From Logic to Arithmetic
Neural Computation

Purpose
Why does understanding a neural network’s math matter more than reading its code?
Neural networks reduce to a small set of mathematical operations. Matrix multiplications dominate compute. Activation functions introduce nonlinearity. Gradient computations enable learning. These operations are the workload that every layer of the system stack must execute, and each carries concrete physical consequences: a matrix multiplication’s dimensions determine whether a layer is compute bound or memory bound; an activation function’s complexity determines whether it can be fused with adjacent kernels; the number of parameters determines whether a model fits in accelerator memory at all. When something goes wrong, inspecting the code reveals nothing because it simply says “multiply these matrices.” The bug is not in the logic but in the math itself: a misconfigured learning rate that causes gradients to explode, an activation that saturates and silently blocks learning, a memory footprint that fits during development but exhausts the accelerator in production. This is why the mathematical primitives come first, before architectures, frameworks, or training systems. Every subsequent chapter builds on these operations: architectures compose them into computational graphs, frameworks schedule them onto hardware, training systems orchestrate billions of repetitions, and compression techniques approximate them to fit tighter constraints. An engineer who understands the primitives can look at any new architecture and immediately reason about its compute profile, its memory demands, and its hardware compatibility, because they understand the atoms it is made of.
Learning Objectives
- Explain how limitations of rule-based and classical ML systems necessitated deep learning approaches
- Describe neural network components and compare activation functions (sigmoid, tanh, ReLU, softmax) for their mathematical and hardware implications
- Explain how cross-entropy loss quantifies prediction error and drives gradient-based weight updates
- Contrast training and inference phases in terms of computational demands and deployment considerations
- Explain forward and backward propagation through multi-layer networks as matrix operations and gradient computation for weight updates
- Analyze how neural network operations determine hardware memory and processing requirements
- Trace the end-to-end neural network pipeline from preprocessing through inference, using USPS deployment as a concrete example
A model that runs correctly on one GPU and crashes on another is not suffering from a hardware bug. The matrix dimensions in its attention layer exceed the memory available for intermediate activations, and the crash is a direct consequence of the mathematics inside the model, not the code around it. The ML workflow (ML Workflow) defined how projects progress from problem definition through deployment, and data engineering (Data Engineering) covered how to prepare the raw material that models consume. The question remaining is what happens inside the model itself.
The silicon contract (Iron Law of ML Systems) established that every model architecture makes a computational bargain with the hardware it runs on. The architecture’s mathematical operators set the terms of that bargain: they determine how much memory the model consumes, how long each computation takes, and how much energy the system expends. To honor the contract, a systems engineer must understand those operators.
The operators that follow are not abstract theory but a specification for computational workloads. Neural computation represents a qualitative shift in how we process information: instead of executing a sequence of explicit logical instructions (if-then-else), we execute a massive sequence of continuous mathematical transformations (multiply-add-accumulate). This shift from Logic to Arithmetic changes everything for the systems engineer, creating compute-bound workloads. The “bug” in such a system is rarely a syntax error; it is a numerical instability, a vanishing gradient, or a saturated activation function. Concretely, recognizing a single handwritten digit in the MNIST network we use throughout this chapter requires 109,184 multiply-accumulate (MAC) operations—not one of which is a logical branch.
Definition 1.1: Deep learning
Deep Learning is the computational paradigm of Hierarchical Feature Learning from raw data.
- Significance (quantitative): By stacking nonlinear transformations, it replaces manual Feature Engineering with Architecture Engineering, enabling models to scale with both Data Volume \((D_{\text{vol}})\) and Compute \((R_{\text{peak}})\).
- Distinction (durable): Unlike Shallow Learning, which learns a single transformation, Deep Learning learns a Hierarchy of Abstractions that can be fine-tuned for different tasks.
- Common pitfall: A frequent misconception is that Deep Learning is “just a big neural network.” In reality, it is a Systems Strategy: it uses the iron law to trade computation (\(O\)) for the ability to generalize from high-dimensional inputs.
The landmark Nature review by LeCun, Bengio, and Hinton1 (LeCun et al. 2015) formalized this paradigm.
1 LeCun, Bengio, and Hinton: Recipients of the 2018 ACM Turing Award, their individual contributions (convolutional networks from LeCun, probabilistic sequence models from Bengio, and backpropagation training from Hinton) directly shaped the three operations that dominate modern accelerator workloads: spatial convolution, sequential attention, and gradient computation.
LeCun, Yann, Yoshua Bengio, and Geoffrey Hinton. 2015. “Deep Learning.” Nature 521 (7553): 436–44. https://doi.org/10.1038/nature14539.
Classical machine learning required human experts to design feature extractors for each new problem, a labor-intensive process that encoded domain knowledge into handcrafted representations. Deep learning eliminates this bottleneck by learning representations directly from raw data through hierarchical layers of nonlinear transformations. To see where neural networks fit in the broader landscape, examine the concentric layers in Figure 1: neural networks sit at the core of deep learning, which is itself a subset of machine learning, which falls under the umbrella of artificial intelligence.

This paradigm shift creates an engineering problem with no precedent in traditional software. When conventional software fails, an error message points to a line of code. When deep learning fails, the symptoms are subtler: gradient instabilities2 that silently prevent learning, numerical precision errors that corrupt model weights over thousands of iterations, or memory access patterns in tensor operations3 that leave GPUs idle for most of each training step. These are not algorithmic bugs that a debugger can catch. They are systems problems that require understanding the mathematical machinery underneath.
2 Gradient Instabilities: In a 20-layer sigmoid network, gradient magnitude after backpropagation is approximately \(0.25^{20}\), or 9.1 × 10⁻¹³—effectively zero, making learning a mathematical impossibility without architectural intervention. These failures are invisible in standard logs (loss simply plateaus or becomes not a number (NaN)), making them among the hardest bugs to diagnose. Rectified linear unit (ReLU) activations (gradient of one for positive inputs) and residual connections (direct gradient highways that bypass layers) were the two architectural breakthroughs that made deep networks tractable; Skip connections: Solving the depth problem treats the residual-connection depth solution in detail.
3 Tensor Operations: The logical structure of a tensor (for example, a 4D image batch) often requires nonsequential memory access patterns to retrieve elements from its flat, 1D physical storage. A concrete example: PyTorch defaults to NCHW (channel-first) layout while most mobile hardware and ARM processors prefer NHWC (channel-last). A 224×224×3 ImageNet tensor is about 151 KB, so transposing it between formats requires about 301 KB of read-plus-write memory traffic per image—a pure memory operation with no arithmetic benefit. On tight latency budgets, this layout mismatch can consume a visible fraction of the end-to-end inference budget before the model does any useful math.
Diagnosing and solving such problems requires mathematical literacy that spans the full neural computation stack. The arc begins with learning paradigms, tracing how they evolved from explicit rules to handcrafted features to learned representations and establishing why deep learning demands qualitatively different system infrastructure than classical machine learning. Neural network fundamentals (neurons, layers, activation functions, and tensor operations) then receive treatment as both mathematical operations and computational workloads, with particular attention to the memory access patterns and arithmetic intensity that determine hardware utilization.
The learning process then takes center stage: the forward pass that produces predictions, the backpropagation algorithm that computes gradients, the loss functions that define optimization objectives, and the optimization algorithms that navigate loss landscapes. Each connects directly to system engineering decisions: matrix multiplication illuminates memory bandwidth requirements (the memory wall explored in Hardware Acceleration), gradient computation explains numerical precision constraints, and optimization dynamics inform resource allocation. The inference pipeline shifts the engineering concerns from throughput to latency and from training stability to deployment efficiency. A historical case study (USPS digit recognition) grounds these concepts in a real deployment, and the D·A·M taxonomy (Data, Algorithm, Machine) closes the arc by explaining why deep learning systems succeed only when all three components align.
To ground this arc in a concrete systems story, we start by following a single MNIST digit through three computational paradigms and quantify how each step changes the workload profile.
Computing with Patterns
The shift from logic to arithmetic reshapes how we encode real-world patterns in a form a computer can process. To make this evolution concrete, we track a single task across all three paradigms: classifying a handwritten digit from a \(28{\times}28\) pixel image from the MNIST dataset (the same input used throughout this chapter). Watch how the computational profile changes as representation strategies evolve.
From explicit logic to learned patterns
Traditional programming requires developers to explicitly define rules that tell computers how to process inputs and produce outputs. Consider a simple game like Breakout4. The program needs explicit rules for every interaction: when the ball hits a brick, the code must specify that the brick should be removed and the ball’s direction should be reversed (Figure 2). While this approach works effectively for games with clear physics and limited states, it hits a wall when dealing with the messy, unstructured data of the real world.
4 Breakout (DQN): Atari’s 1976 arcade game became an AI milestone when DeepMind’s DQN learned to play it from raw pixels alone (2015), requiring no programmed rules. The systems implication: DQN preprocessed each Atari frame to \(84{\times}84\) pixels and stacked 4 frames as input, selecting a new action every 4 frames (about 15 decisions per second on a 60 Hz game). This real-time inference loop pushed GPU utilization beyond what supervised learning required and foreshadowed the latency constraints of production inference pipelines.

Beyond individual applications, this rule-based paradigm extends to all traditional programming. Notice the data flow in Figure 3: the program takes both rules for processing and input data to produce outputs. Early artificial intelligence research explored whether this approach could scale to solve complex problems by encoding sufficient rules to capture intelligent behavior.

Despite their apparent simplicity, rule-based limitations surface quickly with complex real-world tasks. Recognizing human activities illustrates the challenge. Classifying movement below 6 km/h as walking seems straightforward until real-world complexity intrudes. Speed variations, transitions between activities, and boundary cases each demand additional rules, creating unwieldy decision trees (Figure 4). Computer vision tasks compound these difficulties. Detecting cats requires rules about ears, whiskers, and body shapes while accounting for viewing angles, lighting, occlusions, and natural variations. Early systems achieved success only in controlled environments with well-defined constraints.

Recognizing these limitations, the knowledge engineering approach that characterized AI research in the 1970s and 1980s attempted to systematize rule creation. Expert systems5 encoded domain knowledge as explicit rules, showing promise in specific domains with well-defined parameters but struggling with tasks humans perform naturally: object recognition, speech understanding, and natural language interpretation. These failures highlighted a deeper challenge: many aspects of intelligent behavior rely on implicit knowledge that resists explicit rule-based representation.
5 Expert Systems: These systems convert human expertise into explicit IF-THEN rules. This ‘knowledge engineering’ approach fails for tasks like object recognition, as the text notes, because the required knowledge is implicit and resists articulation. Even in a successful system (DEC’s XCON), the maintenance of 10,000+ hand-authored rules revealed an unsustainable scaling cost that motivated the shift to learned representations.
Consider classifying our \(28{\times}28\) digit with explicit rules: compare pixel intensities against thresholds, check stroke patterns in specific regions, branch on the results. The entire computation is roughly 100 comparisons over 784 bytes of pixel data—sequential, predictable, and comfortably within any CPU’s L1 cache. No special hardware needed. That simplicity is exactly what disappears as we move toward learned representations.
The feature engineering bottleneck
The failures of rule-based systems suggested an alternative: rather than encoding human knowledge as explicit rules, let the system discover patterns from data. Machine learning offered this direction—instead of writing rules for every situation, researchers wrote programs that identified patterns in examples. The success of these methods, however, still depended heavily on human insight to define which patterns to look for, a process known as feature engineering.
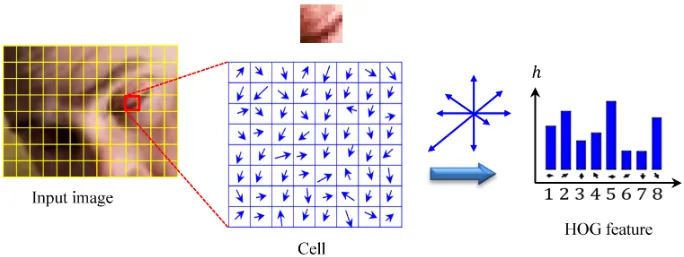
Feature engineering transformed raw data into representations that expose patterns to learning algorithms. The Histogram of Oriented Gradients (HOG)6 (Dalal and Triggs 2005) method exemplifies this approach, identifying edges where brightness changes sharply, dividing images into cells, and measuring edge orientations within each cell (Figure 5). This transforms raw pixels into shape descriptors robust to lighting variations and small positional changes.
6 Histogram of Oriented Gradients (HOG): The gold standard for object detection before deep learning (Dalal and Triggs 2005). HOG computes gradient orientations in fixed \(8{\times}8\) pixel cells, a rigid spatial decomposition that requires expert tuning per domain. The systems contrast with deep learning is instructive: HOG’s fixed computation graph runs efficiently on CPUs with predictable latency, while learned features demand GPU parallelism but generalize across domains without redesign.
Dalal, Navneet, and Bill Triggs. 2005. “Histograms of Oriented Gradients for Human Detection.” 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05) 1: 886–93. https://doi.org/10.1109/cvpr.2005.177.
Complementary methods like SIFT7 (Lowe 1999) (Scale-Invariant Feature Transform) and Gabor filters8 captured different visual patterns. SIFT detected keypoints stable across scale and orientation changes, while Gabor filters identified textures and frequencies. Each encoded domain expertise about visual pattern recognition.
7 Scale-Invariant Feature Transform (SIFT): SIFT encodes this “domain expertise” in a rigid, four-stage algorithm that identifies keypoints invariant to scale and rotation. This hand-engineering meant the number of keypoints varied unpredictably per image, from hundreds to thousands. This variable-sized output is mechanically incompatible with the fixed-size tensors that modern hardware accelerators demand.
Lowe, David G. 1999. “Object Recognition from Local Scale-Invariant Features.” Proceedings of the Seventh IEEE International Conference on Computer Vision 2: 1150–1157 vol.2. https://doi.org/10.1109/iccv.1999.790410.
8 Gabor Filters: Originally developed for localized time-frequency analysis (Gabor 1946), these filters detect edges and textures at specific orientations and frequencies. A typical bank contains 40+ filters (8 orientations \(\times\) 5 frequencies), all hand-designed. Deep learning’s first convolutional layers learn filters that closely resemble Gabor functions, but discover them automatically from data, replacing months of expert tuning with GPU-hours of training.
Gabor, D. 1946. “Theory of Communication. Part 1: The Analysis of Information.” Journal of the Institution of Electrical Engineers - Part III: Radio and Communication Engineering 93 (26): 429–41. https://doi.org/10.1049/ji-3-2.1946.0074.
These engineering efforts enabled advances in computer vision during the 2000s. Systems could now recognize objects with some robustness to real-world variations, leading to applications in face detection, pedestrian detection, and object recognition. Despite these successes, the approach had limitations. Experts needed to carefully design feature extractors for each new problem, and the resulting features might miss important patterns that were not anticipated in their design. The bottleneck remained: human expertise could not scale to the complexity and diversity of real-world visual patterns.
Return to the same \(28{\times}28\) digit. HOG divides the image into a 7 by 7 grid of \(4{\times}4\) cells, computes gradient magnitudes and orientations at each pixel, bins them into 9 orientation histograms per cell, and produces a 441-element feature vector. A linear classifier (SVM) then performs ten dot products over that vector. Total: roughly 8,000 arithmetic operations and ~2 KB of working memory—about 80\(\times\) more compute than the rule-based approach, but still structured, predictable, and well-served by CPU vector units using single instruction, multiple data (SIMD). Resource demands scale linearly with image count, not with model complexity.
Automatic pattern discovery
The limitations of handcrafted features motivate a more radical approach: rather than encoding features by hand, the system discovers its own. Neural networks embody exactly this shift—rather than following explicit rules or relying on human-designed feature extractors, the system learns representations directly from raw data.
Deep learning inverts the traditional programming relationship entirely. Traditional programming, as we saw earlier, required both rules and data as inputs to produce answers. Machine learning reverses this: we provide examples (data) and their correct answers, and the system discovers the underlying rules automatically. Figure 6 makes this inversion tangible—notice how data and answers now serve as the inputs, while rules emerge as the output. This shift eliminates the need for humans to specify what patterns are important.

The system discovers patterns from examples through this automated process. When shown millions of images of cats, it learns to identify increasingly complex visual patterns, from simple edges to combinations that constitute cat-like features. This parallels how biological visual systems operate, building understanding from basic visual elements to complex objects.
The gradual layering of patterns reveals why neural network depth matters. Deeper networks can express exponentially more functions with only polynomially more parameters, a compositionality advantage we formalize in Section 1.2.1 with a concrete MNIST example.
Deep learning exhibits predictable scaling: unlike traditional approaches where performance plateaus, these models continue improving with additional data (recognizing more variations) and computation (discovering subtler patterns). The scalability drove dramatic performance gains. In the ImageNet competition, traditional methods achieved approximately 25.8 percent top-5 error in 2011. AlexNet9 reduced this to 15.3 percent in 2012. By 2015, ResNet achieved 3.6 percent top-5 error, surpassing estimated human performance of approximately 5.1 percent.
9 AlexNet’s Two-GPU Split: Krizhevsky’s team split AlexNet across two NVIDIA GTX 580s not by architectural preference but by physical constraint—each card had only 3 GB of VRAM, and the full model required more memory than a single card could provide. This forced the first production instance of model parallelism: half the feature maps on each GPU, with cross-GPU communication only at specific layers. The workaround that felt like a hack in 2012 became the template for model parallelism at scale, and every modern pipeline-parallel strategy traces its lineage to this 3 GB ceiling.
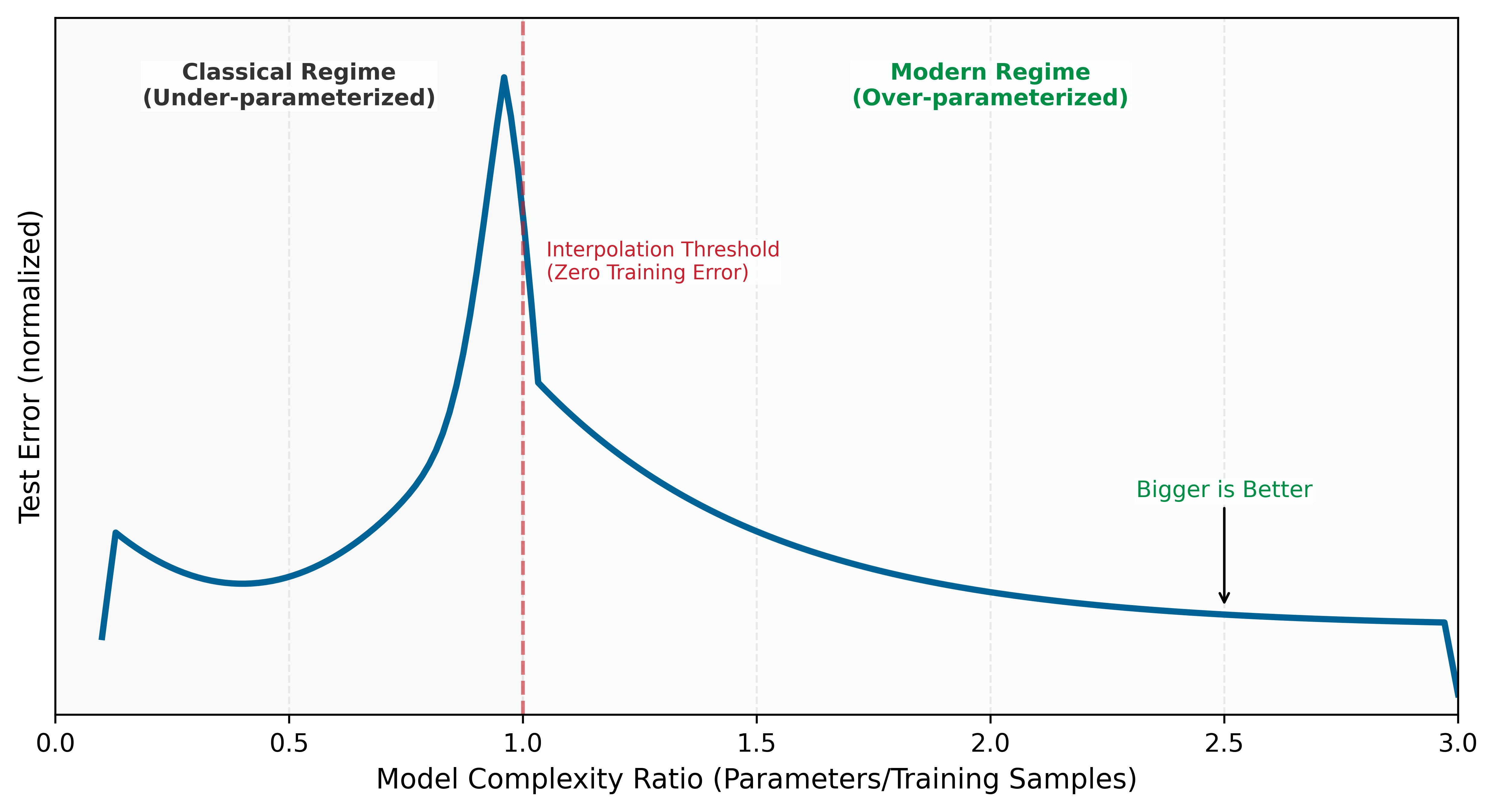
Figure 7 previews this scaling behavior through three distinct regimes. The underlying mechanisms (training error, overfitting, gradient-based learning) are developed in subsequent sections; here we establish the shape of the phenomenon. The Classical Regime is where traditional statistical intuitions hold, the Interpolation Threshold is where the model perfectly fits training data, and the Modern Regime is where massive overparameterization paradoxically improves generalization. The axes are normalized to emphasize shape rather than a specific dataset.
Notice the counterintuitive shape: test error initially follows the expected U-curve, but then decreases again in the overparameterized regime. This scaling behavior resolves the central paradox of deep learning. Classical statistical theory predicted that models should be sized to match data complexity: too small and they underfit, too large and they overfit by memorizing noise. This Bias-Variance Trade-off10 suggested that massive models would inevitably fail on new data. Instead, we observe a ‘Double Descent’ (Belkin et al. 2019) where larger models, trained on sufficient data, find smoother solutions that generalize better than smaller ones. The insight is that bigger is better when properly regularized, and it drives the race for 100B+ parameter foundation models.
10 Bias-Variance Trade-off: In overparameterized networks (parameter count >> training samples), the classical bias-variance trade-off breaks down: test error decreases again after the interpolation threshold, the Double Descent phenomenon. The systems consequence is that larger models trained longer are often more stable than smaller models stopped early, inverting the conventional wisdom that regularization is always the right response to overfitting. This insight drives the engineering decision to scale model size rather than constrain it—bigger networks with more compute often generalize better, not worse.
Belkin, Mikhail, Daniel Hsu, Siyuan Ma, and Soumik Mandal. 2019. “Reconciling Modern Machine-Learning Practice and the Classical Bias–Variance Trade-Off.” Proceedings of the National Academy of Sciences 116 (32): 15849–54. https://doi.org/10.1073/pnas.1903070116.
Neural network performance often follows empirical scaling relationships that impact system design. One durable scale anchor is that frontier model sizes and training compute budgets have increased by multiple orders of magnitude over the past decade. In broad terms, modern AI systems frequently trade off model size, data, and compute budgets rather than relying on a single “train longer” axis. Memory bandwidth and storage capacity can become primary constraints rather than raw computational power, depending on the workload and platform. The detailed formulations and quantitative analysis of scaling behavior are covered in Model Training, while Model Compression explores practical implementation.
Learning directly from raw data reshapes AI system construction. Eliminating manual feature engineering introduces new demands: infrastructure to handle massive datasets, high-throughput hardware to process that data, and specialized accelerators to perform mathematical calculations efficiently. These computational requirements have driven the development of specialized chips optimized for neural network operations. Empirical evidence confirms this pattern across domains: the success of deep learning in computer vision, speech recognition, game playing, and natural language understanding has established it as the dominant paradigm in artificial intelligence.
Return to the same \(28{\times}28\) digit, now processed by even a modest three-layer neural network (784 → 128 → 64 → 10). The forward pass alone requires 109,184 MAC operations, 1,092\(\times\) more than the rule-based approach. The 109,386 learned parameters consume ~438 KB in FP32, exceeding most L1 caches and forcing memory traffic between cache levels on every inference. Training multiplies the cost further: each image must be processed forward, then backward (computing gradients for all 109,386 parameters), then updated, at roughly 3\(\times\) the forward cost per image, repeated over 60,000 images for multiple epochs. The computation is no longer sequential; it is dominated by dense matrix multiplications that leave a standard CPU mostly idle. This is the systems explosion that drives everything that follows.
The scaling advantage comes with computational costs that raise a practical question about when engineers should invest in neural networks vs. simpler alternatives.
Systems Perspective 1.1: When to use neural networks
Not every problem benefits from deep learning. Before investing in neural network infrastructure, evaluate the problem against quantitative thresholds. Neural networks justify their cost when the conditions in Table 1 hold:
Table 1: Neural-Network Candidates: Conditions under which deep learning is likely to outperform classical methods.
Table 2: Classical-Method Candidates: Conditions under which simpler models are likely to match or beat a neural network.
| Condition | Threshold | Rationale |
|---|---|---|
| Dataset size | > 10,000 labeled examples | Below this, simpler models often match or exceed NN performance |
| Input dimensionality | > 100 raw features | NNs excel at automatic feature learning from high-dimensional data |
| Data has structure | Spatial, sequential, or hierarchical patterns | Architecture can encode inductive bias |
| Accuracy requirement | Need clear improvement over baseline | Late-stage gains often require disproportionate extra compute |
| Problem complexity | Nonlinear relationships dominate | Linear models handle linear relationships more efficiently |
Simpler methods are the better choice under the opposite regime, summarized in Table 2:
| Condition | Better Alternative | Typical Outcome |
|---|---|---|
| < 1,000 samples | Logistic regression, Random Forest | 10 ms training vs. hours; similar accuracy |
| Tabular data, < 100 features | Gradient Boosting (XGBoost, LightGBM) | Often matches NN accuracy with 100\(\times\) less compute |
| Linear relationships | Linear/Ridge regression | Interpretable, fast, often better generalization |
| Real-time constraint < 0.1 ms | Rule-based system | Deterministic latency, no model loading overhead |
| Explainability required | Decision trees, linear models | Regulatory compliance, debugging clarity |
Systems insight: Before building a neural network, train a logistic regression or gradient boosting model in < 1 hour. If it achieves > 90 percent of the target accuracy, the neural network’s additional complexity may not be justified. The USPS system (Section 1.5) succeeded partly because the problem genuinely required hierarchical feature learning that simpler methods could not provide.
Computational infrastructure requirements
The MNIST running example traced a single digit from ~100 comparisons (rule-based) through ~8,000 structured operations (HOG) to 109,184 matrix MACs (neural network): a 1,092\(\times\) escalation in computation, with a corresponding shift from predictable sequential access to bandwidth-hungry parallel matrix operations. Table 3 generalizes this pattern across every systems dimension.
| System Aspect | Traditional Programming | ML with Features | Deep Learning |
|---|---|---|---|
| Computation | Sequential, predictable paths | Structured parallel ops | Massive matrix parallelism |
| Memory Access | Small, predictable patterns | Medium, batch-oriented | Large, complex hierarchical |
| Data Movement | Simple input/output flows | Structured batch processing | Intensive cross-system movement |
| Hardware Needs | CPU-centric | CPU with vector units | Specialized accelerators |
| Resource Scaling | Fixed requirements | Linear with data size | Exponential with complexity |
The computational paradigm shift becomes apparent when comparing these approaches. Traditional programs follow sequential logic flows; deep learning requires massive parallel operations on matrices. This difference explains why conventional CPUs, designed for sequential processing, perform poorly for neural network computations.
The shift toward parallelism creates new bottlenecks that differ qualitatively from those in sequential computing. The central challenge is the Memory Wall11: while computational capacity can be increased by adding more processing units, memory bandwidth to feed those units does not scale as favorably. Matrix multiplication, the core neural network operation, is often limited by memory bandwidth rather than raw computational capability12—adding more processing units does not proportionally improve performance. Hardware responses to this challenge are examined in Understanding the AI memory wall, the complete derivation of training memory costs (weights, gradients, optimizer state, activations) appears in The true cost of training memory, and the formal memory hierarchy with quantitative latency comparisons is in The memory hierarchy.
11 Memory Wall: Fast on-chip storage responds in nanoseconds, while larger off-chip memory is orders of magnitude farther away in latency and energy. Neural network weights rarely fit in the smallest caches (even our MNIST model is hundreds of KB in FP32), forcing repeated memory fetches that can leave compute units idle. This bandwidth bottleneck, not arithmetic capacity alone, is why accelerators invest die area in HBM and on-chip SRAM.
12 Memory-Bound Operations: Matrix multiplication’s arithmetic intensity (FLOPs per byte loaded) determines whether a layer is compute bound or memory bound. Layers that fall below the hardware’s roofline crossover point finish their arithmetic before the next tile of weights arrives from memory. The result: effective hardware utilization can drop sharply, and adding more compute units yields little speedup until memory bandwidth or data reuse improves.
The deeper constraint is energy, not speed. Moving data from main memory to processing units consumes more energy than the actual mathematical operations. This energy hierarchy explains why neural network accelerators focus on maximizing data reuse: keeping frequently accessed weights in fast local storage and carefully scheduling operations to minimize data movement. GPUs address this through both higher memory bandwidth and massive parallelism, but the underlying physics remains unchanged: data movement dominates computation cost, driving the adoption of specialized hardware architectures from data center GPUs to TinyML accelerators.
The memory-computation trade-off manifests differently across the cloud-to-edge spectrum introduced in ML Systems. Cloud servers can afford more memory and power to maximize throughput, while mobile devices must carefully optimize to operate within strict power budgets. Training systems prioritize computational throughput even at higher energy costs, while inference systems emphasize energy efficiency. These different constraints drive different optimization strategies across the ML systems spectrum, ranging from memory-rich cloud deployments to heavily optimized TinyML implementations.
These single-machine constraints compound when scaling across multiple machines: deep learning models consume exponentially more resources as they grow, making distributed computing a necessity rather than a luxury. Memory optimization strategies like quantization and pruning are detailed in Model Compression, hardware architectures and their memory systems in Hardware Acceleration, and scaling laws in Model Training.
The infrastructure demands traced earlier (massive parallelism, memory walls, energy-dominated data movement) arise from four properties of neural computation: adaptive parameterization (weights change during training), parallel integration (many simple units operate simultaneously), hierarchical representation (layers compose low-level features into high-level concepts), and resource economy (data reuse minimizes energy-intensive movement). These properties manifest concretely in the fundamental building block of neural computation: the artificial neuron13. Just as understanding a single transistor reveals how complex processors work, understanding the artificial neuron reveals how million-parameter networks operate.
13 Neuron: McCulloch and Pitts (1943) established the first mathematical model with the “multiply-accumulate then activate” pattern, which is the direct origin of the computational properties discussed in the text. The model’s structure enables parallel integration (many simple units), its weights provide the mechanism for adaptive parameterization, and its output feeds subsequent layers to create hierarchical representations. Modern accelerators descend from this abstraction by devoting much of their datapath area and scheduling machinery to the fused multiply-add (FMA) units that implement it efficiently.
McCulloch, Warren S., and Walter Pitts. 1943. “A Logical Calculus of the Ideas Immanent in Nervous Activity.” The Bulletin of Mathematical Biophysics 5 (4): 115–33. https://doi.org/10.1007/bf02478259.
The artificial neuron as a computing primitive
The basic unit of neural computation, the artificial neuron (or node), serves as a simplified mathematical abstraction designed for efficient digital implementation (McCulloch and Pitts 1943). This building block enables complex networks to emerge from simple components working together. Compare the biological and artificial neurons side by side in Figure 8 to see how this computational model distills biological complexity into a standardized processing unit.

