Data Engineering
DALL·E 3 Prompt: Create a rectangular illustration visualizing the concept of data engineering. Include elements such as raw data sources, data processing pipelines, storage systems, and refined datasets. Show how raw data is transformed through cleaning, processing, and storage to become valuable information that can be analyzed and used for decision-making.

Purpose
Why does data quality serve as the foundation that determines whether machine learning systems succeed or fail in production environments?
Machine learning systems depend on data quality: no algorithm can overcome poor data, but excellent data engineering enables even simple models to achieve remarkable results. Unlike traditional software where logic is explicit, ML systems derive behavior from data patterns, making quality the primary determinant of system trustworthiness. Understanding data engineering principles provides the foundation for building ML systems that operate consistently across diverse production environments, maintain performance over time, and scale effectively as data volumes and complexity increase.
Apply the four pillars framework (Quality, Reliability, Scalability, Governance) to evaluate data engineering decisions systematically
Calculate infrastructure requirements for ML systems including storage capacity, processing throughput, and labeling costs
Design data pipelines that maintain training-serving consistency to prevent the primary cause of production ML failures
Evaluate acquisition strategies (existing datasets, web scraping, crowdsourcing, synthetic data) based on quality-cost-scale trade-offs
Architect storage systems (databases, data warehouses, data lakes, feature stores) appropriate for different ML workload patterns
Implement data governance practices including lineage tracking, privacy protection, and bias mitigation throughout the data lifecycle
Data Engineering as a Systems Discipline
The systematic methodologies examined in the previous chapter establish the procedural foundations of machine learning development, yet underlying each phase of these workflows exists a fundamental prerequisite: robust data infrastructure. In traditional software, computational logic is defined by code. In machine learning, system behavior is defined by data. This paradigm shift makes data a first-class citizen in the engineering process, akin to source code, requiring a new discipline, data engineering, to manage it with the same rigor we apply to code.
While workflow methodologies provide the organizational framework for constructing ML systems, data engineering provides the technical substrate that enables effective implementation of these methodologies. Advanced modeling techniques and rigorous validation procedures cannot compensate for deficient data infrastructure, whereas well-engineered data systems enable even conventional approaches to achieve substantial performance gains.
This chapter examines data engineering as a systematic engineering discipline focused on the design, construction, and maintenance of infrastructure that transforms heterogeneous raw information into reliable, high-quality datasets suitable for machine learning applications. In contrast to traditional software systems where computational logic remains explicit and deterministic, machine learning systems derive their behavioral characteristics from underlying data patterns, establishing data infrastructure quality as the principal determinant of system efficacy. Consequently, architectural decisions concerning data acquisition, processing, storage, and governance influence whether ML systems achieve expected performance in production environments.
The critical importance of data engineering decisions becomes evident when examining how data quality issues propagate through machine learning systems. Traditional software systems typically generate predictable error responses or explicit rejections when encountering malformed input, enabling developers to implement immediate corrective measures. Machine learning systems present different challenges: data quality deficiencies manifest as subtle performance degradations that accumulate throughout the processing pipeline and frequently remain undetected until catastrophic system failures occur in production environments. While individual mislabeled training instances may appear inconsequential, systematic labeling inconsistencies systematically corrupt model behavior across entire feature spaces. Similarly, gradual data distribution shifts in production environments can progressively degrade system performance until comprehensive model retraining becomes necessary.
These challenges require systematic engineering approaches that transcend ad-hoc solutions and reactive interventions. Effective data engineering demands systematic analysis of infrastructure requirements that parallels the disciplined methodologies applied to workflow design. This chapter develops a principled theoretical framework for data engineering decision-making, organized around four foundational pillars (Quality, Reliability, Scalability, and Governance) that provide systematic guidance for technical choices spanning initial data acquisition through production deployment. We examine how these engineering principles manifest throughout the complete data lifecycle, clarifying the systems-level thinking required to construct data infrastructure that supports current ML workflows while maintaining adaptability and scalability as system requirements evolve.
Rather than analyzing individual technical components in isolation, we examine the systemic interdependencies among engineering decisions, demonstrating the inherently interconnected nature of data infrastructure systems. This integrated analytical perspective is particularly significant as we prepare to examine the computational frameworks that process these carefully engineered datasets, the primary focus of subsequent chapters.
Four Pillars Framework
Building effective ML systems requires understanding not only what data engineering is but also implementing a structured framework for making principled decisions about data infrastructure. Choices regarding storage formats, ingestion patterns, processing architectures, and governance policies require systematic evaluation rather than ad-hoc selection. This framework organizes data engineering around four foundational pillars that ensure systems achieve functionality, robustness, scalability, and trustworthiness.
The Four Foundational Pillars
Every data engineering decision, from choosing storage formats to designing ingestion pipelines, should be evaluated against four foundational principles. Each pillar contributes to system success through systematic decision-making.
First, data quality provides the foundation for system success. Quality issues compound throughout the ML lifecycle through a phenomenon termed “Data Cascades” (Section 1.3), wherein early failures propagate and amplify downstream. Quality includes accuracy, completeness, consistency, and fitness for the intended ML task. High-quality data is essential for model success, with the mathematical foundations of this relationship explored in Chapter 3: Deep Learning Primer and Chapter 4: DNN Architectures.
Building upon this quality foundation, ML systems require consistent, predictable data processing that handles failures gracefully. Reliability means building systems that continue operating despite component failures, data anomalies, or unexpected load patterns. This includes implementing comprehensive error handling, monitoring, and recovery mechanisms throughout the data pipeline.
While reliability ensures consistent operation, scalability addresses the challenge of growth. As ML systems grow from prototypes to production services, data volumes and processing requirements increase dramatically. Scalability involves designing systems that can handle growing data volumes, user bases, and computational demands without requiring complete system redesigns.
Finally, governance provides the framework within which quality, reliability, and scalability operate. Data governance ensures systems operate within legal, ethical, and business constraints while maintaining transparency and accountability. This includes privacy protection, bias mitigation, regulatory compliance, and establishing clear data ownership and access controls.

Integrating the Pillars Through Systems Thinking
Although understanding each pillar individually provides important insights, recognizing their individual importance is only the first step toward effective data engineering. As illustrated in Figure 1, these four pillars are not independent components but interconnected aspects of a unified system where decisions in one area affect all others. Quality improvements must account for scalability constraints, reliability requirements influence governance implementations, and governance policies shape quality metrics. This systems perspective guides our exploration of data engineering, examining how each technical topic supports and balances these foundational principles while managing their inherent tensions.
As Figure 2 illustrates, data scientists spend 60-80% of their time on data preparation tasks according to various industry surveys1. This statistic reflects the current state where data engineering practices are often ad-hoc rather than systematic. By applying the four-pillar framework consistently to address this overhead, teams can reduce data preparation time while building more reliable and maintainable systems.
1 Data Quality Reality: The famous “garbage in, garbage out” principle was first coined by IBM computer programmer George Fuechsel in the 1960s, describing how flawed input data produces nonsense output. This principle remains critically relevant in modern ML systems.

Framework Application Across Data Lifecycle
This four-pillar framework guides our exploration of data engineering systems from problem definition through production operations. We begin by establishing clear problem definitions and governance principles that shape all subsequent technical decisions. The framework then guides us through data acquisition strategies, where quality and reliability requirements determine how we source and validate data. Processing and storage decisions follow naturally from scalability and governance constraints, while operational practices ensure all four pillars are maintained throughout the system lifecycle.
This framework guides our systematic exploration through each major component of data engineering. As we examine data acquisition, ingestion, processing, and storage in subsequent sections, we examine how these pillars manifest in specific technical decisions: sourcing techniques that balance quality with scalability, storage architectures that support performance within governance constraints, and processing pipelines that maintain reliability while handling massive scale.
Table 1 provides a comprehensive view of how each pillar manifests across the major stages of the data pipeline. This matrix serves both as a planning tool for system design and as a reference for troubleshooting when issues arise at different pipeline stages.
| Stage | Quality | Reliability | Scalability | Governance |
|---|---|---|---|---|
| Acquisition | Representative sampling, bias detection | Diverse sources, redundant collection strategies | Web scraping, synthetic data generation | Consent, anonymization, ethical sourcing |
| Ingestion | Schema validation, data profiling | Dead letter queues, graceful degradation | Batch vs stream processing, autoscaling pipelines | Access controls, audit logs, data lineage |
| Processing | Consistency validation, training-serving parity | Idempotent transformations, retry mechanisms | Distributed frameworks, horizontal scaling | Lineage tracking, privacy preservation, bias monitoring |
| Storage | Data validation checks, freshness monitoring | Backups, replication, disaster recovery | Tiered storage, partitioning, compression optimization | Access audits, encryption, retention policies |
To ground these concepts in practical reality, we follow a Keyword Spotting (KWS) system throughout as our running case study, demonstrating how framework principles translate into engineering decisions.
Data Cascades and the Need for Systematic Foundations
Machine learning systems face a unique failure pattern that distinguishes them from traditional software engineering: “Data Cascades,”2 the phenomenon identified by Sambasivan et al. (2021) where poor data quality in early stages amplifies throughout the entire pipeline, causing downstream model failures, project termination, and potential user harm. Unlike traditional software where bad inputs typically produce immediate errors, ML systems degrade silently until quality issues become severe enough to necessitate complete system rebuilds.
2 Data Cascades: A systems failure pattern unique to ML where poor data quality in early stages amplifies throughout the entire pipeline, causing downstream model failures, project termination, and potential user harm. Unlike traditional software where bad inputs typically produce immediate errors, ML systems degrade silently until quality issues become severe enough to necessitate complete system rebuilds.
Data cascades occur when teams skip establishing clear quality criteria, reliability requirements, and governance principles before beginning data collection and processing work. This fundamental vulnerability motivates our Four Pillars framework: Quality, Reliability, Scalability, and Governance provide the systematic foundation needed to prevent cascade failures and build robust ML systems.
Figure 3 illustrates these potential data pitfalls at every stage and how they influence the entire process down the line. The influence of data collection errors is especially pronounced. As illustrated in the figure, any lapses in this initial stage will become apparent during model evaluation and deployment phases discussed in Chapter 8: AI Training and Chapter 13: ML Operations, potentially leading to costly consequences such as abandoning the entire model and restarting anew. Therefore, investing in data engineering techniques from the onset will help us detect errors early, mitigating these cascading effects.

Establishing Governance Principles Early
With this understanding of how quality issues cascade through ML systems, we must establish governance principles that ensure our data engineering systems operate within ethical, legal, and business constraints. These principles are not afterthoughts to be applied later but foundational requirements that shape every technical decision from the outset.
Central to these governance principles, data systems must protect user privacy and maintain security throughout their lifecycle. This means implementing access controls, encryption, and data minimization practices from the initial system design, not adding them as later enhancements. Privacy requirements directly influence data collection methods, storage architectures, and processing approaches.
Beyond privacy protection, data engineering systems must actively work to identify and mitigate bias in data collection, labeling, and processing. This requires diverse data collection strategies, representative sampling approaches, and systematic bias detection throughout the pipeline. Technical choices about data sources, labeling methodologies, and quality metrics all impact system fairness. Hidden stratification in data—where subpopulations are underrepresented or exhibit different patterns, can cause systematic failures even in well-performing models (Oakden-Rayner et al. 2020), underscoring why demographic balance and representation requires engineering into data collection from the outset.
Complementing these fairness efforts, systems must maintain clear documentation about data sources, processing decisions, and quality criteria. This includes implementing data lineage tracking, maintaining processing logs, and establishing clear ownership and responsibility for data quality decisions.
Finally, data systems must comply with relevant regulations such as GDPR, CCPA, and domain-specific requirements. Compliance requirements influence data retention policies, user consent mechanisms, and cross-border data transfer protocols.
These governance principles work hand-in-hand with our technical pillars of quality, reliability, and scalability. A system cannot be truly reliable if it violates user privacy, and quality metrics are meaningless if they perpetuate unfair outcomes.
Structured Approach to Problem Definition
Building on these governance foundations, we need a systematic approach to problem definition. As Sculley et al. (2021) emphasize, ML systems require problem framing that goes beyond traditional software development approaches. Whether developing recommendation engines processing millions of user interactions, computer vision systems analyzing medical images, or natural language models handling diverse text data, each system brings unique challenges that require careful consideration within our governance and technical framework.
Within this context, establishing clear objectives provides unified direction that guides the entire project, from data collection strategies through deployment operations. These objectives must balance technical performance with governance requirements, creating measurable outcomes that include both accuracy metrics and fairness criteria.
This systematic approach to problem definition ensures that governance principles and technical requirements are integrated from the start rather than retrofitted later. To achieve this integration, we identify the key steps that must precede any data collection effort:
- Identify and clearly state the problem definition
- Set clear objectives to meet
- Establish success benchmarks
- Understand end-user engagement/use
- Understand the constraints and limitations of deployment
- Perform data collection.
- Iterate and refine.
Framework Application Through Keyword Spotting Case Study
To demonstrate how these systematic principles work in practice, Keyword Spotting (KWS) systems provide an ideal case study for applying our four-pillar framework to real-world data engineering challenges. These systems, which power voice-activated devices like smartphones and smart speakers, must detect specific wake words (such as “OK, Google” or “Alexa”) within continuous audio streams while operating under strict resource constraints.
As shown in Figure 4, KWS systems operate as lightweight, always-on front-ends that trigger more complex voice processing systems. These systems demonstrate the interconnected challenges across all four pillars of our framework (Section 1.2): Quality (accuracy across diverse environments), Reliability (consistent battery-powered operation), Scalability (severe memory constraints), and Governance (privacy protection). These constraints explain why many KWS systems support only a limited number of languages: collecting high-quality, representative voice data for smaller linguistic populations proves prohibitively difficult given governance and scalability challenges, demonstrating how all four pillars must work together to achieve successful deployment.

With this framework understanding established, we can apply our problem definition approach to our KWS example, demonstrating how the four pillars guide practical engineering decisions:
Identifying the Problem: KWS detects specific keywords amidst ambient sounds and other spoken words. The primary problem is to design a system that can recognize these keywords with high accuracy, low latency, and minimal false positives or negatives, especially when deployed on devices with limited computational resources. A well-specified problem definition for developing a new KWS model should identify the desired keywords along with the envisioned application and deployment scenario.
Setting Clear Objectives: The objectives for a KWS system must balance multiple competing requirements. Performance targets include achieving high accuracy rates (98% accuracy in keyword detection) while ensuring low latency (keyword detection and response within 200 milliseconds). Resource constraints demand minimizing power consumption to extend battery life on embedded devices and ensuring the model size is optimized for available memory on the device.
Benchmarks for Success: Establish clear metrics to measure the success of the KWS system. Key performance indicators include true positive rate (the percentage of correctly identified keywords relative to all spoken keywords) and false positive rate (the percentage of non-keywords including silence, background noise, and out-of-vocabulary words incorrectly identified as keywords). Detection/error tradeoff curves evaluate KWS on streaming audio representative of real-world deployment scenarios by comparing false accepts per hour (false positives over total evaluation audio duration) against false rejection rate (missed keywords relative to spoken keywords in evaluation audio), as demonstrated by Nayak et al. (2022). Operational metrics track response time (keyword utterance to system response) and power consumption (average power used during keyword detection).
Stakeholder Engagement and Understanding: Engage with stakeholders, which include device manufacturers, hardware and software developers, and end-users. Understand their needs, capabilities, and constraints. Different stakeholders bring competing priorities: device manufacturers might prioritize low power consumption, software developers might emphasize ease of integration, and end-users would prioritize accuracy and responsiveness. Balancing these competing requirements shapes system architecture decisions throughout development.
Understanding the Constraints and Limitations of Embedded Systems: Embedded devices come with their own set of challenges that shape KWS system design. Memory limitations require extremely lightweight models, typically as small as 16 KB to fit in the always-on island of the SoC3, with this constraint covering only model weights while preprocessing code must also fit within tight memory bounds. Processing power constraints from limited computational capabilities (a few hundred MHz of clock speed) demand aggressive model optimization for efficiency. Power consumption becomes critical since most embedded devices run on batteries, requiring the KWS system to achieve sub-milliwatt power consumption during continuous listening. Environmental challenges add another layer of complexity, as devices must function effectively across diverse deployment scenarios ranging from quiet bedrooms to noisy industrial settings.
3 System on Chip (SoC): An integrated circuit that combines all essential computer components (processor, memory, I/O interfaces) on a single chip. Modern SoCs include specialized “always-on” low-power domains that continuously monitor for triggers like wake words while the main processor sleeps, achieving power consumption under 1mW for continuous listening applications.
Data Collection and Analysis: For a KWS system, data quality and diversity determine success. The dataset must capture demographic diversity by including speakers with various accents across age and gender to ensure wide-ranging recognition support. Keyword variations require attention since people pronounce wake words differently, requiring the dataset to capture these pronunciation nuances and slight variations. Background noise diversity proves essential, necessitating data samples that include or are augmented with different ambient noises to train the model for real-world scenarios ranging from quiet environments to noisy conditions.
Iterative Feedback and Refinement: Finally, once a prototype KWS system is developed, teams must ensure the system remains aligned with the defined problem and objectives as deployment scenarios change over time and use-cases evolve. This requires testing in real-world scenarios, gathering feedback about whether some users or deployment scenarios encounter underperformance relative to others, and iteratively refining both the dataset and model based on observed failure patterns.
Building on this problem definition foundation, our KWS system demonstrates how different data collection approaches combine effectively across the project lifecycle. Pre-existing datasets like Google’s Speech Commands (Warden 2018) provide a foundation for initial development, offering carefully curated voice samples for common wake words. However, these datasets often lack diversity in accents, environments, and languages, necessitating additional strategies.
4 Mechanical Turk Origins: Named after the 18th-century chess-playing “automaton” (actually a human chess master hidden inside), Amazon’s MTurk (2005) pioneered human-in-the-loop AI by enabling distributed human computation at scale, ironically reversing the original Turk’s deception of AI capabilities.
To address coverage gaps, web scraping supplements baseline datasets by gathering diverse voice samples from video platforms and speech databases, capturing natural speech patterns and wake word variations. Crowdsourcing platforms like Amazon Mechanical Turk4 enable targeted collection of wake word samples across different demographics and environments, particularly valuable for underrepresented languages or specific acoustic conditions.
Finally, synthetic data generation fills remaining gaps through speech synthesis (Werchniak et al. 2021) and audio augmentation, creating unlimited wake word variations across acoustic environments, speaker characteristics, and background conditions. This comprehensive approach enables KWS systems that perform robustly across diverse real-world conditions while demonstrating how systematic problem definition guides data strategy throughout the project lifecycle.
With our framework principles established through the KWS case study, we now examine how these abstract concepts translate into operational reality through data pipeline architecture.
Data Pipeline Architecture
Data pipelines serve as the systematic implementation of our four-pillar framework, transforming raw data into ML-ready formats while maintaining quality, reliability, scalability, and governance standards. Rather than simple linear data flows, these are complex systems that must orchestrate multiple data sources, transformation processes, and storage systems while ensuring consistent performance under varying load conditions. Pipeline architecture translates our abstract framework principles into operational reality, where each pillar manifests as concrete engineering decisions about validation strategies, error handling mechanisms, throughput optimization, and observability infrastructure.
To illustrate these concepts, our KWS system pipeline architecture must handle continuous audio streams, maintain low-latency processing for real-time keyword detection, and ensure privacy-preserving data handling. The pipeline must scale from development environments processing sample audio files to production deployments handling millions of concurrent audio streams while maintaining strict quality and governance standards.

