Week 10: Optimizing the Optimizers: When LLM Systems Adapt Themselves
Last week, we examined predictive reasoning: the ability to design systems for patterns you can’t fully observe or characterize. Architects designing memory systems must predict access patterns from sparse signals, across heterogeneous workloads, with fundamentally incomplete information.
But what if the patterns don’t just resist characterization? What if they actively change while your system is running?
This week brings a different type of architectural reasoning. We’re no longer just designing for uncertainty. We’re building systems that continuously adapt as reality unfolds, making decisions in real time while serving production traffic, balancing the need to explore new strategies against the pressure to exploit what already works.
How do you design systems that optimize themselves as conditions change?
This isn’t just an operational challenge. It’s a question about the nature of adaptation itself. Traditional systems separate design-time optimization from runtime execution. But modern generative AI systems demand something different: continuous adaptation at multiple timescales, with the system itself participating in its own optimization.
Let’s call this adaptive reasoning: the ability to make informed optimization decisions in real-time, learning from experience while maintaining service guarantees, often with the system reasoning about its own performance.
This is the third type of tacit architectural knowledge we’re exploring in Phase 2. And it reveals a unique moment in systems history: a domain where humans don’t have decades of accumulated wisdom, where we’re learning adaptive reasoning principles alongside AI agents.
Traditional Adaptive Systems: The Heuristic Approach
To understand what makes generative AI serving different, we need to first understand how traditional systems adapt. For decades, systems have used adaptation, but it looked fundamentally different.
Traditional adaptive systems rely on heuristics: hand-coded rules based on observed patterns. Consider a few canonical examples.
TCP congestion control adapts send rates based on network conditions. The rules are explicit: multiplicative decrease when you detect packet loss, additive increase when things seem fine. These heuristics were refined over decades by networking researchers who understood queuing theory and network behavior. The Reno algorithm and its variants encode this human expertise as concrete decision rules.
Database query optimizers adapt execution plans based on table sizes and available indices. The cost models are analytical: “nested loop joins cost O(n×m), hash joins cost O(n+m), choose accordingly.” Database researchers built these cost-based optimizers by deeply understanding access patterns and developing mathematical models of different operations.
Operating system schedulers adapt process priorities based on behavior. If a process blocks frequently waiting for I/O, give it higher priority (it’s interactive). If it runs continuously using CPU, lower its priority (it’s batch workload). These rules, implemented in schedulers like Linux CFS, were developed through careful study of workload characteristics.
What unifies these examples? The adaptation logic is explicit, rule based, and developed by human experts. Someone observed patterns, understood the underlying dynamics, and codified that understanding as heuristics. The system adapts, but it adapts according to predetermined rules.
This approach works well when:
- Patterns are relatively stable over time
- Rules can be expressed as simple conditions
- Human experts can articulate what makes a good decision
- The action space is limited (increase/decrease, choose option A/B)
But this approach struggles when patterns are complex, constantly shifting, or when the optimal strategy depends on intricate interactions that resist simple rules. That’s where machine learning-based adaptation becomes attractive.
And that’s where generative AI workloads create an entirely new challenge.
Why Generative AI Serving Demands Adaptation
Before diving into how systems adapt, we need to understand what makes generative AI fundamentally different from traditional ML workloads. The answer isn’t complexity alone. It’s that resource consumption patterns emerge during execution in ways you simply can’t predict upfront.
The Shift from Fixed to Iterative Computation
Traditional ML inference follows a predictable pattern. Image classification with ResNet or ViT: one forward pass through the network, fixed computation, done. Object detection with YOLO or Faster R-CNN: scan the image, run NMS, predictable memory footprint. These workloads batch efficiently because every request consumes roughly the same resources.
Think about what traditional systems can observe at request arrival: image size, input tensor dimensions, model architecture. From this information alone, you can calculate exactly how much compute and memory the request needs. A 224×224 image through ResNet-50 takes the same resources regardless of what’s in the image. This is why heuristic schedulers work well. FCFS (first come first served) is perfectly reasonable when all requests are roughly equal.
Generative AI shatters this predictability.
Autoregressive language models like GPT, LLaMA, and Claude generate text token by token. Each token requires attending to all previous tokens, so computation grows quadratically with sequence length. A request arrives as a short 10 token prompt but generates a 1,000 token response, consuming 100x more memory than you might have guessed at first glance.