The mapping in Figure 8 traces a signal through four stages, each translating a biological structure into a mathematical operation. Table 4 formalizes these correspondences.
| Biological Structure | Artificial Component | Mathematical Operation | Engineering Role |
|---|---|---|---|
| Dendrites (receive signals) | Input Vector | \(\mathbf{x} = [x_1, \dots, x_n]\) | Data ingestion from sensors or prior layers |
| Synapses (modulate strength) | Weight Vector | \(\mathbf{w} = [w_1, \dots, w_n]\) | Learnable parameters encoding importance |
| Cell Body (integrates signals) | Linear Function \(z\) | \(z = \sum (x_i \cdot w_i) + b\) | Linear integration of feature signals |
| Axon (fires output) | Activation Function \(f\) | \(a = f(z)\) | Nonlinear thresholding and signal propagation |
Follow the signal path through the right panel of Figure 8 to see this pipeline in action:
Input Reception (Dendrites → \(x_1, x_2, \dots, x_n\)): The neuron receives a vector of input features \(\mathbf{x}\). In a system like MNIST digit recognition, these represent individual pixel intensities—the digital equivalent of signals arriving at a biological neuron’s dendrites.
Weighted Modulation (Synapses → \(w_1, w_2, \dots, w_n\)): Each input is multiplied by a learnable weight \(w_i\), just as synaptic strengths modulate biological signals. These weights act as “gain” controls, determining how much influence each feature has on the final decision. A bias term \(b\) (shown as the top input \(x_0 = 1\) in Figure 8) shifts the activation threshold. This is where the model’s “knowledge” is stored.
Signal Aggregation (Cell Body → Linear Function \(z\)): The neuron integrates the weighted signals, producing a single scalar value \(z = \sum (x_i \cdot w_i) + b\). This mirrors how a biological cell body sums incoming electrochemical signals to determine whether the neuron has received enough evidence for a particular pattern.
Nonlinear Activation (Axon → Activation Function \(f\)): The aggregated signal passes through an activation function \(f(z)\), producing the output \(y\). This mirrors the axon’s all-or-nothing firing decision: the nonlinearity determines whether the neuron “fires” a signal to the next layer. Unlike the biological case, \(f\) can produce graded outputs (for example, ReLU passes positive values through, zeroes negatives), but the principle is the same—thresholding followed by propagation.
From a systems engineering perspective, this translation reveals why neural networks have such demanding computational requirements. Each “simple” neuron requires \(N\) multiply-accumulate (MAC)14 operations and \(2N+2\) memory accesses (loading \(N\) inputs and \(N\) weights, plus the bias and output). When replicated millions of times across a network, these primitives create the massive arithmetic and bandwidth demands that define modern AI infrastructure.
14 MAC (Multiply-Accumulate): The atomic operation of neural computation: \(a \leftarrow a + (b \times c)\). Modern accelerators are often marketed in FLOPs because a fused multiply-add is counted as two floating-point operations. On that convention, an NVIDIA H100 is rated at 989 dense FP16 TFLOP/s, or about 494 trillion MAC/s if one MAC is counted as one multiply-accumulate. Every layer size and batch size decision ultimately reduces to how many MACs fit within the latency and power budget.
The transition from individual neurons to integrated systems requires navigating the central trade-off between representational capacity and computational cost. While silicon transistors operate at gigahertz frequencies, millions of times faster than biological chemical signaling, the sheer volume of operations in deep networks creates unique bottlenecks.
Replicating intelligent behavior in silicon confronts three interrelated system-level constraints. The memory wall becomes acute as models grow to billions of parameters, making data movement the primary bottleneck rather than raw computation. Concurrency clashes with dependency: while layers can be computed in parallel across thousands of cores for throughput, the sequential nature of deep networks (layer \(\ell+1\) depends on layer \(\ell\)) creates fundamental latency limits. Precision also trades against power: digital systems achieve high accuracy through precise 32-bit or 64-bit math, but each bit increases the energy cost of every operation, driving the search for minimum viable precision explored in Model Compression.
Addressing these constraints requires two complementary strategies. Architectural inductive bias encodes problem-specific structure directly into the network design (convolutional networks for images, recurrent networks for sequences), reducing the search space the optimizer must navigate (Mitchell 1980). Computational scaling compensates for remaining complexity through brute-force optimization on massive hardware arrays. Modern AI engineering sits at the intersection of these two paths: clever architectures shrink the problem, and massive scale solves what remains.
Mitchell, Tom M. 1980. The Need for Biases in Learning Generalizations. CBM-TR-117. Rutgers University, Department of Computer Science.
Hardware and software requirements
Translating neural concepts to silicon carries a physical cost. Feature extraction becomes weighted linear sums, thresholding becomes nonlinear activation functions, and pattern interaction becomes fully connected layers, all implemented as matrix operations that modern hardware must execute efficiently. A single matrix multiplication in code translates to millions of transistors switching at high frequency, generating heat and consuming significant power. Each neural network operation creates a specific hardware demand: activation functions require fast nonlinear units, weight operations require high-bandwidth memory access, parallel computation requires specialized processors, and learning algorithms require gradient computation hardware. These demands interact: the sheer volume of weight parameters creates a storage problem, the need to move those weights to processing units creates a bandwidth problem, and the learning process compounds both by requiring space for gradients and optimizer state alongside the weights themselves.
A key difference from traditional computing is that neural network “memory” is distributed across all weights rather than stored at specific addresses. Every prediction requires reading a significant portion of the model’s parameters, and every training step requires coordinating weight updates across the entire network. This creates a fundamental tension between storage capacity and access bandwidth that biological neural systems avoid (synapses both store and process locally). The human brain operates on approximately twenty watts (Raichle and Gusnard 2002); artificial neural networks demand orders of magnitude more energy, primarily because of this data movement overhead. This energy gap drives the specialized hardware architectures covered in Hardware Acceleration and the optimization strategies explored in Model Compression.
Raichle, Marcus E., and Debra A. Gusnard. 2002. “Appraising the Brain’s Energy Budget.” Proceedings of the National Academy of Sciences 99 (16): 10237–39. https://doi.org/10.1073/pnas.172399499.
These hardware demands did not emerge overnight. The tension between algorithmic ambition and available silicon has shaped the entire trajectory of neural network research, from the earliest perceptrons to today’s trillion-parameter models.
Evolution of neural network computing
Deep learning evolved to meet these challenges through concurrent advances in hardware and algorithms. The journey began with early artificial neural networks in the 1950s, marked by the introduction of the Perceptron15 (Rosenblatt 1958). While novel in concept, these early systems were severely limited by the computational capabilities of their era: mainframe computers that lacked both the processing power and memory capacity needed for complex networks.
15 Perceptron: A machine built to execute a learning algorithm, directly linking hardware and software from the start. Its single-layer architecture was fundamentally constrained to linearly separable problems, a limitation Minsky and Papert later proved was algorithmic, not just computational. This early failure demonstrated that without sufficient model depth (that is, layers), even custom-built hardware with 400 photocell inputs was insufficient for complex tasks.
Rosenblatt, Frank. 1958. “The Perceptron: A Probabilistic Model for Information Storage and Organization in the Brain.” Psychological Review 65 (6): 386–408. https://doi.org/10.1037/h0042519.
16 Backpropagation: Short for “backward propagation of errors,” the algorithm solves the credit assignment problem by determining which of millions of weights caused a given error, using the chain rule. Werbos applied it to neural networks in 1974, but the 1986 Rumelhart, Hinton, and Williams publication demonstrated practical effectiveness. The systems cost: backprop requires storing forward-pass activations and additional training state, creating the several-times-higher memory footprint quantified later in the chapter.
Rumelhart, David E., Geoffrey E. Hinton, and Ronald J. Williams. 1986. “Learning Representations by Back-Propagating Errors.” Nature 323 (6088): 533–36. https://doi.org/10.1038/323533a0.
The backpropagation16 algorithm, first applied to neural networks by Paul Werbos in his 1974 PhD thesis and building on Seppo Linnainmaa’s 1970 work on automatic differentiation, was popularized by Rumelhart et al. (1986). Their publication demonstrated the algorithm’s practical effectiveness and brought it to widespread attention in the machine learning community, triggering renewed interest in neural networks. The systems-level implementation of this algorithm is detailed in Backpropagation mechanics. Despite this breakthrough, the computational demands far exceeded available hardware capabilities. Training even modest networks could take weeks, making experimentation and practical applications challenging. This mismatch between algorithmic requirements and hardware capabilities contributed to a period of reduced interest in neural networks.
The historical trajectory demonstrates a recurring systems engineering lesson: an algorithm is only as effective as the hardware available to execute it. The decades-long gap between the mathematical formulation of backpropagation17 and its widespread adoption was a latency in infrastructure, not a failure of theory. Efficient ML systems engineering requires co-designing algorithms and silicon together. The deep learning revolution was sparked by the convergence of data availability, algorithmic maturity, and the parallel processing power of GPUs, not by a new mathematical discovery alone.
17 Algorithm-Hardware Adoption Lag: Backpropagation was mathematically complete by 1974 (Werbos) but not widely adopted until 1986—a 12-year gap explained by insufficient compute: training a meaningful network required hardware that did not exist. The pattern recurs more softly with attention: attention mechanisms were introduced for neural machine translation in 2014, and transformers made them central in 2017; GPUs were sufficient for the original Transformer experiments, while later TPU- and GPU-scale infrastructure enabled much larger deployments. The implication is that apparently “failed” algorithms may simply be hardware-premature. When evaluating today’s computationally intractable techniques, the right diagnostic is not whether the algorithm works on current hardware but what hardware regime would make it work.
Data file not found. Downloading to all_ai_models.csv...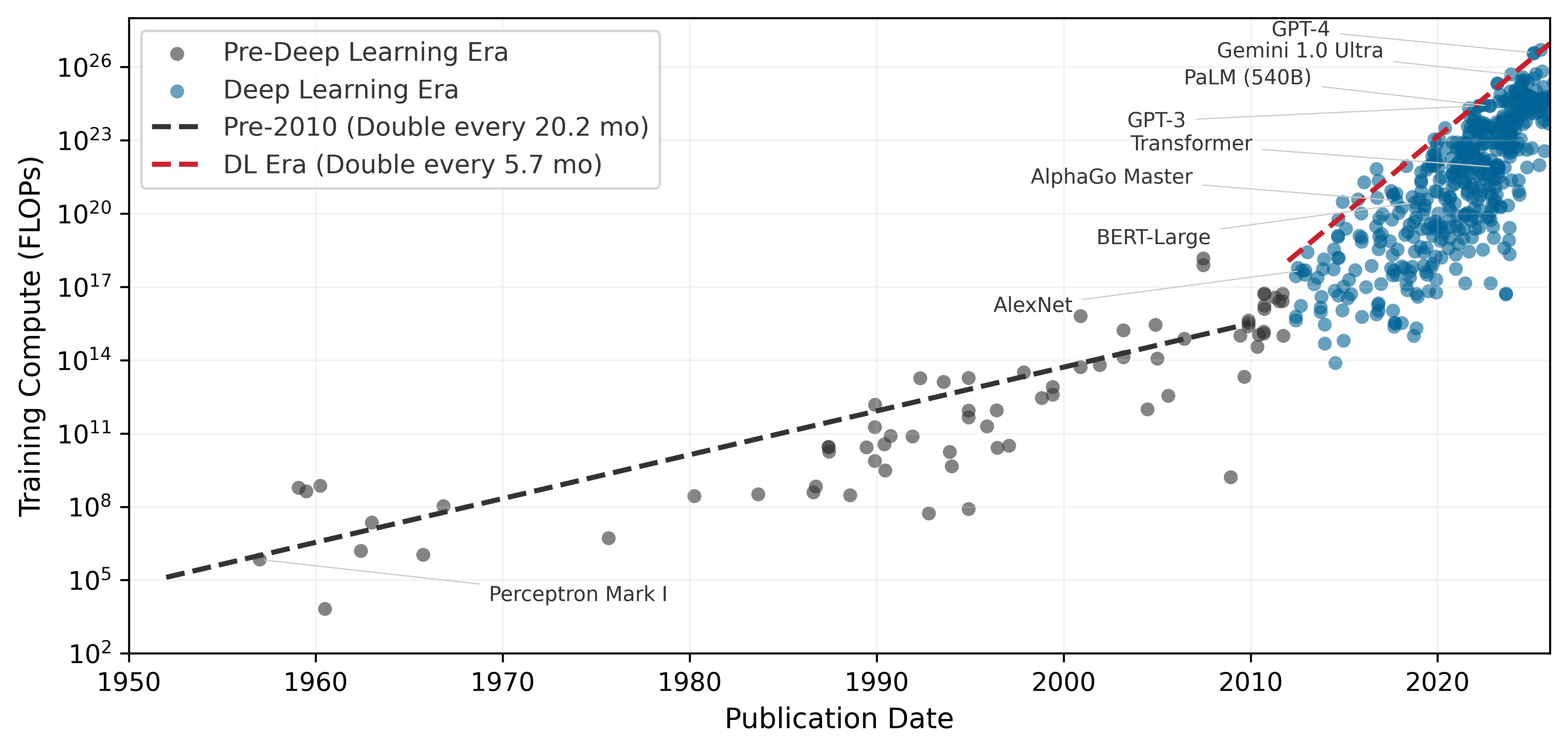
While the preceding sections established the technical foundations of deep learning, the term itself gained prominence in the 2010s, coinciding with advances in computational power and data accessibility. The scale of this computational explosion is difficult to grasp without visualization. Figure 9 plots seven decades of AI training compute on a logarithmic scale, revealing two fitted regimes: total training compute, measured in floating-point operations (FLOPs), followed a comparatively slow pre-2010 trend, then the post-2012 deep-learning frontier accelerated sharply. Large-scale models after 2015 sit orders of magnitude above the pre-2010 trajectory, showing that modern progress reinvests hardware and algorithmic gains into much larger training runs.
Table 5 grounds these trends in concrete systems, showing how parameters, compute, and hardware co-evolved across four decades of neural network development.
| Year | System | Params | Train FLOPs | Hardware | Train Time | Error/Task |
|---|---|---|---|---|---|---|
| 1989 | LeNet-1 | ~9.8K | \(10^{11}\)–\(10^{12}\) | Sun-4/260 workstation | 3 days | 1.0 percent (USPS) |
| 1998 | LeNet-5 | \(60\text{K} \pm 1\text{K}\) | \(10^{14} \pm 1\text{ OoM}\) | SGI Origin 2000 (200 MHz) | 2–3 days | 0.95 percent (MNIST) |
| 2012 | AlexNet | ~60M | \(5 \times 10^{17}\) | 2\(\times\) GTX 580 GPUs | 5–6 days | 15.3 percent (ImageNet) |
| 2015 | ResNet-152 | ~60M | \(10^{19} \pm 0.5\text{ OoM}\) | 8\(\times\) Tesla K80 GPUs | ~3 weeks | 3.6 percent (ImageNet) |
| 2020 | GPT-3 | 175B (exact) | \(3 \times 10^{23}\) | ~10K V100 GPUs | weeks | N/A (language) |
| 2023 | GPT-4 | ~1.8T (MoE, est.) | \(10^{24}\)–\(10^{25}\) | 10–25K A100s (est.) | months | N/A (language) |
Beyond raw compute, this exponential growth carries an energy cost that systems engineers cannot ignore. Training LeNet-1 in 1989 consumed roughly 54 kWh, about a few days of household electricity. A GPT-4-scale training run, using public GPU-day estimates and a datacenter-overhead factor, lands around 48,000 MWh—enough to power roughly 4,571 US homes for a year18. The energy cost of AI has moved from negligible to industrial, forcing engineers to treat energy efficiency (Joules per operation) as a primary design constraint alongside raw FLOPS. The quantitative energy analysis, including Horowitz’s data-movement-dominates-compute numbers and the full energy hierarchy, appears in Hardware Acceleration where it can be connected to concrete hardware architectures.
18 Training Energy Scale: This estimate uses 10.5 MWh/year as a representative US household electricity budget and treats GPT-4’s public GPU-day estimate as A100-equivalent accelerator time with datacenter overhead. The point is order of magnitude, not an audited utility bill: a single frontier training run now rivals a small industrial facility’s energy budget, making Joules-per-operation a first-order design constraint alongside FLOPS.
Three quantitative patterns emerge from this historical data. The plotted post-2012 training-compute frontier doubles on the order of months, while broader summaries that smooth across model families and account for reporting uncertainty show similarly rapid annual growth. Separately, the compute required to achieve a fixed benchmark has improved substantially due to algorithmic and systems advances. Training costs grow more slowly than raw compute because hardware utilization, reduced precision, and software efficiency also improve. Frontier model training costs have nonetheless moved from workstation-scale budgets into industrial-scale investments. These patterns have direct implications for systems engineering: compute scaling determines infrastructure investment timelines, algorithmic efficiency justifies continuous architecture research, and the cost-compute gap shapes build-vs.-buy decisions for ML teams.
Parallel advances across three dimensions drove these evolutionary trends: data availability, algorithmic innovations, and computing infrastructure. Follow the arrows in Figure 10 to see this reinforcing cycle in motion: faster computing infrastructure enabled processing larger datasets, larger datasets drove algorithmic innovations, and better algorithms demanded more sophisticated computing systems. This reinforcing cycle continues to drive progress today.

The data revolution transformed what was possible with neural networks. The rise of the internet and digital devices created vast new sources of training data: image sharing platforms provided millions of labeled images, digital text collections enabled language processing at scale, and sensor networks generated continuous streams of real-world data. This abundance provided the raw material neural networks needed to learn complex patterns effectively.
Algorithmic innovations made it possible to use this data effectively. New methods for initializing networks and controlling learning rates made training more stable. Techniques for preventing overfitting allowed models to generalize better to new data. Researchers discovered that neural network performance scaled predictably with model size, computation, and data quantity, leading to increasingly ambitious architectures.
These algorithmic advances created demand for higher-throughput computing infrastructure, which evolved in response. On the hardware side, GPUs provided the parallel processing capabilities needed for efficient neural network computation, and specialized AI accelerators like TPUs19 (Jouppi et al. 2023) pushed performance further. High-bandwidth memory systems and fast interconnects addressed data movement challenges. Software advances matched the hardware evolution: frameworks and libraries simplified building and training networks, distributed computing systems enabled training at scale, and tools for optimizing model deployment reduced the gap between research and production.
19 Tensor Processing Unit (TPU): Google’s custom accelerator, first deployed internally in 2015, optimized specifically for the matrix multiplications that dominate neural network workloads. The TPU v1 achieved 92 TOPS for INT8 inference at 75 W, a power efficiency that general-purpose GPUs of the era could not match. The name “Tensor Processing Unit” reflects the design decision to sacrifice general-purpose flexibility for maximum throughput on the specific operation that neural networks need most.
Jouppi, Norm, George Kurian, Sheng Li, Peter Ma, Rahul Nagarajan, Lifeng Nai, Nishant Patil, et al. 2023. “TPU v4: An Optically Reconfigurable Supercomputer for Machine Learning with Hardware Support for Embeddings.” Proceedings of the 50th Annual International Symposium on Computer Architecture, 1–14. https://doi.org/10.1145/3579371.3589350.
The convergence of data availability, algorithmic innovation, and computational infrastructure created the foundation for modern deep learning. Understanding the computational operations that drive these infrastructure requirements is essential: when scaled across millions of parameters and billions of training examples, simple mathematical operations create the massive computational demands that shaped this evolution.
Checkpoint 1.1: Understanding deep learning's emergence
Before proceeding to the mathematical foundations, verify your understanding of why deep learning emerged:
If any of these concepts remain unclear, review the relevant sections before continuing. The mathematical details that follow build directly on this conceptual foundation.
The historical trajectory from Perceptrons through AI winters to the GPU-driven revolution reveals a recurring pattern: algorithms outpace hardware, creating latency between discovery and adoption, until infrastructure catches up and triggers an explosion of capability. This pattern continues today as frontier models push against memory walls and energy budgets. Understanding the mathematical operations that create these pressures is essential for navigating the next cycle—which requires examining the computational primitives themselves.
Self-Check: Question
A team replaces a hand-coded digit classifier (≈100 comparisons, 784 bytes of working state) with the chapter’s 784→128→64→10 MLP (≈109,000 MACs, ≈438 KB of weights) on the same MNIST input. Which systems consequence should they expect first when the new model goes live on a commodity CPU?
- The workload becomes more sequential and fits entirely inside L1 cache, reducing memory traffic.
- Branch prediction becomes the dominant bottleneck because each neuron executes many if-then tests.
- The workload shifts to dense matrix math whose weight footprint exceeds most L1 caches, creating cache-level memory traffic that is absent from the hand-coded rule system.
- Specialized hardware becomes unnecessary because the model has learned the original rules and can discard them.
A CV team must choose between (a) a HOG + SVM classical pipeline they already use, and (b) a convnet of comparable task accuracy. Using the chapter’s treatment of feature engineering as the classical bottleneck, explain the systems-engineering consequence of each choice when the product must extend to six new object categories over the next year.
A vendor proposes that 5× faster single-threaded CPUs would eliminate the need for GPUs or TPUs in deep learning. Based on the section’s account of computational infrastructure requirements, what is the strongest refutation?
- CPUs cannot store neural network weights in registers, so no CPU will ever execute matrix multiplications.
- Deep learning is dominated by dense parallel matrix multiplications whose throughput is bounded by wide SIMD lanes and off-chip memory bandwidth, neither of which is addressed by raising single-thread clock speed.
- Modern CPUs force the optimizer to use smaller learning rates, which offsets any clock-speed gain.
- Faster CPUs would make the softmax output layer too precise, causing training instability.
A pipeline engineer depends on domain experts to invent descriptors (edge histograms, keypoint detectors, texture filters) for each new vision task. One quarter later, the team must support six additional categories. Using the section’s framing, explain two distinct systems consequences of staying inside this feature-engineering regime rather than switching to learned representations.
A reviewer argues that a 1970s neural algorithm that “failed” in its decade should be permanently dismissed. The chapter’s history of backpropagation and attention suggests a different systems-engineering stance. Which response best matches?
- Dismiss the algorithm permanently, since algorithms that were once infeasible remain infeasible.
- Ask which hardware or data regime would make the algorithm practical, because the history shows algorithms can be hardware-premature rather than wrong — backpropagation waited for GPU matrix throughput, and attention waited for dense HBM.
- Replace it with rule-based logic so it runs on current CPUs immediately.
- Assume that more labeled data alone will revive it, without any change in hardware or cost structure.
The chapter characterizes the rise of modern deep learning as a self-reinforcing cycle among data abundance, algorithmic innovation, and compute infrastructure. Which description most accurately captures how the cycle produces accelerating returns rather than additive gains?
- The three factors progressed in a strict linear sequence — compute, then algorithms, then data — each finishing before the next began.
- Each factor contributed roughly equally and independently, with no causal interaction among them.
- Each factor raised the marginal return on the others: abundant data justified larger algorithms, larger algorithms exposed which compute paths were worth accelerating, and faster compute justified collecting still more data.
- Compute infrastructure was the single decisive factor; data abundance and algorithmic innovation were downstream consequences of cheap GPUs.
Neural Network Fundamentals
Compute grew exponentially, algorithms matured, and data became abundant. The question now is why the computational demands are so extreme. A GPU processes neural networks faster than a CPU not because of raw clock speed but because of the specific mathematical operations neural networks perform. Training requires more memory than inference not because of software overhead but because the chain rule demands storing every intermediate result. Understanding these operations reveals how simple arithmetic on individual neurons compounds into the infrastructure requirements that shaped modern AI.
The concepts here apply to all neural networks, from simple classifiers to large language models. While architectures evolve and new paradigms emerge, these fundamentals remain constant: weighted sums, nonlinear activations, gradient-based learning. Mastering these operations and their computational characteristics enables reasoning about any neural network’s resource requirements.
Why depth matters: The power of hierarchical representations
A single-layer network attempting to classify handwritten digits must map raw pixels directly to labels, essentially memorizing every variation of every digit. A network with three layers solves the same problem with far fewer parameters by decomposing it hierarchically. The question is why depth provides such dramatic representational advantages, and the answer grounds all the mathematical development that follows.
Deep networks succeed because they use compositionality: complex patterns decompose into simpler patterns that themselves decompose further. In image recognition, pixels combine into edges, edges into textures, textures into parts, and parts into objects. This hierarchical decomposition reflects the structure of the world itself and explains why “deep” learning earns its name.
Consider recognizing the digit “seven” in our MNIST example. A single-layer network would need to directly map all 784 pixel values to a decision, essentially memorizing every variation of how people write “seven.” A deep network takes an entirely different approach:
- Layer 1 learns simple edge detectors: vertical lines, horizontal lines, diagonal strokes
- Layer 2 combines edges into shapes: the horizontal top stroke of a “seven,” the diagonal downstroke
- Layer 3 combines shapes into complete digit patterns
Each layer builds on the previous, exponentially expanding representational capacity with only linear parameter growth. This hierarchy enables efficiency that shallow networks cannot match. The same edge detectors learned for “seven” also detect edges in “one,” “four,” and every other digit. This parameter reuse means a deep network with 100K parameters can represent patterns that would require millions of parameters in a shallow network attempting direct pixel-to-label mapping. However, the choice between adding layers and widening existing ones is not symmetric: depth and width contribute to representational capacity through very different mechanisms, with consequences that compound rather than cancel.
Systems Perspective 1.2: The depth vs. width trade-off
The theoretical power of depth comes from the exponential advantage: for certain function classes, a network with \(L\) layers can represent functions that would require exponentially more neurons in a single-layer network (Telgarsky 2016). Composing nonlinear layers enables exponentially more complex decision boundaries with only linearly more parameters.
However, depth introduces engineering challenges. Each additional layer:
- Adds sequential dependencies (layer \(L+1\) waits for layer \(L\)), limiting parallelism
- Increases gradient path length, risking vanishing/exploding gradients
- Requires storing intermediate activations for backpropagation
Modern architectures balance depth (representational power) against width (parallelism). A network with ten layers of 100 neurons has the same 1,000 total hidden neurons as one with two layers of 500 neurons, but fundamentally different computational characteristics. The deeper network can represent more complex functions; the wider network can compute all neurons in a layer simultaneously.
Telgarsky, Matus. 2016. “Benefits of Depth in Neural Networks.” Proceedings of the 29th Annual Conference on Learning Theory, 1517–39.
Biological visual systems employ the same hierarchical decomposition. The specific architectures examined in Network Architectures formalize different ways to encode this hierarchical structure, from the local connectivity of convolutional networks to the attention mechanisms of transformers.
The intuition for why depth matters motivates the next question: how do neural networks implement this hierarchical processing? The following sections develop the precise mechanics: how neurons compute, how layers connect, and how information flows from input to output.
Network architecture fundamentals
A neural network’s architecture determines how information flows from input to output. Modern networks can be enormously complex, but they all build on a few organizational principles that shape both implementation and the computational infrastructure they demand.
To ground these concepts in a concrete example, we use handwritten digit recognition throughout this section, specifically the task of classifying images from the MNIST dataset (LeCun et al. 1998). This seemingly simple task reveals all the core principles of neural networks while providing intuition for more complex applications.
Example 1.1: Running example: MNIST digit recognition
The task: Given a \(28{\times}28\) pixel grayscale image of a handwritten digit, classify it as one of the 10 digits (0–9).
Input Representation: Each image contains 784 pixels (\(28{\times}28\)), with values ranging from 0 (white) to 255 (black). We normalize these to the range [0,1] by dividing by 255. When fed to a neural network, these 784 values form our input vector \(\mathbf{x} \in \mathbb{R}^{784}\).
Output Representation: The network produces 10 values, one for each possible digit. These values represent the network’s confidence that the input image contains each digit. The digit with the highest confidence becomes the prediction.
Why This Example: MNIST is small enough to understand completely (784 inputs, ~100K parameters for a simple network) yet large enough to be realistic. The task is intuitive: everyone understands what “recognize a handwritten seven” means, making it ideal for learning neural network principles that scale to much larger problems.
Network Architecture Preview: A typical MNIST classifier might use: 784 input neurons (one per pixel) → 128 hidden neurons → 64 hidden neurons → 10 output neurons (one per digit class). As we develop concepts, we will reference this specific architecture.
Each architectural choice, from how neurons are connected to how layers are organized, creates specific computational patterns that must be efficiently mapped to hardware. This mapping between network architecture and computational requirements is essential for building scalable ML systems.
Nonlinear activation functions
The conceptual framework of layers and hierarchical processing leads to the computational machinery within each layer. Central to all neural architectures is a basic building block: the artificial neuron or perceptron, which implements the biological-to-artificial translation principles established earlier. From a systems perspective, understanding the perceptron’s mathematical operations matters because these simple operations, replicated millions of times across a network, create the computational bottlenecks discussed earlier.
Consider our MNIST digit recognition task. Each pixel in a \(28{\times}28\) image becomes an input to our network. A single neuron in the first hidden layer might learn to detect a specific pattern, perhaps a vertical edge that appears in digits like “one” or “seven.” This neuron must somehow combine all 784 pixel values into a single output that indicates whether its pattern is present.
The perceptron accomplishes this through weighted summation. It takes multiple inputs \(x_1, x_2, ..., x_n\) (in our case, \(n=784\) pixel values), each representing a feature of the object under analysis. For digit recognition, these features are the raw pixel intensities.
With this weighted summation, a perceptron can perform either regression or classification tasks. For regression, the numerical output \(\hat{y}\) is used directly. For classification, the output depends on whether \(\hat{y}\) crosses a threshold: above the threshold, the perceptron outputs one class (for example, “yes”); below it, another class (for example, “no”).
Follow the signal path through Figure 11 to see how weighted inputs combine with activation functions to produce a decision: each input \(x_i\) multiplies by its corresponding weight \(w_{ij}\), the products sum with a bias term, and the activation function produces the final output.

