Deployment Paradigm Framework
ML Systems
Purpose
Why does deploying the same model to a phone vs. a data center demand fundamentally different engineering?
The defining insight of ML systems engineering is that constraints drive architecture. The speed of light sets an absolute floor on how quickly distant servers can respond. Thermodynamics limits how much computation can occur in a given volume before heat becomes unmanageable. Memory physics makes moving data often more expensive than processing it. These are not engineering limitations awaiting better technology; they are permanent physical boundaries that partition the world into fundamentally distinct operating regimes. A data center can train billion-parameter models but cannot guarantee low-latency responses to users thousands of miles away. A smartphone can respond instantly but has a fraction of the memory budget. A microcontroller can run on a coin-cell battery for years but has barely enough compute for a simple keyword detector. The same model—the same algorithm applied to the same data—demands radically different engineering in each regime, not because of design preferences but because different physics governs each environment. Teams that treat deployment as an afterthought, training a model in the cloud and then asking “how do we ship this?”, discover too late that the physics of their target environment invalidates months of architectural decisions. Understanding these regimes transforms deployment from an operational detail into a first-order engineering decision: the question is never simply “how do I make this model work?” but rather “which physical constraints govern my problem, and how do they shape what is even possible?”
Learning Objectives
- Explain how physical constraints (speed of light, power wall, memory wall) necessitate the deployment spectrum from cloud to TinyML
- Apply the iron law and bottleneck principle to determine whether a workload is compute bound, memory bound, or I/O-bound
- Map workload archetypes to deployment paradigms using Lighthouse Model examples
- Distinguish the four deployment paradigms (Cloud, Edge, Mobile, TinyML) by their operational characteristics and quantitative trade-offs
- Apply the decision framework to select deployment paradigms based on privacy, latency, computational, and cost requirements
- Analyze hybrid integration patterns to determine which combinations address specific system constraints
- Evaluate deployment decisions by identifying common fallacies (including Amdahl’s Law limits) and assessing architecture-requirement alignment
- Identify universal principles (data pipelines, resource management, architecture) that span deployment paradigms and explain why optimizations transfer between scales
Where an ML model runs shapes what is possible in ways no algorithmic choice can override. Yet deployment is far harder than it appears, and the reason is not the model itself. In production ML systems, the model is often only a small part of the overall system (Sculley et al. 2015). The surrounding infrastructure consists of data collection, feature processing, serving infrastructure, monitoring, and resource management. All of this surrounding infrastructure changes dramatically depending on where the model executes.
Consider two extremes: a wake-word detector on a smartwatch and a recommendation engine in a data center. The wake-word detector represents a TinyML workload operating under milliwatt power budgets and kilobyte memory limits; the recommendation engine exemplifies a cloud ML workload requiring terabytes of embedding tables and megawatt-scale infrastructure. These systems solve different problems under opposite physical constraints, and the infrastructure that supports them shares almost nothing in common. This reality transforms deployment from an operational afterthought into a first-order engineering decision, one that the D·A·M taxonomy shown in The D·A·M Taxonomy helps us reason about by foregrounding infrastructure alongside data and algorithms.
The physical constraints that govern each environment (latency, power, and memory) force ML deployment into four distinct paradigms, each with its own engineering trade-offs and system design patterns. Cloud ML aggregates computational resources in data centers, offering virtually unlimited compute and storage at the cost of network latency. Edge ML moves computation closer to where data originates, including factory floors, retail stores, and hospitals, achieving lower latency and keeping sensitive data on-premises. Mobile ML brings intelligence directly to smartphones and tablets, balancing computational capability against battery life and thermal constraints. TinyML pushes intelligence to the smallest devices: microcontrollers costing dollars and consuming milliwatts, enabling always-on sensing that runs for months on a coin-cell battery. These four paradigms span nine orders of magnitude in power consumption (megawatts to milliwatts) and memory capacity (terabytes to kilobytes), a range so vast that the engineering principles governing one end of the spectrum barely apply at the other.
These four paradigms exist not because of engineering choices but because of physical laws that no amount of optimization can overcome. Three fundamental constraints carve the deployment landscape into distinct operating regimes: the speed of light (establishing latency floors), thermodynamic limits on power dissipation (capping computation per watt), and the energy cost of memory signaling (creating the memory wall). These are not design preferences but physical boundaries: a self-driving car cannot be served from a data center 36 ms away, and a 1.5-billion-parameter model cannot be trained on a microcontroller.
The Architectural Anchor: The Single-Node Stack
To navigate these operating regimes, we anchor our engineering decisions in a four-layer architectural model of the Single-Node Stack. This model provides the foundational framework for analyzing any ML system before it is projected onto a larger distributed fleet. Understanding how these layers interact within a single machine is the technical prerequisite for mastering larger scales.
- Application (The Mission): The top layer where high-level requirements (throughput for training loops, latency for inference serving) are defined. This is where the “Dual Mandate” of accuracy and physics is managed (Model Training, Model Serving).
- ML Framework (The Compiler): The translation layer (PyTorch, JAX) that maps high-level math to hardware-specific execution plans. It manages the computational graph, automatic differentiation, and memory scheduling (ML Frameworks).
- Operating System (The Runtime): The interface between framework and hardware, responsible for the low-level orchestration of resources. This includes the CUDA Runtime for kernel management and PCIe DMA (Direct Memory Access) for efficient data movement between host and device.
- Hardware (The Silicon): The physical foundation where bits are transformed. This layer is defined by HBM (High Bandwidth Memory) capacity and high-speed intra-node interconnects like NVLink (900 GB/s). Here, the memory wall acts as the primary physical constraint (Hardware Acceleration).
Every chapter in the first half of this text interrogates one or more of these layers. Mastery of this single-node regime establishes the “silicon contract” that governs all subsequent optimization and scaling efforts.
These physical constraints interact with the iron law of ML systems (Iron Law of ML Systems), which decomposes end-to-end latency into data movement, computation, and overhead. Different deployment environments stress different terms of this equation: cloud systems are typically compute bound, mobile systems hit power walls, and TinyML devices are memory-capacity-limited. By pairing the physical constraints with the iron law, we develop a quantitative vocabulary for reasoning about which paradigm fits a given workload and why. To anchor this analysis concretely, the chapter introduces five Lighthouse Models (ResNet-50, GPT-2, Deep Learning Recommendation Model (DLRM), MobileNet, and a Keyword Spotter) that span the deployment spectrum and isolate distinct system bottlenecks. These reference workloads recur throughout the book, providing a consistent basis for comparing optimization techniques across chapters.
The physics that creates these paradigm boundaries comes first, followed by the analytical tools (iron law, bottleneck principle, workload archetypes) for mapping workloads to deployment targets. Each paradigm then receives an in-depth treatment covering infrastructure, trade-offs, and representative applications. Figure 1 orients the discussion by showing where each paradigm sits along the centralization spectrum. The chapter closes with a comparative decision framework and the hybrid architectures that combine paradigms when no single deployment target satisfies all requirements.

ABI Research. 2024. TinyML: The Next Big Opportunity in Tech. Whitepaper. ABI Research.
These four paradigms function as distinct operating envelopes, each defined by how much power, memory, and network connectivity is available. Every ML application must fit within at least one of these envelopes, and that fit determines which algorithms, hardware, and engineering trade-offs apply. The four paradigms span a continuous spectrum from centralized cloud infrastructure to distributed ultra-low-power devices. Figure 1 traces this spectrum visually, mapping where each paradigm sits along the centralization axis, while Table 1 pins down the quantitative trade-offs:
| Paradigm | Where | Latency | Power | Memory | Best For |
|---|---|---|---|---|---|
| Cloud ML | Data centers | 100-500 ms | MW | TB | Training, complex inference |
| Edge ML | Local servers | 10-100 ms | 100 W | GB | Real-time inference, privacy |
| Mobile ML | Smartphones | 5-50 ms | 3-5 W | GB | Personal AI, offline |
| TinyML | Microcontrollers | 1-10 ms | mW | KB | Always-on sensing |
The nine-order-of-magnitude span in Table 1 is not an accident of engineering history—it is a consequence of physics. No amount of optimization can make a data center respond faster than light can travel, or make a microcontroller dissipate more heat than its surface area allows. The existence of four paradigms, rather than a single universal solution, follows from three physical laws.
Self-Check: Question
Order the following layers of the Single-Node Stack from the point where high-level requirements are expressed to the point where bits are physically transformed: (1) Hardware (HBM + NVLink), (2) Application (throughput and latency goals), (3) Operating System (CUDA runtime + PCIe DMA), (4) ML Framework (PyTorch / JAX computational graph).
An engineer writes 20 lines of PyTorch defining a Transformer block and a cross-entropy loss. Before any kernel runs on the accelerator, some component must translate this high-level math into a device-specific execution plan: a computational graph, autodiff tape, memory schedule, and selected kernels. Which layer of the Single-Node Stack owns that translation?
- The hardware layer, because the silicon rewrites the computational graph internally before executing any instruction.
- The operating system layer, because the CUDA runtime and PCIe DMA engine set throughput and accuracy goals for the application.
- The ML framework layer, because it constructs the computational graph, performs autodifferentiation, and schedules memory and kernels for the target device.
- The application layer, because business-level throughput and latency requirements are what directly decide kernel launch order.
An engineer inherits a 512-GPU distributed training job that delivers only 22 percent of its expected throughput. Before touching the cluster’s interconnect or scheduler, the section advises reasoning about the single-node stack first. Using the Silicon Contract framing, explain why the single-node diagnosis must come before the distributed one, and name two specific single-node bottlenecks that 512 GPUs would amplify rather than resolve.
A student is deciding which Lighthouse Model from this chapter (ResNet-50, GPT-2, DLRM, MobileNet, Keyword Spotter) to use as the primary example in a lesson on memory-capacity limits versus memory-bandwidth limits in the iron law. Which model is the best pedagogical anchor, and why?
- ResNet-50, because its fixed-size 224×224 inputs make it compute-bound at every batch size, which cleanly isolates the R_peak term.
- DLRM, because its massive sparse embedding tables make the \(D_{vol}\) / capacity dimension the binding constraint — the model cannot execute until the right embedding rows are fetched, regardless of raw FLOPs.
- MobileNet, because its mobile deployment target means all bottlenecks trace to battery energy rather than to memory behavior.
- A Keyword Spotter, because its few-kilobyte footprint eliminates every memory-related iron-law term and leaves only the latency term.
Physical Constraints: Why Paradigms Exist
The physical laws of speed of light, power thermodynamics, and memory signaling dictate that no single “ideal” computer exists. Where a system runs reshapes the contract between model and hardware. These three constraints, which we call the light barrier, power wall, and memory wall, govern the engineering trade-offs ahead.1
1 Deployment Paradigm: A distinct operating regime whose boundaries are set by physics, not convention. The Cloud-to-TinyML spectrum spans nine orders of magnitude in power because thermodynamic and electromagnetic constraints create hard walls that no software optimization can cross, forcing qualitatively different system architectures at each tier. Misidentifying the paradigm boundary wastes engineering effort: optimizing a cloud model for 5 percent higher throughput is pointless if the application’s 10 ms latency budget demands edge deployment.
The light barrier
The light barrier establishes the absolute latency2 floor. The minimum round-trip time is governed by Equation 1: \[\text{Latency}_{\min} = \frac{2 \times \text{Distance}}{c_{\text{fiber}}} \approx \frac{2 \times \text{Distance}}{200{,}000 \text{ km/s}} \tag{1}\]
2 Latency: The time between issuing a request and receiving a result, corresponding to \(L_{\text{lat}}\) in the iron law. The light barrier makes this floor irreducible: the speed of light in fiber imposes a ~36 ms minimum round trip across the continental US, consuming the entire latency budget of a 10 ms safety-critical system before any computation begins. Every millisecond consumed by distance is a millisecond unavailable for model inference, which is why the light barrier forces paradigm selection rather than mere optimization.
California to Virginia (~3,600 km straight-line) requires ~36 ms minimum before any computation begins. Actual cloud services typically add 60–150 ms of software overhead. Applications requiring sub-10 ms response cannot use distant cloud infrastructure—physics forbids it. This constraint creates the need for edge ML and TinyML: when latency budgets are tight, computation must move closer to the data source.
The power wall
The power wall emerged because thermodynamics limits how much computation can occur in a given volume. Under classical Dennard scaling3 (which held until approximately 2006), the relationship between power and frequency was cubic. Here \(C\) is effective capacitance, \(V\) is voltage, and \(f\) is clock frequency. As voltage tracks frequency \((V \propto f)\), power rises as \(f^3\), as Equation 2 shows: \[\text{Power} \propto C \times V^2 \times f \quad \text{where } V \propto f \implies \text{Power} \propto f^3 \tag{2}\]
3 Dennard Scaling: Named after Dennard et al. (1974) at IBM, who showed that as transistors shrink, voltage and current scale proportionally, keeping power density constant. This held for three decades, delivering “free” performance gains each chip generation. When leakage current made further voltage reduction impossible around the 90 nm node (2005–2006), power density began rising with each generation—ending single-core frequency scaling and forcing the industry toward the parallelism and specialization (multi-core, GPU, TPU) that now defines ML hardware.
Dennard, Robert H., Frank H. Gaensslen, Hwa-Nien Yu, Victor L. Rideout, Elias Bassous, and Antoine R. LeBlanc. 1974. “Design of Ion-Implanted MOSFET’s with Very Small Physical Dimensions.” IEEE J. Solid-State Circuits 9 (5): 256–68. https://doi.org/10.1109/jssc.1974.1050511.
Doubling clock frequency required approximately 8\(\times\) more power. The breakdown of this scaling relationship ended the era of “free” speedups via frequency scaling and forced the industry toward the parallelism (multi-core) and specialization (GPUs, Tensor Processing Units (TPUs)) that defines modern ML. Mobile devices hit hard thermal limits at 3-5 W; exceeding this causes “throttling,” where the device reduces performance to prevent overheating. In practice, this means a mobile model that runs at 60 FPS for 1 minute may throttle to 15 FPS as the device heats up. This physical limit gives rise to mobile ML: battery-powered devices cannot simply run cloud-scale models locally.
The memory wall
The memory wall (Wulf and McKee 1995) reflects the widening bandwidth4 gap: \[\frac{\text{Compute Growth Rate}}{\text{Memory Bandwidth Growth Rate}} \approx \frac{1.6}{1.2} \approx 1.33 \tag{3}\]
Wulf, Wm. A., and Sally A. McKee. 1995. “Hitting the Memory Wall: Implications of the Obvious.” ACM SIGARCH Computer Architecture News 23 (1): 20–24. https://doi.org/10.1145/216585.216588.
4 Memory Bandwidth (The memory wall): The term “memory wall” was coined by Wulf and McKee in 1995, who predicted that the processor-memory performance gap would eventually dominate system performance—a prediction that proved prescient for ML workloads where weight loading, not arithmetic, is the typical bottleneck. In the iron law, bandwidth \((\text{BW})\) appears in the denominator of the data term \(D_{\text{vol}}/\text{BW}\), so every doubling of model size that is not matched by a doubling of memory bandwidth directly increases wall-clock time. This asymmetry, growing at roughly 1.33\(\times\) per year, is why modern ML systems are more often memory-bound than compute bound.
Equation 3 quantifies this divergence: processors have doubled in compute capacity roughly every 18 months, but memory bandwidth has improved only ~20 percent annually. This widening gap makes data movement the dominant bottleneck and energy cost for most ML workloads. This constraint affects all paradigms but is especially acute for TinyML, where devices have only kilobytes of memory to work with. We examine the hardware architectural responses to the memory wall, including HBM and on-chip SRAM hierarchies, in detail in Understanding the AI memory wall.
Checkpoint 1.1: Physical constraints and deployment
Deployment choices are governed by physics, not just preference. Check your understanding:
These physical laws explain why the four paradigms exist. Physics creates the boundaries; privacy regulation, economic incentives, and data sovereignty requirements reinforce and sharpen them. We examine these additional drivers within each paradigm section, but the central insight is that the paradigms would exist even without those concerns. No regulation can make the speed of light faster, and no economic model can repeal thermodynamics.
Knowing that these barriers exist is necessary but not sufficient. Given a specific ML workload (say, a recommendation engine or a wake-word detector), we need to determine which paradigm fits and which barrier the workload will hit first. The answer requires analytical tools that connect workload characteristics to these physical constraints: the iron law to decompose latency, the bottleneck principle to identify the dominant constraint, and a set of workload archetypes to classify where each model falls on the spectrum.
Self-Check: Question
A safety-critical control loop has a 10 ms end-to-end latency budget, and the nearest cloud data center is 3,600 km away across a direct fiber path. Applying the section’s light-barrier analysis, what follows?
- Cloud deployment is feasible if the model inference itself takes less than 1 ms.
- Cloud deployment is infeasible because round-trip propagation delay alone is roughly 36 ms, before any compute or software overhead.
- Cloud deployment is feasible if enough parallel GPUs hide the network delay.
- Cloud deployment is blocked only by software overhead, not by physics.
A smartphone runs an image-enhancement model at 60 FPS for the first 90 seconds of recording, then drops to 15 FPS for the rest of the session even though the user has not changed any settings. Using the section’s Dennard-scaling-breakdown and power-wall argument, walk through the mechanism behind this failure and explain why the mobile regime chose efficiency and parallelism over raw clock speed as a response.
A profiler shows a new accelerator generation delivering 3× the peak FP16 TFLOPS of the previous one, but a production inference pipeline’s end-to-end latency improves by only 8 percent. A GPU-busy-time counter reads 91 percent, and HBM bandwidth utilization reads 94 percent. Which interpretation matches the section’s memory-wall argument?
- The workload is still compute-bound, so the remedy is to raise the accelerator’s clock frequency and unlock more FLOPs.
- The immediate constraint is SSD capacity, so a larger disk will let the pipeline cache more weights and restore scaling.
- Compute capability has grown faster than memory bandwidth, so data movement now sets the latency ceiling; the 94 percent HBM figure confirms the kernel is bandwidth-starved, not FLOP-starved.
- The memory wall is a database-query phenomenon and does not bind neural-network kernels, so the 8 percent improvement must come from unrelated software overhead.
Given the memory-wall argument — compute has grown much faster than memory bandwidth — explain which class of optimization techniques becomes disproportionately valuable for ML inference, and why raw accelerator upgrades deliver diminishing returns on memory-bound kernels.
True or False: The four ML deployment paradigms (Cloud, Edge, Mobile, TinyML) are product-marketing categories that solidified because different engineering teams chose different deployment styles over time.
Analyzing Workloads
The central analytical tool for this chapter is the iron law of ML systems, established in Iron Law of ML Systems and restated here as Equation 4: \[T = \frac{D_{\text{vol}}}{\text{BW}} + \frac{O}{R_{\text{peak}} \cdot \eta_{\text{hw}}} + L_{\text{lat}} \tag{4}\]
This equation decomposes total latency into three terms: data movement \((D_{\text{vol}}/\text{BW})\), compute \((O/(R_{\text{peak}} \cdot \eta_{\text{hw}}))\), and fixed overhead \((L_{\text{lat}})\). For a single inference, these costs simply add up—each is paid sequentially. In production systems, however, tasks are processed continuously as a stream, and the question shifts from “how long does one task take?” to “which of these three terms actually limits the system?” The answer depends entirely on the deployment environment: a model that is compute bound during training may become memory bound during inference; a system that runs efficiently in the cloud may hit power limits on mobile devices. To determine which term dominates, we need a companion principle.
The bottleneck principle
The iron law tells us the cost of each term. The bottleneck principle tells us which term matters. Unlike traditional software where optimizing the average case works, ML systems are dominated by their slowest component: optimizing fast operations yields zero benefit while the slowest stage remains unchanged. Modern accelerators use pipelined execution to overlap data movement with computation: while the accelerator computes on batch \(n\), the memory system prefetches batch \(n+1\). With this overlap, whichever operation is slower determines the system’s throughput—the faster one “hides” behind it. The iron law’s sum becomes a maximum, as Equation 5 formalizes: \[ T_{\text{bottleneck}} = \max\left(\frac{D_{\text{vol}}}{\text{BW}}, \frac{O}{R_{\text{peak}} \cdot \eta_{\text{hw}}}, T_{\text{network}}\right) + L_{\text{lat}} \tag{5}\]
- \(\frac{D_{\text{vol}}}{\text{BW}}\) (Memory): Time to move data between memory and processor.
- \(\frac{O}{R_{\text{peak}} \cdot \eta_{\text{hw}}}\) (Compute): Time to execute calculations.
- \(T_{\text{network}}\): Time for network communication (if offloading).
- \(L_{\text{lat}}\) (Overhead): Fixed latency (kernel launch, runtime overhead).
This principle dictates that if a system is memory bound \((D_{\text{vol}}/\text{BW} > O/(R_{\text{peak}} \cdot \eta_{\text{hw}}))\), buying faster processors \((R_{\text{peak}})\) yields exactly 0 percent speedup—just as widening a six-lane highway yields no benefit when all traffic must funnel through a two-lane bridge. Engineers must identify the dominant term before optimizing. This trade-off is governed by the energy of transmission.
Napkin Math 1.1: The energy of transmission
Problem: Should a battery-powered sensor process data locally (TinyML) or send it to the cloud?
Variables:
- Data \((D_{\text{vol}})\): 1 MB (for example, one second of audio).
- Transmission energy \((E_{\text{tx}})\): 100 mJ/MB (Wi-Fi/LTE).
- Compute energy \((E_{\text{op}})\): 0.1 mJ/inference (MobileNet on NPU).
Math:
- Cloud approach: \(E_{\text{cloud}} \approx D_{\text{vol}} \times E_{\text{tx}}\) = 1 MB\(\times\) 100 mJ/MB = 100 mJ.
- Local approach: \(E_{\text{local}} \approx\) Inference = 0.1 mJ.
Systems insight: Transmitting raw data is 1,000\(\times\) more expensive than processing it locally. Even if the cloud had infinite speed \((\text{Time} \approx 0)\), the energy wall makes cloud offloading physically impossible for always-on battery devices. The “machine” constraint (battery) dictates the “algorithm” choice (TinyML).
The iron law’s variables interact differently across deployment scenarios. Before specific workload archetypes are examined, these core performance determinants need a compact definition.
Definition 1.1: The iron law
The iron law is the fundamental physical constraint governing all machine learning performance, expressed as the total time \(T\) required for a workload:
\[T = \frac{D_{\text{vol}}}{\text{BW}} + \frac{O}{R_{\text{peak}} \cdot \eta_{\text{hw}}} + L_{\text{lat}}\]
- Significance (quantitative): It defines the Physical Ceiling for any system by quantifying the relationship between data volume \((D_{\text{vol}})\), compute capacity \((R_{\text{peak}})\), and communication overhead \((L_{\text{lat}})\).
- Distinction (durable): Unlike Amdahl’s Law, which focuses on Parallel Speedup, the iron law addresses the Total Energy and Time required to move and transform data.
- Common pitfall: A frequent misconception is that these terms are independent. In reality, they are Trade-off Axes: for example, increasing batch size may improve the duty cycle \((\eta_{\text{hw}})\) but also increase the data volume \((D_{\text{vol}})\) per request, potentially shifting a compute-bound problem to a memory-bound one.
The iron law quantifies the cost of each ingredient; the bottleneck principle identifies the speed of the assembly line. As a rule of thumb, use the additive form in Equation 4 when analyzing the latency of a single task, and the max form in Equation 5 when analyzing the throughput of a continuous stream of tasks.
Workload archetypes
The bottleneck principle reduces optimization to a single diagnostic: identifying which constraint dominates for a given workload. The answer depends on the D·A·M taxonomy in The D·A·M Taxonomy, which decomposes every ML system into Data, Algorithm, and Machine. Different deployment environments create different bottlenecks along these axes—a cloud server with terabytes of memory faces algorithm constraints, while a microcontroller with kilobytes faces machine constraints.
To navigate these constraints systematically, we categorize ML workloads into four Archetypes5. These represent the primary physical bottlenecks, not just specific model architectures. We introduce each archetype briefly here; the Lighthouse Models that follow will ground each category in concrete, recurring examples.
5 Workload Archetype: A classification of ML workloads by their dominant iron law bottleneck rather than their model family. The distinction matters because the optimization strategy differs fundamentally: a compute-bound workload benefits from faster arithmetic \((R_{\text{peak}})\), while a bandwidth-bound workload benefits only from wider memory buses \((\text{BW})\). Misidentifying the archetype wastes optimization effort on the wrong term of the iron law, as when teams add accelerator FLOPS to a memory-bound inference pipeline and observe zero speedup.
The first archetype, the Compute Beast, describes workloads that perform many calculations per byte of data loaded. The binding constraint is raw computational throughput. Training large neural networks falls into this category.
The second archetype, the Bandwidth Hog, describes workloads that spend more time loading data than computing. Memory bandwidth becomes the binding constraint. Autoregressive text generation (like ChatGPT producing one token at a time) falls into this category.
The third archetype, the Sparse Scatter, describes workloads with irregular memory access patterns and poor cache locality. Memory capacity and access latency constrain performance. Recommendation systems with massive embedding tables are canonical examples.
The fourth archetype, the Tiny Constraint, describes workloads operating under extreme power envelopes (\(< 1\) mW) and memory limits (\(< 256\) KB). The binding constraint is energy per inference—efficiency, not raw speed. Always-on sensing operates in this regime.
These archetypes map naturally to deployment paradigms: compute beasts and sparse scatter workloads gravitate toward cloud ML where resources are abundant. Bandwidth hogs span cloud and edge depending on latency requirements. Tiny constraint workloads are exclusively TinyML territory. To make these abstractions concrete, we anchor each archetype to a specific model that recurs throughout this book as one of five reference workloads.