Diffusion models like Stable Diffusion, DALL-E, and Sora refine outputs through multiple denoising steps. Quality demands determine step count. Simple prompts converge quickly. Complex compositions need extensive refinement. You can’t know from the request how much compute you’ll need. It emerges during generation.
Multimodal generation combines these patterns and amplifies the challenge. Text, images, and video have wildly different resource profiles. A single request might involve reasoning about hundreds of tokens of text, generating millions of pixels of imagery, and producing video where the temporal dimension adds orders of magnitude more data.
The common thread: you can’t predict resource consumption from request characteristics alone. It emerges during generation.
Observable vs Emergent Characteristics: In traditional ML, all relevant information for scheduling decisions is observable at request arrival. You know the input dimensions, the model architecture, the compute requirements. Your heuristics can immediately classify the request and make informed decisions. In generative AI, the most important characteristics (sequence length, generation quality, memory pressure) only become known as the model generates. By the time you know what resources a request needs, you’ve already made scheduling decisions. This inversion, from observable upfront to emergent during execution, is what breaks traditional adaptive systems.
Traditional heuristics assume you can observe what you need to make decisions. Generative AI violates this assumption. The scheduler must make initial decisions with incomplete information, then continuously adapt as the true requirements emerge.
The KV-Cache Problem: Memory That Grows as You Generate
Let’s make this concrete with the KV cache, the architectural challenge that defines LLM serving.
Transformer models process sequences using attention mechanisms. For each generated token, the model must attend to all previous tokens in the sequence. Recomputing attention for all previous tokens at each step would be prohibitively expensive. Instead, we cache the key and value pairs from previous computations. This is the KV cache.
Here’s the problem: the KV-cache grows with every generated token. Start with a 10-token prompt, and you have a small cache. Generate 1,000 tokens, and your cache has grown 100x. Memory pressure increases during serving, not before it.
This creates cascading scheduling challenges. You can’t allocate fixed memory per request because you don’t know how much they’ll need. You can’t predict batch sizes because requests complete at different times. A request that looked small at arrival dominates your memory by the time it finishes.
