On-Device Learning
DALL·E 3 Prompt: Drawing of a smartphone with its internal components exposed, revealing diverse miniature engineers of different genders and skin tones actively working on the ML model. The engineers, including men, women, and non-binary individuals, are tuning parameters, repairing connections, and enhancing the network on the fly. Data flows into the ML model, being processed in real-time, and generating output inferences.

Purpose
Why does on-device learning represent the most fundamental architectural shift in machine learning systems since the separation of training and inference, and what makes this capability essential for the future of intelligent systems?
On-device learning dismantles the assumption governing machine learning architecture for decades: the separation between where models are trained and where they operate. This redefines what systems can become by enabling continuous adaptation in the real world rather than static deployment of pre-trained models. The shift from centralized training to distributed, adaptive learning transforms systems from passive inference engines into intelligent agents capable of personalization, privacy preservation, and autonomous improvement in disconnected environments. This architectural revolution becomes essential as AI systems move beyond controlled data centers into unpredictable environments where pre-training cannot anticipate every scenario or deployment condition. Understanding on-device learning principles enables engineers to design systems that break free from static model limitations, creating adaptive intelligence that learns and evolves at the point of human interaction.
Distinguish on-device learning from centralized training approaches by comparing computational distribution, data locality, and coordination mechanisms
Identify key motivational drivers (personalization, latency, privacy, infrastructure efficiency) and evaluate when on-device learning is appropriate versus alternative approaches
Analyze how training amplifies resource constraints compared to inference, quantifying memory (3-5\(\times\)), computational (2-3\(\times\)), and energy overhead impacts on system design
Evaluate adaptation strategies including weight freezing, residual updates, and sparse updates by comparing their resource consumption, expressivity, and suitability for different device classes
Examine data efficiency techniques for learning with limited local datasets, including few-shot learning, experience replay, and data compression methods
Apply federated learning protocols to coordinate privacy-preserving model updates across heterogeneous device populations while managing communication efficiency and convergence challenges
Design on-device learning systems that integrate thermal management, memory hierarchy optimization, and power budgeting to maintain acceptable user experience
Implement practical deployment strategies that address MLOps integration challenges including device-aware pipelines, distributed monitoring, and heterogeneous update coordination
Distributed Learning Paradigm Shift
Operational frameworks (Chapter 13: ML Operations) establish the foundation for managing machine learning systems at scale through centralized orchestration, monitoring, and deployment pipelines. These frameworks assume controlled cloud environments where computational resources are abundant, network connectivity is reliable, and system behavior is predictable. However, as machine learning systems increasingly move beyond data centers to edge devices, these fundamental assumptions begin to break down.
A smartphone learning to predict user text input, a smart home device adapting to household routines, or an autonomous vehicle updating its perception models based on local driving conditions exemplify scenarios where traditional centralized training approaches prove inadequate. The smartphone encounters linguistic patterns unique to individual users that were not present in global training data. The smart home device must adapt to seasonal changes and family dynamics that vary dramatically across households. The autonomous vehicle faces local road conditions, weather patterns, and traffic behaviors that differ from its original training environment.
These scenarios exemplify on-device learning, where models must train and adapt directly on the devices where they operate1. This paradigm transforms machine learning from a centralized discipline to a distributed ecosystem where learning occurs across millions of heterogeneous devices, each operating under unique constraints and local conditions.
1 A11 Bionic Breakthrough: Apple’s A11 Bionic (2017) was the first mobile chip with sufficient computational power for on-device training, delivering 0.6 TOPS compared to the previous A10’s 0.2 TOPS. This \(3\times\) improvement, combined with 4.3 billion transistors and a dual-core Neural Engine, allowed gradient computation for the first time on mobile devices. Google’s Pixel Visual Core achieved similar capabilities with 8 custom Image Processing Units optimized for machine learning workloads.
The transition to on-device learning introduces fundamental tension in machine learning systems design. While cloud-based architectures leverage abundant computational resources and controlled operational environments, edge devices must function within severely constrained resource envelopes characterized by limited memory capacity, restricted computational throughput, constrained energy budgets, and intermittent network connectivity. These constraints that make on-device learning technically challenging simultaneously enable its most significant advantages: personalized adaptation through localized data processing, privacy preservation through data locality, and operational autonomy through independence from centralized infrastructure.
This chapter examines the theoretical foundations and practical methodologies necessary to navigate this architectural tension. Building on computational efficiency principles (Chapter 9: Efficient AI) and operational frameworks (Chapter 13: ML Operations), we investigate the specialized algorithmic techniques, architectural design patterns, and system-level principles that enable effective learning under extreme resource constraints. The challenge extends beyond conventional optimization of training algorithms, requiring reconceptualization of the entire machine learning pipeline for deployment environments where traditional computational assumptions fail.
The implications of this paradigm extend far beyond technical optimization, challenging established assumptions regarding machine learning system development, deployment, and maintenance lifecycles. Models transition from following predictable versioning patterns to exhibiting continuous divergence and adaptation trajectories. Performance evaluation methodologies shift from centralized monitoring dashboards to distributed assessment across heterogeneous user populations. Privacy preservation evolves from a regulatory compliance consideration to a core architectural requirement that shapes system design decisions.
Understanding these systemic implications requires examining both the compelling motivations driving organizational adoption of on-device learning and the substantial technical challenges that must be addressed. This analysis establishes the theoretical foundations and practical methodologies required to architect systems capable of effective learning at the network edge while operating within stringent constraints.
Motivations and Benefits
Machine learning systems have traditionally relied on centralized training pipelines, where models are developed and refined using large, curated datasets and powerful cloud-based infrastructure (Dean et al. 2012). Once trained, these models are deployed to client devices for inference, creating a clear separation between the training and deployment phases. While this architectural separation has served most use cases well, it imposes significant limitations in modern applications where local data is dynamic, private, or highly personalized.
On-device learning challenges this established model by enabling systems to train or adapt directly on the device, without relying on constant connectivity to the cloud. This shift represents more than a technological advancement, it reflects changing application requirements and user expectations that demand responsive, personalized, and privacy-preserving machine learning systems.
Consider a smartphone keyboard adapting to a user’s unique vocabulary and typing patterns. To personalize predictions, the system must perform gradient updates on a compact language model using locally observed text input. A single gradient update for even a minimal language model requires 50-100 MB of memory for activations and optimizer state. Modern smartphones typically allocate 200-300 MB to background applications like keyboards (varies by OS and device generation). This razor-thin margin, where a single training step consumes 25% of available memory, exemplifies the central engineering challenge of on-device learning. The system must achieve meaningful personalization while operating within constraints so severe that traditional training approaches become architecturally infeasible. This quantitative reality drives the need for specialized techniques that make adaptation possible within extreme resource limitations.
On-Device Learning Benefits
Understanding the driving forces behind on-device learning adoption requires examining the inherent limitations of traditional centralized approaches. Traditional machine learning systems rely on a clear division of labor between model training and inference. Training is performed in centralized environments with access to high-performance compute resources and large-scale datasets. Once trained, models are distributed to client devices, where they operate in a static inference-only mode.
While this centralized paradigm has proven effective in many deployments, it introduces fundamental limitations in scenarios where data is user-specific, behavior is dynamic, or connectivity is intermittent. These limitations become particularly acute as machine learning moves beyond controlled environments into real-world applications with diverse user populations and deployment contexts.
On-device learning addresses these limitations by enabling deployed devices to perform model adaptation using locally available data. On-device learning is not merely an efficiency optimization; it serves as a cornerstone of building trustworthy AI systems, opening Part IV: Trustworthy Systems. By keeping data local, it provides a powerful foundation for privacy. By adapting to individual users, it enhances fairness and utility. By enabling offline operation, it improves robustness against network failures and infrastructure dependencies. This chapter explores the engineering required to build these trustworthy, adaptive systems.
This shift from centralized to decentralized learning is motivated by four key considerations that reflect both technological capabilities and changing application requirements: personalization, latency and availability, privacy, and infrastructure efficiency (Li et al. 2020).
Personalization represents the most compelling motivation, as deployed models often encounter usage patterns and data distributions that differ substantially from their training environments. Local adaptation allows models to refine behavior in response to user-specific data, capturing linguistic preferences, physiological baselines, sensor characteristics, or environmental conditions. This capability proves essential in applications with high inter-user variability, where a single global model cannot serve all users effectively.
Latency and availability constraints provide additional justification for local learning. In edge computing scenarios, connectivity to centralized infrastructure may be unreliable, delayed, or intentionally limited to preserve bandwidth or reduce energy consumption. On-device learning enables autonomous improvement of models even in fully offline or delay-sensitive contexts, where round-trip updates to the cloud are architecturally infeasible.
Privacy considerations provide a third compelling driver. Many modern applications involve sensitive or regulated data, including biometric measurements, typed input, location traces, or health information. Local learning mitigates privacy concerns by keeping raw data on the device and operating within privacy-preserving boundaries, potentially aiding adherence to regulations such as GDPR2, HIPAA (Tomes 1996), or region-specific data sovereignty laws.
2 GDPR’s ML Impact: When GDPR took effect in May 2018 (Rasmussen et al. 2024), it made centralized ML training illegal for personal data without explicit consent. The “right to be forgotten” also meant models trained on personal data could be legally required to “unlearn” specific users, technically impossible with traditional training. This drove massive investment in privacy-preserving ML techniques.
Infrastructure efficiency provides economic motivation for distributed learning approaches. Centralized training pipelines require substantial backend infrastructure to collect, store, and process user data from potentially millions of devices. By shifting learning to the edge, systems reduce communication costs and distribute training workloads across the deployment fleet, relieving pressure on centralized resources while improving scalability.
Alternative Approaches and Decision Criteria
On-device learning represents a significant engineering investment with inherent complexity that may not be justified by the benefits. Before committing to this approach, teams should carefully evaluate whether simpler alternatives can achieve comparable results with lower operational overhead. Understanding when not to implement on-device learning is as important as understanding its benefits, as premature adoption can introduce unnecessary complexity without proportional value.
Several alternative approaches often suffice for personalization and adaptation requirements without local training complexity:
Feature-based Personalization: Provides effective customization by storing user preferences, interaction history, and behavioral features locally. Rather than adapting model weights, the system feeds these stored features into a static model to achieve personalization. News recommendation systems exemplify this approach by storing user topic preferences and reading patterns locally, then combining these features with a centralized content model to provide personalized recommendations without model updates.
Cloud-based Fine-tuning with Privacy Controls: Enables personalization through centralized adaptation with appropriate privacy safeguards. User data is processed in batches during off-peak hours using privacy-preserving techniques such as differential privacy3 or federated analytics. This approach often achieves superior accuracy compared to resource-constrained on-device updates while maintaining acceptable privacy properties for many applications.
User-specific Lookup Tables: Combine global models with personalized retrieval mechanisms. The system maintains a lightweight, user-specific lookup table for frequently accessed patterns while using a shared global model for generalization. This hybrid approach provides personalization benefits with minimal computational and storage overhead.
3 Differential Privacy: Mathematical framework that provides quantifiable privacy guarantees by adding carefully calibrated noise to computations. In federated learning, DP ensures that individual user data cannot be inferred from model updates, even by aggregators. Key parameter ε controls privacy-utility tradeoff: smaller ε means stronger privacy but lower model accuracy. Typical deployments use ε=1-8, requiring noise addition that can increase communication overhead by 2-10\(\times\) and reduce model accuracy by 1-5%. Essential for regulatory compliance and user trust in distributed learning systems.
The decision to implement on-device learning should be driven by quantifiable requirements that preclude these simpler alternatives. True data privacy constraints that legally prohibit cloud processing, genuine network limitations that prevent reliable connectivity, quantitative latency budgets that preclude cloud round-trips, or demonstrable performance improvements that justify the operational complexity represent legitimate drivers for on-device learning adoption.
For applications with critical timing requirements (camera processing under 33 ms, voice response under 500 ms, AR/VR motion-to-photon latency under 20 ms, or safety-critical control under 10 ms), network round-trip times (typically 50-200 ms) make cloud-based alternatives architecturally infeasible. In such scenarios, on-device learning becomes necessary regardless of complexity considerations. Teams should thoroughly evaluate simpler solutions before committing to the significant engineering investment that on-device learning requires.
These motivations are grounded in the broader concept of knowledge transfer, where a pretrained model transfers useful representations to a new task or domain. This foundational principle makes on-device learning both feasible and effective, enabling sophisticated adaptation with minimal local resources. As depicted in Figure 1, knowledge transfer can occur between closely related tasks (e.g., playing different board games or musical instruments), or across domains that share structure (e.g., from riding a bicycle to driving a scooter). In the context of on-device learning, this means leveraging a model pretrained in the cloud and adapting it efficiently to a new context using only local data and limited updates. The figure highlights the key idea: pretrained knowledge allows fast adaptation without relearning from scratch, even when the new task diverges in input modality or goal.
This conceptual shift, enabled by transfer learning and adaptation, enables real-world on-device applications. Whether adapting a language model for personal typing preferences, adjusting gesture recognition to individual movement patterns, or recalibrating a sensor model in changing environments, on-device learning allows systems to remain responsive, efficient, and user-aligned over time.
Real-World Application Domains
Building on these established motivations (personalization, latency, privacy, and infrastructure efficiency), real-world deployments demonstrate the practical impact of on-device learning across diverse application domains. These domains span consumer technologies, healthcare, industrial systems, and embedded applications, each showcasing scenarios where the benefits outlined above become essential for effective machine learning deployment.
Mobile input prediction represents the most mature and widely deployed example of on-device learning. In systems such as smartphone keyboards, predictive text and autocorrect features benefit substantially from continuous local adaptation. User typing patterns are highly personalized and evolve dynamically, making centralized static models insufficient for optimal user experience. On-device learning allows language models to fine-tune their predictions directly on the device, achieving personalization while maintaining data locality.
For instance, Google’s Gboard employs federated learning to improve shared models across a large population of users while keeping raw data local to each device (Hard et al. 2018)4.
4 Gboard Federated Pioneer: Gboard became the first major commercial federated learning deployment in 2017, processing updates from over 1 billion devices. The technical challenge was immense: aggregating model updates while ensuring no individual user’s typing patterns could be inferred. Google’s success with Gboard proved federated learning could work at planetary scale, demonstrating 10-20% accuracy improvements over static models while maintaining strict differential privacy guarantees.
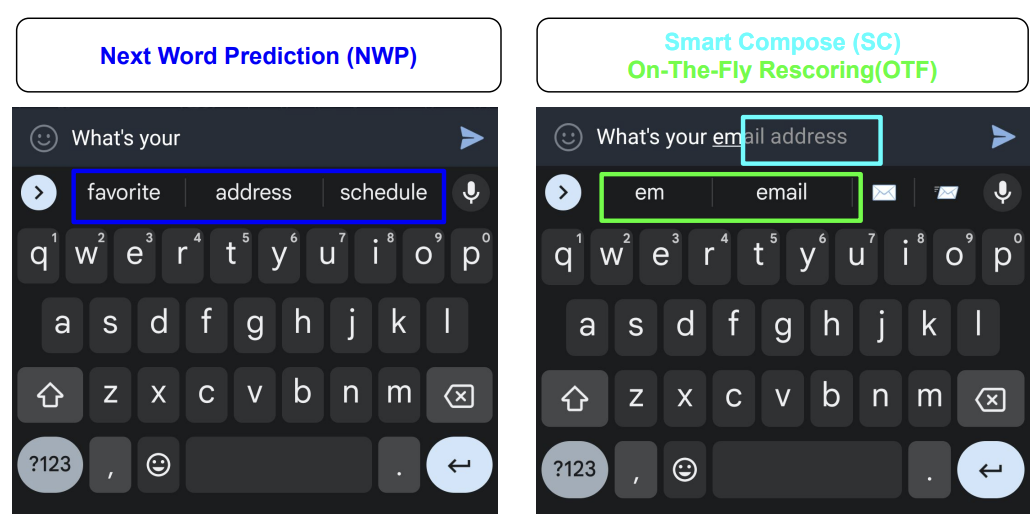
As shown in Figure 2, different prediction strategies illustrate how local adaptation operates in real time: next-word prediction (NWP) suggests likely continuations based on prior text, while Smart Compose uses on-the-fly rescoring to offer dynamic completions, demonstrating the sophistication of local inference mechanisms.
Building on the consumer applications, wearable and health monitoring devices present equally compelling use cases with additional regulatory constraints. These systems rely on real-time data from accelerometers, heart rate sensors, and electrodermal activity monitors to track user health and fitness. Physiological baselines vary dramatically between individuals, creating a personalization challenge that static models cannot address effectively. On-device learning allows models to adapt to these individual baselines over time, substantially improving the accuracy of activity recognition, stress detection, and sleep staging while meeting regulatory requirements for data localization.
Voice interaction technologies present another important application domain with unique acoustic challenges. Wake-word detection5 and voice interfaces in devices such as smart speakers and earbuds must recognize voice commands quickly and accurately, even in noisy or dynamic acoustic environments.
5 Wake-Word Detection: Always-listening keyword spotting that activates voice assistants (“Hey Siri,” “OK Google,” “Alexa”). These systems run continuously at ~1 mW power consumption, roughly 1000\(\times\) less than full speech recognition. They use tiny neural networks (~100 KB) with specialized architectures optimized for sub-100 ms latency and minimal false positive rates (<0.1 activations per hour). Modern systems achieve 95%+ accuracy while processing 16 kHz audio in real-time, making on-device personalization critical for adapting to individual voice characteristics and reducing false activations.
These systems face strict latency requirements: voice interfaces must maintain end-to-end response times under 500 ms to preserve natural conversation flow, with wake-word detection requiring sub-100 ms response times to avoid user frustration. Local training allows models to adapt to the user’s unique voice profile and changing ambient context, reducing false positives and missed detections while meeting these demanding performance constraints. This adaptation proves particularly valuable in far-field audio settings, where microphone configurations and room acoustics vary dramatically across deployments.
Beyond consumer applications, industrial IoT and remote monitoring systems demonstrate the value of on-device learning in resource-constrained environments. In applications such as agricultural sensing, pipeline monitoring, or environmental surveillance, connectivity to centralized infrastructure may be limited, expensive, or entirely unavailable. On-device learning allows these systems to detect anomalies, adjust thresholds, or adapt to seasonal trends without continuous communication with the cloud. This capability proves necessary for maintaining autonomy and reliability in edge-deployed sensor networks, where system downtime or missed detections can have significant economic or safety consequences.
The most demanding applications emerge in embedded computer vision systems, including those in robotics, AR/VR, and smart cameras, which combine complex visual processing with extreme timing constraints. Camera applications must process frames within 33 ms to maintain 30 FPS real-time performance, while AR/VR systems demand motion-to-photon latencies under 20 ms to prevent nausea and maintain immersion. Safety-critical control systems require even tighter bounds, typically under 10 ms, where delayed decisions can have severe consequences. These systems operate in novel or rapidly changing environments that differ substantially from their original training conditions. On-device adaptation allows models to recalibrate to new lighting conditions, object appearances, or motion patterns while meeting these critical latency budgets that fundamentally drive the architectural decision between on-device versus cloud-based processing.
Each domain reveals a common pattern: deployment environments introduce variation and context-specific requirements that cannot be anticipated during centralized training. These applications demonstrate how the motivational drivers (personalization, latency, privacy, and infrastructure efficiency) manifest as concrete engineering constraints. Mobile keyboards face memory limitations for storing user-specific patterns, wearable devices encounter energy budgets that restrict training frequency, voice interfaces must meet sub-100 ms latency requirements that preclude cloud coordination, and industrial IoT systems operate in network-constrained environments that demand autonomous adaptation. This pattern illuminates the fundamental design requirement shaping all subsequent technical decisions: learning must be performed efficiently, privately, and reliably under significant resource constraints that we examine through constraint analysis (Section 1.3), adaptation techniques (Section 1.4), and federated coordination (Section 1.6).
Architectural Trade-offs: Centralized vs. Decentralized Training
These applications demonstrate the practical value of on-device learning across diverse domains. Building on this foundation, we now examine how on-device learning differs from traditional ML architectures, revealing a complete reimagining of the training lifecycle that extends far beyond simple deployment choices.
Understanding the shift that on-device learning represents requires examining how traditional machine learning systems are structured and where their limitations become apparent. Most machine learning systems today follow a centralized learning paradigm that has served the field well but increasingly shows strain under modern deployment requirements. Models are trained in data centers using large-scale, curated datasets aggregated from many sources. Once trained, these models are deployed to client devices in a static form, where they perform inference without further modification. Updates to model parameters, either to incorporate new data or to improve generalization, are handled periodically through offline retraining, often using newly collected or labeled data sent back from the field.
This established centralized model offers numerous proven advantages: high-performance computing infrastructure, access to diverse data distributions, and robust debugging and validation pipelines. It also depends on several assumptions that may not hold in modern deployment scenarios: reliable data transfer, trust in data custodianship, and infrastructure capable of managing global updates across device fleets. As machine learning is deployed into increasingly diverse and distributed environments, the limitations of this approach become more apparent and often prohibitive.
In contrast to this centralized approach, on-device learning embraces an inherently decentralized paradigm that challenges many traditional assumptions. Each device maintains its own copy of a model and adapts it locally using data that is typically unavailable to centralized infrastructure. Training occurs on-device, often asynchronously and under varying resource conditions that change based on device usage patterns, battery levels, and thermal states. Data never leaves the device, reducing privacy exposure but also complicating coordination between devices. Devices may differ dramatically in their hardware capabilities, runtime environments, and patterns of use, making the learning process heterogeneous and difficult to standardize. These hardware variations create significant system design challenges.
This decentralized architecture introduces a new class of systems challenges that extend well beyond traditional machine learning concerns. Devices may operate with different versions of the model, leading to inconsistencies in behavior across the deployment fleet. Evaluation and validation become significantly more complex, as there is no central point from which to measure performance across all devices (McMahan et al. 2017). Model updates must be carefully managed to prevent degradation, and safety guarantees become substantially harder to enforce in the absence of centralized testing and validation infrastructure.
Managing thousands of heterogeneous edge devices exceeds typical distributed systems complexity. Device heterogeneity extends beyond hardware differences to include varying operating system versions, security patches, network configurations, and power management policies. At any given time, 20-40% of devices are offline (Bonawitz et al. 2019), while others have been disconnected for weeks or months, creating persistent coordination challenges.