Lighthouse 1.1: Five reference workloads
Throughout this book, we use the five Lighthouse Models summarized in Table 2: concrete workloads that span the deployment spectrum and isolate distinct system bottlenecks. Network Architectures provides full architectural details and model biographies.
| Lighthouse | Archetype | Deployment Paradigm |
|---|---|---|
| ResNet-50 | Compute Beast | Cloud training, edge inference |
| GPT-2/Llama | Bandwidth Hog | Cloud inference |
| DLRM | Sparse Scatter | Cloud only (distributed) |
| MobileNet | Compute Beast (efficient) | Mobile, edge |
| Keyword Spotting (KWS) | Tiny Constraint | TinyML, always-on |
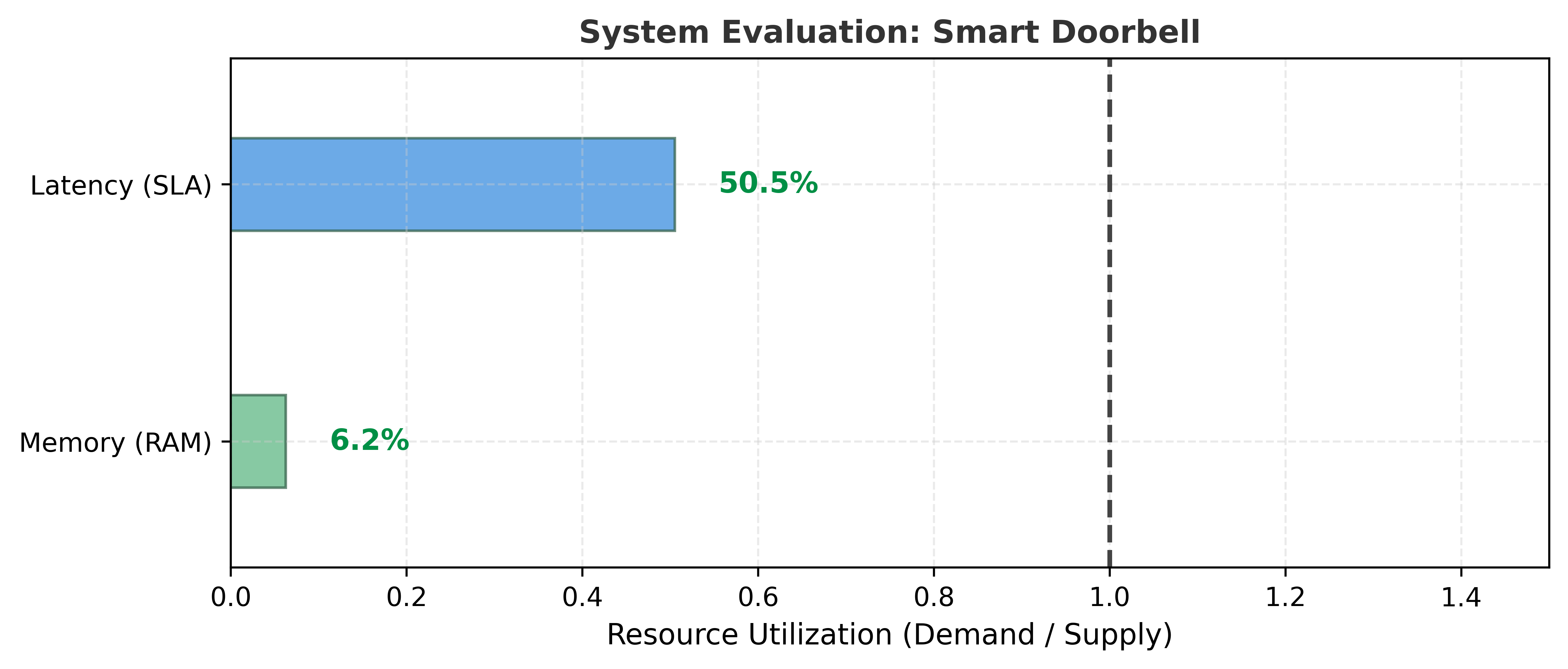
To ground the abstract interdependencies of the iron law in concrete practice, we analyze the Lighthouse Models summarized in Table 2. The following summaries recap each workload from a systems perspective, connecting them to the specific iron law bottlenecks they exemplify, as visualized in the scorecard for our central Smart Doorbell narrative (Figure 2).
The first lighthouse, ResNet-50, classifies images into one thousand categories, processing each image through approximately 4.1 billion floating-point operations using 25.6 million parameters (102 MB at FP32). Used in medical imaging diagnostics, autonomous vehicle perception pipelines, and as the backbone for content moderation systems, its regular, compute-dense structure makes it the canonical benchmark for hardware accelerator performance.
The language models GPT-2/Llama power chatbots, code assistants, and content generation tools. These models generate text one token at a time, requiring the model to read its full parameter set (1.5 billion for GPT-2, 7 to 70 billion for Llama) from memory for each output token. This sequential memory access pattern creates the autoregressive bottleneck that dominates serving costs.
The recommendation lighthouse, DLRM (Deep Learning Recommendation Model), powers the “You might also like” recommendations on platforms like Meta and Netflix. It maps users and items to embedding vectors stored in tables that can exceed 100 GB, making memory capacity rather than computation the binding constraint.
The mobile lighthouse, MobileNet, runs in smartphone camera apps for real-time photo categorization and on-device visual search. It performs the same image classification task as ResNet but uses depthwise separable convolutions to reduce computation by 14\(\times\), enabling real-time inference on smartphones at 2 to 5 watts.
The TinyML lighthouse, Keyword Spotting (KWS), represents the always-on sensing archetype. Used in applications like Smart Doorbells, it detects wake words (“Ding Dong”, “Hello”) using a depthwise separable convolutional neural network (CNN) with approximately 200K parameters (small variants; the DS-CNN benchmark in MLPerf Tiny uses ~200K) fitting in about 800 KB, running continuously at under one milliwatt (Zhang et al. 2017).
Zhang, Yundong, Naveen Suda, Liangzhen Lai, and Vikas Chandra. 2017. Hello Edge: Keyword Spotting on Microcontrollers.
The range in compute requirements and memory footprints explains why no single deployment paradigm fits all workloads. A keyword spotter can operate with roughly 20 MFLOPs and 800 KB, while ResNet-50 requires about 4.1 GFLOPs and roughly 102 MB per image. The reference DLRM example already reaches 100 GB of embeddings, and production DLRM-style recommendation systems can exceed 100 TB. Language models add a bandwidth-dominated regime: billions of parameters streamed repeatedly from memory during autoregressive inference. These five Lighthouse Models serve as concrete anchors throughout the book, each isolating a distinct system bottleneck revisited in every chapter.
Analytical tools alone remain abstract until grounded in real silicon. The next step translates the iron law, bottleneck principle, and workload archetypes into quantitative engineering decisions by examining how system balance (the interplay of compute, memory, and I/O) varies across real hardware platforms.
Self-Check: Question
Two engineers are analyzing the same inference service on the same hardware. Engineer A asks ‘what is the 99th-percentile end-to-end latency of a single request arriving when the queue is empty?’, and Engineer B asks ‘what is the sustained queries-per-second this service delivers when fully loaded with overlapped preprocessing, transfer, and compute?’. Which pair of iron-law formulations matches these two questions?
- Both questions use the additive iron law, because time is always a sum of the three terms regardless of context.
- Engineer A’s single-request-latency question uses the additive form (data + compute + latency add because the one request waits at every stage), while Engineer B’s steady-state throughput question uses the max form (overlapped stages make the slowest one — the bottleneck — set the rate).
- Both questions use the max-form Bottleneck Principle, because deployment systems always pipeline their stages.
- Neither form applies to inference; the iron law is a training-only framework in this chapter.
An inference pipeline has three stages measured per request: preprocessing on a CPU at 50 ms, host-to-device PCIe transfer at 10 ms, and GPU compute at 80 ms. A team doubles the accelerator’s FLOPS by buying a newer GPU; the compute stage falls to 40 ms, but pipelined throughput improves by only 60 percent rather than doubling. Use the Bottleneck Principle to explain the result and identify the optimization that would actually move the needle.
A battery-powered acoustic sensor can either transmit 1 MB of raw audio to a cloud classifier at roughly 100 mJ per megabyte, or run one local inference pass that costs roughly 0.1 mJ. Applying the section’s Energy of Transmission argument, what is the correct conclusion for always-on operation?
- Cloud offloading is usually more energy-efficient because the wireless radio amortizes compute costs across many devices.
- The two approaches are close enough that latency — not energy — should be the deciding factor.
- Local and cloud processing consume energy in the same order of magnitude, so either is viable for multi-month battery operation.
- Local processing is roughly 1,000× more energy-efficient per inference, so always-on battery-constrained sensing is pushed toward TinyML rather than cloud offload regardless of the cloud’s compute capability.
Which pairing of Lighthouse Model and Workload Archetype correctly reflects the section’s mapping?
- GPT-2 / Llama → Sparse Scatter, because autoregressive decoding scatters attention across irregular token positions.
- DLRM → Sparse Scatter, because massive embedding tables create irregular-access, capacity-dominated memory patterns.
- Keyword Spotting → Compute Beast, because always-on classification demands sustained peak arithmetic throughput.
- MobileNet → Bandwidth Hog, because depthwise-separable convolutions saturate HBM bandwidth on every layer.
True or False: A workload’s archetype is primarily determined by its model family (e.g., all language models are one archetype, all vision models are another), so teams can pick optimization strategies by architecture type alone without profiling.
System Balance and Hardware
Physical constraints translate into engineering decisions through concrete numbers. Table 3 provides order-of-magnitude latencies that should inform every deployment decision—spanning eight orders of magnitude from nanosecond compute operations to hundreds of milliseconds for cross-region network calls. Detailed hardware latencies and bandwidth constraints are covered in Hardware Acceleration. The key decision rule is simple: an operation with latency \(> X\) cannot appear on the critical path of a system whose latency budget is \(X\) ms.6
6 Critical Path: The longest sequential chain of dependent operations in a pipeline. The decision rule in the triggering sentence is strict: if a 200 ms cross-region network call appears anywhere on the critical path, a system with a 100 ms total budget is guaranteed to fail regardless of how fast every other stage runs. In practice, ML inference is rarely the longest stage; data preprocessing and postprocessing often dominate, making the critical path longer than the model execution time alone suggests.
These latencies, organized by category in Table 3, span eight orders of magnitude:
| Operation | Latency | Deployment Implication |
|---|---|---|
| Compute | ||
| GPU matrix multiply (per op) | ~1 ns | Compute is rarely the bottleneck |
| NPU inference (MobileNet) | 5–20 ms | Mobile can do real-time vision |
| LLM token generation | 20–100 ms | Perceived as “typing speed” |
| Memory | ||
| L1 cache hit | ~1 ns | Keep hot data in registers |
| HBM read (GPU) | 20–50 ns | 20–50\(\times\) slower than compute |
| DRAM read (mobile) | 50–100 ns | Memory bound on most devices |
| Network | ||
| Same data center | 0.5 ms | Microservices feasible |
| Same region | 1–5 ms | Edge servers viable |
| Cross-region | 50–150 ms | Batch processing only |
| ML Operations | ||
| Wake-word detection (TinyML) | 100 μs | Always-on feasible at <1 mW |
| Face detection (mobile) | 10–30 ms | Real-time at 30 FPS |
| GPT-4 first token | 200–500 ms | User notices delay |
| ResNet-50 training step | 200–400 ms | Throughput-optimized |
The four deployment paradigms gain precision when grounded in concrete hardware. While Table 1 defined the paradigms conceptually, Table 6 (which appears later in this section, after the System Balance discussion) provides specific devices, processors, and quantitative thresholds that practitioners use to select deployment targets.78 The nine-order-of-magnitude range in power (MW cloud facilities vs. mW TinyML devices) and the wide cost spread ($millions vs. $10) determine which paradigm can serve a given workload economically.
7 ML Hardware Cost Spectrum: AI infrastructure spans six orders of magnitude in cost, from $10 microcontrollers to multi-million-dollar GPU clusters. This million-fold range means deployment paradigm selection is simultaneously a physics decision and an economics decision. Even within individual-device choices, the same accuracy target may be achievable on a $2 microcontroller (via aggressive quantization) or a $30,000 GPU (at full precision), with fundamentally different latency, power, and operational cost profiles.
8 Power Usage Effectiveness (PUE): This metric isolates the energy overhead (for example, cooling) that determines the economic viability of the “MW cloud” paradigm. For a data center, the remaining 6 percent overhead of an elite 1.06 PUE still translates to megawatts of noncompute cost. This entire cost category does not exist for the “mW TinyML” paradigm, explaining a key part of the six-order-of-magnitude economic range.
These hardware differences translate directly into performance bottlenecks. To understand which constraint dominates in each paradigm, we apply the bottleneck principle (Section 1.3.1) using the pipelined form of the iron law.
Systems Perspective 1.1: System balance across paradigms
The pipelined form of the iron law of ML systems from Iron Law of ML Systems states that execution time is bounded by the slowest resource, as Equation 6 formalizes: \[T = \max\left( \frac{O}{R_{\text{peak}} \cdot \eta_{\text{hw}}}, \frac{D_{\text{vol}}}{\text{BW}}, \frac{D_{\text{vol}}}{\text{BW}_{\text{IO}}} \right) + L_{\text{lat}} \tag{6}\]
Here, \(O\) represents total operations, \(R_{\text{peak}}\) is peak compute rate, \(\eta_{\text{hw}}\) is hardware utilization efficiency, \(D_{\text{vol}}\) is data volume, \(\text{BW}\) is memory bandwidth, \(\text{BW}_{\text{IO}}\) is I/O bandwidth (storage or network), and \(L_{\text{lat}}\) is fixed overhead. The equation identifies which resource (compute, memory, or I/O) limits performance. For a systematic diagnostic guide to identifying these bottlenecks, consult the D·A·M taxonomy (The D·A·M Taxonomy).
The dominant term varies by paradigm and workload, shifting the optimization strategy entirely; Table 4 names which iron-law term limits each paradigm and the resulting optimization focus.
| Paradigm | Dominant Constraint | Why | Optimization Focus |
|---|---|---|---|
| Cloud Training | \(O/R_{\text{peak}}\) (Compute) | Abundant memory/network; FLOPS limit throughput | Maximize accelerator utilization, batch size |
| Cloud LLM Inference | \(D_{\text{vol}}/\text{BW}\) (Memory BW) | Autoregressive: ~1 FLOP/byte, memory-bound | KV-caching, quantization, batching |
| Edge Inference | \(D_{\text{vol}}/\text{BW}\) (Memory BW) | Limited HBM; models often memory-bound | Model compression, operator fusion |
| Mobile | Energy (implicit) | Battery = \(\int \text{Power} \cdot dt\); thermal throttling | Reduced precision, duty cycling |
| TinyML | \(D_{\text{vol}}/\text{Capacity}\) | 256 KB total; model must fit on-chip | Extreme compression, binary networks |
The same ResNet-50 model is compute-bound during cloud training (high batch size, high arithmetic intensity) but memory-bound during single-image inference (batch=1, low arithmetic intensity) (Williams et al. 2009). Deployment paradigm selection must account for this shift.
Williams, Samuel, Andrew Waterman, and David Patterson. 2009. “Roofline: An Insightful Visual Performance Model for Multicore Architectures.” Communications of the ACM 52 (4): 65–76. https://doi.org/10.1145/1498765.1498785.
This shift between training and inference is critical to understand. Recall the D·A·M taxonomy from The D·A·M Taxonomy: every ML system comprises Data, Algorithm, and Machine. Table 5 shows how each component behaves differently depending on whether the system is training (learning patterns) or serving (applying them).
| Component | Training (Mutable) | Inference (Immutable) |
|---|---|---|
| Data | Massive throughput: large batches, shuffling, augmentation | Low latency: single samples, freshness, speed |
| Algorithm | Bidirectional: forward + backward pass, optimizer state | Unidirectional: forward pass only, weights frozen |
| Machine | Throughput-optimized: high-bandwidth clusters, large memory | Latency-optimized: edge devices, inference accelerators |
A quantitative comparison applies this analysis to ResNet-50 inference on a data-center GPU and a mobile NPU.
Napkin Math 1.2: ResNet-50 on cloud vs. mobile
Problem: Is ResNet-50 inference compute bound or memory bound on (a) a high-end data center GPU (NVIDIA A100 class) and (b) a flagship mobile NPU (Apple/Qualcomm class)?
Given (from Lighthouse Models):
- ResNet-50: 4.1 GFLOPs per inference, 25.6 M parameters (102 MB at FP32, 51 MB at FP16)
Analysis:
(a) Cloud: NVIDIA A100 (batch=1, FP16)
- Peak compute: 312 TFLOPS (FP16)
- Memory bandwidth: 2 TB/s (HBM2e)
- Compute time: \(T_{\text{comp}}\) = \(\frac{4.10 \times 10^{9}}{3.12 \times 10^{14}}\) = 0.013 ms
- Memory time: \(T_{\text{mem}}\) = \(\frac{5.12 \times 10^{7}}{2.04 \times 10^{12}}\) = 0.025 ms
- Bottleneck: Memory (2\(\times\) slower than compute)
- Arithmetic intensity: \(\frac{4.10 \times 10^{9}}{5.12 \times 10^{7}}\) = 80 FLOPs/byte—this ratio of compute operations to bytes loaded measures how efficiently a workload uses the hardware. When arithmetic intensity exceeds the hardware’s compute-to-bandwidth ratio \((R_{\text{peak}}/\text{BW})\), the workload is compute bound; below it, the workload is memory bound. For single-image inference, the low batch size yields low arithmetic intensity, explaining why even powerful GPUs are memory bound at batch=1.
(b) Mobile: Flagship NPU (batch=1, INT8)
- Peak compute: ~35 TOPS (INT8)—representative of modern mobile NPUs
- Memory bandwidth: ~100 GB/s (LPDDR5)
- Model size: 26 MB (INT8 quantized)
- Compute time: \(T_{\text{comp}}\) = \(\frac{4.10 \times 10^{9}}{3.50 \times 10^{13}}\) = 0.12 ms
- Memory time: \(T_{\text{mem}}\) = \(\frac{2.56 \times 10^{7}}{1.00 \times 10^{11}}\) = 0.26 ms
- Bottleneck: Memory (2\(\times\) slower than compute)
Key Insight: Both platforms are memory bound for single-image inference! The A100’s faster memory bandwidth (2 TB/s vs. 100 GB/s = 20\(\times\)) translates to roughly 10\(\times\) faster inference; peak compute alone is not the limiting comparison. This explains why quantization (reducing bytes) often beats faster hardware (increasing FLOPS) for deployment.
ResNet-50 becomes compute bound when batching and data reuse raise arithmetic intensity above the hardware balance point, \(\frac{\text{Ops}}{\text{Compute}} > \frac{\text{Bytes}}{\text{Memory BW}}\). The crossover is architecture- and implementation-dependent because activation traffic, input/output movement, cache reuse, and kernel fusion all change the effective bytes moved per inference.
As systems transition from Cloud to Edge to TinyML, available resources decrease dramatically. Table 6 quantifies this progression with concrete hardware examples: memory drops from 131 TB (cloud) to 520 KB (TinyML), a 250 million-fold reduction, while power budgets span nine orders of magnitude from megawatts to milliwatts9. This resource disparity is most acute on microcontrollers, the primary hardware platform for TinyML, where memory and storage capacities are insufficient for conventional ML models.
9 ML Hardware Cost Spectrum: AI infrastructure spans six orders of magnitude in cost, from $10 microcontrollers to multi-million-dollar GPU clusters. This million-fold range means deployment paradigm selection is simultaneously a physics decision and an economics decision. Even within individual-device choices, the same accuracy target may be achievable on a $2 microcontroller (via aggressive quantization) or a $30,000 GPU (at full precision), with fundamentally different latency, power, and operational cost profiles.
Table 6 grounds these paradigms in concrete hardware platforms and price points.
| Category | Example Device | Processor | Memory | Storage | Power | Price Range |
|---|---|---|---|---|---|---|
| Cloud ML | Google TPU v4 Pod | 4,096 TPU v4 chips, >1 EFLOP | 131 TB HBM2 | Cloud-scale (PB) | ~3 MW | Cloud service (rental) |
| Edge ML | NVIDIA DGX Spark | GB10 Grace Blackwell, 1 PFLOPS AI | 128 GB LPDDR5x | 4 TB NVMe | ~200 W | ~$3,000–5,000 |
| Mobile ML | Flagship Smartphone | Mobile SoC (CPU + GPU + NPU) | 8-16 GB RAM | 128 GB-1 TB | 2 to 5 W | USD 999+ |
| TinyML | ESP32-CAM | Dual-core @ 240 MHz | 520 KB RAM | 4 MB Flash | 0.05–1.2 W active board power | $10 |
These deployment paradigms emerged from decades of hardware evolution, from floating-point coprocessors in the 1980s through graphics processors in the 2000s to today’s domain-specific AI accelerators. Hardware Acceleration traces this historical progression and the architectural principles that drove it. Here, we focus on the consequences of this evolution: the deployment spectrum that results from having qualitatively different hardware available at different points in the infrastructure.
Each paradigm occupies a distinct region of the deployment spectrum, governed by the physical constraints (light barrier, power wall, memory wall) and quantified by the analytical tools (iron law, bottleneck principle) introduced earlier. The quantitative thresholds in Table 7 help practitioners determine which paradigm suits their workload. The following four sections progress from cloud to TinyML, tracing the gradient from maximum computational resources to maximum efficiency constraints.
| Paradigm | Compute | Memory BW | Power | Latency |
|---|---|---|---|---|
| Cloud ML | >1000 TFLOPS | >100 GB/s | MW class (PUE 1.1–1.3) | 100-500 ms |
| Edge ML | ~1 PFLOPS AI | >270 GB/s | 100 W class | 10-100 ms |
| Mobile ML | 15-45 TOPS | 60-100 GB/s | 2 to 5 W | 5-50 ms |
| TinyML | <1 TOPS | — | <1 mW always-on average target | 1-10 ms |
Each section follows a consistent structure: definition, key characteristics, benefits and trade-offs, and representative applications. This parallel treatment reveals both what distinguishes each paradigm and what principles they share, setting the stage for the hybrid architectures that combine them. We begin at the resource-rich end of the spectrum and progressively tighten the constraints.
Self-Check: Question
An application has a strict 30 ms end-to-end latency budget and must choose which operations can appear on its critical path. Using the section’s latency-table decision rule, which operation is automatically disqualified from the critical path regardless of what else happens?
- NPU inference at 5–20 ms.
- Cross-region network communication at 50–150 ms.
- Wake-word detection at 100 microseconds.
- Same-region network communication at 1–5 ms.
The same ResNet-50 model is compute-bound when trained on an A100 at batch 256 but memory-bound when used for single-image inference on the same A100. Explain why the dominant bottleneck flips despite the identical model and hardware, and what the optimization priorities must become in each phase.
ResNet-50 inference on a cloud A100 is only about an order of magnitude faster than on a mobile NPU in the worked example, even though the A100 has much higher peak compute and memory bandwidth. What explains the much smaller-than-expected cloud advantage?
- The A100 and the mobile NPU have similar compute throughput once INT8 quantization is enabled, so the peak-FLOPS gap is illusory.
- Batch-1 inference is memory-bandwidth-bound on both platforms, so the effective speedup tracks bytes moved through memory bandwidth rather than peak compute; the mobile case also uses INT8 weights, reducing the bytes it must move.
- The mobile NPU is compute-bound while the A100 is network-bound, so the bottlenecks are incomparable and no meaningful speedup exists.
- The A100 spends most of its batch-1 inference time on operating-system context switches and Python overhead, erasing its compute advantage.
In a pipelined inference server, one stage’s data-movement time exceeds the sum of all other stages’ compute times. Using the Bottleneck Principle, explain what happens to the accelerator’s realized throughput and utilization, and why adding a faster compute kernel does not fix the problem.
A team profiles batch-1 ResNet-50 inference and confirms memory-access time exceeds compute time on both cloud and mobile targets. Which next optimization aligns with the section’s memory-bound diagnosis?
- Double the accelerator’s peak FLOPS by moving to a newer GPU generation, leaving model precision and size unchanged.
- Apply INT8 weight quantization to shrink model bytes and cut the dominant data-movement term directly.
- Add more cross-region replicas so single-device memory pressure is distributed across the fleet.
- Enlarge the training dataset so the model learns a more efficient internal representation that uses less memory.
Cloud ML: Computational Power
Consider what it took to train GPT-3: 3,634 petaflop-days of computation, 10,000 GPUs running for approximately 15 days, consuming megawatts of power—at an estimated cost of ~$4.6M10. No smartphone, no edge server, no single machine on Earth could have performed this computation. Only a data center, with its virtually unlimited compute, memory, and storage, could aggregate enough resources to make this possible. This is the defining proposition of cloud ML: when latency can be tolerated, it offers computational scale that no other paradigm can match.
10 Large Language Model (LLM) Training Scale: GPT-3 required approximately 3,634 petaflop-days, 10,000 V100 GPUs, and an estimated $4.6M in compute at 2020 cloud rates. This scale illustrates the core cloud ML trade-off: only centralized infrastructure can aggregate enough \(R_{\text{peak}}\) for peta-scale training, but the resulting \(L_{\text{lat}}\) penalty (100–500 ms network round trip) makes that same infrastructure unsuitable for real-time inference.
11 Cloud as Utility Computing: The utility model allows providers to offer a specialized hardware portfolio that is economically infeasible for a single organization to maintain. This provides direct, on-demand access to the specific architectures required by each workload archetype: dense accelerator pods for Compute Beasts, HBM-equipped nodes for Bandwidth Hogs, and high-memory systems with fast interconnects for Sparse Scatter. A team can therefore rent a purpose-built, $10M+ supercomputing pod for a few hours rather than owning it.
Cloud ML aggregates computational resources in data centers11 to handle computationally intensive tasks: large-scale data processing, collaborative model development, and advanced analytics. This infrastructure serves as the natural home for three of the four workload archetypes: compute beasts like ResNet training that demand sustained TFLOPS across thousands of accelerators, bandwidth hogs like large language model inference that benefit from TB/s HBM bandwidth, and sparse scatter workloads like recommendation systems that require terabytes of embedding tables and high-bandwidth interconnects for all-to-all communication patterns.
Cloud deployments range from single-machine instances (workstations, multi-GPU servers, DGX systems) to large-scale distributed systems spanning multiple data centers. This book focuses on single-machine cloud systems, where the reader learns to build and optimize ML systems on individual powerful machines. Future studies can address distributed cloud infrastructure, where systems coordinate computation across multiple networked machines. This follows the principle of establishing foundations before adding complexity.
What unifies these diverse cloud workloads is a single defining trade-off:
Definition 1.2: Cloud ML
Cloud Machine Learning is the deployment paradigm that optimizes for Resource Elasticity by decoupling computational capacity from physical location.
- Significance (quantitative): It enables systems to scale resources \((R_{\text{peak}})\) proportional to workload variance, allowing for bursts of peta-flops that would be economically unfeasible to maintain locally.
- Distinction (durable): Unlike edge ML, which prioritizes data locality, cloud ML prioritizes computational density and centralized management.
- Common pitfall: A frequent misconception is that cloud ML is “unlimited compute.” In reality, it is constrained by the distance penalty \((L_{\text{lat}})\) and the ingestion bottleneck \((\text{BW})\), making it unsuitable for sub-10 ms real-time control loops.
Figure 3 breaks down cloud ML across several dimensions that define its computational paradigm. The Characteristics branch emphasizes centralization and dynamic scalability, which directly enables the Benefits of scalable data processing and global accessibility. This centralization, however, creates the Challenges of latency and internet dependence, shaping the kinds of Examples that thrive in the cloud: virtual assistants, recommendation systems, and fraud detection. The most fundamental of these challenges, network latency, is not an engineering limitation but a physics constraint. A quick calculation of the distance penalty after the figure makes this concrete.

Napkin Math 1.3: The distance penalty
Problem: Consider a real-time safety monitor for a robotic arm. The safety logic requires a 10 ms end-to-end response time to prevent injury. The model runs in a high-performance cloud data center 1,500 km away. Can the safety budget be met?
Physics:
- Light in Fiber: ~200,000 km/s.
- Round-trip propagation: (1,500 km\(\times\) 2)/200,000 km/s = 15 ms.
