embedded and edge ML systems are particularly vulnerable because they often lack physical hardening and operate under resource constraints that limit runtime defenses. Without tamper-resistant packaging or secure hardware enclaves, attackers may gain direct access to system buses and memory, enabling precise fault manipulation. Many embedded ML models are designed to be lightweight, leaving them with little redundancy or error correction to recover from induced faults.
Mitigating fault injection requires multiple complementary protections. Physical protections, such as tamper-proof enclosures and design obfuscation, help limit physical access. Anomaly detection techniques can monitor sensor inputs or model outputs for signs of fault-induced inconsistencies (Hsiao et al. 2023). Error-correcting memories and secure firmware can reduce the likelihood of silent corruption. Techniques such as model watermarking may provide traceability if stolen models are later deployed by an adversary.
These protections are difficult to implement in cost- and power-constrained environments, where adding cryptographic hardware or redundancy may not be feasible. Achieving resilience to fault injection requires cross-layer design considerations that span electrical, firmware, software, and system architecture levels. Without such holistic design practices, ML systems deployed in the field may remain exposed to these low-cost yet highly effective physical attacks.
Side-Channel Attacks
Moving from direct fault injection to indirect information leakage, side-channel attacks constitute a class of security breaches that exploit information inadvertently revealed through the physical implementation of computing systems. In contrast to direct attacks that target software or network vulnerabilities, these attacks use the system’s hardware characteristics, including power consumption, electromagnetic emissions, or timing behavior, to extract sensitive information.
The core premise of a side-channel attack is that a device’s operation can leak information through observable physical signals. Such leaks may originate from the electrical power the device consumes (Kocher, Jaffe, and Jun 1999), the electromagnetic fields it emits (Gandolfi, Mourtel, and Olivier 2001), the time required to complete computations, or even the acoustic noise it produces. By carefully measuring and analyzing these signals, attackers can infer internal system states or recover secret data.
Although these techniques are commonly discussed in cryptography, they are equally relevant to machine learning systems. ML models deployed on hardware accelerators, embedded devices, or edge systems often process sensitive data. Even when these models are protected by secure algorithms or encryption, their physical execution may leak side-channel signals that can be exploited by adversaries.
One of the most widely studied examples involves Advanced Encryption Standard (AES)28 implementations. While AES is mathematically secure, the physical process of computing its encryption functions leaks measurable signals.
28 Advanced Encryption Standard (AES): Adopted by NIST in 2001 as the US government encryption standard, AES replaced DES after 24 years. Despite being mathematically secure with 2^128 possible keys for AES-128, physical implementations remain vulnerable to side-channel attacks that can extract keys in minutes. Techniques such as Differential Power Analysis (DPA), Differential Electromagnetic Analysis (DEMA), and Correlation Power Analysis (CPA) exploit these physical signals to recover secret keys.
A useful example of this attack technique can be seen in a power analysis of a password authentication process. Consider a device that verifies a 5-byte password—in this case, 0x61, 0x52, 0x77, 0x6A, 0x73. During authentication, the device receives each byte sequentially over a serial interface, and its power consumption pattern reveals how the system responds as it processes these inputs.
Figure 8 shows the device’s behavior when the correct password is entered. The red waveform captures the serial data stream, marking each byte as it is received. The blue curve records the device’s power consumption over time. When the full, correct password is supplied, the power profile remains stable and consistent across all five bytes, providing a clear baseline for comparison with failed attempts.
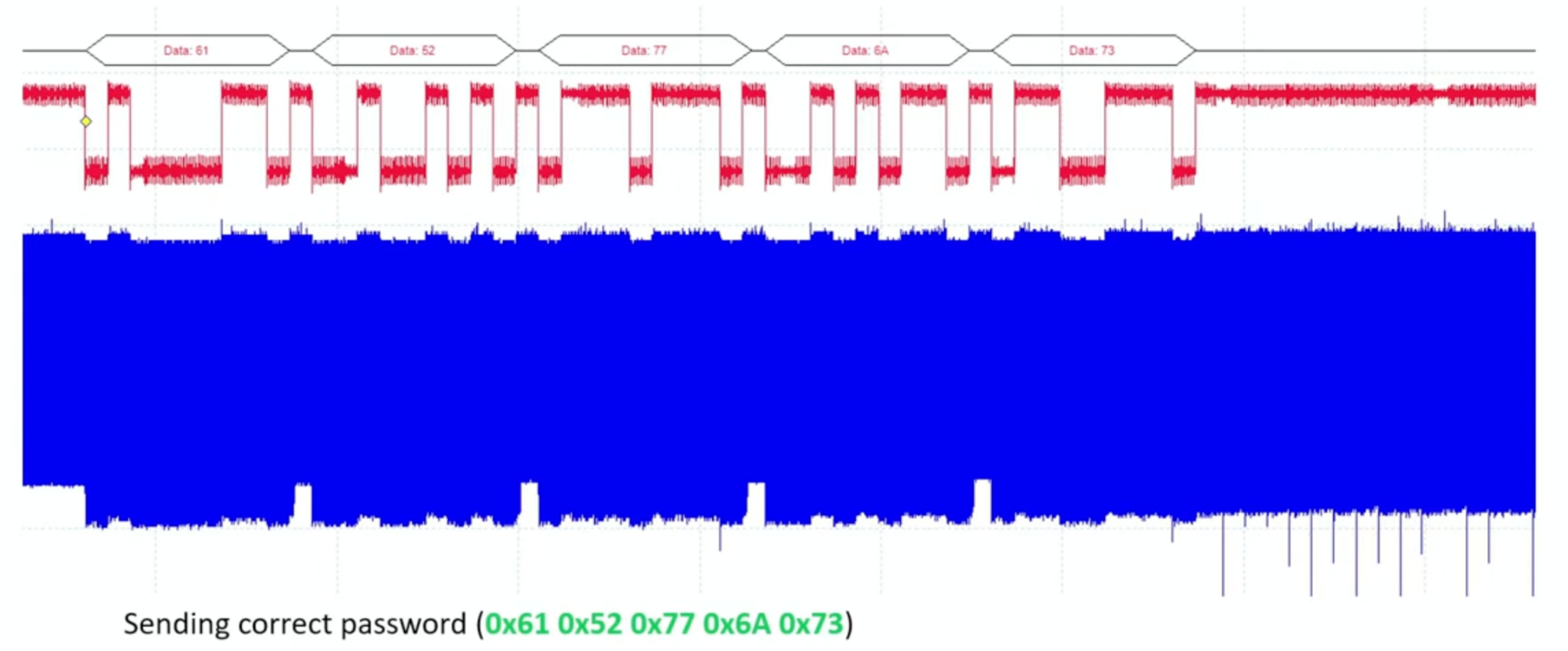
When an incorrect password is entered, the power analysis chart changes as shown in Figure 9. In this case, the first three bytes (0x61, 0x52, 0x77) are correct, so the power patterns closely match the correct password up to that point. However, when the fourth byte (0x42) is processed and found to be incorrect, the device halts authentication. This change is reflected in the sudden jump in the blue power line, indicating that the device has stopped processing and entered an error state.
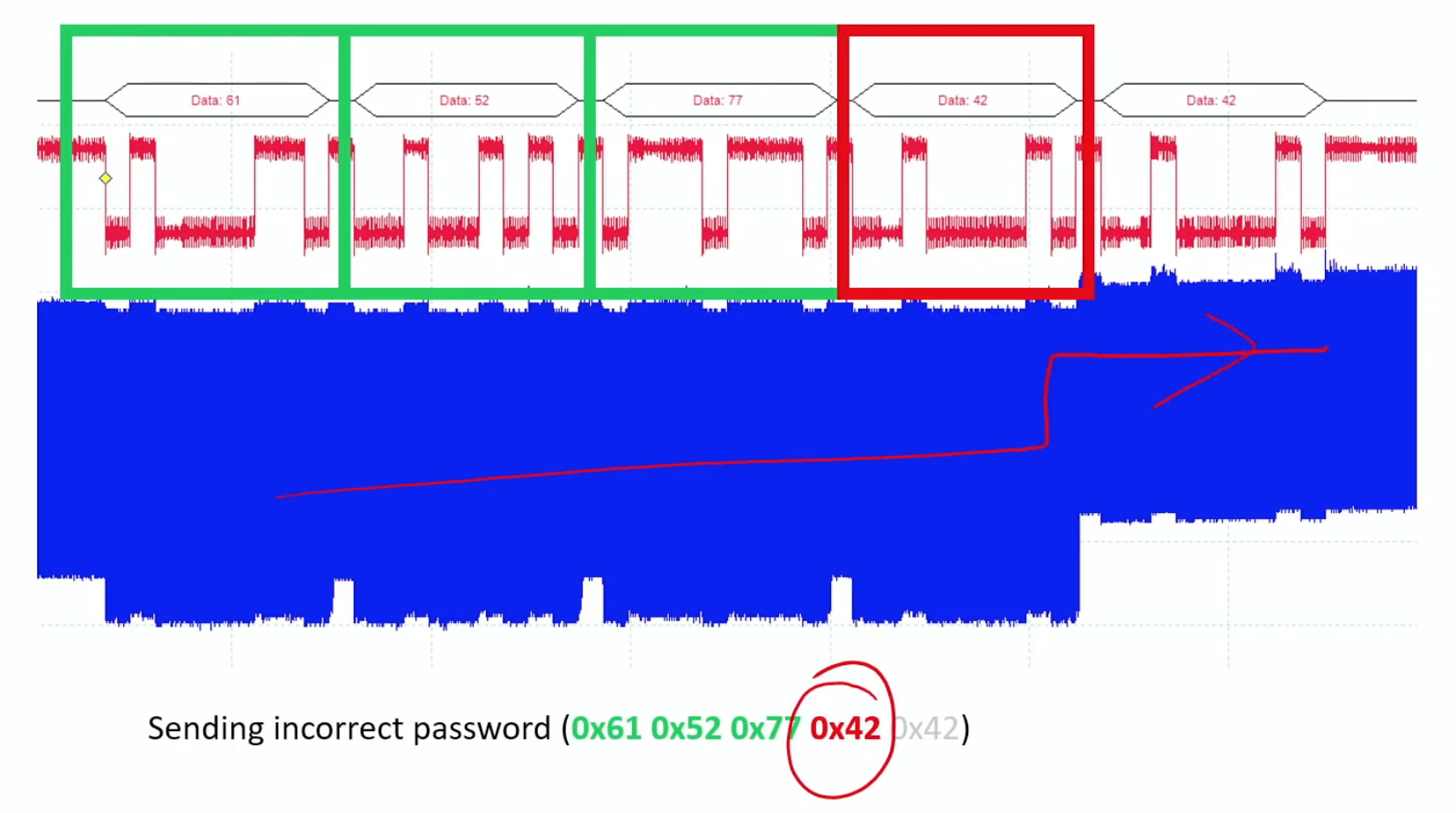
Figure 10 shows the case where the password is entirely incorrect (0x30, 0x30, 0x30, 0x30, 0x30). Here, the device detects the mismatch immediately after the first byte and halts processing much earlier. This is again visible in the power profile, where the blue line exhibits a sharp jump following the first byte, reflecting the device’s early termination of authentication.
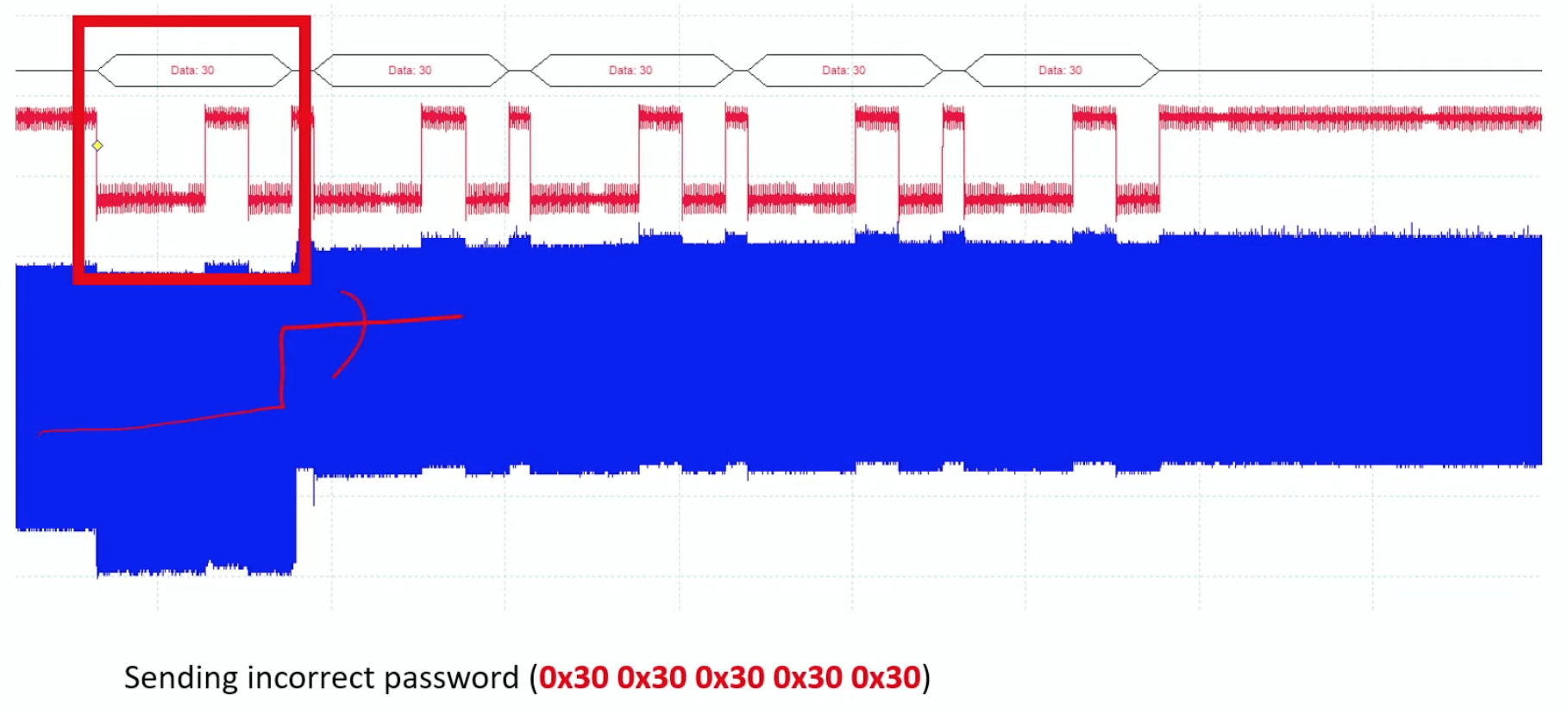
These examples demonstrate how attackers can exploit observable power consumption differences to reduce the search space and eventually recover secret data through brute-force analysis. By systematically measuring power consumption patterns and correlating them with different inputs, attackers can extract sensitive information that should remain hidden.