When disconnected devices reconnect, they require state reconciliation to avoid version conflicts. Update verification becomes critical as devices can silently fail to apply updates or report success while running outdated models. Robust systems implement multi-stage verification: cryptographic signatures confirm update integrity, functional tests validate model behavior, and telemetry confirms deployment success. Rollback strategies must handle partial deployments where some devices received updates while others remain on previous versions, requiring sophisticated orchestration to maintain system consistency during failure recovery.
These challenges require different approaches to system design and operational management compared to centralized ML systems, building on the distributed systems principles from Chapter 13: ML Operations while introducing edge-specific complexities.
Despite these challenges, decentralization introduces opportunities that often justify the additional complexity. It allows for deep personalization without centralized oversight, supports robust learning in disconnected or bandwidth-limited environments, and reduces the operational cost and infrastructure burden for model updates. Realizing these benefits raises questions of how to effectively coordinate learning across devices, whether through periodic synchronization, federated aggregation, or hybrid approaches that balance local and global objectives.
The move from centralized to decentralized learning represents more than a shift in deployment architecture. It reshapes the entire design space for machine learning systems, requiring new approaches to model architecture, training algorithms, data management, and system validation. In centralized training, data is aggregated from many sources and processed in large-scale data centers, where models are trained, validated, and then deployed in a static form to edge devices. In contrast, on-device learning introduces a fundamentally different paradigm: models are updated directly on client devices using local data, often asynchronously and under diverse hardware conditions. This architectural transformation introduces coordination challenges while enabling autonomous local adaptation, requiring careful consideration of validation, system reliability, and update orchestration across heterogeneous device populations.
On-device learning responds to the limitations of centralized machine learning workflows. The transformation from centralized to decentralized learning creates three distinct operational phases, each with different characteristics and challenges.
The traditional centralized paradigm begins with cloud-based training on aggregated data, followed by static model deployment to client devices. This approach works well when data collection is feasible, network connectivity is reliable, and a single global model can serve all users effectively. However, it breaks down when data becomes personalized, privacy-sensitive, or collected in environments with limited connectivity.
Once deployed, local differences begin to emerge as each device encounters its own unique data distribution. Devices collect data that reflects individual user patterns, environmental conditions, and usage contexts. This data is often non-IID (non-independent and identically distributed)6 and noisy, requiring local model adaptation to maintain performance. This transition marks the shift from global generalization to local specialization.
6 Non-IID (Non-Independent and Identically Distributed): In machine learning, data is IID when samples are drawn independently from the same distribution. Non-IID violates this assumption, common in federated learning where each device collects data from different users, environments, or use cases. For example, smartphone keyboard data varies dramatically between users (languages, writing styles, autocorrect needs), making personalized model training essential but challenging for convergence.
The final phase introduces federated coordination, where devices periodically synchronize their local adaptations through aggregated model updates rather than raw data sharing. This enables privacy-preserving global refinement while maintaining the benefits of local personalization.
These three distinct phases (centralized training, local adaptation, and federated coordination) represent an architectural evolution that reshapes every aspect of the machine learning lifecycle. Figure 3 illustrates how data flow, computational distribution, and coordination mechanisms differ across these phases, highlighting the increasing complexity but also the enhanced capabilities that emerge at each stage. Understanding this progression helps frame the challenges that on-device learning systems must address.

Design Constraints
Part III established efficiency principles that shape all machine learning systems. Chapter 9: Efficient AI introduced three efficiency dimensions (algorithmic, compute, and data efficiency) and revealed through scaling laws why brute-force approaches hit fundamental limits. Chapter 10: Model Optimizations developed compression techniques including quantization, pruning, and knowledge distillation that enable deployment on resource-constrained devices. Chapter 11: AI Acceleration characterized edge hardware capabilities from microcontrollers to mobile accelerators, as detailed in the hardware discussions. These chapters focused primarily on inference workloads: running pre-trained models efficiently.
On-device learning operates under these same efficiency constraints but with training-specific amplifications that make optimization dramatically more challenging. Where inference requires a single forward pass through the network, training demands forward propagation, gradient computation through backpropagation, and weight updates, increasing memory requirements by 3-5\(\times\) and computational costs by 2-3\(\times\). The model compression techniques that enable efficient inference become baseline requirements rather than optimizations, as training within edge device constraints would be impossible without aggressive compression.
Given the established motivations for on-device learning, we now examine the fundamental engineering challenges that shape its implementation. Enabling learning on the device requires completely rethinking conventional assumptions about where and how machine learning systems operate. In centralized environments, models are trained with access to extensive compute infrastructure, large and curated datasets, and generous memory and energy budgets. At the edge, none of these assumptions hold, creating a fundamentally different design space.
On-device learning constraints fall into three critical dimensions that parallel but extend the efficiency framework from Part III: model compression requirements (extending algorithmic efficiency), sparse and non-uniform data characteristics (extending data efficiency), and severely limited computational resources (extending compute efficiency). These three dimensions form an interconnected constraint space that defines the feasible region for on-device learning systems, with each dimension imposing distinct limitations that influence algorithmic choices, system architecture, and deployment strategies.
Quantifying Training Overhead on Edge Devices
The transition from inference-only deployment to on-device training creates multiplicative rather than additive complexity. These constraints interact and amplify each other in ways that reshape system design requirements, building on the resource optimization principles from Chapter 9: Efficient AI while introducing new challenges specific to distributed learning environments.
The efficiency constraints introduced in Part III apply to both inference and training, but training amplifies each constraint dimension by 3-10\(\times\). Table 1 quantifies how training workloads intensify the challenges established in Chapter 9: Efficient AI, Chapter 10: Model Optimizations, and Chapter 11: AI Acceleration.
These amplifications explain why simply applying Part III optimization techniques to training workloads proves insufficient. Each constraint category shapes on-device learning system design, requiring approaches that build on but extend beyond the inference-focused methods from earlier chapters.
| Constraint Dimension | Inference (Part III) | Training Amplification | Impact on Design |
|---|---|---|---|
| Memory Footprint | Model weights + single activation map | Weights + full activation cache + gradients + optimizer state | 3-5\(\times\) increase; forces aggressive compression |
| Compute Operations | Forward pass only | Forward + backward + weight update | 2-3\(\times\) increase; limits model complexity |
| Memory Bandwidth | Sequential weight reads | Bidirectional data flow for gradients | 5-10\(\times\) increase; creates bottlenecks |
| Energy per Sample | Single inference operation | Multiple gradient steps with convergence | 10-50\(\times\) increase; requires opportunistic scheduling |
| Data Requirements | Pre-collected, curated datasets | Sparse, noisy, streaming local data | Necessitates sample-efficient methods |
| Hardware Utilization | Optimized for forward passes | Different access patterns for backprop | Inference accelerators may not help training |
Figure 4 illustrates a pipeline that combines offline pre-training with online adaptive learning on resource-constrained IoT devices. The system first undergoes meta-training with generic data. During deployment, device-specific constraints such as data availability, compute, and memory shape the adaptation strategy by ranking and selecting layers and channels to update. This allows efficient on-device learning within limited resource envelopes.

Model Constraints
The first dimension of on-device learning constraints centers on the model itself. Its structure, size, and computational requirements determine deployment feasibility. The structure and size of the machine learning model directly influence whether on-device training is even possible, let alone practical. Unlike cloud-deployed models that can span billions of parameters and rely on multi-gigabyte memory budgets, models intended for on-device learning must conform to tight constraints on memory, storage, and computational complexity. These constraints apply not only at inference time, but become even more restrictive during training, where additional resources are needed for gradient computation, parameter updates, and optimizer state management.
The scale of these constraints becomes apparent when examining specific examples across the device spectrum. The MobileNetV2 architecture, commonly used in mobile vision tasks, requires approximately 14 MB of storage in its standard configuration. While this memory requirement is entirely feasible for modern smartphones with gigabytes of available RAM, it far exceeds the memory available on embedded microcontrollers such as the Arduino Nano 33 BLE Sense7, which provides only 256 KB of SRAM and 1 MB of flash storage. This dramatic difference in available resources necessitates aggressive model compression techniques. In such severely constrained platforms, even a single layer of a typical convolutional neural network may exceed available RAM during training due to the need to store intermediate feature maps and gradient information.
7 Arduino Edge Computing Reality: The Arduino Nano 33 BLE Sense represents typical microcontroller constraints: 256 KB SRAM is roughly 65,000 times smaller than a modern smartphone’s 16 GB RAM (flagship devices). To put this in perspective, storing just one 224×224×3 RGB image (150 KB) would consume 60% of available memory. Training requires 3-5\(\times\) more memory for gradients and activations, making even tiny models challenging. The 1 MB flash storage can hold only the smallest quantized models, forcing designers to use 8-bit or even 4-bit representations.
Beyond static storage requirements, the training process itself dramatically expands the effective memory footprint, creating an additional layer of constraint. Standard backpropagation requires caching activations for each layer during the forward pass, which are then reused during gradient computation in the backward pass. As established in the amplification analysis above, this activation caching multiplies memory requirements compared to inference-only deployment. For a seemingly modest 10-layer convolutional model processing \(64 \times 64\) images, the required memory may exceed 1 to 2 MB, well beyond the SRAM capacity of most embedded systems and highlighting the fundamental tension between model expressiveness and resource availability.
Compounding these memory constraints, model complexity directly affects runtime energy consumption and thermal limits, introducing additional practical barriers to deployment. In systems such as smartwatches or battery-powered wearables, sustained model training can rapidly deplete energy reserves or trigger thermal throttling that degrades performance. Training a full model using floating-point operations on these devices is often infeasible from an energy perspective, even when memory constraints are satisfied. These practical limitations have motivated the development of ultra-lightweight model variants, such as MLPerf Tiny benchmark networks (Banbury et al. 2021), which fit within 100–200 KB and can be adapted using only partial gradient updates. These specialized models employ aggressive quantization and pruning strategies to achieve such compact representations while maintaining sufficient expressiveness for meaningful adaptation.
The practical implications of battery and thermal constraints extend beyond just limiting training duration. Mobile devices must carefully balance training opportunities with user experience. Aggressive on-device training can cause noticeable device heating and rapid battery drain, leading to user dissatisfaction and potential app uninstalls. Modern smartphones typically limit sustained processing to 2-3 W for ML workloads to prevent thermal discomfort, though they can burst to 5-10 W for brief periods before thermal throttling kicks in. Training even modest models can easily exceed these sustainable power limits. This reality necessitates intelligent scheduling strategies: training during charging periods when thermal dissipation is improved, utilizing low-power cores for gradient computation when possible, and implementing thermal-aware duty cycling that pauses training when temperature thresholds are exceeded. Some systems even leverage device usage patterns, scheduling intensive adaptation only during overnight charging when the device is idle and connected to power.
Given these multifaceted constraints, the model architecture itself must be fundamentally designed with on-device learning capabilities in mind from the outset. Many conventional architectures, such as large transformers or deep convolutional networks, are simply not viable for on-device adaptation due to their inherent size and computational complexity. Instead, specialized lightweight architectures such as MobileNets8, SqueezeNet (Iandola et al. 2016), and EfficientNet (Tan and Le 2019) have been developed specifically for resource-constrained environments. These architectures leverage efficiency principles and architectural optimizations, rethinking how neural networks can be structured. These specialized models employ techniques such as depthwise separable convolutions9, bottleneck layers, and aggressive quantization to dramatically reduce memory and compute requirements while maintaining sufficient performance for practical applications.
8 MobileNet Innovation: Google’s MobileNet family revolutionized mobile AI by achieving 10-20\(\times\) parameter reduction compared to traditional CNNs. MobileNetV1 (2017) used depthwise separable convolutions to reduce floating-point operations (FLOPs) by 8-9\(\times\), while MobileNetV2 (2018) added inverted residuals and linear bottlenecks. The breakthrough allowed real-time inference on smartphones: MobileNetV2 runs ImageNet classification in ~75 ms on a Pixel phone versus 1.8 seconds for ResNet-50 (He et al. 2016).
9 Depthwise Separable Convolutions: This technique decomposes standard convolution into two operations: depthwise convolution (applies single filter per input channel) and pointwise convolution (1×1 conv to combine channels). For a 3×3 conv with 512 input/output channels, standard convolution requires 2.4 M parameters while depthwise separable needs only 13.8 K, a 174\(\times\) reduction. The computational savings are similarly dramatic, making real-time inference possible on mobile CPUs.
These architectures are often designed to be modular, allowing for easy adaptation and fine-tuning. For example, MobileNets (Howard et al. 2017) can be configured with different width multipliers and resolution settings to balance performance and resource usage. Concretely, MobileNetV2 with α=1.0 requires 3.4 M parameters (13.6 MB in FP32), but with α=0.5 this drops to 0.7 M parameters (2.8 MB), enabling deployment on devices with just 4 MB available RAM. This flexibility is important for on-device learning, where the model must adapt to the specific constraints of the deployment environment.
While model architecture determines the memory and computational baseline for on-device learning, the characteristics of available training data introduce equally fundamental limitations that shape every aspect of the learning process.
Data Constraints
The second dimension of on-device learning constraints centers on data availability and quality. The nature of data available to on-device ML systems differs dramatically from the large, curated, and centrally managed datasets used in cloud-based training. At the edge, data is locally collected, temporally sparse, and often unstructured or unlabeled, creating a different learning environment. These characteristics introduce multifaceted challenges in volume, quality, and statistical distribution, all of which directly affect the reliability and generalizability of learning on the device.
Data volume represents the first major constraint, severely limited by both storage constraints and the sporadic nature of user interaction. For example, a smart fitness tracker may collect motion data only during physical activity, generating relatively few labeled samples per day. If a user wears the device for just 30 minutes of exercise, only a few hundred data points might be available for training, compared to the thousands or millions typically required for effective supervised learning in controlled environments. This scarcity changes the learning paradigm from data-rich to data-efficient algorithms.
Beyond volume limitations, on-device data is frequently non-IID (non-independent and identically distributed) (Zhao et al. 2018), creating statistical challenges that cloud-based systems rarely encounter. This heterogeneity manifests across multiple dimensions: user behavior patterns, environmental conditions, linguistic preferences, and usage contexts. A voice assistant deployed across households encounters dramatic variation in accents, languages, speaking styles, and command patterns. Similarly, smartphone keyboards adapt to individual typing patterns, autocorrect preferences, and multilingual usage that varies dramatically between users. This data heterogeneity complicates both model convergence and the design of update mechanisms that must generalize across devices while maintaining personalization.
Compounding these distribution challenges, label scarcity presents an additional critical obstacle that severely limits traditional learning approaches. Most edge-collected data is unlabeled by default, requiring systems to learn from weak or implicit supervision signals. In a smartphone camera, for instance, the device may capture thousands of images throughout the day, but only a few are associated with meaningful user actions (e.g., tagging, favoriting, or sharing), which could serve as implicit labels. In many applications, including detecting anomalies in sensor data and adapting gesture recognition models, explicit labels may be entirely unavailable, making traditional supervised learning infeasible without developing alternative methods for weak supervision or unsupervised adaptation.
Data quality issues add another layer of complexity to the on-device learning challenge. Noise and variability further degrade the already limited data available for training. Embedded systems such as environmental sensors or automotive ECUs may experience fluctuations in sensor calibration, environmental interference, or mechanical wear, leading to corrupted or drifting input signals over time. Without centralized validation systems to detect and filter these errors, they may silently degrade learning performance, creating a reliability challenge that cloud-based systems can more easily address through data preprocessing pipelines.
Finally, data privacy and security concerns impose the most restrictive constraints of all, often making data sharing architecturally impossible rather than merely undesirable. Sensitive information, such as health data, personal communications, or user behavioral patterns, must be protected from unauthorized access under legal and ethical requirements. This constraint often completely precludes the use of traditional data-sharing methods, such as uploading raw data to a central server for training. Instead, on-device learning must rely on sophisticated techniques that enable local adaptation without ever exposing sensitive information, changing how learning systems can be designed and validated.
Compute Constraints
Chapter 11: AI Acceleration characterized the edge hardware landscape that provides computational substrate for machine learning: microcontrollers like STM32F4 and ESP32 at the most constrained end, mobile-class processors with dedicated AI accelerators (Apple Neural Engine, Qualcomm Hexagon, Google Tensor) in the middle, and high-capability edge devices at the upper end. That chapter focused on inference capabilities—the computational throughput, memory bandwidth, and energy efficiency achievable when executing pre-trained models.
Training workloads exhibit fundamentally different computational characteristics that reshape hardware utilization patterns. Building on the edge hardware landscape characterized in Chapter 11: AI Acceleration, from microcontrollers to mobile AI accelerators, on-device learning must operate within severely constrained computational envelopes that differ dramatically from cloud-based training infrastructure by factors of hundreds or thousands in raw computational capacity.
The key difference: backpropagation requires significantly higher memory bandwidth than inference due to gradient computation and activation caching, weight updates create write-heavy access patterns unlike inference’s read-only operations, and optimizer state management demands additional memory allocation that inference never encounters. These training-specific demands mean hardware perfectly adequate for inference may prove entirely inadequate for adaptation, even when updating only a small parameter subset.
At the most constrained end of the spectrum, devices such as the STM32F410 or ESP3211 microcontrollers offer only a few hundred kilobytes of SRAM and completely lack hardware support for floating-point operations (Warden and Situnayake 2020). These extreme constraints represent the fundamental limitations of edge hardware (Chapter 11: AI Acceleration). Such severe limitations preclude the use of conventional deep learning libraries and require models to be meticulously designed for integer arithmetic and minimal runtime memory allocation. In these environments, even apparently simple models require highly specialized techniques, including quantization-aware training12 and selective parameter updates, to execute training loops without exceeding memory or power budgets.
10 STM32F4 Microcontroller Reality: The STM32F4 represents the harsh reality of embedded computing: 192 KB SRAM (roughly the size of a small JPEG image) and 1 MB flash storage, running at 168 MHz without floating-point hardware acceleration. Integer arithmetic is 10-100\(\times\) slower than dedicated floating-point units found in mobile chips. Power consumption is ~100 mW during active processing, requiring careful duty-cycling to preserve battery life. These constraints make even simple neural networks challenging: a 10-neuron hidden layer requires ~40 KB for weights alone in FP32.
11 ESP32 Edge Computing: The ESP32 provides 520 KB SRAM and dual-core processing at 240 MHz, making it more capable than STM32F4 but still severely constrained. Its key advantage is built-in WiFi and Bluetooth for federated learning scenarios. However, the lack of hardware floating-point support means all ML operations must use integer quantization. Real-world deployments show 8-bit quantized models can achieve 95% of FP32 accuracy while fitting in ~50 KB memory, enabling basic on-device training for simple tasks like sensor anomaly detection.
12 Quantization-Aware Training: Unlike post-training quantization which converts trained FP32 models to INT8, quantization-aware training simulates low-precision arithmetic during training itself. This allows the model to learn robust representations despite reduced precision. Critical for edge devices where INT8 operations consume \(4\times\) less power and enable \(4\times\) faster inference compared to FP32, while maintaining 95-99% of original accuracy.
13 Stochastic Gradient Descent (SGD): The fundamental optimization algorithm for neural networks, updating parameters using gradients computed on small batches (or single samples). Unlike full-batch gradient descent, SGD’s randomness helps escape local minima while requiring minimal memory, storing only current parameters and gradients. This simplicity makes SGD ideal for microcontrollers where advanced optimizers like Adam would exceed memory budgets.
The practical implications are stark: while the STM32F4 microcontroller can run a simple linear regression model with a few hundred parameters, training even a small convolutional neural network would immediately exceed its memory capacity. In these severely constrained environments, training is often limited to simple algorithms such as stochastic gradient descent (SGD)13 or \(k\)-means clustering, which can be implemented using integer arithmetic and minimal memory overhead, representing a fundamental departure from modern machine learning practice.
Moving up the computational hierarchy, mobile-class hardware represents a significant improvement but still operates under substantial constraints. Platforms including the Qualcomm Snapdragon, Apple Neural Engine14, and Google Tensor SoC15 provide significantly more compute power than microcontrollers, often featuring dedicated AI accelerators and optimized support for 8-bit or mixed-precision16 matrix operations. These accelerators, their capabilities, and their programming models are detailed in Chapter 11: AI Acceleration. While these platforms can support more sophisticated training routines, including full backpropagation over compact models, they still fall dramatically short of the computational throughput and memory bandwidth available in centralized data centers. For instance, training a lightweight transformer17 on a smartphone is technically feasible but must be tightly bounded in both time and energy consumption to avoid degrading the user experience, highlighting the persistent tension between learning capabilities and practical deployment constraints.
14 Apple Neural Engine Evolution: Apple’s Neural Engine has evolved dramatically since the A11 Bionic. The A17 Pro (2023) features a 16-core Neural Engine delivering 35 TOPS, roughly equivalent to an NVIDIA GTX 1080 Ti. This represents a 58\(\times\) improvement over the original A11. The Neural Engine specializes in matrix operations with dedicated 8-bit and 16-bit arithmetic units, enabling efficient on-device training. Real-world performance: fine-tuning a MobileNet classifier takes ~2 seconds versus 45 seconds on CPU alone, while consuming only ~500 mW additional power.
15 Google Tensor SoC Architecture: Google’s Tensor chips (starting with Pixel 6 in 2021) feature a custom TPU v1-derived Edge TPU optimized for ML workloads. Unlike Apple’s Neural Engine, Tensor optimizes for Google’s specific models (speech recognition, computational photography). The TPU provides efficient 8-bit integer operations while consuming only 2 W, making it highly efficient for federated learning scenarios where devices train locally on speech or image data.
16 Mixed-Precision Training: Uses different numerical precisions for different operations, typically FP16 for forward/backward passes and FP32 for parameter updates. This halves memory usage and doubles throughput on modern hardware with Tensor Cores, while maintaining training stability through automatic loss scaling. Mobile implementations often use INT8 for inference and FP16 for gradient computation, balancing accuracy with hardware constraints.
17 Lightweight Transformers: Mobile-optimized transformer architectures like MobileBERT (Sun et al. 2020) and DistilBERT (Sanh et al. 2019) achieve 4-6\(\times\) speedup over full models through techniques like knowledge distillation, layer reduction, and attention head pruning. MobileBERT retains 97% of BERT-base accuracy while running inference in ~40 ms on mobile CPUs versus 160 ms for full BERT. Key optimizations include bottleneck attention mechanisms and specialized mobile-friendly layer configurations.
