Week 7: How Do AI Agents Learn What Was Never Written Down? The Tacit Knowledge Challenge
For six weeks, we’ve been optimizing software. The code was right there, waiting to be read. APIs were documented. Performance metrics were measurable. When ECO optimized CPU code at Google, it could analyze the source, identify patterns, and suggest improvements. When Kevin generated GPU kernels, it could iterate on CUDA code, profile the results, and refine its approach.
This week, we crossed a boundary.
We moved from software optimization into hardware architecture design. Suddenly, everything changed. The problems are harder, yes. But that’s not what makes this fundamentally different. The knowledge we need doesn’t exist in any form an AI agent can read.
The most valuable insights about computer architecture aren’t written in papers. They’re not documented in specifications. They exist as tacit knowledge: intuitions, heuristics, and wisdom accumulated over decades in the minds of experienced architects. Ask a senior architect why they made a particular design choice. You’ll get answers like “experience tells me…” or “we learned the hard way that…” or “it depends on your philosophy about where to push complexity.”
How do you teach an AI agent something that was never written down?
This isn’t just a practical challenge. It’s an epistemological one. And it sits at the heart of Architecture 2.0’s most ambitious promise: that AI agents can become co-designers of computer systems. This week, we confronted this challenge head-on.
PHASE 1: The Transparency Gradient
From Explicit Artifacts to Implicit Wisdom
Let’s trace the journey we’ve taken over the past seven weeks. Each week, we’ve moved one level deeper into the computing stack. And with each step, the knowledge we need to optimize has become progressively less explicit.
Week 3 (Code Generation): AI systems generate source code. The knowledge is maximally explicit, literally written as text in programming languages with defined syntax and semantics. When SWE-bench evaluates whether code is correct, it can run tests, check outputs, verify behavior.
Week 4 (CPU Performance Engineering): ECO optimizes C++ code at Google. Still working with source code, but now the knowledge extends beyond correctness to performance patterns. These patterns remain largely explicit. You can profile the code, measure cache misses, count allocations, observe the outcomes of changes.
Week 5 (GPU Kernel Optimization): Kevin generates CUDA kernels. The complexity increases significantly. Now you’re reasoning about memory hierarchies, warp scheduling, tensor cores. But you can still iterate: write code, profile it, measure performance, refine. The feedback loop remains tight and concrete.
Week 6 (Distributed Systems): COSMIC co-designs workload mappings and network topologies. We entered the realm of systems that exist in time, systems that must adapt to dynamic conditions. Even here, you have telemetry. You have measurements. You have explicit workload traces and network topologies to reason about.
Week 7: We’ve hit a different kind of wall.
📝 Fully Explicit
Source code, tests, syntax] --> B[Week 4: CPU Optimization
📊 Mostly Explicit
Profiles, measurements] B --> C[Week 5: GPU Kernels
🔧 Complex but Measurable
Iterate and profile] C --> D[Week 6: Distributed Systems
🌐 Dynamic & Temporal
Telemetry and traces] D --> E[Week 7: Architecture Design
🧠 Largely Tacit
Experience and intuition] style A fill:#e8f5e9 style B fill:#fff3e0 style C fill:#ffe8e0 style D fill:#ffe0f0 style E fill:#ffebee
The Architecture Knowledge Gap
When you design a new processor architecture, you face a fundamentally different challenge. You can’t just “read the code” because there is no code yet. You can’t profile it because it doesn’t exist. You can’t measure its performance because it hasn’t been built.
Instead, you must predict performance of designs that exist only as specifications. As shown in Figure 1, you navigate a wide range of trade-offs based on incomplete information about future workloads. You make philosophical choices about where to locate complexity in the system. You apply intuitions developed through years of seeing what works and what fails.