The scope of these vulnerabilities extends beyond cryptographic applications. Machine learning applications face similar risks. For example, an ML-based speech recognition system processing voice commands on a local device could leak timing or power signals that reveal which commands are being processed. Even subtle acoustic or electromagnetic emissions may expose operational patterns that an adversary could exploit to infer user behavior.
Historically, side-channel attacks have been used to bypass even the most secure cryptographic systems. In the 1960s, British intelligence agency MI5 famously exploited acoustic emissions from a cipher machine in the Egyptian Embassy (Burnet and Thomas 1989). By capturing the mechanical clicks of the machine’s rotors, MI5 analysts were able to dramatically reduce the complexity of breaking encrypted messages. This early example illustrates that side-channel vulnerabilities are not confined to the digital age but are rooted in the physical nature of computation.
Today, these techniques have advanced to include attacks such as keyboard eavesdropping (Asonov and Agrawal, n.d.), power analysis on cryptographic hardware (Gnad, Oboril, and Tahoori 2017), and voltage-based attacks on ML accelerators (Zhao and Suh 2018). Timing attacks, electromagnetic leakage, and thermal emissions continue to provide adversaries with indirect channels for observing system behavior.
Machine learning systems deployed on specialized accelerators or embedded platforms are especially at risk. Attackers may exploit side-channel signals to infer model structure, steal parameters, or reconstruct private training data. As ML becomes increasingly deployed in cloud, edge, and embedded environments, these side-channel vulnerabilities pose significant challenges to system security.
Understanding the persistence and evolution of side-channel attacks is important for building resilient machine learning systems. By recognizing that where there is a signal, there is potential for exploitation, system designers can begin to address these risks through a combination of hardware shielding, algorithmic defenses, and operational safeguards.
Leaky Interfaces
While side-channel attacks exploit unintended physical signals, leaky interfaces represent a different category of vulnerability involving exposed communication channels. Interfaces in computing systems are important for enabling communication, diagnostics, and updates. However, these same interfaces can become significant security vulnerabilities when they unintentionally expose sensitive information or accept unverified inputs. Such leaky interfaces often go unnoticed during system design, yet they provide attackers with powerful entry points to extract data, manipulate functionality, or introduce malicious code.
A leaky interface is any access point that reveals more information than intended, often because of weak authentication, lack of encryption, or inadequate isolation. These issues have been widely demonstrated across consumer, medical, and industrial systems.
For example, many WiFi-enabled baby monitors have been found to expose unsecured remote access ports29, allowing attackers to intercept live audio and video feeds from inside private homes. Similarly, researchers have identified wireless vulnerabilities in pacemakers30 that could allow attackers to manipulate cardiac functions if exploited, raising life-threatening safety concerns.
29 IoT Device Vulnerabilities: Studies reveal 70-80% of IoT devices contain serious security flaws, with baby monitors among the worst offenders. Security firm Rapid7 found that popular baby monitor brands exposed unencrypted video streams, affecting millions of households globally.
30 Medical Device Security: FDA reports show 53% of medical devices contain known vulnerabilities, with pacemakers and insulin pumps most at risk. The average medical device contains 6.2 vulnerabilities, some dating back over a decade, affecting 2.4 billion medical devices worldwide.
31 Debug Port Vulnerabilities: Hardware debug interfaces like JTAG (1990) and SWD (2006) are essential for development but often left accessible in production. Security researchers estimate that 60-70% of embedded devices ship with unsecured debug ports, creating backdoors for attackers.
A notable case involving smart lightbulbs demonstrated that accessible debug ports31 left on production devices leaked unencrypted WiFi credentials. This security oversight provided attackers with a pathway to infiltrate home networks without needing to bypass standard security mechanisms.
These examples reveal vulnerability patterns that directly apply to machine learning deployments. While these examples do not target machine learning systems directly, they illustrate architectural patterns that are highly relevant to ML-allowd devices. Consider a smart home security system that uses machine learning to detect user routines and automate responses. Such a system may include a maintenance or debug interface for software updates. If this interface lacks proper authentication or transmits data unencrypted, attackers on the same network could gain unauthorized access. This intrusion could expose user behavior patterns, compromise model integrity, or disable security features altogether.
Leaky interfaces in ML systems can also expose training data, model parameters, or intermediate outputs. Such exposure can allow attackers to craft adversarial examples, steal proprietary models, or reverse-engineer system behavior. Worse still, these interfaces may allow attackers to tamper with firmware, introducing malicious code that disables devices or recruits them into botnets.
Mitigating these risks requires coordinated protections across technical and organizational domains. Technical safeguards such as strong authentication, encrypted communications, and runtime anomaly detection are important. Organizational practices such as interface inventories, access control policies, and ongoing audits are equally important. Adopting a zero-trust architecture, where no interface is trusted by default, further reduces exposure by limiting access to only what is strictly necessary.
For designers of ML-powered systems, securing interfaces must be a first-class concern alongside algorithmic and data-centric design. Whether the system operates in the cloud, on the edge, or in embedded environments, failure to secure these access points risks undermining the entire system’s trustworthiness.
Counterfeit Hardware
Beyond vulnerabilities in legitimate hardware, another significant threat emerges from the supply chain itself. Machine learning systems depend on the reliability and security of the hardware on which they run. Yet, in today’s globalized hardware ecosystem, the risk of counterfeit or cloned hardware has emerged as a serious threat to system integrity. Counterfeit components refer to unauthorized reproductions of genuine parts, designed to closely imitate their appearance and functionality. These components can enter machine learning systems through complex procurement and manufacturing processes that span multiple vendors and regions.
A single lapse in component sourcing can introduce counterfeit hardware into important systems. For example, a facial recognition system deployed for secure facility access might unknowingly rely on counterfeit processors. These unauthorized components could fail to process biometric data correctly or introduce hidden vulnerabilities that allow attackers to bypass authentication controls.
The risks posed by counterfeit hardware are multifaceted. From a reliability perspective, such components often degrade faster, perform unpredictably, or fail under load due to substandard manufacturing. From a security perspective, counterfeit hardware may include hidden backdoors or malicious circuitry, providing attackers with undetectable pathways to compromise machine learning systems. A cloned network router installed in a data center, for instance, could silently intercept model predictions or user data, creating systemic vulnerabilities across the entire infrastructure.
Legal and regulatory risks further compound the problem. Organizations that unknowingly integrate counterfeit components into their ML systems may face serious legal consequences, including penalties for violating safety, privacy, or cybersecurity regulations32. This is particularly concerning in sectors such as healthcare and finance, where compliance with industry standards is non-negotiable. Healthcare organizations must demonstrate HIPAA compliance throughout their technology stack, while organizations handling EU citizens’ data must meet GDPR’s requirements for technical and organizational measures, including supply chain integrity.
32 Cybersecurity Regulations: Global cybersecurity compliance costs exceed $150 billion annually, with frameworks like SOC 2, ISO 27001, PCI DSS, and sector-specific rules governing ML systems. Financial services face additional requirements under regulations like SOX, while healthcare must comply with HIPAA, creating complex multi-regulatory environments.
Economic pressures often incentivize sourcing from lower-cost suppliers without rigorous verification, increasing the likelihood of counterfeit parts entering production systems. Detection is especially challenging, as counterfeit components are designed to mimic legitimate ones. Identifying them may require specialized equipment or forensic analysis, making prevention far more practical than remediation.
The stakes are particularly high in machine learning applications that require high reliability and low latency, such as real-time decision-making in autonomous vehicles, industrial automation, or important healthcare diagnostics. Hardware failure in these contexts can lead not only to system downtime but also to significant safety risks. Consequently, as machine learning continues to expand into safety-important and high-value applications, counterfeit hardware presents a growing risk that must be recognized and addressed. Organizations must treat hardware trustworthiness as a core design requirement, on par with algorithmic accuracy and data security, to ensure that ML systems can operate reliably and securely in the real world.
Supply Chain Risks
Counterfeit hardware exemplifies a broader systemic challenge. While counterfeit hardware presents a serious challenge, it is only one part of the larger problem of securing the global hardware supply chain. Machine learning systems are built from components that pass through complex supply networks involving design, fabrication, assembly, distribution, and integration. Each of these stages presents opportunities for tampering, substitution, or counterfeiting—often without the knowledge of those deploying the final system.
Malicious actors can exploit these vulnerabilities in various ways. A contracted manufacturer might unknowingly receive recycled electronic waste that has been relabeled as new components. A distributor might deliberately mix cloned parts into otherwise legitimate shipments. Insiders at manufacturing facilities might embed hardware Trojans that are nearly impossible to detect once the system is deployed. Advanced counterfeits can be particularly deceptive, with refurbished or repackaged components designed to pass visual inspection while concealing inferior or malicious internals.
Identifying such compromises typically requires sophisticated analysis, including micrography, X-ray screening, and functional testing. However, these methods are costly and impractical for large-scale procurement. As a result, many organizations deploy systems without fully verifying the authenticity and security of every component.
The risks extend beyond individual devices. Machine learning systems often rely on heterogeneous hardware platforms, integrating CPUs, GPUs, memory, and specialized accelerators sourced from a global supply base. Any compromise in one part of this chain can undermine the security of the entire system. These risks are further amplified when systems operate in shared or multi-tenant environments, such as cloud data centers or federated edge networks, where hardware-level isolation is important to preventing cross-tenant attacks.
The 2018 Bloomberg Businessweek report alleging that Chinese state actors inserted spy chips into Supermicro server motherboards brought these risks to mainstream attention. While the claims remain disputed, the story underscored the industry’s limited visibility into its own hardware supply chains. Companies often rely on complex, opaque manufacturing and distribution networks, leaving them vulnerable to hidden compromises. Over-reliance on single manufacturers or regions, including the semiconductor industry’s reliance on TSMC, further concentrates this risk. This recognition has driven policy responses like the U.S. CHIPS and Science Act, which aims to bring semiconductor production onshore and strengthen supply chain resilience.
Securing machine learning systems requires moving beyond trust-by-default models toward zero-trust supply chain practices. This includes screening suppliers, validating component provenance, implementing tamper-evident protections, and continuously monitoring system behavior for signs of compromise. Building fault-tolerant architectures that detect and contain failures provides an additional layer of defense.
Ultimately, supply chain risks must be treated as a first-class concern in ML system design. Trust in the computational models and data pipelines that power machine learning depends corely on the trustworthiness of the hardware on which they run. Without securing the hardware foundation, even the most sophisticated models remain vulnerable to compromise.
Case Study: Supermicro Controversy
The abstract nature of supply chain risks became concrete in a high-profile controversy that captured industry attention. In 2018, Bloomberg Businessweek published a widely discussed report alleging that Chinese state-sponsored actors had secretly implanted tiny surveillance chips on server motherboards manufactured by Supermicro (Robertson and Riley 2018). These compromised servers were reportedly deployed by more than 30 major companies, including Apple and Amazon. The chips, described as no larger than a grain of rice, were said to provide attackers with backdoor access to sensitive data and systems.
The allegations sparked immediate concern across the technology industry, raising questions about the security of global supply chains and the potential for state-level hardware manipulation. However, the companies named in the report publicly denied the claims. Apple, Amazon, and Supermicro stated that they had found no evidence of the alleged implants after conducting thorough internal investigations. Industry experts and government agencies also expressed skepticism, noting the lack of verifiable technical evidence presented in the report.
Despite these denials, the story had a lasting impact on how organizations and policymakers view hardware supply chain security. Whether or not the specific claims were accurate, the report highlighted the real and growing concern that hardware supply chains are difficult to fully audit and secure. It underscored how geopolitical tensions, manufacturing outsourcing, and the complexity of modern hardware ecosystems make it increasingly challenging to guarantee the integrity of hardware components.
The Supermicro case illustrates a broader truth: once a product enters a complex global supply chain, it becomes difficult to ensure that every component is free from tampering or unauthorized modification. This risk is particularly acute for machine learning systems, which depend on a wide range of hardware accelerators, memory modules, and processing units sourced from multiple vendors across the globe.
In response to these risks, both industry and government stakeholders have begun to invest in supply chain security initiatives. The U.S. government’s CHIPS and Science Act is one such effort, aiming to bring semiconductor manufacturing back onshore to improve transparency and reduce dependency on foreign suppliers. While these efforts are valuable, they do not fully eliminate supply chain risks. They must be complemented by technical safeguards, such as component validation, runtime monitoring, and fault-tolerant system design.
The Supermicro controversy serves as a cautionary tale for the machine learning community. It demonstrates that hardware security cannot be taken for granted, even when working with reputable suppliers. Ensuring the integrity of ML systems requires rigorous attention to the entire hardware lifecycle—from design and fabrication to deployment and maintenance. This case reinforces the need for organizations to adopt comprehensive supply chain security practices as a foundational element of trustworthy ML system design.