Traditional memory management assumes you know resource needs upfront. Generative AI makes this assumption untenable. Systems like vLLM with PagedAttention tackle this by treating KV cache like virtual memory, allowing more flexible allocation. But even with better memory management, the fundamental challenge remains: you must adapt continuously as resource needs emerge.
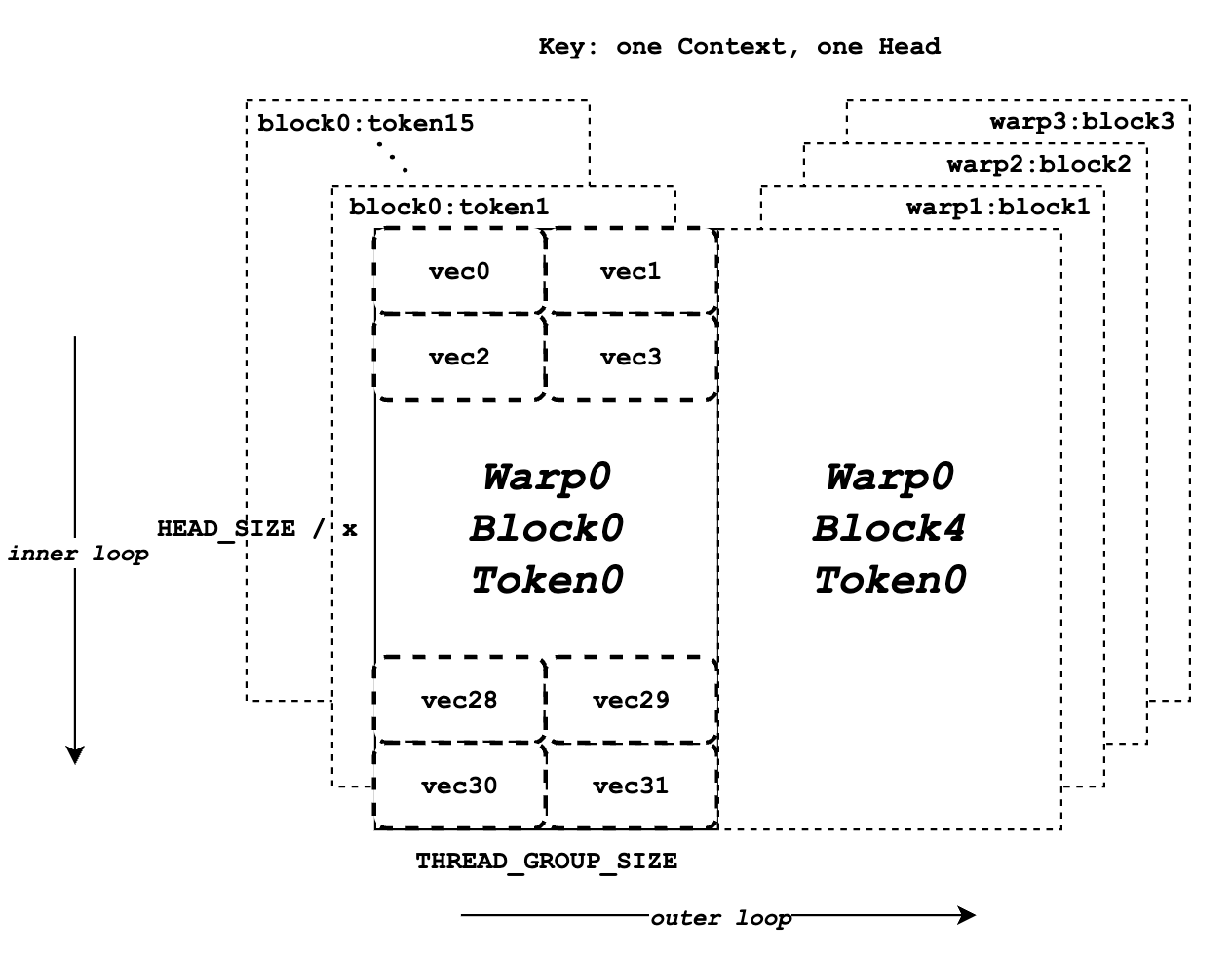
Multi-Phase Workloads with Conflicting Optimization Goals
The KV cache problem connects to another unique characteristic: LLM inference has two distinct phases with opposing optimization strategies.
Prefill phase: Process the input prompt, computing attention for all input tokens simultaneously. This is compute-bound, highly parallelizable, and benefits from large batch sizes. Pack many requests together and process them efficiently.
Decode phase: Generate output tokens one at a time. Each token generation is memory-bound (loading the KV-cache), sequential (can’t parallelize token generation for a single request), and benefits from small batches (less memory contention).
Arrives] --> B[Prefill Phase
Compute-Bound
Large Batches
High Parallelism] B --> C[Decode Phase
Memory-Bound
Small Batches
Low Latency] C --> D{More
Tokens?} D -->|Yes| C D -->|No| E[Complete] style B fill:#ffebee style C fill:#e3f2fd style A fill:#e9ecef style E fill:#e8f5e9
The optimal batching strategy for prefill hurts decode performance, and vice versa. Pack a large batch for efficient prefill, and you’ll thrash memory during decode. Use small batches for decode efficiency, and you waste compute during prefill.
You must dynamically decide: which phase to prioritize? Which requests to batch together? When to accept new requests versus finishing current ones? These decisions ripple through the system, affecting throughput, latency, and fairness.
Quadratic Attention: Computational Complexity Emerges During Generation
The attention mechanism compounds these challenges. Attention scales O(n²) with sequence length. Double the sequence, quadruple the computation.
This creates emergent bottlenecks. A request generating tokens initially consumes modest compute. As the sequence grows, it begins dominating system resources. You can’t predict this from request arrival. It depends on how many tokens the model generates, which you don’t know until generation completes.
Traditional schedulers assume workload characteristics are observable at arrival (job size, resource needs). Generative AI violates this assumption. The computational profile emerges during execution.
Diffusion models show similar patterns. Early denoising steps focus on coarse features and can use lower precision. Late steps refine fine details, demanding higher precision and more memory. The optimal batch composition and compute strategy evolve across the denoising trajectory. Systems like Sarathi-Serve explore how to handle these throughput versus latency tradeoffs dynamically.