These computational limitations become especially acute in real-time or battery-operated systems, as demonstrated in camera processing requirements, where specific latency budgets create hard architectural constraints. Camera applications processing at 30 FPS cannot exceed 33 ms per frame, voice interfaces require rapid response times for natural interaction, AR/VR systems demand sub-20 ms motion-to-photon latency to prevent user discomfort, and safety-critical control systems must respond within 10 ms to ensure operational safety. These quantitative constraints determine whether on-device learning is feasible or whether cloud-based alternatives become architecturally necessary. In a smartphone-based speech recognizer, on-device adaptation must seamlessly coexist with primary inference workloads without interfering with response latency or system responsiveness. Similarly, in wearable medical monitors, training must occur opportunistically during carefully managed windows—typically during periods of low activity or charging—to preserve battery life and avoid thermal management issues.
Beyond raw computational capacity, the architectural implications of these hardware constraints extend into fundamental system design choices. Training operations exhibit fundamentally different memory access patterns than inference workloads: backpropagation requires 3-5\(\times\) higher memory bandwidth due to gradient computation and activation caching, creating bottlenecks that pure computational metrics don’t capture. Modern edge accelerators attempt to address these challenges through increasingly specialized hardware features. Adaptive precision datapaths allow dynamic switching between INT4 for forward passes and FP16 for gradient computation, optimizing both accuracy and efficiency within power budgets. Sparse computation units accelerate selective parameter updates by skipping zero gradients—a capability critical for efficient bias-only and LoRA adaptations. Near-memory compute architectures18 reduce data movement costs by performing gradient updates directly adjacent to weight storage, addressing the memory bandwidth bottleneck. However, most current edge accelerators remain fundamentally optimized for inference workloads, creating significant hardware-software co-design opportunities for future generations of on-device training accelerators specifically designed to handle the unique demands of local adaptation.
18 Near-Memory Computing: Places processing units directly adjacent to or within memory arrays, dramatically reducing data movement costs. Traditional von Neumann architectures spend 100-1000\(\times\) more energy moving data than computing on it. Near-memory designs can perform matrix operations with 10-100\(\times\) better energy efficiency by eliminating costly memory bus transfers. Critical for edge training where gradient computations require intensive memory access patterns that overwhelm traditional cache hierarchies.
Edge Hardware Integration Challenges
Beyond the individual constraints of models, data, and computation, on-device learning systems must navigate the complex interactions between these elements and the underlying physics of mobile computing: power dissipation, thermal limits, and energy budgets. These physical constraints are not mere engineering details; they are fundamental design drivers that determine the entire feasible space of on-device learning algorithms. Understanding these quantitative constraints enables informed design decisions that balance learning capabilities with long-term system sustainability and user acceptance.
Energy and Thermal Constraint Analysis
Energy and thermal management represent perhaps the most challenging aspect of on-device learning system design, as they directly impact user experience and device longevity. Mobile devices operate under strict power budgets that fundamentally determine feasible model complexity and training schedules. The thermal design power (TDP) of mobile processors creates hard constraints that shape every aspect of on-device learning strategies. Modern smartphones typically maintain sustained processing at 2-3 W for ML workloads to prevent thermal discomfort, but can burst to 5-10 W for brief periods before thermal throttling dramatically reduces performance by 50% or more. This thermal cycling behavior forces training algorithms to operate in carefully managed burst modes, utilizing peak performance for only 10-30 seconds before backing off to sustainable power levels, a constraint that fundamentally changes how training algorithms must be designed.
The mobile power budget hierarchy reveals the tight constraints under which on-device learning must operate. Smartphone sustained processing is limited to 2-3 W to prevent user-noticeable heating and maintain acceptable battery life throughout the day. Peak training burst mode can reach 10 W, but this power level is sustainable for only 10-30 seconds before thermal throttling kicks in to protect the hardware. Dedicated neural processing units consume 0.5-2 W for AI workloads, offering optimized power efficiency compared to general-purpose processors. CPU-based AI processing requires 3-5 W and demands aggressive thermal management with duty cycling to prevent overheating, making it the least power-efficient option for sustained on-device learning.
The power consumption characteristics of training workloads create additional layers of constraint that extend beyond simple computational capacity. Power consumption scales superlinearly with model size and training complexity, with training operations consuming 10-50\(\times\) more power than equivalent inference workloads due to the substantial computational overhead of gradient computation (consuming 40-70% of training power), weight updates (20-30%), and dramatically increased data movement between memory hierarchies (10-30%). To maintain acceptable user experience, mobile devices typically budget only 500-1000 mW for sustained ML training, effectively limiting practical training sessions to 10-100 minutes daily under normal usage patterns. This severe power constraint fundamentally shifts the design priority from maximizing computational throughput to optimizing power efficiency, requiring careful co-optimization of algorithms and hardware utilization patterns.
The thermal management challenges extend far beyond simple power limits, creating complex dynamic constraints that vary with environmental conditions and usage patterns. Training workloads generate localized heat that can trigger protective throttling in specific processor cores or accelerator units, often in unpredictable ways that depend on ambient temperature and device design. Modern mobile SoCs implement sophisticated thermal management systems, including dynamic voltage and frequency scaling (DVFS)19, core migration between efficiency and performance clusters, and selective shutdown of non-essential processing units. Successfully deployed on-device learning systems must intimately integrate with these thermal management frameworks, intelligently scheduling training bursts during optimal thermal windows and gracefully degrading performance when thermal limits are approached, rather than simply failing or causing user-visible performance problems.
19 Dynamic Voltage and Frequency Scaling (DVFS): Modern mobile processors continuously adjust operating voltage and clock frequency based on workload and thermal conditions. During ML training, DVFS can reduce clock speeds by 30-50% when temperature exceeds 70°C, directly impacting training throughput. Effective on-device learning systems monitor thermal state and proactively reduce batch sizes or training intensity to maintain consistent performance rather than experiencing sudden throttling events.
Memory Hierarchy Optimization
Complementing the thermal and power challenges, memory hierarchy constraints create another fundamental bottleneck that shapes on-device learning system design. As established in the constraint amplification analysis above, these limitations affect both static model storage and the dynamic memory requirements during training, often pushing systems beyond their practical limits.
The device memory hierarchy spans several orders of magnitude across different device classes, each presenting distinct constraints for on-device learning. The iPhone 15 Pro provides 8 GB total system memory, but only approximately 2-4 GB remains available for application workloads after accounting for operating system requirements and background processes. Budget Android devices operate with 4 GB total system memory, leaving just 1-2 GB available for ML workloads after OS overhead consumes significant resources. IoT embedded systems provide 64 MB-1 GB total memory that must be shared between system tasks and application data, creating severe constraints for any learning algorithms. Microcontrollers offer only 256 KB-2 MB SRAM, requiring extreme optimization and careful memory management that fundamentally limits the complexity of models that can adapt on such platforms.
The memory expansion during training creates particularly acute challenges that often determine system feasibility. Standard backpropagation requires caching intermediate activations for each layer during the forward pass, which are then reused during gradient computation in the backward pass, creating substantial memory overhead. A MobileNetV2 model requiring just 14 MB for inference balloons to 50-70 MB during training, often exceeding the available memory budget on many mobile devices and making training impossible without aggressive optimization. This dramatic expansion necessitates sophisticated model compression techniques that must compound multiplicatively: INT8 quantization provides \(4\times\) memory reduction, structured pruning achieves \(10\times\) parameter reduction, and knowledge distillation enables \(5\times\) model size reduction while maintaining accuracy within 2-5% of the original model. These techniques must be carefully combined to achieve the aggressive compression ratios required for practical deployment.
Given these memory constraints, cache optimization becomes absolutely critical for achieving acceptable performance with constrained memory pools. Modern mobile SoCs feature complex memory hierarchies with L1 cache (32-64 KB), L2 cache (1-8 MB), and system memory (4-16 GB) that exhibit 10-100\(\times\) latency differences between levels, creating severe performance cliffs when working sets exceed cache capacity. Training workloads that exceed cache capacity face dramatic performance degradation due to memory bandwidth bottlenecks that can slow training by orders of magnitude. Successful on-device learning systems must carefully design data access patterns to maximize cache hit rates, often requiring specialized memory layouts that group related parameters for spatial locality, carefully sized mini-batches that fit entirely within cache constraints, and sophisticated gradient accumulation strategies that minimize expensive memory bus traffic.
The memory bandwidth limitations become particularly acute during training. While inference workloads primarily read model weights sequentially, training requires bidirectional data flow for gradient computation and weight updates. This increased memory traffic can saturate the memory subsystem, creating bottlenecks that limit training throughput regardless of computational capacity. Advanced implementations employ techniques such as gradient checkpointing20 to trade computation for memory, and mixed-precision training to reduce bandwidth requirements while maintaining numerical stability.
20 Gradient Checkpointing: A memory optimization technique that trades computation for memory by recomputing intermediate activations during the backward pass instead of storing them. This can reduce memory requirements by 50-80% at the cost of 20-30% additional computation. Particularly valuable for on-device training where memory is more constrained than compute capacity, enabling training of larger models within fixed memory budgets.
Mobile AI Accelerator Optimization
Different mobile platforms provide distinct acceleration capabilities that determine not only achievable model complexity but also feasible learning paradigms. The architectural differences between these accelerators fundamentally shape the design space for on-device training algorithms, influencing everything from numerical precision choices to gradient computation strategies.
Current generation mobile accelerators demonstrate remarkable diversity in their capabilities and optimization focus. Apple’s Neural Engine in the A17 Pro delivers 35 TOPS peak performance specialized for 8-bit and 16-bit operations, optimized primarily for CoreML inference patterns with limited training support, making it ideal for inference-heavy adaptation techniques. Qualcomm’s Hexagon DSP in the Snapdragon 8 Gen 3 achieves 45 TOPS with flexible precision support and programmable vector units, enabling mixed-precision training workflows that can adapt precision dynamically based on training phase and memory constraints. Google’s Tensor TPU in the Pixel 8 is optimized specifically for TensorFlow Lite operations with strong INT8 performance and tight integration with federated learning frameworks, reflecting Google’s strategic focus on distributed learning scenarios. The energy efficiency comparison reveals why dedicated neural processing units are essential: NPUs achieve 1-5 TOPS per watt versus general-purpose CPUs at just 0.1-0.2 TOPS per watt, representing a 5-50\(\times\) efficiency advantage that makes the difference between feasible and infeasible on-device training.
These accelerators determine not just raw performance but feasible learning paradigms and algorithmic approaches. Apple’s Neural Engine excels at fixed-precision inference workloads but provides limited support for the dynamic precision requirements of gradient computation, making it more suitable for inference-heavy adaptation techniques like few-shot learning. Qualcomm’s Hexagon DSP offers greater training flexibility through its programmable vector units and support for mixed-precision arithmetic, enabling more sophisticated on-device training including full backpropagation on compact models. Google’s Tensor TPU integrates tightly with federated learning frameworks and provides optimized communication primitives for distributed training scenarios.
The architectural implications extend beyond computational throughput to memory access patterns and data flow optimization. Training workloads exhibit fundamentally different characteristics than inference: gradient computation requires significantly higher memory bandwidth due to the amplification effects discussed above, weight updates create write-heavy access patterns, and optimizer state management demands additional memory allocation. Modern edge accelerators are beginning to address these challenges through specialized hardware features including adaptive precision datapaths that dynamically switch between INT4 for forward passes and FP16 for gradient computation, sparse computation units that accelerate selective parameter updates by skipping zero gradients, and near-memory compute architectures that reduce data movement costs by performing gradient updates directly adjacent to weight storage.
However, most current edge accelerators remain primarily optimized for inference workloads, creating a significant hardware-software co-design opportunity. Future on-device training accelerators will need to efficiently handle the unique demands of local adaptation, including support for dynamic precision scaling, efficient gradient accumulation, and specialized memory hierarchies optimized for the bidirectional data flow patterns characteristic of training workloads. Architecture selection influences everything from model quantization strategies and gradient computation approaches to federated communication protocols and thermal management policies.
Holistic Resource Management Strategies
The constraint analysis above reveals three fundamental challenge categories that define the on-device learning design space. Each constraint category directly drives a corresponding solution pillar, creating a systematic engineering approach to this complex systems problem. The constraint-to-solution mapping follows naturally from understanding how specific limitations necessitate particular technical responses.
The resource amplification effects—where training increases memory requirements by 3-10\(\times\), computational costs by 2-3\(\times\), and energy consumption proportionally—directly necessitate Model Adaptation approaches. When traditional training becomes impossible due to resource constraints, systems must fundamentally reduce the scope of parameter updates while preserving learning capability.
The information scarcity constraints—limited local datasets, non-IID distributions, privacy restrictions on data sharing, and minimal supervision—directly drive Data Efficiency solutions. When conventional data-hungry approaches fail due to insufficient local information, systems must extract maximum learning signal from minimal examples.
The coordination challenges—device heterogeneity, intermittent connectivity, distributed validation complexity, and scalability requirements—directly motivate Federated Coordination mechanisms. When isolated on-device learning limits collective intelligence, systems must enable privacy-preserving collaboration across device populations.
This constraint-to-solution mapping, illustrated in Table 2, creates a systematic engineering framework where each pillar addresses specific aspects of the deployment challenge while integrating with the others. Rather than viewing these as independent techniques, successful on-device learning systems orchestrate all three approaches to create coherent adaptive systems that operate effectively within edge constraints.
| Constraint Category | Key Challenges | Solution Approach |
|---|---|---|
| Resource Amplification | • Training workloads (3-10× memory) • Memory limitations • Power constraints | Model Adaptation • Parameter-efficient updates • Selective layer fine-tuning • Low-rank adaptations |
| Information Scarcity | • Limited local datasets • Non-IID distributions • Privacy restrictions | Data Efficiency • Few-shot learning • Meta-learning • Transfer learning |
| Coordination Challenges | • Device heterogeneity • Intermittent connectivity • Distributed validation | Federated Coordination • Privacy-preserving aggregation • Robust communication protocols • Asynchronous participation |
The subsequent sections examine each solution pillar systematically, building on the optimization principles from Chapter 10: Model Optimizations and the distributed systems frameworks from Chapter 13: ML Operations. Each pillar provides essential capabilities that the others cannot deliver alone, but their integration creates systems capable of meaningful adaptation within the severe constraints of edge deployment environments.
Model Adaptation
The computational and memory constraints outlined above create a challenging environment for model training, but they also reveal clear solution pathways when approached systematically. Model adaptation represents the first pillar of on-device learning systems engineering: reducing the scope of parameter updates to make training feasible within edge constraints while maintaining sufficient model expressivity for meaningful personalization.
The engineering challenge centers on navigating a fundamental trade-off space: adaptation expressivity versus resource consumption. At one extreme, updating all parameters provides maximum flexibility but exceeds edge device capabilities. At the other extreme, no adaptation preserves resources but fails to capture user-specific patterns. Effective on-device learning systems must operate in the middle ground, selecting adaptation strategies based on three key engineering criteria.
First, available memory, compute, and energy determine which adaptation approaches are feasible. A smartwatch with 1 MB RAM requires fundamentally different strategies than a smartphone with 8 GB. Second, the degree of user-specific variation drives adaptation complexity needs. Simple preference learning may require only bias updates, while complex domain shifts demand more sophisticated approaches. Third, adaptation techniques must integrate with existing inference pipelines, federated coordination protocols, and operational monitoring systems established in Chapter 13: ML Operations.
This systems perspective guides the selection and combination of techniques starting with lightweight approaches (Section 1.4.1) and progressing to more sophisticated methods (Section 1.4.3), moving from lightweight bias-only approaches through progressively more expressive but resource-intensive methods. Each technique represents a different point in the engineering trade-off space rather than an isolated algorithmic solution.
Building on the compression techniques from Chapter 10: Model Optimizations, on-device learning transforms compression from a one-time optimization into an ongoing constraint. The central insight driving all model adaptation approaches is that complete model retraining is neither necessary nor feasible for on-device learning scenarios. Instead, systems can strategically leverage pre-trained representations and adapt only the minimal parameter subset required to capture local variations, operating on the principle: preserve what works globally, adapt what matters locally.
This section systematically examines three complementary adaptation strategies, each specifically designed to address different device constraint profiles and application requirements. Weight freezing addresses severe memory limitations by updating only bias terms or final layers, enabling learning even on severely constrained microcontrollers that would otherwise lack the resources for any form of adaptation. Structured updates use low-rank and residual adaptations to balance model expressiveness with computational efficiency, enabling more sophisticated learning than bias-only approaches while maintaining manageable resource requirements. Sparse updates enable selective parameter modification based on gradient importance or layer criticality, concentrating learning capacity on the most impactful parameters while leaving less important weights frozen.
These approaches build on established architectural principles while strategically applying optimization strategies to the unique challenges of edge deployment. Each technique represents a carefully considered point in the fundamental accuracy-efficiency tradeoff space, enabling practical deployment across the full spectrum of edge hardware capabilities—from ultra-constrained microcontrollers to capable mobile processors.
Weight Freezing
The most straightforward approach to making on-device learning feasible is to dramatically reduce the number of parameters that require updating. One of the simplest and most effective strategies for achieving this reduction is to freeze the majority of a model’s parameters and adapt only a carefully chosen minimal subset. The most widely used approach within this family is bias-only adaptation, in which all weights are held fixed and only the bias terms (typically scalar offsets applied after linear or convolutional layers) are updated during training. This simple constraint creates significant benefits: it reduces the number of trainable parameters (often by 100-1000\(\times\)), simplifies memory management during backpropagation, and helps mitigate overfitting when training data is sparse or noisy.
Consider a standard neural network layer: \[ y = W x + b \] where \(W \in \mathbb{R}^{m \times n}\) is the weight matrix, \(b \in \mathbb{R}^m\) is the bias vector, and \(x \in \mathbb{R}^n\) is the input. In full training, gradients are computed for both \(W\) and \(b\). In bias-only adaptation, we constrain: \[ \frac{\partial \mathcal{L}}{\partial W} = 0, \quad \frac{\partial \mathcal{L}}{\partial b} \neq 0 \] so that only the bias is updated via gradient descent: \[ b \leftarrow b - \eta \frac{\partial \mathcal{L}}{\partial b} \]
This reduces the number of stored gradients and optimizer states, enabling training to proceed under memory-constrained conditions. On embedded devices that lack floating-point units, this reduction enables on-device learning.
The code snippet in Listing 1 demonstrates how to implement bias-only adaptation in PyTorch.
# Freeze all parameters
for name, param in model.named_parameters():
param.requires_grad = False
# Enable gradients for bias parameters only
for name, param in model.named_parameters():
if "bias" in name:
param.requires_grad = TrueThis pattern ensures that only bias terms participate in the backward pass and optimizer update, simplifying the training process while maintaining adaptation capability. It proves valuable when adapting pretrained models to user-specific or device-local data where the core representations remain relevant but require calibration.
The practical effectiveness of this approach is demonstrated by TinyTL, a framework explicitly designed to enable efficient adaptation of deep neural networks on microcontrollers and other severely memory-limited platforms. Rather than updating all network parameters during training (impossible on such constrained devices), TinyTL strategically freezes both the convolutional weights and the batch normalization statistics, training only the bias terms and, in some cases, lightweight residual components. This architectural constraint creates a profound shift in memory requirements during backpropagation, since the largest memory consumers (intermediate activations) no longer need to be stored for gradient computation across frozen layers.
The architectural impact of this approach becomes clear when comparing standard training with the TinyTL approach. Figure 5 illustrates the fundamental differences between a conventional model and the TinyTL approach to on-device adaptation. Given the edge device memory constraints established earlier, the TinyTL approach fundamentally changes the memory equation by eliminating the need to store activations for frozen layers, making adaptation possible within the severe memory constraints of edge devices.

In contrast, the TinyTL architecture freezes all weights and updates only the bias terms inserted after convolutional layers. These bias modules are lightweight and require minimal memory, enabling efficient training with a drastically reduced memory footprint. The frozen convolutional layers act as a fixed feature extractor, and only the trainable bias components are involved in adaptation. By avoiding storage of full activation maps and limiting the number of updated parameters, TinyTL allows on-device training under severe resource constraints.
Because the base model remains unchanged, TinyTL assumes that the pretrained features are sufficiently expressive for downstream tasks. The bias terms allow for minor but meaningful shifts in model behavior, particularly for personalization tasks. When domain shift is more significant, TinyTL can optionally incorporate small residual adapters to improve expressivity, all while preserving the system’s tight memory and energy profile.
These design choices allow TinyTL to reduce training memory usage by 10×. For instance, adapting a MobileNetV2 model using TinyTL can reduce the number of updated parameters from over 3 million to fewer than 50,00021. Combined with quantization, this allows local adaptation on devices with only a few hundred kilobytes of memory—making on-device learning truly feasible in constrained environments.
21 TinyTL Memory Breakthrough: TinyTL’s 60\(\times\) parameter reduction (3.4 M to 50 K) translates to dramatic memory savings. In FP32, MobileNetV2 requires ~12 MB for weights plus ~8 MB for activation caching during training—exceeding most microcontroller capabilities. TinyTL reduces this to ~200 KB weights plus ~400 KB activations, fitting comfortably within a 1 MB memory budget. Real deployments on STM32H7 achieve 85% of full fine-tuning accuracy while using 15\(\times\) less memory and completing updates in ~30 seconds versus 8 minutes for full training.
Structured Parameter Updates
While weight freezing provides computational efficiency and clear memory bounds, it severely limits model expressivity by constraining adaptation to a small parameter subset. When bias-only updates prove insufficient for capturing complex domain shifts or user-specific patterns, residual and low-rank techniques provide increased adaptation capability while maintaining computational tractability. These approaches represent a middle ground between the extreme efficiency of weight freezing and the full expressivity of unrestricted fine-tuning.
Rather than modifying existing parameters, these methods extend frozen models by adding trainable components—residual adaptation modules (Houlsby et al. 2019) or low-rank parameterizations (Hu et al. 2021)—that provide controlled increases in model capacity. This architectural approach enables more sophisticated adaptation while preserving the computational benefits that make on-device learning feasible.
These methods extend a frozen model by adding trainable layers, which are typically small and computationally inexpensive, that allow the network to respond to new data. The main body of the network remains fixed, while only the added components are optimized. This modularity makes the approach well-suited for on-device adaptation in constrained settings, where small updates must deliver meaningful changes.
Adapter-Based Adaptation
A common implementation involves inserting adapters, which are small residual bottleneck layers, between existing layers in a pretrained model. Consider a hidden representation \(h\) passed between layers. A residual adapter introduces a transformation: \[ h' = h + A(h) \] where \(A(\cdot)\) is a trainable function, typically composed of two linear layers with a nonlinearity: \[ A(h) = W_2 \, \sigma(W_1 h) \] with \(W_1 \in \mathbb{R}^{r \times d}\) and \(W_2 \in \mathbb{R}^{d \times r}\), where \(r \ll d\). This bottleneck design ensures that only a small number of parameters are introduced per layer.