- Result: The safety budget is already negative (-5 ms) before the model even starts its first calculation.
Systems insight: Physics has made cloud ML impossible for this application. The model must move to the Edge.
Cloud infrastructure and scale
Cloud ML aggregates computational resources in data centers at unprecedented scale. Figure 4 captures the physical scale behind this abstraction: Google’s Cloud TPU12 data center, where row upon row of specialized accelerators deliver petaflop-scale training throughput. Table 6 quantifies how cloud systems provide orders-of-magnitude more compute and memory bandwidth than mobile devices, at correspondingly higher power and operational cost. Modern cloud accelerator systems operate at petaflops to exaflops of peak reduced-precision throughput and require megawatt-scale facility power in large clusters. These facilities enable workloads that are impractical on resource-constrained devices, but their remote location introduces critical trade-offs: network round-trip latency of 100–500 ms eliminates real-time applications, and operational costs scale linearly with usage.
12 Tensor Processing Unit (TPU): A custom-built processor (ASIC) that delivers petaflop-scale throughput by hard-wiring its architecture for the matrix multiplication operations that dominate ML workloads. This extreme specialization trades general-purpose flexibility for a >10\(\times\) improvement in performance-per-watt compared to a general-purpose accelerator on the same ML task. The high cost of deploying these accelerators at data center scale is therefore only economical for massive, sustained ML computation.
The physical reality of petaflop-scale compute is visible in the infrastructure itself: a single facility floor houses thousands of accelerator chips organized into rows of liquid-cooled racks, each rack consuming kilowatts of power to sustain the aggregate throughput that no individual device can approach.

Google DeepMind. 2024. Gemini: A Family of Highly Capable Multimodal Models.
Cloud ML excels at processing massive data volumes through parallelized architectures, enabling training on datasets requiring hundreds of terabytes of storage and petaflops of computation—resources that remain impractical on constrained devices. The training techniques covered in Model Training and the hardware analysis in Hardware Acceleration explain how practitioners achieve this scale.
Beyond raw computation, cloud infrastructure creates deployment flexibility through cloud APIs, making trained models accessible worldwide across mobile, web, and IoT platforms. Shared infrastructure enables multiple teams to collaborate simultaneously with integrated version control, while pay-as-you-go pricing models13 eliminate upfront capital expenditure and scale elastically with demand.
13 Pay-as-You-Go Pricing: A cloud economic model where users pay for accelerator-hours consumed rather than hardware owned. Elastic pricing converts the fixed cost of idle \(R_{\text{peak}}\) into a variable cost proportional to actual utilization, but the inverse also holds: sustained 24/7 workloads (continuous inference serving) often cost 2–3\(\times\) more on cloud than equivalent on-premises hardware amortized over three years, a crossover that drives the total cost of ownership (TCO) analysis later in this section.
A common misconception holds that cloud ML’s vast computational resources make it universally superior. Exceptional computational power and storage do not automatically translate to optimal solutions for all applications. The Data Gravity Invariant in Napkin math: The physics of data gravity explains why: as data scales, the cost of moving it to compute \((C_{\text{move}}(D) \gg C_{\text{move}}(\text{Compute}))\) eventually dominates. The trade-offs listed in the preceding definition become concrete when we consider where edge and embedded deployments excel: real-time response with sub-10 ms decision-making in autonomous control loops, strict data privacy for medical devices processing patient data, predictable costs through one-time hardware investment vs. recurring cloud fees, or operation in disconnected environments such as industrial equipment in remote locations. The optimal deployment paradigm depends on specific application requirements rather than raw computational capability.
Cloud ML trade-offs and constraints
Cloud ML’s advantages carry inherent trade-offs that shape deployment decisions. Latency is the most consequential: network round-trip delays of 100–500 ms make cloud processing unsuitable for real-time applications requiring sub-10 ms responses, such as autonomous vehicles and industrial control systems. Unpredictable response times further complicate performance monitoring and debugging across geographically distributed infrastructure.
Privacy and security pose serious challenges for cloud deployment. Transmitting sensitive data to remote data centers creates vulnerabilities and complicates regulatory compliance. Organizations handling data subject to regulations like the General Data Protection Regulation (GDPR)14 or the Health Insurance Portability and Accountability Act (HIPAA)15 must implement comprehensive security measures including encryption, strict access controls, and continuous monitoring to meet stringent data handling requirements. Privacy-preserving ML techniques, including federated learning and differential privacy, address these challenges at the systems level.
14 GDPR (General Data Protection Regulation): The European privacy framework (2018) whose “Right to be Forgotten” provision creates a systems constraint unique to ML: deleting a user’s data may require retraining or fine-tuning any model that learned from it, because weight updates are not individually reversible. This transforms a legal requirement into a compute cost that scales with model size and retraining frequency.
15 HIPAA (Health Insurance Portability and Accountability Act): This US law translates the security measures from the context sentence—encryption, access controls, and monitoring—into direct systems-level costs like isolated compute, immutable logging for every inference, and end-to-end data encryption. These nonnegotiable safeguards are the source of the “stringent data handling requirements” and typically add 15–30 percent to infrastructure and operational overhead for a production ML system.
16 Total Cost of Ownership (TCO): This analysis quantifies the gap between sticker price and true system cost by including all direct and indirect costs (power, cooling, labor) over a system’s lifetime. The cloud vs. edge decision makes this explicit, trading high upfront capital expense (CapEx) for hardware against recurring operational expenses (OpEx) for cloud services. For an on-premise GPU, the initial purchase price is often only 30–40 percent of the three-year TCO, with the rest dominated by these operational costs.
Cost management introduces operational complexity requiring TCO16 analysis rather than naive unit comparisons. A worked cloud vs. edge TCO comparison illustrates the gap between sticker price and true system cost.
Napkin Math 1.4: Cloud vs. edge TCO
Scenario: A vision system serving 1M daily inferences (ResNet-50 scale, 10ms latency, 100KB response).
Table 8: Cloud Inference Annual TCO: Itemized GPU, network, load-balancer, and observability costs for the cloud implementation of the ResNet-50-scale vision workload, with the totals used in the break-even comparison.
Table 9: Edge Inference Annual TCO: Itemized hardware, power, cooling, network, and DevOps labor costs for the on-premise T4 implementation, exposing labor as the dominant component that determines edge break-even economics.
Cloud Implementation (illustrative public list pricing). Table 8 itemizes the annual GPU, network, load-balancer, and observability costs:
| Cost Component | Calculation | Annual Cost |
|---|---|---|
| GPU inference (A10G) | 4 instances \(\times\) 8,760 hrs \(\times\) $0.75/hr | ~$26,280 |
| Network egress | 100 GB/day \(\times\) 365 \(\times\) USD 0.09/GB | ~$3,285 |
| Load balancer | USD 0.025/hr + LCU charges | ~$3,723 |
| CloudWatch/logging | Monitoring, alerts | ~$2,000 |
| Total Cloud | ~$35,288/year |
Edge Implementation (On-premise NVIDIA T4 server). Table 9 itemizes the corresponding hardware, power, cooling, network, and labor costs:
| Cost Component | Calculation | Annual Cost |
|---|---|---|
| Hardware CAPEX | $15,000 server ÷ 3-year life | ~$5,000 |
| Power (24/7) | 300W \(\times\) 8,760 hrs \(\times\) $0.12/kWh | ~$315 |
| Cooling overhead | ~30 percent of power | ~$95 |
| Network (fiber) | Fixed line for remote management | ~$1,200 |
| DevOps labor | 0.1 FTE \(\times\) $150,000 salary | ~$15,000 |
| Total Edge | ~$21,610/year |
Break-even Analysis: Equation 7 determines when edge deployment becomes cost-effective. Edge Fixed Costs include hardware amortization and maintenance, Cloud Variable Cost per Unit is the per-inference cloud pricing, and Capacity is the maximum inference rate of the edge system: \[\text{Break-even utilization} = \frac{\text{Edge Fixed Costs}}{\text{Cloud Variable Cost per Unit} \times \text{Capacity}} \tag{7}\]
Under this steady-capacity scenario, edge reaches cost parity at roughly 612K inferences/day, or about 61% of the 1M/day operating point. At high, steady volume, edge wins by ~39%; below the crossover, cloud elasticity usually wins.
Systems insight: Edge TCO is dominated by labor (69%), not hardware. Organizations without existing DevOps capacity should factor in the full cost of maintaining on-premise infrastructure.
Unpredictable usage spikes complicate budgeting, requiring comprehensive monitoring and cost governance frameworks.
Network dependency creates a further constraint: any connectivity disruption directly impacts system availability, particularly where network access is limited or unreliable. Vendor lock-in compounds this problem, as dependencies on specific tools and APIs create portability challenges when transitioning between providers. Organizations must balance these constraints against cloud benefits based on their specific application requirements and risk tolerance.
Despite these trade-offs, cloud ML’s computational advantages make it indispensable for consumer applications operating at global scale.
Large-scale training and inference
Cloud ML’s computational advantages manifest most visibly in consumer-facing applications that require massive scale. Virtual assistants like Siri and Alexa illustrate the hybrid architectures that characterize modern ML systems: wake-word detection runs on dedicated low-power hardware (often sub-milliwatt) directly on the device, enabling always-on listening without draining batteries; initial speech recognition increasingly runs on-device for privacy and responsiveness; and complex natural language understanding and generation use cloud infrastructure for access to larger models and broader knowledge.
Economics drive this architecture as much as latency. Attempting to process voice interactions for billions of devices entirely in the cloud runs into both an economic and an infrastructure ceiling. Quantifying the voice assistant wall shows both limits at once.
Napkin Math 1.5: The voice assistant wall
Scenario: 1 billion voice assistant devices (smartphones, smart speakers, earbuds). Can cloud data centers handle this?
Part 1: the economic wall
- Cloud cost: ~USD 0.50 per device/year → 1 B devices = USD 500,000,000/year. Economically prohibitive for a free feature.
- TinyML alternative: 0.1–1 mW local wake-word detection, <USD 0.01/year per device. Viable at any scale.
Part 2: the infrastructure wall
The economic argument is compelling, but the physics argument is decisive:
- Query volume: 1 B devices\(\times\) 20 queries/day = 20 billion queries/day.
- GPU demand: Each query requires ~200 ms of GPU time. Total: 1,111,111 GPU-hours/day.
- Data center capacity: A large data center (~10,000 GPUs) provides 240,000 GPU-hours/day.
- Average requirement: ~5 dedicated data centers just for voice inference.
- Peak reality: Queries cluster in waking hours (~4.5\(\times\) peak-to-average), requiring ~21 data centers at peak.
The bandwidth wall: Wake-word detection requires continuous audio monitoring. If devices streamed audio to the cloud (16 kHz, 16-bit), each transmits ~32 KB/s. Across 1 billion devices: 32 TB/s—a significant fraction of total global internet backbone capacity.
Systems insight: Cloud-only voice processing is not merely expensive; it is physically impossible at global scale. Local wake-word detection is an infrastructure necessity, not an optimization.
The voice assistant pipeline illustrates a core systems principle: deployment decisions are constrained by performance requirements, economic realities, and infrastructure physics. The hybrid approach reduces end-to-end latency relative to pure cloud processing while maintaining the computational power needed for complex language understanding, all within sustainable cost boundaries.
Recommendation engines deployed by Netflix and Amazon demonstrate another compelling application of cloud resources. These systems process massive datasets using collaborative filtering and deep learning architectures like the Deep Learning Recommendation Model (DLRM)17 to uncover patterns in user preferences. DLRM exemplifies a memory-capacity-bound workload: its massive embedding tables, representing millions of users and items, can exceed terabytes in size, requiring distributed memory across many servers just to store the model parameters. Cloud computational resources enable continuous updates and refinements as user data grows, with Netflix processing over 100 billion data points daily to deliver personalized content suggestions that directly enhance user engagement.
17 Deep Learning Recommendation Model (DLRM): Meta’s 2019 architecture that exemplifies the “Sparse Scatter” archetype. Embedding tables for production recommendation systems can exceed 100 TB, making DLRM constrained by memory capacity and communication \(\text{BW}\) rather than raw \(R_{\text{peak}}\). This inversion of the typical compute-bound assumption forces specialized cluster designs where memory, not arithmetic, is the scarce resource.
These applications share a common thread: they trade latency for scale, accepting hundreds of milliseconds of round-trip delay in exchange for access to computational resources that no other paradigm can provide. Fraud detection systems analyzing millions of transactions, recommendation engines processing terabytes of embedding tables, and language models generating text one token at a time all depend on this bargain. Yet as the voice assistant wall demonstrated, there exist applications where no amount of cloud compute can compensate for the physics of distance. When latency budgets drop below what the speed of light permits, or when data volumes exceed what networks can carry, the computation must move closer to the data source.
Self-Check: Question
Which statement most accurately captures the defining trade-off of the Cloud ML paradigm as framed in this chapter?
- Cloud ML trades latency tolerance for access to effectively unbounded centralized compute, memory, and storage — a bargain that fails precisely when the application cannot tolerate the round-trip time.
- Cloud ML is the right choice whenever privacy is not a regulatory requirement, because remote compute is always cheaper than local compute at any utilization level.
- Cloud ML is the best choice whenever a workload’s compute intensity exceeds local device limits, regardless of whether the latency budget is strict or relaxed.
- Cloud ML eliminates the need to reason about ingestion bandwidth and data movement, because the provider’s backbone makes capacity effectively free from the client’s perspective.
A robotic safety monitor has a 10 ms response budget and the nearest cloud data center is 1,500 km away. A proposal suggests ‘scale the cloud fleet 10× and the problem is solved.’ Using the light-barrier analysis, explain why no amount of cloud provisioning rescues this workload, and name the kind of investment that would actually help.
In the section’s worked cloud-vs-edge TCO example at roughly one million inferences per day, what is the most important engineering lesson for choosing where to deploy?
- Edge is always cheaper because hardware amortization dominates every other cost line.
- Cloud always wins because operational labor on cloud is negligible next to GPU rental.
- At sustained high utilization, edge compute can be cheaper per inference, but operational labor (DevOps, updates, monitoring) often dominates edge TCO enough that minimizing hardware spend alone is a misleading objective.
- Model accuracy is the main determinant of TCO, because higher accuracy reduces the number of servers needed.
The section’s ‘Voice Assistant Wall’ argument concludes that cloud-only voice processing is infeasible at global scale. Which pair of reasons captures the core argument?
- Speech models cannot be trained in the cloud quickly enough to keep up with new device launches.
- Both the annual cloud cost and the aggregate data-center plus bandwidth capacity required become prohibitive when billions of always-listening devices continuously rely on remote processing — the scaling is economic and infrastructural.
- Wake-word detection accuracy always degrades when the model is not co-located on the device.
- Mobile operating systems forbid persistent network connections for audio streaming.
True or False: Because Cloud ML offers effectively unbounded compute and storage, it is the universally best deployment paradigm for any team that can afford it.
Edge ML: Latency and Privacy
When latency budgets drop below 100 ms, cloud infrastructure hits a hard physical wall. The Distance Penalty means the speed of light alone imposes minimum latencies of 40–150 ms for cross-region requests—before any computation begins. When an autonomous vehicle needs to decide whether to brake, or an industrial robot needs to stop before hitting an obstacle, 100 ms is an eternity. The logical engineering response is to move the computation closer to the data source.
Edge ML emerged from this constraint, trading unlimited computational resources for sub-100 ms latency and local data retention. In archetype terms, edge deployment transforms the optimization target: a bandwidth hog workload like LLM inference that is memory bound in the cloud becomes latency-bound at the edge, where the 50–100 ms network penalty dominates the 10–20 ms compute time. Edge hardware with sufficient local memory can eliminate this penalty entirely, shifting the bottleneck back to the underlying memory bandwidth constraint. Recall the iron law from Equation 6: by processing locally, edge deployment eliminates the \(D_{\text{vol}}/\text{BW}_{\text{IO}}\) (network I/O) term entirely, collapsing the latency to \(\max(D_{\text{vol}}/\text{BW}, O/(R_{\text{peak}} \cdot \eta_{\text{hw}})) + L_{\text{lat}}\)—the same memory-vs.-compute trade-off, but without the network penalty that dominates cloud inference.
This paradigm shift is essential for applications where cloud’s 100–500 ms round-trip delays are unacceptable. Autonomous systems requiring split-second decisions and industrial IoT18 applications demanding real-time response cannot tolerate network delays. Similarly, applications subject to strict data privacy regulations must process information locally rather than transmitting it to remote data centers. Edge devices (gateways and IoT hubs) occupy a middle ground in the deployment spectrum, maintaining acceptable performance while operating under intermediate resource constraints.
18 Industrial IoT (IIoT): A domain where latency constraints are set by physical safety, not user perception. The 100+ ms round-trip delay mentioned is intolerable for a robotic arm that must halt within 5 ms of detecting a human. This forces computation to the edge, trading near-zero network latency for significant on-device compute \((R_{\text{peak}})\) constraints.
This locality-first trade-off defines the edge paradigm.
Definition 1.3: Edge ML
Edge Machine Learning is the deployment paradigm optimized for Latency Determinism and Data Locality by locating computation physically adjacent to data sources.
- Significance (quantitative): It circumvents the Distance Penalty \((L_{\text{lat}})\) of the cloud, trading elastic scale for a fixed Local Compute Capacity \((R_{\text{peak}})\).
- Distinction (durable): Unlike Cloud ML, which prioritizes Throughput, edge ML prioritizes Determinism and privacy. Unlike TinyML, edge ML may still use workstation-class accelerators (GPGPUs).
- Common pitfall: A frequent misconception is that edge ML refers to a specific hardware class. In reality, it is a Location Paradigm: it spans from IoT gateways to on-premise servers, unified by physical proximity to the data source.
Figure 5 organizes these trade-offs into four operational dimensions. The Characteristics branch highlights decentralized processing, which drives the key Benefit of reduced latency. This trade-off, however, introduces Challenges in maintenance and security, as the physical hardware is distributed and harder to secure than a centralized data center.

The benefits of lower bandwidth usage and reduced latency become stark when we examine real-world data rates. The defining characteristic of edge deployment is less about where processing occurs than about how much data that location must handle. When the data rate exceeds available network capacity, the resulting bandwidth bottleneck forces processing to the edge regardless of other considerations.
Napkin Math 1.6: The bandwidth bottleneck
Problem: Consider a quality control system for a factory floor with 100 cameras running at 30 FPS with 1080p resolution. Should the system stream to the cloud or process at the edge?
Physics:
- Raw data rate per camera: 1920 \(\times\) 1080 \(\times\) 3 bytes\(\times\) 30 FPS ≈ 187 MB/s.
- Total data rate: 100 cameras\(\times\) 187 MB/s = 18.7 GB/s.
- Cloud transfer exposure: Uploading raw camera feeds is primarily a bandwidth, ingest, storage, and processing problem; USD/GB cloud egress charges apply when data is transferred back out of the cloud. If the raw stream were later retrieved at USD 0.09/GB data-transfer-out pricing, the transfer charge alone would reach USD 4.4 M/month.
- Network reality: Even a dedicated 10 Gbps line (1.25 GB/s) cannot carry the load—the workload demands 15\(\times\) more bandwidth than exists.
Systems insight: Physics has made cloud streaming impossible for this application. Edge processing is not optional—it is mandatory. If an edge server transmits only defect metadata (1 KB per detection at roughly 20 detections/sec across the floor), bandwidth falls by about 933,120\(\times\).
The preceding bandwidth calculation reveals why edge processing is mandatory for high-volume sensor deployments. For battery-powered edge devices (wireless cameras, drones, wearables), the constraint is even more severe: as “The Energy of Transmission” (Section 1.3.1) established, radio transmission costs 1,000\(\times\) more energy than local inference, making cloud offloading physically impossible for battery-powered devices regardless of available bandwidth. Figure 6 quantifies this asymmetry across deployment tiers.
Edge ML benefits and deployment challenges
Edge ML spans wearables, industrial sensors, and smart home appliances that process data locally19 without depending on central servers. Figure 6 quantifies the physical imperative: full-system energy per inference spans eight orders of magnitude across deployment paradigms, from ~10 µJ for a TinyML keyword spotter to ~1 kJ for a cloud LLM query. This 100,000,000\(\times\) gap is not an engineering shortcoming to be optimized away; it reflects the irreducible costs of data movement, cooling, and network overhead that separate deployment tiers. Because edge devices operate within tight power envelopes, their memory bandwidth of 25–100 GB/s constrains deployable models to 100 MB–1 GB of parameters. This constraint, in turn, motivates the optimization techniques covered in Model Compression, which achieve 2–4\(\times\) speedup by compressing models to fit within these hardware budgets. The payoff extends beyond compute: processing raw camera feeds locally can avoid terabit-scale uplink requirements because raw data never leaves the device, reducing recurring cloud-transfer, storage, and processing costs.
19 IoT Data Wall: Connected devices are projected to exceed 25 billion by 2030 (McKinsey Global Institute 2021), each generating continuous sensor streams. The aggregate \(D_{\text{vol}}\) from these devices already exceeds global network \(\text{BW}\) capacity for centralized ingestion, making local edge processing not an optimization but a physical necessity: the data simply cannot all reach the cloud.
McKinsey Global Institute. 2021. The Internet of Things: Catching up to an Accelerating Opportunity. McKinsey & Company.
The data locality invariant
The decision between local edge processing and remote cloud processing is governed by the data locality invariant. This principle establishes that data must stay local when the time to transmit it exceeds the total time for remote processing (including network latency and remote compute).
Definition 1.4: The data locality invariant
The Data Locality Invariant states that a workload necessitates local processing whenever the transmission delay \((D_{\text{vol}}/\text{BW}_{\text{net}})\) dominates the remote response time: \[\text{Data Locality} \iff \frac{D_{\text{vol}}}{\text{BW}_{\text{net}}} > L_{\text{net}} + \frac{O}{R_{\text{peak, remote}}}\]
- Significance (quantitative): It defines the Locality Crossover, the point where adding cloud compute (increasing \(R_{\text{peak}}\)) yields zero benefit because the “Pipe” \((\text{BW}_{\text{net}})\) is too narrow for the “Volume” \((D_{\text{vol}})\).
- Distinction (durable): Unlike The iron law, which optimizes for time-to-result, the locality invariant optimizes for architectural feasibility by identifying when network physics forbids remote offloading.
- Common pitfall: A frequent misconception is that 5G/6G “solves” locality. While these improve \(\text{BW}_{\text{net}}\), they do not reduce \(L_{\text{net}}\) below the light barrier, meaning latency-critical tasks remain inherently local.
The locality crossover is easiest to see by comparing a single high-rate sensor frame with the round-trip budget for remote processing.
Napkin Math 1.7: Napkin math: The locality crossover
Problem: Should a drone’s object avoidance system (4K, 60 FPS) offload to the cloud?
Variables:
- Data \((D_{\text{vol}})\): 4K frame ≈ 25 MB.
- Bandwidth \((\text{BW}_{\text{net}})\): 100 Mbps home broadband (up).
- Remote latency \((L_{\text{net}})\): 110 ms (round-trip + remote compute).
Math:
- Transmission time: 25 MB \(\times\) 8 bits/100 Mbps = 1,991 ms.
- Remote response: 110 ms.
Systems insight: Since 1,991 ms \(\gg\) 110 ms, the system is Bandwidth Blocked. The cloud could have an infinite processor \((R_{\text{peak}} = \infty)\), but the drone would still crash because it cannot move the bits fast enough. This workload is Locality Mandatory.
Physics forces the architectural choice; the engineering trade-offs follow from it. The most immediate benefit is latency: response times drop from 100–500 ms in cloud deployments to 1–50 ms at the edge, enabling safety-critical applications that demand real-time response. Bandwidth savings compound this advantage—a retail store with 50 cameras streaming video can reduce transmission requirements from 100 Mbps (costing $1,000–2,000 monthly) to less than 1 Mbps by processing locally and transmitting only metadata, a 99 percent reduction. Privacy strengthens in turn, because local processing eliminates transmission risks and simplifies regulatory compliance. For industrial deployments, operational resilience is the decisive advantage: systems continue functioning during network outages, a property essential for manufacturing, healthcare, and building management applications where downtime carries immediate cost.
These benefits carry corresponding limitations that compound as deployments scale. Limited computational resources20 sharply constrain model complexity: edge servers often provide an order of magnitude or more less processing throughput than cloud infrastructure, limiting deployable models to millions rather than billions of parameters. Managing distributed networks introduces complexity that scales nonlinearly with deployment size, because coordinating version control and updates across thousands of devices requires sophisticated orchestration systems21, and hardware heterogeneity across diverse platforms demands different optimization strategies for each target.
20 Edge Server Constraints: Edge hardware typically provides 1–8 GB memory and 5–50 W power, roughly 100\(\times\) less than cloud servers in both dimensions. These constraints cap deployable model size at millions (not billions) of parameters, making the compression techniques in Model Compression essential for achieving sustainable inference duty cycles within the thermal envelope.
21 Edge Fleet Coordination: Managing thousands of distributed edge devices introduces failure modes absent from centralized cloud: intermittent connectivity causes model version drift, hardware heterogeneity requires per-target optimization, and physical accessibility makes firmware rollbacks costly. These operational patterns are examined in ML Operations.
Security challenges intensify because edge devices are physically accessible: equipment deployed in retail stores or public infrastructure faces tampering risks that centralized data centers do not, requiring hardware-based protection mechanisms such as secure boot, encrypted storage, and tamper-evident enclosures. Initial deployment costs of $500-2,000 per edge server compound across locations: instrumenting 1,000 sites requires $500,000-2,000,000 upfront, though these capital costs are offset by lower long-term operational expenses compared to equivalent cloud spending.
A realistic retail deployment shows how those constraints turn into throughput, hardware, and fleet-cost requirements.
Napkin Math 1.8: Edge inference sizing
Scenario: A smart retail chain deploying person detection across 500 stores, each with 20 cameras at 15 FPS.
Table 10: Edge Inference Sizing Requirements: Quantitative requirements analysis for the smart-retail person-detection scenario. Cascading the per-store inference rate through YOLOv8-nano’s per-frame FLOP count and a headroom factor yields the required sustained throughput that any candidate edge accelerator must deliver.
Table 11: Edge Accelerator Options: Candidate edge platforms scored against the throughput target from the requirements table. A single Coral Dev Board is undersized after realistic derating, but a small sharded Coral configuration clears the target with lower hardware cost than the Jetson alternative; Jetson remains the simpler single-device option.