Adaptation isn’t optional. It’s mandatory. Static scheduling strategies inevitably misallocate resources because they can’t respond to emergent computational patterns.
Learning to Rank: Treating Scheduling as AI
How do we build schedulers that handle these challenges? This brings us to our first main paper: “Efficient LLM Scheduling by Learning to Rank”. The key insight: treat scheduling not as applying hand-coded heuristics, but as a learning problem.
Why Traditional Scheduling Fails
Traditional schedulers rely on simple policies. First-Come-First-Served (FCFS) is fair but ignores request characteristics. Shortest-Job-First (SJF) prioritizes quick requests but requires knowing job lengths upfront. Priority based schemes need manual tuning and don’t adapt to workload shifts.
The deeper challenge: scheduling decisions interact in complex ways. Batching request A with request B affects memory pressure, which influences whether you can accept request C, which determines head-of-line blocking for request D. These interactions resist simple heuristics.
The Learning-to-Rank Approach
The paper reframes scheduling as a ranking problem. Given pending requests, rank them by priority. Schedule the highest ranked requests first. The ranking function is learned, not hand-coded.Learning to Rank in Information Retrieval: The paper borrows techniques from learning to rank in information retrieval, where search engines learn to rank documents by relevance rather than using hand-crafted scoring functions. The key insight translates naturally to scheduling: instead of ranking documents by relevance to a query, rank requests by priority given current system state. Both involve learning from observed outcomes (which rankings led to user satisfaction vs which led to good throughput) rather than encoding explicit rules.
This makes sense because ranking captures relative priorities naturally. Is request A more important than request B given current system state? The learning framework handles complex interactions between request characteristics, system load, and performance objectives that simple rules struggle with.
You train the ranking model from traces of real LLM serving workloads. Observe which scheduling decisions led to good outcomes: high throughput, low latency, fairness. Train the ranking function to predict which orderings achieve these objectives.
The key innovation is that the model learns patterns heuristics miss. Maybe requests with certain prompt patterns tend to generate long sequences, so rank them lower to avoid memory pressure. Maybe batching specific request types together creates favorable memory access patterns. These patterns emerge from data, not from human intuition.
Adaptation Through Continuous Learning
Static learned policies face the same problem as heuristics: workload patterns shift. What worked yesterday might fail today when users submit different types of queries, or when a new model is deployed with different characteristics.
The paper addresses this through online learning. As the system serves requests, it observes outcomes. Which batching decisions led to good throughput? Which caused memory thrashing? The ranking function updates continuously based on recent experience.
This is adaptive reasoning in action. Not just designing a policy upfront, but learning and adjusting as conditions change. The system builds intuition from experience, similar to how human architects develop scheduling wisdom by observing many workloads.
The challenge is online learning under production constraints. You can’t freely experiment because that would hurt current performance. You must balance exploration, trying new rankings to find better strategies, with exploitation, using known good policies to serve current traffic. This exploration versus exploitation tradeoff is fundamental to adaptive reasoning.
Text-to-Text Regression: Systems as Semantic Understanding
While learning to rank addresses what to schedule, our second paper examines a more fundamental question: can we treat system optimization as language understanding? “Performance Prediction for Large Systems via Text-to-Text Regression” demonstrates something remarkable: semantic understanding of configurations and logs enables more accurate performance prediction than traditional numerical models.
The Limitation of Traditional Performance Modeling
Conventional performance prediction follows a standard pipeline. Extract numerical features from configurations: CPU count (32), memory size (128GB), network bandwidth (10Gbps). Train a regression model on these features. Predict latency, throughput, or efficiency.
The problem is that this loses semantic information. Configuration files aren’t just collections of numbers. They encode relationships, constraints, and context. Consider two configurations. One has 32 CPUs, 128GB memory, and a 10Gbps network. Another has 16 CPUs, 256GB memory, and the same 10Gbps network.
Numerical encoding treats these as independent feature vectors. But there’s semantic meaning here. The first configuration is compute heavy, likely good for parallel workloads. The second is memory heavy, suited for data intensive tasks. The relationship between CPU and memory ratios matters.
Traditional feature engineering tries to capture these relationships manually (add ratio features, interaction terms). But which relationships matter? That requires domain expertise, and the important patterns vary across systems.