The adapters act as learnable perturbations on top of a frozen backbone. Because they are small and sparsely applied, they add negligible memory overhead, yet they allow the model to shift its predictions in response to new inputs.
Low-Rank Techniques
Another efficient strategy is to constrain weight updates themselves to a low-rank structure. Rather than updating a full matrix \(W\), we approximate the update as: \[ \Delta W \approx U V^\top \] where \(U \in \mathbb{R}^{m \times r}\) and \(V \in \mathbb{R}^{n \times r}\), with \(r \ll \min(m,n)\). This reduces the number of trainable parameters from \(mn\) to \(r(m + n)\).
The mathematical intuition behind this decomposition connects to fundamental linear algebra principles: any matrix can be expressed as a sum of rank-one matrices through singular value decomposition. By constraining our updates to low rank (typically \(r = 4\) to \(16\)), we capture the most significant modes of variation while reducing parameters. For a typical transformer layer with dimensions \(768 \times 768\), full fine-tuning requires updating 589,824 parameters. With rank-4 decomposition, we update only \(768 \times 4 \times 2 = 6,144\) parameters, a 96% reduction, while empirically retaining 85-90% of the adaptation quality.
During adaptation, the new weight is computed as: \[ W_{\text{adapted}} = W_{\text{frozen}} + U V^\top \]
This formulation is commonly used in LoRA (Low-Rank Adaptation)22 techniques, originally developed for transformer models (Hu et al. 2021) but broadly applicable across architectures. From a systems engineering perspective, LoRA addresses critical connectivity and resource trade-offs in on-device learning deployment.
22 LoRA (Low-Rank Adaptation): Introduced by Microsoft in 2021, LoRA enables efficient fine-tuning by learning low-rank decomposition matrices rather than updating full weight matrices. For a weight matrix W, LoRA learns rank-r matrices A and B such that the update is BA (where r << original dimensions). This reduces trainable parameters by 100-10000\(\times\) while maintaining 90-95% adaptation quality. LoRA has become the standard for parameter-efficient fine-tuning in large language models.
Consider a mobile deployment where a 7B parameter language model requires 14 GB for full fine-tuning—impossible on typical smartphones with 6-8 GB total memory. LoRA with rank-16 reduces this to ~100 MB of trainable parameters (0.7% of original), enabling local adaptation within mobile memory constraints.
LoRA’s efficiency becomes critical in intermittent connectivity scenarios. A full model update over cellular networks would require 14 GB download (potential cost $140+ in mobile data charges), while LoRA adapter updates are typically 10-50 MB. For periodic federated coordination, devices can synchronize LoRA adapters in under 30 seconds on 3G networks, compared to hours for full model transfers. This enables practical federated learning even with poor network conditions.
Systems typically deploy different LoRA configurations based on device capabilities—flagship phones use rank-32 adapters for higher expressivity, mid-range devices use rank-16 for balanced performance, and budget devices use rank-8 to stay within 2 GB memory limits. Low-rank updates can be implemented efficiently on edge devices, particularly when \(U\) and \(V\) are small and fixed-point representations are supported (Listing 2).
class Adapter(nn.Module):
def __init__(self, dim, bottleneck_dim):
super().__init__()
self.down = nn.Linear(dim, bottleneck_dim)
self.up = nn.Linear(bottleneck_dim, dim)
self.activation = nn.ReLU()
def forward(self, x):
return x + self.up(self.activation(self.down(x)))This adapter adds a small residual transformation to a frozen layer. When inserted into a larger model, only the adapter parameters are trained.
Edge Personalization
Adapters are useful when a global model is deployed to many devices and must adapt to device-specific input distributions. In smartphone camera pipelines, environmental lighting, user preferences, or lens distortion vary between users (Rebuffi, Bilen, and Vedaldi 2017). A shared model can be frozen and fine-tuned per-device using a few residual modules, allowing lightweight personalization without risking catastrophic forgetting. In voice-based systems, adapter modules have been shown to reduce word error rates in personalized speech recognition without retraining the full acoustic model. They also allow easy rollback or switching between user-specific versions.
Performance vs. Resource Trade-offs
Residual and low-rank updates strike a balance between expressivity and efficiency. Compared to bias-only learning, they can model more substantial deviations from the pretrained task. However, they require more memory and compute for training and inference.
When considering residual and low-rank updates for on-device learning, several important tradeoffs emerge. First, these methods consistently demonstrate superior adaptation quality compared to bias-only approaches, particularly when deployed in scenarios involving significant distribution shifts from the original training data (Quiñonero-Candela et al. 2008). This improved adaptability stems from their increased parameter capacity and ability to learn more complex transformations.
This enhanced adaptability comes at a cost. The introduction of additional layers or parameters inevitably increases both memory requirements and computational latency during forward and backward passes. While these increases are modest compared to full model training, they must be considered when deploying to resource-constrained devices.
Implementing these adaptation techniques requires system-level support for dynamic computation graphs and the ability to selectively inject trainable parameters. Not all deployment environments or inference engines support such capabilities out of the box.
Residual adaptation techniques have proven valuable in mobile and edge computing scenarios where devices have sufficient computational resources. Modern smartphones and tablets can accommodate these adaptations while maintaining acceptable performance characteristics. This makes residual adaptation a practical choice for applications requiring personalization without the overhead of full model retraining.
Sparse Updates
As we progress from bias-only updates through low-rank adaptations to more sophisticated techniques, sparse updates represent the most advanced approach in our model adaptation hierarchy. While the previous techniques add new parameters or restrict updates to specific subsets, sparse updates dynamically identify which existing parameters provide the greatest adaptation benefit for each specific task or user. This approach maximizes adaptation expressivity while maintaining the computational efficiency essential for edge deployment.
Even when adaptation is restricted to a small number of parameters through the techniques discussed above, training remains resource-intensive on constrained devices. Sparse updates address this challenge by selectively updating only task-relevant subsets of model parameters, rather than modifying entire networks or introducing new modules. This approach, known as task-adaptive sparse updating (Zhang, Song, and Tao 2020), represents the culmination of principled parameter selection strategies.
The key insight is that not all layers of a deep model contribute equally to performance gains on a new task or dataset. If we can identify a minimal subset of parameters that are most impactful for adaptation, we can train only those, reducing memory and compute costs while still achieving meaningful personalization.
Sparse Update Design
Let a neural network be defined by parameters \(\theta = \{\theta_1, \theta_2, \ldots, \theta_L\}\) across \(L\) layers. In standard fine-tuning, we compute gradients and perform updates on all parameters: \[ \theta_i \leftarrow \theta_i - \eta \frac{\partial \mathcal{L}}{\partial \theta_i}, \quad \text{for } i = 1, \ldots, L \]
In task-adaptive sparse updates, we select a small subset \(\mathcal{S} \subset \{1, \ldots, L\}\) such that only parameters in \(\mathcal{S}\) are updated: \[ \theta_i \leftarrow \begin{cases} \theta_i - \eta \frac{\partial \mathcal{L}}{\partial \theta_i}, & \text{if } i \in \mathcal{S} \\ \theta_i, & \text{otherwise} \end{cases} \]
The challenge lies in selecting the optimal subset \(\mathcal{S}\) given memory and compute constraints.
Layer Selection
A principled strategy for selecting \(\mathcal{S}\) is to use contribution analysis—an empirical method that estimates how much each layer contributes to downstream performance improvement. For example, one can measure the marginal gain from updating each layer independently:
- Freeze the entire model.
- Unfreeze one candidate layer.
- Finetune briefly and evaluate improvement in validation accuracy.
- Rank layers by performance gain per unit cost (e.g., per KB of trainable memory).
This layer-wise profiling yields a ranking from which \(\mathcal{S}\) can be constructed subject to a memory budget.
A concrete example is TinyTrain, a method designed to allow rapid adaptation on-device (C. Deng, Zhang, and Wu 2022). TinyTrain pretrains a model along with meta-gradients that capture which layers are most sensitive to new tasks. At runtime, the system dynamically selects layers to update based on task characteristics and available resources.
Selective Layer Update Implementation
This pattern can be extended with profiling logic to select layers based on contribution scores or hardware profiles, as shown in Listing 3.
# Assume model has named layers: ['conv1', 'conv2', 'fc']
# We selectively update only conv2 and fc
for name, param in model.named_parameters():
if "conv2" in name or "fc" in name:
param.requires_grad = True
else:
param.requires_grad = FalseTinyTrain Personalization
Consider a scenario where a user wears an augmented reality headset that performs real-time object recognition. As lighting and environments shift, the system must adapt to maintain accuracy—but training must occur during brief idle periods or while charging.
TinyTrain allows this by using meta-training during offline preparation: the model learns not only to perform the task, but also which parameters are most important to adapt. Then, at deployment, the device performs task-adaptive sparse updates, modifying only a few layers that are most relevant for its current environment. This keeps adaptation fast, energy-efficient, and memory-aware.
Adaptation Strategy Trade-offs
Task-adaptive sparse updates introduce several important system-level considerations that must be carefully balanced. First, the overhead of contribution analysis, although primarily incurred during pretraining or initial profiling, represents a non-trivial computational cost. This overhead is typically acceptable since it occurs offline, but it must be factored into the overall system design and deployment pipeline.
Second, the stability of the adaptation process becomes important when working with sparse updates. If too few parameters are selected for updating, the model may underfit the target distribution, failing to capture important local variations. This suggests the need for careful validation of the selected parameter subset before deployment, potentially incorporating minimum thresholds for adaptation capacity.
Third, the selection of updatable parameters must account for hardware-specific characteristics of the target platform. Beyond just considering gradient magnitudes, the system must evaluate the actual execution cost of updating specific layers on the deployed hardware. Some parameters might show high contribution scores but prove expensive to update on certain architectures, requiring a more nuanced selection strategy that balances statistical utility with runtime efficiency.
Despite these tradeoffs, task-adaptive sparse updates provide a powerful mechanism to scale adaptation to diverse deployment contexts, from microcontrollers to mobile devices (Levy et al. 2023).
Adaptation Strategy Comparison
Each adaptation strategy for on-device learning offers a distinct balance between expressivity, resource efficiency, and implementation complexity. Understanding these tradeoffs is important when designing systems for diverse deployment targets—from ultra-low-power microcontrollers to feature-rich mobile processors.
Bias-only adaptation is the most lightweight approach, updating only scalar offsets in each layer while freezing all other parameters. This significantly reduces memory requirements and computational burden, making it suitable for devices with tight memory and energy budgets. However, its limited expressivity means it is best suited to applications where the pretrained model already captures most of the relevant task features and only minor local calibration is required.
Residual adaptation, often implemented via adapter modules, introduces a small number of trainable parameters into the frozen backbone of a neural network. This allows for greater flexibility than bias-only updates, while still maintaining control over the adaptation cost. Because the backbone remains fixed, training can be performed efficiently and safely under constrained conditions. This method supports modular personalization across tasks and users, making it a favorable choice for mobile settings where moderate adaptation capacity is needed.
Task-adaptive sparse updates offer the greatest potential for task-specific finetuning by selectively updating only a subset of layers or parameters based on their contribution to downstream performance. While this method allows expressive local adaptation, it requires a mechanism for layer selection, through profiling, contribution analysis, or meta-training, which introduces additional complexity. Nonetheless, when deployed carefully, it allows for dynamic tradeoffs between accuracy and efficiency, particularly in systems that experience large domain shifts or evolving input conditions.
These three approaches form a spectrum of tradeoffs. Their relative suitability depends on application domain, available hardware, latency constraints, and expected distribution shift. Table 3 summarizes their characteristics:
| Technique | Trainable Parameters | Memory Overhead | Expressivity | Use Case Suitability | System Requirements |
|---|---|---|---|---|---|
| Bias-Only Updates | Bias terms only | Minimal | Low | Simple personalization; low variance | Extreme memory/compute limits |
| Residual Adapters | Adapter modules | Moderate | Moderate to High | User-specific tuning on mobile | Mobile-class SoCs with runtime support |
| Sparse Layer Updates | Selective parameter subsets | Variable | High (task-adaptive) | Real-time adaptation; domain shift | Requires profiling or meta-training |
Data Efficiency
Having established resource-efficient adaptation through model techniques, we encounter the second pillar of on-device learning systems engineering: maximizing learning signal from severely constrained data. This represents a fundamental shift from the data-abundant environments assumed by traditional ML systems to the information-scarce reality of edge deployment.
The systems engineering challenge centers on a critical trade-off: data collection cost versus adaptation quality. Edge devices face severe data acquisition constraints that reshape learning system design in ways not encountered in centralized training. Understanding and navigating these constraints requires systematic analysis of four interconnected engineering dimensions.
First, every data point has acquisition costs in terms of user friction, energy consumption, storage overhead, and privacy risk. A voice assistant learning from audio samples must balance improvement potential against battery drain and user comfort with always-on recording. Second, limited data collection capacity forces systems to choose between broad coverage and deep examples. A mobile keyboard can collect many shallow typing patterns or fewer detailed interaction sequences, each strategy implying different learning approaches. Third, some applications demand rapid learning from minimal examples (emergency response scenarios), while others can accumulate data over time (user preference learning). This temporal dimension drives fundamental architectural choices. Fourth, data efficiency techniques must integrate with the model adaptation approaches from Section 1.4, federated coordination (Section 1.6), and the operational monitoring established in Chapter 13: ML Operations.
These engineering constraints create a systematic trade-off space where different data efficiency approaches serve different combinations of constraints. Rather than choosing a single technique, successful on-device learning systems typically combine multiple approaches, each addressing specific aspects of the data scarcity challenge.
This section examines four complementary data efficiency strategies that address different facets of the data scarcity challenge. Few-shot learning enables adaptation from minimal labeled examples, allowing systems to personalize based on just a handful of user-provided samples rather than requiring extensive training datasets. Streaming updates accommodate data that arrives incrementally over time, enabling continuous adaptation as devices encounter new patterns during normal operation without needing to collect and store large batches. Experience replay maximizes learning from limited data through intelligent reuse, replaying important examples multiple times to extract maximum learning signal from scarce training data. Data compression reduces memory requirements while preserving learning signals, enabling systems to maintain replay buffers and training histories within the tight memory constraints of edge devices.
Each technique addresses different aspects of the data constraint problem, enabling robust learning even when traditional supervised learning would fail.
Few-Shot Learning and Data Streaming
In conventional machine learning workflows, effective training typically requires large labeled datasets, carefully curated and preprocessed to ensure sufficient diversity and balance. On-device learning, by contrast, must often proceed from only a handful of local examples—collected passively through user interaction or ambient sensing, and rarely labeled in a supervised fashion. These constraints motivate two complementary adaptation strategies: few-shot learning, in which models generalize from a small, static set of examples, and streaming adaptation, where updates occur continuously as data arrives.
Few-shot adaptation is particularly relevant when the device observes a small number of labeled or weakly labeled instances for a new task or user condition (Y. Wang et al. 2020). In such settings, it is often infeasible to perform full finetuning of all model parameters without overfitting. Instead, methods such as bias-only updates, adapter modules, or prototype-based classification are employed to make use of limited data while minimizing capacity for memorization. Let \(D = \{(x_i, y_i)\}_{i=1}^K\) denote a \(K\)-shot dataset of labeled examples collected on-device. The goal is to update the model parameters \(\theta\) to improve task performance under constraints such as:
- Limited number of gradient steps: \(T \ll 100\)
- Constrained memory footprint: \(\|\theta_{\text{updated}}\| \ll \|\theta\|\)
- Preservation of prior task knowledge (to avoid catastrophic forgetting)
Keyword spotting (KWS) systems offer a concrete example of few-shot adaptation in a real-world, on-device deployment (Warden 2018). These models are used to detect fixed phrases, including phrases like “Hey Siri”23 or “OK Google”, with low latency and high reliability. A typical KWS model consists of a pretrained acoustic encoder (e.g., a small convolutional or recurrent network that transforms input audio into an embedding space) followed by a lightweight classifier. In commercial systems, the encoder is trained centrally using thousands of hours of labeled speech across multiple languages and speakers. However, supporting custom wake words (e.g., “Hey Jarvis”) or adapting to underrepresented accents and dialects is often infeasible via centralized training due to data scarcity and privacy concerns.
23 “Hey Siri” Technical Reality: Apple’s “Hey Siri” system operates under extreme constraints—detection must complete within 100 ms to feel responsive, while consuming less than 1 mW power when listening continuously. The always-on processor monitors audio using a 192 KB model running at ~0.5 TOPS. False positive rate must be under 0.001% of audio frames processed (equivalent to <0.1 activations per hour, or less than once per day under typical usage) while maintaining >95% true positive rate across accents, background noise, and speaking styles. The system processes 16 kHz audio in 200 ms windows, extracting Mel-frequency features for classification.
Few-shot adaptation solves this problem by finetuning only the output classifier or a small subset of parameters, including bias terms, using just a few example utterances collected directly on the device. For example, a user might provide 5–10 recordings of their custom wake word. These samples are then used to update the model locally, while the main encoder remains frozen to preserve generalization and reduce memory overhead. This allows personalization without requiring additional labeled data or transmitting private audio to the cloud.
Such an approach is not only computationally efficient, but also aligned with privacy-preserving design principles. Because only the output layer is updated, often involving a simple gradient step or prototype computation, the total memory footprint and runtime compute are compatible with mobile-class devices or even microcontrollers. This makes KWS a canonical case study for few-shot learning at the edge, where the system must operate under tight constraints while delivering user-specific performance.
Beyond static few-shot learning, many on-device scenarios benefit from streaming adaptation, where models must learn incrementally as new data arrives (Hayes et al. 2020). Streaming adaptation generalizes this idea to continuous, asynchronous settings where data arrives incrementally over time. Let \(\{x_t\}_{t=1}^{\infty}\) represent a stream of observations. In streaming settings, the model must update itself after observing each new input, typically without access to prior data, and under bounded memory and compute. The model update can be written generically as: \[ \theta_{t+1} = \theta_t - \eta_t \nabla \mathcal{L}(x_t; \theta_t) \] where \(\eta_t\) is the learning rate at time \(t\). This form of adaptation is sensitive to noise and drift in the input distribution, and thus often incorporates mechanisms such as learning rate decay, meta-learned initialization, or update gating to improve stability.
Aside from KWS, practical examples of these strategies abound. In wearable health devices, a model that classifies physical activities may begin with a generic classifier and adapt to user-specific motion patterns using only a few labeled activity segments. In smart assistants, user voice profiles are fine-tuned over time using ongoing speech input, even when explicit supervision is unavailable. In such cases, local feedback, including correction, repetition, or downstream task success, can serve as implicit signals to guide learning.
Few-shot and streaming adaptation highlight the shift from traditional training pipelines to data-efficient, real-time learning under uncertainty. They form a foundation for more advanced memory and replay strategies, which we turn to next.
Experience Replay
Experience replay addresses the challenge of catastrophic forgetting—where learning new tasks causes models to forget previously learned information—in continuous learning scenarios by maintaining a buffer of representative examples from previous learning episodes. This technique, originally developed for reinforcement learning (Mnih et al. 2015), proves essential in on-device learning where sequential data streams can cause models to overfit to recent examples.
Unlike server-side replay strategies that rely on large datasets and extensive compute, on-device replay must operate with extremely limited capacity, often with tens or hundreds of samples, and must avoid interfering with user experience (Rolnick et al. 2019). Buffers may store only compressed features or distilled summaries, and updates must occur opportunistically (e.g., during idle cycles or charging). These system-level constraints reshape how replay is implemented and evaluated in the context of embedded ML.
Let \(\mathcal{M}\) represent a memory buffer that retains a fixed-size subset of training examples. At time step \(t\), the model receives a new data point \((x_t, y_t)\) and appends it to \(\mathcal{M}\). A replay-based update then samples a batch \(\{(x_i, y_i)\}_{i=1}^{k}\) from \(\mathcal{M}\) and applies a gradient step: \[ \theta_{t+1} = \theta_t - \eta \nabla_\theta \left[ \frac{1}{k} \sum_{i=1}^{k} \mathcal{L}(x_i, y_i; \theta_t) \right] \] where \(\theta_t\) are the model parameters, \(\eta\) is the learning rate, and \(\mathcal{L}\) is the loss function. Over time, this replay mechanism allows the model to reinforce prior knowledge while incorporating new information.
A practical on-device implementation might use a ring buffer to store a small set of compressed feature vectors rather than full input examples. The pseudocode as shown in Listing 4 illustrates a minimal replay buffer designed for constrained environments.
# Replay Buffer Techniques
class ReplayBuffer:
def __init__(self, capacity):
self.capacity = capacity
self.buffer = []
self.index = 0
def store(self, feature_vec, label):
if len(self.buffer) < self.capacity:
self.buffer.append((feature_vec, label))
else:
self.buffer[self.index] = (feature_vec, label)
self.index = (self.index + 1) % self.capacity
def sample(self, k):
return random.sample(self.buffer, min(k, len(self.buffer)))This implementation maintains a fixed-capacity cyclic buffer, storing compressed representations (e.g., last-layer embeddings) and associated labels. Such buffers are useful for replaying adaptation updates without violating memory or energy budgets.
In TinyML applications24, experience replay has been applied to problems such as gesture recognition, where devices must continuously improve predictions while observing a small number of events per day. Instead of training directly on the streaming data, the device stores representative feature vectors from recent gestures and uses them to finetune classification boundaries periodically. Similarly, in on-device keyword spotting, replaying past utterances can improve wake-word detection accuracy without the need to transmit audio data off-device.
24 TinyML Market Reality: The TinyML market reached $2.4 billion in 2023 and is projected to grow to $23.3 billion by 2030. Over 100 billion microcontrollers ship annually, but fewer than 1% currently support on-device learning due to memory and power constraints. Successful TinyML deployments typically consume <1 mW power, use <256 KB memory, and cost under $1 per chip. Applications include predictive maintenance (vibration sensors), health monitoring (heart rate variability), and smart agriculture (soil moisture prediction).
While experience replay improves stability in data-sparse or non-stationary environments, it introduces several tradeoffs. Storing raw inputs may breach privacy constraints or exceed storage budgets, especially in vision and audio applications. Replaying from feature vectors reduces memory usage but may limit the richness of gradients for upstream layers. Write cycles to persistent flash memory, which are frequently necessary for long-term storage on embedded devices, can also raise wear-leveling concerns. These constraints require careful co-design of memory usage policies, replay frequency, and feature selection strategies, particularly in continuous deployment scenarios.