Table 10 cascades the per-store inference rate through YOLOv8-nano’s per-frame FLOP count to yield the required sustained throughput:
| Metric | Calculation | Result |
|---|---|---|
| Inferences per store | 20 cameras\(\times\) 15 FPS | 300 inferences/sec |
| Model compute | YOLOv8-nano: 8.7 GFLOPs/inference | 2,610 GFLOPs/sec |
| Required throughput | 2,610 GFLOPs\(\times\) 2 (headroom) | ~5.22 TFLOPS |
Table 11 scores three candidate edge platforms against the throughput target:
| Edge Device | INT8 TOPS | Power | Unit Cost | Fleet Cost |
|---|---|---|---|---|
| NVIDIA Jetson Orin NX | 25 TOPS | 10-40 W | USD 600 | USD 300,000 |
| Intel NUC + Movidius | 1 TOPS | 15 W | USD 400 | USD 200,000 |
| Google Coral Dev (3 per store) | 12 TOPS peak 6 TOPS derated |
6 W | USD 450 | USD 225,000 |
Decision: At 5.22 TFLOPS required, one Coral Dev Board (4 TOPS peak, about 2 TOPS after 50 percent derating) is undersized. The low-cost edge choice is a sharded configuration with 3 Coral boards per store, providing 6 derated TOPS and about 1.3\(\times\) lower per-store hardware capex than Jetson. Jetson remains the simpler single-device deployment when integration complexity matters more than hardware cost.
TCO over 3 years (3 Coral boards/store): Hardware USD 225,000 + Power (0.006 kW \(\times\) 500 \(\times\) 8760 h\(\times\) 3 yr\(\times\) USD 0.12/kWh = USD 9,467) = USD 234,467 total vs. cloud inference at ~USD 9,855,000.
Real-time industrial and IoT systems
Industries deploy edge ML widely where low latency, data privacy, and operational resilience justify the additional complexity. Autonomous vehicles represent the most demanding application, where safety-critical decisions must occur within milliseconds based on sensor data that cannot be transmitted to remote servers. Systems like Tesla’s Full Self-Driving process inputs from multiple cameras at high frame rates through custom edge hardware, making driving decisions with end-to-end latency on the order of milliseconds. This response time is infeasible with cloud processing due to network delays.
Smart retail environments demonstrate edge ML’s practical advantages for privacy-sensitive, bandwidth-intensive applications. Amazon Go22 stores process video from hundreds of cameras through local edge servers, tracking customer movements and item selections to enable checkout-free shopping. This edge-based approach addresses both technical and privacy concerns. Transmitting high-resolution video from hundreds of cameras would require substantial sustained bandwidth, while local processing keeps raw video on premises, reducing exposure and simplifying compliance.
22 Amazon Go: The system’s use of local edge servers is a direct response to the immense data volume from hundreds of in-store cameras. This architecture avoids having to upload the raw video—which would saturate a multi-gigabit uplink—while also keeping sensitive customer footage on-premises. The edge-first design is necessitated by the sheer scale of data processed, which can exceed 1 TB per hour in a single store.
23 Industry 4.0: The fourth industrial revolution integrates ML into the sensor-actuator feedback loop on factory floors. The systems consequence is that the control loop latency \((L_{\text{lat}})\) must be shorter than the physical process it governs: a welding robot that detects a defect at 60 Hz has 16.7 ms to halt, a budget only edge inference can meet.
24 Predictive Maintenance: Models that analyze high-frequency sensor data (for example, vibration, thermal) to forecast equipment failure, enabling the simultaneous monitoring of thousands of assets. The “additional deployment complexity” mentioned stems directly from the edge requirement for continuous, 24/7 on-device inference. This imposes a strict power budget where the entire sensor and model must often operate on less than one watt, a major constraint driving model architecture and quantization choices.
The Industrial IoT23 uses edge ML for applications where millisecond-level responsiveness directly impacts production efficiency and worker safety. Manufacturing facilities deploy edge ML systems for real-time quality control, with vision systems inspecting welds at speeds exceeding 60 parts per minute and predictive maintenance24 applications monitoring over 10,000 industrial assets per facility. Across various manufacturing sectors, this approach has demonstrated 25–35 percent reductions in unplanned downtime—savings that justify the additional deployment complexity.
Smart buildings use edge ML to optimize energy consumption while maintaining operational continuity during network outages. Commercial buildings equipped with edge-based building management systems process data from thousands of sensors monitoring temperature, occupancy, air quality, and energy usage. This reduces cloud transmission requirements by an order of magnitude or more while enabling sub-second response times. Healthcare applications similarly use edge ML for patient monitoring and surgical assistance, maintaining HIPAA compliance through local processing while supporting low-latency workflows for real-time guidance.
These applications share a common assumption: the edge device is stationary and plugged into wall power. Recall the iron law in Equation 6: edge deployment eliminated the \(D_{\text{vol}}/\text{BW}_{\text{IO}}\) network term that dominated cloud inference, but it still assumes unlimited energy. A factory edge server consuming hundreds of watts around the clock is unremarkable when connected to mains power. Billions of users, however, carry their computing devices with them, and those devices run on fixed battery budgets. When we shift from stationary edge infrastructure to the smartphone in a user’s pocket, a new term enters the optimization: \(\text{Energy} = \text{Power} \times T\). The dominant constraint changes from latency to energy per inference, and with it, the entire engineering calculus.
Self-Check: Question
Which statement best captures the chapter’s definition of Edge ML?
- Edge ML refers specifically to small, battery-powered hardware with no operating system.
- Edge ML is a location paradigm that places computation physically close to data sources to achieve deterministic latency and keep raw data on-premises.
- Edge ML is any deployment consuming less than 100 W of power.
- Edge ML means running a cloud model unchanged on a local laptop or workstation.
A factory has 100 cameras streaming 1080p video at 30 FPS over a dedicated 10 Gbps uplink. Using the section’s worked example, why is cloud streaming the wrong architecture even with that dedicated bandwidth?
- 10 Gbps networking is too slow for any ML workload, even after aggressive local compression.
- The aggregate raw video rate exceeds the 10 Gbps link by a large factor, and the cloud egress cost at that volume is also prohibitive, so local inference is the only workable architecture.
- Camera inference can only run on TinyML microcontrollers, so no server-class option exists.
- Privacy regulations universally forbid video from leaving any factory.
An autonomous delivery drone captures 4K video at 60 FPS and must classify obstacles with a 30 ms response budget. Its cellular uplink supports bursts of about 50 Mbps and the nearest regional cloud is 200 km away. Apply the Data Locality Invariant to decide whether local inference is mandatory, and justify the answer using the transmission-versus-remote-response comparison.
A hospital is choosing between routing patient-monitor video through a cloud classifier and running the same classifier on on-premises edge servers. Explain why edge deployment can simultaneously improve privacy and resilience, and identify the specific operational complexity it introduces in exchange.
Which application best matches the Edge ML paradigm as framed in this chapter?
- Pretraining a GPT-3-scale language model that requires thousands of accelerators and petabytes of training data.
- A safety-critical industrial inspection loop that must react within 20 ms and keep raw video on the factory floor for regulatory reasons.
- A smartphone camera app that must operate for hours on a battery within a 3 W thermal envelope.
- A coin-cell-powered keyword spotter that must run for years without recharging.
Mobile ML: Offline Intelligence
Edge ML solves the distance problem that limits cloud deployments, achieving sub-100 ms latency through local processing. However, edge devices remain tethered to stationary infrastructure—gateways, factory servers, retail edge systems. Users do not stay in one place, so neither can their AI. To bring ML capabilities to users in motion, we must solve a different constraint: the battery. Unlike plugged-in edge servers that can consume hundreds of watts continuously, mobile devices must operate for hours or days on fixed energy budgets.
Mobile ML addresses this challenge by integrating machine learning directly into portable devices like smartphones and tablets, providing users with real-time, personalized capabilities. This paradigm excels when user privacy, offline operation, and immediate responsiveness matter more than computational sophistication, supporting applications such as voice recognition, computational photography25, and health monitoring while maintaining data privacy through on-device computation. These battery-powered devices must balance performance with power efficiency and thermal management, making them suited to frequent, short-duration AI tasks.
25 Computational Photography: Uses ML algorithms (for example, multi-frame fusion, neural denoising) to overcome the physical limits of small mobile camera sensors. This exemplifies the mobile computing trade-off, as a pipeline of 10–15 models must execute within the user’s perceived shutter delay (~200 ms) while adhering to a strict, shared 3 to 5 W thermal budget.
26 Depthwise Separable Convolutions: An architectural factorization that splits a standard convolution into a depthwise spatial filter and a pointwise channel mixer, reducing FLOPs by 8–9\(\times\) for typical layer configurations. This reduction is not merely an efficiency improvement but a prerequisite for real-time vision on mobile devices, where the power wall caps sustained computation at 3 to 5 W.
The mobile environment introduces a critical constraint absent from stationary deployments: energy per inference becomes a first-order design parameter. Under the iron law in Equation 6, cloud and edge systems optimize for minimizing \(T\), total latency. Mobile systems face an additional constraint: \(\text{Energy} = \text{Power} \times T\), and the power wall described by Equation 2 caps sustained power at 3 to 5 W. In archetype terms, a compute beast workload like image classification must be transformed through architectural efficiency (for example, depthwise separable convolutions26 in MobileNet) to become a compute beast (efficient), reducing FLOPs by 14\(\times\) while preserving accuracy. This is not merely optimization; it represents a qualitative shift in the arithmetic intensity trade-off, accepting lower peak throughput in exchange for sustainable operation within a 3 to 5 W thermal envelope.
This battery-and-thermal boundary gives the mobile paradigm its defining shape.
Definition 1.5: Mobile ML
Mobile Machine Learning is the deployment paradigm bounded by Thermal Design Power (TDP) and battery energy.
- Significance (quantitative): It is constrained by the few-watt heat dissipation capacity of passive cooling, requiring architectures that prioritize sustained energy efficiency over peak throughput \((R_{\text{peak}})\).
- Distinction (durable): Unlike Edge ML, which may have active cooling, mobile ML must operate within a Personal Energy Budget. Unlike TinyML, it still provides a rich OS and multi-watt compute capacity.
- Common pitfall: A frequent misconception is that mobile ML performance is a fixed value. In reality, it is a Time-Varying Constraint: performance often drops as the device hits its thermal wall, triggering throttling that reduces the duty cycle \((\eta_{\text{hw}})\).
These constraints play out concretely in Figure 7, which organizes the unique characteristics of mobile deployment. The Characteristics branch emphasizes sensor integration and on-device processing, which enables key Benefits like real-time processing and enhanced privacy. However, the Challenges branch reveals battery life constraints and limited computational resources that force engineers to optimize for sustained efficiency over raw performance.

The battery life and resource constraints listed earlier translate directly into engineering requirements. Always-on ML features incur what we call the battery tax, because continuous inference spends the phone’s finite energy budget even before the rest of the system runs.
Napkin Math 1.9: The battery tax
Problem: Consider deploying a “real-time” background object detector on a smartphone. The model consumes 2 Watts of continuous power when active. The phone has a standard 15 Watt-hour (Wh) battery. Can the feature stay on all day?
Physics:
- Ideal runtime: \(\frac{15 \,\mathrm{Wh}}{2 \,\mathrm{W}}\) = 7.5 hours
- The reality: A user expects their phone to last 24 hours. Running this single feature continuously for a day would require 320 percent of the phone’s daily energy budget.
Systems insight: The model cannot simply be “deployed.” The techniques in Model Compression (quantization, duty-cycling) must reduce power to <100 mW for the feature to stay on all day.
The battery constraint limits total energy consumption over time. However, even if we could ignore battery life (say, for a plugged-in tablet or a short demo), a second physical law intervenes: thermodynamics. Every watt of computation becomes a watt of heat that must be dissipated. In a data center, massive cooling systems remove this heat. In a thin, sealed mobile device with no fan, the only heat path is through the glass and metal casing to the surrounding air. This creates the thermal wall, a hard ceiling on sustained power consumption that exists independently of battery capacity.
Napkin Math 1.10: The thermal wall
Problem: An unoptimized LLM requires 12 W peak compute. Can it be deployed on a mobile device?
Physics:
- Thermal design power (TDP): A mobile system on chip (SoC) allows approximately 3 W for passive cooling.
- Temperature rise: At 12 W, the device temperature rises at approximately 1\(^\circ\)C per second.
- Thermal trip: Within 60 seconds, the hardware reaches the Thermal Trip Point (80\(^\circ\text{C}\)), triggering OS throttling.
- Result: The 100 FPS model suddenly drops to 30 FPS to stay within the thermal envelope.
Systems insight: Quantization from FP32 to INT8 reduces power by approximately 4\(\times\), but with a baseline of 12 W the result is still 3 W—the absolute limit of the hardware. Physics sets a hard ceiling that no optimization can exceed.
Mobile ML benefits and resource constraints
Mobile devices exemplify intermediate constraints: 8-16 GB RAM (varying from mid-range to flagship), 128 GB-1 TB storage, 15-45 TOPS AI compute through Neural Processing Units27 consuming 3 to 5 W power. System-on-Chip architectures28 integrate computation and memory to minimize energy costs. Memory bandwidth of 60-100 GB/s limits models to 10–100 MB parameters, requiring the aggressive optimization techniques that Model Compression details. Battery constraints (15–22 Wh capacity) make energy optimization critical: adding 1 W of continuous ML processing to a phone that otherwise lasts 24 hours would reduce runtime to roughly 9–11 hours, depending on battery capacity. Specialized frameworks provide hardware-optimized inference enabling <5-50 ms UI response times.
27 Neural Processing Unit (NPU): A dedicated hardware block on a mobile System-on-Chip whose circuits are exclusively designed for low-precision matrix multiplication. This specialization avoids the power-intensive instruction logic of a CPU, yielding a 10–100\(\times\) gain in energy efficiency (TOPS/W) that allows high AI throughput to fit within a mobile device’s strict <500 mW sustained power budget.
28 System-on-Chip (SoC): By integrating CPU, GPU, and NPU cores with shared memory on a single die, the physical energy cost of data movement is minimized. This tight integration imposes the memory bandwidth constraint that limits mobile models to a 10–100 MB scale. The design is mandatory for battery life because accessing off-chip memory consumes over 100\(\times\) more energy than on-chip access.
29 Face ID: Apple’s biometric system projects 30,000 IR dots for 3D face mapping, processed entirely within the Secure Enclave, an isolated cryptographic coprocessor whose memory is inaccessible even to the main OS. Biometric templates never leave the device. This architecture achieves a 1:1,000,000 false acceptance rate while eliminating the network transmission that would otherwise create both a latency penalty and a data breach surface, illustrating that on-device constraints can simultaneously strengthen privacy and improve accuracy.
Mobile ML excels at delivering responsive, privacy-preserving user experiences. Real-time processing can reach sub-10 ms latency for some tasks, enabling imperceptible response in interactive applications. Stronger privacy properties emerge when sensitive inputs are processed locally, reducing data transmission and central storage, and on-device enclaves such as Apple’s Secure Enclave can further protect sensitive computations like biometric processing29, though the strength of privacy guarantees ultimately depends on overall system design and threat model. Offline functionality further differentiates mobile from cloud: navigation, translation, and media processing all run locally within mobile resource budgets, eliminating network dependency. Personalization rounds out the advantage, because models can exploit on-device signals and user context while keeping raw data local.
These benefits require accepting tight resource constraints. Compared to cloud deployments, mobile applications often operate under much tighter memory, storage, and latency budgets, which constrains model size and batch behavior. Battery life presents visible user impact, and thermal throttling can materially limit sustained performance: peak NPU throughput is often substantially higher than what is sustainable under prolonged workloads. Development complexity multiplies across platforms, demanding separate implementations and careful performance tuning, while device heterogeneity requires multiple model variants. Deployment friction adds further challenges: app store review processes can take days, slowing iteration compared to cloud workflows.
Personal assistant and media processing
Mobile ML has achieved success across diverse applications for billions of users worldwide, and the engineering constraints behind these applications illustrate the battery and thermal trade-offs that define this paradigm. Computational photography exemplifies the challenge of running multiple ML pipelines within a thermal envelope. Modern flagships process every photo through 10–15 distinct ML models in real-time: portrait mode30 uses depth estimation and segmentation, night mode captures and aligns 9-15 frames with ML-based denoising, and HDR merging, super-resolution, and scene optimization run in sequence. The engineering challenge is not any individual model but the pipeline: these models must share a 3 to 5 W power budget and complete within the user’s perceived shutter delay, requiring careful scheduling across CPU, GPU, and NPU to avoid thermal throttling.
30 Portrait Mode Pipeline: This is not a single model but a sequence of real-time models for depth estimation, segmentation, and rendering. The core engineering problem is managing the pipeline’s aggregate latency and power, not any single model’s performance. The entire 10–15 model stack must execute within the user’s perceived shutter delay and share the phone’s 3 to 5 W thermal budget, forcing scheduling trade-offs across the CPU, GPU, and NPU to avoid throttling.
Voice-driven interactions demonstrate mobile ML’s layered architecture. Wake-word detection runs continuously at under 1 mW on a dedicated low-power core, speech recognition operates on the NPU at under 10 ms latency, and keyboard prediction uses context-aware neural models to reduce typing effort by 30–40 percent. Each layer operates at a different power tier, illustrating how mobile ML partitions workloads across heterogeneous processing units within a single SoC.
Health monitoring and augmented reality push mobile ML to its sustained-performance limits. Wearables like Apple Watch process ECG and accelerometer data entirely on-device to maintain HIPAA compliance, while AR frameworks demand consistent sub-16 ms frame times at 60 FPS for simultaneous localization, hand tracking, and scene understanding. These applications represent the ceiling of what battery-powered, passively-cooled devices can sustain, and they define the boundary beyond which mobile optimization alone is insufficient.
These successes can create a misleading sense of ease. A common pitfall involves attempting to deploy desktop-trained models directly to mobile or edge devices without architecture modifications. Models developed on powerful workstations often fail when deployed to resource-constrained devices. A desktop ResNet-50 pipeline may require gigabytes once activations, batches, preprocessing buffers, and runtime overhead are included, even though the FP32 weights alone are about 102 MB. Such a pipeline, with 4.1 billion FLOPs per inference, cannot run unchanged on a device with 512 MB of RAM and a 1 GFLOP/s processor. Beyond simple resource violations, desktop-optimized models may use operations unsupported by mobile hardware (specialized mathematical operations), assume floating-point precision unavailable on embedded systems, or require batch processing incompatible with single-sample inference. Successful deployment demands architecture-aware design from the beginning, including specialized architectural techniques for mobile devices such as MobileNet’s depthwise separable convolutions (Howard et al. 2017) (detailed in Network Architectures), integer-only operations for microcontrollers, and optimization strategies that maintain accuracy while reducing computation.
Howard, Andrew G., Menglong Zhu, Bo Chen, Dmitry Kalenichenko, Weijun Wang, Tobias Weyand, Marco Andreetto, and Hartwig Adam. 2017. “MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications.” ArXiv Preprint abs/1704.04861.
Mobile ML demonstrates that useful intelligence can operate within a 3 to 5 W thermal envelope on battery power. However, smartphones still cost hundreds of dollars, require gigabytes of memory, and demand user attention to recharge daily. These requirements make them unsuitable for a vast class of applications: monitoring soil moisture across a thousand-acre farm, detecting structural stress in bridge cables, or listening for endangered species in a remote forest. These scenarios demand not just lower power but a qualitatively different engineering regime, one where the device costs dollars instead of hundreds, memory is measured in kilobytes instead of gigabytes, and the system runs unattended for months or years. Mobile optimization techniques such as quantization and depthwise separable convolutions help, but they cannot bridge a 10,000-fold gap in available memory. What is needed is not a scaled-down smartphone but an entirely different class of hardware and algorithms.
Self-Check: Question
What distinguishes Mobile ML from Edge ML in the chapter’s paradigm framework?
- Mobile ML mainly differs by using smaller training datasets, while Edge ML uses larger ones.
- Mobile ML adds a fixed battery energy budget and a passively-cooled thermal envelope around 3 W, so sustained energy efficiency matters more than peak local compute — edge servers on mains power and active cooling face neither constraint.
- Mobile ML requires constant network connectivity, while Edge ML operates fully offline.
- Mobile ML eliminates latency concerns entirely because all inference happens on-device.
Why does the chapter treat energy per inference as a first-order design parameter on mobile devices rather than a post-hoc optimization detail?
A team wants to ship a large on-device model that draws 12 W before optimization. Aggressive quantization cuts its power by 4×. Using the section’s thermal-wall framing, what is the correct conclusion about sustained deployment?
- The model now sits near the 3 W mobile thermal ceiling, so quantization alone does not create sustained deployment headroom — it reaches the limit rather than clearing it.
- The model is now comfortably below the thermal wall, so sustained performance is no longer a concern and the feature can run continuously.
- The model becomes ideal for always-on mobile inference, since 3 W is well under any battery-tax threshold the section discusses.
- The result proves that enough precision reduction can always overcome mobile thermodynamics, regardless of starting power.
Why is architecture-aware design necessary for mobile deployment rather than taking a desktop-trained model and exporting it to a phone?
- Because mobile deployment failures are primarily caused by lower cellular-network bandwidth.
- Because phones forbid models trained with floating-point arithmetic from executing at all.
- Because desktop-trained models can violate mobile constraints on memory footprint, supported operators, batch-size assumptions, and precision — even when the trained model’s task accuracy is high on desktop benchmarks.
- Because mobile inference requires every model to be rewritten as a hand-authored rules engine before deployment.
True or False: A phone’s published NPU TOPS rating is a good predictor of short interactive bursts (e.g., one or two seconds of inference) but a poor predictor of sustained always-on workloads, because the same silicon that hits its peak in a cold-start burst throttles aggressively once thermal mass saturates.
TinyML: Ubiquitous Sensing
Imagine instrumenting every pallet in a warehouse, every cable on a suspension bridge, every beehive in an apiary. To put “eyes and ears” on this many physical objects, tens of thousands to millions, the device must cost dollars, not hundreds of dollars, and measure millimeters, not centimeters. Smartphones are far too expensive and too large; what is needed is intelligence at the scale of a postage stamp and the price of a cup of coffee.
TinyML (Janapa Reddi et al. 2022) completes the deployment spectrum by pushing intelligence to its physical limits. Devices costing less than $10 and consuming less than one milliwatt31 of power make ubiquitous32 sensing economically practical at massive scale. This is the exclusive domain of the tiny constraint archetype, where the optimization objective shifts from maximizing throughput to minimizing energy per inference. A keyword spotting model consuming 10 µJ per inference can operate for years on a coin-cell battery, achieving million-fold improvements in energy efficiency by trading model capacity for operational longevity.
Janapa Reddi, Vijay, Brian Plancher, Susan Kennedy, Laurence Moroney, Pete Warden, Lara Suzuki, Anant Agarwal, et al. 2022. “Widening Access to Applied Machine Learning with TinyML.” Harvard Data Sci. Rev. 4 (1). https://doi.org/10.1162/99608f92.762d171a.
31 The 1 mW Threshold: Below approximately one milliwatt, a device can be powered indefinitely by ambient energy harvesting—solar cells the size of a thumbnail (~10 mW outdoors, ~10 µW indoors), thermoelectric generators on warm pipes (~100 µW), or RF energy from nearby transmitters (~10 µW). This crossover transforms the deployment model from “battery-limited lifetime” to “deploy and forget,” which is why 1 mW is not an arbitrary target but the physical boundary that makes TinyML a distinct paradigm rather than merely a scaled-down edge device.
32 Ubiquitous Computing: Mark Weiser’s vision of “invisible” technology is achieved when the cost and power of an intelligent sensor become so low that the economic barrier to mass deployment vanishes. This forces the optimization objective to shift from performance (throughput) to power (energy per inference), the central trade-off of the tiny constraint archetype. A keyword spotter achieving a million-fold energy efficiency gain can thus operate for years on a coin-cell battery, making ubiquitous intelligence practical.
33 Microcontroller (MCU): A single-chip computer whose design prioritizes minimal cost and power over performance, creating the “radical constraint” mentioned. This constraint is a hard memory ceiling: ML models must fit entirely within kilobytes of on-chip SRAM (for example, 32–512 KB), as there is no virtual memory or DRAM like in mobile devices. This resource floor, often \(1{,}000\times\) lower than a smartphone’s, forces the development of entirely new, memory-centric ML architectures.
Banbury, Colby, Vijay Janapa Reddi, Peter Torelli, Jeremy Holleman, Nat Jeffries, Csaba Kiraly, Pietro Montino, et al. 2021. “MLPerf Tiny Benchmark.” arXiv Preprint.
Lin, Ji, Wei-Ming Chen, Yujun Lin, John Cohn, Chuang Gan, and Song Han. 2020. “MCUNet: Tiny Deep Learning on IoT Devices.” In Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, Virtual, edited by Hugo Larochelle, Marc’Aurelio Ranzato, Raia Hadsell, Maria-Florina Balcan, and Hsuan-Tien Lin. Curran Associates.
34 TinyML Energy Gap: This differential is rooted in hardware design philosophy; cloud GPUs are optimized for raw throughput, consuming hundreds of watts, while TinyML microcontrollers are designed for near-zero power sleep states. For ordinary cloud inference, a single request may consume ~1 joule while a specialized TinyML device uses less than one microjoule, a \(1{,}000{,}000\times\) gap. Cloud LLM queries can push the comparison even further, as quantified in Table 12.
35 Coin-Cell Deployment: A CR2032 battery (225 mAh at 3 V, ~675 mWh) powers a TinyML model consuming 10–50 µW for 1–10 years. This “deploy-and-forget” operating model constrains models to <100 KB (fitting in on-chip SRAM) and drives innovation in intermittent computing, where the device sleeps between inferences to stretch the energy budget across years of unattended operation.
Where mobile ML requires sophisticated hardware with gigabytes of memory and multi-core processors, TinyML operates on microcontrollers33 with kilobytes of RAM and single-digit dollar price points (Banbury et al. 2021; Lin et al. 2020). This radical constraint forces an entirely different approach to machine learning deployment, prioritizing ultra-low power consumption and minimal cost over computational sophistication. TinyML systems power applications such as predictive maintenance, environmental monitoring, and simple gesture recognition. The energy gap between TinyML and cloud inference spans at least six orders of magnitude34 and reaches eight orders for cloud LLM queries, driving entirely different system architectures and deployment models. This extraordinary efficiency enables operation for months or years on limited power sources such as coin-cell batteries35, as exemplified by the device kits in Figure 8. These systems deliver actionable insights in remote or disconnected environments where power, connectivity, and maintenance access are impractical.
The scale of these constraints becomes tangible when we see the hardware. Figure 8 shows development boards measuring 2 to 5 cm in length, each containing a microcontroller with kilobytes of SRAM and a power budget measured in milliwatts. The entire ML inference pipeline, from sensor input to classification output, must fit within these physical dimensions and energy limits.

Warden, Pete. 2018. “Speech Commands: A Dataset for Limited-Vocabulary Speech Recognition.” arXiv Preprint arXiv:1804.03209, ahead of print. https://doi.org/10.48550/arXiv.1804.03209.
At this endpoint, the deployment target is defined by always-on sensing under kilobyte and milliwatt budgets.
Definition 1.6: TinyML
TinyML is the domain of Always-On Sensing constrained by Kilobyte-Scale Memory and Milliwatt-Scale Power.
- Significance (quantitative): It necessitates models small enough to reside entirely in On-Chip SRAM, avoiding the high energy cost (100\(\times\) higher) of DRAM access to enable continuous inference on milliwatt power budgets.