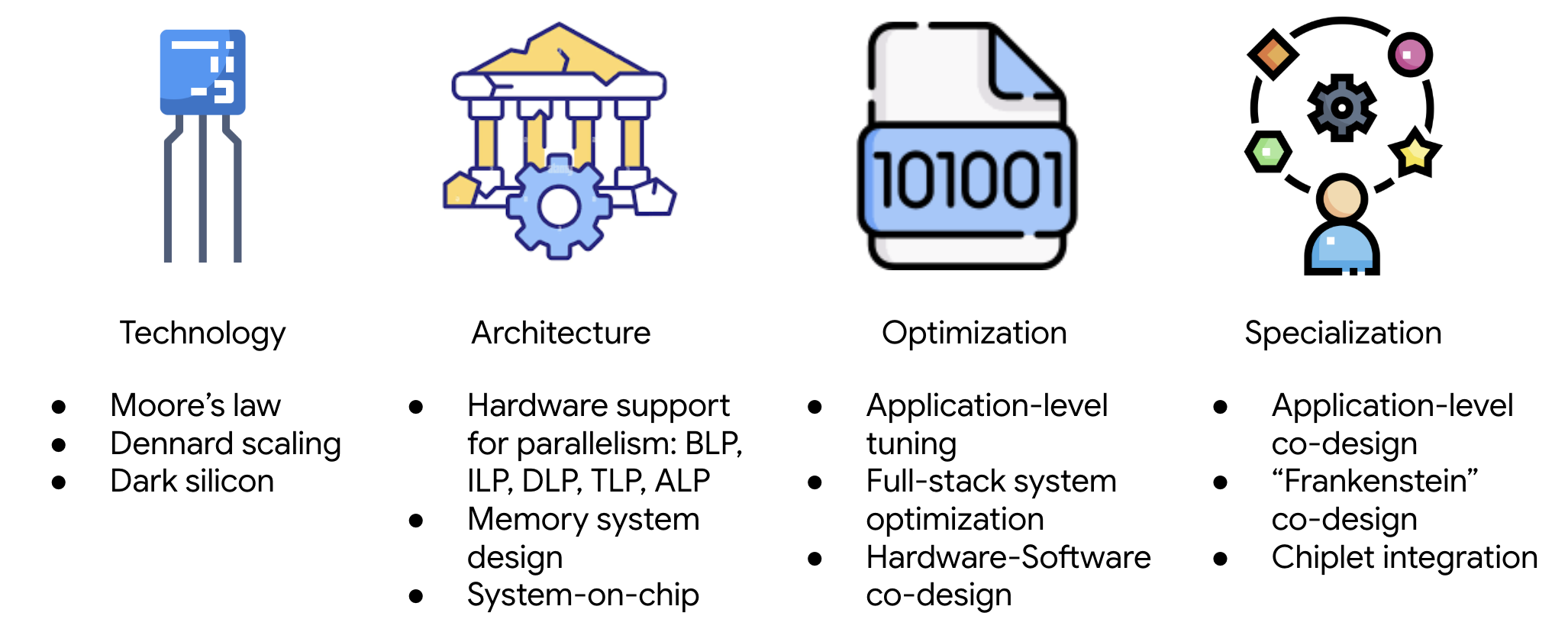
Here’s the crucial point: most of this knowledge is tacit. It exists in the heads of experienced computer architects, accumulated through decades of building systems, seeing designs succeed and fail, understanding the consequences of architectural decisions that ripple through entire systems.
As I emphasized in class: “There’s a lot of hidden science or knowledge that is not transparent. Yes, we’re reading papers and there are insights in there, but there’s also the aspect of why are we reading these papers—because there are things that architects know how to do that are not codified anywhere. It’s not explicitly written down anywhere as to what those best practices are.”
This creates a profound challenge for AI agents. In software optimization, agents could learn from reading millions of lines of open-source code. In hardware architecture, what do they learn from?
Why This Matters for Architecture 2.0
This brings us back to the fundamental promise of Architecture 2.0 that we introduced in Week 1. We talked about design spaces containing 10^14 to 10^2300 possible configurations. Spaces too vast for human exploration. We discussed how AI agents could navigate these spaces and discover optimizations that humans might miss.
But we didn’t fully confront something: even if an agent can explore vast design spaces, how does it know what’s worth exploring? How does it develop the intuition that certain classes of designs are dead ends? How does it learn the philosophical frameworks that guide human architects’ search strategies?
The tacit knowledge problem isn’t just about scale. It’s about the nature of architectural knowledge itself.
PHASE 2: Two Approaches to the Tacit Knowledge Problem
This week’s two main papers (Concorde and ArchGym) represent fundamentally different approaches to making architectural knowledge accessible to AI agents. Understanding these approaches reveals not just technical solutions, but different philosophies about how machine learning can engage with domain expertise.