Data Compression
In many on-device learning scenarios, the raw training data may be too large, noisy, or redundant to store and process effectively. This motivates the use of compressed data representations, where the original inputs are transformed into lower-dimensional embeddings or compact encodings that preserve salient information while minimizing memory and compute costs.
Compressed representations serve two complementary goals. First, they reduce the footprint of stored data, allowing devices to maintain longer histories or replay buffers under tight memory budgets (Sanh et al. 2019). Second, they simplify the learning task by projecting raw inputs into more structured feature spaces, often learned via pretraining or meta-learning, in which efficient adaptation is possible with minimal supervision.
One common approach is to encode data points using a pretrained feature extractor and discard the original high-dimensional input. For example, an image \(x_i\) might be passed through a CNN to produce an embedding vector \(z_i = f(x_i)\), where \(f(\cdot)\) is a fixed feature encoder. This embedding captures visual structure (e.g., shape, texture, or spatial layout) in a compact representation, usually ranging from 64 to 512 dimensions, suitable for lightweight downstream adaptation.
Mathematically, training can proceed over compressed samples \((z_i, y_i)\) using a lightweight decoder or projection head. Let \(\theta\) represent the trainable parameters of this decoder model, which is typically a small neural network that maps from compressed representations to output predictions. As each example is presented, the model parameters are updated using gradient descent: \[ \theta_{t+1} = \theta_t - \eta \nabla_\theta \mathcal{L}\big(g(z_i; \theta), y_i\big) \] Here:
- \(z_i\) is the compressed representation of the \(i\)-th input,
- \(y_i\) is the corresponding label or supervision signal,
- \(g(z_i; \theta)\) is the decoder’s prediction,
- \(\mathcal{L}\) is the loss function measuring prediction error,
- \(\eta\) is the learning rate, and
- \(\nabla_\theta\) denotes the gradient with respect to the parameters \(\theta\).
This formulation highlights how only a compact decoder model, which has the parameter set \(\theta\), needs to be trained, making the learning process feasible even when memory and compute are limited.
Advanced approaches extend beyond fixed encoders by learning discrete or sparse dictionaries that represent data using low-rank or sparse coefficient matrices. A dataset of sensor traces can be factorized as \(X \approx DC\), where \(D\) is a dictionary of basis patterns and \(C\) is a block-sparse coefficient matrix indicating which patterns are active in each example. By updating only a small number of dictionary atoms or coefficients, the model adapts with minimal overhead.
Compressed representations prove useful in privacy-sensitive settings, as they allow raw data to be discarded or obfuscated after encoding. Compression acts as an implicit regularizer, smoothing the learning process and mitigating overfitting when only a few training examples are available.
In practice, these strategies have been applied in domains such as keyword spotting, where raw audio signals are first transformed into Mel-frequency cepstral coefficients (MFCCs)25—a compact, lossy representation of the power spectrum of speech. These MFCC vectors serve as compressed inputs for downstream models, enabling local adaptation using only a few kilobytes of memory.
25 Mel-Frequency Cepstral Coefficients (MFCCs): Audio features that mimic human auditory perception by applying mel-scale frequency warping (emphasizing lower frequencies where speech information concentrates) followed by cepstral analysis. A typical MFCC extraction converts 16 kHz audio windows into 12-13 coefficients, reducing a 320-sample window (20 ms) from 640 bytes to ~50 bytes while preserving speech intelligibility. Widely used in speech recognition since the 1980s due to robustness against noise and computational efficiency. Instead of storing raw audio waveforms, which are large and computationally expensive to process, devices store and learn from these compressed feature vectors directly. Similarly, in low-power computer vision systems, embeddings extracted from lightweight CNNs are retained and reused for few-shot learning. These examples illustrate how representation learning and compression serve as foundational tools for scaling on-device learning to memory- and bandwidth-constrained environments.
Data Efficiency Strategy Comparison
The techniques introduced in this section (few-shot learning, experience replay, and compressed data representations) offer strategies for adapting models on-device when data is scarce or streaming. They operate under different assumptions and constraints, and their effectiveness depends on system-level factors such as memory capacity, data availability, task structure, and privacy requirements.
Few-shot adaptation excels when a small but informative set of labeled examples is available, particularly when personalization or rapid task-specific tuning is required. It minimizes compute and data needs, but its effectiveness depends on the quality of pretrained representations and the alignment between the initial model and the local task.
Experience replay addresses continual adaptation by mitigating forgetting and improving stability, especially in non-stationary environments. It allows reuse of past data, but requires memory to store examples and compute cycles for periodic updates. Replay buffers may also raise privacy or longevity concerns, especially on devices with limited storage or flash write cycles.
Compressed data representations reduce the footprint of learning by transforming raw data into compact feature spaces. This approach supports longer retention of experience and efficient finetuning, particularly when only lightweight heads are trainable. Compression can introduce information loss, and fixed encoders may fail to capture task-relevant variability if they are not well-aligned with deployment conditions. Table 4 summarizes key tradeoffs:
| Technique | Data Requirements | Memory/Compute Overhead | Use Case Fit |
|---|---|---|---|
| Few-Shot Adaptation | Small labeled set (K-shots) | Low | Personalization, quick on-device finetuning |
| Experience Replay | Streaming data | Moderate (buffer & update) | Non-stationary data, stability under drift |
| Compressed Representations | Unlabeled or encoded data | Low to Moderate | Memory-limited devices, privacy-sensitive contexts |
In practice, these methods are not mutually exclusive. Many real-world systems combine them to achieve robust, efficient adaptation. For example, a keyword spotting system may use compressed audio features (e.g., MFCCs), finetune a few parameters from a small support set, and maintain a replay buffer of past embeddings for continual refinement.
Together, these strategies embody the core challenge of on-device learning: achieving reliable model improvement under persistent constraints on data, compute, and memory.
Federated Learning
The individual device techniques examined above—from bias-only updates to sophisticated adapter modules—create powerful personalization capabilities but reveal a fundamental limitation when deployed at scale. While each device can adapt effectively to local conditions, these isolated improvements cannot benefit the broader device population. Valuable insights about model robustness, adaptation strategies, and failure modes remain trapped on individual devices, losing the collective intelligence that makes centralized training effective.
This limitation becomes apparent in scenarios requiring both personalization and population-scale learning. The model adaptation and data efficiency techniques enable individual devices to learn effectively within resource constraints, but they also reveal a fundamental coordination challenge that emerges when sophisticated local learning meets the realities of distributed deployment.
Consider a voice assistant deployed to 10 million homes. Each device adapts locally to its user’s voice, accent, and vocabulary. Device A learns that “data” is pronounced /ˈdeɪtə/, Device B learns /ˈdætə/. Device C encounters the rare phrase “machine learning” frequently (tech household), while Device D never sees it (non-tech household). After six months of local adaptation:
- Each device excels at its specific user’s patterns but only its patterns
- Rare vocabulary gets learned on some devices, forgotten on others
- Local biases accumulate without correction from broader population
- Valuable insights discovered on one device benefit no others
Individual on-device learning, while powerful, faces fundamental limitations when devices operate in isolation. Each device observes only a narrow slice of the full data distribution, limiting generalization. Device capabilities vary dramatically, creating learning imbalances across the population. Valuable insights learned on one device cannot benefit others, reducing overall system intelligence. Without coordination, models may diverge or degrade over time due to local biases.
Federated learning emerges as the solution to distributed coordination constraints. It enables privacy-preserving collaboration where devices contribute to collective intelligence without sharing raw data. Rather than viewing individual device learning and coordinated learning as separate paradigms, federated learning represents the natural evolution when on-device systems deploy at scale. This approach transforms the constraint of data locality from a limitation into a privacy feature, allowing systems to learn from population-scale data while keeping individual information secure.
The privacy requirements here directly connect to security and privacy principles that become crucial in production deployments. Rather than viewing individual device learning and coordinated learning as separate paradigms, federated learning represents the natural evolution of on-device systems when deployed at scale.
To better understand the role of federated learning, it is useful to contrast it with other learning paradigms. Figure 6 illustrates the distinction between offline learning, on-device learning, and federated learning. In traditional offline learning, all data is collected and processed centrally. The model is trained in the cloud using curated datasets and is then deployed to edge devices without further adaptation. In contrast, on-device learning allows local model adaptation using data generated on the device itself, supporting personalization but in isolation—without sharing insights across users. Federated learning bridges these two extremes by enabling localized training while coordinating updates globally. It retains data privacy by keeping raw data local, yet benefits from distributed model improvements by aggregating updates from many devices.

This section explores the principles and practical considerations of federated learning in the context of mobile and embedded systems. It begins by outlining the canonical FL protocols and their system implications. It then discusses device participation constraints, communication-efficient update mechanisms, and strategies for personalized learning. Throughout, the emphasis remains on how federated methods can extend the reach of on-device learning by enabling distributed model training across diverse and resource-constrained hardware platforms.
Privacy-Preserving Collaborative Learning
Federated learning (FL) is a decentralized paradigm for training machine learning models across a population of devices without transferring raw data to a central server (McMahan et al. 2017). Unlike traditional centralized training pipelines, which require aggregating all training data in a single location, federated learning distributes the training process itself. Each participating device computes updates based on its local data and contributes to a global model through an aggregation protocol, typically coordinated by a central server. This shift in training architecture aligns closely with the needs of mobile, edge, and embedded systems, where privacy, communication cost, and system heterogeneity impose significant constraints on centralized approaches.
As demonstrated across the application domains discussed earlier—from Gboard’s keyboard personalization to wearable health monitoring to voice interfaces—federated learning bridges the gap between model improvement and the system-level constraints established throughout this chapter. It enables the personalization, privacy, and connectivity benefits motivating on-device learning while addressing the resource constraints through coordinated but distributed training. However, these benefits introduce new challenges including client variability, communication efficiency, and non-IID data distributions that require specialized protocols and coordination mechanisms.
Building on this foundation, the remainder of this section explores the key techniques and tradeoffs that define federated learning in on-device settings, examining the core learning protocols that govern coordination across devices and investigating strategies for scheduling, communication efficiency, and personalization.
Learning Protocols
Federated learning protocols define the rules and mechanisms by which devices collaborate to train a shared model. These protocols govern how local updates are computed, aggregated, and communicated, as well as how devices participate in the training process. The choice of protocol has significant implications for system performance, communication overhead, and model convergence.
In this section, we outline the core components of federated learning protocols, including local training, aggregation methods, and communication strategies. We also discuss the tradeoffs associated with different approaches and their implications for on-device ML systems.
Local Training
Local training refers to the process by which individual devices compute model updates based on their local data. This step is critical in federated learning, as it allows devices to adapt the shared model to their specific contexts without transferring raw data. The local training process involves the following steps:
- Model Initialization: Each device initializes its local model parameters, often by downloading the latest global model from the server.
- Local Data Sampling: The device samples a subset of its local data for training. This data may be non-IID, meaning that it may not be uniformly distributed across devices.
- Local Training: The device performs a number of training iterations on its local data, updating the model parameters based on the computed gradients.
- Model Update: After local training, the device computes a model update (e.g., the difference between the updated and initial parameters) and prepares to send it to the server.
- Communication: The device transmits the model update to the server, typically using a secure communication channel to protect user privacy.
- Model Aggregation: The server aggregates the updates from multiple devices to produce a new global model, which is then distributed back to the participating devices.
This process is repeated iteratively, with devices periodically downloading the latest global model and performing local training. The frequency of these updates can vary based on system constraints, device availability, and communication costs.
Federated Aggregation Protocols
At the heart of federated learning is a coordination mechanism that allows many devices, each having access to only a small, local dataset, to collaboratively train a shared model. This is achieved through a protocol where client devices perform local training and transmit model updates to a central server. The server aggregates these updates to refine a global model, which is then redistributed to clients for the next training round. This cyclical procedure decouples the learning process from centralized data collection, making it well-suited to the mobile and edge environments characterized throughout this chapter where user data is private, bandwidth is constrained, and device participation is sporadic.
The most widely used baseline for this process is Federated Averaging (FedAvg)26, which has become a canonical algorithm for federated learning (McMahan et al. 2017). In FedAvg, each device trains its local copy of the model using stochastic gradient descent (SGD) on its private data.
26 Federated Averaging (FedAvg): Introduced by Google in 2017, FedAvg revolutionized distributed ML by averaging model weights rather than gradients. Each client performs multiple local SGD steps (typically 1-20) before sending weights to the server, reducing communication by 10-100\(\times\) compared to distributed SGD. The key insight: local updates contain richer information than single gradients, enabling convergence with far fewer communication rounds. FedAvg powers production systems like Gboard, processing billions of devices. After a fixed number of local steps, each device sends its updated model parameters to the server. The server computes a weighted average of these parameters, which are weighted according to the number of data samples on each device, and updates the global model accordingly. This updated model is then sent back to the devices, completing one round of training.
Formally, let \(\mathcal{D}_k\) denote the local dataset on client \(k\), and let \(\theta_k^t\) be the parameters of the model on client \(k\) at round \(t\). Each client performs \(E\) steps of SGD on its local data, yielding an update \(\theta_k^{t+1}\). The central server then aggregates these updates as: \[ \theta^{t+1} = \sum_{k=1}^{K} \frac{n_k}{n} \theta_k^{t+1} \] where \(n_k = |\mathcal{D}_k|\) is the number of samples on device \(k\), \(n = \sum_k n_k\) is the total number of samples across participating clients, and \(K\) is the number of active devices in the current round.
This cyclical coordination protocol forms the foundation of federated learning, as illustrated in Figure 7 that clarifies the core FedAvg process:

This basic structure introduces a number of design choices and tradeoffs. The number of local steps \(E\) impacts the balance between computation and communication: larger \(E\) reduces communication frequency but risks divergence if local data distributions vary too much. The selection of participating clients affects convergence stability and fairness. In real-world deployments, not all devices are available at all times, and hardware capabilities may differ substantially, requiring robust participation scheduling and failure tolerance.
Client Scheduling
Federated learning operates under the assumption that clients, devices, which hold local data, periodically become available for participation in training rounds. In real-world systems, client availability is intermittent and variable. Devices may be turned off, disconnected from power, lacking network access, or otherwise unable to participate at any given time. As a result, client scheduling plays a central role in the effectiveness and efficiency of distributed learning.
At a baseline level, federated ML systems define eligibility criteria for participation. Devices must meet minimum requirements such as being plugged in, connected to Wi-Fi, and idle, to avoid interfering with user experience or depleting battery resources. These criteria determine which subset of the total population is considered “available” for any given training round.
Beyond these operational filters, devices also differ in their hardware capabilities, data availability, and network conditions. Some smartphones contain many recent examples relevant to the current task, while others have outdated or irrelevant data. Network bandwidth and upload speed may vary widely depending on geography and carrier infrastructure. As a result, selecting clients at random can lead to poor coverage of the underlying data distribution and unstable model convergence.
Availability-driven selection introduces participation bias: clients with favorable conditions, including frequent charging, high-end hardware, and consistent connectivity, are more likely to participate repeatedly, while others are systematically underrepresented. This can skew the resulting model toward behaviors and preferences of a privileged subset of the population, raising both fairness and generalization concerns.
The severity of participation bias becomes apparent when examining real deployment statistics. Studies of federated learning deployments show that the most active 10% of devices can contribute to over 50% of training rounds, while the bottom 50% of devices may never participate at all. This creates a feedback loop: models become increasingly optimized for users with high-end devices and stable connectivity, potentially degrading performance for resource-constrained users who need adaptation the most. A keyboard prediction model might become biased toward the typing patterns of users with flagship phones who charge overnight, missing important linguistic variations from users with budget devices or irregular charging patterns.
To address these challenges, systems must balance scheduling efficiency with client diversity. A key approach involves using stratified or quota-based sampling to ensure representative client participation across different groups. Some systems implement “fairness budgets” that track cumulative participation and actively prioritize underrepresented devices when they become available. Others use importance sampling techniques to reweight contributions based on estimated population statistics rather than raw participation rates. For instance, asynchronous buffer-based techniques allow participating clients to contribute model updates independently, without requiring synchronized coordination in every round (Nguyen et al. 2021). This model has been extended to incorporate staleness awareness (Rodio and Neglia 2024) and fairness mechanisms (Ma et al. 2024), preventing bias from over-active clients who might otherwise dominate the training process.
To address these challenges, federated ML systems implement adaptive client selection strategies. These include prioritizing clients with underrepresented data types, targeting geographies or demographics that are less frequently sampled, and using historical participation data to enforce fairness constraints. Systems incorporate predictive modeling to anticipate future client availability or success rates, improving training throughput.
Selected clients perform one or more local training steps on their private data and transmit their model updates to a central server. These updates are aggregated to form a new global model. Typically, this aggregation is weighted, where the contributions of each client are scaled, for example, by the number of local examples used during training, before averaging. This ensures that clients with more representative or larger datasets exert proportional influence on the global model.
These scheduling decisions directly impact system performance. They affect convergence rate, model generalization, energy consumption, and overall user experience. Poor scheduling can result in excessive stragglers, overfitting to narrow client segments, or wasted computation. As a result, client scheduling is not merely a logistical concern; it is a core component of system design in federated learning, demanding both algorithmic insight and infrastructure-level coordination.
Bandwidth-Aware Update Compression
One of the principal bottlenecks in federated ML systems is the cost of communication between edge clients and the central server. Transmitting full model weights or gradients after every training round can overwhelm bandwidth and energy budgets, particularly for mobile or embedded devices operating over constrained wireless links27. To address this, a range of techniques have been developed to reduce communication overhead while preserving learning efficacy.
27 Wireless Communication Reality: Mobile devices face severe bandwidth and energy constraints for federated learning. LTE uploads average 5-10 Mbps versus 50+ Mbps downloads, creating asymmetric bottlenecks. Transmitting a 50 MB model update consumes approximately 100 mAh battery (2-3% of typical capacity, varies by radio efficiency and signal strength) and takes 40-80 seconds. WiFi improves throughput but isn’t always available. Low-power devices using LoRaWAN or NB-IoT face even harsher limits—LoRaWAN maxes at 50 kbps with 1% duty cycle restrictions, making frequent updates impractical without aggressive compression.
These techniques fall into three primary categories: model compression, selective update sharing, and architectural partitioning.
Model compression methods aim to reduce the size of transmitted updates through quantization28, sparsification, or subsampling. Instead of sending full-precision gradients, a client transmits 8-bit quantized updates or communicates only the top-\(k\) gradient elements29 with highest magnitude.
28 Gradient Quantization: Reduces communication by converting FP32 gradients to lower precision (INT8, INT4, or even 1-bit). Advanced techniques like signSGD use only gradient signs, achieving 32\(\times\) compression. Error compensation methods accumulate quantization errors for later transmission, maintaining convergence quality. Real deployments achieve 8-16\(\times\) communication reduction with <1% accuracy loss.
29 Gradient Sparsification: Transmits only the largest gradients by magnitude (typically top 1-10%), dramatically reducing communication. Gradient accumulation stores untransmitted gradients locally until they become large enough to send. This technique exploits the observation that most gradients are small and contribute minimally to convergence, achieving 10-100\(\times\) compression ratios while maintaining training effectiveness. These techniques reduce transmission size with limited impact on convergence when applied carefully.
Selective update sharing further reduces communication by transmitting only subsets of model parameters or updates. In layer-wise selective sharing, clients update only certain layers, typically the final classifier or adapter modules, while keeping the majority of the backbone frozen. This reduces both upload cost and the risk of overfitting shared representations to non-representative client data.
Split models and architectural partitioning divide the model into a shared global component and a private local component. Clients train and maintain their private modules independently while synchronizing only the shared parts with the server. This allows for user-specific personalization with minimal communication and privacy leakage.
All of these approaches operate within the context of a federated aggregation protocol. A standard baseline for aggregation is Federated Averaging (FedAvg), in which the server updates the global model by computing a weighted average of the client updates received in a given round. Let \(\mathcal{K}_t\) denote the set of participating clients in round \(t\), and let \(\theta_k^t\) represent the locally updated model parameters from client \(k\). The server computes the new global model \(\theta^{t+1}\) as: \[ \theta^{t+1} = \sum_{k \in \mathcal{K}_t} \frac{n_k}{n_{\mathcal{K}_t}} \theta_k^t \]
Here, \(n_k\) is the number of local training examples at client \(k\), and \(n_{\mathcal{K}_t} = \sum_{k \in \mathcal{K}_t} n_k\) is the total number of training examples across all participating clients. This data-weighted aggregation ensures that clients with more training data exert a proportionally larger influence on the global model, while also accounting for partial participation and heterogeneous data volumes.
However, communication-efficient updates can introduce tradeoffs. Compression may degrade gradient fidelity, selective updates can limit model capacity, and split architectures may complicate coordination. As a result, effective federated learning requires careful balancing of bandwidth constraints, privacy concerns, and convergence dynamics—a balance that depends heavily on the capabilities and variability of the client population.
Federated Personalization
While compression and communication strategies improve scalability, they do not address a important limitation of the global federated learning paradigm—its inability to capture user-specific variation. In real-world deployments, devices often observe distinct and heterogeneous data distributions. A one-size-fits-all global model may underperform when applied uniformly across diverse users. This motivates the need for personalized federated learning, where local models are adapted to user-specific data without compromising the benefits of global coordination.
Let \(\theta_k\) denote the model parameters on client \(k\), and \(\theta_{\text{global}}\) the aggregated global model. Traditional FL seeks to minimize a global objective: \[ \min_\theta \sum_{k=1}^K w_k \mathcal{L}_k(\theta) \] where \(\mathcal{L}_k(\theta)\) is the local loss on client \(k\), and \(w_k\) is a weighting factor (e.g., proportional to local dataset size). However, this formulation assumes that a single model \(\theta\) can serve all users well. In practice, local loss landscapes \(\mathcal{L}_k\) often differ significantly across clients, reflecting non-IID data distributions and varying task requirements.
Personalization modifies this objective to allow each client to maintain its own adapted parameters \(\theta_k\), optimized with respect to both the global model and local data: \[ \min_{\theta_1, \ldots, \theta_K} \sum_{k=1}^K \left( \mathcal{L}_k(\theta_k) + \lambda \cdot \mathcal{R}(\theta_k, \theta_{\text{global}}) \right) \]
Here, \(\mathcal{R}\) is a regularization term that penalizes deviation from the global model, and \(\lambda\) controls the strength of this penalty. This formulation allows local models to deviate as needed, while still benefiting from global coordination.
Real-world use cases illustrate the importance of this approach. Consider a wearable health monitor that tracks physiological signals to classify physical activities. While a global model may perform reasonably well across the population, individual users exhibit unique motion patterns, gait signatures, or sensor placements. Personalized finetuning of the final classification layer or low-rank adapters allows improved accuracy, particularly for rare or user-specific classes.