- Distinction (durable): Unlike Mobile ML, which uses multi-watt processors and a full OS, TinyML runs on Microcontrollers (MCUs) with no operating system abstraction.
- Common pitfall: A frequent misconception is that TinyML is just “small models.” In reality, it is an Energy-Bound Paradigm: the primary metric is Energy per Inference (micro-joules), not just the parameter count.
TinyML’s milliwatt-scale power consumption represents a six-order-of-magnitude reduction from cloud inference, a gap with profound implications for system design. In terms of Equation 6, TinyML operates in a regime where the dominant constraint is neither \(O/(R_{\text{peak}} \cdot \eta_{\text{hw}})\) nor \(D_{\text{vol}}/\text{BW}\), but a term the equation does not explicitly capture: \(D_{\text{vol}}/\text{Capacity}\). When total memory is measured in kilobytes, the model must fit entirely on-chip, and every byte of data movement costs energy measured in picojoules. The optimization objective shifts from minimizing latency to minimizing energy per inference—efficiency, not speed.
Napkin Math 1.11: Energy per inference
Energy consumption spans eight orders of magnitude across deployment paradigms. Table 12 reports representative full-system energy per inference and the resulting smartphone-battery query counts:
Table 12: Energy per Inference Across Paradigms: Representative full-system energy per inference and resulting smartphone-battery query counts for cloud, edge, mobile, and TinyML workloads, illustrating the eight-order-of-magnitude span that makes always-on sensing feasible only at the TinyML tier.
| Paradigm | Example Workload | Energy/Inference | Battery Life (3.7V, 3000mAh) |
|---|---|---|---|
| Cloud | GPT-4 query | ~1 kJ | ~40 queries |
| Cloud | ResNet-50 (A100) | ~10 J | ~3,996 queries |
| Edge | ResNet-50 (Jetson) | ~500 mJ | ~79,920 queries |
| Mobile | MobileNet (NPU) | ~50 mJ | ~799,200 queries |
| TinyML | Keyword spotting | ~10 µJ | ~4 billion queries |
Energy values represent full-system energy (including server CPUs, memory, networking, and cooling overhead), not isolated accelerator compute energy. For example, the A100 GPU alone executes ResNet-50 inference in under 1 ms (~0.3 J), but the full server draws ~1 kW when amortized across queuing, preprocessing, and idle power.
Systems insight: A TinyML wake-word detector at ten µJ/inference is 100,000,000\(\times\) more energy-efficient than a cloud LLM query. This gap explains why always-on sensing is only practical at the TinyML tier—a smartphone running continuous cloud queries would drain in minutes.
Figure 9 positions TinyML relative to the other paradigms. The Characteristics branch reveals the extreme constraints: milliwatt power and kilobyte memory. These limits enable the Benefit of “always-on” sensing that no other paradigm can sustain, but force engineers to solve the Challenge of extreme model compression.

TinyML advantages and operational trade-offs
TinyML operates at hardware extremes. Compared to cloud systems, TinyML deployments commonly provide roughly \(10^6\) to \(10^9\) times less memory, depending on whether the microcontroller budget is in low megabytes or kilobytes, with power budgets in the milliwatt range. These strict limitations enable months or years of autonomous operation36 but demand specialized algorithms and careful systems co-design. Devices range from palm-sized developer kits to millimeter-scale chips37, enabling ubiquitous sensing in contexts where networking, power, or maintenance are costly. Representative developer kits include the Arduino Nano 33 BLE Sense (256 KB RAM, 1 MB flash, 20–40 mW) and ESP32-CAM (520 KB RAM, 4 MB flash, 50–250 mW).
36 On-Device Training Constraints: Full backpropagation requires storing activations for every layer, consuming memory proportional to model depth. With only 256 KB–2 MB RAM, microcontrollers cannot support this; alternatives like TinyTL fine-tune only the final layers using <50 KB of working memory. This memory constraint is why TinyML devices are predominantly inference-only, with model updates pushed via firmware rather than learned in situ.
37 TinyML Device Range: This physical range reflects a direct trade-off between deployment context and computational capability. Millimeter-scale systems prioritize minimal power (~140 µW) for single-function, long-duration tasks, whereas palm-sized boards trade larger size and higher power for the ability to process multiple complex sensor streams. This co-design choice creates a >10,000\(\times\) power and ~100\(\times\) area difference across the operational spectrum of TinyML devices.
TinyML’s extreme resource constraints paradoxically enable unique advantages. By avoiding network transmission entirely, TinyML devices achieve the lowest end-to-end latency in the deployment spectrum, enabling rapid local responses for sensing and control loops without communication overhead. This self-sufficiency also transforms the economics of large-scale deployments: when per-node costs drop to single-digit dollars, instrumenting an entire factory floor, farm, or building becomes financially viable in ways that edge or cloud alternatives cannot match. Energy efficiency compounds the economic case, enabling multi-year operation on small batteries or even indefinite operation through energy harvesting. Privacy benefits follow naturally from locality, because raw data never leaves the device, reducing transmission risks and simplifying compliance. On-device processing alone does not automatically provide formal privacy guarantees without additional security mechanisms.
These capabilities require substantial trade-offs. Computational constraints impose severe limits: microcontrollers commonly provide \(10^5\) to \(10^6\) bytes of RAM, forcing models and intermediate activations into the tens-of-kilobytes to low-megabytes range depending on the workload. Development complexity requires expertise spanning neural network optimization, hardware-level memory management, embedded toolchains, and specialized debugging across diverse microcontroller architectures.
Beyond these technical constraints, operational challenges compound the difficulty. Model quality can suffer from aggressive compression and reduced precision, limiting suitability for applications requiring high accuracy or robustness. Deployment can also be inflexible: devices may run a small set of fixed models, and updates may require firmware workflows that are slower and riskier than cloud rollouts. Ecosystem fragmentation38 across microcontroller vendors and ML frameworks creates additional overhead and portability challenges.
38 TinyML Ecosystem Fragmentation: Unlike cloud or mobile ML, where PyTorch or TensorFlow Lite provide a single optimization path, TinyML spans dozens of incompatible microcontroller families (ARM Cortex-M, RISC-V, Xtensa), each with different instruction sets, memory layouts, and vendor-specific toolchains. A model optimized for one target often requires re-quantization and re-validation for another, multiplying the engineering cost of multi-device deployment and creating portability barriers absent from higher-resource paradigms.
Environmental and health monitoring
TinyML succeeds across domains where ultra-low power, low per-node cost, and local processing enable applications that no other paradigm can sustain.
Wake-word detection is the most familiar consumer application of TinyML. These systems listen continuously at sub-milliwatt power consumption, processing audio streams locally and activating higher-power components only when a wake phrase is detected—a design that dramatically reduces average device power draw39.
39 Always-On Wake-Word Detection: This sub-milliwatt power target is met by a simple, specialized model that does nothing but listen for the acoustic signature of the wake phrase. This model acts as an aggressive power gate, preventing the needless activation of the main application processor, which consumes 100–1,000\(\times\) more power. The entire energy-saving architecture fails if this always-on component exceeds its stringent power budget of roughly one milliwatt.
Vasisht, Deepak, Zerina Kapetanovic, Jongho Won, Xinxin Jin, Ranveer Chandra, Sudipta N. Sinha, Ashish Kapoor, Madhusudhan Sudarshan, and Sean Stratman. 2017. “FarmBeats: An IoT Platform for Data-Driven Agriculture.” 14th USENIX Symposium on Networked Systems Design and Implementation (NSDI 17), 515–29.
Precision agriculture exploits TinyML’s economic advantages where traditional solutions prove cost-prohibitive (Vasisht et al. 2017). Deployments can instrument thousands of monitoring points with multi-year battery operation, transmitting summaries instead of raw sensor streams to reduce connectivity costs.
Wildlife conservation uses TinyML for remote environmental monitoring. Researchers deploy solar-powered audio sensors consuming 100–500 mW that process continuous audio streams for species identification. By performing local analysis, these systems reduce satellite transmission requirements from 4.3 GB per day to 400 KB of detection summaries, a 10,750\(\times\) reduction that makes large-scale deployments of 100–1,000 sensors economically feasible.
Medical wearables push TinyML into healthcare, where the combination of always-on monitoring and on-device privacy proves uniquely valuable. FDA-cleared cardiac monitors achieve 95–98 percent sensitivity while processing 250–500 ECG samples per second at under 5 mW power consumption. This efficiency enables week-long continuous monitoring vs. hours for smartphone-based alternatives, while reducing diagnostic costs from $2,000–5,000 for traditional in-lab studies to under $100 for at-home testing.
The four deployment paradigms now span the full range from megawatt data centers to milliwatt microcontrollers. Each paradigm emerged as a response to specific physical constraints, and each excels within its operating envelope. The question of how an engineer should choose among them, and what to do when no single paradigm satisfies all requirements, motivates the comparative analysis that follows.
Self-Check: Question
What makes TinyML a qualitatively different deployment paradigm rather than ‘just smaller mobile ML’?
- TinyML is defined mainly by low model parameter count, with energy and memory behavior as secondary considerations.
- TinyML runs on microcontrollers with kilobyte-scale memory and milliwatt-scale power, so the primary optimization targets become microjoule-per-inference energy and on-chip model residency — a regime where mobile techniques are necessary but not sufficient.
- TinyML is identical to mobile deployment except that the devices use weaker CPUs.
- TinyML exists mainly because smartphone operating systems are too complex for simple sensing applications.
Why does the chapter emphasize that a TinyML keyword spotter can be roughly \(10^8\) times more energy-efficient per inference than a cloud LLM query?
- To show that TinyML models always achieve higher task accuracy than cloud models.
- To illustrate why always-on ubiquitous sensing is only feasible at the TinyML tier, because the cloud alternative is not merely slower but energetically incompatible with unattended multi-year battery operation.
- To argue that network transmission becomes free once data is compressed enough.
- To prove that cloud accelerators are poorly designed for any inference workload regardless of scale.
Explain why on-device training is usually not the default design for TinyML systems, and what this implies for how TinyML models reach and stay in the field.
A TinyML engineer is told ‘just stream the weights in from off-chip flash for each inference — flash is cheap and capacity is plentiful.’ Explain the mechanism by which this approach breaks the TinyML energy budget for an always-on workload, and how the resulting design principle follows from the numbers.
Which application best matches the deployment logic of TinyML as framed in this section?
- A global recommendation engine with terabyte-scale embedding tables updated continuously from streaming telemetry.
- A cloud-hosted chatbot that tolerates hundreds of milliseconds of latency per turn.
- A remote wildlife sensor that must analyze audio locally for months on a battery and uplink only compact detection summaries a few times a day.
- A retail-store edge server aggregating data from dozens of cameras while plugged into mains power.
Paradigm Selection
Each paradigm emerged as a response to specific physical constraints: cloud ML accepts latency for unlimited compute, edge ML trades compute for latency, mobile ML trades compute for portability, and TinyML trades compute for ubiquity. Comparing these paradigms quantitatively and selecting among them for a specific application requires a unified comparison framework and a structured decision process.
Quantitative trade-off analysis
Deployment decisions require seeing all four paradigms side by side across the dimensions that matter. A system architect choosing between edge and mobile deployment must compare latency, power, cost, privacy, and development complexity simultaneously.
Table 13 provides this comparison across fourteen dimensions, from compute power and latency to cost and deployment speed.
The resulting fourteen-dimension comparison appears in Table 13:
| Aspect | Cloud ML | Edge ML | Mobile ML | TinyML |
|---|---|---|---|---|
| Processing Location | Centralized cloud servers (Data Centers) | Local edge devices (gateways, servers) | Smartphones and tablets | Ultra-low-power microcontrollers and embedded systems |
| Latency | 100 ms–1000 ms+ | 10–100 ms | 5–50 ms | 1–10 ms |
| Compute Power | Very High (Multiple GPUs/TPUs) | High (Edge GPUs) | Moderate (Mobile NPUs/GPUs) | Very Low (MCU/tiny processors) |
| Storage Capacity | Unlimited (petabytes+) | Large (terabytes) | Moderate (gigabytes) | Very Limited (kilobytes–megabytes) |
| Energy Consumption | Very High (kW–MW range) | High (hundreds of watts) | Moderate (1–10 W) | Very Low (mW range) |
| Scalability | Excellent (virtually unlimited) | Good (limited by edge hardware) | Moderate (per-device scaling) | Limited (fixed hardware) |
| Data Privacy | Basic-Moderate (Data leaves device) | High (Data stays in local network) | High (Data stays on phone) | Very High (Raw data can remain local) |
| Connectivity Required | Constant high-bandwidth | Intermittent | Optional | None |
| Offline Capability | None | Good | Excellent | Complete |
| Real-time Processing | Dependent on network | Good | Very Good | Excellent |
| Cost | High ($1000s+/month) | Moderate ($100s–1000s) | Low ($0–10s) | Very Low ($1-10s) |
| Hardware Requirements | Cloud infrastructure | Edge servers/gateways | Modern smartphones | MCUs/embedded systems |
| Development Complexity | High (cloud expertise needed) | Moderate-High (edge+networking) | Moderate (mobile SDKs) | High (embedded expertise) |
| Deployment Speed | Fast | Moderate | Fast | Slow |
This inverse relationship between privacy and compute is not coincidental—it reflects the inherent trade-off between data locality and computational scale. Data that stays local cannot be processed at data center scale, and data that moves to the cloud cannot remain fully private. The archetype-paradigm mapping established in Section 1.3 connects these characteristics to specific workload requirements, with each archetype gravitating toward paradigms that address its binding constraint.
Figure 10 plots these trade-offs as radar charts, where each paradigm forms a polygon and larger areas indicate stronger performance on that axis. Plot a) contrasts compute power and scalability, where cloud ML excels, against latency and energy efficiency, where TinyML dominates. Edge and mobile ML occupy intermediate positions.

Plot b) emphasizes operational dimensions where TinyML excels (privacy, connectivity independence, offline capability) vs. Cloud ML’s reliance on centralized infrastructure and constant connectivity.
Development complexity varies inversely with hardware capability: Cloud and TinyML require deep expertise (cloud infrastructure and embedded systems, respectively), while Mobile and Edge use more accessible SDKs and tooling. Cost structures follow a similar pattern: Cloud incurs ongoing operational expenses ($1,000s+/month), Edge requires moderate upfront investment ($100s-$1,000s), Mobile uses existing devices ($0-$10s), and TinyML minimizes hardware costs ($1-$10s) while demanding higher development investment.
A critical pitfall in deployment selection is choosing paradigms based solely on model accuracy without considering system-level constraints. A cloud-deployed model achieving 99 percent accuracy becomes useless for autonomous emergency braking if network latency exceeds reaction time requirements; a high-accuracy edge model that drains a mobile device’s battery in minutes fails despite superior accuracy. Successful deployment requires evaluating latency requirements, power budgets, network reliability, data privacy regulations, and total cost of ownership simultaneously. These constraints should be established before model development to avoid expensive architectural pivots late in the project.
Decision framework
Selecting the appropriate deployment paradigm requires systematic evaluation of application constraints rather than organizational biases or technology trends. Follow the decision tree in Figure 11, which filters options through a hierarchy of critical requirements: privacy, latency, computational demands, and cost constraints.

The framework evaluates four critical decision layers sequentially. Privacy constraints form the first filter, determining whether data can be transmitted externally. Applications handling sensitive data under GDPR, HIPAA, or proprietary restrictions mandate local processing, immediately eliminating cloud-only deployments. Latency requirements establish the second constraint through response time budgets: applications requiring sub-10 ms response times cannot use cloud processing, as physics-imposed network delays alone exceed this threshold. Computational demands form the third evaluation layer, assessing whether applications require high-performance infrastructure that only cloud or edge systems provide, or whether they can operate within the resource constraints of mobile or tiny devices. Cost considerations complete the framework by balancing capital expenditure, operational expenses, and energy efficiency across expected deployment lifetimes.
A safety-critical braking example makes the sequencing concrete, because latency can eliminate cloud deployment before compute or cost are considered.
Napkin Math 1.12: Autonomous vehicle emergency braking
Application: Vision-based pedestrian detection for emergency braking.
Walking through the decision framework:
Privacy: Vehicle camera data is not transmitted to third parties → No strong privacy constraint. Could use cloud.
Latency: Emergency braking requires <100 ms total response. At 100 km/h, a car travels 2.8 meters in 100 ms.
- Network latency to cloud: 50–150 ms (variable) → Fails requirement
- Edge processing: 10–30 ms → Passes
- Decision: Cloud eliminated by physics.
Compute: Pedestrian detection requires ~10 GFLOPs at 30 FPS = 300 GFLOPs/s sustained.
- TinyML (<1 GFLOP/s): Fails
- Mobile NPU (~35 TOPS): Possible but thermal constraints limit sustained operation
- Edge GPU (~10+ TFLOPS): Passes with margin
- Decision: Edge or high-end Mobile.
Cost: Safety-critical, high-volume production (millions of vehicles).
- Edge GPU: $500-1000 per vehicle, amortized over 10+ year vehicle life = $50–100/year
- Decision: Edge GPU justified for safety-critical application.
Result: Edge ML with local GPU (NVIDIA Drive Orin class). Cloud used only for training, model updates, and fleet-wide analytics—not real-time inference.
Systems insight: Latency eliminated the cloud option before compute or cost were considered; the full privacy-latency-compute sequence narrowed four paradigms to the edge option.
The preceding decision framework identifies technically feasible options, but feasibility does not guarantee success. Production deployment also depends on organizational capabilities that determine whether a technically sound choice can be implemented and maintained effectively.
Successful deployment requires considering factors beyond pure engineering constraints. Team expertise must align with paradigm requirements: cloud ML demands distributed systems knowledge, edge ML requires device management capabilities, mobile ML needs platform-specific optimization skills, and TinyML requires embedded systems expertise. Organizations lacking appropriate skills face extended development timelines that can undermine even the strongest technical advantages. Monitoring and maintenance capabilities similarly determine viability at scale: edge deployments require distributed device orchestration, while TinyML demands specialized firmware management that many organizations lack. Cost structures add another dimension, because the temporal pattern of expenses varies dramatically across paradigms. Cloud incurs recurring operational costs favorable for unpredictable workloads; Edge requires substantial upfront investment offset by lower ongoing costs; Mobile uses user-provided devices to minimize infrastructure expenses; and TinyML minimizes hardware costs while demanding significant development investment.
These organizational realities surface a broader concern: a machine learning approach is not always the right choice. Every ML deployment carries operational overhead—data pipelines, monitoring, retraining infrastructure—that simpler heuristic systems avoid, and that overhead has to be paid back by measurably better outcomes.
Systems Perspective 1.2: The complexity tax
Before committing to any ML deployment, weigh the Complexity Tax against simpler alternatives.
Consider a classification problem solvable by either a Heuristic (if-then rules) or a Deep Learning Pipeline:
- The heuristic: Fifty lines of code. Near-zero compute cost. Maintenance: ~1 hour/month to update rules. No drift.
- The ML system: Fifty lines of model code + 2,000 lines of infrastructure (data pipelines, monitoring, GPU drivers). Maintenance: ~40 hours/month debugging drift and managing infrastructure.
An ML system that improves accuracy from 90 percent to 95 percent may still be a poor engineering choice if it introduces a 40\(\times\) increase in complexity. ML systems engineering is the art of minimizing this tax through robust architecture. If the operational cost of maintaining model quality over time is unaffordable, the simpler heuristic may be the superior systems choice.
This complexity tax applies to every deployment decision. Before proceeding to hybrid architectures, pause on whether these trade-offs are clear.
Checkpoint 1.2: System design
The central trade-off is often Accuracy vs. Complexity.
Decision Gates
Successful deployment balances technical optimization against organizational capability. Paradigm selection extends well beyond technical requirements to encompass team skills, operational capacity, and economic constraints, all constrained by the physical scaling laws we have examined. Operational aspects are detailed in ML Operations and benchmarking approaches in Benchmarking. In practice, however, the decision framework rarely points to a single winner. Most production systems combine multiple paradigms, such as training in the cloud, serving at the edge, and preprocessing on mobile, to satisfy constraints that no single deployment target can meet alone.
Self-Check: Question
Applying the decision framework to autonomous emergency braking, which constraint eliminates cloud deployment before compute or cost is even considered?
- Latency, because the round-trip network delay alone consumes the millisecond-scale response budget.
- Privacy, because vehicle camera data is always legally forbidden from leaving the car under every jurisdiction.
- Cost, because cloud inference is always more expensive per query than onboard automotive hardware.
- Scalability, because cloud systems cannot support many vehicles simultaneously.
What is the principal lesson of the fourteen-dimension comparison table across the four paradigms?
- Cloud dominates every operational dimension if the team can afford enough compute.
- Each paradigm occupies a distinct trade-off region, so deployment selection requires balancing latency, privacy, power, cost, offline capability, and fleet complexity simultaneously rather than optimizing any single axis.
- TinyML is preferable whenever privacy matters, regardless of compute requirements.
- Mobile and edge are operationally identical once both run inference locally.
Why does the section warn against choosing a deployment paradigm primarily on model accuracy, even when one paradigm’s accuracy is measurably higher?
A team is scoping a new smartwatch health-monitoring feature that must (a) respect medical-data privacy, (b) respond within 50 ms to detected anomalies, (c) run continuously on a battery, and (d) remain cheap per user. Using the chapter’s decision framework, what is the correct sequence of filters to apply and which paradigm does the framework select?
- Apply cost → latency → privacy → compute; the framework picks Cloud ML because it is cheapest per user at scale.
- Apply privacy → latency → compute → cost; privacy forces local processing, latency rules out cloud, continuous battery operation rules out Edge ML, and the compute budget together with the battery constraint select Mobile ML (with TinyML components for always-on sensing).
- Apply compute → cost → latency → privacy; the framework picks TinyML because it has the smallest compute footprint.
- Apply privacy → compute → cost → latency; the framework picks Edge ML because it dominates on privacy.
True or False: The Complexity Tax argument implies that a simpler heuristic can be the better systems choice even when an ML model is somewhat more accurate, because infrastructure, monitoring, and maintenance costs can outweigh a small accuracy gain.
Hybrid Architectures
The decision framework (Figure 11) helps select the best single paradigm for a given application. In practice, however, production systems rarely use just one paradigm. Voice assistants combine TinyML wake-word detection with mobile speech recognition and cloud natural language understanding. Autonomous vehicles pair edge inference for real-time perception with cloud training for model updates. These hybrid architectures exploit the strengths of multiple paradigms while mitigating their individual weaknesses. Three integration strategies formalize how such combinations work in practice.
Definition 1.7: Hybrid ML
Hybrid Machine Learning is the architectural strategy of Hierarchical Distribution across cloud and edge resources.
- Significance (quantitative): It partitions the ML workload across the latency-compute Pareto frontier, minimizing the Distance Penalty \((L_{\text{lat}})\) for reactive tasks while using cloud resources \((R_{\text{peak}})\) for heavy processing.
- Distinction (durable): Unlike Cloud-Only or Edge-Only deployments, Hybrid ML is defined by Dynamic Task Offloading based on resource availability and network status.
- Common pitfall: A frequent misconception is that Hybrid ML is just “running two models.” In reality, it is a Unified Data Fabric where the state must be synchronized across disparate hardware to ensure consistency.
Integration patterns
Three essential patterns address common integration challenges:
The Train-Serve Split places training in the cloud while inference happens on edge, mobile, or tiny devices. This pattern exploits cloud scale for training while benefiting from local inference latency and privacy. Training costs may reach millions of dollars for large models, while inference costs mere cents per query when deployed efficiently.40
40 Train-Serve Cost Asymmetry: Training is a one-time, compute-intensive search for model parameters, while inference is a single, cheap forward pass using those parameters. This creates the economic rationale for the split, as the massive fixed training cost is amortized over billions of subsequent low-cost inference queries. The resulting cost gap between a multi-million dollar training run and a sub-cent inference can exceed 1,000,000\(\times\).
In Hierarchical Processing, data and intelligence flow between computational tiers. TinyML sensors perform basic anomaly detection, edge devices aggregate and analyze data from multiple sensors, and cloud systems handle complex analytics and model updates. Each tier handles tasks appropriate to its capabilities.
Progressive Deployment systematically compresses models for deployment across tiers. A large cloud model becomes progressively optimized versions for edge servers, mobile devices, and tiny sensors. Voice assistants exemplify this pattern: wake-word detection uses small, always-on models, often tens of kilobytes for benchmark TinyML neural networks and sub-milliwatt to milliwatt-scale power on dedicated low-power hardware, while complex natural language understanding requires much larger models in cloud infrastructure.
With three integration patterns available, selection becomes a constraint-matching problem: choose the pattern whose trade-off profile matches the system’s dominant bottleneck.
Systems Perspective 1.3: Pattern selection guide
Train-Serve Split—Trade-off: Training cost vs. inference latency
- Choose when: Training requires scale that inference does not; privacy matters for inference but not training
- Avoid when: Model needs continuous learning from deployed data
Hierarchical Processing—Trade-off: Local autonomy vs. global optimization
- Choose when: Data volume exceeds transmission capacity; decisions needed at multiple timescales
- Avoid when: All processing can occur at one tier; network is reliable and fast
Progressive Deployment—Trade-off: Model quality vs. deployment reach
- Choose when: Same model needed at multiple capability levels; graceful degradation required
- Avoid when: Model cannot be meaningfully compressed; single deployment target
Common combinations: Voice assistants use Train-Serve Split + Progressive Deployment + Hierarchical Processing. Autonomous vehicles combine Hierarchical Processing with Progressive Deployment to run optimized models at each tier.
Additional patterns including federated and collaborative learning enable privacy-preserving distributed training across devices.
Production system integration
Real-world implementations integrate multiple design patterns into cohesive solutions. Figure 12 makes these interactions concrete through specific connection types. Notice the bidirectional flow: “Deploy” paths show how models flow downward from cloud training to various devices, while “Data” and “Results” flow upward from sensors through processing stages to cloud analytics. “Sync” connections demonstrate device coordination across tiers. This bidirectional architecture, models flowing down and data flowing up, is the defining characteristic of production hybrid systems.

Production systems demonstrate these integration patterns across diverse applications. Industrial defect detection exemplifies Train-Serve Split: cloud infrastructure trains vision models on datasets from multiple facilities, then distributes optimized versions to edge servers managing factory floors, tablets for quality inspectors, and embedded cameras on production lines. Agricultural monitoring illustrates Hierarchical Processing: soil sensors perform local anomaly detection at the TinyML tier, edge processors aggregate data from dozens of sensors and identify field-level patterns, while cloud infrastructure handles farm-wide analytics and seasonal planning. Fitness tracking exemplifies Progressive Deployment with gateway patterns: wearables continuously monitor activity using microcontroller-optimized algorithms consuming <1 mW, sync processed summaries to smartphones that combine metrics from multiple sources, then transmit periodic updates to cloud infrastructure for longitudinal health analysis.
Why hybrid approaches work
The success of hybrid architectures stems from a deeper truth: despite their diversity, all ML deployment paradigms share core principles. Figure 13 illustrates this convergence: implementations spanning cloud to tiny devices meet at the same core system challenges—managing data pipelines, balancing resource constraints, and implementing reliable architectures.