As shown in the architecture diagram, ML data pipelines consist of several distinct layers: data sources, ingestion, processing, labeling, storage, and ML training (Figure 5). Each layer plays a specific role in the data preparation workflow, and selecting appropriate technologies for each layer requires understanding how our four framework pillars manifest at each stage. Rather than treating these layers as independent components to be optimized separately, we examine how quality requirements at one stage affect scalability constraints at another, how reliability needs shape governance implementations, and how the pillars interact to determine overall system effectiveness.
Central to these design decisions, data pipeline design is constrained by storage hierarchies and I/O bandwidth limitations rather than CPU capacity. Understanding these constraints enables building efficient systems that can handle modern ML workloads. Storage hierarchy trade-offs, ranging from high-latency object storage (ideal for archival) to low-latency in-memory stores (essential for real-time serving), and bandwidth limitations (spinning disks at 100-200 MB/s versus RAM at 50-200 GB/s) shape every pipeline decision. Detailed storage architecture considerations are covered in Section 1.9.
Given these performance constraints, design decisions should align with specific requirements. For streaming data, consider whether you need message durability (ability to replay failed processing), ordering guarantees (maintaining event sequence), or geographic distribution. For batch processing, the key decision factors include data volume relative to memory, processing complexity, and whether computation must be distributed. Single-machine tools suffice for gigabyte-scale data, but terabyte-scale processing needs distributed frameworks that partition work across clusters. The interactions between these layers, viewed through our four-pillar lens, determine the system’s overall effectiveness and guide the specific engineering decisions we examine in the following subsections.
Quality Through Validation and Monitoring
Quality represents the foundation of reliable ML systems, and pipelines implement quality through systematic validation and monitoring at every stage. Production experience shows that data pipeline issues represent a major source of ML failures, with studies citing 30-70% attribution rates for schema changes breaking downstream processing, distribution drift degrading model accuracy, or data corruption silently introducing errors (Sculley et al. 2021). These failures prove particularly insidious because they often don’t cause obvious system crashes but instead slowly degrade model performance in ways that become apparent only after affecting users. The quality pillar demands proactive monitoring and validation that catches issues before they cascade into model failures.
Understanding these metrics in practice requires examining how production teams implement monitoring at scale. Most organizations adopt severity-based alerting systems where different types of failures trigger different response protocols. The most critical alerts indicate complete system failure: the pipeline has stopped processing entirely, showing zero throughput for more than 5 minutes, or a primary data source has become completely unavailable. These situations demand immediate attention because they halt all downstream model training or serving. More subtle degradation patterns require different detection strategies. When throughput drops to 80% of baseline levels, or error rates climb above 5%, or quality metrics drift more than 2 standard deviations from training data characteristics, the system signals degradation requiring urgent but not immediate attention. These gradual failures often prove more dangerous than complete outages because they can persist undetected for hours or days, silently corrupting model inputs and degrading prediction quality.
Consider how these principles apply to a recommendation system processing user interaction events. With a baseline throughput of 50,000 records per second, the monitoring system tracks several interdependent signals. Instantaneous throughput alerts fire if processing drops below 40,000 records per second for more than 10 minutes, accounting for normal traffic variation while catching genuine capacity or processing problems. Each feature in the data stream has its own quality profile: if a feature like user_age shows null values in more than 5% of records when the training data contained less than 1% nulls, something has likely broken in the upstream data source. Duplicate detection runs on sampled data, watching for the same event appearing multiple times—a pattern that might indicate retry logic gone wrong or a database query accidentally returning the same records repeatedly.
These monitoring dimensions become particularly important when considering end-to-end latency. The system must track not just whether data arrives, but how long it takes to flow through the entire pipeline from the moment an event occurs to when the resulting features become available for model inference. When 95th percentile5 latency exceeds 30 seconds in a system with a 10-second service level agreement, the monitoring system needs to pinpoint which pipeline stage introduced the delay: ingestion, transformation, validation, or storage.
5 95th percentile: A statistical measure indicating that 95% of values fall below this threshold, commonly used in performance monitoring to capture typical worst-case behavior while excluding outliers. For latency monitoring, the 95th percentile provides more stable insights than maximum values (which may be anomalies) while revealing performance degradation that averages would hide.
6 Kolmogorov-Smirnov test: A non-parametric statistical test that quantifies whether two datasets come from the same distribution by measuring the maximum distance between their cumulative distribution functions. In ML systems, K-S tests detect data drift by comparing serving data against training baselines, producing p-values where values below 0.05 indicate statistically significant distribution shifts requiring investigation. When the test produces p-values below 0.05, it signals that serving and training data have diverged significantly—perhaps because user behavior has changed, or because an upstream system modification altered how features are computed.
Quality monitoring extends beyond simple schema validation to statistical properties that capture whether serving data resembles training data. Rather than just checking that values fall within valid ranges, production systems track rolling statistics over 24-hour windows. For numerical features like transaction_amount or session_duration, the system computes means and standard deviations continuously, then applies statistical tests like the Kolmogorov-Smirnov test6 to compare serving distributions against training distributions.
Categorical features require different statistical approaches. Instead of comparing means and variances, monitoring systems track category frequency distributions. When new categories appear that never existed in training data, or when existing categories shift substantially in relative frequency—say, the proportion of “mobile” versus “desktop” traffic changes by more than 20%, the system flags potential data quality issues or genuine distribution shifts. This statistical vigilance catches subtle problems that simple schema validation misses entirely: imagine if age values remain in the valid range of 18-95, but the distribution shifts from primarily 25-45 year olds to primarily 65+ year olds, indicating the data source has changed in ways that will affect model performance.
Validation at the pipeline level encompasses multiple strategies working together. Schema validation executes synchronously as data enters the pipeline, rejecting malformed records immediately before they can propagate downstream. Modern tools like TensorFlow Data Validation (TFDV)7 automatically infer schemas from training data, capturing expected data types, value ranges, and presence requirements.
7 TensorFlow Data Validation (TFDV): A production-grade library for analyzing and validating ML data that automatically infers schemas, detects anomalies, and identifies training-serving skew. TFDV computes descriptive statistics, identifies data drift through distribution comparisons, and generates human-readable validation reports, integrating with TFX pipelines for automated data quality monitoring. For a feature vector containing user demographics, the inferred schema might specify that user_age must be a 64-bit integer between 18 and 95 and cannot be null, user_country must be a string from a specific set of country codes, and session_duration must be a floating-point number between 0 and 7200 seconds but is optional. During serving, the validator checks each incoming record against these specifications, rejecting records with null required fields, out-of-range values, or type mismatches before they reach feature computation logic.
This synchronous validation necessarily remains simple and fast, checking properties that can be evaluated on individual records in microseconds. More sophisticated validation that requires comparing serving data against training data distributions or aggregating statistics across many records must run asynchronously to avoid blocking the ingestion pipeline. Statistical validation systems typically sample 1-10% of serving traffic—enough to detect meaningful shifts while avoiding the computational cost of analyzing every record. These samples accumulate in rolling windows, commonly 1 hour, 24 hours, and 7 days, with different windows revealing different patterns. Hourly windows detect sudden shifts like a data source failing over to a backup with different characteristics, while weekly windows reveal gradual drift in user populations or behavior.
Perhaps the most insidious validation challenge arises from training-serving skew8, where the same features get computed differently in training versus serving environments. This typically happens when training pipelines process data in batch using one set of libraries or logic, while serving systems compute features in real-time using different implementations. A recommendation system might compute “user_lifetime_purchases” in training by joining user profiles against complete transaction histories, while the serving system inadvertently uses a cached materialized view9 updated only weekly.
8 Training-Serving Skew: A ML systems failure where identical features are computed differently during training versus serving, causing silent model degradation. Occurs when training uses batch processing with one implementation while serving uses real-time processing with different libraries, creating subtle differences that compound to degrade accuracy significantly without obvious errors.
9 Materialized view: A database optimization that pre-computes and stores query results as physical tables, trading storage space for query performance. Unlike standard views that compute results on-demand, materialized views cache expensive join and aggregation operations but require refresh strategies to maintain data freshness, creating potential training-serving skew when refresh schedules differ between environments. The resulting 15% discrepancy between training and serving features directly explains seemingly mysterious 12% accuracy drops observed in production A/B tests. Detecting training-serving skew requires infrastructure that can recompute training features on serving data for comparison. Production systems implement periodic validation where they sample raw serving data, process it through both training and serving feature pipelines, and measure discrepancies.
Reliability Through Graceful Degradation
While quality monitoring detects issues, reliability ensures systems continue operating effectively when problems occur. Pipelines face constant challenges: data sources become temporarily unavailable, network partitions separate components, upstream schema changes break parsing logic, or unexpected load spikes exhaust resources. The reliability pillar demands systems that handle these failures gracefully rather than cascading into complete outage. This resilience comes from systematic failure analysis, intelligent error handling, and automated recovery strategies that maintain service continuity even under adverse conditions.
Systematic failure mode analysis for ML data pipelines reveals predictable patterns that require specific engineering countermeasures. Data corruption failures occur when upstream systems introduce subtle format changes, encoding issues, or field value modifications that pass basic validation but corrupt model inputs. A date field switching from “YYYY-MM-DD” to “MM/DD/YYYY” format might not trigger schema validation but will break any date-based feature computation. Schema evolution10 failures happen when source systems add fields, rename columns, or change data types without coordination, breaking downstream processing assumptions that expected specific field names or types. Resource exhaustion manifests as gradually degrading performance when data volume growth outpaces capacity planning, eventually causing pipeline failures during peak load periods.
10 Schema Evolution: The challenge of managing changes to data structure over time as source systems add fields, rename columns, or modify data types. Critical for ML systems because model training expects consistent feature schemas, and schema changes can silently break feature computation or introduce training-serving skew.
11 Dead Letter Queue: A separate storage system for messages that fail processing after exhausting retry attempts, enabling later analysis and reprocessing without blocking the main pipeline. Essential for ML systems where data loss is unacceptable—malformed training examples can be fixed and reprocessed, while failed inference requests can be debugged to improve system robustness.
Building on this failure analysis, effective error handling strategies ensure problems are contained and recovered from systematically. Implementing intelligent retry logic for transient errors, such as network interruptions or temporary service outages, requires exponential backoff strategies to avoid overwhelming recovering services. A simple linear retry that attempts reconnection every second would flood a struggling service with connection attempts, potentially preventing its recovery. Exponential backoff—retrying after 1 second, then 2 seconds, then 4 seconds, doubling with each attempt—gives services breathing room to recover while still maintaining persistence. Many ML systems employ the concept of dead letter queues11, using separate storage for data that fails processing after multiple retry attempts. This allows for later analysis and potential reprocessing of problematic data without blocking the main pipeline (Kleppmann 2016). A pipeline processing financial transactions that encounters malformed data can route it to a dead letter queue rather than losing critical records or halting all processing.
Moving beyond ad-hoc error handling, cascade failure prevention requires circuit breaker12 patterns and bulkhead isolation to prevent single component failures from propagating throughout the system. When a feature computation service fails, the circuit breaker pattern stops calling that service after detecting repeated failures, preventing the caller from waiting on timeouts that would cascade into its own failure.
12 Circuit Breaker: A reliability pattern that monitors service failures and automatically stops calling a failing service after a threshold is reached, preventing cascade failures and system overload. Like an electrical circuit breaker, it has three states: closed (normal operation), open (failing service blocked), and half-open (testing if service has recovered).
Automated recovery engineering implements sophisticated strategies beyond simple retry logic. Progressive timeout increases prevent overwhelming struggling services while maintaining rapid recovery for transient issues—initial requests timeout after 1 second, but after detecting service degradation, timeouts extend to 5 seconds, then 30 seconds, giving the service time to stabilize. Multi-tier fallback systems provide degraded service when primary data sources fail: serving slightly stale cached features when real-time computation fails, or using approximate features when exact computation times out. A recommendation system unable to compute user preferences from the past 30 days might fall back to preferences from the past 90 days, providing somewhat less accurate but still useful recommendations rather than failing entirely. Comprehensive alerting and escalation procedures ensure human intervention occurs when automated recovery fails, with sufficient diagnostic information captured during the failure to enable rapid debugging.
These concepts become concrete when considering a financial ML system ingesting market data. Error handling might involve falling back to slightly delayed data sources if real-time feeds fail, while simultaneously alerting the operations team to the issue. Dead letter queues capture malformed price updates for investigation rather than dropping them silently. Circuit breakers prevent the system from overwhelming a struggling market data provider during recovery. This comprehensive approach to error management ensures that downstream processes have access to reliable, high-quality data for training and inference tasks, even in the face of the inevitable failures that occur in distributed systems at scale.
Scalability Patterns
While quality and reliability ensure correct system operation, scalability addresses a different challenge: how systems evolve as data volumes grow and ML systems mature from prototypes to production services. Pipelines that work effectively at gigabyte scale often break at terabyte scale without architectural changes that enable distributed processing. Scalability involves designing systems that handle growing data volumes, user bases, and computational demands without requiring complete redesigns. The key insight is that scalability constraints manifest differently across pipeline stages, requiring different architectural patterns for ingestion, processing, and storage.
ML systems typically follow two primary ingestion patterns, each with distinct scalability characteristics. Batch ingestion involves collecting data in groups over a specified period before processing. This method proves appropriate when real-time data processing is not critical and data can be processed at scheduled intervals. A retail company might use batch ingestion to process daily sales data overnight, updating ML models for inventory prediction each morning. Batch processing enables efficient use of computational resources by amortizing startup costs across large data volumes—a job processing one terabyte might use 100 machines for 10 minutes, achieving better resource efficiency than maintaining always-on infrastructure.
In contrast to this scheduled approach, stream ingestion processes data in real-time as it arrives. This pattern proves crucial for applications requiring immediate data processing, scenarios where data loses value quickly, and systems that need to respond to events as they occur. A financial institution might use stream ingestion for real-time fraud detection, processing each transaction as it occurs to flag suspicious activity immediately. However, stream processing must handle backpressure13 when downstream systems cannot keep pace—when a sudden traffic spike produces data faster than processing capacity, the system must either buffer data (requiring memory), sample (losing some data), or push back to producers (potentially causing failures). Data freshness Service Level Agreements (SLAs)14 formalize these requirements, specifying maximum acceptable delays between data generation and availability for processing.
13 Backpressure: A flow control mechanism in streaming systems where downstream components signal upstream producers to slow data transmission when processing capacity is exceeded. Critical for preventing memory overflow and system crashes during traffic spikes, backpressure can be implemented through buffering, sampling, or direct producer throttling—each with different trade-offs between data loss and system stability.
14 Service Level Agreement (SLA): A formal contract specifying measurable service quality metrics like latency (95th percentile response time under 100ms), availability (99.9% uptime), and throughput (process 50,000 records/second). In ML systems, SLAs often include data freshness (features available within 5 minutes of event), model accuracy (precision above 85%), and inference latency (predictions returned under 200ms).
Recognizing the limitations of either approach alone, many modern ML systems employ hybrid approaches, combining both batch and stream ingestion to handle different data velocities and use cases. This flexibility allows systems to process both historical data in batches and real-time data streams, providing a comprehensive view of the data landscape. Production systems must balance cost versus latency trade-offs: real-time processing can cost 10-100x more than batch processing. This cost differential arises from several factors: streaming systems require always-on infrastructure rather than schedulable resources, maintain redundant processing for fault tolerance, need low-latency networking and storage, and cannot benefit from the economies of scale that batch processing achieves by amortizing startup costs across large data volumes. Techniques for managing streaming systems at scale, including backpressure handling and cost optimization, are detailed in Chapter 13: ML Operations.
Beyond ingestion patterns, distributed processing becomes necessary when single machines cannot handle data volumes or processing complexity. The challenge in distributed systems is that data must be partitioned across multiple computing resources, which introduces coordination overhead. Distributed coordination is limited by network round-trip times: local operations complete in microseconds while network coordination requires milliseconds, creating a 1000x latency difference. This constraint explains why operations requiring global coordination, like computing normalization statistics across 100 machines, create bottlenecks. Each partition computes local statistics quickly, but combining them requires information from all partitions, and the round-trip time for gathering results dominates total execution time.
Data locality becomes critical at this scale. Moving one terabyte of training data across the network takes 100+ seconds at 10GB/s, while local SSD access requires only 200 seconds at 5GB/s. This similar performance between network transfer and local storage drives ML system design toward compute-follows-data architectures where processing moves to data rather than data moving to processing. When processing nodes access local data at RAM speeds (50-200 GB/s) but must coordinate over networks limited to 1-10 GB/s, the bandwidth mismatch creates fundamental bottlenecks. Geographic distribution amplifies these challenges: cross-datacenter coordination must handle network latency (50-200ms between regions), partial failures during network partitions, and regulatory constraints preventing data from crossing borders. Understanding which operations parallelize easily versus those requiring expensive coordination determines system architecture and performance characteristics.
For our KWS system, these scalability patterns manifest concretely through quantitative capacity planning that dimensions infrastructure appropriately for workload requirements. Development uses batch processing on sample datasets to iterate on model architectures rapidly. Training scales to distributed processing across GPU clusters when model complexity or dataset size (23 million examples) exceeds single-machine capacity. Production deployment requires stream processing for real-time wake word detection on millions of concurrent devices. The system must handle traffic spikes when news events trigger synchronized usage—millions of users simultaneously asking about breaking news.
To make these scaling challenges concrete, consider the engineering calculations required to dimension our KWS training infrastructure. With 23 million audio samples averaging 1 second each at 16 kHz sampling rate (16-bit PCM15), raw storage requires approximately:
15 Pulse Code Modulation (PCM): The standard digital audio representation that samples analog waveforms at regular intervals and quantizes amplitudes to discrete values. 16-bit PCM at 16 kHz captures speech adequately for recognition tasks, storing each sample as a 16-bit integer (65,536 possible values) sampled 16,000 times per second, yielding 32 KB/second of uncompressed audio data.
\[ \text{Storage} = 23 \times 10^6 \text{ samples} \times 1 \text{ sec} \times 16,000 \text{ samples/sec} \times 2 \text{ bytes} = 736 \text{ GB} \]
Processing these samples into MFCC features (13 coefficients, 100 frames per second) reduces storage but increases computational requirements. Feature extraction on a modern CPU processes approximately 100x real-time (100 seconds of audio per second of computation), requiring:
\[\text{Processing time} = \frac{23 \times 10^6 \text{ sec of audio}}{100 \text{ speedup}} = 230,000 \text{ sec} \approx 64 \text{ hours on single core}\]
Distributing across 64 cores reduces this to one hour, demonstrating how parallelization enables rapid iteration. Network bandwidth becomes the bottleneck when transferring training data from storage to GPU servers—at 10 GB/s network throughput, transferring 736 GB requires 74 seconds, comparable to the training epoch time itself. This analysis reveals why high-throughput storage (NVMe SSDs achieving 5-7 GB/s) and network infrastructure (25-100 Gbps interconnects) prove essential for ML workloads where data movement time rivals computation time.
Scalability architecture enables this range from development through production while maintaining efficiency at each stage, with capacity planning ensuring infrastructure appropriately dimensions for workload requirements.
Governance Through Observability
Having addressed functional requirements through quality, reliability, and scalability, we turn to the governance pillar. The governance pillar manifests in pipelines as comprehensive observability—the ability to understand what data flows through the system, how it transforms, and who accesses it. Effective governance requires tracking data lineage from sources through transformations to final datasets, maintaining audit trails for compliance, and implementing access controls that enforce organizational policies. Unlike the other pillars that focus primarily on system functionality, governance ensures operations occur within legal, ethical, and business constraints while maintaining transparency and accountability.
Data lineage tracking captures the complete provenance of every dataset: which raw sources contributed data, what transformations were applied, when processing occurred, and what version of processing code executed. For ML systems, lineage becomes essential for debugging model behavior and ensuring reproducibility. When a model prediction proves incorrect, engineers need to trace back through the pipeline: which training data contributed to this prediction, what quality metrics did that data have, what transformations were applied, and can we recreate this exact scenario for investigation? Modern lineage systems like Apache Atlas, Amundsen, or commercial offerings instrument pipelines to automatically capture this flow. Each pipeline stage annotates data with metadata describing its provenance, creating an audit trail that enables both debugging and compliance.
Audit trails complement lineage by recording who accessed data and when. Regulatory frameworks like GDPR require organizations to demonstrate appropriate data handling, including tracking access to personal information. ML pipelines implement audit logging at data access points: when training jobs read datasets, when serving systems retrieve features, or when engineers query data for analysis. These logs typically capture user identity, timestamp, data accessed, and purpose. For a healthcare ML system, audit trails demonstrate compliance by showing that only authorized personnel accessed patient data, that access occurred for legitimate medical purposes, and that data wasn’t retained longer than allowed. The scale of audit logging in production systems can be substantial—a high-traffic recommendation system might generate millions of audit events daily—requiring efficient log storage and querying infrastructure.
Access controls enforce policies about who can read, write, or transform data at each pipeline stage. Rather than simple read/write permissions, ML systems often implement attribute-based access control where policies consider data sensitivity, user roles, and access context. A data scientist might access anonymized training data freely but require approval for raw data containing personal information. Production serving systems might read feature data but never write it, preventing accidental corruption. Access controls integrate with data catalogs that maintain metadata about data sensitivity, compliance requirements, and usage restrictions, enabling automated policy enforcement as data flows through pipelines.
Provenance metadata enables reproducibility essential for both debugging and compliance. When a model trained six months ago performed better than current models, teams need to recreate that training environment: exact data version, transformation parameters, and code versions. ML systems implement this through comprehensive metadata capture: training jobs record dataset checksums, transformation parameter values, random seeds for reproducibility, and code version hashes. Feature stores maintain historical feature values, enabling point-in-time reconstruction of training conditions. For our KWS system, this means tracking which version of forced alignment generated labels, what audio normalization parameters were applied, what synthetic data generation settings were used, and which crowdsourcing batches contributed to training data.
The integration of these governance mechanisms transforms pipelines from opaque data transformers into auditable, reproducible systems that can demonstrate appropriate data handling. This governance infrastructure proves essential not just for regulatory compliance but for maintaining trust in ML systems as they make increasingly consequential decisions affecting users’ lives.
With comprehensive pipeline architecture established—quality through validation and monitoring, reliability through graceful degradation, scalability through appropriate patterns, and governance through observability—we must now determine what actually flows through these carefully designed systems. The data sources we choose shape every downstream characteristic of our ML systems.
Strategic Data Acquisition
Data acquisition represents more than simply gathering training examples. It is a strategic decision that determines our system’s capabilities and limitations. The approaches we choose for sourcing training data directly shape our quality foundation, reliability characteristics, scalability potential, and governance compliance. Rather than treating data sources as independent options to be selected based on convenience or familiarity, we examine them as strategic choices that must align with our established framework requirements. Each sourcing strategy (existing datasets, web scraping, crowdsourcing, synthetic generation) offers different trade-offs across quality, cost, scale, and ethical considerations. The key insight is that no single approach satisfies all requirements; successful ML systems typically combine multiple strategies, balancing their complementary strengths against competing constraints.
Returning to our KWS system, data source decisions have profound implications across all our framework pillars, as demonstrated in our integrated case study in Section 1.3.3. Achieving 98% accuracy across diverse acoustic environments (quality pillar) requires representative data spanning accents, ages, and recording conditions. Maintaining consistent detection despite device variations (reliability pillar) demands data from varied hardware. Supporting millions of concurrent users (scalability pillar) requires data volumes that manual collection cannot economically provide. Protecting user privacy in always-listening systems (governance pillar) constrains collection methods and requires careful anonymization. These interconnected requirements demonstrate why acquisition strategy must be evaluated systematically rather than through ad-hoc source selection.
Data Source Evaluation and Selection
Having established the strategic importance of data acquisition, we begin with quality as the primary driver. When quality requirements dominate acquisition decisions, the choice between curated datasets, expert crowdsourcing, and controlled web scraping depends on the accuracy targets, domain expertise needed, and benchmark requirements that guide model development. The quality pillar demands understanding not just that data appears correct but that it accurately represents the deployment environment and provides sufficient coverage of edge cases that might cause failures.
Platforms like Kaggle and UCI Machine Learning Repository provide ML practitioners with ready-to-use datasets that can jumpstart system development. These pre-existing datasets are particularly valuable when building ML systems as they offer immediate access to cleaned, formatted data with established benchmarks. One of their primary advantages is cost efficiency, as creating datasets from scratch requires significant time and resources, especially when building production ML systems that need large amounts of high-quality training data. Building on this cost efficiency, many of these datasets, such as ImageNet, have become standard benchmarks in the machine learning community, enabling consistent performance comparisons across different models and architectures. For ML system developers, this standardization provides clear metrics for evaluating model improvements and system performance. The immediate availability of these datasets allows teams to begin experimentation and prototyping without delays in data collection and preprocessing.
Despite these advantages, ML practitioners must carefully consider the quality assurance aspects of pre-existing datasets. For instance, the ImageNet dataset was found to have label errors on 3.4% of the validation set (Northcutt, Athalye, and Mueller 2021). While popular datasets benefit from community scrutiny that helps identify and correct errors and biases, most datasets remain “untended gardens” where quality issues can significantly impact downstream system performance if not properly addressed. As (Gebru et al. 2021) highlighted in her paper, simply providing a dataset without documentation can lead to misuse and misinterpretation, potentially amplifying biases present in the data.
Beyond quality concerns, supporting documentation accompanying existing datasets is invaluable, yet is often only present in widely-used datasets. Good documentation provides insights into the data collection process and variable definitions and sometimes even offers baseline model performances. This information not only aids understanding but also promotes reproducibility in research, a cornerstone of scientific integrity; currently, there is a crisis around improving reproducibility in machine learning systems (Pineau et al. 2021; Henderson et al. 2018). When other researchers have access to the same data, they can validate findings, test new hypotheses, or apply different methodologies, thus allowing us to build on each other’s work more rapidly. The challenges of data quality extend particularly to big data scenarios where volume and variety compound quality concerns (Gudivada, Rao, et al. 2017), requiring systematic approaches to quality validation at scale.
Even with proper documentation, understanding the context in which the data was collected becomes necessary. Researchers must avoid potential overfitting when using popular datasets such as ImageNet (Beyer et al. 2020), which can lead to inflated performance metrics. Sometimes, these datasets do not reflect the real-world data.
Central to these contextual concerns, a key consideration for ML systems is how well pre-existing datasets reflect real-world deployment conditions. Relying on standard datasets can create a concerning disconnect between training and production environments. This misalignment becomes particularly problematic when multiple ML systems are trained on the same datasets (Figure 6), potentially propagating biases and limitations throughout an entire ecosystem of deployed models.