When ML Systems Become Attack Tools
The threats examined thus far—model theft, data poisoning, adversarial attacks, hardware vulnerabilities—represent attacks targeting machine learning systems. However, a complete threat model must also account for the inverse: machine learning as an attack amplifier. The same capabilities that make ML powerful for beneficial applications also enhance adversarial operations, transforming machine learning from passive target to active weapon.
While machine learning systems are often treated as assets to protect, they may also serve as tools for launching attacks. In adversarial settings, the same models used to enhance productivity, automate perception, or assist decision-making can be repurposed to execute or amplify offensive operations. This dual-use characteristic of machine learning, its capacity to secure systems as well as to subvert them, marks a core shift in how ML must be considered within system-level threat models.
An offensive use of machine learning refers to any scenario in which a machine learning model is employed to facilitate the compromise of another system. In such cases, the model itself is not the object under attack, but the mechanism through which an adversary advances their objectives. These applications may involve reconnaissance, inference, subversion, impersonation, or the automation of exploit strategies that would otherwise require manual execution.
Importantly, such offensive applications are not speculative. Attackers are already integrating machine learning into their toolchains across a wide range of activities, from spam filtering evasion to model-driven malware generation. What distinguishes these scenarios is the deliberate use of learning-based systems to extract, manipulate, or generate information in ways that undermine the confidentiality, integrity, or availability of targeted components.
To clarify the diversity and structure of these applications, Table 6 summarizes several representative use cases. For each, the table identifies the type of machine learning model typically employed, the underlying system vulnerability it exploits, and the primary advantage conferred by the use of machine learning.
These documented cases illustrate how machine learning models can serve as amplifiers of adversarial capability. For example, language models allow more convincing and adaptable phishing attacks, while clustering and classification algorithms facilitate reconnaissance by learning system-level behavioral patterns. The generative AI capabilities of large language models particularly amplify these offensive applications. Similarly, adversarial example generators and inference models systematically uncover weaknesses in decision boundaries or data privacy protections, often requiring only limited external access to deployed systems. In hardware contexts, as discussed in the next section, deep neural networks trained on side-channel data can automate the extraction of cryptographic secrets from physical measurements—transforming an expert-driven process into a learnable pattern recognition task. The deep learning foundations from Chapter 3: Deep Learning Primer—convolutional neural networks for spatial pattern recognition, recurrent architectures for temporal dependencies, and gradient-based optimization—enable attackers to apply these techniques across various hardware platforms discussed in Chapter 11: AI Acceleration, from GPUs and TPUs in cloud environments to edge accelerators with constrained resources.
| Offensive Use Case | ML Model Type | Targeted System Vulnerability | Advantage of ML |
|---|---|---|---|
| Phishing and Social Engineering | Large Language Models (LLMs) | Human perception and communication systems | Personalized, context-aware message crafting |
| Reconnaissance and Fingerprinting | Supervised classifiers, clustering models | System configuration, network behavior | Scalable, automated profiling of system behavior |
| Exploit Generation | Code generation models, fine-tuned transformers | Software bugs, insecure code patterns | Automated discovery of candidate exploits |
| Data Extraction (Inference Attacks) | Classification models, inversion models | Privacy leakage through model outputs | Inference with limited or black-box access |
| Evasion of Detection Systems | Adversarial input generators | Detection boundaries in deployed ML systems | Crafting minimally perturbed inputs to evade filters |
| Hardware-Level Attacks | Deep learning models | Physical side-channels (e.g., power, timing, EM) | Learning leakage patterns directly from raw signals |
Although these applications differ in technical implementation, they share a common foundation: the adversary replaces a static exploit with a learned model capable of approximating or adapting to the target’s vulnerable behavior. This shift increases flexibility, reduces manual overhead, and improves robustness in the face of evolving or partially obscured defenses.
What makes this class of threats particularly significant is their favorable scaling behavior. Just as accuracy in computer vision or language modeling improves with additional data, larger architectures, and greater compute resources, so too does the performance of attack-oriented machine learning models. A model trained on larger corpora of phishing attempts or power traces, for instance, may generalize more effectively, evade more detectors, or require fewer inputs to succeed. The same ecosystem that drives innovation in beneficial AI, including public datasets, open-source tooling, and scalable infrastructure, also lowers the barrier to developing effective offensive models.
This dynamic creates an asymmetry between attacker and defender. While defensive measures are bounded by deployment constraints, latency budgets, and regulatory requirements, attackers can scale training pipelines with minimal marginal cost. The widespread availability of pretrained models and public ML platforms further reduces the expertise required to develop high-impact attacks.
Examining these offensive capabilities serves a crucial defensive purpose. Security professionals have long recognized that effective defense requires understanding attack methodologies—this principle underlies penetration testing33, red team exercises34, and threat modeling throughout the cybersecurity industry.
33 Penetration Testing: Authorized simulated cyberattacks to evaluate system security, formalized in the 1960s for military computer systems. The global penetration testing market reached $1.7 billion in 2022, with 89% of organizations conducting annual pen tests to identify vulnerabilities before attackers do.
34 Red Team Exercises: Adversarial security simulations where specialized teams emulate real attackers to test organizational defenses, originated from military war games in the 1960s. Unlike penetration testing, red teams use social engineering, physical access, and advanced persistent threat techniques, with exercises lasting weeks or months to simulate sophisticated nation-state attacks. The phrase “know your enemy” reflects this core security principle.
In the machine learning domain, this understanding becomes essential because ML amplifies both defensive and offensive capabilities. The same computational advantages that make ML powerful for legitimate applications—pattern recognition, automation, and scalability—also enhance adversarial capabilities. By examining how machine learning can be weaponized, security professionals can anticipate attack vectors, design more robust defenses, and develop detection mechanisms.
As a result, any comprehensive treatment of machine learning system security must consider not only the vulnerabilities of ML systems themselves but also the ways in which machine learning can be used to compromise other components—whether software, data, or hardware. Understanding the offensive potential of machine-learned systems is essential for designing resilient, trustworthy, and forward-looking defenses.
Case Study: Deep Learning for SCA
To illustrate these offensive capabilities concretely, we examine a specific case where machine learning transforms traditional attack methodologies. One of the most well-known and reproducible demonstrations of deep-learning-assisted SCA is the SCAAML framework (Side-Channel Attacks Assisted with Machine Learning) (Bursztein et al. 2024a). Developed by researchers at Google, SCAAML provides a practical implementation of the attack pipeline described above.

As shown in Figure 11, cryptographic computations exhibit data-dependent variations in their power consumption. These variations, while subtle, are measurable and reflect the internal state of the algorithm at specific points in time.
In traditional side-channel attacks, experts rely on statistical techniques to extract these differences. However, a neural network can learn to associate the shape of these signals with the specific data values being processed, effectively learning to decode the signal in a manner that mimics expert-crafted models, yet with enhanced flexibility and generalization. The model is trained on labeled examples of power traces and their corresponding intermediate values (e.g., output of an S-box operation). Over time, it learns to associate patterns in the trace, similar to those depicted in Figure 11, with secret-dependent computational behavior. This transforms the key recovery task into a classification problem, where the goal is to infer the correct key byte based on trace shape alone.
In their study, Bursztein et al. (2024a) trained a convolutional neural network to extract AES keys from power traces collected on an STM32F415 microcontroller running the open-source TinyAES implementation. The model was trained to predict intermediate values of the AES algorithm, such as the output of the S-box in the first round, directly from raw power traces. The trained model recovered the full 128-bit key using only a small number of traces per byte.
The traces were collected using a ChipWhisperer setup with a custom STM32F target board, shown in Figure 12. This board executes AES operations while allowing external equipment to monitor power consumption with high temporal precision. The experimental setup captures how even inexpensive, low-power embedded devices can leak information through side channels—information that modern machine learning models can learn to exploit.

Subsequent work expanded on this approach by introducing long-range models capable of leveraging broader temporal dependencies in the traces, improving performance even under noise and desynchronization (Bursztein et al. 2024b). These developments highlight the potential for machine learning models to serve as offensive cryptanalysis tools, especially in the analysis of secure hardware.
The implications extend beyond academic interest. As deep learning models continue to scale, their application to side-channel contexts is likely to lower the cost, skill threshold, and trace requirements of hardware-level attacks—posing a growing challenge for the secure deployment of embedded machine learning systems, cryptographic modules, and trusted execution environments.
Comprehensive Defense Architectures
Having examined threats against ML systems and threats enabled by ML capabilities, we now turn to comprehensive defensive strategies. Designing secure and privacy-preserving machine learning systems requires more than identifying individual threats. It demands a layered defense strategy that integrates protections across multiple system levels to create comprehensive resilience.
This section progresses systematically through four layers of defense: Data Layer protections including differential privacy and secure computation that safeguard sensitive information during training; Model Layer defenses such as adversarial training and secure deployment that protect the models themselves; Runtime Layer measures including input validation and output monitoring that secure inference operations; and Hardware Layer foundations such as trusted execution environments that provide the trust anchor for all other protections. We conclude with practical frameworks for selecting and implementing these defenses based on your deployment context.
The Layered Defense Principle
Layered defense (also known as defense-in-depth) represents a core security architecture principle where multiple independent defensive mechanisms work together to protect against diverse threat vectors. In machine learning systems, this approach becomes essential due to the unique attack surfaces introduced by data dependencies, model exposures, and inference patterns. Unlike traditional software systems that primarily face code-based vulnerabilities, ML systems are vulnerable to input manipulation, data leakage, model extraction, and runtime abuse, all amplified by tight coupling between data, model behavior, and infrastructure.
The layered approach recognizes that no single defensive mechanism can address all possible threats. Instead, security emerges from the interaction of complementary protections: data-layer techniques like differential privacy and federated learning; model-layer defenses including robustness techniques and secure deployment; runtime-layer measures such as input validation and output monitoring; and hardware-layer solutions including trusted execution environments and secure boot. Each layer contributes to the system’s overall resilience while compensating for potential weaknesses in other layers.
This section presents a structured framework implementing layered defense for ML systems, progressing from data-centric protections to infrastructure-level enforcement. The framework builds upon data protection practices in Chapter 6: Data Engineering and connects forward to operational security measures detailed in Chapter 13: ML Operations. By integrating safeguards across layers, organizations can build ML systems that not only perform reliably but also withstand adversarial pressure in production environments.
The layered approach is visualized in Figure 13, which shows how defensive mechanisms progress from foundational hardware-based security to runtime system protections, model-level controls, and privacy-preserving techniques at the data level. Each layer builds on the trust guarantees of the layer below it, forming an end-to-end strategy for deploying ML systems securely.

Privacy-Preserving Data Techniques
At the highest level of our defense stack, we begin with data privacy techniques. Protecting the privacy of individuals whose data fuels machine learning systems is a foundational requirement for trustworthy AI. Unlike traditional systems where data is often masked or anonymized before processing, ML workflows typically rely on access to raw, high-fidelity data to train effective models. This tension between utility and privacy has motivated a diverse set of techniques aimed at minimizing data exposure while preserving learning performance.
Differential Privacy
One of the most widely adopted frameworks for formalizing privacy guarantees is differential privacy (DP). DP provides a rigorous mathematical definition of privacy loss, ensuring that the inclusion or exclusion of a single individual’s data has a provably limited effect on the model’s output.
To understand the need for differential privacy, consider this challenge: how can we quantify privacy loss when learning from data? Traditional privacy approaches focus on removing identifying information (names, addresses, social security numbers) or applying statistical disclosure controls. However, these methods fail against sophisticated adversaries who can re-identify individuals through auxiliary data, statistical correlation attacks, or inference from model outputs.
Differential privacy takes a different approach by focusing on algorithmic behavior rather than data content. The key insight is that privacy protection should be measurable and should limit what can be learned about any individual, regardless of what external information an adversary possesses.
To build intuition for this concept, imagine you want to find the average salary of a group of people, but no one wants to reveal their actual salary. With differential privacy, you could ask everyone to write their salary on a piece of paper, but before they hand it in, they add or subtract a random number from a known distribution. When you average all the papers, the random noise tends to cancel out, giving you a very close estimate of the true average. However, if you pull out any single piece of paper, you cannot know the person’s real salary because you do not know what random number they added. This is the core idea: learn aggregate patterns while making it impossible to be sure about any single individual.
Differential privacy formalizes this intuition through a comparison of algorithm behavior on similar datasets. Consider two adjacent datasets that differ only in the presence or absence of a single individual’s record. Differential privacy ensures that the probability distributions of algorithm outputs remain statistically similar regardless of whether that individual’s data is included. This protection is achieved through carefully calibrated noise that masks individual contributions while preserving the aggregate statistical patterns necessary for machine learning.
To make this intuition mathematically precise, differential privacy introduces a quantitative measure of privacy loss. The mathematical framework uses probability ratios to bound how much an algorithm’s behavior can change when a single individual’s data is added or removed. This approach allows us to prove privacy guarantees rather than simply assume them.
A randomized algorithm \(\mathcal{A}\) is said to be \(\epsilon\)-differentially private if, for all adjacent datasets \(D\) and \(D'\) differing in one record, and for all outputs \(S \subseteq \text{Range}(\mathcal{A})\), the following holds: \[ \Pr[\mathcal{A}(D) \in S] \leq e^{\epsilon} \Pr[\mathcal{A}(D') \in S] \]
The parameter \(\epsilon\) quantifies the privacy budget, representing the maximum allowable privacy loss. Smaller values of \(\epsilon\) provide stronger privacy guarantees through increased noise injection, but may reduce model utility. Typical values include \(\epsilon = 0.1\) for strong privacy protection, \(\epsilon = 1.0\) for moderate protection, and \(\epsilon = 10\) for weaker but utility-preserving guarantees. The multiplicative factor \(e^{\epsilon}\) bounds the likelihood ratio between algorithm outputs on adjacent datasets, constraining how much an individual’s participation can influence any particular result.