Treating Configurations as Text
The paper’s insight is elegant. System configurations are already text. Logs are text. Telemetry includes textual descriptions. Instead of extracting numerical features, treat performance prediction as text-to-text regression.
Take configuration files, system logs, and telemetry as text input. Output performance metrics also rendered as text. Use a 60 million parameter encoder decoder transformer, trained to map input text to output text.
The results on Google’s Borg cluster scheduler are striking. The model achieves 0.99 rank correlation on resource efficiency prediction. It captures patterns that traditional feature engineering misses.
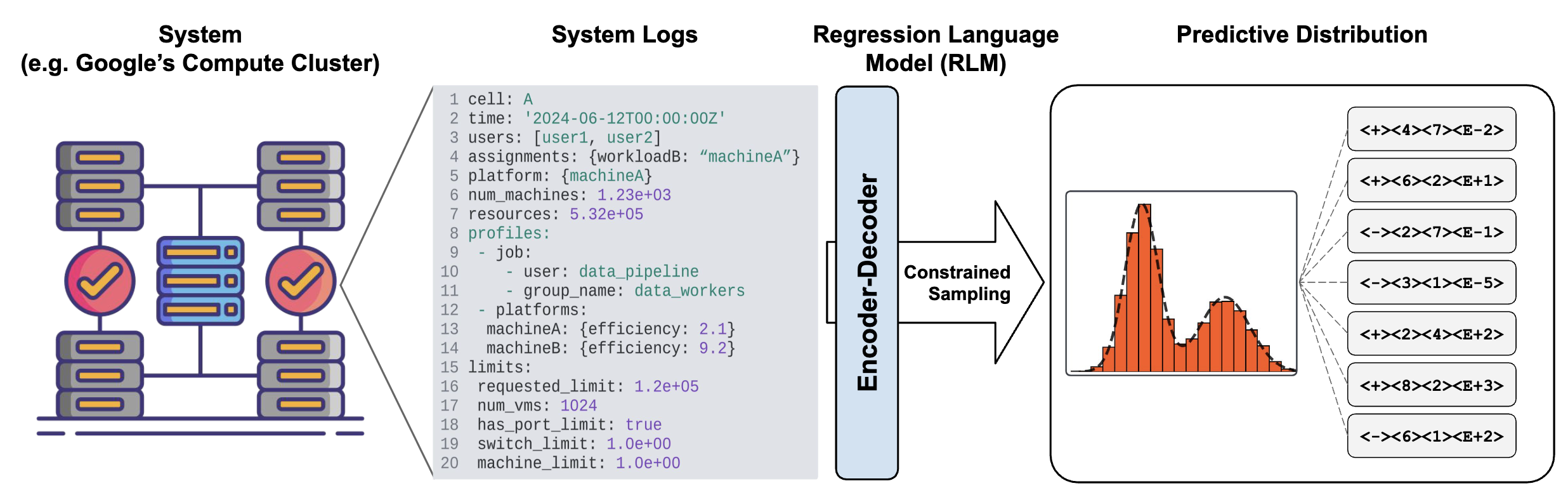
Why Semantic Understanding Works
What does the text-to-text model learn that numerical models don’t? It captures relationships between parameters that manual feature engineering misses. High CPU count with low memory suggests compute bound workloads. Error patterns in logs predict performance degradation through semantic connections, not just disconnected error codes. Labels like “CPU optimized instance” carry meaning beyond raw numbers. The hierarchical structure, comments, and context in configuration files remain intact rather than being discarded during numerical encoding.
This connects to Week 9’s learned index structures. Those systems learned CDFs of data distributions. Text-to-text regression learns semantic patterns in system configurations. Both show that machine learning can extract patterns humans struggle to codify explicitly.
Fine-Tuning with Minimal Data
Another key result: the model fine tunes to new systems with minimal data. Train on Borg scheduler traces, then adapt to a different cluster configuration with just a few hundred examples. The pre trained model already understands system semantics. It just needs to calibrate to the new environment.
This is important for adaptive reasoning. Production systems can’t afford extensive retraining when conditions change. A model that quickly adapts to new workloads, new hardware, or new configurations enables continuous optimization without extensive downtime.
The Meta Nature: LLMs Optimizing LLM Infrastructure
Here’s where it gets interesting. Text-to-text regression uses language models to predict system performance through semantic understanding. But many of the systems being optimized are themselves running language models. LLMs optimizing LLM infrastructure.