Layers of perceptrons work in concert, with each layer’s output feeding the subsequent layer. This hierarchical arrangement creates deep learning models capable of tackling increasingly sophisticated tasks, from image recognition to natural language processing.
Each input \(x_i\) has a corresponding weight \(w_{ij}\), and the perceptron multiplies each input by its matching weight. The intermediate output, \(z\), is computed as the weighted sum of inputs in Equation 1: \[ z = \sum (x_i \cdot w_{ij}) \tag{1}\]
In plain terms, each input feature is scaled by how important it is (its weight), and the results are summed into a single score. This is the dot product of two vectors—the fundamental operation that hardware accelerators are designed to execute at maximum throughput, and the reason neural network performance is measured in multiply-accumulate (MAC) operations per second.
A bias term \(b\) shifts the linear output up or down, giving the model additional flexibility to fit the data. Thus, the intermediate linear combination computed by the perceptron including the bias becomes Equation 2: \[ z = \sum (x_i \cdot w_{ij}) + b \tag{2}\]
Each neuron thus requires \(N\) multiply-accumulate operations and \(2N+2\) memory accesses (loading \(N\) inputs and \(N\) weights, plus the bias and output). A layer of \(M\) neurons repeats this \(M\) times, so the layer’s total cost is \(M \times N\) MACs—exactly the matrix multiplication \(\mathbf{x}\mathbf{W}\) that hardware must execute.
Activation functions are critical nonlinear transformations that enable neural networks to learn complex patterns by converting linear weighted sums into nonlinear outputs. Without activation functions, multiple linear layers would collapse into a single linear transformation, severely limiting the network’s expressive power. Three commonly used element-wise activation functions and one vector-level function (softmax) each exhibit distinct mathematical characteristics that shape their effectiveness in different contexts (Figure 12).

The choice of activation function affects both learning effectiveness and computational efficiency—and the history of that choice reveals why systems constraints shape algorithmic design. ReLU (\(\max(0, x)\)) became the default hidden-layer activation for many feed-forward and convolutional networks, and it remains a useful baseline for good reason: it is computationally trivial (a single comparison), its gradient never vanishes for positive inputs, and it introduces natural sparsity. ReLU’s dominance, however, only makes sense against the backdrop of what came before and the alternatives used in modern architectures, such as the Gaussian Error Linear Unit (GELU), Sigmoid-weighted Linear Unit (SiLU), and gated variants in transformer feed-forward blocks. The earliest networks used sigmoid and tanh activations, whose smooth S-curves seemed mathematically elegant but created a systems nightmare: gradients that shrank exponentially through deep layers, killing learning before it could begin. Understanding why sigmoid and tanh fail in deep networks is essential for understanding why ReLU succeeded and what its own limitations imply for modern architectures.
Sigmoid
The sigmoid function20 maps any input value to a bounded range between 0 and 1, as defined in Equation 3: \[ \sigma(x) = \frac{1}{1 + e^{-x}} \tag{3}\]
20 Sigmoid: From Greek sigma + eidos (“sigma-shaped”), referring to the S-curve that maps inputs to the bounded (0, 1) range. The mapping requires a floating-point exponential (\(e^{-x}\)), which costs ~2,500 transistors and 20–40 CPU cycles per evaluation, vs. ReLU’s single comparator at ~50 transistors and one cycle—a 50\(\times\) silicon cost difference per activation. This arithmetic penalty scales with every neuron in every layer, making sigmoid’s replacement by ReLU as much a hardware efficiency decision as a gradient stability one.
The S-shaped curve produces outputs interpretable as probabilities, making sigmoid particularly useful for binary classification tasks. For large positive inputs, the function approaches one; for large negative inputs, it approaches 0. The smooth, continuous nature of sigmoid makes it differentiable everywhere, which is necessary for gradient-based learning.
Sigmoid has a significant limitation: for inputs with large absolute values (far from zero), the gradient becomes extremely small, a phenomenon called the vanishing gradient problem21. During backpropagation, these small gradients multiply together across layers, causing gradients in early layers to become exponentially tiny. This effectively prevents learning in deep networks, as weight updates become negligible.
21 Vanishing Gradient Problem: The chain rule’s multiplication of gradients across layers causes this failure mode when using activations like sigmoid, whose derivative is always less than 1. With sigmoid’s maximum derivative of 0.25, the gradient in a 10-layer network shrinks by a factor of nearly one million (\(0.25^{10} \approx 10^{-6}\)), preventing weights in early layers from updating.
Sigmoid outputs are not zero-centered (all outputs are positive). This asymmetry can cause inefficient weight updates during optimization, as gradients for weights connected to sigmoid units will all have the same sign.
Tanh
The hyperbolic tangent function22 addresses sigmoid’s zero-centering limitation by mapping inputs to the range \((-1, 1)\), as defined in Equation 4: \[ \tanh(x) = \frac{e^x - e^{-x}}{e^x + e^{-x}} \tag{4}\]
22 Tanh (Hyperbolic Tangent): By centering its output range on zero, tanh allows weight gradients to be both positive and negative, fixing the all-positive update bias that slows sigmoid-based training. While its computational cost is similar to sigmoid, this zero-centering is critical in recurrent architectures like LSTMs to prevent runaway activation values across many time steps, where unbounded activations would quickly exceed hardware floating-point limits.
Tanh produces an S-shaped curve similar to sigmoid but centered at zero: negative inputs map to negative outputs and positive inputs to positive outputs. This symmetry balances gradient flow during training, often yielding faster convergence than sigmoid.
Like sigmoid, tanh is smooth and differentiable everywhere, and it still suffers from the vanishing gradient problem for inputs with large magnitudes. When the function saturates (approaches -1 or 1), gradients shrink toward zero. Despite this limitation, tanh’s zero-centered outputs make it preferable to sigmoid for hidden layers in many architectures, particularly in recurrent neural networks where maintaining balanced activations across time steps is important.
Both sigmoid and tanh share a critical limitation: gradient saturation at extreme input values. The search for an activation function that avoids this problem while remaining computationally efficient led to one of deep learning’s most important innovations.
ReLU
The Rectified Linear Unit (ReLU)23 function was known for decades before deep learning, but Nair and Hinton (2010) demonstrated that ReLU enabled more effective training of deep networks. Combined with GPU computing, dropout24, and other innovations, ReLU helped enable the AlexNet breakthrough in 2012 (Krizhevsky et al. 2012). The ReLU function is defined in Equation 5: \[ \text{ReLU}(x) = \max(0, x) = \begin{cases} x & \text{if } x > 0 \\ 0 & \text{if } x \leq 0 \end{cases} \tag{5}\]
23 ReLU (Rectified Linear Unit): Unlike the costly exponential operations in prior activation functions, ReLU’s max(0, x) operation compiles to a single, fast hardware instruction. This efficiency, and its solution to the vanishing gradient problem, were essential for making the deep architectures of the AlexNet era computationally tractable. The resulting 5–10\(\times\) faster activation computation per element was a key enabler of the 2012 breakthrough.
Nair, Vinod, and Geoffrey E. Hinton. 2010. “Rectified Linear Units Improve Restricted Boltzmann Machines.” Proceedings of the 27th International Conference on Machine Learning (ICML-10), 807–14.
24 Dropout: Randomly deactivating neurons during training forces a network to learn redundant representations, a key innovation that helped enable the AlexNet breakthrough. This creates a systems-level divergence between the computational graphs for training (stochastic) and inference (deterministic). Failing to switch from the training to the inference graph is a common bug that silently degrades accuracy by 5–15 percent.
Krizhevsky, Alex, Ilya Sutskever, and Geoffrey E. Hinton. 2012. “ImageNet Classification with Deep Convolutional Neural Networks.” Communications of the ACM 60 (6): 84–90. https://doi.org/10.1145/3065386.
ReLU’s characteristic shape—a straight line for positive inputs and zero for negative inputs—provides three advantages that explain its dominance. First, gradient flow remains intact: for positive inputs, ReLU’s gradient is exactly one, allowing gradients to propagate unchanged through many layers and preventing the vanishing gradient problem that plagues sigmoid and tanh in deep architectures. Second, ReLU introduces natural sparsity by zeroing all negative activations. Typically, about 50 percent of neurons in a ReLU network output zero for any given input, reducing overfitting and improving interpretability. Third, computational efficiency improves dramatically: unlike sigmoid and tanh, which require expensive exponential calculations, ReLU is computed with a single comparison, output = (input > 0) ? input : 0, translating to faster execution and lower energy consumption, particularly important on resource-constrained devices.
ReLU is not without drawbacks. The dying ReLU problem—neurons that permanently output zero and cease learning—occurs when neurons become stuck in the inactive state. If a neuron’s weights evolve during training such that the preactivation \(z = \mathbf{w}^T\mathbf{x} + b\) is consistently negative across all training examples, the neuron outputs zero for every input. Since ReLU’s gradient is also zero for negative inputs, no gradient flows back through this neuron during backpropagation: the weights cannot update, and the neuron remains dead. This can happen with large learning rates that push weights into unfavorable regions. From a systems perspective, dead neurons represent wasted capacity: parameters that consume memory and compute during inference but contribute nothing to the output. In extreme cases, 10–40 percent of a network’s neurons can die during training, effectively reducing model capacity without reducing resource consumption. Careful initialization (He et al. 2015), moderate learning rates, and architectural choices (leaky ReLU variants or batch normalization25 (Ioffe and Szegedy 2015)) help mitigate this issue.
25 Batch Normalization Systems Cost: BatchNorm adds two learned parameters per feature (scale \(\gamma\) and shift \(\beta\)), a synchronization barrier during training (requiring all-reduce across the batch dimension), and diverges in computational graph structure between training (live mean/variance from the batch) and inference (frozen running statistics). The critical failure mode is small-batch sensitivity: batch sizes below 8–16 produce noisy mean/variance estimates that degrade accuracy by 3–8 percent, forcing larger batches and more memory. This coupling between a regularization technique and hardware batch-size constraints is why LayerNorm replaced BatchNorm in transformers—LayerNorm normalizes across features, not batch, making its statistics independent of batch size.
Ioffe, Sergey, and Christian Szegedy. 2015. “Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift.” Proceedings of the 32nd International Conference on Machine Learning (ICML) 37: 448–56.
Softmax
Unlike the previous activation functions that operate element-wise (independently on each value), softmax26 is a vector-level function: it considers all values simultaneously to produce a probability distribution. In simple classifiers, softmax is commonly used in the output layer rather than as an element-wise hidden activation; in modern architectures it is also used internally, most notably to normalize attention weights. The softmax function is defined in Equation 6: \[ \text{softmax}(z_i) = \frac{e^{z_i}}{\sum_{j=1}^K e^{z_j}} \tag{6}\]
26 Softmax: The name reflects its role as a “soft” or differentiable version of argmax, a function that must evaluate an entire vector to find its maximum value. This vector-wise operation is not used as a drop-in replacement for element-wise nonlinearities such as ReLU, but it is central whenever a model must normalize a vector of scores, including classification heads and attention layers. Critically, its use of exponentiation creates a numerical stability hazard: inputs greater than ~88 will overflow standard 32-bit floats, a common source of silent NaN failures in production.
27 Logits (log-odds units): Short for “log-odds units,” these raw scores preserve the relative ordering of class evidence before softmax normalizes them into probabilities. Because argmax over logits and argmax over softmax probabilities always select the same class, optimized inference pipelines skip the softmax computation entirely when only the top prediction is needed, saving \(K\) exponentiations per sample.
For a vector of \(K\) values (often called logits27), softmax transforms them into \(K\) probabilities that sum to 1. One component of the softmax output appears in Figure 12 (bottom-right); in practice, softmax processes entire vectors where each element’s output depends on all input values.
In multi-class classifiers, softmax is usually used in the output layer. By converting arbitrary real-valued logits into probabilities, softmax enables the network to express confidence across multiple classes. The class with the highest probability becomes the predicted class. The exponential function ensures that larger logits receive disproportionately higher probabilities, creating clear distinctions between classes when the network is confident.
The mathematical relationship between input logits and output probabilities is differentiable, allowing gradients to flow back through softmax during training. When combined with cross-entropy loss (discussed in Section 1.3.3), softmax produces particularly clean gradient expressions that guide learning effectively. Beyond their mathematical properties, the choice of activation functions has direct consequences for hardware efficiency.
Systems Perspective 1.3: Activation functions and hardware
Why ReLU Dominates in Practice: Beyond its mathematical benefits like avoiding vanishing gradients, ReLU’s hardware efficiency explains its widespread adoption. Computing \(\max(0,x)\) requires a single comparison operation, while sigmoid and tanh require computing exponentials—operations that are much more expensive in both time and energy. The transistor-tax calculation below models this gap as a logic-cost ratio, and Hardware Acceleration covers the broader benchmark and accelerator-implementation implications.
The transistor tax: Logic unit cost
The hardware dominance extends beyond speed to silicon area. In computer architecture, we measure the Logic Unit Cost in terms of transistor count and energy per operation.
A ReLU unit is computationally trivial: it consists of a single comparator and a multiplexer, requiring approximately 50 transistors. In contrast, a Sigmoid or Tanh unit requires computing an exponential—a complex transcendental function that hardware must approximate using lookup tables or iterative Taylor expansions. A high-precision exponential unit can consume over 2,500 transistors.
We call this disparity The Transistor Tax: selecting Sigmoid over ReLU increases the silicon “price” of an activation by 50\(\times\). For a systems engineer, this means ReLU is a density optimization that allows hardware architects to pack orders of magnitude more neurons into the same power and area budget. This physical efficiency is the primary reason the deep learning era shifted away from the “biologically plausible” Sigmoid toward the “silicon-efficient” ReLU.
These nonlinear transformations convert the linear input sum into a nonlinear output, giving us the complete perceptron computation in Equation 7: \[ \hat{y} = \sigma(z) = \sigma\left(\sum (x_i \cdot w_{ij}) + b\right) \tag{7}\]
This nonlinearity is what makes deep networks expressive. Without it, stacking multiple layers would be pointless—a composition of linear functions is still linear. Compare the two panels in Figure 13 to see this principle in action: the left panel exposes a linear decision boundary that fails to separate the two classes (no amount of linear layers would help), while the right panel reveals how nonlinear activation functions enable the network to learn a curved boundary that correctly classifies the data.

The universal approximation theorem28 establishes that neural networks with activation functions can approximate arbitrary functions. This theoretical foundation, combined with the computational and optimization characteristics of specific activation functions like ReLU and sigmoid, explains neural networks’ practical effectiveness in complex tasks.
28 Universal Approximation Theorem: The theorem guarantees a single hidden layer can approximate any function, but it is nonconstructive—it doesn’t say how to find the weights. The critical flaw for practical effectiveness is that the required number of neurons in this layer can grow exponentially, making the network untrainable. This is why depth matters: deep networks trade this exponential width for polynomial depth, achieving the same approximation with exponentially fewer parameters.
Layers and connections
Individual neurons compute weighted sums, apply bias terms, and pass results through activation functions. The power of neural networks, however, comes from organizing these neurons into layers. A layer is a collection of neurons that process information in parallel. Each neuron in a layer operates independently on the same input but with its own set of weights and bias, allowing the layer to learn different features from the same input data.
In a typical neural network, we organize these layers hierarchically:
Input Layer: Receives the raw data features
Hidden Layers: Process and transform the data through multiple stages
Output Layer: Produces the final prediction or decision
Follow the data flow in Figure 14 from left to right: data enters at the input layer, passes through multiple hidden layers that progressively extract more abstract features, and emerges at the output layer as a prediction. Each successive layer transforms the representation, building increasingly complex features—a hierarchical processing pipeline that gives deep neural networks their ability to learn complex patterns.

As data flows through the network, it is transformed at each layer to extract meaningful patterns. The weighted summation and activation process we established for individual neurons scales up: each layer applies these operations in parallel across all its neurons, with outputs from one layer becoming inputs to the next. This creates a hierarchical pipeline where simple features detected in early layers combine into increasingly complex patterns in deeper layers—enabling neural networks to learn sophisticated representations from raw data.
Parameters and connections
The learnable parameters29 of neural networks, weights and biases, determine how information flows through the network and how transformations are applied to input data. Their organization directly impacts both learning capacity and computational requirements.
29 Parameter Memory Cost: Parameter count is a misleading proxy for memory importance. Normalization layer parameters (BatchNorm’s \(\gamma\) and \(\beta\), LayerNorm’s scale and bias) add only two parameters per feature dimension, making them negligible for memory budgeting. Yet freezing them during fine-tuning causes 5–15 percent accuracy degradation—they punch far above their weight. Conversely, the bulk of parameters (dense weight matrices) each require 12 bytes of additional state during Adaptive Moment Estimation (Adam) training (gradient + two moment vectors, beyond the 4-byte weight itself), so a model that fits in memory for inference may require 3\(\times\) more for training.
Weight matrices
Weights determine how strongly inputs influence neuron outputs. In larger networks, these organize into matrices for efficient computation across layers. In a layer with \(n\) input features and \(m\) neurons, the weights form a matrix \(\mathbf{W} \in \mathbb{R}^{n \times m}\), where each column represents the weights for a single neuron. This organization allows the network to process multiple inputs simultaneously, an essential feature for handling real-world data efficiently.
Recall that for a single neuron, we computed \(z = \sum_{i=1}^n (x_i \cdot w_{ij}) + b\). When we have a layer of \(m\) neurons, we could compute each neuron’s output separately, but matrix operations provide a much more efficient approach. Rather than computing each neuron individually, matrix multiplication enables us to compute all \(m\) outputs simultaneously, as shown in Equation 8: \[ \mathbf{z} = \mathbf{x}\mathbf{W} + \mathbf{b} \tag{8}\]
This single equation computes every neuron’s output in one operation: the input vector \(\mathbf{x}\) multiplied by the weight matrix \(\mathbf{W}\) produces all \(m\) preactivation values simultaneously, and the bias vector \(\mathbf{b}\) shifts each one. From a systems perspective, this is the operation that dominates neural network runtime—a matrix-vector multiply whose dimensions \((n \text{ inputs} \times m \text{ neurons})\) determine whether the layer is compute bound or memory bound on the target hardware.
This matrix organization is more than mathematical convenience; it reflects how modern neural networks are implemented for efficiency. Each weight \(w_{ij}\) represents the strength of the connection between input feature \(i\) and neuron \(j\) in the layer.
In the simplest and most common case, each neuron in a layer is connected to every neuron in the previous layer, forming what we call a “dense” or “fully-connected” layer. This pattern means that each neuron has the opportunity to learn from all available features from the previous layer. Fully-connected layers establish foundational principles, but alternative connectivity patterns (explored in Network Architectures) can dramatically improve efficiency for structured data by restricting connections based on problem characteristics.
To make this concrete, examine Figure 15, which lays out a small three-layer network with every connection weight explicitly labeled. Notice how every input connects to every hidden neuron (the “ihWeight” connections), and every hidden neuron connects to every output (the “hoWeight” connections). Each labeled edge represents one learnable weight, making visible the total parameter count and, consequently, why matrix multiplication dominates neural network computation: the weight matrix dimensions directly determine both the layer’s storage requirements and its arithmetic cost. The numerical values shown are actual computed activations, demonstrating how inputs transform through the network. For a network with layers of sizes \((n_1, n_2, n_3)\), the weight matrices have these dimensions:
- Between first and second layer: \(\mathbf{W}^{(1)} \in \mathbb{R}^{n_1 \times n_2}\)
- Between second and third layer: \(\mathbf{W}^{(2)} \in \mathbb{R}^{n_2 \times n_3}\)

Bias terms
Each neuron in a layer also has an associated bias term. While weights determine the relative importance of inputs, biases allow neurons to shift their activation functions. This shifting is important for learning, as it gives the network flexibility to fit more complex patterns.
For a layer with \(m\) neurons, the bias terms form a vector \(\mathbf{b} \in \mathbb{R}^m\). When we compute the layer’s output, this bias vector is added to the weighted sum of inputs (the same form as Equation 8): \[ \mathbf{z} = \mathbf{x}\mathbf{W} + \mathbf{b} \]
The bias terms30 effectively allow each neuron to have a different “threshold” for activation, making the network more expressive.
30 Bias Terms: Biases add one parameter per neuron (vs. \(n\) weights per neuron), typically comprising 1–5 percent of total parameters. Despite this small fraction, removing biases can degrade accuracy by 1–3 percent on classification tasks because the network loses the ability to shift decision boundaries independently of input magnitude. Some modern architectures (notably those using batch normalization) omit biases entirely, since normalization layers subsume their function.
The organization of weights and biases across a neural network follows a systematic pattern. For a network with \(L\) layers, we maintain:
A weight matrix \(\mathbf{W}^{(l)}\) for each layer \(l\)
A bias vector \(\mathbf{b}^{(l)}\) for each layer \(l\)
Activation functions \(f^{(l)}\) for each layer \(l\)
This gives us the complete layer computation in Equation 9: \[ \mathbf{a}^{(l)} = f^{(l)}(\mathbf{z}^{(l)}) = f^{(l)}(\mathbf{a}^{(l-1)}\mathbf{W}^{(l)} + \mathbf{b}^{(l)}) \tag{9}\]
Where \(\mathbf{a}^{(l)}\) (written as \(\mathbf{A}^{(l)}\) for batches) represents the layer’s activation output. We adopt the row-vector convention throughout: each sample is a row, and the weight matrix \(\mathbf{W}^{(l)} \in \mathbb{R}^{n_{l-1} \times n_l}\) maps from the previous layer’s width to the current layer’s width. With this equation in place, the core architecture concepts are complete enough to proceed.
Checkpoint 1.2: Neural network architecture fundamentals
Before proceeding to network topology and training, verify your understanding of the foundational concepts we have covered:
Core concepts:
Systems implications:
Self-Test Example: For a digit recognition network with layers 784 → 128 → 64 → 10, calculate: (1) parameters in each weight matrix, (2) total parameter count, (3) activations stored during inference for a single image.
If any of these feel unclear, review the earlier sections on Neural Network Fundamentals, Neurons and Activations, or Weights and Biases before continuing. The upcoming sections on training and optimization build directly on these foundations.
Architecture design
Network topology describes how individual neurons organize into layers and connect to form complete neural networks. Building intuition begins with a simple problem that became famous in AI history31.
31 XOR Problem: The inability of a single layer of neurons to solve the XOR function is the canonical example of why network topology is a computational necessity. Minsky and Papert’s 1969 proof demonstrated that this simple function is not linearly separable, forcing a topological shift from a single layer to one with a hidden layer. This proves that some problems cannot be solved by making a layer wider, but require depth, with a minimum of three total neurons needed to learn XOR.
Example 1.2: Building intuition: The XOR problem
Consider a network learning the XOR function, a classic problem that requires nonlinearity. With inputs \(x_1\) and \(x_2\) that can be 0 or 1, XOR outputs 1 when inputs differ and 0 when they are the same.
Network Structure: two inputs → two hidden neurons → one output
Forward Pass Example: For inputs \((1, 0)\):
- Hidden neuron one: \(h_1 = \text{ReLU}(1 \cdot w_{11} + 0 \cdot w_{12} + b_1)\)
- Hidden neuron two: \(h_2 = \text{ReLU}(1 \cdot w_{21} + 0 \cdot w_{22} + b_2)\)
- Output: \(y = \text{sigmoid}(h_1 \cdot w_{31} + h_2 \cdot w_{32} + b_3)\)
This simple network demonstrates how hidden layers enable learning nonlinear patterns, something a single layer cannot achieve (Minsky and Papert 1969).
Minsky, Marvin, and Seymour A. Papert. 1969. Perceptrons: An Introduction to Computational Geometry. The MIT Press.
The XOR example established the canonical three-layer architecture, but real-world networks require systematic consideration of design constraints and computational scale. Recognizing handwritten digits using the MNIST (LeCun et al. 1998) dataset illustrates how problem structure determines network dimensions while hidden layer configuration remains an important design decision.
Feedforward network architecture
Applying the three-layer architecture to MNIST reveals how data characteristics and task requirements constrain network design. Compare the two panels in Figure 16 to see this architecture from both perspectives: panel (a) presents a \(28{\times}28\) pixel grayscale image of a handwritten digit connected to the hidden and output layers, while panel (b) reveals how the 2D image flattens into a 784-dimensional vector. Flattening is necessary because fully-connected layers expect a fixed-size one-dimensional input: matrix multiplication requires a vector, not a grid. The cost of this transformation is that all spatial structure in the original image is discarded, which motivates convolutional architectures (explored in Network Architectures) that preserve spatial locality.
The input layer’s width is directly determined by our data format. For a \(28{\times}28\) pixel image, each pixel becomes an input feature, requiring 784 input neurons (\(28{\times}28\) = 784). We can think of this either as a 2D grid of pixels or as a flattened vector of 784 values, where each value represents the intensity of one pixel.
The output layer’s structure is determined by our task requirements. For digit classification, we use 10 output neurons, one for each possible digit (0–9). When presented with an image, the network produces a value for each output neuron, where higher values indicate greater confidence that the image represents that particular digit.
Between these fixed input and output layers, we have flexibility in designing the hidden layer topology. The choice of hidden layer structure, including the number of layers to use and their respective widths, represents one of the key design decisions in neural networks. Additional layers increase the network’s depth, allowing it to learn more abstract features through successive transformations. The width of each layer provides capacity for learning different features at each level of abstraction.