Several personalization strategies have emerged to address the tradeoffs between compute overhead, privacy, and adaptation speed. One widely used approach is local finetuning, in which each client downloads the latest global model and performs a small number of gradient steps using its private data. While this method is simple and preserves privacy, it may yield suboptimal results when the global model is poorly aligned with the client’s data distribution or when the local dataset is extremely limited.
Another effective technique involves personalization layers, where the model is partitioned into a shared backbone and a lightweight, client-specific head—typically the final classification layer (Arivazhagan et al. 2019). Only the head is updated on-device, significantly reducing memory usage and training time. This approach is particularly well-suited for scenarios in which the primary variation across clients lies in output categories or decision boundaries.
Clustered federated learning offers an alternative by grouping clients according to similarities in their data or performance characteristics, and training separate models for each cluster. This strategy can enhance accuracy within homogeneous subpopulations but introduces additional system complexity and may require exchanging metadata to determine group membership.
Finally, meta-learning approaches, such as Model-Agnostic Meta-Learning (MAML), aim to produce a global model initialization that can be quickly adapted to new tasks with just a few local updates (Finn, Abbeel, and Levine 2017). This technique is especially useful when clients have limited data or operate in environments with frequent distributional shifts. Each of these strategies reflects a different point in the tradeoff space. These strategies vary in their system implications, including compute overhead, privacy guarantees, and adaptation latency. Table 5 summarizes the tradeoffs.
| Strategy | Personalization Mechanism | Compute Overhead | Privacy Preservation | Adaptation Speed |
|---|---|---|---|---|
| Local Finetuning | Gradient descent on local loss post-aggregation | Low to Moderate | High (no data sharing) | Fast (few steps) |
| Personalization Layers | Split model: shared base + user-specific head | Moderate | High | Fast (train small head) |
| Clustered FL | Group clients by data similarity, train per group | Moderate to High | Medium (group metadata) | Medium |
| Meta-Learning | Train for fast adaptation across tasks/devices | High (meta-objective) | High | Very Fast (few-shot) |
Selecting the appropriate personalization method depends on deployment constraints, data characteristics, and the desired balance between accuracy, privacy, and computational efficiency. In practice, hybrid approaches that combine elements of multiple strategies, including local finetuning atop a personalized head, are often employed to achieve robust performance across heterogeneous devices.
Federated Privacy
While federated learning is often motivated by privacy concerns, as it involves keeping raw data localized instead of transmitting it to a central server, the paradigm introduces its own set of security and privacy risks. Although devices do not share their raw data, the transmitted model updates (such as gradients or weight changes) can inadvertently leak information about the underlying private data. Techniques such as model inversion attacks and membership inference attacks demonstrate that adversaries may partially reconstruct or infer properties of local datasets by analyzing these updates.
To mitigate such risks, modern federated ML systems commonly employ protective measures. Secure Aggregation protocols ensure that individual model updates are encrypted and aggregated in a way that the server only observes the combined result, not any individual client’s contribution. Differential Privacy30 techniques inject carefully calibrated noise into updates to mathematically bound the information that can be inferred about any single client’s data.
30 Differential Privacy: Mathematical framework that provides quantifiable privacy guarantees by adding carefully calibrated noise to computations. In federated learning, DP ensures that individual user data cannot be inferred from model updates, even by aggregators. Key parameter ε controls privacy-utility tradeoff: smaller ε means stronger privacy but lower model accuracy. Typical deployments use ε=1-8, requiring noise addition that can increase communication overhead by 2-10\(\times\) and reduce model accuracy by 1-5%. Essential for regulatory compliance and user trust in distributed learning systems.
While these techniques enhance privacy, they introduce additional system complexity and tradeoffs between model utility, communication cost, and robustness. A deeper exploration of these attacks, defenses, and their implications requires dedicated coverage of security principles in distributed ML systems.
Large-Scale Device Orchestration
Federated learning transforms machine learning into a massive distributed systems challenge that extends far beyond traditional algorithmic considerations. Coordinating thousands or millions of heterogeneous devices with intermittent connectivity requires sophisticated distributed systems protocols that handle Byzantine failures, network partitions, and communication efficiency at unprecedented scale. These challenges fundamentally differ from the controlled environments of data center distributed training, where high-bandwidth networks and reliable infrastructure enable straightforward coordination protocols.
Network and Bandwidth Optimization
The communication bottleneck represents the primary scalability constraint in federated learning systems. Understanding the quantitative transfer requirements enables principled design decisions about model architectures, update compression strategies, and client participation policies that determine system viability.
The federated communication hierarchy reveals the severe bandwidth constraints under which distributed learning must operate. Full model synchronization requires 10-500 MB per training round for typical deep learning models—prohibitive for mobile networks with limited upload bandwidth that averages just 5-50 Mbps in practice. Gradient compression achieves 10-100\(\times\) reduction through quantization (reducing FP32 to INT8), sparsification (transmitting only non-zero gradients), and selective gradient transmission (sending only the most significant updates). Practical deployments demand even more aggressive 100-1000\(\times\) compression ratios, reducing 100 MB models to manageable 100 KB-1 MB updates that mobile devices can transmit within reasonable timeframes and without exhausting data plans. Communication frequency introduces a critical trade-off between model update freshness—more frequent updates enable faster adaptation to changing conditions—and network efficiency constraints that limit sustainable bandwidth consumption.
Network infrastructure constraints directly impact participation rates and overall system viability. Modern 4G networks typically provide upload speeds ranging from 5-50 Mbps under optimal conditions (with significant geographic and carrier variation), meaning an 8 MB model update requires 1.3-13 seconds of sustained transmission. However, real-world mobile networks exhibit extreme variability: rural areas may experience 1 Mbps upload speeds while urban 5G deployments enable 100+ Mbps. This 100\(\times\) variance in network capability necessitates adaptive communication strategies that optimize for lowest-common-denominator connectivity while enabling high-capability devices to contribute more effectively.
The relationship between communication requirements and participation rates exhibits sharp threshold effects. Empirical studies demonstrate that federated learning systems requiring model transfers exceeding 10 MB achieve less than 10% sustained client participation, while systems maintaining updates below 1 MB can sustain 40-60% participation rates across diverse mobile populations. This communication efficiency directly translates to model quality improvements: higher participation rates provide better statistical diversity and more robust gradient estimates for global model updates.
Advanced compression techniques become essential for practical deployment. Gradient quantization reduces precision from FP32 to INT8 or even binary representations, achieving 4-32\(\times\) compression with minimal accuracy loss. Sparsification techniques transmit only the largest gradient components, leveraging the natural sparsity in neural network updates. Top-k gradient selection further reduces communication by transmitting only the most significant parameter updates, while error accumulation ensures that small gradients are not permanently lost.
Asynchronous Device Synchronization
Federated learning operates at the complex intersection of distributed systems and machine learning, inheriting fundamental challenges from both domains while introducing unique complications that arise from the mobile, heterogeneous, and unreliable nature of edge devices.
Federated learning must contend with Byzantine fault tolerance requirements that extend beyond typical distributed systems challenges. Device failures occur frequently as clients crash, lose power, or disconnect during training rounds due to battery depletion or network connectivity issues—far more common than server failures in traditional distributed training. Malicious updates present security concerns as adversarial clients can provide corrupted gradients deliberately designed to degrade global model performance or extract private information from the aggregation process. Robust aggregation protocols implementing Byzantine-resilient averaging ensure system reliability despite the presence of compromised or unreliable participants, though these protocols introduce significant computational overhead. Consensus mechanisms must coordinate millions of unreliable participants without the overhead of traditional distributed consensus protocols like Paxos or Raft, which were designed for small clusters of reliable servers.
Network partitions pose particularly acute challenges for federated coordination protocols. Unlike traditional distributed systems operating within reliable data center networks, federated learning must gracefully handle prolonged client disconnection events where devices may remain offline for hours or days while traveling, in poor coverage areas, or simply powered down. Asynchronous coordination protocols enable continued training progress despite missing participants, but must carefully balance staleness (accepting potentially outdated contributions) against freshness (prioritizing recent but potentially sparse updates).
Fault recovery and resilience strategies form an essential layer of federated learning infrastructure. Checkpoint synchronization through periodic global model snapshots enables recovery from server failures and provides rollback points when corrupted training rounds are detected, though checkpointing large models across millions of devices introduces substantial storage and communication overhead. Partial update handling ensures systems gracefully handle incomplete training rounds when significant subsets of clients fail or disconnect mid-training, requiring careful weighting strategies to prevent bias toward more reliable device cohorts. State reconciliation protocols enable clients rejoining after extended offline periods—potentially days or weeks—to efficiently resynchronize with the current global model while minimizing communication overhead that could overwhelm bandwidth-constrained devices. Dynamic load balancing addresses uneven client availability patterns that create computational hotspots, requiring intelligent load redistribution across available participants to maintain training throughput despite time-varying participation rates.
The asynchronous nature of federated coordination introduces additional complexity in maintaining training convergence guarantees. Traditional synchronous training assumes all participants complete each round, but federated systems must handle stragglers and dropouts gracefully. Techniques such as FedAsync31 enable asynchronous aggregation where the server continuously updates the global model as client updates arrive, while bounded staleness mechanisms prevent extremely outdated updates from corrupting recent progress.
31 Asynchronous Federated Learning (FedAsync): Enables continuous model updates without waiting for slow or unreliable clients. The server maintains a global model that gets updated immediately when client contributions arrive, using staleness-aware weighting to reduce the influence of outdated updates. This approach can improve convergence speed by 2-5\(\times\) in heterogeneous environments while maintaining model quality within 1-3% of synchronous training.
Managing Million-Device Heterogeneity
Real-world federated learning deployments exhibit extreme heterogeneity across multiple dimensions simultaneously: hardware capabilities, network conditions, data distributions, and availability patterns. This multi-dimensional heterogeneity fundamentally challenges traditional distributed machine learning assumptions about homogeneous participants operating under similar conditions.
Real-world federated learning deployments face multi-dimensional device heterogeneity that creates extreme variation across every system dimension. Computational variation spans 1000\(\times\) differences in processing power between flagship smartphones running at 35 TOPS and IoT microcontrollers operating at just 0.03 TOPS, fundamentally limiting what models can train on different device tiers. Memory constraints exhibit even more dramatic 100-10,000\(\times\) differences in available RAM across device categories, ranging from 256KB on microcontrollers to 16 GB on premium smartphones, determining whether devices can perform any local training at all or must rely purely on inference. Energy limitations force training sessions to be carefully scheduled around charging patterns, thermal constraints, and battery preservation requirements, with mobile devices typically limiting ML workloads to 500-1000 mW sustained power consumption. Network diversity introduces orders-of-magnitude performance differences as WiFi, 4G, 5G, and satellite connectivity exhibit vastly different bandwidth (ranging from 1 Mbps to 1 Gbps), latency (10 ms to 600 ms), and reliability characteristics that determine feasible update frequencies and compression requirements.
Adaptive coordination protocols address this heterogeneity through sophisticated tiered participation strategies that optimize resource utilization across the device spectrum. High-capability devices such as flagship smartphones can perform complex local training with large batch sizes and multiple epochs, while resource-constrained IoT devices contribute through lightweight updates, specialized subtasks, or even simple data aggregation. This creates a natural computational hierarchy where powerful devices act as “super-peers” performing disproportionate computation, while edge devices contribute specialized local knowledge and coverage.
The scale challenges extend far beyond device heterogeneity to fundamental coordination overhead limitations. Traditional distributed consensus algorithms such as Raft or PBFT are designed for dozens of nodes in controlled environments, but federated learning requires coordination among millions of participants across unreliable networks. This necessitates hierarchical coordination architectures where regional aggregation servers reduce communication overhead by performing local consensus before contributing to global aggregation. Edge computing infrastructure provides natural hierarchical coordination points, enabling federated learning systems to leverage existing content delivery networks (CDNs) and mobile edge computing (MEC) deployments for efficient gradient aggregation.
Modern federated systems implement sophisticated client selection strategies that balance statistical diversity with practical constraints. Random sampling ensures unbiased representation but may select many low-capability devices, while capability-based selection improves training efficiency but risks statistical bias. Hybrid approaches use stratified sampling across device tiers, ensuring both statistical representativeness and computational efficiency. These selection strategies must also consider temporal patterns: office workers’ devices may be available during specific hours, while IoT sensors provide continuous but limited computational resources.
Production Integration
The theoretical foundation established earlier—model adaptation strategies, data efficiency techniques, and federated coordination algorithms—provides the building blocks for on-device learning systems. However, translating these individual components into production-ready systems requires addressing integration challenges that cut across all constraint dimensions simultaneously.
Real-world deployment introduces systemic complexity that exceeds the sum of individual techniques. Model adaptation, data efficiency, and federated coordination must work together seamlessly rather than as independent optimizations. Different learning strategies have varying computational and memory profiles that must be coordinated within overall device budgets. Training, inference, and communication must be scheduled carefully to avoid interference with user experience and system stability. Unlike centralized systems with observable training loops, on-device learning requires distributed validation and failure detection mechanisms that operate across heterogeneous device populations.
This transition from theory to practice requires systematic engineering approaches that balance competing constraints while maintaining system reliability. Successful on-device learning deployments depend not on individual algorithmic improvements but on holistic system designs that orchestrate multiple techniques within operational constraints. The subsequent sections examine how production systems address these integration challenges through principled design patterns, operational practices, and monitoring strategies that enable scalable, reliable on-device learning deployment.
MLOps Integration Challenges
Integrating on-device learning into existing MLOps workflows requires extending the operational frameworks established in Chapter 13: ML Operations to handle distributed training, heterogeneous devices, and privacy-preserving coordination. The continuous integration pipelines, model versioning systems, and monitoring infrastructure discussed in the preceding chapter provide essential foundations, but must be adapted to address unique edge deployment challenges. Standard MLOps pipelines assume centralized data access, controlled deployment environments, and unified monitoring capabilities that do not directly apply to edge learning scenarios, requiring new approaches to the technical debt management and operational excellence principles established earlier.
Deployment Pipeline Transformations
Traditional MLOps deployment pipelines from Chapter 13: ML Operations follow a standardized CI/CD process: model training, validation, staging, and production deployment of a single model artifact to uniform infrastructure. On-device learning requires device-aware deployment pipelines that distribute different adaptation strategies across heterogeneous device tiers. Microcontrollers receive bias-only updates, mid-range phones use LoRA adapters, and flagship devices perform selective layer updates. The deployment artifact evolves from a static model file to a collection of adaptation policies, initial model weights, and device-specific optimization configurations.
This architectural shift necessitates extending traditional deployment pipelines with device capability detection, strategy selection logic, and tiered deployment orchestration that maintains the reliability guarantees of conventional MLOps while accommodating unprecedented deployment diversity.
This transformation introduces new complexity in version management. While centralized systems maintain a single model version, on-device learning systems must simultaneously track multiple versioning dimensions. The pre-trained backbone distributed to all devices represents the base model version, which serves as the foundation for all local adaptations. Different update mechanisms deployed per device class constitute adaptation strategies, varying from simple bias adjustments on microcontrollers to full layer fine-tuning on flagship devices. Local model states naturally diverge from the base as devices encounter unique data distributions, creating device-specific checkpoints that reflect individual adaptation histories. Finally, federated learning rounds that periodically synchronize device populations establish aggregation epochs, marking discrete points where distributed knowledge converges into updated global models. Successful deployments implement tiered versioning schemes where base models evolve slowly—typically through monthly updates—while local adaptations occur continuously, creating a hierarchical version space rather than the linear version history familiar from traditional deployments.
Monitoring System Evolution
Chapter 13: ML Operations established monitoring practices that aggregate metrics from centralized inference servers. On-device learning monitoring must operate within fundamentally different constraints that reshape how systems observe, measure, and respond to model behavior across distributed device populations.
Privacy-preserving telemetry represents the first fundamental departure from traditional monitoring. Collecting performance metrics without compromising user privacy requires federated analytics where devices share only aggregate statistics or differentially private summaries. Systems cannot simply log individual predictions or training samples as centralized systems do. Instead, devices report distribution summaries such as mean accuracy and confidence histograms rather than per-example metrics. All reported statistics must include differential privacy guarantees that bound information leakage through carefully calibrated noise addition. Secure aggregation protocols prevent the server from observing individual device contributions, ensuring that even the aggregation process itself cannot reconstruct private information from any single device’s data.
Drift detection presents additional challenges without access to ground truth labels. Traditional monitoring compares model predictions against labeled validation sets maintained on centralized infrastructure. On-device systems must detect drift using only local signals available during deployment. Confidence calibration tracks whether predicted probabilities match empirical frequencies, detecting degradation when the model’s confidence estimates become poorly calibrated to actual outcomes. Input distribution monitoring detects when feature distributions shift from training data through statistical techniques that require no labels. Task performance proxies leverage implicit feedback such as user corrections or task abandonment as quality signals that indicate when the model fails to meet user needs. Shadow baseline comparison runs a frozen base model alongside the adapted model to measure divergence, flagging cases where local adaptation degrades rather than improves performance relative to the known-good baseline.
Heterogeneous performance tracking addresses a third critical challenge: global averages mask critical failures when device populations exhibit high variance. Monitoring systems must segment performance across multiple dimensions to identify systematic issues that affect specific device cohorts. Capability-based performance gaps reveal when flagship devices achieve substantially better results than budget devices, indicating that adaptation strategies may need adjustment for resource-constrained hardware. Regional bias issues surface when models perform well in some geographic markets but poorly in others, potentially reflecting data distribution shifts or cultural factors not captured during initial training. Temporal patterns emerge when performance degrades for devices running stale base models that have not received recent updates from federated aggregation. Participation inequality becomes visible when comparing devices that adapt frequently against those that rarely participate in training, revealing potential fairness issues in how learning benefits are distributed across the user population.
Continuous Training Orchestration
Traditional continuous training covered in Chapter 13: ML Operations executes scheduled retraining jobs on centralized infrastructure with predictable resource availability and coordinated execution. On-device learning transforms this into continuous distributed training where millions of devices train independently without global synchronization, creating orchestration challenges that require fundamentally different coordination strategies.
Asynchronous device coordination represents the first major departure from centralized training. Millions of devices train independently on their local data, but the orchestration system cannot rely on synchronized participation. Only 20-40% of devices are typically available in any training round due to network connectivity limitations, battery constraints, and varying usage patterns. The system must exhibit straggler tolerance, ensuring that slow devices on limited hardware or poor network connections cannot block faster devices from progressing with their local adaptations. Devices often operate on different base model versions simultaneously, creating version skew that the aggregation protocol must handle gracefully without forcing all devices to maintain identical model states. State reconciliation becomes necessary when devices reconnect after extended offline periods—potentially days or weeks—requiring the system to integrate their accumulated local adaptations despite having missed multiple federated aggregation rounds.
Resource-aware scheduling ensures that training respects both device constraints and user experience. Orchestration policies implement opportunistic training windows that execute adaptation only when the device is idle, charging, and connected to WiFi, avoiding interference with active user tasks or consuming metered cellular data. Thermal budgets suspend training when device temperature exceeds manufacturer-specified thresholds, preventing user discomfort and hardware damage from sustained computational loads. Battery preservation policies limit training energy consumption to less than 5% of battery capacity per day, ensuring that on-device learning does not noticeably impact device runtime from the user’s perspective. Network-aware communication compresses model updates aggressively when devices must use metered connections, trading computational overhead for reduced bandwidth consumption to minimize user data charges.
Convergence assessment without global visibility poses the final orchestration challenge. Traditional training monitors loss curves on centralized validation sets, providing clear signals about training progress and convergence. Distributed training must assess convergence through indirect signals aggregated across the device population. Federated evaluation aggregates validation metrics from devices that maintain local held-out sets, providing approximate measures of global model quality despite incomplete device participation. Update magnitude tracking monitors how much local gradients change the global model in each aggregation round, with diminishing update sizes signaling potential convergence. Participation diversity ensures broad device representation in aggregated updates, preventing convergence metrics from reflecting only a narrow subset of the deployment environment. Temporal consistency detects when model improvements plateau across multiple aggregation rounds, indicating that the current adaptation strategy has exhausted its potential gains and may require adjustment.
Validation Strategy Adaptation
The validation approaches from Chapter 13: ML Operations assume access to held-out test sets and centralized evaluation infrastructure where model quality can be measured directly against known ground truth. On-device learning requires distributed validation that respects privacy and resource constraints while still providing reliable quality signals across heterogeneous device populations.
Shadow model evaluation provides the primary validation mechanism by maintaining multiple model variants on each device and comparing their behavior. Devices simultaneously run a baseline shadow model—a frozen copy of the last known-good base model that provides a stable reference point—alongside the current locally-adapted version that reflects recent on-device training. Many systems also maintain the latest federated aggregation result as a global model variant, enabling comparison between individual device adaptations and the collective knowledge aggregated from the entire device population. By comparing predictions across these variants on incoming data streams, systems detect when local adaptation degrades performance relative to established baselines. This comparison occurs continuously during normal operation, requiring no additional labeled validation data. When the adapted model consistently underperforms the baseline shadow, the system triggers automatic rollback to the known-good version, preventing performance degradation from persisting in production.
Confidence-based quality gates provide an additional validation signal when labeled validation data is unavailable. Without ground truth labels, systems use prediction confidence as a quality proxy that correlates with model performance. Well-calibrated models should exhibit high confidence on in-distribution samples that resemble their training data, with confidence scores that accurately reflect the probability of correct predictions. Confidence drops indicate either distributional shift—where input data no longer matches training distributions—or model degradation from problematic local adaptations. Threshold-based gating implements this validation mechanism by continuously monitoring average prediction confidence and suspending adaptation when confidence falls below baseline levels established during initial deployment. This approach catches many failure modes without requiring labeled validation data, though it cannot detect all performance issues since overconfident but incorrect predictions can maintain high confidence scores.
Federated A/B testing enables validation of new adaptation strategies or model architectures across distributed device populations. To validate proposed changes, systems implement distributed experiments that randomly assign devices to treatment and control groups while maintaining statistical balance across device tiers and usage patterns. Both groups collect federated metrics using privacy-preserving aggregation protocols that prevent individual device data from being exposed while enabling population-level comparisons. The system compares adaptation success rates—measuring how frequently local adaptations improve over baseline models—along with convergence speed that indicates how quickly devices reach optimal performance, and final performance metrics that reflect ultimate model quality after adaptation completes. Successful strategies demonstrating clear improvements in treatment groups are rolled out gradually across the device population, starting with small percentages and expanding only after confirming that benefits generalize beyond the experimental cohort.