Concorde: Codifying What We Can, Learning What We Can’t
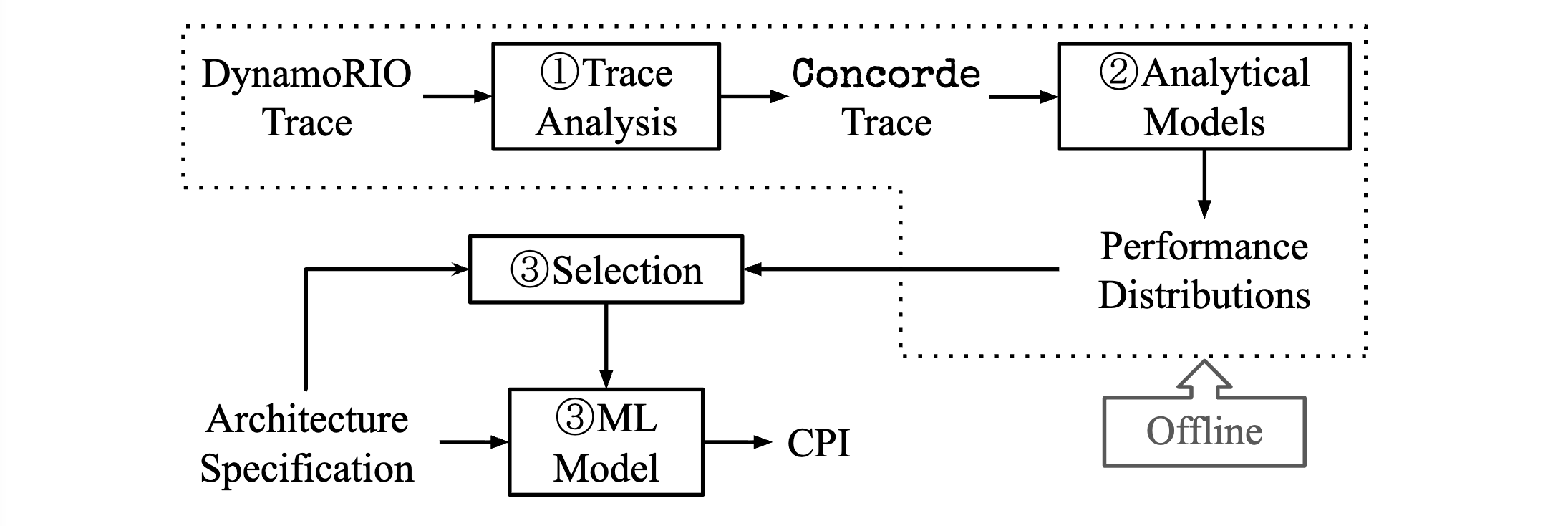
Concorde: Fast and Accurate CPU Performance Modeling with Compositional Analytical-ML Fusion takes a pragmatic stance. Decades of computer architecture research have produced powerful analytical models. These models encode explicit theoretical knowledge: queueing theory, roofline models, Amdahl’s law, Little’s law. This knowledge is precious. It’s been validated, refined, and proven across countless designs.
Why throw it away?
The traditional approach to AI in architecture often treats it as a black box problem: feed in design specifications, train a model, predict performance. This ignores the vast repository of architectural knowledge encoded in analytical models. It’s like teaching a physics student to predict projectile motion purely from observational data, without ever mentioning Newton’s laws.
Concorde’s insight is compositional: combine analytical models (which capture first order effects and fundamental principles) with machine learning (which captures the messy, hard to model interactions and second order effects).
The results are compelling. Concorde achieves accuracy comparable to detailed cycle accurate simulation, but with speedups of 5 orders of magnitude. This isn’t just incrementally better. It changes what’s possible. You can explore design spaces that were previously intractable because simulation was too slow.
The deeper insight? Concorde represents a philosophy about how AI should engage with domain expertise. It doesn’t replace human architectural knowledge. It augments it. The analytical models embody what we do know explicitly. The ML components learn what we don’t know or can’t model analytically: complex cache interactions, branch prediction accuracy under specific workloads, the emergent behavior of out of order execution.
The Compositionality Principle: Concorde’s approach reflects a broader pattern emerging in AI for systems: rather than treating ML as a replacement for human expertise, treat it as a complement. Use explicit models for what we understand, use learning for what we don’t. This pattern appears across domains—Google’s data center cooling system combines physics-based models with learned policies, learned index structures combine traditional indexing principles with neural networks. The sweet spot isn’t pure ML or pure analytical models, but thoughtful composition of both.
This is tacit knowledge made explicit through modeling. But it only works for the knowledge we can make explicit. What about everything else?
ArchGym: Learning Through Exploration
ArchGym: An Open-Source Gymnasium for Machine Learning Assisted Architecture Design takes a radically different approach. Instead of trying to codify architectural knowledge, it creates an environment where agents can develop that knowledge through experience.