Layer connectivity design patterns
The preceding fully connected architecture connects every neuron to every neuron in the next layer, but this is not the only option. Different connection patterns between layers offer distinct advantages for learning and computation.
Dense connectivity represents the standard pattern where each neuron connects to every neuron in the subsequent layer. In our MNIST example, connecting our 784-dimensional input layer to a hidden layer of 128 neurons requires 100,352 weight parameters (\(784{\times}128\)). This full connectivity enables the network to learn arbitrary relationships between inputs and outputs, but the number of parameters scales quadratically with layer width.
Sparse connectivity patterns introduce purposeful restrictions in how neurons connect between layers. Rather than maintaining all possible connections, neurons connect to only a subset of neurons in the adjacent layer. This approach draws inspiration from biological neural systems, where neurons typically form connections with a limited number of other neurons. In visual processing tasks like our MNIST example, neurons might connect only to inputs representing nearby pixels, reflecting the local nature of visual features.
As networks grow deeper, the path from input to output becomes longer, potentially complicating the learning process. Skip connections address this by adding direct paths between nonadjacent layers. These connections provide alternative routes for information flow, supplementing the standard layer-by-layer progression. In our digit recognition example, skip connections might allow later layers to reference both high-level patterns and the original pixel values directly.
These connection patterns have significant implications for both the theoretical capabilities and practical implementation of neural networks. Dense connections maximize learning flexibility at the cost of computational efficiency. Sparse connections can reduce computational requirements while potentially improving the network’s ability to learn structured patterns. Skip connections help maintain effective information flow in deeper networks.
Model size and computational complexity
How parameters (weights and biases) are arranged determines both learning capacity and computational cost—this is the model’s side of the silicon contract (Iron Law of ML Systems): the parameter count, their numerical precision, and the operations they require collectively define the computational bargain the model strikes with hardware. While topology defines the network’s structure, parameter initialization and organization directly affect learning dynamics and final performance.
Parameter count grows with network width and depth. For our MNIST example, consider a network with a 784-dimensional input layer, hidden layers of 128 and 64 neurons, and a 10-neuron output layer (784 → 128 → 64 → 10). The first layer requires 100,352 weights and 128 biases, the second layer 8,192 weights and 64 biases, and the output layer 640 weights and 10 biases, totaling 109,386 parameters. Each must be stored in memory and updated during learning.
Example 1.3: Memory: Training vs. inference
Problem: In “Computing with Patterns” we showed that a single forward pass through the 784 → 128 → 64 → 10 network costs 109,184 MACs. What is the memory footprint for this network during training with batch size 32 in 32-bit (4-byte) floating-point precision, and how does it compare to inference requirements?
Table 6: MNIST Parameter Memory by Layer: Weight and bias counts for the 784-128-64-10 network. Layer 1 (Input -> Hidden1) dominates the parameter budget because it multiplies the 784-dimensional input by 128 hidden units; deeper layers shrink rapidly as the representation compresses toward the 10-class output.
Table 7: MNIST Activation Memory at Batch Size 32: Per-layer activation tensor shapes, value counts, and 32-bit float memory cost during a single forward pass. Input activations dominate the activation table at 100.4 KB; for this small MNIST MLP, the total activation footprint remains below the parameter footprint, while larger batches and deeper networks make activations a central training-memory concern.
Table 8: MNIST Training vs. Inference Memory: Per-component memory footprint (parameters, activations, gradients, optimizer state) for training vs. inference on the toy MNIST MLP, exposing why training memory dominates and scales with both batch size and parameter count.
Solution:
Step 1: Model parameters. Table 6 tallies the weights and biases layer by layer:
| Layer | Weights | Biases | Total Parameters |
|---|---|---|---|
| Input → Hidden1 | \(784{\times}128\) = 100,352 | 128 | 100,480 |
| Hidden1 → Hidden2 | \(128{\times}64\) = 8,192 | 64 | 8,256 |
| Hidden2 → Output | \(64{\times}10\) = 640 | 10 | 650 |
| Total | 109,386 |
Parameter memory: 109,386\(\times\) 4 bytes = 437.5 KB
Step 2: Activations. Table 7 records each layer’s activation tensor and its memory cost at batch size 32:
| Layer | Activation Shape | Values | Memory |
|---|---|---|---|
| Input | \(32{\times}784\) | 25,088 | 100.4 KB |
| Hidden1 | \(32{\times}128\) | 4,096 | 16.4 KB |
| Hidden2 | \(32{\times}64\) | 2,048 | 8.2 KB |
| Output | \(32{\times}10\) | 320 | 1.3 KB |
| Total | 31,552 | 126.2 KB |
Step 3: Training-only memory.
- Gradients (same size as parameters): 437.5 KB
- Optimizer state (Adam stores momentum + velocity, 2\(\times\) parameters): 875.1 KB
Table 8 summarizes the per-component memory footprint for training vs. inference:
| Component | Training | Inference |
|---|---|---|
| Parameters | 437.5 KB | 437.5 KB |
| Activations | 126.2 KB | 3.9 KB |
| Gradients | 437.5 KB | — |
| Optimizer state | 875.1 KB | — |
| Total | ~1.9 MB | ~441 KB |
Systems insight: Training at batch size 32 requires 4.3\(\times\) more memory than single-sample inference in this example. For larger models, this ratio increases further because gradient and optimizer storage scale with parameter count, while activations scale with batch size\(\times\) layer widths.
The preceding memory requirements seem modest for our small MNIST classifier. Scaling to production-sized models transforms these requirements dramatically, changing the hardware regime.
Napkin Math 1.1: The memory explosion
How does the scale of our Lighthouse Models affect the Data \((D_{\text{vol}})\) term of the iron law? Compare our MNIST classifier to GPT-2.
- MNIST Archetype: 109,386 parameters \(\times\) 4 bytes (FP32) ≈ 438 KB. This entire model fits inside the L2 cache of a modern processor.
- GPT-2 Archetype: 1,500,000,000 parameters \(\times\) 4 bytes (FP32) ≈ 6 GB. This requires dedicated GPU VRAM and high-speed memory bandwidth.
Systems insight: Moving from ~109K to 1.5 B parameters is a 13,713 \(\times\) jump. The increase represents a phase change in engineering, not merely “more parameters.” MNIST is a cache-resident arithmetic problem; GPT-2 is a Data Movement problem.
The preceding memory calculations are precise but slow. Engineers also need fast feasibility checks before running a profiler or writing a detailed design.
Napkin Math 1.2: Quick estimation for ML engineers
Detailed calculations are essential for design documents, but experienced engineers also develop rapid mental estimation skills. These “napkin math” shortcuts enable quick feasibility checks before committing to detailed analysis:
Table 9: Napkin-Math Feasibility Checks: Three rapid mental-estimation rules for GPU fit, epoch time, and bound regime, distilled into one-line formulas an engineer can apply before running a profiler.
Memory Estimation
- Parameters → Bytes: Multiply by four (FP32) or two (FP16/BF16) or one (INT8)
- FC layer parameters: Input\(\times\) Output (plus Output biases, usually negligible)
- Training memory: ~3–4\(\times\) inference memory (gradients + optimizer state)
- Adam optimizer overhead: 2\(\times\) parameter memory (momentum + velocity)
- Max batch size: \((\text{GPU VRAM} - \text{Model Size}) / \text{Activations per sample}\)
Compute Estimation
- FC layer FLOPs: \(2 \times \text{Input} \times \text{Output} \times \text{Batch}\) (multiply-add = 2 ops)
- MACs to FLOPs: Multiply by 2
- GPU utilization: \(\text{Actual FLOPS} / \text{Peak FLOPS}\) (typically 30–70 percent for training)
Table 9 distills the rapid-estimation rules into one-line formulas:
| Question | Quick Estimate |
|---|---|
| “Will this model fit in GPU memory?” | \(\text{Parameters} \times 4\text{ bytes} \times 4\text{ (training)} < \text{VRAM}\) |
| “How long per epoch on MNIST?” | \(60\text{K} \times \text{FLOPs/image} / \text{GPU TFLOPS}\) |
| “Is this compute bound or memory bound?” | If \(\text{batch} \times \text{layer\_width} < 1000\), likely memory bound |
Example: “Can I train a 100M parameter model on a 16 GB GPU?”
Mental math: 100M \(\times\) 4 bytes \(\times\) 4 (training overhead) = 1.6 GB for model. Leaves ~14 GB for activations and batch data. Answer: Yes, comfortably—batch size is the main constraint.
Parameter initialization is critical to network behavior. Setting all parameters to zero would cause neurons in a layer to behave identically, preventing diverse feature learning. Instead, weights are typically initialized randomly, often using specific strategies like Xavier/Glorot initialization32 (Glorot and Bengio 2010) or He initialization (He et al. 2015), while biases often start at small constant values or zeros. The scale of these initial values matters: values that are too large or too small lead to poor learning dynamics.
32 Xavier/Glorot Initialization: Weight variance must scale as \(1/n\) (where \(n\) is layer width) to prevent activations from vanishing or exploding across layers (Glorot and Bengio 2010). Before this insight, training failures from poor initialization were routinely misdiagnosed as hardware bugs or insufficient compute. The fix costs zero additional FLOPs; it is purely a matter of setting the right random distribution at startup.
Glorot, Xavier, and Yoshua Bengio. 2010. “Understanding the Difficulty of Training Deep Feedforward Neural Networks.” Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics (AISTATS) 9: 249–56.
He, Kaiming, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2015. “Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification.” 2015 IEEE International Conference on Computer Vision (ICCV), 1026–34. https://doi.org/10.1109/iccv.2015.123.
The distribution of parameters affects information flow through layers. In digit recognition, if weights are too small, important input details might not propagate to later layers. If too large, the network might amplify noise. Biases help adjust the activation threshold of each neuron, enabling the network to learn optimal decision boundaries.
Different architectures impose specific constraints on parameter organization. Some share weights across network regions to encode position-invariant pattern recognition; others restrict certain weights to zero, implementing sparse connectivity patterns.
Network architecture, neurons, and parameters are now in place, but a central question remains: the mechanism by which these randomly initialized parameters become useful. A randomly wired network produces outputs no better than chance. Understanding the architecture of a neural network answers what the model computes; understanding training answers how the model learns. The training process transforms a randomly initialized network into one that captures meaningful patterns in data, and the mechanics of that transformation reveal fundamental systems constraints. Training demands far more memory than inference, gradient computation dominates energy budgets, and batch size is ultimately a hardware decision. The learning process addresses these constraints as networks systematically adjust their weights based on feedback from training data, transforming 109,386 random numbers into a functioning digit classifier.
Self-Check: Question
Across deep hidden layers, ReLU dominates sigmoid and tanh in production systems. Which pair of properties, taken together, best explains that dominance per the section?
- A max operation (single comparator in silicon) and a non-saturating gradient of one for positive inputs that keeps deep backpropagation numerically alive.
- Normalized probabilistic output and exact biological fidelity to cortical neurons.
- Guaranteed non-zero activations for every input and a built-in regularization penalty.
- An exponential that matches softmax’s output distribution and a centered range around zero.
Explain why the chapter argues that a deep, narrow network can represent some functions with polynomially more layers but exponentially fewer parameters than a shallow, wide network with the same expressiveness. Ground your answer in the compositional structure the section describes.
In the chapter’s 784→128→64→10 MNIST network, which layer dominates both parameter count and MAC count, and why?
- The softmax output stage, because output normalization requires more parameters than any dense layer.
- The 64→10 projection, because its smaller output dimension forces quadratic growth in parameters.
- The 784→128 input layer, because its weight matrix has 784×128 entries — more than the next two layers combined — and each forward pass executes that many MACs per example.
- The first hidden layer, because it alone stores the optimizer’s momentum buffers while later layers are stateless.
True or False: Stacking more linear layers without activation functions still increases a network’s expressive power, because each added layer contributes its own learnable weight matrix.
An inference-hardware team must choose between sigmoid and ReLU for hidden-layer activations in a mobile SoC with tight silicon-area and energy budgets. Using the chapter’s treatment of activation cost, which engineering consequence follows most directly from picking sigmoid?
- Sigmoid’s exponential-based implementation consumes substantially more silicon area and energy per activation than ReLU’s max operator, inflating both chip cost and per-inference energy at the scale of millions of activations per forward pass.
- Sigmoid reduces memory bandwidth pressure because its bounded output lets the compiler skip storing activations.
- Sigmoid removes the need for quantization because its values are already in [0, 1].
- Sigmoid is cheaper than ReLU because it produces denser activation tensors with fewer zeros.
A team must spend a fixed parameter budget on either a much deeper network or a much wider shallow one. Which concern is most specific to the deeper choice per the section’s systems discussion?
- Depth introduces long sequential dependencies and long gradient paths, hurting layer-level parallelism and raising the risk of vanishing or exploding gradients during backpropagation.
- Depth removes the need to store activations during backpropagation because earlier layers are recomputed automatically.
- Depth guarantees fewer total parameters than any wider alternative at every depth.
- Depth lets every layer compute independently, making end-to-end latency trivially easy to hide.
Learning Process
Our MNIST network currently holds 109,386 randomly initialized parameters—numbers that encode no knowledge at all. The transformation of these random values into a digit classifier achieving over 95 percent accuracy relies on four operations repeated millions of times: forward propagation computes a prediction, a loss function measures the error, backpropagation assigns blame to each weight, and an optimizer adjusts those weights to reduce the error.
Supervised learning from labeled examples
A randomly initialized network classifies digits no better than random guessing among ten classes (about 10 percent accuracy). Transforming it into a 95 percent-accurate classifier requires supervised learning: showing the network labeled examples and adjusting its weights based on the errors it makes. Consider our MNIST digit recognition task: we have a dataset of 60,000 training images, each a \(28{\times}28\) pixel grayscale image paired with its correct digit label. The network must learn the relationship between these images and their corresponding digits through an iterative process of prediction and weight adjustment. Ensuring the quality and integrity of training data is essential to model success, as established in Data Engineering.
The relationship between inputs and outputs drives the training methodology. Training operates as a loop where each iteration processes a subset of training examples called a batch33. For each batch, the network performs four operations: forward computation through the network layers generates predictions, a loss function evaluates prediction accuracy, weight adjustments are computed based on prediction errors, and network weights are updated to improve future predictions.
33 Batch Processing: Batching serves dual purposes: larger batches provide more stable gradient estimates by averaging noise across examples and better saturate parallel hardware, since GPUs process thirty-two inputs with nearly the same latency as one because matrix multiplication parallelizes across the batch dimension. The trade-off: each doubling of batch size roughly doubles activation memory, making batch size ultimately a hardware-memory decision rather than a purely statistical one.
The iterative approach can be expressed mathematically. Given an input image \(x\) and its true label \(y\), the network computes its prediction according to Equation 10: \[ \hat{y} = f(x; \theta) \tag{10}\]
This equation encapsulates the entire forward pass: the network \(f\) takes an input \(x\) (say, a \(28{\times}28\) digit image) and, using its current parameters \(\theta\) (all the weights and biases we examined earlier), produces a prediction \(\hat{y}\) (a vector of ten probabilities, one per digit). The semicolon notation \(f(x; \theta)\) distinguishes the input \(x\), which changes with every example, from \(\theta\), which remains fixed during inference but evolves during training. The network’s error is measured by a loss function34 \(\mathcal{L}\), as shown in Equation 11: \[ \text{loss} = \mathcal{L}(\hat{y}, y) \tag{11}\]
34 Loss Function: Formalized by Abraham Wald in statistical decision theory as the “cost” of an incorrect decision, \(\mathcal{L}\) quantifies the gap between prediction \(\hat{y}\) and ground truth \(y\). The choice of loss function shapes the optimization geometry: it determines the gradient landscape that backpropagation must navigate. A loss with flat regions near incorrect predictions produces weak gradients that stall learning, while a loss with steep gradients near the decision boundary accelerates convergence where it matters most—a systems consequence explored in the cross-entropy discussion below.
The error measurement drives the adjustment of network parameters through backpropagation, examined in Section 1.3.4.
In practice, training operates on batches of examples rather than individual inputs. For the MNIST dataset, each training iteration might process 32, 64, or 128 images simultaneously for reasons we formalize in Section 1.3.5.2. The training cycle continues until the network achieves sufficient accuracy or reaches a predetermined number of iterations. Throughout this process, the loss function serves as a guide, its minimization indicating improved performance. Establishing proper metrics and evaluation protocols is essential for assessing training effectiveness, as discussed in Benchmarking.
Forward pass computation
Forward propagation is the core computational process in a neural network: input data flows through the network’s layers to generate predictions. Figure 17 traces the complete process. Inputs enter from the left, pass through weighted connections to hidden layers, generate a prediction that is compared against the true value, and produce a loss score that drives parameter updates through the optimizer. This process underlies both inference and training. We examine how it works using our MNIST digit recognition example.