This creates opportunities traditional systems lack. The system can explain its own behavior in natural language. Ask why latency increased, and it can analyze logs with semantic understanding, not just pattern matching. When the scheduler makes a decision, it can articulate its reasoning in terms humans understand, building trust and enabling oversight. The optimizer and the workload speak the same language, literally.
Pre-trained language models already understand system semantics, so fine tuning to new configurations requires minimal data. As the system optimizes itself, humans learn from observing its decisions. The system learns from human corrections. Knowledge transfer flows both ways.
This blurs the boundary between “system” and “agent.” The text-to-text model is simultaneously a performance predictor and an agent participating in system optimization. This meta nature distinguishes modern adaptive systems from traditional control systems. The optimizer doesn’t just react to signals—it understands them semantically.
Industry Perspective: Agentic Workflows at Azure Scale
 Esha Choukse is a Principal Researcher in Microsoft’s Azure Research Systems group, leading the efficient AI project. Her work focuses on optimizing GenAI workloads and systems for efficiency and sustainability at cloud scale. She brings perspectives from deploying ML-driven optimization in production systems serving millions of requests daily, understanding both the promise of agentic workflows and the practical constraints that determine what actually ships.
Esha Choukse is a Principal Researcher in Microsoft’s Azure Research Systems group, leading the efficient AI project. Her work focuses on optimizing GenAI workloads and systems for efficiency and sustainability at cloud scale. She brings perspectives from deploying ML-driven optimization in production systems serving millions of requests daily, understanding both the promise of agentic workflows and the practical constraints that determine what actually ships.
Our guest speaker this week, Esha Choukse, provided context about what happens when adaptive systems meet production reality at scale. The gap between research results and deployed systems reveals much about where adaptive reasoning succeeds and where challenges remain.
The Cross-Stack Optimization Challenge
Azure serves diverse LLM workloads across thousands of GPUs. Models range from small (7B parameters) to massive (175B+). Users have different requirements: some need low latency for interactive applications, others optimize for throughput in batch processing. Hardware spans multiple GPU generations with different memory hierarchies, compute capabilities, and interconnect topologies.
Traditional approaches don’t scale to this complexity. You can’t manually tune for every model × workload × hardware combination. Conditions change faster than humans can react: workload patterns shift hour-by-hour, new models deploy continuously, hardware failures require dynamic rebalancing.
This demands automated adaptation. But adaptation at this scale introduces challenges research papers rarely confront.
Sherlock: Making Agent-Based Workflows Production-Ready
Esha’s work on agent-based optimization explores a provocative idea: systems that use AI agents to make scheduling and placement decisions. Agents observe system state, predict outcomes of different actions, make decisions, learn from results, and improve their policies over time.
The Sherlock project focuses on increasing the accuracy of these agent-based workflows. The key insight: when agents make decisions in production systems, their actions affect the very state they observe next. This creates feedback loops that naive learning approaches struggle with.
Example: An agent learns that batching certain request types together improves throughput. It starts preferentially creating these batches. Now those request types complete faster, changing the workload distribution the agent observes. The agent’s policy affected its own training data.
Handling these feedback loops requires sophisticated techniques.
First, counterfactual reasoning. What would have happened if the agent made a different decision? Comparing actual outcomes to counterfactuals helps disentangle the agent’s impact from natural workload variation.
Second, safe exploration. You can’t freely experiment in production. You must explore new strategies while maintaining service quality. This requires confidence bounds on decisions and gradual rollout mechanisms.
Third, interpretability. When an agent makes a scheduling decision, operators need to understand why. Black box policies don’t build trust. The system must explain its reasoning.
The Deployment Gap: What Ships vs What Stays in Papers
Esha emphasized a pragmatic reality. Many “optimal” strategies from research papers never deploy to production. The reasons reveal important constraints on adaptive reasoning.
Integration complexity is real. Production systems are complex, with many interconnected components. A “drop in” optimization that looks simple in a paper often requires extensive engineering to integrate safely. Changes that might disrupt existing workflows don’t ship, even if they’re theoretically better.