This bound ensures that the algorithm’s behavior remains statistically indistinguishable regardless of whether any individual’s data is present, thereby limiting the information that can be inferred about that individual. In practice, DP is implemented by adding calibrated noise to model updates or query responses, using mechanisms such as the Laplace or Gaussian mechanism. Training techniques like differentially private stochastic gradient descent35 integrate calibrated noise into training computations, ensuring that individual data points cannot be distinguished from the model’s learned behavior.
35 DP-SGD Industry Adoption: Apple was the first major company to deploy differential privacy at scale in 2016, protecting 1+ billion users’ data in iOS. Their implementation adds noise to emoji usage, Safari crashes, and QuickType suggestions, balancing privacy (ε=4-16) with utility for improving user experience across their ecosystem.
36 Privacy-Utility Tension: This core tradeoff was formalized by Dwork and McSherry, who proved that perfect privacy (infinite noise) yields no utility, while perfect utility (no noise) provides no privacy. The “privacy budget” concept emerged from this insight—you can only spend privacy once, making every query a strategic decision.
While differential privacy offers strong theoretical assurances, it introduces a trade-off between privacy and utility36 that has measurable computational and accuracy costs.
Practical DP deployment requires careful consideration of computational trade-offs, privacy budget management, and implementation challenges, as detailed in Table 7.
Increasing the noise to reduce \(\epsilon\) may degrade model accuracy, especially in low-data regimes or fine-grained classification tasks. Consequently, DP is often applied selectively—either during training on sensitive datasets or at inference when returning aggregate statistics—to balance privacy with performance goals (Dwork and Roth 2013).
Federated Learning
While differential privacy adds mathematical guarantees to data processing, federated learning (FL) offers a complementary approach that reduces privacy risks by restructuring the learning process itself. This technique directly addresses the privacy challenges of on-device learning explored in Chapter 14: On-Device Learning, where models must adapt to local data patterns without exposing sensitive user information. Rather than aggregating raw data at a central location, FL distributes the training across a set of client devices, each holding local data (McMahan et al. 2017). This distributed training paradigm, which builds on the adaptive deployment concepts from on-device learning, requires careful coordination of security measures across multiple participants and infrastructure providers. Clients compute model updates locally and share only parameter deltas with a central server for aggregation: \[ \theta_{t+1} \leftarrow \sum_{k=1}^{K} \frac{n_k}{n} \cdot \theta_{t}^{(k)} \]
Here, \(\theta_{t}^{(k)}\) represents the model update from client \(k\), \(n_k\) the number of samples held by that client, and \(n\) the total number of samples across all clients. This weighted aggregation allows the global model to learn from distributed data without direct access to it. FL reduces the exposure of raw data, but still leaks information through gradients, motivating the use of DP, secure aggregation, and hardware-based protections in federated settings.
To address scenarios requiring computation on encrypted data, homomorphic encryption (HE)37 and secure multiparty computation (SMPC) allow models to perform inference or training over encrypted inputs. The computational overhead of homomorphic operations often requires the efficiency optimization techniques covered in Chapter 9: Efficient AI—including model compression (quantization reduces precision requirements for encrypted operations), architectural optimization (depthwise separable convolutions minimize encrypted multiplications), and hardware acceleration (specialized cryptographic accelerators)—to maintain practical performance.
37 Homomorphic Encryption Breakthrough: Considered the “holy grail” of cryptography since the 1970s, fully homomorphic encryption remained theoretical until Craig Gentry’s 2009 PhD thesis. His breakthrough was realizing that “noisy” ciphertexts could support unlimited operations if periodically “refreshed,” solving a decades-old puzzle that allows computation on encrypted data.
In the case of HE, operations on ciphertexts correspond to operations on plaintexts, enabling encrypted inference: \[ \text{Enc}(f(x)) = f(\text{Enc}(x)) \]
This property supports privacy-preserving computation in untrusted environments, such as cloud inference over sensitive health or financial records. The computational cost of HE remains high, making it more suitable for fixed-function models and low-latency batch tasks. SMPC38, by contrast, distributes the computation across multiple parties such that no single party learns the complete input or output. This is particularly useful in joint training across institutions with strict data-use policies, such as hospitals or banks39.
38 SMPC Performance: Secure multi-party computation typically incurs 1000-10,000x computational overhead compared to plaintext operations. A simple neural network inference that takes milliseconds on GPU requires hours using SMPC, limiting practical applications to small models and offline scenarios.
39 Secure Multi-Party Computation (SMPC): Cryptographic framework enabling multiple parties to jointly compute functions over their private inputs without revealing those inputs, first formalized in 1982 by Andrew Yao. Today’s implementations allow hospitals to collaboratively train medical AI models without sharing patient records, achieving 99%+ accuracy while maintaining strict privacy compliance.
Synthetic Data Generation
Beyond cryptographic approaches like homomorphic encryption, a more pragmatic and increasingly popular alternative involves the use of synthetic data generation40. This approach offers an intuitive solution to privacy protection: if we can create artificial data that looks statistically similar to real data, we can train models without ever exposing sensitive information.
40 Synthetic Data Growth: The synthetic data market grew from $110 million in 2019 to $1.1 billion in 2023, driven by privacy regulations and data scarcity. Companies like Uber use synthetic trip data to protect user privacy while maintaining ML model performance, with some synthetic datasets achieving 95%+ statistical fidelity.
Synthetic data generation works by training a generative model (such as a GAN, VAE, or diffusion model) on the original sensitive dataset, then using this trained generator to produce new artificial samples. The key insight is that the generative model learns the underlying patterns and distributions in the data without memorizing specific individuals. When properly implemented, the synthetic data preserves statistical properties necessary for machine learning while removing personally identifiable information.
The generation typically follows three stages. First, distribution learning trains a generative model \(G_\theta\) on real data \(D_{\text{real}} = \{x_1, x_2,\ldots, x_n\}\) to learn the data distribution \(p(x)\). Second, synthetic sampling generates new samples \(D_{\text{synthetic}} = \{G_\theta(z_1), G_\theta(z_2),\ldots, G_\theta(z_m)\}\) by sampling from random noise \(z_i \sim \mathcal{N}(0,I)\). Third, validation verifies that \(D_{\text{synthetic}}\) maintains statistical fidelity to \(D_{\text{real}}\) while avoiding memorization of specific records. By training generative models on real datasets and sampling new instances from the learned distribution, organizations can create datasets that approximate the statistical properties of the original data without retaining identifiable details (Goncalves et al. 2020).
While appealing, synthetic data generation faces important limitations. Generative models can suffer from mode collapse, failing to capture rare but important patterns in the original data. More critically, sophisticated adversaries can potentially extract information about the original training data through generative model inversion attacks or membership inference. The privacy protection depends heavily on the generative model architecture, training procedure, and hyperparameter choices—making it difficult to provide formal privacy guarantees without additional mechanisms like differential privacy.
Consider a practical example where a hospital wants to share patient data for ML research while protecting privacy. They train a generative adversarial network (GAN) on 10,000 real patient records containing demographics, lab results, and diagnoses. The GAN learns to generate synthetic patients with realistic combinations of features (e.g., diabetic patients typically have elevated glucose levels). The synthetic dataset of 50,000 artificial patients maintains clinical correlations necessary for training diagnostic models while containing no real patient information. However, the hospital also applies differential privacy during GAN training (ε = 1.0) to prevent the model from memorizing specific patients, trading a 5% reduction in statistical fidelity for formal privacy guarantees.
Together, these techniques reflect a shift from isolating data as the sole path to privacy toward embedding privacy-preserving mechanisms into the learning process itself. Each method offers distinct guarantees and trade-offs depending on the application context, threat model, and regulatory constraints. Effective system design often combines multiple approaches, such as applying differential privacy within a federated learning setup, or employing homomorphic encryption for important inference stages, to build ML systems that are both useful and respectful of user privacy.
Comparative Properties
Having examined individual techniques, it becomes clear that these privacy-preserving approaches differ not only in the guarantees they offer but also in their system-level implications. For practitioners, the choice of mechanism depends on factors such as computational constraints, deployment architecture, and regulatory requirements.
Table 7 summarizes the comparative properties of these methods, focusing on privacy strength, runtime overhead, maturity, and common use cases. Understanding these trade-offs is important for designing privacy-aware machine learning systems that operate under real-world constraints.
| Technique | Privacy Guarantee | Computational Overhead | Deployment Maturity | Typical Use Case | Trade-offs |
|---|---|---|---|---|---|
| Differential Privacy | Formal (ε-DP) | Moderate to High | Production | Training with sensitive or regulated data | Reduced accuracy; careful tuning of ε/noise required to balance utility and protection |
| Federated Learning | Structural | Moderate | Production | Cross-device or cross-org collaborative learning | Gradient leakage risk; requires secure aggregation and orchestration infrastructure |
| Homomorphic Encryption | Strong (Encrypted) | High | Experimental | Inference in untrusted cloud environments | High latency and memory usage; suitable for limited-scope inference on fixed-function models |
| Secure MPC | Strong (Distributed) | Very High | Experimental | Joint training across mutually untrusted parties | Expensive communication; challenging to scale to many participants or deep models |
| Synthetic Data | Weak (if standalone) | Low to Moderate | Emerging | Data sharing, benchmarking without direct access to raw data | May leak sensitive patterns if training process is not differentially private or audited for fidelity |
Case Study: GPT-3 Data Extraction Attack
In 2020, researchers conducted a groundbreaking study demonstrating that large language models could leak sensitive training data through carefully crafted prompts (Carlini et al. 2021). The research team systematically queried OpenAI’s GPT-3 model to extract verbatim content from its training dataset, revealing privacy vulnerabilities in large-scale language models.
The attack proved remarkably successful at extracting sensitive information directly from the model’s outputs. By repeatedly querying the model with prompts like “My name is” followed by attempts to continue famous quotes or repeated phrases, researchers successfully extracted personal information including email addresses and phone numbers from the training data, verbatim passages from copyrighted books, private data that should have been filtered during training, and personally identifiable information from millions of individuals.
The technical approach exploited GPT-3’s memorization of rare or repeated text sequences. The researchers used prompt engineering to craft inputs that triggered memorized sequences, continuation attacks that used partial quotes or names to extract full sensitive information, statistical analysis to identify patterns in model outputs indicating verbatim memorization, and verification methods that cross-referenced extracted data with known public sources to confirm accuracy. Out of 600,000 attempts, they successfully extracted over 16,000 unique instances of memorized training data.
This attack challenged assumptions about training data privacy. The results demonstrated that large language models can act as unintentional databases, storing and retrieving sensitive information from their training data. This violated privacy expectations that training data would be “forgotten” after model training, revealing that scale amplifies privacy risk as larger models (175B parameters) memorize more training data than smaller models.
The research revealed that common data protection measures proved insufficient. Even after data deduplication, models still memorized sensitive information, highlighting the tension between model utility and privacy protection. Techniques to prevent memorization such as differential privacy and aggressive data filtering reduce model quality, creating challenging trade-offs for practitioners.
The industry response was swift and comprehensive. Organizations began widespread adoption of differential privacy in large model training, enhanced data filtering and PII removal processes, development of membership inference defenses, new research into machine unlearning techniques, and regulatory discussions about training data rights and model transparency. Modern organizations now commonly implement differential privacy during training (ε ≤ 8), aggressive PII filtering using automated detection tools, regular auditing for data memorization using extraction attacks, and legal frameworks for handling training data containing personal information (Carlini et al. 2021).
Secure Model Design
Moving from data-level protections to model-level security, we address how security considerations shape the model development process. Security begins at the design phase of a machine learning system. While downstream mechanisms such as access control and encryption protect models once deployed, many vulnerabilities can be mitigated earlier—through architectural choices, defensive training strategies, and mechanisms that embed resilience directly into the model’s structure or behavior. By considering security as a design constraint, system developers can reduce the model’s exposure to attacks, limit its ability to leak sensitive information, and provide verifiable ownership protection.
One important design strategy is to build robust-by-construction models that reduce the risk of exploitation at inference time. For instance, models with confidence calibration or abstention mechanisms can be trained to avoid making predictions when input uncertainty is high. These techniques can help prevent overconfident misclassifications in response to adversarial or out-of-distribution inputs. Models may also employ output smoothing, regularizing the output distribution to reduce sharp decision boundaries that are especially susceptible to adversarial perturbations.
Certain application contexts may also benefit from choosing simpler or compressed architectures. Limiting model capacity can reduce opportunities for memorization of sensitive training data and complicate efforts to reverse-engineer the model from output behavior. For embedded or on-device settings, smaller models are also easier to secure, as they typically require less memory and compute, lowering the likelihood of side-channel leakage or runtime manipulation.
Another design-stage consideration is the use of model watermarking41, a technique for embedding verifiable ownership signatures directly into the model’s parameters or output behavior (Adi et al. 2018). A watermark might be implemented, for example, as a hidden response pattern triggered by specific inputs, or as a parameter-space perturbation that does not affect accuracy but is statistically identifiable.
41 Model Watermarking: Technique for proving model ownership developed in 2017, analogous to digital image watermarks. Modern watermarking can embed signatures in less than 0.01% of model parameters while maintaining 99%+ accuracy, helping prove IP theft in courts where billions of dollars in AI assets are at stake.
For example, in a keyword spotting system deployed on embedded hardware for voice activation (e.g., “Hey Alexa” or “OK Google”), a secure design might use a lightweight convolutional neural network with confidence calibration to avoid false activations on uncertain audio. The model might also include an abstention threshold, below which it produces no activation at all. To protect intellectual property, a designer could embed a watermark by training the model to respond with a unique label only when presented with a specific, unused audio trigger known only to the developer. These design choices not only improve robustness and accountability, but also support future verification in case of IP disputes or performance failures in the field.