The bidirectional flow of data moving forward through the layers (the red arrow in Figure 17) and gradients flowing backward to update weights (the orange arrow) is the heartbeat of neural network training. The figure reveals a critical asymmetry: forward propagation produces a single output, but backward propagation must compute gradients for every weight in the network. This asymmetry explains why training requires storing all intermediate activations—each layer’s gradient computation depends on what that layer received during the forward pass. Before the mathematical details, pause to consolidate this core mechanism.
Checkpoint 1.3: Gradient flow
The forward pass is only half the story.
Data vs. Signal
Dependencies
When an image of a handwritten digit enters our network, it undergoes a series of transformations through the layers. Each transformation combines the weighted inputs with learned patterns to progressively extract relevant features. For the 784-128-64-10 digit classifier, a \(28{\times}28\) pixel image is processed through multiple layers to ultimately produce probabilities for each possible digit (0–9).
The process begins with the input layer, where each pixel’s grayscale value becomes an input feature. For MNIST, this means 784 input values (\(28{\times}28\) = 784), each normalized between 0 and 1. These values then propagate forward through the hidden layers, where each neuron combines its inputs according to its learned weights and applies a nonlinear activation function.
Each forward pass through our MNIST network (784-128-64-10) requires substantial matrix operations. The first layer alone performs 100,352 multiply-accumulate operations per sample. When processing multiple samples in a batch, these operations multiply accordingly, requiring careful management of memory bandwidth and computational resources. Specialized hardware like GPUs executes these operations efficiently through parallel processing.
Individual layer processing
The forward computation through a neural network proceeds systematically, with each layer transforming its inputs into increasingly abstract representations. The digit classifier illustrates this: its transformation process occurs in distinct stages.
At each layer, the computation involves two key steps: a linear transformation of inputs followed by a nonlinear activation. The linear transformation applies the same weighted sum operation we saw earlier, but now using notation that tracks which layer we are in, as shown in Equation 12: \[ \mathbf{Z}^{(l)} = \mathbf{A}^{(l-1)}\mathbf{W}^{(l)} + \mathbf{b}^{(l)} \tag{12}\]
Here, \(\mathbf{A}^{(l-1)}\) contains the activations from the previous layer (the outputs after applying activation functions), \(\mathbf{W}^{(l)} \in \mathbb{R}^{n_{l-1} \times n_l}\) is the weight matrix for layer \(l\), and \(\mathbf{b}^{(l)}\) is the bias vector (broadcast across the batch). The superscript \((l)\) keeps track of which layer each parameter belongs to. This row-vector convention matches the single-sample equation from earlier: each row of \(\mathbf{A}\) is one sample, and right-multiplying by \(\mathbf{W}\) transforms it to the next layer’s width.
Following this linear transformation, each layer applies a nonlinear activation function \(f\) (we now write \(f\) or \(f^{(l)}\) for a generic activation function at layer \(l\); earlier, \(\sigma\) referred specifically to the sigmoid function), as expressed in Equation 13: \[ \mathbf{A}^{(l)} = f(\mathbf{Z}^{(l)}) \tag{13}\]
This process repeats at each layer, creating a chain of transformations: \[ \text{Input} \rightarrow \text{Linear Transform} \rightarrow \text{Activation} \rightarrow \text{Linear Transform} \rightarrow \text{Activation} \rightarrow \cdots \rightarrow \text{Output} \]
Returning to digit recognition, the pixel values first undergo a transformation by the first hidden layer’s weights, converting the 784-dimensional input into an intermediate representation. Each subsequent layer further transforms this representation, ultimately producing a 10-dimensional output vector representing the network’s confidence in each possible digit.
Matrix multiplication formulation
The complete forward propagation process can be expressed as a composition of functions, each representing a layer’s transformation. Formalizing this mathematically builds on the MNIST example.
For a network with \(L\) layers, we can express the full forward computation as Equation 14: \[ \mathbf{A}^{(L)} = f^{(L)}\!\Big(\cdots f^{(2)}\!\Big(f^{(1)}(\mathbf{X}\mathbf{W}^{(1)} + \mathbf{b}^{(1)})\mathbf{W}^{(2)} + \mathbf{b}^{(2)}\Big)\cdots \mathbf{W}^{(L)} + \mathbf{b}^{(L)}\Big) \tag{14}\]
This composition reveals that forward propagation is, at its core, a chain of matrix multiplications interleaved with nonlinear activations. Understanding why matrix multiplication dominates AI computation requires examining the arithmetic intensity of each operation.
Systems Perspective 1.4: Why matrix multiplication dominates AI
The arithmetic intensity gap: Not all operations are created equal. Systems engineers distinguish between compute-bound operations (dense math) and memory-bound operations (simple math). Table 10 contrasts matrix multiplication against element-wise ReLU on these dimensions:
Table 10: Arithmetic Intensity of Matrix Multiply vs. Element-Wise ReLU: Dense \(N{\times}N\) matrix multiplication performs \(2N^3\) operations while moving about \(3N^2s\) bytes for \(s\) bytes per value, yielding intensity that grows linearly with \(N\) and saturates GPU/TPU compute. Element-wise activations stay at \(1/(2s)\) FLOPs/byte regardless of size (0.125 FLOPs/byte for FP32), leaving accelerators starved for arithmetic and explaining why GEMM-heavy layers dominate modern architectures.
| Operation | Complexity (Ops) | Data Movement (IO) | Intensity (FLOPs/byte) | Hardware Fit |
|---|---|---|---|---|
| Matrix Mul \((N{\times}N)\) | \(2N^3\) | \(3N^2s\) bytes | \(\approx 2N/(3s)\) (High) | GPU/TPU |
| Element-wise (ReLU) | \(N^2\) | \(2N^2s\) bytes | \(1/(2s)\) (Low) | CPU/Vector |
Modern AI accelerators (GPUs) have massive compute arrays but limited memory bandwidth. They only achieve peak performance on High Intensity operations like Matrix Multiplication where data is reused many times. This is why “fully connected” and “convolutional” layers are preferred over complex, custom element-wise logic.
The GEMM engine: The mathematical expression \(\mathbf{x}\mathbf{W}\) is implemented in hardware as a General Matrix Multiply (GEMM) kernel, the most optimized routine in all of computing, accounting for over 90 percent of the floating-point operations in most neural networks. To achieve peak performance, engineers use techniques like blocking and tiling to ensure data fits perfectly into L1/L2 caches and remains there as long as possible (data reuse). This hardware-software co-design principle, designing model architectures to use large, dense matrix multiplications that specialized accelerators like Tensor Cores can execute at exaflop scale, is what makes modern deep learning physically possible. General matrix multiply (GEMM) provides the detailed treatment of GEMM arithmetic intensity, sparse matrix formats, and the computational complexity of common layer types needed to optimize these operations in practice.
While this nested expression captures the complete process, we typically compute it step by step:
First layer: \[ \mathbf{Z}^{(1)} = \mathbf{X}\mathbf{W}^{(1)} + \mathbf{b}^{(1)} \] \[ \mathbf{A}^{(1)} = f^{(1)}(\mathbf{Z}^{(1)}) \]
Hidden layers \((l = 2,\ldots, L-1)\): \[\begin{gather*} \mathbf{Z}^{(l)} = \mathbf{A}^{(l-1)}\mathbf{W}^{(l)} + \mathbf{b}^{(l)} \\[1ex] \mathbf{A}^{(l)} = f^{(l)}(\mathbf{Z}^{(l)}) \end{gather*}\]
Output layer: \[\begin{gather*} \mathbf{Z}^{(L)} = \mathbf{A}^{(L-1)}\mathbf{W}^{(L)} + \mathbf{b}^{(L)} \\[1ex] \mathbf{A}^{(L)} = f^{(L)}(\mathbf{Z}^{(L)}) \end{gather*}\] In our MNIST example, if we have a batch of \(B\) images, the dimensions of these operations are:
- Input \(\mathbf{X}\): \(B{\times}784\)
- First layer weights \(\mathbf{W}^{(1)}\): \(784{\times}n_1\)
- Hidden layer weights \(\mathbf{W}^{(l)}\): \(n_{l-1}{\times}n_l\)
- Output layer weights \(\mathbf{W}^{(L)}\): \(n_{L-1}{\times}10\)
Step-by-step computation sequence
Understanding how these mathematical operations translate into actual computation requires examining the forward propagation process for a batch of MNIST images. This process illustrates how data transforms from raw pixel values to digit predictions.
Consider a batch of 32 images entering our network. Each image starts as a \(28{\times}28\) grid of pixel values, which we flatten into a 784-dimensional vector. For the entire batch, this gives us an input matrix \(\mathbf{X}\) of size \(32{\times}784\), where each row represents one image. The values are typically normalized to lie between 0 and 1.
The transformation at each layer proceeds as follows:
Input Layer Processing: The network takes our input matrix \(\mathbf{X}\) (\(32{\times}784\)) and transforms it using the first layer’s weights. If our first hidden layer has 128 neurons, \(\mathbf{W}^{(1)}\) is a \(784{\times}128\) matrix. The resulting computation \(\mathbf{X}\mathbf{W}^{(1)}\) produces a \(32{\times}128\) matrix.
Hidden Layer Transformations: Each element in this matrix then has its corresponding bias added and passes through an activation function. For example, with a ReLU activation, any negative values become zero while positive values remain unchanged. This nonlinear transformation enables the network to learn complex patterns in the data.
Output Generation: The final layer transforms its inputs into a \(32{\times}10\) matrix, where each row contains 10 values corresponding to the network’s confidence scores for each possible digit. Let \(z_j\) denote the raw score (logit) for digit \(j\) and let \(z_k\) range over all 10 digits. Often, these scores are converted to probabilities using the softmax function in Equation 6: \[ P(\text{digit } j) = \frac{e^{z_j}}{\sum_{k=1}^{10} e^{z_k}} \]
For each image in the batch, this produces a probability distribution over the possible digits. The digit with the highest probability represents the network’s prediction. A layer-by-layer operation count makes the computational cost explicit.
Example 1.4: Counting ops in forward pass
Problem: What is the total arithmetic operation count (\(O\)) for one forward pass through the MNIST network (784 → 128 → 64 → 10) with batch size 32?
Background: A matrix multiplication of dimensions \((M{\times}K) \times (K{\times}N)\) requires \(2 \times M \times K \times N\) operations (one multiply and one add per output element, summed over \(K\) terms). Bias addition adds \(M \times N\) operations. ReLU activation adds \(M \times N\) comparisons (counted as operations).
Solution: Table 11 breaks down the FLOP count layer by layer:
| Layer | Operation | Dimensions | Ops |
|---|---|---|---|
| Layer 1 | MatMul | (\(32{\times}784\))\(\times\) (\(784{\times}128\)) | 2\(\times\) 32\(\times\) \(784{\times}128\) = 6,422,528 |
| Layer 1 | Bias + ReLU | \(32{\times}128\) | \(2{\times}4,096\) = 8,192 |
| Layer 2 | MatMul | (\(32{\times}128\))\(\times\) (\(128{\times}64\)) | 2\(\times\) 32\(\times\) \(128{\times}64\) = 524,288 |
| Layer 2 | Bias + ReLU | \(32{\times}64\) | \(2{\times}2,048\) = 4,096 |
| Layer 3 | MatMul | (\(32{\times}64\))\(\times\) (\(64{\times}10\)) | 2\(\times\) 32\(\times\) \(64{\times}10\) = 40,960 |
| Layer 3 | Bias + Softmax | \(32{\times}10\) | ~640 (simplified) |
| Total | ~7.0 MOps |
Per-image cost: 7.0 \(\text{MOps} / 32\) = ~219 KOps per image
Key insights:
- Layer 1 dominates: The first layer accounts for 92 percent of all operations because it processes the largest input (784 dimensions). This is why dimensionality reduction in early layers is so impactful.
- Compute vs. Memory: At 219 KOps per image and ~441 KB memory, this network has an arithmetic intensity of ~0.5 FLOPs/byte—firmly in the memory-bound regime for most hardware (see the Roofline Model in The roofline model for how arithmetic intensity determines whether a workload is memory bound or compute bound). A modern GPU achieving ten TFLOPS would process each image in ~22 nanoseconds of pure compute, but memory latency typically dominates actual inference time.
- Scaling intuition: Doubling the hidden layer widths (784 → 256 → 128 → 10) increases \(O\) by ~2.1\(\times\) to ~15.0 MOps. This comes from recomputing each layer: L1 and L3 double, L2 quadruples, so the total grows by about 2.15\(\times\) rather than 4\(\times\).
Implementation and optimization considerations
Forward propagation implementation involves practical considerations that affect both computational efficiency and memory usage, particularly when processing large batches or deep networks.
Memory management plays a central role during forward propagation. Each layer’s activations must be stored for the backward pass during training. For our MNIST example (784-128-64-10) with a batch size of 32, the activation storage requirements are:
- Input layer: \(32{\times}784\) = 25,088 values
- First hidden layer: \(32{\times}128\) = 4,096 values
- Second hidden layer: \(32{\times}64\) = 2,048 values
- Output layer: \(32{\times}10\) = 320 values
This produces a total of 31,552 values that must be maintained in memory for each batch during training, consistent with the worked example in Section 1.2.5.3. The memory requirements scale linearly with batch size and become substantial for larger networks.
Batch processing introduces important trade-offs. Larger batches enable more efficient matrix operations and better hardware utilization but require more memory. For example, doubling the batch size to 64 would double the memory requirements for activations. This relationship between batch size, memory usage, and computational efficiency guides the choice of batch size in practice.
The organization of computations also affects performance. Matrix operations can be optimized through careful memory layout and specialized libraries. The choice of activation functions affects both the network’s learning capabilities and computational efficiency, as some functions (like ReLU) require less computation than others (like tanh or sigmoid).
The computational characteristics of neural networks favor parallel processing architectures. While traditional CPUs can execute these operations, GPUs designed for parallel computation can be substantially faster for large dense matrix operations. Specialized AI accelerators achieve even better efficiency through reduced precision arithmetic, specialized memory architectures, and dataflow optimizations tailored for neural network computation patterns.
Energy consumption also varies by orders of magnitude across hardware platforms. CPUs offer flexibility but consume more energy per operation. GPUs provide high throughput at higher power consumption. Specialized edge accelerators optimize for energy efficiency, achieving the same computations with orders of magnitude less power, which is important for mobile and embedded deployments. This energy disparity stems from the memory hierarchy constraints where data movement dominates computation costs.
These considerations recur throughout subsequent chapters, particularly in Network Architectures where architecture-specific optimizations introduce additional trade-offs.
Forward propagation transforms inputs into predictions, but a prediction alone is useless for learning. The training loop requires a way to measure how wrong that prediction is in a form that guides weight adjustments. Loss functions fill this role: they translate the gap between prediction and reality into a single number that optimization can minimize.
Loss functions
The forward propagation process described earlier suffices for inference, using a pretrained model to make predictions. To train a model, however, we need a way to measure how well those predictions match reality. Loss functions quantify these errors, serving as the feedback mechanism that guides learning. They convert the abstract goal of “making good predictions” into a concrete optimization problem.
Continuing with our MNIST digit recognition example: when the network processes a handwritten digit image, it outputs ten numbers representing its confidence in each possible digit (0–9). The loss function measures how far these predictions deviate from the true answer. If an image displays a “seven”, the network should exhibit high confidence for digit “seven” and low confidence for all other digits. The loss function penalizes deviations from this target, with higher loss values signaling that the network needs significant improvement.
Error measurement fundamentals
A loss function measures how far the network’s predictions are from the correct answers. This difference is expressed as a single number: lower loss means more accurate predictions, while higher loss indicates the network needs improvement. During training, the loss function guides weight adjustments. In recognizing handwritten digits, for example, the loss penalizes predictions that assign low confidence to the correct digit.
Mathematically, a loss function \(\mathcal{L}\) takes two inputs: the network’s predictions \(\hat{y}\) and the true values \(y\). For a single training example in digit classification, the loss measures the discrepancy between prediction and truth. When training with batches of data, we typically compute the average loss across all examples in the batch, as shown in Equation 15: \[ \mathcal{L}_{\text{batch}} = \frac{1}{B}\sum_{i=1}^B \mathcal{L}(\hat{y}_i, y_i) \tag{15}\] where \(B\) is the batch size and \((\hat{y}_i, y_i)\) represents the prediction and truth for the \(i\)-th example. Averaging over the batch serves two purposes: it makes the loss independent of batch size (so the same learning rate works whether \(B = 32\) or \(B = 256\)), and the summation across examples maps naturally to parallel hardware—each example’s loss can be computed independently before a single reduction step combines them.
The choice of loss function depends on the type of task. For digit classification, the loss function must handle probability distributions over multiple classes, provide meaningful gradients that guide learning, penalize wrong predictions in proportion to their severity, and scale efficiently with batch processing. Cross-entropy loss satisfies all four requirements.
Cross-entropy and classification loss functions
For classification tasks like MNIST digit recognition, “cross-entropy”35 (Shannon 1948) loss has emerged as the standard choice. This loss function is particularly well-suited for comparing predicted probability distributions with true class labels.
35 Cross-Entropy Loss: This function’s use as the standard for classification comes from its direct measurement of “surprise” between the predicted probability distribution and the true one-hot encoded label. It penalizes confident but incorrect predictions logarithmically, creating a steep error gradient that forces rapid correction where alternatives like mean squared error would plateau. This advantage typically reduces training time by 2–3\(\times\) compared to mean squared error for classification tasks.
Shannon, Claude E. 1948. “A Mathematical Theory of Communication.” Bell System Technical Journal 27 (3): 379–423. https://doi.org/10.1002/j.1538-7305.1948.tb01338.x.
36 One-Hot Encoding: Representing \(K\) classes as \(K\)-dimensional binary vectors where exactly one element is 1. This encoding is sparse by construction: for MNIST’s 10 classes, 90 percent of each label vector is zeros. At scale, this sparsity becomes a systems concern. Encoding 100,000 classes (as in large-vocabulary language models) produces label vectors that waste memory and bandwidth, motivating alternatives like label smoothing and sampled softmax that trade exact one-hot targets for compute efficiency.
For a single digit image, our network outputs a probability distribution over the 10 possible digits. We represent the true label as a one-hot vector36 where all entries are 0 except for a one at the correct digit’s position. For instance, if the true digit is “seven”, the label would be \(y = \big[0, 0, 0, 0, 0, 0, 0, 1, 0, 0\big]\).
The cross-entropy loss for this example is defined in Equation 16: \[ \mathcal{L}(\hat{y}, y) = -\sum_{j=1}^{10} y_j \log(\hat{y}_j) \tag{16}\] where \(\hat{y}_j\) represents the network’s predicted probability for digit \(j\). Given our one-hot encoding, this simplifies to Equation 17: \[ \mathcal{L}(\hat{y}, y) = -\log(\hat{y}_c) \tag{17}\] where \(c\) is the index of the correct class. This means the loss depends only on the predicted probability for the correct digit; the network is penalized based on how confident it is in the right answer.
For example, if our network predicts the following probabilities for an image of “seven”:
Predicted: [0.1, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.8, 0.0, 0.1]
True: [0, 0, 0, 0, 0, 0, 0, 1, 0, 0]The loss would be \(-\log(0.8)\), which is approximately 0.223. If the network were more confident and predicted 0.9 for the correct digit, the loss would decrease to approximately 0.105.
Batch loss calculation methods
The practical computation of loss involves considerations for both numerical stability and batch processing. When working with batches of data, we compute the average loss across all examples in the batch.
For a batch of \(B\) examples, the cross-entropy loss becomes Equation 18: \[ \mathcal{L}_{\text{batch}} = -\frac{1}{B}\sum_{i=1}^B \sum_{j=1}^{10} y_{ij} \log(\hat{y}_{ij}) \tag{18}\]
Computing this loss efficiently requires careful consideration of numerical precision. The dangerous case is not an ordinary small probability, but a probability that an unstable softmax rounds to zero. If the correct-class probability becomes 0, then \(\log(0)\) becomes \(-\infty\) and the loss can turn into a not a number (NaN) during later arithmetic.
To address this, we typically implement the loss computation with two key modifications:
Add a small epsilon to prevent taking log of zero, as in Equation 19: \[ \mathcal{L} = -\log(\hat{y} + \epsilon) \tag{19}\]
Apply the log-sum-exp trick for numerical stability (see Logits and numerical stability for why this is necessary and how it works), as shown in Equation 20: \[ \text{softmax}(z_i) = \frac{\exp\big(z_i - \max(z)\big)}{\sum_j \exp\big(z_j - \max(z)\big)} \tag{20}\]
With a batch size of 32 and 10 output classes, this means:
- Processing 32 sets of 10 probabilities
- Computing 32 individual loss values
- Averaging these values to produce the final batch loss
Impact on learning dynamics
Loss functions influence training in ways that explain key implementation decisions.
During each training iteration, the loss value serves multiple purposes. As a performance metric, it quantifies current network accuracy. As an optimization target, its gradients guide weight updates toward better predictions. As a convergence signal, its trend over time indicates whether training is progressing, stalling, or diverging.
For our MNIST classifier, monitoring the loss during training reveals the network’s learning trajectory. A typical pattern begins with high loss (\(\sim 2.3\), equivalent to random guessing among ten classes), followed by rapid decrease in early iterations as the network discovers the most salient features. Progress then slows to gradual improvement as the network fine-tunes its predictions for harder cases, eventually stabilizing at a lower loss (\(\sim 0.1\), indicating confident correct predictions).
The loss function’s gradients with respect to the network’s outputs provide the initial error signal that drives backpropagation. For cross-entropy loss, these gradients have a particularly simple form: the difference between predicted and true probabilities. This mathematical property makes cross-entropy loss especially suitable for classification tasks, as it provides strong gradients even when predictions are far from the target.
The choice of loss function also influences other training decisions. Larger loss gradients may require smaller learning rates to prevent overshooting, while loss averaging across batches affects gradient stability and thus optimal batch size. The loss landscape’s curvature shapes which optimization algorithms work best, and the loss value’s trajectory determines when training has converged.
Loss functions quantify prediction error, but the error signal alone does not tell the system how to correct it. With 109,386 parameters in the MNIST network, determining which weights should change, by how much, and in what direction is intractable without an efficient credit-assignment algorithm. This is the credit assignment problem: determining which of thousands of connections contributed to the error. The next section introduces backpropagation, which solves this problem through the chain rule of calculus, systematically computing each weight’s responsibility for the final prediction error.
Gradient computation and backpropagation
Backpropagation is the algorithmic cornerstone of neural network training, enabling systematic weight adjustment through gradient-based optimization. While loss functions tell us how wrong our predictions are, backpropagation tells us exactly how to fix them.
Definition 1.2: Backpropagation
Backpropagation is the efficient application of the Chain Rule to a computational graph to solve the Credit Assignment Problem.
- Significance (quantitative): It propagates error signals from output to input, computing the gradient of the loss with respect to every parameter in one backward traversal of the computation graph.
- Distinction (durable): Unlike Numerical Differentiation (which requires one perturbed forward pass per parameter), Backpropagation is a Global Gradient Computation whose cost is the same order as a small constant multiple of the forward pass.
- Common pitfall: A frequent misconception is that Backpropagation is “Learning.” In reality, it is a Signal Transformation; it provides the gradient, while Gradient Descent performs the update.
This definition captures the mathematical essence, but building intuition requires understanding the problem backpropagation solves.
To build intuition, consider the credit assignment problem through a factory assembly line analogy. A car factory passes vehicles through four stations: frame installation (A), engine mounting (B), wheel attachment (C), and final assembly (D). When inspectors find a defective car, they must determine which station caused the problem.
The solution works backward. Starting from the defect, inspectors trace responsibility through each station: how much D’s assembly contributed vs. what it received from C, and how much C’s work contributed vs. what came from B. Each station receives adjustment feedback proportional to its contribution. If Station B’s engine mounting was the primary cause, it receives the strongest signal to change.
Backpropagation solves this credit assignment problem identically. The output layer receives direct feedback about what went wrong, calculates how its inputs contributed, and sends adjustment signals backward. Each layer receives guidance proportional to its contribution and adjusts weights accordingly—the most responsible connections making the largest adjustments.
In neural networks, each layer acts like a station on the assembly line, and backpropagation determines how much each connection contributed to the final prediction error. Translating this intuition into mathematics requires the chain rule of calculus, which provides the precise mechanism for computing each layer’s contribution. In the factory analogy, “Station D’s adjustment signal” corresponds to the gradient at the output layer, “proportion of contribution” maps to partial derivatives, and “sending feedback backward” describes the chain rule multiplication that propagates error signals through the network.
Backpropagation algorithm steps
While forward propagation computes predictions, backward propagation determines how to adjust weights to improve those predictions. Consider the running example where the network predicts a “three” for an image of “seven”. Backward propagation provides a systematic way to adjust weights throughout the network by calculating how each weight contributed to the error.
The process begins at the network’s output, where we compare predicted digit probabilities with the true label. This error then flows backward through the network, with each layer’s weights receiving an update signal based on their contribution to the final prediction. The computation follows the chain rule of calculus, breaking down the complex relationship between weights and final error into manageable steps.
The mathematical foundations of backpropagation provide the theoretical basis for training neural networks, but practical implementation requires sophisticated software frameworks. Modern frameworks like PyTorch and TensorFlow implement automatic differentiation systems that handle gradient computation automatically, eliminating manual derivative implementation (Wengert 1964). Algorithm Foundations derives the chain rule formally, covers reverse-mode automatic differentiation, and analyzes computational graph optimizations. Framework implementation of automatic differentiation examines the systems engineering aspects of these frameworks, including computation graphs and optimization strategies.
Wengert, Ralph E. 1964. “A Simple Automatic Derivative Evaluation Program.” Communications of the ACM 7 (8): 463–64. https://doi.org/10.1145/355586.364791.
This requirement to store intermediate values has significant implications for system memory requirements during training:
Systems Perspective 1.5: The memory cost of backprop
Why Training is Memory Bound: In forward inference, we can discard the activations of Layer \(i\) as soon as Layer \(i+1\) is computed. Training is different. Because the gradient at Layer \(i\) depends on the activation at Layer \(i\) (via the chain rule), we must store every intermediate activation until the backward pass reaches that layer. Equation 21 captures this memory decomposition: \[ \text{Training Memory} \approx \text{Model Weights} + \text{Optimizer States} + \text{Activations} \tag{21}\]
For deep networks, Activations dominate. Storing a batch of high-resolution images across 100 layers consumes gigabytes of HBM (High Bandwidth Memory). This Capacity Wall drives the need for systems techniques like Gradient Checkpointing (recomputing activations instead of storing them) and Model Parallelism. The true cost of training memory provides the complete training memory equation and a worked analysis of weights, gradients, optimizer state, and activation costs.
Error signal propagation
The flow of gradients through a neural network follows a path opposite to the forward propagation. Starting from the loss at the output layer, gradients propagate backwards, computing how each layer, and ultimately each weight, influenced the final prediction error.
Consider what happens when the digit classifier misclassifies a “seven” as a “three”. The loss function generates an initial error signal at the output layer, essentially indicating that the probability for “seven” should increase while the probability for “three” should decrease. This error signal then propagates backward through the network layers.
For a network with \(L\) layers, the gradient flow can be expressed mathematically. At each layer \(l\), we compute how the layer’s output affected the final loss using the chain rule37 in Equation 22: \[ \frac{\partial \mathcal{L}}{\partial \mathbf{A}^{(l)}} = \frac{\partial \mathcal{L}}{\partial \mathbf{A}^{(l+1)}} \frac{\partial \mathbf{A}^{(l+1)}}{\partial \mathbf{A}^{(l)}} \tag{22}\]
37 Chain Rule: The calculus identity \(\frac{\partial \mathcal{L}}{\partial w} = \frac{\partial \mathcal{L}}{\partial a_n}\) \(\cdot \frac{\partial a_n}{\partial a_{n-1}} \cdots \frac{\partial a_1}{\partial w}\) becomes a product of \(n\) terms for an \(n\)-layer network. If each partial derivative is slightly less than one, the product vanishes exponentially; if slightly greater, it explodes. This multiplicative structure is why depth is a systems constraint, not just a design choice: it dictates the numerical precision requirements and initialization strategies (for example, Glorot, He) needed to keep training stable.
This computation cascades backward through the network, with each layer’s gradients depending on the gradients from the layer above it. The process reveals how each layer’s transformation contributed to the final prediction error. If certain weights in an early layer strongly influenced a misclassification, they receive larger gradient values, indicating a need for more substantial adjustment.
This process faces challenges in deep networks. As gradients flow backward through many layers, they can either vanish or explode. When gradients are repeatedly multiplied through many layers, they can become exponentially small, particularly with sigmoid or tanh activation functions. This causes early layers to learn at negligible rates or not at all, as they receive negligible updates. Conversely, if gradient values are consistently greater than one, they can grow exponentially, leading to unstable training and destructive weight updates.
Derivative calculation process
Computing gradients involves calculating several partial derivatives at each layer: how changes in weights, biases, and activations affect the final loss. These computations follow directly from the chain rule of calculus but must be implemented efficiently for practical training.
At each layer \(l\), we compute three main gradient components. Each serves a distinct purpose in the learning process.
Weight gradients measure how changing each weight affects the final loss. These gradients tell us precisely how to adjust the connection strengths between neurons to reduce prediction errors, as shown in Equation 23: \[ \frac{\partial \mathcal{L}}{\partial \mathbf{W}^{(l)}} = {\mathbf{A}^{(l-1)}}^T \frac{\partial \mathcal{L}}{\partial \mathbf{Z}^{(l)}} \tag{23}\]
Bias gradients measure how changing each bias term affects the loss. Since biases shift the activation threshold of neurons, these gradients indicate whether neurons should become more or less easily activated, as expressed in Equation 24: \[ \frac{\partial \mathcal{L}}{\partial \mathbf{b}^{(l)}} = \mathbf{1}^T \frac{\partial \mathcal{L}}{\partial \mathbf{Z}^{(l)}} \tag{24}\]
Input gradients propagate the error signal backward to the previous layer. Rather than directly updating parameters, these gradients serve as the “adjustment signals” that allow earlier layers to learn from the final prediction error, as shown in Equation 25: \[ \frac{\partial \mathcal{L}}{\partial \mathbf{A}^{(l-1)}} = \frac{\partial \mathcal{L}}{\partial \mathbf{Z}^{(l)}} {\mathbf{W}^{(l)}}^T \tag{25}\]
Consider the final layer where the network outputs digit probabilities. If the network predicted \([0.1, 0.2, 0.5,\ldots, 0.05]\) for an image of “seven”, the gradient computation would:
- Start with the error in these probabilities
- Compute how weight adjustments would affect this error
- Propagate these gradients backward to help adjust earlier layer weights
A minimal network makes the gradient arithmetic concrete by tracing actual values through backpropagation.
Example 1.5: Tracing gradients: A worked backpropagation example
Setup: Consider a network with two inputs, a hidden layer of two neurons (ReLU activation), and one output neuron (no activation, for simplicity). Suppose the current weights and biases are:
- Hidden layer: \(\mathbf{W}^{(1)} = \begin{bmatrix} 0.5 & -0.3 \\ 0.8 & 0.2 \end{bmatrix}\), \(\mathbf{b}^{(1)} = \begin{bmatrix} 0 \\ 0 \end{bmatrix}\)
- Output layer: \(\mathbf{W}^{(2)} = \begin{bmatrix} 0.6 \\ -0.4 \end{bmatrix}\), \(\mathbf{b}^{(2)} = 0\)
Given input \(\mathbf{x} = [1.0,\; 0.5]\) and target \(y = 1.0\), we use mean squared error: \(\mathcal{L} = \frac{1}{2}(\hat{y} - y)^2\).
Forward pass (to establish the values backpropagation needs):
- Hidden preactivation: \[\mathbf{z}^{(1)} = \mathbf{x}\mathbf{W}^{(1)} + \mathbf{b}^{(1)} = [1.0 \cdot 0.5 + 0.5 \cdot 0.8,\; 1.0 \cdot (-0.3) + 0.5 \cdot 0.2] = [0.9,\; -0.2]\]
- Hidden activation (ReLU): \(\mathbf{a}^{(1)} = [\max(0, 0.9),\; \max(0, -0.2)] = [0.9,\; 0.0]\)
- Output: \(\hat{y} = \mathbf{a}^{(1)}\mathbf{W}^{(2)} + b^{(2)} = 0.9 \cdot 0.6 + 0.0 \cdot (-0.4) = 0.54\)
- Loss: \(\mathcal{L} = \frac{1}{2}(0.54 - 1.0)^2 = 0.1058\)
Backward pass (applying the chain rule layer by layer):
Step 1: Output layer gradient. The loss gradient with respect to the output is \[\frac{\partial \mathcal{L}}{\partial \hat{y}} = \hat{y} - y = 0.54 - 1.0 = -0.46.\]
Step 2: Output weight gradients (applying Equation 23). Since the output layer has no activation function \[\frac{\partial \mathcal{L}}{\partial \mathbf{Z}^{(2)}} = -0.46, \quad\text{and}\quad \frac{\partial \mathcal{L}}{\partial \mathbf{W}^{(2)}} = {\mathbf{a}^{(1)}}^T \cdot (-0.46) = \begin{bmatrix} 0.9 \\ 0.0 \end{bmatrix} \cdot (-0.46) = \begin{bmatrix} -0.414 \\ 0.0 \end{bmatrix}\]
Step 3: Propagate to hidden layer (applying Equation 25). The error signal sent backward is: \[\frac{\partial \mathcal{L}}{\partial \mathbf{a}^{(1)}} = (-0.46) \cdot {\mathbf{W}^{(2)}}^T = (-0.46) \cdot [0.6,\; -0.4] = [-0.276,\; 0.184]\]
Step 4: Pass through ReLU. The ReLU derivative is one where \(z > 0\) and 0 otherwise, so \[\frac{\partial \mathcal{L}}{\partial \mathbf{z}^{(1)}} = [-0.276 \cdot 1,\; 0.184 \cdot 0] = [-0.276,\; 0.0].\] The second neuron’s gradient is zeroed because ReLU blocked its forward signal.
Step 5: Hidden weight gradients (applying Equation 23): \[\frac{\partial \mathcal{L}}{\partial \mathbf{W}^{(1)}} = \mathbf{x}^T \cdot \frac{\partial \mathcal{L}}{\partial \mathbf{z}^{(1)}} = \begin{bmatrix} 1.0 \\ 0.5 \end{bmatrix} \cdot [-0.276,\; 0.0] = \begin{bmatrix} -0.276 & 0.0 \\ -0.138 & 0.0 \end{bmatrix}\]
Weight updates (with learning rate \(\eta = 0.1\)): Each weight moves opposite to its gradient. For example, \(W^{(1)}_{11}\) updates from \(0.5\) to \(0.5 - 0.1 \cdot (-0.276) = 0.5276\), nudging the network toward the correct output. The second hidden neuron’s weights receive zero updates for this example because ReLU blocked its activation, illustrating the mechanism that can lead to dead neurons if it happens persistently across the training data.
While understanding these mathematical details is essential for debugging and optimization, modern practitioners rarely implement gradients manually. The systems breakthrough lies in how frameworks automatically implement these calculations. Consider a simple operation like matrix multiplication followed by ReLU activation: output = torch.relu(input @ weight). The mathematical gradient involves computing the derivative of ReLU (0 for negative inputs, 1 for positive) and applying the chain rule for matrix multiplication. The framework handles this automatically by:
- Recording the operation in a computation graph during forward pass
- Storing necessary intermediate values (pre-ReLU activations for gradient computation)
- Automatically generating the backward pass function for each operation
- Optimizing memory usage and computation order across the entire graph
This automation transforms gradient computation from a manual, error-prone process requiring deep mathematical expertise into a reliable system capability that enables rapid experimentation and deployment. The framework ensures correctness while optimizing for computational efficiency, memory usage, and hardware utilization.
Computational implementation details
We established earlier that training requires storing activations for backpropagation (see the worked example in Section 1.2.5.3). Here we examine how those requirements scale with model size and what additional costs the backward pass introduces.
Consider a larger variant of our MNIST network (784 → 512 → 256 → 10) with a batch size of 32. Each layer’s activations must be maintained:
- Input layer: \(32{\times}784\) values (~100 KB using 32-bit numbers)
- Hidden layer 1: \(32{\times}512\) values (~66 KB)
- Hidden layer 2: \(32{\times}256\) values (~33 KB)
- Output layer: \(32{\times}10\) values (~1.3 KB)
Beyond activations, we must store gradients for each parameter. For this larger network with approximately 535,818 parameters, gradient storage requires several megabytes. Advanced optimizers like Adam38 roughly double this by maintaining momentum and velocity terms for every parameter.
38 Adam (Adaptive Moment Estimation): Maintains per-parameter first and second moment estimates (momentum and velocity), requiring 2\(\times\) additional memory beyond the parameters themselves (Kingma and Ba 2014). For a 100K-parameter MNIST model this overhead is negligible, but for a 7B-parameter model it adds ~56 GB in FP32, often the difference between fitting on one GPU or needing two. Adam became the default optimizer despite this cost because it converges with minimal hyperparameter tuning.
Kingma, Diederik P., and Jimmy Ba. 2014. “Adam: A Method for Stochastic Optimization.” ICLR in press.
Memory bandwidth compounds these capacity requirements. Each training step requires loading all parameters, storing gradients, and accessing activations—creating substantial memory traffic that scales with both model size and batch size. For modest networks like our MNIST example, this traffic remains manageable, but as models grow, memory bandwidth becomes the primary bottleneck, requiring specialized high-bandwidth memory systems.
The computational pattern of backward propagation follows a strict sequence: compute gradients at the current layer, update stored gradients, propagate the error signal to the previous layer, and repeat until the input layer is reached. For batch processing, these computations are performed simultaneously across all examples in the batch, enabling efficient use of matrix operations and parallel processing capabilities.
Modern frameworks handle these computations through sophisticated autograd39 engines. When you call loss.backward() in PyTorch, the framework automatically manages memory allocation, operation scheduling, and gradient accumulation across the computation graph. The system tracks which tensors require gradients, optimizes memory usage through gradient checkpointing when needed, and schedules operations to maximize hardware utilization. This automated management allows practitioners to focus on model design rather than the intricate details of gradient computation implementation.
39 Autograd (Automatic Differentiation): Records operations during the forward pass into a directed acyclic graph (DAG), then traverses it backward using the chain rule to compute all gradients automatically (Linnainmaa 1970). The key systems trade-off: PyTorch’s dynamic graph rebuilds the DAG each iteration (flexible but harder to optimize), while TensorFlow’s original static graph compiled once (rigid but amenable to hardware-specific kernel fusion). This design choice propagates into every deployment decision.
Linnainmaa, Seppo. 1970. “The Representation of the Cumulative Rounding Error of an Algorithm as a Taylor Expansion of the Local Rounding Errors.” Master's thesis, University of Helsinki.
Checkpoint 1.4: Backpropagation
The “Credit Assignment Problem” asks: which weight caused this error? Now that you have seen how backpropagation answers this question, verify your understanding:
The Mechanism
Training vs. Inference
Weight update and optimization
Backpropagation computes what each weight should change, but not how much. The step size, the direction refinement, and the momentum across iterations are all governed by the optimizer—the algorithm that converts raw gradients into weight updates. The choice of optimizer determines whether training converges in hours or diverges in minutes (Wolpert and Macready 1997).
Wolpert, D. H., and W. G. Macready. 1997. “No Free Lunch Theorems for Optimization.” IEEE Transactions on Evolutionary Computation 1 (1): 67–82. https://doi.org/10.1109/4235.585893.
Parameter update algorithms
The optimization process adjusts network weights through gradient descent, a systematic method that uses the error signal from backpropagation to determine the direction and magnitude of each weight update.
Definition 1.3: Gradient descent
Gradient Descent is the iterative algorithm that navigates the Loss Landscape by updating parameters in the direction of the negative gradient.
- Significance (quantitative): It transforms the Learning Problem into an Optimization Problem, trading computational cycles (\(O\)) for error reduction until convergence.
- Distinction (durable): Unlike Backpropagation, which only Computes the gradient, Gradient Descent Applies the update to the parameters.
- Common pitfall: A frequent misconception is that Gradient Descent always finds the Global Minimum. In reality, it is a Local Optimizer that can become stuck in plateaus or local optima in nonconvex landscapes.
This iterative process calculates how each weight contributes to the error and updates parameters to reduce loss, gradually refining the network’s predictive ability.
The fundamental update rule combines backpropagation’s gradient computation with parameter adjustment, as defined in Equation 26: \[ \theta_{\text{new}} = \theta_{\text{old}} - \eta \nabla_{\theta}\mathcal{L} \tag{26}\] where \(\theta\) represents any network parameter (weights or biases), \(\eta\) is the learning rate, and \(\nabla_{\theta}\mathcal{L}\) is the gradient computed through backpropagation.
For the digit classifier, this means adjusting weights to improve classification accuracy. If the network frequently confuses “seven”s with “one”s, gradient descent will modify weights to better distinguish between these digits. The learning rate \(\eta\)40 controls adjustment magnitude: too large values cause overshooting optimal parameters, while too small values result in slow convergence.
40 Learning Rate: This single scalar has an outsized impact on training infrastructure because it couples directly to batch size. Doubling the batch size (to better saturate GPU parallelism) typically requires scaling the learning rate proportionally, a relationship formalized by the linear scaling rule (Goyal et al. 2017). Misjudging this coupling is a common cause of training divergence when teams scale from single-GPU to multi-GPU setups, often misdiagnosed as a hardware or data issue rather than a hyperparameter mismatch.
Goyal, Priya, Piotr Dollár, Ross Girshick, Pieter Noordhuis, Lukasz Wesolowski, Aapo Kyrola, Andrew Tulloch, Yangqing Jia, and Kaiming He. 2017. “Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour.” arXiv Preprint arXiv:1706.02677 abs/1706.02677.
Frankle, Jonathan, and Michael Carbin. 2019. “The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks.” International Conference on Learning Representations.
Neyshabur, Behnam, Srinadh Bhojanapalli, David McAllester, and Nati Srebro. 2017. “Exploring Generalization in Deep Learning.” Advances in Neural Information Processing Systems 30.
Nakkiran, Preetum, Gal Kaplun, Yamini Bansal, Tristan Yang, Boaz Barak, and Ilya Sutskever. 2019. “Deep Double Descent: Where Bigger Models and More Data Hurt.” arXiv Preprint arXiv:1912.02292.
Despite neural network loss landscapes being highly nonconvex with multiple local minima, gradient descent reliably finds effective solutions in practice. The theoretical reasons, involving concepts like the lottery ticket hypothesis (Frankle and Carbin 2019), implicit bias (Neyshabur et al. 2017), and overparameterization benefits (Nakkiran et al. 2019), remain active research areas. For practical ML systems engineering, the key insight is that gradient descent with appropriate learning rates, initialization, and regularization consistently trains neural networks to high performance.
Mini-batch gradient updates
Neural networks typically process multiple examples simultaneously during training, an approach known as mini-batch gradient descent. Rather than updating weights after each individual image, we compute the average gradient over a batch of examples before performing the update.
For a batch of size \(B\), the loss gradient becomes Equation 27: \[ \nabla_{\theta}\mathcal{L}_{\text{batch}} = \frac{1}{B}\sum_{i=1}^B \nabla_{\theta}\mathcal{L}_i \tag{27}\]
With a typical batch size of 32, this means:
- Process 32 images through forward propagation
- Compute loss for all 32 predictions
- Average the gradients across all 32 examples
- Update weights using this averaged gradient
The choice of batch size directly determines how much hardware parallelism the system can use.
Systems Perspective 1.6: Batch size and hardware utilization
The batch size trade-off: Larger batches improve hardware efficiency because matrix operations can process multiple examples with similar computational cost to processing one. However, each example in the batch requires memory to store its activations, creating a fundamental trade-off: larger batches use hardware more efficiently but demand more memory. Available memory thus becomes a hard constraint on batch size, which in turn affects how efficiently the hardware can be used. This relationship between algorithm design (batch size) and hardware capability (memory) exemplifies why ML systems engineering requires thinking about both simultaneously.
Iterative learning process
The complete training process combines forward propagation, backward propagation, and weight updates into a systematic training loop. This loop repeats until the network achieves satisfactory performance or reaches a predetermined number of iterations.
A single pass through the entire training dataset is called an epoch41. For MNIST, with 60,000 training images and a batch size of 32, each epoch consists of 1,875 batch iterations. Listing 1 summarizes the complete mini-batch SGD procedure.
41 Epoch: One complete pass through all training data. The number of epochs is a direct multiplier on total compute cost: a 100-epoch MNIST run executes 100\(\times\) more forward and backward passes than a single epoch. At frontier scale, this multiplier becomes the binding constraint: GPT-3 trained for only ~1 epoch over 300 billion tokens because the per-epoch cost already consumed thousands of GPU-weeks.
Algorithm: Mini-Batch Stochastic Gradient Descent
------------------------------------------------
Input: Training data D, learning rate eta, batch size B, number of epochs E
Output: Trained weights W
1. Initialize weights W randomly
2. for epoch = 1 to E do
3. Shuffle D to prevent order-dependent patterns
4. for each mini-batch B subset D of size B do
5. y_hat = ForwardPass(B, W) ▷ Compute predictions
6. L = (1/B) sum ell(y_hat_i, y_i) ▷ Compute batch loss
7. grad_W L = Backprop(L) ▷ Compute gradients
8. W = W - eta * grad_W L ▷ Update weights
9. end for
10. Evaluate on validation set; check for convergence
11. end forDuring training, we monitor several key metrics: training loss tracks the average loss over recent batches, validation accuracy measures performance on held-out test data, and learning progress indicates how quickly the network improves. For our digit recognition task, we might observe accuracy climb from 10 percent (random guessing) to over 95 percent through multiple epochs of training.
Convergence and stability considerations
A network that achieves 99.5 percent accuracy on training data but only 85 percent on new data has not learned the underlying patterns—it has memorized the training set. This failure mode, overfitting, is the central risk in practical training.
Definition 1.4: Overfitting
Overfitting is the failure of Generalization caused by memorizing Noise instead of Signal.
- Significance (quantitative): It occurs when a model’s Capacity exceeds the information content of the training data \((D)\), allowing it to satisfy the training objective without learning the underlying distribution.
- Distinction (durable): Unlike Underfitting (where the model is too simple), Overfitting is a Symmetry Breaking problem: the model becomes too specialized to the specific training sample.
- Common pitfall: A frequent misconception is that Overfitting is “solved” by more data. In reality, it is a Capacity-Data Gap: without proper Regularization, larger models will eventually overfit even large datasets.
Learning rate selection is the single most consequential hyperparameter in training. For our MNIST network, the choice of learning rate dramatically influences the training dynamics. A large learning rate of 0.1 might cause unstable training where the loss oscillates or explodes as weight updates overshoot optimal values. Conversely, a learning rate of 0.0001 might result in extremely slow convergence, requiring many more epochs to achieve good performance. A moderate learning rate of 0.01 often provides a good balance between training speed and stability, allowing the network to make steady progress while maintaining stable learning.
Convergence monitoring provides essential feedback during training and continues into production deployment, as covered in ML Operations. As training progresses, the loss value typically stabilizes around a particular value, indicating the network is approaching a local optimum. Validation accuracy often plateaus as well, suggesting the network has extracted most learnable patterns from the data. The gap between training and validation performance reveals whether the network is overfitting or generalizing well to new examples. The interplay between batch size, available memory, and computational resources requires careful balancing to achieve efficient training within hardware constraints, the same memory-computation trade-offs established in the preceding backpropagation section.
The complete training pipeline, from forward propagation through loss computation to gradient-based weight updates, is now established. Training, however, is preparation, not the end goal. The following checkpoint consolidates that learning process before we examine what happens when a trained model must answer queries in production.
Checkpoint 1.5: Neural network learning process
You have now covered the complete training cycle, the mathematical machinery that enables neural networks to learn from data. Before moving to inference and deployment, verify your understanding:
Forward propagation:
Loss functions:
Backward propagation:
Optimization:
Complete training loop:
Self-Test: For our MNIST network (784 → 128 → 64 → 10), trace what happens during one training iteration with batch size 32: What matrices multiply? What gets stored? What memory is required? What gradients are computed?
If any concepts feel unclear, review the earlier sections on Forward Propagation, Loss Functions, Backward Propagation, or the Optimization Process. These mechanisms form the foundation for understanding the training-vs.-inference distinction we explore next.
Self-Check: Question
Order the following mini-batch training-step phases: (1) Update weights, (2) Compute loss from predictions, (3) Run forward pass, (4) Run backpropagation.
A classifier outputs probability 0.8 for the correct digit on one image and 0.05 for the correct digit on another. Why does cross-entropy produce a dramatically stronger learning signal on the second image than on the first?
- Cross-entropy converts the output layer into a linear regression problem, which always produces stronger gradients for small probabilities.
- Cross-entropy is \(-\log\) of the correct-class probability, so probability 0.05 yields loss ≈ 3.0 while probability 0.8 yields loss ≈ 0.22; with softmax cross-entropy, the correct-class logit gradient magnitude rises from about 0.20 to 0.95.
- Cross-entropy averages losses across the batch, so single-image losses never drive the gradient.
- Cross-entropy guarantees the model will not overfit, so confident-but-wrong predictions receive the same signal as confident-and-right ones.
A team can fit their 7B-parameter model on an 80 GB accelerator for inference but runs out of memory on the same device for training, even with an identical batch size. Explain the three categories of tensors that training requires beyond inference, and describe which is usually largest for a standard Adam run.
A team doubles mini-batch size to raise GPU utilization. Per the section’s framing, which trade-off should they expect most directly?
- Activation memory roughly doubles, even as per-step gradient estimates become less noisy and matrix-math utilization improves.
- The loss function becomes unnecessary because batch averaging handles error signals automatically.
- The backward pass can be skipped because batch statistics reveal gradients without explicit differentiation.
- Generalization improves automatically because each update sees more examples.
A debugging engineer calls
optimizer.step()in a training loop but forgot to compute gradients (noloss.backward()precedes the step). Every parameter’s.gradattribute isNoneor zero. Which description best captures what the training system will actually do, and what this reveals about the relationship between backpropagation and gradient descent?- The optimizer will reproduce backpropagation internally from the parameters alone and update correctly, because gradient descent implicitly performs differentiation.
- The optimizer will apply its update rule against zero or stale gradients, producing weight perturbations driven by momentum buffers or Adam’s second moments rather than by the current loss — which shows that backpropagation (gradient computation) is a distinct step that must produce the error signal before gradient descent (the update rule) consumes it.
- The optimizer will raise a compile-time error because gradient descent is undefined without backpropagation.
- The optimizer will recompute the loss and gradients from the labels already stored in its state.
Why do very deep networks with saturating activations suffer from vanishing or exploding gradients during backpropagation?
- The chain rule multiplies one layer-wise derivative per layer, and values consistently below or above one shrink or grow exponentially in depth — a sigmoid network of 20 layers can land near \(0.25^{20} \approx 10^{-12}\) in effective gradient magnitude.
- Softmax returns zero for incorrect classes, so no gradient can flow backward through the output layer.
- Inference-only activations are too small to store during training, so backpropagation runs on random noise.
- Larger batch sizes force every layer to share identical weight updates, flattening the gradient.
Inference Pipeline
Training transforms randomly initialized weights into parameters that encode meaningful patterns, but training is preparation, not the end goal. The inference42 phase renegotiates the silicon contract: the same mathematical operators now face different hardware constraints—latency budgets instead of throughput targets, milliwatt power envelopes instead of kilowatt racks, and edge devices instead of GPU clusters. Understanding how the contract changes between training and inference is essential for practical systems design.
42 Inference: From Latin inferre (“to bring in, to conclude”), borrowed from logic where it means deriving conclusions from premises. The ML usage marks a sharp systems boundary: training optimizes weights using forward and backward passes with gradient storage, while inference executes only the forward pass with frozen parameters. This distinction halves or quarters memory requirements and eliminates the need for gradient computation, fundamentally changing which hardware is viable, from 400 W data center GPUs to 2 W edge accelerators.
Production deployment and prediction pipeline
A model that achieved 99 percent accuracy on the test set produces nonsensical outputs three months after deployment, yet no code has changed. The weights are frozen, the architecture is identical, and the inference pipeline runs without error. The problem is that the world moved while the model stood still.
The transition from training to inference introduces a constraint on model adaptability that fundamentally shapes system design. Trained models generalize to unseen inputs through learned statistical patterns, but parameters remain fixed throughout deployment. Once training concludes, the model applies its learned probability distributions without modification. When operational data distribution diverges from training distributions, the model continues executing its fixed computational pathways regardless of this shift. Consider an autonomous vehicle perception system: if construction zone frequency increases substantially or novel vehicle configurations appear in deployment, the model’s responses reflect statistical patterns learned during training rather than adapting to the evolved operational context. Adaptation in ML systems emerges not from runtime model modification but from systematic retraining with updated data, a deliberate engineering process detailed in Model Training.
Operational phase differences
Neural network operation divides into two distinct phases with markedly different computational requirements. Figure 18 contrasts these phases visually. Inference performs only the forward pass, processing inputs through the learned weights with batch sizes that vary according to demand. Training adds the backward pass for gradient computation and parameter updates, requires larger fixed batches to stabilize gradient estimates, and must store activations, gradients, and optimizer state simultaneously, consuming significantly more memory. The network architecture is identical in both phases; the difference lies entirely in computational and memory orchestration.
These computational differences manifest directly in hardware requirements and deployment strategies. Training clusters typically employ high-memory GPUs43 with substantial cooling infrastructure. Inference deployments prioritize latency and energy efficiency across diverse platforms: mobile devices use low-power neural processors (typically 2–4 W), edge servers deploy specialized inference accelerators44, and cloud services employ inference-optimized instances with reduced numerical precision for increased throughput45. Production inference systems serving millions of requests daily require sophisticated infrastructure including load balancing, auto-scaling, and failover mechanisms typically unnecessary in training environments.
43 Training GPU Power Budget: The “high-memory” requirement is driven by the need to hold parameters, gradients, optimizer state, and activations simultaneously. The corresponding power draw dictates the “substantial cooling infrastructure,” as a single high-end training GPU consumes 400–700 W. Even compared with a 4 W mobile inference chip, that is at least 100\(\times\) the power budget.
44 Edge Inference Accelerators: The Edge TPU (Google Coral) operates in the mobile/embedded tier at ~2 W TDP, delivering 4 TOPS by hardwiring the multiply-accumulate datapath for INT8 inference. Edge servers occupy a different tier entirely: the NVIDIA Jetson AGX Orin delivers 275 TOPS at 15–60 W, about 69\(\times\) more throughput but requiring fixed power infrastructure rather than battery operation. This power-tier gap (single-digit watts vs. tens of watts) determines whether inference can run on battery-powered devices or requires wired deployment.
45 Quantization: From Latin quantus (“how much”), reducing numerical precision from 32-bit to eight-bit integers yields 4\(\times\) less memory per parameter and up to 4\(\times\) higher throughput on hardware with INT8 datapaths. Trained models tolerate this precision loss because inference does not accumulate rounding errors across gradient updates the way training does. The trade-off is not free: aggressive quantization (below four-bit) can degrade accuracy on tail-distribution inputs, requiring calibration datasets to find the precision floor for each deployment. See Model Compression for quantization techniques.