For our KWS system, pre-existing datasets like Google’s Speech Commands (Warden 2018) provide essential starting points, offering carefully curated voice samples for common wake words. These datasets enable rapid prototyping and establish baseline performance metrics. However, evaluating them against our quality requirements immediately reveals coverage gaps: limited accent diversity, predominantly quiet recording environments, and support for only major languages. Quality-driven acquisition strategy recognizes these limitations and plans complementary approaches to address them, demonstrating how framework-based thinking guides source selection beyond simply choosing available datasets.
Scalability and Cost Optimization
While quality-focused approaches excel at creating accurate, well-curated datasets, they face inherent scaling limitations. When scale requirements dominate—needing millions or billions of examples that manual curation cannot economically provide—web scraping and synthetic generation offer paths to massive datasets. The scalability pillar demands understanding the economic models underlying different acquisition strategies: cost per labeled example, throughput limitations, and how these scale with data volume. What proves cost-effective at thousand-example scale often becomes prohibitive at million-example scale, while approaches that require high setup costs amortize favorably across large volumes.
Web scraping offers a powerful approach to gathering training data at scale, particularly in domains where pre-existing datasets are insufficient. This automated technique for extracting data from websites has become essential for modern ML system development, enabling teams to build custom datasets tailored to their specific needs. When human-labeled data is scarce, web scraping demonstrates its value. Consider computer vision systems: major datasets like ImageNet and OpenImages were built through systematic web scraping, significantly advancing the field of computer vision.
Expanding beyond these computer vision applications, the impact of web scraping extends well beyond image recognition systems. In natural language processing, web-scraped data has enabled the development of increasingly sophisticated ML systems. Large language models, such as ChatGPT and Claude, rely on vast amounts of text scraped from the public internet and media to learn language patterns and generate responses (Groeneveld et al. 2024). Similarly, specialized ML systems like GitHub’s Copilot demonstrate how targeted web scraping, in this case of code repositories, can create powerful domain-specific assistants (Chen et al. 2021).
Building on these foundational developments, production ML systems often require continuous data collection to maintain relevance and performance. Web scraping facilitates this by gathering structured data like stock prices, weather patterns, or product information for analytical applications. This continuous collection introduces unique challenges for ML systems. Data consistency becomes crucial, as variations in website structure or content formatting can disrupt the data pipeline and affect model performance. Proper data management through databases or warehouses becomes essential not just for storage, but for maintaining data quality and enabling model updates.
However, alongside these powerful capabilities, web scraping presents several challenges that ML system developers must carefully consider. Legal and ethical constraints can limit data collection, as not all websites permit scraping, and violating these restrictions can have serious consequences. When building ML systems with scraped data, teams must carefully document data sources and ensure compliance with terms of service and copyright laws. Privacy considerations become important when dealing with user-generated content, often requiring systematic anonymization procedures.
Complementing these legal and ethical constraints, technical limitations also affect the reliability of web-scraped training data. Rate limiting by websites can slow data collection, while the dynamic nature of web content can introduce inconsistencies that impact model training. As shown in Figure 7, web scraping can yield unexpected or irrelevant data, for example, historical images appearing in contemporary image searches, that can pollute training datasets and degrade model performance. These issues highlight the importance of thorough data validation and cleaning processes in ML pipelines built on web-scraped data.

Crowdsourcing offers another scalable approach, leveraging distributed human computation to accelerate dataset creation. Platforms like Amazon Mechanical Turk exemplify how crowdsourcing facilitates this process by distributing annotation tasks to a global workforce. This enables rapid collection of labels for complex tasks such as sentiment analysis, image recognition, and speech transcription, significantly expediting the data preparation phase. One of the most impactful examples of crowdsourcing in machine learning is the creation of the ImageNet dataset. ImageNet, which revolutionized computer vision, was built by distributing image labeling tasks to contributors via Amazon Mechanical Turk. The contributors categorized millions of images into thousands of classes, enabling researchers to train and benchmark models for a wide variety of visual recognition tasks.
Building on this massive labeling effort, the dataset’s availability spurred advancements in deep learning, including the breakthrough AlexNet model in 2012 (Krizhevsky, Sutskever, and Hinton 2017) that demonstrated the power of large-scale neural networks and showed how large-scale, crowdsourced datasets could drive innovation. ImageNet’s success highlights how leveraging a diverse group of contributors for annotation can enable machine learning systems to achieve unprecedented performance. Extending beyond academic research, another example of crowdsourcing’s potential is Google’s Crowdsource, a platform where volunteers contribute labeled data to improve AI systems in applications like language translation, handwriting recognition, and image understanding.
Beyond these static dataset creation efforts, crowdsourcing has also been instrumental in applications beyond traditional dataset annotation. For instance, the navigation app Waze uses crowdsourced data from its users to provide real-time traffic updates, route suggestions, and incident reporting. These diverse applications highlight one of the primary advantages of crowdsourcing: its scalability. By distributing microtasks to a large audience, projects can process enormous volumes of data quickly and cost-effectively. This scalability is particularly beneficial for machine learning systems that require extensive datasets to achieve high performance. The diversity of contributors introduces a wide range of perspectives, cultural insights, and linguistic variations, enriching datasets and improving models’ ability to generalize across populations.
Complementing this scalability advantage, flexibility is a key benefit of crowdsourcing. Tasks can be adjusted dynamically based on initial results, allowing for iterative improvements in data collection. For example, Google’s reCAPTCHA system uses crowdsourcing to verify human users while simultaneously labeling datasets for training machine learning models.
Moving beyond human-generated data entirely, synthetic data generation represents the ultimate scalability solution, creating unlimited training examples through algorithmic generation rather than manual collection. This approach changes the economics of data acquisition by removing human labor from the equation. As Figure 8 illustrates, synthetic data combines with historical datasets to create larger, more diverse training sets that would be impractical to collect manually.

Building on this foundation, advancements in generative modeling techniques have greatly enhanced the quality of synthetic data. Modern AI systems can produce data that closely resembles real-world distributions, making it suitable for applications ranging from computer vision to natural language processing. For example, generative models have been used to create synthetic images for object recognition tasks, producing diverse datasets that closely match real-world images. Similarly, synthetic data has been leveraged to simulate speech patterns, enhancing the robustness of voice recognition systems.
Beyond these quality improvements, synthetic data has become particularly valuable in domains where obtaining real-world data is either impractical or costly. The automotive industry has embraced synthetic data to train autonomous vehicle systems; there are only so many cars you can physically crash to get crash-test data that might help an ML system know how to avoid crashes in the first place. Capturing real-world scenarios, especially rare edge cases such as near-accidents or unusual road conditions, is inherently difficult. Synthetic data allows researchers to simulate these scenarios in a controlled virtual environment, ensuring that models are trained to handle a wide range of conditions. This approach has proven invaluable for advancing the capabilities of self-driving cars.
Complementing these safety-critical applications, another important application of synthetic data lies in augmenting existing datasets. Introducing variations into datasets enhances model robustness by exposing the model to diverse conditions. For instance, in speech recognition, data augmentation techniques like SpecAugment (Park et al. 2019) introduce noise, shifts, or pitch variations, enabling models to generalize better across different environments and speaker styles. This principle extends to other domains as well, where synthetic data can fill gaps in underrepresented scenarios or edge cases.
For our KWS system, the scalability pillar drove the need for 23 million training examples across 50 languages—a volume that manual collection cannot economically provide. Web scraping supplements baseline datasets with diverse voice samples from video platforms. Crowdsourcing enables targeted collection for underrepresented languages. Synthetic data generation fills remaining gaps through speech synthesis (Werchniak et al. 2021) and audio augmentation, creating unlimited wake word variations across acoustic environments, speaker characteristics, and background conditions. This comprehensive multi-source strategy demonstrates how scalability requirements shape acquisition decisions, with each approach contributing specific capabilities to the overall data ecosystem.
Reliability Across Diverse Conditions
Beyond quality and scale considerations, the reliability pillar addresses a critical question: will our collected data enable models that perform consistently across the deployment environment’s full range of conditions? A dataset might achieve high quality by established metrics yet fail to support reliable production systems if it doesn’t capture the diversity encountered during deployment. Coverage requirements for robust models extend beyond simple volume to encompass geographic diversity, demographic representation, temporal variation, and edge case inclusion that stress-test model behavior.
Understanding coverage requirements requires examining potential failure modes. Geographic bias occurs when training data comes predominantly from specific regions, causing models to underperform in other areas. A study of image datasets found significant geographic skew, with image recognition systems trained on predominantly Western imagery performing poorly on images from other regions (Wang et al. 2019). Demographic bias emerges when training data doesn’t represent the full user population, potentially causing discriminatory outcomes. Temporal variation matters when phenomena change over time—a fraud detection model trained only on historical data may fail against new fraud patterns. Edge case collection proves particularly challenging yet critical, as rare scenarios often represent high-stakes situations where failures cause the most harm.
The challenge of edge case collection becomes apparent in autonomous vehicle development. While normal driving conditions are easy to capture through test fleet operation, near-accidents, unusual pedestrian behavior, or rare weather conditions occur infrequently. Synthetic data generation helps address this by simulating rare scenarios, but validating that synthetic examples accurately represent real edge cases requires careful engineering. Some organizations employ targeted data collection where test drivers deliberately create edge cases or where engineers identify scenarios from incident reports that need better coverage.
Dataset convergence, illustrated in Figure 6 earlier, represents another reliability challenge. When multiple systems train on identical datasets, they inherit identical blind spots and biases. An entire ecosystem of models may fail on the same edge cases because all trained on data with the same coverage gaps. This systemic risk motivates diverse data sourcing strategies where each organization collects supplementary data beyond common benchmarks, ensuring their models develop different strengths and weaknesses rather than shared failure modes.
For our KWS system, reliability manifests as consistent wake word detection across acoustic environments from quiet bedrooms to noisy streets, across accents from various geographic regions, and across age ranges from children to elderly speakers. The data sourcing strategy explicitly addresses these diversity requirements: web scraping captures natural speech variation from diverse video sources, crowdsourcing targets underrepresented demographics and environments, and synthetic data systematically explores the parameter space of acoustic conditions. Without this deliberate diversity in sourcing, the system might achieve high accuracy on test sets while failing unreliably in production deployment.
Governance and Ethics in Sourcing
The governance pillar in data acquisition encompasses legal compliance, ethical treatment of data contributors, privacy protection, and transparency about data origins and limitations. Unlike the other pillars that focus on system capabilities, governance ensures data sourcing occurs within appropriate legal and ethical boundaries. The consequences of governance failures extend beyond system performance to reputational damage, legal liability, and potential harm to individuals whose data was improperly collected or used.
Legal constraints significantly limit data collection methods across different jurisdictions and domains. Not all websites permit scraping, and violating these restrictions can have serious consequences, as ongoing litigation around training data for large language models demonstrates. Copyright law governs what publicly available content can be used for training, with different standards emerging across jurisdictions. Terms of service agreements may prohibit using data for ML training even when technically accessible. Privacy regulations like GDPR in Europe and CCPA in California impose strict requirements on personal data collection, requiring consent, enabling deletion requests, and sometimes demanding explanations of algorithmic decisions (Wachter, Mittelstadt, and Russell 2017). Healthcare data falls under additional regulations like HIPAA in the United States, requiring specific safeguards for patient information. Organizations must carefully navigate these legal frameworks, documenting data sources and ensuring compliance throughout the acquisition process.
Beyond legal compliance, ethical sourcing requires fair treatment of human contributors. The crowdsourcing example we examined earlier—where OpenAI outsourced data annotation to workers in Kenya paying as little as $1.32 per hour for reviewing traumatic content—highlights governance failures that can occur when economic pressures override ethical considerations. Many workers reportedly suffered psychological harm from exposure to disturbing material without adequate mental health support. This case underscores power imbalances that can emerge when outsourcing data work to economically disadvantaged regions. The lack of fair compensation, inadequate support for workers dealing with traumatic content, and insufficient transparency about working conditions represent governance failures that affect human welfare beyond just system performance.
Industry-wide standards for ethical crowdsourcing have begun emerging in response to such concerns. Fair compensation means paying at least local minimum wages, ideally benchmarked against comparable work in workers’ regions. Worker wellbeing requires providing mental health resources for those dealing with sensitive content, limiting exposure to traumatic material, and ensuring reasonable working conditions. Transparency demands clear communication about task purposes, how contributions will be used, and worker rights. Organizations like the Partnership on AI have published guidelines for ethical crowdwork, establishing baselines for acceptable practices.
While quality, scalability, and reliability focus on system capabilities, the governance pillar ensures our data acquisition occurs within appropriate ethical and legal boundaries. Privacy protection forms another critical governance concern, particularly when sourcing data involving individuals who didn’t explicitly consent to ML training use. Anonymization emerges as a critical capability when handling sensitive data. From a systems engineering perspective, anonymization represents more than regulatory compliance; it constitutes a core design constraint affecting data pipeline architecture, storage strategies, and processing efficiency. ML systems must handle sensitive data throughout their lifecycle: during collection, storage, transformation, model training, and even in error logs and debugging outputs. A single privacy breach can compromise not just individual records but entire datasets, making the system unusable for future development.
Practitioners have developed a range of anonymization techniques to mitigate privacy risks. The most straightforward approach, masking, involves altering or obfuscating sensitive values so that they cannot be directly traced back to the original data subject. For instance, digits in financial account numbers or credit card numbers can be replaced with asterisks, fixed dummy characters, or hashed values to protect sensitive information during display or logging.
Building on this direct protection approach, generalization reduces the precision or granularity of data to decrease the likelihood of re-identification. Instead of revealing an exact date of birth or address, the data is aggregated into broader categories such as age ranges or zip code prefixes. For example, a user’s exact age of 37 might be generalized to an age range of 30-39, while their exact address might be bucketed to city-level granularity. This technique reduces re-identification risk by sharing data in aggregated form, though careful granularity selection is crucial—too coarse loses analytical value while too fine may still enable re-identification under certain conditions.
While generalization reduces data precision, pseudonymization takes a different approach by replacing direct identifiers—names, Social Security numbers, email addresses—with artificial identifiers or “pseudonyms.” These pseudonyms must not reveal or be easily traceable to the original data subject, enabling analysis that links records for the same individual without exposing their identity.
Moving beyond simple identifier replacement, k-anonymity provides a more formal approach, ensuring that each record in a dataset is indistinguishable from at least k-1 other records. This is achieved by suppressing or generalizing quasi-identifiers—attributes that in combination could be used to re-identify individuals, such as zip code, age, and gender. For example, if k=5, every record must share the same combination of quasi-identifiers with at least four other records, preventing attackers from pinpointing individuals simply by looking at these attributes. This approach provides formal privacy guarantees but may require significant data distortion and doesn’t protect against homogeneity or background knowledge attacks.
At the most sophisticated end of this spectrum, differential privacy (Dwork, n.d.) adds carefully calibrated noise or randomized data perturbations to query results or datasets. The goal is to ensure that including or excluding any single individual’s data doesn’t significantly affect outputs, thereby concealing their presence. Introduced noise is controlled by the ε parameter in ε-Differential Privacy, balancing data utility and privacy guarantees. This approach provides strong mathematical privacy guarantees and sees wide use in academic and industrial settings, though added noise can affect data accuracy and model performance, requiring careful parameter tuning to balance privacy and usefulness.
Table 2 summarizes the key characteristics of each anonymization approach to help practitioners select appropriate techniques based on their specific privacy requirements and data utility needs.
| Technique | Data Utility | Privacy Level | Implementation | Best Use Case |
|---|---|---|---|---|
| Masking | High | Low-Medium | Simple | Displaying sensitive data |
| Generalization | Medium | Medium | Moderate | Age ranges, location bucketing |
| Pseudonymization | High | Medium | Moderate | Individual tracking needed |
| K-anonymity | Low-Medium | High | Complex | Formal privacy guarantees |
| Differential Privacy | Medium | Very High | Complex | Statistical guarantees |
As the comparison table illustrates, effective data anonymization balances privacy and utility. Techniques such as masking, generalization, pseudonymization, k-anonymity, and differential privacy each target different aspects of re-identification risk. By carefully selecting and combining these methods, organizations can responsibly derive value from sensitive datasets while respecting the privacy rights and expectations of the individuals represented within them.
For our KWS system, governance constraints shape acquisition throughout. Voice data inherently contains biometric information requiring privacy protection, driving decisions about anonymization, consent requirements, and data retention policies. Multilingual support raises equity concerns—will the system work only for commercially valuable languages or also serve smaller linguistic communities? Fair crowdsourcing practices ensure that annotators providing voice samples or labeling receive appropriate compensation and understand how their contributions will be used. Transparency about data sources and limitations enables users to understand system capabilities and potential biases. These governance considerations don’t just constrain acquisition but shape which approaches are ethically acceptable and legally permissible.
Integrated Acquisition Strategy
Having examined how each pillar shapes acquisition choices, we now see why real-world ML systems rarely use a single acquisition method in isolation. Instead, they combine approaches strategically to balance competing pillar requirements, recognizing that each method contributes complementary strengths. The art of data acquisition lies in understanding how these sources work together to create datasets that satisfy quality, scalability, reliability, and governance constraints simultaneously.
Our KWS system exemplifies this integrated approach. Google’s Speech Commands dataset provides a quality-assured baseline enabling rapid prototyping and establishing performance benchmarks. However, evaluating this against our requirements reveals gaps: limited accent diversity, coverage of only major languages, predominantly clean recording environments. Web scraping addresses some gaps by gathering diverse voice samples from video platforms and speech databases, capturing natural speech patterns across varied acoustic conditions. This scales beyond what manual collection could provide while maintaining reasonable quality through automated filtering.
Crowdsourcing fills targeted gaps that neither existing datasets nor web scraping adequately address: underrepresented accents, specific demographic groups, or particular acoustic environments identified as weak points. By carefully designing crowdsourcing tasks with clear guidelines and quality control, the system balances scale with quality while ensuring ethical treatment of contributors. Synthetic data generation completes the picture by systematically exploring the parameter space: varying background noise levels, speaker ages, microphone characteristics, and wake word pronunciations. This addresses the long tail of rare conditions that are impractical to collect naturally while enabling controlled experiments about which acoustic variations most affect model performance.
The synthesis of these approaches demonstrates how our framework guides strategy. Quality requirements drive use of curated datasets and expert review. Scalability needs motivate synthetic generation and web scraping. Reliability demands mandate diverse sourcing across demographics and environments. Governance constraints shape consent requirements, anonymization practices, and fair compensation policies. Rather than selecting sources based on convenience, the integrated strategy systematically addresses each pillar’s requirements through complementary methods.
The diversity achieved through multi-source acquisition—crowdsourced audio with varying quality, synthetic data with perfect consistency, web-scraped content with unpredictable formats—creates specific challenges at the boundary where external data enters our controlled pipeline environment.
Data Ingestion
Data ingestion represents the critical junction where carefully acquired data enters our ML systems, transforming from diverse external formats into standardized pipeline inputs. This boundary layer must handle the heterogeneity resulting from our multi-source acquisition strategy while maintaining the quality, reliability, scalability, and governance standards we’ve established. This transformation from external sources into controlled pipeline environments presents several challenges that manifest distinctly across our framework pillars. The quality pillar demands validation that catches issues at the entry point before they propagate downstream. The reliability pillar requires error handling that maintains operation despite source failures and data anomalies. The scalability pillar necessitates throughput optimization that handles growing data volumes and velocity. The governance pillar enforces access controls and audit trails at the system boundary where external data enters trusted environments. Ingestion represents a critical boundary where careful engineering prevents problems from entering the pipeline while enabling the data flow that ML systems require.
Batch vs. Streaming Ingestion Patterns
To address these ingestion challenges systematically, ML systems typically follow two primary patterns that reflect different approaches to data flow timing and processing. Each pattern has distinct characteristics and use cases that shape how systems balance latency, throughput, cost, and complexity. Understanding when to apply batch versus streaming ingestion—or combinations thereof—requires analyzing workload characteristics against our framework requirements.
Batch ingestion involves collecting data in groups or batches over a specified period before processing. This method proves appropriate when real-time data processing is not critical and data can be processed at scheduled intervals. The batch approach enables efficient use of computational resources by amortizing startup costs across large data volumes and processing when resources are available or least expensive. For example, a retail company might use batch ingestion to process daily sales data overnight, updating their ML models for inventory prediction each morning (Akidau et al. 2015). The batch job might process gigabytes of transaction data using dozens of machines for 30 minutes, then release those resources for other workloads. This scheduled processing proves far more cost-effective than maintaining always-on infrastructure, particularly when slight staleness in predictions doesn’t affect business outcomes.
Batch processing also simplifies error handling and recovery. When a batch job fails midway, the system can retry the entire batch or resume from checkpoints without complex state management. Data scientists can easily inspect failed batches, understand what went wrong, and reprocess after fixes. The deterministic nature of batch processing—processing the same input data always produces the same output—simplifies debugging and validation. These characteristics make batch ingestion attractive for ML workflows even when real-time processing is technically feasible but not required.
In contrast to this scheduled approach, stream ingestion processes data in real-time as it arrives, consuming events continuously rather than waiting to accumulate batches. This pattern proves crucial for applications requiring immediate data processing, scenarios where data loses value quickly, and systems that need to respond to events as they occur. A financial institution might use stream ingestion for real-time fraud detection, processing each transaction as it occurs to flag suspicious activity immediately before completing the transaction. The value of fraud detection drops dramatically if detection occurs hours after the fraudulent transaction completes—by then money has been transferred and accounts compromised.
However, stream processing introduces complexity that batch processing avoids. The system must handle backpressure when downstream systems cannot keep pace with incoming data rates. During traffic spikes, when a sudden surge produces data faster than processing capacity, the system must either buffer data (requiring memory and introducing latency), sample (losing some data), or push back to producers (potentially causing their failures). Data freshness Service Level Agreements (SLAs) formalize these requirements, specifying maximum acceptable delays between data generation and availability for processing. Meeting a 100-millisecond freshness SLA requires different infrastructure than meeting a 1-hour SLA, affecting everything from networking to storage to processing architectures.
Recognizing the limitations of either approach alone, many modern ML systems employ hybrid approaches, combining both batch and stream ingestion to handle different data velocities and use cases. This flexibility allows systems to process both historical data in batches and real-time data streams, providing a comprehensive view of the data landscape. A recommendation system might use streaming ingestion for real-time user interactions—clicks, views, purchases—to update session-based recommendations immediately, while using batch ingestion for overnight processing of user profiles, item features, and collaborative filtering models that don’t require real-time updates.
Production systems must balance cost versus latency trade-offs when selecting patterns: real-time processing can cost 10-100x more than batch processing. This cost differential arises from several factors: streaming systems require always-on infrastructure rather than schedulable resources that can spin up and down based on workload; maintain redundant processing for fault tolerance to ensure no events are lost; need low-latency networking and storage to meet millisecond-scale SLAs; and cannot benefit from economies of scale that batch processing achieves by amortizing startup costs across large data volumes. A batch job processing one terabyte might use 100 machines for 10 minutes, while a streaming system processing the same data over 24 hours needs dedicated resources continuously available. This 100x difference in cost per byte processed drives many architectural decisions about which data truly requires real-time processing versus what can tolerate batch delays.
ETL and ELT Comparison
Beyond choosing ingestion patterns based on timing requirements, designing effective data ingestion pipelines requires understanding the differences between Extract, Transform, Load (ETL)16 and Extract, Load, Transform (ELT)17 approaches, as illustrated in Figure 9. These paradigms determine when data transformations occur relative to the loading phase, significantly impacting the flexibility and efficiency of ML pipelines. The choice between ETL and ELT affects where computational resources are consumed, how quickly data becomes available for analysis, and how easily transformation logic can evolve as requirements change.
16 Extract, Transform, Load (ETL): A data processing pattern where raw data is extracted from sources, transformed (cleaned, aggregated, validated) in a separate processing layer, then loaded into storage. For example, a traditional ETL pipeline might extract customer purchase logs, transform them by removing duplicates and aggregating daily totals in Apache Spark, then load only the aggregated results into a data warehouse. Ensures only high-quality data reaches storage but requires reprocessing all data when transformation logic changes.
17 Extract, Load, Transform (ELT): A data processing pattern where raw data is extracted and immediately loaded into scalable storage, then transformed using the storage system’s computational resources. For example, an ELT pipeline might extract raw clickstream events directly into a data lake like S3, then use SQL queries in a system like Snowflake or BigQuery to create multiple transformed views: user sessions for analytics, feature vectors for ML models, and aggregated metrics for dashboards. Enables faster iteration and multiple transformation variants but requires more storage capacity and careful governance of raw data.