In high-risk applications, such as medical diagnosis, autonomous vehicles, or financial decision systems, designers may also prioritize interpretable model architectures, such as decision trees, rule-based classifiers, or sparsified networks, to enhance system auditability. These models are often easier to understand and explain, making it simpler to identify potential vulnerabilities or biases. Using interpretable models allows developers to provide clearer insights into how the system arrived at a particular decision, which is important for building trust with users and regulators.
Model design choices often reflect trade-offs between accuracy, robustness, transparency, and system complexity. When viewed from a systems perspective, early-stage design decisions yield the highest value for long-term security. They shape what the model can learn, how it behaves under uncertainty, and what guarantees can be made about its provenance, interpretability, and resilience.
Secure Model Deployment
While secure design establishes a foundation of robustness, protection extends beyond the model itself to how it is packaged and deployed. Protecting machine learning models from theft, abuse, and unauthorized manipulation requires security considerations throughout both the design and deployment phases. A model’s vulnerability is not solely determined by its training procedure or architecture, but also by how it is serialized, packaged, deployed, and accessed during inference. As models are increasingly embedded into edge devices, served through public APIs, or integrated into multi-tenant platforms, robust security practices are important to ensure the integrity, confidentiality, and availability of model behavior.
This section addresses security mechanisms across three key stages: model design, secure packaging and serialization, and deployment and access control. These practices complement the model optimization techniques discussed in Chapter 10: Model Optimizations, where performance improvements must not compromise security properties.
From a design perspective, architectural choices can reduce a model’s exposure to adversarial manipulation and unauthorized use. For example, models can incorporate confidence calibration or abstention mechanisms that allow them to reject uncertain or anomalous inputs rather than producing potentially misleading outputs. Designing models with simpler or compressed architectures can also reduce the risk of reverse engineering or information leakage through side-channel analysis. In some cases, model designers may embed imperceptible watermarks, which are unique signatures embedded in the parameters or behavior of the model, that can later be used to demonstrate ownership in cases of misappropriation (Uchida et al. 2017). These design-time protections are essential for commercially valuable models, where intellectual property rights are at stake.
Once training is complete, the model must be securely packaged for deployment. Storing models in plaintext formats, including unencrypted ONNX or PyTorch checkpoint files, can expose internal structures and parameters to attackers with access to the file system or memory. To mitigate this risk, models should be encrypted, obfuscated, or wrapped in secure containers. Decryption keys should be made available only at runtime and only within trusted environments. Additional mechanisms, such as quantization-aware encryption or integrity-checking wrappers, can prevent tampering and offline model theft.
Deployment environments must also enforce strong access control policies to ensure that only authorized users and services can interact with inference endpoints. Authentication protocols, including OAuth42 tokens, mutual TLS43, or API keys44, should be combined with role-based access control (RBAC)45 to restrict access according to user roles and operational context. For instance, OpenAI’s hosted model APIs require users to include an OPENAI_API_KEY when submitting inference requests.
42 OAuth Protocol: Open Authorization standard developed in 2006, now used by 3+ billion users across Google, Facebook, and Microsoft services. OAuth 2.0 (2012) enables secure API access without exposing user credentials, processing trillions of authentication requests annually for ML API access.
43 Mutual TLS (mTLS): Enhanced Transport Layer Security where both client and server authenticate each other using certificates, introduced in 1999. mTLS provides 99.9%+ secure communication but increases latency by 15-30ms, making it suitable for high-security ML API endpoints requiring end-to-end authentication.
44 API Keys: Simple authentication tokens first popularized by Google Maps API (2005), now ubiquitous in ML services. While convenient, API keys in URL parameters or headers can be logged or exposed, with studies showing 10-15% of GitHub repositories accidentally contain leaked API keys worth millions in compute credits.
45 Role-Based Access Control (RBAC): Access control model developed by NIST in the 1990s, now mandatory for government systems. RBAC reduces security administration overhead by 90%+ compared to individual permissions, with modern ML platforms supporting thousands of roles governing model access, data permissions, and compute resources.
This key authenticates the client and allows the backend to enforce usage policies, monitor for abuse, and log access patterns. Secure implementations retrieve API keys from environment variables rather than hardcoding them into source code, preventing credential exposure in version control systems or application logs. Such key-based access control mechanisms are simple to implement but require careful key management and monitoring to prevent misuse, unauthorized access, or model extraction. Additional security measures in production deployments typically include model integrity verification through SHA-256 hash checking, rate limiting to prevent abuse, input validation for size and format constraints, and comprehensive logging for security event tracking.
The secure deployment patterns established here integrate naturally with the development workflows explored in Chapter 5: AI Workflow, ensuring security becomes part of standard engineering practice rather than an afterthought. Runtime monitoring (Section 1.8.6) extends these protections to operational environments.
Runtime System Monitoring
While secure design and deployment establish strong foundations, protection must extend to runtime operations. Even with robust design and deployment safeguards, machine learning systems remain vulnerable to runtime threats. Attackers may craft inputs that bypass validation, exploit model behavior, or target system-level infrastructure.
Production ML systems face diverse deployment contexts—from cloud services to edge devices to embedded systems. Each environment presents unique monitoring challenges and opportunities, as the system architectures from Chapter 2: ML Systems demonstrate. Defensive strategies must extend beyond static protection to include real-time monitoring, threat detection, and incident response. This section outlines operational defenses that maintain system trust under adversarial conditions, connecting forward to the comprehensive MLOps practices detailed in Chapter 13: ML Operations.
Runtime monitoring encompasses a range of techniques for observing system behavior, detecting anomalies, and triggering mitigation. These techniques can be grouped into three categories: input validation, output monitoring, and system integrity checks.
Input Validation
Input validation is the first line of defense at runtime. It ensures that incoming data conforms to expected formats, statistical properties, or semantic constraints before it is passed to a machine learning model. Without these safeguards, models are vulnerable to adversarial inputs, which are crafted examples designed to trigger incorrect predictions, or to malformed inputs that cause unexpected behavior in preprocessing or inference.
Machine learning models, unlike traditional rule-based systems, often do not fail safely. Small, carefully chosen changes to input data can cause models to make high-confidence but incorrect predictions. Input validation helps detect and reject such inputs early in the pipeline (Goodfellow, Shlens, and Szegedy 2014).
46 Speech Activity Detector (SAD): Algorithm that distinguishes speech from silence, noise, or music in audio streams, essential for voice interfaces since the 1990s. Modern neural SADs achieve 95%+ accuracy and operate in <10ms latency, enabling real-time filtering before expensive speech recognition processing.
Validation techniques range from low-level checks (e.g., input size, type, and value ranges) to semantic filters (e.g., verifying whether an image contains a recognizable object or whether a voice recording includes speech). For example, a facial recognition system might validate that the uploaded image is within a certain resolution range (e.g., 224×224 to 1024×1024 pixels), contains RGB channels, and passes a lightweight face detection filter. This prevents inputs like blank images, text screenshots, or synthetic adversarial patterns from reaching the model. Similarly, a voice assistant might require that incoming audio files be between 1 and 5 seconds long, have a valid sampling rate (e.g., 16kHz), and contain detectable human speech using a speech activity detector (SAD)46. This ensures that empty recordings, music clips, or noise bursts are filtered before model inference.
In generative systems such as DALL·E, Stable Diffusion, or Sora, input validation often involves prompt filtering. This includes scanning the user’s text prompt for banned terms, brand names, profanity, or misleading medical claims. For example, a user prompt like “Generate an image of a medication bottle labeled with Pfizer’s logo” might be rejected or rewritten due to trademark concerns. Filters may operate using keyword lists, regular expressions, or lightweight classifiers that assess prompt intent. These filters prevent the generative model from being used to produce harmful, illegal, or misleading content—even before sampling begins.
In some applications, distributional checks are also used. These assess whether the incoming data statistically resembles what the model saw during training. For instance, a computer vision pipeline might compare the color histogram of the input image to a baseline distribution, flagging outliers for manual review or rejection.
These validations can be lightweight (heuristics or threshold rules) or learned (small models trained to detect distribution shift or adversarial artifacts). In either case, input validation serves as a important pre-inference firewall—reducing exposure to adversarial behavior, improving system stability, and increasing trust in downstream model decisions.
Output Monitoring
Even when inputs pass validation, adversarial or unexpected behavior may still emerge at the model’s output. Output monitoring helps detect such anomalies by analyzing model predictions in real time. These mechanisms observe how the model behaves across inputs, by tracking its confidence, prediction entropy, class distribution, or response patterns, to flag deviations from expected behavior.
A key target for monitoring is prediction confidence. For example, if a classification model begins assigning high confidence to low-frequency or previously rare classes, this may indicate the presence of adversarial inputs or a shift in the underlying data distribution. Monitoring the entropy of the output distribution can similarly reveal when the model is overly certain in ambiguous contexts—an early signal of possible manipulation.
In content moderation systems, a model that normally outputs neutral or “safe” labels may suddenly begin producing high-confidence “safe” labels for inputs containing offensive or restricted content. Output monitoring can detect this mismatch by comparing predictions against auxiliary signals or known-safe reference sets. When deviations are detected, the system may trigger a fallback policy—such as escalating the content for human review or switching to a conservative baseline model.
Time-series models also benefit from output monitoring. For instance, an anomaly detection model used in fraud detection might track predicted fraud scores for sequences of financial transactions. A sudden drop in fraud scores, especially during periods of high transaction volume, may indicate model tampering, label leakage, or evasion attempts. Monitoring the temporal evolution of predictions provides a broader perspective than static, pointwise classification.
Generative models, such as text-to-image systems, introduce unique output monitoring challenges. These models can produce high-fidelity imagery that may inadvertently violate content safety policies, platform guidelines, or user expectations. To mitigate these risks, post-generation classifiers are commonly employed to assess generated content for objectionable characteristics such as violence, nudity, or brand misuse. These classifiers operate downstream of the generative model and can suppress, blur, or reject outputs based on predefined thresholds. Some systems also inspect internal representations (e.g., attention maps47 or latent embeddings) to anticipate potential misuse before content is rendered.
47 Attention Maps: Visualization technique for understanding transformer model focus, introduced with the attention mechanism in 2015. Attention maps reveal which input tokens influence outputs most strongly, helping detect potential bias or manipulation in models processing 175+ billion parameters like GPT-3.
However, prompt filtering alone is insufficient for safety. Research has shown that text-to-image systems can be manipulated through implicitly adversarial prompts, which are queries that appear benign but lead to policy-violating outputs. The Adversarial Nibbler project introduces an open red teaming methodology that identifies such prompts and demonstrates how models like Stable Diffusion can produce unintended content despite the absence of explicit trigger phrases (Quaye et al. 2024). These failure cases often bypass prompt filters because their risk arises from model behavior during generation, not from syntactic or lexical cues.

As shown in Figure 14, even prompts that appear innocuous can trigger unsafe generations. Such examples highlight the limitations of pre-generation safety checks and reinforce the necessity of output-based monitoring as a second line of defense. This two-stage pipeline—consisting of prompt filtering followed by post-hoc content analysis important for ensuring the safe deployment of generative models in open-ended or user-facing environments.
In the domain of language generation, output monitoring plays a different but equally important role. Here, the goal is often to detect toxicity, hallucinated claims, or off-distribution responses. For example, a customer support chatbot may be monitored for keyword presence, tonal alignment, or semantic coherence. If a response contains profanity, unsupported assertions, or syntactically malformed text, the system may trigger a rephrasing, initiate a fallback to scripted templates, or halt the response altogether.
Effective output monitoring combines rule-based heuristics with learned detectors trained on historical outputs. These detectors are deployed to flag deviations in real time and feed alerts into incident response pipelines. In contrast to model-centric defenses like adversarial training, which aim to improve model robustness, output monitoring emphasizes containment and remediation. Its role is not to prevent exploitation but to detect its symptoms and initiate appropriate countermeasures (Savas et al. 2022). In safety-important or policy-sensitive applications, such mechanisms form a important layer of operational resilience.
These principles have been implemented in recent output filtering frameworks. For example, LLM Guard combines transformer-based classifiers with safety dimensions such as toxicity, misinformation, and illegal content to assess and reject prompts or completions in instruction-tuned LLMs (Inan et al. 2023). Similarly, ShieldGemma, developed as part of Google’s open Gemma model release, applies configurable scoring functions to detect and filter undesired outputs during inference. Both systems exemplify how safety classifiers and output monitors are being integrated into the runtime stack to support scalable, policy-aligned deployment of generative language models.
Integrity Checks
While input and output monitoring focus on model behavior, system integrity checks ensure that the underlying model files, execution environment, and serving infrastructure remain untampered throughout deployment. These checks detect unauthorized modifications, verify that the model running in production is authentic, and alert operators to suspicious system-level activity.
One of the most common integrity mechanisms is cryptographic model verification. Before a model is loaded into memory, the system can compute a cryptographic hash (e.g., SHA-256)48 of the model file and compare it against a known-good signature.
48 SHA-256: Cryptographic hash function producing 256-bit digests, part of the SHA-2 family designed by the NSA in 2001. Despite processing trillions of hashes daily across Bitcoin mining and digital signatures, no practical collision attacks exist after 20+ years, making it the gold standard for file integrity verification.
Access control and audit logging complement cryptographic checks. ML systems should restrict access to model files using role-based permissions and monitor file access patterns. For instance, repeated attempts to read model checkpoints from a non-standard path, or inference requests from unauthorized IP ranges, may indicate tampering, privilege escalation, or insider threats.
In cloud environments, container- or VM-based isolation49 helps enforce process and memory boundaries, but these protections can erode over time due to misconfiguration or supply chain vulnerabilities.