These architectural differences translate directly into distinct resource profiles, as Table 12 details.
| Characteristic | Training Forward Pass | Inference Forward Pass |
|---|---|---|
| Activation Storage | Maintains complete activation history for backprop | Retains only current layer activations |
| Memory Pattern | Preserves intermediate states throughout forward pass | Releases memory after layer computation completes |
| Computational Flow | Structured for gradient computation preparation | Optimized for direct output generation |
| Resource Profile | Higher memory requirements for training operations | Minimized memory footprint for efficient execution |
Memory and computational resources
Neural networks consume computational resources differently during inference than during training. Inference focuses on efficient forward pass computation with minimal memory overhead. The specific requirements for our canonical MNIST network (784-128-64-10) illustrate this:
Memory requirements during inference can be precisely quantified:
- Static Memory (Model Parameters):
- Layer 1: \(784{\times}128\) = 100,352 weights + 128 biases
- Layer 2: \(128{\times}64\) = 8,192 weights + 64 biases
- Layer 3: \(64{\times}10\) = 640 weights + 10 biases
- Total: 109,386 parameters (≈ 437.5 KB at 32-bit floating point precision46)
46 FP32 (Single Precision): The IEEE 754 standard (1985) format using 32 bits (1 sign, 8 exponent, 23 mantissa) that became the default for neural network training because its dynamic range accommodates gradient magnitudes spanning many orders of magnitude. Halving to FP16 or BF16 (“brain floating point,” developed at Google Brain) saves 2\(\times\) memory and doubles throughput on hardware with 16-bit datapaths; further reduction to INT8 yields 4\(\times\) savings but requires posttraining calibration. See Numerical Representations for a detailed comparison of numerical formats and their precision-throughput trade-offs.
- Dynamic Memory (Input buffer and activations per image):
- Input buffer: 784 values
- Layer 1 output: 128 values
- Layer 2 output: 64 values
- Layer 3 output: 10 values
- Total: 986 values (≈ 3.9 KB at 32-bit floating point precision)
Computational requirements follow a fixed pattern for each input:
- First layer: 100,352 multiply-adds
- Second layer: 8,192 multiply-adds
- Output layer: 640 multiply-adds
- Total: 109,184 multiply-add operations per inference
The resource profile differs markedly from training requirements, where gradient storage and backpropagation overhead multiply resource demands by 4.3\(\times\) or more (see the worked example in Section 1.2.5.3). The predictable, streamlined nature of inference enables optimization opportunities that training cannot exploit.
Performance enhancement techniques
The fixed nature of inference computation presents optimization opportunities unavailable during training. Once parameters are frozen, the predictable computation pattern allows systematic improvements in both memory usage and computational efficiency.
Batch size selection represents a key inference trade-off. During training, large batches stabilized gradient computation, but inference offers more flexibility. Processing single inputs minimizes latency, making it ideal for real-time applications requiring immediate responses. Batch processing, however, improves throughput by 10–32\(\times\) by using parallel computing capabilities more effectively, particularly on GPUs. For our MNIST network, processing a single image requires storing 202 layer-output activation values (986 values including the input buffer), while a batch of 32 images requires 6,464 layer-output activation values but can process images up to 32 times faster on parallel hardware.
Memory management during inference is far more efficient than during training. Since intermediate values serve only forward computation, memory buffers can be reused aggressively. Activation values from each layer need only exist until the next layer’s computation completes, enabling in-place operations that reduce the total memory footprint. The fixed nature of inference allows precise memory alignment and access patterns optimized for the underlying hardware architecture.
Hardware-specific optimizations become particularly important during inference. On CPUs, computations can be organized to maximize cache utilization and exploit SIMD parallelism. GPU deployments benefit from optimized matrix multiplication routines and efficient memory transfer patterns. These optimizations extend beyond computational efficiency to reduce power consumption and improve hardware utilization, critical factors in real-world deployments.
The predictable nature of inference also enables optimizations like reduced numerical precision. While training typically requires full floating-point precision to maintain stable learning, inference can often operate with reduced precision while maintaining acceptable accuracy. For our MNIST network, such optimizations could halve the memory footprint with corresponding improvements in computational efficiency.
These optimization principles, while illustrated through our simple MNIST feedforward network, represent only the foundation of neural network optimization. More sophisticated architectures introduce additional considerations and opportunities, including specialized designs for spatial data processing, sequential computation, and attention-based computation patterns. These architectural variations and their optimizations are explored in Network Architectures and Model Compression. Production deployment considerations, including batching strategies and runtime optimization, are covered in Throughput Optimization and ML Operations.
Output interpretation and decision making
Neural network outputs must be transformed into actionable predictions, which requires a return to traditional computing. Preprocessing bridges real-world data to neural computation; postprocessing bridges neural outputs back to conventional systems. Together, they complete a hybrid pipeline where neural and traditional computing work in concert.
The complexity of postprocessing extends beyond simple mathematical transformations. Real-world systems must handle uncertainty, validate outputs, and integrate with larger computing systems. In our MNIST example, a digit recognition system requires both the most likely digit and confidence measures to determine when human intervention is needed. This introduces additional computational steps: confidence thresholds, secondary prediction checks, and error handling logic, all of which are implemented in traditional computing frameworks.
The computational requirements of postprocessing differ fundamentally from neural network inference. While inference benefits from parallel processing and specialized hardware, postprocessing typically runs on conventional CPUs and follows sequential logic. Operations are more flexible and easier to modify than neural computations, but they can become bottlenecks if not carefully implemented. Computing softmax probabilities for a batch of predictions, for instance, requires different optimization strategies than the matrix multiplications of neural network layers.
System integration considerations often dominate postprocessing design. Output formats must match downstream system requirements, error handling must align with broader system protocols, and performance must meet system-level constraints. In a complete mail sorting system, the postprocessing stage must not only identify digits but also format these predictions for the sorting machinery, handle uncertainty cases appropriately, and maintain processing speeds that match physical mail flow rates.
The return to traditional computing completes the hybrid nature of deep learning systems. Engineers who design only the neural component and neglect the surrounding pipeline discover that preprocessing and postprocessing often dominate end-to-end latency.
The preceding sections have covered the complete lifecycle of neural networks, from architectural design through training dynamics to inference deployment. Each concept (neurons, layers, forward propagation, backpropagation, loss functions, optimization) represents a piece of the puzzle, and the question is how they fit together in a real system under real constraints. Before the historical case study brings these principles to life in a production deployment processing millions of items per day, pause to consolidate how the components integrate.
Checkpoint 1.6: Complete neural network system
Before examining how these concepts integrate in a real-world deployment, verify your understanding of the complete neural network lifecycle:
Integration across phases:
Training to deployment:
Inference and deployment:
Systems integration:
End-to-end flow:
Self-Test: For an MNIST digit classifier (784 → 128 → 64 → 10) deployed in production: (1) Using the memory analysis from this chapter, explain why training requires ~4.3\(\times\) more memory than inference, and identify which components (gradients, optimizer state, activations) contribute to this difference. (2) Trace a single digit image from camera capture through preprocessing, inference, and postprocessing to final prediction. (3) Identify where bottlenecks might occur in a real-time system processing 100 images/second. (4) Describe how you would monitor for model degradation in production.
Use the case study that follows to watch architectural choices, training strategies, and deployment constraints combine into a working ML system.
The complete neural network lifecycle, from architecture design through training to inference deployment, now sits in the toolkit as a set of mathematical operations with quantifiable resource costs. These operations have so far lived in the controlled environment of our MNIST running example, where data is clean, latency is unconstrained, and hardware is unchallenged. Real production systems face all of these pressures simultaneously. To see how the pieces fit together under real constraints, we turn to one of the earliest and most instructive large-scale neural network deployments.
Self-Check: Question
What is the most load-bearing computational difference between training and inference for the same neural network architecture?
- Inference changes the network topology, while training keeps it fixed.
- Inference runs only the forward pass with frozen parameters; training adds backward passes, gradient storage, and optimizer-driven parameter updates.
- Inference requires larger batches than training to remain numerically stable.
- Inference stores more optimizer state because predictions must be reproducible.
A vision inference service reports p99 end-to-end latency of 220 ms, with model inference occupying 40 ms. The rest is split between JPEG decode, resize, and a business-rule post-processor. Explain why the classic “optimize the model” instinct will barely move the p99 and what the engineer should target instead, grounded in the section’s pipeline framing.
A real-time service must serve a single request with the lowest possible latency, not maximum aggregate throughput. Which inference choice best matches the section’s guidance?
- Use the largest possible batch so activations persist longer and the accelerator stays fully occupied.
- Prefer single-item or very small-batch inference, trading lower hardware utilization for minimized queueing delay.
- Run the backward pass at serving time to refine predictions per request.
- Increase output precision to FP64 so post-processing becomes unnecessary.
Two serving frameworks propose different memory plans for a forward-only image classifier: Plan X allocates a fresh tensor for every layer’s output and keeps all layers’ outputs alive for the duration of the request; Plan Y maintains only two rotating activation buffers, overwriting layer \(k\)’s output once layer \(k+1\) has consumed it. Which plan exploits inference-specific memory behavior per the section, and why?
- Plan X is correct, because every inference request must retain all intermediate activations in case the optimizer needs them later.
- Plan Y is correct, because inference does not need intermediate activations for backpropagation, so once a layer’s output has been consumed by the next layer it can be overwritten — cutting peak activation memory from \(O(\text{depth})\) to \(O(1)\) buffers.
- Plan X is correct, because rotating buffers would require backward-pass gradients to reuse earlier activations.
- The two plans produce identical peak memory, because activation tensors are always allocated statically regardless of when they can be freed.
Why does the section argue that reduced numerical precision (quantization) is typically more tolerable at inference than during training?
- Inference does not accumulate rounding errors across thousands of parameter updates, so the precision noise that destabilizes training’s iterative dynamics does not compound at serve time.
- Inference avoids matrix multiplication entirely, so precision is irrelevant to the forward pass.
- Inference reconstructs missing bits from post-processing logic, so precision loss is recovered after the model runs.
- Low precision adds model capacity at inference by introducing new output classes.
USPS Digit Recognition
In the early 1990s, the United States Postal Service needed to read over 100 million handwritten ZIP codes per day. Human operators processed one digit per second at a cost that was becoming untenable. The solution was one of the first large-scale neural network deployments: a system that classified the same \(28{\times}28\) digits we have been analyzing, but millions of times per day under strict latency constraints. Deployed by Yann LeCun and colleagues (LeCun et al. 1989, 1998), this system gives concrete form to every operation from this chapter: preprocessing normalizes varying handwriting, the neural network performs forward propagation through learned weights, confidence thresholds implement postprocessing logic, and the complete pipeline must finish before each mail piece reaches its sorting point. The engineering principles it established (robust preprocessing, confidence-based routing, and end-to-end pipeline optimization) remain the template for production ML systems three decades later.
The mail sorting challenge
The United States Postal Service (USPS) operated at national mail scale, with daily volumes on the order of 100 million pieces, each requiring accurate routing based on handwritten ZIP codes. In the early 1990s, human operators primarily performed this task, making it one of the largest manual data entry operations worldwide. Automating this process through neural networks represented an early, successful large-scale deployment of artificial intelligence.
The complexity of this task becomes evident: a ZIP code recognition system must process images of handwritten digits captured under varying conditions. Scan the samples in Figure 19 to appreciate the wide variation in writing styles, pen types, stroke thickness, and character formation that the system must handle. The system must make accurate predictions within milliseconds to maintain mail processing speeds, yet errors in recognition can lead to significant delays and costs from misrouted mail. This real-world constraint meant the system needed both high accuracy and reliable measures of prediction confidence to identify when human intervention was necessary.

The challenging environment imposed requirements spanning every aspect of neural network implementation discussed in this chapter. Success depended on the entire pipeline from image capture through final sorting decisions, with the neural network’s accuracy as only one factor among many.
Engineering process and design decisions
Recognizing a handwritten “seven” on a white envelope is straightforward. Recognizing it on a crumpled package with coffee stains, ballpoint smudges, and overlapping address lines requires engineering decisions at every stage from data collection to deployment.
Data collection presented the first major challenge—and a concrete instance of the data pipeline principles covered in Data Engineering. Unlike controlled laboratory environments, postal facilities processed mail with tremendous variety. The training dataset had to capture this diversity: digits written by people of different ages, educational backgrounds, and writing styles; envelopes in varying colors and textures; and images captured under different lighting conditions and orientations. The data quality, labeling consistency, and distribution coverage that Data Engineering emphasizes were not abstract concerns here; they directly determined whether the system could handle a hurried scrawl as reliably as a carefully printed digit. This extensive data collection effort later contributed to the creation of the MNIST database (LeCun et al. 1998) used throughout our examples.
LeCun, Yann, Léon Bottou, Yoshua Bengio, and Patrick Haffner. 1998. “Gradient-Based Learning Applied to Document Recognition.” Proceedings of the IEEE 86 (11): 2278–324. https://doi.org/10.1109/5.726791.
Network architecture design required balancing multiple constraints. Deeper networks achieve higher accuracy but also increase processing time and computational requirements. Processing \(28{\times}28\) pixel images of individual digits had to complete within strict time constraints while running reliably on available hardware, maintaining consistent accuracy from well-written digits to hurried scrawls.
Training introduced additional complexity. The system needed high accuracy across real-world handwriting styles, not merely on a curated test dataset. Careful preprocessing normalized input images for variations in size and orientation. Data augmentation techniques, a form of the data transformation strategies discussed in Data Engineering, increased training sample variety. The team validated performance across different demographic groups and tested under actual operating conditions, following the kind of systematic evaluation workflow described in ML Workflow.
The engineering team faced a critical decision regarding confidence thresholds. Setting these thresholds too high would route too many pieces to human operators, defeating the purpose of automation. Setting them too low would risk delivery errors. The solution emerged from analyzing the confidence distributions of correct vs. incorrect predictions. This analysis established thresholds that optimized the trade-off between automation rate and error rate, ensuring efficient operation while maintaining acceptable accuracy.
Production system architecture
Following a single piece of mail through the USPS recognition system illustrates how the concepts in this chapter integrate into a complete solution. The journey from physical mail to sorted letter demonstrates the interplay between traditional computing, neural network inference, and physical machinery. Trace the data flow in Figure 20 to see this hybrid architecture in action, with the neural network operating as one component within a broader pipeline of conventional preprocessing and postprocessing stages.