ETL is a well-established paradigm in which data is first gathered from a source, then transformed to match the target schema or model, and finally loaded into a data warehouse or other repository. This approach typically results in data being stored in a ready-to-query format, which can be advantageous for ML systems that require consistent, pre-processed data. The transformation step occurs in a separate processing layer before data reaches the warehouse, enabling validation and standardization before persistence. For instance, an ML system predicting customer churn might use ETL to standardize and aggregate customer interaction data from multiple sources—converting different timestamp formats to UTC, normalizing text encodings to UTF-8, and computing aggregate features like “total purchases last 30 days”—before loading into a format suitable for model training (Inmon 2005).
The advantages of ETL become apparent in scenarios with well-defined schemas and transformation requirements. Only cleaned, validated, transformed data reaches the warehouse, reducing storage requirements and simplifying downstream queries. Security and privacy compliance can be enforced during transformation, ensuring sensitive data is masked or encrypted before reaching storage. Quality validation occurs before loading, preventing corrupted or invalid data from entering the warehouse. For ML systems with stable feature pipelines and clear data quality requirements, ETL provides a clean separation between messy source data and curated training data.
However, ETL can be less flexible when schemas or requirements change frequently, a common occurrence in evolving ML projects. When transformation logic changes—adding new features, modifying aggregations, or correcting bugs—all source data must be reprocessed through the ETL pipeline to update the warehouse. This reprocessing can take hours or days for large datasets, slowing iteration velocity during ML development. The transformation layer requires dedicated infrastructure and expertise, adding operational complexity and cost to the data pipeline.
This is where the ELT approach offers advantages. ELT reverses the order by first loading raw data and then applying transformations as needed within the target system. This method is often seen in modern data lake or schema-on-read environments, allowing for a more agile approach when addressing evolving analytical needs in ML systems. Raw source data is loaded quickly into scalable storage, with transformations applied using the warehouse’s computational resources. Modern cloud data warehouses like BigQuery, Snowflake, and Redshift provide massive computational capacity that can execute complex transformations on terabyte-scale data in minutes.
By deferring transformations, ELT can accommodate varying uses of the same dataset, which is particularly useful in exploratory data analysis phases of ML projects or when multiple models with different data requirements are being developed simultaneously. One team might compute daily aggregates while another computes hourly aggregates, each transforming the same raw data differently. When transformation logic bugs are discovered, teams can reprocess data by simply rerunning transformation queries rather than re-ingesting from sources. This flexibility accelerates ML experimentation where feature engineering requirements evolve rapidly.
However, ELT places greater demands on storage systems and query engines, which must handle large amounts of unprocessed information. Raw data storage grows larger than transformed data, increasing costs. Query performance may suffer when transformations execute repeatedly on the same raw data rather than reading pre-computed results. Privacy and compliance become more complex when raw sensitive data persists in storage rather than being masked during ingestion.
In practice, many ML systems employ hybrid approaches, selecting ETL or ELT on a case-by-case basis depending on the specific requirements of each data source or ML model. For example, a system might use ETL for structured data from relational databases where schemas are well-defined and stable, while employing ELT for unstructured data like text or images where transformation requirements may evolve as the ML models are refined. High-volume clickstream data might use ELT to enable rapid loading and flexible transformation, while sensitive financial data might use ETL to enforce encryption and masking before persistence.
When implementing streaming components within ETL/ELT architectures, distributed systems principles become critical. The CAP theorem18 fundamentally constrains streaming system design choices. Apache Kafka19 prioritizes consistency and partition tolerance, making it ideal for reliable event ordering but potentially experiencing availability issues during network partitions. Apache Pulsar emphasizes availability and partition tolerance, providing better fault tolerance but with relaxed consistency guarantees. Amazon Kinesis balances all three properties through careful configuration but requires understanding these trade-offs for proper deployment.
18 CAP Theorem: A fundamental distributed systems principle stating that any distributed data system can guarantee at most two of three properties: Consistency (all nodes see the same data simultaneously), Availability (system remains operational), and Partition tolerance (system continues despite network failures). Critical for ML systems where different workloads prioritize different properties.
19 Apache Kafka: A distributed streaming platform designed for high-throughput, low-latency data streaming with strong durability guarantees. Provides ordered, replicated logs that enable reliable event processing at scale, making it essential for ML systems requiring real-time data ingestion, feature serving, and model prediction logging.
Multi-Source Integration Strategies
Regardless of whether ETL or ELT approaches are used, integrating diverse data sources represents a key challenge in data ingestion for ML systems. Data may originate from various sources including databases, APIs, file systems, and IoT devices. Each source may have its own data format, access protocol, and update frequency. The integration challenge lies not just in connecting to these sources but in normalizing their disparate characteristics into a unified pipeline that subsequent processing stages can consume reliably.
Given this source diversity, ML engineers must develop robust connectors or adapters for each data source to effectively integrate these sources. These connectors handle the specifics of data extraction, including authentication, rate limiting, and error handling. For example, when integrating with a REST API, the connector would manage API keys, respect rate limits specified in API documentation or HTTP headers, and handle HTTP status codes appropriately—retrying on transient errors (500, 503), aborting on authentication failures (401, 403), and backing off when rate limited (429). A well-designed connector abstracts these details from downstream processing, presenting a consistent interface regardless of whether data originates from APIs, databases, or file systems.
Beyond basic connectivity, source integration often involves data transformation at the ingestion point. This might include parsing JSON20 or XML responses into structured formats, converting timestamps to a standard timezone and format (typically UTC and ISO 8601), or performing basic data cleaning operations like trimming whitespace or normalizing text encodings. The goal is to standardize the data format as it enters the ML pipeline, simplifying downstream processing. These transformations differ from the business logic transformations in ETL or ELT—they address technical format variations rather than semantic transformation of content.
20 JavaScript Object Notation (JSON): A lightweight, text-based data interchange format using human-readable key-value pairs and arrays. Ubiquitous in web APIs and modern data systems due to its simplicity and language-agnostic parsing, though less storage-efficient than binary formats like Parquet for large-scale ML datasets.
In addition to data format standardization, it’s essential to consider the reliability and availability of data sources. Some sources may experience downtime or have inconsistent data quality. Implementing retry mechanisms with exponential backoff handles transient failures gracefully. Data quality checks at ingestion catch systematic problems early—if a source suddenly starts producing null values for previously required fields, immediate detection prevents corrupted data from flowing downstream. Fallback procedures enable continued operation when primary sources fail: switching to backup data sources, serving cached data, or degrading gracefully rather than failing completely. A stock price ingestion system might fall back to delayed prices if real-time feeds fail, maintaining service with slightly stale data rather than complete outage.
Case Study: Selecting Ingestion Patterns for KWS
Applying these ingestion concepts to our KWS system, production implementations demonstrate both streaming and batch patterns working in concert, reflecting the dual operational modes we established during problem definition. The ingestion architecture directly implements requirements from our four-pillar framework: quality through validation of audio characteristics, reliability through consistent operation despite source diversity, scalability through handling millions of concurrent streams, and governance through source authentication and tracking.
The streaming ingestion pattern handles real-time audio data from active devices where wake words must be detected within our 200 millisecond latency requirement. This requires careful implementation of publish-subscribe mechanisms using systems like Apache Kafka that buffer incoming audio data and enable parallel processing across multiple inference servers. The streaming path prioritizes our reliability and scalability pillars: maintaining consistent low-latency operation despite varying device loads and network conditions while handling millions of concurrent audio streams from deployed devices.
Parallel to this real-time processing, batch ingestion handles data for model training and updates. This includes the diverse data sources we established during acquisition: new wake word recordings from crowdsourcing efforts discussed in Section 1.5, synthetic data from voice generation systems that address coverage gaps we identified, and validated user interactions that provide real-world examples of both successful detections and false rejections. The batch processing typically follows an ETL pattern where audio data undergoes preprocessing—normalization to standard volume levels, filtering to remove extreme noise, and segmentation into consistent durations—before being stored in formats optimized for model training. This processing addresses our quality pillar by ensuring training data undergoes consistent transformations that preserve the acoustic characteristics distinguishing wake words from background speech.
Integrating these diverse data sources presents unique challenges for KWS systems. Real-time audio streams require rate limiting to prevent system overload during usage spikes—imagine millions of users simultaneously asking their voice assistants about breaking news. Crowdsourced data needs systematic validation to ensure recording quality meets the specifications we established during problem definition: adequate signal-to-noise ratios, appropriate speaker distances, and correct labeling. Synthetic data must be verified for realistic representation of wake word variations rather than generating acoustically implausible samples that would mislead model training.
The sophisticated error handling mechanisms required by voice interaction systems become apparent when processing real-time audio. Dead letter queues store failed recognition attempts for subsequent analysis, helping identify patterns in false negatives or system failures that might indicate acoustic conditions we didn’t adequately cover during data collection. For example, a smart home device processing the wake word “Alexa” must validate several audio quality metrics: signal-to-noise ratio above our minimum threshold established during requirements definition, appropriate sample rate matching training data specifications, recording duration within expected bounds of one to two seconds, and speaker proximity indicators suggesting the utterance was directed at the device rather than incidental speech. Invalid samples route to dead letter queues for analysis rather than discarding them entirely—these failures often reveal edge cases requiring attention in the next model iteration. Valid samples flow through to real-time processing for wake word detection while simultaneously being logged for potential inclusion in future training data, demonstrating how production systems continuously improve through careful data engineering.
This ingestion architecture completes the boundary layer where external data enters our controlled pipeline. With reliable ingestion established—validating data quality, handling errors gracefully, scaling to required throughput, and maintaining governance controls—we now turn to systematic data processing that transforms ingested raw data into ML-ready features while maintaining the training-serving consistency essential for production systems.
Systematic Data Processing
With reliable data ingestion established, we enter the most technically challenging phase of the pipeline: systematic data processing. Here, a fundamental requirement—applying identical transformations during training and serving—becomes the source of approximately 70% of production ML failures (Sculley et al. 2021). This striking statistic underscores why training-serving consistency must serve as the central organizing principle for all processing decisions.
Data processing implements the quality requirements defined in our problem definition phase, transforming raw data into ML-ready formats while maintaining reliability and scalability standards. Processing decisions must preserve data integrity while improving model readiness, all while adhering to governance principles throughout the transformation pipeline. Every transformation—from normalization parameters to categorical encodings to feature engineering logic—must be applied identically in both contexts. Consider a simple example: normalizing transaction amounts during training by removing currency symbols and converting to floats, but forgetting to apply identical preprocessing during serving. This seemingly minor inconsistency can degrade model accuracy by 20-40%, as the model receives differently formatted inputs than it was trained on. The severity of this problem makes training-serving consistency the central organizing principle for processing system design.
For our KWS system, processing decisions directly impact all four pillars as established in our problem definition (Section 1.3.3). Quality transformations must preserve acoustic characteristics essential for wake word detection while standardizing across diverse recording conditions. Reliability requires consistent processing despite varying audio formats collected through our multi-source acquisition strategy. Scalability demands efficient algorithms that handle millions of audio streams from deployed devices. Governance ensures privacy-preserving transformations that protect user voice data throughout processing.
Ensuring Training-Serving Consistency
We begin with quality as the cornerstone of data processing. Here, the quality pillar manifests as ensuring that transformations applied during training match exactly those applied during serving. This consistency challenge extends beyond just applying the same code—it requires that parameters computed on training data (normalization constants, encoding dictionaries, vocabulary mappings) are stored and reused during serving. Without this discipline, models receive fundamentally different inputs during serving than they were trained on, causing performance degradation that’s often subtle and difficult to debug.
Data cleaning involves identifying and correcting errors, inconsistencies, and inaccuracies in datasets. Raw data frequently contains issues such as missing values, duplicates, or outliers that can significantly impact model performance if left unaddressed. The key insight is that cleaning operations must be deterministic and reproducible: given the same input, cleaning must produce the same output whether executed during training or serving. This requirement shapes which cleaning techniques are safe to use in production ML systems.
Data cleaning might involve removing duplicate records based on deterministic keys, handling missing values through imputation or deletion using rules that can be applied consistently, and correcting formatting inconsistencies systematically. For instance, in a customer database, names might be inconsistently capitalized or formatted. A data cleaning process would standardize these entries, ensuring that “John Doe,” “john doe,” and “DOE, John” are all treated as the same entity. The cleaning rules—convert to title case, reorder to “First Last” format—must be captured in code that executes identically in training and serving. As emphasized throughout this chapter, every cleaning operation must be applied identically in both contexts to maintain system reliability.
Outlier detection and treatment is another important aspect of data cleaning, but one that introduces consistency challenges. Outliers can sometimes represent valuable information about rare events, but they can also result from measurement errors or data corruption. ML practitioners must carefully consider the nature of their data and the requirements of their models when deciding how to handle outliers. Simple threshold-based outlier removal (removing values more than 3 standard deviations from the mean) maintains training-serving consistency if the mean and standard deviation are computed on training data and reused during serving. However, more sophisticated outlier detection methods that consider relationships between features or temporal patterns require careful engineering to ensure consistent application.
Quality assessment goes hand in hand with data cleaning, providing a systematic approach to evaluating the reliability and usefulness of data. This process involves examining various aspects of data quality, including accuracy, completeness, consistency, and timeliness. In production systems, data quality degrades in subtle ways that basic metrics miss: fields that never contain nulls suddenly show sparse patterns, numeric distributions drift from their training ranges, or categorical values appear that weren’t present during model development.
To address these subtle degradation patterns, production quality monitoring requires specific metrics beyond simple missing value counts as discussed in Section 1.4.1. Critical indicators include null value patterns by feature (sudden increases suggest upstream failures), count anomalies (10x increases often indicate data duplication or pipeline errors), value range violations (prices becoming negative, ages exceeding realistic bounds), and join failure rates between data sources. Statistical drift detection21 becomes essential by monitoring means, variances, and quantiles of features over time to catch gradual degradation before it impacts model performance. For example, in an e-commerce recommendation system, the average user session length might gradually increase from 8 minutes to 12 minutes over six months due to improved site design, but a sudden drop to 3 minutes suggests a data collection bug.
21 Data Drift: The phenomenon where statistical properties of production data change over time, diverging from training data distributions and silently degrading model performance. Can occur gradually (user behavior evolving) or suddenly (system changes), requiring continuous monitoring of feature distributions, means, variances, and categorical frequencies to detect before accuracy drops.
Supporting these monitoring requirements, quality assessment tools range from simple statistical measures to complex machine learning-based approaches. Data profiling tools provide summary statistics and visualizations that help identify potential quality issues, while advanced techniques employ unsupervised learning algorithms to detect anomalies or inconsistencies in large datasets. Establishing clear quality metrics and thresholds ensures that data entering the ML pipeline meets necessary standards for reliable model training and inference. The key is maintaining the same quality standards and validation logic across training and serving to prevent quality issues from creating training-serving skew.
Transformation techniques convert data from its raw form into a format more suitable for analysis and modeling. This process can include a wide range of operations, from simple conversions to complex mathematical transformations. Central to effective transformation, common transformation tasks include normalization and standardization, which scale numerical features to a common range or distribution. For example, in a housing price prediction model, features like square footage and number of rooms might be on vastly different scales. Normalizing these features ensures that they contribute more equally to the model’s predictions (Bishop 2006). Maintaining training-serving consistency requires that normalization parameters (mean, standard deviation) computed on training data be stored and applied identically during serving. This means persisting these parameters alongside the model itself—often in the model artifact or a separate parameter file—and loading them during serving initialization.
Beyond numerical scaling, other transformations might involve encoding categorical variables, handling date and time data, or creating derived features. For instance, one-hot encoding is often used to convert categorical variables into a format that can be readily understood by many machine learning algorithms. Categorical encodings must handle both the categories present during training and unknown categories encountered during serving. A robust approach computes the category vocabulary during training (the set of all observed categories), persists it with the model, and during serving either maps unknown categories to a special “unknown” token or uses default values. Without this discipline, serving encounters categories the model never saw during training, potentially causing errors or degraded performance.
Feature engineering is the process of using domain knowledge to create new features that make machine learning algorithms work more effectively. This step is often considered more of an art than a science, requiring creativity and deep understanding of both the data and the problem at hand. Feature engineering might involve combining existing features, extracting information from complex data types, or creating entirely new features based on domain insights. For example, in a retail recommendation system, engineers might create features that capture the recency, frequency, and monetary value of customer purchases, known as RFM analysis (Kuhn and Johnson 2013).
Given these creative possibilities, the importance of feature engineering cannot be overstated. Well-engineered features can often lead to significant improvements in model performance, sometimes outweighing the impact of algorithm selection or hyperparameter tuning. However, the creativity required for feature engineering must be balanced against the consistency requirements of production systems. Every engineered feature must be computed identically during training and serving. This means that feature engineering logic should be implemented in libraries or modules that can be shared between training and serving code, rather than being reimplemented separately. Many organizations build feature stores, discussed in Section 1.9.4, specifically to ensure feature computation consistency across environments.
Applying these processing concepts to our KWS system, the audio recordings flowing through our ingestion pipeline—whether from crowdsourcing, synthetic generation, or real-world captures—require careful cleaning to ensure reliable wake word detection. Raw audio data often contains imperfections that our problem definition anticipated: background noise from various environments (quiet bedrooms to noisy industrial settings), clipped signals from recording level issues, varying volumes across different microphones and speakers, and inconsistent sampling rates from diverse capture devices. The cleaning pipeline must standardize these variations while preserving the acoustic characteristics that distinguish wake words from background speech—a quality-preservation requirement that directly impacts our 98% accuracy target.
Quality assessment for KWS extends the general principles with audio-specific metrics. Beyond checking for null values or schema conformance, our system tracks background noise levels (signal-to-noise ratio above 20 decibels), audio clarity scores (frequency spectrum analysis), and speaking rate consistency (wake word duration within 500-800 milliseconds). The quality assessment pipeline automatically flags recordings where background noise would prevent accurate detection, where wake words are spoken too quickly or unclearly for the model to distinguish them, or where clipping or distortion has corrupted the audio signal. This automated filtering ensures only high-quality samples reach model development, preventing the “garbage in, garbage out” cascade we identified in Figure 3.
Transforming audio data for KWS involves converting raw waveforms into formats suitable for ML models while maintaining training-serving consistency. As shown in Figure 10, the transformation pipeline converts audio signals into standardized feature representations—typically Mel-frequency cepstral coefficients (MFCCs)22 or spectrograms23—that emphasize speech-relevant characteristics while reducing noise and variability across different recording conditions.
22 Mel-frequency cepstral coefficients (MFCCs): A compact representation of audio that captures spectral envelope characteristics crucial for speech recognition. MFCCs model human auditory perception by applying mel-scale filtering (emphasizing frequencies humans hear best) followed by discrete cosine transformation, typically extracting 13-39 coefficients that encode timbral properties while discarding pitch information irrelevant for phoneme identification.
23 Spectrogram: A visual representation of audio showing frequency content over time, computed via Short-Time Fourier Transform (STFT) that applies FFT to overlapping windows. In ML systems, spectrograms serve as 2D image-like inputs where the x-axis represents time, y-axis represents frequency, and intensity shows amplitude, enabling convolutional neural networks to process audio as visual patterns. This transformation must be identical in training and serving: if training computes features with one FFT window size but serving uses another, the model receives fundamentally different inputs that degrade our accuracy target. Feature engineering focuses on extracting characteristics that help distinguish wake words from background speech: energy distribution across frequency bands, pitch contours that capture prosody, and duration patterns that differentiate deliberate wake word pronunciations from accidental similar sounds.
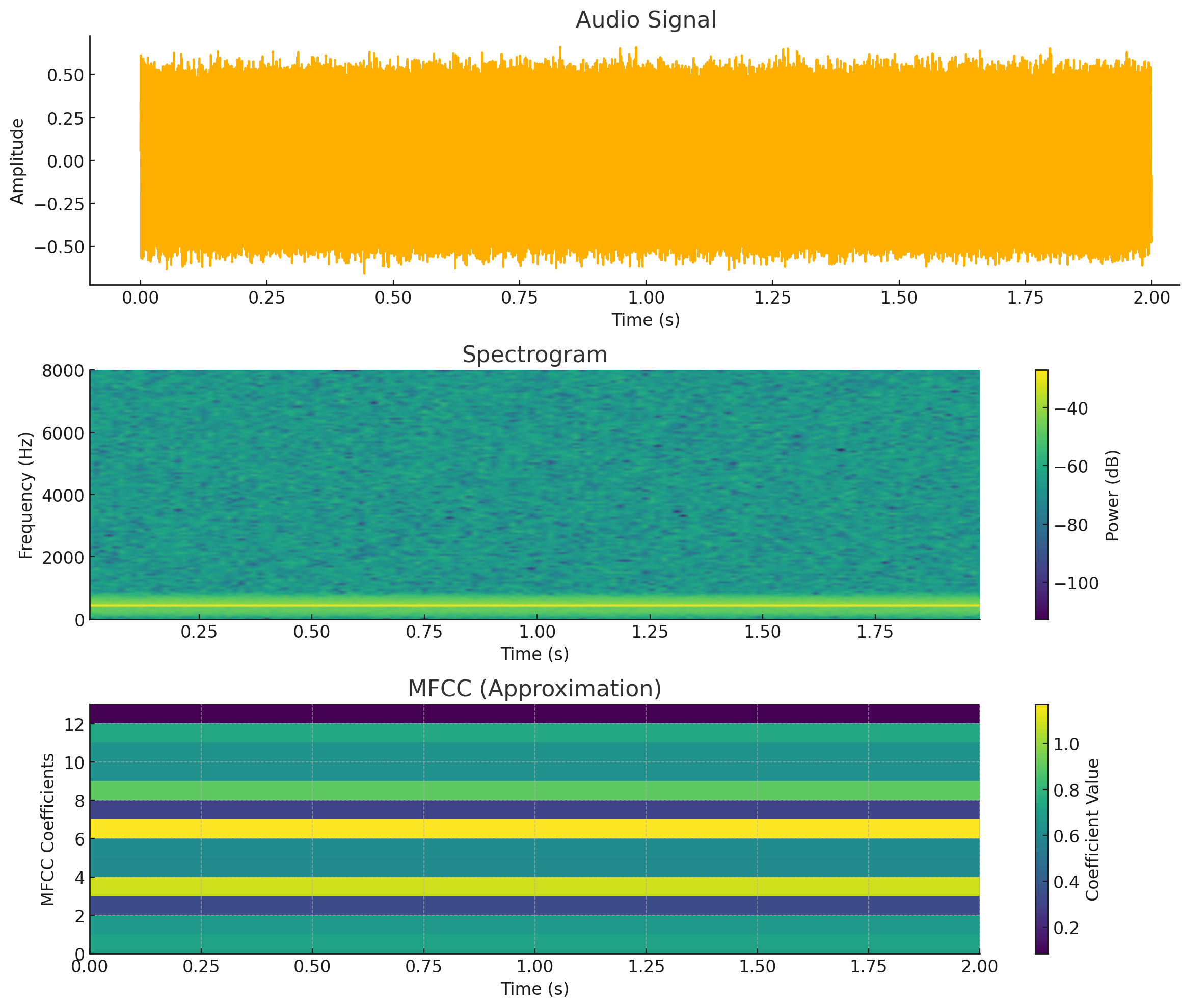
Building Idempotent Data Transformations
Building on quality foundations, we turn to reliability. While quality focuses on what transformations produce, reliability ensures how consistently they operate. Processing reliability means transformations produce identical outputs given identical inputs, regardless of when, where, or how many times they execute. This property, called idempotency, proves essential for production ML systems where processing may be retried due to failures, where data may be reprocessed to fix bugs, or where the same data flows through multiple processing paths.
To understand idempotency intuitively, consider a light switch. Flipping the switch to the “on” position turns the light on. Flipping it to “on” again leaves the light on; the operation can be repeated without changing the outcome. This is idempotent behavior. In contrast, a toggle switch that changes state with each press is not idempotent: pressing it repeatedly alternates between on and off states. In data processing, we want light switch behavior where reapplying the same transformation yields the same result, not toggle switch behavior where repeated application changes the outcome unpredictably.
Idempotent transformations enable reliable error recovery. When a processing job fails midway, the system can safely retry processing the same data without worrying about duplicate transformations or inconsistent state. A non-idempotent transformation might append data to existing records, so retrying would create duplicates. An idempotent transformation would upsert data (insert if not exists, update if exists), so retrying produces the same final state. This distinction becomes critical in distributed systems where partial failures are common and retries are the primary recovery mechanism.
Handling partial processing failures requires careful state management. Processing pipelines should be designed so that each stage can be retried independently without affecting other stages. Checkpoint-restart mechanisms enable recovery from the last successful processing state rather than restarting from scratch. For long-running data processing jobs operating on terabyte-scale datasets, checkpointing progress every few minutes means a failure near the end requires reprocessing only recent data rather than the entire dataset. The checkpoint logic must carefully track what data has been processed and what remains, ensuring no data is lost or processed twice.
Deterministic transformations are those that always produce the same output for the same input, without dependence on external factors like time, random numbers, or mutable global state. Transformations that depend on current time (e.g., computing “days since event” based on current date) break determinism—reprocessing historical data would produce different results. The solution is to capture temporal reference points explicitly: instead of “days since event,” compute “days from event to reference date” where reference date is fixed and persisted. Random operations should use seeded random number generators where the seed is derived deterministically from input data, ensuring reproducibility.
For our KWS system, reliability requires reproducible feature extraction. Audio preprocessing must be deterministic: given the same raw audio file, the same MFCC features are always computed regardless of when processing occurs or which server executes it. This enables debugging model behavior (can always recreate exact features for a problematic example), reprocessing data when bugs are fixed (produces consistent results), and distributed processing (different workers produce identical features from the same input). The processing code captures all parameters—FFT window size, hop length, number of MFCC coefficients—in configuration that’s versioned alongside the code, ensuring reproducibility across time and execution environments.
Scaling Through Distributed Processing
With quality and reliability established, we face the challenge of scale. As datasets grow larger and ML systems become more complex, the scalability of data processing becomes the limiting factor. Consider the data processing stages we’ve discussed—cleaning, quality assessment, transformation, and feature engineering. When these operations must handle terabytes of data, a single machine becomes insufficient. The cleaning techniques that work on gigabytes of data in memory must be redesigned to work across distributed systems.
These challenges manifest when quality assessment must process data faster than it arrives, when feature engineering operations require computing statistics across entire datasets before transforming individual records, and when transformation pipelines create bottlenecks at massive volumes. Processing must scale from development (gigabytes on laptops) through production (terabytes across clusters) while maintaining consistent behavior.
To address these scaling bottlenecks, data must be partitioned across multiple computing resources, which introduces coordination challenges. Distributed coordination is fundamentally limited by network round-trip times: local operations complete in microseconds while network coordination requires milliseconds, creating a 1000x latency difference. This constraint explains why operations requiring global coordination (like computing normalization statistics across 100 machines) create bottlenecks. Each partition computes local statistics quickly, but combining them requires information from all partitions.
Data locality becomes critical at this scale. Moving one terabyte of training data across the network takes 100+ seconds at 10 gigabytes per second, while local SSD access requires only 200 seconds at 5 gigabytes per second, driving ML system design toward compute-follows-data architectures. When processing nodes access local data at RAM speeds (50-200 gigabytes per second) but must coordinate over networks limited to 1-10 gigabytes per second, the bandwidth mismatch creates fundamental bottlenecks. Geographic distribution amplifies these challenges: cross-datacenter coordination must handle network latency (50-200 milliseconds between regions), partial failures, and regulatory constraints preventing data from crossing borders. Understanding which operations parallelize easily versus those requiring expensive coordination determines system architecture and performance characteristics.
Single-machine processing suffices for surprisingly large workloads when engineered carefully. Modern servers with 256 gigabytes RAM can process datasets of several terabytes using out-of-core processing that streams data from disk. Libraries like Dask or Vaex enable pandas-like APIs that automatically stream and parallelize computations across multiple cores. Before investing in distributed processing infrastructure, teams should exhaust single-machine optimization: using efficient data formats (Parquet24 instead of CSV), minimizing memory allocations, leveraging vectorized operations, and exploiting multi-core parallelism. The operational simplicity of single-machine processing—no network coordination, no partial failures, simple debugging—makes it preferable when performance is adequate.
24 Parquet: A columnar storage format optimized for analytical workloads, storing data by column rather than row to enable reading only required features and achieve superior compression. Critical for ML systems where training typically accesses subsets of columns from large datasets, delivering 5-10x I/O reduction compared to row-based formats like CSV.
Distributed processing frameworks become necessary when data volumes or computational requirements exceed single-machine capacity, but the speedup achievable through parallelization faces fundamental limits described by Amdahl’s Law:
\[\text{Speedup} \leq \frac{1}{S + \frac{P}{N}}\]
where \(S\) represents the serial fraction of work that cannot parallelize, \(P\) the parallel fraction, and \(N\) the number of processors. This explains why distributing our KWS feature extraction across 64 cores achieves only a 64x speedup when the work is embarrassingly parallel (\(S \approx 0\)), but coordination-heavy operations like computing global normalization statistics might achieve only 10x speedup even with 64 cores due to the serial aggregation phase. Understanding this relationship guides architectural decisions: operations with high serial fractions should run on fewer, faster cores rather than many slower cores, while highly parallel workloads benefit from maximum distribution as examined further in Chapter 8: AI Training.
Apache Spark provides a distributed computing framework that parallelizes transformations across clusters of machines, handling data partitioning, task scheduling, and fault tolerance automatically. Beam provides a unified API for both batch and streaming processing, enabling the same transformation logic to run on multiple execution engines (Spark, Flink, Dataflow). TensorFlow’s tf.data API optimizes data loading pipelines for ML training, supporting distributed reading, prefetching, and transformation. The choice of framework depends on whether processing is batch or streaming, how transformations parallelize, and what execution environment is available.
Another important consideration is the balance between preprocessing and on-the-fly computation. While extensive preprocessing can speed up model training and inference, it can also lead to increased storage requirements and potential data staleness. Production systems often implement hybrid approaches, preprocessing computationally expensive features while computing rapidly changing features on-the-fly. This balance depends on storage costs, computation resources, and freshness requirements specific to each use case. Features that are expensive to compute but change slowly (user demographic summaries, item popularity scores) benefit from preprocessing. Features that change rapidly (current session state, real-time inventory levels) must be computed on-the-fly despite computational cost.
For our KWS system, scalability manifests at multiple stages. Development uses single-machine processing on sample datasets to iterate rapidly. Training at scale requires distributed processing when dataset size (23 million examples) exceeds single-machine capacity or when multiple experiments run concurrently. The processing pipeline parallelizes naturally: audio files are independent, so transforming them requires no coordination between workers. Each worker reads its assigned audio files from distributed storage, computes features, and writes results back—a trivially parallel pattern achieving near-linear scalability. Production deployment requires real-time processing on edge devices with severe resource constraints (our 16 kilobyte memory limit), necessitating careful optimization and quantization to fit processing within device capabilities.
Tracking Data Transformation Lineage
Completing our four-pillar view of data processing, governance ensures accountability and reproducibility. The governance pillar requires tracking what transformations were applied, when they executed, which version of processing code ran, and what parameters were used. This transformation lineage enables reproducibility essential for debugging, compliance with regulations requiring explainability, and iterative improvement when transformation bugs are discovered. Without comprehensive lineage, teams cannot reproduce training data, cannot explain why models make specific predictions, and cannot safely fix processing bugs without risking inconsistency.
Transformation versioning captures which version of processing code produced each dataset. When transformation logic changes—fixing a bug, adding features, or improving quality—the version number increments. Datasets are tagged with the transformation version that created them, enabling identification of all data requiring reprocessing when bugs are fixed. This versioning extends beyond just code versions to capture the entire processing environment: library versions (different NumPy versions may produce slightly different numerical results), runtime configurations (environment variables affecting behavior), and execution infrastructure (CPU architecture affecting floating-point precision).
Parameter tracking maintains the specific values used during transformation. For normalization, this means storing the mean and standard deviation computed on training data. For categorical encoding, this means storing the vocabulary (set of all observed categories). For feature engineering, this means storing any constants, thresholds, or parameters used in feature computation. These parameters are typically serialized alongside model artifacts, ensuring serving uses identical parameters to training. Modern ML frameworks like TensorFlow and PyTorch provide mechanisms for bundling preprocessing parameters with models, simplifying deployment and ensuring consistency.
Processing lineage for reproducibility tracks the complete transformation history from raw data to final features. This includes which raw data files were read, what transformations were applied in what order, what parameters were used, and when processing occurred. Lineage systems like Apache Atlas, Amundsen, or commercial offerings instrument pipelines to automatically capture this flow. When model predictions prove incorrect, engineers can trace back through lineage: which training data contributed to this behavior, what quality scores did that data have, what transformations were applied, and can we recreate this exact scenario to investigate?
Code version ties processing results to the exact code that produced them. When processing code lives in version control (Git), each dataset should record the commit hash of the code that created it. This enables recreating the exact processing environment: checking out the specific code version, installing dependencies listed at that version, and running processing with identical parameters. Container technologies like Docker simplify this by capturing the entire processing environment (code, dependencies, system libraries) in an immutable image that can be rerun months or years later with identical results.
For our KWS system, transformation governance tracks audio processing parameters that critically affect model behavior. When audio is normalized to standard volume, the reference volume level is persisted. When FFT transforms audio to frequency domain, the window size, hop length, and window function (Hamming, Hanning, etc.) are recorded. When MFCCs are computed, the number of coefficients, frequency range, and mel filterbank parameters are captured. This comprehensive parameter tracking enables several critical capabilities: reproducing training data exactly when debugging model failures, validating that serving uses identical preprocessing to training, and systematically studying how preprocessing choices affect model accuracy. Without this governance infrastructure, teams resort to manual documentation that inevitably becomes outdated or incorrect, leading to subtle training-serving skew that degrades production performance.
End-to-End Processing Pipeline Design
Integrating these cleaning, assessment, transformation, and feature engineering steps, processing pipelines bring together the various data processing steps into a coherent, reproducible workflow. These pipelines ensure that data is consistently prepared across training and inference stages, reducing the risk of data leakage and improving the reliability of ML systems. Pipeline design determines how easily teams can iterate on processing logic, how well processing scales as data grows, and how reliably systems maintain training-serving consistency.
Modern ML frameworks and tools often provide capabilities for building and managing data processing pipelines. For instance, Apache Beam and TensorFlow Transform allow developers to define data processing steps that can be applied consistently during both model training and serving. The choice of data processing framework must align with the broader ML framework ecosystem discussed in Chapter 7: AI Frameworks, where framework-specific data loaders and preprocessing utilities can significantly impact development velocity and system performance.
Beyond tool selection, effective pipeline design involves considerations such as modularity, scalability, and version control. Modular pipelines allow for easy updates and maintenance of individual processing steps. Each transformation stage should be implemented as an independent module with clear inputs and outputs, enabling testing in isolation and replacement without affecting other stages. Version control for pipelines is crucial, ensuring that changes in data processing can be tracked and correlated with changes in model performance. When model accuracy drops, version control enables identifying whether processing changes contributed to the degradation.
This modular breakdown of pipeline components is well illustrated by TensorFlow Extended in Figure 11, which shows the complete flow from initial data ingestion through to final model deployment. The figure demonstrates how data flows through validation, transformation, and feature engineering stages before reaching model training. Each component in the pipeline can be versioned, tested, and scaled independently while maintaining overall system consistency.