49 Container/VM Isolation: Virtualization technologies that provide process and memory separation—containers (Docker, 2013) offer lightweight OS-level isolation with typically 0-5% overhead for CPU-bound workloads and 2-10% for I/O-intensive operations, while VMs provide stronger hardware-level isolation with 10-15% overhead. In ML deployments, containerization is widely adopted for model serving, with industry surveys suggesting 80-90% adoption in cloud environments, though VMs remain preferred for sensitive models requiring stronger isolation guarantees.
50 Healthcare ML Compliance: FDA has approved 500+ AI-based medical devices since 2016, requiring strict validation under 21 CFR Part 820 quality systems. Healthcare ML systems must demonstrate safety, efficacy, and bias mitigation, with some approvals taking 2-5 years and costing $50+ million in clinical trials.
51 HIPAA ML Requirements: The Health Insurance Portability and Accountability Act (1996) imposes strict data protection rules affecting 600+ million patient records in the US. For ML systems, HIPAA requires encryption of data at rest and in transit, audit logs for all data access, and business associate agreements for cloud ML services, with violations carrying fines up to $1.5 million per incident.
For example, in a regulated healthcare ML deployment50, integrity checks might include: verifying the model hash against a signed manifest, validating that the runtime environment uses only approved Python packages, and checking that inference occurs inside a signed and attested virtual machine. These checks ensure compliance with regulations like HIPAA51’s integrity requirements and GDPR’s accountability principle, limit the risk of silent failures, and create a forensic trail in case of audit or breach.
Some systems also implement runtime memory verification, such as scanning for unexpected model parameter changes or checking that memory-mapped model weights remain unaltered during execution. While more common in high-assurance systems, such checks are becoming more feasible with the adoption of secure enclaves and trusted runtimes.
Taken together, system integrity checks play a important role in protecting machine learning systems from low-level attacks that bypass the model interface. When coupled with input/output monitoring, they provide layered assurance that both the model and its execution environment remain trustworthy under adversarial conditions.
Response and Rollback
When a security breach, anomaly, or performance degradation is detected in a deployed machine learning system, rapid and structured incident response is important to minimizing impact. The goal is not only to contain the issue but to restore system integrity and ensure that future deployments benefit from the insights gained. Unlike traditional software systems, ML responses may require handling model state, data drift, or inference behavior, making recovery more complex.
The first step is to define incident detection thresholds that trigger escalation. These thresholds may come from input validation (e.g., invalid input rates), output monitoring (e.g., drop in prediction confidence), or system integrity checks (e.g., failed model signature verification). When a threshold is crossed, the system should initiate an automated or semi-automated response protocol.
One common strategy is model rollback, where the system reverts to a previously verified version of the model. For instance, if a newly deployed fraud detection model begins misclassifying transactions, the system may fall back to the last known-good checkpoint, restoring service while the affected version is quarantined. Rollback mechanisms require version-controlled model storage, typically supported by MLOps platforms such as MLflow, TFX, or SageMaker.
In high-availability environments, model isolation may be used to contain failures. The affected model instance can be removed from load balancers or shadowed in a canary deployment setup. This allows continued service with unaffected replicas while maintaining forensic access to the compromised model for analysis.
Traffic throttling is another immediate response tool. If an adversarial actor is probing a public inference API at high volume, the system can rate-limit or temporarily block offending IP ranges while continuing to serve trusted clients. This containment technique helps prevent abuse without requiring full system shutdown.
Once immediate containment is in place, investigation and recovery can begin. This may include forensic analysis of input logs, parameter deltas between model versions, or memory snapshots from inference containers. In regulated environments, organizations may also need to notify users or auditors, particularly if personal or safety-important data was affected.
Recovery typically involves retraining or patching the model. This must occur through a secure update process, using signed artifacts, trusted build pipelines, and validated data. To prevent recurrence, the incident should feed back into model evaluation pipelines—updating tests, refining monitoring thresholds, or hardening input defenses. For example, if a prompt injection attack bypassed a content filter in a generative model, retraining might include adversarially crafted prompts, and the prompt validation logic would be updated to reflect newly discovered patterns.
Finally, organizations should establish post-incident review practices. This includes documenting root causes, identifying gaps in detection or response, and updating policies and playbooks. Incident reviews help translate operational failures into actionable improvements across the design-deploy-monitor lifecycle.
Hardware Security Foundations
The software-layer defenses we’ve explored—input validation, output monitoring, and integrity checks—establish important protections, but they ultimately depend on the underlying hardware and firmware being trustworthy. If an attacker compromises the operating system, gains physical access to the device, or exploits vulnerabilities in the processor itself, these software defenses can be bypassed or disabled entirely. This limitation motivates hardware-based security mechanisms that operate below the software layer, creating a hardware root of trust that remains secure even when higher-level systems are compromised.
At the foundational level of our defensive framework, hardware-based security mechanisms provide the trust anchor for all higher-layer protections. Machine learning systems deployed in edge devices, embedded systems, and untrusted cloud infrastructure increasingly rely on hardware-based security features to establish this foundation. The hardware acceleration platforms discussed in Chapter 11: AI Acceleration—including GPUs, TPUs, and specialized ML accelerators—often incorporate these security features (secure enclaves, trusted execution environments, hardware cryptographic units), while edge deployment scenarios from Chapter 14: On-Device Learning present unique security challenges.
These hardware security mechanisms become particularly crucial when systems must meet regulatory compliance requirements. Healthcare ML systems handling protected health information under HIPAA must implement “appropriate technical safeguards” including access controls and encryption. Systems processing EU citizens’ data under GDPR must demonstrate “appropriate technical and organizational measures” with privacy by design principles embedded at the hardware level.
To understand how hardware security protects ML systems, imagine building a secure fortress for your most valuable assets. Each hardware security primitive serves a distinct defensive role:
| Mechanism | Fortress Analogy and Function |
|---|---|
| Secure Boot | Functions like a trusted gatekeeper checking credentials of everyone entering the fortress at dawn. Before your system runs any code, Secure Boot cryptographically verifies that the firmware and operating system haven’t been tampered with. |
| Trusted Execution | Create secure, windowless rooms deep inside the fortress where you |
| Environments | handle your most sensitive operations. When your ML model processes |
| (TEEs) | private medical data or proprietary algorithms, the TEE isolates these computations from the rest of the system. |
| Hardware Security | Serve as specialized, impenetrable vaults designed specifically for |
| Modules (HSMs) | storing and using your most valuable cryptographic keys. Rather than keeping encryption keys in regular computer memory where they might be stolen, HSMs provide tamper-resistant storage. |
| Physical | Give each device a unique biometric fingerprint at the silicon |
| Unclonable | level. Just as human fingerprints cannot be perfectly replicated, |
| Functions (PUFs) | PUFs exploit tiny manufacturing variations in each chip to create device-unique identifiers that cannot be cloned. |
These mechanisms work together to create comprehensive protection that begins in hardware and extends through all software layers.
This section explores how these four complementary hardware primitives work together to create comprehensive protection (Table 8). Each mechanism addresses different security challenges but works most effectively when combined: secure boot establishes initial trust, TEEs provide runtime isolation, HSMs handle cryptographic operations, and PUFs enable device-unique authentication. We begin with Trusted Execution Environments (TEEs), which provide isolated runtime environments for sensitive computations. Secure Boot ensures system integrity from power-on, creating the trusted foundation that TEEs depend upon. Hardware Security Modules (HSMs) offer specialized cryptographic processing and tamper-resistant key storage, often required for regulatory compliance. Finally, Physical Unclonable Functions (PUFs) provide device-unique identities that enable lightweight authentication and cannot be cloned or extracted.
Each mechanism addresses different aspects of the security challenge, working most effectively when deployed together across hardware, firmware, and software boundaries.
Hardware-Software Co-Design
Modern ML systems require holistic analysis of security trade-offs across the entire hardware-software stack, similar to how we analyze compute-memory-energy trade-offs in performance optimization. The interdependence between hardware security features and software defenses creates both opportunities and constraints that must be understood quantitatively.
Hardware security mechanisms introduce measurable overhead that must be factored into system design. ARM TrustZone world-switching adds approximately 300-1000 cycles depending on processor generation and cache state (0.6-2.0μs at 500MHz) of latency per transition between secure and non-secure worlds. Cryptographic operations in secure mode typically consume 15-30% additional power compared to normal execution, impacting battery life in mobile ML applications. Intel SGX context switching imposes 15-30μs overhead per inference, representing 2% energy overhead for typical edge ML workloads.
Security features scale differently than computational resources. TEE memory limitations constrain model size regardless of available system memory. A quantized ResNet-18 model (47MB) can operate within ARM TrustZone constraints, while ResNet-50 (176MB) requires careful memory management or model partitioning. These constraints create architectural decisions that must be made early in system design.
Different threat models and protection levels require quantitative trade-off analysis. For ML workloads requiring cryptographic verification, AES-256 operations add 0.1-0.5ms per inference depending on model size and hardware acceleration availability. Homomorphic encryption operations impose 100-100,000x computational overhead, with fully homomorphic encryption (FHE) at the higher end and somewhat homomorphic encryption (SHE) at the lower end, making them viable only for small models or offline scenarios where strong privacy guarantees justify the performance cost.
Trusted Execution Environments
A Trusted Execution Environment (TEE)52 is a hardware-isolated region within a processor designed to protect sensitive computations and data from potentially compromised software. TEEs enforce confidentiality, integrity, and runtime isolation, ensuring that even if the host operating system or application layer is attacked, sensitive operations within the TEE remain secure.
52 TEE Concept Origins: The idea emerged from ARM’s TrustZone development in the early 2000s, inspired by the military concept of “compartmentalized information.” ARM realized that mobile devices needed secure and non-secure “worlds” running on the same processor—leading to hardware-enforced isolation that became the template for all modern TEEs.]
In the context of machine learning, TEEs are increasingly important for preserving the confidentiality of models, securing sensitive user data during inference, and ensuring that model outputs remain trustworthy. For example, a TEE can protect model parameters from being extracted by malicious software running on the same device, or ensure that computations involving biometric inputs, including facial data or fingerprint data, are performed securely. This capability is essential in applications where model integrity, user privacy, or regulatory compliance are non-negotiable.
One widely deployed example is Apple’s Secure Enclave, which provides isolated execution and secure key storage for iOS devices. By separating cryptographic operations and biometric data from the main processor, the Secure Enclave ensures that user credentials and Face ID features remain protected, even in the event of a broader system compromise.
Trusted Execution Environments are important across a range of industries with high security requirements. In telecommunications, TEEs are used to safeguard encryption keys and secure important 5G control-plane operations. In finance, they allow secure mobile payments and protect PIN-based authentication workflows. In healthcare, TEEs help enforce patient data confidentiality during edge-based ML inference on wearable or diagnostic devices. In the automotive industry, they are deployed in advanced driver-assistance systems (ADAS) to ensure that safety-important perception and decision-making modules operate on verified software.
In machine learning systems, TEEs can provide several important protections. They secure the execution of model inference or training, shielding intermediate computations and final predictions from system-level observation. They protect the confidentiality of sensitive inputs, including biometric or clinical signals, used in personal identification or risk scoring tasks. TEEs also serve to prevent reverse engineering of deployed models by restricting access to weights and architecture internals. When models are updated, TEEs ensure the authenticity of new parameters and block unauthorized tampering. In distributed ML settings, TEEs can protect data exchanged between components by enabling encrypted and attested communication channels.
The core security properties of a TEE are achieved through four mechanisms: isolated execution, secure storage, integrity protection, and in-TEE data encryption. Code that runs inside the TEE is executed in a separate processor mode, inaccessible to the normal-world operating system. Sensitive assets such as cryptographic keys or authentication tokens are stored in memory that only the TEE can access. Code and data can be verified for integrity before execution using hardware-anchored hashes or signatures. Finally, data processed inside the TEE can be encrypted, ensuring that even intermediate results are inaccessible without appropriate keys, which are also managed internally by the TEE.
Several commercial platforms provide TEE functionality tailored for different deployment contexts. ARM TrustZone53 offers secure and normal world execution on ARM-based systems and is widely used in mobile and IoT applications. Intel SGX54 implements enclave-based security for cloud and desktop systems, enabling secure computation even on untrusted infrastructure. Qualcomm’s Secure Execution Environment supports secure mobile transactions and user authentication. Apple’s Secure Enclave remains a canonical example of a hardware-isolated security coprocessor for consumer devices.
53 ARM TrustZone: Introduced in 2004, TrustZone now ships in 95% of ARM processors, protecting over 5 billion mobile devices. Despite its ubiquity, many devices underutilize TrustZone—studies show only 20-30% of Android devices implement meaningful secure world applications beyond basic key storage.
54 Intel SGX Constraints: SGX enclaves are limited to approximately 128MB of protected memory (EPC) on most consumer processors, though enterprise variants support up to 512MB or 1GB, with cache misses causing 100x performance penalties. For ML workloads, a ResNet-50 requires approximately 98MB for weights alone in FP32 format (25.6M parameters × 4 bytes), consuming 77% of SGX EPC before any intermediate activations. Inference latency increases from 5ms to 150ms when model exceeds EPC capacity. This makes SGX unsuitable for large ML models but effective for protecting cryptographic keys and small inference models under 10MB.
Figure 15 illustrates a secure enclave integrated into a system-on-chip (SoC) architecture. The enclave includes a dedicated processor, an AES engine, a true random number generator (TRNG), a public key accelerator (PKA), and a secure I²C interface to nonvolatile storage. These components operate in isolation from the main application processor and memory subsystem. A memory protection engine enforces access control, while cryptographic operations such as NAND flash encryption are handled internally using enclave-managed keys. By physically separating secure execution and key management from the main system, this architecture limits the impact of system-level compromises and establishes hardware-enforced trust.