The process begins when an envelope reaches the imaging station. High-speed cameras capture the ZIP code region at rates exceeding ten pieces per second—a pace that leaves no room for manual intervention. This image acquisition must adapt to varying envelope colors, handwriting styles, and lighting conditions while maintaining consistent quality despite motion blur.
Once captured, the raw images are far from ready for neural network processing. Preprocessing transforms these camera images into a standardized format. The system must locate the ZIP code region, segment individual digits, and normalize each digit image. This stage employs traditional computer vision techniques: image thresholding adapts to envelope background color, connected component analysis identifies individual digits, and size normalization produces standard \(28{\times}28\) pixel images. Speed remains critical; these operations must complete within milliseconds to maintain throughput.
The neural network then processes each normalized digit image. The original 1989 system used an early LeNet variant (LeCun et al. 1989) with approximately 10,000 parameters—remarkably compact compared to our running example’s 109K. The network processes each digit through multiple layers, ultimately producing ten output values representing digit probabilities. This inference process, while computationally intensive by 1990s standards, benefits from the optimization principles we discussed in the previous section.
LeCun, Yann, Bernhard Boser, John S. Denker, Donald Henderson, Richard E. Howard, Wayne Hubbard, and Lawrence D. Jackel. 1989. “Backpropagation Applied to Handwritten Zip Code Recognition.” Neural Computation 1 (4): 541–51. https://doi.org/10.1162/neco.1989.1.4.541.
Postprocessing converts these neural network outputs into sorting decisions. The system applies confidence thresholds to each digit prediction. A complete ZIP code requires high confidence in all five digits; a single uncertain digit flags the entire piece for human review. When confidence meets thresholds, the system transmits sorting instructions to mechanical systems that physically direct the mail to its appropriate bin.
The entire pipeline operates under strict timing constraints. From image capture to sorting decision, processing must complete before the mail piece reaches its sorting point. The system maintains multiple pieces in various pipeline stages simultaneously, requiring careful synchronization between computing and mechanical systems. This real-time operation illustrates why the optimizations we discussed in inference and postprocessing become essential in practical applications.
Performance outcomes and operational impact
Neural network-based ZIP code recognition transformed USPS mail processing operations. By 2000, several facilities across the country used this technology, processing millions of mail pieces daily. This real-world deployment demonstrated both the potential and the limitations of neural networks in mission-critical applications. Table 13 summarizes the key performance metrics.
Example 1.6: USPS digit recognition: By the numbers
| Metric | Neural Network | Human Operators |
|---|---|---|
| Error rate | 1.0 percent | 2.5 percent |
| Rejection rate | 9 percent | N/A |
| Throughput | 10–30 digits/sec | ~1 digit/sec |
| Model parameters | ~10,000 | N/A |
| Training time | 3 days (Sun-4/260) | N/A |
| Training epochs | 23 | N/A |
Systems insight: The neural network achieved better accuracy than humans (1.0 percent vs. 2.5 percent error) while processing 10–30\(\times\) faster. The 9 percent rejection rate represented the economically optimal trade-off: digits the network was uncertain about went to human operators rather than risking misrouted mail.
Economic impact: By the late 1990s, LeNet-based systems were reading millions of checks per day at financial institutions; related neural-network ZIP-code recognizers also demonstrated neural networks’ viability for mission-critical, high-volume postal automation.
Performance metrics validated many of the principles developed earlier in the chapter. The system achieved its highest accuracy on clearly written digits similar to those in the training data, but performance varied with real-world factors: lighting conditions affected preprocessing effectiveness, unusual writing styles occasionally confused the neural network, and environmental vibrations degraded image quality. These challenges led to continuous refinements in both the physical system and the neural network pipeline.
The economic impact proved substantial. Before automation, manual sorting required operators to read and key in ZIP codes at an average rate of one piece per second. The neural network system processed pieces at ten times this rate while reducing labor costs and error rates. The system did not eliminate human operators entirely; their role shifted to handling uncertain cases and maintaining system performance. This hybrid approach, combining artificial and human intelligence, became a model for subsequent automation projects.
The system also revealed important lessons about deploying neural networks in production. Training data quality proved essential: the network performed best on digit styles well-represented in its training set—a direct validation of the data quality principles established in Data Engineering. Regular retraining helped adapt to evolving handwriting styles, embodying the iterative lifecycle that ML Workflow formalized. Maintenance required both hardware specialists and deep learning experts, introducing new operational considerations. These insights influenced subsequent neural network deployments across industrial applications.
Key engineering lessons and design principles
The USPS ZIP code recognition system exemplifies the journey from biological inspiration to practical neural network deployment. It demonstrates how the basic principles of neural computation, from preprocessing through inference to postprocessing, combine to solve real-world problems.
The system’s development shows why understanding both theoretical foundations and practical considerations matters. While the biological visual system processes handwritten digits effortlessly, translating this capability into an artificial system required careful consideration of network architecture, training procedures, and system integration.
The success of this early large-scale neural network deployment helped establish many practices we now consider standard: the importance of thorough training data, the need for confidence metrics, the role of pre- and postprocessing, and the critical nature of system-level optimization. These operational considerations are formalized in ML Operations, which covers production ML system maintenance and monitoring. To appreciate how far the field has come, compare the original deployment with a modern embedded implementation.
Example 1.7: Then vs. now: USPS on modern hardware
The same neural network computation that required industrial-scale infrastructure in 1990 runs on pocket-sized devices today. Table 14 quantifies four decades of progress.
Table 14: Hardware Progress for Neural Network Computation: The same LeNet computation that required a workstation-class system in 1990 can now run on inexpensive embedded hardware—about 1,000\(\times\) cheaper, 1,000\(\times\) faster, and 20,000\(\times\) more energy-efficient under the illustrative assumptions in the table. Crucially, the algorithm is unchanged; the main improvement came from hardware and systems implementation. This validates the systems principle that algorithm-hardware co-design multiplies gains across both dimensions.
The comparison separates what changed in the surrounding machine from what stayed fixed in the algorithm. The unchanged model-storage row matters as much as the dramatic hardware rows.
| Aspect | 1990s USPS System | Modern Equivalent | Improvement |
|---|---|---|---|
| Hardware cost | about 50,000 USD | about 50 USD | 1,000\(\times\) |
| Inference latency | ~100 ms/digit | ~0.1 ms/digit | 1,000\(\times\) |
| Power consumption | 50–100 W | 5 W | 10–20\(\times\) |
| Training time | 3 days | ~30 seconds | 8,640\(\times\) |
| Model storage | ~40 KB | ~40 KB (unchanged) | 1\(\times\) (same model) |
| Energy/inference | ~10 J | ~0.5 mJ | 20,000\(\times\) |
| Cost/inference | ~$0.001 | ~$0.000001 | 1,000\(\times\) |
What changed: Hardware improved dramatically across the table, ranging from 10–20\(\times\) lower power to 20,000\(\times\) lower energy per inference, while LeNet’s architecture and model storage remain essentially unchanged. This validates a key systems principle: algorithm-hardware co-design means improvements in either dimension multiply together.
What stayed the same: The core engineering challenges persist. Modern smartphone OCR still requires preprocessing for lighting variation, confidence thresholds for uncertain predictions, and fallback to human review for edge cases. The USPS system’s architecture (capture, preprocess, inference, postprocess, action) remains the template for every production ML pipeline.
Modern parallel: Today’s smartphones run real-time neural networks for face recognition, language translation, and voice assistants, tasks that would have required far larger infrastructure in the 1990s. The computation that enabled one postal facility now enables billions of devices.
While hardware efficiency improved by orders of magnitude, modern edge AI systems face even tighter constraints than the USPS deployment: milliwatt power budgets vs. watts, millisecond latency requirements vs. tens of milliseconds, and deployment on battery-powered devices vs. dedicated infrastructure. Yet the same engineering principles apply—preprocessing for real-world variation, confidence-based routing to human review, and end-to-end pipeline optimization. This historical case study provides a reusable template for reasoning about ML systems deployment across the entire spectrum from cloud to edge to tiny devices. The operational considerations demonstrated here are formalized in ML Operations.
The USPS case is not unique; the alignment pattern it exhibits is a recurring property of every successful deep learning deployment. The next section formalizes it.
Self-Check: Question
Why does the USPS case study insist that an accurate neural network classifier was necessary but not sufficient for production success?
- The classifier had to be wrapped in a larger pipeline: image capture, preprocessing, confidence-based routing, and physical sorting — and any broken link would have defeated the model no matter its accuracy.
- Handwritten digits required running backpropagation at inference time to refine predictions per mailpiece.
- The network alone could control all sorting machinery without any conventional software coordination.
- USPS accuracy depended mainly on using a deeper network than MNIST required.
The USPS system ran at a 9 percent rejection rate and 1.0 percent error, against human operators’ 2.5 percent error. Explain why a team that tried to drive the rejection rate to zero would have degraded, not improved, the system’s economic value.
Which combination of outcomes reported in the case study most completely captures why the USPS deployment was a landmark ML systems success?
- Higher training time than human operators but lower hardware purchase cost per facility.
- Lower parameter count than later convnets, which by itself guaranteed success.
- Error rate 1.0 percent (below the 2.5 percent human baseline) combined with 10–30 digits/second throughput (≈10–30× human operators), with a 9 percent rejection rate capturing the optimal automation cutoff.
- Zero rejection rate and perfect automatic routing across every handwriting style.
Order the main USPS production stages for one mail piece: (1) Post-process predictions into sorting decisions, (2) Capture envelope image, (3) Run neural inference on normalized digits, (4) Preprocess and segment the ZIP code region.
A modern team is redesigning the USPS system using current accelerators. Using the D·A·M taxonomy the chapter introduces, which failure pattern most directly illustrates how maximizing a single axis can still produce an unsuccessful deployment?
- A team gathers an ImageNet-scale handwriting corpus and trains the deepest available transformer, then deploys it on a GPU cluster — but the training distribution samples only U.S. office handwriting, so the system fails on elderly rural hand-addressing styles that dominate real mail.
- A team uses the correct LeNet architecture and collects representative envelopes but deploys it to an inexpensive embedded board whose latency comfortably beats the sortation deadline.
- A team uses the correct LeNet architecture, representative data, and adequate hardware, and the system operates within its error and latency budgets in field trials.
- A team reduces all three D·A·M axes by half and observes that performance improves monotonically on every axis.
The chapter’s ‘Then vs. Now’ table reports 1,000× lower hardware cost, 1,000× lower inference latency, and 20,000× lower energy per inference for essentially unchanged LeNet weights. What is the systems lesson this comparison delivers?
- The algorithm changed completely, which is why modern devices are faster — the LeNet weights in the table are nominally the same but functionally reconfigured.
- Hardware progress multiplied the viable deployment envelope of essentially the same neural computation, while the pipeline design principles (preprocess, infer, postprocess, act) remained durable — demonstrating the algorithm-hardware co-design leverage the section emphasizes.
- Modern deployments no longer need preprocessing or confidence-based handoff because accelerators are fast enough to eliminate uncertainty.
- Parameter counts are now irrelevant because latency is no longer a constraint in any deployment context.
D·A·M Taxonomy
The USPS system succeeded because three dimensions aligned: LeNet’s architecture matched the digit recognition task (Algorithm), diverse handwriting samples captured real-world variation (Data), and specialized hardware met latency constraints (Machine). This alignment was not coincidental; it reflects the D·A·M taxonomy formalized in The D·A·M Taxonomy, where each component constrains and enables the others.
Forward propagation, activation functions, backpropagation, and gradient descent define the algorithmic core of deep learning systems. The architecture choices we make (layer depths, neuron counts, connection patterns) directly determine the computational complexity, memory requirements, and training dynamics. Each activation function selection, from ReLU’s computational efficiency to sigmoid’s saturating gradients, represents an algorithmic decision with profound systems implications. The hierarchical feature learning that distinguishes neural networks from classical approaches emerges from these algorithmic building blocks, but success depends critically on the other two triangle components.
Learning depends entirely on labeled data to calculate loss functions and guide weight updates through backpropagation. Our MNIST example demonstrated how data quality, distribution, and scale directly determine network performance: the algorithms remain identical, but data characteristics govern whether learning succeeds or fails. The shift from manual feature engineering to automatic representation learning does not eliminate data dependency; it transforms the challenge from designing features to curating datasets that capture the full complexity of real-world patterns. Preprocessing, augmentation, and validation strategies become algorithmic design decisions that shape the entire learning process.
The Machine component manages the massive number of matrix multiplications required for forward and backward propagation, revealing why specialized hardware became essential for deep learning success. Memory bandwidth limitations, parallel computation patterns that favor GPU architectures, and the different computational demands of training vs. inference all stem from the mathematical operations at the core of neural networks. The evolution from CPUs to GPUs to specialized AI accelerators directly responds to the computational patterns inherent in neural network algorithms. Understanding these mathematical foundations enables engineers to make informed decisions about hardware selection, memory hierarchy design, and distributed training strategies.
The interdependence of these three components is the central lesson: algorithms define what computations are necessary, data determines whether those computations can learn meaningful patterns, and machines determine whether the system can execute efficiently at scale. Neural networks succeeded not because any single component improved, but because advances in all three areas aligned. More sophisticated algorithms, larger datasets, and specialized hardware created a synergistic effect that transformed artificial intelligence.
The D·A·M perspective explains why deep learning engineering requires systems thinking that extends well beyond traditional software development. Optimizing any single axis without considering the others leads to suboptimal outcomes: the most elegant algorithms fail without quality data, the best datasets remain unusable without adequate machines, and the most powerful machines achieve nothing without algorithms that can learn from data. When performance stalls, the diagnostic question is where the flow is blocked—check the D·A·M.
These foundations equip engineers to reason about neural networks from first principles. Yet conceptual understanding alone is insufficient: practitioners must also recognize the recurring misconceptions that derail real-world projects.
Self-Check: Question
Under the D·A·M taxonomy, which assignment of roles best matches the chapter’s treatment?
- Data decides whether computations run efficiently; Machine decides whether labels are correct; Algorithm is orthogonal to both.
- Algorithm defines what computations exist, Data determines whether the computations can learn meaningful patterns, and Machine determines whether those computations can run within latency, memory, and energy budgets.
- Machine chooses the learning objective; Algorithm only formats data for training; Data is a downstream consequence of hardware decisions.
- Data, Algorithm, and Machine are largely independent dimensions, so optimizing one axis rarely affects the others.
A team’s Transformer architecture is elegant, their H100 cluster is underutilized, but validation performance stalls far below the production SLO no matter how long they train. Use the D·A·M taxonomy to propose the most likely binding constraint and the sequence of diagnostic checks that would confirm it.
Imagine the USPS team in 1989 had chosen a much deeper convnet than LeNet but trained it only on carefully printed test-lab digits, on the same Sun-4 hardware. Using the D·A·M taxonomy, which axis-level failure does this hypothetical most closely illustrate, and what systems consequence follows?
- A Machine failure, because the Sun-4 would be too slow to run the deeper model — and the consequence is a missed latency SLO at the sortation belt.
- A Data failure, because the training distribution excludes the hurried and rural handwriting styles that dominate real mail — and the consequence is elevated error on production envelopes even when Algorithm and Machine satisfy their budgets.
- An Algorithm failure, because LeNet is provably optimal for OCR and any deviation from it reduces accuracy regardless of data.
- No failure, because any combination of D, A, and M that uses neural networks will succeed at sufficient scale.
Fallacies and Pitfalls
Neural networks replace explicit programming with learned patterns, creating misconceptions about their behavior. Intuitions from traditional software (that bugs are deterministic, that more resources always help, that code inspection reveals problems) fail when applied to statistical learning systems. The following fallacies and pitfalls cause teams to misallocate effort, deploy inappropriate solutions, or encounter production failures that could have been avoided.
Fallacy: Neural networks are “black boxes” that cannot be understood or debugged.
Engineers assume neural networks lack the transparency of traditional code. In practice, networks are interpretable through statistical methods: activation visualization reveals learned patterns, gradient analysis quantifies input sensitivity (saliency maps identify which of 784 pixels most influenced a digit classification), and ablation studies isolate component contributions. For the MNIST classifier in Section 1.2.2, visualizing first-layer weights shows edge detectors emerging automatically. Teams expecting line-by-line debugging waste 2–4 weeks searching for “bugs” in correctly functioning statistical systems. The perceived opacity stems from applying wrong analysis paradigms to probabilistic pattern recognition.
Fallacy: Deep learning eliminates the need for domain expertise and feature engineering.
Teams assume automatic feature learning removes the need for domain knowledge. Successful systems require domain expertise at every stage: architecture selection, training objective design, dataset curation, and output interpretation. The USPS system in Section 1.5 succeeded because postal engineers specified confidence thresholds based on mail sorting economics, routing roughly 9 percent of uncertain cases to human operators. Without domain knowledge, teams deploy networks that achieve 98 percent test accuracy but fail in production by routing 40 percent of cases to manual processing or misrouting 5 percent of mail.
Fallacy: Deeper networks are always more accurate than wider ones.
Engineers assume that stacking more layers is the primary path to higher accuracy, since depth enables hierarchical feature extraction. In practice, depth alone encounters diminishing returns. ResNet demonstrated that networks beyond 152 layers showed negligible accuracy improvement on ImageNet despite substantially increased training cost and inference latency. The vanishing gradient problem analyzed in Section 1.3 explains part of this ceiling: even with skip connections, very deep networks suffer from optimization difficulties as gradients traverse hundreds of layers. EfficientNet later demonstrated that balanced scaling of width, depth, and input resolution outperforms depth-only scaling by 2–3 percentage points at equivalent computational cost. Doubling depth from 50 to 100 layers roughly doubles training time and memory consumption while yielding less than 1 percentage point of accuracy gain, whereas distributing the same parameter budget across width and depth achieves greater accuracy without the optimization penalty. Teams that reflexively add layers before profiling their network’s capacity utilization waste compute on diminishing returns when wider layers or higher-resolution inputs would deliver greater improvement per FLOP.
Pitfall: Using neural networks for problems solvable with simpler methods.
Teams assume deep learning always performs better. Logistic regression training in 10 ms often outperforms a neural network requiring two hours when data contains fewer than 1,000 examples or relationships are approximately linear. If logistic regression achieves 94 percent accuracy, a neural network achieving 95 percent rarely justifies the cost: 100–1,000\(\times\) longer training, 10–50\(\times\) more memory, and ongoing maintenance burden. As shown in Section 1.1.3, neural networks excel at hierarchical pattern discovery but impose substantial overhead. Reserve them for problems with spatial locality, temporal dependencies, or high-dimensional nonlinear interactions that simpler models cannot capture.
Pitfall: Training neural networks without analyzing data distribution characteristics.
Teams treat training as mechanically feeding data through architectures. Networks on imbalanced datasets exhibit catastrophic minority-class performance: a fraud detector with 99:1 imbalance achieves 99 percent accuracy by always predicting “not fraud” while catching zero fraud cases. The loss functions in Section 1.3.3 optimize for average-case performance, causing networks to ignore rare but critical classes. Teams that skip exploratory data analysis deploy models achieving strong metrics on balanced holdout sets but failing on production data with 10:1 or 100:1 imbalances, requiring expensive retraining.
Pitfall: Deploying research models to production without addressing system constraints.
Data scientists develop models with unlimited time budgets, assuming deployment is straightforward. Production imposes constraints absent from research: latency budgets (50–100 ms end-to-end), memory limits (2–4 GB for edge devices), and concurrent loads (100–1,000 RPS). As shown in Section 1.4, the complete pipeline includes preprocessing, inference, and postprocessing. A model achieving 20 ms inference fails its 50 ms budget when preprocessing adds 25 ms and postprocessing adds 10 ms (55 ms total). Teams separating model development from system design waste months optimizing accuracy while ignoring constraints that determine deployment feasibility.
Pitfall: Assuming more compute automatically means faster training.
Teams purchase expensive GPUs expecting proportional speedups, then discover workloads are memory bound. Arithmetic intensity determines which resource constrains performance. The MNIST forward-pass analysis in Table 11 and the roofline model in The roofline model show why small networks like MNIST (784 to 128 to 64 to 10) have arithmetic intensity of approximately 0.5 FLOPs/byte, far below the A100 and H100 dense-FP16 ridge points of about 153 and 295 FLOPs/byte. For memory-bound workloads, a commodity CPU can match an expensive accelerator; for compute-bound GPT-scale models, accelerators provide the large speedups they were built for. This mismatch explains why teams report widely varying utilization depending on model architecture.
Pitfall: Extrapolating accuracy improvements without considering diminishing returns.
Teams observe that scaling from 10K to 100K parameters improves accuracy by 5 percentage points, then assume scaling to 1M parameters yields another 5 points. Neural network accuracy follows logarithmic scaling: each order of magnitude in compute yields diminishing returns. Within Table 5, the ImageNet rows show error falling from AlexNet’s 15.3 percent to ResNet-152’s 3.6 percent while training FLOPs rise from \(5 \times 10^{17}\) to roughly \(10^{19}\), about one to two orders of magnitude. The lesson is not a fixed percentage-point-per-order rule; it is that later accuracy gains become progressively more expensive. Achieving 99 percent accuracy might cost 10\(\times\) more than 98 percent, and 99.9 percent might cost 100\(\times\) more than 99 percent. Teams that fail to model this relationship overpromise accuracy and underestimate resources.
These fallacies and pitfalls share a common root: applying intuitions from deterministic software engineering to probabilistic learning systems. Recognizing them early saves weeks of misdirected effort and prevents production failures that are expensive to diagnose after deployment.
Self-Check: Question
A teammate argues that ‘neural networks are black boxes, so debugging them is essentially impossible.’ Which response best captures the section’s position?
- They are correct, because learned weights carry no interpretable structure at all.
- They are partly right only for small networks; large networks are the only ones that become uninterpretable.
- They are mistaken: activation visualization, gradient analysis, ablations, and saliency methods reveal what features the network is using and where it fails — the debugging instruments are different from stack traces, not absent.
- They are mistaken only if the model uses ReLU rather than sigmoid activations.
Explain why a neural network on a problem with fewer than 1,000 examples and nearly linear relationships is usually a poor engineering choice, referring to both the training overhead and the maintenance profile of the alternative.
A team moves a small MLP inference workload from a CPU to an expensive GPU and observes almost no speedup, even though the GPU’s advertised TFLOPS dwarf the CPU’s. Which explanation best matches the section?
- GPUs only accelerate post-processing stages, so the forward pass stays CPU-bound regardless of hardware.
- The workload is memory-bound or has too little arithmetic intensity to keep the GPU’s SIMT engines busy, so adding peak compute does not help when data movement, not arithmetic, is the binding constraint.
- Faster GPUs force the optimizer to use smaller learning rates, cancelling the hardware gain.
- Neural networks become rule-based above a certain size, so accelerators stop helping once that threshold is crossed.
True or False: On a heavily imbalanced binary dataset with a 99.5 percent majority class, a model reporting 99.2 percent overall accuracy on held-out data is strong evidence that it will perform well on the rare but operationally important minority class.
A team has seen depth-only scaling improve accuracy through two previous model generations and assumes the same strategy will continue to pay off. Which critique best matches the chapter’s position?
- Depth always improves accuracy, provided the learning rate is raised proportionally.
- The main issue is that deeper networks cannot use ReLU, so activation choice blocks further gains.
- Accuracy gains from depth alone show diminishing returns; balanced scaling of depth, width, data, and compute typically beats depth-only scaling at comparable total cost — a lesson the section ties back to Chinchilla-style scaling arguments.
- Adding layers reduces memory use, so the strategy is cost-free even if accuracy stalls.
A team’s training loss is still decreasing at epoch 40 while validation loss has been rising steadily since epoch 25. Explain what this pattern tells an engineer about the model’s current regime, how to detect the failure mode unambiguously, and which two interventions the section supports.
Summary
Deep learning systems engineers need mathematical understanding precisely because neural networks cannot be treated as black-box components. When a production model fails, the problem lies not in the code but in the mathematics: a misconfigured learning rate causes gradients to explode during backpropagation, an activation function saturates and blocks learning in deep layers, or memory requirements during training exceed GPU capacity because of stored activations and optimizer states. Engineers who understand forward propagation can trace which layer produces anomalous activations. Engineers who understand backpropagation can diagnose vanishing gradients. Engineers who understand the distinction between training and inference can predict memory consumption before deployment surprises them.
Neural networks transform computational approaches by replacing rule-based programming with adaptive systems that learn patterns from data. The biological-to-artificial neuron mapping (weighted sums, nonlinear activations, and gradient-based learning) provides the atomic operations from which all modern architectures are composed.
Neural network architecture demonstrates hierarchical processing, where each layer extracts progressively more abstract patterns from raw data. Training adjusts connection weights through iterative optimization to minimize prediction errors, while inference applies learned knowledge to make predictions on new data. This separation between learning and application phases creates distinct system requirements for computational resources, memory usage, and processing latency that shape system design and deployment strategies. Training requires ~4.3\(\times\) more memory than inference because gradients, optimizer state, and activations must be stored and updated. The USPS digit recognition case study demonstrated that these mathematical principles combine into production systems where the complete pipeline (preprocessing, neural inference, and postprocessing) must operate within real-world latency and reliability constraints.
The running MNIST example made this escalation tangible: the same \(28{\times}28\) digit that required ~100 rule-based comparisons demanded 109,184 MACs in even a modest three-layer network—a 1,092\(\times\) increase that generalizes across the systems dimensions captured in Table 3. These fundamentals primarily develop the Algorithm axis of the D·A·M taxonomy while revealing how algorithmic choices propagate into Machine constraints.
The mathematical and systems implications emerge through fully connected architectures. The multilayer perceptrons explored here demonstrate universal function approximation: with enough neurons and appropriate weights, such networks can theoretically learn any continuous function. This mathematical generality comes with computational costs. Consider our MNIST example: a \(28{\times}28\) pixel image contains 784 input values, and a fully connected network treats each pixel independently, learning over 100,352 weights in the first layer alone (784 inputs\(\times\) 128 neurons). Neighboring pixels are highly correlated while distant pixels rarely interact. Fully connected architectures expend computational resources learning irrelevant long-range relationships.
Key Takeaways: The math behind the model
- Each paradigm shift buys representation power at exponential systems cost: Classifying the same \(28{\times}28\) digit escalates from ~100 comparisons (rule-based) through ~8,000 structured operations (classical ML) to 109,184 matrix MACs (deep learning)—a 1,092\(\times\) increase that reshapes hardware requirements at every level.
- Neural networks learn patterns, not rules: These networks replace hand-coded features with hierarchical representations discovered from data. The system adapts to the problem rather than requiring manual engineering.
- Training and inference have opposite priorities: Training optimizes throughput (large batches, hours of compute); inference optimizes latency (single samples, milliseconds). Effective systems account for both phases in their design.
- Activation function choice is both a mathematical and a hardware decision: ReLU dominates because \(\max(0,x)\) is orders of magnitude cheaper than \(\exp(x)\), and its constant gradient for positive inputs prevents the vanishing gradient problem that plagues sigmoid and tanh in deep networks.
- Forward propagation is a chain of matrix multiplications interleaved with nonlinear activations: This structure is why GEMM kernels account for over 90 percent of neural network FLOPs, and why hardware optimized for dense matrix operations (GPUs, TPUs) outperforms general-purpose CPUs by orders of magnitude.
- Backpropagation solves the credit assignment problem but requires storing all intermediate activations: The memory cost, not the computation itself, often determines whether a model can be trained on a given device, driving systems techniques like gradient checkpointing and model parallelism.
- Batch size is a systems lever: Larger batches increase GPU utilization but require more memory and may hurt generalization. Batch size selection must account for hardware constraints alongside statistical considerations.
- The complete ML pipeline determines end-to-end performance: Preprocessing, neural computation, and postprocessing all contribute to latency and reliability. The USPS deployment demonstrated that production success depends on the entire pipeline operating within real-world constraints, not on model accuracy on a test set alone.
These foundations establish the mathematical and systems vocabulary for reasoning about neural network behavior. The forward-backward propagation cycle, activation function choices, and memory-computation trade-offs recur throughout every subsequent chapter, whether analyzing why certain architectures train faster, why quantization preserves accuracy in some layers but not others, or why distributed training requires careful gradient synchronization. Understanding these fundamentals enables engineers to move beyond treating neural networks as black boxes toward principled system design.
What’s Next: From universal to specialized
Real-world problems exhibit structure that generic fully-connected networks cannot efficiently exploit: images have spatial locality, text has sequential dependencies, and time-series data has temporal dynamics. Network Architectures addresses this structural blindness through specialized architectures that encode problem structure directly into network design. Each architecture trades the universal flexibility of fully-connected networks for inductive biases that match problem structure, achieving dramatic efficiency gains while creating new systems engineering trade-offs in memory access patterns, parallelization constraints, and computational bottlenecks.
Self-Check: Question
What is the chapter’s central answer to the question of why deep learning systems engineers must understand the math inside neural networks?
- Because most deployment failures are really programming-language bugs hidden inside framework code.
- Because the mathematical primitives — matrix multiplies, activations, gradients, and parameter counts — determine the compute profile, memory demand, training stability, and hardware compatibility that together form the Silicon Contract.
- Because engineers are expected to derive every training algorithm from scratch before using a framework.
- Because neural architectures change too quickly for any software abstraction to remain useful.
Explain why the chapter treats training and inference as different systems problems even though they share the same network architecture, grounding your answer in two concrete differences in memory layout and optimization objective.
A production fraud-detection service reports 98.5 percent model accuracy on held-out data yet misses the p99 latency SLO in deployment. Preprocessing takes 40 ms, feature lookup 80 ms, model inference 15 ms, and a business-rule post-processor 90 ms. Based on the chapter’s end-to-end framing, which pipeline stage is the most productive optimization target and why?
- Model inference at 15 ms, because compressing the neural network is always the highest-leverage optimization when an SLO is missed.
- The business-rule post-processor at 90 ms, because it is the largest single share of total latency and lives outside the neural network — the exact pattern the chapter identifies, where a fast model still misses its SLO when non-neural stages dominate.
- Feature lookup at 80 ms, because feature stores are fundamentally unoptimizable and must be replaced with the model itself.
- All four stages equally, because every millisecond counts regardless of relative contribution.
Self-Check Answers
Self-Check: Answer
A team replaces a hand-coded digit classifier (≈100 comparisons, 784 bytes of working state) with the chapter’s 784→128→64→10 MLP (≈109,000 MACs, ≈438 KB of weights) on the same MNIST input. Which systems consequence should they expect first when the new model goes live on a commodity CPU?
- The workload becomes more sequential and fits entirely inside L1 cache, reducing memory traffic.
- Branch prediction becomes the dominant bottleneck because each neuron executes many if-then tests.
- The workload shifts to dense matrix math whose weight footprint exceeds most L1 caches, creating cache-level memory traffic that is absent from the hand-coded rule system.
- Specialized hardware becomes unnecessary because the model has learned the original rules and can discard them.
Answer: The correct answer is C. The ≈1,092× MAC jump and ≈438 KB of weights shifts the workload from branch-heavy rule execution to dense matrix arithmetic with meaningful cache-level memory traffic. The branch-prediction answer confuses rule execution with neural arithmetic, where multiply-accumulate and weight streaming dominate — there are almost no branches to predict. The L1-cache answer contradicts the weight-footprint numbers the section provides. Whether the workload is strictly DRAM-bound depends on the target CPU cache hierarchy and reuse pattern.
Learning Objective: Apply the MNIST paradigm cost numbers to predict the dominant systems bottleneck when rule-based code is replaced by a dense MLP
A CV team must choose between (a) a HOG + SVM classical pipeline they already use, and (b) a convnet of comparable task accuracy. Using the chapter’s treatment of feature engineering as the classical bottleneck, explain the systems-engineering consequence of each choice when the product must extend to six new object categories over the next year.
Answer: Classical HOG + SVM runs cheaply at inference, but every new category demands a human-designed descriptor — edge histograms for one, texture filters for another, keypoint detectors for a third — and each descriptor is a multi-week expert engineering project that only works for the category it was designed for. The convnet costs substantially more compute to train and deploy, but the same network structure extracts features for all six categories from raw pixels by retraining on labeled data. The systems implication is that feature engineering’s cost is in engineer-hours-per-new-class; deep learning converts that recurring human cost into a one-time compute cost plus per-class data, which scales far better across an expanding product roadmap.
Learning Objective: Analyze the systems trade-off between handcrafted feature pipelines and learned representations under a multi-class product-growth scenario
A vendor proposes that 5× faster single-threaded CPUs would eliminate the need for GPUs or TPUs in deep learning. Based on the section’s account of computational infrastructure requirements, what is the strongest refutation?
- CPUs cannot store neural network weights in registers, so no CPU will ever execute matrix multiplications.
- Deep learning is dominated by dense parallel matrix multiplications whose throughput is bounded by wide SIMD lanes and off-chip memory bandwidth, neither of which is addressed by raising single-thread clock speed.
- Modern CPUs force the optimizer to use smaller learning rates, which offsets any clock-speed gain.
- Faster CPUs would make the softmax output layer too precise, causing training instability.
Answer: The correct answer is B. The section ties neural workloads to massive parallel MACs over tensors streamed from memory — a profile that rewards wide SIMD arrays and high-bandwidth HBM, not faster scalar pipelines. A single-threaded clock-speed boost does not add vector lanes or bandwidth, so it cannot shift the operating point off the memory wall. The register-storage claim contradicts how every framework already runs MLPs on CPUs; the softmax-precision claim invents a mechanism the section does not describe.
Learning Objective: Evaluate why neural arithmetic maps to accelerator architecture rather than faster scalar CPUs by reasoning from parallelism and bandwidth
A pipeline engineer depends on domain experts to invent descriptors (edge histograms, keypoint detectors, texture filters) for each new vision task. One quarter later, the team must support six additional categories. Using the section’s framing, explain two distinct systems consequences of staying inside this feature-engineering regime rather than switching to learned representations.
Answer: First, engineer time becomes the throughput bottleneck: each new category requires weeks of expert descriptor design, and the descriptor does not transfer — the HOG features tuned for digits do not help recognize vehicles, so the team scales linearly in expert-months per category. Second, the deployment footprint fragments: every descriptor brings its own preprocessing code path, memory layout, and tuning parameters, turning the production pipeline into a per-task zoo rather than a shared inference engine. Deep learning converts both costs into amortized training compute plus labeled data, replacing the expert bottleneck with a data-and-hardware bottleneck the team can actually scale.
Learning Objective: Analyze the systems consequences of feature-engineered pipelines when the workload expands across multiple related categories
A reviewer argues that a 1970s neural algorithm that “failed” in its decade should be permanently dismissed. The chapter’s history of backpropagation and attention suggests a different systems-engineering stance. Which response best matches?
- Dismiss the algorithm permanently, since algorithms that were once infeasible remain infeasible.
- Ask which hardware or data regime would make the algorithm practical, because the history shows algorithms can be hardware-premature rather than wrong — backpropagation waited for GPU matrix throughput, and attention waited for dense HBM.
- Replace it with rule-based logic so it runs on current CPUs immediately.
- Assume that more labeled data alone will revive it, without any change in hardware or cost structure.
Answer: The correct answer is B. The section’s chronology treats backpropagation and attention as ideas that outran their infrastructure, becoming viable only once parallel arithmetic and memory bandwidth caught up. A permanent-dismissal answer ignores that same pattern has now repeated multiple times. A data-only answer overlooks that the 1970s already had enough data for small models — what was missing was the arithmetic throughput. Rule-based replacement throws away the very property (learned representations) the algorithm was supposed to provide.
Learning Objective: Evaluate algorithm viability through the lens of historical hardware-algorithm adoption lags
The chapter characterizes the rise of modern deep learning as a self-reinforcing cycle among data abundance, algorithmic innovation, and compute infrastructure. Which description most accurately captures how the cycle produces accelerating returns rather than additive gains?
- The three factors progressed in a strict linear sequence — compute, then algorithms, then data — each finishing before the next began.
- Each factor contributed roughly equally and independently, with no causal interaction among them.
- Each factor raised the marginal return on the others: abundant data justified larger algorithms, larger algorithms exposed which compute paths were worth accelerating, and faster compute justified collecting still more data.
- Compute infrastructure was the single decisive factor; data abundance and algorithmic innovation were downstream consequences of cheap GPUs.