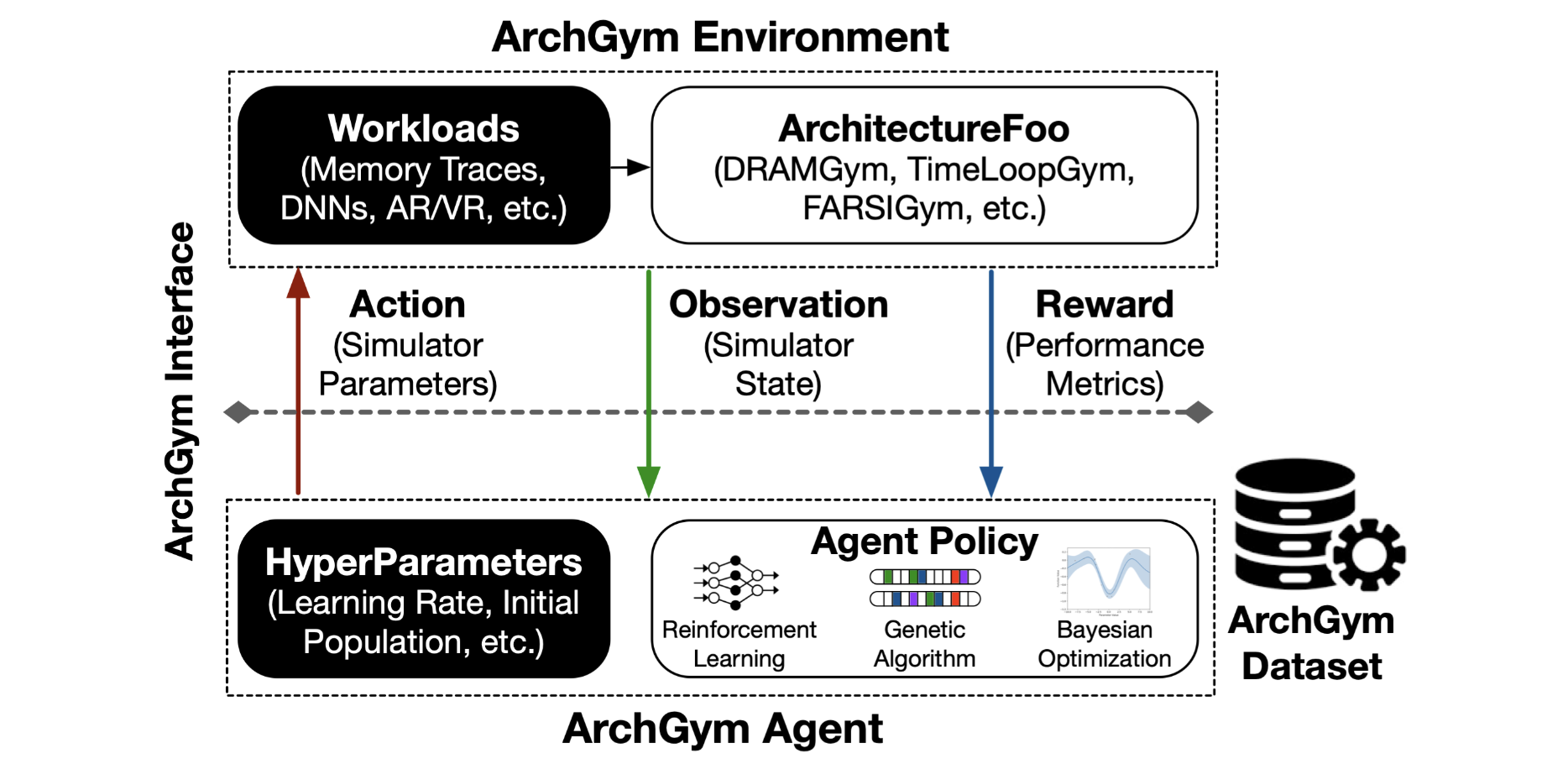
Think about how human architects actually learn their craft. Yes, they read papers and textbooks. But much of their intuition comes from experience. Trying designs. Seeing what works. Understanding why configurations fail. Building mental models through repeated exposure to the consequences of design choices.
ArchGym creates exactly this kind of learning environment for AI agents. It’s a gymnasium (in the reinforcement learning sense) that connects search algorithms (Bayesian optimization, genetic algorithms, reinforcement learning), architecture simulators (gem5, Timeloop, various domain specific tools), and workloads (diverse benchmarks across different application domains).
The framework allows agents to propose designs from the vast configuration space, simulate them to observe performance, power, and area metrics, learn from outcomes to refine their search strategy, and develop intuitions about what configurations work well together.
This is fundamentally about making tacit knowledge learnable rather than explicit. The agent doesn’t get handed rules about good architecture design. It discovers them through exploration.