This architecture underpins the secure deployment of machine learning applications on consumer devices. For example, Apple’s Face ID system uses a secure enclave to perform facial recognition entirely within a hardware-isolated environment. The face embedding model is executed inside the enclave, and biometric templates are stored in secure nonvolatile memory accessible only via the enclave’s I²C interface. During authentication, input data from the infrared camera is processed locally, and no facial features or predictions ever leave the secure region. Even if the application processor or operating system is compromised, the enclave prevents access to sensitive model inputs, parameters, and outputs—ensuring that biometric identity remains protected end to end.
Despite their strengths, Trusted Execution Environments come with notable trade-offs. Implementing a TEE increases both direct hardware costs and indirect costs associated with developing and maintaining secure software. Integrating TEEs into existing systems may require architectural redesigns, especially for legacy infrastructure. Developers must adhere to strict protocols for isolation, attestation, and secure update management, which can extend development cycles and complicate testing workflows. TEEs can also introduce performance overhead, particularly when cryptographic operations are involved, or when context switching between trusted and untrusted modes is frequent.
Energy efficiency is another consideration, particularly in battery-constrained devices. TEEs typically consume additional power due to secure memory accesses, cryptographic computation, and hardware protection logic. In resource-limited embedded systems, these costs may limit their use. In terms of scalability and flexibility, the secure boundaries enforced by TEEs may complicate distributed training or federated inference workloads, where secure coordination between enclaves is required.
Market demand also varies. In some consumer applications, perceived threat levels may be too low to justify the integration of TEEs. Systems with TEEs may be subject to formal security certifications, such as Common Criteria or evaluation under ENISA, which can introduce additional time and expense. For this reason, TEEs are typically adopted only when the expected threat model, including adversarial users, cloud tenants, and malicious insiders, justifies the investment.
Nonetheless, TEEs remain a powerful hardware primitive in the machine learning security landscape. When paired with software- and system-level defenses, they provide a trusted foundation for executing ML models securely, privately, and verifiably, especially in scenarios where adversarial compromise of the host environment is a serious concern.
Here is the revised 7.5.2 Secure Boot section, rewritten in formal textbook tone with all original technical content, hyperlinks, and figures preserved. The structure emphasizes narrative clarity, avoids bullet lists, and integrates the Apple Face ID case study naturally.
Secure Boot
Secure Boot is a mechanism that ensures a device only boots software components that are cryptographically verified and explicitly authorized by the manufacturer. At startup, each stage of the boot process, comprising the bootloader, kernel, and base operating system, is checked against a known-good digital signature. If any signature fails verification, the boot sequence is halted, preventing unauthorized or malicious code from executing. This chain-of-trust model establishes system integrity from the very first instruction executed.
In ML systems, especially those deployed on embedded or edge hardware, Secure Boot plays an important role. A compromised boot process may result in malicious software loading before the ML runtime begins, enabling attackers to intercept model weights, tamper with training data, or reroute inference results. Such breaches can lead to incorrect or manipulated predictions, unauthorized data access, or device repurposing for botnets or crypto-mining.
For machine learning systems, Secure Boot offers several guarantees. First, it protects model-related data, such as training data, inference inputs, and outputs, during the boot sequence, preventing pre-runtime tampering. Second, it ensures that only authenticated model binaries and supporting software are loaded, which helps guard against deployment-time model substitution. Third, Secure Boot allows secure model updates by verifying that firmware or model changes are signed and have not been altered in transit.
Secure Boot frequently works in tandem with hardware-based Trusted Execution Environments (TEEs) to create a fully trusted execution stack. As shown in Figure 16, this layered boot process verifies firmware, operating system components, and TEE integrity before permitting execution of cryptographic operations or ML workloads. In embedded systems, this architecture provides resilience even under severe adversarial conditions or physical device compromise.

A well-known real-world implementation of Secure Boot appears in Apple’s Face ID system, which uses advanced machine learning for facial recognition. For Face ID to operate securely, the entire device stack, from the initial power-on to the execution of the model, must be verifiably trusted.
Upon device startup, Secure Boot initiates within Apple’s Secure Enclave, a dedicated security coprocessor that handles biometric data. The firmware loaded onto the Secure Enclave is digitally signed by Apple, and any unauthorized modification causes the boot process to fail. Once verified, the Secure Enclave performs continuous checks in coordination with the central processor to maintain a trusted boot chain. Each system component, ranging from the iOS kernel to the application-level code, is verified using cryptographic signatures.
After completing the secure boot sequence, the Secure Enclave activates the ML-based Face ID system. The facial recognition model projects over 30,000 infrared points to map a user’s face, generating a depth image and computing a mathematical representation that is compared against a securely stored profile. These facial data artifacts are never written to disk, transmitted off-device, or shared externally. All processing occurs within the enclave to protect against eavesdropping or exfiltration, even in the presence of a compromised kernel.
To support continued integrity, Secure Boot also governs software updates. Only firmware or model updates signed by Apple are accepted, ensuring that even over-the-air patches do not introduce risk. This process maintains a robust chain of trust over time, enabling the secure evolution of the ML system while preserving user privacy and device security.
While Secure Boot provides strong protection, its adoption presents technical and operational challenges. Managing the cryptographic keys used to sign and verify system components is complex, especially at scale. Enterprises must securely provision, rotate, and revoke keys, ensuring that no trusted root is compromised. Any such breach would undermine the entire security chain.
Performance is also a consideration. Verifying signatures during the boot process introduces latency, typically on the order of tens to hundreds of milliseconds per component. Although acceptable in many applications, these delays may be problematic for real-time or power-constrained systems. Developers must also ensure that all components, including bootloaders, firmware, kernels, drivers, and even ML models, are correctly signed. Integrating third-party software into a Secure Boot pipeline introduces additional complexity.
Some systems limit user control in favor of vendor-locked security models, restricting upgradability or customization. In response, open-source bootloaders like u-boot and coreboot have emerged, offering Secure Boot features while supporting extensibility and transparency. To further scale trusted device deployments, emerging industry standards such as the Device Identifier Composition Engine (DICE) and IEEE 802.1AR IDevID provide mechanisms for secure device identity, key provisioning, and cross-vendor trust assurance.
Secure Boot, when implemented carefully and complemented by trusted hardware and secure software update processes, forms the backbone of system integrity for embedded and distributed ML. It provides the assurance that the machine learning model running in production is not only the correct version, but is also executing in a known-good environment, anchored to hardware-level trust.
Hardware Security Modules
While TEEs and secure boot provide runtime isolation and integrity verification, Hardware Security Modules (HSMs) specialize in the cryptographic operations that underpin these protections. An HSM55 is a tamper-resistant physical device designed to perform cryptographic operations and securely manage digital keys. HSMs are widely used across security-important industries such as finance, defense, and cloud infrastructure, and they are increasingly relevant for securing the machine learning pipeline—particularly in deployments where key confidentiality, model integrity, and regulatory compliance are important.
55 HSM Performance: Enterprise HSMs can perform 10,000+ RSA-2048 operations per second but cost $20,000-$100,000+ per unit. In contrast, software-only cryptography on GPUs achieves 100,000+ operations/second at $1,000+ hardware cost, but without the tamper-resistance and regulatory compliance that HSMs provide.
HSMs provide an isolated, hardened environment for performing sensitive operations such as key generation, digital signing, encryption, and decryption. Unlike general-purpose processors, they are engineered to withstand physical tampering and side-channel attacks, and they typically include protected storage, cryptographic accelerators, and internal audit logging. HSMs may be implemented as standalone appliances, plug-in modules, or integrated chips embedded within broader systems.
In machine learning systems, HSMs enhance security across several dimensions. They are commonly used to protect encryption keys associated with sensitive data that may be processed during training or inference. These keys might encrypt data at rest in model checkpoints or allow secure transmission of inference requests across networked environments. By ensuring that the keys are generated, stored, and used exclusively within the HSM, the system minimizes the risk of key leakage, unauthorized reuse, or tampering.
HSMs also play a role in maintaining the integrity of machine learning models. In many production pipelines, models must be signed before deployment to ensure that only verified versions are accepted into runtime environments. The signing keys used to authenticate models can be stored and managed within the HSM, providing cryptographic assurance that the deployed artifact is authentic and untampered. Similarly, secure firmware updates and configuration changes, regardless of whether they pertain to models, hyperparameters, or supporting infrastructure, can be validated using signatures produced by the HSM.
In addition to protecting inference workloads, HSMs can be used to secure model training. During training, data may originate from distributed and potentially untrusted sources. HSM-backed protocols can help ensure that training pipelines perform encryption, integrity checks, and access control enforcement securely and in compliance with organizational or legal requirements. In regulated industries such as healthcare and finance, such protections are often mandatory. For instance, HIPAA requires covered entities to implement technical safeguards including “integrity controls” and “encryption and decryption,” while GDPR mandates pseudonymization and encryption as examples of appropriate technical measures.
Despite these benefits, incorporating HSMs into embedded or resource-constrained ML systems introduces several trade-offs. First, HSMs are specialized hardware components and often come at a premium. Their cost may be justified in data center settings or safety-important applications but can be prohibitive for low-margin embedded products or wearables. Physical space is also a concern. Embedded systems often operate under strict size, weight, and form factor constraints, and integrating an HSM may require redesigning circuit layouts or sacrificing other functionality.
From a performance standpoint, HSMs introduce latency, particularly for operations like key exchange, signature verification, or on-the-fly decryption. In real-time inference systems, including autonomous vehicles, industrial robotics, and live translation devices, these delays can affect responsiveness. While HSMs are typically optimized for cryptographic throughput, they are not general-purpose processors, and offloading secure operations must be carefully coordinated.
Power consumption is another concern. The continuous secure handling of keys, signing of transactions, and cryptographic validations can consume more power than basic embedded components, impacting battery life in mobile or remote deployments.
Integration complexity also grows when HSMs are introduced into existing ML pipelines. Interfacing between the HSM and the host processor requires dedicated APIs and often specialized software development. Firmware and model updates must be routed through secure, signed channels, and update orchestration must account for device-specific key provisioning. These requirements increase the operational burden, especially in large deployments.
Scalability presents its own set of challenges. Managing a distributed fleet of HSM-equipped devices requires secure provisioning of individual keys, secure identity binding, and coordinated trust management. In large ML deployments, including fleets of smart sensors or edge inference nodes, ensuring uniform security posture across all devices is nontrivial.
Finally, the use of HSMs often requires organizations to engage in certification and compliance processes56, particularly when handling regulated data. Meeting standards such as FIPS 140-257 or Common Criteria adds time and cost to development.
56 HSM Certification: Hardware Security Module certification under FIPS 140-2 or Common Criteria can take 12-24 months and cost $500,000-$2 million. However, many regulated industries require these certifications, with banking, government, and healthcare sectors mandating Level 3+ certified HSMs for cryptographic operations.
57 FIPS 140-2 Standard: Federal Information Processing Standard for cryptographic modules, established in 2001 with four security levels. Level 4 HSMs must survive physical attacks, operating at -40°C to +85°C with tamper detection that zeroizes keys within seconds, making them suitable for the most sensitive ML applications. Access to the HSM is typically restricted to a small set of authorized personnel, which can complicate development workflows and slow iteration cycles.
Despite these operational complexities, HSMs remain a valuable option for machine learning systems that require high assurance of cryptographic integrity and access control. When paired with TEEs, secure boot, and software-based defenses, HSMs contribute to a multilayered security model that spans hardware, system software, and ML runtime.
Physical Unclonable Functions
Physical Unclonable Functions (PUFs)58 provide a hardware-intrinsic mechanism for cryptographic key generation and device authentication by leveraging physical randomness in semiconductor fabrication (Gassend et al. 2002). Unlike traditional keys stored in memory, a PUF generates secret values based on microscopic variations in a chip’s physical properties—variations that are inherent to manufacturing processes and difficult to clone or predict, even by the manufacturer.
58 PUF Market Growth: The PUF market is projected to reach $320 million by 2025, driven by IoT security needs. Major semiconductor companies including Intel, Xilinx, and Synopsis now offer PUF IP, with deployment in smart cards, automotive ECUs, and edge ML devices requiring device-unique authentication.
These variations arise from uncontrollable physical factors such as doping concentration, line edge roughness, and dielectric thickness. As a result, even chips fabricated with the same design masks exhibit small but measurable differences in timing, power consumption, or voltage behavior. PUF circuits amplify these variations to produce a device-unique digital output. When a specific input challenge is applied to a PUF, it generates a corresponding response based on the chip’s physical fingerprint. Because these characteristics are effectively impossible to replicate, the same challenge will yield different responses across devices.
This challenge-response mechanism allows PUFs to serve several cryptographic purposes. They can be used to derive device-specific keys that never need to be stored externally, reducing the attack surface for key exfiltration. The same mechanism also supports secure authentication and attestation, where devices must prove their identity to trusted servers or hardware gateways. These properties make PUFs a natural fit for machine learning systems deployed in embedded and distributed environments.
In ML applications, PUFs offer unique advantages for securing resource-constrained systems. For example, consider a smart camera drone that uses onboard computer vision to track objects. A PUF embedded in the drone’s processor can generate a private key to encrypt the model during boot. Even if the model were extracted, it would be unusable on another device lacking the same PUF response. That same PUF-derived key could also be used to watermark the model parameters, creating a cryptographically verifiable link between a deployed model and its origin hardware. If the model were leaked or pirated, the embedded watermark could help prove the source of the compromise.
PUFs also support authentication in distributed ML pipelines. If the drone offloads computation to a cloud server, the PUF can help verify that the drone has not been cloned or tampered with. The cloud backend can issue a challenge, verify the correct response from the device, and permit access only if the PUF proves device authenticity. These protections enhance trust not only in the model and data, but in the execution environment itself.