Integrating these processing components, our KWS processing pipelines must handle both batch processing for training and real-time processing for inference while maintaining consistency between these modes. The pipeline design ensures that the same normalization parameters computed on training data—mean volume levels, frequency response curves, and duration statistics—are stored and applied identically during serving. This architectural decision reflects our reliability pillar: users expect consistent wake word detection regardless of when their device was manufactured or which model version it runs, requiring processing pipelines that maintain stable behavior across training iterations and deployment environments.
Effective data processing is the cornerstone of successful ML systems. By carefully cleaning, transforming, and engineering data through the lens of our four-pillar framework—quality through training-serving consistency, reliability through idempotent transformations, scalability through distributed processing, and governance through comprehensive lineage—practitioners can significantly improve the performance and reliability of their models. As the field of machine learning continues to evolve, so too do the techniques and tools for data processing, making this an exciting and dynamic area of study and practice. With systematic processing established, we now examine data labeling, which introduces human judgment into our otherwise automated pipelines while maintaining the same framework discipline across quality, reliability, scalability, and governance dimensions.
Data Labeling
With systematic data processing established, data labeling emerges as a particularly complex systems challenge within the broader data engineering landscape. As training datasets grow to millions or billions of examples, the infrastructure supporting labeling operations becomes increasingly critical to system performance. Labeling represents human-in-the-loop system engineering where our four pillars guide infrastructure decisions in fundamentally different ways than in automated pipeline stages. The quality pillar manifests as ensuring label accuracy through consensus mechanisms and gold standard validation. The reliability pillar demands platform architecture that coordinates thousands of concurrent annotators without data loss or corruption. The scalability pillar drives AI assistance to amplify human judgment rather than replace it. The governance pillar requires fair compensation, bias mitigation, and ethical treatment of human contributors whose labor creates the training data enabling ML systems.
Modern machine learning systems must efficiently handle the creation, storage, and management of labels across their data pipeline. The systems architecture must support various labeling workflows while maintaining data consistency, ensuring quality, and managing computational resources effectively. These requirements compound when dealing with large-scale datasets or real-time labeling needs. The systematic challenges extend beyond just storing and managing labels—production ML systems need robust pipelines that integrate labeling workflows with data ingestion, preprocessing, and training components while maintaining high throughput and adapting to changing requirements.
Label Types and Their System Requirements
To build effective labeling systems, we must first understand how different types of labels affect our system architecture and resource requirements. Consider a practical example: building a smart city system that needs to detect and track various objects like vehicles, pedestrians, and traffic signs from video feeds. Labels capture information about key tasks or concepts, with each label type imposing distinct storage, computation, and validation requirements.
Classification labels represent the simplest form, categorizing images with a specific tag or (in multi-label classification) tags such as labeling an image as “car” or “pedestrian.” While conceptually straightforward, a production system processing millions of video frames must efficiently store and retrieve these labels. Storage requirements are modest—a single integer or string per image—but retrieval patterns matter: training often samples random subsets while validation requires sequential access to all labels, driving different indexing strategies.
Bounding boxes extend beyond simple classification by identifying object locations, drawing a box around each object of interest. Our system now needs to track not just what objects exist, but where they are in each frame. This spatial information introduces new storage and processing challenges, especially when tracking moving objects across video frames. Each bounding box requires storing four coordinates (x, y, width, height) plus the object class, multiplying storage by 5x compared to classification. More importantly, bounding box annotation requires pixel-precise positioning that takes 10-20x longer than classification, dramatically affecting labeling throughput and cost.
Segmentation maps provide the most comprehensive information by classifying objects at the pixel level, highlighting each object in a distinct color. For our traffic monitoring system, this might mean precisely outlining each vehicle, pedestrian, and road sign. These detailed annotations significantly increase our storage and processing requirements. A segmentation mask for a 1920x1080 image requires 2 million labels (one per pixel), compared to perhaps 10 bounding boxes or a single classification label. This 100,000x storage increase and the hours required per image for manual segmentation make this approach suitable only when pixel-level precision is essential.
Figure 12 illustrates these common label types and their increasing complexity. Given these increasing complexity levels, the choice of label format depends heavily on our system requirements and resource constraints (Johnson-Roberson et al. 2017). While classification labels might suffice for simple traffic counting, autonomous vehicles need detailed segmentation maps to make precise navigation decisions. Leading autonomous vehicle companies often maintain hybrid systems that store multiple label types for the same data, allowing flexible use across different applications. A single camera frame might have classification labels (scene type: highway, urban, rural), bounding boxes (vehicles and pedestrians for obstacle detection), and segmentation masks (road surface for path planning), with each label type serving distinct downstream models.
Extending beyond these basic label types, production systems must also handle rich metadata essential for maintaining data quality and debugging model behavior. The Common Voice dataset (Ardila et al. 2020) exemplifies sophisticated metadata management in speech recognition: tracking speaker demographics for model fairness, recording quality metrics for data filtering, validation status for label reliability, and language information for multilingual support. If our traffic monitoring system performs poorly in rainy conditions, weather condition metadata during data collection helps identify and address the issue. Modern labeling platforms have built sophisticated metadata management systems that efficiently index and query this metadata alongside primary labels, enabling filtering during training data selection and post-hoc analysis when model failures are discovered.
These metadata requirements demonstrate how label type choice cascades through entire system design. A system built for simple classification labels would need significant modifications to handle segmentation maps efficiently. The infrastructure must optimize storage systems for the chosen label format, implement efficient data retrieval patterns for training, maintain quality control pipelines for validation as established in Section 1.7.1, and manage version control for label updates. When labels are corrected or refined, the system must track which model versions used which label versions, enabling correlation between label quality improvements and model performance gains.
Achieving Label Accuracy and Consensus
In the labeling domain, quality takes on unique challenges. The quality pillar here focuses on ensuring label accuracy despite the inherent subjectivity and ambiguity in many labeling tasks. Even with clear guidelines and careful system design, some fraction of labels will inevitably be incorrect Thyagarajan et al. (2022). The challenge is not eliminating labeling errors entirely—an impossible goal—but systematically measuring and managing error rates to keep them within bounds that don’t degrade model performance.
As Figure 13 illustrates, labeling failures arise from two distinct sources requiring different engineering responses. Some errors stem from data quality issues where the underlying data is genuinely ambiguous or corrupted—like the blurred frog image where even expert annotators cannot determine the species with certainty. Other errors require deep domain expertise where the correct label is determinable but only by experts with specialized knowledge, as with the black stork identification. These different failure modes drive architectural decisions about annotator qualification, task routing, and consensus mechanisms.