This convergence explains why techniques transfer effectively between scales. Cloud-trained models deploy to edge because both training and inference minimize the same loss function—only the compute budget differs. Quantization techniques developed for edge deployment reduce cloud serving costs, and distributed training strategies inform edge model parallelism.
Mobile optimization insights inform cloud efficiency because memory bandwidth constraints appear at every scale. Techniques like operator fusion and activation checkpointing, developed for mobile’s tight memory budgets, reduce cloud inference costs by 2–3\(\times\) when applied to batch serving. TinyML innovations drive cross-paradigm advances because extreme constraints force genuinely novel algorithmic breakthroughs: binary neural networks, developed for microcontrollers, now accelerate cloud recommendation systems, and sparse attention mechanisms, essential for fitting transformers in kilobytes, reduce cloud training costs.
The remaining chapters explore each layer: Data Engineering for data pipelines, Model Compression for optimization, and ML Operations for operational aspects. All of these apply whether the target is a TPU Pod or an ESP32. However, shared principles also mean shared vulnerabilities: the same operational challenges (data drift, model decay, monitoring) appear at every tier and demand attention before we consider the chapter’s remaining lessons.
Checkpoint 1.3: Hybrid ML patterns
Hybrid architectures work when you partition work across tiers—not when you copy the same pipeline everywhere.
Integration Patterns
Design Sanity Checks
The shared foundations in Figure 13 also share a vulnerability. Deployment is not the end of the engineering challenge—it is the beginning of a new one. Traditional software, once deployed correctly, remains correct indefinitely: a sorting algorithm that works today will work tomorrow, next year, and a decade from now. ML systems face a fundamentally different reality: System Entropy (statistical decay).
Unlike a sorting algorithm that remains correct as long as the code is unchanged, an ML model’s accuracy degrades as the world drifts away from its training distribution. Equation captures this formally: system quality decays as the distance between the training distribution and the live data distribution grows, at a rate proportional to the model’s sensitivity to distributional shift. Every deployed model is in a state of unobserved decay from the moment it ships. Reliability in ML systems is therefore not a property of the code but a property of the monitoring and retraining infrastructure built to detect and correct this drift. The operational aspects covered in ML Operations address precisely this challenge.
War Story 1.1: The Zillow Offers collapse (2021)
The context: Zillow, a real-estate marketplace, launched “Zillow Offers” to buy homes directly using an algorithmic valuation model (“Zestimate”).
The failure: The model was trained on historical data during a stable market. When the market became volatile (rapid price shifts during COVID-19), the model failed to adapt to the distribution shift. It overpaid for thousands of homes that it could not resell at a profit.
The consequence: Zillow wrote down $304 million in inventory, laid off 25 percent of its workforce (2,000 people), and shut down the Offers division entirely.
The systems lesson: Distribution shift is not just a metric drop; it is a business risk. Automated decision-making systems interacting with dynamic markets require rapid feedback loops and circuit breakers, not just accurate offline models.
Zillow’s collapse is not merely a cautionary tale. It is evidence for why ML systems engineering must exist as a principled discipline. The failure was not one of model accuracy but of systems reasoning: the inability to trace how distributional shift propagates from market data through a valuation model into irreversible financial commitments. A discipline built on the statistical drift invariant and the degradation equation makes such propagation paths visible and such failure modes quantifiable before they compound into $304 million losses.
Beyond statistical decay, engineers also fall prey to common misconceptions about ML deployment. The physical constraints we have examined throughout this chapter create counterintuitive behaviors that challenge intuitions from traditional software engineering. The chapter closes by distilling those lessons into deployment fallacies and pitfalls.
Self-Check: Question
Why do production ML systems frequently use hybrid architectures rather than committing to a single deployment paradigm?
- Because using multiple paradigms is mainly a code-reuse preference that simplifies software engineering.
- Because training, inference, privacy, latency, bandwidth, and power constraints often point to different optimal locations for different stages of the workload, so no single tier satisfies all constraints at once.
- Because cloud providers require on-device inference before they will allow remote training contracts.
- Because edge, mobile, and TinyML devices cannot run any useful inference on their own.
A voice-assistant team has one canonical 7B-parameter speech model trained in the cloud. They must deliver a 1 MB wake-word model on earbuds, a 50 MB on-device command model on phones, and a 1 GB conversational model on home hubs — all derived from the same cloud training artifact. Which integration pattern best describes this arrangement, and why does it fit better than Train-Serve Split alone?
- Train-Serve Split alone, because every artifact is trained centrally and served locally — the multi-tier compression is incidental.
- Progressive Deployment, because the pattern explicitly systematizes compressing one model family into multiple capability-tier artifacts (earbud, phone, home hub) — Train-Serve Split describes central training with local serving but does not by itself capture the multi-tier compression ladder.
- Hierarchical Processing, because the earbud filters requests for the hub, which filters for the cloud.
- Federated retraining, because each tier updates the central model from local data.
Why does the section argue that hybrid architectures work only when work is partitioned across tiers rather than when the same pipeline is copied everywhere?
In a production hybrid ML system, which statement best characterizes the data and model flows between tiers?
- Models and labels flow strictly upward, while raw data remains pinned at the lowest tier forever.
- Models flow downward from centralized training to deployment tiers, while telemetry, data summaries, and inference results flow upward to support analytics, drift detection, and retraining — the structure is bidirectional and asymmetric.
- All tiers continuously exchange identical full-state replicas, so no specialization is needed.
- Only cloud and TinyML tiers communicate directly; edge and mobile tiers serve purely as backup replicas.
True or False: The section argues that optimization ideas (quantization, pruning, kernel fusion, KV-cache management) transfer across cloud, edge, mobile, and TinyML because the four paradigms share deeper principles around data pipelines, resource management, and system architecture despite their different hardware envelopes.
Fallacies and Pitfalls
These fallacies and pitfalls capture architectural mistakes that waste development resources, miss performance targets, or deploy systems critically mismatched to their operating constraints. Each represents a pattern we have seen repeatedly in production ML systems.
Fallacy: One deployment paradigm solves all ML problems.
Physical constraints create hard boundaries that no single paradigm can span. The memory-wall discussion in Section 1.4 shows that bandwidth, memory capacity, and latency scale differently from raw compute, producing qualitatively different bottlenecks across paradigms. Table 13 quantifies this: cloud ML achieves 100–1000 ms latency while TinyML delivers 1–10 ms, a 100\(\times\) difference rooted in speed-of-light limits, not implementation quality. A real-time robotics system requiring sub-10 ms response cannot use cloud inference regardless of optimization, and a billion-parameter language model cannot fit on a microcontroller with 256 KB RAM regardless of quantization. The optimal architecture typically combines paradigms, such as cloud training with edge inference or mobile preprocessing with cloud analysis.
A related misconception holds that moving computation closer to the user always reduces latency, ignoring the processing overhead introduced by less powerful edge hardware—a trade-off explored in inference benchmarks (Inference Benchmarks).
Fallacy: Model optimization overcomes mobile device power and thermal limits.
Compression techniques do not scale indefinitely against physics. Consider a smartphone with a 15 Wh battery:
- Light workload (1 W inference): \(\frac{15 Wh}{1 W}\) = 15 hours
- Heavy workload (5 W, common for large on-device models): \(\frac{15 Wh}{5 W}\) = 3 hours
The 5 W workload also triggers thermal throttling that substantially reduces performance. As Section 1.7.1 establishes, sustained mobile inference cannot exceed approximately 3 W without active cooling. Reducing numerical precision (using fewer bits to represent each weight; see Model Compression) cuts power by approximately 4\(\times\), but aggressive precision reduction often causes accuracy loss. Applications requiring continuous inference beyond mobile thermal envelopes remain physically impossible regardless of algorithmic improvements.
Fallacy: TinyML represents scaled-down mobile ML.
The difference is qualitative, not just quantitative. As Section 1.8.1 establishes, TinyML microcontrollers provide 256 KB to 1 MB of memory vs. mobile devices with 4–12 GB, a 10,000\(\times\) difference requiring entirely different algorithms. Mobile ML uses reduced-precision arithmetic with minimal accuracy loss; TinyML requires extreme precision reduction that sacrifices 10–15 percent accuracy for 32\(\times\) memory reduction. Mobile devices run models with millions of parameters; TinyML models contain 10,000–100,000 parameters, demanding distinct architectural choices such as specialized lightweight operations designed to minimize multiply-accumulate counts. Power budgets show similar discontinuities: mobile inference consumes 1–5 W, while TinyML targets 1–10 mW for battery-free energy harvesting. These thousand-fold gaps make TinyML a distinct problem class, not a smaller version of mobile ML. Teams that apply mobile optimization techniques directly to TinyML projects discover that quantization from FP32 to INT8 (reducing each weight from 32 bits to 8 bits; see Model Compression) is insufficient when models must fit in 64 KB, forcing complete architectural redesign.
Pitfall: Minimizing computational resources minimizes total cost.
Teams optimize per-unit resource consumption while ignoring operational overhead and development velocity. As the decision framework in Section 1.9.2 emphasizes, paradigm selection requires evaluating total cost of ownership, not just compute costs. A cloud inference service costing $2,000 monthly in compute appears expensive vs. $500 monthly edge hardware amortization, but edge deployments add network engineering ($3,000 monthly), hardware maintenance ($500 monthly), and reliability engineering ($2,000 monthly), totaling $6,000—a 3\(\times\) difference. Development velocity compounds the gap: cloud deployments reaching production in two months vs. six months for custom edge infrastructure represent four months of delayed revenue. The optimal cost solution requires total cost of ownership analysis including development time, operational complexity, and opportunity costs, not merely minimizing compute expenses.
Fallacy: Model optimization translates linearly to system speedup.
Amdahl’s Law41, formalized in Amdahl's Law and Gustafson's Law, establishes hard limits that the Bottleneck Principle (Section 1.3.1) makes operational: \(\text{Speedup}_{\text{overall}} = \frac{1}{(1-p) + \frac{p}{s}}\) where \(p\) is the fraction of work that can be improved and \(s\) is the speedup of that fraction. Consider tapping the shutter on a smartphone camera. The image passes through 100 ms of signal processing (auto-exposure, white balance), 60 ms of ML scene classification, and 40 ms of postprocessing (tone mapping, HDR merge)—200 ms total. Optimizing the ML classifier to run 10\(\times\) faster (6 ms instead of 60 ms) drops total time from 200 ms to 146 ms—only 1.37\(\times\) overall, not 10\(\times\). Even eliminating ML entirely \((s = \infty)\) achieves only 1.43\(\times\) speedup, because the remaining 70 percent of the pipeline is untouched. Effective optimization requires profiling the entire pipeline and addressing bottlenecks systematically, because system performance depends on the slowest unoptimized stage.
41 Amdahl’s Law: Formalized by Amdahl (1967) for multiprocessor scaling, this principle applies directly to ML deployment pipelines where the model is only one stage among many. The camera example illustrates the general pattern: ML inference rarely exceeds 30–50 percent of total pipeline time in production systems, meaning even a 100\(\times\) model speedup yields only about 1.4–2.0\(\times\) end-to-end improvement. Teams that benchmark model latency in isolation systematically overestimate deployment gains.
Amdahl, Gene M. 1967. “Validity of the Single Processor Approach to Achieving Large Scale Computing Capabilities.” Proceedings of the April 18-20, 1967, Spring Joint Computer Conference on - AFIPS ’67 (Spring), AFIPS ’67 (spring), 483–85. https://doi.org/10.1145/1465482.1465560.
Pitfall: Assuming more training data always improves deployed model performance.
Three constraints limit data scaling benefits, as the workload archetypes in Section 1.3 illustrate. First, model size limits what can be learned: a keyword spotting model with 250K parameters achieves 95 percent accuracy on 50K samples but only 96.5 percent on 1M samples, a 1.5 percentage point gain for 20\(\times\) more data, storage, and labeling cost. The model simply cannot represent more complex patterns. Second, data quality dominates quantity: 1M curated samples often outperform 100M noisy web-scraped samples, because mislabeled examples and misleading patterns degrade performance even as dataset size grows. Third, deployment distribution matters more than training scale: a model trained on 1B web images may perform worse on medical imaging than one trained on 100K domain-specific samples. Teams that maximize dataset scale without analyzing model capacity waste months of labeling effort for negligible accuracy gains.
Pitfall: Deploying the same model binary across all edge devices without hardware-specific optimization.
Teams build a single model artifact and deploy it identically to every target device, treating deployment as a packaging step rather than an optimization opportunity. In practice, hardware-specific optimizations yield 3–5\(\times\) efficiency gains that generic binaries cannot capture. An INT8 model running on a device with a dedicated Neural Processing Unit (NPU) achieves 3–4\(\times\) higher throughput per watt than the same model running in FP32 on a general-purpose CPU, because the NPU’s fixed-function INT8 datapaths avoid the energy overhead of floating-point arithmetic. Similarly, operator fusion and memory layout tuning for a specific accelerator’s cache hierarchy can halve inference latency without changing the model’s weights. As the deployment paradigm analysis in Deployment Paradigm Framework establishes, each paradigm imposes distinct hardware constraints; a model binary optimized for an Arm Cortex-A78 will underutilize the matrix acceleration units on a device equipped with an Arm Ethos-U NPU. Teams that skip per-target optimization either waste battery life on mobile devices or fail to meet latency service level agreements (SLAs) on edge hardware, forcing costly postdeployment remediation.
Self-Check: Question
Which of the following deployment beliefs does the chapter identify as a fallacy?
- Running inference on-device always provides better user privacy than cloud inference does, because on-device data never reaches a remote data center.
- A single deployment paradigm can cover any ML workload if the team is willing to optimize the model aggressively enough, because physical constraints are engineering choices rather than physical laws.
- Hardware-specific optimization can materially improve edge-device efficiency and latency beyond what generic binaries achieve.
- Total system speedup is bounded by the fraction of the pipeline that remains unoptimized, so optimizing a non-dominant stage yields only modest end-to-end gains.
Why is it a design mistake to treat TinyML as simply scaled-down Mobile ML, and what does that imply for the engineering workflow when moving a mobile feature to a microcontroller?
A smartphone camera pipeline spends 100 ms in image signal processing, 60 ms in ML scene classification, and 40 ms in post-processing. A team makes the ML stage 10× faster. What is the correct Amdahl-grounded conclusion about the full pipeline?
- Total latency drops by roughly 10×, because the ML stage is the ‘intelligent’ part of the workload.
- Total latency drops modestly — from 200 ms to about 146 ms — because 140 ms of non-ML pipeline remains unchanged, and Amdahl’s Law caps system speedup when non-dominant stages are unoptimized.
- Total latency cannot be predicted without knowing how model accuracy changes in response to the speedup.
- The full pipeline becomes network-bound because the ML stage no longer dominates and the system must compensate.
Why can minimizing compute spend fail to minimize total cost of ownership in deployment planning?
- Because development, operations, networking, maintenance, and reliability engineering often dominate TCO, so saving dollars on compute can be overwhelmed by growth in the non-compute cost lines.
- Because reducing compute spend always degrades model accuracy enough to offset any savings.
- Because hardware amortization becomes irrelevant once a model reaches production.
- Because cloud providers bundle labor and networking into free inference tiers that cover those costs automatically.
True or False: Deploying the same model binary unchanged across all edge devices is usually efficient enough, because hardware-specific optimization offers only marginal gains and the engineering effort is not justified.
Summary
Physical constraints explain why the same model demands fundamentally different engineering on a phone and in a data center. Three immutable constraints (the speed of light, the power wall, and the memory wall) carve the deployment landscape into four distinct paradigms spanning about nine orders of magnitude in power and memory. No single paradigm suffices for production systems; hybrid architectures that partition work across Cloud, Edge, Mobile, and TinyML tiers define the state of the art.
Key Takeaways: Same model, different engineering
- Physical constraints are permanent: Speed of light (~36 ms cross-country round-trip), power wall, and memory wall create hard boundaries that engineering cannot overcome, only navigate.
- Identify bottlenecks before optimizing: The same model is compute bound in training but memory bound in inference. The iron law and Bottleneck Principle pinpoint which constraint dominates; optimizing the wrong term yields zero speedup.
- Workload archetypes determine deployment feasibility: A compute beast (ResNet-50 training) requires cloud scale; a tiny constraint (keyword spotting) requires microcontroller efficiency. The same optimization strategy cannot serve both—match the archetype to the paradigm.
- The deployment spectrum spans about nine orders of magnitude in power: Cloud data-center infrastructure operates at megawatt scale, while TinyML systems target milliwatts. This gap enables entirely different application classes rather than representing a limitation.
- Hybrid architectures are prevalent in production systems: Voice assistants span TinyML (wake-word), Mobile (speech-to-text), and Cloud (language understanding). Rarely does one paradigm suffice; integration patterns (Train-Serve Split, Hierarchical Processing, Progressive Deployment) formalize how paradigms combine.
- Latency budgets reveal feasibility: 100 ms round-trip to cloud eliminates real-time applications; 10 ms edge inference enables them. Apply the decision framework (Figure 11) to filter paradigms by privacy, latency, compute, and cost.
- System-level speedup obeys Amdahl’s Law, not model-level gains: A 10\(\times\) faster model yields only 1.37\(\times\) system speedup when ML accounts for 30 percent of the pipeline. Profile the full system before optimizing any component.
- Universal system principles transfer across paradigms: Data pipelines, resource management, and system architecture recur at every scale, which is why optimization ideas can migrate from cloud to edge and back again.
The analytical tools developed here (the iron law, bottleneck principle, workload archetypes, and lighthouse models) recur throughout the remainder of this book. Every subsequent chapter, from data engineering to model compression to serving, operates within the deployment constraints established here. The decision framework (Figure 11) and the quantitative comparison (Table 13) provide the reference points for those discussions. Knowing where to deploy is only the beginning. Every deployed model faces system entropy: accuracy degradation as the world drifts from its training distribution, making the operational infrastructure for monitoring and retraining as important as the deployment decision itself.
What’s Next: From theory to process
Understanding where ML systems run provides the foundation for understanding how to build them. ML Workflow establishes the systematic development process that guides ML systems from conception through deployment, translating the physical constraints examined here into reliable, production-ready systems.
Self-Check: Question
What is the chapter’s central explanation for why the same model requires different engineering on a phone, on an edge server, and in a data center?
- Different product teams prefer different software stacks, so deployment styles diverge over time.
- Physical constraints — the light barrier, the power wall, and the memory wall — carve the deployment landscape into distinct operating regimes that force different architectures, not the other way around.
- Models change their mathematical behavior when they are exported to smaller devices, so the algorithm itself becomes paradigm-dependent.
- Embedded deployments use smaller training datasets than cloud deployments, which drives the downstream engineering divergence.
Why does the summary insist that bottleneck identification precede any optimization decision in an ML system?
True or False: The summary presents hybrid architectures as unusual special cases, implying most production systems should commit to a single deployment paradigm once the right benchmark is chosen.
Self-Check Answers
Self-Check: Answer
Order the following layers of the Single-Node Stack from the point where high-level requirements are expressed to the point where bits are physically transformed: (1) Hardware (HBM + NVLink), (2) Application (throughput and latency goals), (3) Operating System (CUDA runtime + PCIe DMA), (4) ML Framework (PyTorch / JAX computational graph).
Answer: The correct order is: (2) Application (throughput and latency goals), (4) ML Framework (PyTorch / JAX computational graph), (3) Operating System (CUDA runtime + PCIe DMA), (1) Hardware (HBM + NVLink). Requirements originate at the application layer and flow downward: the framework translates the high-level math into a scheduled computational graph, the operating-system runtime dispatches kernels and moves data via DMA, and the hardware finally executes on silicon. Each stage consumes the output of the one above it — a framework cannot schedule without a declared loss, a runtime cannot launch without a kernel, and the hardware cannot fetch without a DMA descriptor. Swapping the framework and the runtime would invert compilation and execution, placing kernel launches before graph construction — an ordering that leaves nothing to launch.
Learning Objective: Sequence the four Single-Node Stack layers from application intent to physical execution and justify why each layer’s output is the next layer’s input.
An engineer writes 20 lines of PyTorch defining a Transformer block and a cross-entropy loss. Before any kernel runs on the accelerator, some component must translate this high-level math into a device-specific execution plan: a computational graph, autodiff tape, memory schedule, and selected kernels. Which layer of the Single-Node Stack owns that translation?
- The hardware layer, because the silicon rewrites the computational graph internally before executing any instruction.
- The operating system layer, because the CUDA runtime and PCIe DMA engine set throughput and accuracy goals for the application.
- The ML framework layer, because it constructs the computational graph, performs autodifferentiation, and schedules memory and kernels for the target device.
- The application layer, because business-level throughput and latency requirements are what directly decide kernel launch order.
Answer: The correct answer is C. The section names the ML framework (PyTorch, JAX) as the translation layer that maps high-level math into hardware-specific execution plans — owning the computational graph, automatic differentiation, and memory scheduling. The silicon-rewrites-graph answer reverses the stack: hardware executes what is handed to it; it does not parse source code. The OS-sets-goals answer confuses low-level orchestration (runtimes, DMA) with semantic translation; the runtime moves data, but it does not choose which kernel implements a matrix multiplication. The application-dictates-kernel-order answer collapses the stack: business requirements define the goal, not the launch schedule.
Learning Objective: Identify the ML framework as the Single-Node Stack layer that translates high-level math into device-specific execution plans.
An engineer inherits a 512-GPU distributed training job that delivers only 22 percent of its expected throughput. Before touching the cluster’s interconnect or scheduler, the section advises reasoning about the single-node stack first. Using the Silicon Contract framing, explain why the single-node diagnosis must come before the distributed one, and name two specific single-node bottlenecks that 512 GPUs would amplify rather than resolve.
Answer: The Silicon Contract — what one node can actually deliver at each layer of the stack — bounds what a cluster can possibly achieve. If a single node is bandwidth-bound on HBM because activations do not fit in cache, scaling to 512 GPUs multiplies the number of bandwidth-starved accelerators rather than fixing any of them; the cluster inherits the per-node ceiling. Two concrete single-node bottlenecks that 512 GPUs amplify: (1) a memory-bound kernel whose arithmetic intensity sits below the HBM roofline — every GPU sees the same low utilization, and the cluster’s realized throughput is 512× a small number; (2) a CPU-side tokenizer saturating a single core so the framework layer starves the accelerator — duplicating the job across 512 nodes duplicates the bottleneck, not the throughput. The system consequence is that single-node mastery is not optional before scaling; it sets the ceiling distributed engineering is trying to reach.
Learning Objective: Justify why single-node stack analysis must precede distributed-systems diagnosis by showing how per-node bottlenecks bound cluster-level throughput.
A student is deciding which Lighthouse Model from this chapter (ResNet-50, GPT-2, DLRM, MobileNet, Keyword Spotter) to use as the primary example in a lesson on memory-capacity limits versus memory-bandwidth limits in the iron law. Which model is the best pedagogical anchor, and why?
- ResNet-50, because its fixed-size 224×224 inputs make it compute-bound at every batch size, which cleanly isolates the R_peak term.
- DLRM, because its massive sparse embedding tables make the \(D_{vol}\) / capacity dimension the binding constraint — the model cannot execute until the right embedding rows are fetched, regardless of raw FLOPs.
- MobileNet, because its mobile deployment target means all bottlenecks trace to battery energy rather than to memory behavior.
- A Keyword Spotter, because its few-kilobyte footprint eliminates every memory-related iron-law term and leaves only the latency term.
Answer: The correct answer is B. The chapter positions DLRM as the Lighthouse Model whose defining bottleneck is memory capacity and access pattern: the embedding tables dominate the working set, and the per-step critical path is the sparse fetch, not the multiply-accumulate. That makes DLRM the cleanest anchor for distinguishing capacity-bound behavior (where \(D_{vol}\) does not fit) from bandwidth-bound behavior (where \(D_{vol}/BW\) dominates). The ResNet-50-is-always-compute-bound claim is not what the chapter teaches; ResNet-50 is a compute-representative workload, but single-image inference on ResNet-50 is explicitly used later in the chapter as a memory-bound example. The MobileNet-all-bottlenecks-are-energy and Keyword-Spotter-no-memory-term answers collapse the iron law’s distinct terms into one, which is exactly what Lighthouse Models are chosen to avoid.
Learning Objective: Apply the iron law’s memory terms to select the Lighthouse Model that best isolates capacity-bound behavior.
Self-Check: Answer
A safety-critical control loop has a 10 ms end-to-end latency budget, and the nearest cloud data center is 3,600 km away across a direct fiber path. Applying the section’s light-barrier analysis, what follows?
- Cloud deployment is feasible if the model inference itself takes less than 1 ms.
- Cloud deployment is infeasible because round-trip propagation delay alone is roughly 36 ms, before any compute or software overhead.
- Cloud deployment is feasible if enough parallel GPUs hide the network delay.
- Cloud deployment is blocked only by software overhead, not by physics.
Answer: The correct answer is B. Fiber signals propagate at roughly two-thirds the speed of light, so 3,600 km one-way takes about 18 ms and the round-trip is near 36 ms — already 3.6× the 10 ms budget before any inference, serialization, or scheduling overhead. The ‘more parallel GPUs hide the delay’ answer confuses compute parallelism with signal propagation: adding accelerators does not shrink a distance. A sub-1-ms inference answer makes the same category error — the 1 ms is irrelevant when the wire alone exceeds 36 ms. The ‘only software blocks cloud’ answer treats a physics limit as an engineering inefficiency.
Learning Objective: Apply the light-barrier equation to determine when cloud deployment is physically infeasible for a given latency budget.
A smartphone runs an image-enhancement model at 60 FPS for the first 90 seconds of recording, then drops to 15 FPS for the rest of the session even though the user has not changed any settings. Using the section’s Dennard-scaling-breakdown and power-wall argument, walk through the mechanism behind this failure and explain why the mobile regime chose efficiency and parallelism over raw clock speed as a response.
Answer: Once voltage could no longer scale down with feature size, dynamic power scales roughly with \(V^2 \cdot f\), and on a passively cooled phone the sustained power budget is capped by the device’s ability to shed heat — around 3 W for a modern smartphone. The first 90 seconds run at the full clock because the die is near ambient; as temperature rises the governor throttles frequency to stay within the thermal envelope, and the effective throughput collapses to 25 percent. This is why the mobile regime exists: a phone cannot adopt a data-center strategy of ‘push the clock higher’ because there is no active cooling to dissipate the resulting power, so architectural answers (efficient per-operation energy, DSP accelerators, neural engines with parallel MAC arrays) replace raw GHz. The system consequence is that mobile performance must be designed for the steady-state thermal floor, not the peak burst.
Learning Objective: Explain how the post-Dennard power wall forces mobile ML to prioritize sustained efficiency and parallelism over peak clock speed.
A profiler shows a new accelerator generation delivering 3× the peak FP16 TFLOPS of the previous one, but a production inference pipeline’s end-to-end latency improves by only 8 percent. A GPU-busy-time counter reads 91 percent, and HBM bandwidth utilization reads 94 percent. Which interpretation matches the section’s memory-wall argument?