The Data Collection Challenge
A Personal Note on Infrastructure: If only NSF CIRC hadn’t rejected our proposal to build this infrastructure… CIRC (Computing Innovation Research Community) is an NSF program that funds shared research infrastructure for the computing community. We proposed building exactly the kind of large-scale architecture simulation data collection infrastructure that would help address this problem—running systematic design space explorations across multiple simulators and workloads, then making those datasets publicly available. The rejection illustrates the very challenge we’re discussing: the incentive structures and funding mechanisms don’t prioritize the unglamorous but essential work of building shared community resources. When even a well-structured proposal with clear community benefit struggles to get funded, it’s no surprise that individual research groups don’t take on this work.
This led to perhaps the most pragmatic discussion of the week: Why hasn’t the community generated massive datasets of architecture simulations?
The answer reveals structural challenges in architecture research. Simulations are slow. Gem5 “cycle accurate” simulation can take days or weeks for realistic workloads. There’s no funding for infrastructure. Generating comprehensive datasets requires sustained computational resources that research grants rarely cover. Incentive structures are missing. Publishing a dataset doesn’t advance academic careers like publishing a novel algorithm does.
As I noted: “The lack of uptake from the community [is] due to the absence of funding and infrastructure… The slow pace of simulations and the need for a coalition to pull data from Gem5.”
This is a microcosm of the tacit knowledge problem. We could create datasets that capture architectural design outcomes at scale. These datasets would help AI agents learn patterns that currently exist only in architects’ heads. But the infrastructure and incentives don’t exist to create them.
The question becomes: Can agents learn architectural wisdom without these massive datasets? Or are we stuck with the tacit knowledge problem until we solve the data problem?
PHASE 3: Insights from the Trenches—Suvinay’s Philosophy of Architecture
 Suvinay Subramanian started his journey at MIT CSAIL before joining Google, where he now works on TPU co-design. He’s spent years in the trenches of hardware/software co-optimization, from sparse cores in TPUs to ML workload optimization for systems running today’s largest language models. What makes his perspective valuable? He’s lived through the full cycle: the excitement of proposing novel architectures, the frustration when simulation results don’t match silicon, the hard lessons about where complexity should actually live in a system. He bridges hardware architecture, systems design, and ML in ways that few people can.
Suvinay Subramanian started his journey at MIT CSAIL before joining Google, where he now works on TPU co-design. He’s spent years in the trenches of hardware/software co-optimization, from sparse cores in TPUs to ML workload optimization for systems running today’s largest language models. What makes his perspective valuable? He’s lived through the full cycle: the excitement of proposing novel architectures, the frustration when simulation results don’t match silicon, the hard lessons about where complexity should actually live in a system. He bridges hardware architecture, systems design, and ML in ways that few people can.
Our guest speaker this week, Suvinay Subramanian, brought a practitioner’s perspective that grounded our theoretical discussions in the reality of designing production systems. As a Staff Software Engineer at Google working on TPU co-design, Suvinay has spent years navigating the exact tacit knowledge challenges we’ve been discussing. (Note: The views expressed are Suvinay’s own and do not necessarily reflect Google’s official positions.)
His insights revealed that architecture is as much philosophy as it is science.
Velocity and Clarity Over Perfection
One of Suvinay’s core principles: “Velocity and clarity” matter more than finding the theoretically optimal solution.
In academic papers, we often see optimization formulated as: find the design d that maximizes performance P(d) subject to constraints. This framing assumes there’s a single “optimal” answer we’re searching for.
Reality is messier. In production architecture design, workloads are moving targets. By the time you optimize for today’s models, tomorrow’s architectures have changed. Requirements are uncertain. You’re betting on which ML paradigms will dominate 2 to 3 years from now when your chip tapes out. Trade-offs are multidimensional: performance, power, area, cost, software complexity, time to market.
In this environment, the goal isn’t finding the optimal solution. It’s finding a good-enough solution quickly enough to iterate on it.
This has profound implications for AI-assisted architecture. An agent that explores the design space exhaustively, searching for the global optimum, might be less valuable than an agent that quickly identifies several promising regions and lets human architects make philosophical choices among them.
The Subjectivity of Hardware Design
Suvinay emphasized something that rarely appears in architecture papers: hardware design involves “subjective bets” based on philosophical preferences about where to locate complexity.
Consider Google’s architectural philosophy (as Suvinay described it): prefer simpler hardware and more complex software. This isn’t a mathematical theorem. It’s a philosophical stance based on several beliefs. Software is more flexible than hardware (can be updated post deployment). Software complexity is more manageable at Google’s scale (strong software engineering culture). Simpler hardware is easier to verify and less risky for tape out.
Other organizations might make the opposite choice: put more complexity in hardware (specialized instructions, complex caching schemes) to simplify software. Neither is universally “correct.” They reflect different organizational capabilities, different tolerance for risk, different assumptions about how the technology landscape will evolve.