Given these fundamental quality challenges, production ML systems implement multiple layers of quality control. Systematic quality checks continuously monitor the labeling pipeline through random sampling of labeled data for expert review and statistical methods to flag potential errors. The infrastructure must efficiently process these checks across millions of examples without creating bottlenecks. Sampling strategies typically validate 1-10% of labels, balancing detection sensitivity against review costs. Higher-risk applications like medical diagnosis or autonomous vehicles may validate 100% of labels through multiple independent reviews, while lower-stakes applications like product recommendations may validate only 1% through spot checks.
Beyond random sampling approaches, collecting multiple labels per data point, often referred to as “consensus labeling,” can help identify controversial or ambiguous cases. Professional labeling companies have developed sophisticated infrastructure for this process. For example, Labelbox has consensus tools that track inter-annotator agreement rates and automatically route controversial cases for expert review. Scale AI implements tiered quality control, where experienced annotators verify the work of newer team members. The consensus infrastructure typically collects 3-5 labels per example, computing inter-annotator agreement using metrics like Fleiss’ kappa which measures agreement beyond what would occur by chance. Examples with low agreement (kappa below 0.4) route to expert review rather than forcing consensus from genuinely ambiguous cases.
The consensus approach reflects an economic trade-off essential for scalable systems. Expert review costs 10-50x more per example than crowdsourced labeling, but forcing agreement on ambiguous examples through majority voting of non-experts produces systematically biased labels. By routing only genuinely ambiguous cases to experts—often 5-15% of examples identified through low inter-annotator agreement—systems balance cost against quality. This tiered approach enables processing millions of examples economically while maintaining quality standards through targeted expert intervention.
While technical infrastructure provides the foundation for quality control, successful labeling systems must also consider human factors. When working with annotators, organizations need robust systems for training and guidance. This includes good documentation with clear examples of correct labeling, visual demonstrations of edge cases and how to handle them, regular feedback mechanisms showing annotators their accuracy on gold standard examples, and calibration sessions where annotators discuss ambiguous cases to develop shared understanding. For complex or domain-specific tasks, the system might implement tiered access levels, routing challenging cases to annotators with appropriate expertise based on their demonstrated accuracy on similar examples.
Quality monitoring generates substantial data that must be efficiently processed and tracked. Organizations typically monitor inter-annotator agreement rates (tracking whether multiple annotators agree on the same example), label confidence scores (how certain annotators are about their labels), time spent per annotation (both too fast suggesting careless work and too slow suggesting confusion), error patterns and types (systematic biases or misunderstandings), annotator performance metrics (accuracy on gold standard examples), and bias indicators (whether certain annotator demographics systematically label differently). These metrics must be computed and updated efficiently across millions of examples, often requiring dedicated analytics pipelines that process labeling data in near real-time to catch quality issues before they affect large volumes of data.
Building Reliable Labeling Platforms
Moving from label quality to system reliability, we examine how platform architecture supports consistent operations. While quality focuses on label accuracy, reliability ensures the platform architecture itself operates consistently at scale. Scaling labeling from hundreds to millions of examples while maintaining quality requires understanding how production labeling systems separate concerns across multiple architectural components. The fundamental challenge is that labeling represents a human-in-the-loop workflow where system performance depends not just on infrastructure but on managing human attention, expertise, and consistency.
At the foundation sits a durable task queue that stores labeling tasks persistently, ensuring no work gets lost when systems restart or annotators disconnect. Most production systems use message queues like Apache Kafka or RabbitMQ rather than databases for this purpose, since message queues provide natural ordering, parallel consumption, and replay capabilities that databases don’t easily support. Each task carries metadata beyond just the data to be labeled: what type of task it is (classification, bounding boxes, segmentation), what expertise level it requires, how urgent it is, and any context needed for accurate labeling—perhaps related examples or relevant documentation.
The assignment service that routes tasks to annotators implements matching logic that’s more sophisticated than simple round-robin distribution. Medical image labeling systems route chest X-rays specifically to annotators who have demonstrated radiology expertise, measured by their agreement with expert labels on gold standard examples. But expertise matching alone isn’t sufficient—annotators who see only chest images or only a specific pathology can develop blind spots, performing well on familiar examples but poorly on less common cases. Production systems therefore constraint assignment to ensure no annotator receives more than 30% of their tasks from a single category, maintaining breadth of exposure that prevents overspecialization from degrading quality on less-familiar examples.
When tasks require multiple annotations to ensure quality, the consensus engine determines both when sufficient labels have been collected and how to aggregate potentially conflicting opinions. Simple majority voting works for clear-cut classification tasks where most annotators naturally agree: identifying whether an image contains a car rarely produces disagreement. But more subjective tasks like sentiment analysis or identifying nuanced image attributes produce legitimate disagreement between thoughtful annotators. A common pattern addresses this by collecting 3-5 labels per example, computing inter-annotator agreement using Fleiss’ kappa (which measures agreement beyond chance), and routing examples with low agreement—typically kappa below 0.4—to expert review rather than forcing consensus from genuinely ambiguous cases.
This tiered approach reflects a fundamental economic trade-off that shapes platform architecture. Expert review costs 10-50x more per example than crowdsourced labeling, but forcing agreement on ambiguous examples through majority voting of non-experts produces systematically biased labels—biased toward easier-to-label patterns that may not reflect the complexity important for model robustness. By routing only genuinely ambiguous cases to experts—often 5-15% of examples identified through low inter-annotator agreement—systems balance cost against quality. The platform must implement this routing logic efficiently, tracking which examples need expert review and ensuring they’re delivered to appropriately qualified annotators without creating bottlenecks.
Maintaining quality at scale requires continuous measurement through gold standard injection. The system periodically inserts examples with known correct labels into the task stream without revealing which examples are gold standard. This enables computing per-annotator accuracy without the Hawthorne effect where measurement changes behavior—annotators can’t “try harder” on gold standard examples if they don’t know which ones they are. Annotators consistently scoring below 85% on gold standards receive additional training materials, more detailed guidelines, or removal from the pool if performance doesn’t improve. Beyond simple accuracy, systems track quality across multiple dimensions: agreement with peer annotators on the same tasks (detecting systematic disagreement suggesting misunderstanding of guidelines), time per task (both too fast suggesting careless work and too slow suggesting confusion), and consistency where the same annotator sees similar examples shown days apart to measure whether they apply labels reliably over time.
The performance requirements of these systems become demanding at scale. A labeling platform processing 10,000 annotations per hour must balance latency requirements against database write capacity. Writing each annotation immediately to a persistent database like PostgreSQL for durability would require 2-3 writes per second, well within database capacity. But task serving—delivering new tasks to 100,000 concurrent annotators requesting work—requires subsecond response times that databases struggle to provide when serving requests fan out across many annotators. Production systems therefore maintain a two-tier storage architecture: Redis caches active tasks enabling sub-100ms task assignment latency, while annotations batch write to PostgreSQL every 100 annotations (typically every 30-60 seconds), providing durability without overwhelming the database with small writes.
Horizontal scaling of these systems requires careful data partitioning. Tasks shard by task_id enabling independent task queue scaling, annotator performance metrics shard by annotator_id for fast lookup during assignment decisions, and aggregated labels shard by example_id for efficient retrieval during model training. This partitioning strategy enables systems handling millions of tasks daily to support 100,000+ concurrent annotators with median task assignment latency under 50ms, proving that human-in-the-loop systems can scale to match fully automated pipelines when properly architected.
Beyond these architectural considerations, understanding the economics of labeling operations reveals why scalability through AI assistance becomes essential. Data labeling represents one of ML systems’ largest hidden costs, yet it is frequently overlooked in project planning that focuses primarily on compute infrastructure and model training expenses. While teams carefully optimize GPU utilization and track training costs measured in dollars per hour, labeling expenses measured in dollars per example often receive less scrutiny despite frequently exceeding compute costs by orders of magnitude. Understanding the full economic model reveals why scalability through AI assistance becomes not just beneficial but economically necessary as ML systems mature and data requirements grow to millions or billions of labeled examples, which Chapter 13: ML Operations examines where operational costs compound across the ML lifecycle.
The cost structure of labeling operations follows a multiplicative model capturing both direct annotation costs and quality control overhead:
\[\text{Total Cost} = N \times \text{Cost}_{\text{label}} \times (1 + R_{\text{review}}) \times (1 + R_{\text{rework}})\]
where \(N\) represents the number of examples, \(\text{Cost}_{\text{label}}\) is the base cost per label, \(R_{\text{review}}\) is the fraction requiring expert review (typically 0.05-0.15), and \(R_{\text{rework}}\) accounts for labels requiring correction (typically 0.10-0.30). This equation reveals how quality requirements compound costs: a dataset requiring 1 million labels at $0.10 per label with 10% expert review (costing 5x more, or $0.50) and 20% rework reaches $138,000, not the $100,000 that naive calculation suggests. For comparison, training a ResNet-50 model on this data might cost only $50 for compute—nearly 3,000x less than labeling, demonstrating why labeling economics dominate total system costs yet receive insufficient attention during planning phases.
The cost per label varies dramatically by task complexity and required expertise. Simple image classification ranges from $0.01-0.05 per label when crowdsourced but rises to $0.50-2.00 when requiring expert verification. Bounding boxes cost $0.05-0.20 per box for straightforward cases but $1.00-5.00 for dense scenes with many overlapping objects. Semantic segmentation can reach $5-50 per image depending on precision requirements and object boundaries. Medical image annotation by radiologists costs $50-200 per study. When a computer vision system requires 10 million labeled images, the difference between $0.02 and $0.05 per label represents $300,000 in project costs—often more than the entire infrastructure budget yet frequently discovered only after labeling begins.
Scaling with AI-Assisted Labeling
As labeling demands grow exponentially with modern ML systems, scalability becomes critical. The scalability pillar drives AI assistance as a force multiplier for human labeling rather than a replacement. Manual annotation alone cannot keep pace with modern ML systems’ data needs, while fully automated labeling lacks the nuanced judgment that humans provide. AI-assisted labeling finds the sweet spot: using automation to handle clear cases and accelerate annotation while preserving human judgment for ambiguous or high-stakes decisions. As illustrated in Figure 14, AI assistance offers several paths to scale labeling operations, each requiring careful system design to balance speed, quality, and resource usage.