Production environments are risk averse. Stability often trumps optimality. A strategy that improves average performance by 20% but occasionally causes catastrophic failures won’t deploy. Operators prefer reliable, predictable performance over higher but variable performance.
Observability and debugging matter immensely. When something goes wrong, operators need to understand why and how to fix it. Adaptive systems that continuously change their behavior are harder to debug than static systems. Unless you provide excellent observability tools, operators won’t trust the system.
Incremental adoption is the only viable path. Radical changes are risky. What actually deploys: incremental improvements that integrate with existing infrastructure, provide clear rollback mechanisms, and demonstrate value on small scale pilots before full rollout.
The deployment gap isn’t a criticism of research. It’s recognition that production systems have constraints around safety, reliability, and observability that research environments can ignore. Understanding these constraints is part of adaptive reasoning: knowing not just what optimizations are possible, but which are deployable given organizational and operational realities.
Energy and Sustainability: A First-Class Constraint
During our class discussion, Esha highlighted an emerging theme: energy efficiency and sustainability are becoming first class optimization objectives, not afterthoughts.Embodied Carbon in Data Centers: Esha’s work on modeling embodied carbon (the emissions from manufacturing hardware) alongside operational carbon (power consumption) reflects a broader industry trend. When a single GPU cluster can consume megawatts of power, and data centers represent growing percentages of global electricity consumption, efficiency isn’t just about cost. It’s about environmental impact. Microsoft’s public commitments to carbon reduction drive research into heat reuse, renewable energy integration, and carbon aware workload scheduling. These constraints shape what “optimal” means for adaptive systems.
This adds complexity to adaptive reasoning. Modern systems must balance multiple objectives in real-time: latency, throughput, fairness, energy efficiency, and carbon optimization. These objectives often conflict. The highest-throughput strategy might waste energy. The most carbon-efficient schedule might increase latency. Adaptive reasoning must navigate these tradeoffs dynamically as conditions change.
Adaptive Reasoning: The Third Type of Tacit Knowledge
Having explored LLM scheduling through learning to rank, system optimization through text-to-text regression, and production deployment challenges at Azure scale, we can now characterize what makes adaptive reasoning distinct and why it matters for AI agents.
Adaptive reasoning operates continuously at runtime, responding to evolving conditions. Unlike co-design reasoning that optimizes static interdependencies, or predictive reasoning that accounts for uncertainty at design-time, adaptive reasoning must learn from live traffic without disrupting service. The exploration versus exploitation tradeoff becomes fundamental: trying new strategies risks hurting current performance, but using only known strategies might miss better solutions.
Meta reasoning emerges: the system must reason about its own reasoning. When should we adapt versus when are changes just noise? Which past decisions led to current state? How do our adaptations affect future states we’ll observe? Multi objective optimization happens in real time, balancing latency, throughput, fairness, energy, and cost simultaneously as objectives shift in relative importance.
What This Requires from AI Agents
For AI agents to master adaptive reasoning, several capabilities become essential. Learning with delayed rewards: a scheduling decision might affect performance minutes or hours later, requiring temporal credit assignment that’s difficult when feedback isn’t immediate. Robustness to distribution shift: workload patterns change continuously (morning vs evening, weekday vs weekend, model updates, hardware failures), so adaptive strategies must generalize rather than overfit to recent observations.
As Esha’s Sherlock project demonstrated, counterfactual reasoning, safe exploration, and interpretability aren’t just nice features but fundamental requirements. These challenges extend beyond algorithms to system design: architecting systems to support safe adaptation, creating interfaces for human oversight of self-optimizing systems. These remain open questions at the frontier of adaptive reasoning.
The Unique Moment: Learning Adaptive Reasoning Together
Throughout Phase 2, we’ve examined domains where humans have accumulated decades of experience. Memory system architects have refined prefetching heuristics over 40+ years. Database designers have developed intuitions about index structures through countless deployments. In these domains, AI agents are catching up to human expertise.
LLM serving is different. Nobody has decades of experience.
Transformers emerged in 2017. Large-scale LLM serving (models with 100B+ parameters) is only 2 to 3 years old. Production diffusion model serving is even newer. The architectural principles for these workloads are being developed right now, and humans don’t have a significant head start. There’s no established playbook to learn from. The tacit knowledge doesn’t exist yet—it’s being created through current experience.