- The workload is still compute-bound, so the remedy is to raise the accelerator’s clock frequency and unlock more FLOPs.
- The immediate constraint is SSD capacity, so a larger disk will let the pipeline cache more weights and restore scaling.
- Compute capability has grown faster than memory bandwidth, so data movement now sets the latency ceiling; the 94 percent HBM figure confirms the kernel is bandwidth-starved, not FLOP-starved.
- The memory wall is a database-query phenomenon and does not bind neural-network kernels, so the 8 percent improvement must come from unrelated software overhead.
Answer: The correct answer is C. The profile signature — near-saturated HBM bandwidth combined with low realized speedup from a compute-ceiling increase — is the memory-wall fingerprint the section diagnoses: compute has widened faster than bandwidth, and the kernel is starved for bytes rather than arithmetic. A clock-frequency increase addresses a compute bottleneck; this kernel does not have one. The SSD-capacity answer confuses the capacity dimension of the memory hierarchy with the bandwidth dimension the profile actually shows is saturated. The ‘database-only’ answer contradicts the chapter’s entire memory-wall argument — neural-network execution is among the workloads most affected by the compute-bandwidth divergence.
Learning Objective: Analyze how a profile signature of saturated HBM bandwidth and modest latency improvement identifies a memory-wall-bound kernel.
Given the memory-wall argument — compute has grown much faster than memory bandwidth — explain which class of optimization techniques becomes disproportionately valuable for ML inference, and why raw accelerator upgrades deliver diminishing returns on memory-bound kernels.
Answer: When the binding constraint is bytes moved rather than FLOPs executed, optimizations that shrink data movement dominate the return curve: operator fusion (keep intermediates in on-chip SRAM), weight quantization (halve or quarter the bytes per weight), pruning (remove bytes entirely), KV-cache compression in serving, and tiling schedules that maximize data reuse. A raw accelerator upgrade raises the roofline’s flat ceiling but leaves the sloped bandwidth line — the part that binds a memory-bound kernel — unchanged; the kernel’s realized performance is still bounded by HBM, so doubling peak FLOPs while holding bandwidth constant yields a near-zero speedup. The practical implication is that architecture-level data-movement optimizations become a better engineering investment than hardware generation upgrades once a workload is memory-bound, and this is why the chapter’s later paradigm sections treat quantization and fusion as first-class tools for every deployment tier.
Learning Objective: Identify which optimization families become disproportionately valuable under the memory wall and explain why raw peak-FLOPS upgrades underperform on memory-bound kernels.
True or False: The four ML deployment paradigms (Cloud, Edge, Mobile, TinyML) are product-marketing categories that solidified because different engineering teams chose different deployment styles over time.
Answer: False. The paradigms exist because the speed of light, thermodynamic limits on power, and memory-signaling energy carve the deployment landscape into regimes nine orders of magnitude apart in power and memory. Different engineering choices did not create the boundaries; the boundaries created the choices. A team that ‘chose’ to run a control loop in a distant data center would still fail the 10 ms budget because 36 ms of fiber is not a convention but a physical fact.
Learning Objective: Distinguish physics-driven deployment regimes from contingent engineering conventions.
Self-Check: Answer
Two engineers are analyzing the same inference service on the same hardware. Engineer A asks ‘what is the 99th-percentile end-to-end latency of a single request arriving when the queue is empty?’, and Engineer B asks ‘what is the sustained queries-per-second this service delivers when fully loaded with overlapped preprocessing, transfer, and compute?’. Which pair of iron-law formulations matches these two questions?
- Both questions use the additive iron law, because time is always a sum of the three terms regardless of context.
- Engineer A’s single-request-latency question uses the additive form (data + compute + latency add because the one request waits at every stage), while Engineer B’s steady-state throughput question uses the max form (overlapped stages make the slowest one — the bottleneck — set the rate).
- Both questions use the max-form Bottleneck Principle, because deployment systems always pipeline their stages.
- Neither form applies to inference; the iron law is a training-only framework in this chapter.
Answer: The correct answer is B. The section distinguishes single-task latency, where costs are paid sequentially and sum, from pipelined throughput, where overlapped stages mean the slowest term determines the rate. Engineer A’s cold-queue single-request question is the additive case; Engineer B’s fully-loaded-overlapped-pipeline question is the max case. The ‘always additive’ answer misses overlap; the ‘always max’ answer misses that a single cold request has no parallel stages to overlap; the ‘training-only’ answer contradicts the chapter’s use of the iron law across both training and inference regimes.
Learning Objective: Match a concrete deployment-analysis question to the correct iron-law formulation (additive for single-task latency, max-form Bottleneck Principle for pipelined throughput).
An inference pipeline has three stages measured per request: preprocessing on a CPU at 50 ms, host-to-device PCIe transfer at 10 ms, and GPU compute at 80 ms. A team doubles the accelerator’s FLOPS by buying a newer GPU; the compute stage falls to 40 ms, but pipelined throughput improves by only 60 percent rather than doubling. Use the Bottleneck Principle to explain the result and identify the optimization that would actually move the needle.
Answer: Under pipelined throughput, total rate is bounded by the slowest stage. Before the upgrade, the bottleneck was GPU compute at 80 ms. After the upgrade, the stage times are 50 ms, 10 ms, and 40 ms, so the 50 ms CPU preprocessing stage becomes the bottleneck. The throughput speedup is therefore 80/50 = 1.6x, a 60 percent improvement, not the 2x improvement the accelerator-only change suggests. The fix is not more compute but restructuring preprocessing — parallelizing the tokenizer across multiple CPU workers, moving preprocessing onto the GPU, or prefetching — to push CPU time under PCIe and compute. The practical implication is that buying faster hardware without diagnosing which stage is currently bottlenecking throughput is a common, expensive mistake.
Learning Objective: Analyze how the Bottleneck Principle causes an accelerator-only optimization to hit a new bottleneck, and identify the stage that actually binds throughput.
A battery-powered acoustic sensor can either transmit 1 MB of raw audio to a cloud classifier at roughly 100 mJ per megabyte, or run one local inference pass that costs roughly 0.1 mJ. Applying the section’s Energy of Transmission argument, what is the correct conclusion for always-on operation?
- Cloud offloading is usually more energy-efficient because the wireless radio amortizes compute costs across many devices.
- The two approaches are close enough that latency — not energy — should be the deciding factor.
- Local and cloud processing consume energy in the same order of magnitude, so either is viable for multi-month battery operation.
- Local processing is roughly 1,000× more energy-efficient per inference, so always-on battery-constrained sensing is pushed toward TinyML rather than cloud offload regardless of the cloud’s compute capability.
Answer: The correct answer is D. The worked example shows transmission costs roughly three orders of magnitude more energy than local inference — 100 mJ versus 0.1 mJ — so the energy wall alone rules out cloud offloading for always-on battery operation, even if the cloud’s inference were free and instantaneous. The ‘radio amortizes compute’ answer misses that the transmission itself is the cost being compared, not the cloud compute. The ‘latency should decide’ answer reduces the problem to one dimension when energy is the binding constraint. The ‘same order of magnitude’ answer is quantitatively wrong by a factor of about 1,000 — the very gap the argument is built on.
Learning Objective: Apply the Energy of Transmission comparison to determine when local inference is mandatory for always-on battery-constrained sensing.
Which pairing of Lighthouse Model and Workload Archetype correctly reflects the section’s mapping?
- GPT-2 / Llama → Sparse Scatter, because autoregressive decoding scatters attention across irregular token positions.
- DLRM → Sparse Scatter, because massive embedding tables create irregular-access, capacity-dominated memory patterns.
- Keyword Spotting → Compute Beast, because always-on classification demands sustained peak arithmetic throughput.
- MobileNet → Bandwidth Hog, because depthwise-separable convolutions saturate HBM bandwidth on every layer.
Answer: The correct answer is B. The section positions DLRM as the canonical Sparse Scatter workload because its huge embedding tables produce irregular memory access and capacity pressure rather than dense compute or streaming bandwidth demand. GPT-2 / Llama maps to the Bandwidth Hog archetype — autoregressive decoding is dominated by streaming weights from HBM, not by sparse scatter. Keyword Spotting is the Tiny Constraint archetype; its binding limit is microjoule-per-inference energy, not sustained peak FLOPs. MobileNet is a Compute Beast (efficient) variant; its point is to reduce FLOPs, not to saturate bandwidth.
Learning Objective: Map each Lighthouse Model to the Workload Archetype that captures its dominant iron-law bottleneck.
True or False: A workload’s archetype is primarily determined by its model family (e.g., all language models are one archetype, all vision models are another), so teams can pick optimization strategies by architecture type alone without profiling.
Answer: False. The section defines archetypes by the dominant iron-law bottleneck — compute, bandwidth, capacity, or energy — and the same model family can shift archetypes depending on deployment regime: ResNet-50 is compute-bound during batched cloud training but memory-bound for single-image inference, and an LLM is a Bandwidth Hog during decoding but closer to compute-bound during prefill. Optimization choices must follow the binding bottleneck, which requires profiling, not model-family pattern-matching.
Learning Objective: Distinguish bottleneck-based Workload Archetypes from architecture-family labels and recognize that the same model can occupy different archetypes in different regimes.
Self-Check: Answer
An application has a strict 30 ms end-to-end latency budget and must choose which operations can appear on its critical path. Using the section’s latency-table decision rule, which operation is automatically disqualified from the critical path regardless of what else happens?
- NPU inference at 5–20 ms.
- Cross-region network communication at 50–150 ms.
- Wake-word detection at 100 microseconds.
- Same-region network communication at 1–5 ms.
Answer: The correct answer is B. The section’s decision rule is categorical: any operation whose minimum latency exceeds the budget cannot appear on the critical path. Cross-region networking at 50–150 ms is already 1.7–5× the entire 30 ms budget before any other work happens. The NPU inference and same-region networking cases consume budget but can still fit; wake-word detection at 100 microseconds is three orders of magnitude under the budget and is easily accommodated.
Learning Objective: Apply latency-budget reasoning to eliminate operations whose minimum latency exceeds the budget from a system’s critical path.
The same ResNet-50 model is compute-bound when trained on an A100 at batch 256 but memory-bound when used for single-image inference on the same A100. Explain why the dominant bottleneck flips despite the identical model and hardware, and what the optimization priorities must become in each phase.
Answer: Arithmetic intensity — FLOPs per byte of data movement — is what determines where a workload sits relative to the roofline’s ridge point, and it changes dramatically with batch size. At batch 256, each weight matrix is reused across 256 examples, so arithmetic intensity is high and the kernel lives to the right of the ridge point — it is compute-bound. At batch 1, each weight matrix is loaded once to process a single image, so arithmetic intensity collapses and the kernel sits far to the left of the ridge — bandwidth-bound. The practical consequence is that training optimization targets R_peak and utilization (batch sizing, mixed precision, kernel fusion for throughput), while inference optimization targets \(D_{vol}\) (quantization, distillation, pruning, weight compression) — the same model with the same hardware requires opposite engineering moves depending on which iron-law term binds.
Learning Objective: Analyze how batch size drives arithmetic intensity to flip a model’s dominant bottleneck between training and inference, and select the matching optimization family for each phase.
ResNet-50 inference on a cloud A100 is only about an order of magnitude faster than on a mobile NPU in the worked example, even though the A100 has much higher peak compute and memory bandwidth. What explains the much smaller-than-expected cloud advantage?
- The A100 and the mobile NPU have similar compute throughput once INT8 quantization is enabled, so the peak-FLOPS gap is illusory.
- Batch-1 inference is memory-bandwidth-bound on both platforms, so the effective speedup tracks bytes moved through memory bandwidth rather than peak compute; the mobile case also uses INT8 weights, reducing the bytes it must move.
- The mobile NPU is compute-bound while the A100 is network-bound, so the bottlenecks are incomparable and no meaningful speedup exists.
- The A100 spends most of its batch-1 inference time on operating-system context switches and Python overhead, erasing its compute advantage.
Answer: The correct answer is B. The section states that batch-1 ResNet-50 inference is memory-bandwidth-bound on both platforms, so the realized speedup is governed by the effective bytes moved divided by available memory bandwidth, not by the ratio of peak compute. The worked example also compares FP16 weights on A100 with INT8 weights on mobile, so the mobile path moves fewer bytes and the cloud advantage is smaller than the raw HBM-to-DRAM bandwidth ratio. The mobile-compute-bound / cloud-network-bound answer invents mismatched regimes that the section explicitly rules out for this comparison. The OS-overhead answer is an order-of-magnitude too small to explain the gap and ignores the diagnosed memory-boundedness.
Learning Objective: Interpret why memory bandwidth, rather than peak FLOPS, governs the cloud-vs-mobile inference speedup on a batch-1 memory-bound workload.
In a pipelined inference server, one stage’s data-movement time exceeds the sum of all other stages’ compute times. Using the Bottleneck Principle, explain what happens to the accelerator’s realized throughput and utilization, and why adding a faster compute kernel does not fix the problem.
Answer: Under pipelined throughput, the system’s rate is bounded by the slowest stage; if data movement for one stage exceeds the compute cost of every other stage combined, the accelerator spends most of its cycles idle waiting on bytes. Realized throughput collapses to the bandwidth-limited stage’s rate, and raw GPU-busy time falls well below 100 percent — though vendor counters may show the compute units as ‘stalled but ready’ rather than ‘idle,’ masking the diagnosis. A faster compute kernel only shortens a stage that was not the bottleneck, so total latency barely changes and the stalled accelerator is stalled at a higher clock. The fix must attack the bandwidth stage directly — operator fusion to keep intermediates in SRAM, quantization to shrink bytes per weight, pinned-memory staging, or restructuring the pipeline so data movement overlaps with compute — because the Bottleneck Principle says no local compute optimization can outrun the rate-limiting resource.
Learning Objective: Analyze how a bandwidth-bound stage sets the pipeline’s throughput ceiling and explain why compute-side optimizations cannot raise it.
A team profiles batch-1 ResNet-50 inference and confirms memory-access time exceeds compute time on both cloud and mobile targets. Which next optimization aligns with the section’s memory-bound diagnosis?
- Double the accelerator’s peak FLOPS by moving to a newer GPU generation, leaving model precision and size unchanged.
- Apply INT8 weight quantization to shrink model bytes and cut the dominant data-movement term directly.
- Add more cross-region replicas so single-device memory pressure is distributed across the fleet.
- Enlarge the training dataset so the model learns a more efficient internal representation that uses less memory.
Answer: The correct answer is B. The worked example finds both platforms memory-bound at batch 1, so the right lever is the \(D_{vol}\) term: shrinking bytes moved through quantization (INT8 weights halve or quarter the byte count) attacks the binding stage directly. Doubling peak FLOPS raises a ceiling the workload does not touch; adding cross-region replicas addresses fleet-wide concurrency, not a single device’s memory bandwidth; enlarging the training dataset does not mechanically reduce a trained model’s runtime memory footprint and confuses a data-centric ML lever with a systems lever.
Learning Objective: Select the optimization whose target iron-law term matches a memory-bound inference diagnosis.
Self-Check: Answer
Which statement most accurately captures the defining trade-off of the Cloud ML paradigm as framed in this chapter?
- Cloud ML trades latency tolerance for access to effectively unbounded centralized compute, memory, and storage — a bargain that fails precisely when the application cannot tolerate the round-trip time.
- Cloud ML is the right choice whenever privacy is not a regulatory requirement, because remote compute is always cheaper than local compute at any utilization level.
- Cloud ML is the best choice whenever a workload’s compute intensity exceeds local device limits, regardless of whether the latency budget is strict or relaxed.
- Cloud ML eliminates the need to reason about ingestion bandwidth and data movement, because the provider’s backbone makes capacity effectively free from the client’s perspective.
Answer: The correct answer is A. The chapter frames cloud as the paradigm that exchanges latency for elastic, centralized scale — the bargain works when the latency budget accommodates a round-trip and breaks when it does not. The ‘privacy-not-required → cloud is always cheaper’ answer is a plausible partial truth that ignores distance-penalty feasibility: a 10 ms control loop cannot use distant compute at any cost. The ‘compute intensity exceeds local → cloud’ answer omits the latency filter the decision framework applies first; a heavy workload with a strict response time is not cloud-feasible just because the compute is big. The ‘bandwidth is free’ answer inverts one of cloud’s central challenges — ingestion cost and data movement at scale are the chapter’s recurring cloud pain points.
Learning Objective: Explain the latency-for-scale trade-off that defines Cloud ML and distinguish it from plausible partial-truth framings.
A robotic safety monitor has a 10 ms response budget and the nearest cloud data center is 1,500 km away. A proposal suggests ‘scale the cloud fleet 10× and the problem is solved.’ Using the light-barrier analysis, explain why no amount of cloud provisioning rescues this workload, and name the kind of investment that would actually help.
Answer: Round-trip propagation across 1,500 km of fiber is about 15 ms at two-thirds the speed of light — already 1.5× the entire response budget before any compute, serialization, or scheduling overhead. Scaling the cloud fleet 10× multiplies available compute, not propagation speed; the signal still has to traverse the same distance. The relevant investment is spatial, not elastic: pushing inference onto an edge appliance co-located with the robot, or onto a regional point-of-presence within ~1,000 km, brings the distance term under the budget. The practical implication is that cloud elasticity and cloud feasibility are orthogonal — elastic compute cannot move silicon closer to the data source.
Learning Objective: Analyze why cloud elasticity cannot compensate for a light-barrier-driven distance penalty and identify the spatial investments that can.
In the section’s worked cloud-vs-edge TCO example at roughly one million inferences per day, what is the most important engineering lesson for choosing where to deploy?
- Edge is always cheaper because hardware amortization dominates every other cost line.
- Cloud always wins because operational labor on cloud is negligible next to GPU rental.
- At sustained high utilization, edge compute can be cheaper per inference, but operational labor (DevOps, updates, monitoring) often dominates edge TCO enough that minimizing hardware spend alone is a misleading objective.
- Model accuracy is the main determinant of TCO, because higher accuracy reduces the number of servers needed.
Answer: The correct answer is C. The worked example shows edge can win on raw compute cost at high steady utilization, but the section emphasizes that operational labor becomes the dominant edge cost line — updates, monitoring, physical maintenance, drift tracking across a distributed fleet — and choosing by hardware price alone misses where most of the money actually goes. The ‘edge always cheaper’ and ‘cloud always wins’ answers collapse the trade-off into a single axis that the section explicitly refuses. The ‘accuracy is the main determinant’ answer substitutes a model-quality concern for the cost decomposition the TCO analysis is built to expose.
Learning Objective: Evaluate cloud-versus-edge deployment using total cost of ownership including operational labor, not hardware price alone.
The section’s ‘Voice Assistant Wall’ argument concludes that cloud-only voice processing is infeasible at global scale. Which pair of reasons captures the core argument?
- Speech models cannot be trained in the cloud quickly enough to keep up with new device launches.
- Both the annual cloud cost and the aggregate data-center plus bandwidth capacity required become prohibitive when billions of always-listening devices continuously rely on remote processing — the scaling is economic and infrastructural.
- Wake-word detection accuracy always degrades when the model is not co-located on the device.
- Mobile operating systems forbid persistent network connections for audio streaming.
Answer: The correct answer is B. The argument runs on two fronts: per-user cloud spend multiplied by billions of concurrent listeners produces an annual bill without precedent, and the aggregate GPU-hours, audio-ingestion bandwidth, and backbone capacity needed exceed what any realistic data-center buildout can sustain. The speech-training answer invents a training-pipeline bottleneck the section does not argue. The accuracy answer makes an empirical claim unrelated to the scaling argument. The OS-forbids answer misstates mobile platform behavior and misses the infrastructure-scale point entirely.
Learning Objective: Analyze how cloud-only inference can fail simultaneously on economic and infrastructure-capacity axes at global scale.
True or False: Because Cloud ML offers effectively unbounded compute and storage, it is the universally best deployment paradigm for any team that can afford it.
Answer: False. Cloud remains constrained by the speed-of-light distance penalty, by ingestion-bandwidth costs that scale with data volume, by privacy and data-sovereignty requirements, and by recurring operating expenses that compound with workload scale. A 10 ms control loop, an always-on wake-word detector, a regulated medical stream, and a global speech assistant all fail cloud-only for distinct reasons that more cloud compute cannot address.
Learning Objective: Evaluate Cloud ML’s limits beyond raw computational scale and identify the constraints that more compute cannot resolve.
Self-Check: Answer
Which statement best captures the chapter’s definition of Edge ML?
- Edge ML refers specifically to small, battery-powered hardware with no operating system.
- Edge ML is a location paradigm that places computation physically close to data sources to achieve deterministic latency and keep raw data on-premises.
- Edge ML is any deployment consuming less than 100 W of power.
- Edge ML means running a cloud model unchanged on a local laptop or workstation.
Answer: The correct answer is B. The section defines edge by physical proximity to the data source, not by any fixed hardware class, power envelope, or operating-system presence — edge systems range from industrial gateways on mains power to factory servers running full Linux. The battery-only answer collapses edge into TinyML. The fixed-power-envelope answer imposes a threshold the section does not use. The ‘unchanged cloud model’ answer misses that edge typically involves real local inference optimization, not re-hosting.
Learning Objective: Distinguish Edge ML as a deployment-location paradigm from narrower hardware-class or power-envelope definitions.
A factory has 100 cameras streaming 1080p video at 30 FPS over a dedicated 10 Gbps uplink. Using the section’s worked example, why is cloud streaming the wrong architecture even with that dedicated bandwidth?
- 10 Gbps networking is too slow for any ML workload, even after aggressive local compression.
- The aggregate raw video rate exceeds the 10 Gbps link by a large factor, and the cloud egress cost at that volume is also prohibitive, so local inference is the only workable architecture.
- Camera inference can only run on TinyML microcontrollers, so no server-class option exists.
- Privacy regulations universally forbid video from leaving any factory.
Answer: The correct answer is B. The worked example shows that 100 cameras at 1080p30 produce an aggregate raw data rate that overwhelms even a 10 Gbps link, and the monthly transfer bill at that volume would be enormous if raw streams later had to be retrieved from the cloud — the physics and the economics both point to local inference before any privacy argument is invoked. The ‘too slow for any ML’ answer over-generalizes; 10 Gbps is ample for many workloads that are not 100 cameras of video. The TinyML-only answer is factually wrong; factory edge servers run full-class models. The ‘privacy always forbids’ answer reaches a correct conclusion for the wrong reason — privacy may be relevant, but the section’s argument here is bandwidth physics and cost.
Learning Objective: Apply bandwidth and egress-cost reasoning to determine when edge processing is mandatory for high-volume video workloads.
An autonomous delivery drone captures 4K video at 60 FPS and must classify obstacles with a 30 ms response budget. Its cellular uplink supports bursts of about 50 Mbps and the nearest regional cloud is 200 km away. Apply the Data Locality Invariant to decide whether local inference is mandatory, and justify the answer using the transmission-versus-remote-response comparison.
Answer: The Data Locality Invariant requires local processing when transmission time exceeds the sum of remote compute plus remote network latency; both the bandwidth physics and the latency budget fail here. First, the data rate: 4K60 compressed video is roughly 40–60 Mbps — comparable to the cellular bursty ceiling, so sustained streaming is infeasible, and any packet loss compounds into seconds of delay. Second, the latency: one-way propagation across 200 km of fiber plus cellular overhead is on the order of 10–30 ms, and the round trip alone consumes most or all of the 30 ms budget before the cloud runs a single inference. The invariant resolves cleanly: transmission time already approaches or exceeds the total budget, so no amount of remote compute can close the gap. Local inference is mandatory, and the practical consequence is that the drone must ship with edge-class inference hardware or be disallowed from a 30 ms response contract.
Learning Objective: Apply the Data Locality Invariant to a bandwidth- and latency-constrained scenario and justify the local-inference decision using the transmission-versus-remote-response comparison.
A hospital is choosing between routing patient-monitor video through a cloud classifier and running the same classifier on on-premises edge servers. Explain why edge deployment can simultaneously improve privacy and resilience, and identify the specific operational complexity it introduces in exchange.
Answer: Processing on-premises means raw patient video never traverses the WAN to a third-party data center, so the attack surface and regulatory exposure around data exfiltration shrink dramatically; the hospital keeps a direct chain of custody over sensitive inputs. Resilience improves for the same structural reason: if the WAN fails, a cloud classifier goes offline, but an on-premises classifier keeps running on local power and local networking, preserving the monitoring loop during the exact windows in which monitoring matters most. The operational price is a distributed-operations burden the cloud absorbs automatically: the hospital must now manage hardware lifecycles, patch security updates, push model versions across sites, detect and roll back deployments per location, and monitor for drift across dozens of independent servers rather than one centralized service. The system consequence is that edge architectures externalize a privacy-and-resilience win but internalize the fleet-management complexity that the cloud made invisible.
Learning Objective: Analyze the trade-off between the privacy and resilience gains of edge deployment and the distributed-operations complexity it introduces.
Which application best matches the Edge ML paradigm as framed in this chapter?
- Pretraining a GPT-3-scale language model that requires thousands of accelerators and petabytes of training data.
- A safety-critical industrial inspection loop that must react within 20 ms and keep raw video on the factory floor for regulatory reasons.
- A smartphone camera app that must operate for hours on a battery within a 3 W thermal envelope.
- A coin-cell-powered keyword spotter that must run for years without recharging.
Answer: The correct answer is B. Edge ML fits applications that need sub-100 ms response, on-premises data retention, and access to gateway or server-class local hardware — industrial inspection and retail video analytics are the canonical cases. The GPT-3-scale option belongs to cloud because of its compute budget. The smartphone case is Mobile ML, defined by battery energy and passive cooling rather than location. The coin-cell case is TinyML, defined by kilobyte-scale memory and microjoule-scale energy — a different regime of physical constraints.
Learning Objective: Map an application’s latency, privacy, and power requirements to the Edge ML paradigm rather than adjacent tiers.
Self-Check: Answer
What distinguishes Mobile ML from Edge ML in the chapter’s paradigm framework?
- Mobile ML mainly differs by using smaller training datasets, while Edge ML uses larger ones.
- Mobile ML adds a fixed battery energy budget and a passively-cooled thermal envelope around 3 W, so sustained energy efficiency matters more than peak local compute — edge servers on mains power and active cooling face neither constraint.
- Mobile ML requires constant network connectivity, while Edge ML operates fully offline.
- Mobile ML eliminates latency concerns entirely because all inference happens on-device.
Answer: The correct answer is B. The section defines Mobile ML by the battery energy budget and the passive-cooling thermal ceiling — constraints that force sustained-efficiency optimization rather than peak-compute optimization. The connectivity answer is inverted; offline operation is a mobile advantage, not a requirement. The ‘no latency’ answer confuses local execution (eliminates the network round-trip) with the absence of latency (a 3 W thermal ceiling still bounds how fast inference can run). The dataset-size answer is unrelated — training dataset size is not the axis that separates these paradigms.
Learning Objective: Distinguish Mobile ML from Edge ML using the battery-energy and thermal-envelope constraints unique to mobile devices.