How does an AI agent learn these philosophical frameworks?
This isn’t something you can extract from simulation results. Two designs might perform identically, but one aligns with your organization’s philosophy and capabilities while the other doesn’t. Human architects navigate this constantly. AI agents need to either:
- Learn these philosophical frameworks from observing human design choices
- Be explicitly taught these frameworks as constraints
- Develop their own frameworks (and convince humans to trust them)
None of these is straightforward.
The Numerics Example: Details That Matter
Suvinay provided a concrete example that illustrates how tacit knowledge operates in practice: the evolution of floating-point formats for ML.
Traditional deep learning used FP32 (32 bit floating point). Then researchers discovered FP16 (16 bit) worked well for many models, offering 2x speedup. Then Google introduced bfloat16 (BF16), which trades precision for range compared to FP16. While the distinction between FP16 and BF16 is subtle, as shown in Figure 4, there are consequential tradeoffs in hardware support, convergence, and end-to-end performance. More recently, INT8, FP8, even FP4 quantization have gained hardware support.

Each of these choices has implications that ripple through the entire system. Hardware complexity: different formats require different arithmetic units. Software stack: frameworks need to support mixed precision training. Numerical stability: some operations are sensitive to precision, others aren’t. Model architectures: some models tolerate lower precision better than others. Future proofing: which formats will dominate in 3 years when your chip ships?
Suvinay noted: “The importance of quality studies and the evolution of standards like bfloat16.” These weren’t purely analytical decisions. They involved running extensive experiments across many models, building prototypes to understand hardware implications, making bets about which ML paradigms would dominate, and coordinating across hardware, systems, and ML teams.
This is tacit knowledge in action. A textbook can teach you how floating point arithmetic works. But knowing which format to choose for your next chip design? That requires the kind of experience based intuition that exists in architects’ heads.
The Three Phases of Architecture Design
Suvinay outlined how AI might help across the architecture design workflow. There’s Phase 1: Experimental Setup, where you define the design space to explore, choose appropriate simulators and models, and set up workloads and benchmarks. Then Phase 2: Design Space Exploration, where you systematically explore configurations, identify promising regions, and balance exploration versus exploitation. Finally Phase 3: Analysis and Insights, where you understand why certain designs perform well, extract principles that generalize, and communicate findings to inform the next iteration.
Current AI approaches focus heavily on Phase 2—using RL or Bayesian optimization to search design spaces efficiently. But Suvinay’s framing highlights that Phases 1 and 3 might benefit even more from AI assistance.
Phase 1 requires setting up the problem correctly—deciding what to optimize, what constraints matter, what design space is even worth exploring. This is where tacit knowledge is most concentrated. Experienced architects “know” which design spaces are promising. How do we teach agents this?
Phase 3 requires extracting insights. Not just finding that Design X performs well, but understanding why, articulating the principles, and generalizing them. This is where human architects add the most value currently. Can AI agents learn to extract these insights?
The discussion revealed an important point: AI for architecture isn’t just about automating design space exploration. It’s about augmenting the entire design process, including the parts where tacit knowledge is most critical.
PHASE 4: The Meta-Challenge—What Does This Mean for AI Agents?
We’ve explored the tacit knowledge problem from multiple angles: through the lens of compositional modeling (Concorde), experiential learning (ArchGym), and practitioner philosophy (Suvinay). Now we need to confront the harder question: What does this mean for the future of AI agents as architecture co-designers?
Three Possible Paths Forward
Path 1: Systematic Codification
One response to tacit knowledge is to make it explicit. This is Concorde’s path. Encode what we know in analytical models, use ML for the rest. Extend this to other forms of architectural knowledge: formalize design patterns and anti patterns, document philosophical frameworks and their rationales, create ontologies of architectural trade offs, build knowledge bases of past designs and their outcomes.
The challenge? This requires enormous effort from experts, and much tacit knowledge resists formalization. How do you codify “experience tells me this won’t work”?
Path 2: Learning Through Massive Exploration
Another response is to let agents develop intuition through experience. This is ArchGym’s path. Create environments where agents explore extensively and learn patterns from outcomes.
The challenge? Architecture exploration is expensive (slow simulations), and we lack the massive datasets that have enabled breakthroughs in other domains. Moreover, exploration in simulation might not transfer to real hardware (the simulation reality gap).
Path 3: Human AI Collaboration
A third path accepts that some knowledge will remain tacit, but creates interfaces for humans and AI to collaborate effectively. Agents handle systematic exploration, humans provide philosophical guidance and intuitive constraints.