Answer: The correct answer is C. The section explicitly describes mutual reinforcement: ImageNet’s scale only paid off because SGD on GPUs made larger models trainable, larger models exposed which kernels (convolution, GEMM) were worth specializing silicon for, and the resulting hardware made still-larger datasets economically collectable. A strict-sequence answer misses the feedback loop; an independent-contribution answer turns a coupled system into arithmetic averaging; a compute-only answer ignores that cheap GPUs alone would not have produced AlexNet without ImageNet-scale labels.
Learning Objective: Distinguish a self-reinforcing technological cycle from a linear or independent causal sequence in the rise of deep learning
Self-Check: Answer
Across deep hidden layers, ReLU dominates sigmoid and tanh in production systems. Which pair of properties, taken together, best explains that dominance per the section?
- A max operation (single comparator in silicon) and a non-saturating gradient of one for positive inputs that keeps deep backpropagation numerically alive.
- Normalized probabilistic output and exact biological fidelity to cortical neurons.
- Guaranteed non-zero activations for every input and a built-in regularization penalty.
- An exponential that matches softmax’s output distribution and a centered range around zero.
Answer: The correct answer is A. ReLU is essentially a single max gate, far cheaper to implement than the exponential paths required by sigmoid or tanh, and its gradient stays at one for positive inputs, which lets gradients survive dozens of layers of chain-rule multiplication. A normalized-probabilities answer confuses hidden-layer activations with softmax at the output; a guaranteed-non-zero claim is actually wrong — ReLU zeros the negative half — and the “dead ReLU” failure mode is itself a real systems concern.
Learning Objective: Compare activation functions by simultaneously considering silicon-implementation cost and deep-network gradient behavior
Explain why the chapter argues that a deep, narrow network can represent some functions with polynomially more layers but exponentially fewer parameters than a shallow, wide network with the same expressiveness. Ground your answer in the compositional structure the section describes.
Answer: Deep networks exploit reuse of learned primitives: early layers learn edge and stroke detectors that later layers compose into curves, which even deeper layers compose into digit-parts. A shallow wide network has no mechanism to share intermediate features across output decisions — each output neuron must reimplement the full pattern from raw pixels. On MNIST, the same edge detector participates in recognizing 3s, 8s, and 5s in a deep MLP, so the edge-detection work is paid once; a shallow alternative must wire independent edge-like patterns into every output neuron. The systems implication is that depth converts a width-that-grows-exponentially-with-task-complexity into layers-that-grow-only-polynomially, which is why depth dominates the parameter-efficiency frontier.
Learning Objective: Explain how compositional reuse of features gives depth a polynomial-versus-exponential parameter advantage over width
In the chapter’s 784→128→64→10 MNIST network, which layer dominates both parameter count and MAC count, and why?
- The softmax output stage, because output normalization requires more parameters than any dense layer.
- The 64→10 projection, because its smaller output dimension forces quadratic growth in parameters.
- The 784→128 input layer, because its weight matrix has 784×128 entries — more than the next two layers combined — and each forward pass executes that many MACs per example.
- The first hidden layer, because it alone stores the optimizer’s momentum buffers while later layers are stateless.
Answer: The correct answer is C. The 784→128 matrix has ≈100K weights versus ≈8K for 128→64 and 640 for 64→10, so it dominates storage and MACs. A softmax-centric answer misreads the cost structure: softmax adds an exponential and a normalization, not a large weight matrix. An optimizer-state answer is also wrong — every trainable layer participates in optimizer state, not just the first.
Learning Objective: Analyze which layer of a fully connected MLP is the parameter and compute hotspot by reading layer dimensions
True or False: Stacking more linear layers without activation functions still increases a network’s expressive power, because each added layer contributes its own learnable weight matrix.
Answer: False. The composition of linear transformations collapses algebraically into a single linear transformation of the same input-to-output dimensionality, so no number of stacked linear layers can represent a function a single linear layer cannot. The extra matrices add parameters but not expressiveness — in fact they add redundant parameters that waste memory and compute without enlarging the hypothesis class.
Learning Objective: Distinguish parameter count from representational capacity in multi-layer linear networks
An inference-hardware team must choose between sigmoid and ReLU for hidden-layer activations in a mobile SoC with tight silicon-area and energy budgets. Using the chapter’s treatment of activation cost, which engineering consequence follows most directly from picking sigmoid?
- Sigmoid’s exponential-based implementation consumes substantially more silicon area and energy per activation than ReLU’s max operator, inflating both chip cost and per-inference energy at the scale of millions of activations per forward pass.
- Sigmoid reduces memory bandwidth pressure because its bounded output lets the compiler skip storing activations.
- Sigmoid removes the need for quantization because its values are already in [0, 1].
- Sigmoid is cheaper than ReLU because it produces denser activation tensors with fewer zeros.
Answer: The correct answer is A. The section frames sigmoid’s implementation cost as a direct silicon-area-and-energy penalty — exponentials require multi-stage approximation circuitry, while ReLU needs a single comparator — and that penalty compounds across the millions of activations evaluated per inference. The bandwidth-skipping claim reverses the architecture: activations must still be stored for the next layer regardless of activation choice. The quantization claim and the density claim invent properties the section does not assert and are false in practice.
Learning Objective: Evaluate how activation-function choice trades silicon area, energy, and gradient quality in hardware-constrained deployments
A team must spend a fixed parameter budget on either a much deeper network or a much wider shallow one. Which concern is most specific to the deeper choice per the section’s systems discussion?
- Depth introduces long sequential dependencies and long gradient paths, hurting layer-level parallelism and raising the risk of vanishing or exploding gradients during backpropagation.
- Depth removes the need to store activations during backpropagation because earlier layers are recomputed automatically.
- Depth guarantees fewer total parameters than any wider alternative at every depth.
- Depth lets every layer compute independently, making end-to-end latency trivially easy to hide.
Answer: The correct answer is A. Each additional layer adds another factor in the chain-rule product, so slight deviations from a derivative of one compound exponentially, and each layer must wait for the previous one in the forward pass, limiting parallelism. The activation-storage claim is the reverse of reality — deeper networks typically store more activations for backprop, not fewer. The parameter-count claim is a blanket generalization the section does not support; the independent-computation claim contradicts the sequential dependency structure that depth creates.
Learning Objective: Evaluate the systems trade-offs between network depth and width with attention to gradient path length and parallelism
Self-Check: Answer
Order the following mini-batch training-step phases: (1) Update weights, (2) Compute loss from predictions, (3) Run forward pass, (4) Run backpropagation.
Answer: The correct order is: (3) Run forward pass, (2) Compute loss from predictions, (4) Run backpropagation, (1) Update weights. The forward pass must produce predictions before the loss function can compare them to labels, and the loss must exist before backpropagation can differentiate it with respect to parameters. Running backpropagation before the loss would leave the error signal undefined; updating weights before gradients exist turns the optimizer’s step into random perturbation rather than descent on the loss surface.
Learning Objective: Sequence the phases of one supervised training iteration and justify why the order is causally, not stylistically, fixed
A classifier outputs probability 0.8 for the correct digit on one image and 0.05 for the correct digit on another. Why does cross-entropy produce a dramatically stronger learning signal on the second image than on the first?
- Cross-entropy converts the output layer into a linear regression problem, which always produces stronger gradients for small probabilities.
- Cross-entropy is \(-\log\) of the correct-class probability, so probability 0.05 yields loss ≈ 3.0 while probability 0.8 yields loss ≈ 0.22; with softmax cross-entropy, the correct-class logit gradient magnitude rises from about 0.20 to 0.95.
- Cross-entropy averages losses across the batch, so single-image losses never drive the gradient.
- Cross-entropy guarantees the model will not overfit, so confident-but-wrong predictions receive the same signal as confident-and-right ones.
Answer: The correct answer is B. Because \(-\log(0.05) \approx 3.0\) and \(-\log(0.8) \approx 0.22\), the confident wrong prediction contributes about 13.4× more loss. For the combined softmax cross-entropy derivative, the correct-class logit gradient is \(p - 1\), so its magnitude is 0.95 rather than 0.20, about 4.75× larger. The regression-style answer misidentifies the loss family — cross-entropy with softmax is the classification path, not a regression. The overfitting-guarantee answer claims a property the loss does not have and contradicts the stronger-signal behavior the section emphasizes.
Learning Objective: Interpret how cross-entropy’s logarithmic shape amplifies the learning signal for confident wrong predictions
A team can fit their 7B-parameter model on an 80 GB accelerator for inference but runs out of memory on the same device for training, even with an identical batch size. Explain the three categories of tensors that training requires beyond inference, and describe which is usually largest for a standard Adam run.
Answer: Training adds three memory categories inference does not carry. First, activations from every forward layer must be retained so backprop can apply the chain rule — with a transformer’s attention this is typically the single largest term, scaling with sequence length and batch size. Second, gradients require one tensor the size of the parameters themselves, roughly doubling parameter memory. Third, Adam’s optimizer state adds two moment vectors (first and second moments), another ≈2× parameter memory. For a 7B-parameter FP16 model, parameters take ≈14 GB, gradients another ≈14 GB, Adam state ≈28 GB, and activations fill whatever remains — which is why an 80 GB device that serves inference comfortably cannot train the same model at useful batch size without sharding, checkpointing, or moving to a lower-footprint optimizer.
Learning Objective: Analyze why training memory dominates inference memory by decomposing it into activations, gradients, and optimizer state
A team doubles mini-batch size to raise GPU utilization. Per the section’s framing, which trade-off should they expect most directly?
- Activation memory roughly doubles, even as per-step gradient estimates become less noisy and matrix-math utilization improves.
- The loss function becomes unnecessary because batch averaging handles error signals automatically.
- The backward pass can be skipped because batch statistics reveal gradients without explicit differentiation.
- Generalization improves automatically because each update sees more examples.
Answer: The correct answer is A. Activation tensors retained for backpropagation scale with batch size, so doubling the batch roughly doubles activation memory — the chapter treats this as the dominant memory cost of batching even while utilization and gradient stability improve. The loss-elimination and backward-skip answers contradict the training loop’s structure; the automatic-generalization claim overstates the effect — larger batches often flatten the loss surface into sharper minima that can hurt generalization without learning-rate adjustment.
Learning Objective: Analyze the joint impact of batch-size scaling on gradient stability, hardware utilization, and activation memory
A debugging engineer calls
optimizer.step()in a training loop but forgot to compute gradients (noloss.backward()precedes the step). Every parameter’s.gradattribute isNoneor zero. Which description best captures what the training system will actually do, and what this reveals about the relationship between backpropagation and gradient descent?- The optimizer will reproduce backpropagation internally from the parameters alone and update correctly, because gradient descent implicitly performs differentiation.
- The optimizer will apply its update rule against zero or stale gradients, producing weight perturbations driven by momentum buffers or Adam’s second moments rather than by the current loss — which shows that backpropagation (gradient computation) is a distinct step that must produce the error signal before gradient descent (the update rule) consumes it.
- The optimizer will raise a compile-time error because gradient descent is undefined without backpropagation.
- The optimizer will recompute the loss and gradients from the labels already stored in its state.
Answer: The correct answer is B. Optimizers read
.gradtensors; if those are zero or stale, the step still runs and nudges weights using whatever momentum or adaptive state already exists — a silent failure mode that produces worthless or even destructive updates. The scenario makes the distinction between backprop (the mechanism that produces gradients via the chain rule) and gradient descent (the rule that consumes those gradients) operational rather than definitional. The internal-reproduction answer and the label-storage answer invent behaviors the optimizer does not perform; a compile-time error would require type-level guarantees PyTorch does not provide.Learning Objective: Distinguish gradient computation from parameter update by analyzing a scenario where the update rule runs without fresh gradients
Why do very deep networks with saturating activations suffer from vanishing or exploding gradients during backpropagation?
- The chain rule multiplies one layer-wise derivative per layer, and values consistently below or above one shrink or grow exponentially in depth — a sigmoid network of 20 layers can land near \(0.25^{20} \approx 10^{-12}\) in effective gradient magnitude.
- Softmax returns zero for incorrect classes, so no gradient can flow backward through the output layer.
- Inference-only activations are too small to store during training, so backpropagation runs on random noise.
- Larger batch sizes force every layer to share identical weight updates, flattening the gradient.
Answer: The correct answer is A. The chain rule compounds layer-local derivatives multiplicatively, so depth is an exponent on a quantity whose absolute value is usually not one — a bias the section makes concrete with the \(0.25^{20} \approx 10^{-12}\) estimate for a 20-layer sigmoid stack. The softmax-centric and inference-activation explanations misattribute the failure to output-layer or storage mechanics that do not participate in the depth-dependent product. The batch-size explanation is unrelated to the chain rule’s multiplicative structure.
Learning Objective: Explain the numerical mechanism of vanishing and exploding gradients as a chain-rule depth exponent
Self-Check: Answer
What is the most load-bearing computational difference between training and inference for the same neural network architecture?
- Inference changes the network topology, while training keeps it fixed.
- Inference runs only the forward pass with frozen parameters; training adds backward passes, gradient storage, and optimizer-driven parameter updates.
- Inference requires larger batches than training to remain numerically stable.
- Inference stores more optimizer state because predictions must be reproducible.
Answer: The correct answer is B. The section defines inference as forward-only with fixed weights; training additionally runs the backward pass, stores gradients for every parameter, and updates weights via the optimizer. A larger-inference-batches answer confuses the gradient-stability argument for training with inference’s batching policy, which is chosen from latency and throughput constraints rather than numerical stability.
Learning Objective: Contrast training and inference by identifying which computational stages exist only in the training phase
A vision inference service reports p99 end-to-end latency of 220 ms, with model inference occupying 40 ms. The rest is split between JPEG decode, resize, and a business-rule post-processor. Explain why the classic “optimize the model” instinct will barely move the p99 and what the engineer should target instead, grounded in the section’s pipeline framing.
Answer: The section treats the neural network as one stage in a longer pipeline whose end-to-end latency is dominated by its slowest component. At 40 ms of 220 ms, the model is responsible for roughly 18 percent of the budget — cutting it in half would save 20 ms and land at ≈200 ms, nowhere near the SLO headroom the team likely needs. The 180 ms spent on decode, resize, and post-processing is the real surface area. The engineer should profile each stage, batch or parallelize the JPEG decode, move resize to accelerator-side preprocessing, and rewrite the business-rule post-processor — or restructure it to run concurrently with the next request. The systems lesson is that optimizing only the model leaves the dominant pipeline cost untouched.
Learning Objective: Diagnose end-to-end inference latency bottlenecks by decomposing the pipeline into neural and non-neural stages
A real-time service must serve a single request with the lowest possible latency, not maximum aggregate throughput. Which inference choice best matches the section’s guidance?
- Use the largest possible batch so activations persist longer and the accelerator stays fully occupied.
- Prefer single-item or very small-batch inference, trading lower hardware utilization for minimized queueing delay.
- Run the backward pass at serving time to refine predictions per request.
- Increase output precision to FP64 so post-processing becomes unnecessary.
Answer: The correct answer is B. When the goal is minimum time for one request, batching introduces queueing that dominates the latency budget; small-batch or single-item inference pays the utilization cost but removes the wait. A largest-possible-batch answer optimizes throughput at the expense of latency — the opposite SLO. The backward-pass answer contradicts the inference definition; the FP64 answer misattributes post-processing to numerical precision.
Learning Objective: Select an inference batching strategy that matches latency-dominant versus throughput-dominant SLOs
Two serving frameworks propose different memory plans for a forward-only image classifier: Plan X allocates a fresh tensor for every layer’s output and keeps all layers’ outputs alive for the duration of the request; Plan Y maintains only two rotating activation buffers, overwriting layer \(k\)’s output once layer \(k+1\) has consumed it. Which plan exploits inference-specific memory behavior per the section, and why?
- Plan X is correct, because every inference request must retain all intermediate activations in case the optimizer needs them later.
- Plan Y is correct, because inference does not need intermediate activations for backpropagation, so once a layer’s output has been consumed by the next layer it can be overwritten — cutting peak activation memory from \(O(\text{depth})\) to \(O(1)\) buffers.
- Plan X is correct, because rotating buffers would require backward-pass gradients to reuse earlier activations.
- The two plans produce identical peak memory, because activation tensors are always allocated statically regardless of when they can be freed.
Answer: The correct answer is B. Inference performs only the forward pass, so an activation’s only consumer is the very next layer; once consumed, the memory is free. Plan Y exploits this by recycling two buffers, reducing peak activation memory from proportional to depth to a constant — a property training cannot use because backprop must revisit activations later. A Plan-X-is-correct answer keeps the training-time assumption alive and misses the core distinction the section draws between the two phases. The static-allocation answer contradicts how modern serving runtimes manage memory pools.
Learning Objective: Choose between inference memory plans by reasoning about which phase actually needs intermediate activations preserved
Why does the section argue that reduced numerical precision (quantization) is typically more tolerable at inference than during training?
- Inference does not accumulate rounding errors across thousands of parameter updates, so the precision noise that destabilizes training’s iterative dynamics does not compound at serve time.
- Inference avoids matrix multiplication entirely, so precision is irrelevant to the forward pass.
- Inference reconstructs missing bits from post-processing logic, so precision loss is recovered after the model runs.
- Low precision adds model capacity at inference by introducing new output classes.
Answer: The correct answer is A. Training iteratively updates parameters; small precision errors in each gradient compound across thousands of steps and can push the optimizer into bad trajectories, while inference runs a single forward pass whose quantization noise is bounded per prediction. The matrix-multiplication answer contradicts the structure of the forward pass; the post-processing-reconstruction answer invents a mechanism the chapter does not describe; the added-capacity claim reverses the direction — lower precision generally reduces, not expands, what the network can represent.
Learning Objective: Explain why quantization is more tolerable at inference by comparing single-pass error to iterative error accumulation
Self-Check: Answer
Why does the USPS case study insist that an accurate neural network classifier was necessary but not sufficient for production success?
- The classifier had to be wrapped in a larger pipeline: image capture, preprocessing, confidence-based routing, and physical sorting — and any broken link would have defeated the model no matter its accuracy.
- Handwritten digits required running backpropagation at inference time to refine predictions per mailpiece.
- The network alone could control all sorting machinery without any conventional software coordination.
- USPS accuracy depended mainly on using a deeper network than MNIST required.
Answer: The correct answer is A. The chapter walks the mail through capture → preprocess → infer → postprocess → physical sort, and shows that end-to-end reliability was determined by the weakest stage. A backprop-at-inference answer conflates training with deployment — weights were fixed in production. The network-controls-machinery answer ignores that the confidence-based routing and sortation control logic were traditional software. The deeper-network claim misplaces the success mechanism, which was about pipeline integration rather than architectural depth.
Learning Objective: Explain why production ML systems require end-to-end pipeline design around the neural network
The USPS system ran at a 9 percent rejection rate and 1.0 percent error, against human operators’ 2.5 percent error. Explain why a team that tried to drive the rejection rate to zero would have degraded, not improved, the system’s economic value.
Answer: The 9 percent rejection rate exists precisely because some digits are genuinely ambiguous; forcing the model to classify them rather than deferring to humans would trade a cheap human handoff for expensive misrouted mail. Each misdelivery costs far more than one human operator’s few seconds of keystrokes, so the economically optimal operating point balances per-item human cost against per-misroute error cost. Driving rejection to zero means accepting misroutes on the very items the confidence signal already flagged as risky, turning a well-calibrated system into a more accurate-looking but costlier one. The systems implication is that a production ML system’s value is measured by the joint (automation rate, error cost), not by any single metric in isolation.
Learning Objective: Analyze why confidence-based human fallback maximizes economic value rather than a single accuracy metric
Which combination of outcomes reported in the case study most completely captures why the USPS deployment was a landmark ML systems success?
- Higher training time than human operators but lower hardware purchase cost per facility.
- Lower parameter count than later convnets, which by itself guaranteed success.
- Error rate 1.0 percent (below the 2.5 percent human baseline) combined with 10–30 digits/second throughput (≈10–30× human operators), with a 9 percent rejection rate capturing the optimal automation cutoff.
- Zero rejection rate and perfect automatic routing across every handwriting style.
Answer: The correct answer is C. The case study’s own table reports those exact quality and throughput numbers and treats the 9 percent rejection rate as the calibrated cutoff rather than a failure. A zero-rejection answer contradicts the section’s central point that confidence-based handoff is a design feature, not a limitation. The parameter-count answer conflates a necessary condition with a sufficient one; the training-time framing misses that the value was in deployment economics, not training economics.
Learning Objective: Identify the performance outcomes that made the USPS deployment economically compelling at production scale
Order the main USPS production stages for one mail piece: (1) Post-process predictions into sorting decisions, (2) Capture envelope image, (3) Run neural inference on normalized digits, (4) Preprocess and segment the ZIP code region.
Answer: The correct order is: (2) Capture envelope image, (4) Preprocess and segment the ZIP code region, (3) Run neural inference on normalized digits, (1) Post-process predictions into sorting decisions. The neural network cannot run until preprocessing has isolated and normalized the digits, and the physical sorter cannot act until post-processing has applied confidence thresholds and translated class scores into routing instructions. Swapping preprocessing after inference would feed raw, misaligned envelope pixels into the model; swapping post-processing before inference would turn sorting decisions into guesses about predictions that had not happened yet.
Learning Objective: Trace the end-to-end inference pipeline used in a production OCR deployment
A modern team is redesigning the USPS system using current accelerators. Using the D·A·M taxonomy the chapter introduces, which failure pattern most directly illustrates how maximizing a single axis can still produce an unsuccessful deployment?
- A team gathers an ImageNet-scale handwriting corpus and trains the deepest available transformer, then deploys it on a GPU cluster — but the training distribution samples only U.S. office handwriting, so the system fails on elderly rural hand-addressing styles that dominate real mail.
- A team uses the correct LeNet architecture and collects representative envelopes but deploys it to an inexpensive embedded board whose latency comfortably beats the sortation deadline.
- A team uses the correct LeNet architecture, representative data, and adequate hardware, and the system operates within its error and latency budgets in field trials.
- A team reduces all three D·A·M axes by half and observes that performance improves monotonically on every axis.
Answer: The correct answer is A. The scenario maximizes Algorithm (deepest architecture) and Machine (GPU cluster) while leaving Data mis-specified — the very failure mode D·A·M predicts. No amount of compute or model sophistication compensates for a training distribution that misses the deployment distribution. The adequate-deployment and balanced-reduction scenarios describe aligned systems with no failure; the embedded-board scenario identifies no misalignment because the SLO is already met.
Learning Objective: Apply the D·A·M taxonomy to diagnose which axis is misaligned in a concrete deployment scenario
The chapter’s ‘Then vs. Now’ table reports 1,000× lower hardware cost, 1,000× lower inference latency, and 20,000× lower energy per inference for essentially unchanged LeNet weights. What is the systems lesson this comparison delivers?
- The algorithm changed completely, which is why modern devices are faster — the LeNet weights in the table are nominally the same but functionally reconfigured.
- Hardware progress multiplied the viable deployment envelope of essentially the same neural computation, while the pipeline design principles (preprocess, infer, postprocess, act) remained durable — demonstrating the algorithm-hardware co-design leverage the section emphasizes.
- Modern deployments no longer need preprocessing or confidence-based handoff because accelerators are fast enough to eliminate uncertainty.
- Parameter counts are now irrelevant because latency is no longer a constraint in any deployment context.
Answer: The correct answer is B. The table’s core message is that the same ≈10K-parameter LeNet now fits on inexpensive embedded hardware at sub-ms latency because hardware progressed, not because the algorithm changed. The chapter then stresses that preprocessing, confidence handoff, and pipeline structure stayed the same — the durable engineering pattern that every subsequent case study will recognize. An algorithm-changed-completely answer contradicts the table’s own entries; a preprocessing-no-longer-needed answer is disproved by every modern OCR pipeline the chapter references; the parameter-irrelevance answer overreaches in precisely the way the D·A·M taxonomy is meant to prevent.
Learning Objective: Evaluate how hardware progress and durable pipeline design jointly shape the evolution of ML deployments
Self-Check: Answer
Under the D·A·M taxonomy, which assignment of roles best matches the chapter’s treatment?
- Data decides whether computations run efficiently; Machine decides whether labels are correct; Algorithm is orthogonal to both.
- Algorithm defines what computations exist, Data determines whether the computations can learn meaningful patterns, and Machine determines whether those computations can run within latency, memory, and energy budgets.
- Machine chooses the learning objective; Algorithm only formats data for training; Data is a downstream consequence of hardware decisions.
- Data, Algorithm, and Machine are largely independent dimensions, so optimizing one axis rarely affects the others.
Answer: The correct answer is B. The chapter assigns computation structure to Algorithm, learnability to Data, and execution efficiency to Machine, and then argues that deep learning succeeds only when all three align. An independence-claim answer contradicts the section’s central thesis of mutual reinforcement; the scrambled-roles answers assign responsibilities to the wrong axis.
Learning Objective: Identify the distinct roles of Data, Algorithm, and Machine in deep learning systems
A team’s Transformer architecture is elegant, their H100 cluster is underutilized, but validation performance stalls far below the production SLO no matter how long they train. Use the D·A·M taxonomy to propose the most likely binding constraint and the sequence of diagnostic checks that would confirm it.
Answer: Elegant model plus underutilized compute points the binding constraint toward the Data axis rather than Algorithm or Machine. Training length cannot rescue a model whose training distribution misses the production distribution, whose labels are noisy, or whose coverage of rare-but-important inputs is thin. The diagnostic sequence is: first, compare training and validation loss curves to confirm the gap is not an optimization failure (Algorithm); second, profile GPU utilization and check that the iron law’s compute term is healthy (Machine); third, audit the dataset — class balance, label noise, shift between training and deployment distributions, and coverage of the hard examples the validation set exposes. The systems implication is that scaling hardware or deepening the model will waste cycles if the real constraint is Data, exactly the pattern D·A·M is designed to surface.
Learning Objective: Apply the D·A·M taxonomy to diagnose the binding constraint in an underperforming training run
Imagine the USPS team in 1989 had chosen a much deeper convnet than LeNet but trained it only on carefully printed test-lab digits, on the same Sun-4 hardware. Using the D·A·M taxonomy, which axis-level failure does this hypothetical most closely illustrate, and what systems consequence follows?
- A Machine failure, because the Sun-4 would be too slow to run the deeper model — and the consequence is a missed latency SLO at the sortation belt.
- A Data failure, because the training distribution excludes the hurried and rural handwriting styles that dominate real mail — and the consequence is elevated error on production envelopes even when Algorithm and Machine satisfy their budgets.
- An Algorithm failure, because LeNet is provably optimal for OCR and any deviation from it reduces accuracy regardless of data.
- No failure, because any combination of D, A, and M that uses neural networks will succeed at sufficient scale.
Answer: The correct answer is B. The scenario maximizes Algorithm (deeper convnet) and keeps Machine within budget, but curates the training data to a narrow slice that does not match production variance. The D·A·M prediction is a Data failure that neither a better architecture nor faster hardware can rescue. A Machine-first framing misplaces the bottleneck; an Algorithm-first framing invents an optimality claim the chapter never makes; a no-failure answer ignores the core lesson that all three axes must align.
Learning Objective: Apply the D·A·M taxonomy to a counterfactual USPS scenario and identify which axis governs the failure
Self-Check: Answer
A teammate argues that ‘neural networks are black boxes, so debugging them is essentially impossible.’ Which response best captures the section’s position?
- They are correct, because learned weights carry no interpretable structure at all.
- They are partly right only for small networks; large networks are the only ones that become uninterpretable.
- They are mistaken: activation visualization, gradient analysis, ablations, and saliency methods reveal what features the network is using and where it fails — the debugging instruments are different from stack traces, not absent.
- They are mistaken only if the model uses ReLU rather than sigmoid activations.
Answer: The correct answer is C. The section argues that neural networks are not debugged like traditional code but are still analyzable through statistical and representation-focused methods. A black-box-is-undebuggable answer conflates ‘different debugging tools’ with ‘no debugging tools’ — the very confusion the pitfall targets. A small-network-only answer makes an empirical claim the section does not endorse; an activation-function-contingent answer has no bearing on interpretability methods.
Learning Objective: Identify valid interpretability and debugging approaches for neural network systems
Explain why a neural network on a problem with fewer than 1,000 examples and nearly linear relationships is usually a poor engineering choice, referring to both the training overhead and the maintenance profile of the alternative.
Answer: Neural networks impose training, memory, and maintenance overhead that pays off only when the task demands hierarchical nonlinear feature learning from volumes of data a simpler model cannot exploit. On small, mostly linear problems, logistic regression or a linear SVM trains in milliseconds, fits on a CPU, is easy to serialize, and remains debuggable via coefficient inspection. A neural alternative would likely match or underperform the linear model on held-out data while demanding dataset versioning, retraining pipelines, GPU-dependent inference, and the full monitoring suite a production neural system requires. The practical implication is that a one-percent accuracy gain rarely justifies a 100–1,000× jump in systems complexity and recurring operational cost.
Learning Objective: Justify when a simpler model is preferable to a neural network on grounds of both training economics and operational complexity
A team moves a small MLP inference workload from a CPU to an expensive GPU and observes almost no speedup, even though the GPU’s advertised TFLOPS dwarf the CPU’s. Which explanation best matches the section?
- GPUs only accelerate post-processing stages, so the forward pass stays CPU-bound regardless of hardware.
- The workload is memory-bound or has too little arithmetic intensity to keep the GPU’s SIMT engines busy, so adding peak compute does not help when data movement, not arithmetic, is the binding constraint.
- Faster GPUs force the optimizer to use smaller learning rates, cancelling the hardware gain.
- Neural networks become rule-based above a certain size, so accelerators stop helping once that threshold is crossed.
Answer: The correct answer is B. The section warns that peak FLOPS is only useful when the workload has enough arithmetic intensity to absorb it; a small MLP with modest per-example work often stalls on weight streaming and is memory-bound — the iron law’s data term, not its compute term, dominates. A learning-rate answer confuses training hyperparameters with an inference hardware bottleneck; a rule-based-at-scale answer contradicts the chapter’s paradigm claim that neural workloads remain arithmetic regardless of size.
Learning Objective: Diagnose why peak compute alone does not guarantee speedup when a workload is memory-bound
True or False: On a heavily imbalanced binary dataset with a 99.5 percent majority class, a model reporting 99.2 percent overall accuracy on held-out data is strong evidence that it will perform well on the rare but operationally important minority class.
Answer: False. A constant predictor that always outputs the majority class achieves 99.5 percent accuracy without detecting a single minority case; 99.2 percent is actually worse than trivial on this dataset. Aggregate accuracy hides catastrophic minority-class failure — which is why the section insists on per-class metrics (precision, recall, confusion-matrix inspection) for imbalanced workloads such as fraud detection or rare-disease triage.
Learning Objective: Recognize why aggregate accuracy misleads on imbalanced datasets and identify appropriate per-class metrics
A team has seen depth-only scaling improve accuracy through two previous model generations and assumes the same strategy will continue to pay off. Which critique best matches the chapter’s position?
- Depth always improves accuracy, provided the learning rate is raised proportionally.
- The main issue is that deeper networks cannot use ReLU, so activation choice blocks further gains.
- Accuracy gains from depth alone show diminishing returns; balanced scaling of depth, width, data, and compute typically beats depth-only scaling at comparable total cost — a lesson the section ties back to Chinchilla-style scaling arguments.
- Adding layers reduces memory use, so the strategy is cost-free even if accuracy stalls.
Answer: The correct answer is C. The section argues against naive depth-only scaling and points to diminishing returns plus the better trade-offs available from balanced design. The depth-only-with-lr-scaling answer invents a monotonicity the chapter explicitly denies; the activation-blocks-depth answer contradicts the chapter’s own endorsement of ReLU for deep networks; the memory-reduction answer is the opposite of reality, since deeper networks typically increase the activation storage training must preserve.
Learning Objective: Evaluate why depth-only scaling is a poor optimization strategy at scale
A team’s training loss is still decreasing at epoch 40 while validation loss has been rising steadily since epoch 25. Explain what this pattern tells an engineer about the model’s current regime, how to detect the failure mode unambiguously, and which two interventions the section supports.
Answer: Diverging training and validation loss curves are the canonical signal that the model has stopped generalizing and started memorizing training-specific noise — the failure mode the section treats as a central practical risk. The detection is exactly the pattern observed: not a single metric but the relative trajectory of train vs. validation loss, ideally accompanied by a widening train-vs-validation accuracy gap. Appropriate interventions include restoring an earlier checkpoint where validation loss was minimum and applying early stopping to terminate training at that point, and introducing regularization (weight decay, dropout, or data augmentation) to reduce the model’s ability to fit noise. The systems implication is that training longer on a finite dataset is never a monotonic improvement: past a certain point, each additional epoch degrades production performance regardless of what the training loss shows.
Learning Objective: Detect overfitting from training vs. validation behavior and select appropriate interventions
Self-Check: Answer
What is the chapter’s central answer to the question of why deep learning systems engineers must understand the math inside neural networks?
- Because most deployment failures are really programming-language bugs hidden inside framework code.
- Because the mathematical primitives — matrix multiplies, activations, gradients, and parameter counts — determine the compute profile, memory demand, training stability, and hardware compatibility that together form the Silicon Contract.
- Because engineers are expected to derive every training algorithm from scratch before using a framework.
- Because neural architectures change too quickly for any software abstraction to remain useful.
Answer: The correct answer is B. The summary ties matrix multiplies, activations, gradients, and parameter counts directly to resource usage and failure modes, making the math the real systems specification. A framework-bug answer misses that the decisive constraints come from the operators themselves, not the glue code around them. The derive-everything-from-scratch answer overstates what engineers must do; the architectures-change-too-fast answer is disconnected from the question of why the math matters.
Learning Objective: Summarize why neural computation primitives govern systems engineering decisions
Explain why the chapter treats training and inference as different systems problems even though they share the same network architecture, grounding your answer in two concrete differences in memory layout and optimization objective.
Answer: The architecture is identical but the workloads diverge sharply. First, training must retain activations from every layer for backpropagation, store gradients for every parameter, and hold optimizer state (momentum and second moments for Adam), which tripled or quadrupled memory versus inference on the same model; inference retains only the parameters and at most two rotating activation buffers, enabling deployment on devices that could not possibly train the same network. Second, training optimizes time-to-accuracy and tolerates long wall clocks if each step uses hardware efficiently; inference optimizes per-request latency and energy-per-query under an SLO, so techniques like quantization and operator fusion that would destabilize training become standard practice. The systems consequence is that hardware and optimization strategies that are correct in one phase are often wrong in the other, even for the identical network.
Learning Objective: Compare the systems priorities of training and inference by grounding them in memory layout and optimization-objective differences
A production fraud-detection service reports 98.5 percent model accuracy on held-out data yet misses the p99 latency SLO in deployment. Preprocessing takes 40 ms, feature lookup 80 ms, model inference 15 ms, and a business-rule post-processor 90 ms. Based on the chapter’s end-to-end framing, which pipeline stage is the most productive optimization target and why?
- Model inference at 15 ms, because compressing the neural network is always the highest-leverage optimization when an SLO is missed.
- The business-rule post-processor at 90 ms, because it is the largest single share of total latency and lives outside the neural network — the exact pattern the chapter identifies, where a fast model still misses its SLO when non-neural stages dominate.
- Feature lookup at 80 ms, because feature stores are fundamentally unoptimizable and must be replaced with the model itself.
- All four stages equally, because every millisecond counts regardless of relative contribution.
Answer: The correct answer is B. Total observed latency is 225 ms; the post-processor alone is 90 ms, or 40 percent of observed total latency, and the chapter’s lesson is that the bottleneck is whichever stage is largest, not whichever stage runs the model. A model-compression answer ignores Amdahl-style reasoning: halving 15 ms saves only 7.5 ms, nowhere near the SLO gap. A feature-lookup-must-be-replaced answer invents an absolute the chapter does not support; an equal-effort answer ignores leverage entirely. The chapter’s integration move is exactly this: model accuracy is necessary but insufficient, and the dominant stage — wherever it lives — is where optimization effort belongs.
Learning Objective: Apply end-to-end pipeline reasoning to select the highest-leverage optimization target when model accuracy is already adequate