Why does the chapter treat energy per inference as a first-order design parameter on mobile devices rather than a post-hoc optimization detail?
Answer: Every inference pulls from a fixed daily battery budget and also dissipates heat into a passively-cooled device, so energy per inference directly controls both how long the feature can run and whether the processor can run it at all without throttling. Concretely, a 2 W always-on detector will drain a typical phone battery in a handful of hours, and a classifier drawing 3 W sits at the device’s sustained thermal ceiling with no headroom for the rest of the system. The practical implication is that a model that is fast per inference but expensive per inference is not a deployable mobile feature; the binding metric is the product of frequency times energy across the day, and architecture, precision, and scheduling must be chosen together with that budget in mind.
Learning Objective: Explain why energy per inference drives Mobile ML architecture selection rather than being a downstream optimization.
A team wants to ship a large on-device model that draws 12 W before optimization. Aggressive quantization cuts its power by 4×. Using the section’s thermal-wall framing, what is the correct conclusion about sustained deployment?
- The model now sits near the 3 W mobile thermal ceiling, so quantization alone does not create sustained deployment headroom — it reaches the limit rather than clearing it.
- The model is now comfortably below the thermal wall, so sustained performance is no longer a concern and the feature can run continuously.
- The model becomes ideal for always-on mobile inference, since 3 W is well under any battery-tax threshold the section discusses.
- The result proves that enough precision reduction can always overcome mobile thermodynamics, regardless of starting power.
Answer: The correct answer is A. Twelve watts reduced by 4× lands at roughly 3 W, which the section identifies as the sustained thermal ceiling of a passively-cooled mobile device — not a comfortable margin. Running at the ceiling leaves zero headroom for the rest of the SoC (radios, display, other tasks) and triggers throttling under minor temperature rises. The ‘comfortably below the wall’ and ‘ideal for always-on’ answers misread the 3 W figure as a floor rather than as the ceiling. The ‘always overcomes thermodynamics’ answer overgeneralizes from one success; the mechanism makes clear that precision reduction has a floor below which accuracy collapses.
Learning Objective: Analyze the limits of quantization as a solution to the mobile thermal wall and recognize that reaching the ceiling is not the same as clearing it.
Why is architecture-aware design necessary for mobile deployment rather than taking a desktop-trained model and exporting it to a phone?
- Because mobile deployment failures are primarily caused by lower cellular-network bandwidth.
- Because phones forbid models trained with floating-point arithmetic from executing at all.
- Because desktop-trained models can violate mobile constraints on memory footprint, supported operators, batch-size assumptions, and precision — even when the trained model’s task accuracy is high on desktop benchmarks.
- Because mobile inference requires every model to be rewritten as a hand-authored rules engine before deployment.
Answer: The correct answer is C. The section identifies a cluster of failure modes when desktop models are exported unchanged: memory footprints that exceed mobile RAM, operators unsupported by mobile runtimes, batch-size assumptions that collapse at batch 1, and precision choices that do not run on mobile NPUs. Architecture-aware design means choosing operators, precisions, batch behavior, and footprints with the mobile constraints in mind from the start. The cellular-bandwidth answer misidentifies the bottleneck. The floating-point answer is factually wrong. The rules-engine answer replaces a systems argument with an implausible implementation restriction.
Learning Objective: Evaluate why Mobile ML requires architecture-aware model design that accounts for memory, operator, precision, and batch constraints from the start.
True or False: A phone’s published NPU TOPS rating is a good predictor of short interactive bursts (e.g., one or two seconds of inference) but a poor predictor of sustained always-on workloads, because the same silicon that hits its peak in a cold-start burst throttles aggressively once thermal mass saturates.
Answer: True. Peak TOPS is measured in a thermally-unloaded state, so it approximates what the device can deliver for brief interactive tasks before the die warms up — matching the section’s observation that mobile performance is time-varying. Once the device operates continuously, governors cut clock and voltage to stay within the passive-cooling envelope, and sustained throughput often falls by 50 percent or more from the published peak; a production always-on workload sees the throttled figure, not the burst figure. The nuance the section makes explicit is that TOPS is not universally misleading — it is misleading for the regime where it matters most to unattended features.
Learning Objective: Distinguish the regimes in which peak NPU TOPS is a valid versus invalid predictor of realized mobile performance.
Self-Check: Answer
What makes TinyML a qualitatively different deployment paradigm rather than ‘just smaller mobile ML’?
- TinyML is defined mainly by low model parameter count, with energy and memory behavior as secondary considerations.
- TinyML runs on microcontrollers with kilobyte-scale memory and milliwatt-scale power, so the primary optimization targets become microjoule-per-inference energy and on-chip model residency — a regime where mobile techniques are necessary but not sufficient.
- TinyML is identical to mobile deployment except that the devices use weaker CPUs.
- TinyML exists mainly because smartphone operating systems are too complex for simple sensing applications.
Answer: The correct answer is B. The section defines TinyML by its microcontroller regime: kilobyte-scale SRAM, milliwatt-scale sustained power, and the consequence that microjoules-per-inference and on-chip fit become first-order constraints the mobile regime does not yet impose. The parameter-count-only answer ignores that the binding constraints are energy and memory, not parameter count. The ‘just weaker CPUs’ answer collapses three orders of magnitude in memory and six in power into a speed difference. The OS-complexity answer confuses a software observation with the chapter’s physics argument.
Learning Objective: Distinguish TinyML from mobile and edge deployment using its defining physical constraints on energy and memory.
Why does the chapter emphasize that a TinyML keyword spotter can be roughly \(10^8\) times more energy-efficient per inference than a cloud LLM query?
- To show that TinyML models always achieve higher task accuracy than cloud models.
- To illustrate why always-on ubiquitous sensing is only feasible at the TinyML tier, because the cloud alternative is not merely slower but energetically incompatible with unattended multi-year battery operation.
- To argue that network transmission becomes free once data is compressed enough.
- To prove that cloud accelerators are poorly designed for any inference workload regardless of scale.
Answer: The correct answer is B. The eight-order-of-magnitude energy gap is not a tuning observation; it is a feasibility boundary. Always-on sensors that must run for months or years on a coin cell have an energy budget per inference that the cloud path — even excluding the network — cannot approach, so the TinyML regime exists because no amount of cloud optimization collapses that gap. The accuracy answer swaps an energy argument for a model-quality one the section does not make. The ‘transmission is free’ answer contradicts the Energy of Transmission argument. The ‘cloud is poorly designed’ answer overgeneralizes from the sensing case to all inference.
Learning Objective: Interpret the \(10^8\)× energy gap as the feasibility boundary that makes always-on ubiquitous sensing a TinyML-only regime.
Explain why on-device training is usually not the default design for TinyML systems, and what this implies for how TinyML models reach and stay in the field.
Answer: Training requires storing activations for backpropagation and optimizer state for every parameter — working sets that run to megabytes or gigabytes even for small models — which cannot coexist with the kilobyte-scale SRAM of a typical TinyML microcontroller. TinyML devices are therefore almost always inference-only: the model is trained once on cloud or edge hardware, compressed and compiled for the target, then pushed as a firmware artifact. The system consequence is that the critical engineering work shifts away from on-device learning and toward the deployment pipeline — over-the-air update mechanisms, compression and quantization toolchains, versioning, rollback, and compatibility with long-lived unattended devices. A TinyML program that ships a model without a production firmware-update pipeline ships a model that can never be corrected.
Learning Objective: Explain why TinyML memory budgets force inference-only design and identify the pipeline consequences for model deployment and updates.
A TinyML engineer is told ‘just stream the weights in from off-chip flash for each inference — flash is cheap and capacity is plentiful.’ Explain the mechanism by which this approach breaks the TinyML energy budget for an always-on workload, and how the resulting design principle follows from the numbers.
Answer: Off-chip memory access costs one to two orders of magnitude more energy per byte than on-chip SRAM access because driving the off-chip bus requires charging long wires and off-package capacitance, and the access traverses pads, PCB traces, and memory-controller logic that on-chip references skip. Concretely, a 1 pJ on-chip read becomes 50–200 pJ off-chip, so streaming a model’s worth of weights off-chip for every inference multiplies the per-inference energy by one to two orders of magnitude. An always-on workload at, say, 10 inferences per second would exhaust a coin cell in days rather than years. The design principle follows mechanically: the model (weights, activations, working tensors) must reside entirely in on-chip SRAM so that the inference-time access cost is SRAM-bounded. The practical consequence is that TinyML model design is constrained first by whether the model fits in on-chip memory, not by accuracy or latency.
Learning Objective: Analyze why off-chip memory access violates the TinyML energy budget for always-on workloads and derive the on-chip-residency design principle.
Which application best matches the deployment logic of TinyML as framed in this section?
- A global recommendation engine with terabyte-scale embedding tables updated continuously from streaming telemetry.
- A cloud-hosted chatbot that tolerates hundreds of milliseconds of latency per turn.
- A remote wildlife sensor that must analyze audio locally for months on a battery and uplink only compact detection summaries a few times a day.
- A retail-store edge server aggregating data from dozens of cameras while plugged into mains power.
Answer: The correct answer is C. The remote wildlife sensor is the section’s canonical TinyML case: months of unattended operation on a battery, local inference at microjoule-scale energy, and radical bandwidth reduction by uploading only detections rather than raw audio. The recommendation engine is cloud-scale. The chatbot is cloud-class inference. The retail-store edge server is Edge ML — it assumes mains power, server-class compute, and a different set of operational concerns from a battery-powered sensor.
Learning Objective: Map a sensing application to the TinyML paradigm based on energy budget, unattended operation, and bandwidth-reduction requirements.
Self-Check: Answer
Applying the decision framework to autonomous emergency braking, which constraint eliminates cloud deployment before compute or cost is even considered?
- Latency, because the round-trip network delay alone consumes the millisecond-scale response budget.
- Privacy, because vehicle camera data is always legally forbidden from leaving the car under every jurisdiction.
- Cost, because cloud inference is always more expensive per query than onboard automotive hardware.
- Scalability, because cloud systems cannot support many vehicles simultaneously.
Answer: The correct answer is A. The worked example prunes cloud first on latency: the braking budget is physically incompatible with a cloud round-trip, so no compute or cost analysis can rescue that option. The privacy answer is a plausible secondary consideration but not the decisive filter the example applies first. The cost-always answer overgeneralizes; cloud cost varies with utilization and is not categorically higher. The scalability answer confuses fleet-wide concurrency with per-request latency.
Learning Objective: Apply the decision framework to eliminate deployment paradigms using the hardest binding constraint first.
What is the principal lesson of the fourteen-dimension comparison table across the four paradigms?
- Cloud dominates every operational dimension if the team can afford enough compute.
- Each paradigm occupies a distinct trade-off region, so deployment selection requires balancing latency, privacy, power, cost, offline capability, and fleet complexity simultaneously rather than optimizing any single axis.
- TinyML is preferable whenever privacy matters, regardless of compute requirements.
- Mobile and edge are operationally identical once both run inference locally.
Answer: The correct answer is B. The table’s pedagogical point is that no paradigm wins every dimension, so architects must reason across multiple axes at once — the choice is a region, not a ranking. The ‘cloud dominates everything’ answer contradicts the privacy, offline, and energy rows of the table. The ‘TinyML for privacy regardless’ answer ignores compute requirements entirely; a heavy workload cannot fit in kilobytes of SRAM. The ‘mobile = edge’ answer collapses distinct power and thermal envelopes the table separates.
Learning Objective: Compare deployment paradigms across multiple operational dimensions rather than a single metric.
Why does the section warn against choosing a deployment paradigm primarily on model accuracy, even when one paradigm’s accuracy is measurably higher?
Answer: Accuracy is irrelevant if the model cannot ship: a 99 percent accurate cloud model is useless for a 10 ms control loop because the network round-trip alone exceeds the budget, and a 95 percent accurate on-device model that drains the battery in 20 minutes is a failed deployment regardless of how good its predictions are. The section frames accuracy as one dimension inside a feasibility envelope defined by latency, power, memory, privacy, and cost; a proposal must fit the envelope before its accuracy number is meaningful. The practical consequence is that feasibility constraints must be fixed as inputs to model development, not retrofitted after accuracy has been optimized against an infeasible target.
Learning Objective: Evaluate deployment choices using feasibility constraints as prerequisites to accuracy rather than as competing objectives.
A team is scoping a new smartwatch health-monitoring feature that must (a) respect medical-data privacy, (b) respond within 50 ms to detected anomalies, (c) run continuously on a battery, and (d) remain cheap per user. Using the chapter’s decision framework, what is the correct sequence of filters to apply and which paradigm does the framework select?
- Apply cost → latency → privacy → compute; the framework picks Cloud ML because it is cheapest per user at scale.
- Apply privacy → latency → compute → cost; privacy forces local processing, latency rules out cloud, continuous battery operation rules out Edge ML, and the compute budget together with the battery constraint select Mobile ML (with TinyML components for always-on sensing).
- Apply compute → cost → latency → privacy; the framework picks TinyML because it has the smallest compute footprint.
- Apply privacy → compute → cost → latency; the framework picks Edge ML because it dominates on privacy.
Answer: The correct answer is B. The flowchart asks privacy first (here: medical data must stay on-device, disqualifying cloud), then latency (here: 50 ms is sub-network-round-trip, reinforcing local), then compute (here: modest, compatible with mobile and some TinyML), then cost (here: per-user hardware already chosen by the form factor). The first option reorders the framework and misattributes the outcome to cost. The third option treats compute as the leading filter, which the section explicitly argues against because compute-first can waste effort on infeasible architectures. The fourth option skips the latency filter entirely, which can select a paradigm that fails a hard constraint.
Learning Objective: Apply the decision framework’s filter ordering (privacy → latency → compute → cost) to a multi-constraint scenario and justify the resulting paradigm selection.
True or False: The Complexity Tax argument implies that a simpler heuristic can be the better systems choice even when an ML model is somewhat more accurate, because infrastructure, monitoring, and maintenance costs can outweigh a small accuracy gain.
Answer: True. The section argues that if a small accuracy improvement from ML requires a disproportionately larger stack — data pipelines, drift monitoring, retraining, on-call coverage, versioning — the simpler heuristic may dominate on total cost, reliability, and time-to-ship. The right question is not ‘which is more accurate?’ but ‘which has the better accuracy-per-unit-complexity ratio at our deployment scale?’
Learning Objective: Evaluate when operational complexity tips a deployment decision away from ML toward a simpler heuristic.
Self-Check: Answer
Why do production ML systems frequently use hybrid architectures rather than committing to a single deployment paradigm?
- Because using multiple paradigms is mainly a code-reuse preference that simplifies software engineering.
- Because training, inference, privacy, latency, bandwidth, and power constraints often point to different optimal locations for different stages of the workload, so no single tier satisfies all constraints at once.
- Because cloud providers require on-device inference before they will allow remote training contracts.
- Because edge, mobile, and TinyML devices cannot run any useful inference on their own.
Answer: The correct answer is B. The section’s examples — voice assistants, autonomous vehicles, health monitoring — show that different pipeline stages sit in different physical regimes: wake-word detection at TinyML energy scale, on-device speech at mobile scale, language understanding at cloud scale. One deployment target rarely satisfies all constraints simultaneously, so hybridization is an architectural response to the physics, not a coding preference. The code-reuse answer misses the physics argument. The provider-contract answer is factually wrong. The ‘devices cannot run inference’ answer contradicts every earlier section of the chapter.
Learning Objective: Explain why production ML systems partition workloads across multiple deployment paradigms in response to conflicting physical and operational constraints.
A voice-assistant team has one canonical 7B-parameter speech model trained in the cloud. They must deliver a 1 MB wake-word model on earbuds, a 50 MB on-device command model on phones, and a 1 GB conversational model on home hubs — all derived from the same cloud training artifact. Which integration pattern best describes this arrangement, and why does it fit better than Train-Serve Split alone?
- Train-Serve Split alone, because every artifact is trained centrally and served locally — the multi-tier compression is incidental.
- Progressive Deployment, because the pattern explicitly systematizes compressing one model family into multiple capability-tier artifacts (earbud, phone, home hub) — Train-Serve Split describes central training with local serving but does not by itself capture the multi-tier compression ladder.
- Hierarchical Processing, because the earbud filters requests for the hub, which filters for the cloud.
- Federated retraining, because each tier updates the central model from local data.
Answer: The correct answer is B. Progressive Deployment is the pattern that specifically addresses one-model-to-many-tiers compression and distillation: the same trained artifact is systematically reduced and adapted for earbud, phone, and hub. Train-Serve Split captures ‘train in cloud, serve locally’ but says nothing about the ladder of tier-specific artifacts that Progressive Deployment is named for. Hierarchical Processing describes a request-routing topology (wake-word → local speech → cloud language), not an artifact-compression pipeline. Federated retraining inverts the data flow and is not what is described here.
Learning Objective: Distinguish Progressive Deployment from Train-Serve Split in a concrete multi-tier product architecture and justify the pattern selection.
Why does the section argue that hybrid architectures work only when work is partitioned across tiers rather than when the same pipeline is copied everywhere?
Answer: Each tier has distinct comparative advantages: TinyML delivers microjoule-scale always-on sensing, mobile handles personalized short-burst inference on battery, edge aggregates and makes real-time decisions on-site, and cloud handles heavy analytics, retraining, and global aggregation. Copying the same pipeline to every tier wastes each tier’s strengths — raw sensor streams flooded upward waste bandwidth that edge aggregation would compress to detections, and heavyweight cloud models pushed downward waste on-device energy that a distilled model would preserve. The right design partitions each stage to its best-fit tier: sensing at the bottom, aggregation in the middle, learning at the top. The system consequence is that tier boundaries should be chosen by identifying where the binding bottleneck shifts — latency, privacy, bandwidth, or power — not by administrative convenience.
Learning Objective: Analyze how hybrid architectures derive their value from task partitioning aligned with each tier’s comparative advantages.
In a production hybrid ML system, which statement best characterizes the data and model flows between tiers?
- Models and labels flow strictly upward, while raw data remains pinned at the lowest tier forever.
- Models flow downward from centralized training to deployment tiers, while telemetry, data summaries, and inference results flow upward to support analytics, drift detection, and retraining — the structure is bidirectional and asymmetric.
- All tiers continuously exchange identical full-state replicas, so no specialization is needed.
- Only cloud and TinyML tiers communicate directly; edge and mobile tiers serve purely as backup replicas.
Answer: The correct answer is B. The section describes a bidirectional, asymmetric flow: trained and distilled models cascade from cloud down to edge, mobile, and TinyML; telemetry, summarized data, and inference outcomes travel upward for analytics, monitoring, and retraining cycles. The ‘strictly upward’ answer truncates half the flow. The ‘identical replicas’ answer contradicts the entire motivation for tier specialization. The ‘cloud-TinyML only’ answer invents a topology the section does not describe.
Learning Objective: Describe the bidirectional, asymmetric data and model flows that characterize production hybrid architectures.
True or False: The section argues that optimization ideas (quantization, pruning, kernel fusion, KV-cache management) transfer across cloud, edge, mobile, and TinyML because the four paradigms share deeper principles around data pipelines, resource management, and system architecture despite their different hardware envelopes.
Answer: True. The convergence argument is that the same core concerns — moving fewer bytes, fitting working sets into the fastest memory tier, keeping pipelines fed, and managing end-to-end latency — recur at every scale. Techniques designed for one tier typically translate with reparameterization rather than reinvention, which is why the rest of the book’s optimization chapters are deliberately written paradigm-agnostically.
Learning Objective: Explain why shared system principles allow optimization techniques to transfer across deployment paradigms.
Self-Check: Answer
Which of the following deployment beliefs does the chapter identify as a fallacy?
- Running inference on-device always provides better user privacy than cloud inference does, because on-device data never reaches a remote data center.
- A single deployment paradigm can cover any ML workload if the team is willing to optimize the model aggressively enough, because physical constraints are engineering choices rather than physical laws.
- Hardware-specific optimization can materially improve edge-device efficiency and latency beyond what generic binaries achieve.
- Total system speedup is bounded by the fraction of the pipeline that remains unoptimized, so optimizing a non-dominant stage yields only modest end-to-end gains.
Answer: The correct answer is B. The section labels as fallacy the belief that any single paradigm can serve all workloads given enough optimization effort — latency, power, memory, and scale create incompatible requirements that no amount of model engineering can dissolve. The privacy claim in the first option is largely true at the mechanism level (on-device data that never leaves the device cannot be exfiltrated in transit), even if it is not absolute; the section does not label it a fallacy. The hardware-specific-optimization answer and the Amdahl-pipeline answer are both cited in the chapter as correct engineering principles, not misconceptions.
Learning Objective: Identify the one-paradigm-solves-all fallacy from a set of plausible deployment beliefs, including partial truths.
Why is it a design mistake to treat TinyML as simply scaled-down Mobile ML, and what does that imply for the engineering workflow when moving a mobile feature to a microcontroller?
Answer: The gap is not incremental; it is orders of magnitude. Mobile devices live around gigabytes of RAM and watts of sustained power; TinyML lives around kilobytes of SRAM and milliwatts of sustained power. That is roughly a 10,000× memory gap and a thousand-fold-class power gap, which forces different model architectures (depthwise-separable convolutions give way to 8-bit or 4-bit integer-only operators), different precision targets (often INT8 or INT4 only), different deployment pipelines (firmware OTA rather than app-store updates), and different feature scopes (always-on classification rather than on-demand conversation). The implication for workflow is that a mobile-to-TinyML port is usually not ‘quantize and re-profile’ but ‘redesign around the energy and on-chip-memory budget from scratch,’ with the mobile model serving only as a reference for what the task looks like — not as the starting point of the compression chain.
Learning Objective: Compare TinyML and Mobile ML design constraints and justify why porting between them requires qualitative architectural redesign.
A smartphone camera pipeline spends 100 ms in image signal processing, 60 ms in ML scene classification, and 40 ms in post-processing. A team makes the ML stage 10× faster. What is the correct Amdahl-grounded conclusion about the full pipeline?
- Total latency drops by roughly 10×, because the ML stage is the ‘intelligent’ part of the workload.
- Total latency drops modestly — from 200 ms to about 146 ms — because 140 ms of non-ML pipeline remains unchanged, and Amdahl’s Law caps system speedup when non-dominant stages are unoptimized.
- Total latency cannot be predicted without knowing how model accuracy changes in response to the speedup.
- The full pipeline becomes network-bound because the ML stage no longer dominates and the system must compensate.
Answer: The correct answer is B. Before: 100 + 60 + 40 = 200 ms. After 10× ML speedup: 100 + 6 + 40 = 146 ms — a 27 percent end-to-end improvement on a nominally ‘10×’ speedup, because 70 percent of the pipeline is unchanged. This is the Amdahl fallacy the section warns against: component benchmarks do not map directly to system-level wins. The accuracy answer confuses a quality metric with latency composition. The network-bound answer invents a bottleneck change unsupported by the stage decomposition given.
Learning Objective: Apply Amdahl’s Law to a staged pipeline to predict the end-to-end speedup from a single-stage optimization.
Why can minimizing compute spend fail to minimize total cost of ownership in deployment planning?
- Because development, operations, networking, maintenance, and reliability engineering often dominate TCO, so saving dollars on compute can be overwhelmed by growth in the non-compute cost lines.
- Because reducing compute spend always degrades model accuracy enough to offset any savings.
- Because hardware amortization becomes irrelevant once a model reaches production.
- Because cloud providers bundle labor and networking into free inference tiers that cover those costs automatically.
Answer: The correct answer is A. The section’s TCO example shows that non-compute cost lines — DevOps headcount, networking, monitoring, drift management, on-call coverage, maintenance windows — routinely dominate cloud or edge deployments, so a purely compute-minimizing decision can raise total cost by inflating those categories. The ‘accuracy always collapses’ answer overgeneralizes. The ‘amortization irrelevant’ answer is factually wrong. The ‘free inference tiers’ answer misstates cloud pricing and misses the operational-cost argument.
Learning Objective: Evaluate total cost of ownership across compute, operational, and engineering cost lines, not compute alone.
True or False: Deploying the same model binary unchanged across all edge devices is usually efficient enough, because hardware-specific optimization offers only marginal gains and the engineering effort is not justified.
Answer: False. Per-target optimizations — quantization paths matched to the accelerator’s native integer width, operator fusion shaped to the on-chip memory hierarchy, and accelerator-aware memory layouts — routinely deliver multi-× efficiency and latency improvements that generic binaries miss. The section argues that hardware-specific optimization is especially high-leverage in heterogeneous edge fleets where devices vary in ISA, memory topology, and NPU capabilities; a one-binary-fits-all policy leaves most of that leverage on the table.
Learning Objective: Recognize why hardware-specific optimization materially changes efficiency and latency in heterogeneous edge fleets.
Self-Check: Answer
What is the chapter’s central explanation for why the same model requires different engineering on a phone, on an edge server, and in a data center?
- Different product teams prefer different software stacks, so deployment styles diverge over time.
- Physical constraints — the light barrier, the power wall, and the memory wall — carve the deployment landscape into distinct operating regimes that force different architectures, not the other way around.
- Models change their mathematical behavior when they are exported to smaller devices, so the algorithm itself becomes paradigm-dependent.
- Embedded deployments use smaller training datasets than cloud deployments, which drives the downstream engineering divergence.
Answer: The correct answer is B. The summary frames the answer as physics: the speed of light, thermodynamic limits on power, and the compute-bandwidth gap partition the deployment landscape into operating regimes. The software-stack answer mistakes a consequence for a cause. The ‘mathematical behavior changes’ answer is wrong; a quantized model’s arithmetic is approximated, not re-specified. The training-data-size answer invokes an axis the chapter does not use to explain paradigm divergence.
Learning Objective: Summarize the chapter’s physics-driven explanation for paradigm diversity.
Why does the summary insist that bottleneck identification precede any optimization decision in an ML system?
Answer: The same model can shift between compute-bound, memory-bound, and latency-bound regimes depending on batch size, phase (training vs inference), and deployment target, so optimizing a non-dominant iron-law term yields near-zero system gain — the chapter’s recurring cautionary pattern. A team that doubles accelerator FLOPS on a memory-bound kernel spends money and engineering effort for no wall-clock improvement; the same team that first identifies the bottleneck can apply quantization or fusion to the actual binding term. The practical consequence is that the iron law and the Bottleneck Principle are not theoretical scaffolding but the instruments engineers use to avoid the most common and expensive class of optimization mistake.
Learning Objective: Explain why bottleneck identification is a prerequisite for effective ML systems optimization.
True or False: The summary presents hybrid architectures as unusual special cases, implying most production systems should commit to a single deployment paradigm once the right benchmark is chosen.
Answer: False. The summary explicitly positions hybrid architectures as the production norm, not an edge case, because real workloads face different constraints at different pipeline stages — TinyML wake-word detection, mobile on-device speech processing, and cloud language understanding coexist routinely within one product. Single-paradigm commitment is the special case; hybrid is the default.
Learning Objective: Recognize hybrid architectures as the common production response to conflicting deployment constraints.