The challenge? This requires rethinking how we design architecture tools and workflows. Current CAD tools and simulators weren’t built for human AI collaboration.
The Epistemological Question
Here’s where I challenge all of you to think deeper:
“We’re reading Concorde and ArchGym, but here’s what you need to grapple with: These papers themselves represent codified knowledge. Someone wrote them down. But what about all the knowledge that isn’t in papers? The trade offs learned from failed tape outs that never got published? The intuitions about what configurations are even worth exploring? The philosophical frameworks that guide which problems to solve in the first place?”
This isn’t just a data problem or an algorithm problem. It’s an epistemological challenge.
What types of knowledge can AI agents access? Explicit knowledge in papers and textbooks? Yes, through training data. Implicit patterns in code and designs? Yes, if we have datasets. Experiential knowledge from exploration? Yes, if we can simulate cheaply enough. Tacit intuitions in experts’ heads? This is the hard problem.
How do agents develop architectural intuition? By reading millions of papers? Necessary but insufficient. By exploring design spaces? Helpful but expensive. By observing expert designers? Requires new infrastructure. By experiencing failures? Need comprehensive failure datasets (which we don’t have).
Can agents discover new architectural principles? Or will they always be bounded by human frameworks? Might they discover philosophical approaches we’ve never considered? How would we even recognize a novel architectural principle?
Is Architecture at a Transition Point?
There’s a pattern in technology history: knowledge that starts as tacit craft eventually becomes codified science. Medieval blacksmiths passed heat treatment knowledge through apprenticeship until metallurgy made it explicit. Early assembly code optimization was craft knowledge until compilers automated it.
Is computer architecture at that transition point? Some areas have already shifted (logic synthesis, place and route, compiler optimization). But microarchitecture design, memory hierarchy design, and ISA design remain craft like. The question for Architecture 2.0 is whether AI can accelerate this transition.
PHASE 5: Looking Forward—The Road Ahead in Phase 2
Week 7 marks not just the beginning of Phase 2 (AI for Architecture), but a fundamental shift in the nature of the challenges we’re tackling. The remaining weeks of Phase 2 will push us deeper into domains where tacit knowledge dominates.
Week 8: Hardware Accelerators & AI Mappings will explore co-designing dataflow architectures and operation mappings. Here, the tacit knowledge includes intuitions about which dataflow patterns work well for which workload patterns. Knowledge that emerges from building and evaluating many accelerators.
Week 9: Memory Systems & Data Management covers cache replacement policies, prefetching strategies, memory hierarchy design. Decades of architectural wisdom about memory behavior that’s never been fully codified.
Week 10: LLM Systems & AI Workload Scheduling examines optimizing for transformer models and attention mechanisms. Interestingly, this is a domain where nobody has decades of tacit knowledge yet. The workloads are too new. This might actually favor AI agents.
Each of these domains will force us to grapple with the same question we confronted this week: How do AI agents access and leverage the hidden wisdom of experienced architects?
The Broader Architecture 2.0 Vision
This connects back to the vision we articulated in Week 1. We talked about AI agents as co-designers, navigating vast design spaces that humans can’t comprehend. But we didn’t fully confront that these spaces aren’t just large. They’re also shaped by decades of accumulated wisdom about what’s worth exploring.
The tacit knowledge problem suggests a more nuanced vision of Architecture 2.0.
Not: AI agents replace human architects by exhaustively searching design spaces
But: AI agents and human architects collaborate, with agents handling systematic exploration and architects providing philosophical guidance, intuitive constraints, and interpretive wisdom

This isn’t a disappointing compromise. It’s actually more powerful. It combines AI’s ability to explore thoroughly, consistently, without cognitive bias with human’s ability to provide context, philosophy, and intuitive leaps.
The challenge is building the interfaces and workflows that enable this collaboration effectively.
Synthesis: Can AI Learn What Humans Never Wrote Down?
We opened with a question: How do you teach an AI agent something that was never written down?
After exploring Concorde’s compositional modeling, ArchGym’s experiential learning, and Suvinay’s practitioner philosophy, we can offer a more nuanced answer:
You don’t teach it directly. You create conditions where it can be learned.
This involves several things. First, codifying what can be codified (Concorde): making explicit the theoretical foundations, the analytical models, the principles that we can articulate. Don’t throw away decades of architectural knowledge. Encode it.
Second, creating rich learning environments (ArchGym): building infrastructure where agents can explore, experience consequences, and develop intuitions through repeated interaction with realistic design spaces.
Third, enabling human AI collaboration (Suvinay): designing workflows where humans provide philosophical guidance and intuitive constraints while agents handle systematic exploration and analysis.