These operational transformations necessitate new tooling and infrastructure that systematically extends traditional MLOps practices from Chapter 13: ML Operations. The CI/CD pipelines, monitoring dashboards, A/B testing frameworks, and incident response procedures established for centralized deployments form the foundation for on-device learning operations. The federated learning protocols (Section 1.6) provide coordination mechanisms for distributed training, while monitoring challenges (Section 1.9.3) address observability gaps created by decentralized adaptation.
Successful on-device learning deployments build upon proven MLOps methodologies while adapting them to the unique challenges of distributed, heterogeneous learning environments. This evolutionary approach ensures operational reliability while enabling the benefits of edge learning.
Bio-Inspired Learning Efficiency
The constraints of on-device learning mirror fundamental challenges solved by biological intelligence systems, offering theoretical insights into efficient learning design. Understanding these connections enables principled approaches to resource-constrained machine learning that leverage billions of years of evolutionary optimization.
Learning from Biological Neural Efficiency
The human brain operates at approximately 20 watts while continuously learning from limited supervision—precisely the efficiency target for on-device learning systems32. This remarkable efficiency emerges from several architectural principles that directly inform edge learning design, demonstrating what is theoretically achievable with highly optimized learning systems.
32 Brain Power Efficiency: The human brain’s 20 W power consumption (equivalent to a bright LED bulb) enables processing 10^15 operations per second—roughly 50,000\(\times\) more efficient than current AI accelerators per operation. This efficiency comes from ~86 billion neurons with only 1-2% active simultaneously, massive parallelism with 10^14 synapses, and adaptive precision where important computations use more resources. Modern edge AI targets similar efficiency: sparse activation patterns, adaptive precision (INT8 to FP16), and event-driven processing that activates only when needed.
The brain’s efficiency characteristics reveal multiple dimensions of optimization that on-device systems should target. From a power perspective, the brain consumes just 20 W total, with approximately 10 W dedicated to active learning and memory consolidation—an energy budget comparable to what mobile devices can sustainably allocate to on-device learning during charging periods. Memory efficiency comes from sparse, distributed representations where only 1-2% of neurons activate simultaneously during any cognitive task, dramatically reducing the computational and storage requirements compared to dense neural networks. Learning efficiency manifests through few-shot learning capabilities that enable adaptation from single exposures, along with continuous adaptation mechanisms that avoid catastrophic forgetting when integrating new knowledge. Hierarchical processing organizes information across multiple scales, from low-level sensory inputs to high-level abstract reasoning, enabling efficient reuse of learned features across different tasks and contexts.
Biological learning exhibits several features that on-device systems must replicate to achieve similar efficiency. Sparse representations ensure efficient use of limited neural resources—only a tiny fraction of brain neurons fire during any cognitive task. This sparsity directly parallels the selective parameter updates and pruned architectures essential for mobile deployment. Event-driven processing minimizes energy consumption by activating computation only when sensory input changes, analogous to opportunistic training during device idle periods.
Unlabeled Data Exploitation Strategies
Mobile devices continuously collect rich sensor streams ideal for self-supervised learning: visual data from cameras, temporal patterns from accelerometers, spatial patterns from GPS, and interaction patterns from touchscreen usage. This abundant unlabeled data enables sophisticated representation learning without external supervision.
The scale of sensor data generation on mobile devices creates unprecedented opportunities for self-supervised learning. Visual streams from cameras operating at 30 frames per second provide approximately 2.6 million frames daily, offering abundant data for contrastive learning approaches that learn visual representations by comparing augmented versions of the same image33. Motion data from accelerometers sampling at 100 Hz generates 8.6 million data points daily, capturing temporal patterns suitable for learning representations of human activities and device movement. Location traces from GPS sensors enable spatial representation learning and behavioral prediction by capturing movement patterns and frequently visited locations without requiring explicit labels. Interaction patterns from touch events, typing dynamics, and app usage sequences create rich behavioral embeddings that reveal user preferences and habits, enabling personalized model adaptation without manual annotation.
33 Mobile Data Generation Scale: A typical smartphone generates ~2-4 GB of sensor data daily from cameras (1-2 GB), accelerometers (~50 MB), GPS traces (~10 MB), and touch interactions (~5 MB). This massive data stream offers unprecedented self-supervised learning opportunities—modern contrastive learning can extract useful representations from just 1% of this data, making effective on-device learning feasible without external labels or cloud processing.
Contrastive learning from temporal correlations offers particularly promising opportunities for leveraging this sensor data. Consecutive frames from mobile cameras naturally provide positive pairs for visual representation learning—images captured milliseconds apart typically show the same scene from slightly different perspectives—while augmentation techniques such as color jittering and random cropping create negative examples. Audio streams from microphones enable self-supervised speech representation learning through masking and prediction tasks, where the model learns to predict masked portions of audio spectrograms. Even device orientation and motion data can be used for self-supervised pretraining of activity recognition models, learning representations that capture the temporal structure of human movement without requiring labeled activity annotations.
The biological inspiration extends to continual learning without forgetting. Brains continuously integrate new experiences while retaining decades of memories through mechanisms like synaptic consolidation and replay. On-device systems must implement analogous mechanisms: elastic weight consolidation prevents catastrophic forgetting by protecting weights important for previous tasks, experience replay maintains stability during adaptation by interleaving new training with replayed examples from previous tasks, and progressive neural architectures expand model capacity as new tasks emerge rather than forcing all knowledge into fixed-capacity networks.
Lifelong Adaptation Without Forgetting
Real-world on-device deployment demands continual adaptation to changing environments, user behavior, and task requirements. This presents the fundamental challenge of the stability-plasticity tradeoff: models must remain stable enough to preserve existing knowledge while plastic enough to learn new patterns.
Continual learning on edge devices faces several interconnected challenges that compound the difficulty of distributed adaptation. Catastrophic forgetting occurs when new learning overwrites previously acquired knowledge, causing models to lose performance on earlier tasks as they adapt to new ones—a particularly severe problem when devices cannot access historical training data. Task interference emerges when multiple learning objectives compete for limited model capacity, forcing difficult tradeoffs between different capabilities that the model must maintain simultaneously. Data distribution shift manifests as deployment environments differ significantly from training conditions, requiring models to adapt to new patterns while maintaining performance on the original distribution. Resource constraints fundamentally limit the available solutions, as limited memory prevents storing all historical data for replay-based approaches that work well in centralized settings but exceed edge device capabilities.
Meta-learning approaches address these challenges by learning learning algorithms themselves rather than just learning specific tasks. Model-Agnostic Meta-Learning (MAML) trains models to quickly adapt to new tasks with minimal data—exactly the capability required for personalized on-device adaptation where collecting large user-specific datasets is impractical. Few-shot learning techniques enable rapid specialization from small user-specific datasets, allowing models to personalize based on just a handful of examples while maintaining general capabilities learned during pretraining.
The theoretical foundation suggests that optimal on-device learning systems will combine sparse representations, self-supervised pretraining on sensor data, and meta-learning for rapid adaptation. These principles directly influence practical system design: sparse model architectures reduce memory and compute requirements, self-supervised objectives utilize abundant unlabeled sensor data, and meta-learning enables efficient personalization from limited user interactions.
A key principle in building practical systems is to minimize the adaptation footprint. Full-model fine-tuning is typically infeasible on edge platforms, instead, localized update strategies, including bias-only optimization, residual adapters, and lightweight task-specific heads, should be prioritized. These approaches allow model specialization under resource constraints while mitigating the risks of overfitting or instability.
The feasibility of lightweight adaptation depends importantly on the strength of offline pretraining (Bommasani et al. 2021). Pretrained models should encapsulate generalizable feature representations that allow efficient adaptation from limited local data. Shifting the burden of feature extraction to centralized training reduces the complexity and energy cost of on-device updates, while improving convergence stability in data-sparse environments.
Even when adaptation is lightweight, opportunistic scheduling remains important to preserve system responsiveness and user experience. Local updates should be deferred to periods when the device is idle, connected to external power, and operating on a reliable network. Such policies minimize the impact of background training on latency, battery consumption, and thermal performance.
The sensitivity of local training artifacts necessitates careful data security measures. Replay buffers, support sets, adaptation logs, and model update metadata must be protected against unauthorized access or tampering. Lightweight encryption or hardware-backed secure storage can mitigate these risks without imposing prohibitive resource costs on edge platforms.
However, security measures alone do not guarantee model robustness. As models adapt locally, monitoring adaptation dynamics becomes important. Lightweight validation techniques, including confidence scoring, drift detection heuristics, and shadow model evaluation, can help identify divergence early, enabling systems to trigger rollback mechanisms before severe degradation occurs (Gama et al. 2014).
Robust rollback procedures depend on retaining trusted model checkpoints. Every deployment should preserve a known-good baseline version of the model that can be restored if adaptation leads to unacceptable behavior. This principle is especially important in safety-important and regulated domains, where failure recovery must be provable and rapid.
In decentralized or federated learning contexts, communication efficiency becomes a first-order design constraint. Compression techniques such as quantized gradient updates, sparsified parameter sets, and selective model transmission must be employed to allow scalable coordination across large, heterogeneous fleets of devices without overwhelming bandwidth or energy budgets (Konečný et al. 2016).
When personalization is required, systems should aim for localized adaptation wherever possible. Restricting updates to lightweight components, including final classification heads or modular adapters, constrains the risk of catastrophic forgetting, reduces memory overhead, and accelerates adaptation without destabilizing core model representations.
Finally, throughout the system lifecycle, privacy and compliance requirements must be architected into adaptation pipelines. Mechanisms to support user consent, data minimization, retention limits, and the right to erasure must be considered core aspects of model design, not post-hoc adjustments. Meeting regulatory obligations at scale demands that on-device learning workflows align inherently with principles of auditable autonomy.
The flowchart in Figure 8 summarizes key decision points in designing practical, scalable, and resilient on-device ML systems.

Systems Integration for Production Deployment
Real-world on-device learning systems achieve effectiveness by systematically combining all three solution pillars rather than relying on isolated techniques. This integration requires careful systems engineering to manage interactions, resolve conflicts, and optimize the overall system performance within deployment constraints.
Consider a production voice assistant deployment across 50 million heterogeneous devices. The system architecture demonstrates systematic integration across three complementary layers that work together to enable effective learning under diverse constraints.
The model adaptation layer stratifies techniques by device capability, matching sophistication to available resources. Flagship phones representing the top 20% of the deployment use LoRA rank-32 adapters that enable sophisticated voice pattern learning through high-dimensional parameter updates. Mid-tier devices comprising 60% of the fleet employ rank-16 adapters that balance adaptation expressiveness with the tighter memory constraints typical of mainstream smartphones. Budget devices making up the remaining 20% rely on bias-only updates that stay comfortably within 1 GB memory limits while still enabling basic personalization.
The data efficiency layer implements adaptive strategies across the entire device population while respecting individual resource constraints. All devices implement experience replay, but with device-appropriate buffer sizes—10 MB on budget devices versus 100 MB on flagship models—ensuring that memory-constrained devices can still benefit from replay-based learning. Few-shot learning enables rapid adaptation to new users within their first 10 interactions, reducing the cold-start problem that plagues systems requiring extensive training data. Streaming updates accommodate continuous voice pattern evolution as users’ speaking styles naturally change over time or as they use the assistant in new acoustic environments.
The federated coordination layer orchestrates privacy-preserving collaboration across the device population. Devices participate in federated training rounds opportunistically based on connectivity status and battery level, ensuring that coordination does not degrade user experience. LoRA adapters aggregate efficiently with just 50 MB per update compared to 14 GB for full model synchronization, making federated learning practical over mobile networks. Privacy-preserving aggregation protocols ensure that individual voice patterns never leave devices while still enabling population-scale improvements in accent recognition and language understanding that benefit all users.
Effective systems integration requires adherence to key engineering principles that ensure robust operation across heterogeneous device populations:
Hierarchical Capability Matching: Deploy more sophisticated techniques on capable devices while ensuring basic functionality across the device spectrum. Never assume uniform capabilities.
Graceful Degradation: Systems must operate effectively when individual components fail. Poor connectivity should not prevent local adaptation; low battery should trigger minimal adaptation modes.
Conflict Resolution: Model adaptation and data efficiency techniques can conflict (limited memory vs buffer size). Systematic resource allocation prevents these conflicts through predefined priority hierarchies.
Performance Validation: Integration creates emergent behaviors that individual techniques don’t exhibit. Systems require comprehensive testing across device combinations and network conditions.
This integrated approach transforms on-device learning from a collection of techniques into a coherent systems capability that provides robust personalization within real-world deployment constraints.
Persistent Technical and Operational Challenges
The solution techniques explored above—model adaptation, data efficiency, and federated coordination—address many fundamental constraints of on-device learning but also reveal persistent challenges that emerge from their interaction in real-world deployments. These challenges represent the current frontiers of on-device learning research and highlight areas where the techniques discussed earlier reach their limits or create new operational complexities. Understanding these challenges provides critical context for evaluating when on-device learning approaches are appropriate and where alternative strategies may be necessary.
Unlike conventional centralized systems, where training occurs in controlled environments with uniform hardware and curated datasets, edge systems must contend with heterogeneity in devices, fragmentation in data, and the absence of centralized validation infrastructure. These factors give rise to new systems-level tradeoffs that test the boundaries of the adaptation strategies, data efficiency methods, and coordination mechanisms we have examined.
Device and Data Heterogeneity Management
Federated and on-device ML systems must operate across a vast and diverse ecosystem of devices, ranging from smartphones and wearables to IoT sensors and microcontrollers. This heterogeneity spans multiple dimensions: hardware capabilities, software stacks, network connectivity, and power availability. Unlike cloud-based systems, where environments can be standardized and controlled, edge deployments encounter a wide distribution of system configurations and constraints. These variations introduce significant complexity in algorithm design, resource scheduling, and model deployment.
At the hardware level, devices differ in terms of memory capacity, processor architecture (e.g., ARM Cortex-M vs. A-series)34, instruction set support (e.g., availability of SIMD or floating-point units), and the presence or absence of AI accelerators. Some clients may possess powerful NPUs capable of running small training loops, while others may rely solely on low-frequency CPUs with minimal RAM. These differences affect the feasible size of models, the choice of training algorithm, and the frequency of updates.
34 ARM Cortex Architecture Spectrum: The ARM Cortex family spans 6 orders of magnitude in capabilities. Cortex-M0+ (IoT sensors) runs at 48 MHz with 32 KB RAM and no floating-point, consuming ~10µW. Cortex-M7 (embedded systems) reaches 400 MHz with 1 MB RAM and single-precision FPU, consuming ~100 mW. Cortex-A78 (smartphones) delivers 3 GHz performance with multi-core processing, NEON SIMD, and advanced branch prediction, consuming 1-5 W. This diversity means federated learning must adapt algorithms dynamically—quantized inference on M0+, lightweight training on M7, and full backpropagation on A78.
35 TensorFlow Lite: Google’s framework for mobile and embedded ML inference, optimized for ARM processors and mobile GPUs. TFLite reduces model size by 75% through quantization and pruning, while achieving \(3\times\) faster inference than full TensorFlow. The framework supports 16-bit and 8-bit quantization, with specialized kernels for mobile CPUs and GPUs. TFLite Micro targets microcontrollers with <1 MB memory, enabling ML on Arduino and other embedded platforms.
Software heterogeneity compounds the challenge. Devices may run different versions of operating systems, kernel-level drivers, and runtime libraries. Some environments support optimized ML runtimes like TensorFlow Lite35 Micro or ONNX Runtime Mobile, while others rely on custom inference stacks or restricted APIs. These discrepancies can lead to subtle inconsistencies in behavior, especially when models are compiled differently or when floating-point precision varies across platforms.
In addition to computational heterogeneity, devices exhibit variation in connectivity and uptime. Some are intermittently connected, plugged in only occasionally, or operate under strict bandwidth constraints. Others may have continuous power and reliable networking, but still prioritize user-facing responsiveness over background learning. These differences complicate the orchestration of coordinated learning and the scheduling of updates.
Finally, system fragmentation affects reproducibility and testing. With such a wide range of execution environments, it is difficult to ensure consistent model behavior or to debug failures reliably. This makes monitoring, validation, and rollback mechanisms more important—but also more difficult to implement uniformly across the fleet.
Consider a federated learning deployment for mobile keyboards. A high-end smartphone might feature 8 GB of RAM, a dedicated AI accelerator, and continuous Wi-Fi access. In contrast, a budget device may have just 2 GB of RAM, no hardware acceleration, and rely on intermittent mobile data. These disparities influence how long training runs can proceed, how frequently models can be updated, and even whether training is feasible at all. To support such a range, the system must dynamically adjust training schedules, model formats, and compression strategies—ensuring equitable model improvement across users while respecting each device’s limitations.
Non-IID Data Distribution Challenges
In centralized machine learning, data can be aggregated, shuffled, and curated to approximate independent and identically distributed (IID) samples—a key assumption underlying many learning algorithms. On-device and federated learning systems fundamentally challenge this assumption, requiring algorithms that can handle highly fragmented and non-IID data across diverse devices and contexts.
The statistical implications of this fragmentation create cascading challenges throughout the learning process. Gradients computed on different devices may conflict, slowing convergence or destabilizing training. Local updates risk overfitting to individual client idiosyncrasies, reducing performance when aggregated globally. The diversity of data across clients also complicates evaluation, as no single test set can represent the true deployment distribution.
These challenges necessitate robust algorithms that can handle heterogeneity and imbalanced participation. Techniques such as personalization layers, importance weighting, and adaptive aggregation schemes provide partial solutions, but the optimal approach varies with application context and the specific nature of data fragmentation. As established in Section 1.3.3, this statistical heterogeneity represents one of the core challenges distinguishing on-device learning from traditional centralized approaches.
Distributed System Observability
The monitoring and observability frameworks from Chapter 13: ML Operations must be fundamentally reimagined for distributed edge environments. Traditional centralized monitoring approaches that rely on unified data collection and real-time visibility become impractical when devices operate intermittently connected and data cannot be centralized. The drift detection and performance monitoring techniques established in MLOps provide conceptual foundations, but require adaptation to handle the distributed, privacy-preserving nature of on-device learning systems.
Unlike centralized machine learning systems, where model updates can be continuously evaluated against held-out validation sets, on-device learning introduces a core shift in visibility and observability. Once deployed, models operate in highly diverse and often disconnected environments, where internal updates may proceed without external monitoring. This creates significant challenges for ensuring that model adaptation is both beneficial and safe.
A core difficulty lies in the absence of centralized validation data. In traditional workflows, models are trained and evaluated using curated datasets that serve as proxies for deployment conditions. On-device learners, by contrast, adapt in response to local inputs, which are rarely labeled and may not be systematically collected. As a result, the quality and direction of updates, whether they enhance generalization or cause drift, are difficult to assess without interfering with the user experience or violating privacy constraints.
The risk of model drift is especially pronounced in streaming settings, where continual adaptation may cause a slow degradation in performance. For instance, a voice recognition model that adapts too aggressively to background noise may eventually overfit to transient acoustic conditions, reducing accuracy on the target task. Without visibility into the evolution of model parameters or outputs, such degradations can remain undetected until they become severe.
Mitigating this problem requires mechanisms for on-device validation and update gating. One approach is to interleave adaptation steps with lightweight performance checks—using proxy objectives or self-supervised signals to approximate model confidence (Y. Deng, Mokhtari, and Ozdaglar 2021). For example, a keyword spotting system might track detection confidence across recent utterances and suspend updates if confidence consistently drops below a threshold. Alternatively, shadow evaluation can be employed, where multiple model variants are maintained on the device and evaluated in parallel on incoming data streams, allowing the system to compare the adapted model’s behavior against a stable baseline.
Another strategy involves periodic checkpointing and rollback, where snapshots of the model state are saved before adaptation. If subsequent performance degrades, as determined by downstream metrics or user feedback, the system can revert to a known good state. This approach has been used in health monitoring devices, where incorrect predictions could lead to user distrust or safety concerns. However, it introduces storage and compute overhead, especially in memory-constrained environments.
In some cases, federated validation offers a partial solution. Devices can share anonymized model updates or summary statistics with a central server, which aggregates them across users to identify global patterns of drift or failure. While this preserves some degree of privacy, it introduces communication overhead and may not capture rare or user-specific failures.
Ultimately, update monitoring and validation in on-device learning require a rethinking of traditional evaluation practices. Instead of centralized test sets, systems must rely on implicit signals, runtime feedback, and conservative adaptation policies to ensure robustness. The absence of global observability is not merely a technical limitation—it reflects a deeper systems challenge in aligning local adaptation with global reliability.
Performance Evaluation in Dynamic Environments
Chapter 12: Benchmarking AI established systematic approaches for measuring ML system performance: inference latency, throughput, energy efficiency, and accuracy metrics. These benchmarking methodologies provide foundations for characterizing model performance, but they were designed for static inference workloads. On-device learning requires extending these metrics to capture adaptation quality and training efficiency through training-specific benchmarks.
Beyond the inference metrics from Chapter 12: Benchmarking AI, adaptive systems require specialized training metrics that capture learning efficiency under edge constraints. Adaptation efficiency measures accuracy improvement per training sample consumed, quantified as the slope of the learning curve under resource constraints—a system achieving 2% accuracy gain per 100 training samples demonstrates higher adaptation efficiency than one requiring 500 samples for the same improvement, directly translating to faster personalization and reduced data collection requirements. Memory-constrained convergence evaluates the validation loss achieved within specified RAM budgets, such as “convergence within 512 KB training footprint,” capturing how effectively systems learn given fixed memory allocations—critical for comparing adaptation strategies across device classes from microcontrollers to smartphones. Energy-per-update quantifies millijoules consumed per gradient update, a metric critical for battery-powered devices where training energy directly impacts user experience—mobile devices typically budget 500-1000 mW for sustained ML workloads, translating to just 1.8-3.6 joules per hour of adaptation before noticeably affecting battery life. Time-to-adaptation measures wall-clock time from receiving new data to achieving measurable improvement, accounting for opportunistic scheduling constraints that defer training to idle periods—this metric captures real-world adaptation speed including waiting for device idleness, charging status, and thermal headroom rather than just raw computational throughput.