This creates both challenge and opportunity. Generative AI is rapidly becoming the dominant workload in production systems, yet no established best practices exist. The workloads themselves evolve rapidly: new model architectures emerge, new modalities appear, scale requirements shift. What works today might not work tomorrow.
But the meta nature of LLMs optimizing LLM infrastructure enables something unprecedented: systems that explain their own behavior, optimization through semantic understanding rather than black box tuning, humans and AI learning together rather than AI catching up to established expertise. The next generation of architects will design systems that adapt themselves, shifting from memorizing optimal configurations to designing meta-policies for self-optimization.
Questions for Reflection
For researchers: How do we build AI systems that learn adaptively under production constraints while maintaining formal guarantees about worst-case behavior? Can we develop theoretical frameworks for safe exploration in closed-loop systems where the agent’s actions affect its own observations?
For practitioners: When should systems adapt themselves autonomously versus when should humans make decisions? What observability and interpretability tools enable operators to trust and oversee self-optimizing systems? How do we validate that adaptive improvements generalize rather than overfit to recent conditions?
For educators: How do we teach adaptive reasoning when the domain is so new? What abstractions help students understand the differences between co-design, predictive, and adaptive reasoning? How do we prepare students for a future where the systems they build will optimize themselves?
For the field: What architectural support does adaptive generative AI need? How do we design hardware for workloads with emergent computational patterns? What benchmarks properly evaluate adaptive systems under dynamic conditions rather than static snapshots?
The deeper question: When systems can reason about their own performance and participate in their own optimization, what does “architecture” mean? Are we designing static structures or meta-policies for self-optimization? Where should human architectural judgment focus when systems adapt themselves? How do we ensure that self-optimizing systems remain aligned with human objectives as they evolve?
Synthesis: The Evolution of Architectural Reasoning
We’ve reached the end of Phase 2, having explored three distinct types of tacit architectural knowledge through concrete systems problems:
Co-design reasoning (Week 8): Handling circular dependencies where tile sizes, memory hierarchies, dataflows, and bandwidth constraints form an interdependent web. Traditional optimization fails because you cannot decompose the problem into independent subproblems.
Predictive reasoning (Week 9): Designing for patterns you can’t fully characterize. Memory prefetchers must learn from sparse signals. Learned indexes exploit data distributions but face retraining challenges. Making informed bets about uncertain futures with incomplete information.
Adaptive reasoning (Week 10): Continuously adjusting in real-time as conditions change. LLM schedulers learning from live traffic. Text-to-text models predicting system behavior semantically. Systems that participate in optimizing themselves.
These aren’t separate skills. They build on each other. Understanding interdependencies (co-design) enables better predictions. Making predictions (predictive) guides adaptation. Adaptation experiences inform future co-design. Together, they constitute what we mean by “architectural thinking.”
Architecture 2.0 Revisited
In Week 1, we introduced Architecture 2.0: the vision of AI agents as co-designers exploring vast design spaces that humans can’t fully navigate. Now, having examined the three types of reasoning this requires, we understand what that vision demands:
Not just search algorithms for optimization. Not just pattern recognition from training data. But the ability to reason about circular dependencies, make informed bets about uncertain futures, and continuously adapt as conditions change, often with the system participating in its own optimization.
Current AI systems possess pieces of these capabilities but don’t fully integrate them. Analytical models (like DOSA from Week 8) encode structural understanding but lack adaptation. Learning-based approaches (like AutoTVM, Learning to Rank) recognize patterns but need structural guidance. Text-to-text regression brings semantic understanding but requires integration with temporal reasoning.
The path forward: hybrid systems that know when to apply which type of reasoning. Human-AI collaboration interfaces for all three. Architectures designed from first principles to support adaptive optimization.
Looking Ahead
Next week, we begin Phase 3: AI for Chip Design. From software optimization to hardware architecture to physical implementation in silicon. Each phase has revealed different types of reasoning, different challenges for AI agents, different forms of human-AI collaboration.
The question continues to evolve: What can AI agents learn to do? What requires human architectural judgment? Where does collaboration amplify both? And how do we build systems that embody the best of both?
The journey from code to chips reveals not just technical challenges, but fundamental questions about intelligence, expertise, and the future of system design.
For detailed readings, slides, and materials for this week, see Week 10 in the course schedule.