Fourth, building methodological rigor (Community): establishing shared benchmarks, evaluation procedures, and datasets that enable cumulative learning rather than perpetuating tacit knowledge.
But we must also acknowledge: Some knowledge may remain tacit. The philosophical frameworks about where to locate complexity, the intuitions about which design patterns will age well, the judgment calls under uncertainty. These may always require human architects.
And perhaps that’s appropriate. Architecture 2.0 isn’t about eliminating human expertise. It’s about augmenting it, amplifying it, and making it accessible to AI agents as collaborative partners.
The tacit knowledge problem isn’t a bug in Architecture 2.0. It’s a feature that shapes what the collaboration between humans and AI agents will look like.
Additional Classroom Insights
Beyond the main narrative, our class discussion surfaced several points worth noting.
We spent time on what we might call the “hyperparameter lottery.” Algorithm performance varies wildly based on hyperparameter choices. This raises a meta question about what we’re really comparing when we evaluate different search strategies. Even choosing how to explore design spaces requires tacit expertise. Is your space smooth or discontinuous? Do you need sample efficiency or ultimate performance? These questions don’t have obvious answers.
The rigor challenge came up repeatedly. When evaluation methodology is inconsistent, when algorithms get cherry picked based on what works for specific cases, we’re not building cumulative knowledge. We’re perpetuating tacit knowledge where every research group has their own tricks. ArchGym’s methodological contribution (standardized benchmarks, fair comparisons) may be as important as its technical contributions. But adoption remains slow due to structural incentives that don’t reward infrastructure building.
Finally, Week 7 marks a shift from optimizing within explicit constraints (code, APIs, measurable performance) to navigating implicit knowledge (design principles, philosophical frameworks, experience based intuitions). This suggests AI for architecture will require fundamentally different techniques than AI for software. Compositional modeling, richer learning environments, human AI collaboration interfaces. The tools that worked for software won’t simply transfer.
Key Takeaways
The Transparency Gradient: As we move from software optimization to hardware architecture, knowledge becomes progressively less explicit, transitioning from code we can read to wisdom that exists only in architects’ heads.
Two Complementary Approaches: Concorde (compositional analytical ML fusion) and ArchGym (experiential learning environments) represent different strategies for making architectural knowledge accessible to AI agents. Codification versus experience.
Architecture as Philosophy: Hardware design isn’t purely optimization. It involves subjective bets, philosophical choices about complexity location, and intuitions that resist formalization (Suvinay’s key insight).
The Epistemological Challenge: The hardest problem isn’t algorithm design or computational efficiency. It’s accessing knowledge that has never been written down and may resist explicit codification.
Methodological Rigor Matters: Converting tacit knowledge into systematic science requires shared infrastructure, datasets, and evaluation procedures. Collective goods that current incentive structures underprovide.
Collaboration Over Replacement: Architecture 2.0’s promise isn’t AI agents replacing human architects, but creating new forms of human AI collaboration where agents handle systematic exploration and humans provide philosophical guidance.
Questions for the Road Ahead
As we continue into Phase 2, several fundamental questions emerge:
For Researchers: How do we balance codifying architectural knowledge explicitly (enabling faster learning) versus letting agents discover it through exploration (enabling novel insights humans might miss)?
For Practitioners: What collaboration interfaces would allow human architects to effectively guide AI agents’ exploration while remaining open to unexpected agent discoveries?
For Educators: How do we teach the next generation of architects to work with AI co-designers? What knowledge becomes more important (philosophical frameworks, intuition) versus less important (routine optimization)?
For the Field: Can we create incentive structures that reward the unglamorous but essential work of building shared infrastructure, datasets, and evaluation methodology that enable cumulative progress?
The Deeper Question: When an AI agent discovers an architectural pattern through exploration that no human architect has articulated, how do we evaluate whether it’s a genuine insight or an artifact of our simulation models? How do we build trust in agent-discovered architectural principles?
The answers to these questions will determine whether Architecture 2.0 achieves its promise of AI agents as true co-designers, or whether agents remain sophisticated tools that still require human architectural wisdom to wield effectively.
Next week, we’ll see how these challenges play out in the specific domain of hardware accelerator design. Co-designing architecture and workload mappings requires exactly the kind of tacit knowledge we’ve been discussing: intuitions about which dataflow patterns work well for which computational patterns, wisdom about balancing flexibility and efficiency, philosophical choices about where to optimize.
The journey deeper into hardware continues. The knowledge becomes increasingly implicit. And the question of how AI agents access architectural wisdom becomes ever more pressing.
For detailed readings, slides, and materials for this week, see Week 7 in the course schedule.