Modern AI-assisted labeling typically employs a combination of approaches working together in the pipeline. Pre-annotation involves using AI models to generate preliminary labels for a dataset, which humans can then review and correct. Major labeling platforms have made significant investments in this technology. Snorkel AI uses programmatic labeling (Ratner et al. 2018) to automatically generate initial labels at scale through rule-based heuristics and weak supervision signals. Scale AI deploys pre-trained models to accelerate annotation in specific domains like autonomous driving, where object detection models pre-label vehicles and pedestrians that humans then verify and refine. Companies like SuperAnnotate provide automated pre-labeling tools that can reduce manual effort by 50-80% for computer vision tasks. This method, which often employs semi-supervised learning techniques (Chapelle, Scholkopf, and Zien 2009), can save significant time, especially for extremely large datasets.
The emergence of Large Language Models (LLMs) like ChatGPT has further transformed labeling pipelines. Beyond simple classification, LLMs can generate rich text descriptions, create labeling guidelines from examples, and even explain their reasoning for label assignments. For instance, content moderation systems use LLMs to perform initial content classification and generate explanations for policy violations that human reviewers can validate. However, integrating LLMs introduces new system challenges around inference costs (API calls can cost $0.01-$1 per example depending on complexity), rate limiting (cloud APIs typically limit to 100-10,000 requests per minute), and output validation (LLMs occasionally produce confident but incorrect labels requiring systematic validation). Many organizations adopt a tiered approach, using smaller specialized models for routine cases while reserving larger LLMs for complex scenarios requiring nuanced judgment or rare domain expertise.
Methods such as active learning complement these approaches by intelligently prioritizing which examples need human attention (Coleman et al. 2022). These systems continuously analyze model uncertainty to identify valuable labeling candidates. Rather than labeling a random sample of unlabeled data, active learning selects examples where the current model is most uncertain or where labels would most improve model performance. The infrastructure must efficiently compute uncertainty metrics (often prediction entropy or disagreement between ensemble models), maintain task queues ordered by informativeness, and adapt prioritization strategies based on incoming labels. Consider a medical imaging system: active learning might identify unusual pathologies for expert review while handling routine cases through pre-annotation that experts merely verify. This approach can reduce required annotations by 50-90% compared to random sampling, though it requires careful engineering to prevent feedback loops where the model’s uncertainty biases which data gets labeled.
Quality control becomes increasingly crucial as these AI components interact. The system must monitor both AI and human performance through systematic metrics. Model confidence calibration matters: if the AI says it’s 95% confident but is actually only 75% accurate at that confidence level, pre-annotations mislead human reviewers. Human-AI agreement rates reveal whether AI assistance helps or hinders: when humans frequently override AI suggestions, the pre-annotations may be introducing bias rather than accelerating work. These metrics require careful instrumentation throughout the labeling pipeline, tracking not just final labels but the interaction between human and AI at each stage.
In safety-critical domains like self-driving cars, these systems must maintain particularly rigorous standards while processing massive streams of sensor data. Waymo’s labeling infrastructure reportedly processes millions of sensor frames daily, using AI pre-annotation to label common objects (vehicles, pedestrians, traffic signs) while routing unusual scenarios (construction zones, emergency vehicles, unusual road conditions) to human experts. The system must maintain real-time performance despite this scale, using distributed architectures where pre-annotation runs on GPU clusters while human review scales horizontally across thousands of annotators, with careful load balancing ensuring neither component becomes a bottleneck.
Real-world deployments demonstrate these principles at scale in diverse domains. Medical imaging systems (Krishnan, Rajpurkar, and Topol 2022) combine pre-annotation for common conditions (identifying normal tissue, standard anatomical structures) with active learning for unusual cases (rare pathologies, ambiguous findings), all while maintaining strict patient privacy through secure annotation platforms with comprehensive audit trails. Self-driving vehicle systems coordinate multiple AI models to label diverse sensor data: one model pre-labels camera images, another handles lidar point clouds, a third processes radar data, with fusion logic combining predictions before human review. Social media platforms process millions of items hourly using tiered approaches where simpler models handle clear violations (spam, obvious hate speech) while complex content routes to more sophisticated models or human reviewers when initial classification is uncertain.
Ensuring Ethical and Fair Labeling
Unlike previous sections where governance focused on data and processes, labeling governance centers on human welfare. The governance pillar here addresses ethical treatment of human contributors, bias mitigation, and fair compensation—challenges that manifest distinctly from governance in automated pipeline stages because human welfare is directly at stake. While governance in processing focuses on data lineage and compliance, governance in labeling requires ensuring that the humans creating training data are treated ethically, compensated fairly, and protected from harm.
However, alongside these compelling advantages of crowdsourcing, the challenges highlighted by real-world examples demonstrate why governance cannot be an afterthought. The issue of fair compensation and ethical data sourcing was brought into sharp focus during the development of large-scale AI systems like OpenAI’s ChatGPT. Reports revealed that OpenAI outsourced data annotation tasks to workers in Kenya, employing them to moderate content and identify harmful or inappropriate material that the model might generate. This involved reviewing and labeling distressing content, such as graphic violence and explicit material, to train the AI in recognizing and avoiding such outputs. While this approach enabled OpenAI to improve the safety and utility of ChatGPT, significant ethical concerns arose around the working conditions, the nature of the tasks, and the compensation provided to Kenyan workers.
Many of the contributors were reportedly paid as little as $1.32 per hour for reviewing and labeling highly traumatic material. The emotional toll of such work, coupled with low wages, raised serious questions about the fairness and transparency of the crowdsourcing process. This controversy highlights a critical gap in ethical crowdsourcing practices. The workers, often from economically disadvantaged regions, were not adequately supported to cope with the psychological impact of their tasks. The lack of mental health resources and insufficient compensation underscored the power imbalances that can emerge when outsourcing data annotation tasks to lower-income regions.
Unfortunately, the challenges highlighted by the ChatGPT Kenya controversy are not unique to OpenAI. Many organizations that rely on crowdsourcing for data annotation face similar issues. As machine learning systems grow more complex and require larger datasets, the demand for annotated data will continue to increase. This shows the need for industry-wide standards and best practices to ensure ethical data sourcing. Fair compensation means paying at least local minimum wages, ideally benchmarked against comparable work in workers’ regions—not just the legally minimum but what would be considered fair for skilled work requiring sustained attention. For sensitive content moderation, this often means premium pay reflecting psychological burden, sometimes 2-3x base rates.
Worker wellbeing requires providing mental health resources for those dealing with sensitive content. Organizations like Scale AI have implemented structured support including: limiting exposure to traumatic content (rotating annotators through different content types, capping hours per day on disturbing material), providing access to counseling services at no cost to workers, and offering immediate support channels when annotators encounter particularly disturbing content. These measures add operational cost but are essential for ethical operations. Transparency demands clear communication about task purposes, how contributions will be used, what kind of content workers might encounter, and worker rights including ability to skip tasks that cause distress.
Beyond working conditions, bias in data labeling represents another critical governance concern. Annotators bring their own cultural, personal, and professional biases to the labeling process, which can be reflected in the resulting dataset. For example, Wang et al. (2019) found that image datasets labeled predominantly by annotators from one geographic region showed biases in object recognition tasks, performing poorly on images from other regions. This highlights the need for diverse annotator pools where demographic diversity among annotators helps counteract individual biases, though it doesn’t eliminate them. Regular bias audits examining whether label distributions differ systematically across annotator demographics, monitoring for patterns suggesting systematic bias (all images from certain regions receiving lower quality scores), and addressing identified biases through additional training or guideline refinement ensure labels support fair model behavior.
25 Chapter 13 covers Security and Privacy in depth, building upon the data governance foundations established here to address comprehensive protection strategies for ML systems.
Data privacy and ethical considerations also pose challenges in data labeling. Leading data labeling companies have developed specialized solutions for these challenges. Scale AI, for instance, maintains dedicated teams and secure infrastructure for handling sensitive data in healthcare and finance, with HIPAA-compliant annotation platforms and strict data access controls. Appen implements strict data access controls and anonymization protocols, ensuring annotators never see personally identifiable information when unnecessary. Labelbox offers private cloud deployments for organizations with strict security requirements, enabling annotation without data leaving organizational boundaries. These privacy-preserving techniques connect directly to the security considerations we explore in future chapters25, where comprehensive approaches to protecting sensitive data throughout the ML lifecycle are examined.
Beyond privacy and working conditions, the dynamic nature of real-world data presents another limitation. Labels that are accurate at the time of annotation may become outdated or irrelevant as the underlying distribution of data changes over time. This concept, known as concept drift, necessitates ongoing labeling efforts and periodic re-evaluation of existing labels. Governance frameworks must account for label versioning (tracking when labels were created and by whom), re-annotation policies (systematically re-labeling data when concepts evolve), and retirement strategies (identifying when old labels should be deprecated rather than used for training).
Finally, the limitations of current labeling approaches become apparent when dealing with edge cases or rare events. In many real-world applications, it’s the unusual or rare instances that are often most critical (e.g., rare diseases in medical diagnosis, or unusual road conditions in autonomous driving). However, these cases are, by definition, underrepresented in most datasets and may be overlooked or mislabeled in large-scale annotation efforts. Governance requires explicit strategies for handling rare events: targeted collection campaigns for underrepresented scenarios, expert review requirements for rare cases, and systematic tracking ensuring rare events receive appropriate attention despite their low frequency.
This case emphasizes the importance of considering the human labor behind AI systems. While crowdsourcing offers scalability and diversity, it also brings ethical responsibilities that cannot be overlooked. Organizations must prioritize the well-being and fair treatment of contributors as they build the datasets that drive AI innovation. Governance in labeling ultimately means recognizing that training data isn’t just bits and bytes but the product of human labor deserving respect, fair compensation, and ethical treatment.
Case Study: Automated Labeling in KWS Systems
Continuing our KWS case study through the labeling stage—having established systematic problem definition (Section 1.3.3), diverse data collection strategies that address quality and coverage requirements, ingestion patterns handling both batch and streaming workflows, and processing pipelines ensuring training-serving consistency—we now confront a challenge unique to speech systems at scale. Generating millions of labeled wake word samples without proportional human annotation cost requires moving beyond the manual and crowdsourced approaches we examined earlier. The Multilingual Spoken Words Corpus (MSWC) (Mazumder et al. 2021) demonstrates how automated labeling addresses this challenge through its innovative approach to generating labeled wake word data, containing over 23.4 million one-second spoken examples across 340,000 keywords in 50 different languages.
This scale directly reflects our framework pillars in practice. Achieving our quality target of 98% accuracy across diverse environments requires millions of training examples covering acoustic variations we identified during problem definition. Reliability demands representation across varied acoustic conditions—different background noises, speaking styles, and recording environments. Scalability necessitates automation rather than manual labeling because 23.4 million examples would require approximately 2,600 person-years of effort at even 10 seconds per label, making manual annotation economically infeasible. Governance requirements mandate transparent sourcing and language diversity, ensuring voice-activated technology serves speakers of many languages rather than concentrating on only the most commercially valuable markets.
As illustrated in Figure 15, this automated system begins with paired sentence audio recordings and corresponding transcriptions from projects like Common Voice or multilingual captioned content platforms. The system processes these inputs through forced alignment26—a computational technique that identifies precise word boundaries within continuous speech by analyzing both audio and transcription simultaneously.
26 Forced alignment: An automated speech processing technique that determines precise time boundaries for words within continuous speech by aligning audio with its transcription using acoustic models. The system computes optimal alignment paths through dynamic programming, matching phonetic sequences to audio frames, enabling extraction of individual words with millisecond precision for training data generation. Tools such as the Montreal Forced Aligner (McAuliffe et al. 2017) map timing relationships between written words and spoken sounds at millisecond-level precision, enabling extraction of individual keywords as one-second segments suitable for KWS training.
Building on these precise timing markers, the extraction system generates clean keyword samples while handling engineering challenges our problem definition anticipated: background noise interfering with word boundaries, speakers stretching or compressing words unexpectedly beyond our target 500-800 millisecond duration, and longer words exceeding the one-second boundary. MSWC provides automated quality assessment that analyzes audio characteristics to identify potential issues with recording quality, speech clarity, or background noise—crucial for maintaining consistent standards across 23 million samples without the manual review expenses that would make this scale prohibitive.
Modern voice assistant developers often build upon this automated labeling foundation. While automated corpora may not contain the specific wake words a product requires, they provide starting points for KWS prototyping, particularly in underserved languages where commercial datasets don’t exist. Production systems typically layer targeted human recording and verification for challenging cases—unusual accents, rare words, or difficult acoustic environments that automated systems struggle with—requiring infrastructure that gracefully coordinates between automated processing and human expertise. This demonstrates how the four pillars guide integration: quality through targeted human verification, reliability through automated consistency, scalability through forced alignment, and governance through transparent sourcing and multilingual coverage.
The sophisticated orchestration of forced alignment, extraction, and quality control demonstrates how thoughtful data engineering directly impacts production machine learning systems. When a voice assistant responds to its wake word, it draws upon this labeling infrastructure combined with the collection strategies, pipeline architectures, and processing transformations we’ve examined throughout this chapter. Storage architecture, which we turn to next, completes this picture by determining how these carefully labeled datasets are organized, accessed, and maintained throughout the ML lifecycle, enabling efficient training iterations and reliable serving at scale.
Strategic Storage Architecture
After establishing systematic processing pipelines that transform raw data into ML-ready formats, we must design storage architectures that support the entire ML lifecycle while maintaining our four-pillar framework. Storage decisions determine how effectively we can maintain data quality over time, ensure reliable access under varying loads, scale to handle growing data volumes, and implement governance controls. The seemingly straightforward question of “where should we store this data” actually encompasses complex trade-offs between access patterns, cost constraints, consistency requirements, and performance characteristics that fundamentally shape how ML systems operate.
ML storage requirements differ fundamentally from transactional systems that power traditional applications. Rather than optimizing for frequent small writes and point lookups that characterize e-commerce or banking systems, ML workloads prioritize high-throughput sequential reads over frequent writes, large-scale scans over row-level updates, and schema flexibility over rigid structures. A database serving an e-commerce application performs well with millions of individual product lookups per second, but an ML training job that needs to scan that entire product catalog repeatedly across training epochs requires completely different storage optimization. This section examines how to match storage architectures to ML workload characteristics, comparing databases, data warehouses, and data lakes before exploring specialized ML infrastructure like feature stores and examining how storage requirements evolve across the ML lifecycle.
ML Storage Systems Architecture Options
Storage system selection represents a critical architectural decision that affects all aspects of the ML lifecycle from development through production operations. The choice between databases, data warehouses, and data lakes determines not just where data resides but how quickly teams can iterate during development, how models access training data, and how serving systems retrieve features in production. Understanding these trade-offs requires examining both fundamental storage characteristics and the specific access patterns of different ML tasks.
The key insight is that different ML workloads have fundamentally different storage requirements based on their access patterns and latency needs:
Databases (OLTP): Excel for online feature serving where you need low-latency, random access to individual records. A recommendation system looking up a user’s profile during real-time inference exemplifies this pattern: millisecond lookups of specific user features (age, location, preferences) to generate personalized recommendations.
Data warehouses (OLAP): Optimize for model training on structured data where you need high-throughput, sequential scans over large, clean tables. Training a fraud detection model that processes millions of transactions with hundreds of features per transaction benefits from columnar storage that reads only relevant features efficiently.
Data lakes: Handle exploratory data analysis and training on unstructured data (images, audio, text) where you need flexibility and low-cost storage for massive volumes. A computer vision system storing terabytes of raw images alongside metadata, annotations, and intermediate processing results requires the schema flexibility and cost efficiency that only data lakes provide.
Databases excel at operational and transactional purposes, maintaining product catalogs, user profiles, or transaction histories with strong consistency guarantees and low-latency point lookups. For ML workflows, databases serve specific roles well: storing feature metadata that changes frequently, managing experiment tracking where transactional consistency matters, or maintaining model registries that require atomic updates. A PostgreSQL database handling structured user attributes—user_id, age, country, preferences—provides millisecond lookups for serving systems that need individual user features in real-time. However, databases struggle when ML training requires scanning millions of records repeatedly across multiple epochs. The row-oriented storage that optimizes transactional lookups becomes inefficient when training needs only 20 of 100 columns from each record but must read entire rows to extract those columns.
Data warehouses fill this analytical gap, optimized for complex queries across integrated datasets transformed into standardized schemas. Modern warehouses like Google BigQuery, Amazon Redshift, and Snowflake use columnar storage formats (Stonebraker et al. 2018) that enable reading specific features without loading entire records—essential when tables contain hundreds of columns but training needs only a subset. This columnar organization delivers five to ten times I/O reduction compared to row-based formats for typical ML workloads. Consider a fraud detection dataset with 100 columns where models typically use 20 features—columnar storage reads only needed columns, achieving 80% I/O reduction before even considering compression. Many successful ML systems draw training data from warehouses because the structured environment simplifies exploratory analysis and iterative development. Data analysts can quickly compute aggregate statistics, identify correlations between features, and validate data quality using familiar SQL interfaces.
However, warehouses assume relatively stable schemas and struggle with truly unstructured data—images, audio, free-form text—or rapidly evolving formats common in experimental ML pipelines. When a computer vision team wants to store raw images alongside extracted features, multiple annotation formats from different labeling vendors, intermediate model predictions, and embedding vectors, forcing all these into rigid warehouse schemas creates more friction than value. Schema evolution becomes painful: adding new feature types requires ALTER TABLE operations that may take hours on large datasets, blocking other operations and slowing iteration velocity.
Data lakes address these limitations by storing structured, semi-structured, and unstructured data in native formats, deferring schema definitions until the point of reading—a pattern called schema-on-read. This flexibility proves valuable during early ML development when teams experiment with diverse data sources and aren’t certain which features will prove useful. A recommendation system might store in the same data lake: transaction logs as JSON, product images as JPEGs, user reviews as text files, clickstream data as Parquet, and model embeddings as NumPy arrays. Rather than forcing these heterogeneous types into a common schema upfront, the data lake preserves them in their native formats. Applications impose schema only when reading, enabling different consumers to interpret the same data differently—one team extracts purchase amounts from transaction logs while another analyzes temporal patterns, each applying schemas suited to their analysis.
This flexibility comes with serious governance challenges. Without disciplined metadata management and cataloging, data lakes degrade into “data swamps”—disorganized repositories where finding relevant data becomes nearly impossible, undermining the productivity benefits that motivated their adoption. A data lake might contain thousands of datasets across hundreds of directories with names like “userdata_v2_final” and “userdata_v2_final_ACTUALLY_FINAL”, where only the original authors (who have since left the company) understand what distinguishes them. Successful data lake implementations maintain searchable metadata about data lineage, quality metrics, update frequencies, ownership, and access patterns—essentially providing warehouse-like discoverability over lake-scale data. Tools like AWS Glue Data Catalog, Apache Atlas, or Databricks Unity Catalog provide this metadata layer, enabling teams to discover and understand data before investing effort in processing it.
Table 3 summarizes these fundamental trade-offs across storage system types:
| Attribute | Conventional Database | Data Warehouse | Data Lake |
|---|---|---|---|
| Purpose | Operational and transactional | Analytical and reporting | Storage for raw and diverse data for future processing |
| Data type | Structured | Structured | Structured, semi-structured, and unstructured |
| Scale | Small to medium volumes | Medium to large volumes | Large volumes of diverse data |
| Performance Optimization | Optimized for transactional queries (OLTP) | Optimized for analytical queries (OLAP) | Optimized for scalable storage and retrieval |
| Examples | MySQL, PostgreSQL, Oracle DB | Google BigQuery, Amazon Redshift, Microsoft Azure Synapse | Google Cloud Storage, AWS S3, Azure Data Lake Storage |
Choosing appropriate storage requires systematic evaluation of workload requirements rather than following technology trends. Databases are optimal when data volume remains under one terabyte, query patterns involve frequent updates and complex joins, latency requirements demand subsecond response, and strong consistency is mandatory. A user profile store serving real-time recommendations exemplifies this pattern: small per-user records measured in kilobytes, frequent reads and writes as preferences update, strict consistency ensuring users see their own updates immediately, and latency requirements under 10 milliseconds. Databases become inadequate when analytical queries must span large datasets requiring table scans, schema evolution occurs frequently as feature requirements change, or storage costs exceed $500 per terabyte per month—the point where cheaper alternatives become economically compelling.
Data warehouses excel when data volumes span one to 100 terabytes, analytical query patterns dominate transactional operations, batch processing latency measured in minutes to hours is acceptable, and structured data with relatively stable schemas represents the primary workload. Model training data preparation, batch feature engineering, and historical analysis fit this profile. The migration path from databases to warehouses typically occurs when query complexity increases—requiring aggregations or joins across tables totaling gigabytes rather than megabytes—or when analytical workloads start degrading transactional system performance. Warehouses become inadequate when real-time streaming ingestion is required with latency measured in seconds, or when unstructured data comprises more than 20% of workloads, as warehouse schema rigidity creates excessive friction for heterogeneous data.
Data lakes become essential when data volumes exceed 100 terabytes, schema flexibility is critical for evolving data sources or experimental features, cost optimization is paramount (often 10 times cheaper than warehouses at scale), and diverse data types must coexist. Large-scale model training, particularly for multimodal systems combining text, images, audio, and structured features, requires data lake flexibility. Consider a self-driving car system storing: terabytes of camera images and lidar point clouds from test vehicles, vehicle telemetry as time-series data, manually-labeled annotations identifying objects and behaviors, automatically-generated synthetic data for rare scenarios, and model predictions for comparison against ground truth. Forcing these diverse types into warehouse schemas would require substantial transformation effort and discard nuances that native formats preserve. However, data lakes demand sophisticated catalog management and metadata governance to prevent quality degradation—the critical distinction between a productive data lake and an unusable data swamp.
Migration patterns between storage types follow predictable trajectories as ML systems mature and scale. Early-stage projects often start with databases, drawn by familiar SQL interfaces and existing organizational infrastructure. As datasets grow beyond database efficiency thresholds or analytical queries start affecting operational performance, teams migrate to warehouses. The warehouse serves well during stable production phases with established feature pipelines and relatively fixed schemas. When teams need to incorporate new data types—images for computer vision augmentation, unstructured text for natural language features, or audio for voice applications—or when cost optimization becomes critical at terabyte or petabyte scale, migration to data lakes occurs. Mature ML organizations typically employ all three storage types orchestrated through unified data catalogs: databases for operational data and real-time serving, warehouses for curated analytical data and feature engineering, and data lakes for raw heterogeneous data and large-scale training datasets.
ML Storage Requirements and Performance
Beyond the functional differences between storage systems, cost and performance characteristics directly impact ML system economics and iteration speed. Understanding these quantitative trade-offs enables informed architectural decisions based on workload requirements.
| Storage Tier | Cost ($/TB/month) | Sequential Read Throughput | Random Read Latency | Typical ML Use Case |
|---|---|---|---|---|
| NVME SSD (local) | $100-300 | 5-7 GB/s | 10-100 μs | Training data loading, active feature serving |
| Object Storage (S3, GCS) | $20-25 | 100-500 MB/s (per connection) | 10-50 ms | Data lake raw storage, model artifacts |
| Data Warehouse (BigQuery, Redshift) | $20-40 | 1-5 GB/s (columnar scan) | 100-500 ms (query startup) | Training data queries, feature engineering |
| In-Memory Cache (Redis, Memcached) | $500-1000 | 20-50 GB/s | 1-10 μs | Online feature serving, real-time inference |
| Archival Storage (Glacier, Nearline) | $1-4 | 10-50 MB/s (after retrieval) | Hours (retrieval) | Historical retention, compliance archives |
As Table 4 illustrates, these metrics reveal why ML systems employ tiered storage architectures. Consider the economics of storing our KWS training dataset (736 GB): object storage costs $15-18/month, enabling affordable long-term retention of raw audio, while maintaining working datasets on NVMe for active training costs $74-220/month but provides 50x faster data loading. The performance difference directly impacts iteration velocity—training that loads data at 5 GB/s completes dataset loading in 150 seconds, compared to 7,360 seconds at typical object storage speeds, a 50x difference that determines whether teams can iterate multiple times daily or must wait hours between experiments.
Beyond the fundamental storage capabilities we’ve examined, ML workloads introduce unique requirements that conventional databases and warehouses weren’t designed to handle. Understanding these ML-specific needs and their performance implications shapes infrastructure decisions that cascade through the entire development lifecycle, from experimental notebooks to production serving systems handling millions of requests per second.
Modern ML models contain millions to billions of parameters requiring efficient storage and retrieval patterns quite different from traditional data. GPT-3 (Brown et al. 2020) requires approximately 700 gigabytes for model weights when stored as 32-bit floats—larger than many organization’s entire operational databases. The trajectory reveals accelerating scale: from AlexNet’s 60 million parameters in 2012 (Krizhevsky, Sutskever, and Hinton 2017) to GPT-3’s 175 billion parameters in 2020, model size grew ~2,900-fold in eight years. Storage systems must handle these dense numerical arrays efficiently for both capacity and access speed. During distributed training where multiple workers need coordinated access to model checkpoints, storage bandwidth becomes critical. Unlike typical files where sequential organization matters for readability, model weights benefit from block-aligned storage enabling parallel reads across parameter groups. When 64 GPUs simultaneously read different parameter shards from shared storage during distributed training initialization, storage systems must deliver aggregate bandwidth approaching the network interface limits—often 25 gigabits per second or higher—without introducing synchronization bottlenecks that would idle expensive compute resources.
The iterative nature of ML development introduces versioning requirements qualitatively different from traditional software. While Git excels at tracking code changes where files are predominantly text with small incremental modifications, it fails for large binary files where even small model changes result in entirely new checkpoints. Storing 10 versions of a 10 gigabyte model naively would consume 100 gigabytes, but most ML versioning systems store only deltas between versions, reducing storage proportionally to how much models actually change. Tools like DVC (Data Version Control) and MLflow maintain pointers to model artifacts rather than storing copies, enabling efficient versioning while preserving the ability to reproduce any historical model. A typical ML project generates hundreds of model versions during hyperparameter tuning—one version per training run as engineers explore learning rates, batch sizes, architectures, and regularization strategies. Without systematic versioning capturing training configuration, accuracy metrics, and training data version alongside model weights, reproducing results becomes impossible when yesterday’s model performed better than today’s but teams cannot identify which configuration produced it. This reproducibility challenge connects directly to the governance requirements Section 1.10 examines where regulatory compliance often requires demonstrating exactly which data and process produced specific model predictions.
Distributed training generates substantial intermediate data requiring storage systems to handle concurrent read/write operations at scale. When training ResNet-50 across 64 GPUs, each processing unit works on its portion of data, requiring storage systems to handle 64 simultaneous writes of approximately 100 megabytes of intermediate results every few seconds during synchronization. Memory optimization strategies that trade computation for storage space reduce memory requirements but increase storage I/O as intermediate values write to disk. Storage systems must provide low-latency access to support efficient synchronization—if workers spend more time waiting for storage than performing computations, distributed processing becomes counterproductive. The synchronization pattern varies by parallelization strategy: some approaches require gathering results from all workers, others require sequential communication between workers, and mixed strategies combine both patterns with complex data dependencies.
The bandwidth hierarchy fundamentally constrains ML system design, creating bottlenecks that no amount of compute optimization can overcome. While RAM delivers 50 to 200 gigabytes per second bandwidth on modern servers, network storage systems typically provide only one to 10 gigabytes per second, and even high-end NVMe SSDs max out at one to seven gigabytes per second sequential throughput. Modern GPUs can process data faster than storage can supply it, creating scenarios where expensive accelerators idle waiting for data. Consider ResNet-50 training where the model contains 25 million parameters totaling 100 megabytes, processing batches of 32 images consuming five megabytes of input data, performing four billion operations per forward pass. This yields 26 bytes moved per operation—extraordinarily high compared to traditional computing workloads operating below one byte per operation. When a GPU could theoretically process 10 gigabytes per second worth of computation but storage can only supply one gigabyte per second of data, the 10-fold bandwidth mismatch becomes the primary bottleneck limiting training throughput. No amount of GPU optimization—faster matrix multiplication kernels, improved memory access patterns, or better parallelization—can overcome this fundamental I/O constraint.
Understanding these quantitative relationships enables informed architectural decisions about storage system selection and data pipeline optimization, which become even more critical during distributed training as examined in Chapter 8: AI Training. The training throughput equation reveals the critical dependencies:
\[\text{Training Throughput} = \min(\text{Compute Capacity}, \text{Data Supply Rate})\]
\[\text{Data Supply Rate} = \text{Storage Bandwidth} \times (1 - \text{Overhead})\]
When storage bandwidth becomes the limiting factor, teams must either improve storage performance through faster media, parallelization, or caching, or reduce data movement requirements through compression, quantization, or architectural changes. Large language model training may require processing hundreds of gigabytes of text per hour, while computer vision models processing high-resolution imagery can demand sustained data rates exceeding 50 gigabytes per second across distributed clusters. These requirements explain the rise of specialized ML storage systems optimizing data loading pipelines: PyTorch DataLoader with multiple worker processes parallelizing I/O, TensorFlow tf.data API with prefetching and caching, and frameworks like NVIDIA DALI (Data Loading Library) that offload data augmentation to GPUs rather than loading pre-augmented data from storage.
File format selection dramatically impacts both throughput and latency through effects on I/O volume and decompression overhead. Columnar storage formats like Parquet or ORC deliver five to 10 times I/O reduction compared to row-based formats like CSV or JSON for typical ML workloads. The reduction comes from two mechanisms: reading only required columns rather than entire records, and column-level compression exploiting value patterns within columns. Consider a fraud detection dataset with 100 columns where models typically use 20 features—columnar formats read only needed columns, achieving 80% I/O reduction before compression. Column compression proves particularly effective for categorical features with limited cardinality: a country code column with 200 unique values in 100 million records compresses 20 to 50 times through dictionary encoding, while run-length encoding compresses sorted columns by storing only value changes. The combination can achieve total I/O reduction of 20 to 100 times compared to uncompressed row formats, directly translating to faster training iterations and reduced infrastructure costs.
Compression algorithm selection involves trade-offs between compression ratio and decompression speed. While gzip achieves higher compression ratios of six to eight times, Snappy achieves only two to three times compression but decompresses at 500 megabytes per second—roughly three to four times faster than gzip’s 120 megabytes per second. For ML training where throughput matters more than storage costs, Snappy’s speed advantage often outweighs gzip’s space savings. Training on a 100 gigabyte dataset compressed with gzip requires 17 minutes of decompression time, while Snappy requires only five minutes. When training iterates over data for 50 epochs, this 12-minute difference per epoch compounds to 10 hours total—potentially the difference between running experiments overnight versus waiting multiple days for results. The choice cascades through the system: faster decompression enables higher batch sizes (fitting more examples in memory after decompression), reduced buffering requirements (less decompressed data needs staging), and better GPU utilization (less time idle waiting for data).
Storage performance optimization extends beyond format and compression to data layout strategies. Data partitioning based on frequently used query parameters dramatically improves retrieval efficiency. A recommendation system processing user interactions might partition data by date and user demographic attributes, enabling training on recent data subsets or specific user segments without scanning the entire dataset. Partitioning strategies interact with distributed training patterns: range partitioning by user ID enables data parallel training where each worker processes a consistent user subset, while random partitioning ensures workers see diverse data distributions. The partitioning granularity matters—too few partitions limit parallelism, while too many partitions increase metadata overhead and reduce efficiency of sequential reads within partitions.
Storage Across the ML Lifecycle
Storage requirements evolve substantially as ML systems progress from initial development through production deployment and ongoing maintenance. Understanding these changing requirements enables designing infrastructure that supports the full lifecycle efficiently rather than retrofitting storage later when systems scale or requirements change. The same dataset might be accessed very differently during exploratory analysis (random sampling for visualization), model training (sequential scanning for epochs), and production serving (random access for individual predictions), requiring storage architectures that accommodate these diverse patterns.
During development, storage systems must support exploratory data analysis and iterative model development where flexibility and collaboration matter more than raw performance. Data scientists work with various datasets simultaneously, experiment with feature engineering approaches, and rapidly iterate on model designs to refine approaches. The key challenge involves managing dataset versions without overwhelming storage capacity. A naive approach copying entire datasets for each experiment would exhaust storage quickly—10 experiments on a 100 gigabyte dataset would require one terabyte. Tools like DVC address this by tracking dataset versions through pointers and storing only deltas, enabling efficient experimentation. The system maintains lineage from raw data through transformations to final training datasets, supporting reproducibility when successful experiments need recreation months later.
Collaboration during development requires balancing data accessibility with security. Data scientists need efficient access to datasets for experimentation, but organizations must simultaneously safeguard sensitive information. Many teams implement tiered access controls where synthetic or anonymized datasets are broadly available for experimentation, while access to production data containing sensitive information requires approval and audit trails. This balances exploration velocity against governance requirements, enabling rapid iteration on representative data without exposing sensitive information unnecessarily.
Training phase requirements shift dramatically toward throughput optimization. Modern deep learning training processes massive datasets repeatedly across dozens or hundreds of epochs, making I/O efficiency critical for acceptable iteration speed. High-performance storage systems must provide throughput sufficient to feed data to multiple GPU or TPU accelerators simultaneously without creating bottlenecks. When training ResNet-50 on ImageNet’s 1.2 million images across 8 GPUs, each GPU processes approximately 4,000 images per epoch at 256 image batch size. At 30 seconds per epoch, this requires loading 40,000 images per second across all GPUs—approximately 500 megabytes per second of decompressed image data. Storage systems unable to sustain this throughput cause GPUs to idle waiting for data, directly reducing training efficiency and increasing infrastructure costs.
The balance between preprocessing and on-the-fly computation becomes critical during training. Extensive preprocessing reduces training-time computation but increases storage requirements and risks staleness. Feature extraction for computer vision might precompute ResNet features from images, converting 150 kilobyte images to five kilobyte feature vectors—achieving 30-fold storage reduction and eliminating repeated computation. However, precomputed features become stale when feature extraction logic changes, requiring recomputation across the entire dataset. Production systems often implement hybrid approaches: precomputing expensive, stable transformations like feature extraction while computing rapidly-changing features on-the-fly during training. This balances storage costs, computation time, and freshness based on each feature’s specific characteristics.
Deployment and serving requirements prioritize low-latency random access over high-throughput sequential scanning. Real-time inference demands storage solutions capable of retrieving model parameters and relevant features within millisecond timescales. For a recommendation system serving 10,000 requests per second with 10 millisecond latency budgets, feature storage must support 100,000 random reads per second. In-memory databases like Redis or sophisticated caching strategies become essential for meeting these latency requirements. Edge deployment scenarios introduce additional constraints: limited storage capacity on embedded devices, intermittent connectivity to central data stores, and the need for model updates without disrupting inference. Many edge systems implement tiered storage where frequently-updated models cache locally while infrequently-changing reference data pulls from cloud storage periodically.
Model versioning becomes operationally critical during deployment. Storage systems must facilitate smooth transitions between model versions, ensuring minimal service disruption while enabling rapid rollback if new versions underperform. Shadow deployment patterns, where new models run alongside existing ones for validation, require storage systems to efficiently serve multiple model versions simultaneously. A/B testing frameworks require per-request model version selection, necessitating fast model loading without maintaining dozens of model versions in memory simultaneously.
Monitoring and maintenance phases introduce long-term storage considerations centered on debugging, compliance, and system improvement. Capturing incoming data alongside prediction results enables ongoing analysis detecting data drift, identifying model failures, and maintaining regulatory compliance. For edge and mobile deployments, storage constraints complicate data collection—systems must balance gathering sufficient data for drift detection against limited device storage and network bandwidth for uploading to central analysis systems. Regulated industries often require immutable storage supporting auditing: healthcare ML systems must retain not just predictions but complete data provenance showing which training data and model version produced each diagnostic recommendation, potentially for years or decades.
Log and monitoring data volumes grow substantially in high-traffic production systems. A recommendation system serving 10 million users might generate terabytes of interaction logs daily. Storage strategies typically implement tiered retention: hot storage retains recent data (past week) for rapid analysis, warm storage keeps medium-term data (past quarter) for periodic analysis, and cold archive storage retains long-term data (past years) for compliance and rare deep analysis. The transitions between tiers involve trade-offs between access latency, storage costs, and retrieval complexity that systems must manage automatically as data ages.
Feature Stores: Bridging Training and Serving
Feature stores27 have emerged as critical infrastructure components addressing the unique challenge of maintaining consistency between training and serving environments while enabling feature reuse across models and teams. Traditional ML architectures often compute features differently offline during training versus online during serving, creating training-serving skew that silently degrades model performance.
27 Feature Store: A centralized infrastructure component that maintains consistent feature definitions and provides unified access for both training (batch, high-throughput) and serving (online, low-latency) environments. Eliminates training-serving skew by ensuring identical feature computation logic across ML lifecycle stages while enabling feature reuse across models and teams.
The fundamental problem feature stores address becomes clear when examining typical ML development workflows. During model development, data scientists write feature engineering logic in notebooks or scripts, often using different libraries and languages than production serving systems. Training might compute a user’s “total purchases last 30 days” using SQL aggregating historical data, while serving computes the same feature using a microservice that incrementally updates cached values. These implementations should produce identical results, but subtle differences—handling timezone conversions, dealing with missing data, or rounding numerical values—cause training and serving features to diverge. A study of production ML systems found that 30% to 40% of initial deployments at Uber suffered from training-serving skew, motivating development of their Michelangelo platform with integrated feature stores.
Feature stores provide a single source of truth for feature definitions, ensuring consistency across all stages of the ML lifecycle. When data scientists define a feature like “user_purchase_count_30d”, the feature store maintains both the definition (SQL query, transformation logic, or computation graph) and executes it consistently whether providing historical feature values for training or real-time values for serving. This architectural pattern eliminates an entire class of subtle bugs that prove notoriously difficult to debug because models train successfully but perform poorly in production without obvious errors.
Beyond consistency, feature stores enable feature reuse across models and teams, significantly reducing redundant work. When multiple teams build models requiring similar features—customer lifetime value for churn prediction and upsell models, user demographic features for recommendations and personalization, product attributes for search ranking and related item suggestions—the feature store prevents each team from reimplementing identical features with subtle variations. Centralized feature computation reduces both development time and infrastructure costs while improving consistency across models. A recommendation system might compute user embedding vectors representing preferences across hundreds of dimensions—expensive computation requiring aggregating months of interaction history. Rather than each model team recomputing embeddings, the feature store computes them once and serves them to all consumers.
The architectural pattern typically implements dual storage modes optimized for different access patterns. The offline store uses columnar formats like Parquet on object storage, optimized for batch access during training where sequential scanning of millions of examples is common. The online store uses key-value systems like Redis, optimized for random access during serving where individual feature vectors must be retrieved in milliseconds. Synchronization between stores becomes critical: as training generates new models using current feature values, those models deploy to production expecting the online store to serve consistent features. Feature stores typically implement scheduled batch updates propagating new feature values from offline to online stores, with update frequencies depending on feature freshness requirements.
Time-travel capabilities distinguish sophisticated feature stores from simple caching layers. Training requires accessing feature values as they existed at specific points in time, not just current values. Consider training a churn prediction model: for users who churned on January 15th, the model should use features computed on January 14th, not current features reflecting their churned status. Point-in-time correctness ensures training data matches production conditions where predictions use currently-available features to forecast future outcomes. Implementing time-travel requires storing feature history, not just current values, substantially increasing storage requirements but enabling correct training on historical data.
Feature store performance characteristics directly impact both training throughput and serving latency. For training, the offline store must support high-throughput batch reads, typically loading millions of feature vectors per minute when training begins epochs. Columnar storage formats enable efficient reads of specific features from wide feature tables containing hundreds of potential columns. For serving, the online store must support thousands to millions of reads per second with single-digit millisecond latency. This dual-mode optimization reflects fundamentally different access patterns: training performs large sequential scans while serving performs small random lookups, requiring different storage technologies optimized for each pattern.
Production deployments face additional challenges around feature freshness and cost management. Real-time features requiring immediate updates create pressure on online store capacity and synchronization logic. When users add items to shopping carts, recommendation systems want updated features reflecting current cart contents within seconds, not hours. Streaming feature computation pipelines process events in real-time, updating online stores continuously rather than through periodic batch jobs. However, streaming introduces complexity around exactly-once processing semantics, handling late-arriving events, and managing computation costs for features updated millions of times per second.
Cost management for feature stores becomes significant at scale. Storing comprehensive feature history for time-travel capabilities multiplies storage requirements: retaining daily feature snapshots for one year requires 365 times the storage of keeping only current values. Production systems implement retention policies balancing point-in-time correctness against storage costs, perhaps retaining daily snapshots for one year, weekly snapshots for five years, and purging older history unless required for compliance. Online store costs grow with both feature dimensions and entity counts: storing 512-dimensional embedding vectors for 100 million users requires approximately 200 gigabytes at single-precision (32-bit floats), often replicated across regions for availability and low-latency access, multiplying costs substantially.
Feature store migration represents a significant undertaking for organizations with existing ML infrastructure. Legacy systems compute features ad-hoc across numerous repositories and pipelines, making centralization challenging. Successful migrations typically proceed incrementally: starting with new features in the feature store while gradually migrating high-value legacy features, prioritizing those used across multiple models or causing known training-serving skew issues. Maintaining abstraction layers that enable application-agnostic feature access prevents tight coupling to specific feature store implementations, facilitating future migrations when requirements evolve or better technologies emerge.
Modern feature store implementations include open-source projects like Feast and Tecton, commercial offerings from Databricks Feature Store and AWS SageMaker Feature Store, and custom-built solutions at major technology companies. Each makes different trade-offs between feature types supported (structured vs. unstructured), supported infrastructure (cloud-native vs. on-premise), and integration with ML frameworks. The convergence toward feature stores as essential ML infrastructure reflects recognition that feature engineering represents a substantial portion of ML development effort, and systematic infrastructure supporting features provides compounding benefits across an organization’s entire ML portfolio.
Case Study: Storage Architecture for KWS Systems
[Use the KWS storage section we already created - lines from earlier]
Completing our comprehensive KWS case study—having traced the system from initial problem definition through data collection strategies, pipeline architectures, processing transformations, and labeling approaches—we now examine how storage architecture supports this entire data engineering lifecycle. The storage decisions made here directly reflect and enable choices made in earlier stages. Our crowdsourcing strategy established in Section 1.3.3 determines raw audio volume and diversity requirements. Our processing pipeline designed in Section 1.7 defines what intermediate features must be stored and retrieved efficiently. Our quality metrics from Section 1.7.1 shape metadata storage needs for tracking data provenance and quality scores. Storage architecture weaves these threads together, enabling the system to function cohesively from development through production deployment.
A typical KWS storage architecture implements the tiered approach discussed earlier in this section, with each tier serving distinct purposes that emerged from our earlier engineering decisions. Raw audio files from various sources—crowd-sourced recordings collected through the campaigns we designed, synthetic data generated to fill coverage gaps, and real-world captures from deployed devices—reside in a data lake using cloud object storage services like S3 or Google Cloud Storage. This choice reflects our scalability pillar: audio files accumulate to hundreds of gigabytes or terabytes as we collect the millions of diverse examples needed for 98% accuracy across environments. The flexible schema of data lakes accommodates different sampling rates, audio formats, and recording conditions without forcing rigid structure on heterogeneous sources. Low cost per gigabyte that object storage provides—typically one-tenth the cost of database storage—enables retaining comprehensive data history for model improvement and debugging without prohibitive expense.
The data lake stores comprehensive provenance metadata required by our governance pillar, metadata that proved essential during earlier pipeline stages. For each audio file, the system maintains source type (crowdsourced, synthetic, or real-world), collection date, demographic information when ethically collected and consented to, quality assessment scores computed by our validation pipeline, and processing history showing which transformations have been applied. This metadata enables filtering during training data selection and supports compliance requirements for privacy regulations and ethical AI practices Section 1.10 examines.
Processed features—spectrograms, MFCCs, and other ML-ready representations computed by our processing pipeline—move into a structured data warehouse optimized for training access. This addresses different performance requirements from raw storage: while raw audio is accessed infrequently (primarily during processing pipeline execution when we transform new data), processed features are read repeatedly during training epochs as models iterate over the dataset dozens of times. The warehouse uses columnar formats like Parquet, enabling efficient loading of specific features during training. For a dataset of 23 million examples like MSWC, columnar storage reduces training I/O by five to 10 times compared to row-based formats, directly impacting iteration speed during model development—the difference between training taking hours versus days.
KWS systems benefit significantly from feature stores implementing the architecture patterns we’ve examined. Commonly used audio representations can be computed once and stored for reuse across different experiments or model versions, avoiding redundant computation. The feature store implements a dual architecture: an offline store using Parquet on object storage for training data, providing high throughput for sequential reads when training loads millions of examples, and an online store using Redis for low-latency inference, supporting our 200 millisecond latency requirement established during problem definition. This dual architecture addresses the fundamental tension between training’s batch access patterns—reading millions of examples sequentially—and serving’s random access patterns—retrieving features for individual audio snippets in real-time as users speak wake words.
In production, edge storage requirements become critical as our system deploys to resource-constrained devices. Models must be compact enough for devices with our 16 kilobyte memory constraint from the problem definition while maintaining quick parameter access for real-time wake word detection. Edge devices typically store quantized models using specialized formats like TensorFlow Lite’s FlatBuffers, which enable memory-mapped access without deserialization overhead that would violate latency requirements. Caching applies at multiple levels: frequently accessed model layers reside in SRAM for fastest access, the full model sits in flash storage for persistence across power cycles, and cloud-based model updates are fetched periodically to maintain current wake word detection patterns. This multi-tier caching ensures devices operate effectively even with intermittent network connectivity—a reliability requirement for consumer devices deployed in varied network environments from rural areas with limited connectivity to urban settings with congested networks.
Data Governance
The storage architectures we’ve examined—data lakes, warehouses, feature stores—are not merely technical infrastructure but governance enforcement mechanisms that determine who accesses data, how usage is tracked, and whether systems comply with regulatory requirements. Every architectural decision we’ve made throughout this chapter, from acquisition strategies through processing pipelines to storage design, carries governance implications that manifest most clearly when systems face regulatory audits, privacy violations, or ethical challenges. Data governance transforms from abstract policy into concrete engineering: access control systems that enforce who can read training data, audit infrastructure that tracks every data access for compliance, privacy-preserving techniques that protect individuals while enabling model training, and lineage systems that document how raw audio recordings become production models.
Our KWS system exemplifies governance challenges that arise when sophisticated storage meets sensitive data. The always-listening architecture that enables convenient voice activation creates profound privacy concerns: devices continuously process audio in users’ homes, feature stores maintain voice pattern histories across millions of users, and edge storage caches acoustic models derived from population-wide training data. These technical capabilities that enable our quality, reliability, and scalability requirements simultaneously create governance obligations around consent management, data minimization, access auditing, and deletion rights that require equally sophisticated engineering solutions. As shown in Figure 16, effective governance addresses these interconnected challenges through systematic implementation of privacy protection, security controls, compliance mechanisms, and accountability infrastructure throughout the ML lifecycle.