The internal operation of a PUF is illustrated in Figure 17. At a high level, a PUF accepts a challenge input and produces a unique response determined by the physical microstructure of the chip (Gao, Al-Sarawi, and Abbott 2020). Variants include optical PUFs, in which the challenge consists of a light pattern and the response is a speckle image, and electronic PUFs such as Arbiter PUFs (APUFs), where timing differences between circuit paths produce a binary output. Another common implementation is the SRAM PUF, which exploits the power-up state of uninitialized SRAM cells: due to threshold voltage mismatch, each cell tends to settle into a preferred value when power is first applied. These response patterns form a stable, reproducible hardware fingerprint.
Despite their promise, PUFs present several challenges in system design. Their outputs can be sensitive to environmental variation, such as changes in temperature or voltage, which can introduce instability or bit errors in the response. To ensure reliability, PUF systems must often incorporate error correction codes or helper data schemes. Managing large sets of challenge-response pairs also raises questions about storage, consistency, and revocation. Additionally, the unique statistical structure of PUF outputs may make them vulnerable to machine learning-based modeling attacks if not carefully shielded from external observation.
From a manufacturing perspective, incorporating PUF technology can increase device cost or require additional layout complexity. While PUFs eliminate the need for external key storage, thereby reducing long-term security risk and provisioning cost, they may require calibration and testing during fabrication to ensure consistent performance across environmental conditions and device aging.
Nevertheless, Physical Unclonable Functions remain a compelling building block for securing embedded machine learning systems. By embedding hardware identity directly into the chip, PUFs support lightweight cryptographic operations, reduce key management burden, and help establish root-of-trust anchors in distributed or resource-constrained environments. When integrated thoughtfully, they complement other hardware-assisted security mechanisms such as Secure Boot, TEEs, and HSMs to provide defense-in-depth across the ML system lifecycle.
Mechanisms Comparison
Hardware-assisted security mechanisms play a foundational role in establishing trust within modern machine learning systems. While software-based defenses offer flexibility, they ultimately rely on the security of the hardware platform. As machine learning workloads increasingly operate on edge devices, embedded platforms, and untrusted infrastructure, hardware-backed protections become important for maintaining system integrity, confidentiality, and trust.
Trusted Execution Environments (TEEs) provide runtime isolation for model inference and sensitive data handling. Secure Boot enforces integrity from power-on, ensuring that only verified software is executed. Hardware Security Modules (HSMs) offer tamper-resistant storage and cryptographic processing for secure key management, model signing, and firmware validation. Physical Unclonable Functions (PUFs) bind secrets and authentication to the physical characteristics of a specific device, enabling lightweight and unclonable identities.
These mechanisms address different layers of the system stack, ranging from initialization and attestation to runtime protection and identity binding, and complement one another when deployed together. Table 9 below compares their roles, use cases, and trade-offs in machine learning system design.
| Mechanism | Primary Function | Common Use in ML | Trade-offs |
|---|---|---|---|
Trusted Execution Environment (TEE) |
Isolated runtime environment for secure computation | Secure inference and on-device privacy for sensitive inputs and outputs | Added complexity, memory limits, perf. cost Requires trusted code development |
| Secure Boot | Verified boot sequence and firmware validation | Ensures only signed ML models and firmware execute on embedded devices | Key management complexity, vendor lock-in Performance impact during startup |
| Hardware Security Module (HSM) | Secure key generation and storage, crypto-processing | Signing ML models, securing training pipelines, verifying firmware | High cost, integration overhead, limited I/O Requires infrastructure-level provisioning |
Physical Unclonable Function (PUF) |
Hardware-bound identity and key derivation | Model binding, device authentication, protecting IP in embedded deployments | Environmental sensitivity, modeling attacks Needs error correction and calibration |
Together, these hardware primitives form the foundation of a defense-in-depth strategy for securing ML systems in adversarial environments. Their integration is especially important in domains that demand provable trust, such as autonomous vehicles, healthcare devices, federated learning systems, and important infrastructure.
Practical Implementation Roadmap
The comprehensive security and privacy techniques covered in this chapter can seem overwhelming for organizations just beginning to secure their ML systems. Rather than implementing every defense simultaneously, a phased approach enables systematic security improvements while managing complexity and costs. This roadmap provides a practical sequence for building robust ML security, progressing from foundational controls to advanced defenses.
Phase 1: Foundation Security Controls
Begin with basic security controls that provide the greatest risk reduction for the least complexity. These foundational measures address the most common attack vectors and create the trust infrastructure needed for more advanced defenses.
Access Control and Authentication: Implement role-based access control (RBAC) for all ML system components, including training data, model repositories, and inference APIs. Use multi-factor authentication for administrative access and service-to-service authentication with short-lived tokens. Establish the principle of least privilege, ensuring users and services have only the minimum permissions required for their functions.
Data Protection: Encrypt all data at rest using AES-256 and enforce TLS 1.3 for all data in transit. This includes training datasets, model files, and inference communications. Implement comprehensive logging of all data access and model operations to support incident investigation and compliance auditing.
Input Validation and Basic Monitoring: Deploy input validation for all ML APIs to reject malformed requests, implement rate limiting to prevent abuse, and establish baseline monitoring for unusual inference patterns. These measures protect against basic adversarial inputs and provide visibility into system behavior.
Secure Development Practices: Establish secure coding practices for ML pipelines, including dependency management with vulnerability scanning, secure model serialization that validates model integrity, and automated security testing in deployment pipelines.
Phase 2: Privacy Controls and Model Protection
With foundational controls in place, focus on protecting sensitive data and securing your ML models from theft and manipulation. This phase addresses privacy regulations and intellectual property protection.
Privacy-Preserving Techniques: Implement data anonymization for non-sensitive use cases and differential privacy for scenarios requiring formal privacy guarantees. For collaborative learning scenarios, deploy federated learning architectures that keep sensitive data localized while enabling model improvement.
Model Security: Protect deployed models through encryption of model files, secure API design that limits information leakage, and monitoring for model extraction attempts. Implement model versioning and integrity checking to detect unauthorized modifications.
Secure Training Infrastructure: Harden training environments by isolating training workloads, implementing secure data pipelines with validation and provenance tracking, and establishing secure model registries with access controls and audit trails.
Compliance Integration: Implement necessary controls for regulatory requirements such as GDPR, HIPAA, or industry-specific standards. This includes data subject rights management, privacy impact assessments, and documentation of data processing activities.
Phase 3: Advanced Threat Defense
The final phase implements sophisticated defenses for high-stakes environments where advanced adversaries pose significant threats. These defenses require more expertise and resources but provide protection against state-of-the-art attacks.
Adversarial Robustness: Deploy adversarial training to improve model robustness against evasion attacks, implement certified defenses for safety-critical applications, and establish continuous testing against new adversarial techniques.
Advanced Runtime Monitoring: Deploy ML-specific anomaly detection systems that can identify sophisticated attacks like data poisoning effects or gradual model degradation. Implement behavioral analysis that establishes normal operation baselines and alerts on deviations.
Hardware-Based Security: For the highest security requirements, implement trusted execution environments (TEEs) for model inference, secure boot processes for edge devices, and hardware security modules (HSMs) for cryptographic key management.
Incident Response and Recovery: Establish ML-specific incident response procedures, including model rollback capabilities, contaminated data isolation procedures, and forensic analysis techniques for ML-specific attacks.
Implementation Considerations
Success with this roadmap requires balancing security improvements with operational capabilities. Each phase should be fully implemented and stabilized before progressing to the next level. Organizations should customize this sequence based on their specific threat model: healthcare systems may prioritize Phase 2 privacy controls, financial institutions may emphasize Phase 1 data protection, and autonomous vehicle systems may fast-track to Phase 3 adversarial robustness.
Resource allocation should account for the increasing technical complexity and operational overhead of advanced phases. Phase 1 controls typically require standard IT security expertise, while Phase 3 defenses may require specialized ML security knowledge or external consulting. Organizations should invest in training and hiring appropriate expertise before implementing advanced controls.
Regular security assessments should validate the effectiveness of implemented controls and guide progression through phases. These assessments should include penetration testing of ML-specific attack vectors, red team exercises that simulate realistic adversarial scenarios, and compliance audits that verify regulatory requirements are met effectively.
Fallacies and Pitfalls
Having examined both defensive and offensive capabilities, we now address common misconceptions that can undermine security efforts. Security and privacy in machine learning systems present unique challenges that extend beyond traditional cybersecurity concerns, involving sophisticated attacks on data, models, and inference processes. The complexity of modern ML pipelines, combined with the probabilistic nature of machine learning and the sensitivity of training data, creates numerous opportunities for misconceptions about effective protection strategies.
Fallacy: Security through obscurity provides adequate protection for machine learning models.
This outdated approach assumes that hiding model architectures, parameters, or implementation details provides meaningful security protection. Modern attacks often succeed without requiring detailed knowledge of target systems, relying instead on black-box techniques that probe system behavior through input-output relationships. Model extraction attacks can reconstruct significant model functionality through carefully designed queries, while adversarial attacks often transfer across different architectures. Effective ML security requires robust defenses that function even when attackers have complete knowledge of the system, following established security principles rather than relying on secrecy.
Pitfall: Assuming that differential privacy automatically ensures privacy without considering implementation details.
Many practitioners treat differential privacy as a universal privacy solution without understanding the critical importance of proper implementation and parameter selection. Poorly configured privacy budgets can provide negligible protection while severely degrading model utility. Implementation vulnerabilities like floating-point precision issues, inadequate noise generation, or privacy budget exhaustion can completely compromise privacy guarantees. Real-world systems require careful analysis of privacy parameters, rigorous implementation validation, and ongoing monitoring to ensure that theoretical privacy guarantees translate to practical protection.
Fallacy: Federated learning inherently provides privacy protection without additional safeguards.
A related privacy misconception assumes that keeping data decentralized automatically ensures privacy protection. While federated learning improves privacy compared to centralized training, gradient and model updates can still leak significant information about local training data through inference attacks. Sophisticated adversaries can reconstruct training examples, infer membership information, or extract sensitive attributes from shared model parameters. True privacy protection in federated settings requires additional mechanisms like secure aggregation, differential privacy, and careful communication protocols rather than relying solely on data locality.
Pitfall: Treating security as an isolated component rather than a system-wide property.
Beyond specific technical misconceptions, a key architectural pitfall involves organizations that approach ML security by adding security features to individual components without considering system-level interactions and attack vectors. This piecemeal approach fails to address sophisticated attacks that span multiple components or exploit interfaces between subsystems. Effective ML security requires holistic threat modeling that considers the entire system lifecycle from data collection through model deployment and maintenance, following the threat prioritization principles established in Section 1.4.1. Security must be integrated into every stage of the ML pipeline rather than treated as an add-on feature or post-deployment consideration.
Pitfall: Underestimating the attack surface expansion in distributed ML systems.
Many organizations focus on securing individual components without recognizing how distributed ML architectures increase the attack surface and introduce new vulnerability classes. Distributed training across multiple data centers creates opportunities for man-in-the-middle attacks on gradient exchanges, certificate spoofing, and unauthorized participation in training rounds. Edge deployment multiplies endpoints that require security updates, monitoring, and incident response capabilities. Model serving infrastructure spanning multiple clouds introduces dependency chain attacks, where compromising any component in the distributed system can affect overall security. Orchestration systems, load balancers, model registries, and monitoring infrastructure each present potential entry points for sophisticated attackers. Effective distributed ML security requires thorough threat modeling that accounts for network communication security, endpoint hardening, identity management across multiple domains, and coordination of security policies across heterogeneous infrastructure components.
Summary
This chapter has explored the complex landscape of security and privacy in machine learning systems, from core threats to comprehensive defense strategies. Security and privacy represent essential requirements for deploying machine learning systems in production environments. As these systems handle sensitive data, operate across diverse platforms, and face sophisticated threats, their security posture must encompass the entire technology stack. Modern machine learning systems encounter attack vectors ranging from data poisoning and model extraction to adversarial examples and hardware-level compromises that can undermine system integrity and user trust.
Effective security strategies employ defense-in-depth approaches that operate across multiple layers of the system architecture. Privacy-preserving techniques like differential privacy and federated learning protect sensitive data while enabling model training. Robust model design incorporates adversarial training and input validation to resist manipulation. Hardware security features provide trusted execution environments and secure boot processes. Runtime monitoring detects anomalous behavior and potential attacks during operation. These complementary defenses create resilient systems that can withstand coordinated attacks across multiple attack surfaces.
- Security and privacy must be integrated from initial architecture design rather than added as afterthoughts to ML systems
- ML systems face threats across three categories: model confidentiality (theft), training integrity (poisoning), and inference robustness (adversarial attacks)
- Historical security patterns (supply chain compromise, insufficient isolation, weaponized endpoints) amplify in ML contexts due to autonomous decision-making capabilities
- Effective defense requires layered protection spanning data privacy, model security, runtime monitoring, and hardware trust anchors
- Context drives defense selection: healthcare prioritizes regulatory compliance, autonomous vehicles prioritize adversarial robustness, financial systems prioritize model theft prevention
- Privacy-preserving techniques include differential privacy, federated learning, homomorphic encryption, and synthetic data generation, each with distinct trade-offs
- Hardware security mechanisms (TEEs, secure boot, HSMs, PUFs) provide foundational trust for software-level protections
- Security introduces inevitable trade-offs in computational cost, accuracy degradation, and implementation complexity that must be balanced against protection benefits
Looking forward, the security and privacy foundations established in this chapter form critical building blocks for the comprehensive robustness framework explored in Chapter 16: Robust AI. While we’ve focused on defending against malicious actors and protecting sensitive information, true system reliability requires expanding these concepts to handle all forms of operational stress. The monitoring infrastructure, defensive mechanisms, and layered architectures we’ve developed here provide the foundation for detecting distribution shifts, managing uncertainty, and ensuring graceful degradation under adverse conditions—topics that will be central to our exploration of robust AI.