Evaluating whether local adaptation actually improves over global models requires personalization gain metrics that justify the overhead of on-device learning. Per-user performance delta measures accuracy improvement for the adapted model versus the global baseline on user-specific holdout data—systems should demonstrate statistically significant improvements, typically exceeding 2% accuracy gains, to justify the computational overhead, energy consumption, and complexity that adaptation introduces. Personalization-privacy tradeoff quantifies accuracy gain per unit of local data exposure, measuring the value extracted from privacy-sensitive information—this metric helps assess whether adaptation benefits outweigh the privacy costs of retaining user data locally, particularly important for applications handling sensitive information like health data or personal communications. Catastrophic forgetting rate measures degradation on the original task as the model adapts to local distributions through retention testing—acceptable forgetting rates depend on the application domain but typically should remain below 5% accuracy loss on original tasks to ensure that personalization does not come at the expense of the model’s general capabilities.
When devices coordinate through federated learning (Section 1.6), federated coordination cost metrics become critical for assessing system viability. Communication efficiency measures model accuracy improvement per byte transmitted, capturing the effectiveness of gradient compression and selective update strategies—modern federated systems achieve 10-100\(\times\) compression through quantization and sparsification techniques while maintaining 95% or more of uncompressed accuracy, making the difference between practical and impractical mobile deployment. Stragglers impact quantifies convergence delay caused by slow or unreliable devices, measured as the difference in convergence time with versus without participation filters—effective straggler mitigation through asynchronous aggregation and selective participation reduces convergence time by 30-50% compared to synchronous approaches that wait for all devices. Aggregation quality evaluates global model performance as a function of device participation rate, revealing minimum viable participation thresholds below which federated learning fails to converge effectively—most federated systems require 10-20% device participation per round to maintain stable convergence, establishing clear requirements for client selection and availability management strategies.
These training-specific benchmarks complement the inference metrics from Chapter 12: Benchmarking AI, creating complete performance characterization for adaptive systems. Practical benchmarking must measure both dimensions: a system that achieves fast inference but slow adaptation, or efficient adaptation but poor final accuracy, fails to meet real-world requirements. The integration of inference and training benchmarks enables holistic evaluation of on-device learning systems across their full operational lifecycle.
Resource Management
On-device learning introduces resource contention modes absent in conventional inference-only deployments. Many edge devices are provisioned to run pretrained models efficiently but are rarely designed with training workloads in mind. Local adaptation therefore competes for scarce resources, including compute cycles, memory bandwidth, energy, and thermal headroom, with other system processes and user-facing applications.
The most direct constraint is compute availability. Training involves additional forward and backward passes through the model, which can exceed the cost of inference. Even when only a small subset of parameters is updated, for instance, in bias-only or head-only adaptation, backpropagation must still traverse the relevant layers, triggering increased instruction counts and memory traffic. On devices with shared compute units (e.g., mobile SoCs or embedded CPUs), this demand can delay interactive tasks, reduce frame rates, or impair sensor processing.
Energy consumption compounds this problem. Adaptation typically involves sustained computation over multiple input samples, which taxes battery-powered systems and may lead to rapid energy depletion. For instance, performing a single epoch of adaptation on a microcontroller-class device can consume several millijoules36—an appreciable fraction of the energy budget for a duty-cycled system operating on harvested power. This necessitates careful scheduling, such that learning occurs only during idle periods, when energy reserves are high and user latency constraints are relaxed.
36 Microcontroller Power Budget Reality: A typical microcontroller consuming 10 mW during training exhausts 3.6 joules per hour, equivalent to a 1000 mAh battery in 2.8 hours. Energy harvesting systems collect only 10-100 mW continuously (solar panels in indoor light), making sustained training impossible. Real deployments use duty cycling: train for 10 seconds every hour, consuming ~1 joule total. This constrains training to 100-1000 gradient steps maximum, requiring extremely efficient algorithms and careful energy budgeting between sensing, computation, and communication.
37 Activation Caching: During backpropagation, forward pass activations must be stored to compute gradients, dramatically increasing memory usage. For a typical CNN, activation memory can be 3-5\(\times\) larger than model weights. Modern techniques like gradient checkpointing trade computation for memory by recomputing activations during backward pass, reducing memory by 80% at the cost of ~30% more compute time. Critical for training on memory-constrained devices where activation storage often exceeds available RAM. These requirements may exceed the static memory footprint anticipated during model deployment, particularly when adaptation involves multiple layers or gradient accumulation. In highly constrained systems, for example, systems with less than 512 KB of RAM, this may preclude certain types of adaptation altogether, unless additional optimization techniques (e.g., checkpointing or low-rank updates) are employed.
From a memory perspective, training incurs higher peak usage than inference, due to the need to cache intermediate activations37, gradients, and optimizer state (Lin et al. 2020).
These resource demands must also be balanced against quality of service (QoS) goals. Users expect edge devices to respond reliably and consistently, regardless of whether learning is occurring in the background. Any observable degradation, including dropped audio in a wake-word detector or lag in a wearable display, can erode user trust. These system reliability concerns parallel the operational challenges discussed in Chapter 13: ML Operations. As such, many systems adopt opportunistic learning policies, where adaptation is suspended during foreground activity and resumed only when system load is low.
In some deployments, adaptation is further gated by cost constraints imposed by networked infrastructure. For instance, devices may offload portions of the learning workload to nearby gateways or cloudlets, introducing bandwidth and communication trade-offs. These hybrid models raise additional questions of task placement and scheduling: should the update occur locally, or be deferred until a high-throughput link is available?
In summary, the cost of on-device learning is not solely measured in FLOPs or memory usage. It manifests as a complex interplay of system load, user experience, energy availability, and infrastructure capacity. Addressing these challenges requires co-design across algorithmic, runtime, and hardware layers, ensuring that adaptation remains unobtrusive, efficient, and sustainable under real-world constraints.
Identifying and Preventing System Failures
Understanding potential failure modes in on-device learning helps prevent costly deployment mistakes. Based on documented challenges in federated learning research (Kairouz et al. 2021) and known risks in adaptive systems, several categories of failures warrant careful consideration.
The most fundamental risk in on-device learning is unbounded adaptation drift, where continuous learning without constraints causes models to gradually diverge from their intended behavior. Consider a hypothetical keyboard prediction system that learns from all user inputs including corrections—it might begin incorporating typos as valid suggestions, leading to progressively degraded predictions. This risk becomes acute in health monitoring applications where gradual changes in user baselines could be learned as “normal,” potentially causing the system to miss important anomalies that would have been detected by a static model. The insidious nature of this drift is that it occurs slowly and locally, making detection difficult without proper monitoring infrastructure.
Beyond individual device drift, federated learning systems face the challenge of participation bias amplification at the population level. Devices with reliable power and connectivity participate more frequently in federated rounds (Li et al. 2020). This uneven participation creates scenarios where models become increasingly optimized for users with high-end devices while performance degrades for those with limited resources. The resulting feedback loop exacerbates digital inequality: better-served users receive increasingly better models, while underserved populations experience declining performance, reducing their engagement and further diminishing their representation in training rounds (J. Wang et al. 2021). These fairness and bias amplification concerns highlight the ethical implications of distributed learning systems.
These systematic biases interact with data quality issues to create autocorrection feedback loops, particularly in text-based applications. When systems cannot distinguish between intended inputs and corrections, they may develop unexpected behaviors. Frequently corrected domain-specific terminology might be incorrectly learned as errors, leading to inappropriate suggestions in professional contexts. This problem compounds the drift issue: not only do models adapt to individual quirks, but they may also learn from their own mistakes when users accept autocorrections without realizing the system is learning from these interactions.
The interconnected nature of these failure modes, from individual drift to population bias to data quality degradation, underscores the importance of implementing comprehensive safety mechanisms. Successful deployments require bounded adaptation ranges to prevent unbounded drift, stratified sampling to address participation bias, careful data filtering to avoid learning from corrections as ground truth, and shadow evaluation against static baselines to detect degradation. While specific production incidents are rarely publicized due to competitive and privacy concerns, the research community has identified these patterns as critical areas requiring systematic mitigation strategies (Li et al. 2020; Kairouz et al. 2021).
Production Deployment Risk Assessment
The deployment of adaptive models on edge devices introduces challenges that extend beyond technical feasibility. In domains where compliance, auditability, and regulatory approval are necessary, including healthcare, finance, and safety-important systems, on-device learning poses a core tension between system autonomy and control.
In traditional machine learning pipelines, all model updates are centrally managed, versioned, and validated. The training data, model checkpoints, and evaluation metrics are typically recorded in reproducible workflows that support traceability. When learning occurs on the device itself, however, this visibility is lost. Each device may independently evolve its model parameters, influenced by unique local data streams that are never observed by the developer or system maintainer.
This autonomy creates a validation gap. Without access to the input data or the exact update trajectory, it becomes difficult to verify that the learned model still adheres to its original specification or performance guarantees. This is especially problematic in regulated industries, where certification depends on demonstrating that a system behaves consistently across defined operational boundaries. A device that updates itself in response to real-world usage may drift outside those bounds, triggering compliance violations without any external signal.
The lack of centralized oversight complicates rollback and failure recovery. If a model update degrades performance, it may not be immediately detectable, particularly in offline scenarios or systems without telemetry. By the time failure is observed, the system’s internal state may have diverged significantly from any known checkpoint, making diagnosis and recovery more complex than in static deployments. This necessitates robust safety mechanisms, such as conservative update thresholds, rollback caches, or dual-model architectures that retain a verified baseline.
In addition to compliance challenges, on-device learning introduces new security vulnerabilities. Because model adaptation occurs locally and relies on device-specific, potentially untrusted data streams, adversaries may attempt to manipulate the learning process by tampering with stored data, such as replay buffers, or by injecting poisoned examples during adaptation, to degrade model performance or introduce vulnerabilities. Any locally stored adaptation data, such as feature embeddings or few-shot examples, must be secured against unauthorized access to prevent unintended information leakage.
Maintaining model integrity over time is particularly difficult in decentralized settings, where central monitoring and validation are limited. Autonomous updates could, without external visibility, cause models to drift into unsafe or biased states. These risks are compounded by compliance obligations such as the GDPR’s right to erasure: if user data subtly influences a model through adaptation, tracking and reversing that influence becomes complex.
The security and integrity of self-adapting models, particularly at the edge, pose important open challenges. A comprehensive treatment of these threats and corresponding mitigation strategies requires specialized security frameworks for distributed ML systems.
Privacy regulations also interact with on-device learning in nontrivial ways. While local adaptation can reduce the need to transmit sensitive data, it may still require storage and processing of personal information, including sensor traces or behavioral logs, on the device itself. These privacy considerations require careful attention to security frameworks and regulatory compliance. Depending on jurisdiction, this may invoke additional requirements for data retention, user consent, and auditability. Systems must be designed to satisfy these requirements without compromising adaptation effectiveness, which often involves encrypting stored data, enforcing retention limits, or implementing user-controlled reset mechanisms.
Lastly, the emergence of edge learning raises open questions about accountability and liability (Brakerski et al. 2022). When a model adapts autonomously, who is responsible for its behavior? If an adapted model makes a faulty decision, such as misdiagnosing a health condition or misinterpreting a voice command, the root cause may lie in local data drift, poor initialization, or insufficient safeguards. Without standardized mechanisms for capturing and analyzing these failure modes, responsibility may be difficult to assign, and regulatory approval harder to obtain.
Addressing these deployment and compliance risks requires new tooling, protocols, and design practices that support auditable autonomy—the ability of a system to adapt in place while still satisfying external requirements for traceability, reproducibility, and user protection. As on-device learning becomes more prevalent, these challenges will become central to both system architecture and governance frameworks.
Engineering Challenge Synthesis
Designing on-device ML systems involves navigating a complex landscape of technical and practical constraints. While localized adaptation allows personalization, privacy, and responsiveness, it also introduces a range of challenges that span hardware heterogeneity, data fragmentation, observability, and regulatory compliance.
System heterogeneity complicates deployment and optimization by introducing variation in compute, memory, and runtime environments. Non-IID data distributions challenge learning stability and generalization, especially when models are trained on-device without access to global context. The absence of centralized monitoring makes it difficult to validate updates or detect performance regressions, and training activity must often compete with core device functionality for energy and compute. Finally, post-deployment learning introduces complications in model governance, from auditability and rollback to privacy assurance.
These challenges are not isolated—they interact in ways that influence the viability of different adaptation strategies. Table 6 summarizes the primary challenges and their implications for ML systems deployed at the edge.
| Challenge | Root Cause | System-Level Implications |
|---|---|---|
| System Heterogeneity | Diverse hardware, software, and toolchains | Limits portability; requires platform-specific tuning |
| Non-IID and Fragmented Data | Localized, user-specific data distributions | Hinders generalization; increases risk of drift |
| Limited Observability and Feedback | No centralized testing or logging | Makes update validation and debugging difficult |
| Resource Contention and Scheduling | Competing demands for memory, compute, and battery | Requires dynamic scheduling and budget-aware learning |
| Deployment and Compliance Risk | Learning continues post-deployment | Complicates model versioning, auditing, and rollback |
Foundations for Robust AI Systems
The operational challenges and failure modes explored in the preceding sections reveal vulnerabilities that extend beyond deployment concerns into fundamental system reliability. When models adapt autonomously across millions of heterogeneous devices, three categories of threats emerge that traditional centralized training never encounters.
First, unlike centralized systems where failures are localized and observable (as discussed in Chapter 13: ML Operations), on-device learning creates scenarios where local failures can propagate silently across device populations. A corrupted adaptation on one device, if aggregated through federated learning, can poison the global model. Hardware faults that would trigger errors in centralized infrastructure may silently corrupt gradients on edge devices with minimal error detection capabilities.
Second, the federated coordination mechanisms that enable collaborative learning also create new attack surfaces. Adversarial clients can inject poisoned gradients38 designed to degrade global model performance. Model inversion attacks can extract private information from shared updates despite aggregation. The distributed nature of on-device learning makes these attacks both easier to execute (compromising client devices) and harder to detect (no centralized validation).
38 Byzantine Fault Tolerance in FL: Distributed systems property that enables correct operation despite some participants being malicious or faulty (named after the Byzantine Generals Problem). In federated learning, up to f malicious clients can be tolerated among n participants using algorithms like Krum or trimmed mean aggregation, which requires n ≥ 3f + 1 total participants. These robust aggregation methods increase communication costs by 2-5\(\times\) and computational overhead by 3-10\(\times\), but prevent poisoning attacks where malicious clients could degrade global model performance by injecting adversarial gradients.
Third, on-device systems must handle distribution shifts and environmental changes without access to labeled validation data. Models may confidently drift into failure modes, adapting to local biases or temporary anomalies. The non-IID data distributions across devices mean that local drift on individual devices may not trigger global alarms, allowing silent degradation.
These reliability threats demand systematic approaches that ensure on-device learning systems remain robust despite autonomous adaptation, malicious manipulation, and environmental uncertainty. Chapter 16: Robust AI examines these challenges comprehensively, establishing principles for fault-tolerant AI systems that can maintain reliability despite hardware faults, adversarial attacks, and distribution shifts. The techniques developed there—Byzantine-resilient aggregation, adversarial training, and drift detection—become essential components of production-ready on-device learning systems rather than optional enhancements.
The privacy-preserving aspects of these robustness mechanisms, including secure aggregation and differential privacy, connect directly to Chapter 15: Security & Privacy, which establishes the cryptographic foundations and privacy guarantees necessary for deploying self-learning systems at scale while maintaining user trust and regulatory compliance.
Fallacies and Pitfalls
On-device learning operates in a fundamentally different environment from cloud-based training, with severe resource constraints and privacy requirements that challenge traditional machine learning assumptions. The appeal of local adaptation and privacy preservation can obscure the significant technical limitations and implementation challenges that determine whether on-device learning provides net benefits over simpler alternatives.
Fallacy: On-device learning provides the same adaptation capabilities as cloud-based training.
This misconception leads teams to expect that local learning can achieve the same model improvements as centralized training with abundant computational resources. On-device learning operates under severe constraints including limited memory, restricted computational power, and minimal energy budgets that fundamentally limit adaptation capabilities. Local datasets are typically small, biased, and non-representative, making it impossible to achieve the same generalization performance as centralized training. Effective on-device learning requires accepting these limitations and designing adaptation strategies that provide meaningful improvements within practical constraints rather than attempting to replicate cloud-scale learning capabilities. This necessitates an efficiency-first mindset and careful optimization techniques.
Pitfall: Assuming that federated learning automatically preserves privacy without additional safeguards.
Many practitioners believe that keeping data on local devices inherently provides privacy protection without considering the information that can be inferred from model updates. Gradient and parameter updates can leak significant information about local training data through various inference attacks. Device participation patterns, update frequencies, and model convergence behaviors can reveal sensitive information about users and their activities. True privacy preservation requires additional mechanisms like differential privacy (mathematical guarantees that individual data points cannot be inferred from model outputs), secure aggregation protocols that prevent parameter inspection, and careful communication protocols rather than relying solely on data locality.
Fallacy: Resource-constrained adaptation always produces better personalized models than generic models.
This belief assumes that any local adaptation is beneficial regardless of the quality or quantity of local data available. On-device learning with insufficient, noisy, or biased local data can actually degrade model performance compared to well-trained generic models. Small datasets may not provide enough signal for meaningful learning, while adaptation to local noise can harm generalization. Effective on-device learning systems must include mechanisms to detect when local adaptation is beneficial and fall back to generic models when local data is inadequate for reliable learning.
Pitfall: Ignoring the heterogeneity challenges across different device types and capabilities.
Teams often design on-device learning systems assuming uniform hardware capabilities across deployment devices. Real-world deployments span diverse hardware with varying computational power, memory capacity, energy constraints, and networking capabilities. A learning algorithm that works well on high-end smartphones may fail catastrophically on resource-constrained IoT devices39.
39 System Heterogeneity Reality: Edge device capabilities span 6+ orders of magnitude—from 32 KB RAM microcontrollers to 16 GB smartphones. Processing power varies from 48 MHz ARM Cortex-M0+ (~10 MIPS) to 3 GHz A-series processors (~100,000 MIPS). Power budgets range from 10 μW (sensor nodes) to 5 W (flagship phones). This extreme diversity means federated learning algorithms must dynamically adapt: quantized inference on low-end devices, selective participation based on capability, and tiered aggregation strategies that account for the 10,000\(\times\) performance differences within a single deployment. This heterogeneity affects not only individual device performance but also federated learning coordination where slow or unreliable devices can bottleneck the entire system. Successful on-device learning requires adaptive algorithms that adjust to device capabilities and robust coordination mechanisms that handle device heterogeneity gracefully. The development and deployment of such systems benefits from robust engineering practices that handle uncertainty and failure gracefully.
Pitfall: Underestimating the complexity of orchestrating learning across distributed edge systems.
Many teams focus on individual device optimization without considering the system-level challenges of coordinating learning across thousands or millions of edge devices. Edge systems orchestration must handle intermittent connectivity, varying power states, different time zones, and unpredictable device availability patterns that create complex scheduling and synchronization challenges. Device clustering, federated rounds coordination, model versioning across diverse deployment contexts, and handling partial participation from unreliable devices require sophisticated infrastructure beyond simple aggregation servers. Additionally, real-world edge deployments involve multiple stakeholders with different incentives, security requirements, and operational procedures that must be balanced against learning objectives. Effective edge learning systems require robust orchestration frameworks that can maintain system coherence despite constant device churn, network partitions, and operational disruptions.
Summary
On-device learning represents a fundamental shift from static, centralized training to dynamic, local adaptation directly on deployment devices. This paradigm enables machine learning systems to personalize experiences while preserving privacy, reduce network dependencies, and respond rapidly to changing local conditions. Success requires integrating optimization principles, understanding hardware constraints, and applying sound operational practices. The transition from traditional cloud-based training to edge-based learning requires overcoming severe computational, memory, and energy constraints that fundamentally reshape how models are designed and adapted.
The technical strategies that enable practical on-device learning span multiple dimensions of system design. Adaptation techniques range from lightweight bias-only updates to selective parameter tuning, each offering different tradeoffs between expressivity and resource efficiency. Data efficiency becomes paramount when learning from limited local examples, driving innovations in few-shot learning40, streaming adaptation, and memory-based replay mechanisms41.
40 Few-Shot Learning: Machine learning paradigm that learns new concepts from only a few (typically 1-10) labeled examples. Originally inspired by human learning capabilities—humans can recognize new objects from just one or two examples. In ML, few-shot learning leverages pre-trained representations and meta-learning to quickly adapt to new tasks. Critical for on-device scenarios where collecting large labeled datasets is impractical. Techniques include prototypical networks, model-agnostic meta-learning (MAML), and metric learning approaches that achieve 80-90% accuracy with just 5 examples per class. Federated learning emerges as a crucial coordination mechanism, allowing devices to collaborate while maintaining data locality and privacy guarantees.
41 Catastrophic Forgetting: When neural networks learn new tasks, they tend to “forget” previously learned information as new gradients overwrite old weights. This is a fundamental challenge for on-device learning where models must continuously adapt without losing prior knowledge. Solutions include elastic weight consolidation (EWC), gradient episodic memory (GEM), and replay buffers that store representative samples. In resource-constrained devices, rehearsal strategies must balance memory overhead (storing old examples) with computational cost (retraining on mixed data), directly impacting system design decisions.
- On-device learning shifts machine learning from static deployment to dynamic local adaptation, enabling personalization while preserving privacy
- Resource constraints drive specialized techniques: bias-only updates, adapter modules, sparse parameter updates, and compressed data representations
- Federated learning coordinates distributed training across heterogeneous devices while maintaining privacy and handling non-IID data distributions
- Success requires co-designing algorithms with hardware constraints, balancing adaptation capability against memory, energy, and computational limitations
Real-world applications demonstrate both the potential and challenges of on-device learning, from keyword spotting systems that adapt to user voices to recommendation engines that personalize without transmitting user data. As machine learning expands into mobile, embedded, and wearable environments, the ability to learn locally while maintaining efficiency and reliability becomes essential for next-generation intelligent systems that operate seamlessly across diverse deployment contexts.
The distributed nature of on-device learning introduces new vulnerabilities that extend beyond individual device constraints. The very capabilities that make these systems powerful—learning from user data, adapting to local patterns, coordinating across devices—also create new attack surfaces and privacy risks. These adaptive systems must not only function correctly but also protect sensitive user information and defend against adversarial manipulation. Security and privacy frameworks (Chapter 15: Security & Privacy) address these critical concerns, showing how to protect on-device learning systems from both privacy breaches and adversarial attacks. Subsequently, the robust AI principles (Chapter 16: Robust AI) extend these protections to encompass system-wide reliability challenges including hardware failures and software faults, while ML Operations (Chapter 13: ML Operations) provides the comprehensive framework for deploying and maintaining these complex adaptive systems in production.