Security and Access Control Architecture
Production ML systems implement layered security architectures where governance requirements translate into enforceable technical controls at each pipeline stage. Modern feature stores exemplify this integration by implementing role-based access control (RBAC) that maps organizational policies—data scientists can read training features, serving systems can read online features, but neither can modify raw source data—into database permissions that prevent unauthorized access. These access control systems operate across the storage tiers we examined: object storage like S3 enforces bucket policies that determine which services can read training data, data warehouses implement column-level security that hides sensitive fields like user identifiers from most queries, and feature stores maintain separate read/write paths with different permission requirements.
Our KWS system requires particularly sophisticated access controls because voice data flows across organizational and device boundaries. Edge devices store quantized models and cached audio features locally, requiring encryption to prevent extraction if devices are compromised—a voice assistant’s model parameters, though individually non-sensitive, could enable competitive reverse-engineering or reveal training data characteristics. The feature store maintains separate security zones: a production zone where serving systems retrieve real-time features using service credentials with read-only access, a training zone where data scientists access historical features using individual credentials tracked for audit purposes, and an operations zone where SRE teams can access pipeline health metrics without viewing actual voice data. This architectural separation, implemented through Kubernetes namespaces with separate IAM roles in cloud deployments, ensures that compromising one component—say, a serving system vulnerability—doesn’t expose training data or grant write access to production features.
Access control systems integrate with encryption throughout the data lifecycle. Training data stored in data lakes uses server-side encryption with keys managed through dedicated key management services (AWS KMS, Google Cloud KMS) that enforce separation: training job credentials can decrypt current training data but not historical versions already used, implementing data minimization by limiting access scope. Feature stores implement encryption both at rest—storage encrypted using platform-managed keys—and in transit—TLS 1.3 for all communication between pipeline components and feature stores. For KWS edge devices, model updates transmitted from cloud training systems to millions of distributed devices require end-to-end encryption and code signing that verifies model integrity, preventing adversarial model injection that could compromise device security or user privacy.
Technical Privacy Protection Methods
While access controls determine who can use data, privacy-preserving techniques determine what information systems expose even to authorized users. Differential privacy, which we examine in depth in Chapter 17: Responsible AI, provides formal mathematical guarantees that individual training examples don’t leak through model behavior. Implementing differential privacy in production requires careful engineering: adding calibrated noise during model development, tracking privacy budgets across all data uses—each query or training run consumes budget, enforcing system-wide limits on total privacy loss—and validating that deployed models satisfy privacy guarantees through testing infrastructure that attempts to extract training data through membership inference attacks.
KWS systems face particularly acute privacy challenges because the always-listening architecture requires processing audio continuously while minimizing data retention and exposure. Production systems implement privacy through architectural choices: on-device processing where wake word detection runs entirely locally using models stored in edge flash memory, with audio never transmitted unless the wake word is detected; federated learning approaches where devices train on local audio to improve wake word detection but only share aggregated model updates, never raw audio, back to central servers; and automatic deletion policies where detected wake word audio is retained only briefly for quality monitoring before being permanently removed from storage. These aren’t just policy statements but engineering requirements that manifest in storage system design—data lakes implement lifecycle policies that automatically delete voice samples after 30 days unless explicitly tagged for long-term research use with additional consent, and feature stores implement time-to-live (TTL) fields that cause user voice patterns to expire and be purged from online serving stores.
The implementation complexity extends to handling deletion requests required by GDPR and similar regulations. When users invoke their “right to be forgotten,” systems must locate and remove not just source audio recordings but also derived features stored in feature stores, model embeddings that might encode voice characteristics, and audit logs that reference the user—while preserving audit integrity for compliance. This requires sophisticated data lineage tracking that we examine next, enabling systems to identify all data artifacts derived from a user’s voice samples across distributed storage tiers and pipeline stages.
Architecting for Regulatory Compliance
Compliance requirements transform from legal obligations into system architecture constraints that shape pipeline design, storage choices, and operational procedures. GDPR’s data minimization principle requires limiting collection and retention to what’s necessary for stated purposes—for KWS systems, this means justifying why voice samples need retention beyond training, documenting retention periods in system design documents, and implementing automated deletion once periods expire. The “right to access” requires systems to retrieve all data associated with a user—in practice, querying distributed storage systems (data lakes, warehouses, feature stores) and consolidating results, a capability that necessitates consistent user identifiers across all storage tiers and indexes that enable efficient user-level queries rather than full table scans.
Voice assistants operating globally face particularly complex compliance landscapes because regulatory requirements vary by jurisdiction and apply differently based on user age, data sensitivity, and processing location. California’s CCPA grants deletion rights similar to GDPR but with different timelines and exceptions. Children’s voice data triggers COPPA requirements in the United States, requiring verifiable parental consent before collecting data from users under 13—a technical challenge when voice characteristics don’t reliably reveal age, requiring supplementary authentication mechanisms. European requirements for cross-border data transfer restrict storing EU users’ voice data on servers outside designated countries unless specific safeguards exist, driving architectural decisions about regional data lakes, feature store replication strategies, and processing localization.
Standardized documentation frameworks like data cards (Pushkarna, Zaldivar, and Kjartansson 2022) (Figure 17) translate these compliance requirements into operational artifacts. Rather than legal documents maintained separately from systems, data cards become executable specifications: training pipelines check that input datasets have valid data cards before processing, model registries require data card references for all training data, and serving systems enforce that only models trained on compliant data can deploy to production. For our KWS training pipeline, data cards document not just the MSWC dataset characteristics but also consent basis (research use, commercial deployment), geographic restrictions (can train global models, cannot train region-specific models without additional consent), and retention commitments (audio deleted after feature extraction, features retained for model iteration).

Building Data Lineage Infrastructure
Data lineage transforms from compliance documentation into operational infrastructure that powers governance capabilities across the ML lifecycle. Modern lineage systems like Apache Atlas and DataHub28 integrate with pipeline orchestrators (Airflow, Kubeflow) to automatically capture relationships: when an Airflow DAG reads audio files from S3, transforms them into spectrograms, and writes features to a warehouse, the lineage system records each step, creating a graph that traces any feature back to its source audio file and forward to all models trained using it. This automated tracking proves essential for deletion requests—when a user invokes GDPR rights, the lineage graph identifies all derived artifacts (extracted features, computed embeddings, trained model versions) that must be removed or retrained.
28 Data Lineage Systems: Apache Atlas (Hortonworks, now Apache, 2015) and DataHub (LinkedIn, 2020) enable lineage tracking at enterprise scale. These systems capture metadata about data flows automatically from pipeline execution logs, creating graphs where nodes represent datasets (tables, files, feature collections) and edges represent transformations (SQL queries, Python scripts, model training jobs). GDPR Article 30 requires detailed records of data processing activities, making automated lineage tracking essential for demonstrating compliance during regulatory audits.
Production KWS systems implement lineage tracking across all stages we’ve examined in this chapter. Source audio ingestion creates lineage records linking each audio file to its acquisition method (crowdsourced platform, web scraping source, synthetic generation parameters), enabling verification of consent requirements. Processing pipeline execution extends lineage graphs as audio becomes MFCC features, spectrograms, and embeddings—each transformation adds nodes that record not just output artifacts but also code versions, hyperparameters, and execution timestamps. Training jobs create lineage edges from feature collections to model artifacts, recording which data versions trained which model versions. When a voice assistant device downloads a model update, lineage tracking records the deployment, enabling recall if training data is later discovered to have quality or compliance issues.
The operational value extends beyond compliance to debugging and reproducibility. When KWS accuracy degrades for a specific accent, lineage systems enable tracing affected predictions back through deployed models to training features, identifying that the training data lacked sufficient representation of that accent. When research teams want to reproduce an experiment from six months ago, lineage graphs capture exact data versions, code commits, and hyperparameters that produced those results. Feature stores integrate lineage natively: each feature includes metadata about the source data, transformation logic, and computation time, enabling queries like “which models depend on user location data” to guide impact analysis when data sources change.
Audit Infrastructure and Accountability
While lineage tracks what data exists and how it transforms, audit systems record who accessed data and when, creating accountability trails required by regulations like HIPAA and SOX29. Production ML systems generate enormous audit volumes—every training data access, feature store query, and model prediction can generate audit events, quickly accumulating to billions of events daily for large-scale systems. This scale necessitates specialized infrastructure: immutable append-only storage (often using cloud-native services like AWS CloudTrail or Google Cloud Audit Logs) that prevents tampering with historical records, efficient indexing (typically Elasticsearch or similar systems) that enables querying specific user or dataset accesses without full scans, and automated analysis that detects anomalous patterns indicating potential security breaches or policy violations.
29 ML Audit Requirements: SOX compliance requires immutable audit logs for financial ML models, while HIPAA mandates detailed access logs for healthcare AI systems. Modern ML platforms generate massive audit volumes—Uber’s Michelangelo platform logs over 50 billion events daily for compliance, debugging, and performance monitoring. Audit log retention periods vary by regulation: HIPAA requires six years, GDPR’s Article 30 doesn’t specify duration but implies logs must cover data subject access requests, and SOX requires seven years for financial data.
KWS systems implement multi-tier audit architectures that balance granularity against performance and cost. Edge devices log critical events locally—wake word detections, model updates, privacy setting changes—with logs periodically uploaded to centralized storage for compliance retention. Feature stores log every query with request metadata: which service requested features, which user IDs were accessed, and what features were retrieved, enabling analysis like “who accessed this specific user’s voice patterns” for security investigations. Training infrastructure logs dataset access, recording which jobs read which data partitions and when, implementing the accountability needed to demonstrate that deleted user data no longer appears in new model versions.
The integration of lineage and audit systems creates comprehensive governance observability. When regulators audit a voice assistant provider, the combination of lineage graphs showing how user audio becomes models and audit logs proving who accessed that audio provides the transparency needed to demonstrate compliance. When security teams investigate suspected data exfiltration, audit logs identify suspicious access patterns while lineage graphs reveal what data the compromised credentials could reach. When ML teams debug model quality issues, lineage traces problems to specific training data while audit logs confirm no unauthorized modifications occurred. This operational governance infrastructure, built systematically throughout the data engineering practices we’ve examined in this chapter, transforms abstract compliance requirements into enforceable technical controls that maintain trust as ML systems scale in complexity and impact.
As ML systems become increasingly embedded in high-stakes applications (healthcare diagnosis, financial decisions, autonomous vehicles), the engineering rigor applied to governance infrastructure will determine not just regulatory compliance but public trust and system accountability. Emerging approaches like blockchain-inspired tamper-evident logs30 and automated policy enforcement through infrastructure-as-code promise to make governance controls more robust and auditable, though they introduce their own complexity and cost trade-offs that organizations must carefully evaluate against their specific requirements.
30 Blockchain for ML Governance: Immutable distributed ledgers provide tamper-proof audit trails for ML model decisions and data provenance. Ocean Protocol (2017) and similar projects use blockchain to track data usage rights and provide transparent data marketplaces. While promising for high-stakes applications like healthcare AI where audit integrity is paramount, blockchain’s energy costs (proof-of-work consensus), throughput limitations (thousands versus millions of transactions per second), and complexity limit widespread ML adoption. Most production systems use centralized append-only logging with cryptographic integrity checks as a pragmatic middle ground.
Fallacies and Pitfalls
Data engineering underpins every ML system, yet it remains one of the most underestimated aspects of ML development. The complexity of managing data pipelines, ensuring quality, and maintaining governance creates numerous opportunities for costly mistakes that can undermine even the most sophisticated models.
Fallacy: More data always leads to better model performance.
This widespread belief drives teams to collect massive datasets without considering data quality or relevance. While more data can improve performance when properly curated, raw quantity often introduces noise, inconsistencies, and irrelevant examples that degrade model performance. A smaller, high-quality dataset with proper labeling and representative coverage typically outperforms a larger dataset with quality issues. The computational costs and storage requirements of massive datasets also create practical constraints that limit experimentation and deployment options. Effective data engineering prioritizes data quality and representativeness over sheer volume.
Pitfall: Treating data labeling as a simple mechanical task that can be outsourced without oversight.
Organizations often view data labeling as low-skill work that can be completed quickly by external teams or crowdsourcing platforms. This approach ignores the domain expertise, consistency requirements, and quality control necessary for reliable labels. Poor labeling guidelines, inadequate worker training, and insufficient quality validation lead to noisy labels that fundamentally limit model performance. The cost of correcting labeling errors after they affect model training far exceeds the investment in proper labeling infrastructure and oversight.
Fallacy: Data engineering is a one-time setup that can be completed before model development begins.
This misconception treats data pipelines as static infrastructure rather than evolving systems that require continuous maintenance and adaptation. Real-world data sources change over time through schema evolution, quality degradation, and distribution shifts. Models deployed in production encounter new data patterns that require pipeline updates and quality checks. Teams that view data engineering as completed infrastructure rather than ongoing engineering practice often experience system failures when their pipelines cannot adapt to changing requirements.
Fallacy: Training and test data splitting is sufficient to ensure model generalization.
While proper train/test splitting prevents overfitting to training data, it doesn’t guarantee real-world performance. Production data often differs significantly from development datasets due to temporal shifts, geographic variations, or demographic changes. A model achieving 95% accuracy on a carefully curated test set may fail catastrophically when deployed to new regions or time periods. Robust evaluation requires understanding data collection biases, implementing continuous monitoring, and maintaining representative validation sets that reflect actual deployment conditions.
Pitfall: Building data pipelines without considering failure modes and recovery mechanisms.
Data pipelines are often designed for the happy path where everything works correctly, ignoring the reality that data sources fail, formats change, and quality degrades. Teams discover these issues only when production systems crash or silently produce incorrect results. A pipeline processing financial transactions that lacks proper error handling for malformed data could lose critical records or duplicate transactions. Robust data engineering requires explicit handling of failures including data validation, checkpointing, rollback capabilities, and alerting mechanisms that detect anomalies before they impact downstream systems.
Summary
Data engineering serves as the foundational infrastructure that transforms raw information into the foundation of machine learning systems, determining not just model performance but also system reliability, ethical compliance, and long-term maintainability. This chapter revealed how every stage of the data pipeline, from initial problem definition through acquisition, storage, and governance, requires careful engineering decisions that cascade through the entire ML lifecycle. The seemingly straightforward task of “getting data ready” actually encompasses complex trade-offs between data quality and acquisition cost, real-time processing and batch efficiency, storage flexibility and query performance, and privacy protection and data utility.
The technical architecture of data systems demonstrates how engineering decisions compound across the pipeline to create either robust, scalable foundations or brittle, maintenance-heavy technical debt. Data acquisition strategies must navigate the reality that perfect datasets rarely exist in nature, requiring sophisticated approaches ranging from crowdsourcing and synthetic generation to careful curation and active learning. Storage architectures from traditional databases to modern data lakes and feature stores represent fundamental choices about how data flows through the system, affecting everything from training speed to serving latency. The emergence of streaming data processing and real-time feature stores reflects the growing demand for ML systems that can adapt continuously to changing environments while maintaining consistency and reliability.
The four pillars—Quality, Reliability, Scalability, and Governance—form an interconnected framework where optimizing one pillar creates trade-offs with others, requiring systematic balancing rather than isolated optimization.
Training-serving consistency represents the most critical data engineering challenge, causing approximately 70% of production ML failures when transformation logic differs between training and serving environments.
Data labeling costs frequently exceed model training costs by 1,000-3,000x, yet receive insufficient attention during project planning. Understanding the full economic model (base cost × review overhead × rework multiplier) is essential for realistic budgeting.
Effective data acquisition requires strategically combining multiple approaches—existing datasets for quality baselines, web scraping for scale, crowdsourcing for coverage, and synthetic generation for edge cases—rather than relying on any single method.
Storage architecture decisions cascade through the entire ML lifecycle, affecting training iteration speed, serving latency, feature consistency, and operational costs. Tiered storage strategies balance performance requirements against economic constraints.
Data governance extends beyond compliance to enable technical capabilities: lineage tracking enables debugging and reproducibility, access controls enable privacy-preserving architectures, and bias monitoring enables fairness improvements throughout system evolution.
The integration of robust data governance practices throughout the pipeline ensures that ML systems remain trustworthy, compliant, and transparent as they scale in complexity and impact. Data cards, lineage tracking, and automated monitoring create the observability needed to detect data drift, privacy violations, and quality degradation before they affect model behavior. These engineering foundations enable the distributed training strategies in Chapter 8: AI Training, model optimization techniques in Chapter 10: Model Optimizations, and MLOps practices in Chapter 13: ML Operations, where reliable data infrastructure becomes the prerequisite for scaling ML systems effectively.